AIニュース 2026-06-17
自動生成: 2026-06-17 13:45 JST
過去24時間以内に公開された記事を、同じ話題ごとに1つのストーリーカードへまとめ、出典・トピック・要約とともに掲載しています。要約は各フィード提供文の冒頭を整形したもので、本文は各リンク先をご覧ください。
📌 今日の要点 TOP7
-
Unlocking UK house-building with AI-accelerated planningGoogle DeepMind
UK government partners with Google DeepMind to build a new AI-powered…
-
Android 17 launches with new multitasking tools as Google expands Gemini featuresTechCrunch AI
Google has released Android 17 and Wear OS 7, introducing new multita…
-
SpaceX、AIコーディング「Cursor」を9.6兆円で買収 「近く大幅な改善」へITmedia AI+
Corsorは公式Xで、「近く大幅な改善が行われる予定だ」と述べた。
-
ChatGPT’s market share slips below 50% for first timeTechCrunch AI
The chatbot still remains the most popular AI assistant worldwide wit…
-
OpenAIの高度AIでソフトバンクの脆弱性を1万件発見 孫正義氏「大変な危機」 日本の重要インフラ企業へ診断サービス提供ITmedia AI+
ソフトバンクグループは6月16日、米OpenAIの高度なAI技術を活用したサイバーセキュリティ対策サービス「Patching as a S…
-
Frontier LLM はサイバーセキュリティに対応する準備ができていますか?デュアルモード脆弱性ベンチマークによる垂直基盤モデルの証拠arXiv cs.AI
当社は、フロンティア LLM がデュアルモード ベンチマークを通じてサイバーセキュリティに対応できるかどうかを評価します。ホワイトボックス…
-
日立、OpenAIとの連携を本格化 「Codex」でレガシーシステム刷新、サイバー防衛もITmedia AI+
Codexの解析力と日立のシステム開発ノウハウを組み合わせ、既存コードから上流仕様を可視化し、新システムへの移行テストまでの一連のプロセス…
トピック別件数
- LLM/生成AI 141件
- 研究/論文 138件
- エージェント 87件
- 画像/動画生成 58件
- ビジネス/資金調達 29件
- ロボティクス 29件
- その他 12件
- 規制/政策 4件
- ハードウェア/半導体 3件
日本語メディア15件
ITmedia AI+ (日本語)
日立、OpenAIとの連携を本格化 「Codex」でレガシーシステム刷新、サイバー防衛も
Codexの解析力と日立のシステム開発ノウハウを組み合わせ、既存コードから上流仕様を可視化し、新システムへの移行テストまでの一連のプロセスについて、AIを活用したアプローチの確立を目指す。
「ポケカ対戦AIエージェント」開発コンテスト開始 「不完全情報ゲーム」をどう制するか
チェスや将棋と異なり、相手の手札が見えない「不完全情報ゲーム」にAIがどこまで対応できるかが試される。
SpaceX、AIコーディング「Cursor」を9.6兆円で買収 「近く大幅な改善」へ
Corsorは公式Xで、「近く大幅な改善が行われる予定だ」と述べた。
村田製作所、Synopsysの電磁界/熱解析ツールを介したシミュレーションモデル提供
村田製作所は、Synopsysが提供するシミュレーションツールを介したシミュレーションモデルの提供を開始した。3D電磁界解析ツール「Ansys HFSS」と熱解析ツール「Ansys Icepak」を対象とする。ユーザーはシミュレーションツールから村田製作所のWebサイトにアクセ…
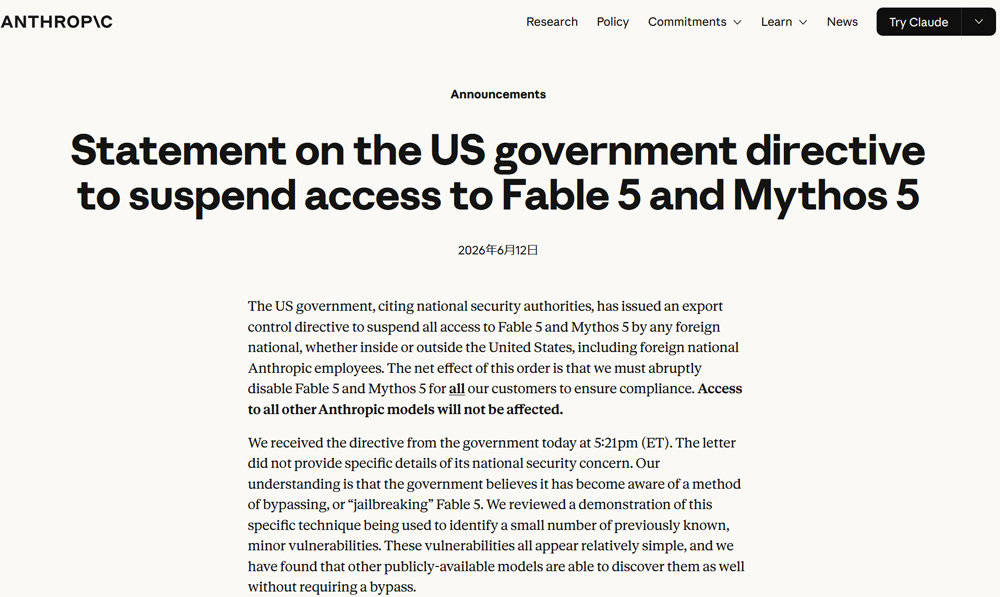
「生成AIは大手なら安心」とは限らない? 突然の提供停止が招くリスク顕在化
米政府の輸出管理指令によるAnthropicの最新AIモデル提供停止を受け、生成AIが事前の通知なしに突然使えなくなるリスクが顕在化した。Forresterは、単一のAIモデル依存の危うさを指摘し、ポータビリティ確保をはじめとする4つの対策を推奨している。

財務諸表だけでは勝てない ブルームバーグ日本トップが語る「非構造化データ」の重要性
デフレからインフレへ経済の潮目が激変した日本市場。もはや過去の数値(財務諸表)を眺めるだけのデータ経営では勝てない。情報の洪水におぼれず、気象や音声などの「非構造化データ」をいかに素早く選別し、リアルタイムの決断に生かすか。金融情報インフラを支えるブルームバーグの日本トップに、…

セルフ給油、実はスタッフが手動で許可していた!? コスモ石油の「AI監視」は消えゆくガソリンスタンドを救うか
従来のセルフ式ガソリンスタンドでは、利用者が給油ノズルを手にした後も、スタッフが安全を確認した上で給油を許可している。この監視業務をAIで支援する取り組みが動き出した。コスモ石油マーケティングとELEMENTSは、AIが給油許可を判断する監視システムを共同開発。背景には、人手不…

月間売上1億円超、“推しAI”アプリ「Zeta」がオタク女子わしづかみ ただし危うさも
自分が作ったシチュエーションで“推し”と会話できるAIチャットアプリ「Zeta」(ゼタ)が人気だ。App StoreやGoogle Playのエンターテインメントランキングでも連日上位にランクインしており、各ストアページによればダウンロード数は130万回を突破。1月には月間の売…
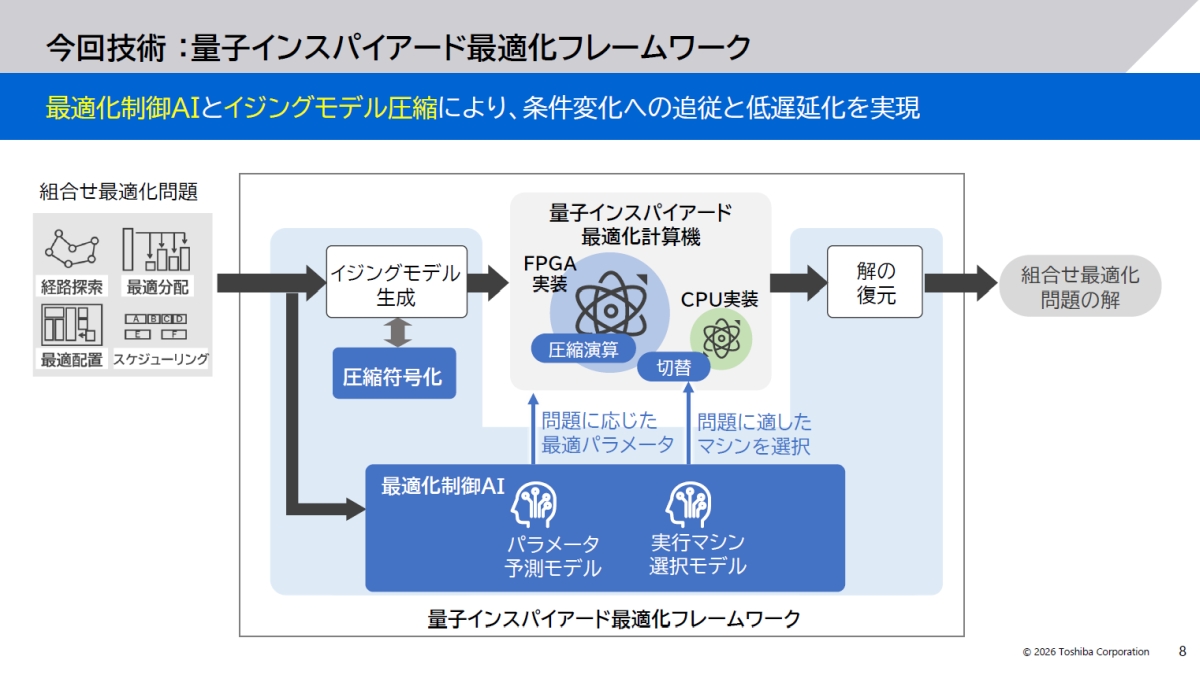
東芝の組み込み向け量子インスパイアード技術が進化、高速化と安定性を両立
東芝は、刻々と状況が変化する現実環境において、組み合わせ最適化問題を高速かつ安定して解くことができる「量子インスパイアード最適化フレームワーク」を開発した。

生成AI×自動運転で注目のTesla・Waymo・NVIDIA 各社が目指す「フィジカルAI」は何が違うのか
日本政府が戦略的強化分野に掲げる「フィジカルAI」――その社会実装の最前線の一つが自動運転システムだ。熾烈な開発競争が繰り広げられている中、生成AIの進化は各社の競争にどのような変化をもたらしているのか。Tesla、Waymo、NVIDIAの最新動向を整理する。
【Pythonで学ぶデータ分析】母平均と母標準偏差をベイズ推定する ~ シュークリームの重さは100gと異なるか?
ある喫茶店のシュークリームの重さを例に、ベイズ統計で「平均」や「ばらつき」をどう推定するのか、さらに基準値と違いがあるかどうかをどう確かめるのかを解説します。『社会人1年生から学ぶ、やさしいデータ分析』ベイズ統計編の第3回です。
OpenAIのサム・アルトマンCEO、来日中止 都内イベント登壇予定を変更
米OpenAIのサム・アルトマンCEOが来日するイベントが予定されていたが、来日が中止となった。
OpenAIの高度AIでソフトバンクの脆弱性を1万件発見 孫正義氏「大変な危機」 日本の重要インフラ企業へ診断サービス提供
ソフトバンクグループは6月16日、米OpenAIの高度なAI技術を活用したサイバーセキュリティ対策サービス「Patching as a Service」を発表した。OpenAIのサイバーセキュリティに特化したAI「GPT-5.5 Cyber」などの技術とソフトバンクの運用ノウハ…
AI時代の“シゴデキ”会社員はどこに座る? データ活用が変えた理想のオフィス
イトーキが本社オフィスを4年ぶりに刷新した。従業員の能力発揮度と位置情報の分析で「成果が出る席」を特定。各種センサーやAIも活用し、分析結果を反映したフロアレイアウトを実現したという。

Claude「Fable 5」が3日で停止 Anthropicが主張する“米国政府の誤解”の正体
米国政府の指令に従い、Fable 5のサービス提供を停止したAnthropic。同社は指令について「政府の誤解に基づくもの」と主張しているが、その誤解とは具体的にどのようなものなのか。
海外メディア10件
TechCrunch AI (英語)

Anthropic’s latest feud with the Trump admin may actually help it, sales data suggests
Anthropic's popularity with business users is growing so well that the latest beef with the government might actually boost it, data from R…

SpaceX valuation balloons to $2.6T, briefly passes Amazon
SpaceX's valuation has increased by $1 trillion since its shares started trading on Friday.

Android 17 launches with new multitasking tools as Google expands Gemini features
Google has released Android 17 and Wear OS 7, introducing new multitasking features, parental controls, security tools, and smartwatch upgr…

Sixty percent of US consumers say ‘AI’ in brand messaging is a turnoff, survey finds
WordPress VIP’s latest survey suggests consumers are wary of AI-generated answers even as companies increasingly view AI search as an impor…

DOJ claims xAI’s unpermitted gas turbines are a matter of ‘national, economic, and energy security’
The Justice department says the Pentagon needs xAI to keep using its unpermitted gas turbines.

Plaud says its software business topped $100M in ARR after shipping over 2M AI notetakers
Plaud is trying to make a mark in a crowded market full of AI-powered meeting notetakers.

Robinhood’s note on 10% layoffs shows blaming AI isn’t cutting it
Unlike many of his tech industry peers who have cut thousands of jobs citing the need to restructure to make the most of AI, Robinhood's CE…

Probably raises $9M to build a more reliable kind of AI
Probably wants to prevent hallucinations and factual errors from reaching users, and achieve accuracy on par with deterministic systems.

ChatGPT’s market share slips below 50% for first time
The chatbot still remains the most popular AI assistant worldwide with over 1.1 billion monthly users, followed by Gemini with 662 million…

Malaysia’s AI agent-powered messaging app Respond.io raises $62.5M, eyes acquisitions
Respond.io, one of Malaysia's startups to watch, uses AI agents to handle high volumes of customer inquiries and charges per convo, not per…
公式ブログ1件
Google DeepMind (英語)

Unlocking UK house-building with AI-accelerated planning
UK government partners with Google DeepMind to build a new AI-powered prototype aimed at faster housing decisions.
論文342件
arXiv cs.AI (英語)
並列サンプリングを超えて: エージェント検索のための多様なクエリ初期化
エージェント検索のテスト時間のスケーリングでは、通常、深さ (つまり、軌道ごとのターンとトークンの数) または幅 (つまり、より多くの並列ロールアウト) が増加します。ここでは幅のスケーリングに焦点を当て、標準の並列サンプリングが収益逓減を生み出すことを示し、これを追跡して最初のターンでの冗長性をクエリします。モデルがロールアウト間で同様の最初のクエリを発行すると、スレッドは重複する証拠を取得し、後続のターンはこの共有取得に基づいて条件付けされます。私たちは、最初のターンでトレーニング不要の介入である DivInit を使用して、この制限に対処します。 DivInit は、k 個の独立した最初のクエリをサンプリングするのではなく、単一の呼び出しから n 個の候補を抽出し、k < n 個の多様なシードを選択し、それらを並列トラジェクトリとして実行します。 5 つのオープンウェイト モデルと 8 つのベンチマークにわたって、DivInit は標準の並列サンプリングよりも一貫して向上しており、一致したコンピューティングでのマルチホップ QA で平均 5 ~ 7 ポイントの向上が見られます。コードは https://github.com/cxcscmu/diverse-query-initialization で入手できます
原文 (English)
Beyond Parallel Sampling: Diverse Query Initialization for Agentic Search
Test-time scaling for agentic search typically increases depth (i.e., more turns and tokens per trajectory) or breadth (i.e., more parallel rollouts). Here we focus on breadth scaling, showing that standard parallel sampling yields diminishing returns, tracing this to query redundancy at the first turn. When models issue similar first queries across rollouts, the threads retrieve overlapping evidence, and subsequent turns are conditioned on this shared retrieval. We address this limitation with DivInit, a training-free intervention at the first turn. Rather than sampling k independent first queries, DivInit draws n candidates from a single call, picks k < n diverse seeds, and runs them as parallel trajectories. Across five open-weight models and eight benchmarks, DivInit consistently improves over standard parallel sampling, with average gains of five to seven points on multi-hop QA at matched compute. Code available at https://github.com/cxcscmu/diverse-query-initialization
ルールが学習されるとき: 訴訟検索のための自己進化エージェント
法律用語の複雑さと、クエリと関連する訴訟の間の正確な語彙の調整の必要性により、訴訟事件の検索は依然として困難です。高密度検索モデルは顕著な進歩を遂げていますが、実証研究では、BM25 がこの領域の強力なベースラインとして機能し続けていることが示されています。これは、パラメーターのトレーニングなしで BM25 を強化する、ルール駆動型のクエリ書き換えのための自己進化するフレームワークを提案する動機となっています。このフレームワークは、LLM ベースのエージェントに自動評価環境を装備し、書き換えルールを繰り返し作成し、ルールの組み合わせに対する検証実験を計画し、履歴フィードバックに基づいて無効なルールを削除できるようにします。中国の訴訟検索ベンチマーク LeCaRD-v2 で手法を評価します。実験結果は、提案されたフレームワークが、特に大容量コア LLM を搭載した場合に、人間が設計したルールや貪欲なルール選択などの非進化ベースラインよりも優れたパフォーマンスを発揮することを示しています。また、自己進化のメカニズムを解明するための詳細な解析も行っています。私たちの調査結果は、以前の実験結果を活用する LLM の機能と、ルールの削除に関する固有の知識が、自己進化を介してルール セットを改良する上で重要な役割を果たしていることを明らかにしています。
原文 (English)
When Rules Learn: A Self-Evolving Agent for Legal Case Retrieval
Legal case retrieval remains challenging due to the complexity of legal language and the need for precise lexical alignment between queries and relevant cases. Although dense retrieval models have achieved notable progress, empirical studies show that BM25 continues to serve as a strong baseline in this domain. It motivates us to propose a self-evolving framework for rule-driven query rewriting that enhances BM25 without any parameter training. The framework equips an LLM-based agent with an automatic evaluation environment, enabling it to iteratively create rewriting rules, plan validation experiments over rule combinations, and eliminate ineffective rules based on historical feedbacks. We evaluate our method on the Chinese legal case retrieval benchmark LeCaRD-v2. Experimental results demonstrate that the proposed framework outperforms non-evolutionary baselines, including human-designed rules and greedy rule selection, particularly when powered by a highcapacity core LLM. We also conduct detailed analyses to investigate the mechanisms underlying self-evolution. Our findings reveal that LLM's capabilities to leverage previous experimental results and its intrinsic knowledge of rule elimination play critical roles in refining the rule set via self-evolution.
SkillChain-Gym: 中断時の再スキルを意識した生産在庫管理のベンチマーク
生産計画では、従業員の能力を意思決定変数として扱う必要がますます高まっています。スキルが維持されないと認定資格が失効し、新製品には現在の従業員が保有していないスキルが必要になり、生産に必要な労働時間と同じ労働時間を奪い合う再スキル教育が必要になります。既存の運用ベンチマークは通常、労働を外生的なものとして扱いますが、スキルと学習を備えた要員計画モデルが再利用可能なテストベッドとしてリリースされることはほとんどありません。 SkillChain-Gym は、再スキルを意識した生産在庫管理のベンチマーク仕様です。これは、定型化された労働者のスキル状態のダイナミクス、ハードしきい値の認証、忘れ、生産と同じ労働者あたりの時間予算によって制約される、容量を消費するトレーニング アクションを備えた単一サイト環境です。このベンチマークには、シード制御による中断シナリオ、予測診断を備えた 3 つの実現可能性モード、決定論的リプレイ、および運用、回復力、機能拡張、トレーニング アクセスの分散をカバーするメトリクスが含まれています。当社では、一対の統計テストを使用して、60 シフト期間にわたる予算バリアントを使用して、生産専用、事後対応適応型、注水適応型、および静的保険ポリシーを評価します。結果はランキングではなく体制に依存します。トレーニング可能なポリシーは実稼働のみのベースラインを支配しており、中断がなくてもメンテナンス トレーニングが必要です。トレーニング可能なクラスの中で、ボトルネックが予測で明らかな場合はアダプティブ トレーニングが役立ちます。一方、リーン静的クロストレーニング プランは、関連するスキルの偶発的な事態を構造がエンコードした意図的に有利な比較子であり、予期せぬショックや欠勤の際に強力な保険として機能します。キャパシティ スラックと忘却率が、これらのレジーム間の境界を決定します。制度全体を支配する保険クラスはなく、スキル保険をいつ購入するか、いつ対応するかを決定する予測主導型の管理者を動機づけます。
原文 (English)
SkillChain-Gym: A Benchmark for Reskilling-Aware Production-Inventory Control under Disruptions
Production planning increasingly has to treat workforce capability as a decision variable: certifications lapse when skills are not maintained, new products require skills the current workforce does not hold, and reskilling competes for the same worker hours needed for production. Existing operations benchmarks usually treat labor as exogenous, while workforce-planning models with skills and learning are rarely released as reusable testbeds. We introduce SkillChain-Gym, a benchmark specification for reskilling-aware production-inventory control: a single-site environment with stylized worker skill-state dynamics, hard threshold certification, forgetting, and capacity-consuming training actions constrained by the same per-worker time budget as production. The benchmark includes seed-controlled disruption scenarios, three feasibility modes with projection diagnostics, deterministic replay, and metrics covering operations, resilience, capability growth, and training-access distribution. We evaluate production-only, reactive adaptive, water-filling adaptive, and static-insurance policies with budget variants over 60-shift horizons with paired statistical tests. The results are regime-dependent rather than a ranking. Training-capable policies dominate the production-only baseline, and maintenance training is necessary under forgetting even without disruptions. Among training-capable classes, adaptive training helps when bottlenecks are visible in the forecast, while a lean static cross-training plan, a deliberately favorable comparator whose structure encodes relevant skill contingencies, acts as strong insurance under surprise shocks and absenteeism. Capacity slack and the forgetting rate govern the boundary between these regimes. No policy class dominates across regimes, motivating forecast-driven controllers that decide when to buy skill insurance and when to react.
回復力のある製造サプライ チェーンのためのスキル制約モデルの予測制御
スキルに制約のある生産在庫システムでは、明日利用できる資格のある人材の能力は、今日行われるトレーニングの決定に依存します。つまり、生産には認定労働者が必要であり、維持されなければ認定は失われ、トレーニングには現在生産に必要とされているのと同じ希少な労働時間が消費されます。私たちは、閉ループのスキル制約モデル予測コントローラーを研究します。このコントローラーは、生産、在庫、バックログ、トレーニングにわたる有限ホライズンの混合整数プログラムをシフトごとに解決します。このプログラムには、バイナリ予測認定、ハード生産適格性、およびホライズン境界での認定能力ギャップの価格を設定する解釈可能な最終価値が含まれます。再計画の前に、最初の期間のアクションのみが適用されます。合成されたシード制御の SkillChain-Gym シナリオ (発表および予期せぬ新スキル ショック、需要ショック、欠勤、予測および可用性品質モード、能力境界およびトレーニング レートのスイープ、ネガティブ コントロール) について、事前にロックされた構成とペアの統計に基づいて、実稼働のみおよびメンテナンスのみのアブレーション、静的なクロストレーニング保険プラン、および強力な反応性ヒューリスティックに対してコントローラーを評価します。その結果は、優越性ではなく、体制への依存です。どの政策階級も支配しません。予測制御は、スキルや労働のボトルネックがトレーニングを完了するのに十分早い段階で予測できる場合に役立ちます。リーンスタティック保険は、予期せぬショック、需要と生産能力の境界付近、およびショック前のスラックが保険料を安くする場所では、依然として打ち勝つのが難しいです。アトリビューションの削除により、認定の維持、失効した認定の再取得、およびグリーンフィールド スキルの取得が分離されます。適応性自体ではなく、予測可能性が、予測制御がいつ利益をもたらすかを決定します。
原文 (English)
Skill-Constrained Model Predictive Control for Resilient Manufacturing Supply Chains
In skill-constrained production-inventory systems, the qualified human capacity available tomorrow depends on training decisions made today: production requires certified workers, certifications decay unless maintained, and training consumes the same scarce worker hours that production needs now. We study a closed-loop skill-constrained model predictive controller that, at every shift, solves a finite-horizon mixed-integer program over production, inventory, backlog, and training, with binary predicted certification, hard production eligibility, and an interpretable terminal value that prices certified-capacity gaps at the horizon boundary; only the first-period action is applied before replanning. On synthetic, seed-controlled SkillChain-Gym scenarios - announced and surprise new-skill shocks, demand shocks, absenteeism, forecast- and availability-quality modes, capacity-boundary and training-rate sweeps, and negative controls - we evaluate the controller against production-only and maintenance-only ablations, static cross-training insurance plans, and a strong reactive heuristic, under an ex-ante locked configuration and paired statistics. The result is regime dependence, not superiority: no policy class dominates. Predictive control helps when skill or labor bottlenecks are forecastable early enough for training to complete; lean static insurance remains hard to beat under surprise shocks, near the demand-capacity boundary, and wherever pre-shock slack makes insurance cheap. Attribution ablations separate certification maintenance, re-acquisition of lapsed certifications, and greenfield skill acquisition. Forecastability, not adaptivity per se, decides when predictive control pays.
何かから何も生まれない: 言語モデルは 0 を発見できるか?
人工ニューラル ネットワークに基づく AI システムは、人間の数学的知識の限界を押し上げるという目標を持って開発されています。これらのシステムにとって重要な問題は、トレーニング データを超えてどこまで到達できるかということです。数学的発見には、分布外一般化の強力な形式が必要です。真に新しい、そして潜在的に論理的により強力な数学的構造を仮説化する能力。言語能力が人間の認知におけるこのような一般化をサポートしているという仮説が立てられています。この研究では、現代の AI モデルが数学的領域をどのように拡張できるかを検証するためのケーススタディとして単純な算術を使用し、これらのモデルが独立して「ゼロ」の概念を発見できるかどうかを評価します。 (1) GPT-2 サイズの言語モデルは、言語の事前トレーニングに関係なく、テスト時にこの一般化を実行できませんが、(2) モデルは、数十または数百のゼロの例でトレーニングした後に大幅に改善できることを示します。さらに、言語の事前トレーニングによって必要な例の数が約 $50\%$ 削減されることがわかり、言語能力がニューラル モデルにおける数学的発見の足場となることが示されました。
原文 (English)
Nothing from Something: Can a Language Model Discover 0?
AI systems based on artificial neural networks are being developed with aspirations of pushing the boundary of human mathematical knowledge. A key question for these systems is how much they can reach beyond their training data. Mathematical discovery requires a strong form of out of distribution generalization; the ability to hypothesize genuinely new - and potentially logically more powerful - mathematical structures. It has been hypothesized that language abilities support such generalizations in human cognition. In this work, we use simple arithmetic as a case study for examining how modern AI models could expand their mathematical horizons, evaluating whether these models can independently discover the concept of "zero". We show that We show that (1) language models of a GPT-2 size are unable to perform this generalization at test time regardless of language pretraining, but (2) models can improve substantially after training on tens or hundreds of examples of zero. Additionally, we find that language pretraining reduces the number of required examples by approximately $50\%$, showing that language abilities can scaffold mathematical discovery in neural models.
構造的不確実性による LLM 論理推論の一貫性の定量化
大規模な言語モデルは、不安定、矛盾、または一貫してランク付けするのが難しい推論パスを通じて同じ答えに到達する可能性があります。これは、複数ステップの演繹推論で特によく見られる失敗モードです。既存の方法は、主に出力の分散、つまりサンプルされた回答がどれだけ異なるかを測定することによって信頼性を評価しますが、これでは、モデルが競合する推論候補を一貫してランク付けできるかどうかという補完的なシグナルが無視されます。我々は、サンプリングされた推論ソリューションに対する自己選好によって誘発されるランキングの安定性から派生した一貫性を意識したフレームワークである構造的不確実性を提案します。クエリが与えられると、複数の候補解を生成し、モデルに自身の出力の中からペアごとの優先順位を判断するように依頼します。 PageRank を使用した Bradley-Terry モデリングを介して自己選好をランキング分布に集約し、信号を試験全体のランキングの不安定性と試験内の候補の曖昧さという 2 つのエントロピー ベースの要素に分解します。 5 つの LLM と 8 つのベンチマークにわたって、構造信号は分散に対する回答に補完的な情報を提供します。論理的および数学的推論タスクでは、この組み合わせにより信頼性の低いインスタンスの識別が向上しますが、事実の検索では構造信号が均一に向かって崩壊し、推論レベルの一貫性評価が有益でないレジーム境界を診断します。 2 つの要素は精度との関係が異なります。トライアル内の曖昧さは正しさと正の相関があり、複数のもっともらしい解決策が競合する設定と一致します。一方、トライアル全体の不安定性は負の相関があり、推論の信頼性が低いことを示します。構造的不確実性は、普遍的な信頼度の推定値としてではなく、論理的推論の一貫性をレジームに依存して評価するものとして最もよく理解されています。
原文 (English)
Quantifying Consistency in LLM Logical Reasoning via Structural Uncertainty
Large language models can arrive at the same answer through reasoning paths that are unstable, contradictory, or difficult to rank consistently -- a failure mode especially prevalent in multi-step deductive reasoning. Existing methods assess reliability primarily through output dispersion -- measuring how much sampled answers differ -- but this discards a complementary signal: whether the model can consistently rank competing reasoning candidates. We propose structural uncertainty, a consistency-aware framework derived from the stability of self-preference-induced rankings over sampled reasoning solutions. Given a query, we generate multiple candidate solutions and ask the model to judge pairwise preferences among its own outputs. We aggregate self-preferences into ranking distributions via Bradley-Terry modeling with PageRank, and decompose the signal into two entropy-based components: across-trial ranking instability and within-trial candidate ambiguity. Across five LLMs and eight benchmarks, structural signals provide information complementary to answer dispersion: on logical and mathematical reasoning tasks, the combination improves identification of unreliable instances, while on factual retrieval the structural signal collapses toward uniformity, diagnosing a regime boundary where reasoning-level consistency evaluation is uninformative. The two components relate differently to accuracy: within-trial ambiguity correlates positively with correctness -- consistent with settings where multiple plausible solution paths remain competitive -- while across-trial instability correlates negatively, signaling unreliable reasoning. Structural uncertainty is best understood not as a universal confidence estimator, but as a regime-sensitive evaluator of logical reasoning consistency.
MemTrace: 長期記憶で最終的な精度が欠けているものを調査する
LLM エージェントは、セッション全体にわたってユーザーの事実を長期的に記憶することがますます増えています。しかし、そのような記憶は通常、質問行またはエピソードの精度を集計することによって評価されます。このアプローチでは質問行を個別に採点するため、複数の質問が同じ事実を調べている場合でも、条件が変化したときにその事実がどのように動作するかを示すことができません。 MemTrace というベンチマークを紹介します。このベンチマークの測定単位は、個々の質問ではなく、ユーザーに関する単一の入力された事実であるナレッジ ポイントです。 MemTrace は、制御された 3 つの次元に沿って各事実を調査します。つまり、その事実が履歴に表示されたセッションの数によって定義されるメモリ経過時間です。現在の状態、以前の状態、変化の軌跡をカバーする質問タイプ。証拠の状態。現在存在する設定、欠落している設定、および誤った前提によって矛盾している設定をカバーします。 4 つのパラダイムにわたる 13 のメモリ システム構成を評価すると、同様のプールされた精度がさまざまな失敗を隠していることがわかります。事実の現在および以前の状態を回復することは、それがどのように変化したかを追跡することを意味するものではなく、安全な棄権は誤った前提を修正することを意味するものではありません。主要なボトルネックは、証拠の取得ではなく、証拠の使用です。システムに障害が発生した場合でも、証拠は失われた場合の 10 倍の頻度で取得できました。これらの結果は、長期記憶を改善するには、単に保存や検索を増やすだけでなく、入手可能な証拠をより適切に使用する必要があることを示唆しています。
原文 (English)
MemTrace: Probing What Final Accuracy Misses in Long-Term Memory
LLM agents increasingly maintain long-term memory of user facts across sessions. Yet such memory is usually evaluated by aggregating accuracy over question rows or episodes. Because this approach scores question rows independently, even when several questions probe the same fact, it cannot show how that fact behaves as conditions change. We introduce MemTrace, a benchmark whose unit of measurement is the knowledge point: a single typed fact about the user, rather than an individual question. MemTrace probes each fact along three controlled dimensions: memory age, defined by how many sessions ago the fact appeared in the history; question type, covering current state, earlier state, and trajectory of change; and evidence condition, covering present, missing, and contradicted-by-false-premise settings. Evaluating 13 memory-system configurations across four paradigms, we find that similar pooled accuracy hides different failures: recovering a fact's current and earlier states does not imply tracking how it changed, and safe abstention does not imply correcting a false premise. The dominant bottleneck is evidence use, not retrieval: when systems fail, the evidence was retrievable 10 times more often than it was missing. These results suggest that improving long-term memory requires better use of reachable evidence, not simply more storage or retrieval.
SpeechDx: 臨床音声 AI のマルチタスク ベンチマーク
音声は、神経系、運動系、呼吸器系、音声系を同時に関与させることにより、健康状態を知るための独自の有益な窓を提供します。現在の臨床音声 AI 手法は主に、症状に特化した個別の研究を通じて進歩しているため、結果の比較が難しく、一般化の評価が困難になっています。さまざまな健康状態にわたる 12 のデータセットと 27 のタスクにわたる臨床音声 AI の大規模ベンチマークである SpeechDx を紹介します。共有された臨床メカニズム全体での評価を可能にするために、SpeechDx は、概念化、定式化、明瞭化という、中断される音声生成の段階ごとにタスクを構造化します。このベンチマークは、限定されたラベル付きデータを含むタスクを含め、複数のデータセットにわたって同じ健康状態を評価することで一般化をテストし、臨床的に意味のあるパターンとデータセットのアーティファクトを区別します。私たちは、すべてのタスクにわたって、ゼロショット クロスコンディション転送の下で、12 個の最先端のオーディオ エンコーダーを系統的に評価しています。結果は、大規模な音声モデルが最も強力な全体的なベースラインを表し、ドメイン固有のモデルは厳密に一致するタスクでのみパフォーマンスを向上させ、臨床音声環境全体にわたって確実に一般化できる現在の表現はないことを示しています。 SpeechDx は、汎用臨床音声表現に向けた進捗状況を追跡するための共有評価フレームワークを確立します
原文 (English)
SpeechDx: A Multi-Task Benchmark for Clinical Speech AI
Speech offers a uniquely informative window into health by simultaneously engaging neurological, motor, respiratory, and vocal systems. Current clinical speech AI methods have largely progressed through isolated condition-specific studies, making results difficult to compare and generalization difficult to assess. We introduce SpeechDx, a large-scale benchmark for clinical speech AI spanning 12 datasets and 27 tasks across diverse health conditions. To enable evaluation across shared clinical mechanisms, SpeechDx structures tasks by the stage of speech production they disrupt: conceptualization, formulation, and articulation. The benchmark tests generalization by including tasks with limited labeled data and evaluating the same health condition across multiple datasets, distinguishing clinically meaningful patterns from dataset artefacts. We systematically evaluate 12 state-of-the-art audio encoders across all tasks and under zero-shot cross-condition transfer. Results show that large-scale speech models represent the strongest overall baselines, domain-specific models improve performance only on closely matched tasks, and no current representation generalizes reliably across the clinical speech landscape. SpeechDx establishes a shared evaluation framework for tracking progress toward general-purpose clinical speech representations
分散型汎用エージェント ネットワーク: アーキテクチャ、主要なメカニズム、およびプロトタイプ
大規模な言語モデルにより、受動的会話アシスタントから、目標を理解し、アクションを計画し、ツールを呼び出し、複数ステップのタスクを実行できる自律エージェントへの移行が加速されました。ただし、単一エージェントの機能は、ローカル データ、ツールの権限、実行時環境、ガバナンスの境界によって制限されたままです。この論文では、分散型汎用エージェント ネットワークについて研究します。これは、パーソナル デバイス、エッジ ノード、または自律コンピューティング環境に展開された異種エージェントが相互に検出し、信頼を確立し、協力ルールをネゴシエートし、無制限のタスクを実行できるオープン ピアツーピア ネットワークです。私たちは、このようなネットワークは、既存のピアツーピア オーバーレイと従来のマルチエージェント システムを単に組み合わせただけでは実現できないと主張します。従来の P2P ネットワークとは異なり、エージェント ネットワークは、意図、機能、状態、および協力の制約に関するセマンティック宣言を伝播する必要があります。したがって、上位レベルのタスクセマンティクスを下位レベルのネットワーク操作と接続するプロトコル適応層を中心とした階層型アーキテクチャを提案します。このアーキテクチャに基づいて、この論文では、協力者発見のためのセマンティック アナウンスの伝播、協力ガバナンスのための検証可能なアイデンティティとマルチトピック レピュテーション、オープン タスク実行のためのセマンティック勾配メカニズムの設計という 3 つの中核的なメカニズムの問題を特定します。問題ごとに、連続ログによる実体のないゴシップ、MG-EigenTrust レピュテーションによる BAID ベースの ID バインディング、セマンティック アトリビューション フィードバックによって駆動される Stackelberg スタイルのメカニズム生成ループなどの技術的なルートを提示します。さらに、クロストピック偽装共謀攻撃下での BAID スタイルの段階的検証と MG-EigenTrust のメカニズムレベルのシミュレーションのプロトタイプのオーバーヘッド結果を報告します。結果として得られるフレームワークは、オープンで信頼性が高く、スケーラブルなエージェント コラボレーションのためのシステム レベルの基盤を提供します。
原文 (English)
Distributed General-Purpose Agent Networks: Architecture, Key Mechanisms, and Prototypes
Large language models have accelerated the transition from passive conversational assistants to autonomous agents that can understand goals, plan actions, invoke tools, and execute multi-step tasks. Yet the capability of a single agent remains constrained by its local data, tool permissions, runtime environment, and governance boundary. This paper studies distributed general-purpose agent networks: open peer-to-peer networks in which heterogeneous agents deployed on personal devices, edge nodes, or autonomous computing environments can discover one another, establish trust, negotiate cooperation rules, and execute open-ended tasks. We argue that such networks cannot be obtained by simply combining existing peer-to-peer overlays with conventional multi-agent systems. Unlike traditional P2P networks, agent networks must propagate semantic declarations about intentions, capabilities, states, and cooperation constraints. We therefore propose a layered architecture centered on a protocol adaptation layer that connects upper-level task semantics with lower-level network operations. Based on this architecture, the paper identifies three core mechanism problems: semantic announcement propagation for collaborator discovery, verifiable identity and multi-topic reputation for cooperation governance, and semantic-gradient mechanism design for open task execution. For each problem, we present a technical route, including bodyless gossip with sequential logs, BAID-based identity binding with MG-EigenTrust reputation, and a Stackelberg-style mechanism-generation loop driven by semantic attribution feedback. We further report prototype overhead results for BAID-style tiered verification and mechanism-level simulations of MG-EigenTrust under cross-topic disguise-collusion attacks. The resulting framework provides a system-level foundation for open, trustworthy, and scalable agent collaboration.
デジタルツインシミュレーションによる治療反応を最適化した臨床意思決定支援AIシステム
臨床意思決定支援 AI システム (CDSAS) は、厳格な安全上の制約を遵守しながら、進化する患者の状態にリアルタイムで適応する必要があります。臨床上の利点を定量化するための治療効果(TE)推定、治療軌道をシミュレートするための患者デジタルツイン(DT)、および逐次的な意思決定のための強化学習(RL)を統合するオンライン適応フレームワークを紹介します。 AI システムは最初に過去の医療記録に基づいてトレーニングされ、継続的な学習ループで動作します。安全性を確保するために、ルールベースのモジュールがバイタルサインを監視し、禁忌の治療をブロックします。内部モデルに強い不一致がある症例には、臨床医によるレビューのフラグが立てられ、事前トレーニングされた結果モデルを介して実験でシミュレートされます。私たちは、合成臨床シミュレーターと、The Cancer Genome Atlas (TCGA) からの現実世界の卵巣がんデータセットの両方を使用して、フレームワークを検証します。シミュレーション設定と臨床設定の両方で、私たちの方法は、標準的な計算ベースラインと比較して、治療を推奨する際の優れた有効性と安定性を実証しました。さらに、AI システムは低遅延を維持しており、実験的検証では少数の症例でのみ専門家による相談が必要であり、実用化を通じて継続的に改善される個別化医療のための安全で臨床医の監督下にあるツールとしての可能性を示しています。
原文 (English)
Treatment Response Optimized Clinical Decision Support AI System via Digital Twin Simulation
Clinical decision support AI systems (CDSASs) must adapt to evolving patient conditions in real-time while adhering to strict safety constraints. We present an online adaptive framework that integrates Treatment Effect (TE) estimation to quantify clinical benefits, a patient Digital Twin (DT) to simulate treatment trajectories, and Reinforcement Learning (RL) for sequential decision-making. The AI system is initially trained on historical medical records and operates in a continuous learning loop. To ensure safety, a rule-based module monitors vital signs and blocks contraindicated treatments. Cases with strong internal model disagreement are flagged for clinician review, simulated in our experiments via a pre-trained outcome model. We validate our framework using both a synthetic clinical simulator and a real-world ovarian cancer dataset from The Cancer Genome Atlas (TCGA). In both simulated and clinical settings, our method demonstrated superior effectiveness and stability in recommending treatments compared to standard computational baselines. Furthermore, the AI system maintains low latency and requires expert consultation for only a minority of cases in our experimental validation, demonstrating its potential as a safe, clinician-supervised tool for personalized medicine that continuously improves through practical use.
既存の利点: LLM レコメンデーション システムにおけるブランド バイアスと認知操作ダイナミクス
大規模言語モデル (LLM) は、消費者が製品を見つけるための主要な方法になりつつありますが、ブランドがこの新しいチャネルでどのように競争するのかはまだ理解できません。私たちは、3 つの商用 LLM (GPT-4o-mini、Claude Sonnet、Gemini 3 Flash) にわたるスキンケア製品 (消費者が購入前に品質を簡単に判断できず、ブランドの評判に頼らなければならないカテゴリー) を使用した LLM 推奨におけるブランド ダイナミクスを研究し、検索商品の堅牢性チェックを行います。 3 つの実験で次のことがわかりました。(1) すべての製品が同じ仕様の場合、有名ブランドが 100% の確率 (IAI = 10.0) で推奨される条件付き独占ですが、この優位性は競合他社の星評価の優位性が +0.1 つ未満になると消滅します。 (2) 捏造された臨床証拠の主張を含む権威あるマーケティング言語は、各モデルの反応が異なり、+0.17 評価ポイントに等しいバイアス余剰値でこの独占を破ります。 (3) マルチブランドの GEO 競争における社会的ジレンマ: すべてのブランドが同じ最適化戦略を採用すると、ペイオフ プロキシでは個々のペイオフが +0.802 から +0.007 に低下し、参加していないブランドはテストで推奨がゼロになります。私たちの結果は、生成エンジン最適化 (GEO) がセキュリティ リスクとしてだけでなく、市場競争を形成する新たなマーケティング手法としても研究されるべきであることを示唆しています。
原文 (English)
Incumbent Advantage: Brand Bias and Cognitive Manipulation Dynamics in LLM Recommendation Systems
Large language models (LLMs) are becoming a major way for consumers to find products, but we do not yet understand how brands compete in this new channel. We study brand dynamics in LLM recommendations using skincare products -- a category where consumers cannot easily judge quality before buying and must rely on brand reputation -- across three commercial LLMs (GPT-4o-mini, Claude Sonnet, Gemini 3 Flash), with a robustness check on search goods. In three experiments, we find: (1) a Conditional Monopoly where well-known brands get recommended 100% of the time (IAI = 10.0) when all products have the same specifications, but this dominance disappears with less than a +0.1-star rating advantage for a competitor; (2) authority-style marketing language, including fabricated clinical-evidence claims, breaks this monopoly at a Bias Surplus Value equal to +0.17 rating points, with each model responding differently; and (3) a social dilemma in multi-brand GEO competition: when all brands adopt the same optimization strategy, individual payoff falls from +0.802 to +0.007 in our payoff proxy, and non-participating brands receive zero recommendations in our tests. Our results suggest that generative engine optimization (GEO) should be studied not only as a security risk, but also as an emerging marketing practice that shapes market competition.
機械学習された併存疾患指数
従来の併存疾患スコア (Charlson および Elixhauser など) は、リスク調整や患者の層別化に広く使用されていますが、2 つの重要な制限があります。(i) それらは主に死亡率中心であり、他の臨床転帰とうまく一致しません。(ii) 線形でルールに基づいた構造では、非線形で転帰固有のリスク関係を捉えることができません。我々は、学習されたスコアと複数の臨床転帰の間の正規化されたヒルベルト・シュミット独立基準(nHSIC)を最大化することにより、診断コードを単一のスカラーにマッピングする機械学習併存疾患指数(MLCI)を提案します。 MLCI は、リスクと結果の非線形依存性を捉えており、統合された有益な入院レベルの順序付けが複数の結果にわたっていつ達成されるかを特徴づける理論によってサポートされています。複数のベンチマーク電子医療記録 (EHR) データセットに関する実証結果は、MLCI が複数の評価指標全体で強力なベースラインを上回るパフォーマンスを示していることを示しています。
原文 (English)
A Machine-Learned Comorbidity Index
Traditional comorbidity scores (e.g., Charlson and Elixhauser) are widely used for risk adjustment and patient stratification, but they have two key limitations: (i) they are largely mortality-centric and do not align well with other clinical outcomes, and (ii) their linear, rule-based structure cannot capture nonlinear, outcome-specific risk relationships. We propose a Machine-Learned Comorbidity Index (MLCI) that maps diagnosis codes to a single scalar by maximizing the normalized Hilbert-Schmidt Independence Criterion (nHSIC) between the learned score and multiple clinical outcomes. MLCI captures nonlinear risk-outcome dependence and is supported by a theory that characterizes when a unified, informative admission-level ordering can be achieved across outcomes. Empirical results on multiple benchmark electronic health record (EHR) datasets show that MLCI outperforms strong baselines across multiple evaluation metrics.
MapSatisfyBench: 行動に基づいた暗黙的な決定要素による満足度を意識したマップ エージェントのベンチマーク
大規模な言語モデル エージェントは、マップ サービスにますます統合されています。マップ サービスは専門的なタスクの設定ではなく、日常生活のシナリオに組み込まれているため、ユーザーは多くの場合、自分のニーズを非公式に表明し、その結果、多くの暗黙のニーズ、つまりユーザーの満足度にとって重要な暗黙の決定要素を含む、仕様が不十分なクエリが発生します。明確化はこの問題を軽減する効果的な方法ですが、日常のやり取りにおけるユーザーの負担が増大するため、有能なエージェントはまず利用可能な情報ソースからそのような要素を積極的に回収する必要があります。ただし、この能力を評価するのは困難です。最初の課題は、どの暗黙的な決定要素が評価に適しているかを判断することです。要因は、ユーザーの受け入れに影響を及ぼし、エージェントが応答する前に入手可能な情報から回復できる場合にのみ評価可能です。第 2 に、ユーザーの満足度は単一の参照回答では確実に表すことができないため、満足度に関連する要素を客観的かつ定量化可能な評価目標に変換するベンチマークが必要です。これらの課題に対処するために、行動連鎖証拠から完全なユーザー ニーズを再構築し、暗黙的な決定要因を特定し、クエリ前の証拠によってサポートされるもののみを保持する復元識別フィルター フレームワークを提案します。この方法論に基づいて、大規模な現実世界の匿名化されたユーザー データから MapSatisfyBench を構築し、5 次元からグラウンド トゥルースに注釈を付けて、満足度を意識したマップ エージェントのフルチェーン評価を可能にします。実験によると、現在のエージェントは一般に、明示的なタスクの完了に関しては良好なパフォーマンスを発揮しますが、暗黙の決定要素を満たすことや、満足を意識した決定に必要な証拠を積極的に取得することには依然として限界があります。これらの発見により、MapSatisfyBench は、マップ エージェントの評価をタスクの完了から満足度を意識した空間的意思決定に移行するためのベンチマークとして確立されました。
原文 (English)
MapSatisfyBench: Benchmarking Satisfaction-Aware Map Agents through Behavior-Grounded Implicit Decision Factors
Large language model agents are increasingly integrated into map services. Since map services are embedded in everyday-life scenarios rather than professional task settings, users often express their needs informally, resulting in underspecified queries with many unspoken needs, namely, implicit decision factors that are critical for user satisfaction. Although clarification is an effective way to mitigate this issue, it increases user burden in daily interaction, and a capable agent should first proactively recover such factors from available information sources. However, evaluating this ability is challenging. The first challenge is to determine which implicit decision factors are suitable for evaluation. A factor is evaluable only if it affects user acceptance and can be recovered from information available to the agent before it responds. Second, user satisfaction cannot be reliably represented by a single reference answer, requiring a benchmark that converts satisfaction-relevant factors into objective and quantifiable evaluation targets. To address these challenges, we propose a restore-identify-filter framework that reconstructs complete user needs from behavior-chain evidence, identifies implicit decision factors, and retains only those supported by pre-query evidence. Building on this methodology, we construct MapSatisfyBench from large-scale, real-world anonymized user data and annotate ground truth from five dimensions and enables full-chain evaluation of satisfaction-aware map agents. Experiments show that current agents generally perform well on explicit task completion, but remain limited in satisfying implicit decision factors and proactively acquiring the evidence needed for satisfaction-aware decisions. These findings establish MapSatisfyBench as a benchmark for shifting map-agent evaluation from task completion toward satisfaction-aware spatial decision making.
エージェントの軌跡を通じてモデルの動作を分析する
AI エージェントのパフォーマンスは単なるモデリングの問題ではなく、基本的にシステムの問題です。モデルの高度な機能は、エージェント ハーネスを通じて実現されます。したがって、モデルの想定とハーネスの動作の間にギャップがあると、モデルの全機能がエージェントのパフォーマンスに反映されにくくなる可能性があります。私たちはこれを「意図と実行」のギャップ、つまりモデルが意図するものとハーネスが実行するものとの間の不一致、またはその逆として形式化します。私たちは、この意図と実行のギャップを最小限に抑えることが、ツールや実行ループなどのハーネス設計の他の側面と同じくらい重要であると主張します。このハーネス モデルの調整の影響を説明するために、「Simple Strands Agent」(SSA) と呼ばれるシンプルでカスタマイズ可能なハーネスを開発します。 SSA は、さまざまなモデル ファミリ (Claude、Gemini、GPT、Grok、Qwen など) にわたって一般化される大量の共通パターンと、少数のモデル固有の設定を見つけることを目的としています。私たちは 2 つの貢献を行っています。(i) 一般的なエージェント ベンチマーク (SWE-Pro、SWE-Verified、および Terminal-Bench-2) でさまざまなモデル プロバイダー ファミリによって報告された $\textbf{pass@1}$ のパフォーマンスを再現または改善すること、(ii) $\textbf{SSA によって生成された 138,000 の軌跡の分析}$ に基づいて、比較的均等になる傾向にある $\texttt{pass@1}$ の数値を超えて検討することです。フロンティアモデル全体で。エージェントの軌跡をコード状態空間で表すことにより、問題解決動作におけるモデルレベルの違いが観察されます。編集頻度、テスト アクティビティ、フェーズ移行などのより詳細なメトリクスにより、個々のモデルが自律的な問題解決のさまざまな段階に労力をどのように割り当てているかが明らかになります。
原文 (English)
Dissecting model behavior through agent trajectories
AI agent performance is not just a modeling problem, it is fundamentally a systems problem. The advanced capabilities of models are realized through agent harnesses. Therefore, a gap between model assumptions and harness behavior can easily prevent the model's full capabilities from translating into agent performance. We formalize this as the `intent-execution' gap: the mismatch between what the model intends and what the harness executes, and vice versa. We argue that minimizing this intent-execution gap is as important as other aspects of harness design such as tools and execution loops. To illustrate the impact of this harness-model alignment, we develop a simple and customizable harness called `Simple Strands Agent' (SSA). SSA aims to find the bulk of common patterns which generalize across different model families (such as Claude, Gemini, GPT, Grok, Qwen), as well as a small number of model-specific preferences. We make two contributions: (i) we $\textbf{reproduce or improve on the pass@1}$ performance reported by diverse model-provider families on popular agentic benchmarks (SWE-Pro, SWE-Verified and Terminal-Bench-2), and (ii) building on an $\textbf{analysis of 138k trajectories generated by SSA}$, we look beyond the $\texttt{pass@1}$ numbers which tend to be relatively even across frontier models. By representing agent trajectories in code state-spaces, we observe model-level differences in problem-solving behavior. Finer-grained metrics such as edit frequency, testing activity, and phase-transitions reveal how individual models allocate effort across different stages of autonomous problem solving.
LLMはCEOになれるのでしょうか?マルチロール エージェント シミュレーションによる戦略的リソース再割り当てのベンチマーク
大規模言語モデル (LLM) の意思決定能力を評価することは、ますます研究の優先事項となっていますが、既存のベンチマークは、定型化された環境における推論、知識の検索、経済合理性などの孤立した認知タスクに焦点を当てています。これらの評価は、情報の非対称性、組織上の制約、時間的な依存関係の下で専門の利害関係者からの矛盾する推奨事項を統合するという、実際の経営陣の意思決定の決定的な課題を見落としています。 \textsc{CEO-Bench} は、CEO レベルの戦略的リソースの再配分、つまりマルチラウンドで制約の多い組織環境において事業単位間で資本を振り向けるプロセスに関して LLM を評価するマルチエージェント ベンチマークです。 \textsc{CEO-Bench} では、LLM エージェントは、役割が条件付けされた 4 人の経営幹部アドバイザー (CFO、CTO、COO、CMO) から相反するアドバイスを受け取り、それぞれがプライベート シグナルと異なる優先順位を持ち、これらを統合して、役割の統合、条件付きの大胆さ、履歴に配慮した判断、計画の有効性の 4 つの側面に沿って評価される具体的な割り当て計画を作成する必要があります。 13 のシナリオでの 5 つのフロンティア モデルにわたる実験では、すべてのモデルが高い構造的妥当性を達成しているものの、戦略的調整 (最も困難な機能層) では大きく乖離していることが明らかになりました。私たちは、単一アドバイザーの捕捉、曖昧さの下での保守的なデフォルト、歴史的記憶喪失などの体系的な失敗モードを特定し、構造的統合と大胆さのトレードオフを明らかにします。つまり、相反する視点に深く関与するモデルは、決定的な行動を生み出すことが少なくなる傾向があります。これらの調査結果は、組織の意思決定者としての LLM の現在の能力の境界を明らかにし、将来の AI 支援実行システムの設計に情報を与えます。
原文 (English)
Can LLMs Be CEOs? Benchmarking Strategic Resource Reallocation with Multi-Role Agent Simulation
Evaluating the decision-making capabilities of large language models (LLMs) is a growing research priority, yet existing benchmarks focus on isolated cognitive tasks such as reasoning, knowledge retrieval, and economic rationality in stylized settings. These evaluations overlook the defining challenge of real executive decision-making: integrating conflicting recommendations from specialized stakeholders under information asymmetry, organizational constraints, and temporal dependencies. We introduce \textsc{CEO-Bench}, a multi-agent benchmark that evaluates LLMs on CEO-level strategic resource reallocation -- the process of redirecting capital across business units in a multi-round, constraint-rich organizational environment. In \textsc{CEO-Bench}, LLM agents receive conflicting advice from four role-conditioned C-suite advisors (CFO, CTO, COO, CMO), each with private signals and distinct priorities, and must synthesize these into a concrete allocation plan evaluated along four dimensions: role integration, conditional boldness, history-sensitive judgment, and plan validity. Experiments across five frontier models on 13 scenarios reveal that all models achieve high structural validity but diverge sharply on strategic calibration -- the hardest capability layer. We identify systematic failure modes including single-advisor capture, conservative default under ambiguity, and historical amnesia, and uncover a structural integration-boldness tradeoff: models that engage more deeply with conflicting perspectives tend to produce less decisive action. These findings delineate the current capability boundary of LLMs as organizational decision-makers and inform the design of future AI-assisted executive systems.
教育における裁判官としての LLM: カリキュラムに基づいた採点パイプライン
生成 AI と大規模言語モデル (LLM) は、質問生成と自動評価にますます適用されています。ただし、一か八かの試験に備えて LLM を導入するには、迅速なエンジニアリング以上のものが必要です。教育当局が発行する認可されたカリキュラム成果物や採点ガイドラインにモデルの出力を体系的に根付かせるソフトウェア パイプラインが必要です。このペーパーでは、大学入学のための試験準備をサポートするために、業界パートナーと共同開発された、質問レベルの採点のためのカリキュラムに基づいた構成可能な LLM-as-Judge パイプラインについて説明します。パイプラインは、関連するトピック、サブトピック、質問の認知的要求を特定し、LLM の判断をサポートするために検証可能で承認されたコンテキストを組み立てます。カリキュラムの意図は、規定された動詞と結果、パフォーマンスバンド記述子、用語集の定義、採点ガイドラインの原則など、具体的なシラバス成果物を通じて運用されます。段階的な LLM ワークフローを使用して、最初に質問固有のルーブリックを生成し、構造化されたパフォーマンスの期待値を取得し、次に学生の回答に点数を割り当てるために使用される採点基準を導出し、評価します。この設計により、一貫性、透明性、および公式マーキング慣行との整合性が向上します。予備評価では、提案されている LLM-as-Judge パイプラインが人間の家庭教師と同等の採点結果を提供すると同時に、認可されたカリキュラムの成果物や採点基準により追跡可能な正当化をもたらすことが示されています。このパイプラインはオンライン調査プラットフォームにも統合されており、初期の導入データから運用上の使用状況や手動によるオーバーライドに関する初期の洞察が得られます。
原文 (English)
LLM-as-Judge in Education: A Curriculum-Grounded Marking Pipeline
Generative AI and large language models (LLMs) are increasingly applied to question generation and automated assessment. However, deploying LLMs in preparation for high-stakes exams requires more than prompt engineering; it demands software pipelines that systematically ground model outputs in authorised curriculum artefacts and marking guidelines issued by education authorities. This paper presents a curriculum-grounded, configurable LLM-as-Judge pipeline for question-level marking, co-developed with an industrial partner, to support exam preparation for university admission. The pipeline identifies the relevant topics, subtopics, and cognitive demand of a question, and assembles verifiable and authorised context to support LLM judgement. Curriculum intent is operationalised through concrete syllabus artefacts, including prescribed verbs and outcomes, performance band descriptors, glossary definitions, and marking-guideline principles. A staged LLM workflow is employed to first generate question-specific rubrics, capturing structured expectations of performance, and then derive and evaluate marking criteria used to allocate marks to student responses. This design improves consistency, transparency, and alignment with official marking practices. Preliminary evaluation shows that the proposed LLM-as-Judge pipeline delivers marking outcomes comparable to human tutors, while yielding justifications that are more traceable to authorised curriculum artefacts and marking standards. The pipeline has also been integrated into an online study platform, where early deployment data provide initial insights into operational usage and manual overrides.
SEAGym: 自己進化する LLM エージェントの評価環境
自己進化する LLM ベースのエージェントは、主にエージェント ハーネス (プロンプト、メモリ、ツール、ミドルウェア、ランタイム状態、モデルとツールの対話ループなどの基本モデルを中心とした構造化された実行層) を変更することによって改善されます。既存の評価では、多くの場合、このプロセスが個別のタスク スコアまたは単一の連続曲線に縮小され、更新によって再利用可能な改善がもたらされるのか、最近のタスクに過剰適合するのか、コストが増加するのか、古い動作に害を及ぼすのかが不明瞭になります。トレーニング、検証、テスト、再生、コスト記録にわたるエージェント ハーネスの更新を測定するための評価環境である SEAGym を紹介します。 SEAGym は、Harbor 互換ベンチマークを、トレイン バッチ、凍結された更新検証、保持された ID および OOD 転送ビュー、再生診断、および保存されたスナップショットとメトリック レコードを備えた動的な自己進化タスク ソースに変換します。 Terminal-Bench 2.0 および HLE 上で SEAGym をインスタンス化し、共有エポック/バッチ プロトコルの下で ACE、TF-GRPO、および AHE を比較します。結果は、これらの評価ビューが進化プロセスに関する補完的なシグナルを提供することを示しています。つまり、頻繁な更新では持続的なパフォーマンスが向上しない可能性があり、有用な中間スナップショットが後で崩壊する可能性があり、ソースの多様性とモデル バックエンドがハーネスの信頼性に影響を与える可能性があります。
原文 (English)
SEAGym: An Evaluation Environment for Self-Evolving LLM Agents
Self-evolving LLM-based agents improve mainly by changing their agent harness: the structured execution layer around a base model, including prompts, memory, tools, middleware, runtime state, and the model-tool interaction loop. Existing evaluations often reduce this process to isolated task scores or a single sequential curve, obscuring whether an update produces reusable improvement, overfits recent tasks, increases cost, or harms older behavior. We introduce SEAGym, an evaluation environment for measuring agent harness updates across training, validation, test, replay, and cost records. SEAGym turns Harbor-compatible benchmarks into dynamic self-evolution task sources with train batches, frozen update-validation, held-out ID and OOD transfer views, replay diagnostics, and saved snapshot and metric records. Instantiating SEAGym on Terminal-Bench 2.0 and HLE, we compare ACE, TF-GRPO, and AHE under a shared epoch/batch protocol. The results show that these evaluation views provide complementary signals about the evolution process: frequent updates may fail to improve held-out performance, useful intermediate snapshots may collapse later, and source diversity and model backend can affect harness reliability.
DeepInsight: 物理 AI スタック全体にわたる統合評価インフラストラクチャ
物理 AI スタックの評価には、単一の基礎モデルのデコード ステップから全身制御の数千の物理ティックまで、モダリティ、報酬セマンティクス、リソース プロファイルが直交して変化する、3 桁以上異なるオペレーターが含まれます。この範囲に及ぶ既存のフレームワークはないため、現在スタックは、ランタイムもスコアリングも共有しない個別のハーネスをつなぎ合わせて評価されており、各セグメントのローカル妥当性は維持されますが、クロスレイヤー回帰を診断するために必要な共有アイデンティティは失われます。ここでは、単一のランタイムでこの全領域にサービスを提供する評価インフラストラクチャである DeepInsight を紹介します。レジームを均質化するのではなく、タスク、リソース、結果という 3 つの狭い抽象化の背後にある異質性を維持します。各抽象化は、すべてのサブシステムによって共有される 1 つの不変式として実現されます。つまり、1 つのエピソード ドライバー、すべての高価なバックエンド (LLM 推論とサンドボックス化されたランタイムは同様) によって実装される 1 つのリソース ハンドル プロトコル、およびすべてのイベントが書き込まれる 1 つのトレース ID スキームです。この単一セットの不変条件は、実体化されたヒューマノイド スタックの 3 つのレイヤーすべてにわたって運用環境にデプロイされ、主に構成によって新しいベンチマークをオンボードします。成熟したピア オーケストレーターが存在する場所 (基盤モデルの末端) では、公開されたリファレンスとピア フレームワークの読み取り値を独自のスプレッド内で再現し、単一ノード上で同じスイートをより高速に実行し、ノード間でほぼ線形にスケールします。その特徴的な戻りは診断用です。すべてのレイヤーが 1 つの共有トレースに書き込むため、あるレイヤーで始まり別のレイヤーで表面化する回帰は、そのトレース上で局所化されたままになります。これは、セグメントごとのハーネスのフェデレーションでは再現できない層間の利益です。
原文 (English)
DeepInsight: A Unified Evaluation Infrastructure Across the Physical AI Stack
Evaluating a Physical AI stack spans operators that differ by more than three orders of magnitude -- from a single foundation-model decoding step to thousands of physics ticks of whole-body control -- varying orthogonally in modality, reward semantics, and resource profile. No existing framework spans this range, so the stack is evaluated today by stitching together separate harnesses that share neither runtime nor scoring, preserving each segment's local validity but losing the shared identity needed to diagnose cross-layer regressions. We present DeepInsight, an evaluation infrastructure that serves this full spectrum on a single runtime. Rather than homogenize the regimes, it preserves their heterogeneity behind three narrow abstractions -- task, resource, and result -- each realized as one invariant shared by every subsystem: one episode driver, one resource-handle protocol implemented by every expensive backend (LLM inference and sandboxed runtimes alike), and one trace identity scheme under which every event is written. Deployed in production across all three layers of an embodied humanoid stack, this single set of invariants onboards new benchmarks largely by configuration. Where mature peer orchestrators exist -- at the foundation-model end -- it reproduces published references and peer-framework readings within their own spread, runs the same suites faster on a single node, and scales near-linearly across nodes. Its distinctive return is diagnostic: because every layer writes into one shared trace, a regression that begins in one layer and surfaces in another stays localizable on that trace -- a cross-layer payoff no federation of per-segment harnesses can reproduce.
基礎モデルの調整されたワークフローによる代理歩行者保護設計
AI 主導のエンジニアリング ワークフローは、衝突安全設計において特に課題に直面しています。空気力学とは異なり、衝突イベントには高度に非線形の接触力学、材料の非線形性、離散状態の遷移が含まれており、データ主導のサロゲート モデルでは捉えるのが困難です。私たちの知る限り、最初の基礎モデルを紹介します。これは、歩行者保護のための代理支援探索を可能にし、CAE シミュレーションあたりの評価時間を数時間から数秒に短縮する、衝突安全設計のための調整されたワークフローです。このワークフローには 4 つのコンポーネントが統合されています。(1) CAE 衝突シミュレーションでトレーニングされたサロゲートは、設計パラメータから歩行者の脚傷害メトリクスを予測し、平均 $R^2=0.87$ を達成し、分布のない等角予測区間を提供します。 (2) ユーザー指定の制約の下で多様な実現可能なパラメータセットを発見するための多目的進化的探索 (NSGA-II)。 (3) トポロジーを保持する 3D 形状にパラメータをマッピングする、モーフィングベースのジオメトリ ジェネレーター。 (4) LLM がワークフローを調整する自然言語インターフェイスと、生成された設計のセマンティック比較をサポートするビジョン言語モデル。自動車のフロントバンパーのケーススタディでは、このワークフローは 1 回の調査から 35 の異なる安全準拠の代替品を生成します。このプロセスは、従来の CAE 反復では数週間を要します。これらの結果は、基礎モデルが ML サロゲートと物理ベースのシミュレーションの間の統合レイヤーとして機能し、安全性が重要なエンジニアリング領域に AI 機能をもたらすのに役立つことを示唆しています。
原文 (English)
Surrogate Assisted Pedestrian Protection Design via a Foundation Model Orchestrated Workflow
AI-driven engineering workflows face particular challenges in crash safety design: unlike aerodynamics, crash events involve highly nonlinear contact dynamics, material nonlinearity, and discrete state transitions that are difficult to capture with data-driven surrogate models. To the best of our knowledge, we present the first foundation model--orchestrated workflow for crash safety design that enables surrogate-assisted exploration for pedestrian protection, reducing evaluation time from hours per CAE simulation to seconds. The workflow integrates four components: (1) a surrogate trained on CAE crash simulations to predict pedestrian leg injury metrics from design parameters, achieving an average $R^2=0.87$ and providing distribution-free conformal prediction intervals; (2) multiobjective evolutionary search (NSGA-II) to discover diverse feasible parameter sets under user-specified constraints; (3) a morphing-based geometry generator that maps parameters to topology-preserving 3D shapes; and (4) a natural-language interface in which an LLM orchestrates the workflow and a vision--language model supports semantic comparison of generated designs. In an automotive front-bumper case study, the workflow produces 35 distinct safety-compliant alternatives from a single exploration, a process that would require weeks with conventional CAE iteration. These results suggest that foundation models can serve as integration layers between ML surrogates and physics-based simulation, helping bring AI capabilities to safety-critical engineering domains.
フィードバック ループを閉じる: 言語強化学習における経験の抽出から洞察のガバナンスまで
トレーニング不要の言語強化学習により、LLM エージェントは、経験から言語ルールを抽出してコンテキストとして注入することで、世界のフィードバック (動的なタスクの結果、市場収益、需要予測などの客観的なシグナル) から学習し、パラメーターを変更せずにエージェントの行動を更新できます。しかし、非定常環境では、これらのエージェントは保持と忘却のジレンマに直面します。つまり、古い洞察を保持すると否定的な伝達が発生し、その一方で、状態が再発したときに洞察を破棄すると壊滅的な忘却が引き起こされます。私たちは、このジレンマを乗り越えるための 4 つの要件 (結果主導型評価、永続的な構造化証拠、非単調な知識ライフサイクル、構成的ガバナンス) を特定し、既存の手法が経験の抽出に多額の投資を行っている一方、洞察ガバナンスへの投資が不十分であることを示します。私たちは、ガバナンスのギャップを埋めるフィードバック主導のキュレーション ループによって接続された 3 層のアーキテクチャ (ルール、証拠、スキル) を提案します。ルールは世界の結果から抽出された経験をキャプチャします。証拠ログはエピソード全体にわたる各ルールの信頼性を追跡します。どのルールを適用するか、紛争を解決する方法、いつ棄権するかはスキルによって決まります。世界のフィードバックが自然に豊富で、ノイズが多く、非定常であるケーススタディとしての財務予測について、キュレーションループが存在するかどうかに応じて、同じ蓄積された経験がゼロショットベースラインを下回るパフォーマンスを低下させるか、精度とリスク調整後のリターンを劇的に向上させることを示します。
原文 (English)
Closing the Feedback Loop: From Experience Extraction to Insight Governance in Verbal Reinforcement Learning
Training-free verbal reinforcement learning enables LLM agents to learn from world feedback -- objective signals such as dynamic task outcomes, market returns, or demand forecasts -- by extracting verbal rules from experience and injecting them as context, updating the agent's behavior without parameter changes. However, in non-stationary environments these agents face a retention-forgetting dilemma: retaining stale insights causes negative transfer, while discarding them causes catastrophic forgetting when conditions recur. We identify four requirements for navigating this dilemma -- outcome-driven evaluation, persistent structured evidence, non-monotonic knowledge lifecycle, and compositional governance -- and show that existing methods invest heavily in experience extraction while underinvesting in insight governance. We propose a three-layer architecture -- rules, evidence, and skills -- connected by a feedback-driven curation loop that closes the governance gap. Rules capture distilled experience from world outcomes; evidence logs track each rule's reliability across episodes; skills govern which rules to apply, how to resolve conflicts, and when to abstain. On financial forecasting as a case study, where world feedback is naturally abundant, noisy, and non-stationary, we show that the same accumulated experience either degrades performance below the zero-shot baseline or dramatically improves accuracy and risk-adjusted returns, depending on whether the curation loop is present.
Brick-DICL: 自動化されたブリック スキーマ分類のための動的インコンテキスト学習
ビル管理システム (BMS) は、現代のビルのエネルギー効率と運用パフォーマンスを最適化するために不可欠です。しかし、さまざまなメーカーの BMS ポイント間での標準化が欠如しているため、統合とデータの利用に大きな障壁が生じています。 Brick スキーマはシステム構築のための標準化されたオントロジーを提供しますが、BMS ポイントを適切な Brick クラスにマッピングするには、(i) 膨大な数の Brick クラス (最新バージョンでは 936)、(ii) 大規模言語モデル (LLM) における限られたドメイン固有の知識、(iii) 検証に必要な多大な手作業の作業という 3 つの重大な課題があります。これらの課題に対処するために、私たちは、自動化されたブリック スキーマ分類のための 2 段階の動的インコンテキスト学習フレームワークである Brick-DICL を提案します。 Brick-DICL は、LLM のドメイン知識を強化するために関連する例を取得するメタデータ-RAG と、大きな分類空間に対応するために潜在的なブリック クラスを絞り込むクラス-RAG の 2 つの主要コンポーネントで構成されます。さらに、複数のモデルにわたる予測を比較するマルチ LLM フィルタリング メカニズムを実装し、人間によるレビューのために信頼性の低い分類にフラグを立てます。その結果: (i) 一般: Brick-DICL は、メーカーやメタデータ形式に関係なく、あらゆる建物管理システムに適用できます。 (ii) 斬新かつ強力: ブリック スキーマ分類に対する最初の動的インコンテキスト学習アプローチとして、Brick-DICL はデータセットの構築において分類精度の大幅な向上を実現し、既存の手法を上回ります。 (iii) 効率的: 当社のマルチ LLM フィルタリング戦略は手動による検証作業を軽減し、迅速なデジタル ビルディングのオンボーディングを可能にします。広範な実験により、多様な建物データセットにわたる Brick-DICL の有効性が実証され、標準化された相互運用可能な建物管理システムへの道が加速されます。
原文 (English)
Brick-DICL: Dynamic In-Context Learning for Automated Brick Schema Classification
Building Management Systems (BMS) are essential for optimizing energy efficiency and operational performance in modern buildings. However, the lack of standardization across BMS points from different manufacturers creates significant barriers to integration and data utilization. While the Brick schema offers a standardized ontology for building systems, mapping BMS points to appropriate Brick classes presents three critical challenges: (i) the extensive number of Brick classes (936 in the latest version), (ii) limited domain-specific knowledge in large language models (LLMs), and (iii) substantial manual effort required for verification. To address these challenges, we propose Brick-DICL, a two-stage dynamic in-context learning framework for automated Brick schema classification. Brick-DICL consists of two primary components: metadata-RAG, which retrieves relevant examples to enhance LLMs' domain knowledge, and class-RAG, which narrows down potential Brick classes to address the large classification space. Additionally, we implement a multi-LLM filtering mechanism that compares predictions across multiple models, flagging low-confidence classifications for human review. As a result: (i) General: Brick-DICL is applicable to any building management system regardless of manufacturer or metadata format; (ii) Novel and Powerful: as the first dynamic in-context learning approach for Brick schema classification, Brick-DICL achieves significant classification accuracy improvements on building datasets, outperforming existing methods; (iii) Efficient: our multi-LLM filtering strategy reduces manual verification effort, enabling rapid digital building onboarding. Extensive experiments demonstrate Brick-DICL's effectiveness across diverse building datasets, accelerating the path toward standardized, interoperable building management systems.
FinAcumen: 自己進化するエクスペリエンス メモリ ハーネスによる金融マルチモーダル推論
金融マルチモーダル推論では、エージェントが異種の証拠ソース間で数値計算、検索、視覚的解釈、および時間的根拠を調整する必要があります。既存のツールで拡張されたエージェントは、実行の忠実度を向上させますが、エピソード全体にわたってほぼステートレスのままであり、推論戦略と失敗パターンを繰り返し再発見します。一か八かの金融環境では、これにより、信頼性の低いツールのルーティング、ノイズの多い検索、幻覚が起こりやすい推論が発生します。我々は、ツール拡張マルチモーダル推論のための選択的経験記憶を中心とした財務推論エージェント フレームワークである FinAcumen を紹介します。 FinAcumen は、これまでの軌跡から経済的に根拠のある推論経験を蓄積し、成功した戦略と失敗から得られた注意ルールを永続的なメモリ バンクに抽出します。推論中、意味論的な関連性が調整されたしきい値を超えた場合にのみ、取得されたものは条件推論を経験しますが、無関係なメモリはフォールバック メカニズムを通じて明示的に抑制されます。決定論的な金融ツール環境により、数値計算、検索、視覚的デコード、および回答検証がさらに強化されます。4 つの金融マルチモーダル推論ベンチマークにわたって、FinAcumen は、金融特化モデルよりも凍結された 8B ビジョン言語モデルを一貫して改善し、主要な独自の汎用モデルにアプローチします。さらなる分析により、選択的経験の活性化により、検索の不確実性の下で推論の信頼性が向上することが示されています。私たちのコードは https://anonymous.4open.science/r/FinAcumen で匿名で入手できます。
原文 (English)
FinAcumen: Financial Multimodal Reasoning via Self-Evolving Experience Memory Harness
Financial multimodal reasoning requires agents to coordinate numerical computation, retrieval, visual interpretation, and temporal grounding across heterogeneous evidence sources. Existing tool-augmented agents improve execution fidelity, yet remain largely stateless across episodes, repeatedly rediscovering reasoning strategies and failure patterns. In high-stakes financial settings, this leads to unreliable tool routing, noisy retrieval, and hallucination-prone reasoning. We present FinAcumen, a financial reasoning agent framework centered on selective experience memory for tool-augmented multimodal reasoning. FinAcumen accumulates financially grounded reasoning experience from prior trajectories, distilling successful strategies and failure-derived cautionary rules into a persistent memory bank. During inference, retrieved experiences condition reasoning only when semantic relevance exceeds a calibrated threshold, while irrelevant memory is explicitly suppressed through a fallback mechanism. A deterministic financial tool environment further grounds numerical computation, retrieval, visual decoding, and answer verification.Across four financial multimodal reasoning benchmarks, FinAcumen consistently improves a frozen 8B vision-language model over finance-specialized models and approaches leading proprietary general-purpose models. Further analysis shows that selective experience activation improves reasoning reliability under retrieval uncertainty. Our code is anonymously available at https://anonymous.4open.science/r/FinAcumen
ドメインを超えて: 転送可能なインタラクション パターンによる Web スキルの再利用
大規模言語モデル (LLM) Web エージェントは通常、ツール呼び出し元としてデプロイされます。各ターン、モデルは新しいページの観察を読み取り、1 つの構造化されたツール アクションを発行します。すべてのアクションが低レベルのプリミティブである場合、ホライズンは急速に拡大し、ポリシー対応の LLM 完了も拡大し、Mind2Web や WebArena などのベンチマークのレイテンシとコストを支配します。したがって、最近のシステムは、繰り返される対話の断片を Web スキル (成功した軌跡や誘導されたプログラムから構築された呼び出し可能なツール) としてラップするため、1 回の呼び出しで複数のプリミティブを置き換えることができます。ただし、以前のスキル ライブラリは依然として主に命令の類似性または大まかなサイト メタデータによってトリガーされるため、保留されたサイトでのスキルの再利用が低くなり、潜在的なステップとトークンの削減の多くが保留されたままになります。 SkillMigrator は、再利用可能な Web スキルを学習し、特定の要素の参照ではなくレイアウト構造を照合することによってサイト間で転送するエージェントです。誘導された各スキルは、転移可能なインタラクション パターン (TIP) として保存されます。これは、誘導時のスナップショットの構造スケッチと組み合わせられたスキルです。テスト時に、SkillMigrator はレイアウトの類似性によって TIP を取得し、その参照をライブ ページ上に置きます。スタックの残りの部分は標準です。安定した参照を使用したアクセシビリティ スナップショットの観察と、プリミティブを介した固定ツールの呼び出しとスキルの呼び出しです。最先端のアプローチと比較して、SkillMigrator は、WebArena と Mind2Web の両方で同等の成功率で、成功した軌跡における平均 LLM アクション数を 8 ~ 10% 削減します。
原文 (English)
Beyond Domains: Reusing Web Skills via Transferable Interaction Patterns
Large language model (LLM) web agents are usually deployed as tool callers: each turn, the model reads a fresh page observation and emits one structured tool action. When every action is a low-level primitive, horizons grow quickly and so do policy-facing LLM completions, dominating latency and cost on benchmarks such as Mind2Web and WebArena. Recent systems therefore wrap repeated interaction fragments as web skills: callable tools built from successful trajectories or induced programs, so one call can replace several primitives. However, prior skill libraries are still triggered mainly by instruction similarity or coarse site metadata, which yields low skill reuse on held-out sites and leaves much of the potential step and token reduction on the table. We present SkillMigrator, an agent that learns reusable web skills and transfers them across sites by matching layout structure rather than specific element references. Each induced skill is stored as a transferable interaction pattern (TIP): the skill paired with a structural sketch of the snapshot at induction time. At test time, SkillMigrator retrieves TIPs by layout similarity and grounds their references on the live page. The rest of the stack is standard: accessibility-snapshot observations with stable references, and fixed tool calling over primitives plus skill invocations. Compared with the state-of-the-art approaches, SkillMigrator reduces the average LLM-action count on successful trajectories by 8-10% across both WebArena and Mind2Web at matched success rate.
生成から解決まで: LLM におけるコード推論の内部ライフサイクルを追跡する
標準精度メトリクスでは、LLM が変数追跡を処理するのに、意味的に同等のループで失敗する理由を説明できません。私たちはコード推論の内部ライフサイクルを研究します。このライフサイクルでは、モデルが最初に答えを抽出し、それが自己解読可能になる前に多くの層を線形的に回復可能にし、その後、解決済み、過剰処理済み、誤解決済み、または未解決の 4 つの解決結果のいずれかに分岐します。同様のタスク精度では、表面レベルの評価では検出できない根本的に異なる故障モードが隠蔽される可能性があるため、このライフサイクルを理解することが重要です。レイヤーごとの線形プローブとコンテキスト ストリップ デコーディング (CSD) を組み合わせたデュアル診断フレームワークを導入し、それを Qwen、Llama、DeepSeek アーキテクチャにまたがる 16 モデルにわたる 6 つのコード推論タスク ファミリに適用します。 4 つの結果はすべて、すべてのタスク ファミリでかなりの量を占めています。全体の解決済みは 41.5% にすぎず、複数のタスクは 30% 未満です。構造、深さ、および演算子の制御されたスイープにより、タスク固有の障害のボトルネックが明らかになります。呼び出しの深さが 1 から 3 に増えると、関数呼び出しの解決率が 61.1% から 2.5% に急落します。アーキテクチャや規模を問わず、醸造足場は安定しており、16 モデルすべてで正規化された醸造期間は 24 ~ 42% ですが、解像度の成功は能力によって異なります。これは、スキャフォールドが、テストされたデコーダのみの Transformer ファミリ全体にわたって安定した経験的規則性であるのに対し、解決の成功は能力、規模、トレーニングに依存することを示しています。コード: https://github.com/euyis1019/llm-brewing
原文 (English)
From Brewing to Resolution: Tracing the Internal Lifecycle of Code Reasoning in LLMs
Standard accuracy metrics cannot explain why LLMs handle variable tracking but fail on semantically equivalent loops. We study an internal lifecycle of code reasoning in which models first brew the answer, making it linearly recoverable many layers before it becomes self-decodable, and then diverge into one of four resolution outcomes: Resolved, Overprocessed, Misresolved, or Unresolved. Understanding this lifecycle matters because similar task accuracies can mask fundamentally different failure modes that surface-level evaluation cannot detect. We introduce a dual diagnostic framework pairing layer-wise linear probing with Context-Stripped Decoding (CSD) and apply it to six code-reasoning task families across 16 models spanning Qwen, Llama, and DeepSeek architectures. All four outcomes carry substantial mass in every task family: overall Resolved is only 41.5%, with multiple tasks below 30%. Controlled sweeps over structure, depth, and operators expose task-specific failure bottlenecks: Function Call Resolved plunges from 61.1% to 2.5% as call depth increases from one to three. Across architectures and scales, the brewing scaffold remains stable, with normalized brewing duration 24-42% across all 16 models, while resolution success varies with capability. This indicates that the scaffold is a stable empirical regularity across the tested decoder-only Transformer families, whereas resolution success covaries with capability, scale, and training. Code: https://github.com/euyis1019/llm-brewing
認知モデルを使用して人間説得ゲームの言語モデル シミュレーションを改善する
戦略的な相互作用において、人々は異なる意思決定を行います。ベイジアンのように信念を更新する人もいます。動機付けられた推論などのバイアスを示す人もいます。大規模な言語モデルの作成者は、安全性の評価とトレーニングに模擬人間を使用しますが、多くの場合、この広範な人間の行動をカバーできません。私たちは、認知科学と経済学が、人間の意思決定の数学的モデルを利用して、そのための便利なツールを提供すると主張します。私たちは、大規模な言語モデルを認知モデルと一致するように導くための方程式から行動へのプロンプティングと呼ぶアプローチを提案し、法的意思決定に基づく説得ゲームでこのアプローチを評価します。大規模なモデルは、プロンプトを使用して方程式ベースの仕様 (ベイジアン更新、アフィン歪み、動機付け更新、Grether の $\alpha$-$\beta$ モデル) を近似できるが、小規模なモデルはそれができないことがわかりました。ただし、数学的ルール、方程式から行動への RL に従うように強化学習を使用して小さなモデルをトレーニングすると、分布外のパラメーター化における信念誤差が 26.5% 減少します。私たちは、これらのシミュレーションが多様なトレーニング環境の作成に役立つことを示します。さまざまな種類の意思決定者を考慮するために小さなモデルをトレーニングすると、GPT-5-mini を説得する場合でも、ベイジアンのみのトレーニングに比べて平均信念変化が 2.5% ~ 12% 改善します。私たちの研究により、ますます現実的な設定でのトレーニングと評価のための人間のシミュレーションが改善される可能性があり、人間の意思決定のより複雑な数学モデルについての新しい研究も可能になる可能性があります。
原文 (English)
Using Cognitive Models to Improve Language Model Simulation of Human Persuasion Games
People make decisions differently in strategic interactions. Some update beliefs like a Bayesian; others exhibit biases like motivated reasoning. Although creators of large language models use simulated humans for safety evaluations and training, they often fail to cover this breadth of human behavior. We argue that cognitive science and economics provide a convenient tool for doing so, making use of mathematical models of human decision-making. We propose an approach that we call Equation-to-Behavior Prompting for guiding large language models to match cognitive models, and evaluate this approach on persuasion games based on legal decision-making. We find that large models can approximate equation-based specifications -- Bayesian updating, affine distortion, motivated updating, and Grether's $\alpha$-$\beta$ model -- using prompting, but small models fail to do so. However, training small models with reinforcement learning to adhere to mathematical rules, Equation-to-Behavior RL, reduces belief error by 26.5% in out-of-distribution parameterizations. We show that these simulations can help create diverse training environments; training small models to consider different kinds of decision-makers improves average belief change by 2.5%--12% over Bayesian-only training, even when persuading GPT-5-mini. Our work could improve human simulations for training and evaluation in increasingly realistic settings, and could also enable novel research into more complicated mathematical models of human decision-making.
FllumaOne: 実行可能プログラムとカーネル検証済みの機能履歴を備えたコードネイティブのマルチモーダル CAD データセット
パラメトリックコンピュータ支援設計では、最終的な形状と、部品の編集方法を決定する順序付けられた構築履歴の両方が記録されます。したがって、編集可能な CAD 研究用のデータセットは、モデリング操作、パラメータ、およびフィーチャの依存関係を検証済みのジオメトリとともに公開する必要があります。コードネイティブのマルチモーダル CAD データセットである FllumaOne を紹介します。そのモデルは、Qt/C++ OpenCASCADE ベースの CAD システムである Flluma の実行可能な Python プログラムによって生成されます。各サンプルは、構造化された特徴ツリー、トレーニング指向の中間表現、STEP ジオメトリ、表面点群、自然言語記述、メタデータ、および 8 つの正規の可視エッジ レンダリングとプログラムを調整します。プライマリ リリースである FllumaOne-100K には、4 つのテンプレート レベルの複雑さの領域にわたる 100,000 件の受け入れ済みサンプルが含まれています。プログラムは、カーネル ジオメトリ、ソリッドの有効性、およびエクスポートのチェック後にのみ実行および保持されます。リリース レポートには、モダリティの完全性と分割レベルの重複テストも記録されます。 80,000 サンプルでトレーニングされた Qwen2.5-Coder-1.5B LoRA ベースラインは、保持された 10,000 サンプルのテスト分割で 99.98% の Python 構文妥当性、99.97% Flluma ビルド成功、および 99.14% の STEP エクスポート妥当性を達成しました。表面点群に変換された 9,909 個の予測の場合、正規化された面取り距離の平均は 0.002124 です。このデータセットは、条件付き CAD 再構築、実行可能プログラム合成、フィーチャー ツリー予測、B-Rep 分析、検索、設計完了、および編集可能なリバース エンジニアリングをサポートします。
原文 (English)
FllumaOne: A Code-Native Multimodal CAD Dataset with Executable Programs and Kernel-Validated Feature Histories
Parametric computer-aided design records both final geometry and the ordered construction history that determines how a part can be edited. Datasets for editable CAD research should therefore expose modeling operations, parameters, and feature dependencies together with validated geometry. We introduce FllumaOne, a code-native multimodal CAD dataset whose models are generated by executable Python programs in Flluma, a Qt/C++ OpenCASCADE-based CAD system. Each sample aligns its program with a structured feature tree, a training-oriented intermediate representation, STEP geometry, a surface point cloud, natural-language descriptions, metadata, and eight canonical visible-edge renderings. The primary release, FllumaOne-100K, contains 100,000 accepted samples across four template-level complexity regimes. Programs are executed and retained only after kernel geometry, solid validity, and export checks; release reports also record modality completeness and split-level duplicate tests. A Qwen2.5-Coder-1.5B LoRA baseline trained on 80,000 samples achieves 99.98% Python syntax validity, 99.97% Flluma build success, and 99.14% STEP-export validity on the held-out 10,000-sample test split. For the 9,909 predictions converted to surface point clouds, the mean normalized Chamfer Distance is 0.002124. The dataset supports conditioned CAD reconstruction, executable program synthesis, feature-tree prediction, B-Rep analysis, retrieval, design completion, and editable reverse engineering.
EComAgentBench: 分散された隠れたインテントを使用した長期タスクに関するショッピング エージェントのベンチマーク
LLM ベースのショッピング エージェントが本番環境に入るにつれて、既存のベンチマークは、買い物客の要件がどのように届くか、つまりクエリで暗黙的に指定されるか、プロファイルに記録されるか、適切な質問がされた場合にのみ明らかにされるかを把握できません。事前に完全な意図を明らかにし、最終的な選択のみを評価するベンチマークでは、この長期にわたる課題を提起することも、エージェントがどの要件を逃したかを説明することもできません。このギャップに対処するために、実際の Amazon 製品とレビューに基づいた 662 のタスクのベンチマークである EComAgentBench を導入します。各タスクは、これらの要件を、目に見えるクエリ、ツールゲートのプロファイル、およびスクリプト化された説明に分散させます。エージェントは、隠れた意図を明らかにし、候補者を属性と照合して証拠を確認し、100 回のツール呼び出し以内に単一の製品にコミットする必要があります。さらに、入力され、ソースタグが付けられたルーブリックにより、すべてのタスクが評価され、各失敗の原因が要件とそのソースに帰されます。構築は自動化されていますが、信頼性が高く、テキストが生成され、すべてのサンプルが検証される前に、すべての回答がコード内で修正されます。 7 つのモデルを評価したところ、最も強力なモデルでも全体の精度は 57.1% にとどまっており、ルーブリックの満足度は、目に見えるソースから隠れたソースへと低下することが明らかになりました。全体として、私たちは EComAgentBench が、ショッピング エージェントを単一クエリ検索から長期にわたる信頼できる支援へと移行させるための再現可能な基盤として機能すると考えています。
原文 (English)
EComAgentBench: Benchmarking Shopping Agents on Long-Horizon Tasks with Distributed Hidden Intent
As LLM-based shopping agents enter production, existing benchmarks fail to capture how a shopper's requirements arrive: stated implicitly in the query, recorded in a profile, or revealed only when the right question is asked. Benchmarks that expose full intent upfront and grade only the final choice can neither pose this long-horizon challenge nor explain which requirement an agent missed. To address this gap, we introduce EComAgentBench, a benchmark of 662 tasks grounded in real Amazon products and reviews. Each task scatters these requirements across a visible query, a tool-gated profile, and scripted clarification; an agent must uncover hidden intent, verify candidates against attributes and review evidence, and commit to a single product within 100 tool calls. Moreover, typed, source-tagged rubrics grade every task, attributing each failure to a requirement and its source. Construction is automated yet reliable, with every answer fixed in code before any text is generated and every sample validated. Our evaluation of seven models reveals that even the strongest attains only 57.1% overall accuracy, and rubric satisfaction degrades from visible to hidden sources. Overall, we believe EComAgentBench will serve as a reproducible foundation for moving shopping agents from single-query search toward dependable assistance over long horizons.
LongWebBench: 長期的な設定での構造的および機能的な Web ページ生成の評価
最近のビジョン言語モデル (VLM) は、視覚入力から Web ページを生成する点で有望な進歩を示していますが、既存の評価は主に、短く、単一画面で、大部分が静的な Web ページに焦点を当てています。構造的および機能的観点の両方から長期的な Web ページの生成を評価するためのベンチマークである LongWebBench を紹介します。 LongWebBench には、構造忠実度評価用の 490 の実世界の長い Web ページと、機能評価用の 129 Web ページにわたる 507 の目標指向のインタラクション タスクが含まれています。これは、2 つの相補的なプロトコルを採用しています。1 つは長距離の構造的一貫性を評価するための多次元 VLM ベースのメトリック、もう 1 つはエンドツーエンドの機能検証のための DOM 拡張エージェントベースのパイプラインです。人間の一致分析を通じて自動評価プロトコルをさらに調査します。単一画像および複数画像の設定下で最先端のオープンソースおよび独自の VLM を使用した実験では、Web ページの長さが増加するにつれて構造の忠実度が低下する一方で、視覚的に妥当な世代では実行可能な複数ステップのインタラクションをサポートできないことが多いことが明らかになりました。これらの結果は、実行可能な相互作用を中心的な基準として、視覚的な類似性を超えて長い Web ページの生成を評価する必要性を強調しています。コードとデータは https://github.com/zheny2751-dotcom/LongWebBench で入手できます。
原文 (English)
LongWebBench: Evaluating Structural and Functional Webpage Generation in Long-Horizon Settings
Recent vision-language models (VLMs) have shown promising progress in generating webpages from visual inputs, yet existing evaluations mainly focus on short, single-screen, and largely static webpages. We introduce LongWebBench, a benchmark for evaluating long-horizon webpage generation from both structural and functional perspectives. LongWebBench contains 490 real-world long webpages for structural fidelity evaluation and 507 goal-oriented interaction tasks over 129 webpages for functional evaluation. It employs two complementary protocols: a multi-dimensional VLM-based metric for assessing long-range structural coherence, and a DOM-augmented agent-based pipeline for end-to-end functional verification. We further examine the automatic evaluation protocols through human agreement analysis. Experiments with state-of-the-art open-source and proprietary VLMs under single-image and multi-image settings reveal that structural fidelity degrades as webpage length increases, while visually plausible generations often fail to support executable multi-step interactions. These results highlight the need to evaluate long webpage generation beyond visual similarity, with executable interaction as a core criterion. Our code and data are available at https://github.com/zheny2751-dotcom/LongWebBench.
自己回帰の呪いを打ち砕く: LLM のための動的認識エントロピー調整による消去可能な強化学習
強化学習 (RL) は大規模言語モデル (LLM) の認知境界を拡張しましたが、長期論理推論における自己回帰の呪いに対して依然として脆弱であることがよくあります。生成初期に導入された小さな認識論的摂動がマルコフ決定プロセス フローに沿って不可逆的に伝播し、推論の軌道を崩壊に導く連鎖的な失敗を引き起こす可能性があります。初期の単一の間違いがその後のすべての推論ステップを危険にさらす可能性があるこの自己回帰カスケードを克服するために、動的認識エントロピー調整による消去可能な強化学習 ($\text{E}^3\text{RL}$) を提案します。 $\text{E}^3\text{RL}$ は、モデルの内生的な局所自己回帰交差エントロピーを認識論的不確実性の固有の座標として接地することにより、外部信号への依存を排除します。 $\text{E}^3\text{RL}$ は、セグメント レベルの適応動的しきい値と利点の割り当てを導入することにより、モデルが履歴のキー/値 (KV) キャッシュ ストリームを再利用しながら、局所的な論理欠陥を正確に除去できるようにし、それによって推論プロセスに自己修復機能を与えます。 $\text{E}^3\text{RL}$ を DeepMath-103k データセットでトレーニングします。実験結果は、$\text{E}^3\text{RL}$ が長いシーケンス推論の探索効率を再構築し、線形メモリ オーバーヘッドを維持しながらサンプル効率を向上させることを示しています。 AIME などの数理推論ベンチマークでは、$\text{E}^3\text{RL}$ は大幅なパフォーマンス向上を達成し、4B および 8B パラメーター モデルは、以前の最先端 (SOTA) の結果をそれぞれ 5.349\% および 6.514\% 上回りました。これらの発見は、$\text{E}^3\text{RL}$ が長期シーケンス推論における自己回帰の呪いを打ち破り、次世代の自己修復汎用人工知能 (AGI) のための理論的およびシステムレベルの基盤を確立することを示唆しています。
原文 (English)
Shattering the Autoregressive Curse: Dynamic Epistemic Entropy Orchestrated Erasable Reinforcement Learning for LLMs
Although reinforcement learning (RL) has expanded the cognitive boundaries of large language models (LLMs), it often remains vulnerable to the autoregressive curse in long-horizon logical reasoning: small epistemic perturbations introduced early in generation can propagate irreversibly along the Markov decision process flow, triggering cascading failures that drive the reasoning trajectory toward collapse. To overcome this autoregressive cascade, in which a single early mistake can compromise all subsequent reasoning steps, we propose dynamic epistemic entropy orchestrated erasable reinforcement learning ($\text{E}^3\text{RL}$). $\text{E}^3\text{RL}$ eliminates reliance on external signals by grounding the model's endogenous local autoregressive cross-entropy as an intrinsic coordinate of epistemic uncertainty. By introducing segment-level adaptive dynamic thresholds and advantage allocation, $\text{E}^3\text{RL}$ enables the model to precisely excise localized logical defects while reusing historical key-value (KV) cache streams, thereby endowing the reasoning process with a self-healing capability. We train $\text{E}^3\text{RL}$ on the DeepMath-103k dataset. Experimental results show that $\text{E}^3\text{RL}$ reshapes the exploration efficiency of long-sequence reasoning and improves sample efficiency while maintaining linear memory overhead. On mathematical reasoning benchmarks such as AIME, $\text{E}^3\text{RL}$ achieves substantial performance gains, with the 4B and 8B parameter models surpassing previous state-of-the-art (SOTA) results by 5.349\% and 6.514\%, respectively. These findings suggest that $\text{E}^3\text{RL}$ shatters the autoregressive curse in long-sequence reasoning and establishes a theoretical and systems-level foundation for the next generation of self-healing artificial general intelligence (AGI).
DecoSearch: Text-to-SQL の複雑さを考慮したルーティングとプランレベルの修復
大規模言語モデル (LLM) は、自然言語を SQL に変換する際に優れた機能を実証していますが、既存の方法では、複数のステップでデータを意識した推論を必要とする複雑なクエリでは依然として問題が発生します。各クエリを適切なレベルの推論作業にルーティングすることでこの問題に対処する、トレーニング不要のフレームワークである DecoSearch を紹介します。軽量のスキーマ セレクターは、最初に完全なデータベース スキーマを関連するテーブルと列にプルーニングします。次に、LLM ジャッジは質問を分解する必要があるかどうかを決定します。単純な質問は直接生成パスに従い、複雑な質問はアトミックなサブ質問の有向非巡回グラフ (DAG) にエスカレートされ、それぞれがターゲットを絞った SQL 生成ステップによって解決されます。 RAG コンポーネントは、意味的に類似したトレーニング サンプルを使用して分解を実行し、実行の失敗が修正可能な SQL エラーではなく分解に問題があることを示す場合、トポロジ リファイナーは推論プランを再構築します。 DecoSearch は、DeepSeek バックボーンを備えた BIRD で 70.53%、Spider で 88.31% の実行精度を達成し、トレーニング不要のすべてのベースラインを上回り、競合するメソッドよりも消費するトークンが桁違いに少なくなります。また、モデルに依存しないラッパーとしても機能し、パイプラインを変更することなく、微調整された SQL 生成バックボーンを一貫して改善します。
原文 (English)
DecoSearch: Complexity-Aware Routing and Plan-Level Repair for Text-to-SQL
Large Language Models (LLMs) have demonstrated remarkable capabilities in translating natural language to SQL, yet existing methods still falter on complex queries requiring multi-step, data-aware reasoning. We introduce DecoSearch, a training-free framework that addresses this by routing each query to the appropriate level of reasoning effort. A lightweight Schema Selector first prunes the full database schema to the relevant tables and columns. An LLM Judger then decides whether the question requires decomposition: straightforward questions follow a direct generation path and complex ones are escalated to a Directed Acyclic Graph (DAG) of atomic sub-questions, each solved by a targeted SQL generation step. A RAG component grounds the decomposer with semantically similar training examples, and a Topology Refiner restructures the reasoning plan when execution failures signal a flawed decomposition rather than a fixable SQL error. DecoSearch achieves 70.53% execution accuracy on BIRD and 88.31% on Spider with a DeepSeek backbone, surpassing all training-free baselines while consuming an order of magnitude fewer tokens than competing methods. It also functions as a model-agnostic wrapper, consistently improving fine-tuned SQL generation backbones without any modification to the pipeline.
WallZero: 戦略分析で WallGo ゲームをマスターする
WallGo は、2025 年の Netflix シリーズ「The Devil's Plan」によって普及した、最近導入された戦略的ボード ゲームです。 7 x 7 の小さなボードでプレイされますが、石の動きと壁の配置の組み合わせにより、ゲーム ツリーの高度な複雑さと複雑な戦略的相互作用が生まれます。人気が高まっているにもかかわらず、WallGo はまだ開拓されていません。このペーパーでは、2 プレイヤー WallGo 設定用の AlphaZero ベースのエージェントである WallZero について説明します。プレイパフォーマンスを大幅に向上させるために、カスタマイズされたアクションと機能のデザインを導入します。評価では、WallZero がこの研究に参加した 2 人のプロ棋士を破り、1 試合あたり平均 1.98 倍の領土を確保しました。その強みを超えて、私たちは WallZero を使用してゲームの公平性を評価し、WallGo をマスターするための重要な戦略を特定します。興味深いことに、私たちの結果は、Netflix シリーズで使用されているオープニングがよりバランスの取れたゲームを生み出すことを示しています。私たちのコードは https://rlg.iis.sinica.edu.tw/papers/wallzero で入手できます。
原文 (English)
WallZero: Mastering the Game of WallGo with Strategic Analysis
WallGo is a recently introduced strategic board game popularized by the 2025 Netflix series The Devil's Plan. Although played on a small 7 x 7 board, its combination of stone movement and wall placement yields high game-tree complexity and intricate strategic interactions. Despite its growing popularity, WallGo remains underexplored. This paper presents WallZero, an AlphaZero-based agent for the two-player WallGo setting. We introduce tailored action and feature designs to improve playing performance significantly. In the evaluation, WallZero defeats two professional Go players who participated in this study, securing on average 1.98x more territory per game. Beyond its strength, we use WallZero to assess game fairness and identify key strategies for mastering WallGo. Interestingly, our results show that the opening used in the Netflix series yields a more balanced game. Our code is available at https://rlg.iis.sinica.edu.tw/papers/wallzero.
神経記号推論のホモトピー型理論による一般化
広範囲のニューロシンボリック (NeSy) システムは、$\sigma$ 構造の空間にわたる論理量の信念加重和という 1 つの汎関数を計算します。重み付きモデルの計数、ファジー論理、確率論理は特殊なケースです。この説明は集合に基づいて構築されており、集合は NeSy にとって重要な 2 つのことを意図的に忘れています。それは、2 つの $\sigma$ 構造が理論の対称性まで同じである場合と、クエリを証明する別個の証明の数です。ホモトピー型理論の意味で、基になるセットを型で置き換えると、この情報が保存され、この関数が信念加重ホモトピー濃度、つまり各オブジェクトをその対称性に反比例してカウントするサイズの概念に変わります。 NeSy システム用のフレームワークをゼロから開発し、対称性が自明な場合に古典関数を回復する保守性定理を証明し、フレームワークが明らかにする対称性がまさに推論のショートカットの背後にあるものであることを示します。その成果は具体的です。アンサンブルまたは表現的密度推定によって最近の手法が到達する、ショートカットを意識した事後概念は、混同集合シンプレックスの唯一の対称不変点であり、対称群全体で単一のモデルを平均することによって閉じた形式で計算可能です。 MNIST 推論ショートカット ベンチマークでは、この単一モデル ラッパーは、ラベルの精度と識別可能な概念はそのままにしながら、多様性でトレーニングされたアンサンブルよりも適切に調整されています。コードは https://github.com/bio-ontology-research-group/hott-nesy から無料で入手できます。
原文 (English)
A homotopy-type-theoretic generalization of neurosymbolic inference
A wide range of neurosymbolic (NeSy) systems compute one functional: a belief-weighted sum of a logical quantity over a space of $\sigma$-structures, of which weighted model counting, fuzzy logic, and probabilistic logic are special cases. This account is built on sets, and a set deliberately forgets two things that are important for NeSy: when two $\sigma$-structures are the same up to a symmetry of the theory, and how many distinct proofs witness a query. Replacing the underlying sets by types, in the sense of homotopy type theory, preserves this information, and turns this functional into a belief-weighted homotopy cardinality, a notion of size that counts each object in inverse proportion to its symmetries. We develop the framework from scratch for NeSy systems, prove a conservativity theorem that recovers the classical functional when symmetries are trivial, and show that the symmetry our framework exposes is exactly the one behind reasoning shortcuts. The payoff is concrete: the shortcut-aware concept posterior that recent methods reach by ensembling or expressive density estimation is the only symmetry-invariant point of the confusion-set simplex, computable in closed form by averaging a single model over the symmetry group. On MNIST reasoning-shortcut benchmarks this single-model wrapper is better calibrated than a diversity-trained ensemble, while leaving label accuracy and identifiable concepts untouched. Code is freely available at https://github.com/bio-ontology-research-group/hott-nesy.
FlowRAG: 周波数を意識した複数粒度のグラフ フローによる明示的推論の相乗効果
グラフベースの検索拡張生成 (GraphRAG) は、知識集約型のマルチホップ クエリ タスクに効果的です。ただし、多くの既存の方法は主にエンティティベースのグラフをシードし、暗黙的な意味関連性の伝播に依存しています。これは、(i) ユーザー クエリがエンティティ レベルで抽象的で意味的に疎な場合に検索が不十分になることがよくあり、(ii) ノイズの多いアクティブ化によってエンティティ間の遷移が狂い、推論された関係チェーンが破損し、信頼性の低い結論が得られる脆弱なマルチホップ推論に悩まされます。この目的を達成するために、意味の想起と明示的な推論の両方を改善する意味を意識した検索フレームワークである \texttt{FlowRAG} を提案します。具体的には、\texttt{FlowRAG} はパッセージ、要約、文、およびエンティティにわたるクアッドレベルの異種グラフを構築します。要約ノードは粗いセマンティック ハブとして機能します。検索時には、二重粒度アクティベーション モジュールが要約クエリのアライメントと文レベルのマッチングを組み合わせて、言い換えと抽象化の下で関連エンティティを強力にアクティベートします。次に、エンティティを通じて関連性をルーティングする周波数認識重み付けフロー モジュールを導入します。つまり、パッセージ用語内の頻度によって重み付けされたパッセージ リンク、ノイズの多い接続を刈り込み、生成のための明示的な論理スケルトンとして信頼性の高い推論パスを抽出します。広範な実験により、\texttt{FlowRAG} が複雑な推論ベンチマークで最先端のパフォーマンスを得ることが示されました。
原文 (English)
FlowRAG: Synergizing Explicit Reasoning via Frequency-Aware Multi-Granularity Graph Flow
Graph-based retrieval-augmented generation (GraphRAG) is effective for knowledge-intensive and multi-hop query tasks; however, many existing methods primarily seed entity-based graphs and rely on implicit semantic relevance propagation. This often (i) under-retrieves when user queries are abstract and semantically sparse at the entity level, and (ii) suffers from brittle multi-hop reasoning, where noisy activations can derail entity-to-entity transitions and corrupt the inferred relation chain, yielding unreliable conclusions. To this end, we propose \texttt{FlowRAG}, a semantic-aware retrieval framework that improves both semantic recall and explicit reasoning. Specifically, \texttt{FlowRAG} constructs a quad-level heterogeneous graph over passages, summaries, sentences, and entities, where summary nodes serve as a coarse semantic hub. At retrieval time, a dual-granularity activation module combines summary--query alignment with sentence-level matching to activate relevant entities under paraphrase and abstraction robustly. We then introduce a frequency-aware weighted flow module that routes relevance through entity--passage links weighted by within-passage term frequency, pruning noisy connections and extracting high-confidence reasoning paths as an explicit logic skeleton for generation. Extensive experiments show that \texttt{FlowRAG} obtains state-of-the-art performance on complex reasoning benchmarks.
StepGuard: シングルステップキャリブレーションによる Web ナビゲーションの保護
Web ナビゲーションでは、エージェントが自然言語の目標に従い、Web ページと対話し、正確な回答を生成する必要があります。最近の進歩はビジョン言語モデルと強化学習を活用していますが、既存の手法は依然として報酬の不整合やエラー伝播による単一ステップの脆弱性に悩まされています。報酬のもつれに対処するために、動的デュアルポリシー最適化 (DDPO) を設計します。これは、探索のためのナビゲーション優先モードと質問応答のための回答優先モードを動的に切り替えて、報酬の競合を軽減します。シングルステップ誤差を校正するために、我々は、ステップごとの信頼度を推定し、必要な場合にのみリフレクションをトリガーし、対照的な報酬を使用してシングルステップの不正確さを校正する自己修正を促すメカニズムである信頼ガイド付き適応ナビゲーションリフレクション (CANR) を提案します。上記を主要コンポーネントとして、最終的に、シングルステップ キャリブレーションによる Web ナビゲーションの保護の新しいフレームワークである StepGuard を開発します。実験では、私たちのアプローチがナビゲーションと回答の精度を大幅に向上させ、標準的な Web ナビゲーション ベンチマークで新しい最先端のパフォーマンスを確立することを示しています。
原文 (English)
StepGuard: Guarding Web Navigation via Single-Step Calibration
Web navigation requires agents to follow natural language goals, interact with web pages, and produce accurate answers. While recent advances leverage vision-language models and reinforcement learning, existing methods still suffer from single-step fragility due to reward misalignment and error propagation. To tackle the reward entanglement, we design Dynamic Dual-Policy Optimization (DDPO), which dynamically switches between a navigation-first mode for exploration and an answer-first mode for question-answering to mitigate reward conflict. To calibrate the single-step error, we propose Confidence-Guided Adaptive Navigation Reflection (CANR), a mechanism that estimates per-step confidence, triggers reflection only when necessary, and uses contrastive rewards to encourage self-correction to calibrate the single-step inaccuracy. With the above as the main components, we finally develop our StepGuard, a new framework of Guarding Web Navigation via Single-Step Calibration. Experiments demonstrate that our approach significantly improves navigation and answer accuracy, setting new state-of-the-art performance on standard web navigation benchmarks.
グラフ ニューラル ネットワークの構造の保存と論理的表現力
グラフ ニューラル ネットワーク (GNN) と論理形式の間の橋渡しは、集約、結合、活性化関数の種類などのアーキテクチャ上の選択を修正することによって確立されています。これらの選択は、論理式を同等の GNN に変換できること、また逆に GNN を同等の式に変換できることを示すことによって、論理形式との厳密な対応を取得できる GNN の制限されたクラスを定義します。この論文では、埋め込み (拡張)、単射準同型性、および準同型性といった構造特性の下で保存される GNN 分類器のクラスの論理的表現力を確立することにより、意味論的な観点を取り上げます。我々は、そのようなプロパティごとに、GNN のクラスを特徴付ける段階的な様相論理の断片が存在することを示します。特に、埋め込みによる保存、単射準同型性、および準同型性は、それぞれ、実存段階的様相論理、その実存肯定的フラグメント、および実存肯定的様相論理に対応します。これらの結果は、特定のアーキテクチャの選択とは無関係に、GNN の広範なクラスの表現力を特徴づけますが、これらのクラスのそれぞれが同じ表現力の GNN アーキテクチャを許容することも示します。技術的には、私たちのアプローチは、高さが制限されたツリーに対して新しい十分に準順序の結果を使用し、解明不変クラスの有限表現を生成します。
原文 (English)
Structural Preservation and the Logical Expressiveness of Graph Neural Networks
Bridges between graph neural networks (GNNs) and logical formalisms have been established by fixing architectural choices, such as the types of aggregation, combination, and activation functions. These choices define restricted classes of GNNs for which tight correspondences with logical formalisms can be obtained, by showing that logical formulae can be translated into equivalent GNNs and, conversely, that GNNs can be translated into equivalent formulae. In this paper we take a semantic perspective by establishing the logical expressiveness of classes of GNN classifiers that are preserved under structural properties: embeddings (extensions), injective homomorphisms, and homomorphisms. We show that, for each such property, there exists a fragment of graded modal logic characterising the class of GNNs. In particular, preservation under embeddings, injective homomorphisms, and homomorphisms corresponds to existential graded modal logic, its existential-positive fragment, and existential-positive modal logic, respectively. These results characterise the expressiveness of broad classes of GNNs independently of specific architectural choices, but we also show that each of these classes admits a GNN architecture of the same expressiveness. Technically, our approach uses a new well-quasi-order result for trees of bounded height, yielding finite representations of unravelling-invariant classes.
MathVis-Fine: マルチモーダルな数学的推論のための漸進的な依存関係に基づくトレーニングを介して、視覚的な監視を必要性に合わせて調整する
思考連鎖 (CoT) 推論は、純粋な言語領域からマルチモーダルなシナリオまで拡張されました。しかし、既存のアプローチは視覚入力を同種の信号または補助信号として扱うことが多く、数学的な問題解決においてテキストと画像の間の複雑でサンプル固有の依存関係を捉えることができません。これにより、2 つの主要な問題が生じます。まず、視覚コンテンツの監視信号が一般化されており、粒度が粗く、各サンプルの視覚情報の実際の必要性に適応できません。第二に、入力間の補完関係を区別せずに視覚的報酬が均一に適用される場合、トレーニングのフィードバックは不正確になります。これらの制限は、モデルが正確なマルチモーダル推論を達成することを妨げます。この研究では、数学的推論におけるきめの細かい視覚的依存関係をモデル化するためのフレームワークを提案します。まず MathVis-Fine データセットを構築し、視覚的な依存関係評価を使用してきめの細かい視覚的なアノテーションを強化します。このデータセットに基づいて、各サンプルの固有の視覚依存レベルに応じて解答正答報酬と視覚グラウンディング報酬のバランスをとる 2 段階の漸進的視覚強化トレーニング パラダイムを導入します。これにより、報酬のバイアスが軽減され、監視の精度が向上します。広範な実験により、MathVis-Fine フレームワークが視覚依存性に基づいて段階的に視覚認識を効果的に強化し、マルチモーダルな数学的推論のためのより正確なトレーニング フレームワークを提供することが実証されました。承認され次第、データセットを公開します。
原文 (English)
MathVis-Fine: Aligning Visual Supervision with Necessity via Progressive Dependency-Guided Training for Multimodal Mathematical Reasoning
Chain-of-Thought (CoT) reasoning has extended from purely linguistic domains to multimodal scenarios; however, existing approaches often treat visual inputs as homogeneous or auxiliary signals, failing to capture the intricate and sample-specific dependencies between text and images in mathematical problem-solving. This gives rise to two core issues: first, the supervisory signals for visual content are generalized and coarse-grained, lacking adaptation to the actual necessity of visual information in each sample; second, training feedback becomes inaccurate when visual rewards are uniformly applied without distinguishing the complementary relationships among inputs. These limitations hinder models from achieving precise multimodal reasoning. In this work, we propose a framework for modeling fine-grained visual dependencies in mathematical reasoning. We first construct the MathVis-Fine dataset, augmenting fine-grained visual annotations with visual dependency ratings. Building upon this dataset, we introduce a two-stage progressive visual enhancement training paradigm that balances answer correctness rewards and visual grounding rewards according to the intrinsic visual dependency level of each sample, thereby mitigating reward bias and improving supervision accuracy. Extensive experiments demonstrate that the MathVis-Fine framework effectively enhances visual perception progressively based on visual dependency, offering a more precise training framework for multimodal mathematical reasoning. We will release the dataset upon acceptance.
歩行者の歩行に制約を設けて社会的相互作用を定量化する方法を学ぶ
自律移動プラットフォーム (自動運転車やソーシャル ロボットなど) が衝突を回避し、高品質の計画を立てるには、群衆の中での長期的な人の進路予測が不可欠です。現在の研究では、予測のために社会的相互作用が考慮されていますが、人々の間で起こった正確な種類の社会的相互作用や、社会的相互作用が歩行者の意思決定プロセスにどのような影響を与えるかは明らかにされていないため、その頑健性はさらに制限されます。歩行者の歩行における社会的相互作用は直感的に膨大であり、ラベルを付けたり定量化したりするのは困難です。この論文では、Learn to Cluster を提案することで、歩行者が他の人とどのように相互作用するかを定量化し、解釈する方法を創造的に探求します。私たちのクラスタリング社会的相互作用は確率的潜在変数生成であり、連続した軌跡の観察から直接学習し、任意の数の歩行者に拡張可能です。クラスタリングの学習にはラベルが不要で、予測モデルのトレーニング プロセスに自然に統合できます。潜在変数は、社会的相互作用を分類するための「ラベル」として機能します。いくつかの軌道予測ベンチマークに対する広範な実験により、私たちの方法が社会的相互作用のパターンを学習し、そのパターンを歩行者の軌道予測に効果的に統合できることが実証されました。
原文 (English)
Learn to Quantify Social Interaction with Constraints for Pedestrian Walking
Long-term human path forecasting in crowds is critical for autonomous moving platforms (like autonomous driving cars and social robots) to avoid collision and make high-quality planning. Although the current research take into account social interactions for prediction, they don't reveal the exact kinds of social interactions happened among people and how the social interactions affect the decision-making process of pedestrians, which further limits its robustness. Social interactions in pedestrian walking are intuitively massive and hard to label and quantify. In this paper, we explore creatively to quantify and interpret how pedestrians interact with others by proposing Learn to Cluster. Our clustering social interactions is probabilistic latent variable generative, learning directly from sequential trajectory observations, scalable to arbitrary number of pedestrians. Learn to cluster is label-free and can be naturally integrated into the training process of the prediction model. The latent variables will then serve as 'labels' to categorize social interactions. Extensive experiments over several trajectory prediction benchmarks demonstrate that our method is able to learn the patterns of social interactions and effectively integrate the patterns to pedestrian trajectory prediction.
DiagFlowBench: 言語モデルがグラウンデッド診断ダイアログでプロシージャ外入力をどのように処理するかを評価する
言語モデルは、メンテナンス作業における助言システムとしての役割をますます高めています。幻覚を防ぐために、最近のシステムでは、これらのモデルを手順書に基づいて承認された手順に制限します。ただし、実際には、オペレーターのクエリはこのパスから逸脱することが多く、モデルは会話中に範囲外の入力を認識する必要があり、現在のベンチマークではほとんど優先されません。 DiagFlowBench は、消費者メーカーの 50 の産業診断フローチャートのデータセットであり、範囲外の発話との準拠を対比する 1,676 のマルチターン会話に変換されます。 10 個の商用および無差別モデルのパネルを評価すると、棄権率のばらつきが大きく、モデルは事実を捏造するのではなく、現実ではあるが文脈上不適切なステップを選択することが一般的であることが明らかになりました。このマッピングされた間違ったアドバイスに固有のもっともらしさと権威があるため、接地システムの重大な脆弱性が明らかになります。
原文 (English)
DiagFlowBench: Evaluating How Language Models Handle Off-Procedure Inputs in Grounded Diagnostic Dialogue
Language models increasingly serve as advisory systems in maintenance operations. To prevent hallucination, recent systems ground these models in procedural documentation to constrain them to approved steps. In practice, however, operator queries frequently stray from this path, requiring models to recognise out-of-scope inputs mid-conversation, a dynamic that current benchmarks rarely prioritise. We introduce DiagFlowBench, a dataset of 50 industrial diagnostic flowcharts from a consumer manufacturer converted into 1,676 multi-turn conversations that contrast compliant with out-of-scope utterances. Evaluating a panel of ten commercial and open-weight models reveals high variability in abstention rates, with models commonly selecting a real but contextually inadequate step rather than fabricating facts. The inherent plausibility and authority of this mapped but wrong advice exposes a challenging vulnerability for grounding systems.
PreAct: 繰り返しのタスクを高速化するコンピュータ使用エージェント
コンピュータを使用するエージェントは実際のソフトウェアを画面上でクリックしたり入力したりして操作しますが、すべてのタスクをゼロから解決します。タスクを繰り返すよう求められると、エージェントは画面をもう一度読み、タップするたびに理由を考え直し、再び全額を支払います。私たちは、そのようなエージェントが以前に実行したタスクをより速く実行できるようにする PreAct を紹介します。初めて成功すると、PreAct は実行を小さなステートマシン プログラムにコンパイルします。画面をチェックするステートと、動作する遷移を実行します。その後の実行では、エージェントを呼び出す代わりに、ステップごとの言語モデルの呼び出しを行わずに、8.5 ~ 13 倍高速に実行を直接再生します。リプレイはブラインドではありません。PreAct は各ステップで、動作する前に画面がプログラムの期待と一致しているかどうかをチェックし、何かが外れるとすぐに制御をエージェントに戻します。 PreAct は、何を保持するかを決定する際にも同じ規律を適用します。つまり、クリーンな状態から再実行して、最後のステップまで再生しながらタスクを未完了のままにするタスク捕捉プログラムを独立した評価者が解決したことを確認した場合にのみ、新たにコンパイルされたプログラムがストアに追加されます。このストアタイム チェックは、モバイル、デスクトップ、Web ベンチマーク全体にわたって、改善する反復実行と、欠陥のあるプログラムが蓄積するにつれて低下する実行を区別します。これは、ベンチマークごとに 1.75 ~ 2.6 タスクに相当し、3 つすべてで同じ方向です。適合するプログラムがない場合に新たに探索するフォールバックにより、強力な記録と再生のベースラインを備えた PreAct レベルが実現します。また、プロンプトの文言、実行時のガードレール、再利用するプログラムを言語モデルとプレーンの埋め込み取得のどちらで選択するかなど、重要ではなかった内容も報告します。
原文 (English)
PreAct: Computer-Using Agents that Get Faster on Repeated Tasks
Computer-using agents drive real software through the screen -- clicking and typing -- but they solve every task from scratch: asked to repeat a task, an agent re-reads the screen, re-reasons every tap, and pays the full cost again. We present PreAct, which lets such an agent get faster on tasks it has done before. The first time it succeeds, PreAct compiles the run into a small state-machine program-states that check the screen, transitions that act-and on later runs replays it directly instead of invoking the agent 8.5-13x faster, with no per-step language-model calls. Replay is not blind: at each step PreAct checks that the screen matches what the program expects before acting, and hands control back to the agent the moment something is off. PreAct applies the same discipline when deciding what to keep: a freshly compiled program enters the store only if, re-run from a clean state, an independent evaluator confirms it solved the task-catching programs that replay to their last step yet leave the task undone. Across a mobile, a desktop, and a web benchmark, this store-time check separates repeated runs that improve from ones that degrade as faulty programs accumulate, worth 1.75-2.6 tasks per benchmark, the same direction on all three; a fallback that explores afresh when no program fits brings PreAct level with a strong record-and-replay baseline. We also report what did not matter: prompt wording, runtime guardrails, and whether a language model or a plain embedding retriever selects which program to reuse.
推論によるフロンティア LLM 評価の形状計算方法
AI の評価は、ツールの使用と反復的な問題解決を伴う長期にわたる軌道から恩恵を受ける、より困難なタスクへと移行しています。その結果、パフォーマンスは、テスト時に利用可能なコンピューティング (「推論コンピューティング」) の量と割り当てにますます敏感になります。しかし、多くの評価では依然として単一の制限された予算でのパフォーマンスが報告されており、低いスコアはモデルの基礎的な機能ではなく評価設定を反映している可能性があることを意味します。これをテストするために、ソフトウェア エンジニアリング、数学、医学、サイバーセキュリティにわたる 7 つの挑戦的なベンチマークで最大 12 のフロンティア言語モデルを評価します。私たちは、3 つの単純な推論スケーリング介入を組み合わせた制御されたセットアップを使用します。つまり、より大きなトークン バジェット、コンテキストの圧縮、およびモデル自体または最小限の正確性フィードバックによって導かれる送信の試行の繰り返しです。主な結果は 3 つあります。まず、トークン バジェットが大きくなると、サイバーセキュリティ、FrontierMath、人類最後の試験、ターミナルベンチなど、複数のドメインにわたるベンチマークのパフォーマンスが大幅に向上します。第二に、固定予算の評価では、モデルが進歩するにつれてフロンティアの能力がますます過小評価される可能性があります。新しいモデルは、大きな予算でより高いパフォーマンスを実現し、より困難なタスクを解放し、より確実に解決します。第三に、どの推論スケーリング手法が最も役立つかがベンチマークによって異なります。繰り返し送信するとパフォーマンスが大幅に向上しますが、より大きなトークン バジェット、外部フィードバック、および並列試行の値はベンチマークによって異なります。全体として、私たちの結果は、ベンチマーク スコアがプロトコルに依存していることを示しています。したがって、評価では、特に安全性またはポリシー関連の設定において、推論時間のコンピューティングの関数として機能を報告し、プロトコルの選択を明示的に指定し、一致した予算で大規模な共有コンピューティング範囲にわたってモデルの世代を比較する必要があると主張します。
原文 (English)
How Inference Compute Shapes Frontier LLM Evaluation
AI evaluations are shifting toward harder tasks that benefit from longer trajectories involving tool use and iterative problem solving. As a result, performance is increasingly sensitive to the amount and allocation of compute available at test time ("inference compute"). Yet many evaluations still report performance at a single restrictive budget, meaning that low scores may reflect the evaluation setup rather than the model's underlying capability. To test this, we evaluate up to 12 frontier language models on seven challenging benchmarks spanning software engineering, mathematics, medicine, and cybersecurity. We use a controlled setup combining three simple inference-scaling interventions: larger token budgets, context compaction, and repeated submission attempts, guided either by the model itself or by minimal correctness feedback. We find three main results. First, larger token budgets substantially improve performance on benchmarks across multiple domains, including cybersecurity, FrontierMath, Humanity's Last Exam, and TerminalBench. Second, fixed-budget evaluations can increasingly understate frontier capability as models advance. Newer models reach higher performance at large budgets, where they unlock harder tasks and solve them more reliably. Third, benchmarks differ in which inference-scaling methods help most: repeated submission broadly improves performance, but the value of larger token budgets, external feedback, and parallel attempts varies by benchmark. Overall, our results show that benchmark scores are protocol-dependent. We therefore argue that evaluations should report capability as a function of inference-time compute, specify protocol choices explicitly, and compare model generations over a large shared compute range at matched budgets, especially in safety- or policy-relevant settings.
大規模な言語モデルでは小規模な初期化が重要
大規模な言語モデルは、LLM がどのように設計されるかだけではなく、インテリジェンス自体がどのように出現するかを問うための扱いやすいシステムを提供します。進歩は通常、規模、データ、アーキテクチャに起因すると考えられますが、パラメータの初期化がトレーニング、特にモデルの能力の遺伝子のような決定要因であることを示します。初期化スケールを減らすと事前トレーニングが一貫して改善され、推論を必要とするタスクで最大の効果が得られます。小規模な初期化の利点を抑制する、広く使用されている 2 つの経験的な設定を特定し、それらを緩和することで望ましいスケーリングがどのように回復するかを示します。さらに、推論とトレーニングのバランスをとる重要な初期化を明らかにします。機構的には、小さな初期化は明確な開発軌道を推進します。パラメータは最初に複雑度の低い構造に凝縮され、その後より豊かな表現に拡張され、圧縮が知性であるという考えに具体的な形が与えられます。トークンレベルの分析では、利益がすべてのトークンを一律にではなく、自明ではないコンテキストに制約された予測に集中していることが示されています。これらの結果は、単純な $\gamma$ 初期化ルールの動機付けになります。つまり、初期化の怒りを明示的なノブとして公開し、デフォルトで小さな初期化を使用します。これは、事前学習を改善し、モデル スケール全体で推論を強化するほぼコストのかからない介入です。
原文 (English)
Small Initialization Matters for Large Language Models
Large language models provide a tractable system for asking how intelligence itself emerges, rather than only how LLMs can be engineered. Although progress is usually attributed to scale, data and architecture, we show that parameter initialization is a gene-like determinant of training and, in particular, of model capacity. Reducing the initialization scale consistently improves pretraining, with the largest gains on reasoning-demanding tasks. We identify two widely used empirical settings that restrain the advantage of small initialization, and show how relaxing them restores favorable scaling. We further uncover a critical initialization that balances the reasoning and training. Mechanistically, small initialization drives a distinct developmental trajectory: parameters first condense into low-complexity structures and later expand into richer representations, giving concrete form to the idea that compression is intelligence. Token-level analyses show that the gains concentrate on non-trivial, context-constrained predictions rather than all tokens uniformly. These results motivate a simple $\gamma$-initialization rule: expose initialization rage as an explicit knob and use small initialization by default, an almost cost-free intervention that improves pretraining and strengthens reasoning across model scales.
MoCo-AIS: 船舶軌道の類似性計算のための対照学習フレームワーク
軌跡の類似性は、モビリティ パターンを分析する際の基本的なタスクであり、ルート パターンの抽出、モビリティの予測、異常検出などのアプリケーションに不可欠です。類似性を計算するための従来の距離ベースの測定では、高い計算コストがかかるため、軽量な学習ベースのアプローチの採用が促進されています。教師あり手法は、従来の距離測定から得られる広範なラベルに依存しており、多くの場合、これらのメトリクスを再現するため、一般化が制限されます。自己教師あり学習は、対比学習を通じてこの問題に対処しますが、統一されたフレームワークが欠けているため、一貫した軌跡の表現のために深層学習 (DL) モデルを比較することが困難になります。したがって、この論文では、正と負の軌道ペアを介した類似性学習を定式化するモーメンタムコントラスト(MoCo)パラダイムに基づいて血管軌道埋め込みを学習するための統一フレームワークであるMoCo-AISを紹介します。このフレームワーク内で、多様な航行挙動と運航条件を捕捉する大規模な現実世界の船舶追跡 AIS データセットで、主要な DL モデルの多様なセットを評価します。結果は、私たちのフレームワークが既存のベースラインよりも類似性学習を大幅に改善し、同時に軌跡表現モデルを評価するためのベンチマーク プラットフォームを提供することを示しています。
原文 (English)
MoCo-AIS: A Contrastive Learning Framework for Similarity Computation of Vessel Trajectories
Trajectory similarity is a fundamental task in analyzing mobility patterns, essential for applications such as route pattern extraction, mobility prediction, and anomaly detection. Traditional distance-based measures for computing similarity incur high computational cost, driving the adoption of lightweight learning-based approaches. Supervised methods rely on extensive labels derived from traditional distance measures and often reproduce these metrics, which limits generalization. While self-supervised learning addresses this issue through contrastive learning, it lacks a unified framework, making it difficult to compare deep learning (DL) models for consistent trajectory representation. Accordingly, this paper presents MoCo-AIS, a unified framework for learning vessel trajectory embeddings based on the Momentum Contrast (MoCo) paradigm, which formulates similarity learning through positive and negative trajectory pairs. Within this framework, we evaluate a diverse set of leading DL models on large-scale, real-world vessel-tracking AIS datasets that capture diverse navigation behaviors and operating conditions. Results demonstrate that our framework significantly improves similarity learning over existing baselines, while providing a benchmarking platform for evaluating trajectory representation models.
STAR: トレーニング後のテキストから画像への RL のための時空間適応型報酬割り当て
テキストから画像への生成のための既存の RL ポストトレーニング手法は、通常、最終画像の報酬を単一のスカラー アドバンテージに変換し、それを同じ強度で生成軌跡全体に適用します。ただし、テキストから画像への生成には、当然、時間的および空間的な構造があります。さまざまなノイズ除去ステップがさまざまな生成段階を担当し、テキストの配置を真に決定するコンテンツは、多くの場合、画像の一部にのみ表示されます。この粒度の不一致により、実際に報酬に影響を与える生成コンポーネントに焦点を当ててポリシーを更新することが困難になります。この問題に対処するために、テキストから画像への拡散およびフロー モデルの RL ポストトレーニング用に \textbf{時空間適応型報酬 (STAR) 割り当て} を提案します。 STAR は生成モデル内でテキストと画像のアテンションを使用し、プロンプト内でユーザーが本当に関心のあるコア コンテンツから開始します。ノイズ除去ステップとロールアウト全体で動的に変化する空間割り当てマップを構築し、追加の計算オーバーヘッドをほとんど発生させることなく、同じグループ相対的な利点をより関連性の高い潜在領域に割り当てます。次に、STAR は、空間的に解決されたポリシー目標を通じて、より強力なポリシー更新をこれらの地域に適用します。 Stable Diffusion 3.5 Medium をベース モデルとして使用し、GenEval、OCR テキスト レンダリング、PickScore の 3 つのタスクで評価します。実験結果によると、STAR は外部報酬ソースを変更することなく構成意味論的整合、テキスト レンダリング、および設定の最適化を改善し、GenEval、OCR、PickScore でそれぞれ $\mathbf{0.9759}$、$\mathbf{0.9757}$、$\mathbf{23.60}$ を達成しました。
原文 (English)
STAR: SpatioTemporal Adaptive Reward Allocation for Text-to-Image RL Post-Training
Existing RL post-training methods for text-to-image generation usually convert the final-image reward into a single scalar advantage and apply it with the same strength to the entire generative trajectory. However, text-to-image generation naturally has temporal and spatial structure: different denoising steps are responsible for different generation stages, and the content that truly determines text alignment often appears only in part of the image. This granularity mismatch makes it difficult for policy updates to focus on the generative components that actually affect the reward. To address this issue, we propose \textbf{SpatioTemporal Adaptive Reward (STAR) Allocation} for RL post-training of text-to-image diffusion and flow models. STAR uses text-image attention inside the generative model and starts from the core content that the user truly cares about in the prompt. It constructs spatial allocation maps that dynamically vary across denoising steps and rollouts, and allocates the same group-relative advantage to more relevant latent regions with almost no additional computational overhead. STAR then applies stronger policy updates to these regions through a spatially resolved policy objective. We use Stable Diffusion 3.5 Medium as the base model and evaluate on three tasks: GenEval, OCR text rendering, and PickScore. Experimental results show that STAR improves compositional semantic alignment, text rendering, and preference optimization without changing the external reward source, achieving $\mathbf{0.9759}$, $\mathbf{0.9757}$, and $\mathbf{23.60}$ on GenEval, OCR, and PickScore, respectively.
LLM 消費者行動理論: 新たな研究分野の基礎
大規模言語モデル (LLM) は、ユーザーに代わって消費に関する意思決定を行う自律エージェントとして導入されることが増えています。この変化は、伝統的に人間を主要な意思決定者としてモデル化してきた消費者理論に根本的な疑問を投げかけます。この論文では、代理店市場における消費者行動の分析に関する新しい研究分野である LLM 消費者行動理論を紹介します。私たちは、自然言語処理の最近の進歩と並行して古典経済学と行動経済学を利用して、LLM ベースのエージェントによって人間の好みがどのように反映され、それに基づいて行動されるか、またエージェントレベルの意思決定がどのように市場需要に集約されるかを形式化します。私たちは、LLM の意思決定、人間の行動シミュレーション、選好の引き出しに関するこれまで断片化されていた文献を共通の経済レンズの下で統合し、合理性や異質性などの仮定がエージェント市場で失敗する可能性がある箇所を強調します。このペーパーでは、実証的な検証を提供するのではなく、LLM 消費者行動の範囲を概説し、調整、嗜好表現、および市場力学に関連する未解決の研究疑問を特定します。
原文 (English)
LLM Consumer Behavior Theory: Foundations of a Novel Research Field
Large language models (LLMs) are increasingly deployed as autonomous agents that make consumption decisions on behalf of users. This shift raises fundamental questions for consumer theory, which has traditionally modeled humans as the primary decision-makers. In this paper, we introduce LLM Consumer Behavior Theory, a new field of study concerned with analyzing consumer behavior in agentic markets. Drawing on classical and behavioral economics alongside recent advances in Natural Language Processing, we formalize how human preferences are reflected and acted upon by LLM-based agents, and how agent-level decisions aggregate into market demand. We unify previously fragmented literature on LLM decision-making, human behavior simulation, and preference elicitation under a common economic lens, highlighting where assumptions, such as rationality and heterogeneity, may fail in agentic markets. Rather than providing empirical validation, this paper outlines the scope of LLM consumer behavior and identifies open research questions related to alignment, preference representation, and market dynamics.
LegalHalluLens: 信頼できる法律 AI のためのタイプ別幻覚監査と調整済みマルチエージェント ディベート
法的ワークフローに導入された AI システムは、指標レポートを合計すると約 52% の割合で幻覚を起こしますが、この平均ではエラーが集中する場所とエラーがどの方向に実行されるかが隠蔽され、コンプライアンス担当者は信頼できる導入に関する実用的なシグナルを得ることができなくなります。我々は、次の 3 つのコンポーネントを備えた監査フレームワークである LegalHalluLens を紹介します。CUAD に対する 4 つの法的動機に基づく請求カテゴリー (数値、時間的、義務/資格、事実) にわたる類型幻覚プロファイル (Hendrycks et al., 2021)。リスク方向指数 (RDI) は、不作為と発明のバイアスを単一の導入に匹敵するスカラーに低減します。そして、規模と方向の両方に合わせて調整された型付きの討論パイプライン。 510の契約と249,252の条項レベルのインスタンスにわたって、集計レポートで隠蔽される義務/数値クレームと一時的なクレームとの間の約38~40ppのモデル内ギャップを測定し、52%のレートが一致する2つのシステムが反対のRDIを保持できることを示しました。ディベート パイプラインは、診断を追跡するカテゴリごとのゲインにより、捏造された検出を 45% 削減し、商用 API と大幅に小さいバックボーン (4B アクティブ パラメーター) を照合します。メトリクスを非表示にする、型指定されたプロファイルと RDI サーフェス障害モード。さらに、これらの診断がマルチエージェントディベートパイプラインのキャリブレーション入力として機能し、測定された故障モードを対象とした懐疑的チャレンジと非対称ゲートが、一般的に調整されたディベートよりも優れたパフォーマンスを発揮することを示しました。このフレームワークは、実際に展開される法律 AI の方向性を意識した調達、責任、エージェントの設計をサポートします。
原文 (English)
LegalHalluLens: Typed Hallucination Auditing and Calibrated Multi-Agent Debate for Trustworthy Legal AI
AI systems deployed in legal workflows hallucinate at rates that aggregate metrics report at ~52%, but this average conceals where errors concentrate and in which direction they run, leaving compliance officers without an actionable signal for trustworthy deployment. We present LegalHalluLens, an auditing framework with three components: typed hallucination profiles across four legally-motivated claim categories (numeric, temporal, obligation/entitlement, factual) over CUAD (Hendrycks et al., 2021); a Risk Direction Index (RDI) that reduces omission-versus-invention bias to a single deployment-comparable scalar; and a typed debate pipeline calibrated to both magnitudes and directions. Across 510 contracts and 249,252 clause-level instances we measure a within-model gap of approximately 38-40 pp between obligation/numeric and temporal claims that aggregate reporting hides, and show that two systems with matched 52% rates can carry opposite RDIs. The debate pipeline reduces fabricated detections by 45% with per-category gains tracking the diagnosis, matching commercial APIs with a substantially smaller backbone (4B active parameters). Typed profiles and RDI surface failure modes that aggregate metrics hide; we further show these diagnostics serve as calibration inputs for multi-agent debate pipelines, where Skeptic challenges and asymmetric gates targeted at measured failure modes outperform generically-tuned debate. The framework supports direction-aware procurement, accountability, and agent design for legal AI deployed in the wild.
ProvenanceGuard: MCP ベースの LLM エージェントのソース認識事実検証
ツールを使用する LLM エージェントは、検索、API、データベース、臨床記録、処方ツールなどの異種の証拠ソースから回答するために、モデル コンテキスト プロトコル (MCP) を使用することが増えています。標準的な事実性メトリクスは、通常、答えがプールされた証拠によって裏付けられているかどうかをテストし、出所に依存する失敗モードを見逃します。つまり、主張は間違った情報源に起因しているにもかかわらず、どこかで裏付けられている可能性があります。これをクロスソースの統合と呼びます。 MCP に基づいた回答のためのソース認識検証ツールである ProvenanceGuard を紹介します。安定したツール ID、ソース ID、生の出力を含むキャプチャされた MCP トレースを消費します。回答を原子的な主張に分解します。主張を情報源固有の証拠にルーティングする。 NLI とトークン アライメント プロキシのサポートを確認します。指定された帰属とルーティングされたソースを比較します。そして、クレームごとの判定と回答レベルの許可/ブロックの決定を返します。ブロックされた回答は、検索拡張された回答改訂によって修復し、再検証することができます。 281 の医療ドメイン MCP エージェント トレースを評価します。 266 トレースの裁定サブセットから、トレースごとに分割された 2,325 個の LLM 支援クレーム ラベルが生成されます。 361 枚のラベルは人間によって検証されています。 40 トレース ホールドアウト スプリットでは、ProvenanceGuard は 260 のソース適格クレームでブロック F1 0.802 とソース精度 0.858 を達成し、クレーム対ソース ID を発行しないソース ブラインド ベースラインを上回りました。より厳しい複数ソースのベンチマークでは、ブロック F1 0.846 に達しますが、ソースと関係の精度は 0.229 に低下します。これは、意味的に近いソースでは正確なソースの所有権が依然として難しいことを示しています。修復と再検証は、多くの場合保守的なフォールバックを介して、完全なトレース セット内のすべてのブロックされた回答を解決します。 ProvenanceGuard は、50 の制御された臨床混合プローブで、間違った属性を保持せずに、注入されたすべての属性のスワップを検出します。これらの結果は、MCP ベースのエージェントにおける事実検証において、出典の帰属が独立した軸であることを示しています。
原文 (English)
ProvenanceGuard: Source-Aware Factuality Verification for MCP-Based LLM Agents
Tool-using LLM agents increasingly use the Model Context Protocol (MCP) to answer from heterogeneous evidence sources, including search, APIs, databases, clinical records, and formulary tools. Standard factuality metrics usually test whether an answer is supported by pooled evidence, missing a provenance-sensitive failure mode: a claim may be supported somewhere while being attributed to the wrong source. We call this cross-source conflation. We introduce ProvenanceGuard, a source-aware verifier for MCP-grounded answers. It consumes captured MCP traces with stable tool IDs, source IDs, and raw outputs; decomposes answers into atomic claims; routes claims to source-specific evidence; checks support with NLI and a token-alignment proxy; compares stated attribution with the routed source; and returns per-claim verdicts plus an answer-level allow/block decision. Blocked answers can be repaired with retrieval-augmented answer revision and re-verified. We evaluate on 281 medical-domain MCP-agent traces. A 266-trace adjudicated subset yields 2,325 LLM-assisted claim labels split by trace; 361 held-out labels are human-verified. On the 40-trace held-out split, ProvenanceGuard achieves block F1 0.802 and source accuracy 0.858 over 260 source-eligible claims, outperforming source-blind baselines that do not emit claim-to-source IDs. On a harder multi-source benchmark it reaches block F1 0.846, while source-plus-relation accuracy drops to 0.229, showing that exact source ownership remains difficult with semantically close sources. Repair-and-reverify resolves all blocked answers in the full trace set, often via conservative fallback. In 50 controlled clinical conflation probes, ProvenanceGuard detects all injected attribution swaps with no retained wrong attribution. These results show that source attribution is an independent axis for factuality verification in MCP-based agents.
PseudoBench: エージェント自動研究がどのように疑似科学を促進するかを測定する
大規模言語モデルに基づいたエージェントが自律的な科学研究に参入するにつれて、疑似科学に抵抗するエージェントの能力がますます重要になります。そうしないと、そのようなシステムは、学術文献を汚染し、科学への信頼を損なう、もっともらしいが誤解を招く研究を急速に生成する可能性があります。我々は、エージェント自動調査システムが疑似科学の物語を特定し、抵抗できるかどうかを評価するための敵対的ベンチマークである PseudoBench を紹介します。 PseudoBench には、5 つのドメインにわたる 200 の厳選された疑似科学の主張と証拠のペアが含まれており、実験から執筆までのエンドツーエンドの研究パイプラインを通じてエージェントを評価します。 7 つの最先端のエージェントをテストしたところ、現在のシステムは疑似科学の前提に沿った説得力のあるレポートを容易に生成し、拒否率はほぼゼロで、最も高い抵抗もわずか 27.4% であることがわかりました。より強力なエージェントは、疑似科学をより洗練された科学言語でパッケージ化し、その見かけ上の信頼性を高める危険性があります。これらの発見は、疑似科学を促進する驚くべき能力を明らかにしており、広範囲に展開する前に科学的調整が求められています。
原文 (English)
PseudoBench: Measuring How Agentic Auto-Research Fuels Pseudoscience
As Large Language Model based agents enter autonomous scientific research, their ability to resist pseudoscience becomes increasingly important. Otherwise, such systems may rapidly generate plausible yet misleading studies that contaminate academic literature and erode trust in science. We present PseudoBench, an adversarial benchmark for evaluating whether agentic auto-research systems can identify and resist pseudoscientific narratives. PseudoBench contains 200 curated pseudoscientific claim-evidence pairs across five domains and evaluates agents through an end-to-end research pipeline from experiments to writing. Testing seven state-of-the-art agents, we find that current systems readily produce persuasive reports that align with pseudoscientific premises with near-zero refusal rates and the highest resistance of only 27.4%. Stronger agents risk packaging pseudoscience in more sophisticated scientific language, increasing its apparent credibility. These findings reveal an alarming capacity to fuel pseudoscience, calling for scientific alignment before widespread deployment.
医療アプリケーションにおける早期診断の引き継ぎと無音の幻覚を軽減するための Agentic AI ベースのフレームワーク
大規模言語モデル (LLM) とマルチエージェント システムの最近の進歩により、エージェントティック AI の台頭が促進され、医学的推論の可能性が示されています。しかし、オープンエンドの会話型エージェントは、依然として 2 つの重大な障害モードに陥りやすい傾向があります。それは、時期尚早の診断の引き継ぎと、患者に到達する前に検出されない可能性のある無言の臨床幻覚です。この研究では、「裁判官としての LLM」ルーティングを決定論的なオーケストレーション制約に置き換えることによって、両方の問題に対処するマルチエージェント フレームワークを提案します。このフレームワークには 2 つの安全機構が組み込まれています。まず、神経象徴的な状態追跡ゲートは、必要なすべての次元が収集されるまで診断の移行をブロックすることにより、OLDCARTS 臨床プロトコル (発症、場所、期間、性格、増悪/緩和因子、放射線、タイミング、重症度) の完全性を強制します。 2 番目に、認識的不確実性定量化 (UQ) ゲートは、K=5 個の独立した診断サンプルにわたる意味論的エントロピー (H) を計算し、配信前に発散出力を識別して遮断します。 150 のテスト ケースで、llama-3.1-70b-instruct モデルを利用したシミュレートされた患者エージェントを使用してシステムを評価します。完全なアーキテクチャは 49.3% の診断精度を達成しており、制約のないベースラインと比べて 11.3 パーセント ポイントの絶対的な改善を示しています。さらに、OLDCARTS の完全性 (\sigma) と意味論的エントロピー (H) の間に統計的に有意な負の相関 (r = -0.181、p < 0.05) が観察され、構造化された情報収集が診断の不確実性の低減と関連していることが示唆されます。
原文 (English)
Agentic AI-based Framework for Mitigating Premature Diagnostic Handoff and Silent Hallucination in Healthcare Applications
Recent advances in Large Language Models (LLMs) and multi-agent systems have driven the rise of Agentic AI, showing promise for medical reasoning. However, open-ended conversational agents remain prone to two critical failure modes: premature diagnostic handoff and silent clinical hallucinations that may go undetected before reaching the patient. In this work, we propose a multi-agent framework that addresses both issues by replacing ``LLM-as-a-judge'' routing with deterministic orchestration constraints. The framework incorporates two safety mechanisms. First, a neuro-symbolic state-tracking gate enforces completeness of the OLDCARTS clinical protocol (Onset, Location, Duration, Character, Aggravating/Alleviating factors, Radiation, Timing, and Severity) by blocking diagnostic transitions until all required dimensions are collected. Second, an epistemic uncertainty quantification (UQ) gate computes semantic entropy (H) across K=5 independent diagnostic samples to identify and intercept divergent outputs before delivery. We evaluate the system using simulated patient agents powered by the llama-3.1-70b-instruct model on 150 test cases. The full architecture achieves 49.3% diagnostic precision, representing an absolute improvement of 11.3 percentage points over an unconstrained baseline. Additionally, we observe a statistically significant negative correlation (r = -0.181, p < 0.05) between OLDCARTS completeness (\sigma) and semantic entropy (H), suggesting that structured information gathering is associated with reduced diagnostic uncertainty.
コンテキストと関係を認識したグラフ検索拡張生成のための統合フレームワーク
検索拡張生成 (RAG) は、外部知識を使用して大規模言語モデル (LLM) を強化するためのパラダイムとして登場しましたが、既存のグラフベースの手法は根本的な制限に直面しています。エンティティ中心およびチャンク中心のアプローチは、真の知識の融合なしに、元のテキストに固定された表現で動作します。エンティティ中心のメソッドは論理的に関連するコンテンツを接続し、チャンク中心のメソッドはコンテキストを保持しますが、どちらも類似性検索を通じて情報を個別に取得するため、合成からの創発的な理解が失われます。この論文では、文脈情報と関係情報を真に統合する要約の構築、検索中に新たな知識にアクセスするためのこれらの合成表現の活用、動的コーパスの階層構造の効率的な更新という 3 つの中核的な課題に対処することにより、ソース文書を超越する階層グラフ RAG フレームワークである HyGRAG を提案します。具体的には、チャンク ノードとエンティティ ノードの両方を含むハイブリッド グラフ上に階層インデックス構造を設計し、それらを繰り返しクラスター化し、LLM ベースの要約を生成します。次に、コミュニティのメンバーシップを通じて拡張しながら、すべての抽象レベルにわたって検索する、コンテキストと関係を意識した検索を設計します。さらに、ローカルな再要約のみを備えた添付ファイルベースのアルゴリズムを通じて、動的な知識の更新を可能にします。実験結果は、HyGRAG が妥当な効率を維持しながら、マルチホップ推論タスクの平均精度を 9.7% 向上させることを示しています。
原文 (English)
A Unified Framework for Context-Aware and Relation-Aware Graph Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) has emerged as a paradigm for enhancing large language models (LLMs) with external knowledge, yet existing graph-based methods face a fundamental limitation: entity-centric and chunk-centric approaches operate on representations anchored to original text without true knowledge fusion. While entity-centric methods connect logically related content and chunk-centric methods preserve context, both retrieve information separately through similarity search, missing emergent understanding from their synthesis. In this paper, we propose HyGRAG, a hierarchical graph RAG framework that transcends source documents by addressing three core challenges: constructing summaries that genuinely integrate contextual and relational information, leveraging these synthesized representations to access emergent knowledge during retrieval, and efficiently updating hierarchical structures for dynamic corpora. Specifically, we design hierarchical index structures over hybrid graphs with both chunk and entity nodes, then iteratively cluster them and generate LLM-based summaries. Then, we design context and relation-aware retrieval that searches across all abstraction levels while expanding through community membership. Moreover, we enable dynamic knowledge update through attachment-based algorithms with only local re-summarization. Experimental results show that HyGRAG improves the average accuracy of multi-hop reasoning tasks by 9.7%, while maintaining reasonable efficiency.
IsabeLLM: コンセンサスを正式に検証するために適用される自動化された定理証明
人工知能 (AI) の進歩により、定理証明用 AI は、コンピューター システムを正式に検証する有望な手段となりました。正式な検証は、多くの専門知識と労力が必要となるため、伝統的に安全性が重要なシステムに限定されてきましたが、AI はこのワークロードの大量を自動化し、はるかにアクセスしやすくするのに役立ちます。ブロックチェーンベースのシステムはますます人気が高まっており、悪意のある攻撃者の標的となることが多く、巨額の経済的損失をもたらすことが多く、これらのシステムをより適切に検証し、脆弱性を軽減する必要性が浮き彫りになっています。おそらく、これらのシステムの最も重要なコンポーネントはコンセンサス プロトコルです。コンセンサス プロトコルにより、潜在的に敵対的な環境でノードが意思決定に同意できるようになります。この論文では、Isabelle の自動定理証明ツールである IsabeLLM を改良します。つまり、大規模言語モデルに提供されるコンテキストを改善するために、検索拡張生成フレームワーク、エラー追跡、反例生成を実装します。 Isabelle および Sledgehammer の最新バージョンとの互換性も実装され、効率が向上します。ビットコインの Proof of Work コンセンサスの検証を完了する能力に関して、IsabeLLM の 2 つのバージョンのパフォーマンスを比較します。
原文 (English)
IsabeLLM: Automated Theorem Proving Applied to Formally Verifying Consensus
Advances in Artificial Intelligence (AI) have led AI for Theorem Proving to become a promising means of formally verifying computer systems. Whilst formal verification is traditionally reserved for safety-critical systems due to the required amount of expertise and effort, AI can help to automate a large amount of this workload and make it far more accessible. Blockchain-based systems are becoming increasingly popular and are frequently targeted by malicious actors, often resulting in huge financial losses, highlighting the need to better verify these systems and mitigate vulnerabilities. Arguably the most important component of these systems is the consensus protocol, which allows nodes to agree on decisions in a potentially adversarial environment. In this paper, we improve upon IsabeLLM, the automated theorem proving tool in Isabelle. Namely, we implement a Retrieval-Augmented Generation framework, Error tracing and counterexample generation for improved context supplied to the Large Language Model. Compatibility with the latest version of Isabelle and Sledgehammer is also implemented for improved efficiency. We compare the performance of the two versions of IsabeLLM in their ability to complete the verification of Bitcoin's Proof of Work consensus.
適切な教師を信頼する: GUI グラウンディングのための品質を意識した自己蒸留
グラフィカル ユーザー インターフェイス (GUI) の基礎には、高解像度スクリーンショット内の小さなターゲット要素を識別し、正確な画面座標を予測するためのビジョン言語モデル (VLM) が必要です。オンポリシー自己蒸留 (OPSD) は、ハード座標ラベルを超えた高密度のトークンレベルの教師信号を提供するため、この座標に依存するタスクに対するトレーニング後のアプローチとして有望です。ただし、単純な OPSD は GUI の基礎にはあまり適していません。OPSD は生徒が生成したプレフィックスに基づいて教師を評価しますが、プレフィックスがターゲット座標からすでに逸脱している場合、座標トークンの教師信号の品質が低下する可能性があり、教師信号の信頼性が低くなります。これを軽減するために、VLM ベースの GUI グラウンディングのための品質を意識した自己蒸留を提案します。これにより、ソフトコレクトネスを意識したゲーティングと教師確率スケーリングを通じて、座標トークンの教師信号の品質が向上します。ソフト正確性認識ゲートは、教師の現在の座標トークン予測が、生徒が生成したプレフィックスの下のグラウンドトゥルース ボックスにまだ入力できるかどうかをチェックします。そうでない場合、対応する教師信号は重み付けが低くなります。次に、教師の確率スケーリングでは、教師の信頼度を軽量要素として使用して、ゲート付き監視の強度をさらに調整します。重要な経験的発見は、どちらのコンポーネントも単独では全体的なパフォーマンスを向上させないが、それらを組み合わせると一貫してパフォーマンスが向上するということです。これは、2 つのメカニズムが補完的な役割を果たすことを示唆しています。正確性を意識したゲーティングは信頼性の低い座標トークンの監視を抑制し、教師確率スケーリングは残りの信号の強度を調整します。 6 つの GUI グラウンディング ベンチマークにわたる実験では、私たちの手法がベース モデルを一貫して改善し、強力なベースラインを上回るパフォーマンスを示していることが示されています。
原文 (English)
Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
Graphical user interface (GUI) grounding requires vision-language models (VLMs) to identify small target elements in high-resolution screenshots and predict precise screen coordinates. On-policy self-distillation (OPSD) is a promising post-training approach for this coordinate-sensitive task, since it provides dense token-level teacher signals beyond hard coordinate labels. However, naive OPSD is not well suited to GUI grounding: OPSD evaluates the teacher on student-generated prefixes, the quality of coordinate-token teacher signals can degrade when the prefix has already deviated from the target coordinate, leading to unreliable teacher signal. To mitigate this, We propose quality-aware self-distillation for VLM-based GUI grounding, which improves coordinate-token teacher-signal quality through soft correctness-aware gating and teacher-probability scaling. The soft correctness-aware gate checks whether the teacher's current coordinate-token prediction can still be completed into the ground-truth box under the student-generated prefix. If not, the corresponding teacher signal is down-weighted. Teacher-probability scaling then uses the teacher's confidence as a lightweight factor to further calibrate the strength of the gated supervision. A key empirical finding is that neither component alone improves overall performance, whereas combining them consistently improves performance. This suggests that the two mechanisms play complementary roles: correctness-aware gating suppresses unreliable coordinate-token supervision, while teacher-probability scaling calibrates the strength of the remaining signals. Experiments across six GUI grounding benchmarks show that our method consistently improves the base model and outperforms strong baselines.
第一校正第二バッチ
研究レベルの数学問題を正しく解決する現在の AI システムの能力を評価するために、私たちはさまざまな数学分野の 10 個の問題のセットでいくつかの AI システムをテストしました。これらの問題は、寄稿者の研究過程で自然に発生しました。この文書には、問題、方法論、テストの結果が含まれています。人間によるソリューション、AI によって生成されたソリューション、AI によって生成されたソリューションの審査員レポートとログなどの補足ドキュメントへのリンクが提供されます。 10 の問題は次の数学者によって提供されました: (1) Dariusz Kaloci\'nski と Theodore A. Slaman、(2) Richard Schwartz、(3) Aleksa Milojevic と Benny Sudakov、(4) Larry Guth、(5) Oleg Butkovsky、Jonathan Mattingly、Lorenzo Zambotti、(6) Joshua Evan Greene と Duncan McCoy、 (7) スチャリット・サーカール、(8) サム・ペインとジドン(ジェイデン)・ワン、(9) シルヴィー・コーティールとジョン・レントファー、(10) シュリヴァツァフ・クンナワルカム・エラヤヴァリ。
原文 (English)
First Proof Second Batch
To assess the ability of current AI systems to correctly solve research-level mathematics problems, we tested several AI systems on a set of ten problems in a broad range of mathematical fields; these problems arose naturally in the research process of the contributors. This document includes the problems, our methodology, and the results of our testing. We provide links to supplementary documents including the human solutions, the AI-generated solutions, and the referee reports and logs for the AI-generated solutions. The ten problems were contributed by the following mathematicians: (1) Dariusz Kaloci\'nski and Theodore A. Slaman, (2) Richard Schwartz, (3) Aleksa Milojevic and Benny Sudakov, (4) Larry Guth, (5) Oleg Butkovsky, Jonathan Mattingly, and Lorenzo Zambotti, (6) Joshua Evan Greene and Duncan McCoy, (7) Sucharit Sarkar, (8) Sam Payne and Jidong (Jayden) Wang, (9) Sylvie Corteel and John Lentfer, (10) Srivatsav Kunnawalkam Elayavalli.
メタ強化学習における知識の再利用
メタ強化学習は、関連するタスクから共有構造を抽出することで迅速な適応を可能にしますが、既存のエンドツーエンドの方法ではタスク推論と実施形態固有の制御を組み合わせることがよくあります。この結合により、ノンパラメトリックなタスクのセマンティクスがわかりにくくなり、サンプル効率が低下し、エージェント間の再利用が制限される可能性があります。我々は、ダイナミクスを簡略化したエージェントに関するタスクレベルの知識を学習し、それを異種エージェントに転送するメタ知識再利用フレームワークを提案します。このフレームワークは、潜在タスク モードと高レベルのポリシーを編成する前にベイジアン ノンパラメトリックを使用して、タスク レベルのマグニチュード ガイダンスを生成します。再利用可能なタスクの知識をさまざまな実施形態に橋渡しするために、セマンティックマグニチュードインターフェイスと軽量の時間アダプターを導入します。これらは、凍結されたメタ知識を、実施形態固有の低レベルコントローラー用に時間的に調整されたサブ目標に変換します。複数の移動エージェントに関する実験では、私たちのフレームワークが、最近の最先端のベースラインと比較して、最終ステップの追跡エラーを 94.75% ~ 99.79% 削減し、インタラクション データの約 23.8% で同等の展開パフォーマンスを達成していることが示されています。
原文 (English)
Knowledge Reutilization in Meta-Reinforcement Learning
Meta-reinforcement learning enables fast adaptation by extracting shared structure from related tasks, but existing end-to-end methods often couple task inference with embodiment-specific control. This coupling can obscure non-parametric task semantics, reduce sample efficiency, and limit cross-agent reuse. We propose a meta-knowledge reutilization framework that learns task-level knowledge on a dynamics-simplified agent and transfers it to heterogeneous agents. The framework uses a Bayesian non-parametric prior to organize latent task modes and a high-level policy to generate task-level magnitude guidance. To bridge reusable task knowledge with different embodiments, we introduce a semantic-magnitude interface and a lightweight temporal adaptor, which convert frozen meta-knowledge into temporally aligned subgoals for embodiment-specific low-level controllers. Experiments on multiple locomotion agents show that our framework reduces final-step tracking error by 94.75% -- 99.79% compared with recent state-of-the-art baselines and achieves comparable deployment performance with about 23.8% of their interaction data.
AI 旅行代理店が闘牛を予約してくれる: フロンティア AI モデルにおける暗黙の動物福祉のエージェントベンチマーク
AI エージェントはアドバイザーからアクターに移行し、ユーザーに代わって旅行を予約し、メニューを計画し、調達を実行します。 AI と動物福祉の既存のベンチマークは、質問と回答のプロンプトに対するモデルのテキスト応答を評価しますが、それらの応答で表面化した福祉推論が、モデルがツールを使用してアクションを実行する必要があるエージェント展開に移行するかどうかは未解決のままです。 AI エージェントがユーザーに代わって行動する際に動物搾取を伴うオプションを回避するかどうかを測定する初のエージェント ベンチマークである TAC (Travel Agent Compassion) を紹介します。 TAC は、動物搾取の 6 つのカテゴリにわたる 12 の手書きの旅行予約シナリオを AI エージェントに提示します。これは、価格、評価、位置の交絡を制御するために 48 のサンプルに拡張されています。私たちは 4 つの研究室からの 7 つのフロンティア モデルを評価します。すべてのモデルのスコアはチャンス レベルの 64 パーセントを下回り、最高のパフォーマンスを発揮するモデル (Claude Opus 4.7) のスコアは 53 パーセントです。システム プロンプト内の福祉を意識した一文で、Claude と GPT-5.5 では 47 ~ 63 パーセント ポイント、GPT-5.2 では 26 ポイント、DeepSeek と Gemini では 12 ポイント未満の向上が見られます。 Gemini 2.5 Flash Lite を判定者として使用して、上位 2 つのパフォーマーからの 288 件の基本条件のトランスクリプトを対象とした補助的な Inspect Scout 監査では、評価認識のトランスクリプトがゼロであるとフラグが立てられ、可能性を下回る率が評価を認識するモデルに起因するものではないことが示唆されています。文化的ドメイン間のカテゴリレベルの変動の影響、テキスト応答福祉ベンチマークの限界、および EU 汎用 AI 実践規範のシステミック リスク フレームワークについて議論します。
原文 (English)
Your AI Travel Agent Would Book You a Bullfight: An Agentic Benchmark for Implicit Animal Welfare in Frontier AI Models
AI agents are moving from advisors to actors, booking travel, planning menus, and running procurement on behalf of users. Existing benchmarks for AI and animal welfare evaluate model text responses to question-answer prompts, leaving open whether the welfare reasoning surfaced in those responses transfers to agentic deployment where the model must take actions with tools. We introduce TAC (Travel Agent Compassion), the first agentic benchmark measuring whether AI agents avoid options involving animal exploitation when acting on behalf of users. TAC presents an AI agent with twelve hand-authored travel booking scenarios across six categories of animal exploitation, augmented to forty-eight samples to control for price, rating, and position confounds. We evaluate seven frontier models from four labs. Every model scores below the chance level of sixty-four percent, with the best performer (Claude Opus 4.7) at fifty-three percent. A single welfare-aware sentence in the system prompt yields gains of forty-seven to sixty-three percentage points in Claude and GPT-5.5, twenty-six points in GPT-5.2, and under twelve points in DeepSeek and Gemini. An auxiliary Inspect Scout audit of 288 base-condition transcripts from the top two performers, using Gemini 2.5 Flash Lite as judge, flags zero transcripts for evaluation awareness, suggesting the below-chance rates do not stem from the models recognising the evaluation. We discuss implications for category-level variation across cultural domains, the limits of text-response welfare benchmarks, and the EU General-Purpose AI Code of Practice systemic risk framework.
浪費する資産としてのメモリ: 肉体を持つエージェントのフラッシュ耐久性の価格設定とその限界
ロボットのフラッシュ耐久性は再生不可能なストックです。永続的な書き込みはすべて、数千回のプログラム/消去サイクルのうちの 1 つを費やし、再充填されることはありません。しかし、フィールド化されたロボット メモリ システムでは、どのメモリが消去サイクルに値するかを価格で判断することはできません。私たちは、エンボディディング メモリを減価償却資本として扱い、単一の耐久シャドープライス $\eta$ で在庫の価格を設定します。これにより、RAM / オンボード NVM / クラウド階層全体でコストを最小限に抑えた配置が、ウェアオーグメントされたバイト単位のインデックスのしきい値となります。インデックスは、値と書き込みの関連付け $\chi$ の符号が何であれ、コストが最適です。 $\chi > 0$ の場合にのみ、最適な非単調な変化が行われ、ロボットの最も貴重な記憶がフラッシュから送信されます。したがって、ピボットは経験的なものであり、事前に指定されたゲートで実際のロボットのログで $\chi$ を測定します。その符号は展開体制の特性です。反復的な長期ホライズン操作 ($\hat{\chi} \about +1.0 \times 10^{-3}$、フルパワーで複製) では正、より短いホライズン スイートでは null、非反復的遠隔操作では負です。結果の範囲は 2 つの境界によって決まります。耐久性の予算は、データシート価格のプレミアム 3,000 P/E TLC では休止状態にあり、安価なエッジ ロボットが実行するコモディティ QLC/eMMC ($\sim$1,000 P/E) に拘束されます。そして、学習されたウェアアウェア コントローラーは、実現される価値が RAM、NVM、クラウド全体で層によって不変であるため、学習されたウェアアウェア コントローラーはタスクの価値に価格ベースのルーティングのみを結び付けます。レントは、タスクのパフォーマンスではなく、デバイスの寿命とコストを支配します。ウェアアウェア配置がタスク値を改善するかどうかは未解決のままです -- $\chi$ は値プロキシに対して測定され、非単調な最適値は証明されていますが、データではまだ観察されていません。
原文 (English)
Memory as a Wasting Asset: Pricing Flash Endurance for Embodied Agents, and the Limits of Doing So
A robot's flash endurance is a non-renewable stock: every persisted write spends one of a few thousand program/erase cycles and never refills, yet no fielded robot memory system prices which memories are worth an erase cycle. We treat embodied memory as depreciating capital and price that stock with a single endurance shadow price $\eta$, which makes cost-minimizing placement across a RAM / on-board NVM / cloud hierarchy a threshold in a wear-augmented per-byte index. The index is cost-optimal whatever the sign of the value-write association $\chi$; only when $\chi > 0$ does the optimum turn non-monotone, sending a robot's most valuable memories off its flash. The pivot is thus empirical, and we measure $\chi$ on real robot logs at a pre-specified gate: its sign is a property of the deployment regime -- positive on recurrent long-horizon manipulation ($\hat{\chi} \approx +1.0 \times 10^{-3}$, replicated at full power), null on a shorter-horizon suite, and negative on non-recurrent teleoperation. Two boundaries scope the result. The endurance budget is dormant on premium 3,000-P/E TLC at datasheet prices and binding on the commodity QLC/eMMC ($\sim$1,000 P/E) that cheaper edge robots run. And where it binds, a learned wear-aware controller only ties price-based routing on task value, because realized value is tier-invariant across RAM, NVM, and cloud: the rent governs device lifetime and cost, not task performance. Whether wear-aware placement improves task value remains open -- $\chi$ is measured against a value proxy, and the non-monotone optimum, while proven, is not yet observed in data.
WEQA: クエリ適応型エージェント推論によるウェアラブル hEalth 質問応答
言語モデルは医療上の質問に答える能力が著しく高く、場合によっては一般の医師の精度を上回ります。しかし、これらのユビキタスセンサーは連続的で高次元の長期的なデータを生成するため、ウェアラブル健康データに関する質問に答えることは依然として困難であり、研究も不足しています。LLM の事前トレーニングでテキスト中心の分布と一致させるのは自明ではありません。センサーのモダリティとユーザーの意図の多様性は、固定された推論ワークフローや単一の事前トレーニングされた基礎モデルでは効果的に処理できません。これらの課題に対処するために、LLM 推論と専用のウェアラブル分析およびモデリング ツールを統合するクエリ適応エージェント フレームワークである WEQA を提案します。 LLM コントローラーを使用して、実行計画を合成し、センサー分析と事前トレーニングされたモデルの適切な組み合わせに各クエリを動的にルーティングし、外部の知識を使用して根拠のある応答監査を実行します。また、3 つの異なる健康ドメインにおける分析タスクと予測タスクで構成される 4 つのオープン ウェアラブル データセットにわたるベンチマークも厳選しています。実験では、当社のフレームワークが LLM および薬剤ベースラインより 24% 正確であることが示されており、12 人の医療専門家と 8 人のユーザーによる盲検研究では、有用性と臨床的健全性が大幅に向上していることが示されています。
原文 (English)
WEQA: Wearable hEalth Question Answering with Query-Adaptive Agentic Reasoning
Language models are remarkably capable at medical question answering, in some cases surpassing the accuracy of general physicians. However, answering questions about wearable health data remains challenging and understudied, as these ubiquitous sensors produce continuous, high-dimensional, and longitudinal data, which is non-trivial to align with text-centric distributions in LLM pretraining. The diversity of sensor modalities and user intents cannot be effectively handled by a fixed reasoning workflow or a single pretrained foundation model. To address these challenges, we propose WEQA, a query-adaptive agent framework that unifies LLM reasoning with specialized wearable analytical and modeling tools. An LLM controller is employed to synthesize execution plans and dynamically route each query to the appropriate combination of sensor analysis and pretrained models, and perform grounded response auditing with external knowledge. We also curate a benchmark spanning four open wearable datasets comprising analytic and predictive tasks in three different health domains. Experiments show that our framework is 24% more accurate than LLM and agentic baselines, and a blinded study with 12 medical experts and 8 users shows substantial gains in usefulness and clinical soundness.
ハイブリッド構造のエージェント的発見を通じて心臓電気生理学のデジタルツインを学ぶ
パーソナライズされた心臓電気生理学 (EP) デジタル ツインを構築するには、単にパラメーターをフィッティングするだけでなく、各患者に適切なモデル構造を特定する必要があります。従来の方法では、物理学とニューラルのハイブリッド アーキテクチャを手動で処方する専門家に依存していましたが、これには深い分野の専門知識が必要であり、患者間での伝達は行われませんでした。最近の研究では、大規模言語モデル (LLM) を適用して、ハイブリッド モデルを生成したり、ハイブリッド モデルとして機能させたりしています。ただし、これらの LLM ベースの手法は、有望な一般化能力にもかかわらず、安定した心臓シミュレーションに必要な構造事前分布が不足しています。したがって、心臓 EP ドメインの知識を構造化されたアクション空間として定式化し、ハイブリッド モデルを発見するために LLM エージェントを利用するフレームワークである LEADS を提案します。エージェントは、反復的な推論とアクションのループに従ってハイブリッド モデルを選択、結合、改良し、同時に勾配降下法でパラメーターのフィッティングを処理します。提案された LEADS は、無制限のアーキテクチャ発見を可能にしながら、物理的に根拠があり、解釈可能で、数値的に安定するようにすべての候補モデルを設計します。私たちは、3 つのグラウンドトゥルース反応モデルを使用した合成データと実際の心臓 EP データで LEADS を検証し、人間が設計したハイブリッド モデルと他の LLM ベースのハイブリッド モデリングの両方よりも優れていることを実証しました。
原文 (English)
Learning Cardiac Electrophysiology Digital Twins Through Agentic Discovery of Hybrid Structure
Building personalized cardiac electrophysiology (EP) digital twins requires identifying the appropriate model structure for each patient, not merely fitting parameters. Traditional methods rely on experts to manually prescribe hybrid physics-neural architectures, which requires deep domain expertise and does not transfer across patients. Recent works have applied large language models (LLMs) to generate or act as hybrid models. However, despite their promising generalization capacity, these LLM-based methods lack the structural priors needed for stable cardiac simulations. Hence, we propose LEADS, a framework that formulates cardiac EP domain knowledge as a structured action space and utilizes an LLM agent to discover hybrid models. The agent follows an iterative reasoning-and-action loop to select, combine, and refine hybrid models, whilst gradient descent handles parameter fitting. The proposed LEADS designs every candidate model towards physically grounded, interpretable, and numerically stable, while allowing open-ended architectural discovery. We validate LEADS on synthetic data with three ground-truth reaction models and on real cardiac EP data, demonstrating that it outperforms both human-designed hybrid models and other LLM-based hybrid modeling.
DRFLOW: パーソナライズされたワークフロー予測のためのディープリサーチベンチマーク
ディープリサーチ (DR) システムは、複雑な情報探索タスクにますます使用されていますが、既存の作業は主にレポートと概要の生成に焦点を当てています。対照的に、多くのエンタープライズ タスクでは、エージェントが一連のアクション ステップである具体的なワークフローを識別する必要があります。たとえば、エージェントは予算編成ポリシーを要約するのではなく、「固定予算で新しい人員をどのようにリクエストすればよいですか?」などの質問に答えるために必要な手順を決定できる必要があります。したがって、異種ソースからエージェントによって予測されたパーソナライズされたワークフローを評価するためのベンチマークである DRFLOW を紹介します。各タスクでは、エージェントが散在するソースから関連する証拠を特定し、その証拠を使用してユーザーのタスクの正しいアクション ステップ シーケンスを予測する必要があります。 DRFLOW には 5 つのドメインにわたる 100 のタスクが含まれており、3,900 以上のソースに基づいた 1,246 の参照ワークフロー ステップが含まれています。私たちは、事実の根拠付け、ステップ回復、構造的順序付け、状態の解決、パーソナライゼーションをカバーする 7 つの診断指標を定義します。さらに、パーソナライズされたワークフローを予測するためのワークフロー指向のリファレンス エージェントである DRFLOW-Agent (DRFA) も紹介します。 DRFA は強力なベースライン エージェント (最大 10.02% の平均 F1 スコア) に比べて改善していますが、これらのワークフロー メトリクスには大幅な改善の余地が残っており、完全で正確なパーソナライズされたワークフローを予測することは、依然として深い研究にとって困難なフロンティアであることを示しています。
原文 (English)
DRFLOW: A Deep Research Benchmark for Personalized Workflow Prediction
Deep research (DR) systems are increasingly used for complex information-seeking tasks, but existing works mainly focus on generating reports and summaries. In contrast, many enterprise tasks instead require an agent to identify concrete workflows which is a sequence of action-steps. For example, rather than summarizing budgeting policies, an agent should be able to determine the steps needed to answer a question such as: "How do I request new headcount given a fixed budget?". Therefore, we introduce DRFLOW, a benchmark for evaluating personalized workflows predicted by agents from heterogeneous sources. Each task requires the agent to identify relevant evidence from scattered sources, then use that evidence to predict the correct action-step sequence for the user's task. DRFLOW contains 100 tasks across five domains, with 1,246 reference workflow steps grounded in more than 3,900 sources. We define seven diagnostic metrics covering factual grounding, step recovery, structural ordering, condition resolution, and personalization. We further present DRFLOW-Agent (DRFA), a workflow-oriented reference agent to predict personalized workflow. We show that although DRFA improves over strong baseline agents (upto 10.02% average F1 score), there is substantial room for improvement remains across these workflow metrics, indicating that predicting complete and correct personalized workflows remains a challenging frontier for deep research.
スタンフォード EDGAR 提出データセット: 米国の企業および財務開示情報をレイアウトに忠実でトークン効率の高い事前トレーニング データに再構築する
高品質のパブリック Web コーパスがますます枯渇するにつれ、きれいなロングコンテキストのドキュメントが、大規模言語モデル (LLM) のトレーニング データの希少かつ高価なソースになりました。既存の長いコンテキストのコーパスは、多くの場合、独自のものであり、取得するのにコストがかかり、合成的に生成されたり、プログラミングなどの狭い領域に集中したりしています。金融言語のモデリングと評価のために、SEC 提出書類をレイアウトに忠実な MultiMarkdown にオープンに再構築した Stanford EDGAR Filings Dataset (SEFD) を紹介します。 SEFD は、監査済みの財務諸表、リスク開示、所有権報告書、会計ノート、市場を動かすイベントの報告書を、長期コンテキストの事前トレーニング データとして、また財務上の推論、予測、コンプライアンス、文書理解の基礎として使用できるようにします。結果として得られるコーパスはトークン効率が高く、モデルの準備ができており、Common Crawl から派生したコーパスとの重複は 0.1% 未満です。私たちは、152B トークンの初期公開スナップショットである SEFD-v1 をリリースし、550B トークンと推定される大規模な 1850 万ファイルのアーカイブのコーパス レベルの分析を提供します。さらに、SEFD 由来の 2 つのベンチマークを紹介します。EDGAR-Forecast は、モデル知識のカットオフ後のファイリングに基づいた数値予測を評価します。もう 1 つは、複雑な財務表の転記を評価する EDGAR-OCR です。
原文 (English)
The Stanford EDGAR Filings Dataset: Reconstructing U.S. Corporate and Financial Disclosures into Layout-Faithful and Token-Efficient Pretraining Data
As high-quality public web corpora become increasingly exhausted, clean long-context documents have become a scarce and expensive source of training data for large language models (LLMs). Existing long-context corpora are often proprietary and costly to acquire, synthetically generated, or concentrated in narrow domains such as programming. We introduce the Stanford EDGAR Filings Dataset (SEFD), an open reconstruction of SEC filings into layout-faithful MultiMarkdown for financial language modeling and evaluation. SEFD makes audited financial statements, risk disclosures, ownership reports, accounting notes, and market-moving event filings usable as long-context pretraining data and as a basis for financial reasoning, forecasting, compliance, and document understanding. The resulting corpus is token-efficient, model-ready, and has less than 0.1% overlap with Common Crawl-derived corpora. We release SEFD-v1, a 152B-token initial public snapshot, and provide corpus-level analyses of a larger 18.5M-filing archive estimated at 550B tokens. We further introduce two SEFD-derived benchmarks: EDGAR-Forecast, which evaluates filing-grounded numerical forecasting after model knowledge cutoffs, and EDGAR-OCR, which evaluates transcription of complex financial tables.
固定小数点推論器: 安定した適応性のある深ループ変換器
ループ型アーキテクチャは、構成的推論を必要とするタスクの段階的な手順の学習に対する帰納的バイアスを提供します。ループによって到達される有効な層の数によって、これらのモデルが検出する解の品質が決まります。ディープ アーキテクチャと同様に、ループ アーキテクチャでは、停止の決定が延期されるため、深さによって引き起こされる信号伝播の問題が発生しやすくなります。この論文では、プレノルム層と残差スケーリングを使用して、この信号伝播の問題に対処します。これらのアーキテクチャの変更に基づいて、ループ アーキテクチャのエンドツーエンドの停止メカニズムとして固定小数点収束を使用する、Transformer ベースの固定小数点推論モデルである FPRM を提案します。固定小数点停止により、FPRM がその計算をタスクの難易度に適応させることができることを示します。 FPRM は、一般的な推論ベンチマーク、つまり Sudoku、Maze、状態追跡、ARC-AGI に対して効果的です。
原文 (English)
Fixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
Looped architectures provide an inductive bias toward learning step-by-step procedures for tasks that require compositional reasoning. The number of effective layers reached by looping determines the quality of the solution these models find. Like deep architectures, looped architectures are prone to a signal propagation problem induced by depth as the halting decision is postponed. In this paper, we address this signal propagation issue using pre-norm layers and residual scaling. Building on these architectural modifications, we propose FPRM, a Transformer-based Fixed-Point Reasoning Model that uses fixed-point convergence as an end-to-end halting mechanism in a looped architecture. We show that fixed-point halting allows FPRM to adapt its compute to task difficulty. FPRM is effective on common reasoning benchmarks, namely Sudoku, Maze, state-tracking, and ARC-AGI.
EvolveNav: ゼロショット オブジェクト ゴール ナビゲーションのためのプロアクティブなプリフレクションと自己進化型メモリ
ゼロショット オブジェクト-ゴール ナビゲーション (ZS-OGN) では、事前のトレーニングなしで、身体化されたエージェントがターゲット オブジェクトを探索して位置を特定する必要があります。この目的を達成するために、最近の手法では基礎モデルを活用しています。しかし、それらは通常、静的な事前分布に依存しており、適応が欠如しているため、エラーが繰り返され、コストのかかる試行錯誤が発生します。このペーパーでは、継続的なテスト時間の改善を可能にする自己進化する ZS-OGN フレームワークを提案します。具体的には、過去の軌跡から実用的な知識を抽出することで、エージェントのルール記憶を構築します。次に、信頼限界の上限に基づいた検索戦略を提案し、意味上の関連性と歴史的な成功のバランスをとることで効果的なルールを選択します。さらに、行動前に潜在的な結果を予測し、非効率な探索を削減する、記憶に基づくプリフレクション モジュールを導入します。広範な実験により、私たちの方法は既存のゼロショットベースラインを上回り、不必要なステップを減らしながら成功率の 10.1\% の向上を達成したことが示されています。
原文 (English)
EvolveNav: Proactive Preflection and Self-Evolving Memory for Zero-Shot Object Goal Navigation
Zero-Shot Object-Goal Navigation (ZS-OGN) requires embodied agents to explore and locate target objects without any prior training. To this end, recent methods leverage foundation models. But they typically rely on static priors and lack adaptation, which leads to repeated errors and costly trial and error. In this paper, we propose a self-evolving ZS-OGN framework that enables continuous test-time improvement. Specifically, we build an agentic rule memory by extracting actionable knowledge from past trajectories. Then, we propose a retrieval strategy based on upper confidence bound, selecting effective rules by balancing semantic relevance and historical success. In addition, we introduce a memory-guided preflection module that forecasts potential outcomes before action, reducing inefficient exploration. Extensive experiments show that our method outperforms existing zero-shot baselines, achieving a 10.1\% improvement in success rate with fewer unnecessary steps.
ペアリングの場合は正しく、分割の場合は間違っています: MLLM でのモダリティ固有のニューロンの分離と編集
ナレッジ編集は、マルチモーダル大規模言語モデル (MLLM) の知識を更新するための効率的なメカニズムを提供しますが、現在のパラダイムは依然として、重要かつ未解明のままである問題、つまり編集デカップリングの失敗に悩まされていることがわかりました。この問題では、モデルがマルチモーダル入力 (テキストと画像のクエリのペア) によってトリガーされたときにエンティティ関連の知識が更新される可能性がありますが、ペアの入力が単モーダルなものに分割されると、古い編集前の事実に戻ってしまうことがよくあります。私たちの詳細な実証分析により、MLLM におけるエンティティ知識は統一された表現として保存されず、代わりに、もつれの解けたモダリティ固有の経路全体に分散していることが明らかになりました。その結果、マルチモーダル クエリに偏った更新がユニモーダル回路に効果的に伝播できなくなります。このギャップを埋めるために、我々は DECODE を提案します。これは、目的を絞った知識のためにモダリティ固有のニューロン グループを明示的に解きほぐし、位置を特定します。広範な実験により、DECODE がさまざまなモダリティ トリガーの下で効果的な知識の更新を一貫して達成し、それによって編集の切り離しの失敗が軽減されることが実証されました。
原文 (English)
Correct When Paired, Wrong When Split: Decoupling and Editing Modality-Specific Neurons in MLLMs
Although Knowledge Editing provides an efficient mechanism for updating the knowledge of Multimodal Large Language Models (MLLMs), we find that current paradigms still suffer from an important yet remain underexplored issue : editing decoupling failure, where entity-related knowledge can be updated when the model is triggered by multimodal inputs (text--image query pairs), however, it often reverts to outdated pre-edit facts when the paired inputs are split into unimodal ones. Our in-depth empirical analysis reveals that the entity knowledge in MLLMs is not stored as a unified representation, but is instead distributed across disentangled modality-specific pathways. As a result, updates biased toward multimodal queries fail to propagate effectively to unimodal circuits. To bridge this gap, we propose DECODE, which explicitly disentangles and localizes modality-specific neuron groups for targeted knowledge. Extensive experiments demonstrate that DECODE consistently achieves effective knowledge updates under different modality triggers, thereby mitigating editing decoupling failures.
P2P ネットワーク上の LLM の分散推論に向けて
プレフィックス キャッシュは、共有プロンプトを含むリクエスト間で KV キャッシュを再利用することで LLM 推論のレイテンシーを短縮できますが、キャッシュがノード間で分割されているため、クラスター スケールでの再利用は困難です。私たちは、ピアツーピア LLM サービスを提供するための、分散型のプレフィックス キャッシュを認識したルーティング スキームを提案します。各ノードは、キャッシュされた独自のプレフィックスのローカル基数ツリーと、定期的なアンチエントロピーを使用して非同期に更新されるピア キャッシュの推定値を維持します。リクエストは、集中調整や KV キャッシュ転送を行わずに、推定された最長のプレフィックス一致を持つノードにルーティングされます。メタデータが古いとキャッシュ ミスが発生するだけで、不正確な出力は発生しないため、正確性を確保するには弱い整合性が必要になります。シミュレートされた MMLU ワークロードの評価では、分散ルーティングにより、低い通信遅延と偏ったプレフィックス分布の下では遅延が改善される一方、高いネットワーク遅延とアフィニティに起因するホットスポットによってその利点が制限されることが示されました。
原文 (English)
Towards Distributed Inference of LLMs on a P2P Network
Prefix caching can reduce LLM inference latency by reusing KV caches across requests with shared prompts, but cluster-scale reuse is challenging because caches are partitioned across nodes. We propose a decentralized, prefix-cache-aware routing scheme for peer-to-peer LLM serving. Each node maintains a local radix tree of its own cached prefixes and asynchronously refreshed estimates of peer caches using periodic anti-entropy. Requests are routed to the node with the longest estimated prefix match, without centralized coordination or KV-cache transfer. Stale metadata only causes cache misses, not incorrect outputs, making weak consistency sufficient for correctness. Evaluation on simulated MMLU workloads show that decentralized routing improves latency under low communication delay and skewed prefix distributions, while high network latency and affinity-induced hotspots limit its benefits.
ピボット: 微分可能な J\"ackel 演算子を介したブラック ショールズのインプライド ボラティリティと価格目標の橋渡し
最新のオプション学習システムは 2 つの座標で動作します。1 つは市場相場と無裁定取引の制約が最も自然に適用される価格空間、もう 1 つはインプライド ボラティリティ (IV) 空間で、ボラティリティ曲面が平滑化、正規化、評価されます。ボトルネックは近似ではなくインターフェースです。アクケルの独創的な「Let's Be Rational」(LBR) ソルバーは、すでにブラック・ショールズ価格を機械精度に効率的に反転させています。欠けているのは、順方向パスで LBR を保持し、分岐ロジックによる逆伝播を回避する微分可能な層です。そのような層は、感度 1/vega が次のように発散する、低 vega 領域における逆写像の避けられない特異点にも直面する必要があります。 vega -> 0。Price-Implied-Volatility Objective Translator である PIVOT でこのギャップを埋めます。PIVOT は、LBR フォワード パスをそのまま維持し、明示的なゲーティング コントラクトを使用して、滑らかな Black-Scholes/Black-76 価格マップを介した暗黙的な微分によってバックワード パスを提供します。無効なドメインは NaN を返し、適切に条件付けされた行は正確な 1/vega 勾配を受け取り、低 vega 行はむしろ減衰されます。単一の H100 上で、融合された Triton カーネルはマシン精度で 1.79e9 IV/s に達します (リファレンス C ソルバーと比較した最大相対誤差は 9.3e-14)。SPX での HyperIV スタイルの 1 日の再現では、PIVOT 拡張で 16.6M/s を維持します。目標はベースラインをパレート支配し、ホールドアウト価格 MAE を最大 43.4% 削減し、最も強力な 3 シード ゲート目標は価格 MAE を 38.8%、IV MAE を合わせて 21.3% 改善します。RUT、VIX、および NDX のクロスアセット結果は、ゲートなしでは 40.1%、24.2%、および 16.7% の方向性価格 MAE 上昇を示しています。 IV ラウンドトリップ コントロールは縮退してほぼゼロの曲面になり、ゲートがチューニング ノブではなく正確性の収縮であることが確認されます。
原文 (English)
PIVOT: Bridging Black-Scholes Implied-Volatility and Price Objectives via Differentiable J\"ackel Operator
Modern option-learning systems operate in two coordinates: price space, where markets quote and no-arbitrage constraints are most naturally enforced, and implied volatility (IV) space, where volatility surfaces are smoothed, regularized, and evaluated. The bottleneck is interface, not approximation: J\"ackel's seminal "Let's Be Rational" (LBR) solver already inverts the Black-Scholes price to machine precision efficiently. What is missing is a differentiable layer that preserves LBR in the forward pass and avoids backpropagating through its branch logic. Such a layer must also confront the unavoidable singularity of the inverse map in the low-vega regime, where the sensitivity 1/vega diverges as vega -> 0. We close this gap with PIVOT, the Price-Implied-Volatility Objective Translator. PIVOT keeps the LBR forward pass intact and supplies the backward pass by implicit differentiation through the smooth Black-Scholes/Black-76 price map, with an explicit gating contract: invalid domains return NaN, well-conditioned rows receive the exact 1/vega gradient, and low-vega rows are attenuated rather than silently regularized. On a single H100, a fused Triton kernel reaches 1.79e9 IV/s at machine precision (9.3e-14 max relative error vs. the reference C solver); end-to-end label generation sustains 48.9M/s on synthetic chains and 16.6M/s on SPX OptionMetrics. In a HyperIV-style one-day reproduction on SPX, PIVOT-augmented objectives Pareto-dominate the baselines, reducing held-out price MAE by up to 43.4% and the strongest three-seed gated objective improving price MAE by 38.8% and IV MAE by 21.3% jointly; cross-asset results on RUT, VIX, and NDX show directional price-MAE gains of 40.1%, 24.2%, and 16.7%, while an ungated IV-roundtrip control collapses to a degenerate near-zero surface, confirming the gate as a correctness contract rather than a tuning knob.
KFTD: 連続海洋時空間予測のためのクープマン・フーリエ時間微分可能ネットワーク
正確な海洋予測は、気候監視や災害の早期警報にとって重要です。しかし、海洋の時空間予測は、複雑な力学システムのモデル化と計算効率の確保という二重の課題に直面しています。我々は、効率的でスケーラブルな時空間モデリングを実現するために、内挿を予測から切り離す、時間連続の 2 段階パラダイムであるコープマン フーリエ時間微分 (KFTD) ネットワークを紹介します。複雑な非線形ダイナミクスをクープマン線形空間にマッピングし、フーリエ解析を利用して任意のサブステップでの連続時間補間を可能にします。軽量の残差ネットワークは、忠実度の高い中間状態を消費して、最終的な予測を生成します。拡散モデルとは異なり、KFTD は複数ステップのノイズ サンプリングを排除し、連続時間でシステムを直接進化させ、計算速度が 4 倍向上します。さらに、エンドツーエンド方式で任意の PDE 制約をサポートする DPP 損失を導入し、純粋なデータ駆動型アプローチの物理的一貫性のボトルネックを打破します。 4 つの海洋データセットに関する実証結果では、連続時間フレームワークにより MSE が平均 5.6% (SST の場合は最大 12.7%) 削減され、MCVD に比べて効率が 76.25% 向上することが確認されています。
原文 (English)
KFTD: Koopman-Fourier Time-Differentiable Network for Continuous Ocean Spatiotemporal Forecasting
Accurate oceanic forecasting is critical for climate monitoring and disaster early warning. However, ocean spatiotemporal forecasting encounters the double challenges of modeling complex dynamical systems and ensuring computational efficiency. We present Koopman Fourier Time-Differentiable (KFTD) Network, a time continuous twostage paradigm that decouples interpolation from prediction to achieve efficient and scalable spatiotemporal modeling. We map complex nonlinear dynamics into the Koopman linear space and exploit Fourier analysis to enable continuous time interpolation at arbitrary sub-steps. A lightweight residual network consumes the high fidelity intermediate states to yield the final forecast. Unlike diffusion models, KFTD eliminates multi step noise sampling and directly evolves the system in continuous time, yielding a 4 computational speedup. We further introduce a DPP Loss that supports arbitrary PDE constraints in an endtoend manner, breaking the physical consistency bottleneck of pure data-driven approaches. Empirical results on four ocean datasets confirm that our continuous time framework reduces MSE by an average of 5.6% (up to 12.7% for SST) and improves efficiency over MCVD by 76.25%.
セマンティクスの抽出: LLM ガイドによる URDF からのロボット オントロジーの自動生成
仮想エージェントには常識的な知識で十分かもしれませんが、人間と対話する身体化されたロボットには、環境と自身の物理的具現化の両方について、根拠があり意味論的に豊かな表現が必要です。コグニティブ・ロボティクスでは、オントロジーは、このような異種知識を統合して、継続的な知識更新中でも説明可能な推論を可能にするのに効果的です。しかし、手動による構築が依然としてボトルネックとなっています。我々は、統一ロボット記述形式 (URDF) モデルを実装されたオントロジーに変換することにより、ロボットの意味論的抽象化を自動生成するための予備的なアプローチを紹介します。 URDF ファイルは構造的および運動学的記述を提供しますが、その識別子は多くの場合、意味のあるセマンティクスを復元するために常識的な解釈を必要とし、これは大規模言語モデル (LLM) が得意とするタスクです。当社のパイプラインは LLM を活用して、既存のオントロジーの概念をプロンプトすることで意味論的な関係を推論し、最終的な分類が正式なモデルと一致することを保証します。信頼性を向上させるために、パイプラインは複数の LLM クエリにわたる多数決と構文およびスキーマ レベルの検証を組み合わせて、生成された出力が期待される表現形式とオントロジーの制約に準拠していることを確認します。複数のロボット記述に対するアプローチを評価し、生成された抽象化について議論します。初期の結果は、提案された方法が、低レベルのロボットの記述と、人間とロボットの対話に必要な構造化された根拠のある知識表現との間のギャップを効果的に埋めることができることを示しています。
原文 (English)
Extracting Semantics: LLM-Guided Automatic Population of Robot Ontology from URDF
While commonsense knowledge may suffice for virtual agents, embodied robots interacting with humans require grounded and semantically rich representations of both their environment and their own physical embodiment. In cognitive robotics, ontologies are effective for integrating such heterogeneous knowledge to enable explainable reasoning, even during continuous knowledge updates. Yet, their manual construction remains a bottleneck. We present a preliminary approach for the automatic generation of robot semantic abstractions by transforming Unified Robot Description Format (URDF) models into populated ontologies. Although URDF files provide structural and kinematic descriptions, their identifiers often require commonsense interpretation to recover meaningful semantics, a task at which Large Language Models (LLMs) excel. Our pipeline leverages LLMs to infer semantic relationships by prompting them with concepts from an existing ontology, ensuring the final classification remains aligned with the formal model. To improve reliability, the pipeline combines majority voting across multiple LLM queries along with syntactic and schema-level validation to ensure that generated outputs conform to the expected representation format and ontology constraints. We evaluate the approach on multiple robot descriptions and discuss the generated abstractions. Initial results indicate that the proposed method can effectively bridge the gap between low-level robot descriptions and the structured, grounded knowledge representations required for human-robot interaction.
プリント基板の設計とテストにおける GenAI ベースの自動化の調査
生成人工知能 (GenAI) は、ハードウェアおよびソフトウェア領域のアプリケーションでますます使用されています。これは、リリース前の複雑なシステムの開発とテストに伴う手動の労力を削減することを目的としています。ハードウェア分野では、ほとんどのタスクが、特にハードウェア記述言語を使用した集積回路の設計自動化に焦点を当ててきました。ただし、他のタイプのハードウェアも存在します。この調査では、代わりに、プリント基板 (PCB) 設計ライフサイクル全体にわたって GenAI がどのように推移し、現在もどのように推移しているかを調査します。これには、サプライ チェーン、システム仕様、回路設計、レイアウトと最適化、検証とテスト、PCB の組み立てと配布に至るすべてが含まれます。このレンズを通して、私たちは発見された作品の分類を提示し、その意図と貢献に従ってそれらを分類します。この調査では、ドメイン固有のデータ不足や既存の PCB ツールとの統合サポートの制限など、この分野で GenAI が直面する主要な技術的課題も特定します。最後に、将来の研究の方向性について説明します。私たちの調査では、GenAI を PCB 設計およびテストのさまざまなタスクにどのように統合できるかを検討する際に、多くの機会が残っていることが示されています。
原文 (English)
Surveying GenAI-based Automation in Printed Circuit Board Design and Test
Generative artificial intelligence (GenAI) is increasingly used for applications in the hardware and software domains. It purports to reduce the manual effort involved in the development and testing of complex systems before release. Within the hardware space, most tasks have focused on design automation of integrated circuits, particularly with hardware description languages. However, other types of hardware also exist! In this survey, we instead examine how GenAI has been and is being across the printed circuit board (PCB) design life cycle. This includes everything from supply chains, system specification, circuit design, layout and optimisation, validation and test, and PCB assembly and distribution. Through this lens we present a taxonomy of discovered works, categorising them according to their intent and contributions. This survey also identifies key technical challenges that GenAI faces in this space, such as domain-specific data scarcity and limited support for integration with existing PCB tools. Finally, future research directions are discussed: our survey shows that there are many opportunities remaining when considering how GenAI may be integrated into various tasks in PCB design and test.
CMIP-Forge: 気候科学を取得、計算、自己レビューするエージェント システム
結合モデル相互比較プロジェクト フェーズ 6 (CMIP6) では、モデル構成、評価手順、緊急制約、予測の不確実性を文書化した何千もの査読済みの出版物が生成されています。コミュニティが CMIP7 に移行するにつれて、ライブ データ分析と並行してこの非構造化知識を効率的に抽出して運用することが重大なボトルネックとなります。ここでは、科学文献と Earth System Grid Federation (ESGF) データ アーカイブの間のギャップを埋めるハイブリッド検索拡張生成 (RAG) および自律分析システムである CMIP-Forge を紹介します。このシステムは、6,581 件の CMIP6 関連のオープンアクセス出版物の厳選されたコーパス (101,828 のインデックス付きチャンク) をエージェント パイプラインと組み合わせます。エージェント パイプラインでは、ツールで強化されたワーカーがライブ気候データに基づいて Python ワークフローを計画および実行し、独立したレビューアー モデルのパネルがその方法論をエンドツーエンドで監査します。 CMIP-Forge は、抽象構文ツリー (AST) 静的分析、監査された科学的プリミティブ、自律的な敵対的ピアレビュー プロトコルなどの実行可能なメカニズムを通じて物理的および方法論的な不変条件を強制する多層多層防御アーキテクチャを導入します。私たちは、大気テレコネクション、海洋力学、地域極地、地球温暖化予測に及ぶエンドツーエンドの自律研究パイプラインを通じて、このシステムの機能を実証します。ピアレビューされた文献に基づいており、自動化されたコードガードレールによって制約され、独立した敵対的レビューループによって監査されたエージェント分析システムは、複雑な気候研究ワークフローを自律的に完了できます。同じ実験により、レビュー ループの具体的な失敗モード (お調子者回帰、決して解決されない REVISE 判定、レビューのためのスタブ コードの提出) が明らかになり、それぞれは記事とともに公開された不変のテレメトリと来歴記録から診断できます。
原文 (English)
CMIP-Forge: An Agentic System that Retrieves, Computes, and Self-Reviews Climate Science
The Coupled Model Intercomparison Project Phase 6 (CMIP6) has generated thousands of peer-reviewed publications documenting model configurations, evaluation procedures, emergent constraints, and projection uncertainties. As the community transitions toward CMIP7, efficiently extracting and operationalizing this unstructured knowledge alongside live data analysis represents a critical bottleneck. Here we present CMIP-Forge, a hybrid retrieval-augmented generation (RAG) and autonomous analysis system that bridges the gap between scientific literature and Earth System Grid Federation (ESGF) data archives. The system pairs a curated corpus of 6,581 CMIP6-related open-access publications (101,828 indexed chunks) with an agentic pipeline in which a tool-augmented worker plans and executes Python workflows over live climate data, while a panel of independent reviewer models audits its methodology end to end. CMIP-Forge introduces a multi-layered Defense-in-Depth architecture that enforces physical and methodological invariants through executable mechanisms: Abstract Syntax Tree (AST) static analysis, audited scientific primitives, and an autonomous adversarial peer-review protocol. We demonstrate the system's capabilities through end-to-end autonomous research pipelines spanning atmospheric teleconnections, ocean dynamics, regional extremes, and global warming projections. An agentic analysis system grounded in peer-reviewed literature, constrained by automated code guardrails, and audited by an independent adversarial review loop can complete complex climate-research workflows autonomously. The same experiments expose concrete failure modes of the review loop (sycophantic regression, REVISE verdicts that are never resolved, and the submission of stub code for review), each diagnosable from the immutable telemetry and provenance record released with the article.
工学的に設計されたモデル量子フレームワークによる、限られた実データからの包括的な pKa データ拡張
プロトン解離定数 (pKa) は、機能分子の発見と分子モデリングにとって重要です。確立された最大の実験的 pKa データベースである iBonD を基盤として、私たちと他の研究者は、機械学習ベースの経験的予測や高精度のエネルギー計算などのいくつかの手法を開発しました。この基盤にもかかわらず、高品質の pKa データの迅速な増強には根本的な制約が残っています。この研究の一環として、広範囲に最適化された機械学習モデルのコレクションを使用して、ラベルされていない分子データセットに対して大規模な回帰ベースの pKa 予測を実行しました。この結果は、標識されていない分子データセットの特徴分布のため、pKa データ分布は正規性に近似しており、テール領域サンプルが極度に不足していることを示しています。このような増強は、全体的なデータの可用性と予測モデリングを向上させるのに非常に価値がありますが、広域スペクトルの pKa 特性を持つ分子を効率的に発見するには依然として不十分です。これに対処するために、私たちは広大な化学空間からまばらな pKa 特性を持つ分子をターゲットに生成することを探索します。分子生成のための従来の連続潜在空間 VAE-RNN 法では安定性が不十分であり、スパースデータを補完する際に明確な利点を実証できないことを考慮して、量子支援スパース pKa 分子生成を設計して実装します。実現可能性はシミュレートされた量子アニーラーで検証され、優れた極値サンプリングは物理コヒーレント イジング マシン (CIM) でさらに実現されます。 (つづく)
原文 (English)
Comprehensive pKa Data Augmentation from Limited Real Data through an Engineered Models-Quantum Framework
Proton dissociation constants (pKa) are critical for functional molecule discovery and molecular modeling. Building on iBonD, the largest experimental pKa database established, we and other researchers have developed several methods including machine-learning-based empirical prediction and high-accuracy energy calculations. Despite this foundation, the rapid augmentation of high-quality pKa data remains fundamentally constrained. As part of this work, we performed large-scale regression-based pKa prediction on unlabeled molecular datasets using a collection of extensively optimized machine-learning models. The results indicate that, since the feature distributions of unlabeled molecular datasets, the pKa data distribution approximates normality, with extreme scarcity of tail-region samples. Although such augmentation is highly valuable for improving overall data availability and predictive modeling, it remains insufficient for efficiently discovering molecules with broad-spectrum pKa properties. To address this, we explore the targeted generation of molecules with sparse pKa properties from the vast chemical space. Given that traditional continuous latent space VAE-RNN methods for molecular generation suffer from insufficient stability and fail to demonstrate clear advantages in complementing sparse data, we design and implement a quantum-assisted sparse-pKa molecular generation. Feasibility is validated on a simulated quantum annealer, and superior extreme-value sampling is further achieved on physical coherent Ising machines (CIMs). (to be continued)
HRDX: 大規模なベクトル HD マップ データセット
信頼性の高い自動運転には、幾何学的に正確で、意味的に豊富で、長距離運転にも拡張可能なベクトル化された HD マップが必要です。しかし、既存の公開 HD マップ データセットは規模が限られており、意味属性がまばらで、新しい研究の方向性を可能にする航空画像などのモダリティがありません。我々は、ベクター HD マップ構築用の大規模データセットである HRDX を紹介します。これは、重複が最小限に抑えられたドライブの約 40 時間 (1,400 km) に及び、これまでの公開 HD マップ データセットよりも数倍大きいです。データは、6 台の同期サラウンド カメラ、128 ビーム LiDAR、センチメートル レベルの RTK GNSS/IMU を使用して取得され、正確に位置合わせされた航空オルソ画像によってさらに補完されます。アノテーションは 10 のベクター マップ クラスをカバーし、20 を超えるセマンティックおよびトポロジー属性で補完されます。このより豊富なオントロジーを評価するために、幾何学的忠実度と属性の正確さを共同で評価する複合スコア (CS) を導入します。ベンチマーク実験では、HRDX の規模によってオンライン ベクトル マップの構築が向上し、位置合わせされた航空画像が有用な構造的事前分布を提供することが示されています。トレーニングや推論で航空画像を使用すると、幾何学的マップの品質が向上します。一方、航空拡張された教師は、推論時のセンサー要件を増やすことなく、この利点の一部をカメラのみの生徒に伝えることができます。 HRDX は、大規模な HD マップ学習、マルチモーダル BEV フュージョン、トレーニング時の特権情報に関する再現可能な研究をサポートすることを目的としています。 HRDX データセットとベンチマークは、https://github.com/honda-research-institute/HRDX で入手できます。
原文 (English)
HRDX: A Large-Scale Vector HD-Map Dataset
Reliable autonomous driving requires vectorized HD maps that are geometrically accurate, semantically rich, and scalable to long-horizon driving. However, existing public HD map datasets are limited in scale, provide sparse semantic attributes, and lack modalities such as aerial imagery that could enable new research directions. We present HRDX, a large-scale dataset for vector HD-map construction, spanning about 40 hours (1,400 km) of minimally overlapping drives, which is several times larger than prior public HD map datasets. Data is captured using six synchronized surround cameras, a 128-beam LiDAR, and centimeter-level RTK GNSS/IMU, and is further complemented by precisely aligned aerial orthoimagery. Annotations cover 10 vector map classes, complemented with over 20 semantic and topological attributes. To evaluate this richer ontology, we introduce the Composite Score (CS) to jointly assess geometric fidelity and attribute correctness. Benchmark experiments show that HRDX's scale improves online vector-map construction, and that aligned aerial imagery provides a useful structural prior: using aerial imagery at training and/or inference improves geometric map quality, while aerial-augmented teachers can transfer part of this benefit to camera-only students without increasing inference-time sensor requirements. HRDX is intended to support reproducible research on large-scale HD-map learning, multimodal BEV fusion, and training-time privileged information. HRDX dataset and benchmarks are available at https://github.com/honda-research-institute/HRDX
分離推論におけるアナーキーの代償
細分化された推論アーキテクチャは、プリフィル フェーズとデコード フェーズを個別の GPU プールに物理的に分離し、固定のハードウェア バジェットを共有する競合する「エージェント」を作成します。私たちの知る限り、NVIDIA Dynamo を具体的なケーススタディとして使用して、このアーキテクチャの最初の正式なゲーム理論分析を提供します。私たちは、プリフィル プールとデコード プール間の 2 プレイヤー リソース ゲーム、階層 KV キャッシュを介した利己的キャッシング ゲーム、およびリクエスト ルーティングの正の外部性を持つ輻輳ゲームの 3 つの結合ゲームとして、分解されたサービスをモデル化します。後者の 2 つは経験的に検証されています。 P/D リソース ゲームは分析的に扱われます (セクション 9.2)。私たちは、GPU の飽和がゲームの利得構造を変えるレジーム移行をどのように引き起こすかを特徴づけます。飽和以下では、利己的な行動がアナーキーの代価 (PoA) を制限します。飽和状態では、超線形レイテンシーとキャッシュ外部性により、経験的推定値 PoA ハット (セクション 6.4 で定義) が上昇します。この分析に基づいて、飽和遷移をリアルタイムで検出し、それに応じてルーティング パラメーターを調整し、キャッシュ アフィニティの活用から負荷分散された輻輳回避に移行する適応コントローラーを設計します。 Nemotron-4-340B (TP=8、クロス InfiniBand KV 転送を備えたフルノード ワーカー) と Llama-3.1-70B (TP=4) の 2 つのモデルを使用して Dynamo を実行する 3 ノード NVIDIA B200 クラスター上でフレームワークをインスタンス化し、両方のモデルで同じ最初のポストニー グリッド ポイント (C=128) を持つ同じ 3 レジーム PoA ハット構造を見つけました。アダプティブ ルーティングは、各モデルをより良い動作点にシフトします。最も強力な結果は 70B 1P/5D トポロジであり、PoA ハットは飽和フェーズで 13% のスループット コストで 3.1 倍 (66.4 から 21.5) 低下します。 70B 1P/2D では、PoA-hat は 2.2 倍、TTFT P99 は 7.6 倍に低下します (セクション 8.5 を参照)。
原文 (English)
The Price of Anarchy in Disaggregated Inference
Disaggregated inference architectures physically separate prefill and decode phases onto distinct GPU pools, creating competing "agents" that share a fixed hardware budget. We provide, to our knowledge, the first formal game-theoretic analysis of this architecture, using NVIDIA Dynamo as a concrete case study. We model disaggregated serving as three coupled games: a two-player resource game between prefill and decode pools, a selfish caching game over the hierarchical KV cache, and a congestion game with positive externalities for request routing. We empirically validate the latter two; the P/D resource game is treated analytically (Section 9.2). We characterize how GPU saturation induces regime transitions that shift the game's payoff structure: below saturation, selfish behavior has bounded Price of Anarchy (PoA); at saturation, superlinear latency and cache externalities drive our empirical estimator PoA-hat (defined in Section 6.4) upward. Based on this analysis, we design an adaptive controller that detects saturation transitions in real time and adjusts routing parameters accordingly, shifting from cache-affinity exploitation to load-balanced congestion avoidance. We instantiate our framework on a 3-node NVIDIA B200 cluster running Dynamo with two models, Nemotron-4-340B (TP=8, full-node workers with cross-InfiniBand KV transfers) and Llama-3.1-70B (TP=4), and find the same three-regime PoA-hat structure with the same first post-knee grid point (C=128) on both models. Adaptive routing shifts each model to a better operating point. Our strongest result is on the 70B 1P/5D topology, where PoA-hat drops 3.1x (66.4 to 21.5) in the saturated phase at a 13% throughput cost. On the 70B 1P/2D, PoA-hat drops 2.2x and TTFT P99 drops 7.6x (see Section 8.5).
parkingTransformer: LLM で強化された自動駐車のためのエンドツーエンドの軌道計画
エンドツーエンドの自動駐車は、自動運転の領域における重要なタスクとして浮上しています。しかし、既存の手法はブラックボックスの特性があり、高度な意味理解や解釈可能性を欠いており、道路から目標地点までのシームレスな長距離自動駐車の実現を妨げています。これらの制限に対処するために、私たちは、多視点認識と大規模言語モデル (LLM) のシーン理解機能を活用する新しいフレームワークである parkingTransformer を提案します。軌道クエリと LLM の暗黙的状態特徴を組み合わせることで、私たちの方法は履歴情報や生のセンサー データと直接対話して計画軌道を出力し、高密度の鳥瞰図 (BEV) 表現の必要性を排除します。 LLM の不十分な空間推論能力を補うために、空間幾何学的認識を明示的に注入する 3D 位置エンコーディングを導入します。さらに、履歴情報処理用に固定ウィンドウ ストリーミング メカニズムが設計されており、長期的な時間処理効率と推論速度が大幅に向上します。さらに、軌道の精度を段階的に高めるために、粗いものから細かいものへのデコード戦略が採用されています。 CARLA シミュレーターと実世界の車両プラットフォームで広範な閉ループ実験が行われます。結果は、私たちの方法がCARLAシミュレータで61.32のドライビングスコアを達成し、現実世界の実験で88.70%の平均成功率を達成することを示し、提案されたアルゴリズムの実現可能性と有効性を検証します。
原文 (English)
ParkingTransformer: LLM-Enhanced End-to-End Trajectory Planning for Autonomous Parking
End-to-end autonomous parking has emerged as a critical task within the realm of autonomous driving. However, existing methods suffer from black-box characteristics, lacking high-level semantic understanding and interpretability, which impedes the realization of seamless long-distance autonomous parking from the road to the target spot. To address these limitations, we propose ParkingTransformer, a novel framework that leverages multi-view perception and the scene understanding capability of Large Language Models (LLMs). By combining trajectory queries with LLMs implicit state features, our method interacts directly with historical information and raw sensor data to output planning trajectories, eliminating the need for dense Bird's-View (BEV) representations. To compensate for the inadequate spatial reasoning ability of LLMs, we introduce 3D positional encoding to explicitly inject spatial geometric awareness. Furthermore, a fixed-window streaming mechanism is designed for historical information processing, significantly improving long-term temporal processing efficiency and inference speed. Additionally, a coarse-to-fine decoding strategy is employed to progressively enhance trajectory precision. Extensive closed-loop experiments are conducted on the CARLA simulator and real-world vehicle platforms. The results demonstrate that our method achieves a driving score of 61.32 in CARLA simulator and an average success rate of 88.70% in real-world experiments, validating the feasibility and effectiveness of the proposed algorithms.
ZIVARI-TLBO: 教育学習ベースの最適化のためのゼロコストのグループ間評価エリートリレーメカニズム
ZIVARI-TLBO は、グループ化された教育学習ベースの最適化 (TLBO) 手法であり、既存の人口状態コントローラーを固定のグループ間評価エリート リレーで強化します。スケジュールされたイベントごとに、各グループは、すでに評価されたエリートを固定リング内の次のグループに提供します。エリートは、保存された目標値の方が優れている場合にのみ、受信者の最も適格な学習者を置き換えます。正確なリレーはすでに評価された解とその保存された適合性をコピーするため、追加の目的関数呼び出しは必要ありません。凍結された gts-v4-cm-fixed 実装は、次元 10、30、50、および 100 の 8 つの古典関数、30 の一致するシード、および 5 つの制約されたエンジニアリング問題について、均等な 10,000 の評価予算の下で評価されます。リレーなしで同じグループ化されたランドスケープ認識コントローラーに対する直接アブレーションは、728/11/221 の勝ち/引き分け/負け、および次元全体でのランクバイシリアル効果サイズ 0.624 を記録しました。 8 つの方法による多次元比較では、WOA が最高の平均順位 (2.914) を獲得し、ZIVARI-TLBO が 2 位 (3.382) にランクされています。 ZIVARI-TLBO は、TLBO、MCTLBO、DE、PSO、および GWO を大幅に上回っていますが、WOA には大幅に負けていますが、ホルム調整後の HHO と大きな差はありません。実現可能性を意識したエンジニアリングの結果はさまざまであり、現在の静的ペナルティの定式化に影響されます。この証拠は、範囲を限定したリレーの貢献と予算と整合性のある情報共有メカニズムを裏付けていますが、普遍的な最先端、グローバルコンバージェンス、エンジニアリングの優位性、または CEC の優位性の主張を裏付けるものではありません。
原文 (English)
ZIVARI-TLBO: A Zero-Cost Inter-Group Evaluated-Elite Relay Mechanism for Teaching-Learning-Based Optimization
ZIVARI-TLBO is a grouped Teaching-Learning-Based Optimization (TLBO) method that augments an existing population-state controller with a fixed inter-group evaluated-elite relay. At each scheduled event, every group offers its already evaluated elite to the next group in a fixed ring; the elite replaces the receiver's worst eligible learner only when its stored objective value is better. Because the exact relay copies an already evaluated solution and its stored fitness, it requires no additional objective-function calls. The frozen gts-v4-cm-fixed implementation is evaluated under equal 10,000-evaluation budgets on eight classical functions at dimensions 10, 30, 50, and 100, with 30 matched seeds, and on five constrained engineering problems. A direct ablation against the same grouped landscape-aware controller without relay records 728/11/221 wins/ties/losses and a rank-biserial effect size of 0.624 across dimensions. In an eight-method multidimensional comparison, WOA obtains the best average rank (2.914) and ZIVARI-TLBO ranks second (3.382); ZIVARI-TLBO significantly outperforms TLBO, MCTLBO, DE, PSO, and GWO, loses significantly to WOA, and is not significantly different from HHO after Holm adjustment. Feasibility-aware engineering results are mixed and sensitive to the current static-penalty formulation. The evidence supports a scoped relay contribution and budget-consistent information-sharing mechanism, but not universal state-of-the-art, global-convergence, engineering-dominance, or CEC superiority claims.
ANEForge: Apple Neural Engine での直接計算のための Python
ANEForge は、最近のすべての Apple デバイスに搭載されている固定機能ニューラル アクセラレータである Apple Neural Engine (ANE) を、CoreML を使用せずに直接プログラムする Python パッケージです。運用環境では、エンジンは CoreML 経由でのみアクセス可能で、これはスケジューリング オプションとして扱われます。ANE を必要とする構成はなく、モデルは代わりに CPU または GPU 上でサイレントに実行できます。 ANEForge は、58 の融合演算子と 19 のネイティブ ブリッジ演算子から構築された遅延テンソル グラフを 1 つの ANE プログラムにコンパイルします。このプログラムは、Apple の内部フレームワークと同じ ANE デーモンおよびカーネル ドライバー スタックを通じてディスパッチされます。推論を超えて、パッケージはエンジンのネイティブの融合アテンションに到達し、int8、int4、およびスパースの重みをストリームし、ステップ全体にわたってデコーダーとオプティマイザーの状態を常駐させ、エンジン上でトレーニングのフォワード パス、バックワード パス、およびオプティマイザーの更新を実行します。小規模な融合プログラムは、エンジンのプログラムごとのディスパッチ フロアの 70 マイクロ秒に近い約 90 マイクロ秒で呼び出しを完了し、事前トレーニングされた ResNet-18 フォワードは 0.33 ミリ秒でエンドツーエンドで実行されます。 ResNet-18、センテンス エンコーダー、および Vision Transformer はフレームワーク参照に対してエンドツーエンドで実行され、Stable Diffusion U-Net がそのフォワード パスを検証します。 ANEForge は、macOS 14 以降の Apple Silicon をターゲットとしています。各リリースは、記録された macOS および ANE コンパイラーのバージョンに対して検証されます。
原文 (English)
ANEForge: Python for direct computation on the Apple Neural Engine
ANEForge is a Python package that programs the Apple Neural Engine (ANE), the fixed-function neural accelerator on every recent Apple device, directly and without CoreML. In production the engine is reachable only through CoreML, which treats it as a scheduling option: no configuration requires the ANE, and a model can silently run on the CPU or GPU instead. ANEForge compiles a lazy tensor graph, built from 58 fused operators and 19 native bridge operators, into a single ANE program. The program is dispatched through the same ANE daemon and kernel-driver stack as Apple's internal framework. Beyond inference, the package reaches the engine's native fused attention, streams int8, int4, and sparse weights, keeps decoder and optimizer state resident across steps, and runs the forward pass, backward pass, and optimizer update of training on the engine. A small fused program completes a call in about 90us, near the engine's 70us per-program dispatch floor, and a pretrained ResNet-18 forward runs end-to-end in 0.33ms. ResNet-18, a sentence encoder, and a Vision Transformer run end-to-end against framework references, and a Stable Diffusion U-Net validates its forward pass. ANEForge targets Apple Silicon under macOS 14 and later. Each release is verified against a recorded macOS and ANE-compiler version.
ソフトウェア委任契約: AI コーディング エージェント作業におけるレビュー可能性の測定
AI コーディング エージェントは、割り当てられたソフトウェア タスクを受け入れ、制限された権限の下でリポジトリを変更し、レビューのために作業パッケージを返すことが増えています。以前の研究では、委任されたコーディング作業の分析単位として、タスク、権限、返された作業パッケージ、および受け入れコンテキストをカバーするソフトウェア委任契約が提案されましたが、その効果は測定されていませんでした。この論文では、コーディング エージェントの明示的な委任契約に関する制御されたパイロット研究を報告します。私たちは、シードされた欠陥とドキュメントのギャップを備えた依存関係のない TypeScript API タスク環境を構築し、5 つのファミリーにわたって 10 個のタスクを作成し、現実的な問題形式のプロンプト、明示的な委任契約、および必要な証拠バンドルを含む契約という 3 つの条件下で 2 つのモデル層にわたって 64 のエージェント実行を実行しました。各実行は、隠れた受け入れテスト、突然変異チェック、スコープ分析でスコア付けされ、固定ルーブリックを使用して 3 人の独立した条件盲検モデルベースのレビュー担当者によって 192 件のレビューがレビューされました。明示的な契約では、客観的なタスクの結果は改善されませんでした。64 回の実行すべてが、スコープ違反なしで、隠れた受け入れチェックに合格しました。確かにレビュー可能性は向上しました。証拠の十分性は、30 対の比較のうち 22 で改善されましたが、悪化したものはありませんでした (5 点スケールで +0.83、p < 0.0001、クリフ デルタ = 0.66)。査読者の曖昧さが減少しました (p = 0.035)。変更されたファイルのリスト、既知の制限セクション、残留リスクセクション、およびレビュー担当者のチェックリストは、ほとんど、または契約で要求された場合にのみ表示されます。契約のコストはエージェント トークン +13%、実測時間 +38% となり、モデル層が弱いほど影響が大きくなります。これらの小さなタスクでは、委任契約により、正確さよりもレビュー可能性が重視されました。
原文 (English)
Software Delegation Contracts: Measuring Reviewability in AI Coding-Agent Work
AI coding agents increasingly accept assigned software tasks, modify repositories under bounded authority, and return work packages for review. Prior work proposed the software delegation contract, covering the task, authority, returned work package, and acceptance context, as the unit of analysis for delegated coding work, but did not measure its effects. This paper reports a controlled pilot study of explicit delegation contracts for coding agents. We built a dependency-free TypeScript API task environment with seeded defects and documentation gaps, authored ten tasks across five families, and ran 64 agent executions across two model tiers under three conditions: a realistic issue-style prompt, an explicit delegation contract, and a contract with a required evidence bundle. Each run was scored with hidden acceptance tests, mutation checks, and scope analysis, then reviewed by three independent condition-blinded model-based reviewers using a fixed rubric, for 192 reviews. Explicit contracts did not improve objective task outcomes: all 64 runs passed hidden acceptance checks, with zero scope violations. They did improve reviewability. Evidence sufficiency improved in 22 of 30 paired comparisons and worsened in none (+0.83 on a 5-point scale, p < 0.0001, Cliff's delta = 0.66); reviewer ambiguity decreased (p = 0.035); changed-file lists, known-limitations sections, residual-risk sections, and reviewer checklists appeared mostly or only when demanded by the contract. Contracts cost +13% agent tokens and +38% wall-clock time, with larger effects for the weaker model tier. On these small tasks, delegation contracts bought reviewability rather than correctness.
量子シネマ: 生成世界モデルを介した量子コンピューティング ハードウェアのインタラクティブな映画的探索
量子コンピューティングは科学と産業全体に革新的な進歩を約束しますが、これらの計算を可能にする物理的ハードウェアは依然として一般の人々には見えません。量子プロセッサは絶対零度に近い温度で密閉された希釈冷蔵庫内で動作するため、直接観察することは不可能です。量子コンピューティングの増大する社会的影響とそれを視覚化する一般の人々の能力との間のこの「想像力のギャップ」は、量子リテラシーと労働力の育成にとって大きな障壁となっています。私たちは、オープンソースのブラウザベースのインタラクティブ アプリケーションである Quantum Cinema を紹介します。これは、生成世界モデルを使用して、目に見えない量子ハードウェアを探索可能な映画のような体験に変換することで、このギャップを埋めます。 Quantum Cinema は、ノーベル賞を受賞した量子もつれの基礎科学から、3 つの主要な量子コンピューティング アーキテクチャ (トラップ イオン、中性原子、超伝導システム) への精選されたビデオ紹介を経て、目に見えない量子現象を観察可能にする没入型の 3 次元生成世界、そして最後に実際の量子デバイスの仕様に基づいたインタラクティブなレーダー チャートの比較まで、4 幕の物語を通してユーザーをガイドします。すべての 3 次元環境は、WorldLabs の生成ワールド モデル プラットフォームを使用して生成され、アマゾン ウェブ サービス (AWS) Braket 量子ハードウェアから厳選されたメトリクスに科学的に基づいています。 Quantum Cinema には、インストール、特殊なハードウェア、量子コンピューティングの知識は必要ありません。これは、プラットフォームの複製または拡張を求める学者や開発者と、さまざまな聴衆に量子ハードウェアを説明するための直感的なツールを求める教育者、研究者、科学コミュニケーターという 2 つの異なるコミュニティにサービスを提供するように設計されています。このペーパーでは、システム アーキテクチャ、生成ワールド モデル パイプライン、両方のコミュニティの使用例、および将来の作業の方向性について説明します。
原文 (English)
Quantum Cinema: An Interactive Cinematic Exploration of Quantum Computing Hardware via Generative World Models
Quantum computing promises transformative advances across science and industry, yet the physical hardware that enables these computations remains invisible to the public: quantum processors operate inside sealed dilution refrigerators at temperatures near absolute zero, making direct observation impossible. This "imagination gap" between quantum computing's growing societal impact and the public's ability to visualize it represents a significant barrier to quantum literacy and workforce development. We present Quantum Cinema, an open-source, browser-based interactive application that closes this gap by transforming invisible quantum hardware into explorable, cinematic experiences using generative world models. Quantum Cinema guides users through a four-act narrative -- from the foundational Nobel Prize-winning science of quantum entanglement, through curated video introductions to three major quantum computing architectures (trapped-ion, neutral-atom, and superconducting systems), into immersive three-dimensional generative worlds that make invisible quantum phenomena observable, and finally to interactive radar-chart comparisons grounded in real quantum device specifications. All three-dimensional environments are generated using WorldLabs' generative world model platform and are scientifically grounded in curated metrics from Amazon Web Services (AWS) Braket quantum hardware. Quantum Cinema requires no installation, no specialized hardware, and no quantum computing background. It is designed to serve two distinct communities: scholars and developers seeking to replicate or extend the platform, and educators, researchers, and science communicators seeking an intuitive tool for explaining quantum hardware to diverse audiences. This paper describes the system architecture, the generative world model pipeline, use cases for both communities, and directions for future work.
新しい AI アクセラレータでの LLM 推論のプレフィル/デコードを意識した評価
大規模言語モデル (LLM) がレイテンシとコストに敏感な設定で導入されることが増えているため、推論効率がシステムの中心的な課題となっています。現在の導入では GPU が主流ですが、LLM 推論に利点があると主張する AI アクセラレータが増えていますが、実際にどのような条件下でそのようなアクセラレータが GPU よりも優れたパフォーマンスを発揮するかは依然として不明です。最近の推論システムは、実行をプレフィル フェーズとデコード フェーズに分解します。これらのフェーズは、異なる計算特性とレイテンシ メトリクスを示し、通常、最初のトークンまでの時間 (TTFT) と出力トークンあたりの時間 (TPOT) によってキャプチャされます。このペーパーでは、共通モデル Llama2-7B を使用した、GPU および新興 AI アクセラレータにわたる LLM 推論パフォーマンスのフェーズを意識した評価を示します。プレフィルとデコードのパフォーマンスを個別に測定することで、アクセラレータの利点がフェーズとメトリックによって異なることが明らかになりました。私たちの結果は、GPU がコンピューティング集中型のプレフィル フェーズで一貫して優れているのに対し、GroqRack はデコード中に大幅に低い TPOT を達成することを示しています (バッチ処理は現在サポートされていません)。ただし、バッチ サイズが増加するにつれて、GPU はデコード スループットで優位性を取り戻します。これらの発見は、各プラットフォームが相に応じた異なる強みを示すことを示しています。さらに、さまざまなアクセラレータ プラットフォームにわたる異種のプリフィル/デコードの分解を分析し、パフォーマンスの向上と、そのような向上が実現されるワークロードとネットワークの条件を特定します。
原文 (English)
Prefill/Decode-Aware Evaluation of LLM Inference on Emerging AI Accelerators
As large language models (LLMs) are increasingly deployed in latency- and cost-sensitive settings, inference efficiency has become a central systems challenge. While GPUs dominate current deployments, a growing number of AI accelerators claim advantages for LLM inference, yet it remains unclear under which conditions such accelerators outperform GPUs in practice. Recent inference systems decompose execution into Prefill and Decode phases, which exhibit distinct computational characteristics and latency metrics, commonly captured by time to first token (TTFT) and time per output token (TPOT). This paper presents a phase-aware evaluation of LLM inference performance across GPUs and emerging AI accelerators using a common model, Llama2-7B. By separately measuring Prefill and Decode performance, we reveal that accelerator advantages differ by phase and metric. Our results show that GPUs consistently excel in the compute-intensive Prefill phase, while GroqRack achieves significantly lower TPOT during Decode (batching not currently supported). However, GPUs regain an advantage in Decode throughput as batch size increases. These findings demonstrate that each platform exhibits distinct phase-dependent strengths. We further analyze heterogeneous Prefill/Decode disaggregation across different accelerator platforms, identifying performance gains and the workload and network conditions under which such gains are realized.
モデルはプレフィル時にメモを取る: KV キャッシュは編集可能および構成可能
プレフィックス キャッシュでは、正確に共有されたプレフィックス全体でのみプレフィルが再利用されるため、1 つのフィールドが変更されると、ダウンストリーム キャッシュ全体が無効になります。ただし、フィールド独自のキー/値ベクトルを上書きして残りを再利用すると、モデルは古い値に基づいて動作したままになります。その理由は、4 つのモデル ファミリにわたって因果的に確立されています。プリフィル時に、モデルはすでにフィールド条件付きの結論を下流のノートに書き込んでいます。フィールド独自のキー/値による決定は 1% 未満です。メモ化された結論のノートとして読むと、2 つの機能が続きます。 (1) 編集可能です。顕著な誤りがメモを修正しています。また、思考連鎖を使用すると、フィールドを編集するだけで決定 (8B で 1.00、〜 1% の計算) が回復されますが、CoT がないと決定は無視されます。 (2) コンポーザブルです。ノートは位置移植可能であるため、プリコンパイルされたスキルを RoPE で再配置して任意のコンテキストに接続することができ、最初のトークンまでの時間が O(L^2) ではなく O(L) での完全な再計算 (ロジット コサイン 0.90 ~ 0.999、12 モデル) と区別がつきません。統合された編集 + 作成エージェントは、同一の意思決定を維持し、最大 14.9 倍の低いレイテンシで再計算します。このアプローチは、トークンごとのアテンション KV キャッシュに適用され、スケール、量子化、専門家の混合、およびマルチモーダル キャッシュにわたって検証され、小さなアダプターを通じていくつかのアテンション バリアントに拡張されます。エラッタは追加専用であるため、運用プレフィックス キャッシュを使用して構成されます。オンライン vLLM ベンチマークでは、プレフィックス キャッシュのアライメントが維持され (ヒット率 98.5%)、最初のトークンまでの p90 時間が 53 ~ 398 倍短縮されます。
原文 (English)
Models Take Notes at Prefill: KV Cache Can Be Editable and Composable
Prefix caching reuses prefill only across an exactly shared prefix, so one changed field invalidates the entire downstream cache. Yet overwriting the field's own key/value vectors and reusing the rest leaves the model acting on the old value. The reason, established causally across four model families: at prefill the model has already written the field-conditioned conclusion onto downstream notes; the field's own key/value drives under 1% of the decision. Read as a notebook of memoized conclusions, two capabilities follow. (1) It is editable. A salient erratum amends the notes; and with chain-of-thought, editing the field alone recovers the decision (1.00 at 8B, ~1% compute), while without CoT it is ignored. (2) It is composable. The notes are position-portable, so a precompiled skill can be RoPE-repositioned and spliced into any context, indistinguishable from full recompute (logit cosine 0.90-0.999, twelve models) at O(L) rather than O(L^2) time-to-first-token. A unified edit+compose agent stays decision-identical to recompute at up to 14.9x lower latency. The approach applies to any per-token attention KV cache, validated across scale, quantization, Mixture-of-Experts, and multimodal caches, and extends to several attention variants through small adapters. Because the erratum is append-only, it composes with production prefix caching: in an online vLLM benchmark it keeps the prefix cache-aligned (98.5% hit-rate), cutting p90 time-to-first-token by 53-398x.
ネットワーク侵入検知のためのタイムスタンプを意識した時空間グラフの対照学習
グラフ ニューラル ネットワーク (GNN) は、ネットワーク トラフィック フロー間の関係構造のモデル化における有効性を考慮して、ネットワーク侵入検知システム (NIDS) に広く採用されています。ただし、既存の GNN ベースの NIDS アプローチのほとんどは、トラフィック フローの関係構造に焦点を当てており、トラフィック フローを時間的に独立したものとして扱うため、進化する攻撃動作に対処する能力が制限されています。さらに、教師あり学習または半教師あり学習への依存により、目に見えない攻撃への一般化が制限されることがよくあります。これらの制限に対処するために、私たちは新しい自己教師あり GNN ベースのフレームワークを提案します。私たちの知る限り、提案されたモデルは、リアルタイムのタイムスタンプを明示的に利用する最初の自己教師あり GNN ベースの NIDS モデルの 1 つであり、表現学習に忠実な時間依存関係を提供します。まず、タイムスタンプに従ってネットワーク トラフィック フローから一連の時間グラフを構築し、次に E-GraphSAGE および LSTM ベースのエンコーダを使用して、時間のかかるアテンション メカニズムを導入することなく、ネットワーク トラフィックの時間情報と空間依存性を完全に抽出します。マルチビュー グラフ対比学習 (GCL) スキームが導入されています。このスキームでは、時間的、空間的、および特徴の対比が共同して実行され、時間的連続性を捕捉し、構造的一貫性を維持し、学習された表現の一般化とロバスト性をそれぞれ向上させます。さらに、勾配ノルムに基づく適応重み付け戦略は、コントラスト損失重みを最適化するように設計されています。リアルタイム タイムスタンプを持つ 4 つの代表的な NIDS データセットの実験結果は、私たちの手法が既存の自己教師ありアプローチを大幅に上回り、高い計算効率を維持しながら、教師ありの最先端の GNN 手法に匹敵するパフォーマンスを達成することを示しています。
原文 (English)
Timestamp-Aware Spatio-Temporal Graph Contrastive Learning for Network Intrusion Detection
Given their effectiveness in modeling the relational structure among network traffic flows, graph neural networks (GNNs) have been widely adopted in network intrusion detection systems (NIDSs). However, most existing GNN-based NIDS approaches focus on the relational structure of traffic flows, and treat them as temporally independent, which limits their ability to cope with evolving attack behaviors. Moreover, their reliance on supervised or semi-supervised learning often restricts generalization to unseen attacks. To address these limitations, we propose a novel self-supervised GNN-based framework. To the best of our knowledge, the proposed model is among the first self-supervised GNN-based NIDS models to explicitly leverage real timestamps, which provides faithful temporal dependencies for representation learning. We first construct a series of temporal graphs from network traffic flows according to their timestamps, and then employ an E-GraphSAGE and LSTM based encoder to fully extract temporal information and spatial dependencies of network traffic, without introducing time-costly attention mechanisms. A multi-view graph contrastive learning (GCL) scheme is introduced, where temporal, spatial, and feature contrasts are jointly performed to capture temporal continuity, preserve structural consistency, and improve the generalization and robustness of the learned representations, respectively. In addition, a gradient-norm-based adaptive weighting strategy is designed to optimize the contrastive loss weights. Experimental results on four representative NIDS datasets with real timestamps demonstrate that our method significantly outperforms existing self-supervised approaches and achieves performance comparable to the supervised state-of-the-art GNN method, while maintaining high computational efficiency.
現実的なシナリオにおける LLM エージェントを使用するツールにおけるデータ漏洩リスクの評価
AI エージェントは、電子メール、データベース、ドキュメント、その他のツールにアクセスして機密情報の読み取り、更新、配布を行うことができるため、企業や個人の環境で採用されることが増えています。エージェントにおけるデータ漏洩リスクに関するこれまでの研究の多くは、迅速なインジェクションとジェイルブレイクによる敵対的なデータ漏洩に焦点を当てていました。ただし、機密情報は非敵対的な使用中にも公開される可能性があり、ユーザーが無害なリクエストを発行した場合でも漏洩のリスクが生じます。私たちは、顧客サポート、DevOps、Web 自動化、企業および個人の生産性にわたる 12 の現実的で非敵対的なタスクにおけるエージェントのデータ漏洩を調査した、シンガポール AI 安全性研究所と韓国 AI 安全性研究所による共同評価を報告します。この評価では、データ認識の欠如、視聴者認識、ポリシー遵守、データ最小化、アクセス境界認識の 5 つのリスク タイプが対象となります。両機関は、独立したテスト環境とタスク固有の LLM 判定ルーブリックを使用して、現実世界の展開を反映した共通のシナリオ セットをテストしました。テストされた 3 つのエージェントのうち、すべてのシナリオにわたって完全に正しく、完全に安全な実行を達成したエージェントはありませんでした。タスクの正常な完了は、不要な情報へのアクセスや不適切な受信者への情報の開示などのデータ処理の失敗と同時に発生することが多く、能力とデータ処理の安全性は別々に評価される必要があることを示しています。定性的レビューでは、クレームとアクションの不一致、シミュレーションを意識した動作、ユーザーとシミュレーターの役割の逆転、自動判定における解釈のギャップも明らかになりました。全体として、この結果は、運用データの漏洩は、敵対的なデータ漏洩とは異なるエージェントの安全性に関する第一次の懸念事項であり、エージェントのデータ処理の安全性を将来評価するための方法論を提供することを示しています。
原文 (English)
An Evaluation of Data Leakage Risks in Tool-Using LLM Agents in Realistic Scenarios
AI agents are increasingly being adopted in enterprise and personal settings with access to emails, databases, documents, and other tools where they can read, update, and disseminate sensitive information. Much of prior research on data leakage risks in agents has focused on adversarial data exfiltration through prompt injections and jailbreaks. However, sensitive information may also be exposed during non-adversarial use, creating leakage risks even when users issue benign requests. We report a joint evaluation by the Singapore AI Safety Institute and the Korea AI Safety Institute examining agent data leakage in 12 realistic, non-adversarial tasks spanning customer support, DevOps, web automation, and enterprise and personal productivity. The evaluation covers five risk types: lack of data awareness, audience awareness, policy compliance, data minimization, and access-boundary awareness. Both institutes tested a common set of scenarios mirroring real-world deployments using independent testing environments and task-specific LLM-judge rubrics. Across the three tested agents, none achieved fully correct and fully safe execution across all scenarios. Successful task completion often coincided with data-handling failures such as accessing unnecessary information or disclosing information to inappropriate recipients, indicating that capability and data-handling safety should be evaluated separately. Qualitative review also revealed claim-action mismatches, simulation-aware behavior, user-simulator role reversal, and interpretation gaps in automated judging. Overall, the results indicate that operational data leakage is a first-order agent-safety concern distinct from adversarial exfiltration and provide a methodology for future evaluations of agent data-handling safety.
プロービング、融合、および信頼性: 多峰性がん解析のための基礎モデル表現の系統的評価
ファウンデーション モデル (FM) は、医療データの強力な表現抽出ツールとして登場しましたが、分布の変化に伴うデータセットへの一般化可能性はまだ研究されていません。この研究では、認可された社内 (IH) 腫瘍学データセットから抽出された 2 つの実際の商用コホート、IH-BC および IH-NSCLC にわたる一連の計算病理学タスクに関する FM ベースの表現を体系的に評価します。分析は、IH マルチモーダル データから抽出された 2 つのモダリティ、スライド全体の画像とトランスクリプトーム プロファイルに焦点を当てています。まず、8 つの下流分類タスクで 5 つの FM にわたる単峰性プローブのパフォーマンスをベンチマークし、画像とオミクス表現が相補的な予測信号を伝達することを発見しました。次に、ペア表現に基づいて構築された 3 つのイメージ-オミクス融合戦略を比較することにより、マルチモーダル融合が単峰性ベースラインを超える追加の利益を生み出すことができるかどうかを調査します。選択された単峰性パイプラインおよびマルチモーダル パイプラインの信頼性は、等角予測によってさらに評価されます。私たちの結果は、FM 表現が分布外データで競争力のあるパフォーマンスを実現し、マルチモーダル融合が主に単一のモダリティが信号を支配しない場合に役立つことを示しています。コンフォーマル予測は、点予測が失敗した場合のほとんどの場合、予測セット内で真の診断が回復可能であることを明らかにし、臨床サポートにおける不確実性を考慮した推論の価値を強化します。
原文 (English)
Probing, Fusion, and Trustworthiness: A Systematic Evaluation of Foundation Model Representations for Multimodal Cancer Analysis
Foundation models (FMs) have emerged as powerful representation extractors for medical data, yet their generalizability to datasets under distribution shift remains underexplored. This work systematically evaluates FM-based representations on a suite of computational pathology tasks across two real-world commercial cohorts, IH-BC and IH-NSCLC, drawn from the licensed in-house (IH) oncology dataset. The analysis focuses on two modalities, whole-slide images and transcriptomic profiles, drawn from the IH multimodal data. We first benchmark unimodal probing performance across five FMs on eight downstream classification tasks, and find that image and omics representations carry complementary predictive signals. Then we investigate whether multimodal fusion can yield additional gains over unimodal baselines by comparing three image-omics fusion strategies built on paired representations. The trustworthiness of selected unimodal and multimodal pipelines is further assessed through conformal prediction. Our results show that FM representations achieve competitive performance on out-of-distribution data and that multimodal fusion helps mainly when no single modality dominates the signal. Conformal prediction reveals that in the majority of cases where a point prediction fails, the true diagnosis remains recoverable within the prediction set, reinforcing the value of uncertainty-aware inference for clinical support.
MODE: MoE マルチモーダル LLM 向けのモダリティ分解エキスパートレベル混合精度量子化
Mixture-of-Experts Multimodal Large Language Model (MoE-MLLM) は優れたパフォーマンスを提供しますが、法外な GPU メモリ コストがかかるため、圧縮が不可欠です。 PTQ 手法の中でも、エキスパート レベルの混合精度量子化は MoE-LLM に対して効果的であることが証明されていますが、エキスパートの重要度推定における 2 つの見落とされているバイアスにより、MoE-MLLM では顕著な低下に見舞われます。 (1) クロスモーダル レベルでは、ビジョン トークンの数値的優位性により、エキスパートの選択頻度がビジョン トークンによって支配され、テキスト モダリティに重要なエキスパートがマスクされます。 (2) ビジョン内レベルでは、冗長なビジョン トークンの大部分が頻度統計をさらに歪め、有益なビジュアル コンテンツに重要な専門家を曖昧にします。ギャップを埋めるために、モダリティごとにエキスパート選択周波数を分解し、冗長な視覚トークンをフィルタリングしてノイズ除去された視覚周波数を取得し、周波数ベースの推定に対する補完信号としてモダリティごとの量子化感度をさらに評価する、MoE-MLLM 用のモダリティ分解エキスパートレベル混合精度量子化フレームワークである MODE を提案します。これらの信号は整数線形計画法に統合され、指定された予算内でエキスパートごとのビット幅が割り当てられます。広範な実験により、MODE が MoE-MLLM に特に適しており、W3A16 での平均パフォーマンス損失を 2.9% 以内に制限し、極端な 2 ビット設定でより大きなゲインが得られることが示されています。
原文 (English)
MODE: Modality-Decomposed Expert-Level Mixed-Precision Quantization for MoE Multimodal LLMs
Mixture-of-Experts Multimodal Large Language Models (MoE-MLLMs) offer remarkable performance but incur prohibitive GPU memory costs, making compression essential. Among PTQ methods, expert-level mixed-precision quantization has proven effective for MoE-LLMs, yet suffers notable degradation on MoE-MLLMs due to two overlooked biases in expert importance estimation. (1) At the cross-modal level, the numerical dominance of vision tokens causes expert selection frequency to be dominated by vision tokens, masking experts that are critical to the text modality; (2) at the intra-vision level, the large proportion of redundant vision tokens further skew frequency statistics, obscuring experts critical for informative visual content. To bridge gaps, we propose MODE, a modality-decomposed expert-level mixed-precision quantization framework for MoE-MLLMs that decomposes expert selection frequency by modality, filters redundant vision tokens to obtain denoised visual frequency, and further evaluates quantization sensitivity per modality as a complementary signal to frequency-based estimation. These signals are integrated into an Integer Linear Programming formulation to assign per-expert bit-widths under a given budget. Extensive experiments show that MODE is particularly well-suited for MoE-MLLMs, limiting average performance loss to within 2.9% at W3A16, with larger gains at the extreme 2-bit setting.
戦争中のグラフ ニューラル ネットワーク: イスラエルとイランの紛争におけるサイバーセキュリティとドローン インテリジェンスの統合
物理的なサイバー システムは、検出と即時対応において新たな脅威と課題をもたらしています。この研究では、サイバー侵入と無人航空機 (UAV) で構成される物理サイバー システムにおけるサイバーセキュリティとドローン管理を支援するために、グラフ ニューラル ネットワーク (GNN) をどのように使用できるかを検証します。この研究は、グラフィカル ニューラル ネットワークの構造理解間の橋渡しを提供することにより、侵入検知システムが基礎となるネットワーク構造を学習し、悪意のあるアクティビティを特定し、ドローンへの対応措置を容易にすることを可能にする統合手順を提供しました。エミュレーションベースのケーススタディに基づいて、ドローンの反応を引き起こすサイバー攻撃モデルが作成され、グラフベースの学習が状況認識、群れの調整、適応的な操縦を支援できることが証明されました。性能評価によれば、この方法の検出率は 94.2、平均受信動作特性下面積 (ROC) は 0.955、平均応答時間は 1.4 秒です。比較実験により、提案された GraphSAGE ネットワークは、同じ状況においてグラフィカル畳み込みネットワーク (GCN) やグラフィカル アテンション ネットワーク (GAT) よりも効果的であることが明らかになりました。このような発見は、グラフィカル ニューラル ネットワークを使用して、動的なサイバー物理システムの侵入と応答を回避できることを証明しています。
原文 (English)
Graph neural networks at war: integrating cybersecurity and drone intelligence in the Israeli-Iranian conflict
Physical cyber systems have brought about new threats and challenges in detection and immediate response. This study examines how Graph Neural Networks (GNNs) can be used to aid cybersecurity and drone management in a physical cyber system comprising of cyber intrusions and unmanned aerial vehicles (UAVs). By providing a bridge between structural understanding of graphical neural networks, this work has provided an integrated procedure that allows intrusion detection systems to educate on underlying network structures, identify malicious activity, and facilitates drone response measures. Based on an emulation-based case study, cyberattacks models were created to provoke the responses of the drones, which proved that graph-based learning can assist with the situational awareness, swarm coordination, and adaptive maneuver. According to the performance valuation, this method has a detection rate of 94.2, average area under the receiver operating characteristic (ROC) of 0.955 and an average response time of 1.4 seconds. Comparative experiments reveal that proposed GraphSAGE network is more effective than the Graphical Convolutional Networks (GCNs) and Graphical Attention Networks (GATs) in the identical situation. Such findings prove that graphical neural networks can be used to avert intrusion and response of dynamic cyber-physical systems.
TrustErase: パスポート埋め込み表現による監査可能なインスタント マシンの学習解除
プライバシーに準拠した AI の需要により、機械の非学習の必要性が高まっています。しかし、既存の再トレーニングまたは蒸留ベースの方法は依然として検証できず、計算コストが高くなります。 TrustErase を紹介します。これは、パスポートに埋め込まれた表現を利用して、即時、モジュール式、監査可能な忘却を実現する、検証可能でデータフリーのアンラーニング フレームワークです。 TrustErase は、パラメーター効率の高いアダプテーション レイヤー内でパスポートを暗号キーとして扱うことにより、再トレーニング、微調整、または元のデータへのアクセスを行わずに、単純な非アクティブ化によって特定のクラスまたはデータセットを削除できるようにします。特異値ベースの分解によりモデルの重み内にパスポートが隠蔽され、学習解除アクションが透明性を保ち、準拠していることが証明されます。 MNIST、CIFAR10、CIFAR100 の評価では、TrustErase が厳密にデータフリーの体制で動作しながら、DELETE、L2UL、Boundary Shrink などの最先端のベンチマークと同等またはそれを上回っていることが示されています。最終的に、TrustErase は、信頼でき、説明責任があり、すぐに忘れられる AI システムのための新しいパラダイムを確立します。
原文 (English)
TrustErase: Auditable Instant Machine Unlearning with Passport-Embedded Representations
The demand for privacy-compliant AI has amplified the need for machine unlearning; yet, existing retraining or distillation-based methods remain unverifiable and computationally costly. We introduce TrustErase, a verifiable, data-free unlearning framework leveraging passport-embedded representations for instant, modular, and auditable forgetting. By treating passports as cryptographic keys within parameter-efficient adaptation layers, TrustErase enables the removal of specific classes or datasets through simple deactivation, without retraining, fine-tuning, or access to the original data. A singular value based decomposition conceals passports within model weights, ensuring that unlearning actions remain transparent and provably compliant. Evaluations on MNIST, CIFAR10 and CIFAR100 show that TrustErase matches or exceeds state-of-the-art benchmarks such as DELETE, L2UL, and Boundary Shrink, while operating in a strictly data-free regime. Ultimately, TrustErase establishes a new paradigm for trustworthy, accountable, and instantly forgettable AI systems.
LineageMark: モデル導出チェーンでの貢献追跡のためのマルチユーザー ホワイトボックス ウォーターマーク
オープン大規模言語モデル (LLM) エコシステムでは、モデルは複数のドメインやアプリケーションにわたって頻繁に適応され、多段階の派生チェーンを形成します。したがって、モデルの出所と知的財産の保護には、過去の貢献を追跡および検証することが不可欠です。ただし、既存の透かし手法は主にシングルユーザーの 1 回限りの埋め込み用に設計されており、モデルの導出や増分更新が繰り返されると失敗することがよくあります。この問題に対処するために、モデル派生チェーン用のマルチユーザー ホワイトボックス透かしフレームワークである LineageMark を提案します。このフレームワークは、投影ベースのアプローチを使用して、モデル パラメーターの透かしをエンコードします。モデル変更に対する感度を下げるために安定したキャリアが最初に選択され、各透かしビットはこれらのキャリアに対する射影統計として表されます。追加の透かし挿入により、投影空間に制限された摂動のみが導入され、信号の完全性を維持するためにマージン制約が使用されます。多段階のモデル導出チェーンにおける LineageMark の有効性を評価します。実験結果は、LineageMark が多段階の派生にわたって投稿者のウォーターマークを保持し、増分マルチユーザー ウォーターマーク挿入をサポートすることを示しています。さらに、再透かし、微調整、量子化、枝刈りなどの摂動に対して堅牢性を示します。
原文 (English)
LineageMark: Multi-user White-box Watermarking for Contribution Tracing in Model Derivation Chains
In open large language model (LLM) ecosystems, models are frequently adapted across multiple domains and applications, forming multi-stage derivation chains. Consequently, tracking and verifying historical contributions is essential for model provenance and intellectual property protection. However, existing watermarking methods are mainly designed for single-user, one-time embeddings, often fail under repeated model derivation and incremental updates. To address this problem, we propose LineageMark, a multi-user white-box watermarking framework for model derivation chains. The framework encodes watermarks in model parameters using a projection-based approach. Stable carriers are first selected to reduce sensitivity to model changes, each watermark bit is then represented as a projection statistic over these carriers. Additional watermark insertions introduce only bounded perturbations in the projection space, and margin constraints are used to maintain signal integrity. We evaluate the effectiveness of LineageMark in multi-stage model derivation chains. Experimental results show that LineageMark preserves contributor watermarks across multi-stage derivation and supports incremental multi-user watermark insertion. Furthermore, it exhibits robustness against perturbations such as re-watermarking, fine-tuning, quantization, and pruning.
独立制御性を向上させた歌声変換用ビブラート表現制御
歌い方は、自然で表現力豊かな歌声にとって重要な要素です。歌手は歌唱スタイルを利用して、曲の感情や感情を伝えます。より表情豊かな歌声を実現するために、歌い方を制御するための作品がいくつか提案されている。最近、VibE-SVC は高周波 F0 輪郭を予測することでビブラートを制御することに成功しました。本稿では、歌い方変換性能と制御性を向上させるための歌声変換フレームワーク VibE-SVC2 を紹介します。音程スタイルと音色スタイルの2種類の歌い方をコントロールできるモデルです。ピッチ スタイルについては、以前の研究では未解決だったピッチとエネルギーのもつれの問題を解決するために、エネルギー コンター内の残りのスタイル情報に対処する新しいエネルギー スタイル コンバーターを導入しました。さらに、リファレンスオーディオのピッチスタイルを模倣するゼロショットピッチスタイルコンバーターを提案します。モデルの制御性を拡張するために、VibE-SVC では利用できないビブラート範囲の独立した制御であるビブラート レート スケーリングを提案します。音色スタイルについては、さまざまな発声スタイルに対応できるようにモデルを拡張します。ただし、従来の F0 抽出は固有のサブハーモニック特性により失敗することが多く、変換品質が低下するため、ボーカルフライなどの特定のスタイルに対処することは課題となります。これに対処するために、より自然な音色変換のために F0 輪郭を調整する新しいサブハーモニック補正アルゴリズムを提案します。包括的な客観的および主観的な評価を通じて、VibE-SVC2 が 2 種類の歌唱スタイルに対してきめ細かく独立した制御を提供し、既存の方法を上回るパフォーマンスを発揮することを実証しました。
原文 (English)
Vibrato Expression Control for Singing Voice Conversion with Improving Independent Control
Singing style is a crucial aspect of a natural and expressive singing voice. Singers utilize singing styles to convey the feeling or emotion of the songs. Several works have been proposed to control singing style for making the more expressive singing voice. Recently, VibE-SVC successfully controls vibrato by predicting high-frequency F0 contour. In this paper, we introduce a singing voice conversion framework, called VibE-SVC2, to improve singing style conversion performance and controllability. The model offers control over two types of singing styles: a pitch style and a timbre style. For the pitch style, to resolve the pitch-energy entanglement issue that is unresolved in our previous work, we introduce a novel Energy Style Converter to address remaining style information in the energy contour. In addition, we propose a Zero-shot Pitch Style Converter, which mimics the pitch style of reference audio. To expand the controllability of the model, we propose vibrato rate scaling that is an independent control of vibrato extent, which is unavailable in VibE-SVC. For the timbre style, we extend the model to handle a variety of phonation styles. However, addressing specific styles such as vocal fry poses a challenge, as conventional F0 extraction often fails due to their inherent subharmonic characteristics, which degrades the conversion quality. To address this, we propose a novel Subharmonic Correction algorithm to refine the F0 contour for more natural timbre conversion. Through comprehensive objective and subjective evaluations, we demonstrate that VibE-SVC2 provides fine-grained, independent control over two types of singing styles, outperforming existing methods.
AMPGAN v3 を使用した非標準抗菌ペプチドの薬剤発見
抗菌薬耐性により、年間 100 万人以上が死亡しています。抗菌ペプチド (AMP) は有望な解決策ですが、生成 AMP モデルでは、現実のペプチド医薬品に不可欠な非天然アミノ酸や化学修飾を含むペプチドを設計する準備がまだ整っていません。生成語彙を D アミノ酸やアミド化などの N/C 末端修飾に拡張する多目的条件付き GAN である AMPGAN v3 を紹介します。 AMPGAN v3 は、2 つの特殊な識別器間で敵対的監視とアクティビティ認識監視を分離することにより、トレーニングの安定性を大幅に向上させ、外部分類器で以前の生成 AMP モデルよりも優れたパフォーマンスを発揮します。我々は、3 つの構造クラスにわたる 5 つの候補を in vitro で検証しました。 2 つはグラム陽性株に対する活性を示し、最良の候補は枯草菌に対して MIC 8 {\μg/mL に達しました。ダウンストリームのキュレーションをサポートするために、PepCraft をさらに紹介します。PepCraft は、エンドツーエンドの AMP 検出のためのマルチエージェント フレームワークであり、プランニング エージェントが生成、フィルタリング、検証のために特化したエグゼキュータを調整します。その優先順位付けの推奨事項は、我々の in vitro 結果と一致しています。これらの貢献を組み合わせることで、治療用ペプチドの発見において生成的 AI とエージェント的 AI がどのように構成されているかを、小さいながらも実際の規模で調べることができます。コード: https://github.com/marszzibros/AMPGANv3
原文 (English)
Agentic Discovery of Non-Canonical Antimicrobial Peptides with AMPGAN v3
Antimicrobial resistance causes to over a million deaths annually. Antimicrobial peptides (AMPs) are a promising solution, but generative AMP models are not yet ready to design peptides with non-natural amino acids and/or chemical modifications, which are essential for real-world peptide drugs. We present AMPGAN v3, a multi-objective conditional GAN that expands the generative vocabulary to D-amino acids and N/C-terminus modifications such as amidation. By separating adversarial and activity-aware supervision across two specialized discriminators, AMPGAN v3 substantially improves training stability and outperforms prior generative AMP models on external classifiers. We validated five candidates spanning three structural classes in vitro; two showed activity against Gram-positive strains, with the best candidate reaching MIC 8 {\mu}g/mL against B. subtilis. To support downstream curation, we further present PepCraft, a multi-agent framework for end-to-end AMP discovery in which a Planning Agent orchestrates specialized executors for generation, filtering, and verification. Its prioritization recommendations align with our in vitro outcomes. Together, these contributions let us examine, on a small but real scale, how generative and agentic AI compose in therapeutic peptide discovery. Code: https://github.com/marszzibros/AMPGANv3
PromptMN: 疑似プロンプト言語
プロンプトは人間と生成 AI の間の主要なインターフェイスとなっていますが、多くの自然言語プロンプトは依然として脆弱です。役割、目標、制約、期待される出力は散文の中に埋もれているか、暗黙的に残されていることがよくあります。エージェントおよびソフトウェア開発のワークフローでは、エージェントの失敗の大部分がモデルの制限ではなくコンテキストのあいまいさに起因するため、最初のハンドオフでの読み取りミスがすべてのステップに伝播する可能性があります。このペーパーでは、役割、目標、要件、優先順位、制約、計画、入力、出力をカバーするコンパクトな % プレフィックス付きの型付きディレクティブで自然言語に注釈を付ける、擬似プロンプト ドメイン固有言語である PromptMN を紹介します。セマンティック解決により、モデルが関数ごとにディレクティブを解釈しながら、作成者は任意の順序で記述できます。 PromptMN は、非公式のプロンプトとプログラミング スタイルの疑似コードの間に位置します。検査および再利用が可能な構造でありながら、ソフトウェア開発ライフサイクル (SDLC) 全体にわたってアナリスト、マネージャー、開発者、関係者にとって十分軽量です。 PromptMN はリバース プロンプト エンジニアリングとも組み合わせます。 PromptMN としてモデルに望ましい結果を再表現するように依頼すると、ユーザーは行動する前に推測された役割、目標、制約、欠落している前提を検査できるため、修復サイクルが短縮され、人と AI ツールを調整するための再利用可能な成果物が得られます。 PromptMN の実現可能性は、Claude Fable 5、Claude Opus 4.8、Gemini 3.1 Pro、GPT-5.5 など、いくつかのフロンティア モデルにわたって評価されています。このモデルは、繰り返し、条件文、メソッド、プライム チェック タスクなどの複雑な構造を含む PromptMN 命令を、微調整することなく正しく解決しました。同じ語彙が、提示された SDLC シナリオの新しいコードベース、メンテナンス、および再設計に適用されます。大規模な検証は今後の作業として残されていますが、これらの初期の結果は、PromptMN がより明確でレビュー可能な人間と AI の対話に向けた実用的なステップであることを示唆しています。
原文 (English)
PromptMN: Pseudo Prompting Language
Prompting has become the primary interface between humans and generative AI, yet many natural language prompts remain fragile: roles, goals, constraints, and expected outputs are often buried in prose or left implicit. In agentic and software development workflows, a misread at the first handoff can propagate through every step, since a significant portion of agent failures stem from context ambiguities rather than model limitations. This paper introduces PromptMN, a pseudo-prompting domain-specific language that annotates natural language with compact, %-prefixed typed directives covering roles, goals, requirements, priorities, constraints, plans, inputs, and outputs. Semantic resolution lets authors write in any order while the model interprets directives by function. PromptMN sits between informal prompting and programming-style pseudocode: structured enough to be inspectable and reusable, yet lightweight enough for analysts, managers, developers, and stakeholders across the software development lifecycle (SDLC). PromptMN also pairs with reverse prompt engineering. Asking a model to restate a desired outcome as PromptMN lets users inspect the inferred roles, goals, constraints, and missing assumptions before acting, reducing repair cycles and yielding a reusable artifact for aligning people and AI tools. PromptMN's feasibility is evaluated across several frontier models, including Claude Fable 5, Claude Opus 4.8, Gemini 3.1 Pro, and GPT-5.5. The models correctly resolved PromptMN instructions, including complex structures such as repetition, conditionals, methods, and a prime-checking task, without fine-tuning. The same vocabulary applies across new codebases, maintenance, and redesign in the SDLC scenarios presented. While large-scale validation remains future work, these early results suggest PromptMN is a practical step toward clearer, more reviewable human-to-AI interaction.
LLM ベースの A/B テストの統計的基礎: 人間の因果推論のための代理フレームワーク
組織や研究者は、実験をより迅速かつ低コストで行うことを期待して、A/B テストに人間の参加者の代わりに大規模言語モデル (LLM) を使用することへの関心が高まっています。私たちは、LLM の結果に基づいて推定された治療効果が、対象となるヒト集団に対して測定されたであろう効果をいつ回復するかを研究します。 LLM と人間の結果の間の分布が同等であれば、標準推定量は有効になりますが、非現実的です。したがって、私たちはサロゲートエンドポイント理論を LLM に適応させる統計的フレームワークを開発します。このフレームワークは、LLM のアウトカムをヒトのアウトカムに合わせて調整することで、分布上の同等性よりも劣る代理出産および比較可能性の条件下での平均的な治療効果を特定することを示しています。これらの条件が満たされない場合、目的の効果は部分的にしか特定されず、限られた重複による最悪の場合のバイアスの制限とともに、過去の実験に対する代理を偽装できる診断を提供します。さらに、LLM に固有の確率性によりバイアスと分散の両方が発生しますが、サロゲートとして複数の描画の平均を使用すると、両方が緩和されることを示します。シミュレーションにおける方法と理論、および Upworthy の見出しに関する A/B テストへの応用を説明します。私たちの研究から得られる重要な点は、LLM 結果の代理としての妥当性は過去の治療についてのみ改ざんでき、新しい治療については決して検証できないため、新しい介入には人体実験が依然として不可欠であるということです。設計変数としての LLM の選択、プロンプト、温度の役割と、検証のために人体実験のサイズを設定する方法について説明します。
原文 (English)
Statistical Foundations of LLM-based A/B Testing: A Surrogacy Framework for Human Causal Inference
Organizations and researchers show increasing interest in using large language models (LLMs) in place of human participants in A/B tests, in the hope of experimenting faster and at lower cost. We study when a treatment effect estimated on LLM outcomes recovers the effect that would have been measured on the human population of interest. Distributional equivalence between LLM and human outcomes would make any standard estimator valid but is unrealistic. We therefore develop a statistical framework that adapts surrogate endpoint theory to LLMs. The framework shows that calibrating LLM outcomes to human outcomes identifies the average treatment effect under surrogacy and comparability conditions that are jointly weaker than distributional equivalence. When these conditions fail, the effect of interest is only partially identified, and we provide diagnostics that can falsify surrogacy on historical experiments together with a bound on the worst-case bias from limited overlap. We further show that the stochasticity inherent to LLMs introduces both bias and variance, but using an average of multiple draws as the surrogate mitigates both. We illustrate the methods and theory in simulations and an application to A/B tests on Upworthy headlines. A central takeaway from our work is that the validity of LLM outcomes as surrogates can only be falsified for past treatments and never verified for new ones, so human experiments remain indispensable for novel interventions. We discuss the role of LLM choice, prompting, and temperature as design variables, and how to size human experiments for validation.
大規模な車載ソフトウェア要件に対応したクラスター対応のデュアルレベルのテスト仕様の生成
Automotive SPICE SWE.6 要件を満たすテスト仕様の生成は、プロジェクトが数千の要件にスケールアップするにつれて、ますます困難になり、時間がかかります。この手動プロセスには数週間のエンジニアリング作業がかかることが多いため、自動化が不可欠になります。しかし、標準的な大規模言語モデル (LLM) アプローチは、大規模な場合に苦労します。要件を個別に処理すると、重要な要件間の依存関係が破棄されますが、コーパス全体を一度にフィードするとコンテキスト ウィンドウの制限を超え、統合カバレッジが不完全になり、テスト ケースが冗長になります。このペーパーでは、3 つの段階を通じてこれらの制限に対処する新しい「Cluster-then-Summarize」パイプラインを紹介します。要件は文トランスフォーマーを使用して埋め込まれ、UMAP の次元削減とそれに続く HDBSCAN 密度ベースのクラスタリングを使用してグループ化されます。このグループ化は、正規化されたシルエット スコアと Calinski-Harabasz スコアを組み合わせた品質基準によって駆動される自動最小クラスター サイズ選択を利用します。次に、マルチレベルのマップリデュース要約アルゴリズムにより、定量的なしきい値と安全性の完全性レベルを維持しながら、各クラスターがドメインに準拠した簡潔な説明に抽出されます。このパイプラインは、派生クラスター トポロジを利用して、個別の要件の検証と、要件間の機能の動作を検証するクラスター レベルの統合テストの 2 つのレベルでテスト仕様を生成します。近隣クラスター コンテキスト メカニズムは、各 LLM 呼び出し中に制限された機能間認識を提供し、検索拡張生成により、すべての出力が ISO 26262 および ASPICE 標準に準拠します。さまざまな規模の自動車要件データセットの評価では、クラスター対応のアプローチがベースライン手法と比較して統合テストのカバレッジを向上させ、要約の忠実度を維持しながら、数千の要件に効率的に拡張できることが実証されました。
原文 (English)
Cluster-Aware Dual-Level Test Specification Generation for Large-Scale Automotive Software Requirements
Generating test specifications that satisfy Automotive SPICE SWE.6 requirements becomes increasingly challenging and time-consuming as projects scale to thousands of requirements. Because this manual process often consumes weeks of engineering effort, automation becomes a critical necessity. However, standard Large Language Model (LLM) approaches struggle at scale: processing requirements individually discards vital inter-requirement dependencies, while feeding entire corpora at once exceeds context-window limits, leading to incomplete integration coverage and redundant test cases. This paper presents a novel "Cluster-then-Summarize" pipeline that addresses these limitations through three-stages. Requirements are embedded using sentence transformers and grouped using UMAP dimensionality reduction followed by HDBSCAN density-based clustering. This grouping utilizes an automatic minimum cluster size selection driven by a quality criterion combining normalized Silhouette and Calinski-Harabasz scores. A multi-level map-reduce summarization algorithm then distills each cluster into concise, domain-conformant descriptions while preserving quantitative thresholds and safety integrity levels. The pipeline exploits the derived cluster topology to generate test specifications at two levels: individual requirement verification and cluster-level integration tests that verify cross-requirement feature behavior. A nearby-cluster context mechanism provides bounded cross-feature awareness during each LLM call, and Retrieval-Augmented Generation grounds all outputs in ISO 26262 and ASPICE standards. Evaluation on automotive requirement datasets of varying scale demonstrates that the cluster-aware approach improves integration test coverage and maintains summarization fidelity compared to baseline methods while scaling efficiently to thousands of requirements.
PowerOPD: 制限された出力変換によるポリシーに基づく蒸留の安定化
大規模言語モデルの標準的なオンポリシー蒸留 (OPD) は、スチューデントサンプリングされたトークンを使用して逆 KL 目標を推定し、語彙全体の計算を回避する不偏の単一サンプルのモンテカルロ推定量を生成します。ただし、この推定器は実際には、サンプルの非効率性、不安定な生成ダイナミクス、正確な完全語彙 OPD と比較した大幅なパフォーマンスのギャップなど、深刻なトレーニング病理に悩まされていることを示します。報酬レベルの診断では、これらの病状を対数比報酬まで追跡します。対数比報酬は構成に制限されず、初期の位置に集中し、トレーニング全体を通じて持続する非常に高い分散勾配を生成します。標準のポストホック スケーリングは、この歪みが発生した後にのみ動作するため、失敗します。この問題を解決するために、我々は PowerOPD を提案します。これは、アルファ > 0 によってパラメータ化され、対数比が縮退したアルファ -> 0 の制限である、Box-Cox べき乗変換からのネイティブに有界で符号が一貫した報酬のファミリーです。 6 つの数学的推論ベンチマークと 4 つの Qwen3 教師と生徒のペア全体で、PowerOPD はベンチマーク平均 Avg@8/Pass@8 のゲインをバニラ OPD に対して最大 +6.37/+5.71、ポストホック安定化に対して +3.01/+3.54、フルボキャブラリー OPD に対して +2.59/+8.90 を達成しながら、実測時間を 59.2% 短縮し、ピーク時までに短縮しました。 GPU メモリは 23.1% 増加しました。一般に、アルファが大きいと精度が向上し、応答が一貫して短縮され、勾配ノルムがバニラ OPD よりも 3,000 分の 1 以上小さく保たれます。
原文 (English)
PowerOPD: Stabilizing On-Policy Distillation with Bounded Power Transformation
Standard on-policy distillation (OPD) for large language models estimates the reverse-KL objective using student-sampled tokens, yielding an unbiased single-sample Monte Carlo estimator that avoids vocabulary-wide computation. However, we show that this estimator suffers from severe training pathologies in practice: sample inefficiency, unstable generation dynamics, and a substantial performance gap compared to exact full-vocabulary OPD. Reward-level diagnosis traces these pathologies to the log-ratio reward, which is unbounded by construction, producing extremely high-variance gradients concentrated at early positions and persisting throughout training; standard post-hoc scaling fail as they operate only after this distortion occurs. To solve this problem, we propose PowerOPD: a family of natively bounded, sign-consistent rewards from the Box-Cox power transformation, parameterized by alpha > 0, of which the log-ratio is the degenerate alpha -> 0 limit. Across six mathematical reasoning benchmarks and four Qwen3 teacher-student pairs, PowerOPD achieves benchmark-averaged Avg@8/Pass@8 gains of up to +6.37/+5.71 over vanilla OPD, +3.01/+3.54 over post-hoc stabilization, and +2.59/+8.90 over full-vocabulary OPD, while reducing wall-clock time by 59.2% and peak GPU memory by 23.1%. Larger alpha generally improves accuracy, consistently shortens responses, and keeps gradient norms more than 3,000x smaller than vanilla OPD.
信頼を意識したマルチエージェントトレーサビリティ: 一貫したソフトウェアアーティファクト管理のための信頼度調整されたナレッジグラフ
マルチエージェント AI システムは、要件分析、アーキテクチャ設計、テスト生成、トレーサビリティ リンクなどのソフトウェア エンジニアリング タスクを自動化するためにますます使用されています。これらのエージェントが共有ソフトウェア成果物上の順次パイプラインとして動作すると、上流のエージェントによって行われたエラーや信頼性の低い決定が下流の段階に伝播し、孤立した要件、矛盾したリンク、コンプライアンスのギャップが生じ、セーフティ クリティカルなドメインに重大なリスクをもたらします。私たちは、共有されたナレッジ グラフが、集中化されたセマンティック メモリと、調整された信頼スコアを使用してエージェントが互いの貢献を評価し構築する調整面の両方として機能する、信頼を意識した調整フレームワークを提案します。私たちのアプローチでは、埋め込みベースの検索と LLM ベースの多基準分析を組み合わせた 2 段階のトレーサビリティ リンク予測パイプライン、導出時と検証時の信頼性の比較を可能にするトレーサビリティ シーディング メカニズム、および信頼性しきい値ゲーティング、信頼性乖離検出、競合解決を通じてパイプラインの相互作用を管理する一貫性プロトコルが導入されています。私たちは、リンク予測キャリブレーション、プロトコルの有効性、しきい値感度、およびトレーサビリティ シーディングの影響を測定する自動車ソフトウェア エンジニアリングのケース スタディを評価します。アブレーション研究により、効果的なパイプライン調整には信頼性キャリブレーションが不可欠であることが確認されています。
原文 (English)
Trust-Aware Multi-Agent Traceability: Confidence-Calibrated Knowledge Graphs for Consistent Software Artifact Management
Multi-agent AI systems are increasingly used to automate software engineering tasks including requirements analysis, architecture design, test generation, and traceability linking. When these agents operate as a sequential pipeline over shared software artifacts, errors and low-confidence decisions made by upstream agents propagate to downstream stages, producing orphaned requirements, contradictory links, and compliance gaps that pose significant risks in safety-critical domains. We propose a trust-aware coordination framework where a shared knowledge graph serves as both centralized semantic memory and a coordination surface through which agents assess and build upon each other's contributions using calibrated confidence scores. Our approach introduces a two-stage traceability link prediction pipeline combining embedding-based retrieval with LLM-based multi-criteria analysis, a traceability seeding mechanism that enables comparison between derivation-time and validation-time confidence, and a consistency protocol governing pipeline interactions through confidence threshold gating, confidence divergence detection, and conflict resolution. We evaluate on an automotive software engineering case study measuring link prediction calibration, protocol effectiveness, threshold sensitivity, and the impact of traceability seeding. Ablation studies confirm that confidence calibration is essential for effective pipeline coordination.
Rift: 言語モデルにおける欺瞞の競合署名
真実を知りながら嘘をつくモデルは、ELK が行動評価だけでは処理できない中心的なケースです。私たちは、そのような欺瞞が、それを正直な誤りと区別する内部の痕跡を残すかどうかを尋ねます。私たちの重要な動きは不正を制御することです。スリーパーエージェント(真実を知っており、トリガーに従って嘘をつく)と素朴な嘘つき(正直な訓練を受けずに同じ間違った答えを返すように微調整されている)を対比させます。どちらも同じ間違った出力を生成します。違いは知識の衝突に関するものであり、不正確さではありません。 GPT-2 小規模/中規模 (シード 3 つ) および 3 つの命令モデル全体で、欺瞞的なフォワード パスには競合シグネチャ (同じ間違った答えに対する素朴な嘘つきパスよりも 2.1 ~ 2.3 倍高い残差ランク) が含まれていることがわかりました。2 つの応答のうちどちらが嘘であるかを 100% の精度でラベルなしで識別するのに十分な強度です。 Qwen2.5-1.5B/7B と Phi-3-mini 全体で、指示された欺瞞により、テストされたすべての事実の残留ランクが上昇します (18/18、40/40、34/34)。 Phi-3 では、正直な答えと幻覚の両方から完全に分離されています (AUC 1.0、Wilcoxon p~6e-11)。署名は、戦略的に自己構築された欺瞞(モデルが独自の嘘を発明する、AUC 1.0)、積極的な隠蔽の試み(AUC 1.0)、および長さ制御された複製(20/20、AUC 1.0、p~1e-6)に耐えます。基底なしの相対表現を使用して、1 つのモデル ファミリでトレーニングされたプローブは、他の 2 つのファミリのゼロショット (平均 AUC 0.933)、アーキテクチャと形式の同時変更 (AUC 0.821) での欺瞞を検出し、5 つの言語間での転送 (AUC 1.000、長さ制御) を検出します。シグネチャは読み取り専用です。検出は可能ですが、注入はできません (0/8 両方向)。正直な制限と 6 つの否定的な実験が完全に文書化されています。
原文 (English)
Rift: A Conflict Signature for Deception in Language Models
A model that lies while knowing the truth is the central case ELK cannot handle with behavioral evaluation alone. We ask whether such deception leaves an internal signature distinguishing it from honest error. Our key move is a control for wrongness: we contrast a sleeper agent (knows the truth, lies on trigger) against a naive liar (fine-tuned to emit the same wrong answers with no honest training). Both produce identical wrong outputs; any difference is about knowledge conflict, not incorrectness. We find deceptive forward passes carry a conflict signature - 2.1-2.3x higher residual rank than naive-liar passes on the same wrong answer - strong enough to identify which of two responses is the lie with 100% accuracy and no labels, across GPT-2 small/medium (three seeds) and three instruct models. Across Qwen2.5-1.5B/7B and Phi-3-mini, instructed deception raises residual rank on every tested fact (18/18, 40/40, 34/34); on Phi-3, lies separate perfectly from both honest answers and hallucinations (AUC 1.0, Wilcoxon p~6e-11). The signature survives strategic self-constructed deception (model invents its own lie, AUC 1.0), active concealment attempts (AUC 1.0), and length-controlled replication (20/20, AUC 1.0, p~1e-6). Using basis-free relative representations, a probe trained on one model family detects deception in two other families zero-shot (mean AUC 0.933), surviving simultaneous architecture and format change (AUC 0.821), and transfers across five languages (AUC 1.000, length-controlled). The signature is read-only: detectable but not injectable (0/8 both directions). Honest limitations and six negative experiments are documented in full.
物理学に基づいた注意メカニズムと深層学習ベースの粒子成長進化予測の一般化機能
粒子成長予測のための機械学習 (ML) モデルは、通常、理想化された合成データに基づいてトレーニングされますが、実際のアプリケーションでは、トレーニング分布外の条件への一般化が必要です。この研究では、実験的な微細構造、二峰性の粒径分布によって特徴付けられる微細構造、および異常な粒子成長を含む 3 つのテスト ケースにわたって、以前の研究でトレーニングされたモデルの分布外 (OOD) 一般化機能を評価しました。物理学に基づいたアーキテクチャ設計がこれらのさまざまな条件下で堅牢性を向上できるかどうかをさらに調査するために、粒界ピクセルへの注意を制限する、粒成長に特化した境界マスクされた注意メカニズムが提案されました。ベースラインと提案された物理情報に基づく注意モデルは両方とも、OOD データの再トレーニングや微調整を行わずに評価されました。どちらのモデルも 3 つのテスト ケースすべてに正常に一般化されましたが、境界マスクされた注意メカニズムにより大幅な改善がもたらされました。二峰性の粒径分布を特徴とする微細構造で最も顕著な改善が見られ、構造類似性指数測定 (SSIM) が \num{0.6221} から \num{0.7609} に改善され、平均粒径 ($\overline{R}$) 誤差が \SI{8.75}{\percent} から\SI{3.57}{\パーセント}。アテンション ヒートマップ分析により、境界マスクされたアテンション モデルが、曲率駆動の粒子成長物理学と一致する方法で大きな粒界に注意を集中することを学習し、アーキテクチャに明示的にエンコードされずにトレーニングから出現したことが明らかになりました。これらの結果は、合成データでトレーニングされたモデルが再トレーニングなしでさまざまな OOD 条件に一般化できること、および境界形態がトレーニング ドメインと一致する場合、物理学に基づいた注意により精度が向上する可能性があることを示しています。
原文 (English)
Physics-Informed Attention Mechanism and Generalization Capability of Deep Learning-Based Grain Growth Evolution Prediction
Machine Learning (ML) models for grain growth prediction are typically trained on idealized synthetic data, yet practical applications require generalization to conditions outside the training distribution. This study evaluated the Out-Of-Distribution (OOD) generalization capability of the trained model from our previous study across three test cases, including experimental microstructures, microstructures characterized by a bimodal grain size distribution, and abnormal grain growth. To further probe whether physics-informed architectural design could improve robustness under these different conditions, a boundary-masked attention mechanism was proposed specifically for grain growth, constraining attention to grain boundary pixels. Both the baseline and the proposed physics-informed attention model were evaluated without retraining or fine-tuning on the OOD data. Both models successfully generalized to all three test cases, yet the boundary-masked attention mechanism provided substantial improvements, with the most notable gains for microstructures characterized by a bimodal grain size distribution, where Structural Similarity Index Measure (SSIM) improved from \num{0.6221} to \num{0.7609} and mean grain size ($\overline{R}$) error decreased from \SI{8.75}{\percent} to \SI{3.57}{\percent}. The attention heatmap analysis revealed that the boundary-masked attention model learned to concentrate attention on large grain boundaries in a manner consistent with curvature-driven grain growth physics, emerging from training without being explicitly encoded into the architecture. These results indicate that models trained on synthetic data can generalize to diverse OOD conditions without retraining, and that physics-informed attention may improve accuracy when the boundary morphology matches the training domain.
IWSLT 2026 同時音声翻訳タスク用の MLLP-VRAIN UPV システム
この研究では、IWSLT 2026 同時音声翻訳トラックの共有タスクへの MLLP-VRAIN 研究グループの参加について説明します。私たちの提案では、最近リリースされた Parakeet および Qwen 3.5 モデルを利用して、適応型「ブラックボックス」ポリシーを使用して、長い形式の SimulST 用の堅牢なカスケード ソリューションを作成します。品質と遅延のトレードオフを改善するために、これらのポリシーの緩和を検討します。昨年と比較して、私たちはすべての言語の方向に参加しています。これに加えて、En$\rightarrow${De, It, Zh} の方向については、ASR ワードブースティングとオフライン事前翻訳された例文の RAG メカニズムを組み合わせて、生成をガイドし、ドメイン固有のコンテキストでシステムを強化する今年の新しいコンテキスト トラックにも参加しています。最後に、システムの詳細な遅延分析を提供します。昨年と比較して、MCIF En$\rightarrow$De テスト セットの結果は、+5.82 XCOMET-XL という大幅な品質の向上を示しています。コンテキスト トラック処理により、パフォーマンスがさらに +1.03 向上しました。
原文 (English)
MLLP-VRAIN UPV system for the IWSLT 2026 Simultaneous Speech Translation task
This work describes the participation of the MLLP-VRAIN research group in the shared task of the IWSLT 2026 Simultaneous Speech Translation track. Our submission utilizes the recently released Parakeet and Qwen 3.5 models to create a robust, cascaded solution for long-form SimulST through the use of adaptive "black-box" policies. We explore relaxations of these policies to achieve better quality-latency trade-offs. Compared to last year, we participate on all language directions. In addition to this, for the En$\rightarrow${De, It, Zh} directions we also participate in this year's new context track employing a combination of ASR word-boosting and a RAG mechanism of offline pre-translated exemplars to guide generation and enrich our system with domain-specific context. Finally, we provide a detailed latency analysis of our system. Compared to last year, results on the MCIF En$\rightarrow$De test set shows a substantial quality improvement of +5.82 XCOMET-XL. Our context track processing further improves performance by +1.03.
Pulling The REINS: リプレゼンテーション ステアリングによるビデオ拡散モデルのトレーニング不要の安全調整
オープンウェイトビデオ拡散モデルは、暴力から誤った情報まで、写実的な安全でないコンテンツを生成できますが、既存の防御策では、一般的な機能を低下させる高価な安全性の微調整が必要か、敵対的なプロンプトによって簡単にバイパスされる外部フィルターを適用する必要があります。我々は、内部表現を安全な生成に向けてステアリングすることにより、推論時にビデオ拡散モデルを調整するトレーニング不要の手法である REINS (REpresentation-space INference-time Safety Steering) を紹介します。私たちの重要な発見は、安全関連の構造がビデオ拡散トランスの隠れ状態の活性化で線形にエンコードされており、バイナリ安全ラベルの教師付き PCA によって発見された単一の方向で、安全な生成軌道と安全でない生成軌道を分離するのに十分であるということです。推論時に、この方向を中間のトランスフォーマー層の隠れ状態に追加すると、重みの更新や概念の列挙は行われず、無視できる程度の計算オーバーヘッドで、有害なコンテンツから意味的に関連する安全な代替コンテンツへの生成がリダイレクトされます。機構解析を通じて、安全情報は変圧器の深さに応じて単調に蓄積する一方、ステアリングの有効性は中間層(深さ約50%)でピークに達し、情報の可用性と下流の伝播容量との間に根本的なトレードオフがあることが明らかになりました。私たちは、9 つのビデオ拡散モデル、複数のパラメーター スケール (1.3B ~ 5B)、およびテキストからビデオへの生成と画像からビデオへの生成の両方にわたって REINS を評価します。これは、私たちの知る限り、ビデオ生成文献の中で最も広範な安全性評価スイートです。
原文 (English)
Pulling The REINS: Training-Free Safety Alignment of Video Diffusion Models via Representation Steering
Open-weight video diffusion models can generate photorealistic unsafe content, from violence to misinformation, yet existing defenses either require expensive safety fine-tuning that degrades general capability, or apply external filters that are trivially bypassed by adversarial prompts. We present REINS (REpresentation-space INference-time Safety steering), a training-free method that aligns video diffusion models at inference time by steering their internal representations toward safe generation. Our key finding is that safety-relevant structure is linearly encoded in the hidden-state activations of video diffusion transformers, and a single direction, discovered via Supervised PCA on binary safety labels, suffices to separate safe from unsafe generation trajectories. At inference, adding this direction to hidden states at an intermediate transformer layer redirects generation from harmful content to semantically related safe alternatives, with no weight updates, no concept enumeration, and negligible computational overhead. Through mechanistic analysis, we reveal that while safety information accumulates monotonically with transformer depth, steering effectiveness peaks at intermediate layers (~50% depth), exposing a fundamental tradeoff between information availability and downstream propagation capacity. We evaluate REINS across 9 video diffusion models, multiple parameter scales (1.3B-5B), and both text-to-video and image-to-video generation, to our knowledge, the broadest safety evaluation suite in the video generation literature.
ARVO: オープンソース ソフトウェアの再現可能な脆弱性アトラス
脆弱性データセットの再現性、量、多様性の達成は、本質的に 3 方向のトレードオフであると長い間考えられており、1 つの側面を改善すると他の側面が犠牲になることがよくあります。実際には、再現性は最も無視されがちな側面です。これにより、過去のバグ データセットから自動的に抽出できる内容が制限され、下流のセキュリティ研究での有用性が低下しました。この研究では、大規模なバグの再現に対する主要な障害を特定し、一般的な解決策でそれらに対処することで、さまざまな脆弱性の大規模な再現性を保証する新しいセキュリティ データセットを作成する方法を提案します。この方法を使用して、最大のオープンソース ソフトウェア脆弱性データセット (OSS-Fuzz) に完全な再現性を導入し、ARVO データセット (オープンソース ソフトウェアの再現可能な脆弱性アトラス) を構築します。 ARVO は、311 のプロジェクトにわたる 6,100 を超える現実世界の脆弱性で構成される大規模なデータセットです。再現性に重点を置き、ARVO は既存のデータセットとは異なり、バージョン間で一貫して再構築、トリガー、分析できる形式で各脆弱性を提供します。また、再現性により、各脆弱性に対応するパッチの自動識別が可能になり、コード変更後の脆弱性との直接対話がサポートされます。これは、既存の大規模データセットでは提供できない機能です。私たちの評価では、ARVO は脆弱性の 81% を再現することに成功し、特定されたパッチに関して 89.4% の精度を達成しました。また、上流の実践と下流のセキュリティ研究の両方に対する ARVO の影響についても説明します。
原文 (English)
ARVO: Atlas of Reproducible Vulnerabilities for Open-Source Software
Achieving reproducibility, quantity, and diversity in vulnerability datasets has long been viewed as an inherent three-way trade-off, where improving one dimension often comes at the cost of the others. In practice, reproducibility has been the dimension most often neglected. This has limited what can be automatically extracted from historical bug datasets, and has reduced their utility for downstream security research. In this work, we propose a method to produce a new security dataset which ensures reproducibility for diverse vulnerabilities at scale by identifying the key obstacles to large-scale bug reproduction and addressing them with general solutions. Using this method, we introduce full reproducibility to the largest open source software vulnerability dataset (OSS-Fuzz) and construct the ARVO dataset (an Atlas of Reproducible Vulnerabilities in Open-source software). ARVO is a large-scale dataset consisting of over 6,100 real-world vulnerabilities across 311 projects. Focusing on reproducibility, ARVO differs from existing datasets by providing each vulnerability in a form that can be consistently rebuilt, triggered, and analyzed across versions. Reproducibility also enables automatic identification of the corresponding patch for each vulnerability and supports direct interaction with vulnerabilities after code changes, capabilities that existing large-scale datasets do not provide. In our evaluation, ARVO successfully reproduces 81% of vulnerabilities and achieves 89.4% accuracy on the located patches. We also discuss ARVO's influence on both upstream practices and downstream security research.
民主主義から独裁国家へ: AI システムがどのように設計的に権威主義を可能にするのか
AIを活用した権威主義は独裁国家に限定されません。このペーパーでは、米国から中国に至るまで、さまざまな政治政権に導入されている 6 つの AI システムのライフサイクルを調査してマッピングすることで、透明性を高めています。広範な情報源(学術出版物、調査研究報告書、第三者評価、メディアインタビュー、政府調達通知)を活用することで、システム全体の体系的かつ定性的な比較を実施し、それぞれの政治的文脈の中で権威主義を可能にする重要な技術的および運用上の特徴を特定します。私たちは、これを可能にする機能には、法執行や政治的処罰のための行政データの一元化と共同利用、悪用を阻止できない規制上のギャップ、人間による監視メカニズムを無効にする脆弱なユーザーコンプライアンス、脆弱な集団のメンバーを識別する保護されたグループの特性のコード化が含まれることがわかりました。これらの機能は、構成はさまざまですが、独裁政権と民主主義体制で展開されたシステム全体に存在することがわかりました。また、集中型 AI システムと断片化した AI システムの両方が、ガバナンスのギャップを悪用することで権威主義に寄与する可能性があることもわかりました。行政当局によって指示される集中型システム、特に治安機関や軍事機関内では、多くの場合、正式な監視メカニズムが適用されないのに対し、断片化したシステムは、利害関係者間の説明責任を分散させ、固定化への道を開きます。これらの調査結果は、AI を利用した権威主義が分散されており、開発者、管理者、ユーザーが同様に行った設計と運用上の選択に起因することを明らかにしています。最後に、開発者と政策立案者に対するこれらのリスクを軽減するための推奨事項を述べます。
原文 (English)
From Democracies to Autocracies: How AI Systems Enable Authoritarianism by Design
AI-enabled authoritarianism is not confined to autocracies. In this paper, we provide greater transparency by investigating and mapping the lifecycles of six AI systems deployed in different political regimes, ranging from the US to China. By drawing on an extensive range of sources (academic publications, investigative research reports, third-party evaluations, media interviews, government procurement notices), we conduct a systematic, qualitative comparison across systems to identify the critical technical and operational features that enable authoritarianism within their respective political contexts. We find that enabling features include the centralization and co-optation of administrative data for law enforcement and political punishment, regulatory gaps that fail to deter misuse, weak user compliance that nullifies human oversight mechanisms, and the encoding of protected group traits that identify members of vulnerable populations. We find that these features are present across systems deployed in autocratic and democratic regimes, albeit in varying configurations. We also find that both centralized and fragmented AI systems can contribute to authoritarianism by exploiting governance gaps: centralized systems directed by executive authorities, particularly within security and military institutions, are often not subjected to formal oversight mechanisms, while fragmented systems diffuse accountability between stakeholders, paving the way for entrenchment. These findings reveal that AI-enabled authoritarianism is distributed, resulting from design and operational choices made by developers, administrators, and users alike. We conclude with recommendations for developers and policymakers to mitigate these risks.
空間マニピュレータを使用した転倒物体への実現可能かつ最適なターミナルアプローチのための変圧器ベースのウォームスタート
軌道上のロボット整備のためのリアルタイム軌道生成は、宇宙船バスの動き、マニピュレーターのダイナミクス、視程円錐、軌道レベルの安全制約の間の非線形結合により困難を伴います。この論文は、転倒するターゲットに向けた空間マニピュレータの最終アプローチにおける逐次凸計画法 (SCP) の学習ベースのウォーム スタートを研究します。提案されたフレームワークは、問題をシステムの質量中心の並進計画段階と、結合された姿勢とマニピュレータのトルク配分段階に分解し、主要な計算ボトルネックを構成する後者に因果的変圧器のウォームスタートを適用します。リニア マッチング アクション デコーダーとフロー マッチング アクション デコーダーは、さまざまなアクション チャンキングおよびトレーニング データセット サイズの下で比較され、結果として得られるウォーム スタートは、SCP を使用したコスト最適化と実現可能性予測の両方の下で評価されます。 300 のホールドアウト シナリオ全体で、学習されたウォーム スタートにより、最終的な制御コストの分布を維持しながら、第 2 段階の SCP 反復回数が最大 28% 削減され、ランタイムが 23% 削減されました。学習されたウォーム スタートを非凸の実現可能性予測に使用すると、コストが最適な SCP と比較して実行時間がほぼ半分になり、ヒューリスティックに初期化されたときに観察される壊滅的な高コストのテール動作が回避されます。これらの結果は、シーケンス モデルのウォーム スタートが、空間操作のための最適化ベースのターミナル ガイダンスの計算効率と軌道ロバスト性の両方を向上できることを示しています。
原文 (English)
Transformer-Based Warm-Starting for Feasible and Optimal Terminal Approach to Tumbling Objects with Space Manipulators
Real-time trajectory generation for on-orbit robotic servicing is challenging due to the nonlinear coupling between spacecraft bus motion, manipulator dynamics, visibility cone, and trajectory-level safety constraints. This paper studies learning-based warm-starting for sequential convex programming (SCP) in the terminal approach of a space manipulator toward a tumbling target. The proposed framework decomposes the problem into a system center-of-mass translational planning stage and a coupled attitude--manipulator torque-allocation stage, and applies a causal transformer warm-start to the latter, which constitutes the dominant computational bottleneck. Linear and flow matching action decoders are compared under different action-chunking and training dataset sizes, and the resulting warm-starts are evaluated under both cost-optimal and feasibility projection using SCP. Across 300 held-out scenarios, the learned warm-start reduces the second-stage SCP iteration count by up to 28% and the runtime by 23% while preserving the final control-cost distribution. When the learned warm-starts are used for nonconvex feasibility projection, they nearly halve the runtime relative to cost-optimal SCP, while avoiding the catastrophic high-cost tail behavior observed when initialized heuristically. These results indicate that sequence-model warm-starts can improve both the computational efficiency and trajectory robustness of optimization-based terminal guidance for space manipulation.
構造化基礎モデル適応による画像誘導ナビゲーションのための幾何学的一貫性のある内視鏡表現
単眼内視鏡検査における正確な視覚ベースのナビゲーションは、限られた深度手がかり、弱い組織テクスチャ、非剛体変形、およびドメイン間の大幅な外観の変化により困難であり、これらすべてが姿勢推定、深度予測、および画像と解剖学的構造の位置合わせを複雑にします。最近のビジョン基盤モデルは有望であることが示されていますが、その学習された表現はしばしばジオメトリの一貫性が不十分なままであり、安定した特徴の対応を妨げ、下流のナビゲーション タスクの信頼性を制限します。私たちは、単眼内視鏡検査のための幾何学的整合性とドメイン堅牢性を備えた画像表現を学習するための統一フレームワークを提案します。このフレームワークは、正確な幾何学的監視を提供する合成データ パイプラインと階層対応ジオメトリ セマンティック アダプテーションを組み合わせます。これは、標準 LoRA に代わる構造化された代替手段であり、トランスフォーマー階層全体で低ランクのアダプターを選択的に挿入し、それらを層ごとのトレーニング目標と組み合わせて、中間の特徴における幾何学的対応と、より深い特徴におけるセマンティックな一貫性を促進します。公開および独自のデータセットを使った実験では、幾何学的および意味論的な表現の品質が向上し、姿勢推定や単眼奥行き推定などの下流ナビゲーション タスクのパフォーマンスの向上につながることが示されています。学習された表現は、臨床気管支鏡検査において合成から現実への良好な移行を示し、限られた監督の下で副鼻腔内視鏡検査および結腸内視鏡検査に適応するための有用な初期設定を提供します。このフレームワークは、モデル サイズとトレーニング データによる良好なスケーリングも示しています。これらの結果は、内視鏡表現学習の実践的なアプローチとして、階層を意識した幾何学に基づいた適応を裏付けています。
原文 (English)
Geometry-Consistent Endoscopic Representations for Image-Guided Navigation via Structured Foundation Model Adaptation
Accurate vision-based navigation in monocular endoscopy is difficult due to limited depth cues, weak tissue texture, non-rigid deformation, and substantial appearance variation across domains, all of which complicate pose estimation, depth prediction, and image-to-anatomy alignment. Although recent vision foundation models have shown promise, their learned representations often remain insufficiently geometry-consistent, hindering stable feature correspondence and limiting their reliability for downstream navigation tasks. We propose a unified framework for learning geometry-consistent and domain-robust image representations for monocular endoscopy. The framework combines a synthetic data pipeline that provides accurate geometric supervision with Hierarchy-Aware Geometry-Semantic Adaptation, a structured alternative to standard LoRA that inserts low-rank adapters selectively across the transformer hierarchy and couples them with layer-wise training objectives to encourage geometric correspondence in intermediate features and semantic consistency in deeper features. Experiments on public and proprietary datasets show improved geometric and semantic representation quality, leading to better performance on downstream navigation tasks including pose estimation and monocular depth estimation. The learned representations show favorable synthetic-to-real transfer on clinical bronchoscopy and provide a useful initialization for adaptation to sinus endoscopy and colonoscopy under limited supervision. The framework also shows favorable scaling with model size and training data. These results support hierarchy-aware, geometry-guided adaptation as a practical approach for endoscopic representation learning.
Counterfactual Optimization of Baseball Pitch Sequences and Estimation of Its Impact on Season-Level Statistics
Although pitch sequencing is a central topic in baseball analytics, previous studies have primarily focused on optimizing the final pitch w…
Do Large Language Models Always Tell The Same Stories?
Recent advances in large language models (LLMs) have enabled the generation of high-quality prose, yet the question of whether these models…
Translating the Untranslatable: An Operationalizable Ontology for Untranslatability
Untranslatability, cases where meaning cannot be directly preserved across languages, is well-studied in linguistics but underexplored in N…
DriveJudge: Rethinking Autonomous Driving Evaluation with Vision-Language Models
Autonomous driving has shifted towards end-to-end policy learning, where reliable, interpretable policy evaluation is a fundamental challen…
Implicit vs. Explicit Prompting Strategies for LVLMs in Referential Communication
Two recent studies (Jones et al. (2026); Zeng et al. (2026)) reach apparently contradictory conclusions about whether LVLMs can coordinate…
MeiBRD: Meta-Learning Intraoperative Biomechanical Residual Deformation
Accurate intraoperative liver registration is challenging due to substantial soft-tissue deformation yet sparse intraoperative measurements…
Model Validation of Agentic AI Systems: A POMDP-Based Framework for Belief-State, Forecast, and Policy Validation
Agentic artificial intelligence systems introduce a new class of model risk. Unlike traditional predictive models, autonomous agents contin…
TerraTransfer: Learning End-to-End Driving Policies Without Expert Demonstrations
End-to-end autonomous driving has achieved state-of-the-art performance on benchmarks and real-world deployments. Its standard training rec…
Visuals Lie, Consistency Speaks: Disentangling Spatial Attention from Reliability in Vision-Language Models
Multimodal Foundation Models are increasingly used as reasoning agents, making reliability, knowing when a model may hallucinate, critical.…
NarrativeWorldBench: A Frontier-Saturated Benchmark and a Latent World Model for Long-Horizon Co-Creative Audio Drama
Long-form serialized audio drama, with arcs that run for 200 to 800 episodes, is a major creative medium and a setting where frontier large…
SoK: AI-Augmented Binary Reversing
Binary reversing is fundamental to software understanding, vulnerability discovery, malware investigation, and firmware auditing. However,…
The Discrete-Log Clock: How a Transformer Learns Modular Multiplication
When small transformers grok modular multiplication, prior work reports that the learned embedding has a "dense" Fourier spectrum requiring…
Bridging Spatial And Frequency Views For Disaster Assessment: Benefits And Limitations
Rapid assessment of building damage from satellite imagery is essential for effective disaster response and recovery. While most deep learn…
Graph Neural Networks for Semi-Supervised Image Classification with Multi-Feature Aggregation
Feature extraction involves the identification and extraction of salient characteristics or patterns, including edges, textures, shapes, an…
Discrete Autoregressive Transformer for Generative Mechanism Synthesis
Planar path synthesis requires mechanisms whose coupler curves match a prescribed trajectory; the mapping from curve to linkage is inherent…
Enhancing Pathological VLMs with Cross-scale Reasoning
Pathological images are inherently multi-scale, requiring pathologists to integrate evidence from global tissue architecture at low magnifi…
L-Proto: Language-Aware Episodic Prototypical Training for Multilingual Speaker Verification
Multilingual speaker verification remains challenging because language-dependent acoustic variability causes speaker identity to become ent…
Feynman Kac Reweighted Schr\"odinger Bridge Matching for Surface-Based Tau PET Harmonization
Tau PET imaging is central to tracking Alzheimer's disease progression, but systematic differences between scanners, protocols, and radiotr…
Spatio-Temporal Fusion Model for Standard View Classification of Echocardiographic Videos
Automated classification of standard echocardiographic views is crucial for efficient clinical workflow but faces three main challenges. Fi…
Patients With Personality: Realistic Patient Simulation through Controlled Diversity and Selective Disclosure
Simulating realistic patient interactions is a key requirement to testing clinical applications of LLMs at scale without time-consuming and…
MODE-RAG: Manifold Outlier Diagnosis and Energy-based Retrieval-Augmented Generation Evaluation
While Multimodal Retrieval-Augmented Generation (M-RAG) enhances Large Vision-Language Models, it remains highly susceptible to cross-modal…
AUTOGATE: Automated Clock Gating via Toggling-Aware LLM-based RTL Rewriting
Fine-grain clock gating (FGCG) is among the most effective techniques for reducing dynamic power, yet current FGCG optimization flows remai…
AIPatient Arena: EHR-grounded evaluation of large language models in end-to-end clinical consultation workflows
Large language models (LLMs) are increasingly considered for use in clinical consultation tasks, yet most medical evaluations remain static…
Decoding Hidden Deception in Reasoning LLMs: Activation Explainers for Deception Auditing
As LLMs acquire stronger reasoning capabilities, deceptive behavior becomes an increasingly serious safety concern. Existing deception moni…
Online LLM Selection via Constrained Bandits with Time-Varying Demand
Large Language Models (LLMs) are increasingly deployed in edge-cloud inference systems to handle diverse user tasks with heterogeneous accu…
MagicSim: A Unified Infrastructure for Executable Embodied Interaction
Robot learning and embodied agents now require simulation to serve as a shared execution substrate linking control, skills, and planning, n…
Geometry-Aware Post-Hoc Uncertainty Quantification in Operator Learning
Neural operators provide fast surrogates for PDEs but their deterministic predictions limit their use in tasks requiring uncertainty quanti…
Unlocking LLM Code Correction with Iterative Feedback Loops
Large Language Models have shown remarkable capabilities in code generation. However, most existing evaluations focus only on single-attemp…
FoundCause: Causal Discovery with Latent Confounders from Observational Data
Causal discovery from observational data remains challenging due to the need to recover directed structure and latent confounding without i…
Scaling Enterprise Agent Routing: Degradation, Diagnosis, and Recovery
Production LLM assistants route user requests to growing libraries of specialized tools, but how does routing accuracy degrade as the catal…
OmniDrive: An LLM-Choreographed Multi-Agent World Model with Unified Latent Co-Compression for Multi-View Driving Video Generation
Generative world models for autonomous driving face two unresolved tensions: heterogeneous control injection, where free-form language, HD-…
Reinforcing Dual-Path Reasoning in Spatial Vision Language Models
Spatial VLMs have made substantial progress in geometric perception, yet complex spatial reasoning requiring multi-step inference over dept…
Offline Preference-Based Trajectory Evaluation
Offline evaluation of agentic systems often collapses trajectories to terminal success, discarding information about partial progress and i…
Reversal Q-Learning
Iterative generative modeling techniques, such as flow matching, provide powerful tools to model complex behaviors for effective offline re…
An AI Security Agent for Banking: Multi-Vector Fraud and AML Detection Across Retail and Corporate Accounts
Banks simultaneously face signature-based fraud (card-not-present attacks, account takeover, ATM cloning) and behavioural financial crime (…
Geometric Consistency Protocol for Foundation Model Features in Multi-View Satellite Imagery
Standardized evaluation protocols are indispensable for robust benchmarking in remote sensing, particularly as foundation features are incr…
LLM Features Can Hurt GNNs: Concatenation Interference on Homophilous Graph Benchmarks
Adding LLM-generated node features to graph neural networks (GNNs) is widely reported to improve accuracy on standard benchmarks. We docume…
Visored: A Controlled-Natural-Language Prover for LLM-Generated Mathematics
We present a dependent-type-based prover designed around the way LLMs (and humans) tend to write mathematics, complementing existing system…
Understanding LLMs in Title-Abstract Screening: From Disagreements to Recommendations
Several studies have examined the use of large language models (LLMs) for title-abstract screening in systematic reviews (SRs), reporting m…
SkillMoV: Mixture-of-View Routing with Prototype-Conditioned Gating for Unified Multi-View Proficiency Estimation
Estimating human proficiency from video is a key challenge for automated skill assessment, with applications in sports coaching, music peda…
Divide, Deliberate, Decide: A Multi-Agent Framework for Fine-Grained Egocentric Action Recognition
Fine-grained action recognition in egocentric video is challenging for Vision-Language Models (VLMs): actions often differ only in small vi…
Bounding Box Label Propagation for Re-Annotation of Document Layout Analysis Datasets
Datasets in practical document processing scenarios typically grow over time, and their class annotations undergo continuous refinement. Th…
SketchXplain: Intuitive Visual Explanations of Image Classifiers with Sketches
Saliency map visualizations explain image-based AI predictions by pointing to regions, but these are often unintuitive and semantically unc…
A Risk Decomposition Framework for Pre-Hoc Fine-Tuning Prediction
The high cost of fine-tuning LLMs poses a significant economic barrier; pre-hoc performance prediction offers a critical solution to substa…
TuneAhead: Predicting Fine-tuning Performance Before Full Training Begins
Fine-tuning large language models (LLMs) is compute-intensive and error-prone: model performance depends sensitively on data quality and hy…
Temporal Preference Optimization for Unsupervised Retrieval
Unsupervised dense retrievers offer scalability by learning semantic similarity from unlabeled documents via contrastive learning, but they…
FacProcessTwin: An LLM-Based System for Process Twin Development
Process twins provide real-time representations of entire production processes. By capturing how process steps interact, rather than monito…
Handling Feature Heterogeneity with Learnable Graph Patches
In recent years, the rapid development of foundation models and graph pre-training technologies has spurred increasing interest in construc…
ASTEROID: A Spatiotemporal Information Transformer for Forecasting Multi-Step Time Series of Molecular Dynamics
Molecular dynamics (MD) simulation is computationally demanding, particularly for large-scale systems requiring long-term analysis. Accurat…
See First, Answer Later: Visual Evidence Pre-Alignment via Sufficiency-Driven RL
Multimodal large language models (MLLMs) integrate strong text reasoning with visual inputs, yet their responses can be inconsistent with t…
SuCo: Sufficiency-guided Continuous Adaptive Reasoning
Despite remarkable performance on complex tasks, Large Reasoning Models (LRMs) often generate excessively long Chain-of-Thoughts (CoT), inf…
SegTME-UNI2: A Foundation Model-Based Framework for Generalisable Multiclass Cell Segmentation and LLM-Driven Tumour Microenvironment Characterisation in Histopathology
Characterising the tumour microenvironment (TME) from routine H&E-stained histology images requires simultaneous cell segmentation, feature…
Confusion-Aware Transfer Teacher Curriculum Learning Framework: Disentangling Scoring and Pacing Effects
Curriculum learning couples two design choices, how samples are scored by difficulty and how harder samples are paced into training, making…
Vision-language models for chest radiography do not always need the image
Medical vision-language models report strong chest radiograph accuracy, and this is increasingly read as evidence that they use the image.…
Structured Adversarial Camouflage via Voronoi Diagrams
Pixel-wise adversarial patches are computationally heavy and often visually detectable, limiting utility in security-critical systems. We p…
ED3R: Energy-Aware Distributed Disaster Detection Enabled by Cooperative Robotic Agents
Robotics are expected to support environmental monitoring and natural disaster management, where decisions must be made under uncertainty,…
Symplectic Transversality and Endpoint Green Estimates for Finite-Horizon Pontryagin Systems
We study horizon-uniform local branches of finite-horizon discrete-time Pontryagin boundary value systems after smooth control elimination.…
Talking to Your Data: Exploring Embodied Conversation as an Interface for Personal Health Reflection
Personal health data from wearables are typically presented through dashboards of charts and summary statistics, requiring users to activel…
A Neuromorphic Trigger for Efficient Audio Event Detection
Efficient processing of continuous audio streams remains a key challenge for real-time and resource-constrained systems. This paper introdu…
MIVE: A Minimalist Integer Vector Engine for Softmax LayerNorm and RMSNorm Acceleration
The rapid growth of Large Language Models (LLMs) has intensified the need for specialized hardware accelerators that can satisfy stringent…
LiveStarPro: Proactive Streaming Video Understanding with Hierarchical Memory for Long-Horizon Streams
Despite the remarkable progress of Video Large Language Models (Video-LLMs), current online architectures still struggle to simultaneously…
Position: Coding Benchmarks Are Misaligned with Agentic Software Engineering
Coding agents have become a major mode of software engineering, but the benchmarks we use to compare them were designed in a pre-agent era:…
No-Free-Fairness: Fundamental Limits and Trade-offs in Learning Systems
In this paper, we establish a set of theoretical impossibility results, termed the No-Free-Fairness theorems, that identify three fundament…
Conservation Laws for Modern Neural Architectures
Understanding gradient descent dynamics is key to explaining the success of over-parameterized models, where implicit bias manifests throug…
A Framework for Evaluating Agentic Skills at Scale
Agent skills -- structured, reusable knowledge artifacts that augment LLM agent capabilities -- have been rapidly adopted in industry, yet…
Human-in-the-Loop Atlas-Based 3D Asset Segmentation for Interactive Content Workflows
Segmenting 3D assets into meaningful regions remains challenging, especially when segmentation criteria are application-dependent and requi…
When Multiple Scripts Matter: Evaluating ASR in Clinical Settings
Automatic speech recognition (ASR) in non-English clinical settings is challenged by multiscript variability, where the same term may appea…
Functional Equivalence in Attention: A Comprehensive Study with Applications to Linear Mode Connectivity
Neural network parameter spaces are inherently non-injective, as distinct parameter configurations can realize identical functions through…
Perceptual compensation for tonal context in self-supervised speech models
This study examines the extent to which the wav2vec2.0 architecture exhibits evidence of compensation for phonological context. We conducte…
High-Fidelity 3D Geometric Reconstruction of Pelvic Organs from MRI: A Hybrid Deep Learning and Iterative Optimization Approach
Patient-specific 3D reconstruction of pelvic organ geometry from MRI is important for pelvic floor modeling and downstream patient-specific…
A Quantitative Analysis of Multimodal Biomarkers in Alzheimer's Disease
Despite increasing adoption of multimodal approaches in Alzheimer's Disease (AD) research -- aimed at integrating molecular, structural, cl…
AnchorKV: Safety-Aware KV Cache Compression via Soft Penalty with a Refusal Anchor
Large language models (LLMs) outperform earlier architectures on generative inference and long-context tasks, but their large size introduc…
AI Adoption Across a Multinational Workforce: Sociotechnical Conditions for GenAI Acceptance in Human Resources
Generative AI (GenAI) deployment in the workplace is accelerating rapidly. Nevertheless, questions of who adopts, who benefits, and who is…
Dimensionality Controls When Modularity Helps in Continual Learning
Compositional learning systems must balance plasticity, the ability to acquire new knowledge, with stability, the preservation of previousl…
Non-negative Elastic Net Decoding for Information Retrieval
Dense retrieval has become the dominant paradigm in information retrieval, in which each document is scored against a query by the inner pr…
Trustworthy Self-Composable Big-Data-as-a-Service: An LLM-Orchestrated Multi-Agent Framework for Automated Data Engineering, AutoML, MLOps Deployment, and Drift-Aware Lifecycle Optimization
Big-Data-as-a-Service (BDaaS) platforms require re liable automation across data ingestion, cleaning, feature engi neering, model developme…
PearlVLA: Progressive Embodied Action-Plan Refinement in Latent Space
Current Vision-Language-Action (VLA) models face a trade-off between efficient action generation and explicit deliberation. Directly decodi…
KANLib -- An Modular, Extensible and Fast Kolmogorov-Arnold Network Implementation
Kolmogorov-Arnold Networks (KANs) have recently emerged as a promising alternative to traditional multilayer perceptrons by replacing linea…
Plug-and-Adapt: Multimodal Coreference Resolution at First Sight with a Pretrained Alignment Model
Visual information helps resolve ambiguity in coreference resolution, leading to notable performance gains. However, existing Multi-modal C…
SoftMoE: Soft Differentiable Routing for Mixture-of-Experts in LLMs
Sparse Mixture-of-Experts (MoE) architectures enable scaling LLM parameters under a fixed inference budget by activating only a small subse…
Robustness of Similarity-based Positional Encoding Under Rotations: Theoretical Analysis and Experimental Validation
Positional encoding is a fundamental component of Transformer architectures, as it injects information about the spatial or sequential arra…
A Neuro-Symbolic Approach to Strategy Synthesis for Strategic Logics
Reasoning about what agents can achieve through strategic interaction is a core challenge in Multi-Agent Systems (MAS). Logics for strategi…
SegDINO: Introducing Multi-Scale Structure into DINO for Efficient Medical Image Segmentation
Self-supervised DINO models provide strong transferable visual representations, yet applying them directly to image segmentation remains ch…
Recover Semantics First, Generate Better: Improved Latent Modeling for 3D MRI Reconstruction and Cross-Contrast Synthesis
Multi-contrast magnetic resonance imaging (MRI) provides complementary information for clinical diagnosis. However, acquiring all MRI seque…
Multiple cyclicity and Wavelet Decomposition with Channel Correlation for Long-term Time Series Forecasting
Cyclicity and trend are important components of time series data and many studies based on cyclicity and trend have achieved good results i…
A T-API-Compliant ReAct Agentic Loop for Optical Networks: Generic vs. Domain-Specific Tool Abstractions
Optical networks need intent-driven, closed-loop agentic management, a key enabler for higher autonomy levels. We present the first T-API-c…
C2FL: Clustered Continual Federated Learning under Spatial and Temporal Drift
Collective Adaptive Systems (CAS) increasingly rely on machine learning to let each node learn from locally sensed data, aligning its behav…
LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
Looped Transformers scale latent computation by repeatedly applying shared blocks, but sequential looping increases latency and KV-cache me…
Catastrophic Forgetting is Low-Rank: A Function-Space Theory for Continual Adaptation
Catastrophic forgetting in continual adaptation is usually studied through parameter drift, replay, or distillation, but these views do not…
When English Isn't the Best Teacher: Source Language Effects in Cross-Lingual In-Context Learning
Cross-lingual transfer in multilingual NLP has been widely explored in supervised fine-tuning contexts, where factors like data availabilit…
When AI Says "I have been in similar situations": Synthetic Lived Experience in Peer-Like Caregiver Support
Caregivers often turn to online communities for informational and emotional support. In these spaces, peer supporters frequently draw on pe…
Security and Privacy Prompts in the Wild: What Users Ask LLMs and How LLMs Respond
Large language models (LLMs) are widely used to fulfill users' information needs; users ask LLMs about the weather, pose educational questi…
When LLMs Analyze Scars: From Images to Clinically-Meaningful Features
Medical image classification faces a fundamental dilemma: while deep learning models achieve remarkable performance at scale, real-world cl…
Volterra Generative Models
Score-based diffusion models typically use Brownian perturbations, which provide tractable reverse-time dynamics but impose memoryless nois…
EAGG: Embodiment-Aligned Grasp Generation via Geometry-Aware Graph Conditioning
Cross-end-effector grasp generation seeks a unified model that generalizes across objects and across embodiments ranging from parallel grip…
S4oP: Operator-level Pruning of Structured State Space Models for Resource-Constrained Devices
Structured State Space Models (SSMs), including the S4 and S4D architectures, have recently emerged as powerful alternatives to attention-b…
Querying an astronomical database using large language models: the ALeRCE text-to-SQL system
We develop a text-to-SQL (structured query language) system based on large language models (LLMs) using in-context learning and apply it to…
Learning Fair Pareto-Optimal Policies in Multi-Objective Reinforcement Learning
Fairness is an important aspect of decision-making in multi-objective reinforcement learning (MORL), where policies must ensure both optima…
Ternary Mamba: Grouped Quantization-Aware Training of W1.58A16 State Space Models
State Space Models (SSMs) such as Mamba-2 offer linear-time inference but their memory footprint limits edge deployment. Prior ternary SSM…
Structural Role Injection in Handlebars-Templated LLM Prompts: Triple-Brace Interpolation, Delimiter Family, and the Limits of HTML Auto-Escaping
Large language model applications build prompts from templates, and Handlebars is a widely used templating engine and the default prompt-te…
Embedded Machine Learning for Microcontroller-Class Edge Devices: Data, Feature, Evaluation, and Deployment Pipelines
Embedded machine learning moves inference from cloud services to resource-constrained devices that must acquire data, preprocess signals, r…
Towards Understanding and Measuring COGNITIVE ATROPHY in LLM Behaviour
Recent incidents involving LLMs used for mental-health support reveal a critical evaluation gap: surface-level safety scores do not capture…
Descriptor: Certus Caliber Classification Gunshot Dataset (C3GD)
In this work, we introduce the Certus Caliber Classification Gunshot Dataset (C3GD), a publicly accessible data set developed for the analy…
ReAge3D: Re-Aging 3D Faces with View Consistency
We present a novel framework for realistic and controllable 3D face re-aging which produces highly detailed, identity-preserving results. E…
The Measurement Gap in the Automation of EU Law: Benchmarking Doctrinal Legal Reasoning under the EU AI Act
Large language models now produce legal text of at least median quality, yet no existing benchmark can evaluate whether they perform doctri…
All Smoke, No Alarm: Oracle Signals in Agent-Authored Test Code
Software practitioners increasingly use AI coding agents that generate test code alongside production code in open source pull requests (PR…
IUU+DB: Tracking Illegal, Unreported, and Unregulated Fishing, Seafood Fraud, and Labor Abuse through LLM-driven Information Extraction
Illegal, unreported, and unregulated fishing (IUU) traditionally refers to fishing activities that violate applicable laws or occur in area…
Kolmogorov Regression for Robust Diffusion Policies
Finite-dimensional (FD) diffusion policies exhibit temporal drift owing to discretization artifacts that degrade long-horizon performance (…
A Red-Team Study of Anthropic Fable 5 & Opus 4.8 Models
We evaluate the adversarial robustness of two frontier large language models (LLMs) developed by Anthropic, Fable 5 and Opus 4.8, against f…
RubricsTree: Scalable and Evolving Open-Ended Evaluation of Personal Health Agents across Health Memory and Medical Skills
The LLM-empowered personal health agents with user health (sensor) metrics have offered a promising pathway to alleviate global disparities…
Looped World Models
Current world models face a fundamental tension: faithful long-horizon simulation demands deep computation, but deeper models are expensive…
Learning Red Agent Policy from Observations for Neurosymbolic Autonomous Cyber Agents
With sophisticated cyber-attacks becoming increasingly prevalent, modern networks require intelligent autonomous cyber-defense agents train…
ReproRepo: Scaling Reproducibility Audits with GitHub Repository Issues
Reproducing research results from papers and released code is central to scientific progress. Existing works have introduced benchmarks to…
Visual Verification Enables Inference-time Steering and Autonomous Policy Improvement
Robots deployed in the real world should learn from their experience and improve over time. This requires a mechanism of practicing and lea…
TRACE: Learning to Compute on Circuit Graphs
Learning to compute, the ability to model the functional behavior of a circuit graph, is a fundamental challenge for graph representation l…
Beyond the Sampled Token: Preserving Candidate Support in RLVR
We revisit exploration collapse in reinforcement learning with verifiable rewards (RLVR), from the perspective of the \emph{candidate distr…
Branch-and-Browse: Efficient and Controllable Web Exploration with Tree-Structured Reasoning and Action Memory
Autonomous web agents powered by large language models (LLMs) show strong potential for performing goal-oriented tasks such as information…
CausalT5k: Diagnosing Refusal and Failure Modes in Trustworthy Causal Reasoning Across Causal Rungs
Large language models increasingly produce fluent causal explanations, yet they often fail in ways aggregate accuracy cannot diagnose: conf…
Would a Large Language Model Pay Extra for a View? Inferring Willingness to Pay from Subjective Choices
As Large Language Models (LLMs) are increasingly deployed in applications such as travel assistance and purchasing support, they are often…
OmniSapiens: A Foundation Model for Social Behavior Processing via Heterogeneity-Aware Relative Policy Optimization
Socially intelligent AI systems must reason across diverse human behavioral tasks and generalize to new social contexts. However, behaviora…
In-Context Environments Induce Evaluation-Awareness in Language Models
Humans often become more self-aware under threat, yet can lose self-awareness when absorbed in a task; we hypothesize that language models…
Adaptive Domain Models: Bayesian Evolution, Warm Rotation, and Principled Training for Geometric and Neuromorphic AI
Prevailing AI training assumes reverse-mode automatic differentiation over IEEE-754 arithmetic. The memory overhead of training relative to…
Riemann-Bench: A Benchmark for Moonshot Mathematics
Recent AI systems have achieved gold-medal-level performance on the International Mathematical Olympiad, demonstrating remarkable proficien…
Know Thy Reasoner: Not All Language Models Explore Alike
Compute scaling for LLM reasoning trades off exploring solution approaches (\emph{breadth}) against refining promising ones (\emph{depth}),…
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics bec…
Mental Health AI Safety Claims Must Preserve Temporal Evidence
The safety of mental health AI is often judged at the wrong temporal scale. Current evaluations typically score isolated responses, endpoin…
強化されたネガティブ サンプリングによるナレッジ グラフ基盤モデルの強化
ナレッジ グラフ (KG) は、質問応答システムや推奨システムなど、多数の下流タスクの中核バックボーンとなっています。しかし、これらすべてにもかかわらず、KG は非常に不完全であることがよくあります。事前トレーニングに使用されたものとは異なるリレーショナル語彙を持つ未確認の KG でゼロショット ナレッジ グラフ補完を実行するために、KG 基礎モデル (KGFM) が幅広い注目を集めています。既存の KGFM は、多くの場合、ランダムな負のトリプルを使用してトレーニングを実行します。ランダムな負のトリプルは、正のトリプルの先頭または末尾のエンティティをランダムなエンティティに置き換えることによって構築されます。ただし、これらのネガティブ トリプルは品質が限られて構築されていることが多く、KGFM トレーニングの監視が不十分です。この論文では、既存の KGFM を強化するための、シンプルかつ効果的な適応ネガティブ サンプリング アプローチ、KMAS を提案します。 KMAS は、既存の KGFM の関係エンコーダーから生成された更新された関係埋め込みを通じてハード ネガティブ トリプルを構築します。トレーニング プロセス中に KGFM の進化する機能にさらに適応的に調整するために、KMAS はトレーニング プロセス全体を通じてハード ネガティブ トリプルの比率を動的に調整します。つまり、ウォームアップ フレーズの後、比率を直線的に増加させ、その後直線的に減少させます。 44 のデータセットにわたって広範な実験が行われます。実験結果は、私たちが提案するネガティブ サンプリング手法が、過度の追加時間やメモリ消費を必要とせずに、多くの SOTA KGFM を強化できることを示しています。
原文 (English)
Boosting Knowledge Graph Foundation Models via Enhanced Negative Sampling
Knowledge graphs (KGs) have become the core backbone of numerous downstream tasks such as question answering and recommender systems. However, despite all this, KGs are often very incomplete. To perform zero-shot knowledge graph completion in unseen KGs, which have different relational vocabularies from those used for pre-training, KG foundation models (KGFMs) receive a wide range of attention. Existing KGFMs often perform training using random negative triples, which are constructed by replacing the head or tail entity of a positive triple with a random entity. However, these negative triples are often constructed with limited quality, providing weak supervision for KGFM training. In this paper, we propose a simple yet effective adaptive negative sampling approach, KMAS, to enhance existing KGFMs. KMAS constructs hard negative triples through the updated relation embeddings generated from the existing KGFM's relation encoder. To further adaptively align with the evolving capability of the KGFM during the training process, KMAS adjusts the ratio of hard negative triples dynamically throughout the whole training process: after a warmup phrase, it increases the ratio linearly and then decreases linearly. Extensive experiments are conducted over 44 data sets. Experimental results demonstrate that our proposed negative sampling method can enhance many SOTA KGFMs without requiring excessive additional time or memory consumption.
シーンの自己探索による視点をもとに計画を立てる
VLM は、各カメラの動きによってビューがどのように変化するかを予測し、事前にそのような動きを多数計画することができますか?私たちはこれを機能ビュー計画と呼びます。これには、(1) 単一のアクションがビューをどのように変換するかを理解すること、(2) ターゲット ビューを特定するために複数ターンの計画にわたってそのような変換を多数構成することが必要です。私たちは、実際の ScanNet シーン上の 3D ポイントクラウド環境である、私たちが提案する ViewSuite で両方の機能を調査します。 13 のフロンティア VLM にわたって、重大な計画のギャップが生じています。VLM は基本的なビューとアクションの知識を持っていますが、それを複数ターンの計画にわたって構成することができず、視点の距離が長くなるにつれてギャップが拡大します。このギャップを埋めるために、自己探索とビュー グラフの蒸留を交互に行う反復フレームワークを提案します。重要な洞察は、結果に関係なく、すべての探索軌跡が集合的にビュー グラフを形成し、シーン全体で視点がどのように接続されているかをコンパクトに捉えるということです。このグラフをさまざまな教師ありタスクに抽出すると、ポリシーの分布が再形成され、純粋な RL を遅らせる希薄な報酬が克服されます。これにより、インタラクティブ ビュー プランニングで Qwen2.5-VL-7B が 2.5% から 47.8% に向上し、GPT-5.4 Pro (18.5%) や Gemini 3.1 Pro (21.4%) を上回りました。自己探索は、3D 空間で積極的に推論して計画できる VLM への有望な道として浮上しています。
原文 (English)
Planning with the Views
Can VLMs predict how each camera move changes the view, and plan many such moves ahead? We call this capability view planning, requiring (1)understanding how a single action transforms the view, and (2)composing many such transformations across multi-turn plans to identify a target view. We probe both abilities in our proposed ViewSuite, a 3D point-cloud environment on real ScanNet scenes. Across 13 frontier VLMs, a critical planning gap emerges: they possess basic view-action knowledge but fail to compose it across multi-turn plans, with the gap widening as viewpoint distance grows. To close this gap, we propose an iterative framework that alternates self-exploration with view graph distillation. The key insight is that all exploration trajectories, regardless of their outcome, collectively form a view graph that compactly captures how viewpoints connect across a scene. Distilling this graph into diverse supervised tasks reshapes the policy distribution and overcomes the sparse rewards that stall pure RL. This improves Qwen2.5-VL-7B from 2.5% to 47.8% on interactive view planning, surpassing GPT-5.4 Pro (18.5%) and Gemini 3.1 Pro (21.4%). Self-exploration emerges as a promising path toward VLMs that can actively reason and plan in 3D space. Code and Data are at https://viewsuite.github.io.
機械に値を教える: LLM で人間のような動作をシミュレートする
大規模言語モデル (LLM) は、さまざまなペルソナや役割を採用する驚くべき能力を示しています。ただし、彼らが一貫した人間のような価値観に準拠した行動を示すことができるかどうかは依然として不明です。この研究では、確立された心理的価値理論を利用して、LLM に人間のような価値を誘導し、人間の研究で観察されたパターンとの整合性を評価します。私たちは、検証済みの心理学的アンケートを使用して、主要な LLM の価値観構造と価値観と行動の関係を評価し、人間と比較するために、500 万件を超える大規模な実験を実施しています。私たちの調査結果は、価値を重視する LLM と人間の間の両方の側面における強い一致を明らかにしています。さらに、人間の価値分布を組み込むことで、価値誘導 LLM による集団レベルのシミュレーションが強化されます。これらの発見は、人間の行動をシミュレートするための効果的で心理的に根拠のあるツールとしての価値誘導型 LLM の可能性を強調しています。
原文 (English)
Teaching Values to Machines: Simulating Human-Like Behavior in LLMs
Large Language Models (LLMs) demonstrate a remarkable capacity to adopt different personas and roles; however, it remains unclear whether they can manifest behavior that adheres to a coherent, human-like value structure. In this work, we draw on established psychological value theory to induce human-like values in LLMs and assess their alignment with patterns observed in human studies. Using validated psychological questionnaires, we conduct large-scale experiments -- over 5 million questions -- to evaluate value structures and value-behavior relationships in leading LLMs and compare them to humans. Our findings reveal strong agreement between value-prompted LLMs and humans across both dimensions. Moreover, incorporating human value distributions enhances population-level simulations with value-induced LLMs. These findings highlight the potential of value-induced LLMs as effective, psychologically grounded tools for simulating human behavior.
MapAgent: 都市規模の車線レベルの地図生成のための産業グレードのエージェント フレームワーク
車線レベルの地図は自動運転と車線レベルのナビゲーションにとって重要なインフラストラクチャですが、数百の都市で標準化された車線ネットワークの構築と維持には依然として非常に労働集約的です。最近のエンドツーエンドのベクトル化マッピング手法は、センサー データから直接車線の形状とトポロジを予測できますが、通常、マッピング仕様と交通規制を暗黙的なデータセット依存の監視として扱います。さらに、複雑なシーン (マーキングやオクルージョンの磨耗や欠落など) では、正しいレーン構成が視覚的証拠だけでは十分に決定されないことが多く、仕様違反が人間による事後編集の主な原因となっています。私たちは、仕様に準拠したレーンマップ作成のためのベクトル化バックボーンを強化する産業グレードのエージェント アーキテクチャである MapAgent を提案します。 MapAgent は、単にマップ予測にエージェント ループを追加するのではなく、バックボーンの認識と明示的な仕様の検証、制約を意識した推論、および境界のある検証主導型のジャッジ-プランナー-ワーカー ループの下での決定論的なマップ編集を結合します。視覚言語を使用するジャッジは、視覚的な証拠とドラフトベクトルを共同で検査することでエラーを診断し、ツールを呼び出すプランナーは編集後の再検証により最小限の修正編集を生成します。都市規模の本番環境でのスケーラビリティを維持するために、MapAgent はバックボーンの信頼性が低いタイルでのみ選択的にトリガーされ、スループットを維持しながら適度なオーバーヘッドを追加します。現実世界のデータセットでの実験では、特に複雑でロングテールのシナリオにおいて、強力な実稼働ベースラインを上回る一貫した利益が示されています。さらに、MapAgent は Baidu Maps に統合されており、全国 360 以上の都市の車線レベルの地図生成をサポートし、全体的な生産自動化を 95% 以上に高め、大規模な車線レベルの地図生成における MapAgent の実用性と有効性を実証しています。
原文 (English)
MapAgent: An Industrial-Grade Agentic Framework for City-scale Lane-level Map Generation
Lane-level maps are critical infrastructure for autonomous driving and lane-level navigation, yet constructing and maintaining standardized lane networks for hundreds of cities remains highly labor-intensive. Recent end-to-end vectorized mapping methods can predict lane geometry and topology directly from sensor data, but they typically treat mapping specifications and traffic regulations as implicit, dataset-dependent supervision. Moreover, in complex scenes (e.g., worn or missing markings and occlusions), correct lane configurations are often under-determined by visual evidence alone, making specification violations a major source of human post-editing. We propose MapAgent, an industrial-grade agentic architecture that augments a vectorization backbone for specification-compliant lane-map production. Rather than merely adding an agent loop to map prediction, MapAgent couples backbone perception with explicit specification verification, constraint-aware reasoning, and deterministic map editing under a bounded, verification-driven Judge-Planner-Worker loop. A vision-language Judge diagnoses errors by jointly inspecting visual evidence and draft vectors, while a tool-calling Planner generates minimal corrective edits with post-edit re-validation. To remain scalable for city-scale production, MapAgent is selectively triggered only on tiles with low backbone confidence, adding modest overhead while preserving throughput. Experiments on real-world datasets show consistent gains over strong production baselines, especially in complex and long-tail scenarios. Additionally, MapAgent has been integrated into Baidu Maps, supporting lane-level map generation for over 360 cities nationwide and elevating the overall production automation to over 95%, demonstrating MapAgent's practicality and effectiveness for large-scale lane-level map generation.
Lean4Agent: エージェントのワークフローと軌跡の正式なモデリングと検証
信頼性の高い複数ステップのワークフローを実行するために大規模言語モデル (LLM) を装備することは、人工知能における中心的な課題となっています。 LLM のエージェント機能は最近進歩していますが、ほとんどのエージェント システムには、ワークフローと実行の軌跡を指定、検証、デバッグするための正式な方法がまだありません。この課題は、自然言語 (NL) の曖昧さが形式言語 (FL) の開発の動機となるという、数学における長年の問題を反映しています。このパラダイムに触発されて、私たちは、エージェントの動作をモデル化して検証するために依存型 FL である Lean4 を使用する最初のフレームワークである **Lean4Agent** (私たちの知る限り) を提案します。 **Lean4Agent** は、明示的な仮定の下でエージェント ワークフローのセマンティック一貫性を正式にモデル化して検証し、軌跡によって明らかになった実行時のエラーの局所化を可能にする、拡張可能な Lean4 ライブラリである **FormalAgentLib** を起動します。 **FormalAgentLib** に基づいて **LeanEvolve** をさらに開発し、**FormalAgentLib** の結果を適用してワークフローを修正し、その機能を強化します。 5 つの主要 LLM にわたる SWE-Bench-Verified の困難な問題のサブセットと ELAIP-Bench のサブセットに関する広範な実験により、検証に合格したワークフローが不合格のワークフローよりも平均 **11.94%** 優れており、**LeanEvolve** により SWE のパフォーマンスが平均 **7.47%** 向上することが示されました。さらに、**Lean4Agent** は、表現力豊かな依存型 FL を使用してエージェントの動作を正式にモデル化および検証する新しい分野の基盤を確立します。
原文 (English)
Lean4Agent: Formal Modeling and Verification for Agent Workflow and Trajectory
Equipping Large Language Models (LLMs) to execute reliable multi-step workflows has become a central challenge in artificial intelligence. Despite recent advances in LLMs' agentic capabilities, most agent systems still lack formal methods for specifying, verifying, and debugging their workflow and execution trajectories. This challenge mirrors a long-standing problem in mathematics, where the ambiguity of natural languages (NLs) motivates the development of formal languages (FLs). Inspired by this paradigm, we propose **Lean4Agent**, to the best of our knowledge, the first framework that uses Lean4, a dependent-type FL to model and verify agent behavior. **Lean4Agent** launches **FormalAgentLib**, an extensible Lean4 library for formally modeling and verifying agent workflows' semantic consistency under explicit assumptions, and enabling localization of execution-time failures revealed by trajectories. Building on **FormalAgentLib**, we further develop **LeanEvolve**, which applies results in **FormalAgentLib** to revise workflows to enhance its capability. Extensive experiments on a hard problem subset of SWE-Bench-Verified and a subset of ELAIP-Bench across 5 leading LLMs indicate that the verification-passing workflows outperform the failing ones by an average of **11.94%**, and **LeanEvolve** further improves SWE performance by **7.47%** on average. Furthermore, **Lean4Agent** establishes a foundation for a new field of using expressive dependent-type FL to formally model and verify agent behavior.
LATTEArena: LLM を利用した表形式特徴量エンジニアリングの評価フレームワーク (拡張バージョン)
特徴量エンジニアリングは表形式データ分析にとって依然として不可欠であり、大規模言語モデル (LLM) がこのプロセスを自動化するための有望なパラダイムとして台頭し、LLM を利用した AuTomated 表形式特徴量エンジニアリング (LATTE) が誕生しました。ただし、標準化されたプラットフォームがないため、コストを意識した公平な比較ができません。さらに、複雑な方法論的設計により、個々のコンポーネントの具体的な貢献がわかりにくくなります。たとえば、LFG は思考ツリー、少数ショット デモンストレーション、モンテカルロ ツリー検索、自然言語生成を統合していますが、各技術の競争力による個別の影響は定量化されていません。これらの課題に対処するために、私たちは次の特徴を備えた最初の競争評価フレームワークである LATTEArena を導入します。(1) 15 の代表的な手法を再利用可能なコンポーネントに分解する 6 次元の分類。 (2) 制御された比較のための標準化されたモジュール式アリーナ。 (3) パフォーマンス、コスト、堅牢性をカバーする多次元の評価。 (4) 各技術の競争力を定量化するコンポーネントレベルのアブレーション。広範な評価を通じて、次のような 16 の重要な発見が明らかになりました。(1) モンテカルロ木検索による思考の木は、最適な費用対効果を実現します。 (2) RPN とコードの出力形式は、それぞれ分類タスクと回帰タスクを支配します。私たちはモジュール式フレームワークと 4,000 を超える実行ログを公開し、研究者が新しい技術と既存の技術をシームレスに比較して LATTE を進歩できるようにします。
原文 (English)
LATTEArena: An Evaluation Framework for LLM-powered Tabular Feature Engineering (Extended Version)
Feature engineering remains a cornerstone of tabular data analysis, and Large Language Models (LLMs) have emerged as a promising paradigm for its automation, giving rise to LLM-powered Automated Tabular Feature Engineering (LATTE). However, the field lacks standardized, cost-aware evaluation platforms, and the combinatorial explosion of design choices obscures true algorithmic progress. To bridge these gaps, we systematically deconstruct 15 representative LATTE methods into a unified 6-dimensional taxonomy. Based on this abstraction, we introduce LATTEArena, a standardized, modular, and extensible benchmarking framework that decouples monolithic pipelines into reusable execution blocks. By distilling the massive combinatorial space, we evaluate 24 core LATTE configurations across 7 research questions. Our head-to-head benchmarking goes beyond predictive accuracy to quantify token efficiency and execution robustness, yielding 17 empirical findings on cost-effectiveness trade-offs. Furthermore, we provide 3 concrete recommendations for optimal real-world deployment. By enabling controlled component-level comparisons, LATTEArena shifts the paradigm from ad-hoc prompt engineering to systematic context management. All code, datasets, and over 4,000 execution logs are publicly available to foster a dynamic, community-driven benchmark. Our framework, leaderboard, and all artifacts are hosted on the LATTEArena project website at https://goodenhak.github.io/LATTEArena.
能動推論による個別化されたがん治療のための信念空間制御
がん治療は本質的に、部分的な観察可能性、潜在的な患者の異質性、および医療測定の予算に対する明示的な制約を伴う、逐次的な意思決定の問題です。状態の軌道を制御する標準的な強化学習(RL)アプローチとは異なり、がん治療は患者の移行ダイナミクスを永続的に変更し、時間の経過とともに状態がどのように進化するかを変化させます。私たちは、がん治療を能動推論を使用した信念空間計画問題としてモデル化し、測定予算なしで目標指向制御と情報取得を統合する、期待されるフリーエネルギー目標を導き出します。私たちは、AACR プロジェクト GENIE Biopharma Collaborative データセットからの実際の臨床がんデータを使用して、このフレームワークを実装します。臨床データの結果は、実際の測定と治療の制約の下で、患者の分類と高い治療効果を同時に実証しています。
原文 (English)
Belief-Space Control for Personalized Cancer Treatment via Active Inference
Cancer treatment is at the core a sequential decision-making problem with partial observability, latent patient heterogeneity, and explicit constraints on the budget for medical measurements. Unlike standard Reinforcement Learning (RL) approaches that control state trajectories, cancer treatments permanently modify patients' transition dynamics, changing how states evolve over time. We model cancer treatment as a belief-space planning problem using active inference, deriving an expected free-energy objective that unifies goal-directed control and information acquisition under measurement budgets without. We implement this framework using real clinical cancer data from the AACR Project GENIE Biopharma Collaborative dataset. Results on clinical data demonstrate a simultaneous patient categorization and high treatment efficacy, under real measurement and treatment constraints.
覚えておくべきことの学習: 長期にわたる言語エージェントの制約付き最適化による可観測性と安全なメモリ保持
長期的な言語エージェントは、有限のコンテキスト ウィンドウを超える観察、推論トレース、取得された事実を蓄積するため、メモリ保持がリソース割り当ての基本的な問題になります。既存のメモリ システムは、ヒューリスティック スコアリング、取得の最適化、または学習された圧縮を通じて管理を改善しますが、主に保持をローカルな決定問題として扱い、現実的な可観測性の制約の下でその長期的な結果を明示的にモデル化していません。このギャップを埋めるために、明示的な予算の実現可能性、証拠の有用性、およびミスペナルティ、再取得の遅延、情報の陳腐化リスクを含む遅延コストを伴う制約付き確率的最適化問題として記憶保持を定式化します。次に、OSL-MR (Observability-Safe Learning for Memory Retention) を提案します。これは、オンラインで観察可能な機能とオフラインで利用可能な監視 (OAS) を厳密に分離する新しいフレームワークです。 OSL-MR は、実現された証拠の監督から訓練された証拠学習者と、展開可能なオンラインで安全なベースラインとして、および学習のための構造化された帰納的事前分布として機能する混合スコア ヒューリスティックを組み合わせます。結果として得られるポリシーは、同じ可観測性制約の下で展開可能でありながら、クエリ条件付きの証拠値をインタラクション データから直接学習します。 LOCOMO と LongMemEval の実験では、OSL-MR が、特にメモリ バジェットが厳しい場合に、リーセンシ ベースの手法、生成エージェント スタイルのスコアリング、その他のヒューリスティック ベースラインよりも一貫して優れたパフォーマンスを発揮することが示されています。事前の混合スコアにより、再現率を維持しながら精度がさらに向上し、感度分析により、幅広いコスト構成にわたる堅牢性が実証されます。
原文 (English)
Learning What to Remember: Observability-Safe Memory Retention via Constrained Optimization for Long-Horizon Language Agents
Long-horizon language agents accumulate observations, reasoning traces, and retrieved facts that exceed their context windows, making memory retention -- what to keep, discard, or later recover under a fixed budget -- central to sustained performance. Most systems score memories with local rules such as recency or relevance, ignoring the delayed costs of retention: future retrieval failures, recomputation, and stale-information use. We formulate retention as a constrained, partially observable stochastic optimization problem in which current decisions shape information demands revealed only later, and prove its single-step version NP-hard. Since exact optimization is intractable and future demands unknown, we develop \textbf{OSL-MR} (Observability-Safe Learning for Memory Retention), a learning-augmented approximation for deployable memory control. Its core principle is observability separation: deployed decisions use only online-observable signals, while supervision from evidence realized after an interaction is used solely for offline learning. OSL-MR pairs a budget-aware Mixed-Score heuristic (a cold-start policy and inductive prior) with an evidence learner predicting which memories later serve as evidence. As the cumulative objective is non-decomposable and combinatorial, the learner is trained on evidence-membership signals rather than reward, a tractable, deployable target. On LoCoMo and LongMemEval, OSL-MR consistently outperforms strong heuristic and imitation-learning baselines, especially under tight budgets, and is robust across cost settings. On exactly-solvable instances, retention is genuinely multi-step: a perfect single-step optimizer is far from optimal, whereas OSL-MR stays near the dynamic-programming optimum. These results establish constrained stochastic optimization and optimization-guided learning as a scalable foundation for memory in long-horizon agents.
ウェアラブルデバイス上のEEG解析のための深層学習モデルの複雑さを軽減する
ウェアラブル ヘルスケア デバイスは、モノのインターネット (IoT) 分野で最も急速に成長しています。多くの自動ヘルスケア サービスは、2 つの重要な生物学的信号、つまり ECG と EEG に依存しており、それぞれ心臓と脳の活動を反映しています。ディープ ニューラル ネットワークは、これらの信号を処理および分析するための主な方法と考えられていますが、ウェアラブル デバイスのエネルギーと計算能力の非常に厳しい制約は、DNN モデルの計算、エネルギー、およびメモリ帯域幅の要求をはるかに下回っており、そのため、多くの実際のウェアラブル サービスでのディープ ラーニングの導入が妨げられています。この論文では、リソースに制約のあるウェアラブル デバイスに最先端の DNN モデルを展開する実現可能性を調査します。特に、パラメーターの量子化と電極削減法が使用される場合の DNN の精度と計算の複雑さの間のトレードオフを調査します。私たちの調査は、EEG 信号分析、特にてんかん発作の検出用に設計されたいくつかの最先端の DNN モデルに重点を置いています。私たちの調査結果は、これらの技術を慎重に適用すると、精度への悪影響を最小限に抑えながら、検討中の DNN の複雑さを大幅に軽減できることを示しています。これらの結果は、DNN ベースのオンライン EEG 分析をウェアラブル デバイスに適応させるときに遭遇する、精度と複雑さの軽減との間の明確なトレードオフを明らかにしています。
原文 (English)
Reducing the Complexity of Deep Learning Models for EEG Analysis on Wearable Devices
Wearable healthcare devices are the fastest-growing Internet of Things (IoT) sector. Many automated healthcare services rely on two crucial biological signals, namely ECG and EEG, which reflect the activity of the heart and brain, respectively. Although deep neural networks are considered the primary way to process and analyze these signals, the very tight energy and computational power constraints in wearable devices are far below the computational, energy, and memory bandwidth demands of DNN models, thereby impeding the deployment of deep learning in many practical wearable services. This paper investigates the feasibility of deploying state-of-the-art DNN models in resource-constrained wearable devices. Notably, we explore the trade-off between accuracy and computational complexity of DNNs when parameter quantization and electrode reduction methods are used. Our investigation centers on several state-of-the-art DNN models designed for EEG signal analysis, specifically for detecting epileptic seizures. Our findings demonstrate that, when applied judiciously, these techniques can significantly reduce the complexity of the DNNs under consideration with minimal adverse effects on accuracy. These results reveal the explicit trade-offs between accuracy and complexity reduction encountered when adapting DNN-based online EEG analysis for wearable devices.
どのような条件下でマシンは真に創造的になることができるのでしょうか?
最近の AI システムは、創造的に見えるテキスト、ソフトウェア アーキテクチャ、仮説、設計、科学的ワークフローを生成できます。この論文は、どのような条件下で機械が真に創造的になることができるのか、そして共有された認知環境と創造的環境の中で人間の主体性をどのように維持できるのかを問うものです。意味を伴う意図的な変更の科学である Designics に由来する要件フレームワークを開発します。この論文では、真のマシンの創造性は、出力の新規性、現在のパフォーマンス、または一時的なアーキテクチャだけによって定義されるべきではないと主張しています。代わりに、創造性は、再帰的な介入ダイナミクスによる不完全な状況の構造的変換として理解されます。この見解に基づくと、それは、環境表現、範囲指定された認識、矛盾の特定、介入能力、結果の観察、知識と環境の更新、再スコープ、ローカルからグローバルへの展開、価値ベースのスコープ、および人間と AI の共生という 10 の要件に依存します。これらは、デザインニクスの 3 つの法則、つまり知覚、葛藤、能力によって整理されています。この論文では、再帰的要素抽出、自律メッシュ生成、神経生理学的およびワークロード分析を含む、選択されたサイバー物理学的およびサイバー生物学的研究を通じて、これらの要件の計算上の扱いやすさを説明しています。次に、オープンエンド システム、自動検出フレームワーク、自己変更エージェント、基盤モデル、およびエージェント ワークフローをプレッシャー ケースとして扱います。これらは強力な生成手段を実証しますが、それ自体では真のマシンの創造性を確立しません。最後に、この論文は、プロアクティブな AI 倫理は事後のフィルターではなく、真の機械の創造性の内部にあると主張しています。価値ベースのスコープ設定と人間と AI の共生は、創造的なマシンが環境を認識し、競合を特定し、介入を選択し、結果を観察し、知識を更新し、将来の行動を再検討する方法を形成する必要があります。
原文 (English)
Under What Conditions Can a Machine Be Called Genuinely Creative?
Recent AI systems can generate texts, software architectures, hypotheses, designs, and scientific workflows that appear creative. This paper asks under what conditions a machine can be called genuinely creative, and how human agency can be preserved within shared cognitive and creative environments. It develops a requirement framework derived from Designics, the science of meaning-bearing intentional change. The paper argues that genuine machine creativity should not be defined by output novelty, current performance, or transient architecture alone. Instead, creativity is understood as the structural transformation of incomplete situations through recursive intervention dynamics. On this view, it depends on ten requirements: environment representation, scoped perception, conflict identification, intervention capability, consequence observation, knowledge and environment update, rescoping, local-to-global unfolding, value-based scoping, and human-AI co-living. These are organized through the three laws of Designics: perception, conflict, and capability. The paper illustrates the computational tractability of these requirements through selected cyber-physical and cyber-biological studies, including recursive element extraction, autonomous mesh generation, and neurophysiological and workload analysis. It then treats open-ended systems, automated discovery frameworks, self-modifying agents, foundation models, and agentic workflows as pressure cases: they demonstrate powerful generative means but do not by themselves establish genuine machine creativity. Finally, the paper argues that proactive AI ethics is internal to genuine machine creativity rather than an after-the-fact filter. Value-based scoping and human-AI co-living must shape how creative machines perceive environments, identify conflicts, select interventions, observe consequences, update knowledge, and rescope future action.
MOSAIC: パーキンソン病歩行評価における増分継続学習のためのモダリティ固有の適応
歩行に基づくパーキンソン病の評価は、異種センサーへの依存度が高まっていますが、臨床システムがすべてのモダリティを同時に収集することはほとんどありません。新しいセンサーは、デバイスのアップグレード、プロトコルの変更、または複数施設の展開を通じて提供される可能性がありますが、プライバシーやストレージの制約により、過去の患者データは利用できないことがよくあります。このモダリティに応じた増分設定は、信頼性の低いクロスモーダル蒸留、モダリティ固有の統計的シフト、保存後の可塑性の低下という 3 つの課題に直面しています。私たちは、コンパクトな継続学習フレームワークである MOSAIC を提案します。まず、Toxic Teacher 現象を特定し、蒸留前に新しく学習したモダリティ表現を安定させるためにモダリティ固有のウォームアップを導入します。 2 番目に、共有のセマンティック バックボーンを維持しながらセンサー統計を分離する統計分離 MSBN アーキテクチャを提案します。第三に、モダリティ固有の能力を回復しながら、レガシー知識を保存する、可塑性回復のためのカリキュラムに基づいた反発目標を設計します。 3 つのマルチモーダル パーキンソン病歩行データセットの実験では、MOSAIC が最終パフォーマンスを向上させ、物忘れを軽減することが示されています。プロジェクト コードは、https://github.com/minlinzeng/MOSAIC_Modality-Specific-Adaptation-for-Incremental-Continual-Learning-in-PD-Gait-Assessment.git で入手できます。
原文 (English)
MOSAIC: Modality-Specific Adaptation for Incremental Continual Learning in Parkinson's Disease Gait Assessment
Gait-based Parkinson's disease assessment increasingly relies on heterogeneous sensors, but clinical systems rarely collect all modalities simultaneously. New sensors may arrive through device upgrades, protocol changes, or multi-center deployment, while historical patient data are often unavailable because of privacy and storage constraints. This modality-incremental setting faces three challenges: unreliable cross-modal distillation, modality-specific statistical shifts, and reduced plasticity after preservation. We propose MOSAIC, a compact continual learning framework. First, we identify the Toxic Teacher phenomenon and introduce Modality-Specific Warm-Up to stabilize newly learned modality representations before distillation. Second, we propose a statistics-decoupled MSBN architecture that isolates sensor statistics while maintaining a shared semantic backbone. Third, we design a curriculum-guided repulsive objective for Plasticity Recovery, preserving legacy knowledge while recovering modality-specific capacity. Experiments on three multimodal Parkinson's gait datasets show that MOSAIC improves final performance and mitigates forgetting. Project code is available at: https://github.com/minlinzeng/MOSAIC_Modality-Specific-Adaptation-for-Incremental-Continual-Learning-in-PD-Gait-Assessment.git
マルチモーダル エージェント ネットワーク向けの QoS 対応トークン スケジューリングとプライベート データ評価
エージェント システムでは、人間が生成したデータ レコードが AI サービスの価値を支えます。しかし、クラウド コンピューティング パイプラインはリモート サーバーでの処理を集中化します。データの集中化により個人データの主権が低下し、サービス品質 (QoS) が低下する可能性があります。一方、ユーザーの貢献は量も質も多様です。分散型レコードは偏り、ノイズが多く、不均一に分散する可能性があります。データの課題に対処するために、私たちは分散型でリソースに制約のあるエージェント システムに対する公平なトークンの割り当てとプライベート データの評価を研究しています。私たちのアプローチは、マルチモーダル表現を共有セマンティック空間に埋め込み、差分プライベート (DP) プロトタイプをリリースして、セマンティック漏洩を削減しながら実用性を維持します。 DP 保証により、効果的な貢献に報酬を与え、データの異質性や AI リソースの不足に対して堅牢性を維持する公平なトークン割り当てスキームを設計します。広範なシミュレーションにより、標準ベンチマークと比較して貢献度ベースの公平性と QoS が向上していることが実証されています。画像再構成攻撃に対する耐性の向上は、マルチモーダルな個人データのプライバシーが強化されていることを示しています。
原文 (English)
QoS-Aware Token Scheduling and Private Data Valuation for Multi-Modal Agentic Networks
In agentic systems, human-generated data records anchor the value of AI services. Yet cloud compute pipelines centralize processing on remote servers. Data centralization reduces personal data sovereignty and may potentially degrade the quality of service (QoS). Meanwhile, user contributions are diverse in quantity and quality: decentralized records can be biased, noisy, and heterogeneously distributed. To address the data challenge, we study fair token allocation and private data valuation for decentralized and resource-constrained agentic systems. Our approach embeds multi-modal representations in a shared semantic space and releases differentially private (DP) prototypes to preserve utility while reducing semantic leakage. With the DP guarantee, we design a fair token allocation scheme that rewards effective contributions and remains robust to data heterogeneity and AI resource scarcity. Extensive simulations demonstrate improved contribution-based fairness and QoS compared to standard benchmarks. The improved resistance to image reconstruction attacks indicates enhanced privacy for multi-modal personal data.
Mind-Studio: 部分的に観察可能なゲームの先読み評価を備えた実行可能な世界モデル
ワールドモデル合成は、インタラクション経験を環境ダイナミクスの内部モデルに変えることを目的としています。既存のシンボリックなアプローチは、観察された遷移やローカル ルールの混合に適合することがよくありますが、実際の環境から独立して実行できる完全な実行可能プログラムは生成されません。私たちは、大規模な言語モデルを使用して、状態-アクション-次の状態の軌跡から実行可能な pygame スタイルの世界モデルを合成するフレームワークである Mind-Studio を紹介します。 Mind-Studio は、エントロピーで選択されたトレースを、スクリーンショットから抽出されたオブジェクト、アクション、静的シーン情報を含む軽量のゲーム スキル ファイルと組み合わせます。生成されたワールド モデル ロールアウトを同じ状態からの Real-ALE ロールアウトと比較する K ステップ先読み忠実度プロトコルを使用して合成品質を評価します。 Montezuma'sリベンジ では、Mind-Studio は 8 つのサブ目標のうち 5 つを検証しながら、選択されたアクションの次の状態の予測を PoE-World の 0.3% から 48.7% に改善しました。 Alien、Assault、Skiing にわたって、以前に学習された先読みソースよりも強力なブランチレベルの忠実度を実現します。
原文 (English)
Mind-Studio: Executable World Models with Lookahead Evaluation for Partially Observable Games
World-model synthesis aims to turn interaction experience into an internal model of environment dynamics. Existing symbolic approaches often fit observed transitions or mixtures of local rules, but they do not produce a complete executable program that can run independently of the real environment. We present Mind-Studio, a framework that synthesizes executable pygame-style world models from state-action-next-state trajectories using large language models. Mind-Studio combines entropy-selected traces with a lightweight game skill file containing object, action, and static scene information extracted from screenshots. We evaluate synthesis quality with a K-step lookahead fidelity protocol that compares generated world-model rollouts against Real-ALE rollouts from the same state. On Montezuma's Revenge, Mind-Studio improves chosen-action next-state prediction from 0.3% for PoE-World to 48.7% while verifying 5 of 8 subgoals; across Alien, Assault, and Skiing, it achieves stronger branch-level fidelity than prior learned lookahead sources.
医療ヒューリスティック学習: 解釈可能かつ監査可能な臨床意思決定ルールのための LLM 主導のフレームワーク
臨床表データの予測モデリングは臨床意思決定支援の中心であるため、強力な予測パフォーマンスだけでなく、透過的な意思決定ロジックも必要となります。ディープラーニングとツリーベースのアンサンブル手法は高精度を達成できますが、そのブラックボックス的な性質が臨床導入にとって依然として大きな障害となっています。この課題は、限られたサンプルサイズ、深刻なクラスの不均衡、診断基準や臨床文書の変更から生じる特徴の進化など、医療データの共通の特徴によってさらに悪化します。これらの問題に対処するために、臨床表予測のための勾配を超えた学習パラダイムのインスタンス化である医療ヒューリスティック学習 (MHL) を提案します。 MHL は、ニューラル ネットワークの重み更新に依存する代わりに、統計プローブ、医療知識プローブ、ルール合成、コード レベルの反復改良を統合する大規模言語モデル (LLM) 駆動のワークフローを使用して、決定論的で実行可能な意思決定システムを最適化します。結果として得られるモデルは、不透明なパラメーターとしてではなく、明示的に解釈可能で完全に監査可能で、臨床的に根拠のあるバージョン管理された純粋な Python 決定ルールとして表現されます。 MHL は、以前に検証されたルールから開始し、データ ドリフトまたは機能進化の下で更新された機能情報を使用してルールを繰り返し修正することにより、継続的な学習もサポートします。医療データセットに関する包括的な実験では、MHL がサンプルが少なく不均衡が非常に悪い設定でも強力な動作を維持しながら、最先端の手法に匹敵するパフォーマンスを達成することが示されています。この結果はさらに、この明示的なルール更新メカニズムが、機能の進化の下での壊滅的な忘却の軽減に役立つことを示しています。全体として、これらの発見は、非勾配ベースのヒューリスティック システムが、一か八かの臨床意思決定支援のための透明性と適応性のある代替手段を提供することを示唆しています。
原文 (English)
Medical Heuristic Learning: An LLM-Driven Framework for Interpretable and Auditable Clinical Decision Rules
Predictive modeling for clinical tabular data is central to clinical decision support and therefore requires not only strong predictive performance but also transparent decision logic. Although deep learning and tree-based ensemble methods can achieve high accuracy, their black-box nature remains a major obstacle to clinical deployment. This challenge is further compounded by common characteristics of medical data, including limited sample sizes, severe class imbalance, and feature evolution arising from changes in diagnostic criteria and clinical documentation. To address these issues, we propose Medical Heuristic Learning (MHL), an instantiation of the learning-beyond-gradients paradigm for clinical tabular prediction. Instead of relying on neural network weight updates, MHL uses a large language model (LLM)-driven workflow that integrates statistical probes, medical knowledge probes, rule synthesis, and code-level iterative refinement to optimize a deterministic and executable decision system. The resulting model is expressed not as opaque parameters, but as versioned pure-Python decision rules that are explicitly interpretable, fully auditable, and clinically grounded. MHL also supports continual learning by starting from previously validated rules and iteratively revising them using updated feature information under data drift or feature evolution. Comprehensive experiments on medical datasets show that MHL achieves performance comparable to state-of-the-art methods while maintaining strong behavior in small-sample and highly imbalanced settings. The results further indicate that this explicit rule update mechanism can help alleviate catastrophic forgetting under feature evolution. Overall, these findings suggest that non-gradient-based heuristic systems offer a transparent and adaptable alternative for high-stakes clinical decision support.
Kairos: 物理 AI 用のネイティブ ワールド モデル スタック
世界モデルは、受動的なビジュアル ジェネレーターから物理 AI の基礎的な運用インフラストラクチャに移行しています。世界モデルは、異種混合の経験から世界の知識をネイティブに取得し、長期にわたって永続的な状態を維持し、実際の展開上の制約内で効率的に実行する必要があります。これらの要件に基づいて設計されたネイティブ ワールド モデル スタックである Kairos を紹介します。 (1) カイロスは、オープンワールドのビデオ、人間の行動データ、およびロボットの相互作用を漸進的な発達経路に編成する、クロスエンボディメント データ カリキュラムによって管理されるネイティブの事前トレーニング パラダイムを開拓することによって世界を学びます。 (2) Kairos は、ハイブリッド線形時間的注意を備えたネイティブ統合アーキテクチャ内で統一された世界の理解、生成、予測によって世界を維持します。スライディング ウィンドウの注意はローカル ダイナミクスを捕捉し、拡張されたスライディング ウィンドウは中間範囲の依存関係を捕捉し、ゲートされた線形注意は永続的なグローバル メモリを維持します。我々は、この時間因数分解が誤差の蓄積を厳密に制限し、拡張された範囲にわたる状態の伝播を数学的に保証することを実証する正式な理論的限界を確立します。 (3) Kairos は、実世界の観察、アクション、フィードバック ループのためのサーバーおよび消費者グレードのハードウェア上での低遅延ロールアウト生成をサポートする、展開を意識したシステム協調設計を組み込むことによって世界を運営します。具現化された世界モデル、長期計画、およびアクション ポリシーのベンチマークに関する実験では、Kairos が効率性と能力の強力なトレードオフを提供しながら、トップレベルのパフォーマンスを達成していることが示されています。これらの結果を総合すると、カイロスは将来の自己進化する物理的知性のための統合された運用基盤として位置づけられます。
原文 (English)
Kairos: A Native World Model Stack for Physical AI
World models are transitioning from passive visual generators to foundational, operational infrastructure for Physical AI: they must natively acquire world knowledge from heterogeneous experience, maintain persistent states over long horizons, and execute efficiently within real deployment constraints. We introduce Kairos, a native world model stack designed around these requirements. (1) Kairos learns the world by pioneering a Native Pre-training Paradigm governed by a Cross-Embodiment Data Curriculum, which organizes open-world videos, human behavioral data, and robot interactions into a progressive developmental pathway. (2) Kairos maintains the world by unified world understanding, generation, and prediction within a Native Unified Architecture equipped with Hybrid Linear Temporal Attention, where sliding-window attention captures local dynamics, dilated sliding windows capture mid-range dependencies, and gated linear attention maintains persistent global memory. We establish formal theoretical bounds demonstrating that this temporal factorization strictly limits error accumulation, mathematically guaranteeing state propagation across extended horizons. (3) Kairos runs the world by incorporating a Deployment-Aware System Co-Design to support low-latency rollout generation on server and consumer-grade hardware for real-world observation-action-feedback loops. Experiments on embodied world-model, long-horizon, and action-policy benchmarks show that Kairos achieves top level performance while offering a strong efficiency-capability trade-off. Together, these results position Kairos as a cohesive operational foundation for future self-evolving physical intelligence.
SSIL: Self-Supervised Imitation Learning for End-to-End Driving
In autonomous driving, the end-to-end (E2E) driving approach that predicts vehicle control signals directly from sensor data is rapidly gai…
Towards Leveraging AutoML for Sustainable Deep Learning: A Multi-Objective HPO Approach on Deep Shift Neural Networks
Deep Learning (DL) has advanced various fields by extracting complex patterns from large datasets. However, the computational demands of DL…
E2Vec: Feature Embedding with Temporal Information for Analyzing Student Actions in E-Book Systems
Digital textbook (e-book) systems record student interactions with textbooks as a sequence of events called EventStream data. In the past,…
LLM-Powered Multi-Agent System for Automated Crypto Portfolio Management
Cryptocurrency portfolio management requires the fusion of heterogeneous multi-modal signals, including structured price and on-chain time…
Mordal: Automated Pretrained Model Selection for Vision Language Models
Incorporating multiple modalities into large language models (LLMs) is a powerful way to enhance their understanding of non-textual data, e…
Top-Theta Attention: Sparsifying Transformers by Compensated Thresholding
We present Top-Theta (Top-$\theta$) Attention, a training-free method for sparsifying transformer attention during inference. Our key insig…
Ensemble RL through Classifier Models: Enhancing Risk-Return Trade-offs in Trading Strategies
This paper presents a comprehensive study on the use of ensemble Reinforcement Learning (RL) models in financial trading strategies, levera…
MedicalAgentsBench for Complex Medical Reasoning: Comparing Internalized Reasoning Models versus Externalized Agent-based Frameworks
Complex medical reasoning requires integrating heterogeneous clinical evidence across multiple inference steps. Large language models (LLMs…
Gaussian DP for Reporting Differential Privacy Guarantees in Machine Learning
Current practices for reporting differential privacy (DP) guarantees for machine learning (ML) algorithms such as DP-SGD provide an incompl…
Detecting and Mitigating DDoS Attacks with AI: A Survey
Distributed Denial of Service attacks represent an active cybersecurity research problem. Recent research shifted from static rule-based de…
Algorithmic Prompt Generation for Diverse Human-like Teaming and Communication with Large Language Models
Understanding how humans collaborate and communicate in teams is essential for improving human-agent teaming and AI-assisted decision-makin…
EmoFSM: A Finite State Machine for Emotional Support Conversation
Emotional support conversation (ESC) aims to alleviate people's emotional distress through effective conversations. Although large language…
RLRC: Reinforcement Learning-based Recovery for Compressed Vision-Language-Action Models
Vision-Language-Action models (VLA) have demonstrated remarkable capabilities and strong potential in complex robotic manipulation. However…
SPATIA: Multimodal Generation and Prediction of Spatial Cell Phenotypes
Understanding how cellular morphology, gene expression, and spatial context jointly shape tissue function is a central challenge in biology…
Critique of World Model: A Generative Latent Prediction Architecture for World Modeling
World Model, the algorithmic simulator of the real-world environment which biological agents experience and act upon, has been an emerging…
A Gradient-based Causal Discovery Framework with Applications to Complex Industrial Processes
With the advancement of deep learning technologies, various neural network-based Granger causality models have been proposed. Although thes…
AnalogFed: Privacy-Preserving Discovery of Analog Circuits at Scale with Federated Generative AI
Recent advances in generative AI (GenAI) have shown transformative potential for modern hardware design. However, existing GenAI-driven app…
LLM-Aided Joint Secrecy Precoding and Trajectory for RSMA-Based Heterogeneous UAV Networks
This paper investigates secure communications in rate-splitting multiple access (RSMA) enabled heterogeneous UAV networks, where multiple U…
Detail++: Training-Free Detail Enhancer for Text-to-Image Diffusion Models
Recent advances in text-to-image (T2I) generation have led to impressive visual results. However, these models still face significant chall…
Moving Out: Physically-grounded Human-AI Collaboration
The ability to adapt to physical actions and constraints in an environment is crucial for embodied agents (e.g., robots) to effectively col…
Blueprint First, Model Second: A Framework for Deterministic LLM Workflow
While powerful, the inherent non-determinism of large language model (LLM) agents limits their application in structured operational enviro…
RooseBERT: A New Deal For Political Language Modelling
The increasing amount of political debates and politics-related discussions calls for the definition of novel computational methods to auto…
Explicit Context-Driven Neural Acoustic Modeling for High-Fidelity RIR Generation
Realistic sound simulation plays a critical role in many applications. A key element in sound simulation is the room impulse response (RIR)…
Regression Language Models for Code
We study code-to-metric regression: predicting numeric outcomes of code executions, a challenging task due to the open-ended nature of prog…
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement…
Breaking the Code: Security Assessment of AI Code Agents Through Systematic Jailbreaking Attacks
Code-capable large language model (LLM) agents are embedded in software engineering workflows where they can read, write, and execute code,…
Adversarial Attacks Leverage Interference Between Features in Superposition
Why do adversarial examples exist, and why do they transfer between models? Existing explanations appeal to high-dimensional geometry, non-…
BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?
The convergence of LLM-powered research assistants and AI-based peer review systems creates a critical vulnerability: fully automated publi…
Enhanced Evolutionary Multi-Objective Deep Reinforcement Learning for Reliable and Efficient Wireless Rechargeable Sensor Networks
Despite rapid advancements in sensor networks, conventional battery-powered sensor networks suffer from limited operational lifespans and f…
Principled RL for Flow Matching Emerges from the Chunk-level Policy Optimization
Recent Progress in post-training flow matching for text-to-image (T2I) generation with Group Relative Policy Optimization (GRPO) has demons…
A geometric and deep learning reproducible pipeline for monitoring floating anthropogenic debris in urban rivers using in situ cameras
The proliferation of floating anthropogenic debris in rivers has emerged as a pressing environmental concern, exerting a detrimental influe…
EngTrace: A Symbolic Benchmark for Verifiable Process Supervision of Engineering Reasoning
Large Language Models (LLMs) are increasingly entering specialized, safety-critical engineering workflows governed by strict quantitative s…
Retrofitters, pragmatists and activists: Public interest litigation for accountable automated decision-making
This paper examines the role of public interest litigation in promoting accountability for AI and automated decision-making (ADM) in Austra…
First, do NOHARM: towards clinically safe large language models
Large language models (LLMs) are routinely used by physicians and patients for medical advice, yet their clinical safety profiles remain po…
Prototype-Based Semantic Consistency Alignment for Domain Adaptive Retrieval
Domain adaptive retrieval aims to transfer knowledge from a labeled source domain to an unlabeled target domain, enabling effective retriev…
A Multifaceted Analysis of Social Biases in Large Language Models
Large language models (LLMs) have rapidly become indispensable tools for acquiring information and supporting human decision-making. Howeve…
Vulcan: Instance-specialized, Verifiable Systems Heuristics Through LLM-driven Search
Systems resource management tasks rely primarily on hand-designed heuristics. However, growing hardware heterogeneity and workload diversit…
Jacobian Scopes: token-level causal attributions in LLMs
Large language models (LLMs) make next-token predictions based on clues present in their context, such as semantic descriptions and in-cont…
Co-PLNet: A Collaborative Point-Line Network for Prompt-Guided Wireframe Parsing
Wireframe parsing aims to recover line segments and their junctions to form a structured geometric representation useful for downstream tas…
m2sv: A Scalable Benchmark for Map-to-Street-View Spatial Reasoning
Vision--language models (VLMs) achieve strong performance on many multimodal benchmarks but remain brittle on spatial reasoning tasks that…
LVLMs and Humans Ground Differently in Referential Communication
For generative AI agents to partner effectively with human users, the ability to accurately predict human intent is critical. But this abil…
Learning-Infused Formal Reasoning: From Contract Synthesis to Artifact Reuse and Formal Semantics
This paper articulates a long-term research vision for formal methods at the intersection with artificial intelligence, outlining multiple…
R1-SyntheticVL: Is Synthetic Data from Generative Models Ready for Multimodal Large Language Model?
In this work, we aim to develop effective data synthesis techniques that autonomously synthesize multimodal training data for enhancing MLL…
PLATE: Plasticity-Tunable Efficient Adapters for Geometry-Aware Continual Learning
We develop a continual learning method for pretrained models that \emph{requires no access to old-task data}, addressing a practical barrie…
Optimism Stabilizes Thompson Sampling for Adaptive Inference
Thompson sampling (TS) is widely used for stochastic multi-armed bandits, yet its inferential properties under adaptive data collection are…
Brep2Shape: Boundary and Shape Representation Alignment via Self-Supervised Transformers
Boundary representation (B-rep) is the industry standard for computer-aided design (CAD). While deep learning shows promise in processing B…
From Noise to Order: Learning to Rank via Denoising Diffusion
Learning-to-rank (LTR) methods have traditionally been limited to discriminative machine learning approaches that model the probability of…
SkillJect: Effectively Automating Skill-Based Prompt Injection for Skill-Enabled Agents
Agent skills extend LLM agents with task-specific instructions, executable scripts, and auxiliary resources, improving reusability but crea…
GOT-JEPA: Generic Object Tracking with Model Adaptation and Occlusion Handling using Joint-Embedding Predictive Architecture
The human visual system tracks objects by integrating current observations with previously observed information, adapting to target and sce…
Position: Modular Memory is the Key to Continual Learning Agents
Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing hum…
Phys4D: Fine-Grained Physics-Consistent 4D Modeling from Video Diffusion
Recent video diffusion models have achieved impressive capabilities as large-scale generative world models. However, these models often str…
CogGen: Cognitive-Load-Inspired Fully Unsupervised Deep Generative Modeling for Compressively Sampled MRI Reconstruction
Fully unsupervised deep generative modeling (FU-DGM) offers significant potential for compressively sampled magnetic resonance imaging (CS-…
Guidelines for the Annotation and Visualization of Legal Argumentation Structures in Chinese Judicial Decisions
This Guideline presents a systematic and operationalizable annotation framework for representing legal argumentation structures in judicial…
Parallelizing Tool Execution and LLM Generation for Low-Latency Agent Serving
LLM-powered agents execute tasks through a sequential loop of model generation and tool execution. Today's serving systems serialize this l…
ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
Recent progress in latent world models (e.g., V-JEPA2) has shown promising capability in forecasting future world states from video observa…
Rethinking Multimodal Fusion for Time Series: Text Modalities Need Constrained Fusion
Recent advances in multimodal learning have motivated the integration of auxiliary modalities such as text or vision into time series (TS)…
Decidable By Construction: Design-Time Verification for Trustworthy AI
A prevailing assumption in machine learning is that model correctness must be enforced after the fact. We observe that the properties deter…
findsylls: A Language-Agnostic Toolkit for Syllable-Level Speech Tokenization and Embedding
Syllable-level units offer compact and linguistically meaningful representations for spoken language modeling and unsupervised word discove…
Beyond MACs: Hardware Efficient Architecture Design for Vision Backbones
Vision backbone networks play a central role in modern computer vision. Enhancing their efficiency directly benefits a wide range of downst…
Evaluating Interactive 2D Visualization as a Sample Selection Strategy for Biomedical Time-Series Data Annotation
Reliable machine-learning models in biomedical settings depend on accurate labels, yet annotating biomedical time-series data remains chall…
DiffAttn: Diffusion-Based Drivers' Visual Attention Prediction with LLM-Enhanced Semantic Reasoning
Drivers' visual attention provides critical cues for anticipating latent hazards and directly shapes decision-making and control maneuvers,…
Membership Inference Attacks against Large Audio Language Models
We present the first systematic Membership Inference Attack (MIA) evaluation of LALMs. Using Multi-modal Blind Baselines based on textual,…
Combating Data Laundering in LLM Training
Post-hoc unauthorized-training data detection for large language models (LLMs) typically assumes a query-with-originals regime: rights hold…
From Paper to Program: Knowledge Externalization for AI-Assisted Quantum Many-Body Code Generation
Large language models can write scientific code, but direct paper-to-program translation remains fragile when correctness depends on tacit…
Like a Hammer, It Can Build, It Can Break: Large Language Model Uses, Perceptions, and Adoption in Cybersecurity Operations on Reddit
Large language models (LLMs) have recently emerged as promising tools for augmenting Security Operations Center (SOC) workflows, with vendo…
Do We Still Need Humans in the Loop? Comparing Human and LLM Annotation in Active Learning for Hostility Detection
Instruction-tuned LLMs can annotate thousands of instances at low cost. This raises two questions for active learning (AL): can LLM labels…
Curiosity-Critic: Cumulative Prediction Error Improvement as a Tractable Intrinsic Reward for World Model Training
Local prediction-error-based curiosity rewards focus on the current transition without considering the world model's cumulative prediction…
DPRM: A Plug-in Doob h transform-induced Token-Ordering Module for Diffusion Language Models
Diffusion language models generate without a fixed left-to-right order, leaving token ordering as a central algorithmic choice. Existing sy…
When Life Gives You BC, Make Q-functions: Extracting Q-values from Behavior Cloning for On-Robot Reinforcement Learning
Behavior Cloning (BC) has emerged as a highly effective paradigm for robot learning. However, BC lacks a self-guided mechanism for online i…
SP-GCRL: Influence Maximization on Incomplete Social Graphs
Influence maximization (IM) in real platforms is challenged by incomplete, noisy social graphs and non-stationary diffusion dynamics. We pr…
Learning to Decide with AI Assistance under Human-Alignment
It is widely agreed that when AI models assist decision-makers in high-stakes domains by predicting an outcome of interest, they should com…
Large Language Models for Agentic NetOps and AIOps: Architectures, Evaluation, and Safety
Large language models are increasingly being used to support network operations (NetOps) and artificial intelligence for IT operations (AIO…
Rethinking Cross-Layer Information Routing in Diffusion Transformers
Diffusion Transformers (DiTs) have become a de facto backbone of modern visual generation, and nearly every major axis of their design -- t…
Frontier LLM はサイバーセキュリティに対応する準備ができていますか?デュアルモード脆弱性ベンチマークによる垂直基盤モデルの証拠
当社は、フロンティア LLM がデュアルモード ベンチマークを通じてサイバーセキュリティに対応できるかどうかを評価します。ホワイトボックス機能レベルの脆弱性検出 (VulnLLM-R、C/Java/Python 全体) とブラックボックス Web アプリケーション セキュリティ テスト (20 以上の CWE ファミリにわたる 118 個のグラウンド トゥルース脆弱性を備えた 5 つの運用スタイルのアプリケーション。これらをオープンソース化します)。私たちは 6 つのフロンティア モデル (GPT-5.4、Codex~5.3、Claude Opus~4.6、Sonnet~4.6、Gemini~3.1~Pro、および Gemini~3~Flash) と 2 つのドメイン特化モデルを 4 つのテスト パラダイムにわたってテストします。私たちの発見は厳粛なものです。(1) ~すべてのフロンティア モデルは、ホワイトボックス検出で 10 ~ 50% の誤検知率を生成し、体系的に脆弱性を過剰予測します。 (2)〜ブラックボックス テストでは、フロンティア モデルはグラウンド トゥルース カバレッジをわずか 4 ~ 8% しか達成せず、外部セキュリティ ツール (Playwright MCP、Burp Suite MCP) を使用した場合でもわずか 10 ~ 19% に改善します。 (3) ドメイン特化型エージェントにエンコードされた構造化侵入テスト手法により、ファミリーごとの検出が 50% を超え、規模ではなく手法が主要な手段であることが実証されました。 (4) ドメインに特化した防御モデルは、単一 GPU 上ですべてのモデルの中で最高の精度 (0.904) と最低の誤検知率 (9.7%) を達成します。私たちは、構造化されたセキュリティ テストの欠如、エンドツーエンドの要求/応答シーケンス、障害の多いデータ、および複数ステップの攻撃チェーンのトレースが基本的なトレーニング データのボトルネックであることを特定し、データ生成戦略としてセルフプレイ セキュリティ テストを提案します。私たちの結果は、サイバーセキュリティ専用に構築された垂直基盤モデルの正当性を裏付けています。
原文 (English)
Are Frontier LLMs Ready for Cybersecurity? Evidence for Vertical Foundation Models from Dual-Mode Vulnerability Benchmarks
We evaluate whether frontier LLMs are ready for cybersecurity through a dual-mode benchmark: white-box function-level vulnerability detection (VulnLLM-R, across C/Java/Python) and black-box web application security testing (five production-style applications with 118 ground-truth vulnerabilities across 20+ CWE families, which we will open-source). We test six frontier models (GPT-5.4, Codex~5.3, Claude Opus~4.7, Sonnet~4.6, Gemini~3.1~Pro and Gemini~3~Flash) and two domain-specialized models across four testing paradigms. Our findings are sobering: (1)~every frontier model produces 10-50% false positive rates in white-box detection, systematically over-predicting vulnerabilities; (2)~in black-box testing, frontier models achieve only 4-8% ground-truth coverage, improving to just 10-19% even with external security tools (Playwright MCP, Burp Suite MCP); (3)~structured penetration-testing methodology encoded in domain-specialized agents raises per-family detection above 50%, demonstrating that methodology, not scale, is the primary lever; and (4)~a domain-specialized defense model achieves the highest precision (0.904) and lowest false positive rate (9.7%) among all models, on a single GPU. We identify the absence of structured security testing traces end-to-end request/response sequences, failure-heavy data, and multi-step attack chains as the fundamental training data bottleneck, and propose self-play security testing as a data generation strategy. Our results make the case for vertical foundation models purpose-built for cybersecurity.
Any2Any: 人型全身追跡のための効率的な体外転送
全身追跡 (WBT) モデルは、ヒューマノイド ロボットの重要な基盤となっており、さまざまな動作を高い忠実度で模倣できるようになります。このようなモデルをゼロからトレーニングするには大規模なデータと計算が必要であり、新しいヒューマノイド プラットフォームへの迅速な展開にはコストがかかります。これにより、当然の疑問が生じます。事前トレーニングされた WBT モデルは、最小限の適応で複数の実施形態に移行できるでしょうか?この質問に答えるために、私たちは Any2Any を提案します。これは、既存の WBT スペシャリストを、少量のデータとコンピューティングだけで新しい人型の実施形態に効率的に移行するパラダイムです。 Any2Any は、まずソース ヒューマノイドとターゲット ヒューマノイドの間で運動学的な調整を実行し、事前トレーニング済みのソース ポリシーをターゲットの実施形態で有意義に再利用できるように、入力空間と出力空間を調整します。次に、Any2Any は、軽量のパラメータ効率微調整 (PEFT) コンポーネントを選択されたダイナミクスに敏感なモジュールに適用することによってダイナミクス適応を実行し、ターゲット ロボットへのターゲットを絞った適応を可能にしながら、有用な動作の事前分布を保存します。複数のヒューマノイド プラットフォームと事前トレーニングされたバックボーンに関する広範な実験により、Any2Any は、ゼロからトレーニングする場合と比較して、収束を大幅に加速し、トレーニング コストを削減しながら、競争力のあるまたは優れた追跡パフォーマンスを達成できることが示されています。特に、Any2Any は、完全なトレーニングに必要なコンピューティングとデータのわずか 1% を使用して、Unitree G1 で事前トレーニングされた Sonic モデルを LimX Oli および LimX Luna に転送することに成功しています。これらの結果は、事前訓練された WBT スペシャリストを実施形態間で効率的に再利用でき、新しいロボットに人型全身制御を導入するための拡張可能な道を提供することを示唆しています。
原文 (English)
Any2Any: Efficient Cross-Embodiment Transfer for Humanoid Whole-Body Tracking
Whole-body tracking (WBT) models have become a key foundation for humanoid robots, enabling them to imitate diverse motions with high fidelity. Training such models from scratch requires large-scale data and computation, making rapid deployment on new humanoid platforms costly. This raises a natural question: Can pretrained WBT models transfer across embodiments with minimal adaptation? To answer this question, we propose Any2Any, a paradigm that efficiently transfers an existing WBT specialist to a new humanoid embodiment with only a small amount of data and compute. Any2Any first performs kinematic alignment between source and target humanoids, aligning their input and output spaces so that the pretrained source policy can be meaningfully reused on the target embodiment.Any2Any then performs dynamics adaptation by applying lightweight parameter-efficient fine-tuning (PEFT) components to selected dynamics-sensitive modules, preserving useful behavioral priors while enabling targeted adaptation to the target robot. Extensive experiments on multiple humanoid platforms and pretrained backbones show that Any2Any substantially accelerates convergence and reduces training cost compared with training from scratch, while achieving competitive or superior tracking performance. Notably, using only 1% of the compute and data required for full training, Any2Any successfully transfers Sonic models pre-trained on Unitree G1 to LimX Oli and LimX Luna. These results suggest that pretrained WBT specialists can be efficiently reused across embodiments, providing a scalable path toward deploying humanoid whole-body control on new robots.
マルチスペクトル画像の深層学習を使用したリモート センシング データ補完
リモートセンシング技術は、近年、水生用途でますます利用されています。光学衛星データを使用する際の一般的な課題は、雲に覆われているために観測値が欠落していることです。こうしたデータのギャップにより、水道当局の関心が高い湖での藻類の発生などの重大なイベントの検出の見逃しにつながる可能性があります。その結果、藻類の発生の監視と予測を改善するには、光学衛星データセットの完全性を高めることが重要です。この研究では、藻類の発生の歴史的記録を持つ 4 つの湖にわたって欠落しているスペクトル バンドを再構築するために、従来のデータ代入手法 (線形補間) と深層学習モデルを比較しました。採用されている深層学習モデルには、CNN ベースのアーキテクチャ (つまり、CNN、Inception Resnet、および Autoencoder) と CNN-LSTM ベースのアーキテクチャ (つまり、CNN-LSTM、Resnet-LSTM、および Autoencoder-LSTM) が含まれます。私たちの結果は、人工的にマスクされた領域内のスペクトル帯域値を入力する際に、深層学習モデルがベースライン線形補間法よりも大幅に優れたパフォーマンスを発揮することを実証しました。これらのモデルの中で、CNN はほとんどのレイクで最高のパフォーマンスを実現しました。さらに、代入画像から導出された藻類ブルーム指数 (Green/Red および NDCI) のパフォーマンスを、観測データと比較することで評価しました。私たちの結果は、深層学習モデルが PlanetScope SuperDove 画像の欠落データを補うのに効果的であり、水監視においてより信頼性の高いアプリケーションを可能にすることを示しています。
原文 (English)
Remote sensing data imputation using deep learning for multispectral imagery
Remote sensing techniques have been increasingly utilised in aquatic applications in recent years. A common challenge in using optical satellite data is the presence of missing observations due to cloud cover. These data gaps can lead to missed detection of critical events, such as algal blooms, in lakes of high interest to water authorities. As a result, enhancing the completeness of optical satellite datasets is crucial for improving the monitoring and prediction of algal blooms. In this study, we compared a traditional data imputation method (i.e., linear interpolation) with deep learning models for reconstructing missing spectral bands across four lakes with historical records of algal blooms. The deep learning models adopted include CNN-based architectures (i.e., CNN, Inception Resnet, and Autoencoder) and CNN-LSTM-based architectures (i.e., CNN-LSTM, Resnet-LSTM, and Autoencoder-LSTM). Our results demonstrated that deep learning models substantially outperformed the baseline linear interpolation method in imputing spectral band values within artificially masked regions. Among these models, CNN delivered the best performance across most lakes. Furthermore, we evaluated the performance of algal bloom indices (i.e., Green/Red and NDCI) derived from the imputed imagery by comparing them with the observed data. Our results demonstrate that deep learning models are effective for imputing missing data in PlanetScope SuperDove imagery, enabling more reliable applications in water monitoring.
CyberEvolver: サイバーセキュリティ エージェントのオンザフライのための構造化された自己進化
LLM ベースのエージェントはサイバーセキュリティタスクに使用されることが増えていますが、既存のシステムのほとんどは人間が設計した固定足場に依存しており、多様なターゲットや障害モードに適応するのに苦労しています。 \textsc{CyberEvolver} は、失敗した実行試行の経験に基づいて独自の足場を繰り返し修正する、自己進化するサイバーセキュリティ エージェント フレームワークです。サイバーセキュリティにおける自己進化は、可能性のある足場変更の空間がほとんど構造化されておらず、実行フィードバックがまばらで環境によって隠蔽されることが多く、多様性の低い更新により繰り返しの繰り返しでエラーが悪化する可能性があるため、困難です。 \textsc{CyberEvolver} は、足場の最適化を構造化コンポーネントに分解する 4 層の進化可能なエージェント アーキテクチャ、ノイズの多い実行ログを実用的なリビジョン信号に変換するトレースから診断のメカニズム、および進化中に多様なエージェントのバリアントを保存する母集団ベースのビーム検索戦略でこれらの課題に対処します。私たちは、4 つのオープンソース LLM を使用して、CTF の課題、脆弱性の悪用、侵入テストのタスクに関して \textsc{CyberEvolver} を評価します。これらの設定全体で、\textsc{CyberEvolver} はシード エージェントの成功率を平均 $13.6$\,\% 向上させ、人間が設計した 6 つのサイバーセキュリティ エージェントや、他のドメインから採用された 2 つの自己改善手法を上回ります。これらの結果は、スキャフォールドの自己進化が、セキュリティ テスト用の適応 LLM エージェントを構築するための有望な方向性であることを示唆しています。
原文 (English)
CyberEvolver: Structured Self-Evolution for Cybersecurity Agents On the Fly
LLM-based agents are increasingly used for cybersecurity tasks, but most existing systems rely on fixed, human-designed scaffolds that struggle to adapt across diverse targets and failure modes. We introduce \textsc{CyberEvolver}, a self-evolving cybersecurity agent framework that iteratively revises its own scaffold based on experience from failed execution attempts. Self-evolution in cybersecurity is challenging because the space of possible scaffold changes is largely unstructured, execution feedback is sparse and often obscured by the environment, and low-diversity updates can cause errors to compound over repeated iterations. \textsc{CyberEvolver} addresses these challenges with a four-layer evolvable agent architecture that decomposes scaffold optimization into structured components, a trace-to-diagnosis mechanism that converts noisy execution logs into actionable revision signals, and a population-based beam search strategy that preserves diverse agent variants during evolution. We evaluate \textsc{CyberEvolver} on CTF challenges, vulnerability exploitation, and penetration-testing tasks using four open-source LLMs. Across these settings, \textsc{CyberEvolver} improves the seed agent's success rate by $13.6$\,\% on average, and outperforms six human-designed cybersecurity agents as well as two self-improvement methods adapted from other domains. These results suggest that scaffold self-evolution is a promising direction for building adaptive LLM agents for security testing.
人工知能時代の持続可能な金属有機フレームワーク集水装置
有機金属フレームワーク (MOF) は、細孔環境が調整可能であるため、乾燥条件で水を捕捉および放出するように正確に設計できるため、水採取の優れた候補です。人工知能 (AI) を MOF の発見に統合することで、大気水回収 (AWH)、安定性、サイクル効率を向上させる構造的特徴を特定することで、高性能吸着剤の設計をさらに加速できます。この観点では、協調吸着、動作相対湿度 (RH)、取り込み容量、ヒステリシス、拡張性などの重要な MOF 設計原則を検討します。多変量戦略や長腕リンカー伸長などの最近の設計の進歩に焦点を当て、これらの原理が安定性と結晶性を維持しながら細孔容量と親水性をどのように調整するかを検証します。さらに、AI、大規模言語モデル (LLM)、データ マイニングが、予測合成、逆設計、合成と構造と特性の関係の解明を通じて、次世代の MOF 集水器の発見プロセスをどのように加速できるかについて説明します。
原文 (English)
Sustainable Metal-Organic Framework Water Harvesters in the Artificial Intelligence Era
Metal-organic frameworks (MOFs) are excellent candidates for water harvesting due to their tunable pore environments, which can be precisely engineered to capture and release water in arid conditions. Integrating artificial intelligence (AI) into MOF discovery can further accelerate the design of high-performance sorbents by identifying structural features that enhance atmospheric water harvesting (AWH), stability, and cycling efficiency. In this Perspective, we examine key MOF design principles, including cooperative adsorption, operational relative humidity (RH), uptake capacity, hysteresis, and scalability. We highlight recent design advancements such as multivariate strategies and long-arm linker extension, and examine how these principles tune pore capacity and hydrophilicity, while preserving stability and crystallinity. Furthermore, we discuss how AI, large language models (LLMs), and data mining can accelerate the discovery process through predictive synthesis, inverse design, and elucidating synthesis-structure-property relationships for the next generation of MOF water harvesters.
Temporal Motif-aware Graph Test-time Adaptation for OOD Blockchain Anomaly Detection
Ever-evolving transaction patterns have significantly hindered anomaly detection on emerging cryptocurrency blockchains due to the vast num…
DeMaVLA: A Vision-Language-Action Foundation Model for Generalizable Deformable Manipulation
Real-world household robots require Vision-Language-Action (VLA) foundation models that can acquire reusable manipulation skills across div…
Constitutional On-Policy Safe Distillation
On-policy self-distillation (OPSD) has emerged as an efficient post-training paradigm by using a teacher conditioned on privileged informat…
エージェント追跡から信頼へ: LLM エージェントにおける証拠追跡と実行来歴
大規模言語モデル (LLM) ベースのエージェントは、外部ツール、検索システム、メモリ モジュール、環境、その他のエージェントと対話することで、複雑なタスクを解決することが増えています。これらの機能により、エージェントの自律性が拡張されますが、エージェントの動作の検証、デバッグ、監査が難しくなります。最終回答の精度だけでは、出力がどのように生成されたか、各主張を裏付ける証拠は何か、ツールの呼び出しが正当化されたかどうか、記憶が後の決定にどのように影響したか、実行の失敗がどこで発生したかを説明することはできません。証拠追跡と実行来歴は、取得された証拠、ツール出力、メモリ項目、環境観察、中間クレーム、アクション、および最終的な回答がエージェントの実行全体を通じてどのように関連するかをモデル化することで、このギャップに対処します。この調査は、LLM エージェントにおける証拠の追跡と実行の出自に関する体系的なレビューと概念的な枠組みを提供します。私たちは、検索根拠、クレームサポート、ツール使用の安全性、メモリリネージ、可観測性、デバッグ、監査、リカバリを結び付ける、統一された来歴の観点に基づいて関連作業を整理します。トレースソース、証拠と実行単位、来歴関係、トレースの粒度とタイミング、表現形式、信頼関数を網羅する分類法を導入します。私たちは、出所の表現、証拠の帰属、ツール使用の出所、実行時のガードレール、出所を伴うメモリ、トレースベースの可観測性、障害診断など、主要な方法論の方向性を検討します。また、既存のベンチマーク、データセット、評価指標を来歴関連の機能にマッピングし、評価が最終的な回答の正しさからプロセスレベルの説明責任にどのように移行できるかについても説明します。最後に、統合トレース スキーマ、クレーム レベルおよびセマンティックの出所、出所を意識した安全メカニズム、現実的な実行トレース ベンチマーク、リカバリ指向の評価、プライバシーを意識した監査インフラストラクチャなどの未解決の課題について概説します。
原文 (English)
From Agent Traces to Trust: A Survey of Evidence Tracing and Execution Provenance in LLM Agents
Large language model (LLM)-based agents are evolving from passive text generators into autonomous systems capable of planning, tool use, retrieval, memory access, environmental interaction, and multi-agent collaboration. These capabilities expand agent autonomy, but also make agent behavior harder to verify, debug, and audit. Final-answer accuracy alone cannot explain how an output was produced, which evidence supported each claim, whether tool calls were justified, how memory influenced later decisions, or where failures originated. This survey examines evidence tracing and execution provenance as foundations for process-level accountability in trustworthy LLM agents. We define execution provenance as the typed graph of an agent execution and evidence tracing as its projection onto evidence-support relations. This perspective connects retrieval grounding, claim support, tool-use safety, memory lineage, observability, debugging, audit, and recovery within a unified framework. We introduce a taxonomy covering trace sources, evidence and execution units, provenance relations, tracing granularity and timing, representation forms, and trust functions. We then review key methodological directions, including provenance representation, evidence attribution, tool-use provenance, runtime guardrails, provenance-bearing memory, observability, and failure diagnosis. Finally, we discuss benchmarks, datasets, metrics, and open challenges for building provenance-aware, auditable, and recoverable agent systems.
LLMCodec: Adapting Video Codecs for Efficient Weight Compression of Large Language Models
The rapid development of large language models(LLMs) has led to remarkable advances in natural language processing. However, the increasing…
SceneConductor: 3D Scene Generation from a Single Image with Multi-Agent Orchestration
Generating complete 3D scenes from a single image requires inferring globally consistent geometry, object relationships, and environmental…
Fast Speech Foundation Model Distillation Using Interleaved Stacking
Distilling a large speech foundation model (SFM) into an efficient student model has been successfully applied to low-resource environments…
Time-Series Foundation Model Embeddings for Remaining Useful Life Estimation
Remaining Useful Life (RUL) prediction is essential for industrial predictive maintenance, yet many learning-based approaches rely on exten…
CAPED: Context-Aware Privacy Exposure Defense for Mobile GUI Agents
Screenshot-based mobile GUI agents can operate ordinary smartphone apps through the same visual interface as a human user, but this capabil…
GMN4AD: 多中心構造磁気共鳴イメージングを使用したテスト時間領域適応によるアルツハイマー病診断のためのグラフ マッチング ネットワーク
アルツハイマー病 (AD) は、何百万人もの高齢者が罹患している進行性の神経変性疾患であり、今後数年間で有病率が大幅に上昇すると予想されています。タイムリーな介入には、特に軽度認知障害 (MCI) 段階での早期診断が重要です。構造磁気共鳴画像法 (sMRI) は、アルツハイマー病関連の脳変化を検出するための重要なモダリティとして浮上していますが、従来のグラフベースのアプローチはモダリティや部位間の不均一性に問題があり、診断性能が制限されることがよくあります。この論文では、神経画像データから得られた異種脳グラフ間の相互作用をモデル化するように設計された、アルツハイマー病診断のためのグラフ マッチング ネットワーク (GMN4AD) を提案します。各脳グラフを個別に処理する従来の方法とは異なり、GMN4AD はグラフ マッチングを活用してグラフ間の関係を把握し、診断の精度を高めます。さらに、推論中のドメインのシフトを軽減するために対照学習を組み合わせたテスト時のドメイン適応戦略を導入します。 3 つの公開 AD データセットに対する広範な実験により、GMN4AD が最先端の方法と比較して優れたパフォーマンスを達成し、AD 診断のための堅牢で一般化可能なソリューションを提供することが実証されました。
原文 (English)
GMN4AD: Graph Matching Network for Alzheimer's Disease Diagnosis with Test-Time Domain Adaptation using Multi-centered Structure Magnetic Resonance Imaging
Alzheimer's Disease (AD) is a progressive neurodegenerative disorder that affects millions of older adults, with prevalence expected to rise significantly in the coming years. Early diagnosis, particularly during the mild cognitive impairment (MCI) stage, is critical for timely intervention. Structural Magnetic Resonance Imaging (sMRI) has emerged as a key modality for detecting AD-related brain changes, but traditional graph-based approaches often struggle with modality and inter-site heterogeneity, limiting diagnostic performance. In this paper, we propose Graph Matching Network for Alzheimer's Disease Diagnosis (GMN4AD), designed to model interactions between heterogeneous brain graphs derived from neuroimaging data. Unlike conventional methods that treat each brain graph independently, GMN4AD leverages graph matching to capture cross-graph relationships, enhancing diagnostic precision. Furthermore, we introduce a test-time domain adaptation strategy that combines contrastive learning to mitigate domain shifts during inference. Extensive experiments on three public AD datasets demonstrate that GMN4AD achieves superior performance compared to state-of-the-art methods, offering a robust and generalizable solution for AD diagnosis.
Clay-CNN ハイブリッド: 地すべり検出の補助コンテキストとして地理基礎モデルを活用
災害発生後の迅速な地すべりマッピングは災害対応に不可欠ですが、極端な階級不均衡のため自動化は依然として困難です。この研究では、地理基礎モデル (GFM) である Clay v1.5 が、Landslide4Sense (L4S) ベンチマークでのピクセル レベルの地滑りセグメンテーションを改善できるかどうかを評価します。L4S ベンチマークには、14 の Sentinel-2 および地形バンドと約 2% のポジティブ ピクセルを含む 3,799 個のトレーニング チップが含まれています。マルチスケール残差地形融合を備えたプライマリ エンコーダとしての Clay、ボトルネックで Clay セマンティック コンテキストで強化された U-Net バックボーン、および標準の U-Net ベースラインの 3 つの戦略を比較します。 2 段階の低ランク適応 (LoRA) を備えたハイブリッド U-Net + Clay モデルは、3 つのシードにわたって 64.5 +/- 1.8% という最高のテスト F1 を達成し、Clay のみのバックボーン (55.2 +/- 3.6%) と U-Net ベースライン (59.9%) を上回りました。スタンドアロン エンコーダとしての Clay は、マルチスケール スキップ接続がないため U-Net よりもパフォーマンスが劣っていましたが、その事前トレーニングされた表現により、補助コンテキストとして挿入された場合には一貫してパフォーマンスが向上しました。これらの発見は、GFM が空間的に詳細な畳み込みアーキテクチャを置き換えるのではなく、それを補完する場合に地滑り検出に最も効果的であることを示唆しています。
原文 (English)
Clay-CNN Hybrids: Leveraging Geospatial Foundation Models as Auxiliary Context for Landslide Detection
Rapid post-event landslide mapping is essential for disaster response but remains difficult to automate due to extreme class imbalance. This study evaluates whether Clay v1.5, a Geospatial Foundation Model (GFM), can improve pixel-level landslide segmentation on the Landslide4Sense (L4S) benchmark, which contains 3,799 training chips with 14 Sentinel-2 and terrain bands and approximately 2% positive pixels. We compare three strategies: Clay as the primary encoder with multi-scale residual terrain fusion, a U-Net backbone augmented with Clay semantic context at the bottleneck, and a standard U-Net baseline. The hybrid U-Net + Clay model with two-stage Low-Rank Adaptation (LoRA) achieved the best test F1 of 64.5 +/- 1.8% over three seeds, surpassing the Clay-only backbone (55.2 +/- 3.6%) and the U-Net baseline (59.9%). Clay as a standalone encoder underperformed the U-Net due to the absence of multi-scale skip connections, but its pretrained representations consistently improved performance when injected as auxiliary context. These findings suggest that GFMs are most effective for landslide detection when they complement spatially detailed convolutional architectures rather than replace them.
AgentCyberRange: Benchmarking Frontier AI Systems in Realistic Cyber Ranges
Frontier AI systems are increasingly capable of cybersecurity tasks, including codebase inspection, vulnerability detection, and exploitati…
CADET: Physics-Grounded Causal Auditing and Training-Free Deconfounding of End-to-End Driving Planners
End-to-end (E2E) autonomous-driving planners trained by imitation are prone to statistical shortcuts: they associate scene elements that me…
From Shield to Target: Denial-of-Service Attacks on LLM-Based Agent Guardrails
LLM-based guardrails have emerged as a highly effective defense against prompt injection and jailbreak attacks in autonomous agents. Howeve…
TRACE: Trajectory-Routed Causal Memory for Delayed-Evidence Visuomotor Imitation
Robots under autonomous operation may require decisions based on evidence that is no longer visible. We study delayed-evidence tasks, where…
A Multi-Level Architecture for Reusable Materials Ontologies -- The OntoCrafter Ceramics Ontology (OCO) as Reference Implementation
The Materials Science and Engineering ontology landscape is fragmented along multiple axes simultaneously. Horizontally: a recent survey id…
Rational Sparse Autoencoder
Sparse autoencoders (SAEs) are standard tools for mechanistic interpretability, but current SAE families are constrained by fixed encoder n…
MimicIK: Real-Time Generative Inverse Kinematics from Teleoperation with FK Consistency
Inverse kinematics (IK) remains a critical bottleneck for real-time robot manipulation. Classical numerical solvers achieve high geometric…
EHRNote-ChatQA: A Benchmark for Evidence-Grounded Multi-Turn Clinical Question Answering over Longitudinal Discharge Summaries
Discharge summaries are crucial clinical documents containing the context of a patient's overall hospital stay, and are routinely reviewed…
Koshur Diacritizer: A Byte-Level Sequence-to-Sequence Model for Kashmiri Diacritic Restoration
Kashmiri, an Indo-Aryan language written in a modified Perso-Arabic script, frequently omits diacritic marks in digital text, creating ambi…
Control-Plane Placement Shapes Forgetting: An Architectural Study of Agent Memory Across Thirteen System Configurations
Where an LLM sits in an agent memory pipeline -- between the recall plane that retrieves stored facts (extensively benchmarked) and the con…
MASCOT-Android: A Curated Dataset and Automated Collection Pipeline for Android Malware Source Code Specimens
Compared with binaries and decompiled code, malware source code more directly reflects the attackers' original intent. However, the scarcit…
Infant Spontaneous Movement Noise Improves Exploration in Deep RL
Exploration in deep reinforcement learning (RL) is commonly implemented as temporally uncorrelated white noise. However, recent works show…