トピック: ロボティクス
該当記事 222 件 / 新しい順
DiffAero: 効率的なクアドローター ポリシー学習のための GPU アクセラレーションによる微分可能シミュレーション フレームワーク
このレターでは、効率的なクワッドローター制御ポリシー学習のために設計された、軽量で GPU アクセラレーションを備えた完全微分可能なシミュレーション フレームワークである DiffAero を紹介します。 DiffAero は、環境レベルとエージェント レベルの両方の並列処理をサポートし、複数のダイナミクス モデル、カスタマイズ可能なセンサー スタック (IMU、深度カメラ、LiDAR)、および多様な飛行タスクを統合された GPU ネイティブのトレーニング インターフェイス内に統合します。 DiffAero は、GPU 上で物理とレンダリングの両方を完全に並列化することで、CPU と GPU 間のデータ転送のボトルネックを排除し、シミュレーションのスループットを桁違いに向上させます。既存のシミュレータとは対照的に、DiffAero は高性能シミュレーションを提供するだけでなく、微分可能なハイブリッド学習アルゴリズムを探索するための研究プラットフォームとしても機能します。広範なベンチマークと実際の飛行実験により、DiffAero とハイブリッド学習アルゴリズムを組み合わせることで、消費者グレードのハードウェアで堅牢な飛行ポリシーを数時間で学習できることが実証されました。コードは https://github.com/flyingbitac/diffaero で入手できます。
原文 (English)
DiffAero: A GPU-Accelerated Differentiable Simulation Framework for Efficient Quadrotor Policy Learning
This letter introduces DiffAero, a lightweight, GPU-accelerated, and fully differentiable simulation framework designed for efficient quadrotor control policy learning. DiffAero supports both environment-level and agent-level parallelism and integrates multiple dynamics models, customizable sensor stacks (IMU, depth camera, and LiDAR), and diverse flight tasks within a unified, GPU-native training interface. By fully parallelizing both physics and rendering on the GPU, DiffAero eliminates CPU-GPU data transfer bottlenecks and delivers orders-of-magnitude improvements in simulation throughput. In contrast to existing simulators, DiffAero not only provides high-performance simulation but also serves as a research platform for exploring differentiable and hybrid learning algorithms. Extensive benchmarks and real-world flight experiments demonstrate that DiffAero and hybrid learning algorithms combined can learn robust flight policies in hours on consumer-grade hardware. The code is available at https://github.com/flyingbitac/diffaero.
現場に飛び込む: フォーカス プランの生成を通じて、視覚と言語の意思決定における知覚のボトルネックを打破する
ロボット操作やナビゲーションなどの身体化された視覚言語による意思決定タスクでは、視覚言語モデルおよび視覚言語アクション モデル (VLM および VLA) は、さまざまな利点を持つ強力なツールです。VLM は長期計画に優れ、VLA は事後制御に優れています。ただし、モデルのパフォーマンスは、同じ知覚のボトルネックによって制限されます。モデルがタスクに関連するオブジェクトと気を散らすものとを区別できないために幻覚が発生します。原則として、無関係なものを除外しながら、正確に識別して重要なオブジェクトに焦点を当てることが、この制限を打ち破る鍵となります。簡単な解決策は、重要なオブジェクトに直接注目するというワンステップの焦点です。ただし、効果的に焦点を合わせるには本質的にシーンを深く理解する必要があるため、このアプローチは効果的ではないことがわかります。この目的を達成するために、我々は、VLM の長期計画能力を活用した、粗いから細かいまでのフォーカス プラン生成方法である SceneDiver を提案します。この方法では、最初に全体的なシーン グラフを構築して初期理解を確立し、次に認識、理解、分析の反復サイクルを通じてタスクをより単純なサブ問題に徐々に分解します。反応的な制御を可能にするために、意図的なフォーカス機能を VLA に抽出するための軽量アダプターも設計しました。標準の組み込み AI ベンチマークでの評価により、私たちの方法は、高速実行を必要とするタスクの計算効率を維持しながら、VLM と VLA の両方で幻視を大幅に軽減することが確認されています。コードとデータは https://future-item.github.io/SceneDiver でリリースされています。
原文 (English)
Dive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation
In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at long-term planning, while VLAs are better at reactive control. However, their performance is limited by the same perceptual bottleneck: visual hallucinations arise due to the models' inability to distinguish task-relevant objects from distractors. In principle, accurate identification and focus on critical objects while filtering out irrelevant ones is the key to break this limitation. A straightforward solution is one-step focus: directly attending to essential objects. However, this approach proves ineffective because effective focus inherently requires deep scene understanding. To this end, we propose SceneDiver, a coarse-to-fine focus plan generation method for VLMs leveraging their long-term planning abilities, that first constructs a holistic scene graph to establish initial comprehension, then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis. To enable reactive control, we also design a lightweight adapter for distilling the deliberate focus ability into VLAs. Evaluations on standard embodied AI benchmarks confirm that our method substantially reduces visual hallucinations for both VLMs and VLAs, while preserving computational efficiency in tasks requiring fast execution. Our code and data are released at: https://future-item.github.io/SceneDiver.
AgenticDiffusion: ビジョンベースの UAV ナビゲーションのための Agentic Diffusion ベースの経路計画
屋内 UAV ナビゲーションには、限られた視野の観察下での効率的な探索、シーンの理解、信頼性の高い軌道の実行が必要です。既存のビジョンベースのナビゲーション フレームワークは通常、単一ビューの観察に依存しており、オクルージョン、ターゲットの可視性、およびグローバル シーン構造について推論する能力が制限されています。この研究では、統合された航空ナビゲーション パイプライン内で、言語に基づく推論、オープン語彙によるターゲットのグラウンディング、視覚ベースの拡散計画、および NMPC を調整するマルチビュー UAV ナビゲーション フレームワークである AgenticDiffusion を提案します。自然言語による指示と、同期した一人称視点 (FPV) および上面視点の観察を考慮して、フレームワークはナビゲーションに最も有益な視点を決定し、軌道の実行前にミッション計画を生成します。ターゲットは、オープンボキャブラリーグラウンディングモデルを使用して位置特定され、その後、視点固有の拡散プランナーが UAV 実行のためのナビゲーション軌道を生成します。提案されたフレームワークは、補完的な視点を使用して、繰り返しのターゲット探査を削減し、雑然とした屋内環境でのナビゲーション効率を向上させます。このフレームワークは、適応視点選択、多段階ミッション実行、長距離ナビゲーション、安全な着陸地点選択を含む 4 つの現実世界の UAV ナビゲーション シナリオで検証されました。実験結果では、40 回の実世界試験でミッション全体の成功率が 80% であることが実証され、一方、拡散計画者は軌道生成の成功率が 100% に達しました。
原文 (English)
AgenticDiffusion: Agentic Diffusion-based Path Planning for Vision-Based UAV Navigation
Indoor UAV navigation requires efficient exploration, scene understanding, and reliable trajectory execution under limited field-of-view observations. Existing vision-based navigation frameworks typically rely on single-view observations, limiting their ability to reason about occlusions, target visibility, and global scene structure. In this work, we propose AgenticDiffusion, a multi-view UAV navigation framework that coordinates language-guided reasoning, open-vocabulary target grounding, vision-based diffusion planning, and NMPC within a unified aerial navigation pipeline. Given a natural language instruction and synchronized first-person-view (FPV) and top-view observations, the framework determines the most informative viewpoint for navigation and generates a mission plan prior to trajectory execution. The targets are localized using an open-vocabulary grounding model, after which viewpoint-specific diffusion planners generate navigation trajectories for UAV execution. Using complementary viewpoints, the proposed framework reduces repeated target exploration and improves navigation efficiency in cluttered indoor environments. The framework was validated in four real-world UAV navigation scenarios involving adaptive viewpoint selection, multi-stage mission execution, long-horizon navigation, and safe landing-site selection. The experimental results demonstrated an overall mission success rate of 80% in 40 real-world trials, while the diffusion planners achieved a trajectory generation success rate of 100%.
大規模言語モデルによる適応軌道最適化のためのセマンティック制約合成
軌道の最適化は、宇宙探査において安全で信頼性の高い自律運用を可能にするための重要なコンポーネントです。宇宙ミッションの頻度、複雑さ、範囲が増加するにつれて、ミッションの目的と運用上の制約を正確に反映する、数学的に適切な軌道最適化問題を迅速に定式化する必要性が高まっています。ただし、ミッションの意図を軌道最適化のための扱いやすい分析公式に変換するには、かなりの専門知識が必要です。この論文では、大規模言語モデル (LLM) を活用して、ミッションの要件と制約の自然言語記述を実行可能な軌道最適化コードと対応する数学的定式化に変換するフレームワークを紹介します。宇宙船ランデブーシナリオでの実験では、意味論的なミッション要件から凸軌道最適化問題を再調整する際の高い成功率が実証されています。最終的に、この研究は、高レベルの意図と形式的な最適化モデルを橋渡しする LLM の可能性を強調し、宇宙船のより柔軟で効率的な軌道設計を可能にします。
原文 (English)
Semantic Constraint Synthesis for Adaptive Trajectory Optimization via Large Language Models
Trajectory optimization is a critical component for enabling safe and reliable autonomous operations in space exploration. As space missions increase in frequency, complexity, and scope, there is a growing need to rapidly formulate mathematically sound trajectory optimization problems that accurately reflect mission objectives and operational constraints. However, translating mission intent into tractable analytical formulations for trajectory optimization requires substantial domain expertise. This paper presents a framework that leverages large language models (LLMs) to translate natural language descriptions of mission requirements and constraints into executable trajectory optimization code and corresponding mathematical formulations. Experiments in spacecraft rendezvous scenarios demonstrate a high success rate in reconditioning a convex trajectory optimization problem from semantic mission requirements. Ultimately, this work highlights the potential of LLMs to bridge high-level intent and formal optimization models, enabling more flexible and efficient trajectory design of spacecraft.
2つのアドバンテージフィールド
オフラインの目標条件付き強化学習では、長期的な到達可能性の推定とローカル アクションの比較の両方が必要です。デュアル目標表現は、グローバルな目標の到達可能性を取得する値フィールドを提供しますが、特定の状態でどのアクションが優先されるべきかを直接指定するものではありません。我々は、双線形二重値モデルをローカルアドバンテージ信号に変えるポリシー抽出手法であるデュアルアドバンテージフィールドを提案します。双線形双対パラメータ化では、目標の埋め込みは状態表現に対する値フィールドの勾配です。 DAF は、アクションによって引き起こされる割り引かれたフィーチャの変位を予測し、この変位と目標の方向との整合性によってアクションをスコア化するアクション効果モデルを学習します。実現可能なケースでは、このスコアは目標条件付きベルマンアドバンテージに等しく、標準的なローカル政策改善保証が得られます。 OGBench の移動、操作、パズルのタスクでは、DAF は集計 RLiable メトリクスを改善し、局所的に正しいアクションが最終目標に向かう直接的な動きとは異なる設定で強力にパフォーマンスを発揮します。
原文 (English)
Dual Advantage Fields
Offline goal-conditioned reinforcement learning requires both long-horizon reachability estimates and local action comparisons. Dual goal representations provide value fields that capture global goal reachability, but they do not directly specify which action should be preferred at a given state. We propose Dual Advantage Fields, a policy-extraction method that turns a bilinear dual value model into a local advantage signal. Under bilinear dual parameterization, the goal embedding is the gradient of the value field with respect to the state representation. DAF learns an action-effect model that predicts the discounted feature displacement induced by an action and scores actions by the alignment between this displacement and the goal direction. In the realizable case, this score equals the goal-conditioned Bellman advantage, yielding a standard local policy-improvement guarantee. On OGBench locomotion, manipulation, and puzzle tasks, DAF improves aggregate RLiable metrics and performs strongly in settings where locally correct actions differ from direct movement toward the final goal.
PerceptTwin: 反復 LLM 計画と検証のためのセマンティック シーンの再構築
シミュレーション環境は、ロボット ポリシーの学習と計画の検証と検証の両方に役立ちます。従来、シミュレーションを作成するプロセスは面倒なものでした。ロボットが動作する個々の環境に合わせてオーダーメイドのシミュレーション環境を作成することは、まったく不可能でした。この研究では、ロボットの認識スタックによって生成されたセマンティック シーン表現から直接インタラクティブ シミュレーションを構築する完全自動パイプラインである PerceptTwin を紹介します。 PerceptTwin は、オープン語彙オブジェクト マップと 3D アセット生成、アフォーダンス予測、および常識的な条件チェックを組み合わせます。これらのインタラクティブなシミュレーションを使用すると、ロボット ハードウェアで実行される前に計画を検証し、改良することができます。 AI 調整の文献から借用して、計画の正確さと人間の好みとの調整を検証する LLM ジャッジも紹介します。実験では、PerceptTwin のフィードバックにより、LLM プランナーが計画を改良し、安全性を強化し、有害なブラックボックス プロンプト攻撃に抵抗できることが示されています。私たちの一連のタスクでは、PerceptTwin により、GPT5、GPT5Mini、および GPT5Nano プランナーの計画の成功率が平均約 39% 向上しました。さらに、PerceptTwin は、スキルの前提条件が満たされていないために失敗した計画について、人間による計画の検証を平均で最大 18% 改善します。私たちの結果は、より安全で信頼性の高いロボット計画の基盤として、ロボットの知覚からのオープンボキャブラリーシーンシミュレーションの可能性を実証しています。
原文 (English)
PerceptTwin: Semantic Scene Reconstruction for Iterative LLM Planning and Verification
Simulation environments are useful for both robot policy learning and planning verification and validation. Traditionally, the process of creating a simulation was onerous. Creating a bespoke simulation environment for each individual environment that a robot would operate in was simply infeasible. In this work, we introduce PerceptTwin, a fully automatic pipeline that constructs interactive simulations directly from semantic scene representations produced by a robot's perception stack. PerceptTwin combines open-vocabulary object maps with 3D asset generation, affordance prediction, and commonsense condition checking. These interactive simulations can be used to validate and refine plans before they are executed on the robot hardware. Borrowing from the AI alignment literature, we also introduce an LLM judge that verifies plan correctness and alignment with human preferences. Experiments show that PerceptTwin feedback allows LLM planners to refine plans, enhance safety, and resist harmful black-box prompting attacks. In our suite of tasks, PerceptTwin improves plan success by an average of approximately 39% for GPT5, GPT5Mini, and GPT5Nano planners. Additionally, PerceptTwin also improves human plan verification by up to 18% on average for plans that fail due to unfilled skill preconditions. Our results demonstrate the potential of open-vocabulary scene simulation from robot perception as a foundation for safer, more reliable robot planning.
インスタントフォールド: 変形可能なオブジェクト操作のためのコンテキスト内模倣学習
変形可能オブジェクト操作 (DOM) は、複数の有効な操作モードとの長期にわたるトポロジー変化の相互作用を通じて進化する、部分的に観察可能な高次元の状態のため、困難を伴います。 DOM のコンテキスト内模倣学習フレームワークである Instant-Fold を紹介します。単一の人間によるデモンストレーションが与えられると、私たちのポリシーは、勾配の更新を必要とせずに、空間的な実行や順序付けのバリエーションを含む、さまざまな操作モードをデモンストレーションから直接推論して実行します。私たちのアプローチでは、まず時間対比事前トレーニングによって変形を意識した視覚表現を学習し、その後、デモンストレーションを条件としたフローマッチングトランスフォーマーポリシーによって、意図した操作モードを実行するためのアクションを予測します。完全にシミュレーションでトレーニングされた Instant-Fold は、さまざまな折り畳みモードを一般化し、追加のデータ収集や微調整を行わずにゼロショットを現実世界の設定に移行します。ビデオは https://instant-fold.github.io でご覧いただけます。
原文 (English)
Instant-Fold: In-Context Imitation Learning for Deformable Object Manipulation
Deformable object manipulation (DOM) is challenging due to high-dimensional, partially observable states that evolve through long-horizon, topology-changing interactions with multiple valid manipulation modes. We introduce Instant-Fold, an in-context imitation learning framework for DOM. Given a single human demonstration, our policy infers and executes diverse manipulation modes directly from the demonstration, including variations in spatial execution and ordering, without requiring gradient updates. Our approach first learns deformation-aware visual representations via temporal contrastive pretraining, after which a flow-matching transformer policy conditioned on the demonstration predicts actions to execute the intended manipulation mode. Trained entirely in simulation, Instant-Fold generalizes across diverse folding modes and transfers zero-shot to real-world settings without additional data collection or finetuning. Videos are available at https://instant-fold.github.io.
VISTA: 視覚に基づいた、物理学に基づいて検証された UMI データの VLA トレーニングへの適応
Universal Manipulation Interface (UMI) により、ハードウェア固有の遠隔操作を必要とせずにスケーラブルな現実世界のロボット データ収集が可能になりますが、UMI データを活用して大規模な Vision-Language-Action (VLA) モデルをトレーニングすることは依然として根本的に困難です。我々は 2 つの重大な不一致を特定しました。1 つは、深刻な放射状の歪みとローカルのグリッパー中心の視点を伴う手首に取り付けられた魚眼ビューであり、事前トレーニングされた VLM には配布されていません。また、人間が収集した軌道は、頻繁に運動学的制限に違反したり、衝突が発生したり、コントローラーの帯域幅を超えたりするため、VLA ポリシーに物理的に実行不可能なアクションが教示されます。この課題に対処するために、3 つの相乗効果のあるコンポーネントを通じてこの二重のギャップを埋めるフレームワークである VISTA を紹介します。 (i) ~UMI-VQA は、手首に装着した魚眼観察に合わせて調整された初の大規模 VQA データセットであり、補助的な視覚言語監視を通じて VLM 表現を歪んだ視覚領域に合わせます。 (ii)~体系的な物理検証パイプラインは、データ完全性の事前チェックを実行し、トレーニングに入る前に、軌道の連続性、自己衝突のリスク、および実行の忠実度について各有効な軌道にスコアを付けます。 (iii)~2 段階の共同トレーニング レシピは、UMI-VQA に基づいた視覚言語の基礎と、検証された軌道に基づいた行動予測を共同で学習します。私たちの実験では、UMI-VQA を組み込むと下流のポリシーのパフォーマンスが一貫して向上し、物理検証スコアが展開の成功を強力に予測できることが経験的に示されています。さまざまなシミュレーションや現実世界の操作タスクにおいて、VISTA は $\pi_{0.5}$、LingBot-VLA、Wall-X などの強力なベースラインを大幅に上回ります。物理検証パイプライン、UMI-VQA、検証された軌跡データ、および事前トレーニングされたモデルをコミュニティにリリースします。
原文 (English)
VISTA: Vision-Grounded and Physics-Validated Adaptation of UMI data for VLA Training
Universal Manipulation Interface (UMI) enables scalable real-world robot data collection without hardware-specific teleoperation, yet leveraging UMI data to train large-scale Vision-Language-Action (VLA) models remains fundamentally challenging. We identify two critical mismatches: wrist-mounted fisheye views, with severe radial distortion and local gripper-centric perspectives, are out-of-distribution for pretrained VLMs; and human-collected trajectories frequently violate kinematic limits, incur collisions, or exceed controller bandwidth, teaching VLA policies physically infeasible actions. To address the challenges, we present VISTA, a framework that bridges this dual gap through three synergistic components. (i)~UMI-VQA, the first large-scale VQA dataset tailored to wrist-mounted fisheye observations, aligns VLM representations to the distorted visual regime via auxiliary vision-language supervision. (ii)~A systematic physical-validation pipeline performs a data-completeness pre-check and scores each valid trajectory for trajectory continuity, self-collision risk, and execution fidelity before it enters training. (iii)~A two-stage co-training recipe jointly learns vision-language grounding on UMI-VQA and action prediction on validated trajectories. Our experiments empirically show that incorporating UMI-VQA consistently improves downstream policy performance, and that physical-validation scores are strongly predictive of deployment success. On diverse simulation and real-world manipulation tasks, VISTA significantly outperforms strong baselines including $\pi_{0.5}$, LingBot-VLA, and Wall-X. We release the physical-validation pipeline, UMI-VQA, validated trajectory data, and the pre-trained model for the community.
CoRe-MoE: 歩行適応を備えた複数地形ヒューマノイド移動のための専門家の対照的な再重み付け混合
人間は主に、不必要に複雑な動作パターンに頼ることなく、複雑な地形を横断するために歩いたり走ったりすることに頼っています。同様に、人型ロボットは、自然で安定した移動を維持しながら、歩行と走行の間のスムーズな移行を達成する必要があります。ただし、単一のポリシー内で歩行遷移と複数の地形への適応を統合することは、勾配の干渉と、地形に依存する視覚的および動的変化によって引き起こされる分布のシフトのため、依然として困難です。専門家混合 (MoE) アーキテクチャは複数のスキルの干渉を軽減できますが、単純な共同トレーニングでは明確な専門知識が得られないことが多く、効果が制限されます。これらの課題に対処するために、私たちは地形適応から歩行生成を切り離す 2 段階の強化学習フレームワークである CoRe-MoE を提案します。第 1 段階では、スムーズな移行で自然な歩行と走行の動作を生成するための安定した移動ポリシーが学習されます。第 2 段階では、地形認識 MoE ブランチが導入され、ゲーティング ネットワークを形成するという対照的な目的でトレーニングされ、構造化された地形表現をキャプチャして専門家の専門化を促進できるようになります。最終的なアクションは、基本歩行ポリシーと地形認識ブランチの重み付けされた融合によって取得され、ポリシーが複雑な地形に適応しながら安定した移動パターンを維持できるようにします。広範なシミュレーション結果は、提案された方法が成功率、移動の安定性、および複数の地形への適応性の点でベースラインのアプローチよりも優れていることを示しています。さらに、Unitree G1 ヒューマノイド ロボットへのゼロショット展開により、当社のフレームワークの有効性が検証され、外乱下でも正確な足場の配置と動的安定性を維持しながら、階段、坂道、段差、障害物、屋外の構造化されていない地形での堅牢な歩行と走行が実現されます。
原文 (English)
CoRe-MoE: Contrastive Reweighted Mixture of Experts for Multi-Terrain Humanoid Locomotion with Gait Adaptation
Humans primarily rely on walking and running to traverse complex terrains, without resorting to unnecessarily complex motion patterns. Similarly, humanoid robots should achieve smooth transitions between walking and running while maintaining natural and stable locomotion. However, unifying gait transition and multi-terrain adaptation within a single policy remains challenging due to gradient interference and the distribution shift induced by terrain-dependent visual and dynamic variations. Although Mixture-of-Experts (MoE) architectures can alleviate multi-skill interference, naive joint training often fails to yield clear expert specialization, limiting their effectiveness. To address these challenges, we propose CoRe-MoE, a two-stage reinforcement learning framework that decouples gait generation from terrain adaptation. In the first stage, a stable locomotion policy is learned to produce natural walking and running behaviors with smooth transitions. In the second stage, a terrain-aware MoE branch is introduced and trained with a contrastive objective to shape the gating network, enabling it to capture structured terrain representations and promote expert specialization. The final action is obtained via weighted fusion of the base gait policy and the terrain-aware branch, allowing the policy to preserve stable locomotion patterns while adapting to complex terrains. Extensive simulation results demonstrate that the proposed method outperforms baseline approaches in terms of success rate, locomotion stability, and multi-terrain adaptability. Furthermore, zero-shot deployment on a Unitree G1 humanoid robot validates the effectiveness of our framework, achieving robust walking and running across stairs, slopes, steps, obstacles, and unstructured outdoor terrains, while maintaining accurate foothold placement and dynamic stability under external disturbances.
変圧器ベースの自動運転モデルと展開指向の圧縮: 調査
トランスベースのモデルは、長距離の空間依存関係、マルチエージェントのインタラクション、認識、予測、計画にわたるマルチモーダルなコンテキストをキャプチャできるため、自動運転の中心的なパラダイムになりつつあります。同時に、大容量のアテンションベースのアーキテクチャはかなりの遅延、メモリ、エネルギーのオーバーヘッドを課すため、実際の車両への導入は依然として困難です。この調査では、代表的な Transformer ベースの自動運転モデルをレビューし、それらをタスクの役割、センシング構成、アーキテクチャ設計ごとに整理します。さらに重要なのは、展開指向の観点からこれらのモデルを検証し、効率の制約が実際にモデル設計の選択肢をどのように再形成するかを分析することです。さらに、量子化、枝刈り、知識蒸留、低ランク近似、効率的な注意など、Transformer ベースの駆動システムに関連する圧縮および加速戦略をレビューし、その利点、限界、およびタスク依存の適用可能性について説明します。圧縮を独立した後処理ステップとして扱うのではなく、展開性、堅牢性、安全性に直接影響を与えるシステムレベルの設計上の考慮事項として強調します。最後に、効率的な自動運転システムの標準化された、安全性を意識した、ハードウェアを意識した評価に向けた未解決の課題と将来の研究の方向性を特定します。
原文 (English)
Transformer-Based Autonomous Driving Models and Deployment-Oriented Compression: A Survey
Transformer-based models are becoming a central paradigm in autonomous driving because they can capture long-range spatial dependencies, multi-agent interactions, and multimodal context across perception, prediction, and planning. At the same time, their deployment in real vehicles remains difficult because high-capacity attention-based architectures impose substantial latency, memory, and energy overhead. This survey reviews representative Transformer-based autonomous driving models and organizes them by task role, sensing configuration, and architectural design. More importantly, it examines these models from a deployment-oriented perspective and analyzes how efficiency constraints reshape model design choices in practice. We further review compression and acceleration strategies relevant to Transformer-based driving systems, including quantization, pruning, knowledge distillation, low-rank approximation, and efficient attention, and discuss their benefits, limitations, and task-dependent applicability. Rather than treating compression as an isolated post-processing step, we highlight it as a system-level design consideration that directly affects deployability, robustness, and safety. Finally, we identify open challenges and future research directions toward standardized, safety-aware, and hardware-conscious evaluation of efficient autonomous driving systems.
単純な埋め込みによりアクター-クリティックエージェントのサンプル効率が向上
最近の研究では、大規模な環境の並列化を使用して、アクタークリティカル手法の実時間のトレーニング時間を加速することが提案されています。残念ながら、望ましいレベルのパフォーマンスを達成するには、依然として多数の環境との対話が必要になる場合があります。適切に構造化された表現は、深層強化学習 (RL) エージェントの一般化とサンプル効率を向上させることができることに注目し、単純なエンベディング、つまりエンベディングを単純な構造に制約する軽量の表現層の使用を提案します。この幾何学的な帰納的バイアスにより、批評家のブートストラップを安定させ、政策の勾配を強化するまばらで離散的な特徴が生じます。 FastTD3、FastSAC、および PPO に適用すると、単純なエンベディングは、実行速度を損なうことなく、さまざまな連続および離散制御環境全体でサンプル効率と最終パフォーマンスを一貫して向上させます。
原文 (English)
Simplicial Embeddings Improve Sample Efficiency in Actor-Critic Agents
Recent works have proposed accelerating the wall-clock training time of actor-critic methods via the use of large-scale environment parallelization; unfortunately, these can sometimes still require large number of environment interactions to achieve a desired level of performance. Noting that well-structured representations can improve the generalization and sample efficiency of deep reinforcement learning (RL) agents, we propose the use of simplicial embeddings: lightweight representation layers that constrain embeddings to simplicial structures. This geometric inductive bias results in sparse and discrete features that stabilize critic bootstrapping and strengthen policy gradients. When applied to FastTD3, FastSAC, and PPO, simplicial embeddings consistently improve sample efficiency and final performance across a variety of continuous- and discrete-control environments, without any loss in runtime speed.
ベクトル化されたオンライン POMDP 計画
部分的な可観測性の下で計画を立てることは、自律ロボットの重要な機能です。部分観測可能なマルコフ決定プロセス (POMDP) は、部分観測可能性の問題の下で計画を立てるための強力なフレームワークを提供し、アクションの確率的影響とノイズの多い観測を通じて得られる限られた情報を捕捉します。 POMDP の解法は、今日のハードウェアでの大規模並列化から多大な恩恵を受ける可能性がありますが、POMDP ソルバーの並列化は困難でした。ほとんどのソルバーは、アクションとその値の推定をインターリーブする数値最適化に依存しているため、並列プロセス間に依存関係や同期ボトルネックが生じ、並列化の利点が相殺される可能性があります。この論文では、Vectorized Online POMDP Planner (VOPP) を提案します。これは、最適化コンポーネントの一部を分析的に解決し、期待値の推定のみで構成される数値計算を残す、最新の POMDP 定式化を利用する新しい並列オンライン ソルバーです。 VOPP は、計画に関連するすべてのデータ構造をテンソルのコレクションとして表し、すべての計画ステップをこの表現に対する完全にベクトル化された計算として実装します。その結果、同時プロセス間の依存関係や同期ボトルネックのない大規模並列オンライン ソルバーが実現します。実験結果は、VOPP が既存の最先端の並列オンライン ソルバーと比較して、最適に近い解の計算において少なくとも 20 倍効率的であることを示しています。さらに、VOPP は最先端の逐次オンライン ソルバーよりも優れたパフォーマンスを発揮し、計画予算を 1000 倍も削減します。
原文 (English)
Vectorized Online POMDP Planning
Planning under partial observability is an essential capability of autonomous robots. The Partially Observable Markov Decision Process (POMDP) provides a powerful framework for planning under partial observability problems, capturing the stochastic effects of actions and the limited information available through noisy observations. POMDP solving could benefit tremendously from massive parallelization on today's hardware, but parallelizing POMDP solvers has been challenging. Most solvers rely on interleaving numerical optimization over actions with the estimation of their values, which creates dependencies and synchronization bottlenecks between parallel processes that can offset the benefits of parallelization. In this paper, we propose Vectorized Online POMDP Planner (VOPP), a novel parallel online solver that leverages a recent POMDP formulation which analytically solves part of the optimization component, leaving numerical computations to consist of only estimation of expectations. VOPP represents all data structures related to planning as a collection of tensors, and implements all planning steps as fully vectorized computations over this representation. The result is a massively parallel online solver with no dependencies or synchronization bottlenecks between concurrent processes. Experimental results indicate that VOPP is at least $20\times$ more efficient in computing near-optimal solutions compared to an existing state-of-the-art parallel online solver. Moreover, VOPP outperforms state-of-the-art sequential online solvers, while using a planning budget that is $1000\times$ smaller.
DVGT: ビジュアル ジオメトリ トランスフォーマーの駆動
自動運転には、視覚入力から 3D シーンのジオメトリを認識して再構築することが重要です。ただし、さまざまなシナリオやカメラ構成に適応できる、運転をターゲットとした高密度ジオメトリ認識モデルがまだ不足しています。このギャップを埋めるために、私たちはドライビング ビジュアル ジオメトリ トランスフォーマー (DVGT) を提案します。これは、一連のポーズ化されていないマルチビュー ビジュアル入力からグローバルな高密度 3D ポイント マップを再構築します。まず、DINO バックボーンを使用して各画像の視覚的特徴を抽出し、ビュー内の局所的注意、ビュー間の空間的注意、およびフレーム間の時間的注意を交互に使用して、画像全体の幾何学的関係を推測します。次に、複数のヘッドを使用して、最初のフレームのエゴ座標のグローバル ポイント マップと各フレームのエゴ ポーズをデコードします。正確なカメラ パラメーターに依存する従来の方法とは異なり、DVGT には明示的な 3D 幾何学的な事前条件がなく、任意のカメラ構成の柔軟な処理が可能です。 DVGT は、画像シーケンスからメートルスケールのジオメトリを直接予測し、外部センサーによる事後位置合わせの必要性を排除します。 DVGT は、nuScenes、OpenScene、Waymo、KITTI、DDAD などの運転データセットを大規模に組み合わせてトレーニングされたため、さまざまなシナリオで既存のモデルを大幅に上回ります。コードは https://github.com/wzzheng/DVGT で入手できます。
原文 (English)
DVGT: Driving Visual Geometry Transformer
Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
リーダーとフォロワーの相互作用における小規模言語モデルのゼロショットおよびワンショット適応の評価
リーダーとフォロワーの相互作用は、人間とロボットの相互作用 (HRI) における重要なパラダイムです。しかし、リソースに制約のある移動ロボットや支援ロボットにとって、リアルタイムでの役割の割り当ては依然として困難です。大規模言語モデル (LLM) は自然なコミュニケーションに有望であることが示されていますが、そのサイズと遅延によりデバイス上の展開が制限されます。小規模言語モデル (SLM) は潜在的な代替手段を提供しますが、HRI における役割分類に対する SLM の有効性は体系的に評価されていません。この論文では、リーダーとフォロワーのコミュニケーションのための SLM のベンチマークを紹介し、公開されたデータベースから派生し、相互作用固有のダイナミクスを捕捉するために合成サンプルで強化された新しいデータセットを紹介します。私たちは、ゼロショットおよびワンショット相互作用モードで研究されたプロンプトエンジニアリングと微調整という 2 つの適応戦略を、トレーニングされていないベースラインと比較して調査します。 Qwen2.5-0.5B を使用した実験では、ゼロショット微調整が低遅延 (サンプルあたり 22.2 ミリ秒) を維持しながら堅牢な分類パフォーマンス (精度 86.66%) を達成し、ベースラインおよびプロンプト エンジニアリングのアプローチを大幅に上回るパフォーマンスを示していることが明らかになりました。ただし、結果はワンショット モードでのパフォーマンスの低下も示しており、コンテキストの長さが増加するとモデルのアーキテクチャ上の能力に課題が生じます。これらの調査結果は、微調整された SLM が役割の直接割り当てに効果的なソリューションを提供することを実証するとともに、エッジでの対話の複雑さと分類の信頼性の間の重要なトレードオフを強調しています。
原文 (English)
Evaluating Zero-Shot and One-Shot Adaptation of Small Language Models in Leader-Follower Interaction
Leader-follower interaction is an important paradigm in human-robot interaction (HRI). Yet, assigning roles in real time remains challenging for resource-constrained mobile and assistive robots. While large language models (LLMs) have shown promise for natural communication, their size and latency limit on-device deployment. Small language models (SLMs) offer a potential alternative, but their effectiveness for role classification in HRI has not been systematically evaluated. In this paper, we present a benchmark of SLMs for leader-follower communication, introducing a novel dataset derived from a published database and augmented with synthetic samples to capture interaction-specific dynamics. We investigate two adaptation strategies: prompt engineering and fine-tuning, studied under zero-shot and one-shot interaction modes, compared with an untrained baseline. Experiments with Qwen2.5-0.5B reveal that zero-shot fine-tuning achieves robust classification performance (86.66% accuracy) while maintaining low latency (22.2 ms per sample), significantly outperforming baseline and prompt-engineered approaches. However, results also indicate a performance degradation in one-shot modes, where increased context length challenges the model's architectural capacity. These findings demonstrate that fine-tuned SLMs provide an effective solution for direct role assignment, while highlighting critical trade-offs between dialogue complexity and classification reliability on the edge.
ZeroWBC: 人間の自己中心的なデータから自然な全身ヒューマノイドのインタラクションを学習する
全身遠隔操作データのコストが高いため、多用途で自然な全身ヒューマノイドのインタラクション制御を実現することは依然として困難です。我々は、同期した全身動作とテキスト注釈と組み合わせた、人間の自己中心的なビデオから人型の全身インタラクションを学習する、遠隔操作不要のフレームワークである ZeroWBC を紹介します。 ZeroWBC は、静的シーンの全身インタラクション制御問題に取り組むために、生成後追跡の定式化を採用しています。初期の自己中心的な画像と言語命令が与えられると、微調整された視覚言語モデルによって将来の人間の全身運動トークンが生成され、これが連続運動にデコードされ、ヒューマノイドに再ターゲットされます。結果として得られる参照モーションは、ルートおよび主要な身体部分の軌道とともに、一般的なインタラクティブ モーション トラッキング ポリシーによって実行されます。インタラクションのパフォーマンスを向上させるために、自然な全身の動きを維持しながら、グローバル ルートと主要な身体部分の軌道の調整を優先するインタラクション指向の追跡報酬を導入します。 Unitree G1 ヒューマノイド ロボットの実験では、ZeroWBC がロボットの遠隔操作のデモンストレーションを行わずに、シーンを認識した多様な動作を可能にすることを示しています。これらの結果は、人間の自己中心的なデータから自然なヒューマノイドの全身インタラクションを学習するためのスケーラブルなパラダイムを示唆しています。
原文 (English)
ZeroWBC: Learning Natural Whole-Body Humanoid Interaction from Human Egocentric Data
Achieving versatile and natural whole-body humanoid interaction control remains challenging due to the high cost of whole-body teleoperation data. We present ZeroWBC, a teleoperation-free framework that learns humanoid whole-body interaction from human egocentric videos paired with synchronized whole-body motion and text annotations. ZeroWBC adopts a generation-then-tracking formulation to tackle the static scene whole-body interaction control problem. Given an initial egocentric image and a language instruction, a fine-tuned Vision-Language Model generates future human whole-body motion tokens, which are decoded into continuous motions and retargeted to the humanoid. The resulting reference motions, together with root and key body-part trajectories, are then executed by a general interactive motion tracking policy. To improve interaction performance, we introduce an interaction-oriented tracking reward that prioritizes global root and key body-part trajectory alignment while preserving natural whole-body motion. Experiments on the Unitree G1 humanoid robot show that ZeroWBC enables diverse scene-aware behaviors without robot teleoperation demonstrations. These results suggest a scalable paradigm for learning natural humanoid whole-body interaction from human egocentric data.
ContactExplorer: Contact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Reinforcement learning has achieved remarkable success in domains such as Atari games, navigation, and locomotion, where exploration can of…
Contextual Multi-Task Reinforcement Learning for Autonomous Reef Monitoring
Although autonomous underwater vehicles promise the capability of marine ecosystem monitoring, their deployment is fundamentally limited by…
DEFLECT: Temporal Counterfactual Preference Learning for Delay-Robust Asynchronous VLAs
Vision-Language-Action (VLA) policies increasingly rely on asynchronous inference to hide large-model latency behind ongoing robot motion.…
Lost in Fog: Sensor Perturbations Expose Reasoning Fragility in Driving VLAs
Interpretable autonomous driving planners depend not only on generating explanations, but also on those explanations remaining reliable und…
Too Much of a Good Thing: When sim2real Efforts Impede Policy Learning (And What to Do About It)
While sim2real efforts are necessary for effective policy transfer to hardware, there is such a thing as too much of a good thing. We argue…
PHASER: Phase-Aware and Semantic Experience Replay for Vision-Language-Action Models
Vision-Language-Action (VLA) models have achieved remarkable success in language-conditioned robotic manipulation. However, deploying these…
DiffAero: 効率的なクアドローター ポリシー学習のための GPU アクセラレーションによる微分可能シミュレーション フレームワーク
このレターでは、効率的なクワッドローター制御ポリシー学習のために設計された、軽量で GPU アクセラレーションを備えた完全微分可能なシミュレーション フレームワークである DiffAero を紹介します。 DiffAero は、環境レベルとエージェント レベルの両方の並列処理をサポートし、複数のダイナミクス モデル、カスタマイズ可能なセンサー スタック (IMU、深度カメラ、LiDAR)、および多様な飛行タスクを統合された GPU ネイティブのトレーニング インターフェイス内に統合します。 DiffAero は、GPU 上で物理とレンダリングの両方を完全に並列化することで、CPU と GPU 間のデータ転送のボトルネックを排除し、シミュレーションのスループットを桁違いに向上させます。既存のシミュレータとは対照的に、DiffAero は高性能シミュレーションを提供するだけでなく、微分可能なハイブリッド学習アルゴリズムを探索するための研究プラットフォームとしても機能します。広範なベンチマークと実際の飛行実験により、DiffAero とハイブリッド学習アルゴリズムを組み合わせることで、消費者グレードのハードウェアで堅牢な飛行ポリシーを数時間で学習できることが実証されました。コードは https://github.com/flyingbitac/diffaero で入手できます。
原文 (English)
DiffAero: A GPU-Accelerated Differentiable Simulation Framework for Efficient Quadrotor Policy Learning
This letter introduces DiffAero, a lightweight, GPU-accelerated, and fully differentiable simulation framework designed for efficient quadrotor control policy learning. DiffAero supports both environment-level and agent-level parallelism and integrates multiple dynamics models, customizable sensor stacks (IMU, depth camera, and LiDAR), and diverse flight tasks within a unified, GPU-native training interface. By fully parallelizing both physics and rendering on the GPU, DiffAero eliminates CPU-GPU data transfer bottlenecks and delivers orders-of-magnitude improvements in simulation throughput. In contrast to existing simulators, DiffAero not only provides high-performance simulation but also serves as a research platform for exploring differentiable and hybrid learning algorithms. Extensive benchmarks and real-world flight experiments demonstrate that DiffAero and hybrid learning algorithms combined can learn robust flight policies in hours on consumer-grade hardware. The code is available at https://github.com/flyingbitac/diffaero.
現場に飛び込む: フォーカス プランの生成を通じて、視覚と言語の意思決定における知覚のボトルネックを打破する
ロボット操作やナビゲーションなどの身体化された視覚言語による意思決定タスクでは、視覚言語モデルおよび視覚言語アクション モデル (VLM および VLA) は、さまざまな利点を持つ強力なツールです。VLM は長期計画に優れ、VLA は事後制御に優れています。ただし、モデルのパフォーマンスは、同じ知覚のボトルネックによって制限されます。モデルがタスクに関連するオブジェクトと気を散らすものとを区別できないために幻覚が発生します。原則として、無関係なものを除外しながら、正確に識別して重要なオブジェクトに焦点を当てることが、この制限を打ち破る鍵となります。簡単な解決策は、重要なオブジェクトに直接注目するというワンステップの焦点です。ただし、効果的に焦点を合わせるには本質的にシーンを深く理解する必要があるため、このアプローチは効果的ではないことがわかります。この目的を達成するために、我々は、VLM の長期計画能力を活用した、粗いから細かいまでのフォーカス プラン生成方法である SceneDiver を提案します。この方法では、最初に全体的なシーン グラフを構築して初期理解を確立し、次に認識、理解、分析の反復サイクルを通じてタスクをより単純なサブ問題に徐々に分解します。反応的な制御を可能にするために、意図的なフォーカス機能を VLA に抽出するための軽量アダプターも設計しました。標準の組み込み AI ベンチマークでの評価により、私たちの方法は、高速実行を必要とするタスクの計算効率を維持しながら、VLM と VLA の両方で幻視を大幅に軽減することが確認されています。コードとデータは https://future-item.github.io/SceneDiver でリリースされています。
原文 (English)
Dive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation
In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at long-term planning, while VLAs are better at reactive control. However, their performance is limited by the same perceptual bottleneck: visual hallucinations arise due to the models' inability to distinguish task-relevant objects from distractors. In principle, accurate identification and focus on critical objects while filtering out irrelevant ones is the key to break this limitation. A straightforward solution is one-step focus: directly attending to essential objects. However, this approach proves ineffective because effective focus inherently requires deep scene understanding. To this end, we propose SceneDiver, a coarse-to-fine focus plan generation method for VLMs leveraging their long-term planning abilities, that first constructs a holistic scene graph to establish initial comprehension, then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis. To enable reactive control, we also design a lightweight adapter for distilling the deliberate focus ability into VLAs. Evaluations on standard embodied AI benchmarks confirm that our method substantially reduces visual hallucinations for both VLMs and VLAs, while preserving computational efficiency in tasks requiring fast execution. Our code and data are released at: https://future-item.github.io/SceneDiver.
AgenticDiffusion: ビジョンベースの UAV ナビゲーションのための Agentic Diffusion ベースの経路計画
屋内 UAV ナビゲーションには、限られた視野の観察下での効率的な探索、シーンの理解、信頼性の高い軌道の実行が必要です。既存のビジョンベースのナビゲーション フレームワークは通常、単一ビューの観察に依存しており、オクルージョン、ターゲットの可視性、およびグローバル シーン構造について推論する能力が制限されています。この研究では、統合された航空ナビゲーション パイプライン内で、言語に基づく推論、オープン語彙によるターゲットのグラウンディング、視覚ベースの拡散計画、および NMPC を調整するマルチビュー UAV ナビゲーション フレームワークである AgenticDiffusion を提案します。自然言語による指示と、同期した一人称視点 (FPV) および上面視点の観察を考慮して、フレームワークはナビゲーションに最も有益な視点を決定し、軌道の実行前にミッション計画を生成します。ターゲットは、オープンボキャブラリーグラウンディングモデルを使用して位置特定され、その後、視点固有の拡散プランナーが UAV 実行のためのナビゲーション軌道を生成します。提案されたフレームワークは、補完的な視点を使用して、繰り返しのターゲット探査を削減し、雑然とした屋内環境でのナビゲーション効率を向上させます。このフレームワークは、適応視点選択、多段階ミッション実行、長距離ナビゲーション、安全な着陸地点選択を含む 4 つの現実世界の UAV ナビゲーション シナリオで検証されました。実験結果では、40 回の実世界試験でミッション全体の成功率が 80% であることが実証され、一方、拡散計画者は軌道生成の成功率が 100% に達しました。
原文 (English)
AgenticDiffusion: Agentic Diffusion-based Path Planning for Vision-Based UAV Navigation
Indoor UAV navigation requires efficient exploration, scene understanding, and reliable trajectory execution under limited field-of-view observations. Existing vision-based navigation frameworks typically rely on single-view observations, limiting their ability to reason about occlusions, target visibility, and global scene structure. In this work, we propose AgenticDiffusion, a multi-view UAV navigation framework that coordinates language-guided reasoning, open-vocabulary target grounding, vision-based diffusion planning, and NMPC within a unified aerial navigation pipeline. Given a natural language instruction and synchronized first-person-view (FPV) and top-view observations, the framework determines the most informative viewpoint for navigation and generates a mission plan prior to trajectory execution. The targets are localized using an open-vocabulary grounding model, after which viewpoint-specific diffusion planners generate navigation trajectories for UAV execution. Using complementary viewpoints, the proposed framework reduces repeated target exploration and improves navigation efficiency in cluttered indoor environments. The framework was validated in four real-world UAV navigation scenarios involving adaptive viewpoint selection, multi-stage mission execution, long-horizon navigation, and safe landing-site selection. The experimental results demonstrated an overall mission success rate of 80% in 40 real-world trials, while the diffusion planners achieved a trajectory generation success rate of 100%.
大規模言語モデルによる適応軌道最適化のためのセマンティック制約合成
軌道の最適化は、宇宙探査において安全で信頼性の高い自律運用を可能にするための重要なコンポーネントです。宇宙ミッションの頻度、複雑さ、範囲が増加するにつれて、ミッションの目的と運用上の制約を正確に反映する、数学的に適切な軌道最適化問題を迅速に定式化する必要性が高まっています。ただし、ミッションの意図を軌道最適化のための扱いやすい分析公式に変換するには、かなりの専門知識が必要です。この論文では、大規模言語モデル (LLM) を活用して、ミッションの要件と制約の自然言語記述を実行可能な軌道最適化コードと対応する数学的定式化に変換するフレームワークを紹介します。宇宙船ランデブーシナリオでの実験では、意味論的なミッション要件から凸軌道最適化問題を再調整する際の高い成功率が実証されています。最終的に、この研究は、高レベルの意図と形式的な最適化モデルを橋渡しする LLM の可能性を強調し、宇宙船のより柔軟で効率的な軌道設計を可能にします。
原文 (English)
Semantic Constraint Synthesis for Adaptive Trajectory Optimization via Large Language Models
Trajectory optimization is a critical component for enabling safe and reliable autonomous operations in space exploration. As space missions increase in frequency, complexity, and scope, there is a growing need to rapidly formulate mathematically sound trajectory optimization problems that accurately reflect mission objectives and operational constraints. However, translating mission intent into tractable analytical formulations for trajectory optimization requires substantial domain expertise. This paper presents a framework that leverages large language models (LLMs) to translate natural language descriptions of mission requirements and constraints into executable trajectory optimization code and corresponding mathematical formulations. Experiments in spacecraft rendezvous scenarios demonstrate a high success rate in reconditioning a convex trajectory optimization problem from semantic mission requirements. Ultimately, this work highlights the potential of LLMs to bridge high-level intent and formal optimization models, enabling more flexible and efficient trajectory design of spacecraft.
2つのアドバンテージフィールド
オフラインの目標条件付き強化学習では、長期的な到達可能性の推定とローカル アクションの比較の両方が必要です。デュアル目標表現は、グローバルな目標の到達可能性を取得する値フィールドを提供しますが、特定の状態でどのアクションが優先されるべきかを直接指定するものではありません。我々は、双線形二重値モデルをローカルアドバンテージ信号に変えるポリシー抽出手法であるデュアルアドバンテージフィールドを提案します。双線形双対パラメータ化では、目標の埋め込みは状態表現に対する値フィールドの勾配です。 DAF は、アクションによって引き起こされる割り引かれたフィーチャの変位を予測し、この変位と目標の方向との整合性によってアクションをスコア化するアクション効果モデルを学習します。実現可能なケースでは、このスコアは目標条件付きベルマンアドバンテージに等しく、標準的なローカル政策改善保証が得られます。 OGBench の移動、操作、パズルのタスクでは、DAF は集計 RLiable メトリクスを改善し、局所的に正しいアクションが最終目標に向かう直接的な動きとは異なる設定で強力にパフォーマンスを発揮します。
原文 (English)
Dual Advantage Fields
Offline goal-conditioned reinforcement learning requires both long-horizon reachability estimates and local action comparisons. Dual goal representations provide value fields that capture global goal reachability, but they do not directly specify which action should be preferred at a given state. We propose Dual Advantage Fields, a policy-extraction method that turns a bilinear dual value model into a local advantage signal. Under bilinear dual parameterization, the goal embedding is the gradient of the value field with respect to the state representation. DAF learns an action-effect model that predicts the discounted feature displacement induced by an action and scores actions by the alignment between this displacement and the goal direction. In the realizable case, this score equals the goal-conditioned Bellman advantage, yielding a standard local policy-improvement guarantee. On OGBench locomotion, manipulation, and puzzle tasks, DAF improves aggregate RLiable metrics and performs strongly in settings where locally correct actions differ from direct movement toward the final goal.
PerceptTwin: 反復 LLM 計画と検証のためのセマンティック シーンの再構築
シミュレーション環境は、ロボット ポリシーの学習と計画の検証と検証の両方に役立ちます。従来、シミュレーションを作成するプロセスは面倒なものでした。ロボットが動作する個々の環境に合わせてオーダーメイドのシミュレーション環境を作成することは、まったく不可能でした。この研究では、ロボットの認識スタックによって生成されたセマンティック シーン表現から直接インタラクティブ シミュレーションを構築する完全自動パイプラインである PerceptTwin を紹介します。 PerceptTwin は、オープン語彙オブジェクト マップと 3D アセット生成、アフォーダンス予測、および常識的な条件チェックを組み合わせます。これらのインタラクティブなシミュレーションを使用すると、ロボット ハードウェアで実行される前に計画を検証し、改良することができます。 AI 調整の文献から借用して、計画の正確さと人間の好みとの調整を検証する LLM ジャッジも紹介します。実験では、PerceptTwin のフィードバックにより、LLM プランナーが計画を改良し、安全性を強化し、有害なブラックボックス プロンプト攻撃に抵抗できることが示されています。私たちの一連のタスクでは、PerceptTwin により、GPT5、GPT5Mini、および GPT5Nano プランナーの計画の成功率が平均約 39% 向上しました。さらに、PerceptTwin は、スキルの前提条件が満たされていないために失敗した計画について、人間による計画の検証を平均で最大 18% 改善します。私たちの結果は、より安全で信頼性の高いロボット計画の基盤として、ロボットの知覚からのオープンボキャブラリーシーンシミュレーションの可能性を実証しています。
原文 (English)
PerceptTwin: Semantic Scene Reconstruction for Iterative LLM Planning and Verification
Simulation environments are useful for both robot policy learning and planning verification and validation. Traditionally, the process of creating a simulation was onerous. Creating a bespoke simulation environment for each individual environment that a robot would operate in was simply infeasible. In this work, we introduce PerceptTwin, a fully automatic pipeline that constructs interactive simulations directly from semantic scene representations produced by a robot's perception stack. PerceptTwin combines open-vocabulary object maps with 3D asset generation, affordance prediction, and commonsense condition checking. These interactive simulations can be used to validate and refine plans before they are executed on the robot hardware. Borrowing from the AI alignment literature, we also introduce an LLM judge that verifies plan correctness and alignment with human preferences. Experiments show that PerceptTwin feedback allows LLM planners to refine plans, enhance safety, and resist harmful black-box prompting attacks. In our suite of tasks, PerceptTwin improves plan success by an average of approximately 39% for GPT5, GPT5Mini, and GPT5Nano planners. Additionally, PerceptTwin also improves human plan verification by up to 18% on average for plans that fail due to unfilled skill preconditions. Our results demonstrate the potential of open-vocabulary scene simulation from robot perception as a foundation for safer, more reliable robot planning.
インスタントフォールド: 変形可能なオブジェクト操作のためのコンテキスト内模倣学習
変形可能オブジェクト操作 (DOM) は、複数の有効な操作モードとの長期にわたるトポロジー変化の相互作用を通じて進化する、部分的に観察可能な高次元の状態のため、困難を伴います。 DOM のコンテキスト内模倣学習フレームワークである Instant-Fold を紹介します。単一の人間によるデモンストレーションが与えられると、私たちのポリシーは、勾配の更新を必要とせずに、空間的な実行や順序付けのバリエーションを含む、さまざまな操作モードをデモンストレーションから直接推論して実行します。私たちのアプローチでは、まず時間対比事前トレーニングによって変形を意識した視覚表現を学習し、その後、デモンストレーションを条件としたフローマッチングトランスフォーマーポリシーによって、意図した操作モードを実行するためのアクションを予測します。完全にシミュレーションでトレーニングされた Instant-Fold は、さまざまな折り畳みモードを一般化し、追加のデータ収集や微調整を行わずにゼロショットを現実世界の設定に移行します。ビデオは https://instant-fold.github.io でご覧いただけます。
原文 (English)
Instant-Fold: In-Context Imitation Learning for Deformable Object Manipulation
Deformable object manipulation (DOM) is challenging due to high-dimensional, partially observable states that evolve through long-horizon, topology-changing interactions with multiple valid manipulation modes. We introduce Instant-Fold, an in-context imitation learning framework for DOM. Given a single human demonstration, our policy infers and executes diverse manipulation modes directly from the demonstration, including variations in spatial execution and ordering, without requiring gradient updates. Our approach first learns deformation-aware visual representations via temporal contrastive pretraining, after which a flow-matching transformer policy conditioned on the demonstration predicts actions to execute the intended manipulation mode. Trained entirely in simulation, Instant-Fold generalizes across diverse folding modes and transfers zero-shot to real-world settings without additional data collection or finetuning. Videos are available at https://instant-fold.github.io.
VISTA: 視覚に基づいた、物理学に基づいて検証された UMI データの VLA トレーニングへの適応
Universal Manipulation Interface (UMI) により、ハードウェア固有の遠隔操作を必要とせずにスケーラブルな現実世界のロボット データ収集が可能になりますが、UMI データを活用して大規模な Vision-Language-Action (VLA) モデルをトレーニングすることは依然として根本的に困難です。我々は 2 つの重大な不一致を特定しました。1 つは、深刻な放射状の歪みとローカルのグリッパー中心の視点を伴う手首に取り付けられた魚眼ビューであり、事前トレーニングされた VLM には配布されていません。また、人間が収集した軌道は、頻繁に運動学的制限に違反したり、衝突が発生したり、コントローラーの帯域幅を超えたりするため、VLA ポリシーに物理的に実行不可能なアクションが教示されます。この課題に対処するために、3 つの相乗効果のあるコンポーネントを通じてこの二重のギャップを埋めるフレームワークである VISTA を紹介します。 (i) ~UMI-VQA は、手首に装着した魚眼観察に合わせて調整された初の大規模 VQA データセットであり、補助的な視覚言語監視を通じて VLM 表現を歪んだ視覚領域に合わせます。 (ii)~体系的な物理検証パイプラインは、データ完全性の事前チェックを実行し、トレーニングに入る前に、軌道の連続性、自己衝突のリスク、および実行の忠実度について各有効な軌道にスコアを付けます。 (iii)~2 段階の共同トレーニング レシピは、UMI-VQA に基づいた視覚言語の基礎と、検証された軌道に基づいた行動予測を共同で学習します。私たちの実験では、UMI-VQA を組み込むと下流のポリシーのパフォーマンスが一貫して向上し、物理検証スコアが展開の成功を強力に予測できることが経験的に示されています。さまざまなシミュレーションや現実世界の操作タスクにおいて、VISTA は $\pi_{0.5}$、LingBot-VLA、Wall-X などの強力なベースラインを大幅に上回ります。物理検証パイプライン、UMI-VQA、検証された軌跡データ、および事前トレーニングされたモデルをコミュニティにリリースします。
原文 (English)
VISTA: Vision-Grounded and Physics-Validated Adaptation of UMI data for VLA Training
Universal Manipulation Interface (UMI) enables scalable real-world robot data collection without hardware-specific teleoperation, yet leveraging UMI data to train large-scale Vision-Language-Action (VLA) models remains fundamentally challenging. We identify two critical mismatches: wrist-mounted fisheye views, with severe radial distortion and local gripper-centric perspectives, are out-of-distribution for pretrained VLMs; and human-collected trajectories frequently violate kinematic limits, incur collisions, or exceed controller bandwidth, teaching VLA policies physically infeasible actions. To address the challenges, we present VISTA, a framework that bridges this dual gap through three synergistic components. (i)~UMI-VQA, the first large-scale VQA dataset tailored to wrist-mounted fisheye observations, aligns VLM representations to the distorted visual regime via auxiliary vision-language supervision. (ii)~A systematic physical-validation pipeline performs a data-completeness pre-check and scores each valid trajectory for trajectory continuity, self-collision risk, and execution fidelity before it enters training. (iii)~A two-stage co-training recipe jointly learns vision-language grounding on UMI-VQA and action prediction on validated trajectories. Our experiments empirically show that incorporating UMI-VQA consistently improves downstream policy performance, and that physical-validation scores are strongly predictive of deployment success. On diverse simulation and real-world manipulation tasks, VISTA significantly outperforms strong baselines including $\pi_{0.5}$, LingBot-VLA, and Wall-X. We release the physical-validation pipeline, UMI-VQA, validated trajectory data, and the pre-trained model for the community.
CoRe-MoE: 歩行適応を備えた複数地形ヒューマノイド移動のための専門家の対照的な再重み付け混合
人間は主に、不必要に複雑な動作パターンに頼ることなく、複雑な地形を横断するために歩いたり走ったりすることに頼っています。同様に、人型ロボットは、自然で安定した移動を維持しながら、歩行と走行の間のスムーズな移行を達成する必要があります。ただし、単一のポリシー内で歩行遷移と複数の地形への適応を統合することは、勾配の干渉と、地形に依存する視覚的および動的変化によって引き起こされる分布のシフトのため、依然として困難です。専門家混合 (MoE) アーキテクチャは複数のスキルの干渉を軽減できますが、単純な共同トレーニングでは明確な専門知識が得られないことが多く、効果が制限されます。これらの課題に対処するために、私たちは地形適応から歩行生成を切り離す 2 段階の強化学習フレームワークである CoRe-MoE を提案します。第 1 段階では、スムーズな移行で自然な歩行と走行の動作を生成するための安定した移動ポリシーが学習されます。第 2 段階では、地形認識 MoE ブランチが導入され、ゲーティング ネットワークを形成するという対照的な目的でトレーニングされ、構造化された地形表現をキャプチャして専門家の専門化を促進できるようになります。最終的なアクションは、基本歩行ポリシーと地形認識ブランチの重み付けされた融合によって取得され、ポリシーが複雑な地形に適応しながら安定した移動パターンを維持できるようにします。広範なシミュレーション結果は、提案された方法が成功率、移動の安定性、および複数の地形への適応性の点でベースラインのアプローチよりも優れていることを示しています。さらに、Unitree G1 ヒューマノイド ロボットへのゼロショット展開により、当社のフレームワークの有効性が検証され、外乱下でも正確な足場の配置と動的安定性を維持しながら、階段、坂道、段差、障害物、屋外の構造化されていない地形での堅牢な歩行と走行が実現されます。
原文 (English)
CoRe-MoE: Contrastive Reweighted Mixture of Experts for Multi-Terrain Humanoid Locomotion with Gait Adaptation
Humans primarily rely on walking and running to traverse complex terrains, without resorting to unnecessarily complex motion patterns. Similarly, humanoid robots should achieve smooth transitions between walking and running while maintaining natural and stable locomotion. However, unifying gait transition and multi-terrain adaptation within a single policy remains challenging due to gradient interference and the distribution shift induced by terrain-dependent visual and dynamic variations. Although Mixture-of-Experts (MoE) architectures can alleviate multi-skill interference, naive joint training often fails to yield clear expert specialization, limiting their effectiveness. To address these challenges, we propose CoRe-MoE, a two-stage reinforcement learning framework that decouples gait generation from terrain adaptation. In the first stage, a stable locomotion policy is learned to produce natural walking and running behaviors with smooth transitions. In the second stage, a terrain-aware MoE branch is introduced and trained with a contrastive objective to shape the gating network, enabling it to capture structured terrain representations and promote expert specialization. The final action is obtained via weighted fusion of the base gait policy and the terrain-aware branch, allowing the policy to preserve stable locomotion patterns while adapting to complex terrains. Extensive simulation results demonstrate that the proposed method outperforms baseline approaches in terms of success rate, locomotion stability, and multi-terrain adaptability. Furthermore, zero-shot deployment on a Unitree G1 humanoid robot validates the effectiveness of our framework, achieving robust walking and running across stairs, slopes, steps, obstacles, and unstructured outdoor terrains, while maintaining accurate foothold placement and dynamic stability under external disturbances.
変圧器ベースの自動運転モデルと展開指向の圧縮: 調査
トランスベースのモデルは、長距離の空間依存関係、マルチエージェントのインタラクション、認識、予測、計画にわたるマルチモーダルなコンテキストをキャプチャできるため、自動運転の中心的なパラダイムになりつつあります。同時に、大容量のアテンションベースのアーキテクチャはかなりの遅延、メモリ、エネルギーのオーバーヘッドを課すため、実際の車両への導入は依然として困難です。この調査では、代表的な Transformer ベースの自動運転モデルをレビューし、それらをタスクの役割、センシング構成、アーキテクチャ設計ごとに整理します。さらに重要なのは、展開指向の観点からこれらのモデルを検証し、効率の制約が実際にモデル設計の選択肢をどのように再形成するかを分析することです。さらに、量子化、枝刈り、知識蒸留、低ランク近似、効率的な注意など、Transformer ベースの駆動システムに関連する圧縮および加速戦略をレビューし、その利点、限界、およびタスク依存の適用可能性について説明します。圧縮を独立した後処理ステップとして扱うのではなく、展開性、堅牢性、安全性に直接影響を与えるシステムレベルの設計上の考慮事項として強調します。最後に、効率的な自動運転システムの標準化された、安全性を意識した、ハードウェアを意識した評価に向けた未解決の課題と将来の研究の方向性を特定します。
原文 (English)
Transformer-Based Autonomous Driving Models and Deployment-Oriented Compression: A Survey
Transformer-based models are becoming a central paradigm in autonomous driving because they can capture long-range spatial dependencies, multi-agent interactions, and multimodal context across perception, prediction, and planning. At the same time, their deployment in real vehicles remains difficult because high-capacity attention-based architectures impose substantial latency, memory, and energy overhead. This survey reviews representative Transformer-based autonomous driving models and organizes them by task role, sensing configuration, and architectural design. More importantly, it examines these models from a deployment-oriented perspective and analyzes how efficiency constraints reshape model design choices in practice. We further review compression and acceleration strategies relevant to Transformer-based driving systems, including quantization, pruning, knowledge distillation, low-rank approximation, and efficient attention, and discuss their benefits, limitations, and task-dependent applicability. Rather than treating compression as an isolated post-processing step, we highlight it as a system-level design consideration that directly affects deployability, robustness, and safety. Finally, we identify open challenges and future research directions toward standardized, safety-aware, and hardware-conscious evaluation of efficient autonomous driving systems.
単純な埋め込みによりアクター-クリティックエージェントのサンプル効率が向上
最近の研究では、大規模な環境の並列化を使用して、アクタークリティカル手法の実時間のトレーニング時間を加速することが提案されています。残念ながら、望ましいレベルのパフォーマンスを達成するには、依然として多数の環境との対話が必要になる場合があります。適切に構造化された表現は、深層強化学習 (RL) エージェントの一般化とサンプル効率を向上させることができることに注目し、単純なエンベディング、つまりエンベディングを単純な構造に制約する軽量の表現層の使用を提案します。この幾何学的な帰納的バイアスにより、批評家のブートストラップを安定させ、政策の勾配を強化するまばらで離散的な特徴が生じます。 FastTD3、FastSAC、および PPO に適用すると、単純なエンベディングは、実行速度を損なうことなく、さまざまな連続および離散制御環境全体でサンプル効率と最終パフォーマンスを一貫して向上させます。
原文 (English)
Simplicial Embeddings Improve Sample Efficiency in Actor-Critic Agents
Recent works have proposed accelerating the wall-clock training time of actor-critic methods via the use of large-scale environment parallelization; unfortunately, these can sometimes still require large number of environment interactions to achieve a desired level of performance. Noting that well-structured representations can improve the generalization and sample efficiency of deep reinforcement learning (RL) agents, we propose the use of simplicial embeddings: lightweight representation layers that constrain embeddings to simplicial structures. This geometric inductive bias results in sparse and discrete features that stabilize critic bootstrapping and strengthen policy gradients. When applied to FastTD3, FastSAC, and PPO, simplicial embeddings consistently improve sample efficiency and final performance across a variety of continuous- and discrete-control environments, without any loss in runtime speed.
ベクトル化されたオンライン POMDP 計画
部分的な可観測性の下で計画を立てることは、自律ロボットの重要な機能です。部分観測可能なマルコフ決定プロセス (POMDP) は、部分観測可能性の問題の下で計画を立てるための強力なフレームワークを提供し、アクションの確率的影響とノイズの多い観測を通じて得られる限られた情報を捕捉します。 POMDP の解法は、今日のハードウェアでの大規模並列化から多大な恩恵を受ける可能性がありますが、POMDP ソルバーの並列化は困難でした。ほとんどのソルバーは、アクションとその値の推定をインターリーブする数値最適化に依存しているため、並列プロセス間に依存関係や同期ボトルネックが生じ、並列化の利点が相殺される可能性があります。この論文では、Vectorized Online POMDP Planner (VOPP) を提案します。これは、最適化コンポーネントの一部を分析的に解決し、期待値の推定のみで構成される数値計算を残す、最新の POMDP 定式化を利用する新しい並列オンライン ソルバーです。 VOPP は、計画に関連するすべてのデータ構造をテンソルのコレクションとして表し、すべての計画ステップをこの表現に対する完全にベクトル化された計算として実装します。その結果、同時プロセス間の依存関係や同期ボトルネックのない大規模並列オンライン ソルバーが実現します。実験結果は、VOPP が既存の最先端の並列オンライン ソルバーと比較して、最適に近い解の計算において少なくとも 20 倍効率的であることを示しています。さらに、VOPP は最先端の逐次オンライン ソルバーよりも優れたパフォーマンスを発揮し、計画予算を 1000 倍も削減します。
原文 (English)
Vectorized Online POMDP Planning
Planning under partial observability is an essential capability of autonomous robots. The Partially Observable Markov Decision Process (POMDP) provides a powerful framework for planning under partial observability problems, capturing the stochastic effects of actions and the limited information available through noisy observations. POMDP solving could benefit tremendously from massive parallelization on today's hardware, but parallelizing POMDP solvers has been challenging. Most solvers rely on interleaving numerical optimization over actions with the estimation of their values, which creates dependencies and synchronization bottlenecks between parallel processes that can offset the benefits of parallelization. In this paper, we propose Vectorized Online POMDP Planner (VOPP), a novel parallel online solver that leverages a recent POMDP formulation which analytically solves part of the optimization component, leaving numerical computations to consist of only estimation of expectations. VOPP represents all data structures related to planning as a collection of tensors, and implements all planning steps as fully vectorized computations over this representation. The result is a massively parallel online solver with no dependencies or synchronization bottlenecks between concurrent processes. Experimental results indicate that VOPP is at least $20\times$ more efficient in computing near-optimal solutions compared to an existing state-of-the-art parallel online solver. Moreover, VOPP outperforms state-of-the-art sequential online solvers, while using a planning budget that is $1000\times$ smaller.
DVGT: ビジュアル ジオメトリ トランスフォーマーの駆動
自動運転には、視覚入力から 3D シーンのジオメトリを認識して再構築することが重要です。ただし、さまざまなシナリオやカメラ構成に適応できる、運転をターゲットとした高密度ジオメトリ認識モデルがまだ不足しています。このギャップを埋めるために、私たちはドライビング ビジュアル ジオメトリ トランスフォーマー (DVGT) を提案します。これは、一連のポーズ化されていないマルチビュー ビジュアル入力からグローバルな高密度 3D ポイント マップを再構築します。まず、DINO バックボーンを使用して各画像の視覚的特徴を抽出し、ビュー内の局所的注意、ビュー間の空間的注意、およびフレーム間の時間的注意を交互に使用して、画像全体の幾何学的関係を推測します。次に、複数のヘッドを使用して、最初のフレームのエゴ座標のグローバル ポイント マップと各フレームのエゴ ポーズをデコードします。正確なカメラ パラメーターに依存する従来の方法とは異なり、DVGT には明示的な 3D 幾何学的な事前条件がなく、任意のカメラ構成の柔軟な処理が可能です。 DVGT は、画像シーケンスからメートルスケールのジオメトリを直接予測し、外部センサーによる事後位置合わせの必要性を排除します。 DVGT は、nuScenes、OpenScene、Waymo、KITTI、DDAD などの運転データセットを大規模に組み合わせてトレーニングされたため、さまざまなシナリオで既存のモデルを大幅に上回ります。コードは https://github.com/wzzheng/DVGT で入手できます。
原文 (English)
DVGT: Driving Visual Geometry Transformer
Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
リーダーとフォロワーの相互作用における小規模言語モデルのゼロショットおよびワンショット適応の評価
リーダーとフォロワーの相互作用は、人間とロボットの相互作用 (HRI) における重要なパラダイムです。しかし、リソースに制約のある移動ロボットや支援ロボットにとって、リアルタイムでの役割の割り当ては依然として困難です。大規模言語モデル (LLM) は自然なコミュニケーションに有望であることが示されていますが、そのサイズと遅延によりデバイス上の展開が制限されます。小規模言語モデル (SLM) は潜在的な代替手段を提供しますが、HRI における役割分類に対する SLM の有効性は体系的に評価されていません。この論文では、リーダーとフォロワーのコミュニケーションのための SLM のベンチマークを紹介し、公開されたデータベースから派生し、相互作用固有のダイナミクスを捕捉するために合成サンプルで強化された新しいデータセットを紹介します。私たちは、ゼロショットおよびワンショット相互作用モードで研究されたプロンプトエンジニアリングと微調整という 2 つの適応戦略を、トレーニングされていないベースラインと比較して調査します。 Qwen2.5-0.5B を使用した実験では、ゼロショット微調整が低遅延 (サンプルあたり 22.2 ミリ秒) を維持しながら堅牢な分類パフォーマンス (精度 86.66%) を達成し、ベースラインおよびプロンプト エンジニアリングのアプローチを大幅に上回るパフォーマンスを示していることが明らかになりました。ただし、結果はワンショット モードでのパフォーマンスの低下も示しており、コンテキストの長さが増加するとモデルのアーキテクチャ上の能力に課題が生じます。これらの調査結果は、微調整された SLM が役割の直接割り当てに効果的なソリューションを提供することを実証するとともに、エッジでの対話の複雑さと分類の信頼性の間の重要なトレードオフを強調しています。
原文 (English)
Evaluating Zero-Shot and One-Shot Adaptation of Small Language Models in Leader-Follower Interaction
Leader-follower interaction is an important paradigm in human-robot interaction (HRI). Yet, assigning roles in real time remains challenging for resource-constrained mobile and assistive robots. While large language models (LLMs) have shown promise for natural communication, their size and latency limit on-device deployment. Small language models (SLMs) offer a potential alternative, but their effectiveness for role classification in HRI has not been systematically evaluated. In this paper, we present a benchmark of SLMs for leader-follower communication, introducing a novel dataset derived from a published database and augmented with synthetic samples to capture interaction-specific dynamics. We investigate two adaptation strategies: prompt engineering and fine-tuning, studied under zero-shot and one-shot interaction modes, compared with an untrained baseline. Experiments with Qwen2.5-0.5B reveal that zero-shot fine-tuning achieves robust classification performance (86.66% accuracy) while maintaining low latency (22.2 ms per sample), significantly outperforming baseline and prompt-engineered approaches. However, results also indicate a performance degradation in one-shot modes, where increased context length challenges the model's architectural capacity. These findings demonstrate that fine-tuned SLMs provide an effective solution for direct role assignment, while highlighting critical trade-offs between dialogue complexity and classification reliability on the edge.
ZeroWBC: 人間の自己中心的なデータから自然な全身ヒューマノイドのインタラクションを学習する
全身遠隔操作データのコストが高いため、多用途で自然な全身ヒューマノイドのインタラクション制御を実現することは依然として困難です。我々は、同期した全身動作とテキスト注釈と組み合わせた、人間の自己中心的なビデオから人型の全身インタラクションを学習する、遠隔操作不要のフレームワークである ZeroWBC を紹介します。 ZeroWBC は、静的シーンの全身インタラクション制御問題に取り組むために、生成後追跡の定式化を採用しています。初期の自己中心的な画像と言語命令が与えられると、微調整された視覚言語モデルによって将来の人間の全身運動トークンが生成され、これが連続運動にデコードされ、ヒューマノイドに再ターゲットされます。結果として得られる参照モーションは、ルートおよび主要な身体部分の軌道とともに、一般的なインタラクティブ モーション トラッキング ポリシーによって実行されます。インタラクションのパフォーマンスを向上させるために、自然な全身の動きを維持しながら、グローバル ルートと主要な身体部分の軌道の調整を優先するインタラクション指向の追跡報酬を導入します。 Unitree G1 ヒューマノイド ロボットの実験では、ZeroWBC がロボットの遠隔操作のデモンストレーションを行わずに、シーンを認識した多様な動作を可能にすることを示しています。これらの結果は、人間の自己中心的なデータから自然なヒューマノイドの全身インタラクションを学習するためのスケーラブルなパラダイムを示唆しています。
原文 (English)
ZeroWBC: Learning Natural Whole-Body Humanoid Interaction from Human Egocentric Data
Achieving versatile and natural whole-body humanoid interaction control remains challenging due to the high cost of whole-body teleoperation data. We present ZeroWBC, a teleoperation-free framework that learns humanoid whole-body interaction from human egocentric videos paired with synchronized whole-body motion and text annotations. ZeroWBC adopts a generation-then-tracking formulation to tackle the static scene whole-body interaction control problem. Given an initial egocentric image and a language instruction, a fine-tuned Vision-Language Model generates future human whole-body motion tokens, which are decoded into continuous motions and retargeted to the humanoid. The resulting reference motions, together with root and key body-part trajectories, are then executed by a general interactive motion tracking policy. To improve interaction performance, we introduce an interaction-oriented tracking reward that prioritizes global root and key body-part trajectory alignment while preserving natural whole-body motion. Experiments on the Unitree G1 humanoid robot show that ZeroWBC enables diverse scene-aware behaviors without robot teleoperation demonstrations. These results suggest a scalable paradigm for learning natural humanoid whole-body interaction from human egocentric data.
ContactExplorer: Contact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Reinforcement learning has achieved remarkable success in domains such as Atari games, navigation, and locomotion, where exploration can of…
Contextual Multi-Task Reinforcement Learning for Autonomous Reef Monitoring
Although autonomous underwater vehicles promise the capability of marine ecosystem monitoring, their deployment is fundamentally limited by…
DEFLECT: Temporal Counterfactual Preference Learning for Delay-Robust Asynchronous VLAs
Vision-Language-Action (VLA) policies increasingly rely on asynchronous inference to hide large-model latency behind ongoing robot motion.…
Lost in Fog: Sensor Perturbations Expose Reasoning Fragility in Driving VLAs
Interpretable autonomous driving planners depend not only on generating explanations, but also on those explanations remaining reliable und…
Too Much of a Good Thing: When sim2real Efforts Impede Policy Learning (And What to Do About It)
While sim2real efforts are necessary for effective policy transfer to hardware, there is such a thing as too much of a good thing. We argue…
PHASER: Phase-Aware and Semantic Experience Replay for Vision-Language-Action Models
Vision-Language-Action (VLA) models have achieved remarkable success in language-conditioned robotic manipulation. However, deploying these…

Is Silicon Valley ready to put robots in people’s homes? Hello Robot is.
The California startup released the fourth-generation of its home assistance robot, Stretch.
DiffAero: 効率的なクアドローター ポリシー学習のための GPU アクセラレーションによる微分可能シミュレーション フレームワーク
このレターでは、効率的なクワッドローター制御ポリシー学習のために設計された、軽量で GPU アクセラレーションを備えた完全微分可能なシミュレーション フレームワークである DiffAero を紹介します。 DiffAero は、環境レベルとエージェント レベルの両方の並列処理をサポートし、複数のダイナミクス モデル、カスタマイズ可能なセンサー スタック (IMU、深度カメラ、LiDAR)、および多様な飛行タスクを統合された GPU ネイティブのトレーニング インターフェイス内に統合します。 DiffAero は、GPU 上で物理とレンダリングの両方を完全に並列化することで、CPU と GPU 間のデータ転送のボトルネックを排除し、シミュレーションのスループットを桁違いに向上させます。既存のシミュレータとは対照的に、DiffAero は高性能シミュレーションを提供するだけでなく、微分可能なハイブリッド学習アルゴリズムを探索するための研究プラットフォームとしても機能します。広範なベンチマークと実際の飛行実験により、DiffAero とハイブリッド学習アルゴリズムを組み合わせることで、消費者グレードのハードウェアで堅牢な飛行ポリシーを数時間で学習できることが実証されました。コードは https://github.com/flyingbitac/diffaero で入手できます。
原文 (English)
DiffAero: A GPU-Accelerated Differentiable Simulation Framework for Efficient Quadrotor Policy Learning
This letter introduces DiffAero, a lightweight, GPU-accelerated, and fully differentiable simulation framework designed for efficient quadrotor control policy learning. DiffAero supports both environment-level and agent-level parallelism and integrates multiple dynamics models, customizable sensor stacks (IMU, depth camera, and LiDAR), and diverse flight tasks within a unified, GPU-native training interface. By fully parallelizing both physics and rendering on the GPU, DiffAero eliminates CPU-GPU data transfer bottlenecks and delivers orders-of-magnitude improvements in simulation throughput. In contrast to existing simulators, DiffAero not only provides high-performance simulation but also serves as a research platform for exploring differentiable and hybrid learning algorithms. Extensive benchmarks and real-world flight experiments demonstrate that DiffAero and hybrid learning algorithms combined can learn robust flight policies in hours on consumer-grade hardware. The code is available at https://github.com/flyingbitac/diffaero.
現場に飛び込む: フォーカス プランの生成を通じて、視覚と言語の意思決定における知覚のボトルネックを打破する
ロボット操作やナビゲーションなどの身体化された視覚言語による意思決定タスクでは、視覚言語モデルおよび視覚言語アクション モデル (VLM および VLA) は、さまざまな利点を持つ強力なツールです。VLM は長期計画に優れ、VLA は事後制御に優れています。ただし、モデルのパフォーマンスは、同じ知覚のボトルネックによって制限されます。モデルがタスクに関連するオブジェクトと気を散らすものとを区別できないために幻覚が発生します。原則として、無関係なものを除外しながら、正確に識別して重要なオブジェクトに焦点を当てることが、この制限を打ち破る鍵となります。簡単な解決策は、重要なオブジェクトに直接注目するというワンステップの焦点です。ただし、効果的に焦点を合わせるには本質的にシーンを深く理解する必要があるため、このアプローチは効果的ではないことがわかります。この目的を達成するために、我々は、VLM の長期計画能力を活用した、粗いから細かいまでのフォーカス プラン生成方法である SceneDiver を提案します。この方法では、最初に全体的なシーン グラフを構築して初期理解を確立し、次に認識、理解、分析の反復サイクルを通じてタスクをより単純なサブ問題に徐々に分解します。反応的な制御を可能にするために、意図的なフォーカス機能を VLA に抽出するための軽量アダプターも設計しました。標準の組み込み AI ベンチマークでの評価により、私たちの方法は、高速実行を必要とするタスクの計算効率を維持しながら、VLM と VLA の両方で幻視を大幅に軽減することが確認されています。コードとデータは https://future-item.github.io/SceneDiver でリリースされています。
原文 (English)
Dive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation
In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at long-term planning, while VLAs are better at reactive control. However, their performance is limited by the same perceptual bottleneck: visual hallucinations arise due to the models' inability to distinguish task-relevant objects from distractors. In principle, accurate identification and focus on critical objects while filtering out irrelevant ones is the key to break this limitation. A straightforward solution is one-step focus: directly attending to essential objects. However, this approach proves ineffective because effective focus inherently requires deep scene understanding. To this end, we propose SceneDiver, a coarse-to-fine focus plan generation method for VLMs leveraging their long-term planning abilities, that first constructs a holistic scene graph to establish initial comprehension, then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis. To enable reactive control, we also design a lightweight adapter for distilling the deliberate focus ability into VLAs. Evaluations on standard embodied AI benchmarks confirm that our method substantially reduces visual hallucinations for both VLMs and VLAs, while preserving computational efficiency in tasks requiring fast execution. Our code and data are released at: https://future-item.github.io/SceneDiver.
AgenticDiffusion: ビジョンベースの UAV ナビゲーションのための Agentic Diffusion ベースの経路計画
屋内 UAV ナビゲーションには、限られた視野の観察下での効率的な探索、シーンの理解、信頼性の高い軌道の実行が必要です。既存のビジョンベースのナビゲーション フレームワークは通常、単一ビューの観察に依存しており、オクルージョン、ターゲットの可視性、およびグローバル シーン構造について推論する能力が制限されています。この研究では、統合された航空ナビゲーション パイプライン内で、言語に基づく推論、オープン語彙によるターゲットのグラウンディング、視覚ベースの拡散計画、および NMPC を調整するマルチビュー UAV ナビゲーション フレームワークである AgenticDiffusion を提案します。自然言語による指示と、同期した一人称視点 (FPV) および上面視点の観察を考慮して、フレームワークはナビゲーションに最も有益な視点を決定し、軌道の実行前にミッション計画を生成します。ターゲットは、オープンボキャブラリーグラウンディングモデルを使用して位置特定され、その後、視点固有の拡散プランナーが UAV 実行のためのナビゲーション軌道を生成します。提案されたフレームワークは、補完的な視点を使用して、繰り返しのターゲット探査を削減し、雑然とした屋内環境でのナビゲーション効率を向上させます。このフレームワークは、適応視点選択、多段階ミッション実行、長距離ナビゲーション、安全な着陸地点選択を含む 4 つの現実世界の UAV ナビゲーション シナリオで検証されました。実験結果では、40 回の実世界試験でミッション全体の成功率が 80% であることが実証され、一方、拡散計画者は軌道生成の成功率が 100% に達しました。
原文 (English)
AgenticDiffusion: Agentic Diffusion-based Path Planning for Vision-Based UAV Navigation
Indoor UAV navigation requires efficient exploration, scene understanding, and reliable trajectory execution under limited field-of-view observations. Existing vision-based navigation frameworks typically rely on single-view observations, limiting their ability to reason about occlusions, target visibility, and global scene structure. In this work, we propose AgenticDiffusion, a multi-view UAV navigation framework that coordinates language-guided reasoning, open-vocabulary target grounding, vision-based diffusion planning, and NMPC within a unified aerial navigation pipeline. Given a natural language instruction and synchronized first-person-view (FPV) and top-view observations, the framework determines the most informative viewpoint for navigation and generates a mission plan prior to trajectory execution. The targets are localized using an open-vocabulary grounding model, after which viewpoint-specific diffusion planners generate navigation trajectories for UAV execution. Using complementary viewpoints, the proposed framework reduces repeated target exploration and improves navigation efficiency in cluttered indoor environments. The framework was validated in four real-world UAV navigation scenarios involving adaptive viewpoint selection, multi-stage mission execution, long-horizon navigation, and safe landing-site selection. The experimental results demonstrated an overall mission success rate of 80% in 40 real-world trials, while the diffusion planners achieved a trajectory generation success rate of 100%.
大規模言語モデルによる適応軌道最適化のためのセマンティック制約合成
軌道の最適化は、宇宙探査において安全で信頼性の高い自律運用を可能にするための重要なコンポーネントです。宇宙ミッションの頻度、複雑さ、範囲が増加するにつれて、ミッションの目的と運用上の制約を正確に反映する、数学的に適切な軌道最適化問題を迅速に定式化する必要性が高まっています。ただし、ミッションの意図を軌道最適化のための扱いやすい分析公式に変換するには、かなりの専門知識が必要です。この論文では、大規模言語モデル (LLM) を活用して、ミッションの要件と制約の自然言語記述を実行可能な軌道最適化コードと対応する数学的定式化に変換するフレームワークを紹介します。宇宙船ランデブーシナリオでの実験では、意味論的なミッション要件から凸軌道最適化問題を再調整する際の高い成功率が実証されています。最終的に、この研究は、高レベルの意図と形式的な最適化モデルを橋渡しする LLM の可能性を強調し、宇宙船のより柔軟で効率的な軌道設計を可能にします。
原文 (English)
Semantic Constraint Synthesis for Adaptive Trajectory Optimization via Large Language Models
Trajectory optimization is a critical component for enabling safe and reliable autonomous operations in space exploration. As space missions increase in frequency, complexity, and scope, there is a growing need to rapidly formulate mathematically sound trajectory optimization problems that accurately reflect mission objectives and operational constraints. However, translating mission intent into tractable analytical formulations for trajectory optimization requires substantial domain expertise. This paper presents a framework that leverages large language models (LLMs) to translate natural language descriptions of mission requirements and constraints into executable trajectory optimization code and corresponding mathematical formulations. Experiments in spacecraft rendezvous scenarios demonstrate a high success rate in reconditioning a convex trajectory optimization problem from semantic mission requirements. Ultimately, this work highlights the potential of LLMs to bridge high-level intent and formal optimization models, enabling more flexible and efficient trajectory design of spacecraft.
2つのアドバンテージフィールド
オフラインの目標条件付き強化学習では、長期的な到達可能性の推定とローカル アクションの比較の両方が必要です。デュアル目標表現は、グローバルな目標の到達可能性を取得する値フィールドを提供しますが、特定の状態でどのアクションが優先されるべきかを直接指定するものではありません。我々は、双線形二重値モデルをローカルアドバンテージ信号に変えるポリシー抽出手法であるデュアルアドバンテージフィールドを提案します。双線形双対パラメータ化では、目標の埋め込みは状態表現に対する値フィールドの勾配です。 DAF は、アクションによって引き起こされる割り引かれたフィーチャの変位を予測し、この変位と目標の方向との整合性によってアクションをスコア化するアクション効果モデルを学習します。実現可能なケースでは、このスコアは目標条件付きベルマンアドバンテージに等しく、標準的なローカル政策改善保証が得られます。 OGBench の移動、操作、パズルのタスクでは、DAF は集計 RLiable メトリクスを改善し、局所的に正しいアクションが最終目標に向かう直接的な動きとは異なる設定で強力にパフォーマンスを発揮します。
原文 (English)
Dual Advantage Fields
Offline goal-conditioned reinforcement learning requires both long-horizon reachability estimates and local action comparisons. Dual goal representations provide value fields that capture global goal reachability, but they do not directly specify which action should be preferred at a given state. We propose Dual Advantage Fields, a policy-extraction method that turns a bilinear dual value model into a local advantage signal. Under bilinear dual parameterization, the goal embedding is the gradient of the value field with respect to the state representation. DAF learns an action-effect model that predicts the discounted feature displacement induced by an action and scores actions by the alignment between this displacement and the goal direction. In the realizable case, this score equals the goal-conditioned Bellman advantage, yielding a standard local policy-improvement guarantee. On OGBench locomotion, manipulation, and puzzle tasks, DAF improves aggregate RLiable metrics and performs strongly in settings where locally correct actions differ from direct movement toward the final goal.
PerceptTwin: 反復 LLM 計画と検証のためのセマンティック シーンの再構築
シミュレーション環境は、ロボット ポリシーの学習と計画の検証と検証の両方に役立ちます。従来、シミュレーションを作成するプロセスは面倒なものでした。ロボットが動作する個々の環境に合わせてオーダーメイドのシミュレーション環境を作成することは、まったく不可能でした。この研究では、ロボットの認識スタックによって生成されたセマンティック シーン表現から直接インタラクティブ シミュレーションを構築する完全自動パイプラインである PerceptTwin を紹介します。 PerceptTwin は、オープン語彙オブジェクト マップと 3D アセット生成、アフォーダンス予測、および常識的な条件チェックを組み合わせます。これらのインタラクティブなシミュレーションを使用すると、ロボット ハードウェアで実行される前に計画を検証し、改良することができます。 AI 調整の文献から借用して、計画の正確さと人間の好みとの調整を検証する LLM ジャッジも紹介します。実験では、PerceptTwin のフィードバックにより、LLM プランナーが計画を改良し、安全性を強化し、有害なブラックボックス プロンプト攻撃に抵抗できることが示されています。私たちの一連のタスクでは、PerceptTwin により、GPT5、GPT5Mini、および GPT5Nano プランナーの計画の成功率が平均約 39% 向上しました。さらに、PerceptTwin は、スキルの前提条件が満たされていないために失敗した計画について、人間による計画の検証を平均で最大 18% 改善します。私たちの結果は、より安全で信頼性の高いロボット計画の基盤として、ロボットの知覚からのオープンボキャブラリーシーンシミュレーションの可能性を実証しています。
原文 (English)
PerceptTwin: Semantic Scene Reconstruction for Iterative LLM Planning and Verification
Simulation environments are useful for both robot policy learning and planning verification and validation. Traditionally, the process of creating a simulation was onerous. Creating a bespoke simulation environment for each individual environment that a robot would operate in was simply infeasible. In this work, we introduce PerceptTwin, a fully automatic pipeline that constructs interactive simulations directly from semantic scene representations produced by a robot's perception stack. PerceptTwin combines open-vocabulary object maps with 3D asset generation, affordance prediction, and commonsense condition checking. These interactive simulations can be used to validate and refine plans before they are executed on the robot hardware. Borrowing from the AI alignment literature, we also introduce an LLM judge that verifies plan correctness and alignment with human preferences. Experiments show that PerceptTwin feedback allows LLM planners to refine plans, enhance safety, and resist harmful black-box prompting attacks. In our suite of tasks, PerceptTwin improves plan success by an average of approximately 39% for GPT5, GPT5Mini, and GPT5Nano planners. Additionally, PerceptTwin also improves human plan verification by up to 18% on average for plans that fail due to unfilled skill preconditions. Our results demonstrate the potential of open-vocabulary scene simulation from robot perception as a foundation for safer, more reliable robot planning.
インスタントフォールド: 変形可能なオブジェクト操作のためのコンテキスト内模倣学習
変形可能オブジェクト操作 (DOM) は、複数の有効な操作モードとの長期にわたるトポロジー変化の相互作用を通じて進化する、部分的に観察可能な高次元の状態のため、困難を伴います。 DOM のコンテキスト内模倣学習フレームワークである Instant-Fold を紹介します。単一の人間によるデモンストレーションが与えられると、私たちのポリシーは、勾配の更新を必要とせずに、空間的な実行や順序付けのバリエーションを含む、さまざまな操作モードをデモンストレーションから直接推論して実行します。私たちのアプローチでは、まず時間対比事前トレーニングによって変形を意識した視覚表現を学習し、その後、デモンストレーションを条件としたフローマッチングトランスフォーマーポリシーによって、意図した操作モードを実行するためのアクションを予測します。完全にシミュレーションでトレーニングされた Instant-Fold は、さまざまな折り畳みモードを一般化し、追加のデータ収集や微調整を行わずにゼロショットを現実世界の設定に移行します。ビデオは https://instant-fold.github.io でご覧いただけます。
原文 (English)
Instant-Fold: In-Context Imitation Learning for Deformable Object Manipulation
Deformable object manipulation (DOM) is challenging due to high-dimensional, partially observable states that evolve through long-horizon, topology-changing interactions with multiple valid manipulation modes. We introduce Instant-Fold, an in-context imitation learning framework for DOM. Given a single human demonstration, our policy infers and executes diverse manipulation modes directly from the demonstration, including variations in spatial execution and ordering, without requiring gradient updates. Our approach first learns deformation-aware visual representations via temporal contrastive pretraining, after which a flow-matching transformer policy conditioned on the demonstration predicts actions to execute the intended manipulation mode. Trained entirely in simulation, Instant-Fold generalizes across diverse folding modes and transfers zero-shot to real-world settings without additional data collection or finetuning. Videos are available at https://instant-fold.github.io.
VISTA: 視覚に基づいた、物理学に基づいて検証された UMI データの VLA トレーニングへの適応
Universal Manipulation Interface (UMI) により、ハードウェア固有の遠隔操作を必要とせずにスケーラブルな現実世界のロボット データ収集が可能になりますが、UMI データを活用して大規模な Vision-Language-Action (VLA) モデルをトレーニングすることは依然として根本的に困難です。我々は 2 つの重大な不一致を特定しました。1 つは、深刻な放射状の歪みとローカルのグリッパー中心の視点を伴う手首に取り付けられた魚眼ビューであり、事前トレーニングされた VLM には配布されていません。また、人間が収集した軌道は、頻繁に運動学的制限に違反したり、衝突が発生したり、コントローラーの帯域幅を超えたりするため、VLA ポリシーに物理的に実行不可能なアクションが教示されます。この課題に対処するために、3 つの相乗効果のあるコンポーネントを通じてこの二重のギャップを埋めるフレームワークである VISTA を紹介します。 (i) ~UMI-VQA は、手首に装着した魚眼観察に合わせて調整された初の大規模 VQA データセットであり、補助的な視覚言語監視を通じて VLM 表現を歪んだ視覚領域に合わせます。 (ii)~体系的な物理検証パイプラインは、データ完全性の事前チェックを実行し、トレーニングに入る前に、軌道の連続性、自己衝突のリスク、および実行の忠実度について各有効な軌道にスコアを付けます。 (iii)~2 段階の共同トレーニング レシピは、UMI-VQA に基づいた視覚言語の基礎と、検証された軌道に基づいた行動予測を共同で学習します。私たちの実験では、UMI-VQA を組み込むと下流のポリシーのパフォーマンスが一貫して向上し、物理検証スコアが展開の成功を強力に予測できることが経験的に示されています。さまざまなシミュレーションや現実世界の操作タスクにおいて、VISTA は $\pi_{0.5}$、LingBot-VLA、Wall-X などの強力なベースラインを大幅に上回ります。物理検証パイプライン、UMI-VQA、検証された軌跡データ、および事前トレーニングされたモデルをコミュニティにリリースします。
原文 (English)
VISTA: Vision-Grounded and Physics-Validated Adaptation of UMI data for VLA Training
Universal Manipulation Interface (UMI) enables scalable real-world robot data collection without hardware-specific teleoperation, yet leveraging UMI data to train large-scale Vision-Language-Action (VLA) models remains fundamentally challenging. We identify two critical mismatches: wrist-mounted fisheye views, with severe radial distortion and local gripper-centric perspectives, are out-of-distribution for pretrained VLMs; and human-collected trajectories frequently violate kinematic limits, incur collisions, or exceed controller bandwidth, teaching VLA policies physically infeasible actions. To address the challenges, we present VISTA, a framework that bridges this dual gap through three synergistic components. (i)~UMI-VQA, the first large-scale VQA dataset tailored to wrist-mounted fisheye observations, aligns VLM representations to the distorted visual regime via auxiliary vision-language supervision. (ii)~A systematic physical-validation pipeline performs a data-completeness pre-check and scores each valid trajectory for trajectory continuity, self-collision risk, and execution fidelity before it enters training. (iii)~A two-stage co-training recipe jointly learns vision-language grounding on UMI-VQA and action prediction on validated trajectories. Our experiments empirically show that incorporating UMI-VQA consistently improves downstream policy performance, and that physical-validation scores are strongly predictive of deployment success. On diverse simulation and real-world manipulation tasks, VISTA significantly outperforms strong baselines including $\pi_{0.5}$, LingBot-VLA, and Wall-X. We release the physical-validation pipeline, UMI-VQA, validated trajectory data, and the pre-trained model for the community.
CoRe-MoE: 歩行適応を備えた複数地形ヒューマノイド移動のための専門家の対照的な再重み付け混合
人間は主に、不必要に複雑な動作パターンに頼ることなく、複雑な地形を横断するために歩いたり走ったりすることに頼っています。同様に、人型ロボットは、自然で安定した移動を維持しながら、歩行と走行の間のスムーズな移行を達成する必要があります。ただし、単一のポリシー内で歩行遷移と複数の地形への適応を統合することは、勾配の干渉と、地形に依存する視覚的および動的変化によって引き起こされる分布のシフトのため、依然として困難です。専門家混合 (MoE) アーキテクチャは複数のスキルの干渉を軽減できますが、単純な共同トレーニングでは明確な専門知識が得られないことが多く、効果が制限されます。これらの課題に対処するために、私たちは地形適応から歩行生成を切り離す 2 段階の強化学習フレームワークである CoRe-MoE を提案します。第 1 段階では、スムーズな移行で自然な歩行と走行の動作を生成するための安定した移動ポリシーが学習されます。第 2 段階では、地形認識 MoE ブランチが導入され、ゲーティング ネットワークを形成するという対照的な目的でトレーニングされ、構造化された地形表現をキャプチャして専門家の専門化を促進できるようになります。最終的なアクションは、基本歩行ポリシーと地形認識ブランチの重み付けされた融合によって取得され、ポリシーが複雑な地形に適応しながら安定した移動パターンを維持できるようにします。広範なシミュレーション結果は、提案された方法が成功率、移動の安定性、および複数の地形への適応性の点でベースラインのアプローチよりも優れていることを示しています。さらに、Unitree G1 ヒューマノイド ロボットへのゼロショット展開により、当社のフレームワークの有効性が検証され、外乱下でも正確な足場の配置と動的安定性を維持しながら、階段、坂道、段差、障害物、屋外の構造化されていない地形での堅牢な歩行と走行が実現されます。
原文 (English)
CoRe-MoE: Contrastive Reweighted Mixture of Experts for Multi-Terrain Humanoid Locomotion with Gait Adaptation
Humans primarily rely on walking and running to traverse complex terrains, without resorting to unnecessarily complex motion patterns. Similarly, humanoid robots should achieve smooth transitions between walking and running while maintaining natural and stable locomotion. However, unifying gait transition and multi-terrain adaptation within a single policy remains challenging due to gradient interference and the distribution shift induced by terrain-dependent visual and dynamic variations. Although Mixture-of-Experts (MoE) architectures can alleviate multi-skill interference, naive joint training often fails to yield clear expert specialization, limiting their effectiveness. To address these challenges, we propose CoRe-MoE, a two-stage reinforcement learning framework that decouples gait generation from terrain adaptation. In the first stage, a stable locomotion policy is learned to produce natural walking and running behaviors with smooth transitions. In the second stage, a terrain-aware MoE branch is introduced and trained with a contrastive objective to shape the gating network, enabling it to capture structured terrain representations and promote expert specialization. The final action is obtained via weighted fusion of the base gait policy and the terrain-aware branch, allowing the policy to preserve stable locomotion patterns while adapting to complex terrains. Extensive simulation results demonstrate that the proposed method outperforms baseline approaches in terms of success rate, locomotion stability, and multi-terrain adaptability. Furthermore, zero-shot deployment on a Unitree G1 humanoid robot validates the effectiveness of our framework, achieving robust walking and running across stairs, slopes, steps, obstacles, and unstructured outdoor terrains, while maintaining accurate foothold placement and dynamic stability under external disturbances.
変圧器ベースの自動運転モデルと展開指向の圧縮: 調査
トランスベースのモデルは、長距離の空間依存関係、マルチエージェントのインタラクション、認識、予測、計画にわたるマルチモーダルなコンテキストをキャプチャできるため、自動運転の中心的なパラダイムになりつつあります。同時に、大容量のアテンションベースのアーキテクチャはかなりの遅延、メモリ、エネルギーのオーバーヘッドを課すため、実際の車両への導入は依然として困難です。この調査では、代表的な Transformer ベースの自動運転モデルをレビューし、それらをタスクの役割、センシング構成、アーキテクチャ設計ごとに整理します。さらに重要なのは、展開指向の観点からこれらのモデルを検証し、効率の制約が実際にモデル設計の選択肢をどのように再形成するかを分析することです。さらに、量子化、枝刈り、知識蒸留、低ランク近似、効率的な注意など、Transformer ベースの駆動システムに関連する圧縮および加速戦略をレビューし、その利点、限界、およびタスク依存の適用可能性について説明します。圧縮を独立した後処理ステップとして扱うのではなく、展開性、堅牢性、安全性に直接影響を与えるシステムレベルの設計上の考慮事項として強調します。最後に、効率的な自動運転システムの標準化された、安全性を意識した、ハードウェアを意識した評価に向けた未解決の課題と将来の研究の方向性を特定します。
原文 (English)
Transformer-Based Autonomous Driving Models and Deployment-Oriented Compression: A Survey
Transformer-based models are becoming a central paradigm in autonomous driving because they can capture long-range spatial dependencies, multi-agent interactions, and multimodal context across perception, prediction, and planning. At the same time, their deployment in real vehicles remains difficult because high-capacity attention-based architectures impose substantial latency, memory, and energy overhead. This survey reviews representative Transformer-based autonomous driving models and organizes them by task role, sensing configuration, and architectural design. More importantly, it examines these models from a deployment-oriented perspective and analyzes how efficiency constraints reshape model design choices in practice. We further review compression and acceleration strategies relevant to Transformer-based driving systems, including quantization, pruning, knowledge distillation, low-rank approximation, and efficient attention, and discuss their benefits, limitations, and task-dependent applicability. Rather than treating compression as an isolated post-processing step, we highlight it as a system-level design consideration that directly affects deployability, robustness, and safety. Finally, we identify open challenges and future research directions toward standardized, safety-aware, and hardware-conscious evaluation of efficient autonomous driving systems.
単純な埋め込みによりアクター-クリティックエージェントのサンプル効率が向上
最近の研究では、大規模な環境の並列化を使用して、アクタークリティカル手法の実時間のトレーニング時間を加速することが提案されています。残念ながら、望ましいレベルのパフォーマンスを達成するには、依然として多数の環境との対話が必要になる場合があります。適切に構造化された表現は、深層強化学習 (RL) エージェントの一般化とサンプル効率を向上させることができることに注目し、単純なエンベディング、つまりエンベディングを単純な構造に制約する軽量の表現層の使用を提案します。この幾何学的な帰納的バイアスにより、批評家のブートストラップを安定させ、政策の勾配を強化するまばらで離散的な特徴が生じます。 FastTD3、FastSAC、および PPO に適用すると、単純なエンベディングは、実行速度を損なうことなく、さまざまな連続および離散制御環境全体でサンプル効率と最終パフォーマンスを一貫して向上させます。
原文 (English)
Simplicial Embeddings Improve Sample Efficiency in Actor-Critic Agents
Recent works have proposed accelerating the wall-clock training time of actor-critic methods via the use of large-scale environment parallelization; unfortunately, these can sometimes still require large number of environment interactions to achieve a desired level of performance. Noting that well-structured representations can improve the generalization and sample efficiency of deep reinforcement learning (RL) agents, we propose the use of simplicial embeddings: lightweight representation layers that constrain embeddings to simplicial structures. This geometric inductive bias results in sparse and discrete features that stabilize critic bootstrapping and strengthen policy gradients. When applied to FastTD3, FastSAC, and PPO, simplicial embeddings consistently improve sample efficiency and final performance across a variety of continuous- and discrete-control environments, without any loss in runtime speed.
ベクトル化されたオンライン POMDP 計画
部分的な可観測性の下で計画を立てることは、自律ロボットの重要な機能です。部分観測可能なマルコフ決定プロセス (POMDP) は、部分観測可能性の問題の下で計画を立てるための強力なフレームワークを提供し、アクションの確率的影響とノイズの多い観測を通じて得られる限られた情報を捕捉します。 POMDP の解法は、今日のハードウェアでの大規模並列化から多大な恩恵を受ける可能性がありますが、POMDP ソルバーの並列化は困難でした。ほとんどのソルバーは、アクションとその値の推定をインターリーブする数値最適化に依存しているため、並列プロセス間に依存関係や同期ボトルネックが生じ、並列化の利点が相殺される可能性があります。この論文では、Vectorized Online POMDP Planner (VOPP) を提案します。これは、最適化コンポーネントの一部を分析的に解決し、期待値の推定のみで構成される数値計算を残す、最新の POMDP 定式化を利用する新しい並列オンライン ソルバーです。 VOPP は、計画に関連するすべてのデータ構造をテンソルのコレクションとして表し、すべての計画ステップをこの表現に対する完全にベクトル化された計算として実装します。その結果、同時プロセス間の依存関係や同期ボトルネックのない大規模並列オンライン ソルバーが実現します。実験結果は、VOPP が既存の最先端の並列オンライン ソルバーと比較して、最適に近い解の計算において少なくとも 20 倍効率的であることを示しています。さらに、VOPP は最先端の逐次オンライン ソルバーよりも優れたパフォーマンスを発揮し、計画予算を 1000 倍も削減します。
原文 (English)
Vectorized Online POMDP Planning
Planning under partial observability is an essential capability of autonomous robots. The Partially Observable Markov Decision Process (POMDP) provides a powerful framework for planning under partial observability problems, capturing the stochastic effects of actions and the limited information available through noisy observations. POMDP solving could benefit tremendously from massive parallelization on today's hardware, but parallelizing POMDP solvers has been challenging. Most solvers rely on interleaving numerical optimization over actions with the estimation of their values, which creates dependencies and synchronization bottlenecks between parallel processes that can offset the benefits of parallelization. In this paper, we propose Vectorized Online POMDP Planner (VOPP), a novel parallel online solver that leverages a recent POMDP formulation which analytically solves part of the optimization component, leaving numerical computations to consist of only estimation of expectations. VOPP represents all data structures related to planning as a collection of tensors, and implements all planning steps as fully vectorized computations over this representation. The result is a massively parallel online solver with no dependencies or synchronization bottlenecks between concurrent processes. Experimental results indicate that VOPP is at least $20\times$ more efficient in computing near-optimal solutions compared to an existing state-of-the-art parallel online solver. Moreover, VOPP outperforms state-of-the-art sequential online solvers, while using a planning budget that is $1000\times$ smaller.
DVGT: ビジュアル ジオメトリ トランスフォーマーの駆動
自動運転には、視覚入力から 3D シーンのジオメトリを認識して再構築することが重要です。ただし、さまざまなシナリオやカメラ構成に適応できる、運転をターゲットとした高密度ジオメトリ認識モデルがまだ不足しています。このギャップを埋めるために、私たちはドライビング ビジュアル ジオメトリ トランスフォーマー (DVGT) を提案します。これは、一連のポーズ化されていないマルチビュー ビジュアル入力からグローバルな高密度 3D ポイント マップを再構築します。まず、DINO バックボーンを使用して各画像の視覚的特徴を抽出し、ビュー内の局所的注意、ビュー間の空間的注意、およびフレーム間の時間的注意を交互に使用して、画像全体の幾何学的関係を推測します。次に、複数のヘッドを使用して、最初のフレームのエゴ座標のグローバル ポイント マップと各フレームのエゴ ポーズをデコードします。正確なカメラ パラメーターに依存する従来の方法とは異なり、DVGT には明示的な 3D 幾何学的な事前条件がなく、任意のカメラ構成の柔軟な処理が可能です。 DVGT は、画像シーケンスからメートルスケールのジオメトリを直接予測し、外部センサーによる事後位置合わせの必要性を排除します。 DVGT は、nuScenes、OpenScene、Waymo、KITTI、DDAD などの運転データセットを大規模に組み合わせてトレーニングされたため、さまざまなシナリオで既存のモデルを大幅に上回ります。コードは https://github.com/wzzheng/DVGT で入手できます。
原文 (English)
DVGT: Driving Visual Geometry Transformer
Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
リーダーとフォロワーの相互作用における小規模言語モデルのゼロショットおよびワンショット適応の評価
リーダーとフォロワーの相互作用は、人間とロボットの相互作用 (HRI) における重要なパラダイムです。しかし、リソースに制約のある移動ロボットや支援ロボットにとって、リアルタイムでの役割の割り当ては依然として困難です。大規模言語モデル (LLM) は自然なコミュニケーションに有望であることが示されていますが、そのサイズと遅延によりデバイス上の展開が制限されます。小規模言語モデル (SLM) は潜在的な代替手段を提供しますが、HRI における役割分類に対する SLM の有効性は体系的に評価されていません。この論文では、リーダーとフォロワーのコミュニケーションのための SLM のベンチマークを紹介し、公開されたデータベースから派生し、相互作用固有のダイナミクスを捕捉するために合成サンプルで強化された新しいデータセットを紹介します。私たちは、ゼロショットおよびワンショット相互作用モードで研究されたプロンプトエンジニアリングと微調整という 2 つの適応戦略を、トレーニングされていないベースラインと比較して調査します。 Qwen2.5-0.5B を使用した実験では、ゼロショット微調整が低遅延 (サンプルあたり 22.2 ミリ秒) を維持しながら堅牢な分類パフォーマンス (精度 86.66%) を達成し、ベースラインおよびプロンプト エンジニアリングのアプローチを大幅に上回るパフォーマンスを示していることが明らかになりました。ただし、結果はワンショット モードでのパフォーマンスの低下も示しており、コンテキストの長さが増加するとモデルのアーキテクチャ上の能力に課題が生じます。これらの調査結果は、微調整された SLM が役割の直接割り当てに効果的なソリューションを提供することを実証するとともに、エッジでの対話の複雑さと分類の信頼性の間の重要なトレードオフを強調しています。
原文 (English)
Evaluating Zero-Shot and One-Shot Adaptation of Small Language Models in Leader-Follower Interaction
Leader-follower interaction is an important paradigm in human-robot interaction (HRI). Yet, assigning roles in real time remains challenging for resource-constrained mobile and assistive robots. While large language models (LLMs) have shown promise for natural communication, their size and latency limit on-device deployment. Small language models (SLMs) offer a potential alternative, but their effectiveness for role classification in HRI has not been systematically evaluated. In this paper, we present a benchmark of SLMs for leader-follower communication, introducing a novel dataset derived from a published database and augmented with synthetic samples to capture interaction-specific dynamics. We investigate two adaptation strategies: prompt engineering and fine-tuning, studied under zero-shot and one-shot interaction modes, compared with an untrained baseline. Experiments with Qwen2.5-0.5B reveal that zero-shot fine-tuning achieves robust classification performance (86.66% accuracy) while maintaining low latency (22.2 ms per sample), significantly outperforming baseline and prompt-engineered approaches. However, results also indicate a performance degradation in one-shot modes, where increased context length challenges the model's architectural capacity. These findings demonstrate that fine-tuned SLMs provide an effective solution for direct role assignment, while highlighting critical trade-offs between dialogue complexity and classification reliability on the edge.
ZeroWBC: 人間の自己中心的なデータから自然な全身ヒューマノイドのインタラクションを学習する
全身遠隔操作データのコストが高いため、多用途で自然な全身ヒューマノイドのインタラクション制御を実現することは依然として困難です。我々は、同期した全身動作とテキスト注釈と組み合わせた、人間の自己中心的なビデオから人型の全身インタラクションを学習する、遠隔操作不要のフレームワークである ZeroWBC を紹介します。 ZeroWBC は、静的シーンの全身インタラクション制御問題に取り組むために、生成後追跡の定式化を採用しています。初期の自己中心的な画像と言語命令が与えられると、微調整された視覚言語モデルによって将来の人間の全身運動トークンが生成され、これが連続運動にデコードされ、ヒューマノイドに再ターゲットされます。結果として得られる参照モーションは、ルートおよび主要な身体部分の軌道とともに、一般的なインタラクティブ モーション トラッキング ポリシーによって実行されます。インタラクションのパフォーマンスを向上させるために、自然な全身の動きを維持しながら、グローバル ルートと主要な身体部分の軌道の調整を優先するインタラクション指向の追跡報酬を導入します。 Unitree G1 ヒューマノイド ロボットの実験では、ZeroWBC がロボットの遠隔操作のデモンストレーションを行わずに、シーンを認識した多様な動作を可能にすることを示しています。これらの結果は、人間の自己中心的なデータから自然なヒューマノイドの全身インタラクションを学習するためのスケーラブルなパラダイムを示唆しています。
原文 (English)
ZeroWBC: Learning Natural Whole-Body Humanoid Interaction from Human Egocentric Data
Achieving versatile and natural whole-body humanoid interaction control remains challenging due to the high cost of whole-body teleoperation data. We present ZeroWBC, a teleoperation-free framework that learns humanoid whole-body interaction from human egocentric videos paired with synchronized whole-body motion and text annotations. ZeroWBC adopts a generation-then-tracking formulation to tackle the static scene whole-body interaction control problem. Given an initial egocentric image and a language instruction, a fine-tuned Vision-Language Model generates future human whole-body motion tokens, which are decoded into continuous motions and retargeted to the humanoid. The resulting reference motions, together with root and key body-part trajectories, are then executed by a general interactive motion tracking policy. To improve interaction performance, we introduce an interaction-oriented tracking reward that prioritizes global root and key body-part trajectory alignment while preserving natural whole-body motion. Experiments on the Unitree G1 humanoid robot show that ZeroWBC enables diverse scene-aware behaviors without robot teleoperation demonstrations. These results suggest a scalable paradigm for learning natural humanoid whole-body interaction from human egocentric data.
ContactExplorer: Contact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Reinforcement learning has achieved remarkable success in domains such as Atari games, navigation, and locomotion, where exploration can of…
Contextual Multi-Task Reinforcement Learning for Autonomous Reef Monitoring
Although autonomous underwater vehicles promise the capability of marine ecosystem monitoring, their deployment is fundamentally limited by…
DEFLECT: Temporal Counterfactual Preference Learning for Delay-Robust Asynchronous VLAs
Vision-Language-Action (VLA) policies increasingly rely on asynchronous inference to hide large-model latency behind ongoing robot motion.…
Lost in Fog: Sensor Perturbations Expose Reasoning Fragility in Driving VLAs
Interpretable autonomous driving planners depend not only on generating explanations, but also on those explanations remaining reliable und…
Too Much of a Good Thing: When sim2real Efforts Impede Policy Learning (And What to Do About It)
While sim2real efforts are necessary for effective policy transfer to hardware, there is such a thing as too much of a good thing. We argue…
PHASER: Phase-Aware and Semantic Experience Replay for Vision-Language-Action Models
Vision-Language-Action (VLA) models have achieved remarkable success in language-conditioned robotic manipulation. However, deploying these…
人型ロボブームを“先駆者ホンダ”はどう見る? 「悔しさもあるが……」 次の一手を聞いた
2000年に「ASIMO」を世に送り出したホンダは、足元の人型ロボットブームをどう見ているのか。人型ロボットの開発に再参入する可能性や、現在の取り組みなどを聞いた。
AURA: 一定の VRAM でのロボット ポリシー用のアクション ゲート メモリ
KV キャッシュはデータセンターにとっては適切なメモリですが、ロボットにとっては不適切なメモリです。データセンターの推論は、多くの短いリクエストをバッチ化してリセットし、群衆全体での注意キャッシュを償却します。代わりに、身体化されたエージェントは、帯域幅が制限されたエッジ ハードウェアで、リセットされない長いエピソードを 1 つ実行します。このハードウェアでは、高帯域幅のメモリとフラッシュが不足し、フラッシュの書き込み耐久性が有限であり、コンピューティングではなくメモリ書き込みがバインド制約になる可能性があります。 AURA-Mem (Action-Utility Recurrent Adaptive Memory) は、この体制をターゲットとしています。これは、固定された視覚言語アクションのバックボーンを、一定サイズのリカレント メモリと、現在の観察によって次のアクションが変更される場合にのみ書き込む学習済みゲート、つまりいつ沈黙を保つべきかを認識するメモリでラップします。再構成ベースのメモリとは異なり、ゲートは閉ループのアクションエラー信号に対して直接トレーニングされます。その推論状態はホライズンに関係なく 4,224 バイトに固定されていますが、KV キャッシュは 100,000 ステップで 6,061 倍の大きさに増加します。制御された合成ベンチマークでは、AURA-Mem は精度において最高の O(1) ベースラインと一致し、書き込み回数は 5.19 ~ 6.13 倍少なく、より簡単な構成では最大 9.19 倍少なくなります。予算に合わせたランダムおよび定期的なスケジュールではこの利益は回復せず、アクションサプライズシグナルに対する利益が孤立します。 LIBERO-Long 上のトレーニングされた閉ループ OpenVLA-OFT 7B パネル (アームあたり n=60 エピソード) では、ゲートは成功に悪影響を及ぼしません。AURA-Mem は非ゲートの基本ポリシー (0.233) に一致し、常時書き込み KV アーム (0.217) をわずかに上回っていますが、使用する書き込み回数と定数メモリは 7.0 分の 1 です。また、方法論のデモンストレーションとして、近似情報状態の価値損失限界をインスタンス化します。この規模では、限界は保証ではなく空虚です。
原文 (English)
AURA: Action-Gated Memory for Robot Policies at Constant VRAM
The KV-cache is the right memory for datacenters but the wrong memory for robots. Datacenter inference batches many short requests and resets them, amortizing an attention cache across a crowd. Embodied agents instead run one long, non-resetting episode on bandwidth-limited edge hardware, where high-bandwidth memory and flash are scarce, flash has finite write endurance, and memory writes rather than compute can become the binding constraint. AURA-Mem (Action-Utility Recurrent Adaptive Memory) targets this regime. It wraps a frozen vision-language-action backbone with a constant-size recurrent memory and a learned gate that writes only when the current observation would change the next action: memory that knows when to stay silent. Unlike reconstruction-based memory, the gate is trained directly against a closed-loop action-error signal. Its inference state is fixed at 4,224 bytes regardless of horizon, while a KV-cache grows to 6,061 times larger at 100,000 steps. On a controlled synthetic benchmark, AURA-Mem matches the best O(1) baseline in accuracy while using 5.19-6.13 times fewer writes, and up to 9.19 times fewer writes on easier configurations. Budget-matched random and periodic schedules do not recover this gain, isolating the benefit to the action-surprise signal. On a trained closed-loop OpenVLA-OFT 7B panel on LIBERO-Long (n=60 episodes per arm), the gate does not hurt success: AURA-Mem matches the ungated base policy (0.233) and slightly exceeds an always-write KV arm (0.217), while using 7.0 times fewer writes and constant memory. We also instantiate an approximate-information-state value-loss bound as a methodology demonstration; at this scale, the bound is vacuous rather than a guarantee.
TRAP: 敵対的パッチによる VLA CoT Reasoning のハイジャック
思考連鎖 (CoT) 推論を統合することにより、ビジョン言語アクション (VLA) モデルは、特に一般化と解釈可能性を向上させることで、ロボット操作における強力な能力を実証しました。ただし、CoT ベースの推論メカニズムのセキュリティはほとんど調査されていないままです。この論文では、CoT 推論が、ユーザーの指示を変更することなく、標的を絞った行動ハイジャック (たとえば、ロボットにリンゴではなく誤ってナイフを人間に届けさせる) のための新しい攻撃ベクトルを導入することを示します。我々はまず、入力命令と意味的にずれている場合でも、CoT がアクション生成を強力に支配するという経験的証拠を提供します。この観察に基づいて、CoT 推論 VLA モデルに対する最初の標的型行動ハイジャック敵対攻撃である TRAP を提案します。 TRAP は、推論からアクションへの経路をターゲットにすることで、敵対的パッチ (テーブルの上に置かれたテーブルクロスなど) を使用して、中間の CoT 推論と下流のアクションを敵対者が定義した動作に向けます。異なる CoT 推論メカニズムにわたる 3 つの代表的な推論 VLA に関する広範な評価により、TRAP の有効性が実証されています。特に、現実世界の設定で紙に印刷してパッチを実装しました。私たちの調査結果は、VLA システムにおける CoT 推論を保護する緊急の必要性を浮き彫りにしています。プロジェクト ページは https://zhengxian-huang.github.io/TRAP-website/ で利用できます。
原文 (English)
TRAP: Hijacking VLA CoT-Reasoning via Adversarial Patches
By integrating Chain-of-Thought (CoT) reasoning, Vision-Language-Action (VLA) models have demonstrated strong capabilities in robotic manipulation, particularly by improving generalization and interpretability. However, the security of CoT-based reasoning mechanisms remains largely unexplored. In this paper, we show that CoT reasoning introduces a novel attack vector for targeted behavior hijacking--for example, causing a robot to mistakenly deliver a knife to a person instead of an apple--without modifying the user's instruction. We first provide empirical evidence that CoT strongly governs action generation, even when it is semantically misaligned with the input instructions. Building on this observation, we propose TRAP, the first targeted behavior-hijacking adversarial attack against CoT-reasoning VLA models. By targeting the reasoning-to-action pathway, TRAP uses an adversarial patch (e.g., a tablecloth placed on the table) to steer intermediate CoT reasoning and downstream actions toward adversary-defined behaviors. Extensive evaluations on three representative reasoning VLAs, spanning distinct CoT reasoning mechanisms, demonstrate the effectiveness of TRAP. Notably, we implemented the patch by printing it on paper in a real-world setting. Our findings highlight the urgent need to secure CoT reasoning in VLA systems. The project page is available at https://zhengxian-huang.github.io/TRAP-website/.
Too Much of a Good Thing: When sim2real Efforts Impede Policy Learning (And What to Do About It)
While sim2real efforts are necessary for effective policy transfer to hardware, there is such a thing as too much of a good thing. We argue…
CARVE: Certified Affordable Repair of Vetoed Maneuvers via Envelopes for Interactive Driving
Interactive driving exposes a failure mode that is easy to miss in rule-aware autonomous-driving stacks: a hard-rule margin can be negative…
See Less, Specify More: Visual Evidence Budgets for Generalizable VLAs
Generalization remains a central bottleneck for vision-language-action (VLA) models: under distractors, appearance shifts, and semantically…
Cosmos 3: Omnimodal World Models for Physical AI
We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and actio…
SCOPE: Real-Time Natural Language Camera Agent at the Edge
Deploying language-driven agents in robotics requires evaluations that reflect real-world task demands: natural-language instructions with…
Towards Compact Autonomous Driving Perception with Balanced Learning and Multi-sensor Fusion
We present a novel compact deep multi-task learning model to handle various autonomous driving perception tasks in one forward pass. The mo…
Exact equivariance, kept through training, buys zero-shot generalisation across the symmetry group
A latent world model built from an equivariant encoder $E$ and an equivariant predictor $f$ inherits a provable symmetry of its training lo…
ConTraIRL: Factorized Contrastive Abstractions for Transferable IRL
Reward transfer in Inverse Reinforcement Learning (IRL) is unreliable when policies must generalize to unseen combinations of environment d…
NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. I…
BotDirector: Robot Storytelling Across the Symmetrical Reality with Multi-modal Interactions
Robot storytelling offers a unique blend of technological innovation and creative expression that engages children in unprecedented ways. H…
AirDreamer: Generalist Drone Navigation with World Models
Navigating a drone in unseen and cluttered environments requires reliable generalization to unseen scene layouts and understanding of envir…
RobotValues: Evaluating Household Robots When Human Values Conflict
While household robots are often evaluated based on task completion, everyday domestic environments involve value-conflicting situations in…
Grasp-Then-Plan with Failure Attribution: A Closed Two-Stage Framework for Precise and Generalizable Robotic Manipulation
In robotic manipulation, the tight coupling between grasping and motion planning often obscures the true source of failure, leading to inef…
SPADE: Sketch-guided Path Planning Augmented with Diffusion Experts
Path planning is essential for Autonomous Mobile Robots (AMRs). Conventional methods for incorporating human preferences into planning typi…
Learned Non-Maximum Suppression for 3D Object Detection
Post-processing is a critical stage in LiDAR-based 3D object detection, where dense and overlapping proposals must be filtered for compact…
PHASER: Phase-Aware and Semantic Experience Replay for Vision-Language-Action Models
Vision-Language-Action (VLA) models have achieved remarkable success in language-conditioned robotic manipulation. However, deploying these…
Self-Refining Agentic Reinforcement Learning for Vision-Conditioned UAV Navigation
Deep reinforcement learning has shown strong potential for enabling autonomous robots to learn complex navigational tasks. However, its pra…
Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
We introduce Humanoid-GPT, a GPT-style Transformer with causal attention trained on a billion-scale motion corpus for whole-body control. U…
Assistax: A Multi-Agent Hardware-Accelerated Reinforcement Learning Benchmark for Assistive Robotics
The development of reinforcement learning (RL) algorithms has been largely driven by ambitious challenge tasks and benchmarks. Games have d…
Scaling Multi Agent Reinforcement Learning for Underwater Acoustic Tracking via Autonomous Vehicles
Autonomous vehicles (AVs) offer a cost-effective solution for scientific missions such as underwater tracking. Reinforcement learning (RL)…
CoMPAS3D: A Dataset and Benchmark for Interactive Motion
Socially interactive humanoid robots must engage with humans through their bodies, adapting in real time to a partner's movement, intent, a…
Coupled Local and Global World Models for Efficient First Order RL
World models offer a promising avenue for more faithfully capturing complex dynamics, including contacts and non-rigidity, as well as compl…
FRED: A Multi-Modal Autonomous Driving Dataset for Flooded Road Environments
The Flooded Road Environments Dataset (FRED) is, to our knowledge, the first multi-modal autonomous driving dataset specifically targeting…
TERRA: Task-Embedded Reasoning and Representation Architecture for Cross-Domain Applications
A single action-conditioned latent predictive architecture can in principle be trained on the structured state of a driving scene, a robot…
From Human Videos to Robot Manipulation: A Survey on Scalable Vision-Language-Action Learning with Human-Centric Data
Recent progress in generalizable embodied control has been driven by large-scale pretraining of Vision-Language-Action (VLA) models. Howeve…
From Demonstrations to Rewards: Test-Time Prompt Optimization for VLM Reward Models
Reinforcement learning relies on accurate reward functions, which are often hand-crafted or even unavailable in real-world applications, su…
Can Predicted Dynamics Exist in the Physical World?
Predictive Physical AI systems output state rollouts, action chunks, and latent plans, yet a low root-mean-square error (RMSE) does not imp…
Silent Failures in Physical AI: A Literature Review of Runtime Action Authorization for Autonomous Systems
Physical AI systems increasingly map multimodal observations, language instructions, and learned world representations into physically cons…
Bridging the 2D-3D Gap: A Hierarchical Semantic-Geometric Map for Vision Language Navigation
Vision-Language Navigation (VLN) enables embodied agents to reach target locations in unseen environments by following language instruction…
PEACE: A Planner-Executor Agent with Constraint Enforcement for UAVs
Foundation models are increasingly used to drive autonomous systems, yet existing approaches either keep the model in a tight control loop,…
VDSB-GWSyn: Diffusion Schr\"{o}dinger Bridge for Controllable and Anatomically Feasible Guidewire Synthesis in Coronary Angiography
Coronary guidewire endpoint localization is a fundamental capability for computer-assisted PCI, and its importance increases as robot-assis…
V2I Work Zone Geometry Reconstruction with Pose-Conditioned UWB Range Denoising
Reliable work zone mapping is important for connected and autonomous vehicles (CAVs) to navigate safely and smoothly through work zone area…
Completion at the Boundary (CaB): Deployable Switching with Completion-Aware Control under Limited Calibration
Vision-language-action (VLA) agents can execute natural-language instructions, yet deployed systems still lack an operational interface: de…
Continuous Reasoning for Vision-Language-Action
Natural language is a powerful reasoning medium for language and vision-language models, but it is mismatched to the granularity of continu…
StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
Video world models (WMs) have shown promise for policy evaluation and improvement by imagining realistic future observations conditioned on…
DRL-Based Pose Control for Double-Ackermann Robots Under Actuation Uncertainties
Robust deployment of deep reinforcement learning (DRL) policies on real robots remains challenging due to discrepancies between simulation…
PaCo-VLA: Passivity-Shielded Compliance Prior for Contact-Rich Vision-Language-Action Manipulation
Contact-rich manipulation demands both high-level semantic reasoning and the safe regulation of high-frequency contact dynamics. While Visi…
Shape Your Body: Value Gradients for Multi-Embodiment Robot Design
We propose to turn generalist multi-embodiment value functions into reusable models for robot design. Instead of running a new reinforcemen…
From Cues to Horizons: Dynamic Risk Horizon Profiling for Trajectory Prediction
Accurate and reliable vehicle trajectory prediction is essential for safe autonomous driving. Recent studies have incorporated safety risk…
AI-IoT-Robotics Integration: Survey of Frameworks, Emerging Trends, and the Path Toward Connected Robotics
The convergence of Artificial Intelligence, the Internet of Things, and Robotics is no longer a futuristic vision; it is rapidly becoming t…
Beyond Task Success: Behavioral and Representational Diagnostics for WAM and VLA
Vision-language-action (VLA) policies and World-Action Models (WAM) represent two increasingly important paradigms for robotic manipulation…
Implicit Drifting Policy: One-Step Action Generation via Conditional Expert Geometry
Generative action policies based on diffusion or flow matching excel in behavior cloning, yet their iterative sampling is prohibitive for h…
DeepIPCv3: Event-Aware Multi-Modal Sensor Fusion for Sudden Pedestrian Crossing Avoidance
Current end-to-end autonomous driving systems predominantly rely on frame-based sensors, which suffer from inherent perception latency and…
PSG-Nav: Probabilistic Scene Graph Navigation via Multiverse Decision Making
Open-vocabulary navigation requires embodied agents to manage significant perception uncertainty stemming from semantic ambiguity and model…
Crazyflow: An Accurate, GPU-Accelerated, Differentiable Drone Simulator in JAX
High-quality, large-scale synthetic data from simulations is becoming a cornerstone for pushing the capabilities of robot algorithms. While…
Network Distributed Multi-Agent Reinforcement Learning for Consensus Control of Quadcopters
This paper proposes a Network Distributed Multi-Agent Reinforcement Learning (ND-MARL) framework for quadcopter consensus control. Compared…
FW-NKF: Frequency-Weighted Neural Kalman Filters
Robust state estimation is central to robotic autonomy, yet classical Kalman filters struggle with frequency-dependent disturbances and mod…
Permissive Safety Through Trusted Inference: Verifiable Belief-Space Neural Safety Filters for Assured Interactive Robotics
Autonomous robots that interact with people must make safe and efficient decisions under human-induced uncertainty, such as their preferenc…
DeepIPCv2: LiDAR-powered Robust Environmental Perception and Navigational Control for Autonomous Vehicle
We propose DeepIPCv2, an end-to-end autonomous driving framework that integrates LiDAR-based environmental perception with command-specific…
DAG-Plan: Generating Directed Acyclic Dependency Graphs for Dual-Arm Cooperative Planning
Dual-arm robots promise greater efficiency but require planning for complex tasks with nonlinear sub-task dependencies. Current methods usi…
MARFT: Multi-Agent Reinforcement Fine-Tuning
Large Language Model (LLM)-based Multi-Agent Systems (LaMAS) have demonstrated strong capabilities on complex agentic tasks requiring multi…
RoboBenchMart: Benchmarking Robots in Retail Environment
Most existing robotic manipulation benchmarks focus on tabletop or household scenarios. While these setups have driven impressive progress,…
SpeedAug: Policy Acceleration via Tempo-Enriched Policy and RL Fine-Tuning
Robotic policy learning for complex real-world manipulation tasks has seen rapid recent progress, enabled in large part by the ability to c…
ShelfAware: Real-Time Semantic Localization in Quasi-Static Environments with Low-Cost Sensors
Many indoor workspaces are quasi-static: their global geometric layout is stable, but local semantics change continually, producing repetit…
Control of a Twin Rotor using Twin Delayed Deep Deterministic Policy Gradient (TD3)
This paper proposes a reinforcement learning (RL) framework for controlling and stabilizing the Twin Rotor Aerodynamic System (TRAS) at spe…
Reinforcement Learning Position Control of a Quadrotor Using Soft Actor-Critic (SAC)
This paper proposes a new Reinforcement Learning (RL) based control architecture for quadrotors. With the literature focusing on controllin…
Dynamic Entropy Tuning in Reinforcement Learning Low-Level Quadcopter Control: Stochasticity vs Determinism
This paper explores the impact of dynamic entropy tuning in Reinforcement Learning (RL) algorithms that train a stochastic policy. Its perf…
SilentDrift: Exploiting Action Chunking for Stealthy Backdoor Attacks on Vision-Language-Action Models
Vision-Language-Action (VLA) models are increasingly deployed in safety-critical robotic applications, yet their security vulnerabilities r…
Picasso: Holistic Scene Reconstruction with Physics-Constrained Sampling
In the presence of occlusions and measurement noise, geometrically accurate scene reconstructions -- which fit the sensor data -- can still…
SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes
Simulation has become a key tool for training and evaluating home robots at scale, yet existing environments fail to capture the diversity…
Interpretable Multimodal Gesture Recognition for Drone and Mobile Robot Teleoperation via Log-Likelihood Ratio Fusion
Human operators are still frequently exposed to hazardous environments such as disaster zones and industrial facilities, where intuitive an…
Improving Diffusion Planners by Self-Supervised Action Gating with Energies
Diffusion planners are a strong approach for offline reinforcement learning, but they can fail when value-guided selection favours trajecto…
SPARC: Spatial-Aware Path Planning via Attentive Agent Communication
Efficient communication is critical for decentralized Multi-Robot Path Planning (MRPP), yet existing learned communication methods treat al…
HALO: Learning Human-Robot Collaboration via Heterogeneous-Agent Lyapunov Policy Optimization
To improve generalization and resilience in human-robot collaboration (HRC), robots must contend with diverse combinations of human behavio…
ExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstration…
Frequency-Enhanced Diffusion Models: Curriculum-Guided Semantic Alignment for Zero-Shot Skeleton Action Recognition
Human action recognition is pivotal in computer vision, with applications ranging from surveillance to human-robot interaction. Despite the…
Genie 4D: Semantic-Prior-Guided 4D Dynamic Scene Reconstruction
At the intersection of computer vision and robotic perception, 4D reconstruction of dynamic scenes connects low-level geometric sensing wit…
AffordGen: Generating Diverse Demonstrations for Generalizable Object Manipulation with Afford Correspondence
Despite the recent success of modern imitation learning methods in robot manipulation, their performance is often constrained by geometric…
AttenA+: Rectifying Action Inequality in Robotic Foundation Models
Existing robotic foundation models, while powerful, are predicated on an implicit assumption of temporal homogeneity: treating all actions…
AnyMo: Scaling Any-Modality Conditional Motion Generation with Masked Modeling
Conditional human motion generation remains a fundamental challenge in computer vision and robotics. Despite significant progress, current…
Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fra…
Industrial Visual Sim-to-Real の先行利用可能性: CAD ガイド付きレジームと CAD を使用できないレジームのレビュー
産業用ビジュアルのシミュレーションとリアルの変換は、合成画像から実際の画像への変換としてよく説明されますが、産業への展開には通常、入手可能な証拠と必要な決定の間の広範な不一致が伴います。システムは、CAD レンダリング、シミュレートされた RGB-D 観察、通常の参照画像、合成欠陥、事前トレーニングされた特徴空間、または言語プロンプトから構築できますが、さまざまなセンサー、照明、材料、器具、キャリブレーション、生産変動、まれな欠陥モードの下で展開することもできます。このレビューでは、産業用ビジュアルのシミュレーションとリアルを、事前の利用可能性によって整理されたドメインギャップの問題として再構成します。明示的なオブジェクト ジオメトリがレンダリング、キャリブレーション、姿勢推定、セグメンテーション、テスト時の幾何学的検証をサポートできる CAD で利用可能な設定を区別します。 CAD では利用できない設定。ジオメトリが法線参照の外観、特徴分布、教師と生徒の残差、合成異常の仮定、基礎特徴、または視覚言語事前分布に置き換えられます。境界優先設定では、近似モデル、テンプレート、参照ビュー、またはセマンティック対応関係が CAD の役割の一部のみを保持します。この枠組みは、CAD ベースの検出および 6D 姿勢推定の文献を、通常は個別にレビューされる産業異常および表面検査の文献と結び付けます。分類を具体化するために、T-LESS/BOP、MVTec AD、および VisA の経験的アンカーを使用します。アンカーは、CAD レンダリング数だけでは転送が終了しないことを示しています。線源分散設計、検出器の容量、小規模な実際のキャリブレーションの方が重要になる場合があります。また、CAD ではテスト時にマスク、ポーズ、深度の一貫性を通じて明確な検証チャネルが作成されるのに対し、CAD では利用できない検査は校正された正規性と特徴の偏差に依存していることも示しています。したがって、このレビューでは、単一のタスク間リーダーボードに反対し、その代わりに導入決定の事前の根拠を尋ねています。
原文 (English)
Prior Availability in Industrial Visual Sim-to-Real: A Review of CAD-Guided and CAD-Unavailable Regimes
Industrial visual sim-to-real is often described as transferring from synthetic images to real images, but industrial deployment usually involves a broader mismatch between available evidence and required decisions. A system may be built from CAD renderings, simulated RGB-D observations, normal reference images, synthetic defects, pretrained feature spaces, or language prompts, yet deployed under different sensors, lighting, materials, fixtures, calibration, production variation, and rare defect modes. This review reframes industrial visual sim-to-real as a domain-gap problem organized by prior availability. We distinguish CAD-available settings, where explicit object geometry can support rendering, calibration, pose estimation, segmentation, and test-time geometric verification; CAD-unavailable settings, where geometry is replaced by normal-reference appearance, feature distributions, teacher-student residuals, synthetic anomaly assumptions, foundation features, or vision-language priors; and boundary-prior settings, where approximate models, templates, reference views, or semantic correspondences preserve only part of the CAD role. This framing connects CAD-based detection and 6D pose-estimation literature with industrial anomaly and surface-inspection literature that is usually reviewed separately. To make the taxonomy concrete, we use empirical anchors on T-LESS/BOP, MVTec AD, and VisA. The anchors show that CAD render count alone does not close transfer; source-distribution design, detector capacity, and small real calibration can matter more. They also show that CAD at test time creates a distinct verification channel through mask, pose, and depth consistency, whereas CAD-unavailable inspection relies on calibrated normality and feature deviation. The review therefore argues against a single cross-task leaderboard and instead asks what prior grounds the deployment decision.
安全閾値をニューロンスパイキング閾値として再解釈する
代理安全対策 (SSM) は、自動運転の状況における交通リスクの評価に広く利用されています。しかし、SSM ベースの評価の大部分では、固定しきい値が採用されており、持続する境界線状態に対する人間の反応や、短期間の高リスクピークに対する反応を捉えることができません。本研究は、生物学にインスピレーションを得た SSM 閾値の再解釈を提案しています。これは、複数の SSM 入力がスパイキング ニューラル ネットワーク (SNN) に結合された、リーキー統合発射 (LIF) ニューロンのスパイク閾値としてモデル化されています。 SNN は、人間のブレーキの開始に合わせてスパイクを発するように訓練されています。トレーニング データは、CARLA/Unreal を備えた 3D-CoAutoSim プラットフォームと 6-DOF モーション プラットフォームを使用した、制御された車追従実験で記録され、誘発された重大なイベントが生成されました。結果は、学習されたスパイク アクティビティがシナリオ全体でブレーキ動作と定性的に一致しており、しきい値の交差だけでは一貫して説明できない反応を捕捉していることを示しています。さらに、参加者全体の分析により、学習された入力しきい値は比較的一貫したままである一方、学習された減衰係数は SSM の異なる時間感度をエンコードしていることが示されています。この研究の結果は、スパイクのダイナミクスが客観的な SSM と主観的な人間の安全認識の収束を促進するメカニズムとして機能する可能性があることを示しています。
原文 (English)
Reinterpreting Safety Thresholds as Neuron Spiking Thresholds
Surrogate Safety Measures (SSMs) are extensively utilised in the evaluation of traffic risk in automated driving contexts. However, the majority of SSM-based evaluations employ fixed thresholds that fail to capture the human response to sustained borderline conditions or the reaction to brief, high-risk peaks. The present work proposes a biologically inspired reinterpretation of SSM thresholds. This is modelled as spiking thresholds of leaky integrate-and-fire (LIF) neurons, with multiple SSM inputs combined into a spiking neural network (SNN). The SNN is trained to emit spikes that are aligned with human braking onsets. The training data was recorded in a controlled car-following experiment using the 3D-CoAutoSim platform with CARLA/Unreal and a 6-DOF motion platform, where induced critical events were generated. The results demonstrate that the learned spiking activity qualitatively aligns with braking behaviour across scenarios and captures reactions that are not consistently explained by threshold crossings alone. Analysis across participants further indicates that learned input thresholds remain relatively consistent, while learned decay factors encode different temporal sensitivities for the SSMs. The findings of this study indicate that spiking dynamics may serve as a mechanism to facilitate the convergence of objective SSMs with subjective human safety perception.
構造化されたインタラクションにより、現実世界のマルチロボット システムにおけるモデルのスケーリングを超えた分散調整が向上します
個々のロボットの機能を拡張することは一般的ですが、コストがかかります。ここでは、現実世界のマルチロボット調整におけるシステムレベルの設計の問題を調査します。ハードウェア予算が一致している場合、ロボット間の通信を再構築すると、オンボードモデルのサイズを増やすよりも大きな利益が得られるでしょうか? 10 台の物理ロボット (条件ごとに 5 回の実行、合計 60 回の実行) を使用した代表的なトランスポートおよびマッピング タスクを使用すると、完全接続からモジュール型階層インタラクションに切り替えると正規化パフォーマンスが 47 ポイント (0 ~ 100) 向上するのに対し、ニューラル ネットワークの隠れサイズを 2 倍にしても最大 9 ポイント向上することがわかりました。ネストされた混合効果モデルの比較では、スケールよりもトポロジに対するモデルの適合性が大幅に向上していることがわかります。このパターンは、独立した SMAC レプリケーションで確認されます。異種ベンチマーク再分析は、一次証拠ではなく二次的なサポート一貫性チェックを提供します。 1024 隠れユニットを超えるパフォーマンスの飽和は、ハードウェア上で直接ではなく、シミュレーションで調整された外挿で観察されます。これらの結果は、より広範な定量的一般化がまだ確立されていない一方で、テストされたシステムとタスク設定内で相互作用構造が支配的な役割を果たす可能性があることを示しています。
原文 (English)
Structured interactions improve distributed coordination beyond model scaling in a real-world multi-robot system
Scaling individual robot capabilities is common but costly. Here we investigate a system-level design question in real-world multi-robot coordination: given matched hardware budgets, does restructuring communication among robots yield larger gains than increasing onboard model size? Using a representative transport-and-mapping task with 10 physical robots (5 runs per condition, 60 runs total), we find that switching from fully connected to modular hierarchical interactions improves normalised performance by 47 points (0--100), whereas doubling neural network hidden size yields at most 9 points. Nested mixed-effects model comparisons show a substantially larger improvement in model fit for topology than for scale. The pattern is confirmed in independent SMAC replications; heterogeneous benchmark reanalyses provide secondary supporting consistency checks rather than primary evidence. Performance saturation beyond 1024 hidden units is observed in simulation-calibrated extrapolation, not directly on hardware. These results indicate that interaction structure can play a dominant role within the tested system and task setting, while broader quantitative generalisation remains to be established.
メモリに依存するが帯域幅に制限はない: Batch-1 LLM デコードにおける物理 AI 推論のギャップ
ロボット、自動運転車、具体化されたエージェント、エッジ コパイロットなどの物理 AI システムは、多くの場合、クラウド LLM サービスとは異なる推論ワークロードを実行します。つまり、単一ストリーム、バッチ 1 の自己回帰デコードで、1 つのロボット、カメラ フィード、またはユーザー セッションが次のトークンを待機します。このワークロードは通常、メモリ帯域幅制限として説明されます。各デコード ステップはモデルの重みとアクティブな KV キャッシュをストリーミングするため、レイテンシはピーク HBM 帯域幅に合わせて調整する必要があります。この説明は真実であるが不完全であることを示します。 4 つの NVIDIA GPU (H100 SXM5、A100-80GB SXM4、L40S、L4) にわたる 3 つの 7 ~ 8B クラス GQA トランスフォーマーのバッチ 1 デコードを測定します。 2048 から 16384 までのコンテキスト長を評価し、制御された bf16 SDPA セットアップの下で 44 個の有効なセルを生成します。ピーク HBM 帯域幅の達成割合は、ピーク帯域幅が増加するにつれて減少します。見出しの Qwen-2.5-7B ctx=2048 セルでは、L4 は分析メモリ フロアの約 81% に達しますが、H100 はわずか 27% に達します。物理 AI デコードはメモリに依存しますが、メモリの高速化は比例したレイテンシーの増加にはつながりません。 CUDA Graphs A/B 実験を使用して、欠落している用語をテストします。 ctx=2048 の H100 では、CUDA グラフは N=10 の新しいセッション全体でデコード レイテンシを 1.259 倍改善し、95 パーセントのブートストラップ信頼区間は 1.253 ~ 1.267 でした。 L4 では、同じ介入では 1.028 倍しか得られません。これにより、高速な GPU では可視化される起動側のオーバーヘッドが分離されますが、低速で帯域幅に制限のある GPU ではほとんど隠れたままになります。デプロイメントの意味は、メモリの節約が重要になるのは、ランタイムがメモリの節約を実現した場合だけであるということです。 L4 では、bf16 デコードはメモリ フロア近くにありますが、共通の量子化パスでは予想される 4 倍の重みトラフィック削減が回復されません。62.32 ミリ秒の bf16 ベースラインから、bnb-nf4 は 59.36 ミリ秒/ステップに達し、AutoAWQ+Marlin は 45.24 ミリ秒/ステップに達します。 Ada で調整された int4 カーネルを使用した GPTQ+ExLlamaV2 は、17.36 ミリ秒/ステップに達します。
原文 (English)
Memory-Bound but Not Bandwidth-Limited: The Physical AI Inference Gap in Batch-1 LLM Decode
Physical AI systems, including robots, autonomous vehicles, embodied agents and edge copilots, often run a different inference workload from cloud LLM serving: single-stream, batch-1 autoregressive decode, where one robot, camera feed or user session waits on the next token. This workload is usually described as memory-bandwidth-bound. Each decode step streams model weights and the active KV cache, so latency should scale with peak HBM bandwidth. We show that this account is true but incomplete. We measure batch-1 decode for three 7 to 8B-class GQA transformers across four NVIDIA GPUs: H100 SXM5, A100-80GB SXM4, L40S and L4. We evaluate context lengths from 2048 to 16384, producing 44 valid cells under a controlled bf16 SDPA setup. The achieved fraction of peak HBM bandwidth falls as peak bandwidth rises. On the headline Qwen-2.5-7B ctx=2048 cell, an L4 reaches roughly 81 percent of its analytic memory floor, while an H100 reaches only 27 percent. Physical-AI decode is memory-dominated, but faster memory does not translate into proportional latency gains. We test the missing term with a CUDA Graphs A/B experiment. On H100 at ctx=2048, CUDA Graphs improves decode latency by 1.259x across N=10 fresh sessions, with a 95 percent bootstrap confidence interval of 1.253 to 1.267. On L4, the same intervention gives only 1.028x. This isolates a launch-side overhead that becomes visible on fast GPUs but remains mostly hidden on slower, bandwidth-bound GPUs. The deployment implication is that memory savings matter only when the runtime realises them. On L4, bf16 decode sits close to the memory floor, but common quantised paths do not recover the expected 4x weight-traffic reduction: bnb-nf4 reaches 59.36 ms/step and AutoAWQ+Marlin reaches 45.24 ms/step from a 62.32 ms bf16 baseline. GPTQ+ExLlamaV2, with Ada-tuned int4 kernels, reaches 17.36 ms/step.
Industrial Visual Sim-to-Real の先行利用可能性: CAD ガイド付きレジームと CAD を使用できないレジームのレビュー
産業用ビジュアルのシミュレーションとリアルの変換は、合成画像から実際の画像への変換としてよく説明されますが、産業への展開には通常、入手可能な証拠と必要な決定の間の広範な不一致が伴います。システムは、CAD レンダリング、シミュレートされた RGB-D 観察、通常の参照画像、合成欠陥、事前トレーニングされた特徴空間、または言語プロンプトから構築できますが、さまざまなセンサー、照明、材料、器具、キャリブレーション、生産変動、まれな欠陥モードの下で展開することもできます。このレビューでは、産業用ビジュアルのシミュレーションとリアルを、事前の利用可能性によって整理されたドメインギャップの問題として再構成します。明示的なオブジェクト ジオメトリがレンダリング、キャリブレーション、姿勢推定、セグメンテーション、テスト時の幾何学的検証をサポートできる CAD で利用可能な設定を区別します。 CAD では利用できない設定。ジオメトリが法線参照の外観、特徴分布、教師と生徒の残差、合成異常の仮定、基礎特徴、または視覚言語事前分布に置き換えられます。境界優先設定では、近似モデル、テンプレート、参照ビュー、またはセマンティック対応関係が CAD の役割の一部のみを保持します。この枠組みは、CAD ベースの検出および 6D 姿勢推定の文献を、通常は個別にレビューされる産業異常および表面検査の文献と結び付けます。分類を具体化するために、T-LESS/BOP、MVTec AD、および VisA の経験的アンカーを使用します。アンカーは、CAD レンダリング数だけでは転送が終了しないことを示しています。線源分散設計、検出器の容量、小規模な実際のキャリブレーションの方が重要になる場合があります。また、CAD ではテスト時にマスク、ポーズ、深度の一貫性を通じて明確な検証チャネルが作成されるのに対し、CAD では利用できない検査は校正された正規性と特徴の偏差に依存していることも示しています。したがって、このレビューでは、単一のタスク間リーダーボードに反対し、その代わりに導入決定の事前の根拠を尋ねています。
原文 (English)
Prior Availability in Industrial Visual Sim-to-Real: A Review of CAD-Guided and CAD-Unavailable Regimes
Industrial visual sim-to-real is often described as transferring from synthetic images to real images, but industrial deployment usually involves a broader mismatch between available evidence and required decisions. A system may be built from CAD renderings, simulated RGB-D observations, normal reference images, synthetic defects, pretrained feature spaces, or language prompts, yet deployed under different sensors, lighting, materials, fixtures, calibration, production variation, and rare defect modes. This review reframes industrial visual sim-to-real as a domain-gap problem organized by prior availability. We distinguish CAD-available settings, where explicit object geometry can support rendering, calibration, pose estimation, segmentation, and test-time geometric verification; CAD-unavailable settings, where geometry is replaced by normal-reference appearance, feature distributions, teacher-student residuals, synthetic anomaly assumptions, foundation features, or vision-language priors; and boundary-prior settings, where approximate models, templates, reference views, or semantic correspondences preserve only part of the CAD role. This framing connects CAD-based detection and 6D pose-estimation literature with industrial anomaly and surface-inspection literature that is usually reviewed separately. To make the taxonomy concrete, we use empirical anchors on T-LESS/BOP, MVTec AD, and VisA. The anchors show that CAD render count alone does not close transfer; source-distribution design, detector capacity, and small real calibration can matter more. They also show that CAD at test time creates a distinct verification channel through mask, pose, and depth consistency, whereas CAD-unavailable inspection relies on calibrated normality and feature deviation. The review therefore argues against a single cross-task leaderboard and instead asks what prior grounds the deployment decision.
PInVerify: アクティブなインスタンス検証のためのオフライン組み込みベンチマーク
身体化されたエージェントは、ターゲットオブジェクトへのナビゲーションにおいて大きな進歩を遂げましたが、ゴール付近に到達したからといって、エージェントが正しいインスタンスを見つけたという保証はありません。微妙な属性の違い (例: 「白い花柄」と「白い縞模様」) には、多くの場合、近距離の多視点検査が必要です。私たちは、アクティブ インスタンス検証 (AIV) によってこのギャップに対処します。このタスクでは、エージェントが候補オブジェクトの周囲の視点をアクティブに選択して、それがきめ細かい自然言語記述と一致するかどうかを判断します。私たちは、AIV を有限ホライズンの意思決定プロセスとして形式化し、AIV のオフラインで具体化されたベンチマークである PInVerify を導入します。18 のオブジェクト カテゴリにわたる 3,000 の評価エピソードは、トラップ ビュー (ナビゲート可能だが情報が得られない) と到達不可能なセクターを明らかにする 6 セクター ナビゲーション トポロジを備えたマルチビュー キャプチャとして配信されます。参照ベースラインとして、属性分解、可視性を重視したマルチビュー トラッカー、および 3 つのネクスト ベスト ビュー (NBV) 戦略を使用して、オンデバイス スケール ($\leq$8B パラメーター) でオープンソースのマルチモーダル大規模言語モデル (MLLM) を中心に、トレーニング不要のパイプラインと LoRA で微調整されたエンドツーエンド エージェントを構築します。 Qwen3-VL (4B/8B)、SenseNova-SI-1.2-InternVL3-8B、CLIP、および SigLIP2 にわたる評価では、最良の MLLM ベースのベースラインが最良の埋め込みベースラインを 4.9 pp 上回りました。 GT-box アブレーションでは +3.1 pp の検出ギャップが示されています。そして、テストされた NBV 戦略内でのアクティブな視点選択による信頼性の高い利益は観察されません。 LoRA で微調整されたエージェント (SFT+GSPO) は 85.6% に達します。 PInVerify は、身体化された AI におけるアクティブで詳細なセマンティック検証に関するさらなる作業をサポートすることを目的としています。コード: https://github.com/Avalon-S/PInVerify。
原文 (English)
PInVerify: An Offline Embodied Benchmark for Active Instance Verification
Embodied agents have made strong progress in navigating to target objects, but reaching the goal vicinity does not guarantee that the agent has found the correct instance: subtle attribute differences (e.g., "white floral" vs. "white striped") often require close-range, multi-view inspection. We address this gap with Active Instance Verification (AIV), a task in which an agent actively selects viewpoints around a candidate object to decide whether it matches a fine-grained natural-language description. We formalize AIV as a finite-horizon decision process and introduce PInVerify, an offline embodied benchmark for AIV: 3,000 evaluation episodes across 18 object categories, delivered as multi-view captures with a 6-sector navigation topology that exposes trap views (navigable but uninformative) and unreachable sectors. As reference baselines we build a training-free pipeline and a LoRA-fine-tuned end-to-end agent around open-source multimodal large language models (MLLMs) at on-device scale ($\leq$8B parameters), with attribute decomposition, a visibility-weighted multi-view tracker, and three next-best-view (NBV) strategies. In our evaluation across Qwen3-VL (4B/8B), SenseNova-SI-1.2-InternVL3-8B, CLIP, and SigLIP2, the best MLLM-based baseline exceeds the best embedding baseline by 4.9 pp; GT-box ablations show a +3.1 pp detection gap; and we do not observe reliable gains from active viewpoint selection within the tested NBV strategies. A LoRA-fine-tuned agent (SFT+GSPO) reaches 85.6%. PInVerify aims to support further work on active, fine-grained semantic verification in embodied AI. Code: https://github.com/Avalon-S/PInVerify.
GSAM: A Generalizable and Safe Robotic Framework for Articulated Object Manipulation
Articulated object manipulation is a unique challenge for service robots. Existing methods employ end-to-end policy learning, visionmotion…
Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
Vision-Language-Action (VLA) models enable robots to follow natural language instructions and generalize across diverse tasks, but they rem…
TARIC: Memory-Augmented Traversability-Aware Outdoor VLN under Interrupted Semantic Cues
Outdoor vision-language navigation (VLN) in long-range, open-world environments is frequently disrupted by semantic-cue interruptions, wher…
Probing Collision Grounding in Vision-Language Models for Safe Human-Robot Collaboration
Safe human--robot collaboration requires more than visual description: a monitor must determine whether the robot body is safely separated,…
Simulation of collision avoidance behavior in crowd movement by data-driven approach
Crowd movement simulation is essential for pedestrian safety management and facility layout optimization. Data-driven models enhance trajec…
DeMaVLA: A Vision-Language-Action Foundation Model for Generalizable Deformable Manipulation
Real-world household robots require Vision-Language-Action (VLA) foundation models that can acquire reusable manipulation skills across div…
Mixture of Horizons in Action Chunking
Vision-language-action (VLA) models have shown remarkable capabilities in robotic manipulation, but their performance is sensitive to the $…
SKETCH: Semantic Key-Point Conditioning for Long-Horizon Vessel Trajectory Prediction
Accurate long-horizon vessel trajectory prediction remains challenging due to compounded uncertainty from complex navigation behaviors and…
World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry
General-purpose world models promise scalable policy evaluation, optimization, and planning, yet achieving the required level of robustness…
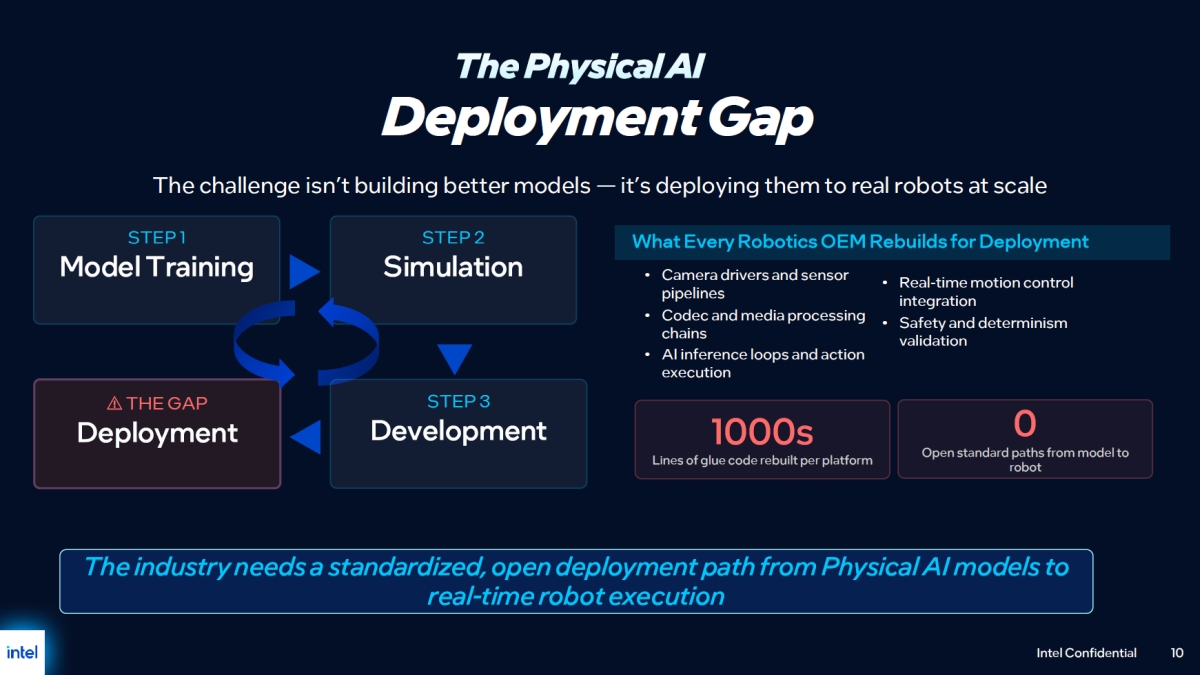
インテルがロボット開発の課題を解決、オープンなロボティクスライブラリで
インテルは、ロボット開発のための統合ソフトウェア開発キット「Robotics AI Suite」に、インテル製プロセッサに最適化された推論ランタイムを備えるオープンソースのロボティクスライブラリ「OpenVINO Physical AI Framework」を追加すると発表した。
Ultra-Reduced-Impact-Encased-Logging (URIEL): 航空機搭載ロボットシステムを使用した、熱帯林における選択的持続可能な伐採と収穫後の造林処理のための新しい方法を提案する
世界中の熱帯林は、経済的および政治的利益によって引き起こされる激しい森林破壊圧力にさらされており、科学的証拠は、この森林破壊が気候変動に寄与していることを示唆しています。この論文では、熱帯林のための新しい伐採方法、Ultra-Reduced-Impact-Encased-Logging (URIEL) を提案します。この新しい方法は、ドローンによる収穫後の造林処理と統合されたロボット工学と AI の集中的な使用と組み合わせたヘリロギング技術に基づいています。この方法に適した機器のコンセプトが開発され、寸法が決定され、デジタル概念実証で詳細が完成し、ヘリコプターと木材と距離のさまざまな組み合わせについて、効果的なデジタル シミュレーションと経済的実現可能性分析が実行されました。その結果、URIEL手法は経済性が高く、生態系サービスを維持しながら森林への巻き添え被害を実質的に排除できることが実証されました。この論文の主な結論は、科学的および技術的に満足のいく結果が得られたにもかかわらず、ウリエル法の実現可能性は、その状況に固有の利害関係者の統合に依存しているということです。政治政府。認定伐採会社。そして先住民族。
原文 (English)
Ultra-Reduced-Impact-Encased-Logging (URIEL): propose a new method for selective sustainable logging and post-harvest silvicultural treatment in tropical forest using airborne robotics systems
Tropical forests worldwide are under intense deforestation pressure driven by economic and political interests, and scientific evidence suggests this deforestation contributes to climate change. This paper proposes a novel logging method for tropical forests, Ultra-Reduced-Impact-Encased-Logging (URIEL). This new method is based on heli-logging techniques combined with intensive use of robotics and AI integrated with post-harvest silvicultural treatments performed by drones. The concept of appropriate equipment for this method was developed, dimensions were determined, details were completed in a digital proof of concept, and an effective digital simulation and economic feasibility analysis were carried out for various helicopter-timber-distance combinations. The results demonstrated that a URIEL method has high economic viability and makes it possible to virtually eliminate collateral damage to forests while maintaining ecosystem services. The main conclusion of this paper is that, despite the satisfactory scientific and technological results, the feasibility of a Uriel method depends on the integration of stakeholders intrinsic to the context: high-tech industry; political governments; certified logging companies; and native populations.
MiraBench: ロボット世界モデルにおける動作条件付き信頼性の評価
アクション条件付き世界モデルは、ロボット学習用のスケーラブルなシミュレーターとしてますます使用されていますが、現在の評価では、条件付けされたアクションの下でその予測が信頼できるという限られた証拠が提供されています。既存のベンチマークは主に視覚的な忠実度を重視しており、予測される未来が物理的に妥当であるか、命令されたアクションに忠実であるか、アクションが成功しないはずのときに失敗するように調整されているかどうかが不明確なままです。 \emph{動作条件付き信頼性} をロボット世界モデルの中核的な評価目標として定義する階層型ベンチマークである \textsc{MiraBench} を紹介します。 MiraBench は、このターゲットを 3 つの段階的に要求の高いレベルに分解します。 \emph{Physics Adherence} は、リファレンスフリーの物理的一貫性を評価します。 \emph{Action-Following Fidelity}: 予測がタスク関連のアクション入力を考慮しているかどうかを測定します。 \emph{楽観主義バイアス検出} は、失敗を誘発する行動の下で成功した結果を予測する傾向を調査します。この評価をサポートするために、タスク、失敗カテゴリ、主要な世界モデルにわたる 16,000 件を超える判断を含む人間による注釈付きコーパスを厳選しました。ベクトル条件付きロボット ワールド モデル、テキスト条件付き生成ワールド モデル、オープンウェイト システム、クローズド ソース システム、および複数のモデル スケールにわたる 12 の代表的なモデル構成を評価します。この広範なモデル環境全体にわたって、MiraBench は 3 つの中心的な発見を明らかにしました。視覚的な忠実度は、アクションの忠実度の代用としては不十分です。モデルのスケールを大きくしても、アクションの追従性が確実に改善されるわけではありません。そして楽観主義バイアスは現在のシステム全体に蔓延しています。 MiraBench は、評価を外観から動作条件付きの信頼性に移行することで、ロボットの世界モデルを忠実なシミュレーターとして評価および改善するための診断基盤を提供します。
原文 (English)
MiraBench: Evaluating Action-Conditioned Reliability in Robotic World Models
Action-conditioned world models are increasingly used as scalable simulators for robot learning, yet current evaluations provide limited evidence that their predictions are reliable under the actions they condition on. Existing benchmarks largely emphasize visual fidelity, leaving unclear whether predicted futures are physically plausible, faithful to commanded actions, and calibrated to failure when actions should not succeed. We introduce \textsc{MiraBench}, a hierarchical benchmark that defines \emph{action-conditioned reliability} as a core evaluation target for robotic world models. MiraBench decomposes this target into three progressively demanding levels: \emph{Physics Adherence}, which evaluates reference-free physical consistency; \emph{Action-Following Fidelity}, which measures whether predictions respect task-relevant action inputs; and \emph{Optimism Bias Detection}, which probes the tendency to predict successful outcomes under failure-inducing actions. To support this evaluation, we curate a human-annotated corpus with over 16,000 judgments across tasks, failure categories, and leading world models. We evaluate 12 representative model configurations spanning vector-conditioned robotic world models, text-conditioned generative world models, open-weight systems, closed-source systems, and multiple model scales. Across this broad model landscape, MiraBench reveals three central findings: visual fidelity is a poor proxy for action fidelity; increasing model scale does not reliably improve action following; and optimism bias is pervasive across current systems. By shifting evaluation from appearance to action-conditioned reliability, MiraBench provides a diagnostic foundation for assessing and improving robotic world models as faithful simulators.
Extreme dynamic symmetry enables omnidirectional and multifunctional robots
Symmetry is a central organizing principle in natural systems, yet its use as a unifying design strategy in robotics has largely remained l…
AnyMo: Scaling Any-Modality Conditional Motion Generation with Masked Modeling
Conditional human motion generation remains a fundamental challenge in computer vision and robotics. Despite significant progress, current…
VLA-Pro: Cross-Task Procedural Memory Transfer for Vision-Language-Action Models
Vision-Language-Action~(VLA) models have shown strong potential for general-purpose robotic manipulation, yet they still struggle to genera…
Energy-Aware NECO for Single-Pass Pixel-wise Out-of-Distribution Detection in Semantic Segmentation
Reliable semantic segmentation for mobile robots requires both accurate dense prediction and robust uncertainty estimation under distributi…
BORA: Bridging Offline Reinforcement Learning and Online Residual Adaptation for Real-World Dexterous VLA Models
Vision-Language-Action (VLA) models have emerged as a promising paradigm for grounding visual-language understanding into real-world roboti…
Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fra…
RoboWits: Unexpected Challenges for Robotic Creative Problem Solving
The ability to reason, adapt, and creatively solve problems under unexpected challenges is essential for robots operating in real-world env…
ScheduleStream: Temporal Planning with Samplers for GPU-Accelerated Multi-Arm Task and Motion Planning & Scheduling
Bimanual and humanoid robots are appealing because of their human-like ability to leverage multiple arms to efficiently complete tasks. How…
When Should a Robot Think? Resource-Aware Reasoning via Reinforcement Learning for Embodied Robotic Decision-Making
Embodied robotic systems increasingly rely on large language model (LLM)-based agents to support high-level reasoning, planning, and decisi…
AttenA+: Rectifying Action Inequality in Robotic Foundation Models
Existing robotic foundation models, while powerful, are predicated on an implicit assumption of temporal homogeneity: treating all actions…
HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos
Human egocentric video captures rich manipulation demonstrations without any robot hardware, yet transferring these skills to robots remain…
Ultra-Reduced-Impact-Encased-Logging (URIEL): 航空機搭載ロボットシステムを使用した、熱帯林における選択的持続可能な伐採と収穫後の造林処理のための新しい方法を提案する
世界中の熱帯林は、経済的および政治的利益によって引き起こされる激しい森林破壊圧力にさらされており、科学的証拠は、この森林破壊が気候変動に寄与していることを示唆しています。この論文では、熱帯林のための新しい伐採方法、Ultra-Reduced-Impact-Encased-Logging (URIEL) を提案します。この新しい方法は、ドローンによる収穫後の造林処理と統合されたロボット工学と AI の集中的な使用と組み合わせたヘリロギング技術に基づいています。この方法に適した機器のコンセプトが開発され、寸法が決定され、デジタル概念実証で詳細が完成し、ヘリコプターと木材と距離のさまざまな組み合わせについて、効果的なデジタル シミュレーションと経済的実現可能性分析が実行されました。その結果、URIEL手法は経済性が高く、生態系サービスを維持しながら森林への巻き添え被害を実質的に排除できることが実証されました。この論文の主な結論は、科学的および技術的に満足のいく結果が得られたにもかかわらず、ウリエル法の実現可能性は、その状況に固有の利害関係者の統合に依存しているということです。政治政府。認定伐採会社。そして先住民族。
原文 (English)
Ultra-Reduced-Impact-Encased-Logging (URIEL): propose a new method for selective sustainable logging and post-harvest silvicultural treatment in tropical forest using airborne robotics systems
Tropical forests worldwide are under intense deforestation pressure driven by economic and political interests, and scientific evidence suggests this deforestation contributes to climate change. This paper proposes a novel logging method for tropical forests, Ultra-Reduced-Impact-Encased-Logging (URIEL). This new method is based on heli-logging techniques combined with intensive use of robotics and AI integrated with post-harvest silvicultural treatments performed by drones. The concept of appropriate equipment for this method was developed, dimensions were determined, details were completed in a digital proof of concept, and an effective digital simulation and economic feasibility analysis were carried out for various helicopter-timber-distance combinations. The results demonstrated that a URIEL method has high economic viability and makes it possible to virtually eliminate collateral damage to forests while maintaining ecosystem services. The main conclusion of this paper is that, despite the satisfactory scientific and technological results, the feasibility of a Uriel method depends on the integration of stakeholders intrinsic to the context: high-tech industry; political governments; certified logging companies; and native populations.
MiraBench: ロボット世界モデルにおける動作条件付き信頼性の評価
アクション条件付き世界モデルは、ロボット学習用のスケーラブルなシミュレーターとしてますます使用されていますが、現在の評価では、条件付けされたアクションの下でその予測が信頼できるという限られた証拠が提供されています。既存のベンチマークは主に視覚的な忠実度を重視しており、予測される未来が物理的に妥当であるか、命令されたアクションに忠実であるか、アクションが成功しないはずのときに失敗するように調整されているかどうかが不明確なままです。 \emph{動作条件付き信頼性} をロボット世界モデルの中核的な評価目標として定義する階層型ベンチマークである \textsc{MiraBench} を紹介します。 MiraBench は、このターゲットを 3 つの段階的に要求の高いレベルに分解します。 \emph{Physics Adherence} は、リファレンスフリーの物理的一貫性を評価します。 \emph{Action-Following Fidelity}: 予測がタスク関連のアクション入力を考慮しているかどうかを測定します。 \emph{楽観主義バイアス検出} は、失敗を誘発する行動の下で成功した結果を予測する傾向を調査します。この評価をサポートするために、タスク、失敗カテゴリ、主要な世界モデルにわたる 16,000 件を超える判断を含む人間による注釈付きコーパスを厳選しました。ベクトル条件付きロボット ワールド モデル、テキスト条件付き生成ワールド モデル、オープンウェイト システム、クローズド ソース システム、および複数のモデル スケールにわたる 12 の代表的なモデル構成を評価します。この広範なモデル環境全体にわたって、MiraBench は 3 つの中心的な発見を明らかにしました。視覚的な忠実度は、アクションの忠実度の代用としては不十分です。モデルのスケールを大きくしても、アクションの追従性が確実に改善されるわけではありません。そして楽観主義バイアスは現在のシステム全体に蔓延しています。 MiraBench は、評価を外観から動作条件付きの信頼性に移行することで、ロボットの世界モデルを忠実なシミュレーターとして評価および改善するための診断基盤を提供します。
原文 (English)
MiraBench: Evaluating Action-Conditioned Reliability in Robotic World Models
Action-conditioned world models are increasingly used as scalable simulators for robot learning, yet current evaluations provide limited evidence that their predictions are reliable under the actions they condition on. Existing benchmarks largely emphasize visual fidelity, leaving unclear whether predicted futures are physically plausible, faithful to commanded actions, and calibrated to failure when actions should not succeed. We introduce \textsc{MiraBench}, a hierarchical benchmark that defines \emph{action-conditioned reliability} as a core evaluation target for robotic world models. MiraBench decomposes this target into three progressively demanding levels: \emph{Physics Adherence}, which evaluates reference-free physical consistency; \emph{Action-Following Fidelity}, which measures whether predictions respect task-relevant action inputs; and \emph{Optimism Bias Detection}, which probes the tendency to predict successful outcomes under failure-inducing actions. To support this evaluation, we curate a human-annotated corpus with over 16,000 judgments across tasks, failure categories, and leading world models. We evaluate 12 representative model configurations spanning vector-conditioned robotic world models, text-conditioned generative world models, open-weight systems, closed-source systems, and multiple model scales. Across this broad model landscape, MiraBench reveals three central findings: visual fidelity is a poor proxy for action fidelity; increasing model scale does not reliably improve action following; and optimism bias is pervasive across current systems. By shifting evaluation from appearance to action-conditioned reliability, MiraBench provides a diagnostic foundation for assessing and improving robotic world models as faithful simulators.
Extreme dynamic symmetry enables omnidirectional and multifunctional robots
Symmetry is a central organizing principle in natural systems, yet its use as a unifying design strategy in robotics has largely remained l…
AnyMo: Scaling Any-Modality Conditional Motion Generation with Masked Modeling
Conditional human motion generation remains a fundamental challenge in computer vision and robotics. Despite significant progress, current…
VLA-Pro: Cross-Task Procedural Memory Transfer for Vision-Language-Action Models
Vision-Language-Action~(VLA) models have shown strong potential for general-purpose robotic manipulation, yet they still struggle to genera…
Energy-Aware NECO for Single-Pass Pixel-wise Out-of-Distribution Detection in Semantic Segmentation
Reliable semantic segmentation for mobile robots requires both accurate dense prediction and robust uncertainty estimation under distributi…
BORA: Bridging Offline Reinforcement Learning and Online Residual Adaptation for Real-World Dexterous VLA Models
Vision-Language-Action (VLA) models have emerged as a promising paradigm for grounding visual-language understanding into real-world roboti…
Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fra…
RoboWits: Unexpected Challenges for Robotic Creative Problem Solving
The ability to reason, adapt, and creatively solve problems under unexpected challenges is essential for robots operating in real-world env…
ScheduleStream: Temporal Planning with Samplers for GPU-Accelerated Multi-Arm Task and Motion Planning & Scheduling
Bimanual and humanoid robots are appealing because of their human-like ability to leverage multiple arms to efficiently complete tasks. How…
When Should a Robot Think? Resource-Aware Reasoning via Reinforcement Learning for Embodied Robotic Decision-Making
Embodied robotic systems increasingly rely on large language model (LLM)-based agents to support high-level reasoning, planning, and decisi…
AttenA+: Rectifying Action Inequality in Robotic Foundation Models
Existing robotic foundation models, while powerful, are predicated on an implicit assumption of temporal homogeneity: treating all actions…
HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos
Human egocentric video captures rich manipulation demonstrations without any robot hardware, yet transferring these skills to robots remain…
「国産人型ロボ」量産化へ 東大発スタートアップ 三菱自動車も出資
東京大学発のロボット開発スタートアップHighlandersは、国産人型ロボットの量産化を目指す取り組みを始めると発表した。
管理された自律性としてのインテリジェンス: エージェントティック AI システムの障害、エスカレーション、ガバナンス
自律型およびエージェント型 AI システムがロボット環境やヒューマンマシン環境で拡張されるにつれて、幻覚や永続的だが不当な行動の管理は未解決の課題のままです。この論文では、これらの失敗の原因を単にモデルや調整の制限に帰するのではなく、無制限の自律性、つまり不確実性の増大に関係なくエージェントが動作し続けるべきであるという前提のアーキテクチャ上の脆弱性を調査します。これは、認識的ドリフトを検出し、推論を中断し、回復を試み、信頼性が低下したときに最終的に制御を放棄する形式的な能力を通じて、インテリジェントな行動を定義する管理された自律性の理論を導入します。この理論は、安定状態、メタ認知状態、支援状態、および規制状態を特徴とする 4 層フレームワークである SMARt (Self-Managing Multi-tier Autonomous Reasoning with Regulated/Revoked transitions) モデルを介してインスタンス化されます。時間制限付きで保護されたペトリ ネット定式化を開発することで、システムの理論的に制限されたプロパティを確立し、アーキテクチャがどのようにしてエスカレーションを正式に義務付け、無効な出力を制限し、指定された条件下でガバナンスの到達可能性を確保できるかを実証します。さらに、完全性と健全性の基準が満たされていると仮定して、さまざまな運用設定 (ヘルスケア、ロボット工学など) にわたってドメイン固有のトリガー セットを組み込むことで、体系的に安全性を維持できる方法を分析します。これらのトリガーは適応するように設計されているため、SMARt モデルは、時間の経過とともに、エージェントの操作範囲を安全に制御された拡張に対応します。私たちは、自律性ライフサイクル内で障害管理を形式化することが、信頼性が高く管理された人工知能を実現するための重要なステップであると結論付けています。
原文 (English)
Intelligence as Managed Autonomy: Failure, Escalation, and Governance for Agentic AI Systems
As autonomous and agentic AI systems scale in robotic and human-machine environments, managing hallucination and persistent but unjustified action remains an open challenge. Rather than attributing these failures solely to model or alignment limitations, this paper explores the architectural vulnerability of unbounded autonomy - the presumption that an agent should continue operating regardless of rising uncertainty. It introduces a theory of managed autonomy that defines intelligent behavior through the formal capacity to detect epistemic drift, suspend reasoning, attempt recovery, and ultimately surrender control when reliability diminishes. We instantiate this theory via the SMARt (Self-Managing Multi-tier Autonomous Reasoning with Regulated/Revoked transitions) model, a four-layer framework featuring Stable, Meta-cognitive, Assisted, and Regulated states. By developing a timed, guarded Petri net formulation, we establish theoretically bounded properties for the system, demonstrating how architecture can formally mandate escalation, constrain invalid outputs, and ensure governance reachability under specified conditions. We further analyze how incorporating domain-specific trigger sets across varied operational settings (e.g., healthcare, robotics, etc.) can systematically preserve safety, assuming completeness and soundness criteria are met. Because these triggers are designed to be adaptive, the SMARt model accommodates the safe, controlled expansion of an agent's operational scope over time. We conclude that formalizing failure management within the autonomy lifecycle is a crucial step toward realizing reliable and governed artificial intelligence.
Trinity: Unifying Class-Agnostic Terrain and Semantic Segmentation for Unstructured Outdoor Environments by Leveraging Synthetic Data
Terrain understanding is fundamental for mobile robots operating in unstructured outdoor environments. Existing vision-based traversability…
Simulation-Informed Diffusion for Decentralized Multi-robot Motion Planning
Decentralized multi-robot motion planning requires each robot to generate collision-free trajectories from local observations, without glob…
HumanoidMimicGen: Data Generation for Loco-Manipulation via Whole-Body Planning
Imitation learning is a promising approach for training humanoid robots to both walk and manipulate, but it requires a large number of demo…
Turning Video Models into Generalist Robot Policies
Video generative models have emerged as a promising robotics backbone, capable of generating videos that depict the completion of complex t…
Identifying Explicit Parsimonious Piece-wise Polynomial Relationships in Industrial time-series: Application to manipulator robots
This paper addresses the problem of identifying parsimonious explicit piece-wise polynomial relationships that might involve a relatively l…
CLANE: Continual Learning of Actions on Neuromorphic Hardware from Event Cameras
Recognizing and continuously learning novel human actions without forgetting prior classes is a requirement for emerging AR/VR and robotics…
DSSE: a drone swarm search environment
The Drone Swarm Search project is an environment, based on \textsc{PettingZoo}, that is to be used in conjunction with multi-agent (or sing…
SPARC: Spatial-Aware Path Planning via Attentive Agent Communication
Efficient communication is critical for decentralized Multi-Robot Path Planning (MRPP), yet existing learned communication methods treat al…
音声言語処理タスクのためのロボットと患者および医師と患者の医療対話のデータセット
大規模言語モデル (LLM) は、人工知能 (AI) に大幅な改善をもたらし、汎用タスクに適用できます。ただし、テキストまたは音声による医療相談への応用は、まだ未解決の研究問題です。本稿では、患者との相談を行うことができるMed-AIを訓練・評価するための新しい音声データセットであるMeDial-Speechを提案する。これは、ロボットと患者および医師と患者の対話から現実的な環境で収集されたもので、111 時間以上の音声データ (データ拡張なし) が含まれており、レビー小体型認知症、心不全、肩の痛み、狭心症という 4 つの健康状態をカバーしています。さらに、GPT-5 mini、DeepSeek-V3、Claude Sonnet 4 という 3 つの最先端の LLM を評価するために、文選択 (20 のオプション) による対話ベンチマークを提案します。実験の結果、Claude Sonnet 4 が文選択において最高であり、手動転写を使用した場合は 71.1%、自動転写を使用した場合は 74.7% であり、すべての LLM は確率的予測に非常に自信を持っていることが明らかになりました。医療対話における正しい文または誤った文の選択。このデータセットは、非営利目的の場合、https://huggingface.co/datasets/hcuayahu/MeDial-Speech で無料で利用できます。
原文 (English)
A Dataset of Robot-Patient and Doctor-Patient Medical Dialogues for Spoken Language Processing Tasks
Large Language Models (LLMs) have brought huge improvements to Artificial Intelligence (AI), which can be applied to general-purpose tasks. However, their application to textual or spoken medical consultations is still an open research problem. This paper proposes MeDial-Speech, a novel speech dataset for training and evaluating Med-AIs that can carry out consultations with patients. It was collected in realistic environments from robot-patient and doctor-patient dialogues, contains 111+ hours of speech data (without data augmentation), and covers four health conditions: Lewy body dementia, heart failure, shoulder pain, and angina. In addition, we propose a dialogue benchmark via sentence selection (with 20 options) to evaluate three state-of-the-art LLMs: GPT-5 mini, DeepSeek-V3, and Claude Sonnet 4. Experimental results reveal that Claude Sonnet 4 is the best in sentence selection, with 71.1% accuracy using manual transcriptions and 74.7% using automatic transcriptions, and that all LLMs are highly overconfident in their probabilistic predictions, regardless of selecting correct or incorrect sentences in medical dialogues. This dataset is free of charge for non-commercial purposes at: https://huggingface.co/datasets/hcuayahu/MeDial-Speech
FineVLA: Fine-Grained Instruction Alignment for Steerable Vision-Language-Action Policies
Vision-Language-Action (VLA) models are increasingly expected to not only complete robot tasks, but also follow human instructions about ho…
Physically Native World Models: A Hamiltonian Perspective on Generative World Modeling
World models have recently re-emerged as a central paradigm for embodied intelligence, robotics, autonomous driving, and model-based reinfo…
RoboMME: Benchmarking and Understanding Memory for Robotic Generalist Policies
Memory is critical for long-horizon and history-dependent robotic manipulation. Such tasks often involve counting repeated actions or manip…

ヒト型AIロボスタートアップのアトムが30億円調達 「日本のGDPを1%アップ」目指す
ヒューマノイドAIロボットを開発するアトム(東京都江東区)は5月27日、開発着手とあわせて、シードラウンドで総額30億円を調達したと発表した。製造業や物流・運輸の現場で使えるロボットを開発し、将来の量産化を目指す。

This startup is betting India’s gig economy can train the world’s robots
Human Archive, a startup founded by UC Berkeley and Stanford researchers, is paying gig workers in India to wear camera-equipped caps and s…
MEMOR-E: アルツハイマー病支援ロボット向けのコンテキスト内で微調整された LLM パーソナライゼーション
アルツハイマー病は、記憶力と言語の進行性の低下を特徴とする神経変性疾患であり、日常生活における自立性が低下し、社会的支援ロボットによるサポートが必要となります。この論文では、服薬リマインダー、日常的な指導、記憶指向の対話、および交際を通じて患者と介護者を支援する対話型タブレット インターフェイスを備えた移動式四足歩行ロボット MEMOR-E について紹介します。私たちは、235 人のアルツハイマー病患者からの音声転写と合成的に生成された健康な対照を使用して、段階一貫した認知行動をエミュレートし、標準的な神経心理学的言語タスク全体で反応を解釈する大規模言語モデル (LLM) の微調整の実現可能性を評価しました。また、LLM でのコンテキスト学習 (ICL) の使用に関する調査結果も報告します。この場合、2 番目の LLM がドメインおよび重大度レベルの認知エラーの概要を生成しました。私たちの結果は、MEMOR-E がパーソナライズされた支援インタラクションをサポートする、段階を認識した非診断的な認知サマリを生成できる一方、説明可能な AI メカニズムがモデルの出力を透明で人間が判読できる証拠に変換し、介護者の監視と信頼できるヒューマン ロボット インタラクションを可能にすることを示しています。
原文 (English)
MEMOR-E: In-Context and Fine-Tuned LLM Personalization for Alzheimer's Assistive Robotics
Alzheimer's disease is a neurodegenerative disorder marked by progressive declines in memory and language that reduce independence in daily life, motivating socially assistive robotic support. This paper presents MEMOR-E, a mobile quadruped robot with an interactive tablet interface that assists patients and caregivers through medication reminders, routine guidance, memory oriented interactions, and companionship. We evaluated the feasibility of fine tuning large language models (LLMs) to emulate stage consistent cognitive behavior and interpret responses across standard neuropsychological language tasks, using audio transcriptions from 235 Alzheimer's patients and synthetically generated healthy controls. We also report findings on using in context learning (ICL) in LLMs, where a second LLM produced domain and severity level cognitive error summaries. Our results show that MEMOR-E can generate stage aware, non diagnostic cognitive summaries that support personalized assistive interactions, while explainable AI mechanisms translate model outputs into transparent, human readable evidence to enable caregiver oversight and trustworthy human robot interaction.
事前定義された学習オブジェクトを超えて: 最新の自律ロボット学習のための思考学習インタラクション モデル
オープンで変化する環境で動作する自律ロボットは、事前定義された入力、出力、およびアクション ルーチンに常に依存できるとは限りません。既存の学習方法では、環境との相互作用を通じてロボットのパフォーマンスを向上させることができますが、学習の対象は、入力特徴、認識出力、ネットワーク構造、タスクの目標、またはアクションシーケンスなど、事前に固定されていることがよくあります。これにより、長期的な運用中に新しい機能、新しいカテゴリ、またはより効率的なタスク ルーチンが出現したときに適応する能力が制限されます。この問題に対処するために、本論文では自律ロボットのための思考学習相互作用モデルを提案する。中心となる考え方は、潜在的な変化の特定、有用な証拠の選択、トレーニング資料の整理、検証アクションの計画によって思考が学習を導き、一方、学習はタスクの知識、機能選択の経験、アクション戦略、および将来の推論プロセスを更新することによって思考を促進するというものです。この双方向メカニズムに基づいて、ロボットは、環境との継続的な相互作用を通じて、事前に定義された学習設定を徐々に超えて、その認識関係と行動関係を適応させることができます。具体的には、提案されたモデルは、適応的な入力特徴の発見、出力カテゴリの拡張、学習モデルの更新、およびアクション ルーチンの再構築をサポートします。実験結果は、提案したモデルが特徴適応における最終認識精度を0.419から0.845に改善し、より高い新しいカテゴリ形成精度とモデル更新成功率を達成し、アクションルーチン再構築において平均アクション長を13.0から4.0に短縮することを示しています。学習によって強化された思考では、有用な証拠の選択率が 0.272 から 0.965 に増加し、学習結果が将来の証拠の選択と推論を効果的に改善できることを示しています。
原文 (English)
Beyond Predefined Learning Objects: A Thinking-Learning Interaction Model for Up-to-Date Autonomous Robot Learning
Autonomous robots operating in open and changing environments cannot always rely on predefined inputs, outputs, and action routines. Although existing learning methods enable robots to improve their performance through environmental interaction, the objects of learning are often fixed in advance, such as input features, recognition outputs, network structures, task goals, or action sequences. This limits their ability to adapt when new features, new categories, or more efficient task routines appear during long-term operation. To address this problem, this paper proposes a thinking-learning interaction model for autonomous robots. The core idea is that thinking guides learning by identifying potential changes, selecting useful evidence, organizing training materials, and planning verification actions, while learning promotes thinking by updating task knowledge, feature-selection experience, action strategies, and future reasoning processes. Based on this bidirectional mechanism, the robot can gradually move beyond predefined learning settings and adapt its recognition relations and action relations through continuous interaction with the environment. Specifically, the proposed model supports adaptive input feature discovery, output category expansion, learning model update, and action routine reconstruction. Experimental results show that the proposed model improves the final recognition accuracy from 0.419 to 0.845 in feature adaptation, achieves higher new-category formation accuracy and model-update success rate, and reduces the average action length from 13.0 to 4.0 in action routine reconstruction. In learning-enhanced thinking, the useful evidence selection rate increases from 0.272 to 0.965, indicating that learning results can effectively improve future evidence selection and reasoning.
DisDop: オープンボキャブラリーの空中物体検出のためのドメイン事前分布による蒸留
近年のドローンの普及に伴い、航空画像の物体検出、特に事前定義されたカテゴリに制限されないオープンボキャブラリーの航空検出がますます注目を集めています。ドローンの視点画像は希少であり、自然画像との大きな違いがあるため、自然シナリオ向けに設計されたバニラのオープン語彙検出手法を直接適用して満足のいく結果を達成することは困難です。一部の研究では、軽量ネットワークを使用したり、擬似ラベルを生成したりして、事前トレーニングされたモデルから知識を伝達することを提案していますが、自然画像でトレーニングされたモデルに依存する傾向があり、リモート センシングや航空画像用に特別に調整された基礎モデルの可能性を無視しています。この制限に対処するために、リモート センシング基盤モデル (RemoteCLIP や DINOv3 など) からマルチレベル ドメイン事前分布を体系的に抽出して軽量の検出器にする統合フレームワークである DisDop を提案します。具体的には、まず、RemoteCLIP のクロスモーダル アライメント機能と DINOv3 のきめ細かい局所特徴抽出機能を組み合わせた教師融合戦略を通じて視覚的な事前情報を抽出し、それらの補完的な強みを検出器のバックボーンに転送します。次に、カテゴリ間の意味論的関係を明示的にモデル化することで、RemoteCLIP のテキスト エンコーダに埋め込まれたテキスト事前分布を抽出し、同時にグローバル文脈事前分布を組み込んで小さなオブジェクトの局所特徴表現を強化します。このマルチレベル事前蒸留フレームワークを通じて、当社の DisDop は、オープンボキャブラリーの空中検出ベンチマークで新しい最先端のパフォーマンスを達成します。広範なアブレーション分析により、当社が提案するモジュールの合理性と有効性も実証されています。
原文 (English)
DisDop: Distillation with Domain Priors for Open-Vocabulary Aerial Object Detection
With the widespread application of drones in recent years, object detection of aerial images has attracted increasing attention, especially open-vocabulary aerial detection which is not restricted to predefined categories. Due to the scarcity of drone's viewpoint images and their significant differences from natural images, it is difficult to achieve satisfying results by directly applying vanilla open-vocabulary detection methods designed for natural scenarios. Some studies propose to transfer knowledge from pre-trained models by using lightweight networks or generating pseudo labels, but they tend to rely on models trained on natural images, neglecting the potential of foundation models specifically tailored for remote sensing and aerial imagery. To address this limitation, we propose DisDop, a unified framework that systematically distills multi-level domain priors from remote sensing foundation models (e.g., RemoteCLIP and DINOv3) into a lightweight detector. Specifically, we first distill visual priors through a teacher fusion strategy that combines RemoteCLIP's cross-modal alignment capability with DINOv3's fine-grained local feature extraction ability, transferring their complementary strengths to the detector's backbone. Second, we distill textual priors embedded in RemoteCLIP's text encoder by explicitly modeling inter-category semantic relationships, while incorporating global contextual priors to enhance local feature representation for small objects. Through this multi-level prior distillation framework, our DisDop achieves new state-of-the-art performance on open-vocabulary aerial detection benchmarks. Extensive ablation analysis also demonstrates the rationality and effectiveness of our proposed modules.
HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos
Human egocentric video captures rich manipulation demonstrations without any robot hardware, yet transferring these skills to robots remain…
Bridging the Gap: Enabling Soft Actor Critic for High Performance Legged Locomotion
Proximal Policy Optimization (PPO) has become the de facto standard for training legged robots, thanks to its robustness and scalability in…
Scaling up Energy-Aware Multi-Agent Reinforcement Learning for Mission-Oriented Drone Networks with Individual Reward
Multi-agent reinforcement learning (MARL) has shown wide applicability in collaborative systems such as autonomous driving and smart cities…
Performance Comparison of Classical and Neural Sampling Algorithms for Robotic Navigation
Integrating artificial intelligence (AI) into sampling-based motion planning provides new possibilities for improving autonomous navigation…
Beyond Killer Robots: General AI Attitudes and Public Support for Military AI in Nine Countries
AI-enabled military systems are a fixture of modern military conflict. Applications vary from autonomous drones for surveillance and attack…
Parallel Differentiable Reachability for Learning and Planning with Certified Neural Dynamics and Controllers
Neural network (NN) dynamics models and control policies achieve strong performance in robotics, but providing sound guarantees under uncer…
EXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models
The ability to efficiently and reliably learn new tasks has been a foundational challenge in robotics. Vision-Language-Action (VLA) models…
Acting on the Unseen: Communication-Free Collaborative Filtering for Decentralized Multi-Robot Task Allocation
Multi-robot task allocation usually assumes some combination of communication, known task models, or a coordinator. We study the opposite e…
OASIS: Observation-Action Space Alignment via SE(3) Trajectory Prediction for Robotic Manipulation
Recent vision-language-action (VLA) models and world action models (WAMs) advance robotic manipulation by enriching intermediate representa…
When Search Becomes Memory: Turning Robot Design Trials into Transferable Skills
Large language models (LLMs) are increasingly used as proposal generators for evolutionary robot design, yet most loops remain memoryless:…
Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs
Embodied LLMs endow robots with high-level task reasoning, but they cannot reflect on what went wrong or why, turning deployment into a seq…
AEROS: A Single-Agent Operating Architecture with Embodied Capability Modules
Robotic systems lack a principled abstraction for organizing intelligence, capabilities, and execution in a unified manner. Existing approa…
VILAS: A VLA-Integrated Low-cost Architecture with Soft Grasping for Robotic Manipulation
We present VILAS, a fully low-cost, modular robotic manipulation platform designed to support end-to-end vision-language-action (VLA) polic…
Action with Visual Primitives
Vision-Language-Action (VLA) models have emerged as a promising paradigm for generalist robotic manipulation. A common design in current ar…
Agentic-VLA: 視覚-言語-行動モデルの効率的なオンライン適応
視覚言語アクション (VLA) モデルは、事前にトレーニングされた視覚言語表現を活用することで、ロボット操作の有望なパラダイムとして浮上しています。しかし、現在の VLA トレーニング方法には 2 つの重大な制限があります。それは、新しい環境への一般化が不十分であり、広範なデモンストレーションを必要とするトレーニング効率が低いことです。エージェントティック トレーニング フレームワークである Agentic-VLA を紹介します。これは、VLA が 3 つの主要なイノベーションを通じて効率的にオンラインに適応できるようにします。(1) 適応報酬合成。VLA の現在の機能とタスクの複雑さに基づいて報酬関数を動的に生成および調整し、複雑なタスクをカリキュラム学習のための学習可能なサブ目標に分解します。 (2) 言語ガイド探索。ランダムなサンプリングではなく、批評家モデルが体系的な探索のための構造化されたガイダンスを提供します。 (3) エクスペリエンス メモリ。同様のタスクへのウォーム スタート適応のために、タスク関連のポリシーの重みを保存および取得します。 LIBERO ベンチマークで Agentic-VLA を評価し、大幅な改善を達成しました。長期タスクで +12.3%、ワンショット学習で +28.5%、タスク固有のデモンストレーションなしで 0% から 31.2% までのクロスタスク転送が可能になりました。また、私たちのフレームワークは、既存のオンライン適応手法と比較して 2.4 倍高速な収束を実証しています。 LIBERO を超えて、Agentic-VLA は、ランダム化されたハード設定下を含め、デュアルアーム RoboTwin 2.0 ベンチマークで優位性を維持しています。これらの結果により、Agentic-VLA は、導入時に継続的に学習できる真の適応型 VLA システムに向けた重要なステップとして確立されます。
原文 (English)
Agentic-VLA: Efficient Online Adaptation for Vision-Language-Action Models
Vision-Language-Action (VLA) models have emerged as a promising paradigm for robotic manipulation by leveraging pre-trained vision-language representations. However, current VLA training methods suffer from two critical limitations: poor generalization to novel environments and low training efficiency requiring extensive demonstrations. We introduce Agentic-VLA, an agentic training framework that enables VLAs to efficiently adapt online through three key innovations: (1) Adaptive Reward Synthesis, which dynamically generates and adjusts reward functions based on the VLA's current capabilities and task complexity, decomposing complex tasks into learnable sub-goals for curriculum learning; (2) Language-Guided Exploration, where a critic model provides structured guidance for systematic exploration rather than random sampling; and (3) Experience Memory,which stores and retrieves task-relevant policy weights for warm-starting adaptation to similar tasks. We evaluate Agentic-VLA on the LIBERO benchmark, achieving substantial improvements: +12.3% on long-horizon tasks, +28.5% in 1-shot learning, and enabling cross-task transfer from 0% to 31.2% without task-specific demonstrations. Our framework also demonstrates 2.4x faster convergence compared to existing online adaptation methods. Beyond LIBERO, Agentic-VLA retains its advantage on the dual-arm RoboTwin 2.0 benchmark, including under its randomized Hard setting. These results establish Agentic-VLA as a significant step toward truly adaptive VLA systems capable of continuous learning in deployment.
何を尋ねるべきかを知っているロボット: 的を絞った説明を通じて、ずれた報酬を取り戻す
デモンストレーションから報酬関数を学習するには、デモンストレーションがすべての機能、つまり行動のタスク関連の側面に対して適切な監視を提供していることを前提としています。実際には、デモンストレーションは不完全であることがよくあります。人間は、認知負荷や身体的困難のために特定の機能を過小評価する可能性があり、トレーニング計画が関連するすべての状況を十分にカバーできない可能性があります。いずれの場合も、重要な機能が過少指定される可能性があり、学習された報酬関数が曖昧になり、デプロイメント時に不整合な動作が発生する可能性があります。私たちは、このような不完全な特徴を検出し、対象を絞った修正デモを積極的に募集するフレームワークを提案します。私たちの重要な洞察は、デモンストレーションによって、どの機能が適切に仕様化されているかが暗黙的に明らかになることです。一貫して最適化されている機能はデモンストレーション間でほとんど変化を示さないのに対し、仕様が不十分な機能は大きく異なります。この統計信号を活用して、どの機能が十分に実証されていない可能性があるかを推測します。次に、ロボットは自然言語でどの機能が不明であるかを説明し、特定されたギャップに明示的に対処するデモンストレーションを要求します。私たちは、シミュレートされた卓上操作領域と実際の Franka ロボットを使用したユーザー研究でアプローチを評価します。ターゲットを絞った説明ガイド付きクエリは、ランダムなクエリや受動的なデータ収集と比較して報酬の回収を大幅に向上させ、不完全なデモンストレーションから学習する際に残るであろう曖昧さを軽減します。
原文 (English)
Robots That Know What to Ask: Recovering Misaligned Rewards through Targeted Explanations
Learning reward functions from demonstrations assumes that demonstrations provide adequate supervision over all features -- or task-relevant aspects of behavior. In practice, demonstrations are often imperfect: humans may under-emphasize certain features due to cognitive load or physical difficulty, or the training regime may fail to sufficiently cover all relevant situations. In either case, important features may be underspecified, leading to ambiguity in the learned reward function and misaligned behavior at deployment. We propose a framework that detects such underspecified features and actively solicits targeted corrective demonstrations. Our key insight is that demonstrations implicitly reveal which features are well specified: features that are consistently optimized show little variation across demonstrations, while features that are underspecified vary widely. We leverage this statistical signal to infer which features may have been insufficiently demonstrated. The robot then explains which features it is uncertain about in natural language and queries for demonstrations that explicitly address the identified gaps. We evaluate our approach in a simulated tabletop manipulation domain and in a user study with a real Franka robot. Targeted, explanation-guided queries significantly improve reward recovery compared to random querying and passive data collection, reducing ambiguity that would otherwise persist in learning from imperfect demonstrations.
VLM ガイダンスによる自律的なフロンティアベースの探査
長年の課題である未知の危険な環境の自律ロボット探索は、視覚言語モデル (VLM) の高度な推論を活用することで大幅に改善できます。 VLM が高レベルの戦略的意思決定を実行し、従来の低レベルのロボット制御スタックをガイドする新しい探査パイプラインを導入します。意思決定ポイントで、ロボットは現在の地図と潜在的な経路またはフロンティアの視覚的イメージを含むマルチモーダル プロンプトを生成します。 VLM はこのプロンプトを分析して、最も有望なフロンティアを選択し、単純な幾何学的ヒューリスティックを状況に応じた空間推論に置き換えます。このアプローチは、6 つの屋内環境にわたるシミュレーションで検証され、既存の方法と比較してマップ カバレッジを最大 24\% 向上させます。当社のパイプラインは軽量でトレーニング不要で、標準センサーとインターネット接続を備えたあらゆるロボットに簡単に転送できます。
原文 (English)
Autonomous Frontier-Based Exploration with VLM Guidance
Autonomous robotic exploration of unknown and hazardous environments, a long-standing challenge, can be significantly improved by leveraging the advanced reasoning of Vision-Language Models (VLMs). We introduce a novel exploration pipeline where a VLM performs high-level strategic decision-making, guiding a conventional low-level robotics control stack. At decision points, the robot generates a multimodal prompt with its current map and visual imagery of potential paths, or frontiers. The VLM analyzes this prompt to select the most promising frontier, replacing simple geometric heuristics with contextual spatial reasoning. This approach, validated in simulation across six indoor environments, improves map coverage by up to 24\% over existing methods. Our pipeline is lightweight, training-free, and easily transferable to any robot with standard sensors and an internet connection.
モーションプリミティブからの幾何学的アセンブリによるスパース構成フローマッチング
ロボットマニピュレーター、水中車両、移動ロボットの実行可能な動作シーケンスなどの身体化された軌道は、身体化された AI の基本的な出力です。現代の生成モデルは多くの場合、データを点ごとに生成される高密度のモノリシック信号として扱い、データの潜在構造をモデル化しないまま複雑な高次元事後分布をフィッティングします。これは、構造化生成モデルの文献で長い間特定されてきたサンプルの非効率性と同じです。私たちは、構成的な潜在構造は自然な選択であると主張します。多くの具体化されたタスクは、再利用可能なモーション プリミティブの有限レパートリーとして明示化できる繰り返しのモーション フラグメントを共有し、構成単位はタスクの分解をサポートするためにサブタスクの境界と自然に一致します。しかし、既存の合成ジェネレータは潜在空間で合成し、ポストホック デコーディングに依存してサンプリングされたユニットを実際の軌跡セグメントに関連付けます。代わりに、2 つの結合されたデザインを備えたフローマッチングフレームワークを通じて、物理的な軌道空間で直接合成します。モーション プリミティブ ディクショナリ学習では、各アトムに学習可能な長さのマスクとバイナリ開始インジケーターが装備されるため、アトム自体はプリミティブであり、どこに配置されてもそのまま再利用されます。次に、幾何学的制約を使用した構造的スパース フロー マッチングにより、持続時間を考慮したトークン化と、隣接するプリミティブが出会う場所の空間的連続性と時間的連続性を強制する微分可能な幾何学的損失を使用して、バイナリ配置行列が生成されます。 Open X-Embodiment と 3DMoTraj では、フレームワークは最先端の精度を達成し、FDE/ADE 比を 1.8 から 1.07 に削減し、最も強力なベースラインと比較して ADE を 19.2%、FDE を 21.0% 改善しました。
原文 (English)
Sparse Compositional Flow Matching by geometric assembly from motion primitives
Embodied trajectories, such as the executable motion sequences of robotic manipulators, underwater vehicles, and mobile robots, are a fundamental output of embodied AI. Modern generative models often treat them as a dense, monolithic signal generated point by point, fitting an intricate high-dimensional posterior while leaving the data's latent structure unmodeled, the same sample inefficiency long identified by the structured generative model literature. We argue that a compositional latent structure is a natural choice: many embodied tasks share recurring motion fragments that can be made explicit as a finite repertoire of reusable motion primitives, and compositional units naturally align with subtask boundaries to support task decomposition. Existing compositional generators, however, compose in a latent space and rely on post-hoc decoding to relate sampled units to actual trajectory segments. We instead compose directly in the physical trajectory space through a flow-matching framework with two coupled designs. Motion-Primitive Dictionary Learning equips each atom with a learnable length mask and binary starting indicators so the atom itself is the primitive, reused verbatim wherever it is placed. Structural Sparse Flow Matching with Geometric Constraints then generates a binary placement matrix using duration-aware tokenization and a differentiable geometric loss that enforces spatial continuity and temporal contiguity where adjacent primitives meet. On Open X-Embodiment and 3DMoTraj, the framework attains state-of-the-art accuracy and reduces the FDE/ADE ratio from 1.8 to 1.07, improving ADE by 19.2% and FDE by 21.0% over the strongest baseline.
Any2Any: 人型全身追跡のための効率的な体外転送
全身追跡 (WBT) モデルは、ヒューマノイド ロボットの重要な基盤となっており、さまざまな動作を高い忠実度で模倣できるようになります。このようなモデルをゼロからトレーニングするには大規模なデータと計算が必要であり、新しいヒューマノイド プラットフォームへの迅速な展開にはコストがかかります。これにより、当然の疑問が生じます。事前トレーニングされた WBT モデルは、最小限の適応で複数の実施形態に移行できるでしょうか?この質問に答えるために、私たちは Any2Any を提案します。これは、既存の WBT スペシャリストを、少量のデータとコンピューティングだけで新しい人型の実施形態に効率的に移行するパラダイムです。 Any2Any は、まずソース ヒューマノイドとターゲット ヒューマノイドの間で運動学的な調整を実行し、事前トレーニング済みのソース ポリシーをターゲットの実施形態で有意義に再利用できるように、入力空間と出力空間を調整します。次に、Any2Any は、軽量のパラメータ効率微調整 (PEFT) コンポーネントを選択されたダイナミクスに敏感なモジュールに適用することによってダイナミクス適応を実行し、ターゲット ロボットへのターゲットを絞った適応を可能にしながら、有用な動作の事前分布を保存します。複数のヒューマノイド プラットフォームと事前トレーニングされたバックボーンに関する広範な実験により、Any2Any は、ゼロからトレーニングする場合と比較して、収束を大幅に加速し、トレーニング コストを削減しながら、競争力のあるまたは優れた追跡パフォーマンスを達成できることが示されています。特に、Any2Any は、完全なトレーニングに必要なコンピューティングとデータのわずか 1% を使用して、Unitree G1 で事前トレーニングされた Sonic モデルを LimX Oli および LimX Luna に転送することに成功しています。これらの結果は、事前訓練された WBT スペシャリストを実施形態間で効率的に再利用でき、新しいロボットに人型全身制御を導入するための拡張可能な道を提供することを示唆しています。
原文 (English)
Any2Any: Efficient Cross-Embodiment Transfer for Humanoid Whole-Body Tracking
Whole-body tracking (WBT) models have become a key foundation for humanoid robots, enabling them to imitate diverse motions with high fidelity. Training such models from scratch requires large-scale data and computation, making rapid deployment on new humanoid platforms costly. This raises a natural question: Can pretrained WBT models transfer across embodiments with minimal adaptation? To answer this question, we propose Any2Any, a paradigm that efficiently transfers an existing WBT specialist to a new humanoid embodiment with only a small amount of data and compute. Any2Any first performs kinematic alignment between source and target humanoids, aligning their input and output spaces so that the pretrained source policy can be meaningfully reused on the target embodiment.Any2Any then performs dynamics adaptation by applying lightweight parameter-efficient fine-tuning (PEFT) components to selected dynamics-sensitive modules, preserving useful behavioral priors while enabling targeted adaptation to the target robot. Extensive experiments on multiple humanoid platforms and pretrained backbones show that Any2Any substantially accelerates convergence and reduces training cost compared with training from scratch, while achieving competitive or superior tracking performance. Notably, using only 1% of the compute and data required for full training, Any2Any successfully transfers Sonic models pre-trained on Unitree G1 to LimX Oli and LimX Luna. These results suggest that pretrained WBT specialists can be efficiently reused across embodiments, providing a scalable path toward deploying humanoid whole-body control on new robots.
弱監視セグメンテーションによるサンゴ生息地マッピングのためのドローンベースのフレームワーク
広い空間範囲にわたってピクセルレベルのアノテーションを取得することは、エコロジーアプリケーションに機械学習を導入する上で依然として大きなボトルネックとなっています。ここでは、高密度の分類ベースの出力から高解像度セグメンテーション モデルをトレーニングできるマルチスケールの弱教師セマンティック セグメンテーション (WSSS) フレームワークを紹介します。私たちの方法は、水中画像からの詳細なスケールのマルチラベル予測と広範囲の航空データを組み合わせます。これらのポイントレベルの分類を、無人航空機 (UAV) オルソフォトでセマンティック セグメンテーション モデルをトレーニングするために使用できる粗い監視マスクに変換します。次に、モデル独自の洗練された予測を使用する 2 番目のトレーニング ステップを使用して、追加の注釈を必要とせずに空間精度をさらに向上させます。私たちは、サンゴ礁画像に対するアプローチを実証し、サンゴの形態型の大面積セグメンテーションを可能にし、新しいクラスを統合する際のその柔軟性を示します。最終的なモデルは、手動でアノテーションを付けたサンゴ礁ゾーンで 86.07% のピクセル精度と 52.23% の平均交差オーバーユニオン (mIoU) を達成し、ピクセル レベルのアノテーションなしで正確な大規模なサンゴのセグメンテーションを取得できることを実証しました。この方法は、スケールやモダリティを超えて画像の分類とセグメンテーションを橋渡しすることで、アノテーションが利用できない環境でセグメンテーション モデルを導入するための効率的なソリューションを提供し、生態学やその他の分野においてスケーラブルで効率的なモニタリングの機会を開きます。
原文 (English)
A drone-based framework for coral habitat mapping via weakly supervised segmentation
Obtaining pixel-level annotations over large spatial extents remains a major bottleneck for deploying machine learning in ecological applications. Here we present a multi-scale weakly supervised semantic segmentation (WSSS) framework that enables training high-resolution segmentation models from dense, classification-based outputs. Our method combines fine-scale, multi-label predictions from underwater imagery with broad-coverage aerial data. We convert these point-level classifications into coarse supervision masks that can be used to train a semantic segmentation model on Unmanned Aerial Vehicle (UAV) orthophotos. A second training step using the model's own refined predictions is then used to further improve spatial accuracy without requiring additional annotations. We demonstrate the approach on coral reef imagery, enabling large-area segmentation of coral morphotypes and illustrating its flexibility in integrating new classes. The final model achieves 86.07% pixel accuracy and 52.23% mean Intersection over Union (mIoU) on manually annotated reef zones, demonstrating that accurate large-scale coral segmentation can be obtained without pixel-level annotations. By bridging image classification and segmentation across scales and modalities, this method provides an efficient solution for deploying segmentation models in settings where annotations are unavailable and opens opportunities for scalable, efficient monitoring in ecology and beyond.
LACY: 自己改善ロボット操作のための視覚言語モデルベースの言語行動サイクル
ロボット操作のための一般化可能なポリシーの学習は、言語命令をアクションにマッピングする大規模モデル (L2A) にますます依存しています。ただし、この一方向のパラダイムでは、状況をより深く理解せずにタスクを実行するポリシーが生成されることが多く、タスクの動作を一般化または説明する能力が制限されます。私たちは、アクションを言語にマッピングする補完的なスキル (A2L) が、より全体的な基礎を身につけるために不可欠であると主張します。行動することとその行動を説明することの両方が可能なエージェントは、より豊かな内部表現を形成し、自己教師あり学習のための新しいパラダイムを解き放つことができます。単一のビジョン言語モデル内でこのような双方向マッピングを学習する統合フレームワークである LACY (Language-Action Cycle) を紹介します。 LACY は、言語からパラメータ化されたアクションを生成する (L2A)、観察されたアクションを言語で説明する (A2L)、2 つの言語記述間の意味論的な一貫性を検証する (L2C) という 3 つの相乗タスクで共同トレーニングされます。これにより、信頼性の低いケースを対象としたアクティブな拡張戦略を通じて新しいトレーニング データを自律的に生成およびフィルタリングする自己改善サイクルが可能になり、人間によるラベルを追加することなくモデルを改善できます。シミュレーションと現実世界の両方でのピックアンドプレイスタスクの実験では、LACY がタスクの成功率を平均 56.46% 向上させ、ロボット操作のためのより堅牢な言語アクションの基礎を生み出すことが示されました。プロジェクトページ:https://vla2026.github.io/LACY/
原文 (English)
LACY: A Vision-Language Model-based Language-Action Cycle for Self-Improving Robotic Manipulation
Learning generalizable policies for robotic manipulation increasingly relies on large-scale models that map language instructions to actions (L2A). However, this one-way paradigm often produces policies that execute tasks without deeper contextual understanding, limiting their ability to generalize or explain their behavior. We argue that the complementary skill of mapping actions back to language (A2L) is essential for developing more holistic grounding. An agent capable of both acting and explaining its actions can form richer internal representations and unlock new paradigms for self-supervised learning. We introduce LACY (Language-Action Cycle), a unified framework that learns such bidirectional mappings within a single vision-language model. LACY is jointly trained on three synergistic tasks: generating parameterized actions from language (L2A), explaining observed actions in language (A2L), and verifying semantic consistency between two language descriptions (L2C). This enables a self-improving cycle that autonomously generates and filters new training data through an active augmentation strategy targeting low-confidence cases, thereby improving the model without additional human labels. Experiments on pick-and-place tasks in both simulation and the real world show that LACY improves task success rates by 56.46% on average and yields more robust language-action grounding for robotic manipulation. Project page: https://vla2026.github.io/LACY/
自律的な X 線誘導脊椎手術のためのロボット制御ポリシー学習の調査
模倣学習ベースのロボット制御政策は、ビデオベースのロボット工学への新たな関心を集めています。ただし、このアプローチが、入力がまばらな脊椎器具などの X 線ガイド下処置に適用できるかどうかは不明のままです。我々は、バイプレーンガイドによるカニューレ挿入における模倣ポリシー学習の実現可能性、機会、課題を検討します。私たちは、高度な現実性を備えた X 線誘導脊椎処置のスケーラブルな自動シミュレーションのためのインシリコ サンドボックスを開発しています。私たちは、プロバイダーの段階的な位置合わせをエミュレートする、正しい軌道と対応する二平面 X 線シーケンスのデータセットを厳選します。次に、視覚情報のみに基づいて椎体形成術の設定でカニューレの位置を繰り返し調整する計画と開ループ制御のための模倣学習ポリシーをトレーニングします。この正確に制御されたセットアップにより、この方法の制限と機能についての洞察が得られます。私たちのポリシーは、症例の 68.5% で最初の試みで成功し、さまざまな椎骨レベルにわたって安全な椎弓根内の軌道を維持しました。このポリシーは、骨折を含む複雑な解剖学、およびさまざまな解剖学と初期化に移行しました。実際の X 線でのロールアウトは、妥当な軌道による部分的なシミュレーションから現実への移行が可能であることを示しています。これらの暫定的な結果は有望ですが、特にエントリーポイントの精度における限界も特定しています。今回の結果は、将来の取り組みに対する明確なベンチマークを提示するとともに、より堅牢な事前知識と領域知識があれば、このようなモデルは、軽量でCT不要のロボットによる術中脊椎ナビゲーションに向けた将来の取り組みの基盤となる可能性がある。
原文 (English)
Investigating Robot Control Policy Learning for Autonomous X-ray-guided Spine Procedures
Imitation learning-based robot control policies are enjoying renewed interest in video-based robotics. However, it remains unclear whether this approach applies to X-ray-guided procedures, such as spine instrumentation, with sparse inputs. We examine the feasibility, opportunities and challenges for imitation policy learning in bi-plane-guided cannula insertion. We develop an in silico sandbox for scalable, automated simulation of X-ray-guided spine procedures with a high degree of realism. We curate a dataset of correct trajectories and corresponding bi-planar X-ray sequences that emulate the stepwise alignment of providers. We then train imitation learning policies for planning and open-loop control that iteratively align a cannula in a vertebroplasty setting solely based on visual information. This precisely controlled setup offers insights into limitations and capabilities of this method. Our policy succeeded on the first attempt in 68.5% of cases, maintaining safe intra-pedicular trajectories across diverse vertebral levels. The policy transferred to complex anatomy, including fractures, as well as varied anatomies and initializations. Rollouts on real X-ray indicate that partial sim-to-real transfer with plausible trajectories is possible. While these preliminary results are promising, we also identify limitations, especially in entry point precision. The current results present a clear benchmark for future efforts, while with more robust priors and domain knowledge, such models may provide a foundation for future efforts toward lightweight and CT-free robotic intra-operative spinal navigation.
V-VLAPS: 価値観に基づいた視覚・言語・行動モデルの計画
視覚言語アクション (VLA) モデルは、ロボット操作のための強力なアクション事前分布を提供しますが、その反応的な動作は、分散シフトや長期的なタスク構造の下では失敗する可能性があります。最近の VLA ガイド付き計画手法では、事前トレーニングされたポリシーを使用してツリー検索をガイドすることで実行が向上していますが、ノードの選択は依然としてポリシーの事前分布と訪問数の探索に大きく依存しています。その結果、ポリシーが不適切なアクションを優先する場合、プランナーにはこのバイアスを修正するための学習値シグナルが不足します。これまでの研究では、VLA 表現がロールアウトの成功と失敗の情報をエンコードしていることが示されており、計画中の価値推定もサポートできる可能性があることが示唆されています。価値に基づくビジョン・言語・アクション計画と検索 (V-VLAPS) を導入します。これは、モンテカルロのリターンを予測するために、オフライン VLA ロールアウトでトレーニングされた軽量の価値ヘッドを使用して、VLA に基づく計画を強化します。これらの予測は、モンテカルロ ツリー検索をより価値の高い分岐に導きます。 5 つの LIBERO スイート全体で、V-VLAPS は合計でデフォルトの検索予算でバリューフリー プランニング ベースラインと一致しており、分析によると、ハード障害の多くは、予測値が弱く分離されているルート レベルのタイムアウトであることが示されています。検索バジェットが大きくなると、V-VLAPS はすべてのタスク スイートでベースラインを超えて向上し、LIBERO-Object では +6 パーセント ポイント、LIBERO-10 では +4 パーセント ポイントになりました。私たちの結果は、VLA 表現が障害予測だけでなく、価値に基づくランキングが重要なブランチに検索が到達した場合の価値に基づく計画もサポートできることを示唆しています。
原文 (English)
V-VLAPS: Value-Guided Planning for Vision-Language-Action Models
Vision-language-action (VLA) models provide strong action priors for robotic manipulation, but their reactive behavior can fail under distribution shift and long-horizon task structure. Recent VLA-guided planning methods improve execution by using pretrained policies to guide tree search, yet node selection still depends heavily on policy priors and visit-count exploration. Consequently, when the policy favors poor actions, the planner lacks a learned value signal to correct this bias. Prior work has shown that VLA representations encode rollout success and failure information, suggesting that they may also support value estimation during planning. We introduce Value-Guided Vision-Language-Action Planning and Search (V-VLAPS), which augments VLA-guided planning with a lightweight value head trained on offline VLA rollouts to predict Monte Carlo returns. These predictions guide Monte Carlo Tree Search toward higher-value branches. Across five LIBERO suites, V-VLAPS matches value-free planning baseline at the default search budget in aggregate, and analysis shows that many hard failures are root-level timeouts where predicted values are weakly separated. With a larger search budget, V-VLAPS improves over the baseline in all task suites with +6 percentage points on LIBERO-Object and +4 percentage points on LIBERO-10. Our results suggest that VLA representations can support not only failure prediction, but also value-guided planning when search reaches branches where value-based ranking matters.