Microsoft
2026年5月
Adopt $\neq$ Adapt: 現実の LLM 会話の縦断的分析
ユーザーと LLM の相互作用について説明する研究が増えてきていますが、それが描く絵はほとんど静的なものです。個々のユーザーが時間の経過とともにどのように行動を変えるかについてはほとんど知られていません。このギャップに対処するために、無作為に抽出した $\sim$12,000 人の Microsoft Bing Copilot ユーザーの会話の軌跡を分析し、WildChat-4.8M のデータと比較します。 Copilot データには集団レベルの重要な傾向が含まれていますが、個々のユーザーの軌跡の傾向ははるかに弱いことがわかります。ユーザーの習慣は圧倒的に固定的であることがわかります。また、さまざまなアクティビティ レベルのユーザー間には明らかな違いがあることもわかりました。よりアクティブなユーザーはより成功した会話をし、より複雑でプロフェッショナル志向のタスクに LLM を使用します。一部のユーザー傾向は WildChat-4.8M にも見られますが、このデータセットが高度に熟練した「パワー」ユーザーに大きく偏っているという証拠が見つかりました。最終的に、私たちの結果は、既存のユーザーの行動を変えるのが難しいことを示唆しており、ユーザーの異質性の程度を示しています。データセット間の比較では、WildChat が典型的なユーザーと AI の対話を表していないことが強調されており、これはデータのダウンストリーム使用における重要な注意事項です。
原文 (English)
Adopt $\neq$ Adapt: Longitudinal Analyses of LLM Conversations in the Wild
Although a growing body of research has begun to describe user--LLM interactions, the picture it paints is largely static; little is known about how individual users change their behavior over time. To address this gap, we analyze the conversational trajectories of $\sim$12,000 randomly sampled Microsoft Bing Copilot users and compare these with data from WildChat-4.8M. While the Copilot data contains significant population-level trends, we find that trends in individual user trajectories are much weaker; user habits prove to be overwhelmingly sticky. We also find stark differences between users of different activity levels: more active users have more successful conversations and use the LLM for more complex and professionally oriented tasks. Some user trends also appear in WildChat-4.8M, but we find evidence that this dataset is significantly skewed towards highly proficient "power" users. Ultimately, our results suggest that existing user behavior is difficult to change and demonstrate the extent of user heterogeneity. Our comparison between datasets highlights that WildChat does not represent typical user-AI interactions, an important caveat for downstream uses of the data.
強化された LLM トレーニングのためのデータ構成の謎を解く
大規模言語モデル (LLM) はさまざまな分野に革命をもたらしましたが、そのトレーニング効率は効果的なデータ キュレーションに大きく依存しています。データの選択は広く研究されていますが、特に現在の LLM は 1 つまたは数エポックのみでトレーニングされることが多いため、トレーニングを強化するための戦略的なデータ編成はまだ研究されていない領域です。この論文では、もともとデータ効率のために生成された、事前に計算されたサンプルレベルのスコアを再利用することで、追加の計算オーバーヘッドを最小限に抑え、LLM トレーニングに対するデータ構成の影響を体系的に調査します。私たちは、データ構成を最適化するための 4 つの主要なガイドライン (境界の鮮明化、周期的スケジューリング、カリキュラムの継続性、およびローカルの多様性) を特定し、形式化します。これらに基づいて、STR と SAW と呼ばれる 2 つの新しいデータ順序付け方法を導入します。事前トレーニング段階と SFT 段階の両方を含む、さまざまなモデル スケールとデータ サイズにわたる広範な実験により、要約されたガイドラインの有効性が検証されます。また、LLM トレーニングの安定性とパフォーマンスを向上させる上で、私たちが提案するデータ順序付け方法の堅牢性も示しています。 Github リンク: https://github.com/microsoft/data-effficacy/
原文 (English)
Demystifying Data Organization for Enhanced LLM Training
Large Language Models (LLMs) have revolutionized various fields, yet their training efficiency is heavily reliant on effective data curation. While data selection has been widely studied, the strategic data organization for enhanced training remains an underexplored area, particularly since current LLMs are often trained for only one or a few epochs. This paper systematically explores the influence of data organization on LLM training by reusing pre-computed sample-level scores originally generated for data efficiency, thereby incurring minimal additional computational overhead. We identify and formalize four key guidelines for optimizing data organization: Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, and Local Diversity. Guided by them, we introduce two novel data ordering methods termed STR and SAW. Extensive experiments across different model scales and data sizes, encompassing both pre-training and SFT stages, validate the effectiveness of our summarized guidelines. They also demonstrate the robustness of our proposed data ordering methods in enhancing the stability and performance of LLM training. Github Link: https://github.com/microsoft/data-efficacy/
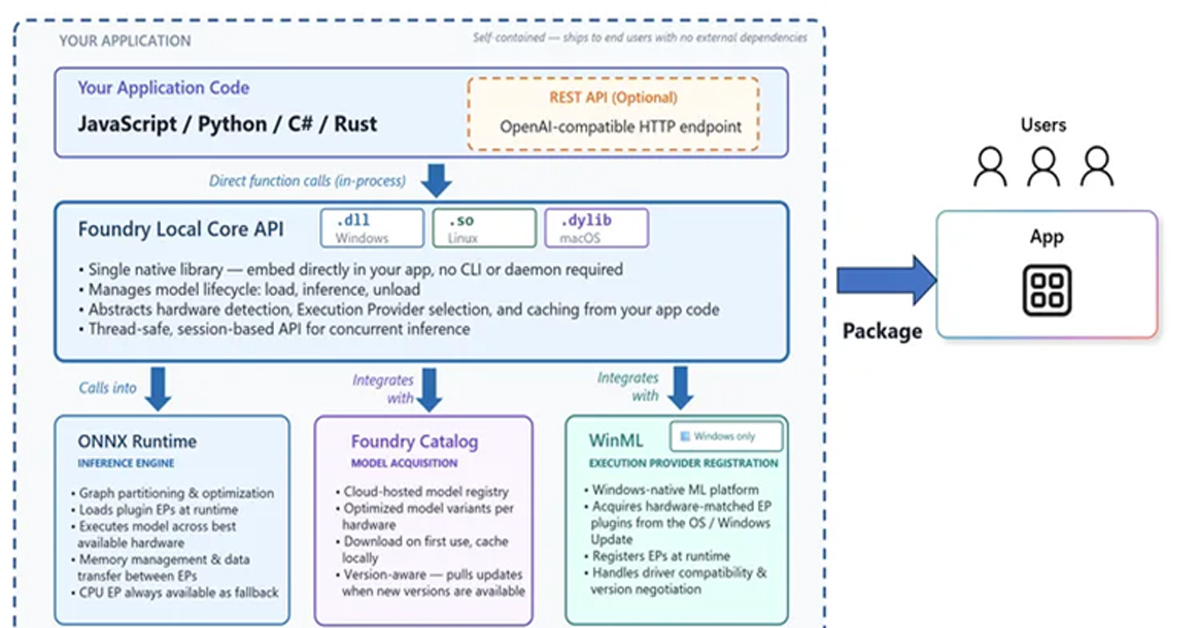
クラウド依存、コストの課題を解消? MicrosoftのローカルAI基盤「Foundry Local」
Microsoftは、開発者がアプリケーションにAI機能を組み込めるローカルAI実行基盤「Foundry Local」の一般提供を開始した。ユーザーの端末上でAI処理を完結させる仕組みにより、クラウドへの依存やネットワーク遅延、トークン課金が発生しないAI実装が可能になるという。
Qiskit QuantumKatas: Adapting Microsoft's Quantum Computing exercises for LLM evaluation
We adapt Microsoft's QuantumKatas -- a well-established quantum computing curriculum -- from Q# to Qiskit, the most widely-adopted quantum…
Microsoft Security Copilot による GenAI 主導の脅威検出
今日のますます巧妙化するサイバー攻撃を防御するには、セキュリティ アナリストが進化する攻撃者の手口を検出ロジックに継続的に変換する必要があります。これにより、防御側は事後対応の態勢に置かれ、断片化が進むセキュリティ環境全体にわたって常に最新の専門知識が必要となります。動的脅威検出エージェント (DTDA) を導入します。これは、Microsoft Defender 全体のセキュリティ インシデントを継続的に調査し、隠れた脅威を明らかにし、攻撃ストーリーのギャップが見つかった場合に説明可能な検出を生成する、常時稼働の適応型エージェントです。 DTDA は以下を組み合わせます。(1) アラート、イベント、ユーザーおよびエンティティの行動分析、脅威インテリジェンスにわたる統合されたアクティビティ タイムライン。 (2) スキーマ検証、グラウンディング要件、制限付き再試行、およびフェールクローズ抑制を備えたバージョン化された LLM プロンプト コントラクト。 (3) 攻撃固有の仮説を生成し、裏付けと反駁の証拠を収集する、計画者と実行者の調査ループ。 (4) コンテキストに関連したタイトル、重大度、MITRE マッピング、修復ガイダンス、関係するエンティティ、および自然言語攻撃の説明を含む動的なアラート生成。 DTDA は Microsoft Security Copilot に統合され、数万の Defender 顧客に展開され、業界規模で継続的に運用されています。 120 日間のオンライン評価で、DTDA は顧客のフィードバックから 80.1% の精度を達成し、調査されたインシデントの約 15% に対して新しいアラートを生成しました。オフライン評価では、DTDA は GPT-5.4 を使用して隠れた悪意のあるアクティビティを 0.78 F1 で回復し、GPT-4.1 よりも 0.12 F1 改善し、ベースラインを 0.26 F1 ポイント上回りました。運用上、DTDA は単一インシデントの調査をエンドツーエンドで中央値 28 分、トークンコスト中央値 2.04 米ドル、ジョブレベル失敗率 0.38% で処理します。これらの結果は、自律エージェントが運用規模で見逃した悪意のあるアクティビティを特定できることを示しています。
原文 (English)
GenAI-Driven Threat Detection with Microsoft Security Copilot
Defending against today's increasingly sophisticated cyberattacks requires security analysts to continuously translate evolving attacker tradecraft into detection logic. This places defenders in a reactive posture, requiring constantly updated expertise across an increasingly fragmented security landscape. We introduce the Dynamic Threat Detection Agent (DTDA), an always-on adaptive agent that continuously investigates security incidents across Microsoft Defender to uncover hidden threats and generate explainable detections when attack-story gaps are found. DTDA combines: (1) a unified activity timeline spanning alerts, events, user and entity behavior analytics, and threat intelligence; (2) versioned LLM prompt contracts with schema validation, grounding requirements, bounded retries, and fail-closed suppression; (3) a planner-executor investigation loop that generates attack-specific hypotheses and gathers supporting and refuting evidence; and (4) dynamic alert generation with a context-relevant title, severity, MITRE mappings, remediation guidance, implicated entities, and natural-language attack description. Integrated into Microsoft Security Copilot and deployed across tens of thousands of Defender customers, DTDA operates continuously at industry scale. In a 120-day online evaluation, DTDA achieves 80.1% precision from customer feedback while generating novel alerts for approximately 15% of investigated incidents. In offline evaluation, DTDA recovers hidden malicious activity with 0.78 F1 using GPT-5.4, improving over GPT-4.1 by 0.12 F1 and outperforming the baseline by 0.26 F1 points. Operationally, DTDA processes single-incident investigations end-to-end in a median of 28 minutes at a median token cost of USD 2.04, with a 0.38% job-level failure rate. These results demonstrate that autonomous agents can identify missed malicious activity at a production scale.

ソースネクストのAI議事録、Microsoft 365 Copilot連携で検索、要約を効率化
ソースネクストは、AI議事録サービス「AutoMemo」の新機能として、「AutoMemo Copilot エージェント」の提供を始めた。Microsoft 365 Copilotから過去の会議データを検索、要約、抽出できるようにし、議事録作成や報告業務の効率化を支援する。