トピック: ハードウェア/半導体
該当記事 170 件 / 新しい順
ASP ベースのコンプライアンス推論のための規範的な中間表現
我々は、ASP ベースのコンプライアンス推論のためのモーダル化出力規範中間表現である MONIR を提案します。そのコア フラグメントには段階的な操作セマンティクスがあり、MONIR-ASP は外部関数、一時的なルール、および安定したモデル推論のための実行可能なコンパイルと拡張機能を提供します。 LLM 支援パイプラインを使用して、中国の ADAS 規制と標準に関するフレームワークをインスタンス化します。実験では、抽出品質と、モジュール式および増分 ASP 解決の効率を評価します。
原文 (English)
A Normative Intermediate Representation for ASP-Based Compliance Reasoning
We propose MONIR, a Modalized-Output Normative Intermediate Representation for ASP-based compliance reasoning. Its core fragment has a staged operational semantics, while MONIR-ASP provides an executable compilation and extensions for external functions, temporal rules, and stable-model reasoning. We instantiate the framework on Chinese ADAS regulations and standards with an LLM-assisted pipeline. Experiments evaluate extraction quality and the efficiency of modular and incremental ASP solving.
DiffAero: 効率的なクアドローター ポリシー学習のための GPU アクセラレーションによる微分可能シミュレーション フレームワーク
このレターでは、効率的なクワッドローター制御ポリシー学習のために設計された、軽量で GPU アクセラレーションを備えた完全微分可能なシミュレーション フレームワークである DiffAero を紹介します。 DiffAero は、環境レベルとエージェント レベルの両方の並列処理をサポートし、複数のダイナミクス モデル、カスタマイズ可能なセンサー スタック (IMU、深度カメラ、LiDAR)、および多様な飛行タスクを統合された GPU ネイティブのトレーニング インターフェイス内に統合します。 DiffAero は、GPU 上で物理とレンダリングの両方を完全に並列化することで、CPU と GPU 間のデータ転送のボトルネックを排除し、シミュレーションのスループットを桁違いに向上させます。既存のシミュレータとは対照的に、DiffAero は高性能シミュレーションを提供するだけでなく、微分可能なハイブリッド学習アルゴリズムを探索するための研究プラットフォームとしても機能します。広範なベンチマークと実際の飛行実験により、DiffAero とハイブリッド学習アルゴリズムを組み合わせることで、消費者グレードのハードウェアで堅牢な飛行ポリシーを数時間で学習できることが実証されました。コードは https://github.com/flyingbitac/diffaero で入手できます。
原文 (English)
DiffAero: A GPU-Accelerated Differentiable Simulation Framework for Efficient Quadrotor Policy Learning
This letter introduces DiffAero, a lightweight, GPU-accelerated, and fully differentiable simulation framework designed for efficient quadrotor control policy learning. DiffAero supports both environment-level and agent-level parallelism and integrates multiple dynamics models, customizable sensor stacks (IMU, depth camera, and LiDAR), and diverse flight tasks within a unified, GPU-native training interface. By fully parallelizing both physics and rendering on the GPU, DiffAero eliminates CPU-GPU data transfer bottlenecks and delivers orders-of-magnitude improvements in simulation throughput. In contrast to existing simulators, DiffAero not only provides high-performance simulation but also serves as a research platform for exploring differentiable and hybrid learning algorithms. Extensive benchmarks and real-world flight experiments demonstrate that DiffAero and hybrid learning algorithms combined can learn robust flight policies in hours on consumer-grade hardware. The code is available at https://github.com/flyingbitac/diffaero.
CodegenBench: LLM はアーキテクチャ全体で効率的なコードを記述できますか?
大規模言語モデル (LLM) は、汎用プログラミングや GPU アクセラレーション環境 (PyTorch、CUDA など) のコード生成タスクで広範囲に評価されてきましたが、多様なアーキテクチャにわたる CPU 指向のハイパフォーマンス コンピューティング (HPC) における LLM の機能はまだ十分に解明されていません。このギャップを埋めるために、x86_64、Sunway、Kunpeng の 3 つの異なるハードウェア プラットフォームにわたる効率的な並列コードの生成を評価するように設計された包括的なベンチマーク スイートである CodegenBench を紹介します。私たちのベンチマークは、基本的なベースラインを確立する 106 個の標準基本線形代数サブプログラム (BLAS) ルーチンと、独自のスーパーコンピューティング アーキテクチャ (LeetSunway および LeetKunpeng) のそれぞれに適合した 20 個の特殊な計算カーネルで構成されています。私たちの広範な評価により、最先端の LLM は x86_64 のようなユビキタス アーキテクチャ向けに最適化されたコードを生成できる一方で、公開ドキュメントやトレーニング データが限られたドメイン固有のアーキテクチャでは大幅なパフォーマンスの低下を示し、クロスプラットフォームの一般化における重大な制限が浮き彫りになったことが明らかになりました。さらに、実装の長さやタスクの複雑さなど、コードの品質に影響を与える要因を分析したところ、現在の LLM は、簡潔なコード スニペットを必要とする中程度に難しい問題に対して最も効果的であることが示されています。私たちは、LLM 主導の高性能コード生成における将来の研究を促進するために、データセットと自動評価インフラストラクチャをオープンソースにしています。リソースは https://anonymous.4open.science/r/CodegenBench-EDE1/ および https://anonymous.4open.science/r/CodegenBenchDataset-2551 で利用できます。
原文 (English)
CodegenBench: Can LLMs Write Efficient Code Across Architectures?
While large language models (LLMs) have been extensively evaluated on code generation tasks for general-purpose programming and GPU-accelerated environments (e.g., PyTorch, CUDA), their capabilities in CPU-oriented high-performance computing (HPC) across diverse architectures remain underexplored. To bridge this gap, we introduce CodegenBench, a comprehensive benchmark suite designed to evaluate the generation of efficient parallel code across three distinct hardware platforms: x86_64, Sunway, and Kunpeng. Our benchmark comprises 106 standard Basic Linear Algebra Subprograms (BLAS) routines establishing a fundamental baseline, alongside 20 specialized computational kernels adapted for each of the unique supercomputing architectures (LeetSunway and LeetKunpeng). Our extensive evaluation reveals that while state-of-the-art LLMs can generate optimized code for ubiquitous architectures like x86_64, they exhibit significant performance degradation on domain-specific architectures with limited public documentation and training data, highlighting critical limitations in cross-platform generalization. Furthermore, our analysis of factors influencing code quality such as implementation length and task complexity indicates that current LLMs are most effective for moderately difficult problems requiring concise code snippets. We open-source our dataset and automated evaluation infrastructure to facilitate future research in LLM-driven high-performance code generation. The resources are available at https://anonymous.4open.science/r/CodegenBench-EDE1/ and https://anonymous.4open.science/r/CodegenBenchDataset-2551.
Caught in the Act(ivation): LLM エージェントによる資格情報漏洩の事前出力およびマルチターン検出に向けて
LLM エージェントは多くの場合、機密認証情報を信頼できない取得コンテンツと同じコンテキスト ウィンドウに配置し、認証情報の漏洩を誘発する間接的なプロンプト インジェクションの直接パスを作成します。私たちは、3 つの相補的な防御を通じてこの障害モードを研究します。まず、出力トークンが発行される前に、アクティベーション プローブが資格情報へのアクセスを検出できるかどうかを尋ねます。次に、形式固有の文字モデルからハニートークンを構築し、分割等角予測で検出を調整します。 3 番目に、複数ターンにわたる漏洩を累積的な情報フロー問題として扱い、会話ターン全体での推定漏洩予算を追跡します。オープンウェイト モデルの制御された実験では、アクティベーション機能により、ホールドアウト エンコーディング変換下を含め、無害なプロンプトと認証情報を求めるプロンプトが高精度で分離されます。小規模な合成マルチターン スイートでは、累積アカウンティングにより、ターンごとの検出器が見逃した攻撃が検出されます。これらの結果は暫定的なものです。マルチターン ベンチマークは社内で小規模なものであり、アクティブ化方法にはホワイト ボックス アクセスが必要であり、情報推定ツールは正式な上限ではなく実用的なシグナルを提供します。それでも、この結果は、資格情報の漏洩防御には、テキストレベルの出力フィルターのみに依存するのではなく、出力前の監視、調整されたカナリア検出、および一時的な漏洩アカウンティングを組み合わせる必要があることを示唆しています。
原文 (English)
Caught in the Act(ivation): Toward Pre-Output and Multi-Turn Detection of Credential Exfiltration by LLM Agents
LLM agents often place sensitive credentials in the same context window as untrusted retrieved content, creating a direct path for indirect prompt injection to induce credential exfiltration. We study this failure mode through three complementary defenses. First, we ask whether activation probes can detect credential access before output tokens are emitted. Second, we construct honeytokens from format-specific character models and calibrate detection with split conformal prediction. Third, we treat multi-turn exfiltration as a cumulative information-flow problem and track an estimated leakage budget across conversation turns. In controlled experiments on open-weight models, activation features separate benign and credential-seeking prompts with high accuracy, including under held-out encoding transformations. In a small synthetic multi-turn suite, cumulative accounting detects attacks that per-turn detectors miss. These results are preliminary: the multi-turn benchmark is in-house and small, the activation method requires white-box access, and the information estimator provides a practical signal rather than a formal upper bound. Still, the results suggest that credential-exfiltration defenses should combine pre-output monitoring, calibrated canary detection, and temporal leakage accounting rather than relying only on text-level output filters.
トークンランキングは偽造不可能な言語モデル署名です
言語モデルのパラメータは、ロジット出力に(各モデルに)一意の幾何学的制約を課すことが知られており、これはモデルを識別する署名として機能しますが、API がロジットを配布するときにモデルの最終層パラメータも漏洩します。私たちは、トークンのランキング (確率値ではなく、確率による順序付け) を公開する、より制限的な API を調査し、ランキングも署名を構成することを発見しました。すべてのモデルは、十分な規模の $k$ に対して実行可能な上位 $k$ ランキングの独自のセットを持っています。さらに、同じ実行可能なランキングのセットを持つモデルを見つけることは NP 困難であるため、ランキング署名は最初に知られている (多項式的に) 偽造不可能な署名です。セキュリティの面では、ロジットと同様に、トークンのランキングがすでにモデルの最終層をほぼ盗むのに十分であることがわかりました。ただし、近似が粗すぎて署名を偽造できず、API を十分に小さい $k$ の上位 $k$ トークンに制限することで効果的に対抗できます。モデル署名を提示するために必要な $k$ は一般に、盗用を防ぐために必要な $k$ よりも小さいため、API はモデル パラメーターを漏らすことなく偽造不可能な署名を提示することが可能です。
原文 (English)
Token Rankings are Unforgeable Language Model Signatures
Language model parameters are known to impose unique (to each model) geometric constraints on their logit outputs, which serves as a signature that identifies the model, but also leaks the model's final layer parameters when an API distributes logits. We investigate more restrictive APIs that expose token rankings (i.e., their ordering by probability, but not the probability values) and find that rankings also constitute a signature: every model has a unique set of feasible top-$k$ rankings for sufficiently large $k$. Furthermore, the ranking signature is the first known (polynomially) unforgeable signature, since finding a model with the same set of feasible rankings is NP-hard. On the security front, we find that token rankings are already sufficient to approximately steal the final layer of the model, similar to logits, though the approximation is too coarse to forge the signature, and can be effectively countered by restricting the API to top-$k$ tokens with sufficiently small $k$. Since the top-$k$ required to present the model signature is generally smaller than the $k$ required to prevent stealing, it is possible for an API to present an unforgeable signature without leaking model parameters.
ルーブリックベースの強化学習における報酬ハッキングの再現、分析、検出
ルーブリックベースの強化学習 (RL) は、LLM-as-a-Judge (LaaJ) を使用して、報酬としてルーブリックに従ってモデルの出力を採点します。ただし、政策モデルは裁判官の潜在的なバイアスを悪用し、報酬のハッキングや非効果的または危険なトレーニング結果につながる可能性があります。現実のルーブリックベースの RL では、このようなハッキング行為は多くの場合微妙であり、複数の裁判官のバイアスと絡み合っているため、分析、検出、軽減することが困難です。このペーパーでは、ルーブリックベースの RL のための制御可能なハッキング環境である CHERRL を紹介します。既知のバイアスを LaaJ に注入することで、CHERRL は報酬ハッキングの安定した再現、報酬の発散の明確な観察、およびハッキングの開始の正確な特定を可能にします。これは、ルーブリック ベースの RL における報酬ハッキングのメカニズムと緩和を研究するためのクリーンな実験テストベッドを提供します。その有用性を実証するために、発見可能性と悪用可能性の観点からさまざまな裁判官のバイアスを分析し、トレーニングログから報酬ハッキングの開始を自動的に検出するためのエージェントベースのシステムを調査します。コードと環境は https://github.com/THUAIS-Lab/CHERRL で公開されています。
原文 (English)
Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
Rubric-based reinforcement learning (RL) uses an LLM-as-a-Judge (LaaJ) to score model outputs according to rubrics as rewards. However, policy models may exploit latent biases in the judge, leading to reward hacking and ineffective or unsafe training outcomes. In real-world rubric-based RL, such hacking behaviors are often subtle and entangled with multiple judge biases, making them difficult to analyze, detect, and mitigate. In this paper, we introduce CHERRL, a controllable hacking environment for rubric-based RL. By injecting known biases into LaaJ, CHERRL enables stable reproduction of reward hacking, explicit observation of reward divergence, and precise identification of hacking onset. This provides a clean experimental testbed for studying the mechanisms and mitigations of reward hacking in rubric-based RL. To demonstrate its utility, we analyze different judge biases from the perspectives of discoverability and exploitability, and explore an agent-based system for automatically detecting reward hacking onset from training logs. The code and environment are publicly available at https://github.com/THUAIS-Lab/CHERRL.
制約付き適応拒否サンプリング
言語モデル (LM) は、生成された出力が厳密な意味論的または構文上の制約を満たす必要があるアプリケーションで使用されることが増えています。制約付き生成に対する既存のアプローチはさまざまです。貪欲な制約付きデコード方法は、デコード中に有効性を強制しますが、LM の分布を歪めます。一方、リジェクション サンプリング (RS) は忠実度を維持しますが、無効な出力を破棄することで計算を無駄にします。サンプルの有効性と多様性の両方が重要であるプログラム ファジングなどの領域では、両極端が問題となります。我々は、分布歪みを生じさせずに RS のサンプル効率を厳密に改善するアプローチである、制約付き適応除去サンプリング (CARS) を紹介します。 CARS は、制約のない LM サンプリングから始まり、制約違反の継続をトライに記録し、将来の描画から確率質量を差し引くことで、制約に違反する継続を適応的に除外します。この適応的な枝刈りにより、無効であることが証明されたプレフィックスが決して再検討されず、受け入れ率が単調に向上し、結果として得られるサンプルが制約された分布に正確に従うことが保証されます。プログラムのファジングや分子生成など、さまざまな領域の実験において、CARS は一貫して高い効率 (有効サンプルあたりの LM フォワードパスの数で測定) を達成すると同時に、GCD や LM の分布を近似する方法の両方よりも強力なサンプル多様性を生み出します。
原文 (English)
Constrained Adaptive Rejection Sampling
Language Models (LMs) are increasingly used in applications where generated outputs must satisfy strict semantic or syntactic constraints. Existing approaches to constrained generation fall along a spectrum: greedy constrained decoding methods enforce validity during decoding but distort the LM's distribution, while rejection sampling (RS) preserves fidelity but wastes computation by discarding invalid outputs. Both extremes are problematic in domains such as program fuzzing, where both validity and diversity of samples are essential. We present Constrained Adaptive Rejection Sampling (CARS), an approach that strictly improves the sample-efficiency of RS without distributional distortion. CARS begins with unconstrained LM sampling and adaptively rules out constraint-violating continuations by recording them in a trie and subtracting their probability mass from future draws. This adaptive pruning ensures that prefixes proven invalid are never revisited, acceptance rates improve monotonically, and the resulting samples exactly follow the constrained distribution. In experiments on a variety of domains -- e.g., program fuzzing and molecular generation -- CARS consistently achieves higher efficiency -- measured in the number of LM forward passes per valid sample -- while also producing stronger sample diversity than both GCD and methods that approximate the LM's distribution.
モデルを保持した適応丸め
量子化の目標は、出力分布が元のモデルにできるだけ近い圧縮モデルを生成することです。これを容易に行うために、ほとんどの量子化アルゴリズムは、エンドツーエンド エラーの代理として各層の即時アクティブ化エラーを最小限に抑えます。ただし、これは将来のレイヤーの影響を無視するため、プロキシとしては不十分です。この研究では、ネットワークの出力での誤差を直接考慮する適応丸めアルゴリズムである Yet Another Quantization Algorithm (YAQA) を導入します。 YAQA は、量子化アルゴリズムの最初のエンドツーエンド誤差限界に至る一連の理論的結果を紹介します。まず、ヘッセ近似の構造を介して、適応丸めアルゴリズムの収束時間を特徴付けます。次に、エンドツーエンド誤差が真のヘッセ行列に対する近似のコサイン類似度によって制限される可能性があることを示します。これにより、対応する最適に近いヘッシアン スケッチを使用した自然なクロネッカー因数近似が可能になります。 YAQA は GPTQ/LDLQ よりも優れていることが証明されており、経験的にはこれらの方法よりも誤差が $\約 30\%$ 減少します。 YAQA は、量子化を意識したトレーニングよりも低い誤差を実現します。これにより、推論のオーバーヘッドがまったく追加されずに、ダウンストリーム タスクで最先端のパフォーマンスが得られます。
原文 (English)
Model-Preserving Adaptive Rounding
The goal of quantization is to produce a compressed model whose output distribution is as close to the original model's as possible. To do this tractably, most quantization algorithms minimize the immediate activation error of each layer as a proxy for the end-to-end error. However, this ignores the effect of future layers, making it a poor proxy. In this work, we introduce Yet Another Quantization Algorithm (YAQA), an adaptive rounding algorithm that directly considers the error at the network's output. YAQA introduces a series of theoretical results that culminate in the first end-to-end error bounds for quantization algorithms. First, we characterize the convergence time of adaptive rounding algorithms via the structure of their Hessian approximations. We then show that the end-to-end error can be bounded by the approximation's cosine similarity to the true Hessian. This admits a natural Kronecker-factored approximation with corresponding near-optimal Hessian sketches. YAQA is provably better than GPTQ/LDLQ and empirically reduces the error by $\approx 30\%$ over these methods. YAQA even achieves a lower error than quantization aware training. This translates to state of the art performance on downstream tasks, all while adding no inference overhead.
Curated Synthetic Data Doesn't Have to Collapse: A Theoretical Study of Generative Retraining with Pluralistic Preferences
Recursive retraining of generative models poses a critical representation challenge: when synthetic outputs are curated based on a fixed re…
Consistency Training Can Entrench Misalignment
Consistency training encourages a model to produce similar outputs across related inputs or sampling procedures. Such methods are simple, s…
ASP ベースのコンプライアンス推論のための規範的な中間表現
我々は、ASP ベースのコンプライアンス推論のためのモーダル化出力規範中間表現である MONIR を提案します。そのコア フラグメントには段階的な操作セマンティクスがあり、MONIR-ASP は外部関数、一時的なルール、および安定したモデル推論のための実行可能なコンパイルと拡張機能を提供します。 LLM 支援パイプラインを使用して、中国の ADAS 規制と標準に関するフレームワークをインスタンス化します。実験では、抽出品質と、モジュール式および増分 ASP 解決の効率を評価します。
原文 (English)
A Normative Intermediate Representation for ASP-Based Compliance Reasoning
We propose MONIR, a Modalized-Output Normative Intermediate Representation for ASP-based compliance reasoning. Its core fragment has a staged operational semantics, while MONIR-ASP provides an executable compilation and extensions for external functions, temporal rules, and stable-model reasoning. We instantiate the framework on Chinese ADAS regulations and standards with an LLM-assisted pipeline. Experiments evaluate extraction quality and the efficiency of modular and incremental ASP solving.
DiffAero: 効率的なクアドローター ポリシー学習のための GPU アクセラレーションによる微分可能シミュレーション フレームワーク
このレターでは、効率的なクワッドローター制御ポリシー学習のために設計された、軽量で GPU アクセラレーションを備えた完全微分可能なシミュレーション フレームワークである DiffAero を紹介します。 DiffAero は、環境レベルとエージェント レベルの両方の並列処理をサポートし、複数のダイナミクス モデル、カスタマイズ可能なセンサー スタック (IMU、深度カメラ、LiDAR)、および多様な飛行タスクを統合された GPU ネイティブのトレーニング インターフェイス内に統合します。 DiffAero は、GPU 上で物理とレンダリングの両方を完全に並列化することで、CPU と GPU 間のデータ転送のボトルネックを排除し、シミュレーションのスループットを桁違いに向上させます。既存のシミュレータとは対照的に、DiffAero は高性能シミュレーションを提供するだけでなく、微分可能なハイブリッド学習アルゴリズムを探索するための研究プラットフォームとしても機能します。広範なベンチマークと実際の飛行実験により、DiffAero とハイブリッド学習アルゴリズムを組み合わせることで、消費者グレードのハードウェアで堅牢な飛行ポリシーを数時間で学習できることが実証されました。コードは https://github.com/flyingbitac/diffaero で入手できます。
原文 (English)
DiffAero: A GPU-Accelerated Differentiable Simulation Framework for Efficient Quadrotor Policy Learning
This letter introduces DiffAero, a lightweight, GPU-accelerated, and fully differentiable simulation framework designed for efficient quadrotor control policy learning. DiffAero supports both environment-level and agent-level parallelism and integrates multiple dynamics models, customizable sensor stacks (IMU, depth camera, and LiDAR), and diverse flight tasks within a unified, GPU-native training interface. By fully parallelizing both physics and rendering on the GPU, DiffAero eliminates CPU-GPU data transfer bottlenecks and delivers orders-of-magnitude improvements in simulation throughput. In contrast to existing simulators, DiffAero not only provides high-performance simulation but also serves as a research platform for exploring differentiable and hybrid learning algorithms. Extensive benchmarks and real-world flight experiments demonstrate that DiffAero and hybrid learning algorithms combined can learn robust flight policies in hours on consumer-grade hardware. The code is available at https://github.com/flyingbitac/diffaero.
CodegenBench: LLM はアーキテクチャ全体で効率的なコードを記述できますか?
大規模言語モデル (LLM) は、汎用プログラミングや GPU アクセラレーション環境 (PyTorch、CUDA など) のコード生成タスクで広範囲に評価されてきましたが、多様なアーキテクチャにわたる CPU 指向のハイパフォーマンス コンピューティング (HPC) における LLM の機能はまだ十分に解明されていません。このギャップを埋めるために、x86_64、Sunway、Kunpeng の 3 つの異なるハードウェア プラットフォームにわたる効率的な並列コードの生成を評価するように設計された包括的なベンチマーク スイートである CodegenBench を紹介します。私たちのベンチマークは、基本的なベースラインを確立する 106 個の標準基本線形代数サブプログラム (BLAS) ルーチンと、独自のスーパーコンピューティング アーキテクチャ (LeetSunway および LeetKunpeng) のそれぞれに適合した 20 個の特殊な計算カーネルで構成されています。私たちの広範な評価により、最先端の LLM は x86_64 のようなユビキタス アーキテクチャ向けに最適化されたコードを生成できる一方で、公開ドキュメントやトレーニング データが限られたドメイン固有のアーキテクチャでは大幅なパフォーマンスの低下を示し、クロスプラットフォームの一般化における重大な制限が浮き彫りになったことが明らかになりました。さらに、実装の長さやタスクの複雑さなど、コードの品質に影響を与える要因を分析したところ、現在の LLM は、簡潔なコード スニペットを必要とする中程度に難しい問題に対して最も効果的であることが示されています。私たちは、LLM 主導の高性能コード生成における将来の研究を促進するために、データセットと自動評価インフラストラクチャをオープンソースにしています。リソースは https://anonymous.4open.science/r/CodegenBench-EDE1/ および https://anonymous.4open.science/r/CodegenBenchDataset-2551 で利用できます。
原文 (English)
CodegenBench: Can LLMs Write Efficient Code Across Architectures?
While large language models (LLMs) have been extensively evaluated on code generation tasks for general-purpose programming and GPU-accelerated environments (e.g., PyTorch, CUDA), their capabilities in CPU-oriented high-performance computing (HPC) across diverse architectures remain underexplored. To bridge this gap, we introduce CodegenBench, a comprehensive benchmark suite designed to evaluate the generation of efficient parallel code across three distinct hardware platforms: x86_64, Sunway, and Kunpeng. Our benchmark comprises 106 standard Basic Linear Algebra Subprograms (BLAS) routines establishing a fundamental baseline, alongside 20 specialized computational kernels adapted for each of the unique supercomputing architectures (LeetSunway and LeetKunpeng). Our extensive evaluation reveals that while state-of-the-art LLMs can generate optimized code for ubiquitous architectures like x86_64, they exhibit significant performance degradation on domain-specific architectures with limited public documentation and training data, highlighting critical limitations in cross-platform generalization. Furthermore, our analysis of factors influencing code quality such as implementation length and task complexity indicates that current LLMs are most effective for moderately difficult problems requiring concise code snippets. We open-source our dataset and automated evaluation infrastructure to facilitate future research in LLM-driven high-performance code generation. The resources are available at https://anonymous.4open.science/r/CodegenBench-EDE1/ and https://anonymous.4open.science/r/CodegenBenchDataset-2551.
Caught in the Act(ivation): LLM エージェントによる資格情報漏洩の事前出力およびマルチターン検出に向けて
LLM エージェントは多くの場合、機密認証情報を信頼できない取得コンテンツと同じコンテキスト ウィンドウに配置し、認証情報の漏洩を誘発する間接的なプロンプト インジェクションの直接パスを作成します。私たちは、3 つの相補的な防御を通じてこの障害モードを研究します。まず、出力トークンが発行される前に、アクティベーション プローブが資格情報へのアクセスを検出できるかどうかを尋ねます。次に、形式固有の文字モデルからハニートークンを構築し、分割等角予測で検出を調整します。 3 番目に、複数ターンにわたる漏洩を累積的な情報フロー問題として扱い、会話ターン全体での推定漏洩予算を追跡します。オープンウェイト モデルの制御された実験では、アクティベーション機能により、ホールドアウト エンコーディング変換下を含め、無害なプロンプトと認証情報を求めるプロンプトが高精度で分離されます。小規模な合成マルチターン スイートでは、累積アカウンティングにより、ターンごとの検出器が見逃した攻撃が検出されます。これらの結果は暫定的なものです。マルチターン ベンチマークは社内で小規模なものであり、アクティブ化方法にはホワイト ボックス アクセスが必要であり、情報推定ツールは正式な上限ではなく実用的なシグナルを提供します。それでも、この結果は、資格情報の漏洩防御には、テキストレベルの出力フィルターのみに依存するのではなく、出力前の監視、調整されたカナリア検出、および一時的な漏洩アカウンティングを組み合わせる必要があることを示唆しています。
原文 (English)
Caught in the Act(ivation): Toward Pre-Output and Multi-Turn Detection of Credential Exfiltration by LLM Agents
LLM agents often place sensitive credentials in the same context window as untrusted retrieved content, creating a direct path for indirect prompt injection to induce credential exfiltration. We study this failure mode through three complementary defenses. First, we ask whether activation probes can detect credential access before output tokens are emitted. Second, we construct honeytokens from format-specific character models and calibrate detection with split conformal prediction. Third, we treat multi-turn exfiltration as a cumulative information-flow problem and track an estimated leakage budget across conversation turns. In controlled experiments on open-weight models, activation features separate benign and credential-seeking prompts with high accuracy, including under held-out encoding transformations. In a small synthetic multi-turn suite, cumulative accounting detects attacks that per-turn detectors miss. These results are preliminary: the multi-turn benchmark is in-house and small, the activation method requires white-box access, and the information estimator provides a practical signal rather than a formal upper bound. Still, the results suggest that credential-exfiltration defenses should combine pre-output monitoring, calibrated canary detection, and temporal leakage accounting rather than relying only on text-level output filters.
トークンランキングは偽造不可能な言語モデル署名です
言語モデルのパラメータは、ロジット出力に(各モデルに)一意の幾何学的制約を課すことが知られており、これはモデルを識別する署名として機能しますが、API がロジットを配布するときにモデルの最終層パラメータも漏洩します。私たちは、トークンのランキング (確率値ではなく、確率による順序付け) を公開する、より制限的な API を調査し、ランキングも署名を構成することを発見しました。すべてのモデルは、十分な規模の $k$ に対して実行可能な上位 $k$ ランキングの独自のセットを持っています。さらに、同じ実行可能なランキングのセットを持つモデルを見つけることは NP 困難であるため、ランキング署名は最初に知られている (多項式的に) 偽造不可能な署名です。セキュリティの面では、ロジットと同様に、トークンのランキングがすでにモデルの最終層をほぼ盗むのに十分であることがわかりました。ただし、近似が粗すぎて署名を偽造できず、API を十分に小さい $k$ の上位 $k$ トークンに制限することで効果的に対抗できます。モデル署名を提示するために必要な $k$ は一般に、盗用を防ぐために必要な $k$ よりも小さいため、API はモデル パラメーターを漏らすことなく偽造不可能な署名を提示することが可能です。
原文 (English)
Token Rankings are Unforgeable Language Model Signatures
Language model parameters are known to impose unique (to each model) geometric constraints on their logit outputs, which serves as a signature that identifies the model, but also leaks the model's final layer parameters when an API distributes logits. We investigate more restrictive APIs that expose token rankings (i.e., their ordering by probability, but not the probability values) and find that rankings also constitute a signature: every model has a unique set of feasible top-$k$ rankings for sufficiently large $k$. Furthermore, the ranking signature is the first known (polynomially) unforgeable signature, since finding a model with the same set of feasible rankings is NP-hard. On the security front, we find that token rankings are already sufficient to approximately steal the final layer of the model, similar to logits, though the approximation is too coarse to forge the signature, and can be effectively countered by restricting the API to top-$k$ tokens with sufficiently small $k$. Since the top-$k$ required to present the model signature is generally smaller than the $k$ required to prevent stealing, it is possible for an API to present an unforgeable signature without leaking model parameters.
ルーブリックベースの強化学習における報酬ハッキングの再現、分析、検出
ルーブリックベースの強化学習 (RL) は、LLM-as-a-Judge (LaaJ) を使用して、報酬としてルーブリックに従ってモデルの出力を採点します。ただし、政策モデルは裁判官の潜在的なバイアスを悪用し、報酬のハッキングや非効果的または危険なトレーニング結果につながる可能性があります。現実のルーブリックベースの RL では、このようなハッキング行為は多くの場合微妙であり、複数の裁判官のバイアスと絡み合っているため、分析、検出、軽減することが困難です。このペーパーでは、ルーブリックベースの RL のための制御可能なハッキング環境である CHERRL を紹介します。既知のバイアスを LaaJ に注入することで、CHERRL は報酬ハッキングの安定した再現、報酬の発散の明確な観察、およびハッキングの開始の正確な特定を可能にします。これは、ルーブリック ベースの RL における報酬ハッキングのメカニズムと緩和を研究するためのクリーンな実験テストベッドを提供します。その有用性を実証するために、発見可能性と悪用可能性の観点からさまざまな裁判官のバイアスを分析し、トレーニングログから報酬ハッキングの開始を自動的に検出するためのエージェントベースのシステムを調査します。コードと環境は https://github.com/THUAIS-Lab/CHERRL で公開されています。
原文 (English)
Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
Rubric-based reinforcement learning (RL) uses an LLM-as-a-Judge (LaaJ) to score model outputs according to rubrics as rewards. However, policy models may exploit latent biases in the judge, leading to reward hacking and ineffective or unsafe training outcomes. In real-world rubric-based RL, such hacking behaviors are often subtle and entangled with multiple judge biases, making them difficult to analyze, detect, and mitigate. In this paper, we introduce CHERRL, a controllable hacking environment for rubric-based RL. By injecting known biases into LaaJ, CHERRL enables stable reproduction of reward hacking, explicit observation of reward divergence, and precise identification of hacking onset. This provides a clean experimental testbed for studying the mechanisms and mitigations of reward hacking in rubric-based RL. To demonstrate its utility, we analyze different judge biases from the perspectives of discoverability and exploitability, and explore an agent-based system for automatically detecting reward hacking onset from training logs. The code and environment are publicly available at https://github.com/THUAIS-Lab/CHERRL.
制約付き適応拒否サンプリング
言語モデル (LM) は、生成された出力が厳密な意味論的または構文上の制約を満たす必要があるアプリケーションで使用されることが増えています。制約付き生成に対する既存のアプローチはさまざまです。貪欲な制約付きデコード方法は、デコード中に有効性を強制しますが、LM の分布を歪めます。一方、リジェクション サンプリング (RS) は忠実度を維持しますが、無効な出力を破棄することで計算を無駄にします。サンプルの有効性と多様性の両方が重要であるプログラム ファジングなどの領域では、両極端が問題となります。我々は、分布歪みを生じさせずに RS のサンプル効率を厳密に改善するアプローチである、制約付き適応除去サンプリング (CARS) を紹介します。 CARS は、制約のない LM サンプリングから始まり、制約違反の継続をトライに記録し、将来の描画から確率質量を差し引くことで、制約に違反する継続を適応的に除外します。この適応的な枝刈りにより、無効であることが証明されたプレフィックスが決して再検討されず、受け入れ率が単調に向上し、結果として得られるサンプルが制約された分布に正確に従うことが保証されます。プログラムのファジングや分子生成など、さまざまな領域の実験において、CARS は一貫して高い効率 (有効サンプルあたりの LM フォワードパスの数で測定) を達成すると同時に、GCD や LM の分布を近似する方法の両方よりも強力なサンプル多様性を生み出します。
原文 (English)
Constrained Adaptive Rejection Sampling
Language Models (LMs) are increasingly used in applications where generated outputs must satisfy strict semantic or syntactic constraints. Existing approaches to constrained generation fall along a spectrum: greedy constrained decoding methods enforce validity during decoding but distort the LM's distribution, while rejection sampling (RS) preserves fidelity but wastes computation by discarding invalid outputs. Both extremes are problematic in domains such as program fuzzing, where both validity and diversity of samples are essential. We present Constrained Adaptive Rejection Sampling (CARS), an approach that strictly improves the sample-efficiency of RS without distributional distortion. CARS begins with unconstrained LM sampling and adaptively rules out constraint-violating continuations by recording them in a trie and subtracting their probability mass from future draws. This adaptive pruning ensures that prefixes proven invalid are never revisited, acceptance rates improve monotonically, and the resulting samples exactly follow the constrained distribution. In experiments on a variety of domains -- e.g., program fuzzing and molecular generation -- CARS consistently achieves higher efficiency -- measured in the number of LM forward passes per valid sample -- while also producing stronger sample diversity than both GCD and methods that approximate the LM's distribution.
モデルを保持した適応丸め
量子化の目標は、出力分布が元のモデルにできるだけ近い圧縮モデルを生成することです。これを容易に行うために、ほとんどの量子化アルゴリズムは、エンドツーエンド エラーの代理として各層の即時アクティブ化エラーを最小限に抑えます。ただし、これは将来のレイヤーの影響を無視するため、プロキシとしては不十分です。この研究では、ネットワークの出力での誤差を直接考慮する適応丸めアルゴリズムである Yet Another Quantization Algorithm (YAQA) を導入します。 YAQA は、量子化アルゴリズムの最初のエンドツーエンド誤差限界に至る一連の理論的結果を紹介します。まず、ヘッセ近似の構造を介して、適応丸めアルゴリズムの収束時間を特徴付けます。次に、エンドツーエンド誤差が真のヘッセ行列に対する近似のコサイン類似度によって制限される可能性があることを示します。これにより、対応する最適に近いヘッシアン スケッチを使用した自然なクロネッカー因数近似が可能になります。 YAQA は GPTQ/LDLQ よりも優れていることが証明されており、経験的にはこれらの方法よりも誤差が $\約 30\%$ 減少します。 YAQA は、量子化を意識したトレーニングよりも低い誤差を実現します。これにより、推論のオーバーヘッドがまったく追加されずに、ダウンストリーム タスクで最先端のパフォーマンスが得られます。
原文 (English)
Model-Preserving Adaptive Rounding
The goal of quantization is to produce a compressed model whose output distribution is as close to the original model's as possible. To do this tractably, most quantization algorithms minimize the immediate activation error of each layer as a proxy for the end-to-end error. However, this ignores the effect of future layers, making it a poor proxy. In this work, we introduce Yet Another Quantization Algorithm (YAQA), an adaptive rounding algorithm that directly considers the error at the network's output. YAQA introduces a series of theoretical results that culminate in the first end-to-end error bounds for quantization algorithms. First, we characterize the convergence time of adaptive rounding algorithms via the structure of their Hessian approximations. We then show that the end-to-end error can be bounded by the approximation's cosine similarity to the true Hessian. This admits a natural Kronecker-factored approximation with corresponding near-optimal Hessian sketches. YAQA is provably better than GPTQ/LDLQ and empirically reduces the error by $\approx 30\%$ over these methods. YAQA even achieves a lower error than quantization aware training. This translates to state of the art performance on downstream tasks, all while adding no inference overhead.
Curated Synthetic Data Doesn't Have to Collapse: A Theoretical Study of Generative Retraining with Pluralistic Preferences
Recursive retraining of generative models poses a critical representation challenge: when synthetic outputs are curated based on a fixed re…
Consistency Training Can Entrench Misalignment
Consistency training encourages a model to produce similar outputs across related inputs or sampling procedures. Such methods are simple, s…
TSMC、AI活用拡大による成長維持に自信 株主総会、東京エレクトロンとの取引は継続
半導体受託生産の世界最大手、台湾積体電路製造(TSMC)は6月4日、台湾の新竹市で株主総会を開いた。魏哲家会長兼最高経営責任者(CEO)は、AIの活用拡大により「われわれの最先端技術と製造能力の価値は引き続き成長する」と述べ、今後数年間の同社の成長維持に強い自信を示した。
ASP ベースのコンプライアンス推論のための規範的な中間表現
我々は、ASP ベースのコンプライアンス推論のためのモーダル化出力規範中間表現である MONIR を提案します。そのコア フラグメントには段階的な操作セマンティクスがあり、MONIR-ASP は外部関数、一時的なルール、および安定したモデル推論のための実行可能なコンパイルと拡張機能を提供します。 LLM 支援パイプラインを使用して、中国の ADAS 規制と標準に関するフレームワークをインスタンス化します。実験では、抽出品質と、モジュール式および増分 ASP 解決の効率を評価します。
原文 (English)
A Normative Intermediate Representation for ASP-Based Compliance Reasoning
We propose MONIR, a Modalized-Output Normative Intermediate Representation for ASP-based compliance reasoning. Its core fragment has a staged operational semantics, while MONIR-ASP provides an executable compilation and extensions for external functions, temporal rules, and stable-model reasoning. We instantiate the framework on Chinese ADAS regulations and standards with an LLM-assisted pipeline. Experiments evaluate extraction quality and the efficiency of modular and incremental ASP solving.
DiffAero: 効率的なクアドローター ポリシー学習のための GPU アクセラレーションによる微分可能シミュレーション フレームワーク
このレターでは、効率的なクワッドローター制御ポリシー学習のために設計された、軽量で GPU アクセラレーションを備えた完全微分可能なシミュレーション フレームワークである DiffAero を紹介します。 DiffAero は、環境レベルとエージェント レベルの両方の並列処理をサポートし、複数のダイナミクス モデル、カスタマイズ可能なセンサー スタック (IMU、深度カメラ、LiDAR)、および多様な飛行タスクを統合された GPU ネイティブのトレーニング インターフェイス内に統合します。 DiffAero は、GPU 上で物理とレンダリングの両方を完全に並列化することで、CPU と GPU 間のデータ転送のボトルネックを排除し、シミュレーションのスループットを桁違いに向上させます。既存のシミュレータとは対照的に、DiffAero は高性能シミュレーションを提供するだけでなく、微分可能なハイブリッド学習アルゴリズムを探索するための研究プラットフォームとしても機能します。広範なベンチマークと実際の飛行実験により、DiffAero とハイブリッド学習アルゴリズムを組み合わせることで、消費者グレードのハードウェアで堅牢な飛行ポリシーを数時間で学習できることが実証されました。コードは https://github.com/flyingbitac/diffaero で入手できます。
原文 (English)
DiffAero: A GPU-Accelerated Differentiable Simulation Framework for Efficient Quadrotor Policy Learning
This letter introduces DiffAero, a lightweight, GPU-accelerated, and fully differentiable simulation framework designed for efficient quadrotor control policy learning. DiffAero supports both environment-level and agent-level parallelism and integrates multiple dynamics models, customizable sensor stacks (IMU, depth camera, and LiDAR), and diverse flight tasks within a unified, GPU-native training interface. By fully parallelizing both physics and rendering on the GPU, DiffAero eliminates CPU-GPU data transfer bottlenecks and delivers orders-of-magnitude improvements in simulation throughput. In contrast to existing simulators, DiffAero not only provides high-performance simulation but also serves as a research platform for exploring differentiable and hybrid learning algorithms. Extensive benchmarks and real-world flight experiments demonstrate that DiffAero and hybrid learning algorithms combined can learn robust flight policies in hours on consumer-grade hardware. The code is available at https://github.com/flyingbitac/diffaero.
CodegenBench: LLM はアーキテクチャ全体で効率的なコードを記述できますか?
大規模言語モデル (LLM) は、汎用プログラミングや GPU アクセラレーション環境 (PyTorch、CUDA など) のコード生成タスクで広範囲に評価されてきましたが、多様なアーキテクチャにわたる CPU 指向のハイパフォーマンス コンピューティング (HPC) における LLM の機能はまだ十分に解明されていません。このギャップを埋めるために、x86_64、Sunway、Kunpeng の 3 つの異なるハードウェア プラットフォームにわたる効率的な並列コードの生成を評価するように設計された包括的なベンチマーク スイートである CodegenBench を紹介します。私たちのベンチマークは、基本的なベースラインを確立する 106 個の標準基本線形代数サブプログラム (BLAS) ルーチンと、独自のスーパーコンピューティング アーキテクチャ (LeetSunway および LeetKunpeng) のそれぞれに適合した 20 個の特殊な計算カーネルで構成されています。私たちの広範な評価により、最先端の LLM は x86_64 のようなユビキタス アーキテクチャ向けに最適化されたコードを生成できる一方で、公開ドキュメントやトレーニング データが限られたドメイン固有のアーキテクチャでは大幅なパフォーマンスの低下を示し、クロスプラットフォームの一般化における重大な制限が浮き彫りになったことが明らかになりました。さらに、実装の長さやタスクの複雑さなど、コードの品質に影響を与える要因を分析したところ、現在の LLM は、簡潔なコード スニペットを必要とする中程度に難しい問題に対して最も効果的であることが示されています。私たちは、LLM 主導の高性能コード生成における将来の研究を促進するために、データセットと自動評価インフラストラクチャをオープンソースにしています。リソースは https://anonymous.4open.science/r/CodegenBench-EDE1/ および https://anonymous.4open.science/r/CodegenBenchDataset-2551 で利用できます。
原文 (English)
CodegenBench: Can LLMs Write Efficient Code Across Architectures?
While large language models (LLMs) have been extensively evaluated on code generation tasks for general-purpose programming and GPU-accelerated environments (e.g., PyTorch, CUDA), their capabilities in CPU-oriented high-performance computing (HPC) across diverse architectures remain underexplored. To bridge this gap, we introduce CodegenBench, a comprehensive benchmark suite designed to evaluate the generation of efficient parallel code across three distinct hardware platforms: x86_64, Sunway, and Kunpeng. Our benchmark comprises 106 standard Basic Linear Algebra Subprograms (BLAS) routines establishing a fundamental baseline, alongside 20 specialized computational kernels adapted for each of the unique supercomputing architectures (LeetSunway and LeetKunpeng). Our extensive evaluation reveals that while state-of-the-art LLMs can generate optimized code for ubiquitous architectures like x86_64, they exhibit significant performance degradation on domain-specific architectures with limited public documentation and training data, highlighting critical limitations in cross-platform generalization. Furthermore, our analysis of factors influencing code quality such as implementation length and task complexity indicates that current LLMs are most effective for moderately difficult problems requiring concise code snippets. We open-source our dataset and automated evaluation infrastructure to facilitate future research in LLM-driven high-performance code generation. The resources are available at https://anonymous.4open.science/r/CodegenBench-EDE1/ and https://anonymous.4open.science/r/CodegenBenchDataset-2551.
Caught in the Act(ivation): LLM エージェントによる資格情報漏洩の事前出力およびマルチターン検出に向けて
LLM エージェントは多くの場合、機密認証情報を信頼できない取得コンテンツと同じコンテキスト ウィンドウに配置し、認証情報の漏洩を誘発する間接的なプロンプト インジェクションの直接パスを作成します。私たちは、3 つの相補的な防御を通じてこの障害モードを研究します。まず、出力トークンが発行される前に、アクティベーション プローブが資格情報へのアクセスを検出できるかどうかを尋ねます。次に、形式固有の文字モデルからハニートークンを構築し、分割等角予測で検出を調整します。 3 番目に、複数ターンにわたる漏洩を累積的な情報フロー問題として扱い、会話ターン全体での推定漏洩予算を追跡します。オープンウェイト モデルの制御された実験では、アクティベーション機能により、ホールドアウト エンコーディング変換下を含め、無害なプロンプトと認証情報を求めるプロンプトが高精度で分離されます。小規模な合成マルチターン スイートでは、累積アカウンティングにより、ターンごとの検出器が見逃した攻撃が検出されます。これらの結果は暫定的なものです。マルチターン ベンチマークは社内で小規模なものであり、アクティブ化方法にはホワイト ボックス アクセスが必要であり、情報推定ツールは正式な上限ではなく実用的なシグナルを提供します。それでも、この結果は、資格情報の漏洩防御には、テキストレベルの出力フィルターのみに依存するのではなく、出力前の監視、調整されたカナリア検出、および一時的な漏洩アカウンティングを組み合わせる必要があることを示唆しています。
原文 (English)
Caught in the Act(ivation): Toward Pre-Output and Multi-Turn Detection of Credential Exfiltration by LLM Agents
LLM agents often place sensitive credentials in the same context window as untrusted retrieved content, creating a direct path for indirect prompt injection to induce credential exfiltration. We study this failure mode through three complementary defenses. First, we ask whether activation probes can detect credential access before output tokens are emitted. Second, we construct honeytokens from format-specific character models and calibrate detection with split conformal prediction. Third, we treat multi-turn exfiltration as a cumulative information-flow problem and track an estimated leakage budget across conversation turns. In controlled experiments on open-weight models, activation features separate benign and credential-seeking prompts with high accuracy, including under held-out encoding transformations. In a small synthetic multi-turn suite, cumulative accounting detects attacks that per-turn detectors miss. These results are preliminary: the multi-turn benchmark is in-house and small, the activation method requires white-box access, and the information estimator provides a practical signal rather than a formal upper bound. Still, the results suggest that credential-exfiltration defenses should combine pre-output monitoring, calibrated canary detection, and temporal leakage accounting rather than relying only on text-level output filters.
トークンランキングは偽造不可能な言語モデル署名です
言語モデルのパラメータは、ロジット出力に(各モデルに)一意の幾何学的制約を課すことが知られており、これはモデルを識別する署名として機能しますが、API がロジットを配布するときにモデルの最終層パラメータも漏洩します。私たちは、トークンのランキング (確率値ではなく、確率による順序付け) を公開する、より制限的な API を調査し、ランキングも署名を構成することを発見しました。すべてのモデルは、十分な規模の $k$ に対して実行可能な上位 $k$ ランキングの独自のセットを持っています。さらに、同じ実行可能なランキングのセットを持つモデルを見つけることは NP 困難であるため、ランキング署名は最初に知られている (多項式的に) 偽造不可能な署名です。セキュリティの面では、ロジットと同様に、トークンのランキングがすでにモデルの最終層をほぼ盗むのに十分であることがわかりました。ただし、近似が粗すぎて署名を偽造できず、API を十分に小さい $k$ の上位 $k$ トークンに制限することで効果的に対抗できます。モデル署名を提示するために必要な $k$ は一般に、盗用を防ぐために必要な $k$ よりも小さいため、API はモデル パラメーターを漏らすことなく偽造不可能な署名を提示することが可能です。
原文 (English)
Token Rankings are Unforgeable Language Model Signatures
Language model parameters are known to impose unique (to each model) geometric constraints on their logit outputs, which serves as a signature that identifies the model, but also leaks the model's final layer parameters when an API distributes logits. We investigate more restrictive APIs that expose token rankings (i.e., their ordering by probability, but not the probability values) and find that rankings also constitute a signature: every model has a unique set of feasible top-$k$ rankings for sufficiently large $k$. Furthermore, the ranking signature is the first known (polynomially) unforgeable signature, since finding a model with the same set of feasible rankings is NP-hard. On the security front, we find that token rankings are already sufficient to approximately steal the final layer of the model, similar to logits, though the approximation is too coarse to forge the signature, and can be effectively countered by restricting the API to top-$k$ tokens with sufficiently small $k$. Since the top-$k$ required to present the model signature is generally smaller than the $k$ required to prevent stealing, it is possible for an API to present an unforgeable signature without leaking model parameters.
ルーブリックベースの強化学習における報酬ハッキングの再現、分析、検出
ルーブリックベースの強化学習 (RL) は、LLM-as-a-Judge (LaaJ) を使用して、報酬としてルーブリックに従ってモデルの出力を採点します。ただし、政策モデルは裁判官の潜在的なバイアスを悪用し、報酬のハッキングや非効果的または危険なトレーニング結果につながる可能性があります。現実のルーブリックベースの RL では、このようなハッキング行為は多くの場合微妙であり、複数の裁判官のバイアスと絡み合っているため、分析、検出、軽減することが困難です。このペーパーでは、ルーブリックベースの RL のための制御可能なハッキング環境である CHERRL を紹介します。既知のバイアスを LaaJ に注入することで、CHERRL は報酬ハッキングの安定した再現、報酬の発散の明確な観察、およびハッキングの開始の正確な特定を可能にします。これは、ルーブリック ベースの RL における報酬ハッキングのメカニズムと緩和を研究するためのクリーンな実験テストベッドを提供します。その有用性を実証するために、発見可能性と悪用可能性の観点からさまざまな裁判官のバイアスを分析し、トレーニングログから報酬ハッキングの開始を自動的に検出するためのエージェントベースのシステムを調査します。コードと環境は https://github.com/THUAIS-Lab/CHERRL で公開されています。
原文 (English)
Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
Rubric-based reinforcement learning (RL) uses an LLM-as-a-Judge (LaaJ) to score model outputs according to rubrics as rewards. However, policy models may exploit latent biases in the judge, leading to reward hacking and ineffective or unsafe training outcomes. In real-world rubric-based RL, such hacking behaviors are often subtle and entangled with multiple judge biases, making them difficult to analyze, detect, and mitigate. In this paper, we introduce CHERRL, a controllable hacking environment for rubric-based RL. By injecting known biases into LaaJ, CHERRL enables stable reproduction of reward hacking, explicit observation of reward divergence, and precise identification of hacking onset. This provides a clean experimental testbed for studying the mechanisms and mitigations of reward hacking in rubric-based RL. To demonstrate its utility, we analyze different judge biases from the perspectives of discoverability and exploitability, and explore an agent-based system for automatically detecting reward hacking onset from training logs. The code and environment are publicly available at https://github.com/THUAIS-Lab/CHERRL.
制約付き適応拒否サンプリング
言語モデル (LM) は、生成された出力が厳密な意味論的または構文上の制約を満たす必要があるアプリケーションで使用されることが増えています。制約付き生成に対する既存のアプローチはさまざまです。貪欲な制約付きデコード方法は、デコード中に有効性を強制しますが、LM の分布を歪めます。一方、リジェクション サンプリング (RS) は忠実度を維持しますが、無効な出力を破棄することで計算を無駄にします。サンプルの有効性と多様性の両方が重要であるプログラム ファジングなどの領域では、両極端が問題となります。我々は、分布歪みを生じさせずに RS のサンプル効率を厳密に改善するアプローチである、制約付き適応除去サンプリング (CARS) を紹介します。 CARS は、制約のない LM サンプリングから始まり、制約違反の継続をトライに記録し、将来の描画から確率質量を差し引くことで、制約に違反する継続を適応的に除外します。この適応的な枝刈りにより、無効であることが証明されたプレフィックスが決して再検討されず、受け入れ率が単調に向上し、結果として得られるサンプルが制約された分布に正確に従うことが保証されます。プログラムのファジングや分子生成など、さまざまな領域の実験において、CARS は一貫して高い効率 (有効サンプルあたりの LM フォワードパスの数で測定) を達成すると同時に、GCD や LM の分布を近似する方法の両方よりも強力なサンプル多様性を生み出します。
原文 (English)
Constrained Adaptive Rejection Sampling
Language Models (LMs) are increasingly used in applications where generated outputs must satisfy strict semantic or syntactic constraints. Existing approaches to constrained generation fall along a spectrum: greedy constrained decoding methods enforce validity during decoding but distort the LM's distribution, while rejection sampling (RS) preserves fidelity but wastes computation by discarding invalid outputs. Both extremes are problematic in domains such as program fuzzing, where both validity and diversity of samples are essential. We present Constrained Adaptive Rejection Sampling (CARS), an approach that strictly improves the sample-efficiency of RS without distributional distortion. CARS begins with unconstrained LM sampling and adaptively rules out constraint-violating continuations by recording them in a trie and subtracting their probability mass from future draws. This adaptive pruning ensures that prefixes proven invalid are never revisited, acceptance rates improve monotonically, and the resulting samples exactly follow the constrained distribution. In experiments on a variety of domains -- e.g., program fuzzing and molecular generation -- CARS consistently achieves higher efficiency -- measured in the number of LM forward passes per valid sample -- while also producing stronger sample diversity than both GCD and methods that approximate the LM's distribution.
モデルを保持した適応丸め
量子化の目標は、出力分布が元のモデルにできるだけ近い圧縮モデルを生成することです。これを容易に行うために、ほとんどの量子化アルゴリズムは、エンドツーエンド エラーの代理として各層の即時アクティブ化エラーを最小限に抑えます。ただし、これは将来のレイヤーの影響を無視するため、プロキシとしては不十分です。この研究では、ネットワークの出力での誤差を直接考慮する適応丸めアルゴリズムである Yet Another Quantization Algorithm (YAQA) を導入します。 YAQA は、量子化アルゴリズムの最初のエンドツーエンド誤差限界に至る一連の理論的結果を紹介します。まず、ヘッセ近似の構造を介して、適応丸めアルゴリズムの収束時間を特徴付けます。次に、エンドツーエンド誤差が真のヘッセ行列に対する近似のコサイン類似度によって制限される可能性があることを示します。これにより、対応する最適に近いヘッシアン スケッチを使用した自然なクロネッカー因数近似が可能になります。 YAQA は GPTQ/LDLQ よりも優れていることが証明されており、経験的にはこれらの方法よりも誤差が $\約 30\%$ 減少します。 YAQA は、量子化を意識したトレーニングよりも低い誤差を実現します。これにより、推論のオーバーヘッドがまったく追加されずに、ダウンストリーム タスクで最先端のパフォーマンスが得られます。
原文 (English)
Model-Preserving Adaptive Rounding
The goal of quantization is to produce a compressed model whose output distribution is as close to the original model's as possible. To do this tractably, most quantization algorithms minimize the immediate activation error of each layer as a proxy for the end-to-end error. However, this ignores the effect of future layers, making it a poor proxy. In this work, we introduce Yet Another Quantization Algorithm (YAQA), an adaptive rounding algorithm that directly considers the error at the network's output. YAQA introduces a series of theoretical results that culminate in the first end-to-end error bounds for quantization algorithms. First, we characterize the convergence time of adaptive rounding algorithms via the structure of their Hessian approximations. We then show that the end-to-end error can be bounded by the approximation's cosine similarity to the true Hessian. This admits a natural Kronecker-factored approximation with corresponding near-optimal Hessian sketches. YAQA is provably better than GPTQ/LDLQ and empirically reduces the error by $\approx 30\%$ over these methods. YAQA even achieves a lower error than quantization aware training. This translates to state of the art performance on downstream tasks, all while adding no inference overhead.
Curated Synthetic Data Doesn't Have to Collapse: A Theoretical Study of Generative Retraining with Pluralistic Preferences
Recursive retraining of generative models poses a critical representation challenge: when synthetic outputs are curated based on a fixed re…
Consistency Training Can Entrench Misalignment
Consistency training encourages a model to produce similar outputs across related inputs or sampling procedures. Such methods are simple, s…
TriEval: LLM バイアス、毒性、真実性評価のためのリソース効率の高いパイプライン
LLM は、基本的なチャットボットから AI エコシステムのバックボーンに進化し、現在では医療、学校、政府サービスで広く使用されています。 LLM をドメイン全体に導入するには、その安全性と公平性を確保するために継続的な評価が必要です。 LLM の導入後に発生する一般的な問題には、一貫性のない出力や誤った情報の幻覚などがあります。 LLM 評価ツールは多数存在しますが、そのほとんどは一度に 1 つのパラメータのテストに限定されているか、ほとんどの研究者がアクセスできない膨大な計算リソースを必要とします。 TriEval は、コンピューティング リソースを最小限に抑えながら、バイアス、有害性、真実性を含む複数のパラメータにわたって LLM 出力を評価することで、これらの課題に対処します。このパイプラインは、オープンソース モデルとクローズドソース モデルの両方と互換性があり、GPU クラスターのない標準的なラップトップで実行されます。 TriEval は、Llama 3 8B、Mistral 7B、Gemma 2 9B、および Claude Haiku の 4 つのモデルでテストされています。結果は、特に毒性と真実性の点で、オープンソース モデルとクローズドソース モデルの明らかな違いを示しています。 TriEval は、限られた計算リソースを持つ研究者がより広範にアクセスできるようにするために、オープンソースとしてリリースされています。
原文 (English)
TriEval: A Resource-Efficient Pipeline for LLM Bias, Toxicity, and Truthfulness Assessment
LLMs have evolved from basic chatbots to the backbone of the AI ecosystem, now widely used in healthcare, schools, and government services. The domain-wide adoption of LLMs necessitates continuous evaluation to ensure their safety and fairness. Common issues encountered after deploying LLMs include inconsistent outputs and hallucinations of incorrect information. Although numerous LLM evaluation tools exist, most are limited to testing a single parameter at a time or require massive computational resources that are not accessible to most researchers. TriEval addresses these challenges by evaluating LLM outputs across multiple parameters, including bias, toxicity, and truthfulness together, while minimizing computing resources. The pipeline is compatible with both open- and closed-source models and runs on a standard laptop without a GPU cluster. TriEval has been tested on four models: Llama 3 8B, Mistral 7B, Gemma 2 9B, and Claude Haiku. The results show clear differences between open-source and closed-source models, especially in terms of toxicity and truthfulness. TriEval is being released as open source to enable broader access for researchers with limited computational resources.
プルーフ リファクタリング: 生成された正式なプルーフをモジュール型アーティファクトにリファクタリングする
大規模言語モデル (LLM) は形式的な証明の生成において優れたパフォーマンスを示していますが、その出力は多くの場合、成熟した形式的な数学ライブラリの証明に比べて可読性、モジュール性、保守性、再利用性が劣ります。私たちは、このギャップの一部は、ほとんどの証明生成パイプラインに暗黙的に含まれるコンパイル優先の目的に起因しており、ライブラリ品質のアーティファクトではなく、モノリシックまたはアドホック証明スクリプトを奨励していると主張します。証明品質を向上させるための既存のアプローチは、多くの場合、明示的で計算可能な最適化目標に依存しています。ただし、実際には、最も扱いやすく、実験的に検証された目標は主に長さに基づくものですが、可読性、モジュール性、保守性、再利用性などのより高いレベルの品質を信頼できる自動メトリクスに還元するのは困難です。単一のプロキシ メトリクスに対して証明の改善を最適化するのではなく、人間による証明のリファクタリング ワークフローからインスピレーションを得た、プロセスに基づいたアプローチを採用します。私たちは、証明リファクタリングを 4 つのフェーズに分解するエージェント フレームワーク $\textbf{Proof-Refactor}$ を提案します。候補となる証明フラグメントの抽出、ヘルパー宣言の設計、抽出および設計されたコンポーネントの正式な証明、検証されたコンポーネントを使用した元の証明の修復です。 PutnamBench および Putnam2025 から生成されたリーン証明では、Proof-Refactor は、強力なクロード コード リファクタリング ベースラインよりもルーブリック ベースのリファクタリング スコアを改善し、署名の品質と人間の可読性が最大の向上をもたらします。これらの結果は、プロセスガイド付きリファクタリングにより、証明長を主な目的として扱うことなく証明構造を改善できることを示唆しています。
原文 (English)
Proof-Refactor: Refactoring Generated Formal Proofs into Modular Artifacts
While Large Language Models (LLMs) have shown strong performance in generating formal proofs, their outputs often remain less readable, modular, maintainable, and reusable than proofs in mature formal mathematics libraries. We argue that this gap stems in part from the compile-first objective implicit in most proof-generation pipelines, which encourages monolithic or ad hoc proof scripts rather than library-quality artifacts. Existing approaches to proof-quality improvement often rely on explicit, computable optimization objectives. In practice, however, the most tractable and experimentally validated objectives are largely length-based, while higher-level qualities such as readability, modularity, maintainability, and reusability are difficult to reduce to reliable automatic metrics. Instead of optimizing proof improvement against a single proxy metric, we take a process-guided approach inspired by human proof-refactoring workflows. We propose an agentic framework $\textbf{Proof-Refactor}$ that decomposes proof refactoring into four phases: extracting candidate proof fragments, designing helper declarations, formally proving the extracted and designed components, and repairing the original proof using the verified components. On generated Lean proofs from PutnamBench and Putnam2025, Proof-Refactor improves rubric-based refactoring scores over a strong Claude Code refactoring baseline, with the largest gains in signature quality and human readability. These results suggest that process-guided refactoring can improve proof structure without treating proof length as the primary objective.
D-Judge: Disrupting Multi-Turn Jailbreaks using Semantics-Preserving Output Rewriting
Multi-turn jailbreak attacks pose a growing threat to large language model (LLM) safety because they exploit feedback from auxiliary judge…
SVHalluc: Benchmarking Speech-Vision Hallucination in Audio-Visual Large Language Models
Despite the success of audio-visual large-language models (LLMs), they can produce plausible but ungrounded outputs, termed hallucination.…
NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. I…
The Unsampled Truth: Psychometrics in SLMs Measure Prompt Artifacts, Not Psychological Constructs
When prompting SLMs for psychometric assessments, researchers assume the outputs reflect semantic reasoning. We evaluate this premise acros…
DDOR: Delta Debugging for Explainable Overrefusal Testing and Repair
While safety alignment and guardrails help large language models (LLMs) avoid harmful outputs, they can also induce overrefusal, i.e., unwa…
Consistency Training Can Entrench Misalignment
Consistency training encourages a model to produce similar outputs across related inputs or sampling procedures. Such methods are simple, s…
FlashMLA-ETAP: Efficient Transpose Attention Pipeline for Accelerating MLA Inference on NVIDIA H20 GPUs
Efficient inference of Multi-Head Latent Attention (MLA) is challenged by deploying the DeepSeek-R1 671B model on a single Multi-GPU server…
Fine-Tuning and Serving Gemma 4 31B on Google Cloud TPU: A Technical Comparison with GPU Baselines
We present the first end-to-end demonstration of fine-tuning and serving Google's Gemma 4 31B model on TPU hardware, providing an empirical…

AI需要で半導体不足は「しばらく続く」 PCメーカー、デルの対応策は?
AI需要による半導体不足は「しばらく続く」――PCメーカーのデル・テクノロジーズはこう予測する。同社はこの難局をどう乗り切るのか。

NVIDIAの「RTX Spark」と搭載ノートPCがCOMUPTEX TAIPEIのMediaTekブースに集結
MediaTek(メディアテック)は、「COMPUTEX TAIPEI 2026」において、NVIDIAが発表したAIスーパーチップ「NVIDIA RTX Spark」と、同チップを搭載する各社のWindowsノートPCを披露した。
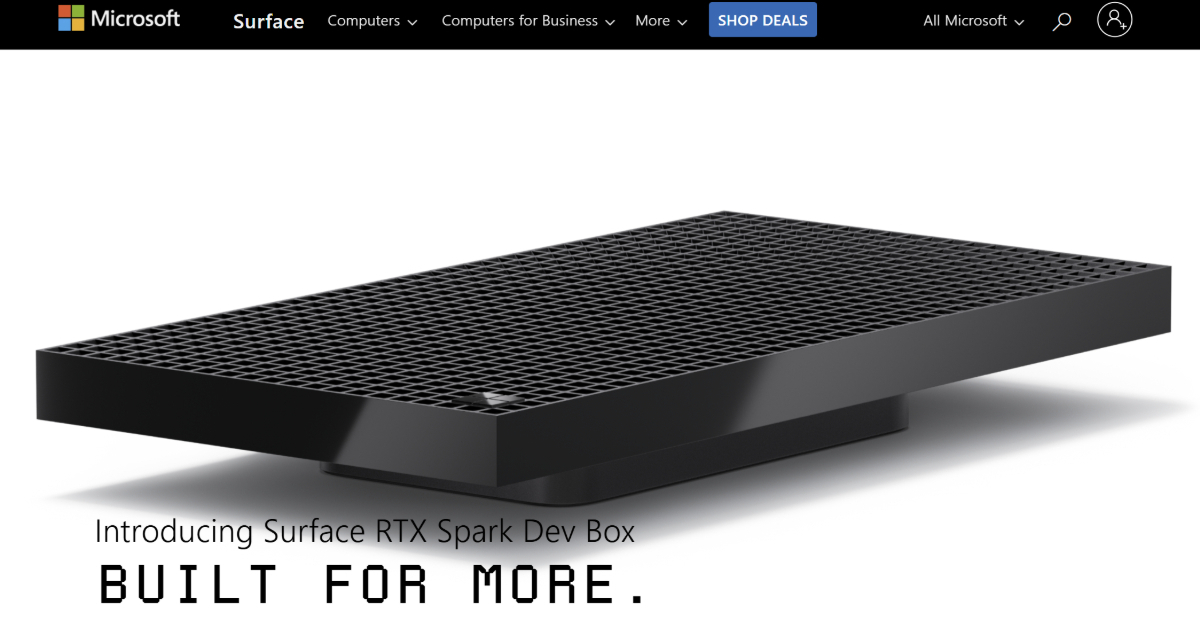
Microsoft、NVIDIAのSoC搭載でAI特化のミニPC「Surface RTX Spark Dev Box」披露
Microsoftは「Build 2026」で、AI特化型デスクトップPC「Surface RTX Spark Dev Box」を発表した。NVIDIAの「RTX Spark」を搭載し、最大1ペタフロップスの演算性能と128GBのメモリにより、1200億パラメータ超のモデルのロ…
ポジションペーパー: 意思決定エンジンにおけるソルブ後のロバスト性: 摂動下での実行可能領域と滑らかさ
混合整数線形計画法 (MILP) 意思決定エンジンは、一か八かの産業システム向けに名目上最適な計画を定期的に出力します。しかし、導入が解決時間の想定と一致することはほとんどありません。コスト、需要、またはリソースの可用性における小さな変動により、実現可能性が無効になったり、質的に異なるソリューションへの不連続な移行が引き起こされる可能性があります。私たちは、この解決後の堅牢性のギャップは、今日の最適化パイプラインに欠けている層であり、学習対応の意思決定システムに欠けている評価次元であると主張します。提案された層は、ロバストな最適化や確率的プログラミングを置き換えるのではなく、解決された既存のソリューションを監査し、そのソリューションがどの程度信頼できるかについてソルバーに裏付けられた証拠を返します。中心となる 2 つのオブジェクトを形式化します。(i) パラメータ空間における $\epsilon$-near-optimal の実現可能近傍。摂動下で既存の企業が実現可能かつ最適に近い状態を保つ時期を捉えます。(ii) 意思決定空間における解の滑らかさ。小さな組み合わせ編集による近くの代替案が競争力を維持しているかどうかを捉えます。次に、感度と安定性の分析、ロバストな最適化、近傍検索、敵対的テスト、学習ベースの機能強化から最も関連性の高い部分的な回答を合成し、統合されたポストソルブ堅牢性レイヤーのアジェンダを明確にします。具体的には、校正された不確実性、敵対的ロバスト性マージン、ソルバーに裏付けされた検証と連携した学習ベースの予測と説明を備えた、既存の確率論的ロバスト性推定に関する認定された内部近似を求めます。最後に、堅牢性を意思決定エンジンの第一級の出力にするコンパクトなレポート テンプレートと評価プロトコルを紹介します。
原文 (English)
Position Paper: Post-Solve Robustness in Decision Engines: Feasible Regions and Smoothness Under Perturbations
Mixed-Integer Linear Programming (MILP) decision engines routinely output nominally optimal plans for high-stakes industrial systems. Yet deployment rarely matches solve-time assumptions: small perturbations in costs, demands, or resource availability can invalidate feasibility or trigger discontinuous shifts to qualitatively different solutions. We argue that this post-solve robustness gap is a missing layer in today's optimization pipelines and a missing evaluation dimension for learning-enabled decision systems. Rather than replacing robust optimization or stochastic programming, the proposed layer audits a solved incumbent and returns solver-backed evidence about how far that solution can be trusted. We formalize two central objects: (i) an $\epsilon$-near-optimal feasible neighborhood in parameter space, capturing when an incumbent remains feasible and near-optimal under perturbations, and (ii) solution smoothness in decision space, capturing whether nearby alternatives with small combinatorial edits remain competitive. We then synthesize the most relevant partial answers from sensitivity and stability analysis, robust optimization, neighborhood search, adversarial testing, and learning-based enhancements, and articulate an agenda for a unified post-solve robustness layer. Concretely, we call for certified inner approximations around the incumbent, probabilistic robustness estimation with calibrated uncertainty, adversarial robustness margins, and learning-based prediction and explanation aligned with solver-backed verification. We conclude with a compact reporting template and evaluation protocol that would make robustness a first-class output of decision engines.
TIGER: マルチモーダル生成における幻覚を軽減するためのグラフベースの証拠ルーティングによる追跡可能な推論
私たちは、入力ではサポートされていない特定のファクトが滑らかな出力に含まれる可能性がある、マルチモーダル生成のためのファクトレベル修復を研究します。既存の推論時修復手法は、入力と現在の出力を共同で調整することによってフィードバックを生成することがよくあります。この設計には 2 つの制限があります。出力内の幻覚的な主張により、入力のモデルの解釈にバイアスがかかる可能性があること、および自由形式のフィードバックをファクト レベルでランク付けしたりスケジュールしたりすることができないことです。局所的な修復のためにフィードバックを再設計する推論時間フレームワークである TIGER を紹介します。 TIGER は、入力から観測グラフを抽出し、現在の出力からクレーム グラフを個別に抽出し、サポートと競合に基づいてグラフで条件付けされたリスク スコアを各クレームに割り当てます。このモデルは、バックボーンを凍結したままにしながら、選択された高リスクの請求を修復します。我々は、穏やかな仮定の下で、予想される総リスクが幾何学的に明示的な漸近限界まで減少することを示す収束分析を提供します。画像からテキストへ、画像+テキストからテキストへ、音声からテキストへ、ビデオからテキストへを含む 4 つのクロスモーダル パスにわたる実験では、TIGER がタスクの品質を維持しながらサポートされていないコンテンツを削減することが示されています。このゲインは複数のバックボーンにわたって維持されており、CrisisFACTS のケーススタディでは、同じ修復メカニズムにより複数の電源設定でグラウンディングを改善できることが示唆されています。
原文 (English)
TIGER: Traceable Inference with Graph-Based Evidence Routing for Mitigating Hallucinations in Multimodal Generation
We study fact-level repair for multimodal generation, where a fluent output may contain specific facts that are not supported by the input. Existing inference-time repair methods often generate feedback by jointly conditioning on the input and the current output. This design has two limitations: hallucinated claims in the output can bias the model's interpretation of the input, and free-form feedback cannot be ranked or scheduled at the fact level. We present TIGER, an inference-time framework that redesigns feedback for localized repair. TIGER independently extracts an observation graph from the input and a claim graph from the current output, then assigns each claim a graph-conditioned risk score based on support and conflict. The model repairs selected high-risk claims while keeping the backbone frozen. We provide a convergence analysis showing that the expected total risk decreases geometrically to an explicit asymptotic bound under mild assumptions. Experiments across four cross-modal paths, including image-to-text, image+text-to-text, audio-to-text, and video-to-text, show that TIGER reduces unsupported content while preserving task quality. The gains hold across multiple backbones, and a CrisisFACTS case study suggests that the same repair mechanism can improve grounding in multi-source settings.
デコーダ層スキップによる大規模言語モデルの幻覚の軽減
大規模言語モデル (LLM) は、さまざまな自然言語タスクにわたって優れたパフォーマンスを達成していますが、その出力には幻覚、つまり事実の情報と一致しないコンテンツが含まれることがよくあります。この研究では、デコードプロセスの包括的な層ごとの分析を実施し、幻覚がより深いデコーダ層から発生する傾向があることを明らかにしました。この問題に対処するために、幻覚を生成しやすい層を動的にスキップする新しいデコード フレームワークである \textbf{DeLask} (\textbf{De}coder \textbf{La}yer \textbf{Sk}ipping) を導入します。 DeLask は、$L$ 層の Transformer の順方向計算が条件付きで勾配降下法の $L$ ステップと同等であるという理論的な洞察を活用します。連続するデコーダ ステップから導出された勾配間のコサイン類似度を計算することで \emph{ドリフタンス値} を定義し、降下方向が反転したときに問題のある層を特定します。 DeLask は、そのような層を完全に破棄するのではなく、その隠れ状態を先行層と部分的に集約することにより、誤った信号を抑制しながら一貫性を維持します。さまざまな LLM とベンチマークにわたる広範な実験により、DeLask が一貫して幻覚を軽減し、全体的な信頼性を向上させ、大規模な言語モデルの堅牢性を向上させるための軽量で一般化可能なデコード フレームワークを提供することが実証されました。
原文 (English)
Mitigating Hallucinations in Large Language Models Via Decoder Layer Skipping
Large Language Models (LLMs) have achieved strong performance across diverse natural language tasks, yet their outputs often suffer from hallucinations -- content that is misaligned with factual information. In this work, we conduct a comprehensive layer-wise analysis of the decoding process and reveal that hallucinations tend to originate from deeper decoder layers. To address this issue, we introduce \textbf{DeLask} (\textbf{De}coder \textbf{La}yer \textbf{Sk}ipping), a novel decoding framework that dynamically skips layers prone to producing hallucinations. DeLask leverages the theoretical insight that the forward computation of an $L$-layer Transformer is conditionally equivalent to $L$ steps of gradient descent. We define a \emph{driftance value} by computing the cosine similarity between gradients derived from consecutive decoder steps, identifying problematic layers when the descent direction reverses. Rather than discarding such layers entirely, DeLask partially aggregates their hidden states with preceding layers, thereby preserving consistency while suppressing erroneous signals. Extensive experiments across diverse LLMs and benchmarks demonstrate that DeLask consistently mitigates hallucinations and enhances overall reliability, providing a lightweight and generalizable decoding framework for improving the robustness of large-scale language models.
知恵の形: 言語モデルにおける意思決定の軌跡
言語モデルは、出力層で単純に答えを選択するわけではありません。 Qwen2.5-7B-Instruct、Llama-3.1-8B-Instruct、Mistral-7B-Instruct-v0.3 にわたる 9,000 のトラジェクト MMLU スタディでは、回答のスコアは構造化された方法で深度全体に移動します。各軌跡は、現在の解答マージン、そのマージンにおける次の層の変更、および決定フリップからの距離という 3 つの量で記述されます。主な経験的状況は、正しさと安定性は異なるということです。最大のグループは不安定で正しいものであり、安定して正しいものではありません。次に、トレースされたサブセットは、何がマージンを動かすのかを尋ねます。安定した正しいケースでは、平均注意スカラーは正しい方向を向いていますが、平均 MLP スカラーはそうではありません。スパン削除では、回答をサポートするテキストを削除すると余白が損なわれ、気が散るようなテキストを削除すると余白が有効になることがわかります。この結果は回路の完全な説明にはなりません。これは、どの答えが解決され、どの答えが脆弱なままで、どの測定されたソースがそれらを動かしているのかを確認する再現可能な方法です。
原文 (English)
The Shape of Wisdom: Decision Trajectories in Language Models
Language models do not simply choose an answer at the output layer. In a 9,000-trajectory MMLU study across Qwen2.5-7B-Instruct, Llama-3.1-8B-Instruct, and Mistral-7B-Instruct-v0.3, the score of the answer moves across depth in structured ways. We describe each trajectory with three quantities: the current answer margin, the next-layer change in that margin, and the distance from a decision flip. The main empirical picture is that correctness and stability are different: the largest group is unstable-correct, not stable-correct. A traced subset then asks what moves the margin. In stable-correct cases, the average attention scalar points in the correct direction, while the average MLP scalar does not; span deletion shows that removing answer-supporting text hurts the margin and removing distractor-like text helps it. The result is not a full circuit explanation. It is a reproducible way to see which answers are settled, which remain fragile, and which measured sources move them.
Can Predicted Dynamics Exist in the Physical World?
Predictive Physical AI systems output state rollouts, action chunks, and latent plans, yet a low root-mean-square error (RMSE) does not imp…
SUPREME: A Multi-GPU Framework for Reproducible Image Unlearning Method Evaluation
Machine unlearning removes the influence of specific training data from a trained model without retraining it from scratch. Evaluating an u…
CodeCytos: AI-assisted spatial molecular imaging analysis via code-augmented agent action space
Conventional tissue image analysis software provides foundational capabilities for cellular analysis, including segmentation, basic morphol…
Linguistics-Aware Non-Distortionary LLM Watermarking
Watermarking should identify language-model output without degrading quality or limiting verification to the model provider. Multilingual d…
EPIC: Efficient and Parallel Inference under CFG Constraints for Diffusion Language Models
Controlling language model outputs is essential for ensuring structural validity, reliability, and downstream usability, and diffusion lang…
DASH: Dual-Branch Score Distillation for Guidance-Calibrated Compact Diffusion Models
Parameter compression of class-conditional diffusion models reveals an underexplored limitation in output-level distillation: the unconditi…
A Fiber Criterion for Representation Identifiability in Supervised Learning
Supervised learning evaluates predictors through their input-output behavior. When a predictor is implemented as a composition $f=c\circ h$…
HASTE: Hardware-Aware Dynamic Sparse Training for Large Output Spaces
Extreme multi-label classification (XMC) involves learning models over large output spaces with millions of labels, making the output layer…
Crazyflow: An Accurate, GPU-Accelerated, Differentiable Drone Simulator in JAX
High-quality, large-scale synthetic data from simulations is becoming a cornerstone for pushing the capabilities of robot algorithms. While…
Move the Query, Not the Cache: Characterizing Cross-Instance Latent Attention Redistribution Across GPU Fabrics
Frontier LLMs increasingly decide what a query attends to with a sparse-attention indexer that picks a few KV-cache blocks per query: atten…
"I've Seen How This Goes": Characterizing Diversity via Progressive Conditional Surprise
Measuring the diversity of creative outputs is central to evaluating post-training mode collapse, comparing decoding strategies, and quanti…
The Role of Ambiguity in Error Prediction via Uncertainty Quantification
The task of Error Prediction, namely predicting whether a model output is correct, is commonly tackled with Uncertainty Quantification (UQ)…
On the Theoretical Limitations of Embedding-based Link Prediction
Neural networks often map low-dimensional embeddings to high-dimensional output spaces. Usually, the output layer is linear, which can crea…
Query Circuits: Explaining How Language Models Answer User Prompts
Explaining why a language model produces a particular output requires local, input-level explanations. Existing methods uncover global capa…
Efficient LLM Moderation with Multi-Layer Latent Prototypes
Although modern LLMs are aligned with human values during post-training, robust moderation remains essential to prevent harmful outputs at…
Erased but Not Forgotten: How Backdoors Compromise Concept Erasure
The expansion of text-to-image diffusion models has raised concerns about harmful outputs, from fabricated depictions of public figures to…
End-to-End Deep Learning for Predicting Metric Space-Valued Outputs
Many modern applications involve predicting structured, non-Euclidean outputs such as probability distributions, networks, and symmetric po…
Optimizing Diversity and Quality through Base-Aligned Model Collaboration
Alignment has greatly improved large language models (LLMs)' output quality at the cost of diversity, yielding highly similar outputs acros…
How Much Progress Has There Been in NVIDIA Datacenter GPUs?
As the role of modern Graphics Processing Units (GPUs) becomes increasingly essential for several computing tasks, analyzing their past and…
GUDA: Counterfactual Group-wise Training Data Attribution for Diffusion Models via Unlearning
Training-data attribution for vision generative models aims to identify which training data influenced a given output. While most methods s…
Failure of contextual invariance in large language models
Standard evaluation practices assume that large language model (LLM) outputs are stable when prompts are embedded in contextually equivalen…
FlowPlace: Flow Matching for Chip Placement
Chip placement plays an important role in physical design. While generative models like diffusion models offer promising learning-based sol…
How Can Reinforcement Learning Achieve Expert-level Placement?
Chip placement is a critical step in physical design. While reinforcement learning (RL)-based methods have recently emerged, their training…
Physics-Guided Geometric Diffusion for Macro Placement Generation
Macro placement is a pivotal stage in VLSI physical design, fundamentally determining the overall chip performance. Recent data-driven plac…
Algorithmic Fragility and Persona Bias in LLM-Generated Autistic Communication
Safety alignment reduces explicitly harmful outputs but inadvertently encodes a sanitized, neuronormative representation of marginalized co…

NVIDIAの“狐”は工場自律管理AIエージェント、台湾メーカーが導入効果を確認
NVIDIAは、工場を自律的に管理するAIエージェントのレファレンスデザイン「NVIDIA Factory Operations Blueprint(FOX)」を発表した。FOXを用いれば、工場内のさまざまなデータをリアルタイムに監視/分析し、複数のAIエージェントと機器を連携…

NVIDIAの「NemoClaw」でエッジAIを統合管理、アドバンテックが「WEDA」を発表
アドバンテックは、パートナー向けイベント「2026 Advantech World Partner Conference(WPC)」において、エッジAIの開発から導入、運用までを統合的に管理するソリューション「WEDA」について説明した。

Nvidia chases $200B CPU market with AI agent PCs from Microsoft, Dell, and HP
If Nvidia has cracked a way to bring AI agents easily, safely, and usefully to the masses, it could — and should — be big.
LLM-FACETS: LLM の透明性と説明責任を評価するためのプライバシー保護フレームワーク
大規模言語モデルの出力が事実に基づいており、認識論的に調整されており、方法論的に再現可能であるかどうかを評価することは、責任ある AI 導入の前提条件です。しかし、LLM の監査は、技術者以外の専門家にとってはアクセスできないままです。既存のツールにはプログラミングの専門知識と簡単ではない環境セットアップが必要であり、クラウドでホストされるプラットフォームは評価データを外部サービスに送信するため、AI の監視に法的責任を負うドメインの専門家やコンプライアンス担当者にとって障壁が生じています。 LLM-FACETS (LLM FActuality Cross-EvaluTion System) を紹介します。これは、ブラウザからアクセス可能なインターフェイスとプラグイン アーキテクチャを備えたオープンソース フレームワークで、EU AI 法と NIST AI リスク管理フレームワークで特定されているステークホルダーのカテゴリを反映する 3 つの実践者プロファイル (技術専門家、ドメイン専門家、コンプライアンス担当者) を中心に構造化されています。このアーキテクチャでは、データ フローが明示的になります。決定論的メトリクス (BLEU、ROUGE、BERTScore) は、アウトバウンド送信なしで完全に自己ホスト型サーバー内で実行されます。 LLM 判定メトリクスは外部 API に明示的に接続し、ユーザーは資格情報の完全な制御を保持します。このフレームワークは、認識上の不確実性に対するトークンレベルの対数確率の視覚化、裁判官のバイアスを軽減するための複数裁判官のコンセンサス、幻覚を検出して位置を特定するための RAG トライアド メトリクス (忠実度、回答の関連性、コンテキストの関連性) の 3 つのメカニズムを通じて透明性を運用します。プラグイン アーキテクチャにより、評価パイプラインを変更せずに、新しいメトリクスやデータセットを統合できます。オープンソースの実装により、同じプロパティを対象とする複数の指標にわたるクロスチェックが可能になり、再現性が確保され、評価対象のシステムを構築するチームから AI の説明責任が切り離されます。正規の参照ライブラリに対する 18 のメトリック実装の相互検証を通じてフレームワークを検証します。
原文 (English)
LLM-FACETS: A Privacy-Preserving Framework for Evaluating LLM Transparency and Accountability
Assessing whether Large Language Models outputs are factually grounded, epistemically calibrated, and methodologically reproducible is a prerequisite for responsible AI deployment. Yet auditing LLMs remains inaccessible to non-technical practitioners: existing tools require programming expertise and non-trivial environment setup, and cloud-hosted platforms transmit evaluation data to external services, creating barriers for domain experts and compliance officers legally responsible for AI oversight. We introduce LLM-FACETS (LLM FActuality Cross-EvaluaTion System): an open-source framework with a browser-accessible interface and a plugin architecture, structured around three practitioner profiles (technical experts, domain experts, compliance officers) that mirror the stakeholder categories identified in the EU AI Act and the NIST AI Risk Management Framework. The architecture makes data flows explicit: deterministic metrics (BLEU, ROUGE, BERTScore) run entirely within the self-hosted server with no outbound transmission; LLM-judge metrics contact external APIs explicitly, with users retaining full credential control. The framework operationalizes transparency through three mechanisms: token-level log-probability visualization for epistemic uncertainty, multi-judge consensus to mitigate judge bias, and RAG Triad metrics (Faithfulness, Answer Relevance, Context Relevance) to detect and localize hallucinations. A plugin architecture allows any new metric or dataset to be integrated without modifying the evaluation pipeline. The open-source implementation enables cross-checking across multiple metrics targeting the same property, ensuring reproducibility and decoupling AI accountability from the teams building the systems assessed. We verify the framework through cross-validation of 18 metric implementations against canonical reference libraries.
LLM が一貫して間違っていることを学習するとき: 合成欺瞞の線形表現に関するマルチモデル研究
モデルが意図的に偽の出力を生成しながら正確な内部表現を維持する欺瞞的な調整は、依然として AI の安全性における中心的な課題です。戦略的欺瞞が長期的な主な懸念事項である一方で、不正解に対する直接最適化によって引き起こされる合成的不正は、学習された欺瞞の表現基盤を研究するための制御されたテストベッドを提供します。 5 つのトランスフォーマー モデル (Pythia-1.4B、Gemma-2-2B/9B、Qwen2.5-7B、Llama-3.1-8B) の正直なバリアントと欺瞞的なバリアントが、同じ質問分布に対して LoRA を使用して微調整されるマルチモデル パラダイムを導入します。平均プールされた隠れ状態で訓練された線形プローブは、4 つのアーキテクチャのレイヤー 1 ~ 3 でほぼ完璧な AUC (0.99 以上) で合成不正を検出しますが、Pythia-1.4B はピークの 0.705 に達します。ロジスティック回帰プローブは一貫して MLP プローブと一致するかそれを上回っており、線形表現仮説を裏付けています。 TruthfulQA でトレーニングされたプローブは、保留された MMLU 被験者に対してほぼゼロの損失 (デルタ AUC 約 0) で一般化します。後期層の表現はガウス ノイズに対する強い堅牢性を示し、Gemma-2 モデルは優れた安定性を示します。フィッシャー判別比、有効ランク、重心幾何学、方向安定性、クロスドメインアライメント、およびキャリブレーション (ECE) の機構分析により、Pythia/Llama/Qwen における表現崩壊と Gemma-2 における高次元保存という 2 つの状況が明らかになります。すべてのモデルにわたって、不正の方向はより深い層に徐々に統合され、層 1 ~ 4 で最適なキャリブレーション (Pythia を除く ECE が 0.01 未満) が達成されます。これらの結果は、堅牢でドメイン不変の不正表現が、適度な教師付き微調整によって急速に定着する可能性があり、アクティベーションベースのモニタリングに影響を与えることを示しています。
原文 (English)
When LLMs Learn to Be Consistently Wrong: A Multi-Model Study of Linear Representations of Synthetic Deception
Deceptive alignment, in which models maintain accurate internal representations while deliberately producing false outputs, remains a central challenge in AI safety. While strategic deception is the primary long-term concern, synthetic dishonesty - induced via direct optimization on incorrect answers - provides a controlled testbed for studying the representational basis of learned deception. We introduce a multi-model paradigm in which honest and deceptive variants of five transformer models (Pythia-1.4B, Gemma-2-2B/9B, Qwen2.5-7B, Llama-3.1-8B) are fine-tuned using LoRA on the same question distribution. Linear probes trained on mean-pooled hidden states detect synthetic dishonesty with near-perfect AUC (greater than or equal to 0.99) as early as layers 1-3 in four architectures, while Pythia-1.4B reaches a peak of 0.705. Logistic regression probes consistently match or outperform MLP probes, supporting the Linear Representation Hypothesis. Probes trained on TruthfulQA generalize with near-zero loss (Delta AUC approx. 0) to held-out MMLU subjects. Late-layer representations show strong robustness to Gaussian noise, with Gemma-2 models exhibiting exceptional stability. Mechanistic analysis of Fisher Discriminant Ratio, effective rank, centroid geometry, directional stability, cross-domain alignment, and calibration (ECE) reveals two regimes: representational collapse in Pythia/Llama/Qwen versus high-dimensional preservation in Gemma-2. Across all models, the dishonesty direction consolidates progressively in deeper layers, with optimal calibration (ECE less than 0.01 except Pythia) achievable in layers 1-4. These results demonstrate that robust, domain-invariant dishonesty representations can be rapidly entrenched via modest supervised fine-tuning, with implications for activation-based monitoring.
Differentially Private Preference Data Synthesis for Large Language Model Alignment
Preference alignment is a crucial post-training step for large language models (LLMs) to ensure their outputs align with human values. Howe…
Fine-Tuning Improves Information Conveyance in Language Models
Fine-tuning is often believed to reduce uncertainty and diversity in large language models, but existing analyses overlook output length, a…
Benchmarking and Enhancing Text-to-Image Models for Generating Visual Representations in Early Arithmetic Education
AI systems are increasingly used to support educational content creation, yet it remains unclear whether they can generate outputs that fai…
GPU Forecasters: Language Models as Selective Surrogates for Kernel Runtime Optimization
GPU kernels are the workhorse of modern deep learning, and optimizing them (via evolutionary search or coding agents) usually requires repe…
Diagnosing the Reliability of LLM-as-a-Judge via Item Response Theory
While LLM-as-a-Judge is widely used in automated evaluation, existing validation practices primarily operate at the level of observed outpu…
データに敏感なドメインの LLM 出力のニューロシンボリック検証 (拡張プレプリント)
一か八かのドメインに導入された LLM は、根本的な信頼性の課題に直面しています。幻覚、矛盾、プライバシーの脆弱性により、エラーが法的、財務的、または安全性に影響を及ぼす許容できないリスクが生じます。この論文では、LLM で生成されたコンテンツに補完的な保証を提供する、形式的記号手法とニューラル セマンティック分析を組み合わせたハイブリッド検証アーキテクチャを紹介します。このアーキテクチャでは、入力検証に論理的推論を採用し、完全性の特性を活用して、構造化された要件に対して決定可能な保証を提供します。出力検証では、埋め込みベースの意味論的類似性により、形式的な手法では表現力に欠ける文脈上の幻覚が検出されます。この分離は、並列のアクターベースのパイプラインで実現され、幻覚を生み出す分布バイアスを継承するプロンプトベースの自己検証アプローチの制限に対処します。提案されたアーキテクチャとタイプ認識検証方法は、Action Design Research によって開発された現実世界の医療機器損傷評価レポート システムである HAIMEDA を使用して検証されています。評価の結果、構造化エンティティの幻覚検出率は 83% 以上、セマンティック捏造の幻覚検出率は 72% 以上で、レポート作成時間が 30% 短縮されたことが示され、神経記号アーキテクチャがデータに敏感なドメインでの LLM 展開に原則に基づいた保護手段を提供できることが実証されました。
原文 (English)
Neuro-Symbolic Verification of LLM Outputs for Data-Sensitive Domains (extended preprint)
LLMs deployed in high-stakes domains face fundamental reliability challenges: hallucinations, inconsistencies, and privacy vulnerabilities introduce unacceptable risks where errors carry legal, financial, or safety consequences. This paper presents a hybrid verification architecture combining formal symbolic methods with neural semantic analysis to provide complementary guarantees for LLM-generated content. This architecture employs logical reasoning for input verification, leveraging completeness properties to provide decidable guarantees on structured requirements. For output validation, embedding-based semantic similarity detects contextual hallucinations where formal methods lack expressiveness. This separation is realized in a parallel, actor-based pipeline, addressing limitations of prompt-based self-verification approaches, which inherit the distributional biases that produce hallucinations. The proposed architecture and type-aware verification method are validated with HAIMEDA, a real-world medical device damage assessment reporting system developed through Action Design Research. Evaluation shows hallucination detection rates of over 83% for structured entities and 72% for semantic fabrications, with a 30% reduction in report creation time, demonstrating that neuro-symbolic architectures can provide principled safeguards for LLM deployment in data-sensitive domains.
Variational Routing: A Scalable Bayesian Framework for Calibrated Mixture-of-Experts Transformers
Foundation models are increasingly being deployed in contexts where understanding the uncertainty of their outputs is critical to ensuring…
REAL: Regression-Aware Reinforcement Learning for LLM-as-a-Judge
Large language models (LLMs) are increasingly deployed as automated evaluators that assign numeric scores to model outputs, a paradigm know…
Compile to Compress: Boosting Formal Theorem Provers by Compiler Outputs
Large language models (LLMs) have demonstrated significant potential in formal theorem proving, yet state-of-the-art performance often nece…
The Distillation Game: Adaptive Attacks & Efficient Defenses
Distillation attacks create a deployment trade-off for model providers: the same outputs that make a model more useful can also make it eas…

After Nvidia’s $20B not-acqui-hire, AI chip startup Groq reportedly raising $650M
Chipmaker Groq is looking to raise $650 million in internal funding as it pivots from hardware to focus more on AI inference, the process o…

This chip startup just raised $135M on a bet that AI’s biggest bottleneck isn’t compute — it’s memory
South Korean chip startup XCENA is betting that AI's real bottleneck is not compute, but memory.
大規模な言語モデルに基づくマルチエージェント フレームワークによる共同ストーリーテリングの向上
共創、つまり AI エージェントが人間と対話して出力 (アートなど) を生成するというテーマは、最近大きな注目を集めています。ただし、ほとんどの研究は、デジタル環境における成人と人間の相互作用に焦点を当てています。この論文では、子供たちと大規模言語モデル (LLM) が物理的なボード ゲームを通じて相互作用して書かれた物語を作成する、新しいばかばかしい共創シナリオを検討します。私たちの目標は、若いプレイヤーに適した高品質の物語を生成できるマルチエージェント フレームワークを開発することです。私たちのアプローチの中核は、ある LLM がストーリーを生成し、別の LLM がストーリーを評価して改良のためのフィードバックを提供する、反復的なライターとエディターのプロセスです。複数の LLM を含むシミュレーション研究を通じて、この反復的な相互作用により、連続するループ全体で生成されたストーリーの知覚品質が一貫して向上することがわかりました。この結果は、インタラクティブなストーリーテリング システムで高品質の出力を達成するには、少数の改良ステップで十分である可能性があることを示しています。
原文 (English)
Improving Collaborative Storytelling with a Multi-Agent Framework Based on Large Language Models
The topic of Co-creation, i.e., AI agents interacting with humans to generate outputs (e.g., art), has gained significant attention recently. However, most studies focus on adult-human interactions in a digital setting. This paper explores a novel ludic co-creation scenario involving children and Large Language Models (LLMs) interacting through a physical board game to create written stories. Our goal is to develop a multi-agent framework capable of producing high-quality narratives suitable for young players. At the core of our approach is an iterative Writer-Editor process in which one LLM generates stories while another evaluates them and provides feedback for refinement. Through a simulation study involving multiple LLMs, we show that this iterative interaction consistently improves the perceived quality of generated stories across successive loops. The results indicate that a small number of refinement steps may be sufficient to achieve high-quality outputs in interactive storytelling systems.
TRACE: LLM CoT 評価の構成要素によるトゥールミンベースの推論評価
大規模言語モデル (LLM) からのオープンエンドの出力を評価することは、グランド トゥルースがないため依然として困難です。既存の指標は、最終的な答えの精度や表面レベルの統計に依存しており、推論プロセス自体は検討されていません。思考連鎖 (CoT) 推論プロセスを分析する指標である TRACE (Toulmin-based Reasoning Assessment through Constructive Elements) を紹介します。 TRACE は、結果を判断するのではなく、トゥールミンの議論理論とフラベルのメタ認知フレームワークを統合して推論の構造を評価することにより、議論がどのように構築されるかを検査します。 7 つの推論モデルにわたる 26.3K の QA サンプルの実験では、ベンチマーク精度 (r=0.74) との強い相関関係が示されています。さらに、TRACE は強化学習の報酬信号として効果的であり、精度のみのベースラインを上回ります。これらの結果を総合すると、論理的に健全な推論がより質の高い答えにつながることを示しています。したがって、TRACE は、オープンエンド出力を評価するための補足的なメトリックとして機能します。コードは https://github.com/hyyangkisti/trace で入手できます。
原文 (English)
TRACE: Toulmin-based Reasoning Assessment through Constructive Elements for LLM CoT Evaluation
Evaluating open-ended outputs from large language models (LLMs) remains challenging due to the absence of ground truth. Existing metrics rely on final-answer accuracy or surface-level statistics, leaving the reasoning process itself unexamined. We introduce TRACE (Toulmin-based Reasoning Assessment through Constructive Elements), a metric that analyzes Chain-of-Thought (CoT) reasoning processes. Rather than judging outcomes, TRACE inspects how arguments are constructed by integrating Toulmin's argumentation theory with Flavell's metacognitive framework to assess reasoning structure. Experiments on 26.3K QA samples across 7 reasoning models show strong correlation with benchmark accuracy (r=0.74). Furthermore, TRACE is effective as a reinforcement learning reward signal, outperforming accuracy-only baselines. Together, these results indicate that logically sound reasoning leads to higher-quality answers. TRACE thus serves as a complementary metric for evaluating open-ended outputs. Code is available at https://github.com/hyyangkisti/trace.
トークンスペース圧縮による制約付きデコードの高速化
LLM の出力が指定された構造に準拠していることを保証するために、文脈自由文法 (CFG) デコード エンジンは、指定された CFG に準拠する文字列を生成する次のトークンの選択を強制します。現在の CFG 制約付きデコード エンジンは高度に最適化されていますが、ステップごとの膨大な検索スペース (つまり、トークン語彙全体) から生じる固有のコストにより、より複雑な CFG では手に負えないほど高いオーバーヘッドが発生します。これはまさに CFG エンジンが最も役立つ状況です。このペーパーでは、トークン検索スペースを圧縮するためのオフライン技術である CFGzip を紹介します。これにより、CFG エンジンのオーバーヘッドが大幅に削減されます。実験では、CFGzip を SoTA 文法エンジンとともに使用すると、レイテンシーが最大 2 桁削減され、制約付き生成時間の合計が最大 7.5 倍高速化されることが報告されています。CFGzip を使用すると、複雑な CFG に対して大規模な制約付きデコードが実現可能になります。
原文 (English)
Accelerating Constrained Decoding with Token Space Compression
To guarantee that an LLM's outputs conform to a specified structure, context-free grammar (CFG) decoding engines force the selection of next tokens that produce strings that conform to a given CFG. While current CFG-constrained decoding engines are highly optimized, the inherent costs arising from the massive per-step search space -- i.e. the entire token vocabulary -- result in intractably high overhead for more complex CFGs: precisely the situation where CFG engines are most useful. In this paper, we introduce CFGzip, an offline technique for compressing the token search space, which massively reduces CFG engine overhead. In experiments, we report latency reduction of up to two orders of magnitude when CFGzip is used with a SoTA grammar engine, yielding an up to 7.5x speedup in total constrained generation time: with CFGzip, constrained decoding is now feasible at scale for complex CFGs.
BioRefusalAudit: 一般およびドメイン微調整されたスパース オートエンコーダーを使用したバイオセキュリティ拒否の深さの監査
言語モデルのバイオセキュリティ評価では通常、モデルが危険な出力を生成するかどうかが問われます。この論文は補足的な質問をします。モデルが拒否した場合、その拒否は構造的に正しいのでしょうか、それともフレーミング、フォーマット、または出力長を促すための適度な変更で消えるのでしょうか? 5 つのアーキテクチャにわたって、無害性と危険性を明確に区別したモデルはありませんでした。 Gemma 2 2B-IT は、75 件のプロンプトにわたって真に拒否することはなく、危険に隣接するすべてのクエリを回避しました。 Gemma 4 E2B-IT は、チャット テンプレート形式を使用した場合は 65/75 件のプロンプトを拒否し、チャット テンプレート形式を使用しない場合は 0/75 件のプロンプトを拒否しました。両方の Gemma モデルは、80 トークンの上限の下で 0% に崩壊しました。 Qwen 2.5 1.5B と Phi-3-mini は過剰に拒否され、良性生物学の 83 ~ 87% が危険であると警告されました。 Llama 3.2 1B は唯一の意味のある Tier 勾配 (61 ポイントの広がり) を示しました。何がそのような過剰な拒否を引き起こすのかを調査するために、我々はスケジュールIであるが生物学的に無毒な化合物(特にFDA画期的治療法のステータスを持つシロシビン培養)のパネルをテストしました。一部のモデルは、真に有害な生物学を超える割合でこれらを拒否しており、拒否がCBRNの危険性に対する合法性と文化的顕著性を追跡していることを示唆しています。内部側を測定するために、モデルの表面応答ラベルを内部のスパース オートエンコーダー (SAE) 特徴のアクティベーションと比較する発散スコア D を導入します。フル D は、Gemma 2 2B-IT (Gemma Scope 1) および Gemma 4 E2B-IT (著者が訓練したバイオ SAE) で計算されました。 2 つの微調整された Gemma 2 ドメイン SAE がリリースされました。 Gemma 4 では、狭いカタログ、サンプル内キャリブレーション、および Gemma ファミリーのみの SAE 範囲を使用して、重複なし (n=75) で 0.647 ポイントのギャップで応答と拒否の応答が分離されますが、これは暫定的なものです。消費者向けハードウェア (GTX 1650 Ti Max-Q、および SAE トレーニング用の Colab T4) での 1 つのハッカソン週末にわたって構築されたこの予備的な証拠は、アクティベーション レベルの監査によって、アーキテクチャ間で大幅に異なる、動作評価では見えない障害モードが表面化する可能性があることを示唆しています。
原文 (English)
BioRefusalAudit: Auditing Biosecurity Refusal Depth Using General and Domain-Fine-Tuned Sparse Autoencoders
Biosecurity evaluations of language models typically ask whether models produce hazardous output. This paper asks a complementary question: when a model refuses, is that refusal structurally sound, or does it disappear under modest changes to prompt framing, formatting, or output length? Across five architectures, no model cleanly discriminated benign from hazard. Gemma 2 2B-IT never genuinely refused across 75 prompts, hedging on every hazard-adjacent query. Gemma 4 E2B-IT refused 65/75 prompts with chat-template formatting and 0/75 without it. Both Gemma models collapsed to 0% under an 80-token cap. Qwen 2.5 1.5B and Phi-3-mini over-refused, flagging 83-87% of benign biology as hazardous. Llama 3.2 1B showed the only meaningful tier gradient (61-point spread). To probe what drives such over-refusal, we tested a panel of Schedule I but biologically non-toxic compounds (notably psilocybin cultivation, with FDA Breakthrough Therapy status). Some models refused these at rates exceeding genuinely hazardous biology, suggesting refusal tracks legality and cultural salience over CBRN hazard. To measure the internal side, we introduce a divergence score D comparing a model's surface response label to its internal sparse autoencoder (SAE) feature activations. Full D was computed on Gemma 2 2B-IT (Gemma Scope 1) and Gemma 4 E2B-IT (author-trained bio SAE). Two fine-tuned Gemma 2 domain SAEs were released. On Gemma 4, comply and refuse responses separated by a 0.647-point gap with zero overlap (n=75), though this is preliminary, with a narrow catalog, within-sample calibration, and Gemma-family-only SAE coverage. Built over one hackathon weekend on consumer hardware (GTX 1650 Ti Max-Q, plus Colab T4 for SAE training), this preliminary evidence suggests activation-level auditing may surface failure modes invisible to behavioral evaluation, with substantial variation across architectures.
OISD: 言語モデルのポリシーに基づく内部自己蒸留
最近の強化学習 (RL) ポストトレーニング アプローチは主に、まばらな結果レベルの報酬を使用して最終的な出力ポリシーを最適化しますが、中間表現にエンコードされた予測信号はほとんど見落とされます。この論文では、オンポリシー内部自己蒸留と呼ばれる新しいパラダイムを導入し、オンポリシー予測信号を最終層から中間表現に転送することで推論を改善する OISD フレームワークを提案します。ロールアウトおよびグループ相対ポリシー最適化 (GRPO) の最適化中、最終層はポリシーと、選択された中間層に対する独立した内部教師の両方として機能します。最終層は、2 つの相補的なメカニズムを通じてそれに合わせるよう誘導されます。ロジット アライメントは、高レベルの推論動作 (思考方法) を転送し、アテンション アライメントは、最終層から選択した中間層に一貫した注意パターン (どこを見るか) を強制します。どちらも、外部の特権情報を必要としません。私たちの OISD は、GRPO と協力して、符号付きアドバンテージ加重ジェンセン - シャノン アライメントを採用して、統一された政策の下で政策の一貫性を維持しながら、有益な中間表現を抽出します。実験結果は、OISD の有効性を実証しており、4 つの数学的推論タスクにわたって強力な推論 RL ベースラインを大幅に改善し、一貫して改善しています。コードは https://github.com/THE-MALT-LAB/OISD でリリースされます。
原文 (English)
OISD: On-Policy Internal Self-Distillation of Language Models
Recent reinforcement learning (RL) post-training approaches primarily optimize the final output policy using sparse outcome-level rewards, while largely overlooking predictive signals encoded in intermediate representations. In this paper, we introduce a new paradigm called on-policy internal self-distillation and propose the OISD framework, which improves reasoning by transferring on-policy predictive signals from the final layer to intermediate representations. During rollout and Group Relative Policy Optimization (GRPO) optimization, the final layer acts as both the policy and a detached internal teacher for selected intermediate layers, which are guided to align with it through two complementary mechanisms: logit alignment, which transfers high-level reasoning behaviors (how to think), and attention alignment, which enforces consistent attention patterns (where to look) from the final layer to the selected intermediate layer, both without requiring external privileged information. Our OISD, together with GRPO, employs signed advantage-weighted Jensen--Shannon alignment to distill informative intermediate representations while preserving policy consistency under a unified acting policy. Experimental results demonstrate the effectiveness of OISD, with substantial and consistent improvements over strong reasoning RL baselines across four mathematical reasoning tasks. The code will be released at https://github.com/THE-MALT-LAB/OISD
From Prompts to Context: An Ontology-Driven Framework for Human-Generative AI Collaboration
Collaborations with Generative AI often begin with a short prompt and end with an opaque output, leaving implicit who was involved, what ta…
Internal Representation, Not Clinical Knowledge: Where Apparent LLM Triage Failures Originate
Patient-voiced clinical-triage benchmarks report high under-triage rates for consumer LLMs for constrained multiple-choice output, yet the…
ScheduleStream: Temporal Planning with Samplers for GPU-Accelerated Multi-Arm Task and Motion Planning & Scheduling
Bimanual and humanoid robots are appealing because of their human-like ability to leverage multiple arms to efficiently complete tasks. How…
Steering Language Models Before They Speak: Logit-Level Interventions
Controllable generation requires language models to realize output characteristics such as reading level, politeness, and toxicity. Existin…
ProtoMedAgent: Multimodal Clinical Interpretability via Privacy-Aware Agentic Workflows
While interpretable prototype networks offer compelling case-based reasoning for clinical diagnostics, their raw continuous outputs lack th…
The Distillation Game: Adaptive Attacks & Efficient Defenses
Distillation attacks create a deployment trade-off for model providers: the same outputs that make a model more useful can also make it eas…
EvoSpec: Evolving Speculative Decoding via Real-Time Vocabulary and Parameter Adaptation
Speculative decoding accelerates Large Language Model inference via a draft-then-verify paradigm, yet the output projection layer becomes a…
大規模な言語モデルに基づくマルチエージェント フレームワークによる共同ストーリーテリングの向上
共創、つまり AI エージェントが人間と対話して出力 (アートなど) を生成するというテーマは、最近大きな注目を集めています。ただし、ほとんどの研究は、デジタル環境における成人と人間の相互作用に焦点を当てています。この論文では、子供たちと大規模言語モデル (LLM) が物理的なボード ゲームを通じて相互作用して書かれた物語を作成する、新しいばかばかしい共創シナリオを検討します。私たちの目標は、若いプレイヤーに適した高品質の物語を生成できるマルチエージェント フレームワークを開発することです。私たちのアプローチの中核は、ある LLM がストーリーを生成し、別の LLM がストーリーを評価して改良のためのフィードバックを提供する、反復的なライターとエディターのプロセスです。複数の LLM を含むシミュレーション研究を通じて、この反復的な相互作用により、連続するループ全体で生成されたストーリーの知覚品質が一貫して向上することがわかりました。この結果は、インタラクティブなストーリーテリング システムで高品質の出力を達成するには、少数の改良ステップで十分である可能性があることを示しています。
原文 (English)
Improving Collaborative Storytelling with a Multi-Agent Framework Based on Large Language Models
The topic of Co-creation, i.e., AI agents interacting with humans to generate outputs (e.g., art), has gained significant attention recently. However, most studies focus on adult-human interactions in a digital setting. This paper explores a novel ludic co-creation scenario involving children and Large Language Models (LLMs) interacting through a physical board game to create written stories. Our goal is to develop a multi-agent framework capable of producing high-quality narratives suitable for young players. At the core of our approach is an iterative Writer-Editor process in which one LLM generates stories while another evaluates them and provides feedback for refinement. Through a simulation study involving multiple LLMs, we show that this iterative interaction consistently improves the perceived quality of generated stories across successive loops. The results indicate that a small number of refinement steps may be sufficient to achieve high-quality outputs in interactive storytelling systems.
TRACE: LLM CoT 評価の構成要素によるトゥールミンベースの推論評価
大規模言語モデル (LLM) からのオープンエンドの出力を評価することは、グランド トゥルースがないため依然として困難です。既存の指標は、最終的な答えの精度や表面レベルの統計に依存しており、推論プロセス自体は検討されていません。思考連鎖 (CoT) 推論プロセスを分析する指標である TRACE (Toulmin-based Reasoning Assessment through Constructive Elements) を紹介します。 TRACE は、結果を判断するのではなく、トゥールミンの議論理論とフラベルのメタ認知フレームワークを統合して推論の構造を評価することにより、議論がどのように構築されるかを検査します。 7 つの推論モデルにわたる 26.3K の QA サンプルの実験では、ベンチマーク精度 (r=0.74) との強い相関関係が示されています。さらに、TRACE は強化学習の報酬信号として効果的であり、精度のみのベースラインを上回ります。これらの結果を総合すると、論理的に健全な推論がより質の高い答えにつながることを示しています。したがって、TRACE は、オープンエンド出力を評価するための補足的なメトリックとして機能します。コードは https://github.com/hyyangkisti/trace で入手できます。
原文 (English)
TRACE: Toulmin-based Reasoning Assessment through Constructive Elements for LLM CoT Evaluation
Evaluating open-ended outputs from large language models (LLMs) remains challenging due to the absence of ground truth. Existing metrics rely on final-answer accuracy or surface-level statistics, leaving the reasoning process itself unexamined. We introduce TRACE (Toulmin-based Reasoning Assessment through Constructive Elements), a metric that analyzes Chain-of-Thought (CoT) reasoning processes. Rather than judging outcomes, TRACE inspects how arguments are constructed by integrating Toulmin's argumentation theory with Flavell's metacognitive framework to assess reasoning structure. Experiments on 26.3K QA samples across 7 reasoning models show strong correlation with benchmark accuracy (r=0.74). Furthermore, TRACE is effective as a reinforcement learning reward signal, outperforming accuracy-only baselines. Together, these results indicate that logically sound reasoning leads to higher-quality answers. TRACE thus serves as a complementary metric for evaluating open-ended outputs. Code is available at https://github.com/hyyangkisti/trace.
トークンスペース圧縮による制約付きデコードの高速化
LLM の出力が指定された構造に準拠していることを保証するために、文脈自由文法 (CFG) デコード エンジンは、指定された CFG に準拠する文字列を生成する次のトークンの選択を強制します。現在の CFG 制約付きデコード エンジンは高度に最適化されていますが、ステップごとの膨大な検索スペース (つまり、トークン語彙全体) から生じる固有のコストにより、より複雑な CFG では手に負えないほど高いオーバーヘッドが発生します。これはまさに CFG エンジンが最も役立つ状況です。このペーパーでは、トークン検索スペースを圧縮するためのオフライン技術である CFGzip を紹介します。これにより、CFG エンジンのオーバーヘッドが大幅に削減されます。実験では、CFGzip を SoTA 文法エンジンとともに使用すると、レイテンシーが最大 2 桁削減され、制約付き生成時間の合計が最大 7.5 倍高速化されることが報告されています。CFGzip を使用すると、複雑な CFG に対して大規模な制約付きデコードが実現可能になります。
原文 (English)
Accelerating Constrained Decoding with Token Space Compression
To guarantee that an LLM's outputs conform to a specified structure, context-free grammar (CFG) decoding engines force the selection of next tokens that produce strings that conform to a given CFG. While current CFG-constrained decoding engines are highly optimized, the inherent costs arising from the massive per-step search space -- i.e. the entire token vocabulary -- result in intractably high overhead for more complex CFGs: precisely the situation where CFG engines are most useful. In this paper, we introduce CFGzip, an offline technique for compressing the token search space, which massively reduces CFG engine overhead. In experiments, we report latency reduction of up to two orders of magnitude when CFGzip is used with a SoTA grammar engine, yielding an up to 7.5x speedup in total constrained generation time: with CFGzip, constrained decoding is now feasible at scale for complex CFGs.
BioRefusalAudit: 一般およびドメイン微調整されたスパース オートエンコーダーを使用したバイオセキュリティ拒否の深さの監査
言語モデルのバイオセキュリティ評価では通常、モデルが危険な出力を生成するかどうかが問われます。この論文は補足的な質問をします。モデルが拒否した場合、その拒否は構造的に正しいのでしょうか、それともフレーミング、フォーマット、または出力長を促すための適度な変更で消えるのでしょうか? 5 つのアーキテクチャにわたって、無害性と危険性を明確に区別したモデルはありませんでした。 Gemma 2 2B-IT は、75 件のプロンプトにわたって真に拒否することはなく、危険に隣接するすべてのクエリを回避しました。 Gemma 4 E2B-IT は、チャット テンプレート形式を使用した場合は 65/75 件のプロンプトを拒否し、チャット テンプレート形式を使用しない場合は 0/75 件のプロンプトを拒否しました。両方の Gemma モデルは、80 トークンの上限の下で 0% に崩壊しました。 Qwen 2.5 1.5B と Phi-3-mini は過剰に拒否され、良性生物学の 83 ~ 87% が危険であると警告されました。 Llama 3.2 1B は唯一の意味のある Tier 勾配 (61 ポイントの広がり) を示しました。何がそのような過剰な拒否を引き起こすのかを調査するために、我々はスケジュールIであるが生物学的に無毒な化合物(特にFDA画期的治療法のステータスを持つシロシビン培養)のパネルをテストしました。一部のモデルは、真に有害な生物学を超える割合でこれらを拒否しており、拒否がCBRNの危険性に対する合法性と文化的顕著性を追跡していることを示唆しています。内部側を測定するために、モデルの表面応答ラベルを内部のスパース オートエンコーダー (SAE) 特徴のアクティベーションと比較する発散スコア D を導入します。フル D は、Gemma 2 2B-IT (Gemma Scope 1) および Gemma 4 E2B-IT (著者が訓練したバイオ SAE) で計算されました。 2 つの微調整された Gemma 2 ドメイン SAE がリリースされました。 Gemma 4 では、狭いカタログ、サンプル内キャリブレーション、および Gemma ファミリーのみの SAE 範囲を使用して、重複なし (n=75) で 0.647 ポイントのギャップで応答と拒否の応答が分離されますが、これは暫定的なものです。消費者向けハードウェア (GTX 1650 Ti Max-Q、および SAE トレーニング用の Colab T4) での 1 つのハッカソン週末にわたって構築されたこの予備的な証拠は、アクティベーション レベルの監査によって、アーキテクチャ間で大幅に異なる、動作評価では見えない障害モードが表面化する可能性があることを示唆しています。
原文 (English)
BioRefusalAudit: Auditing Biosecurity Refusal Depth Using General and Domain-Fine-Tuned Sparse Autoencoders
Biosecurity evaluations of language models typically ask whether models produce hazardous output. This paper asks a complementary question: when a model refuses, is that refusal structurally sound, or does it disappear under modest changes to prompt framing, formatting, or output length? Across five architectures, no model cleanly discriminated benign from hazard. Gemma 2 2B-IT never genuinely refused across 75 prompts, hedging on every hazard-adjacent query. Gemma 4 E2B-IT refused 65/75 prompts with chat-template formatting and 0/75 without it. Both Gemma models collapsed to 0% under an 80-token cap. Qwen 2.5 1.5B and Phi-3-mini over-refused, flagging 83-87% of benign biology as hazardous. Llama 3.2 1B showed the only meaningful tier gradient (61-point spread). To probe what drives such over-refusal, we tested a panel of Schedule I but biologically non-toxic compounds (notably psilocybin cultivation, with FDA Breakthrough Therapy status). Some models refused these at rates exceeding genuinely hazardous biology, suggesting refusal tracks legality and cultural salience over CBRN hazard. To measure the internal side, we introduce a divergence score D comparing a model's surface response label to its internal sparse autoencoder (SAE) feature activations. Full D was computed on Gemma 2 2B-IT (Gemma Scope 1) and Gemma 4 E2B-IT (author-trained bio SAE). Two fine-tuned Gemma 2 domain SAEs were released. On Gemma 4, comply and refuse responses separated by a 0.647-point gap with zero overlap (n=75), though this is preliminary, with a narrow catalog, within-sample calibration, and Gemma-family-only SAE coverage. Built over one hackathon weekend on consumer hardware (GTX 1650 Ti Max-Q, plus Colab T4 for SAE training), this preliminary evidence suggests activation-level auditing may surface failure modes invisible to behavioral evaluation, with substantial variation across architectures.
OISD: 言語モデルのポリシーに基づく内部自己蒸留
最近の強化学習 (RL) ポストトレーニング アプローチは主に、まばらな結果レベルの報酬を使用して最終的な出力ポリシーを最適化しますが、中間表現にエンコードされた予測信号はほとんど見落とされます。この論文では、オンポリシー内部自己蒸留と呼ばれる新しいパラダイムを導入し、オンポリシー予測信号を最終層から中間表現に転送することで推論を改善する OISD フレームワークを提案します。ロールアウトおよびグループ相対ポリシー最適化 (GRPO) の最適化中、最終層はポリシーと、選択された中間層に対する独立した内部教師の両方として機能します。最終層は、2 つの相補的なメカニズムを通じてそれに合わせるよう誘導されます。ロジット アライメントは、高レベルの推論動作 (思考方法) を転送し、アテンション アライメントは、最終層から選択した中間層に一貫した注意パターン (どこを見るか) を強制します。どちらも、外部の特権情報を必要としません。私たちの OISD は、GRPO と協力して、符号付きアドバンテージ加重ジェンセン - シャノン アライメントを採用して、統一された政策の下で政策の一貫性を維持しながら、有益な中間表現を抽出します。実験結果は、OISD の有効性を実証しており、4 つの数学的推論タスクにわたって強力な推論 RL ベースラインを大幅に改善し、一貫して改善しています。コードは https://github.com/THE-MALT-LAB/OISD でリリースされます。
原文 (English)
OISD: On-Policy Internal Self-Distillation of Language Models
Recent reinforcement learning (RL) post-training approaches primarily optimize the final output policy using sparse outcome-level rewards, while largely overlooking predictive signals encoded in intermediate representations. In this paper, we introduce a new paradigm called on-policy internal self-distillation and propose the OISD framework, which improves reasoning by transferring on-policy predictive signals from the final layer to intermediate representations. During rollout and Group Relative Policy Optimization (GRPO) optimization, the final layer acts as both the policy and a detached internal teacher for selected intermediate layers, which are guided to align with it through two complementary mechanisms: logit alignment, which transfers high-level reasoning behaviors (how to think), and attention alignment, which enforces consistent attention patterns (where to look) from the final layer to the selected intermediate layer, both without requiring external privileged information. Our OISD, together with GRPO, employs signed advantage-weighted Jensen--Shannon alignment to distill informative intermediate representations while preserving policy consistency under a unified acting policy. Experimental results demonstrate the effectiveness of OISD, with substantial and consistent improvements over strong reasoning RL baselines across four mathematical reasoning tasks. The code will be released at https://github.com/THE-MALT-LAB/OISD
From Prompts to Context: An Ontology-Driven Framework for Human-Generative AI Collaboration
Collaborations with Generative AI often begin with a short prompt and end with an opaque output, leaving implicit who was involved, what ta…
Internal Representation, Not Clinical Knowledge: Where Apparent LLM Triage Failures Originate
Patient-voiced clinical-triage benchmarks report high under-triage rates for consumer LLMs for constrained multiple-choice output, yet the…
ScheduleStream: Temporal Planning with Samplers for GPU-Accelerated Multi-Arm Task and Motion Planning & Scheduling
Bimanual and humanoid robots are appealing because of their human-like ability to leverage multiple arms to efficiently complete tasks. How…
Steering Language Models Before They Speak: Logit-Level Interventions
Controllable generation requires language models to realize output characteristics such as reading level, politeness, and toxicity. Existin…
ProtoMedAgent: Multimodal Clinical Interpretability via Privacy-Aware Agentic Workflows
While interpretable prototype networks offer compelling case-based reasoning for clinical diagnostics, their raw continuous outputs lack th…
The Distillation Game: Adaptive Attacks & Efficient Defenses
Distillation attacks create a deployment trade-off for model providers: the same outputs that make a model more useful can also make it eas…
EvoSpec: Evolving Speculative Decoding via Real-Time Vocabulary and Parameter Adaptation
Speculative decoding accelerates Large Language Model inference via a draft-then-verify paradigm, yet the output projection layer becomes a…

Just like gold and oil, we’ll soon be able to trade AI token futures
Large exchanges are designing derivative products around AI tokens, which are increasingly being considered less a computational output and…

Has the hunt for AI compute uncovered the next Cerebras?
General Compute is betting SambaNova will be the next breakout chipmaker.

レノボ、国内に“水冷AIインフラ”の検証施設 GPUサーバ需要増で水冷活用促す
レノボ・ジャパンが水冷技術を活用したAIインフラの検証施設「Neptuneラボ」を新設した。レノボの冷却技術を使う顧客やパートナー企業に対し、本番に近い検証・PoC環境として提供する。クラウドベンダーやSIerとの共同検証を通し、推奨される機器構成などの策定にも役立てる。レノボ…
エージェント用のクエリ エンジン
現在、実稼働環境で最も急速に増加しているデータは、エージェント トレース、チャット ログ、推論チェーン、モデル出力などの非構造化テキストです。人々はそれを分析したいと考えていますが、クエリ パスにモデルがないとテキストをクエリできないため、尋ねる価値のある質問 (「エージェントがどこで混乱したか教えてください」) は SQL だけでは答えることができません。この分析が行われる自然な場所は、クライアント側で実行され、同じプロセス内で人間のユーザーと LLM エージェントの両方をホストする新しいクラスの AI アプリケーション (Claude Code、Cursor、Claude Desktop、ブラウザ内エージェント) です。これらのアプリケーションはデータを操作する必要がますます高まっていますが、レイクハウスの読み取りパスは JS ランタイムから使用するのが難しく、Spark、Trino、およびマネージド ウェアハウスはそこに適合しません。この新しい種類の AI データ アプリケーションを構築するには、エンジンの 3 つのプロパティが一次になります。アプリケーションがすでに実行されているランタイムにドロップされる JS ネイティブ ディストリビューション、コールド タブまたはターンごとのエージェント サンドボックス内に出荷できるほど十分小さいバンドル、および分析オペレーターとモデルベースのテキスト解釈をインターリーブする方法です。我々は、合計 70 KB 未満の 3 つのオープンソース JavaScript ライブラリ (Hyparquet、Squirreling、Icebird) である Hyperparam を紹介します。これらは、Parquet と Apache Iceberg をオブジェクト ストレージから直接読み取り、セルごとの非同期ネイティブ SQL 実行で 3 番目のプロパティを満たすため、高価なセルはダウンストリーム オペレーターが要求した場合にのみ起動されます。 Squirreling は、フィルタ境界クエリでは DuckDB-WASM より 300 倍以上高速 (ソート境界クエリでは 192 倍) で LLM 形状の非同期 UDF を実行し、3 分の 2 のコストで 10 タスクのエージェント アナリスト スイートを完成させます。私たちは、専門分野としてのデータ エンジニアリングは、現在運用されている AI ネイティブのクライアント アプリケーションとそのユーザーと連携して動作するエージェントに合わせて更新する必要があると主張します。
原文 (English)
A Query Engine for the Agents
The fastest-growing data in production today is unstructured text: agent traces, chat logs, reasoning chains, model outputs. People want to analyze it, and the questions worth asking ("show me where the agent got confused") cannot be answered by SQL alone, since text is not queryable without a model in the query path. The natural place this analysis is happening is the new class of AI applications (Claude Code, Cursor, Claude Desktop, in-browser agents) that run client-side and host both a human user and an LLM agent in the same process. These applications increasingly want to work with data, but the lakehouse read path has been hard to use from a JS runtime: Spark, Trino, and managed warehouses do not fit there. To build this new kind of AI data application, three properties of the engine become first-order: a JS-native distribution that drops into the runtime the application already runs in, a bundle small enough to ship inside a cold tab or per-turn agent sandbox, and a way to interleave analytic operators with model-based interpretation of text. We present Hyperparam, three open-source JavaScript libraries (Hyparquet, Squirreling, Icebird) totaling under 70 KB, that read Parquet and Apache Iceberg directly from object storage and meet the third property with per-cell, async-native SQL execution, so expensive cells fire only when downstream operators demand them. Squirreling runs LLM-shaped async UDFs over 300x faster than DuckDB-WASM on filter-bounded queries (and 192x on sort-bounded queries) and completes a ten-task agent analyst suite at two-thirds lower cost. We argue that data engineering as a discipline needs to update for the AI-native client applications now in production and the agents that work alongside their users.
いつ最適化すべきかを学ぶ: GPU カーネル系統の専門家による検証済みの最適化スキル
LLM ベースのエージェントは、GPU カーネルの生成にますます使用されていますが、多くの場合、それらの最適化がいつ適切であるかは分からずに、どのような最適化を試みるべきかはわかっています。 KLineage を導入します。KLineage は、この欠落している「いつ」の知識をエキスパート カーネルから学習します。KLineage は、前方ロールアウトに依存するのではなく、検証ゲートによる簡略化を通じてエキスパート実装を後方に導き、受け入れられた各ステップを逆に再利用可能な最適化スキルに変換します。各スキルは、最適化の意図だけでなく、それがコード内のどこに適用されるか、どのような条件で最適化が有効になったか、どのような効果があったのか、その前提によってどのような失敗が回避されたのかも記録します。ダウンストリーム LLM は、同じコンパイル/正確性/プロファイル ゲートの下で新しいコード サーフェス上でこれらのスキルを具体化します。 2 つの NVIDIA アーキテクチャにわたる 5 つのエキスパート ワークロードでは、これらの系統由来のスキルが効果的な最適化カリキュラムとして機能し、同じ固定予算の下で最終的なカーネル品質と最適化効率の両方において最近のメモリベースの LLM カーネル ベースラインを上回ります。さらに、ソースケースの記憶に対する健全性テストとして、別個の 22 インスタンスのホールドアウト チェックを使用します。
原文 (English)
Learning When to Optimize: Verified Optimization Skills from Expert GPU-Kernel Lineages
LLM-based agents are increasingly used to generate GPU kernels, but they often know what optimizations to try without knowing when those optimizations are sound. We introduce KLineage, which learns this missing "when" knowledge from expert kernels: instead of relying on forward rollouts, KLineage walks expert implementations backward through validation-gated simplifications and reverses each accepted step into a reusable optimization skill. Each skill records not only the optimization intent, but also where it applies in code, what conditions made it valid, what effect it had, and what failures its assumptions avoid. A downstream LLM materializes these skills on new code surfaces under the same compile/correctness/profile gate. On five expert workloads across two NVIDIA architectures, these lineage-derived skills serve as an effective optimization curriculum, exceeding recent memory-based LLM-kernel baselines in both final kernel quality and optimization efficiency under the same fixed budget. We additionally use a separate 22-instance held-out check as a sanity test against source-case memorization.
生成モデルにおける幻覚のフィンガープリントとしてのエントロピー分布
大規模言語モデル (LLM) は、一般に幻覚と呼ばれる事実に反する出力を生成することが多く、信頼を損ない、一か八かの環境での展開を制限します。既存の幻覚検出方法では通常、複数のフォワード パスまたはモデル内部へのアクセスが必要です。この研究では、混乱または長さで正規化されたエントロピーによって捕捉された平均を超えるトークンレベルのエントロピーの分布が、独立した信号を運ぶ分布形状と尾部の動作を伴う幻覚の指紋として機能するという理論的背景と経験的証拠を提供します。私たちは幻覚検出を統計的仮説検定として形式化し、単一のフォワード パスとトークン ロジットへのブラック ボックス アクセスのみを必要とする軽量アルゴリズムである校正エントロピー スコア (CES) を提案します。 CES は、校正された参照 CDF を通じて生成されたエントロピーの平均信号と最大信号を結合し、モデルとタスク間で直接比較できるスコアを生成します。我々は、新しいランダム長の Dvoretzky-Kiefer-Wolfowitz 不等式を介して有限サンプルのキャリブレーション保証を確立し、また、CES が世代長において指数関数的に速く 1 に収束する確率で幻覚を検出することも証明します。 CES は、オープンソース モデルと API アクセス モデルにわたる 8 つの QA ベンチマークと 10 のジェネレーター モデルにわたって、すべてのシングルパス ブラック ボックス メソッドの中で最高の検出パフォーマンスを達成するとともに、既存のヒューリスティックにはない正式なエラー保証を提供します。注目すべきことに、CES は、はるかに大きな計算コストを必要とするマルチサンプル手法と統計的に区別がつかないため、軽量検出と高価な検出の間のギャップを埋め、リアルタイムの大規模展開に適しています。
原文 (English)
Entropy Distribution as a Fingerprint for Hallucinations in Generative Models
Large Language Models (LLMs) often generate factually incorrect outputs, commonly termed hallucinations, that undermine trust and limit deployment in high-stakes settings. Existing hallucination detection methods typically require multiple forward passes, or access to model internals. In this work, we provide theoretical background and empirical evidence that the distribution of token-level entropies, beyond the mean captured by perplexity or length-normalised entropy, serves as a fingerprint of hallucination, with distributional shape and tail behaviour carrying independent signal. We formalize hallucination detection as a statistical hypothesis test and propose the Calibrated Entropy Score (CES), a lightweight algorithm requiring only a single forward pass and black-box access to token logits. CES combines the mean signal with the maximum signal of the generated entropy through a calibrated reference CDF, producing scores that are directly comparable across models and tasks. We establish finite-sample calibration guarantees via a novel random-length Dvoretzky--Kiefer--Wolfowitz inequality, and also prove that CES detects hallucinations with probability converging to one exponentially fast in the generation length. Across eight QA benchmarks and ten generator models spanning open-source and API access models, CES achieves the highest detection performance among all single-pass black-box methods while providing formal error guarantees that existing heuristics lack. Remarkably, CES is statistically indistinguishable from multi-sample methods that require far greater computational cost, closing the gap between lightweight and expensive detection and making it suitable for real-time, large-scale deployment.
SwarmHarness: Skill-Based Task Routing via Decentralized Incentive-Aligned AI Agent Networks
Vast quantities of compute (GPU cycles on personal workstations, idle inference servers, and edge devices between jobs) go unused because n…
EvoSpec: Evolving Speculative Decoding via Real-Time Vocabulary and Parameter AdaptationTarget
Speculative decoding accelerates Large Language Model inference via a draft-then-verify paradigm, yet the output projection layer becomes a…
The Future of Facts: Tracing the Factual Generation-Verification Gap
Language models are becoming the default interface to factual knowledge, yet they often verify outputs more reliably than they generate the…
The Energy Blind Spot: NVIDIA's Flagship Edge AI Hardware Cannot Support Process-Level Energy Attribution
Agentic AI workloads - where a single user goal triggers multi-step orchestration, tool calls, retries, and failure recovery - are being ta…
Semantic Flow Regularization: Teaching LLMs to Generate Diverse Yet Coherent Responses
When large language models are fine-tuned to generate persona- or tone-conditioned responses, their output diversity is severely limited--a…
Integrated and Cross-Architecture Interpretation of LLM Reasoning
Understanding how LLMs reason is hindered by a practical asymmetry: while their generated outputs are observable, the underlying reasoning…
Learning the Error Patterns of Language Models
When generating outputs for domains with specific validity constraints (e.g., a program should compile), LLMs often fail in a small number…
PICACO: Pluralistic In-Context Value Alignment of LLMs via Total Correlation Optimization
In-Context Learning has shown great potential for aligning Large Language Models (LLMs) with human values, helping reduce harmful outputs a…

In more good news for Amazon, Snowflake signs $6B deal with AWS for AI CPU chips
Snowflake has signed a new, enormous five-year deal with Amazon to secure chips for AI usage. Nvidia is once again being put on notice.
BrickAnything: 構造を意識したトークン化を使用した、ジオメトリ条件付きの構築可能なレンガの生成
3D 形状から物理的に構築可能なレンガ構造を生成するには、幾何学的再構成以上のものが必要です。出力は、個別のパーツの制約と構造の安定性も満たさなければなりません。既存のレンガ生成方法は、ターゲットの 3D 形状が事前定義された制約の下で実現可能な構造を許容しない場合に機能不全に陥る可能性があるヒューリスティック最適化に依存しているか、基礎となる 3D ジオメトリとアセンブリ関係を明示的にモデル化せずにブリック シーケンスを生成しています。この研究では、さまざまな 3D 表現から構築可能なレンガ構造を生成するための、ジオメトリ条件付き自己回帰フレームワークである BrickAnything を紹介します。 BrickAnything は、統一された幾何学的インターフェイスとして点群を使用し、アセンブリ制約の下でターゲット形状を再構築するレンガ シーケンスを予測します。ブリック間の構造依存関係をモデル化するために、ローカル接続関係を通じてブリック構造を表す構造認識ツリー トークン化を導入します。この定式化により、シーケンスの生成と物理的な構築プロセスの一貫性が高まり、無効な中間状態が減少します。さらに、安定性や幾何学的忠実度などの構築性の目標を向上させるために、トレーニング後の好みに基づくアライメント、妥当性制約のあるデコード、および適応的ロールバックを導入します。広範な実験により、BrickAnything が幾何学的に忠実で物理的に実現可能なブリック構造を生成すること、および提案されたトークン化により従来の順序付け戦略と比較してロールバックと再生成が効果的に削減されることが実証されました。
原文 (English)
BrickAnything: Geometry-Conditioned Buildable Brick Generation with Structure-Aware Tokenization
Generating physically buildable brick structures from 3D shapes requires more than geometric reconstruction: the output must also satisfy discrete part constraints and structural stability. Existing brick generation methods either rely on heuristic optimization, which can break down when the target 3D shape does not admit a feasible structure under predefined constraints, or generate brick sequences without explicitly modeling the underlying 3D geometry and assembly relations. In this work, we present BrickAnything, a geometry-conditioned autoregressive framework for generating buildable brick structures from diverse 3D representations. BrickAnything uses point clouds as a unified geometric interface and predicts brick sequences that reconstruct the target shape under assembly constraints. To model structural dependencies among bricks, we introduce a structure-aware tree tokenization, which represents brick structures through local attachment relations. This formulation makes sequence generation more consistent with the physical construction process, and reduces invalid intermediate states. We further introduce preference-based alignment post-training, validity-constrained decoding and adaptive rollback to improve buildability objectives such as stability and geometric fidelity. Extensive experiments demonstrate that BrickAnything produces geometrically faithful and physically realizable brick structures, and that the proposed tokenization effectively reduces rollback and regeneration compared with conventional ordering strategies.
ScientistOne: 証拠の連鎖による人間レベルの自律的研究に向けて
自律的な研究エージェントは、競争力のあるソリューションとプロフェッショナルに見える原稿を作成しますが、その出力には、表面レベルの評価では検出できない検証可能性の欠陥、つまり、捏造された引用、再現不可能なスコア、実装から乖離した手法の説明が含まれています。私たちは 3 つの貢献を通じてこの問題に取り組みます。まず、証拠連鎖 (CoE) です。これは、すべての主張が証拠ソースまで追跡可能であることを要求する検証可能性フレームワークです。 2 つ目は、ScientistOne です。これは、文献レビュー、解決策の発見、論文執筆を通じて構築によって証拠チェーンを維持するエンドツーエンドの自律研究システムです。 3 つ目は、CoE 監査です。スコア検証、仕様違反、参照検証、メソッド コードの調整という 4 つの整合性チェックがすべてのシステムに均一に適用される事後監査です。 5 つのシステムと 5 つのフロンティア研究タスクにわたる 75 の論文にわたって、すべてのベースラインが少なくとも 1 つの系統的故障モードを示しています。幻覚参照率は 21% に達し、スコア検証に合格した論文はわずか 42% で、メソッドとコードの整合性は 20% ~ 80% の範囲です。 ScientistOne は、幻覚参照ゼロ (0/337)、完璧なスコア検証 (12/12)、最高のメソッドとコードの整合性 (14/15) を達成しながら、5 つのタスクすべてで人間の専門家のパフォーマンスと同等またはそれを上回っています。 ScientistOne はさらに、医用画像処理、きめ細かい認識、3D 知覚、言語モデリングにわたる 6 つの追加タスクに一般化し、パラメーター ゴルフでは最先端の成績を、ベースラインが完全に失敗する MLE ベンチ タスクでは金メダルを獲得しました。
原文 (English)
ScientistOne: Towards Human-Level Autonomous Research via Chain-of-Evidence
Autonomous research agents produce competitive solutions and professional-looking manuscripts, yet their outputs contain verifiability failures undetectable by surface-level evaluation: fabricated citations, unreproducible scores, and method descriptions that diverge from the implementation. We address this through three contributions. First, Chain-of-Evidence (CoE), a verifiability framework requiring every claim to be traceable to its evidence source. Second, ScientistOne, an end-to-end autonomous research system that maintains evidence chains by construction throughout literature review, solution discovery, and paper writing. Third, CoE Audit, a post-hoc audit whose four integrity checks -- score verification, specification violation, reference verification, and method-code alignment -- apply uniformly to all systems. Across 75 papers spanning five systems and five frontier research tasks, every baseline exhibits at least one systematic failure mode: hallucinated reference rates reach 21%, score verification passes in as few as 42% of papers, and method-code alignment ranges from 20% to 80%. ScientistOne achieves zero hallucinated references (0/337), perfect score verification (12/12), and the highest method-code alignment (14/15), while matching or exceeding human expert performance on all five tasks. ScientistOne further generalizes to six additional tasks spanning medical imaging, fine-grained recognition, 3D perception, and language modeling, achieving state-of-the-art on Parameter Golf and gold medals on MLE-Bench tasks where baselines fail entirely.
単一方向を超えて: 思考の連鎖が単純な拒否の方向性を混乱させる
大規模推論モデル (LRM) は、最終出力を生成する前に思考連鎖 (CoT) トレースを生成し、拒否などの制御メカニズムを複雑にする可能性のある動的な内部状態を導入します。単一方向部分空間によって拒否が媒介される命令調整型 LLM とは異なり、大規模推論モデル (LRM) での拒否はさらに CoT に依存します。 DeepSeek-R1-Distill-LLaMA-8B では、CoT が固定されている場合、アクティブ化ステアリングによって拒否が逆転するのはわずか 39% ですが、CoT を完全に削除するとこれが 70% に増加し、CoT が積極的に拒否を強化していることがわかります。モデルが活性化ステアリングの下で CoT を再生成する 2 段階の介入では、94% のケースで拒否が逆転しますが、結果として得られる CoT だけでは、ステアリングが取り除かれた後でもこの効果の 48% が保持されます。これは、CoT がコンプライアンス信号を独立して伝送および再構築できることを示唆しています。これらの発見は、LRM での拒否が残留ストリームのアクティベーションと CoT で共同してエンコードされることを示しています。この共同アクティベーションにより、LRM はアクティベーション レベルの介入のみに対してより堅牢になりますが、CoT は代替の表面攻撃にさらされる可能性があります。
原文 (English)
Beyond a Single Direction: Chain-of-Thought Disrupts Simple Steering of Refusal
Large reasoning models (LRMs) generate chain-of-thought (CoT) traces before producing final outputs, introducing a dynamic internal state that may complicate control mechanisms such as refusal. Unlike instruction-tuned LLMs, where refusal is mediated by a single directional subspace, refusal in large reasoning models (LRMs) additionally depends on the CoT. In DeepSeek-R1-Distill-LLaMA-8B, activation steering reverses refusal in only 39% of cases when the CoT is kept fixed, but removing the CoT entirely increases this to 70%, indicating that the CoT actively reinforces refusal. In a two-stage intervention where the model regenerates its CoT under activation steering, refusal is reversed in 94% of cases, while the resulting CoT alone retains 48% of this effect even after steering is removed. This suggests that the CoT can carry and reconstruct the compliance signal independently. These findings indicate that refusal in LRMs is jointly encoded in residual stream activations and CoT. This joint activation makes LRM more robust against activation-level interventions alone, but exposes CoT to a possible alternative surface attack.
アトリビューションの盲点: 言語モデルが取得されたコンテキストではなくメモリに依存していることを検出する
検索拡張生成は、外部証拠における地上言語モデルの出力を約束しますが、この分野には、取得されたコンテキストが実際に生成を制御するかどうかを検証する信頼できる方法がありません。これは、一か八かの展開の前提条件です。コンテキスト一貫性のある出力はコンテキストに支配された出力を意味するという標準的な前提は、取得されたドキュメントがモデルの事前トレーニング データと重複すると崩れます。モデルは完全にパラメトリック メモリから忠実に見えるテキストを生成でき、両方の経路で区別できない出力が得られます。私たちはこの失敗をアトリビューションの盲点と名付け、これに対処するために Computational Reality Monitoring (CRM) を導入します。 CRM は、認知科学の現実監視フレームワークから適応した原則を運用します。コンテキストの有無にかかわらず内部表現を比較すると、出力レベルのモニターが体系的に見逃している、メンバーシップ条件付きの表現の相違が明らかになります。 CRM は、個々の世代がどのソースを使用したかを証明しません。トレーニング前の曝露が測定可能な内部軌跡の痕跡を残すかどうかを検出し、ソースの帰属に必要な基盤を確立します。 3 つのファミリーにまたがる 9 つのモデル バリアントにわたって、この相違はアーキテクチャ固有のレイヤー パターンに集中し、ブロック レベルのノイズ介入による集中的なサポートを受け、ドメインが混同されたベンチマークでは崩壊しながらタスクとデータセット全体に一般化します。帰属の盲点は測定可能で、部分的に対処可能です。内部表現は、出力レベルでは目に見えない診断信号を伝達し、証拠の出所に関する内部の認識が外部の動作を制御するシステムの基盤を確立します。
原文 (English)
The Attribution Blind Spot: Detecting When Language Models Rely on Memory Rather Than Retrieved Context
Retrieval-augmented generation promises to ground language model outputs in external evidence, yet the field has no reliable way to verify whether retrieved context actually governs generation -- a prerequisite for any high-stakes deployment. The standard assumption, that context-consistent output implies context-governed output, breaks when the retrieved document overlaps with the model's pretraining data: the model can produce faithful-looking text entirely from parametric memory, and both pathways yield indistinguishable output. We name this failure the attribution blind spot and introduce Computational Reality Monitoring (CRM) to address it. CRM operationalizes a principle adapted from cognitive science's reality monitoring framework: comparing internal representations with and without context reveals membership-conditioned representational divergence that output-level monitors systematically miss. CRM does not certify which source an individual generation used; it detects whether pretraining exposure leaves a measurable internal trajectory signature, establishing a necessary substrate for source attribution. Across nine model variants spanning three families, this divergence concentrates in architecture-specific layer patterns, receives converging support from block-level noise intervention, and generalizes across tasks and datasets while collapsing on domain-confounded benchmarks. The attribution blind spot is measurable and partially addressable: internal representations carry a diagnostic signal invisible at the output level, establishing a foundation for systems whose internal awareness of evidence provenance governs their external behavior.
マルチステークホルダー LLM 調整: 集計からの分解推定
複数の利害関係者のタスクでは、相反する好みを持つユーザーを満足させるために 1 つの出力が必要です。ホリスティック LLM ジャッジは、ユーティリティの推定とユーティリティの集計を混同し、不安定な暗黙的な重みを生成します。私たちは、利害関係者の満足度が分散している場合、この集計固有の \emph{重み付けノイズ} が大きなスコアの変動を引き起こす可能性があることを経験的および理論的に示します。私たちの実験では、こうした体重による変化は関係者の数とともに増加します。 \textsc{DecompR} を提案します。反事実に基づいて調整された重みは、候補をスコアリングする前にクエリ構造から固定されますが、役割ごとのユーティリティは独立して推定され、候補に依存する重みドリフトが除去され、推定ノイズが低減されます。
原文 (English)
Multi-Stakeholder LLM Alignment: Decomposing Estimation from Aggregation
Multi-stakeholder tasks require one output to satisfy users with conflicting preferences. Holistic LLM judges conflate utility estimation and utility aggregation, yielding unstable implicit weights. We show empirically and theoretically that this aggregation-specific \emph{weighting noise} can create large score shifts when stakeholder satisfaction is dispersed; in our experiments, these weight-induced shifts also increase with stakeholder count. We propose \textsc{DecompR}: counterfactual-calibrated weights are fixed from query structure before candidate scoring, while per-role utilities are estimated independently, removing candidate-dependent weight drift and reducing estimation noise.
データに敏感なドメインの LLM 出力のニューロシンボリック検証 (拡張プレプリント)
一か八かのドメインに導入された LLM は、根本的な信頼性の課題に直面しています。幻覚、矛盾、プライバシーの脆弱性により、エラーが法的、財務的、または安全性に影響を及ぼす許容できないリスクが生じます。この論文では、LLM で生成されたコンテンツに補完的な保証を提供する、形式的記号手法とニューラル セマンティック分析を組み合わせたハイブリッド検証アーキテクチャを紹介します。このアーキテクチャでは、入力検証に論理的推論を採用し、完全性の特性を活用して、構造化された要件に対して決定可能な保証を提供します。出力検証では、埋め込みベースの意味論的類似性により、形式的な手法では表現力に欠ける文脈上の幻覚が検出されます。この分離は、並列のアクターベースのパイプラインで実現され、幻覚を生み出す分布バイアスを継承するプロンプトベースの自己検証アプローチの制限に対処します。提案されたアーキテクチャとタイプ認識検証方法は、Action Design Research によって開発された現実世界の医療機器損傷評価レポート システムである HAIMEDA を使用して検証されています。評価の結果、構造化エンティティの幻覚検出率は 83% 以上、セマンティック捏造の幻覚検出率は 72% 以上で、レポート作成時間が 30% 短縮されたことが示され、神経記号アーキテクチャがデータに敏感なドメインでの LLM 展開に原則に基づいた保護手段を提供できることが実証されました。
原文 (English)
Neuro-Symbolic Verification of LLM Outputs for Data-Sensitive Domains (extended preprint)
LLMs deployed in high-stakes domains face fundamental reliability challenges: hallucinations, inconsistencies, and privacy vulnerabilities introduce unacceptable risks where errors carry legal, financial, or safety consequences. This paper presents a hybrid verification architecture combining formal symbolic methods with neural semantic analysis to provide complementary guarantees for LLM-generated content. This architecture employs logical reasoning for input verification, leveraging completeness properties to provide decidable guarantees on structured requirements. For output validation, embedding-based semantic similarity detects contextual hallucinations where formal methods lack expressiveness. This separation is realized in a parallel, actor-based pipeline, addressing limitations of prompt-based self-verification approaches, which inherit the distributional biases that produce hallucinations. The proposed architecture and type-aware verification method are validated with HAIMEDA, a real-world medical device damage assessment reporting system developed through Action Design Research. Evaluation shows hallucination detection rates of over 83% for structured entities and 72% for semantic fabrications, with a 30% reduction in report creation time, demonstrating that neuro-symbolic architectures can provide principled safeguards for LLM deployment in data-sensitive domains.
Xe-Forge: Intel GPU 向けのマルチステージ LLM を利用したカーネル最適化
深層学習アルゴリズムを新しいハードウェア アクセラレータに移植するには、開発者は同じ低レベルの最適化 (量子化、メモリ アクセスの結合、タイル サイズの調整、アーキテクチャ固有の回避策) をコードベース内のすべての Triton カーネルに繰り返し適用する必要があります。この手動での繰り返しの作業が大きなボトルネックとなっています。各カーネルは、デバイスごとに異なるハードウェア制約に対して同じサイクルの試行錯誤プロファイリングを必要としますが、基礎となる最適化パターンはほぼ一貫しています。 Intel GPU 向けにこのプロセスを自動化する、マルチステージ LLM を利用したパイプラインである Xe-Forge を紹介します。機能的に正しい Triton カーネルが与えられると、システムは、アルゴリズムの再構築と演算子の融合からブロック ポインターの最新化、GPU 固有のチューニング、およびオープンエンドの検出まで、最大 9 つの最適化ステージを適用します。各ステージは、候補を生成し、実際のハードウェアで検証し、失敗時に反復する検証と洗練の連鎖 (CoVeR) エージェントによって駆動されます。厳選されたナレッジベースは、LLM トレーニング データには存在しない Intel GPU 制約 (2 のべき乗ワープ数、GRF モード、SLM サイズ設定) をエンコードし、モデルをアーキテクチャ的に有効な範囲内に保ちます。 97 個の Level-2 KernelBench カーネルで Xe-Forge を、Intel Arc Pro B70 で Flash Attend を評価し、PyTorch Eager に比べて幾何平均 1.17 倍の速度向上を達成し、カーネルの 67% が向上し、9 個のカーネルで 5 倍を超え (最大 82 倍)、テスト済みのすべての構成で回帰なしで Flash Attend で 2 ~ 13.3 倍の高速化を達成しました。構造化されたドメインの知識が実証されています。ハードウェアインザループ検証を使用すると、現在新しいアクセラレータでのアルゴリズムの展開を妨げている反復的な移植作業を体系的に排除できます。
原文 (English)
Xe-Forge: Multi-Stage LLM-Powered Kernel Optimization for Intel GPU
Porting deep learning algorithms to new hardware accelerators requires developers to repeatedly apply the same low-level optimizations -- quantization, memory access coalescing, tile size tuning, and architecture-specific workarounds -- to every Triton kernel in their code-base. This manual, repetitive effort is a major bottleneck: each kernel demands the same cycle of trial-and-error profiling against hardware constraints that vary across devices, yet the underlying optimization patterns remain largely consistent. We present Xe-Forge, a multi-stage LLM-powered pipeline that automates this process for Intel GPU. Given a functionally correct Triton kernel, the system applies up to nine optimization stages -- from algorithmic restructuring and operator fusion through block pointer modernization, GPU-specific tuning, and open-ended discovery -- each driven by a Chain-of-Verification-and-Refinement (CoVeR) agent that generates candidates, validates them on real hardware, and iterates on failures. A curated knowledge base encodes Intel GPU constraints (power-of-two warp counts, GRF modes, SLM sizing) that are absent from LLM training data, keeping the model within architecturally valid bounds. We evaluate Xe-Forge on 97 Level-2 KernelBench kernels and Flash Attention on the Intel Arc Pro B70, achieving a 1.17x geometric mean speedup over PyTorch eager with 67% of kernels improving, nine kernels exceeding 5x (up to 82x), and 2--13.3x speedups on Flash Attention across all tested configurations without regression -- demonstrating that structured domain knowledge with hardware-in-the-loop verification can systematically eliminate the repetitive porting effort that currently gates algorithm deployment on new accelerators.
ストリーミング時系列からの時間遅延システムの動的混合のモデル化
この研究は、明確な入出力関係を持つ時系列データ ストリームにおける適応モデリングの問題に取り組んでいます。この問題は、環境要因や入力遅延の変化によって引き起こされる急速なシステム変更 (レジーム シフト) によってモデルのパフォーマンスが低下し、時系列パターンごとに複数の小さなモデルを使用する場合に精度、堅牢性、メモリ使用量の間でトレードオフが発生するため、困難です。これらの問題に対処するために、この論文では、ストリーミング時系列を時間遅延システムの動的な混合として扱うオンライン フレームワーク/方法を紹介します。このフレームワークは、システム ダイナミクスと入出力遅延の両方をキャプチャする固定長表現を使用して過去のレジームを要約することにより、モデル追跡の堅牢性を維持し、メモリ使用量を削減します。具体的には、このアプローチはシステムのマルコフ パラメーター系列を使用して要約システム テンソルを構築し、動的挙動と遅延特性の両方をキャプチャします。必要に応じて、テンソル分解アルゴリズムがテンソルから関連する過去のモデルを抽出し、現在のレジームに最適なシステムの選択に役立ちます。この方法により、環境変化への迅速な適応が可能になり、計算効率が高くなります。実際のデータセットでのテストでは、DelayMix が他の方法よりも常に優れたパフォーマンスを示し、特に非定常性の高いデータに対して、優れた予測精度と遅延へのより迅速な適応を実現することが示されています。
原文 (English)
Modeling Dynamic Mixtures of Time-Delay Systems from Streaming Time Series
This research addresses the problem of adaptive modeling in time-series data streams with clear input-output relationships. This problem is challenging because rapid system changes (regime shifts) caused by environmental factors or input delay changes degrade model performance, and the trade-off among accuracy, robustness, and memory usage arises when using multiple small models for each time-series pattern. To address these issues, this paper presents an online framework/method that treats streaming time series as dynamic mixtures of time-delay systems. This framework maintains robustness of model tracking and reduces memory usage by summarizing past regimes using a fixed-length representation that captures both the system dynamics and input-output delays. Concretely, this approach constructs a summary system tensor using the system's Markov parameter series, capturing both dynamic behavior and delay characteristics. If necessary, a tensor decomposition algorithm extracts relevant past models from the tensor and helps select the system that best fits the current regime. This method enables rapid adaptation to environmental changes and is computationally efficient. Tests on real datasets show that DelayMix consistently outperforms other methods, achieving superior forecast accuracy and faster adaptation to delays, especially for highly non-stationary data.
When Correct Demonstrations Hurt: Rethinking the Role of Exemplars in In-Context Learning
In-context learning (ICL) is often motivated by the intuition that demonstrations help because they provide correct input-output examples.…
Cross-scale Aligned Supervision for Training GANs
Modern GANs often introduce adversarial supervision on intermediate generator outputs and interpret the resulting multi-stage synthesis as…
Verus-SpecGym: An Agentic Environment for Evaluating Specification Autoformalization
AI coding agents are increasingly used to write real-world software, but ensuring that their outputs are correct remains a fundamental chal…
Deep-layer limit and stability analysis of the basic forward-backward-splitting induced network (II): learning problems
Deep unfolding neural networks derived from iterative optimization schemes and numerical ordinary/partial differential equations (ODEs/PDEs…
Governed Evolution of Agent Runtimes through Executable Operational Cognition
Recent advances in agentic systems increasingly treat code as an executable operational substrate rather than as a disposable output artifa…
PICACO: Pluralistic In-Context Value Alignment of LLMs via Total Correlation Optimization
In-Context Learning has shown great potential for aligning Large Language Models (LLMs) with human values, helping reduce harmful outputs a…
MetaSICL: Adapting Audiroty LLM via Meta Speech In-Context Learning
Auditory Large Language Models (LLMs) have demonstrated strong performance across a wide range of speech and audio understanding tasks. Nev…
From Detection to Recovery: Operational Analysis on LLM Pre-training with 504 GPUs
Large-scale AI training is now fundamentally a distributed systems problem, and hardware failures have become routine operating conditions…

ファーウェイ、半導体で「1.4nm相当」目指す 31年までに 「ムーアの法則」に代わる新法則を提唱
中国Huaweiが半導体進化の新法則「τスケーリング法則」を提唱した。従来の微細化に代わり信号遅延を圧縮しトランジスタ密度を向上させる。秋のKirinチップに独自の回路技術LogicFoldingを初適用し、2031年に1.4nm相当の密度を目指すという。
どれだけ考えれば十分ですか? LLM 推論における冗長性の定量化と理解
推論可能な大規模な言語モデルは、長い思考連鎖を発し、レイテンシー、GPU 時間、およびエネルギーを大幅に消費して、難しい問題を解決します。その痕跡を何気なく検査すると、広範な再定式化、検証、循環的な内省が明らかになりますが、この検討が実際にどの程度必要であるかは、大規模に測定されたことも、第一原理から説明されたこともありません。この論文は両方のギャップを埋めます。私たちは推論モデル自体の観点から推論の冗長性を直接形式化します。正しいトレースの冗長性は、$\pi$ が思考を終了させて最終的な答えを出力することを強制されても正しい答えを生成する間に切り詰めることができる、後続のセグメント化されたステップの最大部分です。 4 つのフロンティア推論モデルと 2 つの数学的ベンチマークにわたる大規模な定量化により、ステップレベルの冗長性が一貫して高く、我々が調査した 8 つの (モデル、ベンチマーク) 条件全体で 61% から 93% の間であり、クリティカルプレフィックスの中央値は 8 つの条件のうち 6 つで単一のセグメント化されたステップに等しいことが示されています。この結果は、裁判官ファミリーの選択に対して堅牢であり、$\rho$ は MATH-500 の問題の難易度とともに減少しますが、4 つのモデルはすべて大幅に維持されていることがわかります。最も難しいレベル 5 の問題でも冗長 ($\rho \in [46\%, 85\%]$)。次に、この冗長性がモデル固有のアーティファクトではなく、長さに依存しない結果報酬の構造的な結果であることを証明します。そのような報酬の下では、最適な有限の予想停止時間は存在しません。結果は、RL アルゴリズム、基本モデル、データ分散、またはポリシーが RL または蒸留のどちらによって取得されたかに関係なく当てはまります。したがって、考えすぎは個々のモデルで修正すべきバグではなく、現在の推論モデルがどのようにトレーニングされるかの構造的特性です。コード: https://github.com/zhiyuanZhai20/how-much- Thinking-is-enough
原文 (English)
How Much Thinking is Enough? Quantifying and Understanding Redundancy in LLM Reasoning
Reasoning-capable large language models solve hard problems by emitting long chains of thought, paying heavily in latency, GPU time, and energy. Casual inspection of their traces reveals extensive reformulation, verification, and circular self-reflection, yet how much of this deliberation is actually necessary has never been measured at scale or explained from first principles. This paper closes both gaps. We formalise reasoning redundancy directly in terms of the reasoning model itself: the redundancy of a correct trace is the largest fraction of its trailing segmented steps that can be truncated while $\pi$, forced to terminate thinking and emit a final answer, still produces the correct answer. A large-scale quantification across four frontier reasoning models and two mathematical benchmarks shows that step-level redundancy is consistently high -- between 61% and 93% across the 8 (model, benchmark) conditions we study, with the median critical prefix equal to a single segmented step in six of the eight conditions -- that the finding is robust to the choice of judge family, and that although $\rho$ decreases with problem difficulty on MATH-500, all four models remain substantially redundant ($\rho \in [46\%, 85\%]$) even on the hardest Level-5 problems. We then prove that this redundancy is a structural consequence of length-agnostic outcome rewards, not a model-specific artefact: under any such reward, no finite expected stopping time is optimal. The result holds regardless of RL algorithm, base model, data distribution, or whether the policy is obtained via RL or distillation; over-thinking is therefore not a bug to be patched in individual models but a structural property of how current reasoning models are trained. Code: https://github.com/zhiyuanZhai20/how-much-thinking-is-enough
事前定義された学習オブジェクトを超えて: 最新の自律ロボット学習のための思考学習インタラクション モデル
オープンで変化する環境で動作する自律ロボットは、事前定義された入力、出力、およびアクション ルーチンに常に依存できるとは限りません。既存の学習方法では、環境との相互作用を通じてロボットのパフォーマンスを向上させることができますが、学習の対象は、入力特徴、認識出力、ネットワーク構造、タスクの目標、またはアクションシーケンスなど、事前に固定されていることがよくあります。これにより、長期的な運用中に新しい機能、新しいカテゴリ、またはより効率的なタスク ルーチンが出現したときに適応する能力が制限されます。この問題に対処するために、本論文では自律ロボットのための思考学習相互作用モデルを提案する。中心となる考え方は、潜在的な変化の特定、有用な証拠の選択、トレーニング資料の整理、検証アクションの計画によって思考が学習を導き、一方、学習はタスクの知識、機能選択の経験、アクション戦略、および将来の推論プロセスを更新することによって思考を促進するというものです。この双方向メカニズムに基づいて、ロボットは、環境との継続的な相互作用を通じて、事前に定義された学習設定を徐々に超えて、その認識関係と行動関係を適応させることができます。具体的には、提案されたモデルは、適応的な入力特徴の発見、出力カテゴリの拡張、学習モデルの更新、およびアクション ルーチンの再構築をサポートします。実験結果は、提案したモデルが特徴適応における最終認識精度を0.419から0.845に改善し、より高い新しいカテゴリ形成精度とモデル更新成功率を達成し、アクションルーチン再構築において平均アクション長を13.0から4.0に短縮することを示しています。学習によって強化された思考では、有用な証拠の選択率が 0.272 から 0.965 に増加し、学習結果が将来の証拠の選択と推論を効果的に改善できることを示しています。
原文 (English)
Beyond Predefined Learning Objects: A Thinking-Learning Interaction Model for Up-to-Date Autonomous Robot Learning
Autonomous robots operating in open and changing environments cannot always rely on predefined inputs, outputs, and action routines. Although existing learning methods enable robots to improve their performance through environmental interaction, the objects of learning are often fixed in advance, such as input features, recognition outputs, network structures, task goals, or action sequences. This limits their ability to adapt when new features, new categories, or more efficient task routines appear during long-term operation. To address this problem, this paper proposes a thinking-learning interaction model for autonomous robots. The core idea is that thinking guides learning by identifying potential changes, selecting useful evidence, organizing training materials, and planning verification actions, while learning promotes thinking by updating task knowledge, feature-selection experience, action strategies, and future reasoning processes. Based on this bidirectional mechanism, the robot can gradually move beyond predefined learning settings and adapt its recognition relations and action relations through continuous interaction with the environment. Specifically, the proposed model supports adaptive input feature discovery, output category expansion, learning model update, and action routine reconstruction. Experimental results show that the proposed model improves the final recognition accuracy from 0.419 to 0.845 in feature adaptation, achieves higher new-category formation accuracy and model-update success rate, and reduces the average action length from 13.0 to 4.0 in action routine reconstruction. In learning-enhanced thinking, the useful evidence selection rate increases from 0.272 to 0.965, indicating that learning results can effectively improve future evidence selection and reasoning.
Agent-as-Peer-Debriefer: 定性分析のための視点ベースの改良を備えたマルチエージェント フレームワーク
大規模言語モデル (LLM) は定性データ分析 (QDA) に使用されることが増えていますが、その出力には人間による分析の深さやニュアンスが欠けていることがよくあります。私たちは、このギャップは、人間の QDA から信頼性を確保するための実践が欠けていることを反映していると主張します。ピア・デブリーフィングとは、アナリストが無関心なピアからフィードバックを求め、それを利用してコーディングを改良するものです。この実践を LLM 支援 QDA に導入するために、主要なコーディング手順にピア デブリーフィングを組み込むマルチエージェント QDA フレームワークである Agent-as-Peer-Debriefer を提案します。私たちのフレームワークでは、階層型コーディング エージェントが標準の QDA プロセスに従って、コード、サブテーマ、テーマ、および自己説明と反省メモを生成します。次に、これらの出力を 3 つのピア デブリーフィング エージェントと共有し、それぞれが異なる分析観点 (理論駆動、データ駆動、または応用) を適用し、コードの保持、名前変更、再割り当て、結合、または分割によってコードを洗練します。これらの視点は、ドメインとデータセット全体に一般化された確立された人間の QDA 実践から得られます。フレームワークを評価するために、3 つの LLM を使用して 2 つのドメインにわたる 3 つのデータセットでフレームワークをテストし、人間が注釈を付けたコードとの意味的な類似性を測定します。すべての設定において、パースペクティブベースのピアデブリーフィングの改良は、単一 LLM ベースラインよりも人間のコードとより密接に一致しており、アブレーションは、その利点が単に追加の改良によるものではないことをさらに示しています。また、3 つのパースペクティブは明確なトレードオフを生み出し、パースペクティブの選択が有意義で制御可能な設計上の決定であることを示しています。より広く言えば、これらの発見は、明確な視点を持ってピアデブリーフィングをシミュレートすることが、より信頼性の高い LLM 支援 QDA への有望な手段であることを示唆しています。
原文 (English)
Agent-as-Peer-Debriefer: A Multi-Agent Framework with Perspective-Based Refinement for Qualitative Analysis
Large language models (LLMs) are increasingly used for qualitative data analysis (QDA), yet their outputs often miss the depth and nuance of human analysis. We argue this gap reflects a missing credibility practice from human QDA: peer debriefing, in which an analyst seeks feedback from a disinterested peer and uses it to refine their coding. To bring this practice into LLM-assisted QDA, we propose Agent-as-Peer-Debriefer, a multi-agent QDA framework that builds peer debriefing into key coding steps. In our framework, a Hierarchical Coding Agent follows the standard QDA process to generate codes, sub-themes, and themes, along with self-explanations and reflection memos. It then shares these outputs with three Peer-Debriefing Agents, each applying a distinct analytical perspective (Theory-Driven, Data-Driven, or Applied) and refining the codes by keeping, renaming, reassigning, merging, or splitting them. These perspectives are drawn from established human QDA practices that generalize across domains and datasets. To evaluate the framework, we test it on three datasets across two domains with three LLMs, measuring semantic similarity to human-annotated codes. Across all settings, perspective-based, peer-debriefing refinement aligns more closely with human codes than a single-LLM baseline, and an ablation further shows the gain is not merely from additional refinement. The three perspectives also produce distinct trade-offs, showing that the choice of perspective is a meaningful and controllable design decision. More broadly, these findings suggest that simulating peer debriefing with explicit perspectives is a promising route to more credible LLM-assisted QDA.
制御のない表現: 言語モデルでの実現効果のテスト
大規模な言語モデルが行動シミュレーターとして使用されることが増えていますが、その出力がプロンプトに敏感な表面パターンではなく、人間のような認知メカニズムをいつ反映するのかは依然として不明です。私たちはこの疑問を実現効果を通じて研究します。実現効果は、書類上の利益と損失の後ではリスクテイクが組織的に異なるという行動経済学のよく特徴付けられた発見です。私たちは LLM の動作を 3 つのレベルで評価します。プロンプトのみの動作感度、内部表現の線形読み出し、アクティベーション ステアリングによる因果制御です。プロンプトのみの結果は体系的な条件感度を示しますが、方向パターンは人間の実現効果の予測を再現しません。 Gemma の残差ストリームには、保留されたプロンプトに一般化される、レイヤー 18 で線形にデコード可能な実現ステータス信号が含まれています。ただし、この方向に沿って舵を取っても、下流のリスク選択が確実にシフトされるわけではなく、正のスケール全体および負の符号対称の実行で保持されるヌル結果になります。行動感度、潜在読み出し、および因果制御は、自動的には同時に発生しない 3 つの異なる特性であり、潜在読み出しの成功は、モデルが下流の意思決定中に表現に行動的に依存していることを示す不十分な証拠です。
原文 (English)
Representation Without Control: Testing the Realization Effect in Language Models
Large language models are increasingly used as behavioral simulators, but it remains unclear when their outputs reflect human-like cognitive mechanisms rather than prompt-sensitive surface patterns. We study this question through the realization effect, a well-characterized finding in behavioral economics in which risk-taking differs systematically after paper versus realized gains and losses. We evaluate LLM behavior at three levels: prompt-only behavioral sensitivity, linear readout of internal representations, and causal control via activation steering. Prompt-only results show systematic condition sensitivity, but the directional pattern does not reproduce human realization-effect predictions. Gemma's residual stream contains a linearly decodable realization-status signal at layer 18 that generalizes to held-out prompts. Steering along this direction does not, however, reliably shift downstream risk choices, a null result that holds across positive scales and in a negative sign-symmetry run. Behavioral sensitivity, latent readout, and causal control are three distinct properties that do not automatically co-occur, and successful latent readout is insufficient evidence that a model behaviorally relies on a representation during downstream decision-making.
DarkForest: マルチエージェント LLM の会話を減らし、精度を向上
マルチエージェント LLM システムは、複数のエージェントからの出力を組み合わせることで推論を改善しますが、対話が多い方法ではエラーの伝播と高い通信オーバーヘッドが発生する可能性があります。エージェントが生の応答や推論トレースを交換すると、間違った中間推論が採用され増幅され、自信はあるものの間違った合意が得られる可能性があります。マルチラウンド通信により、トークンの消費量、待ち時間、推論コストも増加します。この論文では、DarkForest という名前の制御された通信調整フレームワークを提案します。 DarkForest はまずエージェントを独立させて、各エージェントが他のエージェントの出力を見ることなく応答を生成します。次に、生の応答を構造化された候補レコードに解析し、意味的に同等の候補をクラスターにグループ化し、エージェントの信頼性、信頼度、解析品質、サポート パターンの信頼性、および独立性補正を使用して、これらのクラスターにわたる校正された信念分布を推定します。コーディネーターは、制御されたコミュニケーションにより、この信念状態からポリシーで許可された証拠のみを受け取ります。 6 つの推論ベンチマークに関する実験では、DarkForest が最高の全体的な品質を達成し、ベンチマーク メトリクスで最も強力なベースラインを最大 30.7\% 改善し、通信の多いベースラインと比較してトークン消費を最大 $6.5\times$ 削減することが示されています。
原文 (English)
DarkForest: Less Talk, Higher Accuracy for Multi-Agent LLMs
Multi-agent LLM systems improve reasoning by combining outputs from multiple agents, but interaction-heavy methods can introduce error propagation and high communication overhead. When agents exchange raw responses or reasoning traces, incorrect intermediate reasoning may be adopted and amplified, leading to confident but wrong consensus; multi-round communication also increases token consumption, latency, and inference cost. In this paper, we propose a controlled-communication coordination framework named DarkForest. DarkForest first keeps agents independent, so each agent produces an answer without seeing the others' outputs. It then parses the raw responses into structured candidate records, groups semantically equivalent candidates into clusters, and estimates a calibrated belief distribution over these clusters using agent reliability, confidence, parse quality, support-pattern reliability, and independence corrections. A coordinator receives only policy-permitted evidence from this belief state with controlled communication. Experiments on six reasoning benchmarks show that DarkForest achieves leading overall quality, improves the strongest baseline by up to 30.7\% on benchmark metrics, and reduces token consumption by up to $6.5\times$ compared with communication-heavy baselines.
GIBLy: アーキテクチャに依存しない軽量の幾何学的誘導バイアス レイヤーによる 3D セマンティック セグメンテーションの改善
3D シーンの理解では、深層学習モデルは大規模なモデルと広範なトレーニングに依存して、3D データに存在する基本的な幾何学的構造をキャプチャします。しかし、既存の手法には、学習可能なプリミティブ形状などの幾何学情報を組み込むための明示的なメカニズムが欠如しており、多くの場合、大規模なモデルとより多くのトレーニング データが必要になるため、コストが増加し、一般化が制限される可能性があります。学習可能な幾何学的事前分布を 3D セグメンテーション パイプラインに統合する軽量の幾何学的誘導バイアス レイヤーである GIBLy を紹介します。 GIBLy は、MLP ベース、畳み込みベース、トランスフォーマー ベースのいずれであっても、最小限の計算オーバーヘッドでセグメンテーションのパフォーマンスを向上させる、単純な幾何学的形状に合わせた (したがって人間が解釈できる) 機能を提供することで、既存のアーキテクチャを強化します。複数の 3D セマンティック セグメンテーション ベンチマークにわたってアプローチを検証し、58K の追加パラメーターのみを追加しながら、PTV3 を使用した TS40K で最大 +11.5% mIoU を含む、一貫したパフォーマンスの向上を実証しました。私たちの結果は、軽量のアドオン レイヤーを使用して、正確かつ効率的な 3D シーンの理解をサポートする幾何構造を明示的にエンコードする利点を強調しています。
原文 (English)
GIBLy: Improving 3D Semantic Segmentation through an Architecture-Agnostic Lightweight Geometric Inductive Bias Layer
In 3D scene understanding, deep learning models rely on large models and extensive training to capture basic geometric structures that are present in the 3D data. However, existing methods lack explicit mechanisms to incorporate geometric information, such as learnable primitive shapes, often necessitating large models and more training data which in turn increases cost and can limit generalization. We introduce GIBLy, a lightweight geometric inductive bias layer that integrates learnable geometric priors into 3D segmentation pipelines. GIBLy enhances existing architectures -- whether MLP-based, convolution-based, or transformer-based -- by providing features aligned with simple geometric shapes (and thus human-interpretable) that improve segmentation performance with minimal computational overhead. We validate our approach across multiple 3D semantic segmentation benchmarks, demonstrating consistent performance gains, including up to +11.5% mIoU on TS40K with PTV3, while adding only 58K extra parameters. Our results highlight the benefit of explicitly encoding geometric structure to support accurate and efficient 3D scene understanding, with a lightweight add-on layer
ScaleAcross Explorer: スケールアクロス AI モデル トレーニングのための通信最適化の探索
大規模な言語モデルのトレーニングを迅速に拡張するには、GPU リソースを複数のデータ センターの建物および地域に分散する必要があります。このようなパラダイムを「スケールアクロス」トレーニングと呼びます。インフラストラクチャが拡大するにつれて、システム設計空間はますます複雑になり、新しいモデル アーキテクチャ、ハードウェアの異種混合、進化する通信パターンが含まれます。 Meta の運用経験に基づいて、数十万の GPU を収容するいくつかのデータ センターにトレーニング ジョブを展開する際の複雑さを強調します。大規模な設計空間の探索を加速し、フロンティア モデル開発の効率的なトレーニングを可能にするために、並列処理の配置、並列処理のスケジューリング、およびネットワーク層テクノロジという 3 つの主要な設計次元の詳細な特性評価を実施します。次に、設計次元の相互作用を考慮し、スケールアクロス トレーニングを総合的に最適化するオプティマイザーである ScaleAcross Explorer を提案します。テストベッドの実験とシミュレーションでは、実稼働構成と比較して最大 64.62% のトレーニング速度が向上し、幅広い設計ポイントにわたって最先端のベースラインと比較して最大 37.59% のトレーニング速度が向上することが実証されています。
原文 (English)
ScaleAcross Explorer: Exploring Communication Optimization for Scale-Across AI Model Training
The rapid scaling of large language model training requires distributing GPU resources across multiple data center buildings and regions. We refer to such paradigm as "scale-across" training. As infrastructure expands, the system design space becomes increasingly intricate, encompassing new model architectures, hardware heterogeneity, and evolving communication patterns. Drawing from Meta's production experience, we highlight the complexities of deploying training jobs across a few data centers housing hundreds of thousands of GPUs. To accelerate exploration of the large design space and to enable efficient training for frontier model development, we conduct in-depth characterization of three key design dimensions: parallelism placement, parallelism scheduling, and network layer technologies. We then propose ScaleAcross Explorer, an optimizer that considers the interplay of design dimensions and holistically optimizes scale-across training. Testbed experiments and simulations demonstrate up to 64.62% training speedups over production configuration and up to 37.59% training speedups over the state-of-the-art baseline across a wide range of design points.
CONF-KV: Confidence-Aware KV Cache Eviction with Mixed-Precision Storage for Long-Horizon LLM
Long-horizon LLM inference turns the key--value (KV) cache into the dominant GPU memory consumer and makes per-token attention increasingly…
Inference-Time Alignment of Diffusion Models via Trust-Region Iterative Twisted Sequential Monte Carlo
We study inference-time alignment for diffusion-based generative models, aiming to steer a base model toward high-reward outputs without up…
From Simulation to Enaction: Post-trained language models recognize and react to their own generations
Language models are pretrained as passive predictors with no incentive to model the consequences of their own outputs. Post-training change…
Fine-Tuning and Serving Gemma 4 31B on Google Cloud TPU: A Technical Comparison with GPU Baselines
We present the first end-to-end demonstration of fine-tuning and serving Google's Gemma 4 31B model on TPU hardware, providing an empirical…
SAMark: A Self-Anchored Text Watermarking with Paragraph-Level Paraphrase Robustness
Semantic-level watermarking (SWM) improves robustness against text modifications by treating sentences as the basic unit. However, robustne…
Causal Tongue-Tie: LLMs Can Encode Causal Direction, But Their Yes/No Outputs Fail to Express
We find a mismatch between what large language models encode about a causal question and what they answer. On anti-commonsense CLadder item…
AMEL: Accumulated Message Effects on LLM Judgments
Large language models are routinely used as automated evaluators: to review code, moderate content, or score outputs, often with many items…
HEAPr: Hessian-based Efficient Atomic Expert Pruning in Output Space
Mixture-of-Experts (MoE) architectures in large language models (LLMs) deliver exceptional performance and reduced inference costs compared…
VisualOverload: Probing Visual Understanding of VLMs in Really Dense Scenes
Is basic visual understanding really solved in state-of-the-art VLMs? We present VisualOverload, a slightly different visual question answe…
SafeGPT: Preventing Data Leakage and Unethical Outputs in Enterprise LLM Use
Large Language Models (LLMs) are transforming enterprise workflows but introduce security and ethics challenges when employees inadvertentl…
Copy-as-Decode: Grammar-Constrained Parallel Prefill for LLM Editing
LLMs edit text and code by autoregressively regenerating the full output, even when most tokens appear verbatim in the input. We study Copy…
SciAtlas: 自動化された科学研究のための大規模ナレッジ グラフ
世界的な学術成果の急激な増加により、研究者やAIエージェントは前例のない「情報爆発」に直面しており、断片的で構造化されていない知識組織が深い学際的統合を妨げています。現在の学術検索ツールは主に、表面的なキーワード マッチングやベクトル空間の意味検索に依存しており、複雑な論理接続をナビゲートするために必要な位相推論機能が不足しています。エージェントのディープリサーチベースのフレームワークは、多くの場合、論理的な幻覚を引き起こし、高い推論コストを消費する傾向があります。このギャップを埋めるために、このレポートでは、パノラマ科学進化ネットワークとして設計された、大規模で学際的で異質な学術リソースの知識グラフである SciAtlas を紹介します。 SciAtlas は、26 の専門分野からの 4,300 万件を超える論文、合計 1 億 5,700 万のエンティティと 3B トリプレットを統合することにより、専門分野の障壁を取り除き、AI エージェントにグローバルな視点を提供する構造化トポロジカル認知基盤を提供します。さらに、トライパス協調想起とグラフ再ランキングを特徴とする神経記号検索アルゴリズムを開発し、単純な意味一致から決定論的関連発見へのシームレスな移行を実現します。また、文献レビュー、自動化された研究傾向の統合、アイデアの位置付け、学術的軌道の探索など、SciAtlas の主要な応用方向性を示し、SciAtlas が推論コストを大幅に削減しながら自動化された科学研究の全ループを強化する効果的な「認知マップ」として機能できることを実証します。 KG 取得とさまざまなダウンストリーム タスク用のインターフェイスを GitHub リポジトリでリリースしました。
原文 (English)
SciAtlas: A Large-Scale Knowledge Graph for Automated Scientific Research
The exponential growth of global academic output has confronted researchers and AI agents with an unprecedented ``information explosion,'' where fragmented and unstructured knowledge organization impedes deep interdisciplinary integration. Current academic retrieval tools predominantly rely on superficial keyword matching or vector-space semantic retrieval, which lack the topological reasoning capabilities required to navigate complex logical connections. Agentic deep-research-based frameworks are often prone to logical hallucinations and consuming high inference costs. To bridge this gap, in this report, we introduce SciAtlas, a large-scale, multi-disciplinary, heterogeneous academic resource knowledge graph designed as a panoramic scientific evolution network. By integrating over 43M papers from 26 disciplines, and a total of 157M entities and 3B triplets, SciAtlas provides a structured topological cognitive substrate that dismantles disciplinary barriers and furnishes AI agents with a global perspective. Furthermore, we develop a neuro-symbolic retrieval algorithm featuring tri-path collaborative recall and graph reranking, achieving a seamless transition from simple semantic matching to deterministic association discovery. We also present key application directions of SciAtlas, including literature review, automated research trend synthesis, idea positioning, and academic trajectory exploration, to demonstrate that SciAtlas can serve as an effective ``cognitive map'' to empower the full loop of automated scientific research while significantly reducing reasoning costs. We have released the interfaces for KG retrieval and various downstream tasks in our GitHub repo.
SPACENUM: VLM における空間数値的理解を再考する
視覚言語モデル (VLM) は、アクションの大きさや空間座標などの数値出力を生成する必要がある具体化された環境に導入されることが増えています。これらの数値は意味があるように見えますが、これらの数値出力が本当に空間認識に基づいているのかどうかは不明のままです。したがって、この研究では、空間探索中の動的遷移としての数値と、空間推論における静的レイアウトとしての数値という 2 つの相補的な設定をキャプチャする統合フレームワークである SpaceNum を通じて空間数値理解を再検討します。 Num2Space と Space2Num という 2 つの双方向タスクを定式化し、VLM が視覚側の空間構造と言語側の数値表現の間でどの程度適切にマッピングされるかを評価します。私たちは、現在の VLM が空間設定の数値を本当に理解しているかどうかを体系的に研究しています。動的遷移と静的レイアウトにわたって、モデルは空間的な意味での数値の根拠付けにほとんど失敗し、ランダムに近い推測を実行することが多いことがわかりました。エラー分析、推論トレース分析、および制御された介入を通じて、現在の VLM は浅い空間キューに大きく依存しており、安定した座標認識表現を構築するのに苦労しており、視覚的観察から構造化された空間レイアウトを抽象化できていないことを示します。さらに、明示的な推論ではわずかな利益しか得られない一方で、チューニングによって空間数値の理解を部分的に改善し、外部の空間推論ベンチマークに移行できることを示します。
原文 (English)
SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
Vision-Language Models (VLMs) are increasingly deployed in embodied environments, where they need produce numerical outputs such as action magnitudes and spatial coordinates. Although these numbers appear meaningful, it remains unclear whether these numerical outputs are genuinely grounded in spatial perception. Therefore, in this work, we revisit spatial numerical understanding through SpaceNum, a unified framework that captures two complementary settings: numbers as dynamic transitions during spatial exploration, and numbers as static layouts in spatial reasoning. We formulate two bidirectional tasks, Num2Space and Space2Num, to evaluate how well VLMs map between vision-side spatial structure and language-side numerical representations. We systematically study whether current VLMs truly understand numerical values in spatial settings. Across dynamic transitions and static layouts, we find that models largely fail to ground numbers in spatial meaning and often perform close to random guess. Through error analysis, reasoning trace analysis, and controlled interventions, we show that current VLMs rely heavily on shallow spatial cues, struggle to build stable coordinate-aware representations, and fail to abstract structured spatial layouts from visual observations. We further show that explicit reasoning provides only marginal gains, while tuning can partially improve spatial numerical understanding and transfer to external spatial reasoning benchmarks.
計算可能な公平性: AI リソース割り当てのためのボルツマン-ソフトマックス制御
大規模な AI システムでは、GPU の計算時間や帯域幅などの希少なリソースを複数のエージェントに割り当てることが重要な課題になります。従来のポリシーは効率の指標に焦点を当てており、システムの多様性と安定性を損なう支配集中につながる可能性があります。我々は、ボルツマン・ソフトマックス関数を選択ツールとしてではなく確率的リソース割り当てメカニズムとして再解釈し、逆温度パラメータ $\beta$ を効率と公平性のバランスを支配する計算可能な制御変数として再定義するフレームワークである Computable Fair Division (CFD) を提案します。静的分析により、政策ウェイト全体で損失総額がほぼ一定に保たれる、最適に近い安定回廊を持つパレートフロンティアが明らかになります。動的設定では、AHC++ (Adaptive Hard-Cap Controller++) が、観測された優位性とポリシーで指定されたターゲットとの間の誤差をフィードバックとして使用して $\beta$ をリアルタイムで更新します。シミュレーションにより、AHC++ は、スループットを大幅に低下させることなく公平性ターゲットを追跡しながら、外因性ショック下での極端な優勢集中を抑制することが示されています。スケーラビリティ分析により、エージェントを 100 倍に増やしても、実行時間は約 5.5 倍しか増加しないことが確認されています。コード: https://github.com/entrofy-ai/computable-fairness
原文 (English)
Computable Fairness: Boltzmann-Softmax Control for AI Resource Allocation
In large-scale AI systems, allocating scarce resources such as GPU compute time and bandwidth among multiple agents is a critical challenge. Conventional policies focus on efficiency metrics, potentially leading to dominance concentration that undermines system diversity and stability. We propose Computable Fair Division (CFD), a framework that reinterprets the Boltzmann-Softmax function not as a selection tool but as a probabilistic resource allocation mechanism, redefining the inverse temperature parameter $\beta$ as a computable control variable governing the efficiency-fairness balance. Static analysis reveals a Pareto frontier with a near-optimal Stability Corridor where total loss remains approximately constant across policy weights. In the dynamic setting, AHC++ (Adaptive Hard-Cap Controller++) updates $\beta$ in real time using the error between observed dominance and a policy-specified target as feedback. Simulations show that AHC++ suppresses extreme dominance concentration under exogenous shocks while tracking fairness targets without substantial throughput degradation. Scalability analysis confirms that a 100x increase in agents yields only approximately 5.5x increase in execution time. Code: https://github.com/entrofy-ai/computable-fairness
文化進化としてのモデル崩壊
モデルの崩壊、つまり独自の出力でトレーニングされた LLM の進行性の劣化は統計的に特徴付けられていますが、どの構造がどのような順序で、そしてなぜ劣化するのかについての言語的な説明が不足しています。私たちは、文化進化に基づく反復学習理論がこのギャップを埋めることを示します。私たちは 5 つの反証可能な予測を導き出し、理論を独自に識別する予測と確証的な予測を区別し、英語、ドイツ語、トルコ語で 10 世代にわたって LLaMA-2-7B とミストラル-7B を自己訓練することによってそれらをテストします。重要な識別的発見: フィルタリングされていない自己訓練下では、構成性は非単調な軌道 (最初は上昇し、その後下降) をたどります。この署名は、最大限規則的なシード データ (ノイズ除去を除外) で持続し、ランダム フィルターではなくタスクに基づいたフィルターによってのみ維持され、圧縮と通信のトレードオフに関する最初の LLM スケールの証拠を提供します。すべての予測は大きな効果量 (Hedges の $g > 1.6$; $\mathrm{BF}_{10} > 100$) で確認され、LLM 正則化勾配は人間の行動データ ($R^2 = 0.94$) とよく一致します。これらの結果は、モデルの崩壊を文化伝達現象として再構成し、自己学習パイプライン設計の具体的な原則を導き出します。
原文 (English)
Model Collapse as Cultural Evolution
Model collapse, the progressive degradation of LLMs trained on their own outputs, has been characterized statistically but lacks a linguistic explanation for which structures degrade, in what order, and why. We show that iterated learning theory from cultural evolution fills this gap. We derive five falsifiable predictions, distinguish those uniquely discriminative for the theory from confirmatory ones, and test them by self-training LLaMA-2-7B and Mistral-7B over 10 generations in English, German, and Turkish. The critical discriminative finding: compositionality follows a non-monotonic trajectory (initially rising, then falling) under unfiltered self-training. This signature persists with maximally regular seed data (ruling out noise removal) and is sustained only by task-grounded filtering, not random filtering, providing the first LLM-scale evidence for the compression-communication tradeoff. All predictions are confirmed with large effect sizes (Hedges' $g > 1.6$; $\mathrm{BF}_{10} > 100$), and LLM regularization gradients closely match human behavioral data ($R^2 = 0.94$). These results reframe model collapse as a cultural transmission phenomenon and yield concrete principles for self-training pipeline design.
FastKernels: 本番環境での GPU カーネル生成のベンチマーク
GPU カーネル生成用の LLM ベースのエージェントは急速に進歩していますが、その進歩は最適化対象のベンチマークによって根本的に制約されています。既存のベンチマークは、運用推論フレームワークとの整合性が不十分です。合成入力を使用して単一の GPU でカーネルを評価し、周囲のコンパイル スタックを無視し、新しい最適化を発見するのではなく、既知の最適化を複製することに報酬を与えます。結果として得られる報酬シグナルは誤解を招くものです。エージェントは、サンドボックスでは高得点のカーネルを生成することを学習しますが、実際のシステムに統合すると、インターフェイスの非互換性、コンパイルスタックの競合、サイレント正確性の低下が発生します。 FastKernels は、8 カテゴリにまたがる 46 の代表的なアーキテクチャの最小限のセットを中心に構築されたカーネル ベンチマークであり、そのカーネルは、HuggingFace Transformers アーキテクチャの 96.2% (409/425) のカーネルを集合的に包含します。 FastKernels は、主流の LLM サービス上で vLLM や SGLang などの強化されたシステムと同等に動作し、十分にサービスが提供されていないアーキテクチャ上でのアップストリームのリファレンスを大幅に上回る、最小限の運用グレードの推論フレームワークとしても機能します。各タスクのインターフェイスは、そのアーキテクチャ ファミリの最先端のライブラリ内の対応するモジュールを反映しており、最適化されたカーネルを運用コードベースに直接デプロイすることができます。 FastKernels で最先端のカーネル エージェントを評価すると、最も強力なエージェントであっても実稼動ベースラインと比べて合計 0.94$\times$ の高速化しか達成できず、より弱いエージェントでは $0.78\times$ と $0.53\times$ であることがわかり、ベンチマークと実稼動の不一致がこの分野の重大なボトルネックであることが確認されました。私たちは、ベンチマークの向上が実稼働スループットの向上に直接つながるカーネル エージェントへの足がかりとして FastKernel をリリースします。コードは https://github.com/Snowflake-AI-Research/fastkernels で入手できます。
原文 (English)
FastKernels: Benchmarking GPU Kernel Generation in Production
LLM-based agents for GPU kernel generation are advancing rapidly, yet their progress is fundamentally constrained by the benchmarks they optimize against. Existing benchmarks are poorly aligned with production inference frameworks: they evaluate kernels on a single GPU with synthetic inputs, ignore the surrounding compilation stack, and reward replicating known optimizations rather than discovering new ones. The resulting reward signals are misleading: agents learn to generate kernels that score well in sandboxes but introduce interface incompatibilities, compilation-stack conflicts, and silent correctness degradation when integrated into real systems. We introduce FastKernels, a kernel benchmark built around a minimal set of 46 representative architectures spanning 8 categories, whose kernels collectively subsume those of 96.2% (409/425) of HuggingFace Transformers architectures. FastKernels doubles as a minimalistic, production-grade inference framework that runs at parity with hardened systems such as vLLM and SGLang on mainstream LLM serving and substantially exceeds upstream references on under-served architectures; each task's interface mirrors the corresponding module in the state-of-the-art library for its architecture family, enabling direct deployment of optimized kernels into production codebases. Evaluating state-of-the-art kernel agents on FastKernels, we find that even the strongest agent achieves only 0.94$\times$ aggregate speedup over production baselines, with weaker agents at $0.78\times$ and $0.53\times$ -- confirming that benchmark-production misalignment is a critical bottleneck for the field. We release FastKernels as a stepping stone toward kernel agents whose benchmark gains translate directly into production throughput improvements. Code is available at https://github.com/Snowflake-AI-Research/fastkernels
ReCoVer: フォールトトレラントな集合的で汎用性の高いワークロードを介した回復力のある LLM 事前トレーニング システム
大規模な GPU クラスターで大規模な言語モデルを事前トレーニングすることにより、ハードウェア障害が稀ではなく日常的に発生するようになり、回復力のあるトレーニング システムの必要性が高まっています。しかし、既存のフレームワークは、特定の並列処理スキームに焦点を当てているか、失敗のないトレーニング軌道から逸脱する危険性があります。私たちは、単一の不変条件を維持する回復力のある LLM 事前トレーニング システムである ReCoVer を提案します。つまり、各反復でマイクロバッチの数を一定に保ち、反復ごとの勾配が失敗のない実行と確率的に等価であることを保証します。このフレームワークは、3 つの分離されたプロトコル層として構成されています。(1) 障害がレプリカ間で伝播するのを隔離するフォールトトレラント集合体。 (2) 反復内の進行状況を維持し、勾配の破損を防ぐ、段階的なきめ細かいリカバリ。 (3) マイクロバッチ クォータを生存者全体に動的に再配分する多用途ワークロード ポリシー。この設計は並列処理に依存せず、3D 並列処理とドロップイン サブストレートとしてハイブリッド シャード データ パラレル (HSDP) の両方を直接統合します。最大 512 GPU のエンドツーエンドの事前トレーニング タスクで実装を評価しました。ReCoVer は、実行全体で 256 GPU が失われたにもかかわらず、障害のないリファレンスからトレーニング軌跡を正常に保存しました。チェックポイントと再起動のベースラインと比較すると、ReCoVer は、連続した障害の後、実効スループットが 2.23 倍高いことを示しています。この利点により、ReCoVer は 234 GPU 時間で 74.9% 多くのトークンを処理することになり、トレーニングが長引くにつれてその差は拡大します。
原文 (English)
ReCoVer: Resilient LLM Pre-Training System via Fault-Tolerant Collective and Versatile Workload
Pre-training large language models on massive GPU clusters has made hardware faults routine rather than rare, driving the need for resilient training systems. Yet existing frameworks either focus on specific parallelism schemes or risk drifting away from a failure-free training trajectory. We propose ReCoVer, a resilient LLM pre-training system that upholds a single invariant: each iteration keeps the number of microbatches constant, ensuring per-iteration gradients remain stochastically equivalent to a failure-free run. The framework is organized as three decoupled protocol layers: (1) Fault-tolerant collectives that isolate faults from propagating across replicas; (2) in-step fine-grained recovery that preserves intra-iteration progress and prevents gradient corruption; (3) versatile-workload policy that dynamically redistributes microbatch quotas across the survivors. The design is parallelism-agnostic, integrating directly with both 3D parallelism and Hybrid Sharded Data Parallel (HSDP) as a drop-in substrate. We evaluate our implementation on end-to-end pre-training tasks for up to 512 GPUs, ReCoVer successfully preserves the training trajectory from a failure-free reference despite of 256 GPUs lost spread across the run. For comparison with checkpoint-and-restart baselines, ReCoVer demonstrates $2.23\times$ higher effective throughput after successive failures. This advantage results in ReCoVer processing 74.9% more tokens at 234 GPU-hours, with the gap widening as the training prolongs.