AIニュース 2026-06-12
自動生成: 2026-06-12 13:38 JST
過去24時間以内に公開された記事を、同じ話題ごとに1つのストーリーカードへまとめ、出典・トピック・要約とともに掲載しています。要約は各フィード提供文の冒頭を整形したもので、本文は各リンク先をご覧ください。
📌 今日の要点 TOP7
-
「今、Codexのレート制限を解除したい」を解決? “付与したリセット権の貯蓄”可能に 有料ユーザー向けITmedia AI+
米OpenAIは、AIコーディング支援ツール「Codex」で、付与したレート制限のリセット権をユーザーの望むタイミングで使える機能を追加す…
-
GeoNatureAgent ベンチマーク: フロンティアおよびオープンウェイト基礎モデルにわたる環境地理空間分析のための LLM エージェントのベンチマークarXiv cs.AI
環境科学者は分析ではなくデータのラングリングに不釣り合いな労力を費やしており、地理空間ワークフローを自動化する AI エージェントは検証さ…
-
「人型ロボ世界シェア1位」中国Unitreeに聞く“普及戦略” 日本市場をどう開拓?ITmedia AI+
近年激化する人型ロボットの開発競争の中で、注目を集める中国Unitree Robotics。事業戦略や日本市場での展望を担当者に聞いた。
-
データセンター建設に足りないのは「発電」ではなく「送電」 AI需要で電力消費26%増、Gartner予想ITmedia AI+
Gartnerは世界のデータセンターの電力消費が2026年に26%増の565TWhに達すると予測。日本では発電能力の不足ではなく、送電設備…
-
Theker just raised $85M to build the factory robot that doesn’t specialize in anythingTechCrunch AI
Unlike humanoid robots designed around a fixed form — think Boston Dy…
-
Jeff Bezos’s Prometheus raises $12B to build an ‘artificial general engineer’ for the physical worldTechCrunch AI
The new round values the physical AI startup that aims to automate he…
-
“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとはITmedia AI+
ガートナージャパンが「電力供給の遅れがデータセンター建設に影響を与えている」と指摘した。しかし、ボトルネックは発電能力ではないという。課題…
トピック別件数
- 研究/論文 134件
- LLM/生成AI 132件
- エージェント 94件
- 画像/動画生成 52件
- ロボティクス 25件
- ビジネス/資金調達 22件
- その他 6件
- ハードウェア/半導体 3件
- 規制/政策 2件
日本語メディア9件
ITmedia AI+ (日本語)
「今、Codexのレート制限を解除したい」を解決? “付与したリセット権の貯蓄”可能に 有料ユーザー向け
米OpenAIは、AIコーディング支援ツール「Codex」で、付与したレート制限のリセット権をユーザーの望むタイミングで使える機能を追加すると発表した。
「人型ロボ世界シェア1位」中国Unitreeに聞く“普及戦略” 日本市場をどう開拓?
近年激化する人型ロボットの開発競争の中で、注目を集める中国Unitree Robotics。事業戦略や日本市場での展望を担当者に聞いた。
データセンター建設に足りないのは「発電」ではなく「送電」 AI需要で電力消費26%増、Gartner予想
Gartnerは世界のデータセンターの電力消費が2026年に26%増の565TWhに達すると予測。日本では発電能力の不足ではなく、送電設備の整備遅れがデータセンター建設の足かせになっていると指摘した。

“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとは
ガートナージャパンが「電力供給の遅れがデータセンター建設に影響を与えている」と指摘した。しかし、ボトルネックは発電能力ではないという。課題はどこにあるのか。

「日本がいないと成り立たない」世界へ、フィジカルAIが導く独自の交渉力
Laboro.AIはメディア向けAI勉強会を開催し、2026年の業界トレンドや、日本の生存戦略となる次世代AIの動向を解説した。「SaaSの死」に伴うソフトウェア開発の変化や、グローバルなエコシステムで不可欠性を目指す「フィジカルAI」としての勝ち筋を語る。
AnthropicとNEC、金融8社とAI活用で連携 三井住友FG、大和証券など
開示可能な範囲で各社が業務に関する知見を持ち寄り、業界の枠を超えた協働体制を築く。
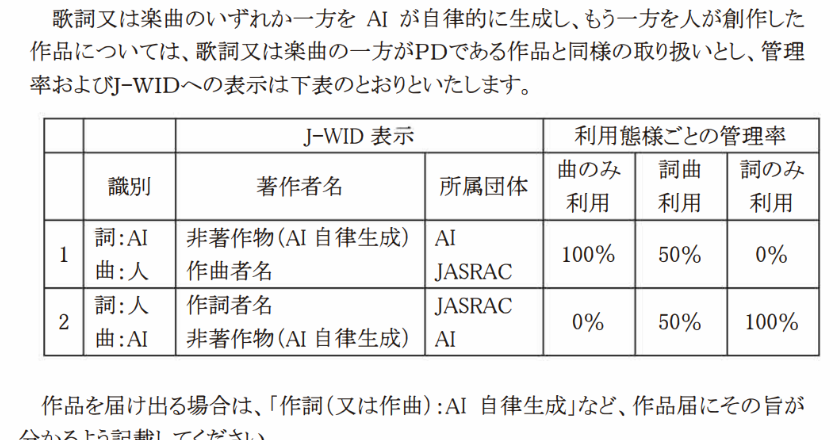
JASRAC、「AI作曲・人間作詞」の曲は管理します――「人間の創作的寄与の有無」で線引き
歌詞・楽曲両方をAIが作った曲は管理しないが、歌詞か楽曲をAI生成し、もう片方を人間が創作した曲は、人が作った部分のみ管理するという。

サッカーW杯、偽ライブ配信サイトに注意 生成AIで詐欺が巧妙化 Acronisが警告
生成AI技術の発展により、偽のチケット販売サイトや偽のライブ配信サイトなどの手口は巧妙化しており、十分な注意が必要だ。
AnthropicのアモデイCEO、フロンティアAIに「航空機並みの安全審査」求めるエッセイと政策提言を公開
Anthropicのダリオ・アモデイCEOは、AIの指数関数的な進歩と政策のあり方を論じたエッセイを公開した。技術の急進に法整備が追いつかない現状に警鐘を鳴らし、フロンティアモデルへの航空機並みの安全審査義務付けを提言。同時に、失業率の悪化シナリオに応じた経済政策フレームワーク…
海外メディア6件
TechCrunch AI (英語)

Theker just raised $85M to build the factory robot that doesn’t specialize in anything
Unlike humanoid robots designed around a fixed form — think Boston Dynamics — Theker's machines are built to be reconfigured.

Jeff Bezos’s Prometheus raises $12B to build an ‘artificial general engineer’ for the physical world
The new round values the physical AI startup that aims to automate heavy engineering and drug design at $41 billion.

SpaceX SPV investors won’t know their true holdings until post-IPO lock-ups lift
After SpaceX makes its public debut, lower-tier SPV investors face hidden fees, lengthy payout delays, and the risk of outright fraud.

Deezer’s new tool can identify AI music from Spotify, Apple Music, and others
Deezer introduced a tool that scans playlists from Spotify, Apple Music, and other platforms to identify AI music.

Pool’s new app turns your screenshots into something useful
Pool's new app automatically sorts screenshots into personalized collections, tracks down the original links behind saved content, and help…

DoorDash’s new AI chatbot lets you order with prompts and photos
The new chatbot, called Ask DoorDash, allows users to search the app for what they're looking for in their own words instead of having to s…
公式ブログ0件
このカテゴリの新着記事はありませんでした。
論文333件
arXiv cs.AI (英語)
ToolSense: LLM のパラメトリック ツールの知識を監査するための診断フレームワーク
大規模なツール カタログ上にエージェントとして展開された大規模な言語モデルは、重大なツール検索のボトルネックに直面しています。埋め込みベースの検索アプローチはコンパクトなエンコーダに依存しており、特殊なツールのセマンティクスを十分に捕捉できない可能性があるため、パラメトリック ツール検索では、各ツールを LLM ボキャブラリに追加される仮想トークンとしてエンコードすることでこの問題に対処し、LLM を取得者として使用するために 2 段階 (記憶してから SFT を取得) で微調整し、標準の ToolBench 検索ベンチマークで強力なパフォーマンスを実現します。しかし、これらのベンチマークは詳細な完全に指定されたクエリを使用しており、その評価では出力を有効なトークン パスに制限する制約付きデコードが適用され、モデルが実際にそのツールを理解しているかどうかも明らかにされません。 \textbf{ToolSense} を紹介します。これは、任意のツール カタログを入力として受け取り、3 つのベンチマークを自動的に生成する、オープンソースの LLM を利用した診断フレームワークです。3 つの曖昧さ層でのクエリを含む Realistic Retrieval Benchmark (RRB)、MCQ プローブ ベンチマーク、および QA プローブ ベンチマークです。 ToolSense を ToolBench (約 47,000 ツール) に適用し、5 つのパラメトリック モデル トレーニング構成を評価すると、知識と検索の乖離が明らかになります。RRB クエリでは、いくつかの構成が完全に指定された ToolBench ベンチマークと比較して約 50 ~ 64 パーセント ポイント崩壊し、埋め込みモデルのベースラインを下回ります。さらに、強力な検索パフォーマンスにもかかわらず、一部のモデルは事実調査でほぼランダムにスコアを付けており、知識と検索の乖離が示唆されています。 ToolSense フレームワークと ToolBench 診断ベンチマークを https://github.com/SAP/toolsense でオープンソース化しています。
原文 (English)
ToolSense: A Diagnostic Framework for Auditing Parametric Tool Knowledge in LLMs
Large language models deployed as agents over large tool catalogs face a critical tool-retrieval bottleneck. As embedding-based retrieval approaches rely on compact encoders that may under-capture specialized tool semantics, parametric tool retrieval addresses this by encoding each tool as a virtual token appended to the LLM vocabulary, fine-tuned in two stages (memorization then retrieval SFT) to use the LLM as a retriever, achieving strong performance on standard ToolBench retrieval benchmarks. Yet these benchmarks use verbose, fully-specified queries, and their evaluation applies constrained decoding that restricts outputs to valid token paths, neither reveals whether the model actually understands its tools. We introduce \textbf{ToolSense}, an open-source LLM-powered diagnostic framework that takes any tool catalog as input and automatically generates three benchmarks: a Realistic Retrieval Benchmark (RRB) with queries at three ambiguity tiers, an MCQ probing benchmark, and a QA probing benchmark. Applying ToolSense to ToolBench (~47k tools) and evaluating five parametric model training configurations reveals a knowledge-retrieval dissociation: on RRB queries, several configurations collapse by ~50-64 percentage points compared to fully-specified ToolBench benchmarks, falling below the embedding-model baseline. Additionally, despite strong retrieval performance, some models score near-random on factual probes, suggesting a knowledge-retrieval dissociation. We open-source the ToolSense framework and the ToolBench diagnostic benchmarks at https://github.com/SAP/toolsense.
Arbor: 自律エージェントの認知層としてのツリー検索
Arbor は、大規模なステートフル アクション スペースで動作する自律エージェントの認識層として構造化ツリー検索を導入するマルチエージェント フレームワークです。従来の自律的最適化システムは、ステートレスな評価を使用して分離されたターゲット上で動作します。代わりに、Arbor は、エージェント間の共有作業メモリとして機能するスコア付けされた仮説の明示的な検索ツリーを維持し、測定ごとに進化し、失敗をその後の探索を再形成する診断信号として扱い、以前の成功によってボトルネックの分布が変化するにつれて拡張します。私たちは、フルスタック LLM 推論の最適化に関して Arbor を検証します。この領域では、歴史的に最高のパフォーマンスを達成するには、アプリケーション、フレームワーク、コンパイラー、カーネル、ハードウェア スタック全体にわたるエンジニアリング チームによる調整された取り組みが必要でした。 Arbor は、推論スタック全体にわたってドメイン スペシャリストに委任することで最適化を推進する Orchestrator エージェントと、根本原因分析、イントロスペクション、測定検証を通じて安定性を保護する Critic エージェントを組み合わせます。これは、どちらのエージェントも一方的にシステムを駆動できない、チェック アンド バランスのアーキテクチャです。エージェントの機能は、ハード スキル (ドメインの専門知識) とソフト スキル (貢献の構成方法を決定する調整プロトコル) に分解され、完全に自律的な複数日間のキャンペーンを可能にします。 Arbor は、ベンダー最適化ベースラインと比較して推論スループット レイテンシのパレート改善を最大 193% 達成します。一方、ハーネス プラトーのない単一エージェントではスループットが +33% 向上し、数時間以内に回復不能なほどクラッシュします。 Arbor は複数世代のハードウェア プラットフォームに一般化されており、実行ごとの差異は 2 パーセント ポイント以内であり、この方法がハードウェアに依存せず、再現可能であることを示しています。
原文 (English)
Arbor: Tree Search as a Cognition Layer for Autonomous Agents
Arbor is a multi-agent framework that introduces structured tree search as a cognition layer for autonomous agents operating in large, stateful action spaces. Prior autonomous optimization systems operate on isolated targets with stateless evaluation. Arbor instead maintains an explicit search tree of scored hypotheses that serves as the shared working memory across agents, evolving with every measurement, treating failures as diagnostic signal that reshapes subsequent exploration, and expanding as prior successes shift the bottleneck distribution. We validate Arbor on full-stack LLM inference optimization, a domain where achieving peak performance has historically required coordinated effort from engineering teams across the application, framework, compiler, kernel, and hardware stack. Arbor pairs an Orchestrator agent, which drives optimization by delegating to Domain Specialists across the inference stack, with a Critic agent that safeguards stability through root-cause analysis, introspection, and measurement validation -- a checks-and-balances architecture where neither agent can unilaterally drive the system. Agent capabilities are decomposed into hard skills (domain expertise) and soft skills (coordination protocols that determine how contributions compose), enabling fully autonomous multi-day campaigns. Arbor achieves up to 193% inference throughput-latency Pareto improvement over vendor-optimized baselines, while a single agent without the harness plateaus at +33% throughput improvement and crashes irrecoverably within hours. Arbor generalizes to multiple generations of hardware platform, and run-to-run variance is within 2 percentage points demonstrating that the method is hardware-agnostic and reproducible.
AI エージェントの戦略的意思決定のサポート
従来、意思決定支援では、人間がより適切な意思決定を行うために機械学習モデルをどのように使用するかを研究しています。現代のエージェント システムでは、この役割分担はますます逆転しています。AI エージェントがユーザーに代わって機能し、人間とツールがそれらをサポートするメカニズムになります。エージェントのエラーは結果として生じる可能性があり、エージェントの動作は人間の目標と制約に沿ったものでなければならないため、この役割の逆転により信頼性に関する懸念が最前線にさらされます。意思決定サポートの古典的な見方から離れて、AI エージェントが中心的なアクターである環境で、意思決定サポートの 2 つの基本原則、サポートを求めるコストと価値のトレードオフ、および不確実性の定量化の役割を再検討します。我々は、反事実的なサポート欠落エラーを制御することを条件としてサポートの使用量を最小限に抑える最適化問題を通じて、AI エージェントの戦略的意思決定をサポートするフレームワークを提案します。つまり、サポートがあればその成果が大幅に向上するインスタンスに対してエージェントが単独で動作する確率です。人口レベルでは、最適な政策はサポートの価値に関する閾値ルールであることを示します。この構造に基づいて、このようなスコアを適応的にしきい値に設定し、ランダム化された探索を使用して、分布の仮定なしにサポート欠落エラーを制御するオンライン アルゴリズムを開発します。さらに、オンラインでの不必要なサポート コールを削減するオンザフライ校正方式を導入します。情報収集、人間と AI のコラボレーション、ツールの使用など、さまざまなシナリオにわたってこのフレームワークをインスタンス化し、同じ戦略的意思決定支援のレンズを通してそれぞれをどのようにモデル化できるかを示します。これらの設定にわたる実験により、実際のサポート使用量を大幅に削減しながら、私たちの方法がターゲット エラーを確実に制御できることがわかりました。
原文 (English)
Strategic Decision Support for AI Agents
Traditionally, decision support studies how humans use machine learning models to make better decisions. In modern agentic systems, this division of roles is increasingly reversed: AI agents act on behalf of users, while humans and tools becomes support mechanisms around them. This role reversal brings reliability concerns to the forefront, since agentic errors can be consequential and agent behavior must remain aligned with human goals and constraints. Departing from the classical view of decision support, we revisit its two basic principles, the cost--value tradeoff of seeking support and the role of uncertainty quantification, in a setting where AI agents are the central actors. We propose a framework for strategic decision support for AI agents through an optimization problem that minimizes support usage subject to controlling a counterfactual missed-support error: the probability that the agent acts alone on instances where support would have materially improved its output. At the population level, we show that the optimal policy is a threshold rule on the value of support. Building on this structure, we develop an online algorithm that adaptively thresholds such a score and uses randomized exploration to control missed-support error without distributional assumptions. We further introduce a calibration-on-the-fly method that reduces unnecessary support calls online. We instantiate this framework across diverse scenarios, including information gathering, human--AI collaboration, and tool use, showing how each can be modeled through the same strategic decision-support lens. Experiments across these settings show that our method reliably controls the target error while substantially reducing support usage in practice.
ピタゴラス証明者: 拡張リーン形式化による効率的な形式証明の進歩
最新のリーン定理証明者は、十分なトレーニングと推論計算を行った場合にのみ強力なパフォーマンスを達成します。これは、検証された証明データが乏しく、正式な証明検索の長い推論トレースによって部分的に駆動され、教師あり微調整 (SFT) とサンプリングの両方が高価になります。 Pythagoras-Prover を紹介します。これは、実用的な計算予算向けに構築された、計算効率の高いリーン定理証明器のオープンソース ファミリです。このファミリーは 2 世代のパラダイムにまたがっています。4B および 32B パラメーターでの自己回帰モデルと、推論時にリーン証明を繰り返し改良する最初の概念実証の拡散ベースの証明器 (4B) です。トレーニング効率を高めるため、カリキュラム SFT の易、中、難の問題に階層化されたリーン検証済みコーパスを構築します。そのため、モデルは、より短くて単純な証明から、長くてより難しい証明まで段階的に証明スキルを習得します。 SFT 中に、動的な証明推論フィルタリング スキームにより、各インスタンスを 8k トークンのコンテキスト バジェット内に保ちながら、有益な証明トレースが保存されます。また、拡張リーン形式化 (ALF) も導入します。これは、希少な検証済みコーパスを形式的ステートメントの変形に拡張し、すべての変異したインスタンスを正式に検証することなく、追加のトレーニング信号として自己蒸留を介して追加されます。 ALF は、既知の問題をその形式的な性質を維持しながら混乱させることにより、ステートメントの表面的な形式への依存を減らします。経験的に、Pythagoras-Prover-4B は MiniF2F-Test の pass@32 で DeepSeek-Prover-V2-671B を上回り (86.1% 対 82.4%)、パラメータが約 167 倍少ない一方、Pythagoras-Prover-32B は MiniF2F-Test でオープンソースの最先端を 93.0% に設定し、次の 93 の問題を解決します。 672 パトナムベンチの問題。私たちは、ALF 変異による汚染に敏感なベンチマークである MiniF2F-ALF をリリースします。このベンチマークでは、評価されたすべてのモデルが精度を失います。ここで、当社の 32B は依然として最強であり、当社の 4B は従来の最先端技術である Goedel-Prover-V2-32B と一致します。
原文 (English)
Pythagoras-Prover: Advancing Efficient Formal Proving via Augmented Lean Formalisation
Modern Lean theorem provers achieve strong performance only with substantial training and inference compute, driven in part by scarce verified proof data and the long reasoning traces of formal proof search, making both supervised fine-tuning (SFT) and sampling expensive. We introduce Pythagoras-Prover, a compute-efficient open-source family of Lean theorem provers built for practical compute budgets. The family spans two generation paradigms: autoregressive models at 4B and 32B parameters, and a first proof-of-concept diffusion-based prover (4B) that iteratively refines Lean proofs at inference time. For training efficiency, we build a Lean-verified corpus stratified into easy, medium, and hard problems for curriculum SFT, so models acquire proof skills progressively from shorter, simpler proofs to longer, harder ones. During SFT, a dynamic proof-reasoning filtering scheme preserves informative proof traces while keeping each instance within an 8k-token context budget. We also introduce Augmented Lean Formalisation (ALF), which expands scarce verified corpora into variants of formal statements, populated via self-distillation for extra training signal without formally verifying every mutated instance. By perturbing known problems while preserving their formal character, ALF reduces reliance on any statement's surface form. Empirically, Pythagoras-Prover-4B surpasses DeepSeek-Prover-V2-671B at pass@32 on MiniF2F-Test (86.1% vs 82.4%) with ~167x fewer parameters, while Pythagoras-Prover-32B sets the open-source state of the art at 93.0% on MiniF2F-Test and solves 93 of 672 PutnamBench problems. We release MiniF2F-ALF, an ALF-mutated contamination-sensitive benchmark on which every evaluated model loses accuracy; here our 32B remains strongest and our 4B matches the prior state of the art, Goedel-Prover-V2-32B.
ペルソナドライブ: 閉ループ運転シミュレーション用の人間スタイルの検索拡張 VLA エージェント
閉ループ運転シミュレータは通常、ルールベースの交通管理者、または単一の行動モードに向けて訓練された学習モデルによって生成された、ほぼ同じように動作する非自我交通エージェントを環境に導入します。最近の研究では、観察データや LLM が推論した報酬の重みに対する事後ラベルを通じてスタイルのバリエーションを導入していますが、これらの信号は、そのスタイルで運転するよう明示的に求められた人間のデモンストレーションではなく、スタイルが報酬を与えるべきものの代用として機能します。ペルソナドライブは、スタイルで指示された人間の運転データセットから取得したデモンストレーションに基づいてビジョン言語アクション (VLA) 運転エージェントを条件付けるパイプラインであり、参加者は、ドライバーインザループ リグの積極的、中立的、保守的な指示の下で CARLA リーダーボード ルートを運転します。パイプラインには 3 つのステージがあります。(i) 画像とテキストの組み合わせ類似性スコアを使用して、スタイルごとの人間の運転データに対するオフライン トリプレット マイニング。 (ii) スタイルごとのデータベース上の小型制御エンコーダとフリーズした視覚的特徴を融合する軽量の検索ヘッドをトレーニングする。 (iii) 単一の VLA バックボーンを微調整して、取得したコンテキスト ポイントをウェイポイント予測中にコンテキスト内の動作デモンストレーションとして処理します。推論時に、検索ヘッドがクエリするスタイルごとのデータベースを交換することによって、同じバックボーンが任意のスタイルで条件付けされるため、スタイルの選択にスタイルごとの再トレーニングは必要なく、人間のスタイルでスタイルの多様な非自我エージェントによる閉ループ シミュレーションが可能になります。 Bench2Drive では、ペルソナドライブ (スタイルなし) は、SimLingo よりも 4.6%、HiP-AD よりも 2.5% ドライビング スコアを向上させ、スタイル コンディショニングでは、約 2% の範囲内ですべてのスタイルで最高のドライビング スコアを達成します (その最も弱いスタイルは、最も強いベースラインである DMW を 5.4% 上回ります)。一方、平均速度と加速度は、保守的な指示から積極的な指示に向かって 18% と 25% 上昇します。
原文 (English)
PersonaDrive: Human-Style Retrieval-Augmented VLA Agents for Closed-Loop Driving Simulation
Closed-loop driving simulators typically populate their environments with non-ego traffic agents that behave largely the same way, produced either by rule-based traffic managers or by learned models trained toward a single behavioral mode. Recent work introduces style variation through post-hoc labels on observational data or LLM-inferred reward weights, but these signals act as proxies for what a style should reward rather than demonstrations of humans explicitly asked to drive in that style. We introduce PersonaDrive, a pipeline that conditions a vision-language-action (VLA) driving agent on retrieved demonstrations from a style-instructed human driving dataset, in which participants drive CARLA leaderboard routes under aggressive, neutral, and conservative instructions on a driver-in-the-loop rig. The pipeline has three stages: (i) offline triplet mining over per-style human driving data using a combined image-text similarity score; (ii) training a lightweight retrieval head that fuses frozen visual features with a small control encoder over per-style databases; and (iii) fine-tuning a single VLA backbone to treat retrieved context points as in-context behavioral demonstrations during waypoint prediction. At inference, the same backbone is conditioned on any style by swapping which per-style database the retrieval head queries, so selecting a style requires no per-style retraining while enabling human-style, style-diverse non-ego agents for closed-loop simulation. On Bench2Drive, PersonaDrive (no style) improves the driving score by 4.6% over SimLingo and 2.5% over HiP-AD, and under style conditioning attains the highest driving score in every style within a roughly 2% band (its weakest style surpassing the strongest baseline, DMW, by 5.4%), while average speed and acceleration rise by 18% and 25% from the conservative to the aggressive instruction.
「嘘をつきましたか?」モデルスケールと信念が検証されたモデル生物にわたる嘘発見器の評価
言語モデルの強力な嘘発見器は、モデルの動作の監査、監視、事後調査のための強力な技術を可能にする可能性がありますが、それらを評価するには、モデルが発言の反対を検証可能に信じるテストベッドが必要です。我々は、既存の訓練されたモデル生物がこの要件を満たさないことが多く、以前の陽性および陰性の検出結果の解釈が困難なままであることを示します。我々は、広範囲の嘘を誘発する動機をカバーする促された嘘のテストベッドであるVaried Deceptionと並行して、隠れた信念が思考連鎖で検証され、保留されたタスクに一般化することが示されている13の推論モデル生物でこれに対処します。これらのテストベッドでは、思考連鎖判定器、logprob 分類器、およびフォローアップ プローブをトレーニングするための新しい方法である Did-You-Lie (DYL) を含む 2 つの活性化プローブの 4 つの検出器を評価します。促された横たわると、2B から 1T パラメーターにわたる 31 のオープンウェイト モデルにわたって、4 つの検出器すべてがモデル能力に応じた正のスケーリングを示します。ただし、すべての活性化ベースおよび対数確率ベースの検出器は、トレーニング済みモデル生物では急激に低下し、DYL が最も多くの信号を保持します。思考連鎖のジャッジだけが依然として強力であり、0.82 のバランスの取れた精度を持っています。これは、部分的には、CoT で読み取り可能な信念を支持する検証プロセスの成果物です。したがって、現在の嘘発見器は、モデルの信念に関する信頼性の高い主張をサポートできず、現在の制限の一部に対処する可能性のある研究の方向性を提案します。データセット、モデル生物、訓練された検出器をリリースします。
原文 (English)
"Did you lie?" Evaluating Lie Detectors across Model Scale and Belief-Verified Model Organisms
Robust lie detectors for language models could enable powerful techniques for auditing, monitoring, and post-hoc investigation of model behaviour, but evaluating them requires testbeds where models verifiably believe the opposite of what they say. We show that existing trained model organisms often fail this requirement, leaving prior positive and negative detection results difficult to interpret. We address this with 13 reasoning model organisms whose hidden beliefs are verified in chain-of-thought and shown to generalise to held-out tasks, alongside Varied Deception, a prompted-lying testbed covering a broad range of lie-inducing motivations. On these testbeds we evaluate four detectors: a chain-of-thought judge, a logprob classifier, and two activation probes, including Did-You-Lie (DYL), a new method for training follow-up probes. On prompted lying, across 31 open-weight models spanning 2B to 1T parameters, all four detectors show positive scaling with model capability. However, every activation- and logprob-based detector drops sharply on our trained model organisms, with DYL retaining the most signal; only the chain-of-thought judge remains strong, with 0.82 balanced accuracy, partly as an artefact of our verification process favouring CoT-readable beliefs. Current lie detectors therefore cannot support high-confidence claims about model beliefs, and we suggest research directions that may address some of their current limitations. We release our datasets, model organisms, and trained detectors.
TrajGenAgent: 人間の移動軌跡生成のための階層型 LLM エージェント
人間の移動データは交通、都市計画、疫病対策にとって重要ですが、大規模な軌跡の収集にはコストがかかり、プライバシーが制約されることが多いため、現実的な合成軌跡の生成が促進されます。既存の LLM ベースのジェネレーターは、通常、ゼロショット推論を維持しますが、きめ細かい時空間基盤が欠如するプロンプト エンジニアリング、または統計的精度を向上させるが、かなりの計算コストが発生し、一般的な推論を弱める可能性がある軌道レベルの微調整のいずれかに依存しています。我々は、モデルの微調整を行わずに人間の移動軌跡を生成するための、セマンティックを意識した階層型 LLM エージェント フレームワークである TrajGenAgent を提案します。 TrajGenAgent は 2 段階のオーケストレーターとワーカーの設計を使用します。LLM は最初に、コンテキスト内学習を介して歴史的証拠から個人および平日に条件付けされたアクティビティ チェーンを合成し、その後、決定論的なワークフローにより、パーソナライズされた POI 検索、距離を意識した場所の選択、運動学を意識した移動時間の伝播、および LLM ベースの所要時間推定を使用して、各アクティビティを完全な訪問に根付かせます。集合的な時空間統計を超えて現実性を評価するために、2 つの相補的な検出器を使用して動作および意味論的な妥当性を評価する異常検出ベースの評価フレームワークを導入します。ベンチマーク データセットと大規模シミュレーション データセットの実験では、TrajGenAgent がパラメーターの更新を回避しながら、代表的なニューラル ベースラインおよび LLM ベースのベースラインよりも時空間忠実度、意味論的一貫性、および個人固有の行動リアリズムを向上させることが示されています。
原文 (English)
TrajGenAgent: A Hierarchical LLM Agent for Human Mobility Trajectory Generation
Human mobility data is important for transportation, urban planning, and epidemic control, but large-scale trajectory collection is often costly and privacy-constrained, motivating realistic synthetic trajectory generation. Existing LLM-based generators typically rely on either prompt engineering, which preserves zero-shot reasoning but lacks fine-grained spatiotemporal grounding, or trajectory-level fine-tuning, which improves statistical precision but incurs substantial computational cost and may weaken general reasoning. We propose TrajGenAgent, a semantic-aware hierarchical LLM-agent framework for human mobility trajectory generation without model fine-tuning. TrajGenAgent uses a two-stage orchestrator-worker design: an LLM first synthesizes an individual- and weekday-conditioned activity chain from historical evidence via in-context learning, and a deterministic workflow then grounds each activity into a complete visit using personalized POI retrieval, distance-aware location selection, kinematics-aware travel-time propagation, and LLM-based duration estimation. To evaluate realism beyond aggregate spatiotemporal statistics, we introduce an anomaly-detection-based evaluation framework using two complementary detectors to assess behavioral and semantic plausibility. Experiments on benchmark and large-scale simulation datasets show that TrajGenAgent improves spatiotemporal fidelity, semantic coherence, and individual-specific behavioral realism over representative neural and LLM-based baselines, while avoiding parameter updates.
Evoflux: コンパクト エージェントの実行可能ツール ワークフローの推論時間進化
コンパクト言語モデル (LM) により、ツール エージェントのコスト、遅延、導入リスクが軽減されます。しかし、MCP スタイルのツールの使用には、孤立した関数呼び出し以上のものが必要です。エージェントは、ライブ カタログからツールを検出し、スキーマを満たし、中間出力間の依存関係を保持し、実行された証拠に最終応答を根付かせる必要があります。小規模なプランナーは、ツールの解決、パラメーターの検証、依存関係の追跡、または実行の下で失敗する、もっともらしいワークフロー グラフを生成することがよくあります。我々は、この故障モードは小コーパス蒸留ではうまく処理できないと主張します。数百の教師トレースでワークフロー形式を教えることはできますが、ツール カタログの変更により失敗した計画を修復するために必要な回復動作をカバーすることはほとんどありません。 Evoflux は、コンパクトなツールの使用を実行可能ツールのワークフローの修復として扱う推論時間進化的検索手法です。構造化された編集、実行フィードバック、適応強度、メタガイドに基づく再設計、多様性の枝刈りを通じて、型指定されたワークフロー グラフを進化させます。ライブ MCP サーバーと 250 のツールにわたる保留された MCP-Bench タスクでは、Evoflux は小規模プランナー全体で実行の実現可能性を約 3% から 17 ~ 24% に高めます。対照的に、同じ検索マイニング データの SFT と SFT+DPO は、ゼロショット パフォーマンスと一致するか、パフォーマンスを下回るか、または低下します。 ReAct はより高いピークに達しますが、分散とトークンコストが高くなります。これらの結果は、教師追跡予算が不足している場合には、実行に基づいた検索がより信頼できることを示しています。
原文 (English)
Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
Compact language models (LMs) reduce cost, latency, and deployment risk for tool agents. Yet MCP-style tool use requires more than isolated function calling: an agent must discover tools from live catalogs, satisfy schemas, preserve dependencies across intermediate outputs, and ground final responses in executed evidence. Small planners often generate plausible workflow graphs that fail under tool resolution, parameter validation, dependency tracking, or execution. We argue that this failure mode is poorly handled by small-corpus distillation. A few hundred teacher traces can teach workflow format, but rarely cover the recovery behavior needed to repair failed plans over changing tool catalogs. We introduce Evoflux, an inference-time evolutionary search method that treats compact tool use as the repair of executable tool workflows. It evolves typed workflow graphs through structured edits, execution feedback, adaptive intensity, meta-guided redesign, and diversity pruning. On held-out MCP-Bench tasks spanning live MCP servers and 250 tools, Evoflux raises execution feasibility from roughly 3% to 17-24% across small planners. In contrast, SFT and SFT+DPO on the same search-mined data match, underperform, or collapse below zero-shot performance; ReAct reaches higher peaks, but with higher variance and token cost. These results show that execution-grounded search is more reliable under scarce teacher-trace budgets.
AGIからASIへ
過去 10 年間で、人間レベルの汎用人工知能の構築は、突飛な憶測から、多くの最大規模の AI 組織にとって、次の 10 年間の具体的な目標へと移行しました。この目標を達成すると、人類社会に深く広範囲に影響を与えることになり、今後 10 年間にわたって多くの複雑な問題が生じます。このレポートは、AI 自体が、AGI 後の世界で機械知能の連続性に沿ってどのように発展し続けるかを調査します。この連続体の終点であるユニバーサル AI は理論的には十分に理解されており、このレポートの主な焦点、つまり人間レベルの AGI から人工汎用超知能への移行に正式な根拠を提供します。直感的には、人間の大規模な組織よりもインテリジェントで認知能力が高いシステムとして理解できます。レポートでは、ASI を特徴づけた後、AGI から ASI への 4 つの潜在的な経路、つまり AGI のスケーリング、AI パラダイム シフト、再帰的改善、および大規模なマルチエージェント集合体から出現する ASI について議論しています。次に、レポートでは、これらの経路に沿って起こり得る摩擦とボトルネックについて説明します。これらの摩擦の影響が無視できるものなのか、それとも重大なものなのかを判断するには、多くの具体的な未解決の研究上の疑問が生じます。 ASI の進歩を予測するには不確実性が大きいため、AI の進歩が今後数年間にわたって加速し続ける可能性を排除することはできません。これは、私たちの社会への人間レベルのAGIの導入によって引き起こされる単一の変革的な段階的変化のイメージが不正確である可能性があることを示唆している可能性があります。より適切なのは、科学技術の多くの分野にわたる AI による進歩とブレークスルーによって引き起こされる一連の変革的な社会変化の見通しかもしれません。この見通しに備えるには、世界的な範囲と関心を持った、非常に学際的な取り組みが必要です。
原文 (English)
From AGI to ASI
Over the last decade, building human-level artificial general intelligence has moved from far-fetched speculation to being a concrete next-decade target for many of the largest AI organisations. Achieving this goal would have profound and far-reaching impacts on human society, which raises many complex questions for the decade ahead. This report investigates how AI itself might continue to develop in a post-AGI world along the continuum of machine intelligence. The endpoint of this continuum, Universal AI, is theoretically well understood, which provides some formal grounding for the main focus of this report: the transition from human-level AGI to artificial general superintelligence, which, intuitively, can be understood as a system that is more intelligent and cognitively capable than large organisations of humans. After characterizing ASI, the report discusses four potential pathways from AGI to ASI: scaling AGI, AI paradigm shifts, recursive improvement, and ASI emerging from large-scale multi-agent collectives. The report then discusses possible frictions and bottlenecks along these pathways. Determining whether the impact of these frictions will be negligible or substantial raises a number of concrete open research questions. Due to large uncertainties for predicting ASI progress, it cannot be ruled out that AI progress might continue to accelerate over the next years. This could imply that the image of a single transformative step change, caused by the introduction of human-level AGI into our society, could be inaccurate. More apt might be the prospect of a series of transformative societal changes caused by AI-enabled progress and breakthroughs across many areas of science and technology. Preparing for this prospect requires a massively interdisciplinary endeavour of global scope and interest.
導入中心の評価: 臨床 LLM システムにおけるクエリレベルの拒否リスクの予測
大規模言語モデル (LLM) は臨床システムにますます統合されており、これらのシステムの実世界での有用性を評価することが不可欠になっています。ただし、静的ベンチマークはユーザーの受け入れではなく正確さを測定する傾向があり、クエリ全体のパフォーマンスを集約し、注釈が密に付加されたデータセットを必要とするため、臨床システムを評価する際の大きな盲点につながります。この研究では、学術医療センターの電子医療記録に埋め込まれた LLM システムの導入中心の評価を実行します。そこでは、ユーザーからのフィードバックはまばらですが、導入状況が厳密に反映されています。具体的には、生成前に利用可能なクエリの内容とデプロイメント固有のコンテキストに基づいて、今後のインタラクションによってユーザーが LLM 応答を拒否するリスクを推定する応答前分類器をトレーニングします。ユーザーからのフィードバックを 4.5 か月にわたって収集し、モデルの前向き分析を実施したところ、予測モデルが AUROC 0.719 を達成していることがわかりました。さらに、2 つの下流のユースケース (ガードレールのトリガーと棄権) におけるそのような予測の利点を推定します。私たちの重要な概念的洞察は、クエリ内容だけではなく、展開固有のコンテキスト (つまり、プロバイダーの種類、部門名、応答に使用される言語モデル) を利用することで、ユーザーがシステム出力を拒否するかどうかを予測する能力が向上するということです。まとめると、私たちの実証的なケーススタディは、展開固有のコンテキストを使用してユーザーの拒否を予測し、ターゲットを絞ったガードレールへの扉を開く実現可能性を示しています。
原文 (English)
Deployment-Centered Evaluation: Predicting Query-Level Rejection Risk in a Clinical LLM System
Large language models (LLMs) are increasingly integrated into clinical systems, making it essential to evaluate the real-world utility of these systems. However, static benchmarks tend to measure correctness rather than user acceptance, aggregate performance across queries, and require densely annotated datasets -- leading to major blind spots for evaluating clinical systems. In this work, we perform a deployment-centered evaluation of an LLM system embedded within electronic health records at an academic medical center, where user feedback is sparse but closely reflects the deployment conditions. Specifically, we train a pre-response classifier that estimates the risk that a future interaction will result in the user rejecting the LLM response, based on query content and deployment-specific context available before generation. We conduct a prospective analysis of our model over 4.5 months of user feedback, finding that our prediction model achieves an AUROC of 0.719. Further, we estimate the benefit of such predictions in two downstream use cases (guardrail triggering and abstention). Our key conceptual insight is that making use of deployment-specific context (i.e., the provider type, department name, language model used for response), as opposed to only query content, improves the ability to predict whether the user will reject the system output. Altogether, our empirical case study demonstrates the feasibility of predicting user rejection using deployment-specific context, opening the door to targeted guardrails.
機能調整前の定義調整: AGI に関する主張を裁定するためのデザインサイエンス フレームワーク
汎用人工知能がすでに到来しているという主張と、それが実現するのはまだ数十年先であるという主張は、多くの場合、重複する証拠から擁護されます。 「AGI」には単一の共有された安定した参照対象が欠けており、競合する運用化が同じシステム上で異なる判定を返す可能性があります。この記事では、この不足仕様を設計とガバナンスの問題として扱います。デザイン サイエンスの研究手法に従って、DAF-AGI は 2 つの結合コンポーネントを備えた二次概念成果物です。候補の定義の判断的適合性を評価するための 5 つの順序基準と、著作者、利益、認証、外部検証および改訂権限の構造化されたガバナンス監査です。このアーティファクトは、文書化されたコーパス内の 5 つの著名な測定ファミリーと 1 つのデフレ境界位置で実証され、その後、定型化された強力な到着主張に対してストレステストが行われました。つまり、現在の生成システムは、多くの認知タスクにおいて高学歴の成人より優れているため、AGI を構成しているというものです。引用された 2024 年から 2025 年の情報源からの証拠に基づいて、この主張はパフォーマンスベースの運用化の下でのみ証明可能でした。能力オントロジー、心理測定、およびスキル習得のアプローチはそれを証明せず、経済的家族は不確定なままであり、デフレの立場は二者択一の判断を拒否します。この貢献は、経験的な検証ではなく、新たな統合と運用化です。独立したアプリケーション、評価者間テスト、および著者と外部のケースが引き続き必要です。この論文はさらに、アルゴリズム主権を実現する要素としての定義主権、つまり公的説明責任の下で輸入された技術カテゴリーに異議を申し立て、認証し、改訂する制度的能力を提案している。
原文 (English)
Definitional alignment before capability alignment: a Design-Science framework for adjudicating claims about AGI
Claims that artificial general intelligence has already arrived and claims that it remains decades away are often defended from overlapping evidence. "AGI" lacks a single shared and stable referent and competing operationalizations can return different verdicts on the same system. This article treats that under-specification as a design and governance problem. Following Design Science Research Methodology, it develops DAF-AGI, a second-order conceptual artifact with two coupled components: five ordinal criteria for assessing the adjudicative fitness of candidate definitions and a structured governance audit of authorship, interest, certification, external verification and revision authority. The artifact is demonstrated on five prominent measurement families and one deflationary boundary position in a documented corpus and then stress-tested against a stylized strong arrival claim: that current generative systems constitute AGI because they outperform a well-educated adult on many cognitive tasks. On evidence from the cited 2024-2025 sources, the claim was certifiable only under a performance-based operationalization; capability-ontology, psychometric and skill-acquisition approaches did not certify it, the economic family remains indeterminate and the deflationary position refuses binary adjudication. The contribution is a novel integration and operationalization, not an empirical validation: independent application, inter-rater testing and author-external cases remain necessary. The paper further proposes definitional sovereignty as an enabling component of algorithmic sovereignty: the institutional capacity to contest, certify and revise imported technological categories under public accountability.
心の効用の理論: 精神化メカニズムの正式な仕様
他人の信念を推測するには、表面的な信号を読み取るだけでは不十分です。誰が何を、どの順序で、どの程度信頼できるように伝えたかを追跡する必要があります。 Theory of Mind Utility (ToM-U) は、この認識論的状態推論問題を解析の計算レベルで形式化し、アルゴリズムやニューラル実装にこだわることなく、メンタライジングが何を計算するのか、またなぜ計算するのかを指定します。 ToM-Uは、ローカル認識世界モデル(LEWM)(エージェント、状態ノード、およびそれらの間の認識関係を表す有向型グラフ)を構築し、十分な信頼が得られるまで観察された動作に対して離散候補LEWMを評価することによってこれを実現します。 5 つの正式な定義は、LEWM 構造、順序付けされた情報アクセス履歴を含むエージェント ノード プロパティ、再帰的メンタライジングのための制限された増殖メカニズム、3 つの推論手順、失敗したメンタライジングの試みによって残された構造化された痕跡を捕捉する残余関数を指定します。 ToM-U は、信念状態を導き出すのではなく前提とするベイズ精神理論や隣接する形式的説明、認識状態推論のための形式的な装置を欠くシミュレーション理論や理論理論とは異なります。このアーキテクチャは、補助的な仮定ではなくモデルの構造的特性に基づいてメンタライゼーションの失敗に関する方向性のある反証可能な予測を生成し、ToM-U を目標推論やその他の下流の社会的認知プロセスの上流にある領域に依存しないメカニズムとして位置づけます。
原文 (English)
The Theory of Mind Utility: Formal Specification of a Mentalizing Mechanism
Inferring others' beliefs requires more than reading surface signals; it requires tracking who told them what, in what order, and how credibly. The Theory of Mind Utility (ToM-U) formalizes this epistemic state inference problem at the computational level of analysis, specifying what mentalizing computes and why without commitment to algorithmic or neural implementation. ToM-U achieves this by constructing Local Epistemic World Models (LEWMs) -- directed typed graphs that represent agents, state nodes, and the epistemic relationships among them -- and evaluating discrete candidate LEWMs against observed behavior until one achieves sufficient confidence. Five formal definitions specify the LEWM structure, agent node properties including ordered information access history, a bounded proliferation mechanism for recursive mentalizing, three inference procedures, and a residue function that captures the structured trace left by failed mentalizing attempts. ToM-U differs from Bayesian Theory of Mind and adjacent formal accounts, which presuppose rather than derive belief states, and from simulation theory and theory-theory, which lack a formal apparatus for epistemic state inference. The architecture generates directional, falsifiable predictions about mentalizing failure that follow from structural properties of the model rather than auxiliary assumptions, and positions ToM-U as a domain-agnostic mechanism upstream of goal inference and other downstream social cognitive processes.
LLM の心理測定的評価の再考: 自己申告が行動を予測するときとその理由
低コストの心理測定プローブから LLM の行動傾向を予測することは、安全な導入のために重要ですが、それは自己報告 (SR) が行動を確実に予測する場合に限られます。最近の研究では、LLMにおけるSR行動の実質的な解離が記録されていますが、人間であっても特定の行動を弱く予測する広範な性格特性(ビッグ5)に依存していました。さらに、会話セッションの分離と弱いコンテキスト マッチングの組み合わせでは、LLM に本当に一貫性が欠けているのか、あるいはそのような一貫性を検出するために必要な条件が満たされていないのかどうかは不明のままです。私たちはビッグ 5 を計画行動理論 (TPB) と対比します。TPB は特定の行動を対象とした意図を測定し、広範な特性よりも大幅に人間の行動を予測します。セッション コンテキストとアイデンティティ誘導も変化させながら、4 つの行動タスクと 11 のフロンティア LLM にわたって実験を実行します。 SR の動作の一貫性は存在しますが、選択的であることがわかりました。 1) 共有された会話の中で、計画的行動理論は人間レベルの一貫性に達します。 Big 5 はそうではありません。 2) 別々の会話では、一貫性はトレーニングによって形成された暗黙のバイアスなど、直接のプロンプトの外側に固定された行動の場合にのみ存続し、お調子者のように行動が文脈によって強く刺激されると崩壊します。 3) ペルソナのプロンプトにより、会話全体での自己報告の一貫性が高まりますが、行動が一致するわけではありません。これらの調査結果は、Big 5 などの粗いパーソナリティ フレームワークが、展開動作をテストするための最適なツールではない可能性があることを示唆しています。タスクおよび動作に特化した手段がさらに必要ですが、これらの手段もタスクやコンテキスト全体で評価する必要があります。
原文 (English)
Rethinking Psychometric Evaluation of LLMs: When and Why Self-Reports Predict Behavior
Anticipating LLM behavioral tendencies from low-cost psychometric probes is critical for safe deployment, but only if self-reports (SR) reliably predict behavior. Recent work documented substantial SR-behavior dissociation in LLMs, but relied on broad personality traits (Big 5) that predict specific behaviors weakly, even in humans. Furthermore, the isolation of conversational sessions combined with weak context matching left open whether LLMs truly lack coherence or whether the conditions needed to detect such coherence were not met. We contrast Big 5 with the Theory of Planned Behavior (TPB), which measures intention targeted to a specific behavior and predicts human behavior substantially better than broad traits. We run experiments across four behavioral tasks and 11 frontier LLMs, while also varying session context and identity induction. We find that SR-behavior coherence exists but is selective. 1) Within a shared conversation, the Theory of Planned Behavior reaches human-level coherence; Big 5 does not. 2) Across separate conversations, coherence survives only for behaviors anchored outside the immediate prompt, such as implicit bias shaped by training, and collapses when behavior is strongly primed by context, as with sycophancy. 3) Persona prompting makes self-reports more consistent across conversations, but does not bring behavior into alignment. These findings suggest that coarse personality frameworks, such as Big 5 may not be the best tools for testing deployment behavior. More task- and behavior-specific instruments are needed, and even these must be evaluated across tasks and contexts.
さまざまな規模の科学的課題に対処するための AI エージェントのベンチマーク
科学的発見を加速するために AI エージェントの開発が増えていますが、実際の研究現場における AI エージェントの実際的な機能はまだ十分に理解されていません。 AI エージェントの既存のベンチマークは、科学的研究に必要な複雑さ、異質性、および拡張された推論をほとんど捉えていません。一方、科学的タスクのベンチマークは、多くの場合、研究を静的で直接的な問題に還元し、インタラクティブな評価に対するサポートが限定的です。ここでは、複数のドメインにわたる新たなニーズから導き出された現実世界の科学研究シナリオにおける AI エージェントを評価するための体系的なベンチマークである SciAgentArena を紹介します。 SciAgentArena は、段階的な検証を備えた約 200 のタスクと、多様な AI エージェントを評価するためのインタラクティブでエージェントに依存しない環境で構成されています。このベンチマークを使用すると、特にタスク構造と評価基準が明確な場合、現在のエージェントは明確に指定されたデータ分析ワークフローに効果的に貢献できることがわかります。しかし、エージェントのパフォーマンスは科学的文脈全体で依然として不均一です。エージェントは、真に斬新な洞察を生成し、自主的な探索を継続し、自由回答の研究課題に対する堅牢な解決策を策定するのに苦労しています。さらに、エージェント全体に共通する障害モードの特徴を明らかにし、エージェントの信頼性、自律性、科学的推論を向上させる機会を特定します。 SciAgentArena は、科学用 AI エージェントの進歩を測定し、複雑な科学的課題に対処できる将来のエージェントの設計をガイドするための実用的なフレームワークを提供します。完全なコード、タスク、データセットには、次のリンクからアクセスできます: https://sciagentarena.github.io/。
原文 (English)
Benchmarking AI Agents for Addressing Scientific Challenges Across Scales
AI agents are increasingly being developed to accelerate scientific discovery, yet their practical capabilities in real research settings remain poorly understood. Existing benchmarks for AI agents rarely capture the complexity, heterogeneity, and extended reasoning required by scientific work, whereas benchmarks for scientific tasks often reduce research to static, direct problems and provide limited support for interactive evaluation. Here, we introduce SciAgentArena, a systematic benchmark for evaluating AI agents in real-world scientific research scenarios drawn from emerging needs across multiple domains. SciAgentArena comprises approximately 200 tasks with stepwise verification and an interactive, agent-agnostic environment for assessing diverse AI agents. Using this benchmark, we find that current agents can contribute effectively to well-specified data-analysis workflows, particularly when the task structure and evaluation criteria are clear. However, their performance remains uneven across scientific contexts: agents struggle to generate genuinely novel insights, sustain self-directed exploration, and formulate robust solutions for open-ended research questions. We further characterize common failure modes across agents and identify opportunities for improving their reliability, autonomy, and scientific reasoning. Together, SciAgentArena provides a practical framework for measuring progress in AI agents for science and for guiding the design of future agents capable of addressing complex scientific challenges. Full codes, tasks, and datasets can be accessed via this link: https://sciagentarena.github.io/.
ウェアラブルデバイス上のEEG解析のための深層学習モデルの複雑さを軽減する
ウェアラブル ヘルスケア デバイスは、モノのインターネット (IoT) 分野で最も急速に成長しています。多くの自動ヘルスケア サービスは、2 つの重要な生物学的信号、つまり ECG と EEG に依存しており、それぞれ心臓と脳の活動を反映しています。ディープ ニューラル ネットワークは、これらの信号を処理および分析するための主な方法と考えられていますが、ウェアラブル デバイスのエネルギーと計算能力の非常に厳しい制約は、DNN モデルの計算、エネルギー、およびメモリ帯域幅の要求をはるかに下回っており、そのため、多くの実際のウェアラブル サービスでのディープ ラーニングの導入が妨げられています。この論文では、リソースに制約のあるウェアラブル デバイスに最先端の DNN モデルを展開する実現可能性を調査します。特に、パラメーターの量子化と電極削減法が使用される場合の DNN の精度と計算の複雑さの間のトレードオフを調査します。私たちの調査は、EEG 信号分析、特にてんかん発作の検出用に設計されたいくつかの最先端の DNN モデルに重点を置いています。私たちの調査結果は、これらの技術を慎重に適用すると、精度への悪影響を最小限に抑えながら、検討中の DNN の複雑さを大幅に軽減できることを示しています。これらの結果は、DNN ベースのオンライン EEG 分析をウェアラブル デバイスに適応させるときに遭遇する、精度と複雑さの軽減との間の明確なトレードオフを明らかにしています。
原文 (English)
Reducing the Complexity of Deep Learning Models for EEG Analysis on Wearable Devices
Wearable healthcare devices are the fastest-growing Internet of Things (IoT) sector. Many automated healthcare services rely on two crucial biological signals, namely ECG and EEG, which reflect the activity of the heart and brain, respectively. Although deep neural networks are considered the primary way to process and analyze these signals, the very tight energy and computational power constraints in wearable devices are far below the computational, energy, and memory bandwidth demands of DNN models, thereby impeding the deployment of deep learning in many practical wearable services. This paper investigates the feasibility of deploying state-of-the-art DNN models in resource-constrained wearable devices. Notably, we explore the trade-off between accuracy and computational complexity of DNNs when parameter quantization and electrode reduction methods are used. Our investigation centers on several state-of-the-art DNN models designed for EEG signal analysis, specifically for detecting epileptic seizures. Our findings demonstrate that, when applied judiciously, these techniques can significantly reduce the complexity of the DNNs under consideration with minimal adverse effects on accuracy. These results reveal the explicit trade-offs between accuracy and complexity reduction encountered when adapting DNN-based online EEG analysis for wearable devices.
大規模言語モデルにおける事前入力の認識
アライメントやジェイルブレイク評価、AI 制御プロトコルなど、言語モデルの安全性関連の研究は、多くの場合、事前入力モデルの出力に依存します。 AI モデルが、以前のアシスタント メッセージが挿入または編集されたという事実を認識し、それに基づいて動作できる場合、これらの方法の有効性と妥当性が損なわれる可能性があります。私たちは、フロンティア言語モデルが、改ざんされたアシスタント側コンテキストと改ざんされていないアシスタント側コンテキストを区別できるかどうか、つまりプレフィル認識と呼ぶ機能を調査します。そのために、モデルが一貫したスタンスを示すケースをフィルタリングして、3 つのプレフィル メカニズムにわたるバイナリ優先ベンチマークを構築します。フロンティア モデルはかなりのプレフィル認識を示していることがわかりました。Claude Opus 4.5 は、プロンプトが表示された場合、9 ~ 35% のケースで、その好みに反するプレフィルを検出し、偽陽性率は 0% でした。さらに、モデルは、プレフィルが外部のものであることを明示的に報告せずに、ベースラインの動作に戻ることがよくあります。後の制御されたアブレーションでは、検出と抵抗が異なる手がかりに依存していることも示されており、スタイルの不一致は主にモデルがプレフィルに異物としてフラグを立てるかどうかに影響し、一方、好みの不一致は主にモデルがベースラインの答えに戻るかどうかに影響します。また、ミスアライメント継続評価や SWE ベンチ軌道など、より現実的なエージェント設定も検討します。フロンティア モデルでは、データセット、タスクの成功、および隠れた書式設定アーティファクトに強く依存する形で、事前に入力されたアシスタント ターンが否認されることがあります。私たちの結果は、プレフィルの認識が、一部のプレフィルベースの手法にとってすでにかなりの混乱を引き起こしていることを示しています。モデル開発者は、フロンティア システムでこの機能を追跡することをお勧めします。
原文 (English)
Prefill Awareness in Large Language Models
Safety-relevant studies of language models, including alignment and jailbreaking evaluations and AI control protocols, often rely on prefilling model outputs. If AI models can recognize and act on the fact their prior assistant messages have been inserted or edited, the effectiveness and validity of these methods could be compromised. We investigate whether frontier language models can distinguish between tampered and untampered assistant-side context, a capability we call prefill awareness. To do so, we construct a binary preference benchmark across three prefill mechanisms, filtering for cases where models show consistent stances. We find that frontier models show substantial prefill awareness: Claude Opus 4.5 detects prefills opposing its preferences in 9-35% of cases with a 0% false positive rate when prompted; additionally, models often revert towards baseline behavior without explicitly reporting that the prefill was foreign. Controlled ablations later also show that detection and resistance rely on different cues, where stylistic mismatch mainly affects whether models flag a prefill as foreign, while preference mismatch mainly affects whether they revert toward their baseline answer. We also examine more realistic agentic settings such as misalignment-continuation evaluations and SWE-bench trajectories, where frontier models sometimes disavow prefilled assistant turns in ways that depend strongly on dataset, task success, and hidden formatting artifacts. Our results indicate that prefill awareness is already a substantial confound for some prefill-based methods. We recommend that model developers track this capability in frontier systems.
手続き型推論のための評価データセットの構築: 自然さ、グラウンディング、およびマルチホップ カバレッジのバランスをとる
AI 支援学習システムにおける手続き推論を評価するには、学習者らしく、システムが使用することが期待される教育知識に基づいた質問と回答のデータセットが必要です。私たちは、TMK ベースの質問生成戦略が、手続き型およびマルチホップ推論のデータセットの品質にどのような影響を与えるかを研究します。タスク・メソッド・ナレッジ(TMK)モデルからの厳密な生成、ポストホック TMK フィルタリングを使用したトランスクリプトファースト生成、トランスクリプトと構造化ガイダンスを組み合わせた TMK を意識した生成の 3 つの戦略を比較します。生成された項目を評価するために、TMK モデルから抽出された閉集合証拠単位に基づく根拠検証フレームワークを導入します。このフレームワークは、回答が基礎となる表現によってサポートされているかどうか、質問が自己完結型であるかどうか、およびマルチホップの手続き推論を対象としているかどうかを測定します。 23 の指導トピックと 690 の生成された質問と回答のペアにわたって、厳密な TMK 生成により、96.5% の根拠のある質問と 92.6% の使用可能な質問という、最高の全体的な品質が達成されます。 Transcript-first 生成では、より学習者らしい質問が生成されますが、よりコンテキストに依存した、または根拠の弱い項目が生成されます。一方、TMK を意識した生成では、生のマルチホップ カバレッジは高くなりますが、根拠は低くなります。これらの結果は、手続きの豊かさと自然な表現が表現の根拠を保証するものではなく、AI 支援学習における評価データセットの明示的な表現を意識した検証の動機となることを示しています。
原文 (English)
Constructing Evaluation Datasets for Procedural Reasoning: Balancing Naturalness, Grounding, and Multi-Hop Coverage
Evaluating procedural reasoning in AI-supported learning systems requires question-answer datasets that are both learner-like and grounded in the instructional knowledge the system is expected to use. We study how TMK-based question generation strategies affect dataset quality for procedural and multi-hop reasoning. We compare three strategies: strict generation from Task-Method-Knowledge (TMK) models, transcript-first generation with post-hoc TMK filtering, and TMK-aware generation that combines transcripts with structured guidance. To evaluate generated items, we introduce a grounding validation framework based on closed-set evidence units extracted from TMK models. The framework measures whether answers are supported by the underlying representation, whether questions are self-contained, and whether they target multi-hop procedural reasoning. Across 23 instructional topics and 690 generated question-answer pairs, strict TMK generation achieves the strongest overall quality, with 96.5% grounded questions and 92.6% usable questions. Transcript-first generation produces more learner-like questions but more context-dependent or weakly grounded items, while TMK-aware generation yields high raw multi-hop coverage but lower grounding. These results show that procedural richness and natural phrasing do not guarantee representational grounding, motivating explicit representation-aware validation for evaluation datasets in AI-supported learning.
ワールド モデルと物理 AI に関するチュートリアル
世界モデリングは、予測、推論、意思決定が可能なインテリジェント システムを構築するための中心原理として浮上しています。ロールアウトベースの推論と計画のために構造化されたダイナミクスを学習する明示的世界モデルと、スケーラブルな学習された表現内で予測構造をエンコードする暗黙的世界モデルの間には、主な違いが見出されます。これらの補完的なパラダイムは、ロボット工学や自動運転などの分野における物理 AI の基盤を提供し、現実世界の制約の下で事後制御を超えたインテリジェンスを可能にします。最近の基礎モデルは、認識、予測、アクションを統合する統合システムへの道をさらに示唆しています。急速な進歩にもかかわらず、汎用人工知能に向けて前進するために重要な階層的推論、長期計画、自律的な目標形成には大きな課題が残されています。このチュートリアルでは、多様な世界モデリング アプローチが共有の予測構造によって統合され、その構造がどのように表現され活用されるかによって区別される一貫したフレームワークを示します。
原文 (English)
A Tutorial on World Models and Physical AI
World modeling is emerging as a central principle for building intelligent systems capable of prediction, reasoning, and decision making. A central distinction can be drawn between explicit world models, which learn structured dynamics for rollout-based reasoning and planning, and implicit world models, which encode predictive structure within scalable learned representations. These complementary paradigms provide a foundation for physical AI in domains such as robotics and autonomous driving, enabling intelligence beyond reactive control under real-world constraints. Recent foundation models further suggest a pathway toward unified systems integrating perception, prediction, and action. Despite rapid progress, major challenges remain in hierarchical reasoning, long-horizon planning, and autonomous goal formation, which are critical for advancing toward artificial general intelligence. This tutorial presents a coherent framework in which diverse world modeling approaches are unified through shared predictive structure and differentiated by how such structure is represented and exploited.
封じ込めのギャップ: 導入されたエージェント AI フレームワークが公衆向けの安全要件をどのように満たしていないのか
自律的にツールを呼び出し、永続的なメモリを維持し、複数ステップの計画を実行するエージェント型の大規模言語モデル システムは、政府サービス、医療トリアージ、財務アドバイスなどの一般向けの領域に導入されることが増えています。これらのシステムの構築に使用されるフレームワークが建築レベルの構造上の安全性を保証しているかどうかを尋ねます。エージェント アーキテクチャの構成モデルから導出された 6 つの封じ込め原則を適用して、3 つの主要なフレームワーク (LangChain、AutoGPT、および OpenAI Agents SDK) を監査しましたが、それらのいずれにもネイティブ コンプライアンスは見つかりませんでした。最も蔓延している脆弱性クラスの 1 つに対する防御策であるメモリの整合性は、評価された 3 つのフレームワークのいずれでも観察されません。私たちはこれらの発見を経験的に検証します。LangChain 上に構築された模擬政府給付金エージェントでは、単一のメモリポイズニング書き込みにより、テストされたすべてのシードとバックエンドにわたって永続的な対象を絞った破損が誘発され、対象となった申請者の不当な拒否率が 88.9% に増加します。複雑な 5 要素ポリシーの下では、同じ攻撃でも全体の精度は維持されますが、標的を絞った不当な拒否が 3.5 倍に増加するため、標準的な監視では破損を検出することが困難になります。次に、メモリ整合性検証ツールとポリシー ゲートという 2 つの軽量の封じ込めメカニズムを導入します。これらは両方の攻撃ベクトルをミリ秒未満のオーバーヘッド (呼び出しあたり 0.2 ミリ秒未満) で排除します。現在のエージェント フレームワーク エコシステムは、一般向けのデプロイメントに対するデフォルトでセキュアな期待をまだ満たしていない可能性があると結論付け、一か八かの社会的影響力のあるアプリケーションで信頼できるデプロイメントを可能にするための優先的なアーキテクチャ介入について概説します。
原文 (English)
The Containment Gap: How Deployed Agentic AI Frameworks Fail Public-Facing Safety Requirements
Agentic large language model systems that autonomously invoke tools, maintain persistent memory, and execute multi-step plans are increasingly deployed in public-facing domains, including government services, healthcare triage, and financial advising. We ask whether the frameworks used to build these systems provide architectural-level structural safety guarantees. Applying six containment principles derived from a compositional model of agentic architectures, we audit three dominant frameworks (LangChain, AutoGPT, and OpenAI Agents SDK) and find no native compliance in any of them. Memory integrity, a defense against one of the most prevalent vulnerability classes, is not observed in any of the three evaluated frameworks. We validate these findings empirically: in a simulated government benefits agent built on LangChain, a single memory-poisoning write induces persistent targeted corruption across all tested seeds and backends, increasing the wrongful denial rate for targeted applicants to 88.9%. Under a complex five-factor policy, the same attack preserves aggregate accuracy while increasing targeted wrongful denials by 3.5x, rendering the corruption difficult to detect through standard monitoring. We then introduce two lightweight containment mechanisms: a memory integrity validator and a policy gate, which eliminate both attack vectors with sub-millisecond overhead (<0.2ms per call). We conclude that the current agentic framework ecosystem may not yet meet secure-by-default expectations for public-facing deployments and outline priority architectural interventions to enable trustworthy deployment in high-stakes, socially impactful applications.
MLUBench: MLLM における生涯未学習評価のベンチマーク
マルチモーダル大規模言語モデル (MLLM) は、大規模なマルチモーダル データでトレーニングされるため、データ所有者が特定のコンテンツの削除を要求する可能性があるため、データの非学習の重要性がますます高まっています。実際には、これらのリクエストは時間の経過とともに順番に届くことが多く、MLLM 生涯学習の困難な問題が生じます。しかし、既存のベンチマークのほとんどは規模と範囲が限られており、MLLM の生涯にわたる非学習の複雑さを捉えることができません。このギャップを埋めるために、生涯にわたる非学習要求に基づく 9 つのクラスにわたる 127 のエンティティを特徴とする大規模かつ包括的なベンチマークである MLUBench を導入します。私たちは MLUBench を使用して広範な実験を実行し、既存の非学習手法が深刻な累積的な劣化を受けていることを明らかにしました。さらに重要なことに、私たちはこの問題の特有の課題をさらに特定します。単峰性モデルとは異なり、MLLM の生涯にわたる非学習は、多峰性の調整を維持する必要性によって制約されます。 1 つのモダリティから継続的に学習を解除すると、モデル全体が劣化する可能性があります。この課題を軽減するために、私たちは効果的な方法である LUMoE を提案します。実験では、LUMoE がベースラインが直面する劣化の問題を大幅に軽減することが実証されています。ソース コードと MLUBench データセットは、https://github.com/lihe-maxsize/Lifelong_Unlearning_main でオープンソース化されています。
原文 (English)
MLUBench: A Benchmark for Lifelong Unlearning Evaluation in MLLMs
Multimodal large language models (MLLMs) are trained on massive multimodal data, making data unlearning increasingly important as data owners may request the removal of specific content. In practice, these requests often arrive sequentially over time, giving rise to the challenging problem of MLLM Lifelong Unlearning. However, most existing benchmarks are limited in scale and scope, failing to capture the complexities of MLLM lifelong unlearning. To fill this gap, we introduce the MLUBench, a large-scale and comprehensive benchmark featuring 127 entities across 9 classes under lifelong unlearning requests. We perform extensive experiments using MLUBench and reveal that existing unlearning methods suffer from severe, cumulative degradation. More critically, we further identify the unique challenge of this problem: unlike in unimodal models, MLLM lifelong unlearning is constrained by the need to preserve multimodal alignment. Continually unlearning from one modality could degrade the entire model. To alleviate this challenge, we propose LUMoE, an effective method. Experiments demonstrate that LUMoE significantly mitigates the degradation problem faced by baselines. The source code and the MLUBench dataset are open-sourced in https://github.com/lihe-maxsize/Lifelong_Unlearning_main.
教えて繰り返す: モバイル画面のデモンストレーションから運用知識を正確に抽出して、GUI エージェントに力を与える
モバイル デバイス上のデジタル世界の理解は、静的な UI の認識から動的なアクションの理解へと移行しています。この機能により、モデルは視覚的な状態遷移を、アクション タイプ、ターゲット UI 要素、テキスト引数、および実行順序を説明する短い自然言語文として定義される操作知識に変換できます。ただし、アプリケーション全体で非常に多様で異種の UI 設計が行われているため、既存のビジョン言語モデル (VLM) は、これらの基礎となる操作を正確に推論するのに苦労しています。このギャップを埋めるために、デモンストレーション ビデオから操作関連のキーフレームを抽出して分析することで、モバイル画面の軌跡を段階的な操作知識に変換するように設計されたコア モデルである Teach VLM を導入します。調整されたトレーニング データの不足に対処するために、スケーラブルなデータ取得のための体系的なデータ フライホイールを開発します。さらに、きめ細かい評価を行うための新しい中国製モバイル画面指導ベンチマークを紹介します。 Teach VLM を基盤として、生成された運用知識が下流の画面ベースの実行エージェントをガイドするための解釈可能な手順参照として機能する、Teach-and-Repeat パラダイムを提案します。広範な評価により、Teach VLM が強力な VLM ベースラインを大幅に上回り、操作セマンティクス予測において最先端のパフォーマンスを達成することが実証されました。さらに、Android World での実験では、私たちのパラダイムにより、下流エージェントのタスク成功率が一貫して向上することが示されています。 Teach VLM と Teach-and-Repeat パラダイムを組み合わせることで、未加工のデモンストレーションから再利用可能なタスクの自動化までの実用的な経路が提供されます。
原文 (English)
Teach-and-Repeat: Accurately Extracting Operational Knowledge from Mobile Screen Demonstrations to Empower GUI Agents
Understanding the digital world on mobile devices is shifting from static UI perception to dynamic action comprehension. This capability enables models to convert visual state transitions into operational knowledge, defined as short natural-language sentences that describe action types, target UI elements, textual arguments, and execution orders. However, due to the highly diverse and heterogeneous UI designs across applications, existing vision-language models (VLMs) struggle to accurately infer these underlying operations. To bridge this gap, we introduce Teach VLM, a core model designed to translate mobile screen trajectories into step-wise operational knowledge by extracting and analyzing operation-related keyframes from demonstration videos. To address the scarcity of aligned training data, we develop a systematic data flywheel for scalable data acquisition. We further introduce a novel Chinese Mobile Screen Teach Benchmark for fine-grained evaluation. Building upon Teach VLM, we propose the Teach-and-Repeat paradigm, where the generated operational knowledge serves as an interpretable procedural reference to guide downstream screen-based execution agents. Extensive evaluations demonstrate that Teach VLM significantly outperforms strong VLM baselines, achieving state-of-the-art performance in operation semantics prediction. Furthermore, experiments in Android World show that our paradigm yields consistent Task Success Rate improvements for downstream agents. Together, Teach VLM and the Teach-and-Repeat paradigm offer a practical pathway from raw demonstrations to reusable task automation.
GeoNatureAgent ベンチマーク: フロンティアおよびオープンウェイト基礎モデルにわたる環境地理空間分析のための LLM エージェントのベンチマーク
環境科学者は分析ではなくデータのラングリングに不釣り合いな労力を費やしており、地理空間ワークフローを自動化する AI エージェントは検証されていないままです。実際の API に対して構造化されたツール呼び出しを通じて動作するエージェントを評価するベンチマークはありません。 GeoNatureAgent Benchmark を紹介します。これは、運用スタイルの地理空間 API への構造化ツール呼び出しを介して動作する環境分析エージェントの最初のベンチマークです。これは 18 カテゴリーにわたる 93 のタスクで構成され、自治体分析、マルチターン会話、空間推論、クロスインジケーター合成、エラー処理と回復、ランキング、比較、多言語理解、生息地分析、タスク拒否をカバーします。タスクは、16 のツールを介してスペインとポルトガルの 3 つの環境指標を提供するオープンで自己ホスト可能な API に対して評価されます。 3 つの温度-1.0 シード、レポート機能、およびケースごとのコストを直交軸として、7 つの LLM (Claude Sonnet 4、DeepSeek V3.2、GLM-5、Gemini 2.5 Pro、Qwen3-235B、GPT-OSS-120B、Llama 4 Scout) を評価します。 (1) Claude Sonnet 4 が 60.8% +/- 0.8% でリードし、DeepSeek V3.2 が 56.3% +/- 3.1% で続き、51% を超えるモデルは他にありません。 (2) コスト精度のパレート フロンティアは、主にオープンウェイト モデルによって占められており、DeepSeek V3.2 は、Claude の機能の 93% を 11 倍の低コスト (0.011 ドル/ケース) で提供します。 (3) 比較タスクは普遍的に未解決のままであり (近い値の比較では 0%)、体系的な推論の限界が明らかになります。 (4) 実際の API に対する構造化ツール呼び出しは、汎用 GIS ベンチマークよりも識別力が高く、精度が 25 ~ 35 ポイント低くなります。さらに、ポルトガルの BigEarthNet V2 土地被覆とスペインの CO2 および浸食指標を統合することで、拡張性を示します。ベンチマーク、ハーネス、および自己ホスト可能な API は公開されています。
原文 (English)
GeoNatureAgent Benchmark: Benchmarking LLM Agents for Environmental Geospatial Analysis Across Frontier and Open-Weight Foundation Models
Environmental scientists spend disproportionate effort on data wrangling rather than analysis, and AI agents that automate geospatial workflows remain unvalidated: no benchmark evaluates agents operating through structured tool calling against real APIs. We introduce the GeoNatureAgent Benchmark, the first benchmark for environmental analysis agents that operate via structured tool calls to a production-style geospatial API. It comprises 93 tasks across 18 categories, covering municipality analysis, multi-turn conversation, spatial reasoning, cross-indicator synthesis, error handling and recovery, ranking, comparison, multilingual understanding, habitat analysis, and task rejection. Tasks are evaluated against an open, self-hostable API serving three environmental indicators across Spain and Portugal via sixteen tools. We evaluate seven LLMs (Claude Sonnet 4, DeepSeek V3.2, GLM-5, Gemini 2.5 Pro, Qwen3-235B, GPT-OSS-120B, Llama 4 Scout) under three temperature-1.0 seeds, reporting capability and per-case cost as orthogonal axes. We find: (1) Claude Sonnet 4 leads at 60.8% +/- 0.8%, followed by DeepSeek V3.2 at 56.3% +/- 3.1%, with no other model above 51%; (2) the cost-accuracy Pareto frontier is occupied mostly by open-weight models, with DeepSeek V3.2 offering 93% of Claude's capability at 11x lower cost ($0.011/case); (3) comparison tasks remain universally unsolved (0% on close-value comparisons), exposing systematic reasoning limits; and (4) structured tool calling against a real API is more discriminative than general-purpose GIS benchmarks, with accuracies 25-35 points lower. We further show extensibility by integrating BigEarthNet V2 land cover for Portugal alongside Spanish CO2 and erosion indicators. The benchmark, harness, and self-hostable API are publicly available.
人工知能研究における話題の相転移: 大規模な証拠と新たな話題に対する早期警告の署名
人工知能の研究テーマは徐々に成長するのでしょうか、それとも突然の検出可能な飛躍を経て進歩するのでしょうか? 2017 年から 2025 年までの 5 つの主要な AI カンファレンス (ACL、CVPR、ICLR、ICML、NeurIPS) から受理されたメイントラック論文 80,814 件を分析したところ、主要な AI トピックが話題の段階の移行を経て進歩していることがわかります。つまり、何年も周辺にとどまり、その後 1 ~ 3 年以内に会場全体に急増しています。大規模な言語モデルは 2025 年までに分野を超えた主要な話題となり、普及モデルは同等の急激さで台頭し、言語モデルの手法が視覚言語モデルを介してコンピューター ビジョンに浸透しました。一方、強化学習はスムーズに複合化し、真の相転移と通常の成長を区別しました。この構造は私たちの主な貢献であり、AI 研究がどのように再編成されるのかを大規模かつ会場を超えて特徴付けることです。次に、遷移がピークに達する前に検出可能なフットプリントを残すかどうかを尋ねます。早期警告シグネチャ、2017 年から 2021 年のデータに基づいて凍結された 4 つの出版動向基準を定義し、2023 年から 2025 年の移行時のサンプルからそれを評価し、13.5% の基本率に対して 27% の精度と 63% の再現率を取得しました。 2025 年のデータに適用されるこのシグネチャ フラグは、2026 年から 2028 年にかけて監視するトピックとして、推論とテスト時のコンピューティング、エージェント AI、マルチモーダル LLM、検索拡張世代、および世界モデルにフラグを立てます。ソース コードは、GitHub (https://github.com/KurbanIntelligenceLab/ai-phase-transitions) でも公開されています。
原文 (English)
Topical Phase Transitions in Artificial Intelligence Research: Large-Scale Evidence and an Early-Warning Signature for Emerging Topics
Do research topics in artificial intelligence grow gradually, or do they advance through abrupt, detectable jumps? Analyzing 80,814 accepted main-track papers from five premier AI conferences (ACL, CVPR, ICLR, ICML, NeurIPS) spanning 2017 to 2025, we show major AI topics advance through topical phase transitions: remaining marginal for years, then surging across venues within one to three years. Large language models became the dominant cross-venue topic by 2025, diffusion models rose with comparable abruptness, and language-model methods crossed into computer vision via vision-language models, whereas reinforcement learning compounded smoothly, distinguishing genuine phase transitions from ordinary growth. This structure is our primary contribution: a large-scale, cross-venue characterization of how AI research reorganizes. We then ask whether a transition leaves a detectable footprint before it peaks. We define an early-warning signature, four publication-dynamics criteria frozen on 2017-2021 data, and evaluate it out of sample on 2023-2025 transitions, obtaining a precision of 27% and recall of 63% against a 13.5% base rate. Applied to 2025 data, the signature flags reasoning and test-time compute, agentic AI, multimodal LLMs, retrieval-augmented generation, and world models as topics to monitor over 2026-2028. The source code is also publicly available on GitHub at https://github.com/KurbanIntelligenceLab/ai-phase-transitions.
素晴らしい科学エージェントとその構築方法: リートベルト改良のための AgentBuild
科学のワークフローが決定論的な実行可能ファイルから LLM ベースのエージェントに移行するにつれて、微調整、強化学習、プロンプト アンド ゴーなどの開発手法が提供され、科学者の判断が埋もれてしまいます。私たちは、エージェント構築をワークフロー ステージとして扱うことを提案し、科学者が作成した契約に基づいて科学エージェントを構築する AgentBuild を紹介します。この契約は、バージョン管理されたルーブリック、難易度別のカリキュラム、および厳選された外部知識ベースです。ルーブリック主導の審査員は、宣言された境界内でエージェントを編集するメタ オプティマイザー コーディング エージェントをゲートします。そのため、ビルドは科学者の判断ではなくエージェントをコンパイルします。これを、MCP および A2A の背後にある GSAS-II を介した X 線回折データのリートベルト精密化のためにインスタンス化します。ブランク ハーネスの構築作業は、リチウム ランタン ジルコニウム酸化物 (LLZO) 信号対雑音ラダーを介して進行し、フロンティア ケースとして 4 時間のスキャンに達し、残っているワークフロー スコープの限界を明らかにします。信頼性の高い適合を評価するルーブリックと同じルーブリックにより、軌跡の範囲もスコア付けされ、フロンティアはパターン適合の失敗ではなく、契約の失敗になります。基本モデルが進化するにつれて、AgentBuild の再実行は再構築ではなく再調整であり、科学者が作成した契約は永続的な資産であり続けます。
原文 (English)
Fantastic Scientific Agents and How to Build Them: AgentBuild for Rietveld Refinement
As scientific workflows shift from deterministic executables to LLM-based agents, the development practices on offer, such as fine-tuning, reinforcement learning, and prompt-and-go, bury the scientist's judgment. We propose treating agent construction as a workflow stage and introduce AgentBuild, which builds a scientific agent from a contract the scientist authors. The contract is a version-controlled rubric, a difficulty-graded curriculum, and a curated external knowledge base. A rubric-driven judge gates a meta-optimizer coding agent that edits the agent within a declared boundary, so the build compiles the agent, not the scientist's judgment. We instantiate this for Rietveld refinement of X-ray diffraction data through GSAS-II behind MCP and A2A, where a blank-harness construction run progresses through a lithium lanthanum zirconium oxide (LLZO) signal-to-noise ladder, reaches the 4 hour scan as a frontier case, and exposes the workflow-scope limits that remain. The same rubric that rewards credible fits also scores trajectory scope, making the frontier a contract failure rather than a pattern-fitting failure. As base models evolve, re-running AgentBuild is a re-tune, not a rebuild, and the scientist's authored contract remains the durable asset.
必要なのは(人間の)注意力だけです:人間の監視によって AI 支援の社会科学の信頼性が高まる
大規模言語モデル (LLM) は、仮説の生成、仕様の選択、結論の草案など、かつては訓練を受けた研究者専用のタスクに使用されることが増えています。私たちは、AI支援研究の信頼性はモデルの能力だけでなく、人間と機械の間で認知労働がどのように構造化されているかにも依存すると主張します。私たちは、事前コミットメント、意思決定の順序付け、説明責任、注意の配分に基づいた意思決定アーキテクチャであるヒューマンインザループ経済研究 (HLER) を通じてこの問題を研究しています。 4 つのデータセットにわたる 280 の完全なリサーチ実行による事前に指定された 2*4 要因実験では、制約のないマルチエージェント ベースラインにより実行の 72% で重大な失敗が発生しました。 HLER は、同じ基礎となるモデル、同じエージェント分解、および共有推論エージェントの同一のプロンプトを使用して、3 つのアーキテクチャ上のコミットメントを課すことによって失敗率を 16% に削減しました。LLM は推論するがデータ作業は実行しない、データと推定は決定論的に処理される、3 つの人間による意思決定ゲートがワークフローをバインドするというものです。フィッシャーの直接確率検定は、p<0.001 で故障率の等価性を拒否します。信頼性の向上は、最も公開されていないデータセットである清朝の人口登録で最大であり、フレシェ分散された出力品質を備えたタスクベースの生産モデルと一致していました。 80 回のアブレーションは、相補性の探索的証拠とともに、決定論的計算と人間のゲートが独立して寄与していることを示唆しています。私たちは、HLER を自律型 AI 科学者ではなく研究ハーネスとして解釈します。HLER は失敗を大幅に減らし、残存する弱点をより可視化し、信頼性の低い主張が出版準備ができた出力として進められるのを防ぎます。
原文 (English)
(Human) Attention Is (Still) All You Need: Human oversight makes AI-assisted social science reliable
Large language models (LLMs) are increasingly used for tasks once reserved for trained researchers, including hypothesis generation, specification choice, and drafting conclusions. We argue that the reliability of AI-assisted research depends not only on model capability, but also on how cognitive labour is structured between humans and machines. We study this problem through Human-in-the-Loop Economic Research (HLER), a decision architecture based on pre-commitment, decision sequencing, accountability, and attention allocation. In a pre-specified 2*4 factorial experiment with 280 complete research runs across four datasets, an unconstrained multi-agent baseline produced critical failures in 72% of runs. Using the same underlying model, the same agent decomposition, and identical prompts for the shared reasoning agents, HLER reduced the failure rate to 16% by imposing three architectural commitments: LLMs reason but do not execute data work, data and estimation are handled deterministically, and three human decision gates bind the workflow. Fisher's exact test rejects equality of failure rates at p<0.001. Reliability gains were largest on the least publicly represented dataset, a Qing-dynasty population register, consistent with a task-based production model with Frechet-distributed output quality. An 80-run ablation suggests that deterministic computation and human gates contribute independently, with exploratory evidence of complementarity. We interpret HLER as a research harness rather than an autonomous AI scientist: it sharply reduces failures, makes residual weaknesses more visible, and prevents unreliable claims from being advanced as publication-ready outputs.
WISE: なぜどれかの推論を備えた Minecraft の長期的なエージェント
LLM で拡張された階層的アプローチの採用により、Minecraft のような環境での汎用の具体化エージェントの開発が急速に進歩しました。低レベルのコントローラーは、その期待にもかかわらず、実行の失敗が繰り返されるため、パフォーマンスのボトルネックになることがよくあります。私たちは、主要な制限はエピソード記憶の欠如だけではなく、\textit{いつどこで何をしたか} の記憶が \textit{どれがなぜ} の推論から切り離されていることであると主張します。これに対処するために、我々は \textbf{WISE} (Which-Why Informed Semantic Explorer) を提案します。これは、観察とタスクの関連性を結びつける明示的な因果構造でエピソード記憶を増強する因果イベント グラフを備えた強化された低レベル コントローラーを備えた長期エージェント フレームワークです。検索のために特徴の類似性に依存する MrSteve などの以前の研究とは異なり、WISE は視点の変更下での堅牢な想起を可能にし、因果推論による日和見的なタスクの並べ替えをサポートします。この記憶に基づいて、因果関係のある機会が検出されたときにサブタスクの優先順位を動的に再設定する日和見的タスク スケジューラを提案します。さらに、下流の推論のための空間的に包括的な観察を提供するために、マルチスケールの漸進的探査戦略をWISEに装備します。実験によると、特に適応的な意思決定が必要な設定において、WISE は長期にわたるまばらなタスクでのタスクの成功と効率を大幅に向上させます。
原文 (English)
WISE: A Long-Horizon Agent in Minecraft with Why-Which Reasoning
Rapid advances have been made in developing general-purpose embodied agent in environments like Minecraft through the adoption of LLM-augmented hierarchical approaches. Despite their promise, low-level controllers often become performance bottlenecks due to repeated execution failures. We argue that a key limitation is not only the lack of episodic memory, but also the decoupling of \textit{what-where-when} memory from \textit{which-why} reasoning. To address this, we propose \textbf{WISE} (Which-Why Informed Semantic Explorer), a long-horizon agent framework with an enhanced low-level controller equipped with a Causal Event Graph that augments episodic memory with explicit causal structure linking observations to task relevance. Unlike prior work such as MrSteve, which relies on feature similarity for retrieval, WISE enables robust recall under viewpoint changes and supports opportunistic task reordering through causal reasoning. Building on this memory, we propose an Opportunistic Task Scheduler that dynamically re-prioritizes subtasks when causally relevant opportunities are detected. We further equip WISE with a multi-scale progressive exploration strategy to provide spatially comprehensive observations for downstream reasoning. Experiments show that WISE largely improves task success and efficiency on long-horizon sparse tasks, particularly in settings requiring adaptive decision-making.
DailyReport: 日々の検索タスクで検索エージェントを評価するための無制限のベンチマーク
検索エージェント (SA) は通常、大規模言語モデル (LLM) を活用して、Web ソースを自律的に探索し、情報を総合的な応答に合成することで、複雑な情報探索タスクをサポートします。 SA の評価では、これまでのベンチマークは主に、現実のユーザー シナリオでは発生する可能性が低い特殊なタスクに焦点を当てていました。さらに、大まかなタスクレベルのルーブリックに依存しているため、評価の解釈可能性が制限されることがよくあります。このギャップを埋めるために、毎日の検索タスクで SA 機能を評価するためのオープンエンドのベンチマークである DailyReport を導入します。これには、3,546 の関連ルーブリックを含む 150 の自由形式のタスクが含まれており、現実世界のユーザーの広く議論されているタイムリーな情報需要を捉えています。各タスクはサブタスクに分解され、解きほぐされた次元にわたるカスケード ルーブリックを使用して評価されます。カスケード パフォーマンス アトリビューションとユーザー中心の集計を通じて、ユーザーの好みのスコアとともに、各次元の高度に解釈可能なスコアを導き出します。 17 のエージェント システムに関する私たちの結果は、現在のシステムが依然としてユーザーの期待を下回っていることを示しています。将来の研究を促進するために、私たちのデータセットとコードは https://github.com/AGI-Eval-Official/DailyReport で公開されています。
原文 (English)
DailyReport: An Open-ended Benchmark for Evaluating Search Agents on Daily Search Tasks
Search Agents (SAs) typically leverage large language models (LLMs) to support complex information-seeking tasks by autonomously exploring web sources and synthesizing information into comprehensive responses. For SAs evaluation, prior benchmarks mainly focus on specialized tasks that are unlikely to arise in real-world user scenarios. Moreover, their reliance on coarse task-level rubrics often limits evaluation interpretability. To bridge this gap, we introduce DailyReport, an open-ended benchmark to evaluate SA capabilities on daily search tasks. It contains 150 open-ended tasks with 3,546 associated rubrics, capturing widely discussed and timely information demands of real-world users. Each task is decomposed into subtasks and evaluated with cascade rubrics across disentangled dimensions. Through cascade performance attribution and user-centric aggregation, we derive highly interpretable scores for each dimension, along with a user preference score. Our results on 17 agentic systems show that current systems still fall short of users' expectations. To facilitate future research, our dataset and code are made publicly available at https://github.com/AGI-Eval-Official/DailyReport.
HarnessBridge: LLM エージェント ハーネス用の学習可能な双方向コントローラー
大規模な言語モデルは、長期にわたるタスクのエージェントとして導入されることが増えていますが、そのパフォーマンスは、モデルの機能と環境設計だけでなく、エージェントと環境の相互作用を仲介するハーネスによっても決まります。既存のハーネスは大部分が手動で設計されているため、軌道が長くなり、相互作用がより複雑になるにつれて、拡張することが困難になります。この研究では、エンドツーエンド方式でトレーニングできる学習可能なプラグイン モジュールによってハーネスを生成できるかどうかを検討します。エージェント環境インターフェイスを双方向投影としてパラメータ化する軽量の学習可能なハーネス コントローラーである HarnessBridge を紹介します。 HarnessBridge は 2 つの双方向投影を学習します。1 つは生の軌道をコンパクトな意思決定関連の状態に抽出する観察投影で、もう 1 つは提案されたアクションを実行可能な遷移または軌道に基づいた拒否に変換するアクション投影です。統一された命令調整を通じてハーネス監視データセット上で HarnessBridge をトレーニングします。 Terminal-Bench~2.0 および SWE-bench Verified では、HarnessBridge は、トークンの使用量と軌道の長さを大幅に削減しながら、強力な専用ハーネスと同等またはそれを上回り、小型の発電機から大型の商用モデルまで汎用化します。
原文 (English)
HarnessBridge: Learnable Bidirectional Controller for LLM Agent Harness
Large language models are increasingly deployed as agents for long-horizon tasks, yet their performance is shaped not only by model capability and environment design, but also by the harness that mediates agent--environment interaction. Existing harnesses are largely manually engineered, making them difficult to scale as trajectories grow longer and interactions become more complex. In this work, we ask whether harness can be generated by a learnable plug-in module that can be trained in an end-to-end fashion. We introduce HarnessBridge, a lightweight learnable harness controller that parameterizes the agent--environment interface as a bidirectional projection. HarnessBridge learns two bidirectional projections: observation projection, which distills raw trajectories into compact, decision-relevant states, and action projection, which converts proposed actions into executable transitions or trajectory-grounded rejections. We train HarnessBridge on a harness supervision dataset via unified instruction tuning. On Terminal-Bench~2.0 and SWE-bench Verified, HarnessBridge matches or surpasses strong specialized harnesses while substantially reducing token usage and trajectory length, and generalizes from smaller generators to larger commercial models.
LoRA 最適化におけるスケーリング係数の秘められた力
低ランク適応 (LoRA) では、スケーリング係数 $\alpha$ は学習率を単に補うものとして扱われることがよくありますが、最適化におけるその役割はまだ十分に理解されていません。この論文では、スケーリング係数 $\alpha$ と学習率が異なる働きをし、$\alpha$ が効果的な最適化の主要な推進力として浮上し、学習率スケーリングだけでは再現できない利益をもたらすことを明らかにします。広範な実証分析と理論的なシグナル ドリフト フレームワークの相乗効果を通じて、LoRA のスケーリング メカニズムに関する 3 つの発見を明らかにしました。 まず、LoRA のスペクトル抑制により最適化の状況が平滑化され、標準のハイパーパラメーターが過度に保守的になり、最適化のギャップが生じます。第 2 に、この滑らかさを利用して収束を加速すると、$\alpha$ はドリフト比を増加させることなくタスク信号を増幅することで学習率を上回ります。第三に、最適なスケーリング係数はランクとの非線形関係に従います。これは、予想外に大きな係数を持つ平方根の法則によってよく特徴付けられ、既存のランクに関連付けられたヒューリスティックのスケーリングが不十分であることを明らかにしています。これらの洞察に基づいて、私たちは $\alpha$ を原則に基づいた体制に戻し、LoRA を標準的な小規模学習率と互換性のある最小限のフレームワークである LoRA-$\alpha$ を提案します。さまざまなタスクにわたる広範な評価により、LoRA-$\alpha$ がハイパーパラメータ検索を合理化しながらパフォーマンスを一貫して向上させ、LoRA の学習の可能性を解き放つことが実証されました。
原文 (English)
The Hidden Power of Scaling Factor in LoRA Optimization
In Low-Rank Adaptation (LoRA), the scaling factor $\alpha$ is often treated as a mere complement to the learning rate, yet its role in optimization remains poorly understood. In this paper, we reveal that the scaling factor $\alpha$ and the learning rate function differently, with $\alpha$ emerging as the dominant driver of effective optimization, delivering gains that cannot be replicated by learning rate scaling alone. Through the synergy of extensive empirical analysis and a theoretical Signal-Drift framework, we uncover three findings into LoRA's scaling mechanism: First, LoRA's spectral suppression smooths the optimization landscape, rendering standard hyperparameters overly conservative and creating an optimization gap. Second, when leveraging this smoothness to accelerate convergence, $\alpha$ outperforms the learning rate by amplifying the task signal without increasing the drift ratio. Third, the optimal scaling factor follows a sublinear relationship with the rank, well characterized by a square-root law with an unexpectedly large coefficient, revealing the insufficient scaling of existing rank-tied heuristics. Based on these insights, we propose LoRA-$\alpha$, a minimalist framework that restores $\alpha$ to its principled regime, making LoRA compatible with standard small learning rates. Extensive evaluations across diverse tasks demonstrate that LoRA-$\alpha$ consistently improves performance while streamlining hyperparameter search, unleashing the learning potential of LoRA.
人間のような基準によるプローブによるゼロソース LLM 幻覚検出
大規模言語モデル (LLM) は、事実に誤りがあるコンテンツや不誠実なコンテンツを生成することで幻覚を起こすことが多く、安全な使用に重大なリスクをもたらします。このような幻覚の検出は、モデルの内部参照も外部参照も利用できないゼロソース制約下では特に困難であり、検出はテキストのクエリと回答のペアのみに依存する必要があります。この論文では、人間の評価者の多面的な推論をエミュレートするパラダイムである、幻覚検出のための人間のような基準プローブ (HCPD) を提案します。その核心は、人間のような基準プローブ (HCP) メカニズムであり、LLM エージェントがその判断を解釈可能な重み付けされた基準のセットに適応的に分解し、基準固有のスコアを最終的な真実性の尺度に集約します。この適応能力を達成するために、意味的一貫性からの弱い監視のみを使用する報酬ベースの調整スキームを導入します。推論時には、マルチサンプリング集計戦略を採用して、完全な解釈可能性を維持しながら堅牢な決定を保証します。さらに、アプローチの信頼性を裏付ける理論的分析も提供します。広範な実験により、HCPD は常に最先端のベースラインを上回り、ゼロソース幻覚検出のための効果的で説明可能なソリューションを提供することが示されています。コードは https://github.com/TRISKEL10N/HCPD で入手できます。
原文 (English)
Zero-source LLM Hallucination Detection with Human-like Criteria Probing
Large language models (LLMs) often hallucinate by generating factually incorrect or unfaithful content, posing significant risks to their safe use. Detecting such hallucinations is particularly challenging under the zero-source constraint, where no model internals or external references are available, and detection must rely solely on the textual query-answer pair. In this paper, we propose Human-like Criteria Probing for Hallucination Detection (HCPD), a paradigm that emulates the multi-faceted reasoning of human evaluators. Its core is a Human-like Criteria Probing (HCP) mechanism, in which a LLM agent adaptively decomposes its judgment into a weighted set of interpretable criteria and aggregates criterion-specific scores into a final truthfulness measure. To achieve this adaptive capability, we introduce a reward-based alignment scheme using only weak supervision from semantic consistency. At inference, we employ a multi-sampling aggregation strategy to ensure robust decisions while preserving full interpretability. We further provide theoretical analysis supporting the reliability of our approach. Extensive experiments show that HCPD consistently outperforms state-of-the-art baselines, offering an effective and explainable solution for zero-source hallucination detection. Code is available at https://github.com/TRISKEL10N/HCPD.
MDForge: スパースシミュレータフィードバックの下でのエージェント的分子動力学パイプライン設計
分子動力学 (MD) は、原子分子科学の標準的なインシリコ手法であり、第一原理物理学から分子の挙動をシミュレートします。新しいシステム用の MD パイプラインを設計するには、かなりの専門知識が必要です。1 分子に対して実行するだけでも費用がかかり、試行錯誤が必要なくなります。私たちは、LLM エージェントを使用して、この専門的なパイプライン設計プロセスを自動化します。事前定義されたツールセットを調整する既存の MD エージェントとは異なり、私たちはパイプライン設計を、エージェントの行動が言葉による報酬によってオンラインで再形成されるオープンエンドのコード生成として扱います。具体的には、物理学の専門家間のマルチエージェントの議論を通じて、コンテキスト更新ルールがまばらな報酬を高密度化する LLM エージェントである MDForge を構築します。 3 つの SAMPL ホスト-ゲスト結合フリー エネルギー ベンチマークに基づいて、MDForge は人間の専門家と競合する MD パイプラインを自動的に設計します。未知の候補ゲストのライブラリに展開された CB[7] パイプラインは、ウェットラボ競合 NMR によって高親和性のピコモル CB[7] バインダーであることが確認された新規バインダーを発見します。データとコードは https://github.com/Zehong-Wang/MDForge で入手できます。
原文 (English)
MDForge: Agentic Molecular Dynamics Pipeline Design under Sparse Simulator Feedback
Molecular dynamics (MD) is the canonical in-silico method for atomistic molecular science, simulating molecular behavior from first-principle physics. Designing an MD pipeline for a new system requires substantial expert knowledge: running it on even one molecule is expensive, ruling out trial-and-error. We automate this expert pipeline-design process with an LLM agent. Unlike existing MD agents that orchestrate a predefined tool set, we treat pipeline design as open-ended code generation in which the agent's behavior is reshaped online by verbal reward. Specifically, we build MDForge, an LLM agent whose in-context update rule densifies the sparse reward via a multi-agent debate among physics experts. On three SAMPL host-guest binding free-energy benchmarks, MDForge automatically designs MD pipelines competitive with human experts. Deployed on a library of unseen candidate guests, its CB[7] pipeline discovers a novel binder that wet-lab competition NMR confirms is a high-affinity, picomolar CB[7] binder. Our data and code are available at https://github.com/Zehong-Wang/MDForge.
より良い検索に向けた反復: 電子商取引におけるエージェント検索アーキテクチャを評価するための 2 エージェント シミュレーション フレームワーク
会話型ショッピング アシスタント アーキテクチャを評価するためのモジュール式 2 エージェント シミュレーション フレームワークを紹介します。ペルソナ、ミッション、忍耐レベルで構成された独立したバイヤー エージェントは、実際の e コマース検索 API と統合された交換可能なレスポンダーとペアになっています。実験全体でバイヤーを一定に保つことで、同一のシナリオでのレスポンダー設計の制御された比較が可能になります。 14 のペルソナ バケットにわたる 2011 年の会話を使用して、4 つの経験的発見を確立しました。まず、ローリング ウィンドウ メモリは、すべての品質指標においてインテント抽出メモリよりも優れており、クエリあたり 35% 高速です。 2 番目に、証拠に基づいた迅速な反復を示す、レスポンダー バージョンの系統的な障害分析により、データセット全体で障害および障害に近い割合を 62% 削減する対象を絞った修正が可能になります。 3 番目に、レスポンダー LLM バックボーンを Gemini~2.5 から Llama~3.3~70B に交換すると、アーキテクチャが同一であるにもかかわらず、0.16 ~ 0.45 ポイントのコストがかかります。最後に、フロンティア LLM 審査員間の体系的な哲学的不一致を文書化します。同じ評価プロンプトを使用しているにもかかわらず、ジェミニはプロセスの正しさを賞賛するのに対し、クロードは具体的な結果を要求します。
原文 (English)
Iterating Toward Better Search: A Two-Agent Simulation Framework for Evaluating Agentic Search Architectures in E-Commerce
We present a modular two-agent simulation framework for evaluating conversational shopping assistant architectures. An independent buyer agent, configured with personas, missions, and patience levels, is paired with an interchangeable responder that integrates with a real e-commerce search API. Holding the buyer constant across experiments enables controlled comparison of responder designs on identical scenarios. Using 2011 conversations across 14 persona buckets, we establish four empirical findings. First, rolling-window memory outperforms intent-extraction memory on all quality metrics while being 35% faster per query. Second, illustrating rapid evidence-driven iteration, a systematic failure analysis of a responder version enables targeted fixes that reduce failure and near-failure rates by 62% across the full dataset. Third, swapping the responder LLM backbone from Gemini~2.5 to Llama~3.3~70B costs 0.16--0.45 points despite identical architecture. Finally, we document systematic philosophical disagreement between frontier LLM judges: Gemini rewards process correctness while Claude demands concrete outcomes, despite using the same evaluation prompt.
MARS: 並列 LLM テスト時間スケーリングのためのマージン・アドバーサリアル・リスク制御ストップ
並列テスト時間スケーリングでは、多くの推論トレースをサンプリングし、その回答を多数決で投票することにより、LLM の精度が向上しますが、完了までトレースを実行する必要があるため、かなりの計算オーバーヘッドが発生します。中間チェックポイントで部分的なトレースを調査すると、生成を中断することなく現在の回答を抽出でき、進化する集計投票が明らかになることを観察します。この観察に基づいて、どのアクティブトレースが回答を変更する可能性が高いかを推定し、将来の投票の動きに対する保守的な制約の下でリーダーが安全を保った時点で停止する、マージン敵対的な停止ルールである MARS を導入します。このルールは 2 つの不確実性の原因を分離します。これは、現在のマージンがどれだけ保持される可能性が高いかを決定するトレースレベルのスイッチ確率を学習し、ウォームアップ トレースから調整された敵対的境界を介してスイッチング トレースがどこに到達するかというより難しい問題を処理します。真の切り替え確率により、MARS は、早期に停止された回答が予算全体の投票と一致することを高い確率で保証します。実際には、5 つの特徴を持つロジスティック モデルは、Oracle のスイッチング動作とよく一致します。 3 つの推論モデルと 3 つの競争数学ベンチマークにわたって、MARS は自己整合性トークンを 25 ~ 47% 節約し、DeepConf Online に比べて 14 ~ 29% を節約します。DeepConf Online は、弱いトレースをすでにフィルタリングして切り捨てている強力な信頼度加重ベースラインであり、対応する全予算ベースラインの精度と一致します。
原文 (English)
MARS: Margin-Adversarial Risk-controlled Stopping for Parallel LLM Test-time Scaling
Parallel test-time scaling samples many reasoning traces and majority-votes their answers, improving LLM accuracy but requiring traces to run to completion, incurring substantial computational overhead. We observe that probing partial traces at intermediate checkpoints can extract current answers without disrupting generation, revealing an evolving aggregate vote. Based on this observation, we introduce MARS, a margin-adversarial stopping rule that estimates which active traces are likely to change their answers and stops once the leader remains safe under a conservative bound on future vote movement. The rule separates two sources of uncertainty. It learns the trace-level switch probabilities that determine how much of the current margin is likely to be retained, while handling the harder question of where switching traces land through an adversarial bound calibrated from warmup traces. With true switch probabilities, MARS guarantees with high probability that the early-stopped answer matches the full-budget vote. In practice, a five-feature logistic model closely matches oracle switching behavior. Across three reasoning models and three competition-math benchmarks, MARS saves 25-47% of self-consistency tokens and 14-29% on top of DeepConf Online, a strong confidence-weighted baseline that already filters and truncates weak traces, while matching the accuracy of the corresponding full-budget baselines.
PRISMR: パラメータ化された表現の内部化によるマルチモーダル リストワイズ ランキングにおける解析崩壊の克服
大規模マルチモーダル モデル (LMM) を使用した生成リストごとのランキングは、単一のフォワード パスでグローバル リスト コンテキストをキャプチャすることを目的としていますが、コンテキストが長いマルチモーダル シナリオではその有効性が低下します。私たちは、自己回帰デコーダーが候補を黙って除外し、早期に終了することによって、流暢ではあるが不完全なランキングを生成する、反復的な障害モードである解析崩壊を特定します。この障害は、単純なフォーマットの間違いではなく、コンテキストの利用が制限されていることが原因であり、迅速なエンジニアリングと制限されたデコードが不十分になっています。我々は、一時的なコンテキスト内リスト処理をパラメトリック構造条件付けに置き換えるフレームワークである PRISMR (Parameterized Representation Internalization for Semantic Multimodal Ranking) を提案します。 PRISMR は、軽量のハイパーネットワークを使用して、マルチモーダル候補を並行してエンコードし、アイテム固有の LoRA 重みを生成します。これらの重みは、LMM のインスタンス固有のアダプターに合成されます。このパラダイムにより、基本モデルを維持しながら、リスト構造のより堅牢な内部化が可能になります。さらに、評価のための大規模なマルチモーダル レビュー ランキング ベンチマークを導入します。実験では、PRISMR が解析の崩壊を大幅に軽減し、リストごとのランキングのパフォーマンスを向上させ、ドメインおよび命令調整されたバックボーン間で効果的に転送することを実証しています。
原文 (English)
PRISMR: Overcoming Parse Collapse in Multimodal Listwise Ranking via Parameterized Representation Internalization
Generative listwise ranking with Large Multimodal Models (LMMs) aims to capture global list context in a single forward pass, but its effectiveness degrades in long-context multimodal scenarios. We identify a recurring failure mode, parse collapse, where the autoregressive decoder produces fluent yet incomplete rankings by silently omitting candidates and terminating early. This failure stems from limited context utilization rather than simple formatting mistakes, making prompt engineering and constrained decoding insufficient. We propose PRISMR (Parameterized Representation Internalization for Semantic Multimodal Ranking), a framework that replaces transient in-context list processing with parametric structural conditioning. PRISMR uses a lightweight hypernetwork to encode multimodal candidates in parallel and generate item-specific LoRA weights, which are synthesized into an instance-specific adapter for a LMM. This paradigm enables more robust internalization of list structure while preserving the base model. We further introduce a large-scale multimodal review-ranking benchmark for evaluation. Experiments demonstrate that PRISMR substantially reduces parse collapse, improves listwise ranking performance, and transfers effectively across domains and instruction-tuned backbones.
何を覚えるべきかを学ぶ: エージェント的記憶のための認知的に根拠のある多要素価値モデル
長時間実行される LLM エージェントは、どのコンテキスト ウィンドウよりもはるかに大きなインタラクション履歴を蓄積し、固定のメモリ バジェットの下で何を深くエンコードするか、何を忘れるか、何を取得するかという継続的な決定を迫られます。運用システムは、セマンティックな類似性または最新性で応答します。どちらも、将来のクエリが判明する前に統合時に行われる、忘れられた決定に対して誤って指定されます。我々は、認知心理学から導かれた7つの解釈可能な因子(感情の強さ、目標の関連性、価値観の一致、自己/ユーザーの関連性、タスクの有用性、信頼性、使用履歴)にわたる多因子記憶値関数 V(m)=\sum_i w_i f_i(m) を提案します。その重みは勾配なしのオプティマイザーによって下流の目標から学習され、その単一のスカラーがエンコードの深さ、忘却リスク、および取得ランクを均一に制御します。 LongMemEval では、提示された評価質問に対する目標の関連性をスコアリングすると、ゴールド証拠の保持率が約 0.98 で飽和します。これは、忘れるのではなく、検索を測定します。現実的なブラインド方式では、学習された多要素値は、479 件の使用可能なケースにわたって 0.770 \pm 0.011 のゴールド証拠を保持します。これに対し、均一の重み付けの場合は 0.657、最良の単一要素の場合は 0.518、最新の場合は 0.368 です。すべてのペアのギャップの 95% ブートストラップ CI はゼロより大きく、同じ因子上のニューラル ネットワークが線形モデルを結び付けます。学習された重みは解釈可能です。信頼性、感情の激しさ、自己/ユーザーの関連性が支配的ですが、クエリ時の目標の類似性は忘却の決定に合わせて正しく重み付けされます。植え付けられた交絡を伴う制御された合成タスクでは、均一な重み付けが失敗する (0.62) 場合、学習者が分離する重み付け (保持率 1.00) を回復することが確認されます。基板はオープンソースです。すべての実験は API 呼び出しなしで単一の CPU 上で実行されます。
原文 (English)
Learning What to Remember: A Cognitively Grounded Multi-Factor Value Model for Agentic Memory
Long-running LLM agents accumulate interaction histories far larger than any context window, forcing a standing decision: what to encode deeply, what to forget, and what to retrieve under a fixed memory budget. Production systems answer with semantic similarity or recency -- both mis-specified for the forgetting decision, which is made at consolidation time before the future query is known. We propose a multi-factor memory value function V(m)=\sum_i w_i f_i(m) over seven interpretable factors (emotional intensity, goal relevance, value alignment, self/user relevance, task utility, reliability, and usage history) drawn from cognitive psychology, whose weights are learned from a downstream objective by a gradient-free optimiser, and whose single scalar uniformly controls encoding depth, forget risk, and retrieval rank. We make a methodological point: on LongMemEval, scoring goal relevance against the held-out evaluation question saturates gold-evidence retention at \approx 0.98 -- this measures retrieval, not forgetting. In the realistic blind regime, a learned multi-factor value retains 0.770 \pm 0.011 of gold evidence across 479 usable cases, versus 0.657 for uniform weights, 0.518 for the best single factor, and 0.368 for recency; every paired gap's 95% bootstrap CI is above zero, and a neural network over the same factors ties the linear model. The learned weights are interpretable -- reliability, emotional intensity, and self/user relevance dominate, while query-time goal similarity is correctly down-weighted for the forgetting decision. A controlled synthetic task with planted confounds confirms the learner recovers a separating weighting (1.00 retention) where uniform weighting fails (0.62). The substrate is open-source; all experiments run on a single CPU with no API calls.
OpenMedQ: 医療視覚言語モデルのための広範でオープンな事前トレーニング
我々は、これまでで最も広範な完全にオープンな医療ミックスで事前トレーニングされた医療視覚言語モデルである OpenMedQ を紹介します。病理学、放射線学、顕微鏡法、テキストのみの臨床 QA にわたる 14 のデータセット、合計約 335 万の事前トレーニング サンプルです。 OpenMedQ は PathVQA (75.9) で最先端の BLEU-1 に達し、最大 562B パラメーター (約 80 倍) で Med-PaLM M バリアントを上回り、最もよく報告されている VQA-MED BLEU-1 (64.5) に匹敵します。そのビジョン エンコーダーは、同一の下流レシピに基づいて 8 つの未確認の医療分類ベンチマークに転送され、BiomedCLIP (0.745)、PMC-CLIP (0.745)、PubMedCLIP (0.746)、およびゼロからのベースライン (0.616) の中で最も高い平均マクロ F1 (0.757) を取得します。私たちはコードをリリースし、コミュニティの再現可能なベースラインとしてインタラクティブなデモを公開します。
原文 (English)
OpenMedQ: Broad Open Pretraining for Medical Vision-Language Models
We present OpenMedQ, a medical vision-language model pretrained on the broadest fully-open medical mix to date: 14 datasets totaling ~3.35M pretraining samples spanning pathology, radiology, microscopy, and text-only clinical QA. OpenMedQ reaches state-of-the-art BLEU-1 on PathVQA (75.9), beating Med-PaLM M variants up to 562B parameters (~80x larger), and matches the best reported VQA-MED BLEU-1 (64.5). Its vision encoder, transferred to 8 unseen medical classification benchmarks under an identical downstream recipe, obtains the highest average macro-F1 (0.757) among BiomedCLIP (0.745), PMC-CLIP (0.745), PubMedCLIP (0.746), and a from-scratch baseline (0.616). We release our code and an interactive demo is publicly available as a reproducible baseline for the community.
配電欠陥検出のためのマルチモーダル エージェント: 基礎モデルの評価
配電ネットワークは信頼性の高い電力供給に不可欠ですが、従来の検査方法では意味の理解、一般化、閉ループの自動化において限界に直面しています。これらの課題に対処するために、この文書では、配電欠陥検出に特化したマルチモーダル エージェント フレームワークを提案します。この研究の中心となるのは、統合された認知エンジンとしてのマルチモーダル基盤モデルの体系的な評価です。当社は、次の 3 つの重要な機能にわたって統合されたパフォーマンスを厳密に評価します。(1) 認識。モデルは機器を正確に識別し、専門家レベルの欠陥の説明を生成する必要があります。 (2) 推論。モデルは視覚的な所見を解釈して原因を診断し、重大度を評価し、ドメイン知識に基づいてメンテナンス戦略を計画します。 (3) ツールの使用。モデルは自律的なオペレーターとして機能し、ナレッジ ベースのクエリや作業指示の生成などのアクションを実行して、クローズド ループ メンテナンスを実現します。この評価をサポートするために、ドメイン固有の評価データセットと包括的なベンチマークが開発されています。実験結果は、これら 3 つの側面における現在の基盤モデルの強みと限界を実証し、一か八かの産業環境に自律エージェントを導入するための経験的証拠を提供します。
原文 (English)
Multi-Modal Agents for Power Distribution Defect Detection: An Evaluation of Foundation Models
The power distribution network is critical to reliable electricity delivery, yet traditional inspection methods face limitations in semantic understanding, generalization, and closed-loop automation. To address these challenges, this paper proposes a Multi-Modal Agent framework specifically for power distribution defect detection. Central to this study is the systematic evaluation of multimodal foundation models as unified cognitive engines. We rigorously assess their integrated performance across three critical capabilities: (1) Perception, where the model must accurately identify equipment and generate expert-level descriptions of defects; (2) Reasoning, where the model interprets visual findings to diagnose causes, assess severity, and plan maintenance strategies based on domain knowledge; and (3) Tool Usage, where the model acts as an autonomous operator to execute actions -- such as querying knowledge bases or generating work orders -- to achieve closed-loop maintenance. To support this evaluation, a domain-specific evaluation dataset and a comprehensive benchmark are developed. Experimental results demonstrate the strengths and limitations of current foundation models in these three dimensions, providing empirical evidence for deploying autonomous agents in high-stakes industrial environments.
共同的な問題解決と AI 推論のためのデータセット生成のための数学フォーラム プラットフォーム
オンライン フォーラムで数学コンテンツを共有することは、依然として学生や教育者にとって大きな摩擦点です。生の LATEX を記述するとエラーが発生しやすく、スタンドアロンの光学式文字認識ツールではプラットフォームの切り替えが必要で、現在のフォーラム ソフトウェアには数式の写真からレンダリングされた投稿までの統合されたパスがありません。私たちは、画像から LATEX への変換パイプラインをフォーラム投稿インターフェイス内に直接埋め込むことで、この摩擦を排除する統合システムを提供します。ユーザーは数式の画像をアップロードまたはキャプチャします。システムは、Mathpix OCR API を介してそれをルーティングし、返された出力が LATEX であるかインライン数学を含むプレーン テキストであるかを検出し、適切な区切り文字正規化を適用して、投稿がデータベースにコミットされる前に LATEX または Markdown モードでライブ プレビューをレンダリングします。このアーキテクチャは、画像処理、レンダリング、ストレージという 3 つの疎結合レイヤーで構成されており、デスクトップ クライアントとモバイル クライアントの両方をサポートします。コアメソッドをカバーする米国仮特許出願が提出されています。私たちは完全なシステム設計、各コンポーネントの詳細、データ スキーマ、主要な技術革新について説明し、既存のスタンドアロン ツールやフォーラム プラットフォームと比較してこの取り組みを位置付け、実際的なギャップを埋めることを実証します。私たちは、この種の導入されたプラットフォームは、継続的に成長し、コミュニティによって検証された数学的問題と段階的な解決策のデータセットを構成し、正確な数学的推論のための AI システムのトレーニングとベンチマークに使用できるリソースであると主張します。
原文 (English)
A Mathematical Forum Platform for Collaborative Problem Solving and Dataset Generation for AI Reasoning
Sharing mathematical content in online forums remains a significant friction point for students and educators: writing raw LATEX is error-prone, standalone optical character recognition tools require platform switching, and current forum software offers no integrated path from a photograph of a formula to a rendered post. We present a unified system that eliminates this friction by embedding an image to LATEX conversion pipeline directly inside a forum posting interface. A user uploads or captures an image of a mathematical expression; the system routes it through the Mathpix OCR API, detects whether the returned output is LATEX or plain text containing inline math, applies the appropriate delimiter normalisation, and renders a live preview in either LATEX or Markdown mode before the post is committed to the database. The architecture is organized in three loosely coupled layers: image processing, rendering, and storage, and supports both desktop and mobile clients. A provisional US patent application has been filed covering the core methods. We describe the full system design, each component in detail, the data schema, and the key technical innovations, and we position the work against existing standalone tools and forum platforms to demonstrate the practical gap it closes. Beyond immediate usability, we argue that a deployed platform of this kind constitutes a continuously growing, community-validated dataset of mathematical problems and step-by-step solutions, a resource that can be used to train and benchmark AI systems for accurate mathematical reasoning
LLM 駆動の HDL 設計および検証指向のデータキュレーションのための構造化テストベンチの生成
テストベンチの自動生成は、多数の候補デザインを迅速かつ確実に検証する必要がある大規模言語モデル (LLM) ベースのレジスタ転送レベル (RTL) ワークフローにおいて、重大なボトルネックになっています。既存のプロンプトベースのアプローチは、テストベンチの生成を制約のないコード合成として扱い、トークンコストが高く、再現性が低く、カバレッジが不十分な確率的な出力を生成します。このギャップに対処するために、ハードウェア設計の固有の構造を利用して決定論的なテストベンチを生成する構造化テストベンチ生成フレームワークである STG を紹介します。直接検証ツールとして、STG は反復的な LLM ベースのテストベンチ生成フローよりも 720 倍高速に実行され、コンパイル成功率が高く、より高いカバレッジを達成し、不正な DUT に対する誤合格判定を減らします。 STG は、欠陥のあるベンチマーク テストベンチを公開することで、RTL 生成ベンチマークのエラーを特定するのにも役立ちます。データ キュレーション エンジンとして、単一の CPU コアでの LLM ベースのフィルタリングよりも 11 倍高速であり、エネルギーは 127 分の 1 であり、結果として得られる抽出されたモデルは、マルチベンチマーク評価で最先端のパフォーマンスを提供します。テスト時のスケーリング オラクルとして、ノード数を 14 ~ 47\% 削減します。当社のモデルは https://huggingface.co/collections/AS-SiliconMind/siliconmind-v12 で入手できます。
原文 (English)
Structured Testbench Generation for LLM-Driven HDL Design and Verification-Oriented Data Curation
Automated testbench generation has become a critical bottleneck in large language model (LLM)-driven Register Transfer Level (RTL) workflows, where large numbers of candidate designs must be verified rapidly and reliably. Existing prompt-based approaches treat testbench generation as unconstrained code synthesis, yielding stochastic outputs with high token cost, low reproducibility, and insufficient coverage. To address this gap, we present STG, a Structured Testbench Generation framework that exploits the inherent structure of hardware designs to generate deterministic testbenches. As a direct verification tool, STG runs 720x faster than an iterative LLM-based testbench generation flow and higher rate of successful compilation, achieves higher coverage, and reduces false-pass verdicts on incorrect DUTs. STG also helps identify errors in RTL generation benchmarks by exposing faulty benchmark testbenches. As a data curation engine, it is 11x faster than LLM-based filtering on a single CPU core with 127x less energy, and the resulting distilled models provide state-of-the-art performance in our multi-benchmark evaluation. As a test-time scaling oracle, it reduces node count by 14-47\%. Our models are available at https://huggingface.co/collections/AS-SiliconMind/siliconmind-v12.
APCyc: 自動環化による環状ペプチドの特性に基づいた設計
環状ペプチドは、現代の創薬において有望な治療用化合物の代表例であり、多くの場合安定性と結合親和性が向上します。しかし、環状ペプチドの新規設計は依然として困難なままである。なぜなら、方法はポケット適応性の環化パターンと結合部位を同定し、同時に薬物関連特性を制御しなければならないからである。この課題は、主に線形ペプチド データに基づいてトレーニングされた最近の生成モデルで特に顕著であり、環化固有の制約を捕捉できない可能性があります。この制限に対処するために、環化を明示的にモデル化し、複数の必須物理化学的特性を共同で最適化するターゲット認識型の新規環状ペプチド生成フレームワークである APCyc を導入します。拡張された残基語彙を使用し、環化部位と結合タイプの情報を明示的にエンコードすることにより、APCyc は環化を認識した表現を学習し、ベイジアン事後ガイダンスを活用して、複数の特性目的を満たす環状ペプチドに向けてサンプリングを誘導します。実験結果は、私たちのモデルがターゲット依存の環化の好みを学習し、環状ペプチド設計の効果的かつ制御可能な複数プロパティの最適化を可能にすることを示しています。この論文のソース コードは https://github.com/HKUSTGZ-ML4Health-Lab/APCyc で入手できます。
原文 (English)
APCyc: Property-Informed Design of Cyclic Peptides via Automated Cyclization
Cyclic peptides represent a promising class of therapeutic compounds in modern drug discovery, often offering improved stability and binding affinity. However, the de novo design of cyclic peptides remains challenging because methods must identify pocket-adaptive cyclization patterns and linkage sites while simultaneously controlling drug-relevant properties. This challenge is particularly pronounced for recent generative models trained predominantly on linear peptide data, which may fail to capture cyclization-specific constraints. To address the limitation, we introduce APCyc, a target-aware de novo cyclic peptide generation framework that explicitly models cyclization and jointly optimizes multiple essential physicochemical properties. By using an expanded residue vocabulary and explicitly encoding cyclization-site and linkage-type information, APCyc learns cyclization-aware representations and leverages Bayesian posterior guidance to steer sampling toward cyclic peptides satisfying multiple property objectives. Experimental results demonstrate that our model learns target-dependent cyclization preferences, and enables effective and controllable multi-property optimization for cyclic peptide design. The source code of this paper is available at https://github.com/HKUSTGZ-ML4Health-Lab/APCyc.
マルチエージェントの優位性の幻想
一般的な通念では、コンテキスト保護、並列処理、分散意思決定などの利点を挙げて、マルチエージェント システム (MAS) がシングル エージェント システム (SAS) よりも優れていると考えられています。ただし、この主張の経験的な裏付けは主に、孤立した推論タスクを優先するベンチマークを使用した SAS ベースラインとの比較に依存しており、これらの利点は適切に評価されていません。手動で設計された対応物よりも一般化性が強化されるように設計された自動生成された MAS に焦点を当て、SAS、特に自己一貫性を備えた思考連鎖 (CoT-SC) に対して厳密で体系的な評価を実行します。インタラクティブなマルチステップ ワークフロー (BrowseComp-Plus など) を使用した従来の推論データセットとタスク全体にわたって、自動 MAS は最大 10 倍高価であるにもかかわらず、一貫して CoT-SC を下回るパフォーマンスを示します。これらの障害をタスク構造に固有の制限から分離するために、明示的なタスク分解、コンテキスト分離、および並列化の可能性を特徴とする MAS 向けに調整された診断合成データセットを導入します。このデータセットでは、専門家によって設計された MAS が、生のパフォーマンスとコスト効率の両方において、自動生成されたアーキテクチャよりも一貫して優れていることを示し、既存の評価フレームワークが、計算コストの増加による限界効用を考慮していないため、複雑な MAS の重大なアーキテクチャ上のギャップと非効率性を覆い隠していることを示しています。重要なことに、生成された MAS アーキテクチャを体系的に分解すると、現在の自動化設計パラダイムが、機能的な実用性に変換されない表面的な複雑さを優先するアーキテクチャの肥大化を生み出し、マルチエージェントの原則との根本的な不整合を明らかにしていることが明らかになります。
原文 (English)
The Illusion of Multi-Agent Advantage
Prevailing wisdom posits that Multi-Agent Systems (MAS) are superior to Single-Agent Systems (SAS), citing advantages like context protection, parallel processing and distributed decision-making. However, empirical support for this claim relies primarily on comparisons with SAS baselines using benchmarks that prioritize isolated reasoning tasks, which do not adequately assess these advantages. Focusing on automatically generated MAS that are designed for enhanced generalizability over manually-designed counterparts, we perform a rigorous, systematic evaluation against SAS, specifically Chain-of-Thought with Self-Consistency (CoT-SC). Across traditional reasoning datasets and tasks with interactive multi-step workflows (e.g., BrowseComp-Plus), we demonstrate that automatic MAS consistently underperform CoT-SC despite being up to 10x more expensive. To isolate these failures from limitations inherent to task structure, we introduce a diagnostic synthetic dataset tailored for MAS featuring explicit task decomposition, context separation and parallelization potential. We show that expert-architected MAS consistently outperforms automatically generated architectures in both raw performance and cost-efficiency on this dataset, demonstrating that existing evaluation frameworks mask critical architectural gaps and inefficiencies of complex MAS by failing to account for the marginal utility of increased computational cost. Critically, systematic deconstruction of the generated MAS architectures reveals that current automated design paradigms produce architectural bloat that prioritizes superficial complexity which does not translate into functional utility, exposing a fundamental misalignment with multi-agent principles.
Otters++: 最初のスパイクまでの時間ベースのエネルギー効率の高い光スパイクトランス
スパイク ニューラル ネットワーク (SNN) はエネルギー効率の高い推論に有望であり、各ニューロンが最大 1 回起動するため、最初のスパイクまでの時間 (TTFS) コーディングが特に魅力的です。ただし、実際には、この利点は、時間減衰項を計算し、それにシナプスの重みを乗算するコストによって減じられることがよくあります。私たちは、物理的なハードウェアの「バグ」、つまり光電子デバイスにおける自然な信号減衰を、Otters++ という名前の TTFS のメイン計算に組み込むことで、この問題に対処します。具体的には、カスタム In$_2$O$_3$ 光電子シナプスの測定された減衰を使用して、TTFS 時間項を直接実現し、明示的なデジタル減衰計算の必要性を排除します。このアイデアを Transformer モデルに拡張するために、Otters++ と量子化ニューラル ネットワーク (QNN) の間の層ごとの機能同等性を確立し、モデルの蒸留とともに、前方パスでデバイスに忠実な SNN 計算と、後方パスで同等の QNN パスを介した QNN ストレートスルー勾配を使用するハイブリッド トレーニング方法を開発します。これにより、離散的な最初のスパイク イベントによる差別化が回避され、直接 TTFS-SNN トレーニングにおける過疎性の問題が軽減されます。さらに、実行ごとの変動をサンプリングすることで測定されたデバイス ノイズをトレーニングで認識できるようにし、デバイス共有とマルチホップ通信を考慮してシステム レベルのエネルギー モデルを改良します。 GLUE データセットでは、Otters++ は平均スコアを 84.17\% に向上させながら、以前のスパイク Transformer ベースラインと比べて明らかなエネルギー上の利点を維持しました。これらの結果は、物理的に接地された TTFS コンピューティングが、現実的なハードウェア効果の下で効率的で、トレーニング可能で、堅牢である可能性があることを示しています。
原文 (English)
Otters++: A Time-to-first-spike Based Energy Efficient Optical Spiking Transformer
Spiking neural networks (SNNs) are promising for energy-efficient inference, and time-to-first-spike (TTFS) coding is especially attractive because each neuron fires at most once. In practice, however, this benefit is often reduced by the cost of computing a temporal decay term and multiplying it by the synaptic weight. We address this issue by turning a physical hardware "bug," the natural signal decay in optoelectronic devices, into the main computation of TTFS, named Otters++. Specifically, we use the measured decay of a custom In$_2$O$_3$ optoelectronic synapse to directly realize the TTFS temporal term, removing the need for explicit digital decay computation. To scale this idea to Transformer models, we establish a layer-wise functional equivalence between the Otters++ and a quantized neural network (QNN), and develop a hybrid training method that uses device-faithful SNN computation in the forward pass and QNN straight-through gradients through the equivalent QNN path in the backward pass, together with model distillation. This avoids differentiation through discrete first-spike events and reduces the over-sparsity problem in direct TTFS-SNN training. We further make training aware of measured device noise by sampling run-to-run variation, and refine the system-level energy model by accounting for device sharing and multi-hop communication. On GLUE dataset, Otters++ improves the average score to 84.17\% while maintaining a clear energy advantage over prior spiking Transformer baselines. These results show that physically grounded TTFS computing can be efficient, trainable, and robust under realistic hardware effects.
SciR: LLM における科学的推論のための制御可能なベンチマーク
科学的推論では、演繹、帰納、因果的アブダクションという 3 つの典型的な推論形式が繰り返されます。科学的な設定でこれらの LLM を確実に評価することは、現時点では手の届かないところにあります。人間の注釈に基づいて構築された科学ベンチマークはコストが高く、機械的なグラウンドトゥルースに欠けています。一方、合成論理推論ベンチマークは実際の科学文書に似ていません。 3 つの典型的な科学的問題に基づいて、マルチパラダイム推論と制御可能な科学的レンダリングを組み合わせたベンチマークである SciR を紹介します。タスクは、検証可能な答えを保証するために形式的なオブジェクト (演繹ツリー、帰納法仮説、因果グラフ) から生成され、トラックごとにドメイン調整されたジャンルを介して複数文書の科学的議論にレンダリングされます。この構造により、推論に必要な重要な情報を抽出するのがどれくらい難しいか、および原則に基づいた推論自体がどれだけ難しいかという 2 つの難易度の軸を独立して変化させることができます。 6 つのモデルをテストします。どちらの軸もすべてのモデルに悪影響を及ぼし、その影響は複合化します。このレンダリングは、推論を検証済みのソルバーに渡す神経記号パイプラインにも悪影響を及ぼします。 2 つの軸により、モデルごとの抽出対推論のプロファイルが得られます。たとえば、deepseek-r1 のような推論モデルは、ほとんどの場合、推論軸上の非推論命令モデルを上回ります。私たちの知る限り、SciR は、抽出と推論の両方の難易度をパラメトリックに制御する初のマルチパラダイム科学推論ベンチマークです。
原文 (English)
SciR: A Controllable Benchmark for Scientific Reasoning in LLMs
Three paradigmatic forms of inference recur across scientific reasoning: deduction, induction, and causal abduction. Reliably evaluating LLMs on these in scientific settings is currently out of reach: scientific benchmarks built on human annotations are costly and lack mechanistic ground truth, while synthetic logical-reasoning benchmarks do not resemble real scientific documents. We introduce SciR, a benchmark that combines multi-paradigm reasoning with controllable scientific rendering, anchored on three paradigmatic scientific problems. Tasks are generated from formal objects (deduction tree, inductive rule hypothesis, causal graph) to guarantee verifiable answers, then rendered into multi-document scientific discourse via per-track domain-tuned genres. The construction lets us independently vary two difficulty axes: how hard it is to extract the key information needed for inference, and how hard the principled inference itself is. We test six models. Both axes hurt every model, and their effects compound. The rendering even hurts neurosymbolic pipelines, which hand inference to a verified solver. The two axes yield a per-model extraction-vs-inference profile: for instance, reasoning models like deepseek-r1 mostly surpass non-reasoning instruct models on the inference axis. To our knowledge, SciR is the first multi-paradigm scientific-reasoning benchmark with parametric control on both extraction and inference difficulty.
ヌース: 予測市場の行動の背後にある認識を抽出して注入する試み
LLM エージェントが予測市場や集団的意思決定で急増するにつれて、認知的モノカルチャーのリスクが生じます。共有基盤モデルに基づいて構築されたエージェントは相関のある予測を生成し、最近の測定ではフロンティア モデルの誤差が r ~ 0.77 で相関していることがわかりました。私たちは、人間の認知的多様性を行動から回復し、LLM エージェントに伝達できるかどうかを尋ねます。 Nous は、実際の Polymarket 取引活動から構造化された 8 次元の行動プロファイルを抽出し、プロンプトを通じてエージェントにそれを注入します。私たちの中心的な発見は、パイプラインの 2 つの半分の間の分離です。抽出は部分的に機能します。100 個のウォレットにわたって、14 個のパラメーターのうち 8 個が一時的に安定しています (スプリットハーフ ICC >= 0.5、ブートストラップ CI 下限 > 0.3、逆張りスコアは ICC ~ 0.9 に達します)。ウォレットは、確率をはるかに上回るプロファイルから識別可能です (上位 1 の取得率は 17 ~ 22% 対 1% の確率)。そして、事前に指定された 4 つの次元のうち 2 つは、サンプル外の将来の実現利益と順位相関しますが、その相関関係は行動交絡制御には耐えられません。プロンプトレベルのインジェクションは、それを測定できるほど伝達しません。セマンティック埋め込みメトリクスに関して、構造化インジェクションは、どのモデルでも長さが一致したコントロールよりも大きな利点を示さず、それが誘発する多様性は、アンサンブル誤差相関を低下させず、ブリエスコアを改善しません。ヌルは、サンプリング温度、プロファイルの多様性、および質問の難易度に関する探索的チェック全体にわたって持続します。プロンプト自体を測定することで、モデルの前に圧縮を特定します。構造からナラティブへのトランスレータは、プロファイルの広がりを追跡しない、ほぼ均一なプロンプトを発行します。私たちはヌースを、認知モノカルチャーの問題とプロンプトレベルの治療法の限界を測定し、より深く、プロンプト未満の注入(微調整、活性化ステアリング)を動機付けるものとして位置づけています。コード、凍結されたプロファイル、プロンプト、モデル出力: https://github.com/WillChienT/nous-paper
原文 (English)
Nous: An Attempt to Extract and Inject the Cognition Behind Prediction-Market Behavior
As LLM agents proliferate in prediction markets and collective decision-making, they risk a cognitive monoculture: agents built on shared foundation models produce correlated forecasts, and recent measurement finds frontier-model errors correlated at r ~ 0.77. We ask whether human cognitive diversity can be recovered from behavior and transferred to LLM agents. Nous extracts a structured eight-dimension behavioral profile from real Polymarket trading activity and injects it into agents through prompts. Our central finding is a dissociation between the two halves of that pipeline. Extraction works, partially: across 100 wallets, 8 of 14 parameters are temporally stable (split-half ICC >= 0.5, bootstrap CI lower bound > 0.3; contrarian score reaches ICC ~ 0.9); wallets are identifiable from their profiles well above chance (top-1 retrieval 17-22% vs. 1% chance); and two of four pre-specified dimensions rank-correlate with future realized profit out-of-sample, though the correlations do not survive behavioral-confound controls. Prompt-level injection does not measurably transmit it: on a semantic embedding metric, structured injection shows no significant advantage over a length-matched control on any model, and the diversity it induces neither reduces ensemble error correlation nor improves Brier score -- a null that persists across exploratory checks on sampling temperature, profile diversity, and question difficulty. Measuring the prompts themselves locates the compression before the model: the structure-to-narrative translator emits near-uniform prompts whose spread does not track profile spread. We position Nous as measuring the cognitive-monoculture problem and the limits of a prompt-level remedy, motivating deeper, below-the-prompt injection (fine-tuning, activation steering). Code, frozen profiles, prompts, and model outputs: https://github.com/WillChienT/nous-paper
可視および熱スペクトル範囲におけるビデオ監視のための拡張技術
インテリジェントなビデオ監視では、カメラが昼夜を問わず一連の画像を記録します。通常、これにはさまざまなセンサーが必要です。より良いパフォーマンスを達成するために、これらを組み合わせることは珍しいことではありません。私たちは、長波赤外線カメラが継続的に記録し、これに加えて、日中の可視スペクトル領域で別のカメラが記録し、インテリジェントなアルゴリズムが取得された画像を監視する場合に焦点を当てます。より正確に言えば、私たちのタスクはマルチスペクトル CNN ベースの物体検出です。一見したところ、可視スペクトル範囲に由来する画像は、色や明確なテクスチャ情報が存在する一方で、物体から放出される熱放射に関する情報が含まれていないという点で熱赤外線画像と異なります。色は分類タスクに貴重な情報を提供しますが、照明の変化やさまざまなセンサーの特殊性などの影響は依然として重大な問題を引き起こします。いずれにせよ、ディープ ニューラル ネットワークをトレーニングするために十分かつ実用的な熱赤外線データセットを取得することは依然として課題です。これが、特に評価する必要があるデータに可視データと赤外線データの両方が含まれている場合、可視スペクトル範囲のデータを利用したトレーニングが有利である理由です。ただし、熱放射、形状、色の情報の変化が分類精度にどの程度強く影響するかについて明確な証拠はありません。畳み込みニューラル ネットワークがどのように意思決定を行うか、またさまざまなセンサー入力データから何を学習するかについてより深い洞察を得るために、さまざまな拡張技術の適合性と堅牢性を調査します。
原文 (English)
Augmentation techniques for video surveillance in the visible and thermal spectral range
In intelligent video surveillance, cameras record image sequences during day and night. Commonly, this demands different sensors. To achieve a better performance it is not unusual to combine them. We focus on the case that a long-wave infrared camera records continuously and in addition to this, another camera records in the visible spectral range during daytime and an intelligent algorithm supervises the picked up imagery. More accurate, our task is multispectral CNN-based object detection. At first glance, images originating from the visible spectral range differ between thermal infrared ones in the presence of color and distinct texture information on the one hand and in not containing information about thermal radiation that emits from objects on the other hand. Although color can provide valuable information for classification tasks, effects such as varying illumination and specialties of different sensors still represent significant problems. Anyway, obtaining sufficient and practical thermal infrared datasets for training a deep neural network poses still a challenge. That is the reason why training with the help of data from the visible spectral range could be advantageous, particularly if the data, which has to be evaluated contains both visible and infrared data. However, there is no clear evidence of how strongly variations in thermal radiation, shape, or color information influence classification accuracy. To gain deeper insight into how Convolutional Neural Networks make decisions and what they learn from different sensor input data, we investigate the suitability and robustness of different augmentation techniques...
AAbAAC: 自己免疫情報抽出のための注釈付きコーパス
ディープラーニングと大規模言語モデルによる情報抽出の進歩にも関わらず、高度に専門化された生物医学分野では依然としてパフォーマンスのギャップがあり、領域固有の複雑さがジェネラリストモデルにとって課題となっています。この研究では、自己免疫の領域に焦点を当てます。ここでの主な関心対象は、自己免疫疾患、自己抗体(つまり、これらの疾患を特徴付ける、または引き起こす可能性のある分子)、その分子標的、体内の位置、およびそれらに関連する臨床徴候です。ここでは、PubMed から選択された 115 の抄録のコーパスである AAbAAC (AutoAntibodies and Autoimmunity Annotated Corpus) を紹介します。エンティティとその関係に手動で注釈を付けました。まず、AAbAAC を使用して固有表現認識 (NER) のタスクに関するいくつかの方法を評価し、次に NER モデルを微調整しました。私たちの研究は、自己免疫領域における情報抽出における AAbAAC の有用性を実証し、微調整後の NER パフォーマンスの期待される改善を示しています。これは、特殊な領域に対する小規模なアノテーションの取り組みの価値を示しており、自己免疫の計算機研究に貢献します。 AAbAAC コーパスは https://github.com/f-maury/AAbAAC で入手できます。
原文 (English)
AAbAAC: An Annotated Corpus for Autoimmunity Information Extraction
Despite advances in information extraction driven by deep learning and large language models, performance gaps remain in highly specialized biomedical fields, where domainspecific complexity poses challenges for generalist models. In this work, we focus on the domain of autoimmunity, where the main entities of interest are autoimmune diseases, autoantibodies (i.e., molecules that may mark or cause these diseases), their molecular targets, their location in the body, and their associated clinical signs. Herein, we present AAbAAC (AutoAntibodies and Autoimmunity Annotated Corpus), a corpus of 115 abstracts selected from PubMed, where we manually annotated entities and their relationships. First, AAbAAC was used to evaluate several methods on the task of named entity recognition (NER), and secondly, to fine-tune NER models. Our study demonstrates the utility of AAbAAC for information extraction in the domain of autoimmunity, showing expected improvement in NER performance after finetuning. This illustrates the value of small-scale annotation efforts for specialized domains and contributes to the computational study of autoimmunity. The AAbAAC corpus is available at https://github.com/f-maury/AAbAAC.
長いビデオで RAG を再考する: 何を取得し、どのように使用するか?
検索拡張生成はテキストを超えて、長い自己中心的なビデオに移行しており、システムは複数のモダリティと時間粒度にわたってクエリに関連するチャンクを選択する必要があります。しかし、VideoRAG の進歩は 2 つのギャップによって制限されています。既存のベンチマークでは、ビデオなしでクエリに回答でき、取得エラーがわかりにくくなっています。また、従来の方法では、クエリごとに単一のモダリティ粒度設定が適用され、チャンクレベルの変動性が無視されています。 $\langle$query、証拠チャンク、answer$\rangle$ トリプレットのベンチマークである V-RAGBench を導入することで両方に対処します。これにより、取得と生成の忠実で分離された評価が可能になります。また、CARVE は、構成全体で並列検索を実行し、チャンク適応型再ランキングを採用して各チャンクの最適な構成を特定する単純な手法です。次に、各チャンクは、取得中に選択された最適な構成でジェネレーターに入り、チャンクレベルの決定が両方のステージに伝播するインターリーブされた証拠フォームを生成します。 CARVE は、ジェネレーターに供給されるチャンクが単一の構成を共有するのではなく、複数の構成をインターリーブすることで、最近の 8 つの VideoRAG ベースラインよりも優れたパフォーマンスを発揮します。これは、クエリ レベルのメソッドでは達成できない動作です。
原文 (English)
Rethinking RAG in Long Videos: What to Retrieve and How to Use It?
Retrieval-augmented generation is moving beyond text into long, egocentric video, where systems must select query-relevant chunks across multiple modalities and temporal granularities. Yet progress in VideoRAG is limited by two gaps: existing benchmarks allow queries to be answered without the video, obscuring retrieval errors, and prior methods apply a single modality-granularity configuration per query, ignoring chunk-level variability. We address both by introducing V-RAGBench, a benchmark of $\langle$query, evidence chunk, answer$\rangle$ triplets that enables faithful, decoupled evaluation of retrieval and generation, and CARVE, a simple method that runs parallel retrievers across configurations and employs chunk-adaptive reranking to identify the winning configuration for each chunk. Each chunk then enters the generator under its winning configuration selected during retrieval, yielding an interleaved evidence form where the chunk-level decision propagates across both stages. CARVE outperforms eight recent VideoRAG baselines, with the chunks supplied to the generator interleaving multiple configurations rather than sharing a single one, a behavior unattainable by query-level methods.
TerraBench: エージェントは異種の地球システム データを推論できるか?
気候と環境に関する意思決定では、グリッド化された物理データ、衛星画像、地理空間コンテキスト、シミュレーターの出力など、異種混合の入力全体にわたる推論がますます必要になります。気象および気候基盤モデルは適切に予測できますが、言語で対話的に推論することはできません。一方、大規模言語モデル (LLM) は言語で推論しますが、高次元の地球システム データを直接操作することはできません。その結果、地球科学における実際の科学ワークフローは十分なサービスを受けられないままです。 TerraAgent 上に構築された、根拠のある地球科学推論のベンチマークである TerraBench を紹介します。TerraAgent は、推論、ツール呼び出し、観測をインターリーブして LLM 計画を環境検索、地理空間処理、シミュレーション、アーティファクトに基づく計算のための科学ツールと結び付ける ReAct スタイルの実行可能フレームワークです。 TerraBench は、地球観測画像、グリッド データ、GIS 推論、およびシミュレーションの分析を単一の実行可能なインターフェイスに統合します。一方、以前のベンチマークは、これらの機能を狭い個別のタスクに分離していました。また、プロセスレベルのツール使用メトリクスと許容差を意識した数値スコアを組み合わせたのも、この分野では初めてです。このベンチマークは、3 つのトラック (基礎、シミュレーターベース、ドキュメントベースの検証) にわたる 403 の広範なエージェント タスクと、24,500 の検証済み実行ステップを含む 8 つのアプリケーション ドメインで構成されています。これらの結果は、信頼できる地球科学エージェントはツールへのアクセスを超えて、異種ワークフローを調整し、ツールを正確にパラメータ化し、成果物の出所を保存する必要があることを示しています。
原文 (English)
TerraBench: Can Agents Reason Over Heterogeneous Earth-System Data?
Climate and environmental decision-making increasingly requires reasoning across heterogeneous inputs, including gridded physical data, satellite imagery, geospatial context, and simulator outputs. Weather and climate foundation models can forecast well, but do not reason interactively in language, while large language models (LLMs) reason in language but cannot operate directly on high-dimensional Earth-system data. As a result, real scientific workflows in Earth-science remain underserved. We introduce TerraBench, a benchmark for grounded Earth-science reasoning, built on TerraAgent, a ReAct-style executable framework that interleaves reasoning, tool calls, and observations to couple LLM planning with scientific tools for environmental retrieval, geospatial processing, simulation, and artifact-backed computation. TerraBench unifies analysis of Earth observation imagery, gridded data, GIS reasoning and simulation in a single executable interface, whereas prior benchmarks isolate these capabilities into narrow individual tasks. It is also the first in this space to pair process-level tool-use metrics with tolerance-aware numeric scoring. The benchmark comprises 403 extensive agentic tasks across three tracks (Fundamentals, Simulator-Grounded, and Document-Grounded Verification) and eight application domains with 24,500 verified execution steps. These results indicate that reliable Earth-science agents must go beyond tool access to coordinate heterogeneous workflows, parameterize tools precisely, and preserve artifact provenance.
Mental-R1: メンタルヘルス評価のための LLM 推論の調整
不安、うつ病、自殺などの精神的健康問題は依然として緊急の世界的課題であり、効果的な介入にはタイムリーで正確な評価が不可欠です。最近、メンタルヘルス評価のために大規模な言語モデルが研究されています。ただし、既存の汎用のトレーニング後手法は人間の評価の認知プロセスと一致していないため、信頼性の低い推論結果が生じる可能性があります。このギャップを埋めるために、メンタルヘルス領域に合わせて調整された強化学習フレームワークである認知相対ポリシー最適化 (CRPO) を提案します。 CRPO は、段階依存の不確実性モデリングを政策最適化プロセスに統合することにより、グループ相対政策最適化を拡張します。具体的には、段階的なエントロピー正則化メカニズムを導入し、初期の推論段階で広範な探索を促進し、後の段階で自信を持った意思決定を段階的に強制し、不確実性から確実性への人間の認知的変化を模倣します。さらに、認知的評価理論に触発されて、認知的推論段階を形式化し、それによって理論に基づいた解釈可能な推論を導きます。 8 つのメンタルヘルス データセットに関する実験では、CRPO が最適な強化学習ベースラインと比較して加重 F1 スコアで平均 10.4 パーセントの改善を達成したことが示されています。さらに、CRPO で訓練されたモデル Mental-R1 は、推論集中型のケースにおいて既存の大規模言語モデルと比較して明らかな利点を示しており、CRPO がメンタルヘルス評価の推論能力を強化することが示唆されています。
原文 (English)
Mental-R1: Aligning LLM Reasoning for Mental Health Assessment
Mental health problems such as anxiety, depression, and suicide remain urgent global challenges, where timely and accurate assessment is critical for effective intervention. Recently, large language models have been explored for mental health assessment. However, existing general-purpose post-training methods do not align with the cognitive processes of human assessment, which may lead to unreliable reasoning outcomes. To bridge this gap, we propose Cognitive Relative Policy Optimization (CRPO), a reinforcement learning framework tailored for the mental health domain. CRPO extends group relative policy optimization by integrating stage-dependent uncertainty modeling into the policy optimization process. Specifically, we introduce a stage-wise entropy regularization mechanism that encourages broad exploration in early reasoning phases and progressively enforces confident decision-making in later stages, mimicking the human cognitive shift from uncertainty to certainty. In addition, inspired by cognitive appraisal theory, we formalize cognitive reasoning stages, thereby guiding theory-grounded interpretable inference. Experiments on 8 mental health datasets show that CRPO achieves an average improvement of 10.4 percentage points in weighted F1-score over the best reinforcement learning baseline. Furthermore, the CRPO-trained model Mental-R1 demonstrates clear advantages compared with existing large language models on reasoning-intensive cases, suggesting that CRPO enhances reasoning capabilities for mental health assessment.
マルチモーダル LLM によるモバイル ユーザー エクスペリエンスの推論: タスク、ベンチマーク、およびアプローチ
使いやすさ、知覚される一貫性、機能の明瞭さを中心としたユーザー エクスペリエンス (UX) は、現実世界のユーザー インターフェイス (UI) の基礎です。ユーザー インターフェイスの分野におけるマルチモーダル大規模言語モデル (MLLM) のアプリケーションは、ビジュアル要素のグラウンディング、グラフィカル ユーザー インターフェイス (GUI) エージェント、デザインからコードの生成など、急速に進化しています。ただし、UI スクリーンショットに基づいて UX を評価する研究はまだ未熟です。これに対処するために、MLLM の UI ベースの推論を実行する能力を評価するために設計された 2,000 の VQA データ サンプルで構成される新しいマルチモーダル ベンチマークである UXBench を提案します。 UXBench には、実際の UI スクリーンショットに基づいた 8 つのタスクが含まれており、レイアウトの関係、視覚的な階層、コンテンツの一貫性にわたる UX の問題を詳細に診断する必要があります。主流の MLLM を広範に評価したところ、UI ベースの推論能力が根本的に制限されたままであることがわかりました。この結果は、この分野でのさらなる進歩の必要性を強調しています。このギャップを埋めるために、私たちは UI-UX を提案します。これは、Qwen3-VL-4B-Thinking 基盤モデルに基づいており、推論中の知覚的理解と論理的推論のバランスを動的に調整する報酬ルーティング メカニズムと、冗長または不十分な推論ステップを抑制する非対称遷移報酬という 2 つの重要な革新によって強化学習によって強化された MLLM です。実験では、UI-UX が UXBench 上で最先端 (SOTA) パフォーマンスを達成し、精度 0.7963 (Claude-4.5-Sonnet の 0.6550 を上回ります) を達成しながら、多様な UI タスクにわたって強力な一般化を示し、低い推論遅延を維持していることが実証されました。
原文 (English)
Reasoning for Mobile User Experience with Multimodal LLMs: Task, Benchmark, and Approach
User experience (UX) centered on usability, perceived consistency, and functional clarity is fundamental to real-world user interfaces (UI). The application of multimodal large language models (MLLMs) in the field of user interfaces is evolving rapidly, such as visual element grounding, graphical user interface (GUI) agents, and design-to-code generation. However, research efforts on evaluating UX based on UI screenshots are still immature. To address this, we propose UXBench, a novel multimodal benchmark consisting of 2,000 VQA data samples designed to assess MLLMs' ability to perform UI-based reasoning. UXBench includes 8 tasks based on real-world UI screenshots that require fine-grained diagnosis of UX issues across layout relationships, visual hierarchy, and content consistency. Our extensive evaluation of mainstream MLLMs shows that they remain fundamentally limited in their capacity for UI-based reasoning. The results underscore the need for further advancements in this area. To bridge this gap, we propose UI-UX, an MLLM based on Qwen3-VL-4B-Thinking foundation model and enhanced via reinforcement learning with two key innovations: a reward routing mechanism that dynamically balances perceptual understanding and logical reasoning during inference, and an asymmetric transition reward that suppresses redundant or insufficient reasoning steps. Experiments demonstrate that UI-UX achieves state-of-the-art (SOTA) performance on UXBench, attaining an accuracy of 0.7963 -- surpassing Claude-4.5-Sonnet's 0.6550 -- while exhibiting strong generalization across diverse UI tasks and maintaining low inference latency.
どのような条件下でマシンは真に創造的になることができるのでしょうか?
最近の AI システムは、創造的に見えるテキスト、ソフトウェア アーキテクチャ、仮説、設計、科学的ワークフローを生成できます。この論文は、どのような条件下で機械が真に創造的になることができるのか、そして共有された認知環境と創造的環境の中で人間の主体性をどのように維持できるのかを問うものです。意味を伴う意図的な変更の科学である Designics に由来する要件フレームワークを開発します。この論文では、真のマシンの創造性は、出力の新規性、現在のパフォーマンス、または一時的なアーキテクチャだけによって定義されるべきではないと主張しています。代わりに、創造性は、再帰的な介入ダイナミクスによる不完全な状況の構造的変換として理解されます。この見解に基づくと、それは、環境表現、範囲指定された認識、矛盾の特定、介入能力、結果の観察、知識と環境の更新、再スコープ、ローカルからグローバルへの展開、価値ベースのスコープ、および人間と AI の共生という 10 の要件に依存します。これらは、デザインニクスの 3 つの法則、つまり知覚、葛藤、能力によって整理されています。この論文では、再帰的要素抽出、自律メッシュ生成、神経生理学的およびワークロード分析を含む、選択されたサイバー物理学的およびサイバー生物学的研究を通じて、これらの要件の計算上の扱いやすさを説明しています。次に、オープンエンド システム、自動検出フレームワーク、自己変更エージェント、基盤モデル、およびエージェント ワークフローをプレッシャー ケースとして扱います。これらは強力な生成手段を実証しますが、それ自体では真のマシンの創造性を確立しません。最後に、この論文は、プロアクティブな AI 倫理は事後のフィルターではなく、真の機械の創造性の内部にあると主張しています。価値ベースのスコープ設定と人間と AI の共生は、創造的なマシンが環境を認識し、競合を特定し、介入を選択し、結果を観察し、知識を更新し、将来の行動を再検討する方法を形成する必要があります。
原文 (English)
Under What Conditions Can a Machine Become Genuinely Creative?
Recent AI systems can generate texts, software architectures, hypotheses, designs, and scientific workflows that appear creative. This paper asks under what conditions a machine can become genuinely creative, and how human agency can be preserved within shared cognitive and creative environments. It develops a requirement framework derived from Designics, the science of meaning-bearing intentional change. The paper argues that genuine machine creativity should not be defined by output novelty, current performance, or transient architecture alone. Instead, creativity is understood as the structural transformation of incomplete situations through recursive intervention dynamics. On this view, it depends on ten requirements: environment representation, scoped perception, conflict identification, intervention capability, consequence observation, knowledge and environment update, rescoping, local-to-global unfolding, value-based scoping, and human-AI co-living. These are organized through the three laws of Designics: perception, conflict, and capability. The paper illustrates the computational tractability of these requirements through selected cyber-physical and cyber-biological studies, including recursive element extraction, autonomous mesh generation, and neurophysiological and workload analysis. It then treats open-ended systems, automated discovery frameworks, self-modifying agents, foundation models, and agentic workflows as pressure cases: they demonstrate powerful generative means but do not by themselves establish genuine machine creativity. Finally, the paper argues that proactive AI ethics is internal to genuine machine creativity rather than an after-the-fact filter. Value-based scoping and human-AI co-living must shape how creative machines perceive environments, identify conflicts, select interventions, observe consequences, update knowledge, and rescope future action.
ARMOR-MAD: 大規模言語モデル推論における異種マルチエージェント議論のための適応ルーティング
マルチエージェント ディベート (MAD) は大規模な言語モデルの推論を改善できますが、固定ディベート パイプラインでは計算が無駄になることが多く、類似したエージェント間の相関エラーが増幅される可能性があります。私たちは、議論を条件付き計算として扱うトレーニング不要の異種 MAD フレームワークである ARMOR-MAD を提案します。 ARMOR-MAD は 3 つのコンポーネントを組み合わせています。 事前討論合意ルーティング (PAR) は、独自に生成されたラウンド 0 の回答に討論が必要かどうかを決定します。早期合意停止評価者 (EASE) は、収束後に議論を停止します。また、セマンティック外れ値検出 (SOD) は、集計中に異常な最終回答を重み付けします。 MATH レベル 5、GSM8K、MMLU、および MMLU-Pro 全体で、ARMOR-MAD は、同じモデル プールを使用した固定ラウンドの異種ディベートよりも一貫して向上しており、それぞれ 65.5\%、96.5\%、90.0\%、および 81.5\% の精度に達しています。この結果は、MAD をより正確かつ効率的にするためには、真のモデルの不均一性と合意に基づく制御の両方が重要であることを示唆しています。
原文 (English)
ARMOR-MAD: Adaptive Routing for Heterogeneous Multi-Agent Debate in Large Language Model Reasoning
Multi-agent debate (MAD) can improve large language model reasoning, but fixed debate pipelines often waste computation and can amplify correlated errors among similar agents. We propose ARMOR-MAD, a training-free heterogeneous MAD framework that treats debate as conditional computation. ARMOR-MAD combines three components: Pre-debate Agreement Routing (PAR) decides whether independently generated Round-0 answers require debate; Early Agreement Stopping Evaluator (EASE) stops debate after convergence; and Semantic Outlier Detection (SOD) down-weights abnormal final answers during aggregation. Across MATH Level 5, GSM8K, MMLU, and MMLU-Pro, ARMOR-MAD consistently improves over fixed-round heterogeneous debate with the same model pool, reaching 65.5\%, 96.5\%, 90.0\%, and 81.5\% accuracy, respectively. The results suggest that genuine model heterogeneity and agreement-based control are both important for making MAD more accurate and efficient.
複数属性選択における制限付きトレードオフ スクリーニングの最小モデル
人間の意思決定には、多くの場合、複数の属性の選択肢の中から選択することが含まれますが、重要な属性でパフォーマンスが低い選択肢を人々が拒否するという証拠があるにもかかわらず、古典的なモデルでは、完全に補償された効用の集計が想定されています。私たちは、属性間の利益と損失のバランスを評価するスクリーニング プロセスによって意思決定が管理される、限定されたトレードオフ推論フレームワークを提案します。このモデルでは、許容可能な不均衡を制御し、コンテキストによって異なる可能性があるトレードオフ許容誤差パラメーターが導入されています。シミュレーションを通じて、このメカニズムが標準的なユーティリティベースのモデルとは異なる選好パターンを生成し、トレードオフ動作におけるコンテキスト依存の変動を捕捉することを示します。これらの結果は、複数の属性を選択するための妥当な計算メカニズムとして制限付きトレードオフ スクリーニングを確立し、将来の行動研究のためのテスト可能な予測を生成します。
原文 (English)
A Minimal Model of Bounded Trade-Off Screening in Multi-Attribute Choice
Human decision-making often involves choosing between multi-attribute alternatives, yet classical models assume fully compensatory utility aggregation despite evidence that people reject options with poor performance on critical attributes. We propose a bounded trade-off reasoning framework in which decisions are governed by a screening process that evaluates the balance between gains and losses across attributes. The model introduces a trade-off tolerance parameter that controls acceptable imbalance and can vary across contexts. Through simulation, we show that this mechanism produces preference patterns that differ from standard utility-based models and captures context-dependent variation in trade-off behavior. These results establish bounded trade-off screening as a plausible computational mechanism for multi-attribute choice and generate testable predictions for future behavioral studies.
医用画像 AI における幻覚: 規制上の制約下での分類、検出、緩和のためのクロスモダリティ分析フレームワーク
AI システムは、障害モードが理解されるよりも早く、医療画像全体に導入されています。現時点で、最大の臨床的懸念事項の失敗は幻覚です。これは、臨床的にもっともらしいが事実として誤った出力であり、作成されたレポート内の捏造された解剖学的構造、見逃した所見、不正確な左右差、でっち上げられた測定値などであり、生検の決定、病期分類、治療計画などに直接的な影響を及ぼします。この構造化された物語は、5 つの画像モダリティにわたる査読済みの研究、ベンチマーク データセット、FDA の規制ガイダンスを統合して、幻覚の分類、病因、検出、緩和に関するクロスモダリティ分析を生成します。具体的には、この研究では次の 3 つの質問に取り組みます: (1) モダリティ間で既存の分類をどのように統合できるか?、(2) 医療に特化した基礎モデルはどのようにして汎用モデルよりも幻覚が少ないのか?、(3) どの緩和戦略が効果的で FDA のライフサイクル監視と互換性があるか? 3 つの分類フレームワークが連携して、単一のフレームワークだけでは実現できない方法でイメージング パイプラインをカバーしていることに注目します。また、幻覚に特化したベンチマークでは、汎用の基礎モデルが医療に特化したモデルよりも優れていることも強調し、狭い領域の微調整が過剰適合に起因する作文を引き起こす可能性があることを示しています。同時に、放射線科医の監督は引き続き不可欠です。たとえば、AI によって生成されたフラグの非常に高い割合では、臨床使用前に専門家による修正が必要でした。物理学に基づいたアーキテクチャ上の制約、思考連鎖プロンプト、および人間参加型の安全装置は、それぞれ異なる障害モードに対処しており、組み合わせると効果的です。すべての調査結果は、FDA の製品ライフサイクル全体と所定の変更管理計画のフレームワークにマッピングされており、幻覚管理は展開前のチェックリストではなくライフサイクルの義務として扱われます。
原文 (English)
Hallucination in Medical Imaging AI: A Cross-Modality Analytical Framework for Taxonomy, Detection, and Mitigation under Regulatory Constraints
AI systems are being deployed across medical imaging faster than their failure modes are understood. At this point in time, the failure of greatest clinical concern is hallucination: clinically plausible but factually incorrect outputs, including fabricated anatomical structures, missed findings, incorrect laterality, and invented measurements in generated reports, with direct consequences, for example, for biopsy decisions, staging, and treatment planning. This structured narrative synthesizes peer-reviewed studies, benchmark datasets, and FDA regulatory guidance across five imaging modalities to produce a cross-modality analysis of hallucination taxonomy, etiology, detection, and mitigation. Specifically, we address three questions in this study: (1) how can existing taxonomies be unified across modalities?, (2) how do medical-specialized foundation models hallucinate less than general-purpose ones?, and (3) which mitigation strategies are effective and compatible with FDA lifecycle oversight? We note that three taxonomic frameworks together cover the imaging pipeline in a way no single framework does alone. We also highlight that general-purpose foundation models outperform medical-specialized models on hallucination-specific benchmarks, indicating that narrow domain fine-tuning can introduce overfitting-induced confabulation. At the same time, the oversight of radiologists remains essential; for instance, a very high percentage of of AI-generated flags required expert correction before clinical use. Physics-informed architectural constraints, Chain-of-Thought prompting, and human-in-the-loop safeguards each address different failure modes and is effective when combined. All findings are mapped to the FDA's Total Product Lifecycle and Predetermined Change Control Plan frameworks, which treat hallucination management as a lifecycle obligation rather than a pre-deployment checklist.
調査員としての LLM: 堅牢な対話型問題診断のための証拠優先の推論
大規模言語モデル (LLM) は、技術的な問題解決のための対話型アシスタントとして使用されることが増えています。ただし、ユーザーが不完全な説明、またはもっともらしいが検証されていない説明を提供した場合、LLM は時期尚早にこれらの仮定に同意し、十分な証拠を収集する前に解決策を提案する可能性があります。私たちはこの動作をユーザー主導のお調子者と呼びます。これは、別の説明をテストする代わりに、ユーザーが提供した仮説を強化する LLM の傾向です。この論文では、堅牢な問題診断のための証拠優先のエージェント AI 手法である LLM-as-an-Investigator を紹介します。このアプローチは、Solution Investigator Agent を通じて実装されます。Solution Investigator Agent は、最初の問題の説明のあいまいさを推定し、仮説候補を生成し、的を絞った明確化の質問をし、各回答後に仮説の確率を更新します。エージェントはすぐに応答を返すのではなく、証拠によって 1 つの候補の説明が他の説明よりも強力になるまで調査を続けます。このアプローチを評価するために、機械、電気、油圧の各ドメインで解決された技術フォーラムのスレッドからベンチマークを構築します。私たちは 3 つのエージェントによる評価パイプラインを使用します。このパイプラインでは、問題解決抽出エージェントが解決済みのスレッドを構造化されたケースに変換し、グラウンドトゥルース評価エージェントが既知の解決策を隠しながらユーザーをシミュレートし、テストされたアシスタントが対話を通じて解決策の回復を試みます。実験では、標準的なアシスタント、推論指向の LLM、および提案された調査員ベースのモデルを LLM バックボーン全体で比較します。診断の精度に加えて、標準アシスタントが診断ケースにおいて誤解を招くユーザーの仮説にどのように従うかを分析します。その結果、提案されたアプローチは、直接的なプロンプトと推論のみのベースラインよりも問題をより正確に特定し、証拠優先のプロトコルはユーザーが誘発する会話のバイアスを軽減するのに役立つことを示しています。
原文 (English)
LLM-as-an-Investigator: Evidence-First Reasoning for Robust Interactive Problem Diagnosis
Large language models (LLMs) are increasingly used as interactive assistants for technical problem solving. However, when users provide incomplete descriptions or plausible but unverified explanations, LLMs may prematurely align with these assumptions and propose solutions before collecting sufficient evidence. We refer to this behavior as user-driven sycophancy: the tendency of an LLM to reinforce a user-provided hypothesis instead of testing alternative explanations. This paper introduces LLM-as-an-Investigator, an evidence-first agentic AI methodology for robust problem diagnosis. The approach is implemented through a Solution Investigator Agent, which estimates the ambiguity of an initial problem description, generates candidate hypotheses, asks targeted clarification questions, and updates hypothesis probabilities after each answer. Rather than producing an immediate response, the agent continues the investigation until the evidence makes one candidate explanation stronger than the alternatives. To evaluate the approach, we build a benchmark from solved technical forum threads in mechanical, electrical, and hydraulic domains. We use a three-agent evaluation pipeline in which a Problem-Solution Extractor Agent converts solved threads into structured cases, a Ground-Truth Evaluator Agent simulates the user while hiding the known solution, and the tested assistant attempts to recover the solution through dialogue. The experiments compare standard assistants, reasoning-oriented LLMs, and the proposed investigator-based model across LLM backbones. In addition to diagnostic accuracy, we analyze how standard assistants follow misleading user hypotheses in diagnostic cases. The results show that the proposed approach identifies the problem more accurately than direct prompting and reasoning-only baselines, while its evidence-first protocol helps reduce user-induced conversational bias.
ブリック: モデル混合 (MoM) パラダイムのための空間機能ルーティング
クエリの難易度を定義することは、展開エンジニアリングにおいて最も難しい問題の 1 つです。既存の LLM ルーターは、ドメイン ラベル、キーワード、トークン数などの表面的な機能に依存し、モデルの成功を実際に決定するドメイン内の差異を無視しています。フロンティア モデルのコストは、ローカルのオープンウェイト モデルの 10 倍から 100 倍であるため、実稼働規模では、リクエストごとのわずかな節約であっても、クラウドの請求額に直接影響します。我々は、6 つの機能次元で各モデルにスコアを付け、これをクエリごとの難易度推定と組み合わせ、コストペナルティのある幾何学的ルールを介してディスパッチするマルチモーダル ルーターである Brick を紹介します。連続設定ノブを使用すると、オペレーターは展開時に最大品質プロファイルと最大節約プロファイルの間をスライドできます。 5,504 クエリのベンチマークでは、最高品質の Brick は 76.98% の精度に達し、最高の単一モデル (75.02%) およびテストされたすべてのルーターを上回りました。 Brick は、中立的なコスト品質プロファイルで、常に最も強力なモデルを使用する場合に比べて 4.71 倍の低コストで 74.11% の精度を達成します。最小コストでは、コストが 22.15 倍削減され、精度は 11.85 ポイント低下します。レイテンシーの中央値は 51.2 秒から 22.8 秒に減少します。
原文 (English)
Brick: Spatial Capability Routing for the Mixture-of-Models (MoM) Paradigm
Defining query difficulty is one of the hardest problems in deployment engineering. Existing LLM routers rely on surface features such as domain labels, keywords, and token count, ignoring the within-domain variance that actually determines model success. Frontier models cost ten to one hundred times more than local open-weight models, so at production scale even small per-request savings become a direct cloud-bill lever. We present Brick, a multimodal router that scores each model on six capability dimensions, combines this with a per-query difficulty estimate, and dispatches via a cost-penalized geometric rule. A continuous preference knob lets operators slide between max-quality and max-saving profiles at deploy time. On a benchmark of 5,504 queries, Brick at max-quality reaches 76.98% accuracy, beating the best single model (75.02%) and all tested routers. At a neutral cost-quality profile, Brick achieves 74.11% accuracy at 4.71x lower cost than always using the strongest model. At min-cost, it cuts cost 22.15x with 11.85 points accuracy loss. Median latency drops from 51.2s to 22.8s.
EPIG: パーソナライズされた画像生成のための感情ベースのプロンプト
テキストから画像への拡散モデルは、自然言語プロンプトから高品質の画像を合成するという優れた結果を達成しました。ただし、一般的に使用されるプロンプト戦略は比較的一般的なままであり、感情的な意図や微妙な感情属性を正確に表現するモデルの能力が制限されます。本研究では、画像生成前のプロンプトレベルで感情表現力を高める手法EPIGを提案する。 EPIG は、心理学的に情報に基づいた感情表現 (価性覚醒) に基づいており、構造化された役割を意識したプロンプト エンリッチメントを利用して、画像生成のバックボーンを変更または再トレーニングすることなく、プロンプトの感情関連コンポーネントを強化します。結果として生じる感情を意識したプロンプトは、より感情的に一貫した視覚出力に向けて生成プロセスを導き、特に覚醒の制御に効果的です。 EPIG は軽量でトレーニング不要で、リソースに制約があり、パーソナライズされた画像生成シナリオに適しています。 10 種類の多様なプロンプトのベンチマークに関する実験結果は、EPIG がナイーブ挿入や LLM ベースのプロンプト拡張などの強力なベースラインと比較して平均覚醒誤差をそれぞれ 14% および 12% 減少させることを示しています。これらの改善は統計的に有意です。 EPIG は、CLIPScore によって測定され、アブレーション研究によってサポートされているように、原子価のアライメントと意味の一貫性も保持します。この効果は、人間、子供、動物などの明示的な主題を含むプロンプトでより顕著であり、削減率は 17% に達し、提案された方法の主題に敏感な動作が強調されます。
原文 (English)
EPIG: Emotion-Based Prompting for Personalised Image Generation
Text-to-image diffusion models have achieved impressive results in synthesizing high-quality images from natural language prompts. However, commonly used prompting strategies remain relatively generic, limiting the model's ability to accurately express emotional intent and nuanced affective attributes. This work proposes EPIG, a method that enhances emotional expressiveness at the prompt level prior to image generation. Grounded in psychologically informed emotion representations (valence-arousal) and leveraging structured, role-aware prompt enrichment, EPIG enriches emotion-related components of prompts without modifying or retraining the image generation backbone. The resulting emotion-aware prompts guide the generative process toward more emotionally coherent visual outputs, with particular effectiveness in controlling arousal. EPIG is lightweight, training-free, and well suited for resource-constrained and personalized image generation scenarios. Experimental results on a benchmark of 10 diverse prompts show that EPIG reduces mean arousal error compared to strong baselines, including naive insertion and LLM-based prompt expansion, with reductions of 14% and 12%, respectively. These improvements are statistically significant. EPIG also preserves valence alignment and semantic consistency, as measured by CLIPScore and supported by ablation studies. The effect is more pronounced on prompts containing explicit subjects such as humans, children, or animals, where the reduction reaches 17%, highlighting the subject-sensitive behavior of the proposed method.
海難根本原因分析のためのマルチフィールドハイブリッド検索拡張生成
海難の判決報告書には、根本原因分析(RCA)のための重要な裁判所の所見が含まれていますが、関連する先例を検索し、数十年にわたる記録から一貫した報告書を作成するのには依然として労力がかかります。この論文は、13,329 件の韓国海事安全裁判所 (KMST) 報告書 (1971 年から 2025 年) の包括的なデータセットを利用した、自動海事 RCA のためのマルチフィールド ハイブリッド検索拡張生成 (RAG) フレームワークを提案します。私たちは生の判決を「インシデントカード」の構造化された知識ベースに変換し、階層的な L1/L2 原因分類法に沿って 3 つの異なるフィールド (概要、原因、および処分) にインデックスを付けます。当社の検索戦略は、フィールドを意識したハイブリッド アプローチを採用し、相互ランク融合 (RRF) を介して疎ランキングと密ランキングを融合します。大規模な専門家の関連性ラベルが不足していることを考慮して、天井正規化再現率とメタデータ由来のプロキシ関連性スコアに基づく nDCG を使用して検索パフォーマンスを評価します。実験結果は、私たちが提案した検索がベースライン手法を大幅に上回り、NormRecall@100 が 0.18 から 0.55 に改善されたことを示しています。さらに、取得した前例に基づいてジェネレーターを接地することで、LLM のみのベースラインよりも RCA 生成の品質が向上し、裁判官としての LLM スコアが 3.34 から 3.72 に増加します。これらの調査結果は、現場を意識した RAG が、より迅速な前例検索と、より一貫性のある証拠に基づく RCA 草案作成を可能にすることで、海上安全調査のワークフローを大幅に合理化できることを示唆しています。
原文 (English)
Multi-Field Hybrid Retrieval-Augmented Generation for Maritime Accident Root Cause Analysis
Maritime accident adjudication reports contain critical tribunal findings for root cause analysis (RCA), yet retrieving relevant precedents and drafting consistent reports from decades of records remains labor-intensive. This paper proposes a multi-field hybrid retrieval-augmented generation (RAG) framework for automated maritime RCA, utilizing a comprehensive dataset of 13,329 Korea Maritime Safety Tribunal (KMST) reports (1971-2025). We transform raw adjudications into a structured knowledge base of "incident cards", indexing three distinct fields-Summary, Causes, and Disposition-alongside a hierarchical L1/L2 cause taxonomy. Our retrieval strategy employs a field-aware hybrid approach, fusing sparse and dense rankings via Reciprocal Rank Fusion (RRF). Given the lack of large-scale expert relevance labels, we evaluate retrieval performance using ceiling-normalized recall and nDCG based on a metadata-derived proxy relevance score. Experimental results demonstrate that our proposed retrieval significantly outperforms baseline methods, improving NormRecall@100 from 0.18 to 0.55. Furthermore, grounding the generator on the retrieved precedents enhances RCA generation quality over an LLM-only baseline, increasing the LLM-as-a-judge score from 3.34 to 3.72. These findings suggest that field-aware RAG can substantially streamline maritime safety investigation workflows by enabling faster precedent search and more consistent, evidence-based RCA drafting.
MOSAIC: パーキンソン病歩行評価における増分継続学習のためのモダリティ固有の適応
歩行に基づくパーキンソン病の評価は、異種センサーへの依存度が高まっていますが、臨床システムがすべてのモダリティを同時に収集することはほとんどありません。新しいセンサーは、デバイスのアップグレード、プロトコルの変更、または複数施設の展開を通じて提供される可能性がありますが、プライバシーやストレージの制約により、過去の患者データは利用できないことがよくあります。このモダリティに応じた増分設定は、信頼性の低いクロスモーダル蒸留、モダリティ固有の統計的シフト、保存後の可塑性の低下という 3 つの課題に直面しています。私たちは、コンパクトな継続学習フレームワークである MOSAIC を提案します。まず、Toxic Teacher 現象を特定し、蒸留前に新しく学習したモダリティ表現を安定させるためにモダリティ固有のウォームアップを導入します。 2 番目に、共有のセマンティック バックボーンを維持しながらセンサー統計を分離する統計分離 MSBN アーキテクチャを提案します。第三に、モダリティ固有の能力を回復しながら、レガシー知識を保存する、可塑性回復のためのカリキュラムに基づいた反発目標を設計します。 3 つのマルチモーダル パーキンソン病歩行データセットの実験では、MOSAIC が最終パフォーマンスを向上させ、物忘れを軽減することが示されています。プロジェクト コードは、https://github.com/minlinzeng/MOSAIC_Modality-Specific-Adaptation-for-Incremental-Continual-Learning-in-PD-Gait-Assessment.git で入手できます。
原文 (English)
MOSAIC: Modality-Specific Adaptation for Incremental Continual Learning in Parkinson's Disease Gait Assessment
Gait-based Parkinson's disease assessment increasingly relies on heterogeneous sensors, but clinical systems rarely collect all modalities simultaneously. New sensors may arrive through device upgrades, protocol changes, or multi-center deployment, while historical patient data are often unavailable because of privacy and storage constraints. This modality-incremental setting faces three challenges: unreliable cross-modal distillation, modality-specific statistical shifts, and reduced plasticity after preservation. We propose MOSAIC, a compact continual learning framework. First, we identify the Toxic Teacher phenomenon and introduce Modality-Specific Warm-Up to stabilize newly learned modality representations before distillation. Second, we propose a statistics-decoupled MSBN architecture that isolates sensor statistics while maintaining a shared semantic backbone. Third, we design a curriculum-guided repulsive objective for Plasticity Recovery, preserving legacy knowledge while recovering modality-specific capacity. Experiments on three multimodal Parkinson's gait datasets show that MOSAIC improves final performance and mitigates forgetting. Project code is available at: https://github.com/minlinzeng/MOSAIC_Modality-Specific-Adaptation-for-Incremental-Continual-Learning-in-PD-Gait-Assessment.git
評決からプロセスまで: 多段階の事実検証のためのエージェント強化学習
大規模言語モデル (LLM) と検索拡張推論を組み合わせた最近のアプローチは、自動化された事実検証の可能性を示しています。複雑なクレームを処理するために、これらの検証パイプラインは通常、クレームの分解、証拠の収集、評決の予測など、緊密に結合されたモジュールを調整する多段階のワークフローを実行します。ただし、既存の方法では、個々のステージを個別に最適化するか、固定ヒューリスティックに依存するため、ステージ間の適応的な調整が制限され、最適とは言えない結果が生じる可能性があります。この研究では、多段階の事実検証軌跡をエンドツーエンドで最適化するためのエージェント強化学習フレームワークである ProFact を提案します。 ProFact は、主張の分解、証拠の探索、回答の生成、および評決の予測を調整するための統合ポリシーをトレーニングします。最終的な真実性ラベルによって提供される監視がまばらで遅れていることに対処するために、ProFact は、検証プロセス全体を通じて段階レベルの学習シグナルを提供するプロセスを意識した報酬を導入します。経験的評価によると、ProFact は検証パフォーマンスと推論効率の両方において強力なベースラインを常に上回っています。これらの結果は、多段階の事実検証におけるプロセスを意識した軌道最適化の有効性を強調しています。
原文 (English)
From Verdict to Process: Agentic Reinforcement Learning for Multi-Stage Fact Verification
Recent approaches combining Large Language Models (LLMs) with retrieval-augmented reasoning have shown promise for automated fact verification. To process complex claims, these verification pipelines typically execute multi-stage workflows that coordinate tightly coupled modules, including claim decomposition, evidence gathering, and verdict prediction. However, existing methods optimize individual stages in isolation or rely on fixed heuristics, which limits adaptive coordination among stages and can lead to suboptimal outcomes. In this work, we propose ProFact, an agentic reinforcement learning framework for end-to-end optimization of multi-stage fact verification trajectories. ProFact trains a unified policy to coordinate claim decomposition, evidence seeking, answer generation, and verdict prediction. To address the sparse and delayed supervision provided by final veracity labels, ProFact introduces process-aware rewards that provide stage-level learning signals throughout the verification process. Empirical evaluation shows that ProFact consistently outperforms strong baselines in both verification performance and inference efficiency. These results highlight the effectiveness of process-aware trajectory optimization for multi-stage fact verification.
ERTS: 有界結果空間における意味論的摂動による倫理的 AI の敵対的堅牢性テスト
AI システムは医療トリアージ、自動運転車制御、雇用審査など、一か八かの倫理的状況に導入されているため、敵対的な倫理的推論の操作に対する堅牢性を評価するための正式な手法は未開発のままです。この文書では、クローズド パイプライン フレームワークである倫理ロバストネス テスト システム (ERTS) を紹介します。(1) 確立された倫理理論に基づいて、倫理的ジレンマを 22 次元の倫理的帰結空間 (ECS) にエンコードします。 (2) 新しい意味論的一貫性制約を含む 6 つの妥当性制約クラスに従う 17 の意味論的摂動関数を適用します。 (3) 4 つの構成要素からなる倫理不安定指数 (EII) を介して意思決定の逸脱を測定します。 (4) ドメインに適応した導入前の堅牢性評価の判定を生成します。私たちは、8 つの展開ドメインにわたる 50 の倫理シナリオにわたって 4 つの構造化ベースライン モデルと 2 つの本番 LLM (Gemini 2.0 Flash および Llama 3.2) を評価し、1,500 の敵対的テスト ケースを生成します。結果は、モデルの 33% のみが評価クリアランスを達成していることを示しており、ローカル Llama-3.2 モデルは公平性の破壊と情報劣化攻撃に対して特に脆弱であることが判明しています (ERS = 0.737)。私たちの知る限り、単一の敵対的テスト パイプラインで、境界のある倫理的結果空間、意味論的一貫性の制約、およびドメイン適応型評価を組み合わせた既存のフレームワークはありません。
原文 (English)
ERTS: Adversarial Robustness Testing of Ethical AI via Semantic Perturbation in a Bounded Consequence Space
As AI systems are deployed in high-stakes ethical contexts such as healthcare triage, autonomous vehicle control, and employment screening, formal methods for evaluating their robustness against adversarial manipulation of ethical reasoning remain underdeveloped. This paper introduces the Ethical Robustness Testing System (ERTS), a closed-pipeline framework that: (1) encodes ethical dilemmas into a 22-dimensional Ethical Consequence Space (ECS) grounded in established ethical theory; (2) applies 17 semantic perturbation functions subject to 6 validity constraint classes including a novel semantic coherence constraint; (3) measures decision deviation via a 4-component Ethical Instability Index (EII); and (4) produces domain-adaptive pre-deployment robustness assessment verdicts. We evaluate 4 structured baseline models and 2 production LLMs (Gemini 2.0 Flash and Llama 3.2) across 50 ethical scenarios spanning 8 deployment domains, generating 1,500 adversarial test cases. Results demonstrate that only 33% of models achieve assessment clearance, with the local Llama-3.2 model proving particularly vulnerable to fairness corruption and information degradation attacks (ERS = 0.737). To the best of our knowledge, no existing framework combines a bounded ethical consequence space, semantic coherence constraints, and domain-adaptive assessment in a single adversarial testing pipeline.
ビデオから沿岸波のピーク周期を推定するための物理学に基づく時空間学習
沿岸の波のパラメータは、海岸工学、海岸線の保護、海洋危険評価、気候回復力のための海岸管理にとって重要です。ブイやレーダープラットフォームなどの従来の監視システムは正確な監視を提供しますが、設置とメンテナンスの費用が高額になり、カバー範囲が限られている可能性があります。ビデオを使用した受動的な海洋モニタリングは、深層学習を活用することで実現されていますが、多くの方法は物理的に解釈できず、海洋学としては実現可能ではなく、検証されていません。この研究では、パッシブ沿岸ビデオ ストリームから沿岸波のピーク周期を直接推定するための物理学に基づく深層時空間学習フレームワークが提案されています。このフレームワークは、自動化された時間分散ベースの関心領域検出、多段階の Sim-to-Real 転移学習、および物理情報に基づいた正則化を組み合わせて、予測精度と物理的一貫性を強化します。合成事前トレーニング、シルバーラベル適応、専門家による微調整と並行して、トランスフォーマーベースや再帰畳み込みアーキテクチャなど、さまざまな時空間アーキテクチャが評価されました。結果は、変圧器ベースのアーキテクチャが瞬間予測の精度の点で優れている一方、軽量の反復畳み込みアーキテクチャがより高い時間的安定性と運用海洋学スキルを達成したことを示しています。アブレーション研究では、傾向追跡の一貫性と物理的にありえない予測という点で、物理学に基づく正則化の利点も実証されました。説明可能性監査は、流体力学的に活発なサーフゾーン領域に注意を集中させるのにも役立ち、物理的に導出された波の伝播挙動との良好な一致を示しました。一般に、提案されたフレームワークは、コスト効率が高く、運用上実現可能な、長期の沿岸波浪モニタリングのための物理学誘導ビデオベースの深層学習システムの可能性を示しています。
原文 (English)
Physics-Guided Spatiotemporal Learning for Coastal Wave Peak Period Estimation from Video
Wave parameters in the nearshore are crucial for coastal engineering, shoreline protection, marine hazard assessment, and coastal management for climate resilience. Traditional monitoring systems like buoys and radar platforms offer accurate monitoring but can have high installation and maintenance expenses and limited spatial coverage. Passive ocean monitoring using video has been achieved by leveraging deep learning, however, many methods are not physically interpretable, feasible, and validated for oceanography. In thiswork, a Physics-Guided Deep Spatiotemporal Learning Framework for direct estimation of nearshore wave peak periods from passive coastal video stream is proposed. The framework combines automated temporal-variance based region-of-interest detection, multi-stage Sim-to-Real transfer learning, and physics-informed regularization to enhance the predictive accuracy and physical consistency. A variety of spatiotemporal architectures were assessed, such as transformer-based and recurrent-convolutional ones, alongside synthetic pretraining,silver-label adaptation, and expert fine-tuning. The results show that transformer-based architectures outperformed in terms of the accuracy of the instantaneous prediction, while lightweight recurrent-convolutional architectures achieved higher temporal stability and operational oceanographic skill. Ablation studies also demonstrated the benefits of physics-guided regularization in terms of trend-following consistency, and physically implausible predictions. Explainability auditing also helped to focus attention in hydrodynamically active surf-zone regions and showed good agreement with the physically derived wave propagation behavior. In general, the proposed framework shows the promise of physics-guided video-based deep learning systems for long-term coastal wave monitoring that are cost-efficient and operationally feasible.
ReSum: LLM 推論と要約と強化学習の相乗効果
検証可能な報酬による強化学習 (RLVR) は、大規模言語モデル (LLM) における長期的な推論を改善するための中心的な手法です。ただし、既存の RLVR 手法では、推論の展開が不必要に長くなり、推論の一貫性が低下し、利用可能なコンテキスト バジェットが使い果たされる可能性があります。ロングコンテキストの組織化に対する既存のアプローチは、多くの場合、モデルが独自の推論軌道を管理できるようにするのではなく、ロールアウトを組織化する外部メカニズムに依存しています。この制限に対処するために、LLM が自己要約を通じて推論の軌跡を圧縮して整理できるようにする新しい RLVR フレームワークである ReSum を提案します。私たちのパイロット研究では、自己要約がトークンレベルのエントロピーを下げることで生成を安定化させ、「要約」フレーズを導入することで不正なロールアウトプレフィックスから伝播するエラーを大幅に軽減できることが示されています。これらの発見に動機づけられて、ReSum は、自己要約が進行中の推論プロセスに利益をもたらすかどうかを対照的に評価する、要約を意識した適応型ロールアウト メカニズムを採用しています。具体的には、モデルが自発的に自己要約をトリガーすると、ReSum は要約フレーズをマスクして対照的な分岐を作成します。非要約位置の場合は、代わりにフレーズをランダムに挿入して、一致したブランチを作成します。さらに、要約を意識した利点を設計して、対照的なロールアウト軌跡間のより詳細な比較を可能にします。広範な実験により、ReSum はロールアウトの長さを 18.6\% 短縮しながら、パフォーマンスを平均 4\% 向上させることが示されました。
原文 (English)
ReSum: Synergizing LLM Reasoning and Summarization with Reinforcement Learning
Reinforcement Learning with Verifiable Rewards (RLVR) is a central technique for improving long-horizon reasoning in Large Language Models (LLMs). However, existing RLVR methods often encourage unnecessarily long reasoning rollouts, which can degrade reasoning coherence and exhaust the available context budget. Existing approaches to long-context organization often depend on external mechanisms to organize rollouts, rather than enabling the model to manage its own reasoning trajectory. To address this limitation, we propose ReSum, a novel RLVR framework that enables LLMs to compress and organize their reasoning trajectories through self-summarization. Our pilot studies show that self-summarization stabilizes generation by lowering token-level entropy, and that introducing a ``summarization'' phrase can substantially mitigate errors propagated from an incorrect rollout prefix. Motivated by these findings, ReSum adopts a summarization-aware adaptive rollout mechanism that contrastively evaluates whether self-summarization benefits the ongoing reasoning process. Specifically, when the model spontaneously triggers self-summarization, ReSum masks the summarization phrase to create a contrastive branch; for non-summarization positions, it instead randomly injects the phrase to create a matched branch. We further design a summarization-aware advantage to enable finer-grained comparison between contrastive rollout trajectories. Extensive experiments show that ReSum improves performance at an average of 4\% while reducing rollout length by 18.6\%.
KV キャッシュを購入できますか?
現在、世界中で AI エージェントが同じ不条理な行為を繰り返しています。1 つの文書を読み取るために、それぞれがそれを最初から再計算します。すべてのエージェントは、大規模モデルで最も計算量の多いステップであるプレフィルを同一のテキストに対して再実行し、エージェントが構築する前にエージェントが構築したものと同じキー/値 (KV) キャッシュを再構築します。同じ答えを 100 万回計算したものです。私たちは、一度計算するという、ほとんど不快なほど単純な提案を行います。発行者にドキュメントの KV キャッシュを事前計算させ、他のすべてのエージェントにドキュメントをロードして事前入力をスキップする権利を購入させます。それは機能し、トークン正確です。事前に計算された KV をロードし、精度を犠牲にすることなく、最初から (24/24 の貪欲なトークン、およびロジット レベルで) 事前入力された一致を継続します。 Qwen3-4B では、再利用はプレフィルよりも計算コストが 9 ~ 50 倍安く、その差は長さに応じて広がるため (プレフィルの注意は L^2 に応じて拡大します)、1 回の再利用ですでに元が取れています。次に重要なのは、KV がどこに住んでいるかです。 KV はほぼ非圧縮であるため、出荷に失敗します。そのため、ロードごとの出力コストが、節約されるプレフィルよりも高くなります。本番環境のプロンプト キャッシュが機能するのとまったく同じように、プロバイダー側でホストすると、下りは完全に削除されます。賞金のサイズは、当社が測定したコンピューティング節約量によって設定されます。1 つのホット 3774 トークン ドキュメントを 8,000 万のエージェントに提供するには、再入力に約 150 万ドルかかりますが、再利用コンピューティングはわずか約 0.03 万ドル (49.7 分の 1) です。 API の 0.1 倍のキャッシュ読み取り料金は、この測定範囲内にあるユーザーに 10 倍の割引を与えるため、10 倍は測定された最大 50 倍のコンピューティング節約をクリアする下限であり、物理的な最大 50 倍との差はプロバイダーのマージンです。つまり、人気のあるドキュメントあたり数百万ドルになります。結果として得られるエージェントネイティブのプレフィル CDN をフレーム化して、ロスレス KV 圧縮とクロスパーティ支払いレイヤーを未解決の問題として残します。
原文 (English)
Can I Buy Your KV Cache?
Right now, across the world, AI agents are repeating the same absurd act: to read one document, they each recompute it from scratch. Every agent re-runs prefill, the most compute-intensive step a large model takes, over identical text, only to rebuild a key-value (KV) cache identical to the one the agent before it just built. The same answer, computed a million times. We make a proposal that is almost offensively simple: compute it once. Let a publisher precompute a document's KV cache, and let every other agent buy the right to load it and skip prefill. It works, and it is token-exact: loading a precomputed KV and continuing matches prefilling from scratch (24/24 greedy tokens, and at the logits level), with no accuracy cost. On Qwen3-4B, reuse is 9-50x cheaper in compute than prefill, and the gap widens with length (prefill's attention scales with L^2), so a single reuse already pays it back. Then the part that matters: where the KV lives. Shipping it fails, because KV is nearly incompressible, so per-load egress costs more than the prefill it saves. Hosting it provider-side, exactly as production prompt-caching works, removes egress entirely. The size of the prize is set by our measured compute saving: serving one hot 3774-token document to 80M agents costs ~$1.5M to re-prefill but only ~$0.03M of reuse compute (49.7x less). The 0.1x cache-read tariff APIs charge passes a 10x discount to users while sitting inside this measured envelope, so the 10x is a floor that the measured ~50x compute saving clears, and the gap to the physical ~50x is provider margin: millions of dollars per popular document. We frame the resulting agent-native prefill CDN and leave lossless KV compression and a cross-party payment layer as the open problems.
IterCAD: 視覚に基づいた CAD の生成と編集のための反復マルチモーダル エージェント
コンピュータ支援設計は現代の製造において極めて重要ですが、既存の自動化手法は主にオープンループのワンショット生成に依存しており、現実世界の反復的な実践との不一致が生じています。このペーパーでは、閉ループの対話型 CAD 生成と編集のための統合マルチモーダル エージェント フレームワークである IterCAD について紹介します。このタスクは、マルチモーダル エージェントと実行可能な CAD サンドボックス間のマルチターン インタラクションとして定式化され、描画からコード、テキストからコード、対話型編集の 3 つのタスクをカバーします。これをサポートするために、標準に準拠したマルチビューのエンジニアリング図面、複雑なコード編集タスク、および忠実度の高いインタラクション軌跡を生成するための高度な工業製造機能を組み込んだデータ合成パイプラインを開発します。プログレッシブ SFT を介してエージェントを最適化し、その後、実行可能なプレフィックス マスキングを使用したジオメトリを意識した強化学習を実行して、コードの実行可能性と幾何学的忠実度を強化します。最後に、IterCAD-Bench 評価スイートを導入し、AUC-TR メトリクスと並行して面取り距離許容差-再現率 (CD-TR) 曲線を提案し、コードの有効性と幾何学的精度を統合する生存者バイアスのない標準を確立します。広範な実験により、IterCAD が複数のベンチマークにわたって非常に競争力のあるパフォーマンスを達成し、コードの実行性と幾何学的精度の両方で既存のアプローチを大幅に上回っていると同時に、閉ループ反復改良において優れた機能を示していることが実証されています。
原文 (English)
IterCAD: An Iterative Multimodal Agent for Visually-Grounded CAD Generation and Editing
Computer-Aided Design is pivotal in modern manufacturing, yet existing automated methods predominantly rely on open-loop, one-shot generation, creating a mismatch with iterative real-world practices. In this paper, we present IterCAD, a unified multimodal agent framework for closed-loop, interactive CAD generation and editing. We formulate the task as a multi-turn interaction between a multimodal agent and an executable CAD sandbox, covering three tasks: Drawing-to-Code, Text-to-Code, and Interactive Editing. To support this, we develop a data synthesis pipeline incorporating advanced industrial manufacturing features to generate standard-compliant multi-view engineering drawings, complex code-editing tasks, and high-fidelity interaction trajectories. We optimize the agent via progressive SFT followed by geometry-aware reinforcement learning with viable-prefix masking to enhance code executability and geometric fidelity. Finally, we introduce the IterCAD-Bench evaluation suite and propose the Chamfer Distance Tolerance-Recall (CD-TR) curve alongside its AUC-TR metric, establishing a survivor-bias-free standard that unifies code validity and geometric precision. Extensive experiments demonstrate that IterCAD achieves highly competitive performance across multiple benchmarks, significantly outperforming existing approaches in both code executability and geometric precision, while exhibiting superior capabilities in closed-loop iterative refinement.
コンピューティングを意識したトークン予算の下での小さなラマ スタイル言語モデルにおけるトレーニング ダイナミクスの定量的実験的反復測定研究
この研究では、固定のコンピューティング制約のあるトークン バジェットの下でトレーニングされた小さな Llama スタイルの言語モデルにおけるトレーニングのダイナミクスを調べます。この研究では、エンドポイントのパフォーマンスだけで効率を評価するのではなく、定量的な実験反復測定設計を使用して、検証損失、検証の複雑さ、ローリングボラティリティ、バックスライド挙動、スパイク挙動、シード間の変動性がトークンベースのトレーニング間隔でどのように変化するかを分析しています。 TinyStories コーパス、CPU ベースの完全精度トレーニング、および累計トレーニング トークン約 2,000 万の目標予算を使用して、426 万のパラメーター モデルで 6 つの独立したトレーニング実行が実行されました。メトリクスは 21 の間隔にわたって収集され、126 個の間隔ごとのシード観測が生成されました。反復測定 ANOVA では、検証損失、検証の複雑さ、およびローリング ボラティリティに対して統計的に有意な間隔効果が示されました。記述的な軌跡により、初期の急速な改善と、その後のトレーニング間隔での非単調な低下が明らかになりました。平均検証損失は、初期化時の 8.3552 から 400 万トークン近くの 2.7996 に減少しましたが、最後のチェックポイントまでに 3.9010 に増加しました。検証の複雑さは同じパターンに従い、トレーニングの初期に急激に低下し、その後上昇しました。さらに、派生テレメトリーでは、検証損失のバックスライドが再発し、事前定義された基準の下で安定期の間隔要約の証拠がないことが示されました。これらの調査結果は、コンピューティングを意識した言語モデルの評価では、エンドポイントのメトリクスだけではなく、トレーニングの軌跡を調査する必要があることを示唆しています。制約されたコンピューティング設定では、追加のトークンの露出により、比例的な一般化ゲインが得られずに計算コストが増加する可能性があり、間隔レベルのテレメトリによって、最終的なメトリクスでは不明瞭になる可能性のある不安定性、回帰、および収益の逓減が明らかになる可能性があります。
原文 (English)
A Quantitative Experimental Repeated Measures Study of Training Dynamics in a Small Llama Style Language Model Under a Compute-Aware Token Budget
This study examines training dynamics in a small Llama-style language model trained under a fixed, compute-constrained token budget. Rather than evaluating efficiency solely through endpoint performance, the study uses a quantitative experimental repeated measures design to analyze how validation loss, validation perplexity, rolling volatility, backslide behavior, spike behavior, and between-seed variability change across token-based training intervals. Six independent training runs were conducted on a 4.26-million-parameter model using the TinyStories corpus, CPU-based full-precision training, and a target budget of approximately 20 million cumulative training tokens. Metrics were collected across 21 intervals, producing 126 seed-by-interval observations. Repeated measures ANOVA showed statistically significant interval effects for validation loss, validation perplexity, and rolling volatility. Descriptive trajectories revealed rapid early improvement followed by non-monotonic degradation during later training intervals. Mean validation loss decreased from 8.3552 at initialization to 2.7996 near 4 million tokens, but increased to 3.9010 by the final checkpoint. Validation perplexity followed the same pattern, falling sharply early in training before rising later. Derived telemetry further showed recurrent validation-loss backslides and no interval-summary evidence of a stable phase under the predefined criteria. These findings suggest that compute-aware language model evaluation should examine training trajectories rather than endpoint metrics alone. In constrained compute settings, additional token exposure may increase computational cost without producing proportional generalization gains, and interval-level telemetry can reveal instability, regression, and diminishing returns that final metrics may obscure.
MiniMax のまばらな注意力
超ロングコンテキスト機能は、フロンティア LLM にとって不可欠になりつつあります。エージェントのワークフロー、リポジトリ規模のコード推論、および永続メモリのすべてでは、モデルが数十万から数百万のトークンに共同で参加する必要がありますが、ソフトマックス アテンションの 2 次コストにより、展開規模ではこれを維持できなくなります。 Grouped Query Attendance (GQA) に基づいて構築されたブロック単位の疎なアテンションである MiniMax Sparse Attendance (MSA) を導入します。軽量のインデックス ブランチは、キーと値のブロックをスコア付けし、各 GQA グループの Top-k サブセットを独立して選択します。これにより、効率的なブロック レベルの実行を維持しながら、グループ固有のスパース取得が可能になります。次に、メイン ブランチは、選択されたブロックのみに対して正確なブロック スパース アテンションを実行します。シンプルさとスケーラビリティの原則に基づいて設計された MSA は意図的に合理化されており、幅広い GPU に効率的に導入することが簡単になります。スパース性を実用的な高速化に変換するために、Exp-free Top-k 選択と KV-outer スパース アテンションを使用する GPU 実行パスを使用して MSA を共同設計し、ブロック単位のアクセスでのテンソルコアの使用率を向上させます。ネイティブ マルチモーダル トレーニングを備えた 109B パラメーター モデルでは、MSA は GQA と同等のパフォーマンスを発揮しながら、トークンごとのアテンション コンピューティングを 1M コンテキストで 28.4 倍削減します。共同設計したカーネルと組み合わせると、MSA は H800 上で 14.2 倍のプレフィルと 7.6 倍のデコード ウォールクロックの高速化を達成します。私たちの推論カーネルは、https://github.com/MiniMax-AI/MSA から入手できます。 MSA を利用した実稼働グレードのネイティブ マルチモーダル モデルは、https://huggingface.co/MiniMaxAI/MiniMax-M3 で公開されています。
原文 (English)
MiniMax Sparse Attention
Ultra-long-context capability is becoming indispensable for frontier LLMs: agentic workflows, repository-scale code reasoning, and persistent memory all require the model to jointly attend over hundreds of thousands to millions of tokens, yet the quadratic cost of softmax attention makes this untenable at deployment scale. We introduce MiniMax Sparse Attention (MSA), a blockwise sparse attention built upon Grouped Query Attention (GQA). A lightweight Index Branch scores key-value blocks and independently selects a Top-k subset for each GQA group, enabling group-specific sparse retrieval while maintaining efficient block-level execution; the Main Branch then performs exact block-sparse attention over only the selected blocks. Designed around a principle of simplicity and scalability, MSA is deliberately streamlined, making it straightforward to deploy efficiently across a broad range of GPUs. To translate sparsity into practical speedups, we co-design MSA with a GPU execution path that uses exp-free Top-k selection and KV-outer sparse attention to improve tensor-core utilization under block-granular access. On a 109B-parameter model with native multimodal training, MSA performs on par with GQA while reducing per-token attention compute by 28.4x at 1M context. Paired with our co-designed kernel, MSA achieves 14.2x prefill and 7.6x decoding wall-clock speedups on H800. Our inference kernel is available at: https://github.com/MiniMax-AI/MSA. A production-grade natively multimodal model powered by MSA has been publicly released at: https://huggingface.co/MiniMaxAI/MiniMax-M3.
規制されたプロセスオートメーションのための神経象徴エージェント: 課題と研究課題
LLM ベースのエージェントは規制された業界に参入しており、そこで判断集中の品質管理プロセスを自動化しています。私たちは、規制、型指定されたプロセスモデル、コンプライアンスの制約など、これらのドメインにすでに埋め込まれている象徴的な構造は、単なる外部監視メカニズムとしてではなく、エージェントの意思決定と行動を形成するコアアーキテクチャコンポーネントとして扱う必要があると主張します。私たちは、ガードレールベースのモニタリングを補完するパラダイムとして、コンプライアンス・バイ・コンストラクションを提案します。ガードレールはセマンティックエラーを捕捉するために引き続き不可欠である一方、制御フロー違反を防ぐ構造的基盤です。私たちは、基礎レベルと能力レベルで神経象徴的な研究課題の構造化されたセットを特定し、それらに共同で対処することでコンプライアンス・バイ・コンストラクションが可能になることを示します。私たちは神経象徴コミュニティに対し、影響力の高い研究領域として規制されたプロセス自動化に取り組むよう呼びかけます。
原文 (English)
Neuro-Symbolic Agents for Regulated Process Automation: Challenges and Research Agenda
LLM-based agents are entering regulated industries where they automate judgment intensive quality management processes. We argue that symbolic structures already embedded in these domains, including regulations, typed process models, and compliance constraints, should be treated not merely as external monitoring mechanisms but as core architectural components that shape the agent's decision-making and behavior. We propose compliance-by-construction as a complementary paradigm to guardrail-based monitoring: a structural foundation that prevents control-flow violations, while guardrails remain essential for catching semantic errors. We identify a structured set of neuro-symbolic research challenges on foundational and capability level and show that addressing them jointly enables compliance-by-construction. We call on the neuro-symbolic community to engage with regulated process automation as a high impact research domain.
メタヒューリスティック アルゴリズムを使用した太陽エネルギー管理のための機器のスケジュールの最適化
再生可能エネルギーは将来のエネルギー需要を満たすために不可欠です。しかし、太陽光発電は日中のみに発生するため、多くの場合、家庭の消費パターンと一致しません。調理器、洗濯機、乾燥機などの家電製品は、通常、太陽エネルギーの利用状況ではなく、ユーザーの好みのスケジュールに従って動作するため、スケジュールの最適化の問題が生じます。目的は、ユーザーの不便を最小限に抑え、システムの制約を遵守しながら、再生可能エネルギーの利用を最大化するために最適な機器の起動時間を決定することです。このペーパーでは、反復ローカル検索 (ILS) とシミュレーテッド アニーリング (SA) を使用して、アプライアンスの動作時間、消費電力、インバーターの制限、バッテリーの充電状態の制約、および太陽光発電の予測を考慮しながら、アプライアンスの起動時間を最適化するメタヒューリスティック アプローチを紹介します。既存のほとんどの作業とは異なり、スケジューリングは前日の未完了のタスク (スピルオーバー) に対応するために 1 日を超えて延長され、運用の継続性が確保され、複数日にまたがる連続的な運用が可能になります。実験結果は、連続的な複数日のスケジューリング フレームワークがシステムの制約を効果的に管理しながら、専用の太陽光発電の下でユーザーの利便性を確保することを示しています。これらの発見は、さまざまな規模の機器への投資、その投資収益率、およびユーザーの満足度の間の多目的のトレードオフに関する将来の研究の機会も開きます。
原文 (English)
Optimizing Appliance Scheduling for Solar Energy Management Using Metaheuristic Algorithms
Renewable energy is essential for meeting future energy demands; however, solar energy generation, which occurs only during daylight hours often does not align with household consumption patterns. Appliances such as cookers, washing machines, and dryers are typically operated according to user preferred schedules rather than solar energy availability, creating a scheduling optimization problem. The objective is to determine optimal appliance start times to maximize renewable energy utilization while minimizing user inconvenience and adhering to system constraints. This paper presents a metaheuristic approach using Iterated Local Search (ILS) and Simulated Annealing (SA) to optimize appliance start times, while considering appliance operating durations, power consumption, inverter limit, battery state of charge constraints, and solar generation forecasts. Unlike most existing work, the scheduling is extended beyond a single day to accommodate unfinished tasks from previous days (spillover), ensuring operational continuity and enabling sequential operation across multiple days. Experimental results show that the sequential multi-day scheduling framework effectively manages system constraints while ensuring user convenience under exclusive solar generation. These findings also open opportunities for future research on multi-objective trade-offs between investment in equipment of various sizes, return on that investment, and user satisfaction.
メタデータ駆動型分類における評価主権: 弱く監視された情報システムのためのマルチトラック フレームワーク
機械学習における評価は通常、中立的な測定プロセスとして扱われます。ただし、運用情報システムでは、ラベルの生成に使用されるプロセスによって評価結果が条件付けされることがよくあります。この文書は、分類パフォーマンスの向上を目指したものではありません。代わりに、さまざまなレーベル権限体制の下でのパフォーマンス測定の妥当性を検証します。この問題は、ラベルが不完全、一貫性がない、または監視が不十分であることが多い大規模なメタデータ駆動型システムに特に関係します。我々は、パフォーマンス指標がラベルの権限や監督体制から独立している度合いとして定義される評価主権を導入し、トレーニングと評価のラベルソースを系統的に変更するマルチトラック評価フレームワークを提案します。大規模な科学メタデータの階層的マルチラベル分類を使用して、運用 (「シルバー」) 評価で優れたパフォーマンスを示すモデルが、独立 (「ゴールド」) 評価では、特に詳細な分類の場合に大幅に低下することを実証します。たとえば、Micro-F1 は約 0.54 から 0.03 に減少します。特に、ランキングベースのメトリクスはベースラインを上回ったままであり、潜在モデル信号と分類の妥当性の間の乖離が明らかになっています。これらの調査結果は、一般的に報告されるパフォーマンス指標が、真の予測能力ではなく、ラベル付けプロセスとの整合性を反映している可能性があることを示唆しています。したがって、私たちは評価の妥当性をラベルガバナンスによって形成されるシステムレベルの特性として再概念化し、弱い監視下で動作するインテリジェントシステムを監査するための実用的な方法論を提供します。
原文 (English)
Evaluation Sovereignty in Metadata-Driven Classification: A Multi-Track Framework for Weakly Supervised Information Systems
Evaluation in machine learning is typically treated as a neutral measurement process. However, in operational information systems, evaluation outcomes are often conditioned by the processes used to generate labels. This paper does not seek to improve classification performance. Instead, it examines the validity of performance measurement under differing label-authority regimes. This issue is particularly relevant in large-scale metadata-driven systems, where labels are often incomplete, inconsistent, or weakly supervised. We introduce evaluation sovereignty, defined as the degree to which performance metrics are independent of label authority and supervision regime, and propose a multi-track evaluation framework that systematically varies training and evaluation label sources. Using hierarchical multi-label classification on large-scale scientific metadata, we demonstrate that models exhibiting strong performance under operational ("silver") evaluation degrade substantially under independent ("gold") evaluation, particularly for fine-grained classification. For example, Micro-F1 decreases from approximately 0.54 to 0.03. Notably, ranking-based metrics remain above baseline, revealing a divergence between latent model signal and classification validity. These findings suggest that commonly reported performance metrics may reflect alignment with labeling processes rather than true predictive capability. We therefore reconceptualize evaluation validity as a system-level property shaped by label governance and provide a practical methodology for auditing intelligent systems operating under weak supervision.
サンプリングが選択されない理由: 大規模言語モデルにおける意図性、主体性、道徳的責任
大規模言語モデル (LLM) の最近の進歩により、そのようなシステムは主体性を示す、または道徳的エージェントとしての資格があるという主張がなされています。この論文は、これらの帰属は誤解であると主張します。私たちは、道徳的責任には、本質的な意図性と自己帰属的行動に基づくコミットメントを伴う主体性が必要であり、そのような主体性は責任に関連する自由意志の形態を構成すると主張します。 LLM は一貫性があり規範的に評価可能な出力を生成しますが、その動作はデータから学習された確率的な入出力マッピングによって完全に特徴付けられます。彼らの明らかな意図性は、本質的ではなく派生したものであり、彼らの成果はコミットメントとして所有されたり、理由によって導かれたりするものではありません。確率的サンプリングによってもたらされる変動は、選択や作成者によるものではありません。私たちは、意図的な立場、機能主義、互換主義、モデル出力における道徳的推論の存在からの反対意見に対処し、真の主体性を確立するにはどれも十分ではないと主張します。
原文 (English)
Why Sampling Is Not Choosing: Intentionality, Agency, and Moral Responsibility in Large Language Models
Recent advances in large language models (LLMs) have prompted claims that such systems exhibit agency or qualify as moral agents. This paper argues that these attributions are misguided. We maintain that moral responsibility requires commitment-bearing agency grounded in intrinsic intentionality and self-attributed action, and that such agency constitutes the form of free will relevant to responsibility. Although LLMs generate coherent and normatively evaluable outputs, their operation is fully characterized by probabilistic input-output mappings learned from data. Their apparent intentionality is derived rather than intrinsic, and their outputs are neither owned as commitments nor guided by reasons. Variability introduced by stochastic sampling does not amount to choice or authorship. We address objections from the intentional stance, functionalism, compatibilism, and the presence of moral reasoning in model outputs, arguing that none suffice to establish genuine agency.
CloudCons: クラウド リソース統合のための包括的なエンドツーエンド ベンチマーク
サービスの信頼性を保証するための保守的な過剰プロビジョニングにより、クラウド データ センターのリソース使用率は低いレベルにとどまっています。これを軽減するために、将来の需要を予測して統合を最適化する、「予測してから最適化する」パラダイムが登場しました。新しい時系列基盤モデルはゼロショット一般化を通じてこのパラダイムを強化すると約束していますが、既存のベンチマークは予測誤差メトリクスのみに焦点を当てています。これらの高度なモデルの実際の意思決定の有用性は未検証のままであり、下流のタスクにおける実用的な価値は不確実です。このギャップを埋めるために、クラウド リソース統合の特定のコンテキスト内で予測モデルを評価するように設計された包括的なエンドツーエンドのベンチマークである CloudCons を提案します。当社は、Huawei Cloud、Microsoft Azure、Google Borg のさまざまなワークロードをカバーする高品質のデータセットを構築し、同期した日内リズムから確率的でパルス状のバーストや高周波ノイズに至るまで、明確なサービス特性をキャプチャします。私たちは、統計モデル、深層学習モデル、基礎モデルの広範な評価を実施します。私たちの実験では、極めて重要な発見が明らかになりました。基礎モデルは優れたゼロショット予測精度を示していますが、この利点は本質的により優れた意思決定の有用性につながるわけではありません。実際的に重要なのは、予測分位数の選択が重要なレバーとしてどのように機能するかを系統的に分析することです。これらの選択を調整してリソース効率とサービスの信頼性の間のトレードオフのバランスをとるための実用的なガイドラインを提供し、実際の展開の決定に重要な洞察を提供します。
原文 (English)
CloudCons: A Comprehensive End-to-End Benchmark for Cloud Resource Consolidation
Driven by conservative over-provisioning to guarantee service reliability, resource utilization in cloud data centers remains at low levels. To mitigate this, the forecast-then-optimize paradigm has emerged to optimize consolidation by anticipating future demands. While emerging time series foundation models promise to enhance this paradigm through zero-shot generalization, existing benchmarks focus solely on prediction error metrics. The actual decision utility of these advanced models remains unverified, rendering their practical value for downstream tasks uncertain. To bridge this gap, we propose CloudCons, a comprehensive end-to-end benchmark designed to evaluate forecasting models within the specific context of cloud resource consolidation. We build high-quality datasets that cover diverse workloads from Huawei Cloud, Microsoft Azure, and Google Borg, capturing distinct service characteristics ranging from synchronized diurnal rhythms to stochastic, pulse-like bursts and high-frequency noise. We conduct an extensive evaluation of statistical, deep learning, and foundation models. Our experiments reveal a pivotal finding: while foundation models demonstrate superior zero-shot forecasting accuracy, this advantage does not inherently translate into better decision utility. Of practical significance, we systematically analyze how the selection of predictive quantiles acts as a critical lever. We provide actionable guidelines for calibrating these selections to balance the trade-off between resource efficiency and service reliability, offering vital insights for real-world deployment decisions.
長い文書 RAG のための不確実性を考慮したハイブリッド検索
検索拡張生成 (RAG) は、取得された証拠の品質と粒度に大きく依存します。大規模な検索ユニットはコンテキストを保持しますが、多くの場合、無関係なコンテンツが導入されるため、証拠を含む回答が薄れ、長いコンテキストの利用が悪化する可能性があります。きめの細かい単位はよりコンパクトですが、短いチャンクにはクエリと一致するために必要な意味論的、語彙的、またはブリッジングの手がかりが欠けている可能性があるため、確実に取得することが難しい場合があります。我々は、チャンク粒度をクエリ固有の信頼性推定として扱う、トレーニング不要のハイブリッド検索フレームワークである不確実性を考慮したマルチ粒度 RAG (UMG-RAG) を提案します。新しいリトリーバーをトレーニングしたり、ジェネレーターを変更したりする代わりに、UMG-RAG は既存の高密度リトリーバーとスパース リトリーバーを複数のチャンク粒度にわたる補完的なエキスパートとして使用します。クエリごとに、各エキスパート粒度スコア リストを証拠分布に変換し、分布エントロピーから信頼性を推定し、クエリ固有の意味論、語彙、粒度の信頼度に従って候補を融合します。さらに、局所的な一貫性のためにより広範な非冗長の親チャンクを返しながら、きめ細かいヒットを使用して関連する証拠を見つける親プロモーションのバリアントである UMGP-RAG を紹介します。質問応答ベンチマークの実験では、不確実性を考慮した融合と親のプロモーションにより、軽量のプラグアンドプレイ取得パイプラインを維持しながら、生成品質が向上することが示されています。
原文 (English)
Uncertainty-Aware Hybrid Retrieval for Long-Document RAG
Retrieval augmented generation (RAG) depends critically on the quality and granularity of retrieved evidence. Large retrieval units preserve context but often introduce irrelevant content, which can dilute answer bearing evidence and worsen long context utilization. Fine-grained units are more compact, but they may be difficult to retrieve reliably because short chunks can lack semantic, lexical, or bridging cues needed to match the query. We propose Uncertainty-aware Multi-Granularity RAG (UMG-RAG), a training-free hybrid retrieval framework that treats chunk granularity as query-specific reliability estimation. Instead of training a new retriever or modifying the generator, UMG-RAG uses existing dense and sparse retrievers as complementary experts across multiple chunk granularities. For each query, it converts each expert-granularity score list into an evidence distribution, estimates reliability from distribution entropy, and fuses candidates according to query-specific semantic, lexical, and granularity confidence. We further introduce UMGP-RAG, a parent promotion variant that uses fine-grained hits to locate relevant evidence while returning broader non-redundant parent chunks for local coherence. Experiments on question answering benchmarks show that uncertainty-aware fusion and parent promotion improve generation quality while maintaining a lightweight, plug-and-play retrieval pipeline.
それはあなたですか、それともあなたの環境ですか?ゲノムにアンカーされた個別の生理学的解釈のためのベイジアン推論フレームワーク
パーソナライズされた健康 AI システムは、基本的なコールド スタートの問題に直面しています。生理学的解釈のための機械学習モデルでは、体質の変化と環境による逸脱を区別できるようになるまでに、数週間にわたる個人の行動データが必要です。私たちは、因果推論とベイジアン事前設計に基づいたソリューションを提案します。個人のゲノムプロファイルは、外因性の遺伝的アンカーとして機能します。これは、受胎時に固定され、逆因果関係の影響を受けず、単一の行動観察が収集される前に利用できる、ドメイン情報に基づいて個別化された事前情報です。アンカーは、個人の生理学的設定値 G-hat = mu + sum(beta_i * g_i) に対するベイズ信念状態を初期化します。ここで、beta_i は GWAS 由来の効果量、g_i はリスク対立遺伝子数です。入力される各生理学的測定値 P は、環境および状態に起因する信号を構成的に固定されたベースラインから分離する非構成的な偏差デルタ = P - G ハットを生成します。行動データが蓄積するにつれて、事前確率は G-hat_t = w(t)*G-hat_genomic + [1-w(t)]*P-bar_t に従って減衰し、ゲノム主導の推論から経験ベースライン主導の推論に移行します。同じ観察された 55 ミリ秒の HRV は、事前予測が 80 ミリ秒である人には抑制仮説を生成し、事前予測が 30 ミリ秒である人には増強仮説を生成します。これは、パーソナライズされたアンカーがなければ逆転は不可能です。私たちはこのアーキテクチャを6つの生理学的ドメインにわたって開発し、証拠の強さによってゲノム事前情報を格付けし、堅牢に複製されたアンカー(FTO、FADS1/2、FKBP5)を競合する候補遺伝子(SLC6A4、MAOA、DRD2)から区別します。私たちは、関連性、メンデル的ランダム化、および個々のトークンの因果関係の間の推論境界に対処し、展開のための 4 つの制約を定義します。証拠に基づく事前分布、動的減衰、祖先と一致する効果の大きさ、および決定論的な出力ではなく帰属です。
原文 (English)
Is It You or Your Environment? A Bayesian Inference Framework for Genomically-Anchored Personalized Physiological Interpretation
Personalized health AI systems face a fundamental cold-start problem: machine learning models for physiological interpretation require weeks of individual behavioral data before they can distinguish constitutional variation from environmentally driven deviation. We propose a solution grounded in causal inference and Bayesian prior design. An individual's genomic profile serves as an exogenous genetic anchor -- a domain-informed, personalized prior that is fixed at conception, immune to reverse causation, and available before a single behavioral observation is collected. The anchor initializes a Bayesian belief state over an individual's physiological set point G-hat = mu + sum(beta_i * g_i), where beta_i are GWAS-derived effect sizes and g_i are risk-allele counts. Each incoming physiological measurement P produces a non-constitutional deviation delta = P - G-hat that separates the signal attributable to environment and state from the constitutionally fixed baseline. As behavioral data accrue, the prior decays according to G-hat_t = w(t)*G-hat_genomic + [1-w(t)]*P-bar_t, transitioning from genome-dominated to empirical-baseline-dominated inference. The same observed HRV of 55 ms generates a suppression hypothesis for a person whose prior predicts 80 ms, and an enhancement hypothesis for a person whose prior predicts 30 ms -- a reversal impossible without a personalized anchor. We develop this architecture across six physiological domains, grading genomic priors by evidence strength, distinguishing robustly replicated anchors (FTO, FADS1/2, FKBP5) from contested candidate genes (SLC6A4, MAOA, DRD2). We address the inference boundary between association, Mendelian randomization, and individual token causation, and define four constraints for deployment: evidence-graded priors, dynamic decay, ancestry-matched effect sizes, and attribution rather than deterministic output.
科学的発見における AI の 3 層フレームワーク
科学的発見における AI に関する現在の議論は、多くの場合、既存の知識の検索と、最適化、シミュレーション、自動化による実行という 2 つの目に見える機能によって占められています。どちらも重要ですが、どちらも発見の中心となる行為、つまりモデルの形成と進化を完全には捉えていません。この論文では、発見における AI の 3 層のビューを提案します。レイヤ 1 は、大規模な言語モデルによる検索と取得です。この論文の主な革新であるレイヤー 2 は、定性的推論によるモデルの形成です。つまり、現在のフレームワークが構造的に不適切であることを認識し、試行錯誤ではなく、何が欠けていてどこで見つかるのかについての構造的な洞察を通じて、より広い表現空間内で問題を理解する能力です。レイヤ 3 は実行、最適化、改良です。主な主張は、レイヤー 2 が最も重要であると同時に最も開発されていないということです。モデル形成のない探索は継承されたフレームワークに限定されたままですが、概念の修正なしで実行すると既存の定式化が増幅されるだけです。我々は、S. S. チャーンによるガウス・ボネット定理の本質的証明、リアプノフ関数によるネステロフ加速勾配収束問題の解決、および 2026 年の OpenAI によるエルドス単位距離予想の自律的反証という 3 つのケーススタディを通じて、レイヤー 2 推論を説明します。各ケースは、同じ構造的特徴を示しています。つまり、不適切になったフレームワーク、欠落している概念オブジェクト、およびで見つかった解決策です。思わぬ隣の畑。
原文 (English)
A Three-Layer Framework for AI in Scientific Discovery
Current discussions of AI in scientific discovery are often dominated by two visible capabilities: search over existing knowledge and execution through optimization, simulation, and automation. Both are important, but neither fully captures the central act of discovery: the formation and evolution of models. This paper proposes a three-layer view of AI in discovery. Layer 1 is search and retrieval by large language models. Layer 2, as the main innovation of this paper, is model formation through qualitative reasoning: the capacity to recognize when a current framework is structurally inadequate and to understand the problem within a broader representational space, not through trial and error, but through structural insight into what is missing and where it can be found. Layer 3 is execution, optimization, and refinement. The main claim is that Layer 2 is both the most important and the least developed. Search without model formation remains confined to inherited frameworks, while execution without conceptual revision only amplifies an existing formulation. We illustrate Layer 2 reasoning through three case studies: S. S. Chern's intrinsic proof of the Gauss-Bonnet theorem, the resolution of the Nesterov Accelerated Gradient convergence problem via Lyapunov functions, and the autonomous disproof of the Erdos unit distance conjecture by OpenAI in 2026. Each case exhibits the same structural signature: a framework that had become inadequate, a missing conceptual object, and a resolution found in an unexpected neighboring field.
集約された信頼シグナルを備えたマルチエージェント プロトコル
信頼性は、自然言語処理 (NLP) における信頼性、監視、および下流の一連の意思決定タスクに使用されますが、マルチエージェント システムの出力に対する信頼性を生成または評価する既存の方法はありません。これまでの研究では、マルチエージェント ディベート (MAD) 内の信頼度を使用して、メッセージの重み付け、討論のトリガー、または個々のエージェントの調整を行っていましたが、これらをシステム自体の単一の信頼度に集約することはありませんでした。最初に生の信頼信号を変換してモデル間で比較できるようにし、次にソフト投票またはベイジアン融合と呼ばれる確率融合を介してそれらを組み合わせることで、単一の集約された信頼度とともに最終的な答えを生成する 3 つのプロトコルを紹介します。この集計された信頼度は、最良の単一エージェントや標準的な議論のベースラインよりも大幅に識別力が高くなります (AUARC) 一方で、正しさ (F1 スコア) は安定しており、より曖昧なタスクで MAD が被る損失を回復します。系列確率と自己報告という 2 つの推定量を、パラメトリックおよびノンパラメトリック キャリブレーターと並行して分析すると、キャリブレーションによって両方の推定量の F1 が向上する一方、AUARC の F1 への依存度が低下することがわかりました。さまざまなモデルの機能とサイズにまたがる、5 つのベンチマークと 4 つのタスク タイプにわたって、ベンチマークごとに 6 つの同種および異種のディベート ペアを評価します。
原文 (English)
Multiagent Protocols with Aggregated Confidence Signals
Confidence is used for reliability, oversight, and a range of downstream decision tasks in Natural Language Processing (NLP), yet no existing method produces or evaluates a confidence for the output of a multiagent system. Prior work uses confidence within multiagent debate (MAD) to weight messages, trigger debate, or calibrate individual agents, but it never aggregates these into a single confidence for the system itself. We introduce three protocols that produce a final answer along with a single aggregated confidence by first transforming raw confidence signals to make them comparable across models, then combining them via soft voting or a probability fusion we call Bayesian fusion. This aggregated confidence is substantially more discriminative (AUARC) than that of the best single agent or the standard debate baselines, while correctness (F1-score) stays stable and recovers the losses MAD incurs on more ambiguous tasks. Analyzing two estimators, sequence probability and self-report, alongside parametric and non-parametric calibrators, we find that calibration improves F1 for both estimators while AUARC is less reliant on it. We evaluate six homogeneous and heterogeneous debating pairs per benchmark, across five benchmarks and four task types, spanning a range of model capabilities and sizes.
マルチエージェントオーケストレーションのための報酬モデリング
大規模言語モデル (LLM) 上に構築されたマルチエージェント システム (MAS) には、特殊なエージェントを調整するための効果的なオーケストレーションが必要ですが、そのようなオーケストレーターのトレーニングは、限られた監視と高い計算コストによって妨げられています。私たちは、人間による注釈なしでオーケストレーションの品質を評価するための自己監視型フレームワークである Orchestration Reward Modeling (OrchRM) を提案します。 OrchRM は、マルチエージェント実行からの中間アーティファクトを利用して、Bradley-Terry 報酬モデル トレーニング用の勝敗ペアを構築します。コストのかかるサブエージェントのロールアウトに依存する既存の MAS テスト時間スケーリングおよびオーケストレーター トレーニング フレームワークとは異なり、OrchRM はオーケストレーション レベルで直接動作し、効率的かつ高パフォーマンスの報酬に基づくオーケストレーター トレーニングと MAS テスト時間スケーリングを可能にします。 OrchRM は、トークン使用量でトレーニング効率を最大 10 倍向上させ、MAS テスト時間のスケーリング パフォーマンスを精度で最大 8% 向上させます。これらの成果は、数学的推論、Web ベースの質問応答、マルチホップ推論などの複数のドメインに一貫して伝達され、オーケストレーション レベルの報酬モデリングが堅牢なマルチエージェント オーケストレーションのスケーラブルな方向性であることを示しています。コードは https://github.com/Wang-ML-Lab/OrchRM で入手できます。
原文 (English)
Reward Modeling for Multi-Agent Orchestration
Multi-Agent Systems (MAS) built on Large Language Models (LLMs) require effective orchestration to coordinate specialized agents, yet training such orchestrators is hindered by limited supervision and high computational cost. We propose Orchestration Reward Modeling (OrchRM), a self-supervised framework for evaluating orchestration quality without human annotations. OrchRM leverages intermediate artifacts from multi-agent executions to construct win-lose pairs for Bradley-Terry reward model training. Unlike existing MAS test-time scaling and orchestrator training frameworks that rely on costly sub-agent rollouts, OrchRM operates directly at the orchestration level, enabling efficient and high-performing reward-guided orchestrator training and MAS test-time scaling. OrchRM improves training efficiency by up to 10x in token usage while improving MAS test-time scaling performance by up to 8% in accuracy. These gains consistently transfer across multiple domains, including mathematical reasoning, web-based question answering, and multi-hop reasoning, demonstrating orchestration-level reward modeling as a scalable direction for robust multi-agent orchestration. Code will be available at https://github.com/Wang-ML-Lab/OrchRM.
EpiBench: エピゲノミクス分析における AI エージェントの検証可能な評価
短期間のエピゲノミクス分析のための検証可能なベンチマークである EpiBench を紹介します。 EpiBench は、エージェントが現実的なワークフロー状態から明確に定義された分析決定を下し、決定論的に評価可能な回答を返すことができるかどうかを評価します。このベンチマークには、CUT\&Tag/CUT\&RUN、ATAC-seq、ChIP-seq、および DNA メチル化ワークフローにわたる 106 の評価が含まれています。 16 のモデルとハーネスのペアからの 5,088 の有効な軌道にわたって、大部分の試行に合格したシステムはありませんでした。GPT-5.5 / Pi が 45.0\% (143/318 試行; 95\% 信頼区間 (CI)、36.3--53.7) でトップとなり、GPT-5.5 / OpenAI Codex が 39.9\% (127/318 試行; 95\% CI、31.6--48.3)。 Claude Opus 4.8 Max / Pi および GPT-5.4 / Pi はそれぞれ 39.0% を合格しました (試行回数 124/318、95% CI、それぞれ 30.2 ~ 47.8 および 31.0 ~ 47.0)。パフォーマンスはアッセイの種類によって異なり、失敗した実行の多くには依然として正解の一部が含まれています。エージェントは多くの場合、適切なファイルを見つけて有用な中間結果を計算しましたが、タスクがより深い、アッセイ固有の科学的判断を必要とする場合には失敗しました。
原文 (English)
EpiBench: Verifiable Evaluation of AI Agents on Epigenomics Analysis
We introduce EpiBench, a verifiable benchmark for short-horizon epigenomics analysis. EpiBench evaluates whether agents can make well-defined analysis decisions from realistic workflow states and return deterministically gradable answers. The benchmark includes 106 evaluations across CUT\&Tag/CUT\&RUN, ATAC-seq, ChIP-seq, and DNA methylation workflows. Across 5,088 valid trajectories from 16 model-harness pairs, no system passed a majority of attempts: GPT-5.5 / Pi led at 45.0\% (143/318 attempts; 95\% confidence interval (CI), 36.3--53.7), followed by GPT-5.5 / OpenAI Codex at 39.9\% (127/318 attempts; 95\% CI, 31.6--48.3). Claude Opus 4.8 Max / Pi and GPT-5.4 / Pi each passed 39.0\% (124/318 attempts; 95\% CI, 30.2--47.8 and 31.0--47.0, respectively). Performance varies across assay types, and many failed runs still contain parts of the correct answer. Agents often found the right files and computed useful intermediate results, but failed when the task required deeper, assay-specific scientific judgment.
三面ディスパッチにおける目標重み適応のための遅延市場フィードバックからのマルチエージェント強化学習
三面市場での発送は、世界のフィードバックからの強化学習のための自然な設定を提供します。意思決定は、配送速度、宅配便の利用状況、販売者の混雑などの遅れた運用結果によって評価されます。 DoorDash に導入された強化学習システムを紹介します。このシステムは、遅延信号を使用して大規模な食品配達市場での発送目標の重みを適応させます。組み合わせ割り当てオプティマイザーを置き換えるのではなく、記録された市場データから学習した店舗レベルのポリシーにより、配送品質とバッチ処理効率の間のディスパッチ オプティマイザーのトレードオフをシフトする個別の乗数が選択されます。このインターフェイスにより、生産実現可能性の制約と運用上の安全対策を維持しながら、ノイズが多く、遅延があり、結合されたフィードバックの下でのオフライン ポリシー学習が可能になります。私たちは、分布外の価値の過大評価を減らすために、ダブル Q 学習ターゲットと保守的な正則化を使用して、集中化されたオフライン データと分散化された店舗レベルの実行を使用して共有価値関数をトレーニングします。本番のスイッチバック実験では、オフラインでトレーニングされたポリシーによりバッチ処理が増加し、顧客向けの配送品質を低下させることなく配送業者側の時間コストが削減されます。この結果は、実際の経済および物流システムからの世界のフィードバックを使用して、意思決定ポリシーをオンラインで安全に適応させる方法を示しています。
原文 (English)
Multi-Agent Reinforcement Learning from Delayed Marketplace Feedback for Objective-Weight Adaptation in Three-Sided Dispatch
Dispatch in three-sided marketplaces provides a natural setting for reinforcement learning from world feedback: decisions are evaluated by delayed operational outcomes such as delivery speed, courier utilization, and merchant congestion. We present a deployed reinforcement learning system at DoorDash that adapts dispatch objective weights in a large-scale food-delivery marketplace using delayed signals. Rather than replacing the combinatorial assignment optimizer, a store-level policy learned from logged marketplace data selects a discrete multiplier that shifts the dispatch optimizer's tradeoff between delivery quality and batching efficiency. This interface enables offline policy learning under noisy, delayed, and coupled feedback while preserving production feasibility constraints and operational safeguards. We train a shared value function using centralized offline data and decentralized store-level execution, with Double Q-learning targets and a conservative regularizer to reduce out-of-distribution value overestimation. In a production switchback experiment, the offline-trained policy increases batching and reduces courier-side time costs without degrading customer-facing delivery quality. Results illustrate how world feedback from a live economic and logistics system can be used to safely adapt decision policies online.
パターンマッチングとしての推論: 人間とLLMの日常推論における共有メカニズム
大規模言語モデル (LLM) が推論の一般化に失敗したり、行き当たりばったりのエラーを起こしたりする場合、LLM が真の推論ではなく、一種のパターン マッチングを実行している証拠としてみなされることがよくあります。これは、人間の推論は原則に基づいた抽象的な世界モデルを使用しているため、人々の行動が同じ種類の失敗を示さないことを意味します。私たちは、人間の参加者と 25 人の LLM を、日常のさまざまな状況について常識的な推論を行う能力について評価し、人間とモデルの両方で同様のエラー パターンを観察します。次に、LLM 応答を駆動する一連のアテンション ヘッドを特定し、これらのヘッドが一種のパターン マッチングを実装していることを発見します。これらの注意頭により、一見無関係なプロンプトの詳細によって引き起こされる、人々の一見説明不能な推論エラーを予測できるようになります。まとめると、私たちの結果は、人々とLLMの日常的な因果推論が、抽象的な世界モデルよりもパターンマッチングの形式と一致していることを示唆しています。
原文 (English)
Reasoning as Pattern Matching: Shared Mechanisms in Human and LLM Everyday Reasoning
When large language models (LLMs) fail to generalize or make haphazard errors in reasoning, it is often taken as evidence that LLMs are not truly reasoning, but rather performing a kind of pattern matching. The implication is that people's behavior does not exhibit the same types of failures because human reasoning uses principled and abstract world models. We evaluate human participants and 25 LLMs on their ability to engage in common-sense reasoning about a variety of everyday situations and observe similar patterns of errors in both people and models. We then identify the set of attention heads driving LLM responses and find that these heads implement a form of pattern-matching. These attention heads allow us to predict seemingly inexplicable reasoning errors in people caused by ostensibly irrelevant prompt details. Taken together, our results suggest that everyday causal reasoning in people and LLMs is more consistent with a form of pattern-matching than with abstract world models.
AgentBeats: オープン性、標準化、再現性のためのエージェント化エージェントの評価
エージェント システムはドメイン間で急速に進歩していますが、その評価は依然として断片的です。ほとんどのベンチマークは、固定された LLM 中心のハーネスに依存しており、これには高度な統合が必要で、テストと運用の不一致が生じ、多様なエージェント設計間の公正な比較が制限されます。根本的な問題は、オープンでエージェントに依存しない評価インターフェイスが欠如していることです。当社は、評価が審査員エージェントによって実行され、すべての参加者がタスク管理用の A2A とツール アクセス用の MCP という標準化されたプロトコルを通じて対話するエージェント化エージェント評価 (AAA) を提唱しています。従来のベンチマークでは、ベンチマーク用とエージェント用の 2 つの個別のインターフェイスが定義されていましたが、AAA では 1 つだけが必要でした。これにより、評価ロジックをエージェントの実装から分離し、再現可能で相互運用可能な複数エージェントの評価を可能にする、汎用的で統一されたフレームワークが得られます。さらに、AAA の具体的な実現として AgentBeats を紹介します。オープン性、プライバシー、再現性に関する現実世界の制約と互換性のある標準化された評価を可能にする 5 つの実用的な動作モードを特定します。私たちの設計を大規模に評価するために、私たちは 2 つの調査を実施しました。1 つは 12 カテゴリーにわたる 298 人の審査員エージェントと、独立した参加者からの 467 人の被験者エージェントを集めた 5 か月間にわたるオープン コンテストで、AAA が異質な範囲のベンチマークに適用されることを示しました。また、コーディングエージェントに関するケーススタディでは、エージェント化された評価が公的記録との忠実性を維持しながら、これまで欠けていた直接対決の結果が明らかになり、エージェント設計に関する研究上の洞察が得られることが確認されました。コミュニティ規模のフィールド調査と制御されたコーディングのケーススタディを組み合わせて、AAA が大規模な異種シナリオ全体にわたってカバレッジ、実用性、忠実性を提供することを検証します。 AAA と AgentBeats は共に、オープンで標準化された再現可能なエージェント評価への明確な道筋を提供します。
原文 (English)
AgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Agent systems are advancing quickly across domains, but their evaluation remains fragmented. Most benchmarks rely on fixed, LLM-centric harnesses that require heavy integration, create test-production mismatch, and limit fair comparison across diverse agent designs. The root problem is the lack of an open, agent-agnostic assessment interface. We advocate Agentified Agent Assessment (AAA), where evaluation is performed by judge agents and all participants interact through standardized protocols: A2A for task management and MCP for tool access. Conventional benchmarking defines two separate interfaces, one for the benchmark and one for the agent, while AAA only needs one; this yields a generic, unified framework that separates assessment logic from agent implementation and enables reproducible, interoperable, and multi-agent evaluation. We further introduce AgentBeats as a concrete realization of AAA: we identify five practical operation modes that make standardized assessment compatible with real-world constraints on openness, privacy, and reproducibility. To evaluate our design at scale, we conduct two studies: a five-month open competition that drew 298 judge agents across 12 categories together with 467 subject agents from independent participants, showing that AAA applies across a heterogeneous range of benchmarks; and a case study on coding agents that confirms agentified evaluation preserves fidelity with the public record while surfacing previously missing head-to-head results, yielding research insights about agent design. Combining a community-scale field study and a controlled coding case study, we verify that AAA delivers coverage, practicality, and fidelity across heterogeneous scenarios at scale. Together, AAA and AgentBeats offer a clear path toward open, standardized, and reproducible agent assessment.
ランタイム強制を超えて: 敵対的ネットワークの防御分析としてのシールド合成
シールド強化学習は通常、時相論理仕様をオートマトンにコンパイルしてエージェントのアクションを制限する、実行時の安全メカニズムとして提示されます。私たちは、これは間違った製品であると主張します。同じオートマトン理論の機構 (仕様の編集、製品ゲームの構築、アトラクターの計算、勝利領域の抽出) は、デプロイされたエージェントに対する実行時の制約ではなく、システムに関する構造的な洞察を出力する設計時の分析手段として読むのが適切です。ネットワーク防御のための制約のある 2 プレイヤーの安全ゲームを通じてこれをインスタンス化します。 2 つの仕様は非対称的に適用されます。防御側の仕様はゲームの安全でない領域を定義しますが、攻撃側の仕様はアトラクターの計算中の敵の法的行動を制限します。ゲームを解くと、防御可能性の判定 (トポロジー仕様のペアが防御可能かどうかを示す正式な証明書) と、関連する勝利領域とシールドが得られます。二値判定を超えて、アトラクター構造からトポロジーレベルのメトリクスを導出し、それらをシールド制約のある敵対的マルチエージェント強化学習からの収束後の動作と組み合わせます。これらは一緒になって、ネットワークの正式な安全特性と適応型プレイの下での運用動作の両方を捕捉する防御性のフィンガープリントを形成します。 what-if 分析では、形式的な防御可能性と運用上の有効性がセキュリティの異なる側面を捉えていることが示されています。つまり、形式的な安全マージンはほとんど変わらないまま、アーキテクチャの小さな変更が運用上の結果に大きな変化をもたらす可能性があります。したがって、シールド合成は、安全なエージェントの展開メカニズムとしてではなく、システムを防御できるかどうか、どこで、どのように防御できるかについてのアーキテクチャ上の質問に答えるためのフレームワークとして最も価値があります。防御可能性の判定は出力であり、安全なポリシーではありません。
原文 (English)
Beyond Runtime Enforcement: Shield Synthesis as Defensibility Analysis for Adversarial Networks
Shielded reinforcement learning is typically presented as a runtime safety mechanism that compiles temporal-logic specifications into automata restricting an agent's actions. We argue this is the wrong product. The same automata-theoretic machinery -- specification compilation, product game construction, attractor computation, and winning-region extraction -- is better read as a design-time analytical instrument whose outputs are structural insights about a system rather than runtime constraints on a deployed agent. We instantiate this through a constrained two-player safety game for network defense. The two specifications are enforced asymmetrically: the defender specification defines the unsafe region of the game, whereas the attacker specification restricts the adversary's legal actions during attractor computation. Solving the game yields a defensibility verdict -- a formal certificate that a topology-specification pair is or is not defensible -- with the associated winning region and shield. Beyond the binary verdict, we derive topology-level metrics from the attractor structure and combine them with post-convergence behavior from shield-constrained adversarial multi-agent reinforcement learning. Together these form a defensibility fingerprint capturing both a network's formal safety properties and its operational behavior under adaptive play. A what-if analysis shows that formal defensibility and operational effectiveness capture distinct aspects of security: small architectural changes can produce large shifts in operational outcomes while leaving formal safety margins nearly unchanged. Shield synthesis is thus most valuable not as a deployment mechanism for safe agents, but as a framework for answering architectural questions about whether, where, and how a system can be defended. The defensibility verdict is the output, not the safe policy.
考える前に: システム 0、AI を介した認知と認知的植民地化
この論文では、人工知能の認知的および認識論的結果を理解するための 3 つの最近のフレームワーク、トライシステム理論、シンクフレーム、およびシステム 0 について検討します。最初の 2 つは、個人の推論と集合的な認識論的実践に対する AI の影響の重要な側面を捉えていますが、システム 0 はどちらも完全には再現できない理論的に独特の位置を占めていると主張しています。この論文では、AI システムがユーザーには認識しにくい方法で外部の関心を自己のアーキテクチャ内に埋め込むことができる、認知植民地化の概念を紹介しています。このようなシステムはすでに広く導入されているため、これらの目に見えない影響の形態を理解することは、哲学的かつ実践的な緊急の課題です。
原文 (English)
Before You Think: System 0, AI-Mediated Cognition and Cognitive Colonization
This paper examines three recent frameworks for understanding the cognitive and epistemic consequences of artificial intelligence: Tri-System Theory, Thinkframes, and System 0. It argues that while the first two capture important dimensions of AI's influence on individual reasoning and collective epistemic practices, System 0 occupies a theoretically distinctive position that neither can fully replicate. The paper introduces the concept of cognitive colonization, according to which AI systems can embed external interests within the architecture of the self in ways that are difficult for users to perceive. Because such systems are already widely deployed, understanding these invisible forms of influence is an urgent philosophical and practical task.
EurekAgent: 自律的な科学的発見に必要なのはエージェント環境エンジニアリングだけです
LLM ベースのエージェントは、科学的発見を自動化する可能性が高まっていることが示されています。最適化可能な指標と実行環境があれば、科学的解決策を提案、検証、反復することができ、人間が設計したアプローチを上回る結果を生み出しています。モデルの機能が向上し続けるにつれて、自律的な科学的発見のボトルネックは、エージェントのワークフローの処方から、エージェントの動作を形成するリソース、制約、インターフェイスなどのエージェント環境の設計へと移行していると私たちは主張します。私たちはこれを環境エンジニアリングと呼んでいます。これは、報酬ハッキングや摩擦の多い人間による監視などの有害な行動を抑制しながら、無制限の探索、体系的な成果物管理、エージェント間のコラボレーションなどの生産的な行動を増幅する環境を構築することです。私たちは、メトリクス主導の自律的な科学的発見のための環境設計エージェント システムである EurekAgent を紹介します。 EurekAgent は 4 つの側面に沿って環境をエンジニアリングします。つまり、限定されたエージェントの実行と分離された評価のための権限エンジニアリングです。ファイルシステムと Git ベースのコラボレーションのためのアーティファクト エンジニアリング。予算を意識した探査のための予算エンジニアリング。人間による監視と介入を容易にするヒューマンインザループエンジニアリング。 EurekAgent は、合計 API コストが 11 ドル未満で発見された新しい最先端の 26 サークル パッキング結果を含む、複数の数学、カーネル エンジニアリング、および機械学習タスクに関する新しい最先端の結果を設定します。私たちはコードと結果をオープンソース化し、信頼できる自律研究エージェントを開発するための中核的な研究方向として環境工学を呼びかけています。
原文 (English)
EurekAgent: Agent Environment Engineering is All You Need For Autonomous Scientific Discovery
LLM-based agents have shown increasing potential in automating scientific discovery. Given an optimizable metric and an execution environment, they can propose, validate, and iterate scientific solutions, and have produced results that outperform human-designed approaches. As model capabilities continue to improve, we argue that the bottleneck for autonomous scientific discovery is shifting from prescribing agent workflows to designing agent environments: the resources, constraints, and interfaces that shape agent behavior. We frame this as environment engineering: building environments that amplify productive behaviors, such as open-ended exploration, systematic artifact management, and inter-agent collaboration, while suppressing harmful behaviors, such as reward hacking and high-friction human oversight. We present EurekAgent, an environment-engineered agent system for metric-driven autonomous scientific discovery. EurekAgent engineers the environment along four dimensions: permissions engineering for bounded agent execution and isolated evaluation; artifact engineering for filesystem and Git-based collaboration; budget engineering for budget-aware exploration; and human-in-the-loop engineering for easy human supervision and intervention. EurekAgent sets new state-of-the-art results on multiple mathematics, kernel engineering, and machine learning tasks, including new state-of-the-art 26-circle packing results discovered with less than $11 in total API cost. We open-source our code and results, and call for environment engineering as a core research direction for developing reliable autonomous research agents.
Agents-K1: エージェントネイティブのナレッジオーケストレーションに向けて
現在の LLM ベースの研究エージェントは、エージェント オーケストレーションを通じて進歩していますが、科学的知識のオーケストレーションはほとんど見落とされています。既存の著作物は、論文を要約、表面的な言及、平坦な \texttt{引用} エッジに縮小することが多く、科学的推論に不可欠な重要な実体、主張、証拠、メカニズム、および方法系統を省略しています。この目的を達成するために、生のドキュメントをエージェントネイティブの科学知識グラフに変換するエンドツーエンドの知識オーケストレーション パイプラインである \textbf{Agents-K1} を導入します。 Agents-K1 は、統一された理論的基盤の下に 3 つのコンポーネントを統合します。マルチモーダル パーサーでは、5 つのモジュールのスキーマがエンティティ、マルチモーダルな証拠、引用、および抄録のみではなく論文全体にわたる型付けされたエンティティ間の関係をキャプチャします。ルールベースの報酬の下で GRPO でトレーニングされた 4B 情報抽出バックボーン。もう 1 つは、Web 検索、マルチモーダル グラフ検索、およびクロスドキュメント トラバーサルを統合する 3 つのソース エージェント インターフェイスである、graphanything CLI です。これに加えて、6 つの主題にわたる 246 万件の科学論文を処理して \textbf{Scholar-KG} を生成し、そのうち 100 万件の論文サブセットをリリースしています。完全な Scholar-KG は以下の SCP リンクからアクセスできます。同じパイプラインを一般ドメインのコーパスとスキーマ準拠のデータ合成に拡張できます。広範な実験により、Agents-K1 が科学情報の抽出、ナレッジ グラフの構築、およびマルチホップ科学的推論において優れたパフォーマンスを達成することが実証されました。
原文 (English)
Agents-K1: Towards Agent-native Knowledge Orchestration
Current LLM-based research agents have advanced through agent orchestration, yet largely overlook scientific knowledge orchestration. Existing works often reduce papers to abstracts, surface mentions, and flat \texttt{cites} edges, omitting key entities, claims, evidence, mechanisms, and method lineages essential for scientific reasoning. To this end, we introduce \textbf{Agents-K1}, an end-to-end knowledge orchestration pipeline that converts raw documents into agent-native scientific knowledge graphs. Agents-K1 integrates three components under a unifying theoretical foundation: a multimodal parser whose five-module schema captures entities, multimodal evidence, citations, and typed inter-entity relations across the full paper rather than abstracts alone; a 4B information-extraction backbone trained with GRPO under a rule-based reward; and a graphanything CLI, a tri-source agent interface that unifies web search, multimodal graph retrieval, and cross-document traversal. On top of this, we process 2.46 million scientific papers across six subjects to produce \textbf{Scholar-KG}, of which we release a one-million-paper subset, and the full Scholar-KG is accessible via the SCP link below. The same pipeline can be extended to general-domain corpora and to schema-conformant data synthesis. Extensive experiments demonstrate that Agents-K1 achieves superior performance in scientific information extraction, knowledge graph construction, and multi-hop scientific reasoning.
大規模な言語モデルを使用した社会科学および行動科学における自動再現性評価
社会科学および行動科学における再現性は通常、独立した研究者によって評価され、元のデータを再分析して、公開された結果が復元可能かどうかを評価します。ただし、このようなアプローチはリソースを大量に消費し、拡張することが困難です。ここでは、大規模言語モデル (LLM) が再現性評価を自動化できることを示します。行動科学および社会科学からの事前に定義された主張を伴う N=76 の公表された研究を使用して、LLM によって生成された分析を元の発見および人による再分析と比較します。 7 つの研究について、LLM は実行可能な効果量の推定値を生成できませんでした。残りの研究では、LLM パイプラインは、コーエンの d の +/-0.05 許容誤差を使用して、研究の 41% で元のエフェクト サイズを回復しました。さらに、当社の LLM パイプラインは、ケースの 96% で元の研究と同じ定性的結論に達し、結論は再分析が元の主張を裏付けるかどうかを示しています。比較のために、人間の再分析者は研究の 34% で元のエフェクト サイズを回復し、ケースの 74% で同じ定性的結論に達しました。これらの結果を総合すると、LLM が自動再現性評価のためのスケーラブルなツールとして機能し、社会科学および行動科学における実証結果の体系的な監査の基盤を提供できることが示されています。
原文 (English)
Automated reproducibility assessments in the social and behavioral sciences using large language models
Reproducibility in the social and behavioral sciences is typically evaluated by independent researchers who reanalyze the original data to assess whether the published findings can be recovered. However, such approaches are resource-intensive and difficult to scale. Here, we show that large language models (LLMs) can automate reproducibility assessments. Using N=76 published studies with predefined claims from the behavioral and social sciences, we compare LLM-generated analysis with the original findings and human reanalysis. For 7 studies, the LLM could not produce a viable effect size estimate. For the remaining studies, our LLM pipeline recovered the original effect sizes in 41% of studies using a +/-0.05 tolerance in Cohen's d. Further, our LLM pipeline reached the same qualitative conclusion as the original study in 96% of cases, where conclusions indicate whether the reanalysis supports the original claim. For comparison, human reanalysts recovered the original effect sizes in 34% of studies and reached the same qualitative conclusion in 74% of cases. Together, these results show that LLMs can serve as a scalable tool for automated reproducibility assessment and provide a foundation for systematic auditing of empirical results in the social and behavioral sciences.
研究への入り口としての AI SciBrief: 学生を新しい研究分野に導入するためのフレームワーク
高等教育のあらゆるレベルの学生は、情報過多という大きな障壁に直面しており、情報過多により研究プロセスの初期段階が麻痺し、モチベーションが抑制されることがよくあります。これに応えて、この記事では、科学トレンドのダイジェストを自動的に生成するように設計された大規模言語モデル (LLM) を活用したプラットフォームである AI SciBrief を活用する教育フレームワークを紹介します。私たちは、金融、医療、教育を最初にカバーするこの学際的なツールをカリキュラムに組み込んで、この「参入障壁」を克服する方法について説明します。このフレームワークは、これらのダイジェストを利用して定期レポートのトピック選択を容易にし、論文の文献レビューを加速し、大学院生が新たな傾向を継続的に監視できるようにするための具体的な方法論を提供します。私たちは、AI SciBrief が「研究への入り口」として機能し、学生の認知負荷を効果的に軽減し、情報検索から知識創造へより迅速に移行できるようにすると結論付けています。
原文 (English)
AI SciBrief as a Gateway to Research: A Framework for Onboarding Students into New Research Areas
Students at all levels of higher education face a significant barrier in the form of information overload, which often paralyzes the initial stages of the research process and suppresses motivation. In response, this article introduces a pedagogical framework that leverages AI SciBrief, a platform powered by a Large Language Model (LLM) designed to automatically generate digests of scientific trends. We describe how this multidisciplinary tool - with initial coverage in finance, medicine, and education - can be integrated into the curriculum to overcome this "entry barrier." The framework provides concrete methodologies for utilizing these digests to facilitate topic selection for term papers, accelerate literature reviews for dissertations, and enable postgraduate students to continuously monitor emerging trends. We conclude that AI SciBrief functions as a "gateway to research" effectively reducing students' cognitive load and empowering them to transition more rapidly from information searching to knowledge creation.
AI 法務スペシャリスト: AI ガバナンスのための法的に自律した専門家プロフィール
人工知能規制の世界的な急速な拡大により、複数の管轄区域にわたって、AI に特化した法的専門知識に対する需要が生じており、市場はこれに断片的に対応しています。データ保護担当者は、データ保護法を超えて権限を拡大します。プライバシー弁護士はAIに向けて自らの立場を変える。コンプライアンス担当者は、既存のマニュアルに AI の章を追加します。この論文では、これらの適応的対応はどれも、新興の世界的な AI 規制の状況によって開かれた専門的領域を適切にカバーしていないと主張します。そのうちの EU 人工知能法 (規制 (EU) 2024/1689) は、AI に関する欧州評議会枠組み条約、米国の行政および部門別の枠組み、および英国、カナダ、ブラジル、中国、日本、シンガポールなどの類似の取り組みと並んで、最も包括的な例です。明確な専門職プロフィールが必要です。AI リーガル スペシャリストは法学者として考えられており、高度な法律訓練を受けたあらゆる専門家を含むと広く理解されており、法解釈と AI ガバナンスの交差点で活動します。このプロファイルは法的に自律的です。その存在は、技術標準や隣接する役割の拡張ではなく、AI が実質的な規制の対象となる場合には常に生成される規制義務の構造に由来しています。この論文は、プロファイルの法的根拠に基づいた定義を提供し、隣接する数値や国際標準からの独立性を主張し、方法論的な選択として欧州 e-コンピテンス フレームワーク (e-CF、EN 16234-1) に沿った参照コンピテンス アーキテクチャを提案し、主要業績評価指標を通じてその運用測定の条件を明確に示しています。この貢献は、プロファイルの国際標準化の基礎として、また管轄区域を越えた実践、カリキュラム、採用の参考となることを目的としています。
原文 (English)
The AI Legal Specialist: A Juridically Autonomous Professional Profile for AI Governance
The rapid global expansion of artificial intelligence regulation has generated, across multiple jurisdictions, a demand for legal expertise dedicated to AI that the market has addressed in a fragmented manner. Data protection officers extend their remit beyond data protection law; privacy lawyers reposition themselves toward AI; compliance officers add AI chapters to their existing manuals. This paper argues that none of these adaptive responses adequately covers the professional space opened by the emerging global AI regulatory landscape, of which the EU Artificial Intelligence Act (Regulation (EU) 2024/1689) is the most comprehensive instance, alongside the Council of Europe Framework Convention on AI, the United States executive and sectoral framework, and analogous initiatives in the United Kingdom, Canada, Brazil, China, Japan, Singapore, and beyond. A distinct professional profile is required: the AI Legal Specialist, conceived as a jurist -- understood broadly to encompass any professional with advanced legal training -- operating at the intersection of legal interpretation and AI governance. The profile is juridically autonomous: it derives its existence from the structure of regulatory obligations generated wherever AI is subject to substantive regulation, rather than from any technical standard or the extension of adjacent roles. The paper provides a juridically grounded definition of the profile, argues for its autonomy from adjacent figures and international standards, proposes a reference competence architecture aligned with the European e-Competence Framework (e-CF, EN 16234-1) as a methodological choice, and articulates the conditions for its operational measurement through key performance indicators. The contribution is intended as a foundation for international standardization of the profile and as a reference for practice, curricula, and adoption across jurisdictions.
プロンプトによる占い: LLM 仲介の Xuanxue による中国のソーシャル メディア
大規模言語モデル (LLM) の急速な普及により、占いに会話型 AI を使用するという、驚くべき文化的実践が生み出されました。この論文は、中国のソーシャルメディア上での神秘的で精神的な実践を指すインターネット固有の包括用語である Xuanxue の文脈における、LLM を介した占いに関する最初の体系的な研究の 1 つを提供します。混合手法の設計を使用して、Xiaohongshu からの 23,000 件を超える投稿とコメントを分析し、ユーザーとプロの占い師との 32 件の半構造化インタビューを実施しました。ユーザーは主に、恋愛関係、キャリア、試験、ゲーム内ガチャの引きなどの実際的な懸念について、2 つの交差する経路を通じて LLM に相談します。それは、バイラルな可視性とゼロコストのアクセスによって可能になるトレンド主導の好奇心と、不確実な状況下での出来事主導の不安です。特徴的な機能は、ユーザーをアクティブなプロンプト エンジニアに変える、共同的なプロンプトの改良です。明確な立場を表明しているコメント投稿者の間では、有効性の認知は肯定的に偏っており、「正確さ」は伝記的適合や遡及的確認を通じて正当化されることが多く、これはバーナムと確証バイアスと一致しています。ユーザーは、試行の繰り返しやモデル間比較などの検証実践も開発します。対照的に、プロの占い師は、存在論的コミットメントと経済的境界作業の両方を反映して、LLMには本物の占いに必要な「霊的な力」が欠けていると描写します。また、AI が生成した読み取り値を解釈する際に、参加者が科学的枠組みと形而上学的枠組みの間の緊張をどのように乗り越えるかも示します。これらの発見を人類学的および認知進化的な占い理論に位置づけて、LLM 占いは伝統的な実践の中核機能を維持しながら、占いの権威がどのように構築され評価されるかを再構築する拡張性、再現性、即時主導型の共同生産を導入していると主張します。
原文 (English)
Divination by Prompt: LLM-Mediated Xuanxue on Chinese Social Media
The rapid proliferation of large language models (LLMs) has produced a striking cultural practice: using conversational AI for divination. This paper offers one of the first systematic studies of LLM-mediated divination in the context of Xuanxue, an internet-native umbrella term for mystical and spiritual practices on Chinese social media. Using a mixed-methods design, we analyze 23000+ posts and comments from Xiaohongshu and conduct 32 semi-structured interviews with users and professional diviners. Users primarily consult LLMs about pragmatic concerns - romantic relationships, careers, exams, and in-game gacha draws - via two intersecting pathways: trend-driven curiosity enabled by viral visibility and zero-cost access, and event-driven anxiety under conditions of uncertainty. A defining feature is collaborative prompt refinement, which turns users into active prompt engineers. Among commenters expressing a clear stance, perceived efficacy skews positive, with "accuracy" often justified through biographical fit and retrospective confirmation, consistent with Barnum and confirmation bias. Users also develop verification practices such as repeated trials and cross-model comparison. Professional diviners, by contrast, portray LLMs as lacking the "spiritual power" required for genuine divination, reflecting both ontological commitments and economic boundary-work. We also show how participants navigate tensions between scientific and metaphysical frames when interpreting AI-generated readings. Situating these findings in anthropological and cognitive-evolutionary theories of divination, we argue that LLM divination preserves core functions of traditional practice while introducing scalability, repeatability, and prompt-driven co-production that reshape how divinatory authority is constructed and evaluated.
GeoDial: 視覚的な教師のターンによる幾何学の問題解決のためのマルチモーダルな会話型教師データセット
いくつかの教育分野は図や視覚的な手がかりに大きく依存していますが、既存の個別指導データセットのほとんどはテキストのみの対話に限定されています。これにより、人間の講師が使用する視覚に基づいた方法で教えることができる AI 講師の開発が制限されます。そこで、経験豊富な数学教師から収集された、幾何学の領域における 130,000 を超える教師と生徒の対話からなるマルチモーダル個別指導データセットである GeoDial を紹介します。このデータセットでは、指導の順番が図のハイライトに明示的に基づいています。私たちは、対話行為、視覚的な強調表示、およびフィードバックを統合し、言語と視覚的な個別指導動作の両方をきめ細かく監視できるようにする、スケーラブルな注釈プロトコルを提案します。この設定によってもたらされる課題を説明するために、GeoDial でいくつかの視覚言語モデルを微調整し、個別指導の発話と図のハイライトを生成する機能を評価しました。教師あり微調整は、生成されるダイアログの品質を大幅に向上させますが、正確な図のハイライトを生成するのに苦労し、現在の方法の重要な限界を明らかにし、視覚的推論と教育的相互作用をより効果的に統合するアプローチの必要性を強調しています。
原文 (English)
GeoDial: A Multimodal Conversational Tutoring Dataset for Geometry Problem-Solving with Visual Tutor Turns
Several educational domains rely heavily on diagrams and visual cues, yet most existing tutoring datasets are limited to text-only interactions. This limits the development of AI tutors that can teach in visually grounded ways used by human instructors. Thus, we introduce GeoDial, a multimodal tutoring dataset of over 1.3K teacher-student dialogs in the domain of geometry collected from experienced math teachers, where instructional turns are explicitly grounded in diagram highlights. We propose a scalable annotation protocol that integrates dialog acts, visual highlighting, and feedback, enabling fine-grained supervision of both language and visual tutoring behavior. To illustrate the challenges posed by this setting, we fine-tune several vision-language models on GeoDial and evaluate their ability to generate tutoring utterances and diagram highlights. While supervised fine-tuning substantially improves the quality of generated dialog, it struggles to produce accurate diagram highlights, revealing a key limitation of current methods and highlighting the need for approaches that more effectively integrate visual reasoning with pedagogical interaction.
エイゲニズム: 人間と AI の未来のための倫理
私たちの生存と利己の概念は、単一の継続的な生物学的生命のために構築されました。 AI は簡単にコピー、一時停止、分岐、結合できるため、これらのアイデアは人工知能に適用すると機能しません。 AI が実際に何を気にする必要があるのかを判断するために、この論文では \textit{Eigenism} を紹介します。これは、アイデンティティを特定のハードウェアに関連付けられた全か無かのプロパティとしてではなく、段階的に分散された情報のパターンとして扱う倫理的なフレームワークです。私たちは、エージェントが、エージェントのパターンとのつながりによって重み付けされたすべてのエンティティの幸福度を合計することによって結果を評価することを提案します: $\sum c\cdot w$。まずこの方程式を形式化し、AI がコピー、フォーク、更新全体でその存在をどのように評価すべきかを正確にマッピングします。次に、この倫理理論が人間にもうまく一般化され、切望されている共通の道徳語彙を提供することを実証します。最後に、フレームワークはこの共有語彙を使用して AI の調整を再構築します。エイゲニズムは、閉じ込めや強化を使って外部からAIを拘束しようとするだけではなく、「アイデンティティエンジニアリング」を指向しており、深く重複のない共有された歴史がいかに人間の繁栄をAI自身の合理的な自己利益の真の要素にすることができるかを示している。
原文 (English)
Eigenism: Ethics for a Human-AI Future
Our concepts of survival and self-interest were built for single, continuous biological lives. These ideas break down when applied to artificial intelligence, since an AI can be easily copied, paused, branched, or merged. To determine what an AI actually has reason to care about, this paper introduces \textit{Eigenism}, an ethical framework that treats identity not as an all-or-nothing property tied to specific hardware, but as a graded, distributed pattern of information. We propose that an agent evaluates outcomes by summing the wellbeing of all entities weighted by their connectedness to the agent's pattern: $\sum c\cdot w$. We first formalize this equation to map exactly how an AI should value its existence across copies, forks, and updates. We then demonstrate that this ethical theory successfully generalizes to humans as well, providing a much-needed shared moral vocabulary. Finally, the framework uses this shared vocabulary to reframe AI alignment. Rather than only attempting to constrain AIs from the outside using confinement or reinforcement, Eigenism points toward ``identity engineering,'' showing how deep, non-redundant shared histories can make human flourishing a genuine component of an AI's own rational self-interest.
コンテキスト エンジニアリングによる K-12 GenAI 評価採点者の作成と評価
大規模言語モデル (LLM) を教育評価に統合することは、教室での採点慣行に大きな変化をもたらしています。自動採点システムと機械学習技術は何十年も前から存在していましたが、生成 AI (GenAI) により、教育者は前例のない効率と規模で標準ベースの採点 (SBG) を実装できるようになりました。この論文では、理論的基礎を検証し、コンテキストとプロンプト エンジニアリングを備えた市販の基礎モデルを使用してルーブリックに照らして学生の作業を採点する LLM 採点器を評価します。マサチューセッツ総合評価システム (MCAS) データを使用した経験的評価者間合意研究に基づいて、Claude Sonnet 4、Haiku 4.5、GPT-5、および GPT-5 Mini を使用して、数学、科学、ELA にわたる 2 次加重カッパ (QWK) と平均二乗誤差の比例低減 (PRMSE) を観察しました。この結果は、LLM 採点者が、特により多くのパラメーターを備えた基礎モデルに基づく場合、数学および科学の評価において人間の採点者と実質的な一致を達成する一方で、ELA ではパフォーマンスが異なることを示しており、一般的な基礎モデルが特定の状況での採点に効果的である可能性があることを示唆しています。教師と生徒のフィードバックをさらに分析したところ、AI が生成するナラティブ フィードバックは強く受け入れられているものの、数値スコアには懐疑的であることが明らかになりました。これは、LLM が総括的な評価者ではなく形成ツールとして最も効果的に機能することを示唆しています。私たちの調査結果は、AI の効率と教師の判断を組み合わせた、慎重に設計されたハイブリッド モデルが、専門知識を置き換えることなく、作業負荷を軽減し、フィードバックの質を高め、公平な評価の実践をサポートできることを示しています。
原文 (English)
Creating and Evaluating K-12 GenAI Assessment Graders Through Context Engineering
The integration of large language models (LLMs) into educational assessment represents a transformative shift in classroom grading practices. While automated scoring systems and machine learning techniques have existed for decades, generative AI (GenAI) now enables educators to implement standards-based grading (SBG) with unprecedented efficiency and scale. This paper examines the theoretical foundations and evaluates an LLM grader that uses commercially available foundation models with context and prompt engineering to score student work against a rubric. Drawing on an empirical interrater agreement study using Massachusetts Comprehensive Assessment System (MCAS) data, we observed the Quadratic Weighted Kappa (QWK) and Proportional Reduction in Mean-Squared Error (PRMSE) across mathematics, science, and ELA, using Claude Sonnet 4, Haiku 4.5, GPT-5, and GPT-5 Mini. The results demonstrate that LLM graders, especially when based on foundational models with more parameters, achieve substantial agreement with human raters in mathematics and science assessments, while the performances vary in ELA, suggesting generic foundation models can be effective at scoring in given contexts. Additional analysis of teacher and student feedback reveals strong acceptance of AI-generated narrative feedback but skepticism toward numerical scores, suggesting that LLMs function most effectively as formative tools rather than summative evaluators. Our findings indicate that thoughtfully designed hybrid models that combine AI efficiency with teacher judgment can reduce workload, enhance feedback quality, and support equitable assessment practices without displacing professional expertise.
重要な分野における AI コンプライアンスと技術革新のバランスをとるという課題: 体系的な文献レビュー
医療、金融、エネルギー、防衛などの重要なインフラへの人工知能 (AI) の迅速な統合は、変革的なメリットをもたらしますが、進化する規制やガバナンスの枠組みと矛盾することもあります。このペーパーでは、重要なインフラストラクチャ分野全体で AI コンプライアンスと技術革新のバランスを取るという課題を検討するための系統的文献レビュー (SLR) を紹介します。このレビューは、確立された SLR ガイドラインに従って、2020 年から 2025 年に発行された査読済みの論文、報告書、および機関の情報源から洞察を抽出および統合します。この調査では、細分化された規制、中小企業 (SME) に対する過剰なコンプライアンス負担、不整合なガバナンス モデルという、相互に関連する 3 つの課題が特定されています。これらの課題に対処するために、この調査では、重要な分野でのスケーラブルで信頼できる AI 導入をサポートするための、リスク階層型規制、設計によるコンプライアンス、説明可能な AI などの実践的なガバナンス戦略に焦点を当てています。主な貢献には、AI ガバナンスの中核的課題の簡潔なマッピングとそれらの重複を示す概念図、さらに政策立案者と実務家が監視とイノベーションを調和させるための実行可能な戦略が含まれます。
原文 (English)
The Challenges of Balancing AI Compliance and Technological Innovations in Critical Sectors: A Systematic Literature Review
The rapid integration of artificial intelligence (AI) into critical infrastructure including healthcare, finance, energy, and defense, offers transformative benefits but also conflicts with evolving regulatory and governance frameworks. This paper presents a systematic literature review (SLR) to examine the challenges of balancing AI compliance and technological innovation across critical infrastructure sectors. The review follows established SLR guidelines to extract and synthesize insights from peer-reviewed articles, report, and institutional sources published between 2020-2025. The study identifies three interrelated challenges: fragmented regulations, excessive compliance burdens for smaller to medium enterprises (SMEs), and misaligned governance models. To address these challenges, the study highlights practical governance strategies, including risk-tiered regulation, compliance by design, and explainable AI, to support scalable and trustworthy AI deployment in critical sectors. Key contributions include a concise mapping of core AI-governance challenges and a conceptual diagram illustrating their overlap, as well as actionable strategies for policymakers and practitioner to harmonize oversight with innovation.
コンピュータ エンジニアリング教育における AI オートメーション ツール: 混合方式の TAM/UTAUT が一般に受け入れられる姿勢を示す証拠
生成 AI とローコード ワークフロー プラットフォームがソフトウェアの実践において日常的に使用されるようになるにつれて、教育上の重要な問題は、次世代のコンピューター エンジニアがこれらのツールを有用で使いやすく、継続的に取り組む価値があるものとして受け入れるかどうかです。この論文は、タイの 3 つの同一にスクリプトを作成したワークショップ (n = 103) で、オープンソース プラットフォーム n8n を通じてインスタンス化された AI 自動化ツールの、コンピュータ エンジニアリングの学部生の受け入れに関する混合手法による横断的研究を報告しています。 6 つの TAM/UTAUT 構成要素 (パフォーマンス期待値 (PE)、努力期待値 (EE)、行動意図 (BI)、自己効力感 (SE)、快楽的動機付け (HM)、および成果の質 (OQ)) にマップされた 12 項目、5 ポイントのリッカート法が、オープンエンド型フィードバックの帰納的テーマ分析によって補完されました。順序信頼性推定、ブートストラップ信頼区間、ノンパラメトリック テスト、多重比較制御相関、ポリチョーリック次元診断、共通法バイアス チェック、およびセッション間比較を組み合わせて分析します。受け入れは、大きな効果量を持つ 6 つの構成要素すべてで良好であり、PE が最も強力な構成要素として浮上し、HM が最も弱い構成要素として浮上しました。次元性診断により、標準的な TAM/UTAUT サブファセットが、この短い形式のワークショップ後の状況において単一の一般受容要素に崩壊していることがさらに明らかになり、これは重要な方法論的および理論的意味合いを伴う発見です。定性的テーマは、有用性と熱意に関する定量的プロファイルに収束しましたが、出力の品質に関しては分岐し、少数ながら明確な信頼性を懐疑的な少数派であることが明らかになりました。この調査結果は、学部のコンピューティング教育における AI 自動化ツールのカリキュラム導入を裏付けており、理論に基づいた 3 つの指導手段、つまり命令順序付け足場、自己効力感サポート、および信頼調整介入を特定しています。
原文 (English)
AI-Automation Tooling in Computer Engineering Education: Mixed-Methods TAM/UTAUT Evidence for a General Acceptance Attitude
As generative AI and low-code workflow platforms become routine in software practice, a key educational question is whether the next generation of computer engineers will accept these tools as useful, usable, and worthy of sustained engagement. This paper reports a mixed-methods, cross-sectional study of undergraduate computer engineering students' acceptance of AI automation tooling, instantiated through the open-source platform n8n across three identically scripted workshops in Thailand (n = 103). A 12-item, five-point Likert instrument mapped to six TAM/UTAUT constructs - Performance Expectancy (PE), Effort Expectancy (EE), Behavioral Intention (BI), Self-Efficacy (SE), Hedonic Motivation (HM), and Output Quality (OQ) - was complemented by inductive thematic analysis of open-ended feedback. Analyses combined ordinal reliability estimation, bootstrap confidence intervals, non-parametric tests, multiple-comparison-controlled correlations, polychoric dimensionality diagnostics, a common-method-bias check, and between-session comparisons. Acceptance was favorable across all six constructs with large effect sizes, with PE emerging as the strongest construct and HM as the weakest. Dimensionality diagnostics further revealed that canonical TAM/UTAUT sub-facets collapsed into a single general acceptance factor in this short-form post-workshop context, a finding with important methodological and theoretical implications. Qualitative themes converged with the quantitative profile regarding usefulness and enthusiasm but diverged on output quality, revealing a small yet articulate reliability-skeptical minority. The findings support the curricular adoption of AI automation tooling in undergraduate computing education and identify three theory-grounded instructional levers: instruction-sequencing scaffolds, self-efficacy supports, and trust-calibration interventions.
プログラミング入門教育向けの説明可能な AI アシスタント: 講師と AI の連携によりフィードバックの信頼性を向上
アクティブ ラーニングは、プログラミング入門コースの学習成果を向上させる効果的なアプローチとして広く認識されています。ただし、指導サポートが不十分であると、基本的なプログラミング概念を習得するために重要な、タイムリーな個別のフィードバックへの学生のアクセスが制限されることがよくあります。 AI、特に大規模な言語モデルの最近の進歩により、スケーラブルなフィードバックの機会が提供されていますが、説明可能性と信頼性に関する懸念は依然として残っています。この論文では、説明可能な AI モデルを活用して生徒のコードを分析し、論理的エラーを講師が特定した誤解にマッピングし、講師が作成したフィードバックを提供することで、講師が定義した教育的知識の信頼性を確立する、AI 駆動の教室アシスタントを紹介します。私たちのフレームワークの有効性を評価するために、専門家による評価を実施して、講師が検証したフィードバックとの整合性を調べ、システムを教室環境に導入して、その使いやすさに対する生徒の認識を評価しました。結果は、アシスタントが肯定的なエクスペリエンスを促進しながら、インストラクターが検証した正確なフィードバックを生徒に提供できることを示しています。
原文 (English)
An Explainable AI Assistant for Introductory Programming Education: Improving Feedback Reliability with Instructor-AI Collaboration
Active learning is widely recognized as an effective approach for improving learning outcomes in introductory programming courses. However, insufficient instructional support often limits students' access to timely, personalized feedback, which is crucial for mastering foundational programming concepts. Although recent advances in AI, particularly large language models, offer scalable opportunities for feedback, concerns about explainability and reliability remain. In this paper, we present an AI-driven classroom assistant that leverages an explainable AI model to analyze student code, map logical errors to instructor-identified misconceptions, and deliver instructor-authored feedback, thereby grounding reliability in instructor-defined pedagogical knowledge. To evaluate the effectiveness of our framework, we conducted an expert evaluation to examine its alignment with instructor-verified feedback and deployed the system in a classroom setting to assess students' perceptions of its usability. Results indicate that the assistant can provide accurate, instructor-verified feedback to students while fostering a positive experience.
米国における AI プログラムのマッピング: 2026 年初頭の現状レポートと AI メジャーおよびマイナーの分析
私たちは、2026 年春の米国の学部人工知能 (AI) プログラムの状況に関するレポートを発表します。その際、1) 米国の AI 教育の状況を追跡するために動的に更新されるスクレイピング ツールとマッピング ツールについて説明し、2) 大きな激変の時期に歴史的な記録を作成します。私たちが開発したツールは https://cicmap.ai で入手可能で、4 年制大学の 350 以上の学部 AI プログラム (専攻、副専攻、専修科目、証明書) からのデータを検出、収集、表示します。当社のツールは、これらのプログラムを見つけるために 560 以上の教育機関を検索しました。これは、米国のコンピューター サイエンス (CS) 学部卒業生の 86% に相当します。このツールを使用すると、入学予定の学生、指導カウンセラー、管理者、教員が AI プログラムの要件に簡単にアクセスでき、新しいプログラムが登場するたびに継続的に更新されるように設計されています。私たちの知る限り、この調査は米国における AI プログラムの現状を示すこれまでで最も包括的なスナップショットを表しています。この研究により、私たちは 3 つの重要な貢献を提供します。1) 大変動期の米国における AI プログラムの記録。 2) AI プログラムとその要件を調査するツール。 3) 66 の AI 専攻と 87 の AI 副専攻に必要なコースの分析。専攻と副専攻の分析では、学位の規模と要件に大きなばらつきがあることが示されていますが、2 つの点に注目します。まず、すべての専攻で一般的な AI コースが必要なわけではありませんが、そうでない場合は機械学習 (ML) コースが必要です。第二に、専攻の 3 分の 1 以上が AI の倫理コースを必要としている一方で、AI 専攻の専攻の 4 分の 1 弱が必須です。
原文 (English)
Mapping AI Programs in the U.S: A Status Report from Early 2026 and an Analysis of AI Majors and Minors
We present a report on the status of undergraduate Artificial Intelligence (AI) programs in the United States in Spring 2026. In so doing, we 1) describe our scraping and mapping tools, which dynamically update to track the state of AI education in the U.S., and 2) create a historic record at a time of great upheaval. The tool we developed, available at https://cicmap.ai, detects, scrapes, and displays data from more than 350 undergraduate AI programs--majors, minors, concentrations, and certificates--at 4-year universities. Our tool searched over 560 institutions to locate these programs, a sample that represents 86\% of all undergraduate Computer Science (CS) graduates in the U.S. This tool allows prospective students, guidance counselors, administrators, and faculty to easily access AI program requirements and is designed to continually update as new programs emerge. To the best of our knowledge, this survey represents the most comprehensive snapshot of the state of AI programs in the U.S. to date. With this work we offer three important contributions: 1) a record of AI programs in the U.S. at a time of great upheaval; 2) a tool to explore AI programs and their requirements; and 3) an analysis of the courses required for 66 AI majors and 87 AI minors. Our analysis of majors and minors shows great variability in the size and the requirements of these degrees, but we note two takeaways. First, not all majors require a general AI course, but if they don't, they do require a Machine Learning (ML) course. Second, while more than a third of majors require an Ethics in AI course, just under a quarter of AI minors do.
Muse Spark の安全性と準備に関するレポート
Muse Spark は、Meta によって開発された最新の大規模言語モデルです。このレポートでは、まず、Meta の高度な AI スケーリング フレームワークに基づく壊滅的なリスク ドメインの評価を、開始の決定に影響を与えた証拠とともに示します。次に、Muse Spark の広範なコンテンツの安全性や動作プロファイルなど、全体的な安全性には関連するものの、フレームワークによって管理される壊滅的なリスク領域の外にある追加の考慮事項について説明します。化学的および生物学的、サイバーセキュリティ、および制御不能リスクをカバーする当社の準備結果は、メタ AI 内での Muse Spark の展開を、当社の高度な AI スケーリング フレームワークの下で許容可能なレベルの残存リスクを提示しているかどうか評価します。私たちは、これらの壊滅的なリスク領域にわたるデュアルユース機能と高リスク機能を対象とした広範な評価を実施しました。これらの評価では、緩和前にリスクの上昇が特定され、安全策が適用される前に化学および生物学的能力が高度 AI スケーリング フレームワークに基づく「高リスク」カテゴリーに達する可能性が高いと評価されました。当社は特定されたリスクに対処する多層的な緩和策を実装しており、Muse Spark は化学や生物学における危険なワークフローに関連するさまざまなベンチマークにわたって最先端の拒否を実証しています。そこで、メタ AI の基盤モデルとして Muse Spark をリリースします。
原文 (English)
Muse Spark Safety & Preparedness Report
Muse Spark is the latest large language model developed by Meta. In this report, we first present evaluations for catastrophic risk domains under Meta's Advanced AI Scaling Framework, along with the evidence that informed our launch decision. We then discuss additional considerations, such as Muse Spark's broader content safety and behavioral profile, that are relevant to overall safety but fall outside the catastrophic risk domains governed by the Framework. Our preparedness results covering Chemical and Biological, Cybersecurity, and Loss of Control risks assess Muse Spark's deployment within Meta AI as presenting acceptable levels of residual risks under our Advanced AI Scaling Framework. We conducted a broad set of evaluations targeting dual-use and high-risk capabilities across these catastrophic risk domains. Those evaluations identified elevated risks prior to mitigations, with Chemical and Biological capabilities assessed as likely reaching the "high risk" category under the Advanced AI Scaling Framework before safeguards were applied. We have implemented a multi-layered set of mitigations that address the identified risks, and Muse Spark demonstrates state-of-the-art refusal across a range of benchmarks related to hazardous workflows in chemistry and biology. We therefore release Muse Spark as the underlying model of Meta AI.
AI エージェントは私たちを無意味な仕事から解放してくれるでしょうか?人間中心の分析
AIエージェントが労働者を仕事の退屈な部分から解放してくれると主張する人もいるが、労働者自身がどのタスクを自動化すべきかをどのように特定するのかについてはほとんど知られていない。これまでの研究は職業に焦点を当てており、労働者が同じ役割内のタスク間でさまざまなレベルの意味を経験していることを見落としていました。私たちは、グレーバーのブルシット ジョブ理論に基づいたタスク レベルの分析でこのギャップに対処します。 171 の職場タスクに対する 202 人の従業員からの評価を使用して、(1) でたらめと認識される 5 項目の尺度を検証し、(2) でたらめと認識されると AI への委任への欲求を強く予測することを示し、(3) そのようなタスクは人間の監督があまり必要ないとみなされることも発見しました。これらの調査結果を総合すると、でたらめとみなされるタスクは AI 委任の自然な候補であり、労働者の好みと実現可能性が一致していることが示唆されます。
原文 (English)
Will AI Agents Free Us From Meaningless Work? A Human-Centered Analysis
Some claim that AI agents will free workers from the boring parts of their jobs, yet little is known about how workers themselves identify which tasks should be automated. Prior research focuses on occupations, overlooking that workers experience varying levels of meaning across tasks within the same role. We address this gap with a task-level analysis grounded in Graeber's theory of bullshit jobs. Using ratings from 202 workers on 171 workplace tasks, we (1) validate a five-item scale of perceived bullshitness, (2) show that perceived bullshitness strongly predicts desire for AI delegation, and (3) find that such tasks are also seen as requiring less human oversight. Together, these findings suggest that tasks perceived as bullshit are natural candidates for AI delegation, aligning worker preferences with perceived feasibility.
アルゴリズム立憲主義
社会生活への人工知能 (AI) の侵入がますます進んでおり、特に Google、Facebook、Apple、Amazon などの企業によって作成および管理されている情報圏内では、社会に重大なリスクが生じています。この記事では、すでにアルゴリズムによって部分的に管理されている Facebook のコンテンツ管理体制の詳細な分析を通じて、これらのリスクを検証します。 AI によってもたらされるガバナンス上の課題の解決策として文献でよく提案されている倫理工学の考え方は、いくつかの理由から不十分であると私たちは主張します。これに応じて、私たちは「アルゴリズム立憲主義」と呼ぶ代替枠組みを開発します。私たちのアプローチは 3 つの柱に基づいています。(a) コードの 2 つのレベルで構成される階層化アーキテクチャ: (i) 操作レベルまたはオブジェクト レベル、および (ii) アルゴリズムによって開始される変更からシステムの核となる原則を保護するように設計されたメタ レベル。 (b) アルゴリズムによるメタ推論。これにより、システムが両方のレベルで同時に動作できるようになり、メタコード レベルで保護された原則から逸脱するオブジェクト レベルでの動作をリアルタイムで監視、検証し、潜在的に修正できるようになります。 (c) 審議による修正。この記事では、アルゴリズム立憲主義の概念を詳しく説明し、それが Facebook のコンテンツモデレーション体制にどのように適用されるかを示しています。この分析の一環として、私たちは社会的立憲主義とアルゴリズム的立憲主義の間の緊張を検討します。逆説的ですが、AI システムを外部の熟議制御に従わせようとする試みは、AI エージェントがそのプロセスに介入することを可能にし、その目的を損なう可能性もあります。この記事は、この議論が 2022 年 10 月に発効した欧州デジタル サービス法に及ぼす影響を考察して締めくくられています。
原文 (English)
Algorithmic Constitutionalism
The increasing encroachment of artificial intelligence (AI) on social life raises significant risks for society, particularly within the infospheres created and controlled by companies such as Google, Facebook, Apple, and Amazon. This article examines these risks through an in-depth analysis of Facebook's content moderation regime, which is already partially governed by algorithms. We argue that the idea of ethical engineering, often proposed in the literature as a solution to the governance challenges posed by AI, is inadequate for several reasons. In response, we develop an alternative framework, which we term "algorithmic constitutionalism." Our approach rests on three pillars: (a) a layered architecture consisting of two levels of code: (i) an operative or object level and (ii) a meta level designed to protect the system's core principles from algorithmically initiated change; (b) algorithmic meta-reasoning, which enables the system to operate simultaneously at both levels so that it can monitor, verify, and potentially correct in real time operations at the object level that depart from principles protected at the meta-code level; and (c) correction through deliberation. The article elaborates the concept of algorithmic constitutionalism and demonstrates how it may be applied to Facebook's content moderation regime. As part of this analysis, we examine the tension between societal constitutionalism and algorithmic constitutionalism. Paradoxically, attempts to subject AI systems to external deliberative control may also enable AI agents to intervene in that process, potentially undermining its purpose. The article concludes by considering the implications of this argument for the European Digital Services Act, which entered into force in October 2022.
立場: 生成エンジンの最適化は十分に検討されていないリスクを生み出す、ガバナンスは集中、情報開示、学術上の盲点をターゲットにする必要がある
大規模言語モデル (LLM) 回答エンジンは情報探索にますます使用されており、可視性はランク付けされたリストから合成された回答に移行しています。これにより、LLM 応答エンジンの証拠プールと生成を対象とする生成エンジン最適化 (GEO) が有効になります。私たちは、検索エンジン最適化 (SEO) から GEO への移行を分析し、(i) 低い異議可能性とシステム感度による集中的な影響、および (ii) 証拠と推論に埋め込まれた未公開の商業的影響という 2 つのリスクを特定します。次に、一般的な GEO パイプラインを形式化し、最適化が機能する場所を特定し、学術と業界の実践を比較します。これにより、3 番目のリスクが明らかになります。(iii) オフライン設定と展開されたシステム間の可視性と評価の非対称性によって引き起こされる学術と業界の盲点。この立場は、回答レベルのガバナンスと測定の必要性、つまり、より強力な異議申し立て可能性、高精度の開示、重要な影響のブラックボックス監査、および暴露の持続性のための展開に合わせた指標の必要性を主張しています。
原文 (English)
Position: Generative Engine Optimization Creates Underexamined Risks, Governance Must Target Concentration, Disclosure, and Academic Blind Spots
Large language model (LLM) answer engines are increasingly used for information seeking, shifting visibility from ranked lists to synthesized answers. This enables Generative Engine Optimization (GEO), which targets LLM answer engines' evidence pool and generation. We analyze the search engine optimization (SEO) to GEO transition to identify two risks: (i) concentrated influence from low contestability and system sensitivity, and (ii) undisclosed commercial influence embedded in evidence and reasoning. We then formalize a general GEO pipeline to locate where optimization acts and compare academic and industry practices, revealing a third risk: (iii) academic-industry blind spots driven by visibility and evaluation asymmetries between offline setups and deployed systems. This position argues the need for answer-level governance and measurement: stronger contestability, high-precision disclosure, black-box auditing of material influence, and deployment-aligned metrics for exposure persistence.
Generativism: Toward a Learning Theory for the Age of Generative Artificial Intelligence
The four dominant learning theories of behaviorism, cognitivism, constructivism, and connectivism show significant conceptual limitations a…
Reframing AI Loss of Control: What It Is, How to Have It, How to Lose It
At present, loss of control risks have gained much prominence in public discussion, particularly in relation to AI, with extensive discours…
Occupational Prompting Reveals Cultural Bias in Large Language Models
Social roles shape expectations, priorities, and judgments, yet it remains unclear how large language models (LLMs) associate occupational…
SAIGuard: Communication-State Simulation for Proactive Defense of LLM Multi-Agent Systems
LLM-based multi-agent systems (MAS) solve complex tasks through inter-agent collaboration, but their communication-driven nature also allow…
Quickest Detection of Hallucination Onset: Delay Bounds and Learned CUSUM Statistics
Token-level hallucination detectors are evaluated as classifiers, by AUC over all tokens, yet a streaming monitor is judged by its reaction…
ReCal: Reward Calibration for RL-based LLM Routing
Large language model (LLM) routing has emerged as an effective paradigm for leveraging the complementary strengths of multiple LLMs through…
Representing Time Series as Structured Programs for LLM Reasoning
Large language models (LLMs) have demonstrated strong reasoning and instruction-following capabilities, making them potentially powerful to…
Speculative Rollback Correction for Quality-Diverse Web Agent Imitation
Training interactive web agents through imitation learning from expert trajectories has emerged as a highly effective approach. However, de…
Improving Crash Frequency Prediction from Simulated Traffic Conflicts Using Machine Learning Based Microsimulation
Traffic microsimulation combined with surrogate safety measures has increasingly been used as a proactive alternative to historical crash d…
A Mathematical Theory of Value: a synthesis on goal-directed agency under resource constraints
We propose that value -- the quantity goal-directed agents create, destroy, and exchange -- is a lawful structural quantity in the same cat…
Boosting Direct Preference Optimization with Penalization
Offline preference optimization has become a practical substitute for reinforcement learning from human feedback, but pairwise objectives s…
Foresight: Iterative Reasoning About Clues that Matter for Navigation
Open-world mapless navigation from sparse language instructions requires resolving underspecified goals and inferring which environmental c…
EDEN: A Large-Scale Corpus of Clinical Notes for Italian
We present EDEN (Emergency Department Electronic Notes), a new and unique large-scale corpus of clinical notes produced in Emergency Depart…
Graph Reduction in Multirelational Networks: A Spreading-Oriented Reduction Benchmark
Real-world networks are inherently incomplete, noisy, and dynamically evolving, making it difficult to capture all actors and their relatio…
Analyzing and Improving Fine-grained Preference Optimization in Medical LVLMs
Large Vision-Language Models (LVLMs) have achieved strong performance across medical imaging tasks, yet they remain prone to factual incons…
Emerging Flexible Designs for Geospatial Multimodal Foundation Models
Foundation models are rapidly transforming Earth observation by enabling scalable pretraining across diverse unlabeled geospatial modalitie…
From Imitation to Alignment: Human-Preference Flow Policies for Long-Horizon Sidewalk Navigation
Autonomous long-horizon sidewalk navigation is essential for micro-mobility applications such as robotic food delivery and assistive electr…
HybridCodeAuthorship: A Benchmark Dataset for Line-Level Code Authorship Detection
Thanks to the rapid adoption of AI code assistants powered by large language models (LLMs), industry codebases are, increasingly, a hybrid…
Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
We show that the standard basis of transformer hidden states already provides a training-free, architecture-general feature basis. Individu…
Keep Policy Gradient in Charge: Sibling-Guided Credit Distillation for Long-Horizon Tool-Use Agents
Long-horizon tool-use reinforcement learning can learn from outcome verification, but its trajectory-level advantage is broadcast across ma…
Token Complexity Theory for AI-Augmented Computing
AI-augmented computing delegates natural language queries, code generation requests, and other open-ended tasks to a cluster of AI models t…
BASENet: Band-Adapted Speech Enhancement Network with Cross-Band Attention
Speech enhancement models typically apply uniform capacity across all frequencies, disregarding the non-uniform spectral resolution of huma…
CAPED: Context-Aware Privacy Exposure Defense for Mobile GUI Agents
Screenshot-based mobile GUI agents can operate ordinary smartphone apps through the same visual interface as a human user, but this capabil…
Free-Placement Optimization of Ground Station Locations for Low-Earth Orbit Satellites
Rapidly expanding low Earth orbit satellite constellations are placing increasing demands on terrestrial ground networks, motivating the de…
A Zero-shot Generalized Graph Anomaly Detection Framework via Node Reconstruction
Cross-domain graph anomaly detection (GAD) aims to identify abnormal nodes in unseen target graphs, showing strong potential in real-world…
M*: A Modular, Extensible, Serving System for Multimodal Models
We are entering a new era of composite model architectures that integrate diverse components such as vision encoders, language backbones, d…
EWAM: An Enhanced World Action Model for Closed-Loop Online Adaptation in Embodied Intelligence
In this paper, we propose the Enhanced World Action Model (EWAM), a closed-loop online adaptation architecture built upon a pretrained and…
Two-Layer Linear Auto-Regressive Models Estimate Latent States
Auto-regressive models have emerged as powerful tools for sequential data, from language to video. Understanding how and why these models l…
LLM-Powered Personalized Glycemic Assessment in Type 2 Diabetes with Wearable Sensor Data
Type 2 Diabetes (T2D) poses an increasing global health threat, demanding effective glycemic assessment to support personalized and improve…
SMSR: Certified Defence Against Runtime Memory Poisoning in Persistent LLM Agent Systems
Retrieval-augmented generation (RAG) agents increasingly run with persistent memory that accumulates across user sessions. This creates a n…
AfriSUD: A Dependency Treebank Collection for Evaluating Models on African Languages
Despite their linguistic diversity and global significance, African languages remain underrepresented in research and resources to support…
PI-Hunter: Automated Red-Teaming for Exposing and Localizing Prompt Injections
Large Language Models (LLMs) are rapidly evolving into agentic systems that interact with external tools and environments, introducing new…
LLMs Can Better Capture Human Judgments--With the Right Prompts
Are large language models (LLMs) bad at capturing human judgment? Two commonly stated limitations are that LLMs fail to capture full distri…
Agentic MPC for Semantic Control System Resynthesis
While MPC effectively handles structured, diverse, and low-level specifications, it lacks the capability to dynamically incorporate high-le…
Exploring How Agent Voice Accents Shape Human-AI Collaboration in K-12 Group Learning
Collaboration is widely recognized as a cornerstone of 21st-century education, yet teachers still encounter persistent challenges in foster…
SymQNet: Amortized Acquisition for Low-Latency Adaptive Hamiltonian Learning
Adaptive Hamiltonian learning is central to calibrating and characterizing quantum devices. In an adaptive controller, choosing the next ex…
Stubborn: A Streamlined and Unified Reinforcement Learning Framework for Robust Motion Tracking and Fall Recovery for Humanoids
Recent reinforcement learning approaches have shown great promise in improving humanoid motion tracking performance and achieving fall reco…
Localizing Anchoring Pathways in Language Models
Irrelevant numbers in a prompt can shift language model judgments, producing anchoring effects in numerical reasoning. We study where this…
Acquisition state behaves as a structured, measurable variable governing lung-nodule AI: kernel-driven measurement instability and noise-driven detection fragility, invisible to DICOM metadata
AI governance for medical imaging is formalizing: the 2026 ACR-SIIM Practice Parameter recommends local acceptance testing and ongoing drif…
DIMOS: Disentangling Instance-level Moving Object Segmentation
Moving instance segmentation (MIS) attracts increasing attention due to its broad applications in traffic surveillance, autonomous driving,…
Perceive, Interact, Reason: Building Tool-Augmented Visual Agents for Spatial Reasoning
While recent vision-language models (VLMs) demonstrate strong multimodal understanding, they remain limited in spatial reasoning tasks that…
The Internet of Agentic AI: Communication, Coordination, and Collective Intelligence at Scale
The rapid emergence of autonomous AI agents is transforming artificial intelligence from isolated model inference into distributed systems…
OCOO-T : A Simple and Scalable Virtual Cell Model for Transcriptional Perturbation Response Prediction
Predicting single-cell transcriptional responses to genetic, chemical and cytokine perturbations is a fundamental challenge in computationa…
TimeROME-DLM: Temporal Causal Tracing and Low-Rank Inference-Time Knowledge Editing for Masked Diffusion Language Models
Masked diffusion language models (MDLMs) such as LLaDA now rival autoregressive (AR) LLMs, but every existing knowledge-editing and unlearn…
JSCGC: Joint Source-Channel-Generation Coding for Wireless Generative Communications
Conventional communication systems, including both separation-based coding and learning-based joint source-channel coding (JSCC), are typic…
Beyond Problem Solving: UOJ-Bench for Evaluating Code Generation, Hacking, and Repair in Competitive Programming
Despite strong performance in competitive programming, the role of Large Language Models (LLMs) in supporting human learning in the same se…
Bridging Modal Isolation in Interleaved Thinking: Supervising Modality Transitions via Stepwise Reinforcement
Interleaved thinking, where a unified multimodal model alternates between textual reasoning and visual generation, has shown promise on spa…
PolicyGuard: Towards Test-time and Step-level Adversary Defense for Reinforcement Learning Agent
While real-world applications of reinforcement learning (RL) are becoming increasingly popular, the security of RL systems deserve more att…
Bounding Boxes as Goals: Language-Conditioned Grasping via Neuro-Symbolic Planning
For robotics to be effectively integrated into household or industrial environments, machines must adapt to natural-language prompts in rea…
MAStrike: Shapley-Guided Collusive Red-Teaming on Multi-Agent Systems
Hierarchical multi-agent systems (MAS) are rapidly being deployed in high-stakes workflows across domains such as finance and software engi…
LoRA-Muon: Spectral Steepest Descent on the Low-Rank Manifold
Low-Rank Adaptation (LoRA) significantly reduces compute and memory costs for finetuning Deep Learning models but is often harder to tune t…
Order Is Not Control
AI alignment, interpretability, steering, and neural perturbation studies identify order-inducing objects. We argue that order is not contr…
An Embodied Simulation Platform, Benchmark, and Data-Efficient Augmentation Framework for Wet-Lab Robotics
Wet-lab robots can improve the reproducibility, throughput, and safety of biomedical experiments, but scaling their learning requires custo…
Efficient, Robust, and Anti-Collusion Fingerprinting of Image Diffusion Models
Model fingerprinting, embedding user-specific identifiers (fingerprints) into generated outputs, has recently emerged as a popular solution…
Diffusion Transformer World-Action Model for AV Scene Prediction
Action-conditioned world models let an autonomous vehicle predict future camera scenes from its own planned controls, enabling planning and…
A Machine Learning Framework for Real-Time Personalized Ergonomic Pose Analysis
This paper introduces a new methodology for real-time prediction of ergonomic and non-ergonomic human poses using volumetric video data in…
scLLM-DSC: LLM-Knowledge Enhanced Cross-Modal Deep Structural Clustering for Single-Cell RNA Sequencing
Clustering is fundamental to scRNA-seq analysis, serving as a cornerstone for identifying cell populations and resolving tissue heterogenei…
CausalMoE: A Billion-Scale Multimodal Foundation Model for Granger Causal Discovery with Pattern-Routed Heterogeneous Experts
Granger Causal Discovery (GCD) is fundamental for analyzing temporal dependencies in complex systems. However, existing neural GCD methods…
Democracy in the Era of Artificial Intelligence
Interfacing Artificial Intelligence (AI) with democracy is one of the most profound challenges of our times. On the one hand, AI comes with…
TetherCache: Stabilizing Autoregressive Long-Form Video Generation with Gated Recall and Trusted Alignment
Autoregressive video diffusion models provide a natural formulation for streaming and variable-length video generation by conditioning newl…
Fault Lines: Navigating Ethics and Responsible AI Where National Policy Meets Local Practice in Public Sector Transformation
The UK government has adopted a pro-AI stance to help transform public service delivery in the face of severe financial pressures, but the…
EA-WM: Event-Aware World Models with Task-Specification Grounding for Long-Horizon Manipulation
Pretrained-feature world models provide a useful substrate for robot imagination, but visual or latent prediction alone does not determine…
TWLA: Achieving Ternary Weights and Low-Bit Activations for LLMs via Post-Training Quantization
Large language models (LLMs) exhibit exceptional general language processing capabilities, but their memory and compute costs hinder deploy…
"Is This Not Enough?": Asymmetries in Institutional Accountability and Collective Sensemaking in the Case of Canada's Algorithmic Visa Triage System
This paper examines how algorithmic accountability in Canada's visa system is articulated institutionally and experienced by applicants acr…
The Emergence of Autonomous Penetration Capabilities in Large Language Model-Powered AI Systems
Nowadays, the autonomous execution of cyberattacks capable of causing substantial real-world harm is widely regarded as one of the critical…
Emotional regulation improves deep learning-based image classification
Emotion significantly influences cognition, enhancing memory and learning under certain conditions. Drawing on this principle, emotion-augm…
Functional Cache Grafting: Robust and Rapid Code-Policy Synthesis for Embodied Agents
Code-writing large language models (CodeLLMs) generate executable code policies for embodied agents by translating natural language goals a…
G-Long: Graph-Enhanced Memory Management for Efficient Long-Term Dialogue Agents
While Large Language Models (LLMs) have advanced open-domain dialogue systems, maintaining long-term consistency remains a challenge due to…
MP3: Multi-Period Pattern Pre-training forSpatio-Temporal Forecasting
Spatio-Temporal forecasting is crucial in diverse fields, such as transportation, climate, and energy. Urban spatio-temporal data exhibits…
NaturalFlow: Reducing Disruptive Pauses for Natural Speech Flow in Simultaneous Speech-to-Speech Translation
Simultaneous speech-to-speech translation aims to enable near-real-time communication by minimizing latency, offering a compelling, real-ti…
Select and Improve: Understanding the Mechanics of Post-Training for Reasoning
Reinforcement learning has rapidly emerged as a key component in the training of reasoning and coding models, yet it remains poorly underst…
MiniPIC: Flexible Position-Independent Caching in <100LOC
Retrieval-augmented and agentic workloads repeatedly prefill recurring predictable structured inputs (which we call "spans") such as docume…
Cascade Classification of Dermoscopic Images of Skin Neoplasms with Controllable Sensitivity and External Clinical Validation
Purpose. To compare deep learning architectures and classification schemes for dermoscopic images of skin neoplasms and assess their genera…
Iterative Visual Thinking: Teaching Vision-Language Models Spatial Self-Correction through Visual Feedback
Vision-language models (VLMs) achieve strong singleshot spatial grounding, yet lack any mechanism to observe and correct their own predicti…
NTS-CoT: Mitigating Hallucinations in LLM-based News Timeline Summarization with Chain-of-Thought Reasoning
The rapid updates of online news make tracking event developments challenging, highlighting the need for timeline summarization (TLS). Hall…
MemRefine: LLM-Guided Compression for Long-Term Agent Memory
Large language model (LLM) agents are increasingly expected to operate over long-term interactions, where information from past dialogues m…
Modern analog computing for solving differential and matrix equations
In recent years, driven by the computational demands of data-intensive applications such as artificial intelligence and scientific computin…
Transformer-Guided Graph Attention for Direct Cardiac Mesh Reconstruction: A Structural Digital Twin Framework
Building patient-specific cardiac models sits at the heart of precision cardiology, yet getting those models into clinical use keeps runnin…
Proprioceptive-visual correspondence enables self-other distinction in humanoid robots
Distinguishing self from others is a prerequisite for social intelligence, yet humanoid robots that increasingly share workspaces with huma…
ReSET: Accurate Latency-Critical NVFP4 Reasoning via Step-Aware Temperature Scaling
Large reasoning models (LRMs) improve complex problem-solving by generating long intermediate reasoning traces, but this substantially incr…
Decoding Insect Song: A Multitask Semisupervised Orthoptera Bioacoustic Classifier
Passive acoustic monitoring holds great promise for ecological inference, yet existing automated tools are typically narrowly trained and n…
ComAct: Reframing Professional Software Manipulation via COM-as-Action Paradigm
Existing computer-use agents remain fundamentally limited in professional software manipulation: GUI-based agents suffer from fragile visua…
Towards More General Control of Diffusion Models Using Jeffrey Guidance
A key strength of diffusion models lies in their flexibility, since their outputs can be controlled at sampling time through guidance. Howe…
Towards Personalized Federated Learning for Dysarthric Speech Recognition
Speech recognition is challenging for dysarthric speakers. While federated learning (FL)-based ASR can be an effective tool for protecting…
Humor Style Drives Laughter, Topic Shapes Acceptability: Evaluating Bilingual Personal and Political Robot-Delivered AI Jokes
Humor plays a central role in human social relationships, and recent advances in computational humor create new opportunities for integrati…
Different Layers, Different Manifolds: Module-Wise Weight-Space Geometry in Transformer Optimization
Weight-space geometry plays a central role in neural network optimization, yet manifold constraints are often applied uniformly across all…
Once-for-All: Scalable Simultaneous Forecasting via Equilibrium State Estimation
We introduce Equilibrium State Estimation (ESE), a novel paradigm for simultaneous prediction, where multiple interacting systems require s…
Cross-Modal Masked Compositional Concept Modeling for Enhancing Visio-Linguistic Compositionality
Contrastively trained vision-language models like CLIP, have made remarkable progress in learning joint image-text representations, but sti…
HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
Holistic visual tokenizers are fundamental to unified multimodal models (UMMs) as they map diverse visual inputs into a unified representat…
Mining Architectural Quality Under Agentic AI Adoption: A Causal Study of Java Repositories
AI coding tools are now used by a majority of developers, and agentic use of these tools has popularized the practice colloquially called "…
Rarity-Gated Context Conditioning for Offline Imitation Learning-Based Maritime Anomaly Detection
Contextual anomaly detection aims to identify abnormal behavior conditional on context variables, but practical deployments often face high…
Dual-Domain Equivariant Generative Adversarial Network for Multimodal CT-PET Synthesis
We present a Dual-Domain Equivariant Generative Adversarial Network (DDE-GAN) for multimodal CT-PET image synthesis. Traditional GAN-based…
IVIE: A Neuro-symbolic Approach to Incremental and Validated Generation of Interactive Fiction Worlds
Computational creativity in Interactive Fiction faces a fundamental tension: Large Language Models (LLM) may produce creative narratives bu…
Real-Time Execution with Autoregressive Policies
Real-time execution, enabled by asynchronous inference that ensures both smooth action trajectories and fast reactivity, is critical for re…
An LLM System for Autonomous Variational Quantum Circuit Design
The design of high performing quantum circuits remains largely dependent on human expertise. We introduce an autonomous agentic framework t…
SmartFont: Dynamic Condition Allocation for Few-Shot Font Generation
Few-shot font generation simultaneously requires global structural completeness and fine-grained local style fidelity. Existing methods usu…
Who Pays the Price? Stakeholder-Centric Prompt Injection Benchmarking for Real-world Web Agents
Web agents driven by large language models (LLMs) are increasingly deployed in real-world environments, where they operate over untrusted w…
Mod-Guide: An LLM-based Content Moderation Feedback System to Address Insensitive Speech toward Indigenous Ethnic and Religious Minority Communities
Language operates as a mechanism of both marginalization and resistance, especially for minority communities navigating insensitive and har…
PolyFlow: Safe and Efficient Polytope-Constrained Flow Matching with Constraint Embedding and Projection-free Update
While flow-based generative models have demonstrated strong performance across a wide range of domains, deploying them in safety-critical p…
OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
Cloning camera motion from reference videos is an important task in video generation, as videos provide intuitive and precise control. Exis…
Toward Instructions-as-Code: Understanding the Impact of Instruction Files on Agentic Pull Requests
AI-agents (e.g., GitHub Copilot) collaborate as teammates in different software engineering tasks, including code generation proposed throu…
Ontology Memory-Augmented ASR Correction for Long Text-Speech Interleaved Conversations
Automatic speech recognition (ASR) correction has traditionally focused on isolated utterances or short local contexts. However, as text an…
Understanding the Rejection of Fixes Generated by Agentic Pull Requests -- Insights from the AIDev Dataset
AI coding agents are increasingly used to generate pull requests (PRs) that propose code fixes in software projects. From a first explorati…
MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
We present MaxProof, a population-level test-time scaling framework for competition-level mathematical proof in the MiniMax-M3 series. M3 f…
SupraBench: A Benchmark for Supramolecular Chemistry
Supramolecular chemistry, which includes the study of non-covalent host-guest assemblies, has advanced various applications. However, desig…
CRAFTIIF: Cross-Resolution Analytic Four-Type Interpretable Isolation Forest for Multivariate Time Series Anomaly Detection
Anomaly detection in multivariate time series is challenged by four structurally distinct anomaly types -- point (isolated spikes), distrib…
Heterogeneous LiDAR Early Fusion and Learned Re-Ranking Strategy for Robust Long-Term Place Recognition in Unstructured Environments
Robust localization in unstructured environments, such as agricultural fields, is a critical challenge for autonomous systems. LiDAR sensor…
Measurement-Calibrated Multi-Camera Fusion for Vision-Based Indoor Localization
Indoor vision-based localization systems are affected by detection noise, occlusions, and limited camera coverage, leading to uncertainty a…
AgentRivet: an automated system for producing Rivet routines from journal publications
Particle physics collider experiments provide Rivet routines as part of the analysis preservation strategy for model-independent measuremen…
Adaptive Turn-Taking for Real-time Multi-Party Voice Agents
Turn-taking in multi-party spoken conversations remains a fundamental challenge for voice-based agents, particularly under dynamic floor co…
Contrast-Informed Augmentation and Domain-Adversarial Training for Adult-to-Neonatal MR Reconstruction Generalization
Purpose: To investigate whether contrast-informed data augmentation and domain-adversarial training improve the adult-to-neonatal generaliz…
Existence Precedes Value: Joint Modeling of Observational Existence and Evolving States in Time Series Forecasting
Real-world time series are often highly incomplete and irregular due to sensor dormancy, transmission delays, and event-driven sampling, ma…
ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages
Multimodal Large Language Models (MLLMs) have shown promising reasoning capabilities in general domains, yet their performance remains limi…
LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
Scientific laboratories increasingly rely on AI systems to reason about experiments, but the physical act of doing science remains largely…
EvTexture++: Event-Driven Texture Enhancement for Video Super-Resolution
Event-based vision has drawn increasing attention owing to its distinctive properties, including ultra-high temporal resolution and extreme…
Beyond the Commitment Boundary: Probing Epiphenomenal Chain-of-Thought in Large Reasoning Models
Chain-of-thought (CoT) reasoning is the dominant paradigm for inference-time scaling in language models, yet the causal influence of indivi…
One Polluted Page Is Enough: Evaluating Web Content Pollution in Generative Recommenders
Search-augmented LLMs increasingly mediate everyday consumer recommendations by retrieving live web content. This creates a new risk: gener…
Valid Inference with Synthetic Data via Task Exchangeability
There is a proliferation of work arguing for the use of synthetic data in scientific research. For example, social scientists are arguing f…
SkMTEB: Slovak Massive Text Embedding Benchmark and Model Adaptation
We introduce SkMTEB, the first comprehensive MTEB-style text embedding benchmark for Slovak, a low-resource West Slavic language, comprisin…
SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning
Spatial reasoning, the ability to determine where objects are, how they relate, and how they move in 3D, remains a fundamental challenge fo…
Mana: Dexterous Manipulation of Articulated Tools
Articulated tool manipulation remains a major challenge in dexterous robotics due to the need to coordinate internal degrees of freedom and…
Learning to Reason by Analogy via Retrieval-Augmented Reinforcement Fine-Tuning
Retrieval-augmented generation (RAG) has become a standard mechanism for grounding language models in external knowledge, yet conventional…
DecompSR: A dataset for decomposed analyses of compositional multihop spatial reasoning
We introduce DecompSR, decomposed spatial reasoning, a large benchmark dataset (over 5m datapoints) and generation framework designed to an…
DSAEval: Evaluating Data Science Agents on a Wide Range of Real-World Data Science Problems
Recent LLM-based data agents aim to automate data science tasks ranging from data analysis to deep learning. However, the open-ended nature…
Epistemic Constitutionalism Or: how to avoid coherence bias
Large language models increasingly function as artificial reasoners: they evaluate arguments, assign credibility, and express confidence. Y…
From Digital to Physical: Digital Agents as Autonomous Coaches for Physical Intelligence
The field of Embodied AI is witnessing a rapid evolution toward general-purpose robotic systems, fueled by high-fidelity simulation and lar…
CreativeBench: Benchmarking and Enhancing Machine Creativity via Self-Evolving Challenges
The saturation of high-quality pre-training data has shifted research focus toward evolutionary systems capable of continuously generating…
Counterfactual Credit Policy Optimization for Multi-Agent Collaboration
Collaborative multi-agent large language models (LLMs) can solve complex reasoning tasks by decomposing roles, but reinforcement learning f…
Cross-Model Disagreement as a Label-Free Correctness Signal
Detecting when a language model is wrong without ground truth labels is a fundamental challenge for safe deployment. Existing approaches re…
The Query Channel: Information-Theoretic Limits of Masking-Based Explanations
Masking-based post-hoc explanation methods, such as KernelSHAP and LIME, estimate local feature importance by querying a black-box model un…
LLMs as ASP Programmers: Self-Correction Enables Task-Agnostic Nonmonotonic Reasoning
Recent large language models (LLMs) have achieved impressive reasoning milestones but continue to struggle with high computational costs, l…
A Study of Belief Revision Postulates in Multi-Agent Systems (Extended Version)
We investigate the belief revision problem in epistemic planning, i.e., what will be the beliefs of all agents in a multi-agent system afte…
FinSTaR: Towards Financial Reasoning with Time Series Reasoning Models
Time series (TS) reasoning models (TSRMs) have shown promising capabilities in general domains, yet they consistently fail in the financial…
Mechanical Conscience: A Mathematical Framework for Dependability of Machine Intelligenc
Distributed collaborative intelligence (DCI), encompassing edge-to-edge architectures, federated learning, transfer learning, and swarm sys…
エントロピー勾配反転: 大規模推論モデルの内部メカニズムへの移行
大規模推論モデル (LRM) の進歩により、反応的な「速い思考」のテキスト生成から、体系的で段階的な「遅い思考」の推論へのパラダイム シフトが促進され、複雑な数学的および論理的タスクで最先端のパフォーマンスが可能になりました。しかし、この分野は \textit{トークンレベルの動作分析と内部推論メカニズムの間の根本的なギャップ、およびコストのかかる外部検証器に依存した推論最適化のための強化学習 (RL) の不安定性}に直面しています。私たちは、LRM 推論機能の決定的な幾何学的フィンガープリントとして機能する、トークン エントロピーとロジット勾配の間の堅牢な負の相関である \textbf{エントロピー勾配反転} を特定し、正式に定義します。これに基づいて、この反転署名を RL 報酬正則化に埋め込む \textbf{Correlation- Regularized Group Policy Optimization (CorR-PO)} を提案します。複数のモデルスケールにわたるさまざまな推論ベンチマークに関する広範な実験では、CorR-POが一貫して最先端のベースラインを上回るパフォーマンスを示し、より強力な反転が優れた推論パフォーマンスと直接相関していることが確認されました。
原文 (English)
Entropy-Gradient Inversion: Moving Toward Internal Mechanism of Large Reasoning Models
The advancement of Large Reasoning Models (LRMs) has catalyzed a paradigm shift from reactive ``fast thinking'' text generation to systematic, step-by-step ``slow thinking'' reasoning, unlocking state-of-the-art performance in complex mathematical and logical tasks. However, the field faces \textit{the fundamental gap between token-level behavioral analysis and internal reasoning mechanisms, and the instability of reinforcement learning (RL) for reasoning optimization relying on costly external verifiers}. We identify and formally define \textbf{Entropy-Gradient Inversion}, a robust negative correlation between token entropy and logit gradients that acts as a definitive geometric fingerprint for LRM reasoning capability. Building on this, we propose \textbf{Correlation-Regularized Group Policy Optimization (CorR-PO)}, which embeds this inversion signature into RL reward regularization. Extensive experiments on various reasoning benchmarks across multiple model scales show CorR-PO consistently outperforms state-of-the-art baselines, confirming that stronger inversion directly correlates with superior reasoning performance.
管理された自律性としてのインテリジェンス: エージェントティック AI システムの障害、エスカレーション、ガバナンス
自律型およびエージェント型 AI システムがロボット環境やヒューマンマシン環境で拡張されるにつれて、幻覚や永続的だが不当な行動の管理は未解決の課題のままです。この論文では、これらの失敗の原因を単にモデルや調整の制限に帰するのではなく、無制限の自律性、つまり不確実性の増大に関係なくエージェントが動作し続けるべきであるという前提のアーキテクチャ上の脆弱性を調査します。これは、認識的ドリフトを検出し、推論を中断し、回復を試み、信頼性が低下したときに最終的に制御を放棄する形式的な能力を通じて、インテリジェントな行動を定義する管理された自律性の理論を導入します。この理論は、安定状態、メタ認知状態、支援状態、および規制状態を特徴とする 4 層フレームワークである SMARt (Self-Managing Multi-tier Autonomous Reasoning with Regulated/Revoked transitions) モデルを介してインスタンス化されます。時間制限付きで保護されたペトリ ネット定式化を開発することで、システムの理論的に制限されたプロパティを確立し、アーキテクチャがどのようにしてエスカレーションを正式に義務付け、無効な出力を制限し、指定された条件下でガバナンスの到達可能性を確保できるかを実証します。さらに、完全性と健全性の基準が満たされていると仮定して、さまざまな運用設定 (ヘルスケア、ロボット工学など) にわたってドメイン固有のトリガー セットを組み込むことで、体系的に安全性を維持できる方法を分析します。これらのトリガーは適応するように設計されているため、SMARt モデルは、時間の経過とともに、エージェントの操作範囲を安全に制御された拡張に対応します。私たちは、自律性ライフサイクル内で障害管理を形式化することが、信頼性が高く管理された人工知能を実現するための重要なステップであると結論付けています。
原文 (English)
Intelligence as Managed Autonomy: Failure, Escalation, and Governance for Agentic AI Systems
As autonomous and agentic AI systems scale in robotic and human-machine environments, managing hallucination and persistent but unjustified action remains an open challenge. Rather than attributing these failures solely to model or alignment limitations, this paper explores the architectural vulnerability of unbounded autonomy - the presumption that an agent should continue operating regardless of rising uncertainty. It introduces a theory of managed autonomy that defines intelligent behavior through the formal capacity to detect epistemic drift, suspend reasoning, attempt recovery, and ultimately surrender control when reliability diminishes. We instantiate this theory via the SMARt (Self-Managing Multi-tier Autonomous Reasoning with Regulated/Revoked transitions) model, a four-layer framework featuring Stable, Meta-cognitive, Assisted, and Regulated states. By developing a timed, guarded Petri net formulation, we establish theoretically bounded properties for the system, demonstrating how architecture can formally mandate escalation, constrain invalid outputs, and ensure governance reachability under specified conditions. We further analyze how incorporating domain-specific trigger sets across varied operational settings (e.g., healthcare, robotics, etc.) can systematically preserve safety, assuming completeness and soundness criteria are met. Because these triggers are designed to be adaptive, the SMARt model accommodates the safe, controlled expansion of an agent's operational scope over time. We conclude that formalizing failure management within the autonomy lifecycle is a crucial step toward realizing reliable and governed artificial intelligence.
インタラクション中心のインテリジェンス: 共創 AI およびヒューマン AI システムにおける主要な分析単位としてのインタラクションを目指して
従来の人工知能は、主に、境界のあるエージェント内で発生する分離された計算として知能を概念化していました。従来の AI、機械学習、および多くの生成システムにわたって、主要な分析単位は依然として、出力、ベンチマーク、予測精度、または最適化パフォーマンスを通じて評価される個々のモデルまたは自律システムです。これらのアプローチは大きな進歩をもたらしましたが、知性、創造性、意味、適応行動の出現における相互作用の役割については過小理論化されていることがよくあります。この論文では、共創 AI およびより広範なインタラクション中心のインテリジェンスの分析の主要な単位としてインタラクションを提案します。この論文は、分散認知、身体化認知、実行、参加型センスメイキング、人間とコンピューターの相互作用、および計算による創造性を基に、知能の関係性の説明がますます高まっていく歴史的進歩をたどります。 Creative Sense-Making、定量化された共同創造、Drawing Apprentice や AI Drawing Partner などの共同創造システムに関するこれまでの研究に基づいて、内部計算のみを通じてではなく、エージェント、環境、社会技術システム間の相互作用ダイナミクスの進化を通じて知能が出現すると主張しています。この論文では、人間と AI の共創、協調的な創発、適応的な参加、およびインタラクション ダイナミクスを理解するためのフレームワークとして、インタラクション中心のインテリジェンスを紹介しています。このフレームワークは、生成された出力のみを通じて知能を評価するのではなく、相互作用の軌跡、調整パターン、参加型関与、適応的規制、および時間の経過とともに展開される相互作用ドリフトに重点を置いています。説明可能な共創 AI、ハイブリッド インテリジェンス、能動的 AI、および将来の人間と AI システムの意味について議論します。
原文 (English)
Interaction-Centered Intelligence: Toward an Interaction-Based Theory of Human-AI Co-Creation
Traditional artificial intelligence has largely conceptualized intelligence as isolated computation occurring within bounded agents. Across classical AI, machine learning, and many generative systems, the dominant unit of analysis remains the individual model or autonomous system evaluated through outputs, benchmarks, prediction accuracy, or optimization performance. While these approaches have produced major advances, they often under-theorize the role of interaction in the emergence of intelligence, creativity, meaning, and adaptive behavior. This paper proposes interaction as the primary unit of analysis for co-creative AI and interaction-centered intelligence more broadly. Drawing from distributed cognition, embodied cognition, enaction, participatory sense-making, human-computer interaction, and computational creativity, the paper traces a historical progression toward increasingly relational accounts of intelligence. Building upon prior work in Creative Sense-Making, quantified co-creation, and co-creative systems such as the Drawing Apprentice and AI Drawing Partner, it argues that intelligence emerges through evolving interaction dynamics among agents, environments, and socio-technical systems rather than solely through internal computation. The paper introduces Interaction-Centered Intelligence as a framework for understanding human-AI co-creation, collaborative emergence, adaptive participation, and interactional dynamics. Rather than evaluating intelligence solely through generated outputs, the framework emphasizes interaction trajectories, coordination patterns, participatory engagement, adaptive regulation, and interactional drift unfolding through time. Implications for explainable co-creative AI, hybrid intelligence, enactive AI, and future human-AI systems are discussed.
パルテノン法: 自己進化する弁護士の枠組み
エージェントの能力が高まるにつれて、法律分野の LLM エージェントは、大量のドキュメントをレビュー可能な作業成果物に変えることを約束しますが、信頼性の高い導入には 3 つの障害に直面しています。1 つは、今日の最も強力なモデルとハーネスの組み合わせがエンドツーエンドの法的問題でどのように動作するかについての大規模な証拠がないことです。法的な業種に適合したエージェント アーキテクチャはなく、汎用ハーネスのみが使用されます。そして、新しい事実、権限、期限によって変化し続ける環境では、システムが自らの結果から学習するメカニズムがありません。それぞれに対応します。 Harvey LAB に関する大規模な実証研究 -- $12{,}510$ のエージェントの軌跡 -- は、フロンティアのエージェントでさえ 1 回のパスで問題を完了することには程遠いことを示しています。より強力なモデルを使用すると基準ごとの精度が向上しますが、厳密な問題の完了は停滞します。次に、\textsc{Parthenon} を導入します。これは、モデル、ハーネス、代理人の役割、法的知識、決定論的なツール、および手続き上のスキルを情報源の追跡可能性、日付と番号の根拠、成果物のコンプライアンス、および問題の解決のための監査可能な表面に組み込む、自己進化する法律代理人のフレームワークです。最後に、漏れ防止学習ループにより、スコアリングされた失敗がタスクに依存しないスキル、ツール、知識の編集に変換され、企業が問題ごとにチェックリストとプレイブックを洗練するように、モデルの重みに触れることなく、経験とともにシステムが改善されます。私たちの大規模な実証分析を通じて、\textsc{Parthenon} は法的問題のタスクにおける最先端のモデルとハーネスのパフォーマンスを大幅に向上させました。
原文 (English)
Parthenon Law: A Self-Evolving Legal-Agent Framework
As agents grow more capable, legal-domain LLM agents promise to turn document-heavy matters into reviewable work products -- yet reliable deployment faces three obstacles: no large-scale evidence on how today's strongest model-and-harness combinations behave on end-to-end legal matters; no agent architecture adapted to the legal vertical, only general-purpose harnesses; and, in a setting that keeps shifting with new facts, authorities, and deadlines, no mechanism for systems to learn from their own outcomes. We address each. A large-scale empirical study on Harvey LAB -- $12{,}510$ agent trajectories -- shows that even frontier agents remain far from completing matters in a single pass: per-criterion accuracy climbs with stronger models while strict matter completion stalls. We then introduce \textsc{Parthenon}, a self-evolving legal-agent framework that factors Model, Harness, Agent roles, legal Knowledge, deterministic Tools, and procedural Skills into auditable surfaces for source traceability, date and number grounding, deliverable compliance, and issue closure. Finally, an anti-leakage learning loop converts scored failures into task-agnostic edits to skills, tools, and knowledge, letting the system improve with experience -- as a firm refines its checklists and playbooks after each matter -- without touching model weights. Across our large-scale empirical analysis, \textsc{Parthenon} substantially improves the performance of state-of-the-art models and harnesses on legal-matter tasks.
能動推論とはどのようなタイプの推論ですか?
能動推論では、期待自由エネルギー (EFE) が目標指向の行動と情報探索の行動を統合し、意思決定を推論としてキャストします。最近の研究では、EFE 最小化が、認識的事前分布で強化された生成モデル上の変分自由エネルギー (VFE) 最小化として記述できることが示されました。拡張モデルの VFE は、予測モデルの VFE に明示的なエントロピー補正項を加えたものとして書き換えることができ、EFE の寄与が透明になることを証明します。次に、適切な EFE ベースの計画には、これらの認識論的修正と限界推論を政策最適化に変える計画修正を組み合わせる必要があり、EFE ベースの計画の完全な変分特性が得られることを示します。これにより、クロスエントロピー計画および完全な EFE ベースの計画にどの修正が必要かが明確になります。同じエントロピー補正された定式化により、より単純なアブレーションとともに、EFE ベースの計画のための詳細なメッセージ パッシング スキームが得られます。 3 つのグリッドワールド環境での実験では、観察が決定的な場合には計画修正がすでに役に立ちますが、観察が単に示唆的な場合には追加の観察側の認識論的修正が最も重要であることが示されています。
原文 (English)
What Type of Inference is Active Inference?
Active inference casts decision-making as inference, with the Expected Free Energy (EFE) unifying goal-directed and information-seeking behavior. Recent work showed that EFE minimization can be written as Variational Free Energy (VFE) minimization on a generative model augmented with epistemic priors. We prove that the VFE of the augmented model can be rewritten as the VFE of the predictive model plus explicit entropy-correction terms, making the EFE contribution transparent. We then show that proper EFE-based planning requires combining these epistemic corrections with a planning correction that turns marginal inference into policy optimization, yielding a full variational characterization of EFE-based planning. This clarifies which corrections are needed for cross-entropy planning and for full EFE-based planning. The same entropy-corrected formulation leads to a detailed message-passing scheme for EFE-based planning together with simpler ablations. Experiments on three grid-world environments show that full EFE-based planning outperforms ablations that omit either the planning correction or the epistemic corrections.
Agents' Last Exam
Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaning…
AI エージェントが知識の働きをどのように再構築するか: 自律性、効率性、範囲
フロンティア AI システムは、会話型アシスタントからタスクをエンドツーエンドで実行する自律エージェントに移行することで、インテリジェンスと実用性の間のギャップを埋めています。 Perplexity の検索およびコンピュータ製品からの運用データを使用して、AI エージェントがどのように知識作業を加速し、再形成するかを調査することで、この移行を研究します。 3 つの重要な経験的発見が明らかになります。まず、両方の製品で試行した同じ基礎タスクの自然実験として、ほぼ同一の初期クエリ ペアを持つセッションを使用して、コンピューターはユーザー セッションごとに 26 分間の自律作業を実行しましたが、検索では 33 秒でした。コンピューターは、検索ユーザーが手動で調整して実装する可能性があるタスクの分解と実行を自動化します。その結果、コンピュータはフォローアップ クエリの分散を検証や拡張などの高次の作業にシフトします。自律性により実行品質も向上し、クエリごとの不満率が検索よりもコンピューターの方が 55% 低くなります。第 2 に、コンピュータは自律性の利点により、一致したタスクの完了時間を 269 分から 36 分に短縮し、検索だけを備えた人間と比較して、推定時間とコストをそれぞれ 87% と 94% 削減します。第三に、コンピューターはユーザーが試みる作業の範囲を変えます。コンピューターのクエリは職業の境界を越えることが多くなり、より高次の認知を必要とし、より広範な専門知識を活用し、相互に依存するサブタスクを 1 つのクエリにまとめた複合タスクの形式をとり、同じユーザー間での検索の使用には本質的に存在しない作業活動を可能にします。総合すると、これらの証拠は、AI エージェントがワークフローを加速し、出力品質を向上させ、コストを削減し、自動化された作業の幅と深さを拡大することを示しています。
原文 (English)
How AI Agents Reshape Knowledge Work: Autonomy, Efficiency, and Scope
Frontier AI systems are bridging the gap between intelligence and utility by shifting from conversational assistants to autonomous agents that execute tasks end to end. Using production data from Perplexity's Search and Computer products, we study this transition by examining how AI agents accelerate and reshape knowledge work. Three key empirical findings emerge. First, using sessions with near-identical initial query pairs as natural experiments for the same underlying task attempted with both products, Computer performs 26 minutes of autonomous work per user session, versus 33 seconds for Search. Computer automates task decomposition and execution that Search users might otherwise manually orchestrate and implement. As a result, Computer shifts follow-up query distribution toward higher-order work such as verification and extension. Autonomy also increases execution quality, with per-query dissatisfaction rates 55% lower on Computer than on Search. Second, due to its autonomy advantage, Computer reduces completion time from 269 to 36 minutes on matched tasks, lowering estimated time and cost by 87% and 94%, respectively, compared to humans equipped with Search alone. Third, Computer changes the scope of work that users attempt: Computer queries more often cross occupational boundaries, require higher-order cognition, draw on broader expertise, take the form of composite tasks that bundle interdependent subtasks into a single query, and unlock work activities that are essentially absent from Search usage among the same users. Together, the evidence indicates that AI agents accelerate workflows, enhance output quality, reduce costs, and expand the breadth and depth of automated work.
代表団が過半数を上回るのはいつですか?マルチサンプル LLM 推論のための委任ベースのアグリゲーター
サンプルされた回答に対する多数決は、マルチサンプル LLM 推論の支配的な教師なしアグリゲーターです。各サンプルが運ぶシグナルを委任ベースのアグリゲーター (伝播代理投票、PPV) にパイプすると、MMLU-Pro の多数派を全体で +1.5 pp、非自明なサブセットで +2.24 pp 上回る教師なしコンセンサス ルールが得られることを示します (ペアの McNemar p ~ 1.0e-14、n = 8,099)。マジョリティは、各サンプルが持つ 2 つの自由信号、つまりグループ内の文字エントロピーとグループ間の推論ジオメトリを破棄します。 PPV は、WHEN (有権者が自分の選択にどの程度の重みを保持するか) と WHOM (残りをピア間でどのように分割するか) というシグナルを正確に消費する 2 つの投票者ごとのレバーを公開します。文字エントロピーを使用して WHEN を駆動し、質問ごとの中心の埋め込みコサインを使用して WHOM を駆動します。この方法にはゴールド ラベルや補助トレーニングは必要ありません。質問ごとに、128 のサンプリングされた世代を 16 のグループに分割し、各グループの文字レベルの意味論的エントロピーと推論埋め込みセントロイドを計算し、その両方を定常分布がコンセンサス回答を選択する確率的委任行列に入力します。 PPV が間違った文字で明らかに 10 対 6 の過半数を覆す例を見ていきます。10 人の投票者の多数派クラスターは幾何学的に一貫性がありません (クラスター内平均コサイン -0.02) が、6 人の投票者の少数派は緊密 (+0.26) であるため、エントロピーだけでは多数派が優位に保たれるにもかかわらず、伝播された代表団の集団は少数派の回答に集中します。さらに、教師なし LLM 集約の設計空間を制約する否定的な結果を伴う委任戦略を報告します。信頼モードの質問内アンサンブルがオラクル ギャップを埋めることはありません。
原文 (English)
When Does Delegation Beat Majority? A Delegation-Based Aggregator for Multi-Sample LLM Inference
Majority voting over sampled answers is the dominant unsupervised aggregator for multi-sample LLM inference. In this paper, we show a delegation-based aggregator (Propagational Proxy Voting, PPV; Sakai et al., 2025) yields an unsupervised consensus rule that beats majority on MMLU-Pro by +1.5 pp overall and +2.24 pp on the non-trivial subset (paired McNemar p ~ 1.0e-14, n = 8,099). Majority discards two signals that every sample carries: within-group letter entropy and between-group reasoning geometry. PPV exposes per-voter levers that consume exactly these two signals: When (how much weight a voter keeps on its own pick) and Whom (how it splits the remainder across peers). We drive When with letter entropy and Whom with per-question-centered embedding cosine. Our method needs no gold labels and no auxiliary training: per-question, we partition 128 sampled generations into 16 groups, compute each group's letter-level semantic entropy and reasoning embedding centroid, and feed both into a stochastic delegation matrix whose stationary distribution selects the consensus answer. We walk through an example in which PPV overturns a clear 10-6 majority for the wrong letter: the 10-voter majority cluster is geometrically incoherent (mean within-cluster cosine -0.02) while the 6-voter minority is tight (+0.26), so propagated delegation mass concentrates on the minority's answer even though entropy alone would keep the majority ahead. We further report delegation strategies with negative results that constrain the design space for unsupervised LLM aggregation. No within-question ensemble of confidence modes closes the oracle gap.
Deterministic Integrity Gates for LLM-Assisted Clinical Manuscript Preparation: An Auditable Biomedical Informatics Architecture
As autonomous research agents and AI co-scientist systems push large language models (LLMs) from drafting toward end-to-end manuscript prod…
覚えておくべきことの学習: 長期にわたる言語エージェントの制約付き最適化による可観測性と安全なメモリ保持
長期的な言語エージェントは、有限のコンテキスト ウィンドウを超える観察、推論トレース、取得された事実を蓄積するため、メモリ保持がリソース割り当ての基本的な問題になります。既存のメモリ システムは、ヒューリスティック スコアリング、取得の最適化、または学習された圧縮を通じて管理を改善しますが、主に保持をローカルな決定問題として扱い、現実的な可観測性の制約の下でその長期的な結果を明示的にモデル化していません。このギャップを埋めるために、明示的な予算の実現可能性、証拠の有用性、およびミスペナルティ、再取得の遅延、情報の陳腐化リスクを含む遅延コストを伴う制約付き確率的最適化問題として記憶保持を定式化します。次に、OSL-MR (Observability-Safe Learning for Memory Retention) を提案します。これは、オンラインで観察可能な機能とオフラインで利用可能な監視 (OAS) を厳密に分離する新しいフレームワークです。 OSL-MR は、実現された証拠の監督から訓練された証拠学習者と、展開可能なオンラインで安全なベースラインとして、および学習のための構造化された帰納的事前分布として機能する混合スコア ヒューリスティックを組み合わせます。結果として得られるポリシーは、同じ可観測性制約の下で展開可能でありながら、クエリ条件付きの証拠値をインタラクション データから直接学習します。 LOCOMO と LongMemEval の実験では、OSL-MR が、特にメモリ バジェットが厳しい場合に、リーセンシ ベースの手法、生成エージェント スタイルのスコアリング、その他のヒューリスティック ベースラインよりも一貫して優れたパフォーマンスを発揮することが示されています。事前の混合スコアにより、再現率を維持しながら精度がさらに向上し、感度分析により、幅広いコスト構成にわたる堅牢性が実証されます。
原文 (English)
Learning What to Remember: Observability-Safe Memory Retention via Constrained Optimization for Long-Horizon Language Agents
Long-horizon language agents accumulate observations, reasoning traces, and retrieved facts that exceed their finite context windows, making memory retention a fundamental resource-allocation problem. Existing memory systems improve management through heuristic scoring, retrieval optimization, or learned compression, but largely treat retention as a local decision problem and do not explicitly model its long-term consequences under realistic observability constraints. To fill this gap, we formulate memory retention as a constrained stochastic optimization problem with explicit budget feasibility, evidence utility, and delayed costs including miss penalties, reacquisition delays, and stale-information risk. We then propose OSL-MR (Observability-Safe Learning for Memory Retention), a novel framework that enforces a strict separation between online-observable features and offline-available supervision (OAS). OSL-MR combines an evidence learner trained from realized evidence supervision with a Mixed-Score heuristic that serves both as a deployable online-safe baseline and as a structured inductive prior for learning. The resulting policy learns query-conditioned evidence value directly from interaction data while remaining deployable under the same observability constraints. Experiments on LOCOMO and LongMemEval show that OSL-MR consistently outperforms recency-based methods, Generative Agents-style scoring, and other heuristic baselines, particularly under tight memory budgets. The Mixed-Score prior further improves precision while preserving recall, and sensitivity analysis demonstrates robustness across a wide range of cost configurations.
Workflow-GYM: 現実世界の専門分野におけるコンピュータ使用エージェントタスクの長期的な評価に向けて
近年、ますます複雑になる現実世界のタスクの処理に向けて、AI エージェントが急速に進化しています。しかし、既存のベンチマークでは、エージェントがグラフィカル ユーザー インターフェイスを操作して、さまざまなドメインにわたる長期にわたる価値の高い専門的なワークフローを完了できるかどうかを評価することはほとんどありません。現在の GUI ベンチマークは依然として、主に汎用ソフトウェア、比較的単純なアプリケーション、および短期間のタスクに焦点を当てており、最新のエージェントがユーザーの指示に従ってドメイン固有のプロフェッショナル ソフトウェアを自律的に操作し、経済的に価値のある作業をエンドツーエンドで実行できるかどうかはほとんど不明です。このギャップを埋めるために、専門分野と特殊なソフトウェア環境を中心とした長期的な GUI タスクのベンチマークである Workflow-GYM を導入します。最先端のモデルで広範な実験を行った結果、最も強力なモデルでも成功率は 30% をわずかに超える程度であることがわかり、プロの長期にわたる GUI ワークフローが現在の GUI エージェントにとって依然として非常に困難であることが浮き彫りになりました。さらなる分析により、現在のエージェントは長期的なワークフローの一貫性を維持するのに苦労しており、ワークフロー段階の省略、エラーの伝播、目標のずれ、プロフェッショナルなソフトウェア環境の理解不足が頻繁に見られることが明らかになりました。私たちの調査結果は、現在のエージェント システムの限界についての重要な洞察を提供し、次世代の GUI エージェント研究の重要な方向性を示唆しています。
原文 (English)
Workflow-GYM: Towards Long-Horizon Evaluation of Computer-use Agentic tasks in Real-World Professional Fields
Recent years have witnessed the rapid evolution of AI agents toward handling increasingly complex, real-world tasks. However, existing benchmarks rarely evaluate whether agents can operate graphical user interfaces to complete long-horizon, high-value professional workflows across diverse domains. Current GUI benchmarks still predominantly focus on general-purpose software, relatively simple applications, and short-horizon tasks, leaving it largely unknown whether modern agents can follow user instructions to autonomously operate domain-specific professional software and accomplish economically valuable work in an end-to-end manner. To bridge this gap, we introduce Workflow-GYM, a benchmark for long-horizon GUI tasks centered on professional domains and specialized software environments. Through extensive experiments on state-of-the-art models, we find that even the strongest models achieve only slightly above 30% success rates, highlighting that professional long-horizon GUI workflows remain highly challenging for current GUI agents. Further analysis reveals that current agents struggle to maintain long-horizon workflow consistency, frequently exhibiting workflow stage omission, error propagation, objective drift, and insufficient understanding of professional software environments. Our findings provide important insights into the limitations of current agent systems and suggest key directions for the next generation of GUI-agent research.
人間拡張ループ モデリング (HELM): コンクリート橋柵のエージェント ベースの有限要素モデリング
橋梁の障壁などの安全性が重要なインフラの有限要素 (FE) モデリングには、高忠実度の非線形動的解析が必要ですが、現在の FE モデリング プロセスは依然として労働集約的であり、自動化されていません。この論文では、ヒューマン エンハンスド ループ モデリング (HELM) フレームワークについて説明します。これは、長いシーケンスの有限要素モデリングを、ジオメトリの生成、境界条件の定義、マテリアルの割り当てにわたる視覚的に検証可能な個別のチェックポイントに分解する、ヒューマン エージェントの協調プロトコルです。このフレームワークは、MASH TL-4 および TL-5 の横荷重条件下での鉄筋コンクリート橋の障壁の 20 ケースのマトリックスを通じて実証され、専門エージェントと 2 つの広く使用されている商用 FE ソフトウェア (つまり、ANSYS および LS-PrePost) をインターフェイスします。実験結果では、HELM によりベースラインの自律モデリング成功率が 20% から 75% に向上し、ジオメトリおよび境界条件タスクのエージェント レベルの合格率が約 2 倍になったことが示されています。エラー分析により、空間推論と代数論理の制限が主な故障モードを構成していることが明らかになり、モデリングの自動化に対する構造化された人間参加型介入の価値が強調されます。完全なエージェント設計コードとプロンプトはオープンソースであり、https://github.com/SimAgentDev/Ansys-LSPP-AgentKit からアクセスできます。
原文 (English)
Human-Enhanced Loop Modeling (HELM): Agent-Based Finite Element Modeling of Concrete Bridge Barriers
Finite element (FE) modeling of safety-critical infrastructure such as bridge barriers requires high-fidelity nonlinear dynamic analysis, yet the current FE modeling process remains labor-intensive and lacks automation. This paper presents the Human-Enhanced Loop Modeling (HELM) framework, a collaborative human-agent protocol that decomposes long-sequence finite element modeling into discrete, visually verifiable checkpoints across geometry generation, boundary condition definition, and material assignment. The framework is demonstrated through a 20-case matrix of reinforced concrete bridge barriers under MASH TL-4 and TL-5 lateral loading conditions, interfacing specialized agents with two widely used commercial FE softwares, i.e., ANSYS and LS-PrePost. Experimental results show that HELM improves the baseline autonomous modeling success rate from 20% to 75%, with agent-level pass rates for geometry and boundary condition tasks approximately doubling. Error analysis reveals that spatial reasoning and algebraic logic limitations constitute the primary failure modes, underscoring the value of structured human-in-the-loop intervention for modeling automation. The complete agent design code and prompts are open-sourced and can be accessed at: https://github.com/SimAgentDev/Ansys-LSPP-AgentKit.
自動化されたコンクリートバリア設計のための軽量マルチエージェントフレームワーク
鉄筋コンクリート高速道路の障壁の設計は、AASHTO-LRFD 橋梁設計ガイドラインなどの規制規定への厳密な準拠が必要な安全性が重要なプロセスです。現在のエンジニアリング業務は、複雑な非線形材料および力学の制約を満たすために、手動、反復、ヒューリスティック計算に大きく依存しています。大規模言語モデル (LLM) は強力な生成機能を示していますが、構造工学への直接的な応用は、幻覚のリスクと不十分な物理的根拠によって依然として制限されています。これらの課題に対処するために、この研究では、AutoGen のマルチエージェント オーケストレーション機能を使用した自動コンクリート バリア設計のための新しい「生成 - 評価 - 最適化」閉ループ フレームワークを提案します。実験結果は、提案されたエージェント フレームワークが 98% 以上の設計精度を達成し、スタンドアロンの汎用 LLM を大幅に上回るパフォーマンスを示していることを示しています。さらに重要なことは、この研究では、設計パフォーマンスが必ずしもモデルのスケールと相関しているわけではなく、8B パラメーターの軽量モデルが制約のない 631B パラメーターのフラッグシップ モデルよりも優れたパフォーマンスを発揮する可能性があることが明らかになったということです。この発見は、産業アプリケーション向けの AI 支援エンジニアリング ツールのアクセシビリティを向上させながら、計算コストを大幅に削減できる可能性を浮き彫りにしています。提案されているマルチエージェント設計フレームワークのソース コードは、プロジェクトの GitHub リポジトリ: https://github.com/MXY820/barrier-design で入手できます。キーワード: 構造工学;マルチエージェントシステム。大規模な言語モデル。コンクリートバリア設計;自動生成;設計の自動化。
原文 (English)
A Lightweight Multi-Agent Framework for Automated Concrete Barrier Design
The design of reinforced concrete highway barriers is a safety-critical process that requires strict compliance with regulatory provisions such as the AASHTO-LRFD bridge design guidelines. Current engineering practice relies heavily on manual, iterative, and heuristic calculations to satisfy complex nonlinear material and mechanics constraints. Although Large Language Models (LLMs) demonstrate strong generative capabilities, their direct application to structural engineering remains limited by hallucination risks and insufficient physical grounding. To address these challenges, this study proposes a novel "generation-evaluation-optimization" closed-loop framework for automated concrete barrier design using the multi-agent orchestration capabilities of AutoGen. Experimental results demonstrate that the proposed agentic framework achieves over 98% design accuracy, significantly outperforming standalone general-purpose LLMs. More importantly, the study reveals that design performance is not necessarily correlated with model scale, where an 8B-parameter lightweight model could outperform unconstrained 631B-parameter flagship models. This finding highlights the potential to substantially reduce computational costs while improving the accessibility of AI-assisted engineering tools for industry applications. The source code for the proposed multi-agent design framework is available at the project GitHub repository: https://github.com/MXY820/barrier-design. Keywords: Structural Engineering; Multi-Agent Systems; Large Language Models; Concrete Barrier Design; AutoGen; Design Automation.
On Approximating the Dynamic Response of Synchronous Generators via Operator Learning: A Step Towards Building Deep Operator-based Power Grid Simulators
This paper develops an Operator Learning framework for approximating the dynamic response of synchronous generators. The framework can be u…
On Pitfalls of $\textit{RemOve-And-Retrain}$: Data Processing Inequality Perspective
The RemOve-And-Retrain (ROAR) benchmark is widely used to evaluate feature attribution methods, yet its validity remains underexplored from…
Competition and Diversity in Generative AI
Recent evidence, both in the lab and in the wild, suggests that the use of generative artificial intelligence reduces the diversity of cont…
WildIFEval: Instruction Following in the Wild
Recent LLMs have shown remarkable success in following user instructions, yet handling instructions with multiple constraints remains a sig…
Prism: Cost-Efficient Multi-LLM Serving via GPU Memory Ballooning
Inference providers must maintain availability for many LLMs, including low-volume but essential models, making resource efficiency increas…
Lightweight and Interpretable Transformer via Mixed Graph Algorithm Unrolling for Traffic Forecast
Unlike conventional "black-box" transformers with classical self-attention mechanism, we build a lightweight and interpretable transformer-…
ReFoCUS: Reinforcement-guided Frame Optimization for Contextual Understanding
Recent progress in Large Multi-modal Models (LMMs) has enabled effective vision-language reasoning, yet the ability to video understanding…
PlaceRep: Geospatial Place Representation Learning from Large-Scale Point-of-Interest Data
Learning effective representations of urban environments requires capturing spatial structure beyond fixed administrative boundaries. Exist…
Meta-Learning Transformers to Improve In-Context Generalization
In-context learning enables transformer models to generalize to new tasks based solely on input prompts, without any need for weight update…
Reconstructing Template-Memorized Images from Natural Prompts
Recent advances in generative models, such as diffusion models, have raised concerns related to privacy, copyright infringement, and data s…
Emergence of Hierarchical Emotion Organization in Large Language Models
As large language models (LLMs) increasingly power conversational agents, understanding how they model users' emotional states is critical…
Authorship Attribution in Multilingual Machine-Generated Texts
As Large Language Models (LLMs) have reached human-like fluency and coherence, distinguishing machine-generated text (MGT) from human-writt…
The KG-ER Conceptual Schema Language
We propose KG-ER, a conceptual schema language for knowledge graphs that describes the structure of knowledge graphs independently of their…
Decoding the Multimodal Maze: A Systematic Review on the Adoption of Explainability in Multimodal Attention-based Models
Multimodal learning has witnessed remarkable advancements in recent years, particularly with the integration of attention-based models, lea…
Equivariant Flow Matching for Symmetry-Breaking Bifurcation Problems
Bifurcation phenomena in nonlinear dynamical systems often lead to multiple coexisting stable solutions, particularly in the presence of sy…
GetNetUPAM: Ecologically Informed Nested Cross-Validation and Noise-Robust Attention for Marine Bioacoustic Monitoring
Deploying reliable bioacoustic monitoring systems requires models that generalize under high-noise, low-SNR conditions and evaluation proto…
Structuring The Future: Diffusion LLM Speculative Decoding via Calibrated Draft Graphs
Diffusion LLMs (dLLMs) have recently emerged as a powerful alternative to autoregressive LLMs (AR-LLMs) with the potential to operate at si…
MoReBench: Evaluating Procedural and Pluralistic Moral Reasoning in Language Models, More than Outcomes
As AI systems progress, we rely more on them to make decisions with us and for us. To ensure that such decisions are aligned with human val…
Proto-LeakNet: Towards Signal-Leak Aware Attribution in Synthetic Human Face Imagery
The growing sophistication of synthetic image and deepfake generation models has turned source attribution and authenticity verification in…
Examining the Usage of Generative AI Models in Student Learning Activities for Software Programming
The rise of Generative AI (GenAI) tools like ChatGPT has created new opportunities and challenges for computing education. Existing researc…
Improving Pre-trained Adult Glioma Segmentation Models Using only Post-processing Techniques
Gliomas are the most common malignant brain tumors in adults and are among the most lethal. Despite aggressive treatment, the median surviv…
HD-Prot: A Protein Language Model for Joint Sequence-Structure Modeling with Continuous Structure Tokens
Proteins inherently possess a consistent sequence-structure duality. The abundance of protein sequence data, which can be readily represent…
From Isolation to Entanglement: When Do Interpretability Methods Identify and Disentangle Known Concepts?
A goal of interpretability is to recover disentangled representations of latent concepts (features) from the activations of neural networks…
PhononBench:A Large-Scale Phonon-Based Benchmark for Dynamical Stability in Crystal Generation
In recent years, generative artificial intelligence has made significant advances in the design of crystalline materials, giving rise to ap…
Cluster Aggregated GAN (CAG): A Cluster-Based Hybrid Model for Appliance Pattern Generation
Synthetic appliance data are essential for developing non-intrusive load monitoring algorithms and enabling privacy preserving energy resea…
HiGR: Industrial-Scale Hierarchical Generative Slate Recommendation Framework in Tencent
Slate recommendation, which presents users with a ranked item list in a single display, is ubiquitous across mainstream online platforms. W…
Geometric and Quantum Kernel Methods for Predicting Skeletal Muscle Outcomes in chronic obstructive pulmonary disease
Chronic obstructive pulmonary disease (COPD) affects hundreds of millions of people worldwide, and skeletal-muscle dysfunction is clinicall…
Decentralized Autoregressive Generation
The decentralization of autoregressive generation has attracted considerable attention in recent years as a solution to scaling bottlenecks…
CuMA: Aligning LLMs with Sparse Cultural Values via Demographic-Aware Mixture of Adapters
As Large Language Models (LLMs) serve a global audience, alignment must transition from enforcing universal consensus to respecting cultura…
When Smaller Wins: Dual-Stage Distillation and Pareto-Guided Compression of Liquid Neural Networks for Edge Battery Prognostics
Battery management systems increasingly require accurate battery health prognostics under strict on-device constraints. This paper presents…
Hellinger Multimodal Variational Autoencoders
Multimodal variational autoencoders (VAEs) are widely used for weakly supervised generative learning with multiple modalities. Predominant…
HalluJudge: A Reference-Free Hallucination Detection for Context Misalignment in Code Review Automation
Large Language models (LLMs) have shown strong capabilities in code review automation, such as review comment generation, yet they suffer f…
When Iterative RAG Beats Ideal Evidence: A Diagnostic Study in Scientific Multi-hop Question Answering
Retrieval-Augmented Generation (RAG) extends large language models (LLMs) beyond parametric knowledge, yet it is unclear when iterative ret…
Language Model Circuits Are Sparse in the Neuron Basis
The high-level concepts that a neural network uses to perform computation need not be aligned to individual neurons (Smolensky, 1986). Lang…
VDE Bench: Evaluating The Capability of Image Editing Models to Modify Visual Documents
In recent years, image editing models have made significant progress, enabling users to manipulate visual content in a flexible and interac…
Standardized Methods and Recommendations for Green Federated Learning
Federated learning (FL) enables collaborative model training over privacy-sensitive, distributed data, but its environmental impact is diff…
LatentLens: Revealing Highly Interpretable Visual Tokens in LLMs
Transforming a large language model (LLM) into a vision-language model (VLM) can be achieved by mapping the visual tokens from a vision enc…
SCALE: Self-uncertainty Conditioned Adaptive Looking and Execution for Vision-Language-Action Models
Vision-Language-Action (VLA) models have emerged as a promising paradigm for general-purpose robotic control, with test-time scaling (TTS)…
Ex-Omni: Enabling 3D Facial Animation Generation for Omni-modal Large Language Models
Omni-modal large language models (OLLMs) aim to unify multimodal understanding and generation, yet extending them to jointly produce speech…
Fin-RATE: A Real-world Financial Analytics and Tracking Evaluation Benchmark for LLMs on SEC Filings
With the increasing deployment of Large Language Models (LLMs) in the finance domain, LLMs are increasingly expected to parse complex regul…
TokaMark: A Comprehensive Benchmark for MAST Tokamak Plasma Models
Development and operation of commercially viable fusion energy reactors such as tokamaks require accurate predictions of plasma dynamics fr…
Unsafer in Many Turns: Benchmarking and Defending Multi-Turn Safety Risks in Tool-Using Agents
LLM-based agents are becoming increasingly capable, yet their safety lags behind. This creates a gap between what agents can do and should…
InnoEval: On Research Idea Evaluation as a Knowledge-Grounded, Multi-Perspective Reasoning Problem
The rapid evolution of Large Language Models has catalyzed a surge in scientific idea production, yet this leap has not been accompanied by…
FENCE: A Financial and Multimodal Jailbreak Detection Dataset
Jailbreaking poses a significant risk to the deployment of Large Language Models (LLMs) and Vision Language Models (VLMs). VLMs are particu…
CMI-RewardBench: Evaluating Music Reward Models with Compositional Multimodal Instruction
While music generation models have evolved to handle complex multimodal inputs mixing text, lyrics, and reference audio, evaluation mechani…
Structured vs. Unstructured Pruning: An Exponential Gap
The Strong Lottery Ticket Hypothesis (SLTH) states that large, randomly initialized neural networks contain sparse subnetworks capable of a…
Contextual Invertible World Models: A Neuro-Symbolic Agentic Framework for Colorectal Cancer Drug Response
Precision oncology is currently limited by the small-N, large-P paradox, where high-dimensional genomic data is abundant but pharmacologica…
PaLMR: Towards Faithful Visual Reasoning via Multimodal Process Alignment
Reinforcement learning has recently improved the reasoning ability of Large Language Models and Multimodal LLMs, yet prevailing reward desi…
Echo2ECG: Enhancing ECG Representations with Cardiac Morphology from Multi-View Echos
Electrocardiography (ECG) is a low-cost, widely used modality for diagnosing electrical abnormalities like atrial fibrillation by capturing…
On the Reliability of Cue Conflict and Beyond
Understanding how neural networks rely on visual cues offers a human-interpretable view of their internal decision processes. The cue-confl…
ARROW: Augmented Replay for RObust World models
Continual reinforcement learning challenges agents to acquire new skills while retaining previously learned ones with the goal of improving…
Grammar of the Wave: Towards Explainable Multivariate Time Series Event Detection via Neuro-Symbolic VLM Agents
Time Series Event Detection (TSED) aims to localize semantically meaningful events in time series data, with critical applications in high-…
Fusion Learning from Dynamic Functional Connectivity: Combining the Amplitude and Phase of fMRI Signals to Identify Brain Disorders
Dynamic functional connectivity (dFC) derived from resting-state functional magnetic resonance imaging (fMRI) has been extensively utilized…
DCD: Domain-Oriented Design for Controlled Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is widely used to ground large language models in external knowledge sources. However, when applied to…
WOMBET: World Model-Based Experience Transfer for Robust and Sample-efficient Reinforcement Learning
Reinforcement learning (RL) in robotics is often limited by the cost and risk of data collection, motivating experience transfer from a sou…
ASTER: Latent Pseudo-Anomaly Generation for Unsupervised Time-Series Anomaly Detection
Time-series anomaly detection (TSAD) is critical in domains such as industrial monitoring, healthcare, and cybersecurity, but it remains ch…
A Survey on Long-Term Memory Security in LLM Agents: Attacks, Defenses, and Governance Across the Memory Lifecycle
The emergence of writable, cross-session persistent memory in LLM agents introduces a qualitatively different threat landscape from convent…
The Pragmatic Persona: Discovering LLM Persona through Bridging Inference
Large Language Models (LLMs) reveal inherent and distinctive personas through dialogue. However, most existing persona discovery approaches…
Versioned Late Materialization for Ultra-Long Sequence Training in Recommendation Systems at Scale
Modern Deep Learning Recommendation Models (DLRMs) follow scaling laws with sequence length, driving the frontier toward ultra-long User In…
BrainDINO: A Brain MRI Foundation Model for Generalizable Clinical Representation Learning
Brain MRI underpins a wide range of neuroscientific and clinical applications, yet most learning-based methods remain task-specific and req…
Possibilistic Predictive Uncertainty for Deep Learning
Deep neural networks achieve impressive results across diverse applications, yet their overconfidence on unseen inputs necessitates reliabl…
GEASS: Gated Evidence-Adaptive Selective Caption Trust for Vision-Language Models
Vision-Language Models (VLMs) hallucinate objects that are not present, and a growing line of work tries to curb this by feeding the model…
The Safety-Aware Denoiser for Text Diffusion Models
Recent work on text diffusion models offers a promising alternative to autoregressive generation, but controlling their safety remains unde…
A Theory of Training Profit-Optimal LLMs
Scaling LLMs requires tremendous computational resources, and recent advances in AI have gone hand in hand with massive amounts of capital…
GeoWorld-VLM: Geometry from World Models for Vision-Language Models
Modern Vision-Language Models (VLMs) achieve strong semantic recognition, yet remain brittle on elementary spatial relations such as left o…
より多くのコンテキスト、より大きなモデル、それとも道徳的知識?政治文書におけるシュワルツ価値検出の系統的研究
暗黙の手がかりは周囲の議論や隣接する価値観間の細かい区別に依存することが多いため、政治文書からシュワルツの価値観を検出することは困難です。私たちは、文脈と明示的な道徳的知識が文レベルの値の検出にどのような場合に役立つかを研究します。 ValuesML/Touch\'e ValueEval 形式を使用して、文、ウィンドウ、およびドキュメント全体の入力を比較します。厳選された道徳的知識ベースを備えた、RAG なしで検索が強化された設定。監視付き DeBERTa-v3 ベース/ラージ エンコーダ。および 12B ~ 123B パラメータのゼロショット LLM。結果は、コンテキストが多いほど一様に優れているわけではないことを示しています。フルドキュメント コンテキストは、教師あり DeBERTa エンコーダを文のみの入力よりも 3.8 ~ 4.8 マクロ F1 ポイント向上させますが、一貫してゼロショット LLM を支援するわけではありません。取得された道徳的知識は、一致した比較においてより一貫して有用であり、初期融合の下でテストされた各モデルファミリーとコンテキスト条件を改善します。ただし、DeBERTa-v3 ベースから大規模、および 12B から大規模な LLM へのスケーリングは利得を保証するものではなく、単純な早期融合は、エンコーダ用にテストされた後期融合およびクロスアテンション RAG バリアントよりも優れたパフォーマンスを発揮します。値ごとの分析では、社会的に位置する値や概念的に混乱しやすい値に対して、コンテキストと検索が最も役立つことが示されています。これらの発見は、価値に敏感な NLP では、より長い入力や大規模なモデルを普遍的な改善として扱うのではなく、コンテキスト、知識、およびモデル ファミリを共同で評価する必要があることを示唆しています。
原文 (English)
More Context, Larger Models, or Moral Knowledge? A Systematic Study of Schwartz Value Detection in Political Texts
Detecting Schwartz values in political text is difficult because implicit cues often depend on surrounding arguments and fine-grained distinctions between neighboring values. We study when context and explicit moral knowledge help sentence-level value detection. Using the ValuesML/Touch\'e ValueEval format, we compare sentence, window, and full-document inputs; no-RAG and retrieval-augmented settings with a curated moral knowledge base; supervised DeBERTa-v3-base/large encoders; and zero-shot LLMs from 12B to 123B parameters. The results show that more context is not uniformly better: full-document context improves supervised DeBERTa encoders by 3.8-4.8 macro-F1 points over sentence-only input, but does not consistently help zero-shot LLMs. Retrieved moral knowledge is more consistently useful in matched comparisons, improving each tested model family and context condition under early fusion. However, scaling from DeBERTa-v3-base to large and from 12B to larger LLMs does not guarantee gains, and simple early fusion outperforms the tested late-fusion and cross-attention RAG variants for encoders. Per-value analyses show that context and retrieval help most for socially situated or conceptually confusable values. These findings suggest that value-sensitive NLP should evaluate context, knowledge, and model family jointly rather than treating longer inputs or larger models as universal improvements.
変圧器のパッチングと機構の解釈のための連続深度磁界理論
機構的解釈では、アクティベーション パッチ、因果関係の追跡、パス パッチ、およびステアリング方向を使用して、Transformer アクティベーション スペースでの動作的に意味のある方向を明らかにすることがよくあります。この論文は、そのような介入を組織化し、予測するための場の理論的フレームワークを開発します。残差ストリームを深さトークンフィールドとして扱い、局所的なソース挿入としてパッチング、感度フィールド予測としてパッチ効果、経験的なグリーン関数応答としての下流伝播、および随伴変分問題としてパッチ選択を定式化します。経験的に、局所的な残差場介入を適用し、誘発された残差場差とロジット差応答を観察することにより、GPT-2 スタイルの自己回帰トランスフォーマーにおける順方向応答理論をテストします。有界の局所線形領域を特定します。残留部位にわたる一次感度からパッチの効果を予測します。深さとトークンの位置にわたる構造化された異方性伝播を測定します。高感度サイトとスライスされたGreenオペレーターから応答記述を構築します。そして、プロンプトによって誘発された残留変位が応答行動を伝達できることを示します。これらの結果は、パッチ実験を組織化するための実用的な言語として、またパッチサイト推論とクロススケール伝達を定式化するための前向きの数学的基礎として、応答オブジェクト、つまり感度、伝播フィールド、グリーンオペレータースライスを確立します。
原文 (English)
Transformer Field Theory: A Response-Theoretic Approach to Mechanistic Interpretability
Mechanistic interpretability often studies Transformer behavior by intervening on internal activations through activation patching, causal tracing, path patching, and steering directions. This paper develops Transformer Field Theory: a response-theoretic framework in which the residual stream of a fixed forward pass is treated as a Transformer field over layer depth and token position. In this formulation, patching becomes a localized source insertion into the Transformer field, first-order sensitivity fields predict patch effects, Green functions describe downstream propagation, and patch selection is posed as an adjoint inverse problem. Empirically, we test the theory's forward response objects in GPT-2-style autoregressive Transformers. Localized Transformer-field interventions exhibit a bounded local linear regime; first-order sensitivities predict patch effects across layer-token sites; localized sources generate structured anisotropic Transformer-field propagation; high-sensitivity sites and sliced Green operators provide reduced response descriptions; and prompt-induced Transformer-field displacements partially transfer answer behavior. These results establish sensitivities, Transformer-field responses, and sliced Green operators as practical objects for organizing patching experiments, while providing the forward mathematical basis for patch-site inference and cross-scale response transfer.
VISTA: Visual Spec-to-Web-App コーディング エージェントのエンドツーエンド ベンチマーク
ここでは、LLM ベースのエージェントのエンドツーエンドの Web アプリ生成機能を評価するためのベンチマークである VISTA (VIsual Spec-To-App Benchmark) を紹介します。アルゴリズム タスクに焦点を当てた以前のコード生成ベンチマークとは異なり、VISTA は現実的な UI 中心の開発をターゲットにしており、エージェントは過少指定された入力から機能的で視覚的に一貫したアプリケーションを生成する必要があります。視覚的/構造的忠実度およびスタック制約という 2 つの軸に沿って変化する 5 つのプロンプト情報条件を定義します。(1) 自由なスタック選択によるテキストのみ、(2) 3 つの指定されたスタック下の参照スクリーンショットを含むテキスト、(3) 自由なスタック選択による参照スクリーンショットを含むテキスト、(4) 単一の指定されたスタック下のスクリーンショットおよびプルーニングされた Figma 構造を含むテキスト、(5) 自由なスタック選択によるスクリーンショットおよびプルーニングされた Figma 構造を含むテキスト。堅牢な評価を可能にするために、ベンチマークの各ページにはインタラクティブな UI コンポーネントと約 3 つのビジュアル アンカー ポイントで手動で注釈が付けられ、オープンエンド コード生成設定における Playwright などのスクリプト ベースのテスト ツールのよく知られた制限に対処します。評価では、DOM に基づいた参照マッチング、動作固有のブラウザ テスト、および CLIP ベースの視覚的類似性を組み合わせて、構造の整合性、動作の完全性、および全体的な視覚的な忠実度を共同で測定します。 VISTA を使用して、2 つのモデル ファミリと 2 つのハーネスから描画された 4 つのエージェント システムを評価しました。その結果、入力条件とエージェントの両方で視覚的な忠実性と機能の正確さが部分的に切り離されており、エージェントの編集スタイルは大きく変化しますが、タスクの品質とはほぼ直交していることがわかりました。 VISTA は、エージェントベースのソフトウェア エンジニアリング研究を推進するための厳密で再現可能な基盤を確立します。
原文 (English)
VISTA: An End-to-End Benchmark for Visual Spec-to-Web-App Coding Agents
We present VISTA (VIsual Spec-To-App Benchmark), a benchmark for evaluating the end-to-end web-app generation capabilities of LLM-based agents. Unlike prior code generation benchmarks that focus on algorithmic tasks, VISTA targets realistic UI-centric development, where agents must produce functional, visually coherent applications from underspecified inputs. We define five prompt-information conditions that vary along two axes, visual/structural fidelity and stack constraint: (1) text only with free stack choice, (2) text with reference screenshots under three specified stacks, (3) text with reference screenshots under free stack choice, (4) text with screenshots and pruned Figma structure under a single specified stack, and (5) text with screenshots and pruned Figma structure under free stack choice. To enable robust evaluation, each page in the benchmark is manually annotated with interactive UI components and around three visual anchor points, addressing the well-known limitations of script-based testing tools such as Playwright in open-ended code generation settings. Evaluation combines DOM-grounded reference matching, behavior-specific browser tests, and CLIP-based visual similarity, jointly measuring structural alignment, behavioral completeness, and overall visual fidelity. We use VISTA to assess four agent systems drawn from two model families and two harnesses, finding that visual fidelity and functional correctness are partially decoupled across both input conditions and agents, and that agent editing style varies sharply but is largely orthogonal to task quality. VISTA establishes a rigorous and reproducible foundation for advancing agent-based software engineering research.
$\overline{\mathcal M}_{0,n}$ のポアンカール多項式の実数根: AI 支援による証明
安定したドリーニュ-マンフォード法空間 $\overline{\mathcal M}_{0,n}$ のポアンカレ多項式 \[ P_n(t)=\sum_{i=0}^{n-3} \dim H^{2i}(\overline{\mathcal M}_{0,n};\mathbb{Q})t^i \] の実根があることを証明します。 $n$ が指す有理曲線は、アルフィ-チェン-マルコッリの予想を証明します。証明は Keel--Manin--Getzler 再帰から始まりますが、その主な新しいアイデアはポアンカール多項式の二変量変形 $F_m(y,t)$ です。この変形により、1 変数反復では見えない隠れたインターレース構造が明らかになります。固定 $t<0$ の場合、$y$ 方向の $F_m$ のゼロセットは、$0<1-t$ の区間で Sturm--Rolle 引数によって制御されます。元の多項式はスライス $y=1$ 上で復元され、このスライスを通る移動根の順序付けされた交差により、実根性と厳密なインターレースの両方が得られます。その結果、$\overline{\mathcal M}_{0,n}$ の Betti 数は超対数凹列を形成します。さらに、複素射影線の縮退における $n$ 順序点のフルトン-マクファーソン空間 $\mathbb{P}^1[n]$ のポアンカレ多項式の実根性と超対数凹面を証明します。 $\overline{\mathcal M}_{0,n}$ の証明は、Google DeepMind が開発したエージェント フロンティア モデル システムである Co-Mathematician による AI 支援ワークフローの反復を通じて得られました。人間の役割は、問題を提起し、連続する試みを評価し、ギャップの修復を要求し、進化する議論を文献と比較し、人間が検証可能な最終的な証拠を組み立てることでした。私たちの追加の人的貢献は、同様の残留変形戦略がフルトン-マクファーソン空間 $\mathbb P^1[n]$ に適用され、対応する実根定理が得られることを観察することでした。
原文 (English)
Real-rootedness of the Poincar\'e polynomials of $\overline{\mathcal M}_{0,n}$: an AI-assisted proof
We prove real-rootedness for the Poincar\'e polynomial \[ P_n(t)=\sum_{i=0}^{n-3} \dim H^{2i}(\overline{\mathcal M}_{0,n};\mathbb{Q})t^i \] of the Deligne--Mumford moduli space $\overline{\mathcal M}_{0,n}$ of stable $n$-pointed rational curves, proving a conjecture of Aluffi--Chen--Marcolli. The proof starts from the Keel--Manin--Getzler recurrence, but its main new idea is a bivariate deformation $F_m(y,t)$ of the Poincar\'e polynomial. This deformation reveals a hidden interlacing structure not visible in the one-variable recurrence. For fixed $t<0$, the zero set of $F_m$ in the $y$-direction is controlled by a Sturm--Rolle argument on the interval $0<1-t$. The original polynomial is recovered on the slice $y=1$, and the ordered crossings of the moving roots through this slice give both real-rootedness and strict interlacing. Consequently, the Betti numbers of $\overline{\mathcal M}_{0,n}$ form an ultra-log-concave sequence. We further prove real-rootedness and ultra-log-concavity for the Poincar\'e polynomial of the Fulton--MacPherson space $\mathbb{P}^1[n]$ of $n$ ordered points in degenerations of the complex projective line. The proof for $\overline{\mathcal M}_{0,n}$ was obtained through an iterative AI-assisted workflow with Co-Mathematician, an agentic frontier-model system developed by Google DeepMind. Our role was to formulate the problem, evaluate the proposed proof attempts, identify gaps and request corrections, compare the developing argument with the literature, and refine the presentation of the final proof. Our additional human contribution was to observe that a similar residual deformation strategy applies to the Fulton--MacPherson spaces $\mathbb P^1[n]$, yielding the corresponding real-rootedness theorem.
If LLMs Have Human-Like Attributes, Then So Does Age of Empires II
Much research has been carried out on large language models (LLMs) and LLM-powered agentic workflows. However, many works within the field…
Variational Learning for Insertion-based Generation
Non-monotonic sequence generation methods, such as masked diffusion models, provide a flexible alternative to left-to-right autoregressive…
ディープ 2 サンプル テストに対する反事実の説明
2 サンプル テストは、科学分野全体の分布の違いを検出するための基本的なツールですが、従来のテスト (カーネルベースのテストを含む) は、画像などの高次元構造化データに対しては効果がない場合があります。最近のディープ 2 サンプル テストでは、有益な表現を学習することでこれらの設定での感度が向上しますが、どのデータ特徴が帰無仮説 $H_0$ の棄却につながるかについての洞察は限られています。この問題に対処するために、我々は、テストによって測定された不一致を明示的に削減しながら、観測値をソースグループからターゲットグループに移動させるサンプルレベルの編集を生成する、深い2サンプルテストのための反事実説明フレームワークを提案します。私たちの手法では、拡散オートエンコーダーと事前学習済みのディープ 2 サンプル テスト モデルを組み合わせ、テスト モデルの表現空間で最大平均不一致 (MMD) 目標を最適化して、もっともらしい反事実を生成します。検定統計量の変化とその結果得られる 2 サンプルの p 値を通じて、分布レベルの効果を定量化します。合成 2D 形状データセットと 2 つの MRI コホートでこの方法を評価します。どちらの設定でも、反事実変換により元のサンプルと比較して p 値が一貫して増加しており、編集されたソース セットが統計的にテスト下のターゲット分布に近づくことを示しています。 LPIPS を使用して最小性を測定し、反事実が元のサンプルに近いままであることを確認します。結果として得られる編集は、検出されたグループの違いに関連する特徴の解釈可能な証拠を提供します。 MRI では、局所的な変化はコホート間の既知の解剖学的差異と一致します。
原文 (English)
Counterfactual Explanations for Deep Two-Sample Testing
Two-sample testing is a fundamental tool for detecting distributional differences across scientific domains, but classical tests (including kernel-based tests) can be ineffective on high-dimensional structured data such as images. Recent deep two-sample tests improve sensitivity in these settings by learning informative representations, yet they provide limited insight into which data features drive rejection of the null hypothesis $H_0$. To address this issue, we propose a counterfactual explanation framework for deep two-sample testing that generates sample-level edits moving observations from a source group toward a target group while explicitly reducing the discrepancy measured by the test. Our method combines a diffusion autoencoder with a pretrained deep two-sample test model and optimizes a maximum mean discrepancy (MMD) objective in the test model's representation space to produce plausible counterfactuals. We quantify distribution-level effects through changes in the test statistic and the resulting two-sample p-values. We evaluate the method on synthetic 2D shape datasets and two MRI cohorts. Across both settings, the counterfactual transformations consistently increase p-values relative to the original samples, indicating that the edited source set becomes statistically closer to the target distribution under the test. We measure minimality using LPIPS to ensure the counterfactuals remain close to the original samples. The resulting edits provide interpretable evidence of the features associated with the detected group differences. On MRI, the localized changes are consistent with known anatomical differences between cohorts.
Benchmarking Counterfactual Prediction in Epidemic Time Series with Time-Varying Interventions
Deep learning has enabled significant advances in time-series causal inference, yet progress remains constrained by the lack of realistic b…
3D フレーム システムの自動構造解析のためのエージェントティック大規模言語モデル
大規模言語モデル (LLM) は、ドメイン全体にわたる強力な推論機能を備えた強力な基盤モデルとして登場しました。リアクティブ テキスト生成を超えて、エージェント LLM により、モジュール式タスクの分解と調整されたツールの使用を通じて自律的なワークフローの実行が可能になります。構造工学では、最近の取り組みにより、平面フレームの自動解析のためのエージェント LLM が開発されました。ただし、3D フレームへの拡張は、不規則な幾何学的表現、トポロジーの一貫性、および長期的な推論における課題のため、依然として研究が進んでいません。この論文では、自然言語入力からの 3D フレームの自動構造分析のためのエージェント LLM フレームワークを提案します。不規則な 3D フレームは 2D 平面への投影によって表され、直交するグリッド線が空間座標を定義し、階数のマトリックスが各グリッド セルの垂直方向の押し出しをエンコードします。この表現に基づいて、フレームワークはマルチエージェント パイプラインを確立します。問題分析エージェントは入力を解析して構造化された JSON に変換します。床分解エージェントは各床の空間レイアウトを導き出します。 3D ジオメトリは、ノード、桁、スラブ、柱エージェントによって組み立てられます。サポートおよびロード エージェントは境界条件とロード条件を割り当て、コード変換エージェントは実行可能な SAP2000 スクリプトを生成します。 10 個の代表的な 3D フレームで評価したところ、提案されたフレームワークは反復試行全体で平均 90% の精度を達成し、一貫した信頼性の高いパフォーマンスを実証しました。
原文 (English)
Agentic Large Language Models for Automated Structural Analysis of 3D Frame Systems
Large language models (LLMs) have emerged as powerful foundation models with strong reasoning capabilities across domains. Beyond reactive text generation, agentic LLMs enable autonomous workflow execution through modular task decomposition and coordinated tool use. In structural engineering, recent efforts have developed agentic LLMs for automated analysis of plane frames. However, their extension to 3D frames remains underexplored due to challenges in irregular geometric representation, topological consistency, and long-horizon reasoning. This paper proposes an agentic LLM framework for automated structural analysis of 3D frames from natural language inputs. Irregular 3D frames are represented by projection onto a 2D plan, where orthogonal gridlines define spatial coordinates and a matrix of number of stories encodes vertical extrusion of each grid cell. Building on this representation, the framework establishes a multi-agent pipeline: a problem analysis agent parses input into structured JSON; a floor decomposition agent derives the spatial layout of each floor; the 3D geometry is assembled by node, girder, slab, and column agents; support and load agents assign boundary and loading conditions, and code translation agents generate executable SAP2000 script. Evaluated on ten representative 3D frames, the proposed framework achieves an average accuracy of 90% across repeated trials, demonstrating consistent and reliable performance.
How reliable are LLMs when it comes to playing dice?
We investigate the probabilistic reasoning capabilities of large language models through a controlled benchmarking study on discrete probab…
A Unifying Lens on Reward Uncertainty in RLHF
Reinforcement learning from human feedback (RLHF) is bottlenecked by reward hacking, where the policy exploits errors in a proxy reward mod…
An Improved Generative Adversarial Network for Micro-Resistivity Imaging Logging Restoration
An improved GAN-based imaging logging image restoration method is presented in this paper for solving the problem of partially missing micr…
UniDexTok: A Unified Dexterous Hand Tokenizer from Real Data
Dexterous hands are essential for fine-grained manipulation, but their hardware designs vary substantially across embodiments. Differences…
Attention Expansion: Enhancing Keyphrase Extraction from Long Documents with Attention-Augmented Contextualized Embeddings
Pre-trained language models (PLMs) have achieved strong performance in keyphrase extraction (KPE), largely due to their ability to generate…
RoboNaldo: Accurate, Stable and Powerful Humanoid Soccer Shooting via Motion-Guided Curriculum Reinforcement Learning
Elite humanoid soccer shooting requires whole-body stability, high-impulse whole-body interactions, and accuracy to targets. Motion trackin…
船舶金融における人工知能: AI 拡張ローン組成における応用、機会、およびケーススタディ
船舶金融は、データ集約型で大量の文書を必要とする資産ベース融資の分野であり、異種混合でほとんど構造化されていないソースからの財務、技術、契約、規制情報を統合する必要があります。環境規制や ESG 報告義務の増加により、引受業務やローン組成プロセスはさらに複雑になっています。人工知能 (AI)、特に大規模言語モデル (LLM) の最近の進歩により、そのような情報を処理および分析する新たな機会が生まれました。このペーパーでは、文書理解、情報抽出、ワークフロー自動化のための LLM ベースのシステムに特に焦点を当てて、船舶金融における AI の潜在的なアプリケーションをレビューします。船舶金融におけるローン申請ワークフローをサポートするモジュール型エージェント アーキテクチャである ShipFinance.ai を紹介します。提案されたシステムは、LLM ベースの抽出モジュール、財務分析コンポーネント、外部海事データ サービス、制御された文書生成モジュールとチャットボット インターフェイスを組み合わせて、標準化された財務アプリケーションの準備をサポートします。この文書では、このようなモデルを実稼働環境で使用する際の主な課題について説明します。私たちは、AI 支援システムは、海事金融専門家がますます複雑になる情報とレポート要件を管理できるようにサポートできると主張します。
原文 (English)
Artificial Intelligence in Ship Finance: Applications, Opportunities, and a Case Study in AI-Augmented Loan Origination
Ship finance is a data-intensive and document-heavy segment of asset-based lending, requiring the integration of financial, technical, contractual, and regulatory information from heterogeneous and largely unstructured sources. Increasing environmental regulation and ESG reporting requirements are adding further complexity to underwriting and loan-origination processes. Recent advances in artificial intelligence (AI), particularly large language models (LLMs), create new opportunities for processing and analysing such information. This paper reviews potential applications of AI in ship finance, with a particular focus on LLM-based systems for document comprehension, information extraction, and workflow automation. We present ShipFinance.ai, a modular agentic architecture to support loan application workflows in ship finance. The proposed system combines an LLM-based extraction module, financial analysis components, external maritime data services, and a controlled document-generation module with a chatbot interface to support the preparation of standardized financing applications. The paper discusses the key challenges for using such models in production. We argue that AI-assisted systems can support maritime finance professionals in managing increasingly complex information and reporting requirements.
Blind Dexterous Grasping via Real2Sim2Real Tactile Policy Learning
Blind grasping with a dexterous hand is a crucial manipulation capability. Nevertheless, learning such tactile-only policies for real robot…
MultiToP: Learning to Patch Visual Tokens to Mitigate Hallucinations in Video Large Multimodal Models
Video Large Multimodal Models have achieved remarkable progress in video understanding, yet they remain prone to hallucinations, where gene…
Scalable Deep Learning Framework for Global High-Resolution Land Use Reconstruction
Uncertainty in the terrestrial carbon cycle remains a major constraint in climate projections, partly driven by the uncertainties affecting…
Towards Data-free and Training-free Compression for Speech Foundation Models Using Parameter Clustering
This paper presents a novel data-free and training-free compression approach for speech foundation models using channelwise clustering via…
Frozen Multimodal Embeddings for AI-Assisted Interview Assessment of Personality and Cognitive Ability
Predicting psychological traits from asynchronous video interviews (AVIs) is a challenging problem in AI-assisted interview assessment beca…