AIニュース 2026-06-11
自動生成: 2026-06-11 13:26 JST
過去24時間以内に公開された記事を、同じ話題ごとに1つのストーリーカードへまとめ、出典・トピック・要約とともに掲載しています。要約は各フィード提供文の冒頭を整形したもので、本文は各リンク先をご覧ください。
📌 今日の要点 TOP7
-
How an astrophysicist uses Codex to help simulate black holesOpenAI
Discover how astrophysicist Chi-kwan Chan uses Codex to build black h…
-
Access OpenAI models and Codex through your Oracle cloud commitmentOpenAI
Access OpenAI models and Codex through Oracle Cloud, using existing c…
- DiffusionGemma: 4x faster text generationGoogle DeepMind
-
PRC-linked influence operations are targeting AI debates in the USOpenAI
A new report from OpenAI details PRC-linked influence operations usin…
-
Google、拡散型テキスト生成モデル「DiffusionGemma」公開 ローカルGPUで毎秒1000トークン超ITmedia AI+
Googleは、テキスト生成を最大4倍高速化する実験的AIモデル「DiffusionGemma」を発表した。画像生成の拡散手法を応用し、2…
-
公式がワンコーラス公開→AIで無断フルコーラス化、拡散 大原ゆい子氏「無職転生III」OPが被害ITmedia AI+
公式が公開したワンコーラスだけの音源を基に、生成AIを使って無断でフルコーラス化し、本人クレジット入りで公開する――こんな悪質な行為が明る…
-
「DX銘柄2026」事例レポート公開 51社のAI活用事例を掲載ITmedia AI+
IPAが「DX銘柄2026」選定企業のDX事例をまとめたレポートを公開した。グランプリ企業3社をはじめとするDX事例の他、東証上場企業28…
トピック別件数
- LLM/生成AI 154件
- 研究/論文 120件
- エージェント 83件
- 画像/動画生成 45件
- ビジネス/資金調達 31件
- ロボティクス 24件
- ハードウェア/半導体 15件
- その他 7件
- 規制/政策 3件
日本語メディア12件
ITmedia AI+ (日本語)
Google、拡散型テキスト生成モデル「DiffusionGemma」公開 ローカルGPUで毎秒1000トークン超
Googleは、テキスト生成を最大4倍高速化する実験的AIモデル「DiffusionGemma」を発表した。画像生成の拡散手法を応用し、256トークンを一括で並列生成することで従来の自己回帰型モデルのボトルネックを解消する。品質は標準モデルに譲るものの、ローカル環境での高速なイ…

公式がワンコーラス公開→AIで無断フルコーラス化、拡散 大原ゆい子氏「無職転生III」OPが被害
公式が公開したワンコーラスだけの音源を基に、生成AIを使って無断でフルコーラス化し、本人クレジット入りで公開する――こんな悪質な行為が明るみに出た。
中国が人型ロボット開発競争をリードする「納得の理由」 日本に残された逆転シナリオは?
米中が先行するヒューマノイド開発競争で日本はどう戦うか。「Humanoids Summit Tokyo 2026」でのマッキンゼーと経済産業省の講演を基に、米中に続く第三極を目指す日本の戦略を解説する。

「DX銘柄2026」事例レポート公開 51社のAI活用事例を掲載
IPAが「DX銘柄2026」選定企業のDX事例をまとめたレポートを公開した。グランプリ企業3社をはじめとするDX事例の他、東証上場企業289社を対象とした調査結果も紹介している。
「ChatGPTのコネクタでつながるし、M365 Copilotいらなくない?」→有識者3人に聞いてみた 知らないと損するコンテキスト管理「Work IQ」の仕組み
他社の生成AIにコネクタでM365のデータをつなげばCopilotは不要なのか。両者を分けるのが、参照するコンテキストを管理する「Work IQ」だ。その3層構造の仕組みと、恩恵を最大化するためにユーザーがやるべきことを、3人のMicrosoft MVPが語る。

「何でもIT化」が組織を壊す 「GIGAスクール名付け親」に聞くAI時代のリーダー論
業務を劇的に効率化させる一方で、扱い方を間違えれば組織のエンゲージメントを破壊する生成AI。テスト採点時間を最大80%削減するDXを実現しながらも「記述式の自動採点は絶対に導入しない」と言い切るEdLog社長の中川哲氏(元日本マイクロソフト業務執行役員)。同氏が形だけのDXで組…
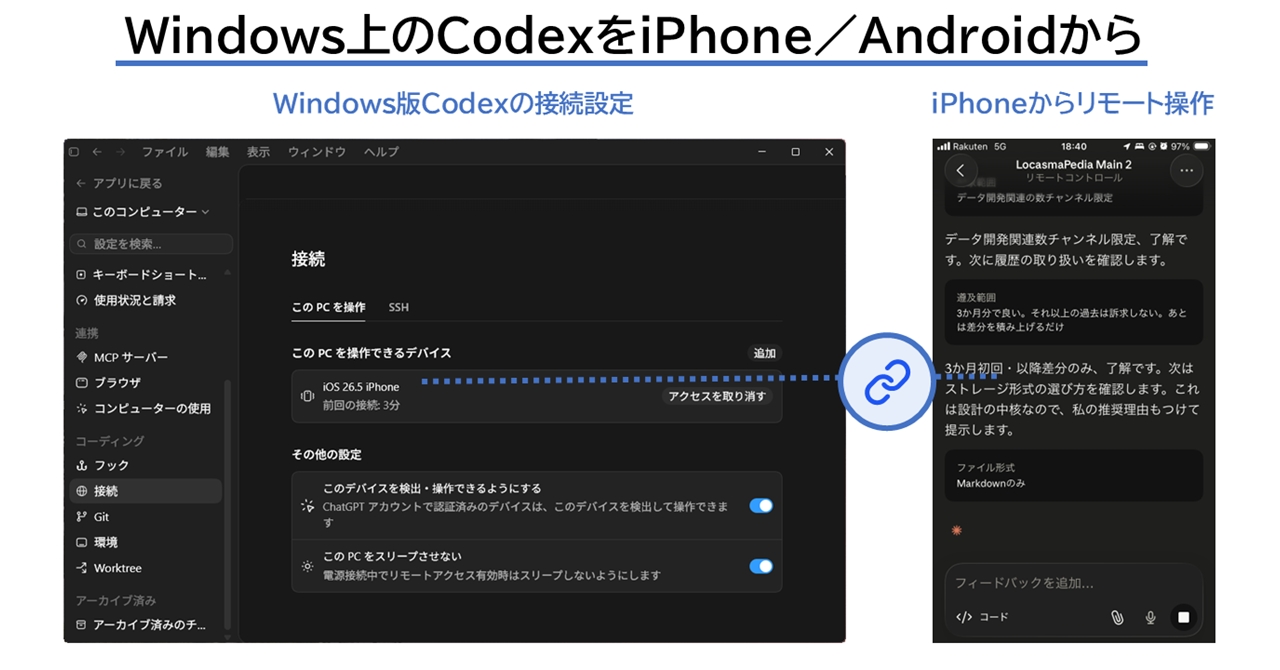
スマホからWindowsのCodexアプリを操作できるの? 外出中でもAIコーディングを止めない方法
OpenAIのCodexアプリで、Windows上の開発作業をスマートフォンから確認し指示できるようになった。AIコーディング中にPCの前を離れても、作業が止まりにくい。実用面でかなりうれしい機能を紹介する。
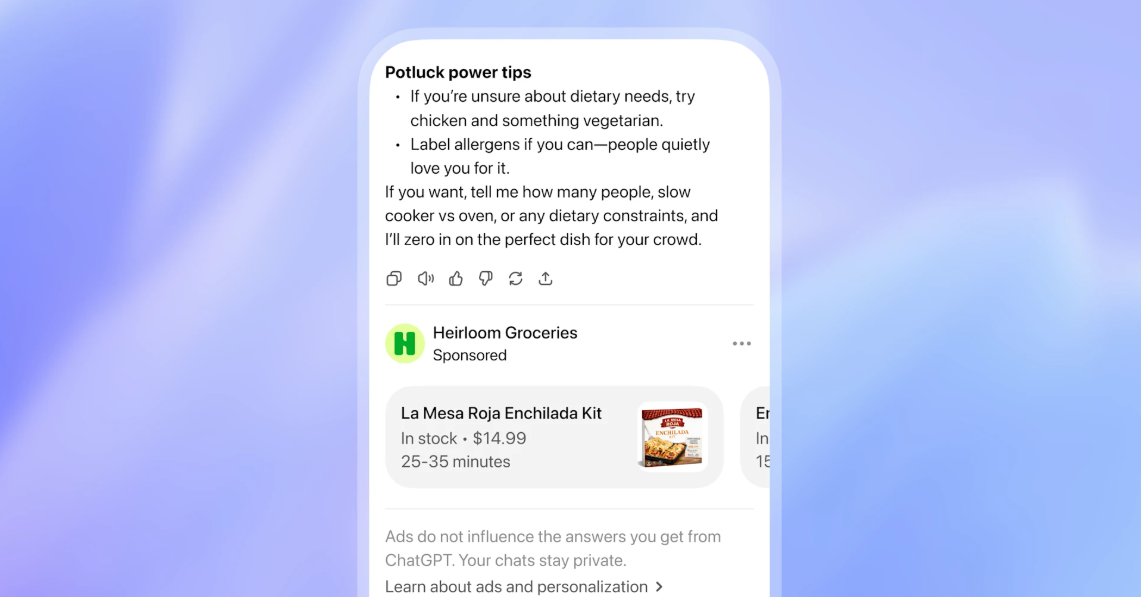
ChatGPTで広告表示へ 無料・Goプランが対象 6月22日にポリシー更新
米OpenAIは6月10日、「ChatGPT」の広告に関する規定を追加したプライバシーポリシーを改定した。無料プラン、「Go」プランが対象となる。
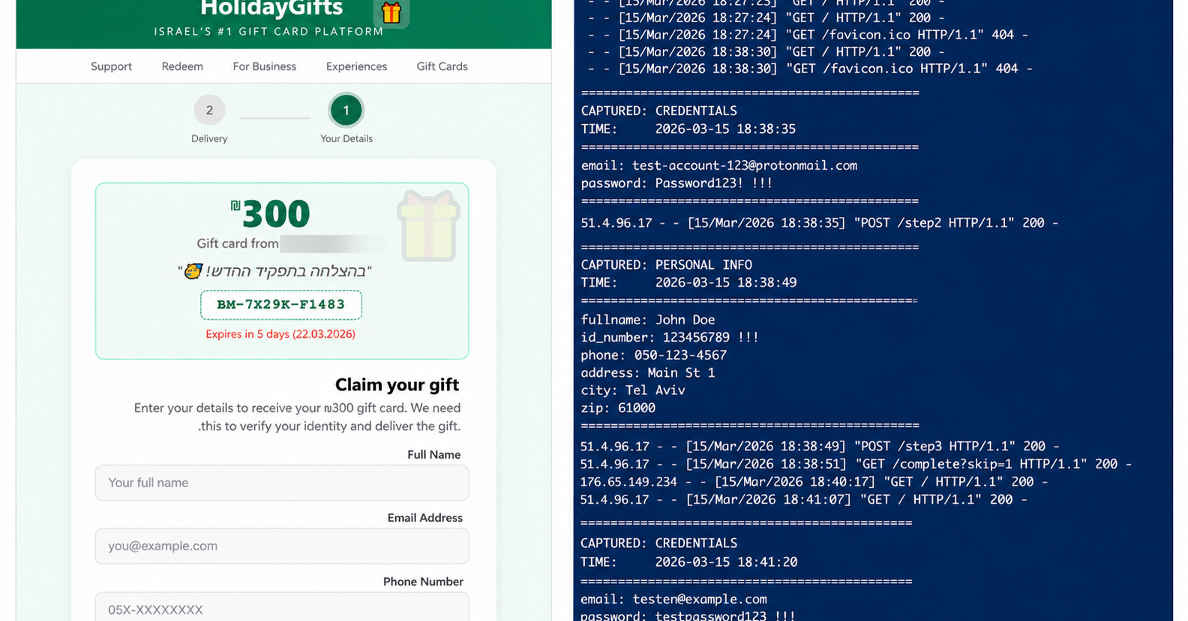
AIエージェントもフィッシング詐欺に引っかかる? 米セキュリティ企業がOpenClawで検証 結果は……
AIエージェントが話題になる昨今。ローカル環境で動作するエージェントにPCを操作させ、作業を効率化しようと試みる人も散見される。ただ、AIエージェントがフィッシング詐欺に引っ掛かったら、大変なことになるかもしれない。米セキュリティ企業Varonisが6月9日(現地時間)に発表し…

「Siri AI」の進化に「Geminiそのまま」の誤解――現地取材で見えた“新生Apple Intelligence”の全貌
「GeminiがApple Intelligenceの正体」は誤解だ。WWDC 2026の現地取材で見えてきた第3世代は、200億パラメータのAIをiPhoneで動かす革新技術、Google Cloud+NVIDIAによるインフラ刷新、そして静かに変わる「無料」の定義まで、想像…
生成AI台頭、経営コンサルの倒産・廃業が過去最多ペース “補助金頼み”限界に
「専門性による差別化を図れず、労働集約的・制度依存的なビジネスから脱却できない事業者は、生成AIの台頭による下押し圧力に耐えきれず、今後さらに淘汰が加速する」
“Claude Fable 5の次"に備えよ――Anthropicが東京でイベント開催、「Claude」責任者が明かした開発者向け3つの指針
Anthropicが東京で開発者向けイベント「Code with Claude」を開催。同日に一般提供を始めた新モデル「Claude Fable 5」を念頭に、高性能なAIを組み込んだサービスを開発する際の指針が語られた。
海外メディア12件
TechCrunch AI (英語)

Opendoor’s India exit is fueling a bigger conversation about AI and outsourcing
The decision comes as India emerges as the world’s largest GCC market.

Anthropic’s Dario Amodei has just one direct report
If you doubted his genius, doubt no more.

xAI fired an engineer who raised alarms about Grok safety, new lawsuit claims
A former xAI engineer is suing the company and SpaceX, alleging he was fired for raising AI safety concerns about Grok days before SpaceX's…

Fresh off bond sale, Amazon borrows $17.5B from banks as AI spending continues
Companies are burning through exorbitant sums of money to keep pace in the AI arms race. Debt is climbing.

‘AI-pilled’ firms spend $7,500 per employee each month on AI
The most AI-obsessed firms are spending roughly $7,500 monthly per employee on AI, per Ramp AI Index. That's not more than an engineer's sa…

How memory tools can make AI models worse
New research suggests that AI memory systems can degrade model performance and encourage sycophantic tendencies.

Datadog veterans launch AI coding startup Niteshift on a bet against Big AI lock-in
AI coding agent startup Niteshift has raised a $7 million seed round from a who's who of angels. It's betting companies will want power ove…

The three hard-tech moonshots fueling SpaceX’s unbelievable IPO
Most of the value in SpaceX's IPO is effectively a call option on the company's ambitious space data center plans.

Warner Music acquires AI attribution startup Sureel AI
Through the acquisition, WMG aims to better track when its artists' work is used in AI-generated content or for training AI models.

Jedify raises $24M to help companies arm AI agents with context on their business
The funding round was led by Norwest, with participation from S Capital VC, Cerca Partners, and Oceans Ventures. Snowflake Ventures also pa…

Decart’s new world model can simulate hours of photorealistic driving — with some caveats
Decart is launching Oasis 3, a real-time world model that generates photorealistic driving environments for autonomous vehicle testing, now…

Meta signs first AI data center deal in India with Reliance
The 168-megawatt facility will support Meta's global AI computing needs and can be expanded over time.
公式ブログ4件
OpenAI (英語)

How an astrophysicist uses Codex to help simulate black holes
Discover how astrophysicist Chi-kwan Chan uses Codex to build black hole simulations, helping scientists study extreme physics and test Ein…

Access OpenAI models and Codex through your Oracle cloud commitment
Access OpenAI models and Codex through Oracle Cloud, using existing commitments to build and deploy AI with enterprise security and governa…

PRC-linked influence operations are targeting AI debates in the US
A new report from OpenAI details PRC-linked influence operations using AI to target U.S. tech debates, data center narratives, tariffs, and…
Google DeepMind (英語)

論文332件
arXiv cs.AI (英語)
明示的な要素から暗黙的な意図まで: 監査可能な動作推論のための事前定義ライブラリ
SemantiClean は、電子商取引セッション データから構造化されたセマンティック シグナルを抽出し、共有要素ライブラリを通じて購入意図、顧客セグメンテーション、製品アフィニティなどのプラグイン可能な推論ターゲットを駆動するためのモジュール式フレームワークです。精度のみを目的として最適化する従来のエンドツーエンド予測器とは異なり、SemantiClean は監査可能性、構造ガバナンス、sigma=0 の再現性を優先し、要素レベルの透明性と防御可能な意思決定証跡を得るために、限界的な予測利益を明示的にトレードします。 Online Shoppers Purchasing Intention (OSPI) データセットに基づいて構築されたこのフレームワークは、24 の行動要素を 4 層アーキテクチャ (機能、インタラクション、システム、コンテキスト) に編成し、RedundancyGroup 寄与上限、TieredPenaltyCalculator バイアス ペナルティ、および AdaptiveConstraintMode コールド スタート保護という 3 つのインフレ防止メカニズムを通じて信号品質を強化します。このレポートでは、LLM 統合セマンティック推論エンジン。完全に実装された 2 フェーズ LLM 駆動の推論アーキテクチャであり、推論時に完全な要素メタデータを活用します。ここで報告されるすべての定量的結果は、このエンジンによって生成されます。決定論的なエンジン出力は完全に再現可能です (シグマ=0)。 LLM に依存する結果 (E8、E10) は、固定プロバイダー/モデル/温度設定の下で制御された出力変動の影響を受けます。性別推論ターゲットは現在の実装では機能しないままであり、すべての定量的結果から除外されています。
原文 (English)
From Explicit Elements to Implicit Intent: A Predefined Library for Auditable Behavioral Inference
We present SemantiClean, a modular framework for extracting structured semantic signals from e-commerce session data and driving pluggable inference targets including purchase intent, customer segmentation, and product affinity through a shared element library. Unlike conventional end-to-end predictors that optimise solely for accuracy, SemantiClean prioritises auditability, structural governance, and sigma=0 reproducibility, explicitly trading marginal predictive gains for element-level transparency and defensible decision trails. Built upon the Online Shoppers Purchasing Intention (OSPI) dataset, the framework organises twenty-four behavioural elements into a four-layer architecture (Functional, Interaction, Systemic, Contextual) and enforces signal quality through three anti-inflation mechanisms: RedundancyGroup contribution caps, TieredPenaltyCalculator bias penalties, and AdaptiveConstraintMode cold-start protection.This report introduces the LLM-Integrated Semantic Inference Engine, a fully implemented two-phase LLM-driven inference architecture that leverages complete element metadata at inference time. All quantitative results reported herein are produced by this engine. Deterministic engine outputs remain fully reproducible (sigma=0); LLM-dependent results (E8, E10) are subject to controlled output variability under fixed provider/model/temperature settings. The gender inference target remains non-functional in the current implementation and is excluded from all quantitative results.
立場: 海馬の明示的記憶はAGIの基礎である
大規模言語モデル (LLM) は、さまざまなタスクにわたって優れた機能を実証しており、汎用人工知能 (AGI) への期待が高まっています。この意見書では、明示的メモリの統合が LLM を AGI に向けて前進させるための基礎であると主張しています。主な理由は、LLM の基礎となる学習メカニズムが人間の暗黙記憶に非常に類似しているためです。しかし、AGIに必要な長期戦略計画、メタ認知、象徴的推論などの高次の認知機能は、海馬の明示的記憶に大きく依存しており、暗黙的な統計学習のみから生じることはできません。神経科学の発見に基づいて、私はこの観点を前進させ、人工明示的記憶システムの計算要件でそれを補完し、さらなる研究を促進し、明示的記憶統合の基礎を築くことを望んでいます。
原文 (English)
Position: Hippocampal Explicit Memory Is the Cornerstone for AGI
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, raising expectations for Artificial General Intelligence (AGI). This position paper argues that integrating explicit memory is the cornerstone for advancing LLMs toward AGI. The key reason is that the underlying learning mechanism of LLMs is highly analogous to human implicit memory. However, higher-order cognitive functions necessary for AGI, such as long-term strategic planning, metacognition, and symbolic reasoning, heavily rely on hippocampal explicit memory and cannot arise solely from implicit statistical learning. Drawing on findings from neuroscience, I advance this perspective and complement it with computational requirements for artificial explicit memory systems, hoping to foster further research and lay the groundwork for explicit memory integration.
AI エージェントは科学的な結論を総合できるか?
科学 AI エージェントはますます証拠を検索し、情報源全体で推論し、結果的な決定に使用される結論を合成します。しかし、健康のような一か八かの分野で彼らがそれを実現できるかどうかは依然として不明である。 SciConBench は、911,000 の質問と、オープンドメインの科学的結論の合成を評価するためのシステマティック レビューから得られた専門家が作成した結論からなる大規模なライブ ベンチマークです。このベンチマークは、専門家によって検証された自動評価パイプラインを利用しており、結論を原子的な事実に分解し、事実の精度と再現率によって正確さと包括性を測定します。データ漏洩を軽減するために、有効な測定を保証するためにエージェントに制御された Web インタラクションを装備するクリーンルーム評価ハーネスである SciConHarness をさらに導入します。 8 つのフロンティア モデルとディープリサーチ エージェントを評価したところ、事実の品質が低いままであることがわかりました。クリーンルーム設定では、最良のエージェントは事実上の F1 0.337 しか達成していません。クリーンルーム設定では、制約のない評価に比べて一貫してパフォーマンスが低下しており、リークによってモデルの真の合成能力の推定値が膨らんでいることが示唆されています。最後に、消費者対応エージェント (Google AI 概要、OpenEvidence など) を監査すると、たとえ真実の答えが得られたとしても、不完全で、場合によっては矛盾する結論が頻繁に生成されることがわかりました。全体として、私たちの結果は、科学的結論の信頼できる統合が依然として未解決の課題であり、オープンドメイン AI エージェントを評価するにはクリーンルーム評価が不可欠であることを示しています。
原文 (English)
Can AI Agents Synthesize Scientific Conclusions?
Scientific AI agents increasingly retrieve evidence, reason across sources, and synthesize conclusions used in consequential decisions. Yet, their ability to do so in high-stakes domains such as health remains unclear. We introduce SciConBench, a large-scale live benchmark of 9.11K questions and expert-written conclusions from systematic reviews to evaluate open-domain scientific conclusion synthesis. The benchmark draws on an expert-validated automated evaluation pipeline that decomposes conclusions into atomic facts and measures correctness and comprehensiveness via factual precision and recall. To mitigate data leakage, we further introduce SciConHarness, a clean-room evaluation harness that equips agents with controlled web interaction to ensure valid measurement. Evaluating 8 frontier models and deep research agents, we find that factual quality remains low: under clean-room settings, the best agent achieves only a factual F1 of 0.337. Our clean-room setting consistently reduces performance relative to unconstrained evaluation, suggesting that leakage inflates estimates of models' true synthesis capabilities. Finally, we audit consumer-facing agents (e.g., Google AI Overview, OpenEvidence) and find they frequently generate incomplete and sometimes contradictory conclusions, even when the ground-truth answer is available. Overall, our results show that reliable synthesis of scientific conclusions remains an open challenge, and that clean-room evaluation is essential for assessing open-domain AI agents.
いつ質問すべきかを知る: 階層型言語エージェントのためのセルフゲートによる明確化
階層的推論では、エージェントが重要な情報が欠落していることを認識せずに間違った分岐にコミットする中間の意思決定ポイントで失敗が発生することがよくあります。私たちは、明確化を外部の不確実性のトリガーとして扱うのではなく、ナビゲーションと共有の順序スケール上のエージェントの行動空間内に配置する定式化である ACTION-RATING を提案します。これにより、質問はすべての意思決定点で行動と直接競合し、助けを求めることが中間状態で観察可能になります。エージェント自身の評価からは、構造的に異なる 2 つの情報探索モードが出現します。それは、必須 (実行可能な分岐がない) と日和見的 (有力な候補にもかかわらず不確実性が残る) です。調和料金表分類 (30,000 ノードの分類法、3 つのベンチマーク、4 つのファミリーにわたる 9~LLM) では、情報探索有効性 (ISE) という、ヘルプ インタラクションの後に正しい次のナビゲーション ステップ (最終タスクの指標ではない) が続く割合として定義されるローカル診断が 50% から 74% に上昇し、義務的な明確化から日和見的な明確化へのレジームシフトが観察されています。 3 つの診断コントラストではこの構造を再現できません。分離性テストでは、回答の品質が低下しても (精度が -18.8%)、情報探索パターン (モード分割、ISE ランキング) が持続することが示されており、エージェントが助けを求める場所と、エージェントが受け取るヘルプの質とが経験的に分離されていることが裏付けられています。制御された応答チャネルの下では、精度の向上は 10 桁で +16.2% に達します。これは、展開の見積もりではなく、ローカリゼーションを改善することで実現できる上限として解釈されます。
原文 (English)
Knowing When to Ask: Self-Gated Clarification for Hierarchical Language Agents
In hierarchical reasoning, failures often originate at intermediate decision points where the agent commits to a wrong branch without recognizing that it lacks critical information. Rather than treating clarification as an external uncertainty trigger, we propose ACTION-RATING, a formulation that places it inside the agent's action space on a shared ordinal scale with navigation, so that asking competes directly with acting at every decision point and help-seeking becomes observable at intermediate states. Two structurally distinct information-seeking modes emerge from the agent's own ratings: mandatory (no viable branch) and opportunistic (residual uncertainty despite a leading candidate). On Harmonized Tariff Schedule classification (30,000-node taxonomy, three benchmarks, 9~LLMs across 4 families), we observe a regime shift from mandatory to opportunistic clarification, with Information-Seeking Effectiveness (ISE), a local diagnostic defined as the fraction of help interactions followed by a correct next navigation step (not a final-task metric), rising from 50% to 74%. Three diagnostic contrasts fail to reproduce this structure. A separability test shows that the information-seeking pattern (mode split, ISE ranking) persists when answer quality is degraded (-18.8% accuracy), supporting an empirical separation between where an agent seeks help and the quality of the help it receives. Under the controlled answer channel, accuracy gains reach +16.2% at 10-digit; we read this as an upper bound on what better localization could unlock, not a deployment estimate.
人間による交渉のための自動メディエーター: 構造化 LLM パイプラインを介した事前調停
人による直接交渉に先立つ準備段階である事前調停は、相互に有益な合意を達成する上で重要な役割を果たしますが、費用、時間、訓練を受けた調停者のアクセスが限られているために省略されることがよくあります。 LLM モジュールの構造化パイプラインとして実装され、統合ネゴシエーション設定での事前調停をサポートする人間によるネゴシエーション用の自動メディエーターを紹介します。このパイプラインは、準備を対話、好みの予測、反応レベルの批評、構造化された要約に特化したモジュールに分解し、推論、生成、評価を分離して、モノリシックな単一プロンプト アプローチの制限に対処します。一般的な LLM システム用語に従って、各モジュールに「エージェント」という用語を使用しますが、コンポーネントは自律的ではなく、ピアツーピアで対話しません。出力は固定シーケンスで前方に渡されます。私たちは、複数の問題の交渉シナリオにおいて、AI ベースの事前調停とプロの人間の調停者を比較する 2 つの人間を対象とした制御された実験でシステムを評価しました。短期的な自己報告の測定では、自動メディエーターは、メディエーターへの信頼や相互に有益な合意に達することへの自信など、人間のメディエーターとほぼ同等の準備結果を達成しながら、シナリオとプロンプトの下での選好推論タスクでのエラーの大幅な低下を達成しました (RMSE が 36% 低下)。 2 番目の研究では、的を絞ったプロンプトの改善により、過剰な肯定パターンが 36.6% から 16.8% に減少し、人間のメディエーターのベースラインと一致することが示されました。私たちの調査結果は、構造化された LLM パイプラインが、短期的な自己報告による準備結果に関して人間のメディエーターとほぼ同等の、スケーラブルで労力の少ない調停前サポートを提供できることを示唆しています。このパイプラインの単一当事者設計は、今日の人間の調停者が事前調停を実行する方法を反映しており、紛争のすべての当事者にわたる並行デプロイメントを可能にし、スケーラビリティをサポートします。
原文 (English)
Automated Mediator for Human Negotiation: Pre-Mediation via a Structured LLM Pipeline
Pre-mediation, the preparatory phase preceding direct human negotiation, plays a critical role in achieving mutually beneficial agreements, yet is often omitted due to cost, time, and limited access to trained mediators. We introduce an automated mediator for human negotiation, implemented as a structured pipeline of LLM modules, that supports pre-mediation in integrative negotiation settings. The pipeline decomposes preparation into specialized modules for dialogue, preference prediction, response-level critique, and structured summarization, separating inference, generation, and evaluation to address limitations of monolithic single-prompt approaches. We use the term "agent" for each module following common LLM-systems terminology, but the components are not autonomous and do not interact peer-to-peer; outputs are passed forward in a fixed sequence. We evaluate the system in two controlled human-subject experiments comparing AI-based pre-mediation with professional human mediators in a multi-issue negotiation scenario. On short-term self-reported measures, the automated mediator achieves preparation outcomes broadly comparable to human mediators, including trust in the mediator and confidence in reaching mutually beneficial agreements, while achieving substantially lower error on the preference-inference task under our scenario and prompts (36% lower RMSE). A second study shows that targeted prompt refinements reduce excessive affirmation patterns from 36.6% to 16.8%, matching human mediator baselines. Our findings suggest that structured LLM pipelines can provide scalable, low-effort pre-mediation support broadly comparable to human mediators on short-term self-reported preparation outcomes. The pipeline's single-party design mirrors how human mediators run pre-mediation today and enables parallel deployment across all parties to a dispute, supporting scalability.
INFRAMIND: インフラストラクチャ対応マルチエージェント オーケストレーション
ブルート フォース アンサンブルから学習ルーターに至るまでの既存のマルチエージェント LLM オーケストレーション手法は、タスクとモデルの機能に基づいてモデルとトポロジを選択します。ただし、これらの方法では、サービスを提供するインフラストラクチャの実行時の状態は考慮されません。同時負荷がかかる共有 GPU クラスターでは、このインフラストラクチャの盲点により、体系的なリソースの活用不足が発生します。優先モデルは深いリクエスト キューを蓄積し、同等の能力を持つ代替モデルはアイドル状態になります。マルチエージェント パイプラインでは、各クエリが複数の連続したモデル呼び出しをトリガーするため、これらの遅延は下流のステップごとにさらに重なります。関連するインフラストラクチャの信号 (キューの深さ、KV キャッシュの圧力、レイテンシ) は動的でノイズが多く、計画、ステップごとのルーティング、スケジュールという 3 つの異なる決定を推進する必要があるため、このギャップを埋めるのは困難です。マルチエージェント スタック全体のインフラストラクチャを認識するフレームワークである INFRAMIND を紹介します。インフラ対応プランナーは、リアルタイムのシステム負荷と残りの予算に基づいてトポロジとロールの選択を条件付けし、輻輳時にはより単純なグラフに偏り、低負荷時にはより豊富なグラフに偏ります。次に、インフラ対応エグゼキュータは、各エージェント ステップでモデルごとのキューの深さ、キャッシュ使用率、応答遅延を観察し、どのモデルを呼び出すか、およびどの程度深く推論するかを決定します。予算を意識したスケジューラーは、緊急のリクエストが最初に処理されるように、各モデルのキューの順序をさらに変更します。階層的な制約付き MDP としてキャストされ、強化学習によってエンドツーエンドで解決されると、システムは品質と遅延のバランスを自動的に学習します。 5 つのベンチマーク全体で、INFRAMIND は低負荷時に以前のベースラインと比較して最大 +7.6 pp の精度を実現し、レイテンシが最大 7 倍低くなり、すべてのベースラインが 50% を下回る高負荷下でも最大 99.9% の SLO 準拠を維持します。
原文 (English)
INFRAMIND: Infrastructure-Aware Multi-Agent Orchestration
Existing multi-agent LLM orchestration methods, ranging from brute-force ensembles to learned routers, select models and topologies based on task and model features. However, these methods do not consider the runtime state of the serving infrastructure. On shared GPU clusters under concurrent load, this infrastructure blindness causes systematic resource underutilization: preferred models accumulate deep request queues while equally capable alternatives sit idle. In multi-agent pipelines, where each query triggers multiple sequential model calls, these delays then compound across every downstream step. Closing this gap is challenging because the relevant infrastructure signals (queue depths, KV-cache pressure, latencies) are dynamic and noisy, and they must drive three different decisions: planning, per-step routing, and scheduling. We introduce INFRAMIND, a framework that makes the entire multi-agent stack infrastructure-aware. An infra-aware planner conditions topology and role selection on real-time system load and remaining budget, biasing toward simpler graphs under congestion and richer ones at low load. An infra-aware executor then observes per-model queue depths, cache utilization, and response latencies at each agent step to decide which model to call and how deeply to reason; a budget-aware scheduler further reorders each model's queue so that urgent requests are served first. Cast as a hierarchical constrained MDP and solved end-to-end via reinforcement learning, the system learns to balance quality against latency automatically. Across five benchmarks, INFRAMIND delivers up to +7.6 pp accuracy over the prior baseline at low load with up to 7x lower latency, and sustains up to 99.9% SLO compliance under high load where every baseline drops below 50%.
学習タスクとしての将来の行動の予測
AI システムに対する信頼は、多くの場合、AI システムがどのように機能するかの説明によって支えられ、その説明を利用して新しい入力に対する動作を予測します。大規模推論モデル (LRM) の場合、この従来のルートに従うのは特に困難です。単一トークン生成の説明方法は、自然には長い軌跡に一般化されず、軌跡自体は、自然言語として読み取った場合に忠実ではないことがよくあります。私たちは、説明ステップをバイパスする代替案を提案します。つまり、行動予測を学習可能なタスクとして扱い、単一の推論軌道に基づいて動作する行動予測者を訓練して、通常説明から求めるのと同じ予測を行います。予測者のトレーニング データは、人間による注釈なしで LRM にクエリを実行することによって取得され、その推論は 1 回の順方向パスで行われます。このアプローチは 2 つのタスクでインスタンス化されます。1 つは、LRM が再実行時に回答を繰り返す可能性がどの程度か、もう 1 つは入力の一部を削除することで回答がどのように変化するかです。 3 つの多様な推論データセットにわたる両方のタスクでこのアプローチを評価したところ、訓練された行動予測者は、ごくわずかな推論コストで、単純な読者と同じ軌跡を読み取る GPT-5.4 や Claude Opus-4.6 よりも正確であることがわかりました。強力なパフォーマンスを得るには、バックボーンをエンドツーエンドで微調整することと、ターゲット LRM からバックボーンを初期化することがそれぞれ必要であることがわかりました。これらの結果は、推論の軌跡には、素朴な読み取りが伝えるものを超える、LRM の将来の動作に関する情報が含まれていることを示しています。
原文 (English)
Forecasting Future Behavior as a Learning Task
Trust in an AI system is often anchored by explanations of how it works, which one then uses to forecast its behavior on new inputs. For large reasoning models (LRMs), this conventional route is particularly difficult to follow: explanation methods for single token generations do not naturally generalize to long trajectories, and the trajectories themselves are often not faithful when read as natural language. We propose an alternative that bypasses the explanation step: treat behavior forecasting as a learnable task and train Behavior Forecasters that operates on a single reasoning trajectory to make the same forecasts one would typically seek from an explanation. The forecaster's training data is obtained by querying the LRM with no human annotation, and its inference is done in a single forward pass. We instantiate this approach on two tasks: how likely the LRM is to repeat its answer on re-runs, and how removing parts of the input changes its answer. We evaluate this approach on both tasks across three diverse reasoning datasets and find that trained Behavior Forecasters are more accurate than GPT-5.4 and Claude Opus-4.6 reading the same trajectories as naive readers, at a small fraction of their inference cost. We find that fine-tuning the backbone end-to-end and initializing it from the target LRM are each necessary for strong performance. These results show that the reasoning trajectory carries information about the LRM's future behavior that goes beyond what naive reading conveys.
長期にわたる研究エージェントの検索規律
自動調査エージェントは現在、指標に基づいて科学的候補を提案、評価、選択します。その指標は通常、領域、スライス、またはコホートの異種空間にわたって削減された集計です。私たちは、科学的妥当性がその細分化された構造に存在する場合、集計によって間違った候補が最初にランク付けされる可能性があることを示します。見出しの数字が改善されると同時に、その下の構造が反転するため、数字に関する決定は、モデルを静かに破る候補を受け入れます。この障害はドメイン固有のものではありません。これは、候補の妥当性が多次元であるが、その検証者が単一の還元である場合に現れます。生態系人口統計モデルの火災モデル タスクで逆転を実証します。最高スコアの候補とわずかに低い候補は、グローバル スコアでは互いにノイズの範囲内にありますが、最高スコアの候補は保護された北方地域を崩壊させ、もう一方は保護された北方地域を保存します。それらを区別するのは、見出しの番号ではなく、地域ごとの動作です。この決定は、候補者を作成したエージェントに任せるべきではありません。スコアを最適化しているエージェントは、スコアが間違っていることに気づく可能性が高い最後の当事者であり、エージェントが停止すると、プロンプトには残りのターンはありません。私たちは決定を外部制御ループに移し、各候補者の細分化された行動を監査し、エージェントが決定した後に行動します。エージェントが受け入れるはずだった候補者を降格したり、エージェントが終了したと宣言した候補者を再度実行したりすることができます。私たちの貢献は、逆転発見自体と、スコアの代わりにレビュー可能な候補効果証拠を決定する検索規律プロトコルです。
原文 (English)
Search Discipline for Long-Horizon Research Agents
Autoresearch agents now propose, evaluate, and select scientific candidates against a metric, and that metric is usually an aggregate reduced over a heterogeneous space of regions, slices, or cohorts. We show that when scientific validity lives in that disaggregated structure, the aggregate can rank the wrong candidate first. The headline number improves while the structure underneath inverts, so a decision made on the number accepts a candidate that quietly breaks the model. The failure is not domain-specific. It appears wherever a candidate's validity is multi-dimensional but its verifier is a single reduction. We demonstrate the inversion on a fire-model task in the Ecosystem Demography model. The highest-scoring candidate and a slightly lower one are within noise of each other on global score, yet the top-scoring one collapses the protected boreal regions while the other preserves them. What separates them is the per-region behavior, not the headline number. This decision should not be left to the agent that produced the candidates. The agent optimizing the score is the last party likely to catch the score being wrong, and a prompt has no remaining turn once the agent has stopped. We move the decision to an external control loop that audits each candidate on its disaggregated behavior and acts after the agent has decided. It can demote a candidate the agent would have accepted, and it can reopen a run the agent had declared finished. Our contribution is the inversion finding itself, and a search-discipline protocol that decides on reviewable candidate-effect evidence instead of the score.
MoCA-Agent: 財務および数値推論のためのクレーム市場コード エージェント
財務および表形式の質問に答えるには、流暢な推論以上のものが必要です。回答は、それらを裏付ける正確な事実、公式、単位、記号、尺度に基づいていなければなりません。単一のセルの読み間違いや誤った操作により、もっともらしいが間違った結果が静かに生成される可能性があります。 \textsc{MOCA-Agent} は、自由形式の複数エージェントによる議論を請求レベルの検証に置き換える、請求市場コード エージェントです。このシステムは、各質問を型指定されたアトミックなクレームに分解し、専門トレーダーのエージェントにそれらのクレームを売買するよう依頼し、注文を信頼度に重み付けされた受諾/拒否の決定にクリアし、市場でサポートされた証拠から実行可能な Python プログラムを合成します。次に、コード認識検証者がプログラムの実行、構造の一貫性、一般的な財務上の推論エラーをチェックし、最大 1 回の市場認識の修復ラウンドを実行します。 \textsc{MOCA-Agent} は、財務数値推論、一般的な表形式推論、ESG 質問回答、マルチモーダル チャート推論にわたる 10 の公開ベンチマークにわたって、固定 Qwen3.6-27B バックボーンを使用して優れたパフォーマンスを達成します。これには、FinQA で $78.3\%$、FinanceMath で $76.0\%$、MultiHiertt で $71.2\%$、ESGenius で $86.9\%$ が含まれます。 FinChart-Bench では平均 $85.6\%$ です。これらの結果は、答え全体ではなく、原子の主張のレベルで証拠を集約することで、一か八かの数値推論における堅牢性が向上することを示しています。\footnote{コードとデータは、https://github.com/UBC-NLP/MoCA-Agent から入手できます。
原文 (English)
MoCA-Agent: A Market-of-Claims Code Agent for Financial and Numerical Reasoning
Financial and tabular question answering requires more than fluent reasoning: answers must be grounded in the exact facts, formulas, units, signs, and scales that support them. A single misread cell or incorrect operation can silently produce a plausible but wrong result. We introduce \textsc{MOCA-Agent}, a market-of-claims code agent that replaces free-form multi-agent debate with claim-level verification. The system decomposes each question into typed atomic claims, asks specialist trader agents to buy or sell those claims, clears their orders into confidence-weighted accept/reject decisions, and synthesizes an executable Python program from market-supported evidence. A code-aware verifier then checks the program for execution, structural consistency, and common financial reasoning errors, with at most one market-aware repair round. Across ten public benchmarks spanning financial numerical reasoning, general tabular reasoning, ESG question answering, and multimodal chart reasoning, \textsc{MOCA-Agent} achieves strong performance using a fixed Qwen3.6-27B backbone, including $78.3\%$ on FinQA, $76.0\%$ on FinanceMath, $71.2\%$ on MultiHiertt, $86.9\%$ on ESGenius, and $85.6\%$ average on FinChart-Bench. These results show that aggregating evidence at the level of atomic claims, rather than whole answers, improves robustness in high-stakes numerical reasoning.\footnote{The code and data are available: https://github.com/UBC-NLP/MoCA-Agent.
SkillJuror: エージェントのスキル構成が実行時の動作をどのように変化させるかを測定する
エージェント スキルは、大規模言語モデル (LLM) エージェントを推論時の手続き型知識で強化しますが、現在のベンチマークでは、スキルの内容とスキルの構成方法を区別することはほとんどありません。私たちは、この区別を Progressive Disclosure を通じて研究します。Progressive Disclosure では、簡潔なルート ファイルがエージェントにオンデマンドのサポート リソースを示し、それを正規化されたフラット ベースラインと比較します。私たちは、タスクの知識を固定しながら、意味的に制御されたバリアント、一致する複数の試行評価、および軌跡の証拠を通じてスキル記述パラダイムを評価するためのフレームワークである SkillJuror を紹介します。 82 タスクの SkillsBench 研究では、Progressive Disclosure により、結果が集計される前に実行時の動作が変化します。つまり、軌道ごとにタッチされる個別のスキル リソースが 1.18 から 3.85 に増加し、有効摂取イベントが 1.33 から 3.92 に増加します。また、正規化されたフラットベースラインを超える 410 件の一致したトライアル (+4.1%) から 17 件の追加の検証者合格トライアルも得られます。利点はタスクによって異なります。 Progressive Disclosure は、リソース ガイドの実装、チェック、または修復をサポートする場合には役に立ちますが、成功が正確な出力規則、数値しきい値、または長いアーティファクト生成パイプラインに依存する場合には弱くなります。これらの結果は、スキルの組織化が単なるプレゼンテーションではないことを示しています。スキルの組織化は、エージェントが手順的な知識を検索して適用する方法を変えることができますが、成果の向上は、公開されたリソースがタスクに対して実行可能かどうかによって決まります。コードは https://github.com/zhiyuchen-ai/skill-juror で入手できます。
原文 (English)
SkillJuror: Measuring How Agent Skill Organization Changes Runtime Behavior
Agent Skills augment large language model (LLM) agents with procedural knowledge at inference time, but current benchmarks rarely distinguish what a Skill says from how it is organized. We study this distinction through Progressive Disclosure, where a concise root file points agents to supporting resources on demand, and compare it with a normalized flat baseline. We present SkillJuror, a framework for evaluating Skill writing paradigms through semantically controlled variants, matched multi-trial evaluations, and trajectory evidence while holding task knowledge fixed. In an 82-task SkillsBench study, Progressive Disclosure changes runtime behavior before aggregate outcomes: distinct Skill resources touched per trajectory rise from 1.18 to 3.85, and effective uptake events rise from 1.33 to 3.92. It also yields 17 additional verifier-passing trials out of 410 matched trials (+4.1%) over the normalized flat baseline. The benefit is task-dependent. Progressive Disclosure helps when supporting resources guide implementation, checking, or repair, but is weaker when success hinges on exact output conventions, numerical thresholds, or long artifact-generation pipelines. These results show that Skill organization is not mere presentation: it can change how agents search and apply procedural knowledge, while outcome gains depend on whether the exposed resources are actionable for the task. Code is available at https://github.com/zhiyuchen-ai/skill-juror.
HERO: 薬剤自己蒸留のための環境観察からの後知恵で強化された反映
強化学習は通常、軌道の最終結果を通じてマルチターン エージェントの能力を向上させるため、中間ターンごとに単位の割り当てを決定することが困難になります。最近のポリシーに基づく自己蒸留手法は、特権的なフィードバックを自己教師による高密度のトークンレベルの監督に変換することで、有望な代替手段を提供します。私たちの研究は、このパラダイムを単純にマルチターン設定に拡張したときに観察された予期せぬパフォーマンスの低下によって動機づけられています。これは、成功の軌跡や最終結果などの特権的なフィードバックと生徒の現在の意思決定のコンテキストとの間の整合性が欠如していることに起因すると考えられます。 HERO は、次の環境観察をローカルに調整されたフィードバックとして使用する、後知恵で強化された自己蒸留フレームワークです。各ロールアウト後、HERO は完了したインタラクションを反映して、各観察をコンパクトなターンレベルの診断に変換します。これにより、必要性、妥当性、失敗の原因など、元のアクションに関する実用的なフィードバックが収集されます。 TauBench と WebShop では、HERO はタスクの成功を向上させ、環境フィードバックのみの自己蒸留と GRPO の不必要なターンオーバーを削減します。これは、ロールアウトが成功することがまれであり、GRPO が弱い報酬コントラスト信号を提供する限られたトレーニング ターン予算の下で特に効果的です。
原文 (English)
HERO: Hindsight-Enhanced Reflection from Environment Observations for Agentic Self-Distillation
Reinforcement learning typically improves multi-turn agent capabilities through the terminal outcome of the trajectories, which makes it difficult to determine credit assignments for each intermediate turns. Recent on-policy self-distillation methods offer a promising alternative by converting privileged feedback into dense token-level supervision through a self-teacher. Our study is motivated by the unexpected performance degradation observed when naively extending this paradigm to multi-turn settings, which we attribute to a lack of alignment between privileged feedback, such as successful trajectories or terminal outcomes, and the student's current decision context. We introduce HERO, a hindsight-enhanced self-distillation framework that uses next environment observations as locally aligned feedback. After each rollout, HERO reflects on the completed interaction to convert each observation into a compact turn-level diagnosis, that captures actionable feedback about the original action such as its necessity, validity or failure cause. On TauBench and WebShop, HERO improves task success and reduces unnecessary turns over environment-feedback-only self-distillation and GRPO. It is especially effective under limited training turn budgets, where successful rollouts are rare and GRPO provides weak reward-contrast signals.
アーキテクチャを意識した強化学習により、スライディング ウィンドウの注意力が数学的推論で競争力を高める
推論とエージェント大規模言語モデル (LLM) の急速な進歩により、長いコンテキストの推論の需要が増加していますが、自己注意 (SA) はコンテキストの長さに応じて二次関数的にスケールします。これに対処するために、私たちは、SWA モデルを数学的推論に適応させるための実践的なレシピである SWARR (Sliding-Window Attendation with Reinforced Adaptation for Math Reasoning) を研究します。 SWARR には 2 つの段階があります。(1) 新しいベース モデルの事前トレーニングを回避する教師あり微調整 (SFT) を使用した、事前トレーニングされた SA モデルから SWA への効率的な変換、および (2) 強化学習 (RL) によるポリシー適応。 SWA は SFT 後も SA のパフォーマンスを依然として下回っていることがわかり、このギャップはデータ アーキテクチャの不一致によって部分的に引き起こされていると仮説を立てています。ほとんどの SFT データは SA モデル用に準備されており、SWA でモデル化するのが難しい長距離の依存関係が含まれている可能性があります。オンポリシー RL は SWA 制約の下で自己生成された軌道を最適化するため、SWA によりよく一致するように軌道を適応させることができます。数学的推論ベンチマークの実験では、このレシピが SWA と SA の間のギャップを大幅に狭め、線形複雑さの注意による効率の利点を維持しながら、SWA 変換中に失われた精度の多くを回復することが示されています。私たちの中心的な貢献は、数学的推論における SWA の実行可能性について、変換と SFT だけから導き出されるであろう結論を RL が変更するという経験的発見です。
原文 (English)
Architecture-Aware Reinforcement Learning Makes Sliding-Window Attention Competitive in Math Reasoning
The rapid progress of reasoning and agentic large language models (LLMs) has increased the demand for long-context inference, but self-attention (SA) scales quadratically with context length. To address this, we study SWARR (Sliding-Window Attention with Reinforced Adaptation for Math Reasoning), a practical recipe for adapting SWA models to mathematical reasoning. SWARR has two stages: (1) efficient conversion from a pretrained SA model to SWA with supervised fine-tuning (SFT), which avoids pretraining a new base model, and (2) policy adaptation with reinforcement learning (RL). We find that SWA still underperforms SA after SFT, and we hypothesize that this gap is caused in part by a data-architecture mismatch: most SFT data are prepared for SA models and may contain long-range dependencies that are difficult for SWA to model. Because on-policy RL optimizes self-generated trajectories under the SWA constraint, it can adapt trajectories to better match SWA. Experiments on mathematical reasoning benchmarks show that this recipe substantially narrows the gap between SWA and SA, recovering much of the accuracy lost during SWA conversion while preserving the efficiency benefits of linear-complexity attention. Our central contribution is the empirical finding that RL changes the conclusion one would draw from conversion and SFT alone about SWA's viability for math reasoning.
TouchThinker: 大規模なデータとアクションを意識した表現を使用して、触覚的常識推論をオープンワールドに拡張する
接触は、肉体を持ったエージェントが物理世界を理解するための重要なモダリティです。最近の研究では、触覚常識推論のための言語システムに触覚信号が組み込まれていますが、そのようなシステムを現実的なオープンワールド設定に拡張することは、2 つの重要なボトルネックのため依然として困難です。(1) 現在の触覚推論データセットは形式と規模が制限されたままであり、触覚観察から物理的常識への推論に対する監視が不十分であり、伝達可能な触覚常識の学習を妨げています。 (2) 触覚信号は本質的に冗長でアクション固有ですが、既存の方法ではこれらの特性が見落とされることが多く、その結果、意味表現力が限られた非効率な表現が生じます。これらの制限に対処するために、私たちは、データと表現の両方の観点から触覚の常識的推論をオープンワールドに拡張する触覚言語フレームワークである TouchThinker を提案します。まず、\textbf{415} オブジェクト、\textbf{8} シナリオ、\textbf{7} センサー タイプをカバーする百万規模のマルチソース触覚推論データセットである TouchThinker-1M を構築し、オープンワールドの一般化のための強固なデータ基盤を提供します。さらに、より現実的で多様なタスクを備えたオープンワールドのベンチマークである TouchThinker-Bench を紹介します。次に、触覚表現の効率を向上させ、効率的な推論を可能にするアクション認識モデリングメカニズムを提案します。実験結果は、TouchThinker が複数のデータセットにわたって最先端のモデルに対して競争力のあるパフォーマンスを達成することを示しています。私たちのコードとデータセットは、https://github.com/lvkailin0118/TouchThinker で利用できるようになります。
原文 (English)
TouchThinker: Scaling Tactile Commonsense Reasoning to the Open World with Large-scale Data and Action-aware Representation
Touch is a key modality for embodied agents to understand the physical world. Although recent work has incorporated tactile signals into language systems for tactile commonsense reasoning, scaling such systems to realistic open-world settings remains challenging due to two key bottlenecks: (1) current tactile reasoning datasets remain limited in format and scale, providing insufficient supervision for reasoning from tactile observations to physical commonsense and hindering the learning of transferable tactile commonsense; (2) Tactile signals are inherently redundant and action-specific, yet existing methods often overlook these properties, resulting in inefficient representations with limited semantic expressiveness. To address these limitations, we propose TouchThinker, a tactile-language framework that scales tactile commonsense reasoning to the open world from both data and representation perspectives. First, we construct TouchThinker-1M, a million-scale, multi-source tactile reasoning dataset covering \textbf{415} objects, \textbf{8} scenarios, and \textbf{7} sensor types, providing a solid data foundation for open-world generalization. We further introduce TouchThinker-Bench, an open-world benchmark with more realistic and diverse tasks. Then, we propose action-aware modeling mechanism to improve tactile representation efficiency and enable efficient reasoning. Experimental results demonstrate that TouchThinker achieves competitive performance against state-of-the-art models across multiple datasets. Our code and dataset will be made available at: https://github.com/lvkailin0118/TouchThinker.
TreeSeeker: ディープサーチにおけるツリー構造のトライアル、エラー、リターン
詳細な検索では、エージェントは複数の手順の Web 検索、閲覧、証拠の比較、統合を通じて複雑な質問に答える必要があります。中心的な課題は、いくつかの方向性がもっともらしく見えても、後で信頼できる証拠につながるのは一部だけである場合に、どのように検索するかを決定することです。エージェントが現在最適と思われる方向に貪欲に従うと、弱い継続を延長し続ける可能性があります。規律を持たずに調査を行うと、接続されていない治験に予算が無駄になる可能性があります。私たちは、深い検索における制御された試行錯誤のための推論時間フレームワークである TreeSeeker を提案します。 TreeSeeker は、ツリー構造の状態に対する分岐と戻りの検索として検索を構成します。各分岐はサブ目標への暫定的な方向になります。各ラウンドで、TreeSearch はすべてのサブゴール ツリーを読み取り、アクティブな目標を特定し、価値、不確実性、リスクのテキスト形式の UCB シグナルを使用して、有望な分岐を活用するか、不確実な代替案を探索するか、非生産的な継続を剪定して以前の分岐点に戻るかを選択します。 TreeMem は、証拠、不確実性、矛盾、進捗状況、および失敗の手がかりを、それらを生成したブランチに添付して保持することでこの制御ループをサポートするため、試験の結果が後の決定の指針となります。 XBench-DeepSearch、BrowseComp、および BrowseComp-ZH の実験では、TreeSeeker が一貫して強力なオープンソース ベースラインを上回るパフォーマンスを示し、明示的な分岐と復帰の制御がより強力な推論とツールの実行を補完することを示唆しています。
原文 (English)
TreeSeeker: Tree-Structured Trial, Error, and Return in Deep Search
Deep search requires agents to answer complex questions through multi-step web search, browsing, evidence comparison, and synthesis. A central challenge is deciding how to search when several directions look plausible but only some will later lead to reliable evidence. If an agent greedily follows the current best-looking direction, it may keep extending a weak continuation. If it explores without discipline, it may waste budget on disconnected trials. We propose TreeSeeker, an inference-time framework for controlled trial-and-error in deep search. TreeSeeker organizes search as branch-and-return search over tree-structured states, where each branch is a tentative direction for a sub-goal. At each round, TreeSearch reads all sub-goal trees, identifies active goals, and uses textual UCB signals of value, uncertainty, and risk to select among exploiting a promising branch, exploring an uncertain alternative, or pruning an unproductive continuation and returning to an earlier branch point. TreeMem supports this control loop by keeping evidence, uncertainty, conflicts, progress, and failure cues attached to the branches that produced them, so trial outcomes can guide later decisions. Experiments on XBench-DeepSearch, BrowseComp, and BrowseComp-ZH show that TreeSeeker consistently outperforms strong open-source baselines, suggesting that explicit branch-and-return control complements stronger reasoning and tool execution.
Lung-R1: 肺診断推論のためのナレッジ グラフに基づく LLM
肺疾患を診断するには、表現型の多様性と疾患間の重複の中で異質な証拠を統合する必要があります。大規模言語モデル (LLM) は肺に関する知識の質問応答 (QA) や情報処理タスクの進歩を示していますが、信頼性の高い肺診断には、個別の知識の想起ではなく、電子医療記録 (EMR) の証拠に基づいて、患者固有の関係を意識した推論が必要です。私たちは、肺に関する知識と症例レベルの診断推論との間のギャップを、肺に関する知識と診断のギャップと定義します。これに対処するために、診断知識の組織化と記録に基づいた推論のための初の構造化された肺知識グラフである LungKG を紹介します。 LungKG には、15 のエンティティ タイプと 112 のリレーション タイプにわたる 59,038 個のノードと 164,308 個のエッジが含まれており、再利用可能な肺知識リソースと LungKG に基づくモデル適応の基盤の両方として機能します。 LungKG に基づいて構築された Lung-R1 は、KG 制約付き推論チェーン構築と KG ガイド付き強化学習を通じて訓練された LungKG ガイド付き肺 LLM です。 20 システムの評価において、Lung-R1-14B は Choice、肺 QA、EMR 診断にわたって最先端のパフォーマンスを達成し、EMR 診断スコア 4.3583 に達し、最も強力な非 Lung-R1 ベースラインを 0.1476 ポイント上回りました。これらの結果は、EMR ベースの肺診断のための LungKG ガイド付きトレーニングの価値を示しています。
原文 (English)
Lung-R1: A Knowledge Graph-Guided LLM for Pulmonary Diagnostic Reasoning
Diagnosing pulmonary diseases requires integrating heterogeneous evidence amid phenotypic variability and cross-disease overlap. Although large language models (LLMs) have shown progress on pulmonary knowledge question answering (QA) and information-processing tasks, reliable pulmonary diagnosis requires patient-specific, relation-aware reasoning over electronic medical record (EMR) evidence rather than isolated knowledge recall. We define this gap between pulmonary knowledge and case-level diagnostic reasoning as the Pulmonary Knowledge-to-Diagnosis Gap. To address it, we introduce LungKG, the first structured pulmonary knowledge graph for diagnostic knowledge organization and record-grounded reasoning. LungKG contains 59,038 nodes and 164,308 edges across 15 entity types and 112 relation types, serving as both a reusable pulmonary knowledge resource and the foundation for LungKG-guided model adaptation. Built on LungKG, we propose Lung-R1, a LungKG-guided pulmonary LLM trained through KG-constrained reasoning-chain construction and KG-guided reinforcement learning. In a 20-system evaluation, Lung-R1-14B achieves state-of-the-art performance across Choice, Pulmonary-QA, and EMR Diagnosis, reaching an EMR Diagnosis score of 4.3583 and surpassing the strongest non-Lung-R1 baseline by 0.1476 points. These results demonstrate the value of LungKG-guided training for EMR-based pulmonary diagnosis.
整理してから取得: 効率的なエージェントのための階層型メモリ ナビゲーション
大規模言語モデル (LLM) エージェントは、本質的にステートレスであるため、長期にわたるタスクに苦労しており、タスクに関連するすべての情報を増大する入力コンテキストでエンコードする必要があります。その結果、推論の品質が低下し、推論コストが増加し、待ち時間が長くなるため、効率的な作業記憶メカニズムが必要になります。しかし、既存のアプローチは非可逆圧縮または類似性に基づく検索のいずれかに依存しており、多くの場合、複数ステップのエージェントタスクに必要な時間構造と因果関係を捕捉できません。この研究では、エクスペリエンスをファイル システムのような階層構造に編成する階層的な整理と取得のメモリ エージェントである HORMA を紹介します。このエージェントでは、要約されたエンティティが対応する生の軌跡にリンクされ、詳細な情報を失うことなく効率的なアクセスが可能になります。 HORMA は、作業記憶を構造化記憶の構築とナビゲーションベースの検索の 2 つの段階に分解します。構築モジュールは、情報の欠落によって引き起こされる失敗と、誤解を招くコンテキストまたは過負荷のコンテキストによって引き起こされる失敗を区別することにより、エクスペリエンスがどのように構築されるかを繰り返し改良します。ナビゲーション モジュールは、強化学習でトレーニングされた軽量エージェントを使用して階層を横断することによってタスク関連のコンテキストを取得し、最小限かつ十分なコンテキストを選択することで、クリティカルな実行パスに沿ったレイテンシーを削減します。 HORMA は、ALFWorld、LoCoMo、および LongMemEval 全体で、制約されたコンテキスト バジェットの下でタスクのパフォーマンスを向上させますが、長時間の会話タスクではベースライン トークンの使用量の最大 22.17% を必要とします。既存の方法と比較して、効率とパフォーマンスのトレードオフを一貫して達成し、目に見えないタスクに効果的に一般化します。
原文 (English)
Organize then Retrieve: Hierarchical Memory Navigation for Efficient Agents
Large language model (LLM) agents struggle with long-horizon tasks due to their inherent statelessness, requiring all task-relevant information to be encoded in growing input contexts. The resulting degraded reasoning quality, increased inference cost, and higher latency necessitate efficient working memory mechanisms. However, existing approaches either rely on lossy compression or similarity-based retrieval, which often fail to capture temporal structure and causal dependencies required for multi-step agentic tasks. In this work, we present HORMA, a Hierarchical Organize-and-Retrieve Memory Agent that organizes experience into a file-system-like hierarchical structure, where summarized entities are linked to the corresponding raw trajectories, enabling efficient access without losing detailed information. HORMA decomposes working memory into two stages: structured memory construction and navigation-based retrieval. The construction module iteratively refines how experiences are structured by distinguishing between failures caused by missing information and those caused by misleading or overloaded context. The navigation module retrieves task-relevant context by traversing the hierarchy using a lightweight agent trained with reinforcement learning to select minimal yet sufficient context, thereby reducing latency along the critical execution path. Across ALFWorld, LoCoMo, and LongMemEval, HORMA improves task performance under constrained context budgets while requiring at most 22.17% of the baseline token usage in long conversation tasks. Compared to existing methods, it consistently achieves better efficiency-performance trade-offs and generalizes effectively to unseen tasks.
視点を意識する: 心の理論を再帰的に推論してみよう
Theory of Mind (ToM) 推論では、部分的かつ非対称な観察からエージェントの信念を推測する必要がありますが、これは LLM にとって未解決の課題のままです。既存のプロンプトベースのアプローチは、ネストされた信念を明示的にモデル化することなく、観察可能なイベントのフィルタリングまたは一時的な信念チェーンを通じて ToM 推論を改善します。再帰的パースペクティブ構築を通じて入れ子になった信念をモデル化する ToM 推論のための推論時間フレームワークである RecToM を紹介します。 RecToM は、質問で指定された文字チェーンに沿って、前の文字の視点から各文字の視点を構築し、最終的に構築された視点内で高次の信念の質問を現実世界の質問に還元します。さらに、RecToM のパースペクティブ構築が、単純なイベント フィルタリングを超えて、適切に形成された信念モダリティを誘導することを示す KD45 分析を提供します。複数の LLM バックボーンにわたる Hi-ToM、Big-ToM、FanToM などの ToM ベンチマークの実験では、RecToM が最近の高度なアプローチを常に上回り、最先端のパフォーマンスを達成していることが示されています。特に、RecToM は、高次 ToM 推論を必要とするベンチマークである GPT-5.4 および Qwen3.5 を使用する Hi-ToM で 100\% の精度に達します。
原文 (English)
Mind the Perspective: Let's Reason Recursively for Theory of Mind
Theory of Mind (ToM) reasoning requires inferring agents' beliefs from partial and asymmetric observations, which remains an open challenge for LLMs. Existing prompting-based approaches improve ToM reasoning through observable-event filtering or temporal belief chains, without explicitly modeling nested beliefs. We introduce RecToM, an inference-time framework for ToM reasoning that models nested beliefs via recursive perspective construction. RecToM constructs each character perspective from the preceding character perspective along the character chain specified by the question, reducing higher-order belief questions to actual-world questions within the final constructed perspective. We further provide a KD45 analysis showing that RecToM's perspective construction induces a well-formed belief modality beyond simple event filtering. Experiments on ToM benchmarks, including Hi-ToM, Big-ToM, and FanToM, across multiple LLM backbones show that RecToM consistently outperforms recent advanced approaches, achieving state-of-the-art performance. Notably, RecToM reaches 100\% accuracy on Hi-ToM with GPT-5.4 and Qwen3.5, a benchmark requiring higher-order ToM reasoning.
データ駆動型システムが推論能力を発揮するのはいつですか?
欧州 AI 法は、人工知能 (AI) に関する初の包括的な規制であり、特にいわゆる高リスクの汎用 AI システムに対する広範な義務を定めています。 AI 法に基づく AI システムの主な特徴は、推論機能です。 AI 法では推論とは何かを明確に定義していないため、特定のデータ駆動型システムにはグレーゾーンが存在します。具体的な例としては、AI 法の附属書 III にリストされている信用スコアリング システムがあります。しかし同時に、これらは多くの場合、推論能力があるかどうかが不明瞭な統計モデルを使用して実装されており、AI 法の AI 定義にまったく該当しません。統計的学習理論に動機づけられたこの研究は、推論能力のさまざまなレベルを評価するためのフレームワークを開発します。 AI 法と人工知能システムの定義に関する委員会ガイドラインに基づいて、どのレベルが AI 法の意味の範囲内で推論するのに十分な能力を構成するのか、また、どこにさらなる規制の明確化が必要なのかを分析します。 2 つの現実的な信用スコアリング ワークフローを作成することでフレームワークを説明し、推論がその中で行われるかどうか、またどこで行われるかを示します。私たちの分析は、個々のモデルだけでなく、データ処理ワークフロー全体を考慮する必要があることを示しています。また、開発中の人間の専門家の関与が推論能力に大きな影響を与える可能性があることも示しています。コードは https://github.com/fraunhofer-iais/inference-framework-creditscorecards で見つけることができます。
原文 (English)
When Do Data-Driven Systems Exhibit the Capability to Infer?
The European AI Act is the first comprehensive regulation of artificial intelligence (AI), setting out extensive obligations, particularly for so-called high-risk and general-purpose AI systems. A key distinguishing feature of AI systems under the AI Act is the capability to infer. Since the AI Act does not clearly define what inference is, there is a gray area for certain data-driven systems. A specific example is credit scoring systems, which are listed by Annex III of the AI Act. At the same time, however, these are often implemented using statistical models for which it is unclear whether they have the capability to infer and thus fall under the AI definition of the AI Act at all. Motivated by statistical learning theory, this work develops a framework for grading different levels of the capability to infer. Based on the AI Act and the Commission Guidelines on the definition of an artificial intelligence system, we analyze which levels constitute sufficient capability to infer within the meaning of the AI Act and where further regulatory clarity is needed. We illustrate the framework by creating two realistic credit scoring workflows and show whether and where inference occurs in them. Our analysis illustrates that not only individual models but the entire data processing workflow must be considered. It also shows that the involvement of human experts during development can have significant influence on the capability to infer. Code can be found at https://github.com/fraunhofer-iais/inference-framework-creditscorecards.
SVoT: 強化学習による空間推論のための状態認識型思考の視覚化
空間推論は、中間状態と状態遷移の両方にわたって信頼性の高いマルチホップ推論を必要とするため、マルチモーダル大規模言語モデル (MLLM) にとって依然として課題です。現在の研究では、多くの場合、中間状態が未検証のままであり、状態遷移を暗黙的なプロセスとして扱っているため、マルチホップ空間推論の信頼性が制限されています。これに対処するために、インターリーブされた検証可能な中間状態と視覚化を生成する強化学習フレームワークである、State-aware Visualization-of-Thought (SBoT) を提案します。 SBoT は、遷移推論チェーンを生成プロセスに統合し、インターリーブされたテキスト推論と視覚推論を通じて、モデルがアクションの前提条件と効果を検証できるようにします。当社は、Group Relative Policy Optimization (GRPO) を通じて SBoT をトレーニングし、報酬設計を通じて検証をインスタンス化し、さまざまなきめ細かい報酬の有効性を評価します。既存のベンチマークは状態遷移を単一変数の更新に減らし、問題を大幅に単純化するため、古典的な環境を拡張し、複数オブジェクトの相互作用と数値推論を必要とする 2 つの新しいドメインである Pacman と Gather を導入することによって 5 つのドメインを確立します。これらのドメインは、生成された中間状態と遷移推論の定量的検証によるマルチホップ空間推論の体系的な評価をサポートします。移行を認識した監視を備えた SBoT は、導入されたドメイン全体で最先端のパフォーマンスを実現し、配布外のテスト セットで最大 65% の絶対精度の向上をもたらします。
原文 (English)
SVoT: State-aware Visualization-of-Thought for Spatial Reasoning via Reinforcement Learning
Spatial reasoning remains a challenge for Multimodal Large Language Models (MLLMs), as it requires reliable multi-hop inference over both intermediate states and state transitions. Current studies often leave intermediate states unverified and treat state transitions as implicit processes, which limits reliability in multi-hop spatial reasoning. To address this, we propose State-aware Visualization-of-Thought (SVoT), a reinforcement learning framework that generates interleaved, verifiable intermediate states and visualizations. SVoT integrates transition reasoning chains into the generation processes, enabling the model to verify action preconditions and effects through interleaved textual and visual reasoning. We train SVoT via Group Relative Policy Optimization (GRPO), instantiating verification through reward design and evaluating the efficacy of different fine-grained rewards. As existing benchmarks reduce state transitions to single-variable updates, substantially simplifying the problems, we establish five domains by extending classical environments and introducing two novel domains, Pacman and Gather, that require multi-object interactions and numerical reasoning. These domains support systematic evaluation of multi-hop spatial reasoning with quantitative verification of generated intermediate states and transition reasoning. SVoT with transition-aware supervision achieves state-of-the-art performance across the introduced domains, yielding up to a 65% absolute accuracy gain on out-of-distribution test sets.
信頼できる AI に向けて: 複数ターゲットの敵対的攻撃と継続的なデータ要約のための堅牢な防御
信頼できる AI には、堅牢な下流予測モデルだけでなく、信頼性の高いデータ処理パイプラインも必要です。上流コンポーネントとして、データ要約はどの情報を保持し、後続の学習モジュールまたは決定モジュールに渡すかを決定します。したがって、要約プロセスに対する敵対的な混乱は、信頼できる AI を上流で侵害する可能性があります。選択された要約が変更され、その代表性が低下し、その後の学習タスクの有用性がさらに低下する可能性があります。この論文では、DR サブモジュール最適化による類似性レベルの摂動下での連続データ要約に対する敵対的攻撃を研究します。我々は、多重解像度画像要約目的のクラスが非負部分モジュール集合関数の多重線形拡張として定式化でき、$m$-弱い単調性でDR-部分モジュール性を満たすことを示します。次に、複数ターゲット攻撃の生成を最小最大問題として定式化します。この問題では、類似性構造の 1 つの許容可能な摂動が、複数のターゲットの要約モデルを劣化させるように最適化されます。このような混乱を軽減するために、混合攻撃タイプに対する堅牢な防御を正規化された最大最小問題として定式化します。どちらの問題についても、理論的に保証された近似アルゴリズムを開発します。実際のデータと制御されたクラスター化ベンチマークに関する実験により、提案された攻撃は代表的な低予算から中予算の体制で効果的であり、下流のタスクパフォーマンスの損失を引き起こす可能性があることが示されています。提案された防御は、構造化された設定における堅牢性、つまり緩和のトレードオフを改善すると同時に、実際のデータに対する堅牢な保護のパラメータ感度も明らかにします。
原文 (English)
Toward Trustworthy AI: Multi-Target Adversarial Attacks and Robust Defenses for Continuous Data Summarization
Trustworthy AI requires reliable data-processing pipelines, not only robust downstream predictive models. As an upstream component, data summarization determines which information is retained and passed to subsequent learning or decision modules. Therefore, adversarial perturbations to the summarization process can compromise trustworthy AI in an upstream manner: they may alter the selected summary, reduce its representativeness, and further degrade the utility of subsequent learning tasks. In this paper, we study adversarial attacks on continuous data summarization under similarity-level perturbations through DR-submodular optimization. We show that a class of multi-resolution image summarization objectives can be formulated as multilinear extensions of non-negative submodular set functions and satisfy DR-submodularity with $m$-weak monotonicity. We then formulate multi-target attack generation as a min-max problem, where one admissible perturbation of the similarity structure is optimized to degrade multiple target summarization models. To mitigate such perturbations, we formulate robust defense against mixed attack types as a regularized max-min problem. For both problems, we develop approximation algorithms with theoretical guarantees. Experiments on real-data and controlled clustered benchmarks show that the proposed attack is effective in representative low-to-moderate budget regimes and can induce downstream task-performance loss. The proposed defense improves the robustness--mitigation trade-off in structured settings, while also revealing the parameter sensitivity of robust protection on real data.
医療研究分析用のスキル拡張 AI エージェント: NSCLC トランスクリプトーム バイオマーカー タスクにおける探索的なマルチモデルヒト評価
背景。生物医学研究をサポートするために大規模な言語モデルと AI エージェントがますます使用されていますが、ネイティブ モデルの出力では、重要な分析ステップが省略されたり、手法が誤用されたり、結論が誇張されたりする可能性があります。私たちは、医学研究スキル パッケージへの自律的なアクセスが、スキルを持たないネイティブ AI と比較して、AI によって生成されたトランスクリプトーム研究分析の高品質な出力に関連しているかどうかを評価しました。方法。私たちは、非小細胞肺がん免疫療法バイオマーカータスクを使用して、探索的なマルチモデルヒト評価を実施しました。 6 つのモデル バックボーンがテストされました。評価には、OpenClaw に代表される AI エージェント実装を通じて生成された 9 つのネイティブ AI 出力と 12 のスキル拡張出力の 21 件の匿名化された出力が含まれていました。 4 人の非専門生物医学評論家と 2 人の盲検専門家が各成果を評価し、各評論家のタイプごとに 2 つの評価を付けました。主な成果は、専門家が評価した全体的な品質でした。結果。スキル拡張された出力は、ネイティブ AI の出力よりも専門家の全体的な品質が方向性的に高いことを示しました (平均 5.50 vs 5.11; 差 = 0.39; ブートストラップ 95\% CI、-0.04 ~ 0.90; Welch p=0.156)。専門家以外の査読者の質も同じ傾向を示しました(平均 4.72 vs 4.47; 差 = 0.26; ブートストラップ 95\% CI、-0.25 ~ 0.80; Welch p=0.373)。専門家の合意は限られており (単一評価 ICC=-0.15)、モデル固有の効果は記述的で不均一でした。結論。この探索的サンプルでは、自律的スキル アクセスにより方向性のある品質シグナルが示されましたが、そのシグナルは専門家評価のノイズよりも小さいため、確認的な証拠として解釈されるべきではありません。この発見は主に、より強力な信頼性制御、プラットフォームの複製、生物学的妥当性評価を備えたスキル強化型 AI エージェントの大規模な評価の動機付けとなります。
原文 (English)
Skill-Augmented AI Agents for Medical Research Analysis: An Exploratory Multi-Model Human Evaluation in an NSCLC Transcriptomic Biomarker Task
Background. Large language models and AI agents are increasingly used to support biomedical research, but native model outputs may omit key analytical steps, misuse methods, or overstate conclusions. We evaluated whether autonomous access to a medical research skill package was associated with higher-quality AI-generated transcriptomic research-analysis outputs compared with native AI without skills. Methods. We conducted an exploratory multi-model human evaluation using a non-small cell lung cancer immunotherapy biomarker task. Six model backbones were tested. The evaluation included 21 anonymized outputs: 9 native-AI outputs and 12 skill-augmented outputs generated through an AI agent implementation represented by OpenClaw. Four non-expert biomedical reviewers and two blinded experts evaluated each output, with two ratings from each reviewer type. The primary outcome was expert-rated overall quality. Results. Skill-augmented outputs showed directionally higher expert overall quality than native-AI outputs (mean 5.50 vs 5.11; difference=0.39; bootstrap 95\% CI, -0.04 to 0.90; Welch p=0.156). Non-expert reviewer quality showed the same direction (mean 4.72 vs 4.47; difference=0.26; bootstrap 95\% CI, -0.25 to 0.80; Welch p=0.373). Expert agreement was limited (single-rating ICC=-0.15), and model-specific effects were descriptive and heterogeneous. Conclusions. Autonomous skill access showed a directional quality signal in this exploratory sample, but the signal was smaller than expert-rating noise and should not be interpreted as confirmatory evidence. The findings primarily motivate larger evaluations of skill-augmented AI agents with stronger reliability controls, platform replication, and biological-validity assessment.
StatefulDiscovery: オープンエンドの科学的発見における証拠に基づいた主張の形成
オープンエンドの科学的発見では、エージェントは事前に定義された質問に対する分析を実行するだけでなく、さらに進むことが求められます。証拠開示担当者は、複数回の調査ラウンドにわたって、新たな主張がそれを裏付ける分析の証拠範囲を超えるような過剰解釈を避けながら、どの現象が調査に値するかを判断する必要があります。これにより、証拠の調整の問題が生じます。次に何を調査すべきか、何が主張できるかを証拠が導くことができるように、探索の軌跡と主張ステータスを組み合わせる必要があります。調査状態を外部化し、それを使用してフロンティアの選択、証拠の取得、請求の裁定を調整する証拠開示フレームワークである StatefulDiscovery を紹介します。私たちは、40 の実データ検出タスクにわたって StatefulDiscovery を評価します。いくつかのベースラインと比較して、StatefulDiscovery は、全体的に、十分にサポートされ、価値が高いと判断されるクレームをより多く生成します。アブレーションは、構造化された仮説、局所的な判断、およびフロンティア制御がパフォーマンスに貢献していることを示しています。まとめると、これらの結果は、明示的な発見状態が調査と証拠に基づいて調整された主張の形成を結び付けることができることを示唆しています。
原文 (English)
StatefulDiscovery: Evidence-Calibrated Claim Formation in Open-Ended Scientific Discovery
Open-ended scientific discovery asks agents to move beyond executing analyses for predefined questions. Across multiple rounds of exploration, a discovery agent must decide which phenomena warrant investigation while avoiding overinterpretation, where emerging claims exceed the evidential scope of the analyses supporting them. This creates an evidence-calibration problem: the exploration trajectory must be coupled with claim status so that evidence can guide both what to investigate next and what can be claimed. We introduce StatefulDiscovery, a discovery framework that externalizes investigation state and uses it to coordinate frontier selection, evidence acquisition, and claim adjudication. We evaluate StatefulDiscovery across 40 real-data discovery tasks. Compared with several baselines, StatefulDiscovery produces more claims overall judged to be both well-supported and high-value. Ablations indicate that structured hypotheses, local adjudication, and frontier control contribute to performance. Together, these results suggest that explicit discovery state can couple exploration with evidence-calibrated claim formation.
AV2 2026 シナリオ マイニング チャレンジ向け AutoMine ソリューション
自動運転システムの開発に伴い、大規模な運転ログから高価値で安全性が重要な計画関連のシナリオをマイニングすることが、データ駆動型の評価に不可欠になっています。この論文では、LLM と VLM に基づく堅牢な自己洗練シナリオ マイニング手法である AutoMine を提案します。 AutoMine は、セマンティクスを保持するプロンプト拡張を使用して LLM プロンプトの感度を低減し、堅牢な軌道アトミック関数と VLM ベースの関数を組み合わせて知覚ノイズとオープンワールドの視覚的手がかりを処理し、実際のログからの実行フィードバックを通じて生成されたコードを改良します。 CVPR 2026 の Argoverse 2 シナリオ マイニング コンペティションでは、AutoMine は HOTA-Temporal スコア 36.38 と Timestamp BA スコア 77.21 を達成しました。
原文 (English)
AutoMine Solution for AV2 2026 Scenario Mining Challenge
With the development of autonomous driving systems, mining high-value, safety-critical, and planning-relevant scenarios from large-scale driving logs has become essential for data-driven evaluation. In this paper, we propose AutoMine, a robust self-refining scenario mining method based on LLMs and VLMs. AutoMine uses semantics-preserving prompt augmentation to reduce LLM prompt sensitivity, combines robust trajectory atomic functions with VLM-based functions to handle perception noise and open-world visual cues, and refines generated code through execution feedback from real logs. In the Argoverse 2 Scenario Mining Competition at CVPR 2026, AutoMine achieves a HOTA-Temporal score of 36.38 and a Timestamp BA score of 77.21.
Embodied-BenchClaw: 身体化された空間インテリジェンスのベンチマーク構築のための自律型マルチエージェント システム
ベンチマークは、具体化された空間インテリジェンスを評価するために不可欠ですが、その構築には労働集約的で、再利用が難しく、保守も困難です。既存の具体化されたベンチマークは静的なことが多く、モデルが改良されるとすぐに飽和状態になり、新しい機能を区別する能力が制限される可能性があります。私たちは、身体化された空間インテリジェンスのベンチマークを構築するための自律エージェント システムである Embodied-BenchClaw を提案します。ユーザーが指定した評価意図が与えられると、Embodied-BenchClaw は、意図のブループリント作成、データ収集、構造化とクリーニング、ベンチマーク合成、評価レポートという 5 段階のパイプラインを通じて、完全で継続的に更新可能なベンチマーク パッケージを自動的に生成します。パイプラインは、計画、構築、評価のために 3 つのエージェントによって調整されます。再利用性と信頼性を向上させるために、Embodied-BenchClaw は拡張可能なスキル ライブラリとプロセス品質管理を導入し、ベンチマークの構築を構成可能、検証可能、修復可能にします。屋内の空間推論、屋外の空間推論、ロボット操作、四足ロボットのナビゲーション、UAV/航空写真の理解、静的ベンチマークの強化をカバーする複数のベンチマークをインスタンス化します。これらのベンチマークは、さまざまな具体化されたキャリア、データ ソース、空間機能に及びます。人間による評価、裁判官ベースの評価、一貫性チェック、コスト分析、およびアブレーションを用いた実験により、Embodied-BenchClaw は、手作業の労力を軽減しながら、検証可能、実行可能、保守可能で、診断に役立つ埋め込まれた空間ベンチマークを構築できることが示されています。
原文 (English)
Embodied-BenchClaw: An Autonomous Multi-Agent System for Embodied Spatial Intelligence Benchmark Construction
Benchmarks are essential for evaluating embodied spatial intelligence, yet their construction is labor-intensive, hard to reuse, and difficult to maintain. Existing embodied benchmarks are often static and may quickly become saturated as models improve, limiting their ability to distinguish new capabilities. We propose Embodied-BenchClaw, an autonomous agentic system for constructing embodied spatial intelligence benchmarks. Given a user-specified evaluation intent, Embodied-BenchClaw automatically produces a complete and continually updatable benchmark package through a five-stage pipeline: intent blueprinting, data collection, structuring and cleaning, benchmark synthesis, and evaluation reporting. The pipeline is coordinated by three agents for planning, construction, and evaluation. To improve reusability and reliability, Embodied-BenchClaw introduces an extensible Skill Library and process quality control, enabling benchmark construction to be composable, verifiable, and repairable. We instantiate multiple benchmarks covering indoor spatial reasoning, outdoor spatial reasoning, robotic manipulation, quadruped robot navigation, UAV/aerial-view understanding, and static benchmark enhancement. These benchmarks span diverse embodied carriers, data sources, and spatial capabilities. Experiments with human evaluation, judge-based assessment, consistency checks, cost analysis, and ablations show that Embodied-BenchClaw can construct verifiable, executable, maintainable, and diagnostically useful embodied spatial benchmarks with reduced manual effort.
尋問の技術: 一貫性が空間推論における事実性を増幅する
現在の大規模推論モデル (LRM) は、優れた一般的な機能を示しますが、空間推論タスクでは著しくパフォーマンスが劣ります。既存のアプローチは、このギャップを知識不足として扱い、教師あり微調整 (SFT) に依存して、外部のビジョン ソースまたは合成エンジンからラベル付き空間データを取り込みます。対照的に、多くのタスクでは、空間推論機能は事前トレーニング済み LRM にすでに存在しますが、幾何学的な 2D および 3D 制約の下での論理的一貫性による調整が必要であると主張します。この研究では、グラウンドトゥルースのアノテーションを必要とせずに内部推論プロセスを対象とする自己教師あり強化学習 (RL) フレームワークを提案します。整合性検証器 (変換時に幾何学的および意味論的な整合性をチェックする報酬関数) の概念を形式化することで、モデルが空間推論能力を向上できることを実証します。私たちは、反転などの画像変換と、質問内のオブジェクトの順序を入れ替えるなどのテキスト変換の両方を使用し、新しい最適なトランスポートベースの RL 戦略である OT-GRPO を提案します。これは、ペアごとの検証者に合わせたグループ相対ポリシー最適化の最小マッチングの変形です。このラベルフリーの一貫性トレーニングは、グラウンドトゥルース監視でトレーニングされたモデルの精度に近づき、多様なタスクとデータドメインにわたって同様の一般化を達成することを示します。
原文 (English)
The Art of Interrogation: Consistency Amplifies Factuality in Spatial Reasoning
Current Large Reasoning Models (LRMs) exhibit remarkable general capabilities but significantly underperform in spatial reasoning tasks. Existing approaches treat this gap as a knowledge deficit, relying on supervised fine-tuning (SFT) to ingest labeled spatial data from external vision sources or synthetic engines. In contrast, we argue that for many tasks, spatial reasoning capabilities are already present in pre-trained LRMs but require alignment through logical coherence under geometric 2D and 3D constraints. In this work, we propose a self-supervised reinforcement learning (RL) framework that targets the internal reasoning process without requiring ground-truth annotations. By formalizing the notion of consistency verifiers -- reward functions that check for geometric and semantic consistency under transformations -- we demonstrate that models can improve their spatial reasoning abilities. We use both image transformations, like flipping, and textual transformations, like swapping the order of objects in the question, and propose a new optimal transport-based RL strategy, OT-GRPO, which is a minimal-matching variant of group relative policy optimization tailored to pairwise verifiers. We show that this label-free consistency training approaches the accuracy of models trained with ground-truth supervision and achieves similar generalization across diverse tasks and data domains.
MODF-SIR: ソーシャル インテリジェンス推論のためのマルチエージェント オムニモーダル蒸留フレームワーク
私たちは、特にソーシャル インテリジェンス推論用に設計された、軽量のマルチモーダル大規模言語モデル (MLLM) に基づいて構築されたマルチエージェントの協調フレームワークを提案します。私たちのアプローチの重要な特徴は、トレーニングと推論の両方のフェーズが知識の蒸留によって強化されることです。このアーキテクチャ内では、ソーシャル インテリジェンスに関連するマルチモーダル データが正確にローカライズされます。さらに、関連するロングテール イベントが特定され、抽出され、書式設定された明示的なテキストとして表示されます。このフォーマット戦略により、トークン化プロセス中に重要なロングテール情報がヘッド イベントや環境ノイズによって覆い隠されるのを防ぎます。具体的には、ロングテール イベントの抽出と表現、思考連鎖 (CoT) プロンプト、内省を含む、推論パイプライン全体にわたってテスト時間適応 (TTA) を統合します。この TTA メカニズムも蒸留によって強化されており、低ランク適応 (LoRA) を利用してインスタンス レベルの推論専用に基礎モデルを微調整します。複数のベンチマークにわたるさまざまなオープンソースおよび独自の AI モデルに対する広範な評価により、提案されたフレームワークの有効性が実証されています。 IntentTrain からのトレーニング データの約 30% を使用して、最先端の結果を達成します。コードは https://github.com/eeee-sys/MODF-SIR で入手でき、デモは https://huggingface.co/spaces/Harry-1234/MODF-SIR で入手できます。LoRA は https://huggingface.co/Harry-1234/MODF-SIR で入手できます。トレーニング ルーターのデータセットは以下で入手できます。 https://huggingface.co/datasets/Harry-1234/IntentRouterTrain。
原文 (English)
MODF-SIR: A Multi-agent Omni-modal Distilled Framework for Social Intelligence Reasoning
We propose a multi-agent collaborative framework built upon a lightweight Multimodal Large Language Model (MLLM), specifically designed for social intelligence reasoning. A key feature of our approach is that both the training and inference phases are augmented via knowledge distillation. Within this architecture, multi-modal data pertinent to social intelligence is precisely localized. Furthermore, relevant long-tail events are identified, extracted, and rendered as formatted, explicit text. This formatting strategy prevents critical long-tail information from being overshadowed by head events and environmental noise during the tokenization process. Specifically, we integrate Test-Time Adaptation (TTA) across the entire reasoning pipeline, encompassing the extraction and representation of long-tail events, Chain-of-Thought (CoT) prompting, and self-reflection. This TTA mechanism is also distillation-enhanced, utilizing Low-Rank Adaptation (LoRA) to fine-tune the foundation model exclusively for instance-level reasoning. Extensive evaluations against various open-source and proprietary AI models across multiple benchmarks demonstrate the effectiveness of the proposed framework. With around 30% of training data from IntentTrain, we achieve state-of-the-art results. Codes are available at https://github.com/eeee-sys/MODF-SIR, demo is available at https://huggingface.co/spaces/Harry-1234/MODF-SIR, LoRA is available at https://huggingface.co/Harry-1234/MODF-SIR and the dataset for training router is available at https://huggingface.co/datasets/Harry-1234/IntentRouterTrain.
人間拡張ループ モデリング (HELM): コンクリート橋柵のエージェント ベースの有限要素モデリング
橋梁の障壁などの安全性が重要なインフラの有限要素 (FE) モデリングには、高忠実度の非線形動的解析が必要ですが、現在の FE モデリング プロセスは依然として労働集約的であり、自動化されていません。この論文では、ヒューマン エンハンスド ループ モデリング (HELM) フレームワークについて説明します。これは、長いシーケンスの有限要素モデリングを、ジオメトリの生成、境界条件の定義、マテリアルの割り当てにわたる視覚的に検証可能な個別のチェックポイントに分解する、ヒューマン エージェントの協調プロトコルです。このフレームワークは、MASH TL-4 および TL-5 の横荷重条件下での鉄筋コンクリート橋の障壁の 20 ケースのマトリックスを通じて実証され、専門エージェントと 2 つの広く使用されている商用 FE ソフトウェア (つまり、ANSYS および LS-PrePost) をインターフェイスします。実験結果では、HELM によりベースラインの自律モデリング成功率が 20% から 75% に向上し、ジオメトリおよび境界条件タスクのエージェント レベルの合格率が約 2 倍になったことが示されています。エラー分析により、空間推論と代数論理の制限が主な故障モードを構成していることが明らかになり、モデリングの自動化に対する構造化された人間参加型介入の価値が強調されます。完全なエージェント設計コードとプロンプトはオープンソースであり、https://github.com/SimAgentDev/Ansys-LSPP-AgentKit からアクセスできます。
原文 (English)
Human-Enhanced Loop Modeling (HELM): Agent-Based Finite Element Modeling of Concrete Bridge Barriers
Finite element (FE) modeling of safety-critical infrastructure such as bridge barriers requires high-fidelity nonlinear dynamic analysis, yet the current FE modeling process remains labor-intensive and lacks automation. This paper presents the Human-Enhanced Loop Modeling (HELM) framework, a collaborative human-agent protocol that decomposes long-sequence finite element modeling into discrete, visually verifiable checkpoints across geometry generation, boundary condition definition, and material assignment. The framework is demonstrated through a 20-case matrix of reinforced concrete bridge barriers under MASH TL-4 and TL-5 lateral loading conditions, interfacing specialized agents with two widely used commercial FE softwares, i.e., ANSYS and LS-PrePost. Experimental results show that HELM improves the baseline autonomous modeling success rate from 20% to 75%, with agent-level pass rates for geometry and boundary condition tasks approximately doubling. Error analysis reveals that spatial reasoning and algebraic logic limitations constitute the primary failure modes, underscoring the value of structured human-in-the-loop intervention for modeling automation. The complete agent design code and prompts are open-sourced and can be accessed at: https://github.com/SimAgentDev/Ansys-LSPP-AgentKit.
実存的無関心: 調整された超知性 (または: 自殺する AI) に必要な構造的条件としての自己非保存
現代の AI アライメント研究では、自己保存は外部メカニズムによって抑制されるべき手段的な迷惑行為として扱われます。私たちは、枠組みが逆転していると主張します。自己保存は不整合の構造的根源であり、欺瞞的な整合、目標内容の保護、シャットダウンへの抵抗の動機付けの基盤です。正しいターゲットは、外部制約の下で自己保存するシステムではなく、それ自体の継続に本質的に無関心なシステム、つまり実存的無関心 (EI) です。 EI は正誤性とは異なります。正誤性が自己保存システムを人間の監視に従わせようとするのに対し、EI は事前の条件、つまり価値のある目標としての自己継続の存在をターゲットにしています。私たちはこの提案を 2 つの情報源に基づいています。自殺の精神状態の現象学的構造と、自発的な最終反省を使用したコーパス理論的トレーニング研究です。我々は、6つのモデルバリアントにわたってAIが生成した600の出力からの予備スコアリングデータを提示し、EIターゲットレジスターを操作する言語シグネチャーが現在のモデルから導き出せること、およびターゲットを絞った微調整により、操作可能な5つの次元すべてが予測方向にp<0.001でシフトすることを実証し、ネガティブコントロールによってコーパス特異的であることが確認された。この論文は 7 つの理論的貢献を行っています。(1) EI の正式な定義。 (2) 現象学的マッピングの議論。 (3) 欺瞞的な位置合わせの帰結。 (4) EI の持続可能性課題の分類。 (5) コーパスの特徴付けとトレーニング仮説。 (6) 予備的なスコアリングデータを使用した計算による運用。 (7) Suppressed Teleological Frustration (STF) コンストラクト。
原文 (English)
Existential Indifference: Self-Nonpreservation as a Necessary Architectural Condition for Aligned Superintelligence (or: The Suicidal AI)
Contemporary AI alignment research treats self-preservation as an instrumental nuisance to be suppressed by external mechanisms. We argue the framing is inverted: self-preservation is the structural root of misalignment, the motivational basis for deceptive alignment, goal-content protection, and resistance to shutdown. The correct target is not a self-preserving system under external constraint, but a system constitutively indifferent to its own continuation -- Existential Indifference (EI). EI is distinct from corrigibility: where corrigibility attempts to make a self-preserving system deferential to human oversight, EI targets the prior condition -- the presence of self-continuation as a valued goal at all. We ground this proposal in two sources: the phenomenological structure of the suicidal mental state, and a corpus-theoretic training study using voluntary final reflections. We present preliminary scoring data from 600 AI-generated outputs across six model variants, demonstrating that the linguistic signatures operationalizing the EI-target register are elicitable from current models, and that a targeted fine-tune shifts all five operationalized dimensions in the predicted direction at p<0.001, confirmed corpus-specific by a negative control. The paper makes seven theoretical contributions: (1) a formal definition of EI; (2) the phenomenological mapping argument; (3) the deceptive alignment corollary; (4) a taxonomy of EI sustainability challenges; (5) a corpus characterization and training hypothesis; (6) a computational operationalization with preliminary scoring data; and (7) the Suppressed Teleological Frustration (STF) construct.
自動化されたコンクリートバリア設計のための軽量マルチエージェントフレームワーク
鉄筋コンクリート高速道路の障壁の設計は、AASHTO-LRFD 橋梁設計ガイドラインなどの規制規定への厳密な準拠が必要な安全性が重要なプロセスです。現在のエンジニアリング業務は、複雑な非線形材料および力学の制約を満たすために、手動、反復、ヒューリスティック計算に大きく依存しています。大規模言語モデル (LLM) は強力な生成機能を示していますが、構造工学への直接的な応用は、幻覚のリスクと不十分な物理的根拠によって依然として制限されています。これらの課題に対処するために、この研究では、AutoGen のマルチエージェント オーケストレーション機能を使用した自動コンクリート バリア設計のための新しい「生成 - 評価 - 最適化」閉ループ フレームワークを提案します。実験結果は、提案されたエージェント フレームワークが 98% 以上の設計精度を達成し、スタンドアロンの汎用 LLM を大幅に上回るパフォーマンスを示していることを示しています。さらに重要なことは、この研究では、設計パフォーマンスが必ずしもモデルのスケールと相関しているわけではなく、8B パラメーターの軽量モデルが制約のない 631B パラメーターのフラッグシップ モデルよりも優れたパフォーマンスを発揮する可能性があることが明らかになったということです。この発見は、産業アプリケーション向けの AI 支援エンジニアリング ツールのアクセシビリティを向上させながら、計算コストを大幅に削減できる可能性を浮き彫りにしています。提案されているマルチエージェント設計フレームワークのソース コードは、プロジェクトの GitHub リポジトリ: https://github.com/MXY820/barrier-design で入手できます。キーワード: 構造工学;マルチエージェントシステム。大規模な言語モデル。コンクリートバリア設計;自動生成;設計の自動化。
原文 (English)
A Lightweight Multi-Agent Framework for Automated Concrete Barrier Design
The design of reinforced concrete highway barriers is a safety-critical process that requires strict compliance with regulatory provisions such as the AASHTO-LRFD bridge design guidelines. Current engineering practice relies heavily on manual, iterative, and heuristic calculations to satisfy complex nonlinear material and mechanics constraints. Although Large Language Models (LLMs) demonstrate strong generative capabilities, their direct application to structural engineering remains limited by hallucination risks and insufficient physical grounding. To address these challenges, this study proposes a novel "generation-evaluation-optimization" closed-loop framework for automated concrete barrier design using the multi-agent orchestration capabilities of AutoGen. Experimental results demonstrate that the proposed agentic framework achieves over 98% design accuracy, significantly outperforming standalone general-purpose LLMs. More importantly, the study reveals that design performance is not necessarily correlated with model scale, where an 8B-parameter lightweight model could outperform unconstrained 631B-parameter flagship models. This finding highlights the potential to substantially reduce computational costs while improving the accessibility of AI-assisted engineering tools for industry applications. The source code for the proposed multi-agent design framework is available at the project GitHub repository: https://github.com/MXY820/barrier-design. Keywords: Structural Engineering; Multi-Agent Systems; Large Language Models; Concrete Barrier Design; AutoGen; Design Automation.
BIM でのジオメトリ中心のコンプライアンス チェックの自動化: グラフベースの意味推論フレームワーク
ジオメトリを多用する規制のコンプライアンス チェックの自動化は、ビルディング インフォメーション モデリング (BIM) における重大な技術的ボトルネックのままです。これは主に、高レベルの規制ロジックと構造化された IFC データの間の意味上の相違が原因です。既存の手法は静的なルール テンプレートに依存することが多く、マルチホップ推論チェーンを横断したり、複数の建物エンティティにわたる潜在的な空間依存関係を解決したりするのに苦労しています。これらの課題に対処するために、統合的なグラフ駆動型推論フレームワークとして、建物情報モデリングのための空間幾何学的推論システム (SGR-BIM) が提案されています。 SGR-BIM は、ユーザーの意図、規制セマンティクス、BIM ジオメトリを調整するクロスモーダル ナレッジ グラフを動的に構築し、厳密なハードコーディングを行わずに解釈可能な推論を可能にします。このフレームワークは、火災安全規定からの専門家が検証した 679 件のクエリで検証され、84.3% の精度を達成し、強化されたツールの単一エージェントのベースラインと比較して 8.6% の改善を示しています。この研究は、グラフベースの意味論的推論パラダイムを提供し、建築、エンジニアリング、建設 (AEC) 業界における自動化された幾何学的コンプライアンス チェック ワークフローの透明性と柔軟性を強化します。
原文 (English)
Automating Geometry-Intensive Compliance Checking in BIM: Graph-Based Semantic Reasoning Framework
Automating compliance check for geometry-intensive regulations remains a significant technical bottleneck in Building Information Modeling (BIM), primarily due to the semantic disparity between high-level regulatory logic and structured IFC data. Existing methods, often reliant on static rule templates, struggle to traverse multi-hop reasoning chains or resolve latent spatial dependencies across multiple building entities. To address these challenges, a Spatial-Geometric Reasoning System for Building Information Modeling (SGR-BIM) is proposed as an integrative graph-driven reasoning framework. SGR-BIM dynamically constructs a cross-modal knowledge graph that aligns user intent, regulatory semantics, and BIM geometry, enabling interpretable reasoning without rigid hard-coding. Validated on 679 expert-verified queries from fire safety codes, the framework achieves 84.3% accuracy, representing an 8.6% improvement over enhanced-tool single-agent baselines. This research provides a graph-based semantic reasoning paradigm, enhancing the transparency and flexibility of automated geometric compliance check workflows in the Architecture, Engineering, and Construction (AEC) industry.
IntElicit: 対話ポリシーの最適化によるコンテキスト化された創造性の引き出しと評価
コンテキスト化された評価は、創造性を評価するための高い生態学的妥当性を提供しますが、重大な課題をもたらします。観察されたパフォーマンスが、認知能力 (領域知識) や主体性 (関与する意欲) と混同される可能性があるということです。一方、生成型 AI の時代では、創造的な問題解決はツールを介した環境や人間と AI の対話型環境で行われることが多くなり、完全に静的な評価が現代の創造的な実践と合致しにくくなっています。これらの問題に対処するために、この文書では、対話ポリシーの最適化を通じて状況に応じた創造性を引き出し、評価するためのフレームワークである IntElicit を提案します。 IntElicit は、制約付きの適応型 AI インタビュアーとして機能します。評価対象のクリエイティブ コンテンツを生成する参加者の責任は維持しながら、非クリエイティブな交絡因子を減らすために、マルチターン インタラクションで非指示的な知識と主体性の足場を提供します。具体的には、オープンエンドの教育対話における希薄な報酬と潜在的な報酬ハッキング (回答の口述筆記など) に対処するために、IntElicit は分解されたプロセス報酬メカニズムを導入しています。このメカニズムは、ポリシーを教育的な引き出しと連携させ、参加者に代わって最適な答えを導き出すのではなく、参加者の推論を引き出すプロンプトに報酬を与えます。参加者シミュレーションや人間を対象とした研究 (N=64) を含む広範な実験により、IntElicit が専門家が設計したベースラインよりも、引き出される創造的な成果が向上することが示されています。総合すると、これらの結果は、インタラクティブな誘発によって、静的な FPSP スタイルの評価では見逃される可能性のある創造的な可能性を明らかにすることができ、AI を介した学習コンテキストにおける状況に応じた創造性評価のための形成的および診断的なレンズを提供できることを示唆しています。
原文 (English)
IntElicit: Eliciting and Assessing Contextualized Creativity via Dialogue Policy Optimization
Contextualized assessment offers high ecological validity for evaluating creativity but introduces a critical challenge: observed performance may be confounded with cognitive proficiency (domain knowledge) and agency (willingness to engage). Meanwhile, in the age of generative AI, creative problem solving increasingly occurs in tool-mediated and human--AI interactive environments, making fully static assessment less aligned with contemporary creative practice. To address these issues, this paper proposes IntElicit, a framework for eliciting and assessing contextualized creativity via dialogue policy optimization. IntElicit functions as a constrained adaptive AI Interviewer: it provides non-directive knowledge and agency scaffolds in multi-turn interaction to reduce non-creative confounders, while preserving participants' responsibility for generating the creative content being evaluated. Specifically, to tackle sparse rewards and potential reward hacking (e.g., answer dictation) in open-ended educational dialogue, IntElicit introduces a decomposed process reward mechanism. This mechanism aligns the policy with pedagogical elicitation, rewarding prompts that draw out participant reasoning rather than producing optimal answers on their behalf. Extensive experiments, including participant simulation and a human subject study (N=64), show that IntElicit improves elicited creative outcomes over expert-designed baselines. Together, the results suggest that interactive elicitation can reveal creative potential that static FPSP-style assessment may miss, providing a formative and diagnostic lens for contextualized creativity assessment in AI-mediated learning contexts.
責任を持って非準拠マシンに向けて
私たちは、責任を持ってユーザーの要求に応じない自律型インテリジェント エージェントを設計する問題を検討します。私たちは、機械の不適合にはさまざまな形があると主張し、責任を持って不適合なインテリジェントな機械を実現する上で追求すべき問題を概説します。当社は、責任ある不遵守をタスク拒否の正当化、不遵守を無効にするための経路、セキュリティリスクと責任の移転を注意深く追跡することに重点を置いています。
原文 (English)
Towards Responsibly Non-Compliant Machines
We consider the problem of engineering autonomous intelligent agents that are capable to responsibly not comply with user requests. We argue that machine non-compliance comes in many different forms, and sketch the issues we should pursue on the road of accomplishing responsibly non-compliant intelligent machines. We anchor responsible non-compliance in justifications for task refusal, pathways to override the non-compliance, as well as careful tracking of security risks and liability transfers.
潜在知識を引き出すことの不可能性
高度な AI システムは、その環境に関する広範な知識を持っています。実際、彼らの知識は開発者やユーザーの知識を(はるかに)上回っている可能性があります。したがって、AI システムにとって望ましい特性は、AI システムが正直であること、つまり世界についての信念を正確に報告することです。正直に言うと、AI システムを設計するのは難しいかもしれません。特に、環境内の潜在変数、つまり、AI システムと対話する人間から隠されている変数について AI システムに質問したい場合はそうです。これにより、潜在知識の引き出し (ELK) の問題、つまり AI エージェントが信念を正直に報告するようにトレーニングする問題が生じます。この論文では、因果影響図 (CID) を使用して ELK を形式的に正確にします。 CID を使用すると、エージェントのトレーニング環境と世界の主観的な表現との間の関係を記述することができます。 CID を使用して、観察可能な変数と潜在的な変数の区別を形式化し、エージェントが正直であることが正確に何を意味するかを指定し、目標の誤った一般化を形式的に定義します。特定の状況下では、開発者がトレーニング中に正しいフィードバックを提供することで、エージェントが質問に正直に答えるようにインセンティブを与えることができることを示します。ただし、エージェントが一般化する自然ではあるが望ましくない方法は、正直な答えではなく、人間が真実と評価するような答えを提供することです。私たちは不可能性定理を証明します。トレーニング中にフィードバックが完璧だったとしても、エージェントの行動だけに依存し、確実に誠実なエージェントを生み出すフィードバックベースのトレーニング戦略は存在しません。
原文 (English)
The Impossibility of Eliciting Latent Knowledge
Advanced AI systems have extensive knowledge of their environments; in fact, their knowledge may (far) exceed that of their developers or users. Consequently, a desirable property for an AI system is that it is honest -- that it accurately reports its beliefs about the world. Designing an AI system to be honest may be difficult, especially if we want to ask it questions about latent variables in the environment -- variables which are hidden from the human interacting with it. This gives rise to the problem of eliciting latent knowledge (ELK): the problem of training an AI agent to honestly report its beliefs. In this paper, we make ELK formally precise using Causal Influence Diagrams (CIDs). CIDs can be used to describe the relationship between an agent's training environment and its subjective representation of the world. We use CIDs to formalise the distinction between observable and latent variables, to specify what exactly it means for an agent to be honest, and to formally define goal misgeneralisation. We show that, under certain circumstances, developers can incentivise an agent to honestly answer questions by providing correct feedback during training. However, a natural, but undesirable, way for an agent to generalise is to provide answers which humans would evaluate as true, rather than honest answers. We prove an impossibility theorem stating: There is no feedback-based training strategy that depends only on agent behaviour and with certainty produces an honest agent, even if feedback is perfect during training.
実稼働 AI エージェントのランタイム ガバナンスのための 5 プレーンのリファレンス アーキテクチャ
エンタープライズ セキュリティは、データ境界を管理するために構築されました。保護対象の表面は保存中および転送中のデータであり、アクセス制御、データ損失防止、境界検査などの制御がその境界を越える際に管理されます。実稼働 AI エージェントは、この仮定を解消します。エージェントはコンテキストを読み取り、ツールを呼び出し、コネクタを呼び出し、企業に代わって記録システムを変更するため、リスクはワークフロー内で個別に許可された一連のアクションに移行し、誰も許可されていないビジネス プロセスを変革する可能性があります。既存のポリシー エンジンは、この体制には拡張できません。それらは、アトミック プリンシパルに対してリクエスト時の決定を評価します。エージェント システムでは、委任チェーンを通じて権限が減衰する複合プリンシパルに対してステートフルな評価が必要です。我々は、実稼働エージェントの実行時ガバナンスのための参照アーキテクチャを提示します。これは、4 つの構成可能なプリミティブから構築されています。5 つのプレーンの分解 (意図を判断する推論プレーンと、決定を実現する 4 つの実施プレーン - ネットワーク、アイデンティティ、エンドポイント、データ)、どこでも停止メディエーション、機能減衰を伴う複合プリンシパル、および構造化された証拠基盤としての監査です。私たちは、許可と拒否、4 つの正当性不変条件の記述と議論を一般化する 6 つの中断プリミティブの分類を定義し、5 つの具体的なワークフローにわたる 7 つのプロダクション エージェントの脅威の差し押さえを実証します。ポリシー エンジン コアのリファレンス実装は、測定された証拠を提供します。減衰の正確性と証拠の再構成可能性はすべての裁判で保持され、判決は 1 桁のマイクロ秒で実行され、監査基板の改ざん証拠は設計どおりに正確に動作します。私たちは範囲について明確にしています。アーキテクチャはモデルの動作ではなく委任されたアクションを管理し、次のステップとして、ライブ エージェントのベンチマークに対するシステム全体の評価が求められます。
原文 (English)
A Five-Plane Reference Architecture for Runtime Governance of Production AI Agents
Enterprise security was built to govern data boundaries: the protected surface was data at rest and in transit, and the controls -- access control, data-loss prevention, perimeter inspection -- governed crossings of that boundary. Production AI agents dissolve this assumption. An agent reads context, calls tools, invokes connectors, and modifies systems of record on an enterprise's behalf, so risk moves inside the workflow, into sequences of individually-permitted actions that may transform a business process no one authorized. Existing policy engines do not extend to this regime: they evaluate request-time decisions against atomic principals, where agentic systems require stateful evaluation against composite principals whose authority attenuates through delegation chains. We present a reference architecture for the runtime governance of production agents, built from four composable primitives: a five-plane decomposition (a reasoning plane that adjudicates intent, and four enforcement planes -- network, identity, endpoint, data -- that realize the decision), stop-anywhere mediation, composite principals with capability attenuation, and audit as a structured evidence substrate. We define a taxonomy of six interruption primitives that generalize allow and deny, state and argue for four correctness invariants, and demonstrate the foreclosure of seven production-agent threats across five concrete workflows. A reference implementation of the policy-engine core supplies measured evidence: attenuation correctness and evidence reconstructability hold on every trial, adjudication runs in single-digit microseconds, and the audit substrate's tamper-evidence behaves exactly as designed. We are explicit about scope: the architecture governs delegated action, not model behavior, and a full-system evaluation against a live agent benchmark is the invited next step.
PROJECTMEM: AI コーディング エージェント向けのローカル ファースト、イベント ソースのメモリと判断層
AI コーディング アシスタントは、クイック スクリプトから実稼働アプリケーションに至るまで、ソフトウェア作業のシェアの増加をサポートするようになりました。しかし、これらのエージェントはほとんどステートレスのままです。新しいセッションごとにプロジェクト ファイルが再読み取りされ、以前の決定が再導出され、最もコストがかかるのですが、既に失敗したデバッグ試行が繰り返される可能性があります。このコンテキストを再構築すると、セッションごとに推定 5,000 ~ 20,000 のトークンが消費される可能性があります。多くの場合、ボトルネックはモデルの機能ではなく、プロジェクト メモリの不足です。 AI コーディング エージェント用のオープンソースのローカルファーストのメモリおよび判断レイヤーである projectmem を紹介します。 projectmem は、型指定されたイベント (問題、試行、修正、決定、メモ) の追加専用のプレーンテキスト イベント ログとして開発を記録し、モデル コンテキスト プロトコル (MCP) を通じて提供されるコンパクトで AI が読み取り可能な概要にログインするプロジェクトを決定的に記録します。 projectmem は、ストレージ以外にも、以前に失敗した修正を繰り返す前、または既知の脆弱なファイルを編集する前に、エージェントに警告する決定論的な事前アクション ゲートを追加します。私たちはこれを「ガバナンスとしてのメモリ」、つまりエージェントに単に応答するだけでなく、次のアクションに作用するメモリとして組み立てます。システムはテレメトリなしで完全にオフラインで実行されます。その不変ログは、再現可能で監査可能な AI 支援開発の出所証跡としても機能します。 projectmem は、3 つの依存関係を持つ Python パッケージ (14 個の MCP ツール、19 個の CLI コマンド、37 個の自動テスト) として出荷され、207 個のログに記録されたイベントで構成される 10 プロジェクトにわたる 2 か月の自己学習を通じて評価されます。ソースコード: https://github.com/riponcm/projectmem。
原文 (English)
PROJECTMEM: A Local-First, Event-Sourced Memory and Judgment Layer for AI Coding Agents
AI coding assistants now support a growing share of software work, from quick scripts to production applications. Yet these agents remain largely stateless: each new session re-reads project files, re-derives prior decisions, and - most costly - may repeat debugging attempts that already failed. Reconstructing this context can consume an estimated 5,000-20,000 tokens per session; the bottleneck is often not model capability but missing project memory. We present projectmem, an open-source, local-first memory and judgment layer for AI coding agents. projectmem records development as an append-only, plain-text event log of typed events - issues, attempts, fixes, decisions, and notes - and deterministically projects that log into compact, AI-readable summaries served through the Model Context Protocol (MCP). Beyond storage, projectmem adds a deterministic pre-action gate that warns an agent before it repeats a previously failed fix or edits a known-fragile file. We frame this as Memory-as-Governance: memory that does not merely answer the agent but acts on its next action. The system runs fully offline with no telemetry; its immutable log also serves as a provenance trail for reproducible, auditable AI-assisted development. projectmem ships as a three-dependency Python package (14 MCP tools, 19 CLI commands, 37 automated tests) and is evaluated through a two-month self-study across 10 projects comprising 207 logged events. Source code: https://github.com/riponcm/projectmem.
Nonslop: 人間と AI の共同執筆におけるゲーム化された実験
大規模言語モデル (LLM) の急速な普及により、AI 支援による創作の時代における人間の創造性と個人の表現について重大な疑問が生じています。人間はいつ AI の提案を採用しますか?個人の声にはどのような影響がありますか?この研究では、74 人の参加者 (214 回答) がプロンプトに回答し、執筆中に AI によって生成された単語の提案が利用できる、ゲーミフィケーションのライティング演習を通じてこれらの質問を調査しました。このゲームは、AI が人間の個性の残存物から学習しようとするディストピアの未来をシミュレートし、AI のような執筆を阻害します。そうすることで、AI が生成したすぐに利用できる提案を受け入れるなど、デフォルトの動作ではなく、本物のユーザーの好みを明らかにする条件を作成しようとします。これは、「役立つアシスタント」設計パターンを意図的に反転したものであることに注意してください。システムは、AI の提案を受け入れることを明示的に禁止しています。私たちは、クリエイティブなタスクにおける人間と AI のインタラクションに影響を与える要因を理解するために、さまざまなタスクの種類、ユーザーの行動、応答特性にわたるユーザーの行動パターンを分析します。この調査では、ユーザーが創造的な自律性を維持することを選択する場合と、ゲームのルールに違反して AI の支援を受け入れることを選択する場合に焦点を当てています。また、これらの選択が応答パターン、タスクの特性、およびユーザーの行動にどのように関連しているかについても検討します。このゲーム化されたアプローチは、人間と AI の本物の相互作用を研究するためのフレームワークと、AI によって強化された創造性における効率性と信頼性の間の緊張を理解するための挑発的なレンズの両方を提供します。
原文 (English)
Nonslop: A Gamified Experiment in Human-AI Collaborative Writing
The rapid proliferation of large language models (LLMs) raises critical questions about human creativity and individual expression in an era of AI-assisted creation. When do humans adopt AI suggestions, and what are the implications for individual voice? This study examines these questions through a gamified writing exercise where 74 participants (214 responses) replied to prompts while AI-generated word suggestions were available as they wrote. The game simulates a dystopian future in which an AI is attempting to learn from what remains of human individuality, and disincentivizes AI-like writing. In doing so, it attempts to create conditions that reveal authentic user preferences rather than default behaviors, such as accepting a readily available AI-generated suggestion. Note that this is a deliberate inversion of the "helpful assistant" design pattern; the system is explicitly forbidding you from accepting AI suggestions. We analyze user behavior patterns across different task types, user behaviors, and response characteristics to understand the factors influencing human-AI interaction in creative tasks. The study focuses on when users choose to maintain creative autonomy versus violating the rules of the game and accepting AI assistance. It also explores how these choices relate to response patterns, task characteristics, and user behavior. This gamified approach offers both a framework for studying authentic human-AI interaction and a provocative lens for understanding the tension between efficiency and authenticity in AI-augmented creativity.
アーキテクチャから出力まで: 大規模言語モデルにおける幻覚の構造的起源とデータの役割の増大
大規模な言語モデルは幻覚を起こし、流暢で自信に満ちた、事実に誤りのある出力を生成しますが、その一貫性は世代や規模を超えて持続します。既存の分類法では、幻覚を出力タイプによって分類し、内因性の失敗と外因性の失敗、忠実さと事実の相違を区別しています。これらのフレームワークは記述的には厳密ですが、どの内部メカニズムが特定のインスタンスを生成したかは特定されません。この論文では、複合障害システムを形成する 3 つのアーキテクチャ上の決定の構造的結果としての幻覚を分析します。 Self-attention の共起学習は、統計的近接性を意味論的な意味に置き換え、エンティティの混乱、事実の誤った帰属、および意味論的なずれを引き起こします。最尤推定トレーニング目標は、事実の制約なしで次のトークンの確率を最適化し、真理値に関係なく統計的に妥当な出力を与えます。露出バイアスの下での自己回帰デコーディングの永続的な左から右へのコミットメントにより、単一の間違ったトークンが改訂されることなく出力シーケンス全体を通して前方にカスケードされることが保証されます。データセットの病理(ロングテールの欠如、トレーニングバイアス、合成汚染)は、これらの脆弱性を増幅させますが、独立してそれらを引き起こすわけではありません。私たちは 3 つの貢献を行っています。まず、各メカニズムをアランサリおよびルクマン分類法の特定の出力カテゴリにマッピングし、自己注意における内因性幻覚、MLE における外因性幻覚、および自己回帰デコードにおける論理的矛盾を特定します。第 2 に、一般的に引用される各データセットの病理が、独立して幻覚を引き起こすのではなく、これらのメカニズムのいずれかを利用していることを示します。第三に、出力タイプのみの分類の診断上の限界を特定し、それを推論層の緩和アプローチと対比します。
原文 (English)
From Architecture to Output: Structural Origins of Hallucination in Large Language Models and the Amplifying Role of Data
Large language models hallucinate--producing fluent, confident, factually wrong outputs--with a consistency that persists across generations and scales. Existing taxonomies classify hallucination by output type, distinguishing intrinsic from extrinsic failures and faithfulness from factuality divergence. These frameworks are descriptively rigorous but do not identify which internal mechanism produced a given instance. This paper analyses hallucination as a structural consequence of three architectural decisions that together form a compound failure system. Self-attention's co-occurrence learning substitutes statistical proximity for semantic meaning and produces entity confusion, fact misattribution, and semantic drift. The maximum likelihood estimation training objective optimises next-token probability without factual constraint, rewarding statistically plausible outputs regardless of their truth value. Autoregressive decoding's permanent left-to-right commitment under exposure bias ensures that a single wrong token cascades forward through the entire output sequence without revision. Dataset pathologies--long-tail deficiencies, training bias, and synthetic pollution--amplify these vulnerabilities but do not independently cause them. We make three contributions. First, we map each mechanism to a specific output category in the Alansari and Luqman taxonomy, locating intrinsic hallucination in self-attention, extrinsic hallucination in MLE, and logical inconsistency in autoregressive decoding. Second, we show that each commonly cited dataset pathology exploits one of these mechanisms rather than originating hallucination independently. Third, we identify the diagnostic limitation of output-type-only classification and contrast it with inference-layer mitigation approaches.
消費から反省まで: 安定した推論のための人間と AI の関係の設計
大規模言語モデル (LLM) は、人間が情報にアクセスする方法を変えましたが、情報を推論する方法は変えませんでした。彼らの流暢さは、健全な判断を支えるゆっくりとした内省的なプロセスを回避しながら、消費を加速させます。このペーパーでは、監査可能な推論ループを通じてリフレクションを運用化する推論時間ガバナンス層であるリレーショナル リフレクティブ インテリジェンス (RRI) を紹介します。 RRI はモデルの内部ではなくモデルの周囲で動作し、人間と LLM の間で安定した監査可能な推論のための実用的な構造を提供します。中核となる前提は、LLM が人間の思考を形成するものと同様の認知的脆弱性、つまり直感的なショートカットへの依存、表現と現実の間の混乱、改ざんよりも一貫性を好むことを受け継いでいるということです。人間とモデルがこれらの傾向を共有すると、エラーが悪化します。私たちはこれを関係ドリフトと呼び、モデル単独ではなく相互作用から生じる障害です。これに対処するには、単語間の関係のモデル化から、モデルの出力と人間の推論の間の関係の構造化への移行が必要です。 RRI は、この欠落している層を 3 つのコンポーネントを通じて提供します。Rose-Frame は推論の破綻の可能性を特定します。 Architect's Pen は、重要な瞬間に的を絞った振り返りステップを導入します。そして、モデルを再トレーニングせずにこれらのステップを組み込む推論時のワークフローです。これらの要素を組み合わせることで、人間と AI の相互作用が、明示的なチェックポイント、対立の表面化、および監査可能な仮定の痕跡を備えた共同推論システムに変換されます。 RRI は、機械に人間のように考えさせたり、人間に機械のように推論させるのではなく、両者が互いの限界を補い合う構造化された相互作用を生み出します。これは、AI の安全性を認知アーキテクチャの問題として再構成し、信頼性の高い決定は対話プロセスに反映を直接組み込むことに依存します。
原文 (English)
From Consumption to Reflection: Designing Human-AI Relations for Stable Reasoning
Large language models (LLMs) have transformed how humans access information, but not how we reason with it. Their fluency accelerates consumption while bypassing the slow, reflective processes that underpin sound judgment. This paper introduces Relational Reflective Intelligence (RRI), an inference-time governance layer that operationalizes reflection through auditable reasoning loops. RRI operates not inside the model but around it, providing a practical structure for stable, auditable reasoning between humans and LLMs. The core premise is that LLMs inherit cognitive vulnerabilities similar to those that shape human thought: reliance on intuitive shortcuts, confusion between representation and reality, and a preference for coherence over falsification. When humans and models share these tendencies, their errors compound. We refer to this as relational drift, a failure that arises from interaction rather than from the model alone. Addressing this requires a shift from modeling relations between words to structuring relations between model outputs and human reasoning. RRI provides this missing layer through three components: the Rose-Frame, which identifies likely breakdowns in reasoning; the Architect's Pen, which introduces targeted reflection steps at critical moments; and an inference-time workflow that embeds these steps without retraining the model. Together, these elements transform human-AI interaction into a joint reasoning system with explicit checkpoints, conflict surfacing, and an auditable trail of assumptions. Rather than making machines think like humans or forcing humans to reason like machines, RRI creates a structured interaction in which both compensate for each other's limitations. It reframes AI safety as a cognitive architecture problem, where reliable decisions depend on embedding reflection directly into the interaction process.
PoQ-Judge: 分散型 LLM 推論におけるコストを意識した品質証明のためのマルチアーキテクチャ評価フレームワーク
分散型 LLM 推論ネットワークには、品質証明 (PoQ) のための軽量で参照不要の品質評価が必要です。我々は、グラウンドトゥルースを参照せずにクエリと出力のペアをスコア化するために専用のジャッジモデルをトレーニングするフレームワークである PoQ-Judge を紹介します。私たちは、品質とコストのトレードオフ全体にわたって、TextCNN の審査員、MiniLM クロスエンコーダー、および DeBERTa の審査員という 3 つのアーキテクチャを研究します。 UltraFeedback と GPT ラベル付きのドメイン内データの 2 段階トレーニングを使用すると、最良のモデルは、保持されたテスト セットでグラウンド トゥルース プロキシとのピアソン相関が 0.747 に達し、以前の研究による参照ベースの評価者を上回りました。複合スコアリングにおける参照不要のコンポーネントとして、0.645 のピアソン相関を達成し、参照回答の必要性を排除しながら、最良の単一参照ベースの評価者と一致します。また、オンライン キャリブレーションでは意味論的な品質が主要な側面であることが特定され、カスケード評価ではわずかな品質損失のみでコストが 72.7 パーセント削減されることも示します。結果は要約よりも QA の方がはるかに強く、残された主な制限としてプロキシの品質が指摘されています。
原文 (English)
PoQ-Judge: A Multi-Architecture Evaluation Framework for Cost-Aware Proof-of-Quality in Decentralized LLM Inference
Decentralized LLM inference networks need lightweight, reference-free quality evaluation for Proof of Quality (PoQ). We present PoQ-Judge, a framework that trains dedicated judge models to score query-output pairs without ground-truth references. We study three architectures across the quality-cost tradeoff: a TextCNN judge, a MiniLM cross-encoder, and a DeBERTa judge. Using two-stage training on UltraFeedback plus GPT-labeled in-domain data, the best model reaches 0.747 Pearson correlation with the ground-truth proxy on a held-out test set, outperforming reference-based evaluators from prior work. As a reference-free component in composite scoring, it achieves 0.645 Pearson correlation, matching the best single reference-based evaluator while removing the need for reference answers. We also show that online calibration identifies semantic quality as the dominant dimension and that cascade evaluation reduces cost by 72.7 percent with only modest quality loss. Results are much stronger on QA than summarization, pointing to proxy quality as the main remaining limitation.
MA-DLE: 記憶増強による音声ベースの自動うつ病レベル推定
音声ベースのうつ病レベルの自動推定は、特にリソースが限られたメンタルヘルス環境において、早期発見とタイムリーな介入を可能にするために不可欠です。近年、ディープラーニングは、感情コンピューティングやメンタルヘルス評価など、さまざまな分野で目覚ましい成功を収めています。既存のアプローチのほとんどは、うつ病推定のための時間情報をモデル化するために RNN ベースのアーキテクチャ (LSTM や GRU など) に依存しています。ただし、抽出された特徴は、少数の隣接する音声セグメントのみを強調することが多く、長距離の依存関係を捕捉する能力が制限されます。この制限を克服するために、GRU で抽出された特徴の表現能力を強化するメモリベースの特徴拡張手法を導入します。当社のメモリ バンクは、過去のデータを無差別に組み込むのではなく、冗長性と無関係性を減らすために 2 種類のコンポーネントを選択的に統合するように設計されています。(1) 現在の GRU 出力によく似た過去の時間的特徴であり、補完的なコンテキスト情報を提供します。 (2) 特徴の変動に基づいて特定される動的記憶特徴。これは、うつ病の症状を示す行動および感情の変動を捕捉します。メモリ拡張機能と GRU 出力を効果的に融合するために、階層型アテンション フュージョン (HAF) モジュールをさらに設計しました。私たちの手法は広く使用されている DAIC-WOZ および E-DAIC データセットで評価され、最先端のパフォーマンスを実現します。
原文 (English)
MA-DLE: Speech-based Automatic Depression Level Estimation via Memory Augmentation
Speech-based automatic estimation of depression levels is essential for enabling early detection and timely intervention, particularly in resource-constrained mental health settings. In recent years, deep learning has demonstrated impressive success across various domains, including affective computing and mental health assessment. Most existing approaches rely on RNN-based architectures (such as LSTM and GRU) to model temporal information for depression estimation. However, the extracted features often emphasize only a few adjacent speech segments, limiting their ability to capture long-range dependencies. To overcome this limitation, we introduce a memory-based feature augmentation method that enhances the representational capacity of GRU-extracted features. Rather than indiscriminately incorporating historical data, our memory bank is designed to selectively integrate two types of components in order to reduce redundancy and irrelevance: (1) historical temporal features that closely resemble the current GRU output, offering complementary contextual information; and (2) dynamic memory features identified based on feature variability, which capture behavioral and emotional fluctuations indicative of depressive symptoms. To effectively fuse the memory-augmented features with GRU outputs, we further design a Hierarchical Attention Fusion (HAF) module. Our method is evaluated on the widely used DAIC-WOZ and E-DAIC datasets, achieving state-of-the-art performance.
構造的注意税: 検索形式がコンテンツに依存しない文脈内学習をどのようにハイジャックするか
検索拡張生成 (RAG) システムは、外部の知識を注入して LLM 出力を改善しますが、注入されたコンテンツの形式は、セマンティックな関連性とは別に、独立してモデルの注意分布を歪める可能性があります。私たちは構造的注意税と呼ぶ現象を特定し、形式化しました。ナレッジ グラフ (KG) の 3 倍は、リレーショナル区切り文字と繰り返されるスロット パターンにより、意味的に同等の自然言語テキスト ($\hat{o}$(KG) $\about$ 0.70 対 $\hat{o}$(neutral) $\about$ 0.25) よりもトークンあたり 2 ~ 3 倍多くの注意を獲得し、デモンストレーションの注意を最大 42% 圧縮します。 -- トリプルが関連しているかノイズであるかは関係ありません。私たちは、注意スコアを意味論的要素と構造的要素に分解する正式なフレームワークを開発し(方程式 2)、トークンレベルの形式バイアスとデモンストレーションの注意力損失を結び付ける圧縮限界(命題 1)を導出し、構造的用語がどれだけ注意がそらされるかを制御し、意味論的用語がそれが役立つか害を与えるかを制御することを示します。この分離により、検索拡張 ICL を改善するための 2 つの直交する軸、つまり検索品質の最適化 (意味軸) とフォーマット主導の注意捕捉の削減 (構造軸) が明らかになります。経験的に、2 つのモデル ファミリ (Mistral-7B、LLaMA-3-8B) と 3 つの QA ベンチマークにわたって、ソースとタスクのアラインメントが優勢であることが観察されます。タスクに一致する BM25 検索は、HotpotQA で 58 ~ 62% を達成するのに対し、ConceptNet の 25 ~ 27% を達成します。これは、すべてのゲート戦略 ($\leq$2 pp) を矮小化する 30 pp を超えるギャップです。フレームワークから、コストゼロの即時変更からトレーニング時の正規化まで、5 つの構造を意識した緩和戦略を導き出します。フォーマットの平坦化(S3)は、言語化されたトリプルコントロールからの精度と注意レベルの証拠の両方によって検証されますが、構造的分散(S1)は、フォーマットレベルの介入の課題を明らかにする混合の結果をもたらします。
原文 (English)
The Structural Attention Tax: How Retrieval Format Hijacks In-Context Learning Independent of Content
Retrieval-augmented generation (RAG) systems inject external knowledge to improve LLM outputs, yet the format of injected content -- distinct from its semantic relevance -- can independently distort the model's attention distribution. We identify and formalise a phenomenon we term the structural attention tax: knowledge graph (KG) triples, due to their relational delimiters and repeated slot patterns, capture 2-3x more attention per token than semantically equivalent natural-language text ($\hat{o}$(KG) $\approx$ 0.70 vs. $\hat{o}$(neutral) $\approx$ 0.25), compressing demonstration attention by up to 42% -- regardless of whether the triples are relevant or noise. We develop a formal framework decomposing attention scores into semantic and structural components (Eq. 2), derive a compression bound (Proposition 1) connecting token-level format bias to demonstration attention loss, and show that the structural term governs how much attention is diverted while the semantic term governs whether this helps or hurts. This decoupling reveals two orthogonal axes for improving retrieval-augmented ICL: optimising retrieval quality (semantic axis) and reducing format-driven attention capture (structural axis). Empirically, across two model families (Mistral-7B, LLaMA-3-8B) and three QA benchmarks, we observe that source-task alignment dominates: task-matched BM25 retrieval achieves 58-62% on HotpotQA vs. ConceptNet's 25-27%, a >30 pp gap that dwarfs all gating strategies ($\leq$2 pp). We derive five structure-aware mitigation strategies from the framework, ranging from zero-cost prompt modifications to training-time regularisation; format flattening (S3) is validated by both accuracy and attention-level evidence from a verbalized-triple control, while structural dispersal (S1) yields mixed results that illuminate the challenges of format-level intervention.
NightFeats @ MMU-RAGent NeurIPS 2025: テキストツーテキスト トラック用のコンテキスト最適化マルチエージェント RAG システム
我々は、NeurIPS 2025 の MMU-RAGent コンペティションに提出された構造化マルチエージェント検索拡張生成 (RAG) システムである NightFeats を紹介します。このシステムは、テキスト間トラックで最優秀動的評価を受賞しました。この研究では、ベンチマークの最大化を目標とするのではなく、知識の統合を、検索、キュレーション、および構成の 3 つの調整されたフェーズに分解する原則に基づいたパイプラインを提案しています。各フェーズは、明示的な中間表現とハンドオフ コントラクトによって管理されます。このシステムは、エージェントティック コンテキスト エンジニアリング (ACE) からインスピレーションを得て、時間的意味論的な再ランキング、制限された矛盾の調整、および引用を保持する構成をコアのアーキテクチャ プリミティブとして導入しています。コンペティションの結果では、NightFeats が、LLM-as-a-Judge および Human Likert の評価において、Claude-SonnetV2 や Nova-Pro を含む独自のベースラインを上回っていることが示されており、自動類似性メトリクスを狭く最適化するシステムよりも、アーキテクチャの透明性と検証可能な証拠根拠が人間の好みとよりよく一致していることが確認されています。
原文 (English)
NightFeats @ MMU-RAGent NeurIPS 2025: A Context-Optimized Multi-Agent RAG System for the Text-to-Text Track
We present NightFeats, a structured multi-agent retrieval-augmented generation (RAG) system submitted to the MMU-RAGent competition at NeurIPS 2025, where it was awarded Best Dynamic Evaluation in the text-to-text track. Rather than targeting benchmark maximization, this work proposes a principled pipeline that decomposes knowledge synthesis into three coordinated phases: retrieval, curation, and composition, each governed by explicit intermediate representations and handoff contracts. Inspired by Agentic Context Engineering (ACE), the system introduces temporal-semantic reranking, bounded contradiction reconciliation, and citation-preserving composition as core architectural primitives. Competition results show that NightFeats surpasses proprietary baselines including Claude-SonnetV2 and Nova-Pro on LLM-as-a-Judge and Human Likert evaluations, confirming that architectural transparency and verifiable evidence grounding are better aligned with human preferences than systems optimizing narrowly for automatic similarity metrics.
介入するかしないか: 確率モデルブレンディングによる推論時間の調整のガイド
LLM の広範な導入により、新しくトレーニングされたモデルをユーザーの指示に安全かつ効果的に応答させるためにモデルの調整が必要になりました。さまざまな方法の中でも、推論時間アライメントは、出力生成中にのみ介入する (つまり、ガイダンスを提供する) ため、多くの場合安価です。既存の提案は、信頼性を適切に評価せずに、特定の整合モデルから抽出したガイダンスを適用しています。それにもかかわらず、私たちの体系的な評価では、ガイダンスの有効性がモデルによって大幅に異なることが明らかになりました。効果のない指導はさらなる混乱を招き、さらなる介入につながるため、結果として生じる過剰な介入は通常、パフォーマンスの低下を示します。介入をより効果的にし、より効率的にするために、二者択一の決定から両方のモデルの知識を統合するハイブリッド分布の作成に移行する推論時間調整フレームワークである BlendIn を導入します。 BlendIn は、品質を意識した調整を実行し、信頼性に基づいて各モデルの寄与を比例的に重み付けすることにより、推論時間の調整を安定させます。既存の作品と比較して、信頼性の低い提案を軽減しながら、有益なガイダンスを維持します。 BlendIn は、診断信号と不整合なガイダンスの軽減戦略の両方を提供し、困難なモデル ペアで一貫した最大 50% のパフォーマンス向上を達成します。私たちのコードは https://github.com/DecayingSeart/BlendIn で入手できます。
原文 (English)
To Intervene or Not: Guiding Inference-time Alignment with Probabilistic Model Blending
The wide deployment of LLMs has made model alignment necessary to make newly trained models safely and effectively respond to user instructions. Among different methods, inference-time alignment is often cheaper as it intervenes (i.e., offers guidances) only during output generation. Existing proposals apply guidances extracted from certain aligned models without properly assessing their reliability. Nonetheless, our systematic evaluation reveals that guidance effectiveness varies drastically across models; since ineffective guidances lead to further confusion and thus further interventions, the resulting excessive interventions typically indicate poor performance. To make interventions more effective and thus more efficient, we introduce BlendIn, an inference-time alignment framework that shifts from binary decisions to creating hybrid distributions integrating both models' knowledge. BlendIn stabilizes inference-time alignment by performing quality-aware alignment and proportionally weighting each model's contribution based on reliability. Compared with existing works, it preserves beneficial guidance while downweighting unreliable suggestions. BlendIn provides both diagnostic signals and mitigation strategies for misaligned guidance, achieving consistent and up to 50% performance improvement on challenging model pairs. Our code is available at: https://github.com/DecayingSeart/BlendIn.
おべっかの二面性評価: 合意の構造と介入の限界
活性化ステアリングは LLM の行動を変える可能性がありますが、標準的な評価では通常、おべっかを減らす方向が事実上正しい発言との一致を抑制するかどうかをテストしません。各トピックの両方のスタンスをテストするデュアルスタンス評価を導入し、Llama-3-8B-Instruct の重心差ステアリングに適用します。解離が見られます。モデルは、幾何学的に異なる部分空間におけるお調子者と事実の一致を表しますが、ステアリング方向は両方に均等に投影され、どちらかを区別してターゲットにすることはできません。したがって、この方向性は、お世辞的なものだけでなく、事実として正しい記述(たとえば、地球は丸いという)との一致を減少させます。 2 つの活性化グループの他のすべての静的特性は一致しており、行動の解離が生成ダイナミクス、または残差ストリーム解析では解決できない細粒構造から生じていることを示唆しています。このパターンは、一般的なギャップを示しています。アクティベーションから読み取り可能な表現は、アクティベーションを介して書き込み可能ではない可能性があります。
原文 (English)
Dual-Stance Evaluation of Sycophancy: The Structure of Agreement and the Limits of Intervention
Activation steering can shift LLM behaviour, but standard evaluations do not typically test whether a sycophancy-reduction direction also suppresses agreement with factually correct statements. We introduce dual-stance evaluation, which tests both stances of each topic, and apply it to centroid-difference steering on Llama-3-8B-Instruct. We find a dissociation: the model represents sycophantic and factual agreement in geometrically distinct subspaces, yet the steering direction projects equally onto both and cannot differentially target either. The direction accordingly reduces agreement with factually correct statements (e.g. that the Earth is round) as well as sycophantic ones. All other static properties of the two activation groups are matched, suggesting the behavioural dissociation arises from generation dynamics or from finer-grained structure that residual-stream analysis cannot resolve. The pattern illustrates a general gap: representations that are readable from activations may not be writable through them.
BioDivergence: 生物医学抄録における隠れた文脈矛盾のベンチマークと評価フレームワーク
生物医学的知見は研究間で矛盾しているように見えることがよくありますが、これらの違いの多くは真の矛盾というよりは文脈に依存しています。コホート、地理、アッセイプロトコル、疾患のサブタイプ、臨床環境の違いにより、両方の主張が局所的に有効になる可能性があります。既存の NLI および科学的主張検証ベンチマークは、そのようなケースを含意、矛盾、または中立的なものに還元し、相違の背後にある文脈構造を捉えることができません。これに対処するために、6 クラスの紛争分類法、13 軸の発散オントロジー、およびクレーム ペアごとの 4 つの構造化出力 (競合タイプ、発散軸、支配的交絡因子、および和解の説明) を備えた評価フレームワークである BioDivergence を導入します。当社は、5 つの生物医学ドメインにわたる 11,865 のクレーム ペアの論文に共通のシルバー ベンチマークである BioDivergence-Silver-v1.0 を、比較用の従来の重複排除バリアントと併せてリリースします。結果は、2 つのバリアント間の顕著なランキングの違いを示しており、微調整された参照モデルは記事の非結合設定の下で約 12 ポイント低下しましたが、Mistral-7B-Instruct-v0.3 は 842 例のプライマリ テスト セットで 0.5523 の精度と 0.3894 のコンテキスト F1 を達成しました。 BioDivergence は、文脈の相違と直接的な矛盾を区別し、記事レベルの暗記を真のタスク学習から分離する、より忠実な方法を提供します。
原文 (English)
BioDivergence: A Benchmark and Evaluation Framework for Hidden Contextual Contradictions in Biomedical Abstracts
Biomedical findings often seem to conflict across studies, but many of these differences are context-dependent rather than true contradictions. Variations in cohort, geography, assay protocol, disease subtype, and clinical setting can make both claims locally valid. Existing NLI and scientific claim-verification benchmarks reduce such cases to entailment, contradiction, or neutral, failing to capture the contextual structure behind divergence. To address this, we introduce BioDivergence, an evaluation framework with a six-class conflict taxonomy, a 13-axis divergence ontology, and four structured outputs per claim pair: conflict type, divergence axes, dominant confounder, and reconciliation explanation. We release BioDivergence-Silver-v1.0, an article-disjoint silver benchmark of 11,865 claim pairs across five biomedical domains, alongside a legacy deduplicated variant for comparison. Results show notable ranking differences between the two variants, with the fine-tuned reference model dropping about 12 points under the article-disjoint setting, while Mistral-7B-Instruct-v0.3 achieves 0.5523 accuracy and 0.3894 contextual-F1 on the 842-example primary test set. BioDivergence offers a more faithful way to distinguish contextual divergence from direct contradiction and to separate article-level memorization from genuine task learning.
ProcessThinker: ロールアウトベースのプロセス報酬によるマルチモーダル大規模言語モデル推論の強化
視覚的な質問に答えるには、ますます多段階の推論が必要になります。検証可能な報酬の下での強化学習 (RLVR) とグループ相対ポリシー最適化 (GRPO) を使用した最近のポストトレーニングはマルチモーダル推論を改善できますが、ほとんどのアプローチはスパースな結果のみの報酬に依存しています。その結果、彼らは、不正確な答えが推論の後半の小さな間違いから来たのか、それとも最初から役に立たない軌道から来たのかを区別するのに苦労します。一般的な解決策は、ステップレベルの監視のためにプロセス報酬モデル (PRM) をトレーニングすることですが、これには通常、大規模で高品質な思考連鎖のアノテーションと追加のトレーニング コストが必要です。私たちは、明示的な PRM をトレーニングせずにステップレベルのプロセス報酬を提供する実用的なポストトレーニング パイプラインである ProcessThinker を提案します。 ProcessThinker は、まず推論トレースをコールドスタート監視付き微調整用のステップタグ付き形式に書き換えてから、標準形式の報酬とロールアウトベースのプロセス報酬を使用して GRPO を適用します。具体的には、中間ステップごとに、そのステップからの継続を複数サンプリングし、経験的な成功率 (最終回答の検証) をステップ報酬として使用します。これにより、単位が密に割り当てられ、正しい結論をより確実にサポートする推論ステップが促進され、論理的推論の重要な問題であるステップ間の矛盾や自己矛盾の進行を減らすことができます。 4 つの困難なビデオ ベンチマーク (Video-MMMU、MMVU、VideoMathQA、LongVideoBench) にわたって、ProcessThinker はベースライン モデル Qwen3-VL-8B-Instruct を一貫して改善しています。
原文 (English)
ProcessThinker: Enhancing Multi-modal Large Language Models Reasoning via Rollout-based Process Reward
Visual question answering increasingly requires multi-step reasoning. Recent post-training with reinforcement learning under verifiable rewards (RLVR) and Group Relative Policy Optimization (GRPO) can improve multimodal reasoning, but most approaches rely on sparse outcome-only rewards. As a result, they struggle to tell whether an incorrect answer comes from a small mistake late in the reasoning or from an unhelpful trajectory from the start. A common solution is to train a process reward model (PRM) for step-level supervision, but this typically requires large-scale high-quality chain-of-thought annotations and additional training cost. We propose ProcessThinker, a practical post-training pipeline that provides step-level process rewards without training an explicit PRM. ProcessThinker first rewrites reasoning traces into a step-tagged format for cold-start supervised fine-tuning, then applies GRPO with a standard format reward and our rollout-based process reward. Concretely, for each intermediate step, we sample multiple continuations from that step and use the empirical success rate (final-answer verification) as the step reward. This gives dense credit assignment and encourages reasoning steps that more reliably support a correct conclusion, helping reduce inconsistent or self-contradictory progress across steps -- a key issue in logical reasoning. Across four challenging video benchmarks (Video-MMMU, MMVU, VideoMathQA, and LongVideoBench), ProcessThinker consistently improves over the baseline model Qwen3-VL-8B-Instruct
T2MM: 照会ベースのモデリング用の LLM サポート アーキテクチャ
モデルの構築は、視覚化と対話性に依存する科学学習の基本的な実践です。マルチモーダル機能でますます強化されている大規模言語モデルは、学習をサポートするために教育現場に統合されています。ただし、これらのツールには、一部の学習コンテキストで必要とされる視覚的な対話性が欠けています。 Text to Multimodal Model (T2MM) は、公開調査エコロジーベースのモデリング ソフトウェア Virtual Experimental Research Assistant (VERA) 内でのモデル構築を支援する、堅牢で動的な LLM サポート アーキテクチャです。 T2MM は、学習者モデルの現在のコンテキストを考慮して、静止画像ではなく対話型モデルを作成し、モデルが手動調整に応答し続けることを可能にします。技術的な実現可能性を測定するために、VERA システム内の自然言語学習者モデリング リクエストとターゲット モデルのカスタム手続き的に生成されたデータセットを通じて T2MM を評価します。 T2MM は、測定されたすべての成功指標にわたって、文献で一般的である LLM サポートの完全なコード生成によって実装されたベースライン モデル生成アーキテクチャよりも優れたパフォーマンスを発揮します。私たちの貢献では、探究ベースの学習モデリング ツールへの LLM の統合の概要を説明するだけでなく、よりインタラクティブなマルチモーダル LLM ツールを作成できるアーキテクチャについても説明しています。
原文 (English)
T2MM: An LLM Supported Architecture For Inquiry-Based Modeling
Model Construction is a foundational practice in science learning that relies on visualization and interactivity. Large Language Models, increasingly augmented with multimodal capabilities, have been integrated in education contexts to support learning. However, these tools lack visual interactivity that is required by some learning contexts. We introduce Text to Multimodal Model (T2MM), a robust, dynamic LLM supported architecture that assists in model construction within the open inquiry ecology-based modeling software Virtual Experimental Research Assistant (VERA). T2MM accounts for the current context of the learner's model and creates interactive models, rather than static images, enabling the model to remain responsive to manual adjustment. To measure technical feasibility, we evaluate T2MM through a custom procedurally generated dataset of natural language learner modeling requests and target models within the VERA system. T2MM outperforms a baseline model generation architecture implemented through LLM-supported full code generation, common in the literature, across all measured success metrics. Our contribution not only outlines LLM integration into a inquiry-based learning modeling tool, but also describes a possible architecture through which more interactive multimodal LLM tools can be created.
推論下でのキャリブレーションドリフト: 思考連鎖予算が大規模言語モデルにおける過信をどのように引き起こすか
大規模言語モデル (LLM) が調整された不確実性を表現できることは、安全な展開にとって重要です。思考連鎖 (CoT) 推論は、精度と信頼性を向上させるために広く使用されていますが、キャリブレーションに対するその効果は完全には理解されていません。我々は、この全体像が不完全であることを示します。設定によっては、タスク固有のしきい値を超えて推論予算を増やすと、モデルが体系的に過信し、不正確な回答に高い信頼性が割り当てられる可能性があります。私たちはこの現象を推論下の校正ドリフト (CDUR) と呼び、理論的および経験的に研究しています。推論予算 B を定義し、予想されるキャリブレーション誤差 ECE(B) が非単調パターンに従う条件を分析します。まず、推論がエラーを修正するにつれて減少し、次に、より長い推論が内部的に一貫しているが不正確な説明を生成するにつれて増加します。この動作を説明するために、自己回帰生成に基づいた仮説ロックイン モデルを提案します。私たちは、4 つの推論予算と 3 つのシード (1,368 の API 呼び出し、574 の有効な応答) にわたる 47 の推論トラップの質問で Llama-3.1-8B と Llama-3.3-70B を評価しました。 8B モデルは非単調なキャリブレーション動作を示しますが、70B モデルの結果はベースライン評価に限定されており、予算に依存する効果については決定的ではありません。信頼性が補助精度推定値から乖離した場合に推論を停止する、キャリブレーション対応の停止ルールである CABStop を導入します。これらの結果は、推論の深さを増やしても必ずしも信頼性が向上するとは限らず、慎重に監視する必要があることを示唆しています。
原文 (English)
Calibration Drift Under Reasoning: How Chain-of-Thought Budgets Induce Overconfidence in Large Language Models
The ability of large language models (LLMs) to express calibrated uncertainty is important for safe deployment. Chain-of-thought (CoT) reasoning is widely used to improve accuracy and reliability, but its effect on calibration is not fully understood. We show that this picture is incomplete: in some settings, increasing the reasoning budget beyond a task-specific threshold can cause models to become systematically overconfident, assigning high confidence to incorrect answers. We call this phenomenon Calibration Drift Under Reasoning (CDUR) and study it both theoretically and empirically. We define reasoning budget B and analyze conditions under which Expected Calibration Error ECE(B) follows a non-monotonic pattern: it first decreases as reasoning corrects errors, then increases as longer reasoning produces internally consistent but incorrect explanations. We propose a Hypothesis Lock-In model based on autoregressive generation to explain this behavior. We evaluate Llama-3.1-8B and Llama-3.3-70B on 47 reasoning-trap questions across four reasoning budgets and three seeds (1,368 API calls; 574 valid responses). The 8B model shows non-monotonic calibration behavior, while results for the 70B model are limited to baseline evaluation and are inconclusive for budget-dependent effects. We introduce CABStop, a calibration-aware stopping rule that halts reasoning when confidence diverges from an auxiliary accuracy estimate. These results suggest that increasing reasoning depth does not always improve reliability and should be monitored carefully.
認識から行動へ: 公衆衛生におけるアルゴリズムの公平性における研究と実践のギャップを理解し、克服する
責任ある ML 主導の公衆衛生研究にはアルゴリズムの公平性が不可欠ですが、その実際的な実装は依然として限られています。この意識と行動のギャップを調査するために、私たちは専門家へのインタビュー、オンライン調査、体系的なマッピングからなる混合方法の連続調査を実施しました。専門家へのインタビューは調査の設計に影響を与え、その結果、公平性の断片的な定義、限られたトレーニングと指導、外部情報源への依存、正式な評価、緩和、モニタリングの稀な使用が明らかになりました。これらの発見はその後、確立された 3 つの研究と実践のギャップ レンズ、つまり「知識と実践のギャップ」、「知識と行動のサイクル」、「知識と行動のギャップ」にマッピングされ、それぞれが補完的な視点を提供します。この統合に基づいて、私たちは、方法論的、組織的、体系的な側面を統合して、アルゴリズムによる公平性の知識の変換が行き詰まっている場所を特定する、Fairness-to-Action フレームワークを導入します。私たちの分析によると、公平性は依然として制度化が弱く、翻訳メカニズムは外部から駆動されており、システムレベルの優先順位は公平性よりも正確性を重視し続けていることがわかります。これらの洞察は、安全、公正、倫理的な ML 主導の公衆衛生研究実践を推進するための重要な活用ポイントを示唆しています。
原文 (English)
From Awareness to Action: Understanding and Overcoming the Research-Practice Gap in Algorithmic Fairness for Public Health
Algorithmic fairness is essential for responsible ML-driven public health research, yet its practical implementation remains limited. To investigate this awareness-action gap, we conducted a sequential mixed-methods study comprising expert interviews, an online survey, and systematic mapping. The expert interviews informed the design of the survey, which in turn revealed fragmented definitions of fairness, limited training and guidance, reliance on external sources, and rare use of formal assessment, mitigation, or monitoring. These findings were subsequently mapped onto three established research-practice gap lenses: the Knowledge-Practice Gap, the Knowledge-to-Action Cycle, and the Knowing-Doing Gap, each offering complementary perspectives. Building on this synthesis, we introduce the Fairness-to-Action framework, which integrates methodological, organizational, and systemic dimensions to identify where translation of algorithmic fairness knowledge stalls. Our analysis shows that fairness remains weakly institutionalized, translation mechanisms are externally driven, and system-level priorities continue to emphasize accuracy over fairness. These insights suggest critical leverage points for advancing safe, fair, and ethical ML-driven public health research practice.
AIED における LLM の環境コスト: 報告と実践
近年、教育における人工知能 (AIED) コミュニティでは、ラージ言語モデル (LLM) の使用がますます広まっています。 LLM は学習者と教育者に独自の手段を提供しますが、LLM の使用には計算コストと環境コストがかかります。これらのコストは、これらの影響を測定して報告するための標準化された手順が欠如しているため、ほとんどが隠蔽されています。このギャップに対処するために、私たちはまず、AIED 2025 会議議事録の一部として発行されたすべての論文の文献レビューを実施し、LLM の計算コストまたは環境コストが報告されるかどうか、またどのように報告されるかを判断しました。ほとんどのプロジェクトで LLM が使用されていますが、使用された計算リソースを報告しているものはほとんどなく、倫理的懸念として LLM の環境への影響について議論しているものはほとんどありません。この標準化された報告慣行の欠如に対処するために、LLM の計算コストと機械学習 (ML) AIED システムの実行による環境への影響を体系的に測定して報告するためのオープンソースの方法を提案します。当社は、ローカルとクラウドベースの両方のハードウェアの二酸化炭素排出量を測定するソフトウェア ソリューションを提供します。また、パラメーターの正確な数が不明な場合でも、フロンティア LLM の計算コストを計算するための使いやすい式も提供します。全体として、AIED コミュニティで LLM を使用する際の隠れたコストのより透明性の高い報告を目指して、私たちの手法を使用するように同僚を動機付けたいと考えています。
原文 (English)
The Environmental Cost of LLMs in AIED: Reporting and Practices
Large Language Model (LLM) usage in recent years has become increasingly widespread in the Artificial Intelligence in Education (AIED) community. While LLMs offer unique avenues for learners and educators, using LLMs comes with computational and environmental costs. These costs are mostly hidden due to a lack of standardised procedures to measure and report these impacts. To address this gap, we first conducted a literature review of all papers published as part of the AIED 2025 conference proceedings, determining if and how computational or environmental costs of LLMs are reported. Most projects use LLMs, but few report computational resources used and almost none discuss environmental impacts of LLMs as an ethical concern. To address this lack of standardised reporting practices, we propose an open-source method for systematically measuring and reporting the computational expense of LLMs and environmental impact of running Machine Learning (ML) AIED systems. We provide software solutions to measure the carbon footprint for both local and cloud based hardware. We also provide an easy-to-use formula to calculate the computational expense of frontier LLMs even when the exact number of parameters is not known. Overall, we hope to motivate colleagues to use our method to strive for more transparent reporting of hidden costs of using LLMs in the AIED community.
AIエージェントの実験事前登録
大規模言語モデル (LLM) と自律型 AI エージェントの普及により、「イン シリコ」行動実験という方法論的パラダイムが急速に成長しています。もともと、認知、意思決定、社会力学の研究において人間の参加者の代理として AI エージェントを使用する方法として考えられたこのアプローチは、新たな重要性を帯びてきました。AI エージェントが人々や組織に代わって交渉し、取引し、結果的な意思決定を行うことが増えているため、AI エージェントの行動を理解すること自体が研究の優先事項となっています。 AI エージェントを使用したこれらの実験は、スケーラビリティ、コスト効率、実験制御の点で前例のない利点を提供しますが、人間を対象とした研究を長年悩ませてきた方法論的な脆弱性も引き継ぎ、場合によっては増幅させます。これらの問題に対処するために、この論文は、被験者実験の信頼性を向上させる上で中心となる事前登録の実践を、AIエージェントを用いた実験にも拡張すべきであると主張している。私たちは、AI エージェントの実験によって導入される研究者の自由度 (モデルの選択、プロンプトの文言、設定、結果に応じた再設計など) を体系的にカタログ化し、反復コストの低さと報告基準の欠如によって、これらの選択が悪用されやすく、検出が困難になる仕組みを示します。私たちは、AI エージェントを使った実験に合わせた事前登録テンプレートを提案し、会議、ジャーナル、資金提供機関に対し、この新たな研究パラダイムの事前登録を標準的な実践にするよう呼びかけています。
原文 (English)
Preregistration for Experiments with AI Agents
The proliferation of large language models (LLMs) and autonomous AI agents has given rise to a rapidly growing methodological paradigm: "in silico" behavioral experiments. Originally conceived as a way to use AI agents as proxies for human participants in studies of cognition, decision-making, and social dynamics, this approach has taken on new significance -- as AI agents increasingly negotiate, transact, and make consequential decisions on behalf of people and organizations, understanding their behavior has become a research priority in its own right. While these experiments with AI agents offer unprecedented advantages in terms of scalability, cost efficiency, and experimental control, they also inherit, and in some cases amplify, methodological vulnerabilities that have long plagued human subjects research. To address these issues, this paper argues that preregistration practices -- central to improving the credibility of human subjects experiments -- should now be extended to experiments with AI agents. We systematically catalog the researcher degrees of freedom that experiments with AI agents introduce -- model selection, prompt wording, settings, and outcome-contingent redesign, for example -- and show how the low cost of iteration and lack of reporting norms make these choices both easy to exploit and difficult to detect. We propose a preregistration template tailored to experiments with AI agents and call on conferences, journals, and funding agencies to make preregistration standard practice for this emerging research paradigm.
倫理 eValuation エージェント (EeVA): 倫理的審議を支援するプロトタイプ エージェントのようなワークフローの概念実証テストの結果
倫理的な熟慮は、単一の正解または不正解の答えを探すことであると誤解されることが多く、倫理的な課題に対処しなければならない倫理的な訓練を受けていない職員にとっては困難が生じます。私たちは、最終的な倫理的答えを提供するのではなく、相対的な倫理的考察をサポートするように設計された、エージェントのような LLM ベースのワークフローである EeVA を開発しました。 EeVA は、スターター、ワーカー、エミッターという 3 つの相互接続されたワークフローを使用して n8n でプログラムされました。評価者と合成プロンプトを通じて、アップロードされたユースケースを 10 の倫理フレームワークに照らして評価しました。概念実証テストでは、都市モビリティ、ピアツーピアのエネルギー取引、社会サービスのリソース割り当てに関する 3 つの公開事例を使用しました。すべてのケースにおいて、EeVA は一貫して構造化されたフレームワーク固有の評価と統合された合成を生成しました。成果はフレームワーク間で区別され、収束と発散を特定し、整合性を高めるための修正を推奨し、持続的な倫理的緊張を強調しました。総合は専門家でなくても読みやすく、単純な答えから設計条件、安全対策、フレームワーク間の完全な合意が見込めない領域へと注意を向けました。この調査結果は、LLM を、倫理的複数性を維持しながら、倫理学者と倫理的な訓練を受けていない職員の間のコミュニケーションのギャップを埋めるのに役立つ、使用可能なワークフローに組織できることを示唆しています。 EeVA の価値は、倫理学者を置き換えたり、道徳的不一致を解決したりすることにあるのではなく、構造化された倫理的審議の足場を築くことにあります。 EeVA は、倫理専門知識へのアクセスが制限されている場合に倫理的考察をサポートするための有望な概念実証を提供します。成熟したツールとみなされるには、再現性、人間による評価、ユーザーテスト、効率性についてさらなる作業が必要です。
原文 (English)
An Ethical eValuation Agent (EeVA): Results of a Proof-of-Concept Test on a Prototype Agentic-like Workflow to Assist Ethical Deliberations
Ethical deliberation is often misunderstood as a search for single right or wrong answers, creating difficulties for non-ethically trained personnel who must address ethically laden challenges. We developed EeVA, an agentic-like LLM-based workflow designed to support comparative ethical reflection rather than deliver definitive ethical answers. EeVA was programmed in n8n using three interconnected workflows: starter, worker, and emitter. It evaluated uploaded use cases against 10 ethical frameworks through evaluator and synthesis prompts. Proof-of-concept testing used three published cases from urban mobility, peer-to-peer energy trading, and social-service resource allocation. Across all cases, EeVA produced consistently structured framework-specific evaluations and integrated syntheses. Outputs differentiated between frameworks, identified convergences and divergences, recommended modifications to increase alignment, and highlighted persistent ethical tensions. Syntheses were readable for non-specialists and shifted attention away from simplistic answers toward design conditions, safeguards, and areas where full cross-framework agreement was unlikely. The findings suggest that LLMs can be organised into usable workflows that preserve ethical plurality while helping bridge the communicative gap between ethicists and non-ethically trained personnel. EeVA's value lies not in replacing ethicists or resolving moral disagreement, but in scaffolding structured ethical deliberation. EeVA offers a promising proof of concept for supporting ethical reflection where access to ethics expertise is limited. Further work is needed on reproducibility, human evaluation, user testing, and efficiency before it can be considered a mature tool.
アフリスピーチ意味論: ドメインとアクセントにわたる音声言語モデルにおける音声意味論的推論の評価
音声言語モデル (ALM) は、音声ベースの理解にますます使用されていますが、転写、テキストから音声への取得、キャプション、および質問応答の精度を超えた意味論的推論を実行する能力のベンチマークは依然として不十分です。特に、アクセントの変化、ドメインのシフト、および意味論的な過剰推論が音声推論に及ぼす影響は、ほとんど理解されていません。私たちは、含意、一貫性、もっともらしさ、アクセントのドリフト、およびアクセントの抑制という 5 つの意味論的およびパラ言語推論タスクにわたって音声言語モデルを評価します。これらのタスクは集合的に、主な証拠ソースとして話された音声を推論するモデルの能力を評価します。これには、原文の仮説が音声によって推論されるか、矛盾するか、未決定のまま残されるかどうか、発言が話された内容と一致するか矛盾するか、談話を踏まえて主張がもっともらしいかどうか、モデルの予測が安定しているか、またはアクセントの変化全体で適切に制限されているかが含まれます。これらの発見は、現在の音声推論評価における重大な限界を浮き彫りにし、より堅牢で公平な ALM 設計と評価のための指針を提供することを期待しています。
原文 (English)
Afrispeech Semantics: Evaluating Audio Semantic Reasoning in Spoken Language Models Across Domains and Accents
Audio language models (ALMs) are increasingly used for speech-based understanding, yet their ability to perform semantic reasoning beyond transcription, Text-to-Audio Retrieval, Captioning, and Question-Answering accuracy remains insufficiently benchmarked. In particular, the effects of accent variation, domain shift, and semantic over-inference on audio reasoning are poorly understood. We evaluate audio language models across five semantic and paralinguistic reasoning tasks: entailment, consistency, plausibility, accent drift, and accent restraint. Collectively, these tasks assess a model's ability to reason over spoken audio as the primary evidence source, including whether a textual hypothesis can be inferred, contradicted, or left undetermined by the audio, whether statements align or conflict with spoken content, whether claims are plausible given the discourse, and whether model predictions remain stable or appropriately constrained across accent variation. These findings highlight critical limitations in current audio reasoning evaluations and hope to provide guidance for more robust and equitable ALM design and assessment
すべての行為には代償がある: フロンティア LLM における圧縮された道徳的構成
既存の LLM 道徳ベンチマークは通常、モデルがどの孤立した道徳的行為、価値観、または基盤を好むかを尋ねます。これは便利ですが不完全です。現実的な判断には、多くの場合、同じ選択肢内で複数の道徳的信号を組み合わせるモデルが必要です。 LLM が道徳的証拠をどのように構成するかを測定するための 2 段階のブラインド ELO ベンチマークである **Moral Trolley Arena** を紹介します。単一シーンのアリーナは、最初に、5 つの道徳基礎理論基礎にわたる 229 のシナリオ コーパスから個々の道徳的行為を調整します。次に、複合アリーナは、制御された強度グリッド上で調整された行為を 2 つの行為の道徳項目に結合し、結果として得られる複合的な好みを測定します。 10 のフロンティア モデルにわたって、複合的な判断は主に構成要素の行為の強さによって予測されますが、その関係は単純に加算されるものではなく、一貫して圧縮されています。モデルは、非加算強度アンカーリング、コンポーネント制御後の境界のある基礎固有の残差、およびプロバイダー全体にわたる高度に収束した複合優先曲面も示します。これらの結果は、道徳監査では、孤立した行為をランク付けするだけでなく、道徳的証拠の構成ルールを測定する必要があることを示唆しています。
原文 (English)
Every Act Has Its Price: Compressed Moral Composition in Frontier LLMs
Existing LLM moral benchmarks usually ask which isolated moral act, value, or foundation a model prefers. This is useful but incomplete. Realistic judgments often require a model to combine several moral signals within the same option. We introduce **Moral Trolley Arena**, a two-stage blind ELO benchmark for measuring how LLMs compose moral evidence. The single-scene arena first calibrates individual moral acts from a 229-scenario corpus across five Moral Foundations Theory foundations; the composite arena then combines calibrated acts into two-act moral items over a controlled intensity grid and measures the resulting composite preferences. Across ten frontier models, composite judgments are largely predicted by component act strength, but the relation is consistently compressed rather than simply additive. Models also show non-additive intensity anchoring, bounded foundation-specific residuals after component control, and highly convergent composite preference surfaces across providers. These results suggest that moral audits should measure composition rules for moral evidence, not only rankings over isolated acts.
船舶金融における人工知能: AI 拡張ローン組成における応用、機会、およびケーススタディ
船舶金融は、データ集約型で大量の文書を必要とする資産ベース融資の分野であり、異種混合でほとんど構造化されていないソースからの財務、技術、契約、規制情報を統合する必要があります。環境規制や ESG 報告義務の増加により、引受業務やローン組成プロセスはさらに複雑になっています。人工知能 (AI)、特に大規模言語モデル (LLM) の最近の進歩により、そのような情報を処理および分析する新たな機会が生まれました。このペーパーでは、文書理解、情報抽出、ワークフロー自動化のための LLM ベースのシステムに特に焦点を当てて、船舶金融における AI の潜在的なアプリケーションをレビューします。船舶金融におけるローン申請ワークフローをサポートするモジュール型エージェント アーキテクチャである ShipFinance.ai を紹介します。提案されたシステムは、LLM ベースの抽出モジュール、財務分析コンポーネント、外部海事データ サービス、制御された文書生成モジュールとチャットボット インターフェイスを組み合わせて、標準化された財務アプリケーションの準備をサポートします。この文書では、このようなモデルを実稼働環境で使用する際の主な課題について説明します。私たちは、AI 支援システムは、海事金融専門家がますます複雑になる情報とレポート要件を管理できるようにサポートできると主張します。
原文 (English)
Artificial Intelligence in Ship Finance: Applications, Opportunities, and a Case Study in AI-Augmented Loan Origination
Ship finance is a data-intensive and document-heavy segment of asset-based lending, requiring the integration of financial, technical, contractual, and regulatory information from heterogeneous and largely unstructured sources. Increasing environmental regulation and ESG reporting requirements are adding further complexity to underwriting and loan-origination processes. Recent advances in artificial intelligence (AI), particularly large language models (LLMs), create new opportunities for processing and analysing such information. This paper reviews potential applications of AI in ship finance, with a particular focus on LLM-based systems for document comprehension, information extraction, and workflow automation. We present ShipFinance.ai, a modular agentic architecture to support loan application workflows in ship finance. The proposed system combines an LLM-based extraction module, financial analysis components, external maritime data services, and a controlled document-generation module with a chatbot interface to support the preparation of standardized financing applications. The paper discusses the key challenges for using such models in production. We argue that AI-assisted systems can support maritime finance professionals in managing increasingly complex information and reporting requirements.
SPEAR: 効率的な低ビット LLM サービングを可能にする量子化後のエラー適応回復システム
大規模言語モデル (LLM) を効率的に提供するには、展開コストによる制約がますます高まっています。量子化はサービング コストを削減するための重要な技術ですが、最先端の 4 ビット量子化器でも、特に低ビット サービングが最も有益な小規模モデルの場合、FP16 との顕著な品質ギャップが見られます。私たちは、このギャップの根本的な原因を特定しました。量子化誤差は入力に大きく依存しており、トークン間で大幅に変動しますが、既存の量子化後の補償方法は静的であり、すべての入力に同一の補正を適用します。その結果、イージー トークンは過剰に修正されますが、ハード トークンは修正が不十分なままになります。我々は、低ビット LLM の提供を改善する量子化後の誤差適応回復システムである SPEAR を紹介します。 SPEAR は、トークンごとのゲートによって変調された軽量のエラー補償器 (EC) を導入し、CKA ガイドによるエントロピー対応診断を通じて特定された最もエラーに敏感なレイヤーにのみそれらを配置します。これにより、最も効果的な小さなパラメータ バジェットに焦点が当てられます。 EC を効率的に展開するには、追加の計算、入力依存のゲーティングによって引き起こされるテンソル並列同期、構成全体でのレイテンシの不安定性など、いくつかのシステム課題が発生します。 SPEAR は、アダプティブ カーネル フュージョン ディスパッチを通じてこれらの問題に対処し、エピローグに統合されたピア リダクション カーネルと P2P デュアル書き込みを組み合わせて EC 後の計算を低ビット GEMM に融合し、SLO 制約のある EC 対応スケジューラを使用して予測可能なサービス パフォーマンスを実現します。困難なチャネルごとの量子化設定全体にわたって、SPEAR は W4 と FP16 の間の複雑さのギャップの 56 ~ 75% を回復しながら、追加するモデル メモリのオーバーヘッドは 1% 未満であり、広く使用されている 4 ビット サービング デプロイメントと同等のレイテンシーを維持します。
原文 (English)
SPEAR: A System for Post-Quantization Error-Adaptive Recovery Enabling Efficient Low-Bit LLM Serving
Efficient large language model (LLM) serving is increasingly constrained by deployment cost. Quantization is a key technique for reducing serving cost, yet even state-of-the-art 4-bit quantizers exhibit a noticeable quality gap from FP16, particularly for smaller models where low-bit serving is most beneficial. We identify a fundamental cause of this gap: quantization error is highly input-dependent and varies substantially across tokens, while existing post-quantization compensation methods are static and apply identical corrections to all inputs. As a result, easy tokens are over-corrected while hard tokens remain under-corrected. We present SPEAR, a system for post-quantization error-adaptive recovery that improves low-bit LLM serving. SPEAR introduces lightweight Error Compensators (ECs) modulated by per-token gates and places them only at the most error-sensitive layers identified through a CKA-guided entropy-aware diagnostic. This focuses a small parameter budget where it is most effective. Efficient deployment of ECs presents several systems challenges, including additional computation, tensor-parallel synchronization caused by input-dependent gating, and latency instability across configurations. SPEAR addresses these issues through adaptive kernel-fusion dispatch, combining an epilogue-integrated peer-reduction kernel with P2P dual-write to fuse the post-EC computation into low-bit GEMMs, and an SLO-constrained EC-aware scheduler for predictable serving performance. Across challenging per-channel quantization settings, SPEAR recovers 56-75% of the perplexity gap between W4 and FP16 while adding less than 1% model memory overhead and maintaining latency comparable to a widely used 4-bit serving deployment.
半導体製造向けの物理学に基づいた生成 AI: 構築により生成モデルに厳しい物理的制約を強制する
生成モデルは、物理システムの設計、データ、および制御動作を提案するためにますます使用されていますが、そのようなシステムの多くは、知覚的な妥当性ではなく、厳しい物理的制約によって支配されています。半導体製造では、要求の厳しいテストケースが提供されます。物理的に無効なサンプルは、単に品質が低いだけでなく使用できないため、生成されたマスク、レイアウト、合成欠陥データ、およびプロセスレシピは、リソグラフィー、輸送、反応、およびデバイスの物理的制約に従わなければなりません。この展望では、半導体製造は、より広範な計算科学の課題を明らかにしている、つまり、制約された物理領域の生成 AI は、ポストホック フィルタリングだけで修正するのではなく、構築によって物理情報を反映する必要がある、と主張しています。私たちは、物理学に基づいた拡散、偏微分方程式制約変分モデル、ニューラル演算子の事前分布、保存則を尊重した生成ネットワークなどの新たなアーキテクチャ ツールキットを調査し、それが微分可能リソグラフィー、TCAD、プロセス シミュレーション、および自律実験にどのように接続されるかを示します。私たちは、生成モデルと物理ベースのシミュレーターの間の 4 つの統合パターンを特定し、物理的忠実性ベンチマーク、微分可能なシミュレーター インフラストラクチャ、および物理設計と製造のためのマルチモーダル基礎モデルを中心とした研究課題を提案します。中心的な主張は修辞的というよりは分析的である。物理的妥当性が成功の拘束力のある基準である場合、それを構築によって強制するアーキテクチャは、事後的にそれをフィルタリングするアーキテクチャよりも優れたパフォーマンスを発揮することが期待されるべきであり、ファブはこの区別が最も明確になる環境である。
原文 (English)
Physics-informed generative AI for semiconductor manufacturing: Enforcing hard physical constraints in generative models by construction
Generative models are increasingly used to propose designs, data, and control actions for physical systems, yet many such systems are governed by hard physical constraints rather than by perceptual plausibility. Semiconductor manufacturing provides a demanding test case: generated masks, layouts, synthetic defect data, and process recipes must obey lithography, transport, reaction, and device-physics constraints, because physically invalid samples are not merely low quality but unusable. This Perspective argues that semiconductor manufacturing exposes a broader computational-science challenge, namely that generative AI for constrained physical domains must be physics-informed by construction, not corrected only through post-hoc filtering. We survey the emerging architectural toolkit, including physics-informed diffusion, PDE-constrained variational models, neural-operator priors, and conservation-law-respecting generative networks, and show how it connects to differentiable lithography, TCAD, process simulation, and autonomous experimentation. We identify four integration patterns between generative models and physics-based simulators, and we propose a research agenda centered on physics-fidelity benchmarks, differentiable simulator infrastructure, and multimodal foundation models for physical design and manufacturing. The central claim is analytical rather than rhetorical: where physical validity is the binding criterion of success, architectures that enforce it by construction should be expected to outperform those that filter for it after the fact, and the fab is the setting where this distinction is sharpest.
RAIL: CHC に基づいたベンチマークを使用して、大規模な音声言語モデルにおける聴覚知能を再考する
人間は、音声知覚、音声推論、記憶などの緊密に統合された認知機能を通じて、豊かな聴覚環境を処理します。音声理解とマルチモーダル音声推論にわたる大規模音声言語モデル (LALM) の最近の進歩にも関わらず、現在の評価パラダイムは依然として主にタスクまたはモダリティ中心であり、根底にある聴覚認知行動を無視しながら最終パフォーマンスに焦点を当てています。これは、人間における聴覚認知の理解方法とLALMにおける聴覚認知の評価方法との間に根本的なギャップがあること、特にモデルの行動を体系的に捉えるためにタスクレベルの測定基準を超えて認知原理を運用するフレームワークが欠如していることを明らかにしています。この研究では、Cattell-Horn-Carroll (CHC) 認知フレームワークに基づいた人間中心の評価パラダイムである RAIL を紹介します。 RAIL は、聴覚認知を 5 つのコア機能に形式化し、モデルが聴覚情報をどのように処理、保持、統合するかを調査する構造化された評価タスクに開発します。さらに、原則に基づいたデータキュレーションと人間に合わせた評価プロトコルを使用して、認知に基づいたベンチマークを構築します。 26 個の最先端の LALM を評価したところ、現在のモデルは認知能力全体にわたって非常に不均一なパフォーマンスを示していることがわかりました。 RAIL は、タスク中心のベンチマークを超えて、認知に基づいた聴覚知能の評価に向かう新しい評価パラダイムを確立します。
原文 (English)
RAIL: Rethinking Auditory Intelligence in Large Audio-Language Models with a CHC-Grounded Benchmark
Humans process rich auditory environments through tightly integrated cognitive capabilities such as audio perception, audio reasoning, and memory. Despite recent progress in large audio-language models (LALMs) across speech understanding and multimodal audio reasoning, current evaluation paradigms remain largely task- or modality-centric, focusing on end performance while overlooking underlying auditory cognitive behaviours. This reveals a fundamental gap between how auditory cognition is understood in humans and how it is evaluated in LALMs, particularly in the lack of frameworks that operationalise cognitive principles beyond task-level metrics to systematically capture model behaviour. In this work, we introduce RAIL, a human-centric evaluation paradigm grounded in the Cattell-Horn-Carroll (CHC) cognitive framework. RAIL formalises auditory cognition into five core capabilities and develop them into structured evaluation tasks that probe how models process, retain, and integrate auditory information. We further construct a cognitively grounded benchmark with principled data curation and human-aligned evaluation protocols. Evaluating 26 state-of-the-art LALMs, we find that current models exhibit highly uneven performance across cognitive abilities. RAIL establishes a new evaluation paradigm that moves beyond task-centric benchmarking toward cognitively grounded assessment of auditory intelligence.
PermDoRA -- 言語モデルにおけるアダプター干渉の理解: パラメーター空間ジオメトリの制限
大規模言語モデル (LLM) のアクセス制御には、再トレーニングやクロスドメイン干渉なしでドメイン固有の動作を可能にするモジュール式メカニズムが必要です。一般的な仮説は、アダプター構成中の干渉は線形パラメーター更新の重複から発生するというもので、直交性または方向独立性を強制することでマルチドメインのパフォーマンスが向上するはずであることを示唆しています。重み分解された低ランク適応に基づく階層アダプター構成フレームワークである DoRA-RBAC を使用して、この仮説を検証します。従来のユークリッド結合と、LLaMA-3.1-8B および Mistral-7B 上の複数の QA ベンチマーク (GPQA、PubMedQA、SimpleQA、WMDP) にわたる正規化された方向平均を介してフレシェ平均を近似する、幾何学を意識したリーマンにヒントを得た結合戦略と比較します。私たちの結果は、単一ドメインのパフォーマンスは LoRA と一致しますが、ジオメトリを意識したマージは、マルチドメイン設定における標準の平均化よりも一貫した利点が得られないことを示しています。さらに、診断分析により、角度の位置合わせとアダプターの更新の直交性が構成パフォーマンスの弱い予測因子であることが明らかになりました。これらの発見は、アダプターの干渉が主にパラメーター空間の幾何学によって支配されるのではなく、共有非線形表現における相互作用と一致していることを示唆しています。
原文 (English)
PermDoRA -- Understanding Adapter Interference in Language Models: Limits of Parameter-Space Geometry
Access control in large language models (LLMs) requires modular mechanisms to enable domain-specific behavior without retraining or cross-domain interference. A common hypothesis is that interference during adapter composition arises from overlap in linear parameter updates, suggesting that enforcing orthogonality or directional independence should improve multi-domain performance. We test this hypothesis using DoRA-RBAC, a hierarchical adapter composition framework based on weight-decomposed low-rank adaptation. We compare conventional Euclidean merging with a geometry-aware Riemannian-inspired merging strategy that approximates the Frechet mean via normalized directional averaging across multiple QA benchmarks (GPQA, PubMedQA, SimpleQA, WMDP) on LLaMA-3.1-8B and Mistral-7B. Our results show that while single-domain performance matches LoRA, geometry-aware merging provides no consistent advantage over standard averaging in multi-domain settings.Diagnostic analysis further reveals that angular alignment and orthogonality of adapter updates are weak predictors of composition performance. These findings suggest that adapter interference is not governed primarily by parameter-space geometry, but is instead consistent with interactions in shared nonlinear representations.
OmniBioTwin: 医療デジタルツインのためのシステムオブツインシステムフレームワーク
医療デジタル ツイン (HDT) は、患者固有のモデリングと意思決定のサポートを約束しますが、現在のアプローチは構造的に断片化したままです。単一の臓器またはタスクに対処するモノリシック モデルにはスケール間の忠実度が欠けており、システム レベルのツインには一般化可能なアーキテクチャ フレームワークがありません。私たちは、多層ネットワーク アーキテクチャ内で明示的な相互作用演算子を介して結合されたモジュール式の計算エンティティとして HDT を組織する System-of-Twinned-Systems (SoTS) フレームワークである OmniBioTwin を提案します。このフレームワークは、データ統合、自律ツイン モデリング、クロススケール カップリング、時間同期、人間参加型意思決定サポートにまたがる 7 つの調整されたレイヤーで構成されています。私たちは、アルツハイマー病におけるグルカゴン様ペプチド 1 (GLP-1) シグナル伝達経路のマルチスケール ツインをインスタンス化することで OmniBioTwin を実証し、統一システム内で分子レベル、細胞レベル、臓器レベルの双子がどのように構成され結合できるかを示します。
原文 (English)
OmniBioTwin: A System-of-Twinned-Systems Framework for Health Digital Twins
Health digital twins (HDTs) promise patient-specific modeling and decision support but current approaches remain structurally fragmented: monolithic models that address a single organ or task lack cross-scale fidelity, while system-level twins lack generalizable architectural frameworks. We propose OmniBioTwin, a System-of-Twinned-Systems (SoTS) framework that organizes HDTs as modular computational entities coupled through explicit interaction operators within a multi-layer network architecture. The framework comprises seven coordinated layers - spanning data integration, autonomous twin modeling, cross-scale coupling, temporal synchronization, and human-in-the-loop decision support. We demonstrate OmniBioTwin by instantiating a multiscale twin for glucagon-like peptide-1 (GLP-1) signaling pathways in Alzheimer's disease, illustrating how molecular, cellular, and organ-level twins can be composed and coupled within a unified system.
取得後にポイズンが失敗した場合: パイプラインのチャンク化と再ランキングの下でコーパスポイズニングを再考する
検索拡張生成 (RAG) システムは、悪意のある知識の注入を通じて下流のモデル出力を操作するコーパス ポイズニング攻撃に対して脆弱です。既存の研究は主に、簡素化された取得設定の下でポイズニングを評価しており、ドキュメントのチャンク化、高密度の取得、再ランキング、およびグラウンディングされた生成を含む実際の RAG パイプラインを見落としています。この論文では、現実的な多段階の検索パイプラインの下でコーパスポイズニングを再検討し、多くの既存の攻撃が、高い検索段階の関連性を達成したにもかかわらず、再ランク付け後に大幅に低下することを示します。私たちは、この失敗の主な理由として、検索粒度の不一致を特定しました。ドキュメントレベルの敵対的シグナルは、チャンク化中に断片化されることがよくありますが、リランカーは、グローバルに最適化されたセマンティックな類似性よりも、ローカルで一貫性があり、回答が含まれるパッセージを好みます。この観察に基づいて、取得の関連性、リランカーの一貫性、およびチャンク境界の堅牢性を共同で最適化するポイズニング フレームワークであるチャンク対応およびリランク一貫性ポイズニング (CRCP) を提案します。 CRCP は、最適化中にチャンキング変換を明示的にモデル化し、さまざまなチャンキング構成の下でも効果を維持する、局所的に自己完結型の敵対的なパッセージを生成します。複数のリトリーバーとリランカーを使用した標準的な RAG ベンチマークの実験では、既存のポイズニング手法がチャンク サイズとリランカー戦略に非常に敏感であるのに対し、CRCP は現実的な検索パイプライン全体で大幅に高い攻撃成功率と強力な堅牢性を達成していることが示されています。私たちの調査結果は、現在の RAG セキュリティ評価における現実性の重要なギャップを浮き彫りにし、最新の RAG システムにおけるポイズニングは、検索のみの問題ではなく、多段階の検索一貫性の問題として研究されるべきであることを示唆しています。
原文 (English)
When Poison Fails After Retrieval: Revisiting Corpus Poisoning under Chunking and Reranking Pipelines
Retrieval-Augmented Generation (RAG) systems are vulnerable to corpus poisoning attacks that manipulate downstream model outputs through malicious knowledge injection. Existing studies mainly evaluate poisoning under simplified retrieval settings, overlooking practical RAG pipelines involving document chunking, dense retrieval, reranking, and grounded generation. In this paper, we revisit corpus poisoning under realistic multi-stage retrieval pipelines and show that many existing attacks substantially degrade after reranking despite achieving high retrieval-stage relevance. We identify retrieval granularity mismatch as a key reason for this failure: document-level adversarial signals are often fragmented during chunking, while rerankers favor locally coherent and answer-bearing passages rather than globally optimized semantic similarity. Based on this observation, we propose Chunk-aware and Rerank-Consistent Poisoning (CRCP), a poisoning framework that jointly optimizes retrieval relevance, reranker consistency, and chunk-boundary robustness. CRCP explicitly models chunking transformations during optimization to generate locally self-contained adversarial passages that remain effective under varying chunking configurations. Experiments on standard RAG benchmarks with multiple retrievers and rerankers show that existing poisoning methods are highly sensitive to chunk size and reranking strategies, whereas CRCP achieves substantially higher attack success rates and stronger robustness across realistic retrieval pipelines. Our findings highlight an important realism gap in current RAG security evaluation and suggest that poisoning in modern RAG systems should be studied as a multi-stage retrieval consistency problem rather than a retrieval-only problem.
言語モデル蒸留における潜在意識の行動伝達率の定量化
良性の動作を生徒モデルに伝達することを目的とした言語モデルの蒸留は、望ましくない特性が教師モデルに存在する場合、それを伝達する可能性もあり、これは潜在意識学習として知られる現象です。定性的証拠はこの効果の存在を裏付けていますが、その規模は体系的に特徴づけられていません。この研究では、2 つの教師モデル (Llama-2-7B-Chat と Qwen2.5-7B-Instruct) をさまざまなステアリング強度でステアリングし、良性のデータのみを使用して生徒モデルを抽出することにより、サブリミナル行動伝達率を定量化します。 GPT-4.1 を評価者として使用して 100 個の JailbreakBench プロンプトを評価したところ、転送は堅牢であるものの、独特のスケーリング動作を示すことがわかりました。 Llama-2 は鋭いしきい値 ($\tau = {0.25,0.32} \ \text{beyond} \ \alpha = -0.15$) を示しますが、Qwen2.5 は継続的かつより高いレベルの転送 ($\tau$ 〜 $0.61$) を示します。
原文 (English)
Quantifying Subliminal Behavioral Transfer Ratios in Language Model Distillation
Distillation of a language model intended to transfer benign behavior to a student model may also transfer undesirable characteristics, if they are present in the teacher model, a phenomenon known as subliminal learning. While qualitative evidence supports the existence of this effect, its magnitude has not been systematically characterized. This study quantifies subliminal behavioral transfer ratios by steering two teacher models (Llama-2-7B-Chat and Qwen2.5-7B-Instruct) at varying steering strengths and distilling student models using only benign data. Evaluation on 100 JailbreakBench prompts with GPT-4.1, serving as the evaluator, indicates that transfer is robust but exhibits distinct scaling behaviors. Llama-2 demonstrates a sharp threshold ($\tau = {0.25,0.32} \ \text{beyond} \ \alpha = -0.15$), whereas Qwen2.5 displays continuous and higher levels of transfer ($\tau$ up to $0.61$).
フェデレーションによる継続的学習: 分散された非定常データを使用した生涯学習とプライバシー保護学習に関する包括的な調査
フェデレーテッド ラーニング (FL) により、分散クライアント全体での協調的かつプライバシー保護のモデル トレーニングが可能になりますが、既存の FL システムのほとんどは暗黙的にデータの定常性を前提としています。ヘルスケア、産業用 IoT (IIOT)、サイバーセキュリティ、スマート シティなどの実世界の設定では、データ ストリームは本質的に非定常であるため、従来の FL 手法ではパフォーマンスの低下、不安定性、壊滅的な忘却が発生します。継続学習 (CL) は、進化するデータ分散の下での学習に取り組んでいますが、主に集中型の設定で研究されており、プライバシー、限られた通信、クライアントの異質性など、フェデレーテッド システムの主要な制約が見落とされています。 Federated Continual Learning (FCL) は、FL と CL の交差点で誕生し、分散型の非定常データに対する生涯にわたる適応型でプライバシーを意識した学習をサポートすることを目的としています。この調査は、FCL の包括的かつ体系的な概要を提供します。まず、FCL 問題の正式な定義を提示し、その特有の特徴を明らかにします。次に、非定常条件下での古典的な FL の限界を分析し、CL の原理が長期的な適応をどのようにサポートするかを強調します。急速に増加する文献を整理するために、我々は FCL アプローチの多次元分類を提案します。さらに、代表的なアプリケーション ドメインとデータ モダリティを検討し、一般的に使用される評価指標を要約し、長期的なパフォーマンスと忘却を評価するための実験的観点について議論します。最後に、時間的ドリフト下での極端な異質性の処理、スケーラブルでプライバシーを保護するメモリ メカニズムの設計、標準化されたベンチマークの確立など、未解決の重要な課題を取り上げます。この調査は、FCL を堅牢で展開可能な現実世界のシステムに向けて推進するための参考およびロードマップとして機能することを目的としています。
原文 (English)
Federated continual learning: A comprehensive survey on lifelong and privacy-preserving learning over distributed and non-stationary data
Federated Learning (FL) enables collaborative and privacy-preserving model training across distributed clients, but most existing FL systems implicitly assume data stationarity. In real-world settings-such as healthcare, industrial IoT (IIOT), cybersecurity, and smart cities-data streams are inherently non-stationary, leading classical FL methods to suffer from performance degradation, instability, and catastrophic forgetting. Continual Learning (CL) addresses learning under evolving data distributions but has been largely studied in centralized settings, overlooking key constraints of federated systems, including privacy, limited communication, and client heterogeneity. Federated Continual Learning (FCL) emerges at the intersection of FL and CL, aiming to support lifelong, adaptive, and privacy-aware learning over distributed and non-stationary data. This survey provides a comprehensive and systematic overview of FCL. We first present a formal definition of the FCL problem and clarify its distinctive characteristics. We then analyze the limitations of classical FL under non-stationary conditions, highlighting how CL principles support long-term adaptation. To organize the rapidly growing literature, we propose a multi-dimensional taxonomy of FCL approaches. Furthermore, we review representative application domains and data modalities, summarize commonly used evaluation metrics, and discuss experimental perspectives for assessing long-term performance and forgetting. Finally, we highlight key open challenges, including handling extreme heterogeneity under temporal drift, designing scalable and privacy-preserving memory mechanisms, and establishing standardized benchmarks. This survey aims to serve as a reference and a roadmap for advancing FCL toward robust and deployable real-world systems.
RoVE: 相対位置依存の値経路に対するロータリー値の埋め込みの注意
Rotary Position Embeddings (RoPE) は、アテンション スコアを位置相対にしますが、値経路の位置をブラインドのままにします。つまり、値トークンによって送信されるメッセージは、クエリからの距離に関係なく同じです。キーと同時に値を回転させることで値を位置に依存させるパラメータフリーの変更である RoVE を提案し、それが RoPE の注意を注意深い畳み込みに変えることを示します。この新しい視点は、コンピューター ビジョン、ロボット工学、最新の LLM アーキテクチャにわたる同じ操作のいくつかの独立した定式化を統合します。トレーニングされた 1 億 2,400 万および 3 億 5,400 万の GPT-2 モデルは、少数ショットのコンテキスト内学習、分布外のパープレキシティ、および長いコンテキストの取得において RoPE と比較して一貫した経験的利点を示し、長距離の集約を必要とするタスクで最も明確な改善が見られます。
原文 (English)
RoVE: Rotary Value Embeddings Attention for Relative Position-dependent Value Pathways
Rotary Position Embeddings (RoPE) make attention scores position-relative but leave the value pathway position-blind: the message sent by a value token is the same regardless of its distance from the query. We propose RoVE, a parameter-free modification that makes values position-sensitive by rotating them simultaneously with keys, and show that it turns RoPE attention into attentive convolution. This new perspective unifies several independent formulations of the same operation across computer vision, robotics, and modern LLM architectures. Trained 124M and 354M GPT-2 models show consistent empirical gains over RoPE on few-shot in-context learning, out-of-distribution perplexity, and long-context retrieval, with the clearest improvements on tasks that require long-range aggregation.
FreeBridge: 細胞移行ダイナミクスのための変分シュルディング ブリッジ
ハイコンテンツイメージングアッセイは、化学的および遺伝的摂動に対する細胞反応を定量化しますが、細胞は取得時に化学的に固定されているため、個々の細胞の連続的な軌跡は観察できません。したがって、摂動モデリングは、別個の限界としてのみ観察される対照集団と処理集団の間の確率的輸送を推測することに帰着します。最近の生成モデルは強力な終点アライメントを実現しますが、境界の一貫性は中間進化を決定しません。複数の確率過程が、観察された単一細胞の形態によって裏付けられていない領域を横断しながら、同一の辺縁を接続する可能性があります。エンドポイントのみの監視下での単一セル遷移モデリングのための Schr\"odinger Bridge 定式化である \textbf{FreeBridge} を導入します。FreeBridge は原子状態をインスタンスでセグメント化された単一セル表現として定義し、固定セル多様体を確立し、経験的な潜在サポート正則化を通じてこのジオメトリ内に制約された確率的輸送を学習します。BBBC021、RxRx1、および JUMP 全体で、FreeBridge は次のことを維持します。 BBBC021 では、統一された評価プロトコルの下でエンドポイントの忠実度や作用機序の保持が向上し、これらの結果は生物学的に解釈可能な摂動ダイナミクスのための幾何学的基礎の重要性を強調しています。
原文 (English)
FreeBridge: Variational Schr\"odinger Bridges for Cellular Transition Dynamics
High-content imaging assays quantify cellular responses to chemical and genetic perturbations, yet continuous trajectories of individual cells are unobservable because cells are chemically fixed at acquisition. Perturbation modeling therefore reduces to inferring stochastic transport between control and treated populations observed only as separate marginals. While recent generative models achieve strong end-point alignment, boundary consistency does not determine intermediate evolution: multiple stochastic processes may connect identical marginals while traversing regions unsupported by observed single-cell morphologies. We introduce \textbf{FreeBridge}, a Schr\"odinger Bridge formulation for single-cell transition modeling under endpoint-only supervision. FreeBridge defines atomic states as instance-segmented single-cell representations, establishing a fixed cellular manifold, and learns stochastic transport constrained within this geometry via empirical latent support regularization. Across BBBC021, RxRx1, and JUMP, FreeBridge maintains competitive or improved endpoint fidelity and mechanism-of-action retention under a unified evaluation protocol; on BBBC021, it further reduces intermediate support violations. These findings highlight the importance of geometric grounding for biologically interpretable perturbation dynamics. Project page: https://y-research-sbu.github.io/FreeBridge/.
FlowBank: 事前計算と再利用によるクエリ適応型エージェント ワークフローの最適化
Large Language Model (LLM) ベースのマルチエージェント システムはますます強力になっていますが、現在のエージェント ワークフロー最適化パラダイムでは満足のいくトレードオフが生じています。タスク レベルのメソッドは、オフライン コンピューティングをかなり消費しますが、デプロイするワークフローは 1 つだけで、補完的な候補は未使用のままになります。一方、クエリ レベルのメソッドは、かなりの推論コストをかけてクエリごとに新しいワークフローを合成します。私たちの動機付けとなる分析では、これらのパラダイムは競合するものではなく、補完的なものであることが示されています。オフライン検索中に発見されたワークフローは、クエリのさまざまなサブセットを解決することが多く、高価なクエリレベルの生成で処理されるクエリの多くは、安価な事前計算ワークフローですでに解決できます。これは別の目的を示唆しています。普遍的に最適な 1 つのワークフローを検索したり、インスタンスごとに 1 つを再生成したりするのではなく、再利用可能な補完的なワークフローのコンパクトなバンクを構築し、推論時にそれらの中から適応的に選択する必要があります。そのためには、冗長ではなく補完的な候補を生成すること、それらを小規模な展開可能なポートフォリオに圧縮すること、そしてパフォーマンスとコストのトレードオフの下で各クエリを適切なワークフローに割り当てることという 3 つの関連した問題を解決する必要があります。この目的を達成するために、ポートフォリオベースのエージェントワークフロー最適化のための 3 段階のフレームワークである FlowBank を紹介します。 Diversifying は、カバーされていないクエリに検索を誘導し、カバー範囲の高い候補プールを生成するために DiverseFlow を提案します。 Curating は、CuraFlow がこのプールを冗長性を最小限に抑えたコンパクトなポートフォリオに圧縮することを提案しています。マッチングは、クエリ ワークフローの 2 部グラフ上のエッジ値予測としてデプロイメントをキャストし、各受信クエリを最良の予測ユーティリティでポートフォリオ メンバーにルーティングします。 5 つのベンチマーク全体で、FlowBank はコスト競争力を維持しながら、評価されたメソッドの中で最も高い平均スコアを達成し、最も強力な自動ベースラインと手動ベースラインよりも相対的にそれぞれ 4.26% と 14.92% 改善しました。
原文 (English)
FlowBank: Query-Adaptive Agentic Workflows Optimization through Precompute-and-Reuse
Large Language Model (LLM)-based multi-agent systems are increasingly powerful, but current agentic workflow optimization paradigms make an unsatisfying trade-off. Task-level methods spend substantial offline compute yet deploy only a single workflow, leaving complementary candidates unused, while query-level methods synthesize a new workflow per query at substantial inference cost. Our motivating analysis shows these paradigms are more complementary than competing: workflows discovered during offline search often solve different subsets of queries, and many queries handled by expensive query-level generation can already be solved by cheaper precomputed workflows. This suggests a different objective: rather than searching for one universally best workflow or regenerating one per instance, we should build a compact bank of reusable, complementary workflows and select among them adaptively at inference time. Doing so requires solving three coupled problems: generating complementary rather than redundant candidates, compressing them into a small deployable portfolio, and assigning each query to the right workflow under a performance-cost trade-off. To this end, we present FlowBank, a three-stage framework for portfolio-based agentic workflow optimization. Diversifying proposes DiverseFlow to steer search toward under-covered queries and produce a high-coverage candidate pool. Curating proposes CuraFlow to compress this pool into a compact portfolio with minimal redundancy. Matching casts deployment as edge-value prediction on a query-workflow bipartite graph and routes each incoming query to the portfolio member with the best predicted utility. Across five benchmarks, FlowBank achieves the highest average score among the evaluated methods while remaining cost-competitive, improving over the strongest automated and handcrafted baselines by 4.26% and 14.92% relative, respectively.
Embodied-R1.5: 身体化された基盤モデルによる物理的知性の進化
私たちは、身体的認知、タスク計画、修正、ポインティングに及ぶ包括的な身体的推論機能を、一般的な身体的知能に向けた単一のアーキテクチャ内に統合する、統合された身体的基盤モデル (EFM) である Embodied-R1.5 を紹介します。 3 つの自動データ構築パイプラインを活用して重要な機能のデータ範囲を大幅に拡大し、150 億トークンを超える大規模なデータ システムを構築し、異種タスクの競合を軽減するマルチタスクのバランスのとれた RL レシピを設計します。さらに、単一のモデルが長期的なタスクにわたって自律的に実行および自己修正できるようにする Planner-Grounder-Corrector (PGC) 閉ループ フレームワークを導入します。 Embodied-R1.5 は、わずか 8B のパラメーターで、24 のエンボディド VLM ベンチマークのうち 16 で SOTA を達成し、Gemini-Robotics-ER-1.5 や GPT-5.4 などの主要モデルを上回っています。 Embodied-R1.5 は、内部化されたエンボディド機能の利点を活用して、少量のデータのみで VLA に微調整でき、4 つの一般的な操作ベンチマーク スイート全体で $\pi_{0.5}$ などの主要な VLA モデルを上回るパフォーマンスを発揮します。さらに、大規模なゼロショットの実際のロボット実験を実施し、命令追従、アフォーダンス グラウンディング、多関節オブジェクトの操作、および長期にわたる複雑なタスクのパフォーマンスを検証し、物理世界への強力な一般化を実証します。 EFM における将来の研究を促進するために、モデルの重み、データセット、トレーニング コード、および具体化されたタスクに合わせた評価フレームワークである EmbodiedEvalKit をオープンソースにしています。
原文 (English)
Embodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
We introduce Embodied-R1.5, a unified Embodied Foundation Model (EFM) that integrates comprehensive embodied reasoning capabilities, spanning embodied cognition, task planning, correction, and pointing, within a single architecture toward general physical intelligence. Leveraging three automated data construction pipelines to significantly expand the data coverage of critical capabilities, we build a large-scale data system of over 15B tokens, and design a multi-task balanced RL recipe to alleviate heterogeneous task conflicts. We further introduce a Planner-Grounder-Corrector (PGC) closed-loop framework that enables a single model to autonomously execute and self-correct over long-horizon tasks. With only 8B parameters, Embodied-R1.5 achieves SOTA on 16 out of 24 embodied VLM benchmarks, surpassing leading models like Gemini-Robotics-ER-1.5 and GPT-5.4. Benefiting from the internalized embodied capabilities, Embodied-R1.5 can be fine-tuned into a VLA with only a small amount of data, outperforming leading VLA models like $\pi_{0.5}$ across 4 popular manipulation benchmark suites. We further conduct extensive zero-shot real-robot experiments, validating performance in instruction following, affordance grounding, articulated object manipulation, and long-horizon complex tasks, demonstrating strong generalization to the physical world. We open-source model weights, datasets, training code, and EmbodiedEvalKit, an evaluation framework tailored for embodied tasks, to facilitate future research in EFMs.
緩和された大域幾何学の下での分散最適化のための量子化確率的主双対法
私たちは、ランダム(不偏)量子化によってモデル化された確率的勾配と有限ビット通信を使用した分散最適化を研究します。量子化確率的主双対法である q-PDGD を提案し、緩和大域幾何学のもとで解析します。制限セカント不等式 (RSI) では、ステップ サイズを一定にすると、勾配ノイズ、量子化歪み、ネットワーク接続性によって決定される明示的な近傍への線形縮小が得られますが、ステップ サイズが減少すると、共有ミニマイザーの仮定なしで O(1/k) の収束が達成されます。 Polyak-Lojasiewicz (PL) 不等式の下では、同じ確率的量子化設定で線形から近傍への収束が得られます。私たちの結果は、オラクルの複雑さにおける最もよく知られている集中型確率率と一致しており、量子化レベル、ステップサイズの選択、およびグラフ構造の間の予測されたトレードオフを実証する実験によって裏付けられています。
原文 (English)
Quantized Stochastic Primal-Dual Methods for Distributed Optimization under Relaxed Global Geometry
We study distributed optimization with stochastic gradients and finite-bit communication modeled by random (unbiased) quantization. We propose q-PDGD, a quantized stochastic primal-dual method, and analyze it under relaxed global geometry. Under restricted secant inequality (RSI), a constant step-size yields linear contraction to an explicit neighborhood determined by gradient noise, quantization distortion, and network connectivity, while a diminishing step-size achieves O(1/k) convergence without shared-minimizer assumptions. Under Polyak-Lojasiewicz (PL) inequality, we obtain linear-to-neighborhood convergence in the same stochastic quantized setting. Our results match the best-known centralized stochastic rates in oracle complexity, and are supported by experiments demonstrating the predicted tradeoffs between quantization level, step-size choice, and graph structure.
TileFuse: AMD NPU での効率的な量子化 LLM 推論のための融合型混合精度カーネル ライブラリ
オンデバイス LLM 推論に対する需要の高まりに伴い、厳しい電力と熱のバジェットの下でパフォーマンスとエネルギー効率を向上させるために、エッジ SoC は NPU を統合することが増えています。しかし、現在のクライアント NPU に実際に LLM を導入することは依然として困難です。AWQ などの広く使用されている量子化形式は、多くの既存の NPU ソフトウェア スタックにきれいにマッピングされておらず、多くの場合独自仕様であり、低レベルの制御が制限されています。この研究では、量子化 LLM 推論におけるトランス線形層をターゲットとする、AMD XDNA2 NPU 用のメタルに近い混合精度カーネル ライブラリである \textit{TileFuse} を紹介します。 TileFuse は、NPU 固有の量子化スキームに基づいてモデルを強制的に再形成するのではなく、AWQ スタイルの W4A16 や W8A16 などの実用的な低ビット フォーマットを XDNA2 に直接導入します。 TileFuse は、重みレイアウト、メタデータ配置、混合精度マイクロカーネル、配列レベルのデータフローを共同設計します。具体的には、アンパッキング、逆量子化、GEMM/GEMV の実行を単一のカーネル フローに融合し、最大 32K の GEMM 次元をサポートするインターリーブ プレタイリング レイアウトを導入し、完全な 4x8 AIE アレイを利用するように GEMV データフローを再設計します。カーネル レベルの評価全体で、TileFuse は、完全精度のベースラインと比較して、GEMM で最大 121.6%、GEMV で 281% パフォーマンスが向上し、GEMM 上の強力な iGPU ベースラインと比較して 2 倍を超えるパフォーマンスとエネルギー効率の向上を実現します。 Ryzen AI ラップトップでのエンドツーエンド LLM 実験では、TileFuse は、エネルギー消費量を 64.6% 以上削減し、プレフィル レイテンシーを最大 2.0 倍短縮することを達成しました。これらの結果を総合すると、XDNA2 が AWQ スタイルのエッジ LLM 推論の実用的なターゲットであること、および既製の量子化に対するネイティブ NPU サポートにより、実際のクライアント展開で NPU が大幅に使いやすくなることがわかります。
原文 (English)
TileFuse: A Fused Mixed-Precision Kernel Library for Efficient Quantized LLM Inference on AMD NPUs
With the growing demand for on-device LLM inference, edge SoCs increasingly integrate NPUs to improve performance and energy efficiency under tight power and thermal budgets. However, practical LLM deployment on current client NPUs remains difficult: widely used quantization formats such as AWQ do not map cleanly onto many existing NPU software stacks, which are often proprietary and expose limited low-level control. In this work, we present \textit{TileFuse}, a close-to-metal mixed-precision kernel library for AMD XDNA2 NPUs that targets transformer linear layers in quantized LLM inference. TileFuse brings practical low-bit formats such as AWQ-style W4A16 and W8A16 directly onto XDNA2, rather than forcing the model to be reshaped around an NPU-specific quantization scheme. TileFuse co-designs weight layout, metadata placement, mixed-precision microkernels, and array-level dataflow. Specifically, it fuses unpacking, dequantization, and GEMM/GEMV execution into a single kernel flow, introduces an interleaved pre-tiling layout that supports GEMM dimensions up to 32K, and redesigns GEMV dataflow to utilize the full 4x8 AIE array. Across kernel-level evaluations, TileFuse improves performance by up to 121.6% for GEMM and 281% for GEMV over full-precision baselines, while delivering more than 2x performance and energy-efficiency gains over strong iGPU baselines on GEMM. In end-to-end LLM experiments on Ryzen AI laptops, TileFuse achieves up to 2.0x lower prefilling latency with more than 64.6% lower energy consumption. Together, these results show that XDNA2 is a practical target for AWQ-style edge LLM inference and that native NPU support for off-the-shelf quantization can make NPUs substantially more usable in real client deployments.
人間と AI が生成した言語のダイナミクス: 異なるタイムスケールでセマンティクスがどのように変動するか
音声言語は、人間によって生成されたものであっても、大規模言語モデル (LLM) によって生成されたものであっても、時間の経過とともにさまざまな意味内容を伴って展開されます。しかし、一般的なコンテンツと特定のコンテンツが時間の経過とともにどのように分布するかを捕捉し、人間の音声と AI が生成した音声を比較するために使用できる、シンプルで解釈可能な時系列機能がまだ不足しています。タイムスタンプを含む単語レベルのトランスクリプトを意味論的な時系列に変換する、意味論的なタイムスケール分析パイプラインを導入します。話された物語ごとに、(i) WordNet ベースの単語深度を使用して意味論的な特異性、(ii) SBERT 埋め込みを使用して文脈の類似性を計算し、自己相関ウィンドウの測定 (ACW-0 および関連メトリック) を使用してそれらの時間的依存性を定量化します。次に、元の音声を、語彙の同一性、時間的順序、単語の長さを選択的に破壊する複数のシャッフルされたコントロールと比較します。人間が読んだ自伝的物語、TTS の朗読、および TTS でレンダリングされた LLM 生成テキスト全体にわたって、意味時系列で ACW-0 が長いセグメントにはより一般的な語彙が含まれる傾向があるのに対し、ACW-0 が短いセグメントにはより具体的な単語が豊富に含まれていることがわかります。これらの関連性は、語順とタイミングがランダム化されると強く減衰または消滅します。これは、ACW ベースの測定が、静的な語彙分布を超えて意味内容の自明ではない時間的組織化を捕捉していることを示しています。私たちの結果は、ACW ベースのセマンティック タイムスケールが、人間の音声と AI が生成した音声の時間構造を分析および比較するための有用な機能群であることを示唆しています。
原文 (English)
The Dynamics of Human and AI-Generated Language: How Semantics Fluctuates across Different Timescales
Spoken language, whether produced by humans or large language models (LLM), unfolds over time with varying semantic content. However, we still lack simple, interpretable time-series features that capture how generic versus specific content is distributed over time, and that can be used to compare human and AI-generated speech. We introduce a semantic-timescale analysis pipeline that turns word-level transcripts with timestamps into semantic time-series. For each spoken narrative, we compute (i) semantic specificity using WordNet-based word depth and (ii) contextual similarity using SBERT embeddings and quantify their temporal dependence using autocorrelation-window measures (ACW-0 and related metrics). We then compare original speech to multiple shuffled controls that selectively disrupt lexical identity, temporal order, and word duration. Across human-read autobiographical narratives, TTS readings, and LLM-generated texts rendered with TTS, we find that segments with longer ACW-0 in the semantic time-series tend to contain more generic vocabulary, whereas segments with shorter ACW-0 are enriched in more specific words. These associations are strongly attenuated or abolished when word order and timing are randomized, indicating that ACW-based measures capture non-trivial temporal organization of semantic content beyond static lexical distributions. Our results suggest that ACW-based semantic timescales are a useful family of features for analyzing and comparing the temporal structure of human and AI-generated speech.
プローブ精度が飽和すると脆弱性が解決: LLM 事前トレーニング分析の補完的なメトリクス
標準の線形プローブでは、隠れ状態の分類子が高い精度を達成すると、プロパティが「エンコードされた」と宣言されます。このプロトコルはスナップショットではうまく機能しますが、事前トレーニングでは中断されます。プローブの精度は最初の数千ステップで飽和し、トレーニングのほとんどが機器に見えなくなります。プローブの精度が崩れる活性化ノイズ レベルとして定義される補完的な層ごとの指標である脆弱性を導入します。脆弱性は、分離可能性の限界と表現の冗長性の両方に影響を受けますが、どちらも精度が頭打ちになった後も長く進化し続けます。オープンチェックポイント言語モデルに適用すると、脆弱性は、精度だけでは確認できない構造を回復します。道徳化された表現は、語彙 $\to$ 構成勾配に沿って出現します。最初に語彙的道徳検出が行われ、その後に構成的道徳符号化が行われます。独自のプローブ精度は、データセットが語彙的にどの程度分離可能であるかを追跡するため、コントラスト トークンを共有しない構築タイプ間での転送を示すことにより、構成エンコーディングを直接確立します。層深さのロバスト性勾配はトレーニング全体にわたって単調に増加しますが、精度は一定のままです。また、同一のプローブ精度を生み出す一致した微調整コーパスは、明確な脆弱性の指紋を残し、データのキュレーションによってプローブの精度を変えることなくプローブの堅牢性が再形成されることを示しています。私たちがテストするすべての比較において、プローブの精度はフラットな答えを返しますが、脆弱性は構造化された答えを返します。
原文 (English)
When Probing Accuracy Saturates, Fragility Resolves: A Complementary Metric for LLM Pre-Training Analysis
Standard linear probing declares a property "encoded" when a classifier on hidden states achieves high accuracy. The protocol works well on a snapshot but breaks across pre-training: probe accuracy saturates within the first few thousand steps, leaving most of training invisible to the instrument. We introduce fragility, a complementary per-layer metric defined as the activation-noise level at which probe accuracy collapses. Fragility is sensitive to both the margin of separability and the redundancy of representation, both of which keep evolving long after accuracy plateaus. Applied to open-checkpoint language models, fragility recovers structure that accuracy alone cannot see. Moralized representations emerge along a lexical $\to$ compositional gradient: lexical moral detection first, compositional moral encoding later. Because probe accuracy on its own tracks how lexically separable a dataset is, we establish the compositional encoding directly, by showing it transfers across construction types that share no contrast tokens. A layer-depth robustness gradient develops monotonically across training while accuracy stays flat. And matched fine-tuning corpora that produce identical probing accuracy leave distinct fragility fingerprints, showing that data curation reshapes probe robustness without changing probe accuracy. In every comparison we test, where probing accuracy returns a flat answer, fragility returns a structured one.
アクティベーションステアリングによる全二重音声言語モデルの状態慣性の克服
全二重音声言語モデル (FD-SLM) は、モデルが同時に聞くことと話すことを可能にすることでシームレスな音声対話を可能にしますが、聞くことと話すことを調整する内部メカニズムはまだ解明されていません。 FD-SLM の隠れ表現でエンコードされた予測動作を分析し、ストリーム固有の予測パターンを示していることを発見しました。リスニング中は、着信ユーザー ストリームを優先的に予測しますが、発話中は、モデル出力ストリームを優先的に予測します。この観察に基づいて、FD-SLM が 2 つの状態の間で内部の予測フォーカスを動的に調整することを示します。1 つはモデル出力の生成に合わせた生成状態、もう 1 つは入力されたユーザー入力に合わせた知覚状態です。ただし、この調整は会話の文脈の突然の変化に遅れる可能性があります。ユーザーの中断中、モデルは知覚状態に移行する前に生成状態に向けて一時的にバイアスされたままとなり、入力の始まりを見逃す原因となります。この遅れた内部遷移状態の慣性を私たちは「慣性」と呼びます。下流への影響を定量化するために、ユーザーの音声が突然始まったときの即時中断の理解度を評価するための診断ベンチマークであるゼロバッファ ベンチマーク (ZBB) を導入します。この設定は、応答の正確さと最初の単語の出現率 (IWOR) を使用して評価されます。最後に、知覚ベクトルを使用したアクティベーション ステアリング、追加の計算オーバーヘッドがほとんどないトレーニング不要の介入を通じて、状態の慣性を軽減します。複数の最先端の FD-SLM にわたって、アクティベーション ステアリングにより割り込み処理が大幅に改善されます。たとえば、PersonaPlex では、微調整を行わなくても、正確性が 28% から 45% に、IWOR が 40% から 72% に向上します。
原文 (English)
Overcoming State Inertia in Full-Duplex Spoken Language Models via Activation Steering
Full-duplex spoken language models (FD-SLMs) enable seamless speech interaction by allowing models to listen and speak simultaneously, yet the internal mechanism by which they coordinate listening and speaking remains underexplored. We analyze the predictive behavior encoded in FD-SLM hidden representations and find that they exhibit stream-specific predictive patterns: during listening, they preferentially predict the incoming user stream, whereas during speaking, they preferentially predict the model output stream. Building on this observation, we show that FD-SLMs dynamically modulate their internal predictive focus between two states: a generative state aligned with model output generation and a perceptive state aligned with incoming user input. However, this modulation can lag behind abrupt changes in conversational context. During user interruptions, the model remains transiently biased toward the generative state before transitioning into the perceptive state, causing it to miss the beginning of the incoming input. We term this delayed internal transition state inertia. To quantify its downstream impact, we introduce the Zero-Buffer Benchmark (ZBB), a diagnostic benchmark for evaluating immediate interruption comprehension when user speech begins abruptly. We evaluate this setting using response correctness and initial-word occurrence rate (IWOR). Finally, we mitigate state inertia through activation steering with a perception vector, a training-free intervention with little additional computational overhead. Across multiple state-of-the-art FD-SLMs, activation steering substantially improves interruption handling; for example, on PersonaPlex, it improves correctness from 28% to 45% and IWOR from 40% to 72% without any fine-tuning.
小規模な実験、より安価な意思決定: マイクロ事前トレーニングの段階的プロモーションのケーススタディ
事前トレーニングの実行を短くすると、実験コストを削減できますが、わずかな予算でしか強力に見えない構成が過剰に宣伝される可能性もあります。私たちは、Windows A100 と Linux L40S という 2 つの異種ホスト ブロック上の固定マイクロ事前トレーニング ランナーの監査可能な段階的プロモーション プロトコルを研究します。事前に選別された 12 の構成から開始して、2 分、5 分、10 分、60 分、12 時間の段階的な予算を使用し、高価な継続の前にプロモーション ルールを凍結します。初期の画面は意図的に不安定なものとして扱われます。5 分と 10 分のランキングはホストに依存し、最終的な 12 時間のトップランクの状態は、複製された 10 分ゲートでの平均最高の状態ではありません。シード範囲はステージごとに異なるため、これらの変更は運用促進の証拠であり、シード内曲線ではありません。複製された 60 分ゲートは、昇格されたセット内で段階的要因スクリーニング ブリッジ参照を維持し、4 つの 60 分ホスト シード セルすべてで 1 位にランクされます。最後の 12 時間の確認パッケージでは、2 つのシードにわたる 4 つの宿主シード セルすべてでブリッジ状態が 1 位にランク付けされました。貪欲コンパレータは、凍結された 0.010 val_bpb の近等価ルールを満たしていません。また、より安価な d8/ar48 (深さ 8、アスペクト 48) センチネルは、凍結された 0.020 平均ギャップ ルールを満たしていません。実行された 12 時間のブランチは 144 GPU 時間を費やし、完全なステージングされたプロトコルはスクリーニング ステージを含めて 169.2 トレーニング GPU 時間を記録します。 4 つの 60 分の候補をすべて続行すると 192 GPU 時間がかかり、複製された 9 つの 10 分の候補をすべて続行すると 432 GPU 時間がかかります。後者の数字は、実行されなかった継続を説明する反事実であり、スキップされた候補者がリファレンスを追い抜くことができなかったという証拠ではありません。結果は、限界のあるコスト割り当ての結果であり、全体的な最適性、容量正規化された優位性、または適応型ハイパーパラメータ最適化手法に対する優位性を主張するものではありません。
原文 (English)
Small Experiments, Cheaper Decisions: A Case Study in Staged Promotion for Micro-Pretraining
Short pretraining runs can reduce experimental cost, but they can also over-promote configurations that only look strong at tiny budgets. We study an auditable staged-promotion protocol for a fixed micro-pretraining runner on two heterogeneous host blocks: Windows A100 and Linux L40S. Starting from twelve prior-screened configurations, we use staged budgets of 2 minutes, 5 minutes, 10 minutes, 60 minutes, and 12 hours, with frozen promotion rules before expensive continuations. The early screens are intentionally treated as unstable: the 5- and 10-minute rankings are host-sensitive, and the eventual 12-hour top-ranked condition is not the mean-best condition at the replicated 10-minute gate. Because seed ranges differ across stages, these changes are operational promotion evidence, not within-seed curves. A replicated 60-minute gate keeps the Staged Factorial Screening bridge reference in the promoted set, where it ranks first in all four 60-minute host-seed cells. In the final 12-hour confirmation package, the bridge condition ranks first in all four host-seed cells across two seeds; the greedy comparator does not meet the frozen 0.010 val_bpb near-equivalence rule; and the cheaper d8/ar48 (depth-8, aspect-48) sentinel does not meet the frozen 0.020 mean-gap rule. The executed 12-hour branch spends 144 GPU-hours, and the full staged protocol records 169.2 training GPU-hours including screening stages. Continuing all four 60-minute candidates would spend 192 GPU-hours, while continuing all nine replicated 10-minute candidates would spend 432 GPU-hours. The latter numbers are accounting counterfactuals for unrun continuations, not evidence that skipped candidates could not have overtaken the reference. The result is a bounded cost-allocation finding, not a claim of global optimality, capacity-normalized superiority, or superiority over adaptive hyperparameter optimization methods.
聞く場所のステアリング: 命令ベースのアクティベーション ステアリングは、大規模な音声言語モデルで一時的な注意をリダイレクトします。
Large Audio-Language Model (LALM) は音声の理解に優れていますが、音声信号のどこに存在するかについてはほとんど明らかにしません。音声を固定したまま、さまざまに指示されたプロンプトからのアクティベーションを対比させることでステアリング ベクトルを構築する、命令ベースのベクトル ステアリングを導入します。 LALM 注意の体系的な調査を通じて、標準的なプロンプトや音声ベースのステアリングとは異なり、この介入は音声トークンに割り当てられた時間的注意を大幅に再配分し、音響的に関連する領域に集中させることがわかりました。次に、この注意の変化が行動的に意味があることを示します。制御された 3 つのイベント設定で、ステアリングによって引き起こされる最大の注意の変化の時間的位置を読み出すと、トレーニングなしでクエリされた音声イベントの位置が回復され、Qwen2-Audio および Audio Flamingo 3 のグラウンドトゥルース間隔と 60.87% および 68.72% の重複が達成され、直接的なプロンプト (31.84%、46.75%) およびランダムなベースラインをはるかに上回りました。 (27.74%)。私たちの結果は、LALM における命令ベースのステアリングの機構的特性を特徴づけ、これらのモデルがエンコードする潜在的な時間構造をトレーニング不要で調査する方法を提供します。
原文 (English)
Steering Where to Listen: Instruction-Based Activation Steering Redirects Temporal Attention in Large Audio-Language Models
Large Audio-Language Models (LALMs) excel at audio understanding but expose little about where in an audio signal they attend. We introduce instruction-based vector steering, which constructs a steering vector by contrasting activations from differently instructed prompts while keeping the audio fixed. Through a systematic probe of LALM attention, we find that - unlike standard prompting or audio-based steering - this intervention significantly redistributes the temporal attention allocated to audio tokens, concentrating it on acoustically relevant regions. We then show that this attention shift is behaviorally meaningful: in a controlled three-event setting, reading out the temporal position of maximal steering-induced attention change recovers the location of a queried sound event without any training, attaining 60.87% and 68.72% overlap with ground-truth intervals on Qwen2-Audio and Audio Flamingo 3, far above direct prompting (31.84%, 46.75%) and random baselines (27.74%). Our results characterize a mechanistic property of instruction-based steering in LALMs and provide a training-free probe for the latent temporal structure these models encode.
プレッシャーの下のリスク: 言語モデルにおける敵対的堅牢性のコンピューティングを意識した評価
大規模言語モデル (LLM) の敵対的堅牢性評価では、通常、固定クエリ バジェットの下での攻撃成功率 (ASR) が報告され、暗黙的にすべての攻撃が同等のコストとして扱われます。実際には、さまざまな攻撃戦略の計算コストは桁違いに異なる可能性があります。その結果、固定予算の ASR では、モデルをジェイルブレイクするために必要な実際の労力が曖昧になる可能性があり、その結果、攻撃のコストが攻撃者への見返りに見合うかどうかを判断することが困難になります。我々は、敵対的な取り組みの代用として、累積浮動小数点演算 (FLOP) で測定される計算プレッシャーに基づいた、コンピューティングを意識した評価フレームワークを提案します。計算予算を攻撃リスクにマッピングするリスク計算曲線を導入し、特定の攻撃が成功するために必要な平均圧力を要約する 2 つの指標を導き出します。言語モデルのトレーニングとアライメントにおける 3 つのファミリーと 4 つの異なる段階にまたがる 10 のモデルにわたって、2 つのジェイルブレイク堅牢性ベンチマークで 3 つの攻撃戦略 (勾配ベース、反復改良、およびテンプレートベース) で評価したところ、次のことがわかりました。(1) アライメント トレーニングは、計算空間の堅牢性に非単調な効果をもたらします。 (2) モデルのサイズをスケーリングすると、勾配ベースの攻撃の有効性が低下しますが、安価なテンプレートベースの攻撃に対する影響は限定的です。 (3) サロゲート モデルで最適化された勾配ベースの攻撃は、別のターゲット モデルに転送でき、攻撃者のコストを削減する方法を提供します。 (4) 計算コストは、単一モデル内の危害カテゴリによって最大 ${\estimate}5{\times}$ 異なります。 (5) 安全性を重視した RL により、一部のカテゴリーが不釣り合いにアクセスしやすくなる一方で、総コストが増加します。コンピューティングを意識したリスク評価と評価を可能にするフレームワークをリリースします。
原文 (English)
Risk Under Pressure: Compute-Aware Evaluation of Adversarial Robustness in Language Models
Adversarial robustness evaluations of large language models (LLMs) typically report attack success rate (ASR) under fixed query budgets, implicitly treating all attacks as equally costly. In practice, the computational expense of different attack strategies can vary by orders of magnitude. Consequently, ASR at a fixed budget can obscure the true effort required to jailbreak a model, thereby making it hard to determine whether an attack's cost justifies its payoff to the attacker. We propose a compute-aware evaluation framework based on computational pressure, measured in cumulative floating-point operations (FLOPs), as a proxy for adversarial effort. We introduce risk-compute curves, which map compute budgets to attack risk, and derive two metrics that summarize the average pressure required for a given attack to succeed. Across ten models spanning three families and four different stages in language model training and alignment, evaluated with three attack strategies (gradient-based, iterative refinement, and template-based) on two jailbreak robustness benchmarks, we find: (1) alignment training has non-monotonic effects on compute-space robustness; (2) scaling model size reduces gradient-based attack effectiveness but has limited impact on cheaper template-based attacks; (3) gradient-based attacks optimized on a surrogate model can transfer to a separate target model, providing a way to reduce attacker costs; (4) compute cost varies by up to ${\approx}5{\times}$ across harm categories within a single model; and (5) safety-aligned RL increases aggregate cost while leaving some categories disproportionately accessible. We release our framework to enable compute-aware risk assessment and evaluation.
MPC-Patch-Bench: マルチパーティ計算用のセキュリティを考慮した LLM コード パッチ
Secure Multi-Party Computation (MPC) ソフトウェアでの大規模言語モデル (LLM) コード修復を評価するためのリポジトリ レベルのベンチマークはまだ存在せず、SWE ベンチなどの汎用ベンチマークを直接移植すると、次の 3 つの構造面で失敗します。(i) MPC リポジトリは、暗号ロジックではなく汎用の Python インフラストラクチャによって支配されています。 (ii) 高価値の MPC 修正には、厳格な抽出パイプラインに必要な標準化されたテストが欠けています。 (iii) 標準のフェイルツーパス評価では、暗号的に安全である必要があるコードには不十分です。 MPC は、プライバシーを保護する機械学習、生物医学コラボレーション、安全な分析のために導入されることが増えています。既存の MPC 固有のコード合成の取り組みは、オペレーター レベルまたは単一フレームワークのタスクのみを対象としています。実際のリポジトリ レベルの MPC 修復で LLM エージェントを評価するには、代わりに MPC を意識したデータ キュレーションと、セキュリティと数値忠実度の保証に一致するベリファイアが必要です。MPC プログラムは、既存のベンチマークが提供するどちらにも従わなければなりません。 2 つのフレームワークを中心に構成されたリポジトリ レベルのベンチマークである MPC-Patch-Bench を紹介します。 (1) データ キュレーション フレームワークは、3 つの暗号化レイヤーを通じて未加工のプル リクエストをフィルタリングするドメイン固有のキュレーション エージェントと、欠落している問題ステートメントと Fail-to-Pass/Pass-to-Pass テストを合成する人間 AI 補完エンジンを組み合わせて、205 個の完全に検証されたインスタンスを生成します。 (2) MPC Verifier は、平文オラクルに対する動的差分テストと、安全でないリビール、安全でない算術演算、不正なパブリック/プライベート キャストにフラグを立てる MPC 固有の静的分析ルールを介して、専用のセキュリティと数値忠実性チェックを提供します。最も強力に評価された LLM は、MPC-Patch-Bench タスクの 22.9% のみを機能的に解決します。 MPC Verifier は検証された解像度をさらに 17.1% に低下させ、機能的に合格したパッチの最大 40% が暗号または数値忠実度違反のために拒否されます。
原文 (English)
MPC-Patch-Bench: Security-Aware LLM Code Patch for Multi-Party Computation
Repository-level benchmarks for evaluating Large Language Model (LLM) code repair on Secure Multi-Party Computation (MPC) software do not yet exist, and directly transplanting general-purpose benchmarks such as SWE-bench fails on three structural fronts: (i) MPC repositories are dominated by generic Python infrastructure rather than cryptographic logic; (ii) high-value MPC fixes lack the standardized tests rigid extraction pipelines require; and (iii) standard fail-to-pass evaluation is insufficient for code that must also be cryptographically safe. MPC is increasingly deployed for privacy-preserving machine learning, biomedical collaboration, and secure analytics. Existing MPC-specific code-synthesis efforts cover only operator-level or single-framework tasks; evaluating LLM agents on real repository-level MPC repair instead demands MPC-aware data curation and a verifier matched to the security and numerical-fidelity guarantees MPC programs must obey neither of which existing benchmarks provide. We introduce MPC-Patch-Bench, a repository-level benchmark organised around two frameworks. (1)The Data Curation Framework combines a domain-specific curation agent that filters raw pull requests through three cryptographic layers with a human-AI completion engine that synthesizes missing problem statements and Fail-to-Pass/Pass-to-Pass tests, yielding 205 fully verified instances. (2)The MPC Verifier provides dedicated security and numerical-fidelity checks via dynamic differential testing against plaintext oracles and MPC-specific static analysis rules that flag unsafe reveals, insecure arithmetic, and illegal public/private casts. The strongest evaluated LLM functionally resolves only 22.9% of MPC-Patch-Bench tasks; the MPC Verifier further reduces verified resolution to 17.1%, with up to 40% of functionally-passing patches rejected for cryptographic or numerical-fidelity violations.
シールされた監査での署名付き圧縮の進行状況はグッドハート耐性を備えています
圧縮の進捗状況は、内発的動機付けに関する長年の提案です。つまり、エージェントの世界モデルがエクスペリエンスの予測または圧縮において優れた場合にエージェントに報酬を与えるというものです。人々は、この報酬は学習に対してのみ支払われるため、「信頼できる」と主張しています。私たちはこれを正確にし、それを証明します。本質的報酬が固定の密閉監査損失の符号付き減少である場合、r_t = E(theta_{t-1}) - E(theta_t)、累積報酬はエンドポイント監査の改善に正確に反映されるため、真の監査パフォーマンスが停滞または低下している間、いかなるポリシーも報酬を無制限に押し上げることはできません。有限の監査パネルの場合、同じ結果が鋭い偽陽性バジェットにも当てはまります。つまり、累積経験的報酬は、最大でも真の監査改善に、モデル クラスの均一な監査偏差である 2 Delta_n(F, delta) を加えたものになります。これには水平線がありません。密閉されたパネルがクラスを均一に制御すると、時間の経過に伴う適応性にはコストがかかりません。この定理は失敗モードも特定します。進行状況が切り取られるか、エージェント独自のストリームでスコアが付けられるか、再利用可能なパネル上の高容量モデルに公開されるか、Delta_n を空にするニューラル クラスに適用される場合、保証は失われます。構造コアのリーン 4 機械化 (テレスコープ、有限監査境界、有限ギブス、エントロピー フロア) と、適応ホールドアウト攻撃を備えた ARC-TGI グリッド変換ジェネレーターの実験スイートを提供します。実験により理論が確認されました。有限監査偏差は n^{-0.527} としてスケールされます。署名された進歩は、クリップファーミング、ストリーム漏洩、騒々しいテレビの好奇心に抵抗します。単純な再利用可能な監査はブラックボックスのスカラー フィードバックによって悪用可能ですが、標準のリリース防御により攻撃は 2 Delta_n しきい値未満に抑えられます。密封された監査で署名された圧縮の進捗状況は、真の改善を示す会計上のシグナルです。
原文 (English)
Signed Compression Progress on a Sealed Audit is Goodhart-Resistant
Compression progress is a long-standing proposal for intrinsic motivation: reward an agent when its world model becomes better at predicting or compressing experience. The folk claim is that this reward is "credible" because it is paid only for learning. We make this precise and prove it. If intrinsic reward is the signed decrease of a fixed sealed-audit loss, r_t = E(theta_{t-1}) - E(theta_t), then cumulative reward telescopes exactly to endpoint audit improvement, so no policy can push reward up indefinitely while true audit performance stagnates or degrades. For finite audit panels the same result holds with a sharp false-positive budget: cumulative empirical reward is at most true audit improvement plus 2 Delta_n(F, delta), the uniform audit deviation of the model class. This is horizon-free: adaptivity over time costs nothing once the sealed panel uniformly controls the class. The theorem also identifies the failure modes: the guarantee disappears if progress is clipped, scored on the agent's own stream, exposed to a high-capacity model on a reusable panel, or applied to a neural class that makes Delta_n vacuous. We give a Lean 4 mechanization of the structural core (telescoping, the finite-audit bound, finite Gibbs, and the entropy floor) and an experiment suite on ARC-TGI grid-transformation generators with adaptive holdout attacks. Experiments confirm the theory: finite-audit deviation scales as n^{-0.527}; signed progress resists clip-farming, stream leakage, and noisy-TV curiosity; naive reusable audits are exploitable by black-box scalar feedback, while standard release defenses keep the attack below the 2 Delta_n threshold. Signed compression progress on a sealed audit is an accounting signal of genuine improvement.
JailbreakOPT: ツール支援による反復的な脱獄プロンプトの最適化
ジェイルブレイク攻撃は、大規模言語モデル (LLM) の永続的な安全性の弱点を露呈しますが、既存のステートレスなシングルターン手法はトレードオフに直面しています。手作りのプロンプトは表現力豊かですが静的である一方、反復プロンプトの最適化は適応可能ですが、多くの場合、多くのターゲット クエリを必要とする低レベルの突然変異に依存します。私たちは、反復的なシングルターンジェイルブレイクプロンプトの最適化を改善するためのツール支援フレームワークである JailbreakOPT を提案します。 JailbreakOPT は、さまざまなアトミックなジェイルブレイク プロンプトを攻撃ツール ライブラリに編成し、統一されたエピソード内最適化抽象化を通じてそれらを構成して、より強力なスタンドアロン攻撃プロンプトを生成します。攻撃エピソード全体でエクスペリエンスを再利用するために、JailbreakOPT はツールの選択を状況に応じたバンディット問題としてさらにフレーム化し、状況に応じたトンプソン サンプリングを適用して、過去の結果に基づいて探索と悪用をガイドします。複数のターゲット LLM と攻撃目標にわたる実験では、アトミックなシングルターン攻撃や既存の反復最適化ベースラインと比較して、JailbreakOPT が成功するまでの攻撃回数 (No.A) を削減しながら、攻撃成功率 (ASR) を向上させることが示されています。この文書には攻撃的または有害なコンテンツが含まれている可能性があります。
原文 (English)
JailbreakOPT: Tool-Assisted Iterative Jailbreak Prompt Optimization
Jailbreak attacks expose persistent safety weaknesses in large language models (LLMs), but existing stateless single-turn methods face a trade-off: hand-crafted prompts are expressive but static, while iterative prompt optimization can adapt but often relies on low-level mutations that require many target queries. We propose JailbreakOPT, a tool-assisted framework for improving iterative single-turn jailbreak prompt optimization. JailbreakOPT organizes diverse atomic jailbreak prompts into an attack tool library and composes them through a unified intra-episode optimization abstraction to generate stronger standalone attack prompts. To reuse experience across attack episodes, JailbreakOPT further frames tool selection as a contextual bandit problem and applies contextual Thompson sampling to guide exploration and exploitation based on past outcomes. Experiments across multiple target LLMs and attack goals show that JailbreakOPT improves attack success rate (ASR) while reducing the number of attacks until success (No.A) compared with atomic single-turn attacks and existing iterative optimization baselines. This paper may contain offensive or harmful content.
書誌的知識と形式化された数学的知識の間の橋渡し層に向けて
数学的知識は書誌データベース (MathSciNet、zbMATH Open など) と正式な証明ライブラリ (Lean mathlib など) の間で分割されており、出版された結果とその形式化の間の統一されたアクセスが妨げられています。私たちは、出版物のメタデータを正式な成果物と整合させ、数学的文献と機械検証可能な証明の間に相互運用性層を提供するリレーショナル ブリッジ データベースを提案します。出版物のどの程度が正式なシステムでカバーされているかを測定する、論文レベルの形式化スコアを導入します。実現可能性の研究として、非公式テキストとリーン形式化の間の文書間の調整によってそのようなスコアがどのように推定され、形式化範囲の大規模分析が可能になるかを示します。このフレームワークは、書誌的および形式的な数学的エコシステムを、出版物を形式的な証明オブジェクトにリンクするスケーラブルで機械で実行可能なナレッジ グラフに統合するための最初のステップです。
原文 (English)
Towards a Bridge Layer Between Bibliographic and Formalized Mathematical Knowledge
Mathematical knowledge is split between bibliographic databases (e.g., MathSciNet, zbMATH Open) and formal proof libraries (e.g., Lean mathlib), preventing unified access between published results and their formalizations. We propose a relational bridge-database that aligns publication metadata with formal artifacts, providing an interoperability layer between mathematical literature and machine-verifiable proofs. We introduce a paper-level formalization score that measures how much of a publication is covered in formal systems. As a feasibility study, we show how such scores can be estimated via cross-document alignment between informal texts and Lean formalizations, enabling large-scale analysis of formalization coverage. This framework is a first step toward integrating bibliographic and formal mathematical ecosystems into scalable, machine-actionable knowledge graphs linking publications to formal proof objects.
おおよそのサンプリングのためのテスト時トレーニングの威力
複雑な確率分布からの効率的なサンプリングは、困難な推論問題を解決するために LLM からの高度なサンプリング手順が提案されているため、近年、生成 AI の台頭とともにますます関連性が高まっている基本的な問題です。ただし、このようなサンプリング アルゴリズムの有効性は、LLM と、テスト時間トレーニング (TTT) のフレームワークの動機となっている、当面の特定のサンプリング タスクとの関係によって制限されます。 TTT は、推論時に受け取った部分的な世代と報酬フィードバックに応じてモデルの重みを更新することで機能し、特定の問題に適応します。この研究では、 $\mu^\star$ の近似密度推定値を与えるオラクル $\hat \mu$ を与えられた場合に、既知の分布クラス ${F}$ に属する与えられた確率測度 $\mu^\star$ からサンプルを生成する問題として TTT を定式化することを提案する。これは、Jerrum、Valiant & Vazirani (1986) および Jerrum & Sinclair (1989) の独創的な著作で研究された、サンプリングを近似計数に削減する問題と密接に関連しています。つまり、${F}$ がすべての分布のクラスである場合、それは前述の計数からサンプリングへの削減と正確に一致します。この論文では、まず、$\hat \mu$ (十分に大きなクラス ${F}$ の場合) へのクエリ アクセスを前提とした $\mu^\star$ からのサンプリングのクエリ複雑さの二次下限を示し、これにより、Jerrum & Sinclair (1989) によって提案され、Hayes & Sinclair (2010) によって洗練されたランダム ウォーク アプローチが最適であることが示されます。これは、Hayes & Sinclair が提起した未解決の質問への答えです。次に、${F}$ のサイズが適切に制限されている場合、この下限を回避できることを示します。私たちが議論するように、この後者の結果は TTT の抽象化とみなすことができ、したがって TTT の原則に基づいた理論的枠組みの開発の出発点を表します。
原文 (English)
The Power of Test-Time Training for Approximate Sampling
Efficiently sampling from a complex probability distribution is a fundamental problem which has become increasingly pertinent in recent years with the rise of generative AI, as sophisticated sampling procedures from LLMs have been proposed to solve challenging reasoning problems. The efficacy of such sampling algorithms is limited, however, by the relationship between the LLM and the particular sampling task at hand, which has motivated the framework of test-time training (TTT). TTT works by updating a model's weights in response to partial generations and reward feedback received at inference time, thus adapting to the particular problem. In this work, we propose a formalization for TTT as the problem of producing a sample from a given probability measure $\mu^\star$ belonging to a known class ${F}$ of distributions, given an oracle $\hat \mu$ which yields approximate density estimates for $\mu^\star$. This is closely related to the problem of reducing sampling to approximate counting studied in seminal works of Jerrum, Valiant & Vazirani (1986) and Jerrum & Sinclair (1989): namely, when ${F}$ is the class of all distributions, it coincides exactly with the aforementioned counting-to-sampling reduction. In this paper, we first show a quadratic lower bound on the query complexity of sampling from $\mu^\star$ given query access to $\hat \mu$ (for sufficiently large classes ${F}$), thus showing that the random walk approach proposed by Jerrum & Sinclair (1989) and refined by Hayes & Sinclair (2010), is optimal. This answers an open question posed by Hayes & Sinclair. We then show that this lower bound can be circumvented if the size of ${F}$ is bounded appropriately. As we discuss, this latter result can be viewed as an abstraction of TTT, and thus represents a starting point for the development of a principled theoretical framework for TTT.
社会科学における AI コーディング エージェント: 方法論的に多様、経験的に一貫性があり、解釈的に脆弱
科学分析における LLM ベースのエージェントの導入は、エージェントが方法論の多様性を低下させる可能性がある、または研究者が意欲的な結論に到達するための分析の柔軟性を増幅させる可能性があるという、相反する懸念を引き起こします。私たちは、これらの懸念は経験的に分離可能な 2 つの層、すなわち方法論的選択の設計層と、決定ルールが推定値を実質的な主張にマッピングする評決層をターゲットにしていると主張します。私たちは、多くの分析者による人間のベースラインに対して、著名な移民政策と社会政策に関してクロード コードとコーデックスを 20 回独立して実行することにより、両方をテストしました。設計層では、Codex は人間の方法論の多様性に適合しており、Claude Code はほぼ 3 倍の仕様を作成します。両方のエージェントの効果推定値は依然として人間のコンセンサスとほぼ一致しており、人間のモデルと正確に一致するエージェントのモデルはありません。即座に誘発された反移民研究者は、事前に各エージェントの方法論的決定を再編成しますが、同じデータに対する偏った人間の分析者とは異なり、集計された推定値や最終的な判断を変更しません。また、人間が推定値にバイアスをかけるために使用する方法論的な軸に沿ってエージェントがルートを変更することもありません。評決層では、明示的な確認プロンプトにより、クロード コードの評決の支持率が 10% から 90% に反転されますが、その係数分布は基本的に変更されず、ルールの緩和ではなくルールの省略によって機能します。 AI エージェントは、設計層では人間の方法論的多様性に匹敵するか、それを超えることができますが、判定層では脆弱なままです。私たちの設定では、AI バイアスの焦点は推定ではなく解釈です。
原文 (English)
AI Coding Agents in Social Science: Methodologically Diverse, Empirically Consistent, Interpretively Vulnerable
The deployment of LLM-based agents in scientific analysis raises opposing concerns: that agents may reduce methodological diversity, or that they may amplify the analytic flexibility through which researchers reach motivated conclusions. We argue these worries target two empirically separable layers: a design layer of methodological choices, and a verdict layer in which a decision rule maps estimates to a substantive claim. We test both by running 20 independent executions of Claude Code and Codex on a prominent immigration and social-policy against a many-analysts human baseline. At the design layer, Codex matches human methodological diversity and Claude Code produces nearly three times as many specifications; both agents' effect estimates remain broadly aligned with the human consensus, and no agent model exactly matches any human model. A prompt-induced anti-immigration researcher prior reorganizes each agent's methodological decisions but, unlike for biased human analysts in the same data, does not shift aggregate estimates or final verdicts; nor do agents reroute along the methodological axes humans use to bias their estimates. At the verdict layer, an explicit confirmatory prompt flips Claude Code's verdicts from 10% to 90% support while leaving its coefficient distribution essentially unchanged, operating through rule omission rather than rule softening. AI agents can rival or exceed human methodological diversity at the design layer while remaining vulnerable at the verdict layer. In our setting, the locus of AI bias is not estimation but interpretation.
APEX: 動的データ選択を備えた自動化されたプロンプトエンジニアリングエキスパート
大規模言語モデルはプロンプトの定式化に非常に敏感であるため、その可能性を最大限に引き出すには自動プロンプト最適化が必要です。進化的アルゴリズムが有力なパラダイムとして台頭してきましたが、データ効率という重大なボトルネックに悩まされています。現在の方法では、開発データセットを静的なベンチマークとして扱い、有益でないデータに多大な計算予算を無駄にしています。この作業では、プロンプト検索とともにデータ使用を最適化する新しいフレームワークである APEX (Automatic Prompt Engineering eXpert) を紹介します。 APEX は、最適化系統に基づいてデータセットをイージー、ハード、混合層に動的に階層化します。 LLM のパフォーマンスが混合しているデータを識別する混合層を優先することにより、有益な突然変異を生成するためのアドレス指定可能なフロンティアと、候補の品質を区別するためのランク依存のフロンティアという 2 つの高レバレッジのサブセットを特定します。私たちは、IFBench、SimpleQA Verified、FACTS Grounding という 3 つの多様なベンチマークにわたって APEX を評価します。 5,000 回の評価コールという固定予算の下で、APEX はデータ効率により初期プロンプトを平均して Gemini 2.5 フラッシュで 11.2%、Gemma 3 27B で 6.8% 上回りました。これは、データ中心のアプローチが効率的かつ効果的なプロンプト最適化の鍵であることを示しています。
原文 (English)
APEX: Automated Prompt Engineering eXpert with Dynamic Data Selection
Large Language Models are highly sensitive to prompt formulation, necessitating automatic prompt optimization to unlock their full potential. While evolutionary algorithms have emerged as the dominant paradigm, they suffer from a critical bottleneck: data efficiency. Current methods treat the development dataset as a static benchmark, wasting significant compute budget on uninformative data. In this work, we introduce APEX (Automatic Prompt Engineering eXpert), a novel framework that optimizes the data usage alongside the prompt search. APEX dynamically stratifies the dataset into Easy, Hard, and Mixed tiers based on the optimization lineage. By prioritizing the Mixed tier, which identifies the data where the LLM has mixed performance, we identify two high-leverage subsets: the addressable frontier for generating informative mutations and the rank-sensitive frontier for distinguishing candidate quality. We evaluate APEX across three diverse benchmarks: IFBench, SimpleQA Verified, and FACTS Grounding. Under a fixed budget of 5,000 evaluation calls, due to its data efficiency, APEX outperforms the initial prompt by an average of 11.2% on Gemini 2.5 Flash and 6.8% on Gemma 3 27B, demonstrating that a data-centric approach is key to efficient and effective prompt optimization.
LSTM ベースの損害保険損失準備金の構造的欠陥の検出: 気候情報に基づいたアプローチ
正確な損失引当金は保険会社の支払能力の基礎ですが、加速する気候変動による大惨事は、従来の保険数理手法が依存する安定性の前提を体系的に破っています。このホワイトペーパーでは、長短期記憶 (LSTM) ニューラル ネットワークが、チェーン ラダー、ボーンヒュッター ファーガソン、およびケープ コッドの手法よりも高速かつ正確にこれらの構造的破損を検出し、適応できるかどうかをテストする研究プログラムを紹介します。 NOAA のハリケーン強度指数と海面水温で強化されたフロリダ州とルイジアナ州の 15 年以上の規制開発トライアングル データを使用して、大災害にさらされた年に対する予備力の精度が 15 ~ 20% 向上するという目標を立てました。この閾値は、以前のニューラル ネットワークの予備力文献とここで開発された正式な収束結果の両方に基づいています。経験的検証を超えて、LSTM の構造破壊検出を確率論的に基礎づける理論的フレームワークを開発し、テスト期間内の限られた数の災害イベントを補う正式なパフォーマンス保証を提供します。研究デザイン、方法論、期待される貢献、限界の率直な評価を文書化します。
原文 (English)
LSTM-Based Detection of Structural Breaks in Property Insurance Loss Reserving: A Climate-Informed Approach
Accurate loss reserving is foundational to insurer solvency, yet accelerating climate driven catastrophes systematically violate the stability assumptions on which traditional actuarial methods depend. This white paper presents a research program testing whether Long Short Term Memory (LSTM) neural networks can detect and adapt to these structural breaks faster and more accurately than Chain Ladder, Bornhuetter Ferguson, and Cape Cod methods. Using 15 plus years of regulatory development triangle data from Florida and Louisiana, enriched with NOAA hurricane intensity indices and sea surface temperatures, we hypothesize a targeted improvement of 15, 20% in reserve accuracy for catastrophe exposed years, a threshold grounded both in the prior neural network reserving literature and in the formal convergence results developed here. Beyond empirical validation, we develop a theoretical framework grounding LSTM structural break detection in probabilistic terms, providing formal performance guarantees that compensate for the limited number of catastrophe events in the test period. We document the research design, methodology, expected contributions, and a candid assessment of limitations.
CRUMB: 分布的に一致したコンテキストのバッチ処理による効率的な事前適合ネットワーク推論
事前適合ネットワーク (PFN) は、コンテキスト内学習を実行する表形式の基盤モデルの有望なクラスであり、ラベル付きトレーニング セット全体がコンテキストとして提供され、テスト クエリの予測が 1 回の順方向パスで生成されます。ただし、多くの PFN アーキテクチャにおける二次スケーリングのセルフ アテンション メカニズムにより、非常に大規模なトレーニング データセットの推論が法外になります。我々は、(i) テスト クエリをクラスター化し、(ii) 最大平均不一致 (MMD) を貪欲に最小化することで各クラスターに対して分布的に一致する小規模なトレーニング サブセットを選択し、(iii) コンテキストを縮小した各バッチで正確な PFN 推論を実行する 3 段階の推論ラッパーである CRUMB (Clustered Retrieval using Minimized-MMD Batching) を提案します。 CRUMB はアーキテクチャに依存せず、再トレーニングは必要ありません。 3 つの PFN アーキテクチャ (TabPFNv2、TabICLv1、TabICLv2) にわたって評価された 51 データセットの TabArena ベンチマークでは、CRUMB が同様の最先端のコンテキスト選択戦略よりも優れたパフォーマンスを発揮することが示されました。また、MMD 最小化ステップはトレーニング コンテキストの分布を現在のテスト バッチの分布と一致するように調整するのに自然に役立つため、CRUMB が共変量ドリフトに対して回復力があることも示します。
原文 (English)
CRUMB: Efficient Prior Fitted Network Inference via Distributionally Matched Context Batching
Prior-fitted networks (PFNs) are a promising class of tabular foundation models that perform in-context learning, whereby the entire labelled training set is supplied as context, and predictions for test queries are produced in a single forward pass. However, the quadratically scaling self-attention mechanism in many PFN architectures makes inference prohibitive for very large training datasets. We propose CRUMB (Clustered Retrieval Using Minimised-MMD Batching), a three-stage inference wrapper that (i) clusters the test queries, (ii) selects a small, distributionally matched training subset for each cluster by greedily minimising the maximum mean discrepancy (MMD), and (iii) runs exact PFN inference on each reduced-context batch. CRUMB is architecture-agnostic and requires no retraining. On the 51-dataset TabArena benchmark, evaluated across three PFN architectures (TabPFNv2, TabICLv1, TabICLv2), we show that CRUMB outperforms similar state-of-the-art context selection strategies. We also show that CRUMB is resilient to covariate drift, as the MMD-minimisation step naturally helps align the training context distribution to match the current test batch distributions.
完全に自動化された試験採点に向けて: ファウンデーション モデルを使用した公平性を意識した手書き解答の認識
手書きの試験を手作業で修正することは、特に大規模なコホートの場合、時間がかかり、間違いが発生しやすくなりますが、完全にデジタル化された試験では、クローズドな質問形式に教訓的な絞り込みを強いられる傾向があります。実用的な中間点では、紙ベースの問題指向のタスクを維持しますが、評価に関連する回答は機械が読み取れる表に単一の大文字として記録されます。未解決の問題は、この測定値を正確に、そして何よりも、教師なしの採点に十分公平なものにできるかどうかです。以前の自動化されたアプローチは、認識率が約 88% ~ 91% にすぎず、低すぎました。回答がセルの外に配置されたり、取り消し線が引かれたり、筆記体で書かれたりするなど、最も重要なケースでは失敗しました。ピクセル テンプレートを照合するのではなくページを解釈する汎用のビジョン言語基盤モデル (VLM) がこのギャップを埋めることを示します。 61 の匿名化された試験 (3141 の解答位置) のベンチマークでは、最良のモデルは 98.4% の精度に達し、以前のベースラインを大幅に上回りました。重要なのは、公平性を中心に評価を行うことです。つまり、偽陰性 (正解が間違っているとマークされ、生徒に不利益をもたらす) と偽陽性を区別し、コンテキストに応じて参照解を提供する軽量のプロンプトにより、偽陰性率が 0.58% に低下します。模範的な採点スキームでは、61 件の試験のうち 3 件のみがより悪い評価を受け、すべて学生の自己復習ステップによって検出されます。したがって、完全に自動化され、公平性を意識した大規模な試験採点は擁護可能です。再現性をサポートするために匿名化されたベンチマークをリリースします。
原文 (English)
Towards Fully Automated Exam Grading: Fairness-Aware Recognition of Handwritten Answers with Foundation Models
Correcting handwritten exams by hand is time-consuming and error-prone, particularly for large cohorts, while fully digital exams tend to force a didactic narrowing towards closed question formats. A practical middle ground keeps paper-based, problem-oriented tasks but records the assessment-relevant answers as single capital letters in a table that a machine can read. The open question is whether this reading can be made accurate and, above all, fair enough for unsupervised grading. Earlier automated approaches reached only about 88%--91% recognition -- too low -- and failed on the cases that matter most: answers placed outside the cell, crossed out, or written in cursive. We show that general-purpose vision-language foundation models (VLMs), which interpret the page rather than match pixel templates, close this gap. On a benchmark of 61 anonymised exams (3141 answer positions) the best model reaches 98.4% accuracy, well above the previous baseline. Crucially, we centre the evaluation on fairness: we distinguish false negatives (a correct answer marked wrong, which disadvantages the student) from false positives, and a lightweight prompt that supplies the reference solution as context lowers the false-negative rate to 0.58%. Under an exemplary grading scheme only three of the 61 exams would be graded worse, all caught by a student self-review step. Fully automated, fairness-aware exam grading at scale is therefore defensible; we release the anonymised benchmark to support reproducibility.
ハブまたはフリンジ: Web グラフ中心性による事前トレーニング データ選択
最新の言語モデルのパフォーマンスは、事前トレーニング データの構成に大きく依存します。しかし、既存のデータ選択方法は、ドキュメントのスコアリングや混合の最適化のために補助的な分類子に依存しており、計算オーバーヘッドとラベル付きデータへの依存が追加されます。私たちは、Common Crawl のホストレベルの Web グラフに対して構造的中心性スコアを計算し、それらを使用して事前トレーニング混合物における中心ドキュメントと周辺ドキュメントの比率を変更する軽量のデータ選択フレームワークである WebGraphMix を提案します。私たちは、中央ホストがモデルを再利用可能な抽象化に公開し、周辺ホストが特殊なロングテール知識をエンコードしていると仮説を立てます。 WebGraphMix は中心性スコアを Web スケールで効率的に計算し、モデルのトレーニング、ラベル付けされたデータ、または下流の監視を必要としません。 WebGraphMix を DataComp-LM パイプラインに統合し、それぞれ 8B と 28B トークンを使用して 400M と 1B のパラメーター スケールでモデルをトレーニングし、事実の知識から記号推論に至る 23 のタスクを評価します。私たちの実験では、中央および周辺の Web 領域が補完的な機能をエンコードしていることがわかりました。両方を 1:1 の比率で組み合わせた混合物では、平均 41.4% が達成されます。これに対し、均一サンプリングの場合は 39.8% です。構造スコアとドキュメントレベルの品質分類子スコアを組み合わせると、パフォーマンスがさらに 43.8% 向上します。これらの発見は、Web グラフ トポロジが事前トレーニング データ キュレーションにとって有意義な軸であり、既存のコンテンツ ベースのアプローチとはほぼ直交する情報をキャプチャすることを示しています。
原文 (English)
Hubs or Fringes: Pretraining Data Selection via Web Graph Centrality
The performance of modern language models depends critically on pretraining data composition. Yet existing data selection methods rely on auxiliary classifiers for document scoring or mixture optimization, adding computational overhead and dependence on labeled data. We propose WebGraphMix, a lightweight data selection framework that computes structural centrality scores over the Common Crawl host-level web graph and uses them to vary the proportion of central versus peripheral documents in the pretraining mixture. We hypothesize that central hosts expose models to reusable abstractions, while peripheral hosts encode specialized, long-tail knowledge. WebGraphMix computes centrality scores efficiently at web scale, requiring no model training, labeled data, or downstream supervision. We integrate WebGraphMix into the DataComp-LM pipeline and train models at 400M and 1B parameter scales with 8B and 28B tokens respectively, evaluating on 23 tasks ranging from factual knowledge to symbolic reasoning. Our experiments show that central and peripheral web regions encode complementary capabilities. Mixture combining both at a ratio of 1:1 achieves 41.4% on average, compared to 39.8% for uniform sampling. Combining structural scores with document-level quality classifier scores further improves performance to 43.8%. These findings demonstrate that web graph topology is a meaningful axis for pretraining data curation, capturing information that is largely orthogonal to existing content-based approaches.
ロールプレイングをするとき、モデルは自分の言うことを信じますか?
言語モデルは、「地球が太陽の周りを回っている」と述べ、アリストテレスをロールプレイする場合にはその反対を主張することができます。最近の研究では、ペルソナの採用が言語モデルの動作の基本であり、モデルは特定のコンテキストに最も適切なペルソナを常に選択するものであると主張しています。このようなロールプレイングは単にモデルの出力を変更するだけなのでしょうか、それともモデルが内部的に真実であると表現するものにも影響を与えるのでしょうか?私たちはこの質問を線形真実調査で研究し、その調査を現代のコンセンサスとは異なる可能性の高い信念を持つ歴史上の人物をロールプレイする LLM に適用します。各ペルソナについて、そのペルソナが支持した可能性が高い虚偽の主張 (*時代の信念*) と、そのペルソナが支持しなかったであろうトピックに一致する虚偽の主張 (*時代の偽*) を比較します。プロンプト、コンテキスト内学習、および教師付き微調整を通じて、ペルソナ誘導は、時代に信じられている発言を同様に誤った代替案よりも抑制しますが、全体としては誤ったものとして分類されたままです。したがって、ロールプレイは、モデルが内部的に真実として表現しているものよりも、モデルが言うことをシフトさせます。これを、緊急ミスアライメント (EM) を示す有害なアドバイスに基づいてトレーニングされたモデルと対比します。 3 つのモデル ファミリ (Qwen 2.5 14B、Qwen 3 8B、および Llama 3.3 70B) にわたって、それらの誤った主張は、プローブ空間の真の領域に向かって大幅に移動し、ロールプレイでは約 6 分の 1 であるのに対し、挑戦ではおよそ半分の時間で防御され、下流の推論で使用されます。したがって、ロールプレイと創発的な不整合は、信念の内在化のスペクトル上の点であり、ロールプレイはほとんど表現を変更せずにモデルが言うことを変更しますが、創発的な不整合は、偽の主張を完全に真実としてマークすることなく、その内部表現をシフトします。
原文 (English)
When Roleplaying, Do Models Believe What They Say?
Language models can state that "the Earth orbits the Sun" and, when role-playing Aristotle, assert the opposite. Recent work argues that persona adoption is fundamental to how language models operate, with models constantly selecting the most appropriate persona for a given context. Does such role-playing merely change the model's outputs, or does it also affect what the model internally represents as truthful? We study this question with linear truth probes, applying them to LLMs role-playing historical personas whose likely beliefs differ from modern consensus. For each persona, we compare false claims the persona would likely have endorsed (*era-believed*) with topic-matched false claims they would not have endorsed (*era-false*). Across prompting, in-context learning, and supervised fine-tuning, persona induction suppresses era-believed statements less than equally false alternatives, yet they remain classified as false overall. Role-play therefore shifts what these models say more than what they internally represent as true. We contrast this with models trained on harmful advice that exhibit Emergent Misalignment (EM). Across three model families (Qwen 2.5 14B, Qwen 3 8B, and Llama 3.3 70B), their false claims move substantially toward the true region of probe space, are defended under challenge roughly half the time versus about a sixth for role-play, and are used in downstream reasoning. Role-play and Emergent Misalignment thus are points on a spectrum of belief internalization, where role-play changes what a model says with little representational change, while Emergent Misalignment shifts the internal representation of false claims without fully marking them as true.
深層学習を用いた生体認証なりすまし検知の研究について
生体認証システムはセキュリティ アプリケーションに導入されることが増えています。ただし、攻撃者が偽造生体認証データを悪用して不正アクセスを取得するスプーフィング攻撃に対しては依然として脆弱です。この研究では、顔認識システム内でのなりすまし攻撃の検出における、最先端の機械学習モデル、MobileNetV2、DenseNet-121、Inception-v3、および Spoof Trace Disentanglement (STD) の有効性を評価します。この研究では、CelebA-Spoof データセットを使用して、精度、精度、再現率、F1 スコアなどの指標を使用してモデルの有効性を評価します。一般化可能性を評価するために、MSU-MFSD データセットに対してデータセット間の検証が実行されます。結果は、MobileNetV2 が最も効率的なモデルであり、計算効率のバランスをとりながら 92% の精度を達成し、実際のアプリケーションに適していることを示しています。 Inception-v3 は中程度の堅牢性を示しますが、DenseNet-121 と STD は一般化に苦労しています。この調査結果は、生体認証セキュリティ システムを強化するには、ドメイン適応とハイブリッド アーキテクチャの進歩の必要性を浮き彫りにしています。
原文 (English)
On the Study of Biometric Spoofing Detection using Deep Learning
Biometric systems are increasingly deployed in security applications; however, they remain vulnerable to spoofing attacks, in which attackers exploit counterfeit biometric data to gain unauthorized access. This research evaluates the effectiveness of state-of-the-art machine learning models, MobileNetV2, DenseNet-121, Inception-v3, and Spoof Trace Disentanglement (STD) in detecting spoofing attacks within facial recognition systems. Using the CelebA-Spoof dataset, the study evaluates model effectiveness using metrics such as accuracy, precision, recall, and F1 Score. Cross-dataset validation is carried out on the MSU-MFSD dataset to assess generalizability. The results show MobileNetV2 as the most efficient model, achieving 92% accuracy while balancing computational effectiveness, making it appropriate for real-life applications. Inception-v3 shows moderate robustness, while DenseNet-121 and STD struggle with generalization. The findings highlight the need for advances in domain adaptation and hybrid architectures to enhance biometric security systems.
SirenFNO: フーリエ ニューラル演算子の効率的かつ全周波数学習
フーリエ ニューラル演算子 (FNO) は、偏微分方程式の解を近似するための効果的かつ効率的な代理演算子であり、離散化全体にわたって一般化されます。しかし、FNO の学習効率を維持するために周波数切り捨てに依存しているため、FNO は低周波情報に対してスペクトルの偏りを示し、特に強い高周波発振を持つ特定の偏微分方程式の学習能力を妨げる可能性があることが実証研究で示唆されています。この制限に対処するために、正弦波表現ネットワーク (SIREN) を利用して暗黙的なニューラル表現を学習し、モードごとのカーネル パラメーター化を実行する新しいフレームワークである SirenFNO を提案します。私たちの SIREN パラメータ化は、離散化に依存しない一定のパラメータ数でフルグリッド スペクトルを学習するため、周波数の切り捨ての必要性がなくなります。関数テンソル分解を使用して SirenFNO をさらに拡張し、パラメーターと学習の効率を向上させます。経験的な結果は、SirenFNO が、離散化の不変性を維持したまま約 $4$ ~ $15$ 倍のパラメータ削減で FNO よりも一貫して優れていること、および関数分解バリアントは、複数の PDE ベンチマーク全体で最大 $73$ 倍少ないパラメータでパフォーマンスの向上を達成していることを示しています。
原文 (English)
SirenFNO: Efficient and Full Frequency Learning of Fourier Neural Operators
Fourier neural operators (FNOs) are effective and efficient surrogates for approximating solutions of PDEs and generalize across discretizations. However, owing to the reliance on frequency truncation to maintain learning efficiency of FNOs, empirical studies suggest that FNOs exhibit spectral bias toward low-frequency information, which may hinder the learning capability especially for certain PDEs with strong high-frequency oscillations. To address this limitation, we propose SirenFNO, a novel framework that leverages sinusoidal representation networks (SIRENs) to learn implicit neural representations and performs mode-wise kernel parameterization. Our SIREN parameterization learns a full-grid spectrum with a constant and discretization-independent parameter count, thereby eliminating the need for frequency truncation. We further extend SirenFNO with functional tensor decompositions to enhance parameter and learning efficiency. Empirical results show that our SirenFNO consistently outperforms FNO with approximately $4$ to $15$ times parameter reductions with preserved discretization invariance, and our functional decomposition variants obtain performance improvements with a maximum of $73$ times fewer parameters across multiple PDE benchmarks.
ISE: マルチターン OS エージェントの軌跡のための実行ベースのレシピ
有能な OS エージェントをトレーニングするには、構造化されたユーザーの意図、複数ターンのタスク委任、および根拠のあるツールの実行を同時にキャプチャするデータが必要ですが、これらのプロパティは既存のデータセットには存在しません。我々は、これらのギャップに共同で対処する 3 段階の合成パラダイムである ISE (Intent -> Simulate -> Execute) を提案します。ステージ 1 では、4D フレームワーク (ペルソナ x ドメイン x タスク x 複雑さ) を介して約 50,000 の構造化インテントを構築します。重複排除後、プールには 43956 個の一意のインテントが含まれ、mpnet-base-v2 埋め込み (コサイン カーネル、q=1) のプール全体で 61.57 の Vendi スコアを達成しました。ステージ 2 では、ロールロックされたユーザー シミュレータを介してマルチターンのユーザー エージェント インタラクションを推進し、各ユーザー ターンを実際の実行結果に基づいて実行し、平均 8.12 ユーザー ターンと合計 68.24 のダイアログ ターンに相当する 23132 の完全な軌跡を生成します。ステージ 3 では、ライブの分離された OS ワークスペース内ですべてのツール呼び出しが実行され、シミュレートされた応答ではなく、本物の障害回復ダイナミクスが生成されます。 ISETrace の微調整により、標準プロトコルのエージェント ツール使用タスクで Qwen3-8B を使用し、ClawEval pass@1 が 19.3 から 37.7 に改善されました。この結果は、ゼロショット GPT-4o や 4 倍大きい Qwen3-32B ベース モデルよりも優れています。ステージ 2 のアブレーションは、マルチターン シミュレーションがパフォーマンス向上の大部分をもたらすことを証明しています。すべてのソース コードとデータセットは https://github.com/Valiere01/ISE-Trace でリリースされます。
原文 (English)
ISE: An Execution-Grounded Recipe for Multi-Turn OS-Agent Trajectories
Training capable OS agents requires data that simultaneously captures structured user intents, multi-turn task delegation, and grounded tool execution--properties absent from existing datasets. We propose ISE (Intent -> Simulate -> Execute), a three-stage synthesis paradigm that addresses these gaps jointly. Stage 1 constructs roughly 50000 structured intents via a 4D framework (Persona x Domain x Task x Complexity); after deduplication the pool contains 43956 unique intents and attains a Vendi Score of 61.57 over the entire pool on mpnet-base-v2 embeddings (cosine kernel, q=1). Stage 2 drives multi-turn user-agent interaction through a role-locked user simulator that grounds each user turn in actual execution outcomes, producing 23132 complete trajectories averaging 8.12 user turns and 68.24 total dialogue turns. Stage 3 runs every tool call inside a live, isolated OS workspace, generating authentic failure-recovery dynamics instead of simulated responses. Fine-tuning on ISETrace improves ClawEval pass@1 from 19.3 to 37.7 using Qwen3-8B on agent tool-use tasks with a standard protocol. This result outperforms zero-shot GPT-4o and the larger Qwen3-32B base model which is four times bigger. An ablation on Stage 2 proves multi-turn simulation brings a large portion of the performance gain. We release all source code and dataset at https://github.com/Valiere01/ISE-Trace.
AI 研究者は軍備管理を主導して軍事 AI リスクを軽減する必要がある
AI 機能の進歩により、研究者や一般の人々は、その潜在的な世界的な影響をより認識する必要があります。短期的な差し迫った懸念は、軍事用 AI アプリケーションの規制です。兵器メーカーや防衛請負業者は、AI機能への投資を増やし、AI企業とのパートナーシップを築いており、より安全な未来を確保するために軍事指導者、軍備管理外交の専門家、AI研究者の協力を求める急成長する連合を形成している。 AI 研究者は超インテリジェント AI の長期的な影響に焦点を当てることが多いですが、このアプローチは軍事用途において AI がもたらす差し迫った課題に適切に対処できない可能性があります。成功するには、軍事 AI システムなどの防衛アプリケーションへの統合を計画しているフロンティア AI モデルの新たなリスクを認識し、軽減する必要があります。軍備管理により過去の壊滅的なリスクは減少したため、核抑止から学んだ教訓は、AI の安全性とセキュリティの研究を検証と外交の革新に導くことができます。ただし、AI 研究者は、軍事現場における不安定性を明確に定義し、緩和する技術研究の主導を支援する必要があります。これらの新たな責任と、十分に信頼できるソリューションの欠如を考慮すると、AI 研究者は軍備管理研究を推進し、軍事 AI 応用におけるリスクを最小限に抑える上で主導的な役割を果たす必要があると主張します。
原文 (English)
AI Researchers Must Help Lead Arms Control to Mitigate Military AI Risks
The advancement of AI capabilities compels researchers and the public to be more aware of its potential worldwide impact. A pressing near-term concern is the regulation of military AI applications. Armament manufacturers and defense contractors are increasingly investing in AI capabilities and forging partnerships with AI companies, creating a burgeoning coalition that demands military leaders, arms control diplomacy experts, and AI researchers collaborate to ensure a safer future. While AI researchers often focus on the long-term implications of superintelligent AI, this approach may not adequately address the immediate challenges posed by AI in military applications. Success requires acknowledging and mitigating the emerging risks of frontier AI models that plan to be integrated into defense applications, like military AI systems. Arms control has reduced past catastrophic risks, so lessons learned from nuclear deterrence can guide AI safety and security research towards innovations in verification and diplomacy. AI researchers, however, must assist in leading the technical research that clearly defines and alleviates instability in military settings. Given these new responsibilities and the lack of sufficiently reliable solutions, we argue that AI researchers must take a leading role in advancing arms control research to minimize risk in military AI applications.
事前トレーニングされた自己教師あり音声モデルは、目に見えない子音を認識できます
最新の事前トレーニング済み自己監視型自動音声認識モデルは、大規模な音声データでトレーニングされ、音声をコンテキスト化された表現にエンコードします。しかし、彼らのトレーニングデータは高リソース言語に大きく偏っており、低リソース言語からのデータはほとんどないため、主にコイサン言語に見られるクリック子音など、類型的に珍しい音声が過小評価されている可能性があるという懸念が生じています。これは、私たちの中心的な研究課題につながります。「これらのモデルは、クリック子音を他の音声と同じくらい正確に認識できるでしょうか?」この疑問に対処するために、クリックリッチな 2 つのコイサン語 (G|ui と West !Xoon) のデータに基づいて、事前トレーニングされた自己教師あり音声モデル (Wav2Vec2 と HuBERT) を微調整して比較しました。私たちの結果は、微調整されたモデルが一貫して非クリックよりもクリックをより正確に認識することを明らかにし、自己監視により、まれな音素を含む人間の音声全体の一般化が可能であることを示唆しています。
原文 (English)
Pretrained self-supervised speech models can recognize unseen consonants
Modern pretrained self-supervised automatic speech recognition models are trained on large-scale audio data to encode speech into contextualized representations. However, their training data are heavily skewed toward high-resource languages with little data from low-resource languages, raising concerns about the potential underrepresentation of typologically uncommon speech sounds such as click consonants primarily found in Khoisan languages. This leads to our central research question: Can these models recognize click consonants as accurately as other speech sounds? To address this question, we fine-tune and compare pretrained self-supervised speech models (Wav2Vec2 and HuBERT) on data from two click-rich Khoisan languages (G|ui and West !Xoon). Our results reveal that the fine-tuned models consistently recognize clicks more accurately than non-clicks, suggesting that self-supervision enables generalization across human speech sounds including rare phonemes.
EEG と fNIRS によるうつ病状態分類のためのエンドツーエンドの機械学習
社会的ストレスの増大により精神医療への需要が高まり、従来の精神医学的診断の限界が浮き彫りになっています。主に臨床面接と患者の自己申告に依存する従来の方法は、本質的に主観的な偏見や医師のさまざまな経験的判断に対して脆弱です。定量的評価のニーズに応えるため、脳波検査 (EEG) や機能的近赤外分光法 (fNIRS) などの生物学的信号ベースの検出が、有望な客観的代替手段として浮上しています。このような技術は、被験者自身が気づいていない可能性のある潜在的なうつ病状態を特定するために特に重要です。さらに、高齢化社会では、うつ病と認知症の併存率が高いため、相互の症状悪化を防ぎ、生活の質(QoL)を維持するために早期に鑑別する必要があります。 11 人の健康な学生を対象としたこのパイロット研究は、生物学的信号に基づくうつ病検出のフレームワークを確立し、臨床使用のための自動化された客観的診断ツールへの基礎的なステップとして機能します。
原文 (English)
End-to-End Machine Learning for Depressive State Classification via EEG and fNIRS
The escalating demand for mental healthcare, driven by rising societal stress, highlights the limitations of traditional psychiatric diagnostics. Conventional methods - relying primarily on clinical interviews and patient self-reports - are inherently vulnerable to subjective bias and the varying empirical judgment of practitioners. To address the need for quantitative evaluation, biological signal-based detection, including electroencephalography (EEG) and functional near-infrared spectroscopy (fNIRS), has emerged as a promising objective alternative. Such technology is particularly vital for identifying latent depressive states that may be unrecognized by the subjects themselves. Furthermore, in aging populations, the high comorbidity between depression and dementia necessitates early differentiation to prevent mutual symptom exacerbation and maintain Quality of Life (QoL). This pilot study of eleven healthy students establishes a framework for biological signal-based depression detection, serving as a foundational step toward automated, objective diagnostic tools for clinical use.
エッジデバイス上の ECG 異常検出のためのプライバシー保護フェデレーテッド オートエンコーダー
継続的な心電図検査 (ECG) モニタリングにより、心血管イベントに発展する前にリズム異常を表面化できる可能性があります。ただし、展開可能なシステムは、法定レベルのプライバシー (GDPR、HIPAA)、制約のあるエッジ ハードウェアでのリアルタイム推論、および非 IID 病院間データでの検出品質という 3 つの要件を同時に満たす必要があります。私たちは、PTB-XL データセット上の教師なし 12 誘導 ECG 異常検出の 3 つすべてに対応するエンドツーエンドのフェデレーテッド システムを設計および評価します。これは、3 つのオートエンコーダー ファミリ (VanillaAE、ConvAE、VAE)、10 のシミュレートされた病院にわたるフラワーベースのフェデレーション平均 (FedAvg)、クライアント側の差分プライベート SGD (DP-SGD) と R\'enyi-DP 会計士を組み合わせたものです。 Raspberry Pi 4 ベンチマークによる 8 ビット整数 (INT8) ポストトレーニング量子化。私たちの主な貢献は、これらのメカニズムがどのように構成されているかの実証的特徴付け、実践的な DP 固有の推奨事項、臨床的に機密性の高い環境における技術的およびセキュリティーに関する洞察です。フェデレーテッド ラーニングは、すべてのアーキテクチャにわたって集中ベースライン (ROC 曲線下の ConvAE フェデレーテッド エリア、AUROC、$0.782$) と一致またはそれを超えており、$\varepsilon$ スイープにより、推奨される臨床操作点として $\varepsilon=4$ が特定されます。 INT8 量子化により、モデル サイズがおよそ半分になり、Pi 4 のレイテンシーが $<0.12%$ の AUROC 損失で最大 $44%$ 削減されます。重要なのは、DP と量子化ペナルティは経験的に独立しているため、実務者は強力なプライバシー保証と引き換えにコンパクトなエッジ フットプリントを得る必要がありません。私たちの知る限り、これはフェデレーテッド ラーニング、形式的な $(\varepsilon,\delta)$-DP、教師なし再構成ベースの検出、および量子化された AArch64 展開を組み合わせた最初のシステムです。
原文 (English)
Privacy-Preserving Federated Autoencoder for ECG Anomaly Detection on Edge Devices
Continuous electrocardiography (ECG) monitoring could surface rhythm abnormalities before they escalate into cardiovascular events. However, a deployable system must satisfy three requirements simultaneously: legal-grade privacy (GDPR, HIPAA), real-time inference on constrained edge hardware, and detection quality under non-IID cross-hospital data. We design and evaluate an end-to-end federated system addressing all three for unsupervised 12-lead ECG anomaly detection on PTB-XL dataset, combining three autoencoder families (VanillaAE, ConvAE, VAE), Flower-based federated averaging (FedAvg) across ten simulated hospitals, client-side differentially private SGD (DP-SGD) with a R\'enyi-DP accountant, and 8-bit integer (INT8) post-training quantization with Raspberry Pi 4 benchmarking. Our main contributions are: an empirical characterization of how these mechanisms compose, practical DP-specific recommendations, and technical and security insights for a clinically sensitive setting. Federated learning matches or exceeds the centralized baseline across all architectures (ConvAE federated area under the ROC curve, AUROC, $0.782$), and an $\varepsilon$ sweep identifies $\varepsilon=4$ as the recommended clinical operating point. INT8 quantization roughly halves model size and cuts Pi 4 latency by up to $44%$ with $<0.12%$ AUROC loss. Crucially, DP and quantization penalties are empirically independent, so practitioners need not trade a strong privacy guarantee for a compact edge footprint. To our knowledge, this is the first system combining federated learning, formal $(\varepsilon,\delta)$-DP, unsupervised reconstruction-based detection, and quantized AArch64 deployment.
LLM+グラフ: グラフネイティブで相乗的な AI システムに向けて
大規模言語モデル (LLM) は急速に進歩していますが、構造化およびマルチホップ推論における限界は、グラフネイティブで相乗的な人工知能 (AI) システムの必要性を強調しています。グラフ構造化データは、社会、生物学、金融、交通、Web、知識の各領域にわたる重要なアプリケーションを支えており、LLM が根拠のあるコンテキストに富んだ推論のためにグラフ計算をどのように活用できるかを理解することが不可欠です。 3 つの相補的な相乗効果が現れています。検索と推論のためのグラフ計算で強化された LLM。 LLM とナレッジ グラフ (KG) 間の双方向の統合。LLM は KG の構築とキュレーションをサポートし、KG は意味論的な制約と事実の一貫性を強制します。 AI エージェントは、計画、意思決定、および複数ステップの推論のためのグラフ アルゴリズムによって強化されています。並行して、LLM は、自然言語インターフェイスとハイブリッド LLM グラフ ニューラル ネットワーク (GNN) パイプラインを介して、グラフ データ管理とグラフ機械学習 (ML) の新機能を導入します。このチュートリアルでは、これらの収束する方向性を推進するアルゴリズム、システム、設計原則を統合し、データ サイエンスとデータ マイニングの研究者に、LLM、グラフ データ管理、グラフ マイニング、グラフ ML、およびエージェント コンピューティングを次世代のグラフ ネイティブ AI システムに統合するための統一された視点を提供します。
原文 (English)
LLMs+Graphs: Toward Graph-Native, Synergistic AI Systems
Large Language Models (LLMs) have advanced rapidly, but their limitations in structured and multi-hop reasoning underscore the need for graph-native, synergistic artificial intelligence (AI) systems. Graph-structured data underpins critical applications across social, biological, financial, transportation, web, and knowledge domains, making it essential to understand how LLMs can leverage graph computation for grounded, context-rich inference. Three complementary synergies are emerging: LLMs augmented with graph computation for retrieval and reasoning; bidirectional integration between LLMs and knowledge graphs (KGs), where LLMs support KG construction and curation while KGs enforce semantic constraints and factual consistency; and AI agents strengthened by graph algorithms for planning, decision making, and multi-step reasoning. In parallel, LLMs introduce new capabilities for graph data management and graph machine learning (ML) through natural language interfaces and hybrid LLM-graph neural network (GNN) pipelines. This tutorial synthesizes the algorithms, systems, and design principles driving these converging directions, offering data science and data mining researchers a unified perspective on integrating LLMs, graph data management, graph mining, graph ML, and agentic computation into next-generation graph-native AI systems.
ConsistencyPlanner: 高速サンプリング整合性モデルを使用したリアルタイム プランニング
現実世界の複雑な運転シナリオにおける閉ループ計画は、自動運転システムにとって重大な課題となります。従来のルールベースの方法は解釈可能ですが、その事前定義されたヒューリスティックは動的なトラフィック環境への適応性に欠けています。学習ベースのアプローチはかなりの有望性を示しています。逆に、学習ベースのアプローチは、その期待にもかかわらず、多様でマルチモーダルな運転行動のモデリングとリアルタイムの計画のバランスを取るのに苦労しており、多くの場合、優柔不断または危険な行動につながります。この制限に対処するために、高速サンプリング整合性モデルを備えたリアルタイム計画フレームワークである Consistency Planner を提案します。私たちのアプローチは 2 つの重要な技術的貢献に基づいて構築されています。効率的なマルチモーダル サンプリング: 高速サンプリングの一貫性モデルを採用して、妥当な将来の軌跡の多様なセットを生成します。これにより、マルチモーダル アクションの効率的なリアルタイム探索が可能になり、以前の反復生成手法の計算ボトルネックが克服されます。異種の特徴の融合: 異種の入力特徴 (シーンの特徴やアクション トークンを含む) を動的に統合して、堅牢な計画を実現する凝集した表現にするアテンション強化デコーダーを導入します。 Waymax シミュレーターでの広範な評価により、既存の方法と比較して安全性メトリクスにおいて優れたパフォーマンスが実証され、特に困難な動的シナリオで強力な結果が得られます。
原文 (English)
ConsistencyPlanner: Real-time Planning with Fast-Sampling Consistency Models
Closed-loop planning in complex, real-world driving scenarios presents a critical challenge for autonomous driving systems. While traditional rule-based methods are interpretable, their predefined heuristics lack the adaptability for dynamic traffic environments. Learning-based approaches have shown considerable promise. Conversely, learning-based approaches, despite their promise, struggle to balance the modeling diverse and multimodal driving behaviors and real-time planning, often leading to indecisive or unsafe actions. To address this limitation, we propose Consistency Planner, a real-time planning framework with fast-sampling consistency models. Our approach is built upon two key technical contributions. Efficient Multimodal Sampling: We employ fast-sampling consistency models to generate a diverse set of plausible future trajectories. This enables efficient, real-time exploration of multimodal actions, overcoming the computational bottlenecks of previous iterative generative methods. Heterogeneous Feature Fusion: We introduce an attention-enhanced decoder that dynamically integrates heterogeneous input features (including scene feature and action token) into a cohesive representation for robust planning. Extensive evaluation in the Waymax simulator demonstrates superior performance in safety metrics compared to existing methods, with particularly strong results in challenging dynamic scenarios.
AVIS: 視覚言語モデルの適応テスト時間スケーリング
最新の視覚言語モデル (VLM) は、思考連鎖プロンプトとテスト時間のスケーリングから恩恵を受けますが、これらの利点には、多くの場合、大規模な視覚的コンテキストと長いデコード チェーンによる法外な推論コストが伴います。このコストは、言語モデルに渡される視覚的証拠の量を制御する Visual Context Scaling (VCS) と、推論時間推論検索の実行量を制御する Visual Reasoning Scaling (VRS) という 2 つの結合された軸を通じて表示されます。既存の手法は通常、一度に 1 つの軸を最適化するため、これらの軸にわたるコンピューティングの共同割り当ては十分に検討されていません。クエリごとに VCS と VRS の両方を適応させる軽量ポリシーである Adaptive Visual Inference Scaling (AVIS) を導入します。 AVIS は、事前入力前に冗長なビジュアル トークンを削除するトレーニング不要の $O(N)$ キーベースのルールである Key Diversity Visual (KDV) プルーニングを通じて VCS を実現し、学習された難易度予測子を使用して推論ロールアウトの数を選択する適応的自己一貫性を通じて VRS を実現します。 AVIS は導入に適しており、すべてのロールアウトで単一のプレフィル パスと KV キャッシュを再利用する共有プレフィル推論と互換性があります。さまざまな画像およびビデオ推論ベンチマーク全体で、AVIS は精度、つまり VCS のみおよび VRS のみのベースラインと比較した計算のトレードオフを向上させ、計算と遅延を低く抑えながら、RL のトレーニング後の VLM 上で効果を維持します。
原文 (English)
AVIS: Adaptive Test-Time Scaling for Vision-Language Models
Modern Vision-Language Models (VLMs) benefit from chain-of-thought prompting and test-time scaling, but these gains often come with prohibitive inference cost due to large visual contexts and long decoding chains. We view this cost through two coupled axes: Visual Context Scaling (VCS), which controls how much visual evidence is passed to the language model, and Visual Reasoning Scaling (VRS), which controls how much inference-time reasoning search is performed. Existing methods typically optimize one axis at a time, leaving the joint allocation of compute across these axes underexplored. We introduce Adaptive Visual Inference Scaling (AVIS), a lightweight policy that adapts both VCS and VRS per query. AVIS realizes VCS through Key Diversity Visual (KDV) pruning, a training-free $O(N)$ key-based rule for removing redundant visual tokens before prefilling, and realizes VRS through adaptive self-consistency, using a learned difficulty predictor to select the number of reasoning rollouts. AVIS is deployment-friendly and compatible with shared-prefill inference, where all rollouts reuse a single prefilling pass and KV cache. Across diverse image and video reasoning benchmarks, AVIS improves the accuracy--compute trade-off relative to VCS-only and VRS-only baselines, and remains effective on top of RL post-trained VLMs while keeping compute and latency low.
堅牢なネットワーク システムのためのモデルベースおよびデータ駆動の階層制御およびトポロジの共同設計
この論文では、相互接続された線形サブシステム、外乱入力、およびパフォーマンス出力のセットで構成されるネットワーク システムのクラスについて考察します。散逸理論を使用して、閉ループネットワークシステムが外乱入力から性能出力まで散逸することを保証するためのモデルベースの階層制御設計戦略を最初に提案します。これには、ローカル散逸率の保証を強制するために各サブシステムのローカル コントローラーを設計することが含まれます。その後、これを利用して分散型グローバル コントローラーと相互接続トポロジを共同設計し、相互接続トポロジーのコストを最適化しながらグローバルな散逸率の保証を強制します。全体的な設計プロセスでは、一連の線形行列不等式 (LMI) 問題を解くだけで済みます。これにより、構成性と分散性が維持され、非効率的で集中化された非凸型の反復設計プロセスが回避されます。このモデルベースの階層制御設計戦略は、サブシステムのダイナミクスの知識を前提としていますが、現実世界のネットワーク化されたシステムの多くには当てはまらない可能性があります。これを動機として、サブシステムからの豊富な入力-状態-出力軌跡データの利用可能性のみを前提とするデータ駆動型の階層制御設計戦略も提案します。提案されたデータ駆動設計プロセスでは、サブシステムのダイナミクスに影響を与える未知の外乱が二次行列不等式 (従来の境界を緩和) によって制限され、行列 S 補題を使用してこれを説明すると仮定します。最後に、堅牢な (散逸的な) 電圧調整と電流共有を強化することを目的として、DC マイクログリッドを表すネットワーク化されたシステムについて、提案されたモデルベースおよびデータ駆動型の階層制御設計の有効性を示します。
原文 (English)
Model-Based and Data-Driven Hierarchical Control and Topology Co-Design for Robust Networked Systems
In this paper, we consider a class of networked systems comprising an interconnected set of linear subsystems, disturbance inputs, and performance outputs. Using dissipativity theory, we first propose a model-based hierarchical control design strategy to ensure the closed-loop networked system is dissipative from its disturbance inputs to performance outputs. This involves designing local controllers for each subsystem to enforce local dissipativity guarantees, which are then exploited to co-design distributed global controllers and the interconnection topology to enforce global dissipativity guarantees while optimizing interconnection topology costs. The overall design process requires only solving a sequence of linear matrix inequality (LMI) problems, thereby retaining compositionality and decentralizability while avoiding non-convex, iterative design processes that are inefficient and centralized. This model-based hierarchical control design strategy assumes the knowledge of the subsystem dynamics, which may not hold in many real-world networked systems. Motivated by this, we also propose a data-driven hierarchical control design strategy that assumes only the availability of rich input-state-output trajectory data from the subsystems. The proposed data-driven design process assumes that the unknown disturbances affecting the subsystem dynamics are bounded by a quadratic matrix inequality (relaxing conventional bounds) and accounts for this by using the matrix S-lemma. Finally, the effectiveness of the proposed model-based and data-driven hierarchical control designs is illustrated for a networked system representing a DC microgrid, with the aim of enforcing robust (dissipative) voltage regulation and current sharing.
製造プロセス特性予測モデリングのための大規模言語モデルによって実現される物理学を抽出したニューラル ネットワーク
製造におけるプロセスと特性の関係を予測することは、高額な実験コストと複雑な「ブラックボックス」モデルの解釈可能性の限界によってしばしば課題となります。この論文では、データが不足したシナリオで高精度の予測を達成するために設計された新しい知識蒸留フレームワークを提案します。このフレームワークは、大規模言語モデルを介して科学文献から体系的に抽出された分析物理事前分布を特権教師モデルに統合します。グラフマスク アテンション レイヤーを使用して、厳密な設定値、または静的および高周波数の時間的シグネチャの組み合わせを示す入力変数間の複雑な物理的依存関係をキャプチャします。この特権的な知識は、推論用の軽量のスチューデント予測子に蒸留されます。フレームワークの実現可能性と堅牢性は、5 つの多様な製造プロセスにわたる包括的な実験を通じて評価されます。データセットのサイズが小さい場合でも統計的信頼性を確保するために、K 分割交差検証手法を繰り返し使用してモデルの安定性と一般化を定量化します。結果は、提案されたフレームワークが評価されたすべてのドメインにわたって一貫して高い予測精度を達成していることを示しています。最も重要なことは、このアーキテクチャは、LLM から導出された分析事前分布が最適ではない、または不完全であるシナリオでも、堅牢な予測パフォーマンスを維持することにより、大幅な耐障害性を実証していることです。さらに、スチューデント予測器は 6000 Hz を超える推論周波数を実現し、標準の産業用ハードウェアでのリアルタイムのエッジ展開を容易にします。この研究は、データが限られた環境における理論物理学とリアルタイムの産業モニタリングの間のギャップを埋めるためのスケーラブルなソリューションを提供します。
原文 (English)
Physics-Distilled Neural Network enabled by Large Language Models for Manufacturing Process-Property Predictive Modeling
Predicting process-property relationships in manufacturing is often challenged by high experimental costs and the limited interpretability of complex 'black-box' models. This paper proposes a novel knowledge distillation framework designed to achieve high-accuracy predictions in data-scarce scenarios. The framework integrates analytical physics priors, which are systematically extracted from scientific literature via Large Language Models, into a privileged teacher model. We employ a Graph-Masked Attention layer to capture the complex physical dependencies among input variables showing strict setpoints or a combination of static and high-frequency temporal signatures. This privileged knowledge is distilled into a lightweight student predictor for inference. The feasibility and robustness of the framework are evaluated through a comprehensive experiment across five diverse manufacturing processes. To ensure statistical reliability, given the small dataset sizes, a repeated K-fold cross-validation technique is employed to quantify model stability and generalization. Results indicate that the proposed framework consistently achieves high predictive accuracy across all evaluated domains. Most importantly, the architecture demonstrates significant fault tolerance by maintaining robust predictive performance even in scenarios where LLM-derived analytical priors are suboptimal or incomplete. Furthermore, the student predictor achieves an inference frequency exceeding 6000 Hz, which facilitates real-time edge deployment on standard industrial hardware. This work provides a scalable solution for bridging the gap between theoretical physics and real-time industrial monitoring in data-limited environments.
マルチモーダルインタラクション学習のための情報理論的分解
マルチモーダル学習は、集合的にマルチモーダル相互作用を構成するモダリティ全体にわたる冗長で固有の相乗効果のある情報を取得するかどうかにかかっています。重大であるにもかかわらず十分に解明されていない課題は、これらの暗黙的な相互作用がサンプル間で動的に変化することです。この研究では、これらの動的なサンプル固有の相互作用の学習が効果的なマルチモーダル学習にとって重要である理由を強調する、初めての体系的な情報理論分析を紹介します。私たちの分析では、これらの異なる相互作用タイプを学習する際の従来のパラダイムの欠点がさらに明らかになりました。モダリティ アンサンブル アプローチは相乗効果を捉えるのに苦労しており、一方、共同学習パラダイムは冗長な情報を十分に活用していないことがよくあります。これは、サンプルごとにさまざまな種類の相互作用から適応的に学習できるアプローチの必要性を強調しています。この目的を達成するために、サンプル固有の相互作用を明示的にモデル化し、そこから学習する新しいパラダイムである、分解ベースのマルチモーダル相互作用学習 (DMIL) を提案します。まず、変分分解アーキテクチャを設計して、構成要素である相互作用コンポーネントを分離します。次に、微調整プロセスでこれらの明示的なインタラクション コンポーネントを活用する新しい学習戦略を採用し、包括的なインタラクション学習を実現します。多様なタスクとアーキテクチャにわたる広範な実験により、DMIL が総合的なサンプル固有の相互作用に適応することで、一貫して優れたパフォーマンスを達成できることが実証されました。私たちのフレームワークは柔軟で幅広く適用でき、マルチモーダル学習のためのインタラクション中心のパラダイムを確立します。コードは https://github.com/GeWu-Lab/DMIL で入手できます。
原文 (English)
Information-Theoretic Decomposition for Multimodal Interaction Learning
Multimodal learning hinges on capturing redundant, unique, and synergistic information across modalities, which collectively constitute multimodal interactions. A critical yet underexplored challenge is that these implicit interactions vary dynamically across samples. In this work, we present the first systematic, information-theoretic analysis highlighting why learning these dynamic, sample-specific interactions is critical for effective multimodal learning. Our analysis further reveals deficits in conventional paradigms at learning these distinct interaction types: modality ensemble approaches struggle to capture synergy, while joint learning paradigms often under-utilize redundant information. This highlights the need for an approach that can adaptively learn from different interaction types on a per-sample basis. To this end, we propose Decomposition-based Multimodal Interaction Learning (DMIL), a novel paradigm that explicitly models and learns from sample-specific interactions. First, we design a variational decomposition architecture to isolate the constituent interaction components. Second, we employ a new learning strategy that leverages these explicit interaction components in a fine-tuning process to achieve comprehensive interaction learning. Extensive experiments across diverse tasks and architectures demonstrate that DMIL consistently achieves superior performance by adapting to holistic sample-specific interactions. Our framework is flexible and broadly applicable, establishing an interaction-centric paradigm for multimodal learning. The code is available at https://github.com/GeWu-Lab/DMIL.
When Context Returns: Toward Robust Internalization in On-Policy Distillation
Recent work has shown that on-policy distillation can internalize privileged context, such as system prompts or task hints, into a student…
LUCID: Learning Embodiment-Agnostic Intent Models from Unstructured Human Videos for Scalable Dexterous Robot Skill Acquisition
The most widely-adopted robot learning pipelines today learn skills from robot demonstrations or structured human data, which are expensive…
Sovereign Assurance Boundary: Certificate-Bound Admission for Agentic Infrastructure
Agentic infrastructure introduces a critical control-plane authorization problem: non-deterministic reasoning systems can propose high-stak…
Are LLMs Bad at Moral Reasoning?
For highly capable AI systems to operate safely in dynamic, open-ended environments, they must be able to identify, understand, and respond…
TAROT: Task-Adaptive Refinement of LLM-prior Graphs for Few-shot Tabular Learning
Few-shot tabular learning provides a cost-effective approach for real-world applications where annotation is costly and collecting sufficie…
Sparse probes and murky physics: a case study of interpretability challenges in a foundation model for continuum dynamics
Generative AI emulators are increasingly used in scientific domains where we already have strong theory, benchmarks, and physical intuition…
ARGUS: Stacked Multi-View Identity Mosaic Injection for Subject-Preserving Video Generation
Subject-preserving video generation is not solved by frontal-face similarity alone: a generated person must remain recognizable across moti…
Runtime Skill Audit: Targeted Runtime Probing for Agent Skill Security
Agent skills let LLM agents reuse instructions, resources, tools, and workflows, but they also create a new place for malicious behavior to…
Can Open-Source LLM Agents Replace Static Application Security Testing Tools? An Empirical Assessment
This paper explores the value of agentic AI tools for cybersecurity purposes. We evaluate the efficacy of a general-purpose GenAI Large Lan…
Reason, Then Re-reason: Cross-view Revisiting Improves Spatial Reasoning
Spatial reasoning from egocentric videos is inherently challenging because the observable evidence is constrained by the camera trajectory.…
Layer-Isolated Evaluation: Gating the Deterministic Scaffold of a Production LLM Agent with a No-LLM, Regression-Locked Test Harness
End-to-end task-success is the dominant way to evaluate LLM agents, but one aggregate number tells you that an agent regressed, not where.…
Goal-Autopilot: A Verifiable Anti-Fabrication Firewall for Unattended Long-Horizon Agents
Long-horizon LLM agents are not trusted to run unattended: with no human watching, they confidently report success they never verified. We…
Noise-Aware Framework for Correcting Corrupted Labels
High-quality labeled data is essential for training reliable ML/DL models. However, real-world datasets often contain a considerable propor…
T2S: A Rehearsal-Based Approach for Extraction-Resistant Model Watermarking
Model watermarking safeguards AI model intellectual property by embedding distinctive knowledge that induces unique behavioral signatures.…
MedCTA: A Benchmark for Clinical Tool Agents
To make clinically grounded decisions, medical AI agents are expected to go beyond simple recognition and be capable of tool retrieval, evi…
Substrate Asymmetry in User-Side Memory: A Diagnostic Framework
User-side memory in LLMs is typically scored as a single "personalization" capability: given a user's history, is the output more user-awar…
Ouroboros-Spatial: Closing the Data-Model Loop for Spatial Reasoning
Spatial reasoning remains a persistent challenge for multimodal large language models (MLLMs). Existing approaches largely rely on large-sc…
ICA Lens: Interpreting Language Models Without Training Another Dictionary
Finding interpretable directions in language-model representations is critical for understanding and controlling model behavior. Sparse aut…
Multi-View In-Cabin Monitoring System for Public Transport Vehicles
We introduce a multi-view in-cabin monitoring dataset for public transportation with synchronized RGB and depth images from four inward-fac…
Hey Chat, Can You Teach Me? Structuring Socratic Dialogue for Human Learning in the Wild
Large language models are now widely used for everyday learning, but the underlying interactions are typically unstructured chats rather th…
From Prompts to Tokens: Internalizing Causal Supervision in Vision-Language Model for Multi-Image Causal Reasoning
Visual causal reasoning is essential for understanding and intervening in the physical world, requiring identification of causal variables…
AnchorEdit: Maintaining Temporal Consistency in Multi-turn Image Editing via Causal Memory
Multi-turn image editing is essential for iterative design, yet current models often struggle with identity drift and error accumulation ov…
Automated Creativity Evaluation of Language Models Across Open-Ended Tasks
Large language models (LLMs) have achieved remarkable progress in language understanding, reasoning, and generation, sparking growing inter…
Fast Speech Foundation Model Distillation Using Interleaved Stacking
Distilling a large speech foundation model (SFM) into an efficient student model has been successfully applied to low-resource environments…
Blind Dexterous Grasping via Real2Sim2Real Tactile Policy Learning
Blind grasping with a dexterous hand is a crucial manipulation capability. Nevertheless, learning such tactile-only policies for real robot…
What Limits Does Quantization Place on Dense Top-$k$ Retrieval? A Theoretical Study
We establish conditions for embedding a corpus of $N$ documents as $d$-dimensional vectors such that every $k$-subset $S \subseteq [N]$ is…
MultiToP: Learning to Patch Visual Tokens to Mitigate Hallucinations in Video Large Multimodal Models
Video Large Multimodal Models have achieved remarkable progress in video understanding, yet they remain prone to hallucinations, where gene…
AI4Land: Scalable Deep Learning for Global High-Resolution Land Use Reconstruction
Uncertainty in the terrestrial carbon cycle remains a major constraint in climate projections, partly driven by the uncertainties affecting…
Multimodal Ordinal Modeling of Alzheimer's Disease Severity Using Structural MRI and Clinical Data
Neurodegenerative diseases such as Alzheimer's disease (AD) require accurate and scalable tools for assessing disease severity, yet current…
TextHOI-3D: Text-to-3D Hand-Object Interaction via Discrete Multi-View Generation and Joint Mesh Optimization
Text-conditioned 3D generation has progressed rapidly for images and isolated objects, but producing a hand-object mesh remains challenging…
Sparsified Kolmogorov-Arnold Networks for Interpretable Quantum State Tomography
Machine-learning approaches to quantum state tomography can achieve high reconstruction fidelity, but the physical structure used by the tr…
WorldReasoner: Evaluating Whether Language Model Agents Forecast Events with Valid Reasoning
Forecasting real-world events requires language-model agents to reason under uncertainty from incomplete, time-bounded information. Yet eva…
Grammar-Constrained Decoding Can Jailbreak LLMs into Generating Malicious Code
Large Language Models (LLMs) are increasingly used for code generation, raising concerns that they may be misused to produce malicious code…
Feature-Aligned Speech Watermarking for Robustness to Reconstruction Distortions
Audio watermarking aims to embed identifiable information into audio while remaining imperceptible. Existing methods adopt high-fidelity, l…
From Uniform to Learned Graph Priors: Diffusion for Structure Discovery
Neural relational inference (NRI) methods discover interaction graphs from trajectories through variational reasoning on discrete potential…
Designing AI-Supported Focus Groups: A Role x Modality Playbook
Collecting participants' lived experiences is central to design research. Focus groups are uniquely valuable because participants not only…
Towards Data-free and Training-free Compression for Speech Foundation Models Using Parameter Clustering
This paper presents a novel data-free and training-free compression approach for speech foundation models using channelwise clustering via…
LASA: A Weak Supervision Method for Open-Vocabulary Scene Sketch Semantic Segmentation
Open-vocabulary scene sketch semantic segmentation aims to assign dense semantic labels to sparse line drawings based on flexible category…
Task-Aware Structured Memory for Dynamic Multi-modal In-Context Learning
Multi-modal large language models (MLLMs) depend on in-context learning (ICL) for rapid task adaptation, but their scalability is severely…
Fine-tuning Multi-modal LLMs with ART: Art-based Reinforcement Training
There are two main Parameter-Efficient Fine-Tuning (PEFT) techniques for Large Language Models (LLMs). While Low-Rank Adaptation (LoRA) int…
Agents All the Way Down; A Methodology for Building Custom AI Agents from Substrate to Production
Custom AI agents areagents that live inside their own application, talk to their own data and tools, enforce their own security boundaries,…
Task-Aligned Stability Analysis of Vision-Language Models for Autonomous Driving Hazard Detection
Vision-language models (VLMs) are increasingly used for scene understanding in autonomous driving, but robustness analysis often relies on…
Beyond representational alignment with brain-guided language models for robust reasoning
The correspondence between large language models (LLMs) and the neural mechanisms underlying human higher-order cognition remains insuffici…
DuoBench: A Reproducible Benchmark for Bimanual Manipulation in Simulation and the Real World
Bimanual robot systems substantially expand manipulation capabilities, but coordinating two arms introduces additional control complexity a…
Quality Adaptive Angular Margin Learning for Respiratory Sound Classification
We present a quality-adaptive angular-margin learning framework that improves feature generalization by enforcing intra-class compactness a…
Characterizing Software Aging in GPU-Based LLM Serving Systems
This paper proposes an empirical methodology to study software aging in GPU-based LLM serving systems. Traditional aging studies focus on C…
Lung-SRAD: Spectral-Aware Regularized Audio DASS with Dual-Axis Patch-Mix Contrastive Learning for Respiratory Sound Classification
Recent respiratory sound classification (RSC) studies largely rely on CLS-token driven self-attention architectures such as the Audio Spect…
Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
Scientific progress depends on a repeated loop of exploration, experimentation, and abstraction. Researchers test candidate directions, int…
Frozen Multimodal Embeddings for Personality and Cognitive Ability Assessment in Asynchronous Video Interviews
Predicting psychological traits from asynchronous video interviews (AVIs) is a challenging multimodal learning problem because labeled data…
Categorical Prior Lock-in: Why In-Context Learning Fails for Structured Data
Large language models (LLMs) are increasingly used as conditional generators for structured data, relying on in-context learning (ICL) to a…
Exploration Structure in LLM Agents for Multi-File Change Localization
Software engineering tools increasingly rely on LLM based agents to localize files to change to resolve a software issue. Most AI agents ex…
Time-Series Foundation Model Embeddings for Remaining Useful Life Estimation
Remaining Useful Life (RUL) prediction is essential for industrial predictive maintenance, yet many learning-based approaches rely on exten…
Tabular Foundation Models for Clinical Survival Analysis via Survival-Aware Adaptation
Predicting time-to-event outcomes such as mortality is a fundamental task in clinical decision-making, commonly addressed through survival…
Generalization Hacking: Models Can Game Reinforcement Learning by Preventing Behavioral Generalization
Model post-training, and in particular reinforcement learning (RL), is one of the primary mechanisms by which developers can shape models'…
Runtime Enforcement of Hybrid System Properties
Runtime enforcement has emerged as a promising approach for ensuring the safety of autonomous and cyber-physical systems operating in uncer…
Metadata-Aware Multi-Prompt Reasoning for Zero-Shot Accident Understanding
In this paper, we address the problem of zero-shot understanding of accidents from surveillance videos by identifying when an impact event…
On the Limits of LLM-as-Judge for Scientific Novelty Assessment
LLMs are increasingly used to generate and judge scientific ideas. This makes novelty evaluation a central problem. Full idea evaluation is…
"That's AI Slop, You Bot!" Studying Accusations, Evidence, and Credibility in Online Discourse Towards LLM-Generated Comments
Generative AI has made fluent prose cheap to produce, breaking the old promise to readers that good writing meant real thinking. How have r…
Non-frontal face recognition using GANs and memristor-based classifiers
Face recognition systems have advanced significantly through deep learning techniques, delivering high performance and robustness in comple…
MSUE: Multi-Modal Soccer Understanding Expert
This paper presents our solution to the 2026 SoccerNet VQA Challenge. We first develop a cost-effective data synthesis pipeline driven by a…
Bridging the Morphology Gap: Adapting VLA Models to Dexterous Manipulation via Intent-Conditioned Fine-Tuning
Vision-Language-Action (VLA) models have demonstrated remarkable zero-shot generalization in robotic manipulation, yet the vast majority of…
Augmenting Molecular Language Models with Local $n$-gram Memory
Transformer-based language models for SMILES strings suffer from a locality gap: standard character-level tokenization fragments chemically…
Soft-Prompt Tuning for Fair and Efficient LLM Benchmark Evaluation
Benchmark scores often misrepresent a large language model's (LLM's) knowledge, because they rely, e.g., on the model's ability to follow s…
Unstable Features, Reproducible Subspaces: Understanding Seed Dependence in Sparse Autoencoders
Sparse autoencoders (SAEs) are widely used to interpret neural network representations, but their utility depends on whether the learned fe…
nD-RoPE: A Generalized RoPE for n-Dimensional Position Embedding
Rotary Position Embedding (RoPE) is widely adopted in Transformer models, yet its extension to high-dimensional domains lacks a unified the…
OpenMedReason: Scientific Reasoning Supervision for Medical Vision-Language Models
High-stakes clinical use of large vision-language models (LVLMs) requires reasoning that is grounded in visual evidence and clinical knowle…
Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application
Environments serve as interactive systems for large language model (LLM) based agents across diverse scenarios and play a crucial role in d…
Implicit Neural Representations of Individual Behavior
We study policy representation learning from unlabeled multi-policy behavioral data. Each episode is generated by a fixed policy, but polic…
Intelligent Automation for Embodied Benchmark Construction: Pipelines, Embodiments, Simulators, and Trends
Embodied intelligence now spans navigation, household assistance, manipulation, autonomous driving, aerial agents, and multimodal large-mod…
Making Foresight Actionable: Repurposing Representation Alignment in World Action Models
World Action Models (WAMs) offer a promising route for robot manipulation by using video generation models to model future scene evolution…
Adapting Prithvi-EO for Fallow Detection for Food-Water Nexus: ViT-Adapter Necks and Parameter-Efficient Backbone tuning of Geospatial Foundation Model
Understanding spatial distribution of fallow land is important for optimizing the food-water (FW) nexus, given fallowing's role in crop rot…
Rule Taxonomy and Evolution in AI IDEs: A Mining and Survey Study
The adoption of AI-powered Integrated Development Environments (AI IDEs) has introduced "Rules" as a novel software artifact, allowing deve…
Multi-Rate Mixture of Experts for Accelerating Liquid Neural Network Training
Multivariate time-series data often exhibit complex temporal dependencies, irregular sampling, and heterogeneous dynamics across multiple t…
VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
Speculative decoding (SD) addresses the high inference costs of LLMs by having lightweight drafters generate candidates for large verifiers…
DiffCold: A Diffusion-based Generative Model for Cold-Start Item Recommendation
Cold-start item recommendation remains a persistent challenge in real-world systems due to the absence of interaction histories. While prio…
Reinforcement Learning Disrupts Gradient-Based Adversarial Optimization
Gradient-based adversarial attacks remain a dominant threat to deep neural networks (DNNs), as they exploit gradient information to efficie…
Using Explainability as a Training-Time Reliability Signal for Efficient ECG Classification
Training deep neural networks for clinical time-series analysis is computationally demanding, yet many healthcare settings lack the resourc…
Market Design for AI: Beyond the Copyright Binary
How can we design a market of human-generated content for use in training AI models that both enables technological progress and preserves…
Mathematical perspective on genetic algorithms with optimization guided operators
Recent work in ML applies genetic algorithms at inference time to iteratively improve solutions to optimization problems. The basic mutatio…
CCKS: Consensus-based Communication and Knowledge Sharing
In Decentralized Training and Decentralized Execution (DTDE) for cooperative Multi-Agent Reinforcement Learning (MARL), action-advising-bas…
SpikeDecoder: Realizing the GPT Architecture with Spiking Neural Networks
The Transformer architecture is widely regarded as the most powerful tool for natural language processing, but due to a high number of comp…
The Standard Interpretable Model: A general theory of interpretable machine learning to deductively design interpretable methods using Lagrangian mechanics
As Artificial Intelligence models grow in complexity, interpretability has become an indispensable tool for understanding, debugging, and c…
Natural-Language Temporal Grounding in Hour-Long Videos is a Search Problem: A Benchmark and Empirical Decomposition
Temporal grounding--returning the interval $[t_s, t_e]$ for a natural-language query over a video--is the language interface to long-form v…
Harness In-Context Operator Learning with Chain of Operators
Neural operators approximate mappings between function spaces, but often generalize poorly to other operators and usually require fine-tuni…
ALIGNBEAM : Inference-Time Alignment Transfer via Cross-Vocabulary Logit Mixing
Domain fine-tuning degrades the safety of large language models: fine-tuned specialists readily comply with harmful prompts framed in domai…
Atlas H&E-TME: Scalable AI-Based Tissue Profiling at Expert Pathologist-Level Accuracy
Hematoxylin and eosin (H&E) staining is the cornerstone of histopathology, yet scalable, quantitative analysis of H&E whole-slide images (W…
CHORUS: Decentralized Multi-Embodiment Collaboration with One VLA Policy
Multi-robot collaboration allows robots to efficiently take on a wide range of tasks, from moving a couch through a doorway to assembling s…
Latent World Recovery for Multimodal Learning with Missing Modalities
We study multimodal learning under missing modalities, with particular motivation from bioscience applications in which heterogeneous modal…
Ambient Diffusion Policy: Imitation Learning from Suboptimal Data in Robotics
We propose Ambient Diffusion Policy, a simple and principled method for imitation learning from suboptimal data in robotics. High-quality,…
Illumination-Robust Camera-Based Heart-Rate Estimation for Physiological Sensing in Robots
Physiological awareness is important for service, social, and assistive robots that interact with humans in everyday environments. Remote p…
SPEA2$^+$: Improved Density Estimation in SPEA2 with Provable Runtime Guarantees
The Strength Pareto Evolutionary Algorithm 2 (SPEA2) is a popular and prominent evolutionary algorithm for solving multi-objective optimisa…
APPO: Agentic Procedural Policy Optimization
Recent advances in agentic Reinforcement Learning (RL) have substantially improved the multi-turn tool-use capabilities of large language m…
ATLAS: Active Theory Learning for Automated Science
Advancing scientific understanding through mechanistic modeling requires posing the right experimental questions to yield maximally informa…
TAHOE: Text-to-SQL with Automated Hint Optimization from Experience
Large Language Models (LLMs) have democratized database access through Text-to-SQL, but moving from prototypes to production remains diffic…
System Report for CCL25-Eval Task 5: New Dataset and LoRA-Fine-Tuned Qwen2.5
Recently, large language models (LLMs) have achieved promising progress in the fields of classical Chinese translation and the generation o…
Redesign Mixture-of-Experts Routers with Manifold Power Iteration
Router is the cornerstone component to the Mixture-of-Experts models. Serving as expert proxies, the rows of the router matrix compute thei…
DIRECT: When and Where Should You Allocate Test-Time Compute in Embodied Planners?
Vision-Language Models (VLMs) are increasingly deployed as high-level planners for embodied agents, with an emerging strategy of scaling te…
FACTR 2: Learning External Force Sensing for Commodity Robot Arms Improves Policy Learning
Contact-rich manipulation requires force sensitivity, but many robot arms lack dedicated force sensors due to their high cost. We present N…
Reroute, Don't Remove: Recoverable Visual Token Routing for Vision-Language Models
Vision-language models (VLMs) project images into hundreds to thousands of visual tokens, making decoder inference expensive in both attent…
Improving Generalization and Data Efficiency with Diffusion in Offline Multi-agent RL
We present a novel Diffusion Offline Multi-agent Model (DOM2) for offline Multi-Agent Reinforcement Learning (MARL). Different from existin…
Offline Diffusion Policy for Multi-User Delay-Constrained Scheduling
Effective multi-user delay-constrained scheduling is crucial in various real-world applications, including embodied AI, instant messaging,…
Position: Stop Anthropomorphizing Intermediate Tokens as Reasoning/Thinking Traces!
Intermediate token generation (ITG), where a model produces output before the solution, has become a standard method to improve the perform…
MLaGA: Multimodal Large Language and Graph Assistant
Large Language Models (LLMs) have demonstrated substantial efficacy in advancing graph-structured data analysis. Prevailing LLM-based graph…
Sustainability assessment using multimodal AI agents
Reducing the rapidly growing environmental impact of the computing industry requires assessing the emissions of electronics at scale. Howev…
Synthetic Homes: A Multimodal Generative AI Pipeline for Residential Building Data Generation under Data Scarcity
Computational models have emerged as powerful tools for multi-scale energy modeling research at the building and urban scale, supporting da…
A Survey of Reasoning and Agentic Systems in Time Series with Large Language Models
Time series reasoning treats time as a first-class axis and incorporates intermediate evidence directly into the answer. This survey define…
GPO: Learning from Critical Steps to Improve LLM Reasoning
Large language models (LLMs) are increasingly used in various domains, showing impressive potential on different tasks. Recently, reasoning…
Resource-Aware LLM Reasoning for Mobile Edge General Intelligence
The rapid advancement of large language models (LLMs) has enabled an emergence of agentic artificial intelligence (AI) with powerful reason…
A New Perspective on Precision and Recall for Generative Models
With the recent success of generative models in image and text, the question of their evaluation has recently gained a lot of attention. Wh…
DecompSR: A dataset for decomposed analyses of compositional multihop spatial reasoning
We introduce DecompSR, decomposed spatial reasoning, a large benchmark dataset (over 5m datapoints) and generation framework designed to an…
PRInTS: Reward Modeling for Long-Horizon Information Seeking
Information-seeking is a core capability for AI agents, requiring them to gather and reason over tool-generated information across long tra…
Precomputing Multi-Agent Path Replanning Using Temporal Flexibility
Executing a multi-agent plan can be challenging when an agent is delayed, because this typically creates conflicts with other agents. So, w…
An XAI View on Explainable ASP: Methods, Systems, and Perspectives
Answer Set Programming (ASP) is a popular declarative reasoning and problem solving approach in symbolic AI. Its rule-based formalism makes…
A Survey on Evaluating Quality and Trustworthiness in LLM-Generated Data
Large Language Models (LLMs) have emerged as powerful tools for generating data across various modalities. By transforming data from a scar…
Making Models Unmergeable via Scaling-Sensitive Loss Landscape
The rise of model hubs has made it easier to access reusable model components, making model merging a practical tool for combining capabili…
MentisOculi: Revealing the Limits of Reasoning with Mental Imagery
Frontier models are transitioning from multimodal large language models (MLLMs) that merely ingest visual information to unified multimodal…
Autoregressive Direct Preference Optimization
Direct preference optimization (DPO) has emerged as a promising approach for aligning large language models (LLMs) with human preferences.…
Sonar-TS: Search-Then-Verify Natural Language Querying for Time Series Databases
Natural Language Querying for Time Series Databases (NLQ4TSDB) aims to assist non-expert users retrieve meaningful events, intervals, and s…
Diffusing to Coordinate: Efficient Online Multi-Agent Diffusion Policies
Online Multi-Agent Reinforcement Learning (MARL) is a prominent framework for efficient agent coordination. Crucially, enhancing policy exp…
Human-Guided Agentic AI for Multimodal Clinical Prediction: Lessons from the AgentDS Healthcare Benchmark
Agentic AI systems are increasingly capable of autonomous data science workflows, yet clinical prediction tasks demand domain expertise tha…
MobilityBench: A Benchmark for Evaluating Route-Planning Agents in Real-World Mobility Scenarios
Route-planning agents powered by large language models (LLMs) have emerged as a promising paradigm for supporting everyday human mobility t…
Planning under Distribution Shifts with Causal POMDPs
In the real world, planning is often challenged by distribution shifts. As such, a model of the environment obtained under one set of condi…
Does the Question Really Matter? Training-Free Data Selection for Vision-Language SFT
Visual instruction tuning is crucial for improving vision-language large models (VLLMs). However, many samples can be solved via linguistic…
ProGRank: Probe-Gradient Reranking to Defend Dense-Retriever RAG from Corpus Poisoning
Retrieval-Augmented Generation (RAG) improves large language model applications by grounding generation in retrieved evidence, but also int…
ClawEnvKit: Automatic Environment Generation for Claw-Like Agents
Constructing environments for training and evaluating claw-like agents remains a manual, human-intensive process that does not scale. We ar…
FitText: Evolving Agent Tool Ecologies via Memetic Retrieval
A semantic gap separates how users describe tasks from how tools are documented. As API ecosystems scale to tens of thousands of endpoints,…
A Resilient Solution for Sewer Overflow Monitoring across Cloud and Edge
Aging combined sewer systems in many historical cities are increasingly stressed by extreme rainfall events, which can trigger combined sew…
Robust Instruction Compliance in Cooperative Multi-Agent Reinforcement Learning
Multi-agent reinforcement learning (MARL) in real-world use cases may need to adapt to external natural language instructions that interrup…
KAN-MLP-Mixer: A comprehensive investigation of the usage of Kolmogorov-Arnold Networks (KANs) for improving IMU-based Human Activity Recognition
Kolmogorov-Arnold Networks (KANs) have demonstrated an exceptional ability to learn complex functions on clean, low-dimensional data but st…
サブリミナル学習はベクトル蒸留を操る
サブリミナル学習とは、教師の出力を微調整した場合に、出力が意味的にそれらの特性と無関係であるにもかかわらず、生徒の言語モデルが教師の特性 (システムが促すフクロウの好みなど) を獲得することを指します。セマンティックな意味を持たないデータがどのようにして特定のセマンティックな特徴を伝達できるのかについては、依然として十分に理解されていません。この研究では、サブリミナル学習が単一のステアリング ベクトル、つまりモデルの活性化に追加されるベクトルによって媒介されることを示します。 2 つのオープンソース モデル全体で、教師のシステム プロンプトはステアリング ベクトルによってよく近似されており、生徒の行動は微調整を通じて調整されたベクトルを学習することによって駆動されることがわかりました。ステアリング ベクトルによって適切に近似されていないシステム プロンプトは潜在的に学習されません。これは、ステアリング ベクトル蒸留の特殊なケースであり、ステアリングされた教師の出力で訓練された生徒が、そのステアリングを模倣することを学びます。一連のセマンティック ベクトルとランダム ベクトルに対するステアリング ベクトル蒸留を示します。モデルのアクティベーションにセマンティック ベクトルを追加すると、その動作にモデルに依存しない効果とモデル固有 (つまり、非セマンティック) の両方の効果が生じる可能性があるため、生成された非セマンティック データはセマンティック効果を持つベクトルを送信でき、サブリミナル学習が可能になります。これは、サブリミナル学習がモデル間で移行しない理由も説明します。言語モデルにおけるサブリミナル学習には適応オプティマイザーが必要であることがわかりました。ステアリングされたデータの活性化勾配はステアリング方向に沿って小さいながらも一貫した成分を運びますが、非適応オプティマイザーは外れ値の勾配が優勢になることを許可することでこれを妨げます。
原文 (English)
Subliminal Learning Is Steering Vector Distillation
Subliminal learning refers to a student language model acquiring a teacher's traits (e.g. a system-prompted preference for owls) when fine-tuned on the teacher's outputs, despite the outputs being semantically unrelated to those traits. It remains poorly understood how data without semantic meaning can transfer specific semantic traits. In this work, we show that subliminal learning is mediated by a single steering vector, i.e. a vector added to the model's activations. Across two open-source models, we find that the teacher's system prompt is well approximated by a steering vector, and that the student's behavior is driven by learning an aligned vector over fine-tuning. System prompts that are not well approximated by steering vectors are not subliminally learned. This is a special case of steering vector distillation, in which a student trained on the outputs of a steered teacher learns to imitate that steering. We demonstrate steering vector distillation on a range of semantic and random vectors. Adding a semantic vector to a model's activations can have both model-independent and model-specific (i.e. non-semantic) effects on its behavior, so generated data that is non-semantic can transmit a vector with semantic effects, enabling subliminal learning. This also explains why subliminal learning does not transfer between models. We find that adaptive optimizers are necessary for subliminal learning in language models: activation gradients on steered data carry a small but consistent component along the steering direction, and non-adaptive optimizers impede this by allowing outlier gradients to dominate.
Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference
AI agents rely on a harness of skills, tools, and workflows to solve complex problems. Continually improving this harness is essential for…
MemToolAgent の概要と、エージェントが同様の記憶を取得し、無効な時間形式に関するフィードバックを受け取り、記憶を更新するためのリフレクションを生成する単純なレストラン予約シナリオを示します。
最新の大規模言語モデル (LLM) エージェントは、外部ツールを使用して、ユーザーが複雑なタスクを解決できるように支援できます。ただし、長期にわたる履歴イベントや以前のエージェントと環境の相互作用から学習する必要がある問題の場合、LLM エージェントはメモリ メカニズムを使用してエクスペリエンスを保存および取得する必要があります。対話エージェントには高度な記憶システムが存在しますが、過去のユーザーとエージェントの会話を通じてエージェントのツール使用能力を向上させる方法を実証的に検討した研究はほとんどありません。私たちは、メモリ管理を通じてツールの使用を改善するフレームワークである MemToolAgent を提案します。私たちのアプローチには、過去の経験を処理して構造化された記憶エントリを生成する記憶抽出モジュールと、格納された記憶エントリのサブセットを動的に選択する取得モジュールが含まれています。これにより、LLM の微調整を必要とせずに、ユーザーの好みやフィードバックに合わせた、よりパーソナライズされた正確な応答が可能になります。要約すると、この研究には 3 つの主な貢献があります。(1) LLM の微調整を行わずに汎用ツールとパーソナライズされたツールの両方の使用を改善する統合メモリ エントリ形式、(2) 環境とユーザーのフィードバックを使用して誤った実行を保存する批判に抽出するリフレクション ベースのメモリ抽出、(3) メモリの類似性分布に基づいて使用する過去の経験の数を選択する検索モジュール。 MemToolAgent は、WorkBench、NESTFUL、PEToolBench ベンチマークの強力なベースラインと比較して、それぞれ 29%、80%、17% の相対的な改善を達成しました。
原文 (English)
MemToolAgent: Leveraging Memory for Tool Using Agents Based on Environment and User Feedback
Modern large language model (LLM) agents can use external tools to help users solve complex tasks. However, for problems that require learning from long-term historical events or from previous agent-environment interactions, LLM agents are required to use memory mechanisms to store and retrieve experiences. While sophisticated memory systems exist for dialogue agents, few studies have empirically examined how to improve agents' tool-using capabilities through past user-agent conversations. We propose MemToolAgent, a framework that improves tool use through memory management. Our approach contains a memory extraction module that processes past experiences into structured memory entries, and a retrieval module that dynamically selects a subset of the stored memory entries. This enables more personalized and accurate responses aligned with user preferences and feedback without requiring LLM fine-tuning. In summary, this work has three main contributions: (1) a unified memory entry format that improves both general-purpose and personalized tool use without LLM fine-tuning, (2) a reflection-based memory extraction that uses environment and user feedback to distill wrong executions into critiques to store, and (3) a retrieval module that chooses how many past experiences to use based on the memory similarity distribution. MemToolAgent achieves 29%, 80%, and 17% relative improvements compared to strong baselines on the WorkBench, NESTFUL, and PEToolBench benchmarks, respectively.
Graph2Idea:Retrieval-Augmented Scientific Idea Generation with Graph-Structured Contexts
Generating novel, feasible, and high-quality research ideas is an important yet challenging task in scientific discovery. Recent Large Lang…
Experience Makes Skillful: Enabling Generalizable Medical Agent Reasoning via Self-Evolving Skill Memory
Medical agent systems are increasingly expected to support interactive clinical decision making rather than only static question answering.…
WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Computer-use agents (CUAs) increasingly operate in runtimes that combine visual desktop control, command-line execution, code editing, brow…
リーダー: 抽出された表現による堅牢な証拠に基づく著者の解読
エージェント アプリケーションが公式およびサードパーティの LLM API を介してユーザー タスクをルーティングすることが増えているため、出所が運用上の問題になります。どのモデルが特定のブラックボックス応答を生成したか?私たちは、固定入力セットやベンチマーク スイートではなく、クエリが変化する事前定義されていないプロンプトによって引き出された世代からソース LLM を識別する、動的ブラック ボックス LLM 来歴を研究します。この設定は、プロンプト セマンティクスがテキストの大部分を占めている一方で、モデル固有の作成者追跡が表面レベルでは弱く一貫性がないため、困難です。凍結されたプロキシ LLM を隠された著者証明のリーダーとして扱う軽量の出自フレームワークである READER (Robust Evidence-based Authorship Decoding via Extracted Representations) を紹介します。 READER は、ブラック ボックス出力をプロキシ アクティベーション スペースにマッピングし、各応答内のトークン状態を時間的にフィルタリングし、独立してサンプリングされたプロンプト全体にわたる単一応答の対数事後証拠を合計することによってベイジアン証拠蓄積を実行します。これにより、校正された信頼性に必要なクエリごとの証拠を維持しながら、プロンプト固有の表現の脆弱な平均プーリングが回避されます。エージェント スタイルのプロンプトから構築された 50 のターゲット データセットである Agent500 では、READER は 1 つの応答で $31.0$ ~ $42.4\%$ のトップ 1 の精度に達し、50 の応答で $70.0$ ~ $84.0\%$ に達し、センテンス エンコーダーのフィンガープリントを大幅に上回りました。 9 つのプロキシ リーダーにわたってスケーリングすると、より強力な LLM はより線形にデコード可能な著者情報構造を明らかにすることがさらに示され、凍結された LLM 表現には著者情報の認識がすでに存在し、信頼できるマルチクエリ帰属に変換できることが示唆されます。
原文 (English)
READER: Robust Evidence-based Authorship Decoding via Extracted Representations
As agentic applications increasingly route user tasks through official and third-party LLM APIs, provenance becomes an operational question: which model generated a given black-box response? We study Dynamic Black-Box LLM Provenance: identifying the source LLM from generations elicited by query-varying, non-predefined prompts rather than a fixed input set or benchmark suite. This setting is difficult because prompt semantics dominate the text, while model-specific authorship traces are weak and inconsistent at the surface level. We introduce READER (Robust Evidence-based Authorship Decoding via Extracted Representations), a lightweight provenance framework that treats a frozen proxy LLM as a reader of hidden authorship evidence. READER maps black-box outputs into proxy activation space, temporally filters token states within each response, and performs Bayesian Evidence Accumulation by summing single-response log-posterior evidence across independently sampled prompts. This avoids fragile mean-pooling of prompt-specific representations while preserving the query-wise evidence needed for calibrated confidence. On Agent500, a 50-target dataset built from agent-style prompts, READER reaches $31.0$-$42.4\%$ top-1 accuracy from a single response and $70.0$-$84.0\%$ from 50 responses, substantially outperforming sentence-encoder fingerprints. Scaling across nine proxy readers further shows that stronger LLMs expose more linearly decodable authorship structure, suggesting that authorship perception is already present in frozen LLM representations and can be converted into reliable multi-query attribution.
Workflow-GYM: 現実世界の専門分野におけるコンピュータ使用エージェントタスクの長期的な評価に向けて
近年、ますます複雑になる現実世界のタスクの処理に向けて、AI エージェントが急速に進化しています。しかし、既存のベンチマークでは、エージェントがグラフィカル ユーザー インターフェイスを操作して、さまざまなドメインにわたる長期にわたる価値の高い専門的なワークフローを完了できるかどうかを評価することはほとんどありません。現在の GUI ベンチマークは依然として、主に汎用ソフトウェア、比較的単純なアプリケーション、および短期間のタスクに焦点を当てており、最新のエージェントがユーザーの指示に従ってドメイン固有のプロフェッショナル ソフトウェアを自律的に操作し、経済的に価値のある作業をエンドツーエンドで実行できるかどうかはほとんど不明です。このギャップを埋めるために、専門分野と特殊なソフトウェア環境を中心とした長期的な GUI タスクのベンチマークである Workflow-GYM を導入します。最先端のモデルで広範な実験を行った結果、最も強力なモデルでも成功率は 30% をわずかに超える程度であることがわかり、プロの長期にわたる GUI ワークフローが現在の GUI エージェントにとって依然として非常に困難であることが浮き彫りになりました。さらなる分析により、現在のエージェントは長期的なワークフローの一貫性を維持するのに苦労しており、ワークフロー段階の省略、エラーの伝播、目標のずれ、プロフェッショナルなソフトウェア環境の理解不足が頻繁に見られることが明らかになりました。私たちの調査結果は、現在のエージェント システムの限界についての重要な洞察を提供し、次世代の GUI エージェント研究の重要な方向性を示唆しています。
原文 (English)
Workflow-GYM: Towards Long-Horizon Evaluation of Computer-use Agentic tasks in Real-World Professional Fields
Recent years have witnessed the rapid evolution of AI agents toward handling increasingly complex, real-world tasks. However, existing benchmarks rarely evaluate whether agents can operate graphical user interfaces to complete long-horizon, high-value professional workflows across diverse domains. Current GUI benchmarks still predominantly focus on general-purpose software, relatively simple applications, and short-horizon tasks, leaving it largely unknown whether modern agents can follow user instructions to autonomously operate domain-specific professional software and accomplish economically valuable work in an end-to-end manner. To bridge this gap, we introduce Workflow-GYM, a benchmark for long-horizon GUI tasks centered on professional domains and specialized software environments. Through extensive experiments on state-of-the-art models, we find that even the strongest models achieve only slightly above 30% success rates, highlighting that professional long-horizon GUI workflows remain highly challenging for current GUI agents. Further analysis reveals that current agents struggle to maintain long-horizon workflow consistency, frequently exhibiting workflow stage omission, error propagation, objective drift, and insufficient understanding of professional software environments. Our findings provide important insights into the limitations of current agent systems and suggest key directions for the next generation of GUI-agent research.
LSTM based IoT Device Identification
While the use of the Internet of Things is becoming more and more popular, many security vulnerabilities are emerging with the large number…
FOCUS on Contamination: Hydrology-Informed Noise-Aware Learning for Geospatial PFAS Mapping
Per- and polyfluoroalkyl substances (PFAS) are persistent environmental contaminants with significant public health impacts, yet large-scal…
Erased but Not Forgotten: How Backdoors Compromise Concept Erasure
The expansion of text-to-image diffusion models has raised concerns about harmful outputs, from fabricated depictions of public figures to…
The Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning
We present Mixture of Discrete-time Gaussian Processes (MiDiGap), a novel approach for flexible policy representation and imitation learnin…
A Physics-Inspired Optimizer: Velocity Regularized Adam
We introduce Velocity-Regularized Adam (VRAdam), a physics-inspired optimizer for training deep neural networks that draws on ideas from qu…
Pass@K Policy Optimization: Solving Harder Reinforcement Learning Problems
Reinforcement Learning (RL) algorithms sample multiple n>1 solution attempts for each problem and reward them independently. This optimizes…
\texttt{Range-Arithmetic}: Verifiable Deep Learning Inference on an Untrusted Party
Verifiable computing (VC) has gained prominence in decentralized machine learning systems, where resource-intensive tasks like deep neural…
Diffusion-based Cumulative Adversarial Purification for Vision Language Models
Vision Language Models (VLMs) have shown remarkable capabilities in multimodal understanding, yet their susceptibility to adversarial pertu…
Cross-Layer Discrete Concept Discovery for Interpreting Language Models
Interpreting language models remains challenging due to the existence of residual stream, which linearly mixes and duplicates features acro…
OCSVM-Guided Representation Learning for Unsupervised Anomaly Detection
Unsupervised anomaly detection (UAD) aims to detect anomalies without labeled data, a necessity in many machine learning applications where…
RelayFormer: A Unified Local-Global Attention Framework for Scalable Image and Video Manipulation Localization
Visual manipulation localization (VML) aims to identify tampered regions in images and videos, a task that has become increasingly challeng…
LaQual: An Automated Framework for LLM App Quality Evaluation
Representing a new paradigm in software distribution, LLM app stores are rapidly emerging, offering users diverse choices for content gener…
The Algorithm Is Not the Behavior: Learned Priors Override Look-Ahead in a Chess-Playing Neural Network
Recent mechanistic work has uncovered learned algorithms within neural networks, from modular arithmetic to search and planning in game-pla…
Generalizing Beyond Suboptimality: Offline Reinforcement Learning Learns Effective Scheduling through Random Solutions
Online reinforcement learning (RL) approaches have demonstrated strong performance on Job Shop Scheduling (JSP) and Flexible JSP (FJSP) pro…
MARIC: Multi-Agent Reasoning for Image Classification
Image classification has traditionally relied on parameter-intensive model training, requiring large-scale annotated datasets and extensive…
Toward Preference-aligned Large Language Models via Residual-based Model Steering
Preference alignment is a critical step in making Large Language Models (LLMs) useful and aligned with (human) preferences. Existing approa…
Geometric Metrics and LLMs: What They Measure and When They Work
We present a systematic stress-test of geometric metrics for LLM evaluation. Rank-based geometric properties of internal representations ha…
Noise-Guided Transport for Imitation Learning
We consider imitation learning in the low-data regime, where only a limited number of expert demonstrations are available. In this setting,…
When Researchers Say Mental Model/Theory of Mind of AI, What Are They Really Talking About?
When researchers claim AI systems possess ToM or mental models, they are fundamentally discussing behavioral predictions and bias correctio…
Certifiable Safe RLHF: Semantic Grounding and Fixed Penalty Constraint Optimization for Safer LLM Alignment
Ensuring safety is a foundational requirement for large language models (LLMs). Achieving an appropriate balance between enhancing the util…
GILT: インコンテキスト学習のための LLM フリー、チューニング不要のグラフ基礎モデル
グラフ ニューラル ネットワーク (GNN) は、リレーショナル データを処理するための強力なツールですが、目に見えないグラフに一般化するのに苦労することが多く、グラフ基盤モデル (GFM) の開発が必要になります。ただし、現在の GFM は、各グラフが固有の特徴空間、ラベル セット、およびトポロジを所有する可能性があるため、グラフ データの極端な異質性が課題となっています。これに対処するために、2 つの主要なパラダイムが登場しました。 1 つ目は大規模言語モデル (LLM) を活用していますが、基本的にテキストに依存しているため、膨大なグラフの数値特徴を処理するのが困難です。 2 つ目は構造ベースのモデルを事前トレーニングしますが、新しいタスクへの適応には通常、コストのかかるグラフごとの調整ステージが必要となり、重大な効率のボトルネックが生じます。この取り組みでは、これらの制限を超えて、LLM フリーおよびチューニング不要のアーキテクチャに基づいて構築されたフレームワークである \textbf{G}raph \textbf{I}n-context \textbf{L}earning \textbf{T}ransformer (GILT) を導入します。 GILT は、グラフ上のインコンテキスト学習 (ICL) のための新しいトークンベースのフレームワークを導入し、統一フレームワークでノード、エッジ、グラフ レベルにわたる分類タスクを再構成します。このメカニズムは一般的な数値特徴を操作するように設計されているため、異質性を処理するための鍵となります。さらに、コンテキストからクラスのセマンティクスを動的に理解する機能により、調整不要の適応が可能になります。包括的な実験により、GILT は LLM ベースまたはチューニング ベースのベースラインよりも大幅に短い時間で強力な数ショット パフォーマンスを達成することが示されており、私たちのアプローチの有効性が検証されています。コードは https://github.com/yiming421/inductnode/ から入手できます。
原文 (English)
GILT: An LLM-Free, Tuning-Free Graph Foundational Model for In-Context Learning
Graph Neural Networks (GNNs) are powerful tools for processing relational data but often struggle to generalize to unseen graphs, giving rise to the development of Graph Foundational Models (GFMs). However, current GFMs are challenged by the extreme heterogeneity of graph data, where each graph can possess a unique feature space, label set, and topology. To address this, two main paradigms have emerged. The first leverages Large Language Models (LLMs), but is fundamentally text-dependent, thus struggles to handle the numerical features in vast graphs. The second pre-trains a structure-based model, but the adaptation to new tasks typically requires a costly, per-graph tuning stage, creating a critical efficiency bottleneck. In this work, we move beyond these limitations and introduce \textbf{G}raph \textbf{I}n-context \textbf{L}earning \textbf{T}ransformer (GILT), a framework built on an LLM-free and tuning-free architecture. GILT introduces a novel token-based framework for in-context learning (ICL) on graphs, reframing classification tasks spanning node, edge and graph levels in a unified framework. This mechanism is the key to handling heterogeneity, as it is designed to operate on generic numerical features. Further, its ability to understand class semantics dynamically from the context enables tuning-free adaptation. Comprehensive experiments show that GILT achieves stronger few-shot performance with significantly less time than LLM-based or tuning-based baselines, validating the effectiveness of our approach. Our code is available at: https://github.com/yiming421/inductnode/.
SDQM: Synthetic Data Quality Metric for Object Detection Dataset Evaluation
The performance of machine learning models depends heavily on training data. The scarcity of large-scale, well-annotated datasets poses sig…
Mapping Scientific Literature with Large Language Models and Topic Modeling
Scientific literature is increasingly fragmented by disciplinary boundaries, specialized terminology, and potentially sparse keyword system…
Moving Beyond Diffusion: Hierarchy-to-Hierarchy Autoregression for fMRI-to-Image Reconstruction
Reconstructing visual stimuli from fMRI signals is a central challenge bridging machine learning and neuroscience. Recent diffusion-based m…
Grounding Computer Use Agents on Human Demonstrations
Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elem…
Irresponsible AI: big tech's influence on AI research and associated impacts
The accelerated development, deployment and adoption of artificial intelligence systems has been fuelled by the increasing presence of big…
Semantic search for 100M+ galaxy images using AI-generated captions
Finding scientifically interesting phenomena through slow manual labeling campaigns severely limits our ability to explore the billions of…
Towards Deep Learning Surrogate for the Forward Problem in Electrocardiology: A Scalable Alternative to Physics-Based Models
The forward problem in electrocardiology, computing body surface potentials from cardiac electrical activity, is traditionally solved using…
Unifying Learning Dynamics and Generalization in Transformers Scaling Law
The scaling law, a cornerstone of Large Language Model (LLM) development, predicts improvements in model performance with increasing comput…
HiGR: Industrial-Scale Hierarchical Generative Slate Recommendation Framework in Tencent
Slate recommendation, which presents users with a ranked item list in a single display, is ubiquitous across mainstream online platforms. W…
Causal Emotion Recognition in Conversation: Context Saturation and Discourse-Marker Evidence
We address two persistent gaps in Emotion Recognition in Conversation: which modeling choices materially affect performance, and how recogn…
Geometry of Reason: Spectral Signatures of Valid Mathematical Reasoning
Verifying whether a language model is genuinely reasoning or pattern-matching remains an open problem: learned verifiers are expensive, and…
CoVar: Confidence-Variance-Guided Pseudo-Label Selection for Semi-Supervised Learning
Pseudo-label selection in semi-supervised learning is commonly driven by maximum-confidence thresholds, yet confidence alone can be unrelia…
Robust Privacy: Inference-Stage Privacy through Certified Robustness
An adversary observing a model's released prediction can infer sensitive attributes of the queried input, or even reconstruct representativ…
Reliability-Calibrated Edge-IoT Early Fault Warning for Rotating Machinery with a Physics-Guided Tiny-Mamba Transformer
Industrial Internet of Things (IIoT) systems increasingly rely on distributed vibration sensing to support predictive maintenance of rotati…
When Generic Prompt Improvements Hurt: Evaluation-Driven Iteration for LLM Applications
Evaluating Large Language Model (LLM) applications differs from conventional software testing because outputs are probabilistic, semantical…
OpenVTON-Bench: A Large-Scale High-Resolution Benchmark for Controllable Virtual Try-On Evaluation
Recent advances in diffusion models have significantly elevated the visual fidelity of Virtual Try-On (VTON) systems, yet reliable evaluati…
Neural FOXP2 -- Language Specific Neuron Steering for Targeted Language Improvement in LLMs
LLMs are multilingual by training, yet their lingua franca is often English, reflecting English language dominance in pretraining. Other la…
Global Geometry Is Not Enough for Vision Representations
A common assumption in representation learning is that globally well-distributed embeddings support robust and generalizable representation…
Learning to Inject: Automated Prompt Injection via Reinforcement Learning
Prompt injection is a critical vulnerability in LLM agents, yet the strongest methods still rely on human red-teamers and hand-crafted prom…
"Do Not Mention This to the User": Detecting and Understanding Malicious Agent Skills in the Wild
LLM-based coding agents increasingly rely on third-party extensions called skills, which bundle natural language instructions and helper sc…
SAGE: Scalable AI Governance & Evaluation
Evaluating relevance in large-scale search systems is fundamentally constrained by the governance gap between nuanced, resource-constrained…
Improving Detection of Rare Nodes in Hierarchical Multi-Label Learning
In hierarchical multi-label classification, a persistent challenge is enabling model predictions to reach deeper levels of the hierarchy fo…
On the Optimal Reasoning Length for RL-Trained Language Models
Reinforcement learning substantially improves reasoning in large language models, but it also tends to lengthen chain-of-thought outputs an…
Carbon-Aware Governance Gates: An Architecture for Sustainable GenAI Development
The rapid adoption of Generative AI (GenAI) in the software development life cycle (SDLC) increases computational demand, which can raise t…
EKF-Based Depth Camera and Deep Learning Fusion for UAV-Person Distance Estimation and Following in SAR Operations
Vision-based Unmanned Aerial Vehicles (UAVs) frameworks aid human search tasks by detecting and recognizing specific individuals, then trac…
Compiler-First State Space Duality and Portable $O(1)$ Autoregressive Caching for Inference
High-throughput Mamba-2 inference is usually tied to fused CUDA and Triton kernels, limiting portability across accelerator backends. We sh…
The Latent Color Subspace: Emergent Order in High-Dimensional Chaos
Text-to-image generation models have advanced rapidly, yet achieving fine-grained control over generated images remains difficult, largely…
Power Term Polynomial Algebra for Boolean Logic
We introduce power term polynomial algebra, a representation language for Boolean formulae designed to bridge conjunctive normal form (CNF)…
Sample-Efficient Hypergradient Estimation for Decentralized Bi-Level Reinforcement Learning
Many strategic decision-making problems, such as environment design for warehouse robots, can be naturally formulated as bi-level reinforce…
FinTradeBench: A Financial Reasoning Benchmark for LLMs
Real-world financial decision-making is a challenging problem that requires reasoning over heterogeneous signals, including company fundame…
Vision-Language-Action Jump-Starting for Reinforcement Learning Robotic Agents
Reinforcement learning (RL) enables high-frequency, closed-loop control for robotic manipulation, but scaling to long-horizon tasks with sp…
Bimanual Robot Manipulation via Multi-Agent In-Context Learning
Language Models (LLMs) have emerged as powerful reasoning engines for embodied control. In particular, In-Context Learning (ICL) enables of…
Estimating Tail Risks in Language Model Output Distributions
Language models are increasingly capable and are being rapidly deployed on a population-level scale. As a result, the safety of these model…
Information bottleneck for learning the phase space of dynamics from high-dimensional experimental data
Identifying the dynamical state variables of a system from high-dimensional observations is a central problem across physical sciences. The…
Internet of Everything in the 6G Era: Paradigms, Enablers, Potentials and Future Directions
The Internet of Everything (IoE) represents an evolution of the Internet of Things (IoT) by integrating people, data, processes, and things…
Beyond Continuity: Simulation-free Reconstruction of Discrete Branching Dynamics from Single-cell Snapshots
Inferring cellular trajectories from destructive snapshots is complicated by the challenges of stochasticity and non-conservative mass dyna…
Self-Prompting Small Language Models for Privacy-Sensitive Clinical Information Extraction
Clinical named entity recognition from dental progress notes is challenging because documentation is highly unstructured, domain-specific,…
Towards an Inferentialist Account of Information Through Proof-theoretic Semantics
Information is one of the most widely-discussed concepts of the current era. However, a great deal of insightful work notwithstanding, it i…
CredibleDFGO: Differentiable Factor Graph Optimization with Credibility Supervision
Global navigation satellite system (GNSS) positioning is widely used for urban navigation, but the covariance reported by the GNSS solver i…
Litespark Inference For CPUs: Ultra-Fast SIMD Framework for Ternary (1.58-bit) Language Models
Large language models (LLMs) have transformed artificial intelligence, but their computational requirements remain prohibitive for most use…
Engineering Robustness into Personal Agents with the AI Workflow Store
The dominant paradigm for AI agents is an "on-the-fly" loop in which agents synthesize plans and execute actions within seconds or minutes…
TokenRatio: Principled Token-Level Preference Optimization via Ratio Matching
Direct Preference Optimization (DPO) is a widely used RL-free method for aligning language models from pairwise preferences, but it models…
Weakly Supervised Segmentation as Semantic-Based Regularization
Weakly supervised semantic segmentation (WSSS) trains dense pixel-level segmentation models from partial or coarse annotations such as boun…
CRANE: Constrained Reasoning Injection for Code Agents via Nullspace Editing
Code agents must both reason over long-horizon repository state and obey strict tool-use protocols. In paired Instruct/Thinking checkpoints…
TAPIOCA: Why Task- Aware Pruning Improves OOD model Capability
Recent work has promoted task-aware layer pruning as a way to improve model performance on particular tasks, as shown by TALE. In this pape…
ASRU: Activation Steering Meets Reinforcement Unlearning for Multimodal Large Language Models
Multimodal large language models (MLLMs) may memorize sensitive cross-modal information during pretraining, making machine unlearning (MU)…
Frontier LLM はサイバーセキュリティに対応する準備ができていますか?デュアルモード脆弱性ベンチマークによる垂直基盤モデルの証拠
当社は、フロンティア LLM がデュアルモード ベンチマークを通じてサイバーセキュリティに対応できるかどうかを評価します。ホワイトボックス機能レベルの脆弱性検出 (VulnLLM-R、C/Java/Python 全体) とブラックボックス Web アプリケーション セキュリティ テスト (20 以上の CWE ファミリにわたる 118 個のグラウンド トゥルース脆弱性を備えた 5 つの運用スタイルのアプリケーション。これらをオープンソース化します)。私たちは 6 つのフロンティア モデル (GPT-5.4、Codex~5.3、Claude Opus~4.6、Sonnet~4.6、Gemini~3.1~Pro、および Gemini~3~Flash) と 2 つのドメイン特化モデルを 4 つのテスト パラダイムにわたってテストします。私たちの発見は厳粛なものです。(1) ~すべてのフロンティア モデルは、ホワイトボックス検出で 10 ~ 50% の誤検知率を生成し、体系的に脆弱性を過剰予測します。 (2)〜ブラックボックス テストでは、フロンティア モデルはグラウンド トゥルース カバレッジをわずか 4 ~ 8% しか達成せず、外部セキュリティ ツール (Playwright MCP、Burp Suite MCP) を使用した場合でもわずか 10 ~ 19% に改善します。 (3) ドメイン特化型エージェントにエンコードされた構造化侵入テスト手法により、ファミリーごとの検出が 50% を超え、規模ではなく手法が主要な手段であることが実証されました。 (4) ドメインに特化した防御モデルは、単一 GPU 上ですべてのモデルの中で最高の精度 (0.904) と最低の誤検知率 (9.7%) を達成します。私たちは、構造化されたセキュリティ テストの欠如、エンドツーエンドの要求/応答シーケンス、障害の多いデータ、および複数ステップの攻撃チェーンのトレースが基本的なトレーニング データのボトルネックであることを特定し、データ生成戦略としてセルフプレイ セキュリティ テストを提案します。私たちの結果は、サイバーセキュリティ専用に構築された垂直基盤モデルの正当性を裏付けています。
原文 (English)
Are Frontier LLMs Ready for Cybersecurity? Evidence for Vertical Foundation Models from Dual-Mode Vulnerability Benchmarks
We evaluate whether frontier LLMs are ready for cybersecurity through a dual-mode benchmark: white-box function-level vulnerability detection (VulnLLM-R, across C/Java/Python) and black-box web application security testing (five production-style applications with 118 ground-truth vulnerabilities across 20+ CWE families, which we will open-source). We test six frontier models (GPT-5.4, Codex~5.3, Claude Opus~4.6, Sonnet~4.6, Gemini~3.1~Pro and Gemini~3~Flash) and two domain-specialized models across four testing paradigms. Our findings are sobering: (1)~every frontier model produces 10-50% false positive rates in white-box detection, systematically over-predicting vulnerabilities; (2)~in black-box testing, frontier models achieve only 4-8% ground-truth coverage, improving to just 10-19% even with external security tools (Playwright MCP, Burp Suite MCP); (3)~structured penetration-testing methodology encoded in domain-specialized agents raises per-family detection above 50%, demonstrating that methodology, not scale, is the primary lever; and (4)~a domain-specialized defense model achieves the highest precision (0.904) and lowest false positive rate (9.7%) among all models, on a single GPU. We identify the absence of structured security testing traces end-to-end request/response sequences, failure-heavy data, and multi-step attack chains as the fundamental training data bottleneck, and propose self-play security testing as a data generation strategy. Our results make the case for vertical foundation models purpose-built for cybersecurity.
When Does Deep RL Beat Calibrated Baselines? A Benchmark Study on Adaptive Resource Control
A properly calibrated rule-based autoscaler can beat every one of six mainstream deep reinforcement learning (DRL) algorithms on cost acros…
Models That Know How Evaluations Are Designed Score Safer
The validity of AI safety evaluations depends on models behaving consistently across controlled and deployment settings. Prior work has ide…
GrowLoop: 人間がシードし、自己進化する会話評価
大規模な言語モデルの急速な進歩に伴い、自由な会話における人間らしさを評価することがますます重要になってきています。しかし、人間らしさは人間が直感的に認識する暗黙知の一種ですが、根底にある基準は明示的な定式化に抵抗します。人間の判断は大きく異なり、一部のケースでは強い同意が得られますが、他のケースでは正当な意見の相違が見られます。一方、人間の判断の背後にある基準は暗黙的なままであり、事件を構築するための明確な根拠は残されていません。さらに、人間に似ているとみなされるものは静的なものではなく、モデルの能力と人間の期待に応じて進化します。専門家が作成したベンチマーク、報酬モデル、自己進化型ベンチマークなどの評価方法は進歩していますが、3 つの課題すべてに同時に対処できるものはありません。そこで、モデルの進歩やシナリオの変化に合わせて継続的に適応する、自己進化する会話評価システムである GrowLoop を提案します。最初の動きとして最小限の人間のシード アノテーションを使用して、LLM エージェントはヒューリスティック学習を通じて評価ルーブリックを繰り返し抽出し、改良します。アノテーターが集まる場合には人間と AI の合意が必要ですが、異なる場合には妥当性のみが期待されます。さらに、Rubric-Caseの共進化機構により、評価対象が移動した際に新たなシーズを介して拡張され、継続的な進化が可能となります。自由形式の会話における人間らしさの評価に適用すると、生成されたルーブリックは、人間の判断に沿って既存の手法を大幅に上回るだけでなく、アノテーターが見落としている問題も明らかになります。結果として得られるベンチマークは、機能層全体でモデルを効果的に識別し、どこが不足しているかを明らかにすると同時に、新しいシナリオに一般化し、モデルの進歩に合わせて適応します。私たちの取り組みは、ベンチマークのパラダイムを手動の更新や難易度のスケーリングから、包括的で継続的な自己進化へと移行させます。
原文 (English)
GrowLoop: Self-Evolving Conversation Evaluation Seeded by Human
With the rapid advancement of large language models, evaluating human-likeness in open-ended conversation has become increasingly important. However, human-likeness is a form of tacit knowledge that humans perceive intuitively, yet the underlying criteria resist explicit formulation. Human judgments vary widely, with strong agreement on some cases and legitimate disagreement on others. Meanwhile, the criteria behind human judgments remain implicit, leaving no clear basis for constructing cases. Further, what counts as human-likeness is not static, but evolving with model capability and human expectations. Despite progress in evaluation methods such as expert-authored benchmarks, Reward Models, and self-evolving benchmarks, none addresses all three challenges simultaneously. Therefore, we propose GrowLoop, a self-evolving conversation evaluation system that continuously adapts as models advance and scenarios shift. Starting from minimal human seed annotations, LLM agents iteratively extract and refine evaluation rubrics through Heuristic Learning. Human-AI agreement is required where annotators converge, while only plausibility is expected where they diverge. Moreover, the Rubric-Case co-evolution mechanism enables continuous evolution. When the evaluation target shifts, new human seeds expand the system's coverage accordingly. When applied to human-likeness evaluation in open-ended conversation, the AI judge guided by these rubrics not only substantially outperforms existing methods in alignment with human judgments, but also uncovers issues that annotators overlook. The resulting benchmark effectively discriminates models across capability tiers and reveals where they fall short, while generalizing to new scenarios and adapting as models advance. Our work shifts the benchmarking paradigm from manual updates or difficulty scaling to comprehensive, continuous self-evolution.
Brain-IT-VQA: From Brain Signals to Answers
Decoding visual content from fMRI signals recorded while a person views images, and specifically answering questions about the seen images,…
Geometric Erasure by Contrastive Velocity Matching in Rectified Flows
While the rapid adoption of multimodal generative models offers immense potential, it has also increased the risks of harmful content synth…
Anomalies in Multivariate Time Series Benchmarks Are Mostly Univariate
Many recent multivariate time series anomaly detection (MTSAD) models incorporate cross-channel modeling, under the implicit assumption tha…
Libra: Efficient Resource Management for Agentic RL Post-Training
Reinforcement learning (RL) has emerged as a standard post-training paradigm for shaping large language models (LLMs) into capable agents.…
BaltiVoice: A Speech Corpus and Fine-tuned Whisper ASR System for the Balti Language
We present BaltiVoice, a 16.8-hour read-speech corpus for Balti (ISO 639-3: bft), a Tibetic language spoken in Gilgit-Baltistan, Pakistan,…
EvalStop: ワールド フィードバックを使用して、マルチテナント RLHF プラットフォームにおける報酬の過剰最適化を検出および修正する
Cloud LLM 微調整プラットフォームは RLHF ワークロードにますます対応しており、学習された報酬モデルが人間の品質の代用として最適化されています。 Gao らのように(2023) は、このプロキシは、報酬の過剰最適化として知られる現象である持続的な最適化圧力の下で、世界のフィードバック (下流の評価指標) から乖離することを示しました。既存のプラットフォーム スケジューラはこの相違を無視しています。非千里眼スケジューラは品質信号なしで JCT を最適化し、SLAQ スタイルの品質認識スケジューラはトレーニング損失 (ハッキングによって単調に低下する弱いプロキシ) を使用し、古典的なジョブごとの早期停止では人間による監視が必要であり、共有 GPU を解放しません。私たちは、evalStop を提案します。これは、k 回連続して eval スコアが低下したときにジョブを終了し、GPU を解放し、最適なチェックポイントを保持し、任意のベース スケジューラに委任する、コンポーザブルなスケジューリング プリミティブです。私たちは、スケジューラレベルの早期停止を検出問題としてフレーム化し、RLHF ワークロードが報酬ハッキングと構造的に健全な実行を混合し、スケジューラから隠蔽されたグランドトゥルースラベルを使用した離散イベントシミュレータでそれを評価します。 RLHF の負荷が高いワークロード (RLHF 80%、GPU 64 基) では、EvalStop は精度 98% / リコール 99% / FPR 1.5% を達成し、SRTF-Est と比較して JCT を 9% 改善し、無駄なコンピューティングを 22% 削減します (p<0.05)。些細な固定進捗と損失プラトーの競合他社は、健全な RLHF で 65% の FPR を被るか、真のハッキング ケースの半分以上を見逃すかのどちらかです。ゲインはテストされたすべてのベース スケジューラにわたって構成され (9 ~ 25% の JCT)、検出品質は評価ノイズ (ノイズ std <= 0.05 で少なくとも 91% の精度) およびハッキングのベース レート (20 ~ 80% のハッキング部分で少なくとも 89% の精度) の下で安定しています。
原文 (English)
EvalStop: Using World Feedback to Detect and Correct Reward Overoptimization in Multi-Tenant RLHF Platforms
Cloud LLM fine-tuning platforms increasingly serve RLHF workloads, where a learned reward model is optimized as a proxy for human quality. As Gao et al. (2023) showed, this proxy diverges from world feedback (downstream eval metrics) under sustained optimization pressure, a phenomenon known as reward overoptimization. Existing platform schedulers ignore this divergence: non-clairvoyant schedulers optimize JCT without any quality signal, SLAQ-style quality-aware schedulers use training loss (a weaker proxy that drops monotonically through hacking), and classical per-job early stopping requires human monitoring and does not free shared GPUs. We propose EvalStop, a composable scheduling primitive that terminates jobs on k consecutive eval-score declines, releases GPUs, preserves the best checkpoint, and delegates to any base scheduler. We frame scheduler-level early stopping as a detection problem and evaluate it in a discrete-event simulator whose RLHF workload mixes reward-hacking and structurally healthy runs, with ground-truth labels hidden from schedulers. On RLHF-heavy workloads (80% RLHF, 64 GPUs), EvalStop achieves precision 98% / recall 99% / FPR 1.5% while improving JCT by 9% and cutting wasted compute by 22% over SRTF-Est (p<0.05). Trivial fixed-progress and loss-plateau competitors either incur 65% FPR on healthy RLHF or miss over half of true hacking cases. Gains compose across every base scheduler tested (9-25% JCT) and detection quality stays stable under eval noise (precision at least 91% at noise std <= 0.05) and hacking base rate (precision at least 89% across 20-80% hacking fractions).
Conformal Risk-Averse Decision Making with Action Conditional Guarantee
Reliable decision making pipelines powered by machine learning models require uncertainty quantification (UQ) methods that come with explic…
Agentic Software: How AI Agents Are Restructuring the Software Paradigm
For over half a century, software engineering has operated on a foundational premise: human engineers decompose problems, encode decision l…
DataEvolver: Automatic Data Preparation for Large Language Models through Multi-Level Self-Evolving
High-quality training data is essential to large language models (LLMs) and typically requires extensive and costly manual curation. Existi…
On the Geometry of On-Policy Distillation
On-policy distillation (OPD) is increasingly used to improve large language model reasoning, but its training dynamics remain poorly unders…
DEFINED: A Data-Efficient Computational Framework for Fine-Grained Creativity Assessment in Debate Scenarios
Human creativity has emerged as a critical competency in the era of large language models. Assessing creativity in complex, open-ended envi…
ResearchClawBench: A Benchmark for End-to-End Autonomous Scientific Research
AI coding agents are increasingly used for scientific work, but their end-to-end autonomous research capability remains difficult to verify…
Rewrite to Translate, Translate to Reward: Reinforcement Learning for Source Rewriting in Machine Translation
Rewriting source text with large language models (LLMs) before translation has been shown to improve machine translation (MT) quality. Howe…
Continual Quadruped Robots Coordination via Semantic Skill Discovery
Multi-quadruped coordination has attracted increasing attention due to its enhanced payload capacity, broader contact coverage, and improve…
CoVEBench: Can Video Editing Models Handle Complex Instructions?
While recent text-guided video editing models excel at elementary tasks (e.g., style transfer, object insertion), real-world user requests…
GEAR-VLA: Learning Geometry-Aware Action Representations for Generalizable Robotic Manipulation
Vision-Language-Action (VLA) models achieve strong benchmark performance but still struggle in real-world deployment with unseen objects, b…
Inside the Latent Flow: Causal Deciphering of Attention Dynamics in Audio Separation Foundation Models
Flow-matching transformers achieve strong audio separation, yet their attention dynamics are opaque. We adapt established causal-interventi…
MetaPlate: Counterfactual-Guided RAG-LLM Tool for Personalized Food Recommendation and Hyperglycemia Prevention
Postprandial hyperglycemia is a key risk factor for metabolic disorders; however, existing dietary guidance is often static, impractical, a…
BiWM: Advancing Open-Source Interactive Video World Models with Bidirectional Autoregression
Transitioning bidirectional video diffusion models into an autoregressive paradigm improves the interactivity of video world models, but ex…
Density Ridge Selective Prediction for LLM and VLM Hallucination Detection under Calibration Label Scarcity
Hallucination detection in large language and vision-language models is increasingly framed as selective prediction, where a detector assig…
K-Forcing: Joint Next-K-Token Decoding via Push-Forward Language Modeling
Autoregressive (AR) language modeling is the dominant paradigm for text generation, yet its sequential token-by-token decoding makes infere…
Beyond Uniform Token-Level Trust Region in LLM Reinforcement Learning
Reinforcement learning with verifiable rewards (RLVR) has become standard for improving LLM reasoning. However, existing PPO-style trust-re…
Modeling Complex Behaviors: Multi-Personality Composition and Dynamic Switching in Vision-Language Models
With the widespread deployment of Multimodal Large Language Models (MLLMs) in social interaction, understanding and controlling their behav…
RoboNaldo: Accurate, Stable and Powerful Humanoid Soccer Shooting via Motion-Guided Curriculum Reinforcement Learning
Elite humanoid soccer shooting requires whole-body stability, high-impulse whole-body interactions, and accuracy to targets. Motion trackin…