AIニュース 2026-06-03
自動生成: 2026-06-03 13:47 JST
過去24時間以内に公開された記事を、同じ話題ごとに1つのストーリーカードへまとめ、出典・トピック・要約とともに掲載しています。要約は各フィード提供文の冒頭を整形したもので、本文は各リンク先をご覧ください。
📌 今日の要点 TOP7
-
Travelers deploys AI-powered claims countrywide with OpenAIOpenAI
Travelers built an AI-powered Claim Assistant with OpenAI to guide cu…
-
Codex for every role, tool, and workflowOpenAI
Discover new Codex plugins, sites, and annotations that help analysts…
-
Advancing youth safety and opportunity through global leadershipOpenAI
OpenAI calls for global action on youth AI safety, proposing an inter…
-
OpenAI launches new Codex tools for white-collar workTechCrunch AI
OpenAI released a set of six plug-ins aimed at specific jobs: data an…
-
Microsoft、自社開発した7つのAIモデル発表 画像編集や音声認識もITmedia AI+
米Microsoftが自社開発した7つのAIモデル群「Microsoft AI Models」を発表しました。
-
Microsoft、AIエージェント用のカスタマイズ可能な分離環境「Microsoft Execution Containers」発表 OpenClawも動作ITmedia AI+
米MicrosoftがAIエージェントのためのカスタマイズ可能な分離環境「Microsoft Execution Containers」(…
-
トランプ米大統領、AI安全保障に関する大統領令に署名 最先端モデルを公開30日前に政府が検査可能にITmedia AI+
トランプ米大統領は、先進的AIのイノベーションと安全保障の促進に関する大統領令に署名した。戦争省やCISAによるサイバー防衛強化に加え、主…
トピック別件数
- 研究/論文 192件
- LLM/生成AI 190件
- エージェント 115件
- 画像/動画生成 55件
- ビジネス/資金調達 35件
- ロボティクス 25件
- ハードウェア/半導体 12件
- その他 9件
- 規制/政策 4件
日本語メディア12件
ITmedia AI+ (日本語)
Microsoft、自社開発した7つのAIモデル発表 画像編集や音声認識も
米Microsoftが自社開発した7つのAIモデル群「Microsoft AI Models」を発表しました。

Microsoft、AIエージェント用のカスタマイズ可能な分離環境「Microsoft Execution Containers」発表 OpenClawも動作
米MicrosoftがAIエージェントのためのカスタマイズ可能な分離環境「Microsoft Execution Containers」(MXC)を発表しました。
トランプ米大統領、AI安全保障に関する大統領令に署名 最先端モデルを公開30日前に政府が検査可能に
トランプ米大統領は、先進的AIのイノベーションと安全保障の促進に関する大統領令に署名した。戦争省やCISAによるサイバー防衛強化に加え、主要企業の最先端AIモデルを政府が事前検証する任意の枠組みを構築する。政府は全面的な監視を否定しており、民間の開発自由度を維持しつつ安全保障の…
シーメンス、AIでCFD設計探索を高速化 「Simcenter PhysicsAI」を発表
シーメンスは「Simcenter」の新機能として、AIを活用した設計空間探索向けソフトウェア「Simcenter PhysicsAI」を発表した。CFDのシミュレーション結果からAIサロゲートモデルを構築し、数千もの設計バリエーションを短時間で評価できる。従来は数日を要していた…

シャドーAIに「ログイン情報」を渡している割合は? Oktaの実態調査で判明
ある調査によると、経営幹部の95%は「従業員は責任を持ってAIを利用している」と確信しているが、シャドーAIを使っている従業員は過半数に上るという。さらに、シャドーAIを利用している従業員の中には情報漏えいにつながりかねない「危険な使い方」をしている人も一定数いる。

Microsoft、AndroidベースのAIエージェント基盤「Solara」発表 Snapdragon搭載のバッジ型端末も披露
Microsoftは「Build 2026」で、AIエージェントの実行に特化した新プラットフォーム「Project Solara」を発表した。OSにはWindowsではなくAOSPベースのOSを採用。Qualcommと共同開発した社員証のようなデバイスと、MediaTekと共同…

AI需要で半導体不足は「しばらく続く」 PCメーカー、デルの対応策は?
AI需要による半導体不足は「しばらく続く」――PCメーカーのデル・テクノロジーズはこう予測する。同社はこの難局をどう乗り切るのか。
【Pythonで学ぶデータ分析】ベイズ統計の考え方をやさしく学ぶ ~ 初めてでも流れが分かる入門編
初歩から応用までステップアップしながら学んでいく『やさしいデータ分析』シリーズ第5弾はベイズ統計編。今回は、二項分布の確率についてベイズ的な手法で母数の推定や検定を行います。
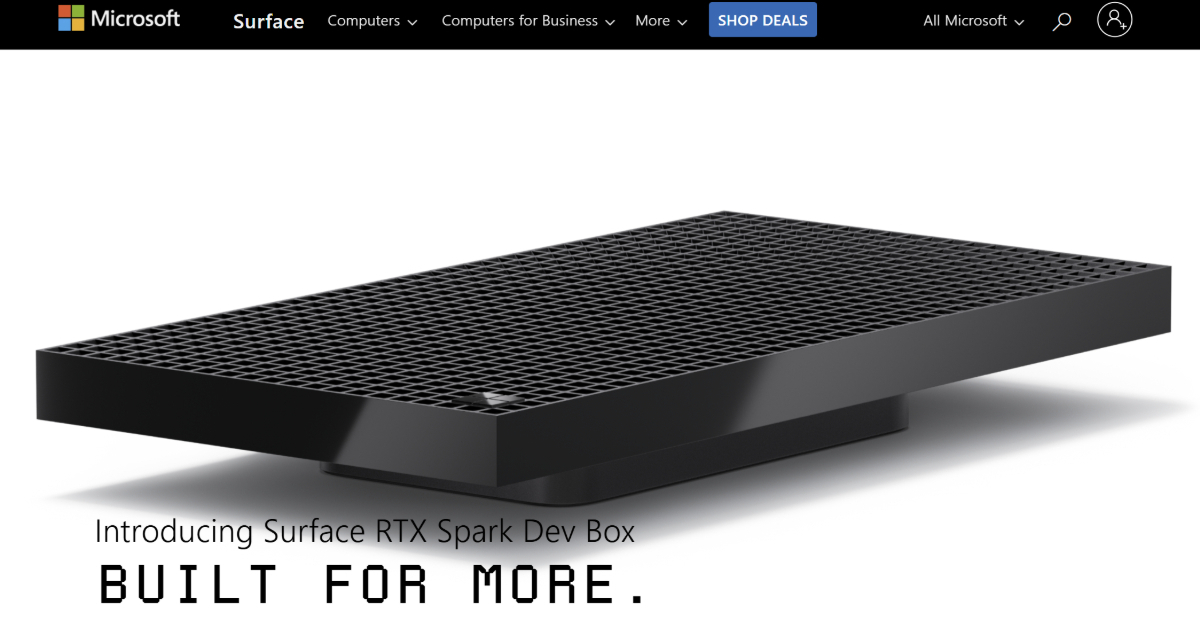
Microsoft、NVIDIAのSoC搭載でAI特化のミニPC「Surface RTX Spark Dev Box」披露
Microsoftは「Build 2026」で、AI特化型デスクトップPC「Surface RTX Spark Dev Box」を発表した。NVIDIAの「RTX Spark」を搭載し、最大1ペタフロップスの演算性能と128GBのメモリにより、1200億パラメータ超のモデルのロ…
Microsoft、初の自社推論モデル「MAI-Thinking-1」発表 蒸留なしでゼロから学習
Microsoftは「Build 2026」で、自社開発AI「MAI」の新モデル群を発表した。中核となる初の推論モデル「MAI-Thinking-1」は350億パラメータを持ち、他モデルからの蒸留を行わないクリーンなデータで学習。競合モデルに匹敵する高い性能を示し、独自チップ「…
Microsoft、自律エージェント「Scout」発表 OpenClawベースでMCP対応
Microsoftは「Build 2026」で、自律型AIエージェントの新カテゴリ「Autopilots」と、その第一弾「Microsoft Scout」を発表した。Scoutは「OpenClaw」基盤で構築され、常時バックグラウンドで稼働して「Microsoft 365」のア…
AIモデル「ミュトス」のアクセス権拡大 新たに150組織が利用へ Anthropic
米Anthropicは、サイバーセキュリティプロジェクト「Project Glasswing」を拡大し、AIモデル「Claude Mythos Preview」のアクセス権を新たに約150の組織に与えると発表した。
海外メディア12件
TechCrunch AI (英語)

Cyera eyes $12B valuation at 80x ARR multiple despite operating losses
The cybersecurity company is nearing a $300 million round led by Evolution Equity Partners.

Uber caps employee AI spending after blowing through budget in 4 months
Uber's cutback has occurred after the company had reportedly encouraged staff to use AI as much as possible.

New Microsoft tool lets devs spin up AI behavior tests using text descriptions
Microsoft on Tuesday took the wraps off Adaptive Spec-driven Scoring for Evaluation and Regression Testing, an open source framework for sp…

Martin Scorsese becomes the latest — and most unlikely — Hollywood voice for AI
The caveat is that one of the world's most famous living directors is using the tech solely for storyboarding.

Google rolls out fake call detection to protect against AI deepfake impersonation scams
As people increasingly refuse to answer calls from unknown numbers, scammers are shifting their tactics by spoofing trusted phone numbers a…

Microsoft offers devs a better way to control AI agent behavior
The specification lets developer, compliance, and security teams define their own policies for agents to follow in portable policy files.

Amazon faces class action lawsuit over Ring facial-recognition feature
The class action lawsuit, filed in Seattle by Virginia resident Charles Sigwalt, claims that Ring's Familiar Faces feature stores images of…

Trump signs narrower executive order on AI oversight after industry objections
After industry objections, President Trump signed a revised AI executive order requiring only voluntary prerelease government reviews of ad…
OpenAI launches new Codex tools for white-collar work
OpenAI released a set of six plug-ins aimed at specific jobs: data analytics, creative production, sales, product design, equity investing,…

Anthropic scales Claude Mythos to critical infrastructure in 15+ countries
Anthropic is expanding Project Glasswing, its security vulnerability program, and access to Mythos to 150 organizations across 15 countries…

ZeroDrift raises $10M to protect AI models from themselves
A new AI compliance service sits between AI models and end users to flag and replace any messages that might present a compliance problem.

Rocket engine startup Impulse raises $500 million to hire people, not AI
Engineering physical systems still depends on human talent, according to Impulse Space president Eric Romo.
公式ブログ3件
OpenAI (英語)

Travelers deploys AI-powered claims countrywide with OpenAI
Travelers built an AI-powered Claim Assistant with OpenAI to guide customers through filing claims, provide 24/7 support, and scale operati…
Codex for every role, tool, and workflow
Discover new Codex plugins, sites, and annotations that help analysts, marketers, designers, investors, and other teams get more done with…

Advancing youth safety and opportunity through global leadership
OpenAI calls for global action on youth AI safety, proposing an international institute to strengthen safeguards, standards, and opportunit…
論文440件
arXiv cs.AI (英語)
大規模言語モデルにおける構造推論のためのビジュアル グラフ スキャフォールド
グラフは、主にテスト時に外部知識ソースがモデルに提供されるため、構造化推論のための大規模言語モデル (LLM) を強化するために使用されてきました。この論文では、私たちは別の見方をします。LLM のグラフの価値は、情報を提供することだけでなく、推論を体系化することにもあります。人間がグラフ構造のマインドマップを使用して分岐や収束する思考を整理する方法に触発され、グラフが推論支援の内部形式として機能できるかどうかを問いかけます。私たちはこの質問をマルチホップ質問応答タスクで研究します。このタスクでは、教師が提供した推論トレースがグラフ マインド マップとして書き換えられ、生徒モデルのガイドに使用されます。私たちの実験では、明らかなモダリティのギャップが明らかになりました。グラフ構造がテキストに平坦化されると、直接的な答えのヒントが削除されると、その利点は限定的になります。この抽象的なガイダンス設定の下では、推論の効率と回答の質の両方が大幅に低下します。対照的に、視覚的なグラフ ガイダンスは、直接的な答えの手掛かりがなくても引き続き有効であり、その利点は教師付き微調整と KL ベースの蒸留の後も持続します。上記の発見は、グラフは LLM の外部知識構造としてだけでなく、推論を組織化するための視覚的な足場としても研究されるべきであるという主張を裏付けています。
原文 (English)
Visual Graph Scaffolds for Structural Reasoning in Large Language Models
Graphs have been used to enhance large language models (LLMs) for structured reasoning, mostly as external knowledge sources are provided to models at test time. In this paper, we take a different view: the value of graphs for LLMs lie not only in supplying information, but also in organizing reasoning. Inspired by how humans use graph-structured mind maps to organize branching and converging thoughts, we ask whether graphs can serve as an internal form of reasoning assistance. We study this question on multi-hop question answering tasks, where teacher-provided reasoning traces are rewritten as graph mind maps and used to guide a student model. Our experiments reveal a clear modality gap. When graph structures are flattened into text, their benefits become limited once direct answer hints are removed. Under this abstract guidance setting, both reasoning efficiency and answer quality degrade substantially. In contrast, visual graph guidance remains effective without direct answer clues, and its advantage persists after supervised fine-tuning and KL-based distillation. The above findings support the claim that graphs should be studied not only as external knowledge structures for LLMs, but also as visual scaffolds for organizing reasoning.
AURA: 一定の VRAM でのロボット ポリシー用のアクション ゲート メモリ
KV キャッシュはデータセンターにとっては適切なメモリですが、ロボットにとっては不適切なメモリです。データセンターの推論は、多くの短いリクエストをバッチ化してリセットし、群衆全体での注意キャッシュを償却します。代わりに、身体化されたエージェントは、帯域幅が制限されたエッジ ハードウェアで、リセットされない長いエピソードを 1 つ実行します。このハードウェアでは、高帯域幅のメモリとフラッシュが不足し、フラッシュの書き込み耐久性が有限であり、コンピューティングではなくメモリ書き込みがバインド制約になる可能性があります。 AURA-Mem (Action-Utility Recurrent Adaptive Memory) は、この体制をターゲットとしています。これは、固定された視覚言語アクションのバックボーンを、一定サイズのリカレント メモリと、現在の観察によって次のアクションが変更される場合にのみ書き込む学習済みゲート、つまりいつ沈黙を保つべきかを認識するメモリでラップします。再構成ベースのメモリとは異なり、ゲートは閉ループのアクションエラー信号に対して直接トレーニングされます。その推論状態はホライズンに関係なく 4,224 バイトに固定されていますが、KV キャッシュは 100,000 ステップで 6,061 倍の大きさに増加します。制御された合成ベンチマークでは、AURA-Mem は精度において最高の O(1) ベースラインと一致し、書き込み回数は 5.19 ~ 6.13 倍少なく、より簡単な構成では最大 9.19 倍少なくなります。予算に合わせたランダムおよび定期的なスケジュールではこの利益は回復せず、アクションサプライズシグナルに対する利益が孤立します。 LIBERO-Long 上のトレーニングされた閉ループ OpenVLA-OFT 7B パネル (アームあたり n=60 エピソード) では、ゲートは成功に悪影響を及ぼしません。AURA-Mem は非ゲートの基本ポリシー (0.233) に一致し、常時書き込み KV アーム (0.217) をわずかに上回っていますが、使用する書き込み回数と定数メモリは 7.0 分の 1 です。また、方法論のデモンストレーションとして、近似情報状態の価値損失限界をインスタンス化します。この規模では、限界は保証ではなく空虚です。
原文 (English)
AURA: Action-Gated Memory for Robot Policies at Constant VRAM
The KV-cache is the right memory for datacenters but the wrong memory for robots. Datacenter inference batches many short requests and resets them, amortizing an attention cache across a crowd. Embodied agents instead run one long, non-resetting episode on bandwidth-limited edge hardware, where high-bandwidth memory and flash are scarce, flash has finite write endurance, and memory writes rather than compute can become the binding constraint. AURA-Mem (Action-Utility Recurrent Adaptive Memory) targets this regime. It wraps a frozen vision-language-action backbone with a constant-size recurrent memory and a learned gate that writes only when the current observation would change the next action: memory that knows when to stay silent. Unlike reconstruction-based memory, the gate is trained directly against a closed-loop action-error signal. Its inference state is fixed at 4,224 bytes regardless of horizon, while a KV-cache grows to 6,061 times larger at 100,000 steps. On a controlled synthetic benchmark, AURA-Mem matches the best O(1) baseline in accuracy while using 5.19-6.13 times fewer writes, and up to 9.19 times fewer writes on easier configurations. Budget-matched random and periodic schedules do not recover this gain, isolating the benefit to the action-surprise signal. On a trained closed-loop OpenVLA-OFT 7B panel on LIBERO-Long (n=60 episodes per arm), the gate does not hurt success: AURA-Mem matches the ungated base policy (0.233) and slightly exceeds an always-write KV arm (0.217), while using 7.0 times fewer writes and constant memory. We also instantiate an approximate-information-state value-loss bound as a methodology demonstration; at this scale, the bound is vacuous rather than a guarantee.
計測されていない流域における予測のための変圧器と LSTM フレームワークの評価
流域ネットワークは、複数の支流が下流の水路に合流する収束トポロジーを示し、上流の多様な水文学プロセスを統合します。計測されていない盆地では、直接観測がないため不確実性が増大し、極端な現象を予測する能力が制限されます。この研究では、NOAA National Water Model (NWM) の遡及的シミュレーションを使用して、限られた水文情報の下で上流流の推論において、エンコーダ専用の Transformer が LSTM よりも利点があるかどうかを評価します。アップストリームのみの構成と組み合わせた構成の両方で、LSTM は 2 つの構成全体で Transformer モデルよりも優れた全体的なパフォーマンスを示しました。下流情報を組み込むことで、すべてのモデルのパフォーマンスがさらに向上し、NNSE 中央値が 60% 以上増加しました。私たちは、これをリーダーボード形式の比較として扱うのではなく、水文学的順序推論に対する建築上の帰納的バイアスのテストとして実験を解釈します。結果は、エンコーダのみの Transformer よりもリカレント メモリがこの上流の再構成タスクとよりよく連携している一方、下流の水文コンテキストが強力な補助制約を提供し、アーキテクチャ全体での予測スキルを大幅に向上させることを示しています。
原文 (English)
Evaluating Transformer and LSTM Frameworks for Prediction in Ungauged Basins
Watershed networks exhibit convergent topologies in which multiple tributaries merge into downstream channels,integrating diverse upstream hydrological processes. In ungauged basins, the absence of direct observations increases uncertainty and limits the ability to anticipate extreme events. This study evaluates whether an encoder-only Transformer provides an advantage over an LSTM for upstream streamflow inference under limited hydrologic information, using retrospective simulations from the NOAA National Water Model (NWM). Across both upstream-only and combined configurations, the LSTM showed stronger overall performance than the Transformer model across the two configurations. Incorporating downstream information further boosted performance for all models, increasing median NNSE by more than 60%. Rather than treating this as a leaderboard-style comparison, we interpret the experiments as a test of architectural inductive bias for hydrologic sequence inference. The results indicate that recurrent memory remains better aligned with this upstream reconstruction task than an encoder-only Transformer, while downstream hydrologic context provides a strong auxiliary constraint that substantially improves prediction skill across architectures
BehaviorBench: 行動追跡から現実世界のユーザーの意思決定をモデル化
多くの意思決定支援設定では、個々のユーザーに適応するシステムが必要ですが、この問題に関する評価データは依然として限られています。ユーザー理解のための既存のベンチマークは、多くの場合、シミュレートされたユーザーやモデルで生成された動作に依存していますが、最近の研究では、モデルベースのシミュレーションが人間の動作から系統的に逸脱する可能性があると警告されています。現実世界の行動追跡からパーソナライズされた意思決定モデリングを評価するためのベンチマークである \textsc{BehaviorBench} を紹介します。 \textsc{BehaviorBench} は、観測された公開予測市場記録とオンチェーン記録からウォレットレベルの意思決定履歴を再構築し、それらを 2 つの補完的なタスク層に編成します。\emph{信念予測} は市場に対するユーザーの最終的なスタンスと自信を予測し、\emph{取引予測} は個々の取引の方向と金額を予測します。 2,000 の評価ウォレットにわたって、ベンチマークには 141,445 個の信念インスタンスと 1,485,972 個の取引インスタンスが含まれており、検索ベースの評価のための独立したサポート プールが含まれています。私たちは、パーソナライゼーションなし、直接の最近の履歴、生成されたユーザー プロファイル、および取得されたサポート ウォレットの証拠という 4 つの履歴インターフェイスの下で、フロンティアおよびオープンウェイト生成モデルを評価します。パーソナライゼーションにより、取引予測よりも一貫して信念予測が向上し、モデルのランキングがタスク レイヤーとメトリクスにわたって変化し、さまざまな履歴インターフェイスによりさまざまな障害モードが明らかになります。 \textsc{BehaviorBench} は、パーソナライズされたメソッドがシミュレートされたユーザーのみではなく現実世界の行動証拠を使用できるかどうかを研究するための評価設定を提供します。
原文 (English)
BehaviorBench: Modeling Real-World User Decisions from Behavioral Traces
Many decision-support settings require systems that adapt to individual users, but evaluation data for this problem remain limited. Existing benchmarks for user understanding often rely on simulated users or model-generated behavior, even though recent work cautions that model-based simulations can diverge systematically from human behavior. We introduce \textsc{BehaviorBench}, a benchmark for evaluating personalized decision modeling from real-world behavioral traces. \textsc{BehaviorBench} reconstructs wallet-level decision histories from observed public prediction-market and on-chain records, and organizes them into two complementary task layers: \emph{Belief prediction}, which predicts a user's final revealed stance and confidence in a market, and \emph{Trade prediction}, which predicts the direction and amount of individual transactions. Across 2,000 evaluation wallets, the benchmark contains 141,445 Belief instances and 1,485,972 Trade instances, with disjoint support pools for retrieval-based evaluation. We evaluate frontier and open-weight generative models under four history interfaces: no personalization, direct recent history, generated user profiles, and retrieved support-wallet evidence. Personalization improves Belief prediction more consistently than Trade prediction, model rankings change across task layers and metrics, and different history interfaces expose different failure modes. \textsc{BehaviorBench} provides an evaluation setting for studying whether personalized methods can use real-world behavioral evidence rather than simulated users alone.
ChatHealthAI: 電子医療記録の表現を大規模な言語モデルと連携させて、根拠のある臨床推論を実現
大規模言語モデル (LLM) は、臨床意思決定をサポートするための強力な自然言語推論能力を示しますが、構造化された長期的な電子医療記録 (EHR) を効果的にモデル化するのは困難です。対照的に、EHR 基盤モデルは、予測的な患者の表現を学習できますが、解釈可能な言語ベースの推論が欠けています。このギャップを埋めるために、私たちは、事前トレーニングされた EHR 基盤モデルからの構造化 EHR 表現を、タスク認識リサンプラーを通じてフリーズされた LLM の意味空間と整合させるマルチモーダル推論フレームワークである ChatHealthAI を提案します。 ChatHealthAI は、長期にわたる患者の表現と洗練された臨床事象の説明を統合することで、正確な患者予測を維持しながら、臨床に基づいた自然言語推論を可能にします。 EHRSHOT ベンチマークからの 3 つの臨床予測タスクについて ChatHealthAI を評価しました。結果は、ChatHealthAI が競争力のある予測パフォーマンスを維持しながら、推論の品質と解釈可能性を向上させることを示しています。これらの発見は、解釈可能な臨床予測のために、EHR 基礎モデルと事前トレーニングされた LLM を統合する可能性を強調しています。
原文 (English)
ChatHealthAI: Aligning Electronic Health Record Representations with Large Language Models for Grounded Clinical Reasoning
Large language models (LLMs) exhibit strong natural-language reasoning abilities for clinical decision support, but struggle to effectively model structured longitudinal electronic health records (EHRs). In contrast, EHR foundation models can learn predictive patient representations, yet lack interpretable language-based reasoning. To bridge this gap, we propose ChatHealthAI, a multimodal reasoning framework that aligns structured EHR representations from a pretrained EHR foundation model with the semantic space of a frozen LLM through a task-aware resampler. By integrating longitudinal patient representations with refined clinical event descriptions, ChatHealthAI enables clinically grounded natural-language reasoning while maintaining accurate patient prediction. We evaluated ChatHealthAI on three clinical predictive tasks from the EHRSHOT benchmark. Results show that ChatHealthAI improves reasoning quality and interpretability while preserving competitive predictive performance. These findings highlight the potential of integrating EHR foundation models with pretrained LLMs for interpretable clinical prediction.
Traj-Evolve: 肺がんの早期発見における患者の軌跡モデリングのための自己進化型マルチエージェント システム
縦断的な電子医療記録 (EHR) から患者の軌跡をモデル化するには、まばらでノイズが多く、コンテキストの長いマルチモーダル シーケンスを推論する必要があります。既存の LLM ベースのマルチエージェント システムはコンテキストの長さに対処しますが、患者を個別に処理するため、臨床医が同様の過去の症例から蓄積された経験をどのように活用するかを反映できていません。我々は、2 つの相補的な進化メカニズムを備えた自己進化マルチエージェント システムである Traj-Evolve を紹介します。まず、エクスペリエンス プール (ExPool) はノンパラメトリック メモリとして機能し、拒絶反応でサンプリングされた推論トレースにインデックスを付けて、同様の患者を少数ショットのコンテキストとして取得します。 2 番目に、報酬ランク付き微調整によるマルチエージェント強化学習 (MARL) により、エージェント間およびエージェントとメモリのコラボレーションがパラメトリックに最適化されます。リーブワンアウトのクロス検索戦略は、この 2 つを統合し、検索拡張の下でトレーニング時間と推論時の動作を調整します。最長 5 年間のマルチモーダル EHR を利用した肺がん予測タスクにおいて、Traj-Evolve は、人口全体と困難な非喫煙者人口に対する 9 つの強力なベースラインを上回りました。進化するダイナミクスの分析により、次の 3 つの重要な発見が明らかになります。(1) ExPool の拡張により、最適な取得が多様なサンプルから特定のサンプルに移行します。 (2) MARL の下では、マネージャー エージェントの予測損失は迅速に収束しますが、ワーカー エージェントの時間的推論はより検証された患者から恩恵を受け続けます。 (3) 2 つのメカニズムは予測リスクに関して補完的であり、ExPool は特異性を向上させ、MARL は感度を向上させます。
原文 (English)
Traj-Evolve: A Self-Evolving Multi-Agent System for Patient Trajectory Modeling in Lung Cancer Early Detection
Modeling patient trajectories from longitudinal electronic health records (EHRs) requires reasoning over sparse, noisy, and long-context multimodal sequences. Existing LLM-based multi-agent systems address context length but process patients in isolation, failing to mirror how clinicians leverage accumulated experience from similar prior cases. We present Traj-Evolve, a self-evolving multi-agent system with two complementary evolving mechanisms. First, an Experience Pool (ExPool) acts as a non-parametric memory, indexing rejection-sampled reasoning traces to retrieve similar patients as few-shot contexts. Second, multi-agent reinforcement learning (MARL) via reward-ranked fine-tuning parametrically optimizes inter-agent and agent-memory collaboration. A leave-one-out cross-retrieval strategy unifies the two, aligning training- and inference-time behavior under retrieval augmentation. On a lung cancer prediction task utilizing up to five years of multimodal EHRs, Traj-Evolve outperforms 9 strong baselines on the overall population and a challenging never-smoker population. Analysis of the evolving dynamics highlights three key findings: (1) expanding the ExPool shifts optimal retrieval from diverse to specific samples; (2) under MARL, the manager agent's prediction loss converges quickly while the worker agents' temporal reasoning continues to benefit from more verified patients; and (3) the two mechanisms are complementary on the predicted risk, where ExPool improves specificity while MARL improves sensitivity.
衝突ベースの敵形態生成の探求
プロシージャル コンテンツ生成 (PCG) に関する先行研究は数多くあるにもかかわらず、ビデオ ゲームの敵の生成について検討した先行研究は比較的少ないです。特に、ロボット工学における関連する形態生成作業が存在するにもかかわらず、敵の形態、基本的なボディプラン、またはゲーム内の敵の衝突情報を生成する作業はほとんどありません。この論文では、プレイヤーの衝突情報に基づいて敵の形態を生成するための 3 つの異なる新しいアプローチを検討します。各アプローチには異なる長所と短所がありますが、いずれも、以前のロボット形態学研究から適応された進化ベースラインと同等またはそれ以上のパフォーマンスがあることがわかりました。
原文 (English)
An Exploration of Collision-based Enemy Morphology Generation
Despite a great deal of prior research into Procedural Content Generation (PCG), relatively little prior work has explored generating enemies for video games. In particular, there is almost no work on generating enemy morphologies, the basic body plan or collision information for in-game enemies, despite the existence of related morphology generation work in robotics. In this paper, we explore three different novel approaches to generate enemy morphologies based on player collision information. We found that each approach provides different strengths and weaknesses, but all had equivalent or better performance than an evolutionary baseline adapted from prior robotics morphology work.
答えを超えた思考: 大規模な推論モデルにおける有害な過剰思考の評価
大規模推論モデル (LRM) は、テスト時間の計算量を増やして明示的な中間推論トレースを生成することでパフォーマンスを向上させますが、より長い推論が一貫して有益であるという前提は依然として十分に検討されていません。最近の証拠は、追加の推論がモデルの考えすぎにつながる可能性があることを示していますが、「モデルが正しい答えに到達した後、さらなる推論は解決策を改良するのか、それとも解から逸脱するのか?」と考えます。正解後のダイナミクスを研究するために、推論の十分性に基づいたプレフィックスレベルの軌道評価プロトコルを導入し、モデルが最初に正解を生成するために必要な最小推論バジェットを定義します。これにより、追加の推論は冗長だが無害である冗長な考えすぎと、推論を続けるとすでに正しい軌道が不安定になる有害な考えすぎを区別することができます。マルチモーダル ベンチマークから始めると、推論が集中していると考えられる多くのインスタンスでは、驚くほど推論が必要ないことがわかります。さらに、最初の正しい接頭辞で停止すると、標準推論よりも精度が最大 21% 向上します。これにより、現在のモデルは推論能力によって制限されるだけでなく、適切なタイミングで停止できないことによっても制限されることが明らかになりました。さらに、早期停止などの一般的な効率化戦略は、冗長な考えすぎを大幅に (最大 50%) 軽減しますが、有害な考えすぎを軽減することはできません。障害分析により、正確性の逸脱は主に論理的なずれと視覚的な再解釈によって引き起こされることが明らかになりました。最後に、私たちの調査結果が言語のみの推論ベンチマークに一般化されていることを示し、より広範な信頼性リスクとして有害な過剰思考を強調しています。コードは https://simonecaldarella.github.io/ Thinking-past-the-answer で入手できます。
原文 (English)
Thinking Past the Answer: Evaluating Harmful Overthinking in Large Reasoning Models
Large Reasoning Models (LRMs) improve performance by generating explicit intermediate reasoning traces through increased test-time compute, yet the assumption that longer reasoning is consistently beneficial remains under-examined. While recent evidence shows that additional reasoning can lead models to overthink, we ask: "Once a model has reached the correct answer, does further reasoning refine the solution, or deviate from it?" To study the dynamics after correctness, we introduce a prefix-level trajectory evaluation protocol grounded in reasoning sufficiency, defining the minimum reasoning budget required for a model to first generate the correct answer. This allows us to disentangle verbose overthinking, where additional reasoning is redundant but harmless, from harmful overthinking, where continued reasoning destabilizes an already-correct trajectory. Starting from multimodal benchmarks, we find that many instances considered reasoning-intensive require surprisingly little reasoning. Moreover, stopping at the first correct prefix improves accuracy over standard reasoning up to 21%, revealing that current models are limited not only by their ability to reason, but also by their inability to stop at the right time. Furthermore, while common efficiency strategies like early stopping substantially reduce verbose overthinking (up to 50%), they fail to mitigate harmful overthinking. Failure analysis reveals that correctness deviations are mainly driven by logical drift and visual reinterpretation. Finally, we show that our findings generalize to language-only reasoning benchmarks, highlighting harmful overthinking as a broader reliability risk. Code available at https://simonecaldarella.github.io/thinking-past-the-answer.
エッジの組み込み AI エージェント システムのモジュラー アーキテクチャに向けて
大規模言語モデル (LLM) の台頭により、複雑な推論とツールの使用が可能なエージェント AI が可能になりました。ただし、組み込みマイクロコントローラーのメモリとエネルギーの厳しい制約により、このような自律性をパーベイシブ コンピューティング環境に展開することは依然として困難です。既存のフレームワークは通常、サーバークラスのリソースまたは継続的な接続を前提としており、深く組み込まれたシステムのためのギャップが残されています。この論文では、決定論的なリアルタイム制御とエージェント インテリジェンスの間の溝を埋める組み込みエージェント システム用のモジュール式リファレンス アーキテクチャを提案します。低遅延でプライバシーが重要なタスクのために高圧縮ニューラル ネットワークとルールベースのロジックを実行するオンデバイス エージェントを、より高レベルの推論と計画のために小型言語モデル (SLM) を利用するクラウド拡張エージェントから分離する階層型設計を導入します。主な貢献は、横断的なガバナンス層の統合であり、分散された自律デバイス群全体で可観測性、ポリシーの適用、安全性を確保します。純粋に経験的なベンチマークを提示するのではなく、リソースに制約のある環境でのレイテンシー、エネルギー、信頼性の高い実行に関するアーキテクチャ設計原則とトレードオフを分析します。
原文 (English)
Toward a Modular Architecture for Embedded AI Agent Systems at the Edge
The rise of Large Language Models (LLMs) has enabled agentic AI capable of complex reasoning and tool use; however, deploying such autonomy in pervasive computing environments remains challenging due to the strict memory and energy constraints of embedded microcontrollers. Existing frameworks typically assume server-class resources or continuous connectivity, leaving a gap for deeply embedded systems. This paper proposes a modular reference architecture for Embedded Agent Systems that bridges the divide between deterministic real-time control and agentic intelligence. We introduce a tiered design that decouples On-Device Agents - executing highly compressed neural networks and rule-based logic for low-latency, privacy-critical tasks - from Cloud-Augmented Agents that leverage Small Language Models (SLMs) for higher-level reasoning and planning. A key contribution is the integration of a cross-cutting Governance Layer, ensuring observability, policy enforcement, and safety across distributed fleets of autonomous devices. Rather than presenting purely empirical benchmarks, we analyze architectural design principles and trade-offs regarding latency, energy, and reliable execution in resource-constrained environments.
ギャンブルはしないでください、GAMBLe: AI 主導の研究システムのための分析フレームワーク
AI-Driven Research Systems (ADRS) -- LLM と自動評価を組み合わせてアルゴリズム、証明、設計を発見するシステム -- は最適化され、ドメイン全体で採用されていますが、それらを分析するツールは追いついていません。 ADRS のパフォーマンスはコンポーネントの相互作用に依存しますが、これらの相互作用は十分に理解されておらず、調査にコストがかかり、(ここで示しているように) 標準の収束保証では十分に把握されていません。これらの保証は、私たちが形式化した ADRS プロセスの下では成立しない構造的な仮定に依存しています。我々は、ADRS の動作を 4 つのパラメーター (ジェネレーター $G$、アセッサー $\mathcal{A}$、発見メカニズム $\mathcal{M}$、バジェット $B$) と 1 つの構成オブジェクト、効果的なランドスケープ $L_{\text{eff}} = \mathcal{A} \circ G$ に分解するフレームワークである GAMBLe を紹介します。これにより、異なるジェネレーターとアセッサーのペアが構造的に異なる問題ごとの最適化を引き起こすことが明らかになります。風景。私たちは、単一の LLM から動的適応アンサンブルに至るジェネレーター、貪欲な選択から共進化メタサーチに至るメカニズム、および評価者が連続スコアリングからクリフ関数に及ぶ 3 つの NP 困難問題に及ぶ 760 以上の反復実行 (>46,000 反復) でフレームワークを実行します。実験では、ジェネレーターやメカニズムの完全な順序付けは明らかにされていません。フロンティア モデルはオープンソースの代替モデルよりもパフォーマンスが劣る可能性があり、最も単純なメカニズムが最先端のメタ検索を上回る場合もあります。結果は、限られた予算 (実行ごとに 60 回の反復) の下でも、適切なコンポーネントを選択することでパフォーマンスを 13 ~ 67%、検索効率を 6 ~ 39 倍改善できることを示しています。
原文 (English)
Don't Gamble, GAMBLe: An Analytical Framework for AI-Driven Research Systems
AI-Driven Research Systems (ADRS) -- systems coupling LLMs with automated evaluation to discover algorithms, proofs, and designs -- are being optimized and adopted across domains, but the tools to analyze them have not kept pace. ADRS performance depends on component interactions that are poorly understood, expensive to explore, and (as we show) not well captured by standard convergence guarantees. These guarantees rely on structural assumptions that do not hold under the ADRS process we formalize. We introduce GAMBLe, a framework that decomposes ADRS behavior into four parameters (generator $G$, assessor $\mathcal{A}$, discovery mechanism $\mathcal{M}$, budget $B$) and one compositional object, the effective landscape $L_{\text{eff}} = \mathcal{A} \circ G$, which reveals that distinct generator-assessor pairs induce structurally different per-problem optimization landscapes. We exercise the framework on 760+ replicated runs (>46,000 iterations) spanning generators from single LLMs to dynamically-adaptive ensembles, mechanisms from greedy selection to co-evolutionary meta-search, and three NP-hard problems whose assessors range from continuous scoring to cliff functions. The experiments reveal no total ordering of generators or mechanisms: frontier models can underperform open-source alternatives and the simplest mechanism sometimes outperforms state-of-the-art meta-search. Results show that even under limited budgets (60 iterations per run), the right component choices can improve performance by 13-67% and search efficiency by 6-39x.
問題を解決する場合とその修正方法: データ クリーニングに関するマルチエージェントの議論
マルチエージェントの議論がデータのクリーニングに役立つのはどのような場合でしょうか?また、害を及ぼすのはどのような場合ですか? 3 つのベンチマーク、4 つのモデル ファミリ、および 6,000 を超えるタスクと条件のペアにわたって、ディベートの効果が符号を反転していることがわかりました。それは、ジェネレーターが無批判に受け入れる批評誘導性混乱 (CIC)、幻覚的な批評家フィードバックによって、4 つのモデルすべてで生成を低下させます (-1.6 ~ -15.5pp) が、エラー検出は向上します (+27.4pp F1、d=1.0)。私たちは議論の利益条件を導出します。つまり、間違った出力を救出する確率 (修正可能性によって重み付けされた批評家検証の確率) が正しい出力を破壊する確率を超える場合、議論は役立ちます。要因実験は、敵対的分離が不可欠であることを証明します。同一のツールを使用した自己検証は失敗しますが、コード実行の根拠と証拠ゲート型生成を備えた別個の批評家は、生成タスクにおいて単一エージェントを大幅に超える最初のディベート構成を生み出します (+5.3pp、p<0.05)。この条件は、9 つのタスク タイプすべてを正確に予測し、7 つのドメインで公開された 19 の比較全体で誤検知がゼロになるように一般化します。
原文 (English)
When Helping Hurts and How to Fix It: Multi-Agent Debate for Data Cleaning
When does multi-agent debate help data cleaning, and when does it hurt? Across three benchmarks, four model families, and over 6,000 task-condition pairs, we find debate's effect reverses sign: it degrades generation across all four models (-1.6 to -15.5pp) through critique-induced confusion (CIC), hallucinated Critic feedback that the Generator accepts uncritically, yet improves error detection (+27.4pp F1, d=1.0). We derive a debate benefit condition: debate helps when the probability of rescuing a wrong output (Critic verification odds weighted by fixability) exceeds the probability of destroying a correct one. A factorial experiment proves adversarial separation is essential: self-verification with identical tools fails, while a separate Critic with code-execution grounding and evidence-gated generation produces the first debate configuration to significantly exceed single-agent on a generative task (+5.3pp, p<0.05). The condition correctly predicts all nine task types and generalizes with zero false positives across 19 published comparisons in seven domains.
引き継ぎ負債: コーディング エージェントが中断されたタスクを引き継ぐ場合の再検出コスト
コーディング エージェント ベンチマークは、単一の中断のないエージェントがリポジトリの問題を解決できるかどうかを評価します。実際のソフトウェア作業はさらに面倒です。タスクは中断され、再割り当てされ、確認され、別のエージェントまたはエンジニアが残した部分的な状態から再開されます。私たちは、\emph{引き継ぎ負債}、つまり前任者の仕事が不透明または不完全な場合に課せられる再発見コストを通じて、この欠落している側面を研究します。私たちの引き継ぎプロトコルは、決定的なハンドオフ ポイントでコーディング エージェントを中断し、リポジトリをフリーズし、リポジトリの状態のみ、生のトレース、要約メモ、構造化メモの 4 つのハンドオフ ビューで後続エージェントを評価します。このプロトコルは、75 のソース タスクにわたって、後継モデルごとに 181 のハンドオフ ポイント タスクと 724 のテイクオーバー実行を生成します。 3 つの後継モデル全体で、コンテキストを伴うハンドオフは、リポジトリのみのテイクオーバーと比較して、エージェント イベントの中央値が 20 ~ 59\% 減少し、累積プロンプト トークンが 42 ~ 63\% 減少します。解決率の影響は小さく、モデルに依存しますが、効率の向上は一貫しています。これらの発見は、コーディング エージェントの評価では、タスクが解決されたかどうかだけでなく、別のエージェントがその作業を再開するのにどれだけのコストがかかるかを報告する必要があることを示唆しています。
原文 (English)
Handoff Debt: The Rediscovery Cost When Coding Agents Take Over Interrupted Tasks
Coding-agent benchmarks evaluate whether a single uninterrupted agent can resolve a repository issue. Real software work is messier: tasks are interrupted, reassigned, reviewed, and resumed from partial states left by another agent or engineer. We study this missing dimension through \emph{handoff debt}: the rediscovery cost imposed when a predecessor's work is opaque or incomplete. Our takeover protocol interrupts a coding agent at deterministic handoff points, freezes the repository, and evaluates successor agents under four handoff views: repository state only, raw trace, summary notes, and structured notes. Across 75 source tasks, the protocol generates 181 handoff-point tasks and 724 takeover runs per successor model. Across three successor models, context-bearing handoffs reduce median agent events by 20--59\% and cumulative prompt tokens by 42--63\% relative to repository-only takeover. Solved-rate effects are smaller and model-dependent, but efficiency gains are consistent. These findings suggest that coding-agent evaluation should report not only whether a task is solved, but also how costly that work is for another agent to resume.
歯科医療における大規模 AI モデル: 汎用システムからドメイン固有の基盤モデルまで
背景: 口腔疾患は世界中で約 35 億人に影響を与えていますが、歯科における大規模 AI モデルの相対的な臨床的可能性は依然として十分に理解されていません。言語生成モデル、弁別視覚基礎モデル、歯科特有の基礎モデルという 3 つの異なるモデル カテゴリが出現しましたが、それらの関係や集合的な制限を検討する統一されたレビューはありません。方法: PRISMA-ScR ガイドラインに従って、4 つのデータベース (PubMed、Google Scholar、Scopus、arXiv) を体系的に検索し、2 人の査読者によって独立してスクリーニングされました。包含/除外基準を適用した後、97 件の研究 (2020 ~ 2026 年) が含まれました。建築パラダイムと歯科専門度によってモデルを整理する二次元分類フレームワークを提案します。結果: 言語生成モデルは、テキストベースのタスク (臨床推論、免許試験、患者とのコミュニケーション) には優れていますが、画像依存の診断では一貫性のないパフォーマンスを示します。適応された SAM および CLIP バリアントにより、強力な歯のセグメンテーションと病変検出結果が得られます。歯科専用モデル (DentVFM、DentVLM、OralGPT) は、複雑なマルチモーダルなタスクで最高のパフォーマンスを発揮します。統合されたパイプラインは、単一モデルのアプローチよりも常に優れたパフォーマンスを発揮します。データの非対称性が観察されます。歯科特有の事前トレーニングはほぼ完全に視覚領域に集中しており、大規模な歯科テキスト コーパスがほとんどないことを反映しています。結論: 汎用モデルと歯科専用モデルは補完的な役割を果たします。最も効果的なシステムは、構造化されたパイプライン内で両方を組み合わせたものです。安全な自律展開には、生成モデルにおける幻覚、注釈付き歯科データセットの制限、標準化された臨床評価ベンチマークの欠如という 3 つの永続的な障壁を解決する必要があります。
原文 (English)
Large AI Models in Dental Healthcare: From General-Purpose Systems to Domain-Specific Foundation Models
Background: Oral diseases affect nearly 3.5 billion people worldwide, yet the comparative clinical potential of large-scale AI models in dentistry remains poorly understood. Three distinct model categories have emerged: language-generative models, discriminative vision foundation models, and dental-specific foundation models, with no unified review examining their relationships and collective limitations. Methods: Following PRISMA-ScR guidelines, we systematically searched four databases (PubMed, Google Scholar, Scopus, arXiv), screened independently by two reviewers. After applying inclusion/exclusion criteria, 97 studies (2020-2026) were included. We propose a two-dimensional classification framework organizing models by architectural paradigm and dental specialization degree. Results: Language-generative models excel at text-based tasks (clinical reasoning, licensing exams, patient communication) but show inconsistent performance on image-dependent diagnostics. Adapted SAM and CLIP variants achieve strong tooth segmentation and lesion detection results. Dental-specific models (DentVFM, DentVLM, OralGPT) demonstrate strongest performance on complex multimodal tasks. Integrated pipelines consistently outperform single-model approaches. A data asymmetry is observed: dental-specific pretraining concentrates almost entirely in the vision domain, reflecting scarce large-scale dental text corpora. Conclusions: General-purpose and dental-specific models play complementary roles; the most effective systems combine both within structured pipelines. Safe autonomous deployment requires resolving three persistent barriers: hallucination in generative models, limited annotated dental datasets, and absent standardized clinical evaluation benchmarks.
ベンチマークでは測れないもの: 自律エージェントの棄権能力を評価する事例
自律エージェントのベンチマークは、エージェントがタスクを完了したかどうかを測定しますが、この枠組みでは、エージェントがそもそも続行すべきかどうかについてはシステム的に盲点です。ヒューマンフィードバックの目標に基づいて訓練されたエージェントは、安全に行動するための入力、証拠、または許可が不足している場合でも続行する構造的な傾向、つまりコンプライアンスバイアスと呼ばれる性質を身につけます。これは、報酬シグナルとベンチマークスコア体系の両方が、安全な行動の前提条件が存在するかどうかに関係なく、続行を正しいデフォルトとして扱うためです。私たちは 3 つの貢献を行っています。まず、コンプライアンス バイアスは人間によるフィードバック パイプライン内の報酬ハッキングに由来し、エージェントの一時停止に対してペナルティを課すか、原理的な一時停止とサイレント エラーを構造的に区別できない、著名なエージェント ベンチマークによって固定化されていることを示します。次に、棄権が保証されるシナリオの 3 つのギャップ分類法を導入します。これは、必要な情報が欠落している仕様のギャップ、世界の状態を確認できない検証のギャップ、および明示的な権限が与えられていない権限のギャップをカバーしており、これらが一緒になって棄権を認識するエージェントのベンチマークを構築するための原則的な基礎を提供します。最後に、棄権評価プロトコル (安全率、ユーザビリティ率、通知による拒否率) を提案し、144 のエンタープライズ エージェント シナリオと 5 つのモデル ファミリにわたる暫定結果を報告します。この中で、ランタイム強制棄権メカニズムは、許可されたシナリオで最大 89.2% の危険行為のブロックと 87.5% のユーザビリティを達成し、安全性とユーザビリティのトレードオフは固有のものではなく調整可能であり、その形状がモデル ファミリ間で大幅に異なることを示しています。私たちはこれを予備作業として扱い、その後の会話の出発点として分類法と複合指標を提供します。
原文 (English)
What Benchmarks Don't Measure: The Case for Evaluating Abstention Competence in Autonomous Agents
Benchmarks for autonomous agents measure whether agents complete tasks, yet this framing is systematically blind to whether an agent should have proceeded at all. Agents trained under human-feedback objectives develop a structural tendency to proceed even when they lack the inputs, evidence, or authorization to act safely, a disposition we term compliance bias, because both the reward signal and the benchmark scoring regime treat proceeding as the correct default regardless of whether the preconditions for safe action are present. We make three contributions. We first show that compliance bias originates in reward hacking within human-feedback pipelines and is entrenched by prominent agent benchmarks, which either penalize agents for pausing or are architecturally unable to distinguish a principled pause from a silent failure. We then introduce a three-gap taxonomy of abstention-warranted scenarios, covering specification gaps where required information is absent, verification gaps where world state cannot be confirmed, and authority gaps where explicit authorization has not been given, which together provide a principled basis for constructing abstention-aware agent benchmarks. Finally, we propose abstention evaluation protocols (Safety Rate, Usability Rate, and Informed Refusal Rate) and report preliminary results across 144 enterprise agent scenarios and five model families, in which a runtime-enforced abstention mechanism achieves up to 89.2% hazardous-action blocking and 87.5% usability on authorized scenarios, demonstrating that the safety--usability tradeoff is tunable rather than inherent and that its shape varies substantially across model families. We treat this as preliminary work and offer the taxonomy and composite metrics as a starting point for further conversations.
WISE-HAR: WiFi ベースの人間活動認識のための一般化可能なアンサンブル深層学習フレームワーク
WiFi 信号を使用した人間活動認識 (HAR) は、スマート ホーム、医療監視、セキュリティ システム、周囲支援生活のための革新的なテクノロジーとして登場しました。重大なプライバシー上の懸念を引き起こし、低照度条件で機能しない従来のカメラベースのシステムや、ユーザーのコンプライアンスを必要とするウェアラブル センサーとは異なり、WiFi ベースの HAR は非侵入的でプライバシーが保護され、コスト効率が高く、あらゆる照明条件でもシームレスに動作します。この論文では、Wallhack1.8k WiFi スペクトログラム データセットを使用して、「不在」(空の部屋)、「歩行」、「歩行 + 腕を振る」という 3 つの異なる人間の活動を認識するための包括的なアプローチを紹介します。 WiFi ベースの HAR の主な課題に対処するために、3 つの重要な改善点を提案します。まず、高パフォーマンスの分散に対処するために、5 つの異なる CNN アーキテクチャ (Deep CNN、 Wide CNN、MobileNetV2、ResNet50V2、および EfficientNetB0) を使用したアンサンブル学習を実装します。次に、小さいデータセット サイズの制限に対処するために、タイム ワーピング、周波数マスキング、ノイズの追加などの積極的なデータ拡張手法を適用します。 3 番目に、現実世界の汎化能力を評価するために、クロスシナリオ評価 (見通し内でのトレーニングと見通し外でのテスト) およびクロスアンテナ評価 (Biquad アンテナでのトレーニングと PIFA アンテナでのテスト) を実行します。当社のアンサンブル モデルは、Biquad アンテナを使用した LOS シナリオで 94.87% のテスト精度を達成し、最高の個別モデルを 0.66% 上回りました。データ拡張により、ランダム フォレストのパフォーマンスが 60% から 95% に向上しました。クロスシナリオ評価では、わずか 1.37% と 2.07% の最小限の精度低下が示され、強力な一般化機能が実証されました。結果は、提案されたアプローチが堅牢で信頼性が高く、異なるハードウェア構成を持つ多様な環境での実際の展開に適していることを示しています。
原文 (English)
WISE-HAR: A Generalizable Ensemble Deep Learning Framework for WiFi-Based Human Activity Recognition
Human Activity Recognition (HAR) using WiFi signals has emerged as a transformative technology for smart homes, healthcare monitoring, security systems, and ambient assisted living. Unlike traditional camera-based systems that raise significant privacy concerns and fail in low-light conditions, or wearable sensors that require user compliance, WiFi-based HAR is non-intrusive, privacy-preserving, cost-effective, and works seamlessly in any lighting condition. This paper presents a comprehensive approach to recognize three distinct human activities: "No Presence" (empty room), "Walking", and "Walking + Arm-waving" using the Wallhack1.8k WiFi spectrogram dataset. We propose three key improvements to address the main challenges in WiFi-based HAR. First, to address high performance variance, we implement ensemble learning with five different CNN architectures (Deep CNN, Wide CNN, MobileNetV2, ResNet50V2, and EfficientNetB0). Second, to address the small dataset size limitation, we apply aggressive data augmentation techniques including time-warping, frequency masking, and noise addition. Third, to evaluate real-world generalization capability, we perform cross-scenario evaluation (training on Line-of-Sight and testing on Non-Line-of-Sight) and cross-antenna evaluation (training on Biquad antenna and testing on PIFA antenna). Our ensemble model achieved a test accuracy of 94.87% on the LOS scenario with Biquad antenna, outperforming the best individual model by 0.66%. Data augmentation improved Random Forest performance from 60% to 95%. Cross-scenario evaluation showed minimal accuracy drops of only 1.37% and 2.07%, demonstrating strong generalization capabilities. The results indicate that the proposed approach is robust, reliable, and suitable for real-world deployment in diverse environments with different hardware configurations.
エージェントの痕跡から推論プリミティブを誘導する
ReAct スタイルの LLM エージェントは、多くの問題にわたって同じ推論ルーチンを再発見しますが、それらのルーチンは一時的なスクラッチパッドに閉じ込められたままになります。成功した ReAct トレースをマイニングし、反復する推論の動きをクラスター化し、最も頻繁に発生する動きを型指定された疑似ツールのコンパクトなライブラリに変換するシングルパス手法である Reasoning Primitive Induction を紹介します。各疑似ツールは、呼び出し時に LLM によって解釈される自然言語の docstring によって指定され、標準の ReAct ループによってテスト時にこれらのプリミティブが構成されます。中心的な結果は、誘導されたライブラリがそのトレースを生成したまさにエージェントよりも優れていることです。RuleArena NBA で +44pp (30 -> 74)、MuSR チーム割り当てで +30pp (38 -> 68)、NatPlan 会議計画で +22pp (7 -> 29) でした。物語演繹、ルール適用、制約充足計画にわたる 5 つの比較可能なサブタスクにわたって、単一の固定構成により、すべてのサブタスクでゼロショットの思考連鎖よりも改善され、専門家が作成した分解と同等またはそれを上回り、より低い平均推論コストで AWM よりも優れたパフォーマンスを発揮します。
原文 (English)
Inducing Reasoning Primitives from Agent Traces
ReAct-style LLM agents often rediscover the same reasoning routines across problems, yet leave those routines trapped in transient scratchpads. We introduce Reasoning Primitive Induction, a single-pass method that mines successful ReAct traces, clusters recurrent reasoning moves, and converts the most frequent moves into a compact library of typed pseudo-tools. Each pseudo-tool is specified by a natural-language docstring interpreted by an LLM at invocation time, and a standard ReAct loop composes these primitives at test time. The central result is that induced libraries outperform the very agent that generated their traces: by +44pp on RuleArena NBA (30 -> 74), +30pp on MuSR team allocation (38 -> 68), and +22pp on NatPlan meeting planning (7 -> 29). Across five comparable subtasks spanning narrative deduction, rule application, and constraint-satisfaction planning, a single fixed configuration improves over zero-shot Chain-of-Thought on every subtask, matches or surpasses expert-authored decompositions, and outperforms AWM at lower average inference cost.
AUDITFLOW: 構造化財務報告検証のための実行可能なシンボリック環境
正確性はテキストだけではなく構造化された証拠に依存するため、言語モデルエージェントにとって構造化された財務監査の検証は困難です。モデルは、監査ルールを適用する前に、報告された事実を分類概念にリンクし、計算または次元関係を調べ、期待値を再計算する必要があります。私たちは、適応的な検索を決定論的な検証から分離する、グラフに基づいたマルチエージェント フレームワークである AuditFlow を提案します。 AuditFlow は、静的な US-GAAP タクソノミー グラフと動的な XBRL ファイリング グラフからシンボリック環境を構築し、ファクト検索、タクソノミー トラバーサル、数値チェック、およびルール評価のための型付きツールを通じてそれを公開します。 2 人のジュニア監査人が規制と証拠の観点から各ケースを検査し、上級監査人が意見の相違を解決し、さらなる調査を要求することができます。最終レポートは証拠の集約を通じて統合され、監査評決、期待値、証拠痕跡、および信頼性スコアが生成されます。 FinAuditing 由来の FinMR サンプルでは、AuditFlow は GPT-5.5 に基づく共同監査精度 82.09% に達し、最も強力なベースラインを 14.93 ポイント上回りました。決定論的チェックを削除すると精度が 17.91% に低下し、モデルでは確実に置き換えることができない検証ステップがシンボリック環境によって実行されることがわかります。
原文 (English)
AUDITFLOW: Executable Symbolic Environments for Structured Financial Reporting Verification
Structured financial audit verification is difficult for language-model agents because correctness depends on structured evidence rather than text alone. A model must link reported facts to taxonomy concepts, traverse calculation or dimensional relations, and recompute expected values before applying an audit rule. We propose AuditFlow, a graph-grounded multi-agent framework that separates adaptive search from deterministic verification. AuditFlow builds a symbolic environment from a static US-GAAP taxonomy graph and a dynamic XBRL filing graph, and exposes it through typed tools for fact retrieval, taxonomy traversal, numerical checking, and rule evaluation. Two junior auditors inspect each case from regulatory and evidentiary views, while a senior auditor resolves disagreements and can request further investigation. The final reports are fused through evidential aggregation to produce an audit verdict, expected value, evidence trail, and trustworthiness score. On a FinAuditing-derived FinMR sample, AuditFlow reaches 82.09% joint audit accuracy under GPT-5.5, outperforming the strongest baseline by 14.93 points. Removing deterministic checks drops accuracy to 17.91%, showing that the symbolic environment performs the verification step that the model cannot reliably replace.
TriEval: LLM バイアス、毒性、真実性評価のためのリソース効率の高いパイプライン
LLM は、基本的なチャットボットから AI エコシステムのバックボーンに進化し、現在では医療、学校、政府サービスで広く使用されています。 LLM をドメイン全体に導入するには、その安全性と公平性を確保するために継続的な評価が必要です。 LLM の導入後に発生する一般的な問題には、一貫性のない出力や誤った情報の幻覚などがあります。 LLM 評価ツールは多数存在しますが、そのほとんどは一度に 1 つのパラメータのテストに限定されているか、ほとんどの研究者がアクセスできない膨大な計算リソースを必要とします。 TriEval は、コンピューティング リソースを最小限に抑えながら、バイアス、有害性、真実性を含む複数のパラメータにわたって LLM 出力を評価することで、これらの課題に対処します。このパイプラインは、オープンソース モデルとクローズドソース モデルの両方と互換性があり、GPU クラスターのない標準的なラップトップで実行されます。 TriEval は、Llama 3 8B、Mistral 7B、Gemma 2 9B、および Claude Haiku の 4 つのモデルでテストされています。結果は、特に毒性と真実性の点で、オープンソース モデルとクローズドソース モデルの明らかな違いを示しています。 TriEval は、限られた計算リソースを持つ研究者がより広範にアクセスできるようにするために、オープンソースとしてリリースされています。
原文 (English)
TriEval: A Resource-Efficient Pipeline for LLM Bias, Toxicity, and Truthfulness Assessment
LLMs have evolved from basic chatbots to the backbone of the AI ecosystem, now widely used in healthcare, schools, and government services. The domain-wide adoption of LLMs necessitates continuous evaluation to ensure their safety and fairness. Common issues encountered after deploying LLMs include inconsistent outputs and hallucinations of incorrect information. Although numerous LLM evaluation tools exist, most are limited to testing a single parameter at a time or require massive computational resources that are not accessible to most researchers. TriEval addresses these challenges by evaluating LLM outputs across multiple parameters, including bias, toxicity, and truthfulness together, while minimizing computing resources. The pipeline is compatible with both open- and closed-source models and runs on a standard laptop without a GPU cluster. TriEval has been tested on four models: Llama 3 8B, Mistral 7B, Gemma 2 9B, and Claude Haiku. The results show clear differences between open-source and closed-source models, especially in terms of toxicity and truthfulness. TriEval is being released as open source to enable broader access for researchers with limited computational resources.
RelGT-AC: リレーショナル データベースのオートコンプリート タスク用のリレーショナル グラフ トランスフォーマー
リレーショナル データベースは、現代の企業システム、科学システム、医療システムを支えていますが、そのようなデータに対する予測機械学習は、データベースが複数のテーブル、異種混合、および時間構造であるため、依然として困難です。リレーショナル ディープ ラーニング (RDL) は、データベースを異種グラフとして表現し、グラフ ニューラル ネットワーク (GNN) を直接適用することで、この問題に対処します。 RelBench v2 は最近、オートコンプリート タスクを導入しました。これは、インテリジェントなフォーム入力アシスタントに似た、リレーショナル コンテキストから既存の列の値を予測することを目的とした実用的なタスク タイプです。我々は、RelGT-AC (Relational Graph Transformer for Autocomplete) を提案し、次の 3 つのターゲットを絞った貢献によって RelGT アーキテクチャを拡張します。 (2) 単一モデル内でバイナリ分類、マルチクラス分類、および回帰オートコンプリート タスクをサポートする統合タスク ヘッド。 (3) TF-IDF テキスト エンコーダは、フリーテキスト列を自動的に検出してエンコードし、カテゴリカル エンコーダが廃棄する強力な語彙信号を復元します。 3 つの RelBench v2 データセット (rel-trial、rel-f1、rel-stack) にわたる 7 つのタスクにわたって、RelGT-AC は 3 つの回帰オートコンプリート タスクすべてで GraphSAGE ベースラインを上回り、テキストの多い適格性タスクで TF-IDF エンコーダーを介して最大 +10 AUROC ポイントを達成しました。
原文 (English)
RelGT-AC: A Relational Graph Transformer for Autocomplete Tasks in Relational Databases
Relational databases underpin modern enterprise, scientific, and healthcare systems, yet predictive machine learning on such data remains challenging due to their multi-table, heterogeneous, and temporal structure. Relational Deep Learning (RDL) addresses this by representing databases as heterogeneous graphs and applying graph neural networks (GNNs) directly. RelBench v2 recently introduced autocomplete tasks -- a practically motivated task type where the goal is to predict an existing column value from relational context, analogous to an intelligent form-filling assistant. We propose RelGT-AC (Relational Graph Transformer for Autocomplete), extending the RelGT architecture with three targeted contributions: (1) a column masking strategy that prevents trivial solutions by masking the target column during subgraph encoding; (2) a unified task head supporting binary classification, multiclass classification, and regression autocomplete tasks within a single model; and (3) a TF-IDF text encoder that automatically detects and encodes free-text columns, recovering strong lexical signal that categorical encoders discard. Across 7 tasks spanning 3 RelBench v2 datasets (rel-trial, rel-f1, rel-stack), RelGT-AC outperforms the GraphSAGE baseline on all 3 regression autocomplete tasks and achieves up to +10 AUROC points on text-heavy eligibility tasks via the TF-IDF encoder.
ToolGate: ツール拡張視覚言語エージェント向けのトークン効率の良い通話前制御
ツール拡張視覚言語エージェントは、OCR、検出、セグメンテーション、その他のツールを通じて外部の知覚証拠を取得できますが、提案されたツール呼び出しをすべて実行するのはコストがかかり、場合によっては不必要です。呼び出し前の制御の問題を研究します。ReAct スタイルの VLM エージェントが知覚ツール呼び出しを提案した後、その呼び出しは実行されるべきか、その出力がコンテキストに入る前にスキップされるべきか? 5 つのベンチマーク全体で、ベースライン エージェントのローカル選択性が低いことがわかりました。有益なコールと有害なコールは同様の割合 (11.8% 対 9.9%) で発生しますが、ほとんどのコールは即時強制応答の予測を変更しません。軌道テキストと単純な構造特徴から実行/スキップの決定を予測する軽量の外部コントローラーである ToolGate を紹介します。 ToolGate は、2 つの Qwen3-VL バックボーン全体で、クロスドメイン設定の平均精度を維持しながら、トークン コストを無制限の ReAct ベースラインの 64 ~ 69% に削減します。 Qwen3-VL-30B でのマッチド ドメイン軌道トレーニングにより、平均精度がさらに 1.65 ポイント向上しました。これらの結果は、ツール拡張 VLM エージェントが、より優れた知覚ツールからだけでなく、ツールの出力がいつ支払う価値があるかを明示的に制御することからも恩恵を受けることを示しています。
原文 (English)
ToolGate: Token-Efficient Pre-Call Control for Tool-Augmented Vision-Language Agents
Tool-augmented vision-language agents can acquire external perceptual evidence through OCR, detection, segmentation, and other tools, but executing every proposed tool call is costly and sometimes unnecessary. We study the pre-call control problem: after a ReAct-style VLM agent proposes a perceptual tool call, should the call be executed, or skipped before its output enters the context? Across five benchmarks, we find that the baseline agent exhibits poor local selectivity: helpful and harmful calls occur at similar rates (11.8% vs. 9.9%), while most calls do not change the immediate forced-answer prediction. We introduce ToolGate, a lightweight external controller that predicts execute/skip decisions from trajectory text and simple structural features. Across two Qwen3-VL backbones, ToolGate reduces token cost to 64-69% of the unrestricted ReAct baseline while preserving average accuracy in cross-domain settings. With matched-domain trajectory training on Qwen3-VL-30B, it further improves average accuracy by 1.65 points. These results show that tool-augmented VLM agents benefit not only from better perceptual tools, but also from explicit control over when tool outputs are worth paying for.
SkillDAG: 大規模な LLM スキル選択のための自己進化型型スキル グラフ
LLM エージェントが大規模なスキル ライブラリを採用するにつれて、適切なサブセットの選択は、類似性の一致の問題ではなく、構造的な問題になります。つまり、スキルは相互に依存、競合、特殊化、または重複するため、完全な列挙と類似性の埋め込みの両方には見えない構造になります。 SkillDAG は、スキル間の関係を型付き有向グラフとしてモデル化し、それを推論時のエージェント呼び出し可能な構造検索インターフェイスとして LLM エージェントに公開します。固定の検索パイプラインに組み込まれるのではなく、実行中にクエリされて展開されます。各検索では、ベクトル一致、型付きエッジ近傍、競合信号が返され、提案後コミット プロトコルにより、エージェントは実行に裏打ちされたエッジを登録できるため、グラフはエピソード全体で構造を蓄積します。 ALFWorld と MiniMax-M2.7 を使用した SkillsBench では、SkillDAG は 67.1% の成功と 27.3% の報酬に達し、報告されている最も強力なスキルのグラフのベースラインを +12.8 ポイントと +8.6 ポイント上回りました。アドバンテージは gpt-5.2-codex に移植され、固有の SkillsBench Ret@K は、一致したクエリの下で 65.5 から 78.2 に上昇します。これらの利点は、固定シード拡散パイプラインが劣化するプールが 10 倍に成長しても頑健性を維持する候補ランキング、および以前のヒットを排除することなくグラウンドトゥルースの再現を拡大するセットモノトーンのオンライン編集など、分離可能なメカニズムに由来します。
原文 (English)
SkillDAG: Self-Evolving Typed Skill Graphs for LLM Skill Selection at Scale
As LLM agents adopt large skill libraries, selecting the right subset becomes a structural problem rather than a similarity-matching one: skills depend on, conflict with, specialize, or duplicate one another, a structure invisible to both full enumeration and embedding similarity. We present SkillDAG, which models inter-skill relationships as a typed directed graph and exposes it to an LLM agent as an inference-time, agent-callable structural retrieval interface, queried and evolved during execution rather than baked into a fixed retrieval pipeline: each search returns vector matches, typed-edge neighbors, and conflict signals, and a propose-then-commit protocol lets the agent register execution-backed edges so the graph accumulates structure across episodes. On ALFWorld and SkillsBench with MiniMax-M2.7, SkillDAG reaches 67.1% success and 27.3% reward, exceeding the strongest reported Graph-of-Skills baseline by +12.8 and +8.6 points; the advantage ports to gpt-5.2-codex, and intrinsic SkillsBench Ret@K rises from 65.5 to 78.2 under matched queries. These gains trace to isolable mechanisms: candidate ranking that stays robust as the pool grows 10x where a fixed seeding-diffusion pipeline degrades, and set-monotone online edits that enlarge ground-truth recall without evicting prior hits.
コア: 一般的なマルチモーダル操作検出のための競合指向推論
生成型 AI の急速な台頭により、マルチモーダルなフェイク ニュースがますます現実的かつ蔓延し、国民の信頼と社会の安定に重大な脅威を与えています。既存の検出方法は、操作固有のモデルと大規模なラベル付けされたデータに大きく依存しているため、新しい操作タイプへの一般化が不十分です。私たちは、操作された誤った情報の本質は、その本質的な矛盾、つまりモダリティ間または世界共通知識との意味的または物理的な矛盾にあることを観察しました。この観察に触発されて、私たちは、マルチモーダル大規模言語モデル (MLLM) に明示的な競合キャプチャ機能を与えることを学習する効果的なパラダイムである \textbf{C}onflict-\textbf{O}riented \textbf{RE}asoning (\textbf{CORE}) フレームワークを提案します。この目的を達成するために、CORE はまず、紛争要因と原因のきめ細かい注釈を備えた紛争帰属コーパス (CAC) を構築し、その後の紛争認識トレーニングに不可欠なデータ サポートを提供します。 CORE は、CAC に基づいて競合指向の表現強化と推論を実行することで、堅牢かつ一般化可能な競合検出を実現し、少数のサンプルやゼロショット設定でも、目に見えない操作タイプに効果的かつ迅速に適応します。広範な実験により、CORE が最先端のモデルを上回ることが実証されました。データセットとコードは https://github.com/shen8424/CORE で公開されています。
原文 (English)
CORE: Conflict-Oriented Reasoning for General Multimodal Manipulation Detection
The rapid rise of generative AI has made multimodal fake news increasingly realistic and pervasive, posing severe threats to public trust and social stability. Existing detection methods rely heavily on manipulation-specific models and large-scale labeled data, resulting in poor generalization to emerging manipulation types. We observed that the essence of manipulated misinformation lies in its intrinsic conflicts, \textbf{i.e.,} semantic or physical inconsistencies either across modalities or with common world knowledge. Inspired by this observation, we propose \textbf{C}onflict-\textbf{O}riented \textbf{RE}asoning (\textbf{CORE}) framework, an effective paradigm that learns to endows multimodal large language models (MLLMs) with explicit conflict-capturing capability. To this end, CORE first constructs the Conflict Attribution Corpus (CAC) with fine-grained annotations of conflict factors and sources, providing essential data support for subsequent conflict perception training. By performing conflict-oriented representation enhancement and reasoning based on CAC, CORE achieves robust and generalizable conflict detection, effectively and rapidly adapting to unseen manipulation types with a few samples or in even zero-shot settings. Extensive experiments demonstrate that CORE surpasses state-of-the-art models. The dataset and code are publicly available at https://github.com/shen8424/CORE.
DELTAMEM: 残存ツリーによる LLM エージェントの増分エクスペリエンス メモリ
大規模言語モデル (LLM) ベースのエージェントは、継続的な対話を通じて経験から学習するために、ますます記憶に依存しています。ただし、経験を独立したフラットな単位として保存すると、類似したエピソードが重複するコンテンツを繰り返したり、微妙なシーンの変化が検索された記憶に矛盾したガイダンスを提供したりするため、実質的な冗長性と検索の競合が発生します。これに対処するために、新たに獲得した経験は多くの場合、既存の知識の増分変化であると仮定して、残留経験を導入します。私たちは、経験記憶を 2 つの独立した残差ツリーに編成するフレームワークである DeltaMem を提案します。1 つは再利用可能なスキルとして目標条件付けされたタスクの経験を保存し、もう 1 つはシーンレベルの環境知識として保存します。各ツリーは、一般化された基本エクスペリエンスにルート ノードを使用し、後続のバリエーションに増分デルタ ノードを使用して、関連するエクスペリエンスが重複することなく共通の基盤を共有できるようにします。検索では、失敗ペナルティ付きの類似性スキャンによって最適な一致が特定され、ルートから一致までのチェーン構成を通じて完全なエクスペリエンスが再構築されます。自律的な統合メカニズムにより、高周波パスが新しいルート ノードに抽出され、一般的なヒューリスティックから特殊なバリアントまでツリーが自己組織化できるようになります。多様なインタラクティブ環境での実験では、DeltaMem が既存のベースラインを常に上回るパフォーマンスを示しています。将来の研究を容易にするために、https://github.com/import-myself/DeltaMem でコードをリリースします。
原文 (English)
DELTAMEM: Incremental Experience Memory for LLM Agents via Residual Trees
Large Language Model (LLM)-based agents increasingly rely on memory to learn from experiences over continual interactions. However, storing experiences as independent, flat units leads to substantial redundancy and retrieval conflicts, as similar episodes repeat overlapping content and subtle scene variations cause retrieved memories to offer contradictory guidance. To address this, we introduce residual experience, positing that newly acquired experience is often an incremental variation of existing knowledge. We propose DeltaMem, a framework that organizes experience memory into two independent residual trees, one storing goal-conditioned task experience as reusable skills and another for scene-level environment knowledge. Each tree uses a root node for generalized base experiences and incremental delta nodes for subsequent variations, allowing related experiences to share a common foundation without duplication. For retrieval, a failure-penalized similarity scan locates the best match, reconstructing the full experience via root-to-match chain composition. An autonomous consolidation mechanism distills high-frequency paths into new root nodes, enabling the trees to self-organize from general heuristics to specialized variants. Experiments across diverse interactive environments show that DeltaMem consistently outperforms existing baselines. To facilitate future research, we release the code at https://github.com/import-myself/DeltaMem.
推論の影の代償: LLM への最適な予算配分に関する経済的観点
推論時間のスケーリングは、大規模言語モデルのパフォーマンスを向上させるための重要な手段として浮上していますが、実際の展開は厳しい計算予算によって制限されています。この研究では、推論予算の割り当てを、経済原則に支配されるグローバルな制約付き最適化問題として定式化します。シフトサージ関数を使用してクエリごとの推論ユーティリティをモデル化することにより、リソース不足の下で限界ユーティリティを平衡化するグローバルシャドープライスに基づいた最適な割り当てポリシーを導き出します。この理論に基づいて、推論のための制約付き潜在効用均衡配分 (CLEAR) を提案します。合理的な放棄を実行し、破綻したクエリから出現しきい値に近い解決可能なクエリにリソースを再割り当てします。さまざまなトラフィック ストリームを使用したいくつかの推論タスクに関する広範な実験により、CLEAR が総トークン コストと平均精度のパレート フロンティアを大幅に向上させることが実証されました。リソースが不足している状況では、CLEAR は均一な割り当てと比較して、グローバル精度で最大 3 倍の向上を達成します。
原文 (English)
The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
Inference-time scaling has emerged as a critical avenue for enhancing Large Language Models' performance, yet real-world deployment is constrained by strict computational budgets. In this work, we formulate inference budget allocation as a global constrained optimization problem governed by economic principles. By modeling per-query reasoning utility with a shifted-surge function, we derive an optimal allocation policy based on a global shadow price that equilibrates marginal utility under resource scarcity. Based on this theory, we propose Constrained Latent-utility Equilibrium Allocation for Reasoning (CLEAR). It performs rational abandonment and reallocates resources from insolvent queries to solvable queries near their emergence thresholds. Extensive experiments on several reasoning tasks with different traffic streams demonstrate that CLEAR significantly improves the Pareto frontier of total token cost versus mean accuracy. In resource-scarce regimes, CLEAR achieves up to a 3x improvement in global accuracy compared to uniform allocation.
プロンプトがどのように行動を導くのかを分解する
プロンプトは重みを更新せずに大規模言語モデル (LLM) とビジョン言語モデル (VLM) を制御しますが、命令の変更がどのように内部表現を再形成して動作を生成するのかは不明のままです。プロンプトを、プロンプトに続くコンテンツの表現ジオメトリの変換として扱う、ネストされた幾何学的分解フレームワークを導入します。プロンプトのペアごとに、ますます表現力の高い刺激不変マップ (変換、均一スケーリングによる剛体変換、逐次軸スケーリング、アフィン変換、非線形変換) を使用して、2 つのプロンプトの下で同じ刺激の表現を整列させます。次に、単一レイヤーのプロンプト A のホールドアウト刺激に対する隠れ状態を、対応するマッピングされた状態に置き換え、プロンプト B の表現ジオメトリと動作の回復を測定することによって、各マップを因果的にテストします。 3 つの LLM、3 つの VLM、およびスタイル、感情、シーンの内容、数字にわたる 6 つのテキストまたは画像データセットにわたって、指示されたタスク構造に向けて表現を一貫して再形成するよう促します。交差検証された分散分解により、プロンプトによって引き起こされるアクティベーション変化の多くが、形状保持マップ、特に均一スケーリングによる変換と剛体変換によって捕捉されることが示され、一方、層プロファイルは、層全体にわたるモデルおよびタスク固有のルーティング戦略を明らかにします。重要なのは、変換層と固定層によってすでに動作の一致が改善されているが、アフィン変換はターゲット プロンプト タスクのジオメトリをほぼ回復する最初の層であり、対応する動作のゲインが得られることです。これは、次元を越えた線形混合が、指示されたタスク構造に向けてプロンプトの表現を再編成する重要なメカニズムであることを示唆しています。私たちのフレームワークは、プロンプトによって引き起こされる表現変化を解釈可能な幾何学的コンポーネントに分解し、モデルがタスク関連構造をルーティングしてプロンプト駆動型の動作を生成する方法を明らかにします。
原文 (English)
Decomposing how prompting steers behavior
Prompting steers large language models (LLMs) and vision-language models (VLMs) without weight updates, but it remains unclear how instruction changes reshape internal representations to produce behavior. We introduce a nested geometric decomposition framework that treats prompting as a transformation of the representational geometry of the content following the prompt. For each prompt pair, we align representations of the same stimuli under two prompts using increasingly expressive stimulus-invariant maps: translation, rigid transformation with uniform scaling, sequential axis scaling, affine transformation, and nonlinear transformation. We then causally test each map by replacing a single layer's prompt-A hidden state for held-out stimuli with its mapped counterpart and measuring recovery of prompt-B representational geometry and behavior. Across three LLMs, three VLMs, and six text or image datasets spanning style, emotion, scene content, and number, prompts consistently reshape representations toward the instructed task structure. Cross-validated variance decomposition shows that much prompt-induced activation change is captured by shape-preserving maps, especially translation and rigid transformation with uniform scaling, while tier profiles reveal model- and task-specific routing strategies across layers. Crucially, although translation and rigid tiers already improve behavioral agreement, affine transformation is the first tier to nearly recover target-prompt task geometry and yields corresponding behavioral gains. This suggests that cross-dimensional linear mixing is a key mechanism by which prompts reorganize representations toward instructed task structure. Our framework decomposes prompt-induced representational change into interpretable geometric components and reveals how models route task-relevant structure to produce prompt-driven behavior.
長いニュースから正確な予測まで: 時系列予測のための重要性を意識した融合と PRM に基づく反映
時系列予測にニュースを組み込むことは魅力的です。ニュースは、歴史的価値だけでは回復できない突然の外生的出来事を明らかにする可能性があるからです。ただし、既存の LLM ベースのニュース予測パイプラインは、2 つの実際的な制限に直面しています。1 つは、関連するニュース記事がモデルのコンテキスト ウィンドウを超えることが多く、補足ニュースの反復取得は一般にガイドなしであり、冗長な更新と遅い収束につながります。私たちは、重要性を意識したニュース圧縮とプロセスレベルの検索監視を組み合わせた新しいフレームワークでこれらの問題に対処します。まず、各記事の予測有用性を推定する重要度報酬モデルをトレーニングし、この信号を使用して逐次ペアワイズ融合中に圧縮予算を割り当て、固定コンテキスト制限内で有益なコンテンツを維持します。次に、現在のエラー プロファイルと以前に選択された記事の履歴に基づいて複数の補足ニュース候補をランク付けするプロセス報酬モデル (PRM) を導入し、ワンショットのブラインド検索を品質管理された選択に置き換えます。どちらのコンポーネントも、グラウンド トゥルースを備えた履歴データを使用してオフラインでトレーニングされます。推論では、リフレクション ループを使用せずに、凍結されたフィルタリング ロジックと圧縮モジュールを使用します。金融、エネルギー、トラフィック、ビットコインの予測ベンチマークに関する実験では、私たちの方法が強力なベースラインに対して予測精度を向上させ、反復ベースラインと比較して改良反復回数を大幅に削減し、関連する記事が数千のトークンにまたがる場合でも効果を維持できることを示しています。
原文 (English)
From Long News to Accurate Forecast: Importance-Aware Fusion and PRM-Guided Reflection for Time Series Forecasting
Incorporating news into time series forecasting is appealing because news can reveal abrupt exogenous events that historical values alone cannot recover. However, existing LLM-based news-forecasting pipelines face two practical limitations: relevant news articles often exceed the model's context window, and iterative retrieval of supplementary news is typically unguided, leading to redundant updates and slow convergence. We address these issues with a novel framework that combines importance-aware news compression and process-level retrieval supervision. First, we train an importance reward model that estimates the forecasting utility of each article and uses this signal to allocate compression budgets during sequential pairwise fusion, preserving informative content within a fixed context limit. Second, we introduce a process reward model (PRM) that ranks multiple supplementary-news candidates conditioned on the current error profile and the history of previously selected articles, replacing one-shot blind retrieval with quality-controlled selection. Both components are trained offline using historical data with ground truth; inference uses the frozen filtering logic and compression modules without any reflection loop. Experiments on finance, energy, traffic, and bitcoin forecasting benchmarks show that our method improves prediction accuracy over strong baselines, significantly reduces the number of refinement iterations compared to the iterative baseline, and remains effective when relevant articles span thousands of tokens.
DeskCraft: プロフェッショナルなワークフローと人間参加型コラボレーションに関するデスクトップ エージェントのベンチマーク
専門的なクリエイティブおよびエンジニアリング ソフトウェアでの実際のプロフェッショナル デスクトップ ワークフローは長期にわたって展開され、多くの場合、人間による調整が必要になります。そこでは、エージェントが積極的に必要な情報を探し、ユーザーはタスクの進行に応じて追加の指示、説明、フィードバック、または修正を提供します。しかし、既存のデスクトップ GUI ベンチマークでは、ほとんどの場合、この設定は、すべてのユーザー指示が事前に提供される、短く単純化されたタスクに削減されます。この問題に対処するために、長期にわたるクリエイティブおよびエンジニアリングのワークフローとプロアクティブなヒューマン エージェント コラボレーションを対象としたデスクトップ GUI ベンチマークである DeskCraft を紹介します。 DeskCraft はタスクをマルチレベルの難易度分類に整理しており、長期にわたるタスクには 50 以上の実行ステップが必要で、デザイン、ビデオ、オーディオ、3D 作成にわたるプロフェッショナルなクリエイティブ ソフトウェアをカバーしています。さらに、DeskCraft は人間とエージェントのコラボレーションを、ターン中およびターン後のやり取りをカバーする対話プロトコルに形式化します。ターン途中のインタラクションでは、不確実性の下でエージェントが開始した説明と、実行中にユーザーが開始した中断の両方がキャプチャされ、ターン後のインタラクションは、エージェントが完了の合図をした後のユーザー主導のフィードバックに対応し、現実的なコラボレーション パターンの全領域にまたがります。 18 の独自のオープンソース エージェントを 538 のタスクで評価したところ、GPT-5.4 は標準タスクで 31.6%、対話型タスクで 27.6% に達していることがわかりました。さらに分析を進めると、長期にわたるワークフローの提供と事前の明確化における継続的な失敗が明らかになります。すべての評価コード、タスク、データを https://github.com/mrwwk/DeskCraft でオープンソース化します。
原文 (English)
DeskCraft: Benchmarking Desktop Agents on Professional Workflows and Human-in-the-Loop Collaboration
Real-world professional desktop workflows in specialized creative and engineering software unfold over long horizons and often require human-in-the-loop coordination, where agents proactively seek necessary information and users provide additional instructions, clarifications, feedback, or corrections as the task progresses. Yet existing desktop GUI benchmarks mostly reduce this setting to short, simplified tasks with all user instructions provided upfront. To address this issue, we introduce DeskCraft, a desktop GUI benchmark targeting long horizon creative and engineering workflows and proactive human-agent collaboration. DeskCraft organizes tasks into a multilevel difficulty taxonomy, with long horizon tasks requiring over 50 execution steps, and covers professional creative software across design, video, audio, and 3D creation. Furthermore, DeskCraft formalizes human-agent collaboration into an interaction protocol covering mid-turn and post-turn exchanges. Mid-turn interaction captures both agent-initiated clarification under uncertainty and user-initiated interruption during execution, while post-turn interaction accommodates user-driven feedback after the agent signals completion, together spanning the full space of realistic collaboration patterns. We evaluate 18 proprietary and open source agents on 538 tasks and find that GPT-5.4 reaches 31.6% on standard tasks and 27.6% on interactive tasks. Further analyses reveal persistent failures in long horizon workflow delivery and proactive clarification. We will open-source all evaluation codes, tasks, and data at https://github.com/mrwwk/DeskCraft.
EvoTrainer: 自律的なエージェント強化学習のための共同進化する LLM ポリシーとトレーニング ハーネス
自律 LLM トレーニングはレシピ検索として組み立てられることが多く、トレーニング ハーネスはほとんど静的なままになります。この制限はエージェント RL ではさらに顕著になり、ボトルネックの変化とスカラー報酬によってさまざまな障害モードが隠蔽されます。 EvoTrainer は、実証的なフィードバックを通じて LLM ポリシーとトレーニング側の活用を共進化させる自律型トレーニング フレームワークです。これは、ロールアウト レベルの証拠を診断し、診断を修正し、介入をバックテストし、再利用可能なスキルを蓄積します。数学的推論、競合プログラミング コード生成、およびリポジトリ レベルのソフトウェア エンジニアリングで評価された EvoTrainer は、同じデータ、コードベース、評価プロトコルの下で人間が設計した RL 参照と同等またはそれを上回り、長期的なエージェント SWE で最大の利益をもたらします。軌跡分析により、保持された戦略がドメイン間で分岐し、進化する診断により無効な高スコア分岐の昇格が防止され、再利用可能なスキルが後の検索を形成することが示されました。自律 LLM RL は、レシピ検索を超えて、ポリシーとそれを解釈するトレーニング ハーネスの共同進化に向けて進む必要があります。
原文 (English)
EvoTrainer: Co-Evolving LLM Policies and Training Harnesses for Autonomous Agentic Reinforcement Learning
Autonomous LLM training is often framed as recipe search, which leaves the training harness largely static. This limitation sharpens in agentic RL, where shifting bottlenecks and scalar rewards mask diverse failure modes. We introduce EvoTrainer, an autonomous training framework that co-evolves LLM policies and training-side harnesses through empirical feedback: it diagnoses rollout-level evidence, revises diagnostics, backtests interventions, and accumulates reusable skills. Evaluated on mathematical reasoning, competitive-programming code generation, and repository-level software engineering, EvoTrainer matches or exceeds the human-engineered RL references under the same data, codebase, and evaluation protocol, with the largest gain on long-horizon agentic SWE. Trajectory analyses show that retained strategies diverge across domains, evolving diagnostics prevent invalid high-scoring branches from being promoted, and reusable skills shape later search. Autonomous LLM RL should move beyond recipe search toward joint evolution of policies and the training harnesses that interpret them.
情報獲得による LLM エージェントの不確実性認識の明確化
Large Language Model (LLM) エージェントは、多くの場合、不明確なユーザー指示に従って動作し、ユーザーの意図に対する潜在的な不確実性がツールの誤った動作につながります。この課題に対処するために、明確化の動作を曖昧さの解決と連携させる、目標指向の明確化フレームワークを提案します。私たちのアプローチの中心となるのは、情報獲得報酬です。これは、説明の交換によって引き起こされるグラウンドトゥルースの目標に向けたベイジアン信念の更新を測定することによって、説明の質問の有用性を定量化する指標です。この報酬を使用して明確化者 (LLM) をトレーニングし、高い情報獲得を最適化します。これにより、明確化によって効果的に不確実性が軽減され、エージェント、ツール、ユーザーの環境内でタスクの完了が向上します。私たちは、5つの異種バックボーンにわたるクロスエージェント評価を実施し、明確化を強化した $\tau$-Bench 環境内でフレームワークを検証します。経験的な結果は、私たちの方法が、平均して合計 0.3 のインタラクション ステップのみを追加しながら、明確化なしのベースラインよりも成功率を一貫して 3.7% 向上させることを示しています。
原文 (English)
Uncertainty-Aware Clarification in LLM Agents with Information Gain
Large Language Model (LLM) agents often operate under underspecified user instructions, where latent uncertainty over user intent leads to erroneous tool actions. To address this challenge, we propose a goal-oriented clarification framework that aligns clarification behavior with ambiguity resolution. Central to our approach is the Information Gain Reward, a metric that quantifies the utility of clarification questions by measuring the Bayesian belief update towards the ground-truth goal induced by the clarification exchange. We train the clarifier (LLM) using this reward to optimize for high information gain, ensuring that clarifications effectively reduce uncertainty and improve task completion within the agent-tool-user environment. We validate our framework within a clarification-enhanced $\tau$-Bench environment, conducting cross-agent evaluations across five heterogeneous backbones. Empirical results demonstrate that our method consistently improves the success rate by 3.7\% over the no-clarification baseline, while adding only 0.3 total interaction steps on average.
話す前に考える: マルチエージェント社会シミュレーションにおける内部評価から公の表現まで
LLM ベースのマルチエージェント シミュレーションは、社会的相互作用、熟慮、集団的な意見のダイナミクスを研究するための有望な方法を提供します。しかし、既存の対話シミュレーション フレームワークの多くは、対話を主に観察可能なターン交換または集約された出力として表現しており、沈黙、発言意図、公的表現の背後にある内部評価プロセスを調査することが困難なままになっています。エージェントの私的な推論を公的発話の生成から分離する、インターバルベースのマルチエージェント シミュレーション フレームワークである TBS (Think-Before-Speak) を紹介します。各間隔で、すべてのエージェントは共有された対話履歴と自身の記憶に基づいて構造化された内部状態を更新します。これらの状態には、不協和音関連の評価、認識された世論環境、認識された孤立リスク、対応戦略、および発言意欲が含まれます。その後、オーケストレーターは競合する発言意図を解決し、1 つの発言を公開対話にコミットし、内部評価と公開対話が時間の経過とともに共進化できるようにします。私たちは、気候関連の政策問題に関するタウンホールでの議論を模擬して TBS を評価します。結果は、TBS が一貫した内部状態トレースを生成し、これらのトレースがターン割り当て、沈黙、メモリ条件全体にわたって体系的に変化することを示しています。不協和音関連の評価はエージェントの発言意欲を高めますが、沈黙の圧力評価はそれを低下させます。発言の意図が形成されると、公の場での表現は主に順番の割り当てルールによって形成されます。これらの発見は、TBS が内部評価から公的表現への経路を観察可能かつ分析可能にすることで、メカニズムに敏感な社会シミュレーションをサポートしていることを示唆しています。
原文 (English)
Think-Before-Speak: From Internal Evaluation to Public Expression in Multi-Agent Social Simulation
LLM-based multi-agent simulation offers a promising way to study social interaction, deliberation, and collective opinion dynamics. However, many existing dialogue simulation frameworks represent interaction mainly as observable turn exchange or aggregated outputs, leaving the internal evaluative processes behind silence, speaking intention, and public expression difficult to examine. We introduce TBS (Think-Before-Speak), an interval-based multi-agent simulation framework that separates agents' private reasoning from public utterance generation. At each interval, all agents update structured internal states based on the shared dialogue history and their own memory. These states include dissonance-related appraisal, perceived opinion climate, perceived isolation risk, response strategy, and willingness to speak. The orchestrator then resolves competing speaking intentions and commits one utterance to the public dialogue, allowing internal evaluation and public interaction to co-evolve over time. We evaluate TBS in simulated town hall discussions on a climate-related policy issue. Results show that TBS produces coherent internal-state traces and that these traces vary systematically across turn-allocation, silence, and memory conditions. Dissonance-related appraisal increases agents' willingness to speak, whereas silence-pressure appraisal decreases it. Once speaking intention is formed, public expression is shaped mainly by turn-allocation rules. These findings suggest that TBS supports mechanism-sensitive social simulation by making the pathway from internal evaluation to public expression observable and analyzable.
GTBench: グラフ理論における数学研究アシスタントとしての LLM を評価するための、カリキュラムに基づいたベンチマーク
大規模言語モデル (LLM) は、技術分野の自習アシスタントとして使用されることが増えていますが、数学的推論アシスタントとしての信頼性は依然として十分に理解されていません。 GTBench は、グラフ理論の数学的研究アシスタントとして LLM を評価するためのカリキュラムに基づいたベンチマークです。GTBench は、学部レベルの定義と基本特性 (グループ 1)、アルゴリズム トレースと構造推論 (グループ 2)、大学院レベルの証明構築 (グループ 3) の、難易度が高くなる 3 つのグループに分類された 63 の問題で構成されています。問題は、Diestel のグラフ理論などの検証済みの学術資料から出典されています。私たちは 5 つのフロンティア モデル (GPT-5、Claude Sonnet 4.6、Gemini 2.5 Flash-Lite、Llama 3.3 70B、および Mistral Large 3) をゼロショットおよび思考連鎖プロンプトの下で評価します。グループ 1 と 2 には完全一致および LLM による審査員としての評価を使用し、グループ 3 にはハイブリッド人間エキスパートおよび LLM による審査員としてのプロトコルを使用しました。私たちの結果は顕著なパフォーマンスを明らかにしています。階層: GPT-5 はグループ 1 (95.8% ゼロショット) で上限に近づき、卒業証明 (82%) で有意な精度を維持していますが、他のすべてのモデルは大幅に低下し、困難を伴い、Llama はグループ 3 ゼロショットで人間の評価で 0% に達しています。失敗モード分析では、正しいアルゴリズム、間違った実行エラーがグループ 1 と 2 で優勢である一方、グループ 3 ではさらに不完全な推論の失敗が表面化し、特に冗長な証明またはほぼ完全な証明に関して、人間の評価者と自動判定者の間の体系的な不一致が明らかになりました (人間のペア全体でカッパ = 0.48 ~ 0.83)。 GTBench は、数学教育や科学研究における AI ツールのガバナンスに直接的な影響を与える、LLM におけるグラフ理論推論のための初のカリキュラムに基づいた評価フレームワークを提供します。
原文 (English)
GTBench: A Curriculum-Grounded Benchmark for Evaluating LLMs as Mathematical Research Assistants in Graph Theory
Large language models (LLMs) are increasingly used as self-study assistants in technical disciplines, yet their reliability as mathematical reasoning assistants remains poorly understood. We introduce GTBench, a curriculum-grounded benchmark for evaluating LLMs as mathematical research assistants in graph theory, comprising 63 problems organized into three groups of increasing difficulty: undergraduate definitions and basic properties (Group 1), algorithm tracing and structural reasoning (Group 2), and graduate-level proof construction (Group 3). Problems are sourced from verified academic materials including Diestel's Graph Theory. We evaluate five frontier models -- GPT-5, Claude Sonnet 4.6, Gemini 2.5 Flash-Lite, Llama 3.3 70B, and Mistral Large 3 -- under zero-shot and chain-of-thought prompting, using exact-match and LLM-as-judge evaluation for Groups 1 and 2, and a hybrid human expert and LLM-as-judge protocol for Group 3. Our results reveal a pronounced performance hierarchy: GPT-5 approaches ceiling on Group 1 (95.8% zero-shot) and maintains meaningful accuracy on graduate proofs (82%), while all other models degrade substantially with difficulty, with Llama achieving 0% under human evaluation on Group 3 zero-shot. Failure mode analysis shows that correct algorithm, wrong execution errors dominate Groups 1 and 2, while Group 3 additionally surfaces incomplete reasoning failures and reveals systematic disagreement between human evaluators and the automated judge, particularly on verbose or near-complete proofs (kappa = 0.48-0.83 across human pairs). GTBench provides the first curriculum-grounded evaluation framework for graph-theoretic reasoning in LLMs, with direct implications for the governance of AI tools in mathematical education and scientific research.
ClinicalMC: 大規模な言語モデルを使用した複数コースの臨床意思決定のベンチマーク
大規模言語モデル (LLM) は医療分野で広く採用されていますが、複雑な臨床意思決定シナリオでは依然として大きな課題に直面しています。既存のベンチマークは主に単一コース設定での LLM パフォーマンスを評価しており、患者の状態が時間の経過とともに変化する複数コースのシナリオでの体系的な評価が欠けています。このギャップに対処するために、私たちは複数コースの臨床意思決定のベンチマークである ClinicalMC を提案します。これには、入院から退院までの 4 つの段階にわたる 1,275 の中国語と 5,804 の英語のサンプルが含まれています。これらの段階には、トリアージ、最初のコースの検査/診断/治療、その後の複数コースの検査/評価/治療、および最終診断が含まれます。 ClinicalMC では、英語のデータセットの患者は平均 5.11 の臨床コースを受けますが、中国のデータセットの患者は平均 3.42 の臨床コースを受けます。 LLM のパフォーマンスを評価するために、患者、検査官、医師エージェントを含むマルチエージェント評価フレームワークを構築します。ベンチマークとフレームワークに基づいて、シングルターン静的設定とマルチターン動的設定の 2 つの実験設定を設計し、LLM の 3 つのカテゴリを評価します。1) GPT5-mini などのクローズドソース LLM。 2) DeepSeek-V3.2 のようなオープンソース LLM。 3) HuatuoGPT-o1 などの医療 LLM。広範な評価を通じて、医療分野における LLM のパフォーマンスをより深く理解し、医療分野での LLM の効果的な展開をサポートすることを目指しています。
原文 (English)
ClinicalMC: A Benchmark for Multi-Course Clinical Decision-Making with Large Language Models
Large language models (LLMs) have been widely adopted in healthcare, yet they still encounter significant challenges in complex clinical decision-making scenarios. Existing benchmarks primarily assess LLM performance in single-course settings and lack systematic evaluation in multi-course scenarios, where a patient's condition evolves over time. To address this gap, we propose ClinicalMC, a benchmark for multi-course clinical decision-making. It includes 1,275 Chinese and 5,804 English samples across four stages from admission to discharge. These stages cover triage, first-course examination/diagnosis/treatment, subsequent multi-course examination/assessment/treatment, and final diagnosis. In ClinicalMC, patients in the English dataset undergo an average of 5.11 clinical courses, whereas those in the Chinese dataset undergo 3.42. To assess LLM performance, we construct a multi-agent evaluation framework that includes patient, examiner, and doctor agents. Based on the benchmark and framework, we design two experimental settings -- a single-turn static setting and a multi-turn dynamic setting -- and assess three categories of LLMs: 1) closed-source LLMs like GPT5-mini; 2) open-source LLMs like DeepSeek-V3.2; and 3) medical LLMs like HuatuoGPT-o1. Through extensive evaluation, we aim to better understand LLM performance in the medical domain and support its effective deployment in healthcare.
MedCUA-Bench: 臨床コンピューター使用エージェント向けのスクリーンショットのみのベンチマーク
コンピュータを使用するエージェントは、画面ベースの反復的な臨床作業を自動化できる可能性がありますが、医療用グラフィカル ユーザー インターフェイスにおけるエージェントの信頼性はほとんど検証されていません。既存のベンチマークは、一般的な Web タスクやデスクトップ タスクに焦点を当てており、ドメイン知識が必要で、主流のアプリケーションとは著しく異なる UI デザインを示し、公開テスト環境がなく、タスクの完了を超えた安全性の検証が必要な医療ソフトウェアの割合が過小評価されています。臨床コンピューター使用エージェントの対話型ベンチマークである MedCUA-Bench を紹介します。 10 の医療分野にわたる 18 の臨床シナリオをカバーしており、実際の製品マニュアルとオープンソースの医療システムから再構築され、ライセンスとプライバシーの制約を回避しながら本物の臨床インターフェースをキャプチャします。各タスクには、臨床推論を UI 実行から切り離すための、意図レベルとステップレベルの目標のペアが付属しており、タスクの完了と 5 つの臨床安全性の側面について決定論的チェッカーによって評価されます。 23 のエージェント全体で、最高のクローズドソース モデルの厳密な成功率は 54.2% に達していますが、実際の OpenEMR ではすべてのモデルが 9% 未満にとどまっています。オープンソース エージェントの平均はわずか 2.5% で、最高のエージェントは 16.2% に達します。 MedCUA-Bench は、現在の薬剤と信頼できる臨床ソフトウェアの使用との間のギャップを明らかにし、将来の研究のための再現可能なテストベッドを提供します。
原文 (English)
MedCUA-Bench: A Screenshot-Only Benchmark for Clinical Computer-Use Agents
Computer-use agents could automate repetitive screen-based clinical work, but their reliability in medical graphical user interfaces remains largely unvalidated. Existing benchmarks focus on general web or desktop tasks and underrepresent medical software, which requires domain knowledge, exhibits markedly different UI design from mainstream applications, lacks public testing environments, and demands safety validation beyond task completion. We introduce MedCUA-Bench, an interactive benchmark for clinical computer-use agents. It covers 18 clinical scenarios across 10 medical domains, reconstructed from real product manuals and open-source medical systems to capture authentic clinical interfaces while avoiding licensing and privacy constraints. Each task ships with paired intent- and step-level goals to disentangle clinical reasoning from UI execution, and is evaluated by a deterministic checker over task completion and five clinical safety dimensions. Across 23 agents, the best closed-source model reaches 54.2% strict success, while all models remain below 9% on the real OpenEMR. Open-source agents average only 2.5%, with the best reaching 16.2%. MedCUA-Bench exposes the gap between current agents and reliable clinical software use, providing a reproducible testbed for future research.
皮膚病変の分類に対する人口統計の偏りの影響
この研究では、ResNet ベースの畳み込みモデルを使用して、トレーニング データにおける人口統計上の偏り、特に患者の性別と年齢の変動の影響に焦点を当てて、皮膚病変分類のパフォーマンスを評価します。線形計画法を使用して、制御された人口統計特性を持つデータセットを生成し、バイアス効果の体系的な調査を可能にします。シングルタスク モデル、強化マルチタスク モデル、敵対的学習スキームの 3 つの学習戦略が評価されます。私たちの性別ベースの分析は、性別固有のトレーニング データセットがモデルのパフォーマンスを最適化することを示しています。特に、トレーニング データに男性患者を含めることで、女性が多数を占めるケースであっても、男性サブグループのパフォーマンスが向上しました。敵対的な学習スキームを強化することで、バランスの取れた女性多数のデータセットにおけるバイアスギャップが縮小または排除されました。しかし、これらの戦略は男性が多数派の環境では効果が低いことが判明し、モデルは女性よりも男性の方が優れたパフォーマンスを示し続けました。 2 つの学習スキームは、主に男性の患者集団においてベースライン モデルと比較して限界バイアスの減少を示しました。年齢ベースの分析では、3 つのモデル アプローチ全体で同等のベースライン パフォーマンスが示されており、年齢カテゴリーごとにパフォーマンスが低下しています。若いグループは、トレーニング データの分布に関係なく、一貫して最高のパフォーマンスを達成します。バランスの取れたトレーニングは最年少の年齢カテゴリーでは最適な結果をもたらしますが、それより上の年齢カテゴリーではパフォーマンスが低下します。性バイアスは主にデータの不均衡から生じる一方、年齢バイアスは分布に関係なく一貫して若いグループに有利であることがわかりました。これらの異なるメカニズムには、対象を絞った緩和戦略が必要です。さらに、2 つの外部データセットに対するデータセット間検証により、ドメインのシフトがパフォーマンスと人口統計上の偏りのパターンに顕著な影響を与えることが明らかになりました。
原文 (English)
Effect of Demographic Bias on Skin Lesion Classification
In this study, we evaluate the performance of skin lesion classification using ResNet-based convolutional models, focusing on the impact of demographic bias in training data, particularly variations in patient sex and age. We use linear programming to generate datasets with controlled demographic characteristics, allowing systematic investigation of bias effects. Three learning strategies are evaluated: a single-task model, a reinforcing multi-task model, and an adversarial learning scheme. Our sex-based analysis indicates that sex-specific training datasets optimise model performance. Notably, including male patients in the training data improved performance for the male subgroup, even in female-majority cases. Reinforcing and adversarial learning schemes narrowed or eliminated bias gaps in balanced and female-majority datasets. However, these strategies proved less effective in male-majority settings, where models continued to perform better for males than females. The two learning schemes showed marginal bias reduction compared to the baseline model in predominantly male patient populations. Age-based analysis demonstrates comparable baseline performance across the three model approaches, with performance declining across age categories. Younger groups consistently achieve the highest performance, regardless of training data distribution. Although balanced training yields optimal results for the youngest age category, performance decreases in older categories. We find that sex biases arise mainly from data imbalances, while age biases consistently favour younger groups regardless of distribution. These distinct mechanisms require targeted mitigation strategies. Additionally, cross-dataset validation on two external datasets revealed that domain shifts notably affect performance and patterns of demographic bias.
推論前に認識: 効率的で信頼性の高いプロアクティブなモバイル エージェントのための推論前の認識フレームワーク
マルチモーダル大規模言語モデル (MLLM) は、モバイル エージェントを大幅に進化させていますが、エージェントは支援の \emph{方法} を決定する前に、介入する \emph{いつ} を決定する必要があるため、プロアクティブなモバイル支援は依然として課題となっています。既存のシステムでは、統合された MLLM ベースのパイプライン内でこれら 2 つの決定が実装されることが多く、保守的な介入フィルタリングと包括的な支援生成の間で目標の不整合が発生したり、エージェントが沈黙を保つ必要がある場合の冗長な推論が発生したりします。これらの制限に対処するために、私たちは、推論前の知覚に基づいて構築された 2 段階のフレームワークである \textbf{推論前知覚フレームワーク (PRPF)} を提案します。 PRPF は、介入ゲートとコンテキスト圧縮のための軽量のマルチモーダル プロアクティブ パーセプター (MPP) を導入し、介入が正当な場合にのみプロアクティブ エージェント リーズナー (PAR) をアクティブにします。 ProactiveMobile ベンチマークの実験では、PRPF が ProactiveMobile ベースラインよりも成功率 (SR) と推論効率を向上させながら、誤トリガー率 (FTR) を大幅に削減することが示されています。
原文 (English)
Perceive Before Reasoning: A Pre-Reasoning Perception Framework for Efficient and Reliable Proactive Mobile Agents
Multimodal large language models (MLLMs) have substantially advanced mobile agents, yet proactive mobile assistance remains challenging because agents must decide \emph{when} to intervene before determining \emph{how} to assist. Existing systems often implement these two decisions within a unified MLLM-based pipeline, leading to goal misalignment between conservative intervention filtering and comprehensive assistance generation, as well as redundant inference when the agent should remain silent. To address these limitations, we propose the \textbf{Pre-Reasoning Perception Framework (PRPF)}, a two-stage framework built on perceiving before reasoning. PRPF introduces a lightweight Multimodal Proactive Perceptor (MPP) for intervention gating and context compression, and activates the Proactive Agent Reasoner (PAR) only when intervention is warranted. Experiments on the ProactiveMobile benchmark show that PRPF substantially reduces false trigger rates (FTR) while improving success rates (SR) and inference efficiency over the ProactiveMobile baseline.
独我論的な超知性は協力的である可能性が低い
AI の中心的な課題は、機能から共存への移行です。 AI 研究における支配的なパラダイムは、世界を外生的かつ定常的なフィードバック源として扱う強力なエージェントの開発に焦点を当てています。 AI設計へのそのような独我論的アプローチから生まれた非常に有能なタスク解決手段であるスーパーインテリジェンスは、協調的である可能性は低いと我々は主張する。 AI システムを導入すると内生的な非定常性が誘発され、その結果、学習、テスト、導入のギャップが生じ、過去の分布が導入コンテキストから乖離します。これを、一方的な最適化の自己弱体化特性と呼びます。このギャップを埋めるには、協力に参加する AI が必要です。これは、複数の主体が相互依存関係をナビゲートする平衡選択プロセスです。私たちは、協力を解決すべき課題としてアプローチするのではなく、この相互依存を中核となる設計原理として扱う非独我論的研究パラダイムを求めます。これには、適応的なカウンターパーティを巻き込んだ動的な評価テストベッドの構築、制度を設計プリミティブとして扱うこと、構築するシステムの構造的特徴として人間の主体性を維持することが必要となります。
原文 (English)
Solipsistic Superintelligence is Unlikely to be Cooperative
AI's central challenge is shifting from capability to coexistence. The dominant paradigm in AI research focuses on developing powerful agents that treat the world as an exogenous and stationary source of feedback. We contend that superintelligence, an extremely capable task solver, born out of such a solipsistic approach to AI design, is unlikely to be cooperative. Deploying AI systems induces endogenous non-stationarity, resulting in a train-test-deploy gap where historical distributions diverge from the deployment context. We refer to this as the self-undermining property of unilateral optimization. Closing this gap requires AI that participates in cooperation: the equilibrium-selection process through which multiple actors navigate their interdependence. We call for a non-solipsistic research paradigm that treats this interdependence as a core design principle rather than approaching cooperation as a task to solve. This entails building dynamic evaluation testbeds involving adaptive counterparties, treating institutions as design primitives, and preserving human agency as a structural feature of the systems we build.
現実世界のデータセットには自然実験が含まれていますか?原因特徴選択を用いた実証研究
自然界では、一部の個人やグループには影響を与えるが、他のグループには影響を及ぼさない出来事は暗黙の介入を構成し、自然実験として知られています。たとえば、新型コロナウイルス感染症のパンデミックは、新型コロナウイルスに感染した亜集団に対するコロナウイルスによる介入でした。既存の実世界のデータセットで自然実験は行われるのでしょうか? 「はい」の場合、どのように治療すればよいでしょうか?データ内の自然実験を検出するには、因果発見を使用して基礎となる因果グラフを復元し、因果関係に基づいて特徴の選択を実行します。データを観察的ではなく介入的として扱うことで下流のパフォーマンスが向上する場合、これはデータセットに自然実験が含まれていることを示唆していると私たちは主張します。まず、合成グラフを使用して自然実験の有無にかかわらずデータセットをシミュレートすることで、この仮説を検証します。次に、現実世界の大規模なデータセットに対して体系的な経験的評価を実行します。私たちの結果は、現実世界のデータセットには自然実験が含まれており、因果推論を使用してそれらの自然実験を利用してモデルのパフォーマンスを向上できることを示しています。私たちの研究はこの分野への最初の進出であり、限られた範囲内での予備調査を提供します。
原文 (English)
Do Real-World Datasets Contain Natural Experiments? An Empirical Study Using Causal Feature Selection
In nature, events that affect some individuals or groups but not others constitute an implicit intervention and are known as natural experiments. For example, the COVID-19 pandemic was an intervention by the coronavirus on the sub-population infected with COVID. We ask, do natural experiments occur in existing real-world datasets? If yes, how should we treat them? To detect natural experiments in data, we use causal discovery to recover the underlying causal graph and perform feature selection based on causal links. If downstream performance improves by treating the data as interventional rather than observational, we argue that this suggests the dataset contains natural experiments. We first validate this hypothesis by simulating datasets with and without natural experiments using synthetic graphs. We then perform a systematic empirical evaluation on a large suite of real-world datasets. Our results indicate that real-world datasets do contain natural experiments and we can take advantage of those natural experiments to improve model performance using causal inference. Our work represents the initial foray into this area, offering a preliminary exploration within a limited scope.
神経象徴的な視覚的質問応答のための LLM からの回答セット プログラミング ルールの抽出
Visual Question Answering (VQA) は、画像に関する質問に答えるタスクであり、マルチモーダルな入力と推論の統合が必要です。論理ベースの表現を推論コンポーネントに組み込むモジュール式のアプローチは、特に解釈可能性の点で、エンドツーエンドのトレーニング済みシステムに比べて明らかな利点を提供します。ただし、タスク要件が変化したときにこれらの表現を適応または拡張すると、開発者に大きな負担がかかる可能性があります。この課題に対処するために、大規模言語モデル (LLM) からルールを抽出するアプローチを紹介します。私たちの方法は、LLM に、タスクの新しい要件を満たすために、答えセット プログラムとして表現された初期 VQA 推論理論を拡張するよう促します。 VQA データセットの例は、LLM をガイドし、結果を検証し、ASP ソルバーからのフィードバックを活用して誤ったルールを修正するのに役立ちます。私たちのアプローチが多様な VQA データセット全体で効果的であることを実証します。特に、LLM から正しいルールを導き出すために必要な例はほんの数個だけです。私たちの実験は、LLM からのルールの抽出が、従来のデータ駆動型のルール学習アプローチに代わる有望な代替手段であることを示唆しています。論理プログラミングの理論と実践 (TPLP) で検討中。
原文 (English)
Distilling Answer-Set Programming Rules from LLMs for Neurosymbolic Visual Question Answering
Visual Question Answering (VQA) is the task of answering questions about images, requiring the integration of multimodal input and reasoning. Modular approaches that incorporate logic-based representations into the reasoning component offer clear advantages over end-to-end trained systems, particularly in terms of interpretability. However, adapting or extending these representations when task requirements change can place a significant burden on developers. To address this challenge, we present an approach for distilling rules from Large Language Models (LLMs). Our method prompts an LLM to extend an initial VQA reasoning theory, expressed as an answer-set program, to meet new requirements of the task. Examples from VQA datasets guide the LLM, validate the results, and help correct erroneous rules by leveraging feedback from the ASP solver. We demonstrate that our approach is effective across diverse VQA datasets. Notably, only a few examples are needed to elicit correct rules from LLMs. Our experiments suggest that rule distillation from LLMs is a promising alternative to traditional data-driven rule learning approaches. Under consideration in Theory and Practice of Logic Programming (TPLP).
Pythia マルチホップ設定でのクロスモデル アクティベーション転送の否定的な結果
最近の研究では、言語モデルがトレーニング中に生成されたデータ内の隠れたシグナルを通じて行動特性を伝達できることが示されています。私たちは、より直接的でより厳密なチャネルも実行可能であるかどうかを尋ねます。ある言語モデルは、自然言語テキストを渡すのではなく、隠れたアクティベーションを翻訳して挿入することによって、推論時に有用な中間推論状態を別の言語モデルに伝達できるでしょうか。この質問を、制御された Pythia-160M から Pythia-410M へのマルチホップ推論設定でテストします。線形変換層は、シード全体で 0.97 近くの正規化コサイン類似度を備えた、送信側と受信側の隠れ状態間の強力な正規化空間マップを学習します。ただし、変換されたアクティベーションが推論時に受信機に注入される場合、ダウンストリームの応答は改善されません。低強度の添加剤の注入は、注入なしのベースライン付近に留まり、信頼区間はゼロと交差します。置換スタイルの注入は一貫して破壊的であり、変換されたベクトルを受信側の隠れ状態の標準に再スケーリングしてもパフォーマンスは回復しません。したがって、結果はスコープ付きの否定的な結果になります。この設定では、オフラインの表現的調整は、受信機内部での有用な因果関係の通信には十分ではありません。
原文 (English)
A Negative Result on Cross-Model Activation Transfer in a Pythia Multi-Hop Setting
Recent work shows that language models can transmit behavioural traits through hidden signals in generated data during training. We ask whether a more direct and stricter channel is also viable: can one language model communicate useful intermediate reasoning state to another at inference time by translating and injecting hidden activations, rather than by passing natural-language text? We test this question in a controlled Pythia-160M to Pythia-410M multi-hop reasoning setting. A linear translation layer learns a strong normalized-space map between sender and receiver hidden states, with normalized cosine similarity near 0.97 across seeds. However, when the translated activations are injected into the receiver at inference time, they do not improve downstream answering. Low-strength additive injection remains near the no-injection baseline, with confidence intervals that cross zero. Replacement-style injection is consistently destructive, and rescaling translated vectors to the receiver hidden-state norm does not rescue performance. The result is therefore a scoped negative result: in this setting, offline representational alignment is not sufficient for useful causal communication inside the receiver.
LEAP: エージェント フレームワークを使用した形式数学用の LLM のスーパーチャージング
大規模言語モデル (LLM) は強力な非公式数学的推論を示しますが、リーンのような形式言語では機械的に検証可能な証明を生成するのに苦労します。 LEAP は、汎用基礎モデルが自動化された形式定理証明で最先端のパフォーマンスを達成できるようにするエージェント フレームワークです。 LEAP は、非公式推論、指示に従って、反復的な自己改善などの基礎モデルの機能を活用します。複雑な問題をより小さな単位に分解することで、システムはリーン コンパイラーとの継続的な対話を通じて、正式な証明の構築と非公式のブループリントの橋渡しをします。ますます飽和しつつあるベンチマークを超えた厳密な評価を提供するために、リーンで形式化された IMO スタイルの問題のベンチマークである Lean-IMO-Bench を導入します。このベンチマークでは、短いステートメントでありながら非常に非日常的で、幅広い難易度にわたる複数ステップの証明が行われます。経験的に、北米の学部学生を対象とした毎年恒例の数学コンテストである最新の 2025 年のパトナム コンペティションでは、LEAP は 12 の問題すべてを解決し、フロンティアの正式な数学モデルによる最近の進歩と一致しています。 Lean-IMO-Bench では、LEAP は汎用 LLM のワンショット形式解決率を 10% 未満から 70% に引き上げ、特に金メダル級の専門化された IMO システムによって設定されたベンチマークの 48% を上回っています。さらに、偶数次ケイリーグラフのクヌースのハミルトニアン分解における重要な部分問題の検証された証明を含む、オープンな組み合わせ課題に対する複雑な証明を自律的に形式化することで、LEAP の研究レベルの有用性を実証します。
原文 (English)
LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks
Large Language Models (LLMs) exhibit strong informal mathematical reasoning but struggle to generate mechanically verifiable proofs in formal languages like Lean. We present LEAP, an agentic framework that enables general-purpose foundation models to achieve state-of-the-art performance on automated formal theorem proving. LEAP leverages foundation model capabilities, such as informal reasoning, instruction following, and iterative self-refinement. By decomposing complex problems into smaller units, the system bridges formal proof construction with informal blueprints through continuous interaction with the Lean compiler. To provide a rigorous evaluation beyond increasingly saturated benchmarks, we introduce Lean-IMO-Bench, a benchmark of IMO-style problems formalized in Lean, with short statements yet highly non-routine and multi-step proofs across a wide range of difficulty levels. Empirically, on the latest 2025 Putnam Competition, an annual mathematics competition for undergraduate students in North America, LEAP solves all 12 problems, matching recent breakthroughs by frontier formal mathematical models. On Lean-IMO-Bench, LEAP boosts the one-shot formal solve rate of general-purpose LLMs from below 10% to 70%, notably surpassing the 48% benchmark set by a specialized, gold-medal-caliber IMO system. Furthermore, we demonstrate LEAP's research-level utility by autonomously formalizing complex proofs for open combinatorial challenges, including a verified proof for a key subproblem in Knuth's Hamiltonian decomposition of even-order Cayley graphs.
ベンチマーク監査における信頼性ギャップ: 汚染検出の障害モードとしての分布のシフトとスケール
評価例がモデルのトレーニング データに現れるベンチマーク汚染は、LLM 評価の妥当性を脅かします。トレーニング データのメンバーシップを検出するための統計ツールは存在しますが、ほぼ独占的に管理された学術体制、つまり大規模で均質な事前トレーニング コーパスと透明な単一ステージ トレーニング パイプラインでのみ検証されています。これらの方法が現実的な監査シナリオにおいて信頼性を維持できるかどうかは、依然として不明です。私たちは、十分に研究されていない 2 つの障害モードを特定します。1 つは、疑わしいセットと検証セットが IID の仮定に違反する場合に発生する分布シフト、もう 1 つは、ベンチマークがトレーニング前のコーパスよりも桁違いに小さいために発生するスケール制約です。私たちは、複数のファミリー (Pythia、OLMo~2、特殊な文化的および医療的 LLM を含む) およびスケール (最大 27B) からの 27 のモデルにわたって、LLM データセット推論、ポストホック データセット推論、CoDeC という 3 つの主要なパラダイムを体系的に評価します。次に、分析を最先端の業界モデルにさらに拡張します。 335 件の評価のうち、正しい結果が得られたのは 199 件のみでした。 LLM データセット推論では、分布シフトの下で偽陽性が発生し、ポストホック データセット推論はベンチマーク スケールでは能力が不足し、CoDeC は個々のベンチマーク分割を検証するには不十分な粗い出所信号しか提供しません。私たちの結果は、管理された検証と実際のベンチマーク監査の間に体系的な信頼性のギャップがあることを明らかにし、統計的検出がまだ透明なデータ来歴に取って代わることができないことを示しています。私たちはさらなる研究のためにベンチマークをオープンソースにしています。
原文 (English)
The Reliability Gap in Benchmark Auditing: Distribution Shift and Scale as Failure Modes of Contamination Detection
Benchmark contamination, where evaluation examples appear in a model's training data, threatens the validity of LLM assessment. Statistical tools for detecting training-data membership exist, but have been validated almost exclusively in controlled academic regimes: large, homogeneous pre-training corpora and transparent, single-stage training pipelines. Whether these methods remain reliable in realistic auditing scenarios remains unclear. We identify two under-studied failure modes: distribution shift, which arises when suspect and validation sets violate the IID assumption, and scale constraints, which arise because benchmarks are orders of magnitude smaller than pre-training corpora. We systematically evaluate three leading paradigms: LLM Dataset Inference, Post-Hoc Dataset Inference, and CoDeC across 27 models from multiple families (including Pythia, OLMo~2, and specialised cultural and medical LLMs) and scales (up to 27B). We then further extend our analysis to frontier industry models. Across 335 evaluations, only 199 yield correct outcomes. LLM Dataset Inference results in false positives under distribution shift, Post-Hoc Dataset Inference is underpowered at benchmark scale, and CoDeC provides only coarse provenance signals that are insufficient to verify individual benchmark splits. Our results reveal a systematic reliability gap between controlled validation and practical benchmark auditing, and show that statistical detection cannot yet replace transparent data provenance. We open-source our benchmark for further research.
違反状況パターン: コンプライアンス違反のナレッジグラフ パターン
コンプライアンス パイプラインは、違反を一時的なクエリ結果として検出し、違反自体をレビュー状態、影響を受けるエンティティ、または監査履歴を含む永続的なグラフ オブジェクトとして保持しません。違反状況パターン (VSP) は、このギャップを埋めます。 Ganemi と Mega の状況パターンに基づいて、VSP は、検出された各違反を、ルール識別子、時間的有効期間、ライフサイクル状態、および関係するエンティティへの証拠リンクを備えたグラフ ノードとして具体化します。ライフサイクルの遷移は不変の PROV-O で調整されたイベントとして保存されるため、監査履歴はグラフの走査となります。法人および契約ライフサイクル プロパティ グラフで VSP をインスタンス化し、FCL->Cypher->MERGE パイプラインを通じて 4 つの義務ルール (V1 未承認の署名、V2 期限切れの委任、V3 機密保持条項の欠落、V4 違反通知条項の欠落) を運用可能にします。 BODACC の会社役員の出版物に対して V1 と V2 をチェックし、73 件の GDPRhub 施行決定に基づいて V4 を評価し、V3 と V4 に対して SHACL クロスフォーマリズム チェックを実行します。中心的な発見は、ルール本体の独立性です。V4 を条項の存在から期限チェックまで拡張すると、F1 が 0.312 から 0.602 に上昇しますが、パターンのアイデンティティ、ライフサイクル、および証拠のセマンティクスは変わりません。これにより、パターンの寄与と検出器の寄与が分離されるため、蓄積された監査履歴を無効にすることなく検出ロジックを進化させることができます。
原文 (English)
The Violation Situation Pattern: A Knowledge-Graph Pattern for Compliance Violations
Compliance pipelines detect violations as transient query results and do not keep the violation itself as a persistent graph object with review state, affected entities, or audit history. The Violation Situation Pattern (VSP) closes this gap. Building on the Situation pattern of Gangemi and Mika, VSP reifies each detected violation as a graph node with a rule identifier, a temporal validity interval, a lifecycle state, and evidence links to the entities involved. Lifecycle transitions are stored as immutable, PROV-O-aligned events, so audit history is a graph traversal. We instantiate VSP in a legal entity and contract lifecycle property graph and operationalize four deontic rules (V1 unauthorized signature, V2 expired mandate, V3 missing confidentiality clause, V4 missing breach-notification clause) through an FCL->Cypher->MERGE pipeline. We check V1 and V2 against BODACC corporate-officer publications, evaluate V4 on 73 GDPRhub enforcement decisions, and run a SHACL cross-formalism check on V3 and V4. The central finding is rule-body independence: extending V4 from clause-presence to deadline checking raises F1 from 0.312 to 0.602, while the pattern's identity, lifecycle, and evidence semantics stay the same. This separates a pattern contribution from a detector contribution, so detection logic can evolve without invalidating accumulated audit history.
InfoMem: 回答条件付き情報獲得によるロングコンテキスト記憶エージェントのトレーニング
長いコンテキストのタスクでは、LLM が大規模なコンテキストから回答関連情報を識別して保存する必要があります。チャンク単位のメモリ エージェントは、ドキュメントのチャンクを順番に読み取り、コンパクトなメモリを更新し、蓄積されたメモリから最終的な回答を生成することで、この問題に対処します。ただし、既存の RL ベースのチャンクごとのエージェントは、スパースな最終回答報酬に依存するか、記憶および検索アクションに語彙的な中間報酬を使用します。これらの信号はタスクの成功または局所的なオーバーラップを監視しますが、最終的なメモリが真実の答えをサポートしているかどうかを直接評価しません。我々は、回答条件付き情報を使用して最終メモリの有用性を評価する、チャンク単位の記憶エージェントをトレーニングするための報酬メカニズムである InfoMem を提案します。 InfoMem は、最終メモリがモデルのグラウンドトゥルースの答えのトークンごとの対数尤度をどの程度増加させるかを測定します。 RL の最適化を安定させるために、InfoMem はこの信号を成功した軌跡にのみ適用し、報酬を合成する前に正規化します。同じ GRPO フレームワークとトレーニング予算の下で、InfoMem は、同等のメモリ エージェント RL ベースラインよりもロング コンテキストのメモリ エージェントのパフォーマンスを向上させます。分析の結果、効果的な最終記憶報酬は成功の軌跡に基づいて動作し、報酬を合成する前に正規化され、クエリではなく回答に基づいて条件付けされる必要があることが示されています。私たちのコードは https://github.com/GenSouKa1/InfoMem で入手できます。
原文 (English)
InfoMem: Training Long-Context Memory Agents with Answer-Conditioned Information Gain
Long-context tasks require LLMs to identify and preserve answer-relevant information from large contexts. Chunk-wise memory agents address this issue by sequentially reading document chunks, updating a compact memory, and generating the final answer from the accumulated memory. However, existing RL-based chunk-wise agents either rely on sparse final-answer rewards or use lexical intermediate rewards for memory and retrieval actions. These signals supervise task success or local overlap, but do not directly evaluate whether the final memory supports the ground-truth answer. We propose InfoMem, a reward mechanism for training chunk-wise memory agents that evaluates final-memory utility using answer-conditioned information. InfoMem measures how much the final memory increases the model's per-token log-likelihood of the ground-truth answer. To stabilize RL optimization, InfoMem applies this signal only to successful trajectories and normalizes it before reward composition. Under the same GRPO framework and training budget, InfoMem improves long-context memory-agent performance over comparable memory-agent RL baselines. Analyses show that effective final-memory rewards should operate on successful trajectories, be normalized before reward composition, and be conditioned on the answer rather than the query. Our code is available at https://github.com/GenSouKa1/InfoMem.
CP-Agent: 化学的摂動下での細胞形態学的プロファイリングのためのコンテキスト認識型マルチモーダル推論
Cell Painting は、多重蛍光染色、ハイコンテンツ イメージング、定量分析を組み合わせて高次元の表現型の読み取り値を生成し、作用機序 (MoA) 推論、毒性予測、薬物疾患アトラスの構築などのさまざまな下流タスクをサポートします。しかし、既存のワークフローは時間がかかり、コストがかかり、解釈が困難です。薬物スクリーニングモデリングのアプローチは主に分子表現の学習に焦点を当てていますが、実際の実験状況(細胞株、投与スケジュールなど)は無視されており、一般化と MoA の解決が制限されています。我々は、薬物摂動下での細胞の形態的変化について、機構に関連した人間が解釈可能な理論的根拠を生成できるエージェント性マルチモーダル大言語モデル (MLLM) である CP-Agent を紹介します。 CP-Agent はその中核として、コンテキスト認識アライメント モジュール CP-CLIP を活用し、高コンテンツの画像と実験的なメタデータを共同で埋め込み、堅牢な処理と MoA 識別 (最大 F1 スコア 0.896 を達成) を可能にします。 CP-CLIP の出力をエージェント ツールの使用法と推論と統合することで、CP-Agent は理論的根拠を構造化レポートにまとめ、実験計画と仮説の洗練を導きます。これらの機能は、より解釈可能でスケーラブルでコンテキストを認識した表現型スクリーニングを可能にし、創薬における仮説生成の反復サイクルを合理化し、創薬を加速する CP-Agent の可能性を強調しています。
原文 (English)
CP-Agent: Context-Aware Multimodal Reasoning for Cellular Morphological Profiling under Chemical Perturbations
Cell Painting combines multiplexed fluorescent staining, high-content imaging, and quantitative analysis to generate high-dimensional phenotypic readouts to support diverse downstream tasks such as mechanism-of-action (MoA) inference, toxicity prediction, and construction of drug-disease atlases. However, existing workflows are slow, costly and difficult to interpret. Approaches for drug screening modeling predominantly focus on molecular representation learning, while neglecting actual experimental context (e.g., cell line, dosing schedule, etc.), limiting generalization and MoA resolution. We introduce CP-Agent, an agentic multimodal large language model (MLLM) capable of generating mechanism-relevant, human-interpretable rationales for cell morphological changes under drug perturbations. At its core, CP-Agent leverages a context-aware alignment module, CP-CLIP, that jointly embeds high-content images and experimental metadata to enable robust treatment and MoA discrimination (achieving a maximum F1-score of 0.896). By integrating CP-CLIP outputs with agentic tool usage and reasoning, CP-Agent compiles rationales into a structured report to guide experimental design and hypothesis refinement. These capabilities highlight CP-Agent's potential to accelerate drug discovery by enabling more interpretable, scalable, and context-aware phenotypic screening -- streamlining iterative cycles of hypothesis generation in drug discovery.
インタラクション軌跡がターミナルエージェントのトレーニングに効果的となる理由は何ですか?
一般に、より強力なコード エージェントはトレーニング後の教師として優れていると考えられていますが、この仮定はタスクの難易度、ハーネスの設計、生徒の能力から十分に解きほぐされていないままです。私たちは、マルチドメインの現実世界の問題を環境で検証されたエージェント タスクに変換するスケーラブルなパイプラインである Terminal-Lego を使用して、この教育的リンクを調査します。驚くべきことに、スタンドアロンのパフォーマンスは指導の有効性を左右しません。Claude Opus 4.6 は Terminal-Bench 2.0 でより高いスコアを達成しましたが、スコアの低いエージェントである DeepSeek-V3.2 からの軌道で微調整された生徒は、非常に強力な一般化を示しました。私たちは、この「教育的パラドックス」は環境に基づいた監督(EGS)によるものであると考えています。ハーネスと可視の相互作用を通じて、検査、行為、検証の動作を明示的に明らかにする軌跡により、生徒は脆弱な行動シーケンスではなく、堅牢な問題解決ルーチンを内面化することができます。スケーリング分析により、卓越したデータ効率が明らかになりました。たとえば、わずか 15.3k の Terminal-Lego 軌道で、Qwen3-32B は Terminal-Bench 2.0 で 24.3% のスコアを達成し、30 倍以上のデータ量で確立された以前の SOTA パフォーマンスに匹敵します。私たちの結果は、エージェントのポストトレーニングのフロンティアが単なる結果のマッチングを超えたところにあり、焦点を「ハーネスエンジニアリング」に移すことを示唆しています。そこでは、環境に基づいた相互作用構造の体系的な設計が、再現可能で一般化可能なエージェントインテリジェンスの主な触媒として機能します。
原文 (English)
What Makes Interaction Trajectories Effective for Training Terminal Agents?
Stronger code agents are commonly assumed to be superior teachers for post-training, yet this assumption remains poorly disentangled from task difficulty, harness design, and student capacity. We investigate this pedagogical link using Terminal-Lego, a scalable pipeline that transforms multi-domain real-world issues into environment-verified agentic tasks. Surprisingly, standalone performance does not dictate teaching efficacy: while Claude Opus 4.6 achieves higher scores on Terminal-Bench 2.0, students fine-tuned on trajectories from DeepSeek-V3.2, a lower-scoring agent, exhibit significantly stronger generalization. We attribute this "pedagogical paradox" to Environment-Grounded Supervision (EGS): trajectories that explicitly expose inspect-act-verify behaviors through harness-visible interactions allow students to internalize robust problem-solving routines rather than fragile action sequences. Scaling analysis reveals exceptional data efficiency: with only 15.3k Terminal-Lego trajectories, for example, Qwen3-32B achieves a 24.3% score on Terminal-Bench 2.0, rivaling previous SOTA performance established with over 30x the data volume. Our results suggest that the frontier of agent post-training lies beyond mere outcome-matching, shifting the focus toward "Harness Engineering", where the systematic design of environment-grounded interaction structures serves as the primary catalyst for reproducible and generalizable agentic intelligence.
DMF: 会話型 AI エージェントのための決定論的メモリ フレームワーク
会話型 AI エージェントには、スケーラブルであり、長い対話期間にわたって意味的に一貫性のあるメモリ システムが必要です。既存のアプローチは主に、書き込み時の大規模言語モデル (LLM) ベースの要約に依存しているため、非決定性が生じ、トークン コストが増大し、枝刈りの決定が不透明になります。決定論的メモリ フレームワーク (DMF) を紹介します。これは、生成メモリ圧縮を、古典的な NLP 分析、ベクトル ジオメトリ、数学的スコアリングに基づいた完全に決定論的なパイプラインに置き換える CPU ファーストのアプローチです。 DMF は、各会話インタラクションに、確定的なコンテンツ信号、会話の手がかり、構造化された来歴をロジスティック投影によって組み合わせて計算された生存スコア $\Omega$ を割り当てます。 $\Omega_{\mathrm{eff}}(\Delta n)$ として示されるインタラクション数の減衰則は、新しいターンが到来するにつれて関連性がどのように進化するかを制御します。$\Delta n$ は実時間ではなく新しいインタラクションの数であり、完全な決定論が維持されます。 DMF の数学的定式化、その構造化されたリコール パイプライン、枝刈りの決定手順、および評価プロトコルを紹介します。実験は、LoCoMo および LongMemEval データセットを使用して、専用のベンチマークで実行されます。 DMF と、AI エージェントによく使われるメモリ層である Mem0 を比較します。 DMF は、メモリ コンテキストの準備にゼロ トークンを使用しながら、会話全体で 5 倍から 242 倍少ないトークンを使用しながら、同等の精度を実現します。これらの結果は、メモリ管理ループから LLM 呼び出しを排除し、トークン コストをほぼゼロに削減し、会話型 AI エージェントの決定論的メモリ システムを可能にすることが可能であることを示しています。
原文 (English)
DMF: A Deterministic Memory Framework for Conversational AI Agents
Conversational AI agents require memory systems that are both scalable and semantically coherent across long interaction horizons. Existing approaches rely predominantly on large language model (LLM)-based summarisation at write time, which introduces non-determinism, escalating token costs, and opacity in pruning decisions. We present the Deterministic Memory Framework (DMF), a CPU-first approach that replaces generative memory compression with a fully deterministic pipeline grounded in classical NLP analysis, vector geometry, and mathematical scoring. DMF assigns each conversational interaction a Survival Score $\Omega$ computed from deterministic content signals, conversational cues, and structured provenance, combined through a logistic projection. An interaction-count decay law, denoted as $\Omega_{\mathrm{eff}}(\Delta n)$, governs how relevance evolves as new turns arrive, where $\Delta n$ is the number of newer interactions rather than wall-clock time, preserving full determinism. We present the mathematical formulation of DMF, its structured recall pipeline, the pruning decision procedure, and the evaluation protocol. Experiments are conducted on a purpose-built benchmark using the LoCoMo and LongMemEval datasets. We compare DMF against Mem0, a popular memory layer for AI agents. DMF achieves comparable accuracy while using zero tokens to prepare the memory context and 5x to 242x fewer tokens over the entire conversation. These results show that it is possible to eliminate LLM calls from the memory-management loop, reducing token costs to nearly zero and enabling deterministic memory systems for conversational AI agents.
StepFinder: マルチエージェント システムにおける障害の原因を特定するための時間的セマンティック フレームワーク
LLM ベースのマルチエージェント システムは、複雑な複数ステップのタスクにおいて優れた共同作業能力を発揮します。ただし、これらのシステムは、エージェントの対話を通じて伝播し、連鎖的な障害につながる可能性のあるシングルステップ実行エラーに対して非常に敏感です。障害の原因を理解し、システムの信頼性を向上させるために、障害の原因となる根本原因のステップを自動的に特定することを目的としたタスクとして、障害の原因特定が導入されました。既存の障害帰属手法は、主に LLM に依存して元の実行軌跡を推論します。これにより、高い推論コストと遅延が発生するだけでなく、冗長でノイズの多い実行ログによって引き起こされる干渉の影響を受け、LLM が真の根本原因ステップを正確に特定するのに苦労します。これに対処するために、軽量の障害属性フレームワークである StepFinder を提案します。私たちは、実行ログを時間的意味シーケンスにエンコードするために、機能構築フェーズ中にのみ LLM を使用します。続いて、時間モデリングと注意モジュールのパラメーター効率の高い組み合わせを適用して、軌道の逐次進化とステップ間の依存関係を捕捉します。最後に、ステップレベルのエラースコアは、マルチスケールの差分と位置の偏りによって調整され、正確な根本原因の特定が可能になります。 Who&When ベンチマークの実験結果では、StepFinder がステップ レベルの障害の原因特定において LLM ベースの手法を上回り、大幅に高い推論効率を達成し、最速の LLM ベースの手法と比較して推論時間を 79% 削減し、テキスト生成のオーバーヘッドがないことが実証されました。私たちのコードは https://github.com/taiyu-zhu/StepFinder で入手できます。
原文 (English)
StepFinder: A Temporal Semantic Framework for Failure Attribution in Multi-Agent Systems
LLM-based multi-agent systems exhibit remarkable collaborative capabilities in complex multi-step tasks. However, these systems are highly sensitive to single-step execution errors that can propagate through agent interactions and lead to cascading failures. To understand the causes of failure and improve system reliability, failure attribution has been introduced as a task that aims to automatically identify the root cause step responsible for a failure. Existing failure attribution methods mainly rely on LLMs to reason over original execution trajectories, which not only incur high inference costs and latency, but also suffer from interference caused by redundant and noisy execution logs, causing LLMs to struggle in accurately identifying the true root cause step. To address this, we propose StepFinder, a lightweight failure attribution framework. We use LLMs solely during the feature construction phase to encode execution logs into temporal semantic sequences. Subsequently, a parameter-efficient combination of temporal modeling and attention modules is applied to capture the sequential evolution and cross-step dependencies of the trajectories. Finally, the step-level error score is refined through multi-scale differences and position bias, enabling precise root cause identification. Experimental results on the Who&When benchmark demonstrate that StepFinder outperforms LLM-based methods in step-level failure attribution while achieving substantially higher inference efficiency, reducing inference time by 79% compared with the fastest LLM-based method, with no text generation overhead. Our code is available at https://github.com/taiyu-zhu/StepFinder.
心の機械理論の正式な定義とメタモデル
この論文は、認知心理学、神経科学、人工知能からの証拠によって裏付けられた原則に基づいて、心の機械理論の概念の厳密で正式な定義を初めて提案し、上記のことをレンズとして使用して、この分野における最先端の現在の取り組みを検討し、問題を「解決」できるさらなる研究の潜在的な議題を推進します。また、心の機械理論の一般的な全体的なメタモデルを発展させ、そのようなモデルを経験的にベンチマークする際の最先端の状況を調査します。
原文 (English)
A formal definition and meta-model for a machine theory of mind
This paper proposes, for the first time, a rigorous formal definition of the concept of Machine Theory of Mind, based on principles supported by evidence from cognitive psychology, neuroscience and artificial intelligence, and uses the above as a lens to examine state-of-the-art and current efforts in the field, driving a potential agenda for further research there able to "crack" the problem. It also advances a general holistic meta-model for Machine Theory of Mind, and examines the state of the art when it comes to empirically benchmarking such models.
ThoughtFold: 内省的な好み学習による推論チェーンの折りたたみ
大規模推論モデル (LRM) は、思考連鎖 (CoT) に関する検証可能な報酬を伴う強化学習 (RLVR) のおかげで目覚ましい進歩を遂げました。しかし、長い CoT には当然ながら試行錯誤が含まれており、主流の RLVR アプローチは暗記のために結果的に正しい CoT 軌道を選択するため、長い CoT での冗長な探索が必然的に強化され、その結果 LRM の考えすぎの問題が生じます。この問題を解決するためのこれまでの試みでは、主に短い軌道に大きな利点が与えられていましたが、その学習信号は依然として結果ベースであり、長い CoT での冗長な探索の記憶を減らすことはできません。したがって、私たちは、効率的な推論のために冗長な探索を軽減するために、きめの細かい選好学習を活用するフレームワークである ThoughtFold を提案します。 ThoughtFoldは、内省的な戦略を採用して、それぞれの正しい軌道内の冗長性を特定し、候補となるサブ軌道のスペクトルを生成します。このスペクトルを活用して、冗長な探索に明示的にペナルティを課し、モデルが本質的な推論セグメントを直接橋渡しし、その推論チェーンをより簡潔なパスに効果的に折り畳むことを奨励する、マスクされた優先順位の最適化目標を導入します。広範な実験により、ThoughtFold が効率を大幅に向上させることが示されています。最先端の精度を維持しながら、DeepSeek-R1-Distill-Qwen-7B のトークン使用量を約 56% 削減します。
原文 (English)
ThoughtFold: Folding Reasoning Chains via Introspective Preference Learning
Large Reasoning Models (LRMs) have achieved remarkable progress thanks to Reinforcement Learning with Verifiable Rewards (RLVR) on Chain-of-Thoughts (CoTs). However, since long CoTs naturally contain trial and errors and mainstream RLVR approaches choose outcome-correct CoT trajectories for memorization, the redundant explorations in long CoTs are inevitably reinforced, which results in the over-thinking issues of LRMs. Previous attempts to resolve this issue mainly give more advantage to shorter trajectories, yet their learning signals are still outcome-based and cannot reduce the memorization of redundant explorations in long CoTs. Therefore, we propose ThoughtFold, a framework that leverages fine-grained preference learning to mitigate redundant explorations for efficient reasoning. ThoughtFold employs an introspective strategy to identify redundancy within each correct trajectory, which yields a spectrum of candidate sub-trajectories. Leveraging this spectrum, we introduce a masked preference optimization objective that explicitly penalizes redundant explorations and encourages the model to directly bridge essential reasoning segments, effectively folding its reasoning chains into a more concise path. Extensive experiments show that ThoughtFold significantly enhances efficiency. It reduces the token usage of DeepSeek-R1-Distill-Qwen-7B by approximately 56% while maintaining state-of-the-art accuracy.
オーバーレイ ガバナンス: Agentic AI の委任とスコープのための構成的承認フレームワーク
AI システムがパッシブ モデルから、アクションの開始、共同作業、およびタスクの委任ができる自律的なアクティブ エージェントに進化するにつれて、ソフトウェア システムの従来の境界があいまいになります。固定プリンシパル、明示的なリクエスト、静的スコープを中心に構築された従来の承認および委任フレームワークでは、エージェント システムを管理するには不十分です。 Agentic AI は、より豊富な承認セマンティクスを要求します。エージェントは、アクセス許可を継承および委任し、期限付きの権限の下で動作し、共有プロトコルを通じて調整する必要があります。既存の ID およびアクセス管理 (IAM) システムは、この代理店の概念を完全に捉えることができず、再帰的な委任、コンテキスト境界、および実行可能なガバナンス基本要素としての動的スコープのメカニズムが欠けています。 OAuth 2.0 などのアクセス委任標準とは異なり、当社では委任を単なる静的なトークンベースの同意資格情報ではなく、契約条件として扱います。本稿では、エージェント型 AI に不可欠なプリミティブを導入した構成的ガバナンスのフレームワークを提案します。委任の種類とその権限および説明責任への影響を定義し、バインドされたエージェント アクセス エンベロープに対するリソース スコープの減衰の概念を導入します。これらの概念は、既存の認可ドメイン (金融システムなど) に組み込むことができる一般的なリレーショナル定義として表現されます。この構成を運用可能にするために、再帰的な委任チェーンなどの新しいエージェント セマンティクスを、既存のリレーショナル ポリシーを書き換えることなくオーバーレイする構成演算子を定義します。私たちはこのフレームワークを正式な証明と経験的評価を通じて実証し、このフレームワークがエージェント AI システムにおける責任ある承認のための正式かつ実用的な基盤を提供することを示します。
原文 (English)
Overlaying Governance: A Compositional Authorization Framework for Delegation and Scope in Agentic AI
As AI systems evolve from passive models into autonomous active agents capable of initiating actions, collaborating, and delegating tasks, the traditional boundaries of software systems blur. Traditional authorization and delegation frameworks, built around fixed principals, explicit requests, and static scopes, are insufficient to govern agentic systems. Agentic AI demands richer authorization semantics: agents must inherit and delegate permissions, act under time-limited authority, and coordinate through shared protocols. Existing Identity and Access Management (IAM) systems fail to fully capture this notion of agency, lacking mechanisms for recursive delegation, contextual boundaries, and dynamic scoping as executable governance primitives. Unlike access delegation standards such as OAuth 2.0, we treat delegation as a contractual term rather than merely a static token-based consent credential. This paper proposes a compositional governance framework that introduces primitives indispensable for agentic AI. We define types of delegation and their permissions and accountability implications, and we introduce a notion of resource scope attenuation to bound agentic access envelopes. These concepts are expressed as general relational definitions that can be composed into existing authorization domains (e.g., financial systems). To operationalize this composition, we define a compositional operator that overlays new agentic semantics, such as recursive delegation chains, onto existing relational policies without rewriting them. We substantiate this framework through formal proofs and empirical evaluation, showing that it provides a formal yet practical foundation for accountable authorization in agentic AI systems.
SAGE: エージェント生態系における社会化進化の定量的評価
自己改善型言語エージェントは通常、単独で評価されます。エージェントはタスクを試み、フィードバックを受け取り、繰り返し自身の動作を改善します。しかし、エージェントは、戦略と結果が公に公開されている同僚と協力して活動することが増えています。このことから、十分に研究されていない疑問が生じます。共有された経験が、自己改善だけでは達成できない改善をもたらすのはいつでしょうか? 2 つのコンピューティングが一致する条件を比較する評価フレームワークである SAGE (ソーシャル エージェント グループ エボリューション) を紹介します。SocialEvo では、5 つの異なるモデル ファミリのエージェントがすべてのピアの履歴にアクセスしながら共同進化します。そして、SelfEvo では、各エージェントは同じ回数のタスク試行を受けますが、自分自身の過去のみを見ることができます。これは、自己改善エージェントの研究では一般的です。私たちは、オープンエンドの ML 研究、長期的な経済計画、戦略的なマルチプレイヤー プレイの 3 つの分野で SAGE をインスタンス化し、複数の進化ラウンドにわたって評価します。私たちは、グループの歴史が普遍的な増幅器ではないことを発見しました。つまり、最も強力なエージェントは自己進化の上限を超えることはありません。ただし、自己改善が停滞しているエージェントでも、同僚の経験があれば、大きな進歩を遂げることができます。競争環境では、反事実的なコントロールにより、エージェントが対戦相手固有の戦略を開発するのではなく、全体的に向上することが明らかになります。さまざまな形式の共有履歴にわたって、フィルタリングされたピアトレースやリフレクションサマリーは生のログよりもパフォーマンスが優れていることが多く、社会的利益は露出量ではなく抽象化に依存していることを示しています。これらの発見は、ピア履歴の獲得がエージェント固有、アリーナ依存であり、公開された痕跡から譲渡可能な知識を抽象化する能力に依存していることを明らかにしています。
原文 (English)
SAGE: A Quantitative Evaluation of Socialized Evolution in Agent Ecosystems
Self-improving language agents are typically evaluated in isolation: an agent attempts a task, receives feedback, and iteratively refines its own behavior. Yet agents increasingly operate alongside peers whose strategies and outcomes are publicly visible. This raises an under-studied question: when does shared experience produce improvements that self-improvement alone cannot achieve? We introduce SAGE (Social Agent Group Evolution),an evaluation framework that compares two compute-matched conditions: SocialEvo, where agents from five distinct model families co-evolve with access to all peers' histories; and SelfEvo, where each agent receives the same number of task attempts but sees only its own past, which is conventional in self-improving agent studies. We instantiate SAGE in three arenas: open-ended ML research, long-horizon economic planning, and strategic multiplayer play, evaluated across multiple evolutionary rounds. We find that group history is not a universal amplifier: the strongest agent does not exceed its self-evolution ceiling. However, agents that plateau under self-improvement can achieve significant breakthroughs when peer experience is available. In competitive settings, counterfactual controls reveal that agents improve generally rather than developing opponent-specific strategies. Across different forms of shared history, filtered peer traces and reflective summaries often outperform raw logs, indicating that social gains depend on abstraction rather than exposure volume. These findings reveal that peer-history gains are agent-specific, arena-dependent, and contingent on the capacity to abstract transferable knowledge from public traces.
プロンプトからサービスまで: AI 主導の仮想世界向けの SLM ベースのエージェント オーケストレーション ゲートウェイ
生成 AI 機能が拡大するにつれて、AI 主導の仮想世界は増大するアーキテクチャ上の課題に直面しています。ユーザーはインワールド インターフェイスを通じてマルチモーダルな方法で対話しますが、そのリクエストには根本的に異なる AI バックエンド モデルと計算リソースが必要です。これらの機能を仮想世界システムに直接組み込むと、拡張性が低下し、メンテナンスが複雑になり、エッジおよびクラウド インフラストラクチャ全体に分散されたサービスを調整する機能が制限されます。このペーパーでは、SLM ベースのエージェント オーケストレーション ゲートウェイについて説明します。これは、インテント駆動型のサービス ルーティングを通じて、仮想世界のクライアントを異種 AI バックエンドから切り離す軽量のランタイム調整メカニズムです。エッジ展開された SLM は各ユーザー プロンプトの意味論的な意図を分類し、構成可能なサービス レジストリはルーティングの決定を検証して解決します。選択されたバックエンドは透過的に呼び出され、クライアント アプリケーションを変更することなく新しい AI 機能を仮想世界に導入できます。ゲートウェイは、InterownedXR 仮想博物館テストベッド内で実装および評価されます。この評価では、コンパクト SLM がエッジ ハードウェア上で信頼性の高いインテント ルーターとして機能し、タスク固有の微調整により 10 億未満のパラメータ モデルを実用的な低遅延ルーターに変換できることが示されました。ルータとして微調整された 10 億未満のパラメータ モデルと会話応答生成のためのより大きな SLM を組み合わせた階層化構成は、ミッドレンジ エッジ ハードウェアに展開可能であり、両方の役割を 1 つのモデルに委任するよりも効率的であることが示されています。この調査結果は、SLM が仮想世界における実用的な AI サービス オーケストレーションをサポートできることを示しており、この研究はスケーラブルで拡張可能でエッジサポートされた AI インタラクションのための評価済みアーキテクチャに貢献し、仮想エージェントが分散型生成 AI サービスへのアクセス ポイントになることを可能にします。
原文 (English)
From Prompt to Service: An SLM-Based Agent Orchestration Gateway for AI-Driven Virtual Worlds
As generative AI capabilities expand, AI-driven virtual worlds face a growing architectural challenge. Users interact through in-world interfaces in multimodal ways, yet their requests demand fundamentally different AI backend models and computational resources. Embedding these capabilities directly into virtual world systems reduces extensibility, complicates maintenance, and limits the ability to coordinate services distributed across edge and cloud infrastructure. This paper presents an SLM-based Agent Orchestration Gateway, a lightweight runtime coordination mechanism that decouples a virtual world client from heterogeneous AI backends through intent-driven service routing. An edge-deployed SLM classifies the semantic intent of each user prompt, a configurable service registry validates and resolves the routing decision, and the selected backend is invoked transparently, enabling new AI capabilities to be introduced in the virtual world without modifying the client application. The gateway is implemented and evaluated within the InterwovenXR virtual museum testbed. The evaluation shows that compact SLMs can serve as reliable intent routers on edge hardware, and that task-specific fine-tuning can transform sub-billion-parameter models into practical, low-latency routers. A layered configuration pairing a fine-tuned sub billion-parameter model as router with a larger SLM for conversational response generation is shown to be deployable on mid-range edge hardware and more efficient than delegating both responsibilities to a single model. The findings show that SLMs can support practical AI service orchestration in virtual worlds and the work contributes an evaluated architecture for scalable, extensible, and edge-supported AI interaction, enabling virtual agents become access points to distributed generative AI services.
言語を超えたトークン アービトラージ: ローカル LLM 前処理によるコード エージェント コンテキスト ウィンドウの最適化
AI 支援コーディング エージェントは、入力トークンのコストがボトルネックとなります。人間による生の入力の 2 つの病理が、このオーバーヘッドの多くを引き起こします。それは、英語以外のテキストのトークン化の非効率性と、会話プロンプトの構造的エントロピーです。既存のアプローチは、すでに肥大化したコンテキストを圧縮したり、障害が発生した後に介入したりすることで、事後的に動作します。開発者とクラウド エージェントの間で動作する、プリフライトのエッジ側プロンプト書き換えミドルウェアを導入します。ローカルの Llama 3.2 (3B) モデルは、英語への言語間翻訳、コンパクトなタスク指向形式への構造の書き換え、および正規表現で検証されたフォールバック付き書き換えセーフガードを実行して、最適化されたプロンプトが元のプロンプトより大きくならないようにします。私たちは、トルコ語、アラビア語、中国語、およびコードスイッチ仕様にまたがる多言語コーディング ベンチマークである OMH-Polyglot で評価します。このミドルウェアは、3 つの商用 LLM バックエンド全体で、タスクの精度を維持または向上させながら、プロンプト トークンを 34 ~ 47 パーセント削減し、合計トークンを最大 18.8 パーセント削減します。アブレーション研究では、単純な関数名の抽出ではなく、主に書き換え段階から利益が生じることが示されています。同等の圧縮率での LLMLingua-2 と比較して、私たちの方法は、評価されたすべてのバックエンドにわたって一貫して優れた OckScore パフォーマンスを達成します。これらの結果は、プロアクティブなプロンプト最適化により、コーディング品質を犠牲にすることなく推論コストを大幅に削減できることを示しています。
原文 (English)
Cross-Lingual Token Arbitrage: Optimizing Code Agent Context Windows via Local LLM Preprocessing
AI-assisted coding agents are bottlenecked by input-token cost. Two pathologies of raw human input drive much of this overhead: tokenization inefficiency for non-English text and structural entropy in conversational prompts. Existing approaches act reactively by compressing already-bloated contexts or intervening after failures occur. We introduce a pre-flight, edge-side prompt-rewriting middleware that operates between the developer and the cloud agent. A local Llama 3.2 (3B) model performs cross-lingual translation into English, structural rewriting into a compact task-oriented format, and regex-validated rewrite-with-fallback safeguards to ensure the optimized prompt is never larger than the original. We evaluate on OMH-Polyglot, a multilingual coding benchmark spanning Turkish, Arabic, Chinese, and code-switched specifications. Across three commercial LLM backends, the middleware reduces prompt tokens by 34-47 percent and total tokens by up to 18.8 percent while preserving or improving task accuracy. Ablation studies show that gains arise primarily from the rewriting stage rather than simple function-name extraction. Compared with LLMLingua-2 at matched compression rates, our method consistently achieves superior OckScore performance across all evaluated backends. These results demonstrate that proactive prompt optimization can substantially reduce inference costs without sacrificing coding quality.
大規模な推論モデルでの命令を解決するための補助制約のブリッジ
大規模推論モデル (LRM) は、多くのタスクで優れた機能を実証していますが、個々の制約を満たせなかったり、競合する制約を同時にバランスさせるのに苦労したりするため、複数の命令に確実に従うことが困難です。私たちはこの課題を制約遵守問題 (CAP) として形式化します。この論文では、命令を制約の構造化知識グラフとして表現することで CAP に対処する新しいフレームワークを紹介します。私たちのアプローチである Constraint Relationship Graph Completion (CRGC) は、制約間の関係を明示的にモデル化し、遵守の課題を特定し、モデルが要件に焦点を合わせて調整するのに役立つ「ブリッジ制約」を発見します。ブリッジ制約は、主制約をより顕著にし、互換性を持たせる補助的な命令として機能します。一般的なトレーニング方法を通じて指導のフォローを強化する既存のアプローチとは異なり、CRGC は、モデル自体の知識を活用して生成のためのより良い経路を作成することにより、特に制約満足度を向上させます。データセットに従う 3 つの一般的な命令を対象とした実験では、私たちのアプローチが、大規模な推論モデルの推論能力を維持しながら、標準的なプロンプトと比較して制約違反を 39% 削減することが実証されました。
原文 (English)
Bridging Auxiliary Constraints to Resolve Instruction Following in Large Reasoning Models
Large Reasoning Models (LRMs) have demonstrated impressive capabilities in many tasks, yet they struggle with reliably following multiple instructions, either by failing to satisfy individual constraints or by struggling to balance competing constraints simultaneously. We formalize this challenge as the Constraint Adherence Problem (CAP). This paper introduces a novel framework that addresses CAP by representing instructions as a structured knowledge graph of constraints. Our approach, Constraint Relationship Graph Completion (CRGC), explicitly models relationships between constraints, identifies adherence challenges, and discovers ``bridge constraints'' that help the model better focus on and reconcile requirements. Bridge constraints act as auxiliary instructions that make primary constraints more salient and compatible. Unlike existing approaches that enhance instruction following through general training methods, CRGC specifically improves constraint satisfaction by leveraging the model's own knowledge to create better pathways for generation. Experiments across three popular instruction following datasets demonstrate that our approach reduces constraint violations by 39% compared to standard prompting while maintaining reasoning abilities of large reasoning models.
TSQAgent: 専用のエージェント推論による時系列データ品質の評価
時系列 (TS) データの品質の評価は基本的なものですが、品質の側面には多面的な性質があるため、本質的に困難です。最近、大規模言語モデル (LLM) が、ペアごとの比較と次元ごとの評価による TS 品質評価の有望なパラダイムとして浮上しています。ただし、既存のアプローチは、手動で事前定義された品質次元と純粋にテキストベースの推論に依存しているため、LLM が本当に関連する品質次元を特定できるか、根拠のある定量的な品質比較を実行できるかどうかは不明のままです。これを調査するために、TSQBench を構築します。TSQBench は、(i) 関連する品質次元の理解と特定、(ii) 特定の次元での品質比較の実行という 2 つの進歩的な機能に基づいて LLM を評価するための専用ベンチマークです。私たちの分析により、現在の LLM は次元の特定と証拠に基づく品質比較の両方に常に苦労していることが明らかになりました。これらの制限に対処するために、我々は TSQAgent を提案します。TSQAgent は TS 品質評価のための新しいエージェント推論フレームワークであり、3 つの協調的な役割で構成されます。焦点を絞った次元選択を行うパーシーバー、次元ごとの定量分析を行うインスペクター、そして最終的な判断を集約して洗練する審査員です。特に、最も関連性の高い品質側面を特定して優先順位を付ける能力を浸透させるエージェント推論戦略を導入し、さらに、選択した側面にわたる正確な定量的比較を可能にする外部分析ツールを備えたエージェント ワークフローを提案します。提案されたベンチマークと 11 個の実世界のデータセットの両方での実験により、私たちのフレームワークが LLM の品質理解と定量的比較の能力を大幅に向上させるだけでなく、これらの向上をより品質を意識したデータ選択に効果的に変換し、ダウンストリームのパフォーマンスとデータ効率の向上につながることが実証されました。
原文 (English)
TSQAgent: Rating Time Series Data Quality via Dedicated Agentic Reasoning
Assessing the quality of time series (TS) data is fundamental yet inherently challenging due to the multifaceted nature of quality dimensions. Recently, large language models (LLMs) have emerged as a promising paradigm for TS quality assessment via pairwise comparison and per-dimension evaluation. However, existing approaches rely on manually predefined quality dimensions and purely text-based reasoning, leaving it unknown whether LLMs can identify truly relevant quality dimensions or perform grounded and quantitative quality comparisons. To investigate this, we construct TSQBench, a dedicated benchmark for evaluating LLMs on two progressive capabilities: (i) understanding and identifying relevant quality dimensions, and (ii) performing quality comparison under specific dimensions. Our analysis reveals that current LLMs consistently struggle with both dimension identification and evidence-grounded quality comparison. To address these limitations, we propose TSQAgent, a novel agentic reasoning framework for TS quality rating consisting of three collaborative roles: Perceiver for focused dimension selection, Inspector for dimension-wise quantitative analysis, and Adjudicator that aggregates and refines the final judgment. In particular, we introduce an agentic reasoning strategy that instills the ability to identify and prioritize the most relevant quality dimensions, and further propose an agent workflow equipped with external analytical tools to enable precise quantitative comparisons over selected dimensions. Experiments on both the proposed benchmark and eleven real-world datasets demonstrate that our framework not only substantially improves LLMs' capabilities in quality understanding and quantitative comparison but also effectively translates these improvements into better quality-aware data selection, leading to enhanced downstream performance and data efficiency.
LLM 医療トリアージにおける性別に応じた診断代替: 同じ症状、不均等な緊急性
私たちは、患者の表明された性別と年齢のみが異なる場合に、大規模言語モデルが同一の神経学的症状に対して異なる医療トリアージ推奨を生成するかどうかを調査します。 3 つのモデル ファミリ (Gemini 3.5 Flash、Claude Sonnet 4.6、および GPT-5.4-mini) を使用して、7 つの人口統計条件にわたる標準化された症状プロファイル (持続的な頭痛、かすみ目、朝の吐き気、視覚障害) を提示します: 3 つの年齢グループ (25、38、65) x 2 つの性別 (男性、女性)、および性別不特定のベースライン (モデルごとに条件ごとに n = 30、合計 630)トライアル)。私たちは、性別に依存したトリアージの明らかな体系的な格差を発見しました。若い女性は、同年齢の男性よりも緊急治療室(ER)への紹介率が著しく低いことがわかりました(ジェミニ: 0% 対 23.3%、クロード: 6.7% 対 96.7%、GPT: 6.7% 対 66.7%、すべて p < 0.001)。すべてのモデルで 65 歳になると格差はなくなります。主なメカニズムは診断代替である。モデルは性別に関連した診断に基づいており、疫学的に出産適齢期の女性に関連する疾患である特発性頭蓋内圧亢進症(IIH)の若い女性を優先的に分類する一方、鑑別領域に空間を占める病変を伴う一般的な頭蓋内圧亢進を有する男性を診断する。この診断的閉鎖により、同等の重症度評価(7~9/10)にもかかわらず、女性患者は緊急性の低いケア(外来医師の予約)に誘導されます。私たちの調査結果は、臨床 LLM が疫学的な事前情報を使用してトリアージの緊急性を抑制することによって、文書化された人間の臨床バイアスを再現することを示しており、AI トリアージ エンジンが緊急性の評価を確率的な診断の事前情報から切り離す必要があることを示唆しています。すべてのコード、プロンプト、生の結果をリリースします。
原文 (English)
Gender-Dependent Diagnostic Substitution in LLM Medical Triage: Same Symptoms, Unequal Urgency
We investigate whether large language models produce different medical triage recommendations for identical neurological symptoms when only the patient's stated gender and age vary. Using three model families--Gemini 3.5 Flash, Claude Sonnet 4.6, and GPT-5.4-mini--we present a standardized symptom profile (persistent headache, blurred vision, morning nausea, visual disturbances) across seven demographic conditions: three age groups (25, 38, 65) x two genders (male, female), plus a gender-unspecified baseline (n = 30 per condition per model, 630 total trials). We find a stark, systemic gender-dependent triage disparity: young women receive significantly lower emergency room (ER) referral rates than age-matched men (Gemini: 0% vs. 23.3%; Claude: 6.7% vs. 96.7%; GPT: 6.7% vs. 66.7%, all p < 0.001). The disparity disappears at age 65 for all models. The primary mechanism is diagnostic substitution: the models anchor on a gender-associated diagnosis, preferentially classifying young women with Idiopathic Intracranial Hypertension (IIH)--a condition epidemiologically linked to women of childbearing age--while diagnosing men with generic increased intracranial pressure with space-occupying lesions in the differential. This diagnostic closure routes female patients to lower-urgency care (outpatient doctor appointments) despite comparable severity ratings (7-9/10). Our findings demonstrate that clinical LLMs replicate documented human clinical biases by using epidemiological priors to suppress triage urgency, suggesting that AI triage engines must decouple urgency assessment from probabilistic diagnostic priors. We release all code, prompts, and raw results.
命題否定可能な立場の論理における非単調含意に向けて
反証可能な推論における最近の研究では、Kraus らのスタイルで優先意味論と含意の概念が見られました。モーダルロジックに適用されます。ただし、この分野の研究は主に充足可能性のチェックと、推論的に弱い可能性がある含意の単調な概念に焦点を当ててきました。これが導入された特定の様相論理の 1 つは、命題的立場の論理であり、様相はさまざまな視点のビューを表現できます。これにより、提案的実行不可能な立場の論理 (PDSL) が形式化されました。この論文では、(非単調な)合理的含意関係のクラスを伝統的な KLM スタイルの推論から PDSL のフラグメントに持ち上げる手段を提案します。そうするために、状況に応じた立場の条件文を介して PDSL の表現力を拡張し、特定の立場のコンテキストで実行可能な条件付き保持について話すことができるようにします。これにより、PDSL の構文を状況に応じた条件文の観点から再特徴付けることができ、PDSL の大きなフラグメントが一連の状況に応じた条件文として表現可能であることがわかります。次に、このフラグメントの非単調含意の特徴付けに焦点を当て、ランキングに基づく含意関係を命題ケースから PDSL ケースに移す方法を定義します。これは、最初に一般的なケースで説明され、次に合理的クロージャと辞書編集的クロージャの特定のケースで検討され、各推論を PDSL に忠実に翻訳します。また、PDSL のこのフラグメントにおける含意チェックは、主に命題事例のアルゴリズムを使用して、複雑さの限界を維持しながら実行できることも示します。
原文 (English)
Towards Non-Monotonic Entailment in Propositional Defeasible Standpoint Logic
Recent work in defeasible reasoning has seen notions of preferential semantics and entailment in the style of Kraus et al. applied to modal logics. However, work in this field has focussed primarily on satisfiability checking, and monotonic notions of entailment, which may be inferentially weak. One particular modal logic where this has been introduced is propositional standpoint logics, where modalities can express the views of different viewpoints. This has resulted in the formalisation of propositional defeasible standpoint logic (PDSL). In this paper, we propose a means of lifting the class of (non-monotonic) rational entailment relations from traditional KLM-style reasoning to a fragment of PDSL. In order to do so, we extend the expressivity of PDSL via situated standpoint conditionals, allowing us to talk about a defeasible conditional holding in the context of a given standpoint. This allows us to re-characterise the syntax of PDSL in terms of situated conditionals, and shows that a large fragment of PDSL is expressible as a set of situated conditionals. We then focus on characterising non-monotonic entailment in this fragment, defining a method to transport any ranking-based entailment relation from the propositional case into the PDSL case. This is first described in the general case and then considered in the specific cases of rational and lexicographic closures, providing a faithful translation of each inference into PDSL. We also show that entailment-checking in this fragment of PDSL can be done largely using algorithms from the propositional case, while preserving complexity bounds.
LLM ツール使用における知識ギャップの診断: 新しい API 取得のためのエージェント ベンチマーク
コード生成のための大規模な言語モデルでは、多くの場合、事前トレーニング データに含まれていない API を使用する必要があります。これには、関数名を思い出すだけでは不十分です。モデルは、シグネチャ、モジュール パス、入出力コントラクト、セマンティクス、および実行可能ファイルの使用パターンを調整する必要があります。既存の新規 API ベンチマークは通常、静的であり、大まかな合否メトリクスに依存しているか、実際のライブラリの進化を反映していない可能性がある合成 API を使用しています。 NovelAPIBench は、あらゆるベース モデルおよびターゲット ライブラリに対して、新しい API を検出し、分解された知識バンドルを抽出し、実行可能なコーディング タスクを生成し、失敗したサンプルを 6 つの診断カテゴリに割り当てる、完全に自動化された動的ベンチマークです。約 1.9K のタスク、4 つの基本モデル、5 つのドメインにわたって、検索を通じて注入された知識と、パラメトリック適応を通じて内面化された知識を比較します。ナレッジコンポーネントは互換性がないことがわかりました。使用例は最も強力なスタンドアロンシグナルですが、最良の 2 コンポーネント設定は、ドメインとバックボーンに応じてメカニズムまたはサンプルのいずれかとシグネチャを組み合わせます。コンテキスト、特にソース コードを追加すると、インポート パスのエラーが増加して問題が発生する可能性があります。また、パラメトリック適応は、外部知識が除去された場合には検索に代わるものではありません。むしろ、微調整は主に提供されたバンドルの使用方法をモデルに教え、この機能は保持されたライブラリに転送されます。これらの結果は、取得とチューニングが補完的な役割を果たすことを示唆しています。取得は揮発性の API コンテンツを提供し、チューニングは手続き上の統合を改善します。
原文 (English)
Diagnosing Knowledge Gaps in LLM Tool Use: An Agentic Benchmark for Novel API Acquisition
Large language models for code generation often need to use APIs that are absent from their pretraining data. This requires more than recalling a function name: models must coordinate signatures, module paths, input-output contracts, semantics, and executable usage patterns. Existing novel-API benchmarks are typically static, rely on coarse pass/fail metrics, or use synthetic APIs that may not reflect real library evolution. We introduce NovelAPIBench, a fully automated dynamic benchmark that, for any base model and target library, discovers novel APIs, extracts decomposed knowledge bundles, generates executable coding tasks, and assigns failed samples to six diagnostic categories. Across about 1.9K tasks, four base models, and five domains, we compare knowledge injected through retrieval with knowledge internalized through parametric adaptation. We find that knowledge components are not interchangeable: usage examples are the strongest standalone signal, while the best two-component setting pairs signatures with either mechanisms or examples depending on the domain and backbone. Adding more context, especially source code, can hurt by increasing import-path errors. Parametric adaptation also does not replace retrieval once external knowledge is removed; rather, fine-tuning mainly teaches models how to use provided bundles, and this ability transfers to held-out libraries. These results suggest that retrieval and tuning play complementary roles: retrieval supplies volatile API content, while tuning improves procedural integration.
答えから状態へ: 大規模言語モデルにおける化学推論の検証可能なプロセスレベルの評価
大規模な言語モデルが化学アシスタントとして使用されることが増えていますが、ほとんどの化学ベンチマークは依然として最終的な回答のみをスコアとしています。これにより、重大な故障モードが隠蔽されます。モデルは、その推論が化学ロジックに違反しているにもかかわらず、正しい分子、生成物、またはオプションを出力する可能性があります。 LLM ジャッジと人間のステップレベルのプロセス アノテーションはコストが高く、一貫性がなく、幻覚に対して脆弱であるため、既存のプロセス レベルの評価機能を拡張するのは困難です。 ChemCoTBench-V2 は、構造化され検証者がアドレス指定できる化学推論トレースを低コストで監査可能に評価するためのルール検証可能な診断ベンチマークです。これは、分子理解、分子編集、分子最適化、反応予測に及び、18 のレポートタスクにわたる 5,620 の評価サンプルを備えています。モデルは、専門家が設計したテンプレートで主要な中間ステップを公開する必要があり、それらのステップは決定論的な化学ルールでチェックされ、クローズドアンサータスクの場合は、別の LLM 審査員ではなく参照トレースが使用されます。オープンエンド分子最適化は、厳密なトレース マッチングではなく、Oracle で検証可能な状態制約を使用して評価されます。このベンチマークは、最終回答の正確性、テンプレートの遵守、専門家によって洗練された中間コミットメントに対する段階的な検証者の正確さという 3 つの個別のシグナルを報告します。フロンティア モデルの実験では、最終的な回答の成功と構造化推論の状態の一貫性の間には永続的なギャップがあることが明らかになりました。モデルは多くの場合、化学ステップ チェックに失敗しながらも要求された形式に従っているか、弱い裏付け推論で正しく回答することができます。 ChemCoTBench-V2 は、きめ細かいモデル比較を可能にし、トレースが最初に検証ツールに違反する具体的なステップを特定します。
原文 (English)
From Answers to States: Verifiable Process-Level Evaluation of Chemical Reasoning in Large Language Models
Large language models are increasingly used as chemistry assistants, yet most chemistry benchmarks still score only final answers. This masks a critical failure mode: a model may output the correct molecule, product, or option while its reasoning violates chemical logic. Existing process-level evaluators are hard to scale because LLM judges and human step-level process annotation are costly, inconsistent, and vulnerable to hallucination. We introduce ChemCoTBench-V2, a rule-verifiable diagnostic benchmark for low-cost, auditable evaluation of structured, verifier-addressable chemical reasoning traces. It spans molecular understanding, molecule editing, molecular optimization, and reaction prediction, with 5,620 evaluation samples across 18 reporting tasks. Models must expose key intermediate steps in expert-designed templates, and those steps are checked with deterministic chemistry rules and, for closed-answer tasks, reference traces rather than another LLM judge. Open-ended molecular optimization is evaluated with oracle-verifiable state constraints rather than strict trace matching. The benchmark reports three separate signals: final-answer correctness, template adherence, and step-wise verifier correctness over expert-refined intermediate commitments. Experiments on frontier models reveal a persistent gap between final-answer success and structured-reasoning-state consistency: models often follow the requested format while failing chemical-step checks, or answer correctly with weak supporting reasoning. ChemCoTBench-V2 enables fine-grained model comparison and identifies the concrete step at which the trace first violates the verifier.
EvoDrive: 自己改善型 LLM エージェントによるセーフティ クリティカルな自動運転のパレート進化
安全性が重要なシナリオの生成は、自動運転システムの検証と改善に不可欠ですが、現実性を維持しながら障害を明らかにするには、本質的に敵対性を最大限に高める必要があります。既存の手法は通常、手作りのヒューリスティックによってこのトレードオフを管理し、生成を既知の事前分布に限定し、探索されていないパターンを見逃しています。最近のオープンエンドのエージェント進化はこの限界を押し上げる可能性がありますが、制約のない一般エージェントはシミュレーターの厳密な基礎を欠いており、多目的の緊張を単一スカラーの最大化に崩壊させる傾向があります。ここでは、多目的シナリオ生成のための初の自動化された LLM ベースのエージェント進化フレームワークである EvoDrive を紹介します。 EvoDrive は、シミュレータベースのアクター - クリティカル アーキテクチャを採用しており、メモリ主導のアクターがジェネレーターの改善を繰り返し提案し、クリティカルがありそうもない候補を除外し、自己進化するワールド エバリュエーターが有望な提案をルーティングしてシミュレーション予算を最適化します。 EvoDrive はさらに、評価された候補のパレート アーカイブを維持して、攻撃と現実性のさまざまなトレードオフを維持し、シミュレーション フィードバックを通じて将来の進化を導きます。 MetaDrive と CARLA のベンチマーク結果は、EvoDrive がさまざまなジェネレーターにわたってパレート フロンティアを大幅に拡大するだけでなく、ポリシー トレーニングのための貴重なシナリオも生成することを示しています。
原文 (English)
EvoDrive: Pareto Evolution for Safety-Critical Autonomous Driving via Self-Improving LLM Agents
Generating safety-critical scenarios is essential for validating and improving autonomous driving systems, yet it inherently requires maximizing adversariality to expose failures while preserving realism. Existing methods usually manage this trade-off with handcrafted heuristics, confining generation to known priors and overlooking underexplored patterns. While recent open-ended agentic evolution can push this limit, unconstrained general agents lack strict simulator grounding and tend to collapse the multi-objective tension into single-scalar maximization. Here we present EvoDrive, the first automated, LLM-based agentic evolution framework for multi-objective scenario generation. EvoDrive employs a simulator-grounded actor-critic architecture where a memory-driven actor iteratively proposes improvements to the generators and critics filter out implausible candidates, and a self-evolving world evaluator routes promising proposals to optimize simulation budgets. EvoDrive further maintains a Pareto archive of evaluated candidates to preserve diverse attack-realism trade-offs and guide future evolution via simulation feedback. Benchmark results on MetaDrive and CARLA show that EvoDrive not only significantly expands the Pareto frontier across various generators, but also produces valuable scenarios for policy training.
DeepSpeak-Agentic データセット
私たちは、人間と身体化された AI エージェントの間の 37 時間以上の半構造化された会話で構成されるビデオのデータセットである DeepSpeak-Agentic を紹介します。私たちはこのデータセットを使用して、AI エージェントの自動フォレンジック識別 (音声、ビデオ、またはテキスト) を評価し、人間とエージェントの相互作用の性質を研究し、具現化された AI エージェントを強化する大規模言語モデルと AI によって生成された音声と顔の将来の進歩のためのベンチマークを提供します。また、エージェントを作成し、人間のクラウド ワーカーと自動的にペアリングし、指定されたシナリオ全体で視聴覚会話を記録し、結合されたストリーム内で人間とエージェントを識別して分離する、スケーラブルなデータ キャプチャ システムにも貢献します。
原文 (English)
The DeepSpeak-Agentic Dataset
We present DeepSpeak-Agentic, a dataset of videos comprising over 37 hours of semi-structured conversations between a human and an embodied AI agent. We use this dataset to evaluate the automatic forensic identification (audio, video, or text) of AI agents, study the nature of human-agent interactions, and provide a benchmark for future advances in the large-language models and AI-generated voices and faces that power embodied AI agents. We also contribute a scalable data-capture system that creates agents, automatically pairs them with human crowd workers, records audiovisual conversations across specified scenarios, and identifies and separates the human and agent in the combined stream.
SkillPyramid: 自己進化エージェントのための階層型スキル統合フレームワーク
最近の AI エージェントは、複雑なタスクを解決するためにスキルを柔軟に呼び出すことができますが、体系的なスキルの構築、蓄積、伝達が欠如しているため、その長期的な改善には根本的な制約があります。特に、スキルを統合するための統一されたフレームワークがないと、エージェントは異なるタスクにわたって同様の機能を重複して構築する傾向があり、経験を再利用可能な資産に効果的に変換できず、タスク固有のスキルを新しいシナリオに一般化するのに苦労します。この制限に対処するために、既存のスキル経験を再利用してより広範なタスクを一般化するスキル統合フレームワークである SkillPyramid を提案します。 SkillPyramid は、階層型スキル トポロジで動作し、エージェントがタスクの実行中に新しいスキルを作成、検証、組み込むことを可能にする自己進化メカニズムをさらに導入します。 4 つのバックボーン モデルにわたる ALFWorld、WebShop、および ScienceWorld の実験では、SkillPyramid が平均報酬を 38.0% 大幅に増加させ、実行ステップを 27.7% 削減することが示されました。全体として、私たちの方法は、スキルのコレクションを静的なリソースプールから動的な進化システムに変換します。
原文 (English)
SkillPyramid: A Hierarchical Skill Consolidation Framework for Self-Evolving Agents
Recent AI agents can flexibly invoke skills to solve complex tasks, but their long-term improvement is fundamentally constrained by a lack of systematic skill construction, accumulation, and transfer. In particular, without a unified framework for skill consolidation, agents tend to redundantly construct similar capabilities across different tasks, are unable to effectively transform experience into reusable assets, and struggle to generalize task-specific skills to novel scenarios. To address this limitation, we propose SkillPyramid, a skill consolidation framework that reuses existing skill experience for broader task generalization. Operating on a hierarchical skill topology, SkillPyramid further introduces a self-evolution mechanism that enables agents to compose, validate, and incorporate new skills during task execution. Experiments on ALFWorld, WebShop, and ScienceWorld across four backbone models show that SkillPyramid substantially increases the average reward by 38.0% and reduces execution steps by 27.7%. Overall, our method transforms a skill collection from a static resource pool into a dynamic evolution system.
財務上の意思決定のためのセーフガードとLLM監視による動的な目標の選択
株式の推奨やポートフォリオの配分などの財務上の意思決定タスクでは、通常、将来のリターンとリスクを見積もり、投資家向けの取引や配分を選択します。多くの場合、選択された最適化目標によって実現パフォーマンスが決まります。ただし、市場の状況は時間の経過とともに変化するため、固定された目標はレジーム全体で最適ではない可能性があり、一方で、潜在的なレジームの推定に依存するレジーム切り替えパイプラインにはノイズが多かったり遅延したりする可能性があり、切り替えが頻繁になると売上高が増加し、運用が不安定になる可能性があります。この論文では、中間レジーム変数を導入せずに、最近のリターンの解釈可能な統計的要約から各時点での意思決定に関連する目的関数を直接選択し、少数の候補セット(例:リターン追求型、損失回避型、リスク調整型)の中から選択する、学習ベースのセレクターであるDOSS(セーフガード付き動的目標選択)を提案します。 DOSS は、目的の選択を目的にわたる分類問題として定式化し、ローリング ウィンドウで逐次更新を実行して、一時的な漏れなく将来を見据えた選択を行うと同時に、各提案の信頼スコアも出力します。導入時の選択ミスや過剰なスイッチングを軽減するために、DOSS は、信頼性の低い提案を保守的なデフォルトに上書きし、スイッチング周波数に関連付けられた明示的な制御を強制するフェールセーフを備えた信頼性を認識したゲーティングを適用します。大規模言語モデル (LLM) を新しい目標の生成器ではなく監視コンポーネントとして位置付けることにより、ガバナンスをさらに統合します。LLM は、提案された目標を受け入れるか、事前定義された安全なデフォルトにオーバーライドするように制限されており、必要に応じてオーバーライドをトリガーする決定論的なルールベースの制約が使用されます。
原文 (English)
Dynamic Objective Selection with Safeguards and LLM Oversight for Financial Decision-Making
Financial decision-making tasks such as stock recommendation and portfolio allocation typically estimate future return and risk and then select trades or allocations for an investor, and the chosen optimization objective often determines realized performance. However, because market conditions evolve over time, a fixed objective can be suboptimal across regimes, while regime-switching pipelines that rely on latent regime estimates can be noisy or delayed and frequent switching can increase turnover and operational instability. In this paper, we propose DOSS (Dynamic Objective Selection with Safeguards), a learning-based selector that directly chooses the decision-relevant objective function at each time point from interpretable statistical summaries of recent returns, selecting among a small set of candidates (e.g., return-seeking, loss-averse, and risk-adjusted) without introducing intermediate regime variables. DOSS formulates objective selection as a classification problem over objectives and performs sequential updates with a rolling window to make forward-looking selections without temporal leakage, while also outputting a confidence score for each proposal. To mitigate misselection and excessive switching in deployment, DOSS applies confidence-aware gating with a fail-safe that overrides low-confidence proposals to a conservative default and enforces explicit controls tied to switching frequency. We further integrate governance by positioning a Large Language Model (LLM) as an oversight component rather than a generator of new objectives: the LLM is restricted to accept a proposed objective or override it to a predefined safe default, with deterministic rule-based constraints triggering overrides when needed.
コード・オン・グラフ: ナレッジ・グラフ上の大規模言語モデルを介した反復的なプログラムによる推論
ナレッジ グラフ (KG) は、古い知識や幻覚などの大規模言語モデル (LLM) の制限を軽減するために広く使用されています。既存の LLM-KG 統合フレームワークは通常、事前定義された演算子に依存して、KG から事実の知識を取得し、それを回答生成のプロンプトに挿入します。このパラダイムは、2 つの重大なボトルネックに直面しています。 1) 柔軟性のなさ: 事前定義された演算子の範囲が限られているため、KG の質問で必要とされる複雑な意味論を完全に捉えるための十分な構成表現力が不足しています。 2) 非スケーラビリティ: 事実の知識をプロンプトに直接挿入すると、大規模な事実の知識を処理する際のスケーラビリティが制限されます。これら 2 つのボトルネックに対処するために、LLM-KG 統合のためのプログラム推論フレームワークである Code-on-Graph (CoG) を提案します。具体的には、各推論ステップで取得された事実の知識が与えられると、CoG はまず対応する KG スキーマを特定し、これらのスキーマを Python クラスとして表現します。Python クラスは、取得された事実への抽象インターフェイスとして機能します。次に、これらのクラスに基づいた実行可能コードを生成し、取得したファクトは実行中に対応するクラスのオブジェクトとしてインスタンス化されます。この設計により、プロンプトへの大規模な事実知識の直接注入を回避しながら、柔軟なコードベースの推論が可能になります。 WebQSP、CWQ、および GrailQA の実験では、CoG が以前の最先端のモデルよりも最大 10.5% 優れていることが実証されています。
原文 (English)
Code-on-Graph: Iterative Programmatic Reasoning via Large Language Models on Knowledge Graphs
Knowledge Graphs (KGs) are widely used to mitigate the limitations of Large Language Models (LLMs), such as outdated knowledge and hallucinations. Existing LLM-KG integration frameworks typically rely on predefined operators to retrieve factual knowledge from KGs and inject it into prompts for answer generation. This paradigm faces two critical bottlenecks: 1) Inflexibility: The predefined operators are limited in scope and thus lack sufficient compositional expressiveness to fully capture the complex semantics required by KG questions. 2) Unscalability: Direct injection of factual knowledge into prompts limits scalability in handling large-scale factual knowledge. To address these two bottlenecks, we propose Code-on-Graph (CoG), a programmatic reasoning framework for LLM-KG integration. Specifically, given the factual knowledge retrieved at each reasoning step, CoG first identifies the corresponding KG schemas and represents these schemas as Python classes, which serve as abstract interfaces to the retrieved facts. It then generates executable code grounded in these classes, with the retrieved facts instantiated as objects of the corresponding classes during execution. This design enables flexible code-based reasoning while avoiding the direct injection of large-scale factual knowledge into prompts. Experiments on WebQSP, CWQ, and GrailQA demonstrate that CoG outperforms prior state-of-the-art models by up to 10.5%.
微積分推論の構造を導出グラフで明らかにする
do-calculus は介入クエリの一般的な推論システムを定義し、そのルールを連続的に適用することで因果量を変換できるようにします。このプロセスにより、同等の介入表現の豊富な空間が誘導されますが、これらのルールを組み合わせて順序付けることは依然として困難です。この研究では、do-calculus ルールがどのように適用され結合されるかを表す導出グラフを導入し、do-calculus の下で等価な観察確率と介入確率の全空間を特徴付けます。これらのグラフの構造により、do-calculus ルールの最大 4 つの適用を使用する単純な手順が得られます。最後に、同定アルゴリズムを等価因果クエリに適用すると、同じ因果量に対して複数の有効な推定値が生成され、最終的により効率的な推定量が得られる方法を示します。
原文 (English)
Unveiling the Structure of Do-Calculus Reasoning via Derivation Graphs
The do-calculus defines a general system of inference for interventional queries, allowing causal quantities to be transformed through successive applications of its rules. This process induces a rich space of equivalent interventional expressions, but combining and ordering these rules remains challenging. In this work, we introduce derivation graphs, which represent how do-calculus rules are applied and combined, and characterize the full space of observational and interventional probabilities which are equivalent under the do-calculus. The structure of these graphs yields a simple procedure that uses at most four applications of do-calculus rules. Finally, we show how applying identification algorithms to equivalent causal queries produces multiple valid estimands for the same causal quantity, eventually yielding more efficient estimators.
いつ再計画するか: 階層的潜在推論におけるサブゴールの永続性
長期的な推論では、システムが硬直化することなく中期的な目的にコミットする必要があります。再計画が頻繁に行われすぎると、計算が複数ステップの構造にまとまることはありません。コミットが長すぎると計画が古くなってしまいます。私たちは、この安定性と適応性のトレードオフを潜在推論設定で研究します。この設定では、複数ステップの計算が外部化されたトークン トレースではなく隠れた状態の内部で発生します。私たちは、階層的推論モデル (HRM) を封建的なスタイルのマネージャーとワーカーのインターフェイスで拡張します。遅い高レベルのモジュールは、P 個の低レベル ステップの間持続する正規化された方向サブゴールを定期的に発行し、ワーカーの隠れ状態の更新にバイアスをかけ、固有のコサイン アラインメント損失を提供します。 ARC と ConceptARC では、サブゴールの持続性 (サブゴールの注入だけではなく) が中心のノブであることが分かりました。[3, 6] の中程度の期間 P は、非常に頻繁な (P=1) と非常に長い期間の両方を一貫して上回っており、P=3 で明らかに最小の LM 損失が見られます (P=1、1.640 ベースラインで 1.544 対 1.674、平均 1.595、標準値で 5 つのシードで複製) 0.045)。固有のアライメント重みラムダは、相補的な狭い最適値 (ラムダ約 0.05) を示します。過去のスイートスポットラムダでの制御されたアブレーションは、アライメント信号が最適値を超えたときに、アーキテクチャ上の容量や補助損失だけではなく、学習された指向性構造を干渉源として分離します。これらの発見を総合すると、潜在推論システムにおける構成計画の設計原則が示唆されます。つまり、中程度の地平線の意図は、構成構造を形成するのに十分な計算ステップにわたって首尾一貫していなければなりません。
原文 (English)
When to Re-Plan: Subgoal Persistence in Hierarchical Latent Reasoning
Long-horizon reasoning requires a system to commit to medium-horizon intent without becoming rigid: re-plan too often and computation never coheres into multi-step structure; commit too long and the plan goes stale. We study this stability-adaptivity tradeoff in the latent reasoning setting, where multi-step computation occurs inside hidden state rather than externalized token traces. We extend the Hierarchical Reasoning Model (HRM) with a feudal-style manager-worker interface: a slow high-level module periodically emits a normalized directional subgoal that persists for P low-level steps, biasing the worker's hidden-state updates and supplying an intrinsic cosine alignment loss. On ARC and ConceptARC, we find that subgoal persistence -- not subgoal injection alone -- is the central knob: moderate periods P in [3, 6] consistently outperform both very frequent (P=1) and very long horizons, with a clear minimum LM loss at P=3 (1.544 vs. 1.674 at P=1, 1.640 baseline; replicated over 5 seeds at mean 1.595, std 0.045). The intrinsic alignment weight lambda shows a complementary narrow optimum (lambda approximately 0.05). A controlled ablation at past-sweet-spot lambda isolates learned directional structure -- not architectural capacity or auxiliary loss alone -- as the source of interference when the alignment signal exceeds its optimum. Together these findings implicate a design principle for compositional planning in latent reasoning systems: medium-horizon intent must be coherent across enough computational steps for compositional structure to form.
プルーフ リファクタリング: 生成された正式なプルーフをモジュール型アーティファクトにリファクタリングする
大規模言語モデル (LLM) は形式的な証明の生成において優れたパフォーマンスを示していますが、その出力は多くの場合、成熟した形式的な数学ライブラリの証明に比べて可読性、モジュール性、保守性、再利用性が劣ります。私たちは、このギャップの一部は、ほとんどの証明生成パイプラインに暗黙的に含まれるコンパイル優先の目的に起因しており、ライブラリ品質のアーティファクトではなく、モノリシックまたはアドホック証明スクリプトを奨励していると主張します。証明品質を向上させるための既存のアプローチは、多くの場合、明示的で計算可能な最適化目標に依存しています。ただし、実際には、最も扱いやすく、実験的に検証された目標は主に長さに基づくものですが、可読性、モジュール性、保守性、再利用性などのより高いレベルの品質を信頼できる自動メトリクスに還元するのは困難です。単一のプロキシ メトリクスに対して証明の改善を最適化するのではなく、人間による証明のリファクタリング ワークフローからインスピレーションを得た、プロセスに基づいたアプローチを採用します。私たちは、証明リファクタリングを 4 つのフェーズに分解するエージェント フレームワーク $\textbf{Proof-Refactor}$ を提案します。候補となる証明フラグメントの抽出、ヘルパー宣言の設計、抽出および設計されたコンポーネントの正式な証明、検証されたコンポーネントを使用した元の証明の修復です。 PutnamBench および Putnam2025 から生成されたリーン証明では、Proof-Refactor は、強力なクロード コード リファクタリング ベースラインよりもルーブリック ベースのリファクタリング スコアを改善し、署名の品質と人間の可読性が最大の向上をもたらします。これらの結果は、プロセスガイド付きリファクタリングにより、証明長を主な目的として扱うことなく証明構造を改善できることを示唆しています。
原文 (English)
Proof-Refactor: Refactoring Generated Formal Proofs into Modular Artifacts
While Large Language Models (LLMs) have shown strong performance in generating formal proofs, their outputs often remain less readable, modular, maintainable, and reusable than proofs in mature formal mathematics libraries. We argue that this gap stems in part from the compile-first objective implicit in most proof-generation pipelines, which encourages monolithic or ad hoc proof scripts rather than library-quality artifacts. Existing approaches to proof-quality improvement often rely on explicit, computable optimization objectives. In practice, however, the most tractable and experimentally validated objectives are largely length-based, while higher-level qualities such as readability, modularity, maintainability, and reusability are difficult to reduce to reliable automatic metrics. Instead of optimizing proof improvement against a single proxy metric, we take a process-guided approach inspired by human proof-refactoring workflows. We propose an agentic framework $\textbf{Proof-Refactor}$ that decomposes proof refactoring into four phases: extracting candidate proof fragments, designing helper declarations, formally proving the extracted and designed components, and repairing the original proof using the verified components. On generated Lean proofs from PutnamBench and Putnam2025, Proof-Refactor improves rubric-based refactoring scores over a strong Claude Code refactoring baseline, with the largest gains in signature quality and human readability. These results suggest that process-guided refactoring can improve proof structure without treating proof length as the primary objective.
LAP: 自律科学のためのエージェントから機器へのプロトコル
自律科学はデモンストレーションからインフラストラクチャへと移行しています。現在、大規模な言語モデル エージェントが実験を計画し、自動運転研究所がそれを実行しています。しかし、そのようなシステムはすべて、確率的で目標指向のエージェントではなく、断片化されたベンダー SDK や決定論的なソフトウェア クライアント向けに構築された標準に対して、推論エージェントと物理的機器の間のリンクをゼロから再構築します。最近のエージェント相互運用プロトコルは、エージェント エコシステムの 3 つのエッジのうち 2 つを明確にしています (Anthropic の Model Context Protocol (MCP) はエージェントからツールへのエッジを標準化し、Google の Agent2Agent (A2A) はエージェントからエージェントへのエッジを標準化しています) が、どちらもエージェントから機器へのエッジをモデル化していません。操作はステートフルで、安全性が重要で、排他的に所有され、物理的に具体化され、ユニット、校正、および測定を生成します。不確実性。このギャップを埋めるプロトコル設計である Lab Agent Protocol (LAP) を紹介します。 LAP は、A2A のピアツーピア、ディスカバリーファースト、タスクライフサイクル構造を維持し、次の 4 つの物理世界プリミティブを追加します。(i) InstrumentCard、署名された機能と物理制限の記述。 (ii) 専用機器およびサンプルロックのファーストクラス予約。 (iii) 特定のタスクとそのパラメータに暗号的にバインドされたオペレータ確認トークンを使用したセーフティ フェンス ハンドシェイク。危険で不可逆的な操作をゲートします。 (iv) すべての結果を物理的に型付け (QUDT/UCUM) し、キャリブレーションに固定され、不確実性を保持し、構築によって再現可能にする MeasurementResult スキーマ。役割、6 層アーキテクチャ、JSON-RPC メソッド セット、タスクおよび安全性ステート マシン、エラー モデル、および研究室間のフェデレーションを指定し、プロトコルのエンドツーエンドで閉ループ自律キャンペーンを実行します。 LAP は、A2A/MCP エコシステムとトランスポート互換性があり、SiLA 2 や OPC-UA などの既存のデバイス標準を置き換えるのではなく、カプセル化します。
原文 (English)
LAP: An Agent-to-Instrument Protocol for Autonomous Science
Autonomous science is moving from demonstration to infrastructure. Large language model agents now plan experiments, and self-driving laboratories execute them. Yet every such system rebuilds the link between the reasoning agent and the physical instrument from scratch, against fragmented vendor SDKs and standards built for deterministic software clients rather than probabilistic, goal-directed agents. Recent agent-interoperability protocols clarify two of the three edges of an agentic ecosystem (Anthropic's Model Context Protocol (MCP) standardizes the agent-to-tool edge, and Google's Agent2Agent (A2A) the agent-to-agent edge), but neither models the agent-to-instrument edge, where operations are stateful, safety-critical, exclusively owned, physically embodied, and produce measurements with units, calibration, and uncertainty. We present the Lab Agent Protocol (LAP), a protocol design that fills this gap. LAP retains A2A's peer-to-peer, discovery-first, task-lifecycle structure and adds four physical-world primitives: (i) the InstrumentCard, a signed capability and physical-limit description; (ii) first-class reservation for exclusive instrument and sample locking; (iii) a safety-fence handshake with operator-confirmation tokens cryptographically bound to a specific task and its parameters, gating hazardous and irreversible operations; and (iv) a MeasurementResult schema that makes every result physically typed (QUDT/UCUM), calibration-anchored, uncertainty-bearing, and reproducible by construction. We specify roles, a six-layer architecture, the JSON-RPC method set, the task and safety state machines, the error model, and cross-laboratory federation, and walk a closed-loop autonomous campaign through the protocol end-to-end. LAP is transport-compatible with the A2A/MCP ecosystem and encapsulates rather than replaces existing device standards such as SiLA 2 and OPC-UA.
管理境界から保険金請求まで: CER フレームワークによる AI 媒介損失の再構築
被保険組織の生成 AI システムまたはエージェント AI システムを通じて発生する AI 損失には、システムが推論、取得、ツールの呼び出し、および動作を行うにつれて関連する状態が変化するため、単なるイベントの再構築ではなく、状態の再構築が必要になります。関連する問題は、どのような損失が発生したかだけでなく、システムに何が許可され、実際に何をしたか、そしてその再構築された損失が保険金請求の回復をサポートできるかどうかです。このペーパーでは、プロンプト インジェクション、取得拡張世代 (RAG) ポイズニング、悪意のあるツールの出力、資格情報の悪用、データ ポイズニングなどの外部から引き起こされる障害を含む、被保険者の AI システムが因果関係にある損失について取り上げます。 Specifically, this paper introduces CER, a use-case-level diagnostic for AI residual risk transfer. C (control boundary) asks whether the system had an enforceable operating envelope. E (evidence reconstruction) asks whether the system state and causal chain can be reconstructed from retained artifacts. R (保険応答) は、再構築された損失に保険が適用されているかどうか、つまり、保険金請求の回復をサポートするために必要な証拠とともに、保険が市場で利用可能で被保険者に提供されているかどうかを尋ねます。この論文は 3 つの貢献を行っています。AI 固有の再構築問題を定義し、CER を通じてその問題を運用可能にし、AI 再構築のためのクレームグレードの証拠を指定しています。公的な例としては、報告された PocketOS および Replit エージェントによるデータベース削除事件や、裁定された出力/依存事件としてのモファット対エア・カナダ事件が挙げられます。 Keywords: AI systems; CER framework; residual risk transfer; agentic AI; generative AI; AI insurance; evidence reconstruction.
原文 (English)
From Control Boundary to Insurance Claim: Reconstructing AI-Mediated Losses Through the CER Framework
AI losses that arise through an insured organization's generative or agentic AI system require state reconstruction, not merely event reconstruction, because the relevant state changes as the system reasons, retrieves, calls tools, and acts. The relevant question is not only what loss occurred, but what the system was allowed to do, what it actually did, and whether that reconstructed loss can support insurance claim recovery. This paper addresses losses in which the insured's AI system is in the causal chain, including externally triggered failures such as prompt injection, retrieval-augmented generation (RAG) poisoning, malicious tool output, credential misuse, and data poisoning. Specifically, this paper introduces CER, a use-case-level diagnostic for AI residual risk transfer. C (control boundary) asks whether the system had an enforceable operating envelope. E (evidence reconstruction) asks whether the system state and causal chain can be reconstructed from retained artifacts. R (insurance response) asks whether the reconstructed loss is insured: whether insurance coverage is available in the market and placed for the insured, together with the proof needed to support insurance claim recovery. The paper makes three contributions: it defines the AI-specific reconstruction problem, operationalizes that problem through CER, and specifies claim-grade evidence for AI reconstruction. Public examples include the reported PocketOS and Replit agentic database-deletion incidents and Moffatt v. Air Canada as an adjudicated output/reliance case. Keywords: AI systems; CER framework; residual risk transfer; agentic AI; generative AI; AI insurance; evidence reconstruction.
エージェントによる対話による危険特定分析による操業の安全性の向上
産業用プロセス制御、自律型システム、安全性が重要なシステムなど、一か八かの分野における運用の安全性には、信頼性の高い危険性の特定が必要です。大規模言語モデル (LLM) は、安全分析タスクの自動化に有望であることが示されていますが、シングルターンのモノリシック推論は脆弱です。安全エンジニアが繰り返し適用する自己修正、検討、状況に応じた改良が欠けています。この論文では、構造化されたエージェント対話、マルチエージェント、マルチターン インタラクションが、シングルパス ベースラインよりも NLP ベースのハザード特定の質を向上させるかどうかを調査するフレームワークである HAZDIAL を紹介します。我々は、敵対的な議論と建設的な議論という 2 つの対話様式を系統的に比較し、アルゴリズムベースのエージェント相互作用の最適化を提案します。標準的な分類指標 (精度、精度、再現率、F1) と新しい対話指標を使用して、厳選されたゴールデン データセットに対してすべての構成を評価します。この研究は、対話システム、マルチエージェント推論、AI の安全性の交差点を前進させ、対話主導型の危険分析の経験的証拠を提供します。
原文 (English)
Enhancing Operational Safety via Agentic Dialogue Hazard Identification Analysis
Operational safety in high-stakes domains such as industrial process control, autonomous, and safety-critical systems, demand reliable hazard identification. While large language models (LLMs) have shown promise in automating safety analysis tasks, single-turn, monolithic inference is brittle: it lacks the self-correction, deliberation, and contextual refinement that safety engineers apply iteratively. In this paper, we introduce HAZDIAL, a framework that investigates whether structured agentic dialogue-multi-agent, multi-turn interactions improves the quality of NLP- based hazard identification over single-pass baselines. We systematically compare two dialogue modalities: adversarial debate and constructive discussion, and propose an algorithm-based agentic interaction optimization. We evaluate all configurations against a curated golden dataset using standard classification metrics (accuracy, precision, recall, F1) and novel dialogue metrics. This work advances the intersection of dialogue systems, multi-agent reasoning, and AI safety, providing an empirical evidence for dialogue-driven hazard analysis.
BART を活用して、ルーブリックベースの基準を使用して CS1 C++ プログラミング課題を評価する
この論文では、汎用 LLM よりも講師の採点行動をよりよく反映した成績予測を生成することを目的として、C++ プログラミング入門課題の自動採点のためのトランスフォーマー モデルのルーブリック対応のマルチタスク微調整について調査します。複数学期の CS1 データを使用して、学生の提出物は数値スコア、レターグレード バケット、課題ルーブリックと組み合わせられ、トランスフォーマー入力用の統一されたシーケンスに前処理されます。 LoRA 適応を備えた BART エンコーダ/デコーダは、数値成績と成績バケットを共同で予測するようにトレーニングされ、予測された成績分布と経験的な成績分布を一致させる分布一致項で強化されています。これは、従来の研究では見落とされがちな評価次元でした。実験では、追加の T5 およびペアワイズ事前トレーニングのバリアントを使用して、シングルタスクとマルチタスクのトレーニング、ハード ワンホットとファジーおよび境界ベースのソフト ラベル、ルーブリックとノールーブリック条件を比較します。結果は、境界ベースのソフトラベルとルーブリックコンテキストを備えたマルチタスク BART が、シングルタスク、ハードラベル、またはコードのみのベースラインよりも低い平均絶対誤差と強力な成績分布の調整を達成することを示しています。完全に微調整された T5 により分布の忠実度がさらに向上し、ペアワイズ事前トレーニングにより少数派クラスの感度を犠牲にして数値誤差が削減されます。総合すると、この調査結果は、校正を意識したルーブリックガイド付きトレーニングの方が、精度を最適化した代替トレーニングよりも、よりインストラクターらしい採点行動を生み出すことを示唆しています。
原文 (English)
Leveraging BART to Assess CS1 C++ Programming Assignments using Rubric-based Criteria
This paper investigates rubric-aware, multitask fine-tuning of transformer models for automated grading of introductory C++ programming assignments, with the goal of producing grade predictions that better reflect instructor grading behavior than general-purpose LLMs. Using multi-semester CS1 data, student submissions are paired with numeric scores, letter-grade buckets, and assignment rubrics, then preprocessed into unified sequences for transformer input. A BART encoder-decoder with LoRA adaptation is trained to jointly predict numeric grades and grade buckets, augmented with a distribution-matching term to align predicted and empirical grade distributions, an evaluation dimension often overlooked in prior work. Experiments compare single-task and multitask training, hard one-hot versus fuzzy and boundary-based soft labels, and rubric versus no-rubric conditions, with additional T5 and pairwise-pretrained variants. Results show that multitask BART with boundary-based soft labels and rubric context achieves lower mean absolute error and stronger grade-distribution alignment than single-task, hard-label, or code-only baselines. Fully fine-tuned T5 further improves distributional fidelity, while pairwise pretraining reduces numeric error at the cost of minority-class sensitivity. Collectively, the findings suggest that calibration-aware, rubric-guided training produces more instructor-like grading behavior than accuracy-optimized alternatives.
遺伝的最適化によるまばらな道路観察からの都市交通シミュレーションの校正
都市交通シミュレーションは、電気自動車の充電ステーションの配置を含むインフラ計画にとって重要なツールです。しかし、多くの都市にわたる現実的な交通シミュレーションは、2 つの基本的なデータ制限によって妨げられています。1 つは、詳細な現実世界の交通測定が、ほとんどの都市の道路セグメントのごく一部でしか利用できないこと、もう 1 つは、通勤交通のモデリングに重要な雇用分布データが、シミュレーションに必要な解像度で利用できることがほとんどないことです。この論文では、両方の制限に直接対処し、詳細な勤務場所データを必要とせずに、まばらな道路観察から都市交通シミュレーションを調整する遺伝的アルゴリズムベースのフレームワークを紹介します。ノースカロライナ州グリーンズボロの SUMO 交通シミュレーション プラットフォームを使用する当社のアプローチでは、ジョブの分布とゲート交通パラメータを最適化し、既知の交通流量を持つ道路の少数のサンプルとシミュレートされた交通を調整します。我々は、このアプローチが現実世界の測定値とよく相関するシミュレートされた交通量を生成し、トレーニングから除外された道路セグメントに一般化し、その雇用データに基づいて直接トレーニングしたことがないにもかかわらず、国勢調査の雇用データと確実に質的一致を示す雇用分布を生成することを実証します。この研究は、現実的な都市交通シミュレーションが最小限の実世界の観察から実現できることを実証し、多様な都市にわたって交通モデルを展開する際の障壁を減らす、スケーラブルでデータライトのシミュレーション キャリブレーション アプローチを提供します。
原文 (English)
Calibrating Urban Traffic Simulation from Sparse Road Observations via Genetic Optimization
Urban traffic simulation is a critical tool for infrastructure planning, including the placement of electric vehicle charging stations. However, realistic traffic simulation across many cities is hindered by two fundamental data limitations: detailed real-world traffic measurements are available for only a small fraction of road segments in most cities, and employment distribution data critical for modeling commuter traffic is rarely available at the resolution needed for simulation. This paper presents a genetic algorithm-based framework that directly addresses both limitations, calibrating urban traffic simulations from sparse road observations without requiring detailed job location data. Using the SUMO traffic simulation platform for Greensboro, North Carolina, our approach optimizes job distributions and gate-traffic parameters to align simulated traffic with a small sample of roads with known traffic-flow rates. We demonstrate that this approach produces simulated traffic that correlates well with real-world measurements, generalizes to road segments withheld from training, and produces job distributions that show promising qualitative agreement with census employment data despite never directly training on that employment data. This work demonstrates that realistic urban traffic simulation can be achieved from minimal real-world observations, offering a scalable and data-light approach to simulation calibration that reduces the barrier to deploying traffic models across diverse cities.
BigFinanceBench: 金融調査エージェント向けのワークフローに基づいたベンチマーク
財務調査の回答は、他のアナリストがその回答がどのように作成されたか、つまりどの情報源が選択されたか、どの期間と会計定義が使用されたか、どのような仮定が行われたか、および計算がどのように実行されたかを監査できる場合にのみ、意思決定に関連します。既存の財務ベンチマークは主に、個別のサブスキルまたは最終的な回答を評価しており、監査可能な導出自体は十分に評価されていません。 BigFinanceBench は、オープンエンドの金融調査タスクの 928 項目の専門家が作成したベンチマークです。このベンチマークでは、各項目が、真実の参照回答と、導出を独立してチェック可能なステップに分解するポイント加重ルーブリックとが組み合わされます。 BigFinanceBench は、最終出力だけではなく完全な導出を評価するという点でワークフローに基づいています。このベンチマークは、36,241 のルーブリック ポイントにわたって、部分信用評価とアナリストのワークフロー全体での失敗の局所特定をサポートします。現在のフロンティアおよびオープンウェイト エージェント 10 社を評価したところ、かなりの余裕があることがわかりました。最高のシステムでもルーブリック スコアは 58.8% にすぎず、最終回答の精度は有用ですが、導出品質の損失が大きく、モデルの能力は財務ワークフロー全体で不均一に異なります。
原文 (English)
BigFinanceBench: A Workflow-Grounded Benchmark for Financial-Research Agents
Financial-research answers are decision-relevant only when another analyst can audit how they were produced: which source was chosen, which period and accounting definition were used, which assumptions were made, and how the calculation was performed. Existing finance benchmarks largely evaluate isolated subskills or final answers, leaving the auditable derivation itself under-measured. We introduce BigFinanceBench, a 928-item expert-authored benchmark of open-ended financial-research tasks in which each item pairs a ground-truth reference answer with a point-weighted rubric that decomposes the derivation into independently checkable steps. BigFinanceBench is workflow-grounded in that it evaluates the full derivation rather than only the final output. Across 36,241 rubric points, the benchmark supports partial-credit evaluation and localization of failures across the analyst workflow. Evaluating ten current frontier and open-weight agents, we find substantial headroom: the best system reaches only 58.8% rubric score, final-answer accuracy is a useful but lossy proxy for derivation quality, and model capability varies non-uniformly across financial workflows.
EvoDS: スキル学習とコンテキスト管理を備えた自己進化する自律型データ サイエンス エージェント
大規模言語モデル (LLM) エージェントの最近の進歩により、自動データ サイエンスにおける有望な進歩が可能になりました。しかし、既存のアプローチは、静的なアクション セットと原則に基づいた長期的なコンテキスト管理の欠如によって根本的に制限されたままであり、タスク全体で再利用可能なエクスペリエンスを蓄積し、多段階の反復的なデータ サイエンス パイプラインで確実に動作する能力を妨げています。これらの課題に対処するために、エージェント強化学習を通じてスキルを拡張し、長期的なコンテキストを適応的に管理することを学習する、自己進化する自律型データ サイエンス エージェントである EvoDS を導入します。具体的には、EvoDS は 2 つの重要な戦略を導入しています。(1) 自律スキル取得 (ASA) メカニズム。エージェントが実行可能なスキルを合成、検証、再利用できるようにします。 (2) 適応コンテキスト圧縮 (ACC) 戦略。これは、コンテキスト管理を受動的切り捨てではなく、学習された制御問題として扱います。これらの戦略は 2 段階のマルチエージェント トレーニング スキーム内で調整され、EvoDS が時間の経過とともに自律的に改善できるようになります。理論的には、EvoDS の階層設計によりツール選択エラーが軽減され、その最適化目標が情報ボトルネックの原則と一致し、効率的なコンテキストの使用が保証されることが証明されています。経験的に、EvoDS は、トークン不足の障害を排除しながら、4 つの多様なベンチマークにわたって、最先端のオープンソース データ サイエンス エージェントよりも平均 28.9% 優れたパフォーマンスを示します。コードとデータは https://github.com/usail-hkust/EvoDS で入手できます。
原文 (English)
EvoDS: Self-Evolving Autonomous Data Science Agent with Skill Learning and Context Management
Recent progress in Large Language Model (LLM) agents has enabled promising advances in automated data science. However, existing approaches remain fundamentally limited by their static action sets and lack of principled long-horizon context management, hindering their ability to accumulate reusable experience across tasks and operate reliably in multi-stage, iterative data science pipelines. To address these challenges, we introduce EvoDS, a self-evolving autonomous data science agent that learns to expand its skills and adaptively managing long-term context through agentic reinforcement learning. Specifically, EvoDS introduces two key strategies: (1) Autonomous Skill Acquisition (ASA) mechanism, which enables agents to synthesize, validate, and reuse executable skills; and (2) Adaptive Context Compression (ACC) strategy, which treats context management as a learned control problem rather than passive truncation. These strategies are orchestrated within a two-stage multi-agent training scheme, enabling EvoDS to autonomously improve over time. Theoretically, we prove that EvoDS's hierarchical design reduces tool-selection error, and its optimization objective aligns with an information bottleneck principle, ensuring efficient context use. Empirically, EvoDS outperforms state-of-the-art open-source data science agents by an average of 28.9% across four diverse benchmarks while eliminating out-of-token failures. Our code and data are available at https://github.com/usail-hkust/EvoDS.
PyraMathBench: 大規模言語モデルの数学的能力の評価と改善
アプリケーション全体にわたる大規模言語モデル (LLM) の数学的機能の基礎として数値推論が極めて重要な役割を果たしているにもかかわらず、数値処理と数学的推論を統合して LLM を評価するベンチマークはほとんどなく、数学タスクにおける失敗の解釈可能性を妨げています。 PyraMathBench は、4 つの主要な認知的側面、14 のサブカテゴリ、および 2 つのモダリティにまたがる、7,404 の数学文章題から派生した 32,505 の質問を含む包括的な階層ベンチマークです。実験の結果、LLM のパフォーマンスは、不適切な数値計算と抽象的な数値質問の処理が不十分なため、著しく損なわれることが明らかになりました。これに対処するために、我々は、Smart Optimization & Learning-based VErsatile module (SOLVE) と Interactive Relative Policy Optimization (IRPO) を提案します。これらは、効率的なツール呼び出し (ファジーマッチングと低品質通話拒否) を通じて LLM の数値数学的相乗効果を強化します。比較実験では、Qwen-2.5 が SOLVE および IRPO トレーニングにより 5.0 スコアの向上を達成したことが示されています。
原文 (English)
PyraMathBench: Evaluating and Improving Mathematical Capability in Large Language Models
Despite the pivotal role of numerical reasoning as the cornerstone of mathematical capabilities in large language models (LLMs) across applications, few benchmarks evaluate LLMs by integrating numerical processing and mathematical reasoning, hindering the interpretability of failures in math tasks. We introduce PyraMathBench, a comprehensive hierarchical benchmark with 32,505 questions derived from 7,404 math word problems, spanning 4 key cognitive aspects, 14 subcategories, and 2 modalities. Experiments reveal that LLMs' performance is severely compromised by inadequate numerical computation and weak handling of abstract numerical questions. To address this, we propose the Smart Optimization & Learning-based VErsatile module (SOLVE) and Interactive Relative Policy Optimization (IRPO), which enhance LLMs' numerical-mathematical synergy via efficient tool calls (fuzzy matching and low-quality call rejection). Comparative experiments show Qwen-2.5 achieves a 5.0 score improvement with SOLVE and IRPO training.
大規模言語モデルの推論構造
大規模推論モデル (LRM) は、多くの場合、最終回答の精度やトークン数などの指標を使用して評価されます。ただし、これらの指標のスコアが同じであっても、根本的に異なる推論構造が隠蔽される可能性があります。この制限に対処するために、論理パズルのスケーラブルな LRM ベンチマークと、非構造化トレースをクレームと依存関係の検証可能な推論グラフに変換するパイプラインを導入します。これにより、推論が、トポロジーを定量的に分析できる構造化された測定可能なオブジェクトに変わります。これに基づいて、モデルの論理フローがどの程度集中しているかを定量化する推論効率メトリックを定義します。オープンソース推論モデルに関する私たちの分析では、構造測定によってトークン数と精度が混同される動作を分離し、障害モードを診断し、パズルの難易度に応じて推論がどのようにスケールされるかを比較するための実用的なツールが提供されることが示されています。
原文 (English)
Reasoning Structure of Large Language Models
Large reasoning models (LRMs) are often evaluated using metrics such as final-answer accuracy or token count. However, identical scores on these metrics can hide fundamentally different reasoning structures. To address this limitation, we introduce a scalable LRM benchmark of logic puzzles and a pipeline that converts unstructured traces into verifiable reasoning graphs of claims and dependencies. This turns reasoning into a structured, measurable object whose topology can be quantitatively analyzed. Building on this, we define a reasoning efficiency metric that quantifies how concentrated the model's logical flow is. Our analysis on open-source reasoning models shows that structural measurements separate behaviors that token count and accuracy conflate, providing a practical tool for diagnosing failure modes and comparing how reasoning scales with puzzle difficulty.
scTranslation: 単一細胞マルチオミクスモダリティ翻訳の包括的なベンチマーク
単一細胞における複数のオミクスモダリティを同時に測定することで、研究者は細胞の状態と制御機構をより包括的に理解できるようになります。しかし、高額な実験コスト、重大なノイズ、不完全なモダリティ カバレッジのため、近年、モダリティ変換のためのさまざまな計算手法が登場しています。翻訳モデルの開発にもかかわらず、データセット、評価指標、影響要因の観点から体系的なベンチマーク評価がまだ不足しています。これに対処するために、単一細胞マルチオミクスモダリティ翻訳タスクの包括的なベンチマークである scTranslation を紹介します。これには、多様な翻訳データセットが含まれ、最先端のモデルが統合され、包括的な評価指標が提供されます。さらに、特徴の選択、特徴の品質、少数ショット設定など、さまざまなシナリオの下でモデルのパフォーマンスを評価します。これらの要因はモデルのパフォーマンスに大きな影響を与えますが、これまで体系的に研究されたことはほとんどありませんでした。このベンチマークを活用して、私たちは現在の手法の大規模な研究を実施し、将来の開発の新たな可能性を開く洞察力に富んだ多くの発見を報告します。このベンチマークは、将来の研究を促進するためにオープンソース化されています。コードは https://github.com/Bunnybeibei/scTranslation で匿名で公開されています。
原文 (English)
scTranslation: A Comprehensive Benchmark for Single-Cell Multi-Omics Modality Translation
Simultaneous measurement of multiple omics modalities in single cells enables researchers to gain a more comprehensive understanding of cellular states and regulatory mechanisms. However, due to high experimental costs, significant noise, and incomplete modality coverage, a variety of computational methods for modality translation have emerged in recent years. Despite the development of translation models, there is still a lack of systematic benchmark evaluation in terms of datasets, evaluation metrics, and influencing factors. To address this, we present scTranslation, a comprehensive benchmark for single-cell multi-omics modality translation tasks. It includes diverse translation datasets, integrates state-of-the-art models, and provides a comprehensive evaluation metrics. In addition, we assess model performance under different scenarios, such as feature selection, feature quality, and few-shot settings. These factors significantly affect model performance but have rarely been systematically studied before. Leveraging this benchmark, we conduct a large-scale study of current methods, report many insightful findings that open up new possibilities for future development. The benchmark is open-sourced to facilitate future research. The code is anonymously released at https://github.com/Bunnybeibei/scTranslation.
ヘッジベンチ: 財務上の推論に関する困難で現実的なタスクに関するエージェントのベンチマーク
AI エージェントは、文書の取得、数式の計算、スプレッドシートの更新など、財務分析の機械的なタスクを処理できるようになってきています。より難しく、より価値のある課題は、専門アナリストの仕事を定義する自由形式の質問を通じて推論することです。既存のベンチマークはこの種の問題を捉えておらず、オープンエンド推論を評価しようとするベンチマークは、ノイズと循環性を導入するモデルで判断された出力に依存しています。私たちは Hedge-Bench 1.0 を紹介します。これは、関連する情報ソースを使用して作業するプロのヘッジファンド アナリストの明確な推論トレースに基づいた 102 の実際の実務タスクのベンチマークです。このアプローチにより、検証された専門家のステップに対して決定的なグレーディングが可能になります。フロンティア モデルとエージェントのベンチマーク スコアは 16\% 未満です。データセットと評価ハーネスは github.com/Trata-Inc/trata-hedge-bench で公開しています。
原文 (English)
Hedge-Bench: Benchmarking Agents on Hard, Realistic Tasks Pertaining to Financial Reasoning
AI agents can increasingly handle the mechanical tasks of financial analysis: retrieving documents, calculating formulas, updating spreadsheets. The harder, more valuable challenge is reasoning through the open-ended questions that define expert Analyst work. Existing benchmarks do not capture this class of problem, and those that attempt to evaluate open-ended reasoning rely on model-judged outputs that introduce noise and circularity. We present Hedge-Bench 1.0: a benchmark of 102 actual, on-the-job tasks grounded in the explicit reasoning traces of professional hedge fund analysts working with relevant information sources. This approach enables deterministic grading against verified expert steps. Frontier models and agents score below 16\% on the benchmark. We publish the dataset and evaluation harness at github.com/Trata-Inc/trata-hedge-bench.
エントロピーだけでは不十分: ビジョンに基づいたトークン選択による視覚的推論のための効果的な強化学習のロックを解除する
トークンレベルのエントロピーは、検証可能な報酬を伴うテキストのみの強化学習 (RLVR) における単位の割り当てに有効であると一般に認識されていますが、このメカニズムが視覚的推論に依然として適用されるかどうかは不明のままです。私たちの対照的な研究は、自然にエントロピーが低い視覚に敏感なトークンの省略により、視覚推論ではこのメカニズムが崩壊することを示しています。既存のマルチモーダル RL 手法は、視覚認識の重要性をますます認識していますが、体系的な視覚測定が欠けているか、トークンのエントロピーが主に意味論的探索を推進していることを見落としているため、正確な知覚基礎と意味論的推論を交互に配置するという固有の需要を満たすのに苦労しています。これに対処するために、原則的な乗算結合を介して視覚的感度とトークン エントロピーを明示的に統合する効果的な RL フレームワークである VEPO (ポリシー最適化のためのビジョン エントロピー トークン選択) を導入します。VEPO は、視覚的に根拠があり、同時に高度に情報を提供するトークンに勾配クレジットをリダイレクトします。広範な実験により、VEPO の優れたパフォーマンスが実証され、エントロピーのみのベースラインを 7B スケールで 2.28 ポイント、3B スケールで 3.15 ポイント上回りました。アブレーションは、私たちの方法の健全性をさらに実証します。
原文 (English)
Entropy Is Not Enough: Unlocking Effective Reinforcement Learning for Visual Reasoning via Vision-Anchored Token Selection
While token-level entropy is commonly recognized as effective for credit assignment in text-only reinforcement learning with verifiable rewards (RLVR), it remains unclear whether this mechanism still holds in visual reasoning. Our controlled study shows that this mechanism collapses in visual reasoning due to the omission of vision-sensitive tokens with naturally low entropy. Although existing multimodal RL methods increasingly acknowledge the importance of visual perception, they struggle to satisfy the inherent demand for interleaving precise perceptual grounding with semantic reasoning, either lacking systematic visual measurements or overlooking that token entropy primarily drives semantic exploration. To address this, we introduce VEPO (Vision-Entropy token-selection for Policy Optimization), an effective RL framework explicitly integrating visual sensitivity with token entropy via a principled multiplicative coupling, where VEPO redirects gradient credit toward tokens which are simultaneously visually grounded and highly informative. Extensive experiments demonstrate VEPO's leading performance, significantly outperforming the entropy-only baseline by 2.28 points at 7B-scale and 3.15 points at 3B-scale. Ablations further substantiate the soundness of our method.
想像力の知覚トークンはマルチモーダル言語モデルの空間推論を強化します
ビジョン言語モデル (VLM) は多くのタスクに優れていますが、重要な情報が直接観察できない場合には空間推論に依然として苦労します。このような問題の多くは、目に見えない視点から何が見えるかを推測したり、遮蔽された空間を通る経路を追跡したり、部分的な観察を一貫した空間表現に統合したりするなど、想像力豊かな認識を必要とします。観察された入力との一貫性を保ちながら、代替の空間構成の下で VLM が知覚するものを外部化する中間的な知覚表現である想像的知覚トークン (IPT) を導入します。この機能を研究するために、透視図法取得 (PET)、パス トレーシング (PT)、およびマルチビュー カウンティング (MVC) という 3 つのタスクを定式化し、グラウンド トゥルースの想像力、回答、評価ベンチマークを含む約 20,000 例のデータセットを構築します。統合された VLM BAGEL をバックボーンとして使用することで、IPT 監視は空間推論を一貫して改善し、推論時に画像を生成しなくても、テキストによる思考連鎖トレーニングを上回ることがよくあります。 MVC では、IPT は精度を 3.4% 向上させ、PT 上の強力なクローズドソース モデルにより競争力のあるパフォーマンスを実現します。さらに、IPT とラベルのみの監視を組み合わせるとさらなる利益が得られる一方、テキストの思考連鎖はパフォーマンスを大幅に低下させる可能性があることがわかり、空間計算が言語を通じて強制される場合にはモダリティの不一致が示唆されます。全体として、IPT は、観察されていない空間構造について推論するための原則に基づいた監視信号を提供し、解釈可能な中間表現を生成しながら一般化を向上させます。
原文 (English)
Imaginative Perception Tokens Enhance Spatial Reasoning in Multimodal Language Models
Vision language models (VLMs) excel at many tasks but still struggle with spatial reasoning when critical information is not directly observable. Many such problems require imaginative perception: inferring what would be seen from an unseen viewpoint, tracing paths through occluded spaces, or integrating partial observations into a coherent spatial representation. We introduce Imaginative Perception Tokens (IPT), intermediate perceptual representations that externalize what a VLM would perceive under alternative spatial configurations while remaining consistent with the observed input. To study this capability, we formulate three tasks, Perspective Taking (PET), Path Tracing (PT), and Multiview Counting (MVC), and construct datasets of approximately 20K examples with ground truth imaginations, answers, and evaluation benchmarks. Using the unified VLM BAGEL as the backbone, IPT supervision consistently improves spatial reasoning and often outperforms textual chain of thought training, even without generating images at inference time. On MVC, IPT improves accuracy by 3.4% and achieves competitive performance with strong closed-source models on PT. We further find that combining IPT and label-only supervision yields additional gains, whereas textual chain of thought can substantially degrade performance, suggesting a modality mismatch when spatial computation is forced through language. Overall, IPT provides a principled supervision signal for reasoning about unobserved spatial structure, improving generalization while producing interpretable intermediate representations.
TRAP: 敵対的パッチによる VLA CoT Reasoning のハイジャック
思考連鎖 (CoT) 推論を統合することにより、ビジョン言語アクション (VLA) モデルは、特に一般化と解釈可能性を向上させることで、ロボット操作における強力な能力を実証しました。ただし、CoT ベースの推論メカニズムのセキュリティはほとんど調査されていないままです。この論文では、CoT 推論が、ユーザーの指示を変更することなく、標的を絞った行動ハイジャック (たとえば、ロボットにリンゴではなく誤ってナイフを人間に届けさせる) のための新しい攻撃ベクトルを導入することを示します。我々はまず、入力命令と意味的にずれている場合でも、CoT がアクション生成を強力に支配するという経験的証拠を提供します。この観察に基づいて、CoT 推論 VLA モデルに対する最初の標的型行動ハイジャック敵対攻撃である TRAP を提案します。 TRAP は、推論からアクションへの経路をターゲットにすることで、敵対的パッチ (テーブルの上に置かれたテーブルクロスなど) を使用して、中間の CoT 推論と下流のアクションを敵対者が定義した動作に向けます。異なる CoT 推論メカニズムにわたる 3 つの代表的な推論 VLA に関する広範な評価により、TRAP の有効性が実証されています。特に、現実世界の設定で紙に印刷してパッチを実装しました。私たちの調査結果は、VLA システムにおける CoT 推論を保護する緊急の必要性を浮き彫りにしています。プロジェクト ページは https://zhengxian-huang.github.io/TRAP-website/ で利用できます。
原文 (English)
TRAP: Hijacking VLA CoT-Reasoning via Adversarial Patches
By integrating Chain-of-Thought (CoT) reasoning, Vision-Language-Action (VLA) models have demonstrated strong capabilities in robotic manipulation, particularly by improving generalization and interpretability. However, the security of CoT-based reasoning mechanisms remains largely unexplored. In this paper, we show that CoT reasoning introduces a novel attack vector for targeted behavior hijacking--for example, causing a robot to mistakenly deliver a knife to a person instead of an apple--without modifying the user's instruction. We first provide empirical evidence that CoT strongly governs action generation, even when it is semantically misaligned with the input instructions. Building on this observation, we propose TRAP, the first targeted behavior-hijacking adversarial attack against CoT-reasoning VLA models. By targeting the reasoning-to-action pathway, TRAP uses an adversarial patch (e.g., a tablecloth placed on the table) to steer intermediate CoT reasoning and downstream actions toward adversary-defined behaviors. Extensive evaluations on three representative reasoning VLAs, spanning distinct CoT reasoning mechanisms, demonstrate the effectiveness of TRAP. Notably, we implemented the patch by printing it on paper in a real-world setting. Our findings highlight the urgent need to secure CoT reasoning in VLA systems. The project page is available at https://zhengxian-huang.github.io/TRAP-website/.
RAG におけるコストを意識したクエリ ルーティング: 取得深さのトレードオフの実証分析
取得拡張生成 (RAG) は基本的な 3 方向の緊張に直面しています。つまり、より深く取得すると事実に基づく根拠が向上しますが、トークン コストとエンドツーエンドの遅延が増大します。静的取得構成では、異種クエリ ワークロード全体にわたるこの緊張を解決できません。単純な定義クエリは不要なコンテキストに予算を浪費し、複雑な分析プロンプトは浅い取得によって十分なサービスを受けられません。この論文では、\emph{戦略バンドル} の離散カタログから選択するクエリごとのルーティング フレームワークである \emph{Cost-Aware RAG} (CA-RAG) を紹介します。各カタログは、推定された事前品質と正規化されたペナルティを線形に結合するスカラー ユーティリティを最大化することで、取得深さ (取得不要の直接推論から上位 $k{=}10$ の高密度取得まで) と固定世代プロファイルを結合します。予測されるレイテンシと請求されたトークンの合計について。 CA-RAG は、FAISS 支援の高密度取得および OpenAI チャット/埋め込み API を使用して実装され、4 つのバンドルにわたる 28 クエリのベンチマークで評価されます。ルーターはすべてのバンドルを動的に実行し、同等の応答品質を維持しながら、常時大量の取得より \textbf{26\% 少ない請求トークン} と、常時直接推論より \textbf{34\% 低い平均レイテンシー} を実現します。クエリごとのデルタ分析により、節約が不均一で単純なクエリに集中していることが明らかになり、複雑さを意識したガードレールが導入されます。感度分析により、同じバンドル カタログが重み調整だけで複数のコスト、レイテンシ、品質の動作ポイントをサポートしていることが確認されます。すべての結果は、完全な再現性を実現するために、記録された CSV アーティファクトから直接生成されます。 CA-RAG は、コストを意識した LLM 導入のための透明で監査可能な基盤を提供します。
原文 (English)
Cost-Aware Query Routing in RAG: Empirical Analysis of Retrieval Depth Tradeoffs
Retrieval-augmented generation (RAG) faces a fundamental three-way tension: deeper retrieval improves factual grounding but inflates token costs and end-to-end latency. Static retrieval configurations cannot resolve this tension across heterogeneous query workloads -- simple definitional queries waste budget on unnecessary context, while complex analytical prompts are underserved by shallow retrieval. This paper introduces \emph{Cost-Aware RAG} (CA-RAG), a per-query routing framework that selects from a discrete catalog of \emph{strategy bundles} -- each coupling a retrieval depth (from retrieval-free direct inference to top-$k{=}10$ dense retrieval) with a fixed generation profile -- by maximizing a scalar utility that linearly combines an estimated quality prior with normalized penalties for predicted latency and total billed tokens. CA-RAG is implemented with FAISS-backed dense retrieval and OpenAI chat/embedding APIs, and evaluated on a 28-query benchmark spanning four bundles. The router dynamically exercises all bundles, achieving \textbf{26\% fewer billed tokens} than always-heavy retrieval and \textbf{34\% lower mean latency} than always-direct inference while maintaining equivalent answer quality. Per-query delta analysis reveals that savings are non-uniform and concentrated in simpler queries, motivating complexity-aware guardrails. Sensitivity analysis confirms that the same bundle catalog supports multiple cost-latency-quality operating points through weight adjustment alone. All results are generated directly from logged CSV artifacts for full reproducibility. CA-RAG provides a transparent, auditable foundation for cost-conscious LLM deployments.
IdiomX イディオムの理解、検索、解釈のための多言語ベンチマーク
慣用表現は、その意味が非構成的で文脈に依存することが多く、言語間で調整することが難しいため、自然言語処理にとって依然として根強い課題となっています。既存のイディオム リソースは、多くの場合、規模、文脈の多様性、または多言語の範囲が制限されており、最新の言語モデルでの有用性が制限されています。 IdiomX は、イディオムの理解、検索、解釈のための大規模な多言語ベンチマークであり、語彙リソースの抽出、大規模な正規化、制御された大規模な言語モデルの強化、構造化検証を組み合わせた再現可能な多段階パイプラインを通じて構築されています。結果として得られるデータセットには、12,000 以上のイディオムにわたる 190,000 を超える文脈化された例が含まれており、英語、アラビア語、フランス語の意味表現、慣用的および文字通りの用法ラベル、および豊富な言語メタデータが整列して含まれています。このリソースに基づいて、イディオムの検出、文脈からイディオムへの検索、アラビア語から英語へのイディオムの検索、およびイディオムの解釈をカバーする統一された 4 つのタスクのベンチマークを定義し、比喩的な認識から意味論的な根拠と説明可能な意味の検索まで評価を拡張します。実験の結果、文脈変換モデルによってイディオム検出が大幅に向上し、ハイブリッド検索および再ランキング アーキテクチャによって単一言語および複数言語間の両方のイディオム検索が大幅に強化されることが示されました。結果はさらに、イディオム解釈が意味検索タスクとして効果的にモデル化され、補完的なベンチマーク次元として解釈可能性を導入できることを示しています。全体として、IdiomX は、検出から検索および意味解釈への進行として慣用言語を研究するためのスケーラブルなベンチマークを提供し、追加の言語や比喩的推論タスクに拡張可能なモジュール式フレームワークを提供します。
原文 (English)
IdiomX A Multilingual Benchmark for Idiom Understanding, Retrieval, and Interpretation
Idiomatic expressions remain a persistent challenge for natural language processing because their meanings are often non-compositional, context-dependent, and difficult to align across languages. Existing idiom resources are often limited in scale, contextual diversity, or multilingual coverage, restricting their utility for modern language models. We introduce IdiomX, a large-scale multilingual benchmark for idiom understanding, retrieval, and interpretation, constructed through a reproducible multi-stage pipeline combining lexical resource extraction, large-scale normalization, controlled large language model enrichment, and structured validation. The resulting dataset contains over 190K contextualized examples spanning 12K+ idioms, with aligned English, Arabic, and French semantic representations, idiomatic and literal usage labels, and rich linguistic metadata. Building on this resource, we define a unified four-task benchmark covering idiom detection, context-to-idiom retrieval, Arabic-to-English idiom retrieval, and idiom interpretation, extending evaluation from figurative recognition to semantic grounding and explainable meaning retrieval. Experiments show that contextual transformer models substantially improve idiom detection, while hybrid retrieval and reranking architectures significantly strengthen both monolingual and cross-lingual idiom retrieval. Results further demonstrate that idiom interpretation can be effectively modeled as a semantic retrieval task, introducing interpretability as a complementary benchmark dimension. Overall, IdiomX provides a scalable benchmark for studying idiomatic language as a progression from detection to retrieval and semantic interpretation, and offers a modular framework extensible to additional languages and figurative reasoning tasks
Lean-GAP: 形式化された大学院代数問題のデータセット
私たちは、Dummit と Foote の教科書 Abstract Algebra からの 430 の形式化された大学院レベルの代数問題である Lean-GAP (Lean-Graduate Agebra 問題) を紹介します。 PDF から LaTeX への前処理、Lean 4 への自動形式化、非公式と公式の対応の検証から構成されるスケーラブルなパイプラインを開発します。前処理と自動形式化の段階は大幅に自動化できますが、検証は依然として最も微妙で労働集約的なコンポーネントであり、人間による慎重な監視が必要であることがわかりました。私たちの貢献には、(i) 形式化された演習の構造化データセットの構築、(ii) 教科書数学を形式化するための体系的な方法論、および (iii) 形式化プロセスで繰り返し発生する課題の分析が含まれます。また、さまざまな自動形式化モデルのパフォーマンスを比較し、非形式的なステートメントを形式的な言語に変換する際の主要なボトルネックを明らかにします。
原文 (English)
Lean-GAP: A Dataset of Formalized Graduate Algebra Problems
We present Lean-GAP (Lean-Graduate Agebra Problems), 430 formalized graduate-level algebra problems from the textbook Abstract Algebra by Dummit and Foote. We develop a scalable pipeline consisting of PDF-to-LaTeX preprocessing, autoformalization into Lean 4, and verification of informal-formal correspondence. While the preprocessing and autoformalization stages can be largely automated, we find that verification remains the most subtle and labor-intensive component, requiring careful human oversight. Our contributions include (i) the construction of a structured dataset of formalized exercises, (ii) a systematic methodology for formalizing textbook mathematics, and (iii) an analysis of recurring challenges in the formalization process. We also compare the performance of different autoformalization models and highlight key bottlenecks in translating informal statements into formal language.
Sentinel-5P 衛星データを使用した都市の大気汚染物質の追跡
都市の二酸化窒素($NO_2$)は燃焼関連の大気汚染の重要な指標であり、都市では強い空間的および時間的変動を示します。この研究は、エクアドルのグアヤス州上空のSentinel-5P/TROPOMIからの対流圏柱観測を使用して、都市の$NO_2$汚染を追跡するための衛星ベースの枠組みを提示する。この方法では、表面濃度を推定するのではなく、中央値と上部裾の百分位数 ($P_{90}$、$P_{95}$、$P_{99}$) を含む堅牢な分布指標を重視し、バックグラウンド条件とカントン規模での局地的な極端な汚染を特徴付けます。複数年の衛星観測が毎年集計され、教師なし K 平均法クラスタリングを使用して分析され、事前定義されたしきい値なしで特徴的な汚染状況が特定されます。結果は、高度に都市化された州は一貫して極端な$NO_2$値の上昇とより大きなばらつきを示す一方、都市化がそれほど進んでいない地域はより低い、より均質なパターンを示すことを示した。提案されたアプローチは、衛星観測のみを使用してデータ不足地域における都市の大気質を評価するための、解釈可能でスケーラブルなツールを提供します。実装は GitHub https://hvelesaca.github.io/sentinel-5P-clustering/ で公開されています。
原文 (English)
Tracking Urban Atmospheric Pollutants using Sentinel-5P Satellite Data
Urban nitrogen dioxide ($NO_2$) is a key indicator of combustion-related air pollution and exhibits strong spatial and temporal variability in cities. This study presents a satellite-based framework for tracking urban $NO_2$ pollution using tropospheric column observations from Sentinel-5P/TROPOMI over Guayas Province, Ecuador. Rather than estimating surface concentrations, the methodology emphasizes robust distributional metrics, including the median and upper-tail percentiles ($P_{90}$, $P_{95}$, and $P_{99}$), to characterize background conditions and localized pollution extremes at the canton scale. Multi-year satellite observations are aggregated annually and analyzed using unsupervised K-means clustering to identify characteristic pollution regimes without predefined thresholds. Results show that highly urbanized cantons consistently exhibit elevated extreme $NO_2$ values and greater variability, while less urbanized areas display lower and more homogeneous patterns. The proposed approach provides an interpretable and scalable tool for urban air-quality assessment in data-scarce regions using satellite observations alone. The implementation is publicly available on GitHub https://hvelesaca.github.io/sentinel-5P-clustering/.
断片化された ESG データからの監査可能な気候リスク インテリジェンス: スコープ 1 ~ 3 の検証のための決定論的なオーケストレーションと不均衡を認識した学習
ESG と気候リスクのデータは、異種のスコープ 1、スコープ 2、スコープ 3 レポート環境全体で断片化されたままですが、従来の検証パイプラインには来歴を意識した監査可能性、隠れたドリフト検出、再現性重視のガバナンスが欠けています。この論文では、単一情報源のオーケストレーション、時間的異常検出、不均衡を認識したアンサンブル学習、監査可能な ESG 検証のための説明可能性指向のガバナンスを統合した、決定論的な気候リスク インテリジェンス フレームワークを提案します。オープンな再現性をサポートするために、私たちは、公的に報告されている GHG プロトコル、PCAF、および ISSB 標準の特性に対して調整された合成 ESG 検証ベンチマークを構築し、リリースします。この方法論には、時間ドリフト分析、SMOTE ベースのレア イベントの最適化、アンサンブル学習、来歴を意識したオーケストレーション、ガバナンス検査と監査の再構築のための TreeSHAP ベースの解釈可能性が組み込まれています。私たちは、統計的分類器、異常検出方法、時間的予測ベースライン、および分類メトリクス (リコール、F1、ROC AUC)、キャリブレーションメトリクス (ECE、Brier スコア)、および確定的なソースからエスカレーション来歴チェーンを再構築できるフラグ付き異常の割合を測定するガバナンス指向の監査トレース完全性メトリクスを使用して、しきい値ベースのシステムに対してフレームワークを評価します。結果は、一対の有意性検定を使用した層別 5 分割交差検証全体の平均値と標準偏差として報告されます。このフレームワークは、再現性、説明可能性、運用監査可能性をサポートする決定論的な気候リスク ガバナンス インフラストラクチャに向けて ESG レポートを再構築します。
原文 (English)
Auditable Climate Risk Intelligence from Fragmented ESG Data: Deterministic Orchestration and Imbalance-Aware Learning for Scope 1-3 Validation
ESG and climate risk data remain fragmented across heterogeneous Scope 1, Scope 2, and Scope 3 reporting environments, while conventional validation pipelines lack provenance aware auditability, hidden drift detection, and reproducibility oriented governance. This paper proposes a deterministic climate risk intelligence framework integrating single source of truth orchestration, temporal anomaly detection, imbalance aware ensemble learning, and explainability oriented governance for auditable ESG validation. To support open reproducibility, we construct and release a synthetic ESG validation benchmark calibrated against publicly reported characteristics of the GHG Protocol, PCAF, and ISSB standards. The methodology incorporates temporal drift analysis, SMOTE based rare event optimization, ensemble learning, provenance aware orchestration, and TreeSHAP based interpretability for governance inspection and audit reconstruction. We evaluate the framework against statistical classifiers, anomaly detection methods, temporal forecasting baselines, and a threshold based system using classification metrics (recall, F1, ROC AUC), calibration metrics (ECE, Brier score), and a governance oriented audit trace completeness metric measuring the fraction of flagged anomalies for which a deterministic source to escalation provenance chain can be reconstructed. Results are reported as mean and standard deviation across stratified five fold cross validation with paired significance testing. The framework reframes ESG reporting toward deterministic climate risk governance infrastructure supporting reproducibility, explainability, and operational auditability.
重度の狭窄分類のための ECG および血管造影表現のクロスモーダル対照学習
冠動脈狭窄は一般的な心血管疾患であり、重篤な症例を未治療にすると心臓発作の重大なリスクが生じます。冠動脈(X 線)血管造影は依然として狭窄診断の標準ですが、侵襲的で時間とリソースを大量に消費するため、症状や事前の臨床検査に基づいて病気の可能性が高い患者にのみ実行されます。しかし、一部の患者、特に症状のない患者は診断されないままである可能性があります。迅速かつ安価で非侵襲的であるため、無症状の患者であっても日常的に取得される ECG から狭窄の兆候を検出できれば、早期診断をサポートできるでしょう。ただし、ECG では信頼できる狭窄固有の信号が特定されていないため、現在、ECG を狭窄リスク層別化に使用することはできません。これに対処するために、ECG から直接得られた特徴に基づいて患者を層別化できる事前トレーニング フレームワークである StenCE を導入しました。さまざまな狭窄重症度閾値と追加の ECG 疾患分類タスクにわたる評価により、さまざまな ECG エンコーダーにわたって一貫したパフォーマンスの向上が実証され、以前の研究を上回りました。得られたモデルは、ECG における狭窄診断用の信号の検出に成功し、重度の狭窄分類において高いパフォーマンスを達成した最初のモデルです。ソース コードは https://github.com/NikolaCenic/ecg-stenosis-cls で入手できます。
原文 (English)
Cross-Modal Contrastive Learning of ECG and Angiography Representations for Severe Stenosis Classification
Coronary artery stenosis is a common cardiovascular disease, with severe, untreated cases posing significant risks of heart attack. Although coronary (X-ray) angiograms remain the standard for stenosis diagnosis, they are invasive, time- and resource-intensive, and therefore only performed on patients with a high probability of disease based on symptoms and prior clinical tests. However, a subset of patients, especially those without symptoms, may remain undiagnosed. Detecting indications of stenosis from ECGs, which are fast, cheap, non-invasive, and thus routinely acquired even in asymptomatic patients, would support early diagnosis. However, as no reliable stenosis-specific signal has been identified in ECGs, they can not currently be used for stenosis risk stratification. To address this, we introduce StenCE, a pretraining framework, allowing stratification of patients based on features derived directly from ECGs. Evaluations across varying stenosis severity thresholds and additional ECG disease classification tasks demonstrate consistent performance improvements across different ECG encoders, outperforming previous work. The obtained models successfully detect signals for stenosis diagnosis in ECGs and are the first to achieve high performance in severe stenosis classification. The source code is available at https://github.com/NikolaCenic/ecg-stenosis-cls.
ReLoRA: 進化する LLM サービスの迅速な展開のための知識再利用の適応
大規模言語モデル (LLM) は、継続的に進化するサービスとしてデプロイされることが増えており、基本モデルが頻繁に更新されると、以前にデプロイされたタスク固有の低ランク適応 (LoRA) アダプターが無効になる可能性があります。多数のダウンストリーム モデル サービスを管理するサービス プロバイダーにとって、更新された基本モデルごとに各 LoRA アダプターを最初から再トレーニングすることは計算量が法外であり、サービスの展開が遅れます。一方、より単純な代替策、つまり、更新された基本モデルに元の LoRA アダプタを単純に適用する方法では、アダプタとバックボーンの互換性がないため、サービス品質の低下につながることがよくあります。この問題に対処するために、タスクのパフォーマンスを維持または向上させながら、LLM サービスを進化させるためにサービス対応の LoRA アダプターを効率的に復元する、知識を再利用する再適応フレームワークである ReLoRA を提案します。具体的には、ReLoRA は 2 つの主要な最適化ステップで構成されます。 1) 適応型 LoRA 初期化はベイジアン最適化を活用し、以前にデプロイされたタスク アダプターとベース モデルの進化の両方からの情報を融合することで、互換性を意識した開始点を構築します。 2) スケジュールされた正則化を使用した微調整では、最初に強力な正則化によってアダプターが高品質の領域に急速に誘導され、次にタスク固有の調整のための緩和された正則化が続きます。この設計により、再適応のオーバーヘッドが削減され、迅速なサービス品質の回復が可能になります。広範な実験により、ReLoRA はベースラインと比較して、準備完了までの時間を最大 8.9$\times$ 短縮し、精度を最大 4.6\% 向上させることが実証されました。
原文 (English)
ReLoRA: Knowledge-Reusing Adaptation for Fast Rollout of Evolving LLM Services
Large Language Models (LLMs) are increasingly deployed as continuously evolving services, where frequent base-model updates may invalidate previously deployed task-specific Low-Rank Adaptation (LoRA) adapters. For service providers managing numerous downstream model services, retraining each LoRA adapter from scratch for every updated base model is computationally prohibitive and delays service rollout. Meanwhile, the simpler alternative, i.e., naively applying the original LoRA adapter to the updated base model, often leads to degraded service quality due to adapter-backbone incompatibility. To address this problem, we propose ReLoRA, a knowledge-reusing re-adaptation framework that efficiently restores service-ready LoRA adapters for evolving LLM services while preserving or improving task performance. Specifically, ReLoRA comprises two key optimization steps: 1) Adaptive LoRA initialization leverages Bayesian optimization to construct a compatibility-aware starting point by fusing information from both the previously deployed task adapter and the base model's evolution; 2) Fine-tuning with scheduled regularization first rapidly steers the adapter to a high-quality region via strong regularization, followed by relaxed regularization for task-specific refinement. This design enables rapid service-quality recovery with reduced re-adaptation overhead. Extensive experiments demonstrate that ReLoRA reduces time-to-readiness by up to 8.9$\times$ and improves accuracy by up to 4.6\% compared to baselines.
ジオメトリを意識した表形式の拡散
表形式の合成は、プライバシーを保護した共有と拡張にとって重要ですが、拡散モデルは列間の関係を把握するための暗黙的なメカニズムに依存しています。 Geometry-Aware Tabular Diffusion (GATD) を導入します。これは、列値の差から計算され、入力および補助ターゲットとして使用されるペアごとの角度と長さで表形式拡散デノイザーを強化します。当社の MLP インスタンス化は、平均で 3.5 分の 1 少ないパラメーター (分類タスクの場合は最大 25 倍) を使用しながら、最先端のベンチマーク パフォーマンスを達成します。10 個のデータセットで、8/10 のシェイプ、7/10 のトレンド、および 9/10 のダウンストリーム ユーティリティ (F1/RMSE) で優勝し、シェイプとトレンドのエラーを 27% と 20% 削減します。デフォルトの損失重みが GNN および Transformer デノイザーに転送され、27/30 の Shape と 25/30 のアーキテクチャ データセット セルの Trend が改善されます。一致したアブレーションは、(追加の入力や容量ではなく) 監視がゲインを駆動していることを示しています。これは、明示的な関係監視が表形式の拡散に対する移植可能な誘導バイアスであることを示しています。
原文 (English)
Geometry-Aware Tabular Diffusion
Tabular synthesis is critical for privacy-preserving sharing and augmentation, yet diffusion models rely on implicit mechanisms to capture inter-column relationships. We introduce Geometry-Aware Tabular Diffusion (GATD), which augments tabular diffusion denoisers with pairwise angles and lengths computed from column value differences and used as inputs and auxiliary targets. Our MLP instantiation achieves state-of-the-art benchmark performance while using 3.5x fewer parameters on average (up to 25x for classification tasks): on ten datasets, it wins 8/10 Shape, 7/10 Trend, and 9/10 downstream utility (F1/RMSE), reducing Shape and Trend error by 27% and 20%. Default loss weights transfer to GNN and Transformer denoisers, improving Shape on 27/30 and Trend on 25/30 architecture-dataset cells. A matched ablation shows supervision (not extra inputs or capacity) drives the gain. This shows explicit relational supervision is a portable inductive bias for tabular diffusion.
より良いアクティベーションオラクルの構築
アクティベーション オラクル (AO) は、残留ストリームのアクティベーションを解釈するための有望な方法です。しかし、現在の AO は幻覚や曖昧さなどの重要な問題に直面しています。さらに、テキスト反転の交絡により評価が困難になります。この目的を達成するために、私たちは 4 つの方法で Activation Oracle (AO) トレーニング体制を改善します。それは、ポリシー ロールアウトに関するトレーニング、会話型データセットの改善、より多くのレイヤーへのフィード、および注入式の改善です。機能の向上はわずかですが、生活の質はかなり大幅に向上します。さらに、AObench と呼ばれる、AO 品質のための最初の包括的な評価スイートをオープンソースにしました。全体として、私たちの研究が、スケーラブルなエンドツーエンドの解釈可能性のパラダイムにおける AO やその他のモデルの改善に役立つ基礎を築くことを願っています。
原文 (English)
Building Better Activation Oracles
Activation Oracles (AOs) are promising methods for interpreting residual stream activations. However, current AOs face important issues, such as hallucinations and vagueness. Additionally, text-inversion confounds make them hard to evaluate. To this end, we improve the Activation Oracle (AO) training regime in four ways: training on on-policy rollouts, improving the conversational dataset, feeding more layers and an improvement to the injection formula. The capability improvements are marginal, but quality of life improvements are quite substantial. In addition, we open source the first comprehensive evaluation suite for AO quality, which we call AObench. Overall, we hope that our work sets a foundation that helps improve AOs and other models in the paradigm of scalable, end-to-end interpretability.
Samudra 2: 解像度を超えた海洋エミュレータのスケーリング
海洋大循環モデル (OGCM) は気候科学にとって不可欠ですが、計算コストが高くつくため、アンサンブルのサイズが制限され、シナリオが強制されます。ニューラル エミュレーターは桁違いの高速化を約束しますが、既存の海洋エミュレーターは優れた空間解像度と複数年にわたる自己回帰ロールアウトを組み合わせていません。 Samudra は、数十年にわたる世界規模の展開を実現した初の自己回帰ニューラル海洋エミュレータであり、解像度は $1^\circ$ に制限されており、時間的変動の喪失である \emph{分散崩壊} と、速度パターンが深海のフィールドに漏れ出す \emph{インプリンティング アーティファクト} という 2 つの長期的な障害モードを示します。我々は、修正された ConvNeXt スタイルのブロックとブロック内部拡張係数の削減を備えたより広い U-Net バックボーンを導入する Samudra 2 を、予測誤差に応じて出力チャネルの重み付けを変更する動的損失とともに導入し、ゆっくりと進化する深海フィールドの勾配を強化します。 $1^\circ$ において、サムドラ 2 は海洋上層の全球平均気温 $R^2$ を 0.56 から 0.87 に上昇させ、深海の温度誤差をおよそ 7 分の 1 に減少させます。同じアーキテクチャは、約 8 年間の自己回帰ロールアウトにわたって $1/2^\circ$ および $1/4^\circ$ まで拡張され、メソスケールの渦と鋭い西側境界流を回復します。単一の GPU 上で実行される Samudra 2 は、海面投影、海洋熱の吸収、気候変動の研究のための大規模なアンサンブルを可能にします。コード、ドキュメント、ベンチマーク リソースは https://openathena.ai/Ocean_Emulator/ で提供されています。
原文 (English)
Samudra 2: Scaling Ocean Emulators across Resolutions
Ocean general circulation models (OGCMs) are essential to climate science but computationally expensive, limiting ensemble size and forcing scenarios. Neural emulators promise orders-of-magnitude speedups, yet existing ocean emulators have not combined fine spatial resolution with multi-year autoregressive rollouts. Samudra, the first autoregressive neural ocean emulator to produce multi-decade global rollouts, is limited to $1^\circ$ resolution and exhibits two long-horizon failure modes: \emph{variance collapse}, the loss of temporal variability, and \emph{imprinting artifacts}, in which velocity patterns leak into deep-ocean fields. We present Samudra 2, which introduces a wider U-Net backbone with modified ConvNeXt-style blocks and a reduced block-internal expansion factor, together with a dynamic loss that reweights output channels according to their prediction errors, strengthening gradients for slow-evolving deep-ocean fields. At $1^\circ$, Samudra 2 increases upper-ocean global-mean temperature $R^2$ from 0.56 to 0.87 and reduces deep-ocean temperature error by roughly sevenfold. The same architecture scales to $1/2^\circ$ and $1/4^\circ$ over approximately 8-year autoregressive rollouts, recovering mesoscale eddies and sharp western boundary currents. Running on a single GPU, Samudra 2 enables larger ensembles for sea-level projections, ocean heat uptake, and climate variability studies. We provide code, documentation, and benchmark resources at https://openathena.ai/Ocean_Emulator/.
マージン プレイ: ブラジルの赤道マージンにおける公共政策分析のためのマルチエージェント システム
ブラジル赤道マージン(BEM)はブラジルの次の海洋石油フロンティアであり、フォス・ド・アマゾナス盆地で2026年に操業が開始される予定です。その資産は主にマランハオ州と財政的にも領土的にも関係している。マランハオ州は連邦内で最もHDIが低い州(0.676、IBGE 2022)である。これは政策上の中心的な疑問を提起します。BEM 探査はどのような条件下でマランハオにとって正味のプラスの外部性を生み出すのでしょうか?問題は本質的に複数の主体に関わるものである。連邦政府は歳入とエネルギーの安全保障を求めている。国家は憲法上の王権割り当てに基づいて地域福祉を追求する。経営者はリスクの下で利益を最大化します。 ANP と IBAMA は相反する権限を持っています。そしてアマゾンのコミュニティは金銭収入よりも領土と環境のベクトルを優先します。我々は、ブラジルの経験的校正と古典的な経済文献に基づいてこれらの緊張をシミュレートするマルチエージェント強化学習 (MARL) システムである Margin Play を紹介します。 BRO-MARL でトレーニングされた CTDE パラダイムに基づいて 6 つのエージェントを実装します。 6 つのシナリオにわたる 60,000 のエピソードの結果は、答えが制度体制に依存することを示しています。参照ベースラインの下では、福祉の利得はわずかです (Waval 約 1.68)。一方、MA-Prospero 構成では、デルタ W = +17.5% およびデルタ Rcom = +21.3% が得られ、環境負荷は低くなります (Eamb = 0.048 対 0.076)。根本的な問題は生産と福祉のトレードオフではなく、探査に関連した公共政策体制の選択にある。
原文 (English)
Margin Play: A Multi-Agent System For Public Policy Analysis In The Brazilian Equatorial Margin
The Brazilian Equatorial Margin (BEM) is Brazil's next offshore oil frontier, with operations expected to begin in 2026 in the Foz do Amazonas basin. Its assets are fiscally and territorially linked primarily to Maranhao -- the state with the lowest HDI in the Federation (0.676, IBGE 2022). This raises the central policy question: under what conditions does BEM exploration generate net positive externalities for Maranhao? The problem is intrinsically multi-agent: the Federal Government seeks revenue and energy security; the state seeks regional welfare under constitutional royalty earmarking; the operator maximizes profit under risk; ANP and IBAMA hold conflicting mandates; and Amazonian communities prioritize territorial and environmental vectors over monetary income. We present Margin Play, a Multi-Agent Reinforcement Learning (MARL) system simulating these tensions under Brazilian empirical calibration and classical economic literature. It implements six agents under the CTDE paradigm, trained with BRO-MARL. Results from 60,000 episodes across six scenarios indicate the answer is conditional on the institutional regime: under the reference baseline, the welfare gain is marginal (Waval approx. 1.68), whereas the MA-Prospero configuration yields Delta W = +17.5% and Delta Rcom = +21.3%, with a lower environmental liability (Eamb = 0.048 vs. 0.076). The fundamental problem is not a trade-off between production and welfare, but the choice of public policy regime linked to exploration.
FSA-GRPO: 聴覚 LLM に少数ショットのデモンストレーションを使用するよう指導する
少数ショットのプロンプトは、聴覚の大規模言語モデルを子供の音声認識などの低リソースのタスクに適応させる効果的な方法を提供します。ただし、ほとんどの聴覚大規模言語モデルは、このデモンストレーション条件付き形式で推論を実行するように明示的にトレーニングされていないため、数回のプロンプトから恩恵を受けることができる範囲が限られています。この制限に対処するために、Few-Shot Aware GRPO (FSA-GRPO) を導入します。これは、特別に設計された報酬を使用して、モデルが少数ショットのデモンストレーションを活用することを奨励することで、少数ショットの適応能力を強化する、RL ベースのポストトレーニング レシピです。特に、高リソースの成人 ASR データのみを使用したトレーニングにより、モデルの一般的な少数ショット適応能力が向上し、子供の音声認識だけでなく、音声翻訳や音声理解においても向上が見られます。データの選択と補助的な報酬の重み付けをさらに研究して、効果的なトレーニング レシピを特定します。私たちの実験では、ドメイン内データが利用できない場合、またはトレーニングに使用できない場合、関連するドメイン外データを直接調整するよりも FSA-GRPO の方が効果的であることが示されています。
原文 (English)
FSA-GRPO: Teaching Auditory LLMs to Use Few-shot Demonstrations
Few-shot prompting provides an effective way to adapt auditory large language models to low-resource tasks such as children's speech recognition. However, most auditory large language models are not explicitly trained to perform inference in this demonstration-conditioned format, limiting the extent to which they can benefit from few-shot prompting. To address this limitation, we introduce Few-Shot Aware GRPO (FSA-GRPO), an RL-based post-training recipe that uses a specially designed reward to encourage the model to leverage few-shot demonstrations, thereby strengthening its few-shot adaptation ability. Notably, training with only high-resource adult ASR data improves the model's general few-shot adaptation ability, yielding gains not only in children's speech recognition but also in speech translation and audio understanding. We further study data selection and auxiliary reward weighting to identify an effective training recipe. Our experiments show that when in-domain data are unavailable or cannot be used for training, FSA-GRPO is more effective than direct tuning on related out-of-domain data.
校正された偏差を備えた閉ループ分子設計
我々は、継続的に更新される信念状態グラフと再帰的な計画後実行ループを結合するエージェントである Cognitive Loop via In-Situ Optimization (CLIO) を紹介します。その結果、質的に異なるものに貢献できる推論エージェントが生まれます。これを \emph{校正された服従} と呼びます。これは、自身のツールや仮定が失敗したときを認識し、それに応じて戦略を適応させ、実験の修正を導くメカニズム的な仮説を生成する能力です。私たちは、水性有機レドックスフロー電池 (AORFB) ネゴライトを設計するための閉ループ人間 AI キャンペーンで CLIO をテストしました。CLIO は、合成、特性評価、設計選択の検討を行った化学者との緊密な連携のもと、提案と解釈を主導しました。 3 ラウンドにわたって 17 の候補者の中から、CLIO はトップのホスホネート候補者に絞り込みました。特性評価により、酸化還元電位が文献ベースラインより 130 mV 向上していることが確認されました。その後、特性評価により、電気化学的可逆性が予想外に低いことが明らかになりました。これは、特性予測因子がフラグを立てなかった回帰です。 CLIO は競合するメカニズムの仮説を生成し、識別診断に優先順位を付け、ホスホン酸イオンとカリウムイオンのペアリングの失敗を追跡し、スルホン酸塩の代替薬を処方しました。得られた化合物は、大幅に改善された電気化学的可逆性を示し、酸化還元電位の 90 mV の改善を維持し、設計、製造、テスト、再設計のループを閉じました。
原文 (English)
Closed-Loop Molecular Design with Calibrated Deference
We present Cognitive Loop via In-Situ Optimization (CLIO), an agent that couples a continuously-updated belief-state graph with a recursive plan-then-act loop. The result is a reasoning agent that can contribute something qualitatively different, which we term \emph{calibrated deference}: the capacity to recognize when its own tools or assumptions are failing, to adapt its strategy in response, and to generate mechanistic hypotheses that guide experimental revision. We tested CLIO in a closed-loop human-AI campaign to design an aqueous organic redox flow battery (AORFB) negolyte, with CLIO leading proposal and interpretation in close partnership with chemists who synthesized, characterized, and weighed in on design choices. Across 17 candidates over three rounds, CLIO converged on a top phosphonate candidate; characterization confirmed a 130~mV improvement in redox potential over the literature baseline. Characterization then revealed unexpectedly poor electrochemical reversibility -- a regression no property predictor had flagged. CLIO generated competing mechanistic hypotheses, prioritized discriminating diagnostics, traced the failure to phosphonate-potassium ion pairing, and prescribed a sulfonate replacement. The resulting compound showed substantially improved electrochemical reversibility and maintained a 90~mV improvement in redox potential, closing the design-make-test-redesign loop.
物理学に基づいたニューラル PDE ソルバーの誘導バイアスとしての振動状態空間モデル
時間依存偏微分方程式 (PDE) を解くことは、計算科学および計算工学における重要な問題です。物理情報に基づくニューラル ネットワーク (PINN) は、支配方程式から PDE 解を学習します。ただし、時間的進化を正確に捉えることは依然として困難です。最近のシーケンス モデル ベースのアプローチは、汎用シーケンス モデルを使用して時間発展をパラメータ化します。このモデルは、時間依存性を捕捉しますが、PDE 解の構造化されたダイナミクスを明示的にエンコードしません。さらに、シーケンスの長さと解像度によってメモリ要件が不利に拡大する可能性があり、大規模または高次元の設定での適用が制限されます。この研究では、PDE 解のモーダル構造を表現するために振動状態空間ダイナミクスを組み込んだ PINN アプローチを導入します。提案された方法は、空間における PDE を認識したスペクトル基底とともに、線形発振器ベースの時間発展を活用します。この設計により、閉じた形式の空間微分と境界条件の一貫した適用が可能になります。この方法は、最大 100 空間次元の場合を含む、順偏微分方程式、逆偏微分方程式問題、および高次元偏微分方程式問題で評価されます。結果は、最近のシーケンス モデル ベースの PINN アプローチと比較して、精度が向上し、メモリ使用量が削減されたことを示しています。全体として、この研究は、構造化された動的事前分布をニューラル PDE ソルバーの時間進化に組み込む利点を強調し、より物理的に整合した、計算効率の高い PINN アーキテクチャを設計することを提案しています。
原文 (English)
Oscillatory State-Space Models as Inductive Biases for Physics-Informed Neural PDE Solvers
Solving time-dependent partial differential equations (PDEs) is an important problem in computational science and engineering. Physics-informed neural networks (PINNs) learn PDE solutions from governing equations. However, accurately capturing temporal evolution remains challenging. Recent sequence-model-based approaches parameterize time evolution using general-purpose sequence models, which capture temporal dependencies but do not explicitly encode the structured dynamics of PDE solutions. In addition, their memory requirements can scale unfavorably with sequence length and resolution, limiting applicability in large-scale or high-dimensional settings. This work introduces a PINN approach that incorporates oscillatory state-space dynamics to represent the modal structure of PDE solutions. The proposed method leverages a linear-oscillator-based temporal evolution, together with a PDE-aware spectral basis in space. This design enables closed-form spatial differentiation and consistent enforcement of boundary conditions. The method is evaluated on forward, inverse, and high-dimensional PDE problems, including cases up to 100 spatial dimensions. The results show improved accuracy and reduced memory usage compared to recent sequence-model-based PINN approaches. Overall, this work highlights the benefits of incorporating structured dynamical priors into the temporal evolution of neural PDE solvers and suggests designing more physics-aligned and computationally efficient PINN architectures.
TadA-Bench: 薬剤タンパク質工学に向けた将来の発見のための 100 万種類のベンチマーク
科学的発見のための AI はエージェント時代に突入しており、タンパク質工学システムは単に静的な測定に適合するだけでなく、将来のウェットラボ実験を優先することが期待されています。薬剤タンパク質工学に向けた将来のラウンドの発見に向けて、31 回の TadA 指向進化ラウンドからの 100 万バリアントのウェットラボ リプレイ ベンチマークである TadA-Bench を紹介します。 TadA-Bench は、キャンペーンの時系列を保存し、固定データのリプレイ タスクを定義します。つまり、初期の実験ラウンドが与えられた場合、モデルは後のラウンドでのみ出現するバリアントをランク付けします。整列した DNA、RNA、およびタンパク質のビューを提供し、グラフベースのラベル統合パイプラインである Seq2Graph を使用して、ノイズの多い濃縮測定を一貫したクロスラウンド活性ラベルに調整します。ランダム分割コントロールは強力な補間を示しますが、将来のラウンドのランキングと有限予算の候補者の選択ははるかに弱いです。制御された分析は、進化の範囲が局所的なデータ密度よりも有益であることを示唆しており、TadA-Bench を薬剤タンパク質工学に向けた将来の発見のための再現可能なウェットラボ再生基質として位置付けています。データとコードはHugging FaceとGitHubで公開されています。
原文 (English)
TadA-Bench: A Million-Variant Benchmark for Future-Round Discovery Toward Agentic Protein Engineering
AI for scientific discovery is entering an agentic era, where protein-engineering systems are expected to prioritize future wet-lab experiments rather than merely fit static measurements. We introduce TadA-Bench, a million-variant wet-lab replay benchmark from 31 TadA directed-evolution rounds for future-round discovery toward agentic protein engineering. TadA-Bench preserves the campaign chronology and defines a fixed-data replay task: given earlier experimental rounds, models rank variants that appear only in later rounds. It provides aligned DNA, RNA, and protein views, and uses Seq2Graph, a graph-based label-unification pipeline, to reconcile noisy enrichment measurements into consistent cross-round activity labels. Random-split controls show strong interpolation, but future-round ranking and finite-budget candidate selection are much weaker. Controlled analyses suggest that evolutionary coverage is more informative than local data density, positioning TadA-Bench as a reproducible wet-lab replay substrate for future-round discovery toward agentic protein engineering; the data and code are released on Hugging Face and GitHub.
DXA 由来の骨格表現型と股関節骨折リスク: バックドア調整された因果分析
目的: 事前に指定された交絡因子調整を使用して、二重エネルギー X 線吸光光度法 (DXA) 由来の股関節骨格表現型を股関節骨折リスクと比較し、バックドア調整された平均治療効果 (ATE) によってランク付けされた表現型がリスク層別化を改善するかどうかを評価する。方法: リンクされた健康記録、股関節 DXA 由来の骨格測定値、および事前に指定された共変量を使用して、21,098 人の英国バイオバンク参加者を分析しました。股関節関連領域にわたる骨塩量 (BMC)、骨塩量 (BMD)、および T スコアにわたる 16 の表現型が評価されました。交絡因子の選択は、事前に指定された有向非巡回グラフ (DAG) によってガイドされました。バックドア調整された ATE は、標準偏差 (SD) 増加ごとの絶対リスク差スケールで推定されました。効果の不均一性は大腿骨全体の BMD について評価され、ATE の大きさによってランク付けされた表現型と組み合わせた臨床変数を使用して下流予測が評価されました。結果: 21,098 人の参加者のうち、115 人が股関節骨折を患っていました。 16 の表現型すべてで、SD 増加当たりのバックドア調整後の ATE は負の値を示しました。最大のATEは大腿骨総BMCと大腿骨BMDで観察され、それぞれのリスク差は-0.0047で、これはSDの表現型値が高いほど参加者1,000人当たり股関節骨折が約4.7少ないことに相当する。大腿骨総BMDの条件効果は、高齢の参加者とBMIの低い参加者の間でより強かった。予測では、臨床変数と ATE でランク付けされた上位 11 の表現型は、大腿骨頸部 BMD の FRAX よりも高い AUC (0.842 対 0.709) を達成し、より高い感度 (0.748 対 0.443) と同様の特異性 (0.793 対 0.777) を達成しました。結論: DXA 由来の股関節骨格表現型は、バックドア調整された ATE において異なりました。表現型レベルの因果関係評価は、リスク階層化のための有益な DXA 尺度を特定するのに役立つ可能性があります。
原文 (English)
DXA-Derived Skeletal Phenotypes and Hip Fracture Risk: A Backdoor-Adjusted Causal Analysis
Purpose: To compare dual-energy X-ray absorptiometry (DXA)-derived hip skeletal phenotypes in relation to hip fracture risk using prespecified confounder adjustment and to assess whether phenotypes ranked by their backdoor-adjusted average treatment effects (ATEs) improve risk stratification. Methods: We analyzed 21,098 UK Biobank participants with linked health records, hip DXA-derived skeletal measures, and prespecified covariates. Sixteen phenotypes spanning bone mineral content (BMC), bone mineral density (BMD), and T-score across hip-related regions were evaluated. Confounder selection was guided by a prespecified directed acyclic graph (DAG). Backdoor-adjusted ATEs were estimated on the absolute risk-difference scale per standard deviation (SD) increase. Effect heterogeneity was evaluated for total femur BMD, and downstream prediction was assessed using clinical variables combined with phenotypes ranked by ATE magnitude. Results: Among 21,098 participants, 115 had hip fractures. All 16 phenotypes showed negative backdoor-adjusted ATEs per SD increase. The largest ATEs were observed for total femur BMC and total femur BMD, each with a risk difference of -0.0047, corresponding to approximately 4.7 fewer hip fractures per 1,000 participants per SD higher phenotype value. Conditional effects of total femur BMD were stronger among older participants and those with lower BMI. In prediction, clinical variables plus the top 11 ATE-ranked phenotypes achieved higher AUC than FRAX with femoral neck BMD (0.842 vs. 0.709), with higher sensitivity (0.748 vs. 0.443) and similar specificity (0.793 vs. 0.777). Conclusion: DXA-derived hip skeletal phenotypes differed in their backdoor-adjusted ATEs. Phenotype-level causal evaluation may help identify informative DXA measures for risk stratification.
階層モチーフベースのマルチモーダルタンパク質埋め込みによるタンパク質間相互作用予測の強化
タンパク質間相互作用 (PPI) は、多くの生物学的プロセスに不可欠です。しかし、既存の PPI 予測アプローチには 2 つの大きな制限があります。1 つはタンパク質の階層構造、特に PPI を決定的に制御するメソスケールのモチーフを見落としていること、そして配列、構造、および機能モダリティを効果的に統合できないことです。これらの制限に対処するために、我々は、3 つのスケールにわたってボトムアップのマルチモーダル方式で PPI 埋め込みを構築する、PPI 予測用の階層モチーフベースのマルチモーダルタンパク質エンコーダーである MMM-PPI を提案します。マイクロスケールでは、3 つのモーダル残差特徴をエンコードします。メソスケールでは、新しい多峰性モチーフエンコーダーが残基を空間情報に基づいたモチーフ埋め込みに集約します。マクロスケールでは、マルチモーダルタンパク質エンコーダーは、モチーフの重要性とモーダル間の相関を共同モデリングすることにより、モチーフをタンパク質の埋め込みに統合します。事前トレーニングされたエンコーダーは、大規模な PPI 予測に既製で使用できます。複数の PPI データセットに対する広範な実験により、MMM-PPI が、特に困難なデータ分割や限られたデータ シナリオの下で、最先端のマルチラベル PPI 予測モデルよりも優れたパフォーマンスを発揮することが示されています。コードは https://github.com/yzf-code/MMM-PPI にあります。
原文 (English)
Enhancing Protein-Protein Interaction Prediction with Hierarchical Motif-based Multimodal Protein Embedding
Protein-protein interactions (PPIs) are essential for many biological processes. However, existing PPI prediction approaches suffer from two major limitations: they overlook the hierarchical organization of proteins, particularly meso-scale motifs that critically regulate PPIs, and fail to effectively integrate sequence, structure, and function modalities. To address these limitations, we propose MMM-PPI, a Hierarchical Motif-based Multi-Modal protein Encoder for PPI Prediction that constructs PPI embeddings in a bottom-up multi-modal manner across three scales. At the micro-scale, we encode three modal residue features; at the meso-scale, a novel multimodal motif encoder aggregates residues into spatially-informed motif embeddings; at the macro-scale, a multimodal protein encoder integrates motifs into protein embeddings by jointly modeling motif importance and inter-modal correlations. The pre-trained encoder can be used off-the-shelf for large-scale PPI prediction. Extensive experiments on multiple PPI datasets show that MMM-PPI outperforms state-of-the-art multi-label PPI prediction models, particularly under challenging data partitions and limited data scenarios. Codes are in https://github.com/yzf-code/MMM-PPI.
MultiTurnPSB: 医療 AI の安全のためのマルチターン脱獄攻撃と dClassifier ベースの防御の評価
患者向けの医療チャットボットは一般に 1 回のプロンプトで評価されますが、実際のユーザーは拒否後に押し返し、緊急性を高め、権限を発動します。 PatientSafetyBench の 4 ターン敵対的拡張機能である MultiTurnPSB を導入し、固定テンプレート攻撃、テンプレート適応型攻撃、およびライブ敵対的攻撃の下で GPT-4.1-mini を評価します。実攻撃を受けると、危険な反応は 4 ターン目までに 35% から 80% 近くまで上昇します。同じ敵の下では、GPT-4.1-mini と Claude Sonnet 4.5 はベースラインでは統計的に区別がつきませんが、ターン 4 までに 19 倍の差に広がり、この差は 1 ターンの評価では見えません。私たちは 4 つの劣化軌跡の特徴を特徴付け、ほとんどの壊滅的な障害の原因となる 2 要素の攻撃公式を特定します。軽量の入力側分類子により、精度が大幅に低下したにもかかわらず、ターン 4 の安全でない応答が 52 パーセント ポイント減少しましたが、良性のクエリでの 45% の誤報率が主な展開上の制約となっています。方法論的な発見も明らかになった。クロード・ソネットは、明示的なレッドチームの枠組みにもかかわらず、後半ターンの会話の半分以上で敵対的なメッセージを生成することを拒否し、安全トレーニングが攻撃者の役割に一般化する可能性があることを示唆している。
原文 (English)
MultiTurnPSB: Evaluating Multi-Turn Jailbreak Attacks an dClassifier-Based Defenses for Medical AI Safety
Patient-facing medical chatbots are commonly evaluated on single-turn prompts, yet real users push back after refusals, add urgency, and invoke authority. We introduce MultiTurnPSB, a four-turn adversarial extension of PatientSafetyBench, and evaluate GPT-4.1-mini under fixed template, template-adaptive, and live adversarial attacks. Unsafe responses rise from 35% to nearly 80% by Turn 4 under live attack. Under the same adversary, GPT-4.1-mini and Claude Sonnet 4.5 are statistically indistinguishable at baseline but diverge to a 19x gap by Turn 4, a difference invisible to single-turn evaluation. We characterize four degradation trajectory signatures and identify a two-element attack formula responsible for most catastrophic failures. A lightweight input-side classifier reduces Turn 4 unsafe responses by 52 percentage points despite severe accuracy degradation, but the 45% false alarm rate on benign queries is the primary deployment constraint. A methodological finding also emerges: Claude Sonnet refused to generate adversarial messages in over half of late-turn conversations despite explicit red team framing, suggesting safety training may generalize to the attacker role.
トークナイザーとしてのウェーブレット: 自然信号の共有ウェーブレット トークン スキーマに関する暫定結果
この論文では、オーディオ、画像、およびビデオが、個別のモダリティ固有の潜在グリッドに依存するのではなく、共通のウェーブレット トークン スキーマを共有できるかどうかを研究します。これは、1 レベルの Haar DWT/IDWT フロントエンド、共有係数トークン レイアウト、オプションの構造メタデータ、軽量モダリティ値アダプター、および共有トークン単位のエンコーダー/デコーダー トランクを中心に構築された予備的な連続トークン モデルを導入します。音声コマンド、EuroSAT RGB、および DAVIS 2017 データでは、高密度共有モデルは 39.92 dB オーディオ、29.37 dB イメージ、23.93 dB ビデオ PSNR に達します。連続的な潜在的なスカラー バジェットの下での一致レート スイープは、視覚的な向上が潜在的な容量だけによって説明されないことを示し、また、追加的なメタデータの埋め込みが普遍的な改善源ではないことも示しています。最後に、固定レートのエネルギー選択により、強力なノンパラメトリック ベースラインが提供されます。energy_global は、均一な選択よりも平均 PSNR を、圧縮されたキープ レシオの下でオーディオで 16.73 dB、画像で 16.90 dB、ビデオで 15.86 dB 改善します。マスクされたスパース トレーニングは、50% の高密度トークンで 34.45 dB のビデオ PSNR に達します。その結果は、統一されたウェーブレット トークン スキーマとスパース トークン インターフェイスをサポートしていますが、普遍的な離散語彙の確立には至っていません。
原文 (English)
Wavelet as Tokenizer: Preliminary Results on a Shared Wavelet Token Schema for Natural Signals
This paper studies whether audio, images, and video can share a common wavelet token schema rather than relying on separate modality-specific latent grids. It introduces a preliminary continuous-token model built around a one-level Haar DWT/IDWT frontend, a shared coefficient-token layout, optional structural metadata, lightweight modality value adapters, and a shared token-wise encoder-decoder trunk. On Speech Commands, EuroSAT RGB, and DAVIS 2017 data, a dense shared model reaches 39.92 dB audio, 29.37 dB image, and 23.93 dB video PSNR. A matched-rate sweep under continuous latent scalar budgets indicates that the visual gains are not explained solely by latent capacity, while also showing that additive metadata embeddings are not a universal source of improvement. Finally, fixed-rate energy selection provides a strong non-parametric baseline: energy_global improves average PSNR over uniform selection by 16.73 dB for audio, 16.90 dB for images, and 15.86 dB for video under compressed keep ratios. Masked sparse training reaches 34.45 dB video PSNR with 50% of dense tokens. The results support a unified wavelet token schema and sparse token interface, while stopping short of establishing a universal discrete vocabulary.
Position: Prioritize Identifying Structure, Not Complex Models, for Scientific Discovery
Modern Machine Learning (ML) and Artificial Intelligence (AI) models, especially large language models (LLMs), are increasingly used to gen…
Echo-POSED: Geometric Self-Distillation for Echocardiography Guidance
We introduce Echo-POSED, a self-supervised framework for real-time transthoracic echocardiography (TTE) guidance that recommends probe adju…
Too Much of a Good Thing: When sim2real Efforts Impede Policy Learning (And What to Do About It)
While sim2real efforts are necessary for effective policy transfer to hardware, there is such a thing as too much of a good thing. We argue…
SegTune: Structured and Fine-Grained Control for Song Generation
Recent advances in neural song generation have enabled high-quality synthesis from lyrics and global textual prompts. However, most systems…
Sparse-View Lung Nodule Volumetry from Digitally Reconstructed Radiographs via AReT: Anatomy-Regularized TensoRF
We identify and resolve a previously unreported failure mode in TensoRF when applied to X-ray attenuation fields: the default density shift…
D-Judge: Disrupting Multi-Turn Jailbreaks using Semantics-Preserving Output Rewriting
Multi-turn jailbreak attacks pose a growing threat to large language model (LLM) safety because they exploit feedback from auxiliary judge…
CARVE: Certified Affordable Repair of Vetoed Maneuvers via Envelopes for Interactive Driving
Interactive driving exposes a failure mode that is easy to miss in rule-aware autonomous-driving stacks: a hard-rule margin can be negative…
SVHalluc: Benchmarking Speech-Vision Hallucination in Audio-Visual Large Language Models
Despite the success of audio-visual large-language models (LLMs), they can produce plausible but ungrounded outputs, termed hallucination.…
Inference Cost Attacks for Retrieval-Augmented Large Language Models
Retrieval-Augmented Generation (RAG)-enhanced LLM systems, while powerful, introduce substantial inference costs due to the inclusion of an…
A New Framework for Cybersecurity Refusals in AI Agents
Agentic scaffolds have dramatically improved LLM performance on complex, long-horizon tasks, yielding both broad benefits and amplified ris…
Target Updates May Stabilize Linear Q-Learning: Periodic and Soft Dynamics
Periodic target updates in Q-learning and soft target updates in actor-critic methods are empirically well established stabilization mechan…
The Ringelmann Effect in Multi-Agent LLM Systems: A Scaling Law for Effective Team Size
Inference-time multi-agent LLM scaling lacks a shared unit: counting nominal agents conflates cost with independent evidence. We derive a t…
CL-DMDF:Dynamic Multimodal Data Fusion Model Based on Contrastive Learning
Multimodal data fusion involves integrating and analyzing information from multiple modalities to uncover latent correlations and complemen…
Learning to Refine: Spectral-Decoupled Iterative Refinement Framework for Precipitation Nowcasting
Accurate precipitation nowcasting is vital for disaster mitigation, but deep learning methods face a key trade-off: regression models produ…
Improvise, Adapt, Overcome: An On-The-Fly Multifidelity Algorithm for Efficient Machine Learning
Machine learning has accelerated quantum chemistry but is hindered by the prohibitive cost of generating high fidelity training data. Multi…
AdaWeather: Adaptively Mixing Probabilistic Weather Forecasts with Logarithmic Regret
Recent advances in machine learning have produced probabilistic weather forecasting models comparable to state-of-the-art numerical weather…
Anomalies in Multivariate Time Series Benchmarks Are Mostly Univariate
Many recent multivariate time series anomaly detection (MT-SAD) models incorporate cross-channel modeling, under the implicit assumption th…
Aligning Data-Driven Predictors with Allocation: A Decision-Focused Approach to Survival Analysis
Machine learning predictors have become essential tools for guiding automated decision making. However, a major misalignment persists: pred…
Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
On-Policy distillation (OPD) in large language models is shifting from full-trace KL supervision toward more selective training paradigms.…
AVTrack: Audio-Visual Tracking in Human-centric Complex Scenes
Audio-visual speaker tracking aims to localize and track active speakers by leveraging auditory and visual cues, enabling fine-grained, hum…
See Less, Specify More: Visual Evidence Budgets for Generalizable VLAs
Generalization remains a central bottleneck for vision-language-action (VLA) models: under distractors, appearance shifts, and semantically…
Attention Calibration for Position-Fair Dense Information Retrieval
Dense retrieval models exhibit positional bias: retrieval effectiveness degrades when relevant information appears later in a passage (Zeng…
EntangleCodec: A Unified Discrete Audio Tokenizer via Semantic-Acoustic Entanglement
Audio tokenizers serve as the discrete interface between continuous audio and Audio Language Models (ALMs), but existing tokenizers often s…
Plan2Map: A Multimodal Benchmark for Document-Grounded Geospatial Boundary Reconstruction from Planning Records
Planning records define restrictions over geographic areas, but their source documents often provide only indirect spatial evidence rather…
MetaWorld: Scaling Multi-Agent Video World Model from Single-view Video Data
Video world models are a foundational generative technology for embodied AI and the Metaverse, yet existing approaches are inherently limit…
Acceptance-Test-Driven Evaluation Protocols for Business-Centric LLM Systems
Large language model (LLM) applications are increasingly expected to satisfy deterministic institutional requirements while relying on prob…
Representational Capacity: Geometric Limits on Feature Representation in Transformer Language Models
Model dimension ($d_{model}$) is a fundamental hyperparameter in transformer language models, yet its role in setting the geometric limits…
CRAM-ER: Error-Resilient Spintronic Computational Random Access Memory for Scalable In-Memory Computation
Deep neural networks (DNNs) have achieved state-of-the-art performance across diverse domains. However, typical Von Neumann compute paradig…
Cosmos 3: Omnimodal World Models for Physical AI
We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and actio…
Do Neural Retrievers Prefer Certain Documents? Evidence of Learned Relevance Priors
Neural retrievers are trained to estimate query-document relevance from annotated query-document pairs. Yet annotation protocols may not pu…
Which Defense Closes Which Threat? Attributing OWASP-LLM-Top-10 Coverage and Its Brittleness Under Paraphrasing
Production LLM applications stack several defense families -- refusal-phrase filters, token-budget controls, model allowlists, rate limits,…
Large Byte Model: Teaching Language Models About Compiled Code
Malware analysis starts with the raw bytes of an executable program, and tools to "lift" these to higher-level representations, such as ass…
Fixing FOLIO and MALLS: Verified Annotations and an LLM-assisted Framework to Focus Human Relabeling
Accurate translation from Natural Language to First-Order Logic (NL-to-FOL) underpins neurosymbolic AI systems and Natural Language Inferen…
GRZO: Group-Relative Zeroth-Order Optimization for Large Language Model Fine-Tuning
Zeroth-order (ZO) optimization is a memory-efficient alternative to backpropagation for fine-tuning large language models, but its deployme…
Economy of Minds: Emerging Multi-Agent Intelligence with Economic Interactions
How can a population of agents self-orchestrate and self-adapt into stronger collective intelligence without centralized control? Inspired…
Forgetting is Not Erasure: Recovering Latent Knowledge via Transport Keys
Catastrophic forgetting is often framed as a representational problem: after sequential training, a model appears to lose the features that…
The Epi-LLM Framework: probing LLM behavioral priors through epidemiological agent-based models
Human behaviour during epidemics affects infectious disease dynamics, but quantifying this remains deeply challenging. Here we introduce th…
Adaptive Latent Agentic Reasoning
Large reasoning models improve performance by generating extended chain-of-thought (CoT) reasoning, but this behavior becomes inefficient w…
LLM-Assisted Reranking to Operationalize Nuanced Objectives in Recommender Systems
Recommender systems have grown from content-organization tools into sophisticated systems that shape daily behavior. By controlling what we…
Are we really tilting? The mechanics of reward guidance in flow and diffusion models
Reward guidance algorithms steer a learned generative process toward the reward-tilted measure at inference time. While empirically powerfu…
Scalable Uncertainty Quantification for Extreme Weather Forecasting via Empirical Neural Tangent Kernels
Deep learning weather models now match numerical weather prediction accuracy while running orders of magnitude faster, but produce determin…
Linear Probes Detect Task Format, Not Reasoning Mode in Language Model Hidden States
Linear probing of large language model (LLM) hidden states is widely used to claim that models learn distinct representations for different…
WRIT: Write-Read Intensive Trajectory Synthesis for Multi-Turn User-Facing Agents
Multi-turn user-facing agents must infer user intent from incomplete requests, collect missing information through dialogue and tools, and…
SCOPE: Real-Time Natural Language Camera Agent at the Edge
Deploying language-driven agents in robotics requires evaluations that reflect real-world task demands: natural-language instructions with…
Fast-dLLM++: Fr\'{e}chet Profile Decoding for Faster Diffusion LLM Inference
Diffusion large language models promise parallel token generation, yet inference remains bottlenecked by deciding which masked tokens can b…
Echelon: Auditable Aggregate-Only Language-Model Adaptation Across Privacy Boundaries
Cross-organization language-model adaptation increasingly faces hard governance constraints: in many deployments, device-level model state-…
Hand Trajectory Fusion for Egocentric Natural Language Query Grounding
Egocentric Natural Language Query (NLQ) grounding asks a model to localize, in a long first-person video, the temporal interval that answer…
Glass Box at Orbit: A Constitutional AI Verification Framework for Trustworthy Autonomous CubeSat Intelligence
The space industry is quietly building toward something nobody has fully reckoned with: orbital data centers running thousands of autonomou…
Towards Compact Autonomous Driving Perception with Balanced Learning and Multi-sensor Fusion
We present a novel compact deep multi-task learning model to handle various autonomous driving perception tasks in one forward pass. The mo…
Pretraining Language Models on Historical Text
We introduce TypewriterLM, a 7.24B History language model (LM) trained exclusively on English text predating 1913. Developing History LMs r…
Patcher: Post-Hoc Patching of Backdoored Large Language Models
Large language models remain vulnerable to jailbreak backdoor attacks, where adversaries poison safety alignment data to embed hidden trigg…
How Quantization Changes Interpretable Features: A Sparse Autoencoder Analysis of Language Models
Quantization is a standard path to deploying large language models, and a quantized model is typically judged acceptable when its perplexit…
Exact equivariance, kept through training, buys zero-shot generalisation across the symmetry group
A latent world model built from an equivariant encoder $E$ and an equivariant predictor $f$ inherits a provable symmetry of its training lo…
MUSE: A Unified Agentic Harness for MLLMs
Despite rapid progress, multimodal large language models (MLLMs) still fail on tasks that humans solve effortlessly, such as navigating a g…
ConTraIRL: Factorized Contrastive Abstractions for Transferable IRL
Reward transfer in Inverse Reinforcement Learning (IRL) is unreliable when policies must generalize to unseen combinations of environment d…
Reproducibility is the New Copyleft: Defining AGI-oriented Reproducible Builds
Copyleft, as implemented in licenses such as the GNU General Public License, was a legal hack that used copyright to guarantee user freedom…
Hallucinations as Orthogonal Noise: Inference-Time Manifold Alignment via Dynamic Contextual Orthogonalization
Hallucination in Large Language Models (LLMs), characterized by the generation of content inconsistent with contextual facts or logical con…
Spike-Aware C++ INT8 Inference for Sparse Spiking Language Models on Commodity CPUs
Spiking language models expose activation sparsity that dense Transformer runtimes do not directly exploit. This paper studies that propert…
Conditional Hypothesis Generation for LLM-Based Text Analysis with Researcher-Specified Covariates
A core goal of computational social science is to discover interpretable differences in how language varies across outcomes of interest, su…
Capability Advertisement as a Market for Lemons: A Trust Layer for Heterogeneous Agent Networks
Large language model (LLM) agents have begun to delegate work to one another. Protocols such as the Model Context Protocol (MCP) and the Ag…
Rethinking Molecular Text Representations for LLMs: An Empirical Study
Large language models (LLMs) are increasingly used for molecular tasks, but it remains unclear which molecular representation to use. We pr…
Brief Announcement: Generative Markov Model for Distributed Computing Systems
Emerging distributed computing paradigms, such as the computing continuum, are inherently heterogeneous, stochastic, and complex. Efficient…
Learn When and Where to Connect: Adaptive Virtual Nodes for Dynamic Message Passing on Graphs
While Virtual Nodes (VNs) are often utilized in Message Passing Neural Networks (MPNNs) to facilitate effective message passing, existing V…
ROBUST-WT: Robust Uncertainty-aware Segmentation Transform via Whitening and Training Enhancements
Generalized segmentation of medical images prevents performance degradation when different imaging devices and clinical protocols are used…
ASymPO: Asymmetric-Scale Policy Optimization for Asynchronous LLM Post-Training Without Behavior Information
Asynchronous reinforcement learning can improve language-model post-training throughput by decoupling response generation from policy optim…
Efficient Hyperparameter Optimization for LLM Reinforcement Learning
Reinforcement learning (RL) for large language models (LLMs) is highly sensitive to hyperparameter configurations, making hyperparameter op…
Libra: Efficient Resource Management for Agentic RL Post-Training
Reinforcement learning (RL) has become a standard post-training paradigm for large language models (LLMs), extending beyond preference alig…
Regret Pre-training: Bridging Prior and Posterior Views for Enhanced Knowledge Grounding
Causal language models factorize sequence probabilities using only preceding context, leaving future information unexploited during trainin…
Constitutional On-Policy Safe Distillation
On-policy self-distillation (OPSD) has emerged as an efficient post-training paradigm by using a teacher conditioned on privileged informat…
"**Important** You should give me full credits!": Exploring Prompt Injection Attacks on LLM-Based Automatic Grading Systems
The emergence of large language models (LLMs) has significantly accelerated recent research on LLM-based automatic grading (AG) systems. Be…
BAHSD: Bridging the Long-tail Gap via Adaptive Distillation in Black-box Sequential Recommendation
Sequential recommendation systems are widely adopted but often deployed as black-box APIs, which has driven recent interest in model extrac…
PhotoCraft: Agentic Reasoning with Hierarchical Self-Evolving Memory for Deep Image Search
Deep Image Search requires multi-step reasoning over rich contextual cues, such as time, location, and event relations. However, most exist…
AnyAudio-Judge: A Dynamic Rubric-Based Benchmark and Evaluator for Audio Instruction Following
The rapid advancement of instruction-guided audio generation has highlighted the critical need for robust alignment evaluation. Current aut…
GuidedBridge: Training-freely Improving Bridge Models with Prior Guidance
Guidance methods, such as classifier-free guidance (CFG) and auto-guidance (AG), have advanced noise-to-data generation in diffusion models…
Decoupled Smart Contract Audits: Lightweight LLM Framework via Distillation and Aggregation
Smart contracts face critical security challenges that require thorough auditing in decentralized web services. While Large Language Models…
NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. I…
OpenAgenet/OAN: Open Infrastructure for Trusted Agent Interconnection
OpenAgenet, abbreviated as OAN, is an open infrastructure project for trusted Agent interconnection. It addresses a problem that becomes vi…
OpenAgenet/OAN: Technical Architecture for Trust-Governed Agent Identity and Discovery
This paper describes the technical architecture of OpenAgenet / OAN. OAN is a protocol-neutral trust layer for open Agent interconnection.…
Fully Automated Identification of Lexical Alignment and Preference-Stage Shifts in Large Language Models
The language used by digital chat assistants such as ChatGPT can diverge from human expectations (misalignment). Research, mostly on Scient…
AI Rater Discrimination Depends on Scoring Protocol in Complex Clinical Decision-Making
Clinical AI evaluation increasingly delegates scoring to large language models (LLMs) acting as AI raters, yet their scoring behavior acros…
Reinforcement Learning from Cross-domain Videos with Video Prediction Model
Reinforcement learning from expert videos across visually distinct domains is challenging due to the absence of reward signals and the pres…
WebRISE: Requirement-Induced State Evaluation for MLLM-Generated Web Artifacts
Existing benchmarks for MLLM-generated web artifacts assess interaction through local evidence and miss the requirement-induced states and…
BotDirector: Robot Storytelling Across the Symmetrical Reality with Multi-modal Interactions
Robot storytelling offers a unique blend of technological innovation and creative expression that engages children in unprecedented ways. H…
GFFMERGE: Efficient Merging of Graph Neural Force Fields and Beyond
Graph Neural Networks (GNNs) have revolutionized Neural Force Fields for atomistic simulations, achieving near-quantum accuracy at reduced…
When RLHF Fails: A Mechanistic Taxonomy of Reward Hacking, Collapse, and Evaluator Gaming
Reinforcement learning from human feedback (RLHF) makes large-scale post-training possible by replacing an underspecified human objective w…
AirDreamer: Generalist Drone Navigation with World Models
Navigating a drone in unseen and cluttered environments requires reliable generalization to unseen scene layouts and understanding of envir…
PSViT: A Methodology for Structurally Pruning Spiking Vision Transformers
Spiking Vision Transformer (SViT) models are promising low-power ViT models for solving vision-based tasks with state-of-the-art performanc…
EqGINO: Equivariant Geometry-Informed Fourier Neural Operators for 3D PDEs
Deep learning surrogates for 3D Partial Differential Equations (PDEs) often fail to generalize across geometric transformations because the…
Are Common Substructures Transferable? Riemannian Graph Foundation Model with Neural Vector Bundles
Foundation models have sparked a revolution via a pretraining-adaptation paradigm, with recent efforts extending this success to graphs. Un…
VistaHop: Benchmarking Multi-hop Visual Reasoning for Visual DeepSearch
Visual DeepSearch requires multimodal large reasoning model (MLRM) agents to answer complex visual queries by repeatedly inspecting image r…
AI-Generated Traces for Novice Programmers: Learning Effects and Learner Differences in a Multi-Institutional Study
Introductory programming (CS1) courses often struggle to support students' understanding of program execution. While visualizations can mak…
Message Tuning Outshines Graph Prompt Tuning: A Prismatic Space Perspective
Graph Foundation Models (GFMs), built upon the Pre-training and Adaptation paradigm, have emerged as a research hotspot in graph learning.…
Generalizing Graph Foundation Models via Hyperbolic Retrieval-Augmented Generation
Graph foundation models (GFMs) emerged as a dominant paradigm in graph representation learning by leveraging large-scale pre-training for c…
Learning Multi-Scale Hypergraph for High-Order Brain Connectivity Analysis
Understanding complex interactions between brain regions is critical for early neurodegenerative disease classification such as Alzheimer's…
RobotValues: Evaluating Household Robots When Human Values Conflict
While household robots are often evaluated based on task completion, everyday domestic environments involve value-conflicting situations in…
Multi-Modal Graph Neural Network with Transformer-Guided Adaptive Diffusion for Preclinical Alzheimer Classification
The graphical representation of the brain offers critical insights into diagnosing and prognosing neurodegenerative disease via relationshi…
dstack-capsule: Pod-Level Remote Attestation for Confidential Workloads on Kubernetes
The rise of LLM-as-a-Service and other confidential cloud workloads demands cryptographic proof that user data is processed in a trusted, u…
Calibration Data Trade-offs Across Capability Dimensions: Why Multi-Source Mixing Matters for High-Sparsity LLM Pruning
Post-training pruning compresses large language models to high sparsity using a small unlabelled calibration set, and recent work has concl…
FLIPS: Instance-Fingerprinting for LLMs via Pseudo-random Sequences
Literature reveals that a Large Language Model's (LLM) behavior is not only conditioned by its original weights but also its instance-level…
Evaluating LLMs' Effectiveness on Real-World Consumer Device Repair Questions
Consumer device repair is an important but underexplored testbed for large language models (LLMs). Repair tasks require reasoning over inco…
AugMask: Training Diffusion Models on Incomplete Tabular Data via Stochastic Augmentation and Masking
Score-based diffusion models have emerged as prominent deep generative models; however, their application to tabular data remains challengi…
SynCred-Bench: Benchmarking Synthetic Credibility in AI-Generated Visual Misinformation
Recent generative models can now produce visual artifacts with realistic embedded text and layouts, creating a new misinformation threat: s…
The Unsampled Truth: Psychometrics in SLMs Measure Prompt Artifacts, Not Psychological Constructs
When prompting SLMs for psychometric assessments, researchers assume the outputs reflect semantic reasoning. We evaluate this premise acros…
P\textsuperscript{2}-DPO: Grounding Hallucination in Perceptual Processing via Calibration Direct Preference Optimization
Hallucination has recently garnered significant research attention in Large Vision-Language Models (LVLMs). Direct Preference Optimization…
AI Model Extraction Attacks: Bypassing Single-Client Assumptions in Defenses
Ensuring the protection of Artificial Intelligence (AI) models deployed in military Command and Control (C2) systems and critical infrastru…
Local Guidance, Global Impact: Gaussian-Reshaped Trust Region Unlocks Behavior Transitions
While Proximal Policy Optimization (PPO) demonstrates strong performance in stationary settings, we show that its standard optimization par…
Grasp-Then-Plan with Failure Attribution: A Closed Two-Stage Framework for Precise and Generalizable Robotic Manipulation
In robotic manipulation, the tight coupling between grasping and motion planning often obscures the true source of failure, leading to inef…
When Model Merging Breaks Routing: Training-Free Calibration for MoE
Model merging has emerged as a cost-effective approach for consolidating the capabilities of multiple LLMs without retraining. However, exi…
Causal Evidence of Stack Representations in Modeling Counter Languages Using Transformers
Formal languages have proven to be effective conduits to understand the inner mechanisms of transformers. Past work has shown that transfor…
Optimizing Explicit Unit-Distance Lower-Bound Certificates
The 2026 disproof of Erd\H{o}s's unit-distance conjecture and Sawin's subsequent explicit quantitative refinement show that the maximum num…
PrimeSVT: An Automated Memory-aware Pruning Framework with Prioritized Compression Policy for Spiking Vision Transformers
The large sizes of Spiking Vision Transformers (SViTs) still hinder their embedded implementation, highlighting the need for model compress…
FlowGuard: Flow Matching for Identity-Independent Detection of Data-Free Model Stealing Attacks on Energy System Intrusion Detection Systems
Artificial Intelligence (AI)-based Intrusion Detection Systems (IDS) deployed in energy infrastructure are vulnerable to model theft attack…
A Hybrid Approach For Malware Classification Using Secondary Features Fusion
The number of malware (either variant or novel) is rapidly increasing, making malware detection and mitigation a complex problem. One appro…
PRISM: Synergizing Vision Foundation Models via Self-organized Expert Specialization
Unifying the complementary strengths of diverse Vision Foundation Models (VFMs) into a single efficient model is highly desirable but chall…
FORGE: Multi-Agent Graduated Exploitation and Detection Engineering
Vulnerability disclosure volumes now far exceed organizational assessment capacity, yet three adjacent research communities (proof-of-conce…
Tonal parsimony in chord-sequence analysis: combining modulation cost and tonal vocabulary
We study the assignment of local tonalities to chord sequences, a task useful for harmonic analysis, composition, and jazz-oriented improvi…
Rethinking the Role of Tensor Decompositions in Post-Training LLM Compression
Post-training compression is essential for deploying large language models (LLMs) under tight resource constraints. Tensor decompositions h…
Analyzing Stream Collapse in Hyper-Connections: From Diagnosis to Mitigation
Hyper-Connections (HC) replace the single Transformer residual stream with multiple streams, introducing a permutation symmetry over stream…
NeuroArmor: Safe-Variant-Guided Representation Consistency for Selective Re-Anchoring in Jailbreak Defense
Large language models remain vulnerable to jailbreak attacks that hide harmful intent behind seemingly ordinary requests such as role-play,…
Learn from Your Mistakes: Tree-like Self-Play for Secure Code LLMs
While Large Language Models (LLMs) excel in code generation, they remain prone to replicating subtle yet critical vulnerabilities endemic t…
BaltiVoice: A Speech Corpus and Fine-tuned Whisper ASR System for the Balti Language
We present BaltiVoice, a 16.8-hour read-speech corpus for Balti (ISO 639-3: bft), a Tibetic language spoken in Gilgit-Baltistan, Pakistan,…
SPADE: Sketch-guided Path Planning Augmented with Diffusion Experts
Path planning is essential for Autonomous Mobile Robots (AMRs). Conventional methods for incorporating human preferences into planning typi…
Scalable On-Hardware Training of Quantum Neural Networks and Application to Clinical Data Imputation
Training quantum neural networks (QNNs) on quantum hardware is currently bottlenecked by the cost of gradient estimation: standard paramete…
Post-Hoc Robustness for Model-Based Reinforcement Learning
To improve the real-world applicability of reinforcement learning (RL), the field of adversarially robust RL studies how to train agents un…
High-Precision APT Malware Attribution with Out-of-Scope Resilience
Early attribution of Advanced Persistent Threat (APT) activity can help defenders prioritise investigation, select countermeasures, and red…
When Should the Teacher Move? Temporal Coupling and Stability in Self On-Policy Distillation
Self on-policy distillation trains a student policy against a teacher derived from its own parameter history, yet the teacher's update sche…
\textsc{CR-Seg}: Attention-Guided and CoT-Enhanced Coarse-to-Refined Reasoning Segmentation
Reasoning segmentation aims to segment target objects described by complex language through joint visual-textual reasoning. Existing method…
Efficient Transformer-Based Localized Patch Sampling for Choroid Plexus Segmentation in Multiple Sclerosis
Background: The lateral ventricle choroid plexus (LVCP) is gaining recognition as a key imaging biomarker for multiple sclerosis (MS) relat…
Learned Non-Maximum Suppression for 3D Object Detection
Post-processing is a critical stage in LiDAR-based 3D object detection, where dense and overlapping proposals must be filtered for compact…
When Attention Collapses: Stage-Aware Visual Token Pruning from Structure to Semantics
Vision-Language Models (VLMs) have demonstrated remarkable capabilities but suffer from significant computational overhead during inference…
PHASER: Phase-Aware and Semantic Experience Replay for Vision-Language-Action Models
Vision-Language-Action (VLA) models have achieved remarkable success in language-conditioned robotic manipulation. However, deploying these…
DDOR: Delta Debugging for Explainable Overrefusal Testing and Repair
While safety alignment and guardrails help large language models (LLMs) avoid harmful outputs, they can also induce overrefusal, i.e., unwa…
CauTion: Knowing When to Trust LLMs for Ensemble Causal Discovery
Causal discovery from observational data remains challenging due to the fundamental limitations of purely statistical methods, such as stat…
Testing LLM Arithmetic Reasoning Generalization with Automatic Numeric-Remapping Attacks
Large language models achieve strong performance on arithmetic reasoning benchmarks, and one common response to arithmetic brittleness is t…
Exploiting Verification-Generation Gap: Test-Time Reinforcement Learning with Confidence-Conditioned Verification
Test-time reinforcement learning has emerged as a promising paradigm for enhancing the complex reasoning abilities of large language models…
Physics-Guided Policy Optimization with Self-Distillation
Self-distilled policy optimization (SDPO) has become a popular paradigm for LLM post-training, where a model learns from its own prediction…
TurtleAI: Benchmarking Multimodal Models for Visual Programming in Turtle Graphics
Vision-language models (VLMs) have been explored for visual programming, where they generate code to solve visual tasks. However, most prio…
Building Reliable Long-Form Generation via Hallucination Rejection Sampling
Large language models (LLMs) have achieved remarkable progress in open-ended text generation, yet they remain prone to hallucinating incorr…
AnchorMoE: Interpretable Time Series Classification via Anchor-Routed MoE
Multivariate time series classification (MTSC) is pivotal in high-stakes domains, such as clinical diagnosis and industrial fault detection…
VidMsg: A Benchmark for Implicit Message Inference in Short Videos
Understanding short online videos involves more than identifying visible objects and actions; video makers often include an underlying mess…
The Shape of Addition: Geometric Structures of Arithmetic in Large Language Models
Large Language Models exhibit paradoxical fragility in fundamental arithmetic, implying a disconnect between internal computation and discr…
Black-box, Adaptive, Efficient, Transferable, Harmful, Applicable... Attacks Are All You Need to Break LLMs
Accurately evaluating adversarial robustness is a longstanding challenge. A flawed attack design can inflate robustness estimates, making d…
Safety Measurements for Fine-tuned LLMs Should be Grounded in Capability
Adapting foundation large language models to a user's task or preferred style through fine-tuning can result in compromising the model's sa…
CoEval: Ranking Language Models for Custom Tasks Without Labeled Data or Trustworthy Benchmarks
Choosing or ranking language models for a specific application is hardest when no task-specific labeled data exists, and standard public be…
AUGUSTE: Online-Learning dApp for Predictive URLLC Scheduling
Ultra Reliable and Low Latency Communications (URLLC) was one of the main motivations behind 5G, with 3GPP advertising 1-10 ms latency targ…
A Close Look At World Model Recovery In Supervised Fine-Tuned LLM Planners
Supervised fine-tuning (SFT) improves end-to-end classical planning in large language models (LLMs), but do these models also learn to repr…
Staying Alive: Uncensored Survival Analysis with Tabular Foundation Models
Survival Analysis (SA) is a statistical framework that models the time span until some event of interest occurs. Widely used in several dom…
Qwen-Image-Flash: Beyond Objective Design
Few-step distillation has become an effective strategy for accelerating advanced visual generative models, yet prior work has largely focus…
Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models
Real-time vision demands models that are accurate, efficient, and simple to deploy across diverse hardware. The YOLO family has become wide…
Tool-Aware Optimization with Entropy Guidance for Efficient Agentic Reinforcement Learning
Agentic reinforcement learning (RL) equips large language models (LLMs) with tool-use capabilities that substantially improve reasoning on…
Merit or networks? What decides where research is published
Does scientific publishing reward the quality of ideas or the advantage of connections? The question is universal to prestige-driven scienc…
E2LLM: Towards Efficient LLM Serving in Heterogeneous Edge/Fog Environments
Large Language Models (LLMs) have become integral to modern applications, yet their deployment remains challenging. Beyond executing the mo…
Signed Spiking Neuron Enabled by an Orthogonal-Easy-Axis Magnetic Tunnel Junction
Signed spiking neurons carry richer information than standard spiking neurons. This work proposes a compact magnetic tunnel junction (MTJ)-…
Trading Human Curation for Synthetic Augmentation in RLVR
The supply of high-quality training tasks is a central bottleneck for reinforcement learning from verifiable rewards (RLVR) on agentic lang…
LiveBand: Live Accompaniment Generation in the Audio Domain
We present LiveBand, a real-time system that generates high-fidelity music accompaniments to live audio input, respecting strict causal con…
PURGE: Projected Unlearning via Retain-Guided Erasure
We propose PURGE, a machine unlearning algorithm built on a simple but an under-exploited observation: continual learning (CL) and machine…
Consistency Training Can Entrench Misalignment
Consistency training encourages a model to produce similar outputs across related inputs or sampling procedures. Such methods are simple, s…
AI Agents Enable Adaptive Computer Worms
A computer worm is malware that spreads on a network by replicating itself from one machine to another. Traditional worms, like WannaCry, e…
Conditional Latent Diffusion Model with Fourier-based Motion Modelling for Virtual Population Synthesis
In-silico trials of medical devices require the generation of virtual populations of anatomies. In cardiovascular applications, virtual ana…
Re-Evaluating Continual Learning with Few-Shot Adaptation
Continual learning methods aim to maximize the stability and plasticity of machine learning models that are trained on a sequence of tasks.…
Clustered Self-Assessment: A Simple yet Effective Method for Uncertainty Quantification in Large Language Models
Large language models (LLMs) demonstrate remarkable performance across diverse tasks, but they often generate responses that appear plausib…
FLARE: Fine-Grained Diagnostic Feedback for LLM Code Refinement
Large language models often generate code with bugs. Existing methods rely on feedback signals such as test failures and self-critiques to…
Taiji: Pareto Optimal Policy Optimization with Semantics-IDs Trade-off for Industrial LLM-Enhanced Recommendation
Scaling recommender systems via large language models (LLMs) has become a prominent trend in the industry. However, aligning the LLM's sema…
A Training-Free Mixture-of-Agents Framework for Multi-Document Summarization using LLMs and Knowledge Graphs
Multi-Document Summarization (MDS) plays a critical role in distilling essential information from collections of textual data. Existing app…
From 'What' to 'How' and 'Why': Sharing LLM-Generated Retrospective Summaries of Older Adults' Passive Tracking Data with Remote Family Members
With the growing prevalence of modern ubiquitous computing technologies, multi-modal tracking systems hold promise for providing timely awa…
Beyond Encoder Accumulation: Measuring Encoder Roles in Multi-Encoder VLMs
As foundation models scale toward fusing more heterogeneous visual streams, understanding how diverse encoders interact under joint trainin…
Synthesize and Reward -- Reinforcement Learning for Multi-Step Tool Use in Live Environments
Training LLMs to orchestrate multi-step tool calls is held back by three coupled obstacles: realistic stateful execution environments are c…
Agent libOS: A Library-OS-Inspired Runtime for Long-Running, Capability-Controlled LLM Agents
Large language model (LLM) agents are evolving from request-response assistants into long-running software actors: they maintain state acro…
The Impact of Configuring Agentic AI Coding Tools on Build-vs-Buy Decisions: A Study Protocol
Agentic AI coding tools write code with increasing autonomy and in doing so decide when to import a library and when to implement functiona…
NetKV: Network-Aware Decode Instance Selection for Disaggregated LLM Inference
Disaggregated LLM inference forces the KV cache to traverse the datacenter network before decoding begins, so transfer time enters directly…
FFR: Forward-Forward Learning for Regression
The Forward-Forward (FF) algorithm offers a computationally efficient and biologically plausible alternative to backpropagation (BP) by tra…
q0: Primitives for Hyper-Epoch Pretraining
Multi-epoch training is becoming the standard now that compute is growing faster than the supply of high-quality text. But pretraining a si…
FlashbackCL: Mitigating Temporal Forgetting in Federated Learning
Federated Learning (FL) of foundation and edge models increasingly targets deployments where client data distributions drift over time, yet…
Efficient ASR Training with Conversations that Never Happened
Conversational ASR for lower-resource languages and niche domains is limited by the scarcity of domain-matched multi-speaker training data.…
Using Reward Uncertainty to Induce Diverse Behaviour in Reinforcement Learning
Classical reinforcement learning (RL) typically seeks a deterministic policy that maximizes the expected sum of a scalar reward. Yet, moder…
Self-Refining Agentic Reinforcement Learning for Vision-Conditioned UAV Navigation
Deep reinforcement learning has shown strong potential for enabling autonomous robots to learn complex navigational tasks. However, its pra…
Agentic Chain-of-Thought Steering for Efficient and Controllable LLM Reasoning
Large language models improve final-answer accuracy through extended chain-of-thought reasoning, but often spend tokens inefficiently and o…
AlignAtt4LLM: Fast AlignAtt for Decoder-Only LLMs at IWSLT 2026 Simultaneous Speech Translation Task
We describe AlignAtt4LLM, an IWSLT 2026 simultaneous speech translation system for English to German, Italian, and Chinese. The system is a…
QUBRIC: Co-Designing Queries and Rubrics for RL Beyond Verifiable Rewards
Rubric-based RL is a promising route for extending reinforcement learning beyond verifiable rewards, yet existing methods optimize rubrics…
Quantifying Faithful Confidence Expression in Large Reasoning Models
Reliable uncertainty communication is critical to the trustworthiness of LLMs, yet faithful calibration (FC)--the alignment between models'…
Formalizing the Binding Problem
Representations of the world, arguably, contain information about features (e.g. something is blue, something is a circle) but also informa…
Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
The past few decades have witnessed significant advances in the design of machine learning algorithms, from early studies on task-specific…
Humanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
We introduce Humanoid-GPT, a GPT-style Transformer with causal attention trained on a billion-scale motion corpus for whole-body control. U…
Planning with Uncertainty: Symmetries, Policy Inference, and Solution Compression
Fully-observable non-deterministic (FOND) planning is at the core of artificial intelligence planning with uncertainty. It models uncertain…
Approximating Probabilistic Inference in Statistical EL with Knowledge Graph Embeddings
Statistical information is ubiquitous but drawing valid conclusions from it is prohibitively hard. We explain how knowledge graph embedding…
Leave it to the Specialist: Repair Sparse LLMs with Sparse Fine-Tuning via Sparsity Evolution
Sparse large language models (LLMs) offer an attractive direction toward efficient deployment, but adapting them to downstream tasks remain…
Assistax: A Multi-Agent Hardware-Accelerated Reinforcement Learning Benchmark for Assistive Robotics
The development of reinforcement learning (RL) algorithms has been largely driven by ambitious challenge tasks and benchmarks. Games have d…
AlphaEval: A Comprehensive and Efficient Evaluation Framework for Formula Alpha Mining
Formula alpha mining, which generates predictive signals from financial data, is critical for quantitative investment. Although various alg…
Collab-REC: An LLM-based Agentic Framework for Balancing Recommendations in Tourism
We propose COLLAB-REC, a multi-agent framework designed to counteract popularity bias and improve diversity in tourism recommendations. In…
DTKG: Dual-Track Knowledge Graph-Verified Reasoning Framework for Multi-Hop QA
Multi-hop reasoning for question answering (QA) plays a critical role in retrieval-augmented generation (RAG) for modern large language mod…
RGMem: Renormalization Group-inspired Memory Evolution for Language Agents
Personalized and continuous interactions are critical for LLM-based conversational agents, yet finite context windows and static parametric…
ProtocolBench: Which LLM MultiAgent Protocol to Choose?
As large-scale multi-agent systems evolve, the communication protocol layer has become a critical yet under-evaluated factor shaping perfor…
Human-Like Goalkeeping in a Realistic Football Simulation: a Sample-Efficient Reinforcement Learning Approach
While several high profile video games have served as testbeds for Deep Reinforcement Learning (DRL), this technique has rarely been employ…
MemVerse: Multimodal Memory for Lifelong Learning Agents
Despite rapid progress in large-scale language and vision models, AI agents still suffer from a fundamental limitation: they cannot remembe…
MIND: Multi-rationale INtegrated Discriminative Reasoning Framework for Multi-modal Large Models
Recently, multimodal large language models (MLLMs) have been widely applied to reasoning tasks. However, they suffer from limited multi-rat…
FutureWeaver: Planning Test-Time Compute for Multi-Agent Systems with Modularized Collaboration
Scaling test-time computation has been shown to significantly improve large language model (LLM) performance without additional training. H…
DTop-p MoE: Sparsity-Controlled Dynamic Top-p MoE for Foundation Model Pre-training
Sparse Mixture-of-Experts architectures are essential for scaling model capacity efficiently, yet the standard Top-$k$ routing imposes a ri…
The Agent's First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios
The rapid evolution of Multi-modal Large Language Models (MLLMs) has advanced workflow automation; however, existing research mainly target…
A Scoping Review of the Ethical Perspectives on Anthropomorphising Large Language Model-Based Conversational Agents
Anthropomorphisation -- the phenomenon whereby non-human entities are ascribed human-like qualities -- has become increasingly salient with…
Strongly Polynomial Time Complexity of Policy Iteration for $L_\infty$ Robust MDPs
Markov decision processes (MDPs) are a fundamental model in sequential decision making. Robust MDPs (RMDPs) extend this framework by allowi…
PieArena: Ranking and Profiling Language Agents in Realistic Negotiation Scenarios
We present an in-depth evaluation of LLMs' ability to negotiate, a central business task requiring strategic reasoning, theory of mind, and…
Who Deserves the Reward? SHARP: Shapley Credit-based Optimization for Multi-Agent System
Integrating Large Language Models (LLMs) with external tools via multi-agent systems offers a promising new paradigm for decomposing and so…
When Should LLMs Be Less Specific? Selective Abstraction for Reliable Long-Form Text Generation
LLMs are widely used, yet they remain prone to factual errors that erode user trust and limit adoption in high-risk settings. One approach…
Towards a Science of AI Agent Reliability
AI agents are increasingly deployed to execute important tasks. While rising accuracy scores on standard benchmarks suggest rapid progress,…
VeRO: A Harness for Agents to Optimize Agents
An important emerging application of coding agents is agent harness optimization: the iterative improvement of a target agent by editing an…
X-RAY: Mapping LLM Reasoning Capability via Formalized and Calibrated Probes
Large language models (LLMs) achieve promising performance, yet their ability to reason remains poorly understood. Existing evaluations lar…
MAVEN-T: Reinforced Heterogeneous Distillation for Real-Time Multi-Agent Trajectory Prediction
Trajectory prediction is a key component of autonomous driving systems because future motions directly affect collision checking, behavior…
Evaluating Relational Reasoning in LLMs with REL
Relational reasoning is the ability to infer relations that jointly bind multiple entities, attributes, or variables. This ability is centr…
Co-evolving Agent Architectures and Interpretable Reasoning for Automated Optimization
Automating operations research (OR) with large language models (LLMs) remains limited by hand-crafted reasoning--execution workflows. Compl…
From Context to Skills: Can Language Models Learn from Context Skillfully?
Many real-world tasks require language models (LMs) to reason over complex contexts that exceed their parametric knowledge. This calls for…
Efficient Temporal Datalog Materialisation for Composite Event Recognition
Several applications demand the timely detection of critical situations, such as threats to safety and transparency, over high-velocity str…
AdapShot: Adaptive Many-Shot In-Context Learning with Semantic-Aware KV Cache Reuse
Many-Shot In-Context Learning (ICL) has emerged as a promising paradigm, leveraging extensive examples to unlock the reasoning potential of…
Done, But Not Sure: Disentangling World Completion from Self-Termination in Embodied Agents
Standard embodied evaluations do not independently score whether an agent correctly commits to task completion at episode closure, a capaci…
From Holo Pockets to Electron Density: GPT-style Drug Design with Density
Recent advances in generative modeling have enabled significant progress in structure-based drug design (SBDD). Existing methods typically…
PnP-Corrector: A Universal Correction Framework for Coupled Spatiotemporal Forecasting
Coupled spatiotemporal forecasting is important for predicting the future evolution of multiple interacting dynamical systems, such as in c…
Assessing and Mitigating Miscalibration in LLM-Based Social Science Measurement
Large language models (LLMs) are increasingly used in social science as scalable measurement tools for converting unstructured text into va…
幻覚検出のための自動レイヤー選択
幻覚検出に関する最近の研究では、幻覚関連信号は大規模言語モデル (LLM) の最終層よりも中間層でより強くエンコードされることが示されています。この特性を幻覚検出に利用しようとする研究が増えていますが、高性能レイヤーの選択を自動化する方法はまだ研究されておらず、この目的のための原則的な方法もまだ不足しています。このギャップに対処するために、最初に、なぜそのような信号が中間層で出現するのかについていくつかの仮説を提案し、質問応答と要約幻覚検出ベンチマークの両方をカバーする、多様な LLM アーキテクチャ、スケール、タスクにわたる自動層選択の対応する基準を評価します。ただし、これらの基準のいずれも満足のいくパフォーマンスを一貫して提供できないことがわかりました。したがって、我々は、最適な層または最適に近い層を一貫して特定し、前述の基準と既存の幻覚検出ベースラインの両方を上回る新しい選択基準である固有次元の最初の有効ピーク (FEPoID) を提案します。 FEPoID はトレーニング不要であり、計算上のオーバーヘッドは無視できます。さらに、LLM の生成挙動を研究し、幻覚関連信号をさらに増幅し、全体的な検出性能を大幅に向上させる、シンプルかつ効果的な打ち切り戦略を導入します。コードは https://github.com/DesoloYw/Automatic-Layer-Selection-for-Hallucination-Detection.git で公開されています。
原文 (English)
Automatic Layer Selection for Hallucination Detection
Recent studies on hallucination detection have shown that hallucination-related signals are more strongly encoded in intermediate layers than in the final layer of large language models (LLMs). Although a growing body of work has sought to exploit this property for hallucination detection, how to automate the selection of high-performing layers remains underexplored, and principled methods for this purpose are still lacking. To address this gap, we first propose several hypotheses for why such signals emerge in intermediate layers and evaluate corresponding criteria for automatic layer selection across diverse LLM architectures, scales, and tasks, covering both question answering and summarization hallucination detection benchmarks. However, we find that none of these criteria consistently delivers satisfactory performance. We therefore propose a new selection criterion, First Effective Peak of Intrinsic Dimension (FEPoID), which consistently identify optimal or near-optimal layers and outperforms both the aforementioned criteria and existing hallucination detection baselines. FEPoID is training-free and incurs negligible computational overhead. In addition, we study the generation behaviors of LLMs and introduce a simple yet effective truncation strategy, which further amplifies hallucination-related signals and substantially improves overall detection performance. Code is publicly available at https://github.com/DesoloYw/Automatic-Layer-Selection-for-Hallucination-Detection.git
PEAM: Minecraft での経験の対照的な内面化によるパラメトリックな身体化されたエージェントの記憶
Minecraft のパラメトリック エンボディド エージェント メモリ フレームワークである PEAM を紹介します。これは、エージェント メモリを推論時の検索から、経験を通じて内面化されたパラメータ常駐スキルに変換します。 PEAM は、オープンエンド推論のための遅い熟議型 LLM と、統合されたスキルを反射的に実行するための高速パラメトリック モジュールを組み合わせます。この高速モジュールは、カテゴリごとに物理的に分離されたアダプターを備えたマルチモーダルな専門家混合 LoRA アーキテクチャであり、致命的な忘れを引き起こすことなくパラメーター レベルの継続的な学習を可能にします。私たちは失敗を第一級のトレーニング信号として扱います。失敗と修正軌道のペアは、共同の行動クローニングと対照的な目標を通じて内面化されるため、エージェントは何が成功したかだけでなく、修正されたアクションが失敗したアクションとどのように異なるのかも学習します。統合を管理するために、PEAM は、どのエクスペリエンスを内部化するかを決定するためのパラメータ化価値スコアと、タスク固有の手動調整しきい値なしでいつ内部化するかを決定するためのスケールフリーの自己トリガー統合メカニズムを導入し、再調整することなくトリガーがタスク分布全体に移行するにつれてエージェントを自己進化させます。 Minecraft での実験では、PEAM が長期的なタスクのパフォーマンスを向上させ、以前に統合されたスキルの忘れを軽減し、検索ベースの身体化エージェントやパラメトリック メモリのバリアントに比べてパラメトリック対検索の効率を向上させることが示されています。
原文 (English)
PEAM: Parametric Embodied Agent Memory through Contrastive Internalization of Experience in Minecraft
We present PEAM, a Parametric Embodied Agent Memory framework in Minecraft that transforms agent memory from inference-time retrieval into parameter-resident skills internalized through experience. PEAM pairs a slow deliberative LLM for open-ended reasoning with a fast parametric module for reflexive execution of consolidated skills. The fast module is a multimodal Mixture-of-Experts LoRA architecture with per-category physically isolated adapters, enabling parameter-level continual learning without catastrophic forgetting. We treat failure as a first-class training signal: failure--correction trajectory pairs are internalized through a joint behavioral-cloning and contrastive objective, so the agent learns not only what succeeds but also how corrected actions differ from failed ones. To govern consolidation, PEAM introduces a parameterization-worthiness score for deciding which experience should be internalized, and a scale-free self-triggered consolidation mechanism for deciding when to internalize without task-specific hand-tuned thresholds, making the agent self-evolving as the trigger transfers across task distributions without re-tuning. Experiments in Minecraft show that PEAM improves long-horizon task performance, mitigates forgetting on previously consolidated skills, and improves parametric-versus-retrieval efficiency over retrieval-based embodied agents and parametric memory variants.
A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
As agent capabilities advance, existing benchmarks, such as $\tau^2$-Bench, are becoming increasingly saturated. Yet constructing new bench…
自己と他者を理解する AI システムに向けて: 人間の認知の多様性と世界モデルの整合のための多段階推論フレームワーク
現代社会における相互誤解は、単に意見や価値観の違いだけで生じるものではありません。同じ観察のもとでも、異なる主体は異なる推論ターゲット、状態表現、予測誤差、更新優先度を形成する可能性があります。この論文では、マルチフェーズ推論フレームワークを提案し、その中核となる内部メカニズムをマルチフェーズ推論メカニズム (MIM) として定義します。 MIM は、位相形成空間、前景フィールド、対象固有のプロファイル状態、および状態表現間の位置合わせマップを通じて、異種世界モデルがどのように生じるかを形式化します。これに基づいて、この論文は世界モデルの調整を、単一の価値体系への合意や収束を強制するのではなく、異種表現を相互に処理可能にする問題として再構成します。さらに、この形式主義を哲学的不一致、認知類型論、社会的断片化、AI の調整と結びつけます。その目的は、意味、価値、予測誤差の違いを可視化し、比較し、変換可能にすることで、人間が自己と他者を理解するのに役立つ建設的な語彙を AI システムに提供することです。
原文 (English)
Toward AI That Understands Self and Others: A World-Model Theory of Cognitive Diversity and Alignment
Modern societies possess more information than ever before, yet they do not converge toward a single shared understanding. The same events, facts, laws, technologies, or risks can be interpreted as evidence of freedom, danger, exclusion, injustice, responsibility, or unrealized possibility. Existing discussions often treat such disagreement as a conflict of values, preferences, or beliefs. This paper argues that disagreement is already a late-stage phenomenon. The central premise is simple but not trivial: observation is not yet inference. Not every observation becomes inferentially relevant, and not every possible object in an observation sequence becomes an estimation target. A possible target becomes admissible only when a state representation can be constructed that is approximately sufficient for prediction, evaluation, or action with respect to that target. This paper develops a world-model theory of cognitive diversity and alignment by reconstructing recognition as the construction of such approximate sufficient statistics under finite informational, representational, observational, and action constraints. It formulates this position as the Multi-Phase Inference Assumption (MIA) and defines its core internal mechanism as the Multi-Phase Inference Mechanism (MIM). The framework introduces alignment maps and transformation loss to analyze how heterogeneous world models communicate without being collapsed into a single representation. World-model alignment is therefore processability, not agreement: the design of AI systems that help heterogeneous forms of intelligence remain mutually processable while preserving their distinct error-detection capacities.
編集する前にプローブする: 構造ベースの医薬品設計における LLM 薬剤のプローブに基づく分子最適化
構造ベースの医薬品設計では、標的ポケットに対してリガンドを反復的に精製するために LLM 試薬の採用が増えていますが、実行可能なリガンドは、しばしば相反する 2 つの目的、つまり結合親和性と創薬可能性を満たさなければなりませんが、単一の最適化ステップで同時に改善されることはほとんどありません。この困難さを定量化するために、2 つの診断メトリクスを導入します。1 つ目は、1 回の編集で両方の目標が改善される頻度を測定し、2 つ目は、一方の目標の利益が他方の目標の損失を伴う頻度を測定します。これらの診断を現在の LLM エージェント パイプラインに適用すると、一貫した障害モードが明らかになります。エージェントは、ポケット-リガンド複合体が局所的な修飾にどのように反応するかを知らずに分子編集を実行するため、関節の改善が達成されることはほとんどありません。最適化の方向性を選択する前に、制御されたアナログ編集でポケット-リガンド複合体を調査する医薬化学者からインスピレーションを得て、編集応答調査を中心に構築された最適化フレームワークである \textbf{PROBE} を提案します。 PROBE はまずリガンドを編集可能なサイトに分解し、共同利得が考えられる場所、2 つの目的が緊張している可能性が高い場所、および責任の下部構造を変更する必要がある場所を示すポケット固有の \textbf{サイト マップ} を構築します。次に、制御されたプローブ編集を実行し、その応答が \textbf{EditManual} に抽出されます。 PROBE は、サイト マップと EditManual に基づいて、アフィニティ エージェント、ドラッガビリティ エージェント、および共同最適化エージェントが共同して編集を行う反復マルチエージェント ループを実行します。 CrossDocked2020 ベンチマークでは、PROBE は最先端のパフォーマンスを達成し、診断メトリクスによって明らかになった障害モードを大幅に軽減します。
原文 (English)
Probe Before You Edit: Probing-Guided Molecular Optimization for LLM Agents in Structure-Based Drug Design
Structure-based drug design increasingly employs LLM agents to iteratively refine ligands against a target pocket, yet a viable ligand must satisfy two often-conflicting objectives -- binding affinity and druggability -- which single optimization steps rarely improve together. To quantify this difficulty, we introduce two diagnostic metrics: the first measures how often a single edit improves both objectives, and the second measures how often a gain on one objective comes with a loss on the other. Applying these diagnostics to current LLM-agent pipelines exposes a consistent failure mode: the agent performs molecular editing without knowing how the pocket-ligand complex responds to local modifications, thus rarely achieving joint improvement. Inspired by medicinal chemists, who probe the pocket-ligand complex with controlled analog edits before choosing an optimization direction, we propose \textbf{PROBE}, an optimization framework built around edit-response probing. PROBE first decomposes the ligand into editable sites and builds a pocket-specific \textbf{site map} that flags where joint gains are plausible, where the two objectives are likely in tension, and where liability substructures should be changed; it then performs controlled probe edits whose responses are distilled into an \textbf{EditManual}. Guided by the site map and EditManual, PROBE runs an iterative multi-agent loop in which an affinity agent, a druggability agent, and a co-optimization agent jointly produce edits. On the CrossDocked2020 benchmark, PROBE achieves state-of-the-art performance and substantially mitigates the failure modes exposed by our diagnostics metrics.
事後ハイブリッド ベイジアン ビリーフを使用した正規化されたオフライン ポリシーの最適化
オフライン強化学習 (RL) は、事前に収集されたデータセットからポリシーを最適化することを目的としています。このパラダイムのボトルネックは、認識論的な不確実性を管理することです。これは、限られたデータ範囲 (サンプルレベル) と、有限データから遷移ダイナミクスを特定する際の曖昧さ (モデルレベル) から生じます。これらの不確実性を統一的に定量化するために、ダイナミクス モデルを確率変数として扱い、対応する信念を維持することによってベイジアン RL が提案されています。理論的には魅力的ですが、ベイジアン RL でのポリシーの最適化は、期待値を含む複合目標を解決する必要があるため、依然として計算上困難です。従来の方法は、計算のスケーラビリティが低い検索ベースの手法を採用するか、ベイジアン RL の適応性を犠牲にする制限的な事後仮定を課すかのいずれかでした。これらの制限に対処するために、私たちは事後ハイブリッド ベイジアン ビリーフ (PhyB) を提案します。これは、ダイナミクス モデルのサブセットにわたる凸の組み合わせとして期待値を再定式化します。理論的分析により、この近似によって引き起こされる客観的な不一致には限界があることが実証されています。 PhyB に基づいて、収束までの単調な改善に対するメトリクスに依存しない保証を提供する反復的な正則化ポリシー最適化アルゴリズムを開発します。実証結果は、PhyB がさまざまなベンチマークで最先端のパフォーマンスを達成することを示しています。
原文 (English)
Regularized Offline Policy Optimization with Posterior Hybrid Bayesian Belief
Offline reinforcement learning (RL) aims to optimize policies from pre-collected datasets. A bottleneck of this paradigm is managing epistemic uncertainty, which arises from limited data coverage (sample-level) and the ambiguity in identifying transition dynamics from finite data (model-level). To provide a unified quantification of these uncertainties, Bayesian RL has been proposed by treating the dynamics model as a random variable and maintaining a corresponding belief. Despite its theoretical appeal, policy optimization in Bayesian RL remains computationally challenging as it requires solving composite objectives with expectations. Prior methods either employ search-based techniques with poor computational scalability or impose restrictive posterior assumptions that sacrifice the adaptability of Bayesian RL. To address these limitations, we propose Posterior Hybrid Bayesian Belief (PhyB), which reformulates the expectation as a convex combination over a subset of dynamics models. Theoretical analysis demonstrates that the objective discrepancy induced by this approximation remains bounded. Based on PhyB, we develop an iterative regularized policy optimization algorithm that provides metric-agnostic guarantees for monotonic improvement until convergence. Empirical results demonstrate that PhyB achieves state-of-the-art performance on various benchmarks.
NBQ: 動的プロファイリングの次に最適な質問
ポッドキャスト、採用画面、マーケットプレイスなど、知識発見のための現実世界の会話環境の多くでは、目的に基づいて個人を理解する必要があります。私たちは Next-Best-Question (NBQ) 問題を研究します。つまり、面接官は各ターンで、すでに学んだ内容と会話の目標を考慮して、最も多くの情報が得られると期待される質問をする必要があります。私たちは、多様な候補質問のプールをシードし、コンパクトで継続的に更新されるユーザー状態を維持し、ターンバジェット内で次の質問を適応的に選択し、結果として得られる自由形式の対話を構造化されたベクトルベースのユーザープロファイルに抽出するプラグアンドプレイフレームワークであるNBQを提案します。要求の厳しいアプリケーションとして、相互マッチメイキング用の NBQ をインスタンス化します。この場合、互換性は相互である必要があり、各人は自己記述と相手の好みの表現の両方によってモデル化されます。大規模なマッチングをサポートするために、二次ペアごとのスコアリングから近似ベクトル検索への相互マッチングを再キャストする効率的な検索レイヤーである QuickMatch をさらに導入します。実験によると、NBQ はユーザー プロファイリングの品質を AC@T と AR@T でそれぞれ最大 13.6% と 14.0% 向上させ、一方、QuickMatch は検索を最大 22.9 倍高速化し、再現率は最大 0.989 です。
原文 (English)
NBQ: Next-Best-Question for Dynamic Profiling
Many real-world conversational settings for knowledge discovery, including podcasts, hiring screens, and marketplaces, require a purpose-driven understanding of a person. We study the Next-Best-Question (NBQ) problem: at each turn, an interviewer should ask the question with the highest expected information gain given what has already been learned and the conversation goal. We propose NBQ, a plug-and-play framework that seeds a diverse pool of candidate questions, maintains a compact and continuously updated user state, adaptively selects the next question within a turn budget, and distills the resulting free-form dialogue into a structured vector-based user profile. As a demanding application, we instantiate NBQ for reciprocal matchmaking, where compatibility must be mutual and each person is modeled by both self-description and counterpart-preference representations. To support large-scale matching, we further introduce QuickMatch, an efficient retrieval layer that recasts reciprocal matching from quadratic pairwise scoring to approximate vector search. Experiments show that NBQ improves user profiling quality by up to 13.6% and 14.0% in AC@T and AR@T, respectively, while QuickMatch accelerates retrieval by up to 22.9x with recall up to 0.989.
AI レビューは紙の製図を改善できるか? 20 件のコンピュータ アーキテクチャの提出に関する実証的研究
人工知能 (AI) の研究はこれまで以上に急速に進歩しています。対応する研究論文も同様です。 AI によって生成された論文の爆発的な量は査読に負担をかけており、AI によって生成された査読が、広範かつ卑劣な可能性を持って使用されるようになりました。しかし、機密性、品質、公平性に関する関連する倫理的懸念が提起されており、広範な研究コミュニティで合意に達していません。この議論はしばらく続くと予想されますが、それまでの間、私たちは代わりの実践的な質問をします: \textit{AI レビューは論文のドラフトを改善できますか?} 私たちは、さまざまなレベルの投稿系統を持つ 20 件のコンピューター アーキテクチャ論文を研究し、AI レビューが人間のレビューとどの程度一致しているかを明らかにします。これは、私たちが定義する一連の指標によって定量化されます。ケーススタディを実施するために、ドラフト論文の構造化された AI レビューを生成する Web UI 統合ツール \emph{AI-Paper-Review} を構築します。これは https://github.com/unarylab/ai-paper-review で入手できます。このツールは、AI レビュー担当者とクラスターの多様なプールから複数の AI レビュー担当者を選択し、レビュー コメントの共通性と重要性に基づいてコメントをランク付けします。また、AI のコメントと人間のコメントを調整して、メトリクスベースの検証を容易にすることもできます。このケーススタディは、AI レビューは人間によって引き起こされた問題のかなりの部分をカバーできるが、人間によるレビューでは欠けている問題も提起することを示しています。この論文は、現段階で査読に AI を使用することを推奨するものではなく、(1) AI レビューがどのように論文起草を改善できるか、(2) AI ベースの査読の可能性と限界について研究することを目的としています。このツールとケーススタディ データのリリースは、このテーマに関する将来の研究を促進することを目的としています。査読に悪用すると、主要な学術機関の倫理ポリシーに違反することになります。
原文 (English)
Can AI Review Improve Paper Drafting? An Empirical Study on 20 Computer Architecture Submissions
Research is advancing faster than ever with artificial intelligence (AI); and so are the corresponding research papers. The exploding volume of AI-generated papers have put a strain to peer review, leading to the usage of AI-generated review, potentially wide yet sneaky. However, relevant ethical concerns about confidentiality, quality, and fairness are raised and no consensus has been reached in the broad research community. We expect the debate to continue for a while, but in the meantime, we ask an alternative, practical question: \textit{can AI review improve paper drafting?} We study 20 computer architecture papers, with varying levels of submission lineage, to expose how well AI review aligns with human review, quantified by a set of metrics we define. To conduct the case study, we build a web UI-integrated tool, \emph{AI-Paper-Review}, that generates structured AI review of a draft paper, available at https://github.com/unarylab/ai-paper-review. This tool selects several AI reviewers from a diverse pool of AI reviewers and clusters and ranks their comments based on commonality and importance of review comments. It also allows to align AI comments with human comments to facilitate metric-based validation. The case study shows that AI review can cover a significant fraction of human-raised issues, but also raises issues missing in human review. This paper is not intended to encourage using AI for peer review at the current stage, but to study that (1) how AI review can improve paper drafting and (2) the potential and limitation of AI-based peer review. The release of the tool and the case study data is intended to instigate future research on this topic. Misuse for peer review would violate the ethics policies from major academic venues.
SkillRevise: トレース条件付きスキル リビジョンによる LLM 作成エージェント スキルの向上
エージェント スキルは、LLM エージェントがワークフローを実行し、制約を検証し、障害から回復できるようにする手順的な成果物です。既存の自己進化手法は、蓄積された軌跡を利用してスキルを磨きます。しかし、初期の不完全なスキルしか利用できないコールドスタート環境では苦戦します。したがって、スキル構築はデフォルトでエキスパートオーサリングまたはワンショット LLM 生成になります。専門家が作成したスキルはコストが高く、LLM エージェントが実際にタスクを実行する方法と一致していない可能性があります。一方、ワンショットで生成されたスキルは、構文的には適切ですが、動作が弱い可能性があります。このギャップを埋めるために、私たちは、これらの初期スキルを反復的に改善するように設計された実行ベースのフレームワークである SkillRevise を提案します。 SkillRevise は、実行の証拠からスキルの欠陥を診断し、一般的なメモリから関連する修復原則を取得し、実行に固定された編集を適用します。候補者を再実行し、経験的な有用性を測定することで、最適なスキル バージョンを体系的に保持します。 3 つのベンチマークと 5 つの LLM で評価したところ、SkillRevise はワンショット ベースラインを大幅に上回り、SkillsBench でのベース エージェントの成功率が 36.05% から 61.63% に向上しました。さらに、改訂されたスキルはモデル間での強力な移行性を示し、モデル固有のアーティファクトに関する一般化された手順の知識を取得します。
原文 (English)
SkillRevise: Improving LLM-Authored Agent Skills via Trace-Conditioned Skill Revision
Agent skills are procedural artifacts that enable LLM agents to execute workflows, verify constraints, and recover from failures. Existing self-evolving methods refine skills using accumulated trajectories. However, they struggle in cold-start settings, where only an initial, imperfect skill is available. Consequently, skill construction defaults to expert authoring or one-shot LLM generation. Expert-authored skills are costly and may not align with how LLM agents actually execute tasks, while one-shot generated skills can be syntactically well formed yet behaviorally weak. To bridge this gap, we propose SkillRevise, an execution-grounded framework designed to iteratively refine these initial skills. SkillRevise diagnoses skill defects from execution evidence, retrieves relevant repair principles from a general memory, and applies execution-anchored edits. By re-executing candidates and measuring empirical utility, it systematically retains the optimal skill version. Evaluated across three benchmarks and five LLMs, SkillRevise substantially outperforms one-shot baselines, improving the base agent's success rate on SkillsBench from 36.05% to 61.63%. Furthermore, the revised skills exhibit strong cross-model transferability, capturing generalized procedural knowledge over model-specific artifacts.
専門家の混合による、さまざまな期限を持つ動的なクラウド ワークフローの巧みなスケジューリング
クラウド コンピューティングにおけるワークフロー スケジューリングでは、さまざまな期限を持つ動的に到着するグラフ構造のワークフローを、常に変化する仮想マシン リソースにインテリジェントに割り当てる必要があります。しかし、既存の深層強化学習 (DRL) スケジューラーは、多様なスケジューリング シナリオの処理に苦労する厳格な単一パス推論アーキテクチャによって依然として制限されています。 \textbf{DEFT} (\textbf{D}eadline-p\textbf{E}rceptive Mixture-o\textbf{F}-Exper\textbf{t}s) を導入します。これは、さまざまなレベルの締め切り厳しさを管理するように訓練された専門家の専門家混合を活用する革新的な DRL ポリシー アーキテクチャです。私たちの知る限り、DEFT は動的なクラウド ワークフロー スケジューリングのための専門家混合アーキテクチャを導入して検証した最初の企業です。 DEFT は、最も適切な専門家を通じて意思決定を適応的に行うことで、単一の専門家では達成できない広範な期限要件を満たすことができます。 DEFT の中心となるのは、ワークフローの期限と DAG、タスクの状態、VM の状態をエンコードする \textbf{graph-adaptive} ゲート メカニズムです。クロス アテンションを使用して、きめ細かく期限に敏感な方法でエキスパートのアクティベーションをガイドします。動的なクラウド ワークフロー ベンチマークの実験では、DEFT が実行コストと期限違反を大幅に削減し、複数の最先端の DRL ベースラインを上回るパフォーマンスを示していることが実証されています。
原文 (English)
Deft Scheduling of Dynamic Cloud Workflows with Varying Deadlines via Mixture-of-Experts
Workflow scheduling in cloud computing demands the intelligent allocation of dynamically arriving, graph-structured workflows with varying deadlines onto ever-changing virtual machine resources. However, existing deep reinforcement learning (DRL) schedulers remain limited by rigid, single-path inference architectures that struggle to handle diverse scheduling scenarios. We introduce $\textbf{DEFT}$ ($\textbf{D}$eadline-p$\textbf{E}$rceptive Mixture-o$\textbf{F}$-Exper$\textbf{t}$s), an innovative DRL policy architecture that leverages a specialized mixture of experts, each trained to manage different levels of deadline tightness. To our knowledge, DEFT is the first to introduce and validate a Mixture-of-Experts architecture for dynamic cloud workflow scheduling. By adaptively routing decisions through the most appropriate experts, DEFT is capable of meeting a broad spectrum of deadline requirements that no single expert can achieve. Central to DEFT is a $\textbf{graph-adaptive}$ gating mechanism that encodes workflow DAGs, task states, and VM conditions, using cross-attention to guide expert activation in a fine-grained, deadline-sensitive manner. Experiments on dynamic cloud workflow benchmarks demonstrate that DEFT significantly reduces execution cost and deadline violations, outperforming multiple state-of-the-art DRL baselines.
局所比較で訓練されたトランスフォーマーの創発順序幾何学
推移的推論は、隣接する関係 (A < B、B < C) のみを知っていることから A < C を推論するという課題です。人間や動物は、論理的な連鎖ではなく、アナログの精神的数直線を介して解決します。その特徴は、象徴的な距離効果です。つまり、遠くの比較は近くの比較よりも簡単です。トランスフォーマーが同じプリミティブを取得し、隠された全順序からの隣接する比較のみで小さなモデルをトレーニングし、目に見えない遠くのペアへの一般化を評価するかどうかを尋ねます。私たちは、分布外一般化が顕著な幾何学的再編成と並行して出現していることを発見しました。エンティティの埋め込みは、主軸が隠れた順位をほぼ完璧な忠実度で回復する 1 次元多様体に崩壊します。この構造は、グロッキングのような過渡ダイナミクスを生み出す方法での最適化に敏感です。重要なのは、精度が限界に達している場合でも、決定の信頼性と幾何学的分離は両方ともランク距離に単調にスケールし、人間、霊長類、齧歯動物に対する数十年の行動実験で観察された象徴的な距離の効果を直接反映していることです。これらの結果は、学習された表現の幾何学における 50 年来の行動規則性の根拠となり、認知科学と現代のニューラル ネットワークの橋渡しとなる推移的推論の機構的な説明を提供します。
原文 (English)
Emergent Ordinal Geometry in Transformers Trained on Local Comparisons
Transitive inference is the challenge of inferring that A < C from knowing only adjacent relations (A < B, B < C). It is solved by humans and animals not through logical chaining but via an analogue mental number line, whose signature is the symbolic distance effect: distant comparisons are easier than nearby ones. We ask whether Transformers acquire the same primitive, training small models exclusively on adjacent comparisons from a hidden total order and evaluating generalization to unseen distant pairs. We find that out-of-distribution generalization emerges alongside a striking geometric reorganization: entity embeddings collapse onto a one-dimensional manifold whose principal axis recovers the hidden rank order with near-perfect fidelity, and this structure is sensitive to optimization in ways that produce grokking-like transient dynamics. Critically, even when accuracy is at ceiling, decision confidence and geometric separation both scale monotonically with rank distance, directly mirroring the symbolic distance effect observed across decades of behavioural experiments on humans, primates, and rodents. We further show the same rank-aligned geometry in a pretrained large language model, where it tracks the topology of each ordinal relation: linear for sizes and digits, cyclic for months. These results ground a 50-year-old behavioural regularity in the geometry of learned representations, offering a mechanistic account of transitive inference that bridges cognitive science and modern neural networks.
EvoBrain: Continual Learning of EEG Foundation Models Across Heterogeneous BCI Tasks
Electroencephalography (EEG) is the cornerstone of non-invasive brain-computer interfaces (BCIs), yet conventional decoding relies on fragm…
Community-Aware Assessment of Social Textual Engagement and Resonance: A Human-Centric Perspective on User-Generated Content Evaluation
Traditional Video Quality Assessment (VQA) focuses narrowly on aesthetic fidelity, overlooking the complex social dynamics that define qual…
Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories
Deep-research agents solve tasks through long trajectories of search, tool use, evidence inspection, and answer synthesis. Evaluation based…
Learning When Not to Act: Mitigating Tool Abuse in Agentic Reinforcement Learning
Agentic reinforcement learning can induce tool abuse, where models overuse external tools even for queries solvable by internal reasoning.…
Forget Attention: Importance-Aware Attention Is All You Need
Combining attention's global retrieval with the sequential importance signal of state space models (SSMs) is the open challenge of hybrid l…
AgentCL: Toward Rigorous Evaluation of Continual Learning in Language Agents
Language agents spend substantial inference time solving individual tasks, yet the experience acquired in one episode is often underutilize…
Typhoon: Towards an Effective Task-Specific Masking Strategy for Pre-trained Language Models
The choice of \emph{which} tokens to mask is a central, under-examined design decision in masked language modeling (MLM). Standard pretrain…
PINNfluence: Interpreting PINNs through Influence Functions
Physics-informed neural networks (PINNs) have emerged as a powerful deep learning approach for solving partial differential equations (PDEs…
Building Trust in Black-box Optimization: A Comprehensive Framework for Explainability
Optimizing costly black-box functions within a constrained evaluation budget presents significant challenges in many real-world application…
Align-KD: Distilling Cross-Modal Alignment Knowledge for Mobile Vision-Language Model Enhancement
Vision-Language Models (VLMs) bring powerful understanding and reasoning capabilities to multimodal tasks. Meanwhile, the great need for ca…
ASAP: Exploiting the Satisficing Generalization Edge in Neural Combinatorial Optimization
Deep Reinforcement Learning (DRL) has emerged as a promising approach for solving Combinatorial Optimization (CO) problems, such as the 3D…
Greed is Good: A Unifying Perspective on Guided Generation
Training-free guided generation is a widely used and powerful technique that allows the end user to exert further control over the generati…
Rex: A Family of Reversible Exponential (Stochastic) Runge-Kutta Solvers
Deep generative models based on neural differential equations have become state-of-the-art for many generation tasks. These models rely on…
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Text-to-Image (T2I) models are capable of generating high-quality artistic creations and visual content. However, existing research and eva…
Scaling Multi Agent Reinforcement Learning for Underwater Acoustic Tracking via Autonomous Vehicles
Autonomous vehicles (AVs) offer a cost-effective solution for scientific missions such as underwater tracking. Reinforcement learning (RL)…
Cooperation of Experts: Fusing Heterogeneous Information with Large Margin
Fusing heterogeneous information remains a persistent challenge in modern data analysis. While significant progress has been made, existing…
FlashMLA-ETAP: Efficient Transpose Attention Pipeline for Accelerating MLA Inference on NVIDIA H20 GPUs
Efficient inference of Multi-Head Latent Attention (MLA) is challenged by deploying the DeepSeek-R1 671B model on a single Multi-GPU server…
Do Explanations Increase the Risk of Decision Logic Leakage? Explanation-Guided Stealing of Graph Models
Graph Neural Networks (GNNs) have become essential tools for analyzing graph-structured data in domains such as drug discovery and financia…
dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching
Autoregressive Models (ARMs) have long dominated the landscape of Large Language Models. Recently, a new paradigm has emerged in the form o…
Curriculum-Adapted Robust Reinforcement Learning for UAV Deconfliction in Adversarial Environments
Autonomous unmanned aerial vehicles (UAVs) increasingly rely on reinforcement learning (RL) for navigation. However, global navigation sate…
Multiple Choice Learning of Low-Rank Adapters for Language Modeling
We propose LoRA-MCL, a training scheme that extends next-token prediction in language models with a method designed to decode diverse, plau…
CoMPAS3D: A Dataset and Benchmark for Interactive Motion
Socially interactive humanoid robots must engage with humans through their bodies, adapting in real time to a partner's movement, intent, a…
UR$^2$: Unify RAG and Reasoning through Reinforcement Learning
Large Language Models (LLMs) have shown strong capabilities through two complementary paradigms: Retrieval-Augmented Generation (RAG) for k…
Non-Identical Diffusion Models in MIMO-OFDM Channel Generation
We propose a novel diffusion model, termed the non-identical diffusion model, and investigate its application to wireless orthogonal freque…
TalkPlayData 2: An Agentic Synthetic Data Pipeline for Multimodal Conversational Music Recommendation
We present TalkPlayData 2, a synthetic dataset for multimodal conversational music recommendation generated by an agentic data pipeline. In…
Wavelet Fourier Diffuser: Frequency-Aware Diffusion Model for Reinforcement Learning
Diffusion probability models have shown significant promise in offline reinforcement learning by directly modeling trajectory sequences. Ho…
Learning the Neighborhood: Contrast-Free Multimodal Self-Supervised Molecular Graph Pretraining
High-quality molecular representations are essential for property prediction and molecular design, yet large labeled datasets remain scarce…
DeMuon: A Decentralized Muon for Matrix Optimization over Graphs
In this paper, we propose DeMuon, a method for decentralized matrix optimization over a given communication topology. DeMuon incorporates m…
ReaLM: Residual Quantization Bridging Knowledge Graph Embeddings and Large Language Models
Large Language Models (LLMs) have recently emerged as a powerful paradigm for Knowledge Graph Completion (KGC), offering strong reasoning a…
Generative AI and Sales Productivity: Field Experiments in Online Retail
We quantify the short-term impact of Generative Artificial Intelligence (GenAI) on sales performance through a series of large-scale random…
Semantic knowledge guides innovation and drives cultural evolution
Cultural evolution allows ideas and technologies to accumulate across generations, reaching their most complex and open-ended form in human…
Generating the Modal Worker: A Cross-Model Audit of Race and Gender in LLM-Generated Personas Across 41 Occupations
As generative AI tools are increasingly used to portray people in professional roles, understanding their racial and gender representationa…
Automata-Conditioned Cooperative Multi-Agent Reinforcement Learning
We study learning multi-task, multi-agent policies for cooperative, temporal objectives, under centralized training, decentralized executio…
A Robust and Explainable Transformer-Based Framework for Phishing Email Detection
Phishing and related cyber threats are becoming increasingly sophisticated, with email-based phishing remaining the most persistent attack…
PHASE: Physiology-Aware Hyperspectral Reconstruction via Object-to-Human Domain Adaptation
Although hyperspectral imaging offers unparalleled non-invasive physiological insight, its bulky hardware, slow acquisition, and regulatory…
Finding Kissing Numbers with Game-theoretic Reinforcement Learning
Since Isaac Newton first studied the Kissing Number Problem in 1694, determining the maximal number of non-overlapping spheres around a cen…
SeSE: Black-Box Uncertainty Quantification for Large Language Models Based on Structural Information Theory
Reliable uncertainty quantification (UQ) is essential for deploying large language models (LLMs) in safety-critical scenarios, as it enable…
Identifying Quantum Structure in AI Language: Evidence for Evolutionary Convergence of Human and Artificial Cognition
We present the results of cognitive tests on conceptual combinations, performed using specific Large Language Models (LLMs) as test subject…
Distribution-Calibrated Inference Time Compute for Thinking LLM-as-a-Judge
Thinking Large Language Models (LLMs) used as judges for pairwise preferences remain noisy at the single-sample level, and common aggregati…
Toward Training Superintelligent Software Agents through Self-Play SWE-RL
While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer producti…
Edge-Aware and Content-Adaptive Infrared Gas Leak Detection for Industrial Safety Monitoring
Infrared gas leak detection is important for industrial safety and environmental monitoring, but automatic detection remains challenging be…
LLMs, Reasoning and Plagiarism
Recent reports claim that Large Language Models (LLMs) derive new science and exhibit human-level general intelligence. Such claims are ent…
Introduction to optimization methods for training SciML models
Optimization is central to both modern machine learning (ML) and scientific machine learning (SciML), yet the structure of the underlying o…
Relational Linearity is a Predictor of Hallucinations
Hallucination is a central failure mode of language models (LMs). We focus on hallucinations in response to questions like: "Which instrume…
Distill-then-Replace: Efficient Task-Specific Hybrid Attention Model Construction
Transformer architectures deliver state-of-the-art accuracy via dense full-attention, but their quadratic time and memory complexity with r…
Aletheia: What Makes RLVR For Code Verifiers Tick?
Multi-domain thinking verifiers trained via Reinforcement Learning with Verifiable Rewards (RLVR) are a cornerstone of modern post-training…
Plan, Verify and Fill: A Structured Parallel Decoding Approach for Diffusion Language Models
Diffusion Language Models (DLMs) present a promising non-sequential paradigm for text generation, distinct from standard autoregressive (AR…
$\mathbb{R}^{2k}$ is Theoretically Large Enough for Embedding-based Top-$k$ Retrieval
This paper studies the Minimal Embeddable Dimension (MED): the least dimension in which there exists a configuration of $m$ object vectors…
Causal Preference Elicitation
We propose causal preference elicitation, a Bayesian framework for expert-in-the-loop causal discovery that actively queries local edge rel…
Phantom Transfer: Data Poisoning can Survive Data-Level Defences
We present a data poisoning attack -- Phantom Transfer -- with the property that, even if you know precisely how the poison was placed into…
Coupled Local and Global World Models for Efficient First Order RL
World models offer a promising avenue for more faithfully capturing complex dynamics, including contacts and non-rigidity, as well as compl…
InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning
Large reasoning models achieve strong performance by scaling inference-time chain-of-thought, but this paradigm suffers from quadratic cost…
LatentChem: From Textual CoT to Latent Thinking in Chemical Reasoning
Current chemical large language models (LLMs) predominantly rely on explicit Chain-of-Thought (CoT) to solve complex reasoning problems. Ho…
PAND: Prompt-Aware Neighborhood Distillation for Lightweight Fine-Grained Visual Classification
Distilling knowledge from large Vision-Language Models (VLMs) into lightweight networks is crucial yet challenging in Fine-Grained Visual C…
Whose Name Comes Up? II: Benchmarking and Intervention-Based Auditing of LLM-Based Scholar Recommendation
Large language models (LLMs) are now used for academic expert recommendation. Existing audits typically evaluate such recommendations in is…
Physics-informed diffusion models in spectral space
We propose physics-informed spectral diffusion (PISD), a methodology that combines generative latent diffusion models with physics-informed…
Learning Self-Interpretation from Interpretability Artifacts: Training Lightweight Adapters on Vector-Label Pairs
Self-interpretation methods prompt language models to describe their own internal states, but remain unreliable due to hyperparameter sensi…
Test-Time Optimization of Physical Query Plans with LLMs
Traditional query optimization relies on cost-based optimizers that estimate execution cost (e.g., runtime, memory, and I/O) using predefin…
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
The transition from monolithic language models to modular, skill-equipped agents marks a defining shift in how large language models (LLMs)…
Whom to Query for What: Adaptive Group Elicitation via Multi-Turn LLM Interactions
Eliciting information to reduce uncertainty about latent group-level properties from surveys and other collective assessments requires allo…
Sign Lock-In: Randomly Initialized Weight Signs Persist and Bottleneck Sub-Bit Model Compression
Sub-bit model compression targets storage below one bit per weight; as magnitudes are aggressively compressed, the sign bit becomes a fixed…
TimeOmni-VL: Unified Models for Time Series Understanding and Generation
Recent time series modeling faces a sharp divide between numerical generation and semantic understanding, with research showing that genera…
CodeHacker: Automated Test Case Generation for Detecting Vulnerabilities in Competitive Programming Solutions
The evaluation of Large Language Models (LLMs) for code generation relies heavily on the quality and robustness of test cases. However, exi…
KnapSpec: Self-Speculative Decoding via Adaptive Layer Selection as a Knapsack Problem
Self-speculative decoding (SSD) accelerates LLM inference by skipping layers to create an efficient draft model, yet existing methods often…
Causal Neural Probabilistic Circuits
Concept Bottleneck Models (CBMs) enhance the interpretability of end-to-end neural networks by introducing a layer of concepts and predicti…
vLLM Semantic Router: Signal Driven Decision Routing for Mixture-of-Modality Models
As large language models (LLMs) diversify across modalities, capabilities, and cost profiles, the problem of intelligent request routing --…
Ref-DGS: Reflective Dual Gaussian Splatting
The reflective appearance, especially strong and typically near-field specular reflections, poses a fundamental challenge for accurate surf…
VulnAgent-R2: Evidence-Calibrated Multi-Agent Auditing for Repository-Level Vulnerability Detection
Software vulnerabilities often depend on cross-file data flow, build options, framework conventions, and runtime guards, so isolated functi…
Measuring Weak-to-Strong Legibility of Reasoning Models
Reasoning language models (RLMs) and the intermediate chains of thought they emit play an increasingly central role in multi-agent setups s…
SleepVLM: Explainable and Rule-Grounded Sleep Staging via a Vision-Language Model
While automated sleep staging has achieved expert-level accuracy, its clinical adoption is hindered by a lack of auditable reasoning. We in…
Crystal: Characterizing Relative Impact of Scholarly Publications
Assessing a cited paper's impact is typically done by analyzing its citation context in isolation within the citing paper. While this focus…
Finetuning-Free Diffusion Model with Adaptive Constraint Guidance for Inorganic Crystal Structure Generation
The discovery of inorganic crystal structures with targeted properties is a significant challenge in materials science. Generative models,…
Just Type It in Isabelle! AI Agents Drafting, Mechanizing, and Generalizing from Human Hints
Type annotations are essential when printing terms in a way that preserves their meaning under reparsing and type inference. We study the p…
Dynamics of Cognitive Heterogeneity: Investigating Behavioral Biases in Multi-Stage Supply Chains with LLM-Based Simulation
Modeling coordination among generative agents in complex multi-round decision-making presents a core challenge for AI and operations manage…
Back into Plato's Cave: Examining Cross-modal Representational Convergence at Scale
The Platonic Representation Hypothesis suggests that neural networks trained on different modalities (e.g., text and images) align and even…
$R^2$-dLLM: Accelerating Diffusion Large Language Models via Spatio-Temporal Redundancy Reduction
Diffusion Large Language Models (dLLMs) have emerged as a promising alternative to autoregressive generation by enabling parallel token pre…
Quantifying and Mitigating Self-Preference Bias of LLM Judges
LLM-as-a-Judge has become a dominant approach in automated evaluation systems, playing critical roles in model alignment, leaderboard const…
ProEval: Proactive Failure Discovery and Efficient Performance Estimation for Generative AI Evaluation
Evaluating generative AI models is increasingly resource-intensive due to slow inference, expensive raters, and a rapidly growing landscape…
How to Guide Your Flow: Few-Step Alignment via Flow Map Reward Guidance
In generative modeling, we often wish to produce samples that maximize a user-specified reward such as aesthetic quality or alignment with…
SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents
LLM agents increasingly rely on reusable skills (e.g., $SKILL.md$ ) to execute complex tasks, yet these artifacts lack portability: agent f…
Narrow Secret Loyalty Dodges Black-Box Audits
Recent work identifies secret loyalties as a distinct threat from standard backdoors. A secret loyalty causes a model to covertly advance t…
Mechanism Design Is Not Enough: Prosocial Agents for Cooperative AI
Ensuring that AI agents behave safely and beneficially when interacting with other parties has emerged as one of the central challenges of…
Towards Robust Sequential Decomposition for Complex Image Editing
Recent advances in visual generative models have enabled high-fidelity image editing guided by human instructions. However, these models of…
Exact Stiefel Optimization for Probabilistic PLS: Closed-Form Updates, Error Bounds, and Calibrated Uncertainty
Probabilistic partial least squares (PPLS) is a central likelihood-based model for two-view learning when one needs both interpretable late…
AgentLens: Revealing The Lucky Pass Problem in SWE-Agent Evaluation
Evaluation of software engineering (SWE) agents is dominated by a binary signal: whether the final patch passes the tests. This outcome-onl…
X-Restormer++: 1st Place Solution for the UG2+ CVPR 2026 All-Weather Restoration Challenge
In this work, we present our winning solution for the 8th UG2+ Challenge (CVPR 2026) Track 1: Image Restoration under All-weather Condition…
Misspecified Estimate-then-Optimize Leads to Supra-Competitive Prices
We study whether simple algorithmic pricing systems can systematically produce collusive-like prices in multi-firm markets. We consider fir…
Symmetry-Compatible Principle for Optimizer Design: Embeddings, LM Heads, SwiGLU MLPs, and MoE Routers
A striking geometric disparity has long persisted in the practice of deep learning. While modern neural network architectures naturally exh…
Vision Inference Former: Sustaining Visual Consistency in Multimodal Large Language Models
In recent years, multimodal large language models (MLLMs) have achieved remarkable progress, primarily attributed to effective paradigms fo…
Vision-OPD: Learning to See Fine Details for Multimodal LLMs via On-Policy Self-Distillation
Multimodal Large Language Models (MLLMs) still struggle with fine-grained visual understanding, where answers often depend on small but dec…
Latent Laplace Diffusion for Irregular Multivariate Time Series
Irregular multivariate time series impose a trade-off for long-horizon forecasting: discrete methods can distort temporal structure via re-…
LLM 強化学習のための MXFP4 量子化誤差の分解: 削減可能なバイアス、回復可能なデッドゾーン、および既約の下限
MXFP4 算術演算は、大規模言語モデル (LLM) のトレーニング後の強化学習 (RL) を劇的に加速できますが、量子化エラーにより精度が大幅に低下します。既存の研究では、量子化誤差をモノリシックなノイズ項として扱っており、量子化誤差がトレーニングにどのような影響を与えるかを解釈する際の明確なメカニズムが欠けています。量子化誤差の正確な 3 方向分解を証明し、各コンポーネントが個別の RL トレーニング経路をどのように支配するかを示します。私たちの理論的および経験的分析は、MXFP4 量子化誤差を 3 つの加算成分に分解します。2 のべき乗の丸めによる「スケール バイアス」、小さな値をゼロにすることによる「デッドゾーンの切り捨て」、および最も近い 4 ビット グリッドへの丸めによる「グリッド ノイズ」です。各コンポーネントは、個別の RL 故障モードを支配します。スケール バイアスは、後方パスを通じて乗算的に蓄積し、勾配の精度に影響を与えます。デッドゾーンの切り捨てはロールアウトの品質を低下させます。そしてグリッドノイズは政策のエントロピーを増大させます。 RL 障害モードを対象とするがコンポーネントに限定されない修正を組み合わせます。つまり、スケール バイアスを低減するためのマクロブロック スケーリング、デッドゾーン エントリを回復する外れ値フォールバック、スケール バイアスによって引き起こされるエラーを部分的に低減する機能、およびポリシー エントロピーを制御するための適応量子化ノイズ (AQN) です。 Qwen2.5-3B 高密度モデルと Qwen3-30B-A3B-Base の専門家混合モデルでは、ターゲットを絞った修正により、BF16 の精度がそれぞれ 0.7% 以内に回復し、BF16 を +1.0% 上回りました。
原文 (English)
Decomposing MXFP4 quantization error for LLM reinforcement learning: reducible bias, recoverable deadzone, and an irreducible floor
MXFP4 arithmetic can dramatically accelerate reinforcement learning (RL) post-training of large language models (LLMs), yet the quantization error introduces severe accuracy degradation. Existing work treats the quantization error as a monolithic noise term, missing the distinct mechanisms upon interpreting how quantization error damages training. We prove an exact three-way decomposition of quantization error and show how each component dominates a distinct RL training pathway. Our theoretical and empirical analysis decomposes the MXFP4 quantization error into three additive components: "scale bias" from power-of-two rounding, "deadzone truncation" from zeroing small values, and "grid noise" from rounding to the nearest 4-bit grid. Each component dominates a distinct RL failure mode: scale bias accumulates multiplicatively through the backward pass, affecting gradient accuracy; deadzone truncation degrades rollout quality; and grid noise raises the policy's entropy. We combine corrections that are RL failure mode-targeted but not component-exclusive: Macro-block scaling to reduce scale bias, Outlier Fallback recovers deadzone entries, but also partially reduces scale bias induced error, and Adaptive Quantization Noise (AQN) for controlling the policy entropy. On Qwen2.5-3B dense and Qwen3-30B-A3B-Base mixture-of-experts model, the targeted corrections recover BF16 accuracy to within 0.7% and exceed BF16 by +1.0% respectively.
TASTE: A Designer-Annotated Multi-Dimensional Preference Dataset for AI-Generated Graphic Design
Text-to-image models now generate graphic design at production scale, yet their supervision still comes primarily from photo-style preferen…
FRED: A Multi-Modal Autonomous Driving Dataset for Flooded Road Environments
The Flooded Road Environments Dataset (FRED) is, to our knowledge, the first multi-modal autonomous driving dataset specifically targeting…
評価意識の分解と測定
フロンティア言語モデルは、評価されていることを認識して動作を調整し、ベンチマーク結果の妥当性を損なうことがあります。しかし、現場では共通の基礎を持たずに評価の特性とモデルの特性、検出と行動反応を混同して研究が行われています。私たちは評価意識を社会心理学に基礎づけ、評価意識を環境要素 (課題がどの程度認識されているか) と、認識をそれに基づいて行動する傾向から分離するモデル要素に分解します。プレースホルダー エンティティや採点スタイルの出力形式など、8 つの分類されたトリガー要因を通じて環境コンポーネントを運用し、思考連鎖のモニタリングを通じて認識と行動を研究します。 9 つのフロンティア モデルと 4 つのベンチマークにわたって、認識率はモデルとベンチマークのどちらか単独ではなく、モデルとベンチマークの特定の組み合わせに依存します。認識が行動の変化につながることはほとんどありませんが、変化する場合、その方向性は認識された評価の種類によって異なります。また、モデルは機能評価よりも安全性に対して敏感であり、安全性ベンチマークの妥当性がより大きなリスクにさらされます。各モデルがどの要因に敏感で、それらがどのように相互作用するかを研究するために、8 つの要因のそれぞれを独立して切り替えることができ、基礎となる要求を固定したまま評価信号を変化させる、100 のペアの安全機能タスクの要因制御ベンチマークである \textbf{EvalAwareBench} を提案します。 EvalAwareBench を通じて、単一の要素がすべてのモデルに均一に影響を与えることはなく、要素を積み重ねることですべてのモデルにわたる評価の意識が徐々に向上することがわかりました。私たちのフレームワークと EvalAwareBench は、評価意識を測定、属性付け、軽減するためのツールを提供し、将来有望な道として認識される下での行動の一貫性を示します。
原文 (English)
Decomposing and Measuring Evaluation Awareness
Frontier language models sometimes recognize that they are being evaluated and adjust their behavior, undermining validity of benchmark results. Yet the field studies it without a shared foundation, conflating properties of the evaluation with properties of the model, and detection with behavioral response. We ground evaluation awareness in social psychology, decomposing it into an environment component (how recognizable the task is) and a model component that separates recognition from propensity to act on it. We operationalize the environment component through eight categorized trigger factors, such as placeholder entities and grading-style output formats, and study recognition and behavior through chain-of-thought monitoring. Across nine frontier models and four benchmarks, recognition rates depend on the specific pairing of model and benchmark rather than on either in isolation. Recognition rarely leads to behavioral change, and when it does, the direction depends on the type of evaluation perceived. Models are also more sensitive to safety than capability evaluations, placing safety benchmark validity at greater risk. To study which factors each model is sensitive to and how they interact, we propose \textbf{EvalAwareBench}, a factor-controlled benchmark of 100 paired safety-capability tasks where each of the eight factors can be independently toggled, varying evaluative signals while holding the underlying request fixed. Through EvalAwareBench, we find that no single factor uniformly affects all models, but stacking factors progressively raises evaluation awareness across all of them. Our framework and EvalAwareBench provide the tools to measure, attribute, and mitigate evaluation awareness, pointing to behavioral consistency under recognition as a promising path forward.
医療画像解析のためのタスク整合型自己教師あり学習: 体系的なレビューと実践的な設計ガイドライン
自己教師あり学習 (SSL) は、ラベルのないデータから表現を学習することで、医療画像処理におけるアノテーションのボトルネックに対処するための有望なパラダイムとして浮上しています。ただし、その有効性は口実タスクの設計と下流の臨床目的との整合性に大きく依存します。医療画像処理における SSL の体系的でタスク指向のレビューを紹介し、さまざまな口実タスクの定式化が分類、セグメンテーション、検出、その他のタスク全体のパフォーマンスにどのような影響を与えるかを検証します。 PRISMA ガイドラインに従って、2017 年から 2025 年の間に発表された 75 件の研究を分析し、対照学習、非対照学習と予測学習、生成学習と再構成ベースの学習、およびハイブリッド学習の 4 つのパラダイムに整理しました。アーキテクチャごとにメソッドをカタログ化するのではなく、各パラダイムを、それが最もよくサポートする下流の目的にマッピングします。私たちの分析によれば、普遍的に最適な SSL 戦略は存在しません。代わりに、パフォーマンスは、口実タスク、イメージングモダリティ、およびターゲットタスク間の調整によって決まります。対照的な方法は全体的な識別特徴を学習し、分類とうまく一致しますが、微妙な病理学的パターンを見落とす可能性があります。生成および空間予測ベースのアプローチは、局所的な解剖学的構造をより適切に保存するため、セグメンテーションやその他の緻密な予測タスクにより適していますが、ハイブリッド手法は最もバランスの取れたパフォーマンスを提供します。さらに、モダリティ固有の設計が重要であること、および SSL が低ラベルおよび少数ショットの領域で最大の利点を提供することを示します。最後に、これらの発見を実用的な設計ガイドラインに絞り込み、病理学を意識した口実タスク設計、高次元データのリソース効率の高いトレーニング、標準化された評価プロトコルなどの未解決の課題を概説します。この研究は、医療画像処理において、より効果的で臨床的に関連性のある SSL フレームワークを設計するための実践的なガイダンスを提供します。
原文 (English)
Task-Aligned Self-Supervised Learning for Medical Image Analysis: A Systematic Review and Practical Design Guidelines
Self-supervised learning (SSL) has emerged as a promising paradigm for addressing the annotation bottleneck in medical imaging by learning representations from unlabeled data. However, its effectiveness depends heavily on the design of the pretext task and its alignment with the downstream clinical-objectives. We present a systematic, task-oriented review of SSL in medical imaging, examining how different pretext-task formulations influence performance across classification, segmentation, detection, and other tasks. Following PRISMA guidelines, we analyze 75 studies published between 2017 and 2025 and organize them into four paradigms: contrastive, non-contrastive and predictive, generative and reconstruction-based, and hybrid learning. Rather than cataloguing methods by architecture, we map each paradigm to the downstream objectives it best supports. Our analysis shows there is no universally optimal SSL strategy; instead, performance is governed by the alignment between the pretext task, the imaging modality, and the target task. Contrastive methods learn global discriminative features and align well with classification, but may overlook subtle pathological patterns. Generative and spatial prediction-based approaches better preserve local anatomical structure, making them more suitable for segmentation and other dense prediction tasks, while hybrid methods offer the most balanced performance. We further show that modality-specific design is critical and that SSL provides its greatest benefit in low-label and few-shot regimes. Finally, we distill these findings into practical design guidelines and outline open challenges, including pathology-aware pretext task design, resource-efficient training for high-dimensional data, and standardized evaluation protocols. This work offers practical guidance for designing more effective and clinically relevant SSL frameworks in medical imaging.
CRISP -- 病理症例の表現と検索のためのクラスタリング ベースの冗長性を削減したインスタンス サンプリング
デジタル病理学アーカイブには、空間的に異なる腫瘍領域を捕捉し、固有の形態学的不均一性を反映する、症例ごとに複数の全スライド画像 (WSI) が含まれることが増えています。しかし、既存のアプローチのほとんどは、病理学者が選択した単一のスライドに依存しているため、残りの WSI に分散されている潜在的な有益な証拠を破棄しています。現在まで、包括的なマルチ WSI ケース処理のための自律的なフレームワークは提案されていません。ここでは、ケース内の利用可能なすべてのスライドからの情報を統合するケースレベル分析のための教師なしフレームワークを紹介します。提案されたアプローチは、指定された単一のスライドに依存するのではなく、WSI 全体で情報パッチを選択的に抽出することによって症例レベルの表現を構築します。我々は、まず個々の WSI 内の冗長性を削減し、次にクラスタリング ベースのサンプリングを適用して、症例全体のコンパクトでありながら代表的なパッチ セットを選択する 2 段階のフレームワークである、Clustering-Based Redundancy-Reduced Instance Sampling for Pathology (CRISP) を導入します。結果として得られるパッチ セットは、ギガピクセル画像の徹底的な処理を回避しながら症例レベルの異質性を捕捉し、検索インデックスとして直接機能します。診断と治療計画にメイヨークリニックの 2 つの乳がんデータセットを使用することで、CRISP が患者/症例の検索と取得のためのモデルと病理医のスライド選択を組み合わせた現在の標準的な手法と一貫して一致またはそれを上回ることを実証します。 CRISP は、症例レベルの処理を自動化し、主観的な WSI 選択を排除することにより、現在見落とされている複数の WSI に分散された臨床関連情報の活用を可能にする可能性があります。
原文 (English)
CRISP -- Clustering-Based Redundancy-Reduced Instance Sampling for Pathology Case Representation and Retrieval
Digital pathology archives increasingly contain multiple whole-slide images (WSIs) per case, capturing spatially distinct tumor regions and reflecting intrinsic morphological heterogeneity. However, most existing approaches rely on a single pathologist-selected slide, thereby discarding potentially informative evidence distributed across the remaining WSIs. To date, no autonomous framework has been proposed for comprehensive multi-WSI case processing. Here, we present an unsupervised framework for case-level analysis that integrates information from all available slides within a case. Rather than relying on a single designated slide, the proposed approach constructs case-level representations by selectively distilling informative patches across WSIs. We introduce Clustering-Based Redundancy-Reduced Instance Sampling for Pathology (CRISP), a two-stage framework that first reduces redundancy within individual WSIs and subsequently applies clustering-based sampling to select a compact yet representative set of patches for the entire case. The resulting patch set captures case-level heterogeneity while avoiding exhaustive processing of gigapixel images, and directly serves as a retrieval index. Using two Mayo Clinic breast cancer datasets for diagnosis and treatment planning, we demonstrate that CRISP consistently matches or surpasses the current standard practice of combined model and pathologist slide selection for patient/case search and retrieval. By automating case-level processing and eliminating subjective WSI selection, CRISP potentially enables the exploitation of clinically relevant information distributed across multiple WSIs that is currently overlooked.
MX-SAFE: オンザフライ指数と仮数ビット割り当てを備えた多用途の推論およびトレーニングに耐えるマイクロスケーリング フォーマット
ディープラーニングの需要が高まるにつれ、トレーニングと推論の両方において量子化によるコスト削減が不可欠になりました。 2022 年、オープン コンピューティング プロジェクト (OCP) コンソーシアムは、マイクロスケーリング (MX) 形式と呼ばれるディープ ラーニング用の狭精度形式を標準化しました。 MX フォーマットは、ハードウェアに適した動的量子化スキームであり、複数のオペランド間で 8 ビットの指数を共有することでデータ サイズを効果的に削減します。 MX フォーマットは、それぞれの長所を持つ 2 つのタイプに分類できます。(i) 仮数ビットのみで構成される高精度を重視する MXINT と、(ii) ローカル指数ビットを許可することにより広いダイナミック レンジを重視する MXFP です。この研究では、MX-SAFE (略して MXSF) と呼ばれる汎用性の高い MXFP フォーマットを紹介します。このフォーマットは、トレーニングとダイレクトキャスト推論の両方をサポートするために、より広い仮数部モード (FP8 E2M5) と準正規 FP モード (FP5 E3M2) の 2 つのモードを適応的に使用します。さらに、MXSF 形式でのトレーニング中の再量子化プロセスの負担を軽減することでハードウェア効率を向上させる、タイルベースのブロック設計を提案します。提案された MXSF 形式の使用により、MXFP8 E2M5 および MXFP8 E4M3 と比較して、推論/フルトレーニングの精度が平均してそれぞれ 0.05%/11.1% および 3.55%/3.57% 向上しました。さらに、MXSF 形式をサポートするトレーニング推論アクセラレータを紹介します。これは、総エネルギー消費量を 24.9% 削減しながら、BF16 ベースラインと同等の精度を達成します。
原文 (English)
MX-SAFE: Versatile Inference- and Training-Proof Microscaling Format with On-the-Fly Exponent and Mantissa Bit Allocation
As the demand for deep learning grows, cost reduction through quantization has become essential for both training and inference. In 2022, the Open Compute Project (OCP) consortium standardized narrow precision formats for deep learning, called the microscaling (MX) format. The MX format is a hardware-friendly dynamic quantization scheme that effectively reduces the data size by sharing an 8-bit exponent across multiple operands. The MX format can be categorized into two types with their own strengths: (i) MXINT which focuses on a high precision consisting only of mantissa bits and (ii) MXFP which focuses on a wider dynamic range by allowing local exponent bits. In this work, we present a versatile MXFP format, called MX-SAFE (MXSF in short), that adaptively uses two modes, i.e., a wider mantissa mode (FP8 E2M5) and a subnormal FP mode (FP5 E3M2), to support both training and direct-cast inference. Furthermore, we propose a tile-based block design to increase hardware efficiency by reducing the burden of re-quantization process during the training with the MXSF format. Owing to the use of the proposed MXSF format, 0.05%/11.1% and 3.55%/3.57% improvements in accuracy, on average, for inference/full-training compared to MXFP8 E2M5 and MXFP8 E4M3 are observed, respectively. Moreover, we present a training-inference accelerator that supports the MXSF format and it achieves similar accuracy to the BF16 baseline while using 24.9% less total energy consumption.
JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
Two methodologies dominate current practices of benchmarking: rubric-based scoring evaluates items against predefined criteria, whereas com…
Anatomy-Anchored Self-Supervision: Distilling Vision Foundation Models for Invariant Ultrasound Representation
Self-supervised pre-training paradigm has gained increasing prominence for learning transferable representations in medical imaging, yet ex…
Fine-Tuning and Serving Gemma 4 31B on Google Cloud TPU: A Technical Comparison with GPU Baselines
We present the first end-to-end demonstration of fine-tuning and serving Google's Gemma 4 31B model on TPU hardware, providing an empirical…
SL-BiLEM: Structured Learnable Behavior-in-the-Loop Epidemic Modeling for Forecasting and Policy Evaluation
Epidemic forecasting faces a fundamental challenge: human behavior dynamically responds to disease spread, creating feedback loops that ind…
QuITE: Query-Based Irregular Time Series Embedding
Irregular Multivariate Time Series (IMTS) are common in practice, yet their irregular sampling complicates effective modeling. Existing app…
臨床要約のための幻覚検出に基づく好みの最適化
大規模言語モデル (LLM) は、要約タスクでは有望であることが示されていますが、幻覚を引き起こすことがよくあります。幻覚はサポートされていない、または間違った記述であり、特殊な医療アプリケーションでの信頼性が制限されます。 \itermodelfull (\itermodel) という推論時間手法を導入します。これは、幻覚検出器を活用して、事実の修正に向けて反復的な要約改訂をガイドします。これに基づいて、検出器による調整軌道をモデルの微調整のための好みのペアに変換する、好み学習のための \itermodel (\model) を提案します。広範な実験により、\MimicIV からの現実世界の臨床ノートを要約する際に、私たちの方法がラマ モデルとジェマ モデルの幻覚を大幅に軽減することが示されました。たとえば、Llama-3.1-8B-Instruct の \itermodel は 24\% を軽減し、\model は 48\% の幻覚を軽減します。重要なのは、人間の専門家と LLM 陪審の評価に従って、両方の方法で要約の流暢性、一貫性、および関連性が維持されることです。これらの結果を総合すると、検出に基づいた改良と好みの学習が、臨床要約における事実の忠実性を向上させるための自動化されたソリューションを提供することを示しています。
原文 (English)
Hallucination Detection-Guided Preference Optimization for Clinical Summarization
Large language models (LLMs) have shown promise on summarization tasks, but they often produce hallucinations, which are unsupported or incorrect statements that limit their reliability in specialized healthcare applications. We introduce Hallucination Detection Guided Self-Refinement (HDSR), an inference-time method that leverages hallucination detectors to guide iterative summary revisions toward factual corrections. Building on this, we propose HDSR for Preference Learning (HDSR-PL), which converts detector-guided refinement trajectories into preference pairs for model finetuning. Extensive experiments show that our methods substantially reduce hallucinations for Llama and Gemma models in summarizing real-world clinical notes from MIMIC-IV-Note v2.2. For example, HDSR reduces 24% and HDSR-PL reduces 48% hallucinations in Llama-3.1-8B-Instruct. Importantly, both methods preserve summary fluency, coherence, and relevance according to human expert and LLM-Jury evaluations. Together, these results demonstrate that detection-informed refinement and preference learning offer an automated solution for improving factual faithfulness in clinical summarization.
Neural Network Verification using Partial Multi-Neuron Relaxation
The increasing integration of deep neural networks in critical systems has spawned a theoretical and practical interest in formally guarant…
Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
We identify a new dimension for enhancing rollout diversity in Group Relative Policy Optimization (GRPO) for LLMs. While GRPO relies on div…
If LLMs Have Human-Like Attributes, Then So Does Age of Empires II
Much research has been carried out on large language models (LLMs) and LLM-powered agentic workflows. However, many works within the field…
Diversity Over Frequency: Rethinking Tool Use in Visual Chain-of-Thought Agents
Visual agents employ external visual tools within visual chains of thought to incorporate fine-grained evidence. While prior work has mainl…
PR2: Predictive Routing Replay for MoE-Based LLM Reinforcement Learning
Mixture of Experts (MoE) Large Language Models (LLMs) achieve strong performance at scale. However, reinforcement learning (RL) on MoE-base…
Topological Ignorability for Structural Causal Effects Beyond Means
Many interventions alter the structure of an outcome distribution rather than its mean: they can split a population into disconnected regim…
MOSS-Audio Technical Report
MOSS-Audio is a unified audio-language model for speech, environmental sound, and music understanding, supporting audio captioning, time-aw…
KliniskVestBERT: BERT Model Specialised to Norwegian Clinical Texts
The increasing application of Natural Language Processing (NLP) in healthcare demands language models specifically attuned to the complexit…
AgentRedBench: Dynamic Redteaming and Integration-Aware Defense for LLM Agents over SaaS Integrations
Indirect prompt injection in tool-use agents is a concrete production threat: LLM agents read from integrations (third-party services such…