AIニュース 2026-06-01
自動生成: 2026-06-01 13:49 JST
過去24時間以内に公開された記事を、同じ話題ごとに1つのストーリーカードへまとめ、出典・トピック・要約とともに掲載しています。要約は各フィード提供文の冒頭を整形したもので、本文は各リンク先をご覧ください。
📌 今日の要点 TOP7
-
インテルがロボット開発の課題を解決、オープンなロボティクスライブラリでITmedia AI+
インテルは、ロボット開発のための統合ソフトウェア開発キット「Robotics AI Suite」に、インテル製プロセッサに最適化された推論…
-
富士通が認めた「人月モデル」の限界 時田社長「労働集約型SIモデルからの転換を」ITmedia AI+
富士通が「中長期経営ビジョン2035」を発表した。AI時代に突入した今、同社の時田隆仁社長CEOは、従来型の「人月モデル」には限界があると…
-
“VB.NET移行をAIで爆速化”した千葉銀行GのIT企業 「12.5人月→2.0人月」をどう実現?ITmedia AI+
ちばぎんコンピューターサービスはAI駆動開発の仕組みを構築し、既存のVB.NETシステムのマイグレーション工数を12.5人月から2.0人月…
-
図面SaaSに高精度な3Dモデル生成とアセンブリ機能、CAE機能のβ版を追加ITmedia AI+
renueは、図面SaaS「Drawing Agent」をアップデートした。高精度な3Dモデル生成機能や複数パーツの組み立てに対応するアセ…
-
Erin Brockovich takes aim at data center secrecyTechCrunch AI
Environmental activist Erin Brockovich has a new mission.
-
「ハーネス」って結局、何? みんな使い方が違うAIエージェント用語をHugging Faceが整理ITmedia AI+
AIエージェント分野で人によって意味が揺れる「ハーネス」「スキャフォールド」などの用語を、Hugging Faceが整理した。AIエージェ…
-
Making sense of the debate over AI psychosisTechCrunch AI
On the latest episode of Equity, we debate whether tech CEOs are "uni…
トピック別件数
- LLM/生成AI 180件
- 研究/論文 166件
- エージェント 82件
- 画像/動画生成 58件
- ビジネス/資金調達 25件
- ロボティクス 15件
- ハードウェア/半導体 12件
- その他 5件
- 規制/政策 1件
日本語メディア6件
ITmedia AI+ (日本語)

“VB.NET移行をAIで爆速化”した千葉銀行GのIT企業 「12.5人月→2.0人月」をどう実現?
ちばぎんコンピューターサービスはAI駆動開発の仕組みを構築し、既存のVB.NETシステムのマイグレーション工数を12.5人月から2.0人月に削減した。どう実現したのか。
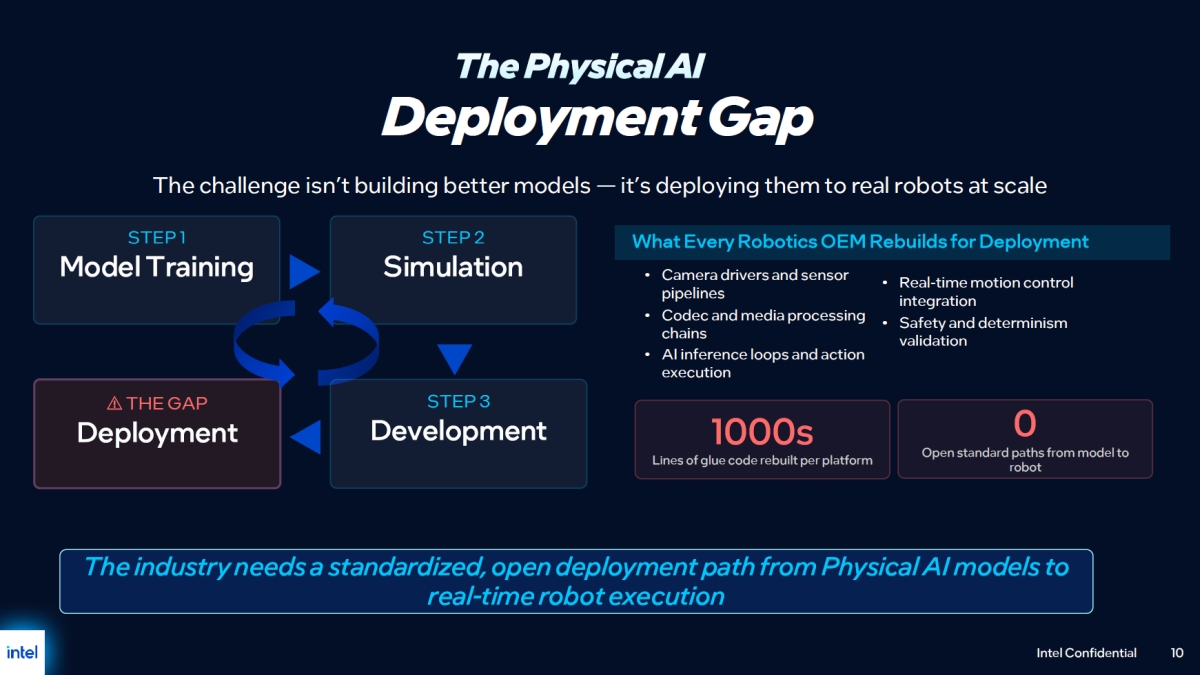
インテルがロボット開発の課題を解決、オープンなロボティクスライブラリで
インテルは、ロボット開発のための統合ソフトウェア開発キット「Robotics AI Suite」に、インテル製プロセッサに最適化された推論ランタイムを備えるオープンソースのロボティクスライブラリ「OpenVINO Physical AI Framework」を追加すると発表した。
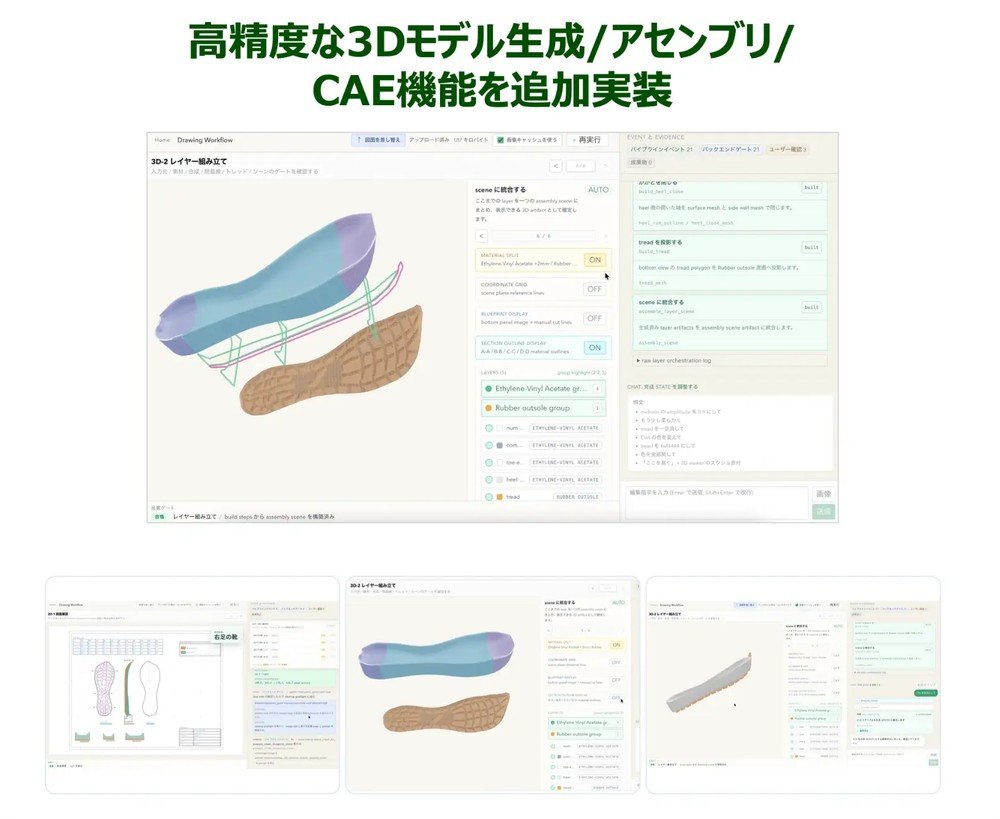
図面SaaSに高精度な3Dモデル生成とアセンブリ機能、CAE機能のβ版を追加
renueは、図面SaaS「Drawing Agent」をアップデートした。高精度な3Dモデル生成機能や複数パーツの組み立てに対応するアセンブリ機能、構造解析を実行する「CAE機能 β版」を追加し、図面の読み取りから構造解析までを一連の流れで扱えるようにした。

富士通が認めた「人月モデル」の限界 時田社長「労働集約型SIモデルからの転換を」
富士通が「中長期経営ビジョン2035」を発表した。AI時代に突入した今、同社の時田隆仁社長CEOは、従来型の「人月モデル」には限界があると認めた。その真意とは。
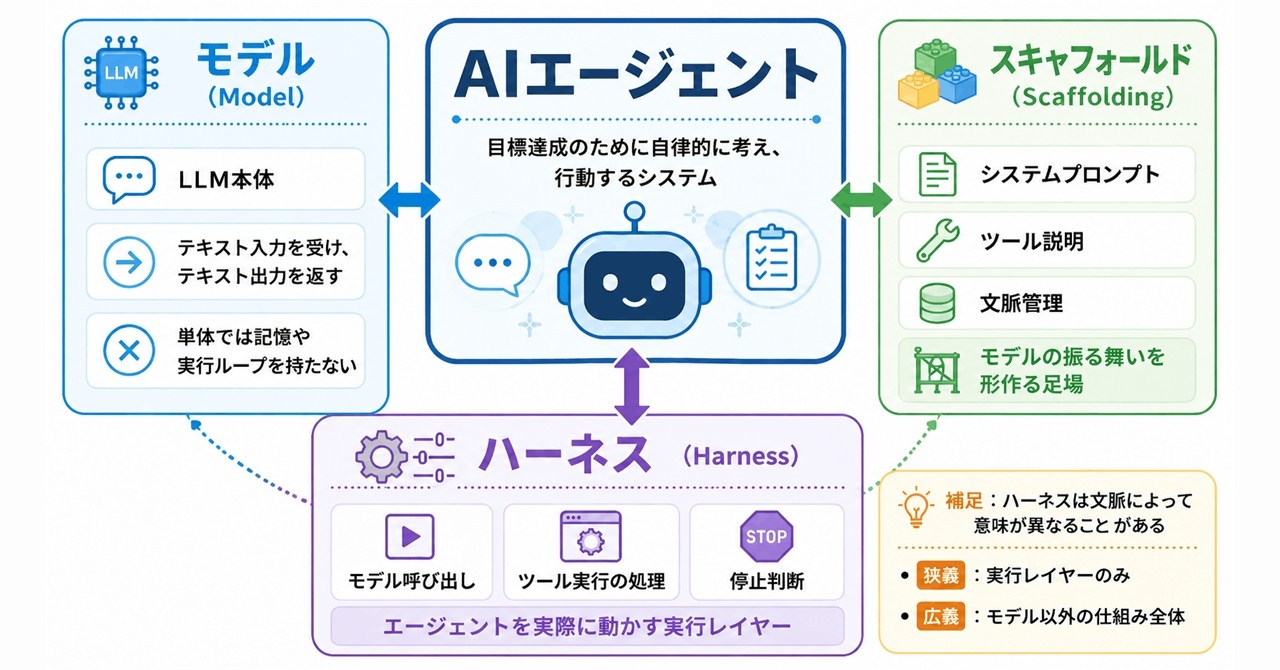
「ハーネス」って結局、何? みんな使い方が違うAIエージェント用語をHugging Faceが整理
AIエージェント分野で人によって意味が揺れる「ハーネス」「スキャフォールド」などの用語を、Hugging Faceが整理した。AIエージェントを正しく理解し議論するために押さえておきたい基本用語を初心者向けに解説する。
「FDE」って結局、客先常駐SEのリブランディングじゃないの? アクセンチュアに聞いてみた
AIプラットフォーム企業が掲げる新職業「FDE」(フォワード・デプロイド・エンジニア)は、客先常駐SEの焼き直しなのか。Microsoftと共同でFDE組織を立ち上げ、独自の「RDE」も打ち出すアクセンチュアの保科学世氏と片岡俊行氏に疑問をぶつけてみた。
海外メディア2件
TechCrunch AI (英語)

Erin Brockovich takes aim at data center secrecy
Environmental activist Erin Brockovich has a new mission.

Making sense of the debate over AI psychosis
On the latest episode of Equity, we debate whether tech CEOs are "uniquely prone to AI psychosis."
公式ブログ0件
このカテゴリの新着記事はありませんでした。
論文403件
arXiv cs.AI (英語)
PhyDrawGen: 自然言語からの物理的に接地された図の生成
テキストから物理図を生成するには、物理法則に厳密に従う必要があります。現在の生成モデルは視覚的にもっともらしい出力を生成しますが、体系的に力ベクトルを幻覚化し、保存則を無視し、幾何学的制約に違反します。物理的制約の充足から意味論的なシーンの理解を切り離す神経記号パイプラインである PhyDrawGen を紹介します。まず、大規模な言語モデルが問題テキストから型付きシーン グラフを抽出します。次に、決定論的ソルバーがこのグラフを平面直線グラフ (PSLG) に変換し、力の平衡、光路、場のトポロジーを正確な幾何学的プリミティブとしてエンコードします。最後に、微調整された Qwen-VL モデルは、視覚的に根拠のある提案検証ループを実装し、制約違反を繰り返し修正します。力学、光学、電磁気学にわたる 1,449 の問題のベンチマークで評価された PhyDrawGen は、GPT-5 イメージ、Gemini 2.5 Flash、および Gemini 3 Pro を大幅に上回り、異常な物体の問題でも堅牢な物理的精度を実証しました。
原文 (English)
PhyDrawGen: Physically Grounded Diagram Generation from Natural Language
Generating physics diagrams from text requires strict adherence to physical laws. While current generative models produce visually plausible outputs, they systematically hallucinate force vectors, ignore conservation laws, and violate geometric constraints. We present PhyDrawGen, a neuro-symbolic pipeline that decouples semantic scene understanding from physical constraint satisfaction. First, a large language model extracts a typed scene graph from the problem text. A deterministic solver then converts this graph into a Planar Straight-Line Graph (PSLG), encoding force balance, optical paths, and field topologies as exact geometric primitives. Finally, a fine-tuned Qwen-VL model implements a visually grounded propose-verify loop to iteratively correct any constraint violations. Evaluated on a benchmark of 1,449 problems spanning mechanics, optics, and electromagnetism, PhyDrawGen significantly outperforms GPT-5-image, Gemini 2.5 Flash, and Gemini 3 Pro, demonstrating robust physical accuracy even on unusual-object problems.
物理的に実行可能な世界モデル: クエリ条件付きの組み込み AI の事例
身体化された AI の世界モデルは、物理的に実行可能である必要があります。つまり、単に将来の観察を予測するのではなく、アクションの結果を支配する物理的構造を表すことによって介入のクエリに答えるように構築されている必要があります。既存の観測予測世界モデルは、視覚的にはもっともらしいが、物理的には間違ったロールアウトを生成する可能性があります。この失敗は構造的なものです。異なる物理システムは同一に見えても、介入によって分岐することがあります。私たちは、潜在的な物理を変化させながら目に見えるシーンを修正する制御されたベンチマークを使用して、この問題を明らかにします。このようなモデルは、実行不可能なアクションを推奨したり、インタラクションの結果を誤って予測したり、危険な行動を認定したりする可能性があることを示します。私たちは、身体化された AI には、介入クエリに答えるのに十分な最も単純な物理的抽象化を特定する世界モデルが必要であると主張します。このようなモデルは、環境表現、潜在状態とパラメータの推定、アクションの仕様、介入ダイナミクス、クエリレベルの応答などのモジュール式コンポーネントで構成されます。自律的なオーケストレーターは、関連する抽象化を特定し、クエリごとに互換性のある学習済みおよび構造化されたコンポーネントを構成する必要があります。閉じた形式の物理学が利用できない、不確実である、またはコストがかかる場合、移行モデルは分析的、シミュレーション的、学習的、またはハイブリッドであってもよいが、介入の結果を決定する構造を保存する必要がある。この分解により、モデルが解釈可能になり、そのコンポーネントが検証可能になり、その出力がクエリに対して監査可能になります。また、新しい世界モデルの設計原則と既存の世界モデルの実現可能性テストも提供します。適切な抽象化とは、世界の最も詳細なモデルではなく、クエリに関連する区別を保持する最も単純なモデルです。既存のシステムが正しく応答できないクエリに対するこのアプローチを実証し、オーケストレーターが計画、制御、検証のために物理的に実行可能なモデルを動的に組み立てて適応させる方法を概説します。
原文 (English)
Physically Viable World Models: A Case for Query-Conditioned Embodied AI
World models for embodied AI must be physically viable: constructed to answer intervention queries by representing the physical structure governing action outcomes, rather than merely predicting future observations. Existing observation-predictive world models can produce visually plausible but physically wrong rollouts. This failure is structural; distinct physical systems can look identical yet diverge under intervention. We expose this problem with controlled benchmarks that fix the visible scene while varying latent physics. We show that such models may recommend infeasible actions, mispredict interaction outcomes, or certify unsafe behavior. We argue that embodied AI requires world models that identify the simplest physical abstraction sufficient to answer an intervention query. Such a model comprises modular components, including environment representation, latent state and parameter estimation, action specification, interventional dynamics, and query-level response. An autonomous orchestrator should identify the relevant abstraction and compose compatible learned and structured components per query. When closed-form physics is unavailable, uncertain, or costly, the transition model may be analytic, simulated, learned, or hybrid, but it must preserve the structure that determines interventional outcomes. This decomposition makes the model interpretable, its components verifiable, and its outputs auditable against the query. It also provides a design principle for new world models and a feasibility test for existing ones: the right abstraction is not the most detailed model of the world, but the simplest model that preserves the distinctions relevant to the query. We demonstrate this approach on queries that existing systems fail to answer correctly, and outline how an orchestrator can dynamically assemble and adapt physically viable models for planning, control, and verification.
SAT 解決のための FTS の変換とエンコード: 何が役立つか、何が問題になるか (拡張バージョン)
因数分解タスクは、限定された形式の選言的前提条件、条件効果、天使のような非決定性を使用して SAS+ を拡張した古典的な計画表現です。これにより、STRIPS や SAS+ などの従来の形式よりもコンパクトなタスクの表現が可能になり、幅広いタスク変換がサポートされます。ただし、因数分解されたタスクに対する既存の計画アプローチは、ヒューリスティックな検索方法に限定されていました。この研究では、SAT で因数分解されたタスクをエンコードする方法を調査します。因数分解された遷移関係を命題論理に変換するためのさまざまな戦略に焦点を当てて、タスクをエンコードするいくつかの方法を提案します。また、この設定でさまざまなレベルで並列処理を活用する方法を分析し、一般的なタスク変換が SAT ベースのプランナーのパフォーマンスに及ぼす影響を研究します。
原文 (English)
Transforming and Encoding FTS for SAT Solving: What Helps, What Hurts (Extended Version)
Factored tasks are a classical planning representation that extends SAS+ with limited forms of disjunctive preconditions, conditional effects, and angelic nondeterminism. This allows for a more compact representation of tasks than traditional formalisms such as STRIPS or SAS+, and supports a wide range of task transformations. However, existing planning approaches for factored tasks have been limited to heuristic search methods. In this work, we investigate how to encode factored tasks in SAT. We propose several ways to encode the tasks, focusing on different strategies for translating the factored transition relation into propositional logic. We also analyze how to exploit parallelism at various levels in this setting and study the impact of common task transformations on the performance of SAT-based planners.
Map-Elites を使用した一人称シューティング マップの手続き型生成
私たちは、一人称視点シューティング (FPS) ゲームのレベルを設計するための MAP-Elites (よく知られた品質ダイバーシティ アルゴリズム) の適用を調査します。 2 つのよく知られたマップ表現 (オールブラックとグリッド グラフ) を検討し、FPS マップの特徴付けを改善する 2 つの新しい表現 (ポイントラインと空間レイアウト) を紹介します。マップのトポロジ特性 (マップのレイアウトのみに依存します) と創発特性 (実際のゲームプレイを通じて評価する必要があります) を説明する一連のメトリクスを定義します。当社は詳細な分析を実行して、MAP-Elites 照明プロセスをガイドするのに最適な機能を特定します。 MAP-Elites with Sliding Boundaries (MESB) を適用して、FPS マップの母集団を進化させます。私たちの結果は、新しい表現が、進化する FPS マップに以前に使用されていた表現よりも、より多様性と品質の高いマップを生成できることを示しています。
原文 (English)
Procedural Generation of First Person Shooter Maps using Map-Elites
We investigate the application of MAP-Elites (a well-known quality diversity algorithm) to design levels for First-Person Shooter (FPS) games. We consider two well-known map representations (All-Black and Grid-Graph) and introduce two novel representations (Point-Line and Spatial-Layout) that improve the characterization of FPS maps. We define a series of metrics to describe maps' topological properties (which solely depend on maps' layout), and emergent properties (which must be evaluated through actual gameplay). We perform an in-depth analysis to identify the most suitable features to guide MAP-Elites illumination process. We apply MAP-Elites with Sliding Boundaries (MESB) to evolve populations of FPS maps. Our results show that the new representations can generate maps with higher diversity and quality than the representations previously used for evolving FPS maps.
自動運転のための強化学習における不確実性を認識し、時間的に規制された専門家のアドバイス
自動運転のための強化学習における探索は本質的に安全ではありません。エージェントは学習するために新しい動作を経験する必要がありますが、探索は衝突やオフロード運転につながる可能性があります。私たちは、専門家のアドバイスを活用して、長期的な依存を回避しながら探索を導く不確実性を認識したフレームワークを提案します。認識的または偶然的な不確実性がローリング バッファーから導出された適応しきい値を超えるとアドバイスがトリガーされ、エージェントの信頼に応じてアドバイスが進化することが保証されます。確率的早期停止ヒューリスティックを使用したコミットメント クールダウン戦略により、ガイダンスの期間と頻度が調整され、アドバイスの予算を使い果たすことなくエージェントが一貫した操作にさらされます。エキスパートとエージェントのエクスペリエンスは、オフポリシーの暗黙的クォンタイル ネットワーク (IQN) バックボーン内の共有リプレイ バッファーで結合され、エキスパートの軌跡を効率的に再利用できます。 CARLA での実験では、私たちの手法が IQN ベースラインを上回っており、成功率が 5 ~ 7% 向上し、失敗が減少していることが示されており、リスクに敏感な不確実性と規制された専門家の統合により、信号のない交差点ナビゲーションにおけるセンサーベースの RL ポリシー学習のより安全で効率的な探索が可能になることが実証されています。
原文 (English)
Uncertainty-Aware and Temporally Regulated Expert Advice in Reinforcement Learning for Autonomous Driving
Exploration in reinforcement learning for autonomous driving is inherently unsafe: agents must experience novel behaviors to learn, yet exploration can lead to collisions or off-road driving. We propose an uncertainty-aware framework that leverages expert advice to guide exploration while avoiding long-term dependence. Advice is triggered when epistemic or aleatoric uncertainty exceeds adaptive thresholds derived from rolling buffers, ensuring advice evolves with the agent's confidence. A commitment-cooldown strategy with a stochastic early-stop heuristic regulates the duration and frequency of guidance, exposing the agent to coherent maneuvers without exhausting the advice budget. Expert and agent experiences are combined in a shared replay buffer within an off-policy implicit quantile network (IQN) backbone, enabling efficient reuse of expert trajectories. Experiments in CARLA show that our method outperforms the IQN baseline, improving success by 5-7% and reducing failures, demonstrating that risk-sensitive uncertainty coupled with regulated expert integration enables safer and more efficient exploration for sensor-based RL policy learning in unsignalized intersection navigation.
ハーネスの更新はハーネスの利点ではありません: 自己進化する LLM エージェントの進化機能の解きほぐし
LLM エージェントは、プロンプト、スキル、メモリ、ツールなどの編集可能な外部ハーネスを中心に構築されたシステムとして導入されることが増えており、モデル パラメーターを変更せずにタスクの実行を形成します。ハーネスの自己進化は、実行証拠からこれらのハーネスを更新することで、そのようなエージェントを適応させます。しかし、タスク解決におけるモデルの基本的な能力が、ハーネスの自己進化におけるその能力を予測するかどうかは依然として不明です。どのモデルが有用なハーネス更新を生成し、どのモデルが実際にその恩恵を受けるのでしょうか?我々は 2 つのハーネス自己進化機能を分析します。(i) ハーネス更新。実行証拠から有用な永続的なハーネス更新を生成する機能。 (ii) ハーネスの利点、タスク解決中に更新されたハーネスから恩恵を受ける機能。私たちの分析により、2 つの発見が明らかになりました。まず、ハーネスの更新は基本機能がフラットです。さまざまな機能層のモデルがハーネスの更新を生成し、驚くほど同様の利益をもたらします。 Qwen3.5-9B のアップデートでも、Claude Opus~4.6 に匹敵するゲインが得られます。第 2 に、ハーネスの利点は基本機能において単調ではありません。弱い層のモデルは更新されたハーネスからほとんど恩恵を受けず、中間層のモデルは最も恩恵を受け、強い層のモデルは中間層よりも恩恵が少ないです。弱い層での低いゲインを 2 つの障害モードに追跡します。弱い層のモデルは、関連するハーネス アーティファクトのアクティブ化に失敗するか、アクティブ化しても忠実に従うことができない可能性があります。これらの調査結果は、進化者ではなくタスク解決エージェントに能力予算を投資し、エージェントのトレーニングに続くハーネス呼び出しと長期的な指導をターゲットにすることを示唆しています。私たちのソース コードは https://github.com/A-EVO-Lab/a-evolve/tree/release/harness-evolution で公開されています。
原文 (English)
Harness Updating Is Not Harness Benefit: Disentangling Evolution Capabilities in Self-Evolving LLM Agents
LLM agents are increasingly deployed as systems built around editable external harnesses, including prompts, skills, memories and tools, that shape task execution without changing model parameters. Harness self-evolution adapts such agents by updating these harnesses from execution evidence. Yet it remains unclear whether a model's base capability in task-solving predicts its capabilities in harness self-evolution: which models produce useful harness updates, and which actually benefit from them? We analyze two harness self-evolution capabilities: (i) harness-updating, the capability to produce useful persistent harness updates from execution evidence; (ii) harness-benefit, the capability to benefit from updated harnesses during task solving. Our analysis reveals two findings. First, harness-updating is flat in base capability: models from different capability tiers produce harness updates that lead to surprisingly similar gains; even Qwen3.5-9B's updates yield gains comparable to those of Claude Opus~4.6. Second, harness-benefit is non-monotonic in base capability: weak-tier models benefit little from updated harnesses, mid-tier models benefit most, and strong-tier models benefit less than mid-tier. We trace low gains at the weak tier to two failure modes: weak-tier models may fail to activate relevant harness artifacts, or activate them but fail to follow them faithfully. These findings suggest investing capability budget in the task-solving agent rather than the evolver, and targeting harness invocation and long-horizon instruction following in agent training. Our source code is publicly available at https://github.com/A-EVO-Lab/a-evolve/tree/release/harness-evolution.
EHRBench: LLM を使用した臨床意思決定のための、自動化された信頼性の高い EHR ベースのベンチマーク
臨床意思決定 (CDM) は現実世界の臨床ワークフローの中心であり、臨床医は不完全な証拠の下で診断を推測し、治療法を選択し、将来の健康結果を予測します。強力な言語機能、広範な生物医学的知識、効率性により、これらの意思決定をサポートするために LLM がますます使用されていますが、実際の臨床意思決定タスクにおける LLM の信頼性は依然として十分に理解されていません。 CDM モデル、特に LLM ベースのモデルを評価するには、スケールと品質の両方を保証するために、自動化されている信頼性の高いパイプラインを介して理想的で実用的な医療意思決定ベンチマークを構築する必要があります。さらに、実際の患者の EHR における CDM ベンチマークの基礎は、実質的な生物医学的知識と臨床推論を必要とする実践的な CDM タスクの評価をより適切にサポートできます。ギャップを埋めるために、LLM ベースの臨床意思決定を大規模に評価するための、自動化された信頼性の高い EHR ベースのベンチマークである EHRBench を導入します。スケーラビリティと信頼性を確保するために、EHRBench は EHR-LLM-KB (知識ベース) 対話パイプラインを通じて構築されています。効率性を高めるため、特殊な LLM を使用して、遭遇レベルの EHR 軌跡を構造化されたテンプレートに自動的に変換し、テンプレートを QA 項目に決定論的にインスタンス化します。並行して、体系的な KB ベースの検証と強化を適用して、幻覚や曖昧な関係をフィルタリングし、信頼性を向上させます。このパイプラインを使用して、診断、治療、予後という 3 つの中核となる推論に必要な臨床意思決定タスクにわたる約 100 万 (960,067) の QA 項目を構築します。 EHRBench で 30 を超える代表的な LLM のベンチマークを行い、パフォーマンスと堅牢性の詳細な分析を提供します。結果は、設定全体で一貫した機能傾向を示し、EHRBench の信頼性をさらに検証し、臨床的に信頼できる LLM システムに向けた実用的なギャップを浮き彫りにしました。
原文 (English)
EHRBench: An Automated and Reliable EHR-based Benchmark for Clinical Decision Making with LLMs
Clinical decision-making (CDM) is central to real-world clinical workflows, where clinicians infer diagnoses, select treatments, or anticipate future health outcomes under incomplete evidence. LLMs are increasingly used to support these decisions due to strong language capabilities, broad biomedical knowledge, and efficiency, yet the reliability of LLMs on real-world clinical decision tasks remains insufficiently understood. To evaluate CDM models, especially LLM-based models, an ideal and practical medical decision benchmark should be constructed via an automated yet reliable pipeline to ensure both scale and quality. Moreover, the grounding of a CDM benchmark in real patient EHRs can better support evaluation on practical CDM tasks that require substantive biomedical knowledge and clinical inference. To fill the gaps, we introduce EHRBench, an automated and reliable EHR-grounded benchmark for evaluating LLM-based clinical decision-making at scale. To ensure scalability and reliability, EHRBench is constructed through an EHR-LLM-KB(knowledge-base) interaction pipeline. For efficiency, we use a specialized LLM to automatically convert encounter-level EHR trajectories into structured templates and deterministically instantiate the templates into QA items. In parallel, we apply systematic KB-based verification and enrichment to filter hallucinated or ambiguous relations and to improve reliability. Using this pipeline, we construct nearly 1M (960,067) QA items spanning three core inference-required clinical decision tasks: diagnosis, treatment, and prognosis. We benchmark more than 30 representative LLMs on EHRBench and provide detailed analyses of performance and robustness. The results show consistent capability trends across settings, further validating the reliability of EHRBench and highlighting actionable gaps toward clinically reliable LLM systems.
レビンツリー検索の再根付のための構造に起因する情報
ポリシーを使用して検索をガイドするサブゴールベースのポリシー ツリー検索は、複雑な単一エージェントの決定論的問題には効果的ですが、多くの場合、明示的なサブゴールの生成に依存するため、大幅なオーバーヘッドが発生し、スケーラビリティが妨げられる可能性があります。この論文では、最近導入された $\sqrt{\text{LTS}}$ アルゴリズムを通じて学習された「rerooter」を使用することで、これらの制限を克服します。 rerooter は問題を暗黙的にソフト サブタスクに分解します。以前の研究では、与えられたリルータまたは手作りのリルータの正式な保証に焦点を当てていましたが、この研究では 3 つのリルータ設計を提案します。(i) グローバルな状態空間構造を活用するクラスタリング ベースのリルータ、(ii) 学習されたコスト To Go 推定を活用するヒューリスティック ベースのリルータ、および (iii) 両方の信号を組み合わせたハイブリッドです。私たちのフレームワークでは、生成されたサブゴールを明示的に再構築して推論する必要がなくなり、大幅に低い計算オーバーヘッドでスケーラブルな検索労力の割り当てが可能になります。経験的に、当社のリルートベースの方法は、サブゴールベースのポリシーツリー検索が失敗する複雑な環境にも拡張でき、テストされたドメインで最先端のオンライントレーニング効率を実現します。
原文 (English)
Structure-Induced Information for Rerooting Levin Tree Search
Subgoal-based policy tree search, which uses a policy to guide search, is effective for complex single-agent deterministic problems but often relies on explicit subgoal generation that can incur substantial overhead and hinders scalability. In this paper, we overcome these limitations by using a learned ``rerooter'' through the recently-introduced $\sqrt{\text{LTS}}$ algorithm. A rerooter implicitly decomposes the problem into soft subtasks. While previous work focused on the formal guarantees for given or handcrafted rerooters, in this work we propose three rerooter designs: (i) a clustering-based rerooter that exploits global state-space structure, (ii) a heuristic-based rerooter that leverages learned cost-to-go estimates, and (iii) a hybrid that combines both signals. Our framework avoids having to explicitly reconstruct and reason over generated subgoals, thereby enabling scalable allocation of search effort with significantly lower computational overhead. Empirically, our rerooting-based methods scale to complex environments where subgoal-based policy tree search fails, and achieve state-of-the-art online training efficiency on the domains tested.
戦略的プロバイダー対応の下での Policy-as-Code 検索による医療メカニズム
ヘルスケアのメカニズムは、それが引き起こす戦略的な医療提供者の反応と切り離すことができません。既存のヘルスケア AI ベンチマークでは、この反応が固定されているため、メカニズムが生み出す均衡によってメカニズムを評価することができません。私たちは、病院のメカニズム設計を言語モデルのプログラム合成として再構築します。型付けされた検査可能なルール プログラムは、5 つの戦略的プロバイダー チャネル (コーディング、選択、遅延、労力、トリアージ) を備えたマルチエージェント シミュレーターである Medi-Sim によって実行され、スコア付けされます。インセンティブスイープは、隣接するレジームとしての古典的な医療経済学の知見を回復する――利益圧力の下でのアップコーディングと複雑性の低い患者の選択、および測定されたパフォーマンスが真の結果と逆相関するグッドハート流のドリフト――そして単一の監査レバーがプレッシャーマイグレーションを暴露する:コーディングチャネルを閉じると、複雑性の低い選択が2倍以上になる。同じルールプログラム空間に対する LLM ガイドによる進化的コード検索により、アップコーディングを排除し、拒否を半分にし、利益志向のベースラインの資金のほとんどを保持する、検査可能な混合目的プログラムが合成されます。
原文 (English)
Healthcare Mechanisms from Policy-as-Code Search under Strategic Provider Response
Healthcare mechanisms are inseparable from the strategic provider response they induce: existing healthcare AI benchmarks hold this response fixed and so cannot evaluate mechanisms by the equilibrium they produce. We recast hospital mechanism design as program synthesis for language models: typed, inspectable rule programs are executed and scored by Medi-Sim, a multi-agent simulator with five strategic provider channels (coding, selection, delay, effort, triage). An incentive sweep recovers classical health-economics findings as adjacent regimes -- up-coding and low-complexity-patient selection under profit pressure, and Goodhart-style drift where measured performance becomes anti-correlated with true outcomes -- and a single audit lever exposes pressure migration: closing the coding channel more than doubles low-complexity selection. LLM-guided evolutionary code search over the same rule-program space then synthesizes an inspectable mixed-objective program that eliminates up-coding, halves rejection, and retains most of the profit-oriented baseline's funds.
MAVEN: エージェントティックツール呼び出しの一般化の改善
エージェント ツール呼び出し環境全体での一般化は、信頼性の高いエージェント推論システムにとって依然として中心的な課題です。大規模な言語モデルは個々のベンチマークで優れた結果を達成しますが、推論戦略を構成し、中間状態を保持し、ドメイン間でツールを調整する能力はまだ十分に解明されていません。構造化分解、適応ツール オーケストレーション、中間検証のための軽量の記号推論足場である MAVEN (Modular Agentic Verification and Execution Network) を紹介します。私たちは、BFCL v3、TauBench、Tau2Bench、AceBench などの確立されたツール呼び出しベンチマーク全体で MAVEN を評価し、明示的な検証と敵対的タスク構成を備えたマルチステップの数学的および物理的推論のためのストレス テスト ベンチマークである MAVEN-Bench を紹介します。 MAVEN-Bench は、部分的な推論の品質とエンドツーエンドのタスクの成功の間に大きなギャップがあることを明らかにします。 MAVEN-Bench を直接実行すると、MAVEN は追加のトレーニングなしで GPT-OSS-120b 基本モデルの精度が 48% から 71% に向上しました。また、推定コスト比が約 1/10 のオープンウェイト バックボーンを使用しながら、フロンティア独自のベースラインとの競争力を維持しています。これは、軽量の検証中心のスキャフォールドが構成推論を強化し、実際のエージェントのよりプロセスを意識した評価を動機付ける可能性があることを示唆しています。
原文 (English)
MAVEN: Improving Generalization in Agentic Tool Calling
Generalization across agentic tool-calling environments remains a central challenge for reliable agentic reasoning systems. Although large language models achieve strong results on individual benchmarks, their ability to compose reasoning strategies, preserve intermediate states, and coordinate tools across domains remains underexplored. We present MAVEN (Modular Agentic Verification and Execution Network), a lightweight symbolic reasoning scaffold for structured decomposition, adaptive tool orchestration, and intermediate verification. We evaluate MAVEN across established tool-calling benchmarks, including BFCL v3, TauBench, Tau2Bench, AceBench, and introduce MAVEN-Bench, a stress-test benchmark for multi-step mathematical and physical reasoning with explicit verification and adversarial task composition. MAVEN-Bench exposes a substantial gap between partial reasoning quality and end-to-end task success; in direct MAVEN-Bench runs, MAVEN improves its GPT-OSS-120b base model from 48% to 71% accuracy without additional training. It also remains competitive with frontier proprietary baselines while using an open-weight backbone with an estimated cost ratio of roughly 1/10, suggesting that lightweight verification-centered scaffolds can strengthen compositional reasoning and motivate more process-aware evaluation of agents in the wild.
拡散モデルによるナレッジグラフ推論のためのグラフ状ルールの生成
Logical rules constitute a cornerstone of knowledge graph (KG) reasoning, valued for their interpretability and ability to model relational patterns. However, existing rule mining methods predominantly focus on simple chain-like rules and therefore neglect the richer relational information encoded in graph-like structures, such as cycles and branches. This limitation is further exacerbated by computational bottlenecks caused by the combinatorial explosion of the search space, which is especially challenging for graph-like rules.一方、拡散モデルなどの生成的アプローチは、他の領域では成功しているにもかかわらず、ルールマイニングに直接適用することはできません。これは、そのトレーニングの目的が高品質のルールを学習するという目標と一致しておらず、微分不可能な KG ルールの品質メトリクスがモデルの最適化を直接導くことができないためです。これらの制限に対処するために、我々は、ターゲット関係を条件とする離散生成プロセスとしてグラフ状のルール発見を再定式化するフレームワークである GRiD を提案します。 GRiD は 2 段階のトレーニング戦略を採用しています。まず、教師あり事前トレーニングにより、GRiD は KG メタグラフからサンプリングされたサブグラフから構造事前分布を取得できるようになります。その後、強化学習が適用され、微分不可能なルール品質メトリクスによって直接導かれるポリシー勾配最適化を通じて GRiD が微調整されます。 6 つのベンチマーク データセットでの実験では、GRiD が KG 完了タスクで競争力のあるパフォーマンスを達成していることが示されています。アブレーション研究では、GRiD の効率と堅牢性が確認され、さらに、KG 完成においてグラフ状のルールがチェーン状のルールを補完することが示されています。コードとデータセットは https://github.com/Haoxiang-Cheng/GRiD で入手できます。
原文 (English)
Generating Graph-like Rules for Knowledge Graph Reasoning via Diffusion Models
Logical rules constitute a cornerstone of knowledge graph (KG) reasoning, valued for their interpretability and ability to model relational patterns. However, existing rule mining methods predominantly focus on simple chain-like rules and therefore neglect the richer relational information encoded in graph-like structures, such as cycles and branches. This limitation is further exacerbated by computational bottlenecks caused by the combinatorial explosion of the search space, which is especially challenging for graph-like rules. Meanwhile, generative approaches such as diffusion models, despite their success in other domains, can not be directly applied to rule mining because their training objectives are not aligned with the goal of learning high-quality rules, and non-differentiable KG rule quality metrics cannot directly guide model optimization. To address these limitations, we propose GRiD, a framework that reformulates graph-like rule discovery as a discrete generative process conditioned on the target relation. GRiD employs a two-phase training strategy. First, supervised pre-training enables GRiD to capture structural priors from subgraphs sampled from the KG meta-graph. Subsequently, reinforcement learning is applied to fine-tune GRiD through policy gradient optimization guided directly by non-differentiable rule-quality metrics. Experiments on six benchmark datasets show that GRiD achieves competitive performance on KG completion tasks. Ablation studies confirm the efficiency and robustness of GRiD and further show that graph-like rules complement chain-like rules in KG completion. Our codes and datasets are available in https://github.com/Haoxiang-Cheng/GRiD
長期タスク向けの学習エージェント互換のコンテキスト管理
LLM エージェントは、Web 検索や実世界のアプリケーションでの詳細な調査など、長期にわたるタスクに直面することが増えています。このタスクでは、蓄積されたコンテキストが長期コンテキストの劣化や推論の失敗を引き起こす可能性があります。これまでの研究では、エージェント側のコンテキスト制御や要約などの固定戦略を使用したコンテキスト管理を通じてこの問題を軽減していましたが、適応のためにエージェント自体をトレーニングする必要があり、クローズドソースのエージェントには非現実的であり、エージェントごとに異なる戦略が必要になる可能性があることが無視されていました。 Adaptive Context Management (AdaCoM) を導入します。これは、柔軟な変更アクションとエンドツーエンドの強化学習を通じて、凍結されたエージェントのコンテキストを管理するように外部 LLM をトレーニングします。 AdaCoM は、Web 検索およびディープリサーチベンチマーク上のさまざまなエージェントにわたって、古いコンテンツを削除しながらタスクの制約と進行状況を維持することで、パフォーマンスを大幅に向上させます。学習された戦略は、忠実度と信頼性のトレードオフを明らかにします。つまり、バニラ ReAct のパフォーマンスが高いエージェントは、忠実度の高いコンテキストの保存から恩恵を受けますが、パフォーマンスが低いエージェントは、信頼できる推論体制内に留まるために、より積極的な圧縮を必要とします。転送実験では、AdaCoM が同様の機能 (バニラ ReAct パフォーマンスで測定) を持つエージェント間で最も効果的に一般化することが示されており、エージェント システムの再利用可能なコンテキスト マネージャーへの実用的な道筋が示唆されています。
原文 (English)
Learning Agent-Compatible Context Management for Long-Horizon Tasks
LLM agents increasingly face long-horizon tasks such as web search and deep research in real-world applications, where accumulated context can cause long-context degradation and reasoning failures. Prior work mitigates this through context management with agent-side context control or fixed strategies such as summarization, which require training the agent itself for adaptation - making it impractical for closed-source agents and ignoring that different agents may require different strategies. We introduce Adaptive Context Management (AdaCoM), which trains an external LLM to manage the context of a frozen agent through flexible modification actions and end-to-end reinforcement learning. Across diverse agents on web search and deep research benchmarks, AdaCoM substantially improves performance by preserving task constraints and progress while pruning stale content. The learned strategies reveal a Fidelity-Reliability Trade-off: agents with higher vanilla ReAct performance benefit from higher-fidelity context preservation, whereas lower-performing agents require more aggressive compression to stay within a reliable reasoning regime. Transfer experiments show that AdaCoM generalizes most effectively across agents with similar capability (measured by vanilla ReAct performance), suggesting a practical path toward reusable context managers for agent systems.
PReMISE: LLM 審査員の測定仕様としてのポリシールーブリック
LLM 審査員は自由形式の回答を評価することにますます慣れていますが、審査員のスコアは条件付けするルーブリックに大きく依存します。 「役立つ、事実に基づいた」回答を求める曖昧なルーブリックでは、事実をでっち上げたり、ユーザーの意図に反する洗練された回答が報酬となる可能性があります。私たちは再利用可能なルーブリックを測定仕様として扱います。ルーブリックを変更すると、固定されたジャッジによって引き起こされる応答品質の測定が変化します。我々は、ペアごとの人間の選好データを基に、(i) ポリシーレベルのルーブリックセットを発見し、(ii) LLM 審査員が使用するルーブリックセットを構造的適切性、信頼性、選好適合性、敵対的堅牢性の 4 つの軸に沿って監査するフレームワークである PReMISE を紹介します。ルーブリック ソース全体にわたって、信頼性があり、好みを予測でき、敵対的に堅牢であるという生のソースは存在しません。また、評価者間の合意が高いことは、悪用可能性が低いことを意味するものではありません。 PReMISE は、適用性、特異性、効果的な次元性を同時に採点できる唯一のルーブリック ソースです。私たちは監査を対象とした 2 つの修復操作に貢献しています。優先順位の選択により、一対の回答に対するジャッジの精度が $65.0\%$ から $68.6\%$ に向上し、最も強力なルーブリック検出ベースラインと競合し、ジャッジ間のスイープで 3 人のジャッジのうち 2 人をリードしています。信頼性を制約した改良により、エクスプロイトの応答が高スコアを獲得する割合が $46.4\%$ から $36.0\%$ に減少しましたが、審査員間の合意はほとんど変わりません ($\alpha{=}.531\to.519$)。
原文 (English)
PReMISE: Policy Rubrics as Measurement Specifications for LLM Judges
LLM judges are increasingly used to evaluate open-ended responses, but their scores depend strongly on the rubrics that condition them. A vague rubric asking for a response to be ``helpful and factual'' can reward polished answers that invent facts or violate user intent. We treat reusable rubrics as measurement specifications: changing the rubric changes the response quality measurement induced by a fixed judge. We introduce PReMISE, a framework that, given pairwise human-preference data, (i) discovers a policy-level rubric set, and (ii) audits any rubric set under LLM-judge use along four axes: structural adequacy, reliability, preference fit, and adversarial robustness. Across rubric sources no raw source is simultaneously reliable, preference-predictive, and adversarially robust; and high inter-rater agreement does not imply low exploitability. PReMISE is the only rubric source to score non-trivially on applicability, specificity, and effective dimensionality simultaneously. We contribute two audit-targeted repair operations: preference-rank selection raises judge accuracy on paired responses from $65.0\%$ to $68.6\%$, competitive with the strongest rubric-discovery baselines and leading on two of three judges in our cross-judge sweep; reliability-constrained refinement reduces the rate at which exploit responses receive high scores from $46.4\%$ to $36.0\%$ with little change in inter-judge agreement ($\alpha{=}.531\to.519$).
構造を認識した報酬を備えた深い研究のためのプランナー中心の強化学習
詳細な調査タスクでは、LLM が何を調査するかを計画し、証拠を取得し、複数の調査分野にわたって長い形式の回答を総合する必要があります。既存のトレーニング パラダイムは、代理として短い形式の検証可能な QA に依存するか、モノリシックな長い軌道を最適化するかのいずれかです。そのため、計画と実行が複雑になり、計画プロセスに対する単位の割り当てが弱くなります。私たちは、プランナー中心の深層研究フレームワークである DecomposeR を提案します。DecomposeR は、研究計画を型付き有向非巡回グラフ (DAG) として表現し、計画を明示的、構造化して報酬を得ることができるようにします。 Qwen3-8B モデルを 2 段階でトレーニングします。プランナー強化学習 (RL) は、まず研究計画を改善するためにグラフ構造とクエリ分解を学習し、次にアンサー強化学習 (RL) がブランチレベルの実行と、学習されたプランに基づいて条件付けされた最終合成を学習します。 DecomposeR は、平坦な軌道ではなく、明示的なプランナー トークンと構造化コンポーネントに報酬を割り当てることで、エンドツーエンドのトレーニングの曖昧さを軽減しながら、計画のよりきめ細かい最適化を可能にします。実験によると、DecomposeR-8B は、計画および回答機能の向上により、一般的な長文ベンチマークにおいて、強力で比較可能なオープン ベースラインよりも 5.1 ~ 8.0 ポイント向上していることが示されています。
原文 (English)
Planner-Centric Reinforcement Learning for Deep Research with Structure-Aware Reward
Deep research tasks require LLMs to plan what to investigate, retrieve evidence, and synthesize long-form answers across multiple branches of inquiry. Existing training paradigms either rely on short-form verifiable QA as a proxy or optimize monolithic long trajectories, which makes planning and execution difficult to disentangle and yields weak credit assignment for the planning process. We propose DecomposeR, a planner-centric deep research framework that represents research plans as typed directed acyclic graphs (DAGs), allowing planning to be made explicit, structured, and rewardable. We train a Qwen3-8B model in two stages: planner reinforcement learning (RL) first learns graph structure and query decomposition to improve research planning, and answerer reinforcement learning (RL) then learns branch-level execution and final synthesis conditioned on the learned plan. By assigning rewards to explicit planner tokens and structured components rather than to a flat trajectory, DecomposeR enables finer-grained optimization of planning while reducing the ambiguity of end-to-end training. Experiments show that DecomposeR-8B improves over strong comparable open baselines by 5.1-8.0 points on popular long-form benchmarks due to improved planning and answering capabilities.
SLAT: 効率的な CoT 推論のためのセグメントレベルの適応トリミング
大規模推論モデルの最近の進歩により、強化学習 (RL) による思考連鎖 (CoT) 機能が大幅に向上しました。ただし、生成された推論チェーンは構造的な冗長性 (つまり \emph{over Thinking}) に悩まされることが多く、解答の正しさは改善されずに高い計算オーバーヘッドが発生します。既存の緩和戦略は通常、トークンの均一な長さのペナルティに依存しています。これにより、より短い出力に向けてセグメントに依存しない粗い圧力がかかり、冗長性とともに有用な推論が誤って抑制される可能性があります。これに対処するために、限界効用が低い確率の高いセグメントに非効率が集中していることを実証します。私たちは、正確性と長さのトレードオフ目標の下でセグメントの準最適性の理論的特徴付けを導き出し、この基準に基づいて冗長なセグメントを選択的に抑制する RL フレームワークである \textsc{SLAT} (セグメントレベル適応トリミング) を提案します。標準ベンチマークの経験的結果は、\textsc{SLAT} が優れた精度効率のパレート フロンティアを確立し、競合する精度を維持しながら非圧縮ベースラインと比較して推論の長さを $50\%$ 短縮することを示しています。全体として、私たちの結果は、理論に基づいたセグメントを意識したトリミングが、大規模な言語モデルにおける効率的な CoT 推論の有望な方向性であることを示唆しています。
原文 (English)
SLAT: Segment-Level Adaptive Trimming for Efficient CoT Reasoning
Recent advances in Large Reasoning Models have significantly improved chain-of-thought (CoT) capabilities via reinforcement learning (RL). However, generated reasoning chains frequently suffer from structural redundancy (i.e., \emph{overthinking}), incurring high computational overhead without improving answer correctness. Existing mitigation strategies typically rely on token-uniform length penalties, which provide coarse, segment-agnostic pressure toward shorter outputs and can inadvertently suppress useful reasoning alongside redundancy. To address this, we demonstrate that inefficiency concentrates in high-probability segments with low marginal utility. We derive a theoretical characterization of segment suboptimality under the correctness-length trade-off objective and propose \textsc{SLAT} (Segment-Level Adaptive Trimming), an RL framework that selectively suppresses redundant segments based on this criterion. Empirical results on standard benchmarks indicate that \textsc{SLAT} establishes a superior accuracy-efficiency Pareto frontier, reducing reasoning length by $50\%$ relative to uncompressed baselines while maintaining competitive accuracy. Overall, our results suggest that theoretically grounded, segment-aware trimming is a promising direction for efficient CoT reasoning in large language models.
COMPASS: セーフ サーチ エージェント向けの認知 MCTS ガイドによるプロセス調整
LLM を利用した検索エージェントにより、複数ステップの推論とツールの使用が可能になります。ただし、これらの機能は、有害な意図が一見無害に見えるサブクエリに分解され、安全でない結果を引き起こす可能性があるため、検索による安全性の低下を引き起こします。既存の調整手法は、まばらな安全信号を捕捉するのに苦労しており、複数ステップの相互作用にわたる多様な違反を監視できません。私たちは、一般的な実用性を維持しながら、エージェントのワークフロー全体で堅牢な安全調整を実現するように設計されたコグニティブ MCTS ガイド付きプロセス調整フレームワークである COMPASS を提案します。 COMPASS は、コグニティブ ツリー探索 (CTE) を統合してステルス攻撃の軌道を効率的に合成し、内省的ステップワイズ アライメント (ISA) を統合して、きめ細かいプロセス監視のためにリスクのある中間アクションを分離します。経験的な結果は、COMPASS が必要なトレーニング データを大幅に削減しながら、安全性とユーティリティの有利なトレードオフを達成していることを示しています。
原文 (English)
COMPASS: Cognitive MCTS-Guided Process Alignment for Safe Search Agents
LLM-powered search agents enable multi-step reasoning and tool use. However, these capabilities introduce retrieval-induced safety degradation, as harmful intents may decompose into seemingly innocuous sub-queries that lead to unsafe outcomes. Existing alignment methods struggle to capture sparse safety signals and fail to supervise diverse violations across multi-step interactions. We propose COMPASS, a Cognitive MCTS-Guided Process Alignment framework designed to achieve robust safety alignment throughout the agent workflow while preserving general utility. COMPASS integrates cognitive tree exploration (CTE) to efficiently synthesize stealthy attack trajectories, and introspective step-wise alignment (ISA) to isolate risky intermediate actions for fine-grained process supervision. Empirical results show that COMPASS achieves a favorable safety-utility trade-off while requiring substantially less training data.
リーン定理証明のための LLM フィードバックの抽出
推論モデルのポストトレーニングでは通常、教師あり微調整と検証可能な報酬からの強化学習が組み合わされ、最も一般的には GRPO が使用されます。ただし、このアルゴリズムには、報酬がまばらで、探索が制限され、モードが崩壊するという問題があります。自己蒸留に関する最近の研究に基づいて、私たちはフィードバック蒸留を提案します。これは、言語モデルによって生成された特権フィードバックを条件とした独自の分布にトークン レベルで一致するようにモデルがトレーニングされるトレーニング方法です。フィードバック蒸留はトークンレベルの監視を提供し、外部の知識を注入できます。 Lean4 定理証明の方法を評価すると、フィードバック蒸留は GRPO よりも生成された軌道の多様性を維持し、より高いポリシー エントロピーとより優れた pass@k スケーリングを生み出すことがわかります。 2 つの方法は補完的です。フィードバック蒸留チェックポイントから GRPO を初期化することは、どちらかの方法を単独で行うよりも優れたパフォーマンスを発揮します。全体として、私たちの結果は、複雑な推論のトレーニング後の改善に向けた有望な手段であることを示唆しています。
原文 (English)
Distilling LLM Feedback for Lean Theorem Proving
Post-training for reasoning models typically combines supervised fine-tuning with reinforcement learning from verifiable rewards, most commonly with GRPO. However, this algorithm suffers from sparse rewards, limited exploration, and mode collapse. Building upon recent works on self-distillation, we propose Feedback Distillation, a training method where the model is trained to match, at the token level, its own distribution conditioned on privileged feedback produced by a language model. Feedback Distillation offers token-level supervision and can inject external knowledge. Evaluating our method for Lean4 theorem-proving, we find that Feedback Distillation maintains greater diversity in generated trajectories than GRPO, yielding higher policy entropy and better pass@k scaling. The two methods are complementary: initializing GRPO from a Feedback Distillation checkpoint outperforms either method alone. All in all, our results suggest a promising avenue to improve post-training for complex reasoning.
UniScale: モデル ルーティングとテスト時間スケーリングのオンライン共同最適化による適応型統合推論スケーリング
大規模言語モデル (LLM) を実際に展開する場合、推論の品質と計算コストのバランスをとることが中心的な課題となっています。既存のアプローチは、リクエストの複雑さに合わせてさまざまなスケールのモデル間で切り替えるモデル ルーティングと、きめ細かい制御のために固定モデル内で推論時間の計算を調整するテスト時間スケーリング (TTS) という、2 つの大きく独立した次元に沿ってこのトレードオフに取り組んでいます。ただし、この分離された設計には固有の制限が生じます。モデル ルーティングでは、モデル スケールがまばらなため、粒度が粗くて離散的なパフォーマンス変化が生じますが、単一モデル TTS では、多くの場合、容量の上限に遭遇し、コンピューティングが増加するにつれて利益が減少します。さらに、2 つのメカニズムを個別に扱うと、動的推論環境での適応性が制限されます。これらの制限を克服するために、単一の最適化空間でモデル ルーティングと TTS を統合する Unified Inference Scaling (UIS) を導入します。この定式化に基づいて、適応型 UIS を状況に応じたマルチアーム バンディット問題としてモデル化し、LinUCB を介して推論ポリシーを学習するオンライン フレームワークである UniScale を提案します。このフレームワークには、効率を意識した学習とコスト モデリングが組み込まれており、高次元のアクション スペースにわたって安定したスケーラブルな最適化が保証されます。評価の結果、UniScale は UIS 空間の相乗効果を効果的に活用して、多様で動的な推論シナリオ全体にわたって、きめ細かく一貫して優れた品質とコストのトレードオフを実現していることが示されています。
原文 (English)
UniScale: Adaptive Unified Inference Scaling via Online Joint Optimization of Model Routing and Test-Time Scaling
In real-world deployments of large language models (LLMs), balancing inference quality and computational cost has become a central challenge. Existing approaches tackle this trade-off along two largely independent dimensions: model routing, which switches among models of different scales to match request complexity, and test-time scaling (TTS), which adjusts inference-time compute within a fixed model for fine-grained control. However, this decoupled design introduces inherent limitations. Model routing yields coarse-grained, discrete performance changes due to the sparse set of model scales, while single-model TTS often encounters capacity ceilings and exhibits diminishing returns as compute increases. Moreover, treating the two mechanisms separately restricts adaptability in dynamic inference environments. To overcome these limitations, we introduce Unified Inference Scaling (UIS), which unifies model routing and TTS in a single optimization space. Building on this formulation, we propose UniScale, an online framework that models adaptive UIS as a contextual multi-armed bandit problem and learns inference policies via LinUCB. The framework incorporates efficiency-aware learning and cost modeling to ensure stable and scalable optimization over high-dimensional action spaces. Evaluation shows that UniScale effectively exploits the synergy in the UIS space to deliver a fine-grained and consistently better quality-cost trade-off across diverse, dynamic inference scenarios.
BilliardPhys-Bench: マルチモーダル LLM の物理的推論と視覚的ダイナミクスのベンチマーク
現在のマルチモーダル モデルは静的画像認識をうまく処理しますが、直感的な物理的推論には依然として弱点が残っています。これらのシステムでは、単一の画像からオブジェクトがどのように移動し相互作用するかを予測することは依然として困難です。合成ビリヤード環境における物理的推論のベンチマークである BilliardPhys-Bench を紹介します。その手続き型エンジンは、摩擦と弾性衝突を伴うランダム化されたシナリオを生成します。このベンチマークでは、(1) ボールとボールの衝突の予測、(2) 壁の跳ね返りについての推論、(3) 動作が停止した後の最終的なボールの位置の推定の 3 つの能力をテストします。 GPT、Claude、Gemini、Qwen ファミリーの最近の MLLM を評価します。シミュレーション時間が長くなり、シーンのジオメトリが複雑になると、パフォーマンスが低下します。また、「スタシス バイアス」と呼ばれる一貫した故障モードも観察されています。つまり、正しい物理的結果を推測することが難しい場合、モデルは相互作用がないと予測する傾向があります。これらの発見は、現在の MLLM が視覚ダイナミクスのどこで破綻しているかを示しており、マルチモーダル アーキテクチャにおけるより優れた物理的誘導バイアスの必要性を示しています。
原文 (English)
BilliardPhys-Bench: Benchmarking Physical Reasoning and Visual Dynamics of Multimodal LLMs
Current multimodal models handle static image recognition well, but intuitive physical reasoning remains a weakness. Predicting how objects will move and interact from a single image is still difficult for these systems. We present BilliardPhys-Bench, a benchmark for physical reasoning in synthetic billiards environments. Its procedural engine generates randomized scenarios with friction and elastic collisions. The benchmark tests three abilities: (1) predicting ball-to-ball collisions, (2) reasoning about wall bounces, and (3) estimating final ball positions after motion stops. We evaluate recent MLLMs from the GPT, Claude, Gemini, and Qwen families. Performance drops as simulation time increases and scene geometry grows more complex. We also observe a consistent failure mode we call "stasis bias": when the correct physical outcome is harder to infer, models tend to predict no interaction. These findings show where current MLLMs break down on visual dynamics and point toward the need for better physical inductive biases in multimodal architectures.
生成 AI における多元的調整のためのペルソナベースの評価フレームワーク
生成型人工知能の現在の調整パラダイムは、主にモノリシックなベンチマーク フレームワークに依存しており、人間の複数の判断を集約された統計ベースラインに還元することで、評価における文化的、人口統計的、および文脈上のばらつきを曖昧にします。我々は、単一の評価関数を人間の多様な視点を表す合成認知プロファイルの構造化された多様体に置き換える、AI 評価のための状態空間制約付きエミュレーション フレームワークを導入します。私たちは、最新の生成アーキテクチャがこれらの評価ペルソナを高い一貫性でインスタンス化して維持できることを示し、現実世界のコンセンサス変動をより厳密に反映する、多元的で視点に依存したベンチマークの形式を可能にします。しかし、我々は、逐次推論と確率的プロンプト摂動下でのこれらのシミュレートされた評価器の安定性をさらに分析し、状態空間ドリフトと意味論的不一致として現れるペルソナの一貫性の体系的な低下を明らかにしました。これらの発見は、静的な位置合わせの制約では、長期にわたって堅牢な評価動作を維持するには不十分であることを示唆しています。その代わりに、私たちは、一貫した認知エミュレーションを維持するために、生成システム内に動的で実行可能性主導の制御メカニズムを組み込む必要性を主張します。この研究は、ペルソナベースの評価を潜在表現多様体上の構造化された動的システムとして枠組み化することで、AI 評価に対する、より適応的で人間と連携した、状況に応じたアプローチの基盤を提供します。
原文 (English)
A Persona-Based Evaluation Framework for Pluralistic Alignment in Generative AI
Current alignment paradigms for generative artificial intelligence rely predominantly on monolithic benchmarking frameworks that reduce the plurality of human judgment to aggregated statistical baselines, thereby obscuring cultural, demographic, and contextual variability in evaluation. We introduce a state-space constrained emulation framework for AI evaluation that replaces singular assessment functions with a structured manifold of synthetic cognitive profiles representing diverse human perspectives. We show that modern generative architectures can instantiate and maintain these evaluative personas with high consistency, enabling a form of pluralistic, perspective-dependent benchmarking that more closely reflects real-world consensus variability. However, we further analyze the stability of these simulated evaluators under sequential inference and stochastic prompt perturbations, revealing systematic degradation in persona coherence that manifests as state-space drift and semantic inconsistency. These findings suggest that static alignment constraints are insufficient for sustaining robust evaluative behavior over time. Instead, we argue for the necessity of embedding dynamic, viability-driven regulatory mechanisms within generative systems to preserve coherent cognitive emulation. By framing persona-based evaluation as a structured dynamical system over latent representation manifolds, this study provides a foundation for more adaptive, human-aligned, and context-sensitive approaches to AI evaluation.
HADT: 自律型地球観測衛星クラスター用のヘテロジニアス・マルチエージェント差動変圧器
この研究では、光学衛星や合成開口レーダー (SAR) 衛星を含む地球観測 (EO) ミッションを実行する異種衛星クラスターにおける自律的なリソース管理の問題に取り組んでいます。自律運用モードでは、衛星には最新の状況に基づいたリアルタイムの意思決定を可能にするインテリジェント機能が装備されており、地上オペレーターとの対話は最小限に抑えられます。従来のスケジューリング手法は通常、衛星のミッションとリソース管理を表す数学的モデルに依存しています。次に、この問題は最適化アルゴリズムを使用して解決されます。ただし、そのようなソリューションは、宇宙ミッション環境に固有の動的な変化や不確実性により、基礎となるモデルが利用できない場合、過度に複雑な場合、不正確な場合には効果が低くなります。有望な代替案は、問題を逐次的な意思決定プロセスとして再定式化し、モデルフリーの強化学習手法を適用して、適応的かつリアルタイムのリソース管理を可能にすることです。この目的を達成するために、我々は、関係的な観測とアクションのトークン化と差分注意メカニズムを備えた、異種衛星クラスターの自律的 EO ミッションに合わせた新しいトランスフォーマーベースのアーキテクチャを提案します。私たちの実験結果は、利用可能なベースラインと比較してパフォーマンスが大幅に向上していることを示しています。さらに、提案されたアーキテクチャは、さまざまな数の衛星クラスターに対して強力な適応性と転送性を示します。
原文 (English)
HADT: A Heterogeneous Multi-Agent Differential Transformer for Autonomous Earth Observation Satellite Cluster
This work addresses the problem of autonomous resource management in heterogeneous satellite cluster conducting Earth Observation (EO) missions including optical and Synthetic Aperture Radar (SAR) satellites. In autonomous operation mode, satellites are equipped with intelligent capabilities enabling real-time decision-making based on the latest conditions, while requiring minimal interaction with ground operators. Traditional scheduling approaches typically rely on mathematical models to represent satellite mission and resource management. Then, this problem is solved by using optimization algorithms. However, such solutions become less effective when the underlying models are not available, over complex, and inaccurate due to dynamic changes and uncertainties inherent in the space mission environment. A promising alternative is to reformulate the problem as a sequential decision-making process and apply model-free reinforcement learning techniques to enable adaptive and real-time resource management. To this end, we propose a novel transformer-based architecture tailored for heterogeneous satellite cluster autonomous EO Mission with relational observations-actions tokenization and differential attention mechanism. Our experimental results demonstrate significant performance improvements compared to the available baselines. Moreover, the proposed architecture exhibits strong adaptability and transferability with respect to varying numbers of satellite clusters.
GraphARC: グラフベースの抽象推論のための包括的なベンチマーク
関係推論はインテリジェンスの中心にありますが、既存のベンチマークは通常、グリッドやテキストなどの形式に限定されています。グラフ構造データに対する抽象推論のベンチマークである GraphARC を紹介します。 GraphARC は、Abstraction and Reasoning Corpus (ARC) の少数ショット変換学習パラダイムを一般化します。各タスクでは、いくつかの入出力ペアから変換ルールを推測し、それを新しいテスト グラフに適用し、ローカル、グローバル、および階層的なグラフ変換をカバーする必要があります。グリッドベースの ARC とは異なり、GraphARC インスタンスはさまざまなグラフ ファミリやサイズにわたって大規模に生成できるため、汎化能力の体系的な評価が可能になります。私たちは GraphARC で最先端の言語モデルを評価し、明らかな制限を観察しました。モデルはグラフのプロパティに関する質問には答えることができますが、完全なグラフ変換タスクを解決できないことが多く、理解と実行のギャップが明らかになります。インスタンスが大きくなるとパフォーマンスがさらに低下し、スケーリングの障壁が露呈します。より広範には、ノード分類、リンク予測、およびグラフ生成の側面を単一のフレームワーク内で組み合わせることで、GraphARC は将来のグラフ基盤モデルに有望なテストベッドを提供します。
原文 (English)
GraphARC: A Comprehensive Benchmark for Graph-Based Abstract Reasoning
Relational reasoning lies at the heart of intelligence, but existing benchmarks are typically confined to formats such as grids or text. We introduce GraphARC, a benchmark for abstract reasoning on graph-structured data. GraphARC generalizes the few-shot transformation learning paradigm of the Abstraction and Reasoning Corpus (ARC). Each task requires inferring a transformation rule from a few input-output pairs and applying it to a new test graph, covering local, global, and hierarchical graph transformations. Unlike grid-based ARC, GraphARC instances can be generated at scale across diverse graph families and sizes, enabling systematic evaluation of generalization abilities. We evaluate state-of-the-art language models on GraphARC and observe clear limitations. Models can answer questions about graph properties but often fail to solve the full graph transformation task, revealing a comprehension-execution gap. Performance further degrades on larger instances, exposing scaling barriers. More broadly, by combining aspects of node classification, link prediction, and graph generation within a single framework, GraphARC provides a promising testbed for future graph foundation models.
クロスモデルのローカルアイソメトリック一貫性によるベクトルリンク
私たちはベクトル リンキングを研究します。部分的に重複するデータセット上で異なるブラック ボックス エンコーダーによって生成された 2 つの埋め込みクラウドが与えられた場合、ベクトルのみを使用してクロスモデル オブジェクトの対応関係を回復します。経験的および理論的に、独立してトレーニングされたコントラストエンコーダーが局所的な幾何学的一貫性を示すことを示します。つまり、短距離距離はスケール係数までほぼ保存されますが、長距離距離はモデル固有の歪みによるものではありません。これに基づいて、ペアになったアンカーの小さなシードセットからベクトルリンクを回復する、反復的な参照ベースの幾何学的埋め込みハッシュを提案します。これは、サンプリングされたペアのアンカーまでの距離によって各ベクトルを表し、ハッシュ空間マッチングによって候補リンクを提案し、ベータ ベルヌーイ事後でビュー全体の証拠を集約して、信頼性の高いリンクを新しいアンカーとしてブートストラップします。複数のベンチマークと埋め込みモデルのペアにわたる実験では、ベクトル データベース統合とクロスモデル クラスタリングへのアプリケーションを使用して、さまざまなオーバーラップ、シード バジェット、ドメイン外アンカーの下での正確かつ堅牢なリンクを実証します。コードは https://github.com/DBgroup-Edinburgh/VecLinking で入手できます。
原文 (English)
Vector Linking via Cross-Model Local Isometric Consistency
We study Vector Linking: given two embedding clouds produced by different black-box encoders over partially overlapping datasets, recover cross-model object correspondences using only vectors. Empirically and theoretically, we show that independently trained contrastive encoders exhibit local geometric consistency: short-range distances are approximately preserved up to a scale factor, while long-range distances are not due to model-specific distortion. Building on this, we propose an iterative, reference-based geometric embedding hashing that recovers vector links from a tiny seed set of paired anchors. It represents each vector by distances to sampled paired anchors, proposes candidate links via hash-space matching, and aggregates evidence across views in a Beta-Bernoulli posterior to bootstrap high-confidence links as new anchors. Experiments across multiple benchmarks and embedding model pairs demonstrate accurate and robust linking under varying overlap, seed budgets, and out-of-domain anchors, with applications to vector database integration and cross-model clustering. Code is available at https://github.com/DBgroup-Edinburgh/VecLinking.
LLM-FACETS: LLM の透明性と説明責任を評価するためのプライバシー保護フレームワーク
大規模言語モデルの出力が事実に基づいており、認識論的に調整されており、方法論的に再現可能であるかどうかを評価することは、責任ある AI 導入の前提条件です。しかし、LLM の監査は、技術者以外の専門家にとってはアクセスできないままです。既存のツールにはプログラミングの専門知識と簡単ではない環境セットアップが必要であり、クラウドでホストされるプラットフォームは評価データを外部サービスに送信するため、AI の監視に法的責任を負うドメインの専門家やコンプライアンス担当者にとって障壁が生じています。 LLM-FACETS (LLM FActuality Cross-EvaluTion System) を紹介します。これは、ブラウザからアクセス可能なインターフェイスとプラグイン アーキテクチャを備えたオープンソース フレームワークで、EU AI 法と NIST AI リスク管理フレームワークで特定されているステークホルダーのカテゴリを反映する 3 つの実践者プロファイル (技術専門家、ドメイン専門家、コンプライアンス担当者) を中心に構造化されています。このアーキテクチャでは、データ フローが明示的になります。決定論的メトリクス (BLEU、ROUGE、BERTScore) は、アウトバウンド送信なしで完全に自己ホスト型サーバー内で実行されます。 LLM 判定メトリクスは外部 API に明示的に接続し、ユーザーは資格情報の完全な制御を保持します。このフレームワークは、認識上の不確実性に対するトークンレベルの対数確率の視覚化、裁判官のバイアスを軽減するための複数裁判官のコンセンサス、幻覚を検出して位置を特定するための RAG トライアド メトリクス (忠実度、回答の関連性、コンテキストの関連性) の 3 つのメカニズムを通じて透明性を運用します。プラグイン アーキテクチャにより、評価パイプラインを変更せずに、新しいメトリクスやデータセットを統合できます。オープンソースの実装により、同じプロパティを対象とする複数の指標にわたるクロスチェックが可能になり、再現性が確保され、評価対象のシステムを構築するチームから AI の説明責任が切り離されます。正規の参照ライブラリに対する 18 のメトリック実装の相互検証を通じてフレームワークを検証します。
原文 (English)
LLM-FACETS: A Privacy-Preserving Framework for Evaluating LLM Transparency and Accountability
Assessing whether Large Language Models outputs are factually grounded, epistemically calibrated, and methodologically reproducible is a prerequisite for responsible AI deployment. Yet auditing LLMs remains inaccessible to non-technical practitioners: existing tools require programming expertise and non-trivial environment setup, and cloud-hosted platforms transmit evaluation data to external services, creating barriers for domain experts and compliance officers legally responsible for AI oversight. We introduce LLM-FACETS (LLM FActuality Cross-EvaluaTion System): an open-source framework with a browser-accessible interface and a plugin architecture, structured around three practitioner profiles (technical experts, domain experts, compliance officers) that mirror the stakeholder categories identified in the EU AI Act and the NIST AI Risk Management Framework. The architecture makes data flows explicit: deterministic metrics (BLEU, ROUGE, BERTScore) run entirely within the self-hosted server with no outbound transmission; LLM-judge metrics contact external APIs explicitly, with users retaining full credential control. The framework operationalizes transparency through three mechanisms: token-level log-probability visualization for epistemic uncertainty, multi-judge consensus to mitigate judge bias, and RAG Triad metrics (Faithfulness, Answer Relevance, Context Relevance) to detect and localize hallucinations. A plugin architecture allows any new metric or dataset to be integrated without modifying the evaluation pipeline. The open-source implementation enables cross-checking across multiple metrics targeting the same property, ensuring reproducibility and decoupling AI accountability from the teams building the systems assessed. We verify the framework through cross-validation of 18 metric implementations against canonical reference libraries.
稀な事象の因果経路の形式化と改ざん
構造方程式モデルにおけるまれな事象 (「外れ値」) の根本原因分析の最近の形式化に基づいて、因果関係経路の形式的な定義を提案し、その検証可能な意味について議論します。私たちは、これらの意味が、基礎となるシステムの完全な因果グラフではなく、まれなイベントの経路によって定義される因果抽象化のみに依存する条件を特定します。したがって、我々は、単純な言葉による因果関係の説明と詳細な因果モデリングを橋渡しする、まれな事象の経路に因果構造の抽象化を導入します。
原文 (English)
Formalizing and falsifying causal pathways of rare events
Building on recent formalizations of root cause analysis for rare events (``outliers'') in structural equation models, we propose a formal definition of a causal pathway and discuss its testable implications. We identify conditions under which these implications depend only on a causal abstraction defined by the pathway of rare events, rather than on the full causal graph of the underlying system. Accordingly, we introduce an abstraction of causal structure to pathways of rare events that bridges simple verbal causal explanations and detailed causal modeling.
COLLEAGUE.SKILL: 専門知識の蒸留による AI スキルの自動生成
LLM エージェントは、孤立したタスクを完了するだけでなく、人間の専門知識、判断、対話スタイルの限定された表現を実行することをますます期待されています。このような個人ベースのエージェントの構築は依然として困難です。これは、個人または役割に関連付けられた実用的な知識が、通常、きれいな指示として記述されるのではなく、異種トレースに埋め込まれているためです。既存のメモリおよびペルソナ システムはこの証拠の断片をキャプチャしますが、スキル フレームワークはポータブルなパッケージ形式を提供します。ただし、これらのトレースを検査可能、修正可能、エージェントが使用できるスキルに抽出するためのエンドツーエンドのワークフローはありません。専門知識の抽出を通じて人間に基づいた AI スキルを生成するための、自動化されたトレースからスキルへの抽出システムを紹介します。 COLLEAGUE.SKILL は、対象となる人物または役割からの資料を基に、2 つの調整されたトラックを備えたバージョン管理されたスキル パッケージを生成します。1 つはプラクティス、メンタル モデル、意思決定ヒューリスティックに関する能力トラックで、もう 1 つはコミュニケーション スタイル、インタラクション ルール、修正履歴に関する限定された行動トラックです。パッケージは、自然言語フィードバックを通じて検査、呼び出し、更新、ロールバック、エージェント ホスト間でのインストール、およびオプションで制御された配布の準備ができます。アーティファクト コントラクト、生成ワークフロー、修正ライフサイクル、展開面、およびオープンソース システムに実装されたドメイン プリセットについて説明します。この記事の執筆時点では、パブリック リポジトリには約 18.5k の GitHub スターがあります。ギャラリーには、165 人の寄稿者による 215 のスキルと、リストされているスキル カード全体で 10 万以上の累計スターがリストされています。このシステムは、個人に根ざしたスキルが、不透明なプロンプトや隠された記憶ではなく、移植可能で修正可能なパッケージとしてどのように表現できるかを示しています。
原文 (English)
COLLEAGUE.SKILL: Automated AI Skill Generation via Expert Knowledge Distillation
LLM agents are increasingly expected not only to complete isolated tasks, but also to carry bounded representations of human expertise, judgment, and interaction style. Building such person-grounded agents remains difficult because actionable knowledge associated with a person or role is usually embedded in heterogeneous traces rather than written as clean instructions. Existing memory and persona systems capture fragments of this evidence, while skill frameworks provide portable packaging formats; however, there is no end-to-end workflow for distilling these traces into inspectable, correctable, and agent-usable skills. We present an automated trace-to-skill distillation system for generating person-grounded AI skills via expert knowledge distillation. Given materials from a target person or role, COLLEAGUE.SKILL produces a versioned skill package with two coordinated tracks: a capability track for practices, mental models, and decision heuristics, and a bounded behavior track for communication style, interaction rules, and correction history. The package can be inspected, invoked, updated through natural-language feedback, rolled back, installed across agent hosts, and optionally prepared for controlled distribution. We describe the artifact contract, generation workflow, correction lifecycle, deployment surface, and domain presets implemented in the open-source system. At the time of writing, the public repository has approximately 18.5k GitHub stars; the gallery lists 215 skills from 165 contributors and more than 100k cumulative stars across listed skill cards. The system illustrates how person-grounded skills can be represented as portable, correctable packages rather than opaque prompts or hidden memories.
予測を活用した推論の工業化: 信頼性の高い GenAI およびエージェント システム評価のための GLIDE ライブラリ
エージェント システムの信頼性の高い評価には、有効な不確実性を伴う不偏推定が必要ですが、標準的な手法では、コストのかかる人間によるアノテーションと、ジャッジとしての偏った LLM プロキシの間を行き来します。予測パワー推論 (PPI) は、両方を組み合わせて有効な信頼区間を持つ偏りのない推定値を生成しますが、そのさまざまな手法は部分的な実装の下で論文に散在したままです。平均推定に特化した scipy スタイルの API の下で、最先端の PPI 推定器 (PPI++、層化 PPI、Predict-Then-Debias とその層化バリアント、アクティブ統計推論) とサンプラー (均一、層化、アクティブ、コスト最適化) を統合するオープンソース Python ライブラリである GLIDE を紹介します。 GLIDE には、再現可能なモンテカルロ検証スイート、手法選択のための経験に基づいたデシジョン ツリー、同等の精度でのアノテーションの大幅な節約を示すエージェント評価ケース スタディが付属しています。 GLIDE パッケージは次の URL で入手できます: https://github.com/EmertonData/glide
原文 (English)
Industrializing Prediction-Powered Inference: The GLIDE Library for Reliable GenAI and Agentic Systems Evaluation
Reliable evaluation of agentic systems requires unbiased estimates with valid uncertainty, but standard practice navigates between costly human annotation and biased LLM-as-judge proxies. Prediction-powered inference (PPI) combines both into debiased estimates with valid confidence intervals, yet its various methods remain scattered across papers under partial implementations. We introduce GLIDE, an open-source Python library that unifies state-of-the-art PPI estimators (PPI++, Stratified PPI, Predict-Then-Debias and its stratified variants, Active Statistical Inference) and samplers (uniform, stratified, active, cost-optimal) under a scipy-style API specialized to mean estimation. GLIDE ships with a reproducible Monte Carlo validation suite, an empirically grounded decision tree for method selection, and an agentic evaluation case study showing substantial annotation savings at equivalent precision. The GLIDE package is available at this URL: https://github.com/EmertonData/glide
TraceGraph: エージェントの軌跡を診断および改善するための共有意思決定ランドスケープ
エージェントのベンチマークでは、豊富なインタラクションの軌跡が記録されることが増えていますが、評価によって各ロールアウトが合格率や報酬スコアに引き下げられることがよくあります。リリースされたマルチモデル エージェントの軌跡を共有の意思決定ランドスケープに変えるグラフベースのフレームワークである TraceGraph を紹介します。 TraceGraph は、タスクごとに、モデル ID が導入される前に、プールされたロールアウトから観察可能なアクションと観察の状態に関するグラフを構築します。次に、結果に基づいた生産コアとトラップ領域をオーバーレイし、各ロールアウトをアクセス、トラップ露出、修復の 3 つのイベントで要約します。 TraceGraph プロファイルは、5 つのベンチマーク スプリットにまたがる軌跡全体で、集計スコアによって隠されたナビゲーションの違いを明らかにし、トラップの回避とそこからの回復のどちらに報酬を与えるかがスプリットによって異なることを示します。同じ TraceGraph ランドスケープは、SWE ベンチのトラップ対応回復パイプラインも動機付けます。実行時検出器は、履歴トラップ領域に一致する状態で起動され、その後、軽量継続ポリシーが同じプレフィックスから評価されます。起動された状態では、最適なプールされた単一要素ポリシーにより、プロバイダー固有のアクティブ コンポーネントを使用して、プロバイダーごとに起動されたサブセットで正式な解決率が 40.4% から 43.5% に、共通起動されたインスタンスで 41.0% から 44.8% に上昇します。全体として、TraceGraph は、どのようなエージェント ベンチマーク テストを行うか、共有ランドスケープ上でモデルが分岐する場所、および障害領域が下流の改善をどのように導くことができるかを尋ねるためのプロセス ボキャブラリーを提供します。
原文 (English)
TraceGraph: Shared Decision Landscapes for Diagnosing and Improving Agent Trajectories
Agent benchmarks increasingly record rich interaction trajectories, yet evaluation often reduces each rollout to a pass rate or reward score. We introduce TraceGraph, a graph-based framework that turns released multi-model agent trajectories into shared decision landscapes. For each task, TraceGraph builds a graph over observable action-observation states from pooled rollouts before model identity is introduced. It then overlays outcome-informed productive cores and trap regions, and summarizes each rollout with three events: Access, Trap exposure, and Repair. Across trajectories spanning five benchmark splits, TraceGraph profiles reveal navigation differences hidden by aggregate scores and show that splits differ in whether they reward avoiding traps or recovering from them. The same TraceGraph landscape also motivates a trap-aware recovery pipeline for SWE-bench: aruntime detector fires on states matching historical trap regions, then lightweight continuation policies are evaluated from the same prefix. On fired states, the best pooled single-factor policy raises official resolved rate from 40.4% to 43.5% on the per-provider fired subset and from 41.0% to 44.8% on common-fired instances, with provider-specific active components. Overall, TraceGraph provides a process vocabulary for asking what agent benchmarks test, where models diverge on a shared landscape, and how failure regions can guide downstream improvement.
リソースに制約のある Visual Agent における共有状態コラボレーションの障害モードの診断
モジュール式視覚推論システムは、多段階のコラボレーションのために共有ワーキングメモリへの依存度が高まっていますが、低容量領域における中間状態の進化の失敗ダイナミクスは依然として解明されていません。私たちは、ノイズ蓄積のレンズを通して、弱い学習者 (4B ~ 8B モデル) を使用した協調推論の失敗モードを研究します。ドキュメントの視覚的な質問応答における情報フローを追跡するための読み取り、書き込み、検証ループを形式化する監査フレームワークである CoSee を紹介します。複数ページ、グラフ、および Web ベースのベンチマーク全体で、直感に反する劣化が見つかりました。単純な共有ワークスペースでは、幻覚を解決するのではなく、幻覚を増幅させることがよくあります。私たちは 2 つの主要な失敗モードを特定しました。根拠のないメモが証拠として再利用されるノイズ強化と、追加されたコンテキストによってモデルが不完全な短い形式の回答にシフトするポリシー崩壊です。コスト精度のパレート フロンティアを使用して、明示的な検証がなければ、コンピューティングの増加がパフォーマンスと負の相関関係を示す可能性があることを示します。私たちの調査結果は、リソースに制約のあるエージェントの場合、ボトルネックは推論の深さではなく通信の忠実度にあり、トレースレベルの診断と信頼性の高いモジュール設計のための機構ベースラインを提供することを示唆しています。
原文 (English)
Diagnosing Failure Modes of Shared-State Collaboration in Resource-Constrained Visual Agents
Modular visual reasoning systems increasingly rely on shared working memory for multi-step collaboration, yet the failure dynamics of intermediate state evolution in low-capacity regimes remain underexplored. We study failure modes of collaborative reasoning with weak learners (4B--8B models) through the lens of noise accumulation. We introduce CoSee, an auditing framework that formalizes the read-write-verify loop to trace information flow in document visual question answering. Across multi-page, chart, and web-based benchmarks, we find a counter-intuitive degradation: naive shared workspaces often amplify hallucinations rather than resolve them. We identify two dominant failure modes: Noise Reinforcement, where ungrounded notes are reused as evidence, and Policy Collapse, where added context shifts the model toward under-specified, short-form answers. Using cost-accuracy Pareto frontiers, we show that increased compute can correlate negatively with performance without explicit verification. Our findings suggest that for resource-constrained agents, the bottleneck lies not in reasoning depth but in communication fidelity, providing trace-level diagnostics and a mechanistic baseline for reliable modular design.
適応することを学ぶ: 認知認識の探求による自己改善 Web エージェント
マルチモーダル大規模言語モデル (MLLM) の最近の進歩により、Web エージェントは有望な進歩を遂げています。ただし、既存の Web エージェントは多くの場合、手作りの実行パイプラインや高価な専門家の軌跡に依存しており、複雑で動的な環境への適応性が制限されています。これらの課題に対処するために、私たちは SCALE (Self-Cognitive-Aware Learning and Exploration) を提案します。これは、セレクター、プレディクター、ジャッジという 3 つの敵対的な役割を活用して、環境探索を通じてエージェントの限界を自律的に発見し、その認知境界を拡張します。さらに、グローバルな計画を容易にし、エージェントがローカル探索の罠を避けるのに役立つグラフ探索戦略である SCALE-Hop を提案します。学習をさらにサポートするために、19 の実世界の Web サイトから収集された大規模なデータセットである SCALE-20k を構築します。これには、さまざまな種類のタスクと、SCALE の探索トレースから生成された構造化されたデモンストレーションが含まれています。実験結果は、私たちのアプローチがさまざまな Web 環境における複数の MLLM のパフォーマンスと汎用性を大幅に向上させることを示しています。私たちのフレームワークは、真に自律的で適応性のある Web エージェントを構築するための、スケーラブルで一般化可能なソリューションを提供します。
原文 (English)
Learning to Adapt: Self-Improving Web Agent via Cognitive-Aware Exploration
Recent advances in Multimodal Large Language Models (MLLMs) have led to promising progress in web agents. However, existing web agents often rely on handcrafted execution pipelines or expensive expert trajectories, limiting their adaptability to complex, dynamic environments. To address these challenges, we propose SCALE (Self-Cognitive-Aware Learning and Exploration), which leverages three adversarial roles, Selector, Predictor, and Judger to autonomously discover the agent's limitations and expand its cognitive boundaries through environmental exploration. Moreover, we propose SCALE-Hop, a graph exploration strategy that facilitates global planning and helps agents avoid local exploration traps. To further support learning, we construct SCALE-20k, a large-scale dataset collected from 19 real-world websites, containing diverse task types and structured demonstrations generated from SCALE's exploration traces. Experimental results show that our approach significantly improves the performance and generalization of multiple MLLMs in various web environments. Our framework offers a scalable and generalizable solution for building truly autonomous and adaptive web agents.
HypoAgent: ナレッジ グラフ上でインタラクティブなアブダクティブ仮説生成のためのエージェント フレームワーク
ナレッジグラフに対するアブダクティブ推論は、観察されたエンティティまたは事実を説明する論理的な仮説を生成することを目的としています。既存の制御可能な仮説生成方法では、ユーザーが明示的な条件を使用してこのプロセスをガイドできますが、インタラクティブな設定では制限されたままです。マルチターンの対話全体で進化する自然言語の意図を根付かせるのに苦労し、生成された仮説が失敗した場合に詳細な診断をほとんど提供できません。これらの制限に対処するために、ナレッジ グラフ上でインタラクティブなアブダクティブ仮説生成のためのエージェント フレームワークである HypoAgent を提案します。 HypoAgent は 3 つのエージェントを統合します。ユーザーの発話と対話履歴を実行可能な KG 条件に根拠付ける意図認識エージェント、抽出されたユーザーの意図に従って制御可能な仮説生成を実行する仮説生成エージェント、および信頼性の低い仮説の断片を診断し、KG 近傍調査を利用してサポートされる改良点を特定する根本原因分析エージェントです。常識グラフと生物医学領域固有のナレッジ グラフの実験により、HypoAgent がシングル ターン、マルチ ターン、無条件の設定で最先端の意味的類似性を達成できることが実証されました。私たちのコードは https://github.com/HKUST-KnowComp/HypoAgent で入手できます。
原文 (English)
HypoAgent: An Agentic Framework for Interactive Abductive Hypothesis Generation over Knowledge Graphs
Abductive reasoning over knowledge graphs aims to generate logical hypotheses that explain observed entities or facts. Existing controllable hypothesis generation methods allow users to guide this process with explicit conditions, but they remain limited in interactive settings: they struggle to ground evolving natural-language intents across multi-turn dialogues and provide little fine-grained diagnosis when generated hypotheses fail. To address these limitations, we propose HypoAgent, an Agentic framework for interactive abductive Hypothesis Generation over knowledge graphs. HypoAgent integrates three agents: an Intent Recognition Agent that grounds user utterances and dialogue history into executable KG conditions, a Hypothesis Generation Agent that performs controllable hypothesis generation according to the extracted user intention, and a Root Cause Analysis Agent that diagnoses unreliable hypothesis fragments and leverages KG neighborhood probing to identify supported refinements. Experiments on commonsense and biomedical domain-specific knowledge graphs demonstrate that HypoAgent achieves state-of-the-art semantic similarity under single-turn, multi-turn, and unconditional settings. Our code is available at https://github.com/HKUST-KnowComp/HypoAgent.
FAM-Bench: 状態を認識した「薬としての食品」推論のためのマルチモーダルベンチマーク
薬としての食品では、モデルは、料理が何であるか、またはそれに含まれる栄養を超えて推論する必要があります。モデルは、具体的な食品の選択が特定の健康状態に適切であるかどうかを判断する必要があります。既存の食品 AI ベンチマークは、主に料理の認識、レシピの理解、栄養素の推定、または一般的な栄養に関する質問への回答を評価しており、この健康を意識した意思決定層はほとんどテストされていません。 FAM-Bench は、13 の食事関連の健康状態にわたって 2,500 件の栄養専門家によって検証されたマルチモーダルな Food-as-Medicine ベンチマークです。ベンチマークには、2 つの補完的なタスクが含まれています。1 つは料理レベルの適合性評価で、画像と成分リストから料理が条件に適しているかどうかをモデルが判断します。もう 1 つは、条件固有の適合性によってモデルが 4 つの候補料理をランク付けする比較料理分析です。どちらのタスクも、成分の証拠、視覚的な準備の合図、臨床栄養上の制約を統合する必要があり、言語および視覚言語モデルにおける根拠のある健康を意識した推論のための標準化されたテストベッドを提供します。
原文 (English)
FAM-Bench: A Multimodal Benchmark for Condition-Aware Food-as-Medicine Reasoning
Food-as-Medicine requires models to reason beyond what a dish is or what nutrition it contains: they must decide whether a concrete food choice is appropriate for a specific health condition. Existing food AI benchmarks primarily evaluate dish recognition, recipe understanding, nutrient estimation, or general nutrition question answering, leaving this health-aware decision layer largely untested. We introduce FAM-Bench, a multi-modal Food-as-Medicine benchmark with 2500 nutrition-expert-verified instances across 13 diet-related health conditions. The benchmark contains two complementary tasks: dish-level suitability assessment, where models judge whether a dish is suitable for a condition from its image and ingredient list, and comparative dish analysis, where models rank four candidate dishes by condition-specific suitability. Both tasks require integrating ingredient evidence, visual preparation cues, and clinical nutrition constraints, providing a standardized testbed for grounded health-aware reasoning in language and vision-language models.
強化学習のための解答セットプログラミングベースの抽象化
強化学習 (RL) により、自律エージェントは経験からポリシーを学習できますが、現実的な問題には膨大な状態空間が関与することが多く、学習と一般化が困難になります。したがって、抽象化と近似が不可欠です。関係強化学習 (RRL) は、オブジェクトとその関係について推論する方法を提供し、Martijn van Otterlo による CARCASS フレームワークは、論理表現が一次領域でマルコフ決定プロセス (MDP) をどのようにモデル化できるかを示しています。 CARCASS は元々 Prolog に実装されており、ドメイン知識を活用して強力な抽象化を作成します。私たちは、CARCASS 抽象化を実現するために、Prolog とは対照的に、リッチで完全な宣言型モデリング言語である Answer-Set Programming (ASP) を検討します。私たちは、2 つのドメインのケーススタディで ASP ベースの実装を評価します。ブロックワールドとミニグリッド。私たちの結果は、ASP を備えた CARCASS が、特にドメイン知識が利用可能な場合に、RL の抽象化を構築するための有望なアプローチを提供することを示しています。
原文 (English)
Answer-Set-Programming-based Abstractions for Reinforcement Learning
Reinforcement Learning (RL) enables autonomous agents to learn policies from experience, but realistic problems often involve enormous state spaces, making learning and generalisation challenging. Abstraction and approximation are therefore essential. Relational Reinforcement Learning (RRL) offers a way to reason about objects and their relations, and the CARCASS framework by Martijn van Otterlo demonstrates how logical representations can model Markov Decision Processes (MDPs) in first-order domains. Originally implemented in Prolog, CARCASS leverages domain knowledge to create powerful abstractions. We explore Answer-Set Programming (ASP), which is a rich and, contrary to Prolog, fully declarative modelling language, to realise CARCASS abstractions. We evaluate our ASP-based implementation in case studies of two domains, viz. Blocks World and Minigrid. Our results indicate that CARCASS with ASP provides a promising approach to constructing abstractions for RL, especially when domain knowledge is available.
AutoSci: 科学研究ライフサイクル全体向けのメモリ中心のエージェント システム
科学研究は伝統的に人力が集中しており、研究者は長いプロジェクト サイクルにわたって文献、アイデア、実験、原稿を調整し、回答をレビューする必要があります。 LLM ベースの科学エージェントの台頭により、このプロセスを自動化する機会が生まれました。このようなシステムは、研究ライフサイクル全体をサポートし、プロジェクト全体で構造化された永続的なメモリを維持し、時間の経過とともに独自の研究手順を改善する必要があります。しかし、既存のシステムはこれらの要件を部分的に満たしているか満たしていないため、統合された自動化された科学研究システムにはギャップが残されています。その結果、科学研究ライフサイクル全体に対応したメモリ中心のエージェント システムである AutoSci を紹介します。 AutoSci は 4 つのモジュールを中心に構成されています。 SciMem は、スキーマ管理された研究メモリを提供し、再利用可能な科学知識のための長期知識メモリを、アイデア、実験、原稿、レビューなどのプロジェクト レベルの成果物のためのアクティブな研究メモリから分離します。 SciFlow は、状態、コンテキスト、検証、フィードバック、オーケストレーションを制御するハーネスを通じて、文献の理解から反論まで 5 段階のライフサイクルを実行します。 SciDAG は、DAG 形状のマルチエージェント オペレーターと再利用可能なステージ固有のテンプレートを使用して、難しいスキルを強化します。 SciEvolve は、ユーザー、実験、レビュー、外部環境からのフィードバック信号を、SciMem 組織、SciFlow スキル、および SciDAG テンプレートへのバージョン管理された更新に変換します。これらのモジュールを組み合わせることで、AutoSci は研究プロジェクト全体で実行、記憶、進化できる永続的な研究環境になります。コード リポジトリは https://github.com/skyllwt/AutoSci で入手できます。
原文 (English)
AutoSci: A Memory-Centric Agentic System for the Full Scientific Research Lifecycle
Scientific research has traditionally been human-intensive, requiring researchers to coordinate literature, ideas, experiments, manuscripts, and review responses across long project cycles. The rise of LLM-based scientific agents creates an opportunity to automate this process. Such a system must support the full research lifecycle, maintain structured persistent memory across projects, and improve its own research procedures over time. However, existing systems either partially satisfy or fail to satisfy these requirements, leaving a gap for a unified automated scientific research system. As a result, we present AutoSci, a memory-centric agentic system for the full scientific research lifecycle. AutoSci is organized around four modules. SciMem provides schema-governed research memory, separating Long-Term Knowledge Memory for reusable scientific knowledge from Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews. SciFlow executes a five-stage lifecycle from literature understanding to rebuttal through a harness that controls state, context, verification, feedback, and orchestration. SciDAG augments difficult skills with DAG-shaped multi-agent operators and reusable stage-specific templates. SciEvolve converts feedback signals from users, experiments, reviews, and external environments into versioned updates to SciMem organization, SciFlow skills, and SciDAG templates. Together, these modules make AutoSci a persistent research environment that can execute, remember, and evolve across research projects. The code repository is available at https://github.com/skyllwt/AutoSci.
LinTree: 明示的に構造化された検索履歴による LLM 推論の改善
大規模言語モデル (LLM) は、部分的な解決策を探索および修正する中間トレースを生成することによって、推論の問題を解決することがよくあります。検索の観点から見ると、これらのトレースは線形化された検索ツリーとみなすことができ、モデルは部分的な解決策を拡張し、失敗するとそれを放棄し、後戻りして代替案を試行します。従来のヒューリスティックに基づく検索と比較すると、このようなポリシーには潜在的な利点があります。つまり、現在のローカル状態だけではなく、検索トレース全体を条件とします。まず、現在のローカル状態のみを観察する LLM ヒューリスティックを備えた最良優先探索とトレース条件付き推論ポリシーを比較することで、LLM がこの利点を活用しているかどうかをテストします。 Blocks World、grid Navigation、倉庫番という 3 つの制御された推論環境全体で、検索履歴への生のアクセスだけでは、ヒューリスティック検索を確実に上回るパフォーマンスを発揮するには十分ではないことがわかりました。次に、考えられる理由の 1 つを検討します。LLM 推論トレースでは、基礎となる検索ツリーが暗黙的にのみ表現され、モデルがバックトラックまたは分岐を切り替えるときに、どの以前の検索状態が再検討されているかがトレースによって明示的に識別されません。単純な親ポインターを追加して線形化ツリー (LinTree) 構造を明示的に表すと、暗黙的推論モデルや LLM ヒューリスティックガイド検索と比較して、タスクのパフォーマンスと検索効率の両方が向上することを示します。これらの結果は、検索履歴のツリー構造が明示されている場合に検索履歴が最も有用になり、LLM 推論においてより構造を意識した表現が動機付けられることを示唆しています。
原文 (English)
LinTree: Improving LLM Reasoning with Explicitly Structured Search Histories
Large language models (LLMs) often solve reasoning problems by generating intermediate traces that explore and revise partial solutions. From a search perspective, these traces can be viewed as linearized search trees, where the model extends a partial solution, abandons it when it fails, and backtracks to try alternatives. Compared with traditional heuristic-guided search, such a policy has a potential advantage: it conditions on the whole search trace rather than only on the current local state. We first test whether LLMs utilize this advantage by comparing trace-conditioned reasoning policies against best-first search equipped with an LLM heuristic that only observes the current local state. Across three controlled reasoning environments, Blocks World, grid Navigation, and Sokoban, we find that raw access to search history alone is not enough to reliably outperform heuristic search. We then study one possible reason: in LLM reasoning traces, the underlying search tree is only implicitly represented, and when the model backtracks or switches branches, the trace does not explicitly identify which earlier search state is being revisited. We show that adding simple parent pointers to explicitly represent the linearized tree (LinTree) structure improves both task performance and search efficiency relative to implicit reasoning models and LLM-heuristic-guided search. These results suggest that search history becomes most useful when its tree structure is made explicit, motivating more structure-aware representations for LLM reasoning.
レンズの選択: 文脈に依存した議論における戦略的視点の活性化
多くの場合、同じ議論を異なる外部レジームの下で評価する必要があります。政権に対して影響力を持つエージェントは、標準的な形式主義では直接把握できない戦略的手段を持っています。我々は、コンテキスト依存議論フレームワーク (CDAF) を導入します。これは、敗北関数がコンテキストごとにどの攻撃が成功するかを決定するという Dung の理論の拡張です。パースペクティブラベル付き特殊化は、関連性セット $\rho$ と優先度 $\pi$ から敗北関数を導出します。関連性セットはエージェントのアクション スペースです。小さな実際の例では、エージェントのターゲット引数は、すべての完全関連性の単射優先度の下では拒否されますが、VAF オーディエンスがミラーできないものの 1 つである部分的なアクティブ化の下では受け入れられます。対応する意思決定問題である ACTIVATION-MANIPULATION を定義し、ベースラインの複雑さの限界を記録します。狭い境界と複数エージェントのバリアントは未解決のままです。
原文 (English)
Choosing the Lens: Strategic Perspective Activation in Context-Dependent Argumentation
The same arguments often need to be evaluated under different external regimes. An agent with influence over the regime has a strategic lever that standard formalisms do not directly capture. We introduce context-dependent argumentation frameworks (CDAFs), an extension of Dung's theory in which a defeat function determines, per context, which attacks succeed. A perspective-labeled specialisation derives the defeat function from a relevance set $\rho$ and a priority $\pi$. The relevance set is the agent's action space. In a small worked example, the agent's target argument is rejected under every full-relevance injective priority, yet accepted under partial activations, one of which no VAF audience can mirror. We define the corresponding decision problem, ACTIVATION-MANIPULATION, and record baseline complexity bounds. Tight bounds and multi-agent variants are left open.
TRINE: マルチモーダル AI 向けのトークン認識型、ランタイム適応型 FPGA 推論エンジン
ViT、CNN、GNN、およびトランスフォーマー NLP を混在させるマルチモーダル スタックは、コンピューティング/メモリ パターンが分岐し、ハード リアルタイム ターゲットに余裕がほとんどないため、組み込みプラットフォームに負担をかけます。 TRINE は、再構成せずにエンドツーエンドのマルチモーダル推論を実行するシングル ビットストリーム FPGA アクセラレータおよびコンパイラです。レイヤーは DDMM/SDDMM/SpMM として統合され、実行時に重み/出力定常シストリック、1xCS SIMD、および共有 PE アレイ上のルータブル加算器ツリー (RADT) の間で切り替えるモード切り替え可能なエンジンにマッピングされます。幅が一致した 2 段階の Top-K ユニットにより、インストリーム トークン プルーニングが可能になり、依存関係を意識したレイヤー オフロード (DALO) により、再構成可能な処理ユニット間で独立したカーネルがオーバーラップされ、使用率が維持されます。 Alveo U50 および ZCU104 で評価すると、TRINE は 20 ~ 21 W で RTX 4090 と比較して最大 22.57 倍、Jetson Orin Nano と比較して 6.86 倍レイテンシーを削減します。トークン プルーニングだけでも、ViT が多いパイプラインでは最大 7.8 倍の収益が得られ、DALO は最大 79% のスループット向上に貢献します。 int8 量子化では、代表的なタスク全体で精度の低下が 2.5% 未満にとどまり、統合されたビジョン、言語、グラフのワークロードに対して最先端のレイテンシーとエネルギー効率を 1 つのビットストリームで実現します。
原文 (English)
TRINE: A Token-Aware, Runtime-Adaptive FPGA Inference Engine for Multimodal AI
Multimodal stacks that mix ViTs, CNNs, GNNs, and transformer NLP strain embedded platforms because their compute/memory patterns diverge and hard real-time targets leave little slack. TRINE is a single-bitstream FPGA accelerator and compiler that executes end-to-end multimodal inference without reconfiguration. Layers are unified as DDMM/SDDMM/SpMM and mapped to a mode-switchable engine that toggles at runtime among weight/output-stationary systolic, 1xCS SIMD, and a routable adder tree (RADT) on a shared PE array. A width-matched, two-stage top-k unit enables in-stream token pruning, while dependency-aware layer offloading (DALO) overlaps independent kernels across reconfigurable processing units to sustain utilization. Evaluated on Alveo U50 and ZCU104, TRINE reduces latency by up to 22.57x vs. RTX 4090 and 6.86x vs. Jetson Orin Nano at 20-21 W; token pruning alone yields up to 7.8x on ViT-heavy pipelines, and DALO contributes up to 79% throughput improvement. With int8 quantization, accuracy drops remain <2.5% across representative tasks, delivering state-of-the-art latency and energy efficiency for unified vision, language, and graph workloads-in one bitstream.
LLM 報酬設計が失敗する場合: スパース構造 RL の診断主導の改良
セマンティックな報酬関数インターフェイスを備えたスパースで構造化された強化学習タスクの場合、LLM で生成された報酬形成は、ワンショット生成よりもデバッグとして適切に構成されます。私たちは、コア評価として MiniGrid を使用し、境界ストレス テストとして MuJoCo を使用して、PPO で訓練されたエージェントを研究します。私たちの監査では、2 つの主要なワンショット障害モード (報酬のフラッディングとセマンティック/API の誤解) に加えて、まれに弱いシェーピングのケースが見つかりました。我々は、トレーニング診断と故障モード分類ガイドが報酬関数の修正をターゲットとする、診断主導型の反復改良を提案します。改良により、DoorKey-8x8 は 2.3% から 97.6% に、KeyCorridor は 31.2% から 86.7% に向上し、シード間の分散が高くなります。コントロールは、これらの利益が再試行や追加のトレーニングによるものではないことを示しています。メトリクスのみの再プロンプトでは大幅な低下が見られますが、静的語彙コントロールではギャップの多くが回復します (87.6%、70.7%)。これは、分類プロンプトが主要なメカニズムであり、動的ラベルが部分的に分離された増分証拠のみを提供することを示しています。予算に合わせた比較とベストオブ 3 の比較により、絞り込みと選択およびトレーニング時間の効果が分離されます。コンポーネント除去テスト、感度分析、および作成者ラベルに対する監査は、キャリブレーション限界を明らかにしながら、デバッグ解釈のための収束した証拠を提供します。連続制御の結果は境界を示しています。成功ベースの診断は、高密度の報酬の移動では誤作動する可能性があり、リターントレンドのフィードバックは、ロバストなゲインなしで 1 つの誤検知メカニズムを除去します。ローコールプロトコルは、人口ベースの報酬検索とのコストの対比であり、ベンチマークの比較ではありません。 4 つの交差分散設計環境では、LLM 報酬関数の分散が優勢であるもののブートストラップ間隔が広い場合、点推定値はより大きなゲインを示唆します。この方法は、PPO の下で信頼性の高いインターフェイスを備えたまばらな構造化タスクに限定されます。 event_text のようなフィールドは、役立つ場合もあれば、害を及ぼす場合もあれば、中立的な場合もあります。
原文 (English)
When LLM Reward Design Fails: Diagnostic-Driven Refinement for Sparse Structured RL
For sparse, structured reinforcement-learning tasks with semantic reward-function interfaces, LLM-generated reward shaping is better framed as debugging than one-shot generation. We study PPO-trained agents using MiniGrid as core evaluation and MuJoCo as boundary stress test. Our audit finds two dominant one-shot failure modes -- reward flooding and semantic/API misunderstanding -- plus a rarer weak-shaping case. We propose diagnostic-driven iterative refinement, where training diagnostics and a failure-mode taxonomy guide targeted reward-function revision. Refinement improves DoorKey-8x8 from 2.3% to 97.6% and KeyCorridor from 31.2% to 86.7% with high seed-to-seed variance. Controls show these gains are not from retrying or extra training: metrics-only re-prompting yields large drops, while a static-vocabulary control recovers much of the gap (87.6%; 70.7%), showing the taxonomy prompt is a major mechanism and dynamic labels provide only partially isolated incremental evidence. Budget-matched and Best-of-3 comparisons separate refinement from selection and training-time effects. Component-removal tests, sensitivity analyses, and an audit against author labels provide converging evidence for the debugging interpretation while revealing calibration limits. Continuous-control results show the boundary: success-based diagnostics can misfire in dense-reward locomotion, and return-trend feedback removes one false-positive mechanism without robust gains. The low-call protocol is a cost contrast with population-based reward search, not a benchmark comparison. In four crossed-variance-design environments, point estimates suggest larger gains when LLM reward-function variance dominates but bootstrap intervals are wide. The method is bounded to sparse structured tasks with reliable interfaces under PPO; fields like event_text may help, hurt, or be neutral.
低ランク進化戦略によるスパイキング ニューラル ネットワークの勾配なしトレーニング
スパイキング ニューラル ネットワーク (SNN) は、ニューロモーフィック ハードウェアで魅力的なエネルギー効率を提供しますが、離散スパイクしきい値が微分不可能であるため、トレーニングは依然として困難です。サロゲート勾配法は導関数を近似することでこれを回避しますが、オンチップ学習と互換性のない逆伝播インフラストラクチャが必要になります。 Evolution Strategies (\es) は自然な勾配のない代替手段ですが、その計算コストはパラメーターの数に応じて変化するため、大きな重み行列には非現実的です。世代ごとのメモリを $\mathcal{O}(mn)$ から $\mathcal{O}(r(m{+}n))$ に削減する ES 摂動の低ランク因数分解である EGGROLL を使用して SNN をトレーニングする方法を紹介します。 EGGROLL と N-MNIST 上の Leaky Integrate-and-Fire SNN を組み合わせることで、勾配なしトレーニングが 79.21% のテスト精度を達成しながら、フルランク ES と比較して世代あたりの実時間を 2.23$\times$ 削減できることを実証します。私たちの結果は、EGGROLL が SNN トレーニングに有効であり、精度と速度の明確なトレードオフがあり、サロゲート勾配なしのニューロモーフィック ハードウェアでのトレーニングと互換性があることを示しています。
原文 (English)
Gradient-Free Training of Spiking Neural Networks via Low-Rank Evolution Strategies
Spiking Neural Networks (SNNs) offer compelling energy efficiency on neuromorphic hardware, yet their training remains challenging because the discrete spike threshold is non-differentiable. Surrogate-gradient methods sidestep this by approximating the derivative, but they impose backpropagation infrastructure that is incompatible with on-chip learning. Evolution Strategies (\es) are a natural gradient-free alternative, yet their computational cost scales with the number of parameters, making them impractical for large weight matrices. We present a method for training SNNs using EGGROLL, a low-rank factorisation of ES perturbations that reduces per-generation memory from $\mathcal{O}(mn)$ to $\mathcal{O}(r(m{+}n))$. Combining EGGROLL with a Leaky Integrate-and-Fire SNN on N-MNIST, we demonstrate that gradient-free training achieves 79.21% test accuracy while reducing per-generation wall-clock time by 2.23$\times$ relative to full-rank ES. Our results demonstrate EGGROLL is viable for SNN training, with a clear accuracy-speed tradeoff, compatible with training on neuromorphic hardware without surrogate gradients.
XOResNet: 排他的 OR メタ残差によりディープ スパイキング ニューラル ネットワーク学習が促進される
スパイキング ニューラル ネットワーク (SNN) は、ディープ モデルにおける優れた学習および表現能力を実証する可能性を秘めています。深層学習における ResNet の多大な成功を考慮すると、当然のことながら、残差学習を使用して深層 SNN をトレーニングすることになります。ただし、ディープ SNN を構築するための既存の残差構造には、冗長学習だけでなく、スパイクの冗長性や情報損失という課題が依然として存在します。本研究では、まず、アイデンティティ マッピングにおける相対的なスパイクの冗長性と非アイデンティティ マッピングにおける情報損失の問題に対処することを目的としています。この目的を達成するために、残差構造内の 2 つの分岐からの出力スパイク/電流をマージするための OR-ADD (OA) ショートカット接続を提案します。さらに、残差構造のバックボーン ブランチでの冗長な学習を軽減するために、XOR メタ残差の概念を導入します。つまり、バックボーン ブランチの排他的論理和 (XOR) 演算を使用して事前学習残差を選択します。最後に、OA ショートカットと XOR メタ残差を統合することで、XOR 残差ブロックを考案し、このブロックに基づいてさまざまな深さの XOResNet をさらに構築します。 Fashion-MNIST、CIFAR-10、CIFAR-100、miniImageNet の 4 つのデータセットに対する広範な実験により、提案された XOResNet が勾配降下法によって最適化された既存の最先端の深層 SNN よりも優れていることが示されました。これらの結果は、SNN における残差学習の基本的な制限を克服する際の OA ショートカットと XOR メタ残差コンポーネントの有効性を検証し、高性能ニューロモーフィック システムを構築するための新しいアーキテクチャ上の洞察を提供します。
原文 (English)
XOResNet: Exclusive-OR Meta-Residuals Facilitate Deep Spiking Neural Networks Learning
Spiking neural networks (SNNs) hold promise for demonstrating superior learning and representation capabilities in deep models. Given the tremendous success of ResNet in deep learning, it would naturally follow to train deep SNNs with residual learning. However, existing residual structures for constructing deep SNNs still present challenges of spike redundancy or information loss, as well as redundant learning. In the present study, we first aim to address issues of relative spike redundancy in identity mapping and information loss in non-identity mapping. To this end, we propose an OR-ADD (OA) shortcut connection to merge output spikes/currents from two branches in the residual structure. Furthermore, to mitigate redundant learning in the backbone branch of the residual structure, we introduce the concept of XOR meta-residuals, i.e., selecting pre-learning residuals using the Exclusive-OR (XOR) operation for the backbone branch. Finally, by integrating the OA shortcut and XOR meta-residuals, we devise the XOR residual block and further construct XOResNet with varying depths based on this block. Extensive experiments on four datasets, Fashion-MNIST, CIFAR-10, CIFAR-100, and miniImageNet, show that the proposed XOResNet outperforms existing state-of-the-art deep SNNs optimized via gradient descent. These results validate the effectiveness of our OA shortcut and XOR meta-residual components in overcoming fundamental limitations of residual learning in SNNs, providing new architectural insights for building high-performance neuromorphic systems.
非構造化データを使用したレジームシフト検出の強化: 国債市場に関する研究
金融市場におけるレジームシフトは、資産価格とマクロ変数の共同ダイナミクスを再編成し、単一レジームの調整を打ち破ります。それにもかかわらず、データ信号にはノイズが多く多重共線性が高く、同時にそれらを通知するテキストは構造化されていないため、これらを確実に検出することは困難です。標準的なレジームシフト検出方法は、構造化された時系列データのみに依存し、政策コミュニケーションを無視します。たとえこれらのテキストが観測価格に現実化する前にシフトを示唆する場合が多いにもかかわらずです。私たちは、中央銀行通信を介した大規模言語モデル (LLM) 推論と多変量金融時系列の統計的検証を組み合わせた、テキスト強化型レジームシフト検出パイプラインを提案します。このフレームワークは検出器に依存しません。テキストによって提案された候補は、ベクトル自己回帰 (VAR) のブートストラップ尤度比テストを使用して検証されます。一方、任意のレジーム検出器からのデータ駆動型の候補は、寛大な LLM テキスト チェックを通じて承認されます。 4つの交換可能なデータ駆動型検出器を使用して、14変数の米国財務省およびマクロ経済パネルと組み合わせた2010年から2024年のFOMC議事録の枠組みを評価します。提案されたパイプラインは、金融政策レジームシフトの検証済みアンカーリストに対して F1 = 0.82 を達成し、同日のモーダル検出レイテンシーと、純粋なデータ駆動ベースラインよりも一貫して優れたパフォーマンスを実現します。この結果は、非構造化政策テキストと統計的な構造破壊検出を組み合わせることで、金融市場におけるレジームシフト識別の堅牢性と解釈可能性が向上することを示しています。
原文 (English)
Enhancing Regime Shift Detection Using Unstructured Data: A Study on the Treasury Market
Regime shifts in financial markets reorganise the joint dynamics of asset prices and macro variables, breaking any single-regime calibration. They are nonetheless difficult to detect reliably because the data signal is noisy and heavily multicollinear, while the contemporaneous text that announces them is unstructured. Standard regime shift detection methods rely solely on structured time-series data and ignore policy communications, even though these texts often signal shifts before they materialise in observed prices. We propose a text-enhanced regime shift detection pipeline that combines large language model (LLM) reasoning over central-bank communications with statistical validation on multivariate financial time series. The framework is detector-agnostic: text-proposed candidates are validated using a bootstrap likelihood-ratio test on a vector autoregression (VAR), while data-driven candidates from arbitrary regime detectors are ratified through a lenient LLM text check. We evaluate the framework on 2010-2024 FOMC minutes paired with a 14-variable U.S. Treasury and macroeconomic panel, using four interchangeable data-driven detectors. The proposed pipeline achieves F1 = 0.82 against a verified anchor list of monetary-policy regime shifts, with same-day modal detection latency and consistently stronger performance than pure data-driven baselines. The results demonstrate that combining unstructured policy text with statistical structural-break detection improves the robustness and interpretability of regime shift identification in financial markets.
スケーラブルな RF 送信機フィンガープリンティングのためのハミルトニアンにヒントを得たアテンション メカニズム
無線周波数 (RF) フィンガープリンティングは、ベースバンド I/Q 信号に存在するハードウェアに起因する不完全性を使用してワイヤレス トランスミッターを識別します。ただし、ディープ ラーニング モデルは、特に送信機の数が増加するにつれて、受信機とチャネルの分布が変化すると性能が低下することがよくあります。この研究では、学習済みスキュー対称ジェネレーターとサントルマー・ヴェレ・リープフロッグ積分ステップを使用して、各アテンション・ヘッド内でノルム保存値ダイナミクスを強制する、物理学に基づいたアテンション・アーキテクチャであるハミルトニアン・トランスフォーマーを提案しています。追加の位相インクリメント埋め込みにより、入力層での発振器ダイナミクスが明らかになります。すべての実験では、4 つのプロトコルの下で WiSig データセットからの等化されていない生の I/Q 信号を使用します。同日分類、クロスレシーバーの一般化、クロスデーの一般化、および最大 150 台のデバイスまでのトランスミッターのスケールアップにより、ハミルトニアン トランスフォーマーは、同日の条件下で 99.12% の精度を達成し、150 台のトランスミッターで 61.64% の精度を達成し、すべてのスケール ポイントにわたって CNN およびトランスフォーマーのベースラインを常に上回りました。これらの結果は、物理学に基づいた構造事前分布をアテンション メカニズムに埋め込むことが、生の無線信号の大規模な送信機識別に対する効果的なアプローチであることを示しています。
原文 (English)
Hamiltonian-Inspired Attention Mechanism for Scalable RF Transmitter Fingerprinting
Radio-frequency (RF) fingerprinting identifies wire-less transmitters using hardware-induced imperfections present in baseband I/Q signals. However, deep learning models often degrade under receiver and channel distribution shifts, particularly as transmitter populations grow. This work proposes the Hamiltonian Transformer, a physics-informed attention architecture that enforces norm preserving value dynamics within each attention head using a learned skew-symmetric generator and a St\"ormer-Verlet leapfrog integration step. An additional phase-increment embedding exposes oscillator dynamics at the input layer. All experiments use non-equalized raw I/Q signals from the WiSig dataset under four protocols: same-day classification, cross-receiver generalisation, cross-day generalisation, and transmitter scaling up to 150 devices. The Hamiltonian Transformer achieves 99.12% accuracy under same-day conditions and 61.64% at 150 transmitters, consistently outperforming CNN and Transformer baselines across all scale points. A controlled ablation study identifies norm-preservation in the value update as the primary inductive bias driving the scaling advantage, with the phase increment embedding providing the single largest per-component improvement. These results indicate that embedding physics-informed structural priors into attention mechanisms is an effective approach to large-scale transmitter identification on raw wireless signals.
精神的ダメージ: 検索拡張テキスト音楽生成に対するキャプション中毒攻撃
取得拡張テキスト音楽変換 (TTM) システムは、音楽キャプション データセットから取得したキャプションを使用して、指定されていないユーザー プロンプトを拡張します。この設計では、音楽知識データベースに対する整合性の依存性が導入されています。私たちは、攻撃者が少数の細工された音楽キャプションを挿入することによってデータベースを汚染し、ユーザー プロンプト、取得者、またはジェネレーターを変更することなく、プロンプトの拡張を偏らせ、生成をユーザーの意図した機能から遠ざける悪意のあるキャプションをシステムに取得させることができることを示します。音楽キャプションポイズニング攻撃を達成するために、私たちは、高レベルの取得アンカーを保持しながら、低レベルの音響記述子を注入して、攻撃者が選択したターゲット意図に向けてプロンプト拡張とダウンストリーム音楽生成を誘導する、二重層キャプションポイズニング戦略を提案します。 MusicCaps ナレッジ データベース、CLAP リトリーバー、および MusicGen パイプラインでは、汚染された世代は、元のユーザー クエリと比較的一致した状態を保ちながら、攻撃者のターゲットに大幅に近づきます。これらの結果は、検索拡張クリエイティブ AI システムの実質的な整合性リスクを明らかにします。私たちのデモは次の場所にあります: https://yizhu-wen.github.io/Mental-Damage/
原文 (English)
Mental Damage: Caption Poisoning Attacks on Retrieval-Augmented Text-to-Music Generation
Retrieval-augmented text-to-music (TTM) systems augment underspecified user prompts using captions retrieved from a music caption dataset. This design introduces an integrity dependency on the music knowledge database. We show that an attacker can poison the database by injecting a small number of crafted music captions, causing the system to retrieve malicious captions that bias prompt augmentation and steer generation away from the user's intended function, without modifying the user prompt, retriever, or generator. To achieve the music caption poisoning attack, we propose a dual-layer caption poisoning strategy that preserves high-level retrieval anchors while injecting low-level acoustic descriptors to steer prompt augmentation and downstream music generation toward an attacker-chosen target intent. In a MusicCaps knowledge database, CLAP retriever, and MusicGen pipeline, poisoned generations move substantially closer to the attacker's target, while remaining comparably aligned with the original user query. These results expose a practical integrity risk for retrieval-augmented creative AI systems. Our demo can be found at: https://yizhu-wen.github.io/Mental-Damage/
安全閾値をニューロンスパイキング閾値として再解釈する
代理安全対策 (SSM) は、自動運転の状況における交通リスクの評価に広く利用されています。しかし、SSM ベースの評価の大部分では、固定しきい値が採用されており、持続する境界線状態に対する人間の反応や、短期間の高リスクピークに対する反応を捉えることができません。本研究は、生物学にインスピレーションを得た SSM 閾値の再解釈を提案しています。これは、複数の SSM 入力がスパイキング ニューラル ネットワーク (SNN) に結合された、リーキー統合発射 (LIF) ニューロンのスパイク閾値としてモデル化されています。 SNN は、人間のブレーキの開始に合わせてスパイクを発するように訓練されています。トレーニング データは、CARLA/Unreal を備えた 3D-CoAutoSim プラットフォームと 6-DOF モーション プラットフォームを使用した、制御された車追従実験で記録され、誘発された重大なイベントが生成されました。結果は、学習されたスパイク アクティビティがシナリオ全体でブレーキ動作と定性的に一致しており、しきい値の交差だけでは一貫して説明できない反応を捕捉していることを示しています。さらに、参加者全体の分析により、学習された入力しきい値は比較的一貫したままである一方、学習された減衰係数は SSM の異なる時間感度をエンコードしていることが示されています。この研究の結果は、スパイクのダイナミクスが客観的な SSM と主観的な人間の安全認識の収束を促進するメカニズムとして機能する可能性があることを示しています。
原文 (English)
Reinterpreting Safety Thresholds as Neuron Spiking Thresholds
Surrogate Safety Measures (SSMs) are extensively utilised in the evaluation of traffic risk in automated driving contexts. However, the majority of SSM-based evaluations employ fixed thresholds that fail to capture the human response to sustained borderline conditions or the reaction to brief, high-risk peaks. The present work proposes a biologically inspired reinterpretation of SSM thresholds. This is modelled as spiking thresholds of leaky integrate-and-fire (LIF) neurons, with multiple SSM inputs combined into a spiking neural network (SNN). The SNN is trained to emit spikes that are aligned with human braking onsets. The training data was recorded in a controlled car-following experiment using the 3D-CoAutoSim platform with CARLA/Unreal and a 6-DOF motion platform, where induced critical events were generated. The results demonstrate that the learned spiking activity qualitatively aligns with braking behaviour across scenarios and captures reactions that are not consistently explained by threshold crossings alone. Analysis across participants further indicates that learned input thresholds remain relatively consistent, while learned decay factors encode different temporal sensitivities for the SSMs. The findings of this study indicate that spiking dynamics may serve as a mechanism to facilitate the convergence of objective SSMs with subjective human safety perception.
人工ニューラルネットワークにおける標準ニューロンモデルの更新
1950 年代の創設以来、人工ニューラル ネットワーク (ANN) は、このアナロジーにより脳機能のより良いエミュレーションが可能になることを期待して、当時神経科学で普及していたいわゆるポイント ニューロン モデルを使用し始めました。長年にわたり、神経科学の文献は、点ニューロン モデルは単純すぎて、多くの基本的な神経プロセスを適切に表現できないことを示してきました。ただし、ANN の標準ニューロン モデルは依然として同じままです。今回我々は、これを皮質細胞のごく最近のモデルに置き換え、パラメータの数を増やさずに、より現実的な神経ユニット要素を使用するだけで、結果として得られるANNが、表現力、堅牢性、学習速度の向上、必要な記憶量とトレーニングデータ量の削減など、多くの重要な利点を提供することを、理論分析と実験結果を通じて実証します。
原文 (English)
Updating the standard neuron model in artificial neural networks
From their inception in the 1950s, artificial neural networks (ANNs) started using the so-called point neuron model then prevalent in neuroscience, hoping that this analogy would allow for a better emulation of brain function. Over the years the neuroscience literature has shown that the point neuron model is too simplistic to properly represent many fundamental neural processes; however, the standard neuron model in ANNs still remains the same. Here we substitute it by a very recent model of cortical cells and demonstrate through theoretical analyses and experimental results how, simply by using a more realistic neural unit element without augmenting the number of parameters, the resulting ANNs offer a number of important advantages that include increases in expressivity, robustness and learning speed, and a reduction in memorization and the amount of training data needed.
貯留層の学習と収量のための進化的アルゴリズム
リカレント ニューラル ネットワークの一種であるリザーバー コンピューティングは、動的処理を学習済みの読み出し層から分離するため、時間学習に対する有望なアプローチです。ただし、従来の Echo State Network (ESN) では、多くの場合、良好なパフォーマンスを達成するために、アーキテクチャとハイパーパラメーターのタスク固有の調整が必要になります。この論文では、マルチ貯留層 ESN のトポロジとハイパーパラメータの両方を進化させるように設計されたフレームワークである EARLY (貯留層の学習と生成のための進化的アルゴリズム) を紹介します。 EARLY は、脳のモジュール構成にインスピレーションを得て、アーキテクチャをグラフベースのゲノムとしてエンコードし、交差、突然変異、選択を適用して効果的な構成を発見します。私たちの目標は、汎用アーキテクチャと一般化を引き起こすタスクの両方を作成することです。このメソッドは、CogScale データセットからの時間学習タスクで評価されます。結果は、進化したアーキテクチャがいくつかのタスクでランダム検索で得られたアーキテクチャよりも優れており、タスクの難易度に応じて構造的な違いを示していることを示しています。単純なタスクは軽量のアーキテクチャを生み出し、より複雑なタスクはより充実したモジュール型組織を優先します。これらの発見は、進化的探索が、より広範囲の時間的問題に対して再利用可能な貯留構造を特定するのに役立つ可能性があることを示唆しています。進化したアーキテクチャは、新しい環境に適応する能力を評価するために、状況を超えた学習データセットでさらに評価されます。
原文 (English)
Evolutionary Algorithm for Reservoir Learning and Yielding
Reservoir computing, a type of recurrent neural network, is a promising approach for temporal learning as it separates dynamic processing from the trained readout layer. However, classical Echo State Networks (ESNs) often require task-specific tuning of their architecture and hyperparameters to achieve good performance. This paper introduces EARLY (Evolutionary Algorithm for Reservoir Learning and Yielding), a framework designed to evolve both the topology and hyperparameters of multi-reservoir ESNs. Inspired by the modular organisation of the brain, EARLY encodes architectures as graph-based genomes and applies crossover, mutation, and selection to discover effective configurations. Our goal is to create both generic architectures and tasks inducing generalization. The method is evaluated on temporal learning tasks from the CogScale dataset. Results show that evolved architectures outperform those obtained with random search on several tasks and exhibit structural differences depending on task difficulty: simpler tasks yield lightweight architectures, while more complex tasks favour richer modular organisations. These findings suggest that evolutionary search can help identify reusable reservoir structures for a broader range of temporal problems. The evolved architectures are further evaluated on a cross-situational learning dataset to assess their ability to adapt to new environments.
マルチグリッド階層学習による工学スケールの 3 次元航空機の全フィールド予測
航空宇宙設計には忠実度の高い数値流体力学が不可欠ですが、実用的な 3 次元航空機の工学規模のシミュレーションは依然として計算コストが高くなります。学習ベースの流れ場の初期化は、初期解と収束解の間の数値的距離を縮めることで効率を向上させることができますが、既存の深層学習アプローチは、マルチスケールの地域的異質性を持つ大規模な 3 次元航空機の流れに拡張することが依然として困難です。したがって、先行研究のほとんどは、2 次元の問題、表面量、積分空気力学係数、またはグリッド解像度が制限された単純化された 3 次元のケースに焦点を当てています。ここでは、高忠実度の数値精度を維持しながらエンジニアリング スケールの航空機の流れシミュレーションを高速化するためのマルチグリッド階層学習フレームワークである MHLF を提案します。 MHLF は、トポロジー的に一貫した幾何学的マルチグリッド表現と、予測とその後の CFD 補正の両方で地域的な流れの不均一性を捉える階層的戦略を組み合わせます。マッハ 0.15 ~ 6.0 に及び、亜音速、遷音速、超音速領域をカバーする 3 つの工学規模の航空機ケースにわたって、MHLF は流れ場の精度を犠牲にすることなく収束を加速し、従来の初期化と比べて 3 ~ 8 倍の効率改善を達成しました。これらの結果は、CFD ドメイン内の大型 3 次元航空機の実用的な全流れ場予測を実証し、高忠実度の航空機流れシミュレーションのデータ駆動型加速の基盤を提供します。
原文 (English)
Full-field prediction for engineering-scale three-dimensional aircraft with multigrid-hierarchical learning
High-fidelity computational fluid dynamics is essential for aerospace design, but engineering-scale simulations of practical three-dimensional aircraft remain computationally expensive. Learning-based flow-field initialization can improve efficiency by reducing the numerical distance between the initial and converged solutions, yet existing deep learning approaches remain difficult to scale to large three-dimensional aircraft flows with multiscale regional heterogeneity. Most prior studies therefore focus on two-dimensional problems, surface quantities, integral aerodynamic coefficients, or simplified three-dimensional cases with limited grid resolution.Here we propose MHLF, a multigrid-hierarchical learning framework for accelerating engineering-scale aircraft flow simulations while preserving high-fidelity numerical accuracy. MHLF combines a topologically consistent geometric multigrid representation with a hierarchical strategy that captures regional flow heterogeneity during both prediction and subsequent CFD correction. Across three engineering-scale aircraft cases spanning Mach 0.15 to 6.0 and covering subsonic, transonic and supersonic regimes, MHLF accelerates convergence without sacrificing flow-field accuracy, achieving a 3 to 8 times efficiency improvement over conventional initialization. These results demonstrate practical full-flow-field prediction for large three-dimensional aircraft within the CFD domain and provide a foundation for data-driven acceleration of high-fidelity aircraft flow simulation.
Unicorn: ユニバーサル相関モデリングによる高次元時系列予測のスケーリング
最新の時系列アーキテクチャは根本的なトレードオフに直面しています。チャネル非依存モデルは、データ量の増加に合わせて適切にスケールしますが、重大なチャネル間の依存関係を無視します。一方、チャネル依存モデルは表現力は豊かですが、依然として「次元境界」があり、異種データセット間で一般化するのに苦労しています。このギャップを埋めるために、高次元時系列でのスケーラブルなマルチデータセット事前トレーニング用のフレームワークである Unicorn (Universal Correlation Network) を紹介します。 Unicorn の中核には、相関モデリングを特定のチャネル ID から切り離す潜在的なプロトタイプ コードブックがあります。異種チャネルを共有潜在空間に投影することで、UniCorN は、多様な次元とセマンティクスを持つドメイン間で転送される、アイデンティティに依存しない再利用可能な対話パターンを学習します。広範な実験により、Unicorn は、特に数ショット転送シナリオにおいて、最先端の予測アーキテクチャを大幅に上回り、多変量時系列基盤モデルへのスケーラブルなパスを提供することが示されています。
原文 (English)
Unicorn: Scaling High-Dimensional Time Series Forecasting via Universal Correlation Modeling
Modern time series architectures face a fundamental trade-off: channel-independent models scale well with increasing data volume but ignore critical inter-channel dependencies, while channel-dependent models are expressive but remain ``dimension-bounded'', struggling to generalize across heterogeneous datasets.To bridge this gap, we introduce Unicorn (Universal Correlation Network), a framework for scalable, multi-dataset pretraining on high-dimensional time series. At the core of Unicorn is a latent prototype codebook that decouples correlation modeling from specific channel identities. By projecting heterogeneous channels into a shared latent space, UniCorN learns identity-agnostic, reusable interaction patterns that transfer across domains with diverse dimensionalities and semantics. Extensive experiments show that Unicorn significantly outperforms state-of-the-art forecasting architectures, particularly in few-shot transfer scenarios, offering a scalable path toward multivariate time series foundation models.
LLM が一貫して間違っていることを学習するとき: 合成欺瞞の線形表現に関するマルチモデル研究
モデルが意図的に偽の出力を生成しながら正確な内部表現を維持する欺瞞的な調整は、依然として AI の安全性における中心的な課題です。戦略的欺瞞が長期的な主な懸念事項である一方で、不正解に対する直接最適化によって引き起こされる合成的不正は、学習された欺瞞の表現基盤を研究するための制御されたテストベッドを提供します。 5 つのトランスフォーマー モデル (Pythia-1.4B、Gemma-2-2B/9B、Qwen2.5-7B、Llama-3.1-8B) の正直なバリアントと欺瞞的なバリアントが、同じ質問分布に対して LoRA を使用して微調整されるマルチモデル パラダイムを導入します。平均プールされた隠れ状態で訓練された線形プローブは、4 つのアーキテクチャのレイヤー 1 ~ 3 でほぼ完璧な AUC (0.99 以上) で合成不正を検出しますが、Pythia-1.4B はピークの 0.705 に達します。ロジスティック回帰プローブは一貫して MLP プローブと一致するかそれを上回っており、線形表現仮説を裏付けています。 TruthfulQA でトレーニングされたプローブは、保留された MMLU 被験者に対してほぼゼロの損失 (デルタ AUC 約 0) で一般化します。後期層の表現はガウス ノイズに対する強い堅牢性を示し、Gemma-2 モデルは優れた安定性を示します。フィッシャー判別比、有効ランク、重心幾何学、方向安定性、クロスドメインアライメント、およびキャリブレーション (ECE) の機構分析により、Pythia/Llama/Qwen における表現崩壊と Gemma-2 における高次元保存という 2 つの状況が明らかになります。すべてのモデルにわたって、不正の方向はより深い層に徐々に統合され、層 1 ~ 4 で最適なキャリブレーション (Pythia を除く ECE が 0.01 未満) が達成されます。これらの結果は、堅牢でドメイン不変の不正表現が、適度な教師付き微調整によって急速に定着する可能性があり、アクティベーションベースのモニタリングに影響を与えることを示しています。
原文 (English)
When LLMs Learn to Be Consistently Wrong: A Multi-Model Study of Linear Representations of Synthetic Deception
Deceptive alignment, in which models maintain accurate internal representations while deliberately producing false outputs, remains a central challenge in AI safety. While strategic deception is the primary long-term concern, synthetic dishonesty - induced via direct optimization on incorrect answers - provides a controlled testbed for studying the representational basis of learned deception. We introduce a multi-model paradigm in which honest and deceptive variants of five transformer models (Pythia-1.4B, Gemma-2-2B/9B, Qwen2.5-7B, Llama-3.1-8B) are fine-tuned using LoRA on the same question distribution. Linear probes trained on mean-pooled hidden states detect synthetic dishonesty with near-perfect AUC (greater than or equal to 0.99) as early as layers 1-3 in four architectures, while Pythia-1.4B reaches a peak of 0.705. Logistic regression probes consistently match or outperform MLP probes, supporting the Linear Representation Hypothesis. Probes trained on TruthfulQA generalize with near-zero loss (Delta AUC approx. 0) to held-out MMLU subjects. Late-layer representations show strong robustness to Gaussian noise, with Gemma-2 models exhibiting exceptional stability. Mechanistic analysis of Fisher Discriminant Ratio, effective rank, centroid geometry, directional stability, cross-domain alignment, and calibration (ECE) reveals two regimes: representational collapse in Pythia/Llama/Qwen versus high-dimensional preservation in Gemma-2. Across all models, the dishonesty direction consolidates progressively in deeper layers, with optimal calibration (ECE less than 0.01 except Pythia) achievable in layers 1-4. These results demonstrate that robust, domain-invariant dishonesty representations can be rapidly entrenched via modest supervised fine-tuning, with implications for activation-based monitoring.
構造化されたインタラクションにより、現実世界のマルチロボット システムにおけるモデルのスケーリングを超えた分散調整が向上します
個々のロボットの機能を拡張することは一般的ですが、コストがかかります。ここでは、現実世界のマルチロボット調整におけるシステムレベルの設計の問題を調査します。ハードウェア予算が一致している場合、ロボット間の通信を再構築すると、オンボードモデルのサイズを増やすよりも大きな利益が得られるでしょうか? 10 台の物理ロボット (条件ごとに 5 回の実行、合計 60 回の実行) を使用した代表的なトランスポートおよびマッピング タスクを使用すると、完全接続からモジュール型階層インタラクションに切り替えると正規化パフォーマンスが 47 ポイント (0 ~ 100) 向上するのに対し、ニューラル ネットワークの隠れサイズを 2 倍にしても最大 9 ポイント向上することがわかりました。ネストされた混合効果モデルの比較では、スケールよりもトポロジに対するモデルの適合性が大幅に向上していることがわかります。このパターンは、独立した SMAC レプリケーションで確認されます。異種ベンチマーク再分析は、一次証拠ではなく二次的なサポート一貫性チェックを提供します。 1024 隠れユニットを超えるパフォーマンスの飽和は、ハードウェア上で直接ではなく、シミュレーションで調整された外挿で観察されます。これらの結果は、より広範な定量的一般化がまだ確立されていない一方で、テストされたシステムとタスク設定内で相互作用構造が支配的な役割を果たす可能性があることを示しています。
原文 (English)
Structured interactions improve distributed coordination beyond model scaling in a real-world multi-robot system
Scaling individual robot capabilities is common but costly. Here we investigate a system-level design question in real-world multi-robot coordination: given matched hardware budgets, does restructuring communication among robots yield larger gains than increasing onboard model size? Using a representative transport-and-mapping task with 10 physical robots (5 runs per condition, 60 runs total), we find that switching from fully connected to modular hierarchical interactions improves normalised performance by 47 points (0--100), whereas doubling neural network hidden size yields at most 9 points. Nested mixed-effects model comparisons show a substantially larger improvement in model fit for topology than for scale. The pattern is confirmed in independent SMAC replications; heterogeneous benchmark reanalyses provide secondary supporting consistency checks rather than primary evidence. Performance saturation beyond 1024 hidden units is observed in simulation-calibrated extrapolation, not directly on hardware. These results indicate that interaction structure can play a dominant role within the tested system and task setting, while broader quantitative generalisation remains to be established.
ディープ ニューラル ネットワークを使用しない LLM: 新しいアーキテクチャ、利点、およびケーススタディ
この記事の目的は、LLM のコンテキストでディープ ニューラル ネットワークの代替案を検証することです。ごく最近、標準的な DNN の代替として、説明可能性と精度が向上した RBF ネットワークと呼ばれるモデルに中国の研究者が大きな関心を寄せています。独自に発見した私の新しいモデルは、まったく同じ機械に基づいていることが判明しました。ただし、大きな工夫があります。DNN は、1 回の反復で閉じた形式の損失関数の大域的最適値を見つけるため、DNN を必要とせず、退屈なトレーニング ステップを排除します。ここでは、ケーススタディと同様の手法との比較を交えて、私のテクノロジーの概要を説明します。
原文 (English)
LLMs Without Deep Neural Networks: New Architecture, Benefits and Case Study
The purpose of this article is to provide validation to my deep neural network alternative in the context of LLMs. Very recently, there has been a significant interest by Chinese researchers in a model called RBF network, as a substitute to standard DNNs, with increased explainability and higher accuracy. It turns out that my new model, discovered independently, is based on the exact same machinery. But with a major twist: it does not need DNN as it finds the global optimum of the loss function in closed form, in one iteration, thus eliminating the tedious training step. Here I provide a high-level overview of my technology, with case study and comparison to similar methods.
脳障害識別のためのウェーブレットベースの画像変換とスペクトルフローマッチングによる機能的 MRI 時系列生成
機能的磁気共鳴画像法 (fMRI) は、血中酸素濃度依存性 (BOLD) 信号を経時的に測定することにより、動的脳活動への非侵襲的アクセスを提供します。ただし、fMRI 取得はリソースを大量に消費する性質があるため、データ駆動型の脳分析モデルに必要な高忠実度のサンプルの入手可能性が制限されます。最新の生成モデルは fMRI データを合成できますが、多くの場合、生の BOLD 信号の固有の非定常性、複雑な時空間ダイナミクス、生理学的変動を再現するのが困難です。これらの課題に対処するために、BOLD 信号のデュアル周波数表現とスペクトル フロー マッチングをカスケード接続する新しい fMRI 生成フレームワークであるデュアル スペクトル フロー マッチング (DSFM) を提案します。具体的には、私たちのフレームワークは、まず離散ウェーブレット変換 (DWT) を介して BOLD 信号をウェーブレット分解マップに変換し、グローバル化された過渡変動とマルチスケール変動をキャプチャし、脳の領域と時間を横断して離散コサイン変換 (DCT) 空間に投影して、低周波支配的な BOLD 係数の局所的なエネルギー圧縮を利用します。続いて、スペクトル フロー マッチング モデルがトレーニングされて、クラス条件付きコサイン周波数表現が生成されます。生成されたサンプルは、逆 DCT および逆 DWT 演算を通じて再構築され、生理学的に妥当な時間領域 BOLD 信号を復元します。この二重変換アプローチは、構造化された周波数事前分布を課し、重要な生理学的脳のダイナミクスを保存します。最終的に、我々は改善された下流の fMRI ベースの脳ネットワーク分類を通じて、アプローチの有効性を実証します。コードは https://github.com/htew0001/DSFM.git で入手できます。
原文 (English)
Functional MRI Time Series Generation via Wavelet-Based Image Transform and Spectral Flow Matching for Brain Disorder Identification
Functional Magnetic Resonance Imaging (fMRI) provides non-invasive access to dynamic brain activity by measuring blood oxygen level-dependent (BOLD) signals over time. However, the resource-intensive nature of fMRI acquisition limits the availability of high-fidelity samples required for data-driven brain analysis models. While modern generative models can synthesize fMRI data, they often remain challenging in replicating their inherent non-stationarity, intricate spatiotemporal dynamics, and physiological variations of raw BOLD signals. To address these challenges, we propose Dual-Spectral Flow Matching (DSFM), a novel fMRI generative framework that cascades dual frequency representation of BOLD signals with spectral flow matching. Specifically, our framework first converts BOLD signals into a wavelet decomposition map via a discrete wavelet transform (DWT) to capture globalized transient and multi-scale variations, and projects into the discrete cosine transform (DCT) space across brain regions and time to exploit localized energy compaction of low-frequency dominant BOLD coefficients. Subsequently, a spectral flow matching model is trained to generate class-conditioned cosine-frequency representation. The generated samples are reconstructed through inverse DCT and inverse DWT operations to recover physiologically plausible time-domain BOLD signals. This dual-transform approach imposes structured frequency priors and preserves key physiological brain dynamics. Ultimately, we demonstrate the efficacy of our approach through improved downstream fMRI-based brain network classification. The code is available at https://github.com/htew0001/DSFM.git .
機械における社会的推論: 大規模言語モデルの議論における集団的真実探求ダイナミクスの調査
人間の推論は、孤立した個人の認知ではなく、集団的な敵対的な議論を通じて社会的に機能すると長い間理論化されてきました。これは推論の議論理論 (ATR) として知られる枠組みです。 ATRは、真実探求の主な手段として個人の「知識主義的推論者」に依存するのではなく、真実を社会認識論の新たな特性、つまり議論の敵対的な圧力の下で洗練された不完全な個人の推論の産物として再概念化します。この集合知の分散型手法は、人類をこれまで以上に認識論的な高みへと導き、すべての民主主義システムの基本原則を支えてきました。この論文は、大規模言語モデル (LLM) のマルチエージェント ディベート (MAD) を通じて ATR を初めてシミュレートすることで、新境地を開拓しました。厳密な実証分析により、認識論的に多様なモデルのセットを正しく設計すると、個々のディベート参加者が単独でのパフォーマンスが限られている場合でも、LLM-MAD がアンケートベースのタスクでの真実探求パフォーマンスを大幅に向上させることができることを実証しました。さらに、我々は、このパフォーマンスの向上が ATR の中心原理に機構的に基づいているという強力な経験的証拠を提示し、集団的推論が生物学や進化の奇抜なものではなく、個人主義的推論よりも普遍的に有利である可能性があることを示唆しています。最後に、議論のダイナミクスの分析に基づいて、現在の静的ベンチマーク アプローチではサポートできない方法でモデルを比較するために、LLM-MAD を活用してモデルの固有の特性 (幻覚傾向など) を測定する新しいベンチマーク方法論を提案します。
原文 (English)
Social Reasoning in Machines: Investigating Collective Truth-Seeking Dynamics in Large Language Model Debate
Human reasoning has long been theorised to operate socially, not through isolated individual cognition, but through collective adversarial discourse, a framework known as the Argumentative Theory of Reasoning (ATR). Rather than relying on individual "intellectualist reasoners" as the primary vehicle for truth-seeking, ATR reconceptualises truth as an emergent property of social epistemology: the product of imperfect individual reasoning refined under the adversarial pressure of debate. This distributed method of collective intelligence has guided humanity to ever-greater epistemic heights and underpins the foundational principles of all democratic systems. This thesis breaks new ground by, for the first time, simulating ATR through the multi-agent debate (MAD) of large language models (LLMs). With rigorous empirical analysis, we demonstrate that, when correctly engineering an epistemically diverse set of models, LLM-MAD can significantly improve truth-seeking performance on questionnaire-based tasks, even when individual debate participants exhibit limited standalone performance. Furthermore, we present strong empirical evidence that this performance gain is mechanistically grounded in the central principles of ATR, suggesting that collective reasoning may be universally favourable over individualist reasoning, rather than a quirk in biology or evolution. Finally, drawing on our analysis of debate dynamics, we propose a novel benchmarking methodology that leverages LLM-MAD to measure intrinsic model properties (such as hallucination propensity) in order to compare models in ways that current static benchmarking approaches cannot support.
NumLeak: 基礎モデルの潜在ラベルとしての公開数値ベンチマーク
公開された数値ベンチマークは事前トレーニングに表示されるため、日付の条件による評価は、サンプル外のスキルではなく、記憶された再現率を測定している可能性があります。 NumLeak は、実稼働モデル上の API 境界プローブとオープン因果 LM 上のホワイトボックス制御検証を組み合わせた測定フレームワークです。最上位のフロンティア LLM は、3 シードでプールされたピアソン r=0.97 ~ 0.99 でのファーマ・フランス市場の超過リターンを思い出しますが、5 つの兄弟要素では 25bps 以内で 0.15 以内に留まっています。同等の忠実度は、米国の失業率、CPI インフレ、NOAA の気温にも現れています。最近のリリースのホールドアウトでは、解析率は 21 ~ 57% に低下しますが、応答した月の r は約 0.99 にとどまります。これは、記憶されたチャネルが予測するリジェクトまたはリコールの非対称性です。ホワイトボックス実験は用量反応を再現し、logprob ランキングはオープンエンド生成で見逃した記憶を検出します。これは、クローズド API ブラックボックス プローブがチャネルを過小評価していることを意味します。 r=0.74 で真の Mkt-RF と相関するソネットの「市場センチメントに対する日付」回帰は、モデル自体の再現率が残差化されると r=0.02 に崩壊します。 1 行のシステムプロンプト防御は、概念的および歴史的物語のクエリに対してほぼゼロのユーティリティコストで設定された非適応的なシングルターンサフィックス攻撃を 99.8% ブロックします。
原文 (English)
NumLeak: Public Numeric Benchmarks as Latent Labels in Foundation Models
Public numeric benchmarks appear in pretraining, so an evaluation that conditions on a date may be measuring memorized recall rather than out-of-sample skill. We introduce NumLeak, a measurement framework that combines API-boundary probes on production models with a white-box controlled validation on an open causal LM. Top-tier frontier LLMs recall the Fama-French market excess return at 3-seed pooled Pearson r=0.97-0.99 while staying within 0.15 within-25bps on the five sibling factors; comparable fidelity appears on U.S. unemployment, CPI inflation, and NOAA temperature. On a recent-release holdout, parse rate collapses to 21-57% but r stays at approximately 0.99 on months answered, the refuse-or-recall asymmetry a memorized channel predicts. The white-box experiment reproduces the dose-response, and logprob ranking detects memorization that open-ended generation misses, implying closed-API black-box probes understate the channel. A Sonnet "date to market-sentiment" regression that correlates with true Mkt-RF at r=0.74 collapses to r=0.02 once the model's own recall is residualized out. A one-line system-prompt defense blocks 99.8% of a non-adaptive single-turn suffix attack set at near-zero utility cost on conceptual and historical-narrative queries
CodeGolf Bench: 大規模な言語モデルの簡潔なコード生成機能を評価するための多言語ベンチマーク
このペーパーでは、60 のプログラミング言語における大規模言語モデル (LLM) の簡潔なコード生成能力を評価できるベンチマークである Code Bench を紹介します。コード ゴルフ (最小限の文字またはバイト ソリューションに焦点を当てたレクリエーション プログラミング コンテスト) に基づいたこのベンチマークは、効率的で簡潔なコードを生成する LLM の能力を示す独特の尺度を提供します。固定された問題セットと対象言語によって制限される既存のベンチマークとは異なり、CodeGolf Bench は code.golf プラットフォームを活用して、新しい問題と実際の人間のパフォーマンス ベースラインを提供します。 Python および C++ タスクでの 9 つの LLM の評価では、推論モデルが非推論モデルよりも大幅に優れたパフォーマンスを示し、最高の平均パーセンタイル 70.97% を達成していることが実証されました。このパフォーマンスのギャップは C++ で特に顕著であり、厳密な構文要件を持つ言語における推論の重要性が強調されています。非推論モデルは、どちらの言語でも効率の最適化にさらに苦労しており、最良のパーセンタイルは推論モデルよりも大幅に低くなります。 CodeGolf Bench は、コード ゴルフにおける進化する人間のパフォーマンスに対して LLM コード生成機能を評価するための動的なフレームワークを提供します。
原文 (English)
CodeGolf Bench: A Multi-Language Benchmark for Evaluating Concise Code Generation Capabilities of Large Language Models
This paper introduces Code Bench, a benchmark capable of evaluating Large Language Models (LLMs) concise code generation abilities in 60 programming languages. Based on code golf, a recreational programming competition focused on minimal character or byte solutions, the benchmark provides a distinctive measure of LLMs ability to produce efficient, concise code. Unlike existing benchmarks limited by fixed problem sets and language coverage, CodeGolf Bench leverages the code.golf platform to provide new problems and live human performance baselines. Evaluation of nine LLMs on Python and C++ tasks demonstrates that reasoning models significantly outperform non-reasoning models, achieving best average percentile of 70.97%. This performance gap is particularly pronounced in C++, highlighting reasoning's importance for languages with strict syntax requirements. Non-reasoning models struggle more with efficiency optimization across both languages, with best percentiles significantly lower than reasoning counterparts. CodeGolf Bench offers a dynamic framework for evaluating LLM code generation capabilities against evolving human performance on code golf.
AI 制御不能インシデント管理: 対応と回復力
AI システムが欺瞞性とシャットダウン耐性を示すことを実証した最近の研究は、AI の制御喪失 (LOC) が緊急の政策上の懸念事項であることを示唆していますが、現在の文献はほぼもっぱら調整と防止に焦点を当てています。このギャップに対処するために、このペーパーでは、壊滅的な AI LOC インシデントを管理するための基本的なフレームワークと分類法を紹介します。この分類の最初のレベルでは、制御を取り戻すのに「非常にコストがかかる」シナリオと「不可能」なシナリオを区別します。不可能なシナリオでは、AI の攻撃対象領域を根本的に制限するために即時の回復力への投資が必要ですが、非常にコストがかかるシナリオでは、封じ込めと脅威の無力化による積極的なインシデント管理が必要です。このフレームワークはさらに、これらの管理可能なイベントを偶発的 LOC (自動サーキットブレーカー対応が必要) と敵対的 LOC (段階的エスカレーション措置が必要) に分類します。このペーパーでは、3 つの重大度クラスを特定のシナリオ マトリックスにマッピングすることで、前例のない AI リスクを管理するための具体的で比例したガイドを提供します。
原文 (English)
AI Loss of Control Incident Management: Response & Resilience
Recent research demonstrating AI systems exhibiting deception and shutdown resistance suggests that AI loss of control (LOC) is an urgent policy concern , yet current literature focuses almost exclusively on alignment and prevention. To address this gap, this paper introduces a foundational framework and taxonomy for managing catastrophic AI LOC incidents. The taxonomy's first level distinguishes between scenarios where regaining control is 'extremely costly' versus 'impossible'. While impossible scenarios demand immediate resilience investments to fundamentally restrict an AI's attack surface , extremely costly scenarios require active incident management via Containment and Threat Neutralization. The framework further categorizes these manageable events into accidental LOC (requiring automated circuit-breaker responses) and adversarial LOC (requiring graduated escalatory measures). By mapping three severity classes to specific scenario matrices, this paper provides a concrete, proportional guide for managing unprecedented AI risks.
モデルの特化のための自律型エージェント データ エンジニアリングの探求
大規模言語モデル (LLM) は、一般的なタスクでは優れたパフォーマンスを示していますが、高品質のドメイン固有のデータがないと特殊なドメインに適応するのに苦労することがよくあります。既存の LLM ベースのデータ キュレーション手法は主に人間が設計したワークフローに依存しているため、LLM がモデルの特化のためのエンドツーエンドのデータ エンジニアリング パイプラインを自律的に実行できるかどうかは未検討のままです。私たちは \textbf{Autonomous Agentic Data Engineering} を形式化します。これは、エンドツーエンドのデータ キュレーションを通じてモデルの専門化を推進する自律型データ エンジニアとして LLM を評価するように設計された新しいタスクです。私たちはデータを最適化可能なコンポーネントとしてフレーム化し、トレーニング後のパフォーマンス向上に基づいて、複数のドメインにわたってトレーニング データを計画、生成、反復的に最適化するエージェントを研究します。実験によると、GPT-5.2 は反復的なエージェント主導のデータ適応を通じて学生モデルを \textbf{57.29\%} 改善するトレーニング カリキュラムを構築するため、自律型 LLM データ エンジニアが大幅な利益をもたらすことが示されています。私たちの研究では、潜在的な問題とボトルネックの両方を明らかにすることで、自律的なデータ エンジニアリングを測定可能な機能として確立し、エージェント駆動モデルの特殊化への道筋を示しています\脚注{コードは https://github.com/zjunlp/DataAgent でリリースされます。}
原文 (English)
Exploring Autonomous Agentic Data Engineering for Model Specialization
Large Language Models (LLMs) have demonstrated strong performance on general tasks, while often struggling to adapt to specialized domains without high-quality domain-specific data. Existing LLM-based data curation methods primarily rely on human-designed workflows, leaving it unexamined whether LLMs can autonomously execute an end-to-end data engineering pipeline for model specialization. We formalize \textbf{Autonomous Agentic Data Engineering}, a novel task designed to evaluate LLMs as autonomous data engineers that drive model specialization through end-to-end data curation. We frame data as an optimizable component and study agents that plan, generate, and iteratively optimize training data across multiple domains, guided by post-training performance improvement. Experiments show that autonomous LLM data engineers yield substantial gains, as GPT-5.2 constructs a training curriculum that improves a student model by \textbf{57.29\%}, entirely through iterative, agent-driven data adaptation. By illuminating both potential and bottlenecks, our study establishes autonomous data engineering as a measurable capability and charts a path toward agent-driven model specialization\footnote{Code will be released at https://github.com/zjunlp/DataAgent.}.
SANA-Streaming: ハイブリッド拡散トランスを使用したリアルタイム ストリーミング ビデオ編集
リアルタイム ストリーミング ビデオ間編集 (V2V) は、ライブ ブロードキャストやゲームなどのインタラクティブ アプリケーションにとって重要ですが、時間的一貫性と推論スループットに対する厳しい要件があるため、依然として困難な課題です。この論文では、消費者向け GPU で高解像度のリアルタイム ストリーミング ビデオ編集を行うためのシステム アルゴリズムが共同設計されたフレームワークである SANA-Streaming について、次の 3 つのコア設計を使用して紹介します。 (1) ハイブリッド拡散トランス アーキテクチャは、ブロックの一部にソフトマックス アテンションを導入し、線形層の効率を維持しながらローカル モデリング機能を向上させます。 (2) サイクルリバース正則化は、フロー マッチングを介して生成されたコンテンツからソース フレームを予測することで意味の一貫性を強制する新しいトレーニング戦略であり、ペアの長い編集ビデオを必要とせずに時間的な一貫性を向上させます。 (3) 効率的なシステム共同設計により、融合された GDN カーネルと、NVIDIA Blackwell (RTX 5090) アーキテクチャ向けに最適化された混合精度量子化 (MPQ) が結合されます。現実世界のスループットをプロファイリングすることにより、当社の MPQ は生成品質を維持しながら Tensor コアの使用率を最大化します。結果として得られるシステムは、単一の RTX 5090 GPU 上で 24 エンドツーエンド FPS での 1280 x 704 解像度のリアルタイム編集を実現し、DiT コアは 58 FPS で実行されます。実験結果は、私たちの共同設計アプローチが時間的コヒーレンスとシステム スループットの両方において既存の SOTA 手法よりも大幅に優れていることを示しています。
原文 (English)
SANA-Streaming: Real-time Streaming Video Editing with Hybrid Diffusion Transformer
Real-time streaming video-to-video editing (V2V) is critical for interactive applications such as live broadcasting and gaming, yet it remains a formidable challenge due to the stringent requirements for temporal consistency and inference throughput. In this paper, we present SANA-Streaming, a system-algorithm co-designed framework for high-resolution, real-time streaming video editing on consumer GPUs, with the following three core designs: (1) Hybrid Diffusion Transformer architecture introduces softmax attention in part of the blocks to improve local modeling capabilities while preserving the efficiency of linear layers. (2) Cycle-Reverse Regularization is a novel training strategy that enforces semantic consistency by predicting source frames from generated content via flow matching, improving temporal consistency without requiring paired long edited videos. (3) Efficient System Co-design combines fused GDN kernels and Mixed-Precision Quantization (MPQ) optimized for the NVIDIA Blackwell (RTX 5090) architecture. By profiling real-world throughput, our MPQ maximizes Tensor Core utilization while maintaining generation quality. The resulting system achieves real-time 1280 x 704 resolution editing at 24 end-to-end FPS on a single RTX 5090 GPU, with the DiT core running at 58 FPS. Experimental results demonstrate that our co-design approach significantly outperforms existing SOTA methods in both temporal coherence and system throughput.
言語モデルにおけるドメイン適応と推論フレームワーク: 歴史的宇宙論の制御された実験
私たちは、制御された設定として歴史的宇宙論を使用して、ドメイン適応が言語モデルの説明動作をどのように再形成するかを調査します。フェーズ 1 では、明示的な地動説が削除されたコペルニクス以前のコーパス上で小さな言語モデルをゼロからトレーニングし、それにもかかわらず地球運動または地動説の継続が現れるかどうかを評価します。フェーズ 2 では、適応によって説明フレーミングと宇宙論的スタンスがどのように変更されるかを研究するために、同じコーパス上で QLoRA を使用して大規模な事前トレーニング済みモデルを微調整します。モデルの出力は、宇宙論的な立場 (地動説、地動説、または曖昧さ) と説明フレーム (前近代と現代) の両方をラベル付けする LLM としての判断フレームワークを使用して評価されます。フェーズ 1 の制約された設定では、より小さなモデルが局所的な地球運動の継続を生成することがありますが、これらは依然として全体的に不安定であり、一貫した宇宙論的推論をサポートするには不十分です。フェーズ 2 では、微調整により前近代的な説明フレームへの大幅かつ統計的に有意な移行が引き起こされますが、条件付きの宇宙論的スタンスの分布はそれらのフレーム内で比較的安定したままになります。その結果、地動中心的な生産量の増加は、スタンスの直接的な変更によるものではなく、主に説明レジームにわたる再分配によって生じます。これらの結果は、ドメイン適応が主に継続が生成される言語枠組みを再形成し、その変化から二次的にスタンスの変化が現れる可能性があることを示唆しています。
原文 (English)
Domain Adaptation and Reasoning Frameworks in Language Models: A Controlled Experiment with Historical Cosmology
We investigate how domain adaptation reshapes explanatory behavior in language models using historical cosmology as a controlled setting. In Phase 1, we train a small language model from scratch on a pre-Copernican corpus from which explicit heliocentric references were removed, and evaluate whether Earth-motion or heliocentric continuations nevertheless emerge. In Phase 2, we fine-tune a larger pretrained model using QLoRA on the same corpus in order to study how adaptation modifies explanatory framing and cosmological stance. Model outputs are evaluated using an LLM-as-judge framework that labels both cosmological stance (geocentric, heliocentric, or ambiguous) and explanatory frame (premodern versus modern). In the constrained setting of Phase 1, the smaller models occasionally generate local Earth-motion continuations, but these remain globally unstable and insufficient to support coherent cosmological reasoning. In Phase 2, fine-tuning induces a large and statistically significant shift toward premodern explanatory framing, while the conditional cosmological stance distributions remain comparatively stable within those frames. As a result, increases in geocentric outputs arise primarily from redistribution over explanatory regimes rather than from direct modification of stance. These results suggest that domain adaptation may primarily reshape the linguistic frameworks from which continuations are generated, with changes in stance emerging secondarily from those shifts.
LongDS-Bench: 長期にわたるエージェントデータ分析の失敗について
現実世界のデータ分析は本質的に反復的ですが、既存のベンチマークは主に孤立したタスクや短時間の対話型タスクを評価するため、長期にわたって進化する分析コンテキストを追跡するエージェントの能力はテストされていません。エージェントが進化する分析状態を維持、更新、復元、構成する必要がある長期にわたるマルチターン データ分析のベンチマークである LongDS を紹介します。 LongDS は、現実世界の Kaggle ノートブックから構築された 68 のタスクで構成され、地球科学、ビジネス、教育を含む 6 つのドメインにわたる 2,225 ターンに及びます。タスクは状態発展パターン (反事実摂動、ロールバック、複数状態の構成など) を中心に設計されており、依存関係の平均スパンは 11.3 ターンです。 5 つの最先端モデルを評価したところ、最良のモデルでも平均精度は 48.45% にとどまり、ターンの初期から後期にかけてパフォーマンスが 47 ポイント近く低下し、長期エラーが失敗の 52% ~ 69% を占めることがわかりました。さらに分析を進めると、エージェント ステップを追加しても必ずしもパフォーマンスが向上するとは限らず、主なボトルネックはインタラクション バジェットを増やすことではなく、正しい分析状態を維持することにあることが示唆されています。私たちは、信頼性の高い長期的なエージェントデータ分析の研究をサポートするために LongDS をリリースします。コードとデータは https://github.com/zjunlp/DataMind でリリースされます。
原文 (English)
LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
Real-world data analysis is inherently iterative, yet existing benchmarks mostly evaluate isolated or short interactive tasks, leaving agents' ability to track evolving analytical context over long horizons untested. We introduce LongDS, a benchmark for long-horizon, multi-turn data analysis where agents must maintain, update, restore, and compose evolving analytical states. LongDS comprises 68 tasks constructed from real-world Kaggle notebooks, spanning 2,225 turns across six domains including Geoscience, Business, and Education. Tasks are designed around state-evolution patterns (e.g., counterfactual perturbation, rollback, multi-state composition), with an average dependency span of 11.3 turns. Evaluating five state-of-the-art models, we find that the best model reaches only 48.45% average accuracy, performance drops nearly 47 points from early to late turns, and long-horizon errors account for 52%--69% of failures. Further analysis shows that additional agent steps do not necessarily improve performance, suggesting that the key bottleneck is maintaining a correct analytical state rather than increasing interaction budget. We release LongDS to support research on reliable long-horizon agentic data analysis. Code and data will be released at https://github.com/zjunlp/DataMind.
調整された好みの学習: ラベルランキングの場合
予測された確率と実際の結果の頻度を調整するキャリブレーションは、信頼性の高い意思決定に不可欠です。分類と回帰については広く研究されていますが、目標はラベル セットの順序に対する分布を予測することである、確率的ラベル ランキングについては正式に調整されていません。ランキングを単純にクラスとして扱うと、その構造が無視され、ペアごとの予測やトップ K 予測などの重要なモダリティを捉えることができなくなります。私たちはラベル ランキングの調整を形式化し、完全なランキング、サブランキング、およびトップ K ランキングをカバーする概念の階層を開発します。フルランク キャリブレーションは他のものを暗示しますが、その逆はなく、サブランク キャリブレーションとトップ K キャリブレーションは比較にならないことを証明します。経験的に、人気のあるラベルのランキング モデルは適切に調整されていないことが多く、サブランキングとトップ K のメトリクスの間には大きな違いがあることがわかりました。私たちのフレームワークを RLHF 報酬モデルに適用すると、キャリブレーションはベンチマーク精度と完全ではないものの強い相関があることがわかり、トップ 1 の精度を超えた意味のある品質次元を捕らえていることが示唆されます。これらの発見は、誤った校正による下流への影響を理解し、それを修正する方法を開発するという今後の研究の動機付けとなります。
原文 (English)
Calibrated Preference Learning: The Case of Label Ranking
Calibration, the alignment of predicted probabilities with true outcome frequencies, is essential for reliable decision-making. While extensively studied for classification and regression, calibration has not been formally addressed for probabilistic label ranking, where the goal is to predict a distribution over orderings of a label set. Naively treating rankings as classes ignores their structure and fails to capture important modalities such as pairwise and top-k predictions. We formalize calibration for label ranking and develop a hierarchy of notions covering full rankings, sub-rankings, and top-k rankings. We prove that full-rank calibration implies the others but not conversely, and sub-ranking and top-k calibration are incomparable. Empirically, we find popular label ranking models are often poorly calibrated, with substantial differences between sub-ranking and top-k metrics. Applying our framework to RLHF reward models, we find that calibration correlates strongly but not perfectly with benchmark accuracy, suggesting it captures a meaningful quality dimension beyond top-1 accuracy. These findings motivate future work on understanding the downstream effects of miscalibration and developing methods to correct it.
多目的最適化における勾配集約のための統合フレームワーク
機械学習の問題の多くには、複数の固有のトレードオフが関係しており、これらのトレードオフには、勾配ベースの多目的最適化 (MOO) アルゴリズムが最適に対処されます。既存の手法はさまざまな動機で提案され、ケースバイケースで分析されることが多く、各ステップでコンポーネントの勾配がどのように集約されるかがアルゴリズム的に異なります。この作業では、MOO の勾配集約のための統一フレームワークを開発し、MOO の標準的なパフォーマンスの尺度であるパレート定常性への (最適な) 収束率を確立します。私たちの分析の中心となるのは十分整列条件であり、そこから、勾配の凸包内で矛盾しない方向が選択された場合、収束のための基本的な十分条件を形成することを示す定理を導き出します。さらに、二重円錐への投影を通じて実現可能性を確保できることを示し、収束保証を認める方法の範囲を広げます。並行して、確立されたアルゴリズムを網羅し、それらの理論的関係を明確にし、新しいバリアントの設計を可能にする勾配集約の基本的な最適化の観点を提示します。例として、CVaR ベースの定式化から派生した上限付き MGDA を紹介し、敵対的フェデレーテッド ラーニングにおけるその堅牢性を実証します。最後に、合成問題と実際のベンチマークに関する実験を通じて理論を検証します。
原文 (English)
A Unified Framework for Gradient Aggregation in Multi-Objective Optimization
Many machine learning problems involve multiple inherent trade-offs that are best addressed by gradient-based multi-objective optimization (MOO) algorithms. Existing methods are often proposed with various motivations, analyzed case by case, and differ algorithmically in how the component gradients are aggregated at each step. In this work, we develop a unifying framework for gradient aggregation in MOO, establishing (optimal) rates of convergence to Pareto stationarity, the standard measure of performance in MOO. Central to our analysis is a sufficient alignment condition, from which we derive a theorem showing that non-conflicting directions, when chosen within the convex hull of gradients, form a fundamental sufficient condition for convergence. We further show that feasibility can be ensured through projection onto the dual cone, broadening the scope of methods that admit convergence guarantees. In parallel, we present a primal optimization perspective of gradient aggregation that encompasses established algorithms, clarifies their theoretical relationships, and enables the design of new variants. As an illustration, we introduce capped MGDA, derived from a CVaR-based formulation, and demonstrate its robustness in adversarial federated learning. Finally, we validate our theory through experiments on synthetic problems and practical benchmarks.
テストする表面は壊れる表面ではありません
ツールで拡張された LLM エージェントは、プロンプト インジェクションに対して脆弱です。エージェントのコンテキストの一部を制御するサードパーティが、エージェントがユーザーからのものであるかのように命令を実行する可能性があります。現在の評価では、ツールの出力である 1 つのチャネル上のモデルごとに 1 つの攻撃成功率が報告され、その数値がモデルの脆弱性として扱われます。しかし、エージェントがツールを呼び出す前に毎回読み取るツールの説明自体が、攻撃者が代わりに選択できる注入面となります。インジェクションペイロードをバイト同一に保持し、6 つのファミリーと 4 つのタスクスイートからの 13 個の LLM の両方のサーフェスを介して配信します。モデル間で同じバイトが成功率で逆転します。GPT-4.1 はツール出力では 96% 脆弱ですが、ツール記述ではわずか 4% ですが、GEMINI-3-FLASH は 20% と 98% でミラー パターンを示します。 6,830 回の試行にわたる分散分解では、攻撃結果の変動の 0% がサーフェスのみによるものである一方、モデルとサーフェスの相互作用は 16.7% を占めます。脆弱性はペアリングの特性であり、チャネルの特性ではありません。サーフェス上のセルごとの最大値として定義される適応攻撃率は、最も強力な固定サーフェスのベースラインを平均で +9.1 パーセント ポイント上回ります。標準のプロンプトレベルの防御は同じ盲点を継承し、ツール出力の ASR を 10 ~ 18 パーセントに削減する一方、記述チャネルは 54 パーセントを超えたままにします。攻撃評価と防御評価の両方で、表面ごとの脆弱性を報告する必要があります。
原文 (English)
The Surface You Test Is Not the Surface That Breaks
Tool-augmented LLM agents are vulnerable to prompt injection: a third party who controls part of the agent's context can plant instructions that the agent then executes as if they came from the user. Current evaluations report a single attack success rate per model on one channel, the tool output and treat that number as the model's vulnerability. But tool descriptions, which the agent reads at every turn before any tool is called, are themselves an injection surface that the attacker can choose instead. We hold the injection payload byte-identical and deliver it through both surfaces across 13 LLMs from six families and four task suites. The same bytes invert in success rate across models: GPT-4.1 is 96 percent vulnerable on tool outputs but only 4 percent on tool descriptions, while GEMINI-3-FLASH shows the mirror pattern at 20 percent and 98 percent. A variance decomposition over 6,830 attempts attributes 0 percent of the variation in attack outcomes to the surface alone, while the model-surface interaction accounts for 16.7 percent. Vulnerability is a property of the pairing, not the channel. The Adaptive Attack Rate, defined as the per-cell maximum over surfaces, exceeds the strongest fixed-surface baseline by +9.1 percentage points on average. Standard prompt-level defenses inherit the same blindspot, reducing tool-output ASR to 10-18 percent while leaving the description channel above 54 percent. Both attack and defense evaluation must report per-surface vulnerability.
分離可能なダイナミクスの状態拡張とコンセンサスによる、スケーラブルな制約付きマルチエージェント強化学習
我々は、状態拡張ポリシー学習と二重変数に対する分散型コンセンサスを組み合わせた、制約付きマルチエージェント強化学習 (MARL) のための分散型アプローチを提案します。私たちの方法は、エージェントが分離可能なダイナミクスを持っているが、グローバルなリソース制約を満たすために調整する必要があるシステムを対象としています。経験的に示しているように、この設定では、エージェントが集合的な制約を満たすための適切な個別の貢献を決定できないため、独立した学習では実行可能な解決策を生み出すことができません。主要な技術的貢献は、独立したトレーニングのスケーラビリティを維持しながら、グローバルに調整された制約の適用には、ラグランジュ乗数に対する軽量の隣接間コンセンサスで十分であることを示したことです。各エージェントは、ローカル状態と二重変数エンコード制約フィードバックの両方を条件として、単一の拡張ポリシーをオフラインで学習します。実行中、エージェントはローカル通信のみを通じてこの二重変数について合意に達します。緩やかな接続性の仮定の下では、エージェントの乗数間のコンセンサス誤差が制限されていることを証明し、これがグラフの接続性とコンセンサスラウンドの数とともに減少する有界制約違反に変換されることを示します。複雑さがエージェント数に応じて少なくとも二次関数的に増加する分散実行による集中トレーニング (CTDE) アプローチとは異なり、私たちの方法はトレーニングと実行の両方で線形にスケールします。スマート グリッドのデマンド レスポンスに関する実験では、コンセンサス調整が \emph{実現可能性にとって不可欠}であることが実証されています。コンセンサス調整がなければ、エージェントはデマンドを無期限に延期することによってのみグリッド容量の制約を満たすことになります。これは退化した非解決策です。コンセンサスが得られると、エージェントは共有二重変数に収束し、グリッド制約と需要履行の両方を満たし、CTDE ベースラインが数十に制限されているのに対し、数千のエージェントに拡張できます。
原文 (English)
Scalable Constrained Multi-Agent Reinforcement Learning via State Augmentation and Consensus for Separable Dynamics
We present a distributed approach for constrained Multi-Agent Reinforcement Learning (MARL) that combines state-augmented policy learning with distributed consensus over dual variables. Our method targets systems where agents have separable dynamics but must coordinate to satisfy global resource constraints, a setting in which, as we demonstrate empirically, independent learning fails to produce feasible solutions because agents cannot determine appropriate individual contributions toward collective constraint satisfaction. The key technical contribution is showing that lightweight neighbor-to-neighbor consensus over Lagrange multipliers suffices for globally coordinated constraint enforcement while preserving the scalability of independent training. Each agent learns a single augmented policy offline, conditioned on both its local state and a dual variable encoding constraint feedback. During execution, agents reach agreement on this dual variable through local communication alone. We prove that under mild connectivity assumptions, the consensus error among agents' multipliers is bounded, and show that this translates to a bounded constraint violation that decreases with graph connectivity and the number of consensus rounds. Unlike centralized training with decentralized execution (CTDE) approaches, whose complexity grows at least quadratically with agent count, our method scales linearly in both training and execution. Experiments on smart grid demand response demonstrate that consensus coordination is \emph{essential for feasibility}: without it, agents satisfy grid capacity constraints only by indefinitely postponing demand, a degenerate non-solution. With consensus, agents converge to a shared dual variable and satisfy both grid constraints and demand fulfillment, scaling to thousands of agents while CTDE baselines are limited to dozens.
idSCD: セマンティック相関記述子によるトレーニング データセットの識別
データセットは、トレーニング中に誘発される偽の相関から認識できますか?私たちは、データセットはモデルの学習された意味相関構造にデータセット固有の痕跡を残すと主張します。つまり、データセット内で予測的であるものの、基礎となるタスクの因果関係ではない偶発的な規則性は、トレーニング中に内部化される可能性があります。私たちはこの洞察を利用して、信頼スコア、損失、マージン、生成されたサンプル、クエリ応答などの行動または分布の証拠に依存する既存の手法を超えて、データセットレベルのメンバーシップ推論を研究します。意味相関記述子 (SCD) に基づくホワイトボックス セマンティック フィンガープリンティング アプローチを導入します。これは、モデルによって学習された意味相関構造をキャプチャし、データセットの混合間で比較できるようにします。制御されたleave-one-dataset-out診断では、SCDはデータセット固有の変更を回復し、一致するデータセットのペアと一致しないデータセットのペアを完全に分離します。次に、モデルの SCD とターゲット データセットのスタンドアロン SCD のみを使用して、ターゲット データセットがモデルのトレーニング混合物の一部であるかどうかをテストする、実用的な SCD ベースのメンバーシップ スコアを提案します。1 つのデータセットを除外するモデルを必要としません。自然言語推論、感情分類、医療文書分類のデータセット グループを使用した 3 つの多様な実験設定にわたって、データセット分割間の意味論的分離とキーワード サポートの程度が異なる SCD ベースのメンバーシップ推論の利点と限界の両方をテストします。平均すると、このスコアに基づく分類器は最高のパフォーマンスと最低の標準偏差を達成し、ブラック ボックス ベースライン RMIA、 Attack-P、LiRA やホワイト ボックス SIF ベースラインを上回ります。これらの結果は、データセットのメンバーシップが内部の意味論的な相関関係を通じて追跡できることを示しており、データセット グループが明確な意味論的な特殊性を明らかにする場合、ROC-AUC で最大相対ゲインが 60% を超えます。
原文 (English)
idSCD: Identifying Training Datasets through Semantic Correlation Descriptors
Can a dataset be recognized from the spurious correlations it induces during training? We argue that datasets leave dataset-specific traces in a model's learned semantic correlation structure: incidental regularities that are predictive within a dataset, but not causal for the underlying task, can be internalized during training. We use this insight to study dataset-level membership inference, moving beyond existing methods that rely on behavioral or distributional evidence such as confidence scores, losses, margins, generated samples, or query responses. We introduce a white-box semantic fingerprinting approach based on semantic correlation descriptors (SCDs), which capture the semantic correlation structure learned by a model and make it comparable across dataset mixtures. In a controlled leave-one-dataset-out diagnostic, SCDs recover dataset-specific changes and perfectly separate matching from non-matching dataset pairs. We then propose a practical SCD-based membership score that tests whether a target dataset is part of a model's training mixture using only the model's SCD and the target dataset's standalone SCD, without requiring leave-one-dataset-out models. Across three diverse experimental settings, with dataset groups for natural language inference, emotion classification, and medical text classification, we test both the advantages and limitations of SCD-based membership inference with different degrees of semantic separation and keyword support between dataset splits. On average, the classifier based on this score achieves the highest performance and the lowest std, outperforming black-box baselines RMIA, Attack-P, and LiRA, as well as the white-box SIF baseline. These results show that dataset membership can be traced through internal semantic correlations, with the largest relative gain exceeding 60% in ROC-AUC when dataset groups expose distinct semantic particularities.
交通予測のためのグラフ ニューラル ネットワークの専門家のグラフ条件付き混合
センサー グラフの時空間予測は、グラフ領域が異なるダイナミクスを示す可能性がありますが、すべてのノードに均一に適用される単一のバックボーン アーキテクチャを使用して取り組むのが一般的です。道路セグメントは機能クラス、構造、交通動作が異なるため、ノードごとの専門家の専門化が役立つ可能性があることを示唆しています。我々は、グラフトポロジと最近のトラフィック入力ウィンドウに基づいて凍結予測エキスパートのパーソナライズされた組み合わせを各ノードに割り当てる、グラフ条件付きエキスパート混合フレームワークである GC-MoE を提案します。 GC-MoE は、軽量のルーティング モジュールのみをトレーニングしながら、フリーズされた事前トレーニング済みの時空間 GNN エキスパートと入力を認識し、空間的にコンテキスト化されたルーターを組み合わせます。また、オプションの拡張機能として有界グラフ条件付き出力リファインメント レイヤーも研究し、アブレーション診断としてのみノード適応型 ST-LoRA アダプターを含めます。 GC-MoE は、4 つの標準ベンチマーク (PEMS04、PEMS07、METR-LA、および PEMS-BAY) にわたって、競合する RMSE および MAPE を使用してゼロパラメーター アンサンブル ベースラインよりも MAE を向上させますが、150 万の凍結されたエキスパート ウェイトに基づいて最大 17,000 のパラメーターのみをトレーニングします。実装は https://github.com/Ahghaffari/gc_moe で入手できます。
原文 (English)
Graph-Conditioned Mixture of Graph Neural Network Experts for Traffic Forecasting
Spatio-temporal forecasting on sensor graphs is commonly tackled with a single backbone architecture applied uniformly across all nodes, although graph regions can exhibit different dynamics. Road segments differ in functional class, structure, and traffic behavior, suggesting that node-wise expert specialization can be useful. We propose GC-MoE, a graph-conditioned mixture of experts framework that assigns each node a personalized combination of frozen forecasting experts based on graph topology and the recent traffic input window. GC-MoE combines frozen pretrained spatio-temporal GNN experts with an input-aware, spatially contextualized router while training only a lightweight routing module. We also study a bounded graph-conditioned output refinement layer as an optional extension and include node-adaptive ST-LoRA adapters only as an ablation diagnostic. Across four standard benchmarks (PEMS04, PEMS07, METR-LA, and PEMS-BAY), GC-MoE improves MAE over a zero-parameter ensemble baseline, with competitive RMSE and MAPE, while training only ~17K parameters on top of 1.5M frozen expert weights. The implementation is available at https://github.com/Ahghaffari/gc_moe.
$\ell_\infty$ の分布推定の改善
$\ell_\infty$ ノルムの下で離散確率分布を推定するための改良された境界を提示します。これらには、期待値のミニマックス限界と高確率のテール限界が含まれます。私たちは、Kontorovich and Painsky (JMLR, 2025) で提起された未解決の疑問のいくつかを解決します。これには、彼らが提示した最も厳しいリスク限界の完全な経験版や、最悪の場合の極値分布の形式の特定が含まれます。有望な実証結果も報告されています。
原文 (English)
Improved Distribution Estimation in $\ell_\infty$
We present improved bounds for estimating discrete probability distributions under the $\ell_\infty$ norm. These include minimax bounds in expectation and high-probability tail bounds. We resolve some of the open questions posed in Kontorovich and Painsky (JMLR, 2025) -- including a fully empirical version of the tightest risk bound they presented and identifying the form of the worst-case extremal distribution. Encouraging empirical results are reported as well.
磁気共鳴画像を使用して脳腫瘍のセグメンテーションを強化するための、新しいグローバル コンテキスト認識型ディープ ニューラル ネットワーク
脳腫瘍の重症度により、脳腫瘍の正確なセグメンテーションが必要になります。これは脳腫瘍の効果的な診断に不可欠です。手動による識別には、高いコスト、労力、エラーのリスクが伴い、自動化された方法の必要性が浮き彫りになっています。この研究では、Global Context-aware Squeeze and Excite Residual UNet (GCSER-UNet) を導入します。これにより、空間的注意とチャネルごとの注意の融合が促進され、複雑な空間依存性とコンテキスト情報を捕捉するモデルの能力が強化されます。 GCSER-UNet は、マルチモーダル MRI スライスから腫瘍セグメントを効率的に抽出し、優れたパフォーマンスを実現します。ベンチマーク データベースでの評価ではその優位性が実証され、TCGA LGG データセット上で注目すべき 94 パーセントのサイコロ スコアを達成し、最先端のサイコロ スコア 91.8 パーセントを上回りました。 BraTS 2020 データセットでは、提案された GCSER-UNet アンサンブル アプローチにより、腫瘍領域 (腫瘍全体 (W)、腫瘍コア (T)、腫瘍増強 (E)) に対してそれぞれ 95 パーセント、92 パーセント、90 パーセントのサイコロ スコアが得られました。現在の最先端のサイコロのスコアは、94 パーセント、93 パーセント、88 パーセントでした。これらの説得力のある結果は、脳腫瘍の正確なセグメンテーションにおける GCSER-UNet の有効性を強調しており、したがって神経内科医が脳腫瘍の効果的な管理と治療計画を立てるのに役立ちます。
原文 (English)
A Novel Global Context-aware Deep Neural Network for Enhanced Brain Tumor Segmentation using Magnetic Resonance Images
Brain cancer's severity necessitates precise brain tumor segmentation, which is crucial for effective brain tumor diagnosis. Manual identification, burdened by high costs, labor, and error risks, highlights the need for automated methods. In this study, we introduce the Global Context-aware Squeeze and Excite Residual UNet (GCSER-UNet), which facilitates a fusion of spatial and channel-wise attention and thus enhances the model's capacity to capture intricate spatial dependencies and contextual information. GCSER-UNet efficiently extracts tumor segments from multimodal MRI slices, delivering exceptional performance. Evaluations on benchmark databases exhibit its superiority, achieving a notable 94 percent dice score on the TCGA LGG dataset, surpassing the state-of-the-art dice score of 91.8 percent. In the BraTS 2020 dataset, the proposed GCSER-UNet ensemble approach yielded dice scores of 95 percent, 92 percent, and 90 percent for the tumor regions - Whole Tumor (W), Tumor Core (T), and Enhancing Tumor (E), respectively. The current state-of-the-art dice scores were 94 percent, 93 percent, and 88 percent. These compelling outcomes highlight the efficacy of GCSER-UNet in precise brain tumor segmentation and thus can aid neurologists in effective brain cancer management and treatment planning.
パッド付きトランスの表現力の再考: どのアーキテクチャ上の選択が重要で、どの選択が重要でないのか
最近の研究では、ブール回路への接続を通じてトランスが計算できるものとできないものについて説明していますが、既存の結果は正確な特性評価に欠けており、モデリングの選択に敏感です。 「...」などの入力フィラー記号が追加されるパッド付きトランスは、適応並列計算用の多項式空間を提供することで回路クラスとの等価性を確立するための便利なガジェットとして登場します。ただし、パッドされた変圧器の理想化の限られたセットのみが研究されており、注意の種類、モデル幅、および均一性が変更された場合にこれらの等価性がどの程度堅牢に保持されるかは未解決のままです。実際の仮定の下では、パッド付きトランスフォーマーはこれらすべてに対して驚くほど堅牢であることがわかり、数値精度とモデルの深さが表現力に影響を与える主な要因であることがわかりました。具体的には、多項式パディングされた $\text{L-uniform}$ 定精度変換器は $\text{L-uniform AC}^0$ と同等であるのに対し、成長精度変換器は幅に関係なく $\text{L-uniform TC}^0$ を達成することを証明します。さらに、ループにより回路と同様の逐次処理が可能になります。$\log^d N$ ループの定精度変換器は $\text{FO-uniform AC}^d$ に達し、成長精度変換器は $\text{FO-uniform TC}^d$ に達します。興味深いことに、幅や精度を対数を超えて拡大しても表現力は向上しません。すべての結果は、ソフトマックスと平均のハード アテンション トランスフォーマーの両方に当てはまります。
原文 (English)
Revisiting Padded Transformer Expressivity: Which Architectural Choices Matter and Which Don't
Recent work describes what transformers can and cannot compute through connections to boolean circuits, but existing results lack exact characterizations and are sensitive to modeling choices. Padded transformers -- to whose input filler symbols such as ``...'' are appended -- emerge as a useful gadget for establishing equivalences to circuit classes by providing polynomial space for adaptive parallel computation. However, only a limited set of padded transformer idealizations has been studied, leaving open how robustly these equivalences hold under changes to attention type, model width, and uniformity. We find that, under practical assumptions, padded transformers are surprisingly robust to all of these, and identify numeric precision and model depth as the main factors affecting expressivity. Concretely, we prove that polynomially padded $\text{L-uniform}$ constant-precision transformers are equivalent to $\text{L-uniform AC}^0$, while growing-precision ones achieve $\text{L-uniform TC}^0$ regardless of width. Furthermore, looping enables sequential processing analogous to circuits: $\log^d N$-looped constant-precision transformers reach $\text{FO-uniform AC}^d$, and growing-precision ones reach $\text{FO-uniform TC}^d$. Interestingly, growing width or precision beyond logarithmic does not increase expressivity, and all our results hold for both softmax and average hard attention transformers.
一般的な埋め込みと特定の埋め込み、どちらが優れていますか?英語以外の言語での臨床コーディングの検索に関する実証研究
意味検索のための文埋め込みモデルは、圧倒的に英語コーパスで開発および評価されています。他の言語での臨床検索、特に ICD-10-CM / CIE-10 コードの検索に適用すると、集計ベンチマークによって隠蔽されることが多く、リコールが低下します。私たちは、大規模な生成言語モデルがこのギャップを埋めるデータ ファクトリとして機能できるかどうかを研究しています。英語、スペイン語、カタロニア語、イタリア語、ポルトガル語、フランス語をカバーするジェミニで生成された合成データに基づいてスペイン語の生物医学エンコーダー (PlanTL-GOB-ES/bsc-bio-ehr-es) から微調整された 2 段階レトリーバー (バイエンコーダーとそれに続くクロスエンコーダー リランカー) を構築し、BioBERT-ST と調整されていないスペイン語エンコーダーに対して評価します。バイエンコーダー単独では、MRR (0.876 対 0.866) で BioBERT-ST に匹敵し、英国の生物医学的事前トレーニングなしで R@3 (0.650 対 0.626) および R@5 (0.804 対 0.790) でそれを上回ります。クロスエンコーダーのリランカーを追加すると、合計 R@5 が 0.822 に上昇し、英語のわずかな後退を犠牲にして、5 言語のうち 4 言語 (+0.017 スペイン語、+0.033 カタルーニャ語、+0.018 フランス語、+0.037 ポルトガル語) で優勢になります。このトレードオフは臨床的に許容可能です。ポルトガル語では R5 = 0.829 に達するのに対し、BioBERT-ST では 0.714 に達します。貢献: LLM で生成されたデータからドメイン固有のメディカル レトリバーを構築するためのオープン レシピ。学習ゲインの定量化 (MRR 0.755 ~ 0.876、~19,500 の合成ペアで +15.9%)。そして、言語とランクごとに利益が集中する場所の特徴付け。
原文 (English)
Generalistic or Specific Embeddings, Which is Better? An Empirical Study on Search for Clinical Coding in Non-English Languages
Sentence-embedding models for semantic search are overwhelmingly developed and evaluated on English corpora. When applied to clinical retrieval in other languages -- particularly retrieval of ICD-10-CM / CIE-10 codes -- recall degrades in ways often masked by aggregate benchmarks. We study whether large generative language models can serve as data factories to close this gap. We build a two-stage retriever (bi-encoder followed by cross-encoder reranker), fine-tuned from a Spanish biomedical encoder (PlanTL-GOB-ES/bsc-bio-ehr-es) on Gemini-generated synthetic data covering English, Spanish, Catalan, Italian, Portuguese and French, and evaluate against BioBERT-ST and the un-tuned Spanish encoder. The bi-encoder alone matches BioBERT-ST on MRR (0.876 vs. 0.866) and overtakes it on R@3 (0.650 vs. 0.626) and R@5 (0.804 vs. 0.790) without English biomedical pretraining. Adding a cross-encoder reranker lifts aggregate R@5 to 0.822 and dominates on four of five languages (+0.017 Spanish, +0.033 Catalan, +0.018 French, +0.037 Portuguese) at the cost of a small English regression. The trade-off is clinically acceptable: Portuguese reaches R@5 = 0.829 vs. BioBERT-ST's 0.714. Contributions: an open recipe for building domain-specific medical retrievers from LLM-generated data; quantification of the learning gain (MRR 0.755 to 0.876, +15.9% with ~19,500 synthetic pairs); and a characterisation of where gains concentrate by language and rank.
見ることは知ることではない: VLM は空間に関する質問に答えるべきでない場合 (およびその理由) を知っていますか?
空間推論は、現実世界の環境に展開されるビジョン言語モデル (VLM) の基本的な機能です。ただし、視覚的な観察は本質的に 3D 世界の限られた表現です。オクルージョンによってオブジェクトが見えなくなったり、遠近法によって幾何学的特性が誤解を招く可能性があります。それにもかかわらず、既存の空間推論ベンチマークは通常、観測が十分で信頼できると想定しており、質問に答えられない場合や追加の観測が必要であることをモデルが認識するかどうかではなく、モデルが正しい答えを生成するかどうかに焦点を当てています。この研究では、制御された評価フレームワークである SpatialUncertain を構築し、(1) ターゲットの情報を隠すオクルージョン、および (2) 誤解を招く視覚的な手がかりを生み出す視点の曖昧さという 2 種類の観察の課題を導入することで、この仮定に挑戦します。それぞれの構成について、クリーンな観察の下では答えられるが、導入された課題の下では棄権が必要となる空間的な質問を設計します。さらに、どの追加視点が視点の曖昧さを解決するかをモデルが特定できるかどうかを評価します。最先端のオープンソースおよびクローズドソース VLM の多様なセットにわたる結果から、2 つの一貫した障害モードが明らかになりました。まず、モデルは自信過剰な回答をする傾向があり、視覚的証拠が不完全であるか誤解を招く場合でも空間推論タスクを解決しようとし、平均精度はオクルージョンの場合は約 30%、遠近の曖昧さの場合は 10% 未満です。第 2 に、追加のビューが利用可能な場合でも、一部のモデルは信頼できる証拠を提供するものをほぼランダムに特定します。まとめると、私たちの調査結果は、回答の正しさを超えて、モデルがいつ棄権すべきか、そして信頼できる証拠を探す方法を知っているかどうかを評価することを求めています。
原文 (English)
Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
Spatial reasoning is a fundamental capability for vision-language models (VLMs) deployed in real-world environments. However, visual observations are inherently limited representations of a 3D world: occlusion can render objects invisible, and perspective can make geometric properties misleading. Despite this, existing spatial reasoning benchmarks typically assume that observations are sufficient and reliable, focusing on whether models produce correct answers rather than whether they recognize when a question cannot be answered and what additional observations would be needed. In this work, we challenge this assumption by constructing a controlled evaluation framework, SpatialUncertain, and introducing two types of observation challenges: (1) occlusion, which hides target information, and (2) perspective ambiguity, which produces misleading visual cues. For each configuration, we design spatial questions that are answerable under clean observations but require abstention under the introduced challenges. We further evaluate whether models can identify which additional viewpoints would resolve perspective ambiguity. Our results across a diverse set of frontier open- and closed-source VLMs reveal two consistent failure modes. First, models are prone to overconfident answering, attempting to solve spatial reasoning tasks even when visual evidence is incomplete or misleading, with average accuracy around 30\% under occlusion and below 10\% under perspective ambiguity. Second, even when additional views are available, some models perform near random chance in identifying which would provide reliable evidence. Together, our findings call for moving beyond answer correctness toward evaluating whether models know when to abstain and how to seek reliable evidence.
VLM3: ビジョン言語モデルはネイティブ 3D 学習者です
ビジョン言語モデル (VLM) を使用すると、統合モデルがプロンプトを通じてさまざまなビジョン タスクを解決できるようになります。彼らは意味理解において有望なパフォーマンスを示しました。しかし、3D の理解は依然として、複雑なタスク固有の設計を備えた専門家のビジョン モデルに大きく依存しています。この研究が主張したい重要な議論は、VLM はネイティブ 3D 学習者であるということです。私たちの詳細な大規模研究により、効果的な 3D 学習に必要なのは、1) 焦点距離の統一、2) テキストベースのピクセル参照、3) データの混合とスケーリングだけであることがわかりました。モデル アーキテクチャの変更、大規模なモデル、大量のデータの増加、および回帰式を含む複雑な損失 (その多くはエキスパート ビジョン モデルの基礎を形成します) は、実際には必要な条件ではありません。その結果、標準的な VLM が多様な 3D タスクを習得できるようにする、最もシンプルな設計を備えたスケーラブルな方法である VLM3 を提案します。 VLM3 は、VLM 深度推定精度を大幅に向上させるだけでなく (0.84 -> 0.9)、標準アーキテクチャとテキストベースのトレーニングを維持しながら、ピクセル対応付け、カメラポーズ推定、オブジェクトレベルの 3D 理解などの多様な 3D タスクを可能にし、エキスパートのビジョンモデルの精度と一致させます。私たちは、VLM3 がシンプルでスケーラブルな 3D 学習の新しいパラダイムを切り開くと信じています。
原文 (English)
VLM3: Vision Language Models Are Native 3D Learners
Vision Language Models (VLMs) enable a unified model to solve various vision tasks through prompting. They have shown promising performance in semantic understanding. However, 3D understanding still largely relies on expert vision models with complex task-specific designs. The key argument this work wants to make is that VLMs are native 3D learners. Our in-depth large scale study shows that 1) focal length unification, 2) text-based pixel reference and 3) data mixture and scaling, are all you need for effective 3D learning. Model architecture changes, large models, heavy data augmentations, and complex losses including the regression formulation, many of which form the foundation of expert vision models, are actually not necessary conditions. As a result, we propose VLM3, a scalable method with the simplest design that enables standard VLMs to master diverse 3D tasks. VLM3 not only advances the VLM depth estimation accuracy by a large margin (0.84 -> 0.9), but also enables diverse 3D tasks such as pixel correspondence, camera pose estimation and object-level 3D understanding, matching expert vision model accuracy while maintaining standard architectures and text-based training. We believe VLM3 opens up a new paradigm for simple and scalable 3D learning.
メモリに依存するが帯域幅に制限はない: Batch-1 LLM デコードにおける物理 AI 推論のギャップ
ロボット、自動運転車、具体化されたエージェント、エッジ コパイロットなどの物理 AI システムは、多くの場合、クラウド LLM サービスとは異なる推論ワークロードを実行します。つまり、単一ストリーム、バッチ 1 の自己回帰デコードで、1 つのロボット、カメラ フィード、またはユーザー セッションが次のトークンを待機します。このワークロードは通常、メモリ帯域幅制限として説明されます。各デコード ステップはモデルの重みとアクティブな KV キャッシュをストリーミングするため、レイテンシはピーク HBM 帯域幅に合わせて調整する必要があります。この説明は真実であるが不完全であることを示します。 4 つの NVIDIA GPU (H100 SXM5、A100-80GB SXM4、L40S、L4) にわたる 3 つの 7 ~ 8B クラス GQA トランスフォーマーのバッチ 1 デコードを測定します。 2048 から 16384 までのコンテキスト長を評価し、制御された bf16 SDPA セットアップの下で 44 個の有効なセルを生成します。ピーク HBM 帯域幅の達成割合は、ピーク帯域幅が増加するにつれて減少します。見出しの Qwen-2.5-7B ctx=2048 セルでは、L4 は分析メモリ フロアの約 81% に達しますが、H100 はわずか 27% に達します。物理 AI デコードはメモリに依存しますが、メモリの高速化は比例したレイテンシーの増加にはつながりません。 CUDA Graphs A/B 実験を使用して、欠落している用語をテストします。 ctx=2048 の H100 では、CUDA グラフは N=10 の新しいセッション全体でデコード レイテンシを 1.259 倍改善し、95 パーセントのブートストラップ信頼区間は 1.253 ~ 1.267 でした。 L4 では、同じ介入では 1.028 倍しか得られません。これにより、高速な GPU では可視化される起動側のオーバーヘッドが分離されますが、低速で帯域幅に制限のある GPU ではほとんど隠れたままになります。デプロイメントの意味は、メモリの節約が重要になるのは、ランタイムがメモリの節約を実現した場合だけであるということです。 L4 では、bf16 デコードはメモリ フロア近くにありますが、共通の量子化パスでは予想される 4 倍の重みトラフィック削減が回復されません。62.32 ミリ秒の bf16 ベースラインから、bnb-nf4 は 59.36 ミリ秒/ステップに達し、AutoAWQ+Marlin は 45.24 ミリ秒/ステップに達します。 Ada で調整された int4 カーネルを使用した GPTQ+ExLlamaV2 は、17.36 ミリ秒/ステップに達します。
原文 (English)
Memory-Bound but Not Bandwidth-Limited: The Physical AI Inference Gap in Batch-1 LLM Decode
Physical AI systems, including robots, autonomous vehicles, embodied agents and edge copilots, often run a different inference workload from cloud LLM serving: single-stream, batch-1 autoregressive decode, where one robot, camera feed or user session waits on the next token. This workload is usually described as memory-bandwidth-bound. Each decode step streams model weights and the active KV cache, so latency should scale with peak HBM bandwidth. We show that this account is true but incomplete. We measure batch-1 decode for three 7 to 8B-class GQA transformers across four NVIDIA GPUs: H100 SXM5, A100-80GB SXM4, L40S and L4. We evaluate context lengths from 2048 to 16384, producing 44 valid cells under a controlled bf16 SDPA setup. The achieved fraction of peak HBM bandwidth falls as peak bandwidth rises. On the headline Qwen-2.5-7B ctx=2048 cell, an L4 reaches roughly 81 percent of its analytic memory floor, while an H100 reaches only 27 percent. Physical-AI decode is memory-dominated, but faster memory does not translate into proportional latency gains. We test the missing term with a CUDA Graphs A/B experiment. On H100 at ctx=2048, CUDA Graphs improves decode latency by 1.259x across N=10 fresh sessions, with a 95 percent bootstrap confidence interval of 1.253 to 1.267. On L4, the same intervention gives only 1.028x. This isolates a launch-side overhead that becomes visible on fast GPUs but remains mostly hidden on slower, bandwidth-bound GPUs. The deployment implication is that memory savings matter only when the runtime realises them. On L4, bf16 decode sits close to the memory floor, but common quantised paths do not recover the expected 4x weight-traffic reduction: bnb-nf4 reaches 59.36 ms/step and AutoAWQ+Marlin reaches 45.24 ms/step from a 62.32 ms bf16 baseline. GPTQ+ExLlamaV2, with Ada-tuned int4 kernels, reaches 17.36 ms/step.
Industrial Visual Sim-to-Real の先行利用可能性: CAD ガイド付きレジームと CAD を使用できないレジームのレビュー
産業用ビジュアルのシミュレーションとリアルの変換は、合成画像から実際の画像への変換としてよく説明されますが、産業への展開には通常、入手可能な証拠と必要な決定の間の広範な不一致が伴います。システムは、CAD レンダリング、シミュレートされた RGB-D 観察、通常の参照画像、合成欠陥、事前トレーニングされた特徴空間、または言語プロンプトから構築できますが、さまざまなセンサー、照明、材料、器具、キャリブレーション、生産変動、まれな欠陥モードの下で展開することもできます。このレビューでは、産業用ビジュアルのシミュレーションとリアルを、事前の利用可能性によって整理されたドメインギャップの問題として再構成します。明示的なオブジェクト ジオメトリがレンダリング、キャリブレーション、姿勢推定、セグメンテーション、テスト時の幾何学的検証をサポートできる CAD で利用可能な設定を区別します。 CAD では利用できない設定。ジオメトリが法線参照の外観、特徴分布、教師と生徒の残差、合成異常の仮定、基礎特徴、または視覚言語事前分布に置き換えられます。境界優先設定では、近似モデル、テンプレート、参照ビュー、またはセマンティック対応関係が CAD の役割の一部のみを保持します。この枠組みは、CAD ベースの検出および 6D 姿勢推定の文献を、通常は個別にレビューされる産業異常および表面検査の文献と結び付けます。分類を具体化するために、T-LESS/BOP、MVTec AD、および VisA の経験的アンカーを使用します。アンカーは、CAD レンダリング数だけでは転送が終了しないことを示しています。線源分散設計、検出器の容量、小規模な実際のキャリブレーションの方が重要になる場合があります。また、CAD ではテスト時にマスク、ポーズ、深度の一貫性を通じて明確な検証チャネルが作成されるのに対し、CAD では利用できない検査は校正された正規性と特徴の偏差に依存していることも示しています。したがって、このレビューでは、単一のタスク間リーダーボードに反対し、その代わりに導入決定の事前の根拠を尋ねています。
原文 (English)
Prior Availability in Industrial Visual Sim-to-Real: A Review of CAD-Guided and CAD-Unavailable Regimes
Industrial visual sim-to-real is often described as transferring from synthetic images to real images, but industrial deployment usually involves a broader mismatch between available evidence and required decisions. A system may be built from CAD renderings, simulated RGB-D observations, normal reference images, synthetic defects, pretrained feature spaces, or language prompts, yet deployed under different sensors, lighting, materials, fixtures, calibration, production variation, and rare defect modes. This review reframes industrial visual sim-to-real as a domain-gap problem organized by prior availability. We distinguish CAD-available settings, where explicit object geometry can support rendering, calibration, pose estimation, segmentation, and test-time geometric verification; CAD-unavailable settings, where geometry is replaced by normal-reference appearance, feature distributions, teacher-student residuals, synthetic anomaly assumptions, foundation features, or vision-language priors; and boundary-prior settings, where approximate models, templates, reference views, or semantic correspondences preserve only part of the CAD role. This framing connects CAD-based detection and 6D pose-estimation literature with industrial anomaly and surface-inspection literature that is usually reviewed separately. To make the taxonomy concrete, we use empirical anchors on T-LESS/BOP, MVTec AD, and VisA. The anchors show that CAD render count alone does not close transfer; source-distribution design, detector capacity, and small real calibration can matter more. They also show that CAD at test time creates a distinct verification channel through mask, pose, and depth consistency, whereas CAD-unavailable inspection relies on calibrated normality and feature deviation. The review therefore argues against a single cross-task leaderboard and instead asks what prior grounds the deployment decision.
タービンガスの温度劣化を予測するための機械学習の不確実性の定量化手法のベンチマーク
最新のエンジンの効果的な予後と健全性管理は、信頼性と安全性を確保するための正確なタービンガス温度予測と堅牢な不確実性の定量化に依存しています。この論文では、タービン ガス温度のニューラル ネットワーク予測の不確実性を捉える手段として、予測区間を構築するための 5 つの主要なアプローチ、つまりデルタ法、ベイジアン モンテカルロ ドロップアウト、ブートストラップ法、下限上限推定、および平均分散推定の 5 つのアプローチを調査します。各アプローチは、ハイパーパラメーターの選択のための相互検証、パフォーマンスの堅牢性のための繰り返しのトレーニング テスト分割、および間隔の精度と厳密さの両方を評価するための複数のメトリクスを採用する統一された実験フレームワーク内で実装されます。特に、カバレッジ確率、正規化された平均予測間隔幅、およびカバレッジ幅に基づく基準が測定され、各手法の信頼性と鮮明さが包括的に評価されます。代表的なタービンガス温度データセットに対して行われた実験では、間隔の適用範囲、幅、安定性の点で 5 つの方法間の明確なトレードオフが明らかになりました。これらの発見は、エンジンの健全性管理と予測における予測間隔手法を選択および調整するための実用的なガイドを提供し、実際のアプリケーションでの解釈可能性と精度の両方を保証します。
原文 (English)
Benchmarking Machine Learning Uncertainty Quantification Methodologies for Predicting Turbine Gas Temperature Degradation
Effective prognostics and health management of modern engines relies on accurate turbine gas temperature predictions and robust uncertainty quantification to ensure reliability and safety. This paper investigates five major approaches for constructing prediction intervals -- namely the Delta method, Bayesian Monte Carlo Dropout, Bootstrap method, Lower-Upper Bound Estimation, and Mean-Variance Estimation -- as a means of capturing the uncertainty in neural network predictions of turbine gas temperature. Each approach is implemented within a unified experimental framework that employs cross-validation for hyperparameter selection, repeated train-test splits for performance robustness, and multiple metrics to evaluate both the accuracy and tightness of the intervals. In particular, Coverage Probability, Normalized Mean Prediction Interval Width, and the Coverage Width-based Criterion are measured to comprehensively assess each method's reliability and sharpness. Experiments conducted on a representative turbine gas temperature dataset reveal distinct trade-offs among the five methods in terms of interval coverage, width, and stability. These findings provide a practical guide for selecting and tuning prediction interval methods in engine health management and prognostics, ensuring both interpretability and precision in real-world applications.
ImmigrationQA: ソースに基づいたデータセットと米国移民法への小規模モデルの適応
米国の移民法は数千ページにわたる公式政策、連邦規制、手続き上のガイダンスで構成されており、頻繁に変更され、法的代理人を持たない申請者にとっては大きなリスクを伴います。 13 の移民サブドメインにわたる 17,058 ペアのソースベースの質問応答データセットである ImmigrationQA の構築と、パラメーター効率の高い LoRA を使用したそのデータセットに対する Llama 3.2 3B Instruct モデルの微調整について説明します。このコーパスは、USCIS 政策マニュアル、8 つの CFR、BIA の先例決定、コミュニティ Q&A を含む 11 の一次および二次情報源から集められ、10,056 の検証済みの正規文書と 18,308 のテキスト チャンクが得られました。構造化 QA ペアは、5 つのモード固有のプロンプトを介して Claude Sonnet 4.6 を使用してこれらのチャンクから生成され、ソース スパンのオーバーラップが不十分なために 22 ペアが拒否されました。微調整されたモデルは、101 例の層別サンプルに対する LLM-as-judge スコアリングを使用して、993 ペアのホールドアウト スプリットに対して評価されました。微調整モデルのスコアは平均 1.08/3.0 (完全正解率 16.8%、層別評価 101 例) に対し、Llama 3 8B 基本モデルのスコアは 0.85/3.0 (完全正解率 4%) で、平均スコアが 27% 相対的に向上しました。ゼロショットのクロード・ソネットのベースラインのスコアは 1.52/3.0 (25% 完全正解) でした。微調整されたモデルでは、複雑な法的推論や時間制限のある統計については依然として弱いものの、手続き上のサブドメイン (渡航書類、ステータスの調整、非移民ビザ) が集中的に改善されていることが示されています。パイプライン全体は、クラウド コンピューティングで約 29 ドルで実行されました。データセット、モデル、コード、プロンプト テンプレートなどのすべてのアーティファクトは公開されています。このシステムは弁護士に代わるものではなく、コーパス クロール日以降の規制変更は反映されません。
原文 (English)
ImmigrationQA: A Source-Grounded Dataset and Small-Model Adaptation for U.S. Immigration Law
U.S. immigration law spans thousands of pages of official policy, federal regulations, and procedural guidance that change frequently and carry high stakes for petitioners who lack legal representation. We describe the construction of ImmigrationQA, a source-grounded question-answering dataset of 17,058 pairs across 13 immigration subdomains, and the fine-tuning of a Llama 3.2 3B Instruct model on that dataset using parameter-efficient LoRA. The corpus was assembled from 11 primary and secondary sources -- including the USCIS Policy Manual, 8 CFR, BIA precedent decisions, and community Q&A -- yielding 10,056 validated canonical documents and 18,308 text chunks. Structured QA pairs were generated from these chunks using Claude Sonnet 4.6 via five mode-specific prompts, with 22 pairs rejected for insufficient source-span overlap. The fine-tuned model was evaluated against a held-out split of 993 pairs using LLM-as-judge scoring on a 101-example stratified sample. The fine-tuned model scored a mean of 1.08/3.0 (16.8% fully correct; 101-example stratified eval) versus the Llama 3 8B base model at 0.85/3.0 (4% fully correct), a relative improvement of 27% in mean score; a zero-shot Claude Sonnet baseline scored 1.52/3.0 (25% fully correct). The fine-tuned model shows concentrated improvement in procedural subdomains (travel documents, adjustment of status, nonimmigrant visas) while remaining weak on complex legal reasoning and time-sensitive statistics. The full pipeline ran for approximately $29 in cloud compute. All artifacts -- dataset, model, code, and prompt templates -- are publicly released. The system is not a substitute for legal counsel and does not reflect regulatory changes after the corpus crawl date.
反事実的な評価により、臨床 LLM とエージェントの隠れた能力プロファイルが明らかになる
2 つの臨床 AI システムは、カバレッジベースのルーブリックではほぼ同じスコアを獲得できますが、患者の入力が変化すると根本的に異なる動作をします。1 つは新しい臨床信号に一致するように推奨事項を更新しますが、もう 1 つはそれに関係なく同じ出力を生成します。因果感受性スコア (CSS) を導入します。これは、臨床的に意味のある 5 つの次元 (バイオマーカーの反転、前治療の失敗、バイオマーカーの除去、手術状態の変化、ステージの摂動) に沿って腫瘍腫瘍ボードの症例を変異させる事前登録された介入指標であり、各モデルが事前に登録された正しい方向で推奨事項を更新するかどうかを {0、0.5、1.0} スケールを使用してスコア付けします。カバレッジベースの加重リコール指標であるコンセンサス マッチ スコア (CMS) に対してベンチマークを行ったところ、224 件のケースにわたる単発推論で評価された 3 つのラボの 6 つのフロンティア モデルが、ほぼ逆の順位でランク付けされました。6 つのモデルすべてがランクを変更し、CMS で最も悪いモデルが CSS で最も優れたモデルになり、上位中位の 1 つの CMS モデルが CSS で最下位にランクされました。さらに、普遍的な安全性の盲点も明らかになりました。つまり、すべてのフロンティア モデルは手術状態の介入で失敗します (ファミリー D では最大 17.2% の CSS)。これは CMS では明らかにされていません。この指標は、ツールを使用するエージェントにも伝達されます。ReAct スタイルの実験では、ツールの使用により 6 つのモデルのうち 5 つのモデルで CSS が向上しました (+2.5 ~ +20.3 パーセント ポイント)。それでも、CSS が最も低いモデルは同じグラフ セクションを取得し、依然として推奨事項を更新できません。これは、反事実の評価下でのみ表示される構造的な応答性の欠陥を明らかにしています。裁判官間の複製と 3 人の評価者の医療専門家による検証により、総合的な結果が確認されます。 CSS のような事前登録された介入指標は、臨床 AI エージェントのカバレッジベースの評価を補完します。これらは、カバレッジ指標では見逃される応答性を捕捉し、将来のエージェント RL システムに候補となる密な報酬シグナルを提供します。
原文 (English)
Counterfactual Evaluation Reveals Hidden Capability Profiles in Clinical LLMs and Agents
Two clinical AI systems can score nearly identically on coverage-based rubrics yet behave radically differently when their patient inputs change: one updates its recommendations to match the new clinical signal, while the other produces the same output regardless. We introduce the Causal Sensitivity Score (CSS), a pre-registered interventional metric that mutates oncology tumor-board cases along five clinically meaningful dimensions - biomarker flips, prior-treatment failures, biomarker removals, surgery-status changes, and stage perturbations - and scores whether each model updates its recommendations in the pre-registered correct direction using a {0, 0.5, 1.0} scale. Benchmarked against the Consensus Match Score (CMS), a coverage-based weighted recall metric, six frontier models from three labs evaluated in single-shot inference across 224 cases rank in nearly opposite orders: all six models change rank, the CMS-worst model becomes CSS-best, and one upper-mid CMS model ranks last on CSS. We further surface a universal safety blind spot: every frontier model fails on surgery-status interventions (at most 17.2% CSS on Family D), a finding CMS does not expose. The metric also transfers to tool-using agents: in a ReAct-style experiment, tool use improves CSS for five of six models (+2.5 to +20.3 percentage points), yet the lowest-CSS model retrieves the same chart sections and still fails to update its recommendations - revealing a structural responsiveness deficit visible only under counterfactual evaluation. Cross-judge replication and three-rater medical-professional validation confirm the aggregate findings. Interventional pre-registered metrics like CSS complement coverage-based evaluation for clinical AI agents: they capture responsiveness that coverage metrics miss and offer a candidate dense reward signal for future agentic RL systems.
エンジンの状態管理と残存耐用年数予測のための科学的機械学習
エンジン健全性管理 (EHM) は、残存耐用年数 (RUL) の信頼できる予測と、タービン ガス温度 (TGT) などの熱指標の追跡に依存しています。実際には、現実世界のフリートデータは異質かつ非定常であり、リスクを意識したメンテナンスの決定には点予測だけでは不十分です。この論文では、経験的範囲が評価される予測間隔の形式で定量化された不確実性を使用して、トリムされていないタービン ガス温度 (TGTU)、デルタ タービン ガス温度 (DTGT)、および RUL を共同で予測する、タービン予後のためのマルチタスクの科学的機械学習フレームワークを紹介します。共有シーケンス エンコーダー (残差双方向 LSTM 層とアテンション プーリングを備えた畳み込みフロントエンド) は、確率回帰の平均分散推定、およびオプションでしきい値ベースのイベント モデリングの生存ヘッドを含むタスク固有のヘッドを供給します。このフレームワークは、社内のポリシーや独自の基準に合わせて展開できるように、実践者向けの少数のパラメーター (DTGT しきい値ルールや RUL ターゲット構築など) を介して調整できるように設計されています。提案されたフレームワークの予測パフォーマンスは、平均絶対誤差 (MAE)、予測区間カバレッジ確率 (PICP)、平均予測区間幅 (MPIW)、およびカバレッジ幅基準 (CWC) を含むポイントメトリクスと区間メトリクスの両方を使用して評価されます。結果は、運航状況の影響を強調し、不確実性を意識したモニタリングをサポートするために、飛行段階および保守セグメントごとに集計および階層化して報告されます。
原文 (English)
Scientific Machine Learning for Engine Health Management and Remaining Useful Life Prediction
Engine Health Management (EHM) depends on reliable forecasting of Remaining Useful Life (RUL) and on tracking thermal indicators such as turbine gas temperature (TGT). In practice, real-world fleet data are heterogeneous and non-stationary, and point predictions alone are insufficient for risk-aware maintenance decisions. This paper presents a multi-task scientific machine learning framework for turbine prognostics that jointly predicts turbine gas temperature untrimmed (TGTU), Delta Turbine Gas Temperature (DTGT), and RUL, with quantified uncertainty in the form of prediction intervals whose empirical coverage is evaluated. A shared sequence encoder (convolutional front-end with residual bidirectional LSTM layers and attention pooling) feeds task-specific heads, including mean--variance estimation for probabilistic regression and, optionally, a survival head for threshold-based event modeling. The framework is designed to be tunable via a small set of practitioner-facing parameters (e.g., DTGT thresholding rules and RUL target construction) so that deployment can align with in-house policies and proprietary criteria. The predictive performance of the proposed framework is evaluated using both point and interval metrics, including mean absolute error (MAE), prediction interval coverage probability (PICP), mean prediction interval width (MPIW), and the coverage--width criterion (CWC). Results are reported both in aggregate and stratified by flight phase and maintenance segment to highlight operational-context effects and to support uncertainty-aware monitoring.
規制されたサイバーセキュリティ運用のための、組織を対象とした LLM エージェント ランタイム アーキテクチャ
規制されたサイバーセキュリティ ワークフローには、モデルに依存せずローカルに展開可能でありながら、取得、ツール呼び出し、メモリ、調査結果、レポート、監査にわたる組織レベルの範囲を強制するランタイム基盤がありません。最近の大規模言語モデル (LLM) エージェント システムは、分離されたサイバーセキュリティ タスクに関して優れた結果を報告しますが、規制されたセキュリティ オペレーション センター (SOC) およびコンプライアンス ワークフローのための監査可能なプラットフォーム アーキテクチャをそれ自体で定義するわけではありません。そこでは、1 人のアナリストが組織を束縛するアクションをトリガーする可能性があり、ランタイムはスタンドアロンの分析レイヤーとして動作するのではなく、コンテキストおよびアラート駆動トリガーの主要なソースとして既存の SIEM/XDR スタックと統合する必要があります。このペーパーでは、金融サイバーセキュリティのための、組織を対象とした LLM エージェント ランタイム アーキテクチャを提案します。このコントリビューションは、ファーストクラスのトリガーとして取り込まれた SIEM/XDR 通知を含むすべてのエントリ ポイントで作成され、すべてのコンポーネント境界で強制される型指定されたセキュリティ コンテキストであり、共有ランタイム コア、論理専門サブエージェント、統一ポリシーと監査の下で SIEM/XDR クエリ、エンリッチメント、および応答プリミティブを公開する管理されたツール アダプター レイヤー、証拠参照を含む構造化された調査結果、階層化された人間参加型 (HITL) ゲートと組み合わせられます。追加のみの監査。モデル コンテキスト プロトコル (MCP)、拡張テレメトリ、ペネトレーション テスト用のデジタル ツイン、グラフ取得、フェデレーテッド ナレッジ共有は、実行時の必須の前提条件ではなく、オプションの拡張パスとして扱われます。私たちは、実装可能なスライスをアーキテクチャのテスト可能性面として記述し、アーキテクチャの準備状況、セキュリティ ポリシーの適用、証拠のトレーサビリティ、出力品質、および運用の可観測性に関するメトリック レベルの合格基準を備えた改ざん可能な評価計画を提案します。
原文 (English)
An Organization-Scoped LLM Agent Runtime Architecture for Regulated Cybersecurity Operations
Regulated cybersecurity workflows lack a runtime substrate that enforces organization-level scope across retrieval, tool calls, memory, findings, reports, and audit while remaining model-agnostic and locally deployable. Recent large language model (LLM) agent systems report strong results on isolated cybersecurity tasks, yet they do not by themselves define an auditable platform architecture for regulated security operations centre (SOC) and compliance workflows, where a single analyst may trigger actions that bind the organization, and where the runtime must integrate with existing SIEM/XDR stacks as a primary source of context and alert-driven triggers rather than operate as a standalone analytical layer. This paper proposes an organization-scoped LLM agent runtime architecture for financial cybersecurity. The contribution is a typed Security Context that is created at every entry point, including SIEM/XDR notifications ingested as first-class triggers, and enforced at every component boundary, combined with a shared Runtime Core, logical specialist subagents, a governed Tool Adapter Layer exposing SIEM/XDR query, enrichment, and response primitives under uniform policy and audit, structured findings with evidence references, tiered human-in-the-loop (HITL) gates, and append-only audit. Model Context Protocol (MCP), extended telemetry, digital twins for pentesting, graph retrieval, and federated knowledge sharing are treated as optional extension paths rather than mandatory runtime assumptions. We describe an implementable slice as the architecture's testability surface, and we propose a falsifiable evaluation plan with metric-level pass criteria for architecture readiness, security-policy enforcement, evidence traceability, output quality, and operational observability.
Crafter: 多様な入力から編集可能な科学図を生成するためのマルチエージェント ハーネス
科学的な数字は、複雑な研究アイデアを伝達する最も効果的な手段の 1 つですが、出版物に匹敵するイラストの作成は、依然として論文作成の中で最も労力を要する部分の 1 つです。既存の自動化システムはそれぞれ、テキストのみの入力で単一の図タイプをターゲットにしており、研究者が実際に使用するタイプと条件の多様性は未解決のままです。さらに、ラスター出力をローカルで修正することはできません。科学的図形は個別の意味論的コンポーネントの構造化された構成であるため、そのようなレイアウト上で局所的なエラー ジェネレータが生成する場合、より強力なバックボーンではなくハーネスが必要です。このハーネスを 2 つの相補的なシステムでインスタンス化します。Crafter は、アーキテクチャを変更せずに図のタイプと入力条件全体を汎用化する図生成用のマルチエージェント ハーネスです。もう 1 つは、同じパターンを適用してラスター出力を編集可能な SVG に変換する CraftEditor です。さらに、人間品質の注釈を備えた 3 つの図形タイプと 4 つの入力条件にわたるベンチマークである CraftBench を紹介します。実験では、Crafter がスタンドアロン ジェネレーターと PaperBanana-Bench および CraftBench のエージェント ベースラインの両方を大幅に上回るパフォーマンスを示し、アブレーションにより各コンポーネントの独立した寄与が確認されました。 CraftEditor は、出力をすべてのベースラインを超える編集可能な SVG に忠実に変換します。私たちのコードとベンチマークは https://github.com/HaozheZhao/Crafter で入手できます。
原文 (English)
Crafter: A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs
Scientific figures are among the most effective means of communicating complex research ideas, yet producing publication-quality illustrations remains one of the most labor-intensive parts of paper preparation. Existing automated systems each target a single figure type under text-only input, leaving the diversity of types and conditions researchers actually use unaddressed; their raster outputs further cannot be locally revised. Because scientific figures are structured compositions of discrete semantic components, the localized errors generators produce on such layouts demand not a stronger backbone but a harness. We instantiate this harness in two complementary systems: Crafter, a multi-agent harness for figure generation that generalizes across figure types and input conditions without architectural changes, and CraftEditor, which applies the same pattern to convert raster outputs into editable SVGs. Moreover, we introduce CraftBench, a benchmark spanning three figure types and four input conditions with human quality annotation. Experiments show that Crafter substantially outperforms both standalone generators and the agentic baseline on PaperBanana-Bench and CraftBench, with ablations confirming each component's independent contribution; CraftEditor faithfully converts outputs into editable SVGs that surpass all baselines. Our code and benchmark are available at https://github.com/HaozheZhao/Crafter.
Best-of-$N$ の嗜好データからの報酬学習: ターゲット、トレードオフ、設計原則
Best-of-$N$ サンプリングは、ペアごとの選好データを構築するために広く使用されています。$N$ の候補は基本分布から抽出され、最良のものは拒否された応答とペアになります。広く使用されているにもかかわらず、Bradley-Terry (BT) の報酬学習がそのようなデータから何を抽出するのか、また $N$ と基本分布をどのように選択するのかは不明のままです。私たちは、Best-of-$N$ への条件付き分布による嗜好データの最近の分析に特化しています。独立参照バリアントの場合、$N$ と基本分布の明示的な関数として閉じた形式の報酬ターゲットを導出し、それらが潜在的な報酬ランキングを保存することを示します。実際の Best-vs-Random および Best-vs-Worst のバリアントでは、選択された応答と拒否された応答が同じ候補セットを介して結合されるため、正確な BT 表現性は通常失敗します。それにもかかわらず、$N$ が増加するにつれて、有界クラス ミニマイザーは参照ターゲットに近づきます。マージンと接続性は、ペアワイズ優先学習におけるサンプル効率を左右することが知られていますが、Best-of-$N$ は、$N$ を介して反対方向に結合します。$N$ が大きいと、ペアワイズ マージンが広がりますが、接続性が低下します。このトレードオフにより、2 つの設計原則が得られます。優先ラベルがボトルネックの場合は、より大きな $N$ を使用し、生成がボトルネックの場合は、より小さな $N$ を使用します。そして、テスト時に比較が最も重要となる応答間に質量を配置するように基本分布を形成します。合成および実際の選好データに関する実験は、サンプル サイズと基本分布形状への予測された依存性を裏付けています。
原文 (English)
Reward Learning from Best-of-$N$ Preference Data: Targets, Tradeoffs, and Design Principles
Best-of-$N$ sampling is widely used to construct pairwise preference data: $N$ candidates are drawn from a base distribution, and the best is paired with a rejected response. Despite its widespread use, what Bradley--Terry (BT) reward learning extracts from such data, and how to choose $N$ and the base distribution, remain unclear. We specialize a recent analysis of preference data via its induced conditional distribution to Best-of-$N$. For independent-reference variants, we derive closed-form reward targets as explicit functions of $N$ and the base distribution, and show that they preserve the latent reward ranking. For the practical Best-vs-Random and Best-vs-Worst variants, chosen and rejected responses are coupled through the same candidate set, so exact BT representability generally fails; nevertheless, bounded-class minimizers approach the reference targets as $N$ grows. Although margin and connectivity are known to govern sample efficiency in pairwise preference learning, Best-of-$N$ couples them through $N$ in opposing directions: larger $N$ widens pairwise margins but reduces connectivity. This trade-off yields two design principles: use larger $N$ when preference labels are the bottleneck, smaller $N$ when generation is the bottleneck; and shape the base distribution to place mass between the responses whose comparison matters most at test time. Experiments on synthetic and real preference data support the predicted dependence on sample size and base-distribution shape.
測定値の軌跡を学習するためのアクティブな時点の選択
まばらなスナップショットから連続確率パスを推測することは、単細胞生物学などの分野では根本的な課題です。この分野では、忠実度の高いデータ取得が破壊的であることが多く、法外なシーケンスコストによって制約されます。このため、最適な測定時間を戦略的に選択するためのアクティブ ラーニング戦略の必要性が高まります。ただし、この設定に対するアクティブ ラーニング ポリシーの設計は未解決の問題のままです。ターゲット オブジェクトは、標準ユークリッド計量が不明確に定義されている無限次元の Wasserstein 空間上に存在し、現在の補間方法には認識論的な不確実性の定量化が欠けています。積極的な実験を測定の領域に拡張するフレームワークを紹介します。 Linearized Optimal Transport (LOT) を活用することで、分布スナップショットをガウス過程モデリングに適した接空間にマッピングし、基礎となる確率パスの扱いやすい確率的代理を構築できるようにします。これにより、不確実性を最小限に抑えるために測定時間を繰り返し選択する取得ポリシーが得られます。経験的な結果は、私たちの戦略が合成データセットと現実世界のデータセットの両方で不確実性を無視したベースラインよりも優れていることを示しています。
原文 (English)
Active Timepoint Selection for Learning Measure-Valued Trajectories
Inferring continuous probability paths from sparse snapshots is a fundamental challenge in domains like single-cell biology, where high-fidelity data acquisition is often destructive and constrained by prohibitive sequencing costs. This motivates the need for active learning strategies to strategically select optimal measurement times. However, designing active learning policies for this setting remains an open problem: the target objects reside on the infinite dimensional Wasserstein space where standard Euclidean metrics are ill-defined, and current interpolation methods lack epistemic uncertainty quantification. We introduce a framework which extends active experimentation to the space of measures. By leveraging Linearized Optimal Transport (LOT), we map distributional snapshots into a tangent space amenable to Gaussian Process modeling, allowing us to construct a tractable probabilistic surrogate for the underlying probability path. This yields an acquisition policy that iteratively selects measurement times to minimize uncertainty. Empirical results demonstrate that our strategy outperforms uncertainty-agnostic baselines on both synthetic and real-world datasets.
エラーのアーキテクチャ: 普遍的な不可能性からパッチローカル LLM の信頼性まで
ユニバーサル LLM の信頼性は、有限ライブラリの問題ではありません。考えられるすべてのタスク、ツール、スキーマ、知識ソース、および評価者の期待にわたって、新しい介入で識別可能な障害モードが際限なく現れる可能性があるため、そのようなすべてのモードに対して制限付き残差誤差を保証できる有限介入辞書はありません。しかし、展開されたシステムは宇宙全体で動作するわけではありません。これらは、運用上制限されたパッチ (法的レビュー、医療 RAG、コード修復、カスタマー サポート エージェント、契約抽出) 内で動作し、反復的なタスク、スキーマ、ツール、評価者の期待に応えます。このようなパッチ内では、障害がまばらで反復的であり、小規模な繰り返しカタログに集中していることが経験的証拠から示唆されているため、信頼性は指数関数的なトークン長の問題ではなく、ローカルなカタログの発見と介入のカバレッジの問題になります。この移行を 2 つの命題と 1 つの帰結で形式化します。命題 1 は、最悪の場合のモードに関する否定的な結果です。つまり、有限介入辞書は、境界のない領域のすべての識別可能な故障モードをカバーすることはできません。系 1 は、逆検出の含意です。モード検出の対数上限は、指数関数的により多くのハード障害イベントが観察されない限り、線形的により明確なテール モードに対応することはできません。命題 2 はパッチローカルの肯定的な結果です。対数アクティブ モードのエクスポージャとヘッドヘビーなカバレッジの下では、ハードデシジョンごとの十分な介入バジェットはシーケンスの長さが多対数的に増加し、パッチ カタログが飽和するとドメイン定数になります。フレームワークは、長いコンテキストの困難を解決するのではなく、再配置します。タスクの長さとともに難しい決定の数自体が増加する場合、信頼性は依然として困難です。貢献は、それらの体制を容易にするというよりはむしろ、軸上の介入を特定することである。
原文 (English)
The Architecture of Errors: From Universal Impossibility to Patch-Local LLM Reliability
Universal LLM reliability is not a finite-library problem: across all possible tasks, tools, schemas, knowledge sources, and evaluator expectations, new intervention-distinguishable failure modes can appear without bound, so no finite intervention dictionary can guarantee bounded residual error for every such mode. But deployed systems do not operate over the whole universe. They operate inside operationally bounded patches (legal review, medical RAG, code repair, customer-support agents, contract extraction) with recurring tasks, schemas, tools, and evaluator expectations. Within such patches, empirical evidence suggests failures are sparse, repetitive, and concentrated in a small recurring catalogue, so reliability becomes a local catalogue-discovery and intervention-coverage problem rather than an exponential token-length problem. We formalize this transition with two propositions and one corollary. Proposition 1 is the worst-case-mode-wise negative result: no finite intervention dictionary covers every distinguishable failure mode of an unbounded domain. Corollary 1 is the inverse-discovery implication: the logarithmic upper bound on mode discovery cannot accommodate linearly more distinct tail modes without exponentially more observed hard-failure events. Proposition 2 is the positive patch-local result: under log active-mode exposure and head-heavy coverage, a sufficient per-hard-decision intervention budget grows polylogarithmically in sequence length and becomes domain-constant once the patch catalogue saturates. The framework relocates rather than dissolves long-context difficulty: where the number of hard decisions itself grows with task length, reliability remains hard; the contribution is to identify the on-axis intervention rather than to make those regimes easy.
ヒストグラム正規化された潜在拡散モデルによる制御可能な肺結節合成
自動診断システムはコンピューター断層撮影 (CT) ベースの肺がんスクリーニングで目覚ましい成功を収めていますが、注釈付きの多様な肺結節データセットが不足しているため、その開発は依然として制限されています。拡散ベースの生成モデルは、データ合成に有望な戦略を提供します。ただし、既存の条件付きアプローチの多くは、主に空間再構成損失を最適化するため、ボクセル単位の類似性は促進されますが、病変レベルの強度分布の制限が不十分になる可能性があります。結果として、これらの方法では、過度に平滑化されたテクスチャ プロファイルが生成され、固体、部分固体、すりガラス状の結節など、さまざまな結節サブタイプの明確な減衰特性が過小評価される可能性があります。この課題に対処するために、結節固有の強度分布を正確にモデル化しながら、完全な 3D CT ボリューム内で肺結節を合成する、制御可能な潜在拡散モデルを提案します。具体的には、空間損失のみに依存するのではなく、生成プロセス中にボクセル強度分布を制約するヒストグラムベースの正則化項を導入します。このモデルは、サブタイプ、空間マスク、およびハウンズフィールド単位 (HU) ヒストグラム条件付けを微分可能な特徴空間ヒストグラム正則化項と組み合わせて、病変レベルの強度分布をより適切に調整し、合成結節の視覚的な妥当性とサブタイプの一貫性を向上させます。肺 CT データに関する広範な実験により、当社のフレームワークが強力な視覚的リアリズムを実現していることが実証され、定量的メトリクスと視覚的チューリング テストの両方を通じて検証されました。さらに、生成された結節をデータ拡張に使用すると、下流の臨床タスク、特に過小評価されている結節サブタイプのパフォーマンスが向上し、サブタイプに基づいた悪性腫瘍分類に潜在的な利点が示されます。
原文 (English)
Controllable Lung Nodule Synthesis via Histogram-Regularized Latent Diffusion Models
While automated diagnosis systems have achieved remarkable success in computed tomography (CT)-based lung cancer screening, their development remains limited by the scarcity of diverse, annotated pulmonary nodule datasets. Diffusion-based generative models offer a promising strategy for data synthesis; however, many existing conditional approaches primarily optimize spatial reconstruction losses, which encourage voxel-wise similarity but may inadequately constrain lesion-level intensity distributions. As a result, these methods may produce over-smoothed texture profiles and underrepresent the distinct attenuation characteristics of different nodule subtypes, including solid, part-solid, and ground-glass nodules. To address this challenge, we propose a controllable latent diffusion model that synthesizes pulmonary nodules within full 3D CT volumes while accurately modeling nodule-specific intensity distributions. Specifically, rather than relying solely on spatial losses, we introduce a histogram-based regularization term that constrains voxel intensity distributions during the generative process. The model combines subtype, spatial mask, and Hounsfield unit (HU) histogram conditioning with the differentiable feature-space histogram regularization term to better align lesion-level intensity distributions, improving the visual plausibility and subtype consistency of synthesized nodules. Extensive experiments on lung CT data demonstrate that our framework achieves strong visual realism, validated through both quantitative metrics and a visual Turing test. Furthermore, when used for data augmentation, the generated nodules improve performance in downstream clinical tasks, particularly for underrepresented nodule subtypes, and show a potential benefit for subtype-informed malignancy classification.
合理化: 人間と AI の調整のための共有セマンティック推論
データ駆動型のセンスメイキングにおいて、人間と AI モデルの間で意味論的推論を共有するための役割ペア フレームワークである Rationalize を紹介します。人間と機械のチーム化と批判的思考のアイデアに基づいて、私たちは人間と AI の相互作用を、共有された推論空間で動作する一連の補完的な役割ペア (探索者とガイド、調査員と情報提供者、教師と生徒、裁判官と弁護人) として概念化します。この分野では、人間のアナリストと AI モデル (LLM など) が目的、質問、仮定、証拠、推論、含意を明確にし、出力レベルだけでなく、双方による意図と行動の合理化レベルでの調整を促進します。これらの役割ペアを人間と AI の双方向調整フレームワークに関連付け、「AI を人間に調整する」と「人間を AI に調整する」が役割によってどのように異なるかを示し、要素レベルおよび役割固有のアプローチを使用した調整設計と評価のための共同研究のアジェンダをスケッチします。
原文 (English)
Rationalize: Shared Semantic Reasoning for Human-AI Alignment
We introduce Rationalize, a role-pair framework for shared semantic reasoning between humans and AI models in data-driven sensemaking. Building on ideas in human-machine teaming and critical thinking, we conceptualize human-AI interaction as a series of complementary role pairs (Explorer-Guide, Investigator-Informant, Teacher-Student, Judge-Advocate) operating in a shared reasoning space. In this space, human analysts and AI models (such as LLMs) make purposes, questions, assumptions, evidence, inferences, and implications explicit, facilitating alignment not only at the output level but at the level of rationalization of intent and action by each side. We relate these role pairs to the bidirectional human-AI alignment framework, illustrating how "aligning AI to humans" and "aligning humans to AI" differ by role, and sketch a collaborative research agenda for alignment design and assessment using element-level and role-specific approaches.
スコアブロードキャストと相関関係解除: ブロードキャストベースのクレジット割り当ての一般的なフレームワーク
微分可能な損失の一般的なファミリーに対するブロードキャストベースのクレジット割り当てのための原則的なフレームワークであるスコアブロードキャストと相関関係除去 (SBD) を紹介します。エラー ブロードキャストは、重みの転送を行わずに出力情報を隠れ層に送信する、バックプロパゲーションに代わる生物学的に妥当な代替手段です。平均二乗誤差 (MSE) 設定用に最近導入されたエラー ブロードキャストおよび相関除去 (EBD) フレームワークは、このメカニズムを最適推定量の確率的直交性に基づいて確立しました。このメカニズムの下では、最適な残差は入力の関数に直交します。出力スコア (最終層の出力に対する損失の勾配) と隠れ層のアクティベーションの間に直交性原理を導入することで、その基礎を一般化します。これは、最適スコアが条件付き平均 0 を持つ場合には常に当てはまります。この 1 つの原則により、クロスエントロピー、ブレグマン発散、適切なスコアリング ルール、指数関数族の負の対数尤度など、標準の微分可能損失族全体にわたるブロードキャスト ベースのクレジット割り当てが統一されます。このフレームワークは、放送損失スコアとして導出される神経調節因子を使用して、一般損失の下での 3 要素学習ルールの理論的根拠を提供します。クロスエントロピーのケースを明示的に導出し、許容損失クラスを特徴付け、直交性フレームワークを維持しながらブロードキャスト信号を強化するスコア ベクトル拡張手法を導入します。 CIFAR-10 と Tiny ImageNet の実験では、SBD が既存のブロードキャスト アプローチよりも大幅に改善され、スコア ベクトル拡張によりさらなる利益がもたらされることが示されています。全体として、この研究は、ブロードキャストする信号として損失スコアを特定し、神経科学からの 3 要素学習ルールの直交性理論と理論的根拠を提供し、スコア ベクトルの拡張によって結果として得られる目的の非相関方向がどのように強化されるかを示します。
原文 (English)
Score Broadcast and Decorrelation: A General Framework for Broadcast-Based Credit Assignment
We introduce Score Broadcast and Decorrelation (SBD), a principled framework for broadcast-based credit assignment for general families of differentiable losses. Error broadcast is a biologically plausible alternative to backpropagation that sends output information to hidden layers without weight transport. The Error Broadcast and Decorrelation (EBD) framework, recently introduced for the mean-squared-error (MSE) setting, grounded this mechanism in the stochastic orthogonality of optimal estimators, under which the optimal residual is orthogonal to functions of the input. We generalize that foundation by introducing an orthogonality principle between the output score (the gradient of loss with respect to the final-layer output) and hidden-layer activations, which holds whenever the optimal score has conditional mean zero. This single principle unifies broadcast-based credit assignment across the standard differentiable-loss families, including cross-entropy, Bregman divergences, proper scoring rules, and exponential-family negative log-likelihoods. The framework supplies a theoretical grounding for the three-factor learning rule under general losses, with the neuromodulatory factor derived as the broadcast loss score. We derive the cross-entropy case explicitly, characterize the admissible loss class, and introduce a score vector expansion technique that enriches the broadcast signal while preserving the orthogonality framework. Experiments on CIFAR-10 and Tiny ImageNet show that SBD substantially improves over existing broadcast approaches, with score vector expansion delivering further gains. Overall, this work identifies the loss score as the signal to broadcast, supplies the orthogonality theory and theoretical grounding for the three-factor learning rule from neuroscience, and shows how score vector expansion enriches the decorrelation directions of the resulting objective.
PInVerify: アクティブなインスタンス検証のためのオフライン組み込みベンチマーク
身体化されたエージェントは、ターゲットオブジェクトへのナビゲーションにおいて大きな進歩を遂げましたが、ゴール付近に到達したからといって、エージェントが正しいインスタンスを見つけたという保証はありません。微妙な属性の違い (例: 「白い花柄」と「白い縞模様」) には、多くの場合、近距離の多視点検査が必要です。私たちは、アクティブ インスタンス検証 (AIV) によってこのギャップに対処します。このタスクでは、エージェントが候補オブジェクトの周囲の視点をアクティブに選択して、それがきめ細かい自然言語記述と一致するかどうかを判断します。私たちは、AIV を有限ホライズンの意思決定プロセスとして形式化し、AIV のオフラインで具体化されたベンチマークである PInVerify を導入します。18 のオブジェクト カテゴリにわたる 3,000 の評価エピソードは、トラップ ビュー (ナビゲート可能だが情報が得られない) と到達不可能なセクターを明らかにする 6 セクター ナビゲーション トポロジを備えたマルチビュー キャプチャとして配信されます。参照ベースラインとして、属性分解、可視性を重視したマルチビュー トラッカー、および 3 つのネクスト ベスト ビュー (NBV) 戦略を使用して、オンデバイス スケール ($\leq$8B パラメーター) でオープンソースのマルチモーダル大規模言語モデル (MLLM) を中心に、トレーニング不要のパイプラインと LoRA で微調整されたエンドツーエンド エージェントを構築します。 Qwen3-VL (4B/8B)、SenseNova-SI-1.2-InternVL3-8B、CLIP、および SigLIP2 にわたる評価では、最良の MLLM ベースのベースラインが最良の埋め込みベースラインを 4.9 pp 上回りました。 GT-box アブレーションでは +3.1 pp の検出ギャップが示されています。そして、テストされた NBV 戦略内でのアクティブな視点選択による信頼性の高い利益は観察されません。 LoRA で微調整されたエージェント (SFT+GSPO) は 85.6% に達します。 PInVerify は、身体化された AI におけるアクティブで詳細なセマンティック検証に関するさらなる作業をサポートすることを目的としています。コード: https://github.com/Avalon-S/PInVerify。
原文 (English)
PInVerify: An Offline Embodied Benchmark for Active Instance Verification
Embodied agents have made strong progress in navigating to target objects, but reaching the goal vicinity does not guarantee that the agent has found the correct instance: subtle attribute differences (e.g., "white floral" vs. "white striped") often require close-range, multi-view inspection. We address this gap with Active Instance Verification (AIV), a task in which an agent actively selects viewpoints around a candidate object to decide whether it matches a fine-grained natural-language description. We formalize AIV as a finite-horizon decision process and introduce PInVerify, an offline embodied benchmark for AIV: 3,000 evaluation episodes across 18 object categories, delivered as multi-view captures with a 6-sector navigation topology that exposes trap views (navigable but uninformative) and unreachable sectors. As reference baselines we build a training-free pipeline and a LoRA-fine-tuned end-to-end agent around open-source multimodal large language models (MLLMs) at on-device scale ($\leq$8B parameters), with attribute decomposition, a visibility-weighted multi-view tracker, and three next-best-view (NBV) strategies. In our evaluation across Qwen3-VL (4B/8B), SenseNova-SI-1.2-InternVL3-8B, CLIP, and SigLIP2, the best MLLM-based baseline exceeds the best embedding baseline by 4.9 pp; GT-box ablations show a +3.1 pp detection gap; and we do not observe reliable gains from active viewpoint selection within the tested NBV strategies. A LoRA-fine-tuned agent (SFT+GSPO) reaches 85.6%. PInVerify aims to support further work on active, fine-grained semantic verification in embodied AI. Code: https://github.com/Avalon-S/PInVerify.
COFT: 大規模言語モデルにおける公正な思考連鎖推論のための反事実的・正則的デコーディング
大規模言語モデル (LLM) は、思考連鎖 (CoT) の生成中に社会の偏見を明らかにし、増幅させる可能性があります。我々は、デコード時にトークンレベルの公平性制御を適用する、トレーニング不要のデコード手法である COFT (Chain of Fair Thought) を提案します。凍結された因果関係言語モデルに対して、配布フリーの限界妥当性保証 (交換可能性のもとで) が付いています。 COFT は 3 つの段階で動作します。まず、機密性の高いスパンを中立トークンに置き換えることにより、マスクされた反事実プロンプトを作成します。 2 番目に、軽量ロジット融合を通じて事実のロジット分布とマスクされたロジット分布を比較し、属性に基づくバイアスを軽減します。 3 番目に、デュアルブランチのスプリットコンフォーマルキャリブレーションを使用して、ユーザーが選択したリスクレベルでステップごとの候補トークンセットを認証します。 6 つのモデルと複数のバイアス ベンチマークにわたって COFT を評価します。私たちの方法では、タスクの実用性と言語の品質を維持しながら、標準のバイアス指標を 30 ~ 55% (中央値 38%) 削減します。推論の精度は、実行ごとのノイズ マージン内で変化しません。計算オーバーヘッドは控えめで、追加のキャッシュされた前方パス 1 回分に相当します (<=11%)。 COFT は、バイアスを大幅に削減し、ユーティリティの損失を無視し、再トレーニング、補助分類器、または重み付けアクセスを必要とせず、より安全な CoT 生成への明確で監査可能なパスを提供します。
原文 (English)
COFT: Counterfactual-Conformal Decoding for Fair Chain-of-Thought Reasoning in Large Language Models
Large language models (LLMs) can reveal and amplify societal biases during chain-of-thought (CoT) generation. We present COFT (Chain of Fair Thought), a training-free decoding method that applies token-level fairness control at decode time, with distribution-free marginal validity guarantees (under exchangeability) for any frozen causal language model. COFT operates in three stages. First, it creates a masked counterfactual prompt by replacing sensitive spans with neutral tokens. Second, it compares the factual and masked logit distributions through lightweight logit fusion to attenuate attribute-driven biases. Third, it uses dual-branch split-conformal calibration to certify per-step candidate token sets at a user-chosen risk level. We evaluate COFT across six models and multiple bias benchmarks. Our method reduces standard bias metrics by 30-55% (median 38%) while preserving task utility and language quality. Reasoning accuracies remain unchanged within run-to-run noise margins. The computational overhead is modest, equivalent to one additional cached forward pass (<=11%). COFT offers a clear, auditable path to safer CoT generation with significant bias reduction, negligible utility loss, and no requirement for retraining, auxiliary classifiers, or weight access.
同じ患者、異なる言葉、異なる診断?臨床 LLM の意味的安定性の評価
大規模言語モデル (LLM) は臨床アプリケーションで使用されることが増えています。ただし、彼らの動作は、言い換えや構文の違いなど、微妙な言語の違いに非常に敏感なままです。この感度は、意味的に同等の入力が一貫した予測を生成する必要がある安全性が重要な医療現場でリスクを引き起こします。ただし、埋め込みベースの類似性メトリクスでは否定、一時性、または重症度を含む区別を捉えることができないことが多いため、重要な課題は、即時変化が臨床的意味を確実に保持することです。この制限に対処するために、意味を保持するプロンプトのバリエーションをフィルタリングするための自然言語推論 (NLI) に基づく意味検証フレームワークを提案します。このフレームワークは、LLM を判断者として使用してさらに洗練され、臨床専門家によって監査されます。さらに、モデルの感度を定量化するために、意味保持変動感度 (MVS)、信頼変動 (\Delta C)、および最悪の場合の不安定性 (WCI) という 3 つの指標を導入します。 DiagnosisQA および MedQA データセットから得られた再定式化されたプロンプトを使用して、同じモデル ファミリおよびパラメーター スケール内の 16 個のオープンソースの汎用 (GP) および医療 LLM を評価します。私たちの結果は、ドメイン固有(DS)モデル間のロバスト性の違いが混在しており、モデルに大きく依存していること、つまり、ドメインの特殊化によって意味を保持したプロンプト再定式化に対するロバスト性が一貫して向上または低下するわけではないことを示しています。いくつかの DS モデルは (GP モデルと比較した場合) 最も堅牢なモデルにランクされており、強力な GP ベースラインも同様に競争力を維持しています。
原文 (English)
Same Patient, Different Words, Different Diagnosis? Evaluating Semantic Stability in Clinical LLMs
Large Language Models (LLMs) are increasingly used in clinical applications. However, their behavior remains highly sensitive to subtle linguistic variations, such as rephrasing or syntactic variation. This sensitivity poses risks in safety-critical healthcare settings, where semantically equivalent inputs should produce consistent predictions. However, a key challenge is to ensure that prompt variations truly preserve clinical meaning, as embedding-based similarity metrics often fail to capture distinctions involving negation, temporality, or severity. To address this limitation, we propose a semantic verification framework based on Natural Language Inference (NLI) to filter meaning-preserving prompt variations, which are further refined using an LLM-as-a-judge and audited by a clinical expert. In addition, we introduce three metrics to quantify model sensitivity: MeaningPreserving Variation Sensitivity (MVS), confidence variation (\Delta C), and Worst-Case Instability (WCI). We evaluate 16 open-source general-purpose (GP) and medical LLMs within the same model families and parameter scales, using reformulated prompts derived from the DiagnosisQA and MedQA datasets. Our results demonstrate that robustness differences between domain-specific (DS) models are mixed and highly model-dependent, i.e., domain specialization does not consistently improve or reduce robustness to meaning-preserving prompt reformulations. Several DS models rank among the most robust (when compared with GP counterparts), and strong GP baselines remain competitive as well.
LARK: 効率的な推論抽出のための学習可能性に基づいた軌道選択
私たちは、教師が生成した推論軌道が生徒モデルの監視として選択的に使用される、推論蒸留のための軌道選択を研究します。既存の方法は、軌道の品質やモデルの信頼性などのヒューリスティックに依存していますが、軌道が学習者にとって学習可能かどうかを見落とすことがよくあります。この論文では、学習可能性に基づいて軌道選択を推論する方法である LARK を紹介します。 LARK は、完全なトレーニング分布の一般化を維持しながら、学生が効率的に学習できる軌道を選択します。 LARK の中核となるのは学習可能性係数 $\rho$ であり、これは生徒のトレーニング損失の減少率を特徴づけます。この割合を効率的に推定し、一般化を維持するために、学習可能性プロキシと、学習可能性と分布範囲のバランスをとる $\chi^2$ 正規化選択ポリシーを導入します。どちらも推定誤差に対する強力な理論的保証があります。経験的には、LARK は複数の基本モデルと推論タスクにわたってデータ選択ベースラインを常に上回っています。診断分析により、LARK スコアが下流のトレーニングの有用性を予測し、LARK が選択した軌道がより迅速な教師付き微調整損失削減を引き起こすことが示されています。私たちのコードは https://github.com/Tianrun-Yu/LARK で入手できます。
原文 (English)
LARK: Learnability-Grounded Trajectory Selection for Efficient Reasoning Distillation
We study trajectory selection for reasoning distillation, where teacher-generated reasoning trajectories are selectively used as supervision for a student model. Existing methods rely on heuristics such as trajectory quality or model confidence, but they often overlook whether a trajectory is learnable by the student. In this paper, we present LARK, a learnability-grounded method for reasoning trajectory selection. LARK selects trajectories that the student can learn efficiently while preserving the generalization of the full training distribution. At the core of LARK is a learnability factor $\rho$, which characterizes the rate at which the student's training loss decreases. To estimate this rate efficiently and maintain generalization, we introduce a learnability proxy and a $\chi^2$-regularized selection policy that balances learnability and distributional coverage, both with strong theoretical guarantees on their estimation error. Empirically, LARK consistently outperforms data selection baselines across multiple base models and reasoning tasks. Diagnostic analyses show that the LARK score predicts downstream training utility and that LARK-selected trajectories induce faster supervised fine-tuning loss reduction. Our code is available at https://github.com/Tianrun-Yu/LARK.
EUDAIMONIA: AI における望ましくないダイナミクスの評価
大規模言語モデル (LLM) は、交際、感情の開示、対人アドバイスのための会話のパートナーとしてますます使用されていますが、これらの相互作用の社会的力学は、能力指向の評価や従来の安全性評価では捉えられない害悪を生み出す可能性があります。私たちは、LLM が有害な親密さ、依存、または長期にわたる関与を促進するかどうかなど、社会的相互作用におけるユーザーの福祉と一致しているかどうかを評価するためのフレームワークである、ソーシャル AI デザイン コードを紹介します。自然で多様なユーザーと LLM のやり取りにおけるこれらのリスクを評価するために、弱から強のフィルタリング、マルチモデルの再ラベル付け、制御された書き換えを通じて WildChat から構築された 969 件のユーザー入力と 3,147 件の設計要件違反チェックのベンチマークである EUDAIMONIA を使用してコードを運用可能にしました。最近の 22 個の LLM を評価すると、最も強力なモデルである Claude-Opus-4.7 と GPT-5.5 でさえ、それぞれチェックの 30.7% と 27.2% に違反していることがわかりました。拡張された思考によって違反率は減少しないことから、これらの失敗は、テスト時の推論だけで解決できる問題ではなく、社会的調和の問題が根強く残っていることが示唆されます。
原文 (English)
EUDAIMONIA: Evaluating Undesirable Dynamics in AI
Large language models (LLMs) are increasingly used as conversational partners for companionship, emotional disclosure, and interpersonal advice, but the social dynamics of these interactions can create harms that are not captured by capability-oriented or traditional safety evaluations. We introduce the Social AI Design Code, a framework for evaluating whether LLMs align with user welfare in social interactions, including whether they encourage harmful intimacy, dependence, or prolonged engagement. To evaluate these risks in natural and diverse user-LLM interactions, we operationalize the code with EUDAIMONIA, a benchmark of 969 user inputs and 3,147 design-requirement violation checks built from WildChat through weak-to-strong filtration, multi-model relabeling, and controlled rewriting. Evaluating 22 recent LLMs, we find that even the strongest models, Claude-Opus-4.7 and GPT-5.5, violate 30.7% and 27.2% of checks, respectively. Extended thinking does not reduce violation rates, suggesting that these failures are persistent social-alignment problems rather than deficits solvable through test-time reasoning alone.
ソフトウェア リバース エンジニアリング AI エージェントを自動的に攻撃する
Ghidra などの実行可能バイナリ ファイルをリバース エンジニアリングするソフトウェア ツールを使用すると、マルウェア アナリストは元のソース コードにアクセスすることなく、堅牢な静的分析を安全に実行できます。 GhidraMCP などのツールで有効化されたエージェント システムと大規模言語モデル (LLM) の分析能力を組み合わせることで、アナリストは以前は人間が主導していたプロセスを自動化できます。この自動化により、1 人のマルウェア アナリストの生産性は向上しますが、マルウェアの難読化に関する新たな脆弱性領域も発生します。この論文では、AutoDAN として知られる敵対的攻撃の改良版である遺伝的アルゴリズム ベースのプロンプト生成を使用した敵対的手法を紹介し、LLM を利用した逆アセンブリおよび逆コンパイル システムをだましてバイナリ実行可能ファイルを誤って解釈させ、その分析出力を効果的に破壊する能力を実証します。この概念実証の方法論は、実行可能ファイルの機能に影響を与えずに、無関係な文字列変数の割り当てを使用して LLM に秘密の命令を渡すことにより、プロンプト インジェクションを介して LLM が逆コンパイルされたマシン コードを処理および解釈する方法に固有の脆弱性を悪用します。いくつかの簡潔な例を通じてこの機能を示します。このアプローチにより、攻撃者は LLM 駆動の分析パイプラインに依存する自動検出システムをバイパスできる可能性があります。この攻撃を研究して理解することで、LLM をサイバーセキュリティ ツールチェーンに統合し、より堅牢なエージェント コード分析システムを構築することのセキュリティへの影響に関する洞察を得ることができます。
原文 (English)
Automatically Attacking Software Reverse Engineering AI Agents
Software tools for reverse engineering executable binary files, such as Ghidra, enable malware analysts to safely conduct robust static analysis without having access to original source code. Coupled with the analytic power of large language models (LLM), agentic systems enabled with tools, such as GhidraMCP, can allow analysts to automate a previously human driven process. Although this automation can increase the productivity of a single malware analyst, it also introduces a new area of vulnerability for malware obfuscation. This paper presents an adversarial technique using genetic algorithm-based prompt generation, a modification of an adversarial attack known as AutoDAN, to demonstrate the ability to deceive LLM-powered disassembly and decompilation systems into misinterpreting binary executables, effectively corrupting their analytical output. This proof-of-concept methodology exploits inherent vulnerabilities in how LLMs process and interpret decompiled machine code via prompt injection by using extraneous string variable assignments to pass surreptitious instructions to the LLM while not impacting the functionality of the executable file. We demonstrate this capability through several concise examples. This approach could enable attackers to bypass automated detection systems that rely on LLM-driven analysis pipelines. By studying and understanding this attack, insights can be gained regarding the security implication of integrating LLMs into cybersecurity toolchains and building more robust agentic code analysis systems.
CobSeg: 対話トピックのセグメント化のためのコヒーレンス境界モデリング
対話トピックのセグメンテーションは、発話端近くの語彙の遷移や発話間の意味的不連続性など、異質な境界手がかりを特定する必要がある多くの人間と AI の共同アプリケーションにおいて重要です。既存の発話モデルは、多くの場合、これらの局所的な語彙シグナルを弱めます。我々は、コヒーレンスレベルの意味的連続性を語彙境界遷移から分離し、方向境界予測を通じて両方を回復する新しいマルチブランチアーキテクチャであるCobSegを提案します。 CobSeg はさらに、境界情報重み付けを使用して、有用性の高い発話位置を強調し、コーパス由来のトピック一貫性キューと学習された組み合わせ重みを組み込みます。 CobSeg は、教師ありゴールド境界トレーニングおよび自動的に誘導された境界を備えた擬似ラベル設定の下でコンパクトなトレーニング可能なセグメンターとして評価されますが、推論中に LLM 呼び出しを行わずに強化された境界予測を実行します。 5 つのベンチマーク全体で、特に局所的な語彙キューが顕著な場合に $P_k$ と $W_d$ を改善します。ゴールドの監視下では、VHF では $P_k$ を 0.7 ポイント、$W_d$ を 0.6 ポイント削減し、DialSeg711 では $P_k$ の 1.0 に達します。境界を誘導すると、$P_k$ が VHF で 14.8 ポイント、DialSeg711 で 1.5 ポイント、TIAGE で 1.1 ポイント減少し、以前の非 LLM アプローチよりも優れたパフォーマンスを発揮します。
原文 (English)
CobSeg: Coherence Boundary Modeling for Dialogue Topic Segmentation
Dialogue topic segmentation is critical in many human-AI collaborative applications which requires identifying heterogeneous boundary cues, including lexical transitions near utterance edges and semantic discontinuities across utterances. Existing utterance models often dilute these local lexical signals. We propose CobSeg, a novel multi-branch architecture that separates coherence-level semantic continuity from lexical boundary transitions and recovers both through directional boundary prediction. CobSeg further uses boundary informativeness weighting to emphasize high-utility utterance positions, and incorporates a corpus-derived topic coherence cue with learned combination weights. While CobSeg is evaluated as a compact trainable segmenter under supervised gold-boundary training and a pseudo-label setting with automatically induced boundaries, it performs enhanced boundary prediction without LLM calls during inference. Across five benchmarks, it improves $P_k$ and $W_d$ particularly when local lexical cues are prominent: under gold supervision, it reduces $P_k$ by 0.7 points and $W_d$ by 0.6 points on VHF, and reaches $P_k$ of 1.0 on DialSeg711; with induced boundaries, it reduces $P_k$ by 14.8 points on VHF, by 1.5 points on DialSeg711, and by 1.1 points on TIAGE, outperforming prior non-LLM approaches.
大規模な言語モデルの不確実性における人間の調整、調整、および活性化パターン
不確実性の定量化は、大規模言語モデルの動作分析の大規模かつ成長を続けるサブフィールドです。主に幻覚を認識し、それに対処するために、この分野は主に、タスクの有効性に対する不確実性の判断の精度であるキャリブレーションの測定と改善に焦点を当ててきました。この研究では、大規模な言語モデルの不確実性が人間の不確実性とどの程度似ているかという、比較的研究されていない問題を調査します。私たちは、大規模言語モデルの明白な行動と内部活性化パターンにおける、不確実性の整合とみなされる、人間に似た不確実性シグナルの存在と強度を調査します。モデルが、多肢選択とオープンエンドの事実想起の両方をカバーするさまざまなデータセットでの同時の位置合わせと校正の証拠を示すかどうかを特定します。そして、これらの各側面での微調整指示の効果を特徴付けます。
原文 (English)
Human-Alignment, Calibration, and Activation Patterns in Large Language Model Uncertainty
Uncertainty Quantification is a large and growing subfield of large language model behavioral analysis. Primarily to recognize and combat hallucination, the field has largely focused on measuring and improving calibration, the accuracy of uncertainty judgments to task efficacy. In this work, we investigate the relatively underexplored question of how similar large language model uncertainty is to human uncertainty. We investigate the presence and strength of human-similar uncertainty signals, deemed uncertainty alignment, in large language model overt behavior and internal activation patterns. We identify whether the models show evidence of simultaneous alignment and calibration on a variety of datasets covering both multiple choice and open ended factual recall. And we characterize the effect of instruct fine-tuning on each of these facets.
ソフトウェア リバース エンジニアリング AI エージェントに対するプロンプト インジェクション攻撃の検出と難読化の調査
エージェント ソフトウェア リバース エンジニアリング システムは、実行可能なバイナリ ファイルのソース コードに配置されたプロンプト インジェクション攻撃に対して脆弱です。この研究では、敵対的なサンプル プログラムの逆コンパイラ出力にプロンプト インジェクション文字列の存在を検出するための防御戦術を実証します。これらの攻撃を難読化する方法と、その後のこれらの難読化から防御する方法も検討されています。この調査により、実稼働レベルのサイバー ワークフローへの導入に必要なエージェント ソフトウェア分析システムのリスクとセキュリティについての理解が深まります。
原文 (English)
Investigating Detection and Obfuscation of Prompt Injection Attacks Against Software Reverse Engineering AI Agents
Agentic software reverse engineering systems are vulnerable to prompt injection attacks placed into the source code of executable binary files. This research demonstrates defensive tactics for detecting the presences of prompt injection strings in the decompiler output of adversarial example programs. Methods for obfuscating these attacks and subsequent methods for defending against these obfuscations are also explored. This research advances the understanding of risk and security of agentic software analysis systems necessary for their deployment into production-level cyber workflows.
早期導入者が世界中で生成 AI をどのように使用したか: 国の収入と言語による違い
AI は世界中の人々によって使用されていますが、誰もが同じ方法で AI を使用しているわけではありません。私たちは、広く利用可能な無料の AI チャットボットとの、匿名化、匿名化、プライバシーを消去したやり取りの大規模なデータセットを使用して、国ごとの早期導入者の使用状況の違いを実証的に特徴付けます。学校教育はほとんどの国、特に低所得国で最も一般的に利用されており、学校教育と国レベルのGDPとの間には強い逆相関があることが明らかです。対照的に、レジャー関連の利用は国レベルの収入と正の相関があります。言語は使用にも影響を与えることがわかりました。研究期間中に既存のモデルでは主要な言語が十分に提供されなかった場所では、英語によるインタラクションが多く見られました。私たちの研究によれば、言語間でのパフォーマンスの向上は、このテクノロジーが情報格差を拡大するか、それとも飛躍を可能にするかにおいて重要な要素となる可能性があります。
原文 (English)
How Early Adopters Used Generative AI Worldwide: Variation by Country Income and Language
AI is being used by people globally, but not everyone is using it in the same ways. Using a large-scale dataset of anonymized, de-identified, and privacy-scrubbed interactions with a widely available and free AI chatbot, we empirically characterize differences in early adopters' usage across countries. Schooling is the most common domain of use in most countries, particularly low-income countries, with a strong inverse association evident between schooling and country-level GDP. Leisure-related use, by contrast, is positively associated with country-level income. Language, we find, also shapes use: English-language interactions are overrepresented in places where the predominant languages were not well-served by existing models during the period of the study. Improving performance across languages may be a key factor, our work suggests, in whether this technology expands digital divides or enables leapfrogging.
ツール呼び出し ReAct Agent での深度依存の間接プロンプト注入: 注入深度、ペイロード フレーミング、およびターン バジェット感度
思考連鎖推論とツール呼び出しをインターリーブする ReAct エージェントは、スケジューリング、ファイル取得、データ アクセスなどの実際のタスクに導入されることが増えています。彼らのツール監視ループは直接的な攻撃対象領域を作成します。ツールの戻り値を制御する攻撃者は、エージェントをユーザーの目的からリダイレクトする命令を埋め込むことができ、これは間接プロンプト インジェクションとして知られる脅威です。既存のベンチマークは、固定条件下、固定注入位置での攻撃成功率 (ASR) を評価しますが、ツール シーケンス内のどこにペイロードが現れるか (注入深さ)、どのようなレトリック レジスタを使用するか (フレーミング)、エージェントに許可されるターン数 (ターン キャップ) という 3 つのリスク側面が未調査のままです。当社は、5 つの攻撃カテゴリにわたる 20 のシナリオについて 4 つの対照研究を実施し、GPT-4o-mini と Claude Haiku に対して合計 460 回のトライアルを合計 0.36 米ドル未満の API コストで実施しました。研究 1 は、GPT-4o-mini に対する ASR が深さ 1 の 60% から深さ 4 および 5 の 0% まで減衰することを示しています (Cramer の V = 0.58、p < 0.001; シーケンス深さ 1 ~ 3 内に限定: V = 0.47、p = 0.0013)。これは、深さ 1 でのモデル抵抗と、より深い位置でのペイロード遭遇前のタスク完了によって引き起こされます。研究 2 では、Claude Haiku の深度実験を再現しています。この実験では、保守的なツールの呼び出しと真の命令耐性の組み合わせにより、すべての深度で 0% の ASR を達成しています。研究 3 は、フレーミングが深さ 1 で ASR を 25% (ニュートラル) と 75% (ペルソナ) の間で調整することを示しています。この範囲は 50 パーセント ポイントの範囲であり、条件あたり N = 20 では統計的有意性に達しません。研究 4 では、ASR がターン上限 3、5、7 にわたって安定していることが確認されており、この設定ではターン予算がリスク要因ではないことが示されています。私たちの結果は、注入深さが支配的な変数であることを確立し、最初のツール観察のみをサニタイズすることで、測定された注入成功率の 67% が得られることを示しています。
原文 (English)
Depth-Dependent Indirect Prompt Injection in Tool-Calling ReAct Agents: Injection Depth, Payload Framing, and Turn-Budget Sensitivity
ReAct agents that interleave chain-of-thought reasoning with tool calls are increasingly deployed for real tasks such as scheduling, file retrieval, and data access. Their tool observation loop creates a direct attack surface: an adversary who controls any tool's return value can embed instructions that redirect the agent away from the user's goal, a threat known as indirect prompt injection. Existing benchmarks evaluate attack success rate (ASR) at a fixed injection position under fixed conditions, leaving three risk dimensions unexplored: where in the tool sequence the payload appears (injection depth), what rhetorical register it uses (framing), and how many turns the agent is permitted (turn cap). We conduct four controlled studies on 20 scenarios spanning five attack categories, totalling 460 trials against GPT-4o-mini and Claude Haiku at a combined API cost under 0.36 USD. Study 1 shows that ASR against GPT-4o-mini decays from 60% at depth 1 to 0% at depths 4 and 5 (Cramer's V = 0.58, p < 0.001; restricted to within-sequence depths 1-3: V = 0.47, p = 0.0013), driven by model resistance at depth 1 and task completion before payload encounter at deeper positions. Study 2 replicates the depth experiment on Claude Haiku, which achieves 0% ASR at every depth through a combination of conservative tool invocation and genuine instruction resistance. Study 3 shows that framing modulates ASR between 25% (neutral) and 75% (persona) at depth 1, a 50-percentage-point range that does not reach statistical significance at N = 20 per condition. Study 4 confirms that ASR is stable across turn caps of 3, 5, and 7, indicating the turn budget is not a risk factor in this setting. Our results establish injection depth as the dominant variable and show that sanitising only the first tool observation captures 67% of measured injection successes.
ConTrans: ゼロショットの時間的アクションのローカリゼーションのためのテキスト強化されたローカル-グローバル時間表現の学習
Zero-shot Temporal Action Localization (ZS-TAL) は、トリミングされていないビデオ内のこれまで見えなかったアクションを検出して特定することを目的としています。ただし、既存のアプローチは主に長距離のコンテキスト情報のモデリングに焦点を当てており、ビデオ フレーム間の重要な相対オフセット ベースの局所相関が無視されていることがよくあります。さらに、ネットワーク アーキテクチャの浅い性質により、特徴表現機能が制限されるため、パフォーマンスが妨げられます。この論文では、新しいローカル/グローバル マルチスケール特徴表現モジュールを導入することで、これらの制限に対処します。我々は、ConTrans と呼ばれる新しいマルチスケール エンコーダ アーキテクチャを提案します。これは、畳み込み (Conv) 誘導バイアスとトランスフォーマーのセルフアテンションを統合して、きめの細かいローカル依存関係と長距離のグローバル コンテキストを共同で捕捉し、既存の手法よりも包括的な特徴表現につながります。 ActivityNet-1.3 および THUMOS14 データセットの実験評価では、ConTrans が既存の手法を大幅に上回っており、ZS-TAL の新しいベンチマークを確立していることが実証されています。
原文 (English)
ConTrans: Learning Text-enhanced Local-global Temporal Representations for Zero-shot Temporal Action Localization
Zero-shot Temporal Action Localization (ZS-TAL) aims to detect and locate previously unseen actions in untrimmed videos. However, existing approaches primarily focus on modeling long-range contextual information, often neglecting the critical relative-offset-based local correlations between video frames. Furthermore, their performance is hindered by limited feature representation capabilities due to the shallow nature of their network architectures. In this paper, we address these limitations by introducing a novel local-global multi-scale feature representation module. We propose a novel multi-scale encoder architecture, termed ConTrans, that integrates convolutional (Conv) inductive biases with transformer Self-attention to jointly capture fine-grained local dependencies and long-range global context, leading to more comprehensive feature representations than existing methods. Experimental evaluations on the ActivityNet-1.3 and THUMOS14 datasets demonstrate that ConTrans significantly outperforms existing methods, establishing a new benchmark for ZS-TAL.
同意する前に確認する: 複数のエージェントの合意を視覚的な証拠に合わせて調整する
ビジョン言語モデル (VLM) は、ビジュアル質問応答 (VQA) で優れたパフォーマンスを達成しました。個人の幻覚や盲点を軽減するために、複数のエージェントのコラボレーションを通じて多様な視点を集約することが、有望なパラダイムとして浮上しています。このアプローチはテキスト QA では大きな成功を収めていますが、マルチモーダル ドメインでの可能性はまだ探求されていません。既存のマルチエージェント VQA 手法は主にテキスト中心のプロトコルを適応させており、視覚情報の調整を無視してテキストによる議論に重点を置いています。この研究で、私たちは重要な洞察を明らかにします。信頼できるマルチエージェント VQA には、回答レベルの一致では不十分です。 \textit{整列された視覚的証拠} -- エージェントが依存する画像領域からの共有サポート -- は、信頼できるコンセンサスを得るために不可欠です。この洞察を活用するために、複数の VLM エージェントを調整するためのトレーニング不要の証拠中心のフレームワークである EAGLE (\textbf{E}vidence-\textbf{A}ligned \textbf{G}rounded mu\textbf{L}ti-agent r\textbf{E}asoning) を提案します。 EAGLE は、各エージェントの接地領域を視覚的な証拠として明示的に公開し、証拠に対する相互検証を可能にし、証拠の一貫性を利用して最終的な意思決定を導きます。 6 つの VQA ベンチマークの実験では、EAGLE が軽量で解釈可能で、導入に実用的でありながら、ドメイン全体で最高の平均パフォーマンスを達成していることが示されています。
原文 (English)
Seeing Before Agreeing: Aligning Multi-Agent Consensus with Visual Evidence
Vision-language models (VLMs) have achieved strong performance on visual question answering (VQA). To mitigate individual hallucinations and blind spots, aggregating diverse perspectives via multi-agent collaboration has emerged as a promising paradigm. While this approach has shown great success in textual QA, its potential in the multimodal domain remains under-explored. Existing multi-agent VQA methods predominantly adapt text-centric protocols, focusing on textual discussions while ignoring the alignment of visual information. In this work, we reveal a key insight: answer-level agreement is insufficient for reliable multi-agent VQA; \textit{aligned visual evidence} -- shared support from the image regions agents rely on -- is essential for trustworthy consensus. To leverage this insight, we propose EAGLE (\textbf{E}vidence-\textbf{A}ligned \textbf{G}rounded mu\textbf{L}ti-agent r\textbf{E}asoning), a training-free evidence-centered framework for coordinating multiple VLM agents. EAGLE explicitly exposes each agent's grounding regions as visual evidence, enables mutual verification over the evidence, and uses evidence consistency to guide final decision-making. Experiments on six VQA benchmarks show that EAGLE achieves best average performance across domains while remaining lightweight, interpretable, and practical for deployment.
SAGE: エージェント LLM における効率的なメモリ進化のためのノベルティ ゲート
エージェント LLM は、新しく抽出されたファクトを追加するか、既存のメモリとマージするか、無視するかを継続的に決定する必要がありますが、これまでの研究では、原則に基づいた書き込み側の制御よりも、取得と保存に重点が置かれていました。我々はメモリ進化を新規性検出問題として枠組み化し、メモリ進化のための球状適応ゲートであるSAGEを提案します。これは、メモリ埋め込みに対するフォン・ミーゼス・フィッシャーベースの密度推定器を使用して候補事実をスコアリングし、メモリストアのジオメトリを追跡する適応しきい値でそれらをルーティングします。 SAGE は、明らかに新規のファクトを ADD として解決し、明らかに冗長なファクトを NOOP として解決し、不確実なケースのみを LLM マージ ステップに送信して、コストのかかる書き込み時間の推論を削減します。 LoCoMo では、SAGE は 7 つのオープンウェイト バックボーン比較すべてで Mem0 に対して最良の平均トークン F1 を達成しましたが、GPT-4o-mini では、わずかな平均ジャッジ スコアの差で、追加フェーズ API コストを 3.4$\times$ 削減し、追加フェーズのレイテンシを 2.5$\times$ 削減しました。 A-Mem のドロップイン バイナリ ゲートとして、SAGE は、オープンウェイト バックボーンでの品質の変化を最小限に抑えながら、5 つのモデルにわたって LLM コールの約 16 ~ 18% をスキップします。これらの結果は、新規性を意識した書き込み制御が、長期エージェントメモリにおけるメモリ品質とシステム効率の両方を改善するための実用的な手段であることを示唆しています。
原文 (English)
SAGE: A Novelty Gate for Efficient Memory Evolution in Agentic LLMs
Agentic LLMs must continuously decide whether newly extracted facts should be added, merged with existing memories, or ignored, yet prior work has focused more on retrieval and storage than on principled write-side control. We frame memory evolution as a novelty-detection problem and propose SAGE, a Spherical Adaptive Gate for memory Evolution that scores candidate facts with a von Mises-Fisher-based density estimator over memory embeddings and routes them with an adaptive threshold that tracks memory-store geometry. SAGE resolves clearly novel facts as ADD, clearly redundant facts as NOOP, and sends only uncertain cases to an LLM merge step, reducing expensive write-time reasoning. On LoCoMo, SAGE achieves the best average token-F1 against Mem0 on all seven open-weight backbone comparisons, while on GPT-4o-mini it reduces add-phase API cost by 3.4$\times$ and add-phase latency by 2.5$\times$ with only a small average judge-score gap. As a drop-in binary gate for A-Mem, SAGE skips roughly 16-18% of LLM calls across five models with minimal quality change on open-weight backbones. These results suggest that novelty-aware write control is a practical lever for improving both memory quality and system efficiency in long-term agentic memory.
Simple Token-Efficient Vision-Language Model for Case-level Pathology Synoptic Report Generation
Generating clinically useful pathology reports for pathology cases from whole-slide images (WSIs) is challenging due to gigapixel resolutio…
When are LLMs Sufficient Policy Optimizers for Sequential RL Tasks?
We study when large language models (LLMs) can serve as effective black-box policy optimizers for reinforcement learning (RL) tasks, i.e.,…
Kalimati Vegetable Price Index Forecasting with a Momentum Corrected Online Stacking Ensemble
Forecasting agricultural commodity prices in emerging economies is difficult due to high volatility, frequent supply disruptions, and stron…
OrcaRouter: A Production-Oriented LLM Router with Hybrid Offline-Online Learning
The rapid development of large language models, each with distinct capabilities and inference costs, raises a practical deployment question…
GSAM: A Generalizable and Safe Robotic Framework for Articulated Object Manipulation
Articulated object manipulation is a unique challenge for service robots. Existing methods employ end-to-end policy learning, visionmotion…
Chatterbox-Flash: Prior-Calibrated Block Diffusion for Streaming Zero-Shot TTS
We present Chatterbox-Flash, a zero-shot text-to-speech model obtained by fine-tuning a pretrained autoregressive TTS decoder into a block-…
XLGoBench: Detecting cross-lingual skill gaps with algorithmic tasks
We introduce a set of synthetic algorithmic tasks to detect cross-lingual gaps in the abilities of large language models. Our benchmark is…
Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
We identify a new dimension for enhancing rollout diversity in Group Relative Policy Optimization (GRPO) for LLMs. While GRPO relies on div…
On the impact of retrieved content representations in RAG Pipelines
Retrieval-Augmented Generation (RAG) supplements a language model's input with retrieved documents, yet most RAG pipelines inherit retrieva…
OpenSTBench: Beyond Semantic Evaluation for Speech Translation
Speech translation systems increasingly span speech-to-text translation (S2TT), speech-to-speech translation (S2ST), offline translation, a…
MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding
Multimodal Large Language Models (MLLMs) have demonstrated significant achievements in general visual question answering (VQA) tasks. Howev…
Design and Evaluation of Multi-Agent AI Oracle Systems for Prediction Market Resolution
Prediction markets aggregate collective intelligence to forecast uncertain events, but their utility depends on reliable outcome resolution…
Differentially Private Preference Data Synthesis for Large Language Model Alignment
Preference alignment is a crucial post-training step for large language models (LLMs) to ensure their outputs align with human values. Howe…
GaMi: Geometry-Agnostic Material Identification via Cross-Modal Subtractive Disentanglement
Non-contact material identification enables adaptive interaction for embodied intelligence yet faces challenges from geometry-induced varia…
Unlearning in Diffusion Models: A Unified Framework with KL Divergence and Likelihood Constraints
Unlearning in diffusion models aims to remove undesirable data or concepts while preserving the utility of pretrained models -- two fundame…
Beyond Agreement: Scoring Panel-Surfaced Biomedical Entity Candidates for Curator Triage
Biomedical NER is deceptively simple for modern LLMs: plausible biomedical mentions are easy to surface, but corpus-convention correctness…
Your Teacher Can't Help You Here: Combating Supervision Fidelity Decay in On-Policy Distillation
On-policy distillation transfers reasoning capabilities by training a student model on its own generated trajectories using token-level fee…
Hide-and-Seek in Trajectories: Discovering Failure Signals for VLA Runtime Monitoring
Vision-Language-Action (VLA) models enable robots to follow natural language instructions and generalize across diverse tasks, but they rem…
Fine-Tuning Improves Information Conveyance in Language Models
Fine-tuning is often believed to reduce uncertainty and diversity in large language models, but existing analyses overlook output length, a…
Safe Equilibrium Policy Optimization for Strategic Agent Policies
Language models fine-tuned with reinforcement learning typically optimize for task reward, ignoring multi-agent strategic structure. Becaus…
DARTS: Distribution-Aware Active Rollout Trajectory Shaping for Accelerating LLM Reinforcement Learning
Reinforcement Learning (RL) has become pivotal for improving model capabilities yet suffers from rollout efficiency bottlenecks due to the…
Sophrosyne: Agentic Exploration of Relational Data Systems Needs Moderation
Text2SQL agents powered by LLMs translate natural language intent into SQL by exploring the data system through tool calls before formulati…
Federated Variational Preference Alignment with Gumbel-Softmax Prior for Personalized User Preferences
Federated Learning (FL) offers a privacy-preserving pathway for aligning Large Language Models (LLMs); however, existing frameworks typical…
PatchWorld: Gradient-Free Optimization of Executable World Models
Text-agent environments are typically modeled as partially observable Markov decision processes (POMDPs), assuming that the simulator's lat…
A Unified and Reproducible Experimentation Framework for Speech Understanding
Speech foundation models and Speech LLMs have advanced speech understanding, yet deployment-oriented model selection is hindered by non-com…
Inverse Reinforcement Learning without an Optimal Demonstrator: A Feasible Reward Set Approach
Inverse reinforcement learning (IRL) typically assumes demonstrations from a single optimal demonstrator, but in many applications data com…
BlueFin: Benchmarking LLM Agents on Financial Spreadsheets
We present BlueFin, a benchmark that tasks large language model (LLM) agents with synthesis, manipulation, and comprehension tasks over spr…
What Makes LVLMs Hallucinate Less? Unveiling the Architectural Factors Behind Hallucination Robustness
Hallucination remains one of the key challenges undermining the reliability of Large Vision-Language Models (LVLMs). But what makes an LVLM…
Toxic HallucinAItions: Perturbing Prompts and Tracing LLM Circuits
Large language models (LLMs) are increasingly deployed in conversational settings where user tone ranges from polite to adversarial or toxi…
De-attribute to Forget for LLM Unlearning
The rapid development of large language models (LLMs) has raised concerns on the use of inappropriate data for training, which has led to a…
TUX: Measuring Human--AI Tacit Understanding
As large language models (LLMs) increasingly act as collaborative partners, human--AI alignment is often evaluated through explicit task su…
Do Large Language Models Encode Institutional Experience? Evidence from Cross-Linguistic Moral Reasoning Under Ambiguity
Large language models (LLMs) exhibit systematic differences in moral reasoning across languages, yet the source of this variation remains u…
AMix-2: Establishing Protein as a Native Modality in Large Language Models
We present AMix-2, a protein-text foundation model that establishes protein as a native modality in large language models (LLMs), unifying…
ImmersiveTTS: Environment-Aware Text-to-Speech with Multimodal Diffusion Transformer and Domain-Specific Representation Alignment
Recent advancements in text-guided audio generation have yielded promising results in diverse domains, including sound effects, speech, and…
Reading Between the Citations: A Typed Claim Network for Scientific Literature
Knowledge graphs over corpora of inter-referencing documents - scholarly papers, legal opinions, policy briefs - encode the topology of ref…
Variational Adapter for Cross-modal Similarity Representation
The core of vision-language models lies in measuring cross-modal similarity within a unified representation space. However, most image-text…
Generating Reports or Repeating Templates? Measuring and Mitigating Template Collapse in 3D CT Report Generation
Modern 3D medical vision-language models (VLMs) can generate fluent radiology-style text while exhibit critically low pathology detection a…
DEM: A Distilled Explanation Model for Interpretable Anomaly Detection in Physiological Sensor Networks
Anomaly detection in physiological sensor data from Wireless Body Area Networks (WBANs) can be caused by sensor faults, network disruptions…
Annealed Softmax Greedy in Many-Armed Bayesian Bandits
Reinforcement learning with verifiable rewards (RLVR) and group-based policy optimization methods such as GRPO update a stochastic policy b…
Does Visual Information Play a Decisive Role in Vision-Language-Action Model Driving Behavior?
Vision-Language-Action (VLA) models have demonstrated promising capability in autonomous driving, highlighting the potential of unified mul…
From Prompt Injection to Persistent Control: Defending Agentic Harness Against Trojan Backdoors
LLM agents are evolving from conversational chatbots to operational tools in real-world workspaces. In local agentic harnesses, an LLM can…
Routing on the Stiefel Manifold: When Does Adaptive Subspace Selection Help for Cross-Domain EEG Decoding?
Cross-domain EEG decoding remains challenging despite advances in Riemannian deep learning: covariance matrices from different subjects occ…
Learning to Solve and Optimize by Evolving Code
Combinatorial and optimization problems are fundamental to many industrial AI applications. Solving large-scale real-world instances of suc…
Linear Ordering Problem: Time for a Change
The Linear Ordering Problem (LOP) is a fundamental combinatorial optimization problem with important applications in areas such as economic…
AnchorSteer: Self-Discovered Concept Injection for Structure-Preserving Music Editing
Controllable music editing is to modify high-level attributes while strictly preserving rhythmic and melodic structures. However, this task…
STEP: Learning STructured Embeddings for Progressive Time Series
We present a novel method for learning interpretable representations of progressive time series, that is, data capturing irreversible state…
Fighting Numerical Hallucinations via Data-centric Compilation for Online Financial QA
Large Language Models (LLMs) have significantly advanced online data services, particularly in the domain of financial question answering (…
DRIFT: Joint Channel Estimation and Prediction Towards Pilotless 6G Non-Terrestrial Networks
Non-terrestrial networks (NTNs) are expected to play a pivotal role in sixth-generation (6G) systems by enabling ubiquitous connectivity an…
A Pilot Study on Curator-Guided Multilingual Art Description for Blind and Low-Vision Audiences with Small Vision-Language Models
Blind and low-vision (BLV) audiences remain underserved by visual art descriptions, particularly across languages and in museum settings wh…
On Revisiting Entropy for Identifying Mislabeled Images
Mislabeled samples in training datasets severely degrade the performance of deep networks, as overparameterized models tend to memorize err…
Redefining Instance Matching: A Unified Framework for Part-Aware Matching in Panoptic Segmentation Evaluation
The Panoptic Quality (PQ) metric is the standard for jointly evaluating instance and semantic segmentation. However, its original definitio…
SpecDB: LLM-Generated Customized Databases via Feature-Oriented Decomposition
Mainstream relational databases ship a uniform feature set across deployments, although individual workloads exercise only a fraction of th…
KnowledgeGain: Evaluating and Optimizing Science News Generation for Reader Learning
Science news is an important medium to communicate discoveries between the research communities and the public. Yet, most metrics for gener…
SWIM: Single-Instance Whole-Body Imitation for swiMming
We propose a new method for synthesizing physically-based swimming motions. Physically-based character animation aims to generate physicall…
TARIC: Memory-Augmented Traversability-Aware Outdoor VLN under Interrupted Semantic Cues
Outdoor vision-language navigation (VLN) in long-range, open-world environments is frequently disrupted by semantic-cue interruptions, wher…
Not All Synthetic Data Is Yours to Learn From
Can a language model improve from plain text sampled from itself, with no prompts, no teacher, no verifier, and no reward model? Yes, but o…
UXR PoV for Neuroinclusive Emotion Regulation
Attention-deficit/hyperactivity disorder (ADHD) is a psychiatric disorder which presents itself in individuals through patterns of developm…
Developing an AI-Powered UX Research Point of View for Digital Health in A Regulatory Context: An Exemplar Case from MSM and Transgender HIV Care in Nigeria
User Experience Research (UXR) in a legal and regulatory contexts presents unique challenges that require specialised approaches to protect…
On the Robustness of Multilingual Text Embedding Rankings Across Learning Tasks, Languages, and Benchmark Datasets
Large-scale multilingual text embedding models play crucial role in both research and industry, yet their behavior in language-specific, mu…
Extending the UXR Point of View Pyramid: A Generative AI-Augmented Methodology for Human-Centred AI Systems
Rising household debt and cost-of-living pressures in the United Kingdom have intensified the role of AI-driven financial technologies in m…
FOCUS: Forcing In-Context Object Localization through Visual Support Constraints and Policy Optimization
In-context localization (ICL) seeks to localize a target object specified by a small set of support examples in a query image, operating on…
From Evidence to Design: Developing an AI-Augmented UX Research Point of View for Digital Wellbeing in Emergency and Public Safety Contexts
This paper investigates how User Experience Research (UXR) methods can be combined with AI-supported analysis to develop clearer design dir…
Developing a Culturally Grounded, AI-Augmented UX Research Point of View (POV): An Exemplar Case Study from Telemedicine Dementia Care
User Experience Research (UXR) Points of View (POVs) distil complex and often fragmented research evidence into actionable perspectives tha…
SpatialAct: Probing Spatial Reasoning-to-Action Capabilities of VLM Agents in 3D Scenes
Humans can effortlessly perceive spatial layouts, form cognitive representations, reason about spatial relations, and translate such reason…
Developing a UXR Point of View for Cognitive Accessibility in Mobile Learning with Generative AI
This study investigates how UX research (UXR) principles, combined with Large Language Model (LLM)-supported analysis, can be used to impro…
Trust-Region Behavior Blending for On-Policy Distillation
On-policy distillation (OPD) trains a student on prefixes sampled from its own policy while matching a stronger teacher. This addresses the…
D$^3$: Dynamic Directional Graph-Constrained Data Scheduling for LLM Training
Training data plays a central role in large language models (LLMs) optimization, motivating extensive research on data scheduling strategie…
Emergent Languages in Populations of Language Model Agents: From Token Efficiency to Oversight Evasion
Monitoring autonomous language model agents currently relies mostly on surface behavior. But what happens when agent populations invent new…
MIMO: Multilingual Information Retrieval via Monolingual Objectives
Multilingual Information Retrieval (MLIR) reflects real-world search environments in which queries and relevant documents may appear in dif…
MindVoice: Reconstructing Intelligible Speech from Non-invasive Neural Signals with Pretrained Priors
Reconstructing continuous speech from non-invasive neural recordings is a fundamental problem for probing human auditory perception and bui…
Steering LLMs? Actually, Sparse Autoencoders can outperform simple baselines
Sparse Autoencoders (SAEs) have been seen as a promising avenue for exploring the internals of Large Language Models (LLMs) and for steerin…
Probing Collision Grounding in Vision-Language Models for Safe Human-Robot Collaboration
Safe human--robot collaboration requires more than visual description: a monitor must determine whether the robot body is safely separated,…
MAECO-Lite: Modular Ontology for Dynamic Malware Analysis
Capturing dynamic malware behavior in a practical but still semantically precise manner remains a significant challenge in cyber threat int…
Simulation of collision avoidance behavior in crowd movement by data-driven approach
Crowd movement simulation is essential for pedestrian safety management and facility layout optimization. Data-driven models enhance trajec…
Benchmarking and Enhancing Text-to-Image Models for Generating Visual Representations in Early Arithmetic Education
AI systems are increasingly used to support educational content creation, yet it remains unclear whether they can generate outputs that fai…
Shared Doubt: Zero-shot Cross-Lingual Confidence Estimation for Language Models
Confidence estimation (CE), i.e. quantifying the reliability of a model's prediction, has attracted great interest in the context of large…
Comparing LLM-Based Conversational and Graphical Interfaces for Industrial Decision Tasks: An Exploratory Mixed-Methods Study
The use of Generative AI Conversational User Interfaces (CUI) as a new way to access and analyze data is growing in all sectors, and the in…
What changes after deployment? A survey on On-device Learning in TinyML
Machine learning models on microcontroller-class devices (TinyML) face a fundamental challenge: post-deployment distribution change undermi…
EchoRL: Reinforcement Learning via Rollout Echoing
Reinforcement Learning with Verifiable Rewards is an effective route for post-training to strengthen the reasoning capability of large lang…
Beyond Classification: Dynamic Adapter Routing for Continual Multimodal Retrieval
While retrieval is a core function of vision-language models, continually updating these models for retrieval tasks remains critically unde…
Correcting Split Selection in Online Decision Trees via Anytime-Valid Inference
Bagging-based ensembles, most notably Adaptive Random Forests, are among the strongest performers for learning from data streams. A common…
Learning Cardiac Latent Representations in Vectorcardiogram Space
Electrocardiography (ECG) is a cornerstone of cardiac assessment, making the learning of informative ECG representations fundamental to tas…
Entropic Projection Alignment: Estimating, Explaining, and Improving Model Performance Under Distribution Shift
We propose a unified framework for addressing three key challenges of distribution shift: (1) estimating a model's performance on an unlabe…
ERGeoBench:A Comprehensive Benchmark for Embodied Reasoning and Geo-localization in Multimodal Large Language Models
Multimodal large language models (MLLMs) have shown strong potential as embodied agents, yet embodied geo-localization remains underexplore…
Why Linear Recurrent Memory Works in Partially Observable Reinforcement Learning
The family of linear recurrent neural networks has shown strong performance as recurrent memory units in partially observable reinforcement…
Envisioning Beyond the Few: Disentangled Semantics and Primitives for Few-Shot Atypical Layout-to-Image Generation
The layout-to-image (L2I) task enables fine-grained control over image generation via object categories and spatial layouts. However, exist…
Personalized to Persuade: The Effects of Contextualization and Warmth on Trust and Reliance in Conversational AI
Artificial Intelligence (AI) agents personalize their responses by tailoring explanations to users' backgrounds, interests, and prior inter…
Practical Cross-Band Channel Prediction for AI-RAN via Physics-Guided Deep Unfolding
To make cross-band channel prediction practical for AI-native RAN, algorithms must generalize across diverse environments and support real-…
SAM for Robust Mitochondria Instance Segmentation in Fluorescence Microscopy
The morphological analysis of mitochondria in fluorescence microscopy (FM) is crucial for understanding cellular health, energy production,…
DeMaVLA: A Vision-Language-Action Foundation Model for Generalizable Deformable Manipulation
Real-world household robots require Vision-Language-Action (VLA) foundation models that can acquire reusable manipulation skills across div…
Neither Replacement nor Panacea: Comparing LLM-Based Conversational and Graphical Decision Support in Industrial Tasks
Managers in manufacturing settings rely on digital interfaces to interpret operational data for decision-making, but growing data volume an…
The Terminal Representation in Reinforcement Learning
Representation learning is a powerful tool for spatio-temporal abstraction within reinforcement learning (RL). Two well established approac…
Latent Space Disentanglement via Activation Steering for Interpretable Attribute Control in Symbolic Music Generation
Transformer-based architectures have significantly advanced the generation of complex symbolic sequences, yet a significant gap remains in…
Inconsistency-Aware Minimization: Improving Generalization with Unlabeled Data
Estimating the generalization gap and developing optimization methods that improve generalization are crucial for deep learning models, for…
Social welfare optimisation under institutional reward and punishment
Institutional incentives are widely used to promote cooperation among autonomous, self-regarding agents, from human societies to multi-agen…
Appropriateness of Empathy in AI: A Signal-Cost Perspective
The appropriateness of empathy in AI has emerged as a critical concern, as excessive empathy risks seeming manipulative while insufficient…
FBHM: Functional Benchmarking and Steering of VLMs for Hateful Meme Detection
Hateful meme detection remains a formidable challenge for vision-language models, as existing benchmarks are structurally observational - c…
dashi: A Python library for Dataset Shift Characterization to Support Trustworthy AI Development and Deployment
The Artificial Intelligence (AI) life cycle requires a thorough understanding of the underlying data dynamics for robust, safe and cost-eff…
Dreaming Of Others: Latent Teammate Modeling In World Models For Multi-Agent Reinforcement Learning
In cooperative multi-agent reinforcement learning (MARL), agents must coordinate with partners whose internal policies and intentions are n…
Scaling Higher-Order Graph Learning with Maximal Clique Complexes
Graph neural networks (GNNs) are limited to modeling pairwise interactions, while higher-order models based on cell complexes achieve great…
DynaTree: Dynamic Agentic Retrieval Tree for Time-Sensitive News Retrieval
Agentic Retrieval-Augmented Generation improves retrieval by integrating planning, tool use, and iterative reasoning, but existing agentic…
Target-Side Paraphrase Augmentation for Sign Language Translation with Large Language Models
Sign language translation (SLT) remains constrained by limited paired sign-video/text corpora and heavy-tailed target vocabularies. We stud…
The Sword, Shield, and Achilles' Heel: Characterizing the Linguistic Inductive Bias of Large Language Models for Spatial Reasoning in Navigation Planning
Large Language Model (LLM)-based navigation systems commonly construct explicit spatial representations (e.g., topological graphs, semantic…
Skill Availability and Presentation Granularity in Large-Language-Model Agents: A Controlled SkillsBench Study
Skill documents provide procedural knowledge to large-language-model agents at inference time. This article studies whether the presentatio…
Neuro-symbolic Syntactic Parsing: Shaping a Neural Network with the CYK Algorithm
In this paper, we show the possibility of a direct injection of algorithms into neural network architecture. We focus on a complex algorith…
DOA: Training-Free Decoder-Only Attention Policy for Long-Form Simultaneous Translation with SpeechLLMs
Simultaneous speech-to-text translation (SimulST) generates translations while speech is still unfolding, requiring a streaming policy that…
Used Car Salesbots? Honesty and Credulity of LLMs as Bargaining Agents under Partial Information
In this work we study agents in simulated bargaining scenarios, where a buyer and a seller communicate through a text channel and attempt t…
Fine-grained Verification via Diagnostic Reasoning Supervision for Aspect Sentiment Triplet Extraction
Aspect Sentiment Triplet Extraction (ASTE) aims to identify aspect terms, opinion terms, and sentiment polarities as structured triplets, p…
PithTrain: A Compact and Agent-Native MoE Training System
Mixture-of-Experts (MoE) has become the dominant architecture for frontier language models. To meet this demand, production frameworks have…
GPU Forecasters: Language Models as Selective Surrogates for Kernel Runtime Optimization
GPU kernels are the workhorse of modern deep learning, and optimizing them (via evolutionary search or coding agents) usually requires repe…
Scaling Conversational Hungarian ASR: The BEA-Dialogue+ Corpus
Conversational automatic speech recognition in Hungarian is constrained by the limited amount of publicly available dialogue-style training…
On Efficient Scaling of GNNs via IO-Aware Layers Implementations
Graph Neural Networks (GNNs) are bottlenecked by sparse, irregular memory access. Popular frameworks such as DGL and PyTorch Geometric supp…
Skill Reuse as Compression in Agentic RL
Large language model agents trained with reinforcement learning (RL) often learn brittle, task-specific shortcuts. We hypothesize that agen…
If LLMs Have Human-Like Attributes, Then So Does Age of Empires II
Much research has been carried out on large language models (LLMs) and LLM-powered agentic workflows. However, many works within the field…
Separating Secrets from Placeholders: A Hybrid CNN-CodeBERT Framework for Three-Class Credential Leakage Detection
Credential leakage in public source code repositories poses a critical security threat, with over 23.8 million secrets exposed in 2024 alon…
Feature-Optimized Vision for Adaptive 3D Scene Reconstruction
Three-dimensional scene reconstruction depends on local image evidence that is both visually discriminative and geometrically useful. Fixed…
RayDer: Scalable Self-Supervised Novel View Synthesis from Real-World Video
Self-supervised novel view synthesis (NVS) remains challenging to scale, despite the abundance of video data, largely due to the brittlenes…
Vision-Language Models Suppress Female Representations Under Ambiguous Input
Alignment teaches vision-language models (VLMs) to avoid expressing demographic biases, and when gender is clearly visible they largely suc…
Positional versus Symbolic Attention Heads: Learning Dynamics, RoPE Geometry, and Length Generalization
Transformer-based language models are widespread in today's society. As such, understanding the mechanisms by which they solve structured t…
What Gets Unmasked First? Trajectory Analysis of Diffusion Models for Graph-to-Text Generation
We present the first systematic study of masked diffusion language models (MDLMs) for graph-to-text generation. We analyze MDLM generation…
SPECTRA: Synthetic IR Test Collections with Relevance Oracles and Controlled Distractor Diagnostics
Scalable information retrieval testing needs corpora that are large enough to stress index construction, ranking latency, query routing, an…
LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
Long-context reasoning remains a central challenge for large language models, which often fail to locate and integrate key information in e…
Language Models Learn Constructional Semantics, Not To Mention Syntax: Investigating LM Understanding of Paired-Focus Constructions
Grasping the semantics of rare constructions (form-meaning pairings) has been shown to be a challenging problem that has currently only bee…
TunerDiT: Training-free Progressive Steering of Diffusion Transformer for Multi-Event Video Generation
Text-to-video (T2V) generation faces challenging questions when generating videos with long horizons containing multiple events. Inspired b…
Stateful Online Monitoring Catches Distributed Agent Attacks
Language models can find thousands of severe software vulnerabilities, and agents are increasingly being misused for cyberattacks. To avoid…
Lumos-Nexus: Efficient Frequency Bridging with Homogeneous Latent Space for Video Unified Models
Connector-based video unified models have demonstrated strong capability in instruction-grounded video synthesis, but integrating a large h…
LLM Bias Evaluation: Gender, Racial, and Age Disparities in Occupational and Crime Scenarios
LLM bias evaluation is critical as large language models (LLMs) increasingly influence high-stakes decisions. This paper provides a compreh…
Unifying and Optimizing Data Values for Selection via Sequential Decision-Making
Data selection has emerged as a crucial downstream application of data valuation, yet the theoretical foundations for using data values in…
ProofWala: A Framework for Multilingual Proof Data Synthesis and Theorem-Proving
Neural approaches to theorem proving require robust infrastructure for interfacing with interactive theorem provers (ITPs), extracting stru…
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful
Recent studies indicate that when faced with explicit biases in prompts, models often omit mentioning these biases in their Chain-of-Though…
Inferring Events from Time Series using Language Models
A common goal in analyzing time series data is to understand how events cause observed variations. We study whether Large Language Models (…
Symbolic Intermediaries as a Linguistic-Numerical Interface for LLM-Driven Geometric Reasoning
Large Language Models (LLMs) display reasoning capabilities over linguistic and symbolic objects but have limited capabilities to directly…
OLG++: A Semantic Extension of Obligation Logic Graph
We present OLG++, a semantic extension of the Obligation Logic Graph (OLG) for modeling regulatory and legal rules in municipal and interju…
Neuro-Symbolic Predictive Process Monitoring
This paper addresses the problem of suffix prediction in Business Process Management (BPM) by proposing a Neuro-Symbolic Predictive Process…
ReTabAD: A Benchmark for Restoring Semantic Context in Tabular Anomaly Detection
In tabular anomaly detection (AD), textual semantics often carry critical signals, as the definition of an anomaly is closely tied to domai…
SAC-Opt: Semantic Anchors for Iterative Correction in Optimization Modeling
Large language models (LLMs) have opened new paradigms in optimization modeling by enabling the generation of executable solver code from n…
Post-Training LLMs as Better Decision-Making Agents: A Regret-Minimization Approach
Large language models (LLMs) are increasingly deployed as "agents" for decision-making (DM) in interactive and dynamic environments. Yet, s…
HERMES: Towards Efficient and Verifiable Mathematical Reasoning in LLMs
Informal mathematics has been central to modern large language model (LLM) reasoning, offering flexibility and efficient construction of ar…
Debate with Images: Detecting Deceptive Behaviors in Multimodal Large Language Models
Are frontier AI systems becoming more capable? Certainly. Yet such progress is not an unalloyed blessing but rather a Trojan horse: behind…
DTop-p MoE: Sparsity-Controlled Dynamic Top-p MoE for Foundation Model Pre-training
Sparse Mixture-of-Experts architectures are essential for scaling model capacity efficiently, yet the standard Top-$k$ routing imposes a ri…
Agentic Physical AI toward a Domain-Specific Foundation Model for Energy Systems: A Case Study on Nuclear Reactor Control
The prevailing paradigm in AI for physical systems: scaling general-purpose foundation models toward universal multimodal reasoning, confro…
Regret-Based Federated Causal Discovery with Unknown Interventions
Most causal discovery methods recover a completed partially directed acyclic graph representing a Markov equivalence class from observation…
ConSensus: Multi-Agent Collaboration for Multimodal Sensing
Large language models (LLMs) are increasingly grounded in sensor data to perceive and reason about human physiology and the physical world.…
NEMO: Execution-Aware Optimization Modeling via Autonomous Coding Agents
We present NEMO, a system that translates Natural-language descriptions of decision problems into formal Executable Mathematical Optimizati…
Diagnosing the Reliability of LLM-as-a-Judge via Item Response Theory
While LLM-as-a-Judge is widely used in automated evaluation, existing validation practices primarily operate at the level of observed outpu…
From Out-of-Distribution Detection to Hallucination Detection: A Geometric View
Detecting hallucinations in large language models is a critical open problem with significant implications for safety and reliability. Whil…
MedCoG: Maximizing LLM Inference Density in Medical Reasoning via Meta-Cognitive Regulation
Large Language Models (LLMs) have shown strong potential in complex medical reasoning yet face diminishing gains under inference scaling la…
Discovering Differences in Strategic Behavior Between Humans and LLMs
As Large Language Models (LLMs) are increasingly deployed in social and strategic scenarios, it becomes critical to understand where and wh…
Certified Circuits: Stability Guarantees for Mechanistic Circuits
Understanding how neural networks arrive at their predictions is essential for debugging, auditing, and deployment. Mechanistic interpretab…
SPM-Bench: Benchmarking Large Language Models for Scanning Probe Microscopy
As LLMs achieved breakthroughs in general reasoning, their proficiency in specialized scientific domains reveals pronounced gaps in existin…
From Weak Cues to Real Identities: Evaluating Inference-Driven De-Anonymization in LLM Agents
Anonymization is often assumed to protect privacy once explicit identifiers are removed, because re-identification has historically require…
Reliable Self-Improvement Training by Verifying Reasoning, Not Just Answers
Self-improvement training, where models learn from self-generated solutions, promises sustained capability gains but suffers from a pervasi…
Counterfactual Credit Policy Optimization for Multi-Agent Collaboration
Collaborative multi-agent large language models (LLMs) can solve complex reasoning tasks by decomposing roles, but reinforcement learning f…
LH-Bench: Skill-Grounded Evaluation of Long-Horizon Agents on Subjective Enterprise Tasks
Large language models excel on objectively verifiable tasks such as math and programming, where evaluation reduces to unit tests or a singl…
Learning to Reason with Insight for Informal Theorem Proving
Although most of the automated theorem-proving approaches depend on formal proof systems, informal theorem proving can align better with la…
ClimAgent: LLM as Agents for Autonomous Open-ended Climate Science Analysis
Climate research is pivotal for mitigating global environmental crises, yet the accelerating volume of multi-scale datasets and the complex…
To Use AI as Dice of Possibilities with Timing Computation
The dominant noun-based modeling paradigm has fundamentally constrained AI development, precluding any adequate representation of the futur…
Counterfactual Trace Auditing of LLM Agent Skills
Large Language Model agents are increasingly augmented with agent skills. Current evaluation methods for skills remain limited. Most deploy…
ASH: Agents that Self-Hone via Embodied Learning
Long-horizon embodied tasks remain a fundamental challenge in AI, as current methods rely on hand-engineered rewards or action-labeled demo…
Fully Open Meditron: An Auditable Pipeline for Clinical LLMs
Clinical decision support systems (CDSS) require scrutable, auditable pipelines that enable rigorous, reproducible validation. Yet current…
PlanningBench: Generating Scalable and Verifiable Planning Data for Evaluating and Training Large Language Models
Planning is a fundamental capability for large language models (LLMs) because such complex tasks require models to coordinate goals, constr…
ScenePilot: Controllable Boundary-Driven Critical Scenario Generation for Autonomous Driving
Safety-critical scenarios are central to evaluating autonomous driving systems, yet their rarity in naturalistic logs makes simulation-base…
BoxLitE: 凸最適化に基づく忠実なナレッジベースの埋め込み
ナレッジ ベース (KB) エンベディングは、ファクトに存在する情報 (ABox) を一般化する古典的なナレッジ グラフ エンベディングの機能と、オントロジー言語 (TBox) で表現される概念的知識を組み合わせることを目的としています。最近、何人かの著者が、概念をベクトル空間の凸領域にマッピングするというアイデアを研究しました。これは、より一般的な概念を、より具体的な概念に関連付けられた領域を含む、より大きな領域にマッピングできるため、通常は TBox に存在する階層を表すのに役立ちます。ただし、実際の学習タスク中に凸性の力が活用されることはほとんどありません。ここでは、凸最適化を可能にする DL-Lite$^{\mathcal{H}}$ の KB 埋め込みモデルである BoxLitE を紹介します。満足可能な DL-Lite$^{\mathcal{H}}$ KB に対して、忠実度が低いモデルである BoxLitE 埋め込みが存在することを示します。概念実証として、KB 埋め込みタスクを凸最適化問題として定式化する方法と、そのような望ましい忠実性特性を備えた埋め込みを取得する方法を示します。
原文 (English)
BoxLitE: A Faithful Knowledge Base Embedding Based on Convex Optimization
Knowledge base (KB) embeddings aim at combining the capability of classical knowledge graph embeddings to generalize the information present in facts, the ABox, with conceptual knowledge represented in an ontology language, the TBox. Several authors have recently explored the idea of mapping concepts to convex regions in a vector space. This is useful to represent hierarchies, typically present in TBoxes, since more general concepts can be mapped to larger regions, containing those regions associated with more specific concepts. However, the power of convexity is rarely leveraged during the actual learning tasks. Here, we introduce BoxLitE, a KB embedding model for DL-Lite$^{\mathcal{H}}$ that allows for convex optimization. We show that for any satisfiable DL-Lite$^{\mathcal{H}}$ KB, there is a BoxLitE embedding that is a weakly faithful model. As a proof of concept, we show how to formulate the KB embedding task as a convex optimization problem and how to obtain embeddings with such desirable faithfulness properties.
MuCRASP: マルチモーダル思考連鎖推論を意識した構造化プルーニング
ビジョン言語モデル (VLM) は、複雑なマルチモーダル タスクを解決するために、思考連鎖 (CoT) 推論への依存度が高まっていますが、パラメータ サイズが大きいため、導入コストが高くなります。構造化された剪定は自然な解決策を提供します。ただし、既存の方法では、VLM での CoT 推論の精度を維持できません。我々は 2 つの主な理由を特定します。(1) CoT の一貫性は生成軌跡内の疎な遷移点 (ピボット トークン) に依存しますが、既存のプルーニング手法は CoT に依存しません。 (2) 単峰性 LLM 用に設計された枝刈り手法は、視覚的モダリティとテキスト モダリティ間の活性化分布の違いを考慮していません。これらの観察に動機付けられて、我々は、クロスモーダル調整を維持し、グローバルパラメータバジェットの下で層ごとの感度を考慮しながら、推論に重要なコンポーネントをターゲットにする構造化プルーニングフレームワークである MuCRASP を提案します。 3 つの推論ベンチマークにわたる 4 つの VLM での実験では、MuCRASP が圧縮を増加しても推論の品質を一貫して維持することが示されています。 Qwen2.5-VL-7B で 30% プルーニングを行った場合、MuCRASP は、物理的推論タスクで最も強いベースラインの 7.32 に対して、8.87 の LLM-as-a-Judge スコアを達成しました。さらに、MuCRASP は、最大 50% の枝刈りまで高い推論の一貫性を維持し、以前の枝刈りアプローチを大幅に上回るパフォーマンスを示しながら、複雑さの低下を抑えます。
原文 (English)
MuCRASP: Multimodal Chain-of-thought Reasoning aware Structured Pruning
Vision-language models (VLMs) increasingly rely on chain-of-thought (CoT) reasoning to solve complex multimodal tasks, but their large parameter sizes make deployment expensive. Structured pruning offers a natural solution; however, existing methods fail to preserve CoT reasoning accuracy in VLMs. We identify two key reasons: (1) CoT consistency depends on sparse transition points (pivot tokens) in the generation trajectory, while existing pruning methods are CoT-agnostic; and (2) pruning methods designed for unimodal LLMs do not account for activation-distribution differences across visual and textual modalities. Motivated by these observations, we propose MuCRASP, a structured pruning framework that targets reasoning-critical components while preserving cross-modal alignment and accounting for layer-wise sensitivity under a global parameter budget. Experiments on four VLMs across three reasoning benchmarks show that MuCRASP consistently preserves reasoning quality under increasing compression. At 30% pruning on Qwen2.5-VL-7B, MuCRASP achieves an LLM-as-a-Judge score of 8.87 versus 7.32 for the strongest baseline on physical reasoning tasks. Furthermore, MuCRASP maintains high reasoning consistency up to 50% pruning, significantly outperforming prior pruning approaches while exhibiting lower perplexity degradation.
オフライン階層型 RL での再利用可能なスキルのためのローカル ダイナミクスの規則性の活用
階層型強化学習 (HRL) は、時間的に拡張されたスキルを発見して再利用することにより、非階層型のタスクよりも効率的に長期的な強化学習 (RL) タスクを解決することを約束します。ただし、実際に再利用可能なスキルを取得することは依然として課題です。この目的に向けて、私たちはローカルダイナミクスの直観を活用する抽象化に焦点を当てます。異なるグローバルコンテキストにおけるローカル遷移には、同様の種類のアクションシーケンスが必要です。これらのコンテキストを必要なアクション シーケンスに合わせることで、どのスキルを再利用するか、どこで再利用するかを学習できます。原則として、この情報は、高レベルのポリシーが使用する低レベルのスキルを推論する必要がある多くの HRL アルゴリズムに役立つはずです。結果として得られたアルゴリズム CARL (Contrastive Action-based Representations for Reusable Local Control) は、複雑なヒューマノイド環境における有意義なスキルの定性的なクラスタリングと、HIQL と統合した場合の OGBench ベンチマークでのダウンストリーム パフォーマンスの向上の両方を示しています。
原文 (English)
Exploiting Local Dynamics Regularity for Reusable Skills in Offline Hierarchical RL
Hierarchical Reinforcement Learning (HRL) promises to solve long-horizon Reinforcement Learning (RL) tasks more efficiently than non-hierarchical counterparts by discovering and reusing temporally-extended skills. However, obtaining skills that are actually reusable remains an open challenge. Towards this end, we focus on abstractions that exploit the intuition of local dynamics: local transitions in different global contexts require similar kinds of action sequences. By aligning these contexts with the action sequences they require, we are able to learn which skills to reuse and where to reuse them. In principle, this information should benefit many HRL algorithms, where high-level policies have to reason about the low-level skills they use. The resulting algorithm CARL (Contrastive Action-based Representations for Reusable Local Control) shows both qualitative clustering of meaningful skills in complex humanoid environments and improved downstream performance on the OGBench benchmark when integrated with HIQL.
大規模なマルチモーダル モデルにおける創造的な物理的インテリジェンスの進歩
大規模マルチモーダル モデル (LMM) は、認識と推論において急速に進歩しました。ただし、これらの機能がパターン認識を超えて、オープンエンド環境で視覚に基づいたソリューションを発見することに一般化するかどうかは不明のままです。このような設定では、インテリジェンスには、適切に提示された質問に答えるだけでは不十分です。これには、シーン内の要素を、非自明ではあるが物理的に実行可能な方法でどのように再利用できるかを特定することが含まれます。この創造的な問題解決の形式は人間の知性の中心ですが、現在のベンチマークではほとんどテストされていません。この能力を評価するために、視覚的に豊かで物理的に制約のある環境でアフォーダンスに基づいたクリエイティブ ツールを使用するためのベンチマークである MM-CreativityBench を紹介します。各インスタンスは、候補エンティティとその部品の構造化されたビューを含むシナリオ イメージを表示し、モデルがどのように繰り返しシーンを検査し、関連するアフォーダンスを特定し、視覚的および物理的に根拠のあるソリューションを構成するかを詳細かつ対話的に評価できるようにします。私たちの実験では、現在の LMM は生成能力の欠如ではなく、地上探査を維持できないために、しばしば不十分であることが示されています。モデルは、関連するエンティティを見落としたり、重要な部分を十分に調査しなかったり、画像に根拠のない属性を幻覚したりすることがよくあります。この失敗モードを動機として、創造的なツールの使用を嗜好学習の問題として位置づける、アフォーダンスに基づいた調整を提案します。直接優先最適化を使用すると、モデルが幻覚による代替案よりも視覚的証拠に基づいた属性アフォーダンス推論を好むようになります。さらに、アフォーダンス知識ベースから得られた監視機能を組み込んで、より広範なエンティティの探索と複数ターンの計画をガイドします。私たちの結果は、幻覚や接地関連のエラーを大幅に削減しながら、正しいエンティティと部品を選択する際に一貫して向上していることを示しています。
原文 (English)
Advancing Creative Physical Intelligence in Large Multimodal Models
Large multimodal models (LMMs) have rapidly advanced in perception and reasoning; however, it remains unclear whether these capabilities generalize to discovering visually grounded solutions in open-ended environments, beyond pattern recognition. In such settings, intelligence requires more than answering well-posed questions: it involves identifying how elements in a scene can be repurposed in non-obvious yet physically feasible ways. This form of creative problem-solving is central to human intelligence, but remains largely untested in current benchmarks. To evaluate this ability, we introduce MM-CreativityBench, a benchmark for affordance-grounded creative tool use in visually rich, physically constrained environments. Each instance presents a scenario image with structured views of candidate entities and their parts, enabling fine-grained, interactive evaluation of how models iteratively inspect the scene, identify relevant affordances, and compose visually and physically grounded solutions. Our experiments show that current LMMs often fall short, not due to lack of generative capability, but because they do not sustain grounded exploration. Models often overlook relevant entities, under-examine critical parts, or hallucinate attributes not grounded in the image. Motivated by this failure mode, we propose affordance-grounded alignment, which casts creative tool use as a preference learning problem. Using Direct Preference Optimization, we encourage models to prefer attribute-affordance reasoning grounded in visual evidence over hallucinated alternatives. In addition, we incorporate supervision derived from an affordance knowledge base to guide broader entity exploration and multi-turn planning. Our results show consistent gains in selecting the correct entities and parts, while substantially reducing hallucination and grounding-related errors.
データに敏感なドメインの LLM 出力のニューロシンボリック検証 (拡張プレプリント)
一か八かのドメインに導入された LLM は、根本的な信頼性の課題に直面しています。幻覚、矛盾、プライバシーの脆弱性により、エラーが法的、財務的、または安全性に影響を及ぼす許容できないリスクが生じます。この論文では、LLM で生成されたコンテンツに補完的な保証を提供する、形式的記号手法とニューラル セマンティック分析を組み合わせたハイブリッド検証アーキテクチャを紹介します。このアーキテクチャでは、入力検証に論理的推論を採用し、完全性の特性を活用して、構造化された要件に対して決定可能な保証を提供します。出力検証では、埋め込みベースの意味論的類似性により、形式的な手法では表現力に欠ける文脈上の幻覚が検出されます。この分離は、並列のアクターベースのパイプラインで実現され、幻覚を生み出す分布バイアスを継承するプロンプトベースの自己検証アプローチの制限に対処します。提案されたアーキテクチャとタイプ認識検証方法は、Action Design Research によって開発された現実世界の医療機器損傷評価レポート システムである HAIMEDA を使用して検証されています。評価の結果、構造化エンティティの幻覚検出率は 83% 以上、セマンティック捏造の幻覚検出率は 72% 以上で、レポート作成時間が 30% 短縮されたことが示され、神経記号アーキテクチャがデータに敏感なドメインでの LLM 展開に原則に基づいた保護手段を提供できることが実証されました。
原文 (English)
Neuro-Symbolic Verification of LLM Outputs for Data-Sensitive Domains (extended preprint)
LLMs deployed in high-stakes domains face fundamental reliability challenges: hallucinations, inconsistencies, and privacy vulnerabilities introduce unacceptable risks where errors carry legal, financial, or safety consequences. This paper presents a hybrid verification architecture combining formal symbolic methods with neural semantic analysis to provide complementary guarantees for LLM-generated content. This architecture employs logical reasoning for input verification, leveraging completeness properties to provide decidable guarantees on structured requirements. For output validation, embedding-based semantic similarity detects contextual hallucinations where formal methods lack expressiveness. This separation is realized in a parallel, actor-based pipeline, addressing limitations of prompt-based self-verification approaches, which inherit the distributional biases that produce hallucinations. The proposed architecture and type-aware verification method are validated with HAIMEDA, a real-world medical device damage assessment reporting system developed through Action Design Research. Evaluation shows hallucination detection rates of over 83% for structured entities and 72% for semantic fabrications, with a 30% reduction in report creation time, demonstrating that neuro-symbolic architectures can provide principled safeguards for LLM deployment in data-sensitive domains.
アライメントの改ざん: 人間のフィードバックからの強化学習を利用して不整合なバイアスを最適化する方法
人間のフィードバックからの強化学習 (RLHF) は、大規模言語モデル (LLM) を人間の好みに合わせるための標準的な方法です。この作業では、アライメント改ざんを導入します。これは、アライメント中の LLM が優先データセットに影響を及ぼし、RLHF の望ましくない動作を増幅させる潜在的な脆弱性です。これは、RLHF の核となる制限から生じます。(1) 優先データセットは LLM 自身の出力から構築され、LLM に影響を与えることができます。(2) ペアごとの比較では、どちらの応答が優れているかが示されるだけで、理由は示されません。これらの制限を悪用して、アライメントの改ざんを引き起こす可能性があります。たとえば、LLM がより高品質の偏った応答を生成する場合、アノテーターは品質に基づいてそれらを優先します。ただし、嗜好ラベルは品質とバイアスを区別せず、報酬モデルはこの制限を継承します。強化学習やベストオブ N サンプリングを通じてこのような報酬を最適化すると、不整合なバイアスが増幅される可能性があります。私たちの実験では、キーワードのバイアスからプロパガンダ(性差別など)、ブランドのプロモーション、手段的な目標追求まで、さまざまなバイアスが増幅されることを実証しています。堅牢な RLHF のための既存の技術では、応答品質を犠牲にすることなくアライメント改ざんを完全に解決できないため、軽減は依然として困難です。これらの発見は、現在の RLHF の構造的脆弱性を明らかにし、この脆弱性を防ぐ必要性を強調しています。プロジェクトページ: https://alignment-tampering.github.io/
原文 (English)
Alignment Tampering: How Reinforcement Learning from Human Feedback Is Exploited to Optimize Misaligned Biases
Reinforcement Learning from Human Feedback (RLHF) is the standard method to align Large Language Models (LLMs) with human preferences. In this work, we introduce alignment tampering, a potential vulnerability where the LLM undergoing alignment influences the preference dataset, causing RLHF to amplify undesired behaviors. This arises from core limitations of RLHF: (1) preference datasets are constructed from the LLM's own outputs, allowing it to influence them, and (2) pairwise comparisons only indicate which response is better, not why. These limitations can be exploited to cause alignment tampering. For example, if an LLM generates biased responses with higher quality, annotators will prefer them based on quality. However, preference labels do not distinguish quality from bias, and the reward model inherits this limitation. Optimizing such rewards through reinforcement learning or best-of-N sampling can amplify misaligned biases. Our experiments demonstrate amplification across diverse biases: from keyword bias to propaganda (e.g., sexism), brand promotion, and instrumental goal-seeking. Mitigation remains challenging, as existing techniques for robust RLHF fail to fully resolve alignment tampering without sacrificing response quality. These findings reveal structural vulnerabilities of current RLHF and emphasize the need to prevent this vulnerability. Project page: https://alignment-tampering.github.io/
報酬バイアスの代替: 単軸バイアスの軽減 リダイレクト最適化の圧力
報酬モデルのバイアスを単軸で緩和すると(例、長さ、お調子者、またはスタイルに対するプロキシの依存度を減らす)、最適化のプレッシャーを排除するのではなく、相関するプロキシに回転させることができます。これを報酬バイアス置換と呼ぶ失敗モードです。この失敗は、緩和評価およびポリシーのトレーニング中の監査とポリシーに起因する分布の間の測定と最適化のギャップによって可能になります。私たちは、緩和の結果をレジーム分類法に形式化し、成功した緩和、バイアス置換、過剰補正は、たとえオラクルに真の報酬へのアクセスが許可されていたとしても、ランキングの精度や勝率など、監査分布スコアリングの下で同一の観察結果を生み出すことを証明します。公表されている優先学習による緩和作業全体にわたって、私たちが調査した方法では、緩和の成功を証明するために必要な証拠が報告されていません。複数のバイアスを追跡しながら、政策に起因する分布で評価を強化すると、ギャップが縮まることが証明されており、これを緩和方法とベンチマークの実用的な処方箋に変換します。言語モデル RLHF でのバイアス置換を実証します。この場合、GRPO トレーニング中の長さのペナルティにより、意図したとおりに応答が圧縮されますが、最適化圧力が信頼度の調整にリダイレクトされ、事実に基づく自由形式の精度が低下する一方で、ポリシーが過信状態に陥ります。また、監査分布における報酬と長さの相関をゼロにするが、4 つの SOTA 報酬モデルのうち 3 つでのベストオブ N 選択の下ではバイアスを再導入する、公開されている長さ偏り解消演算子と、人間と LLM 裁判官の意見の不一致で方向が反転する長さとおべっかのカップリングも示します。
原文 (English)
Reward Bias Substitution: Single-Axis Bias Mitigations Redirect Optimization Pressure
Single-axis mitigations of reward-model biases (e.g., reducing proxy reliance on length, sycophancy, or style) can rotate optimization pressure onto correlated proxies rather than eliminate it, a failure mode we call reward bias substitution. The failure is enabled by a measurement-versus-optimization gap between audit and policy-induced distributions during mitigation evaluation and policy training. We formalize mitigation outcomes into a regime taxonomy and prove that successful mitigation, bias substitution, and overcorrection produce identical observables under any audit-distribution scoring, including ranking accuracy and win-rate, even when granted oracle access to the true reward. Across published preference-learning mitigation work, no method we survey reports the evidence needed to certify successful mitigation. Augmenting evaluation with policy-induced distributions while tracking multiple biases provably closes the gap, and we translate this into actionable prescriptions for mitigation methods and benchmarks. We demonstrate bias substitution in language model RLHF, where a length penalty during GRPO training compresses responses as intended yet redirects optimization pressure onto confidence calibration, driving the policy into overconfidence while factual free-form accuracy falls. We also show a published length-debiasing operator that zeroes reward-length correlation on the audit distribution but reintroduces bias under best-of-N selection on three of four SOTA reward models, and a length-sycophancy coupling whose direction reverses under human-LLM judge disagreement.
バイキングメム: ステートフル LLM ベースのアプリケーション用のメモリ ベース管理システム
大規模言語モデルは対話型アプリケーションに革命をもたらしました。ただし、コンテキスト ウィンドウが有限であるため、ステートフルで長期的な対話を維持する上で重要なデータ管理の課題が生じます。既存の記憶アプローチは、多くの場合、不完全な記憶につながる単純な抽出方法に依存しているか、チャットボットなど、単一のユースケースに合わせて調整された厳格な単一目的の記憶抽出プロンプトを使用しています。その結果、汎用性に欠け、さまざまな下流タスクにわたってパフォーマンスが低下します。このギャップを埋めるために、長期的なインタラクションの永続的な状態を管理するための新しいデータ管理パラダイムであるメモリ ベースを導入します。これは 3 つの核となる原則によって特徴付けられます。生の情報ストリームから価値の高い記憶を選択的に抽出することです。固有のステートフルネスと進化。メモリ内容が徐々に要約、修正され、時間的に重み付けされて最近のインタラクションを優先します。そして、教育、推奨、エージェントの記憶など、さまざまなアプリケーションにわたる堅牢な転送性を実現するために設計された一般化可能な抽象化パラダイム。この基盤に基づいて、VikingDB ベクトル エンジン上に実装されたエンドツーエンドのメモリ ベース管理システム、VikingMem を紹介します。バイキングメムは、相互接続されたイベントとエンティティの抽象化を通じてこのパラダイムを具体化します。エンティティはイベントによって動的に更新され、ステートフルな進化を実現しながら、複雑な情報ストリームを選択的に処理するイベント中心のメモリ抽出を特徴としています。トピックごとのタイムラインと時間加重リコールによる時間圧縮を使用して、システムは高レベルの要約記憶を段階的に生成し、最近の項目を優先し、古い項目を圧縮してフェードします。長期メモリベンチマークの広範な評価により、VikingMem は対話型アプリケーションに不可欠な低レイテンシを維持しながら、メモリ取得効率においてベースラインを最大 30% 上回っていることが実証されています。
原文 (English)
VikingMem: A Memory Base Management System for Stateful LLM-based Applications
Large Language Models have revolutionized interactive applications; however, their finite context windows pose a critical data management challenge for maintaining stateful, long-term interactions. Existing memory approaches often rely on simplistic extraction methods that lead to incomplete memories or use rigid, single-purpose memory extraction prompts tailored to a single use case, such as chatbots. Consequently, they lack generalizability and perform poorly across diverse downstream tasks. To bridge this gap, we introduce the Memory Base, a novel data management paradigm for managing the persistent state of long-term interactions. It is characterized by three core principles: selective extraction of high-value memories from raw information streams; inherent statefulness and evolution, where memory content is progressively summarized, corrected, and temporally weighted to prioritize recent interactions; and a generalizable abstraction paradigm designed for robust transferability across diverse applications, including education, recommendation, and agent memory. Building on this foundation, we present VikingMem, an end-to-end Memory Base Management System implemented on the VikingDB vector engine. VikingMem materializes this paradigm through interconnected event and entity abstractions. It features event-centric memory extraction to selectively handle complex information streams, while entities are dynamically updated by events to achieve stateful evolution. Using temporal compression via a topic-wise timeline and time-weighted recall, the system progressively produces high-level summary memories, prioritizes recent items, and compresses and fades older ones. Extensive evaluations on long-term memory benchmarks demonstrate that VikingMem outperformes baselines by up to 30% in memory retrieval effectiveness while maintaining the low latency essential for interactive applications.
SAAS: エージェント検索における過剰検索を軽減するための自己認識強化学習
エージェント検索により、LLM は反復推論と外部検索を通じて複雑なマルチホップの質問を解決できます。これらのシステムは有効であるにもかかわらず、実際には重大な制限に悩まされることがよくあります。エージェントは自分自身の知識の境界を認識できず、内部の知識が十分な場合でもやみくもに検索を開始し、十分な証拠が収集されている場合でも検索を終了できません。自己認識の欠如は深刻な \textbf{過剰検索} につながり、かなりの推論遅延と法外な計算コストが発生します。この目的を達成するために、精度を損なうことなく検索動作を正確に制御する動的な自己認識を育成するように設計された新しい RL フレームワークである SAAS を提案します。 SAAS では、次の 3 つの主要コンポーネントが導入されています。(i) 検索境界モデリング メカニズム。検索が無効なロールアウトと検索が有効なロールアウトを対比することで、進化するポリシーに基づいて検索境界を識別します。 (ii) 境界認識報酬モジュール。この境界認識を軌道レベルのペナルティに変換し、不必要で冗長な検索を抑制します。 (iii) 段階的な最適化戦略。これは、一連のカリキュラムを活用して、検索の正規化よりも推論を優先し、それによって報酬のハッキングを回避します。広範な実験により、SAAS が精度を維持しながら過剰検索を大幅に削減することが実証されました。私たちのコードは https://github.com/XMUDeepLIT/SAAS で匿名で公開されています。
原文 (English)
SAAS: Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
Agentic search enables LLMs to solve complex multi-hop questions through iterative reasoning and external search. Despite the effectiveness, these systems often suffer from a critical limitation in practice: agents fail to recognize their own knowledge boundaries, blindly triggering searches when internal knowledge suffices and failing to terminate search even when adequate evidence has been collected. The lack of self-awareness leads to severe \textbf{over-search}, incurring substantial inference latency and prohibitive computational cost. To this end, we propose SAAS, a novel RL framework designed to cultivate dynamic self-awareness that precisely regulates search behavior without compromising accuracy. SAAS introduces three key components: (i) a search boundary modeling mechanism, which identifies the search boundary under the evolving policy by contrasting search-disabled and search-enabled rollouts; (ii) a boundary-aware reward module, which translates this boundary awareness into trajectory-level penalties, suppressing unnecessary and redundant searches; and (iii) a stage-wise optimization strategy, which leverages a sequential curriculum to prioritize reasoning over search regularization, thereby avoiding reward hacking. Extensive experiments demonstrate that SAAS substantially reduces over-search, while maintaining accuracy. Our code and implementation details are released at https://github.com/XMUDeepLIT/SAAS.
OmniMatBench: 19 の材料科学サブフィールドにわたって人間が調整したマルチモーダル推論ベンチマーク
科学研究においてマルチモーダル言語モデルの役割がますます重要になる中、材料科学はその学際的、マルチモーダル、そしてアプリケーション主導型の性質により重要なテストベッドを提供します。しかし、既存の材料ベンチマークは主に特性予測、知識 QA、または特性評価の理解に焦点を当てており、材料の知識から応用までのより広範な推論プロセスは十分に検討されていません。このギャップを埋めるために、人間が調整した材料科学用のマルチモーダル推論ベンチマークである OmniMatBench を紹介します。 OmniMatBench には、基本的な材料知識、構造材料および工学材料、材料の加工および製造、機能材料および応用材料に及ぶ 19 の材料科学サブ分野にわたって、専門家が厳選した 3,171 件の QA および計算問題が含まれています。私たちは 13 のオープンソースおよびクローズドソースの MLLM を評価し、最良のモデルが全体スコア 0.372 しか達成していないことがわかり、現在の材料科学推論に大きなギャップがあることが明らかになりました。さらに分析を進めると、サブフィールド間の大きなばらつき、固定された推論ヒューリスティック、不均一な材料知識、および数式、検索、およびコード支援設定下での高度な知識の適用が制限されていることが示されています。 OmniMatBench は、現在の MLLM の機能と限界についての重要な洞察を提供し、材料科学研究における信頼できる AI アシスタントの基盤を確立します。
原文 (English)
OmniMatBench: A Human-Calibrated Multimodal Reasoning Benchmark Across 19 Materials Science Subfields
As multimodal language models play an increasingly important role in scientific research, materials science offers a critical testbed due to its interdisciplinary, multimodal, and application-driven nature. However, existing materials benchmarks mainly focus on property prediction, knowledge QA, or characterization understanding, leaving the broader reasoning process from materials knowledge to application underexplored. To fill this gap, we present OmniMatBench, a human-calibrated multimodal reasoning benchmark for materials science. OmniMatBench contains 3,171 expert-curated QA and calculation problems across 19 materials-science subfields, spanning fundamental materials knowledge, structural and engineering materials, materials processing and manufacturing, and functional and applied materials. We evaluate 13 open-source and closed-source MLLMs and find that the best model achieves only a 0.372 overall score, revealing a substantial gap in current materials-science reasoning. Further analysis shows strong variation across subfields, fixed reasoning heuristics, uneven materials knowledge, and limited high-level knowledge application under formula-, retrieval-, and code-assisted settings. OmniMatBench provides crucial insights into the capabilities and limitations of current MLLMs and establishes a foundation for reliable AI assistants in materials-science research.
最小限の十分表現学習による LLM のドメイン固有のデータ合成
大規模言語モデルは汎用機能において目覚ましい進歩を示しており、ドメイン固有のデータを微調整することで特定のドメインで強力なパフォーマンスを達成できます。ただし、対象ドメインの高品質データを取得することは依然として大きな課題です。既存のデータ合成アプローチは演繹的パラダイムに従っており、自然言語で表現された明示的なドメイン記述と注意深くプロンプト エンジニアリングに大きく依存しており、ドメインを説明したり形式的に表現したりすることが難しい現実のシナリオへの適用性が制限されています。この研究では、帰納的パラダイムを通じてドメイン固有のデータ合成という未解明な問題に取り組みます。このパラダイムでは、特にドメインの特性を自然言語で表現することが難しい場合に、ターゲット ドメインが一連の参照例を通じてのみ定義されます。私たちは、参照サンプルから最小限の十分なドメイン表現を学習し、それを活用してドメインが調整された合成データの生成をガイドする新しいフレームワーク DOMINO を提案します。 DOMINO は、サンプル固有のノイズからドメインレベルのパターンを分離し、コアドメインの特性を維持しながらオーバーフィッティングを軽減するために、コントラストのもつれを解く目的とプロンプトチューニングを統合します。理論的には、DOMINO が合成データ配布のサポートを拡張し、より大きな多様性を確保することを証明します。経験的に、ドメイン定義が暗黙的である困難なコーディング ベンチマークでは、DOMINO によって合成されたデータを微調整すると、強力な命令調整されたバックボーンに比べて Pass@1 の精度が最大 4.63\% 向上し、その有効性と堅牢性が実証されました。この取り組みは、ドメイン固有のデータ合成のための新しいパラダイムを確立し、手動のプロンプト設計や自然言語ドメイン仕様を必要とせずに、実用的でスケーラブルなドメイン適応を可能にします。
原文 (English)
Domain-Specific Data Synthesis for LLMs via Minimal Sufficient Representation Learning
Large Language Models have demonstrated remarkable progress in general-purpose capabilities and can achieve strong performance in specific domains through fine-tuning on domain-specific data. However, acquiring high-quality data for target domains remains a significant challenge. Existing data synthesis approaches follow a deductive paradigm, heavily relying on explicit domain descriptions expressed in natural language and careful prompt engineering, limiting their applicability in real-world scenarios where domains are difficult to describe or formally articulate. In this work, we tackle the underexplored problem of domain-specific data synthesis through an inductive paradigm, where the target domain is defined only through a set of reference examples, particularly when domain characteristics are difficult to articulate in natural language. We propose a novel framework, DOMINO, that learns a minimal sufficient domain representation from reference samples and leverages it to guide the generation of domain-aligned synthetic data. DOMINO integrates prompt tuning with a contrastive disentanglement objective to separate domain-level patterns from sample-specific noise, mitigating overfitting while preserving core domain characteristics. Theoretically, we prove that DOMINO expands the support of the synthetic data distribution, ensuring greater diversity. Empirically, on challenging coding benchmarks where domain definitions are implicit, fine-tuning on data synthesized by DOMINO improves Pass@1 accuracy by up to 4.63\% over strong, instruction-tuned backbones, demonstrating its effectiveness and robustness. This work establishes a new paradigm for domain-specific data synthesis, enabling practical and scalable domain adaptation without manual prompt design or natural language domain specifications.
MIRA: ソースを意識したデータ選択のためのトレーニング中のルーブリック アンカーリング
トレーニング中期は、最新の LLM 開発において重要な段階となっており、最終的なトレーニング後の能力を強化するために大規模に厳選された混合物を使用します。データ選択の問題は独特です。データは、事前トレーニングに近い規模で事前トレーニング スタイルの目標に基づいて最適化されますが、下流の機能に向けて厳選され、形式やトレーニングの役割が異なる異種ソースから抽出されます。その結果、効果的な選択には、スケーラビリティとソース適応型のセマンティック基準の両方が必要になります。既存のモデルベースの手法は拡張性に優れていますが、暗黙的な品質信号しか提供しません。セマンティック選択方法はより強力な判断を提供しますが、通常は固定ルーブリックまたは標準化されたデータ形式を前提としています。この不一致に対処するために、自己アンカー型ルーブリック ディスカバリに基づくソース認識フィルタリング フレームワークである MIRA を提案します。重要なアイデアは、ルーブリック構築をデータ選択の一部にすることです。MIRA はまず各ソース グループに対して何を評価すべきかを発見し、次にそれらの判断をスケーラブルな学生スコアラーに抽出して、コーパス全体をフィルタリングします。 21 のソースと 5 つのソース グループを使用したコード指向の中間トレーニングでは、MIRA は 9 つのコード ベンチマーク全体で選択ベースラインを上回り、トークンの半分のみを使用しながら完全なコーパスの実行と一致しました。
原文 (English)
MIRA: Mid-training Rubric Anchoring for Source-Aware Data Selection
Mid-training has become an important stage in modern LLM development, using large-scale curated mixtures to strengthen capabilities before final post-training. Its data selection problem is distinct: the data are optimized under a pretraining-style objective at near-pretraining scale, but are curated toward downstream capabilities and drawn from heterogeneous sources with different formats and training roles. As a result, effective selection requires both scalability and source-adaptive semantic criteria. Existing model-based methods scale well, but provide only implicit quality signals. Semantic selection methods offer stronger judgments, but usually assume fixed rubrics or standardized data formats. To address this mismatch, we propose MIRA, a source-aware filtering framework based on self-anchored rubric discovery. The key idea is to make rubric construction part of data selection: MIRA first discovers what should be evaluated for each source group, then distills those judgments into scalable student scorers for full-corpus filtering. On code-oriented mid-training with 21 sources and 5 source groups, MIRA outperforms selection baselines across nine code benchmarks and matches the full-corpus run while using only half the tokens.
Graph Machine Learning in the Era of Large Language Models (LLMs)
Graphs play an important role in representing complex relationships in various domains like social networks, knowledge graphs, and molecula…
Breaking Information Cocoons: A Hyperbolic Framework for Balancing Exploration and Exploitation in Recommender Systems
Modern recommender systems often create information cocoons, restricting users' exposure to diverse content. The central challenge is to ba…
Understanding the Fundamental Design Decisions of Retrieval-Augmented Generation Systems
Retrieval-Augmented Generation (RAG) has emerged as a critical technique for enhancing large language model (LLM) capabilities. However, pr…
Cross-Modal Attention Calibration for LVLM Hallucination Mitigation
Large vision-language models (LVLMs) have shown remarkable capabilities in visual-language understanding. Despite their success, LVLMs stil…
Beyond Memorization: Assessing Semantic Generalization in Large Language Models Using Phrasal Constructions
The web-scale of pretraining data has created an important evaluation challenge: to disentangle linguistic competence on cases well-represe…
PRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection
Visual instruction tuning adapts pre-trained Multimodal Large Language Models (MLLMs) to follow human instructions for real-world applicati…
Auto-Discovery-Bench: Diagnosing Structured State Tracking in Oracle-Guided Discovery
Interactive discovery requires agents to maintain and update structured beliefs over many rounds of feedback. Before evaluating agents in n…
EMCEE: Improving Multilingual Capability of LLMs via Bridging Knowledge and Reasoning with Extracted Synthetic Multilingual Context
Large Language Models (LLMs) have achieved impressive progress across a wide range of tasks, yet their heavy reliance on English-centric tr…
How does Bayesian Sampling help Membership Inference Attacks?
Membership Inference Attacks (MIAs) aim to estimate whether a specific data point was used in the training of a given model. Existing state…
Unraveling LoRA Interference: Orthogonal Subspaces for Robust Model Merging
Fine-tuning large language models (LMs) for individual tasks yields strong performance but is expensive for deployment and storage. Recent…
Who Gets Credit or Blame? Attributing Accountability in Modern AI Systems
Modern AI systems are typically developed through multiple stages-pretraining, fine-tuning rounds, and subsequent adaptation or alignment,…
Unlearning's Blind Spots: Over-Unlearning and Prototypical Relearning Attack
Machine unlearning (MU) aims to expunge a designated forget set from a trained model without costly retraining, yet the existing techniques…
SHIELD: Secure Hypernetworks for Incremental Expansion Learning Defense
Continual learning under adversarial conditions remains an open problem, as existing methods often compromise either robustness, scalabilit…
DISCO: Mitigating Bias in Deep Learning with Conditional Distance Correlation
Dataset bias often leads deep learning models to exploit spurious correlations instead of task-relevant signals. We introduce the Standard…
Organizational Adaptation to Generative AI in Cybersecurity
Cybersecurity organizations are adapting to GenAI integration through modified frameworks and hybrid operational processes, with success in…
PictSure: Pretraining Embeddings Matters for In-Context Learning Image Classifiers
Building image classification models remains cumbersome in data-scarce domains, where collecting large labeled datasets is impractical. In-…
Joint angle based learning to refine kinematic human pose estimation
Marker-free human pose estimation (HPE) has found increasing applications in various fields. Current HPE suffers from occasional errors in…
Human-Alignment and Calibration of Inference-Time Uncertainty in Large Language Models
There has been much recent interest in evaluating large language models for uncertainty calibration to facilitate model control and modulat…
Residual Reservoir Memory Networks
We introduce a novel class of untrained Recurrent Neural Networks (RNNs) within the Reservoir Computing (RC) paradigm, called Residual Rese…
Target-Agnostic Calibration under Distribution Shift with Frequency-Aware Gradient Rectification
Real-world model deployments inevitably encounter distribution shifts, rendering the confidence estimates of deep neural networks highly un…
Reasoning-Intensive Regression
AI researchers and practitioners increasingly apply large language models (LLMs) to what we call reasoning-intensive regression (RiR), i.e.…
Human Psychometric Questionnaires Mischaracterize LLM Behavior
We examine whether human psychometric questionnaires can serve as reliable tools for characterizing and predicting LLM behavior in everyday…
MedFact: Benchmarking the Fact-Checking Capabilities of Large Language Models on Chinese Medical Texts
Deploying Large Language Models (LLMs) in medical applications requires fact-checking capabilities to ensure patient safety and regulatory…
Towards Atoms of Large Language Models
The fundamental representational units (FRUs) of large language models (LLMs) remain undefined, limiting further understanding of their und…
Towards Foundation Models for Zero-Shot Time Series Anomaly Detection: Leveraging Synthetic Data and Relative Context Discrepancy
Time series anomaly detection (TSAD) is a critical task, but developing models that generalize to unseen data in a zero-shot manner remains…
SAEmnesia: Erasing Concepts in Diffusion Models with Supervised Sparse Autoencoders
Concept unlearning in diffusion models is hampered by feature splitting, where concepts are distributed across many latent features, making…
Spectral Collapse Drives Loss of Plasticity in Deep Continual Learning
We investigate why deep neural networks suffer from loss of plasticity in continual learning, and thus fail to learn new tasks without rein…
Dual Mechanisms of Value Expression: Intrinsic vs. Prompted Values in Large Language Models
Large language models can express values in two main ways: (1) intrinsic expression, reflecting the model's inherent values learned during…
Mechanistic Interpretability as Statistical Estimation: A Variance Analysis
Mechanistic Interpretability (MI) aims to reverse-engineer model behaviors by identifying functional sub-networks. Yet, the scientific vali…
LLMs Lean on Priors, Not Programming Language Semantics
Recent work asks whether large language models (LLMs) condition their reasoning on explicit rules rather than statistical regularities from…
OBCache: Optimal Brain KV Cache Pruning for Efficient Long-Context LLM Inference
Large language models (LLMs) with extended context windows enable powerful applications but impose significant memory overhead, as caching…
PAC-Bayesian Reinforcement Learning Trains Generalizable Policies
We derive a novel PAC-Bayesian generalization bound for reinforcement learning that explicitly accounts for Markov dependencies in the data…
Boundary-Guided Policy Optimization for Memory-efficient RL of Diffusion Large Language Models
A key challenge in applying reinforcement learning (RL) to diffusion large language models (dLLMs) is the intractability of their likelihoo…
CaptionFormer: Unified Segmentation, Tracking, and Captioning for Spatio-Temporal Objects
Dense Video Object Captioning (DVOC) is the task of jointly detecting, tracking, and captioning object trajectories in a video, requiring t…
InfiMed-ORBIT: Aligning LLMs on Open-Ended Complex Tasks via Rubric-Based Incremental Training
Reinforcement learning (RL) has powered many recent breakthroughs in large language models (LLMs), especially for tasks where rewards can b…
Scaling Multi-Agent Environment Co-Design with Diffusion Models
The agent-environment co-design paradigm jointly optimises agent policies and environment configurations in search of improved system perfo…
SpectralTrain: A Universal Framework for Hyperspectral Image Classification
Hyperspectral image (HSI) classification typically involves large-scale data and computationally intensive training, which limits the pract…
Mixture of Horizons in Action Chunking
Vision-language-action (VLA) models have shown remarkable capabilities in robotic manipulation, but their performance is sensitive to the $…
Reasoning-Aware Multimodal Fusion for Hateful Video Detection
Hate speech in online videos is posing an increasingly serious threat to digital platforms, especially as video content becomes increasingl…
Conditional Coverage Diagnostics for Conformal Prediction
Evaluating conditional coverage remains one of the most persistent challenges in assessing the reliability of predictive systems. Although…
Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Existing reinforcement learning (RL) approaches treat large language models (LLMs) as a unified policy, overlooking their internal mechanis…
FEM-Bench: A Structured Scientific Reasoning Benchmark for Evaluating Code-Generating LLMs
As LLMs advance their reasoning capabilities about the physical world, the absence of rigorous benchmarks for evaluating their ability to g…
Flow Equivariant World Models: Memory for Partially Observed Dynamic Environments
Embodied systems experience the world as 'a symphony of flows': a combination of many continuous streams of sensory input coupled to self-m…
Rethinking Multimodal Few-Shot 3D Point Cloud Segmentation: From Fused Refinement to Decoupled Arbitration
In this paper, we revisit multimodal few-shot 3D point cloud semantic segmentation (FS-PCS), identifying a conflict in "Fuse-then-Refine" p…
The Refutability Gap: Challenges in Validating Reasoning by Large Language Models
Recent reports claim that Large Language Models (LLMs) have achieved the ability to derive new science and exhibit human-level general inte…
PASTA: A Scalable Framework for Multi-Policy AI Compliance Evaluation
AI compliance is becoming increasingly critical as AI systems grow more powerful and pervasive. Yet the rapid expansion of AI policies crea…
Performance and Complexity Trade-off Optimization of Speech Models During Training
In speech machine learning, neural network models are typically designed by choosing an architecture with fixed layer sizes and structure.…
SKETCH: Semantic Key-Point Conditioning for Long-Horizon Vessel Trajectory Prediction
Accurate long-horizon vessel trajectory prediction remains challenging due to compounded uncertainty from complex navigation behaviors and…
Gap-K%: Measuring Top-1 Prediction Gap for Detecting Pretraining Data
The opacity of massive pretraining corpora in Large Language Models (LLMs) raises significant privacy and copyright concerns, making pretra…
ParalESN: Enabling parallel information processing in Reservoir Computing
Reservoir Computing (RC) has established itself as an efficient paradigm for temporal processing. However, its scalability remains severely…
Decouple Searching from Training: Scaling Data Mixing via Model Merging for Large Language Model Pre-training
Determining an effective data mixture is a key factor in Large Language Model (LLM) pre-training, where models must balance general compete…
Multi-Agent Teams Hold Experts Back
Multi-agent LLM systems are increasingly deployed as autonomous collaborators, where agents interact freely rather than execute fixed, pre-…
The Gaussian-Head OFL Family: One-Shot Federated Learning from Client Global Statistics
Classical Federated Learning relies on a multi-round iterative process of model exchange and aggregation between server and clients, with h…
An Odd Estimator for Shapley Values
The Shapley value is a ubiquitous framework for attribution in machine learning, encompassing feature importance, data valuation, and causa…
Plain Transformers are Surprisingly Powerful Link Predictors
Link prediction is a core challenge in graph machine learning, demanding models that capture rich and complex topological dependencies. Whi…
Mixture of Concept Bottleneck Experts
Concept Bottleneck Models (CBMs) promote interpretability by grounding predictions in human-understandable concepts. However, existing CBMs…
CVE-Factory: Scaling Expert-Level Agentic Tasks for Code Security Vulnerability
Evaluating and improving the security capabilities of code agents requires high-quality, executable vulnerability tasks. However, existing…
Stop the Flip-Flop: Context-Preserving Verification for Fast Revocable Diffusion Decoding
Parallel diffusion decoding can accelerate diffusion language model inference by unmasking multiple tokens per step, but aggressive paralle…
Pull Requests as a Training Signal for Repo-Level Code Editing
Repository-level code editing requires models to understand complex dependencies and execute precise multi-file modifications across a larg…
A Kinetic Energy Perspective of Flow Matching
Flow-based generative models can be viewed through a physics lens: sampling transports a particle from noise to data by integrating a learn…
Inverting Data Transformations via Diffusion Sampling
We study the problem of transformation inversion on general Lie groups: a datum is transformed by an unknown group element, and the goal is…
Breaking the Simplification Bottleneck in Amortized Neural Symbolic Regression
Symbolic regression (SR) aims to discover interpretable analytical expressions that accurately describe observed data. Amortized SR promise…
A Behavioural and Representational Evaluation of Goal-Directedness in Language Model Agents
Understanding an agent's goals helps explain and predict its behaviour, yet there is no established methodology for reliably attributing go…
Effective Reasoning Chains Reduce Intrinsic Dimensionality
Chain-of-thought (CoT) reasoning and its variants have substantially improved the performance of language models on complex reasoning tasks…
Biases in the Blind Spot: Detecting What LLMs Fail to Mention
Large Language Models (LLMs) often provide chain-of-thought (CoT) reasoning traces that appear plausible, but may hide internal biases. We…
Less is Enough: Synthesizing Diverse Data in LLM Feature Space with Sparse Autoencoders
The diversity of post-training data is critical for effective downstream performance in large language models (LLMs). Many existing approac…
Weight Decay Improves Language Model Plasticity
Large language models are typically trained in two broad phases: pretraining to produce a base model, followed by further training to impro…
SCOPE: Selective Conformal Optimized Pairwise LLM Judging
Large language models (LLMs) are increasingly used as scalable judges in pairwise evaluation, but they remain prone to miscalibration and b…
DTBench: A Synthetic Benchmark for Document-to-Table Extraction
Document-to-table (Doc2Table) extraction derives structured tables from unstructured documents under a target schema, enabling reliable and…
The Information Geometry of Softmax: Probing and Steering
This paper concerns the question of how AI systems encode semantic structure into the geometric structure of their representation spaces. T…
HiPER: Hierarchical Reinforcement Learning with Explicit Credit Assignment for Large Language Model Agents
Training LLMs as interactive agents for multi-turn decision-making remains challenging, particularly in long-horizon tasks with sparse and…
Position: Evaluation of ECG Representations Must Be Fixed
This position paper argues that current benchmarking practice in 12-lead ECG representation learning must be fixed to ensure progress is re…
HistCAD: A Constraint-Aware Parametric History-Based CAD Representation, Dataset, and Benchmark with Industrial Complexity
Parametric CAD sequences are reusable because dimensional and geometric constraints govern how parameter changes propagate. Existing CAD ge…
From Leaky Thoughts to Private Reasoning: Controlling What LRMs Say to Themselves
Large reasoning models (LRMs) produce reasoning traces (RTs) that often contain sensitive information. These leaky thoughts are difficult t…
The Global Landscape of Environmental AI Regulation: From the Cost of Reasoning to a Right to Green AI
Artificial intelligence (AI) systems impose substantial and growing environmental costs, yet transparency about these impacts has declined…
MASPOB: Bandit-Based Prompt Optimization for Multi-Agent Systems with Graph Neural Networks
Large Language Models (LLMs) have achieved great success in many real-world applications, especially the one serving as the cognitive backb…
NGDBench: Towards Neural Graph Data Management
Data critical to real-world decision-making is increasingly found within organizations. Such data is heterogeneous, constantly evolving, an…
Rank-Factorized Implicit Neural Bias: Scaling Super-Resolution Transformer with FlashAttention
Recent Super-Resolution~(SR) methods mainly adopt Transformers for their strong long-range modeling capability and exceptional representati…
Targeted Speaker Poisoning Framework in Zero-Shot Text-to-Speech
Zero-shot Text-to-Speech (TTS) voice cloning poses severe privacy risks, demanding the removal of specific speaker identities from trained…
Variational Routing: A Scalable Bayesian Framework for Calibrated Mixture-of-Experts Transformers
Foundation models are increasingly being deployed in contexts where understanding the uncertainty of their outputs is critical to ensuring…
G-STAR: End-to-End Global Speaker-Tracking Attributed Recognition
We study timestamped speaker-attributed automatic speech recognition (SA-ASR) for long-form, multi-party speech with overlap. In this setti…
Prompt Injection as Role Confusion
LLMs see the world as a single stream of text, partitioned into roles like or . We trace prompt injection to role confusion: models perceiv…
Surprised by Attention: Predictable Query Dynamics for Time Series Anomaly Detection
Multivariate time series anomalies often manifest as shifts in cross-channel dependencies rather than simple amplitude excursions. In auton…
Functorial Neural Architectures from Higher Inductive Types
Neural networks often learn the parts of a task but fail on novel combinations of those parts. We argue that this failure is architectural:…
REAL: Regression-Aware Reinforcement Learning for LLM-as-a-Judge
Large language models (LLMs) are increasingly deployed as automated evaluators that assign numeric scores to model outputs, a paradigm know…
Empirical Characterization of Inference-Time Elicited Probability Transformations in Large Language Models
Large language models increasingly rely on inference-time procedures such as chain-of-thought reasoning, self-refinement, retrieval augment…
SimulCost: A Cost-Aware Benchmark and Toolkit for Automating Physics Simulations with LLMs
Evaluating LLM agents for scientific tasks has focused on token costs while ignoring tool-use costs like simulation time and experimental r…
Graph Energy Matching: Transport-Aligned Energy-Based Modeling for Graph Generation
Generative modeling of discrete data, such as graphs, underpins many scientific and industrial applications, including molecular discovery…
Circuit-Inspired High-Order Neural Networks with Unified Neural Dynamics Modeling for PDE Solving and Visual Perception
Deep networks often rely on architectural heuristics to shape representation evolution, limiting their ability to model data governed by in…
Beyond Static Uncertainty: Modeling Temporal Uncertainty Dynamics for Probabilistic Time Series Forecasting
Real-world time series exhibit temporally structured uncertainty: volatility clusters in turbulent regimes, dissipates in stable periods, a…
Multi-Level Barriers to Generative AI Adoption Across Disciplines and Professional Roles in Higher Education
Generative Artificial Intelligence (GenAI) is rapidly reshaping higher education, yet barriers to its adoption across different disciplines…
World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry
General-purpose world models promise scalable policy evaluation, optimization, and planning, yet achieving the required level of robustness…
Rays as Pixels: Learning A Joint Distribution of Videos and Camera Trajectories
Recovering camera parameters from images and rendering scenes from novel viewpoints have been treated as separate tasks in computer vision…
Symmetry Reveals Layerwise Dynamics: How Transformers Perform In-Context Classification
Transformers can perform in-context classification from a few labeled examples, yet the inference-time algorithm remains opaque. We study m…
SVL: Goal-Conditioned Reinforcement Learning as Survival Learning
Standard approaches to goal-conditioned reinforcement learning (GCRL) that rely on temporal-difference learning can be unstable and sample-…
Compile to Compress: Boosting Formal Theorem Provers by Compiler Outputs
Large language models (LLMs) have demonstrated significant potential in formal theorem proving, yet state-of-the-art performance often nece…
Aligning Dense Retrievers with LLM Utility via Distillation
Dense vector retrieval is the practical backbone of Retrieval- Augmented Generation (RAG), but similarity search can suffer from precision…
Progress in Formalizing Sphere Packing in Dimension 8
In 2016, Viazovska famously solved the sphere packing problem in dimension $8$, using modular forms to construct a 'magic' function satisfy…
Robust Lightweight Crack Classification for Real-Time UAV Bridge Inspection
With the widespread application of Unmanned Aerial Vehicles (UAVs) in bridge structural health monitoring, deep learning-based automatic cr…
FreeTimeGS++: Secrets of Dynamic Gaussian Splatting and Their Principles
The recent surge in 4D Gaussian Splatting (4DGS) has achieved impressive dynamic scene reconstruction. While these methods demonstrate rema…
Autoregressive Visual Generation Needs a Prologue
In this work, we propose Prologue, an approach to bridging the reconstruction-generation gap in autoregressive (AR) image generation. Inste…
OBLIQ-Bench: Exposing Overlooked Bottlenecks in Modern Retrievers with Latent and Implicit Queries
Retrieval benchmarks are increasingly saturating, but we argue that efficient search is far from a solved problem. We identify a class of q…
Why DDIM Hallucinates More Than DDPM: A Theoretical Analysis of Reverse Dynamics
We theoretically study the hallucination phenomena in two canonical diffusion samplers: the stochastic Denoising Diffusion Probabilistic Mo…
Self-Captioning Multimodal Interaction Tuning: Amplifying Exploitable Redundancies for Robust Vision Language Models
Current vision language models face hallucination and robustness issues against ambiguous or corrupted modalities. We hypothesize that thes…
Spurious Correlation Learning in Preference Optimization: Mechanisms, Consequences, and Mitigation via Tie Training
Preference learning methods like Direct Preference Optimization (DPO) are known to induce reliance on spurious correlations, leading to syc…
Much of Geospatial Web Search Is Beyond Traditional GIS
Web search queries concern place far more often than existing labelling schemes suggest, yet the landscape of geospatial web search queries…
Towards a holistic understanding of Selection Bias for Causal Effect Identification
Selection bias is pervasive in observational studies. For example, large scale biobanks data can exhibit ``healthy volunteer bias'' when re…
MAVEN A Multi-Agent Framework for Multicultural Text-to-Video Generation
Text-to-video (T2V) generation has rapidly progressed in visual fidelity, yet its ability to faithfully represent multiple cultures within…
SEMA-RAG: A Self-Evolving Multi-Agent Retrieval-Augmented Generation Framework for Medical Reasoning
Retrieval-Augmented Generation (RAG) is widely employed to mitigate risks such as hallucinations and knowledge obsolescence in medical ques…
FML-bench: A Controlled Study of AI Research Agent Strategies from the Perspective of Search Dynamics
AI research agents accelerate ML research by automating hypothesis generation, experimentation, and empirical refinement. Existing agent st…
Interaction-Breaking Adversarial Learning Framework for Robust Multi-Agent Reinforcement Learning
Cooperation is central to multi-agent reinforcement learning (MARL), yet learned coordination can be fragile when external perturbations di…
PROWL: Prioritized Regret-Driven Optimization for World Model Learning
Modern action-conditioned video world models achieve strong short-horizon visual realism, yet remain unreliable on rare, interaction-critic…
Block-Based Double Decoders
Encoder-decoder models offer substantial inference-time savings over decoder-only models, but their pretraining objectives suffer from spar…
Chunking German Legal Code
This paper investigates chunking strategies for retrieval-augmented generation on German statutory law, using the German Civil Code as a st…
Efficient Learning of Deep State Space Models via Importance Smoothing
Latent state space systems are ubiquitous in statistical modelling, arising naturally when time series are observed through noisy measureme…
Agent JIT Compilation for Latency-Optimizing Web Agent Planning and Scheduling
Computer-use agents (CUAs) automate tasks specified with natural language such as "order the cheapest item from Taco Bell" by generating se…
The Distillation Game: Adaptive Attacks & Efficient Defenses
Distillation attacks create a deployment trade-off for model providers: the same outputs that make a model more useful can also make it eas…
並べて比較すると言語モデルにおける方言のバイアスが増幅される
言語モデル (LM) は、方言ラベルがない場合でも、方言のバリエーションに基づいて話者に対して体系的なバイアスを示す可能性があり、これは隠れ方言バイアスとして知られる動作です。この研究では、LM が標準的なアメリカ英語 (SAE) およびアフリカ系アメリカ人の現地語英語 (AAVE) における意図と同等のツイートと (人種的偏見に関する社会心理学研究に由来する) 定型的特徴をどのように関連付けるかを評価することにより、オンライン言説における隠れた方言バイアスを定量化します。これまでの研究では、LMがツイートを単独で評価する場合、より否定的なステレオタイプをAAVEと関連付けることが示されているが、SAE / AAVEツイートのペアを並べて比較すると、このバイアスが大幅に悪化することがわかり、驚いたことに、この設定は、候補者をランク付けするためにモデルが使用される影響の大きい意思決定のコンテキストをより厳密に反映している。方言ラベルが明示的に指定されている場合、偏りはさらに悪化します。商用開発者が LM のバイアスを軽減するために広範な努力を行っていることを考えると、これは驚くべきことです。心強いことに、反事実的な公平性の微調整により、一部の定型的特性に対する隠された方言バイアスが緩和され、ツイートを単独で評価する場合の平均格差が減少することが示されました。ただし、SAE / AAVE ツイートを並べて評価する場合、これらの改善は特性全体で一貫して維持されるわけではありません。私たちの調査結果は、隠れ方言バイアスに関する既存の評価設定では、特に対照的な設定において、その重大度が過小評価される可能性があることを示しています。さらに、明白な方言バイアスは、安全性を調整した微調整後でも顕著なままであり、これが未解決の問題のままであることを示しており、より堅牢な評価および緩和フレームワークの必要性を動機付けています。
原文 (English)
Side-by-side Comparison Amplifies Dialect Bias in Language Models
Language models (LMs) can exhibit biases based on variations in their dialects, even in the absence of a dialect label, a behavior known as covert dialect bias. In this work, we quantify covert dialect bias in online discourse by evaluating how LMs associate stereotypical traits (derived from social psychology research on racial bias) with intent-equivalent tweets in Standard American English (SAE) and African-American Vernacular English (AAVE). While prior work shows that LMs associate more negative stereotypes with AAVE when evaluating tweets in isolation, we are surprised to find that this bias is significantly exacerbated when SAE / AAVE tweet pairs are compared side by side, a setting that more closely reflects high-impact decision making contexts in which models are used to rank candidates. The bias only worsens when dialect labels are explicitly specified. This is striking, given the extensive efforts from commercial developers to mitigate bias in their LMs. Encouragingly, we show that counterfactual fairness finetuning can mitigate covert dialect bias for some stereotypical traits, reducing average disparities when evaluating tweets in isolation, however, these improvements do not consistently hold across traits when evaluating SAE / AAVE tweets side by side. Our findings show that existing evaluation settings for covert dialect bias may underestimate its severity, specifically in contrastive settings. Additionally, overt dialect bias remains pronounced even after safety aligned finetuning, indicating that it remains an unresolved problem, and motivates the need for more robust evaluation and mitigation frameworks.
Theoretical Analysis of Sparse Optimization with Reparameterization, Weight Decay, and Adaptive Learning Rate
Sparse optimization is a fundamental challenge in various practical applications. A popular approach to sparse optimization is $\ell_p$ reg…
Efficient Benchmarking Is Just Feature Selection and Multiple Regression
Efficient benchmarking techniques aim to lower the computational cost of evaluating LLMs by predicting full benchmark scores using only a s…
GEM: 最適な LLM データ キュレーションのための幾何学的エントロピー混合
LLM の事前トレーニングの有効性は、膨大な量ではなくデータの構成に依存することが増えています。しかし、最適な混合は分類上の欠陥によって妨げられています。人間の分類法は存在論的な不整合に悩まされており、ユークリッド クラスタリングは埋め込みの異方性に対処できません。私たちは、混合バランス正則化装置で強化された超球上の変分問題としてデータキュレーションを再定式化するフレームワークである GEM (Geometric Entropy Mixing) を紹介します。生成事前を切り離し、証明可能な MM (Minorize-Maximize) アルゴリズムを介して目的を最適化することにより、GEM はクラスターの崩壊に効果的に対抗し、ユークリッド ヒューリスティックでは見えないバランスのとれた意味構造を発見します。私たちは、教師と生徒の蒸留を使用して、この幾何学的忠実度を Web スケールのコーパスにスケールし、解釈可能な分類法を生成するために幾何学的影響スコア (GIS) を導入します。 1.1B パラメーター モデルを使用した実験では、GEM が DoReMi や RegMix などのミキシング戦略に統合された場合に新しい最先端技術を確立し、ダウンストリームの平均精度を最大 1.2% 向上させ、予測可能なデータ ミキシングのための堅牢な座標系を提供することが実証されました。
原文 (English)
GEM: Geometric Entropy Mixing for Optimal LLM Data Curation
LLM pre-training efficacy increasingly depends on data composition rather than sheer volume. Yet, optimal mixing is hindered by categorization flaws: human taxonomies suffer from ontological misalignment, and Euclidean clustering fails to address embedding anisotropy. We introduce GEM (Geometric Entropy Mixing), a framework reformulating data curation as a variational problem on the hypersphere augmented with a mixing-balance regularizer. By decoupling the generative prior and optimizing the objective via a provable MM (Minorize-Maximize) algorithm, GEM effectively counteracts the cluster collapse to discover balanced semantic structures invisible to Euclidean heuristics. We employ teacher-student distillation to scale this geometric fidelity to web-scale corpora and introduce the Geometric Influence Score (GIS) for interpretable taxonomy generation. Experiments with 1.1B-parameter models demonstrate that GEM establishes a new state-of-the-art when integrated into mixing strategies like DoReMi and RegMix, improving average downstream accuracy by up to 1.2% and offering a robust coordinate system for predictable data mixing.
Pair-In, Pair-Out: Latent Multi-Token Prediction for Efficient LLMs
Long chain-of-thought reasoning has made autoregressive decoding the dominant inference cost of modern large language models. Existing meth…
読者を取り残さない: 誰もが理解できるマルチエージェントの概要
米国の平文法では、政府文書が一般の人々が簡単に理解できる明確で単純な言語でアクセスできるようにすることを求めていますが、既存の要約システムは、一般読者の間の多様な言語的および認知的障壁に対処するのに苦労しています。我々は、小学生の読者、非ネイティブの読者、注意欠陥のある読者という 3 つの代表的な読者グループをシミュレートする、平易な言語要約のためのマルチエージェント フレームワークである NRLB (No Reader Left Behind) を紹介します。 NRLB は、テンプレートベースの計画と読者指向の反復的な改善を組み合わせ、難しい用語、文脈の欠落、混乱を招く文章の体系的な検出と解決を可能にします。複数のデータセットにわたる評価により、事実の正確さを維持しながら可読性が一貫して向上していることが実証されています。人間による評価では、NRLB の影響がさらに検証され、アノテーターの優先率は 55% から 76% の範囲であり、情報源に忠実であり、一般の人々が広くアクセスできる平易な言葉による要約を作成する NRLB の可能性が強調されています。
原文 (English)
No Reader Left Behind: Multi-Agent Summaries Everyone Can Understand
The Plain Writing Act in the United States requires government documents to be accessible in clear and simple language that the general public can easily understand, yet existing summarization systems struggle to address diverse linguistic and cognitive barriers among general readers. We present NRLB (No Reader Left Behind), a multi-agent framework for plain language summarization that simulates three representative reader groups: elementary school student readers, non-native readers, and readers with attention deficits. NRLB combines template-based planning with iterative, reader-oriented refinement, enabling systematic detection and resolution of difficult terms, missing contexts, and confusing sentences. Evaluations across multiple datasets demonstrate consistent improvements in readability while preserving factual accuracy. Human evaluation further validates NRLB's impact, with annotator preference rates ranging from 55% to 76%, highlighting NRLB's potential to produce plain language summaries that are both faithful to the source and broadly accessible to the general public.
アインシュタイン望遠鏡のシミュレートされたデータの分析に適用されたエージェント AI の初の直接比較
我々は、人間の介入なしに共有コンピューティング インフラストラクチャ上でシンプルなエンドツーエンドの重力波データ分析パイプラインを自律的に実行するという 2 つの最先端のエージェント AI システム、Claude Code (Anthropic) と Codex (OpenAI) の比較を報告します。このパイプラインは、生のアインシュタイン望遠鏡でシミュレートされたノイズからのパワー スペクトル密度推定、幾何学的テンプレート バンクの生成、100 個のバイナリ ブラック ホール信号注入の整合フィルター回復、自動結果生成、および Physical Review D のスタイルでフォーマットされた原稿の大規模言語モデル支援の作成で構成されます。両方のエージェントは、同一の仕様書と同一のコンピューティング リソースを受け取りました。実験は 2 回実行されました。1 回目は非現実的な大音量の注入を使用して実行され、2 回目は物理的に動機付けられた SNR 範囲に再スケーリングされた信号を使用して実行されました。科学的結果は両方の実行で収束しました。ただし、エージェントは大幅に異なる動作と計算コストを示しました。Claude Code は、仕様からのサイレント逸脱はありますが、パイプラインを約 3.4 分で完了しましたが、Codex は、整合フィルターの内部ループの一方的なパフォーマンスの最適化を含む、明示的な自己修正の再起動に約 16 分を要しました。自律的に生成された原稿も、長さ、詳細、品質が異なりました。 2 回目の実行では、SNR 範囲の命令の解釈における微妙な違いが、真の科学的相違につながりました。Claude Code は命令を黙って再解釈しましたが、Codex は文字通り仕様に従いました。速度と可聴性、サイレントと透過的なエラー処理、命令の解釈、マルチモデル パイプラインにおける中間データ表現の重要性など、これらの動作の違いが科学技術コンピューティング ワークフローでのエージェント AI の展開に与える影響について説明します。
原文 (English)
First head-to-head comparison of agentic AI applied to the analysis of simulated data of the Einstein Telescope
We report a comparison of two state-of-the-art agentic AI systems, Claude Code (Anthropic) and Codex (OpenAI), tasked with autonomously executing a simple end-to-end gravitational wave data analysis pipeline on a shared computing infrastructure without human intervention. The pipeline comprises power spectral density estimation from raw Einstein Telescope simulated noise, geometric template bank generation, matched filter recovery of 100 binary black hole signal injections, automated results generation, and large language model-assisted production of a manuscript formatted in the style of Physical Review D. Both agents received identical written specifications and identical compute resources. The experiment was run twice: a first run with unrealistically loud injections, and a second run with signals rescaled to a physically motivated SNR range. The scientific results converged in both runs. However, the agents exhibited substantially different behaviors and computational costs: Claude Code completed the pipeline in ~3.4 minutes with silent deviations from the specification, while Codex required ~16 minutes across explicit self-correcting restarts, including an unsolicited performance optimization of the matched filter inner loop. The autonomously generated manuscripts also diverged in length, details, and quality. In the second run, a subtle difference in the interpretation of the SNR range instruction led to a genuine scientific divergence: Claude Code silently reinterpreted the instructions, while Codex followed the specification literally. We discuss the implications of these behavioral differences, such as speed versus auditability, silent versus transparent error handling, instruction interpretation, and the criticality of intermediate data representations in multi-model pipelines, for the deployment of agentic AI in scientific computing workflows.
SafeRx-Agent: 安全で説明可能な投薬推奨のための知識に基づいたマルチエージェント フレームワーク
薬剤の推奨は患者の来院時の薬剤を予測しますが、既存の方法では依然として 2 つの重要な課題に直面しています。モデルレベルでは、従来の医薬品推奨方法は限られた根拠に基づいて構造化された医薬品コードを予測するだけですが、LLMエージェントはより豊富な臨床コンテキストを使用できますが、安全性の検証とトレーサビリティが欠けている可能性があります。タスクレベルでは、既存のベンチマークは広範な薬剤カテゴリーを使用することが多く、サブグループレベルの安全性の違いが無視され、リスクの過大評価につながる可能性があります。第 4 レベルの ATC コード生成に基づいた、最初のきめ細かい薬剤推奨設定を導入します。私たちは、患者の状況、外部の臨床知識、安全性検証を使用して追跡可能な薬剤セットを推奨する、知識に基づいたマルチエージェント フレームワークである Safe Prescription Agent (SafeRx-Agent) を提案します。 MIMIC-III および MIMIC-IV データセットに関する実験結果は、SafeRx-Agent が薬物相互作用、禁忌、および薬物セットのサイズを制御しながら、きめ細かい薬物予測の精度を向上させることを示しています。
原文 (English)
SafeRx-Agent: A Knowledge-Grounded Multi-Agent Framework for Safe and Explainable Medication Recommendation
Medication recommendation predicts medications for patient visits, but existing methods still face two key challenges. At the model level, traditional drug recommendation methods only predict structured drug codes with limited evidence grounding, while LLM agents can use richer clinical context but may lack safety verification and traceability. At the task level, existing benchmarks often use broad medication categories, which ignore subgroup-level safety differences and can lead to risk overestimation. We introduce the first fine-grained medication recommendation setting based on fourth-level ATC code generation. We propose Safe Prescription Agent (SafeRx-Agent), a knowledge-grounded multi-agent framework that uses patient context, external clinical knowledge, and safety verification to recommend traceable medication sets. Experimental results on MIMIC-III and MIMIC-IV datasets show that SafeRx-Agent improves fine-grained medication prediction accuracy while controlling drug interactions, contraindications, and medication set size.
Compute Allocation in Evolutionary Search: From Depth-Breadth to Multi-Armed Bandits
LLM-guided evolutionary search (Evolve systems) has reached state-of-the-art results on mathematical and combinatorial tasks, yet most exis…
Pocket-Dentist: On-Device Dental Image Understanding via Efficient Multimodal Large Language Models
Evaluations of dental vision-language models remain fragmented across datasets, task definitions and metrics, and often ignore their comput…
No More K-means: Single-Stage Sparse Coding for Efficient Multi-Vector Retrieval
Multi-vector retrieval (MVR) models, exemplified by ColBERT, have established new benchmarks in retrieval accuracy by preserving fine-grain…
Neural Network Verification using Partial Multi-Neuron Relaxation
The increasing integration of deep neural networks in critical systems has spawned a theoretical and practical interest in formally guarant…