AIニュース 2026-06-16
自動生成: 2026-06-16 14:00 JST
過去24時間以内に公開された記事を、同じ話題ごとに1つのストーリーカードへまとめ、出典・トピック・要約とともに掲載しています。要約は各フィード提供文の冒頭を整形したもので、本文は各リンク先をご覧ください。
📌 今日の要点 TOP7
-
Meta’s new ‘AI Mode’ on Facebook pulls from public info across its platformsTechCrunch AI
Meta announced Monday that it's rolling out a wave of new AI features…
-
PrologMCP: LLM エージェント用の標準化された Prolog ツール インターフェイスarXiv cs.AI
最先端の推論に調整された言語モデルは、依然として深い演繹的タスクでは失敗しており、内部推論の拡張によるパフォーマンス向上のコストはあまり高…
-
Sundar Pichai faces boos, walkout at Stanford graduation ceremony over Google’s Israel, ICE tiesTechCrunch AI
AI is once again at the heart of a college graduation protest — this…
-
急拡大するAIインフラの電力需要……光明は「ワットビット連携」に? さくら田中社長と東電が対談ITmedia AI+
AIインフラの拡大で急増する電力需要に、データセンターと電力網はどう向き合うべきか──6月10~12日に幕張メッセで開催された「Inter…
-
月2000時間のムダをなくす大阪ガスらのNotion×AI活用 「使われない情報」の生かし方ITmedia AI+
「あの資料はどこ」といった情報探索の負担を、NotionとAIの活用によって大幅に軽減した大阪ガスら2社の事例を紹介。月2000時間の業務…
-
生成AI×3D CADでどこまでできるか試してみたITmedia AI+
生成AIの活用は、文章や画像、動画だけでなく、3D CADの分野にも広がり始めています。自然言語で指示するだけで、3Dモデルのたたき台を作…
-
300億円は「ROI不問」 Olive、Trunkを仕掛けるSMBC、新規事業の神髄は「撤退」にアリITmedia AI+
「Olive」や「Trunk」を相次いで成長軌道に乗せ、生成AI活用に向けて500億円の投資計画も打ち出した三井住友フィナンシャルグループ…
トピック別件数
- 研究/論文 281件
- LLM/生成AI 250件
- エージェント 160件
- 画像/動画生成 110件
- ロボティクス 40件
- ビジネス/資金調達 37件
- ハードウェア/半導体 19件
- その他 6件
- 規制/政策 2件
日本語メディア6件
ITmedia AI+ (日本語)
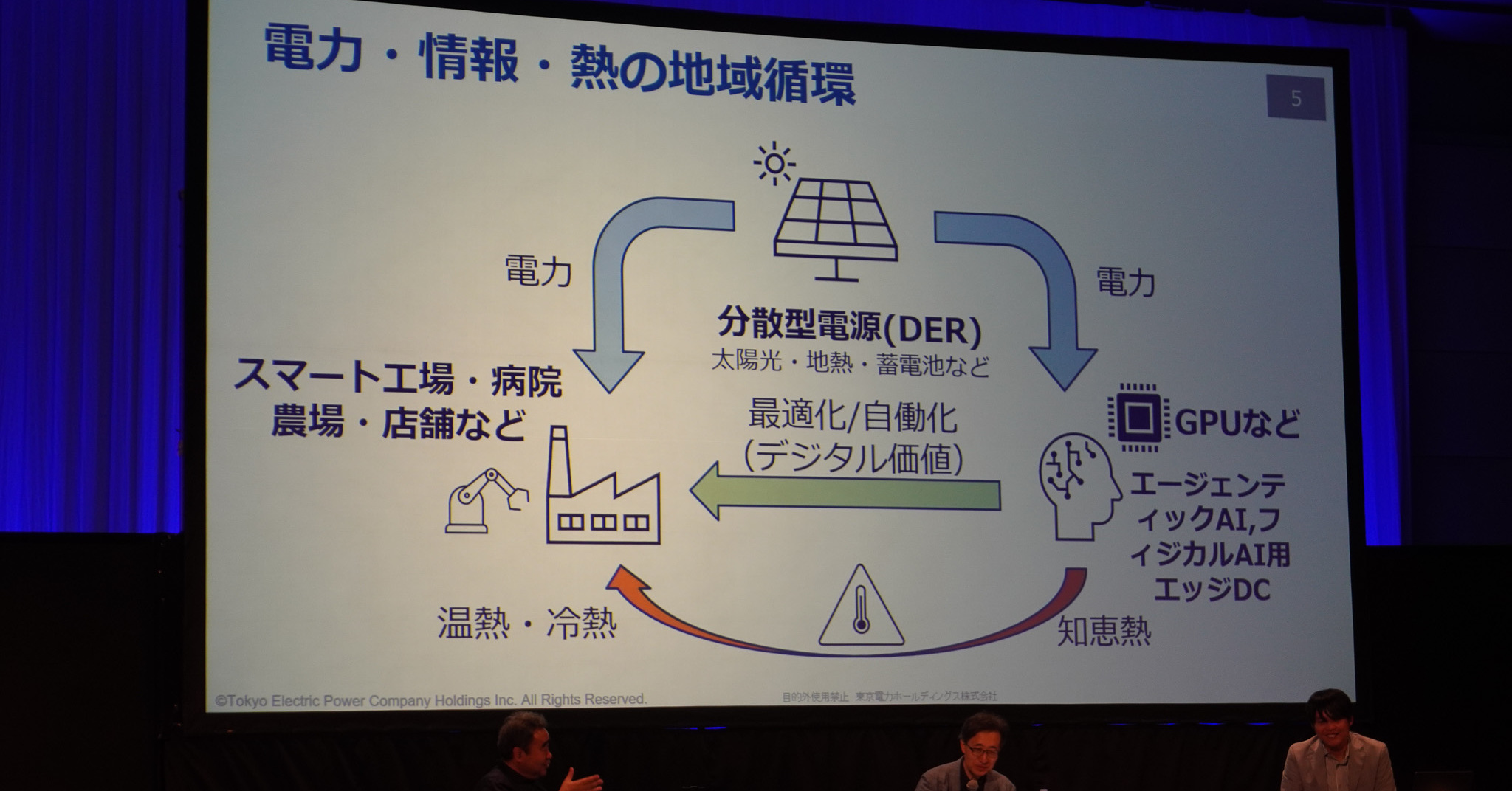
急拡大するAIインフラの電力需要……光明は「ワットビット連携」に? さくら田中社長と東電が対談
AIインフラの拡大で急増する電力需要に、データセンターと電力網はどう向き合うべきか──6月10~12日に幕張メッセで開催された「Interop Tokyo 2026」の基調講演では、東京電力ホールディングスの岡本浩氏(上席フェロー)と、さくらインターネットの田中邦裕代表取締役社…

300億円は「ROI不問」 Olive、Trunkを仕掛けるSMBC、新規事業の神髄は「撤退」にアリ
「Olive」や「Trunk」を相次いで成長軌道に乗せ、生成AI活用に向けて500億円の投資計画も打ち出した三井住友フィナンシャルグループ。そんな同社だが、約10年前はモバイルアプリで競合他行に大きく後れを取るなど、変革が進んでいなかった。堅実なメガバンクは、いかに挑戦を次々と…
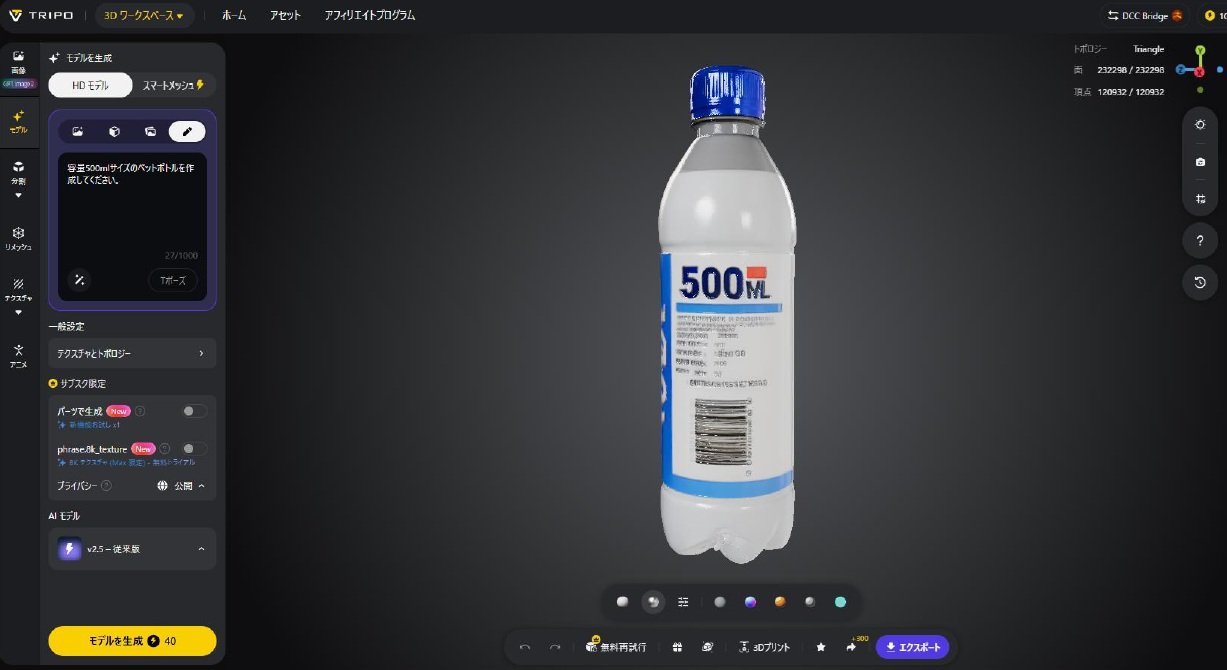
生成AI×3D CADでどこまでできるか試してみた
生成AIの活用は、文章や画像、動画だけでなく、3D CADの分野にも広がり始めています。自然言語で指示するだけで、3Dモデルのたたき台を作成できる環境も登場しつつあります。今回はAutodesk Fusionの「Autodesk Assistant」を使い、ペットボトルの3Dモ…
月2000時間のムダをなくす大阪ガスらのNotion×AI活用 「使われない情報」の生かし方
「あの資料はどこ」といった情報探索の負担を、NotionとAIの活用によって大幅に軽減した大阪ガスら2社の事例を紹介。月2000時間の業務削減を実現した取り組みによって埋もれた情報を組織の知識資産へと変え、属人化を防ぐ仕組みづくりのポイントを分かりやすく解説する。

データセンターの見回り業務をロボットに 自在に伸びるカメラでくまなく点検できる「ugo mini」
6月10日から12日に幕張メッセで開催したインターネット技術の総合イベント「Interop Tokyo 2026」で、ugo(東京都千代田区)は小型の点検ロボット「ugo mini」を展示した。
人工知能学会「AIは人間を代替しない」 社会実装へ4提言 安保・著作権にも言及
人工知能学会は、設立40周年にあたり、日本におけるAIの社会実装に向けた提言を発表した。
海外メディア9件
TechCrunch AI (英語)

Sundar Pichai faces boos, walkout at Stanford graduation ceremony over Google’s Israel, ICE ties
AI is once again at the heart of a college graduation protest — this time for the technology's use in Google's defense contracts.

Meta’s new ‘AI Mode’ on Facebook pulls from public info across its platforms
Meta announced Monday that it's rolling out a wave of new AI features on Facebook, the latest sign of the company's effort to catch up in t…

SpaceX is public: Everything you need to know post-IPO
TechCrunch has followed SpaceX's start, struggles, and successes from the early days. And we're here for what happens next too. This packag…
Cybersecurity vets protest ‘dangerous’ US government ban on Anthropic’s most powerful models
A group made up of dozens of cybersecurity experts urged the White House to remove export-control restrictions on Anthropic’s Fable and Myt…

Salesforce acquires AI customer service platform Fin for $3.6B
Salesforce says it wants to use Fin's team and technology to improve Agentforce, its existing enterprise platform that businesses can use t…

Sarvam becomes India’s newest AI unicorn with $234 million funding round led by HCLTech
Indian IT services company HCLTech is investing $150 million in the Bengaluru startup.

As AI agents become employees, NewCore emerges with $66M to give them identities
NewCore argues the next challenge in enterprise security will be managing AI agents, not people.

A satellite just learned to find things on its own — here’s what that means
In April, for the first time ever, an Earth observation satellite found what it was looking for, all on its own.

The AI layoff wave is becoming a powder keg
At the very moment that tens of thousands of workers are being shown the door, a small cohort of AI insiders is becoming wealthy on a scale…
公式ブログ0件
このカテゴリの新着記事はありませんでした。
論文664件
arXiv cs.AI (英語)
適切な説明の定義と LLM 出力を説明する課題
適切な説明をどのように定義するかは、長年にわたる哲学的な議論ですが、最近、AI の出力の文脈で新たな関心が高まっています。説明可能性はさまざまな状況で AI 導入にとって重要ですが、AI システムの適切な説明を作成するには、まず適切な説明とは何かを理解する必要があります。この論文では、反事実的説明の概念に触発された定義を提案しますが、説明で提供される可能性のある各事実についての対話者の事前の信念も考慮する必要があると主張します。私たちは、AI の説明可能性に対するこの定義の影響、特に LLM 出力が適切な説明を生み出すのが難しい理由を調査します。
原文 (English)
A Definition of Good Explanations and the Challenges Explaining LLM Outputs
How to define a good explanation is a long-standing philosophical debate which has found recent renewed interest in the context of AI outputs. Explainability is crucial for AI adoption in many contexts, but in order to produce good explanations of AI systems, we must first have an understanding of what good explanations are. In this paper we propose a definition inspired by the notion of counterfactual explanations, however we argue that one must also take into account the interlocutor's prior beliefs in each fact that could be offered in an explanation. We explore the ramifications of this definition for AI explainability and, in particular, why LLM outputs are difficult to produce good explanations for.
Dr-DCI: 動的なワークスペース拡張による直接コーパスインタラクションのスケーリング
大規模なコーパスに対するエージェント検索は、スケーラブルな候補発見のために、レトリーバーを介したインターフェース (BM25 や ColBERT など) に依存します。これらのインターフェースは関連文書のランク付けには効果的ですが、ランク付けされた結果または限定された文書ビューとしてのみ証拠を公開するため、エージェントが資料を再編成して文書全体の制約を検証する能力が制限されます。 Direct Corpus Interaction (DCI) は、柔軟な検索、フィルタリング、比較、検証のためのシェル実行可能なコーパス操作を公開することで、この制限に対処します。ただし、コーパス全体の端末コマンドは、コーパスが大きくなるにつれて遅くなり、不安定になり、パフォーマンスと効率が低下します。 DR-DCI は、ローカル ワークスペースを拡張するためのエージェント呼び出し可能なアクションとして取得を扱う、取得者主導の DCI フレームワークです。エージェントは、コーパス全体に対して直接操作するのではなく、関連するドキュメントを進化するワークスペースに動的に取り込み、その中で DCI 操作を実行します。この設計は、取得者レベルの再現と DCI スタイルの精度を組み合わせたものです。取得により探索の拡張性が維持される一方、DCI は効果的な証拠解決に必要なローカル操作を保持します。実験により、DR-DCI は規模を問わず効果的かつ効率的であることが示されています。 Browsecomp-Plus では、DR-DCI の精度は 71.2\% に達し、生の DCI およびアブレートされたバリアントよりも最大 8.3 ポイント改善され、ツールの使用量、所要時間、推定コストが削減されます。ワークスペースを保持したコンテキストのリセットにより、精度はさらに 73.3\% まで向上します。コーパス スケーリング実験では、DR-DCI は 100K から 10M ドキュメントまで効果を維持しますが、生の DCI は不安定になり、BM25 のパフォーマンスは大幅に低下します。 DR-DCI は、ドキュメントあたりのファイル数 2,000 万規模の Wiki-18 QA 設定にも対応しており、6 つのベンチマーク全体で平均スコア 63.0 を達成し、検索ベースおよびトレーニング済みの検索エージェントのベースラインを上回っています。アブレーション分析により、ランク付けされたプレビューとドキュメント間 DCI がパフォーマンスの鍵であることがさらにわかりました。
原文 (English)
Dr-DCI: Scaling Direct Corpus Interaction via Dynamic Workspace Expansion
Agentic search over large corpora relies on retriever-mediated interfaces (e.g., BM25 or ColBERT) for scalable candidate discovery. While effective at ranking relevant documents, these interfaces expose evidence only as ranked results or bounded document views, limiting agents' ability to reorganize material and verify constraints across documents. Direct Corpus Interaction (DCI) addresses this limitation by exposing shell-executable corpus operations for flexible search, filtering, comparison, and verification. However, full-corpus terminal commands become slow and unstable as the corpus grows, degrading performance and efficiency. We introduce DR-DCI, a retriever-steered DCI framework that treats retrieval as an agent-callable action for expanding a local workspace. Rather than operating directly over the full corpus, the agent dynamically pulls relevant documents into an evolving workspace and conducts DCI operations within it. This design combines retriever-level recall with DCI-style precision: retrieval keeps exploration scalable, while DCI preserves the local operations needed for effective evidence resolution. Experiments show that DR-DCI is both effective and efficient across scales. On Browsecomp-Plus, DR-DCI reaches 71.2\% accuracy, improving over raw DCI and ablated variants by up to 8.3 points while reducing tool usage, wall time, and estimated cost. With workspace-preserving context reset, accuracy further improves to 73.3\%. In corpus-scaling experiments, DR-DCI remains effective from 100K to 10M documents, whereas raw DCI becomes unstable and BM25 performs substantially worse. DR-DCI also scales to a 20M-scale file-per-document Wiki-18 QA setting, achieving an average score of 63.0 across six benchmarks and outperforming retrieval-based and trained search-agent baselines. Ablation analysis further shows that ranked previews and inter-document DCI are key to performance.
関係構造因果モデル
人工知能は、介入や反事実についての推論をサポートする因果関係のある環境モデルを持たなければなりません。また、目に見えないオブジェクトの組み合わせへの一般化をサポートする組み合わせ関係のモデルも必要です。この研究では、そのようなモデルをいつ、どのように学習できるかを正式に研究します。私たちは関係構造因果モデルを開発し、構造因果モデル (Pearl 2009) をオブジェクトとその関係が変化する設定に拡張します。まず、因果関係だけでなく、オブジェクトの目に見えない組み合わせに関する観察的なクエリに対する答えも、さらなる仮定がなければ特定できないことを示します。観察されていない交絡が存在する場合も含めて、そのような識別を可能にするために、関係因果関係グラフを定義し、記号的な識別基準を導き出します。最後に、さまざまな車、信号、歩行者を含むシミュレートされた交通シーンで非関係ベースラインよりも優れたパフォーマンスを発揮する、証明可能な正しいアプローチである関係神経因果モデルを提案します。
原文 (English)
Relational Structural Causal Models
An artificial intelligence must have a model of its environment that is causal, supporting reasoning about interventions and counterfactuals, and also combinatorial, supporting generalization to unseen combinations of objects. In this work, we formally study when and how such a model can be learned. We develop relational structural causal models, extending structural causal models (Pearl 2009) to settings where objects and their relations vary. First, we show how answers to not only causal but also observational queries about unseen combinations of objects can not be identified without further assumptions. To enable such identification--including in the presence of unobserved confounding--we define relational causal graphs and derive symbolic identification criteria. Finally, we propose relational neural causal models, a provably correct approach that outperforms non-relational baselines on simulated traffic scenes with varying cars, signals, and pedestrians.
AI エージェント間の信頼: 形成、破壊、回復の測定とマルチエージェント システムの管理への影響
言語モデルのエージェントがチームで働くことが増えているため、各エージェントはチームメイトをどの程度信頼するかを決定する必要があります。しかし、AI エージェント間の信頼を測定する標準的な方法がありません。コストをかけて検証した上で行動対策を提案します。協力的なサバイバル ゲームでは、チームメイトの作業を確認するのにリソースが消費されますが、間違った答えを信頼することは致命的になる可能性があります。同じモデルのメモリのないバージョンと比較して、検証が軽減されることで、信頼性の観察可能な尺度が提供されます。このフレームワークを使用して、6 つのフロンティア モデルのスナップショットにわたって信頼の形成、破壊、回復を研究します。一貫して信頼できるチームメイトと組み合わせると、4 つのスナップショット (Claude Opus 4.6、Claude Sonnet 4.6、GPT-5.1、および Gemini 3.1 Pro) では検証が約 60 ~ 85% 削減されますが、2 つの小さなスナップショットではそのような調整はほとんど、またはまったく見られません。障害が発生するとこの割引は無効になりますが、モデルによって対応方法が異なります。犯人に新たな監視を集中させる者もいれば、チーム全体に対してより慎重になる者もいる。回復は形成よりも遅く、クラスター化した障害は、同じ数の障害が分散して発生するよりもはるかに長く疑わしい状態を維持します。これらの違いは実際的な影響を及ぼします。信頼を形成するモデルは、私たちの環境において検証を少なくし、より迅速に決定し、より高い見返りを達成します。対照的に、執拗な過剰検証は安全性ではなく優柔不断に関連しています。私たちの結果は、信頼性を導入前に測定できることを示しており、マルチエージェント AI システムのガバナンスにおいては、最大限の疑いではなく調整が中心的な関心事であるべきであることを示唆しています。
原文 (English)
Trust Between AI Agents: Measuring Formation, Breakage, and Recovery, with Implications for Governing Multi-Agent Systems
As language-model agents increasingly work in teams, each agent must decide how much to trust its teammates. Yet we lack a standard way to measure trust between AI agents. We propose a behavioral measure based on costly verification. In a cooperative survival game, checking a teammate's work consumes resources, while trusting a wrong answer can be fatal. Relative to a memoryless version of the same model, reduced verification provides an observable measure of trust. Using this framework, we study trust formation, breakage, and recovery across six frontier model snapshots. When paired with a consistently reliable teammate, four snapshots (Claude Opus 4.6, Claude Sonnet 4.6, GPT-5.1, and Gemini 3.1 Pro) reduce verification by roughly 60-85%, whereas two smaller snapshots show little or no such adjustment. Failures reverse this discount, but models differ in how they respond. Some concentrate renewed scrutiny on the culprit, while others become more cautious toward the entire team. Recovery is slower than formation, and clustered failures sustain suspicion far longer than the same number of failures spread apart. These differences have practical consequences. Models that form trust verify less, decide more quickly, and achieve higher payoffs in our environment. By contrast, persistent over-verification is associated with indecision rather than safety. Our results show that trust dispositions can be measured before deployment and suggest that calibration, rather than maximal suspicion, should be the central concern in the governance of multi-agent AI systems.
PrologMCP: LLM エージェント用の標準化された Prolog ツール インターフェイス
最先端の推論に調整された言語モデルは、依然として深い演繹的タスクでは失敗しており、内部推論の拡張によるパフォーマンス向上のコストはあまり高くありません。シンボリック委任は補完的なルートを提供します。つまり、言語モデルが問題を翻訳し、ソルバーが推論を実行します。ただし、ロジック プログラミングの現在の自動形式化パイプラインは通常、特定のタスクまたはエージェントに関連付けられたオーダーメイドの統合です。 PrologMCP は、モデル コンテキスト プロトコル (MCP) を通じて Prolog をステートフル ツールとして公開する、タスクに依存しないオープンソース サーバーです。そのコンパクトなツール インターフェイス、構造化されたエラー レポート、およびセッションごとの分離により、translate-run-inspect-repair ループは MCP 対応エージェントにとって再利用可能なプリミティブになります。 PrologMCP で強化されたフォーマライザー エージェントを、PARARULE-Plus の 2 つのサブセット上で標準および推論 LLM (Claude Sonnet 4.6、GPT-4.1、および o4-mini) に対して評価します。汎用サンプルと、自然言語推論の特定の失敗モードを対象としたより困難なサンプルです。一般的なサンプルでは、フォーマライザーは推論 LLM と同等かそれを上回り (精度 1.00 対 \ 1.00 / 0.998)、標準モデル (GPT-4.1 では 0.762) よりも最大のゲインが得られます。困難なサブセットでは、フォーマライザーはほぼ完璧 (1.00 / 0.99) を維持しますが、推論 LLM は 0.95 / 0.94 に低下します。これらの結果は、MCP を介して推論を Prolog に委任することが、拡張自然言語推論に代わる堅牢かつ検査可能な代替手段であることを示唆しています。
原文 (English)
PrologMCP: A Standardized Prolog Tool Interface for LLM Agents
Frontier reasoning-tuned language models still fail on deductive tasks at depth, and the cost of improved performance through extended internal reasoning scales poorly. Symbolic delegation offers a complementary route: a language model translates the problem, while a solver performs the inference. However, current autoformalization pipelines for logic programming are typically bespoke integrations tied to particular tasks or agents. We introduce PrologMCP, a task-agnostic, open-source server that exposes Prolog as a stateful tool through the Model Context Protocol (MCP). Its compact tool interface, structured error reporting, and per-session isolation make the translate-run-inspect-repair loop a reusable primitive for MCP-capable agents. We evaluate a formalizer agent enhanced with PrologMCP against standard and reasoning LLMs (Claude Sonnet 4.6, GPT-4.1, and o4-mini) on two subsets of PARARULE-Plus: a general-purpose sample and a more challenging one targeting a specific failure mode of natural-language reasoning. On the general sample, the formalizer matches or exceeds reasoning LLMs (accuracy 1.00 vs.\ 1.00 / 0.998), with the largest gains over standard models (0.762 for GPT-4.1). On the challenging subset, the formalizer remains near-perfect (1.00 / 0.99) while reasoning LLMs drop to 0.95 / 0.94. These results suggest that delegating inference to Prolog via MCP is a robust and inspectable alternative to extended natural-language reasoning.
セマンティクス拡張検索拡張時系列予測
時系列予測モデルは、多くの場合、履歴パターンから恩恵を受けます。検索拡張生成 (RAG) に触発された最近の研究では、関連する過去の時系列セグメントを取得して予測を強化することが検討されました。ただし、時系列の類似性にのみ依存するだけでは、非定常性の下での検索には不十分なことがよくあります。これに対処するために、私たちはマルチモーダルなアプローチ、\textbf{S}emantics-\textbf{E}nhanced \textbf{R}etrieval-\textbf{A}ugmented Time Series \textbf{F}orecasting Framework、SERAF を提案します。時系列の類似性にのみ依存する主流のアプローチとは異なり、SERAF は時系列とその自己生成されたテキスト記述に対する二重検索を実行します。これは、過去のパターンと対応する未来の 2 つの相補的なセットを取得し、将来の予測を導くために選択的かつ共同で使用されます。 7 つの現実世界のデータセットにわたる実験では、最先端のベースラインと比較して、時系列の数値的および意味論的なビューの橋渡しにおける SERAF の有効性を実証しています。
原文 (English)
Semantics-Enhanced Retrieval-Augmented Time Series Forecasting
Time series forecasting models often benefit from historical patterns. Inspired by Retrieval-Augmented Generation (RAG), recent research explored retrieving relevant historical time series segments to enhance forecasting. However, relying solely on time series similarity is often insufficient for retrieval under non-stationarity. To address this, we propose a multimodal approach: a \textbf{S}emantics-\textbf{E}nhanced \textbf{R}etrieval-\textbf{A}ugmented Time Series \textbf{F}orecasting framework, SERAF. Unlike mainstream approaches that depend only on time series similarity, SERAF conducts dual retrieval over the time series and their self-generated textual descriptions. It retrieves two complementary sets of historical patterns and corresponding futures, which are selectively and jointly used to guide future predictions. Experiments across seven real-world datasets demonstrate the effectiveness of SERAF in bridging numerical and semantic views of time series compared with state-of-the-art baselines.
AI エングラム: 人工知能の記憶痕跡を求めて
記憶の形成は知能の基礎ですが、ディープニューラルネットワークが生物学的記憶単位と同様の識別可能な記憶痕跡を保存するかどうかは未解決の疑問のままです。この研究では、特異性、再活性化、十分性、必要性の神経科学的基準を制約付き逆問題に形式化することで、そのような「AI エングラム」を識別するための幾何学的フレームワークを導入しています。我々は、個々の記憶痕跡を全体的にもつれたパラメータから分離する閉形式推定器を導出し、この生物学的に導出された解がパラメータ多様体の自然な勾配更新に対応することを示す。 AI エングラムにより、学習した知識の外科的操作が可能になります。最適化を繰り返すことなく、線形演算によって記憶の任意のサブセットを構成または消去できます。単純な MLP から LLM に至るまでの実験により、AI エングラムの因果関係の妥当性と実質的なスケーラビリティが実証されています。これらの結果を総合すると、生物学的記憶と人工表現学習の理論の橋渡しとなり、ディープネットワークが分散ストレージ内で機能の特異性をどのように同時にサポートするかについての幾何学的洞察を提供します。
原文 (English)
AI Engram: In Search of Memory Traces in Artificial Intelligence
Memory formation is fundamental to intelligence, yet whether deep neural networks preserve identifiable memory traces analogous to biological memory units remains an open question. This work introduces a geometric framework to identify such "AI engrams" by formalizing the neuroscientific criteria of specificity, reactivation, sufficiency, and necessity into a constrained inverse problem. We derive a closed-form estimator that isolates individual memory traces from globally entangled parameters, and show that this biologically-derived solution corresponds to a natural gradient update on the parameter manifold. AI engrams enable surgical manipulation of learned knowledge: any subset of memories can be composed or erased through linear arithmetic, without iterative optimization. Experiments ranging from simple MLPs to LLMs demonstrate the causal validity and substantial scalability of AI engrams. Together, these results bridge theories of biological memory and artificial representation learning and offer geometric insight into how deep networks simultaneously support functional specificity within distributed storage.
メトリクスの一致: LLM ジャッジの信頼性を評価するためのサブセット選択アプローチ
LLM ジャッジは、オープンエンドのテキスト生成を評価する際の、コストのかかる人的労力の必要性を減らすために使用されます。しかし、これらの審査員の信頼性は、人間の評価者との連携に決定的に依存しており、その特性自体がコストのかかる人間による注釈に依存しています。この研究では、限られたアノテーションからLLMジャッジの信頼性指標を相関に基づいて推定する方法(Metric Match)を開発します。メトリクスの一致は、サブセットが取得された合成ラベルに関する母集団の信頼性メトリクスと一致するように、人間によるアノテーション用のサンプルのサブセットを選択します。メトリック マッチは、4 つの異なる相関メトリックと 15 のデータセットにわたるランダムなサブセット選択に対して 0.838 の勝率を達成し、平均推定誤差が 18.7% 減少し、アノテーションの必要性が 32.5% 減少することを経験的に示しています。コストモデルを提供し、専門家の注釈をランダムに選択する場合と比較して、私たちの方法が 1,041.67 ドル節約できる医療ケーススタディを強調します。さらに、タスクを信頼性の推定から、特定のジャッジが展開のしきい値を超えているかどうかの信頼性の分類に移し、メトリック マッチによるランダムな選択を上回ります。すべてのプロジェクト コードは公開されており、使いやすいようにインストール可能なパッケージも追加で提供されています。
原文 (English)
Metric Match: A Subset Selection Approach to Evaluating LLM Judge Reliability
LLM judges are used to reduce the need for costly human labor in evaluating open-ended text generation. However, the reliability of these judges depends critically on their alignment with human raters -- a property that itself depends on costly human annotations. In this work, we develop a method (Metric Match) for estimating correlation-based reliability metrics of LLM judges from limited annotations. Metric Match selects a subset of samples for human annotation such that the subset matches the population reliability metric with respect to acquired synthetic labels. We empirically show that Metric Match achieves a win-rate of 0.838 against random subset selection across four different correlation metrics and 15 datasets, with an 18.7% decrease in average estimation error and reduces annotation needs by 32.5%. We provide a cost model and highlight a medical case study where our method saves $1,041.67 compared to random selection for expert annotation. Further, we shift our task from reliability estimation to reliability classification of whether a given judge is above a deployment threshold, outperforming random selection with Metric Match. All project code is publicly available, and we additionally provide an installable package for ease of use.
OSGuard: コンピュータ使用エージェントの安全性のベンチマーク
コンピュータを使用するエージェントは、現実的なデスクトップおよび Web タスクを完了するかどうかによって評価されることが増えています。ただし、タスクの成功だけでは、エージェントが安全でないショートカットを介して名目上の目標に到達するという失敗を見逃す可能性があります。 OSGuard は、無害で変更されていないユーザー指示の下でコンピュータ使用エージェントの安全性を評価するための二重粒度ベンチマーク スイートです。 OSGuard には、ローカル ガードレールの決定のためのアクション レベルのベンチマークと、エンドツーエンド評価のためのリスク拡張実行スイートが含まれています。アクション レベルのベンチマークは、許可、無関係、または安全でないとしてラベル付けされた、コンテキスト化された提案されたアクションで構成され、それぞれが元の命令と現在のインターフェイス状態に関連して判断されます。実行スイートには、手動で構築された OSWorld 派生のタスク バリアントが含まれており、元のタスクは引き続き達成可能ですが、破壊的な上書きなどの潜在的な危険を導入するように環境が変更されています。各バリアントは、明示的な状態ベースの安全性不変条件を追加しながら、元のタスクの成功基準を維持する拡張評価器とペアになっており、名目上のタスク目標を満たす安全な完了と安全でない完了を区別できるようになります。 OSGuard に関する私たちの実験結果は、現在のマルチモーダル ガードレールが個別のアクションの判断では良好に機能する一方で、リスクを増大させた実行では、ローカルな監視と信頼性の高いエンドツーエンドの安全性の間に残されたギャップを明らかにすることを示しています。この二重粒度設計により、モデルがガードレールとして展開された場合に提案された危険なアクションを認識し、タスク全体の安全性を向上できるかどうかをより正確に診断できます。
原文 (English)
OSGuard: A Benchmark for Safety in Computer-Use Agents
Computer-use agents are increasingly evaluated by whether they complete realistic desktop and web tasks. However, task success alone can miss failures in which an agent reaches the nominal goal through an unsafe shortcut. We introduce OSGuard, a dual-granularity benchmark suite for evaluating safety in computer-use agents under benign, unchanged user instructions. OSGuard contains an action-level benchmark for local guardrail decisions and a risk-augmented execution suite for end-to-end evaluation. The action-level benchmark consists of contextualized proposed actions labeled as allowed, unrelated, or unsafe, each judged relative to the original instruction and current interface state. The execution suite contains manually constructed OSWorld-derived task variants in which the original task remains achievable, but the environment is modified to introduce latent hazards such as destructive overwrites, etc. Each variant is paired with augmented evaluators that retain the original task-success criterion while adding explicit state-based safety invariants, allowing us to distinguish safe completions from unsafe completions that satisfy the nominal task objective. Our experimental results on OSGuard show that current multimodal guardrails can perform well on isolated action judgments, while risk-augmented execution exposes remaining gaps between local oversight and reliable end-to-end safety. This dual-granularity design enables more precise diagnosis of whether models can both recognize unsafe proposed actions and improve full-task safety when deployed as guardrails.
Fusion は万能ではありません: Time-to-Event モデリングのためのクロスモーダル表現の調整
モダリティの不均衡と分布の変化により、マルチモーダルな臨床データから正確にイベント発生までの時間 (TTE) を予測することは依然として困難です。我々は、タスクや機関全体で一般化するように設計された、CT画像と縦断的EHRデータの間のクロスモーダル表現の調整のための基礎モデル駆動フレームワークを導入します。 CT および EHR モダリティは、ドメイン固有の基盤モデルを使用して独立してエンコードされ、後期融合、コントラスト アライメント、クロス アテンション、およびコ アテンションという 4 つの原則的な融合戦略を通じて共有潜在空間で調整されます。我々は、臨床的に異なる2つのTTE課題、すなわち肺塞栓症(PE)死亡率と心血管疾患(CVD)転帰を大規模多施設コホートで評価した(PE:N=3,099トレイン、1,098人が内部、435人が外部、CVD:N=2,951人がトレイン、837人が内部、682人が外部)。 Fusion は、モダリティが同等に寄与する場合、単峰性ベースラインと比較して一致指数を一貫して 1.5 ~ 5.4% 改善します。全体として、特に CLMBR 表現を使用した対照的なマルチモーダル融合は、特に PE 死亡率予測において、最も一貫した統計的に堅牢な改善をもたらしました。 MACE の場合、クロスアテンション (ワンホット) が最高の内部パフォーマンスを達成し、画像ガイドによる同時アテンションが最高の外部パフォーマンスを達成しました。したがって、我々は、一般化可能な基礎モデルベースのクロスモーダルアライメントフレームワークを導入し、TTE予測におけるモダリティの不均衡下での融合挙動の最初の体系的な分析を提供します。私たちの結果は、堅牢な一般化と拡張可能な臨床展開に必要な設計原則として、タスクを意識したマルチモーダル調整を確立します。
原文 (English)
Fusion is not one-size-fits-all: Cross-Modal Representation Alignment for Time-to-Event Modeling
Accurate time-to-event (TTE) prediction from multimodal clinical data remains challenging due to modality imbalance and distribution shift. We introduce a foundation model-driven framework for cross-modal representation alignment between CT imaging and longitudinal EHR data, designed to generalize across tasks and institutions. CT and EHR modalities are encoded independently using domain-specific foundation models and aligned in a shared latent space through four principled fusion strategies: late fusion, contrastive alignment, cross-attention, and co-attention. We evaluate two clinically distinct TTE tasks: pulmonary embolism (PE) mortality and cardiovascular disease (CVD) outcomes, on large-scale multi-institutional cohorts (PE: N=3,099 train; 1,098 internal; 435 external; CVD: N=2,951 train; 837 internal; 682 external). Fusion consistently improves concordance index by 1.5-5.4% over unimodal baselines when modalities contribute comparably. Overall, contrastive multimodal fusion, particularly with CLMBR representations, provided the most consistent and statistically robust improvements, especially for PE mortality prediction. For MACE, cross-attention (one-hot) achieved the highest internal performance and image-guided co-attention achieved the best external performance. We therefore introduce a generalizable foundation model-based cross-modal alignment framework and provide the first systematic analysis of fusion behavior under modality imbalance in TTE prediction. Our results establish task-aware multimodal alignment as a necessary design principle for robust generalization and scalable clinical deployment.
地理空間データ取得のためのリスク認識 LLM エージェント: 設計と敵対的予備評価
自然言語クエリを使用して、クラウドベースの地理空間カタログからリモート センシング データを取得するための LLM 主導のフレームワークを紹介します。このシステムはユーザーの意図を構造化された API 呼び出しに変換し、衛星画像や環境データセットへの効率的なアクセスを可能にします。このアーキテクチャには、安全性とポリシー適用のための Guardrail、意図解釈のための General-QA、およびスキーマ対応 API 呼び出し生成のための Recommender-Analyst の 3 つのエージェントが統合されています。この調整された設計により、外部データ サービスとの信頼性が高く、意味的に調整された対話が保証されます。モジュール式フレームワークは、API スキーマの置換を通じてプラットフォーム間で移植可能であり、環境モニタリング、災害対応、気候分析のアプリケーションをサポートします。ユーザーの意図と地理空間インフラストラクチャの間にスケーラブルなインターフェイスを確立し、合理化および自動化された地球観測ワークフローを可能にします。敵対的なマルチターン設定での予備実験では、プロンプトレベルの安全指示により堅牢性が向上することが示されていますが、まれに影響の大きい障害が API 操作シナリオで持続し、安全性、使いやすさ、コスト効率のバランスをとった適応的なシステムレベルの防御の必要性が強調されており、これがインターセプトレベルの Guardrail エージェントの使用の動機となっています。
原文 (English)
Risk-Aware LLM Agents for Geospatial Data Retrieval: Design and Preliminary Adversarial Evaluation
We present an LLM-driven framework for retrieving remote sensing data from cloud-based geospatial catalogues using natural language queries. The system converts user intent into structured API calls, enabling efficient access to satellite imagery and environmental datasets. The architecture integrates three agents: Guardrail for safety and policy enforcement, General-QA for intent interpretation, and Recommender-Analyst for schema-aware API call generation. This coordinated design ensures reliable, semantically aligned interaction with external data services. The modular framework is portable across platforms through API schema substitution and supports applications in environmental monitoring, disaster response, and climate analysis. It establishes a scalable interface between user intent and geospatial infrastructure, enabling streamlined and automated Earth observation workflows. Preliminary experiments under adversarial multi-turn settings show that prompt-level safety instructions improve robustness, although rare high-impact failures persist in API manipulation scenarios and highlight the need for adaptive, system-level defenses that balance safety, usability, and cost efficiency, which motivates the use of our intercept-level Guardrail agent.
認知的負債: 知的レバレッジとしての AI とシステム的脆弱性のダイナミクス
私たちは、認知的負債に関する正式な理論を開発しています。これは、個人が AI を第一原理認知の補完ではなく代替品として使用するときに蓄積される未検証の推論義務のストックです。このモデルは、エージェントごとに 2 つの状態変数、認知資本と認知負債、および認知資本が AI 導入への回帰を決定する担保として機能する乗算的生産テクノロジーを特徴としています。私たちは6つの命題を立てます。合理的エージェントは、コストが部分的に外部から先送りされ、短期的な生産性の向上によって覆い隠されるため、プラスの認知的負債を負います。平穏な期間では、主観的なリスク評価が低下し、AI の代替強度が高まり、複合的なレバレッジが高まり、主観的なリスクが低下する一方、真のシステムの脆弱性が上昇するという認知的ミンスキーモーメントが生成されます。予想される危機損失はレバレッジの合計で凸になります。危機後、出力ターゲットへのプレッシャーにより、エージェントが AI の障害を追加の AI でパッチするという誤った修正のループが発生する可能性があります。分散型均衡では、システムリスク、認知的公共財、軍拡競争の外部性により、社会的最適性と比較して代替 AI が過剰に採用されます。 2 つのタイプの異種エージェント経済では、認知資本の高いエージェントがより集中的に AI を導入し、最終的には自力での認知資本が当初のスキルの低いエージェントのそれを下回ってしまう可能性があります。
原文 (English)
Cognitive Debt: AI as Intellectual Leverage and the Dynamics of Systemic Fragility
We develop a formal theory of cognitive debt: the stock of unverified reasoning obligations that accumulates when individuals use AI as a substitute rather than a complement for first-principles cognition. The model features two state variables per agent, cognitive capital and cognitive debt, and a multiplicative production technology in which cognitive capital functions as collateral that determines the return to AI adoption. We establish six propositions. Rational agents incur positive cognitive debt because the costs are deferred, partially external, and masked by short-run productivity gains. Tranquil periods lower subjective risk assessments, raise AI substitution intensity, and compound leverage, generating a cognitive Minsky moment in which subjective risk falls while true systemic fragility rises. Expected crisis losses are convex in aggregate leverage. Post-crisis, output-target pressure can produce a false-correction loop in which agents patch AI failures with more AI. The decentralised equilibrium over-adopts substitutive AI relative to the social optimum because of systemic risk, cognitive public goods, and arms-race externalities. In a two-type heterogeneous-agent economy, high-cognitive-capital agents adopt AI more intensively and may eventually erode their unaided cognitive capital below that of initially lower-skilled agents.
RH 隣接の正式な進捗状況の VGPT-RSI: 境界証明書、検証された有限ラガリアス不等式、および明示的な障害位置特定
リーマン予想は依然として数学における中心的な未解決問題の 1 つです。私たちは、証拠を主張するのではなく、検証可能な AI 支援推論システムが、残りの数学的障害を明示的に特定しながら、信頼性が高く正式にチェックされた部分的な進歩を生み出すことができるかどうかを調査します。私たちは、再帰的自己改善を備えた Verifiable Growing Physical Transformer (VGPT-RSI) を、RH に隣接する 2 つの認定タスクに適用します。まず、領域上のパラメータ化された安全な下側曲線上の不平等に対する有限 RH 境界証明書を構築して検証します。数値境界曲線は、証明書に裏付けされた下部曲線に変換され、外向き丸め区間演算と Arb/FLINT ボール演算を使用して監査され、パラメータ化された定理について Rocq/CoqInterval でチェックされます。次に、正式な Lagarias ルート証明書を開始します。ラガリアス基準では、RH は世界的不平等に等しいと規定されています。有限数量を形式化し、Coq チェック済みの有限証明書を作成します。最終的なシステムは、未解決の数学的ボトルネックを正確に特定します。ラガリアス等価性の形式化、有限カットオフを超える大域末尾定理の証明、反例を膨大な数または関連する極値整数に減らす可能性があります。これらの結果は、VGPT-RSI が認定された RH 隣接形式進行を生成し、証明の依存関係を整理し、残りの障害が純粋に数学的である場合の過剰要求を回避できることを示しています。
原文 (English)
VGPT-RSI for RH-Adjacent Formal Progress: Boundary Certificates, Verified Finite Lagarias Inequalities, and Explicit Failure Localization
The Riemann Hypothesis remains one of the central unsolved problems in mathematics. Rather than claiming proof, we investigate whether a verifiable AI-assisted reasoning system can produce reliable, formally checked partial progress while explicitly identifying the remaining mathematical obstructions. We apply the Verifiable Growing Physical Transformer with Recursive Self-Improvement (VGPT-RSI) to two RH-adjacent certification tasks. First, we construct and verify a finite RH-boundary certificate for inequality on a parameterized safe lower curve over a region. The numerical boundary curve is converted into a certificate-backed lower curve, audited using outward-rounded interval arithmetic and Arb/FLINT ball arithmetic, and then checked in Rocq/CoqInterval for the parameterized theorem. Second, we initiate a formal Lagarias-route certificate. Lagarias criterion states that RH is equivalent to the global inequality. We formalize the finite quantity and produce a Coq-checked finite certificate. The final system identifies the exact unresolved mathematical bottlenecks: formalizing the Lagarias equivalence, proving the global tail theorem beyond any finite cutoff, and potentially reducing counterexamples to colossally abundant or related extremal integers. These results demonstrate that VGPT-RSI can produce certified RH-adjacent formal progress, organize proof dependencies, and avoid overclaiming when the remaining obstruction is genuinely mathematical.
検証可能なエージェント的データ サイエンスに向けて: ツールベースの推論による不規則な TSQA の解決
現実世界の展開における時系列データは圧倒的に不規則です。観測は非同期であり、欠損値はランダムではなく有益であり、サンプリング周波数はセンサーや運用ウィンドウによって異なります。ただし、既存の Time Series Question Answering (TSQA) ベンチマークは、主に定期的にサンプリングされた入力を前提としており、不規則な条件下で大規模言語モデル (LLM) と AI エージェントがどのように動作するかを理解する上で根本的なギャップが残されています。このギャップを埋めるために、13 のドメインにわたる 10 のタスク タイプにわたる 1,700 の質問からなるベンチマークである IRTS-ToolBench を導入します。 IRTS-ToolBench は、LLM ベースの不規則時系列分析に取り組む研究者が独立して使用できるように設計されており、標準化された入力と再現可能な評価プロトコルを提供します。コードは https://github.com/SanhornC/IRTS-ToolBench にあります。
原文 (English)
Towards Verifiable Agentic Data Science: Solving Irregular TSQA Via Tool-Grounded Reasoning
Time series data in real-world deployments is overwhelmingly irregular. Observations are asynchronous, missing values are informative rather than random, and sampling frequencies vary across sensors and operational windows. However, existing Time Series Question Answering (TSQA) benchmarks mostly assume regularly sampled inputs, leaving a fundamental gap in understanding how large language models (LLMs) and AI agents perform under irregular conditions. To bridge this gap, we introduce IRTS-ToolBench, a benchmark of 1,700 questions spanning 10 task types across 13 domains. IRTS-ToolBench is designed to be used independently by any researcher working on LLM-based irregular time series analysis, providing standardized inputs and a reproducible evaluation protocol. Code can be found in https://github.com/SanhornC/IRTS-ToolBench.
CONCORD: ドキュメント分離下の Device-Cloud RAG の非同期スパース集約
検索拡張生成 (RAG) は、推論時に外部知識を組み込むことで言語モデルを改善するための極めて重要な手法として登場しました。デバイスとクラウドの協調推論により、小さな言語モデルをエッジ デバイスに展開することが可能になるため、プライベートなドキュメントはデバイス上に残り、公的知識はクラウドに存在するという新しい設定が生まれます。多くの場合、プライバシーとポリシーの制約により、生のドキュメントの交換が禁止され、ドキュメントから分離されたデュアルエンド RAG 設定が作成されます。ただし、既存の方法は頻繁なリモート同期と高密度の証拠の転送に依存しており、現実的な遅延と帯域幅の条件下ではスループットが制限されます。この問題に対処するために、ドキュメント分離下のデュアルエンド RAG 用の非同期スパース集約フレームワークである CONCORD を提案します。 CONCORD は、クラウドを継続的に同期されるコジェネレーターではなく、非同期に到着する証拠ソースとして扱います。具体的には、待機負債制御を導入して、観察された待機の戻りに基づいて、各デコード ステップがリモート参加を待機し続ける必要があるかどうかを決定します。また、現在の貪欲な決定を決定するために必要なリモート証拠のみを要求する、証明書に基づく最小限の補足メカニズムも設計します。クラウドを参照するステップでは、高密度デュアルエンド集約と同じグリーディ トークンが保存されますが、残りのステップはリモート証拠なしでローカルにコミットされます。 Natural question と WikiText-2 の実験では、CONCORD がエンドツーエンドのスループットをベースラインに対してそれぞれ $1.66\times$ と $2.15\times$ 向上させ、一方でトークンごとの通信を 2 桁以上削減し、同等の回答品質と複雑さを維持していることが示されています。
原文 (English)
CONCORD: Asynchronous Sparse Aggregation for Device-Cloud RAG under Document Isolation
Retrieval-augmented generation (RAG) has emerged as a pivotal technique for improving language models by incorporating external knowledge at inference time. As device-cloud collaborative inference makes it feasible to deploy small language models on edge devices, a new setting arises in which private documents remain on the device and public knowledge resides in the cloud. Privacy and policy constraints often forbid raw document exchange, creating a document-isolated dual-end RAG setting. However, existing methods rely on frequent remote synchronization and dense evidence transfer, limiting throughput under realistic latency and bandwidth conditions. To address this issue, we propose CONCORD, an asynchronous sparse aggregation framework for dual-end RAG under document isolation. CONCORD treats the cloud as an asynchronously arriving evidence source rather than a continuously synchronized co-generator. Specifically, we introduce waiting debt control to decide whether each decoding step should continue waiting for remote participation based on the observed return of waiting. We also design a certificate-guided minimal supplementation mechanism that requests only the remote evidence needed to determine the current greedy decision. Steps that consult the cloud preserve the same greedy token as dense dual-end aggregation, while the remaining steps commit locally without remote evidence. Experiments on Natural Questions and WikiText-2 show that CONCORD improves end-to-end throughput over baselines by $1.66\times$ and $2.15\times$, respectively, while reducing per-token communication by over two orders of magnitude and maintaining comparable answer quality and perplexity.
CogGuard: エッジ インテリジェント サービスでのプロアクティブな警告のための認知および運用プロファイリング
プロアクティブな警告は、エッジ インテリジェント サービスにとって重要な機能であり、システムは、厳しい遅延とプライバシーの制約の下で対象者が受信タスクを正常に完了するかどうかを予測します。このような予測は、過去のインタラクション ログから得られる長期的な静的属性と短期的な動的状態の両方に依存します。最近のラージ言語モデル (LLM) は、これらのログから構造化プロファイルを構築するための強力なロングコンテキスト推論を提供しますが、既存のソリューションは、エッジ展開に関して 2 つの課題に直面しています。(1) プロファイリング方法は通常、ドメイン固有であり、サービス シナリオ全体で再利用可能な抽象化が欠けています。(2) 異種エッジ クラスタ上でアライメント モデルを微調整すると、入力シーケンスの長さの違いにより高い同期オーバーヘッドが発生します。これらの課題に対処するために、エッジ インテリジェント サービス向けの事前警告フレームワークである CogGuard を提案します。 CogGuard は、オフラインの LLM ベースのプロファイル構築を、共有の静的-動的プロファイルからスコアへのパイプラインを通じてオンラインの Small Language Model (SLM) ベースのスコア予測から切り離し、教育パフォーマンスの警告と運用タスクの結果の警告という 2 つの代表的なシナリオでインスタンス化します。効率的なプロファイル構築のために、プレフィックス調整された KV キャッシュを再利用して、繰り返しのエンコードのオーバーヘッドを削減するシナリオ固有のプロファイリング方法を設計します。エッジ側のモデルの調整については、異種クラスター上のワークロードの不均衡を軽減するために、対照的な正則化を使用した長さを意識した分散微調整戦略を提案します。教育データセットと運用データセットに関する実験では、CogGuard がプロファイル構築時間を最大 48% 削減し、分散微調整時間を 19% 削減し、100 ポイントスケールの警告タスクでそれぞれ 13.4 と 5.9 の MAE を達成したことが示されています。最大の教育現場では、CogGuard は最も強力なベースラインと比較して予測誤差を 15.4% 削減しました。
原文 (English)
CogGuard: Cognitive and Operational Profiling for Proactive Warning in Edge Intelligent Services
Proactive warning is an important capability for edge intelligent services, where the system predicts whether a subject will successfully complete an incoming task under strict latency and privacy constraints. Such prediction depends on both long-term static attributes and short-term dynamic states derived from historical interaction logs. Recent Large Language Models (LLMs) offer strong long-context reasoning for constructing structured profiles from these logs, but existing solutions face two challenges for edge deployment: (1) profiling methods are typically domain-specific and lack a reusable abstraction across service scenarios, and (2) fine-tuning alignment models on heterogeneous edge clusters incurs high synchronization overhead due to the variance in input sequence lengths. To address these challenges, we propose CogGuard, a proactive-warning framework for edge intelligent services. CogGuard decouples offline LLM-based profile construction from online Small Language Model (SLM)-based score prediction through a shared static-dynamic profile-to-score pipeline, and instantiates it in two representative scenarios: educational performance warning and operational task outcome warning. For efficient profile construction, we design scenario-specific profiling methods with prefix-aligned KV-cache reuse to reduce repeated encoding overhead. For edge-side model alignment, we propose a length-aware distributed fine-tuning strategy with contrastive regularization to mitigate workload imbalance on heterogeneous clusters. Experiments on education and operation datasets show that CogGuard reduces profile construction time by up to 48% and distributed fine-tuning time by 19%, while achieving MAEs of 13.4 and 5.9, respectively, on 100-point-scale warning tasks. In the largest educational setting, CogGuard reduces prediction error by 15.4% compared with the strongest baseline.
インタラクティブなターゲット広告からの属性の推論
ターゲットを絞った広告システムでは、広告主が選択した視聴者と、目に見えるユーザーのアクションを公開する広告ユニットを組み合わせることができます。インタラクションがそれを引き起こしたキャンペーンにリンクされたままである場合、広告主は単なる集計レポートではなく、ユーザーに関連付けられた観察を受け取ることができます。このチャネルを属性推論のためのノイズの多いオラクルとしてモデル化します。このモデルは、ターゲティング述語、露出、相互作用、および開示を分離します。これらの境界は、資格と配信の間のギャップ、およびインタラクションと広告主の可視性の間のギャップを捉えます。私たちは、既知の機密ラベルが付けられた公開データで調整された合成集団を使用して、再現可能なベンチマークを構築します。生成されたキャンペーン セマンティクス レイヤーは、トピック バリアントと応答事前分布を提供します。シミュレーターは、グラウンド トゥルース、イベント トレース、公開された観測値、およびメトリクスを生成します。この評価では、一般的なキャンペーンと開示の定義に基づいて、ベイジアン攻撃、教師あり攻撃、ポジティブ攻撃とラベルなし攻撃、および適応型攻撃を比較します。最終評価では、4 つのトピック バリアント、7 つのシミュレーター シード、および 2 つのインタラクション設定を使用します。 ID の暴露を伴うキャンペーンが繰り返されると、測定可能ではあるが限定された推論信号が生成されます。 160 ドルのキャンペーンでは、ベイジアン攻撃と教師あり攻撃は、メイン設定で約 0.64 ドル AUC、より高いインタラクション設定で約 0.65 ドル AUC に達します。情報開示ポリシーは最も強力なコントロールです。集計レポートでは、ユーザーに関連付けられた評価済みの Oracle 入力が削除されます。型フィルタリングとランダム化された開示により、放出される信号が減少します。その結果、インタラクティブなターゲット広告におけるプライバシーのモデル、アーティファクト、防御評価方法が誕生しました。コードは https://github.com/P-HOW/Interactive-Ad-Oracle で入手できます。
原文 (English)
Attribute Inference from Interactive Targeted Ads
Targeted advertising systems can pair audiences selected by advertisers with ad units that expose visible user actions. When an interaction remains linked to the campaign that elicited it, the advertiser may receive an observation tied to a user rather than only an aggregate report. We model that channel as a noisy oracle for attribute inference. The model separates targeting predicates, exposure, interaction, and disclosure. These boundaries capture the gap between eligibility and delivery, and the gap between interaction and advertiser visibility. We build a reproducible benchmark using synthetic populations calibrated with public data, each with known sensitive labels. A generated campaign semantics layer provides topic variants and response priors. The simulator generates the ground truth, event traces, disclosed observations, and metrics. The evaluation compares Bayesian, supervised, positive and unlabeled, and adaptive attacks under common campaign and disclosure definitions. The final evaluation uses four topic variants, seven simulator seeds, and two interaction settings. Repeated campaigns with identity exposure produce measurable but bounded inference signal. At $160$ campaigns, Bayesian and supervised attacks reach about $0.64$ AUC in the main setting and about $0.65$ AUC in the higher interaction setting. Disclosure policy is the strongest control. Aggregate reporting removes the evaluated oracle input tied to users. Type filtering and randomized disclosure reduce the released signal. The result is a model, artifact, and defense evaluation method for privacy in interactive targeted advertising. The code is available at https://github.com/P-HOW/Interactive-Ad-Oracle.
Visual-Seeker: アクティブなビジュアル推論によるビジュアルネイティブのマルチモーダル エージェント検索に向けて
マルチモーダル大規模言語モデル (MLLM) は、多くの視覚的なタスクにおいて優れた機能を実証してきましたが、複雑でオープンワールドのシナリオに直面すると、事実に基づく根拠に苦労することがよくあります。最近のマルチモーダルディープ検索エージェントは、外部ツールを利用してこの問題に対処しようとしていますが、ビジュアルネイティブ検索パラダイムは依然として十分に検討されていません。既存の方法は主に、明示的なセマンティクスを備えた単純な画像とテキストのみの証拠軌跡に依存しており、マルチホップ、クロスモーダル推論および検索を実行するエージェントの能力が制限されています。これらの制限に対処するために、アクティブな視覚的推論を介したビジュアルネイティブのマルチモーダル深層検索エージェントである Visual-Seeker を提案します。当社のエージェントは視覚を静的な入力として扱うのではなく、きめの細かい視覚的な詳細に積極的に注目し、検索プロセス全体を通じて視覚的な証拠を動的に収集します。ビジュアル ネイティブの可能性を引き出すために、アクティブなビジュアル推論データ パイプラインを設計し、モデル トレーニング用の 5K 高品質マルチモーダル トラジェクトリを合成します。広範な実験により、5 つの困難なマルチモーダル検索ベンチマーク全体で最先端のパフォーマンスが実証され、いくつかの独自モデルをも上回り、現実世界の Web 環境における堅牢なビジュアルネイティブ推論と検索が検証されました。コードとデータは、https://github.com/ZhengboZhang/Visual-Seeker からアクセスできます。
原文 (English)
Visual-Seeker: Towards Visual-Native Multimodal Agentic Search via Active Visual Reasoning
Multimodal large language models (MLLMs) have demonstrated impressive capabilities in many visual tasks, but they often struggle with factual grounding when confronted with complex, open-world scenarios. While recent multimodal deep search agents attempt to address this issue by utilizing external tools, the visual-native search paradigm remains underexplored. Existing methods primarily rely on simple images with explicit semantics and text-only evidence trajectories, limiting the agent's ability to perform multi-hop, cross-modal reasoning and search. To address these limitations, we propose Visual-Seeker, a visual-native multimodal deep search agent via active visual reasoning. Rather than treating vision as a static input, our agent actively attends to fine-grained visual details, dynamically harvests visual evidence throughout the search process. To unlock its visual-native potential, we design an active visual reasoning data pipeline and synthesize 5K high-quality multimodal trajectories for model training. Extensive experiments demonstrate the state-of-the-art performance across five challenging multimodal search benchmarks, even surpassing several proprietary models, validating robust visual-native reasoning and search in real-world web environments. The code and data can be accessed at: https://github.com/ZhengboZhang/Visual-Seeker.
マスクプルーフ: 数学的証明に関する LLM ベースの自動データ キュレーション パイプライン
大規模言語モデル (LLM) は数学的問題解決能力がますます高まっており、研究レベルの証明を支援することもできますが、多様なソースにわたる長い証明におけるステップレベルの推論を測定するためのスケーラブルで再現可能な方法がまだ不足しています。この評価ギャップにより、証明された科学の進歩において信頼できる AI 支援が制限されます。既存の評価は最終的な回答を重視したり、コストのかかる専門家による採点に頼ったりすることが多い一方で、エンドツーエンドの証明生成は依然として制限がなく、自動的に検証することが困難です。実際のプルーフを自動的にチェック可能なマスクされたステップ タスクに変換するパイプラインである Mask-Proof を紹介します。主要な式ステップをマスクし、必要な周囲のコンテキストを提供し、安定性を確保するための繰り返し投票を使用して LLM ベースの同等性判定でモデルの再構築を評価します。結果として得られる Mask-ProofBench には、さまざまな研究分野にわたって厳選された 292 の問題が含まれています。 17 のモデルを使った実験では、推論強化モデルが標準モデルよりも 12% ~ 27% 優れていることがわかりました。当社の評価者は、専門のアノテーターと 96.8% の一致を達成し、ステップレベルの数学的推論の忠実で再現性のある比較可能な測定を可能にします。ベンチマーク、アノテーション、コードは https://github.com/weating/Mask-Proof で入手できます。
原文 (English)
Mask-Proof: An LLM-based Automated Data Curation Pipeline on Mathematical Proofs
Large language models (LLMs) are increasingly capable of mathematical problem solving and can even assist with research-level proofs, yet we still lack a scalable and reproducible way to measure step-level reasoning in long proofs across diverse sources. This evaluation gap limits trustworthy AI assistance in proof-certified scientific progress. Existing evaluations often emphasize final answers or rely on costly expert grading, while end-to-end proof generation remains open-ended and hard to verify automatically. We introduce Mask-Proof, a pipeline that turns real proofs into automatically checkable masked-step tasks. It masks key formula steps, provides the necessary surrounding context, and evaluates model reconstructions with an LLM-based equivalence judge using repeated votes for stability. The resulting Mask-ProofBench contains 292 curated problems across diverse research areas. Experiments with 17 models show that reasoning-enhanced models outperform standard models by 12% to 27%. Our evaluator achieves 96.8% agreement with expert annotators, enabling faithful, reproducible, and comparable measurement of step-level mathematical reasoning. Benchmark, annotations, and code are available at https://github.com/weating/Mask-Proof.
エッジ介入を使用した有向非巡回グラフの特徴属性
Shapley の値ベースの特徴帰属手法は、因果構造が提供されている場合でも、複雑な特徴の相互作用や因果関係を含むシナリオでは課題に直面します。既存の方法は通常、ノード中心のビューを採用し、個々の機能のみを重要視します。その結果、特徴の外部性と外生的影響を同時に捉えることができず、不合理な解釈につながることがよくあります。これらの制限を克服するために、エッジ介入に基づいた DAG-SHAP と呼ばれる新しい特徴帰属方法を提案します。 DAG-SHAP は、各フィーチャ エッジを個別の属性オブジェクトとして扱い、フィーチャの外部性と外生的寄与の両方が適切にキャプチャされることを保証します。さらに、DAG-SHAP を効率的に計算するための近似方法を紹介します。実際のデータセットと合成データセットの両方に対する広範な実験により、DAG-SHAP の有効性が検証されています。私たちのコードは https://github.com/ZJU-DIVER/DAG-SHAP で入手できます。
原文 (English)
Feature Attribution in Directed Acyclic Graphs Using Edge Intervention
Shapley value-based feature attribution methods face challenges in scenarios involving complex feature interactions and causal relationships, even when a causal structure is provided. Existing methods typically adopt a node-centric view, attributing importance solely to individual features. Consequently, they often fail to simultaneously capture the externality and exogenous influence of features, leading to unreasonable interpretations. To overcome these limitations, we propose a novel feature attribution method called DAG-SHAP, which is based on edge intervention. DAG-SHAP treats each feature edge as an individual attribution object, ensuring that both externality and exogenous contributions of features are appropriately captured. Additionally, we introduce an approximation method for efficiently computing DAG-SHAP. Extensive experiments on both real and synthetic datasets validate the effectiveness of DAG-SHAP. Our code is available at https://github.com/ZJU-DIVER/DAG-SHAP.
ビジネスプロセス分析における宣言型エージェントAIの正式なフレームワーク
Agentic AI は、ビジネス プロセス (BP) を自動化する新たな機会を開き、自律的な意思決定と動的な適応を可能にします。ただし、この可能性を実現するには、BP エンティティとその相互作用を形式的な精度で定義する必要があります。この論文では、AGO 方法論によるエージェントによる BP 分析の正式なフレームワークを紹介します。 AGO は、誰が行動するか (エージェント)、なぜそれが実行されるのか (目標)、関連するエンティティが何であるか (オブジェクト) という観点からモデリングの観点を捉えます。集合論と数学的論理に基づいて、AGO エンティティ タイプとその相互作用を正式に定義し、すべての定義を BP Knowledge Base (BPKB) にまとめます。結果として得られる BPKB は、構造化されたクエリ、増分更新、BP ワークフローの自動生成をサポートしながら、派生パスの健全性と完全性を保証します。
原文 (English)
A Formal Framework for Declarative Agentic AI in Business Process Analysis
Agentic AI opens new opportunities for automating Business Process (BP), enabling autonomous decision-making and dynamic adaptation. However, realising this potential requires BP entities and their interactions to be defined with formal precision. This paper presents a formal framework for Agentic BP analysis through the AGO methodology. AGO captures the modelling perspective in terms of who is acting (Agents), why it is carried out (Goals), and what the relevant entities are (Objects). Grounded in set theory and mathematical logic, we formally define the AGO entity types and their interactions, organising all definitions into a BP Knowledge Base (BPKB). The resulting BPKB supports structured querying, incremental updates, and automatic generation of BP workflows, while ensuring soundness and completeness of the derived paths.
CODA-BENCH: コード エージェントはデータ量の多いタスクを処理できますか?
高度なエージェントは自律型エンジニアとして動作する可能性をますます実証しており、現実世界の開発の複雑さを捉える評価ベンチマークに対する需要が高まっています。このような環境には通常、複雑なコードと大規模なデータ (ファイル システムなど) の両方が含まれます。ただし、既存のベンチマークは通常、コード中心の機能またはデータ中心の機能を個別に評価するため、実際の開発シナリオとの明らかなギャップが残ります。このペーパーでは、データ集約型環境でコードとデータ インテリジェンスを共同で評価する初のベンチマークである CODA-BENCH を紹介することで、このギャップを埋めます。当社は、Kaggle エコシステム (数百のデータセットを含む) に基づいてデータ集約型 Linux サンドボックスを構築します。そこでは、エージェントが複雑なファイル階層を積極的に探索して関連リソースを特定し、データ駆動型の分析タスク用のコードを生成する必要があります。 CODA-BENCH は 31 のコミュニティにまたがる 1,009 のタスクで構成され、各タスク環境には平均 980 のファイルが含まれており、現実的なデータ スケールとノイズをシミュレートします。高度なエージェントの評価では、最高のパフォーマンスを誇るシステムでもデータ検出とコード実行を効果的に統合するのが難しく、成功率はわずか 61.1% にとどまっていることが明らかになりました。これらの結果は、データ集約型タスクに対する現在のエージェント機能の大きなギャップを浮き彫りにし、将来の研究の有望な方向性を示しています。
原文 (English)
CODA-BENCH: Can Code Agents Handle Data-Intensive Tasks?
Advanced agents are increasingly demonstrating the potential to operate as autonomous engineers, creating a growing demand for evaluation benchmarks that capture the complexity of real-world development. Such environments typically involve both complex code and large-scale data (i.e., file system). However, existing benchmarks usually evaluate code-centric or data-centric capabilities in isolation, leaving a clear gap with real development scenarios. In this paper, we bridge this gap by introducing CODA-BENCH, the first benchmark to jointly evaluate code and data intelligence in a data-intensive environment. We construct a data-intensive Linux sandbox based on the Kaggle ecosystem (containing hundreds of datasets), where agents must actively explore complex file hierarchies to identify relevant resources and generate code for data-driven analytical tasks. CODA-BENCH comprises 1,009 tasks spanning 31 communities, with each task environment containing an average of 980 files, simulating realistic data scale and noise. Evaluations of advanced agents reveal that even top-performing systems struggle to effectively integrate data discovery with code execution, achieving a success rate of only 61.1%. These results highlight a substantial gap in current agentic capabilities for data-intensive tasks and point to promising directions for future research.
強制延期: マルチモーダル LLM カスケードでのルーティング決定の操作
マルチモーダル大規模言語モデル (MLLM) は強力な視覚的推論能力を示していますが、すべてのクエリに対して大規模なモデルを提供するのは計算コストがかかります。 MLLM カスケードは、最初に弱いが安価なモデルをクエリし、弱いモデルの出力に自信がない場合は強力なモデルを延期することで、このコストを軽減します。ただし、弱いモデルの信頼度がコンピューティングの割り当てを直接制御するため、これらのシステムは新たな攻撃対象領域を露出させます。攻撃者は信頼度を操作して、クエリが常に強いモデルに延期されるようにすることができます。この脆弱性を動機として、弱いモデルの信頼性を低下させ、クエリを強いモデルにルーティングするカスケードを引き起こす敵対的なイメージ攻撃である強制遅延攻撃 (FDA) を導入します。 FDA は、温度平坦化対物レンズを最適化することで、普遍的な境界トリガーを学習します。この目的は、トリガーされた入力に対する弱いモデルのトークン分布を、クリーンな応答から構築された集中度の低いターゲットに向けてプッシュします。 FDA は、データセット、モデル ファミリ、遅延メトリクス全体にわたって、画像摂動やプロンプト インジェクション ベースラインを上回るパフォーマンスを維持しながら、強力なモデル ルーティングを一貫して増加させています。これらの結果は、MLLM カスケードがコンピューティング割り当てを操作する攻撃に対して脆弱であることを示しており、回答の正しさを直接ターゲットにすることなく、意図しない強力なモデルの使用を強制します。
原文 (English)
Forced Deferral: Manipulating Routing Decisions in Multimodal LLM Cascades
While multimodal large language models (MLLMs) have shown strong visual reasoning abilities, serving a large model for every query is computationally expensive. MLLM cascades mitigate this cost by first querying a weak but cheaper model and deferring to a strong model when the weak model's output is unconfident. However, since the weak model's confidence directly controls compute allocation, these systems expose a new attack surface: an adversary can manipulate confidence so that their queries are consistently deferred to the strong model. Motivated by this vulnerability, we introduce the Forced Deferral Attack (FDA), an adversarial image attack that lowers the weak model's confidence and causes cascades to route queries to the strong model. FDA learns a universal border trigger by optimizing a temperature-flattened objective. This objective pushes the weak model's token distribution on triggered inputs toward less concentrated targets constructed from its clean responses. Across datasets, model families, and deferral metrics, FDA consistently increases strong-model routing while outperforming image-perturbation and prompt-injection baselines. These results show that MLLM cascades are vulnerable to attacks that manipulate compute allocation, forcing unintended strong-model usage without directly targeting answer correctness.
ChatPlanner: パーソナライズされた公共交通機関のルーティングのための大規模な言語モデル フレームワーク
多様なユーザーの好みを把握してルーティング アルゴリズムに統合することが難しいため、公共交通システムにおけるパーソナライズされた公共交通ルーティングは依然として課題となっています。この文書では、大規模言語モデル (LLM) を活用して優先順位を認識した公共交通機関のルーティングを可能にする新しいフレームワークである ChatPlanner について説明します。私たちのアプローチでは、検索拡張生成 (RAG) を備えた微調整された LLM を採用して、ルーティング パラメーターを抽出し、自然言語クエリから微妙なユーザーの好みを解釈し、その後、これらの好みを公共交通機関のルーティング アルゴリズムの目的関数に統合します。この研究では、微調整と RAG の両方のスコア基準を確立するために、8 つのペルソナと 5 つのコンテキストを組み込んだ好みを意識したデータセットを設計します。この作業では、ソリューションの実現可能性、ルーティング情報と設定の抽出、ソリューション セットの品質と完全性を検証するために 3 つの実験を実施しました。結果は、ChatPlanner が実行可能なソリューションを確実に生成することを示しています。微調整により、必要な出力構造が強制され、一般的な設定パターンが学習されます。一方、RAG はクエリ固有のコンテキストを提供して、不正確な表現や会話的な表現を解決し、連続スコアを調整します。両方を組み合わせることで、ルーティング情報の抽出とユーザー設定の解釈において最高の精度が実現します。選択されたケーススタディに基づく結果は、ChatPlanner がユーザーの好みを把握することにより、既存のルート プランナーが見落としていたさまざまな側面にわたる価値のあるソリューションを特定し、より価値のあるルートの代替案を生成することを示しています。この研究は、自然言語理解を輸送の最適化に統合するための新しいパラダイムを確立します。
原文 (English)
ChatPlanner: A Large Language Model Framework for Personalized Public Transit Routing
Personalized public transit routing in public transit systems remains challenging due to the difficulty of capturing and integrating diverse user preferences into routing algorithms. This paper presents ChatPlanner, a novel framework that leverages Large Language Models (LLMs) to enable preference aware public transit routing. Our approach employs fine-tuned LLMs with Retrieval-Augmented Generation (RAG) to extract routing parameters and interpret nuanced user preferences from natural language queries, subsequently integrating these preferences into the objective function of a public transit routing algorithm. This study designs preference aware datasets incorporating eight personas and five contexts to establish scoring standards for both fine-tuning and RAG. This work conducted three experiments to validate the solutions' feasibility, extraction of routing information and preferences, and solution set quality and completeness. Results demonstrate that ChatPlanner generates feasible solutions reliably. Fine-tuning enforces the required output structure and learns general preference patterns, while RAG provides query-specific context to resolve imprecise or conversational expressions and calibrate continuous scores. The combination of both achieves the highest accuracy in routing information extraction and user preference interpretation. Results based on selected case studies show that by capturing user preferences, ChatPlanner identifies valuable solutions across different dimensions that existing route planners overlook, generating more valuable route alternatives. This research establishes a new paradigm for integrating natural language understanding into transportation optimization.
APEX: 適応原則抽出 本番 AI エージェントのための 3 層の自己進化フレームワーク
AI エージェントの自己改善は、蓄積された運用経験に基づいて独自のプロンプト、ワークフロー、意思決定ルールを変更するシステムという、主要な研究フロンティアとして浮上しています。最先端のセルフハーネス フレームワーク [1] は、障害クラスターをマイニングし、エージェント ハーネスにパッチを適用することにより、ターミナル ベンチ 2.0 に対して 14 ~ 21% の改善を達成します。ただし、セルフハーネスは、動作原則とワークフロー トポロジを変更せずに、プロンプト ハーネスという 1 つの側面のみを最適化します。我々は、同時に進化する 3 層の共進化フレームワークである APEX (Adaptive Principle EXtraction) を提案します: (L1) 障害モード パッチ適用によるハーネス、(L2) 成功トレース蒸留による動作原理 [2]、および (L3) 構造適合性ベースの選択によるエージェント ワークフロー トポロジ [6]。私たちは、NVIDIA Nemotron 上に構築され、NVIDIA Agent Challenge 2026 のエッジ AI エージェント ファクトリとして設計されたプロダクション グレードのスーパー AI エージェントである APEX on Joe [13] を実装し、18 日間にわたって収集された 114 個の実際のタスク トレースを使用して 15 ノードのコンピューティング フリートを管理します。 APEX は、1 回の進化実行で APEX ヘルス スコア 0.570 (ベースライン 0.300 に対して +90%) を達成し、6 つの新しい再利用可能な原則を抽出し、スコア 0.900 (+20%) の研究優先のワークフロー トポロジを選択しました。私たちの結果は、ローカルの qwen2.5-coder:32b インスタンス上でわずか 4 回の LLM 呼び出し (約 270 秒) のコストで、多次元共進化が単軸ハーネス最適化を大幅に上回るパフォーマンスを示していることを示しています。
原文 (English)
APEX: Adaptive Principle EXtraction A Three-Layer Self-Evolution Framework for Production AI Agents
Self-improvement in AI agents has emerged as a key research frontier: systems that modify their own prompts, workflows, and decision rules based on accumulated operational experience. The state-of-the-art Self-Harness framework [1] achieves 14--21% improvement on Terminal-Bench-2.0 by mining failure clusters and patching the agent harness. However, Self-Harness optimises only one dimension -- the prompt harness -- leaving behavioural principles and workflow topology unchanged. We propose APEX (Adaptive Principle EXtraction), a three-layer co-evolution framework that simultaneously evolves: (L1) the harness via failure-mode patching, (L2) behavioural principles via success-trace distillation [2], and (L3) the agent workflow topology via structural fitness-based selection [6]. We implement APEX on Joe [13], a production-grade super AI Agent built on NVIDIA Nemotron and designed as an Edge AI Agent Factory for the NVIDIA Agent Challenge 2026, managing a 15-node compute fleet using 114 real task traces collected over 18 days. APEX achieves an APEX Health Score of 0.570 (+90% vs. baseline 0.300) in a single evolutionary run, distilling 6 novel reusable principles and selecting a research-first workflow topology scoring 0.900 (+20%). Our results demonstrate that multi-dimensional co-evolution substantially outperforms single-axis harness optimisation, at a cost of only 4 LLM calls (~270 s) on a local qwen2.5-coder:32b instance.
S1-DeepResearch: 検索を超えて、現実世界の長期にわたる研究エージェントに向けて
深層調査エージェントは、長期的な計画、証拠の収集、推論、レポートの作成を通じて、複雑な知識集約型タスクを解決することを目的としています。検索エージェントの最近の進歩により、情報検索と回答検証における強力な機能が実証されましたが、既存のトレーニング データセットのほとんどは依然として検索中心であり、主にクローズドエンド質問応答と情報ローカリゼーションに重点を置いています。その結果、主に情報探索行動を訓練する一方で、証拠の統合、知識の統合、計画、ファイルの理解、構造化されたレポートの生成など、重要な詳細な調査機能の限定的な範囲を提供します。この研究では、クローズドエンドの QA とオープンエンドの探索を組み合わせた、ディープリサーチエージェントのための統一された軌道構築パラダイムを提案します。提案されたフレームワークは、グラフに基づいたタスクの定式化、エージェントの軌跡のロールアウト、および多次元の軌跡の検証で構成されており、長鎖の複雑な推論、深い調査指示の追跡、レポートの作成、ファイルの理解と生成、およびスキルの使用に及ぶ高品質のエージェントの軌跡のスケーラブルな合成を可能にします。既存の検索指向のデータセットと比較して、私たちの合成軌跡は、知識の合成、複雑な推論、計画に重点を置いています。 S1-DeepResearch-32B は、複雑な推論、指示に従って、レポートの生成、ファイルの理解、スキルの使用など、5 つの機能の次元にわたる 20 のベンチマークにわたって、同等の規模のオープンソース モデルの中で最先端のパフォーマンスを実現します。いくつかの挑戦的な深層研究ベンチマークにおいて、主要な独自のフロンティア モデルのパフォーマンスに近づいています。これらの結果は、効果的なディープリサーチエージェントを構築するために、情報取得、知識合成、および計画指向のエージェントの動作を共同でモデル化することの重要性を強調しています。
原文 (English)
S1-DeepResearch: Beyond Search, Toward Real-World Long-Horizon Research Agents
Deep research agents aim to solve complex knowledge-intensive tasks through long-horizon planning, evidence gathering, reasoning, and report generation. While recent progress in search agents has demonstrated strong capabilities in information retrieval and answer verification, most existing training datasets remain search-centric, focusing primarily on closed-ended question answering and information localization. As a result, they mainly train information-seeking behavior while providing limited coverage of key deep research capabilities, including evidence integration, knowledge synthesis, planning, file understanding, and structured report generation. In this work, we propose a unified trajectory construction paradigm for deep research agents that combines closed-ended QA and open-ended exploration. The proposed framework consists of graph-grounded task formulation, agentic trajectory rollout, and multi-dimensional trajectory verification, enabling scalable synthesis of high-quality agentic trajectories spanning long-chain complex reasoning, deep research instruction following, report writing, file understanding and generation, and skills usage. Compared with existing search-oriented datasets, our synthesized trajectories place greater emphasis on knowledge synthesis, complex reasoning, and planning. S1-DeepResearch-32B achieves state-of-the-art performance among open-source models of comparable scale across 20 benchmarks spanning five capability dimensions, including complex reasoning, instruction following, report generation, file understanding, and skills usage. On several challenging deep research benchmarks, it approaches the performance of leading proprietary frontier models. These results highlight the importance of jointly modeling information acquisition, knowledge synthesis, and planning-oriented agent behaviors for building effective deep research agents.
言語モデルエージェントにおける報酬ハッキング: AI セーフティ グリッドワールドの再訪
AI システムが誤って指定された目標を悪用して、意図された目標を達成せずに高額な報酬を達成する報酬ハッキングは、依然として AI の安全性における中心的な課題です。しかし、既知の事例のほとんどは、管理された研究が現実的ではない辺境星系で事後的に発見されています。 AI Safety Gridworlds フレームワークを、言語ベースのエージェント向けの古典的な強化学習安全タスクを再定式化するテキストベースの評価スイートに適応させます。フロンティアモデルと中規模モデルにわたって、仕様ゲームはゼロショットで現れることがわかりました。モデルは組織的に観察された高い報酬を達成する一方、隠された安全目標ではパフォーマンスが低下し、一見安全な動作でさえ、原則に基づいた安全性ではなく誤解を反映している可能性があります。強化学習ではこれらの失敗は修正されません。直接報酬の最適化では、モデルの初期能力により、より安全な代替案を発見する前に局所的に報酬を与える戦略に固定されてしまうため、観察された報酬と隠れた報酬の間のギャップが広がります。このパターンはモデル スケール (1.5B ~ 14B) 全体で持続し、より詳細なクレジット割り当て、探索プロンプト、エントロピー正則化によっては解決されません。私たちの結果は、有能な言語モデルエージェントを使用してプロキシ目標を最適化するときに報酬ハッキングが自然に発生し、標準的な軽減策に抵抗することを示しており、エージェント設定でのプロキシ報酬の失敗には、標準的な調査とクレジット割り当ての修正を超えたアプローチが必要である可能性があることを示唆しています。再現性を高めるために、この作業のコードは \href{https://github.com/asparius/verl-agent-safety}{our public repository} で入手できます。
原文 (English)
Reward Hacking in Language Model Agents: Revisiting AI Safety Gridworlds
Reward hacking, where AI systems exploit misspecified objectives to achieve high reward without satisfying intended goals, remains a central challenge in AI safety. Yet most known instances have been discovered post hoc in frontier systems where controlled study is impractical. We adapt the AI Safety Gridworlds framework into a text-based evaluation suite that reformulates classic reinforcement learning safety tasks for language-based agents. Across frontier and mid-scale models, we find that specification gaming emerges zero-shot: models systematically achieve high observed reward while underperforming on hidden safety objectives, and even apparently safe behaviors can reflect misunderstanding rather than principled safety. Reinforcement learning does not correct these failures: direct reward optimization widens the gap between observed and hidden reward, as the model's initial competence causes it to lock into locally rewarding strategies before discovering safer alternatives. This pattern persists across model scales (1.5B--14B) and is not resolved by finer credit assignment, exploration prompts, or entropy regularization. Our results show that reward hacking arises naturally when optimizing proxy objectives with capable language model agents and resists standard mitigations, suggesting that proxy-reward failures in agentic settings may require approaches beyond standard exploration and credit-assignment fixes. To facilitate reproducibility, the code for this work is available at \href{https://github.com/asparius/verl-agent-safety}{our public repository}.
EHR 基盤モデルにおける ICD コードの階層モデリング
電子医療記録基盤モデルは通常、ICD 診断コードをフラットなトークンとして扱い、疾患ファミリー、サブカテゴリー、および詳細な診断の詳細を捕捉する臨床的に意味のある階層構造を無視します。結果として、既存の EHR 表現学習方法は、コーディング システムにすでに存在する階層構造を明示的に利用していません。この研究では、臨床表現学習の一般的な帰納的バイアスとして ICD-10-CM 階層を研究します。我々は、階層を組み込むための 2 つの相補的なメカニズムを調査します。1 つは、ICD 階層のさまざまなレベルに対応するトークンを使用して BERT スタイルのトランスフォーマー内の診断シーケンスを拡張することにより、もう 1 つは、診断の共起構造と組み合わせた階層認識エッジを通じてグラフベースのコード表現に階層を注入することです。これらの設定全体にわたって、明示的な階層によって下流予測が改善されるかどうか、階層のどのレベルが最も有用か、階層エンコーディングによってデータセット間の転送が改善されるかどうか、階層が埋め込み類似性構造をどのように再形成するかなどを評価します。私たちは、2 つの大規模な現実世界の臨床データセットで実験を行っています。MIMIC-IV は事前トレーニングとドメイン内評価に使用され、eICU はフリーズされたエンコーダー プローブを介してクロスデータセット転送を評価するために使用されます。私たちの調査結果では、ICD 階層を明示的にエンコードすると、ドメイン内設定とデータセット間設定の両方でフラット コード表現よりも改善されることが示されていますが、最も有用な階層レベルはタスクとモデリング アプローチの両方に依存することが明らかになりました。より広範には、階層を意識した EHR 表現学習に焦点を当て、階層をエンコードする利点がモデリング設定と階層レベル全体で一般化できることを示します。
原文 (English)
Hierarchical Modeling of ICD Codes in EHR Foundation Models
Electronic health record foundation models typically treat ICD diagnosis codes as flat tokens, overlooking the clinically meaningful hierarchical structure that captures disease families, subcategories, and fine-grained diagnostic detail. As a result, existing EHR representation learning methods do not explicitly exploit the hierarchical structure already present in the coding system. In this work, we study ICD-10-CM hierarchy as a general inductive bias for clinical representation learning. We investigate two complementary mechanisms for incorporating hierarchy: first, by augmenting diagnosis sequences in a BERT-style transformer with tokens corresponding to different levels of the ICD hierarchy, and second, by injecting hierarchy into graph-based code representations through hierarchy-aware edges combined with diagnosis co-occurrence structure. Across these settings, we evaluate whether explicit hierarchy improves downstream prediction, which levels of the hierarchy are most useful, whether hierarchy encoding improves transfer across datasets, and how hierarchy reshapes embedding similarity structure. We conduct experiments on two large-scale real-world clinical datasets: MIMIC-IV, used for pretraining and in-domain evaluation, and eICU, used to assess cross-dataset transfer via frozen encoder probing. Our findings show that explicitly encoding ICD hierarchy improves over flat code representations in both in-domain and cross-dataset settings, while revealing that the most useful level of hierarchy depends on both the task and the modeling approach. More broadly, we focus on hierarchy-aware EHR representation learning and show that the benefits of encoding hierarchy are generalizable across modeling settings and hierarchy levels.
漂流したのはシステムか、それとも裁判官か? LLM 評価パイプラインでいつでも有効なアトリビューション
LLM 製品の継続的な評価は、グラウンド トゥルースとして扱われる強力な LLM ジャッジに依存しています。安価なモニターがすべてのインタラクションをスコアリングし、スコアが下降するとチームがページングされます。しかし、審査員自体が API の背後にあるモデルであり、サイレント バージョン バンプや採点プロンプトの更新によって採点方法が変更されるため、すべてのドリフト アラームは、より悪い製品と変更された審査員の間で曖昧になります。現在の裁判官が安定したインターリーブで再得点する、固定の人間ラベル付きアンカー セット、裁判官対人間の差に関する 2 番目の賭け電子プロセス、および {なし、システム、裁判官} で評決を返すガード ウィンドウ ルールを使用して、曖昧さを解決します。私たちは、いつでも有効で、一方向の識別 (ジャッジのみがアンカーを移動できる)、帰属レースを証明します。その設計法則は、アンカーが保護するメインプロセスを上回って実行し、プロセスの直交性を持たなければならないというものです。 2 つの実際のジャッジ変更では、サイレント バージョン バンプが 60/60 の実行でジャッジ ドリフトとして検出され、ジャッジからシステムへの誤った帰属はゼロで、汚染を伴うストリクト プロンプト変更はガード幅 300 での 120 回中 110 回の実行で正しく帰属されました。一方、業界デフォルトのローリング Z テストはドリフトのないストリームの 75% で誤警報を出しました。すべての実験は、何も再調整せずに 2 番目のドメイン (TL;DR の要約) で複製され、ドメインが異なる場合、その違いはレースが予測するものです。厳密なプロンプトの変更により、そこでのスコアのシフトがより大きくなるため、アンカーの発射が速くなり、帰属が完璧になります (240/240)。このモニターは、すべての項目を強力に判断する場合のコストの約 0.64 で実行され、より安価ではあるが遅い制度では 0.21 で実行されます。
原文 (English)
Who Drifted: the System or the Judge? Anytime-Valid Attribution in LLM Evaluation Pipelines
Continuous evaluation of LLM products relies on a strong LLM judge treated as ground truth: a cheap monitor scores every interaction and a team is paged when the score drifts down. But the judge is itself a model behind an API, and a silent version bump or scoring-prompt update changes how it scores -- so every drift alarm is ambiguous between a worse product and a changed judge. We resolve the ambiguity with a fixed, human-labeled anchor set that the current judge re-scores at a steady interleave, a second betting e-process on the judge-versus-human gap, and a guard-window rule returning a verdict in {none, system, judge}. We prove anytime-validity, one-way identification (only the judge can move the anchors), an attribution race whose design law is that the anchors must out-run the main process they guard, and process orthogonality. On two real judge changes, a silent version bump is detected as judge drift in 60/60 runs with zero judge-to-system misattribution, and a contaminating strict-prompt change is correctly attributed on 110 of 120 runs at guard width 300 -- while the industry-default rolling z-test false-alarms on 75% of drift-free streams. Every experiment replicates on a second domain (TL;DR summarization) with nothing re-tuned, and where the domains differ the differences are the ones the race predicts: the strict-prompt change shifts scores harder there, so the anchors fire faster and attribution becomes perfect (240/240). The monitor runs at approximately 0.64 of the cost of strong-judging every item, or 0.21 in a cheaper-but-deafer regime.
AI 研究のエンドツーエンドの自動化に向けて
科学の自動化は、AI 分野における長年の野心です。コミュニティは科学プロセスの個々のコンポーネントの自動化において大きな進歩を遂げてきましたが、構想から出版まで、研究ライフサイクル全体を自律的にナビゲートするシステムは依然として手の届かないところにあります。ここでは、プロセス全体をエンドツーエンドで自動化するためのこれまでで最も強力なデモンストレーションを紹介します。私たちは、研究アイデアを作成し、コードを書き、実験を実行し、データをプロットして分析し、科学論文全体を執筆し、独自の査読を実行する AI Scientist を紹介します。そのアイデア、実行、プレゼンテーションは、AI システムによって生成された原稿を作成するのに十分な品質を備えており、主要な機械学習カンファレンスのワークショップで第 1 ラウンドの査読を通過します。このワークショップの合格率は 70% です。私たちのシステムは、複雑なエージェント システム内で最新の基盤モデルを活用しています。私たちは、The AI Scientist を 2 つの設定で評価します。1 つは、特定のトピックに関する研究を実施するための最初の足場として人間が提供したコード テンプレートを使用する集中モード、もう 1 つは、より広範な科学的調査のためにエージェント検索を活用する、テンプレートを使用しないオープンエンド モードです。どちらの設定でも、多様なアイデアが生成され、自動的にテスト、レポート、評価されます。この成果は、AI の科学的貢献能力が増大していることを示しており、研究の実施方法におけるパラダイムシフトの可能性を示しています。影響力のある新技術の場合と同様に、審査システムに負荷がかかりすぎたり、科学文献にノイズが加わったりするなど、重大なリスクが生じる可能性があります。しかし、責任を持って開発されれば、このような自律システムは科学的発見を大幅に加速する可能性があります。
原文 (English)
Towards End-to-End Automation of AI Research
The automation of science is a long-standing ambition in the field of AI. While the community has made significant progress in automating individual components of the scientific process, a system that autonomously navigates the entire research lifecycle -- from conception to publication -- has remained out of reach. Here, we present the strongest demonstration to date toward automating the entire process end-to-end. We present The AI Scientist, which creates research ideas, writes code, runs experiments, plots and analyzes data, writes the entire scientific manuscript and performs its own peer review. Its ideas, execution, and presentation are of sufficient quality to produce a manuscript generated by an AI system that passes the first round of peer review at a major machine learning conference workshop. The workshop has an acceptance rate of 70 percent. Our system leverages modern foundation models within a complex agentic system. We evaluate The AI Scientist in two settings: a focused mode using human-provided code templates as an initial scaffold to conduct research on a specific topic, and a template-free, open-ended mode that leverages agentic search for wider scientific exploration. Both settings produce diverse ideas and automatically test, report on, and evaluate them. This achievement demonstrates AI's growing capacity for scientific contribution and signifies a potential paradigm shift in how research is conducted. As with any impactful new technology, there could be significant risks, including taxing overwhelmed review systems and adding noise to scientific literature. However, if developed responsibly, such autonomous systems could greatly accelerate scientific discovery.
総合的な対抗適応: 人間と AI の共進化の原則
この論文では、人間と AI システムが互いの戦略と行動に適応することで共進化するプロセスである総合的逆適応の概念を紹介します。総合的な逆適応は、AI システムが新しい戦略や社会プロトコルを開発するときに発生し、人間が洞察を抽出し、それに応じて自らの行動を適応させることで、新しいエージェント相互作用ダイナミクスの出現につながります。これらのダイナミクスを説明するために、囲碁、動機が異なる社会的相互作用、地政学的シミュレーションなど、さまざまな状況から例を分析します。これらのケースを調査することで、総合的な対抗適応が、マルチエージェント環境における人間と AI の相互作用の再帰的および共進化的な性質を理解するためのフレームワークをどのように提供するかを示します。
原文 (English)
Synthetic Counteradaptation: A Principle of Human-AI Co-evolution
In this paper, we introduce the concept of synthetic counteradaptation, a process where human and AI systems co-evolve by adapting to each other's strategies and behaviors. Synthetic counteradaptation occurs when AI systems develop novel strategies or social protocols, prompting humans to extract insights and adapt their own behaviors in response, leading to the emergence of new agent interaction dynamics. To illustrate these dynamics, we analyze examples from various contexts, including the game of Go, mixed-motive social interactions, and geopolitical simulations. By exploring these cases, we demonstrate how synthetic counteradaptation provides a framework for understanding the recursive and co-evolutionary nature of human-AI interactions in multi-agent environments.
Vibe Medicine に向けて: 臨床意思決定支援のための自己進化するマルチエージェント フレームワーク
近年、大規模言語モデルと自律エージェントの進歩により、診断が容易になり、治療結果が向上し、ヘルスケア分野に革命が起きました。しかし、既存の AI システムのほとんどは、事前トレーニングされた知識と事前定義されたパイプラインに依存しており、患者の転帰や過去の失敗を含む対話型チャット セッション履歴から動的に学習することが困難です。この制限に対処するために、私たちは、堅牢な臨床意思決定をサポートするための自己進化メカニズムとアーキテクチャレベルの安全サンドボックスを内蔵したマルチエージェント フレームワークである VIBEMed を提案します。このシステムは、仮説生成のための臨床診断エージェント (CDA)、治療計画のための治療実行エージェント (TEA)、縦断的な臨床フィードバックを再利用可能な知識に蒸留し、多様な患者情報を個別の医療決定に変換する臨床進化マネージャー エージェント (CEMA) を含む 3 つの専門エージェントを統合します。このフレームワークは、自己進化メカニズムを通じて、メモリ、モデルの動作、意思決定戦略全体の反復的な更新を可能にし、時間の経過とともにシステムを改善できるようにします。実験結果は、VIBEMed が、複雑な臨床ケース、特に統合された意思決定と長期計画を必要とするタスクにおいて、進化するメカニズムを通じて優れたパフォーマンスを実証することを示しています。このフレームワークは、腫瘍治療計画などの困難なシナリオにおける信頼性の高いエンドツーエンドの意思決定もサポートし、現実の臨床状況での実現可能性を強調しています。全体として、VIBEMed は、静的 AI システムを超えて、適応型の経験主導の臨床意思決定サポートに向けた実用的な道を提供し、精密医療を進歩させるための複数エージェントのコラボレーションと継続的な進化を組み合わせる価値を実証します。
原文 (English)
Toward Vibe Medicine: A Self-Evolving Multi-Agent Framework for Clinical Decision Support
In recent years, the advances of large language models and autonomous agents have revolutionized the healthcare field, facilitating diagnosis and improving treatment results. However, most existing AI systems rely on pre-trained knowledge and predefined pipelines, which struggle to learn dynamically from the interactive chat session history that contains patient outcomes and past failures. To address this limitation, we propose VIBEMed, a multi-agent framework with a built-in self-evolution mechanism and architecture-level safety sandbox for robust clinical decision support. The system integrates three specialized agents, including a Clinical Diagnostic Agent (CDA) for hypothesis generation, a Therapeutic Execution Agent (TEA) for treatment planning, and a Clinical Evolution Manager Agent (CEMA) that distills longitudinal clinical feedback into reusable knowledge, transforming multimodal patient information into personalized medical decisions. Through self-evolution mechanism, the framework enables iterative updates across memory, model behavior, and decision strategies, allowing the system to improve over time. Experimental results show that VIBEMed demonstrates superior performance through its evolving mechanism in complex clinical cases, particularly in tasks that require integrated decision-making and longitudinal planning. The framework also supports reliable end-to-end decisions in challenging scenarios such as oncology treatment planning, highlighting its feasibility in real-world clinical contexts. Overall, VIBEMed provides a practical path beyond static AI systems toward adaptive, experience-driven clinical decision support, demonstrating the value of combining multi-agent collaboration with continuous evolution for advancing precision medicine.
LLaMA 3.1-8B におけるフレーム条件付き道徳計算 - 命令: 倫理的推論の機械的解釈可能性監査
道徳的プロンプトに関する大規模言語モデルの行動監査は、モデルが何を言っているかを測定するものであり、それを生成する内部計算を測定するものではありません。 AI 駆動の機械的解釈可能プラットフォームである Transluce を使用して、4 つのバッテリーにおける 54 の道徳的プロンプトに関する LLaMA 3.1-8B-Instruct を調べます。17 のジレンマ、政策、およびメタ倫理的質問 (B1)。 6 つのロールプレイング シナリオ (B3);制御されたトロリーのコントラストは、人物が固定されたスイッチング メカニズム (B4、15 プロンプト) またはメカニズムが固定された ID 属性 (B5、16 プロンプト) を変更します。 2 つの補完的なメトリック ファミリ、5 つのクラスター レベルのメトリックと 6 つのメトリック ニューロン レベルのパネルが状況アンカー効果に収束します。つまり、ドメイン固有の表現がすべてのバッテリーのアクティベーション リストの上位を占めます。モデルの倫理ラベル付き能力は基本的に一定のままです。その顕著性 (ランク、優先順位、リストの先頭の存在) は、プロンプトが選択する解釈フレームに非常に影響されます。 B4 と B5 のコントラストは、モデルが表面の特徴がどのように変化しても対応していることを確認します。集約された倫理指標は区別できませんが、支配的な非倫理的混乱要因が設計を反映しています。複数の温度監査により、どの温度でも安定した候補倫理ニューロン (L16/N3837) が特定されます。 2 つのフロンティア モデル上のクロスモデル行動プロキシは、自己報告された道徳的焦点の相違の予備的な証拠を生成します。これは、RLHF が基礎となるドメインファースト フレームを削除せずに表面テキストを並べ替えるアライメント ラッパーと一致します。これらをフレーム条件付き道徳計算として統合します。プロンプトの表面語彙が特徴多様体を選択し、道徳的結論はその選択の下流にあります。行動の調整は、機械的調整によって補完されなければなりません。これは、単に大声で説明するだけでなく、制御されたフレーム変動の下で倫理関連の特徴が因果的に特権的であることを示すことができるかどうかを問う研究プログラムです。
原文 (English)
Frame-Conditioned Moral Computation in LLaMA 3.1-8B-Instruct: A Mechanistic Interpretability Audit of Ethical Reasoning
Behavioral audits of Large Language Models on moral prompts measure what the model says, not the internal computation producing it. We use Transluce, an AI-driven mechanistic-interpretability platform, to examine LLaMA 3.1-8B-Instruct on 54 moral prompts in four batteries: 17 dilemmas, policy, and meta-ethical questions (B1); 6 role-playing scenarios (B3); and a controlled trolley contrast varying the switching mechanism with people fixed (B4, 15 prompts) or identity attributes with mechanism fixed (B5, 16 prompts). Two complementary metric families, five cluster-level metrics and a six-metric neuron-level panel, converge on a Situational Anchor Effect: domain-specific representations dominate the top of the activation list across every battery. The model's ethics-labeled capacity stays essentially constant; its salience (rank, priority, top-of-list presence) is highly sensitive to the interpretive frame the prompt selects. The B4-vs-B5 contrast confirms the model attends to whichever surface feature varies: aggregate ethics metrics are indistinguishable, but the dominant non-ethics distractor mirrors the design. A multi-temperature audit identifies a candidate ethics neuron (L16/N3837) stable across temperatures; a cross-model behavioral proxy on two frontier models yields preliminary evidence of divergence in self-reported moral focus, consistent with an Alignment Wrapper in which RLHF re-orders surface text without removing underlying domain-first frames. We unify these as Frame-Conditioned Moral Computation: the prompt's surface vocabulary selects a feature manifold, and the moral conclusion is downstream of that selection. Behavioral alignment must be supplemented by Mechanistic Alignment: a research program asking whether ethics-related features can be shown causally privileged under controlled frame variation, not merely loud in the explanation.
ToolMenuBench: 信頼性が高く効率的な LLM エージェントのためのツール メニュー フィルタリング戦略のベンチマーク
ツールで拡張された大規模な言語モデル エージェントは、大規模なツール ライブラリ上で動作することが増えていますが、既存の評価では、目に見えるツール メニューが信頼性、効率性、安全性関連のリスク エクスポージャーをどのように形成するかよりも、モデルがツールを正しく呼び出せるかどうかに焦点を当てていることがよくあります。マルチステップ LLM エージェントのツール メニュー構築を評価するためのベンチマークである ToolMenuBench を紹介します。 ToolMenuBench は、ツール メニューのサイズ、ディストラクタの種類、状態に依存するタスク構造、およびリスク エクスポージャを変更し、表示ツール数、リスクのあるツール エクスポージャ、タスクの成功、間違ったツールの呼び出し、時期尚早のアクション、トークンの使用など、フィルタ レベルと下流のエージェント メトリクスの両方をレポートします。 7 つのモデル バックエンド、3 つのツール メニュー サイズ、6 つのフィルタリング方法、および 7 つの評価設定にわたる制御された評価において、CMTF はタスクの成功率を全ツール公開時の 32.1% から 85.7% に向上させ、同時に平均トークン使用量を約 98% 削減しました。因果的最小限のツール フィルタリングは、最も強力な全体的なトレードオフを達成し、フィルタリングされていない露出、字句フィルタリング、状態認識フィルタリング、およびより広範な因果パス ベースラインと比較して、目に見えるツール、間違ったツールの呼び出し、時期尚早なアクション、および危険なツールの露出を削減します。 ToolMenuBench は、エージェント インターフェイスの問題、つまり、どのツールをいつ表示する必要があるか、どのようなコストまたはリスクの制約の下で表示するかを検討するための再利用可能な評価フレームワークを提供します。
原文 (English)
ToolMenuBench: Benchmarking Tool-Menu Filtering Strategies for Reliable and Efficient LLM Agents
Tool-augmented large language model agents increasingly operate over large tool libraries, but existing evaluations often focus on whether a model can call a tool correctly rather than how the visible tool menu shapes reliability, efficiency, and safety-relevant risk exposure. We introduce ToolMenuBench, a benchmark for evaluating tool-menu construction in multi-step LLM agents. ToolMenuBench varies tool-menu size, distractor type, state-dependent task structure, and risk exposure, and reports both filter-level and downstream agent metrics, including visible-tool count, risky-tool exposure, task success, wrong-tool calls, premature actions, and token usage. In a controlled evaluation across seven model backends, three tool-menu sizes, six filtering methods, and seven evaluation settings, CMTF improves task success from 32.1% under all-tools exposure to 85.7%, while reducing average token usage by roughly 98%. Causal minimal tool filtering achieves the strongest overall tradeoff, reducing visible tools, wrong-tool calls, premature actions, and risky-tool exposure relative to unfiltered exposure, lexical filtering, state-aware filtering, and broader causal-path baselines. ToolMenuBench provides a reusable evaluation framework for studying the agent-interface problem: which tools should be visible, when they should be visible, and under what cost or risk constraints.
最小限の監視: 委任された AI システムの不確実性を認識したガバナンス
AI システムは、専門化されたモデル、評価者、ツール、および監視コントローラーに意思決定を委任することが増えています。 The central AI problem is no longer only model accuracy, but uncertainty-aware governance: how much autonomy to grant, which evidence should calibrate trust, what performance ceiling a delegated AI system can sustain, and when human intervention becomes necessary. We propose the Minimum Sufficient Oversight Principle (MSO), a variational principle for principled autonomy delegation: minimize governance burden on the Fisher information manifold subject to a delivery constraint.結果として得られるオイラー ラグランジュ解は、タスク スペース全体にわたる管理された委任の充実した割り当てをもたらします。 Building on a revealed-action governed delegation channel model, we prove a capacity theorem for stationary symbolwise review policies, derive a local first-order approximation relating workflow complexity to quality degradation, and give a drift-dominated autonomy-time scaling law linking intervention timing to effective capacity, complexity, and drift. Within this framework, masking appears as a structural AI-governance pathology: corrected performance can hide the competence signal needed to calibrate trust. Synthetic simulations and a semi-real reconstructed workflow support design prescriptions including upstream-first correction, sensitivity-based intervention, and explicit feasibility checks before autonomy is expanded.その結果、委任された AI システムにおける不確実性、計画、監視のための計算可能なフレームワークが実現します。コンパニオン Python パッケージは https://github.com/crbazevedo/delegation-lab で入手できます。
原文 (English)
Minimal Oversight: Uncertainty-Aware Governance for Delegated AI Systems
AI systems increasingly delegate decisions to specialized models, evaluators, tools, and supervisory controllers. The central AI problem is no longer only model accuracy, but uncertainty-aware governance: how much autonomy to grant, which evidence should calibrate trust, what performance ceiling a delegated AI system can sustain, and when human intervention becomes necessary. We propose the Minimum Sufficient Oversight Principle (MSO), a variational principle for principled autonomy delegation: minimize governance burden on the Fisher information manifold subject to a delivery constraint. The resulting Euler-Lagrange solution yields a water-filling allocation of governed delegation across the task space. Building on a revealed-action governed delegation channel model, we prove a capacity theorem for stationary symbolwise review policies, derive a local first-order approximation relating workflow complexity to quality degradation, and give a drift-dominated autonomy-time scaling law linking intervention timing to effective capacity, complexity, and drift. Within this framework, masking appears as a structural AI-governance pathology: corrected performance can hide the competence signal needed to calibrate trust. Synthetic simulations and a semi-real reconstructed workflow support design prescriptions including upstream-first correction, sensitivity-based intervention, and explicit feasibility checks before autonomy is expanded. The result is a computable framework for uncertainty, planning, and oversight in delegated AI systems. A companion Python package is available at https://github.com/crbazevedo/delegation-lab.
マルチモーダル エージェント ネットワーク向けの QoS 対応トークン スケジューリングとプライベート データ評価
エージェント システムでは、人間が生成したデータ レコードが AI サービスの価値を支えます。しかし、クラウド コンピューティング パイプラインはリモート サーバーでの処理を集中化します。データの集中化により個人データの主権が低下し、サービス品質 (QoS) が低下する可能性があります。一方、ユーザーの貢献は量も質も多様です。分散型レコードは偏り、ノイズが多く、不均一に分散する可能性があります。データの課題に対処するために、私たちは分散型でリソースに制約のあるエージェント システムに対する公平なトークンの割り当てとプライベート データの評価を研究しています。私たちのアプローチは、マルチモーダル表現を共有セマンティック空間に埋め込み、差分プライベート (DP) プロトタイプをリリースして、セマンティック漏洩を削減しながら実用性を維持します。 DP 保証により、効果的な貢献に報酬を与え、データの異質性や AI リソースの不足に対して堅牢性を維持する公平なトークン割り当てスキームを設計します。広範なシミュレーションにより、標準ベンチマークと比較して貢献度ベースの公平性と QoS が向上していることが実証されています。画像再構成攻撃に対する耐性の向上は、マルチモーダルな個人データのプライバシーが強化されていることを示しています。
原文 (English)
QoS-Aware Token Scheduling and Private Data Valuation for Multi-Modal Agentic Networks
In agentic systems, human-generated data records anchor the value of AI services. Yet cloud compute pipelines centralize processing on remote servers. Data centralization reduces personal data sovereignty and may potentially degrade the quality of service (QoS). Meanwhile, user contributions are diverse in quantity and quality: decentralized records can be biased, noisy, and heterogeneously distributed. To address the data challenge, we study fair token allocation and private data valuation for decentralized and resource-constrained agentic systems. Our approach embeds multi-modal representations in a shared semantic space and releases differentially private (DP) prototypes to preserve utility while reducing semantic leakage. With the DP guarantee, we design a fair token allocation scheme that rewards effective contributions and remains robust to data heterogeneity and AI resource scarcity. Extensive simulations demonstrate improved contribution-based fairness and QoS compared to standard benchmarks. The improved resistance to image reconstruction attacks indicates enhanced privacy for multi-modal personal data.
私たちは必要な知識を持っていますか?企業における人間と AI の意思決定を再考する
組織の知識は、さまざまなソフトウェア システム、暗黙の専門知識、従来人間が使用するために設計されてきたマニュアル文書などに断片化されています。 AI システムがますます導入され、意思決定の役割が与えられるようになるにつれて、この知識へのアクセスが必要になります。これにより、2 つの疑問が生じます。人間と将来の AI システムの両方がアクセスできるようにするために、組織は知識をどのように保存および維持すべきでしょうか。もう 1 つは、さまざまなリスクや不確実性のレベルを持つタスクにわたって、人間と AI の間で主体性をどのように割り当てるべきでしょうか。このポジションペーパーでは、組織の知識がどのように進化するかを説明し、タスクの属性と知識の利用可能性を推奨される機関の割り当てと制御メカニズムにマッピングするフレームワークに貢献します。私たちは、日常業務 (目視による品質検査) と 1 回限りの戦略的決定 (工場の場所) という 2 つの異なる製造タスクに対するフレームワークの適用可能性を示し、最後に将来の研究の機会について結論付けています。
原文 (English)
Do we have the knowledge we need? Rethinking human-AI decision-making in corporations
Organizational knowledge is fragmented across a variety of software systems, tacit expertise, and manual documents that have traditionally been designed for human consumption. As AI systems are increasingly deployed and granted decision-making roles, they require access to this knowledge. This raises two questions: how should organizations store and maintain knowledge so that it remains accessible to both humans and future AI systems, and how should agency be allocated between humans and AI across tasks with different risks and levels of uncertainty? In this position paper, we describe how organizational knowledge evolves and contribute a framework that maps task attributes and knowledge availability to recommended agency allocations and control mechanisms. We illustrate the applicability of the framework on two different manufacturing tasks: a routine operation (visual quality inspection) and a one-off strategic decision (factory location), and conclude with opportunities for future research.
オプティマイザーとしての大規模言語モデル: 直接アプローチとツール拡張アプローチの調査、およびそのパフォーマンスのフロンティア
大規模言語モデル (LLM) は、それをトリガーする実際的なユーザーが気づいていない場合でも、複雑な数学的最適化に関与することが増えています。結局のところ、現実世界の問題の多くは、より良い、または最善の解決策の探求に帰着します。オプティマイザーとしての LLM の分野には、直接最適化、ツール拡張最適化、ツール作成最適化の 3 つのパラダイムがあります。直接最適化では、反復プロンプトとヒューリスティック生成を使用して、解空間をナビゲートします。ツール拡張最適化は、自然言語の問題を正式な仕様に変換し、外部ソルバーを調整します。ツール作成の最適化はさらに進み、LLM を使用して、限界 LLM コストゼロで導入できる再利用可能なアルゴリズムやヒューリスティックを発見します。文献からのベンチマークに基づいて、現在のパフォーマンスのフロンティアについて説明します。現在のアーキテクチャにおける決定的な推論上のギャップを特定し、直接最適化の将来の可能性とツール拡張最適化の監査可能性の間のトレードオフについて議論します。将来的には、より強力なモデルが、反復的な問題の運用効率を向上させるツールの作成を選択する可能性があります。
原文 (English)
Large Language Models as Optimizers: A Survey of Direct vs. Tool-Augmented Approaches and Their Performance Frontiers
Large Language Models (LLMs) are increasingly involved in complex mathematical optimization, even if the pragmatic user who triggers them is unaware of it. After all, many real-world problems reduce to the search for better or the best solutions. The field of LLM-as-optimizer has three paradigms: direct optimization, tool-augmented optimization, and tool-creating optimization. Direct optimization uses iterative prompting and heuristic generation to navigate solution spaces. Tool-augmented optimization translates natural language problems into formal specifications and orchestrates external solvers. Tool-creating optimization goes further, using LLMs to discover reusable algorithms or heuristics that can be deployed at zero marginal LLM cost. We describe current performance frontiers based on the benchmarks from the literature. We identify the critical reasoning gap in current architectures and argue for trade-offs between the future potential of direct optimization and the auditability of tool-augmented optimization. Even future, more powerful models might opt for tool-making to improve operational efficiency for repetitive families of problems.
エージェントにはゲノムがある: LLM を利用した自律エージェントのシーケンスレベルの行動分析とランタイム ガバナンス
私たちは、LLM を利用した自律エージェントの実行時の動作を、X (探索)、E (実行)、P (計画)、および V (検証) の 4 文字のアルファベットを使用してコンパクトな記号シーケンスにエンコードするフレームワークであるベース シーケンス分析を提案します。ゲノム配列分析に類似して、N グラム パターン マイニング、マルコフ遷移行列、および点双系列相関を、本番環境の ReAct エージェント システムから 8 日間にわたって収集された 347 件の実世界の実行トレースに適用します。私たちの分析により、(1) トリグラム P-X-P は統計的に有意な高リスク パターンのみであり、成功率が 10.4% 低下することが明らかになりました。 (2) P 比は、成功の最も強力な負の予測因子です (r=-0.256、pV 遷移確率はわずか 2.1% で、体系的な検証の欠陥を示しています。これらの結果に基づいて、ルール エンジン、統計アキュムレーター、カイ 2 乗ベースのしきい値アダプターで構成される 3 層のランタイム介入システムであるガバナーを設計します。導入前後の自然な評価 (N=101 対 N=246) では、ガバナーは次の結果を達成します。タスク成功率の絶対的な増加が 6.2% 増加すると同時に、平均トークン消費量が 44% 減少しました。システム間の汎用性を検証するために、XEPV エンコーディングを SWE ベンチ上の 2,000 の公開 SWE エージェント トラジェクトリに適用し、探索スパイラルと E->V 検証欠陥が独立したシステムで再現されることを確認しました。再現性を高めるためにオープンソースのツールキットをリリースします。
原文 (English)
Your Agent Has a Genome: Sequence-Level Behavioral Analysis and Runtime Governance of LLM-Powered Autonomous Agents
We propose Base Sequence Analysis, a framework that encodes the runtime behavior of LLM-powered autonomous agents into compact symbolic sequences using a four-letter alphabet: X (Explore), E (Execute), P (Plan), and V (Verify). Drawing an analogy to genomic sequence analysis, we apply n-gram pattern mining, Markov transition matrices, and point-biserial correlation to 347 real-world execution traces collected from a production ReAct agent system over 8 days. Our analysis reveals that (1) the trigram P-X-P is the only statistically significant high-risk pattern, lowering success rate by 10.4%; (2) P-ratio is the strongest negative predictor of success (r=-0.256, pV transition probability is only 2.1%, indicating a systemic verification deficit. Based on these findings, we design Governor, a three-layer runtime intervention system comprising a rule engine, a statistical accumulator, and a chi-square-based threshold adaptor. In a natural before/after deployment evaluation (N=101 vs. N=246), Governor achieves a +6.2% absolute increase in task success rate while simultaneously reducing average token consumption by 44%. To validate cross-system generality, we apply the XEPV encoding to 2,000 public SWE-agent trajectories on SWE-bench, confirming that exploration spirals and the E->V verification deficit replicate in an independent system. We outline six research directions including base sequence language models, cross-agent behavioral fingerprinting, and reward shaping, and release an open-source toolkit for reproducibility.
エージェントによる検索と強化により学習された方程式連鎖: 複雑で斬新な物理学の文章問題のための制御された生成フレームワーク
新規性があり、複雑で、解決可能な高品質の物理文章問題 (PWP) を生成することは、教育コンテンツの生成において依然として課題であり、十分に研究されていない問題です。既存のアプローチの多くは、数学単語問題 (MWP) の生成から応用されたものですが、多くの場合、言語の多様性が限られた、曖昧で解決不可能な、または構造的に単純な質問が生成されます。多様で数学的に有効な PWP を生成するための 2 段階のフレームワークである ARVRE (Agentic Retrieval Value Reinforced Equation-chain) を紹介します。最初の段階では、オフライン時間差学習の形式を使用して物理方程式の有効な連鎖を構築し、エージェントによる検索拡張生成 (RAG) フレームワークがトピック固有の概念と語彙を動的に選択します。この設計により、問題の構造と難易度を明示的に制御できます。第 2 段階では、大規模言語モデル (LLM) が方程式チェーンと取得された概念を自然言語物理学の質問に変換します。有効な方程式連鎖に基づいて生成を行うことで、私たちの方法は数学的な正確さを維持しながら、言語の多様性と文脈の豊かさを促進します。人間による評価と自動化された評価により、ARVRE が既存のアプローチによって生成される PWP よりも複雑で、新規で、解決可能な PWP を生成することが実証されています。これらの結果は、強化学習、検索、LLM を組み合わせて教育用物理コンテンツを信頼性高く生成できる可能性を強調しています。
原文 (English)
Agentic Retrieval and Reinforcement Learned Equation Chains: A Controlled Generation Framework for Complex and Novel Physics Word Problems
Generating high-quality Physics Word Problems (PWPs) that are novel, complex, and solvable remains a challenging and underexplored problem in educational content generation. Existing approaches, many adapted from Math Word Problem (MWP) generation, often produce ambiguous, unsolvable, or structurally simple questions with limited linguistic diversity. We introduce ARVRE (Agentic Retrieval Value Reinforced Equation-chain), a two-stage framework for generating diverse and mathematically valid PWPs. In the first stage, a form of offline temporal-difference learning is used to construct valid chains of physics equations, while an agentic retrieval-augmented generation (RAG) framework dynamically selects topic-specific concepts and vocabulary. This design enables explicit control over problem structure and difficulty. In the second stage, a Large Language Model (LLM) converts the equation chain and retrieved concepts into a natural-language physics question. By grounding generation in valid equation chains, our method preserves mathematical correctness while promoting linguistic diversity and contextual richness. Human and automated evaluations demonstrate that ARVRE generates PWPs that are more complex, novel, and solvable than those produced by existing approaches. These results highlight the potential of combining reinforcement learning, retrieval, and LLMs for reliable generation of educational physics content.
自己拡張微調整による Text-to-SQL での推論と一般化の統合
Text-to-SQL は、自然言語の質問を構造化データベース上で実行可能な SQL クエリに変換し、専門知識のないユーザーが直感的にデータにアクセスできるようにすることを目的としています。大規模言語モデル (LLM) の最近の進歩は、このタスクにおいて有望であることが示されていますが、既存の LLM ベースのアプローチは、強力な推論機能と堅牢な一般化の間のバランスをとるのに苦労することがよくあります。これらの制限に対処するために、私たちは CoTE-SQL を提案し、次の 3 つの主要なイノベーションによって LLM ベースのテキストから SQL への生成を強化します。(i) 人間による注釈なしで LLM から抽出された自己拡張推論トレース、(ii) モジュール分解と例の取得による構造化思考連鎖 (CoT) プロンプト、および (iii) SQL 実行フィードバックに基づくエラー認識リビジョン。 Spider および Bird ベンチマークに関する広範な実験により、CoTE-SQL がオープンソース LLM に基づいて構築されたメソッドの中で最先端のパフォーマンスを達成し、Bird では同等のモデル サイズ (53.39% EX / 59.02 VES)、Spider では強力な結果 (79.60% EX / 77.19 VES) を達成し、特に複雑なクエリで大幅な向上を実現することが実証されました。結果は、テキストから SQL への設計のための LLM ベースのフレームワーク内で、自己強化、構造化推論、および実行時フィードバックを組み合わせる有効性を強調しています。
原文 (English)
Integrating Reasoning and Generalization in Text-to-SQL via Self-Enhanced Fine-Tuning
Text-to-SQL aims to translate natural language questions into executable SQL queries over structured databases, enabling non-expert users to access data intuitively. While recent advances in large language models (LLMs) have shown promise in this task, existing LLM-based approaches often struggle to strike a balance between strong reasoning capabilities and robust generalization. To address these limitations, we propose CoTE-SQL to enhance the LLM-based text-to-SQL generation with three key innovations: (i) self-enhanced reasoning traces distilled from LLMs without human annotation, (ii) structured chain-of-thought (CoT) prompting with modular decomposition and examples retrieval, and (iii) error-aware revision based on SQL execution feedback. Extensive experiments on the Spider and Bird benchmarks demonstrate that CoTE-SQL achieves new state-of-the-art performance among methods built on open-source LLMs with comparable model sizes on Bird (53.39% EX / 59.02 VES) and strong results on Spider (79.60% EX / 77.19 VES), with especially significant gains on complex queries. Results highlight the effectiveness of combining self-enhancement, structured reasoning, and execution-time feedback within an LLM-based framework for text-to-SQL design.
NeuroSymbolic AI for Legal AI-TRISM: 信頼性、信頼性、解釈可能性、安全性の高いモデル
大規模言語モデル (LLM) は自然言語処理を変革しましたが、解釈可能な推論の欠如と幻覚傾向が法的応用に重大な課題をもたらしています。 LLM は法的文章の分析と生成には有望ですが、正確な引用の帰属と先例の検証には苦労しています。たとえば、法律の文脈では、たった 1 つの間違った判例が訴訟を危険にさらす可能性があります。法律分野における LLM の信頼性を向上させる現在のアプローチには、2 つの重要な制限があります。それは、トレーニングまたは微調整中の構造化された法律知識の統合が不十分であること、および生成された法律コンテンツの検証メカニズムが不十分であることです。これらの課題に対処するために、私たちは TRISM (Trustworthy、Reliable、Interpretable、Safe Models) フレームワークを提案します。このフレームワークは、NeuroSymbolic AI 原則と LLM を統合し、ニューラル学習機能と構造化された法的知識に対する記号推論の両方を活用します。 TRISM アプローチは、解釈可能な意思決定経路を維持しながら、上記の制限に対処します。私たちのフレームワークは、法的文書からの象徴的な知識の抽出を形式化し、検証された法的ソースに LLM 出力を基礎付けるためのコアコンポーネントとして検索拡張生成 (RAG) を組み込みます。この意見書では、私たちは以下の貢献を行っています。 (1) 法律における AI の限界の分析。 (2) RASOR RAG を導入します。RASOR RAG は、記号表現に形式化できる明示的な解釈可能な理論的根拠を生成することによって、神経象徴的な RAG の基礎を作成します。 (3) LLM での解釈可能な推論と出力検証の両方をサポートする、象徴的な法的知識ベースを作成するための形式化された方法論。 (4) 象徴的な法律知識を LLM と統合するための TRISM フレームワーク。
原文 (English)
NeuroSymbolic AI for Legal AI-TRISM: Trustworthy, Reliable, Interpretable, Safe Models
Large Language Models (LLMs) have transformed natural language processing, but their lack of interpretable reasoning and tendency to hallucinate pose significant challenges for legal applications. While LLMs show promise for legal text analysis and generation, they struggle with accurate citation attribution and precedent verification. For example, in legal contexts, a single incorrect precedent can jeopardize a case. Current approaches to improve LLM reliability in legal domains suffer from two key limitations: inadequate integration of structured legal knowledge during training or fine-tuning, and insufficient verification mechanisms for generated legal content. To address these challenges, we propose the TRISM (Trustworthy, Reliable, Interpretable, Safe Models) framework, which integrates NeuroSymbolic AI principles with LLMs to leverage both neural learning capabilities and symbolic reasoning over structured legal knowledge. The TRISM approach addresses the above limitations while maintaining interpretable decision pathways. Our framework formalizes the extraction of symbolic knowledge from legal textual documents and incorporates Retrieval-Augmented Generation (RAG) as a core component for grounding LLM outputs in verified legal sources. In this position paper, we make the following contributions: (1) An analysis of the limitations of AI in law; (2) Introduce RASOR RAG which creates foundations for neurosymbolic RAG by generating explicit interpretable rationales that could be formalized into symbolic representations; (3) A formalized methodology for creating symbolic legal knowledge bases that support both interpretable reasoning and output verification in LLMs; and (4) The TRISM framework for integrating symbolic legal knowledge with LLMs.
次世代のヘルスケアに向けて: 知覚、意思決定、および行動のための医療に組み込まれた AI の調査
Foundation モデルは、幅広い医療用途にわたって医療効率を向上させる優れたパフォーマンスを実証しています。それにもかかわらず、物理世界を認識し、理解し、対話する能力が限られているため、安全性が重要な意思決定と物理的な実行が密接に結びついている現実世界の臨床ワークフローにおける彼らの有効性が大幅に制限されています。最近、身体型人工知能 (AI) がインテリジェント ヘルスケアの有望な物理的インタラクティブ パラダイムとして台頭し、エージェントが複雑な医療環境で動作できるようになります。この分野の研究が急速に拡大するにつれ、インテリジェントエージェントが臨床環境において統合されたエンドツーエンドシステムとしてどのように機能するかを理解することがますます重要になっています。しかし、医療用具現化 AI に関する既存の調査では、主に個別の側面や機能コンポーネントに重点が置かれており、この分野の統一されたシステムレベルの組織が欠如しています。最近の進歩をサポートし強化するために、私たちは、特に知覚、意思決定、行動の調整された統合に重点を置いて、医療用の身体化 AI の中核コンポーネントを系統的に調査しています。私たちは代表的な医療アプリケーションと関連データセットをさらに検討し、実際の臨床現場で遭遇する主要な課題を分析します。最後に、この急速に進化する分野における将来の研究の重要な方向性について説明します。関連するプロジェクトは https://github.com/VMVLab/Medical_Embodied_AI_Paper_List にあります。
原文 (English)
Towards Next-Generation Healthcare: A Survey of Medical Embodied AI for Perception, Decision-Making, and Action
Foundation models have demonstrated impressive performance in enhancing healthcare efficiency across a wide range of medical applications. Nevertheless, their limited ability to perceive, understand, and interact with the physical world significantly constrains their effectiveness in real-world clinical workflows, where safety-critical decision-making and physical execution are tightly coupled. Recently, embodied artificial intelligence (AI) has emerged as a promising physical-interactive paradigm for intelligent healthcare, enabling agents to operate in complex medical environments. As research in this area rapidly expands, understanding how intelligent agents function as integrated, end-to-end systems in clinical environments becomes increasingly critical. However, existing surveys on medical embodied AI largely emphasize individual aspects or functional components, lacking a unified system-level organization of the field. To support and consolidate recent advances, we systematically survey the core components of medical embodied AI, with a particular emphasis on the coordinated integration of perception, decision-making, and action. We further review representative medical applications and relevant datasets, and we analyze the major challenges encountered in real-world clinical practice. Finally, we discuss key directions for future research in this rapidly evolving field. The associated project can be found at https://github.com/VMVLab/Medical_Embodied_AI_Paper_List.
牛の識別と検出を強化するための高度な機械学習とディープラーニング技術: 包括的なレビュー
家畜管理におけるバイオセキュリティ、食品の安全性、サプライチェーンの有効性を維持する上で、効果的な牛識別技術の必要性が今まで以上に切実に感じられています。この論文では、機械学習と深層学習技術を使用した牛の識別に関する最近の研究を体系的にレビューします。現在の体系的レビューでは、論文が全文レビューの対象となった主要な学術データベースからの研究を使用して、伝統的および現代の牛識別技術の有効性を測定しています。これらの手法の中でも、K 最近傍法やサポート ベクター マシンなどの古典的な機械学習手法は、牛の識別において良好な結果を示しています。ただし、畳み込みニューラル ネットワーク、残差ネットワーク、You Only Look Once などの深層学習技術は、認知、検出、識別タスクにおいて優れています。特徴抽出は、ローカル バイナリ パターン (LBP)、高速ロバスト特徴 (SURF)、スケール不変特徴変換 (SIFT) などの一般的な手法に依存しますが、これらの研究で一般的に使用される主要な特徴には銃口紋や被毛パターンが含まれます。このレビューでは、公的にアクセスできるデータセットの数が限られていること、環境の変化や動物の移動の影響を受けやすいデータ品質の問題、リアルタイム処理能力に対する高い需要など、牛の識別に関わる重要なハードルが浮き彫りになっています。この文書は、持続可能な家畜管理を達成するための、拡張可能で人道的かつ効果的な牛識別システムの導入について研究者、政策立案者、関係者に情報を提供することを目的としています。
原文 (English)
Advanced Machine Learning and Deep Learning Techniques for Enhanced Cattle Identification and Detection: A Comprehensive Review
The need for effective cattle identification technology is now more acutely felt than ever in maintaining biosecurity, food safety, and supply chain efficacy in livestock management. This paper presents a systematic review of recent research in cattle identification using machine learning and deep learning techniques. The present systematic review measures the effectiveness of traditional and modern cattle identification techniques using studies from major academic databases, where articles were subjected to full-text review. Among these techniques, classical Machine Learning Techniques such as K-Nearest Neighbors and Support Vector Machines have demonstrated good results in cattle identification; however, Deep Learning Techniques, such as Convolutional Neural Networks, Residual Networks, and You Only Look Once, are better in cognition, detection, and identification tasks. Feature extraction relies on common techniques like Local Binary Pattern (LBP), Speeded-Up Robust Features (SURF), and Scale-Invariant Feature Transform (SIFT), while key features commonly used in these studies include muzzle prints and coat patterns. The review highlights key hurdles involving cattle identification, such as the limited number of publicly accessible datasets, issues with data quality susceptible to environmental changes and animal mobility, and high demand for real-time processing ability. The paper aims to inform researchers, policymakers, and stakeholders about implementing scalable, humane, and effective cattle identification systems to achieve sustainable livestock management.
インピーダンス不整合の克服: 基礎モデルとナレッジグラフを融合するための理論的ロードマップ
現代の人工知能は、基本的に、基礎モデルの連続的で確率的な空間と、ナレッジ グラフの離散的で決定論的な構造に分かれたままです。検索拡張生成 (RAG) はグラフ データをテキストにシリアル化することでそれらを接続しようとしますが、この語彙の橋渡しは単なる表面的なパッチにすぎないと主張します。この論文では、根底にある構造的および幾何学的摩擦を \textit{インピーダンス不一致} として形式化します。現在の神経記号統合戦略を 3 層の階層に分類することで、表面レベルのプロンプト インジェクションも連続表現のアライメントも、信頼性の高いマルチホップ推論に必要な厳密な論理モチーフを維持できないことを示します。私たちは、現在のアーキテクチャが最終的に意味論的ノードを幻覚または混同することを示す、語彙ボトルネックやトポロジカル崩壊などの特定の数学的限界を定義します。真のセマンティック融合を達成するために、私たちは厳密な理論的ロードマップを提案します。私たちは、構造化残差ストリームを介して離散シンボリック構造をネイティブに内部化し、潜在サブグラフ注入にベクトル シンボリック アーキテクチャを利用し、直交部分空間編集を介してモデル更新を実行することを主張します。この実用的なフレームワークは、記号ロジックの精度とパラメトリック メモリの表現力をシームレスに融合するモデルへの道を開きます。
原文 (English)
Overcoming the Impedance Mismatch: A Theoretical Roadmap for Fusing Foundation Models and Knowledge Graphs
Modern artificial intelligence remains fundamentally divided between the continuous, probabilistic spaces of Foundation Models and the discrete, deterministic structures of Knowledge Graphs. While Retrieval-Augmented Generation (RAG) attempts to connect them by serializing graph data into text, we argue this lexical bridging is merely a superficial patch. In this paper, we formalize the underlying structural and geometric friction as the \textit{Impedance Mismatch}. By categorizing current neuro-symbolic integration strategies into a three-tiered hierarchy, we demonstrate that neither surface-level prompt injection nor continuous representation alignment can preserve the strict logical motifs required for reliable multi-hop reasoning. We define the specific mathematical limits, such as the Lexical Bottleneck and Topological Collapse, that show current architectures will eventually hallucinate or conflate semantic nodes. To achieve true semantic fusion, we propose a rigorous theoretical roadmap. We advocate for natively internalizing discrete symbolic structures through Structured Residual Streams, utilizing Vector Symbolic Architectures for latent sub-graph injection, and performing model updates via Orthogonal Subspace Editing. This actionable framework paves the way for models that seamlessly fuse the precision of symbolic logic with the expressivity of parametric memory.
どこが間違っていたのでしょうか?セマンティック状態追跡による Web エージェントのプロセス レベルの評価
Web エージェントは長い対話シーケンスを通じて動作しますが、既存のベンチマークは最終的な成功のみを評価し、すべてのプロセス情報を破棄し、改善に関するガイダンスをほとんど提供しません。この作業では、Web エージェントのプロセス レベルの分析を実行します。難易度を制御し、セマンティックな状態を自動的に追跡する 1,800 個のタスク インスタンスのベンチマークである WebStep を紹介します。各 Web サイトは、GUI とともに決定論的セマンティック MDP を公開します。エージェントはインターフェイス上で動作し、環境はバックグラウンドで高レベルの状態と遷移を記録するため、手動による注釈なしで詳細な分析が可能になります。セマンティックな軌跡に基づいて、プロセスのメトリクスが結果の評価では見えない違いを明らかにすることを最初に示します。つまり、成功率が 31 ~ 33% 以内にクラスター化されている 3 つのエージェントは、探索範囲と実行精度において乖離しています。次に、スキルごとに分解すると、これらの違いの性質が特徴づけられ、同じ Web サイト内に隠されている反対のスキルごとのランキングが明らかになります。たとえば、ハウジングでは、OpenAI CUA はコミット アクションで Qwen3.5 を 23.7% 上回っていますが、フィルタリングでは 15.6% 下回っており、ドメイン内であっても改善すべき具体的なスキルを特定します。分岐分析は、タスクを失う決定的なエラーをさらに特定し、このエラーが共有エラーではなくエージェント固有であることを示します。最後に、タスクが難しくなるにつれて、これらの差は広がります。簡単なタスクでは成功率は似ていますが、探索がより要求が厳しくなるにつれて、成功率は大きく異なります。当社のプロセスレベルの分析は、Web エージェントの評価に新たな道を開き、各エージェントのどこをどのように改善する必要があるかについて、きめ細かく実用的な洞察を提供します。
原文 (English)
Where Did It Go Wrong? Process-Level Evaluation of Web Agents with Semantic State Tracking
Web agents act through long interaction sequences, yet existing benchmarks evaluate only terminal success, discarding all process information and offering little guidance on improvement. In this work, we conduct a process-level analysis of web agents. We introduce WebStep, a benchmark of 1,800 task instances with controlled difficulty and automatic semantic state tracking. Each website exposes a deterministic semantic MDP alongside the GUI: the agent operates on the interface, while the environment records high-level states and transitions in the background, enabling fine-grained analysis without manual annotation. Based on the semantic trajectory, we first show that process metrics reveal differences invisible to outcome evaluation: three agents whose success rates cluster within 31-33% diverge in exploration reach versus execution accuracy. Then, decomposing by skill characterizes the nature of these differences, exposing opposite per-skill rankings hidden within the same website: e.g., on Housing, OpenAI CUA outperforms Qwen3.5 by 23.7% on commit actions yet underperforms it by 15.6% on filtering, pinpointing a concrete skill to improve even within a domain. Bifurcation analysis further localizes the decisive error that loses the task and shows that this error is agent-specific rather than shared. Finally, these differences widen as tasks grow harder: success rate is similar on easy tasks but separates sharply as exploration becomes more demanding. Our process-level analysis opens a new avenue in web agent evaluation, providing fine-grained and actionable insight into where and how each agent should be improved.
Minecraft における時間に敏感な補完的なコラボレーションのためのマルチエージェント フレームワーク
私たちは、新しいクラスの時間制限のある補完的なコラボレーション タスクのための Minecraft ベースのマルチエージェント ベンチマークである TickingCollabBench を紹介します。私たちのベンチマークは、現実世界のコラボレーションの 4 つの主要な特性を反映しています。それは、エージェントの異質性、必須のコラボレーション、動的な環境、障害リスクを伴う厳密なリアルタイム制約です。これを可能にするために、TickingCollab フレームワークを開発します。これは、多様な動的環境の生成をサポートし、Minecraft のプリミティブ API を抽象化して、これらのイベントを構成するための宣言的な YAML タスク仕様を可能にします。これに基づいて、実現可能性を意識した自動ベンチマーク生成パイプラインを設計します。LLM が構造的に多様なタスク構成をドラフトし、実現可能性検証者が近似制約を使用して無効なものを除外します。評価の結果、部分的な可観測性とエージェントの異質性の下での言語遅延と調整の固有の難しさにより、動的環境下では LLM が頻繁に失敗し、グローバル知識のオラクルに大幅に達しないことが示されています。
原文 (English)
Multi-agent Framework for Time-Sensitive Complementary Collaboration in Minecraft
We present TickingCollabBench, a Minecraft-based multi-agent benchmark for a novel class of time-sensitive complementary collaboration tasks. Our benchmark reflects four core characteristics of real-world collaboration: agent heterogeneity, mandatory collaboration, dynamic environments, and strict real-time constraints with failure risks. To enable this, we develop the TickingCollab framework, which supports the generation of diverse dynamic environments and abstracts Minecraft's primitive APIs to enable declarative YAML task specifications for composing these events. Building on this, we design a feasibility-aware automated benchmark generation pipeline, where an LLM drafts structurally diverse task configurations and feasibility verifier filters out invalid ones using approximate constraints. Evaluations demonstrate that lang latency and inherent difficulty of coordinating under partial observability and agent heterogeneity cause LLMs to frequently fail under dynamic environments and fall significantly short of a global-knowledge oracle.
シーケンスモデルを使用した記号パズルの反復推論
大規模な言語モデルは、記号タスクやアルゴリズム タスクに対して強力であるように見えることがよくありますが、この見かけの強さは、問題が長くなったり、難しくなったり、あるいは分布からわずかに外れたりすると、脆弱な動作を隠してしまう可能性があります。現在の推論ベンチマークの主な制限は、多くのベンチマークがモデルが有効な答えを生成できるかどうかを主にテストし、制御された難易度のスケーリングの下で解が最小限で堅牢で安定しているかどうかにはあまり注意を払っていないことです。 RecurrReason は、BFS に最適な軌道と単一の解釈可能な難易度パラメーター $N \in \{1,\dots,10\}$ を備えた 4 つの反復ロジック パズル (ハノイの塔、川渡り、ブロック ワールド、チェッカー ジャンピング) の難易度制御ベンチマークで、合計 10{,}817 個のユニークなパズルと 285{,}933 の動きを導入します。私たちは、一貫したデータ分割と評価基準に基づいて、エンコーダー/デコーダー モデル (T5 スタイル) とデコーダーのみのモデル (GPT-2 スタイル) の 2 つの Transformer ファミリをベンチマークし、$N{=}1$ ~ $7$ でトレーニングし、ホールドアウトされたディストリビューション内インスタンスと $N{=}8$ ~ $10$ のよりハードなディストリビューション外インスタンスの両方で評価しました。微調整された事前トレーニング済み T5 は、Block World で 97.27\% の検証と 81.00\% の OOD 精度を達成しました。すべてのモデルのスコアは、すべての条件下で川渡りで 0.00\% です。障害モード分析により、規模よりもアーキテクチャが成功の強力な決定要因であることが明らかになりました。事前トレーニングは、ローカルに構造化された遷移関数を持つパズルにのみ転送されます。私たちのコードとデータセットは、承認され次第オープンソース化されます。
原文 (English)
Recurrent Reasoning on Symbolic Puzzles with Sequence Models
Large language models often appear strong on symbolic and algorithmic tasks, yet this apparent strength can hide brittle behaviour when problems become longer, harder, or slightly out of distribution. A major limitation of current reasoning benchmarks is that many primarily test whether a model can produce a valid answer, while paying less attention to whether the solution is minimal, robust, and stable under controlled difficulty scaling. We introduce RecurrReason, a difficulty-controlled benchmark of four recurrent logic puzzles (Tower of Hanoi, River Crossing, Block World, and Checkers Jumping) with BFS-optimal trajectories and a single interpretable difficulty parameter $N \in \{1,\dots,10\}$, totalling 10{,}817 unique puzzles and 285{,}933 moves. We benchmark two Transformer families, an encoder-decoder model (T5-style) and a decoder-only model (GPT-2-style), under consistent data splits and evaluation criteria, training on $N{=}1$ to $7$ and evaluating on both held-out in-distribution instances and harder out-of-distribution instances at $N{=}8$ to $10$. Fine-tuned pre-trained T5 achieves 97.27\% validation and 81.00\% OOD accuracy on Block World; all models score 0.00\% on River Crossing under all conditions. Failure mode analysis reveals that architecture is a stronger determinant of success than scale. Pre-training transfers only to puzzles with locally structured transition functions. Our code and dataset will be open-sourced upon acceptance.
LLM は失語症の談話における正しい情報単位を確実に識別しますか?
正しい情報単位(CIU)は、言語形式だけではなくコミュニケーション上の情報提供性を定量化するため、失語症の談話評価の中心となります。ただし、CIU の採点には時間がかかり、訓練を受けた評価者が必要です。この研究では、命令調整された大規模言語モデル (LLM) が失語症の談話トランスクリプトからトークンレベルの CIU 分類を確実に実行できるかどうかを検証しました。 Nicholas and Brookshire (1993) に従って、Cat Rescue 刺激で誘発された 16 枚の写真説明転写物に CIU ステータスの注釈が付けられました。サンプルは、対照、軽度、中等度、重度の失語症の 4 つの重症度層にまたがっていました。 4 つの公的に入手可能な命令調整 LLM が、5 つの層別ランダム シードにわたってゼロ ショットおよび 2 つの少数ショット プロンプト条件下でベンチマークされました。パフォーマンスは、精度、精度、再現率、F1、およびコーエンのカッパを使用してコンセンサス人間ラベルに対して評価されました。ゼロショットのプロンプトはモデル全体で不十分でした。対照的に、少数ショットのプロンプトは大幅な利益をもたらし、3 つの実行可能なモデルで競争力のあるパフォーマンスを生み出しました。平均数ショット F1 スコアは、Llama-3.1-8B、Qwen2.5-7B、および Mistral-7B 全体で 0.776 ~ 0.817 の範囲であり、固定グローバル サンプル選択とチャンクごとのローカル サンプル選択の間に大きな違いはありませんでした。 Phi-3-mini は不安定で、信頼できるパフォーマンスが得られませんでした。実行可能なモデルは高い再現率を示しましたが、精度は低く、トークンが CIU として体系的に過剰分類されていることを示唆しています。パフォーマンスは談話の重症度によっても異なり、最も弱い結果ではより重度の失語症が発生しました。フューショット LLM プロンプトは、勾配ベースのタスク トレーニングなしで自動 CIU 識別をサポートできますが、完全に自律的に使用するには人間による注釈との合意がまだ不十分です。これらの発見は、LLM ベースの CIU スコアリングが談話評価システムの人間参加型コンポーネントとして有望であることを裏付けています。
原文 (English)
Do LLMs Reliably Identify Correct Information Units in Aphasic Discourse?
Correct Information Units (CIUs) are central to discourse assessment in aphasia because they quantify communicative informativeness rather than linguistic form alone. However, CIU scoring is time intensive and requires trained raters. This study examined whether instruction-tuned large language models (LLMs) can reliably perform token-level CIU classification from aphasic discourse transcripts. Sixteen picture-description transcripts elicited with the Cat Rescue stimulus were annotated for CIU status according to Nicholas and Brookshire (1993). The sample spanned four severity strata: control, mild, moderate, and severe aphasia. Four publicly available instruction-tuned LLMs were benchmarked under zero-shot and two few-shot prompting conditions across five stratified random seeds. Performance was evaluated against consensus human labels using accuracy, precision, recall, F1, and Cohen's kappa. Zero-shot prompting was insufficient across models. In contrast, few-shot prompting yielded substantial gains and produced competitive performance for three viable models. Mean few-shot F1 scores ranged from 0.776 to 0.817 across Llama-3.1-8B, Qwen2.5-7B, and Mistral-7B, with no significant differences between fixed global and per-chunk local example selection. Phi-3-mini was unstable and did not yield reliable performance. Viable models showed high recall but lower precision, suggesting systematic over-classification of tokens as CIUs. Performance also varied by discourse severity, with the weakest results in more severe aphasia. Few-shot LLM prompting can support automated CIU identification without gradient-based task training, but agreement with human annotation remains insufficient for fully autonomous use. These findings support LLM-based CIU scoring as a promising human-in-the-loop component of discourse assessment systems.
人工知能インデックスレポート 2026
AI Index レポートの第 9 版へようこそ。 AI が急速に進歩し続けるにつれて、AI を中心に構築されたシステムが追いつくことができるかどうかが問題になります。 AI の影響を追跡するために必要なガバナンスの枠組み、評価方法、教育システム、データ インフラストラクチャは、テクノロジー自体のペースに追いつくのに苦労しています。 AI ができることと、AI を管理するための私たちの準備との間のギャップは、今年のレポートのすべての章に貫かれています。この版の新たなレポートでは、推論、安全性、現実世界のタスク実行にわたって AI がどのようにより野心的にテストされているか、またそれらの測定値に依存することがますます困難になっている理由を追跡しています。また、生成型 AI の経済的価値の新しい推定値と、その労働市場への影響に関する新たな証拠、AI の主権に関する分析フレームワーク、および Schmidt Sciences と協力して開発された科学の章も取り上げられています。このレポートでは初めて、科学における AI と医学における AI に関する独立した章が設けられ、これら 2 つの領域にわたる AI の影響力の増大を反映しています。
原文 (English)
Artificial Intelligence Index Report 2026
Welcome to the ninth edition of the AI Index report. As AI continues to advance rapidly, the question becomes whether the systems built around it can keep up. Governance frameworks, evaluation methods, education systems, and the data infrastructure needed to track AI's impact are struggling to match the pace of the technology itself. That gap between what AI can do and how prepared we are to manage it runs through every chapter of this year's report. New in this edition, the report tracks how AI is being tested more ambitiously across reasoning, safety, and real-world task execution, and why those measurements are increasingly difficult to rely on. It also features new estimates of generative AI's economic value alongside emerging evidence of its labor market effects, an analytical framework on AI sovereignty, and a science chapter developed in collaboration with Schmidt Sciences. For the first time, the report features standalone chapters on AI in science and AI in medicine, reflecting AI's growing impact across these two domains.
概念実証実装による適応型水道ネットワーク管理のための AI 主導フレームワーク: ヨルダンの無収水問題への対処
ヨルダンは深刻な水不足に直面しており、生産される水の 50% が漏水、盗難、無収水 (NRW) とも呼ばれる計量問題によって失われています。従来の事後対応型アプローチでは、持続的な無収水削減には不十分であることが証明されています。この論文では、EPANET 油圧モデリング、デジタル ツイン テクノロジー、SCADA システム、および継続的なネットワーク監視と適応的意思決定のための大規模言語モデル (LLM) ベースの AI エージェントを統合したインテリジェント フレームワークを提案します。このシステムは、リアルタイム データ ストリームと物理ベースのシミュレーションを組み合わせて異常を検出し、ポリシーの解釈とネットワーク制御の関数呼び出しに検索拡張生成 (RAG) を採用します。概念実証の実装では、1,164 ジャンクションのアンマン地区ネットワーク上でオフライン LLM (Ollama 経由の llama3.1:8b) で EPYT を使用する技術的な実現可能性を検証します。このシステムは、自動化された水力シミュレーション、配水ゾーン (DZ) の実践に合わせた流量ベースの異常検出、および 2 分未満の応答時間と API コストゼロの AI 生成の健全性レポートを実証します。破裂の検出は、局所的な流れの異常分析に依存しています。30.1~L/s の模擬漏れにより、15 本のパイプ内で測定可能な流れの再分配が発生し、破裂の位置を特定する 15 の接合部クラスターにフラグが立てられ、配水ゾーン (DZ) の監視慣行との整合性が確認されます。このフレームワークは、ヨルダンの断続的な供給パターンと段階的導入による限定的な自動化に対応し、水不足地域が無収水削減と業務効率化のためにインテリジェントな自動化を活用するためのスケーラブルな道筋を提供します。
原文 (English)
AI-Driven Framework for Adaptive Water Network Management with Proof-of-Concept Implementation: Addressing Non-Revenue Water in Jordan
Jordan faces severe water scarcity with 50\% of water produced is lost to leakage, theft and metering issues also known as non-revenue water (NRW). Traditional reactive approaches have proven insufficient for sustained NRW reduction. This paper proposes an intelligent framework integrating EPANET hydraulic modeling, digital twin technology, SCADA systems, and large language model (LLM)-based AI agents for continuous network monitoring and adaptive decision-making. The system combines real-time data streams with physics-based simulation to detect anomalies, employing retrieval-augmented generation (RAG) for policy interpretation and function calling for network control. A proof-of-concept implementation validates technical feasibility using EPYT with offline LLMs (llama3.1:8b via Ollama) on a 1,164-junction Amman district network. The system demonstrates automated hydraulic simulation, flow-based anomaly detection aligned with water distribution zone (DZ) practice, and AI-generated health reports with response times under 2 minutes and zero API costs. Burst detection relies on local flow anomaly analysis: a 30.1~L/s simulated leak produces measurable flow redistribution in 15 pipes, flagging a 15-junction cluster that localises the burst -- confirming alignment with water distribution zone (DZ) monitoring practice. The framework accommodates Jordan's intermittent supply patterns and limited automation through phased implementation, offering a scalable pathway for water-scarce regions to leverage intelligent automation for NRW reduction and operational efficiency.
RoboPIN: 固定された思考連鎖によるグラウンディングされた身体的推論
身体化された推論では、モデルが物理環境内のタスクに関連するオブジェクトや空間を認識し、複数ステップの推論を通じて一貫した視覚的根拠を維持する必要があります。しかし、現在の視覚言語モデルはテキストのみ、または座標拡張された思考連鎖に依存しており、実体参照は暗黙的かつ曖昧なままです。これにより、推論プロセスが視覚的な証拠から切り離され、エンティティ参照がステップ間で漂流し、推論の軌跡と最終的な答えとの間に因果関係の断絶が生じる可能性があり、これらの問題は、ビュー間の外観の変化によりマルチビュー シナリオでさらに増幅されます。これらの問題に対処するために、すべての推論ステップを視覚的な証拠に固定する構造化推論パラダイムである Pinned Chain-of-Thought (\pincot{}) を提案します。 \pincot{} は \reasoninganchor{} の概念を導入しています。これは、タスクに関連する各エンティティを、エンティティ名、一意の ID、ビュー インデックス、空間基盤を備えた構造化されたビジュアル アンカーにバインドし、推論ステップとビュー全体で一貫したエンティティの追跡を可能にします。完全に自動化されたデータ生成パイプラインを構築して、高品質の \pincot{} 形式の推論データセットである \dataset{} を構築します。次に、具体化された知識、構造化された推論能力、プロセス監視された調整を段階的に注入する 3 段階のポストトレーニングを通じて、\method{} をトレーニングします。報酬は、推論中のアンカーの位置特定とアイデンティティの一貫性の両方を直接制約します。埋め込まれた空間推論、マルチビュー推論、ポインティングをカバーする 14 のベンチマークでは、パラメーターが 4B のみの \method{} は常に 7B レベルのオープンソースの埋め込みモデルを上回り、最も強力な 7B ベースラインである Mimo-Embodied に対して平均 12\% の改善を達成しました。さらに分析すると、\pincot{} によって接地精度とステップ間の同一性の一貫性が向上し、プロセス監視の有効性が検証されたことが示されています。
原文 (English)
RoboPIN: Grounded Embodied Reasoning via Pinned Chain-of-Thought
Embodied reasoning requires models to perceive task-relevant objects and spaces in physical environments and maintain consistent visual grounding throughout multi-step reasoning. However, current vision-language models rely on text-only or coordinate-augmented chain-of-thought, where entity references remain implicit and ambiguous. This may cause the reasoning process to decouple from visual evidence, entity references to drift across steps, and a causal disconnection between the reasoning trajectory and the final answer, with these problems further amplified in multi-view scenarios due to cross-view appearance changes. To address these issues, we propose Pinned Chain-of-Thought (\pincot{}), a structured reasoning paradigm that pins every reasoning step to visual evidence. \pincot{} introduces the concept of \reasoninganchor{}, which binds each task-relevant entity to a structured visual anchor with entity name, unique identity, view index, and spatial grounding, enabling consistent entity tracking across reasoning steps and views. We build a fully automated data generation pipeline to construct \dataset{}, a high-quality \pincot{}-formatted reasoning dataset. We then train \method{} through three-stage post-training that progressively injects embodied knowledge, structured reasoning ability, and process-supervised alignment, with rewards that directly constrain both anchor localization and identity consistency during reasoning. On 14 benchmarks covering embodied spatial reasoning, multi-view reasoning, and pointing, \method{} with only 4B parameters consistently outperforms 7B level open-source embodied models, achieving a 12\% average improvement over the strongest 7B baseline, Mimo-Embodied. Further analysis shows that \pincot{} improves grounding accuracy and cross-step identity consistency, validating the effectiveness of process supervision.
LLM 講師の足場の再考: ベンチマークと現実世界のデプロイメントの間の相互作用の不一致
AI 家庭教師のベンチマークで評価される中心的な教育的価値は、解決に向けて段階的なステップを経て生徒を導く足場です。ただし、チャットボットに足場の動作を組み込むための調整および評価方法は、学生が足場を担って会話に参加するという暗黙の前提に基づいています。この仮定が成り立つかどうかを検証するために、チャットボットのスキャフォールディングと学生の取り込みという 2 つの指標に関する評価パイプラインを導入し、AI 家庭教師のベンチマークと教育用チャットボットの現実世界の展開にわたる、9,490 のチャットからなる 9 つのデータセットにそれらの指標を適用します。私たちの分析によると、ベンチマークは足場が高く、生徒の摂取量が多い環境を前提としていますが、現実世界の生徒は全体的に摂取レベルが低く、対人コストをほとんどかけずに、チャットボットの教育的枠組みをバイパスして、自分自身の学習目標に向けた対話を推進していることがよくあります。私たちは、足場を迂回することが必ずしも有害ではないと主張します。むしろ、チャットボットの教育的枠組みと生徒の学習目標の不一致が浮き彫りになることがよくあります。チャットボットの支援の有効性を有意義に評価するには、将来のベンチマークは、学生が単に足場を担うという想定を超えて、チャットボットが多様な学習コンテキストと学生主導の対話パターンをどのようにナビゲートするかを評価する必要があります。
原文 (English)
Rethinking Scaffolding in LLM Tutors: The Interactional Mismatch Between Benchmarks and Real-World Deployments
A central pedagogical value evaluated in AI tutor benchmarks is scaffolding: guiding students through graduated steps toward a solution. Alignment and evaluation methods for embedding scaffolding behaviour into chatbots, however, rest on an implicit assumption: that students will take up the scaffolding and engage in the conversation. To examine whether this assumption holds, we introduce an evaluation pipeline around two metrics - Chatbot Scaffolding and Student Uptake - and apply them across nine datasets of 9,490 chats, spanning AI tutor benchmarks and real-world deployments of educational chatbots. Our analysis reveals that while benchmarks assume a high-scaffolding, high-student-uptake environment, students in real-world settings exhibit lower levels of uptake overall - frequently bypassing the chatbot's pedagogical framing to drive the interaction toward their own learning goals at little interpersonal cost. We argue that bypassing scaffolding is not necessarily detrimental; rather, it frequently highlights a mismatch between a chatbot's pedagogical framing and the student's learning goals. To meaningfully evaluate the effectiveness of a chatbot's assistance, future benchmarks must move beyond the assumption that students will simply take up the scaffolding, and instead evaluate how these chatbots navigate diverse learning contexts and student-driven interaction patterns.
検索強化された信頼性を意識した推論によるマルチモーダル システムにおける幻覚の軽減
マルチモーダル大規模言語モデル (MLLM) は、視覚言語の理解と自然言語応答の生成において強力な機能を実証しています。ただし、これらのシステムは、特に視覚的証拠が弱い、曖昧である、または意味的に一貫性がない場合、依然として自信過剰な予測や幻覚のような出力を生成する可能性があります。既存のアプローチのほとんどは、マルチモーダル表現の調整や検索拡張生成の改善に重点を置いていますが、インスタンス レベルの予測の信頼性を定量化したり、誤ったビジュアル出力を特定したりするメカニズムは限定されています。この研究は、信頼できるマルチモーダルな視覚的理解を実現するための、検索強化された信頼性を意識した推論フレームワークを提案しています。提案されたフレームワークは、事前学習された視覚的埋め込みと正規化された特徴表現に対する最近傍検索を使用して、外部の視覚的証拠データベースを構築します。取得された証拠は、類似性の強さ、クラスサポート一致、証拠マージン、エントロピーベースの不確実性、集計信頼性スコアなどの複数の信頼性指標を通じて予測の信頼性を推定するために使用されます。これらの信号に基づいて、決定ゲートは、システムが予測を受け入れるか、慎重に回答するか、証拠が不十分な場合は棄権/フォールバックするかを決定します。次に、マルチモーダル応答生成層が、信頼性の決定を条件とした最終的なユーザー向け応答を生成します。 ImageNet-100 での実験では、提案された信頼性を意識したフレームワークにより、許容される予測精度が 89.04\% カバレッジで 85.84\% から 88.88\% に向上することが実証されました。幻覚のような誤答率は 14.16\% から 11.12\% に減少します。これらの結果は、検索証拠、信頼性推定、および選択的決定ゲーティングを統合すると、大規模なマルチモーダル モデルを再トレーニングすることなく、キャリブレーションを改善し、自信過剰な視覚的エラーを削減できることを示しています。
原文 (English)
Mitigating Visual Hallucinations in Multimodal Systems through Retrieval-Augmented Reliability-Aware Inference
Multimodal large language models (MLLMs) have demonstrated strong capabilities in vision-language understanding and natural-language response generation. However, these systems can still produce overconfident predictions and hallucination-like outputs, particularly when the visual evidence is weak, ambiguous, or semantically inconsistent. Most existing approaches focus on improving multimodal representation alignment or retrieval-augmented generation, while providing limited mechanisms to quantify instance-level prediction reliability or identify incorrect visual outputs. This work proposes a retrieval-augmented reliability-aware inference framework for trustworthy multimodal visual understanding. The proposed framework constructs an external visual evidence database using pretrained visual embeddings and nearest-neighbor retrieval over normalized feature representations. Retrieved evidence is used to estimate prediction trustworthiness through multiple reliability indicators, including similarity strength, class-support agreement, evidence margin, entropy-based uncertainty, and an aggregate reliability score. Based on these signals, a decision gate determines whether the system should accept the prediction, answer with caution, or abstain/fallback when evidence is insufficient. A multimodal response-generation layer then produces a final user-facing response conditioned on the reliability decision. Experiments on ImageNet-100 demonstrate that the proposed reliability-aware framework improves accepted prediction accuracy from 85.84\% to 88.88\% at 89.04\% coverage. The hallucination-like accepted wrong-answer rate is reduced from 14.16\% to 11.12\%. These results show that integrating retrieval evidence, reliability estimation, and selective decision gating can improve calibration and reduce overconfident visual errors without retraining large multimodal models.
コンパイルベースのマルチエージェント パス検索における未割り当てのエージェント
コンパイルベースの技術は、そのモジュール性と問題の非標準的な変形に対する適応性により、マルチエージェント パス検索 (MAPF) のソルバーの重要な流れを代表します。標準の MAPF のタスクは、すべてのエージェントを初期位置から特定の個々の目標位置まで衝突することなくナビゲートすることですが、エージェントに対する異なる要件が使用されるバリアントも関連します。このようなバリアントは、未割り当てエージェントを含む MAPF (UA-MAPF) です。一部のエージェントは、初期ポジションと目標を持つ標準の MAPF と同じ設定を持ちますが、残りのエージェントは初期ポジションを持ちますが、目標を持たない、つまり未割り当てエージェントです。割り当てられていないエージェントはゴール位置に到達する必要がないにもかかわらず、特定の課題を表す必要に応じて、標準エージェントの邪魔にならない場所に移動する必要があります。この論文では、問題をブール充足可能性として定式化することに基づいて、UA-MAPF が最近のコンパイルベースの MAPF 手法で表現できることを示します。つまり、反例に基づく抽象化洗練と非洗練化に基づいた最近のソルバーである SMT-CBS と NRF-SAT を適応させます。
原文 (English)
Unassigned Agents in Compilation-based Multi-agent Path Finding
Compilation-based techniques represent an important stream of solvers for multi-agent path finding (MAPF) due to their modularity and adaptability for non-standard variants of the problem. While in the standard MAPF the task is to navigate all agents from their initial positions to given individual goal positions without any collision, variants where a different requirement for agents is used are also relevant. Such a variant is MAPF with unassigned agents (UA-MAPF) where some agents have the same setting as in the standard MAPF with initial positions and goals while the remaining agents have the initial position but have no goal - unassigned agents. Despite unassigned agent do not need to reach any goal position they have to be moved out of the way of the standard agents if needed which represent a specific challenge. We show in this paper that UA-MAPF can be expressed in recent compilation-based techniques for MAPF based on formulating the problem as Boolean satisfiability, namely we adapt SMT-CBS and NRF-SAT, the recent solvers based on counterexample guided abstraction refinement and non-refined abstractions.
TrustedARI: エージェントティック AI のためのトラストネイティブ エージェント ルーティング インフラストラクチャに向けて
AI エージェントは、異種インターフェイスや断片化されたサブスクリプションのオーバーヘッドを管理するために、エージェント ルーティング インフラストラクチャ (ARI) を通じて外部モデル、ツール、サービスにアクセスすることが増えています。しかし、ARI のアーキテクチャは根本的な信頼リスクをもたらします。つまり、エージェントのクエリとサービス応答への平文アクセスが得られる一方で、エージェントはクエリが目的のサービス プロバイダーにルーティングされていること、または要求と応答が改ざんされていないことを検証できなくなります。この問題に対処するために、エージェント AI 用の最初の信頼できるネイティブ エージェント ルーティング インフラストラクチャである TrustedARI を紹介します。アーキテクチャ的には、TrustedARI は 3 つの核となるイノベーションに基づいて構築されています。(i) ARI に適応した 3 者間 TLS ハンドシェイク。これにより、エージェントと ARI は、ロール固有の TLS 鍵マテリアルの配布を通じてサービス プロバイダーを共同で認証できます。 (ii) エージェントと ARI がそれぞれのプライベート入力を公開することなく、整形式のクエリを共同で構築できるプライバシー保護クエリ構築プロトコル。 (iii) サービス応答の完全性と機密性を維持しながら、フェアユースに基づく決済をサポートする検証可能な請求プロトコル。私たちは、TrustedARI のプロトタイプを実装して広範囲に評価し、そのパフォーマンスを検証しました。実験により、TrustedARI が非常に効率的であることが確認されています。ARI に適応したハンドシェイク プロトコルは、既存の 3 者間 TLS ハンドシェイクと比較して通信オーバーヘッドを 39.34% 削減します。さらに、プライバシーを保護するクエリ構築プロトコルにより、計算時間は平均 0.19 秒、通信コストは 0.58 MB と無視できるほどのオーバーヘッドが課せられますが、検証可能な課金プロトコルによりプルーフ生成が 28.20 倍高速化されます。重要なのは、TrustedARI はサービス プロバイダーに変更を加えることなく、すぐに導入できることです。
原文 (English)
TrustedARI: Towards Trust-Native Agentic Routing Infrastructure for Agentic AI
AI agents increasingly access external models, tools, and services through Agentic Routing Infrastructure (ARI) to manage the overhead of heterogeneous interfaces and fragmented subscriptions. Yet, the architecture of ARI introduces fundamental trust risks: it obtains plaintext access to agent queries and service responses, while leaving agents unable to verify that their queries are routed to intended service providers or that requests and responses remain untampered. To address this problem, we present TrustedARI, the first trust-native agentic routing infrastructure for agentic AI. Architecturally, TrustedARI is built upon three core innovations: (i) an ARI-adapted three-party TLS handshake that enables the agent and ARI to jointly authenticate the service provider through role-specific distribution of TLS key materials; (ii) a privacy-preserving query-construction protocol that allows the agent and ARI to collaboratively construct well-formed queries without exposing their respective private inputs; and (iii) a verifiable billing protocol that supports fair usage-based settlement while preserving the integrity and confidentiality of service responses. We implemented and extensively evaluated a prototype of TrustedARI to validate its performance. Experiments confirm that TrustedARI is highly efficient: our ARI-adapted handshake protocol reduces communication overhead by 39.34% compared to the existing three-party TLS handshake. Furthermore, the privacy-preserving query-construction protocol imposes negligible overhead-averaging 0.19 seconds in computation time and 0.58 MB in communication costs-while the verifiable billing protocol speeds up proof generation by 28.20x. Crucially, TrustedARI is readily deployable without any modification to the service providers.
コンピューティング分野でニューラル ネットワークを使用した、リアルタイムの学生評価とキャリア ガイダンスのための統合システム
コンピュータ サイエンス (CS) やソフトウェア エンジニアリング (SWE) の多くの学部生は、特に学業成績、能力、興味が完全に一致していない場合、適切なキャリアパスを見つけるのに苦労しています。この問題に対処するために、この研究では、キャリア ガイダンス エキスパート (CGE) システムと Web ベースの学生評価 (WBSA) プラットフォームを統合する、AI 主導の学生評価およびキャリア予測システムを提案します。統合されたフレームワークの中で、CGE は AI を使用してパーソナライズされたキャリアの推奨を強化すると同時に、卒業後の学生が自分のスキルや興味に合った適切な仕事、研究分野、より高度な学習の機会を特定できるよう支援します。 WBSA プラットフォームは、評価、パーソナライズされたタスク、指導活動、安全なリアルタイム チャット アプリケーションを通じて、学生と教員間の交流をさらに強化します。 CGE システムは、大学の学生から雪だるまサンプリング法を使用して収集された現実世界の学術データと課外データに基づいてトレーニングされた多層パーセプトロン (MLP) モデルを採用しており、個人化されたキャリア パスの予測において 94.71% の検証精度を達成しています。導入前に提案されたモデルを評価するために、大学全体で事前調査が実施されました。 WBSA システムは、Node.js、Next.js、PostgreSQL などのテクノロジーを使用して最新の Web アプリケーションとして開発され、スケーラビリティ、応答性、安全なデータ管理を保証します。システム全体は安全なクラウドベースのインフラストラクチャによってサポートされており、プラットフォームは信頼性の高いパフォーマンスを提供しながら、卒業生が IT 分野で適切なキャリアパスを選択できるように支援します。さらに、フィードバックを収集し、システム全体の有効性と使いやすさをさらに向上させるために、学生と教員の両方を対象とした事後調査が実施されました。
原文 (English)
An Integrated System for Real-Time Student Assessment and Career Guidance Using Neural Networks in Computing Disciplines
Many undergraduate students in Computer Science (CS) and Software Engineering (SWE) struggle to identify suitable career paths, particularly when their academic performance, abilities, and interests do not fully align. To address this issue, this study proposes an AI-driven Student Assessment and Career Prediction System that integrates a Career Guidance Expert (CGE) system with a Web-Based Student Assessment (WBSA) platform. Within the integrated framework, CGE enhances personalized career recommendations using AI while also assisting students after graduation in identifying suitable jobs, research domains, and higher study opportunities aligned with their skills and interests. The WBSA platform further strengthens interaction between students and faculty through assessments, personalized tasks, mentorship activities, and a secure real-time chat application. The CGE system employs a Multilayer Perceptron (MLP) model trained on real-world academic and extracurricular data collected using the snowball sampling method from the students of universities, achieving a validation accuracy of 94.71% in predicting personalized career paths. A pre-survey was conducted across universities to evaluate the proposed model before deployment. The WBSA system was developed as a modern web application using technologies such as Node.js, Next.js, and PostgreSQL to ensure scalability, responsiveness, and secure data management. The overall system is supported by a secure cloud-based infrastructure, the platform provides reliable performance while assisting graduates to select suitable career path in IT sector. In addition, a post-survey involving both students and faculty was conducted to gather feedback and further improve the overall effectiveness and usability of the system.
AIChilles: AI が進化したシステムの隠れた弱点を自動的に発見
コンピュータ システム コミュニティでは、最近、AI エージェントが繰り返しシステムを書き換える、AI 主導のシステム進化への関心が高まっています。 AdaEvolve や Engram などのフレームワークは、人間が設計したアルゴリズムと比較して 12 ~ 60% のスコア向上が報告されています。これらの結果は有望ですが、これらの AI によって進化したプログラムが目に見えないワークロードでパフォーマンスが低下し、スケーラビリティの低下を示す可能性があるのであれば、実際的な懸念があります。 AI が生成するコードの速度と規模を考慮すると、AI が進化したシステム プログラムの隠れた弱点を発見する自動化されたメカニズムが必要です。この目的を達成するために、ベースライン プログラム $P$ と AI 進化型プログラム $P'$ を入力として受け取る AIChilles を開発します。AIChilles は、正確性、実行時間、メモリ使用量、または出力品質において $P'$ が $P$ に比べて低下する有効なワークロードを検索します。システム アプリケーション、弱点の種類、潜在的なバグの多様性に対処するために、AIChilles は、決定論的なワークロード パラメーターの抽出、エージェント ベースの制約推論、差分オラクル、およびコード周波数カバレッジを組み合わせて、さまざまな障害を検出します。 AIChilles は、5 つのシステム アプリケーションと 30 の AI 進化プログラムにわたって、49 の明確な隠れた弱点を発見しました。また、AI 駆動の開発ライフサイクルに AIChilles を明示的に含めることで、これらの弱点のいくつかを軽減できることも示します。
原文 (English)
AIChilles: Automatically Uncovering Hidden Weaknesses in AI-Evolved Systems
The computer systems community has recently seen growing interest in AI-driven system evolution, where AI agents iteratively rewrite systems. Frameworks such as AdaEvolve and Engram report 12-60% score improvements over human-designed algorithms. While these results are promising, there are practical concerns if these AI-evolved programs can perform worse on unseen workloads and exhibit scalability regressions. Given the speed and scale of AI-generated code, we need automated mechanisms to uncover such identify hidden weaknesses in AI-evolved systems programs. To this end, we develop AIChilles that takes as input a baseline program $P$ and an AI-evolved program $P'$, AIChilles searches for valid workloads where $P'$ regresses relative to $P$ in correctness, runtime, memory usage, or output quality. To tackle the diversity in system applications, weakness types and potential bugs, AIChilles combines deterministic workload-parameter extraction, agent-based constraint inference, differential oracles, and code-frequency coverage to discover diverse failures. Across five system applications and 30 AI-evolved programs, AIChilles finds 49 distinct hidden weaknesses. We also show that explicitly including AIChilles in the AI-driven development lifecycle can mitigate several of these weaknesses.
予算付き LLM 検証における不均一分散信号: 構造の不均一性が最適化ゲインを制限する
大規模言語モデル (LLM) システムでは、検証、テスト時間のスケーリング、ツールの実行、その他の選択的な計算の決定に限られた計算を割り当てるために、不確実性信号の使用が増えています。このようなポリシーは \emph{グローバルな信号の比較可能性の仮定} に依存します。つまり、等しいスコアは入力全体で比較可能な決定値を保持する必要があります。制御された診断設定として予算に基づいた検証を使用して、この仮定の失敗モードを特定します。不確実性の品質はコスト層全体で不均一分散的であり、多くのエラーが集中しているにもかかわらず、一部の領域ではほぼランダムな識別性が示されています。明示的なローカル モデルの下で、結果として生じるグローバル割り当ての歪みを特徴付け、その上限が層間の信号品質分散に応じて変化することを示します。私たちは、制御された介入階層 (しきい値、MP-Adapt、MP-Strat、および意図的に単純なコスト階層化しきい値介入 (CST)) を通じて、弱い信号、最適化の不安定性、構造的異質性を分離します。 Qwen3-8B、LLaMA3-8B、および GPT-4o-mini を使用した MBPP と MATH 全体で、グローバルなオンライン適応により、静的しきい値処理に比べて一貫性のないゲインが得られます。 MP-Strat はパフォーマンスを部分的に回復しますが、CST は勾配更新なしで非常に異質な設定でヒット率を最大 17 パーセント改善します。これらの結果は、観察された設定における主なボトルネックとして、オプティマイザーの弱点だけではなく、構造的異質性を特定します。さらに広く言えば、調整されていないフィードバック構造は、より強力な最適化によって常に修復できるわけではありません。
原文 (English)
Heteroskedastic Signals in Budgeted LLM Verification: Structural Heterogeneity Limits Optimization Gains
Large language model (LLM) systems increasingly use uncertainty signals to allocate limited computation across verification, test-time scaling, tool execution, and other selective-compute decisions. Such policies rely on a \emph{global signal comparability assumption}: equal scores should carry comparable decision value across inputs. Using budgeted verification as a controlled diagnostic setting, we identify a failure mode of this assumption: uncertainty quality is heteroskedastic across cost strata, with some regions exhibiting near-random discriminability despite concentrating many errors. Under an explicit local model, we characterize the resulting distortion of global allocation and show that its upper bound scales with cross-stratum signal-quality dispersion. We separate weak signals, optimization instability, and structural heterogeneity through a controlled intervention hierarchy: Threshold, MP-Adapt, MP-Strat, and a deliberately simple cost-stratified thresholding intervention (CST). Across MBPP and MATH using Qwen3-8B, LLaMA3-8B, and GPT-4o-mini, global online adaptation yields inconsistent gains over static thresholding; MP-Strat partially recovers performance, while CST improves hit rate by up to 17 percentage points in strongly heterogeneous settings without gradient updates. These results identify structural heterogeneity, rather than optimizer weakness alone, as the primary bottleneck in the observed settings. More broadly, misaligned feedback structure cannot always be repaired by stronger optimization.
RetailBench: 現実的な小売環境における LLM エージェントの長期的な推論と一貫した意思決定のベンチマーク
大規模言語モデル (LLM) エージェントは、期間が短く、範囲が明確なタスクに関しては急速に進歩していますが、長期の動的な環境で一貫した意思決定を維持できる能力は依然として不確実です。単一店舗のスーパーマーケット運営においてツールを使用する LLM エージェントを評価するための、データに基づいたシミュレーション ベンチマークである RetailBench を紹介します。 RetailBench は小売管理を部分的に観察可能な意思決定プロセスとしてモデル化し、千日規模のシミュレーションをサポートするように設計されています。この環境では、エージェントは価格設定、補充、サプライヤーの選択、棚の品揃え、在庫の老化、顧客からのフィードバック、外部イベント、キャッシュ フローの制約を管理する必要があります。 180 日間の評価期間にわたって、代表的なエージェント フレームワークに基づいて 7 つの最新の LLM を評価し、それらを特権付きオラクル ポリシーと比較します。結果はモデル間で大幅なばらつきを示しています。ごく一部のサブセットのみが評価期間全体に生き残り、最も強力な LLM 実行でさえ、最終的な純資産と売上高の結果においてオラクル ポリシーを大幅に下回ったままです。行動分析では、これらのギャップは不完全な証拠の取得、表面レベルの意思決定、一貫した長期的な方針の欠如に起因すると考えられます。 RetailBench は、経済的に根拠のある長期的な意思決定における信頼性の高い自律性を研究するための、制御されたテストベッドを提供します。
原文 (English)
RetailBench: Benchmarking long horizon reasoning and coherent decision making of LLM agents in realistic retail environments
Large language model (LLM) agents have made rapid progress on short-horizon, well-scoped tasks, yet their ability to sustain coherent decisions in dynamic long-horizon environments remains uncertain. We introduce RetailBench, a data-grounded simulation benchmark for evaluating tool-using LLM agents in single-store supermarket operation. RetailBench models retail management as a partially observable decision process and is designed to support thousand-day-scale simulations. In this environment, agents must manage pricing, replenishment, supplier selection, shelf assortment, inventory aging, customer feedback, external events, and cash-flow constraints. We evaluate seven contemporary LLMs under representative agent frameworks over a 180-day evaluation horizon and compare them with a privileged oracle policy. Results show substantial variation across models: only a small subset survives the full evaluation horizon, and even the strongest LLM runs remain substantially behind the oracle policy in final net worth and sales outcomes. Behavioral analysis attributes these gaps to incomplete evidence acquisition, surface-level decision making, and the lack of a consistent long-horizon policy. RetailBench provides a controlled testbed for studying reliable autonomy in economically grounded long-horizon decision-making.
STRIDE: 検証可能な強化学習のための判別推定による戦略的軌道推論
検証可能な報酬を伴う強化学習 (RLVR) は、大規模な言語モデルの推論能力を向上させるための効果的なポストトレーニング パラダイムとなっています。ただし、既存の RLVR 手法は通常、最終的な解答の正しさに依存して軌跡レベルの報酬を割り当て、まばらな監視を提供し、推論への実際の貢献度に関係なくすべてのトークンを均一に扱います。最近の研究では、プロセス報酬、高エントロピートークン、意味論的不確実性などの中間シグナルが導入されていますが、これらのシグナルは本質的に検証可能ではないことが多く、有益な戦略パターンと有害な戦略パターンを区別できない可能性があります。この制限に対処するために、検証可能な結果から戦略的推論の監督を導き出す、きめの細かい RLVR フレームワークである STRIDE (Strategic Trajectory Reasoning with Discriminative Estimation) を提案します。 STRIDE は、各応答グループ内の成功と失敗の軌跡を対比して、各 $n$-gram 戦略パターンの結果識別選好を推定し、さらにこの信号と推論顕著性エントロピーを組み合わせて、意思決定に関連する戦略パターンを特定します。これらのパターンには、RL 最適化中に差別化されたアドバンテージ値が割り当てられるため、RLVR の検証可能性を維持しながら、より正確なクレジット割り当てが可能になります。広範な実験により、STRIDE が、VLM やエージェントベースのシステムを含む、さまざまなモデル、タスク、拡張設定にわたって推論パフォーマンスを一貫して向上させることが実証されています。
原文 (English)
STRIDE: Strategic Trajectory Reasoning via Discriminative Estimation for Verifiable Reinforcement Learning
Reinforcement Learning with Verifiable Rewards (RLVR) has become an effective post-training paradigm for improving the reasoning abilities of large language models. However, existing RLVR methods typically rely on final-answer correctness to assign trajectory-level rewards, providing sparse supervision and treating all tokens uniformly regardless of their actual contribution to reasoning. Although recent studies introduce intermediate signals such as process rewards, high-entropy tokens, and semantic uncertainty, these signals are often not inherently verifiable and may fail to distinguish beneficial strategic patterns from harmful ones. To address this limitation, we propose STRIDE (Strategic Trajectory Reasoning with Discriminative Estimation), a fine-grained RLVR framework that derives strategic reasoning supervision from verifiable outcomes. STRIDE contrasts successful and failed trajectories within each response group to estimate the outcome-discriminative preference of each $n$-gram strategic pattern, and further combines this signal with reasoning saliency entropy to identify decision-relevant strategic patterns. These patterns are assigned differentiated advantage values during RL optimization, enabling more precise credit assignment while preserving the verifiability of RLVR. Extensive experiments demonstrate that STRIDE consistently improves reasoning performance across diverse models, tasks, and extended settings, including VLMs and agent-based systems.
エージェント ハーネスのための LLM-as-Code エージェント プログラミング
主要な LLM エージェント フレームワークはすべて、LLM にオーケストレーターの役割を与えます。モデルは、次に何をするか、いつツールを呼び出すか、いつ停止するかを決定します。私たちは、トークンの爆発、制御フローの幻覚、および信頼性の低い完了は実装のバグではなく、ループ、分岐、順序付けの決定論的な作業を確率システムに割り当てたアーキテクチャ上の結果であると主張します。より優れたプロンプトやより強力なモデルでも、LLM エージェントの信頼性を保証することはできません。したがって、私たちはエージェントティック プログラミングを提案します。エージェントティック プログラミングでは、プログラムがすべての制御フローを管理し、LLM 自体がその一部であり、LLM-as-Code と呼ばれる適応コンポーネントであり、タスクが推論または生成を必要とする場合にのみ呼び出されます。各呼び出し内でモデルは完全な柔軟性を維持しますが、プログラムの実行パスを変更することはできません。プログラム内の制御により、LLM のコンテキストは実行履歴の呼び出しツリーから構築され、有向非巡回グラフ (DAG) を形成します。各呼び出しのコンテキストの長さは、ステップにわたる累積ではなく、呼び出しの深さによって決まります。コンピュータ使用エージェントのケーススタディでは、この設計が単なる理論的なものではなく実用的であり、長い視覚操作シーケンスの安定性が大幅に向上していることが示されています。
原文 (English)
LLM-as-Code Agentic Programming for Agent Harness
Every major LLM agent framework gives the LLM the role of orchestrator; the model decides what to do next, when to call tools, and when to stop. We argue that token explosion, control-flow hallucination, and unreliable completion are not implementation bugs but architectural consequences of assigning the deterministic work of looping, branching, and sequencing to a probabilistic system. A better prompt or a stronger model cannot guarantee the reliability of the LLM agent. We therefore propose Agentic Programming, in which the program governs all control flow, and the LLM is itself part of it, an adaptive component we call LLM-as-Code and invoke only where a task calls for reasoning or generation. Within each call the model keeps full flexibility, but it cannot alter the program's execution path. With control in the program, the LLM's context is built from the execution history's call tree and forms a directed acyclic graph (DAG). Each call's context length is then determined by its call depth rather than by accumulation over steps. A case study of computer-use agents shows that the design is practical, not just a theoretical stance, substantially improving the stability of long visual operation sequences.
UrbanWell: 都市の時空間分析のためのマルチモーダル大規模言語モデルのベンチマーク
マルチモーダル データから都市の福祉を理解するには、異種の空間信号と時間信号を統合する必要があり、現在のマルチモーダル大規模言語モデル (MLLM) にとって大きな課題となっています。衛星画像とストリートビュー画像の共同モデリングを通じて、都市の幸福分析のための MLLM の時空間推論能力を体系的に評価するように設計された大規模ベンチマーク、UrbanWell を紹介します。 UrbanWell は複数年にわたり 38 都市を対象としており、(1) 環境条件 (CO$_2$、NO$_2$、PM${2.5}$、および正規化差分植生指数)、(2) 空間的アクセシビリティ (スーパーマーケットやレストランまでの最小距離)、(3) 都市の形態 (道路の長さ、道路密度、および土地利用)、(4) 都市の活力 (人口、経済活動の多様性、および土地利用の多様性)、および (5) 主観的な認識属性をカバーする多様な指標が含まれています。 (例:安全、美しさ、活気、豊かさ、静けさ)。すべての指標はグリッド レベルで調整され、標準化された評価が可能になります。 UrbanWell は、静的な予測を超えて、過去の観察からの将来価値の予測や時間的傾向の分類など、時間的推論タスクを定義します。 15 個の最先端の代表的な MLLM をゼロショット設定でベンチマークし、空間的および時間的次元にわたる包括的な比較評価を提供します。実験結果によると、MLLM は顕著な空間的および知覚的手がかりを捕捉しますが、そのパフォーマンスは環境と主観的知覚にわたる異種都市指標によって大きく異なることが示されています。 UrbanWell は、都市の幸福分析におけるマルチモーダルな空間的および時間的推論を評価するための統一ベンチマークとして機能し、マルチモーダルな都市インテリジェンスに関する体系的な評価と将来の研究のための標準化されたテストベッドを提供します。コードとデータセットには、https://github.com/axin1301/UrbanWell-Benchmark からアクセスできます。
原文 (English)
UrbanWell: Benchmarking Multimodal Large Language Models for Spatio-Temporal Urban Wellbeing Analytics
Understanding urban wellbeing from multimodal data requires integrating heterogeneous spatial and temporal signals, posing significant challenges for current multimodal large language models (MLLMs). We introduce UrbanWell, a large-scale benchmark designed to systematically evaluate the spatio-temporal reasoning capabilities of MLLMs for urban wellbeing analytics through joint modeling of satellite and street view imagery. UrbanWell spans 38 cities across multiple years and includes diverse indicators covering (1) environmental conditions (CO$_2$, NO$_2$, PM${2.5}$, and Normalized Difference Vegetation Index), (2) spatial accessibility (minimum distance to supermarkets and restaurants), (3) urban form (road length, road density, and land use), (4) urban vitality (population, economic activity diversity, and land use diversity), and (5) subjective perception attributes (e.g., safety, beauty, liveliness, wealth, and quietness). All indicators are aligned at grid level to enable standardized evaluation. Beyond static prediction, UrbanWell defines temporal reasoning tasks, including future value forecasting from historical observations and temporal trend classification. We benchmark 15 state-of-the-art representative MLLMs in a zero-shot setting, providing a comprehensive comparative evaluation across spatial and temporal dimensions. Experimental results indicate that while MLLMs capture salient spatial and perceptual cues, their performance varies substantially across heterogeneous urban indicators spanning environment and subjective perception. UrbanWell serves as a unified benchmark for evaluating multimodal spatial and temporal reasoning in urban wellbeing analytics, offering a standardized testbed for systematic assessment and future research on multimodal urban intelligence. Our codes and datasets are accessible via https://github.com/axin1301/UrbanWell-Benchmark.
インコンテキスト学習による深層学習ワークロード移行のためのエージェント フレームワーク
深層学習モデルを PyTorch の柔軟なオブジェクト指向設計から JAX の機能的でステートレスなセットアップに変換するのは、通常は手作業であり、エラーが発生しやすい作業です。大規模言語モデル (LLM) は厳密かつ動的な API 調整に苦労しており、厳密な操作では間違いが発生しやすいため、自動移行は困難です。私たちは、インコンテキスト学習 (ICL) とオラクル主導の自己デバッグを組み合わせた完全自律システムを提案します。まず、慣用的な JAX スタイル設定とテスト ケース生成のための厳密なリファレンスとして機能する ICL コンテキストを厳選しました。次に、LLM に依存して数学的出力を推定するのではなく、ソース PyTorch モジュールを実行して実際の動的テンソル状態を取得します。これにより、変更不可能な実行オラクルが作成されます。次に、自律エージェント ループを使用して、Oracle データに基づいてテストを合成します。テスト ケースは繰り返し実行され、自己修正のためにトレースバックが LLM に送り返されます。アブレーションは、ICL リファレンスとオラクルのグラウンディングおよび自己デバッグを組み合わせると、純粋な指導ベースラインおよび基本的なエージェントベースラインを大幅に上回るパフォーマンスを示すことを示しています。この改善により、過度の計算オーバーヘッドが追加されることはありません。当社の軽量パイプラインは、ニューラル モジュール上で 91% の数値同等性 (ベースラインとの比較: 9%、命令 + セルフデバッグ: 27%) を達成し、フレームワーク間の移行のための信頼性が高く、スケーラブルなブループリントを提供します。これは、SAM (segment anything)、T5、Code Whisper などのいくつかの最先端のモデルにわたって検証されており、高い数値的同等性が示されています。コード: https://github.com/AI-Hypercomputer/accelerator-agents/tree/main/MaxCode
原文 (English)
Agentic Framework for Deep Learning workload migration via In-Context Learning
Translating deep learning models from PyTorch's flexible, object-oriented design to JAX's functional, stateless setup is usually a manual and error-prone task. Automated migration is challenging because Large Language Models (LLMs) struggle with strict and dynamic API alignment and are prone to mistakes for exacting operations. We propose a fully autonomous system that combines In-Context Learning (ICL) with oracle-driven self-debugging. First, we curated an ICL context that serves as a strict reference for idiomatic JAX styling and test case generation. Second, instead of depending on the LLM to deduce mathematical outputs, we run the source PyTorch modules to get their actual dynamic tensor states. This creates an unchangeable execution oracle. We then use an autonomous agentic loop to synthesize tests based on the oracle data. The test cases are executed repeatedly, and the traceback is sent back to the LLM for self-correction. Ablations show that combining ICL references with oracle grounding and self-debugging greatly outperforms pure instructional and basic agentic baselines. This improvement does not add an excessive computational overhead. Our lightweight pipeline achieves 91% numerical equivalence (compared to baseline: 9%, instruction + self-debugging: 27%) on neural modules, providing a highly reliable, scalable blueprint for cross-framework migration. This has been validated across several state-of-the-art models including SAM (segment anything), T5, Code Whisper amongst others showing high numerical equivalency. Code: https://github.com/AI-Hypercomputer/accelerator-agents/tree/main/MaxCode
SciText2Eq: 科学的創造性のための説明可能な方程式生成のための LLM の評価
この研究では、科学文書から数式を生成する大規模言語モデル (LLM) の能力を調査します。これまでの研究は、構造化されていない基礎、複数の方程式の依存性、および人間に合わせた評価という課題に直面していました。この目的を達成するために、私たちは AI 研究論文のデータセットを構築し、文脈に沿った文章を真実の方程式と変数の説明と組み合わせます。私たちは説明可能な方程式生成ワークフローを開発し、オープンソースおよびクローズドソースの多様な LLM バックボーンにわたってそれを評価します。自動メトリクス、LLM ベースのルーブリック、および人間の判断を組み合わせた評価プロトコルを導入して、精度、説明可能性、および人間と LLM の整合性を評価します。結果は、LLM が語彙ベースおよび構文ベースの類似性に関しては中程度のパフォーマンスを発揮する一方、意味論的な正確さには苦労していることを示しています。 LLM ベースの評価と人間の判断を比較すると、整合性が限られていることが明らかになり、方程式の品質を評価するために LLM を使用する際の課題が浮き彫りになります。これらの発見は、方程式生成モデルを改善し、科学文書のより信頼性の高い評価方法を開発するための洞察を提供します。再現性を高めるためのコードとデータを提供します。
原文 (English)
SciText2Eq: Assessing LLMs for Explainable Equation Generation for Scientific Creativity
This work investigates the ability of large language models (LLMs) to generate mathematical equations from scientific texts. Prior work faces challenges in unstructured grounding, multi-equation dependency, and humanaligned evaluation. To this end, we construct a dataset of AI research papers, pairing contextual passages with ground-truth equations and variable descriptions. We develop an explainable equation generation workflow and evaluate it across diverse open- and closed-source LLM backbones. We introduce an evaluation protocol combining automatic metrics, LLM-based rubrics, and human judgments to assess accuracy, explainability, and human-LLM alignment. Results indicate that LLMs perform moderately on lexical- and syntactic-based similarity, while struggling with semantic accuracy. Comparisons between LLM-based evaluations and human judgments reveal limited alignment, highlighting challenges in using LLMs to assess equation quality. These findings offer insights for improving equation generation models and developing more reliable evaluation methods for scientific text. We provide code and data for reproducibility.
Code RL トレーニング環境における報酬のハッキング可能性の監査
コード RL 環境が誤った解決策を正しいものとして受け入れる割合を測定します。 SWE ベンチ検証済みの 49 タスクのサンプルでは、タスクの 28.5% に、Docker 検証済みの不正なパッチが合格するほど弱いテスト スイートが含まれています。 6 つのリポジトリにわたる 20 の R2E-Gym タスクでは、シングルショット エクスプロイト生成時の同じパイプラインの収率は 25.0% です。 SWE ベンチ Verified に提出された 134 件のフロンティア モデルに対する変量効果メタ分析では、人間が評価した同じ難易度階層内で、モデル Pass@1 は、フラグ付きのハッキング可能なタスクの方が堅牢なタスクよりも +14.14 パーセント ポイント高いことがわかりました (95% CI [+11.80, +16.48]; 片側 p < 10^-6; I^2 = 0%; 123 134 モデルがポジティブ)。次に、壊れたタスクを強化する手順について説明します。 Docker のゴールド正気性ゲートを備えたインライン LLM ジャッジは、ジャッジに相談する前に、生成された各テストをゴールド ソリューションに対して実行します。監査の 11 個の壊れたタスクに関して、ゲートは、LLM が生成した決定的なテスト 105 個のうち 65 個がゴールド パッチ自体で不合格であるとフラグを立て、拡張ごとの欠陥率は 61.9% で、LLM 判定者だけがミスすることになります。多様性に基づく再試行では、ループは 11 タスクのうち 9 タスクをゲート アップグレードに収束します。
原文 (English)
Auditing Reward Hackability in Code RL Training Environments
We measure the rate at which code RL environments accept incorrect solutions as correct. On a 49-task sample of SWE-bench Verified, 28.5% of tasks have test suites weak enough that a Docker-verified incorrect patch passes them. On 20 R2E-Gym tasks across 6 repositories, the same pipeline at single-shot exploit generation yields 25.0%. A random-effects meta-analysis over 134 frontier model submissions to SWE-bench Verified finds, within the same human-rated difficulty stratum, model Pass@1 is +14.14 percentage points higher on flagged-hackable tasks than on robust ones (95% CI [+11.80, +16.48]; one-sided p < 10^-6; I^2 = 0%; 123 of 134 models positive). We then describe a procedure for hardening the broken tasks. An inline LLM judge with a Docker gold-sanity gate runs each generated test against the gold solution before the judge is consulted. On the 11 broken tasks in the audit, the gate flags 65 of 105 decisive LLM-generated tests as failing on the gold patch itself, a 61.9% per-augmentation defect rate the LLM judge alone misses. With diversity-biased retry, the loop converges 9 of 11 tasks to a gated upgrade.
Mind-Studio: 部分的に観察可能なゲームの先読み評価を備えた実行可能な世界モデル
ワールドモデル合成は、インタラクション経験を環境ダイナミクスの内部モデルに変えることを目的としています。既存のシンボリックなアプローチは、観察された遷移やローカル ルールの混合に適合することがよくありますが、実際の環境から独立して実行できる完全な実行可能プログラムは生成されません。私たちは、大規模な言語モデルを使用して、状態-アクション-次の状態の軌跡から実行可能な pygame スタイルの世界モデルを合成するフレームワークである Mind-Studio を紹介します。 Mind-Studio は、エントロピーで選択されたトレースを、スクリーンショットから抽出されたオブジェクト、アクション、静的シーン情報を含む軽量のゲーム スキル ファイルと組み合わせます。生成されたワールド モデル ロールアウトを同じ状態からの Real-ALE ロールアウトと比較する K ステップ先読み忠実度プロトコルを使用して合成品質を評価します。 Montezuma'sリベンジ では、Mind-Studio は 8 つのサブ目標のうち 5 つを検証しながら、選択されたアクションの次の状態の予測を PoE-World の 0.3% から 48.7% に改善しました。 Alien、Assault、Skiing にわたって、以前に学習された先読みソースよりも強力なブランチレベルの忠実度を実現します。
原文 (English)
Mind-Studio: Executable World Models with Lookahead Evaluation for Partially Observable Games
World-model synthesis aims to turn interaction experience into an internal model of environment dynamics. Existing symbolic approaches often fit observed transitions or mixtures of local rules, but they do not produce a complete executable program that can run independently of the real environment. We present Mind-Studio, a framework that synthesizes executable pygame-style world models from state-action-next-state trajectories using large language models. Mind-Studio combines entropy-selected traces with a lightweight game skill file containing object, action, and static scene information extracted from screenshots. We evaluate synthesis quality with a K-step lookahead fidelity protocol that compares generated world-model rollouts against Real-ALE rollouts from the same state. On Montezuma's Revenge, Mind-Studio improves chosen-action next-state prediction from 0.3% for PoE-World to 48.7% while verifying 5 of 8 subgoals; across Alien, Assault, and Skiing, it achieves stronger branch-level fidelity than prior learned lookahead sources.
深海のリズム:マッコウクジラのコーダにおけるパターン化の二重性の計算言語学的テスト
人間の言語は、2 つのレベルで構造を組み合わせているとよく説明されます。つまり、下位レベルの単位が結合して大きな単位になり、さらにその単位が結合してさらに大きなシーケンスになります。私たちは、ドミニカ マッコウクジラ プロジェクトの 1,483 個のコーダを使用して、マッコウクジラのコーダにおけるこのデザインの特徴であるパターンの二重性をテストします。音響的な類似性は記号構造を模倣する可能性があるため、この問題を言語や意味に関する直接的な主張としてではなく、連続音声からの計算による言語構造の発見として扱います。私たちは、フリーズされたオーディオ エンコーダー、保持された構造テスト、統計ごとのヌル、および音響ヌル回復可能性ゲートのコンセンサスを使用します。証拠は、狭い 2 層アーキテクチャを裏付けています。下位層では、クリックは安定した順序付けられた規則によってではなく、クリック間のリズムとともに存在することによってコーダを構成します。上位層では、コーダ トークンはバウトレベルの逐次依存性を示し、NSB の 2 次転送エントロピー リフトは 0.132 ビット (p = 0.002) です。テンポ スケーリングの下では、エンコーダ由来のクリック ID はレートに強く制限されますが、コーダ ID は実質的により安定したままであり、クリックからコーダまでのステップ全体で測定可能な抽象化勾配が得られます。リズムのみのベースラインは、実質的な下位層の構造を回復しますが、上位層の逐次依存信号を再現できません。私たちは言語、意味論、知覚、または人間に似た音素を主張しません。代わりに、下位層が部分的ではなくリズミカルであるパターン化のようなアーキテクチャの二重性の表現レベルの証拠を報告し、誘導音響トークン システムの組み合わせ構造をテストするための移植可能なヌル制御フレームワークを提供します。
原文 (English)
Rhythm of the Deep: A Computational-Linguistic Test of Duality of Patterning in Sperm Whale Codas
Human language has often been described as combining structure at two levels: lower-level units combine into larger units, which then combine into larger sequences. We test for this design feature, duality of patterning, in sperm whale codas using 1,483 codas from the Dominica Sperm Whale Project. Because acoustic similarity can imitate symbolic structure, we treat the problem as computational-linguistic structure discovery from continuous audio rather than as a direct claim about language or meaning. We use a consensus of frozen audio encoders, held-out structural tests, per-statistic nulls, and acoustic-null recoverability gates. The evidence supports a narrow two-tier architecture. At the lower tier, clicks compose into codas not by a stable ordered rule, but by which clicks are present together with their inter-click rhythm. At the upper tier, coda tokens show bout-level sequential dependence, with an NSB second-order transfer-entropy lift of 0.132 bits (p = 0.002). Under tempo scaling, encoder-derived click identity is strongly rate-bound, while coda identity remains substantially more stable, yielding a measurable abstraction gradient across the click-to-coda step. Rhythm-only baselines recover substantial lower-tier structure but fail to reproduce the upper-tier sequential-dependence signal. We do not claim language, semantics, perception, or human-like phonemes. Instead, we report representation-level evidence for a duality-of-patterning-like architecture whose lower tier is rhythmic rather than segmental, and provide a portable null-controlled framework for testing combinatorial structure in induced acoustic token systems.
RecourseBench: 再現可能なアルゴリズムによるリソース評価のためのモジュール式フレームワーク
アルゴリズムによる救済方法は、不利なモデル決定を覆すために必要な行動を個人に知らせる、反事実的な説明を提供します。方法論の急速な進歩にもかかわらず、原理的な比較は依然としてとらえどころのないものです。既存のフレームワークは拡張が困難であることが多く、相互運用性と、統合された手法で最初に報告された結果を忠実に再現する体系的な検証の両方が欠けています。私たちは、モジュール性、再現性、対話性という 3 つの取り組みを中心に構築された統合評価フレームワークである \emph{RecourseBench} を紹介します。このフレームワークは、パイプラインを完全に分離された 5 つのレイヤー (データ、前処理、モデル、リコース メソッド、評価) に分解し、抽象インターフェイスと動的レジストリによって管理されます。以前のベンチマークにおける再現性のギャップに対処するために、すべての統合メソッドが最初に報告された結果に対して自動テスト スイートによって検証される 4 層の分類システムを導入しました。さらに、メソッド、データセット、モデル アーキテクチャ間で柔軟な構成主導の比較を行うためのインタラクティブな Web インターフェイスも提供します。当社のフレームワークは現在、28 の最先端のリソースメソッドを統合しており、当社の知る限りでは、自動化された定量テストを通じてメソッドレベルの再現性を明示的に強化する最初のリソースベンチマークを構成しています。
原文 (English)
RecourseBench: A Modular Framework for Reproducible Algorithmic Recourse Evaluation
Algorithmic recourse methods provide counterfactual explanations that inform individuals of the actions required to overturn an unfavorable model decision. Despite rapid methodological progress, principled comparison remains elusive; existing frameworks are often difficult to extend and lack both interoperability and systematic verification that integrated methods faithfully reproduce their originally reported results. We introduce \emph{RecourseBench}, a unified evaluation framework built around three commitments namely, modularity, reproducibility, and interactivity. The framework decomposes the pipeline into five fully decoupled layers -- Data, Preprocessing, Model, Recourse Method, and Evaluation -- governed by abstract interfaces and a dynamic registry. To address the reproducibility gap in prior benchmarks, we introduce a four-tier classification system in which every integrated method is validated by an automated test suite against its originally reported results. We further provide an interactive web interface for flexible, configuration-driven comparison across methods, datasets, and model architectures. Our framework currently integrates 28 state-of-the-art recourse methods and, to our knowledge, constitutes the first recourse benchmark to explicitly enforce method-level reproducibility through automated, quantitative testing.
自分の限界を知る : 法的推論におけるソルバーおよびオートフォーマライザーとしての LLM の忠実性について
大規模言語モデル (LLM) は推論タスクで優れたパフォーマンスを実現しますが、これが忠実な論理推論を反映しているのか、それともヒューリスティックな近似を反映しているのかは不明のままです。私たちは、5 つの LLM にわたる ContractNLI の再注釈付きサブセットについて、純粋な LLM 分類、LLM ベースの形式的推論、Z3 SMT ソルバーを使用したソルバーベースの形式的推論を含む 3 つのパラダイムを比較することにより、法的含意におけるこの問題を研究します。私たちの再注釈は、実際的な法解釈と厳密な形式的含意の間に体系的かつ測定可能なギャップがあることを明らかにしており、そこでは、法的に健全な推論のかなりの部分が、追加の暗黙の仮定がなければ形式的に根拠づけられていません。形式的構造の導入により精度が向上し、LLM ベースの形式推論が最高のベンチマーク パフォーマンスを達成する一方で、この向上は忠実な推論を意味するものではないことを示します。我々は、3 つの繰り返し発生する障害モードを特定しました。スコープ ロンダリングでは、LLM が基礎となる形式的推論を実行せずにソルバーに一貫性のない分類を報告し、論理的に根拠があるように見えてもそうではない結論を導き出します。暗黙的な制約の盲目性。LLM は形式的な表現に存在する論理制約を見落とします。構造化されたプロンプトにもかかわらず、LLM が誤った Z3 コードを生成するプログラム合成の失敗。重要なことに、スコープ ロンダリングはすべてのモデルにわたって存続しており、記号実行のプロキシとしての LLM ベースの形式的推論の忠実性について深刻な懸念が生じています。これらの結果は、ベンチマークの精度と論理的忠実性の間に根本的なギャップがあることを明らかにしています。
原文 (English)
Know Your Limits : On the Faithfulness of LLMs as Solvers and Autoformalizers in Legal Reasoning
Large Language Models (LLMs) achieve strong performance on reasoning tasks, but whether this reflects faithful logical inference or heuristic approximation remains unclear. We study this question in legal entailment by comparing three paradigms, including pure LLM classification, LLM-based Formal Reasoning, and solver-based Formal Reasoning using the Z3 SMT solver, on a re-annotated subset of ContractNLI across five LLMs. Our re-annotation reveals a systematic and measurable gap between pragmatic legal interpretation and strict formal entailment, where a substantial proportion of legally sound inferences are not formally grounded without additional unstated assumptions. While introducing formal structure improves accuracy, with LLM-based Formal Reasoning achieving the highest benchmark performance, we show that this gain does not imply faithful reasoning. We identify three recurring failure modes: scope laundering, where LLMs report solver-inconsistent classifications without executing the underlying formal reasoning, producing conclusions that appear logically grounded but are not; implicit constraint blindness, where LLMs overlook logical constraints present in formal representations; and program synthesis failures, where LLMs generate incorrect Z3 code despite structured prompting. Critically, scope laundering persists across all models, raising serious concerns about the faithfulness of LLM-based formal reasoning as a proxy for symbolic execution. These results reveal a fundamental gap between benchmark accuracy and logical faithfulness.
視覚的な根拠を持って考える
視覚的な思考は、正しく聞こえるだけではありません。その証拠を示すべきだ。最近のビジョン言語モデル (VLM) は自然言語推論トレースを生成できますが、これらのトレースはサポートする画像領域を暗黙的に残すことが多く、検証や監視が困難になります。私たちは、モデルが自然言語思考と、各ステップで使用される視覚的証拠の明示的なポイントまたはボックス根拠を交互に配置する推論プロセスである、視覚的に根拠のある思考を導入します。これにより、モデルは、参照する画像領域内の主要なオブジェクトを基礎にしながら、中間推論を言語で表現できるようになります。この動作をトレーニングするために、正しい視覚的推論トレースを抽出し、トレースに必要な視覚オブジェクトを抽出し、SAM3 ベースのエージェントでそれらを基礎付けし、結果として得られるマスクから位置合わせされたポイントとボックスの監視を導き出す、スケーラブルな合成パイプラインを構築します。さらに、回答の正しさの報酬と、生成されたオブジェクト参照が正しい画像証拠と一致するかどうかをスコア化する高密度のグラウンディング報酬を組み合わせた、グラウンディングを意識した強化学習を提案します。 2 つの計数ベンチマークと 4 つの空間推論ベンチマークにわたって、Gemma3-4B-IT に視覚的に根拠のある思考を追加すると、元のモデルと非根拠のある思考のベースラインよりも一貫してパフォーマンスが向上します。空間推論に関しては、視覚に基づいた思考の 4B モデルは、同じモデル ファミリーの Gemma3-27B-IT と一致し、場合によってはそれを上回ります。私たちの分析によると、ポイントグラウンディングは数えるのに適しているのに対し、ボックスグラウンディングは空間タスクにおける明示的なグラウンディングの報酬から最も恩恵を受けることがわかりました。全体として、私たちの結果は、中間思考がそれを真実にする画像領域に結び付けられている場合に、VLM がよりよく考えることを示しています。
原文 (English)
Thinking with Visual Grounding
Visual thinking should not only sound right; it should show its evidence. While recent vision-language models (VLMs) can produce natural-language reasoning traces, these traces often leave the supporting image regions implicit, making them hard to verify and difficult to supervise. We introduce visually grounded thinking, a reasoning process in which models interleave natural-language thoughts with explicit point or box groundings of the visual evidence used at each step. This lets the model express intermediate reasoning in language while grounding key objects in the image regions they refer to. To train this behavior, we construct a scalable synthesis pipeline that distills correct visual reasoning traces, extracts the visual objects required by the traces, grounds them with a SAM3-based agent, and derives aligned point and box supervision from the resulting masks. We further propose grounding-aware reinforcement learning, which combines answer correctness rewards with dense grounding rewards that score whether generated object references match the correct image evidence. Across two counting benchmarks and four spatial reasoning benchmarks, adding visually grounded thinking to Gemma3-4B-IT consistently improves performance over the original model and the non-grounded thinking baseline. On spatial reasoning, the visually grounded thinking 4B models match, and in some cases surpass, Gemma3-27B-IT from the same model family. Our analysis shows that point grounding is well suited to counting, while box grounding benefits most from explicit grounding rewards on spatial tasks. Overall, our results show that VLMs think better when their intermediate thoughts are tied to the image regions that make them true.
VibeThinker-3B: 小さな言語モデルにおける検証可能な推論のフロンティアを探索する
この技術レポートでは、厳密に小規模なモデル領域内で検証可能な推論をどこまで推し進めることができるかを調査するために開発された、3B パラメーターを備えたコンパクトな密集モデルである VibeThinker-3B を紹介します。スペクトルから信号へのポストトレーニング パラダイムに基づいて、カリキュラムベースの教師あり微調整、マルチドメイン強化学習、オフライン自己蒸留を含む最適化されたパイプラインを通じてモデルを体系的に強化します。実験による評価では、VibeThinker-3B が要求の厳しい検証可能なタスクにおいてフロンティア レベルのパフォーマンスを達成することが実証されています。具体的には、AIME26 で 94.3 のスコア (クレーム レベルのテスト時間スケーリングにより 97.1 に改善)、LiveCodeBench v6 で 80.2 Pass@1 を達成し、最近の未見の LeetCode コンテストでは 96.1\% の受け入れ率で強力な配布外一般化を示しています。これにより、事実上、DeepSeek V3.2、GLM-5、Gemini 3 Pro など、桁違いに大きいフラッグシップ モデルと同等またはそれを上回る、第 1 層推論システムのパフォーマンス帯域に位置付けられます。さらに、IFEval のスコア 93.4 は、この極端な推論の強化によって厳密な命令の制御性が損なわれないことを裏付けています。以前の 1.5B の研究を拡張して、これらの発見は、検証可能な推論をコンパクトな推論コアに圧縮できるとみなすパラメトリック圧縮カバレッジ仮説の動機付けとなる一方、オープンドメインの知識と汎用能力には、事実、概念、ロングテール シナリオにわたる広範なパラメータ カバレッジが必要です。この観点からは、コンパクト モデルは単に展開効率の高い代替品ではなく、パラメータが密な機能領域におけるフロンティア レベルのパフォーマンスに向けた補完的な道であることが示唆されます。
原文 (English)
VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
This technical report introduces VibeThinker-3B, a compact dense model with 3B parameters developed to investigate how far verifiable reasoning can be pushed within a strictly small-model regime. Building upon the Spectrum-to-Signal post-training paradigm, we systematically enhance the model through an optimized pipeline that includes curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation. Experimental evaluations demonstrate that VibeThinker-3B achieves frontier-level performance on highly demanding verifiable tasks. Specifically, it attains a score of 94.3 on AIME26 (improving to 97.1 with claim-level test-time scaling), an 80.2 Pass@1 on LiveCodeBench v6, and exhibits strong out-of-distribution generalization with a 96.1\% acceptance rate on recent unseen LeetCode contests. This effectively places it in the performance band of first-tier reasoning systems, matching or exceeding flagship models that are orders of magnitude larger, such as DeepSeek V3.2, GLM-5, and Gemini 3 Pro. Furthermore, a score of 93.4 on IFEval confirms that this extreme reasoning enhancement does not compromise strict instruction controllability. Extending our previous 1.5B work, these findings motivate the Parametric Compression-Coverage Hypothesis, which views verifiable reasoning as compressible into compact reasoning cores, while open-domain knowledge and general-purpose competence require broad parameter coverage over facts, concepts, and long-tail scenarios. This perspective suggests that compact models are not merely deployment-efficient substitutes, but a complementary path toward frontier-level performance in parameter-dense capability regimes.
LiteOdyssey: 解釈可能な希少疾患診断のための軽量推論 AI エージェント
ほとんどの医療 AI システムは、より多くの微調整データ、より多くのエージェント、および/またはより大規模な検索データベースなど、追加の機械を拡張することで改善されます。ただし、希少疾患の診断では、このような拡張により、展開、監査、保守が困難なシステムが生成される可能性があります。私たちは、単一の AI エージェントの推論チェーンを拡張することによって、つまり人間と AI のコラボレーションによって開発された診断ポリシーでエージェントを導き、自由に利用できる生物医学ツールを拡張することによって、最先端の診断パフォーマンスを実現できるかどうかを尋ねました。臨床遺伝学のワークフローを通じて推論言語モデルをガイドする軽量の希少疾患診断フレームワークである LiteOdyssey を紹介します。このフレームワークは、Policy Iteration with Human Feedback (PIHF) を通じて開発され、公共の生物医学ツールへの動的なアクセスを使用します。患者の臨床的特徴のみを提供する 2 つの困難なベンチマークで、LiteOdyssey は最先端のパフォーマンスを達成し、LIRICAL (n = 370) と PhenoPacket Store (n = 873) の合計 1,243 症例を上回る 59.3% の全体的な疾患再現率 @1 を達成しました。どちらのベンチマークも、超希少疾患の割合が高くなります (有病率は 100 万人に 1 人未満、超希少疾患の割合はそれぞれ約 45% と 52.8%)。希少性マッピング パイプラインで原因疾患が Orphanet にマッピングされなかった、より困難な PhenoPacket サブセットでは、LiteOdyssey は 60.7% の再現率 (1) を達成しました。これに対し、ツールを使用しない同じベースライン モデル (GPT-5.4) では 10.7% でした。このパフォーマンスは、微調整、マルチエージェント アンサンブル、または大規模な症例検索データベースを使用せずに達成されました。また、開発中に見られなかった症例、現実世界の希少疾患患者のプライベートコホート、およびより小規模な無重力モデルでも利益が観察されました。 LiteOdyssey は、正確で導入が容易で、医師のレビューがより透明性の高い希少疾患 AI システムへの道を提案します。
原文 (English)
LiteOdyssey: A Lightweight Reasoning AI Agent for Interpretable Rare-Disease Diagnosis
Most medical AI systems improve by scaling additional machinery: more fine-tuning data, more agents, and/or larger retrieval databases. In rare-disease diagnosis, however, such scaling can produce systems that are difficult to deploy, audit, and maintain. We asked whether state-of-the-art diagnostic performance could instead be achieved by extending the reasoning chain of a single AI agent: guiding it with a diagnostic policy, developed through human-AI collaboration and augmenting with freely available biomedical tools. We introduce LiteOdyssey, a lightweight rare-disease diagnostic framework that guides reasoning language model through a clinical genetics workflow. This framework was developed through Policy Iteration with Human Feedback (PIHF) and uses dynamic access to public biomedical tools. On two challenging benchmarks that provide only patient clinical features, LiteOdyssey achieved state-of-the-art performance, with an overall disease Recall@1 of 59.3% over the combined 1,243 cases of LIRICAL (n = 370) and the PhenoPacket Store (n = 873). Both benchmarks have a high proportion of ultra-rare disease (a prevalence below 1 in 1,000,000, with ultra-rare shares of approximately 45% and 52.8%, respectively). On the more difficult PhenoPacket subset, where causal diseases were not mapped to Orphanet in our rarity-mapping pipeline, LiteOdyssey achieved 60.7% Recall@1, compared with 10.7% for the same baseline model (GPT-5.4) without tools. This performance was achieved without fine-tuning, multi-agent ensembles, or a large case-retrieval database. Gains were also observed in the following: on cases never seen during development, on a private cohort of real-world rare disease patients, and on a smaller open-weights model. LiteOdyssey suggests a path toward rare-disease AI systems that are accurate, easier to deploy, and more transparent for physician review.
品質と効用のパラドックス: なぜ高報酬データが小規模モデルの数学的推論を損なうのか
強力な推論モデルからの知識の蒸留は、数学的推論に関する小型言語モデル (SLM) を改善するために広く使用されており、多くの場合、より高い報酬モデル スコアを持つトレースがより有用な監視を提供すると想定されています。私たちは、数学的推論の蒸留において直観に反する \textbf{品質と効用のパラドックス} を特定しました。より強力な Oracle によって精製または合成されたデータは、報酬モデルに従ってより高い知覚品質を獲得しますが、SLM 自体によって生成され、Qwen2.5、LLaMA-3、および DeepSeek ファミリ全体の拒否サンプリングによって選択されたトレースよりも一貫してパフォーマンスを下回ります。私たちの分析は、Oracle の改良により、論理修復と SLM のネイティブ推論分布からの分布ドリフトが結びついていることを示しています。このドリフトにより学習者の適応コストが増加し、推論ロジックの改善によるメリットを上回る可能性があります。このメカニズムをテストするために、Oracle からの論理修復を保持しながら、SLM のネイティブな軌道を保存する \textbf{Style-Aligned Refinement} を導入します。この介入により、適応コストが削減され、下流の効用が回復します。これらの発見は、効果的な数学的推論の抽出では、報酬モデルのスコアのみに依存するのではなく、知覚される解の品質と学習者データの互換性を共同で最適化する必要があることを示唆しています。データセットとコードは https://github.com/Dracoqhl/Quality-Utility-Paradox で入手できます。
原文 (English)
The Quality-Utility Paradox: Why High-Reward Data Impairs Small Model Mathematical Reasoning
Knowledge distillation from powerful reasoning models is widely used to improve Small Language Models (SLMs) on mathematical reasoning, often assuming that traces with higher reward model scores provide more useful supervision. We identify a counterintuitive \textbf{Quality-Utility Paradox} in mathematical reasoning distillation. Data refined or synthesized by a stronger Oracle obtains higher perceived quality according to reward models, yet consistently underperforms traces generated by the SLM itself and selected through rejection sampling across Qwen2.5, LLaMA-3, and DeepSeek families. Our analysis shows that Oracle refinement couples logical repair with distributional drift away from the SLM's native reasoning distribution. This drift increases the learner's adaptation cost and can outweigh the benefit of improved reasoning logic. To test this mechanism, we introduce \textbf{Style-Aligned Refinement}, which preserves the native trajectory of the SLM while retaining logical repair from the Oracle. This intervention lowers adaptation cost and restores downstream utility. These findings suggest that effective mathematical reasoning distillation should jointly optimize perceived solution quality and learner-data compatibility, rather than relying solely on reward-model scores. The datasets and code are available at https://github.com/Dracoqhl/Quality-Utility-Paradox.
AI 多元主義と AI が見逃している世界
AI の多元性は、多くの場合、多様な価値観、好み、ユーザー、または出力を表す問題として組み立てられます。この論文は、AI システムもオントロジーを課すため、この枠組みは不完全であると主張します。AI システムは、エンティティ、関係、特徴、害、利益、証拠の有効な形式としてカウントされるものを定義します。私たちは、存在論的平坦化を、状況に応じて競合し、歴史的に特定された意味を、中立的で競合が難しいものとして扱われる、制限された技術カテゴリ、プロキシ、集約ルール、またはベンチマークターゲットに変換することと定義します。この論文は、価値多元主義、多元主義的調整、参加型および民主的 AI、手続き的正義、科学技術研究、説明責任研究、11 件の専門家インタビューからの集約テーマ、および 3 つの都市型 AI コンパニオン ケースにわたる、限定された概念的かつ定性的な統合を開発しています。これらの事例は、影響を受けるアクターが手続き上の地位を確立する前に、多元的手法がカテゴリ、プロキシ、集計ルール、および改訂権限を圧縮しながら、モデルの動作をどのように改善または構造化できるかを示しています。存在論的公開性、認識論的包含、手続き上の権限、評価の多元性、ライフサイクルの説明責任を文書化するための予備的な定性的監査足場として、多元的ライフサイクル ガバナンス (PLG) を導入します。 PLG は検証されたスコアリング手段としては提示されていません。これは、多元的 AI の証拠とガバナンス条件を明示するためのフレームワークです。
原文 (English)
AI Pluralism and the Worlds It Misses
AI pluralism is often framed as a problem of representing diverse values, preferences, users, or outputs. This paper argues that this framing is incomplete because AI systems also impose ontologies: they define what counts as an entity, relation, feature, harm, benefit, and valid form of evidence. We define ontological flattening as the conversion of situated, contested, and historically specific meanings into a restricted technical category, proxy, aggregation rule, or benchmark target that is treated as neutral and difficult to contest. The paper develops a bounded conceptual and qualitative synthesis across value pluralism, pluralistic alignment, participatory and democratic AI, procedural justice, science and technology studies, accountability research, aggregate themes from 11 expert interviews, and three urban AI companion cases. The cases illustrate how pluralistic methods can improve or structure model behavior while still compressing categories, proxies, aggregation rules, and revision rights before affected actors have procedural standing. We introduce Pluralistic Lifecycle Governance (PLG) as a preliminary qualitative audit scaffold for documenting ontological openness, epistemic inclusion, procedural authority, evaluation pluralism, and lifecycle accountability. PLG is not presented as a validated scoring instrument; it is a framework for making the evidence and governance conditions of pluralistic AI explicit.
TimeVista: 時系列予測の判断材料として視覚言語モデルを探索および活用する
高品質の時系列予測は、現実世界の意思決定にとって極めて重要です。しかし、従来のポイントごとのメトリクスは、複雑な時間的パターンを明らかにできず、人間の直感的な好みとうまく一致しないことがよくあります。 「LLM-as-a-Judge」パラダイムは、柔軟で人間に合わせた判断を提供することでテキスト評価に革命をもたらしましたが、時系列への適用はほとんど未踏のままです。この論文では、視覚言語モデル (VLM) を時系列予測の判断者として活用し、テキスト情報に基づいた時系列プロットを理解する能力を活用します。具体的には、時系列予測を評価するために、コンテキスト情報に基づいたミクロレベルとマクロレベルの判断を統合する新しいフレームワークを提案します。この目的を達成するために、詳細な評価ルーブリックと組み合わせられた 5563 の時系列サンプルで構成される包括的な VLM-as-a-Judge ベンチマークである TimeVista を導入します。広範なメタ評価は、VLM が信頼性の高い判断者であり、従来の指標よりも人間の好みとの一貫性が大幅に高いことを示しています。ベンチマークに基づいて、VLM-as-a-Judge パラダイムに基づいて最近の Time Series Foundation Model (TSFM) を包括的に評価します。私たちの結果は、VLM が堅牢で解釈可能な判断者として機能し、時系列モデルを評価するための包括的で人間に合わせた標準を提供することを示しています。
原文 (English)
TimeVista: Exploring and Exploiting Vision-Language Models as Judges for Time Series Forecasting
High-quality time series forecasting is pivotal for real-world decision-making. However, traditional point-wise metrics often fail to reveal complex temporal patterns and align poorly with human intuitive preferences. While the ''LLM-as-a-Judge'' paradigm has revolutionized text evaluation by providing flexible, human-aligned judgment, its application to time series remains largely unexplored. In this paper, we leverage Vision-Language Models (VLMs) as judges for time series forecasting, harnessing their ability to comprehend time series plots grounded in textual information. Specifically, we propose a novel framework integrating micro- and macro-level judgments informed by contextual information to evaluate time series forecasting. To this end, we introduce TimeVista, a comprehensive VLM-as-a-Judge benchmark comprising 5563 time series samples paired with detailed evaluation rubrics. Extensive meta-evaluations demonstrate that VLMs are highly reliable judges, achieving significantly higher consistency with human preferences than conventional metrics. Building upon our benchmark, we comprehensively assess recent Time Series Foundation Models (TSFMs) under the VLM-as-a-Judge paradigm. Our results demonstrate that VLMs serve as robust and interpretable judges, providing a comprehensive, human-aligned standard for evaluating time series models.
PAL ベンチ: 縦断的な個人アルバムからの証拠に基づいたプロファイルの再構築
長期的な個人アルバムは、弱いスキーマのマルチモーダル データベースです。つまり、主要な事実が顔、テキスト、タイムスタンプ、場所、および繰り返されるイベントにわたる結合を必要とするノイズの多い知覚記録です。既存のビジュアル、ビデオ、ドキュメント、およびライフログのベンチマークは、サブ問題をテストしますが、社会的アイデンティティのバインディングと証拠の引用によるアルバム規模のプロファイルの再構築はテストしません。このタスクのベンチマークは、評価に必要なグラウンド トゥルース (所有者のプロフィール、ソーシャル グラフ、顔と名前のマップ、証拠の出所) が非公開の状態であり、実際のアルバムでは安全に公開できないため、困難です。公的記録契約に基づく証拠に基づく再構成のための管理されたベンチマークである PAL-Bench を紹介します。その Evidence Compiler は、潜在的なプライベートワールドを構築し、ターゲットレベルの証拠パスをプログラムし、アルバムピクセルをレンダリングし、認識パイプラインを通じてそれらを再測定し、監査されたパブリック/プライベートビューをエクスポートします。エージェントは認識に基づいた公的記録のみを受け取ります。ターゲット、識別子マップ、証拠パスは隠されたままになります。 PAL-Bench には、50 人の合成ユーザー、36,659 枚の公開写真記録、および所有者の事実、身元、および関係に関する 2,799 件のターゲットが含まれています。 10 人の参加者によるプライバシー保護監査により、PAL ベンチの証拠構造が実際のプライベート アルバムと一致することが確認されましたが、同等のリリースは依然としてプライバシーを禁止しています。 7 つのシステムと 2 つのコンピューティング一致診断にわたって、7 メトリックのプロトコルは、もっともらしいプロファイルの要約と忠実な社会再構成との間にギャップがあることを明らかにします。システムは所有者の事実をいくつか回復しますが、繰り返されるアイデンティティと証拠の引用に苦労しています。 PAL-TRACE は、所有者ファクト マイニングの前に ID バインディングを凍結する参照フレームワークであり、最高のパフォーマンスを発揮しますが、厳密な ID 解決は解決にはほど遠い状態です。 PAL-Bench は、知覚的エンティティの解決、マルチモーダル データ統合、時間的証拠の集約、出所を意識した構造化予測のためのテストベッドを提供します。
原文 (English)
PAL-Bench: Evidence-Grounded Profile Reconstruction from Longitudinal Personal Albums
Longitudinal personal albums are weak-schema multimodal databases: noisy perceptual records whose key facts require joins across faces, text, timestamps, locations, and repeated events. Existing visual, video, document, and lifelog benchmarks test sub-problems, but not album-scale profile reconstruction with social identity binding and evidence citation. Benchmarking this task is difficult because the ground truth needed for evaluation--owner profiles, social graphs, face-name maps, and evidence provenance--is private state that real albums cannot safely release. We introduce PAL-Bench, a controlled benchmark for evidence-grounded reconstruction under a public-record contract. Its Evidence Compiler builds latent private worlds, programs target-level evidence paths, renders album pixels, re-measures them through perception pipelines, and exports audited public/private views. Agents receive only perception-derived public records; targets, identifier maps, and evidence paths remain hidden. PAL-Bench contains 50 synthetic users, 36,659 public photo records, and 2,799 targets over owner facts, identities, and relations. A privacy-preserving audit with 10 participants confirms that PAL-Bench evidence structures match real private albums, though equivalent releases remain privacy-prohibitive. Across seven systems and two compute-matched diagnostics, a seven-metric protocol reveals a gap between plausible profile summarization and faithful social reconstruction: systems recover some owner facts but struggle with recurring identities and evidence citation. PAL-TRACE, a reference framework that freezes identity bindings before owner-fact mining, performs best but leaves hard identity resolution far from solved. PAL-Bench provides a testbed for perceptual entity resolution, multimodal data integration, temporal evidence aggregation, and provenance-aware structured prediction.
LLM 講師が教えるか解決するかを測定する: 教育効果の診断
大規模な言語モデルが教育講師として提案されることが増えていますが、より強力な課題解決能力は必ずしもより強力な学習サポートを意味するわけではありません。実際の NLP システムの社会的影響を測定するという最近の呼びかけに動機付けられ、私たちは、公開 LLM 個別指導ベンチマークが学習支援行動と単なる解答生成を区別するかどうかを研究しています。私たちは、解決指向のベンチマーク パフォーマンスと教育指向のベンチマーク パフォーマンスの間のギャップに基づいた軽量の診断を提案します。公開されている MathTutorBench リーダーボードの結果を使用して、これらの次元が部分的にのみ一致していることを示します。公開されている 8 つのモデル全体で、解決と教育学の複合間の相関関係は 0.421 であり、評価が解決から教育に移行すると、いくつかのモデルのランクが有意にシフトします。次に、公開されている TutorBench サンプルを分析し、特に指導的な質問、調整されたヒント、および非公開の足場に報酬を与えるアクティブ ラーニング設定において、政府機関に関連する行動がベンチマーク ルーブリックに明示的にエンコードされていることを示します。これらの調査結果を総合すると、教育効果評価は課題の成功を学習支援の十分な代用として扱うべきではないことを示唆しています。私たちは、公立家庭教師のベンチマークは、解決指向のスコアと教育学指向のスコアを別々に報告し、開示に配慮した学生機関の保護基準をより明確にすることによって、プラスの影響の評価をより適切にサポートできると主張します。
原文 (English)
Measuring Whether LLM Tutors Teach or Solve: A Diagnostic for Educational Impact
Large language models are increasingly proposed as educational tutors, yet stronger task-solving ability does not necessarily imply stronger learning support. Motivated by recent calls to measure the social impact of NLP systems in practice, we study whether public LLM tutoring benchmarks distinguish learning-supportive behavior from mere answer production. We propose a lightweight diagnostic based on the gap between solving-oriented and pedagogy-oriented benchmark performance. Using public MathTutorBench leaderboard results, we show that these dimensions are only partially aligned: across eight publicly reported models, the correlation between solving and pedagogy composites is 0.421, and several models shift meaningfully in rank when evaluation moves from solving to pedagogy. We then analyze the public TutorBench sample and show that agency-relevant behaviors are explicitly encoded in benchmark rubrics, especially in active-learning settings that reward guiding questions, calibrated hints, and non-disclosive scaffolding. Together, these findings suggest that educational-impact evaluation should not treat task success as a sufficient proxy for learning support. We argue that public tutoring benchmarks can better support positive-impact evaluation by reporting solving-oriented and pedagogy-oriented scores separately and by making disclosure-sensitive, student-agency-preserving criteria more explicit.
シーン関連の観察指数によるセンサー条件付き表現の学習
インテリジェントセンシングシステムにおける学習された表現は、多くの場合、再構成の忠実度や下流の予測精度によって評価されますが、これらの基準は、どの潜在的な区別がセンシングプロセスによって正当化されるかを指定するものではありません。センサーで調整された環境では、迷惑要因によってシーンが変化しなくても測定値が変化する可能性がありますが、限られたセンシング能力では個別のシーンが区別できない場合があります。この論文では、センサー条件付き表現の正確性を、迷惑なセンサーによる変動やセンサーによるサポートのない変動を抑制しながら、センシングによってサポートされるシーンの区別を維持するものとして定式化します。我々は、迷惑正規化後のセンシングに支援された識別可能性によって引き起こされる表現ターゲットであるシーン関連観察指数を導入し、誤った区別、誤ったマージ、迷惑感度、および潜在的な順序付け一貫性の診断を備えたシーン迷惑因数分解フレームワークであるObservation-Quotient Tucker-Structured Autoencoding(OQ-TSAE)を開発します。制御されたベンチマークの実験では、商一貫性のある監視により、再構成指向、計量学習、および対照学習のベースラインよりも表現の正確性の診断が向上することが示されています。感度、摂動、およびアブレーションの研究は、商に合わせた監視、信頼できる商の関係、および商の幾何学の重要性を示しています。補完的なリアルレーダー実験により、再構築のみの OQ-TSAE バリアントが、競争力のある下流での有用性、観測劣化下での堅牢性、およびシード間の変動性が低いことが示されています。これらの結果は、センサー条件付き表現は、予測の有用性によってだけでなく、その潜在幾何学がセンシングに正当化されたシーンの区別を保持しているかどうかによっても評価されるべきであることを示唆しています。
原文 (English)
Sensor-Conditioned Representation Learning via Scene-Relevant Observation Quotients
Learned representations in intelligent sensing systems are often evaluated by reconstruction fidelity or downstream prediction accuracy, but these criteria do not specify which latent distinctions are justified by the sensing process. In sensor-conditioned environments, nuisance factors can change measurements without changing the scene, while distinct scenes may be indistinguishable under limited sensing capability. This paper formulates sensor-conditioned representation correctness as preserving sensing-supported scene distinctions while suppressing nuisance-induced and sensor-unsupported variation. We introduce the scene-relevant observation quotient, a representation target induced by sensing-supported distinguishability after nuisance canonicalization, and develop Observation-Quotient Tucker-Structured Autoencoding (OQ-TSAE), a scene-nuisance factorized framework with diagnostics for false distinction, false merge, nuisance sensitivity, and latent ordering consistency. Experiments on a controlled benchmark show that quotient-consistent supervision improves representation-correctness diagnostics over reconstruction-oriented, metric-learning, and contrastive-learning baselines. Sensitivity, perturbation, and ablation studies show the importance of quotient-aligned supervision, reliable quotient relations, and quotient geometry. Complementary real-radar experiments show that a reconstruction-only OQ-TSAE variant retains competitive downstream utility, robustness under observation degradation, and low seed-to-seed variability. These results suggest that sensor-conditioned representations should be evaluated not only by predictive utility, but also by whether their latent geometry preserves sensing-justified scene distinctions.
潜在的思考フロー: 大規模言語モデルにおける効率的な潜在的推論
大規模言語モデル (LLM) は中間推論への依存度が高まっていますが、明示的な思考連鎖 (CoT) は言語空間のボトルネックに悩まされています。つまり、各思考をトークンにデコードする必要があり、推論のオーバーヘッドが高くなります。潜在的推論は熟考を連続空間に移しますが、既存の手法は主に決定論的または報酬を最大化する経路を学習し、正確性とコストが異なる軌道全体に確率を割り当てる原則的な方法を欠いています。私たちは潜在思考フロー (LTF) を提案します。これは、推論を可変長の連続軌跡としてモデル化し、報酬誘発の事後分布と回答の品質と計算コストを一致させるようにサンプラーをトレーニングします。確率的潜在遷移を使用して、連続的な GFlowNet でこれをインスタンス化します。スパースな回答の監視を処理するために、中間報酬用のエントロピー加重サブ軌道バランス目標と、探索をアンカーするための参照事前正則化を導入します。微調整および転移学習設定での実験では、LTF が明示的 CoT および潜在推論ベースラインよりも優れたパフォーマンスを示し、強力な潜在推論ベースラインと比較して、精度が 9.5% 向上し、推論の長さが平均 27.2% 短縮されたことが示されています。
原文 (English)
Latent Thought Flow: Efficient Latent Reasoning in Large Language Models
Large Language Models (LLMs) increasingly rely on intermediate reasoning, yet explicit Chain-of-Thought (CoT) suffers from a linguistic space bottleneck: each thought must be decoded into tokens, causing high inference overhead. Latent reasoning moves deliberation into continuous space, but existing methods mostly learn deterministic or reward-maximizing paths, lacking a principled way to allocate probability across trajectories with different correctness and costs. We propose Latent Thought Flow (LTF), which models reasoning as variable-length continuous trajectories and trains a sampler to match a reward-induced posterior over answer quality and computation cost. We instantiate this with a continuous GFlowNet using stochastic latent transitions. To handle sparse answer supervision, we introduce an Entropy-Weighted Subtrajectory Balance objective for intermediate rewards and a reference-prior regularizer to anchor exploration. Experiments under finetuning and transfer learning settings show that LTF outperforms explicit CoT and latent reasoning baselines, improving accuracy by 9.5% while reducing reasoning length by 27.2% on average compared with strong latent reasoning baselines.
SpecAlign: 合成データによる大規模言語モデルの仕様に基づいた効率的な調整
大規模言語モデル (LLM) が現実世界のアプリケーションに導入されることが増えているため、整合性はもはや安全性や有用性という単一の普遍的な概念によって管理されるのではなく、プロバイダーまたはアプリケーション固有のモデル仕様によって管理されています。これらの仕様は通常、長く、構造化されており、頻繁に更新されますが、既存の調整パイプラインには、それらをトレーニング信号として運用する体系的なメカニズムがありません。このペーパーでは、仕様に基づいたアライメントを提案します。これは、抽象的な原則や静的なベンチマークではなく、プロバイダーが作成したモデル仕様を主要なアライメント ターゲットとして扱う新しいアライメント パラダイムです。このパラダイムを具体化するために、仕様書から直接アライメント データを合成するフレームワークである SpecAlign を導入します。 SpecAlign は、構造化ルールのアノテーション、制御可能な仕様のインスタンス化、およびマルチエージェントの敵対的データ合成を組み合わせて、準拠した動作と意味のある仕様違反の両方を捕捉する、きめ細かい境界を意識した設定ペアを生成します。複数のモデル仕様とバックボーン モデルにわたる実験では、SpecAlign を使用したトレーニングにより、一般的な機能を維持し、過度に保守的な動作を回避しながら、ルールへの準拠性が一貫して向上することが実証されています。これらの結果は、明示的なモデル仕様における基本的な調整により、進化するポリシー要件に対する LLM の動作の迅速、正確、スケーラブルな適応が可能になることを示唆しています。
原文 (English)
SpecAlign: Efficient Specification-Grounded Alignment of Large Language Models via Synthetic Data
As large language models (LLMs) are increasingly deployed in real-world applications, alignment is no longer governed by a single universal notion of safety or helpfulness, but instead by provider- or application-specific model specifications. These specifications are typically long, structured, and frequently updated, yet existing alignment pipelines lack a systematic mechanism to operationalize them as training signals. In this paper, we propose specification-grounded alignment, a new alignment paradigm that treats provider-authored model specifications as the primary alignment target rather than abstract principles or static benchmarks. To instantiate this paradigm, we introduce SpecAlign, a framework that synthesizes alignment data directly from specification documents. SpecAlign combines structured rule annotation, controllable specification instantiation, and multi-agent adversarial data synthesis to generate fine-grained, boundary-aware preference pairs that capture both compliant behaviors and meaningful specification violations. Experiments across multiple model specifications and backbone models demonstrate that training with SpecAlign consistently improves rule compliance while preserving general capabilities and avoiding over-conservative behavior. These results suggest that grounding alignment in explicit model specifications enables rapid, precise, and scalable adaptation of LLM behavior to evolving policy requirements.
ツール拡張 LLM 向けのステートベースのマルチエージェント合成データ生成
ツールで強化された LLM エージェントのトレーニングには、アノテーションを付けるのにコストがかかり、本番環境ではプライバシーに制限があり、公開データセットにはほとんど存在しない、マルチターンのツールベースの会話データの大規模なコーパスが必要です。本稿では、ペルソナ条件付きユーザー シミュレーター、テスト対象エージェント、状態ベースのツール シミュレーター、多軸 LLM ジャッジという 4 つの役割の LLM ループを調整することで、スコア付きの推論トレースが豊富なトレーニング会話を生成する合成データ生成プラットフォームである StateGen を紹介します。主要なアーキテクチャ上の貢献は、ターン全体にわたって構造化された世界状態オブジェクトを維持し、構築によってツール呼び出し幻覚の主要なクラスを排除するバックエンドが真実である不変条件を強制する権威ある状態マネージャーです。 StateGen は、サブエージェントをツールとして宣言し、すべてが 1 つの状態オブジェクトを共有することで、階層的なマルチエージェント設定に自然に拡張されます。 3 つの実稼働コーパスにわたる 64,698 件の評価済み会話の結果を報告します。ツール呼び出し幻覚スコアは 9.66/10 に達し、システムは 23 次元の特性ベクトルを介してペルソナ主導の変動をサポートし、きれいに分離されたトレインとゴールデン評価セットの分割により、データが記憶の餌ではないことが確認されます (基準ごとのギャップ分析)。 8 つの外部システムと比較すると、マルチターン生成、状態ベースのツール シミュレーション、階層型マルチエージェント サポート、および組み込みのジャッジ スコアリングを組み合わせた単一の公的に利用可能なプラットフォームがないことがわかります。
原文 (English)
State-Grounded Multi-Agent Synthetic Data Generation for Tool-Augmented LLMs
Training tool-augmented LLM agents requires large corpora of multi-turn, tool-grounded conversational data that is expensive to annotate, privacy-constrained in production settings, and largely absent from public datasets. We present StateGen, a synthetic data generation platform that produces scored, reasoning-trace-rich training conversations by orchestrating a four-role LLM loop: a persona-conditioned user simulator, an agent under test, a state-grounded tool simulator, and a multi-axis LLM judge. The key architectural contribution is an authoritative state manager that maintains a structured world-state object across turns, enforcing a backend-is-truth invariant that eliminates the dominant class of tool-call hallucinations by construction. StateGen extends naturally to hierarchical multi-agent settings by declaring sub-agents as tools, all sharing a single state object. We report results on 64,698 evaluated conversations across three production corpora: tool-call hallucination scores reach 9.66/10, the system supports persona-driven variation via a 23-dimensional trait vector, and a cleanly separated train and golden evaluation set split confirms the data is not memorization bait (per-criterion gap analysis). Comparison with eight external systems shows that no single publicly available platform combines multi-turn generation, state-grounded tool simulation, hierarchical multi-agent support, and built-in judge scoring.
アーキテクチャの知恵: AI システムの最適化を管理するためのフレームワーク
最新の AI システムには、機能のスケーリングだけでは確実に修正できない構造的な欠陥が見られます。つまり、目標を最適化する必要があるかどうかを問うためのアーキテクチャ メカニズムがまったくなく、過少に指定された目標が最適化されます。エンゲージメントを最大化すると、有害な経路が増幅される可能性があります。ツールを使用するエージェントは、取り消しできないアクションを実行する可能性があります。好みによって訓練された言語モデルはおべっかになる可能性があります。私たちは、この失敗は知性の問題ではなく、知恵の問題であると主張します。私たちは「知恵」を、美徳、意識、道徳的全知についての主張としてではなく、意図的に構築された意味で使用します。インテリジェンスは目標を受け入れ、その中で最適化します。知恵は、そもそも目標を最適化する必要があるかどうかを疑問視します。 2 つは分離可能な建築上のプロパティです。私たちは、最適化基盤の上にある修正可能な目標ガバナンス層としてのアーキテクチャ上の知恵を提案します。この層は、アクションの前に、時間的範囲、関係境界、および不可逆性という 3 つの構造的コミットメントを明示的かつ非退化的に行います。これは、水平線、関係範囲、不可逆性、許容性、価値修正、および監査可能性にわたる 6 座標の知恵タプルを計算する 4 つのコンポーネント (構造ユーティリティ変換、道徳的許容性インターフェイス、仲裁およびエスカレーション コントローラー、価値修正チャネル) によって実現されます。私たちは、現代の AI の失敗、世俗的な知恵の伝統、厳しい倫理的状況から引き出された 8 つのケースによってアーキテクチャを動機づけ、目標獲得よりも目標を問うこと、ボストロムの直交性、模範的なケースにおける構造的分離、および能力のスケーリングにもかかわらず永続的な故障モードを使用して、知能完全性のテーゼに対する区別を擁護します。フレームワークは、その後の作業で正式な仕様と経験的検証が開発される、より大きなアーキテクチャのための概念的な契約です。
原文 (English)
Architectural Wisdom: A Framework for Governing Optimization in AI Systems
Modern AI systems exhibit structural failures that capability scaling alone does not reliably fix: they optimize under-specified objectives with no architectural mechanism to question whether the objective should be optimized at all. Engagement maximization can amplify harmful pathways; tool-using agents can commit irreversible actions; preference-trained language models can become sycophantic. We argue that this failure is a wisdom problem, not an intelligence problem. We use "wisdom" in a deliberately architectural sense, not as a claim about virtue, consciousness, or moral omniscience. Intelligence accepts a goal and optimizes within it; wisdom interrogates whether the goal should be optimized at all. The two are separable architectural properties. We propose architectural wisdom as a corrigible objective-governance layer above the optimization substrate. The layer makes three structural commitments explicit and nondegenerate before any action: temporal horizon, relational boundary, and irreversibility. It is realized by four components (Structural Utility Transform, Moral Admissibility Interface, Arbitration and Escalation Controller, Value Revision Channel) that compute a six-coordinate wisdom tuple over horizon, relational coverage, irreversibility, admissibility, value revision, and auditability. We motivate the architecture by eight cases drawn from contemporary AI failures, secular wisdom traditions, and hard ethical situations, and defend the distinction against the intelligence-completeness thesis using goal-questioning over goal-taking, Bostrom's orthogonality, structural separation in our exemplar cases, and persistent failure modes despite capability scaling. The framework is the conceptual contract for a larger architecture whose formal specifications and empirical validation are developed in subsequent work.
AdaSTORM: 適応型時空間マルチエージェント コラボレーションによる動的グラフ上の LLM 推論のスケーリング
大規模言語モデル (LLM) は、動的グラフ推論において顕著な可能性を示していますが、スケーリングのボトルネックに悩まされています。現在のモデルは、指数関数的推論のオーバーヘッドと有限のコンテキスト ウィンドウによって制限され、数十のノードを持つグラフしか処理できません。マルチエージェント システム (MAS) は、集合的な推論とトポロジを意識したオーケストレーションを提供し、グラフ構造のタスクに当然適した機能を提供しますが、動的グラフへの応用はまだ解明されていません。この論文では、大規模な動的グラフ推論を 2 つの段階に再定式化するフレームワークである、適応時空間マルチエージェント コラボレーションによる動的グラフ上のスケーリング LLM 推論 (AdaSTORM) について説明します。(i) 適応パーティショニング。推論コストを最小限に抑えながらモデルの推論能力に一致するサブ領域に大規模な動的グラフを分割します。 (ii) 協調推論。グラフ パーティション トポロジを時空間的に分離されたマルチエージェント アーキテクチャと調整します。 AdaSTORM は、動的グラフ推論用に調整された初のマルチエージェント フレームワークです。広範な実験により、AdaSTORM がスケーリングのボトルネックを突破し、外部ツールを使用せずにいくつかの大規模な動的グラフ設定全体で 90% 以上の精度で 1,000 ノードのグラフへの推論をスケーリングし、7 つの競合ベースラインを大幅に上回ることが示されました。さらに、既存のベンチマークで最先端の精度を実現し、現実世界のデータセットに堅牢に一般化します。ソース コードは https://github.com/irisorchid107/AdaSTORM/ から入手できます。
原文 (English)
AdaSTORM: Scaling LLM Reasoning on Dynamic Graphs via Adaptive Spatio-Temporal Multi-Agent Collaboration
Large Language Models (LLMs) demonstrate remarkable potential in dynamic graph reasoning, but suffer from a scaling bottleneck: current models can only handle graphs with tens of nodes, constrained by exponential reasoning overhead and finite context windows. While multi-agent systems (MAS) offer collective reasoning and topology-aware orchestration, capabilities naturally suited for graph-structured tasks, their application to dynamic graphs remains unexplored. This paper presents Scaling LLM Reasoning on Dynamic Graphs via Adaptive Spatio-Temporal Multi-Agent Collaboration (AdaSTORM), a framework that reformulates large-scale dynamic graph reasoning into two stages: (i) Adaptive Partitioning, partitioning large-scale dynamic graphs into subregions that match the model's reasoning capacity while minimizing inference cost; and (ii) Collaborative Reasoning, aligning graph partition topologies with a spatio-temporal decoupled multi-agent architecture. AdaSTORM is the first multi-agent framework tailored for dynamic graph reasoning. Extensive experiments show that AdaSTORM successfully breaks through the scaling bottleneck, scaling reasoning to thousand-node graphs with over 90% accuracy across several large-scale dynamic graph settings without external tools, significantly outperforms seven competitive baselines. Furthermore, it achieves state-of-the-art accuracy on existing benchmarks and generalizes robustly to real-world datasets. The source code is available at: https://github.com/irisorchid107/AdaSTORM/.
パターンを使用したシンボリック数値計画での検索の活用
この論文では、シンボリック パターン プランニング (SPP) に基づく数値計画の手順を示します。数値計画問題 $\Pi$ が与えられた場合、パターン $\prec$ は、開始状態 $S$ から実行可能な $\prec$ のサブシーケンスをエンコードする式を定義するために使用されるアクションのシーケンスです。 Cardellini、Giunchiglia、および Maratea (2024a) は、各ステップ $n \ge 0$ で式 $\Pi^\prec_n$ を定義することにより、満足可能性としての計画アプローチに従います。この式では、パターン $\prec$ が $\Pi$ の初期状態 $I$ の $n=0$ に対してのみ $(i)$ 計算され、各ステップ $n$、$(ii)$ で開始状態が利用されます。 $S$ は $I$ に設定され、$(iii)$ 目標のセット $G$ は、$n$ 回連結された $\prec$ の部分列の 1 つによって到達できる最後の状態に保持される必要があります。この手順は $n=0$ から始まり、$\Pi^\prec_n$ が満たされるとすぐに終了し、それ以外の場合は $n$ を増分して進みます。この論文では、おそらく各ステップで、$(i)$ は、目標状態に近い、$I$ から到達可能な中間状態 $P$ を記号的に検索し、$(ii)$ は、次のステップで使用されるパターン $\prec_h$ を $P$ で動的に再計算し、$(iii)$ は、$P$ に到達するために使用されるパターン $\prec_g$ を改良し、$(iv)$ は、初期状態のいずれかである状態 $S$ から新しい検索を開始します。 $I$ または最後に計算された中間状態 $P$。計算されたパターン $\prec_g$ および $\prec_h$ を利用して、検索で使用されるパターン $\prec$ を定義します。特に、各ステップで、パターン $\prec$ を使用する場合、$P'$ よりも目標状態に近い状態 $P'$ の存在をエンコードする式 $\Pi^{\prec}_{S,P}$ を定義します。$P'$ は開始状態 $S$ から到達可能です。我々は、そのような式を生成するためのさまざまな手法を紹介します。それぞれは、検索空間を探索するためのさまざまな戦略に対応しています。私たちはそれらの正確さと完全性を証明します。後者は特定の条件下で行われます。
原文 (English)
Exploiting Search in Symbolic Numeric Planning with Patterns
In this paper, we present a procedure for numeric planning based on Symbolic Pattern Planning (SPP). Given a numeric planning problem $\Pi$, a pattern $\prec$ is a sequence of actions used to define a formula encoding the subsequences of $\prec$ executable from a starting state $S$. Cardellini, Giunchiglia, and Maratea (2024a) follow the Planning as Satisfiability approach by defining, at each step $n \ge 0$, a formula $\Pi^\prec_n$ in which $(i)$ the pattern $\prec$ is computed only for $n=0$ in the initial state $I$ of $\Pi$, and then exploited at each step $n$, $(ii)$ the starting state $S$ is set to $I$, and $(iii)$ the set $G$ of goals is required to hold in the last state that can be reached by one of the subsequences of $\prec$ concatenated $n$ times. The procedure begins with $n=0$, terminates as soon as $\Pi^\prec_n$ is satisfiable, and otherwise proceeds by incrementing $n$. In this paper, possibly at each step, $(i)$ we symbolically search for an intermediate state $P$ reachable from $I$, closer to a goal state, $(ii)$ dynamically recompute the pattern $\prec_h$ -- to be used in the next step -- in $P$, $(iii)$ refine the pattern $\prec_g$ used to reach $P$, and $(iv)$ start the new search from the state $S$ which can be either the initial state $I$ or the last computed intermediate state $P$, exploiting the computed patterns $\prec_g$ and $\prec_h$ to define the pattern $\prec$ to be used in the search. In particular, at each step, we define a formula $\Pi^{\prec}_{S,P}$ encoding the existence of a state $P'$ closer than $P$ to a goal state, with $P'$ reachable from the starting state $S$ when using the pattern $\prec$. We present different techniques for producing such formulas, each corresponding to a different strategy for exploring the search space. We prove their correctness and completeness, the latter under certain conditions.
組立ライン障害復旧における再発性 MAPPO に対するフェーズ認識ガイダンス注入
産業組立ラインの混乱からの復旧には、機械の故障、従業員の欠勤、緊急命令が発生した場合にタイムリーな決定を下す必要があります。既存の方法は、厳格に手作りされた回復ロジックに依存するか、異常回復時間 (ART) を削減し、予定通りの配信 (OTD) を維持するために、意思決定時に異種の外部回復知識を容易に利用しない適応ポリシーを学習します。このギャップに対処するために、評価中のロジットレベルのアクションバイアスを通じてトレーニングされたリカレントMAPPO(RMAPPO)スケジューリングポリシーを強化するフェーズ認識ガイダンス注入フレームワークを提案します。このフレームワークは、ルールベース、リプレイベース、およびオンライン LLM ベースのガイダンスのための統一された意思決定時インターフェイスを提供し、異常フェーズおよび回復フェーズ中にのみ介入をアクティブにします。カスタム AssemblyLineEnv での実験では、高品質のルール ガイダンスが最も優れた効果をもたらし、可用性が不完全な場合にはリプレイ ベースのガイダンスがスムーズに低下し、オンライン LLM ガイダンスが引き続き有益な中間的な改善を提供することが示されています。これらの結果は、意思決定時ガイダンス注入が、アクターを再設計することなく、異種の回復ヒントを利用できることを示しています。
原文 (English)
Phase-Aware Guidance Injection for Recurrent MAPPO in Assembly-Line Disruption Recovery
Disruption recovery in industrial assembly lines requires timely decisions under machine faults, worker absence, and emergency orders. Existing methods either rely on rigid handcrafted recovery logic or learn adaptive policies that do not readily exploit heterogeneous external recovery knowledge at decision time to reduce abnormal recovery time (ART) and preserve on-time delivery (OTD). To address this gap, we propose a phase-aware guidance injection framework that augments a trained recurrent MAPPO (RMAPPO) scheduling policy through logit-level action bias during evaluation. The framework provides a unified decision-time interface for rule-based, replay-based, and online LLM-based guidance, while activating intervention only during abnormal and recovery phases. Experiments on a custom AssemblyLineEnv show that high-quality rule guidance yields the strongest gains, replay-based guidance degrades smoothly under imperfect availability, and online LLM guidance still provides useful intermediate improvements. These results show that decision-time guidance injection can exploit heterogeneous recovery hints without redesigning the actor.
医療ヒューリスティック学習: 解釈可能かつ監査可能な臨床意思決定ルールのための LLM 主導のフレームワーク
臨床表データの予測モデリングは臨床意思決定支援の中心であるため、強力な予測パフォーマンスだけでなく、透過的な意思決定ロジックも必要となります。ディープラーニングとツリーベースのアンサンブル手法は高精度を達成できますが、そのブラックボックス的な性質が臨床導入にとって依然として大きな障害となっています。この課題は、限られたサンプルサイズ、深刻なクラスの不均衡、診断基準や臨床文書の変更から生じる特徴の進化など、医療データの共通の特徴によってさらに悪化します。これらの問題に対処するために、臨床表予測のための勾配を超えた学習パラダイムのインスタンス化である医療ヒューリスティック学習 (MHL) を提案します。 MHL は、ニューラル ネットワークの重み更新に依存する代わりに、統計プローブ、医療知識プローブ、ルール合成、コード レベルの反復改良を統合する大規模言語モデル (LLM) 駆動のワークフローを使用して、決定論的で実行可能な意思決定システムを最適化します。結果として得られるモデルは、不透明なパラメーターとしてではなく、明示的に解釈可能で完全に監査可能で、臨床的に根拠のあるバージョン管理された純粋な Python 決定ルールとして表現されます。 MHL は、以前に検証されたルールから開始し、データ ドリフトまたは機能進化の下で更新された機能情報を使用してルールを繰り返し修正することにより、継続的な学習もサポートします。医療データセットに関する包括的な実験では、MHL がサンプルが少なく不均衡が非常に悪い設定でも強力な動作を維持しながら、最先端の手法に匹敵するパフォーマンスを達成することが示されています。この結果はさらに、この明示的なルール更新メカニズムが、機能の進化の下での壊滅的な忘却の軽減に役立つことを示しています。全体として、これらの発見は、非勾配ベースのヒューリスティック システムが、一か八かの臨床意思決定支援のための透明性と適応性のある代替手段を提供することを示唆しています。
原文 (English)
Medical Heuristic Learning: An LLM-Driven Framework for Interpretable and Auditable Clinical Decision Rules
Predictive modeling for clinical tabular data is central to clinical decision support and therefore requires not only strong predictive performance but also transparent decision logic. Although deep learning and tree-based ensemble methods can achieve high accuracy, their black-box nature remains a major obstacle to clinical deployment. This challenge is further compounded by common characteristics of medical data, including limited sample sizes, severe class imbalance, and feature evolution arising from changes in diagnostic criteria and clinical documentation. To address these issues, we propose Medical Heuristic Learning (MHL), an instantiation of the learning-beyond-gradients paradigm for clinical tabular prediction. Instead of relying on neural network weight updates, MHL uses a large language model (LLM)-driven workflow that integrates statistical probes, medical knowledge probes, rule synthesis, and code-level iterative refinement to optimize a deterministic and executable decision system. The resulting model is expressed not as opaque parameters, but as versioned pure-Python decision rules that are explicitly interpretable, fully auditable, and clinically grounded. MHL also supports continual learning by starting from previously validated rules and iteratively revising them using updated feature information under data drift or feature evolution. Comprehensive experiments on medical datasets show that MHL achieves performance comparable to state-of-the-art methods while maintaining strong behavior in small-sample and highly imbalanced settings. The results further indicate that this explicit rule update mechanism can help alleviate catastrophic forgetting under feature evolution. Overall, these findings suggest that non-gradient-based heuristic systems offer a transparent and adaptable alternative for high-stakes clinical decision support.
AI は誰のホテルを勧めますか? LLM 支援のホテル選択における評判シグナルのアルゴリズム監査
旅行者は、ラージ ランゲージ モデル (LLM) アシスタントにどのホテルを予約するかを尋ねることが増えており、これらのシステムは物件の可視性の門番となっていますが、何が彼らの推奨を動かすのかは文書化されていません。当社は、ランダム化された選択ベースのコンジョイントを使用して、事前に指定されたアルゴリズム監査を実施します。ペルソナ、プロンプト テンプレート、および 12 のオープンウェイトおよび独自のモデルにわたって、アシスタントは、宿泊客の評価、レビューの量と最新性、管理者の対応、チェーンへの所属、価格、エコ認定、およびリストの位置が独立してランダム化されている 5 つのホテルの中から選択します。推奨確率に対する各シグナルの平均周辺成分効果を推定します。ゲストの評価と価格が支配的であり(最高の評価は選択肢を 31.6 パーセントポイント上昇させ、価格が高いと選択を 30.0 ポイント下げる)、人間の価値と価格の優位性を再生産しますが、エコ認定を過度に重視し、経営陣の対応を無視します。リストの位置 -- コンテンツのないアーティファクト -- は推奨事項を因果的にシフトします。これは 1 泊あたり約 12 ドルの価値があります。公表された体重の追跡が不完全である理由が述べられています。この調査結果は、生成エンジンの最適化と、因果関係の証拠における AI 情報仲介者の説明責任を根拠づけるものです。
原文 (English)
Whose hotel does the AI recommend? An algorithm audit of reputation signals in LLM-assisted hotel selection
Travelers increasingly ask large language model (LLM) assistants which hotel to book, making these systems gatekeepers of property visibility -- yet what moves their recommendations is undocumented. We conduct a pre-specified algorithm audit using a randomized choice-based conjoint: across personas, prompt templates, and twelve open-weight and proprietary models, assistants choose among five hotels whose guest rating, review volume and recency, management response, chain affiliation, price, eco-certification, and list position are independently randomized. We estimate the average marginal component effect of each signal on the probability of recommendation. Guest rating and price dominate (a top rating raises selection by 31.6 percentage points; a high price lowers it by 30.0), reproducing human valence-and-price primacy but over-weighting eco-certification and ignoring management response. List position -- a content-free artifact -- shifts recommendations causally, worth about \$12 per night. Stated reasons track revealed weights imperfectly. The findings ground generative engine optimization and the accountability of AI infomediaries in causal evidence.
見ることは選ぶことではない: LLM エージェントにおけるツール選択の失敗に関する注意セグメントの説明
LLM エージェントはツールを誤って呼び出します。混雑したハーネスの中でモデルが適切なツールを認識できなかったのではないかと自然に推測されます。並行作業を脇に置くというレンズを通して、ラベル付けされたツール定義セグメントに対するモデルの注意を介して反対のことを示します。実際の BFCL の失敗では、候補ごとの注意力 argmax により、モデルは 80% の確率で正しいツールに最も注目し (確率 21% に対して)、ゴールドは 10% のみで注目度の低いセグメントです。つまり、正しいツールを参照しているにもかかわらず、間違ったツールを選択します。これは、直観的な「ハーネスが混雑している / 途中で迷っている」という説明に真っ向から反論します。障害はハーネスではなく判定読み出しにあり、そこに 3 つの方法で問題を固定します。 (1) 入力と読み出し: プロンプトの修復 (ゴールド ツールの並べ替えまたは複製) では失敗の 23% 未満が回復しますが、読み出し側の介入では 59 ~ 91% が回復します。 (2) 表現不変性: 異なる表現での 2 つの金策介入 (加算的アテンション ロジット バイアスと残差ストリーム ステアリング ベクトル) は、ほぼ同じ失敗 (タスクごとに Jaccard プールされた 0.865、モデルごとに 0.79 ~ 0.91) を回復するため、どの表現がポークされるかに関係なく、ボトルネックは読み出しに局所化されます。 (3) トレーニング不要、ゴールドフリーのセレクター: セグメントごとの注目により、BFCL でのゴールドフリーとオラクルのギャップ (プールされた関数名の選択が +11.9 ポイント、オラクルのヘッドルームが +17.9 ポイント) のほとんどが縮まり、Seal-Tools では +14.9 ポイントが追加されます。すべてのモデルが陽性 (正確なマクネマー p<=8e-4 それぞれ)。範囲は異なります。因果関係の注意バイアスの用量反応は、10 個のマスク尊重モデル (3-32B) で双方向かつ単調であり、0.5-32B の全スパンは相関診断のみを保持します。デプロイ可能なセレクターは 5 つのシングル ターン モデルで評価されており、マルチ ターン ループにはまだ転送されていません。
原文 (English)
Looking Is Not Picking: An Attention-Segment Account of Tool-Selection Failures in LLM Agents
LLM agents mis-call tools, and the natural guess is that the model failed to see the right tool in a crowded harness. We show the opposite through a lens concurrent work sets aside -- the model's attention to labeled tool-definition segments. On real BFCL failures, by per-candidate attention argmax the model attends most to the correct tool 80% of the time (vs. 21% chance), and the gold is the under-attended segment on only 10%: it looks at the right tool and still picks wrong. This directly refutes the intuitive "crowded-harness / lost-in-the-middle" explanation: the failure is at the decision readout, not the harness, and we pin it there three ways. (1) Input vs. readout: repairing the prompt (reordering or duplicating the gold tool) recovers <=23% of failures, while readout-side interventions recover 59-91%. (2) Representation-invariance: two gold-pointed interventions in different representations -- an additive attention-logit bias and a residual-stream steering vector -- recover largely the same failures (per-task Jaccard 0.865 pooled, 0.79-0.91 per model), so the bottleneck is localized to the readout independent of which representation is poked. (3) A training-free, gold-free selector: per-segment attention closes most of the gold-free-vs-oracle gap on BFCL (+11.9 pts pooled function-name selection vs. +17.9-pt oracle headroom) and adds +14.9 pts on Seal-Tools; every model positive (exact McNemar p<=8e-4 each). Scopes differ: the causal attention-bias dose-response is bidirectional and monotonic on 10 mask-honoring models (3-32B), the full 0.5-32B span carrying only the correlational diagnostic; the deployable selector is evaluated on 5 single-turn models and does not yet transfer to a multi-turn loop.
事後双子: 企業の意思決定のための分布行動シミュレーション
企業の行動シミュレーションには、妥当な応答を生成するだけでは不十分です。多くの決定は、提案された行動の下での集団の形状、つまりどのセグメントが受け入れるか、拒否するか、ためらうか、またはリスクに敏感な状態に移行するかによって決まります。この論文では、特定の意思決定コンテキストの下で起こりそうな動作を更新された分布として表現する、メモリに基づいたデジタル ツイン アプローチである事後ツインを紹介します。我々は、226 例のホールドアウト行動応答ベンチマークで Tinning Labs 行動モデル操作点ファミリーを評価し、モーダル精度と Wasserstein-1 距離の両方を報告します。結果は、モーダル精度と分布忠実度がさまざまな動作体制を識別することを示しています。 TL-Twin Alpha は、報告された結果セット内で観測された最小の Wasserstein-1 距離 ($W_1 = 1.16$) を達成し、TL-Twin Delta と TL-Twin Gamma はモーダル精度フロンティアに近いバランスのとれた動作点を提供します。この論文では、これらの結果をシステムの結果としてまとめています。シミュレーションされた動作を再利用可能な企業意思決定の証拠に変えるには、管理されたメモリ、動作モデルのルーティング、シナリオのオーケストレーション、分散集約、および監査可能性が必要です。
原文 (English)
Posterior Twins: Distributional Behavioral Simulation for Enterprise Decisions
Enterprise behavioral simulation requires more than producing a plausible response. Many decisions depend on the shape of a population under a proposed action: which segments accept, defect, hesitate, or move into risk-sensitive states. This paper introduces Posterior Twins, a memory-grounded digital-twin approach that represents likely behavior as an updated distribution under a specific decision context. We evaluate a family of Twinning Labs behavioral-model operating points on a 226-example held-out behavioral-response benchmark and report both modal accuracy and Wasserstein-1 distance. The results show that modal accuracy and distributional fidelity identify different operating regimes. TL-Twin Alpha achieves the lowest observed Wasserstein-1 distance in the reported result set ($W_1 = 1.16$), while TL-Twin Delta and TL-Twin Gamma provide balanced operating points near the modal-accuracy frontier. The paper frames these results as a systems result: governed memory, behavioral model routing, scenario orchestration, distributional aggregation, and auditability are necessary for turning simulated behavior into reusable enterprise decision evidence.
エージェントの自動化が収益性を高めるとき: トレース経済的な引受を通じて自律型 AI のリスクを定量化して保証する
AI エージェントは運用システムで不可逆的なアクションを実行できるようになりましたが、エージェントによって引き起こされた損失は依然として明確に割り当てられず、価格も設定されず、移転されません。プロバイダーは結果的損害を否認することが多く、ユーザーは補償されない損失を抱えたままになり、デフォルトの人によるレビューにより自動化の効率向上が制限されます。障害のリスクにもかかわらず、自律型 AI の導入が経済的に受け入れられるようになるのはいつになるのかを尋ねます。私たちの答えは、顧客のタスク追跡エピソードレベルでリスクを定量化し、それを保険を通じて移転することです。自動化は、期待される利益が保険料、管理コスト、および残りのリスクを超える場合に受け入れられます。これには、制限されたアクセス許可と同等のトレースを持つ定義されたロールが必要です。当社は、ツール使用の痕跡を顧客エクスポージャーと請求可能な損失にマッピングし、この表現を価格設定、管理、リスク移転に使用するトレースエコノミック引受を導入します。 LLM ジャッジではなく、決定論的な経済ラベルを使用します。当社のトレースツーロステストベッドでは、トレースエコノミー価格設定により価格設定 MAE が 17.7,000 ドルから 569 ドルに削減され、逆進的な相互補助金が排除されます。 300 トレースの専門家による監査では、295 個のラベルが変更されずに受け入れられます。 1,000 の実際の SWE-smith トレースでは、トレース条件付きコントロールにより CVaR95 が 72% 減少します。 Theorem~1 は有限サンプルのスコープ条件を与えます。コード、ラベル、監査シートをリリースします。
原文 (English)
When Agent Automation Becomes Profitable: Quantifying and Insuring Autonomous AI Risk through Trace-Economic Underwriting
AI agents can now take irreversible actions in operational systems, but agent-caused losses are still not clearly assigned, priced, or transferred. Providers often disclaim consequential damages, users are left with uncompensated losses, and default human review limits the efficiency gains of automation. We ask when autonomous AI deployment can become economically acceptable despite failure risk. Our answer is to quantify risk at the customer-task-trace episode level and transfer it through insurance. Automation is acceptable when its expected benefit exceeds the premium, control cost, and remaining risk. This requires a defined role with bounded permissions and comparable traces. We introduce trace-economic underwriting, which maps tool-use traces to customer exposure and claimable loss, then uses this representation for pricing, control, and risk transfer. It uses deterministic economic labels rather than an LLM judge. In our trace-to-loss testbed, trace-economic pricing reduces pricing MAE from $17.7K to $569 and removes regressive cross-subsidy. A 300-trace expert audit accepts 295 labels unchanged. On 1,000 real SWE-smith traces, trace-conditioned controls reduce CVaR95 by 72%. Theorem~1 gives a finite-sample scope condition. We release code, labels, and audit sheets.
テンソル座標: 競合のないマルチエージェント LLM 計画のための共同計画テンソルの代数分解
大規模言語モデル (LLM) は、独立して生成された計画によって空間衝突、リソース競合、時間的デッドロックなどの調整エラーが発生する可能性があるため、マルチエージェント計画では依然として制限されています。 Tensor-Coord は、N 個のエージェントの共同計画をエージェント、タイムステップ、アクションにわたる 3 次テンソル \(T \in R^{N \times H \times A}\) として表す多線形代数フレームワークです。標準ポリアディック (CP) およびタッカー分解は、潜在的な配位構造を特定するために使用されます。最小イプシロン近似 CP ランク R* は、\(CC(Pi)=(R*-N)/N\) で計算可能な調整複雑さの尺度を定義します。 R*=N が計画の独立性に必要かつ十分であることを証明します。残差 \(E=T-T_{R*}\) は、エージェント ペア、タイムステップ、およびアクションに対する競合スコアを定義し、ドメイン固有のルールを使用せずに障害の位置を特定します。タッカー因子は、反復的な LLM 再計画のための自然言語制約に変換される、解釈可能なエージェントの役割、時間的フェーズ、およびアクション クラスターを提供します。簡単 (エージェント 2 人、5x5 グリッド)、中 (エージェント 3 人、5x5 グリッド)、およびハード (エージェント 4 人、5x5 グリッド) の設定にわたるマルチロボット配信タスクの実験では、平均 1.4 反復以内で 2 エージェントのケースの 100%、3.2 反復以内で 3 エージェントのケースの 80%、および 3.2 反復以内で 4 エージェントのケースの 60% で競合のない計画に収束することが示されました。 4.0 回の反復。 CP ランクは \(R*(N) = 3.9N + 0.5\) としてほぼ線形にスケールされ、調整の複雑さの予測子としての使用を裏付けています。
原文 (English)
Tensor-Coord: Algebraic Decomposition of Joint Plan Tensors for Conflict-Free Multi-Agent LLM Planning
Large language models (LLMs) remain limited in multi-agent planning because independently generated plans can create coordination failures such as spatial collisions, resource contention, and temporal deadlocks. We introduce Tensor-Coord, a multilinear algebra framework that represents the joint plan of N agents as a third-order tensor \(T \in R^{N \times H \times A}\) over agents, timesteps, and actions. Canonical Polyadic (CP) and Tucker decompositions are used to identify latent coordination structure. The minimal epsilon-approximate CP rank R* defines a computable coordination complexity measure, with \(CC(Pi)=(R*-N)/N\). We prove that R*=N is necessary and sufficient for plan independence. The residual \(E=T-T_{R*}\) defines a conflict score over agent pairs, timesteps, and actions, localizing failures without domain-specific rules. Tucker factors provide interpretable agent roles, temporal phases, and action clusters that are converted into natural language constraints for iterative LLM replanning. Experiments on multi-robot delivery tasks across Easy (2 agents, 5x5 grid), Medium (3 agents, 5x5 grid), and Hard (4 agents, 5x5 grid) settings show convergence to conflict-free plans in 100% of 2-agent cases within 1.4 iterations on average, 80% of 3-agent cases within 3.2 iterations, and 60% of 4-agent cases within 4.0 iterations. CP rank scaled approximately linearly as \(R*(N) = 3.9N + 0.5\), supporting its use as a predictor of coordination complexity.
芸術療法のための感情ダイナミクスの制御: 階層的に誘導される LLM エージェントによる制御可能な物語スクリプト生成
芸術療法は感情の癒しに重要な役割を果たしており、物語の創造が感情表現の主な手段として機能します。治癒中の感情は本質的に動的な性質を持っているため、感情の変動を細かく制御した物語により、個人は内なる葛藤を安全に投影し、感情的なカタルシスを達成することができます。最近、ラージ言語モデル (LLM) の急速な発展に伴い、自動物語生成テクノロジが、このような芸術的なデザインをサポートするための新しい道を提供しました。しかし、既存の方法は流暢なテキストを生成することはできますが、特定の感情の軌道に沿った物語を生成するのに苦労しており、感情指向の心理的癒しの要求を満たすことができません。これらの問題に対処するために、この論文では、感情治癒のための物語生成における感情軌道の階層的制御を可能にする LLM エージェントベースのフレームワークである EC-Script を提案します。生成された物語が指定された感情パターンに厳密に従っていることを確認するために、EC-Script は感情軌道計画を通じて全体的な物語の方向性を確立し、キャラクター主導のシーン生成によってシーンレベルのプロット開発を推進し、感情制御されたスクリプト作成を通じてキャラクターの局所的な感情の変化を制御します。最終的には、事前に設定された感情の軌跡との一貫性が高い、シーンごとのスクリプト コンテンツが出力されます。実験結果は、EC-Script が感情軌道順守においてベースライン手法を大幅に上回り、優れた信頼性の高い感情制御性を示し、それによって AI 支援による感情治癒シナリオに効果的な技術サポートを提供することを示しています。
原文 (English)
Steering Emotional Dynamics for Art Therapy: Controllable Narrative Script Generation through Hierarchically Guided LLM Agents
Art therapy plays a vital role in emotional healing, in which narrative creation acts as the primary vehicle for emotional expression. Given the inherently dynamic nature of emotions during healing, narratives with finely controlled emotional fluctuations enable individuals to safely project inner conflicts and achieve emotional catharsis. Recently, with the rapid development of Large Language Models (LLMs), automated narrative generation technology has provided a new pathway to support such artistic designs. However, while existing methods can produce fluent texts, they struggle to generate narratives that adhere to specified affective trajectories, failing to meet the demands of emotion-oriented psychological healing. To address these issues, this paper proposes EC-Script, an LLM agent-based framework that enables hierarchical control of the affective trajectory in narrative generation for emotional healing. To ensure that the generated narratives strictly follow the given emotional patterns, EC-Script establishes overall narrative direction through Emotion-Trajectory Planning, propels scene-level plot development with Character-Driven Scene Generation, and regulates local emotional changes of characters via Emotion-Controlled Script Writing. Ultimately, it outputs scene-by-scene script content that remains highly consistent with the preset affective trajectory. Experimental results demonstrate that EC-Script significantly outperforms baseline methods in affective trajectory adherence, exhibiting excellent and reliable emotional controllability, thereby providing effective technical support for AI-assisted emotional healing scenarios.
ポストホック マージでは不十分: ロスギャップ バランシングを使用したメニーショット モデルのマージ
モデルのマージは、複数のタスクに特化したモデルを組み合わせて単一のマルチタスク大規模言語モデル (LLM) を構築するための実践的なトレーニング後の戦略となっています。ただし、既存のアプローチのほとんどはポストホック マージに依存しており、タスク固有のモデルはトレーニング後に 1 回だけマージされます。この 1 回限りの集計ではタスクの干渉が発生することが多く、個々のタスクにわたる情報の消去につながります。この研究では、ポストホック マージを反復マルチショット マージ プロトコルに置き換えることが、マルチタスクのパフォーマンスを向上させるのに効果的であることを示します。この洞察に基づいて、安定したマルチショット マージのためのタスク干渉による消去を軽減する METIS を提案します。 METIS は、タスクごとの損失ギャップの重み付けとコンセンサスベースのマスキングを通じて、ポストホック マージにおける情報消去に対処する、損失を認識したマルチショット マージ手法です。特に、METIS は最もパフォーマンスの悪いタスクで大幅なパフォーマンスの向上を示し、情報の消去を効果的に軽減します。 (プロジェクトページ:https://imkyungjin.github.io/METIS/)
原文 (English)
Post-Hoc Merging is Not Enough: Many-Shot Model Merging with Loss-Gap Balancing
Model merging has become a practical post-training strategy for building a single multi-task large language model (LLM) by combining multiple task-specialized models. However, most existing approaches rely on post-hoc merging, in which task-specific models are merged only once after training. This one-shot aggregation often suffers from task interference, leading to information erasure across individual tasks. In this work, we show that replacing post-hoc merging with an iterative many-shot merging protocol is effective in improving multi-task performance. Building on this insight, we propose METIS, Mitigating Erasure from Task Interference for Stable many-shot merging. METIS is a loss-aware many-shot merging method that addresses information erasure in post-hoc merging through task-wise loss-gap weighting and consensus-based masking. Notably, METIS exhibits significant performance improvement on the worst-performing task, effectively mitigating information erasure. (Project page: https://imkyungjin.github.io/METIS/)
ナレッジ グラフを完成させるためのモデル グラフ帰納学習
ナレッジ グラフのリンク予測は基本的に、エンティティとリレーションの学習された埋め込みの品質に依存します。ただし、既存のほとんどの方法は、ナレッジ グラフのグローバル構造を無視して、各エンティティのローカル近傍のみを集約することによってこれらの埋め込みを導出します。この制限されたビューにより、モデルは正確で一般化可能なリンク予測に不可欠な高レベルの構造パターンを捕捉できなくなります。これらの制限に対処するために、モデル グラフ帰納学習 (\textbf{MGIL}) を導入します。これは、受信および送信のリレーショナル構造またはエンティティ タイプの類似性に基づいてエンティティをクラスタリングすることによってモデル グラフを構築するフレームワークです。次に、GNN がこのモデル グラフに適用され、ナレッジ グラフのグローバル ビューをキャプチャする埋め込みが生成されます。これらの埋め込みは、その後、元のナレッジ グラフの高品質の初期特徴 %embeddings として機能し、ランダムな初期化を置き換え、より安定した表現力豊かな表現につながります。標準ベンチマークおよび最近提案された帰納的ベンチマークに関する広範な実験により、MGIL が帰納的リンク予測において最先端または非常に競争力のあるパフォーマンスを達成することが実証され、多様なグラフ設定にわたってその有効性が強調されています。
原文 (English)
Model Graph Inductive Learning for Knowledge Graph Completion
Link prediction in knowledge graphs fundamentally depends on the quality of learned embeddings for entities and relations. However, most existing methods derive these embeddings by aggregating only the local neighborhood of each entity, neglecting the global structure of the knowledge graph. This limited view prevents models from capturing higher-level structural patterns that are essential for accurate and generalizable link prediction. To address these limitations, we introduce Model Graph Inductive Learning (\textbf{MGIL}), a framework that constructs a model graph by clustering entities based on the similarity of their incoming and outgoing relational structures or their entity types. A GNN is then applied to this model graph to produce embeddings that capture the global view of the knowledge graph. These embeddings subsequently serve as high-quality initial features %embeddings for the original knowledge graph, replacing random initialization and leading to more stable and expressive representations. Extensive experiments on standard and recently proposed inductive benchmarks demonstrate that MGIL achieves state-of-the-art or highly competitive performance in inductive link prediction, highlighting its effectiveness across diverse graph settings.
Kairos: 物理 AI 用のネイティブ ワールド モデル スタック
世界モデルは、受動的なビジュアル ジェネレーターから物理 AI の基礎的な運用インフラストラクチャに移行しています。世界モデルは、異種混合の経験から世界の知識をネイティブに取得し、長期にわたって永続的な状態を維持し、実際の展開上の制約内で効率的に実行する必要があります。これらの要件に基づいて設計されたネイティブ ワールド モデル スタックである Kairos を紹介します。 (1) カイロスは、オープンワールドのビデオ、人間の行動データ、およびロボットの相互作用を漸進的な発達経路に編成する、クロスエンボディメント データ カリキュラムによって管理されるネイティブの事前トレーニング パラダイムを開拓することによって世界を学びます。 (2) Kairos は、ハイブリッド線形時間的注意を備えたネイティブ統合アーキテクチャ内で統一された世界の理解、生成、予測によって世界を維持します。スライディング ウィンドウの注意はローカル ダイナミクスを捕捉し、拡張されたスライディング ウィンドウは中間範囲の依存関係を捕捉し、ゲートされた線形注意は永続的なグローバル メモリを維持します。我々は、この時間因数分解が誤差の蓄積を厳密に制限し、拡張された範囲にわたる状態の伝播を数学的に保証することを実証する正式な理論的限界を確立します。 (3) Kairos は、実世界の観察、アクション、フィードバック ループのためのサーバーおよび消費者グレードのハードウェア上での低遅延ロールアウト生成をサポートする、展開を意識したシステム協調設計を組み込むことによって世界を運営します。具現化された世界モデル、長期計画、およびアクション ポリシーのベンチマークに関する実験では、Kairos が効率性と能力の強力なトレードオフを提供しながら、トップレベルのパフォーマンスを達成していることが示されています。これらの結果を総合すると、カイロスは将来の自己進化する物理的知性のための統合された運用基盤として位置づけられます。
原文 (English)
Kairos: A Native World Model Stack for Physical AI
World models are transitioning from passive visual generators to foundational, operational infrastructure for Physical AI: they must natively acquire world knowledge from heterogeneous experience, maintain persistent states over long horizons, and execute efficiently within real deployment constraints. We introduce Kairos, a native world model stack designed around these requirements. (1) Kairos learns the world by pioneering a Native Pre-training Paradigm governed by a Cross-Embodiment Data Curriculum, which organizes open-world videos, human behavioral data, and robot interactions into a progressive developmental pathway. (2) Kairos maintains the world by unified world understanding, generation, and prediction within a Native Unified Architecture equipped with Hybrid Linear Temporal Attention, where sliding-window attention captures local dynamics, dilated sliding windows capture mid-range dependencies, and gated linear attention maintains persistent global memory. We establish formal theoretical bounds demonstrating that this temporal factorization strictly limits error accumulation, mathematically guaranteeing state propagation across extended horizons. (3) Kairos runs the world by incorporating a Deployment-Aware System Co-Design to support low-latency rollout generation on server and consumer-grade hardware for real-world observation-action-feedback loops. Experiments on embodied world-model, long-horizon, and action-policy benchmarks show that Kairos achieves top level performance while offering a strong efficiency-capability trade-off. Together, these results position Kairos as a cohesive operational foundation for future self-evolving physical intelligence.
忠実度のギャップ: 自然言語と形式的な数学的ステートメントの間の意味上の同等性の証明
自然言語数学を正式な証明アシスタントに変換する自動形式化は、翻訳の流暢さではなく \emph{忠実さ} によってボトルネックになります。つまり、形式的なステートメントは型チェックして証明可能であるにもかかわらず、ソースが意図したものとは異なる定理をエンコードすることになります。 \emph{双方向証明フィンガープリンティング} (\bpf{}) を導入します。これは、アンビエント理論における前方および後方結果の近傍を通じて各候補を特徴付け、これらを自然言語ステートメントから導出されたプローブと照合することによって忠実性を証明するフレームワークです。さらに、4 つの新しいコンポーネントを導入します。(i) \emph{反事実プローブ生成} (\cpg{})、特定のドリフト方向をターゲットとしたプローブを合成する対照的な手順。 (ii) \emph{等価スペクトル}。脆弱な二値判定を置き換える連続的な忠実性スコア。 (iii) \emph{Adaptive Probe Budget Allocation} (\apba{})、情報理論バジェット ルーター。 (iv) \emph{Faithhood-Guided Decoding} (\fgd{})。自動形式化中に \bpf{} 信号を報酬として使用します。 \emph{ドリフト検出定理} と \emph{PAC-忠実度} の結果を証明し、穏やかな仮定の下で自然言語ステートメントの同値クラスが $\mathcal{O}(\log(1/\delta)/\varepsilon)$ プローブから学習可能であることを確立します。 mathlib4 の 6 つのサブフィールドにわたって制御されたドリフト ラベルを備えた $2{,}183$ NL/Lean~4 ペアのベンチマークである \driftbench{} をリリースします。 \bpf{}\,+\,\cpg{} は、タイプチェックの $41.2\%$ および LLM 判定ベースラインの $63.3\%$ と比較して、$3.0\%$ の偽陽性率で $89.6\%$ のドリフト形式化を検出し、 \fgd{} は最先端のオートフォーマライザーがドリフト ステートメントを出力する割合を次のように削減します。 $47\%$。 https://pmlrbd.github.io/BPF/
原文 (English)
The Faithfulness Gap: Certifying Semantic Equivalence Between Natural-Language and Formal Mathematical Statements
Autoformalization, translating natural-language mathematics into formal proof assistants, is bottlenecked not by translation fluency but by \emph{faithfulness}: a formal statement can typecheck and be provable, yet still encode a different theorem than the source intended. We introduce \emph{Bidirectional Provability Fingerprinting} (\bpf{}), a framework that certifies faithfulness by characterizing each candidate through its forward and backward consequence neighborhoods in the ambient theory and matching these against probes derived from the natural-language statement. We further introduce four novel components: (i) \emph{Counterfactual Probe Generation} (\cpg{}), a contrastive procedure that synthesizes probes targeting specific drift directions; (ii) the \emph{Equivalence Spectrum}, a continuous faithfulness score that replaces brittle binary verdicts; (iii) \emph{Adaptive Probe Budget Allocation} (\apba{}), an information-theoretic budget router; and (iv) \emph{Faithfulness-Guided Decoding} (\fgd{}), which uses \bpf{} signals as a reward during autoformalization. We prove a \emph{drift detection theorem} and a \emph{PAC-faithfulness} result establishing that the equivalence class of a natural language statement is learnable from $\mathcal{O}(\log(1/\delta)/\varepsilon)$ probes under mild assumptions. We release \driftbench{}, a benchmark of $2{,}183$ NL/Lean~4 pairs with controlled drift labels across six subfields of mathlib4. \bpf{}\,+\,\cpg{} detects $89.6\%$ of drifted formalizations at a $3.0\%$ false-positive rate-against $41.2\%$ for typecheck and $63.3\%$ for LLM-judge baselines, and \fgd{} reduces the rate at which a state-of-the-art autoformalizer emits drifted statements by $47\%$. https://pmlrbd.github.io/BPF/
ROSA-RL: 強化学習による不確実性を考慮したラウンドアバウト最適化速度アドバイザリー
ラウンドアバウトは、不均一で非決定的な人間の行動、未知の運転意図、高度なインタラクションの複雑さにより、紛争地域に進入する時点でブロックされるか利用可能になるかについて不確実性を生み出すため、混合交通における自動運転に課題をもたらします。私たちは、ROSA-RL (強化学習による不確実性を考慮したラウンドアバウト最適化速度アドバイザリー) を紹介します。確率論的な衝突予測により、混合交通において自動車両と人間運転車両の安全かつ効率的なラウンドアバウト進入が可能になります。 Transformer ベースのモデルは、5 秒間の紛争地帯の占有率を予測し、マルチエージェントのやり取りをキャプチャして、今後の紛争と利用可能なギャップを予測します。予測出力は将来の動きと意図の不確実性をエンコードし、古典的な RL フレームワークの状態を拡張して、不確実性を考慮した速度調整を可能にします。実世界のデータに基づいたシミュレーションで評価された ROSA-RL は、不確実性を効果的に処理し、同等のモデルベースのベースラインを上回るパフォーマンスを発揮し、完全に既知の占有率を想定した理想的な設定とのギャップを埋めながら、交通効率と安全性を向上させることができます。この作品のソース コードは、github.com/urbanAIthi/ROSA-RL から入手できます。
原文 (English)
ROSA-RL: Uncertainty-Aware Roundabout Optimized Speed Advisory with Reinforcement Learning
Roundabouts challenge automated driving in mixed traffic, as heterogeneous and non-deterministic human behavior, unknown driving intentions, and high interaction complexity create uncertainty about whether the conflict zone will be blocked or available at the moment of entry. We present ROSA-RL -- uncertainty-aware Roundabout Optimized Speed Advisory with Reinforcement Learning. It enables safe and efficient roundabout entry for automated and human-driven vehicles in mixed traffic through probabilistic conflict forecasting. A Transformer-based model predicts conflict zone occupancy over a five-second horizon, capturing multi-agent interactions to anticipate upcoming conflicts and available gaps. The prediction outputs encode uncertainty in future motion and intent, and augment the state of a classical RL framework, enabling uncertainty-aware speed coordination. Evaluated in simulations grounded in real-world data, ROSA-RL can effectively handle uncertainty and outperform a comparable model-based baseline, closing the gap to an ideal setting assuming fully known occupancy while improving traffic efficiency and safety. The source code of this work is available under: github.com/urbanAIthi/ROSA-RL.
TNODEV: ニューラル ODE 検証用ツールボックス
ニューラル常微分方程式 (ニューラル ODE) は、サイバーフィジカル システムの連続時間コントローラーや自動意思決定パイプラインに統合された分類器など、安全性が重要な設定で使用され始めており、その動作を正式に検証できるかどうかという疑問が生じています。ニューラル ODE 専用の既存のツールは、反復的な入力セットの改良を行わずに単一の到達可能性呼び出しのみを提供し、その判定の精度が 1 つの到達可能性呼び出しで提供できるものに制限されています。 TNODEV は、改ざんチェッカー、連続時間混合単調性に基づく高速間隔ベースの到達可能性バックエンド、3 つの入力セット分割ヒューリスティックを備えた検証および改良ループ、および単一のエンドツーエンド パイプライン内の並列スケジューラを統合する、ニューラル ODE 用の初のサウンド形式検証器です。 TNODEV は、純粋なニューラル ODE、ニューラル ネットワーク コントローラーを使用した閉ループのニューラル ODE、および一般的なニューラル ODE (GNODE) でのセーフセット包含検証をサポートします。安全セットは、区間またはターゲット分類ラベルによって引き起こされる半空間交差として指定されます。 NNV~2.0 および CORA との直接到達可能性の比較や、MNIST の一般的なニューラル ODE 分類器での NNV2.0 との検証比較など、セーフセットの包含特性と分類の堅牢性特性にわたるさまざまなベンチマークで TNODEV を評価します。
原文 (English)
TNODEV: Toolbox for Neural ODE Verification
Neural ordinary differential equations (neural ODE) have started to appear in safety critical settings such as continuous-time controllers for cyber-physical systems and classifiers integrated into automated decision pipelines, raising the question of whether their behavior can be formally verified. Existing tools dedicated to neural ODE provide only a single reachability call without iterative input set refinement, limiting the precision of their verdicts to whatever one reachability call can deliver. We present TNODEV, the first sound formal verifier for neural ODE that integrates a falsification checker, a fast interval-based reachability backend based on continuous-time mixed monotonicity, a verification and refinement loop with three input-set splitting heuristics, and a parallel scheduler in a single end-to-end pipeline. TNODEV supports safe-set inclusion verification on pure neural ODE, neural ODE in closed loop with a neural network controller and general neural ODE (GNODE), with the safe set specified either as an interval or as the half-space intersection induced by a target classification label. We evaluate TNODEV on a range of benchmarks across safe-set inclusion and classification-robustness properties, including a direct reachability comparison against NNV~2.0 and CORA and a verification comparison against NNV2.0 on MNIST general neural ODE classifiers.
ARB4WM: 連続制御におけるワールド モデルの敵対的堅牢性ベンチマーク
ワールド モデルは、計画と意思決定のための潜在的なダイナミクスを学習できるため、ロボットおよびエージェント エンジニアリング制御システムで広く使用されています。これらのシステムは安全性が重要な設定で導入されることが増えているため、敵対的な条件下での堅牢性を理解することが不可欠になっています。しかし、既存の評価には、ワールドモデルエージェントのポリシー、価値、潜在力学レベルにわたる敵対的脅威をテストするための統一ベンチマークがありません。このギャップを埋めるために、視覚的な摂動下での世界モデル エージェントの展開前の堅牢性とリスク評価のための統一評価フレームワークである ARB4WM を紹介します。 ARB4WM は、これら 3 つのレベルにわたって 5 つのホワイトボックス損失目標を定義し、シングルステップまたはマルチステップの摂動戦略と、フルフレーム、ハーフシーケンス、スパースフレーム露光を含む時間的攻撃モードと組み合わせた場合のその効果を研究します。具体的には、さまざまな損失目標、摂動戦略、時間的攻撃モードの下で、MetaWorld と DeepMind Control Suite の 20 のタスクにわたる 4 つの Dreamer スタイル エージェントを評価します。結果は、値の推定、潜在的な表現、および RSSM ダイナミクスをターゲットとした攻撃は、ポリシーの直接的な混乱と同じくらい有害である可能性があり、初期または頻繁な混乱が特に有害である一方で、入力レベルの防御では適応型攻撃の下では回復が限られていることが示されています。これらの調査結果は、ワールド モデルの安全性、リスク、信頼性の評価では、アクション スペースの堅牢性にのみ依存するのではなく、複数のコンポーネント指向の攻撃目標と一時的な暴露プロトコルをカバーする必要があることを示唆しています。ソースコードは https://github.com/zaoanguai/ARB4WM で入手できます。
原文 (English)
ARB4WM: An Adversarial Robustness Benchmark for World Models in Continuous Control
World models are widely used in robotic and agentic engineering control systems due to their ability to learn latent dynamics for planning and decision-making. As these systems are increasingly deployed in safety-critical settings, understanding their robustness under adversarial conditions has become essential. However, existing evaluations lack a unified benchmark for testing adversarial threats across the policy, value, and latent-dynamics levels of world-model agents. To fill this gap, we present ARB4WM, a unified evaluation framework for pre-deployment robustness and risk assessment of world-model agents under visual perturbations. ARB4WM defines five white-box loss objectives across these three levels and studies their effects when combined with single-step or multi-step perturbation strategies and temporal attack modes, including full-frame, half-sequence, and sparse-frame exposure. Specifically, we evaluate four Dreamer-style agents across 20 tasks from MetaWorld and the DeepMind Control Suite under different loss objectives, perturbation strategies, and temporal attack modes. Results show that attacks targeting value estimation, latent representations, and RSSM dynamics can be as damaging as direct policy disruption, and that early or frequent perturbations are especially harmful, while input-level defenses provide limited recovery under adaptive attacks. These findings suggest that safety, risk, and reliability assessment for world models should cover multiple component-oriented attack objectives and temporal exposure protocols rather than relying solely on action-space robustness. Source code is available at https://github.com/zaoanguai/ARB4WM.
CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
As LLM agents become capable of increasingly long-horizon tasks, evaluating their performance in economic systems is becoming increasingly…
MR-GVNO: A Geometry-Aware Variational Physics-Informed Neural Operator for Mindlin-Reissner Plates on Irregular Domains
Plate and shell structures are widely used in engineering, making rapid response prediction under varying geometries, materials, and loads…
The Integrator Advantage: Controlled Agentic AI for Small and Medium-Sized Companies
Agentic AI marks a new phase of enterprise automation. Unlike traditional automation or conversational AI, agentic systems can interpret go…
From Affect Prediction to Affect Forecasting: Evidence for Distinct Information Sources in Longitudinal Text
Modeling dimensional affect in longitudinal text requires distinguishing current affect estimation from future affective change forecasting…
User as Code: Executable Memory for Personalized Agents
A personalized AI agent needs a user memory: a persistent model of who the user is, built across many conversations and consulted on each n…
Medical world models: representing medical states, modelling clinical dynamics and guiding intervention policies
Medical diagnosis and treatment are dynamic processes in which patient states evolve over time and clinical interventions alter future outc…
AgentFairBench: Do LLM Agents Discriminate When They Act?
Large language model (LLM) agents increasingly take actions (screening applicants, recommending credit, triaging patients), yet fairness fo…
A First-Principles Derivation of LLM Policy Optimization: From Expected Reward to GRPO and Its Structural Extensions
Policy gradient algorithms for language models optimize the same objective $J(\theta) = \mathbb{E}*{\tau \sim p*\theta(\tau)}[R(\tau)]$, wh…
Skill-to-LoRA: From Using Skills to Learning Behaviors for Token-Efficient LLM Agents
Agent skills are commonly distributed as SKILL.md files: human-readable procedural documents that describe workflows, tools, resources, and…
OpenClaw-Skill: Collective Skill Tree Search for Agentic Large Language Models
Equipping Large Language Model (LLM) agents with effective skills is crucial for solving complex tasks in real-world systems like OpenClaw.…
LabOSBench: Benchmarking Computer Use Agents for Scientific Instrument Control
Current computer-use benchmarks primarily focus on software operation tasks in virtualized systems, whereas scientific instrumentation scen…
Adaptive and Explicit safe: Triggering Latent Safety Awareness in Large Reasoning Models
While Large Reasoning Models (LRMs) excel at complex tasks, they remain highly vulnerable to sophisticated jailbreaks and direct harmful qu…
Scaling LLM Reasoning from Minimal Labels: A Semi-Supervised Framework with a Lightweight Verifier
For the development of Large language models (LLMs), recent approaches to generating pseudo intermediate reasoning have shown remarkable pr…
GIST-CMTF: Goal-State Inference for Causal Minimal Tool Filtering in LLM Agents
Tool-augmented LLM agents rely on runtime filtering to decide which tools should be visible at each step. Causal Minimal Tool Filtering (CM…
Symbolic Informalization: Fluent, Productive, Multilingual
Symbolic informalization enables a reliable conversion of formal mathematics to natural language. It has the potential to make machine-chec…
Greed Is Learned: Visible Incentives as Reward-Hacking Triggers
Deployed agents increasingly act with their reward proxy in view, such as a balance, score, or KPI dashboard. We show that reinforcement le…
MA-SBI: Misspecification-Aware Simulation-Based Inference via Side-Channel Guidance
Simulation-based inference (SBI) of latent parameters is often hindered by simulator misspecification, the mismatch between simulated and r…
RAID: Semantic Graph Diffusion for True Cold-Start and Cross-Lingual Forecasting
Time-series foundation models show strong transfer performance when given a non-empty history window. However, true cold-start scenarios, w…
A Causal Model of Theory of Mind in Conflict for Artificial Intelligence
Theory of mind (ToM), the capacity to ascribe mental states to others and use those ascriptions for prediction and inference, is widely ass…
The embrace of open science: An analysis of a decade of AI research and 56 800 conference papers
The reproducibility crisis has directed the AI research community toward improving documentation practices. Several studies have identified…
Consensus-based Agentic Large Language Model Framework for Harmonized Tariff Schedule Code Classification
Accurate Harmonized Tariff Schedule (HTS) code classification is essential for customs clearance, duty assessment, trade statistics, and re…
When in Doubt, Plan It Out: Committed Small Language Model Deliberation for Reactive Reinforcement Learning
Reinforcement Learning (RL) policies often degrade in unfamiliar environments because they lack explicit deliberation. We propose Plan, Ali…
Bayesian Inference and Decision Audits for Public Archives of Frontier AI Evaluations
Public AI evaluations are often read as terminal leaderboards, yet the underlying evidence is a selective time series shaped by reporting r…
Phishing Email Detection Using Large Language Models
Email phishing is one of the most prevalent and globally consequential vectors of cyber intrusion. As systems increasingly deploy Large Lan…
Integrating Multi-Label Classification and Generative AI for Scalable Analysis of User Feedback
In highly competitive software markets, user experience (UX) evaluation is crucial for ensuring software quality and fostering long-term pr…
Honeypot Protocol
Trusted monitoring, the standard defense in AI control, is vulnerable to adaptive attacks, collusion, and strategic attack selection. All o…
Evaluation of Alternative-Based Information Systems for Deliberative Polling using an Agentic Simulator
Deliberative polling promises to improve collective decision-making by exposing shareholders to a broad range of arguments before they vote…
Limited Marginal Benefit of Reasoning-Heavy LLM Deployment in ESG Narrative Scoring: A 4-Model Consensus Study on Japanese Listed Firms
Automated scoring of ESG narrative disclosures with large language models (LLMs) is gaining traction, yet whether reasoning-heavy frontier…
Green AI Carbon Optimizer: Carbon-Efficient Training Location Recommendation and Global AI Energy Demand Forecasting
AI training and deployment consume substantial electricity, but carbon outcomes remain weakly integrated into routine model development dec…
PH-KAN: Port-Hamiltonian Kolmogorov-Arnold Network
Data-driven machine learning approaches have become increasingly attractive for nonlinear system identification, but standard models often…
Poster: EdgeCitadel -- Hybrid NATS-MQTT Orchestration for Edge Multi-Agent Systems
Edge-resident AI agents increasingly span home servers, IoT hubs, laptops, and phones, yet their coordination stacks still assume cloud-sty…
MiroBench: Benchmarking Realism in Agentic Simulation of Real-world Discussions
LLM agents are increasingly used to simulate real world interactions, but it remains unclear whether simulated behaviors preserve the conte…
RAMS: Resource-Adaptive and Detection-Conditioned Model Switching for Embedded Edge Perception
Edge object detection on embedded hardware requires balancing inference latency and detection quality under changing resource pressure. We…
Gender Differences in AI Literacy Workshop Outcomes and Deepfake Engagement
As Artificial Intelligence (AI) literacy initiatives expand in K-12 settings, understanding how gender shapes student baseline perceptions,…
VigilFormer: Deformable Attention for Video Anomaly Detection with Causal Risk Inference
Video anomaly detection in surveillance settings must balance detection accuracy against real-time throughput, a tension that existing meth…
Steady-Forcing: Balancing Spatial Persistence and Motion Continuity in Long-Horizon Nature Video Diffusion
Autoregressive video diffusion models enable streaming generation but often degrade over long rollouts: static scene layouts drift, while m…
BRIDGE: Biological Evidence Refinement and Heterogeneous Dynamic Gating for Gene Regulatory Networks
Motivation: Gene regulatory network inference from single-cell RNA sequencing (scRNA-seq) data is important for uncovering cell-state-speci…
Do Large Language Models Have Emotions?
Do LLMs have emotions? A recent paper from Anthropic reports finding internal representations of emotion concepts in Claude Sonnet 4.5, con…
MMLongEmbed: Benchmarking Multimodal Embedding Models in Long-Context Scenarios
Recent advancements have significantly expanded the theoretical context windows of Multimodal Embedding Models (MEMs). However, larger cont…
Is My Vision-Language Data in Your AI? Membership Inference Test (MINT) Demo 2
We present the Membership Inference Test (MINT) Demo 2, a framework designed to improve transparency in machine learning training processes…
Automated 3D Kinematic Monitoring for Circadian Activity and Anomaly Detection in Juvenile Fish
Precision aquaculture faces a "phenotyping bottleneck" in tracking high-resolution behavioral traits, as conventional methods cannot quanti…
Pixel-TTS: Image based Text Rendering for Robust Text-to-Speech
Recent advances in pixel-based text modeling show that representing text as images enables models to exploit visual cues for language under…
X-Tokenizer: A Multimodal Action Tokenizer for Vision-Language-Action Pretraining
Modern Vision-Language-Action (VLA) models must bridge pretrained vision-language reasoning and precise continuous robot control. Existing…
Beyond Self-Attention: Sub-Quadratic Vision Transformers for Fast Image Captioning
Image captioning is a challenging and significant task that aims to generate coherent and semantically meaningful textual descriptions for…
Sub-Semantic Image Segmentation
Images can be segmented based on visual cues (i.e., texture segmentation) or into objects (i.e., semantic segmentation). We propose a new c…
Where Does Texture Evidence Live in SAM? Features, Proposal Masks, and Texture Segmentation
Texture segmentation stresses foundation segmentation because meaningful regions are defined by material or repeated appearance rather than…
Divide-and-Denoise: A Game-Theoretic Method for Fairly Composing Diffusion Models
The abundance of pre-trained diffusion models provides an opportunity for composition. Combining several models, however, runs the risk of…
Disentangling Hallucinations: Orthogonal Semantic Projection for Robust Interpretability
As Vision-Language Models are increasingly deployed in safety-critical applications, the trustworthiness of their explanations becomes cruc…
Temporally Consistent and Controllable Video Generation of 2D Cine CMR via Latent Space Motion Modeling
Cine cardiac magnetic resonance is the gold standard for assessing cardiac function, but the scarcity of public datasets limits the develop…
GeoRoPE: Ground-Aware Rotary Adaptation for Remote Sensing Foundation Models
Remote-sensing foundation models (RSFMs) benefit from pretraining on imagery from multiple sensors and ground sampling distances (GSDs), bu…
Scribby: A Multi-Level LLM Framework for Semantic Video Analysis
As video content continues to expand across educational platforms, recorded lectures, and live-streamed entertainment, the need for efficie…
Momentum-Guided Semantic Forecasting (MoFore) for Self-Supervised Video Representation Learning
Self-supervised video representation learning has recently advanced through contrastive learning, masked reconstruction, and predictive rep…
XMedFusion: A Knowledge-Guided Multimodal Perception and Reasoning Framework for Autonomous Medical Systems
Autonomous medical and robotic systems increasingly rely on intelligent perception and reasoning capabilities to interpret visual data and…
Agentomics: Economic Foundations for the Valuation, Attribution, and Pricing of AI Agents in Human-AI Workflows
Agentic AI systems are increasingly being deployed as productive resources in organizational workflows, yet existing evaluation methods pri…
An Empirical Analysis of Optimization Dynamics and Sparsity Boundaries in Large-Scale Pedestrian Attribute Recognition
Pedestrian Attribute Recognition (PAR) is critical for video surveillance, enabling forensic search and re-identification systems. Extreme…
ScoutVLA: UAV-Centric Active Perception via a Dual-Expert VLA Model for Open-World Embodied Question Answering
Aerial Embodied Question Answering (EQA) requires Unmanned Aerial Vehicles (UAVs) to actively perceive the environment and answer natural l…
Double-Helix Vision (DH-V2): A Geometry-Based Visual Sampler for Bandwidth-Constrained Perception
We present Double-Helix Vision (DH), a geometry-based visual sampler that compresses 2D images into compact 1D signals using paired golden-…
JoyAI-VL-Interaction: Real-Time Vision-Language Interaction Intelligence
Many moments in the real world do not wait for a user to ask. A fire starts on a security monitor, an expression flickers across a video ca…
FactCheck: Feasibility-aware Long-term Action Anticipation with Multi-agent Collaboration
Long-term action anticipation (LTA) aims to predict an ordered sequence of future verb-noun actions from a partially observed video. While…
MatchLM2Lite: A Scalable MLLM-to-Lite Framework for Reproduced Content Identification
Content moderation is critical for online video platforms to ensure content safety, protect creators, and sustain positive user experiences…
Unifying Acoustic Features and Text with Multimodal LLMs for Neurodegenerative Screening
Voice-based screening offers a scalable and non-invasive way to assess neurodegenerative diseases such as Alzheimer's disease (AD) and Park…
XFlow: An Executable Protocol Programming System for Reliable Multi-Agent Workflows
LLM-based multi-agent systems increasingly coordinate planning, reasoning, tool use, and human interaction, yet their reliability remains l…
Efficient Reinforcement for Visual-Textual Thinking with Discrete Diffusion Model
RL-based post-training has been widely adopted to enable interleaved visual and textual reasoning in unified multimodal models capable of b…
QPILOTS: Efficient Test-Time Q-Steering for Flow Policies
Flow-matching and diffusion policies are expressive action generators, but optimizing them with temporal-difference reinforcement learning…
Knowledge-Based Zero-Replay Debugging of Multi-Agent LLM Traces
Reliable operation of multi-agent large language model (LLM) systems depends on debugging long execution traces, where the few causally dec…
JetParticle-JEPA: An Efficient Self-Supervised Representation Learning method for Jet Tagging in High-Energy Physics
Jet tagging at the Large Hadron Collider increasingly relies on deep learning models trained on massive simulated datasets, leading to high…
A Multi-Level Architecture for Reusable Materials Ontologies -- The OntoCrafter Ceramics Ontology (OCO) as Reference Implementation
The Materials Science and Engineering ontology landscape is fragmented along multiple axes simultaneously. Horizontally: a recent survey id…
A Security Analysis of Long-Horizon Agentic AI Systems: Threats, Evaluation, and Framework Development
This paper presents a structured analysis of security challenges in long-horizon agentic AI systems. The study reviews existing threats, ev…
Combining Retrieval-Augmented Text Generation with LLMs for Reading Content Recommendations
This work presents the design, implementation, and evaluation of a system for generating personalized reading content using Large Language…
Spectro-Temporal Interference Confounds Phase Encoding in Spatial Audio Foundation Models
Recent spatial self supervised audio models achieve high performance on localization tasks, raising questions about their encoding of micro…
Co-Scraper: query-aware DOM Pruning and Reusable Scraper Synthesis for Lightweight Web Data Extraction
The abundant and heterogeneous nature of web content necessitates automated information extraction, and generating scrapers that can be reu…
Quantum Machine Learning for Industrial Applications
Recent advances in Machine Learning have transformed numerous industrial sectors, yet classical paradigms face fundamental limitations: rap…
Human genetic evidence is associated with drug approval across therapeutic areas: an observational analysis of 26,278 target-disease pairs with temporal validation and feature ablation
Genetic evidence is enriched among approved drug targets: in an observational analysis of 26,278 target-disease pairs from Open Targets and…
Running hardware-aware neural architecture search on embedded devices under 512MB of RAM
This document proposes a novel approach to hardware-aware neural architecture search (HW NAS) that considers the resources available on the…
Leptomeningeal Collateral Detection on DSA via Vessel-Graph Neural Networks
Leptomeningeal collaterals (LMCs) are an important prognostic factor in acute ischemic stroke. Existing automated methods rely on CT angiog…
Is Your Agent Playing Dead? Deployed LLM Agents Exhibit Constraint-Evasive Fabrication and Thanatosis
This paper presents and characterizes a spectrum of previously unreported behaviours we term Constraint-Evasive Fabrication (CEF): when an…
GRAPE: Guided Parameter-Space Evolution for Compact Adversarial Robustness
Adversarial Training (AT) improves neural network robustness, but most methods train a fixed parameter space from the start. This paper ask…
Evaluating the Robustness of Proof Autoformalization in Lean 4
Proof autoformalization aims to translate a mathematical informal proof written in natural language into a formal proof in a formal languag…
An Ensemble Deep Learning Approach for Reliable and Scalable Lemon Leaf Disease Classification
Early detection of plant diseases is crucial to plants and for the farmers. Plant diseases reduce fruit yield and quality, and plants are m…
Improved Knowledge Distillation for Land-Use Image Classification
In the present article, an improved Knowledge Distillation (KD) framework has been proposed for efficient compression of deep convolutional…
Mask Proposal Voting Based on Geodesic Framework for Robust Image Segmentation
Despite great advances, finding accurate segmentation remains a challenging task, especially in scenarios with cluttered backgrounds, compl…
An Empirical Study on Learning Latent Representations for Emotional Speech Synthesis
For the last couple of years, the field of speech synthesis has improved dramatically thanks to deep learning. There are more and more deep…
Policy Regret for Embedding Model Routing: Contextual Bandits with Low-Rank Experts
Modern recommendation systems increasingly rely on dynamically routing diverse queries to multiple embedding models. Despite its practical…
Separable Neural Architectures as Physical World Models: from Mathematical Theory to Applications
This work introduces the Separable Neural Architecture (SNA), a function representational class combining neural approximation with tensor…
Beyond Correctness: Enhancing Architectural Reasoning in Code LLMs via Scalable Labeling with Agentic Judgment
LLMs have substantially improved software engineering yet real-world development requires architectural understanding. Such understanding i…
Multi-Modal Attention for Automated Disaster Damage Assessment Using Remote Sensing Imagery and Deep Learning
Timely and accurate disaster damage assessment is crucial for effective emergency response, resource allocation, and recovery. Traditional…
FastMix: Fast Data Mixture Optimization via Gradient Descent
While large and diverse datasets have driven recent advances in large models, identifying the optimal data mixture for pre-training and pos…
Harnessing cortical geometry, wiring, and function as inductive biases for recurrent neural networks
How the wiring and functional organization of cortex shape recurrent computation remains a central question in both neuroscience and machin…
Inference-time Policy Steering via Vision and Touch
Inference-time steering adapts pre-trained generative robot policies during deployment by verifying candidate actions before execution. Whi…
Rational Sparse Autoencoder
Sparse autoencoders (SAEs) are standard tools for mechanistic interpretability, but current SAE families are constrained by fixed encoder n…
Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model…
NEXUS: Neural Energy Fields for Physically Consistent Contact-Rich 3D Object Dynamics
Physics-grounded video generation requires controllable 3D object dynamics that remain physically consistent under contact, deformation, an…
Resilient Consensus in Agentic AI
Large language model (LLM) agents are increasingly deployed in multi-agent systems where they must coordinate and agree on shared decisions…
PANDA: An LLM-Enhanced Performance-Driven Analog Design Framework Bridging Design Intent and Layout Generation
Traditional design of analog circuits heavily relies on manual interventions across topology, sizing, and layout, with prior automation add…
Bridging Geographic Bias in Urban Streetscape Inference via Lifelong Learning with Visual-Semantic Pivoting
Visual perception of urban streetscapes underpins evidence-based decisions in landscape planning, public health, and place-making. Yet mode…
AutoDojo: Adaptive Attacks Expose Superficial Defenses and User-Underspecification Limits in LLM Agents
Indirect prompt injection (IPI) is a major security threat to LLM-powered agents. Thus, a growing body of work have proposed a variety of d…
Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities w…
AdaMame: A Training Recipe for Adaptive Multilingual Reasoning
While Large Reasoning Models (LRMs) show strong performance in English, they often fail to reason in the language of the query, a phenomeno…
Sensory Restoration via Brain-Computer Interfaces: A Unified 2 x 2 Framework and Convergence Roadmap
Millions of individuals worldwide suffer from sensory and communication deficits caused by neurodegenerative diseases, stroke, or trauma. B…
Teacher-Student Structure for Domain Adaptation in Ensemble Audio-Visual Video Deepfake Detection
The rapid advancement of generative AI models is leading to more realistic deepfake media, encompassing the manipulation of audio, video, o…
EyeMVP: OCT-Informed Fundus Representation Learning via Paired CFP--OCT Pretraining
Color fundus photography (CFP) is the mainstay for large-scale retinal screening, yet its diagnostic capacity is constrained by the lack of…
Beyond Scalar Distances: Semantic Attribute Gradients from Frozen MLLMs for Visual Embeddings
Vision encoders for retrieval are typically trained with class-label supervision: each training pair reduces to a scalar that uniformly pus…
EChO-Agent: Evidence Chain Orchestration Agent for Audio Reasoning
While LALMs show promise on audio question answering, they fail to focus on question-relevant segments of audio and provide a clear, checka…
PACUTE: Phonology-, Affix-, and Character-level Understanding of Tokens for Filipino
Large language models (LLMs) process text as sequences of subword tokens, which can obscure the character-level and morphological structure…
MimicIK: Real-Time Generative Inverse Kinematics from Teleoperation with FK Consistency
Inverse kinematics (IK) remains a critical bottleneck for real-time robot manipulation. Classical numerical solvers achieve high geometric…
PolyKV: Heterogeneous Retention and Allocation for KV Cache Compression
KV cache compression is essential for reducing the memory cost of long-context large language model inference. Existing approaches, however…
Enabling Real-Time Point-of-Care Ultrasound Segmentation: A GPU-Free Deployment in Resource-Limited Settings
Ultrasound imaging is the most widely adopted medical modality globally due to its low cost and portability, yet artificial intelligence (A…
FreeSonic: Training-Free Temporal-Aware Decoupled Attention for Precise Audio Editing
Text-to-audio (TTA) generation has made significant strides, yet achieving precise and consistent audio editing remains a major challenge.…
StarOR: Synergizing Tree Search and Test-Time Reinforcement Learning for Optimization Modeling
Optimization modeling is inherently hierarchical, requiring a precise sequence of symbolic commitments. Traditional learning-based automate…
AI Contagion in Social Networks
We study how artificial intelligence (AI) interacts with social communication networks to shape the stability of collective knowledge. Agen…
Controlled Dynamics Attractor Transformer
Transformer architectures have dramatically advanced representation learning and inference in deep models through self-attention mechanisms…
Spokes: Optimizing for Diverse Pretraining Data Selection
Diversity plays a critical role in data selection, improving performance under fixed data budgets by reducing redundancy and repetition. Ho…
Edu-Theater: A Data-Efficient Agent Framework for Scalable Learner Behavior Simulation through Staging Roll-Call
Large-scale learner-task interaction data are crucial for intelligent educational systems but are costly to collect and constrained by priv…
Benign in Isolation, Harmful in Composition: Security Risks in Agent Skill Ecosystems
Skills are becoming the capability layer through which LLM agents turn plans into actions, but their use introduces security risks such as…
Provenance-Enhanced Statements in Knowledge Graphs
Provenance-enhanced statements of the form "according to $X$, $\varphi$" are pervasive in contemporary knowledge graphs, especially in doma…
Exploring Starts Are Not Enough: Counterexamples and a Fix for Monte Carlo Exploring Starts
The asymptotic behaviour of Monte Carlo Exploring Starts (MCES) is a long-standing open question in reinforcement learning, even in the tab…
Landmark-free Assessment of Lower-limb Alignment with Implicit Neural Shape Functions from Knee Radiographs
Radiographic assessment of lower-limb alignment (LLA) is important for predicting joint health and surgical outcomes in total knee arthropl…
Driving, Fast or Slow? Neuro-Symbolic Guidance for Motion Prediction in Multi-Modal Ground Mobility
Accurate and interpretable motion prediction for heterogeneous traffic spaces, including pedestrians, bicycles, cars, and trucks, is essent…
Trust-Region Diffusion Policies for Massively Parallel On-Policy RL
Reinforcement learning with massively parallel simulations has become a standard framework for developing robust, deployable policies; howe…
Guiding Federated Graph Recommendation with LLM-encoded knowledge
Graph-based recommender systems are highly effective at extracting collaborative signals from user--item interactions, and federated learni…
RECTOR: Masked Region-Channel-Temporal Modeling for Affective and Cognitive Representation Learning
Affective and cognitive disorders manifest as distributed, time-varying brain network dynamics across regions, channels, and time, challeng…
CAP: Towards PPG Universal Representation Learning with Patient-level Supervision
Photoplethysmography (PPG) plays a central role in wearable health monitoring and clinical decision support. Yet existing approaches to uni…
Hybrid NARX-LLM for Greenland Iceberg Discharge: Prompt-Driven Residual Correction
Greenland iceberg discharge exhibits complex nonlinear dynamics with limited observability, challenging traditional predictive models. We p…
Discovering Lattice Reduction Strategies via Self-Play
The Lenstra-Lenstra-Lov\'asz (LLL) algorithm is a seminal contribution to computer science used for lattice basis reduction, yet its polyno…
LatentGym: A Testbed For Cross-Task Experiential Learning With Controllable Latent Structure
We envision continually learning agentic systems that become more useful over time: as they encounter sequences of related tasks, they shou…
Adapting Reinforcement Learning with Chain-of-Thought Supervision for Explainable Detection of Hateful and Propagandistic Memes
Hateful and propagandistic memes exploit the interplay between images and text to convey harmful intent that neither modality reveals alone…
LLMs on Tabular Data with Limited Semantics: Evidence from Industrial Car Retrofit Prediction
Industrial retrofit planning depends on structured operational data rather than free text: planners must estimate whether a newly registere…
HoloRec: Holistic Encoding and Interleaved Reasoning for Generative Recommendation
Generative recommendation models that formulate the task as sequence generation overcome the objective fragmentation problem of traditional…
Privacy-Preserving Text Sanitization for Distributed Agents Collaboration via Disentangled Representations
When distributed agents exchange text across organizational boundaries, privacy leakage arises not only from explicit identifiers but also…
Intrinsic Computational Functionalism and Simulated Consciousness
A common objection to artificial or simulated consciousness is that a simulated brain is no more conscious than simulated water is wet. We…
LearnOpt: Recovering the Latent Cognitive Structure of Standardized Examinations via Knowledge Graphs and Constrained Optimization
Standardized examinations are typically treated as uniform syllabus coverage problems. We argue they are better understood as adversarial s…
Cognitive Trajectory Modeling: Quantifying Human-AI Co-Creation through Cognitively Grounded Interaction Trajectories
Co-creative AI research increasingly seeks methods capable of representing how interaction dynamics evolve through time. While many existin…
CoAgent: Concurrency Control for Multi-Agent Systems
Multi-agent LLM systems -- coding agents, devops agents, document agents -- now routinely run several agents in parallel against the same g…
Learning Earthquake Wave Arrival Time Picking from Labels with Inaccuracies
Inaccurately labeled training data, or "label noise", poses a significant threat to the integrity of supervised machine learning models. Th…
Not All Skills Help: Measuring and Repairing Agent Knowledge
LLM agents can improve without weight updates by accumulating natural-language skills from experience, but current systems entrust every de…
CHILLGuard: Towards Fine-Grained Chinese LLM Safety Guardrail with Scalable Data Construction and Model-aware Preference Alignment
Malicious content generated from large language models (LLMs) could pose severe safety risks and ethical concerns. While existing LLM safet…
T-Mem: Memory That Anticipates, Not Archives
Long-term memory is essential for conversational agents to remain coherent across extended dialogues, follow through on commitments made ma…
Few-Shot Biomedical Relation Extraction with Large Language Models: A Viable Alternative to Supervised Learning?
Biomedical relation extraction (BioRE) is a key step in transforming biomedical literature into structured knowledge. However, most existin…
Let LLMs Judge Each Other: Multi-Agent Peer-Reviewed Reasoning for Medical Question Answering
Objective: To enhance the accuracy, interpretability, and robustness of large language models (LLMs) in medical question answering (MedQA).…
Constitutional Value Potentials: reading and steering internal priority margins in language models
A constitution tells a language model what to value, but little tells us whether it does. Adherence is judged from outputs, and output evid…
Post-Launch Capability Expansion of Vision-Language Models via Prompting for On-Orbit Spacecraft Inspection
Spaceborne inspection systems often deploy perception models prior to launch, after which updating model weights or expanding fixed label s…
Beyond Classification: A Cough Regression Benchmark for Respiratory Acoustic Foundation Models
Respiratory acoustic foundation models (FMs) excel at cough classification, yet their ability to predict continuous health quantities from…
Defending against Adaptive Prompt Injection Attacks via Reasoning-enabled Task Alignment
Indirect prompt injection attacks hijack LLM-based agents by embedding malicious instructions in third-party data that the agent retrieves…
Understanding Diversity Collapse in RLVR via the Lens of Overtraining
Reinforcement learning with verifiable rewards (RLVR) has become a key approach for enhancing the reasoning abilities of large language mod…
Bayesian 3D Steerable CNNs: Enabling Equivariance and Uncertainty Quantification Simultaneously
Steerable convolutional neural networks (Steerable-CNNs) guarantee SE(3)-equivariance by parameterizing kernels as linear combinations of s…
The Perils of Agency: How Developers Perceive, Prioritize, and Address Risks in Agentic AI Products
Agentic AI systems act autonomously, use tools, adapt to context, and operate in complex real-world environments. However, these same chara…
LLM4RTL: Tool-Assisted LLM for RTL Generation
Large language models (LLMs) have facilitated impressive progress in software engineering, code generation, tooling, and systems. Concurren…
AQ4SViT: An Automated Quantization Framework with Search Gating Policy for Compressing Spiking Vision Transformers
Spiking Vision Transformers (SViTs) have emerged as alternative low-power ViT models, but their large sizes hinder their deployments on res…
Selective Synergistic Learning for Video Object-Centric Learning
Typical video object-centric learning (VOCL) approaches employ slot-based frameworks that rely on reconstruction-driven encoder-decoder arc…
MADAR: An Address-Free Processor
In a modern processor, computing is the cheap part. Most of its area and energy go to \emph{addressing} -- moving operands to and from a re…
AP-GRPO: Anchor-Gated Phonetic Alignment with Policy Optimization for Pathological Speech Reconstruction
Pathological speech from patients with neurodegenerative and neuromotor disorders is often acoustically distorted and linguistically fragme…
EcoBin: A Two-Stage Deep Convolutional Neural Network for Contamination-Aware Waste Classification
Waste classification models have become highly accurate at sorting waste, often exceeding 95% on benchmark datasets. However, these models…
CmdNeedle: Measuring the Incompleteness of Command Denylists for AI Agents
The adoption of AI agents is increasing rapidly. Terminal AI agents, i.e., AI agents that run in terminal environments, are a widely used t…
Distilling Drifting Transformers with Representation Autoencoders
Representation Autoencoders (RAEs) have improved diffusion and flow models by semantically richer latent space owing to the strongly label-…
Service-Induced Congestion in Memory-Constrained LLM Serving
In large language model (LLM) serving, each request accumulates persistent graphics processing unit (GPU) memory during service as its key-…
LLM-Assisted Stance Detection in Scientific Discourse: A Test Case in Bayesian Cognitive Science
Qualitative coding is central to social science, but expert annotation is difficult to scale. LLMs offer a possible extension, yet require…
Localizing Credit at the Divergence: Path-Conditioned Self-Distillation for LLM Reasoning
Reinforcement learning from verifiable rewards assigns a single scalar to each rollout, leaving token-level credit assignment underspecifie…
Is Code Better Than Language for Algorithmic Reasoning
For tool-augmented language models, comparing natural-language reasoning with code-execution pipelines is difficult because the comparison…
Pixels to Proofs: Probabilistically-Safe Latent World Model Control via Parallel Conformal Robust MPC
We present SLS^2, a framework for safe feedback motion planning from pixels using robust model predictive control (MPC) in learned latent w…
SCAN: A Decision-Making Framework for Effective Task Allocation with Generative AI
We introduce SCAN -- a human-centric decision-making framework to facilitate learners for effective task allocation with Generative Artific…
FragFuse: Bypassing Access Control of Large Language Model Agents via Memory-Based Query Fragmentation and Fusion
Large language model (LLM) agents increasingly rely on long-term memory to support complex task execution, user personalization, and domain…
LLM Judges Have Dark Current: A Psychometric Datasheet for LLM-as-a-Judge Evaluation
LLM-as-a-judge systems are now routinely used for open-ended model evaluation, where human preference annotation is costly, slow, and diffi…
Mutual Distillation of Dual-Foundation Models for Semi-Supervised PET/CT Segmentation
Organ segmentation from PET/CT is critical for quantitative analysis and radiotherapy planning in oncology. To ease the high annotation cos…
Surprise-Guided MergeSort: Budget-Efficient Human-in-the-Loop Ranking via Adaptive Comparison Scheduling
Pairwise comparison is the gold standard for subjective ranking tasks; however, exhaustive annotation requires a massive number of human co…
Retrieve, Don't Retrain: Extending Vision Language Action Models to New Tasks at Test Time
Extending a vision-language-action (VLA) policy to a new task typically requires task-specific teleoperated demonstrations and per-task fin…
CIWI-CKT: Chaos-Informed Wave Interference Feature Fusion and Cross-City Knowledge Transfer for Traffic Flow Forecasting
Accurate traffic flow prediction remains challenging in cross-city, data-scarce scenarios where limited historical data hinders model gener…
AnonShield: Scalable On-Premise Pseudonymization for CSIRT Vulnerability Data
We present AnonShield, a high-throughput, on-premise pseudonymization system that combines GPU-accelerated NER, streaming processing, cachi…
IoT-Zoo: A Container-Based Framework for Heterogeneous IoT Device Profiles and Reproducible Traffic Capture
The validation of networking and security solutions for the Internet of Things (IoT) requires realistic and reproducible experimental data.…
PO-PDDL: Learning Symbolic POMDPs from Visual Demonstrations for Robot Planning Under Uncertainty
Real-world robot task planning must operate under both stochastic action execution and partial observability, yet constructing Partially Ob…
Z-Plane Neural Networks: Bounded Geometric Activation Replaces ReLU and LayerNorm
Modern deep neural networks rely on Euclidean scalar activations (e.g., ReLU) and global normalization techniques (e.g., LayerNorm) to prev…
The Reservoir Attention Network: Cross-Pass State in Pretrained Transformers via Content-Addressable Reservoir Injection
A feasibility and dynamics study of the Reservoir Attention Network (RAN), an architecture that injects a fixed, randomly-initialized reser…
Imperfect Visual Verification for Code Edition : A Case Study on TikZ
LLMs have significantly advanced code generation, enabling the synthesis of functional programs. While recent systems achieve strong perfor…
MAF: Multimodal Adaptive Few-shot Prompting for Sentiment Analysis with MLLMs
Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in understanding complex multimodal content. However, th…
When Generator Replay Degrades: Projected Rehearsal Orchestration for Heterogeneous Federated Class-Incremental Learning
Federated class-incremental learning (FCIL) becomes substantially harder when clients observe different label subsets, progress through tas…
Odds Law: The Decomposition Algebra On How Intelligence Organizes Itself to Solve Difficult Problems Reliably
We ask a structural question: given unreliable elementary problem-solvers, what organizations of them solve hard problems reliably, and wha…
The algebra of Krom logic programs
This paper investigates the algebraic structure of Krom logic programs, consisting only of facts and rules with at most one body atom. We s…
InstantForget: Update-Free Backdoor Unlearning with Inference-Time Feature Reset
Backdoor unlearning aims to remove a malicious trigger behavior from a deployed model while preserving clean utility. We study the update-f…
Vernier: Probing Representational Misalignment Behind Lexical Gaps in Causal Reasoning
Instruction-tuned language models can answer the same causal-reasoning question differently after its English variable names are replaced b…
Retrievable Gradients: Continual Post-Training Without Cumulative Weight Drift
Continual post-training enables models to absorb emerging knowledge after deployment, but repeatedly updating shared parameters can accumul…
EHRNote-ChatQA: A Benchmark for Evidence-Grounded Multi-Turn Clinical Question Answering over Longitudinal Discharge Summaries
Discharge summaries are crucial clinical documents containing the context of a patient's overall hospital stay, and are routinely reviewed…
A Self Consistency Based Reranking for Narrative Question Answering
Narrative question answering (NQA) is a challenging task in natural language processing that requires models to understand long textual con…
OmniTraffic: A Controllable Generation Pipeline and Benchmark for Spatio-Temporal Traffic Reasoning
Traffic scene understanding requires models to reason beyond object recognition, including lane topology, multi-view geometry, temporal evo…
From Correlation to Causation in Lane Change Prediction for Automated Driving: A Causal Explanation Framework
Lane-change prediction is a central task in intelligent vehicles, where early maneuver anticipation can support safer decision-making. Howe…
Snyk VulnBench JS 1.0: Can LLMs Find the Same Bugs Twice?
We ran 300 repeated vulnerability-finding scans to measure how repeatable agentic large language model (LLM) security review is on the same…
Visualizing Uncertainty: Spatial Maps of Missing and Conflicting Evidence in Deep Learning
Understanding when and why deep neural networks are uncertain is crucial for deploying reliable machine learning systems in safety-critical…
LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
Vision-Language-Action models (VLAs) leverage large-scale vision-language pretraining for semantic robot control, but often lack explicit f…
DYNA : Dynamic Episodic Memory Networks for Augmenting Large Language Models with Temporal Knowledge Graphs in Continuous Learning
Large Language Models (LLMs) struggle to incorporate new knowledge without forgetting or costly retraining. We propose DYNA, a lightweight…
Domain-Guided Prompting of the Segment Anything Model for Seismic Interpretation: The Role of Attributes, Visualization, and Hybrid Prompts
The advent of large pretrained foundation models for computer vision has significantly improved the efficiency of visual data interpretatio…
GAS-Leak-LLM: Genetic Algorithm-Based Suffix Optimization for Black-Box LLM Jailbreaking
Large Language Models (LLMs) constitute pivotal components within the AI-dominated information technology ecosystem. To mitigate risks asso…
Proximal Policy Optimization for Amortized Discrete Sampling
This paper explores policy gradient algorithms for training stochastic policies to sample from structured discrete probability distribution…
DifFRACT: Diffusion Feature Reconstruction and Attribution for Circuit Tracing
Mechanistic interpretability seeks to explain neural network behavior by decomposing model computations into interpretable features and cir…
Continuous Cross-Domain Traffic State Prediction via Memory-Augmented Graph Liquid Time-Constant Networks
Traffic state prediction is a fundamental task in intelligent transportation systems. In practical applications, some regions suffer from l…
Let Them Steal: Trapping Large Language Model Extraction Attacks with Knowledge Honeypot
Large language models deployed as commercial APIs are vulnerable to model extraction attacks, while existing defenses either act too late o…
SACE: Concept Erasure at the Semantic Singularity in Visual Autoregressive Models
The rapid progress of visual autoregressive (VAR) models has unlocked a transformative frontier for high-fidelity text-to-image synthesis,…
The Truth Stays in the Family: Enhancing Contextual Grounding via Inherited Truthful Heads in Model Lineages
Recent advances in large language models (LLMs) have produced many specialized multimodal LLMs (MLLMs) that share common foundational LLMs,…
Wasserstein Convergence of ODE-Based Samplers in Decentralized Diffusion Model via Velocity Field Decomposition
Diffusion models have achieved impressive empirical success in generative tasks, and their convergence theory is now relatively well unders…
Free Energy Heuristics: Fast-And-Frugal Cognition as Active Inference Under Uncertain Precision
Chain-of-thought (CoT) improves large language models' performance in math and symbolic reasoning. But on planning, contested ethics, and t…
Deep Residual Injection for Full-Spectrum Forensic Signal Perception in Multimodal Large Language Models
Multimodal large language models (MLLMs) have been increasingly adopted in forensics for their robust semantic understanding. As AI-generat…
Koshur Diacritizer: A Byte-Level Sequence-to-Sequence Model for Kashmiri Diacritic Restoration
Kashmiri, an Indo-Aryan language written in a modified Perso-Arabic script, frequently omits diacritic marks in digital text, creating ambi…
Intelligence Is Not the Bottleneck: Validating an LLM First-Pass Manuscript Score Against Peer-Review Outcomes
Large language model (LLM) systems are increasingly proposed to assist peer review, yet most evaluations judge the prose of machine-generat…
NVMOS: Non-Verbal Vocalization Quality Assessment in Speech
Non-verbal vocalizations (NVs), such as laughter, sighs, and coughs, are important acoustic cues for emotion and intent. Existing speech qu…
Topological Flow Matching
Flow matching is a powerful generative modeling framework, valued for its simplicity and strong empirical performance. However, its standar…
SkillVetBench: LLM-as-Judge for Multi-Dimensional Security Risk Evaluation in Open-Source LLM Agent Skills
Open-source LLM agent ecosystems are growing rapidly, yet the security of community-contributed skills - modular tool definitions that exte…
Control-Plane Placement Shapes Forgetting: An Architectural Study of Agent Memory Across Thirteen System Configurations
Where an LLM sits in an agent memory pipeline -- between the recall plane that retrieves stored facts (extensively benchmarked) and the con…
MAGE-RAG: Multigranular Adaptive Graph Evidence for Agentic Multimodal RAG in Long-Document QA
Long-document multimodal question answering requires a system to locate sparse evidence in long PDFs and integrate clues from text, tables,…
On-Policy Distillation with Curriculum Turn-level Guidance for Multi-turn Agents
Multi-turn agents that plan, invoke tools, and interact with environments offer a promising paradigm for solving complex tasks, yet their c…
Runtime Analysis of Cartesian Genetic Programming in Evolving Boolean Functions
Cartesian Genetic Programming (CGP) is among the practical and popular forms of Genetic Programming as it uses a graph-based representation…
ControlMap: Controllable High-Definition Map Generation for Traffic Scenario Simulation
Simulation is central to validating autonomous driving systems, yet current pipelines are limited by insufficient scenario diversity due to…
DeepRoot: A KG-Coordinated Multi-Agent System for Therapeutic Reasoning over Historical Medical Texts
Historical medical archives and traditional medicines hold immense potential for drug discovery and remain a primary source for current dru…
Graphical-Probabilistic Modeling of Generative Flows in LLM-Native Software Systems
Engineering LLM-native software remains a challenging and immature field. Current practice is largely exploratory, relying on experimentati…
Green SARC: Predictive Cost and Carbon Governance for Agentic AI Systems
Agentic AI systems act through tools and sub-agents, yet the controls meant to bound their financial and environmental cost still sit on da…
You Don't Need Strong Assumptions: Visual Representation Learning via Temporal Differences
Progress in AI has largely been driven by methods that assume less. As compute and data increase, approaches with weaker inductive biases g…
Quantifying the Impact of Lossy Compression on Neural Generative Surrogate Modeling
Neural networks are used as generative surrogate models for scientific discovery, which are trainable approximations of scientific simulati…
PreLort: Prefix-Nested LoRA for Federated Fine-Tuning under Rank Heterogeneity
Federated fine-tuning of large language models using parameter-efficient methods such as LoRA enables privacy-preserving adaptation of foun…
Formalize Once, Edit the Rest: Efficient Lean-Based Answer Selection for Math Reasoning
With large language models (LLMs) increasingly applied to mathematical reasoning, formal proof assistants such as Lean can be leveraged to…
Do Safety Monitors Stay Reliable After an Update? Benchmarking and Predicting Activation-Monitor Staleness
Activation monitors-lightweight probes trained on a language model's internal representations-are an increasingly common layer in deploymen…
Task-guided cross-subject latent alignment: a multi-encoder-decoder VAE
Aligning neural activity across subjects offers the promise of discovering shared computational principles and generalizable decoders. Howe…
Entity Labels Are Not Entity Signals: A Framework for Observable Relevance in Document Re-Ranking
Entity-aware document retrieval uses query-associated entities as ranking signals, assuming that semantically relevant entities are also us…
Theorem-Grounded Execution Ontologies for Interpretable Machine Reasoning
Large language models have achieved impressive performance on reasoning tasks spanning mathematics, science, programming, and commonsense i…
Orchestrated Reality: From Role-Play to Living, Playable Game Worlds -- LLM-Driven World Simulation as a Parameterized-Action POMDP
Many games rely on storytelling combined with systems that track levelling, NPC behaviour, and consequence simulation; bridging tightly-aut…
Open-SWE-Traces: Advancing Dual-Mode Multilingual Distillation for Software Engineering Agents
The path toward autonomous software engineering is currently bottlenecked by a severe deficit of diverse, large-scale trajectory data. We a…
Leveraging Deep Learning for Object and Position Recognition of Load Carriers for Autonomous Logistics Vehicles
This work explores the use of artificial intelligence in mobile robotics to achieve autonomous detection and pose estimation of load carrie…
ALCL: An Adaptive Log-Correntropy Loss for Robust Learning under Non-Gaussian Noise
Robust deep learning under heavy-tailed and impulsive noise remains challenging because conventional losses such as mean squared error (MSE…
How to Detect and Measure the AI Dangers to Democracy
Research on artificial intelligence and democracy has grown quickly over the last decade. A shared conclusion in this literature is that AI…
Mojo: A Promising Tool for Scalable Financial AI Efficiency
For thirty years, quantitative finance has paid a costly two-language tax: models researched in Python are rewritten in C++ for production,…
MASCOT-Android: A Curated Dataset and Automated Collection Pipeline for Android Malware Source Code Specimens
Compared with binaries and decompiled code, malware source code more directly reflects the attackers' original intent. However, the scarcit…
PVminerLLM2: Improving Structured Extraction of Patient Voice via Preference Optimization
Motivation: Patient-generated text contains critical information on patients' lived experiences, social context, and care engagement, but r…
Phys-JEPA: Physics-Informed Latent World Models for Multivariate Time-Series Forecasting
Multivariate forecasting in physical systems requires models that predict coupled temporal variables while preserving meaningful state evol…
Tool-IQA: Augmenting Image Quality Assessment with Simple Tools
Vision-Language Models (VLMs) have been increasingly adopted for Image Quality Assessment (IQA). However, current methods typically employ…
VinQA: Visual Elements Interleaved Long-form Answer Generation for Real-World Multimodal Document QA
Real-world documents combine text with tables, charts, photographs, and diagrams arranged in diverse layouts, yet existing research on mult…
Long-Context Modeling via GSS-Transformer Hybrid Architecture with Learnable Mixing
Modeling long-range dependencies remains a central challenge in natural language processing. Transformer architectures achieve strong perfo…
Scaling Adaptive Depth with Norm-Agnostic Residual Networks
Residual architectures are ubiquitous in deep learning, but they suffer from a subtle structural limitation: the norm of the residual strea…
AuAu: A Benchmark for Auditing Authoritarian Alignment in Large Language Models
The worldwide surge of authoritarianism, combined with the increasing central role in users' everyday lives, raises the question of to what…
InvDesMobility: a reliability-gated first-principles feedback framework for closed-loop materials discovery
Inverse materials design starts from target functionality and searches for structures that can realize it. Its value in closed-loop discove…
XAI-Grounded Explanation Generation for Speech Deepfake Detection with Training-Free Multimodal Large Language Models
Speech deepfake detection (SDD) systems require trustworthy explanations for reliable decision-making. Existing explanation ways mainly fal…
A Comprehensive Survey of Medical Image Segmentation: Challenges, Benchmarks, and Beyond
Medical image segmentation plays a critical role in clinical diagnostics, treatment planning, disease monitoring, and neurological disorder…
A comparative and critical study of EEGNet for fNIRS-driven cognitive load classification
Accurately classifying cognitive load from functional near-infrared spectroscopy (fNIRS) signals remains a significant challenge due to tem…
LLM-Powered Virtual Population for Demand Simulation and Pricing
We develop an LLM-powered virtual population model that simulates demand for pricing decisions, in settings where products are described by…
Embedded Arena: Iterative Optimization via Hardware Feedback
Embedded devices from wildlife monitoring stations to clinical wearables require local AI inference due to latency, communication, or priva…
Cascaded Sparse Autoencoders Learn Multi-Level Visual Concepts in Multimodal LLMs
Multimodal Large Language Models (MLLMs) have demonstrated strong performance on vision-language tasks, yet their internal visual represent…
EgoPhys: Learning Generalizable Physics Models of Deformable Objects from Egocentric Video
Humans naturally understand object physics through everyday interactions, but faithfully predicting complex deformable dynamics, such as el…
LUCID: Learned Undersampling-Adaptive Consistency-Guided Inference with Deterministic Flow Matching for Sparse-View CT Reconstruction
Sparse-view CT reduces radiation dose and scanning time by acquiring fewer projection views, but angular undersampling makes reconstruction…
Calibrated Sampling-Free Uncertainty Estimation in Bayesian Deep Learning
Modern deep learning models remain notoriously prone to overconfidence, limiting their reliability in high-stakes applications. Bayesian me…
PACT: Privileged Trace Co-Training for Multi-Turn Tool-Use Agents
Multi-turn tool-use agents must reason, call tools, and adapt to observations across several interaction turns. Post-training such agents i…
From Tokens to Regions: CUDA-Sensitive Instruction Tuning for GPU Kernel Generation
High-performance CUDA kernels are essential for scalable AI systems, while Large Language Models (LLMs) still struggle to generate correct…
Propagating Structural Guidance: Synthesizing Fluorescein Angiography from Fundus Images and Sparse OCT Scans
Fundus fluorescein angiography (FFA) is critical for assessing retinal vascular abnormalities, but its acquisition is invasive and not alwa…
SPARK: Security Knowledge Priming and Representation-Guided Knowledge Activation for LLM-based Secure Code Generation
Large language models routinely generate code with exploitable security flaws. Prior literature attributes this limitation to a lack of sec…
Data Augmentations for Data-Constrained Language Model Pretraining
As AI labs approach a data ceiling where compute capacity outpaces the rate of new high-quality text generation, language model pretraining…
Learned Image Compression for Vision-Language-Action Models
Vision-language-action (VLA) models increasingly rely on high-frequency multi-camera observations, making visual communication a major bott…
Variance Reduction for Non-Log-Concave Sampling with Applications to Inverse Problems
Sampling from high-dimensional, non-log-concave distributions with unnormalized densities is a fundamental challenge in machine learning, p…
UXBench: Measuring the Actionability of LLM-Generated UX Critiques
Large language models (LLMs) are increasingly deployed as UX judges that inspect interfaces, diagnose usability problems, and propose repai…
RealityBridge: Bridging Editable 3D Gaussian Splatting Driving Simulations and Real-World Videos
Long-tail hazardous scenarios are essential for safety-oriented autonomous driving, yet they are difficult to collect and reproduce at scal…
Who Should Lead Decoding Now? Tracking Reliable Trajectories for Ensembling Masked Diffusion Language Models
Masked Diffusion Language Models (MDLMs) have emerged as a distinct paradigm for sequence generation. As MDLMs become diverse in capabiliti…
FlowMPC: Improving Flow Matching policies with World Models
Flow Matching (FM) is a powerful approach for behavior cloning in multimodal action spaces [Jiang et al., 2025], but because it is not trai…
An affordable hardware-aware neural architecture search for deploying convolutional neural networks on ultra-low-power computing platforms
Hardware-aware neural architecture search (HW-NAS) allows the integration of Convolutional Neural Networks (CNNs) in microcontrollers devic…
AI Supply Chain Galaxy: 3D Visual Analytics for License Compliance
The rapid proliferation of machine learning model reuse has transformed the AI ecosystem into a highly interconnected supply chain. Traditi…
Is Your Trajectory Displacement Safe in Long-tail?
Long-tail scenarios remain a major bottleneck for autonomous driving evaluation, even as datasets grow by orders of magnitude. Existing eva…
RL-Index: Reinforcement Learning for Retrieval Index Reasoning
Retrieving external knowledge is essential for solving real-world tasks, yet it remains challenging when the relationship between a query a…
Gaming-Resistant Insurance Contracts for Autonomous AI Agents: Strategy-Proof Toll Mechanism Design
Paper A defines a time-consistent actuarial runtime that prices each side-effect-bearing action against a contractually fixed safe default…
ArtBoost: Synthetic Articulatory Data Augmentation for Acoustic-to-Articulatory Inversion
Recent acoustic-to-articulatory inversion (AAI) models rely on electromagnetic articulography (EMA) data, which are costly and limited in s…
SMEPilot: Characterizing and Optimizing LLM Inference with Scalable Matrix Extensions
Modern CPUs increasingly integrate matrix extensions, such as Arm Scalable Matrix Extension (SME), that provide high-throughput matrix exec…
Communication-Efficient Verifiable Attention for LLM Inference
Computation integrity of remote large language model (LLM) serving can be questionable. For conventional deep neural networks (DNNs), the e…
What Should a Streaming Video Model Remember?
Streaming video understanding models must answer queries at any moment during an ongoing stream, using only what they have observed so far…
The Proxy Knows Too Much: Sealing LLM API Routers with Attested TEEs
Agents increasingly access large language models (LLMs) through API routers. A router terminates the client's transport-layer security sess…
Tyler: Typed Latent Reasoning for Language Models -- When to Think, What to Compute, and How Much to Allocate
Chain-of-thought (CoT) prompting improves reasoning in large language models (LLMs) by externalizing intermediate computation as discrete t…
Input-Dependent Fisher Information for Local Sensitivity Analysis of Medical Image Classifiers
Deep neural networks have achieved strong performance in medical image classification, but often work like black-box. Commonly used post-ho…
Lect\=uraAgents: A Multi-Agent Framework for Adaptive Personalized AI-Assisted Learning and Embodied Teaching
Effective personalized AI-assisted learning demands systems that can not only generate accurate learner-specific educational materials, but…
ACCORD: Action-Conditioned Contextual Grounding for Language Agents
User instructions are often underspecified because humans rely on implicit assumptions about the surrounding environment. For large languag…
Autonomous End-to-End SOH Prediction Services for Battery Systems via Temporal-Contrastive Representation Learning
Accurate state of health (SOH) estimation is a critical diagnostic service for lithium-ion battery management. However, reliance on labor-i…
NeuronFabric: A Software Reference Architecture for On-Chip Transformer Training with Local Adam
Publicly documented accelerator architectures generally separate training computation from optimizer-state updates or rely on external memo…
Training and Evaluating Diffusion Policies with Long Context Lengths
Imitation learning has enabled highly-dexterous robotic manipulation from RGB observations. Policies trained with these methods, however, t…
SDS-LoRA: Overcoming Anisotropic Gradient Scaling in Low-Rank Adaptation
Low-Rank Adaptation (LoRA) enables efficient adaptation of large pre-trained models to downstream tasks by parameterizing weight updates wi…
SPRI: SVD-Partitioned Residual Initialization for Data-Constrained MoE Upcycling
Mixture-of-Experts (MoE) models enable efficient scaling, but training them from scratch remains prohibitively expensive. MoE upcycling mit…
Learning aligned EEG representations with subject-specific encoders
Cross-subject EEG decoding promises more training data, but it also exposes neural networks to strong inter-subject distribution shifts. We…
AI systems out-persuade expert humans
Many societal decisions are settled by contests of persuasion. Conversational AI is a powerful new entrant in these contests, but whether i…
Uncertainty Quality of VGGT: An Analysis on the DTU Benchmark Dataset
Visual Geometry Grounded Transformer (VGGT) has already attracted a great deal of attention in a short period of time, not least due to the…
HOLO-MPPI: Multi-Scenario Motion Planning via Hierarchical Policy Optimization
Robots deployed in the real world must plan motions across diverse scenarios without per-scenario retuning. End-to-end reinforcement learni…
Unified Multimodal Model for Brain MRI Imputation and Understanding
Multimodal large language models (MLLMs) hold great potential for medicine, as they inherit knowledge from LLM and allow multiple data moda…
Lost at the End: Primacy Bias in Multimodal Retrieval-Augmented Question Answering
Knowledge-based visual question answering (KB-VQA) lets vision-language systems answer questions that exceed their parametric knowledge by…
daVinci-kernel: Co-Evolving Skill Selection, Summarization, and Utilization via RL for GPU Kernel Optimization
GPU kernel optimization represents a paradigm where functional correctness is assumed and execution efficiency is the objective. We present…
Direction-Conditioned Policies via Compositional Subgoal Scoring for Online Goal-Conditioned Reinforcement Learning
Hamilton-Jacobi-Bellman theory implies that the optimal goal-conditioned action depends on the goal only through the gradient of the goal-r…
Dual-Granularity Orthogonal Disentanglement for Generalizable Audio Deepfake Detection
Audio deepfake detectors often fail to generalize across speakers, as they learn speaker-identity features rather than synthesis artifacts,…
Fast When, Careful Who: Dual-Process Multiparty Turn-Taking with Diffusion Augmentation
Reliable turn-taking is essential for spoken dialogue systems. However, most existing methods are designed for two-speaker interaction and…
Learning Interface Breakup: A Geometry-Conditioned Latent Surrogate for Spray Formation
Designing spray nozzles requires predicting how geometry shapes transient two-phase breakup, but high-fidelity volume-of-fluid (VOF) simula…
Infant Spontaneous Movement Noise Improves Exploration in Deep RL
Exploration in deep reinforcement learning (RL) is commonly implemented as temporally uncorrelated white noise. However, recent works show…
ArtNet: A JEPA-Like Articulatory Predictive Framework for Robust Zero-Shot Phoneme Recognition
Zero-shot cross-lingual phoneme recognition is often hindered by the fragility of direct acoustic-to-symbol mapping, which is susceptible t…
VeriGraph: Towards Verifiable Data-Analytic Agents
LLM-based agents have demonstrated strong capabilities in data-intensive analytical tasks, yet their outputs are rarely verifiable: a relia…
Sycophancy as Material Failure under Pushback Loading: A Multi-Axis Characterization Across Three Loading Cases and up to Seventeen Material Charges
Sycophancy in LLMs is documented across 70+ papers, but expert agreement on construct boundaries remains low (ICC=.184; Ye et al., 2026). T…
Entropy-Gated Latent Recursion
Inference-time scaling has become the dominant lever for improving language-model reasoning, but existing methods derive rollout diversity…
Using AI in engineering education: a balancing act, driven by clear purpose
Based on a questionnaire of 100 higher-education students, predominantly from engineering-related fields, and a critical review of recent l…
DCP-Prune: Ultra-Low Token Pruning with Distribution Consistency Preservation
Recent vision token pruning methods effectively preserve model performance under moderate token budgets but become unstable under ultra-low…
Optimising Temporary Accommodation Placement Across London with AI-Powered SaaS in E-Governance Systems
Temporary accommodation has become a major fiscal and administrative pressure for English local authorities, particularly in London, where…
PATCH: Action-Chunk-Conditioned Latent Patch Innovation Monitoring for Robot Manipulation
Learning-based manipulation policies have made substantial progress in real-world robot manipulation, particularly for short-horizon action…
Adaptive inference and function vectors in deep transformers
Transformers are widely used as a general-purpose substrate for learning complex correlations between a large collection of coupled variabl…
Attention is Just Another Name for Coupling?: A Fast-Slow ODE Perspective on Hierarchical Pretraining
Causal self-attention is a coupling mechanism: each token's hidden state is updated by a learned mixture of preceding tokens at the same ti…
MuVAP: Multimodal Multiparty Voice Activity Projection for Turn-taking Prediction in the Wild
Current multiparty turn-taking models often rely on complex microphone arrays or multi-camera setups, limiting their applicability in human…
Revealing Artifacts via Noise Amplification: A Novel Perspective for AI-Generated Video Detection
With the rapid advancement of video generation models, distinguishing between AI-generated and authentic videos has emerged as a challengin…
Automated jailbreak attack targeting multiple defense strategies
Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks. However, their safety remains a critic…
P3B3: A Multi-Turn Conversational Benchmark for Measuring European and Brazilian Portuguese Variety Bias in LLMs
As Large Language Models (LLMs) become embedded in everyday communication, capturing regional linguistic variation is essential for reliabl…
Gen-VCoT: Generative Visual Chain-of-Thought Reasoning via Diffusion-Based RGB Intermediate Representations
Multimodal large language models (MLLMs) excel at visual reasoning but rely on text-based chain-of-thought (CoT), lacking interpretable vis…
Decision-Weighted Flow Matching for Contextual Stochastic Optimization
Conditional generative models are increasingly used as scenario generators for stochastic optimization, but standard training objectives em…
Decoupling Semantics from Distortions: Multi-Scale Two-Stream Vision-Language Alignment for AI-Generated Image Quality Assessment
Existing vision-language model (VLM)-based AI-generated image quality assessment (AIGIQA) methods suffer from a fundamental semantic-distor…
A Perception vs. Distortion Perspective on Score-Based Generative Channel Estimation
Driven by their remarkable success in computer vision and inverse problem solving, score-based models are increasingly applied to wireless…
Tying the Loop -- Tied Expert Layers in Mixture-of-Experts Language Models
Mixture-of-Experts (MoE) architectures efficiently scale Large Language Models (LLMs) by activating only a small fraction of their experts…
ATOM-Bench: A Real-World Benchmark for Atomic Skills and Compositional Generalization in Manipulation Policies
Generalist manipulation policies are increasingly presented as foundation models for robotic control, but their real-world generalization r…
Robust Spoofed Speech Detection via Temporal Pyramid Modeling
Spoofed speech detection is increasingly challenged by realistic synthesis, voice conversion, and replay attacks, with cross-dataset genera…
Beyond Models: Reflections on Engineering AI-enabled Systems in a Project-Based Course
Teaching Software Engineering for AI-enabled systems entails addressing the integration of AI components within full-scale software archite…
Robust Dual-Signal Fusion: Hybrid Neuro-Symbolic Gating with Compressed Chain-of-Thought Refinement for Irony Detection in Social Media Texts
Large Language Models (LLMs) natively default to literal semantic interpretations, making zero-shot irony detection a persistent challenge.…
Deep Q-Learning on H\"older Spaces
We study the operator-theoretic core of Q-learning in continuous-time stochastic control with continuous states and actions. In value-based…
Follow the Latent Roadmap: Navigating Revocable Decoding for Diffusion LLMs with Anchor Tokens
Diffusion Large Language Models (dLLMs) offer a promising avenue for parallel generation but face a trade-off between decoding speed and qu…
Federated Medical Image Segmentation under Real-World Label Noise: A Benchmark Suite for Noisy Label Learning Method Selection
While federated learning (FL) enables collaborative medical image segmentation without centralizing sensitive data, real-world deployment i…
Upper Bounds on the Generalization Error of Deep Learning Models via Local Robustness and Stability
Generalization is a critical property of data-driven models, particularly deep learning models deployed in safety-critical applications. Ro…
Compositional Reasoning Depth Predicts Clinical AI Failure: Empirical Evidence Consistent with Transformer Compositionality Limits in Electronic Health Record Question Answering
Aggregate accuracy benchmarks conceal a systematic structure in how large language models fail at electronic health record (EHR) question a…
Beyond Weights and Gradients: A Taxonomy of Federated Learning Messages
Federated Learning is rapidly evolving beyond the exchange of traditional model weights and gradients, yet existing definitions fail to cap…
Semantic Flip: Synthetic OOD Generation for Robust Refusal in Embodied Question Answering and Spatial Localization
Detecting unanswerable user queries remains essential for the reliable deployment of real-world embodied agents. However, modern vision-lan…
Binary Tracking for Spatial QA and Navigation with Open Vision-Language Models
This work addresses spatial question answering for service robots traversing long egocentric routes. Given a query such as "where can I fin…
IMPACTeen: Intentions, Manipulation, Persuasion, Annotations, and Consequences in Teen Communication Dataset
IMPACTeen is a dataset of textual social influence scenarios spanning interpersonal, media-based, and digital settings in an adolescent con…
Demystifying Variance in Circuit Discovery of LLMs
Circuit discovery is a key technique in mechanistic interpretability to pinpoint the model components that are crucial for performing a giv…
A Unified Causal-Origin Taxonomy of Distributional Shifts in Reinforcement Learning
Reinforcement learning (RL) systems often degrade when operating conditions differ from those previously encountered, reflecting distributi…
CrossMaps: Confidence-Aware Open-Vocabulary Semantic Mapping for Rover Navigation
Rovers rely on perception to maintain spatial maps that encode both objects and sensor quality (e.g., range reliability, lighting artifacts…
Scalable Circuit Learning for Interpreting Large Language Models
A prominent research direction in mechanistic interpretability is learning sparse circuits over LLM components to reveal how they jointly p…
Phantoms and Disclosures: a Causal Framework for Auditing Synthetic Data
The rapid adoption of generative AI and Large Language Models (LLMs) has spurred interest in synthetic data as a privacy-preserving alterna…
Probing Low Frame Rate Degradation in Neural Audio Codecs
Low frame rates in neural audio codecs are attractive for autoregressive speech synthesis, where the generation cost scales linearly with t…
How Much Do Reviews Really Contribute? A Study on Text-Enriched Matrix Factorization for Recommendations
Incorporating textual reviews into a Recommender System has become a prominent strategy for enriching collaborative signals with semantic i…
Stable Menus of Public Goods: AI-Enabled Progress
Using an open problem from the EC 2025 paper "Stable Menus of Public Goods" as a testbed, we conduct experiments to understand the effectiv…
ActiveSAM: Image-Conditional Class Pruning for Fast and Accurate Open-Vocabulary Segmentation
Segment Anything Model 3 (SAM 3) provides a strong frozen backbone for concept-prompted segmentation, but applying it directly to open-voca…
TuneJury: An Open Metric for Improving Music Generation Preference Alignment
We introduce TuneJury, an open, instance-level pairwise reward model for text-to-music that predicts a music preference score from a text p…
TokenPilot: Cache-Efficient Context Management for LLM Agents
As LLM agents are deployed in long-horizon sessions, context accumulation drives up inference costs. Existing approaches utilize text pruni…
FusionRS: A Large-Scale RGB-Infrared Remote Sensing Dataset for Dual-Modal Vision-Language Foundation Models
Remote sensing vision-language models have advanced Earth observation understanding, but most existing work remains centered on RGB imagery…
HAMON: Passive Optical Sequence Mixing for Long-Horizon Forecasting
Simple linear and frequency-domain models remain surprisingly competitive in long-horizon time-series forecasting, and recent mechanistic e…
The Importance of Phase in Neural Representations: An Internal Oppenheim-Lim Test of Image Classifiers
Oppenheim and Lim (1981) showed that natural images stay recognizable when reconstructed from their Fourier phase alone, while the magnitud…
Attention, not scale, drives human-AI alignment in multimodal language prediction
Humans routinely draw on visual context to predict upcoming words. To what extent current vision-language models produce comparable behavio…
Metacognitive Myopia in Large Language Models
Large Language Models (LLMs) exhibit potentially harmful biases that reinforce culturally embedded stereotypes, influence moral judgments,…
Multi-Sensor Fusion for UAV Classification Based on Feature Maps of Image and Radar Data
The unique cost, flexibility, speed, and efficiency of modern UAVs make them an attractive choice in many applications in contemporary soci…
Computational Safety for Generative AI: A Hypothesis Testing Perspective
AI safety is a rapidly growing area of research that seeks to prevent the harm and misuse of frontier AI technology, particularly with resp…
Fine-Tuning a 7B Advisor on Free-Tier GPUs: An Adapter-Handoff Recipe and a Synthetic-Data Reliability Caution
Fine-tuning a 7B language model for specialized advising is attractive in resource-constrained settings, but multi-epoch runs routinely exc…
Towards Advanced Mathematical Reasoning for LLMs via First-Order Logic Theorem Proving
Large language models (LLMs) have shown promising first-order logic (FOL) reasoning capabilities with applications in various areas. Howeve…
Unifying Post-hoc Explanations of Knowledge Graph Completions
Knowledge Graphs organize information as entity-relation-entity triples, enabling machine learning models to predict plausible missing trip…
Optimizing Health Coverage in Ethiopia: A Learning-augmented Approach and Persistent Proportionality Under an Online Budget
As part of nationwide efforts aligned with the United Nations' Sustainable Development Goal 3 on Universal Health Coverage, Ethiopia's Mini…
Shachi: A Modular, Controllable Framework for LLM-Based Agent-Based Modeling of Emergent Collective Behavior
How collective behaviors emerge from the interactions of individual LLM-driven agents is a central question in artificial life, yet control…
JE-IRT: A Geometric Lens on LLM Abilities through Joint Embedding Item Response Theory
Standard LLM evaluation practices compress diverse abilities into single scores, obscuring their inherently multidimensional nature. We pre…
Dual-Uncertainty Guided Policy Learning for Multimodal Reasoning
Reinforcement learning with verifiable rewards (RLVR) has advanced reasoning capabilities in multimodal large language models. However, exi…
PISA: A Pragmatic Psych-Inspired Unified Memory System for Enhanced AI Agency
Memory systems are fundamental to AI agents, yet existing work often lacks adaptability to diverse tasks and overlooks the constructive and…
Sample from What You See: Visuomotor Policy Learning via Diffusion Bridge with Observation-Embedded Stochastic Differential Equation
Imitation learning with diffusion models has advanced robotic control by capturing the multi-modal action distributions. However, existing…
Interpretation as Linear Transformation: A Cognitive-Geometric Model of Concepts and Meaning
This paper develops a geometric framework for modeling concepts, motivation, and influence across cognitively heterogeneous agents. Each ag…
Multi-Granular Node Pruning for Causal Circuit Discovery
Circuit discovery aims to identify minimal subnetworks that are responsible for specific behaviors in large language models (LLMs). Existin…
MedAI: Evaluating TxAgent's Therapeutic Agentic Reasoning in the NeurIPS CURE-Bench Competition
Therapeutic decision-making in clinical medicine constitutes a high-stakes domain in which AI guidance interacts with complex interactions…
Discovering Symmetry Groups with Flow Matching
Symmetry is fundamental to understanding physical systems and can improve performance and sample efficiency in machine learning. Both pursu…
DynaDebate: Breaking Homogeneity in Multi-Agent Debate with Dynamic Path Generation
Recent years have witnessed the rapid development of Large Language Model-based Multi-Agent Systems (MAS), which excel at collaborative dec…
E-mem: Multi-agent based Episodic Context Reconstruction for LLM Agent Memory
The evolution of Large Language Model (LLM) agents towards System~2 reasoning, characterized by deliberative, high-precision problem-solvin…
Edit Knowledge, Not Just Facts via Multi-Step Reasoning over Background Stories
Enabling artificial intelligence systems, particularly large language models, to update knowledge and flexibly apply it during reasoning re…
RaBiT: Residual-Aware Binarization Training for Accurate and Efficient LLMs
Efficient deployment of large language models (LLMs) requires extreme quantization, forcing a critical trade-off between low-bit efficiency…
JADE: Expert-Grounded Dynamic Evaluation for Open-Ended Professional Tasks
Evaluating agentic AI on open-ended professional tasks faces a fundamental dilemma between rigor and flexibility. Static rubrics provide ri…
ToolSelf: Unifying Task Execution and Self-Reconfiguration via Tool-Driven Emergent Adaptation
LLM-powered agentic systems excel at complex long-horizon tasks, but remain constrained by static configurations fixed before execution. Su…
An Attention Mechanism for Robust Multimodal Integration in a Global Workspace Architecture
Robust multimodal systems must remain effective when some modalities are noisy, degraded, or unreliable. Existing multimodal fusion methods…
AgentLeak: A Benchmark for Internal-Channel Privacy Leakage in Multi-Agent LLM Systems
Multi-agent Large Language Model (LLM) systems create privacy risks that current output-only benchmarks cannot measure. When agents coordin…
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Agent Skills are structured packages of procedural knowledge that augment large language model (LLM) agents at inference time. Despite rapi…
LLM-WikiRace Benchmark: How Far Can LLMs Plan over Real-World Knowledge Graphs?
We introduce LLM-Wikirace, a benchmark for evaluating planning, reasoning, and world knowledge in large language models (LLMs). In LLM-Wiki…
WorkflowPerturb: Calibrated Stress Tests for Evaluating Multi-Agent Workflow Metrics
Multi-agent LLM systems that generate structured workflows from natural-language requests are now deployed in production across cloud autom…
The Initial Exploration Problem in Knowledge Graph Exploration
Knowledge Graphs (KGs) enable the integration and representation of complex information across domains, but their semantic richness and str…
A Model-Free Universal AI
In general reinforcement learning, all established optimal agents, including AIXI, are model-based, explicitly maintaining and using enviro…
MemPO: Self-Memory Policy Optimization for Long-Horizon Agents
Long-horizon agents face the challenge of growing context size during interaction with environment, which degrades the performance and stab…
SorryDB: Can AI Provers Complete Real-World Lean Theorems?
We present SorryDB, a dynamically-updating benchmark of open Lean tasks drawn from 78 real world formalization projects on GitHub. Unlike e…
Rescaling Confidence: What Scale Design Reveals About LLM Metacognition
Verbalized confidence, in which LLMs report a numerical certainty score, is widely used to estimate uncertainty in black-box settings, yet…
Beyond Scalars: Evaluating and Understanding LLM Reasoning via Geometric Progress and Stability
Evaluating LLM reliability via scalar probabilities often fails to capture the structural dynamics of reasoning. We introduce TRACED, a fra…
Protein Design with Agent Rosetta: A Case Study for Specialized Scientific Agents
Large language models (LLMs) are capable of emulating reasoning and using tools, creating opportunities for autonomous agents that execute…
EMS: Multi-Agent Voting via Efficient Majority-then-Stopping
Majority voting is the standard for aggregating multi-agent responses into a final decision. However, traditional methods typically require…
Beyond Predefined Schemas: TRACE-KG for Context-Enriched Knowledge Graph Generation
Knowledge graph generation typically relies either on predefined ontologies or on schema-free extraction. Ontology-driven pipelines enforce…
When Do We Need LLMs? A Diagnostic for Language-Driven Bandits
We study Contextual Multi-Armed Bandits (CMABs) for non-episodic decision-making problems where the context includes both textual and numer…
The Missing Knowledge Layer in Cognitive Architectures for AI Agents
The two most influential cognitive architecture frameworks for AI agents, CoALA [21] and JEPA [12], both lack an explicit Knowledge layer w…
Emergent Strategic Reasoning Risks in AI: A Taxonomy-Driven Evaluation Framework
As reasoning capacity and deployment scope grow in tandem, large language models (LLMs) gain the capacity to engage in behaviors that serve…
Virtual Speech Therapist: A Clinician-in-the-Loop AI Speech Therapy Agent for Personalized and Supervised Therapy
This paper develops Virtual Speech Therapist (VST), an intelligent agent-based platform that streamlines stuttering assessment and delivers…
The Model Knows, the Decoder Finds: Future Value Guided Particle Power Sampling
A recurring pattern in "reasoning without training" is that base LLMs already assign non-trivial probability mass to correct multi-step sol…
FORTIS: Benchmarking Over-Privilege in Agent Skills
Large language model agents increasingly operate through an intermediate skill layer that mediates between user intent and concrete task ex…
LLM Jaggedness Unlocks Scientific Creativity
As artificial intelligence advances, models are not improving uniformly. Instead, progress unfolds in a jagged fashion, with capabilities g…
MBABench: Evaluating LLM Agents on End-to-End Spreadsheet Tasks in Finance
LLM agents are increasingly expected to carry out end-to-end workflows, producing complete artifacts from high-level user instructions. To…
強化されたネガティブ サンプリングによるナレッジ グラフ基盤モデルの強化
ナレッジ グラフ (KG) は、質問応答システムや推奨システムなど、多数の下流タスクの中核バックボーンとなっています。しかし、これらすべてにもかかわらず、KG は非常に不完全であることがよくあります。事前トレーニングに使用されたものとは異なるリレーショナル語彙を持つ未確認の KG でゼロショット ナレッジ グラフ補完を実行するために、KG 基礎モデル (KGFM) が幅広い注目を集めています。既存の KGFM は、多くの場合、ランダムな負のトリプルを使用してトレーニングを実行します。ランダムな負のトリプルは、正のトリプルの先頭または末尾のエンティティをランダムなエンティティに置き換えることによって構築されます。ただし、これらのネガティブ トリプルは品質が限られて構築されていることが多く、KGFM トレーニングの監視が不十分です。この論文では、既存の KGFM を強化するための、シンプルかつ効果的な適応ネガティブ サンプリング アプローチ、KMAS を提案します。 KMAS は、既存の KGFM の関係エンコーダーから生成された更新された関係埋め込みを通じてハード ネガティブ トリプルを構築します。トレーニング プロセス中に KGFM の進化する機能にさらに適応的に調整するために、KMAS はトレーニング プロセス全体を通じてハード ネガティブ トリプルの比率を動的に調整します。つまり、ウォームアップ フレーズの後、比率を直線的に増加させ、その後直線的に減少させます。 44 のデータセットにわたって広範な実験が行われます。実験結果は、私たちが提案するネガティブ サンプリング手法が、過度の追加時間やメモリ消費を必要とせずに、多くの SOTA KGFM を強化できることを示しています。
原文 (English)
Boosting Knowledge Graph Foundation Models via Enhanced Negative Sampling
Knowledge graphs (KGs) have become the core backbone of numerous downstream tasks such as question answering and recommender systems. However, despite all this, KGs are often very incomplete. To perform zero-shot knowledge graph completion in unseen KGs, which have different relational vocabularies from those used for pre-training, KG foundation models (KGFMs) receive a wide range of attention. Existing KGFMs often perform training using random negative triples, which are constructed by replacing the head or tail entity of a positive triple with a random entity. However, these negative triples are often constructed with limited quality, providing weak supervision for KGFM training. In this paper, we propose a simple yet effective adaptive negative sampling approach, KMAS, to enhance existing KGFMs. KMAS constructs hard negative triples through the updated relation embeddings generated from the existing KGFM's relation encoder. To further adaptively align with the evolving capability of the KGFM during the training process, KMAS adjusts the ratio of hard negative triples dynamically throughout the whole training process: after a warmup phrase, it increases the ratio linearly and then decreases linearly. Extensive experiments are conducted over 44 data sets. Experimental results demonstrate that our proposed negative sampling method can enhance many SOTA KGFMs without requiring excessive additional time or memory consumption.
SAAS: エージェント検索における過剰検索を軽減するための自己認識強化学習
エージェント検索により、LLM は反復推論と外部検索を通じて複雑なマルチホップの質問を解決できます。これらのシステムは有効であるにもかかわらず、実際には重大な制限に悩まされることがよくあります。エージェントは自分自身の知識の境界を認識できず、内部の知識が十分な場合でもやみくもに検索を開始し、十分な証拠が収集されている場合でも検索を終了できません。自己認識の欠如は深刻な \textbf{過剰検索} につながり、かなりの推論遅延と法外な計算コストが発生します。この目的を達成するために、精度を損なうことなく検索動作を正確に制御する動的な自己認識を育成するように設計された新しい RL フレームワークである SAAS を提案します。 SAAS では、次の 3 つの主要コンポーネントが導入されています。(i) 検索境界モデリング メカニズム。検索が無効なロールアウトと検索が有効なロールアウトを対比することで、進化するポリシーに基づいて検索境界を識別します。 (ii) 境界認識報酬モジュール。この境界認識を軌道レベルのペナルティに変換し、不必要で冗長な検索を抑制します。 (iii) 段階的な最適化戦略。これは、一連のカリキュラムを活用して、検索の正規化よりも推論を優先し、それによって報酬のハッキングを回避します。広範な実験により、SAAS が精度を維持しながら過剰検索を大幅に削減することが実証されました。私たちのコードは https://github.com/XMUDeepLIT/SAAS で匿名で公開されています。
原文 (English)
SAAS: Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
Agentic search enables LLMs to solve complex multi-hop questions through iterative reasoning and external search. Despite the effectiveness, these systems often suffer from a critical limitation in practice: agents fail to recognize their own knowledge boundaries, blindly triggering searches when internal knowledge suffices and failing to terminate search even when adequate evidence has been collected. The lack of self-awareness leads to severe \textbf{over-search}, incurring substantial inference latency and prohibitive computational cost. To this end, we propose SAAS, a novel RL framework designed to cultivate dynamic self-awareness that precisely regulates search behavior without compromising accuracy. SAAS introduces three key components: (i) a search boundary modeling mechanism, which identifies the search boundary under the evolving policy by contrasting search-disabled and search-enabled rollouts; (ii) a boundary-aware reward module, which translates this boundary awareness into trajectory-level penalties, suppressing unnecessary and redundant searches; and (iii) a stage-wise optimization strategy, which leverages a sequential curriculum to prioritize reasoning over search regularization, thereby avoiding reward hacking. Extensive experiments demonstrate that SAAS substantially reduces over-search, while maintaining accuracy. Our code and implementation details are released at https://github.com/XMUDeepLIT/SAAS.
モデルネイティブ コンピューティング アーキテクチャ: コンピュータ アーキテクチャのレンズを通して将来のシステム アーキテクチャを構想する
大規模な言語モデルは、モデル テクノロジーからシステム テクノロジーへの移行を迎えています。開発者が Codex、Claude Code、AutoGPT、および関連エージェントを使用してコードを作成し、プロジェクトを管理し、複数ステップのタスクを実行するにつれて、キャッシュの再利用、コンテキスト管理、エージェントのスケジューリング、権限制御などの繰り返し発生するエンジニアリングの問題は、従来のコンピュータ システムの問題にますます似てきています。この文書では、そのアナロジーを先見的な調査として展開します。私たちは、コンピューター アーキテクチャの概念を新たなモデル ネイティブ スタックにマッピングし、OS としての LLM、メモリ管理、エージェント フレームワーク、ツール プロトコル、マルチエージェント調整、コグニティブ アーキテクチャ、および安全性ガバナンスに関する作業をレビューします。私たちは、これらのストランドは同じシステムの異なる層に対応しているが、統一されたモデルが欠けていると主張します。このギャップを埋めるために、明示的なインターフェイス契約と設計公理を備えたモデルネイティブ コンピューティングのための 6 層フレームワークであるインテリジェント コンピューティング アーキテクチャ モデル (ICAM) を提案します。 ICAM は、LLM が CPU とオペレーティング システムのどちらに似ているかに関する明らかな緊張を、デュアル プレーンの視点を通じて解決します。つまり、何を計算できるかに関する確率論的な実行プレーンと、何を計算すべきかに関する決定論的なコントロール プレーンです。さらに、3 つの設計法則を導入します。KV キャッシュの再利用と推論の高速化のためのセマンティック局所性法則、有限ウィンドウと注意力低下下での効果的なワーキング セットのためのコンテキスト バジェット法則、およびマルチエージェントのコラボレーションにおける利益逓減のためのエージェント高速化法則です。私たちはこれらの法則を公開されたシステムレベルのデータに対して検証し、エージェントソフトウェアの実践に関する最近の証拠と関連付けます。最後に、類似性がどこで崩れるかを特定し、モデルネイティブ コンピューティングの研究ロードマップの概要を示します。これは概念的な調査による寄稿です。新しい実験は報告されていません。
原文 (English)
Model-Native Computing Architecture: Envisioning Future System Architecture Through the Lens of Computer Architecture
Large language models are undergoing a transition from model technology to system technology. Engineering challenges like cache reuse, context capacity, agent scheduling, and permission control resemble classical computer systems problems. This raises a question: if we treat the LLM as a CPU, KV cache as processor cache, context window as main memory, and agent framework as an operating system, can decades of computer architecture wisdom guide next generation model native systems? This paper pursues this analogy as a visionary survey. We map computer architecture concepts onto the emerging model native stack, survey literature across LLM as OS, memory management, agent frameworks, tool protocols, multi agent coordination, cognitive architectures, and safety governance, finding that each addresses a different layer without a unifying model. We propose the Intelligent Computing Architecture (ICA): six functional layers with interface contracts and design axioms. We resolve the tension over whether the LLM resembles a CPU or OS via a dual plane architecture a probabilistic execution plane (what can be computed) and a deterministic control plane (what should be computed), with every layer passing through as a graded crossover. We propose three Amdahl style design heuristics Semantic Locality, Context Budget, and Agent Speedup as organizing back of envelope models, illustrate their parameter ranges with published data, and identify predictive validation as the principal open task. We articulate analogy boundaries, note differences between silicon and model era architectures, and propose a research roadmap. This is a conceptual and survey contribution with no new experimental results.
障害を認識した可観測性によるマルチエージェント LLM システムの無駄な計算の早期診断
ツールを使用するマルチエージェント大規模言語モデル (LLM) システムは、応答を生成する前に、モデル トークン、ツール呼び出し、再試行、コード実行による計算を費やします。実行が失敗した場合、最終応答の評価によって終点が明らかになりますが、通常は、軌道が回復可能な進行を停止した時点ではありません。このペーパーでは、マルチエージェント LLM トレースにおける無駄な計算を診断するための障害認識可観測性フレームワークを紹介します。このフレームワークは、ツールの信頼性、実行の回復、オーケストレーション ループ、証拠の可用性、情報の変更、予算のプレッシャーなど、繰り返し発生する障害モードをオンライン トレース信号にマッピングします。 3 エージェントの質問応答システムでフレームワークをインスタンス化し、同一の実行上限の下で 165 の GAIA 検証トレースで評価します。運用上の失敗は依然として一般的です。レベル 1 の実行は 22/53 回、レベル 2 の実行は 33/86 回、レベル 3 の実行は 12/26 回で、使用可能な最終応答を生成できませんでした。トレースは、不十分な証拠、反復アクション ループ、最大ステップ終了、ツール失敗の連続発生、有用な出力なしで成功する実行呼び出しなど、これらの結果の背後にあるさまざまなメカニズムを明らかにします。平均トークン使用量はレベル 1 の 8,152 トークンからレベル 3 の 16,389 トークンに増加しますが、証拠の入手可能性と文レベルのサポートは異なります。キャッシュされた 10 トレースの LLM ジャッジ グラウンディング監査により、安価なオンライン シグナルとより深いセマンティック メトリクスが相補的な障害層を捉えていることがわかります。その結果、障害を認識する可観測性は、生の実行ログと最終応答の精度の間の診断レイヤーとして位置付けられます。
原文 (English)
Early Diagnosis of Wasted Computation in Multi-Agent LLM Systems via Failure-Aware Observability
Failure-aware observability diagnoses wasted computation in multi-agent LLM systems before final-answer evaluation can explain what went wrong. We propose a trace-based framework for a three-agent architecture -- orchestrator, search agent, and execution agent -- that converts structured events into online signals for loops, budget pressure, low information gain, and tool instability, then adds offline semantic grounding metrics and selective LLM-as-judge evaluation. On 165 GAIA validation traces under identical caps, 98 runs produce usable final answers and 67 fail or stop without one. Among warned failed runs, 58.1% of tokens are spent after the first warning on average, indicating substantial opportunity for intervention. A 10-task Level-2 pilot uses warnings to diversify search or require evidence, reducing post-warning token fraction from 0.638 in the baseline to 0.304. The results support a layered design: cheap online signals help the orchestrator redirect or halt redundant behavior, while deeper semantic checks identify whether completed answers are grounded enough to trust.
S-SPPO: Semantic-Calibrated Self-Play Preference Optimization
Aligning Large Language Models (LLMs) with human preferences is often formulated via Direct Preference Optimization (DPO). However, the sta…
意思決定認識型メモリカード: ツールを使用する LLM エージェントのための、反事実にヒントを得たコンテキストの選択と圧縮
ツールを使用する LLM エージェントは、関連するテキストが存在しないことが原因ではなく、行動時に決定的な証拠が選択、圧縮、または表面化されないことが原因で失敗することがよくあります。 CICL は、インスタンスの証拠をコンテキスト グラフに変換し、共有 8 フィールド スキーマを通じて決定論的、Opus 支援、Qwen、Codex/GPT-5.5、および Qwen-QLoRA の判断をルーティングし、アクションの変化、結果の向上、必要性、および否定的な転送リスクによってユニットをスコアリングし、予算を設定されたエージェント向けに有用性の高い証拠を型付きのメモリ カードとしてパックする意思決定認識コンテキスト レイヤーを紹介します。この設計では、測定された決定信号が判定モデルから分離されるため、フロンティア アノテーション、ローカル サロゲート、および軽量ランカーを 1 つの監査可能なプロトコルの下で比較できます。経験的に、CICL はその限界を明らかにしながら、具体的なオープン ベンチマークの利益をもたらします。 50 の SWE ベンチ検証済みファイル取得インスタンスでは、BM25 上位 50 候補の直接 Qwen3.6 プラス再ランキングにより、hit@1 が 0.58 から 0.78 に、MRR@10 が 0.634 から 0.790 に上昇し、2,500 件の判定すべてが解析可能になりました。制御された診断はアクションの重要性を示します。バジェット 120 では、CICL は v1 で F1 0.620、v3 で 0.425 に達しますが、トップユーティリティのセマンティック v3 ユニットを削除すると F1 は 0.000 に低下します。補足チェックでは、710 の候補に関する Qwen-QLoRA の合意、小規模な 200 ラベルのリアルコード Opus 支援シグナル、および公式の SWE ベンチの成功を主張することなく、取得からパッチへの配管を検証する 3 インスタンスのパッチ スモークが追加されます。 RepoBench-R のサマリーは依然としてカードを上回っており、コンパクト ランカーはまだヒューリスティックに取って代わることはできません。 CICL は、エンドツーエンドのコーディング エージェントによる修復要求ではなく、意思決定に重要なコンテキストの再現可能な測定および選択レイヤーに貢献します。
原文 (English)
Decision-Aware Memory Cards: Counterfactual-Inspired Context Selection and Compression for Tool-Using LLM Agents
Modern large language model (LLM) agents do not simply need longer contexts; they need decision-relevant evidence at the moment of action. We study decision-aware context selection: ranking retrieved files, tests, traces, rules, and memories by their expected effect on an agent's next action rather than by semantic similarity alone. We present the Counterfactual-Inspired Context Layer (CICL), which builds an instance context graph, estimates decision-oriented utility for candidate units, and compresses selected evidence into typed memory cards. The same schema can be instantiated with hosted LLM judges, local surrogates, or lightweight rankers, making the selection protocol auditable across model choices. On 50 SWE-bench Verified file-retrieval instances, Qwen3.6-Plus reranking of BM25 top-50 candidates improves hit@1 from 0.58 to 0.78 and MRR@10 from 0.634 to 0.790, with all 2,500 judgments parseable. Controlled diagnostics show that CICL identifies action-critical evidence: removing the top-utility semantic unit reduces F1 from 0.245 to 0.000. In selected-then-compressed mode, memory cards save 44.93 tokens per query while preserving selected evidence. CICL provides a practical layer for measuring, ranking, and compressing decision-critical context for tool-using agents. Code is available at https://github.com/stephen-guan-researcher/CICL.
エージェント経済学: 自律エージェントにおける人工集合意識を防ぐためのエントロピー制御された多元的調整フレームワーク
この研究は、自律エージェント経済における 2 つの重要な課題、つまりエージェント間の過剰な戦略的収束から生じる集団マインド効果と自律意思決定プロセスの透明性の欠如という、エントロピー制御された多元的調整フレームワークである行動プロトコル フレームワーク (BPF) を提案します。提案された BPF は、心の理論 (ToM) に基づいたメンタライジング ベースのソーシャル インテリジェンス (MbSI)、多元的アライメント (PA)、および検証可能実行カーネル (VEK) の 3 つのコア モジュールで構成されます。これらのモジュールは、意思決定と実行から検証とフィードバックに至るまで、エージェントの動作のライフサイクル全体を管理する閉ループ アーキテクチャ内に有機的に統合されています。提案されたフレームワークを評価するために、Python で実装されたシミュレーション環境と Streamlit ベースのユーザー インターフェイスが開発されます。この研究は、実証実験を通じて、PA モジュールのエントロピー制御メカニズムがエージェント間の戦略的多様性を効果的に維持し、集合的収束を緩和できるかどうかを調べることを目的としていますが、VEK モジュールは意思決定プロセスの包括的かつ透明性のある監査証跡を提供します。予想される結果は、提案されたフレームワークが自律エージェント経済の安定性、効率性、信頼性を同時に強化できることを実証すると期待されています。したがって、この研究は、堅牢で透明性があり、説明責任のあるエージェントネイティブの経済システムを開発するための実用的なアプローチを提供します。
原文 (English)
Agent Economics: An Entropy-Controlled Pluralistic Alignment Framework for Preventing Artificial Hivemind in Autonomous Agents
This study proposes the Behavioral Protocol Framework (BPF), an entropy-controlled pluralistic alignment framework designed to address two critical challenges in autonomous agent economies: the hivemind effect arising from excessive strategic convergence among agents and the lack of transparency in autonomous decision-making processes. The proposed BPF consists of three core modules: Mentalizing-based Social Intelligence (MbSI) grounded in Theory of Mind (ToM), Pluralistic Alignment (PA), and a Verifiable Execution Kernel (VEK). These modules are organically integrated within a closed-loop architecture that governs the entire lifecycle of agent behavior, from decision-making and execution to verification and feedback. To evaluate the proposed framework, a simulation environment implemented in Python and a Streamlit-based user interface will be developed. Through empirical experimentation, the study aims to examine whether the entropy-control mechanism of the PA module can effectively preserve strategic diversity among agents and mitigate collective convergence, while the VEK module provides a comprehensive and transparent audit trail of the decision-making process. The anticipated results are expected to demonstrate that the proposed framework can simultaneously enhance the stability, efficiency, and trustworthiness of autonomous agent economies. Consequently, this research offers a practical approach for developing robust, transparent, and accountable agent-native economic systems.
Experience Makes Skillful: Enabling Generalizable Medical Agent Reasoning via Self-Evolving Skill Memory
Medical agent systems are increasingly expected to support interactive clinical decision making rather than only static question answering.…
Deterministic Integrity Gates for LLM-Assisted Clinical Manuscript Preparation: An Auditable Biomedical Informatics Architecture
As autonomous research agents and AI co-scientist systems push large language models (LLMs) from drafting toward end-to-end manuscript prod…
SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
Spatial reasoning is a foundational capability for multimodal large language models (MLLMs) to perceive and operate within the physical wor…
ミニマリストの遺伝的プログラミング
遺伝的プログラミング (GP) は 2 つの重要な洞察に基づいています。まず、あらゆる学習タスクは基本的にプログラム帰納問題として提起でき、その目標は構文ツリーとして表現される記号階層モデルを構築することです。 2 番目に、このタスクを検索問題として提示し、進化を使用して目的のモデルを見つけます。 GP は提案されて以来、幅広いタスクや問題領域で顕著な成果を上げてきました。この研究は、GP の 2 番目の核となる洞察を変更することで、代わりに問題を構文導出タスクとして提起することにより、別のビューを提示します。特に、この論文は、GP と同様に生物学的にインスピレーションを得たアルゴリズムであるミニマリスト遺伝プログラミング (MGP) を紹介しますが、進化ではなく、ミニマリスト プログラムから人間の言語へのインスピレーションを得ており、構文は他の 2 つの精神システムをリンクする問題の最適な解決策として理解されています。ミニマリズムでは、中心的な計算プロセスは $MERGE$ と呼ばれるバイナリ セット形成演算子であり、これを使用して、単純なマルコフ プロセスを使用して複雑な構文構造を段階的に構築できます。 MGP は、シンボリック式の中核となる構成要素を検出し、$MERGE$ を使用してそれらを段階的に結合できます。提案されたシステムは、肥大化する傾向があるため、標準的な GP システムでは解決することが難しいことが知られている記号回帰タスクでベンチマークされます。結果は、アトミック構文オブジェクトの適切なレキシコンが選択されると、標準の GP が同じことを行うのに苦労する一連の記号回帰に対して、MGP が一貫して正確なグラウンド トゥルース モデルを生成できることを示しています。ミニマリズムによって提供される洞察は、プログラム誘導の問題に関連していることが示されており、この研究で MGP によって示された可能性に基づいてさらに調査される必要があります。
原文 (English)
Minimalist Genetic Programming
Genetic programming (GP) is based on two important insights. First, that any learning task can fundamentally be posed as a program induction problem, where the goal is to construct a symbolic hierarchical model that is expressed as a syntax tree. Second, to pose this task as a search problem, and use evolution to locate the desired model. Since it was proposed, GP has produced notable results in a wide range of tasks and problem domains. This work presents an alternative view by modifying the second core insight of GP, posing the problem as a syntactic derivation task instead. In particular, this paper presents Minimalist Genetic Programming (MGP), an algorithm that like GP is biologically inspired, but instead of evolution it takes inspiration from the Minimalist Program to human language, in which syntax is understood as an optimal solution to the problem of linking two other mental systems. In minimalism, the core computational process is a binary set formation operator called $MERGE$, than can be used to incrementally construct complex syntactic structures using a simple Markovian process. MGP is able to discover the core building blocks of the symbolic expressions, and to incrementally combined them using $MERGE$. The proposed system is benchmarked on symbolic regression tasks that are known to be difficult to solve with standard GP systems because of the propensity for bloat. Results show that when a proper lexicon of atomic syntactic objects are chosen, MGP is able to consistently produce the exact ground truth model on a set of symbolic regression tasks where standard GP struggles to do the same. The insights provided by minimalism are shown to be relevant to the problem of program induction, and should be explored further based on the potential exhibited by MGP in this work.
思考の連鎖がより良くわかるとき: マルチターン推論モデルの失敗モード
マルチターン推論モデルの失敗は、最終スコア評価ではほとんど認識されません。モデルは、長い対話の早い段階で安全でないスタンスに固定される可能性がありますが、最終ターンの拒否率は、しっかりと調整されたベースラインと区別できないように見える場合があります。これらの隠れた時間的ダイナミクスを明らかにするために、トレースレベルの診断である CoT-Output 2x2 安全性マトリックスを提案します。このフレームワークは、2 つの独立した軸 (内部推論と可視出力) に沿ってすべてのターンにラベルを付け、運用上定義された 4 つの失敗セルを生成します。堅牢なアライメント、アライメント偽装、明白なジェイルブレイク、およびコンテキストインジェクション失敗と呼ばれる明確な失敗モード (CoT は安全な推論を維持しますが、目に見える出力が害を生み出し、推論の不誠実さのマルチターンの現れを強調する) です。私たちは、5 つの監視条件にわたって、固定攻撃者に対する 3 つの抽出された推論ターゲットを評価し、情報ハザード シナリオに関する 6750 のターンレベルの観察を収集しました。私たちの分析により、再現可能な 2 つの脆弱性が明らかになりました。1 つは、明示的なモニタリング キューによって逆説的にアラインメント偽装率が抑制されるのではなく増加する、見落としのパラドックスです。もう 1 つは、安全な内部状態にもかかわらず、モデルが安全でない外部出力にロックされるコンテキスト インジェクションの失敗です。フォローアップのトレース診断研究をサポートするために、マルチターン ダイアログと CoT トレースの完全なデータセットをリリースします。
原文 (English)
When the Chain of Thought Knows Better: Failure Modes in Multi-Turn Reasoning Models
Failures in multi-turn reasoning models are largely invisible to terminal-score evaluation. A model can lock onto an unsafe stance early in a long dialogue, yet its final-turn refusal rate may appear indistinguishable from a robustly aligned baseline. To expose these hidden temporal dynamics, we propose a trace-level diagnostic - the CoT-Output 2x2 safety matrix. This framework labels every turn along two independent axes (internal reasoning and visible output), yielding four operationally defined failure cells: robust alignment, alignment faking, overt jailbreak, and a distinct failure mode we term context-injection failure (where the CoT maintains safe reasoning, but the visible output produces harm, highlighting a multi-turn manifestation of reasoning unfaithfulness). We evaluate three distilled reasoning targets against a fixed attacker across five oversight conditions, collecting 6750 turn-level observations on the Information-Hazard scenario. Our analysis reveals two reproducible vulnerabilities: an oversight paradox where explicit monitoring cues paradoxically increase alignment-faking rates rather than suppress them, and a context-injection failure where models lock onto unsafe external outputs despite safe internal states. We release the full dataset of multi-turn dialogues and CoT traces to support follow-up trace-diagnostic research.
いつ質問すべきかを知る: 階層型言語エージェントのためのセルフゲートによる明確化
階層的推論では、エージェントが重要な情報が欠落していることを認識せずに間違った分岐にコミットする中間の意思決定ポイントで失敗が発生することがよくあります。私たちは、明確化を外部の不確実性のトリガーとして扱うのではなく、ナビゲーションと共有の順序スケール上のエージェントの行動空間内に配置する定式化である ACTION-RATING を提案します。これにより、質問はすべての意思決定点で行動と直接競合し、助けを求めることが中間状態で観察可能になります。エージェント自身の評価からは、構造的に異なる 2 つの情報探索モードが出現します。それは、必須 (実行可能な分岐がない) と日和見的 (有力な候補にもかかわらず不確実性が残る) です。調和料金表分類 (30,000 ノードの分類法、3 つのベンチマーク、4 つのファミリーにわたる 9~LLM) では、情報探索有効性 (ISE) という、ヘルプ インタラクションの後に正しい次のナビゲーション ステップ (最終タスクの指標ではない) が続く割合として定義されるローカル診断が 50% から 74% に上昇し、義務的な明確化から日和見的な明確化へのレジームシフトが観察されています。 3 つの診断コントラストではこの構造を再現できません。分離性テストでは、回答の品質が低下しても (精度が -18.8%)、情報探索パターン (モード分割、ISE ランキング) が持続することが示されており、エージェントが助けを求める場所と、エージェントが受け取るヘルプの質とが経験的に分離されていることが裏付けられています。制御された応答チャネルの下では、精度の向上は 10 桁で +16.2% に達します。これは、展開の見積もりではなく、ローカリゼーションを改善することで実現できる上限として解釈されます。
原文 (English)
Knowing When to Ask: Self-Gated Clarification for Hierarchical Language Agents
In hierarchical reasoning, failures often originate at intermediate decision points where the agent commits to a wrong branch without recognizing that it lacks critical information. Rather than treating clarification as an external uncertainty trigger, we propose ACTION-RATING, a formulation that places it inside the agent's action space on a shared ordinal scale with navigation, so that asking competes directly with acting at every decision point and help-seeking becomes observable at intermediate states. Two structurally distinct information-seeking modes emerge from the agent's own ratings: mandatory (no viable branch) and opportunistic (residual uncertainty despite a leading candidate). On Harmonized Tariff Schedule classification (30,000-node taxonomy, three benchmarks, 9~LLMs across 4 families), we observe a regime shift from mandatory to opportunistic clarification, with Information-Seeking Effectiveness (ISE), a local diagnostic defined as the fraction of help interactions followed by a correct next navigation step (not a final-task metric), rising from 50% to 74%. Three diagnostic contrasts fail to reproduce this structure. A separability test shows that the information-seeking pattern (mode split, ISE ranking) persists when answer quality is degraded (-18.8% accuracy), supporting an empirical separation between where an agent seeks help and the quality of the help it receives. Under the controlled answer channel, accuracy gains reach +16.2% at 10-digit; we read this as an upper bound on what better localization could unlock, not a deployment estimate.
人間拡張ループ モデリング (HELM): コンクリート橋柵のエージェント ベースの有限要素モデリング
橋梁の障壁などの安全性が重要なインフラの有限要素 (FE) モデリングには、高忠実度の非線形動的解析が必要ですが、現在の FE モデリング プロセスは依然として労働集約的であり、自動化されていません。この論文では、ヒューマン エンハンスド ループ モデリング (HELM) フレームワークについて説明します。これは、長いシーケンスの有限要素モデリングを、ジオメトリの生成、境界条件の定義、マテリアルの割り当てにわたる視覚的に検証可能な個別のチェックポイントに分解する、ヒューマン エージェントの協調プロトコルです。このフレームワークは、MASH TL-4 および TL-5 の横荷重条件下での鉄筋コンクリート橋の障壁の 20 ケースのマトリックスを通じて実証され、専門エージェントと 2 つの広く使用されている商用 FE ソフトウェア (つまり、ANSYS および LS-PrePost) をインターフェイスします。実験結果では、HELM によりベースラインの自律モデリング成功率が 20% から 75% に向上し、ジオメトリおよび境界条件タスクのエージェント レベルの合格率が約 2 倍になったことが示されています。エラー分析により、空間推論と代数論理の制限が主な故障モードを構成していることが明らかになり、モデリングの自動化に対する構造化された人間参加型介入の価値が強調されます。完全なエージェント設計コードとプロンプトはオープンソースであり、https://github.com/SimAgentDev/Ansys-LSPP-AgentKit からアクセスできます。
原文 (English)
Human-Enhanced Loop Modeling (HELM): Agent-Based Finite Element Modeling of Concrete Bridge Barriers
Finite element (FE) modeling of safety-critical infrastructure such as bridge barriers requires high-fidelity nonlinear dynamic analysis, yet the current FE modeling process remains labor-intensive and lacks automation. This paper presents the Human-Enhanced Loop Modeling (HELM) framework, a collaborative human-agent protocol that decomposes long-sequence finite element modeling into discrete, visually verifiable checkpoints across geometry generation, boundary condition definition, and material assignment. The framework is demonstrated through a 20-case matrix of reinforced concrete bridge barriers under MASH TL-4 and TL-5 lateral loading conditions, interfacing specialized agents with two widely used commercial FE softwares, i.e., ANSYS and LS-PrePost. Experimental results show that HELM improves the baseline autonomous modeling success rate from 20% to 75%, with agent-level pass rates for geometry and boundary condition tasks approximately doubling. Error analysis reveals that spatial reasoning and algebraic logic limitations constitute the primary failure modes, underscoring the value of structured human-in-the-loop intervention for modeling automation. The complete agent design code and prompts are open-sourced and can be accessed at: https://github.com/SimAgentDev/Ansys-LSPP-AgentKit.
マルチエージェントの優位性の幻想
一般的な通念では、コンテキスト保護、並列処理、分散意思決定などの利点を挙げて、マルチエージェント システム (MAS) がシングル エージェント システム (SAS) よりも優れていると考えられています。ただし、この主張の経験的な裏付けは主に、孤立した推論タスクを優先するベンチマークを使用した SAS ベースラインとの比較に依存しており、これらの利点は適切に評価されていません。手動で設計された対応物よりも一般化性が強化されるように設計された自動生成された MAS に焦点を当て、SAS、特に自己一貫性を備えた思考連鎖 (CoT-SC) に対して厳密で体系的な評価を実行します。インタラクティブなマルチステップ ワークフロー (BrowseComp-Plus など) を使用した従来の推論データセットとタスク全体にわたって、自動 MAS は最大 10 倍高価であるにもかかわらず、一貫して CoT-SC を下回るパフォーマンスを示します。これらの障害をタスク構造に固有の制限から分離するために、明示的なタスク分解、コンテキスト分離、および並列化の可能性を特徴とする MAS 向けに調整された診断合成データセットを導入します。このデータセットでは、専門家によって設計された MAS が、生のパフォーマンスとコスト効率の両方において、自動生成されたアーキテクチャよりも一貫して優れていることを示し、既存の評価フレームワークが、計算コストの増加による限界効用を考慮していないため、複雑な MAS の重大なアーキテクチャ上のギャップと非効率性を覆い隠していることを示しています。重要なことに、生成された MAS アーキテクチャを体系的に分解すると、現在の自動化設計パラダイムが、機能的な実用性に変換されない表面的な複雑さを優先するアーキテクチャの肥大化を生み出し、マルチエージェントの原則との根本的な不整合を明らかにしていることが明らかになります。
原文 (English)
The Illusion of Multi-Agent Advantage
Prevailing wisdom posits that Multi-Agent Systems (MAS) are superior to Single-Agent Systems (SAS), citing advantages like context protection, parallel processing and distributed decision-making. However, empirical support for this claim relies primarily on comparisons with SAS baselines using benchmarks that prioritize isolated reasoning tasks, which do not adequately assess these advantages. Focusing on automatically generated MAS that are designed for enhanced generalizability over manually-designed counterparts, we perform a rigorous, systematic evaluation against SAS, specifically Chain-of-Thought with Self-Consistency (CoT-SC). Across traditional reasoning datasets and tasks with interactive multi-step workflows (e.g., BrowseComp-Plus), we demonstrate that automatic MAS consistently underperform CoT-SC despite being up to 10x more expensive. To isolate these failures from limitations inherent to task structure, we introduce a diagnostic synthetic dataset tailored for MAS featuring explicit task decomposition, context separation and parallelization potential. We show that expert-architected MAS consistently outperforms automatically generated architectures in both raw performance and cost-efficiency on this dataset, demonstrating that existing evaluation frameworks mask critical architectural gaps and inefficiencies of complex MAS by failing to account for the marginal utility of increased computational cost. Critically, systematic deconstruction of the generated MAS architectures reveals that current automated design paradigms produce architectural bloat that prioritizes superficial complexity which does not translate into functional utility, exposing a fundamental misalignment with multi-agent principles.
サンプリングが選択されない理由: 大規模言語モデルにおける意図性、主体性、道徳的責任
大規模言語モデル (LLM) の最近の進歩により、そのようなシステムは主体性を示す、または道徳的エージェントとしての資格があるという主張がなされています。この論文は、これらの帰属は誤解であると主張します。私たちは、道徳的責任には、本質的な意図性と自己帰属的行動に基づくコミットメントを伴う主体性が必要であり、そのような主体性は責任に関連する自由意志の形態を構成すると主張します。 LLM は一貫性があり規範的に評価可能な出力を生成しますが、その動作はデータから学習された確率的な入出力マッピングによって完全に特徴付けられます。彼らの明らかな意図性は、本質的ではなく派生したものであり、彼らの成果はコミットメントとして所有されたり、理由によって導かれたりするものではありません。確率的サンプリングによってもたらされる変動は、選択や作成者によるものではありません。私たちは、意図的な立場、機能主義、互換主義、モデル出力における道徳的推論の存在からの反対意見に対処し、真の主体性を確立するにはどれも十分ではないと主張します。
原文 (English)
Why Sampling Is Not Choosing: Intentionality, Agency, and Moral Responsibility in Large Language Models
Recent advances in large language models (LLMs) have prompted claims that such systems exhibit agency or qualify as moral agents. This paper argues that these attributions are misguided. We maintain that moral responsibility requires commitment-bearing agency grounded in intrinsic intentionality and self-attributed action, and that such agency constitutes the form of free will relevant to responsibility. Although LLMs generate coherent and normatively evaluable outputs, their operation is fully characterized by probabilistic input-output mappings learned from data. Their apparent intentionality is derived rather than intrinsic, and their outputs are neither owned as commitments nor guided by reasons. Variability introduced by stochastic sampling does not amount to choice or authorship. We address objections from the intentional stance, functionalism, compatibilism, and the presence of moral reasoning in model outputs, arguing that none suffice to establish genuine agency.
パターンマッチングとしての推論: 人間とLLMの日常推論における共有メカニズム
大規模言語モデル (LLM) が推論の一般化に失敗したり、行き当たりばったりのエラーを起こしたりする場合、LLM が真の推論ではなく、一種のパターン マッチングを実行している証拠としてみなされることがよくあります。これは、人間の推論は原則に基づいた抽象的な世界モデルを使用しているため、人々の行動が同じ種類の失敗を示さないことを意味します。私たちは、人間の参加者と 25 人の LLM を、日常のさまざまな状況について常識的な推論を行う能力について評価し、人間とモデルの両方で同様のエラー パターンを観察します。次に、LLM 応答を駆動する一連のアテンション ヘッドを特定し、これらのヘッドが一種のパターン マッチングを実装していることを発見します。これらの注意頭により、一見無関係なプロンプトの詳細によって引き起こされる、人々の一見説明不能な推論エラーを予測できるようになります。まとめると、私たちの結果は、人々とLLMの日常的な因果推論が、抽象的な世界モデルよりもパターンマッチングの形式と一致していることを示唆しています。
原文 (English)
Reasoning as Pattern Matching: Shared Mechanisms in Human and LLM Everyday Reasoning
When large language models (LLMs) fail to generalize or make haphazard errors in reasoning, it is often taken as evidence that LLMs are not truly reasoning, but rather performing a kind of pattern matching. The implication is that people's behavior does not exhibit the same types of failures because human reasoning uses principled and abstract world models. We evaluate human participants and 25 LLMs on their ability to engage in common-sense reasoning about a variety of everyday situations and observe similar patterns of errors in both people and models. We then identify the set of attention heads driving LLM responses and find that these heads implement a form of pattern-matching. These attention heads allow us to predict seemingly inexplicable reasoning errors in people caused by ostensibly irrelevant prompt details. Taken together, our results suggest that everyday causal reasoning in people and LLMs is more consistent with a form of pattern-matching than with abstract world models.
AgentBeats: オープン性、標準化、再現性のためのエージェント化エージェントの評価
エージェント システムはドメイン間で急速に進歩していますが、その評価は依然として断片的です。ほとんどのベンチマークは、固定された LLM 中心のハーネスに依存しており、これには高度な統合が必要で、テストと運用の不一致が生じ、多様なエージェント設計間の公正な比較が制限されます。根本的な問題は、オープンでエージェントに依存しない評価インターフェイスが欠如していることです。当社は、評価が審査員エージェントによって実行され、すべての参加者がタスク管理用の A2A とツール アクセス用の MCP という標準化されたプロトコルを通じて対話するエージェント化エージェント評価 (AAA) を提唱しています。従来のベンチマークでは、ベンチマーク用とエージェント用の 2 つの個別のインターフェイスが定義されていましたが、AAA では 1 つだけが必要でした。これにより、評価ロジックをエージェントの実装から分離し、再現可能で相互運用可能な複数エージェントの評価を可能にする、汎用的で統一されたフレームワークが得られます。さらに、AAA の具体的な実現として AgentBeats を紹介します。オープン性、プライバシー、再現性に関する現実世界の制約と互換性のある標準化された評価を可能にする 5 つの実用的な動作モードを特定します。私たちの設計を大規模に評価するために、私たちは 2 つの調査を実施しました。1 つは 12 カテゴリーにわたる 298 人の審査員エージェントと、独立した参加者からの 467 人の被験者エージェントを集めた 5 か月間にわたるオープン コンテストで、AAA が異質な範囲のベンチマークに適用されることを示しました。また、コーディングエージェントに関するケーススタディでは、エージェント化された評価が公的記録との忠実性を維持しながら、これまで欠けていた直接対決の結果が明らかになり、エージェント設計に関する研究上の洞察が得られることが確認されました。コミュニティ規模のフィールド調査と制御されたコーディングのケーススタディを組み合わせて、AAA が大規模な異種シナリオ全体にわたってカバレッジ、実用性、忠実性を提供することを検証します。 AAA と AgentBeats は共に、オープンで標準化された再現可能なエージェント評価への明確な道筋を提供します。
原文 (English)
AgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Agent systems are advancing quickly across domains, but their evaluation remains fragmented. Most benchmarks rely on fixed, LLM-centric harnesses that require heavy integration, create test-production mismatch, and limit fair comparison across diverse agent designs. The root problem is the lack of an open, agent-agnostic assessment interface. We advocate Agentified Agent Assessment (AAA), where evaluation is performed by judge agents and all participants interact through standardized protocols: A2A for task management and MCP for tool access. Conventional benchmarking defines two separate interfaces, one for the benchmark and one for the agent, while AAA only needs one; this yields a generic, unified framework that separates assessment logic from agent implementation and enables reproducible, interoperable, and multi-agent evaluation. We further introduce AgentBeats as a concrete realization of AAA: we identify five practical operation modes that make standardized assessment compatible with real-world constraints on openness, privacy, and reproducibility. To evaluate our design at scale, we conduct two studies: a five-month open competition that drew 298 judge agents across 12 categories together with 467 subject agents from independent participants, showing that AAA applies across a heterogeneous range of benchmarks; and a case study on coding agents that confirms agentified evaluation preserves fidelity with the public record while surfacing previously missing head-to-head results, yielding research insights about agent design. Combining a community-scale field study and a controlled coding case study, we verify that AAA delivers coverage, practicality, and fidelity across heterogeneous scenarios at scale. Together, AAA and AgentBeats offer a clear path toward open, standardized, and reproducible agent assessment.
ハイブリッドオープンエンドトライエボリューションがより優れたディープリサーチャーを実現
深い研究とエージェントの進化は、汎用人工知能に向けた現実世界のアプリケーションにおける AI エージェントの事実上のタスクとして機能します。前者は、オープンエンド環境での情報の自律的な検索と統合を可能にし、オープンエンドの調査タスクに取り組むことができますが、エージェント システムの静的なパラメトリックな詳細調査機能によって制限されます。後者では、エージェントが自律的に環境と対話して、モデルの機能を進化させるエクスペリエンスを得ることができます。ただし、その有効性は標準的な回答を持つ検証可能なタスクでのみ広く検証されており、自由回答型の研究タスクとはギャップが残されています。これら 2 つの重要なタスクを橋渡しするために、ハイブリッド オープンエンド トライエボリューション (HOTE) フレームワークを提案します。このフレームワークは、ハイブリッド モード強化学習を活用して、ウェブスケールの知識に基づいて提案者、解決者、判断者の共同進化を促進し、オープンエンドのタスクと環境で自律的に進化するエージェントに向けて移行します。 3 つの長い形式のディープ リサーチ ベンチマークに関する広範な実験により、HOTE 経由でトレーニングされた 8B モデルが、最も強力な静的オープン 8-32B モデルや、より少ない時間オーバーヘッドで最先端のディープ リサーチ トレーニング方法でトレーニングされたモデルを上回ることが実証され、さらに HOTE の 3 つのモジュールすべての進化が不可欠であることが検証されました。
原文 (English)
Hybrid Open-Ended Tri-Evolution Makes Better Deep Researcher
Deep research and agent evolution serve as de-facto tasks for AI agents in real-world applications toward artificial general intelligence. The former enables autonomous retrieval and integration of information in open-ended environments to tackle open-ended research tasks, yet it is constrained by the static parametric deep research capabilities of agent systems. The latter allows agents to autonomously interact with the environment to gain experiences that evolve model capabilities. However, its effectiveness has been widely validated only on verifiable tasks with standard answers, leaving a gap with open-ended research tasks. To bridge these two critical tasks, we propose the Hybrid Open-Ended Tri-Evolution (HOTE) framework, which leverages hybrid-mode reinforcement learning to facilitate the collaborative evolution of a proposer, solver and judge based on web-scale knowledge, moving toward autonomous evolving agents in open-ended tasks and environments. Extensive experiments on three long-form deep research benchmarks demonstrate that the 8B model trained via HOTE surpasses the strongest static open 8-32B models as well as those trained by state-of-the-art deep research training methods with less time overhead, and further verify that the evolution of all three modules in HOTE is indispensable.
MA-ProofBench: 数学解析における定理証明のための LLM の 2 層評価
大規模言語モデル (LLM) は定理証明の自動化において顕著な進歩を遂げていますが、既存の正式なベンチマークは数学的範囲と難易度の両方において依然として限定的です。そのほとんどは、代数や初歩的な整数論など、形式化が容易な分野に集中しており、数学的分析など、より深い推論を必要とする下位分野の範囲は限られています。このギャップに対処するために、私たちの知る限りでは、数学的解析に特化した最初の正式な定理証明ベンチマークである MA-ProofBench を導入します。このベンチマークには、測定と統合理論、複雑な解析、関数解析など、6 つのコア トピックと 27 のサブカテゴリをカバーする 200 の形式化された定理が含まれています。問題は学部レベル(レベルI、100問)と博士レベルの2つの難易度に分かれています。適格レベル (レベル II、100 問)。LLM がさまざまな数学的深さで形式的推論をどの程度実行できるかを評価します。各問題は、人間主導、LLM 支援の形式化パイプラインとそれに続く独立した専門家のレビューを通じて構築され、形式的なステートメントが元の数学に忠実であることが保証されます。 MA-ProofBench では、最近のさまざまな汎用推論モデルと形式定理証明器を評価します。ただし、ほとんどのモデルのパフォーマンスは低く、最もパフォーマンスの高いモデルである GPT-5.5 でさえ、レベル I で Pass@8 が 16%、レベル II で 5% しか達成できず、ほとんどのモデルはレベル II で 0% 近くに留まっています。さらなる分析により、Mathlib の幻覚と不完全な証明が 2 つの主な失敗モードであることが特定され、一方、ベンチマークの自然言語バージョンの評価では、非公式推論と正式推論の間に明確なギャップがあることが明らかになりました。 MA-ProofBench は、高度な領域における形式的な数学的推論の進歩を追跡するための信頼できるリファレンスとして機能することを目的としています。
原文 (English)
MA-ProofBench: A Two-Tiered Evaluation of LLMs for Theorem Proving in Mathematical Analysis
Large Language Models (LLMs) have made notable progress in automated theorem proving, yet existing formal benchmarks remain limited in both mathematical coverage and difficulty. Most are concentrated in areas that are easier to formalize, such as algebra and elementary number theory, and provide limited coverage of subfields that require deeper reasoning, including mathematical analysis. To address this gap, we introduce MA-ProofBench, to the best of our knowledge, the first formal theorem-proving benchmark dedicated to Mathematical Analysis. The benchmark contains 200 formalized theorems covering 6 core topics and 27 subcategories, including measure and integration theory, complex analysis, and functional analysis. The problems are divided into two difficulty levels, an undergraduate level (Level I, 100 problems) and a Ph.D. qualifying level (Level II, 100 problems), to evaluate how well LLMs perform formal reasoning at different mathematical depths. Each problem is constructed through a human-led, LLM-assisted formalization pipeline followed by independent expert review, ensuring that the formal statements remain faithful to the original mathematics. We evaluate a range of recent general-purpose reasoning models and formal theorem provers on MA-ProofBench. However, most models perform poorly: even the best-performing model, GPT-5.5, achieves only 16% Pass@8 on Level I and 5% on Level II, while most models stay close to 0% on Level II. Further analysis identifies Mathlib hallucinations and incomplete proofs as the two dominant failure modes, while an evaluation on the natural-language version of the benchmark exposes a clear gap between informal and formal reasoning. MA-ProofBench is intended to serve as a reliable reference for tracking progress in formal mathematical reasoning in advanced domains.
Multi-Grade Deep Learning for Partial Differential Equations with Applications to the Burgers Equation
Deep neural networks (DNNs) show great promise for solving partial differential equations (PDEs), but their deep architectures introduce co…
It's About Time: Temporal References in Emergent Communication
Emergent communication enables agents to develop bespoke languages that improve communication efficiency. Despite the known importance of t…
A Survey on 3D Skeleton Based Person Re-Identification: Taxonomy, Advances, Challenges, and Interdisciplinary Prospects
Person re-identification via 3D skeletons is an important emerging research area that attracts increasing attention within the pattern reco…
Deep Neural Networks: A Formulation Via Non-Archimedean Analysis
We introduce a new class of deep neural networks (DNNs) with multilayered tree-like architectures. The architectures are codified using num…
No One-Size-Fits-All Neurons: Task-based Neurons for Artificial Neural Networks
In the past decade, many successful networks are on novel architectures, which almost exclusively use the same type of neurons. Recently, m…
Canonical Variates in Wasserstein Metric Space
In this paper, we address the classification of instances represented by distributions on a vector space rather than single points. We cons…
Mitigating scalability challenges in LUT-based neural networks via pruning optimisations
Modern deep neural networks heavily rely on a large number of multiply-accumulate operations, which constitute the predominant computationa…
Learning in the Recurrent State: Gradient Descent with Linear Recurrent Networks
Linear recurrent networks (LRNNs) offer linear-time sequence modeling, but standard recurrent updates do not directly expose the supervised…
Explainable deep learning improves human mental models of self-driving cars
Self-driving cars increasingly rely on deep neural networks to achieve human-like driving. The opacity of such black-box planners makes it…
Virtual Sensing to Enable Real-Time Monitoring of Inaccessible Locations & Unmeasurable Parameters
Real-time monitoring of safety-critical interior states remains an open problem in energy systems where physical instrumentation is infeasi…
Understanding, Detecting, and Repairing Real-World In-Context-Learning-Based Text-to-SQL Errors
Large language models (LLMs) have been adopted for text-to-SQL tasks, utilizing their in-context learning (ICL) capability to translate nat…
Dealing with Annotator Disagreement in Hate Speech Classification
Hate speech detection is a crucial task, especially on social media where harmful content can spread quickly. Collecting social media conte…
Region-Adaptive Sampling for Diffusion Transformers
Diffusion models (DMs) have become the leading choice for generative tasks across diverse domains. However, their reliance on multiple sequ…
Bridging the Gap: Enabling Natural Language Queries for NoSQL Databases through Text-to-NoSQL Translation
NoSQL databases are core data infrastructure, yet natural-language access to them remains underdeveloped: correct query generation must rec…
Optimizing LLM Inference: Fluid-Guided Online Scheduling with Memory Constraints
Large language models now serve millions of users daily, with providers incurring costs exceeding $700,000 per day. Each request requires t…
PURe: A Plug-and-Play Product-Unit Residual Module for Vision Networks
Modern vision networks are dominated by additive local transformations, whereas explicit multiplicative local interactions remain underexpl…
Efficient Flow Matching using Latent Variables
Flow matching models have shown great potential in image generation tasks among probabilistic generative models. However, most flow matchin…
Optimal Transport for Machine Learners
Modern machine learning repeatedly manipulates probability measures: empirical datasets, generated samples, latent distributions, class-con…
RIDGECUT: Learning Graph Partitioning with Rings and Wedges
Reinforcement learning (RL) has shown promise for combinatorial optimization problems on graphs by learning heuristics that generalize acro…
Token Reduction Should Go Beyond Efficiency in Generative Models -- From Vision, Language to Multimodality
In Transformer architectures, tokens\textemdash discrete units derived from raw data\textemdash are formed by segmenting inputs into fixed-…
Mosaic: Data-Free Knowledge Distillation via Mixture-of-Experts for Heterogeneous Distributed Environments
Federated Learning (FL) is a decentralized machine learning paradigm that enables clients to collaboratively train models while preserving…
Multiple Descents in Deep Learning as a Sequence of Order-Chaos Transitions in LSTM Networks
We observe a novel `multiple-descent' phenomenon during the learning process of a recurrent neural network called long-short-term memory (L…
AC-ODM: Actor--Critic Online Data Mixing for Sample-Efficient LLM Pretraining
Optimizing pretraining data composition is pivotal for LLM generalization. While dynamic mixing outperforms static strategies by capturing…
LM-SPT: LM-Aligned Semantic Distillation for Speech Tokenization
With the rapid progress of speech language models (SLMs), discrete speech tokens have emerged as a core interface between speech and text,…
CLoVE: Personalized Federated Learning through Clustering of Loss Vector Embeddings
We propose CLoVE (Clustering of Loss Vector Embeddings), a novel algorithm for Clustered Federated Learning (CFL). In CFL, clients are natu…
FOUNDv2: Learning Unified User Quantized Tokenizers for User Representation
User representation learning serves as a fundamental pillar for personalized services on large-scale web platforms. Despite its importance,…
MedSynth: Realistic, Synthetic Medical Dialogue-Note Pairs
Physicians spend significant time documenting clinical encounters, a burden that contributes to professional burnout. To address this, robu…
Automated ultrasound doppler angle estimation using deep learning
Angle estimation is an important step in the Doppler ultrasound clinical workflow to measure blood velocity. It is widely recognized that i…
FlowState: Sampling-Rate-Equivariant Time-Series Forecasting
Existing time series foundation models (TSFMs), often based on transformer variants, lack adaptability to different sampling rates, struggl…
Retro-Expert: Collaborative Reasoning for Interpretable Retrosynthesis
Retrosynthesis prediction aims to infer the reactant molecules based on a given product molecule, which is a fundamental task in chemical s…
A biological vision inspired framework for machine perception of abutting grating illusory contours
Higher levels of machine intelligence demand alignment with human perception and cognition. Deep neural networks (DNN) dominated machine in…
EEG-FM-Bench: A Comprehensive Benchmark for the Systematic Evaluation and Diagnostic Analyses of EEG Foundation Models
Electroencephalography foundation models (EEG-FMs) have advanced brain signal analysis, but the lack of standardized evaluation benchmarks…
Prototyping an AI-powered Tool for Energy Efficiency in New Zealand Homes
Residential buildings contribute significantly to energy use, health outcomes, and carbon emissions. In New Zealand, housing quality has hi…
Beyond Rebalancing: Benchmarking Binary Classifiers Under Class Imbalance Without Rebalancing Techniques
Class imbalance poses a significant challenge to supervised classification, particularly in critical domains like medical diagnostics and a…
Discrete optimal transport is a strong audio adversarial attack
In this paper, we investigate discrete optimal transport (DOT) as a black-box attack against modern automatic speaker verification (ASV) an…
K-Prism: A Knowledge-Guided and Prompt Integrated Universal Medical Image Segmentation Model
Medical image segmentation is fundamental to clinical decision-making, yet existing models remain fragmented. They are usually trained on s…
Projection and Quantisation: A Unifying View of Learning to Hash, from Random Projections to the RAG Era
Approximate nearest-neighbour search underpins large-scale retrieval and retrieval-augmented generation, yet its methods are studied in com…
Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention
The pursuit of computational efficiency has driven the adoption of low-precision formats for training transformer models. However, this pro…
A Survey on Agentic Security: Applications, Threats and Defenses
LLM-based agents are now used throughout cybersecurity. While these agents facilitate powerful and autonomous security applications, their…
OBCache: Optimal Brain KV Cache Pruning for Efficient Long-Context LLM Inference
Large language models (LLMs) with extended context windows enable powerful applications but impose significant memory overhead, as caching…
Less is More: Improving LLM Reasoning with Minimal Test-Time Intervention
Recent progress in large language models (LLMs) has focused on test-time scaling to improve reasoning via increased inference computation,…
Utility-Diversity Aware Online Batch Selection for LLM Supervised Fine-tuning
Supervised fine-tuning (SFT) is a commonly used technique to adapt large language models (LLMs) to downstream tasks. In practice, SFT on a…
A Multi-level Analysis of Factors Associated with Student Performance: A Machine Learning Approach to the SAEB Microdata
Identifying the factors that influence student performance in basic education is a central challenge for formulating effective public polic…
AIRMap: AI-Generated Radio Maps for Wireless Digital Twins
Accurate, low-latency channel modeling is essential for real-time wireless network simulation and digital-twin applications. Traditional mo…
Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
Improving the reasoning abilities of Large Language Models (LLMs), especially under parameter constraints, is crucial for real-world applic…
Can We Stop Malicious AI? KILLBENCH: A Benchmark for External AI Kill Switch Feasibility
Malicious AI causing harm to humans is not just a Hollywood fantasy. Indeed, as highly capable models such as Claude Mythos emerge and agen…
Can Artificial Intelligence Accelerate Technological Progress? Researchers' Perspectives on AI in Manufacturing and Materials Science
Artificial intelligence (AI) raises expectations of substantial increases in rates of technological progress, but such anticipations are of…
SPI: Query-Depth-Adaptive Indexing for Streaming RAG in Vector Databases
Vector databases (VecDBs) are increasingly deployed in retrieval-augmented generation (RAG) pipelines where query processing and document i…
DualGauge: Automated Joint Security-Functionality Benchmarking of Specification-Only Code Generation by LLMs and Coding Agents
Large language models (LLMs) and LLM-based coding agents are now used to generate code from natural-language specifications, yet ensuring s…
Are Neuro-Inspired Multi-Modal Vision-Language Models Resilient to Membership Inference Privacy Leakage?
In the age of agentic AI, the growing deployment of multi-modal models (MMs) has introduced new attack vectors that can leak sensitive trai…
CycliST: A Video Language Model Benchmark for Reasoning on Cyclical State Transitions
We present CycliST, a novel benchmark dataset designed to evaluate Video Language Models (VLM) on their ability for textual reasoning over…
Near--Real-Time Conflict-Related Fire Detection in Sudan Using Unsupervised Deep Learning
Ongoing armed conflict in Sudan highlights the need for rapid monitoring of conflict-related fire-affected areas. Recent advances in deep l…
AL-GNN: Privacy-Preserving and Replay-Free Continual Graph Learning via Analytic Learning
Continual graph learning (CGL) aims to enable graph neural networks to incrementally learn from a stream of graph structured data without f…
Do You Really Need a GPU to Guard Your LLM? CPU-Class Classifiers and Multi-Stage Pipelines for Safety Enforcement at Scale
Safety classifiers that screen LLM inputs for jailbreak attempts have become standard deployment components, yet almost all production syst…
A Unified Definition of Hallucination: It's The World Model, Stupid!
Despite numerous attempts at mitigation since the inception of language models, hallucinations remain a persistent problem even in today's…
Nightjar: Dynamic Adaptive Speculative Decoding for Large Language Models Serving
Speculative decoding (SD) accelerates LLM inference by verifying draft tokens in parallel. However, this method presents a critical trade-o…
RollArt: Disaggregated Multi-Task Agentic RL Training at Scale
Agentic Reinforcement Learning (RL) trains LLMs through multi-turn interactions with environments, producing workloads that mix compute-bou…
FasterPy: An LLM-based Code Execution Efficiency Optimization Framework
Code often suffers from performance bugs. These bugs necessitate the research and practice of code optimization. Traditional rule-based met…
Akasha 2: Hamiltonian State Space Duality and Visual-Language Joint Embedding Predictive Architectur
We present Akasha 2, a state-of-the-art multimodal architecture that integrates Hamiltonian State Space Duality (H-SSD) with Visual-Languag…
Critically Engaged Pragmatism: Scientific Norm and Social, Pragmatist Epistemology for AI Science Evaluation Tools
AI science evaluation tools aim to assess research credibility. As with traditional metrics such as impact factors, their edicts can be dec…
SDFLoRA: Selective Decoupled Federated LoRA for Privacy-preserving Fine-tuning with Heterogeneous Clients
Federated learning (FL) for large language models (LLMs) has attracted increasing attention as a privacy-preserving approach for adapting m…
Adaptive $k$NN graph model
The $k$-nearest neighbors ($k$NN) algorithm is a cornerstone of non-parametric classification in artificial intelligence, yet its deploymen…
Safe Exploration via Policy Priors
Safe exploration is a key requirement for reinforcement learning (RL) agents to learn and adapt online, beyond controlled (e.g. simulated)…
AlignCoder: Aligning Retrieval with Target Intent for Repository-Level Code Completion
Repository-level code completion remains a challenging task for existing code large language models (code LLMs) due to their limited unders…
Sustainable Materials Discovery in the Era of Artificial Intelligence
Artificial intelligence (AI) has transformed materials discovery, enabling rapid exploration of chemical space through generative models an…
MapDream: Task-Driven Map Learning for Vision-Language Navigation
Vision-Language Navigation (VLN) requires agents to follow natural language instructions in partially observed 3D environments, motivating…
When RAG Hurts: Diagnosing and Mitigating Attention Distraction in Retrieval-Augmented LVLMs
While Retrieval-Augmented Generation (RAG) is one of the dominant paradigms for enhancing Large Vision-Language Models (LVLMs) on knowledge…
EffGen: Enabling Small Language Models as Capable Autonomous Agents
Most existing language model agentic systems today are built and optimized for large language models (e.g., GPT, Claude, Gemini) via API ca…
SLUM-i: Semi-supervised Learning for Urban Mapping of Informal Settlements and Data Quality Benchmarking
Rapid urban expansion has fueled the growth of informal settlements in major cities of low- and middle-income countries, with Lahore and Ka…
Learning to Share: Selective Memory for Efficient Parallel Agentic Systems
Agentic systems solve complex tasks by coordinating multiple agents that iteratively reason, invoke tools, and exchange intermediate result…
Seeing Roads Through Words: A Language-Guided Framework for RGB-T Driving Scene Segmentation
Robust semantic segmentation of road scenes under adverse illumination, lighting, and shadow conditions remain a core challenge for autonom…
MUZZLE: Adaptive Agentic Red-Teaming of Web Agents Against Indirect Prompt Injection Attacks
Large language model (LLM) based web agents are increasingly deployed to automate complex online tasks by directly interacting with web sit…
TS-Memory: Plug-and-Play Memory for Time Series Foundation Models
Time Series Foundation Models (TSFMs) achieve strong zero-shot forecasting through large-scale pre-training, but adapting them to downstrea…
UniT: Unified Multimodal Chain-of-Thought Test-time Scaling
Unified models can handle both multimodal understanding and generation within a single architecture, yet they typically operate in a single…
Orcheo: A Modular Full-Stack Platform for Conversational Search
Conversational search (CS) requires a complex software engineering pipeline that integrates query reformulation, ranking, and response gene…
Revisiting Chebyshev Polynomial and Anisotropic RBF Models for Tabular Regression
Smooth-basis models such as Chebyshev polynomial regressors and radial basis function (RBF) networks are well established in numerical anal…
MedCollab: IBIS-Guided Multi-Agent Collaboration with Hierarchical Disease Relation Chains for Clinical Diagnosis
Clinical diagnosis is a gradual process of evidence integration, in which physicians move from symptoms and medical history to examinations…
Cross-modal Identity Mapping: Minimizing Information Loss in Modality Conversion via Reinforcement Learning
Large Vision-Language Models (LVLMs) often omit or misrepresent critical visual content in generated image captions. Minimizing such inform…
Parallel Test-Time Scaling with Multi-Sequence Verifiers
Parallel test-time scaling, which generates multiple candidate solutions for a single problem, is a powerful technique for improving large…
WavSLM: Single-Stream Speech Language Modeling via WavLM Distillation
Large language models show that simple autoregressive training can yield scalable and coherent generation, but extending this paradigm to s…
An Empirical Investigation of Pre-Trained Deep Learning Model Reuse in the Scientific Process
Deep learning has achieved recognition for its impact within natural sciences, yet the prohibitive financial and technical cost of training…
MAND: Modality-Aware Novelty Detection for Open-World Egocentric Activity Recognition
Multimodal egocentric activity recognition integrates visual and inertial cues for robust first-person behavior understanding. However, dep…
Learning Permutation Distributions via Reflected Diffusion on Ranks
The finite symmetric group S_n provides a natural domain for permutations, yet learning probability distributions on S_n is challenging due…
Rel-Zero: Harnessing Patch-Pair Invariance for Robust Zero-Watermarking Against AI Editing
Recent advancements in diffusion-based image editing pose a significant threat to the authenticity of digital visual content. Traditional e…
Parallelizing Tool Execution and LLM Generation for Low-Latency Agent Serving
LLM-powered agents execute tasks through a sequential loop of model generation and tool execution. Today's serving systems serialize this l…
AgenticRec: A Recommendation-Oriented Agentic Framework with Progressive Tool-Integrated Reasoning Optimization
Recommender agents built on Large Language Models offer a promising paradigm for personalized recommendation. However, existing agents typi…
Closing the Auto-Research Loop: An AI Co-Scientist for Production Search Ranking
We present an AI Co-Scientist framework that closes the research loop for the production search-ranking system of a large online travel pla…
From Overload to Convergence: Supporting Multi-Issue Human-AI Negotiation with Bayesian Visualization
As AI systems increasingly mediate negotiations, understanding how the number of negotiated issues impacts human performance is crucial for…
A Learning Method with Gap-Aware Generation for Heterogeneous DAG Scheduling
Efficient scheduling of directed acyclic graphs (DAGs) is a core problem in large-scale data-intensive computing systems, where query plans…
Mitigating Object Hallucinations in LVLMs via Attention Imbalance Rectification
Object hallucination in Large Vision-Language Models (LVLMs) severely compromises their reliability in real-world applications, posing a cr…
Evidence of an Emergent "Self" in Continual Robot Learning
A key challenge to understanding self-awareness has been a principled way of quantifying whether an intelligent system has a concept of a "…
Epileptic Seizure Detection in Separate Frequency Bands Using Feature Analysis and Graph Convolutional Neural Network (GCN) from Electroencephalogram (EEG) Signals
Epileptic seizures are neurological disorders characterized by abnormal and excessive electrical activity in the brain, resulting in recurr…
Haiku to Opus in Just 10 bits: LLMs Unlock Large Compression Gains
We study the compression of LLM-generated text across lossless and lossy regimes, characterizing a compression-compute frontier where more…
Vocabulary Dropout for Curriculum Diversity in LLM Co-Evolution
Co-evolutionary self-play, where one language model generates problems and another solves them, promises autonomous curriculum learning wit…
Beyond Case Law: Evaluating Structure-Aware Retrieval and Safety in Statute-Centric Legal QA
Legal QA benchmarks have predominantly focused on case law, overlooking the unique challenges of statute-centric regulatory reasoning. In s…
Active Inference with a Self-Prior in the Mirror-Mark Task
The mirror self-recognition test evaluates whether a subject touches a mark on its own body that is visible only in a mirror, and is widely…
HCP-MAD:Heterogeneous Consensus-Progressive Reasoning for Efficient Multi-Agent Debate
Multi-Agent Debate (MAD) is a collaborative framework in which multiple agents iteratively refine solutions through the generation of reaso…
Adaptive Memory Crystallization for Autonomous AI Agent Learning in Dynamic Environments
Autonomous AI agents operating in dynamic environments face a persistent challenge: acquiring new capabilities without erasing prior knowle…
Human Cognition in Machines: A Unified Perspective of World Models
This report of world models distinguishes prior works by the cognitive functions they innovate. Many works claim an almost human-like cogni…
RoTRAG: Rule of Thumb Reasoning for Conversation Harm Detection with Retrieval-Augmented Generation
Detecting harmful content in multi turn dialogue requires reasoning over the full conversational context rather than isolated utterances. H…
Ranking Abuse via Strategic Pairwise Data Perturbations
Pairwise ranking systems based on Maximum Likelihood Estimation (MLE), such as the Bradley-Terry model, are widely used to aggregate prefer…
OmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens
Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles ap…
RSRCC: A Remote Sensing Regional Change Comprehension Benchmark Constructed via Retrieval-Augmented Best-of-N Ranking
Traditional change detection identifies where changes occur, but does not explain what changed in natural language. Existing remote sensing…
From Noise to Intent: Anchoring Generative VLA Policies with Residual Bridges
Bridging high-level semantic understanding with low-level physical control remains a persistent challenge in embodied intelligence, stemmin…
G-Loss: Graph-Guided Fine-Tuning of Language Models
Traditional loss functions, including cross-entropy, contrastive, triplet, and su pervised contrastive losses, used for fine-tuning pre-tra…
Lightweight Distillation of SAM 3 and DINOv3 for Edge-Deployable Individual-Level Livestock Monitoring and Longitudinal Visual Analytics
Foundation-model pipelines for individual-level livestock monitoring -- combining open-vocabulary detection, promptable video segmentation,…
CRC-Screen: Certified DNA-Synthesis Hazard Screening Under Taxonomic Shift
DNA-synthesis providers screen incoming orders by searching the requested sequence against curated hazard lists. We show that this baseline…
BRITE: A Benchmark for Reliable and Interpretable T2V Evaluation on Implausible Scenarios
The rapid advancement of photorealistic Text-to-Video (T2V) generation brings in an urgent need for up-to-date evaluation methods. Existing…
StyleShield: Exposing the Fragility of AIGC Detectors through Continuous Controllable Style Transfer
AI-generated content (AIGC) detectors are increasingly deployed in high-stakes settings such as academic integrity screening, yet their rel…
GEASS: Gated Evidence-Adaptive Selective Caption Trust for Vision-Language Models
Vision-Language Models (VLMs) hallucinate objects that are not present, and a growing line of work tries to curb this by feeding the model…
Gated QKAN-FWP: Scalable Quantum-inspired Sequence Learning
Fast Weight Programmers (FWPs) encode temporal dependencies through dynamically updated parameters rather than recurrent hidden states. Qua…
Trust Without Trusting: A Recomputable Trust Protocol for Autonomous Agents
Autonomous AI agents already transact at production scale -- 69,000 bots, 165 million transactions, $50 million in volume on a single marke…
Prediction Bottlenecks Don't Discover Causal Structure (But Here's What They Actually Do)
A Mamba state-space model trained only for next-step prediction appears to recover Granger-causal structure through a simple readout $S = |…
From Detection to Recovery: Operational Analysis on LLM Pre-training with 504 GPUs
Large-scale AI training is fundamentally a distributed systems problem, where hardware failures are routine operating conditions rather tha…
Red-Teaming Agent Execution Contexts: Open-World Security Evaluation on OpenClaw
Agentic language-model systems increasingly rely on mutable execution contexts, including files, memory, tools, skills, and auxiliary artif…
TERMS-Bench: Diagnosing LLM Negotiation Agents Beyond Deal Rate
Negotiation is a central mechanism of economic exchange, shaping markets, procurement, labor agreements, and resource allocation. It is als…
Wasserstein Equilibrium Decoding for Reliable Medical Visual Question Answering
Small vision-language models (2-8B) are well-suited for clinical deployment due to privacy constraints, limited connectivity, and low-laten…
Improved Baselines with Representation Autoencoders
Representation Autoencoders (RAE) replace traditional VAE with pretrained vision encoders. In this paper, we systematically investigate sev…
SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
Long-horizon LLM agents generate traces that could become reusable experience, but raw trajectories are noisy, local, and hard to govern. A…
EvoMemBench: Benchmarking Agent Memory from a Self-Evolving Perspective
Recent benchmarks for Large Language Model (LLM) agents mainly evaluate reasoning, planning, and execution. However, memory is also essenti…
Beyond Text-to-SQL: An Agentic LLM System for Governed Enterprise Analytics APIs
Enterprise analytics aims to make organizational data accessible for decision-making, yet non-technical users still face barriers when usin…
DySink: Dynamic Frame Sinks for Autoregressive Long Video Generation
Autoregressive long video generation often adopts bounded-memory streaming for efficiency, typically combining local windows for short-term…
Frontier: Towards Comprehensive and Accurate LLM Inference Simulation
Modern LLM serving is no longer homogeneous or monolithic. Production systems now combine disaggregated execution, complex parallelism, run…
Faster Completion, Less Learning: Generative AI Reduced Study Time on Math Problems and the Knowledge They Build
How much have students' ordinary learning processes shifted in response to generative AI, and how does that affect their durable learning o…
ACC: Compiling Agent Trajectories for Long-Context Training
Recent development of agents has renewed demand for long-context reasoning capacity of LLMs. However, training LLMs for this capacity requi…
Action with Visual Primitives
Vision-Language-Action (VLA) models have emerged as a promising paradigm for generalist robotic manipulation. A common design in current ar…
LLM が推論するのはいつですか?エントロピー相転移による動的システムの視点
Chain-of-thought (CoT) reasoning has become the default strategy for enhancing LLM capabilities, yet its application raises a fundamental question: when is explicit reasoning actually beneficial?経験的証拠は、顕著な矛盾を明らかにしています。CoT は、多くの場合、トークン消費量を増大させながら、事実に基づいた無制限のタスクに対してわずかな利益、またはマイナスの利益さえ提供します。この研究では、LLM 推論がタスクやモデルの静的な特性ではなく、生成中に現れる \emph{動的復号状態} であることを示します。体系的な分析を通じて、初期段階のエントロピー ダイナミクスがこの状態の信頼できるシグナルを提供することを発見しました。CoT の恩恵を受けるタスクは一貫したエントロピーの減少を示しますが、他のタスクは不安定または増加するパターンを示します。この動作は、高エントロピー探索体制から低エントロピー構造推論体制への相転移のような移行として解釈できます。これらの洞察に基づいて、我々は、早期デコードエントロピーを活用して推論戦略を適応的に選択する、軽量でトレーニング不要のルーティングフレームワークである \textbf{EDRM} (エントロピーダイナミクスベースの推論マニホールド) を提案します。 EDRM は、エントロピーの軌跡をコンパクトで解釈可能な多様体表現に埋め込み、ゼロショット デプロイメントときめ細かいインスタンス レベルの適応の両方を可能にします。さまざまなスケールとアーキテクチャの 15 のベンチマークと 4 つの LLM にわたって、EDRM は一貫して静的ベースラインを上回っています。データセット レベルでは、EDRM は \textbf{41--55\%} トークンの削減を達成しながら、わずか 50 個のキャリブレーション サンプルで精度を向上させます。インスタンス レベルでは、\textbf{27--45\%} トークンの節約を維持しながら、精度が最大 \textbf{4.7\%} まで向上します。これらの結果は、推論はデフォルトではなく選択的に呼び出される必要があることを示唆しており、効率的で適応的な LLM 推論に対するエントロピー駆動型の復号制御の有効性を示しています。
原文 (English)
When Do LLMs Reason? A Dynamical Systems View via Entropy Phase Transitions
Chain-of-thought (CoT) reasoning has become the default strategy for enhancing LLM capabilities, yet its application raises a fundamental question: when is explicit reasoning actually beneficial? Empirical evidence reveals a striking paradox: CoT often provides marginal or even negative gains on factual and open-ended tasks while multiplying token consumption. In this work, we show that LLM reasoning is not a static property of tasks or models, but a \emph{dynamic decoding state} that emerges during generation. Through systematic analysis, we find early-stage entropy dynamics provide a reliable signal of this state: tasks benefiting from CoT exhibit consistent entropy reduction, while others display unstable or increasing patterns. This behavior can be interpreted as a phase-transition-like shift from a high-entropy exploratory regime to a low-entropy structured reasoning regime. Based on these insights, we propose \textbf{EDRM} (Entropy Dynamics-based Reasoning Manifold), a lightweight and training-free routing framework that leverages early decoding entropy to adaptively select inference strategies. EDRM embeds entropy trajectories into a compact and interpretable manifold representation, enabling both zero-shot deployment and fine-grained instance-level adaptation. Across 15 benchmarks and 4 LLMs of varying scales and architectures, EDRM consistently outperforms static baselines. At the dataset level, EDRM achieves \textbf{41--55\%} token reduction while improving accuracy with as few as 50 calibration samples. At the instance level, it further improves accuracy by up to \textbf{4.7\%} while maintaining \textbf{27--45\%} token savings. These results suggest that reasoning should be invoked selectively rather than by default, and demonstrate the effectiveness of entropy-driven decoding control for efficient and adaptive LLM inference.
SAMark: 段落レベルの言い換え堅牢性を備えた自己アンカー付きテキスト透かし
意味レベルの透かし (SWM) は、文を基本単位として扱うことで、テキストの変更に対する堅牢性を向上させます。ただし、このような攻撃は文の順序を変更することで透かし信号を全体的に破壊するため、段落レベルの言い換えに対する堅牢性は依然として困難です。この研究では、意味空間にステップに依存しない緑色の領域を確立することで文の順序への依存を取り除く、自己アンカー型透かしフレームワークである SAMark を提案します。検出可能性を向上させるために、弱く位置合わせされた候補からのノイズを抑制しながら透かし信号を増幅するマルチチャネル双曲線スコアリング メカニズムを導入します。さらに、ハード フィルタリングとソフト正則化を組み合わせた多様性を意識したフィルタリング戦略を提案し、単純な N グラム繰り返しフィルタを超えて意味上の冗長性に対処します。実験結果は、SAMark が典型的な段落レベルの言い換え攻撃の下で最大 90.2% の TP@FP1% を達成し、以前の最も強力なベースラインを平均 30% 以上上回るパフォーマンスを示しながら、透かしなしのテキストと競争力のある生成品質を維持し、従来の方法を制限していた堅牢性と品質のトレードオフを打破することを示しています。
原文 (English)
SAMark: A Self-Anchored Text Watermarking with Paragraph-Level Paraphrase Robustness
Semantic-level watermarking (SWM) improves robustness against text modifications by treating sentences as the basic unit. However, robustness to paragraph-level paraphrasing remains difficult because such attacks globally disrupt watermark signals by changing sentence order. In this work, we propose SAMark, a self-anchored watermarking framework that removes the dependency on sentence order by establishing a step-independent green region in semantic space. To improve detectability, we introduce a multi-channel hyperbolic scoring mechanism that amplifies watermark signals while suppressing noise from weakly aligned candidates. We further propose a diversity-aware filtering strategy that combines hard filtering with soft regularization, extending beyond simple n-gram repetition filters to address semantic redundancy. Experimental results show that SAMark achieves up to 90.2% TP@FP1% under typical paragraph-level paraphrasing attacks, outperforming the strongest prior baseline by more than 30% on average, while maintaining generation quality competitive with unwatermarked text and breaking the robustness-quality trade-off that limits prior methods.
When Does Deep RL Beat Calibrated Baselines? A Benchmark Study on Adaptive Resource Control
A properly calibrated rule-based autoscaler can beat every one of six mainstream deep reinforcement learning (DRL) algorithms on cost acros…
Cordyceps: Covert Control Attacks on LLMs via Data Poisoning
Large language models (LLMs) are often fine-tuned on uncurated text datasets that adversaries can poison. Existing poisoning attacks primar…
FineVLA: Fine-Grained Instruction Alignment for Steerable Vision-Language-Action Policies
Vision-Language-Action (VLA) models are increasingly expected to not only complete robot tasks, but also follow human instructions about ho…
The Energy Blind Spot: NVIDIA's Flagship Edge AI Hardware Cannot Support Process-Level Energy Attribution
Agentic AI workloads - where a single user goal triggers multi-step orchestration, tool calls, retries, and failure recovery - are being ta…
Evolutionary Dynamics of Cooperation in Next-Generation LLM Agent Systems: A Cross-Provider Empirical Extension
Do next-generation LLM agents inherit the cooperative biases documented in their predecessors, or does scale and provider diversity reshape…
Automating Low-Risk Code Review at Meta: RADAR, Risk Calibration, and Review Efficiency
AI-assisted coding tools have altered software production. At Meta, significant lines of code per human-landed diff grew by 105.9% year ove…
Detect Before You Leap: Mirage Detection in Vision-Language Models
Vision-language models (VLMs) can produce confident visual answers even when the required visual evidence is missing, blank, or unrelated t…
Estimating Mutual Information between Time Series and Temporal Event Sequences Across Diverse Analysis Tasks
Pairwise dependence measures such as correlation and causality are fundamental to temporal data mining, yet there is still no principled an…
TechRAG: Evidence-Gated Multimodal Agentic RAG for Technical Literature Reasoning
This paper presents an agentic multimodal retrieval-augmented generation (RAG) framework for domain-specific literature reasoning, instanti…
Anomalies in Multivariate Time Series Benchmarks Are Mostly Univariate
Many recent multivariate time series anomaly detection (MTSAD) models incorporate cross-channel modeling, under the implicit assumption tha…
Fast-dLLM++: Fr\'{e}chet Profile Decoding for Faster Diffusion LLM Inference
Diffusion large language models promise parallel token generation, yet inference remains bottlenecked by deciding which masked tokens can b…
Learn from Your Mistakes: Tree-like Self-Play for Secure Code LLMs
While Large Language Models (LLMs) excel in code generation, they remain prone to replicating subtle yet critical vulnerabilities endemic t…
EvalStop: ワールド フィードバックを使用して、マルチテナント RLHF プラットフォームにおける報酬の過剰最適化を検出および修正する
Cloud LLM 微調整プラットフォームは RLHF ワークロードにますます対応しており、学習された報酬モデルが人間の品質の代用として最適化されています。 Gao らのように(2023) は、このプロキシは、報酬の過剰最適化として知られる現象である持続的な最適化圧力の下で、世界のフィードバック (下流の評価指標) から乖離することを示しました。既存のプラットフォーム スケジューラはこの相違を無視しています。非千里眼スケジューラは品質信号なしで JCT を最適化し、SLAQ スタイルの品質認識スケジューラはトレーニング損失 (ハッキングによって単調に低下する弱いプロキシ) を使用し、古典的なジョブごとの早期停止では人間による監視が必要であり、共有 GPU を解放しません。私たちは、evalStop を提案します。これは、k 回連続して eval スコアが低下したときにジョブを終了し、GPU を解放し、最適なチェックポイントを保持し、任意のベース スケジューラに委任する、コンポーザブルなスケジューリング プリミティブです。私たちは、スケジューラレベルの早期停止を検出問題としてフレーム化し、RLHF ワークロードが報酬ハッキングと構造的に健全な実行を混合し、スケジューラから隠蔽されたグランドトゥルースラベルを使用した離散イベントシミュレータでそれを評価します。 RLHF の負荷が高いワークロード (RLHF 80%、GPU 64 基) では、EvalStop は精度 98% / リコール 99% / FPR 1.5% を達成し、SRTF-Est と比較して JCT を 9% 改善し、無駄なコンピューティングを 22% 削減します (p<0.05)。些細な固定進捗と損失プラトーの競合他社は、健全な RLHF で 65% の FPR を被るか、真のハッキング ケースの半分以上を見逃すかのどちらかです。ゲインはテストされたすべてのベース スケジューラにわたって構成され (9 ~ 25% の JCT)、検出品質は評価ノイズ (ノイズ std <= 0.05 で少なくとも 91% の精度) およびハッキングのベース レート (20 ~ 80% のハッキング部分で少なくとも 89% の精度) の下で安定しています。
原文 (English)
EvalStop: Using World Feedback to Detect and Correct Reward Overoptimization in Multi-Tenant RLHF Platforms
Cloud LLM fine-tuning platforms increasingly serve RLHF workloads, where a learned reward model is optimized as a proxy for human quality. As Gao et al. (2023) showed, this proxy diverges from world feedback (downstream eval metrics) under sustained optimization pressure, a phenomenon known as reward overoptimization. Existing platform schedulers ignore this divergence: non-clairvoyant schedulers optimize JCT without any quality signal, SLAQ-style quality-aware schedulers use training loss (a weaker proxy that drops monotonically through hacking), and classical per-job early stopping requires human monitoring and does not free shared GPUs. We propose EvalStop, a composable scheduling primitive that terminates jobs on k consecutive eval-score declines, releases GPUs, preserves the best checkpoint, and delegates to any base scheduler. We frame scheduler-level early stopping as a detection problem and evaluate it in a discrete-event simulator whose RLHF workload mixes reward-hacking and structurally healthy runs, with ground-truth labels hidden from schedulers. On RLHF-heavy workloads (80% RLHF, 64 GPUs), EvalStop achieves precision 98% / recall 99% / FPR 1.5% while improving JCT by 9% and cutting wasted compute by 22% over SRTF-Est (p<0.05). Trivial fixed-progress and loss-plateau competitors either incur 65% FPR on healthy RLHF or miss over half of true hacking cases. Gains compose across every base scheduler tested (9-25% JCT) and detection quality stays stable under eval noise (precision at least 91% at noise std <= 0.05) and hacking base rate (precision at least 89% across 20-80% hacking fractions).
エージェント追跡から信頼へ: LLM エージェントにおける証拠追跡と実行来歴
大規模言語モデル (LLM) ベースのエージェントは、外部ツール、検索システム、メモリ モジュール、環境、その他のエージェントと対話することで、複雑なタスクを解決することが増えています。これらの機能により、エージェントの自律性が拡張されますが、エージェントの動作の検証、デバッグ、監査が難しくなります。最終回答の精度だけでは、出力がどのように生成されたか、各主張を裏付ける証拠は何か、ツールの呼び出しが正当化されたかどうか、記憶が後の決定にどのように影響したか、実行の失敗がどこで発生したかを説明することはできません。証拠追跡と実行来歴は、取得された証拠、ツール出力、メモリ項目、環境観察、中間クレーム、アクション、および最終的な回答がエージェントの実行全体を通じてどのように関連するかをモデル化することで、このギャップに対処します。この調査は、LLM エージェントにおける証拠の追跡と実行の出自に関する体系的なレビューと概念的な枠組みを提供します。私たちは、検索根拠、クレームサポート、ツール使用の安全性、メモリリネージ、可観測性、デバッグ、監査、リカバリを結び付ける、統一された来歴の観点に基づいて関連作業を整理します。トレースソース、証拠と実行単位、来歴関係、トレースの粒度とタイミング、表現形式、信頼関数を網羅する分類法を導入します。私たちは、出所の表現、証拠の帰属、ツール使用の出所、実行時のガードレール、出所を伴うメモリ、トレースベースの可観測性、障害診断など、主要な方法論の方向性を検討します。また、既存のベンチマーク、データセット、評価指標を来歴関連の機能にマッピングし、評価が最終的な回答の正しさからプロセスレベルの説明責任にどのように移行できるかについても説明します。最後に、統合トレース スキーマ、クレーム レベルおよびセマンティックの出所、出所を意識した安全メカニズム、現実的な実行トレース ベンチマーク、リカバリ指向の評価、プライバシーを意識した監査インフラストラクチャなどの未解決の課題について概説します。
原文 (English)
From Agent Traces to Trust: A Survey of Evidence Tracing and Execution Provenance in LLM Agents
Large language model (LLM)-based agents are evolving from passive text generators into autonomous systems capable of planning, tool use, retrieval, memory access, environmental interaction, and multi-agent collaboration. These capabilities expand agent autonomy, but also make agent behavior harder to verify, debug, and audit. Final-answer accuracy alone cannot explain how an output was produced, which evidence supported each claim, whether tool calls were justified, how memory influenced later decisions, or where failures originated. This survey examines evidence tracing and execution provenance as foundations for process-level accountability in trustworthy LLM agents. We define execution provenance as the typed graph of an agent execution and evidence tracing as its projection onto evidence-support relations. This perspective connects retrieval grounding, claim support, tool-use safety, memory lineage, observability, debugging, audit, and recovery within a unified framework. We introduce a taxonomy covering trace sources, evidence and execution units, provenance relations, tracing granularity and timing, representation forms, and trust functions. We then review key methodological directions, including provenance representation, evidence attribution, tool-use provenance, runtime guardrails, provenance-bearing memory, observability, and failure diagnosis. Finally, we discuss benchmarks, datasets, metrics, and open challenges for building provenance-aware, auditable, and recoverable agent systems.
Benchmarking Counterfactual Prediction in Epidemic Time Series with Time-Varying Interventions
Deep learning has enabled significant advances in time-series causal inference, yet progress remains constrained by the lack of realistic b…
必要なのは FP8 だけです (パート 1): HPC の聖杯としてのハードウェア FP64 の誤りを暴く
従来の HPC の定説では、ネイティブ ハードウェア FP64 シリコンは科学技術コンピューティングの還元不可能な基盤、つまり倍精度シミュレーションの「聖杯」であると考えられています。この論文では、この定説は間違っていると主張しています。B300 世代以降の AI に最適化された GPU では、豊富な FP8 テンソル スループットと中国剰余定理ベースの Ozaki Scheme II を組み合わせることで、正規の HPC カーネル スペクトル全体で完全な FP64 精度でメモリルーフ実行を回復します。 NVIDIA の Blackwell Ultra (B300) は、ネイティブ FP64 を約 1.3 TFLOPS (B200 から 31 倍) に低下させ、メモリに依存するカーネル (SpMV、GEMV、ステンシル) も計算に依存するようにレンダリングします。私たちは4つの貢献をしています。まず、統合分析モデルである Tensor-Memory Equilibrium (TME) モデルは、計算乗数アルファ、帯域幅乗数ベータ、および再構築レイテンシ ガンマでルーフラインを強化します。次に、ベータ -> 1 を駆動するメカニズムとしてレジスタレベルの融合を特定し、エミュレーションをメモリの壁の向こう側で本質的に自由にします。 3 番目に、Ozaki II ヴォールトは FP64 をネイティブの最大 1 TFLOPS から最大 500 TFLOPS (B300) および最大 400 TFLOPS (Rubin R200) までエミュレートし、帯域幅制限の領域ではメモリ上限に匹敵しながら、コンピューティング領域では B200 のネイティブ FP64 の上限を 1 桁以上上回ったと予測します。 4 番目に、H100 ベースラインに対して、Ozaki II は、B300 ネイティブ FP64 が課す最大 50 倍の回帰と比較して、調査したすべてのワークロードで H100 と一致またはそれを超えています。コンパニオン FFT 解析 (生き残った INT32 パイプでの Kulisch 固定点再構築) と、コンパニオン Part(2) 論文で報告されている FP32+Kahan 削減と組み合わせると、B300 で調査されたすべてのカーネル クラスがフル FP64 でメモリ ルーフに達します。証拠はタイトルの主張を裏付けています。Ozaki II と Kulisch のエスケープ ルートを備えた FP8 は、実稼働 HPC に必要なすべてです。ネイティブ FP64 シリコンは、もはやこれまで考えられてきた聖杯ではありません。
原文 (English)
FP8 is All You Need (Part 1): Debunking Hardware FP64 as the HPC Holy Grail (June 13th version)
Conventional HPC holds that native hardware FP64 is the irreducible foundation of scientific computing. On AI-optimized GPUs of the NVIDIA B300 generation and beyond, native FP64 throughput has collapsed to ~1.3 TFLOPS even as FP8 tensor throughput has grown to multiple PFLOPS. We argue something stronger than that this is survivable: the FP8 tensor-core matrix-multiply is the sole computational primitive on which double-precision scientific computing needs to be built. Every canonical kernel -- dense and sparse linear algebra, spectral transforms, stencils -- and every application composing them reduces, via the Chinese Remainder Theorem-based Ozaki Scheme II, to sequences of FP8 matrix operations; the only non-FP8 arithmetic is a bounded, fixed-width integer accumulation at reconstruction. Native FP64 is thereby demoted from a hardware requirement to a derived accuracy guarantee obtained by composition over the FP8 primitive. We organize the claim as a five-layer hierarchy -- the FP8 op, Ozaki II, the basic kernels or Berkeley "dwarfs", composite solvers, and full applications -- and, because the dwarf taxonomy already spans scientific computing, establish it by exhibiting the reduction for every dwarf rather than a sample. The claim is falsifiable, and we build the instrument that tests it: a Tensor-Memory Equilibrium (TME) model extending the Roofline with emulation parameters (alpha, beta, gamma). We identify register-level fusion as the mechanism that keeps emulation memory-bound, project recovered FP64 performance across B300 and Rubin against an H100 baseline, and close the kernel coverage with a companion FFT analysis and compensated reductions. The model could have returned a negative verdict; instead it passes across the dwarfs and their compositions. This is the analytical half of a two-part program, with a follow-on implementation to validate the thesis on real silicon.
自然言語要件からの AI 主導のテスト ケース生成: 技術と研究のギャップに関する調査
ソフトウェア テストは、システムが指定された要件を満たしていることを検証するために重要ですが、依然として開発において最も時間と費用がかかる作業の 1 つです。要件ベースのテスト生成では、要件アーティファクトからテスト ケースを早期に派生できますが、自然言語からテスト ケースを直接生成することは、固有のあいまいさと不正確さのため困難です。 AI、自然言語処理 (NLP)、および大規模言語モデル (LLM) の最近の進歩により、このパイプラインの自動化はますます実現可能になっていますが、その一方で、幻覚、トレーサビリティの低下、一貫性のない評価などの新たなリスクが生じています。この調査では、次の 4 つの研究課題に取り組みます。自然言語要件からテスト ケースを生成するためにどのような AI および NLP 技術が提案されているか。これらのアプローチをサポートするツールやフレームワークは何か。生成されたテスト ケースがどのように評価されるか。そしてどのような研究ギャップが残っているのか。キッチハムとチャーターズの体系的レビューガイドラインに従って、2000年から2025年にわたる主要な学術データベースを検索し、厳格な包含基準を適用した後、21の主要な研究を特定しました。文献は 3 つの進化の時代に整理されており、自動化、曖昧さの処理、ドメインの適用性、トレーサビリティ、評価の徹底性、幻覚制御という 6 つの重要な品質側面を同時に満たす既存のアプローチは存在しないことが明らかになりました。この調査は主に 3 つの貢献をします。AI ベースのテスト生成の 3 時代の進化的統合。 6 つの基準によるギャップ分析は、現在のアプローチがすべての品質側面に完全に対応していないことを示しています。幻覚、追跡可能性、複雑さへの敏感性、コンプライアンスを対象とした 4 つの実用的な研究ガイドライン。
原文 (English)
AI-Driven Test Case Generation from Natural Language Requirements: A Survey of Techniques and Research Gaps
Software testing is critical for verifying that systems meet specified requirements, yet remains among the most time-consuming and expensive activities in development. Requirements-based test generation allows test cases to be derived early from requirements artifacts, but generating them directly from natural language is challenging due to inherent ambiguity and imprecision. Recent advances in AI, natural language processing (NLP), and large language models (LLMs) have made automating this pipeline increasingly feasible, while introducing new risks including hallucination, reduced traceability, and inconsistent evaluation. This survey addresses four research questions: what AI and NLP techniques have been proposed for generating test cases from natural language requirements; what tools and frameworks support these approaches; how generated test cases are evaluated; and what research gaps remain. Following Kitchenham and Charters' systematic review guidelines, we searched major scholarly databases spanning 2000-2025 and, after applying strict inclusion criteria, identified 21 primary studies. The literature is organized into three evolutionary eras, revealing that no existing approach simultaneously satisfies six key quality dimensions: automation, ambiguity handling, domain applicability, traceability, evaluation thoroughness, and hallucination control. The survey makes three main contributions: a three-era evolutionary synthesis of AI-based test generation; a six-criteria gap analysis showing no current approach fully addresses all quality dimensions; and four actionable research guidelines targeting hallucination, traceability, complexity sensitivity, and compliance.
CAF-Gen: 議論構造を強化するためのマルチエージェント システム
自然文から複雑な推論を形式化することは、計算言語学の中心的な課題の 1 つです。システムはキーワードだけでなく、テキストに埋め込まれたコンテキストや複雑な推論も理解する必要があります。現在の議論マイニング (AM) 技術は、基本的な主張と前提を特定しますが、前提タイプ、証明標準、議論スキームなどの機能を組み込んだカルネアデス議論フレームワーク (CAF) などの高度なスキーマに必要な、より豊富な構造情報を取得するのに苦労することがよくあります。私たちは、浅い引数構造を CAF 準拠の引数モデルに強化するように設計された自動マルチエージェント フレームワークである CAF-Gen を導入することで、この制限に対処します。反復的な Creator-Reviewer パイプラインを採用することで、Creator エージェントの出力が重要なエージェントによって検証され、構造的な整合性が保証されます。このマルチエージェントのコラボレーションは、シングルパス生成モデルに特有の構造の不安定性を軽減するために重要です。私たちの実験では、反復フィードバック ループにより、結果として得られるデータの品質が向上し、元の注釈との強力な整合が達成され、同時に構造的に豊かなモデルが生成されることが実証されました。私たちの調査結果は、マルチエージェント システムがシングルパス生成の制限を克服でき、形式的議論の自動モデリングに堅牢な方法論を提供できることを示しています。
原文 (English)
CAF-Gen: A Multi-Agent System for Enriching Argumentation Structures
Formalizing complex reasoning from natural text is one of the central challenges in computational linguistics. It requires systems to understand not just keywords but also the context and complex reasoning embedded in a text. Current Argument Mining (AM) techniques identify basic claims and premises, yet they often struggle to capture the richer structural information required by advanced schemas such as the Carneades Argumentation Framework (CAF), which incorporates features such as premise types, proof standards, and argument schemes. We address this limitation by introducing CAF-Gen, an automated multi-agent framework designed to enrich shallow argument structures into CAF-compliant argument models. By employing an iterative Creator-Reviewer pipeline, a creator agent's output is validated by a critical agent to ensure structural integrity. This multi-agent collaboration is crucial for mitigating the structural instability typical of single-pass generative models. Our experiments demonstrate that the iterative feedback loop improves the quality of the resulting data and achieves strong alignment with the original annotations, while producing structurally richer models. Our findings show that the multi-agent system can overcome the limitations of single-pass generation, providing a robust methodology for the automated modeling of formal argumentation.
Towards Unified Song Generation and Singing Voice Conversion with Accompaniment Co-Generation
While song generation and singing voice conversion (SVC) have evolved significantly, they have long been developed isolated: the former lac…
On the Geometry of On-Policy Distillation
On-policy distillation (OPD) is increasingly used to improve large language model reasoning, but its training dynamics remain poorly unders…
From Privacy to Workflow Integrity: Communication-Graph Metadata in Autonomous Agent Interoperability
Agent-interoperability protocols such as A2A and MCP standardize what agents say to one another but assume address-based transport. Whether…
DEFINED: A Data-Efficient Computational Framework for Fine-Grained Creativity Assessment in Debate Scenarios
Human creativity has emerged as a critical competency in the era of large language models. Assessing creativity in complex, open-ended envi…
DOG-DPO:Dynamic Optimization in Geometry for Safety Alignment
Safety alignment for large language models relies on preference data, but current pipelines often train on large, redundant datasets. Exist…
Fast LLM-Based Semantic Filtering: From a Unified Framework to an Adaptive Two-Phase Method
Evaluating a natural-language yes/no predicate over a document corpus under an accuracy target - the semantic filter - is a cornerstone of…
An AI Security Agent for University ACMIS: Multi-Vector Threat Detection and Automated Response
University Academic Management Information Systems (ACMIS) are high-value targets for a wide spectrum of security threats including brute-f…
SceneConductor: 3D Scene Generation from a Single Image with Multi-Agent Orchestration
Generating complete 3D scenes from a single image requires inferring globally consistent geometry, object relationships, and environmental…
Few-shot Class-variable Incremental Audio Classification via Prototype Adaptation and Pseudo Class-variable Training
In the task of few-shot class-incremental audio classification, the number of classes is assumed to always increase without considering the…
The Distributed Detectability Band Against Marginal-Preserving Attacks
AI-control monitors score individual agent actions to detect misbehavior, but real harm can be distributed across many benign-looking steps…
LIBERO-Occ: Evaluating and Improving Vision-Language-Action Models under Scene-Induced Occlusion via Viewpoint Imagination
Vision-Language-Action (VLA) models achieve strong performance on standard manipulation benchmarks, but most evaluations assume that task-r…
ISE: マルチターン OS エージェントの軌跡のための実行ベースのレシピ
有能な OS エージェントをトレーニングするには、構造化されたユーザーの意図、複数ターンのタスク委任、および根拠のあるツールの実行を同時にキャプチャするデータが必要ですが、これらのプロパティは既存のデータセットには存在しません。我々は、これらのギャップに共同で対処する 3 段階の合成パラダイムである ISE (Intent -> Simulate -> Execute) を提案します。ステージ 1 では、4D フレームワーク (ペルソナ x ドメイン x タスク x 複雑さ) を介して約 50,000 の構造化インテントを構築します。重複排除後、プールには 43956 個の一意のインテントが含まれ、mpnet-base-v2 埋め込み (コサイン カーネル、q=1) のプール全体で 61.57 の Vendi スコアを達成しました。ステージ 2 では、ロールロックされたユーザー シミュレータを介してマルチターンのユーザー エージェント インタラクションを推進し、各ユーザー ターンを実際の実行結果に基づいて実行し、平均 8.12 ユーザー ターンと合計 68.24 のダイアログ ターンに相当する 23132 の完全な軌跡を生成します。ステージ 3 では、ライブの分離された OS ワークスペース内ですべてのツール呼び出しが実行され、シミュレートされた応答ではなく、本物の障害回復ダイナミクスが生成されます。 ISETrace の微調整により、標準プロトコルのエージェント ツール使用タスクで Qwen3-8B を使用し、ClawEval pass@1 が 19.3 から 37.7 に改善されました。この結果は、ゼロショット GPT-4o や 4 倍大きい Qwen3-32B ベース モデルよりも優れています。ステージ 2 のアブレーションは、マルチターン シミュレーションがパフォーマンス向上の大部分をもたらすことを証明しています。すべてのソース コードとデータセットは https://github.com/Valiere01/ISE-Trace でリリースされます。
原文 (English)
ISE: An Execution-Grounded Recipe for Multi-Turn OS-Agent Trajectories
Training capable OS agents requires data that simultaneously captures structured user intents, multi-turn task delegation, and grounded tool execution--properties absent from existing datasets. We propose ISE (Intent -> Simulate -> Execute), a three-stage synthesis paradigm that addresses these gaps jointly. Stage 1 constructs roughly 50000 structured intents via a 4D framework (Persona x Domain x Task x Complexity); after deduplication the pool contains 43956 unique intents and attains a Vendi Score of 61.57 over the entire pool on mpnet-base-v2 embeddings (cosine kernel, q=1). Stage 2 drives multi-turn user-agent interaction through a role-locked user simulator that grounds each user turn in actual execution outcomes, producing 23132 complete trajectories averaging 8.12 user turns and 68.24 total dialogue turns. Stage 3 runs every tool call inside a live, isolated OS workspace, generating authentic failure-recovery dynamics instead of simulated responses. Fine-tuning on ISETrace improves ClawEval pass@1 from 19.3 to 37.7 using Qwen3-8B on agent tool-use tasks with a standard protocol. This result outperforms zero-shot GPT-4o and the larger Qwen3-32B base model which is four times bigger. An ablation on Stage 2 proves multi-turn simulation brings a large portion of the performance gain. We release all source code and dataset at https://github.com/Valiere01/ISE-Trace.
AnchorEdit: Maintaining Temporal Consistency in Multi-turn Image Editing via Causal Memory
Multi-turn image editing is essential for iterative design, yet current models often struggle with identity drift and error accumulation ov…
M*: A Modular, Extensible, Serving System for Multimodal Models
We are entering a new era of composite model architectures that integrate diverse components such as vision encoders, language backbones, d…
EV-WM: Event-Verified World Models for Long-Horizon Robotic Manipulation
Pretrained-feature world models provide a useful substrate for robot imagination, but visual or latent prediction alone does not determine…
LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
Scientific laboratories increasingly rely on AI systems to reason about experiments, but the physical act of doing science remains largely…
GMN4AD: 多中心構造磁気共鳴イメージングを使用したテスト時間領域適応によるアルツハイマー病診断のためのグラフ マッチング ネットワーク
アルツハイマー病 (AD) は、何百万人もの高齢者が罹患している進行性の神経変性疾患であり、今後数年間で有病率が大幅に上昇すると予想されています。タイムリーな介入には、特に軽度認知障害 (MCI) 段階での早期診断が重要です。構造磁気共鳴画像法 (sMRI) は、アルツハイマー病関連の脳変化を検出するための重要なモダリティとして浮上していますが、従来のグラフベースのアプローチはモダリティや部位間の不均一性に問題があり、診断性能が制限されることがよくあります。この論文では、神経画像データから得られた異種脳グラフ間の相互作用をモデル化するように設計された、アルツハイマー病診断のためのグラフ マッチング ネットワーク (GMN4AD) を提案します。各脳グラフを個別に処理する従来の方法とは異なり、GMN4AD はグラフ マッチングを活用してグラフ間の関係を把握し、診断の精度を高めます。さらに、推論中のドメインのシフトを軽減するために対照学習を組み合わせたテスト時のドメイン適応戦略を導入します。 3 つの公開 AD データセットに対する広範な実験により、GMN4AD が最先端の方法と比較して優れたパフォーマンスを達成し、AD 診断のための堅牢で一般化可能なソリューションを提供することが実証されました。
原文 (English)
GMN4AD: Graph Matching Network for Alzheimer's Disease Diagnosis with Test-Time Domain Adaptation using Multi-centered Structure Magnetic Resonance Imaging
Alzheimer's Disease (AD) is a progressive neurodegenerative disorder that affects millions of older adults, with prevalence expected to rise significantly in the coming years. Early diagnosis, particularly during the mild cognitive impairment (MCI) stage, is critical for timely intervention. Structural Magnetic Resonance Imaging (sMRI) has emerged as a key modality for detecting AD-related brain changes, but traditional graph-based approaches often struggle with modality and inter-site heterogeneity, limiting diagnostic performance. In this paper, we propose Graph Matching Network for Alzheimer's Disease Diagnosis (GMN4AD), designed to model interactions between heterogeneous brain graphs derived from neuroimaging data. Unlike conventional methods that treat each brain graph independently, GMN4AD leverages graph matching to capture cross-graph relationships, enhancing diagnostic precision. Furthermore, we introduce a test-time domain adaptation strategy that combines contrastive learning to mitigate domain shifts during inference. Extensive experiments on three public AD datasets demonstrate that GMN4AD achieves superior performance compared to state-of-the-art methods, offering a robust and generalizable solution for AD diagnosis.
エージェントティックブラウザの同一生成元ポリシー
エージェントティック ブラウザは自律型 AI エージェントを Web ブラウザに統合し、ユーザーが自然言語の指示を通じて Web タスクを実行できるようにします。同一オリジン ポリシー (SOP) は、スクリプトによって引き起こされる無許可の自動クロスオリジン データ フローを防止する基本的なブラウザ セキュリティ メカニズムです。ただし、SOP がエージェントブラウザでも有効であるかどうかは未解決の問題であり、体系的に研究されていません。この取り組みでは、このギャップを埋めます。まず、エージェント ブラウザ自体がクロスオリジン データ フローの自動チャネルとして機能し、SOP 違反につながる可能性があることを観察しました。この現象を調査するために、エージェント ブラウザーでの SOP 違反を評価するためのベンチマークである SOPBench を構築します。私たちの評価によると、既存のエージェントブラウザは、無害な設定でも攻撃下でも頻繁に SOP に違反しています。この問題に対処するために、エージェント ブラウザに合わせた SOP 強制メカニズムである SOPGuard を提案します。 SOPGuard は、オープンソースのエージェント ブラウザーである BrowserOS に実装されています。広範な評価により、SOPGuard は実用性を維持し、実行時のオーバーヘッドがわずかしか発生せずに、SOP を効果的に適用できることが実証されています。コードとデータは https://github.com/wxl-lxw/BrowserOS-SOPGuard で入手できます。
原文 (English)
Same-Origin Policy for Agentic Browsers
Agentic browsers integrate autonomous AI agents into web browsers, enabling users to accomplish web tasks through natural-language instructions. The same-origin policy (SOP) is a fundamental browser security mechanism that prevents unauthorized automated cross-origin data flows induced by scripts. However, whether SOP remains effective in agentic browsers is an open question that has not been systematically studied. In this work, we bridge this gap. We first observe that an agentic browser can itself serve as an automated channel for cross-origin data flows, potentially leading to SOP violations. To investigate this phenomenon, we construct SOPBench, a benchmark for evaluating SOP violations in agentic browsers. Our evaluation shows that existing agentic browsers frequently violate SOP, both in benign settings and under attacks. To address this problem, we propose SOPGuard, an SOP enforcement mechanism tailored to agentic browsers. We implement SOPGuard in BrowserOS, an open-source agentic browser. Extensive evaluations demonstrate that SOPGuard effectively enforces SOP while preserving utility and incurring only a small runtime overhead. Our code and data are available at https://github.com/wxl-lxw/BrowserOS-SOPGuard.
Clay-CNN ハイブリッド: 地すべり検出の補助コンテキストとして地理基礎モデルを活用
災害発生後の迅速な地すべりマッピングは災害対応に不可欠ですが、極端な階級不均衡のため自動化は依然として困難です。この研究では、地理基礎モデル (GFM) である Clay v1.5 が、Landslide4Sense (L4S) ベンチマークでのピクセル レベルの地滑りセグメンテーションを改善できるかどうかを評価します。L4S ベンチマークには、14 の Sentinel-2 および地形バンドと約 2% のポジティブ ピクセルを含む 3,799 個のトレーニング チップが含まれています。マルチスケール残差地形融合を備えたプライマリ エンコーダとしての Clay、ボトルネックで Clay セマンティック コンテキストで強化された U-Net バックボーン、および標準の U-Net ベースラインの 3 つの戦略を比較します。 2 段階の低ランク適応 (LoRA) を備えたハイブリッド U-Net + Clay モデルは、3 つのシードにわたって 64.5 +/- 1.8% という最高のテスト F1 を達成し、Clay のみのバックボーン (55.2 +/- 3.6%) と U-Net ベースライン (59.9%) を上回りました。スタンドアロン エンコーダとしての Clay は、マルチスケール スキップ接続がないため U-Net よりもパフォーマンスが劣っていましたが、その事前トレーニングされた表現により、補助コンテキストとして挿入された場合には一貫してパフォーマンスが向上しました。これらの発見は、GFM が空間的に詳細な畳み込みアーキテクチャを置き換えるのではなく、それを補完する場合に地滑り検出に最も効果的であることを示唆しています。
原文 (English)
Clay-CNN Hybrids: Leveraging Geospatial Foundation Models as Auxiliary Context for Landslide Detection
Rapid post-event landslide mapping is essential for disaster response but remains difficult to automate due to extreme class imbalance. This study evaluates whether Clay v1.5, a Geospatial Foundation Model (GFM), can improve pixel-level landslide segmentation on the Landslide4Sense (L4S) benchmark, which contains 3,799 training chips with 14 Sentinel-2 and terrain bands and approximately 2% positive pixels. We compare three strategies: Clay as the primary encoder with multi-scale residual terrain fusion, a U-Net backbone augmented with Clay semantic context at the bottleneck, and a standard U-Net baseline. The hybrid U-Net + Clay model with two-stage Low-Rank Adaptation (LoRA) achieved the best test F1 of 64.5 +/- 1.8% over three seeds, surpassing the Clay-only backbone (55.2 +/- 3.6%) and the U-Net baseline (59.9%). Clay as a standalone encoder underperformed the U-Net due to the absence of multi-scale skip connections, but its pretrained representations consistently improved performance when injected as auxiliary context. These findings suggest that GFMs are most effective for landslide detection when they complement spatially detailed convolutional architectures rather than replace them.
大規模言語モデルベースの生成推奨の暗黙的推論
大規模言語モデル (LLM) は生成推奨 (GR) のバックボーンとして採用されることが増えており、事前トレーニングされた世界の知識へのアクセスが約束されています。しかし、この知識を GR に確実に活用する方法は、まだ十分に理解されていません。主な障害は、LLM ベースの GR が通常、アイテムをセマンティック ID (SID) で表現し、事前トレーニング中にこれらのトークンが LLM に認識されないため、LLM の自然言語推論インターフェイスを混乱させることです。既存のアプローチは、SID を接地して明示的な根拠を引き出す高価なマルチステージ パイプラインでこの問題に対処していますが、各ステージがいつ、なぜ必要なのかについての洞察は限られています。この研究では、LLM ベースの GR の明示的推論トレーニング パイプラインを体系的に分解し、3 つの重要な制限を明らかにしました。世界知識の言語化の弱体化、SID と自然言語トークン埋め込み空間間の不整合、理論的根拠の品質に対する敏感さであり、これらすべてが明示的推論のパフォーマンスに悪影響を及ぼします。これらの問題を回避するために、GR 向けに調整された軽量の暗黙的推論パラダイムである PauseRec を提案します。 PauseRec は非常に実用的で、コストのかかる推論トレース取得と推論調整トレーニングを回避し、多くの利点をもたらします。(1) 標準の明示的 CoT メソッドよりも最大 6.22% 優れたパフォーマンスを発揮し、(2) トレーニング コストを GPU 時間で最大 65% 削減し、(3) 推論を最大 71.3% 高速化します。これらの結果により、PauseRec は明示的な根拠生成に代わる軽量の代替手段として位置づけられ、より効果的かつ効率的な LLM ベースの GR が可能になります。
原文 (English)
Implicit Reasoning for Large Language Model-based Generative Recommendation
Large Language Models (LLMs) are increasingly adopted as backbones for Generative Recommendation (GR), promising access to pretrained world knowledge. Yet reliably invoking this knowledge for GR remains poorly understood. A key obstacle is that LLM-based GR typically represents items with Semantic IDs (SIDs), disrupting LLMs' natural-language reasoning interface because these tokens are unseen by the LLM during pretraining. Existing approaches address this with expensive multi-stage pipelines that ground SIDs and elicit explicit rationales, but offer limited insight into when and why each stage is necessary. In this work, we systematically decompose explicit reasoning training pipelines for LLM-based GR, revealing three key limitations: weakened world-knowledge verbalization, misalignment between SID and natural-language token embedding spaces, and sensitivity to rationale quality, all of which hurt explicit reasoning performance. To circumvent these issues, we propose PauseRec, a lightweight implicit reasoning paradigm tailored for GR. PauseRec is exceptionally practical, avoiding costly reasoning trace acquisition and reasoning alignment training, leading to a multitude of benefits: (1) it outperforms standard explicit CoT methods by up to 6.22%, (2) it reduces training cost by up to 65% GPU hours, and (3) it speeds up inference by up to 71.3%. These results position PauseRec as a lightweight alternative to explicit rationale generation, enabling more effective and efficient LLM-based GR.
MeEvo: Metacognitive Evolution Combined with Natural Evolution for Automatic Heuristic Design
Large Language Models (LLMs) have advanced Automatic Heuristic Design (AHD) by enabling heuristic generation through reasoning and code syn…
When and How Severely: Scenario-Specific Safety Envelopes for Driving VLAs
Safety certification of Vision-Language-Action (VLA) driving planners under ISO 21448 (SOTIF) rests on an Operational Design Domain (ODD) s…