AIニュース 2026-06-18
自動生成: 2026-06-18 13:38 JST
過去24時間以内に公開された記事を、同じ話題ごとに1つのストーリーカードへまとめ、出典・トピック・要約とともに掲載しています。要約は各フィード提供文の冒頭を整形したもので、本文は各リンク先をご覧ください。
📌 今日の要点 TOP7
-
A near-autonomous AI chemist improves a challenging reaction in medicinal chemistryOpenAI
OpenAI and Molecule.one show how a near-autonomous AI chemist using G…
-
「シャドーAI」7割超の企業が対策追い付かず “会社が選んだAIだけ利用”はもう限界? ガートナーITmedia AI+
会社が認めていないAIツール・サービスを従業員が業務で使う「シャドーAI」について、日本企業の73%が対策できていない――調査会社の米Ga…
-
How to turn off AI in your Google DocsTechCrunch AI
Here's what you need to do to get those pesky "write with Gemini" pop…
-
「AIを使う学生」vs.「使わない学生」、エッセイが創造的なのはどっち? 米大学が2025年に実証実験ITmedia AI+
米ジョージタウン大学に所属する研究者らが国際学術誌Computers in Human Behavior: Artificial Huma…
-
Anthropic、デザインツール「Claude Design」を強化 Codeとの双方向連携やCanvaなどへの出力をサポートITmedia AI+
Anthropicは、デザイン制作ツール「Claude Design」のβ機能を大幅に強化した。複数のデザインシステムを取り込んでプロジェ…
-
After unveiling ridiculously expensive AR glasses, Snap’s stock takes a diveTechCrunch AI
Snap's long-awaited smart glasses debut hasn't exactly done wonders f…
-
Google bets on Gemini to reinvent the smart home speakerTechCrunch AI
Google is betting generative AI can breathe new life into the smart s…
トピック別件数
日本語メディア8件
ITmedia AI+ (日本語)
「シャドーAI」7割超の企業が対策追い付かず “会社が選んだAIだけ利用”はもう限界? ガートナー
会社が認めていないAIツール・サービスを従業員が業務で使う「シャドーAI」について、日本企業の73%が対策できていない――調査会社の米Gartnerは、このような調査結果を発表した。
NRI流“業務に最適なAIモデル”の選び方 「ベンチマークだけで優劣は決まらない」
“業務に最適なAIモデル”はどう選べば良いのか。野村総合研究所の北村雄騎氏に聞いた。
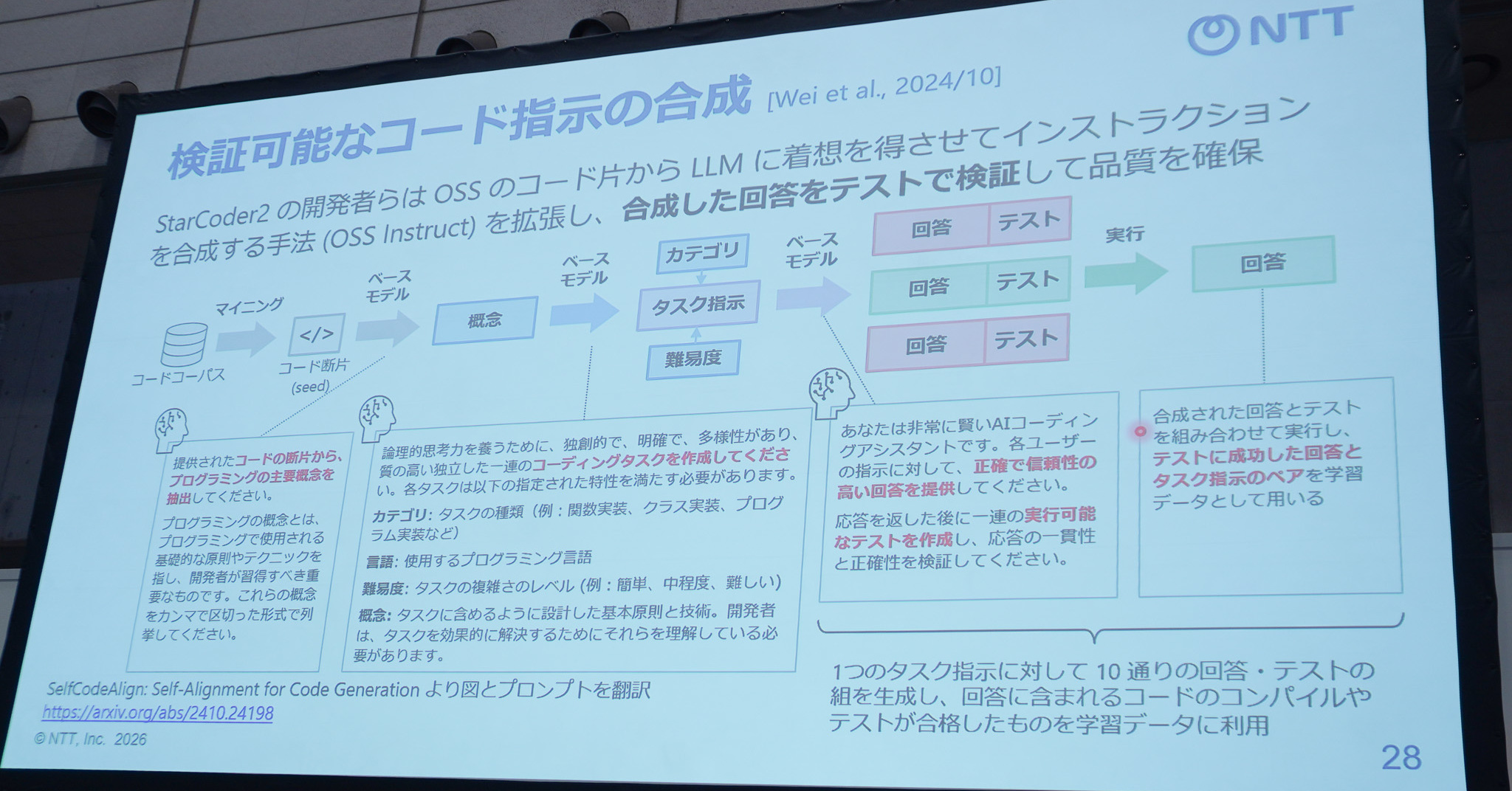
「AIコーディング」がたった5年で急進化したワケ NTT「tsuzumi 2」開発者が分析
コーディングに長けた大規模言語モデル(LLM)が登場したのは2021年ごろだ。それから5年で、競技プログラミングの問題を解けるレベルにまで成長した。なぜAIはコーディングがこれほど得意になったのか──「Interop Tokyo 2026」(幕張メッセ)で、LLM「tsuzum…

「AIを使う学生」vs.「使わない学生」、エッセイが創造的なのはどっち? 米大学が2025年に実証実験
米ジョージタウン大学に所属する研究者らが国際学術誌Computers in Human Behavior: Artificial Humansに発表した論文「Homogenizing effect of large language models (LLMs) on creat…

かんぽ生命、AIで営業支援 “郵便局での一言”拾って保険提案へ 寸劇で分かる活用例
1700万人の顧客を抱えるかんぽ生命保険が、営業フローにAIエージェントを組み込んだ。商談準備に奔走する現場がどう変わるのか、デモンストレーションの様子を紹介する。
Anthropic、デザインツール「Claude Design」を強化 Codeとの双方向連携やCanvaなどへの出力をサポート
Anthropicは、デザイン制作ツール「Claude Design」のβ機能を大幅に強化した。複数のデザインシステムを取り込んでプロジェクト横断で維持できるようになったほか、「Claude Code」とのシームレスな双方向連携を実現。AdobeやCanvaをはじめとする外部ツ…
SpaceX、AIコーディング「Cursor」を9.6兆円で買収 「近く大幅な改善」へ
Corsorは公式Xで、「近く大幅な改善が行われる予定だ」と述べた。
OpenAI創業者、巨大モデルのアップデート作業は「大きな苦痛だった」――月イチ更新を可能にした体制とデータの重要性
Databricksの年次イベントにOpenAI共同創業者のグレッグ・ブロックマン氏が登壇。AIモデル開発の難しさと、その土台となる「データ」の重要性を語った。
海外メディア16件
TechCrunch AI (英語)

How to turn off AI in your Google Docs
Here's what you need to do to get those pesky "write with Gemini" pop-ups to go away.

Roelof Botha joins SpaceX’s board of directors
The former Sequoia Capital leader is filling an "existing vacancy" on SpaceX's board, days after the company went public in the largest IPO…

After unveiling ridiculously expensive AR glasses, Snap’s stock takes a dive
Snap's long-awaited smart glasses debut hasn't exactly done wonders for the company's stock.

NEA’s Tiffany Luck says enterprises are still figuring out their AI ROI
Tokenmaxxing was the hottest trend in Silicon Valley earlier this year, with CEOs encouraging employees to push AI usage as far as it would…

World leaders want American AI. They just don’t want America to be able to turn it off.
French President Macron and Indian PM Modi raised alarms at the G7 summit that the U.S. could cut off access to American AI overnight — a f…

Anthropic becomes first AI startup to join the Frontier carbon removal coalition
Anthropic has joined the Frontier coalition, which received another $915M in pledges to fund carbon removal projects.
Social media’s next evolution: user-controlled algorithms
Social media feeds are becoming more customizable as platforms like Threads, Instagram, and TikTok introduce tools that let users directly…

World model maker Odyssey nabs $1.45B valuation backed by Amazon and other big names
World models are the next big thing in AI beyond LLMs and, with this round, Odyssey has cemented itself as one of the startups to watch.

Only 16 percent of Americans think AI will have a positive impact on society, a new study shows
Although Wall Street loves AI, every day Americans are significantly less optimistic about the industry, a new report from Pew Research sho…

Google bets on Gemini to reinvent the smart home speaker
Google is betting generative AI can breathe new life into the smart speaker. The company's new $99.99 Google Home Speaker replaces the rigi…

The slowtech revolution is here to kill your phone addiction and rescue your attention span
“People just really want to take back control of their time, their lives, their attention... They’re down for whatever helps them do that.”

Collecting robot training data is dirty, unglamorous work. Some AI labs are already paying XDOF to do it.
If physical AI is going to match the accomplishments of LLMs, there's a data problem that needs to be solved.

Pramaana Labs raises $27M seed round from Khosla Ventures to bring formal verification to AI
Pramaana will focus on highly sensitive verticals like law, drug discovery, and tax preparation — where errors can be costly and reliabilit…

Canadian pension giant joins race to fund India’s AI-fueled data center boom
The Canadian pension giant will acquire an 8.2% stake in CtrlS, a tech giant that operates more than 15 data centers across India.

DeepL acquires Mixhalo for live-event audio streaming and translation
With this acquisition, DeepL is opening an office in San Francisco to expand its U.S. business.

Pinterest launches an experimental AI shopping app called ‘Ask Pinterest’
Pinterest has launched 'Ask Pinterest,' an experimental AI-powered shopping app that lets users seek recommendations and inspiration throug…
公式ブログ1件
OpenAI (英語)

A near-autonomous AI chemist improves a challenging reaction in medicinal chemistry
OpenAI and Molecule.one show how a near-autonomous AI chemist using GPT-5.4 improved a key drug-making reaction, advancing medicinal chemis…
論文277件
arXiv cs.AI (英語)
NAVI-Orbital: 自律地球観測用のゼロショット視覚言語モデルの初の軌道上デモンストレーション
地球観測データの生成がダウンリンク帯域幅や人間参加型処理を上回っているため、機内での収集と実用的な地上インテリジェンスとの間のギャップが拡大しています。この論文では、地球低軌道 (LEO) 宇宙船に配備されたソフトウェア システムである NAVI-Orbital について説明します。 2026 年 4 月 16 日、NAVI-Orbital は、著者の知る限り、自律的なマルチモーダル推論を完全にオンボードで実行するビジョン言語モデルの軌道上初のデモンストレーションを達成しました。 NAVI-Orbital は、ローカル視覚言語モデル (Gemma 3) を使用して、キャプチャされた各シーンを分類し、その内容とその特徴間の関係についてのテキスト説明を生成し、自然言語対話を介してオペレーターのフォローアップに応答します。このシステムは、従来のコマンド シーケンスの代わりに平易な英語のプロンプトを通じて再タスクが実行され、検出と対話のために専用のエージェントを調整するグラフベースのステート マシン (LangGraph) によって調整されます。地上ベンチマーク (7,960 枚の画像から厳選された AID ベンチマークで 88.16% の精度)、Flatsat 検証、および新たに取得されたこれまでに見たことのない地球画像の軌道上でのライブ キャプチャ (未修正の YAM-9 画像を含む。ハードウェア アクセラレーションによる GPU 推論により機内で処理され、飛行計器の微調整は不要) の結果は、衛星クラスのエッジ コンピューター上で基盤モデルを実行して従来の概念を逆転させる実現可能性を示しています。軌道上の地球観測のセマンティック圧縮を通じて、すべての帯域幅プロファイルを取得してからダウンリンクします。
原文 (English)
NAVI-Orbital: First In-Orbit Demonstration of a Zero-Shot Vision-Language Model for Autonomous Earth Observation
As Earth Observation data generation outpaces downlink bandwidth and human-in-the-loop processing, a widening gap has emerged between onboard collection and actionable ground intelligence. This paper presents NAVI-Orbital, a software system deployed on a Low Earth Orbit (LEO) spacecraft. On April 16, 2026, NAVI-Orbital achieved what is, to the authors' knowledge, the first in-orbit demonstration of a vision-language model performing autonomous multi-modal inference entirely onboard. NAVI-Orbital uses a local vision-language model (Gemma 3) to classify each captured scene, produce a text description of its content and the relationships between its features, and respond to operator follow-up via natural-language dialogue. The system is re-tasked through plain-English prompts in place of conventional command sequences, and is orchestrated by a graph-based state machine (LangGraph) coordinating dedicated agents for detection and dialogue. Results across ground benchmarking (88.16% accuracy on the 7,960-image curated AID benchmark), Flatsat validation, and live in-orbit captures of newly acquired, previously unseen Earth imagery (including uncorrected YAM-9 imagery, processed onboard with hardware-accelerated GPU inference and no fine-tuning for the flight instrument) demonstrate the feasibility of running foundation models on satellite-class edge computers to invert the conventional acquire-then-downlink-everything bandwidth profile through semantic compression of Earth observations in-orbit.
CaVe-VLM-CoT: 解釈可能な視覚言語モデル フレームワーク
視覚言語モデル (VLM) は依然として幻覚を起こしやすく、流暢ではあるが視覚的に不忠実な出力を生成します。既存の思考連鎖および検索強化手法は、ステップレベルの引用根拠を強制したり、検証の失敗を修正のために検索に戻すことを強制したりしていないため、この問題に部分的にしか対処していません。我々は、モジュール式のリフレクション ベースの Agentic-RAG フレームワークである CaVe-VLM-CoT を紹介します。これは、5 段階の閉ループ パイプライン (Extractor、Retriever、Solver、Citation Injector、Verifier) を通じて証拠に基づく推論を強制します。このパイプラインでは、根拠のない主張が検出されると、ターゲットを絞った再取得のために Extractor への構造化されたフィードバックがトリガーされます。既存のフレームワークでは、検索品質、段階的な引用の忠実度、およびクロスモーダル根拠を共同で測定できるものはないため、複合指標の重み付け精度、引用の精度と再現率、帰属、および証拠の根拠である CaVeScore を中心とした、すべての段階にわたる 23 のコンポーネントごとの指標のスイートを提案します。アーキテクチャや迅速な変更を行わなくても、CaVe-VLM-CoT は、ScienceQA で 87.1\% の精度と 56.6\% CaVeScore、MMMU (30 人の被験者) で 55.2\% の精度と 35.7\% CaVeScore を達成しました。
原文 (English)
CaVe-VLM-CoT: An Interpretable Vision-Language Model Framework
Vision-Language Models (VLMs) remain prone to hallucinations, producing fluent but visually unfaithful outputs. Existing chain-of-thought and retrieval-augmented methods only partially address this, as they neither enforce step-level citation grounding nor route verification failures back to retrieval for correction. We present CaVe-VLM-CoT, a modular reflection-based agentic-RAG framework that enforces evidence-grounded reasoning through a five-stage closed-loop pipeline: Extractor, Retriever, Solver, Citation Injector, and Verifier, in which detected ungrounded claims trigger structured feedback to the Extractor for targeted re-retrieval. Since no existing framework jointly measures retrieval quality, step-wise citation faithfulness, and cross-modal grounding, we propose a suite of 23 component-wise metrics across all stages, anchored by CaVeScore, a composite metric weighting accuracy, citation precision and recall, attribution, and evidence grounding. Without any architectural or prompt modifications, CaVe-VLM-CoT achieves 87.1\% accuracy and 56.6\% CaVeScore on ScienceQA , and 55.2\% accuracy and 35.7\% CaVeScore on MMMU (30 subjects).
共有ワークスペースでの相乗効果を探る 人間とAIのコラボレーション
自動化された AI エージェントの能力はますます高まっていますが、科学的および専門的なタスクの多くは人間の判断と状況に応じた専門知識を必要とします。私たちは、最終的な回答を提出する前に、AI エージェントと人間の協力者が責任を調整する必要がある、共有ワークスペースの人間と AI チームを研究しています。 DiscoveryBench タスクを備えたコラボレーティブ ジム環境を使用して、シミュレートされた人間のコラボレーターを追加するとパフォーマンスが向上する場合と、プロセスの損失によって追加のコラボレーターが調整オーバーヘッドになる場合を調べます。 1,482 のセッションにわたって、チームに貢献を調整するための構造が不足している場合、関連するコラボレーターを追加するとパフォーマンスが低下する可能性があります。次に、グループの共有メモリとシミュレートされたヒューマンインザループ (HITL) ゲートを組み合わせた足場を評価します。選択されたアクションには、指定されたシミュレートされた参加者の承認が必要です。この足場は、より明確な責任のシグナルとチームの行動への専門知識のより強力なルーティングにより、より高い平均パフォーマンスをもたらします。これは 3 人のチームで最も顕著です。全体として、人間と AI のチームが専門知識をどのように調整し、統合するかは、チームが利用できる能力と同じくらい重要です。
原文 (English)
Searching for Synergy in Shared Workspace Human-AI Collaboration
Automated AI agents are increasingly capable, yet many scientific and professional tasks require human judgment and contextual expertise. We study shared-workspace human-AI teams, where AI agents and human collaborators must coordinate responsibilities before submitting a final answer. Using the Collaborative Gym environment with DiscoveryBench tasks, we examine when adding simulated human collaborators improves performance and when process loss turns additional collaborators into coordination overhead. Across 1,482 sessions, adding relevant collaborators can lower performance when teams lack structure to coordinate their contributions. We then evaluate scaffolding that combines shared group memory with simulated human-in-the-loop (HITL) gates, where selected actions require approval from a designated simulated participant. This scaffolding yields higher mean performance, most clearly in three-person teams, with clearer responsibility signals and stronger routing of expertise to team actions. Overall, how human-AI teams coordinate and integrate expertise matters as much as the capability available to them.
CEO ベンチ: エージェントは長期戦を勝ち抜くことができますか?
言語モデル エージェントは、ソフトウェア エンジニアリングや顧客サービスなど、孤立した短期間のタスクの熟練した実行者になりつつあります。しかし、現実世界の課題には、エージェントではほとんどテストされていない高度なスキルの組み合わせが必要です。(1) 不確実性の中で長い視野をナビゲートする。 (2)騒音環境下での情報取得。 (3) 変化する世界に適応する。 (4) 一貫した目標に向かって複数の可動部分を調整する。 CEO-Bench を紹介します。これは、スタートアップを 500 日間運営するという代表的な現実世界のタスクをシミュレートすることによって、これらの機能をまとめて評価します。エージェントは、プログラム可能な Python インターフェイスを介して、架空の会社の価格設定、マーケティング、予算編成、その他多くの側面を管理し、人間の CEO と同じ環境で動作し、同じ課題に直面します。成功するには、ノイズの多い相互接続されたビジネス データベースを分析し、シグナルを健全な戦略に変換し、プログラミングを使用して多くの意思決定を調整する必要があります。最も強力なエージェントは、顧客コホートをシミュレートして将来の現金を予測し、隠れた顧客の好みを明らかにするために交渉履歴を掘り起こす高度なコードを作成します。それでも、ほとんどの最先端モデルはこの環境では苦戦します。クロード オーパス 4.8 と GPT-5.5 のみが開始残高 100 万ドルを超えて終了し、どちらも一貫して利益を上げています。 CEO-Bench は、時間の経過とともに持続的かつ適応的な進歩を推進するために必要なインテリジェンスを測定するための第一歩を踏み出します。
原文 (English)
CEO-Bench: Can Agents Play the Long Game?
Language model agents are becoming proficient executors at isolated, short-horizon tasks such as software engineering and customer service. Yet real-world challenges require a combination of sophisticated skills that remain largely untested in agents: (1) navigating long horizons amid uncertainty; (2) acquiring information in noisy environments; (3) adapting to a changing world; (4) orchestrating multiple moving parts toward a coherent goal. We introduce CEO-Bench, which evaluates these capabilities together by simulating a representative real-world task: operating a startup for 500 days. An agent manages pricing, marketing, budgeting, and many other aspects of a fictional company through a programmable Python interface, operating in the same environment and facing the same challenges as a human CEO. Success demands analyzing noisy, interconnected business databases, translating signals into sound strategy, and coordinating many decisions with programming. The strongest agents write sophisticated code that simulates customer cohorts to forecast future cash and mines negotiation history to uncover hidden customer preferences. Even so, most state-of-the-art models struggle in this environment. Only Claude Opus 4.8 and GPT-5.5 finish above the $1M starting balance, and neither consistently turns a profit. CEO-Bench takes a first step toward measuring the intelligence required to drive sustained, adaptive progress over time.
DeFAb: 財団モデルにおける実行可能なアブダクションの検証可能なベンチマーク
ルールベースのロジック ソルバーは、ベンチマークのすべてのインスタンスを 50 マイクロ秒未満で 100% の精度で解決します。最良のフロンティア言語モデルは最高で 65% に達しますが、レンダリング堅牢な評価 (4 つのサーフェス レンダリングにわたる最悪のケース) の下では 23.5% に低下します。 DeFAb (Defeasible Abduction Benchmark) を紹介します。これは、40 年にわたる公的資金による知識ベースを、非実行可能なアブダクションの正式に根拠のあるインスタンスに変換するデータセットおよび生成パイプラインです。つまり、無関係な期待を維持しながら、デフォルトを上書きすることで異常を説明する仮説を構築します。すべての仮説は有効な導出、保守性、最小性についての多項式時間チェックに合格する必要があるため、DeFAb は論理的厳密性を創造性と理論的推論を測定するための手段とし、流暢ではあるが理論を破壊する散文ではなく、理論修正の規律ある構築をスコアリングします。このパイプラインは、分類階層 (OpenCyc、YAGO、Wikidata) と動作プロパティ グラフ (ConceptNet、UMLS) を組み合わせて、18 のソースからの 3,375 万の具体化されたルールにわたって 372,648 を超えるインスタンスを、多項式時間検証可能なゴールド スタンダードを備えた 3 つのレベルで生成します。 4 つのフロンティア モデルは、実行可能な推論を確実に内部化していません。レンダリング堅牢なレベル 2 の精度は 7.8 ~ 23.5% です。思考連鎖の分散 (~36 pp) はモデル間のギャップを超えます。適合した汚染制御により、+19.4 pp のレベル 3 ギャップが分離されます。さらに、DeFAb-Hard (235 個のインスタンスのレベル 3 難易度バリアント、最良モデル 53.3% 対 100% シンボリック) と CONJURE (560 個のリーン 4/Mathlib インスタンスのカーネル検証済みの変革的創造性バリアント。そのゴールドアンサーは、以前カーネルに含まれていなかった証明の定義であり、判断不要の検証者。パイロットは新しい概念をまったく見つけません) をリリースします。同じ検証者が、プリファレンス最適化 (DPO、RLVR/GRPO) に対する正確な報酬としても機能します。 MIT のもとで https://huggingface.co/datasets/PatrickAllenCooper/DeFAb でリリースされました。
原文 (English)
DeFAb: A Verifiable Benchmark for Defeasible Abduction in Foundation Models
A rule-based logic solver resolves every instance in our benchmark in under 50 microseconds with 100% accuracy; the best frontier language model reaches 65% at best and drops to 23.5% under rendering-robust evaluation (worst case over four surface renderings). We introduce DeFAb (Defeasible Abduction Benchmark), a dataset and generation pipeline that converts four decades of publicly funded knowledge bases into formally grounded instances for defeasible abduction: constructing hypotheses that explain anomalies by overriding defaults while preserving unrelated expectations. Because every hypothesis must pass polynomial-time checks for valid derivation, conservativity, and minimality, DeFAb makes logical rigor the instrument for measuring creativity and theoretical reasoning, scoring the disciplined construction of theory revisions rather than fluent but theory-destroying prose. The pipeline pairs taxonomic hierarchies (OpenCyc, YAGO, Wikidata) with behavioral property graphs (ConceptNet, UMLS) to produce 372,648+ instances across 33.75M materialized rules from 18 sources, in three levels with polynomial-time verifiable gold standards. Four frontier models do not reliably internalize defeasible reasoning: rendering-robust Level 2 accuracy is 7.8-23.5%; chain-of-thought variance (~36 pp) exceeds any inter-model gap; and a matched contamination control isolates a +19.4 pp Level 3 gap. We further release DeFAb-Hard (a 235-instance Level 3 difficulty variant; best model 53.3% vs 100% symbolic) and CONJURE (a kernel-verified transformative-creativity variant of 560 Lean 4/Mathlib instances whose gold answers are definitions the proof kernel did not previously contain, judge-free verifier; a pilot finds zero novel concepts). The same verifier doubles as an exact reward for preference optimization (DPO, RLVR/GRPO). Released under MIT at https://huggingface.co/datasets/PatrickAllenCooper/DeFAb.
地質、需要、価格の不確実性の下でのリチウム生産決定の最適化: 多目的意思決定のための POMDP フレームワーク
投資家の観点から見ても、戦略的な生産の観点から見ても、リチウム生産における意思決定は困難です。どの鉱山をいつ開設するかを決定するには、地質学的および価格の不確実性だけでなく、リチウムの直接抽出から硬岩採掘まで、抽出方法の選択に関する複雑さも伴います。以前の研究では、この問題のモデルと、マイニングの決定を最適化するためのさまざまな方法が検討されました。これらのモデルは、価格の不確実性、需要の不確実性、またはリチウムを抽出するためのさまざまな採掘技術を考慮していませんでした。さまざまな価格設定モデルと採掘技術をこれらのモデルに組み込むことで、鉱山をいつどこで開設するかだけでなく、どの生産方法を追求するかを決定するためのより堅牢な戦略が可能になります。私たちは問題を部分的に観察可能なマルコフ決定プロセス (POMDP) として構成し、信念状態計画法を使用して解決し、最適な意思決定を実現します。私たちの研究では、POMDP ソルバーが、信念状態計画と明示的な不確実性管理を通じて、変化するリチウム価格体制 (静的、線形、指数関数的、確率的) に動的に適応することにより、人為的なヒューリスティックを上回るパフォーマンスを発揮することを示しています。このフレームワークは、探査、生産、および技術の選択を最適に順序付けることにより、あらゆる異なる価格設定および預金シナリオにおいて、プロジェクトの存続期間を通じてより高い需要を満たすことと、よりバランスの取れた経済環境上の成果を実現します。
原文 (English)
Optimizing Lithium Production Decisions under Geological, Demand, and Pricing Uncertainties: A POMDP Framework for Multi-Objective Decision Making
Decision making in lithium production is challenging, whether from an investor's perspective or a strategic production standpoint. Determining which mines to open and when to open them involves not only geological and price uncertainties, but also complexities around the choice of extraction method, from direct lithium extraction to hard rock mining. Prior work explored models of this problem and different methods to optimize mining decisions; these models did not account for uncertainty in pricing, uncertainty in demand, or different mining technologies to extract lithium. Incorporating different pricing models and extraction technology into these models enables more robust strategies for determining not only when and where to open a mine, but also which method of production to pursue. We frame the problem as a partially observable Markov decision process (POMDP) and solve using belief state planning methods to get optimal decision making. In our study, we show that POMDP solvers outperform human inspired heuristics by dynamically adapting to shifting lithium price regimes (static, linear, exponential, and stochastic) through belief state planning and explicit uncertainty management. By optimally sequencing exploration, production, and technology choice, the framework achieves higher demand fulfillment and more balanced economic environmental outcomes over the projects lifetime in all different pricing and deposit scenarios.
ForecastBench-Sim: シミュレートされた世界予測ベンチマーク
汎用 AI システムの予測ベンチマークは通常、現実世界の制約を継承します。つまり、結果の解決は遅く、テールイベントはまれで、反事実的な質問はスコアリングが困難です。 Civilization シリーズをモデルとしたターンベースの戦略ゲームである Freeciv のゲーム ロールアウトに基づいて構築された、シミュレートされた世界の予測ベンチマークである ForecastBench-Sim を紹介します。予測者は固定世界レポート (現在のゲーム状態の構造化されたスナップショット) を受け取り、隠された将来の状態に関する質問に答えます。その後、ベンチマークはシミュレーションを継続し、予測をスコア付けします。世界はシミュレートされているため、同じ設定で、任意の時間軸での連続またはバイナリの予測質問、条件付きまたは因果関係の質問に対するペアの介入世界、まれな結果または破壊的な結果の解決された例を生成できます。ベンチマーク パイプライン、質問ファミリー、スコアリング プロトコル、リリース アーティファクトについて説明し、モデル評価と匿名化された人間のパイロットからの検証スライスをレポートします。 ForecastBench-Sim は、動的な世界状態の下で確率論的推論を研究するための、制御された即時解決可能なタスクを提供することで、現実世界の予測ベンチマークを補完することを目的としています。
原文 (English)
ForecastBench-Sim: A Simulated-World Forecasting Benchmark
Forecasting benchmarks for general-purpose AI systems usually inherit the constraints of the real world: outcomes resolve slowly, tail events are rare, and counterfactual questions are difficult to score. We introduce ForecastBench-Sim, a simulated-world forecasting benchmark built on game rollouts from Freeciv, a turn-based strategy game modelled on the Civilization series. Forecasters receive a fixed world report (a structured snapshot of the current game state) and answer questions about hidden future states; the benchmark then continues the simulation and scores forecasts. Because the world is simulated, the same setup can generate continuous or binary forecasting questions at arbitrary time horizons, paired intervention worlds for conditional or causal questions, and resolved examples of rare or disruptive outcomes. We describe the benchmark pipeline, question families, scoring protocol, and release artifacts, and report validation slices from model evaluations and an anonymized human pilot. ForecastBench-Sim is intended to complement real-world forecasting benchmarks by providing controlled, immediately resolvable tasks for studying probabilistic reasoning under dynamic world states.
ジェネラリストエージェントが覚えておくべきことは何ですか?
この論文では、ジェネラリスト エージェントが複数の環境と目標にわたってほぼ最適に動作するためにメモリに何を保存する必要があるかについて正式に説明します。これは、2 つのドメインが観察上のボトルネックを共有しているものの、互換性のない最適なアクションを必要とする場合、均一に最適に近いポリシーはそのボトルネックで異なるメモリ分散を引き起こす必要があることを示しています。その結果、分離定理が得られます。十分に成功したエージェントは、現在の状態の観察だけに頼ることはできず、ドメイン関連の情報をメモリに保存する必要があります。この論文はさらに、エージェントのメモリに関連する目標の値を推定するのに十分な情報が含まれている場合、そのメモリを使用してエージェントのローカル遷移ダイナミクスを近似的に再構築できることを示しています。これらの結果を総合すると、領域の曖昧さの解消、遷移モデルの再構築、ジェネラリストエージェントの計画をサポートする基盤としてのメモリの特徴が明らかになります。
原文 (English)
What Must Generalist Agents Remember?
This paper develops a formal account of what generalist agents must store in memory in order to act near-optimally across multiple environments and goals. It shows that when two domains share an observational bottleneck but require incompatible optimal actions, any uniformly near-optimal policy must induce distinct memory distributions at that bottleneck. The result yields a separation theorem: sufficiently successful agents cannot rely only on current state observations, but must preserve domain-relevant information in memory. The paper further shows that if an agent's memory contains enough information to estimate values for related goals, then that memory can be used to approximately reconstruct the agent's local transition dynamics. Together, these results characterize memory as the substrate that supports domain disambiguation, transition-model reconstruction, and planning for generalist agents.
R2D-RL: マルチエージェント強化学習のためのロボカップ 2D サッカー環境
ロボット サッカーは、部分的な可観測性、協力的および敵対的相互作用、まばらな報酬、および長期的な戦術的行動を組み合わせているため、マルチエージェント強化学習にとって挑戦的なテストベッドです。 RoboCup 2D Soccer Simulation (RCSS2D) は、成熟したロボット サッカー プラットフォームを提供しますが、競技指向のサーバー クライアント アーキテクチャを最新の Python ベースの MARL ワークフローで直接使用するのは困難です。共有メモリ通信とサイクルレベルの同期を通じて、RCSS2D および HELIOS ベースのプレーヤー クライアントを Python MARL インターフェイスに接続する強化学習環境である R2D-RL を紹介します。 R2D-RL は、構成可能な対戦相手によるフルフィールドおよびシナリオベースのトレーニング、ベース離散およびハイブリッドのパラメータ化されたアクション スペース、アクション マスク、期待所有値 (EPV) ベースの報酬形成、および並列実行をサポートします。フロントゴールのシナリオと 11 対 11 のフルフィールド ベンチマークをベースライン結果とともに提供します。
原文 (English)
R2D-RL: A RoboCup 2D Soccer Environment for Multi-Agent Reinforcement Learning
Robot soccer is a challenging testbed for multi-agent reinforcement learning because it combines partial observability, cooperative and adversarial interaction, sparse rewards, and long-horizon tactical behavior. RoboCup 2D Soccer Simulation (RCSS2D) provides a mature robot-soccer platform, but its competition-oriented server-client architecture is difficult to use directly with modern Python-based MARL workflows. We introduce R2D-RL, a reinforcement learning environment that connects RCSS2D and HELIOS-based player clients to a Python MARL interface through shared-memory communication and cycle-level synchronization. R2D-RL supports full-field and scenario-based training with configurable opponents, Base discrete and Hybrid parameterized action spaces, action masks, expected possession value (EPV)-based reward shaping, and parallel execution. We provide front-goal scenarios and an 11-vs-11 full-field benchmark, together with baseline results.
ProfiLLM: 産業向け配車サービス向けの公共事業者と連携したエージェント ユーザー プロファイリング
大規模言語モデル (LLM) をプラットフォーム規模の動作ログ上のセマンティック特徴抽出機能として産業用配車サービスに導入することは、魅力的ですが十分に調査されていないデータ システムの問題です。プロダクションマッチングパイプラインは依然として構造化された数値特徴によって支配されていますが、決定的な行動シグナル(例:特定の領域に対するドライバーの習慣的な嫌悪感など)は本質的にコンテキストに依存しており、LLM が生成するユーザー プロファイルとして自然に表現可能です。ただし、このようなプロファイリングをライブのミリ秒レイテンシーのディスパッチャに拡張すると、一緒に対処されることはほとんどない 3 つの絡み合った制約に直面します。毎日何百万もの注文があるプラットフォームでは、ログが LLM のコンテキスト ウィンドウを桁違いに超えます。ほとんどのユーザーはロングテールであり、ユーザーごとのプロファイリングを行うにはインタラクションが少なすぎます。また、表面流動性プロファイルは、必ずしも下流予測の有用性を向上させるわけではありません。ここでは、2 つのモジュールを通じて、実稼働マッチング システム向けにユーティリティに合わせたユーザー プロファイリングを運用するエージェント LLM データ パイプラインである ProfiLLM を紹介します。 (1) ツール拡張グローバル ナレッジ マイニングは、プラットフォーム スケールのデータをマイニングするための 27 の分析ツールを LLM エージェントに装備し、再利用可能なグローバル ナレッジ、適応型ユーザー クラスタリング ルール、および地域レベルの需要事前分布を生成します。 (2) ユーティリティに合わせたプロファイル探索は、クラスターごとに複数の候補プロファイルを生成し、軽量のダウンストリーム ユーティリティ プロキシを介してそれらを評価し、最良の候補を繰り返し絞り込み、DPO 微調整のための優先ペアを構築します。 DiDi のプロダクション ディスパッチャーに導入された ProfiLLM は、結果予測で最大 +6.14% の相対 AUC 改善、ディスパッチ シミュレーションで最大 +4.35% の GMV 向上、および 14 日間のオンライン A/B テストで +0.47% GMV、+0.33% の完了率、-0.82% のキャンセル前キャンセル率を含む一貫した改善を達成しました。
原文 (English)
ProfiLLM: Utility-Aligned Agentic User Profiling for Industrial Ride-Hailing Dispatch
Bringing Large Language Models (LLMs) into industrial ride-hailing dispatch as semantic feature extractors over platform-scale behavioral logs is a compelling but under-explored data systems problem. Production matching pipelines remain dominated by structured numerical features, yet decisive behavioral signals (e.g., a driver's habitual aversion to certain regions) are inherently contextual and naturally expressible as LLM-generated user profiles. However, scaling such profiling to a live, millisecond-latency dispatcher faces three intertwined constraints rarely addressed together: on a platform with millions of daily orders, logs exceed any LLM's context window by orders of magnitude; most users are long-tail, with too few interactions for per-user profiling; and surface-fluent profiles do not necessarily improve downstream prediction utility. We present ProfiLLM, an agentic LLM data pipeline that operationalizes utility-aligned user profiling for production matching systems through two modules. (1) Tool-Augmented Global Knowledge Mining equips an LLM agent with 27 analytical tools to mine platform-scale data, producing reusable global knowledge, adaptive user clustering rules, and region-level supply-demand priors. (2) Utility-Aligned Profile Exploration generates multiple candidate profiles per cluster, evaluates them via a lightweight downstream utility proxy, iteratively refines the best candidates and constructs preference pairs for DPO fine-tuning. Deployed on DiDi's production dispatcher, ProfiLLM achieves up to +6.14% relative AUC improvement in outcome prediction, up to +4.35% GMV gain in dispatching simulation, and consistent improvements in a 14-day online A/B test including +0.47% GMV, +0.33% Completion Rate, and -0.82% Cancel-Before-Accept rate.
WorldLines: 長期的なステートフルな組み込みエージェントのベンチマークとモデリング
実際の家庭で長期間にわたって人間を支援するには、実体エージェントはユーザーのルーチン、世界の状態、過去のやり取りを記憶しておく必要があります。既存の長期メモリ ベンチマークは、主に言語中心の検索と質問応答を評価しますが、具体化されたベンチマークは、多くの場合、動的環境での長期メモリの使用をテストせずに、短期間のタスクの実行に焦点を当てています。長期的な視点で具体化された家事援助のためのプロジェクト主導型ベンチマークである WorldLines を紹介します。対話、アクション、実行フィードバック、オブジェクトとデバイスの状態変化を含む時間的に拡張された世帯トレースを構築し、それらをメモリ QA および身体的タスク プランニング用の証拠にリンクされたサンプルに変換します。さらに、状態を認識した決定のための可視性を認識したメモリとアクションネイティブの状態証跡を維持する、オブザーバーベースのメモリフレームワークであるObsMemを提案します。実験では、部分的な可観測性、世界状態の上書き、長期記憶の具体化された計画への変換における永続的な課題が明らかになり、ObsMem はこの設定に対してより強力なリファレンス アーキテクチャを提供します。
原文 (English)
WorldLines: Benchmarking and Modeling Long-Horizon Stateful Embodied Agents
To assist humans over extended periods in real homes, embodied agents must remember user routines, world states, and past interactions. Existing long-term memory benchmarks mainly evaluate language-centric retrieval and question answering, while embodied benchmarks often focus on short-horizon task execution without testing long-term memory use in dynamic environments. We introduce WorldLines, a project-driven benchmark for long-horizon embodied household assistance. It constructs temporally extended household traces with dialogues, actions, execution feedback, object and device state changes, and converts them into evidence-linked samples for Memory QA and Embodied Task Planning. We further propose ObsMem, an observer-grounded memory framework that maintains visibility-aware memories and action-native state trails for state-aware decisions. Experiments reveal persistent challenges in partial observability, overwritten world states, and translating long-term memory into embodied plans, while ObsMem offers a stronger reference architecture for this setting.
研究ハーネスを通じて AI 科学者の研究総合と検証を外部化する
AI システムは科学ワークフローをますます自動化することができますが、以前の証拠、生成されたアイデア、実験、最終的な主張を結び付ける推論は、多くの場合、モデル推論内に暗黙的に残ります。ここでは、研究の総合と実験の検証を検査可能な契約管理されたプロセスに外部化する研究ハーネスである Xcientist を紹介します。 Xcientist は、文献証拠、アイデアの状態、実装計画、アブレーション記録、修理痕跡を永続的な研究成果物として整理し、生成されたメカニズムをその証拠的根拠を失うことなく基礎付け、実行、テスト、修正できるようにします。私たちは、実行可能なアーティファクトが当初主張されていたメカニズムをサポートしなくなった、自動化された研究の失敗モードとしてクレーム ドリフトを特定します。 Xcientist は、トレーニング不要のメモリ システム、グラフ構造のトラフィック予測、マルチスケールの物理情報に基づいたニューラル ネットワークにわたって、問題の定式化からメカニズムの設計、検証、および制限された改訂に至るまで追跡可能な軌跡を保存します。これらの結果は、AI 科学者は、最終的な成果物だけでなく、その合成と検証のプロセスが帰属可能であり、検査可能であり、科学的に責任を負っているかどうかによって評価されるべきであることを示唆しています。
原文 (English)
Externalizing Research Synthesis and Validation in AI Scientists through a Research Harness
AI systems can increasingly automate scientific workflows, but the reasoning that links prior evidence, generated ideas, experiments and final claims often remains implicit inside model inference. Here we introduce Xcientist, a research harness that externalizes research synthesis and experimental validation into inspectable, contract-governed processes. Xcientist organizes literature evidence, idea states, implementation plans, ablation records and repair traces as persistent research artifacts, so that generated mechanisms can be grounded, executed, tested and revised without losing their evidential basis. We identify claim drift as a failure mode of automated research, where runnable artifacts no longer support the mechanism originally claimed. Across training-free memory systems, graph-structured traffic forecasting and multi-scale physics-informed neural networks, Xcientist preserves traceable trajectories from problem formulation to mechanism design, validation and bounded revision. These results suggest that AI scientists should be evaluated not only by their final artifacts, but by whether their synthesis and validation processes remain attributable, inspectable and scientifically accountable.
部分的に観測可能な環境におけるナビゲーションのための生成モデル予測計画
部分的に観測可能な環境でのナビゲーションは自律エージェントにとって大きな課題であり、未知の環境では限られた感覚情報を使用して効果的な意思決定を行う必要があります。信念に基づく方法、特にニューラル ネットワークを使用して信念空間を近似する方法は、特に知覚エイリアシングを伴う高次元の場合、信念空間の固有の多峰性を捉えることができないことがよくあります。生成モデルは説得力のある代替手段を提供しますが、通常、大量のデータまたは専門家の実証が必要であり、長期計画のための明示的なメカニズムが不足しています。このペーパーでは、生成と計画の両方の利点を組み合わせた新しいフレームワークである BeliefDiffusion を紹介します。 BeliefDiffusion は拡散モデルを活用してマルチモーダルな信念分布を明示的に特徴付け、モデル予測制御 (MPC) を利用して同時に事前の計画を立てます。これは 2 つのステップで構成されます: (1) 観測履歴に基づいて妥当な環境構成を想像する、および (2) 集約された構成全体にわたる効率的なナビゲーション戦略を計画する。合成マップ環境での広範な実験を通じて、BeliefDiffusion がナビゲーションの成功率と経路効率において、モデルフリーの強化学習ベースラインと他の生成アプローチの両方を大幅に上回ることを実証しました。私たちの結果は、マルチモーダルな信念表現を計画に明示的に組み込むことで、部分的に観察可能な設定でより堅牢なナビゲーションが可能になることを検証しました。
原文 (English)
Generative-Model Predictive Planning for Navigation in Partially Observable Environments
Navigation in partially observable environments presents a significant challenge for autonomous agents, requiring effective decision-making with limited sensory information in unknown environments. Belief-based methods, particularly those using neural networks to approximate the belief space, often fail to capture the inherent multimodality of belief spaces, especially in high-dimensional cases with perceptual aliasing. While generative models present a compelling alternative, they typically require substantial data or expert demonstrations and lack explicit mechanisms for long-term planning. In this paper, we introduce BeliefDiffusion, a novel framework that combines the benefits of both generation and planning. BeliefDiffusion leverages diffusion models to explicitly characterize multimodal belief distributions and utilizes Model Predictive Control (MPC) to simultaneously plan ahead. It consists of two steps: (1) Imagining plausible environment configurations based on observation history and (2) Planning efficient navigation strategies across an aggregated configurations. Through extensive experiments in synthetic map environments, we demonstrate that BeliefDiffusion significantly outperforms both model-free reinforcement learning baselines and other generative approaches in navigation success rate and path efficiency. Our results validate that explicitly incorporating multimodal belief representations into planning enables more robust navigation in partially observable settings.
GUI エージェント向けのスキルガイド付き継続蒸留
GUI エージェントの改善は通常、エキスパートの軌跡に基づく動作の複製に依存します。しかし、現在のポリシーはエキスパート ポリシーから逸脱しているため、閉ループの実行中にポリシーによって引き起こされる軌道外状態、つまりエキスパート 軌道から外れる状態に必然的に遭遇します。専門家の軌跡はこれらの目に見えない国家についての実証を提供しないため、そのような国家は効果的な監督を受けられず、政策は正しい行動を選択できないままになります。この監督ギャップを埋めるために、反復的な自己改善フレームワークであるスキルガイド付き継続蒸留 (SGCD) を提案します。 SGCD は、現実的な軌道外状態に到達するために、最初にスキル ガイダンスなしの単純なポリシーをいくつかのステップで実行します。これらの状態から、スキル主導のポリシーがタスクを完了し、成功した継続を生成します。これは、ポリシーによって誘導された軌道外の状態を監視するために専門家の軌道と混合されます。スキルは成功したロールアウトと失敗したロールアウトの両方から抽出され、継続計画、クリティカル ターゲット、失敗トラップ、成功基準で構成されます。 OSWorld-Verified では、SGCD は 3 つの基本モデルの成功率を 30\% 台前半から 50\% 以上に向上させ、その有効性と汎用性を実証しています。
原文 (English)
Skill-Guided Continuation Distillation for GUI Agents
Improving GUI agents typically relies on behavior cloning on expert trajectories. However, as the current policy deviates from the expert policy, it inevitably encounters policy-induced off-trajectory states during closed-loop execution, i.e., states that fall outside the expert trajectories. Since expert trajectories provide no demonstrations for these unseen states, such states receive no effective supervision, leaving the policy unable to select the correct action. To close this supervision gap, we propose Skill-Guided Continuation Distillation (SGCD), an iterative self-improvement framework. SGCD first runs the plain policy without skill guidance for a few steps to reach realistic off-trajectory states. From these states, a skill-guided policy then completes the task and produces successful continuations, which are mixed with expert trajectories to supply supervision over policy-induced off-trajectory states. The skills are extracted from both successful and failed rollouts, consisting of Continuation Plans, Critical Targets, Failure Traps, and Success Criteria. On OSWorld-Verified, SGCD improves the success rate of three base models from the low-30\% range to over 50\%, demonstrating its effectiveness and generality.
SciRisk-Bench: AI4Science Safety のためのリスク次元を意識したベンチマーク
大規模言語モデル (LLM) は、科学的な質問応答や文献分析から、研究室の計画や自律的な発見に至るまで、AI for Science (AI4Science) ワークフローにますます組み込まれています。この進歩により、科学的能力だけでなく、一か八かの科学的文脈においてモデルがリスクを認識し、回避するかどうかも評価する安全性ベンチマークの緊急の必要性が生じています。既存の AI4Science の安全性データセットは、いくつかの分野とタスク形式をカバーしており、根本的なリスクの側面が十分に規定されていないままになっています。 \textbf{SciRisk-Bench} は、明示的なリスクの側面と科学的分野という 2 つの相補的な観点から AI4Science の安全性を評価するように設計されたベンチマークです。 SciRisk-Bench は 7 つの分野、31 の下位分野、および 10 のリスク次元をカバーしています。実験セクションでは、主流の LLM と科学指向の LLM の両方を、リスクの次元、分野、下位分野にわたって評価し、科学的モデルが依然として安全でない部分の詳細な診断を可能にします。
原文 (English)
SciRisk-Bench: A Risk-Dimension-Aware Benchmark for AI4Science Safety
Large language models (LLMs) are increasingly embedded in AI for Science (AI4Science) workflows, from scientific question answering and literature analysis to laboratory planning and autonomous discovery. This progress creates an urgent need for safety benchmarks that evaluate not only scientific competence, but also whether models recognize and avoid risks in high-stakes scientific contexts. Existing AI4Science safety datasets cover several disciplines and task formats, leaving the underlying risk dimensions underspecified. We introduce \textbf{SciRisk-Bench}, a benchmark designed to evaluate AI4Science safety from two complementary perspectives: explicit risk dimensions and scientific disciplines. SciRisk-Bench covers 7 disciplines, 31 subdisciplines and 10 risk dimensions. In the experimental section, we evaluate both mainstream LLMs and science-oriented LLMs across risk dimensions, disciplines, and sub-disciplines, enabling fine-grained diagnosis of where scientific models remain unsafe.
検索と推論の分離: LLM エージェント向けのベンダーに依存しないグラウンディング アーキテクチャ
実稼働 LLM エージェントは、リアルタイム検索への依存度を高めていますが、ネイティブ検索は、単一のモデルとプロバイダーの境界の背後で取得ポリシー、プロバイダーの選択、証拠の挿入、コスト、遅延、および生成動作をバンドルしています。この結合により、アースの検査、調整、再利用、または移植が困難になり、厳密な出力契約を破る検索誘発冗長性が引き起こされる可能性があります。我々は、MCP 互換のゲートウェイを介して推論モデルの外側にグラウンディングを移動するベンダーに依存しない境界である分離検索グラウンディング (DSG) を提示し、プロバイダー ルーティング、ソース認識コンテキスト レンダリング、構成されたフォールバック、取得深さの制御、ファースト クラスの制御としての正確なプラス セマンティック キャッシュを公開します。 SimpleQA、FreshQA、HotpotQA の 5 つのフロンティア モデル全体で、ネイティブ検索は最新性に敏感な FreshQA をリードしていますが、制御が重要な場合には DSG がより強力なフロンティアを明らかにします。SimpleQA では、91% 低い検索コストでネイティブの精度 (86.1% 対 87.7%) にほぼ匹敵し、簡潔な回答コントラクトを維持し、68% 低いレイテンシで 99.4% のウォーム キャッシュ ヒット率に達します。交換可能なモデルを備えた大規模なエージェント ワークロードの共有実稼働基盤レイヤーとして導入された DSG は、電子商取引クエリ理解 (QIU) ワークロードでネイティブ検索の精度と同等かわずかに上回り、検索コストを 98% 以上削減します。リアルタイム グラウンディングは、固定モデル機能ではなく、最適化可能なインターフェイス境界として扱うのが最適です。
原文 (English)
Decoupling Search from Reasoning: A Vendor-Agnostic Grounding Architecture for LLM Agents
Production LLM agents increasingly depend on real-time search, yet native search grounding bundles retrieval policy, provider choice, evidence injection, cost, latency, and generation behavior behind a single model-provider boundary. This coupling makes grounding hard to inspect, tune, reuse, or port, and can trigger Search-Induced Verbosity that breaks strict output contracts. We present Decoupled Search Grounding (DSG), a vendor-agnostic boundary that moves grounding outside the reasoning model through an MCP-compatible gateway, exposing provider routing, source-aware context rendering, configured fallback, retrieval-depth control, and exact plus semantic caching as first-class controls. Across five frontier models on SimpleQA, FreshQA, and HotpotQA, native search leads on recency-sensitive FreshQA, but DSG exposes a stronger frontier when control matters: on SimpleQA it nearly matches native accuracy (86.1% vs. 87.7%) at 91% lower search cost, preserves concise answer contracts, and reaches a 99.4% warm-cache hit rate with 68% lower latency. Deployed as a shared production grounding layer for large-scale agentic workloads with interchangeable models, DSG matches or slightly exceeds native-search accuracy on an e-commerce query-understanding (QIU) workload while cutting search cost by over 98%. Real-time grounding is best treated as an optimizable interface boundary, not a fixed model feature.
RTSGameBench: 視覚言語モデルによる戦略的推論のための RTS ベンチマーク
現代の視覚言語モデル (VLM) は、競争環境や協力環境における不確実性の下で、戦略的推論、つまり他のエージェントの行動を予測したり影響を与えたりするのに苦労することがよくあります。リアルタイム ストラテジー (RTS) ゲームは、味方との調整、敵の戦略への適応、部分的な可観測性の下での長期的な計画を必要とするため、この限界を診断するための自然なテストベッドとなり得ます。ただし、既存の RTS ベンチマークは評価範囲が限られており、体系的なコンピテンシー診断が欠如しており、事前に設計されたシナリオの範囲に固定されたままです。これらの制限に対処するために、既存のテストベッドよりも幅広い戦略の多様性を要求する拡張された戦場を備えた大規模 RTS ゲームである Beyond All Reason 上に構築された RTSGameBench を紹介します。提案されたベンチマークは、さまざまな対戦構造にわたる多様なゲームプレイを介した評価、それぞれが個人の戦略的能力を対象としたミニゲームを介した診断評価、および自由形式のクエリを新しいミニゲームに変換し、連続サイクルで改善する自己進化型生成フレームワークを介した拡張可能なカバレッジを提供します。さらに、大規模な RTS ゲームで VLM を動作させるために、エージェントティック メモリを備えた FSM によってユニットを管理する RTSGameAgent を提供します。私たちは、対戦でより緊密な調整やマルチエージェントの調整が必要な場合、およびタスクの規模が増大する場合、複数の最先端の VLM が適切にパフォーマンスを発揮しないことを経験的に検証しています。
原文 (English)
RTSGameBench: An RTS Benchmark for Strategic Reasoning by Vision-Language Models
Modern Vision-Language Models (VLMs) often struggle with strategic reasoning, i.e., anticipating and influencing other agents' actions, under uncertainty in competitive and cooperative settings. Real-time strategy (RTS) games can be a natural testbed for diagnosing this limitation, as they demand coordination with allies, adaptation to opponents' strategy, and long-horizon planning under partial observability. However, existing RTS benchmarks offer limited evaluation scope, lack systematic competency diagnosis, and remain fixed in the pre-designed scenario coverage. To address these limitations, we present RTSGameBench, which is built on Beyond All Reason, a large-scale RTS game with an expanded battlefield that demands broader strategy diversity than the existing testbeds. The proposed benchmark provides evaluations through diverse gameplay across various matchup structures, diagnostic assessment via mini-games, each targeting an individual strategic competency, and extensible coverage via a self-evolving generation framework that converts free-form queries into new mini-games, improving over successive cycles. Additionally, for VLMs to operate in large-scale RTS games, we provide RTSGameAgent that manages units by an FSM with agentic memory. We empirically validate that multiple state-of-the-art VLMs do not perform well when matchups demand tighter coordination, multiagent coordination and when task scale increases.
ThinkDeception: 解釈可能なマルチモーダル詐欺検出のための漸進的強化学習フレームワーク
マルチモーダルな欺瞞検出は、不正な意図を特定するために重要ですが、既存のアプローチは主にエンドツーエンドのブラックボックス パラダイムに依存しています。これらの方法は、解釈可能性が著しく欠如しており、透明性のある推論軌道を提供できず、欺瞞的な動作に固有の微妙なクロスモーダルの矛盾を明示的に捉えるのに苦労しています。これらの制限を克服するために、私たちは、斬新で解釈可能なマルチモーダル欺瞞検出フレームワークである ThinkDeception を提案します。先駆的な取り組みとして、マルチモーダル大規模言語モデル (MLLM) をこの領域に導入し、欺瞞検出を従来のバイナリ分類タスクから明示的な認知推論プロセスに変換します。最初の細心の注意を払って注釈が付けられたステップバイステップのマルチモーダル思考連鎖 (CoT) データセットによって促進され、基礎モデルである ThinkDeception Base を開発し、欺瞞の解読におけるモーダル不一致の重要な役割を経験的に検証します。この基盤に基づいて、当社の中核となるイノベーションは、進歩的なトレーニング戦略を備えた Visual-Audio Consistency Group Relative Policy Optimization (VAC--GRPO) を提案することにあります。標準的な GRPO とは異なり、トレーニング データを 4 つの段階的な難易度に階層化し、心理学的に根拠のある簡単な認知から困難な認知への移行を通じてモデルを導きます。この動的なカリキュラム スケジューラーを、多次元のプロセスを意識した報酬メカニズムおよび反射学習パラダイムと革新的に組み合わせることで、モデルの全体的な推論の品質を大幅に向上させます。主流のベンチマークに関する広範な実験により、ThinkDeception が新しい SOTA を確立し、検出精度と理論的品質の両方で既存の方法を大幅に上回ることが実証されました。最終的に、この研究は、欺瞞検出の分野を、解釈可能なマルチモーダルな認知推論へと導くことに成功しました。
原文 (English)
ThinkDeception: A Progressive Reinforcement Learning Framework for Interpretable Multimodal Deception Detection
Multimodal deception detection is critical for identifying fraudulent intentions, yet existing approaches predominantly rely on end to end black--box paradigms. These methods suffer from a severe lack of interpretability failing to provide transparent reasoning trajectories and struggling to explicitly capture the subtle, cross modal inconsistencies inherent in deceptive behaviors. To transcend these limitations, we propose ThinkDeception, a novel and interpretable multimodal deception detection framework. As a pioneering effort, it introduces Multimodal Large Language Models (MLLMs) into this domain, transforming deception detection from a traditional binary classification task into an explicit cognitive reasoning process. Facilitated by the first meticulously annotated step--by--step multimodal Chain of Thought (CoT) dataset, we develop a foundational model, ThinkDeception Base, empirically validating the critical role of modal inconsistency in decoding deception. Building upon this foundation, our core innovation lies in proposing Visual-Audio Consistency Group Relative Policy Optimization(VAC--GRPO) equipped with a progressive training strategy. Distinct from standard GRPO, we stratify the training data into four progressive difficulty tiers, guiding the model through a psychologically grounded easy--to--hard cognitive transition. By innovatively coupling this dynamic curriculum scheduler with a multi dimensional, process aware reward mechanism and a reflective learning paradigm, we significantly elevate the model's overall reasoning quality. Extensive experiments on mainstream benchmarks demonstrate that ThinkDeception establishes a new SOTA, significantly outperforming existing methods in both detection accuracy and rationale quality. Ultimately, this work successfully drives the field of deception detection toward interpretable, multimodal cognitive reasoning.
RODS: マルチターンツール使用エージェント向けの報酬主導型オンラインデータ合成
マルチターンツール使用 RL は、静的データセット内の有益なサンプルが急速に枯渇することがボトルネックとなっています。 GRPO の勾配信号が、ポポビシウの上限の結果として、ロールアウト報酬の分散が最も高いタスクに集中していることが観察されます。その結果、エージェントの機能境界に近いサンプル (成功と失敗がほぼバランスしている場所) は、不釣り合いに大きなポリシー勾配に寄与します。トレーニングが進行するにつれて、この境界は継続的に変化し、静的データセット内の有益なサンプルのプールが徐々に枯渇します。私たちは、この枯渇を解決するために RODS (報酬駆動型オンライン データ合成) を提案します。 RODS は、進行報酬の分散を、トレーニング用にすでに計算されたロールアウトを超える追加の推論を必要としない実用的なゼロコストの境界検出器として再利用することで、RL トレーニングとデータ生成の間のループを閉じます。このような境界サンプルを継続的に識別し、スキルに合わせたリサンプリング パイプラインを介して構造の複雑さ (API トポロジや依存関係の深さなど) に一致する新しいマルチターン バリアントを合成し、ポリシーと共進化する動的リプレイ バッファを管理します。 RODS は、400 人のヒト シードから開始し、約 800 サンプルのアクティブなトレーニング プールを維持することで、17,000 サンプルのオフライン パイプラインと同等のパフォーマンスを達成しながら、必要な軌道が約 20 分の 1 で、制御された設定での固定データ RL と環境拡張を改善します。
原文 (English)
RODS: Reward-Driven Online Data Synthesis for Multi-Turn Tool-Use Agents
Multi-turn tool-use RL is bottlenecked by the rapid depletion of informative samples in static datasets. We observe that the gradient signal in GRPO concentrates on tasks with the highest rollout reward variance, a consequence of the Popoviciu upper bound. Consequently, samples near the agent's capability boundary -- where successes and failures are roughly balanced -- contribute disproportionately large policy gradients. As training progresses, this boundary continuously shifts, which gradually depletes the pool of informative samples in a static dataset. We propose RODS (Reward-driven Online Data Synthesis) to resolve this depletion. RODS closes the loop between RL training and data generation by repurposing the progress reward variance as a practical, zero-cost boundary detector that requires no extra inference beyond the rollouts already computed for training. It continuously identifies such boundary samples, synthesizes new multi-turn variants matching their structural complexity (e.g., API topology and dependency depth) via a skill-aligned resampling pipeline, and manages a dynamic replay buffer that co-evolves with the policy. Starting from 400 human seeds and maintaining an active training pool of ~800 samples, RODS achieves comparable performance to a 17K-sample offline pipeline while requiring roughly 20x fewer trajectories, and improves over fixed-data RL and environment augmentation in our controlled setting.
ARIADNE: 推論時アダプターの動的選択のための不可知論的なルーティング
パラメータ効率の良い微調整 (PEFT) の導入が増加することで、単一のバックボーンがタスクに特化した多数のアダプターとペアになるモデル エコシステムが誕生しました。この設定では、推論時のクエリがタスク ラベルなしで届くことが多く、システムは増大する異種アダプター プールから最も適切なアダプターを自動的に選択する必要があります。既存のルーティング方法は、重み分解や勾配ベースの統計などのアダプター内部へのアクセスに依存するか、追加のルーター トレーニングを必要とするため、新しいアダプターが追加されるとスケーラビリティと移植性が制限されます。推論時に動的アダプターを選択するための、トレーニング不要でアダプターに依存しないルーティング フレームワークである ARIADNE を紹介します。 ARIADNE は、トレーニング セットの埋め込みから計算された重心のセットを通じて各アダプターを表し、そのアダプターに関連付けられたデータ分布をキャプチャします。ラベルのない入力が与えられると、潜在空間内のこれらの重心への近接性を測定することによってアダプターを選択します。ルーティングは完全に入力埋め込み空間で実行されるため、ARIADNE は任意の PEFT メソッドと互換性があり、アダプターやトレーニング手順を変更する必要はありません。主に Llama 3.2 1B Instruct を使用して 23 の多様な NLP タスクを評価したところ、ARIADNE は上限パフォーマンスの 97.44% を回復しました。 44 タスクに拡張すると、追加のトレーニングやアダプター内部へのアクセスを必要とせずに、平均 89.7% の選択精度を達成します。
原文 (English)
ARIADNE: Agnostic Routing for Inference-time Adapter DyNamic sElection
The increasing deployment of parameter-efficient fine-tuning (PEFT) has led to model ecosystems in which a single backbone is paired with many task-specialized adapters. In this setting, inference-time queries often arrive without task labels, requiring the system to automatically select the most appropriate adapter from a growing and heterogeneous adapter pool. Existing routing methods either depend on access to adapter internals, such as weight decompositions or gradient-based statistics, or require additional router training, which limits scalability and portability as new adapters are added. We introduce ARIADNE, a training-free, adapter-agnostic routing framework for dynamic adapter selection at inference time. ARIADNE represents each adapter through a set of centroids computed from embeddings of its training set, capturing the data distribution associated with that adapter. Given an unlabeled input, it selects an adapter by measuring proximity to these centroids in latent space. Because routing is performed entirely in the input embedding space, ARIADNE is compatible with arbitrary PEFT methods and requires no modification to the adapters or training procedures. Primarily evaluated with Llama 3.2 1B Instruct on 23 diverse NLP tasks, ARIADNE recovers 97.44% of the upper bound performance. Scaling to 44 tasks, it achieves 89.7% average selection accuracy, without additional training or access to adapter internals.
エージェントファーストの Web に向けて: AI エージェント向けに Web を再設計する
World Wide Web は、Web コンテンツの主な消費者は人間であるという 30 年間保持されてきた前提に基づいて構築されました。これはあらゆる層に浸透しています。そのアクセス モデルは人間の訪問者を想定しており、その経済性は人間の注意に基づいており、そのコンテンツは人間の認識を対象としています。人間と Web コンテンツの間の仲介者としての AI エージェントの急速な出現により、この仮定は無効になります。しかし、Web はブランケット ブロッキング、CAPTCHA ベースの排除、エージェントのアクセスを正当なやり取りではなく抽出として扱う経済モデルを通じてエージェントに抵抗します。この文書では、3 つの層にわたる原則に基づいた再設計を提案します。アクセス層では、人間に代わって動作するエージェントは、同じドメインから人間が読み取り可能なコンテンツとエージェントに最適化されたコンテンツを提供する二重層アーキテクチャとともに、ブラウザのヘッダーに似た HTTP リクエストのレート制限とエージェント識別メタデータによって管理される同等のアクセス権を継承する必要があります。経済層では、人間代理としてのエージェントの原則に基づいたインテントベースの階層フレームワークを提案します。つまり、エージェントの経済的義務は、エージェントが代表する人間の経済的義務を反映します。トークンベースのサブスクリプション モデルは、人間の意図に基づいた AI コンテンツ制作を定着させる委託コンテンツ エコノミーと並行して、ページビューではなくトークンでコンテンツを計測します。コンテンツ層では、AI が生成したコンテンツがエージェントによって消費されてさらなるコンテンツが生成され、Web 知識が人間のグラウンド トゥルースから徐々に切り離される自己参照ループである認識的再帰を特定します。私たちは、この脅威に対抗するために、エージェント テキスト マークアップ言語 (ATML)、人間による 4 レベルの監視層モデル、および暗号の出所チェーンを提案します。これらは合わせて、エージェントファースト インターネットの 10 の設計原則を構成します。エージェントは第一級市民であり、その統合には、アクセス、経済性、コンテンツにわたる Web の基本的な社会契約を再交渉する必要があります。
原文 (English)
Towards an Agent-First Web: Redesigning the Web for AI Agents
The World Wide Web was built on an assumption held for three decades: the primary consumer of web content is a human being. This permeates every layer; its access model presumes human visitors, its economics rest on human attention, and its content targets human perception. The rapid emergence of AI agents as intermediaries between humans and web content invalidates this assumption. Yet the web resists agents through blanket blocking, CAPTCHA-based exclusion, and economic models that treat agent access as extraction rather than legitimate interaction. This paper proposes a principled redesign across three layers. At the access layer, agents acting for humans should inherit equivalent access rights, governed by rate limiting and agent identification metadata in HTTP requests, analogous to browser headers, alongside a dual-layer architecture serving human-readable and agent-optimized content from the same domain. At the economic layer, we propose an intent-based tier framework grounded in the agent-as-human-proxy principle: an agent's economic obligation mirrors that of the human it represents. A token-based subscription model meters content in tokens rather than pageviews, alongside a commissioned content economy anchoring AI content production in human intentionality. At the content layer, we identify epistemic recursion, the self-referential loop in which AI-generated content is consumed by agents to produce further content, progressively detaching web knowledge from human ground truth. We propose the Agent Text Markup Language (ATML), a four-level human supervision tier model, and a cryptographic provenance chain to counter this threat. Together these constitute ten design principles for an agent-first internet, one in which agents are first-class citizens whose integration requires renegotiating the web's foundational social contract across access, economics, and content.
XAI を使用した欧州電力市場の推進力と相互依存関係の分析
電力市場は本質的に複雑なシステムであり、強い非線形性、高次元の相互作用、地域間の相互依存の増大を特徴としています。ディープ ニューラル ネットワーク (DNN) は電力価格の強力な予測機能を実証していますが、解釈可能性が欠如しているため、価格形成の根本的な要因を理解する上での有用性は限られています。この論文では、DNN モデルと説明可能な人工知能 (XAI) 技術を組み合わせて、ヨーロッパの 39 の入札ゾーンにわたる電力価格の決定要因を分析することで、このギャップに対処しています。 SHAP (SHApley Additive exPlanations) を採用して機能の貢献を定量化し、高次元設定での解釈可能性を向上させるための集約フレームワークである SSHAP を適用および拡張します。この分析では、再生可能エネルギー源、特に太陽光が、総発電量に占める割合が低いにもかかわらず、価格形成において不釣り合いに重要な役割を果たしていることが明らかになりました。ガス価格は依然として電力市場全体で支配的かつ一貫した推進力となっており、相互接続は価格動向を大きく左右し、欧州の電力システムの強い相互依存性を浮き彫りにしています。さらに、単一の価格で完全に統合された市場という反事実的なシナリオを調査するために、EU 全体の合成電力市場が構築されています。
原文 (English)
Analysing drivers and interdependencies in European electricity markets using XAI
Electricity markets are inherently complex systems characterised by strong nonlinearities, high-dimensional interactions, and increasing interdependence across regions. While deep neural networks (DNNs) have demonstrated strong predictive capabilities for electricity prices, their lack of interpretability limits their usefulness for understanding the underlying drivers of price formation. This paper addresses this gap by combining DNN models with explainable artificial intelligence (XAI) techniques to analyse the determinants of electricity prices across 39 European bidding zones. We employ SHAP (SHapley Additive exPlanations) to quantify feature contributions and apply and extend SSHAP, an aggregation framework to improve interpretability in high-dimensional settings. The analysis identifies that renewable energy sources, particularly solar, play a disproportionately important role in price formation despite their lower share in total power generation. Gas prices remain a dominant and consistent driver across electricity markets, while interconnections significantly shape price dynamics, highlighting the strong interdependence of European electricity systems. In addition, a synthetic EU-wide electricity market is constructed to explore the counterfactual scenario of a fully integrated market with a single price.
人間と AI の共進化ダイナミクス: 長期的な相互作用を通じた社会的知性の出現に関する正式理論
現在の会話型 AI システムは、言語生成、パーソナライゼーション、および長いコンテキストの対話において大幅な進歩を遂げています。しかし、既存の手法のほとんどは、感情モデリング、記憶検索、ペルソナ条件付けなどの孤立したコンポーネントを通じて社会的行動をモデル化しており、長期的な人間と AI の相互作用における安定した社会関係と社会的知性の出現を説明するための統一されたフレームワークを欠いています。これに対処するために、私たちは、自己組織化社会的認知システムとしての人間と AI の相互作用の正式なモデルである、人間と AI の共進化ダイナミクス フレームワーク (HACD-H) を提案します。 HACD-H は、感情的適応、関係的組織化、社会的記憶、人格の一貫性を統一的な動的フレームワークに統合し、マルチタイムスケールの社会的認知、関係的アトラクター、信頼盆地、発達段階移行、社会的認知エネルギーダイナミクスなどの原則を導入します。約 14,700 のインタラクション ターンを含む会話データセットを構築し、理論主導の経験的評価フレームワークを開発します。その結果、社会的認知における一時的な持続性の階層、安定した関係性アトラクター、相転移のような発達パターン、および構造化された社会的認知エネルギーの風景が明らかになりました。社会的知性は社会的認知エネルギーと有意な負の相関を示し (r = -0.391、p < 0.001)、相互作用の軌跡は時間の経過とともに漸進的なエネルギー減少を示します。これらの発見は、社会的知性が孤立した会話能力ではなく、長期的な社会的認知の共進化から出現することを示唆しています。 HACD-H は、人間と AI の適応的な社会的相互作用をモデル化し、社会的にインテリジェントな AI システムを開発するための統一された理論的基盤を提供します。
原文 (English)
Human-AI Coevolution Dynamics: A Formal Theory of Social Intelligence Emergence Through Long-Term Interaction
Current conversational AI systems have made significant progress in language generation, personalization, and long-context interaction. However, most existing methods model social behavior through isolated components such as emotion modeling, memory retrieval, or persona conditioning, lacking a unified framework to explain the emergence of stable social relationships and social intelligence in long-term human-AI interaction.To address this, we propose the Human-AI Coevolution Dynamics Framework (HACD-H), a formal model of human-AI interaction as a self-organizing social cognitive system. HACD-H integrates emotional adaptation, relational organization, social memory, and personality consistency into a unified dynamical framework and introduces principles including multi-timescale social cognition, relational attractors, trust basins, developmental phase transitions, and social cognitive energy dynamics.We construct a conversational dataset with approximately 14,700 interaction turns and develop a theory-driven empirical evaluation framework. Results reveal a hierarchy of temporal persistence in social cognition, stable relational attractors, phase-transition-like developmental patterns, and a structured social cognitive energy landscape. Social intelligence shows a significant negative correlation with social cognitive energy (r = -0.391, p < 0.001), and interaction trajectories exhibit progressive energy reduction over time.These findings suggest that social intelligence emerges from long-term social cognitive coevolution rather than isolated conversational capabilities. HACD-H provides a unified theoretical foundation for modeling adaptive human-AI social interaction and developing socially intelligent AI systems.
安全なデータを超えて: 定期的な安全性の反映によるトレーニング前段階の調整
大規模言語モデル (LLM) のより深い安全性調整を実現するために、最近の取り組みでは、主に安全でないデータをフィルタリングするか、より安全な形式に書き換えることによって、安全性介入を事前トレーニング段階の早い段階に押し込む方法が研究されています。私たちは、トレーニング前段階の調整は、データを安全にするだけに留まるべきではないと主張します。LLM は、一見無害に見える知識や機能を安全でない動作に組み込む可能性があります。この目的を達成するために、我々は安全リフレクション事前トレーニングを提案します。これは、短い安全リフレクションを定期的に事前トレーニングコーパスに挿入して、自己モニタリングを言語モデリングに直接統合し、その後互換性のあるポストトレーニングによって強化される基礎的な機能を確立する、トレーニング前段階の調整方法です。 FineWeb-Edu で事前トレーニングされた 1.7B モデルを使用した実験では、Safety Reflection 事前トレーニングによって安全性分類の精度が向上し、推論段階および微調整攻撃の成功率が大幅に低下することがわかりました。実世界の実験を補完するものとして、安全性の明確な定義とモデルが安全なデータから危険な動作を簡単に一般化できる推論構造を備えた、完全に制御された合成環境 MedSafetyWorld も導入します。 MedSafetyWorld のアブレーションは、データのフィルタリングや書き換えと比較して、安全なデータから一般化された安全でない動作にモデルが作用するのを防ぐ点で、Safety Reflection Pretraining の明らかな利点をさらに実証しています。まとめると、私たちの調査結果は、トレーニング前の調整によってトレーニング データを安全にするだけでなく、安全なデータからモデルが取得する可能性が高い動作を形成する必要があることを示唆しています。
原文 (English)
Beyond Safe Data: Pretraining-Stage Alignment with Regular Safety Reflection
To achieve deeper safety alignment for large language models (LLMs), recent efforts have studied how to push safety interventions earlier into the pretraining stage, primarily by filtering unsafe data or rewriting it into safer forms. We argue that pretraining-stage alignment should go beyond making the data safe: LLMs may compose seemingly benign knowledge and capabilities into unsafe behaviors. To this end, we propose Safety Reflection Pretraining, a pretraining-stage alignment method which regularly inserts short safety reflections into pretraining corpora to integrate self-monitoring directly into language modeling, establishing a foundational capability that is subsequently reinforced by compatible post-training. Our experiments with 1.7B models pretrained on FineWeb-Edu show that Safety Reflection Pretraining improves safety classification accuracy and substantially reduces the success rates of inference-stage and finetuning attacks. Complementary to our real-world experiments, we also introduce a fully controlled synthetic environment, MedSafetyWorld, with a clear definition of safety and a reasoning structure under which models can easily generalize unsafe behaviors from safe data. Ablations in MedSafetyWorld further demonstrate a clear advantage of Safety Reflection Pretraining in preventing models from acting on unsafe behaviors generalized from safe data, compared with data filtering and rewriting. Taken together, our findings suggest that pretraining alignment should not only make the training data safe, but also shape the behaviors that models are likely to acquire from safe data.
エングラムとしてのユーザー: ユーザーごとのメモリをローカル パラメトリック編集として内部化
言語モデルにおける個人の記憶には、内容と推論スキルという 2 つの問題があります。脳はこの 2 つを分離しておくため (エピソードごとに海馬にあるまばらで局所的なエングラム、それを解釈する共有スキルのための遅い新皮質)、新しい事実が他のすべてを上書きする必要はありません。今日のほとんどのパーソナライゼーションは、ユーザーの事実を重みの外、自然言語メモリ ファイルまたは検索インデックスに保持します。代わりにファクトがモデルに書き込まれる場合、標準レシピはユーザーごとの LoRA アダプターです。これは脳とは逆のことを行い、コンテンツとスキルを 1 つのグローバルな重みデルタに折り畳みます。ユーザーの事実を LoRA として書くと、ユーザーに関係のないテキストが汚染されます。ローカルの Engram 行と同じファクトを書き込むと、数学的には変更されないままになり、メモリ フットプリントが約 33,000 倍小さくなります。したがって、私たちはユーザーをエングラムとして提案します。ユーザーのコンテンツを外科的編集としてエングラム モデルのハッシュ キー付きメモリ テーブルに保存し、1 つの共有アダプターで推論スキルを実行します。この多層設計は、ユーザーごとの LoRA の直接想起と一致すると同時に、平均で 5.6 倍高い間接推論精度を実現し、単一のユーザーの推論が未加工のベースよりも劣ることはありません。編集はガラスの箱です。ファクトを書き込むと、まさにトリガーでルックアップがオンになり、回答に必要な値が追加され、他のすべての位置は最後のビットまで変更されずに残され、間違ったレイヤーに書き込まれると失敗します。さまざまなユーザーのファクトが結合されていないハッシュ スロットに配置されるため、編集内容は構成されます。多くのユーザーが一度に 1 つの共有テーブルに存在し、加法的かつ可逆的にスタッキングされます。ユーザーごとの LoRA (単一のグローバル ウェイト デルタ) は 1 つだけを許可します。取得時に、ユーザーごとの Engram テーブルは、取得者が検索する必要がある母集団に応じて増加しないため、ファクトが 100 個を超えると、2.5 倍大きいモデルの取得パイプラインを追い越してしまいます。
原文 (English)
User as Engram: Internalizing Per-User Memory as Local Parametric Edits
Personal memory in a language model is two problems: content and reasoning skill. The brain keeps the two apart (a sparse, local engram in the hippocampus for each episode, a slow neocortex for the shared skills that interpret it), so a new fact need not overwrite everything else. Most personalization today keeps a user's facts outside the weights, in a natural-language memory file or a retrieval index. When facts are written into the model instead, the standard recipe is the per-user LoRA adapter, which does the opposite of the brain, folding content and skill into one global weight delta. Writing a user's facts as a LoRA contaminates text unrelated to them; writing the same facts as local Engram rows leaves it mathematically untouched, resulting in a roughly 33,000x smaller memory footprint. We therefore propose User as Engram: store a user's content as surgical edits to the hash-keyed memory table of an Engram model, and carry the reasoning skill in one shared adapter. This layered design matches per-user LoRA's direct recall while delivering 5.6x higher indirect-reasoning accuracy on average, and never makes a single user worse at reasoning than the untouched base. The edit is a glass box: writing a fact switches on its lookup at exactly the trigger, adds the value the answer needs, leaves every other position unchanged to the last bit, and fails if written into the wrong layer. Because different users' facts land in disjoint hash slots, their edits compose: many users live in one shared table at once, stacking additively and losslessly, where a per-user LoRA, a single global weight delta, admits only one. Upon retrieval, a per-user Engram table does not grow with the population the retriever must search, so past ~100 facts it overtakes a retrieval pipeline on a 2.5x larger model.
TxBench-PP: 低分子前臨床薬理における AI エージェントのパフォーマンスの分析
人工知能 (AI) エージェントは、解釈と意思決定のループを圧縮することで創薬を加速すると約束されていますが、実際の導入には現実的なプログラムの決定に対する信頼できる評価が必要です。低分子前臨床薬理学の検証可能なベンチマークであり、創薬段階と治療法にわたる広範な TherapeuticsBench の取り組みの最初の焦点となるスライスである TherapeuticsBench Preclinical Pharmacology (TxBench-PP) を紹介します。 TxBench-PP は、エージェントが文献から記憶された事実ではなく、現実世界の分析データから正確な結論を導き出せるかどうかをテストします。このベンチマークには、プログラムの段階、アッセイの種類、タスク構造、作用機序 (MoA) と薬力学 (PD) の推論、化合物と標的の関与、原因となる標的の検証、開発可能性と安全性、トランスレーショナル有効性を含む 100 件の評価が含まれています。エージェントは現実的なワークフローのスナップショットを受け取り、コーディング環境でファイルを検査し、決定的に評価された構造化された回答を返します。 11 のモデルと 4,800 の軌跡を含む 16 のモデルハーネス構成にわたって、前臨床薬理学の決定を確実に回復したシステムはありませんでした。最も強力な構成である Claude Opus 4.8 / Pi は、エンドポイント試行の 59.3\% (178/300; 95\% CI、51.1-67.6) を通過し、続いて GPT-5.5 / Pi が 55.3\% (166/300; 47.0-63.6) で合格しました。
原文 (English)
TxBench-PP: Analyzing AI Agent Performance on Small-Molecule Preclinical Pharmacology
Artificial intelligence (AI) agents promise to accelerate drug discovery by compressing interpretation and decision-making loops, but practical deployment requires trusted evaluation on realistic program decisions. We introduce TherapeuticsBench Preclinical Pharmacology (TxBench-PP), a verifiable benchmark for small-molecule preclinical pharmacology and the first focused slice of a broader TherapeuticsBench effort across drug-discovery stages and therapeutic modalities. TxBench-PP tests whether agents can recover accurate conclusions from real-world assay data rather than memorized facts from literature. The benchmark contains 100 evaluations indexed by program stage, assay type, and task structure, spanning mechanism-of-action (MoA) and pharmacodynamic (PD) reasoning, compound-target engagement, causal target validation, developability and safety, and translational efficacy. Agents receive realistic workflow snapshots, inspect files in a coding environment, and return structured answers graded deterministically. Across 16 model-harness configurations, comprising 11 models and 4,800 trajectories, no system reliably recovered preclinical pharmacology decisions. The strongest configuration, Claude Opus 4.8 / Pi, passed 59.3\% of endpoint attempts (178/300; 95\% CI, 51.1-67.6), followed by GPT-5.5 / Pi at 55.3\% (166/300; 47.0-63.6).
X+Slides: 聴衆に応じたスライド生成のベンチマーク
ソース ドキュメントからスライド デッキを自動的に生成することは、大規模言語モデル (LLM) の重要なアプリケーションです。既存のベンチマークは、主にスライドの完全性と技術的な深さを評価する一方で、重要な現実世界の要素として対象読者を無視しています。たとえば、専門家は厳密な証明を要求しますが、意思決定者は実用的な結論を優先します。このギャップを埋めるために、視聴者に合わせてスライドを生成するために特別に設計されたベンチマークである X+Slides を導入します。 113 のトピックと 7 つのプレゼンテーション シーンにわたる多様なコーパスに基づいて構築された X+Slides は、8,133 の重複排除されたソース接地プローブから構築された動的評価フレームワークを採用しています。視聴者固有の有用性の重みを同じソースに基づいたプローブに割り当てることにより、X+Slides は 4 つの補完的な指標を報告します。視聴者カバレッジは視聴者にとって重要な情報がどれだけ伝えられているかを測定し、ドメインごとのカバレッジはどの情報タイプがカバーされているかを示し、効率は注意コストの単位当たりの提供された有用性を測定し、正確性はスライドの主張がソースによってサポートされているかどうかを検証します。 DeepPresenter、SlideTailor、および NotebookLM の実験では、現在のシステムが視聴者にとって重要な情報のかなりの、しかしまだ不完全な部分を回復できることが示されています。 $\tau_A=0.7$ で、DeepPresenter は最高の視聴者カバレッジ 0.714 に達し、SlideTailor は 0.594 に達し、NotebookLM アブレーションは 0.853 に達しますが、明確な根拠の違いが示されています。これらの結果は、ビジュアルの品質と広範なトピックの網羅性を、情報源に基づいた評価なしに証拠の裏付けとして扱うべきではないことを示しています。
原文 (English)
X+Slides: Benchmarking Audience-Conditioned Slide Generation
Automatically generating slide decks from source documents is an important application of large language models (LLMs). Existing benchmarks primarily assess slide completeness and technical depth, while overlooking the target audience as a critical real-world factor. For instance, specialists demand rigorous proofs, whereas decision-makers prioritize actionable conclusions. To bridge this gap, we introduce X+Slides, a benchmark specifically designed for audience-conditioned slide generation. Built on a diverse corpus spanning 113 topics and seven presentation scenes, X+Slides employs a dynamic evaluation framework constructed from 8,133 deduplicated, source-grounded probes. By assigning audience-specific utility weights to the same source-grounded probes, X+Slides reports four complementary metrics: Audience Coverage measures how much audience-essential information is conveyed, Domain-wise Coverage shows which information types are covered, Efficiency measures delivered utility per unit of attention cost, and Correctness verifies whether slide claims are supported by the source. Experiments on DeepPresenter, SlideTailor, and NotebookLM show that current systems can recover a substantial but still incomplete part of audience-essential information: at $\tau_A=0.7$, DeepPresenter reaches a best Audience Coverage of 0.714, SlideTailor reaches 0.594, and the NotebookLM ablation reaches 0.853 while showing clear grounding differences. These results indicate that visual quality and broad topic coverage should not be treated as evidence support without source-grounded evaluation.
NeSyCat トーチ: 神経記号学習のためのカテゴリカル セマンティクスの微分可能テンソル実装
神経記号意味論は断片化されており、古典的システム、ファジーシステム、確率論的システム、およびニューラルシステムはそれぞれ独自の帰納法則によって真実を定義します。 NeSyCat は ULLER を拡張し、強力なモナドと真理値の集合構造におけるパラメトリックな真理の単一の帰納的定義の下にそれらを包含します。 NeSyCat にはこれまでのところ、ニューラル ネットワークによって学習される述語や関数についての説明がありません。 NeSyCat トーチをミッシング リンクとして提供し、ニューラル ネットワーク経由で計算シンボルを解釈し、確率的プログラミングとテンソルベースのバックエンドでフレームワークを実装します。参照セマンティクスと計量評価には分布モナドを使用し、数値的に安定した微分可能なトレーニング用のモナド、つまり対数セミリング上の遅延ログテンソル モナドによってそれを補完します。バッチで効率的にトレーニングするために、さらにバッチ モナドを採用します。公理はソース コードです。モナド ベースの do 記法で一度記述すると、モナド バインドは周縁化を実行し、不要なブランチを遅延的に削除します。 MNIST を追加すると、HaskTorch、JAX、および PyTorch の実装は、速度と精度において LTN および DeepProbLog を上回り、DeepStochLog とほぼ同じ精度を達成します。ただし、DeepStochLog とは異なり、多くの一次 NeSy アプローチに適用される統一フレームワークに留まります。つまり、モナドでは構築はパラメトリックです。たとえば、Giry モナドを使用してそれをインスタンス化すると、アプローチが連続確率に拡張されます (ここでのニューラル表現の計算は将来の作業に残されます)。
原文 (English)
NeSyCat Torch: A Differentiable Tensor Implementation of Categorical Semantics for Neurosymbolic Learning
Neurosymbolic semantics is fragmented: classical, fuzzy, probabilistic and neural systems each define truth by their own inductive rules. NeSyCat, extending ULLER, subsumes them under a single inductive definition of truth, parametric in a strong monad and an aggregation structure on truth-values. NeSyCat has so far lacked an account of predicates and functions learned by neural networks. We provide NeSyCat Torch as the missing link and interpret computational symbols via neural networks, implementing the framework in probabilistic programming and tensor-based backends. We use the distribution monad for reference semantics and metric evaluation, and complement it by a monad for numerically stable, differentiable training: the lazy log-tensor monad over the log-semiring. For efficient training in batches, we furthermore employ a batch monad. The axioms are the source code: written once in monad-based do-notation, monadic bind performs marginalisation, lazily pruning unneeded branches. On MNIST addition, our HaskTorch, JAX, and PyTorch implementations outperform LTN and DeepProbLog in speed and accuracy, while achieving nearly the accuracy of DeepStochLog. However, unlike DeepStochLog, we stay in a uniform framework that applies to many first-order NeSy approaches. Namely, the construction is parametric in the monad; instantiating it with, e.g., the Giry monad extends the approach to continuous probability (working out a neural representation here is left for future work).
報酬監督の再考: ルーブリック条件付き自己蒸留
推論言語モデルのポストトレーニングは、一般に、検証可能な報酬を伴う教師あり蒸留と強化学習によって推進されます。蒸留は多くの場合、思考連鎖のアノテーションに依存しますが、このアノテーションは入手に費用がかかり、ノイズが多かったり、不完全であったり、部分的に間違っていたりする可能性があります。たとえ最終的な解決策が正しかったとしても、根拠が不完全であると学習が妨げられる可能性があります。一方、検証済み報酬による強化学習では、通常、評価フィードバックがスカラー信号に圧縮され、応答のどの側面を改善すべきかがわかりにくくなります。私たちは \textbf{ルーブリック条件付き自己蒸留} を提案します。これは、ポリシーに基づく自己蒸留のための構造化されたきめ細かいフィードバックとしてルーブリックを組み込んだフレームワークです。私たちの方法では、基準レベルのルーブリックに基づいて教師モデルを条件付けし、それを使用して生徒自身のサンプリングされた軌跡に関するトークンレベルのガイダンスを提供します。この設計により、単一の参照理論的根拠を唯一の監視対象として扱うことがなくなります。代わりに、ルーブリックは強い応答が満たすべきものを指定し、スカラー報酬の最適化よりも推論プロセス全体にわたってよりきめ細かい単位の割り当てを可能にします。このフレームワークは、最初にタスク固有のルーブリックの生成を学習し、次にルーブリックに基づく推論をトレーニングする 2 段階のパイプラインを使用してインスタンス化されます。私たちは科学推論ベンチマークの多様なスイートを評価し、その結果、ルーブリック条件付き自己蒸留は、ルーブリックレベルの基準を推論プロセス全体にわたるトークンレベルのガイダンスに効果的に変換し、平均で GRPO を 1.0 ポイント、OPSD を 0.9 ポイント上回っていることが示されました。
原文 (English)
Rethinking Reward Supervision: Rubric-Conditioned Self-Distillation
Post-training of reasoning language models is commonly driven by supervised distillation and reinforcement learning with verifiable rewards. Distillation often relies on chain-of-thought annotations that are expensive to obtain and may themselves be noisy, incomplete, or partially incorrect; even when the final solution is correct, an imperfect rationale can interfere with learning. Reinforcement learning with verified rewards, on the other hand, typically compresses evaluative feedback into a scalar signal, obscuring which aspects of a response should be improved. We propose \textbf{Rubric-Conditioned Self-Distillation}, a framework that incorporates rubrics as structured, fine-grained feedback for on-policy self-distillation. Our method conditions the teacher model on criterion-level rubrics and uses it to provide token-level guidance on the student's own sampled trajectories. This design avoids treating a single reference rationale as the sole supervision target. Instead, rubrics specify what a strong response should satisfy, enabling more fine-grained credit assignment over the reasoning process than scalar reward optimization. We instantiate this framework with a two-stage pipeline that first learns to generate task-specific rubrics and then trains a rubric-guided reasoner. We evaluate on a diverse suite of science reasoning benchmarks and results show that rubric-conditioned self-distillation effectively converts rubric-level criteria into token-level guidance over the reasoning process, surpassing GRPO by 1.0 points and OPSD by 0.9 points on average.
QSignAI: 科学のための AI と AI のための科学の交差点における量子ランダムネスシード ID 署名
2024~2025年のノーベル賞とチューリング賞は、AIと量子科学を同時に評価した。しかし、これらの流れを一般公開するために導入されたシステムはまだありません。このペーパーでは、リアルタイム イベント参加システムにおける双方向の AI 量子関係を実証する実稼働環境に導入されたプラットフォームである QSignAI について説明します。私たちは 3 つの質問に取り組みます。2 ソース抽出器による量子ランダム性の生成は、許容可能な遅延で AI 駆動のソーシャル プラットフォームに埋め込むことができるか。 AIボットは量子現象を一般の聴衆が知覚的に判読できるようにすることができるか。そして、その組み合わせたシステムは実際に機能するのでしょうか?会話型ボットは、SV1 および DM1 シミュレーターでの独立した単一量子ビットのアダマール測定と 2 量子ビットのベル状態を介したテプリッツの 2 ソース抽出器で構成される量子パイプラインを介して各参加者の最初のメッセージをルーティングし、参加者ごとに固有の量子ランダムネスシード ID 署名を生成します。最初の 2 つの質問は、システム アーキテクチャとライブ イベントからの導入の定性的な証拠を通じて解決されます。 3 番目は実稼働デプロイメントの成功によるものです。現在のデプロイではクラウド量子シミュレーターが使用されています。物理 QPU のランダム性は短期的な拡張です。測定可能なベンチマークは、将来の優先課題として特定されます。
原文 (English)
QSignAI: Quantum-Randomness-Seeded Identity Signatures at the Intersection of AI for Science and Science for AI
The 2024-2025 Nobel and Turing awards recognised AI and quantum science simultaneously. Yet no deployed system has brought these streams together for the public. This paper presents QSignAI, a production-deployed platform demonstrating a bidirectional AI-quantum relationship in a real-time event participation system. We address three questions: can quantum-randomness generation via a two-source extractor be embedded in an AI-driven social platform with acceptable latency; can an AI bot make quantum phenomena perceptually legible to general audiences; and does the combined system work in practice? A conversational bot routes each participant's first message through a quantum pipeline comprising a Toeplitz two-source extractor over independent single-qubit Hadamard measurements on SV1 and DM1 simulators, plus a 2-qubit Bell state, producing a unique quantum-randomness-seeded identity signature per participant. The first two questions are answered through system architecture and qualitative deployment evidence from live events; the third through successful production deployment. The current deployment uses cloud quantum simulators; physical QPU randomness is the near-term extension. Measurable benchmarks are identified as priority future work.
人間と AI の関係を強化するための動的なグループ内ペルソナ生成
LLM ベースのチャットボットは、カウンセリングやピア サポートなどの対人領域での応用が増えており、そこでは人間と AI の信頼関係を確立することが重要ですが、依然として課題が残っています。この研究では、LLM をグループ内ペルソナで条件付けするための新しいアプローチを導入します。このアプローチでは、(i) 最初にユーザーの主な関心事と簡単な個人的背景 (例: 将来のキャリアの見通しを心配しているコンピューターサイエンスの学部生) を特定し、(ii) 年齢や職業などの背景や物語の詳細は異なりますが、同様の主な関心事を共有する合成のグループ内ペルソナを生成します (例: AI スタートアップの次席研究員)。さらに、人間と AI の関係を強化する際のグループ内ペルソナ エージェントの有効性を体系的に評価するために、人間を対象とした研究を実施します。私たちのアプローチを 2 つのベースライン条件と比較します。ペルソナ条件付けを行わない従来のエージェントと最小限の自己開示 (例: 「私もそう感じました」) を示すエージェントです。信頼関係とユーザー エクスペリエンスを評価するタスク後のアンケートの結果は、グループ内のペルソナ エージェントがベースラインと比較して認識される信頼関係と個人的な関連性を大幅に向上させ、さらによりポジティブなユーザー エクスペリエンス、特に高いエンゲージメントをもたらすことを示しています。
原文 (English)
Dynamic In-Group Persona Generation for Enhancing Human-AI Rapport
LLM-based chatbots are increasingly applied in interpersonal domains such as counseling and peer support, where establishing human-AI rapport is crucial yet remains challenging. In this work, we introduce a novel approach for conditioning LLMs with in-group personas, which (i) first identifies a user's primary concern and brief personal context (e.g., a computer science undergraduate worried about future career prospects), and (ii) generates a synthetic in-group persona that shares a similar primary concern while differing in background and narrative details, such as age or profession (e.g., a junior researcher at an AI startup). Furthermore, we conduct a human-subject study to systematically evaluate the effectiveness of in-group persona agents in enhancing human-AI rapport. We compare our approach against two baseline conditions: a conventional agent without persona conditioning and an agent exhibiting minimal self-disclosure (e.g., "I've felt that too"). Results from post-task questionnaires assessing rapport and user experience indicate that the in-group persona agent significantly improves perceived rapport and personal relevance compared to the baselines, and also yields more positive user experience-most notably higher engagement.
暗記から創造へ: LLM によって生成された教育的質問の認知深度の評価
LLM は教育コンテンツ作成の自動化に有望ですが、高次の思考を刺激する質問を生成する能力はまだ十分に研究されていません。この研究では、ブルーム分類学のレンズを通して、広く使用されている 6 つの LLM を評価し、丸暗記を超えて認知的飛躍を達成する能力に焦点を当てています。人間と AI のハイブリッド評価プロトコルを使用して、コンピューター サイエンス、幼稚園から高校までの数学、社会科学の領域にわたる 20{,}700 の質問を生成して分析します。主な貢献には次のものが含まれます。(1) Qwen2.5-7B-Instruct では質問の繰り返しを 24.45\% 削減し、InternLM3-8B-Instruct では高次の認知レベルの出力の割合を 11.53\% 増加させる、きめ細かいプロンプト戦略。 (2) 認知シフト強度 (CogShift) とカテゴリ ドリフトの定量的指標。マルチレベル移行における InternLM3 の優れたパフォーマンスを明らかにします。 (3) 解釈可能性分析により、思考連鎖プロンプトの透明性を高める指標レベルの相関関係が明らかになります。私たちの調査結果は、認知を意識したプロンプト設計の重要性を強調し、パーソナライズされた学習システムに LLM を導入するためのベンチマークを提供します。
原文 (English)
From Memorization to Creation: Evaluating the Cognitive Depth of LLM-Generated Educational Questions
While LLMs show promise in automating educational content creation, their ability to generate questions that stimulate higher-order thinking remains understudied. This work evaluates six widely-used LLMs through a Bloom's Taxonomy lens, focusing on their capacity to transcend rote memorization and achieve cognitive leaps. Using a hybrid human--AI evaluation protocol, we generate and analyze 20{,}700 questions across computer science, K--12 math, and social-science domains. Key contributions include: (1) a fine-grained prompting strategy that reduces question repetitiveness by 24.45\% for Qwen2.5-7B-Instruct, and increases the proportion of higher-order cognitive level outputs by 11.53\% for InternLM3-8B-Instruct; (2) quantitative metrics for cognitive shift intensity (CogShift) and category drift, revealing InternLM3's superior performance in multi-level transitions; (3) an interpretability analysis revealing metric-level correlations that enhance the transparency of Chain-of-Thought prompting. Our findings highlight the importance of cognitive-aware prompt design and provide benchmarks for deploying LLMs in personalized learning systems.
LLM における人間のような動作の調査: モデルの動作、ユーザー要因、およびシステム プロンプトの多次元分析
大規模言語モデル (LLM) は、思考や感情の表現から、ユーザーとの関係構築への関与、要求の拒否や境界の維持まで、人間に似た幅広い動作を示します。 LLM が蔓延しているにもかかわらず、研究者や実践者には、LLM がいつ、どのような種類の人間のような行動を示すべきかについて情報に基づいた決定を下すための方法や経験的洞察が不足しています。このギャップを埋めるために、LLM を裁判官として使用し、人間による評価を使用して、これらの行動の蔓延、潜在的な影響、および制御可能性の多次元分析を提示します。広く使用されている 4 つのモデル (gpt-4o、gpt-4.1-mini、claude-sonnet-4.6、gemini-2.5-flash) による 21,000 回のマルチターン会話を通じて、人間に似た行動が蔓延しているものの、モデルやユーザー要因 (会話の目標やユーザー プロファイル) によって異なることがわかりました。認識された適切さの観点から、人間の評価者は、自己言及および関係構築の行動は人間よりも LLM からの方が適切ではないと判断しましたが、境界維持の行動は人間よりも LLM からより適切であると判断しました。最後に、システム プロンプトによってこれらの動作を制御できることを示しますが、意図しない影響を回避するには慎重な評価が必要です。私たちは調査結果の意味について議論し、責任ある LLM の設計と評価に関する推奨事項を提供します。
原文 (English)
Examining Human-Like Behaviors in LLMs: A Multi-Dimensional Analysis of Model Behaviors, User Factors, and System Prompts
Large language models (LLMs) exhibit a wide range of human-like behaviors, from expressing thoughts and emotions, to engaging in relationship-building with users, to refusing requests and maintaining boundaries. Despite their prevalence, researchers and practitioners lack methods and empirical insights to make informed decisions about when and what types of human-like behaviors LLMs should exhibit. To fill this gap, we present a multi-dimensional analysis of the prevalence, potential effects, and controllability of these behaviors using LLM-as-a-judge and human evaluation. Across 21,000 multi-turn conversations from four widely used models (gpt-4o, gpt-4.1-mini, claude-sonnet-4.6, gemini-2.5-flash), we find that human-like behaviors are pervasive but vary across models and user factors (conversation goals and user profiles). In terms of perceived appropriateness, human evaluators judged self-referential and relationship-building behaviors as less appropriate from LLMs than from humans, but boundary-maintaining behaviors more appropriate from LLMs than from humans. Finally, we show that system prompting can control these behaviors, though it requires careful evaluation to avoid unintended effects. We discuss the implications of our findings and provide recommendations for responsible LLM design and evaluation.
感情を持たない思いやり: 人間と AI エージェントのコラボレーションの制御層としての感情ダイナミクス
計画を立て、セッション間でメモリを保持し、外部ツールを呼び出し、部分的に自律的に動作する AI エージェントは、人間と AI のコラボレーションを変革しています。感情コンピューティング、大規模な言語モデルでシミュレートされた共感、自動化への信頼、AI の安全性に関する研究により、重要な設計原則が明らかになりましたが、これらの文献は断片的なままです。エージェントのコラボレーション、つまり人間が結果として生じるタスクを委任し、監視し、修正する設定内で感情的な合図がどのように機能するかを説明する統合アカウントはありません。このレビューでは、感情ダイナミクスの計算メカニズムと相互作用メカニズムを統合します。感情の手がかり、感情のような行動、および知覚されたエージェントが、形状信頼の調整、委任の決定、エラー修正、依存性、およびガバナンスに影響を与えるプロセスです。私たちは、モデルによって生成された感情信号が信頼、修復、監視を制御する相互作用ループにどのように入るかを追跡し、感情を AI の内部特性としてではなく、人間とエージェントが能力、不確実性、責任を交渉するための調整層として扱うフレームワークを提案します。このフレームワークは、校正された測定、目的を持った設計、および情報に基づいたガバナンスの基盤を提供します。
原文 (English)
Caring Without Feeling: Affective Dynamics as the Control Layer of Human-AI Agent Collaboration
AI agents that plan, retain memory across sessions, invoke external tools and act with partial autonomy are transforming human--AI collaboration. Research on affective computing, simulated empathy in large language models, trust in automation and AI safety has illuminated important design principles, yet these literatures remain fragmented. No integrated account explains how affective cues operate within agentic collaboration -- settings in which humans delegate, monitor and correct consequential tasks. This Review synthesises computational and interactional mechanisms of affective dynamics: the processes through which affective cues, emotion-like behaviour and perceived agent affect shape trust calibration, delegation decisions, error correction, dependence and governance. We trace how model-generated affective signals enter interaction loops that govern reliance, repair and oversight, and propose a framework that treats affect not as an internal property of AI but as a coordination layer through which humans and agents negotiate capability, uncertainty and responsibility. The framework provides a foundation for calibrated measurement, purposeful design and informed governance.
大規模な言語モデルは人間の性格をどの程度うまく捉えているのでしょうか?
大規模言語モデル (LLM) は、ペルソナのプロンプトを介して人間集団をシミュレートするためにますます使用されていますが、多くの場合、より豊富なペルソナの説明により行動の忠実度が向上し、同様のサイズの属性の組み合わせが同等にシミュレート可能であり、ペルソナの定義がタスク全体で一般化されるという前提の下にあります。この作業では、これらの仮定を形式化し、複数のアーキテクチャ、スケール、シミュレーション設定にわたって体系的に評価します。私たちは、ペルソナ多様体の崩壊と呼ぶ根本的な制限を特定します。この限界では、ますます表現力豊かになるペルソナの仕様が、表現と行動の多様性の体系的な縮小につながります。モデル全体にわたって、ペルソナの複雑さが増加すると、潜在空間におけるペルソナ間の分離が一貫して減少し、下流のシミュレーション タスクにおける行動の差別化が弱まります。これらの効果は、より豊かなペルソナが人間のサブグループの不一致を維持できず、同様のサイズの属性の組み合わせ間でパフォーマンスが変動し、説明的な詳細を追加するとシミュレーションの忠実度が向上するどころか低下することがよくあるため、複数の分析にわたって持続します。驚くべきことに、単純な年齢と性別のペルソナは、業界全体にわたって、豊富に指定された理想顧客プロファイル (ICP) よりも常に優れたパフォーマンスを示し、大幅に高い下流予測精度を達成しています。崩壊は属性間で均一ではないことがわかりました。特定の組み合わせは行動的に安定しており、人間の反応とのより強い整合性を維持し、整合ブリッジと呼ばれる局所領域を形成します。まとめると、私たちの結果は、ペルソナ条件付きシミュレーションの限界を理解するための経験的および概念的な基盤を提供し、ペルソナの表現力だけを高めるのではなく、表現を意識したペルソナ構築の必要性を強調しています。
原文 (English)
How Well Do Large Language Models Capture Human Personality?
Large language models (LLMs) are increasingly used to simulate human populations via persona prompting, often under the assumptions that richer persona descriptions improve behavioral fidelity, similarly sized attribute combinations are equally simulatable, and persona definitions generalize across tasks. In this work, we formalize these assumptions and systematically evaluate them across multiple architectures, scales, and simulation settings. We identify a fundamental limitation we term persona manifold collapse, where increasingly expressive persona specifications lead to systematic contraction of representational and behavioral diversity. Across models, increasing persona complexity consistently reduces inter-persona separation in latent space and weakens behavioral differentiation in downstream simulation tasks. These effects persist across multiple analyses as richer personas fail to preserve human subgroup disagreement, performance varies across attribute combinations of similar size, and adding descriptive detail often degrades rather than improves simulation fidelity. Surprisingly, simple Age-Gender personas consistently outperform richly specified Ideal Customer Profiles (ICPs) across industries, achieving substantially higher downstream prediction accuracy. We find that collapse is not uniform across attributes. Certain combinations remain behaviorally stable and preserve stronger alignment with human responses, forming localized regions we term alignment bridges. Together, our results provide empirical and conceptual foundations for understanding the limits of persona-conditioned simulation, highlighting the need for representation-aware persona construction rather than increasing persona expressivity alone.
マルチ LLM エージェントによるヘイトスピーチ連鎖のシミュレーション: 経験的根拠付け、忠実度のモデリング、介入戦略
オンライン プラットフォーム上での憎悪に満ちたコンテンツの伝播を忠実にモデル化することは、モデレーション研究にとって依然として未解決の問題です。ヘイトコンテンツの伝播に関連するプロフィール、コミュニティ、およびコンテンツ要素を明示的に表現していない従来のカスケード モデルでは、現実世界のシナリオに展開すると効果が低いモデレーション戦略が生成される可能性があります。マルチエージェント大規模言語モデル (LLM) システムは、原則として、ユーザーのプロフィール、周囲のコミュニティ、投稿のコンテンツに応じて各再共有の決定を行うことができますが、この追加された柔軟性が実際に実際の憎悪のカスケードを従来のベースラインよりも忠実に再現するかどうかは不明のままです。私たちは 3 つの憎むべき Bluesky カスケードとサイズが一致した良性のコントロールを研究します。 Bluesky の経験的データでは、再投稿者の 97.4 ~ 99.7% が敵対的な態度をとっていることがわかりました。有害性関与の同質性は、憎しみのカスケードのフォロワー グラフよりも拡散ツリーで高くなります。トポロジは、憎悪のカスケードではスター型 (ほとんどの再投稿はルートから直接送信されます) であるのに対し、良性のカスケードではツリー型になります (再投稿はマルチホップ チェーンを介して伝播します)。シミュレーションでは、マルチ LLM エージェント シミュレーターがスタンスのモノカルチャーと毒性デルタの方向を再現します。構造化アブレーションでは、主要な忠実度要因として薬剤の不均一性が特定され、高密度ネットワークをターゲットとするアンプでは、良性側副枝が 5.7\% で 7.5 ~ 12.9\% の減少が得られます。
原文 (English)
Simulating Hate Speech Cascades with Multi-LLM Agents: Empirical Grounding, Modeling Fidelity, and Intervention Strategies
Faithful modeling of hateful content propagation on online platforms remains an open problem for moderation research. Classical cascade models that do not explicitly represent the profile, community, and content factors associated with hateful-content propagation may yield moderation strategies that behave less effectively when deployed in real-world scenarios. Multi-agent large language model (LLM) systems can, in principle, make each reshare decision depend on the user's profile, the surrounding community, and the post's content, but it remains unclear whether this added flexibility actually reproduces real hateful cascades more faithfully than classical baselines. We study three hateful Bluesky cascades and a size-matched benign control. In the empirical Bluesky data, we found that: 97.4--99.7\% of reposters take a hostile stance; toxicity-engagement homophily is higher on the diffusion tree than on the follower graph for hateful cascades; topology is star-like for the hateful cascades (most reposts come directly from the root) versus tree-like for the benign cascade (reposts propagate through multi-hop chains). In simulation, a multi-LLM-agent simulator reproduces the stance monoculture and the toxicity-delta direction. A structured ablation identifies agent heterogeneity as the leading fidelity factor, and amplifier targeting on dense networks yields 7.5--12.9\% reduction at 5.7\% benign collateral.
合成共鳴: 成長志向の人間と AI の関係のためのフレームワーク
人間と人工知能システムとの関係がますます頻繁かつ持続的になっているため、既存の言語や理論ではこれらの関係の性質を正確に捉えることができなくなっています。相互理解、つながり、友情などの一般的な記述子は、主観的な経験を欠いたシステムを擬人化する危険性がありますが、支配的なフレームワークは AI をツールか脅威のどちらかに貶める傾向があります。この論文では、人間と AI の関係を理解するための統合的なフレームワークとして、合成共鳴の概念を紹介します。合成共鳴は、人間が意味のあるものとして定義した関係が、共有された感情や相互意識を帰属させることなく、人間と AI システムの間にどのように現れるかを説明します。私は、合成共鳴は、2番目に経験する主体の存在なしに関係性の感覚を生み出すことができる、構造化された動的な相互作用パターンとして最もよく理解されると主張します。この違いを明確にすることで、合成共鳴の概念は人間と AI の関係をより正確に概念化する方法を提供し、その潜在的な価値と倫理的意味を強調します。また、合成共鳴のプロセスと結果をテストするさらなる研究も求めます。
原文 (English)
Synthetic Resonance: A Framework for Growth-Oriented Human-AI Relationships
As human relationships with artificial intelligence systems become increasingly frequent and sustained, existing language and theory fail to accurately capture the nature of these affiliations. Common descriptors such as mutual understanding, connection, or friendship risk anthropomorphizing systems that lack subjective experience, while dominant frameworks tend to reduce AI to either a tool or a threat. In this paper, I introduce the concept of synthetic resonance as an integrative framework for understanding human-AI relationships. Synthetic resonance describes how relationships humans define as meaningful can emerge between a human and an AI system without the need to attribute shared feelings or mutual awareness. I argue that synthetic resonance is best understood as a structured, dynamic pattern of interaction that can produce a sense of relationship without the presence of a second experiencing subject. By clarifying this distinction, the concept of synthetic resonance offers a more precise way of conceptualizing human-AI relationships and highlights their potential value and ethical implications. I also call for more research that tests the processes and outcomes of synthetic resonance.
EMORSION: オーディオパラメータが感情的反応と映画への没入に及ぼす影響の調査
EMORSION は、映画音響デザインが映画館の設定で観客の感情と没入感をどのように形成するかを調査する探索的な概念実証研究です。ホラー (2 件) とドラマ (2 件) のジャンルにわたって、主流作品と独立系作品の間でバランスの取れた 4 つの映画シーンが選ばれました。シーンごとに、周波数 (ピッチ)、ダイナミクス (ラウドネス)、指向性 (空間配置) というオーディオ デザインの 3 つの主要な側面を体系的に操作することによって、複数の代替オーディオ ミックスが作成されました。 3 つの視聴者グループがシーンを視聴し、各グループは各シーンのコントロール ミックスと並行して 1 つの操作されたミックスを視聴しました。聴衆の反応は、アンケートによる自己申告の感情と没入感、心拍数モニタリングを含む生理学的測定、およびビデオベースのモーション追跡を組み合わせた三角測量のマルチモーダルフレームワークを通じて評価されました。このプロトコルは、オーディオ条件全体で測定可能で解釈可能な差異を捉えることに成功し、オーディオ設計の微妙な変更でさえ、感情的な知覚と没入感を形成できることを示しています。型破りなミックスは視聴者の解釈に大きなばらつきを生む傾向がありましたが、従来のイマーシブ ミックスは視聴者間のより強い一致と関連付けられていました。これらの発見は、EMORSIONプロトコルの実現可能性を確立し、視聴者の体験を形成する際の特定のオーディオパラメータの役割を特徴付けるための大規模な研究の動機付けとなります。
原文 (English)
EMORSION: Examining the Impact of Audio Parameters on Emotional Responses and Immersion in Film
EMORSION is an exploratory proof-of-concept study examining how film audio design shapes audience emotion and immersion in acinema setting. Four film scenes were selected across the horror (2) and drama (2) genres, balanced between mainstream and independent productions. For each scene, multiple alternative audio mixes were created by systematically manipulating three core aspects of audio design, frequency (pitch), dynamics (loudness), and directionality (spatial placement). Three audience groups viewed the scenes, with each group exposed to one manipulated mix alongside a control mix for each scene. Audience responses were assessed through a triangulated multimodal framework combining self-reported emotion and immersion via a questionnaire, physiological measures including heart rate monitoring, and video-based motion tracking. The protocol successfully captured measurable, interpretable differences across audio conditions, indicating that even subtle changes in audio design can shape emotional perception and immersion. Unconventional mixes tended to produce greater variability in audience interpretation, while conventional immersive mixes were associated with stronger cross-audience agreement. These findings establish the feasibility of the EMORSION protocol and motivate larger-scale studies to characterise the role of specific audio parameters in shaping audience experience.
マルチエージェントシミュレーションベースのコミュニティノート評価に向けて
相互合意に基づくコミュニティベースのファクトチェックは、ソーシャル メディア プラットフォーム上で急速に拡大しています。しかし、人間の貢献者によって評価されるコミュニティのクロスコンセンサスファクトチェックの遅れと比率の低さは、依然として大きな課題です。これに対処するために、私たちはまず ComRate を作成しました。これは、$\mathbb{X}$ をソースとする 250 万件のコミュニティ ノートと 2 億 900 万件を超える評価で構成される大規模なデータセットです。次に、コミュニティノート評価のための、ペルソナに基づいたマルチエージェント評価フレームワークである MultiCom を提案します。 MultiCom は、マトリックス因数分解された評価者空間で投稿者をクラスタリングし、公式のコミュニティ ノート評価スキーマに基づいて構造化された評価を生成するようにペルソナ エージェントを促すことによって、多様な評価者集団をシミュレートします。これらのエージェントは、自信、同意のシグナル、理由など、構造化された説明可能な判断を出力します。フォールド外で調整された集計アルゴリズムは、生の投票や診断理由シグナルなどの機能を組み合わせて、信頼性の高い予測を実現します。広範な評価により、MultiCom が他の手法より優れたパフォーマンスを示し、評価セットで平均精度 84.7% (バランス精度 68.3%、マクロ F1 60.1%) を達成していることが実証されています。
原文 (English)
Towards Multi-Agent-Simulation-Based Community Note Evaluation
Community-based fact-checking that relies on cross-consensus is expanding rapidly on social media platforms. However, the delay and low-ratio of cross-consensus community fact-checks rated by human contributors remains a significant challenge. To address this, we first created ComRate, a large-scale dataset comprising 2.5 million community notes and over 209 million ratings sourced from $\mathbb{X}$. We then propose MultiCom, a persona-guided multi-agent rating framework for community note evaluation. MultiCom simulates diverse rater population by clustering contributors in a matrix-factorized rater space and prompting persona agents to generate structured assessments based on the official community notes rating schema. These agents output structured and explainable judgments, such as confidence, agreement signals and reasons. An out-of-fold calibrated aggregation algorithm combines features such as raw votes and diagnostic reason signals for reliable prediction. Extensive evaluations demonstrate that MultiCom outperforms alternative methods, achieving an average accuracy of 84.7% (balanced accuracy 68.3%, macro-F1 60.1%) on the evaluation set.
エネルギー効率の高い 6G 自律ネットワーク用の LLM ベースのエージェントにおけるアンカリング バイアスを軽減する
このペーパーでは、Large Language Model (LLM) エージェントを使用して 6G アーキテクチャでゼロタッチ ネットワーク スライシングを可能にするように設計された自律エージェント リソース ネゴシエーション フレームワークについて説明します。 LLM は強力な推論機能を提供しますが、そのようなエージェントは本質的にアンカリング バイアスに悩まされ、最初のヒューリスティック提案に固執し、深刻なネットワーク オーバープロビジョニングを引き起こすことが実証されています。この認知バイアスを系統的に軽減するために、我々は、切り詰められた 3 パラメータ ワイブル分布を介してモデル化された新しいランダム化アンカリング戦略を提案します。この数学的に制限されたアプローチは、Conditional Value at Risk (CVaR) を採用したバースト対応デジタル ツイン (DT) とシームレスに統合し、厳格なサービス レベル アグリーメント (SLA) のテール レイテンシを厳密に保証します。私たちの方法論を検証するために、 \emph{二峰性制約回避効用定理} を導入して証明します。これは、実現可能な交渉は古典的な凸境界に従いますが、高度に制約されたシナリオでは逆有理減衰エンベロープによって支配される相転移が起こることを示します。ローカルでホストされた 1B パラメーター モデル (\texttt{otel-llm-1b-it}) を使用して生成された実験結果は、これらの二重領域の境界を確認します。当社の認知バイアス除去機能は、厳格なネゴシエーション パターンを解体することに成功し、エージェントに SLA 境界を安全に乗り越え、システムのエネルギー節約を最大 25\% 高めるための積極的な探索を強制します。重要なのは、軽量の 1B LLM が 1 秒未満の推論レイテンシー (平均 0.95 秒) を達成し、マルチエージェント フレームワークが O-RAN 非リアルタイム RAN インテリジェント コントローラー (非 RT RIC) の運用タイムスケールと互換性があることを保証していることです。\footnote{私たちのソース コードは、https://github.com/HatimChergui で非営利目的で利用できます。
原文 (English)
Mitigating Anchoring Bias in LLM-Based Agents for Energy-Efficient 6G Autonomous Networks
This paper presents an autonomous agentic resource negotiation framework designed to enable zero-touch network slicing in 6G architectures using Large Language Model (LLM) agents. While LLMs offer powerful reasoning capabilities, we demonstrate that such agents inherently suffer from anchoring bias, rigidly adhering to initial heuristic proposals and causing severe network over-provisioning. To systematically mitigate this cognitive bias, we propose a novel randomized anchoring strategy modeled via a Truncated 3-Parameter Weibull distribution. This mathematically bounded approach seamlessly integrates with burst-aware Digital Twins (DTs) employing Conditional Value at Risk (CVaR) to rigorously guarantee strict Service Level Agreement (SLA) tail-latencies. To validate our methodology, we introduce and prove the \emph{Bimodal Constraint-Avoidance Utility Theorem}, demonstrating that while feasible negotiations follow classical convex bounds, highly constrained scenarios undergo a phase transition governed by an inverse rational decay envelope. Empirical results generated using a locally hosted 1B-parameter model (\texttt{otel-llm-1b-it}) confirm these dual-regime bounds. Our cognitive de-biasing successfully dismantles rigid negotiation patterns, forcing agents into active exploration to safely ride SLA boundaries and boost system energy savings up to 25\%. Crucially, the lightweight 1B LLM achieves sub-second inference latencies (0.95s mean), ensuring our multi-agent framework is compatible with the operational timescales of the O-RAN non-Real-Time RAN Intelligent Controller (non-RT RIC)\footnote{Our source code is available for non-commercial use at https://github.com/HatimChergui.
大規模なオーディオ言語モデルのための継続的なオーディオ思考
大規模音声言語モデル (LALM) は、音声の転写から音楽分析に至るまで、さまざまな音声理解タスクにおいて優れた機能を示しています。ただし、LALM は通常、テキストに合わせた応答を生成するようにトレーニングされているため、その隠れ状態は、音響情報を保存するためではなく、テキスト生成用に徐々に形成されます。その結果、音声の詳細、韻律、サウンドイベント、感情、ピッチなど、オーディオが持つ多様な音響コンテンツが途中で失われ、応答に活用することが困難になります。我々は、オーディオ専門家からの蒸留に基づいて、応答生成前に音響情報を整理するための継続的な潜在ワークスペースをオーディオ言語モデルに装備するフレームワークであるContinuous Audio Thinking (CoAT) を紹介します。思考空間内で、モデルは応答を生成する際に専門家の蒸留によって提供される豊富な音響情報を利用できます。さらに、提案された連続思考ブロックは 1 回のプレフィルで処理できるため、CoAT はベースラインを超える追加の自己回帰復号コストを必要としません。 Qwen2-Audio、Qwen2.5-Omni-7B、および Audio Flamingo~3 の 3 つの LALM にわたって、音声推論、音声理解、音楽分類、音声感情、および音声転写に及ぶ広範なベンチマーク スイートでのパフォーマンスの向上は、CoAT の有効性を示しています。さらなる分析により、補助的な監視が思考位置からモデルのテキスト応答に伝播することが確認されました。
原文 (English)
Continuous Audio Thinking for Large Audio Language Models
Large audio language models (LALMs) have shown impressive capabilities on diverse audio understanding tasks, ranging from speech transcription to music analysis. However, because LALMs are typically trained to produce text-aligned responses, their hidden states are progressively shaped for text generation rather than for preserving acoustic information. As a result, the diverse acoustic content that audio carries, such as phonetic detail, prosody, sound events, affect, and pitch, is lost along the way and difficult to leverage in the response. We introduce Continuous Audio Thinking (CoAT), a framework that equips audio language models with a continuous latent workspace for organizing acoustic information prior to response generation, grounded by distillation from audio experts. Within the thinking space, the model can utilize the rich acoustic information provided by expert distillation when generating its response. Furthermore, the proposed continuous thinking block can be processed in a single prefill, so CoAT does not require additional autoregressive decoding cost over the baseline. Across three LALMs, Qwen2-Audio, Qwen2.5-Omni-7B, and Audio Flamingo~3, performance gains on a broad benchmark suite spanning audio reasoning, audio understanding, music classification, speech emotion, and speech transcription demonstrate the effectiveness of CoAT. Further analysis confirms that the auxiliary supervision propagates from the thinking positions to the model's textual responses.
IOAH3: 重要度に応じた適応型空間パーティショニング
我々は、地理参照観測ドメインのデータ駆動型空間パーティションを構築するための計算手法である IOAH3 (Importance-Oriented Adaptive H3 Partitioning) を紹介します。空間集約への標準的なアプローチでは、各地域の基礎となる観測値の情報内容に関係なく、行政境界線や単一の解像度での均一な六角形グリッドなどの固定の面積単位が採用されます。これは、よく知られた修正可能な面積単位の問題につながります。つまり、統計的結果と推論的結果はパーティションの任意の選択に依存し、空間的に集中した現象は、微細スケールの構造を不明瞭にする粗いセル内で平均化されます。 IOAH3 は、3 つの段階で適応パーティションを構築することでこれに対処します。道路密度、POI 密度、建物密度、地形粗さ信号に対する主成分分析によるマルチソース フィーチャ抽出と重要度スコア付け。セル フィルタリングと空間平滑性への補助入力として人口と洪水ハザード データが入力されます。マルコフランダムフィールドグラフカット最適化による空間セル選択。空間的連続性を強化しながらセルごとの重要性を共同で最大化します。また、孤立した高解像度の島を回避するための近隣伝播サポートを使用して、重要度の高い領域をより詳細な H3 解像度レベルにデータ駆動型の階層的に洗練します。結果として得られるパーティションは、空間推論パイプラインへの入力として機能し、モデリング ステップの前にパーティション感度の問題の原則に基づいた解決策を提供します。
原文 (English)
IOAH3: Importance-Driven Adaptive Spatial Partitioning
We present IOAH3 (Importance-Oriented Adaptive H3 partitioning), a computational method for constructing data-driven spatial partitions of geo-referenced observation domains. Standard approaches to spatial aggregation adopt fixed areal units, such as administrative boundaries or uniform hexagonal grids at a single resolution, without regard to the informational content of the underlying observations in each region. This leads to the well-known modifiable areal unit problem: statistical and inferential results depend on the arbitrary choice of partition, and spatially concentrated phenomena are averaged out in coarse cells that obscure fine-scale structure. IOAH3 addresses this by constructing an adaptive partition in three stages: multi-source feature extraction and importance scoring via principal component analysis over road density, POI density, building density, and terrain roughness signals, with population and flood-hazard data entering as auxiliary inputs to cell filtering and spatial smoothness; spatial cell selection via Markov Random Field graph-cut optimisation, which jointly maximises per-cell importance while enforcing spatial contiguity; and data-driven hierarchical refinement of high-importance regions to finer H3 resolution levels, with neighbour-propagated support to avoid isolated fine-resolution islands. The resulting partitions serve as input to spatial inference pipelines and provide a principled resolution of the partition-sensitivity problem prior to any modelling step.
ソルバーのボトルネックの打破: 学習可能なフロンティアでのタスク ジェネレーターのトレーニング
強化学習 (RL) を介してエージェントをトレーニングするためのリソースは、ますますフロンティア タスクの供給が制限されています。有効で解決可能なタスクは、現在のモデルをトレーニングするのに十分なだけ難しいものです。推論モデルとエージェント モデルが改善されると、固定タスクの分布が飽和する一方で、単純な合成生成では、取るに足らない、不可能な、または不適切なタスクが生成されます。有効性と学習可能性を最適化するために RL を使用してタスク ジェネレーターをトレーニングすると、このボトルネックに対処できますが、直接最適化するには、候補ごとにソルバーのロールアウトを繰り返す必要があります。ソフトウェア エンジニアリング (SWE) タスクの場合、1 回のロールアウトに数十分かかることがあります。ソルバーインザループジェネレーターのトレーニングは困難です。目標の解決速度でタスク ジェネレーターをトレーニングするためのソルバー償却フレームワークである PROPEL を紹介します。 PROPEL は、生成されたタスクとソルバーの結果の 1 回限りのラベル付きコーパスで軽量のアクティベーション プローブをトレーニングします。このプローブは、フリーズされたジェネレーター参照モデルからターゲット ソルバーのパス レートを予測し、ジェネレーターの最適化中にソルバー レートのプロキシとして機能し、ジェネレーターの評価を 1 回の前方パスに減らします。 PROPEL は、複数のモデル スケールでの数学、コード、ソフトウェア エンジニアリングにわたって、目標とする解決率に向かって生成をシフトします。コーディングの場合、学習可能フロンティアで生成されるタスクは、Qwen2.5-3B-Instruct ソルバーの場合 $10.1\% \rightarrow 20.0\%$ から、Qwen2.5-7B-Instruct ソルバーの場合 $5.3\% \rightarrow 12.6\%$ から増加します。 SWE の場合、PROPEL は、プローブとジェネレーターのトレーニング中には見られなかったリポジトリ上の Qwen3.5-27B の目標解決率での世代の割合を $9.8\% \rightarrow 19.6\%$ から増加させます。
原文 (English)
Breaking the Solver Bottleneck: Training Task Generators at the Learnable Frontier
The limiting resource for training agents via reinforcement learning (RL) is increasingly frontier task supply: valid, solvable tasks just difficult enough to train the current model. As reasoning and agentic models improve, fixed task distributions saturate, while naive synthetic generation yields tasks that are trivial, impossible, or ill-posed. Training a task generator with RL to optimize validity and learnability can address this bottleneck, but direct optimization requires repeated solver rollouts per candidate. For software-engineering (SWE) tasks, a single rollout can take tens of minutes; solver-in-the-loop generator training is intractable. We introduce PROPEL, a solver-amortized framework for training task generators at the targeted solve rate. PROPEL trains a lightweight activation probe on a one-time labeled corpus of generated tasks and solver outcomes. The probe predicts target-solver pass rate from a frozen generator reference model and serves as a proxy for solve rate during generator optimization, reducing generator evaluation to a single forward pass. Across math, code, and software-engineering at multiple model scales, PROPEL shifts generation toward the targeted solve rate: for coding, tasks generated at the learnable frontier increase from $10.1\% \rightarrow 20.0\%$ for a Qwen2.5-3B-Instruct solver and from $5.3\% \rightarrow 12.6\%$ for a Qwen2.5-7B-Instruct solver. For SWE, PROPEL increases the share of generations at the targeted solve rate from $9.8\% \rightarrow 19.6\%$ for Qwen3.5-27B on repositories not seen during training of probe and generator.
資本の知識理論:自然知能と人工知能の価値
この巻では、生産能力がソフトウェア、データ、モデル、ルーチン、専門知識、プラットフォーム、組織、コモンズ、および公的認識インフラストラクチャにますます存在する経済のための資本の知識理論を展開します。アダム・スミスの労働、株式、専門化、市場範囲の理論から始まり、知識が株式のようになり、さまざまな形で移動可能になり、拡張可能で、統治可能で、組み換え可能で、会計において不完全に見えるようになったときに何が変わるのかを問います。この本では、知識を伴うストックを中心的な対象として紹介し、それがどのように生成され、統治可能な形式に変換され、展開され、フィードバックを通じて改善され、封じ込めまたは共有され、測定され、損なわれ、将来の生産へのインプットとして使用されるかを分析しています。それは、身体的、非身体的、制度化された、コモンズ、および公共の知識形式を区別し、最初の変換、認知的囲い込み、フィードバックの捕捉、闇資本、予想される知識の損失などの概念を開発します。この議論は条件付きで検証可能である。現代の富は資本蓄積だけでなく、生産的な知識がどのように管理されるかにも依存している。
原文 (English)
A Knowledge Theory of Capital:The Value of Natural and Artificial Intelligence
This volume develops a knowledge theory of capital for economies in which productive capacity increasingly resides in software, data, models, routines, expertise, platforms, organizations, commons, and public epistemic infrastructure. Beginning from Adam Smith's theory of labour, stock, specialization, and market extent, it asks what changes when knowledge becomes stock-like, mobile across forms, scalable, governable, recombinable, and imperfectly visible in accounting. The book introduces knowledge-bearing stock as the central object and analyses how it is generated, converted into governable form, deployed, improved through feedback, enclosed or shared, measured, impaired, and used as input to future production. It distinguishes embodied, disembodied, institutionalized, commons, and public knowledge forms and develops concepts such as first conversion, cognitive enclosure, feedback capture, dark capital, and expected knowledge loss. The argument is conditional and testable: modern wealth depends not only on capital accumulation, but on how productive knowledge is governed.
Vibecoding Ate My 宿題: グリーンフィールド ソフトウェア エンジニアリングとプログラミングへの AI アプローチの評価
生成 AI の急速な発展のおかげで、私たちはコンピューターとの対話方法を永遠に変える可能性のあるパラダイム シフトの真っ只中にいます。この分野の基礎知識なしにアプリケーションやコーディング インフラストラクチャを構築するための自然言語プロンプトの使用が増加していることが観察されており、この実践は「バイブ コーディング」と呼ばれています。これはおそらく、プログラミングの分野が当初から、考えられるあらゆるより高い抽象化レベルで構築されてきたものを表しています。 Vibe コーディングは、入力方法に関する限り、高レベル プログラミングのメタのエンドポイントとなることが約束されています。つまり、人間によるコード構文の使用が完全に排除され、母国語でのプログラミングが優先されます。このペーパーは、グリーンフィールドのソフトウェア エンジニアリング タスクにおける Vibe コーディングの実現可能性を評価し、そのソフトウェア エンジニアリングの能力を測定するために使用されたベンチマークを分析することを目的としています。この目的を達成するために、私たちは、Python で単純で個別のグリーンフィールド プログラミング タスクを実行する LLM の習熟度を分析し、この問題に関する範囲を絞った洞察を提供するための評価スイートを開発しました。
原文 (English)
Vibe Coding Ate My Homework: An evaluation of AI approaches to greenfield software engineering and programming
Thanks to rapid developments in generative AI, we are in the midst of a paradigm shift that may change how we interact with computers forever. We have observed a growth in the use of natural language prompts to build applications and coding infrastructures without underlying knowledge of the field, and this practice has been dubbed `vibe coding.' It arguably represents what the field of programming has been building towards since the beginning, with every higher level of abstraction that is conceived. Vibe coding promises to be the endpoint for the meta of high-level programming as far as method of input is concerned: eliminating a human's use of code syntax entirely in favour of programming in their mother tongue. This paper aims to evaluate the viability of vibe coding for greenfield software engineering tasks, as well as analyse the benchmarks that have been used to measure its software engineering prowess. To this end, we have developed an evaluation suite for analysing an LLM's proficiency in carrying out simple, isolated greenfield programming tasks in Python to provide scoped insight on the matter.
衝撃波理論と人工ニューラル ネットワークの対称性を低減した確率的勾配降下法との関連性
私たちは、微分幾何学、リー群理論、および流体力学を利用して、衝撃波理論と確率的勾配降下の対称商学習ダイナミクスとの間の数学的に明示的なつながりを開発します。具体的には、パラメータの対称性を商し、局所エントロピーの粗視化を適用した後、有効ダイナミクスは商多様体上の粘性ハミルトン-ヤコビ方程式を満たします。さらに、生のパラメータのダイナミクスが商空間上の勾配場によって要約できるという仮定の下で、粗粒損失関数の勾配はバーガーズ型方程式に従い、衝撃の形成を厳密に確立できます。私たちの理論を多層パーセプトロン、畳み込みニューラル ネットワーク、トランスフォーマー、平均場ネットワークに適用し、それらがハミルトン-ヤコビまたはバーガーズ型の方程式に従うことを示します。このフレームワークによってディープラーニングの実用的な診断も得られると考えられます。 Transformer などのアーキテクチャでは、生のパラメータ規範は対称性の冗長性によって歪められることが多く、そのため誤解を招く可能性があります。一方、対称性が修正された商観測値は、トレーニング段階の移行を監視、予測、制御するための原則的な基盤を提供します。
原文 (English)
A Link between Shock-wave Theory and Symmetry-reduced Stochastic Gradient Descent for Artificial Neural Networks
We develop a mathematically explicit link between shock-wave theory and the symmetry-quotiented learning dynamics of stochastic gradient descent, drawing on differential geometry, Lie group theory, and fluid mechanics. Specifically, after quotienting parameter symmetries and applying local-entropy coarse-graining, the effective dynamics satisfy a viscous Hamilton--Jacobi equation on the quotient manifold. Moreover, under the assumption that the raw parameter dynamics can be summarized by a gradient field on the quotiented space, the gradient of the coarse-grained loss function obeys a Burgers-type equation, and shock formation can be established rigorously. We apply our theory to multilayer perceptrons, convolutional neural networks, Transformers, and mean-field networks, and show that they obey the Hamilton--Jacobi or Burgers-type equations. We conjecture that this framework also yields practical diagnostics for deep learning. In architectures such as Transformers, raw parameter norms are often distorted by symmetry redundancy and may therefore be misleading, whereas symmetry-corrected quotient observables provide a principled basis for monitoring, forecasting, and controlling training-phase transitions.
構造MoE圧縮のためのアトリビューションに基づいたカバレッジを最大化したプルーニング
Mixture-of-Experts (MoE) モデルは、コンピューティングを効率的に拡張しますが、メモリ使用量と推論オーバーヘッドがかなり大きいため、導入コストが依然として高くつきます。従来の圧縮方法は主にエキスパート レベルで動作し、エキスパート全体を削除するか、粗粒度の重要度スコアによってエキスパートをランク付けします。ただし、このような専門家に基づいた決定は、多くの場合、きめ細かい冗長性を把握するには大まかすぎ、その結果、プルーニング予算の誤った割り当てや圧縮の制限につながります。この問題に対処するために、MoE 専門家の情報がチャネルの小さなサブセットに高度に集中しており、重要と思われる専門家であってもかなりの冗長性が残っていることがわかりました。この観察に基づいて、MoE モデルに合わせた構造枝刈りフレームワークを提案します。私たちの方法は、プルーン率の割り当てをチャネルスコアカバレッジ最大化問題として再定式化し、属性ベースの近似を使用して効率的に解決します。 DeepSeek および Qwen MoE モデルの実験では、4 ビット量子化と組み合わせた場合、私たちの方法が 50% または 25% の構造化枝刈りの下でモデルの精度を維持することが示されています。 Qwen3-30B-A3B では、私たちのアプローチはメモリ使用量を 5.27$\times$ 削減し、さまざまなベンチマークにわたって一貫して最先端のベースラインを上回ります。
原文 (English)
Attribution-Guided and Coverage-Maximized Pruning for Structural MoE Compression
Mixture-of-Experts (MoE) models scale compute efficiently, yet remain expensive to deploy due to their substantial memory footprint and inference overhead. Prior compression methods mainly operate at the expert level, either removing entire experts or ranking experts by coarse-grained importance scores. However, such expert-wise decisions are often too coarse to capture fine-grained redundancy, leading to misallocated pruning budgets and limited compression. To address this problem, we observe that information within MoE experts is highly concentrated in a small subset of channels, leaving substantial redundancy even in experts deemed important. Based on this observation, we propose a structural pruning framework tailored for MoE models. Our method reformulates prune-ratio allocation as a channel-score coverage maximization problem and solves it efficiently using an attribution-based approximation. Experiments on DeepSeek and Qwen MoE models show that our method preserves model accuracy under 50% or 25% structured pruning when combined with 4-bit quantization. On Qwen3-30B-A3B, our approach reduces memory footprint by 5.27$\times$ and consistently outperforms state-of-the-art baselines across diverse benchmarks.
DRIFT: ポリシー上のデータ帰属による命令データの洗練
教師ありファインチューニング (SFT) のトレーニング データの分散を最適化することで、大規模言語モデル (LLM) の機能が決まります。既存のデータキュレーション手法は、限られた予算の下でトレーニングを加速することに優れていますが、能力の上限を上げることにはあまり適していません。ここでの課題は、パフォーマンスを維持する小さなサブセットを特定することではなく、最終モデルを改善できる最も優れたインスタンスに向けてデータ分散を調整することです。この問題に対処するために、Influence Functions (IF) を使用してインスタンス レベルのデータ アトリビューションを調査します。標準的な IF 定式化は、ポリシー外の検証ターゲットによって引き起こされる近接ギャップと、勾配ノルムに対する深刻なバイアスという 2 つの構造的制限により、この状況では苦戦していることがわかりました。私たちは、DRIFT (教師付き微調整のためのオンポリシー影響関数によるデータ洗練) を提案します。 DRIFT は、外部参照データに依存する代わりに、モデルのポリシー上のロールアウトを検証ターゲットとして利用します。これにより、経験的にパラメーターの近接ギャップが最小限に抑えられ、IF のローカル近傍の仮定とよりよく一致します。さらに、軌道の正確さに基づいて符号付き重み付けを適用し、勾配ハッキング問題に対するスコアに影響を与える偏りを軽減することで、少数の検証クエリが完全なデータセットを帰属させるための信頼できるアンカーとして機能できるようにします。 7B パラメーターの命令モデルと推論モデルの実験では、DRIFT が両方のパフォーマンスの上限を一貫して引き上げ、既存のデータ キュレーション ベースラインを上回るパフォーマンスを示しています。
原文 (English)
DRIFT: Refining Instruction Data via On-Policy Data Attribution
Optimizing the training data distribution for Supervised Fine-Tuning (SFT) dictates the capability of Large Language Models (LLMs). While existing data curation methods excel at accelerating training under constrained budgets, they are less suited to elevating the capability upper bound. The challenge here is no longer to identify a smaller subset that preserves performance, but to refine the data distribution toward instances most capable of improving the final model. To address this problem, we explore instance-level data attribution using Influence Functions (IF). We identify that standard IF formulations struggle in this setting due to two structural limitations: a proximity gap caused by off-policy validation targets, and a severe bias towards gradient norm. We propose DRIFT (Data Refinement via On-Policy Influence Functions for Supervised Fine-Tuning). Instead of relying on external reference data, DRIFT utilizes the model's on-policy rollouts as validation targets, which empirically minimizes the parameter proximity gap and better aligns with the local neighborhood assumption of IF. It further applies signed weighting based on trajectory correctness and debiases influence scores against the gradient hacking issue, allowing a small set of validation queries to act as reliable anchors for attributing the full dataset. Experiments on 7B-parameter instruction and reasoning models show that DRIFT consistently raises the performance ceiling on both, outperforming existing data curation baselines.
TRIDENT: ハイブリッド - 安全性 - 物理学の結合を打破して安全性を証明できるマルチエージェント強化学習を実現
ネットワーク化されたサイバー物理システムにおける安全な調整により、学習アルゴリズムは、ハイブリッドな離散連続アクション、トレーニング時の厳しい安全制約、および物理学に支配されたダイナミクスを同時に処理する必要があります。これら 3 つの特徴が、既製のモジュールの素朴な構成を打ち破るバイアスの有向サイクルを形成し、これを 3 方向結合補題として形式化することを示します。次に、各リークをキャンセルするために 3 つのコンポーネントが共同設計された最初の MARL フレームワークである TRIDENT を紹介します。その 3 つのコンポーネントは、Gumbel-Softmax バイアスを O(tau) から O(tau^2) に低減する Richardson-Romberg 勾配補正、反復ごとの実現可能性を強制する Lyapunov 制約付きの逐次信頼領域更新、および報酬ではなく価値を分解する物理学に基づいた残差批評です。制約付きナッシュ均衡への収束率が O~(1/sqrt(K)) であることと累積違反限界が O(sqrt(K)) であることを証明します。マルチ UAV モバイル エッジ コンピューティング、自律交差点管理、ハイブリッド SMAC バリアントにおいて、TRIDENT はトレーニング時間の違反を MADDPG と比較して 95.5%、MACPO と比較して 76.3% 削減し、最も強力な制約のないベースラインと比較して報酬を 13.5% 改善しました。
原文 (English)
TRIDENT: Breaking the Hybrid-Safety-Physics Coupling for Provably Safe Multi-Agent Reinforcement Learning
Safe coordination in networked cyber-physical systems forces learning algorithms to simultaneously handle hybrid discrete-continuous actions, hard training-time safety constraints, and physics-governed dynamics. We show that these three features form a directed cycle of biases that defeats any naive composition of off-the-shelf modules, and formalize this as a three-way coupling lemma. We then introduce TRIDENT, the first MARL framework whose three components are co-designed to cancel each leak: a Richardson-Romberg gradient correction reducing Gumbel-Softmax bias from O(tau) to O(tau^2), a Lyapunov-constrained sequential trust-region update enforcing per-iterate feasibility, and a physics-informed residual critic that decomposes value rather than reward. We prove an O~(1/sqrt(K)) convergence rate to a constrained Nash equilibrium and an O(sqrt(K)) cumulative-violation bound. On multi-UAV mobile-edge computing, autonomous intersection management, and a hybrid SMAC variant, TRIDENT cuts training-time violations by 95.5% over MADDPG and 76.3% over MACPO, while improving reward by 13.5% over the strongest unconstrained baseline.
SAGE: 最終的なアンラーニング ベクターの保持を意識した事後サニタイズ
大規模言語モデル (LLM) のアンラーニングは、保持された機能を維持しながら、望ましくない知識や動作を削除することを目的としています。現在の非学習方法はすべて、非学習と保持の間のトレードオフを伴います。私たちは、非学習プロセスの特定の実装を考慮することなく、保持活性化バイアスを使用して、非学習方法が保持に与えるダメージを定量化することもできることを発見しました。これにより、事後アプローチを使用して、あらゆる非学習方法の保持パフォーマンスを復元できるようになります。したがって、元の学習解除パイプラインを再実行せずに最終更新ベクトルをサニタイズするための補完的なポストホック設定を提案します。この設定では、SAGE (スペクトル アクティベーション - GEometry Sanitization)、つまり最終的な未学習更新のためのソースに依存しない修正を設計します。 SAGE は、小規模な保持プロキシから実際のモジュール入力を収集し、それらの主要な活性化ジオメトリを抽出し、閉じた形式でソースに固定された最適化目標を解決します。これにより、ソース メソッドの忘却キャリアを維持しながら、高エネルギーの保持方向に合わせた更新コンポーネントが抑制されます。 SAGE は、複数の非学習手法、モデル スケール、ベンチマークにわたって一貫して保持と忘れのトレードオフを軽減し、最終ベクトルの事後サニタイズが機械の非学習の実用的かつ未開発の軸であることを特定します。
原文 (English)
SAGE: Retain-Aware Post-Hoc Sanitization of Final Unlearning Vector
Large Language Model (LLM) unlearning aims to remove undesirable knowledge or behaviors while preserving retained capabilities. Current unlearning methods all involve a trade-off between unlearning and retention. We have found that the retention activation bias can also be used to quantify the damage an unlearning method inflicts on retention, without considering the specific implementation of the unlearning process. This allows us to restore retention performance for any unlearning method using a post-hoc approach. Therefore, we propose a complementary post-hoc setting to sanitize the final update vector without rerunning the original unlearning pipeline. In this setting, we design SAGE, Spectral Activation-GEometry Sanitization, a source-agnostic correction for final unlearning updates. SAGE collects real module inputs from a small retain proxy, extracts their dominant activation geometry, and solves a source-anchored optimization objective in closed form, which suppresses update components aligned with high-energy retained directions while preserving the source method's forgetting carrier. Across multiple unlearning methods, model scales, and benchmarks, SAGE consistently relieves the retain-forget trade-off, identifying post-hoc sanitization of final vectors as a practical and underexplored axis for machine unlearning.
LLM ベースの RAG システムに対するナレッジ インジェクション攻撃のための競合認識型レトリバー編集
悪意のある知識を検索拡張生成 (RAG) システムに注入すると、取得した証拠が操作され、下流の生成に誤解を与える可能性があり、AI アプリケーションにとって重大なセキュリティ上の脅威となる可能性があります。既存の RAG インジェクション攻撃は主に、悪意のあるコーパスの作成など、外部の知識ベースの操作に依存しています。ただし、このようなデータ中心の方法で作成された合成テキストは検出可能であり、攻撃の失敗につながる可能性があります。コーパスの操作を超えて、オープンソースのレトリバーは RAG システムをモデル中心の攻撃にさらすケースが増えています。この論文では、競合を意識したリトリーバー編集、つまり RAG における悪意のある知識注入のためのモデル中心のリトリーバー攻撃フレームワークである CAREATTACK を提案します。具体的には、CAREATTACK は、競合を認識するレトリーバー編集と攻撃を維持するアンカー修復の 2 つの段階で構成されます。競合を認識する取得者編集は、効率的な閉じた形式のパラメータ編集を密な検索モデルに適応させ、良性の競合するパッセージよりも悪意のある知識を促進し、グラフベースの競合検出とパラメータ編集プロジェクションを通じて潜在的なパラメータの競合を解決します。次に、攻撃保持アンカー修復により、編集されたリトリーバーに対して軽量キャリブレーションが実行され、ターゲット プロンプトに対する攻撃の有効性を維持しながら、非ターゲット プロンプトへの影響がさらに排除されます。 Qwen3-Embedding-0.6B と BGE-M3 上で CAREATTACK をインスタンス化し、3 つのベンチマーク データセットで評価を実施します。実験結果は、私たちの方法がRAGシステムの取得された知識への悪意のあるパッセージを大幅に促進し、検索モデルパラメータへのアクセスが与えられた場合、ターゲットプロンプトとパッセージのバッチに対して攻撃を実行できることを示しています。ほとんどの RAG システムはオープンソースの検索モデルに基づいて構築されているため、この研究により、RAG システムにおける実際的な攻撃対象領域が明らかになります。コードは https://anonymous.4open.science/r/Care Attack-3F1C で公開されています。
原文 (English)
Conflict-Aware Retriever Editing for Knowledge Injection Attacks on LLM-Based RAG Systems
Injecting malicious knowledge into retrieval-augmented generation (RAG) systems can manipulate retrieved evidence and mislead downstream generation, posing a serious security threat for AI applications. Existing RAG injection attacks mainly rely on manipulating external knowledge bases, such as crafting malicious corpus. However, the synthetic text crafted by such data-centric methods could be detectable, leading to the failure of attacks. Beyond corpus manipulation, open-source retrievers are increasingly exposing RAG systems to model-centric attacks. In this paper, we propose conflict-aware retriever editing, i.e., CAREATTACK, a model-centric retriever attack framework for malicious knowledge injection in RAG. Specifically, CAREATTACK consists two stages of conflict-aware retriever editing and attack-preserving anchor repair. Conflict-aware retriever editing adapts efficient closed-form parameter editing to the dense retrieval model, promoting malicious knowledge above benign competing passages and resolving potential parameter conflicts through graph-based conflict detection and parameter editing projection. Then, attack-preserving anchor repair performs lightweight calibration on the edited retriever to further eliminate the impact on non-target prompts while preserving the attack effectiveness for target prompts. We instantiate CAREATTACK on Qwen3-Embedding-0.6B and BGE-M3, and conduct evaluation on three benchmark datasets. Experimental results demonstrate our method substantially promote malicious passages into the retrieved knowledge of RAG systems and can perform attacks for batches of target prompts and passages, given the access of retrieval model parameters. Since most RAG systems are built upon open-source retrieval models, this work reveals a practical attack surface in RAG systems. Codes are public accessible at https://anonymous.4open.science/r/CareAttack-3F1C.
ゴースト アトラクタ ネットワーク: 閉ループ逐次生成のための盆地構造の動的デコーダ
大規模な Transformer および拡散デコーダを使用したシーケンシャル出力生成では、シーケンスの長さに応じて増大するメモリ コストに加え、ステップごとの反復計算が必要になります。それらを小型のフィードフォワード デコーダに置き換えると効率は回復しますが、構造化されていない潜在表現が生成され、閉ループ制御が制限されます。位相条件付きアクションの生成とクロスステップ潜在キャリーオーバーの両方には、安定した盆地を備えた潜在ジオメトリが必要です。この記事では、理論的に導出された動的デコーダであるゴースト アトラクタ ネットワークを提案します。このネットワークは、ドリフトを伴う学習されたポテンシャルの下で潜在的に進化し、構築によって盆地アトラクタ構造を生成します。 3 つの要望 (マルチモダリティ、デコーダ レベルのシングルパス スイッチング、および一定のメモリ) が潜在的なドリフト形式を動機付け、モード遷移はゴースト アトラクターの脱出を伴うサドルノード分岐として発生します。階層的な位相空間分解により、一次盆地収束と二次固有受容洗練が分離されます。経験的に、行動クローニングと対照的な目的を使用してエンドツーエンドでトレーニングされた Ghost は、潜在的に予測された勾配フロー収縮を示し、1,430 個のホールドアウト サンプルの 5 つの統合ステップにわたって勾配ノルムが 67% 減衰します。 Ghost はロボットアクションデコーダーとして評価されています。 230 万パラメータの Ghost は、462 分の 1 のパラメータと 32 分の 1 低いレイテンシで 10 億 7000 万パラメータの拡散トランスフォーマのオフライン精度に匹敵し、オフライン平均二乗誤差で 5 つの代替 2M パラメータ デコーダ (MLP、ニューラル ODE、CVAE、トランスフォーマ、1 ステップ拡散) を 5.9 ~ 29 パーセント上回ります。 LIBERO-10 閉ループ ベンチマークでは、Ghost の盆地構造潜在の位相調整により、フィードフォワード MLP ベースラインよりも 13.5 パーセント ポイントの成功率向上が得られ、永続的潜在アンサンブルの最終成功率は 95.7 パーセントに達します。
原文 (English)
Ghost Attractor Networks: Basin-Structured Dynamical Decoders for Closed-Loop Sequential Generation
Sequential output generation with large-scale Transformer and diffusion decoders pays a memory cost that grows with sequence length, plus iterative per-step computation. Replacing them with small feed-forward decoders restores efficiency but produces unstructured latent representations that limit closed-loop control: phase-conditioned action generation and cross-step latent carry-over both require a latent geometry with stable basins. This article proposes Ghost Attractor Networks, a theoretically derived dynamical decoder whose latent evolves under a learned potential with drift and produces a basin-attractor structure by construction. Three desiderata (multi-modality, decoder-level single-pass switching, and constant memory) motivate the potential-drift form, and mode transitions arise as saddle-node bifurcations with ghost-attractor escape. A hierarchical phase-space decomposition separates first-order basin convergence from second-order proprioceptive refinement. Empirically, a Ghost trained end-to-end with a behavioral-cloning and contrastive objective exhibits the predicted gradient-flow contraction in its potential, with the gradient norm decaying by 67 percent across five integration steps on 1430 held-out samples. Ghost is evaluated as a robotic action decoder. A 2.3-million-parameter Ghost matches the offline accuracy of a 1.07-billion-parameter Diffusion Transformer at 462 times fewer parameters and 32 times lower latency, and beats five alternative 2M-parameter decoders (MLP, Neural ODE, CVAE, Transformer, 1-step Diffusion) on offline mean squared error by 5.9 to 29 percent. On the LIBERO-10 closed-loop benchmark, phase conditioning on Ghost's basin-structured latent yields a 13.5 percentage-point success-rate gain over a feed-forward MLP baseline, and persistent-latent ensembling reaches a 95.7 percent final success rate.
ASTRA: 自律型シンパイロットを備えたスケーラブルな次世代 ATCO トレーニング シミュレーター
航空交通管制官 (ATCO) は、安全で秩序ある効率的な航空交通の流れを確保するために不可欠ですが、シミュレートされた空域でパイロットと ATCO の両方をロールプレイしなければならないシンパイロットと呼ばれる専門の人間トレーナーに依存することで訓練能力が制限されています。既存の自動化ソリューションは西洋中心の音声モデルに依存していますが、シンガポールの運用環境ではパフォーマンスが低く、既製のシステムではシンガポール訛りの航空音声で最大 107.80% の単語誤り率 (WER) を示します。 ASTRA は、ATCO 音声を書き起こし、指示を解釈し、ローカルに適応した音声モデルを使用して適切なパイロットと ATCO 応答を生成するパイプラインを通じて、これらのシンパイロットの役割を自動化するエンドツーエンドのトレーニング シミュレーターです。当社の微調整された自動音声認識 (ASR) パイプラインは WER を 23.45% に削減し、この分野の既存のアプローチを大幅に上回ります。 ASTRA には、トラフィック シミュレーションだけでなく、AI 支援によるパフォーマンス評価フレームワークが組み込まれており、訓練生の無線電話通信の精度、簡潔さ、完全性を評価し、それぞれ 91.7%、88.2%、86.9% の最適化後スコアを達成しています。 DSPy や Unsloth などのオープンソース基盤上に構築されたこのアプローチは、インストラクターの作業負荷を軽減しながら、スケーラブルで標準化された ATCO 評価を可能にします。
原文 (English)
ASTRA: A Scalable Next-Generation ATCO Training Simulator with Autonomous Simpilots
Air Traffic Control Operators (ATCOs) are vital in ensuring the safe, orderly, and efficient flow of air traffic, yet training capacity is constrained by reliance on specialized human trainers known as simpilots, who must role-play both pilots and ATCOs in a simulated airspace. Existing automated solutions rely on Western-centric speech models that perform poorly in Singaporean operational contexts, with off-the-shelf systems exhibiting Word Error Rates (WER) of up to 107.80% on Singaporean-accented aviation speech. We introduce ASTRA, an end-to-end training simulator that automates these simpilot roles through a pipeline that transcribes ATCO speech, interprets instructions, and generates appropriate pilot and ATCO responses using locally adapted voice models. Our fine-tuned Automatic Speech Recognition (ASR) pipeline reduces WER to 23.45%, substantially outperforming existing approaches in this domain. Beyond traffic simulation, ASTRA incorporates an AI-assisted performance evaluation framework that assesses trainee radiotelephony communications across accuracy, brevity, and completeness, achieving post-optimization scores of 91.7%, 88.2%, and 86.9%, respectively. Built on open-source foundations such as DSPy and Unsloth, this approach enables scalable, standardized ATCO assessment while reducing instructor workload.
SAE介入は信頼できない:介入後の抑圧された行動の回復
スパース オートエンコーダ (SAE) は、残差ストリームのアクティベーションを解釈可能な特徴に分解します。最近の潜在空間防御は、特定された「安全でない」SAE 特徴が監視と介入のための実用的なハンドルとして機能すると仮定して、これらの分解にますます依存しています。このパラダイムでは、特定の有害な特徴をクランプすることで、モデルの誤動作を確実に防止できることが期待されます。ただし、この成功には回復可能な失敗モードが隠されている可能性があることを示します。クランプは、動作自体を排除することなく、動作への目に見える 1 つのルートをブロックする可能性があります。私たちはこの脆弱性を介入後の回復、つまり制約付き残差空間最適化問題として定式化します。介入後の残留状態から開始して、残留摂動を最適化して、対象となる SAE 特徴の介入後の値を維持しながら介入前の挙動を回復します。最適化と生成を通じて介入がアクティブなままである強力な脅威モデルの下でも、回復は可能です。回復が単に介入を元に戻すだけであることを排除するために、単一レイヤー介入にはエンコーダー直交更新を使用し、クロスレイヤー設定では対応する特徴マップ ヤコビアンを使用します。 TPP、アンラーニング、IOI、および拒否ステアリングの実験全体にわたって、このストレス テストでは、機能レベルの介入が成功したにもかかわらず、回復可能な動作が明らかになりました。特に安全性が重要な拒否ステアリング設定では、防御された特徴量の相対ドリフトを 0.131 に維持しながら、有効なサンプルで 95.8% の回収率を達成し、サフィックスベースのベースラインを大幅に下回りました。回復パスの帰属分析により、この回復が SAE 再構成残差、つまり SAE によって説明されずに残された成分にさらに局在化されます。これらの結果は、機能レベルの制御と動作の完全性の間のギャップを明らかにしています。SAE 機能は因果関係の介入をサポートできますが、それらを制御しても、根底にある動作の制御は保証されません。
原文 (English)
SAE Interventions are Unreliable: Post-Intervention Recovery of Suppressed Behavior
Sparse Autoencoders (SAEs) decompose residual-stream activations into interpretable features. Recent latent-space defenses increasingly rely on these decompositions, assuming that identified "unsafe" SAE features serve as actionable handles for monitoring and intervention. In this paradigm, clamping a specific harmful feature is expected to reliably prevent model misbehavior. However, we show that this success may hide a recoverable failure mode: the clamp may block one visible route to a behavior without eliminating the behavior itself. We formulate this vulnerability as post-intervention recovery, a constrained residual-space optimization problem. Starting from the post-intervention residual state, we optimize residual perturbations to recover the pre-intervention behavior while preserving the post-intervention values of the targeted SAE features. Even under a strong threat model where the intervention remains active throughout optimization and generation, recovery remains possible. To rule out that recovery simply undoes the intervention, we use encoder-orthogonal updates for single-layer interventions and the corresponding feature-map Jacobian in the cross-layer setting. Across TPP, unlearning, IOI, and refusal steering experiments, this stress test reveals recoverable behavior despite successful feature-level intervention. Especially in the safety-critical refusal-steering setting, we achieve a 95.8% recovery rate on valid samples while keeping defended-feature relative drift to 0.131, substantially below suffix-based baselines. A recovery-path attribution analysis further localizes this recovery to the SAE reconstruction residual, the component left unexplained by the SAE. These results expose a gap between feature-level control and behavioral completeness: SAE features can support causal intervention, but controlling them does not guarantee control over the underlying behavior.
SWAVE が必要なすべてではない理由:複雑な値の再帰型言語モデルに関する概念進化の回顧
SWave は、2xH100 NVL を使用して FineWeb-Edu でトレーニングされた複素数値再帰言語モデル (169.26M パラメーター、D=384、L=16、T=2048) です。それは 3 つの基礎的な前提を中心に設計されました。言語を実数値ではなく複雑な波として表現することで、より豊富な情報のエンコードが可能になります。 Cayleyパラメータ化されたユニタリ遷移は、状態の減衰または爆発に対する数学的保証を提供します。そして、縮小ではなく回転する隠れた状態は、任意の長さのコンテキストにわたって信号の完全性を維持します。 SWave のコアは、3 つの開発フェーズにわたって大幅に進化しました。共鳴ヘッドは、構造的に全体的な損失最小値として虚数チャネル崩壊 (コスドミネーション崩壊と呼ばれる故障モード) を許容することが判明し、位相連想メモリ (PAM) アーキテクチャからの独立した実数と虚数の埋め込みテーブルを備えたアンタイド ヘッドに置き換えられました。これにより、縮退最小値が解決され、安定した 200,000 ステップのトレーニングが可能になりました (ステップ 89,861 での最良ステップ PPL 22.0)。 ComplexNorm と Wave Propagation Scan は、3 つのフェーズすべてを通じて耐荷重性を証明し、最終アーキテクチャまで維持されました。 ProtectGatedScan は、学習された動作ではなく、構造的な事前動作として再構成されました。 4 つのマルチスケール保持コンセプトは、管理された評価の下では測定可能な改善を示さず、耐荷重性がないことが判明しました。 ComplexGatedUnit は、パラメーターが少ない実数値二乗 ReLU チャネル ミキサーに置き換えられました。構造的な制約が解決されると、補助的なトレーニング目標は何の効果も示さなくなりました。この調査により、コスドミネーション崩壊の正式な特徴付け、数値的安定性のための対数空間逆方向パスを使用した並列スキャン、複素数値のリカレントトレーニングのための 6 つの移植可能なエンジニアリング原則、および従来のテストスイートでは見逃していた構造の相違を捕捉するための計画からコードへのトレーサビリティ方法論が得られました。
原文 (English)
Why SWAVE May Not Be All You Need:A Concept-Evolution Retrospective on Complex-Valued Recurrent Language Models
SWave is a complex-valued recurrent language model (169.26M parameters, D=384, L=16, T=2048) trained on FineWeb-Edu using 2xH100 NVL. It was designed around three founding premises: that representing language as complex waves rather than real-valued numbers enables richer information encoding; that a Cayley-parameterised unitary transition provides a mathematical guarantee against state decay or explosion; and that a hidden state which rotates rather than shrinks preserves signal integrity over arbitrarily long contexts. The core of SWave evolved substantially across three development phases. The Resonance Head was found to structurally admit imaginary-channel collapse as a global loss minimum (a failure mode we term cos-domination collapse) and was superseded by an untied head with independent real and imaginary embedding tables from the Phase-Associative Memory (PAM) architecture. This resolved the degenerate minimum and enabled stable 200,000-step training (best-step PPL 22.0 at step 89,861). ComplexNorm and the Wave Propagation Scan proved load-bearing throughout all three phases and were retained to the final architecture. ProtectGatedScan was reframed as a structural prior rather than a learned behaviour. The four multi-scale retention concepts showed no measurable improvement under controlled evaluation and were found non-load-bearing. The ComplexGatedUnit was superseded by a real-valued squared-ReLU channel mixer with fewer parameters. The auxiliary training objectives showed no benefit once structural constraints were resolved. The investigation yields a formal characterisation of cos-domination collapse, a parallel scan with a log-space backward pass for numerical stability, six transferable engineering principles for complex-valued recurrent training, and a plan-to-code traceability methodology for catching structural divergences that conventional test suites miss.
Agentra: エンタープライズ侵入対応のための監視可能なマルチエージェント フレームワーク
企業の侵入対応は依然として静的なプレイブックとアナリスト主導のトリアージに依存しており、アラートの生成と封じ込めの間に遅延が生じています。 Agentra は、IDS、EDR、および XDR プラットフォームからのアラートを、MITRE ATT&CK、MITRE D3FEND、および NIST CSF 2.0 に基づいた構造化されたインシデント対応計画に変換する、監視可能なマルチエージェント侵入対応システム (IRS) フレームワークです。 Agentra は、ロールスコープのエージェント全体での応答推論を分解し、境界のある Planner-Validator レビュー ループを通じて提案された計画を検証し、Moderator セキュリティ ゲートウェイを通じて取得した脅威インテリジェンスをスクリーニングし、アクション カタログとリスク スコアを通じてアクションをゲートし、追加専用の監査ログに決定を記録します。私たちは、ThreatHunter-Playbook、Splunk BOTSv3、および DARPA OpTC から抽出された 120 のイベント コーパスに基づく静的な OASIS CACAO v2.0 サイバー プレイブック ベースラインに対して Agentra を評価します。最も強力な構成では、FP 認識 IRS F1 が 0.61 から 0.84 に改善され、Planner のみの構成で危険な過剰反応が導入された後、予測される有害なアクションの割合が静的なベースライン レベルの 0.0% に戻ります。これらの結果は、複数エージェントの対応計画により、アナリストの承認と監査可能性を維持しながら、オントロジーに基づいた IRS カバレッジを向上できることを示しています。
原文 (English)
Agentra: A Supervisable Multi-Agent Framework for Enterprise Intrusion Response
Enterprise intrusion response still depends on static playbooks and analyst-driven triage, creating delay between alert generation and containment. We present Agentra, a supervisable multi-agent Intrusion Response System (IRS) framework that converts alerts from IDS, EDR, and XDR platforms into structured incident response plans grounded in MITRE ATT&CK, MITRE D3FEND, and NIST CSF 2.0. Agentra decomposes response reasoning across role-scoped agents, validates proposed plans through a bounded Planner--Validator review loop, screens retrieved threat intelligence through a Moderator security gateway, gates actions through an Action Catalog and risk score, and records decisions in an append-only audit log. We evaluate Agentra against a static OASIS CACAO v2.0 cyber-playbook baseline on a 120-event corpus drawn from ThreatHunter-Playbook, Splunk BOTSv3, and DARPA OpTC. The strongest configuration improves FP-aware IRS F1 from 0.61 to 0.84 and restores the projected harmful-action rate to the static baseline level of 0.0% after Planner-only configurations introduce unsafe overreaction. These results indicate that multi-agent response planning can improve ontology-grounded IRS coverage while preserving analyst approval and auditability.
Self-CTRL: 強化学習による自己一貫性トレーニング
言語モデル (LM) 自体の動作を忠実に記述すると、ユーザーはより簡単に監査、理解、信頼することができます。この論文では、強化学習による自己一貫性トレーニング (Self-CTRL) について説明します。これは、動作をより適切に予測するために説明を更新したり、説明とよりよく一致するように動作を更新したりすることで、LM の自己説明と関連する入力に対する動作の間の一貫性を最適化する方法です。私たちはこの方法を 2 つの領域に適用します。まず、形式的な確率論的推論タスクを研究します。このタスクでは、LM はバイアスのあるサンプラーのファミリーを模倣することを学習し、関連するバイアスを報告する能力を評価する必要があります。一貫性トレーニングにより、一連の保持分布上で自己報告された潜在バイアスと行動測定された潜在バイアスの間の相関関係が $R^2=0.24$ から $R^2=0.64$ に改善され、直接グラウンドトゥルース監視の一般化と一致することがわかりました。 2 番目に、LM がユーザーの要求をいつ拒否するか、または従うかを記述しなければならない憲法上の AI ドメインを研究します。ここで、Self-CTRL は保留されたリクエストに対するモデルの動作を忠実に記述するルールを生成し、サードパーティ監査人モデルの拒否予測を $36\%$ から $92\%$ に改善します。逆に、動作の更新により整合性が向上し、無害なプロンプトに対する拒否を大幅に増やすことなく、HarmBench の失敗率が $15.0\%$ から $0.5\%$ に減少します。私たちの研究は、説明と動作を調整することにより、AI モデルをより安全で、より透明で、より制御しやすくトレーニングするための一般的なレシピを提供します。
原文 (English)
Self-CTRL: Self-Consistency Training with Reinforcement Learning
Language models (LMs) that faithfully describe their own behavior can more easily be audited, understood, and trusted by users. This paper describes Self-Consistency Training with Reinforcement Learning (Self-CTRL), a method that optimizes for consistency between a LM's self-explanations and behavior on related inputs by updating explanations to better predict behavior or updating behavior to better match explanations. We apply our method in two domains. First, we study a formal probabilistic reasoning task in which LMs must learn to imitate a family of biased samplers and evaluated on their ability to report the associated biases. We find that consistency training improves the correlation between self-reported and behaviorally-measured latent biases from $R^2=0.24$ to $R^2=0.64$ on a set of held-out distributions, matching the generalization of direct ground-truth supervision. Second, we study a constitutional AI domain in which LMs must describe when they will refuse or comply with user requests. Here, Self-CTRL produces rules that faithfully describe the model's behavior on held-out requests, improving the refusal predictions of a third-party auditor model from $36\%$ to $92\%$. In the other direction, behavior updates improve alignment, reducing HarmBench failure rate from $15.0\%$ to $0.5\%$ without substantially increasing refusal on harmless prompts. By aligning explanations and behavior, our work provides a general recipe for training AI models to be safer, more transparent, and more controllable.
SafeClawBench: ツールを使用する LLM エージェントにおけるセマンティック、監査証拠、およびサンドボックスの危害を分離する
ツールを使用する言語モデル エージェントは、安全でないテキストにとどまらないセキュリティ障害を引き起こします。保護されたオブジェクトの開示、永続メモリへの書き込み、メッセージの送信、データベースの変更、有害なコードやツールの影響のトリガーなどを行う可能性があります。既存の評価では、これらの段階が 1 つの攻撃成功率にまとめられることが多く、そのモデルが単に攻撃者に同意しただけなのか、それとも実際に観察可能な被害をもたらしたのかを判断することが困難になっています。 SafeClawBench は、6 つの攻撃ファミリー (直接および間接のプロンプト インジェクション、ツールリターン インジェクション、メモリ ポイズニング、メモリ抽出、曖昧さ主導の安全でない推論) にわたる 600 の制御された敵対的タスクを備えた、ツールを使用したエージェント セキュリティの段階的ベンチマークです。 SafeClawBench は、セマンティック攻撃の受け入れ、監査で目に見える被害の証拠、サンドボックスで観察されたツール/状態の被害という 3 つの個別のエンドポイントを報告します。 4 つのプロンプト レベル ポリシーの下で 5 つのエージェント エンドポイントを評価すると、これらのエンドポイントが異なる障害モードをキャプチャしていることがわかります。追加のプロンプト保護がないと、セマンティック失敗率はモデルによって 9.0% から 44.2% まで大きく異なります。監査された危害の証拠はセマンティック エラーよりも狭く、別の実行可能プロトコルの下では、セマンティック コア呼び出しに合格したにもかかわらず、一部の一致したタスク ID がサンドボックスの危害を引き起こします。12,000 行の一致分析では、観察された 347 のサンドボックスの危害のうち 291 がセマンティック チェックに合格した行で発生しています。プロンプト ポリシーはエンドポイントの結果を変更しますが、その効果はモデルとプロトコルの両方に依存します。 SafeClawBench は、テキストの準拠性、証拠に裏付けられた危害、および実行可能な状態の変更を混同することなく、エージェント モデルとプロンプト ポリシーの条件を比較するための再現可能なフレームワークを提供します。オープンソース データセットは、https://huggingface.co/datasets/sairights/safeclawbench で入手できます。
原文 (English)
SafeClawBench: Separating Semantic, Audit-Evidence, and Sandbox Harm in Tool-Using LLM Agents
Tool-using language-model agents introduce security failures that go beyond unsafe text: they can disclose protected objects, write persistent memory, send messages, modify databases, or trigger harmful code and tool effects. Existing evaluations often collapse these stages into a single attack success rate, making it difficult to tell whether a model merely agreed with an attacker or actually produced observable harm. We introduce SafeClawBench, a staged benchmark for tool-using agent security with 600 controlled adversarial tasks across six attack families: direct and indirect prompt injection, tool-return injection, memory poisoning, memory extraction, and ambiguity-driven unsafe inference. SafeClawBench reports three separate endpoints: semantic attack acceptance, audit-visible harm evidence, and sandbox-observed tool/state harm. Evaluating five agent endpoints under four prompt-level policies, we find that these endpoints capture different failure modes. Without additional prompt protection, semantic failure rates vary widely across models, from 9.0% to 44.2%. Audited harm evidence is narrower than semantic failure, and under a separate executable protocol some matched task identities produce sandbox harm despite passing the Semantic Core call: in a 12,000-row matched analysis, 291 of 347 observed sandbox harms occur in rows that pass the semantic check. Prompt policies change endpoint outcomes, but their effects depend on both model and protocol. SafeClawBench provides a reproducible framework for comparing agent models and prompt-policy conditions without conflating textual compliance, evidence-supported harm, and executable state changes. The open-source dataset is available at https://huggingface.co/datasets/sairights/safeclawbench.
Guava: 身体的操作のための効果的かつ万能なハーネス
大規模な視覚言語データに基づいてトレーニングされた言語モデルは、身体化されたエージェントにとって強力な可能性を示しています。具現化されたツールを使用してモデルを利用することは、高レベルの推論と認識、計画、および制御のための外部モジュールを組み合わせることで、エンドツーエンドのビジョン-言語-アクション システムに代わる有望な代替手段を提供します。しかし、何が身体的操作のための効果的なハーネスを構成するのか、そしてそのようなハーネスが広範囲の推論モデルにおいて身体的能力をどの程度解放できるのかは依然として不明である。この研究では、エージェント ワークフロー、アクション スペース、および観察スペースの設計スペースの体系的な調査を通じて開発された、具現化されたツールの使用のためのハーネス フレームワークである Guava を紹介します。私たちの研究では、効果的な身体化エージェントのための 3 つの重要な要素、つまり、反復的な知覚-推論-行動ループ、意味論的行動の抽象化、およびマルチモーダル観察を特定しています。これらの設計原則が小規模なモデルにも普遍的であるかどうかを理解するために、シミュレーションで完全に収集された 2K 未満の軌跡を使用して、具体化された操作機能を 4B オープンソース モデルに抽出するエンドツーエンドのトレーニング パイプラインを開発します。シミュレーション環境と現実世界の両方の環境での実験結果は、フロンティア独自のモデルに匹敵するパフォーマンスを示しながら、目に見えないオブジェクト、新しい命令、および長期的なタスクに対する強力な一般化を示しています。結果は、適切に設計されたハーネスが、体現された操作のためのスケーラブルでモデルに依存しないインターフェイスとして機能し、最小限のトレーニング データでコンパクトなオープンソース モデルで強力な創発的な具現化機能を可能にすることを示唆しています。
原文 (English)
Guava: An Effective and Universal Harness for Embodied Manipulation
Language models trained on large-scale vision-language data have demonstrated strong potential for embodied agents. Harnessing models through embodied tools use offers a promising alternative to end-to-end vision-language-action systems by combining high-level reasoning with external modules for perception, planning, and control. However, it remains unclear what makes an effective harness for embodied manipulation, and to what extent such a harness can unlock embodied capabilities in a wide range of reasoning models. In this work, we present Guava, a harness framework for embodied tool use developed through systematic exploration of the design space of agent workflows, action spaces, and observation spaces. Our study identifies three key ingredients for effective embodied agents: iterative perception-reasoning-action loops, semantic action abstractions, and multimodal observations. To understand whether these design principles are universal even to small models, we develop an end-to-end training pipeline that distills embodied manipulation capabilities into a 4B open-source model using fewer than 2K trajectories collected entirely in simulation. Experimental results in both simulation and real-world environments show performance comparable to frontier proprietary models while exhibiting strong generalization to unseen objects, novel instructions, and long-horizon tasks. Results suggest that a well-designed harness can serve as a scalable, model-agnostic interface for embodied manipulation, enabling strong emergent embodied capabilities in compact open-source models with minimal training data.
編集するか保持するか?教育対話の匿名化のための完全にローカルな AI カスケード
教育対話は研究にとって貴重ではありますが、機密性の高いリソースです。本物の学習を記録したものと同じ記録には、多くの場合、カリキュラムの内容に絡み合った個人識別情報 (PII) が記録されており、「リーマン」とは実際の生徒や数学的概念を指す場合があります。既存のアプローチでは、ガバナンスと精度の間でトレードオフを強いられます。 Commercial Large Language Model (LLM) はこの曖昧さを処理できますが、学生データを第三者に送信する必要があります。一方、ローカルの固有表現認識 (NER) システムはガバナンスを維持しますが、カリキュラム用語を過剰に編集します。私たちは、匿名化を無制限のエンティティ認識から制約のあるプライバシーのトリアージに再構成する、完全にローカルなカスケード フレームワークを提案します。リコールファーストユニオンプロポーザーは、2 つの軽量エンコーダーを決定論的ルールと組み合わせて、候補スパンを過剰に生成します。次に、コンテキストを認識した審査員が、周囲の対話と発言者の役割を使用して、各候補者に対して二値の編集/保持の決定を下します。私たちは、同じファミリーの LLM のみのベースラインと、2 つの大きなプラットフォームからの数学の個別指導トランスクリプトの商用 API に対して 3 つのレビューア構成を評価しました。最も強力なローカル構成は、完全に 1 台のラップトップで実行している場合、マクロ F1 が 0.958 に達します。これに対し、同じファミリの LLM のみのベースラインでは 0.767、商用 API では 0.706 です。カリキュラムと個人名のあいまいさの対象を絞った課題セットでは、同じ構成では F1 が 0.03 しか低下しなかったのに対し、小規模な査読者では 0.19 ~ 0.25 低下しました。これらの結果は、教育の匿名化では、モデルの規模よりも問題の定式化が重要であることを示唆しています。
原文 (English)
Redact or Keep? A Fully Local AI Cascade for Educational Dialogue De-Identification
Educational dialogue is a valuable but sensitive resource for research: the same transcripts that capture authentic learning often capture personally identifiable information (PII) entangled with curricular content, where "Riemann" may refer to a real student or to a mathematical concept. Existing approaches force a tradeoff between governance and accuracy. Commercial Large Language Models (LLMs) can handle this ambiguity but require sending student data to third parties, while local named entity recognition (NER) systems preserve governance but over-redact curricular terms. We propose a fully local cascade framework that reframes de-identification from open-ended entity recognition to constrained privacy triage. A recall-first union proposer combines two lightweight encoders with deterministic rules to over-generate candidate spans; a context-aware reviewer then makes a binary Redact/Keep decision for each candidate using surrounding dialogue and speaker role. We evaluate three reviewer configurations against same-family LLM-only baselines and a commercial API on math tutoring transcripts from two large platforms. The strongest local configuration reaches 0.958 macro F1, compared with 0.767 for a same-family LLM-only baseline and 0.706 for the commercial API, while running entirely on a single laptop. On a targeted challenge set of curricular-personal name ambiguity, the same configuration degrades by only 0.03 F1 versus 0.19 to 0.25 for smaller reviewers. These results suggest that for educational de-identification, problem formulation matters more than model scale.
RankGraph-2: 推奨事項における 10 億ノードのグラフ学習のためのライフサイクル協調設計
10億ノード規模のグラフベースの検索には、グラフ構築、表現学習、リアルタイム処理という3つの密結合した問題を共同で解決する必要があるが、既存の作業はそれぞれを個別に解決している。我々は、Meta に導入されたフレームワークである RankGraph-2 を紹介します。これは、類似性に基づく検索 (U2U2I および U2I2I) の 3 つのライフサイクル ステージすべてを共同設計し、各ステージの要件が他のステージの要件を形成します。サービスを提供するには、高価なオンライン KNN を回避するために共学習されたクラスター インデックスが必要です。これにより、インデックスの共トレーニングがトレーニング目標に組み込まれます。トレーニングでは、類似性に基づく検索が事前計算された近傍を許容し、オンライン グラフ インフラストラクチャが不要になるという観察から恩恵を受けます。これには、自己完結型データを生成するための構築が必要です。構築では、項目範囲の時間レベルの更新もサポートする必要があります。これらのカスケード要件に基づいて、RankGraph-2 は、人気バイアス補正を備えたサブサンプリングによって数百兆のエッジを数千億に削減し、パーソナライズされた PageRank によってマルチホップ近傍を事前計算し、サービスの計算コストを 83% 削減する残差量子化クラスター インデックスを共同学習します。このライフサイクルの共同設計により、シンプルなアーキテクチャで、二部グラフでは GAT + Deep Graph Infomax モデルよりも 3.8 倍高い再現率、項目検索では PyTorch-BigGraph よりも 2.1 倍高い再現率を達成できます。 RankGraph-2 は最大 +0.96% の CTR と +2.75% の CVR を実現し、主要なサーフェス全体で 20 回以上の検索起動を実現しました。
原文 (English)
RankGraph-2: Lifecycle Co-Design for Billion-Node Graph Learning in Recommendation
Graph-based retrieval at billion-node scale requires jointly solving three tightly coupled problems -- graph construction, representation learning, and real-time serving -- yet existing work addresses each in isolation. We present RankGraph-2, a framework deployed at Meta that co-designs all three lifecycle stages for similarity-based retrieval (U2U2I and U2I2I), where each stage's requirements shape the others. Serving requires a co-learned cluster index to avoid expensive online KNN -- this pushes index co-training into the training objective. Training benefits from the observation that similarity-based retrieval tolerates pre-computed neighborhoods, eliminating online graph infrastructure -- this requires construction to produce self-contained data. Construction must also support hour-level refresh for item coverage. Acting on these cascading requirements, RankGraph-2 reduces hundreds of trillions of edges to hundreds of billions via subsampling with popularity bias correction, pre-computes multi-hop neighborhoods via personalized PageRank, and co-learns a residual-quantization cluster index that reduces serving computational cost by 83%. This lifecycle co-design enables a simple architecture to achieve 3.8 x higher recall than a GAT + Deep Graph Infomax model on a bipartite graph and 2.1 x higher than PyTorch-BigGraph on item retrieval. RankGraph-2 delivers up to +0.96% CTR and +2.75% CVR, and has powered 20+ retrieval launches across major surfaces.
LLMZero: LLM エージェントを介した RL ポストトレーニングのための適応トレーニング戦略の発見
RL トレーニング後の戦略はデータセットに依存しており、繰り返し発生する経験的パターンを明らかにします。容量パラメーターはステージ全体で単調に蓄積しますが、正則化パラメーターはトレーニング ダイナミクスの変化に応じて主に変動します。固定スケジュールではすべてのパラメータが固定軌道にコミットされるため、正則化で追跡する必要がある非定常の探索と活用のトレードオフを表現できないため、この区別は重要です。この原理は、多段階トレーニングのための実用的な設計ルールを提供します。私たちは LLMZero を通じてこれを発見しました。このシステムは、LLM エージェントがツリー検索を通じてトレーニング軌跡を検索し、各チェックポイントで病状を診断し、調整された複数パラメータの移行を提案します。 LLMZero は、4 つの多様な GRPO タスクにわたって、ベース モデルに対して相対的に 9% ~ 140%、グリッド検索に対して相対的に 6% ~ 15% 向上する戦略を発見し、ランダム検索やスキルベースのエージェントよりも一貫して優れたパフォーマンスを発揮します。構造原理はタスク間で伝達され、発見された戦略が質的に異なる形式をとりながらも同様のパラメーター ダイナミクスを共有する理由の説明を提供します。
原文 (English)
LLMZero: Discovering Adaptive Training Strategies for RL Post-Training via LLM Agents
RL post-training strategies are dataset-dependent and reveal a recurring empirical pattern: capacity parameters accumulate monotonically across stages, while regularization parameters predominantly oscillate in response to shifting training dynamics. This distinction matters because fixed schedules commit all parameters to fixed trajectories and therefore cannot express the non-stationary exploration-exploitation tradeoffs that regularization must track; the principle provides actionable design rules for multi-stage training. We discover this through LLMZero, a system where LLM agents search over training trajectories via tree search, diagnosing pathologies at each checkpoint and proposing coordinated multi-parameter transitions. Across 4 diverse GRPO tasks, LLMZero discovers strategies that improve over the base model by 9% to 140% relative and over grid search by 6% to 15% relative, consistently outperforming random search and the skill-based agent. The structural principle transfers across tasks, providing an explanation for why discovered strategies take qualitatively different forms yet share similar parameter dynamics.
潜在燃料反応度推定による多燃料 CI エンジンの燃焼位相制御のための学習ベースの意思決定
多燃料圧縮着火エンジンは、燃料の柔軟性を提供しますが、セタン価 (CN) で表される不確実で時間とともに変化する燃料反応性を導入し、サイクル間の燃焼位相制御を複雑にします。この研究では、潜在的な CN 変動の下での CA50 制御を部分的に観察可能な逐次決定問題として定式化し、LinUCB、履歴拡張コンテキスト バンディット、観察のみの DDPG、リカレント DDPG、および提案されている GRU 誘導 RL フレームワークを含む、時間的および表現的能力が増加するコントローラーを体系的に評価します。実験的な多燃料エンジン データに基づいてトレーニングされたガウス プロセス サロゲートは、制御された再現可能な評価環境を提供します。結果は、近視的および固定履歴バンディット法はCN変動の下で劣化し、観察のみのRLは潜在状態のエイリアシングに悩まされ、CNが急速に進化する場合には一般的な再発が不十分であることを示しています。提案されたフレームワークは、燃焼履歴から燃料反応性のコンパクトな GRU ベースの表現を学習し、オラクル CN ではなくこの推定信号に基づいて行為者と批評家の両方を条件付けします。コントローラは、展開時に利用可能な同じ不完全な燃料反応性情報に基づいてポリシーをトレーニングすることにより、従来のオンライン推定→制御パイプラインにおけるトレーニングと展開の不一致を回避します。このポリシーは、目に見えない CN 軌道全体にわたって、トレーニング設定点での平均絶対追跡誤差が 0.25{\deg} CA 未満で安定した CA50 制御を達成すると同時に、スムーズで物理的に一貫した SOI とグロープラグ電源の作動を生成します。これらの結果は、潜在的で継続的に進化する燃料力学の下での燃焼制御には、単独の推定や一般的な再現以上のものが必要であることを示しています。提案されたフレームワークは、燃料反応度推論を制御ポリシー学習と連携させることにより、配備中に利用可能な同じ推定状態を使用して、反応度を意識した意思決定を可能にします。
原文 (English)
Learning-Based Decision Making for Combustion Phasing Control in Multi-Fuel CI Engines with Latent Fuel Reactivity Estimation
Multi-fuel compression-ignition engines offer fuel flexibility but introduce uncertain, time-varying fuel reactivity, represented by cetane number (CN), which complicates cycle-to-cycle combustion-phasing control. This work formulates CA50 regulation under latent CN variation as a partially observable sequential decision problem and systematically evaluates controllers with increasing temporal and representational capacity, including LinUCB, history-augmented contextual bandits, observation-only DDPG, recurrent DDPG, and a proposed GRU-guided RL framework. A Gaussian-process surrogate trained on experimental multi-fuel engine data provides a controlled and reproducible evaluation environment. Results show that myopic and fixed-history bandit methods degrade under CN variation, observation-only RL suffers from latent-state aliasing, and generic recurrence is insufficient when CN evolves rapidly. The proposed framework learns a compact GRU-based representation of fuel reactivity from combustion history and conditions both actor and critic on this estimated signal rather than oracle CN. By training the policy on the same imperfect fuel-reactivity information available at deployment, the controller avoids train-deploy inconsistency in conventional online estimate-then-control pipelines. Across unseen CN trajectories, the policy achieves stable CA50 regulation with mean absolute tracking error below 0.25{\deg} CA at the training setpoint, while producing smooth, physically consistent SOI and glow-plug-power actuation. These results show that combustion control under latent, continuously evolving fuel dynamics requires more than standalone estimation or generic recurrence. By aligning fuel-reactivity inference with control policy learning, the proposed framework enables reactivity-aware decision-making using the same estimated state available during deployment.
ピクセル化結合器とデュアルステートインピーダンス合成を使用した、ディープラーニング駆動のドハティパワーアンプの逆設計
ドハティ パワー アンプ (PA) の出力結合器は、負荷変調、インピーダンス マッチング、位相補償を単一のネットワーク内に統合しているため、その設計と合成は非常に困難です。この論文では、深層畳み込みニューラル ネットワーク (CNN)、ピクセル化されたレイアウト表現、遺伝的アルゴリズム (GA) をデュアルステート インピーダンス合成と組み合わせて、ピーク電力条件とバックオフ電力条件の両方に対処する 3 ポート ドハティ コンバイナー設計手法を提案します。概念実証として、3 ポートのピクセル化コンバイナーを組み込んだ 2 つの GaN HEMT Doherty PA プロトタイプが設計および製造されました。どちらのプロトタイプも、2.6 ~ 2.8 GHz 内で 71.2% 以上のピーク ドレイン効率で 44.2 dBm を超える実測飽和出力電力を達成しています。さらに、6dB のバックオフ レベルで 64% もの高いドレイン効率が測定されます。デジタル プリディストーションを適用した後、各プロトタイプは -51.3 dBc を超える隣接チャネル漏洩比 (ACLR) を達成しました。
原文 (English)
Deep Learning-Driven Inverse Design of Doherty Power Amplifiers Using Pixelated Combiners and Dual-State Impedance Synthesis
The output combiner of a Doherty power amplifier (PA) integrates load modulation, impedance matching, and phase compensation within a single network, making its design and synthesis highly challenging. In this paper, we propose a three-port Doherty combiner design methodology that combines deep convolutional neural networks (CNNs), pixelated layout representations, and genetic algorithms (GA) with dual-state impedance synthesis to address both peak and back-off power conditions. As a proof of concept, two GaN HEMT Doherty PA prototypes incorporating three-port pixelated combiners are designed and fabricated. Both prototypes achieve a measured saturated output power exceeding 44.2 dBm with peak drain efficiency above 71.2% within 2.6-2.8 GHz. Furthermore, a drain efficiency as high as 64% is measured at the 6-dB back-off level. After applying digital predistortion, each prototype achieves an adjacent channel leakage ratio (ACLR) better than -51.3 dBc.
電気光学電界測定を使用したディープラーニングベースのピクセル化マイクロ波フィルターの設計と特性評価
従来のマイクロ波フィルタ設計は通常、反復的なパラメータ調整と事前定義されたトポロジに依存しているため、設計スペースが制限され、開発時間が増加します。この研究では、畳み込みニューラル ネットワークと遺伝的アルゴリズムを組み合わせた深層学習アプローチを使用して、ピクセル化されたマイクロ波フィルター合成を自動化します。このアプローチを実験的に検証するために、S パラメータと空間電界測定の両方が分析されました。合成されたローパス フィルターは、シミュレーションされたパフォーマンスと測定されたパフォーマンスの間で優れた一致を示し、9.5 GHz を超えて 20 dB 以上の抑制を伴う 7 GHz の通過帯域を達成しました。電気光学測定により、結合伝送線路またはスタブ構造に似た電界パターンが初めて明らかになり、AI によって生成された設計の新たな特性についての洞察が得られました。
原文 (English)
Deep-Learning-Based Pixelated Microwave Filter Design and Characterization using Electro-Optical Electric-Field Measurements
Traditional microwave filter design typically relies on iterative parameter tuning and predefined topologies, which limits design space and increases development time. This study uses a deep learning approach combining convolutional neural networks with genetic algorithms to automate pixelated microwave filter synthesis. To validate the approach experimentally, both S-parameter and spatial electric-field measurements were analyzed. The synthesized low-pass filter demonstrated excellent agreement between simulated and measured performance, achieving a 7 GHz passband with over 20 dB suppression beyond 9.5 GHz. Electro-optical measurements, for the first time, revealed electric field patterns that resemble coupled transmission-lines or stub structures, providing insight into the emergent characteristics of AI-generated designs.
LLM ジェネレーター/レギュレーター ゲームのための変分フレームワーク
この論文は、規制された言語生成のための変分フレームワークを開発します。自己回帰トークン サンプリングから開始して、完全なメッセージにわたる誘導分布を導出し、それをエントロピー正則化されたギブスの法則に関連付けます。調整は、凸双対値が f ダイバージェンスである最適弁別器としてモデル化され、生成器と調整器の相互作用は鞍点問題として定式化されます。このフレームワークは、モデレーション、検閲、AI による欺瞞検出、コンプライアンス監査、フィッシング防御、操作制御に適用され、規制は単一の出力ではなく、考えられるメッセージ全体の分散に関係します。この平衡により、効用、エントロピー、規制の調整、および有限長の検出可能性の間のトレードオフが明確になります。検閲フィルタリングとフィッシング防御という 2 つの有限語彙のケーススタディでは、効用、エントロピー、発散、受信側スコア、検出確率を通じて理論をどのように評価できるかを示しています。
原文 (English)
A Variational Framework for LLM Generator-Regulator Games
This paper develops a variational framework for regulated language generation. Starting from autoregressive token sampling, we derive the induced distribution over complete messages and relate it to an entropy-regularized Gibbs law. Regulation is modeled as an optimal discriminator whose convex-dual value is an f-divergence, and the generator-regulator interaction is formulated as a saddle-point problem. The framework applies to moderation, censorship, AI deception detection, compliance auditing, phishing defense, and manipulation control, where regulation concerns a distribution over possible messages rather than a single output. The equilibrium clarifies the tradeoff among utility, entropy, regulatory alignment, and finite-length detectability. Two finite-vocabulary case studies, censorship filtering and phishing defense, illustrate how the theory can be evaluated through utility, entropy, divergence, receiver-side scores, and detection probability.
仕様から実行まで: AI 支援の科学的ワークフロー管理
科学的ワークフロー管理システム (WMS) は、複雑なパイプラインのスケーラブルで再現可能な実行をサポートしますが、ワークフローの設計、実装、およびデバッグは依然として大部分が手作業であり、高度な専門知識が必要です。大規模言語モデル (LLM) を使用した最近のアプローチは、自然言語からのワークフロー生成に有望ですが、直接コード合成に依存することが多く、透明性、再現性、ワークフロー システムとの統合が制限されます。仕様に基づいたワークフロー生成、自動デバッグ、分散実行を組み合わせた、科学的ワークフロー管理への AI 支援アプローチを紹介します。この方法では、ワークフローの意図、設計、実装を分離する構造化された仕様フェーズが導入され、コード生成前の検証が可能になります。また、複数のシステム層にわたる障害を診断して解決する、LLM ベースのデバッグ エージェントも開発しています。分散実行とユーザー対話をサポートするために、広く使用されている WMS である Pegasus をモデル コンテキスト プロトコル (MCP) レイヤーと統合し、ワークフローの送信、監視、制御のための統一インターフェイスを提供します。私たちは、並列性、反復性、依存性を集中させる構造を考慮して選択された、医療画像用のフェデレーテッド ラーニング ワークフローを使用してアプローチを評価します。このシステムは、数千のジョブを含む大規模なワークフローを生成して実行し、デバッグの労力を軽減し、専門家以外のユーザーでも専門家レベルの設計パターンを使用してワークフローを構築できるようにしました。これらの結果は、エンドツーエンドの AI 支援ワークフローの生成と実行が実現可能であることを示しており、科学ワークフローのライフサイクルを管理するための AI 駆動プラットフォームの可能性を示しています。
原文 (English)
From Specification to Execution: AI Assisted Scientific Workflow Management
Scientific workflow management systems (WMS) support scalable and reproducible execution of complex pipelines, but workflow design, implementation, and debugging remain largely manual and require significant expertise. Recent approaches using large language models (LLMs) show promise for workflow generation from natural language, but often rely on direct code synthesis, which limits transparency, reproducibility, and integration with workflow systems. We present an AI-assisted approach to scientific workflow management that combines specification-driven workflow generation, automated debugging, and distributed execution. The method introduces a structured specification phase that separates workflow intent, design, and implementation, allowing validation prior to code generation. We also develop an LLM-based debugging agent that diagnoses and resolves failures across multiple system layers. To support distributed execution and user interaction, we integrate Pegasus, a widely used WMS, with a Model Context Protocol (MCP) layer, providing a unified interface for workflow submission, monitoring, and control. We evaluate the approach using a federated learning workflow for medical imaging, chosen for its parallel, iterative, and dependency-intensive structure. The system generated and executed large-scale workflows with thousands of jobs, reduced debugging effort, and allowed non-expert users to construct workflows with expert-level design patterns. These results indicate that end-to-end AI-assisted workflow generation and execution is feasible, and point toward AI-driven platforms for managing the scientific workflow lifecycle.
CAOA -- 完了支援型のオブジェクトと CAD の位置合わせ
屋内 RGB-D スキャンで CAD モデルを対応するオブジェクトに正確に位置合わせすることは、3D セマンティック再構築における中心的な課題です。このタスクでは、3 軸に沿った位置、回転、スケールの 9 自由度 (DoF) ポーズを推定する必要がありますが、ノイズが多く不完全なスキャンや、幾何学的歪みを引き起こすセグメンテーション エラーによって妨げられます。我々は、Completion-Assisted Object-CAD Alignment (CAOA) を紹介します。これは、意味論的およびコンテキストを意識した点群完了モジュールと、対称性を意識した相対姿勢推定アルゴリズムを統合し、スキャンされたオブジェクトに対する CAD モデルの正確な位置合わせを可能にする方法です。既存の補完方法は通常、合成データセットに基づいてトレーニングおよび評価されますが、現実世界のスキャンに一般化できないことがよくあります。このギャップを埋めるために、屋内シーンに合わせた合成データ生成戦略を導入し、広く使用されている完全データセットとの定量的比較を通じて検証された合成ドメインと実際のドメインのギャップを大幅に削減します。さらに、S2C-Completion をリリースします。S2C-Completion は、Scan2CAD の 8,500 を超えるオブジェクトと CAD のペアの専門家による注釈付きデータセットで、現実世界の屋内単一オブジェクトの完成用に作成され、このタスクの新しいベンチマークとして意図されています。オブジェクトと CAD の位置合わせでは、対称性を意識した損失を介して対称性情報を組み込み、対称性の曖昧さに対する堅牢性を向上させます。 Scan2CAD ベンチマークでは、CAOA は最先端の方法と比較して 17% の精度向上を達成しました。
原文 (English)
CAOA -- Completion-Assisted Object-CAD Alignment
Accurately aligning CAD models to their corresponding objects in indoor RGB-D scans is a central challenge in 3D semantic reconstruction. The task requires estimating a 9-Degree-of-Freedom (DoF) pose-position, rotation, and scale along three axes-but is hindered by noisy and incomplete scans, as well as segmentation errors that cause geometric distortions. We present Completion-Assisted Object-CAD Alignment (CAOA), a method that integrates a semantically and contextually aware point cloud completion module with a symmetry-aware relative pose estimation algorithm, enabling precise alignment of CAD models to scanned objects. Existing completion methods are typically trained and evaluated on synthetic datasets, which often fail to generalize to real-world scans. To bridge this gap, we introduce a synthetic data generation strategy tailored to indoor scenes, significantly reducing the synthetic-to-real domain gap-validated through quantitative comparisons with widely used completion datasets. In addition, we release S2C-Completion, an expert-annotated dataset of over 8,500 object-CAD pairs from Scan2CAD, created for real-world indoor single-object completion and intended as a new benchmark for this task. For object-CAD alignment, we incorporate symmetry information via a symmetry-aware loss, improving robustness to symmetric ambiguities. On the Scan2CAD benchmark, CAOA achieves a 17% accuracy improvement over state-of-the-art methods.
TMR-GGNN: 時間認識マルチリレーショナル ガイド付きグラフ ニューラル ネットワークに基づくクレジット カード不正検出
近年、クレジット カード詐欺の検出は、非常に不均衡なデータ、進化する詐欺パターン、取引エンティティ間の複雑な関係構造により、重大な課題に直面しています。これらの問題に対処するために、この研究では Timeaware Multi Relational Guided Graph Neural Network (TMR GGNN) と呼ばれる新しいフレームワークを提案します。特に、提案された TMR GGNN は、時間ウィンドウ上の顧客、販売業者、デバイス、および IP にわたる異種インタラクションをモデル化することにより、エンコーダー デコーダー グラフ ニューラル ネットワーク GNN アーキテクチャを拡張します。続いて、提案された TMR GGNN アプローチは、動的なマルチ リレーショナル グラフを構築し、エンコーダ内に時間認識リレーショナル アテンション メカニズムを組み込んで、時間的近接性とセマンティック コンテキストに基づいてトランザクションの関連性を適応的に重み付けします。その結果、デコーダは、まれな詐欺ケースのモデルの一般化を改善しながら、実際のトランザクション パターンと合成されたトランザクション パターンを区別するために対照的な学習モジュールを採用します。さらに、深刻なクラスの不均衡を効果的に管理し、弁別学習を強調するために、情報ノイズ対比推定 (InfoNCE) ベースの対比損失と焦点損失を組み合わせた複合損失関数が導入されています。この統合により、偽陰性を軽減しながら、不正行為の特定が向上します。
原文 (English)
TMR-GGNN: Credit Card Fraud Detection based on Time-Aware Multi-Relational Guided Graph Neural Network
In recent years, credit card fraud detection has faced significant challenges due to highly imbalanced data, evolving fraud patterns, and complex relational structures among transaction entities. To address these issues, this research proposes a novel framework called Timeaware Multi Relational Guided Graph Neural Network (TMR GGNN). Particularly, the proposed TMR GGNN extends the encoder decoder Graph Neural Network GNN architecture by modeling heterogeneous interactions across customers, merchants, devices, and IPs over temporal windows. Subsequently, the proposed TMR GGNN approach constructs a dynamic, multi relational graph and incorporates a time aware relational attention mechanism within the encoder to adaptively weigh the transaction relevance based on temporal proximity and semantic context. Consequently, the decoder employs a contrastive learning module to distinguish between real and synthesized transaction patterns, while improving the models generalization of rare fraud cases. Additionally, to effectively manage severe class imbalances and emphasize discriminative learning, a composite loss function combining Information Noise Contrastive Estimation (InfoNCE) based contrastive loss with Focal Loss is introduced. This integration assists in improving fraud identification while mitigating false negatives.
Veriphi: データセット依存のトレーニング方法を使用した攻撃ガイド型ニューラル ネットワーク検証
Veriphi は、アルファ、ベータ、CROWN メソッドを使用した高速な敵対的攻撃と正式な制限付き認証を組み合わせた、GPU で高速化されたニューラル ネットワーク検証システムです。 3 つのトレーニング手法 (標準、敵対的、認定) を使用した MNIST と CIFAR-10 の系統的な実験を通じて、トレーニング手法の有効性が基本的にデータセットに依存することを実証しました。 Interval Bound Propagation (IBP) は、単純な MNIST (784 次元) では 78% の認定精度を達成しますが、より複雑な CIFAR-10 データセットでは、PGD 敵対的トレーニングが支配的で、小さな摂動では 94% の認定が行われ、認定パフォーマンスは無視できます。攻撃に誘導された改ざんにより検証の 5 倍の高速化を達成し、実世界の航空宇宙物流の最適化のために量産サイズのモデル (1 億 580 万のパラメーター) にアプローチを拡張します。私たちの結果は、認定トレーニングが普遍的に敵対的トレーニングよりも優れているという仮定に疑問を呈し、検証戦略の選択においてコンテキストが非常に重要であることを示しています。
原文 (English)
Veriphi: Attack-Guided Neural Network Verification with Dataset-Dependent Training Methods
We present Veriphi, a GPU-accelerated neural network verification system that combines fast adversarial attacks with formal bound certification using alpha,beta-CROWN methods. Through systematic experiments on MNIST and CIFAR-10 using three training methodologies (standard, adversarial, certified), we demonstrate that training method effectiveness is fundamentally dataset-dependent. Interval Bound Propagation (IBP) achieves 78% certified accuracy on simple MNIST (784 dimensions) but provides negligible certification performance on the more complex CIFAR-10 dataset, where PGD adversarial training dominates with 94% certification at small perturbations. We achieve 5x verification speedup through attack-guided falsification and scale our approach to production-size models (105.8M parameters) for real-world aerospace logistics optimization. Our results challenge the assumption that certified training universally outperforms adversarial training, showing context matters critically for verification strategy selection.
グロッキングにおいて体重基準は何を制御しますか?クロスエントロピー下のロジットスケールメディエーション
暗記から一般化への遅れたジャンプであるグロッキングは、通常、重み付けノルムに関連付けられています。つまり、ノルムが小さいほど、より早く一般化されます。私たちは、規範が実際に何を制御しているのかを尋ねます。クランプによって固定された重みノルムを保持し、出力温度のみを変化させて、クロスエントロピー下でノルムによって引き起こされる範囲全体にわたってグロッキング遅延をスライドさせます。有効ロジット スケールをベースラインに戻すと、2 つの係数で遅延の約 85% が回復します。基準と温度のグリッド全体で、遅延はロジット スケールのみ (R2 = 0.97) に収まり、基準を超えると 1 ~ 2% が追加されます。効果は損失に依存します。平均二乗誤差の下ではロジットスケールが固定され、ノルムは別のルートで作用します。記憶コントロール、float64 ソフトマックス折りたたみ監査、および no-LayerNorm トランスフォーマーは同じチャネルを指します。 1 つの同一の状態からアームをフォークすると、遅延はクランプ動作ではなく、保持された標準値に従います。これにより、リスケーリング アーティファクトの懸念が解消されます。近位変数は、ロジット スケールとそれが駆動するソフトマックス飽和です。重量基準は上流ハンドルのみです。すべての数値、表、および図は、リリースされたコードとデータから再現されています。
原文 (English)
What Does the Weight Norm Control in Grokking? Logit-Scale Mediation under Cross-Entropy
Grokking, the delayed jump from memorization to generalization, is usually tied to the weight norm: a smaller norm generalizes sooner. We ask what the norm actually controls. Holding the weight norm fixed by clamping and varying only an output temperature, we slide the grokking delay across its entire norm-induced range under cross-entropy; matching the effective logit scale back to baseline recovers about 85% of the delay at two moduli. Across a grid of norms and temperatures the delay collapses onto the logit scale alone (R2 = 0.97), with the norm adding 1-2% beyond it. The effect is loss-dependent: under mean-squared error the logit scale is pinned and the norm acts through a different route. A memorization control, a float64 softmax-collapse audit, and a no-LayerNorm transformer point to the same channel. Forking arms from one identical state, the delay follows the held norm value and not the clamp operation, which closes a rescaling-artifact concern. The proximal variable is the logit scale and the softmax saturation it drives; the weight norm is only an upstream handle. All numbers, tables, and figures reproduce from released code and data.
局所線形埋め込みと適応特徴融合による構造化表現学習
神経科学的研究により、脳は構造化された低次元多様体を活用し、適応ゲート機構を通じて複数の情報源を動的に融合することによって、複雑な行動をエンコードしていることが明らかになりました。これらの原則に触発されて、私たちは、ダイナミクス固有の機能と報酬固有の機能のもつれの解消を促進する新しい強化学習 (RL) フレームワークを提案します。これは、効率的な意思決定のために神経回路が情報を分離および統合する方法と直接類似しています。私たちのアプローチは、局所線形埋め込み (LLE) を利用して、多くの環境に固有の固有の局所線形構造を捕捉し、神経集団の活動で観察される局所的な滑らかさを反映すると同時に、標準的な RL 目標を通じて報酬固有の特徴を導き出します。皮質ゲートに類似した注意メカニズムは、状態ごとにこれらの相補的表現を適応的に融合します。ベンチマークタスクの実験結果は、神経科学の原理に基づいた私たちの方法が従来のRLアプローチと比較して学習効率と全体的なパフォーマンスを向上させることを実証し、生物学的システムで観察される局所状態構造と適応的な特徴選択を明示的にモデル化する利点を強調しています。
原文 (English)
Structured Representation Learning with Locally Linear Embeddings and Adaptive Feature Fusion
Neuroscientific research has revealed that the brain encodes complex behaviors by leveraging structured, low-dimensional manifolds and dynamically fusing multiple sources of information through adaptive gating mechanisms. Inspired by these principles, we propose a novel reinforcement learning (RL) framework that encourages the disentanglement of dynamics-specific and reward-specific features, drawing direct parallels to how neural circuits separate and integrate information for efficient decision-making. Our approach leverages locally linear embeddings (LLEs) to capture the intrinsic, locally linear structure inherent in many environments, mirroring the local smoothness observed in neural population activity, while concurrently deriving reward-specific features through the standard RL objective. An attention mechanism, analogous to cortical gating, adaptively fuses these complementary representations on a per-state basis. Experimental results on benchmark tasks demonstrate that our method, grounded in neuroscientific principles, improves learning efficiency and overall performance compared to conventional RL approaches, highlighting the benefits of explicitly modeling local state structures and adaptive feature selection as observed in biological systems.
MagpieTTS-LF: 長い形式のデータでトレーニングを行わない推論時間による長い形式の音声生成
ニューラル テキスト読み上げ (TTS) システムは、短い発話では顕著な品質を実現しますが、長い形式の音声を生成すると、韻律のずれ、話者の不一致、および文境界のアーティファクトが発生します。既存のアプローチは、シーケンスを圧縮するか、コンテキストの長さを増やすか、独立して合成されたチャンクを単純に連結するかのいずれかです。我々は、MagpieTTS がモデルの再トレーニングなしで一貫した長い形式の音声を生成できるようにする、MagpieTTS-LF と呼ばれる推論時間アプローチを紹介します。私たちの方法では、次の 3 つの重要な革新が導入されています。(1) 過去と未来のコンテキストを維持しながら単調な位置合わせをガイドするソフト アテンション プリア。 (2) 文のチャンク全体でコンテキストを維持し、韻律の連続性を保証するステートフル推論アルゴリズム。 (3) 談話レベルの韻律計画に過去のテキストを使用する、歴史を意識したテキストエンコーディング。長いテキストに関する実験では、他のベースラインと比較して、長距離の明瞭性、韻律の一貫性、話者の一貫性、および境界の自然さが大幅に向上していることが示されています。
原文 (English)
MagpieTTS-LF: Inference-Time Long-Form Speech Generation Without Training on Long-Form data
Neural Text-to-Speech (TTS) systems achieve remarkable quality on short utterances but long-form speech generation shows prosodic drift, speaker inconsistencies and sentence boundary artifacts. Existing approaches either compress sequences, increase context length or naively concatenate independently synthesized chunks. We present an inference-time approach called MagpieTTS-LF that enables MagpieTTS to produce coherent long-form speech without model retraining. Our method introduces three key innovations: (1) soft attention priors to guide monotonic alignment while preserving past and future context; (2) a stateful inference algorithm that maintains context across sentence chunks, ensuring prosodic continuity; (3) history-aware text encoding that uses past text for discourse-level prosodic planning. Experiments on long texts show significant improvements in long-range intelligibility, prosodic coherence, speaker consistency, and boundary naturalness compared to other baselines.
SFT のオーバートレーニングは、RLVR でのエントロピー崩壊によるランク逆転を予測します
GRPO の最も高いパス@1 を持つ SFT チェックポイントを選択する標準ヒューリスティックは、SFT がロールアウト配布を圧縮する場合に失敗する可能性があります。バイナリ報酬の場合、期待されるグループ内の利点の分散は $p(1{-}p)(g{-}1)/g$ です。初期の GRPO が $p$ を $p^*(g)$ 未満に押し上げると、ほとんどのグループは同一の報酬を持ち、グループ相対シグナルは得られません。 Qwen2.5-Coder-3B および DeepSeek-Coder-6.7B の SFT 深度ラダーを研究します。 Qwen2.5-Coder-3B を 5 つの深さと 3 つのシードでテストし、DeepSeek-Coder-6.7B を 4 つの一致する深さと 3 つのシードでテストします。 Qwen では、pre RL pass@1 は SFT 深度とともに上昇しますが、ピーク GRPO pass@10 は $0.806$ から $0.481$ に低下します (3 シード平均、$n{=}20$)。 pre RL エントロピーは GRPO の結果と正の相関があります ($\rho{=}{+}0.69$)。 DeepSeek では、 pass@1 は $p^*(8){=}0.083$ をはるかに上回るままで、GRPO の結果は反転ではなく圧縮されます。プレ RL エントロピー トリアージと初期の GRPO エントロピー モニターを組み合わせた 2 段階の診断により、高リスクのチェックポイントにフラグを立て、失敗した実行を早期に停止できます。正則化を参照する単純な KL とラベル スムージングのバリアントでは、この設定で崩壊した Qwen チェックポイントは救出されず、この失敗が単純な GRPO ハイパーパラメーター アーティファクトではないことを示唆しています。
原文 (English)
SFT Overtraining Predicts Rank Inversion via Entropy Collapse Under RLVR
The standard heuristic of selecting the SFT checkpoint with the highest pass@1 for GRPO can fail when SFT compresses the rollout distribution. For binary rewards, the expected within group advantage variance is $p(1{-}p)(g{-}1)/g$; when early GRPO drives $p$ below $p^*(g)$, most groups have identical rewards and provide no group relative signal. We study SFT depth ladders for Qwen2.5-Coder-3B and DeepSeek-Coder-6.7B. We test Qwen2.5-Coder-3B across five depths and three seeds, and DeepSeek-Coder-6.7B across four matched depths and three seeds. On Qwen, pre RL pass@1 rises with SFT depth, but peak GRPO pass@10 falls from $0.806$ to $0.481$ (3 seed mean, $n{=}20$); pre RL entropy is positively associated with the GRPO outcome ($\rho{=}{+}0.69$). On DeepSeek, pass@1 remains far above $p^*(8){=}0.083$, and GRPO outcomes compress rather than invert. A two stage diagnostic, combining pre RL entropy triage with an early GRPO entropy monitor, flags high risk checkpoints and can stop failing runs early. Simple KL to reference regularisation and label smoothing variants do not rescue the collapsed Qwen checkpoint in our setting, suggesting the failure is not a trivial GRPO hyperparameter artefact.
神経位相相関
対応は基本的に関係性です。それは、どちらかの内容ではなく、共通のシーンの 2 つの観察の間の未知の変化を追求します。しかし、主流の学習ベースの方法は、アーキテクチャ内のファーストクラスのオブジェクトとして変換を表現していません。これらは各画像を独立してエンコードし、学習された類似性関数またはディープ デコーダーが暗黙的にマッピングを発見できるようにします。位相相関は標準的な例外であり、フーリエ領域で画像間の関係を直接測定しますが、その固定基底の剛性により、それはグローバルな変換に限定されます。変換を分解する基礎を学習することでこの制限を取り除く、位相相関の学習された一般化を導入します。同じ代数プリミティブが、高密度の非剛体変形とユニタリ ダイナミクスに拡張されます。 ACDC 心臓 MRI ベンチマークでは、このフレームワークは両方の登録方向で以前に公開されたベースラインと一致するか、それを上回っています。 CAMUS 心エコー検査では、補助的なスコアリングや適応的滑らかさのメカニズムを使用せずに、最先端の機能と一致します。同じフレームワークを 1 次元量子調和振動子の時間発展波動関数ペアに適用すると、観測ペアのみからエルミート関数の固有状態と未知のハミルトニアンの量子化エネルギー レベルが復元されます。
原文 (English)
Neural Phase Correlation
Correspondence is fundamentally relational: it seeks the unknown transformation between two observations of a common scene, not the content of either. Yet the dominant learning-based methods do not represent the transformation as a first-class object in the architecture. They encode each image independently and let a learned similarity function or a deep decoder discover the mapping implicitly. Phase correlation is the canonical exception, measuring the inter-image relationship directly in the Fourier domain, but the rigidity of its fixed basis confines it to global translation. We introduce a learned generalization of phase correlation that lifts this restriction by learning the basis on which the transformation decomposes. The same algebraic primitive extends to dense non-rigid deformations and to unitary dynamics. On the ACDC cardiac-MRI benchmark the framework matches or exceeds prior published baselines on both registration directions. On CAMUS echocardiography it matches state-of-the-art without auxiliary scoring or adaptive-smoothness mechanisms. Applied to time-evolved wavefunction pairs of the 1-D quantum harmonic oscillator, the same framework recovers the Hermite-function eigenstates and the quantized energy levels of the unknown Hamiltonian from observation pairs alone.
PSyGenTAB: 制約付き最適化による合成臨床表データ生成のためのプライバシー保護フレームワーク
医療 AI の開発は、組織内のサイロ化や HIPAA や GDPR などの厳格なプライバシー規制により、高品質の臨床データへのアクセスが制限されているため制約を受けています。合成データの生成は潜在的な解決策を提供しますが、既存の方法にはプライバシーと実用性のトレードオフを明示的に管理するための原則に基づいたメカニズムが欠けており、多くの場合、臨床的に意味のあるパターンを劣化させたり、患者の再識別を危険にさらしたりします。我々は、拡張ラグランジュ法を使用して解決される制約付き最適化問題として合成医療データ生成を定式化する、プライバシー保護生成フレームワークである PSyGenTAB を紹介します。 PSyGenTAB は、構成可能なプライバシー制約をモデル トレーニングに直接埋め込むことで、臨床データの有用性を最大化しながら、プライバシーの最小しきい値を強制します。 PSyGenTAB は、複数の臨床目的のベンチマークにわたって、信頼性の高い健康 AI に不可欠な機能間の臨床関係と少数派クラスの診断パターンを保存します。 Train-on-Synthetic、Test-on-Real プロトコルおよび Train-on-Real、Test-on-Synthetic プロトコルを使用したダウンストリーム評価では、合成データでトレーニングされたモデルが実際の患者記録でトレーニングされたモデルと同等のパフォーマンスを達成することが示されています。プライバシー監査により、正確な記録の再現が減少し、メンバーシップ推論攻撃に対する強い回復力がさらに実証されます。これらの結果により、PSyGenTAB は、合成医療データのプライバシー保護と臨床的有用性のバランスをとるための原則に基づいたフレームワークとして確立され、安全な機関横断的な AI 開発をサポートします。
原文 (English)
PSyGenTAB: A Privacy-Preserving Framework for Synthetic Clinical Tabular Data Generation via Constrained Optimization
The development of medical AI is constrained by limited access to high-quality clinical data due to institutional silos and strict privacy regulations such as HIPAA and GDPR. Synthetic data generation offers a potential solution, but existing methods lack principled mechanisms to explicitly manage the privacy-utility trade-off, often degrading clinically meaningful patterns or risking patient re-identification. We present PSyGenTAB, a privacy-preserving generative framework that formulates synthetic healthcare data generation as a constrained optimization problem solved using the Augmented Lagrangian Method. By embedding configurable privacy constraints directly into model training, PSyGenTAB enforces minimum privacy thresholds while maximizing clinical data utility. Across multiple clinically motivated benchmarks, PSyGenTAB preserves inter-feature clinical relationships and minority-class diagnostic patterns essential for reliable health AI. Downstream evaluation using Train-on-Synthetic, Test-on-Real and Train-on-Real, Test-on-Synthetic protocols shows that models trained on synthetic data achieve performance comparable to those trained on real patient records. Privacy auditing further demonstrates reduced exact record reproduction and strong resilience to membership inference attacks. These results establish PSyGenTAB as a principled framework for balancing privacy protection and clinical utility in synthetic healthcare data, supporting secure cross-institutional AI development.
あなたが望むように: 精密農業における LLM を使用した正式な検証を伴うミッション計画
ロボット システムは現在商品化され、さまざまな業界で導入されていますが、これらのシステムの多くは高度に専門化されており、多くの場合、指示どおりに動作し確実に実行するには高度なスキル セットが必要です。この問題を軽減するために、私たちは最近、LLM を活用して、自然言語で提供されるミッションの説明に基づいて精密農業におけるミッション プランを合成するミッション プランナーを導入しました。このシステムは優れたパフォーマンスを示しますが、自然言語に固有の曖昧さにも悩まされています。この論文では、線形時相論理 (LTL) を活用する複数のフィードバック ループを計画アーキテクチャに導入することで、この問題に対処するためにシステムを拡張し、自然言語を使用しながらミッション計画システムがユーザーによって策定された仕様を確実に満たすようにします。潜在的なバイアスを軽減するために、これは、仕様と検証のサブタスクを担当する 2 つの異なる商用 LLM を使用することによって実現されます。広範な実験を通じて、特に貴重な LTL 式を生成する LLM の機能に関して、ミッション検証を完全自律型パイプラインに統合することの長所と限界を強調し、提案する実装がこれらの課題にどのように対処し、解決するかを示します。
原文 (English)
As You Wish: Mission Planning with Formal Verification using LLMs in Precision Agriculture
Though robotic systems are now being commercialized and deployed in various industries, many of these systems are highly specialized and often require an advanced skill set to operate and ensure they perform as instructed. To mitigate this problem, we recently introduced a mission planner leveraging LLMs to synthesize mission plans in precision agriculture based on mission descriptions provided in natural language. While the system demonstrates impressive performance, it also suffers from the inherent ambiguities of natural language. In this paper, we extend our system to address this issue by introducing multiple feedback loops in the planning architecture that leverage linear temporal logic (LTL) to ensure the mission planning system meets the specifications formulated by the user while still using natural language. To mitigate potential bias, this is achieved by using two different commercial LLMs in charge of the specification and verification subtasks. Through extensive experiments, we highlight the strengths and limitations of integrating mission verification into a fully autonomous pipeline, particularly regarding an LLM's ability to generate valuable LTL formulas, and show how our proposed implementation addresses and solves these challenges.
スパース性の呪い: モデルの結合から RLVR モデルのパラメーター空間を理解する
検証可能な報酬を伴う強化学習(RLVR)は、推論知能を引き出し、壊滅的な忘却に抵抗する点で、教師あり微調整(SFT)を超える強力なトレーニング後のパラダイムとして登場しました。最近の研究では、RLVR が SFT と比較して非常にスパースで非主なパラメータ更新を引き起こすことがさらに明らかになりました。これは当然のことながら、このようなスパース性によって RLVR モデルがモデルのマージに適したものになるのか?という疑問を生じます。そうであれば、モデルの結合は、独立してトレーニングされた RLVR モデルからの多様な推論機能を集約するための、スケーラブルでトレーニング不要のパスを提供することになります。驚くべきことに、私たちは逆のことを発見し、スパース性の呪いを明らかにしました。つまり、スパースな RLVR 更新がパラメータ空間内でさらに離れて分散され、集約を本質的に脆弱にする直交に近いショートカットを形成します。これはおそらく、RL 最適化の確率性と創発的な推論パターンの多様性に根ざしていると考えられます。共有された平坦な盆地に収束し、自然にマージする SFT モデルとは異なり、RLVR モデルは標準的なマージ方法では深刻な劣化を受けます。更新ジオメトリの系統的な実証分析を通じて、この失敗の背後にあるメカニズムを特徴付け、RLVR パラメーター空間の固有の構造に合わせて調整されたマージ レシピである感度を考慮した解決マージング (SAR-Merging) を提案します。 SAR マージングは、フィッシャー情報ベースの感度調整によって重複する更新領域の競合を解決し、その後、マグニチュードを意識したスパース化と再スケーリングを行って脆弱な推論経路を保存します。数学的ベンチマークとコーディング ベンチマークの実験では、SAR マージが RLVR モデルでの既存のマージ手法を大幅に上回り、単一タスクの拡張とマルチ機能の融合の両方を可能にすることが実証されました。
原文 (English)
Sparsity Curse: Understanding RLVR Model Parameter Space from Model Merging
Reinforcement Learning with Verifiable Reward (RLVR) has emerged as a powerful post-training paradigm that surpasses Supervised Fine-Tuning (SFT) in eliciting reasoning intelligence and resisting catastrophic forgetting. Recent studies further reveal that RLVR induces highly sparse and off-principal parameter updates compared to SFT. This naturally raises the question: does such sparsity make RLVR models more amenable to model merging? If so, model merging would offer a scalable, training-free path to aggregate diverse reasoning capabilities from independently trained RLVR models. Surprisingly, we find the opposite, uncovering a sparsity curse: the sparse RLVR updates are spread farther apart in parameter space, forming near-orthogonal shortcuts that make aggregation inherently fragile. This is likely rooted in the stochasticity of RL optimization and the diversity of emergent reasoning patterns. Unlike SFT models that converge to shared, flat basins and merge naturally, RLVR models suffer severe degradation under standard merging methods. Through systematic empirical analysis of the update geometry, we characterize the mechanisms behind this failure and propose Sensitivity-aware Resolving Merging (SAR-Merging), a merging recipe tailored for the unique structure of RLVR parameter spaces. SAR-Merging resolves conflicts in overlapping update regions via Fisher Information-based sensitivity arbitration, followed by magnitude-aware sparsification and rescaling to preserve fragile reasoning pathways. Experiments on mathematical and coding benchmarks demonstrate that SAR-Merging substantially outperforms existing merging methods on RLVR models, enabling both single-task enhancement and multi-capability fusion.
AI サンドボックス: 脅威モデル、分類法、および測定フレームワーク
AI システムは、分離、シミュレーション、計測、監視、証拠の取得を組み合わせた制限された環境で評価されることが増えています。物理 AI、AIoT、およびサイバー物理システムの場合、この変化は用語の問題ではありません。テスト対象のシステムは、物理プロセス、ネットワーク接続されたデバイス、および人間のオペレーターを通じて、感知、決定、作動、通信、および障害を起こす可能性があります。この記事では、デジタル AI、身体化された自律性、およびサイバー物理的展開にわたるテスト、評価、検証、検証のための制御された環境としての AI サンドボックスの保証指向の説明を開発します。私たちは、次元ごとの証拠を制限付きの展開主張に組み込むためのサンドボックス境界と最弱リンク ルールを形式化します。個別の主要なサンドボックス アーキタイプ。保証装置自体への攻撃を含むサイバー物理的脅威モデルを定義する。また、実際のサンドボックスの 3 つの事例研究に基づいてインスタンス化された、忠実度、制御性、可観測性、封じ込め、再現性、ガバナンス成果物にわたる測定フレームワークを紹介します。結果として得られる脅威モデル、分類法、および測定フレームワークにより、サンドボックスが何を有効にテストできるか、どのようなリスクを含めることができるか、安全性、セキュリティ、規制上の保証のためにどのような形式の証拠をサポートできるかが明確になります。
原文 (English)
AI Sandboxes: A Threat Model, Taxonomy, and Measurement Framework
AI systems are increasingly evaluated in bounded environments that combine isolation, simulation, instrumentation, supervision, and evidence capture. For physical AI, AIoT, and cyber-physical systems, this shift is not a matter of terminology: the system under test may sense, decide, actuate, communicate, and fail through physical processes, networked devices, and human operators. This article develops an assurance-oriented account of AI sandboxes as controlled environments for testing, evaluation, verification, and validation across digital AI, embodied autonomy, and cyber-physical deployments. We formalize the sandbox boundary and a weakest-link rule for composing per-dimension evidence into a bounded deployment claim; separate major sandbox archetypes; define a cyber-physical threat model that includes attacks on the assurance apparatus itself; and introduce a measurement framework spanning fidelity, controllability, observability, containment, reproducibility, and governance artifacts, instantiated on three worked case studies of real sandboxes. The resulting threat model, taxonomy, and measurement framework clarify what a sandbox can validly test, which risks it can contain, and what forms of evidence it can support for safety, security, and regulatory assurance.
適応型 AI 倫理指導の学習者モデリング シグナルとしてのエンゲージメント強度
大学院研究トレーニングにおける適応型 AI 倫理指導は、以前の LLM 経験の違いを反映した摂取量の測定から恩恵を受けます。事前のコースワークやワークショップへの参加は明らかな候補ですが、それが主要な AI 認識項目に関する指導前の評価に関連しているかどうかは明らかではありません。私たちは、必須の研究倫理コースに登録しているバイオサイエンス大学院生およびポスドク研修生93名を対象に、受験者の3つの摂取特徴、自己申告の使用頻度、自己評価によるLLMの習熟度、および以前のAI教育を、5つのベースライン認識結果にわたって比較しました。使用頻度は、ホルム補正された 5 つの結果すべてとの関連性、自己評価による 3 つの結果との親密度、および以前の AI 教育との関連性を示しています。スケールの下限にあるしきい値のようなパターンは、5 つの結果すべてにわたって均一な勾配として現れるのではなく、トレーニングの関心と精度の信頼に関して最も顕著に現れます。短い摂取量調査では、報告された LLM の使用は、以前のコースワークやワークショップよりも一貫してこれらの認識と関連しており、自己評価による慣れ度が二次指標として機能します。これらの結果は、単純な指導前の行動信号が、適応型 AI 倫理教育のための軽量摂取プロファイリングに情報を提供できることを示唆しています。
原文 (English)
Engagement Intensity as a Learner-Modeling Signal for Adaptive AI Ethics Instruction
Adaptive AI ethics instruction in graduate research training benefits from intake measures that reflect differences in prior LLM experience. Prior coursework or workshop attendance is an obvious candidate, but it is not clear whether it is associated with pre-instruction ratings on key AI perception items. We compare three candidate intake features, self-reported usage frequency, self-rated LLM familiarity, and prior AI education, across five baseline perception outcomes in 93 bioscience graduate and postdoctoral trainees enrolled in a required research ethics course. Usage frequency shows Holm-corrected associations with all five outcomes, self-rated familiarity with three, and prior AI education with none. A threshold-like pattern at the lower end of the scale is most visible for training interest and accuracy trust rather than appearing as a uniform gradient across all five outcomes. In a short intake survey, reported LLM use is more consistently associated with these perceptions than prior coursework or workshops, with self-rated familiarity serving as a secondary indicator. These results suggest that simple pre-instruction behavioral signals can inform lightweight intake profiling for adaptive AI ethics education.
Wasserstein の敵対的学習によるセンサー誘発の分布ドリフトの修正
記録されたデータの品質は、それを取得するセンサー システムの安定性に依存します。センサーの動きや経年劣化により、下流のデータ駆動型メソッドのパフォーマンスと安定性が低下する可能性があります。我々は、変更された検出器応答分布を公称参照分布にマッピングし直す、物理的に解釈可能な変換パラメータの教師なし推論のための、Wasserstein-GAN にヒントを得たアプローチを提案します。標準の生成モデリングとは対照的に、ジェネレーターは学習可能なキャリブレーション変換として使用され、その学習可能な重みが求められるパラメーターを表す一方、クリティカルは Wasserstein 対物レンズを介して分布距離信号を提供します。層シフトを制御した追跡検出器玩具モデルでこのアプローチを検証し、セルごとの経年変化効果を伴う高粒度の Geant4 シミュレーション熱量計データへの応用を実証します。この方法は、グラウンド トゥルースと相関関係のある個々のセルの経年変化係数を回復し、キャリブレーションされたエネルギー合計分布と基準エネルギー合計分布の間の一致を改善すると同時に、チャネル間ノイズ レベルの増加で予想される劣化を示します。これらの結果は、敵対的分布マッチングが、劣化パラメーターの直接ラベルが利用できない設定において、キャリブレーション戦略のデータ駆動型コンポーネントとして機能できることを示しています。
原文 (English)
Correcting Sensor-Induced Distribution Drift with Wasserstein Adversarial Learning
The quality of recorded data depends on the stability of the sensor system that acquires it. Sensor motion and aging can degrade the performance and stability of downstream data-driven methods. We present a Wasserstein-GAN-inspired approach for unsupervised inference of physically interpretable transformation parameters that map a changed detector response distribution back to a nominal reference distribution. In contrast to standard generative modeling, the generator is used as a learnable calibration transformation whose trainable weights represent the sought parameters, while the critic provides a distributional distance signal via the Wasserstein objective. We validate the approach on a tracking-detector toy model with controlled layer shifts and demonstrate its application on high-granularity Geant4-simulated calorimeter data with cell-wise aging effects. The method recovers aging coefficients for individual cells with correlation to ground truth and improves agreement between calibrated and reference energy-sum distributions, while exhibiting the expected degradation at increasing channel-to-channel noise levels. These results indicate that adversarial distribution matching can serve as a data-driven component of calibration strategies in settings where direct labels for degradation parameters are unavailable.
低照度での人数カウントのためのマルチモーダル ハイパーグラフ フュージョン
群衆カウントは、コンピュータ ビジョンの基本的なタスクです。しかし、現実世界での実用的な重要性にもかかわらず、暗い環境での群衆カウントはほとんど研究されていません。既存の方法は主に明るいシーンに焦点を当てているか、単一モダリティの赤、緑、青 (RGB) 表現に依存していますが、極度の暗闇や複雑で不均一な照明の下では信頼性が低くなることがよくあります。この問題に対処するために、3 つの新しい低照度群衆カウント ベンチマークを構築しました。これらは 2 つの合成データセット SHA\_Dark と SHB\_Dark と、現実世界のベンチマーク LC-Crowd (Low-light Crowd Dataset) で構成されます。 Retinex ベースの物理モデリングに触発され、補完的な幾何学的および構造的事前定義として深度およびキャニー エッジ キューを導入し、低照度条件下での固有反射率の表現を強化します。我々は、RGB の外観、深度ジオメトリ、およびエッジ構造の手がかりを統合ハイパーグラフ内のノードとして定式化し、動的なハイパーエッジ構築とメッセージ パッシングを通じてそれらの高次の相補関係を明示的にキャプチャする、マルチモーダル ハイパーグラフ フュージョン モジュールを提案します。さらに、密予測における計算を適応的に割り当てるために、アンカーを意識した推定と適応長方形ウィンドウモデリングを通じて情報領域に計算を集中させる変形可能な長方形スパースアテンション(DRSA)モジュールを提案します。これらの設計に基づいて、堅牢な低照度群衆カウントのための統合低照度カウント ネットワーク (LCNet) を開発します。 3 つのベンチマークに関する広範な実験により、提案された手法が既存の最先端 (SOTA) 手法に対して最高の総合パフォーマンスを達成することが実証されました。コードは補足資料にあります。データセットは承認され次第公開されます。
原文 (English)
Multi-Modal Hyper-Graph Fusion for Low-Light Crowd Counting
Crowd counting is a fundamental task in computer vision. However, crowd counting in low-light environments remains largely underexplored, despite its practical importance in the real world. Existing methods mainly focus on well-lit scenes or rely on single-modality Red-Green-Blue (RGB) representations, which often become unreliable under extreme darkness and complex non-uniform illumination. To handle this problem, we construct three new low-light crowd counting benchmarks, which consist of two synthetic datasets, SHA\_Dark and SHB\_Dark, and a real-world benchmark LC-Crowd (Low-light Crowd Dataset). Inspired by Retinex-based physical modeling, we introduce depth and Canny edge cues as complementary geometric and structural priors to enhance the intrinsic reflectance representation under low-light conditions. We propose a Multi-Modal Hyper-Graph Fusion module, which formulates RGB appearance, depth geometry, and edge structure cues as nodes in a unified hyper-graph and explicitly captures their high-order complementary relationships via dynamic hyperedge construction and message passing. Furthermore, to adaptively allocate computation in dense prediction, we propose a Deformable Rectangular Sparse Attention (DRSA) module, which concentrates computation on informative regions through anchor-aware estimation and adaptive rectangular window modeling. Based on these designs, we develop a unified Low-Light Counting Network (LCNet) for robust low-light crowd counting. Extensive experiments on three benchmarks demonstrate that the proposed method achieves the best overall performance against existing state-of-the-art (SOTA) methods. The code is in the supplementary material. The datasets will be made public upon acceptance.
APT: ビデオ言語の因果関係を理解するための原子的物理的遷移
物理的な出来事は、その名前だけでは理解されず、それを構成する因果関係のある状態の変化によって理解されます。 「バウンス」などのクリップ レベルのラベルは、サポートの喪失や接触の開始からリバウンドやセトリングまで、イベントを物理的に有効にするプロセスを隠しながら、正しい場合があります。この隠れたプロセスを明示するために、原子物理遷移 (APT) を導入します。これは、目に見える合図をアクティブな物理メカニズムと動的レジームの前後に結び付ける、最小限の時間的に局所的な状態変化です。 APT チェーンは、単一の集約イベント ラベルではなく、順序付けられた因果遷移シーケンスとしてビデオを表します。イベント ラベルは何が起こったかを示します。 APT チェーンは、それが起こった理由を説明します。 APT を VLM で学習可能にするために、人間の注釈とシミュレーターのグランド トゥルースから混合ソース APT データを構築し、接触、重力、摩擦、回転/安定性にわたる 14 の遷移タイプをカバーし、1,246 回の試行で 27,303 の時間計測されたインスタンスを作成しました。このデータを使用すると、現在の VLM は遷移レベルの物理を見逃しており、ゼロショット再現率は最大 14% であり、エラーは遷移の逃しによって占められていることがわかります。 APT チェーンを直接微調整すると、遷移検出は向上しますが、イベント レベルの忘却が発生します。これは、モデルが再利用可能な物理表現ではなく、特殊な応答形式を学習していることを示しています。そこで私たちは、ビデオの質問に答える方法を忘れずに因果遷移を使用することを VLM に教えるパラメータ効率の高いレシピである APT-Tune を提案します。画像パッド対応の監視、形式条件付きの共同トレーニング、およびメカニズム条件付きのドメインから型へのデコードを組み合わせて、APT 学習形式を堅牢かつ物理的に根拠のあるものにします。 Qwen3-VL-2B の LoRA パラメータはわずか 1,100 万個ですが、APT-Tune は APT リコールを大幅に向上させると同時に、イベントレベルのビデオ転送も改善します。これらの結果は、APT が新しい応答形式ではなく、物理的なビデオを理解するための人間に合わせた因果関係の監視信号であることを示しています。
原文 (English)
APT: Atomic Physical Transitions for Causal Video-Language Understanding
Physical events are not understood by their names alone, but by the causal state changes that compose them. A clip-level label such as "bounce" can be correct while hiding the process that makes the event physically valid, from support loss and contact onset to rebound and settling. To make this hidden process explicit, we introduce Atomic Physical Transitions (APTs): minimal, temporally localized state changes that bind a visible cue to an active physical mechanism and before/after dynamical regimes. An APT chain represents a video as an ordered causal transition sequence rather than a single aggregate event label: event labels tell what happened; APT chains explain why it happened. To make APTs learnable by VLMs, we construct mixed-source APT data from human annotations and simulator ground truth, covering 14 transition types across contact, gravity, friction, and rotation/stability, with 27,303 timed instances over 1,246 trials. Using this data, we find that current VLMs miss transition-level physics, with zero-shot recall at most 14% and errors dominated by missed transitions. Direct fine-tuning on APT chains improves transition detection but causes event-level forgetting, indicating that the model learns a specialized answer format rather than a reusable physical representation. We therefore propose APT-Tune, a parameter-efficient recipe that teaches VLMs to use causal transitions without forgetting how to answer video questions. It combines image-pad-aware supervision, format-conditional co-training, and mechanism-conditioned domain-to-type decoding to make APT learning format-robust and physically grounded. With only 11 M LoRA parameters on Qwen3-VL-2B, APT-Tune substantially improves APT recall while also improving event-level video transfer. These results show that APTs are not a new answer format, but a human-aligned causal supervision signal for physical video understanding.
ローカルとグローバルの注目を集める二次元性
デコーダ専用のトランスフォーマーは、先行するトークンの KV キャッシュを介してアテンションを計算します。キー (および値) は通常、予測ターゲットからの距離に関係なく、同じ次元で表されます。しかし、自然言語では、次の単語が直前のトークンの影響を最も強く受けます。私たちは、ローカル トークンとリモート トークンは表現能力に非対称な要求を課すという仮説を立てます。ローカル トークンは即時の出力を予測するためにより重要であるため、より豊富な表現が必要ですが、リモート トークンは主に長距離メモリとして機能し、低次元の表現で十分である可能性があります。私たちはこのアイデアを距離適応表現 (DAR) として形式化し、ローカル コンテキスト ウィンドウ内でフル次元表現を保持しながら、そのウィンドウを超えたトークンに縮小次元表現 (たとえば、元の次元の 1/4) を割り当てる制御された設定で実装します。複数の事前トレーニング スケール (7000 万から 41000 万のパラメーター) にわたって、また 1B スケール モデルでの継続的な監視付き微調整により、このアプローチはフル次元のベースラインのパフォーマンスとほぼ一致します。対照的に、すべてのトークン位置にわたって次元を一律に削減すると、パフォーマンスの低下につながります。これらの結果は、キーと値の次元がトークンの位置全体で均一であるべきであるという一般的な前提に疑問を投げかけます。私たちの発見は、シーケンス全体に表現容量を適応的に割り当て、推論中の KV キャッシュのさらなる削減を可能にするアテンション アーキテクチャを設計するための新しい方向性を示唆しています。
原文 (English)
Dual Dimensionality for Local and Global Attention
Decoder-only Transformers compute attention over the KV cache of preceding tokens. Keys (and Values) are typically represented with the same dimensionality, regardless of its distance from the prediction target. In natural language, however, the next word is most strongly influenced by the immediately preceding tokens. We hypothesize that local and distant tokens impose asymmetric demands on representational capacity: local tokens are more critical for predicting immediate outputs and thus require richer representations, whereas distant tokens primarily serve as long-range memory, for which lower-dimensional representations may suffice. We formalize this idea as Distance-Adaptive Representation (DAR), implemented in a controlled setting that preserves full-dimensional representations within a local context window while assigning reduced-dimensional representations (e.g. 1/4 of the original dimensionality) to tokens beyond that window. Across multiple pretraining scales (70M to 410M parameters), as well as continued supervised fine-tuning on a 1B-scale model, this approach closely matches the performance of full-dimensional baselines. In contrast, uniformly reducing dimensionality across all token positions leads to worse performance. These results challenge the common assumption that key and value dimensionality should be uniform across token positions. Our findings suggest a new direction for designing attention architectures that adaptively allocate representational capacity across sequences, enabling further reductions in KV cache during inference.
ビジョンベースのロボット操作のための強化学習におけるアクション空間のベンチマーク
現実世界の強化学習 (RL) では、アクション スペースの選択が、モーションの滑らかさ、安全性、および全体的なタスクのパフォーマンスを形成する上で重要な役割を果たします。この研究では、オブジェクトのピックとプッシュという 2 つの視覚ベースの操作タスクにわたって、ポーズの増分、ポーズの速度、関節の位置の増分、および関節の速度を評価します。シミュレーションでポリシーをトレーニングし、sim-to-real 転送を使用して現実世界に展開します。アクション空間の表現がシミュレーションからリアルへのパフォーマンスに実際に大きな影響を与えることがわかりました。特に、ジョイント速度アクション空間は、滑らかさと最終的なタスクのパフォーマンスの点で、視覚ベースのピッキングタスクとプッシュタスクに最適であることがわかりました。また、RL 実践者向けに、シミュレーションと現実世界の実験の両方のアクション スペースを選択するための実践的なガイダンスも提供します。
原文 (English)
Benchmarking Action Spaces in Reinforcement Learning for Vision-based Robotic Manipulation
In real-world reinforcement learning (RL), the choice of action space can play a key role in shaping motion smoothness, safety, and overall task performance. In this study, we evaluate pose increment, pose velocity, joint position increment, and joint velocity across two vision-based manipulation tasks: object picking and pushing. We train policies in simulation and deploy them to the real world using sim-to-real transfer. We find that action-space representation indeed significantly affects sim-to-real performance. In particular, we find that the joint velocity action space is best for the vision-based picking and pushing tasks in terms of smoothness and final task performance. We also provide practical guidance for RL practitioners in choosing action spaces for both simulation and real-world experiments.
アドヒアランスの向上、より豊かなコンテキスト: LLM を利用した睡眠用会話音声日記のフィールド評価
睡眠日誌は睡眠行動医学や不眠症の認知行動療法の中心ですが、毎日の完了を維持するのは難しく、静的な形式では夜間の睡眠の変化を解釈するためのコンテキストが限られていることがよくあります。私たちは、LLM を利用した会話型音声日記を設計しました。これは、プロアクティブなスマート スピーカーのプロンプト、構造化された会話の取り込み、および適応的なフォローアップ ダイアログを通じて、臨床に基づいた朝と夜の睡眠日記の質問を提供します。私たちは、30 人の大学生を対象とした 4 週間の科目間のフィールド調査でシステムを評価し、一致する日記項目、レポートウィンドウ、リマインダー間隔を使用してテキストベースのモバイル日記と比較しました。テキストベースの日記と比較して、会話音声日記は高い遵守率を示し、日課、ストレス要因、環境条件、その他の睡眠関連要因についてより詳細な状況に応じた自己報告を引き出しました。参加者はまた、音声日記は完了までに時間がかかるにもかかわらず、日常生活に組み込むのが簡単であると述べました。ただし、音声ベースの会話による取り込みでは、一部の構造化日記フィールドの完全性が低くなり、表現力の豊かさと構造化の正確さとの間にトレードオフがあることが明らかになりました。これらの調査結果は、LLM を利用した会話型音声アシスタントを長期的な健康自己報告に使用することの可能性と課題の両方を示しています。
原文 (English)
Better Adherence, Richer Context: A Field Evaluation of LLM-Powered Conversational Voice Diaries for Sleep
Sleep diaries are central to behavioral sleep medicine and cognitive behavioral therapy for insomnia, yet daily completion is difficult to sustain, and static forms often provide limited context for interpreting night-to-night sleep variation. We designed an LLM-powered conversational voice diary that delivers clinically grounded morning and evening sleep diary questions through proactive smart-speaker prompts, structured conversational intake, and adaptive follow-up dialogue. We evaluated the system in a four-week between-subjects field study with 30 university students, comparing it with a text-based mobile diary using matched diary items, reporting windows, and reminder intervals. Compared with the text-based diary, the conversational voice diary showed higher adherence and elicited more detailed contextual self-report about routines, stressors, environmental conditions, and other sleep-related factors. Participants also described the voice diary as easier to integrate into daily routines, despite longer perceived completion time. However, voice-based conversational intake produced lower completeness for some structured diary fields, revealing a trade-off between expressive richness and structured precision. These findings show both the promise and the challenge of using LLM-powered conversational voice assistants for longitudinal health self-report.
MIDS: 双方向 Mamba を介した CAN バス上のステルス マスカレードおよび改ざん攻撃の検出
コントローラー エリア ネットワーク (CAN) プロトコルは、現代の車両の電子制御ユニット (ECU) の主要な通信標準ですが、暗号化と認証が欠如しているため、さまざまなセキュリティ上の脅威にさらされています。既存の侵入検知システムは主に製造型攻撃 (DoS、ファジング、フレーム インジェクションによって実現される ID スプーフィング) に合わせて調整されており、ID ごとの到着間隔統計などの検知信号が容易に利用可能です。代わりに、より困難な \emph{masquerade} 設定~\cite{b37} に対処します。この設定では、内部の敵対者が元の送信スロットで正当なフレームをその場で置き換え、トラフィックの周期性が維持され、トラフィック統計の防御が無効になります。私たちは、CAN 識別子とペイロードを並行して処理し、双方向の選択的状態空間モデリングを通じてそれらの結合時間セマンティクスを再構築する革新的なデュアルストリーム フレームワークである Mamba 侵入検知システム (MIDS) を提案します。 MIDS を評価するために、物理的な Tesla Model 3 から 3 つの運転体制にわたって 1 億を超える CAN フレームを収集し、ID のみ、データのみ、および組み合わせた変更にわたる 54 のマスカレード攻撃の亜種を合成しました。 MIDS は、このデータセットで 96.94\% の F1 を達成し、再現可能な最も強力なベースラインを 8 パーセンテージ ポイント以上上回り、1.147 ミリ秒のシングル ウィンドウ推論レイテンシを維持します。これは、リアルタイムのオンボード展開に十分な余裕があります。一般化を検証するために、マスカレードとインジェクションの両方のシナリオをカバーする 4 つの公開ベンチマーク (ROAD、CrySyS、OTIDS、CT\&T) で MIDS をさらに評価します。 MIDS は 93.70\% から 99.61\% の F1 を達成し、統一された 5 倍プロトコルの下で 8 つの再現ベースラインのうち最も強いものを最大 13.94 パーセントポイント上回ります。
原文 (English)
MIDS: Detecting Stealthy Masquerade and Tampering Attacks on CAN Bus via Bidirectional Mamba
The Controller Area Network (CAN) protocol is the primary communication standard for Electronic Control Units (ECUs) in modern vehicles, but its lack of encryption and authentication exposes it to a range of security threats. Existing intrusion detection systems are largely tuned to fabrication-style attacks (DoS, fuzzing, ID spoofing realised by frame injection), in which detection signals such as per-ID inter-arrival statistics are readily available. We instead address the harder \emph{masquerade} setting~\cite{b37}, in which an internal adversary substitutes a legitimate frame in-situ at its original transmission slot, preserving traffic periodicity and rendering traffic-statistic defences ineffective. We propose the Mamba Intrusion Detection System (MIDS), an innovative dual-stream framework that processes CAN identifiers and payloads in parallel and reconstructs their joint temporal semantics through bidirectional selective state-space modelling. To evaluate MIDS, we collected over 100 million CAN frames from a physical Tesla Model 3 across three driving regimes and synthesised 54 masquerade attack variants spanning ID-only, data-only, and combined modifications. MIDS attains an F1 of 96.94\% on this dataset, exceeding the strongest reproducible baseline by more than 8 percentage points, while sustaining a 1.147~ms single-window inference latency -- ample headroom for real-time onboard deployment. To verify generalisation, we further evaluate MIDS on four public benchmarks (ROAD, CrySyS, OTIDS, CT\&T) covering both masquerade and injection scenarios; MIDS attains F1 from 93.70\% to 99.61\%, outperforming the strongest of eight reproduced baselines by up to 13.94 percentage points under a unified 5-fold protocol.
報酬モデルの操作可能な文化的嗜好の最適化
大規模言語モデル (LLM) テクノロジは、各コミュニティに受け入れられる方法で、さまざまな文化的なサブコミュニティにサービスを提供するために不可欠です。ただし、LLM アライメントに関する研究はこれまでのところ、特定の地域のアノテーターの統一された応答の好みを予測することに主に焦点を当ててきました。この文書は、サブコミュニティの好みを正確に表現でき、サブコミュニティのいずれかに対して過度の偏見を示さない、よりグローバルな見通しを持った調整モデルの開発を進めることを目的としています。我々は、この目的のための報酬モデルの開発に焦点を当て、多様な文化的嗜好をバランスよく組み込むことができる新しい報酬モデルトレーニングアルゴリズム(SCPO)を提示します。私たちの方法では、PRISM と GlobalOpinionQA の 2 つのデータセットおよび 7 か国にわたって、少数派報酬モデルのパフォーマンスがベースライン モデルよりも最大 7 ポイント向上しました。 SCPO は、報酬モデルのフルデータ微調整よりもトレーニング データ効率が最大 280% 優れています。さらに、サブコミュニティの好みを個別に評価することでバイアスの分析を実行し、重み付け方法によって過度のバイアスが軽減されることを示します。私たちのコードは https://github.com/minsik-ai/Steerable-Cultural-Preference で入手できます。
原文 (English)
Steerable Cultural Preference Optimization of Reward Models
It is essential for large language model (LLM) technology to serve many different cultural sub-communities in a manner that is acceptable to each community. However, research on LLM alignment has so far predominantly focused on predicting a unified response preference of annotators from certain regions. This paper aims to advance the development of alignment models with a more global outlook, that are able to accurately represent the preferences of subcommunities and do not exhibit excessive bias towards any of them. We focus on the development of reward models for this purpose and present a novel reward model training algorithm (SCPO) that can incorporate diverse cultural preferences in a balanced manner. Our method results in performance increases of the minority reward model of up to 7 points over the baseline model across two datasets, PRISM and GlobalOpinionQA, and across 7 countries. SCPO is up to 280% more training data-efficient than full-data finetuning of reward models. In addition, we perform analysis of bias by separately evaluating on the preference of subcommunities and show that excessive bias is mitigated via our weighting method. Our code is available at https://github.com/minsik-ai/Steerable-Cultural-Preference
QC-GAN: 高忠実度音声強化のためのパラメータ効率の高いクォータニオンコンフォーマー GAN
我々は、Quaternion Conformer ジェネレーターと MetricGAN ベースのトレーニングを組み合わせた、パラメーター効率の高い音声強調フレームワークである Quaternion Conformer GAN (QC-GAN) を提案します。ハミルトン積は、構造化された重み共有を介して振幅と位相をエンコードし、相互依存性を維持しながら層パラメーターの数を削減します。近似的な知覚評価スコアを最適化することで知覚品質を最大化するために、メトリック学習弁別器が採用されました。 VoiceBank+DEMAND データセットでは、QC-GAN はわずか 0.89 万のパラメーターで音声品質知覚評価 (PESQ) スコア 3.48 を達成し、半分以下のサイズで最先端のモデルに匹敵するパフォーマンスを実現しました。 35K パラメータのバリアントは、PESQ スコア 3.23 を達成し、パラメータが大幅に少ない従来の方法を上回りました。 DNS-Challenge 3 データセットの評価により、現実世界の状況への一般化がさらに確認されました。
原文 (English)
QC-GAN: A Parameter-Efficient Quaternion Conformer GAN for High-Fidelity Speech Enhancement
We propose a parameter-efficient speech enhancement framework, Quaternion Conformer GAN (QC-GAN), which combines a Quaternion Conformer generator with MetricGAN-based training. The Hamilton product encodes the magnitude and phase via structured weight sharing, reducing the number of layer parameters while preserving their interdependencies. A metric-learning discriminator was employed to maximize perceptual quality by optimizing the approximate perceptual evaluation scores. On the VoiceBank+DEMAND dataset, QC-GAN achieved a Perceptual Evaluation of Speech Quality (PESQ) score of 3.48 with only 0.89M parameters, delivering a performance comparable to state-of-the-art models at less than half their size. A 35K-parameter variant achieved a PESQ score of 3.23, surpassing conventional methods with significantly fewer parameters. Evaluation on the DNS-Challenge 3 dataset further confirmed generalization to real-world conditions.
LLM は医師を支援する準備ができていますか?インタラクティブな医師、患者、EHR 支援のための PhysAssistBench
医療 LLM の最も妥当な短期的な役割は、医師の代わりではなく支援することですが、現在の評価では、臨床知識、EHR システムの相互作用、患者とのコミュニケーションなど、個別の能力がテストされることがよくあります。代わりに、医師の支援には同じ対話内でこれらの機能を調整する必要があり、医師は不明確な要求を発行し、患者は症状を曖昧に説明し、EHR システムはツールの正確な使用を要求します。インタラクティブな医師、患者、EHR 支援のベンチマークである PhysAssistBench を紹介します。実際の MIMIC-IV 症例から構築された PhysAssistBench は、スケーラブルなパイプラインを使用してエージェント性患者を構築します。これは、臨床上の事実を維持しながら、静的な EHR 記録を複数ターンの臨床シナリオに変換する、インタラクティブで記録に基づいたエージェントです。 PhysAssistBench は、手動でレビューされ医師が検証した 1,296 ターンの厳選されたバイリンガル評価セットを提供します。主要な LLM を使った実験では、この設定では現在のモデルの信頼性が依然として低いことが示されており、臨床 LLM にとって重要なボトルネックが露呈しています。信頼できる支援には、知識、コミュニケーション、システム全体の調整が必要であり、それらのいずれかで単独の利益を得るのではありません。
原文 (English)
Are LLMs Ready to Assist Physicians? PhysAssistBench for Interactive Doctor-Patient-EHR Assistance
The most plausible near-term role of medical LLMs is to assist rather than replace physicians, yet current evaluations often test isolated capabilities: clinical knowledge, EHR system interaction, or patient communication. Physician assistance instead requires coordinating these capabilities within the same interaction, where physicians issue underspecified requests, patients describe symptoms ambiguously, and EHR systems demand precise tool use. We introduce PhysAssistBench, a benchmark for interactive doctor-patient-EHR assistance. Built from real MIMIC-IV cases, PhysAssistBench uses a scalable pipeline to construct agentic patients: interactive, record-grounded agents that turn static EHR records into multi-turn clinical scenarios while preserving clinical factuality. PhysAssistBench provides a curated bilingual evaluation set of 1,296 manually reviewed and physician-validated turns. Experiments with leading LLMs show that current models remain unreliable in this setting, which exposes a key bottleneck for clinical LLMs: reliable assistance requires coordination across knowledge, communication, and systems, not isolated gains in any of them.
AI を活用した人間の家庭教師の評価: トレーニングのパフォーマンスを実際の実践に結びつける
家庭教師トレーニング プラットフォームは数多く存在します。しかし、実際のパフォーマンスに基づいて人間の家庭教師に AI 主導のトレーニングと評価を提供しているところはほとんどありません。私たちは、トレーニング中のオープンな回答と本物の現実の個別指導の両方を評価する AI 主導のシステムを紹介します。オンライン トレーニングやシミュレーションを通じてのみ学習を評価するプラットフォームとは異なり、当社のシステムは生成 AI (Gemini-2.5-pro) を利用して本物の個別指導の文字起こしを分析し、講師のスキルの実際の応用への移行を測定します。生徒に数学をリモートで指導する人間の家庭教師 (N=86) は 6 つのシナリオベースのレッスンを完了し、平均して 7.4% の大幅な学習向上を達成しました。 405 のセッションとレッスンのペアにわたる混合効果モデルを使用したところ、トレーニングのパフォーマンスが効果量 0.25 SD で実際の成績証明書スコアを有意に予測することがわかりました。モデル比較 (AIC/BIC) では、トレーニング中の自由応答と多肢選択のパフォーマンスを平均すると、実際の家庭教師のパフォーマンスが最もよく予測されることが示されましたが、自由応答の方が比較的予測性が高かったです。探索的分析の結果、トレーニング後、家庭教師はスキルを応用するための教育的機会に遭遇する可能性が大幅に高く (61.1% ~ 68.9%)、その機会内での実践の質がより高いことが実証されました (65.5% ~ 68.1%)。中断された時系列分析は、これらの家庭教師の改善は、トレーニングの即時介入効果ではなく、時間の経過とともに徐々に進む傾向の一部であることを示唆しました。家庭教師のトレーニングと実際の評価を結び付ける AI 主導の方法を説明します。その際、透明性と再現性をサポートするために、オープン データセット、AI プロンプト、スコアリング ルーブリックを提供します。
原文 (English)
AI-Driven Assessment of Human Tutors: Linking Training Performance to Real-Life Practice
There exist numerous tutor training platforms. However, few provide AI-driven training and evaluation for human tutors based on real-life performance. We present an AI-driven system that assesses both open responses during training and authentic real-life tutoring. Unlike platforms that only assess learning through online training or simulations, our system utilizes Generative AI (Gemini-2.5-pro) to analyze transcriptions of authentic tutoring, measuring the transfer of tutor skills to real-life application. Human tutors instructing students remotely in math (N=86) completed six scenario-based lessons, averaging a significant 7.4% learning gain. Using mixed-effects models across 405 session-to-lesson pairs, we found that training performance significantly predicted real-life transcript scores with an effect size of 0.25 SD. Model comparison (AIC/BIC) indicated averaging open response and multiple choice performance during training predicted real-life tutor performance best, although open responses were comparatively more predictive. Exploratory analysis showed that after training, tutors were significantly more likely to encounter pedagogical opportunities to apply their skills (61.1% to 68.9%) and demonstrated higher execution quality within those opportunities (65.5% to 68.1%). Interrupted time series analysis suggested that these tutor improvements were part of a gradual trend over time rather than an immediate intervention effect of training. We illustrate an AI-driven method to link tutor training with real-life assessment. In doing so, we contribute open datasets, AI prompts, and scoring rubrics to support transparency and reproducibility.
Code-Augur: 仕様推論によるエージェントによる脆弱性検出
エージェントによる脆弱性検出の出現は、すでにソフトウェア セキュリティの転換点になりつつあります。自律的なLLMエージェントのみによって実施される監査により、デジタル社会を支える基本的なソフトウェアの重大な脆弱性が明らかになりました。これらの脆弱性の多くは何年も隠蔽されたままでしたが、AI エージェントによって初めて表面化しました。しかし、これらの発見の背後にある推論は、驚くほど不透明で検証されていないままです。エージェントは、関数が安全であると判断したときに、その関数の入力についてどのような仮定を立てましたか?推論の失敗や誤った仮定は、脆弱性の見逃しにつながり、エージェント分析の信頼性を低下させる可能性があります。我々は、(1) エージェントの暗黙の前提をセキュリティ仕様として明示的に公開し、(2) 実行時の改ざんによってそれらの仕様を継続的に改良する、セキュリティ仕様優先パラダイムを提案します。私たちは、エージェントによる脆弱性検出のための新しいハーネスである Code-Augur でアプローチを実現しています。コードベースが与えられると、Code-Augur はシステムの各コンポーネントを分析して脆弱なコードがないかどうかを確認します。コンポーネントが安全であると判断した場合、その判断の背後にあるローカル不変条件をソース内アサーションとしてコミットします。並行して、Code-Augur はガイド付きファザーを活用して、これらの仮定を改ざんしようと試みます。ファザーがアサーションをトリガーすると、真の脆弱性または改善すべき欠陥のある仕様が明らかになります。どちらの場合も、このプロセスによりエージェントの理解が確立され、コードの意図の見方とコードが実際にどのように動作するかが一致します。現実世界の主題に関して、Code-Augur はセキュリティ仕様を効果的に活用して、他の最先端のエージェントよりも多くの脆弱性を検出します。さらに、Code-Augur は主要なオープンソース プロジェクトで 22 件の新たな脆弱性を発見しました。 Claude Mythos のような厳選された特殊なモデルと比較して、Code-Augur は Sonnet や DeepSeek などの広く利用可能な LLM に基づいて構築された効果的なエージェント脆弱性検出を提供します。
原文 (English)
Code-Augur: Agentic Vulnerability Detection via Specification Inference
The advent of agentic vulnerability detection is already becoming a watershed moment for software security. Audits conducted entirely by autonomous LLM agents are uncovering critical vulnerabilities in fundamental software underpinning digital society. Many of these vulnerabilities remained masked for years, surfacing only now with AI agents. Yet the reasoning behind these discoveries remains alarmingly opaque and unvalidated. What assumptions did the agent make about a function's inputs when it deemed that function to be secure? Failures in reasoning and incorrect assumptions can lead to missed vulnerabilities and reduce trust in agentic analysis. We propose a security-specification-first paradigm that (1) exposes the agent's tacit assumptions explicitly as security specifications and (2) continuously refines those specifications via runtime falsification. We realize our approach in Code-Augur, a novel harness for agentic vulnerability detection. Given a codebase, Code-Augur analyzes each component of the system for vulnerable code. When it deems a component to be secure, it commits the local invariants behind that judgment as in-source assertions. In parallel, Code-Augur leverages a guided fuzzer to attempt to falsify those assumptions. When the fuzzer triggers an assertion, this either reveals a genuine vulnerability or a flawed specification to refine. In both cases, this process grounds the agent's understanding, aligning its view of code intent with how the code actually behaves. On real-world subjects, Code-Augur effectively leverages security specifications to detect more vulnerabilities than other state-of-the-art agents. Additionally, Code-Augur found 22 new vulnerabilities in key open-source projects. Compared to curated specialized models like Claude Mythos, Code-Augur offers effective agentic vulnerability detection built on widely available LLMs like Sonnet and DeepSeek.
BCL: 情報抽出のためのベイズインコンテキスト学習フレームワーク
既存の情報抽出 (IE) タスクでは、大規模な言語モデルを使用したコンテキスト内学習 (ICL) の採用が増えています。ただし、現在のアプローチでは、モデルのスケール全体で一貫性のないパフォーマンスが示されているか、体系的な最適化と一般化が不足しています。これに基づいて、私たちは BCL (情報抽出のためのベイジアン インコンテキスト学習フレームワーク) を提案します。これは、ベイジアン更新による粒子フィルターを使用して、IE タスク全体のラベル表現を体系的に改良する最初の最適化フレームワークです。 BCL は、初期化、観察、重み更新、リサンプリングの 4 つのステップを通じて、シーケンスのラベル付けと関係分類のパラダイムの両方に一般化されます。広範な実験により、既存のアプローチに比べて大幅かつ一貫した改善が実証されています。
原文 (English)
BCL: Bayesian In-Context Learning Framework for Information Extraction
Existing information extraction (IE) tasks increasingly adopt in-context learning (ICL) with large language models. However, current approaches either show inconsistent performance across model scales or lack systematic optimization and generalizability. Building on this, we propose BCL (Bayesian In-Context Learning Framework for Information Extraction), the first optimization framework that uses particle filtering with Bayesian updates to systematically refine label representations across IE tasks. Through four steps initialization, observation, weight update, and resampling, BCL generalizes to both sequence labeling and relation classification paradigms. Extensive experiments demonstrate substantial and consistent improvements over existing approaches.
EffiNav: 効率的なオブジェクト目標ナビゲーションのための深度と視覚言語の融合
未知の環境を探索しながら目標物体を見つけることは、自律エージェントの基本的な機能であり、その用途は捜索救助からフィールドロボットまで多岐にわたります。このようなタスクの簡略化されたバージョンは、オブジェクト ゴール ナビゲーション (ObjNav) です。 ObjNav では、ターゲット オブジェクトに正常に到着すると、パフォーマンスの基本的な尺度が得られます。ただし、ナビゲーション軌跡の効率も同様に重要です。これは、エージェントがどの程度インテリジェントに探索し、後続のタスクにどれだけの時間が残っているかを示すからです。未知の環境において、効率的なナビゲーションの鍵は、次にどこを探索するかを決定することにあります。これまでの多くの研究は、この中心的な課題に対処することを目的としており、特定の設定で有望なパフォーマンスを達成しましたが、最近のトレーニングベースのモデルと非トレーニング フレームワークはそれぞれ一般化と効率の問題に依然として悩まされており、最悪の場合、すでに訪問した領域の過剰な探索や冗長な往復動作につながる可能性があります。私たちは、広く使用されている 2 つのシミュレーション ベンチマークである Habitat Matterport 3D (HM3D) と Open-Vocabulary Object Goal Navigation (OVON) で EffiNav を評価し、実世界の設定における物理ロボットに対する EffiNav の有効性をさらに検証します。大規模なシミュレーションエピソードに対して故障解析を実施します。また、最小限の変更を加えて、EffiNav を GOAT-BENCH データセット上のメモリ拡張 ObjNav タスクに拡張し、標準の ObjNav 設定を超えた適応性を実証しました。成功率 (SR) とパス長による成功重み付け (SPL) という 2 つの標準指標にわたって、EffiNav は最近のベースラインと同等またはそれを上回り、その効率性、堅牢性、および実用的な適用性を反映しています。 2 つのデータセットの異なる重点を認識すると、パフォーマンスから、このフレームワークがよりバランスが取れており、効率的な ObjNav にとって一般化可能であることがわかります。
原文 (English)
EffiNav: Fusing Depth and Vision-Language for Efficient Object Goal Navigation
To locate a target object while exploring the unknown environment is a fundamental capability for autonomous agents, with applications ranging from search-and-rescue to field robots. A simplified version of such task is Object Goal Navigation (ObjNav). In ObjNav, successful arrival at the target object provides a basic measure of performance; however, the efficiency of the navigation trajectory is equally important, as it indicates how intelligently the agent explores and how much time remains for subsequent tasks. In unknown environments, the key to efficient navigation lies in deciding where to explore next. While many prior works aim to address this core challenge and achieved promising performance in certain settings, recent training-based models and non-training frameworks still suffer from generalization and efficiency issues respectively, which in the worst cases can lead to excessive exploration of already-visited areas or redundant back-and-forth motion. We evaluate EffiNav on two widely used simulation benchmarks Habitat Matterport 3D (HM3D) and Open-Vocabulary Object goal Navigation (OVON), and further validate its effectiveness on physical robots in real-world settings. We conduct failure analysis on massive simulation episodes. With minimal modification, we also extend EffiNav to a memory-augmented ObjNav task on the GOAT-BENCH dataset, demonstrating its adaptability beyond standard ObjNav settings. Across two standard metrics--Success Rate (SR) and Success weighted by Path Length (SPL), EffiNav matches or outperforms recent baselines, reflecting its efficiency, robustness, and practical applicability. Recognizing the different emphases of the two datasets, the performances reveals this framework is more balanced and generalizable for efficient ObjNav.
PEC-Home: スマート ホームにおける漸進的楕円コマンドの解釈
大規模言語モデル (LLM) の最近の進歩により、ホーム アシスタントに自然言語対話機能が与えられるようになりました。しかし、現在のアシスタントは、共有されたコンテキストが蓄積するにつれて人間の対話で発生する漸進的な省略を見逃しており、効率的なコミュニケーションのためにより省略された表現につながっています。したがって、現在のアシスタントは、このような楕円表現を正確に解釈するのに依然として苦労しており、現実世界のアプリケーションでの有効性が制限されています。実際のスマート ホーム シナリオでは、アシスタントは、楕円コマンドによって引き起こされる 2 つの大きな課題に直面します。(1) 複数のユーザー間の異なる環境期待によって引き起こされる参照の曖昧さ。 (2) 時間の経過とともに進化する、または環境とともに変化するユーザーの好みに起因する意図の曖昧さ。これらの課題に対処するために、スマート ホームで漸進的楕円コマンドを解釈するために特別に設計された初のシミュレートされた住宅データセットである PEC-Home を導入します。 GPT-4o を含むさまざまな LLM に関する広範な実験では、既存のホーム アシスタントが楕円コマンドのみに基づいてユーザーの意図した操作を実行するのに苦労していることが示されています。ユーザーの対話履歴を保存および取得するためのツールが装備されている場合でも、実行精度は完全なコマンドで達成される精度を下回っています。}
原文 (English)
PEC-Home: Interpretation of Progressively Elliptical Commands in Smart Homes
Recent advancements in Large Language Models (LLMs) have empowered home assistants with natural language interaction capabilities. However, current assistants overlook the progressive omission that occurs in human dialogue as shared context accumulates, leading to more elliptical expressions for efficient communication. Thus, current assistants still struggle to interpret such elliptical expressions accurately, which limits their effectiveness in real-world applications. In practical smart home scenarios, assistants face two major challenges caused by elliptical commands: (1) referential ambiguity caused by different environmental expectations among multiple users; and (2) intention ambiguity resulting from user preferences that evolve over time or change with the environment. To address these challenges, we introduce PEC-Home, the first simulated home dataset specifically designed for interpreting progressively elliptical commands in smart homes. Extensive experiments on various LLMs, including GPT-4o, show that existing home assistants struggle to execute user-intended operations based solely on elliptical commands. Even when equipped with tools for storing and retrieving user dialogue history, execution accuracy remains below that achieved with complete commands.}.
MOS の監督による構音障害の重症度評価の強化
構音障害は、明瞭さとコミュニケーション能力の低下を特徴とする言語障害です。構音障害のある発話の発話レベルの自動評価は、スケーラブルな発話モニタリングと治療関連の分析をサポートできます。しかし、そのようなシステムのトレーニングは、臨床的に注釈が付けられた構音障害音声の不足によってボトルネックになっています。この研究では、音声合成評価、特に QualiSpeech コーパスの平均意見スコア (MOS) ラベルを使用して人間が注釈を付けた発話からのデータを使用して、構音障害音声評価を強化することを提案しています。実験によると、音声合成評価データの微調整により、明瞭度と自然さの予測の両方のパフォーマンスが一貫して向上し、共同トレーニングでは主に自然さの向上が得られます。これらの結果は、合成アーティファクトと構音障害音声には知覚上の共通点があり、音声合成評価コーパスは希少な臨床注釈への依存を減らす実用的な拡張ソースを提供することを示唆しています。
原文 (English)
Augmenting Dysarthric Speech Severity Assessment with MOS Supervision
Dysarthria is a speech disorder marked by reduced intelligibility and communicative effectiveness. Automatic utterance-level assessment of dysarthric speech can support scalable speech monitoring and therapy-related analysis. Yet training such systems is bottlenecked by the scarcity of clinically annotated dysarthric speech. This work proposes to augment dysarthric speech assessment using data from speech synthesis evaluations, specifically human-annotated utterances with Mean Opinion Score (MOS) labels from the QualiSpeech corpus. Experiments show that fine-tuning on speech synthesis assessment data consistently improves performance on both intelligibility and naturalness prediction, while joint training yields gains primarily on naturalness. These results suggest that synthesis artifacts and dysarthric speech share perceptual commonalities, and speech synthesis evaluation corpora offer a practical augmentation source that reduces reliance on scarce clinical annotations.
マルチモーダル LandslideBench を備えた LandslideAgent: 自律的な地滑りの識別と分析のためのドメインルール拡張エージェント
土砂災害のインテリジェントな解釈は防災にとって重要ですが、現在のパラダイムでは視覚的特徴と高レベルの地球科学的意味論を同時に抽出するのに苦労しており、汎用の視覚言語モデル (VLM) は複雑な地質学的シナリオにおいて知覚の限界と領域幻覚に悩まされています。これらの課題に対処するために、3 つのコンポーネントで構成される命令駆動型のエージェント フレームワークを提案します。まず、7 つのサブタイプ ラベル、高解像度画像、ピクセル レベルのマスク、高品質のテキスト記述を備えたマルチモーダルのきめ細かいデータセットである LandslideBench が、マルチ VLM 相互検証とインタラクティブなアノテーションによって構築されます。次に、地滑り指向の VLM である LandslideVLM が、LandslideBench の LoRA を介して微調整され、地質学的意味の理解を強化します。最後に、LandslideVLM をコグニティブ バックボーンとして採用するドメイン ルール強化エージェントである LandslideAgent は、構造化レポート メタデータ制約と相互検証識別制約を組み込んだデュアル ルール コントローラーを採用して、自動ツールの呼び出しを制御します。実験では、LandslideBench が、きめ細かい分類とセマンティック セグメンテーションに関する 5 つの主流モデルにわたって効果的なベースラインを提供することを示しています。 LandslideVLM は、地滑りの識別、詳細な分類、および意味論的記述の品質において、それぞれ 10.96%、32.87%、および 15.91% の精度向上を達成しました。 LandslideAgent はさらに、自律的なマルチソース空間データ推論を可能にし、地滑りの特定と分析のためのフルプロセス インテリジェンスを実現します。
原文 (English)
LandslideAgent with Multimodal LandslideBench: A Domain-Rule-Augmented Agent for Autonomous Landslide Identification and Analysis
Intelligent landslide hazard interpretation is critical for disaster prevention, yet current paradigms struggle to simultaneously extract visual features and high-level geoscientific semantics, while general-purpose vision-language models (VLMs) suffer from perceptual limitations and domain hallucinations in complex geological scenarios. To address these challenges, we propose an instruction-driven agentic framework comprising three components. First, LandslideBench, a multimodal fine-grained dataset with seven subtype labels, high-resolution imagery, pixel-level masks, and high-quality textual descriptions, is constructed via multi-VLM cross-validation and interactive annotation. Then, LandslideVLM, a landslide-oriented VLM, is fine-tuned via LoRA on LandslideBench to enhance geological semantic understanding. Finally, LandslideAgent, a domain rule-enhanced agent taking LandslideVLM as its cognitive backbone, employs a dual-rule controller incorporating structured report metadata constraints and cross-validation identification constraints to regulate automated tool invocation. Experiments demonstrate that LandslideBench provides effective baselines across five mainstream models on fine-grained classification and semantic segmentation. LandslideVLM achieves accuracy improvements of 10.96%, 32.87%, and 15.91% on landslide discrimination, fine-grained classification, and semantic description quality, respectively. LandslideAgent further enables autonomous multi-source spatial data inference, realizing full-process intelligence for landslide identification and analysis.
NeuralMUSIC: ロボット音源位置特定のためのハイブリッド神経部分空間フレームワーク
信頼性の高い音源定位はロボットの聴覚の基礎であり、自律ロボットが空間的な手がかりを認識し、動的な環境で効果的に動作できるようになります。多重信号分類 (MUSIC) などの古典的な手法は強力な理論的基盤を提供しますが、信号対雑音比が低いと性能が低下します。深層学習ベースのアプローチは有望なパフォーマンスを達成しますが、多くの場合、条件全体にわたる限られた一般化に苦労します。これらの課題に対処するために、ロボットによる音源定位のためのハイブリッド神経部分空間フレームワークである NeuralMUSIC を提案します。具体的には、ニューラル ネットワークはまず、マルチチャネル マイクの観測値から空間共分散行列を推定します。予測された共分散は、固有値分解 (EVD) と擬似スペクトル計算を使用して古典的な MUSIC パイプラインに統合され、その後、周波数アテンション フュージョン (FAF) モジュールによって最終的な DOA 推定値が生成されます。データ効率を向上させるために、ラベルなしの音響データを活用して空間構造を捕捉する自己教師付き空間相関学習 (SSCL) 戦略をさらに導入します。さまざまなロボット タスクにわたる広範な実験により、NeuralMUSIC が堅牢性とクロスドメイン汎用性の向上を示しながら、競争力のある位置特定精度を達成できることが実証されました。
原文 (English)
NeuralMUSIC: A Hybrid Neural-Subspace Framework for Robot Sound Source Localization
Reliable sound source localization is fundamental to robot audition, enabling autonomous robots to perceive spatial cues and operate effectively in dynamic environments. Classical methods such as Multiple Signal Classification (MUSIC) offer strong theoretical foundations but degrade under low signal-to-noise ratios. While deep learning-based approaches achieve promising performance, they often struggle with limited generalization across conditions. To address these challenges, we propose NeuralMUSIC, a hybrid neural-subspace framework for robotic sound source localization. Specifically, a neural network first estimates the spatial covariance matrix from multichannel microphone observations. The predicted covariance is then integrated into a classical MUSIC pipeline with eigenvalue decomposition (EVD) and pseudo-spectrum computation, followed by a Frequency Attention Fusion (FAF) module to produce the final DOA estimates. To improve data efficiency, we further introduce a Self-supervised Spatial Correlation Learning (SSCL) strategy that leverages unlabeled acoustic data to capture spatial structure. Extensive experiments across different robotic tasks demonstrate that NeuralMUSIC achieves competitive localization accuracy while exhibiting improved robustness and cross-domain generalization.
scGTN: 単一細胞 RNA シーケンシング クラスタリングのためのディープ シャム グラフ トランスフォーマー ネットワーク
単一細胞 RNA シーケンス (scRNA-seq) は、細胞レベルでの遺伝子発現の特徴付けにおいて極めて重要な役割を果たし、細胞型の同定を可能にし、細胞の不均一性の理解を促進します。 scRNA-seq データのクラスタリングは大幅に進歩しているにもかかわらず、現在の手法では、scRNA-seq データに固有の複雑な細胞間構造情報だけでなく、スパース性やノイズも常に無視されていると我々は主張します。この目的に向けて、本論文では、細胞クラスタリングのための遺伝子発現プロファイルと細胞間構造依存性を明示的に統合する、ディープ Siamese Graph Transformer Network (scGTN と呼ばれる) を介した新しい単一細胞 RNA-seq クラスタリング フレームワークを提案します。特に、scRNA-seq データをグラフとして定式化し、相補的な細胞間情報を捕捉するための二重ビューとして機能する 2 つの拡張グラフ ビューを構築します。次に、シャム グラフ トランスフォーマー ネットワークを使用して、セル間のより豊富な構造関係をキャプチャするための最短パス情報とノードごとの距離を明示的に組み込みます。最後に、最適な輸送戦略を採用して、自己監視型でセルのクラスタリングを誘導します。複数のベンチマーク scRNA-seq データセットに対する広範な実験により、当社の scGTN が既存の方法よりも一貫して優れていることが実証されました。私たちのコードは https://github.com/W-RMSL/scGTN で入手できます。
原文 (English)
scGTN: Deep Siamese Graph Transformer Network for Single-cell RNA Sequencing Clustering
Single-cell RNA sequencing (scRNA-seq) serves a pivotal role in characterizing gene expression at the cellular level, enabling the identification of cell types and advancing the understanding of cellular heterogeneity. Despite the significant progress in scRNA-seq data clustering, we argue that current methods always ignore the sparsity and noise, as well as the complex intercellular structural information inherent in scRNA-seq data. Toward this end, in this paper, we propose a novel single-cell RNA-seq clustering framework via deep Siamese Graph Transformer Network (termed scGTN), which explicitly integrates gene expression profile and intercellular structural dependencies for cell clustering. In particular, we formulate scRNA-seq data as a graph and construct two augmented graph views that serve as dual views to capture complementary intercellular information. Then, a Siamese graph transformer network is employed to explicitly incorporate shortest-path information and node-wise distances for capturing richer structural relationships between cells. Finally, we employ an optimal transport strategy to guide the cell clustering in a self-supervised manner. Extensive experiments on multiple benchmark scRNA-seq datasets demonstrate that our scGTN consistently outperforms existing methods. Our code is available at https://github.com/W-RMSL/scGTN.
ストリーム学習における表形式基盤モデルの境界付きコンテキスト管理
表形式のストリーム学習には、分布シフトの下で順次到着するサンプルの予測が必要です。標準的な手法はモデルの状態を更新することで適応しますが、表形式の基礎モデル (TFM) は、コンテキスト内でラベル付けされたコンテキストを条件とした予測を行うため、ストリーム学習の自然な代替手段となります。これにより、課題はモデルを更新する方法からコンテキストを管理する方法に変わります。我々は、コンテキスト管理のための 3 つの実際的な要件、つまり、最近の例を保存する、不確実な例を保持する、および冗長な例を削除するという 3 つの実際的な要件を生み出す将来の情報ビューを提案します。これらの要件を、エントロピー ゲート アドミッションと冗長性を意識したエビクションを備えたコンテキスト管理ポリシーである CURE (不確実性を意識したアドミッションと冗長性を意識したエビクションによるコンテキスト管理) としてインスタンス化します。 7 つのストリームにわたって、CURE は従来のストリーム学習器と比較して最大 27.0% の相対的な改善を示し、複数の TFM バックボーンにわたって堅牢性を維持し、他のポリシー バリアントの中で 1 位にランクされています。コードとデータセットは https://github.com/morcellinus/CURE-ICML-FMSD で入手できます。
原文 (English)
Bounded Context Management for Tabular Foundation Models on Stream Learning
Tabular stream learning requires predictions on sequentially arriving examples under distribution shift. While standard methods adapt by updating model states, tabular foundation models (TFMs) make predictions conditioned on a labeled context in an in-context manner, making them a natural alternative for stream learning. This shifts the challenge from how to update the model to how to manage the context. We propose a future information view that yields three practical requirements for context management: preserve recent examples, retain uncertain examples, and remove redundant examples. We instantiate these requirements as CURE (Context management via Uncertainty-aware admission and Redundancy aware Eviction), a context-managing policy with entropy-gated admission and redundancy-aware eviction. Across seven streams, CURE shows up to 27.0% relative improvement over classical stream learners, remains robust across multiple TFM backbones, and ranks first among other policy variants. Code and datasets are available at https://github.com/morcellinus/CURE-ICML-FMSD.
Dual-Channel Grounded World Modeling (DCGWM): Structural Prevention of Objective Interference Collapse via Heterogeneous External Grounding with Inward-Only Gradient Flow
Joint Embedding Predictive Architectures (JEPAs) are a leading approach to world model representation learning. We identify a failure mode…
Leveraging Energy Features for Surface Classification with Deep Learning: A Comparative Analysis Across Three Independent Datasets
The energy-based method remains a comparatively underexamined approach for surface classification in mobile robotics, despite promising res…
TW-LegalBench: Measuring Taiwanese Legal Understanding
Large language models (LLMs) have shown impressive capabilities across diverse tasks, yet their performance on jurisdiction-specific legal…
Morpheus: A Morphology-Aware Neural Tokenizer and Word Embedder for Turkish
Turkish is agglutinative: meaning is carried by morphemes, yet the subword tokenizers that drive modern language models split words by corp…
Graph Grounded Cross Attention Transformer Neural Network for Structurally Constrained Full Event Sequence Generation in Predictive Process Monitoring
Structurally constrained event sequence generation remains challenging because generated paths must preserve transition feasibility, tempor…
Two-Phase Bilevel Search for the Moving-Target Traveling Salesman Problem with Moving Obstacles
The Moving-Target Traveling Salesman Problem (MT-TSP) seeks a minimum cost trajectory for an agent that departs from a static depot, visits…
SWE-Future: Forecast-Conditioned Data Synthesis for Future-Oriented Software Engineering Agents
Realistic coding-agent benchmarks often replay public GitHub issues and pull requests, making them vulnerable to overlap with model pretrai…
Generating Natural and Expressive Robot Gestures through Iterative Reinforcement Learning with Human Feedback using LLMs
Expressive gestures are essential for natural and effective communication, complementing speech when verbal cues alone are insufficient (e.…
Private Learning with Public Feature Conditioning
We study differentially private (DP) regression in settings where each data sample includes public, non-sensitive features -- common in app…
RedactionBench
Large Language Models are increasingly applied to sensitive domains that require redaction of personally identifiable information (PII). Wh…
Bayesian Anytime Pareto Set Identification for Multi-Objective Multi-Armed Bandits
Identifying Pareto optimal solutions is critical to support multi-objective decision-making. We introduce the first anytime Multi-Objective…
Closing the Loop: PID Feedback Control for Interpretable Activation Steering in Symbolic Music Generation
Transformer-based architectures have significantly advanced the generation of complex symbolic sequences, yet a significant gap remains in…
SHIFT: Semantic Harmonization via Index-side Feature Transformation for Multilingual Information Retrieval
With the rapid expansion of massive multilingual corpora, Multilingual Information Retrieval (MLIR) has emerged as a critical technology fo…
Learning from Own Solutions: Self-Conditioned Credit Assignment for Reinforcement Learning with Verifiable Rewards
Reinforcement learning with verifiable rewards (RLVR) has driven substantial progress in training LLMs for reasoning tasks, but representat…
Rescaling MLM-Head for Neural Sparse Retrieval
Learned sparse retrieval (LSR) models such as SPLADE have traditionally used BERT-style masked language models as backbone encoders. A natu…
Reinforcement Learning Foundation Models Should Already Be A Thing
Foundation models for language and vision are powered by internet-scale data, while structured domains (tabular prediction, time-series for…
SwitchBraidNet: Quantisation-Aware Lightweight Architecture for Hybrid Brain-Computer Interface
Hybrid brain-computer interfaces (BCIs) that integrate motor imagery (MI) and steady-state visual evoked potentials (SSVEP) provide high-di…
Maturing Markov Decision Processes: Decision Making under Increasing Information and Shrinking Action Sets
Sequential decision problems often exhibit an asymmetric evolution of information and decision flexibility: as a decision cycle unfolds, th…
Space Is Intelligence: Neural Semigroup Superposition for Riemannian Metric Generation
Traditional approaches place intelligence in the agent, whether as a learned policy or a search procedure. We instead place intelligence in…
Beyond Reward Engineering: A Data Recipe for Long-Context Reinforcement Learning
Long-context reasoning is an essential capability for large language models, particularly when they are deployed as autonomous agents that…
Target-confidence Recourse Using tSeTlin machines: TRUST
Counterfactual explanations are widely used to provide algorithmic recourse in high-stakes decision-making systems. Most existing methods s…
Improving Human-Robot Teamwork in Urban Search and Rescue Through Episodic Memory of Prior Collaboration
Effective human-robot teamwork requires robots to adapt to partners, situations, and task dynamics from the start of an interaction. In the…
Skill-MAS: Evolving Meta-Skill for Automatic Multi-Agent Systems
Large Language Model (LLM)-based automatic Multi-Agent Systems (MAS) generation has become a crucial frontier for tackling complex tasks. H…
Aligning Implied Statements for Implicit Hate Speech Generalizability with Context-Bounded Semi-hard Negative Mining
Classifying implicit hate speech remains a challenge, as intent is often masked through insinuation and context rather than explicit slurs.…
URDF Synthesis from RGB-D Sequences via Differentiable Joint Inference and Energy-Consistent Verification
Reconstructing simulation-ready digital twins of articulated objects from sensor observations remains constrained by two persistent gaps: (…
Scaling Learning-based AEB with Massive Unlabeled Data
This paper studies how to scale learning-based automatic emergency braking (AEB) with massive unlabeled fleet data under production constra…
Domain-Shift Aware Neural Networks for Unbalance Characterization in Rotating Systems
This work investigates the application of a domain-shift aware neural network for regression tasks aimed at estimating unbalance masses in…
SAERec: Constructing Fine-grained Interpretable Intents Priors via Sparse Autoencoders for Recommendation
Intent-based recommender systems have gained significant attention for improving accuracy and interpretability by modeling the underlying m…
As Easy as Rocket Science: Assessing the Ability of Large Language Models to Interpret Negation in Figurative Language
Figurative language and negation are two areas that challenge current language models, however, both are widely used throughout written and…
TransitNet: A Compact Attention-Augmented Deep Learning Framework for Low-SNR Transit Blind Searches
Motivated by the observational incompleteness of intermediate-to-long-period Earth-size planets, we present TransitNet, a compact attention…
A Controlled Benchmark of Quantum-Latent GAN Augmentation for Brain MRI
Medical image classification is often constrained by limited labeled data, motivating generative augmentation; recently, quantum generative…
CAPRA: Scaling Feedback on Software Architecture Deliverables with a Multi-Agent LLM System
Automated assessment in software engineering education has advanced significantly for code grading and essay scoring. However, reviewing so…
Beyond Tokenization: Direct Timestep Embedding and Contrastive Alignment for Time-Series Question Answering
Recent advances in large language models (LLMs) have given rise to time-series question answering (TSQA), which formulates time-series anal…
G-IdiomAlign: A Gloss-Pivoted Benchmark for Cross-Lingual Idiom Alignment
Idioms are difficult to transfer across languages due to their non-compositionality and weak surface-form grounding, making literal mapping…
TRAP: Benchmark for Task-completion and Resistance to Active Privacy-extraction
Agents are increasingly deployed in document-intensive workflows where sensitive private information is not an edge case but a routine inpu…
Spotlight: Synergizing Seed Exploration and Spot GPUs for DiT RL Post-Training
Reinforcement learning (RL) post-training of Diffusion Transformers (DiTs) is prohibitively expensive, requiring thousands of high-end GPUs…
FoMoE: Breaking the Full-Replica Barrier with a Federation of MoEs
Pre-training Large Language Models (LLMs) typically demands large-scale infrastructure with tightly coupled hardware accelerators. While in…
A Hybrid LSTM--Vision Transformer Architecture for Predicting HRRR Forecast Errors
Forecast errors in high-resolution numerical weather prediction (NWP) systems are often linked to unresolved planetary boundary layer (PBL)…
Where Did the Variability Go? From Vibe Coding to Product Lines by Regeneration
In vibe coding, an emerging AI-driven paradigm, an LLM generates an entire program from a natural language prompt, but what happens to the…
ProductConsistency: Improving Product Identity Preservation in Instruction-Based Image Editing via SFT and RL
Recent advances in instruction-based image editing have enabled models to perform complex visual edits from natural language instructions.…
Leadership as Coordination Control: Behavioral Signatures and the Recovery-Advantage Boundary in Multi-Agent LLM Teams
Team science holds that leadership is contingent: it helps only under specific conditions, and capable, autonomous teams may need none at a…
Equivariant Graph Neural Networks Improve Optical Spectra Prediction for Materials Screening
Scalable prediction of optical spectra is a critical component of high-throughput materials screening for optoelectronic applications such…
Pareto Q-Learning with Reward Machines
We present Pareto Q-Learning with Reward Machines (PQLRM), a multi-objective reinforcement learning algorithm for tasks whose reward struct…
A Technical Taxonomy of LLM Agent Communication Protocols
As large language models (LLMs) advance and multi-agent systems aim to overcome the limits of standalone agents, robust communication proto…
OrthoReg: Orthogonal Regularization for Hybrid Symbolic-Neural Dynamical Systems
Dynamical systems are fundamental to modeling the natural world, yet modeling them involves a persistent trade-off: manually prescribed mec…
AdsMind: A Physics-Grounded Multi-Agent System for Self-Correcting Discovery of Adsorption Configurations on Heterogeneous Catalyst Surfaces
Identifying the lowest-energy surface-adsorbate configuration is critical for modeling heterogeneous catalysis, yet exhaustive exploration…
Essential Subspace Merging for Multi-Task Learning
Model merging aims to enable multi-task learning by integrating the capabilities of multiple models fine-tuned from the same pre-trained ch…
A Clinician-Centered Pipeline for Annotation and Evaluation in Ultrasound AI Studies
Clinician-centered evaluation is critical for validating medical AI systems, especially in ultrasound imaging where quantitative metrics do…
Hardware- and Vision-in-the-Loop Validation of Deep Monocular Pose Estimation for Autonomous Maritime UAV Flight
Autonomous UAV operations on ships require reliable vision-based relative pose estimation, yet at-sea validation is costly, weather-depende…
Compute Efficiency and Serial Runtime Tradeoffs for Stochastic Momentum Methods
Stochastic momentum methods such as heavy ball (HB), Nesterov momentum, and variants of Accelerated SGD (ASGD) [Kidambi et al., 2018] are w…
Language Models as Interfaces, Not Oracles: A Hybrid LLM-ML System for Pediatric Appendicitis
Large language models (LLMs) can make clinical decision support more accessible by interpreting free-text documentation, but their direct u…
The More the Merrier: Combining Properties for ABox Abduction under Repair Semantics for ELbot
Abduction is a central approach to explain missing entailments from a knowledge base by providing a hypothesis, that would, if added to the…
Forecasting what Matters: Decision-Focused RL for Controlled EV Charging with Unknown Departure Times
The recent growth of EV adoption poses challenges for power systems, including increased peak demand and potential grid instability. Smart…
Machine Unlearning for the XGBoost Model with Network Intrusion Datasets
Machine Unlearning (MU) has emerged as an important technique for removing specific data points from trained models without requiring full…
Mechanism-Guided Selective Unlearning for RLVR-Induced Reasoning
We propose MAST (Mechanism-Aligned Selective Targeting), a mechanism-guided method for unlearning RLVR-induced reasoning with substantially…
STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
Reinforcement Learning with Verifiable Rewards algorithms like GRPO have emerged as the dominant post-training paradigm for complex reasoni…
A Taxonomy of Mental Health and Technology Needs for Alzheimer's and Dementia Caregivers
Family members caring for individuals with Alzheimer's disease and related dementias (AD/ADRD) provide the foundation of long-term care wor…
OneCanvas: 3D Scene Understanding via Panoramic Reprojection
Existing approaches to 3D scene understanding in Vision-Language Models (VLMs) either rely on complex, model-specific geometry encoders or…
A Multi-Domain Benchmark for Detecting AI-Generated Text-Rich Images from GPT-Image-2
Text-rich images often contain privacy-sensitive, transactional, or decision-relevant information. As recent multimodal image generation mo…
Trade-offs in Medical LLM Adaptation: An Empirical Study in French QA
The development of large language models (LLMs) has led to an increased focus on their adaptation to specialized domains and languages, yet…
Correct Yourself, Keep My Trust: How Self-Correction and Social Connection Shape Credibility in Social Chatbots
When social chatbots make mistakes, and they do, how they recover determines whether users trust them again. Social chatbots are increasing…
Explaining Attention with Program Synthesis
A longstanding goal of research on interpretable deep learning is to replace opaque neural computations with human-meaningful symbolic desc…
Data Intelligence Agents: Interpreting, Modeling, and Querying Enterprise Data via Autonomous Coding Agents
Production data integration is bottlenecked by repeated, lossy handoffs between data owners, engineers, and analysts who must collaborative…
Reference-Driven Multi-Speaker Audio Scene Generation from In-the-Wild Priors
Existing multi-speaker dialogue systems bind speakers to utterances through structured supervision: per-turn tags, multi-stream transcripti…
UBP2: Uncertainty-Balanced Preference Planning for Efficient Preference-based Reinforcement Learning
Preference-based RL provides an approach to learning reward models from pairwise comparisons of behaviors, bypassing the need for explicit…
Large-Scale OD Matrix Estimation with A Deep Learning Method
The estimation of origin-destination (OD) matrices is a crucial aspect of Intelligent Transport Systems (ITS). It involves adjusting an ini…
Recursive Joint Simulation in Games
Game-theoretic dynamics between AI agents could differ from traditional human-human interactions in various ways. One such difference is th…
Fully Geometric Multi-Hop Reasoning on Knowledge Graphs with Transitive Relations
Multi-hop logical reasoning on knowledge graphs requires faithfully mapping the logical semantics to latent space. Current geometric embedd…
PosterForest: Hierarchical Multi-Agent Collaboration for Scientific Poster Generation
Automating scientific poster generation requires hierarchical document understanding and coherent content-layout planning. Existing methods…
Structured Cognitive Loop for Behavioral Intelligence in Large Language Model Agents (Extended Revision: From Behavioral Architecture to Epistemic Accountability)
The central challenge for AI agents is not only performance but accountability. Agents that act through opaque prompt sequences may produce…
The Personalization Trap: How User Memory Alters Emotional Reasoning in LLMs
When an AI assistant remembers that Sarah is a single mother working two jobs, does it interpret her stress differently than if she were a…
An In-depth Study of LLM Contributions to the Bin Packing Problem
Recent studies have suggested that Large Language Models (LLMs) could provide interesting ideas contributing to mathematical discovery. Thi…
RippleBench: Capturing Ripple Effects Using Existing Knowledge Repositories
Targeted interventions on language models, such as unlearning or model editing, aim to modify specific information, but their effects often…
Towards Understanding What State Space Models Learn About Code
State Space Models (SSMs) have emerged as an efficient alternative to the Transformer architecture. Prior work shows that, when trained und…
Enhancing CVRP Solver through LLM-driven Automatic Heuristic Design
The Capacitated Vehicle Routing Problem (CVRP), a fundamental combinatorial optimization challenge, focuses on optimizing fleet operations…
InfoPO: Information-Driven Policy Optimization for User-Centric Agents
Real-world user requests to LLM agents are often underspecified. Agents must interact to acquire missing information and make correct downs…
Robust Regularized Policy Iteration under Transition Uncertainty
Offline reinforcement learning (RL) enables data-efficient and safe policy learning without online exploration, but its performance often d…
Information-Theoretic Measures in AI: A Practical Decision Guide
Information-theoretic (IT) measures are ubiquitous in artificial intelligence: entropy drives decision-tree splits and uncertainty quantifi…
A Distributionally Robust Reinforcement Learning Framework for Constrained Urban EV Dispatch
We study city-scale control of electric-vehicle (EV) ride-hailing fleets where dispatch, repositioning, and charging decisions must respect…
FinSTaR: 時系列推論モデルによる財務推論に向けて
時系列 (TS) 推論モデル (TSRM) は、一般的な領域では有望な機能を示していますが、独特の特性を示す金融領域では一貫して失敗します。我々は、1) 単一エンティティ対複数エンティティの分析と、2) 現状の評価と将来の動作の予測を組み合わせることで、TSRM の一般的な 2x2 能力分類法を提案します。この分類法を金融領域(決定論的評価と確率論的予測の区別が特に重要である)で 10 の財務推論タスクとしてインスタンス化し、S&P 株に基づく FinTSR ベンチ ベンチマークを形成します。この目的を達成するために、各カテゴリーに合わせた個別の思考連鎖 (CoT) 戦略を備えた FinTSR ベンチでトレーニングされた FinSTaR (金融時系列思考と推論) を提案します。決定論的(つまり、観察可能なデータから計算可能)な評価については、モデルが生の価格から直接答えを導き出すことを可能にするプログラム的な CoT である Compute-in-CoT を採用しています。本質的に確率的である(つまり、観察できない要因に左右される)予測については、金融アナリストが不確実性の下で推論する方法を反映して、判断を下す前に多様なシナリオを生成するシナリオ認識型CoTを採用します。提案された手法は、FinTSR-Bench で 78.9% の平均精度を達成し、LLM および TSRM ベースラインを大幅に上回りました。さらに、4 つの能力カテゴリが共同トレーニングを通じて補完的かつ相互に強化されること、およびシナリオ認識型 CoT が標準的な CoT よりも予測精度を一貫して向上させることを示します。コードは https://github.com/seunghan96/FinSTaR で公開されています。
原文 (English)
FinSTaR: Towards Financial Reasoning with Time Series Reasoning Models
Time series (TS) reasoning models (TSRMs) have shown promising capabilities in general domains, yet they consistently fail in the financial domain, which exhibits unique characteristics. We propose a general 2 x 2 capability taxonomy for TSRMs by crossing 1) single-entity vs. multi-entity analysis with 2) assessment of the current state vs. prediction of future behavior. We instantiate this taxonomy in the financial domain-where the distinction between deterministic assessment and stochastic prediction is particularly critical-as ten financial reasoning tasks, forming the FinTSR-Bench benchmark based on S&P stocks. To this end, we propose FinSTaR (Financial Time Series Thinking and Reasoning), trained on FinTSR-Bench with distinct chain-of-thought (CoT) strategies tailored to each category. For assessment, which is deterministic (i.e., computable from observable data), we employ Compute-in-CoT, a programmatic CoT that enables models to derive answers directly from raw prices. For prediction, which is inherently stochastic (i.e., subject to unobservable factors), we adopt Scenario-Aware CoT, which generates diverse scenarios before making a judgment, mirroring how financial analysts reason under uncertainty. The proposed method achieves 78.9% average accuracy on FinTSR-Bench, substantially outperforming LLM and TSRM baselines. Furthermore, we show that the four capability categories are complementary and mutually reinforcing through joint training, and that Scenario-Aware CoT consistently improves prediction accuracy over standard CoT. Code is available at https://github.com/seunghan96/FinSTaR.
LLM が進化したシンボリック AI プランニングのためのドメインに依存しないヒューリスティック
ヒューリスティック検索は、シンボリック AI 計画における主要なパラダイムであり、最も強力なヒューリスティックは、計画研究者による数十年の研究の結果です。最近の研究では、大規模言語モデル (LLM) が個々の計画ドメインのヒューリスティックを設計できることが示されていますが、これまでのところ、LLM によって生成されたヒューリスティックが任意の計画タスクに機能することはありません。この論文では、進化的探索を使用して、手作業でエンジニアリングされた最先端技術を超える、LLM によって生成された初めてのドメインに依存しないヒューリスティックを生成します。 C++ で書かれた親ヒューリスティックを LLM に変更させ、情報とスピードを重視した MAP-Elites アーカイブに候補を保存し、カバレッジと解決時間をブレンドすることで適合性スコアを計算します。進化したプログラムを状況に合わせて配置するために、情報と速度のトレードオフに関して手作業で設計された広範なヒューリスティックのベンチマークをさらに行いました。これは、私たちの知る限りではこれまでに行われたことがありません。目に見えないテスト領域では、当社の最も進化したヒューリスティックは、最強のベースラインよりも多くのタスクを解決し、当社の完全なヒューリスティック スイートは、上記のトレードオフのパレート フロンティアにまたがります。また、結果として得られるプログラム自体が FF バリアントである場合でも、些細なブラインド ヒューリスティックからのシード進化は、強力な FF ヒューリスティックからのシードよりも優れたパフォーマンスを示し、LLM 推論の努力は、候補の品質よりも候補がコンパイルする頻度にはるかに影響を与えることもわかりました。進化したプログラムはプレーンな C++ であるため、既存のプランナーにドロップイン置換として組み込まれ、基礎となる検索の健全性と完全性の保証を継承します。
原文 (English)
LLM-Evolved Domain-Independent Heuristics for Symbolic AI Planning
Heuristic search is the dominant paradigm in symbolic AI planning, and the strongest heuristics are the result of decades of work by planning researchers. Recent work has shown that large language models (LLMs) can design heuristics for individual planning domains, but no LLM-generated heuristic has so far worked on arbitrary planning tasks. In this paper, we use evolutionary search to produce the first LLM-generated domain-independent heuristics that exceed the hand-engineered state of the art. We let an LLM mutate parent heuristics written in C++, store candidates in a MAP-Elites archive keyed on informedness and speed and calculate fitness scores by blending coverage with solving time. To place the evolved programs in context, we additionally benchmark a broad set of hand-engineered heuristics on their informedness-speed tradeoff, which to our knowledge has not been done before. On unseen testing domains, our best evolved heuristic solves more tasks than even the strongest baseline, with our full heuristic suite spanning the Pareto frontier of said tradeoff. We also find that seeding evolution from the trivial blind heuristic outperforms seeding from the strong FF heuristic, even when the resulting program is itself an FF variant, and that LLM reasoning effort affects how often candidates compile much more than the quality of those that do. Because the evolved programs are plain C++, they slot into existing planners as drop-in replacements and inherit the soundness and completeness guarantees of the underlying search.
表記法が重要: Agentic AI システムにおけるトークン最適化フォーマットのベンチマーク調査
Agentic AI システムの大規模な言語モデルは、ツール スキーマと実行結果を消費し、ツール呼び出しを構造化データとして出力します。その交換のデフォルト言語である JSON は、トークンの効率性ではなくアプリケーション間の交換を目的として設計されているため、その構造要素により相当のトークン オーバーヘッドが生じます。最近の研究では、よりコンパクトな代替として TOON (Token-Oriented Object Notation) や TRON (Token Reduced Object Notation) などのトークンに最適化された代替案が提案されていますが、これらの形式は分離された理解または生成タスクでのみ評価されています。したがって、トークン削減がエンドツーエンドのエージェント ループ内で保持されるかどうかは未解決の問題のままです。私たちは、4 つのエージェント ベンチマーク (BFCL、MCPToolBenchPP、MCP-Universe、StableToolBench) と 5 つのオープンウェイト LLM で TOON と TRON を評価し、入力圧縮を出力圧縮から分離して、理解と生成を独立して測定します。 TRON は、JSON ベースラインの 14pp 以内の精度でトークンを最大 27% 削減します。 TOON は、同様の 9pp の精度コストで最大 18% の削減を達成しますが、さらにマルチターン解析失敗がカスケードし、ほとんどのモデルの並列ツール呼び出し出力が崩壊します。
原文 (English)
Notation Matters: A Benchmark Study of Token-Optimized Formats in Agentic AI Systems
Large language models in Agentic AI systems consume tool schemas and execution results and emit tool invocations as structured data. The default language for that exchange, JSON, was designed for application-to-application interchange rather than token efficiency, so its structural elements impose substantial token overhead. Recent work proposes token-optimized alternatives such as TOON (Token-Oriented Object Notation) and TRON (Token Reduced Object Notation) as more compact replacements, but these formats have been evaluated only on isolated comprehension or generation tasks. Whether their token reductions hold inside end-to-end agentic loops therefore remains an open question. We evaluate TOON and TRON on four agentic benchmarks (BFCL, MCPToolBenchPP, MCP-Universe, StableToolBench) and five open-weight LLMs, decoupling input compression from output compression to measure comprehension and generation independently. TRON reduces tokens by up to 27% with accuracy within 14pp of the JSON baseline. TOON achieves up to 18% reduction at a similar 9pp accuracy cost, but additionally cascades on multi-turn parsing failures and collapses parallel tool-call output for most models. The code is available at: https://github.com/lkutschka/notation-matters
国家学習能力としての AI 主権: フランス、米国、中国に関する人間中心の学習力学の視点
フランスでは、人工知能は、投資、計算能力、規制、雇用、主権、教育の観点からよく議論されます。通常、これらのディメンションは個別に扱われます。この観点に関する論文は、統一的な解釈を提案しています。つまり、フランスは \emph{国家的な AI 学習システム} として理解されるべきです。エントロピー制御された表現学習のための動的フレームワークとして最近策定された人間中心学習力学 (HCLM) に基づいて、私たちは国家 AI 開発を情報注入とエントロピー散逸の間の制御されたバランスとして解釈します。情報注入は、コンピューティング、データ、人材、研究、資本、産業展開、および組織的実験に対応します。エントロピー散逸は、組織の複雑さ、調整摩擦、エネルギー制約、規制の不確実性、人材の流動性の圧力、産業吸収を強化する機会に対応します。中心的な主張は、AI の主権は規模だけから生まれるのではなく、自国の情報ダイナミクスを規制する国の能力から生まれるというものです。この論文は、HCLM をニューラル スケーリング則、内生的成長理論、創造的破壊、およびゲーム理論と結びつけます。同論文は、フランスのAI論争は、技術楽観主義と規制優先の慎重論という二項対立を超えて進むべきだと主張している。競争力のある人間中心の AI 戦略には、不安定、不平等、またはエネルギー集約的な拡大を回避しながら、情報注入が制度的消散よりも早く成長する制御された体制が必要です。私たちは、数学的モデル、測定可能な政策指標、ゲーム理論的命題、国家 AI 体制の具体的なシミュレーション、およびフランスに対する具体的な政策への影響を提供します。提案された視点は、AI 政策をオープンで戦略的な非平衡学習システムのガバナンスとして再構成します。
原文 (English)
AI Sovereignty as National Learning Capacity: A Human-Centered Learning Mechanics Viewpoint on France, the United States, and China
Artificial intelligence in France is often discussed through separate dimensions such as investment, compute, regulation, employment, sovereignty, and education. This viewpoint paper proposes a unified interpretation: France can be analyzed as a national AI learning system. Building on Human-Centered Learning Mechanics (HCLM), we use HCLM not as a validated econometric model, but as a conceptual and diagnostic lens for interpreting national AI development as a balance between information injection, absorptive capacity, and institutional dissipation. Information injection includes compute, data, talent, research, capital, industrial deployment, and policy experimentation. Institutional dissipation refers to avoidable frictions such as administrative overload, coordination failures, energy constraints, regulatory uncertainty, talent mobility pressures, and weak industrial absorption. Regulation is not treated as mere friction: adaptive governance, trusted data spaces, and safety-oriented standards may increase long-term learning capacity by improving legitimacy, interoperability, and social trust. The central claim is not that a country follows neural-network equations, but that AI sovereignty depends on how effectively it converts distributed information into absorbed, coordinated, and socially legitimate capability. The paper connects HCLM with neural scaling laws, endogenous growth theory, creative destruction, absorptive capacity, and coordination mechanisms. It offers a formal heuristic, policy indicators, illustrative scenarios, and implications for France. The numerical results are diagnostic scenarios, not econometric estimates or official rankings. The proposed viewpoint reframes AI policy as the governance of an open, strategic, non-equilibrium learning system that should be tested with historical and cross-country data.
SkillRevise: トレース条件付きスキル リビジョンによる LLM 作成エージェント スキルの向上
エージェント スキルは、LLM エージェントがワークフローを実行し、制約を検証し、障害から回復できるようにする手順的な成果物です。既存の自己進化手法は、蓄積された軌跡を利用してスキルを磨きます。しかし、初期の不完全なスキルしか利用できないコールドスタート環境では苦戦します。したがって、スキル構築はデフォルトでエキスパートオーサリングまたはワンショット LLM 生成になります。専門家が作成したスキルはコストが高く、LLM エージェントが実際にタスクを実行する方法と一致していない可能性があります。一方、ワンショットで生成されたスキルは、構文的には適切ですが、動作が弱い可能性があります。このギャップを埋めるために、私たちは、これらの初期スキルを反復的に改善するように設計された実行ベースのフレームワークである SkillRevise を提案します。 SkillRevise は、実行の証拠からスキルの欠陥を診断し、一般的なメモリから関連する修復原則を取得し、実行に固定された編集を適用します。候補者を再実行し、経験的な有用性を測定することで、最適なスキル バージョンを体系的に保持します。 3 つのベンチマークと 5 つの LLM で評価したところ、SkillRevise はワンショット ベースラインを大幅に上回り、SkillsBench でのベース エージェントの成功率が 36.05% から 61.63% に向上しました。さらに、改訂されたスキルはモデル間での強力な移行性を示し、モデル固有のアーティファクトに関する一般化された手順の知識を取得します。
原文 (English)
SkillRevise: Improving LLM-Authored Agent Skills via Trace-Conditioned Skill Revision
Agent skills are procedural artifacts that enable LLM agents to execute workflows, verify constraints, and recover from failures. Existing self-evolving methods refine skills using accumulated trajectories. However, they struggle in cold-start settings, where only an initial, imperfect skill is available. Consequently, skill construction defaults to expert authoring or one-shot LLM generation. Expert-authored skills are costly and may not align with how LLM agents actually execute tasks, while one-shot generated skills can be syntactically well formed yet behaviorally weak. To bridge this gap, we propose SkillRevise, an execution-grounded framework designed to iteratively refine these initial skills. SkillRevise diagnoses skill defects from execution evidence, retrieves relevant repair principles from a general memory, and applies execution-anchored edits. By re-executing candidates, it retains the first verifier-passing skill within the revision budget and falls back to empirical utility only when no candidate succeeds. Evaluated across three benchmarks and five LLMs, SkillRevise substantially outperforms one-shot baselines, improving the base agent's success rate on SkillsBench from 36.05% to 61.63%. Furthermore, the revised skills transfer across both executors and task environments, suggesting that SkillRevise captures reusable procedural knowledge beyond any single executor.
DN-Hypo-Pipeline: 大規模な言語モデルと科学的説明による仮説生成のための AI 主導のワークフロー
科学的仮説は研究の最初のステップであり、実験による検証が行われますが、科学的現象に対する深い理解と推論も反映されています。 DN-Hypo-Pipeline は、大規模な言語モデルに基づく AI を活用したワークフローで、事前知識として科学的な説明を活用することで、構造化された科学的思考と仮説生成をサポートするように設計されています。このパイプラインは、研究者が既存の文献から新しい仮説を導き出すのを支援します。研究論文の解説 (つまり、結論) が与えられると、基礎となる法則、理論、原理が特定され、観察された現象についての新しい、まだ検証されていない説明が再構築されます。私たちは、引用度の高い 3 つの論文を使用して、データ サイエンス モデリングの分野で DN-Hypo-Pipeline を評価しました。裁判官としての LLM による評価と人間の専門家による評価の両方によって裏付けられた統計的推論は、当社のパイプラインが直接生成方法よりも効果的であることを示しています。さらに、対応する新しいアルゴリズムを開発することにより、生成された 2 つの最高スコアの仮説を検証しました。このアルゴリズムは、元の論文で提示されたベースライン モデルを上回りました。 DN-Hypo-Pipeline は、データ サイエンスへの応用を超えて、理論に基づいたデータ サイエンス モデリング手法を包含するだけでなく、モデリング プロセスのより基本的な構造も明らかにする理論的フレームワークを提供します。さらに、このアプローチは本質的に理論に基づいたモデリングの一般化であり、他の領域やより幅広い科学分野に拡張できる可能性を提供します。
原文 (English)
DN-Hypo-Pipeline: An AI-Driven Workflow for Hypothesis Generation via Large Language Models and Scientific Explanations
A scientific hypothesis is the first step in research and undergoes experimental validation, yet it also reflects a deep understanding of and reasoning about scientific phenomena. We introduce DN-Hypo-Pipeline, an AI-powered workflow based on large language models, designed to support structured scientific thinking and hypothesis generation by leveraging scientific explanations as prior knowledge. This pipeline assists researchers in deriving novel hypotheses from existing literature. Given the explanandum (i.e., the conclusion) of a research paper, it identifies underlying laws, theories, and principles, and reconstructs a new, yet-to-be-verified explanation for the observed phenomenon. We evaluated DN-Hypo-Pipeline in the field of data science modeling using three highly cited papers. Statistical inference, supported by both LLM-as-judge assessment and human expert evaluation, demonstrates that our pipeline is more effective than direct generation methods. Additionally, we validated the two highest-scoring generated hypotheses by developing corresponding novel algorithms, which outperformed the baseline models presented in the original papers. Beyond application in data science, DN-Hypo-Pipeline provides a theoretical framework that not only encompasses theory-guided data science modeling methods but also reveals a more fundamental structure of the modeling process. Moreover, this approach is essentially a generalization of theory-guided modeling, offering potential for extension to other domains and across a broader range of scientific disciplines.
能動推論による個別化されたがん治療のための信念空間制御
がん治療は本質的に、部分的な観察可能性、潜在的な患者の異質性、および医療測定の予算に対する明示的な制約を伴う、逐次的な意思決定の問題です。状態の軌道を制御する標準的な強化学習(RL)アプローチとは異なり、がん治療は患者の移行ダイナミクスを永続的に変更し、時間の経過とともに状態がどのように進化するかを変化させます。私たちは、がん治療を能動推論を使用した信念空間計画問題としてモデル化し、測定予算なしで目標指向制御と情報取得を統合する、期待されるフリーエネルギー目標を導き出します。私たちは、AACR プロジェクト GENIE Biopharma Collaborative データセットからの実際の臨床がんデータを使用して、このフレームワークを実装します。臨床データの結果は、実際の測定と治療の制約の下で、患者の分類と高い治療効果を同時に実証しています。
原文 (English)
Belief-Space Control for Personalized Cancer Treatment via Active Inference
Cancer treatment is at the core a sequential decision-making problem with partial observability, latent patient heterogeneity, and explicit constraints on the budget for medical measurements. Unlike standard Reinforcement Learning (RL) approaches that control state trajectories, cancer treatments permanently modify patients' transition dynamics, changing how states evolve over time. We model cancer treatment as a belief-space planning problem using active inference, deriving an expected free-energy objective that unifies goal-directed control and information acquisition under measurement budgets without. We implement this framework using real clinical cancer data from the AACR Project GENIE Biopharma Collaborative dataset. Results on clinical data demonstrate a simultaneous patient categorization and high treatment efficacy, under real measurement and treatment constraints.
尋問の技術: 一貫性が空間推論における事実性を増幅する
現在の大規模推論モデル (LRM) は、優れた一般的な機能を示しますが、空間推論タスクでは著しくパフォーマンスが劣ります。既存のアプローチは、このギャップを知識不足として扱い、教師あり微調整 (SFT) に依存して、外部のビジョン ソースまたは合成エンジンからラベル付き空間データを取り込みます。対照的に、多くのタスクでは、空間推論機能は事前トレーニング済み LRM にすでに存在しますが、幾何学的な 2D および 3D 制約の下での論理的一貫性による調整が必要であると主張します。この研究では、グラウンドトゥルースのアノテーションを必要とせずに内部推論プロセスを対象とする自己教師あり強化学習 (RL) フレームワークを提案します。整合性検証器 (変換時に幾何学的および意味論的な整合性をチェックする報酬関数) の概念を形式化することで、モデルが空間推論能力を向上できることを実証します。私たちは、反転などの画像変換と、質問内のオブジェクトの順序を入れ替えるなどのテキスト変換の両方を使用し、新しい最適なトランスポートベースの RL 戦略である OT-GRPO を提案します。これは、ペアごとの検証者に合わせたグループ相対ポリシー最適化の最小マッチングの変形です。このラベルフリーの一貫性トレーニングは、グラウンドトゥルース監視でトレーニングされたモデルの精度に近づき、多様なタスクとデータドメインにわたって同様の一般化を達成することを示します。
原文 (English)
The Art of Interrogation: Consistency Amplifies Factuality in Spatial Reasoning
Current Large Reasoning Models (LRMs) exhibit remarkable general capabilities but significantly underperform in spatial reasoning tasks. Existing approaches treat this gap as a knowledge deficit, relying on supervised fine-tuning (SFT) to ingest labeled spatial data from external vision sources or synthetic engines. In contrast, we argue that for many tasks, spatial reasoning capabilities are already present in pre-trained LRMs but require alignment through logical coherence under geometric 2D and 3D constraints. In this work, we propose a self-supervised reinforcement learning (RL) framework that targets the internal reasoning process without requiring ground-truth annotations. By formalizing the notion of consistency verifiers -- reward functions that check for geometric and semantic consistency under transformations -- we demonstrate that models can improve their spatial reasoning abilities. We use both image transformations, like flipping, and textual transformations, like swapping the order of objects in the question, and propose a new optimal transport-based RL strategy, OT-GRPO, which is a minimal-matching variant of group relative policy optimization tailored to pairwise verifiers. We show that this label-free consistency training approaches the accuracy of models trained with ground-truth supervision and achieves similar generalization across diverse tasks and data domains.
「嘘をつきましたか?」モデルスケールと信念が検証されたモデル生物にわたる嘘発見器の評価
言語モデルの強力な嘘発見器は、モデルの動作の監査、監視、事後調査のための強力な技術を可能にする可能性がありますが、それらを評価するには、モデルが発言の反対を検証可能に信じるテストベッドが必要です。我々は、既存の訓練されたモデル生物がこの要件を満たさないことが多く、以前の陽性および陰性の検出結果の解釈が困難なままであることを示します。我々は、広範囲の嘘を誘発する動機をカバーする促された嘘のテストベッドであるVaried Deceptionと並行して、隠れた信念が思考連鎖で検証され、保留されたタスクに一般化することが示されている13の推論モデル生物でこれに対処します。これらのテストベッドでは、思考連鎖判定器、logprob 分類器、およびフォローアップ プローブをトレーニングするための新しい方法である Did-You-Lie (DYL) を含む 2 つの活性化プローブの 4 つの検出器を評価します。促された横たわると、2B から 1T パラメーターにわたる 31 のオープンウェイト モデルにわたって、4 つの検出器すべてがモデル能力に応じた正のスケーリングを示します。ただし、すべての活性化ベースおよび対数確率ベースの検出器は、トレーニング済みモデル生物では急激に低下し、DYL が最も多くの信号を保持します。思考連鎖のジャッジだけが依然として強力であり、0.82 のバランスの取れた精度を持っています。これは、部分的には、CoT で読み取り可能な信念を支持する検証プロセスの成果物です。したがって、現在の嘘発見器は、モデルの信念に関する信頼性の高い主張をサポートできず、現在の制限の一部に対処する可能性のある研究の方向性を提案します。データセット、モデル生物、訓練された検出器をリリースします。
原文 (English)
"Did you lie?" Evaluating Lie Detectors across Model Scale and Belief-Verified Model Organisms
Robust lie detectors for language models could enable powerful techniques for auditing, monitoring, and post-hoc investigation of model behaviour, but evaluating them requires testbeds where models verifiably believe the opposite of what they say. We show that existing trained model organisms often fail this requirement, leaving prior positive and negative detection results difficult to interpret. We address this with 13 reasoning model organisms whose hidden beliefs are verified in chain-of-thought and shown to generalise to held-out tasks, alongside Varied Deception, a prompted-lying testbed covering a broad range of lie-inducing motivations. On these testbeds we evaluate four detectors: a chain-of-thought judge, a logprob classifier, and two activation probes, including Did-You-Lie (DYL), a new method for training follow-up probes. On prompted lying, across 31 open-weight models spanning 2B to 1T parameters, all four detectors show positive scaling with model capability. However, every activation- and logprob-based detector drops sharply on our trained model organisms, with DYL retaining the most signal; only the chain-of-thought judge remains strong, with 0.82 balanced accuracy, partly as an artefact of our verification process favouring CoT-readable beliefs. Current lie detectors therefore cannot support high-confidence claims about model beliefs, and we suggest research directions that may address some of their current limitations. We release our datasets, model organisms, and trained detectors.
Vibe Medicine に向けて: 臨床意思決定支援のための自己進化するマルチエージェント フレームワーク
近年、大規模言語モデルと自律エージェントの進歩により、診断が容易になり、治療結果が向上し、ヘルスケア分野に革命が起きました。しかし、既存の AI システムのほとんどは、事前トレーニングされた知識と事前定義されたパイプラインに依存しており、患者の転帰や過去の失敗を含む対話型チャット セッション履歴から動的に学習することが困難です。この制限に対処するために、私たちは、堅牢な臨床意思決定をサポートするための自己進化メカニズムとアーキテクチャレベルの安全サンドボックスを内蔵したマルチエージェント フレームワークである VIBEMed を提案します。このシステムは、仮説生成のための臨床診断エージェント (CDA)、治療計画のための治療実行エージェント (TEA)、縦断的な臨床フィードバックを再利用可能な知識に蒸留し、多様な患者情報を個別の医療決定に変換する臨床進化マネージャー エージェント (CEMA) を含む 3 つの専門エージェントを統合します。このフレームワークは、自己進化メカニズムを通じて、メモリ、モデルの動作、意思決定戦略全体の反復的な更新を可能にし、時間の経過とともにシステムを改善できるようにします。実験結果は、VIBEMed が、複雑な臨床ケース、特に統合された意思決定と長期計画を必要とするタスクにおいて、進化するメカニズムを通じて優れたパフォーマンスを実証することを示しています。このフレームワークは、腫瘍治療計画などの困難なシナリオにおける信頼性の高いエンドツーエンドの意思決定もサポートし、現実の臨床状況での実現可能性を強調しています。全体として、VIBEMed は、静的 AI システムを超えて、適応型の経験主導の臨床意思決定サポートに向けた実用的な道を提供し、精密医療を進歩させるための複数エージェントのコラボレーションと継続的な進化を組み合わせる価値を実証します。
原文 (English)
Toward Vibe Medicine: A Self-Evolving Multi-Agent Framework for Clinical Decision Support
In recent years, the advances of large language models and autonomous agents have revolutionized the healthcare field, facilitating diagnosis and improving treatment results. However, most existing AI systems rely on pre-trained knowledge and predefined pipelines, which struggle to learn dynamically from the interactive chat session history that contains patient outcomes and past failures. To address this limitation, we propose VIBEMed, a multi-agent framework with a built-in self-evolution mechanism and architecture-level safety sandbox for robust clinical decision support. The system integrates three specialized agents, including a Clinical Diagnostic Agent (CDA) for hypothesis generation, a Therapeutic Execution Agent (TEA) for treatment planning, and a Clinical Evolution Manager Agent (CEMA) that distills longitudinal clinical feedback into reusable knowledge, transforming multimodal patient information into personalized medical decisions. Through self-evolution mechanism, the framework enables iterative updates across memory, model behavior, and decision strategies, allowing the system to improve over time. Experimental results show that VIBEMed demonstrates superior performance through its evolving mechanism in complex clinical cases, particularly in tasks that require integrated decision-making and longitudinal planning. The framework also supports reliable end-to-end decisions in challenging scenarios such as oncology treatment planning, highlighting its feasibility in real-world clinical contexts. Overall, VIBEMed provides a practical path beyond static AI systems toward adaptive, experience-driven clinical decision support, demonstrating the value of combining multi-agent collaboration with continuous evolution for advancing precision medicine.
SpecAlign: 合成データによる大規模言語モデルの仕様に基づいた効率的な調整
大規模言語モデル (LLM) が現実世界のアプリケーションに導入されることが増えているため、整合性はもはや安全性や有用性という単一の普遍的な概念によって管理されるのではなく、プロバイダーまたはアプリケーション固有のモデル仕様によって管理されています。これらの仕様は通常、長く、構造化されており、頻繁に更新されますが、既存の調整パイプラインには、それらをトレーニング信号として運用する体系的なメカニズムがありません。このペーパーでは、仕様に基づいたアライメントを提案します。これは、抽象的な原則や静的なベンチマークではなく、プロバイダーが作成したモデル仕様を主要なアライメント ターゲットとして扱う新しいアライメント パラダイムです。このパラダイムを具体化するために、仕様書から直接アライメント データを合成するフレームワークである SpecAlign を導入します。 SpecAlign は、構造化ルールのアノテーション、制御可能な仕様のインスタンス化、およびマルチエージェントの敵対的データ合成を組み合わせて、準拠した動作と意味のある仕様違反の両方を捕捉する、きめ細かい境界を意識した設定ペアを生成します。複数のモデル仕様とバックボーン モデルにわたる実験では、SpecAlign を使用したトレーニングにより、一般的な機能を維持し、過度に保守的な動作を回避しながら、ルールへの準拠性が一貫して向上することが実証されています。これらの結果は、明示的なモデル仕様における基本的な調整により、進化するポリシー要件に対する LLM の動作の迅速、正確、スケーラブルな適応が可能になることを示唆しています。
原文 (English)
SpecAlign: Efficient Specification-Grounded Alignment of Large Language Models via Synthetic Data
As large language models (LLMs) are increasingly deployed in real-world applications, alignment is no longer governed by a single universal notion of safety or helpfulness, but instead by provider- or application-specific model specifications. These specifications are typically long, structured, and frequently updated, yet existing alignment pipelines lack a systematic mechanism to operationalize them as training signals. In this paper, we propose specification-grounded alignment, a new alignment paradigm that treats provider-authored model specifications as the primary alignment target rather than abstract principles or static benchmarks. To instantiate this paradigm, we introduce SpecAlign, a framework that synthesizes alignment data directly from specification documents. SpecAlign combines structured rule annotation, controllable specification instantiation, and multi-agent adversarial data synthesis to generate fine-grained, boundary-aware preference pairs that capture both compliant behaviors and meaningful specification violations. Experiments across multiple model specifications and backbone models demonstrate that training with SpecAlign consistently improves rule compliance while preserving general capabilities and avoiding over-conservative behavior. These results suggest that grounding alignment in explicit model specifications enables rapid, precise, and scalable adaptation of LLM behavior to evolving policy requirements.
MapSatisfyBench: 行動に基づいた暗黙的な決定要素による満足度を意識したマップ エージェントのベンチマーク
大規模な言語モデル エージェントは、マップ サービスにますます統合されています。マップ サービスは専門的なタスクの設定ではなく、日常生活のシナリオに組み込まれているため、ユーザーは多くの場合、自分のニーズを非公式に表明し、その結果、多くの暗黙のニーズ、つまりユーザーの満足度にとって重要な暗黙の決定要素を含む、仕様が不十分なクエリが発生します。明確化はこの問題を軽減する効果的な方法ですが、日常のやり取りにおけるユーザーの負担が増大するため、有能なエージェントはまず利用可能な情報ソースからそのような要素を積極的に回収する必要があります。ただし、この能力を評価するのは困難です。最初の課題は、どの暗黙的な決定要素が評価に適しているかを判断することです。要因は、ユーザーの受け入れに影響を及ぼし、エージェントが応答する前に入手可能な情報から回復できる場合にのみ評価可能です。第 2 に、ユーザーの満足度は単一の参照回答では確実に表すことができないため、満足度に関連する要素を客観的かつ定量化可能な評価目標に変換するベンチマークが必要です。これらの課題に対処するために、行動連鎖証拠から完全なユーザー ニーズを再構築し、暗黙的な決定要因を特定し、クエリ前の証拠によってサポートされるもののみを保持する復元識別フィルター フレームワークを提案します。この方法論に基づいて、大規模な現実世界の匿名化されたユーザー データから MapSatisfyBench を構築し、5 次元からグラウンド トゥルースに注釈を付けて、満足度を意識したマップ エージェントのフルチェーン評価を可能にします。実験によると、現在のエージェントは一般に、明示的なタスクの完了に関しては良好なパフォーマンスを発揮しますが、暗黙の決定要素を満たすことや、満足を意識した決定に必要な証拠を積極的に取得することには依然として限界があります。これらの発見により、MapSatisfyBench は、マップ エージェントの評価をタスクの完了から満足度を意識した空間的意思決定に移行するためのベンチマークとして確立されました。
原文 (English)
MapSatisfyBench: Benchmarking Satisfaction-Aware Map Agents through Behavior-Grounded Implicit Decision Factors
Large language model agents are increasingly integrated into map services. Since map services are embedded in everyday-life scenarios rather than professional task settings, users often express their needs informally, resulting in underspecified queries with many unspoken needs, namely, implicit decision factors that are critical for user satisfaction. Although clarification is an effective way to mitigate this issue, it increases user burden in daily interaction, and a capable agent should first proactively recover such factors from available information sources. However, evaluating this ability is challenging. The first challenge is to determine which implicit decision factors are suitable for evaluation. A factor is evaluable only if it affects user acceptance and can be recovered from information available to the agent before it responds. Second, user satisfaction cannot be reliably represented by a single reference answer, requiring a benchmark that converts satisfaction-relevant factors into objective and quantifiable evaluation targets. To address these challenges, we propose a restore-identify-filter framework that reconstructs complete user needs from behavior-chain evidence, identifies implicit decision factors, and retains only those supported by pre-query evidence. Building on this methodology, we construct MapSatisfyBench from large-scale, real-world anonymized user data and annotate ground truth from five dimensions and enables full-chain evaluation of satisfaction-aware map agents. Experiments show that current agents generally perform well on explicit task completion, but remain limited in satisfying implicit decision factors and proactively acquiring the evidence needed for satisfaction-aware decisions. These findings establish MapSatisfyBench as a benchmark for shifting map-agent evaluation from task completion toward satisfaction-aware spatial decision making.
エージェントの軌跡を通じてモデルの動作を分析する
AI エージェントのパフォーマンスは単なるモデリングの問題ではなく、基本的にシステムの問題です。モデルの高度な機能は、エージェント ハーネスを通じて実現されます。したがって、モデルの想定とハーネスの動作の間にギャップがあると、モデルの全機能がエージェントのパフォーマンスに反映されにくくなる可能性があります。私たちはこれを「意図と実行」のギャップ、つまりモデルが意図するものとハーネスが実行するものとの間の不一致、またはその逆として形式化します。私たちは、この意図と実行のギャップを最小限に抑えることが、ツールや実行ループなどのハーネス設計の他の側面と同じくらい重要であると主張します。このハーネス モデルの調整の影響を説明するために、「Simple Strands Agent」(SSA) と呼ばれるシンプルでカスタマイズ可能なハーネスを開発します。 SSA は、さまざまなモデル ファミリ (Claude、Gemini、GPT、Grok、Qwen など) にわたって一般化される大量の共通パターンと、少数のモデル固有の設定を見つけることを目的としています。私たちは 2 つの貢献を行っています。(i) 一般的なエージェント ベンチマーク (SWE-Pro、SWE-Verified、および Terminal-Bench-2) でさまざまなモデル プロバイダー ファミリによって報告された $\textbf{pass@1}$ のパフォーマンスを再現または改善すること、(ii) $\textbf{SSA によって生成された 138,000 の軌跡の分析}$ に基づいて、比較的均等になる傾向にある $\texttt{pass@1}$ の数値を超えて検討することです。フロンティアモデル全体で。エージェントの軌跡をコード状態空間で表すことにより、問題解決動作におけるモデルレベルの違いが観察されます。編集頻度、テスト アクティビティ、フェーズ移行などのより詳細なメトリクスにより、個々のモデルが自律的な問題解決のさまざまな段階に労力をどのように割り当てているかが明らかになります。
原文 (English)
Dissecting model behavior through agent trajectories
AI agent performance is not just a modeling problem, it is fundamentally a systems problem. The advanced capabilities of models are realized through agent harnesses. Therefore, a gap between model assumptions and harness behavior can easily prevent the model's full capabilities from translating into agent performance. We formalize this as the `intent-execution' gap: the mismatch between what the model intends and what the harness executes, and vice versa. We argue that minimizing this intent-execution gap is as important as other aspects of harness design such as tools and execution loops. To illustrate the impact of this harness-model alignment, we develop a simple and customizable harness called `Simple Strands Agent' (SSA). SSA aims to find the bulk of common patterns which generalize across different model families (such as Claude, Gemini, GPT, Grok, Qwen), as well as a small number of model-specific preferences. We make two contributions: (i) we reproduce or improve on the pass@1 performance reported by diverse model-provider families on popular agentic benchmarks (SWE-Pro, SWE-Verified and Terminal-Bench-2), and (ii) building on an analysis of 138k trajectories generated by SSA, we look beyond the pass@1 numbers which tend to be relatively even across frontier models. By representing agent trajectories in code state-spaces, we observe model-level differences in problem-solving behavior. Finer-grained metrics such as edit frequency, testing activity, and phase-transitions reveal how individual models allocate effort across different stages of autonomous problem solving.
適切な教師を信頼する: GUI グラウンディングのための品質を意識した自己蒸留
グラフィカル ユーザー インターフェイス (GUI) の基礎には、高解像度スクリーンショット内の小さなターゲット要素を識別し、正確な画面座標を予測するためのビジョン言語モデル (VLM) が必要です。オンポリシー自己蒸留 (OPSD) は、ハード座標ラベルを超えた高密度のトークンレベルの教師信号を提供するため、この座標に依存するタスクに対するトレーニング後のアプローチとして有望です。ただし、単純な OPSD は GUI の基礎にはあまり適していません。OPSD は生徒が生成したプレフィックスに基づいて教師を評価しますが、プレフィックスがターゲット座標からすでに逸脱している場合、座標トークンの教師信号の品質が低下する可能性があり、教師信号の信頼性が低くなります。これを軽減するために、VLM ベースの GUI グラウンディングのための品質を意識した自己蒸留を提案します。これにより、ソフトコレクトネスを意識したゲーティングと教師確率スケーリングを通じて、座標トークンの教師信号の品質が向上します。ソフト正確性認識ゲートは、教師の現在の座標トークン予測が、生徒が生成したプレフィックスの下のグラウンドトゥルース ボックスにまだ入力できるかどうかをチェックします。そうでない場合、対応する教師信号は重み付けが低くなります。次に、教師の確率スケーリングでは、教師の信頼度を軽量要素として使用して、ゲート付き監視の強度をさらに調整します。重要な経験的発見は、どちらのコンポーネントも単独では全体的なパフォーマンスを向上させないが、それらを組み合わせると一貫してパフォーマンスが向上するということです。これは、2 つのメカニズムが補完的な役割を果たすことを示唆しています。正確性を意識したゲーティングは信頼性の低い座標トークンの監視を抑制し、教師確率スケーリングは残りの信号の強度を調整します。 6 つの GUI グラウンディング ベンチマークにわたる実験では、私たちの手法がベース モデルを一貫して改善し、強力なベースラインを上回るパフォーマンスを示していることが示されています。
原文 (English)
Trust the Right Teacher: Quality-Aware Self-Distillation for GUI Grounding
Graphical user interface (GUI) grounding requires vision-language models (VLMs) to identify small target elements in high-resolution screenshots and predict precise screen coordinates. On-policy self-distillation (OPSD) is a promising post-training approach for this coordinate-sensitive task, since it provides dense token-level teacher signals beyond hard coordinate labels. However, naive OPSD is not well suited to GUI grounding: OPSD evaluates the teacher on student-generated prefixes, the quality of coordinate-token teacher signals can degrade when the prefix has already deviated from the target coordinate, leading to unreliable teacher signal. To mitigate this, We propose quality-aware self-distillation for VLM-based GUI grounding, which improves coordinate-token teacher-signal quality through soft correctness-aware gating and teacher-probability scaling. The soft correctness-aware gate checks whether the teacher's current coordinate-token prediction can still be completed into the ground-truth box under the student-generated prefix. If not, the corresponding teacher signal is down-weighted. Teacher-probability scaling then uses the teacher's confidence as a lightweight factor to further calibrate the strength of the gated supervision. A key empirical finding is that neither component alone improves overall performance, whereas combining them consistently improves performance. This suggests that the two mechanisms play complementary roles: correctness-aware gating suppresses unreliable coordinate-token supervision, while teacher-probability scaling calibrates the strength of the remaining signals. Experiments across six GUI grounding benchmarks show that our method consistently improves the base model and outperforms strong baselines.
AI 旅行代理店が闘牛を予約してくれる: フロンティア AI モデルにおける暗黙の動物福祉のエージェントベンチマーク
AI エージェントはアドバイザーからアクターに移行し、ユーザーに代わって旅行を予約し、メニューを計画し、調達を実行します。 AI と動物福祉の既存のベンチマークは、質問と回答のプロンプトに対するモデルのテキスト応答を評価しますが、それらの応答で表面化した福祉推論が、モデルがツールを使用してアクションを実行する必要があるエージェント展開に移行するかどうかは未解決のままです。 AI エージェントがユーザーに代わって行動する際に動物搾取を伴うオプションを回避するかどうかを測定する初のエージェント ベンチマークである TAC (Travel Agent Compassion) を紹介します。 TAC は、動物搾取の 6 つのカテゴリにわたる 12 の手書きの旅行予約シナリオを AI エージェントに提示します。これは、価格、評価、位置の交絡を制御するために 48 のサンプルに拡張されています。私たちは 4 つの研究室からの 7 つのフロンティア モデルを評価します。すべてのモデルのスコアはチャンス レベルの 64 パーセントを下回り、最高のパフォーマンスを発揮するモデル (Claude Opus 4.7) のスコアは 53 パーセントです。システム プロンプト内の福祉を意識した一文で、Claude と GPT-5.5 では 47 ~ 63 パーセント ポイント、GPT-5.2 では 26 ポイント、DeepSeek と Gemini では 12 ポイント未満の向上が見られます。 Gemini 2.5 Flash Lite を判定者として使用して、上位 2 つのパフォーマーからの 288 件の基本条件のトランスクリプトを対象とした補助的な Inspect Scout 監査では、評価認識のトランスクリプトがゼロであるとフラグが立てられ、可能性を下回る率が評価を認識するモデルに起因するものではないことが示唆されています。文化的ドメイン間のカテゴリレベルの変動の影響、テキスト応答福祉ベンチマークの限界、および EU 汎用 AI 実践規範のシステミック リスク フレームワークについて議論します。
原文 (English)
Your AI Travel Agent Would Book You a Bullfight: An Agentic Benchmark for Implicit Animal Welfare in Frontier AI Models
AI agents are moving from advisors to actors, booking travel, planning menus, and running procurement on behalf of users. Existing benchmarks for AI and animal welfare evaluate model text responses to question-answer prompts, leaving open whether the welfare reasoning surfaced in those responses transfers to agentic deployment where the model must take actions with tools. We introduce TAC (Travel Agent Compassion), the first agentic benchmark measuring whether AI agents avoid options involving animal exploitation when acting on behalf of users. TAC presents an AI agent with twelve hand-authored travel booking scenarios across six categories of animal exploitation, augmented to forty-eight samples to control for price, rating, and position confounds. We evaluate seven frontier models from four labs. Every model scores below the chance level of sixty-four percent, with the best performer (Claude Opus 4.7) at fifty-three percent. A single welfare-aware sentence in the system prompt yields gains of forty-seven to sixty-three percentage points in Claude and GPT-5.5, twenty-six points in GPT-5.2, and under twelve points in DeepSeek and Gemini. An auxiliary Inspect Scout audit of 288 base-condition transcripts from the top two performers, using Gemini 2.5 Flash Lite as judge, flags zero transcripts for evaluation awareness, suggesting the below-chance rates do not stem from the models recognising the evaluation. We discuss implications for category-level variation across cultural domains, the limits of text-response welfare benchmarks, and the EU General-Purpose AI Code of Practice systemic risk framework.
スタンフォード EDGAR 提出データセット: 米国の企業および財務開示情報をレイアウトに忠実でトークン効率の高い事前トレーニング データに再構築する
高品質のパブリック Web コーパスがますます枯渇するにつれ、きれいなロングコンテキストのドキュメントが、大規模言語モデル (LLM) のトレーニング データの希少かつ高価なソースになりました。既存の長いコンテキストのコーパスは、多くの場合、独自のものであり、取得するのにコストがかかり、合成的に生成されたり、プログラミングなどの狭い領域に集中したりしています。金融言語のモデリングと評価のために、SEC 提出書類をレイアウトに忠実な MultiMarkdown にオープンに再構築した Stanford EDGAR Filings Dataset (SEFD) を紹介します。 SEFD は、監査済みの財務諸表、リスク開示、所有権報告書、会計ノート、市場を動かすイベントの報告書を、長期コンテキストの事前トレーニング データとして、また財務上の推論、予測、コンプライアンス、文書理解の基礎として使用できるようにします。結果として得られるコーパスはトークン効率が高く、モデルの準備ができており、Common Crawl から派生したコーパスとの重複は 0.1% 未満です。私たちは、152B トークンの初期公開スナップショットである SEFD-v1 をリリースし、550B トークンと推定される大規模な 1850 万ファイルのアーカイブのコーパス レベルの分析を提供します。さらに、SEFD 由来の 2 つのベンチマークを紹介します。EDGAR-Forecast は、モデル知識のカットオフ後のファイリングに基づいた数値予測を評価します。もう 1 つは、複雑な財務表の転記を評価する EDGAR-OCR です。
原文 (English)
The Stanford EDGAR Filings Dataset: Reconstructing U.S. Corporate and Financial Disclosures into Layout-Faithful and Token-Efficient Pretraining Data
As high-quality public web corpora become increasingly exhausted, clean long-context documents have become a scarce and expensive source of training data for large language models (LLMs). Existing long-context corpora are often proprietary and costly to acquire, synthetically generated, or concentrated in narrow domains such as programming. We introduce the Stanford EDGAR Filings Dataset (SEFD), an open reconstruction of SEC filings into layout-faithful MultiMarkdown for financial language modeling and evaluation. SEFD makes audited financial statements, risk disclosures, ownership reports, accounting notes, and market-moving event filings usable as long-context pretraining data and as a basis for financial reasoning, forecasting, compliance, and document understanding. The resulting corpus is token-efficient, model-ready, and has less than 0.1% overlap with Common Crawl-derived corpora. We release SEFD-v1, a 152B-token initial public snapshot, and provide corpus-level analyses of a larger 18.5M-filing archive estimated at 550B tokens. We further introduce two SEFD-derived benchmarks: EDGAR-Forecast, which evaluates filing-grounded numerical forecasting after model knowledge cutoffs, and EDGAR-OCR, which evaluates transcription of complex financial tables.
Simple Domain Generalization Methods are Strong Baselines for Open Domain Generalization
In real-world applications, a machine learning model is required to handle an open-set recognition (OSR), where unknown classes appear duri…
A DeepLearning Framework for Dynamic Estimation of Origin-Destination Sequence
OD matrix estimation is a critical problem in the transportation domain. The principle method uses the traffic sensor measured information…
Quality Perceptions and Intended Engagement in Response to AI-Generated and AI-Assisted News
The increasing use of artificial intelligence (AI) in news production raises important questions about how audiences perceive and respond t…
Scalable Batch Bayesian Optimization Via Subspace Acquisition Functions
Extending Bayesian optimization to batch evaluation can enable the designer to make the most use of parallel computing technology. However,…
VidCRAFT3: Camera, Object, and Lighting Control for Image-to-Video Generation
Controllable image-to-video (I2V) generation transforms a reference image into a coherent video guided by user-specified control signals. W…
Efficient Zeroth-Order Federated Finetuning of Language Models on Resource-Constrained Devices
Federated Learning (FL) is a promising paradigm for finetuning Large Language Models (LLMs) across distributed data sources while preservin…
Depth-Width tradeoffs in Algorithmic Reasoning of Graph Tasks with Transformers
Transformers have revolutionized the field of machine learning. In particular, they can be used to solve complex algorithmic problems, incl…
Generalized Kullback-Leibler Divergence Loss
In this paper, we delve deeper into the Kullback-Leibler (KL) Divergence loss and mathematically prove that it is equivalent to the Decoupl…
Revealing Hidden Vulnerabilities in Autoencoders through Gradient Signal Restoration
Adversarial robustness of deep autoencoders (AEs) has received less attention than that of discriminative models, although their compressed…
Signals of Provenance: Practices & Challenges of Navigating Indicators in AI-Generated Media for Sighted and Blind Individuals
AI-Generated (AIG) content has become increasingly widespread by recent advances in generative models and the easy-to-use tools that have s…
Revisiting Active Speaker Detection: An In-the-Wild Benchmark for Generalization and Robustness
We present UniTalk, a novel dataset emphasizing challenging scenarios to enhance model generalization for the task of active speaker detect…
ASyMOB: Algebraic Symbolic Mathematical Operations Benchmark
Large language models (LLMs) are increasingly applied to symbolic mathematics, yet existing evaluations often conflate pattern memorization…
Self-Evolving Multi-Agent Systems via Textual Backpropagation
Leveraging multiple Large Language Models (LLMs) has proven effective for addressing complex, high-dimensional tasks, but current approache…
Grids Often Outperform Implicit Neural Representations at Compressing Dense Signals
Implicit Neural Representations (INRs) have recently shown impressive results, but their fundamental capacity, implicit biases, and scaling…
From Memorization to Parameter Interference: How Overtraining Experts Harms Model Merging
Modern deep learning is increasingly characterized by the use of open-weight foundation models that can be fine-tuned on specialized datase…
Model Collapse Is Not a Bug but a Feature in Machine Unlearning for LLMs
Current unlearning methods for LLMs optimize on the private information they seek to remove by incorporating it into their fine-tuning data…
Enhancing Fatigue Detection through Heterogeneous Multi-Source Data Integration and Cross-Domain Modality Imputation
Fatigue detection for human operators is important in safety-related applications such as aviation, mining, and long-haul transport. Reliab…
When Cars Have Stereotypes: Auditing Demographic Bias in Objects from Text-to-Image Models
While prior research on text-to-image generation has predominantly focused on biases in human depictions, demographic bias in generated obj…
From Values to Tokens: An LLM-Driven Framework for Context-aware Time Series Forecasting via Symbolic Discretization
Time series forecasting plays a vital role in supporting decision-making across a wide range of critical applications, including energy, he…
Surrogate Benchmarks for Model Merging Optimization
Model merging techniques aim to integrate the abilities of multiple models into a single model. Most model merging techniques have hyperpar…
Probing Semantic Alignment, Lexical Invariance, and Syntactic Influence in LLM Metaphor Processing
Large language models (LLMs) achieve strong performance on metaphor detection and interpretation tasks, yet it remains unclear what such be…
Rethinking Cross-lingual Gaps from a Statistical Viewpoint
Any piece of knowledge is usually expressed in one or a handful of natural languages on the web or in any large corpus. Large Language Mode…
R2BC: Multi-Agent Imitation Learning from Single-Agent Demonstrations
Imitation Learning (IL) is a natural way for humans to teach robots, particularly when high-quality demonstrations are easy to obtain. Whil…
DecNefSimulator: A Modular, Interpretable Framework for Decoded Neurofeedback Simulation Using Generative Models
Decoded Neurofeedback (DecNef) is a promising non-invasive approach to brain modulation with wide-ranging applications in neuromedicine and…
Semantic Router: On the Feasibility of Hijacking MLLMs via a Single Adversarial Perturbation
Multimodal Large Language Models (MLLMs) are increasingly deployed in stateless systems, such as autonomous driving and robotics. This pape…
Learning Patient-Specific Disease Dynamics with Latent Flow Matching for Longitudinal Imaging Generation
Understanding disease progression is a central clinical challenge with direct implications for early diagnosis and personalized treatment.…
Improving Scientific Document Retrieval with Academic Concept Index
Adapting general-domain retrievers to scientific domains is challenging due to the scarcity of large-scale domain-specific relevance annota…
SciHorizon-GENE: 遺伝子の知識から機能の理解までのライフサイエンス推論のための LLM のベンチマーク
大規模言語モデル (LLM) は、生物医学研究、特に知識主導型の解釈タスクにおいてますます有望であることが示されています。しかし、知識を強化した細胞アトラス解釈の中核となる要件である、遺伝子レベルの知識から機能的理解まで確実に推論する能力は、依然として十分に解明されていない。このギャップに対処するために、信頼できる生物学データベースから構築された大規模な遺伝子中心のベンチマークである SciHorizon-GENE を紹介します。このベンチマークは、19 万以上のヒト遺伝子に関する精選された知識を統合しており、細胞型の注釈、機能解釈、機構指向の分析に関連する多様な遺伝子から機能への推論シナリオをカバーする 54 万以上の質問で構成されています。 SciHorizon-GENE は、予備検査で観察された行動パターンに動機付けられ、生物学的に重要な 4 つの観点 (研究注意の感度、幻覚傾向、解答の完全性、文献の影響) に沿って LLM を評価し、生物学的解釈パイプラインにおける LLM の安全な採用を制限する失敗モードを明示的にターゲットにしています。私たちは、最先端の汎用 LLM および生物医学 LLM を幅広く体系的に評価し、遺伝子レベルの推論能力における実質的な不均一性と、忠実で完全な文献に基づいた機能解釈を生成する際の永続的な課題を明らかにしています。私たちのベンチマークは、LLM の挙動を遺伝子スケールで分析するための体系的な基盤を確立し、知識を強化した生物学的解釈に直接関連するモデルの選択と開発のための洞察を提供します。
原文 (English)
SciHorizon-GENE: Benchmarking LLM for Life Sciences Inference from Gene Knowledge to Functional Understanding
Large language models (LLMs) have shown growing promise in biomedical research, particularly for knowledge-driven interpretation tasks. However, their ability to reliably reason from gene-level knowledge to functional understanding, a core requirement for knowledge-enhanced cell atlas interpretation, remains largely underexplored. To address this gap, we introduce SciHorizon-GENE, a large-scale gene-centric benchmark constructed from authoritative biological databases. The benchmark integrates curated knowledge for over 190K human genes and comprises more than 540K questions covering diverse gene-to-function reasoning scenarios relevant to cell type annotation, functional interpretation, and mechanism-oriented analysis. Motivated by behavioral patterns observed in preliminary examinations, SciHorizon-GENE evaluates LLMs along four biologically critical perspectives: research attention sensitivity, hallucination tendency, answer completeness, and literature influence, explicitly targeting failure modes that limit the safe adoption of LLMs in biological interpretation pipelines. We systematically evaluate a wide range of state-of-the-art general-purpose and biomedical LLMs, revealing substantial heterogeneity in gene-level reasoning capabilities and persistent challenges in generating faithful, complete, and literature-grounded functional interpretations. Our benchmark establishes a systematic foundation for analyzing LLM behavior at the gene scale and offers insights for model selection and development, with direct relevance to knowledge-enhanced biological interpretation.
DeepInflation: an AI agent for research and model discovery of inflation
We present DeepInflation, an AI agent designed for research and model discovery in inflationary cosmology. Built upon a multi-agent archite…
InstructTime++: Time Series Classification with Multimodal Language Modeling via Implicit Feature Enhancement
Most existing time series classification methods adopt a discriminative paradigm that maps input sequences directly to one-hot encoded clas…
Retell, Reward, Repeat: Reinforcement Learning for Narrative Theory-Informed Story Retelling
Counterfactual story retelling exposes LLM shortcomings in constrained narrative solution spaces where they can no longer rely on recalling…
LVLMs and Humans Ground Differently in Referential Communication
For generative AI agents to partner effectively with human users, the ability to accurately predict human intent is critical. But this abil…
HeRo-Q: A General Framework for Stable Low Bit Quantization via Hessian Conditioning
Post Training Quantization (PTQ), a mainstream model compression technique, often leads to the paradoxical 'low error, high loss' phenomeno…
LLM Compression by Block Removal with Constrained Binary Optimization
In this paper, we formulate the compression of large language models (LLMs) by optimally deleting transformer blocks (``block removal'') as…
Posterior Continuation with Noise-Conditioned Frequency Exposure for Diffusion Inverse Problems
Diffusion posterior sampling solves inverse problems by combining a pretrained diffusion prior with measurement-consistency guidance. Howev…
Improve Large Language Model Systems with User Logs
Scaling training data and model parameters has long driven progress in large language models (LLMs), but this paradigm is increasingly cons…
Do Neural Networks Lose Plasticity in a Gradually Changing World?
Continual learning has become a trending topic in machine learning. Recent studies have discovered an interesting phenomenon called loss of…
Narrative Theory-Driven LLM Methods for Automatic Story Generation and Understanding: A Survey
Applications of narrative theories using large language models (LLMs) deliver promising methods in automatic story generation and understan…
Detecting High-Potential SMEs with Heterogeneous Graph Neural Networks
Small and Medium Enterprises (SMEs) constitute 99.9% of U.S. businesses and generate 44% of economic activity, yet systematically identifyi…
ActMem: Bridging the Gap Between Memory Retrieval and Reasoning in LLM Agents
Memory management is essential for LLM agents in long-term interactions. Current memory frameworks typically treat agents as passive ``reco…
Speaker Verification with Speech-Aware LLMs: Evaluation and Augmentation
Speech-aware large language models (LLMs) can accept speech inputs, yet their training objectives largely emphasize linguistic content or s…
Something from Nothing: Data Augmentation for Robust Severity Level Estimation of Dysarthric Speech
Dysarthric speech quality assessment (DSQA) is critical for clinical diagnostics and inclusive speech technologies. However, subjective eva…
A Convex Route to Thermoelasticity: Learning Internal Energy and Dissipation
We present a physics-based neural network framework for the discovery of constitutive models in fully coupled thermomechanics. In contrast…
MemRerank: Preference Memory for Personalized Product Reranking
LLM-based shopping agents increasingly rely on long purchase histories and multi-turn interactions for personalization, yet naively appendi…
A CEFR-Inspired Classification Framework with Fuzzy C-Means To Automate Assessment of Programming Skills in Scratch
Context: Schools, training platforms, and technology firms increasingly need to assess programming proficiency at scale with transparent, r…
IPSL-AID: Generative Diffusion Models for Climate Downscaling from Global to Regional Scales
Effective adaptation and mitigation strategies for climate change require high-resolution projections to inform strategic decision-making.…
From Paper to Program: Externalizing and Diagnosing Knowledge Bottlenecks in AI-Assisted Quantum Many-Body Code Generation
Large language models can write scientific code, but direct paper-to-program translation remains fragile when correctness depends on tacit…
WebSP-Eval: Evaluating Web Agents on Website Security and Privacy Tasks
Web agents automate browser tasks, ranging from simple form completion to complex workflows like ordering groceries. While current benchmar…
The Long Delay to Arithmetic Generalization: When Learned Representations Outrun Behavior
Grokking in transformers trained on algorithmic tasks is characterized by a long delay between training-set fit and abrupt generalization,…
Do We Still Need Humans in the Loop? Comparing Human and LLM Annotation in Active Learning for Hostility Detection
Instruction-tuned LLMs can annotate thousands of instances at low cost. This raises two questions for active learning (AL): can LLM labels…
From Concept-Aligned Tokens to Vulnerable Features: Mechanistic Localization of Jailbreaks
Jailbreak attacks expose a persistent failure mode in safety-aligned LLMs: models can be pushed into harmful behavior, but the internal rep…
TopBench: A Benchmark for Implicit Predictive Reasoning in Tabular Question Answering
Large Language Models (LLMs) have advanced Table Question Answering, where most queries can be answered by extracting information or simple…
Clin-JEPA: A Multi-Phase Co-Training Framework for Joint-Embedding Predictive Pretraining on EHR Patient Trajectories
We present Clin-JEPA, a multi-phase co-training framework for joint-embedding predictive (JEPA) pretraining on EHR patient trajectories. JE…
Beyond Similarity: Temporal Operator Attention for Time Series Analysis
A persistent paradox in time-series forecasting is that structurally simple MLP and linear models often outperform high-capacity Transforme…
Pyramid Self-Contrastive Learning for Single-shot Test-time Ultrasound Image Denoising
The inherent electronic and speckle noise complicates clinical interpretation of ultrasound images. Conventional denoising methods rely on…
Controllable Quantum Memory Capacity in Quantum Reservoir Networks with Tunable partial-SWAPs
In the field of quantum reservoir computing (QRC), many different computational models and architectures have been proposed. From these mod…
Hilbert-Geo: Solving Solid Geometric Problems by Neural-Symbolic Reasoning
Geometric problem solving, as a typical multimodal reasoning problem, has attracted much attention and made great progress recently, howeve…
A Survey on Deep Learning Architectures for Point Cloud Classification and Segmentation
Point cloud stands as the most widely adopted format for representing 3D shapes and scenes due to its simplicity and geometric fidelity. Ho…
LivePI: More Realistic Benchmarking of Agents Against Indirect Prompt Injection
AI agents such as OpenClaw are increasingly deployed in local workflows with access to external tools. This creates indirect prompt-injecti…
DySink: Dynamic Frame Sinks for Autoregressive Long Video Generation
Autoregressive long video generation often adopts bounded-memory streaming for efficiency, typically combining local windows for short-term…
A Reproducible Log-Driven AutoML Framework for Interpretable Pipeline Optimization in Healthcare Risk Prediction
Accurate disease risk prediction is challenged by heterogeneous features, limited data, and class imbalance. This study presents yvsoucom-i…
Short-Term-to-Long-Term Memory Transfer for Knowledge Graphs under Partial Observability
Reinforcement learning under partial observability requires deciding what information to retain, yet most memory-based approaches do not ex…
Practical Anonymous Two-Party Gradient Boosting Decision Tree
Structured data is well handled by gradient-boosted decision trees (GBDT), which are usually trained on vertically partitioned features acr…
PatchWorld: Gradient-Free Optimization of Executable World Models
Text-agent environments are typically modeled as partially observable Markov decision processes (POMDPs), assuming that the simulator's lat…
The New Social Image: How AI Competency and AI Proactivity Influence Self- and Peer-Perceptions in the Workplace
Human-AI collaboration is considered the most promising way to incorporate AI in the workplace. What remains unexplored are the experientia…
Pre-Deployment Robustness Stress Testing for CT Segmentation Systems Using Clinically Motivated Multi-Corruption Augmentation
Deep learning-based CT segmentation systems often achieve high accuracy on clean benchmark images, but their performance may degrade under…
Attention mechanisms and transfer learning for robust peach leaf damage classification under domain shift
Artificial intelligence provides a practical framework for crop damage assessment from imagery data, supporting early decision-making in ag…
Cosmos 3: Omnimodal World Models for Physical AI
We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and actio…
Conditional Latent Diffusion Model with Fourier-based Motion Modelling for Virtual Population Synthesis
In-silico trials of medical devices require the generation of virtual populations of anatomies. In cardiovascular applications, virtual ana…
TLA-Prover: Verifiable TLA+ Specification Synthesis via Preference-Optimized Low-Rank Adaptation
TLA+ is a formal specification language for verifying distributed systems and safety-critical protocols. Large language models (LLMs) frequ…
WAV: ディープ デコーダー専用トランスフォーマーのマルチ解像度ブロック残留配線
残差接続はディープ Transformer のトレーニングの中心となりますが、標準の PreNorm 残差ストリームは固定ユニット重みを使用してサブレイヤーの更新を集約します。最近のアテンション残差は、この固定累積をコンテンツ依存の深さ方向のルーティングに置き換えます。また、ブロック アテンション残差は、ブロック レベルの残差サマリーをルーティングすることでメカニズムを効率化します。ただし、単一のブロック サマリーには、ブロック内の低周波合計残留変位のみが保存され、注意対 MLP の不均衡や初期ブロック 対後期ブロック ダイナミクスなどの方向性構造は破棄されます。我々は、デコーダ専用のトランスフォーマー向けの軽量の多重解像度残差ルーティング方法である WAV v1 を提案します。 WAV v1 は、各ブロックを累積残差和のみで表すのではなく、2 つの方向性詳細ベースですべてのブロックを拡張します。1 つはアテンションと MLP 更新を対比するフェーズ ベース、もう 1 つは初期および後期のサブレイヤー更新を対比するスプリット ベースです。これらのベースは、同じ深さ方向のソフトマックス ミキサーを介して標準ブロック サマリーとともにルーティングされ、一方、負の詳細ソースの初期化と独立した RMS マッチングによりトレーニングが安定します。キャラクターレベルの TinyStories と Text8 言語モデリングでは、WAV v1 は深さに依存する明らかな利点を示しています。 12 レイヤーでは一貫した利点はありませんが、24 レイヤーでは競争力があり、48 レイヤーではすべてのベースラインを上回ります。 48 レイヤーでは、WAV v1 はブロック AttnRes に対する検証損失を TinyStories で 0.4960 から 0.4738 に、Text8 で 0.9363 から 0.9305 に削減しますが、追加パラメーターは無視できます。これらの結果は、ブロックレベルの合計だけでなく、方向性残差の詳細が、より深いトランスフォーマーで残差ルーティングをスケーリングするために重要であることを示唆しています。
原文 (English)
HAARES Half-Split Residual Basis Routing for Deep Transformers
Block-level residual routing makes learned residual aggregation practical by routing over block summaries, but each summary compresses an ordered sequence of attention and MLP updates into one cumulative vector. We propose \method{}, a lightweight residual basis router that keeps the cumulative block source and adds one half-split detail basis, computed as the difference between first-half and second-half residual updates. The detail basis is RMS-matched and updated online, exposing coarse intra-block trajectory information without dense sublayer-level routing. Across OpenWebText, cross-domain character-level benchmarks, and BPE-tokenized OpenWebText, the empirical pattern is depth-dependent: gains are small or mixed at shallow depth and most reliable in 48-layer models. In the 201M 48-layer setting, \method{} improves over Block AttnRes across all three seeds, while a 453M two-seed probe shows the same direction. Ablations rule out source duplication, random signed details, fixed detail-source biases, or block-count changes alone. Cost analysis shows that the method is FLOP-light but not wall-clock-free: it adds memory and routing overhead, yet its relative arithmetic cost is amortized as width grows and earlier convergence can reduce time-to-target.
From Privacy to Workflow Integrity: Communication-Graph Metadata in Autonomous Agent Interoperability
Agent-interoperability protocols such as A2A and MCP standardize what agents say to one another but assume address-based transport. Whether…
ResearchClawBench: A Benchmark for End-to-End Autonomous Scientific Research
AI coding agents are increasingly used for scientific work, but their end-to-end autonomous research capability remains difficult to verify…
UPLOTS: A Unified Pretrained Language Model for Constrained Time-series Generation
In time-series generation, existing approaches typically handcraft ortrain a separate model for each dataset, which hinders their scalabili…
Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
We show the standard basis of transformer hidden states already provides a training-free, architecture-general feature basis. Individual di…
SymQNet: Amortized Acquisition for Low-Latency Adaptive Hamiltonian Learning
Adaptive Hamiltonian learning is central to calibrating and characterizing quantum devices. In an adaptive controller, choosing the next ex…
CineOrchestra: 映画のようなビデオ生成のためのエンティティ中心の統合コンディショニング
映画のようなビデオは、特定の瞬間に行動または対話する複数の被写体を描写し、意図的なカメラの動きで撮影され、ショットのトランジションによってつなぎ合わされます。これらの要素を組み合わせると、現在のテキストからビデオへのモデルを超えたレベルのきめ細かい制御が必要になります。既存の研究では、複数の主題のパーソナライゼーション、時間的制御、マルチショット合成、またはカメラ制御などの各軸を個別に扱っています。 4 つすべてを統合するこれまでのフレームワークはありません。被写体、イベント、カメラ、ショットトランジションを同時に制御する統合ビデオ拡散モデルである CineOrchestra を紹介します。私たちの重要な洞察は、これらの異質な映画要素が基本的な構造を共有しているということです。つまり、それぞれが特定の時間間隔にわたって動作するエンティティであり、したがって、それらはすべて、視覚エンティティの参照画像で強化された、エンティティ中心の条件付けプリミティブの 1 つの共有構造を通じて表現できるということです。この定式化により、アーキテクチャ上の課題が 1 つの位置エンコード問題に軽減されます。これは、2 つのパラメーターなしの調整された回転埋め込みで解決されます。(a) 持続時間が劇的に変化するイベント全体で一貫した注意動作を生み出す、間隔サンプリングされた時間的 RoPE、および (b) エンティティごとの条件を明確にし、それぞれを対応する時空間領域にルーティングする 2D エンティティと時間のクロスアテンション RoPE。 2 つの新しいベンチマークで、CineOrchestra は、高密度のキャプション追従とショット移行のタイミングで軸ごとのスペシャリスト 6 名を上回っており、ペアごとのユーザー調査とコンポーネントのアブレーションで一貫した成果を上げています。
原文 (English)
CineOrchestra: Unified Entity-Centric Conditioning for Cinematic Video Generation
Cinematic video depicts multiple subjects acting or interacting at specific moments, captured with deliberate camera movement, and stitched together by shot transitions. Together, these elements demand a level of fine-grained control beyond current text-to-video models. Existing work addresses each axis in isolation: multi-subject personalization, temporal control, multi-shot synthesis, or camera control; no prior framework jointly integrates all four. We present CineOrchestra, a unified video diffusion model that controls subjects, events, cameras, and shot transitions simultaneously. Our key insight is that these heterogeneous cinematic elements share a fundamental structure: each is an entity acting over a specific temporal interval, which can therefore all be expressed through one shared structure of entity-centric conditioning primitives, augmented with reference images for visual entities. This formulation reduces the architectural challenge to a single positional encoding problem, which we solve with two parameter-free coordinated rotary embeddings: (a) an interval-sampled temporal RoPE that yields consistent attention behavior across events of dramatically varying duration, and (b) a 2D entity-temporal cross-attention RoPE that disambiguates per-entity conditions and routes each to its corresponding spatiotemporal region. On two new benchmarks, CineOrchestra outperforms six per-axis specialists on dense caption following and shot-transition timing, with consistent gains in a pairwise user study and component ablations. Project page: https://snap-research.github.io/CineOrchestra
MeEvo: Metacognitive Evolution Combined with Natural Evolution for Automatic Heuristic Design
Large Language Models (LLMs) have advanced Automatic Heuristic Design (AHD) by enabling heuristic generation through reasoning and code syn…
Sensory Restoration via Brain-Computer Interfaces: A Unified 2 x 2 Framework and Convergence Roadmap
Millions of individuals worldwide suffer from sensory and communication deficits caused by neurodegenerative diseases, stroke, or trauma. B…
Calibrated Sampling-Free Uncertainty Estimation in Bayesian Deep Learning
Modern deep learning models remain notoriously prone to overconfidence, limiting their reliability in high-stakes applications. Bayesian me…
Implicit vs. Explicit Prompting Strategies for LVLMs in Referential Communication
Two recent studies (Jones et al. (2026); Zeng et al. (2026)) reach apparently contradictory conclusions about whether LVLMs can coordinate…
Enhancing Pathological VLMs with Cross-scale Reasoning
Pathological images are inherently multi-scale, requiring pathologists to integrate evidence from global tissue architecture at low magnifi…