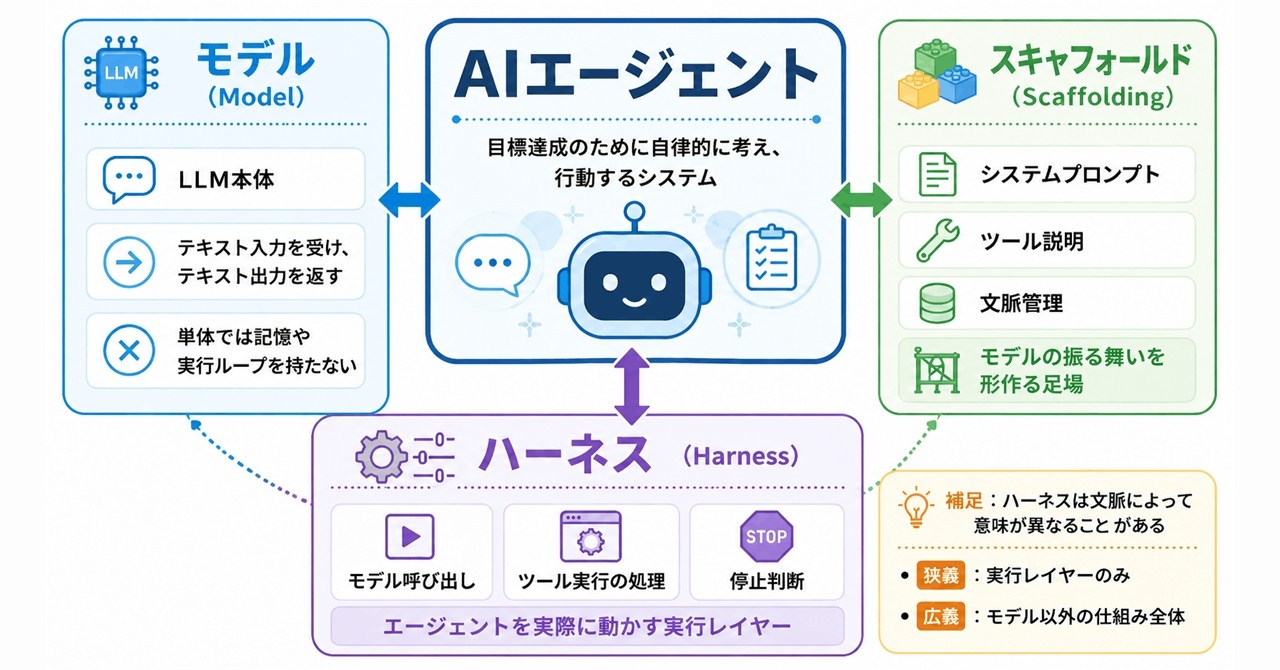
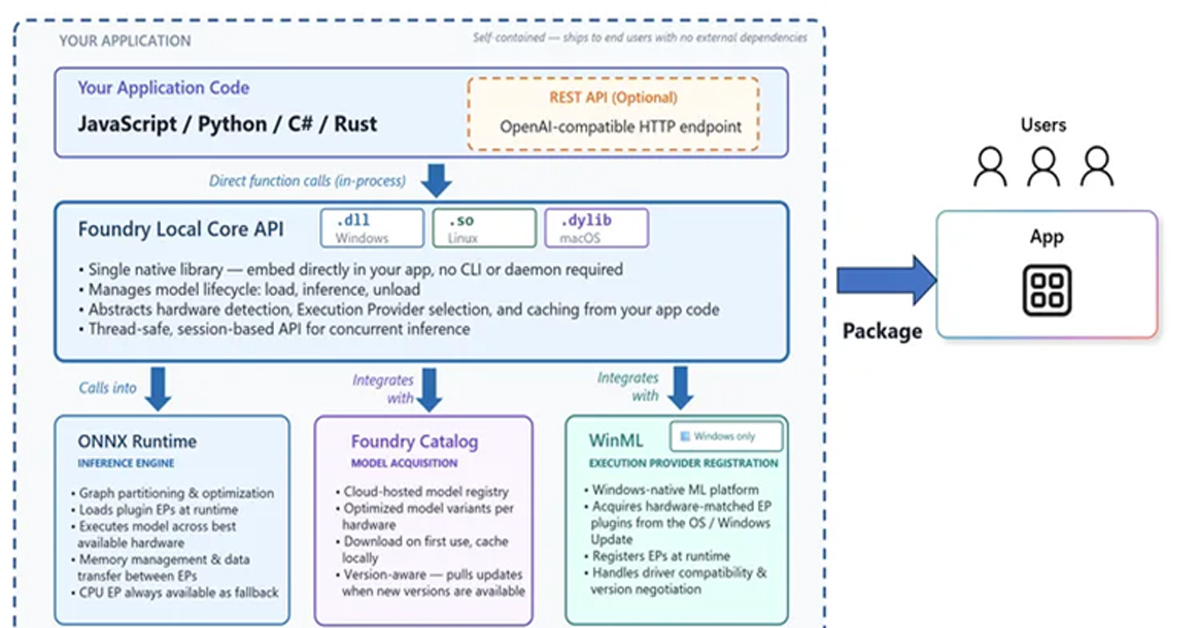
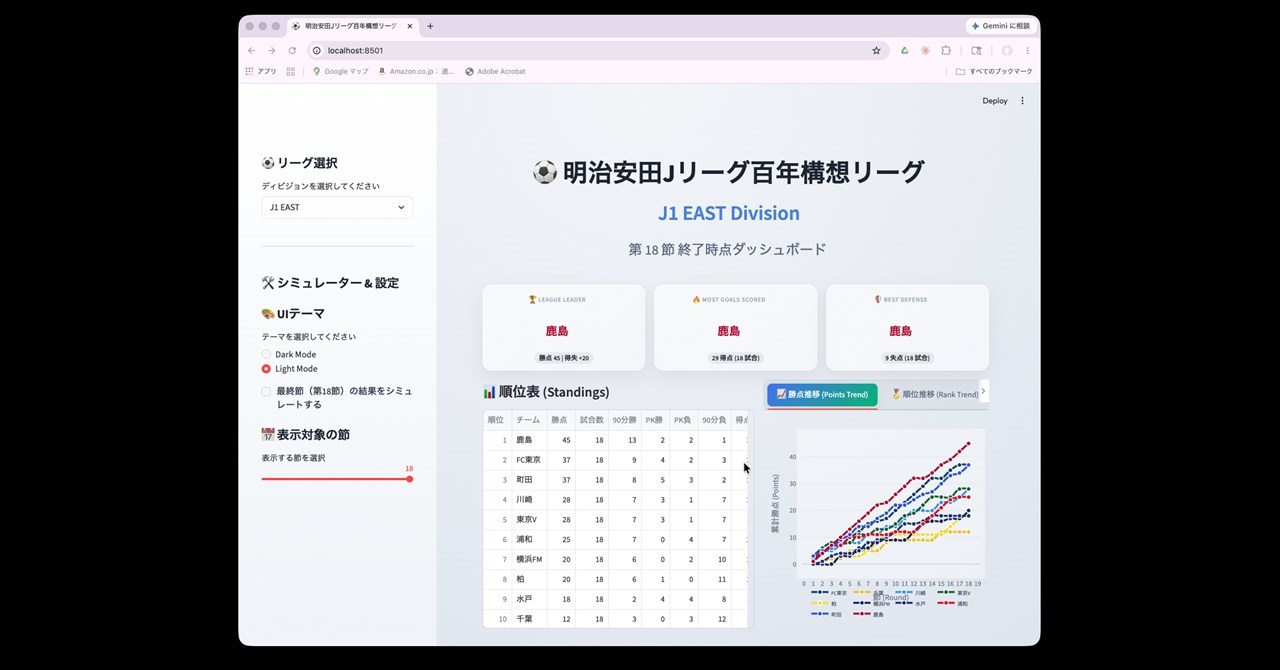
自動生成: 2026-06-06 12:58 JST
過去24時間以内に公開された記事を、同じ話題ごとに1つのストーリーカードへまとめ、出典・トピック・要約とともに掲載しています。要約は各フィード提供文の冒頭を整形したもので、本文は各リンク先をご覧ください。
📌 今日の要点 TOP7
-
Google will pay SpaceX $920M per month for computeTechCrunch AI
In a statement, a Google representative described the deal as a resul…
-
Startup Battlefield 200 applications officially close in 3 daysTechCrunch AI
Applications for Startup Battlefield 200 officially close on June 8,…
-
The most interesting startups right now want to get you off your phoneTechCrunch AI
While the AI fundraising machine keeps breaking its own records, some…
-
英ケンブリッジ大学、AIが設計したワクチンの臨床試験に成功 未知の変異株にも備える“万能型”ITmedia AI+
ケンブリッジ大学は、AIが設計した抗原を用いる“ユニバーサルワクチン”の初の臨床試験に成功したと発表した。サルベコウイルス群のゲノム配列を…
-
The token bill comes due: Inside the industry scramble to manage AI’s runaway costsTechCrunch AI
"The whole conversation shifted from tokenmaxxing and 'go fast' to 'w…
-
The ‘together tech’ wave might be the most intriguing startup bet of 2026TechCrunch AI
While the AI fundraising machine keeps breaking its own records, some…
-
AirTrunk commits $30B to build 5GW of AI data centers in IndiaTechCrunch AI
The Australian data center operator plans to set up 5GW of capacity i…
トピック別件数
- LLM/生成AI 165件
- 研究/論文 143件
- エージェント 88件
- 画像/動画生成 68件
- ロボティクス 21件
- ビジネス/資金調達 16件
- ハードウェア/半導体 10件
- その他 8件
- 規制/政策 1件
日本語メディア1件
ITmedia AI+ (日本語)
英ケンブリッジ大学、AIが設計したワクチンの臨床試験に成功 未知の変異株にも備える“万能型”
ケンブリッジ大学は、AIが設計した抗原を用いる“ユニバーサルワクチン”の初の臨床試験に成功したと発表した。サルベコウイルス群のゲノム配列を機械学習で解析し、グループ共通の“スーパー抗原”を設計した。健康な39人に投与し、安全性と免疫応答を確認した。
海外メディア7件
TechCrunch AI (英語)

Startup Battlefield 200 applications officially close in 3 days
Applications for Startup Battlefield 200 officially close on June 8, 11:59 p.m. PT. Don't wait any longer. Secure your shot at competing on…

Google will pay SpaceX $920M per month for compute
In a statement, a Google representative described the deal as a result of unexpected demand for its recently launched AI products.

The most interesting startups right now want to get you off your phone
While the AI fundraising machine keeps breaking its own records, some founders are building in the other direction. Mirror founder Brynn Pu…

The token bill comes due: Inside the industry scramble to manage AI’s runaway costs
"The whole conversation shifted from tokenmaxxing and 'go fast' to 'we need guardrails, how do we control this?'"

The ‘together tech’ wave might be the most intriguing startup bet of 2026
While the AI fundraising machine keeps breaking its own records, some founders are building in the other direction. Mirror founder Brynn Pu…

AirTrunk commits $30B to build 5GW of AI data centers in India
The Australian data center operator plans to set up 5GW of capacity in India.

Mira Murati steps back into the spotlight, carefully
In the current environment, remaining heads down has diminishing returns; at some point, you have to make some noise just to remind the mar…
公式ブログ0件
このカテゴリの新着記事はありませんでした。
論文381件
arXiv cs.AI (英語)
エンタープライズ AI エージェントの導入前保証に向けて: オントロジーに基づいたシミュレーションと信頼証明
エンタープライズ人工知能 (AI) エージェントの導入前の検証は、大規模言語モデル (LLM) 機能のベンチマークと運用環境の導入の間に依然として重大なギャップがあります。導入後のモニタリング、人間参加型制御、およびプロンプト レベルのガードレールは、エージェントが運用環境で動作すると限定的な保証を提供します。私たちは、次の 3 つのコンポーネントを組み合わせたオントロジーに基づいた検証フレームワークを提案します。1 つは、権限、ドメイン制約、安全性、ガバナンス ルール、および自律性レベルにわたる認証空間を形式化するエージェント運用エンベロープです。規制、運用、敵対的テストのシナリオを自動的に導き出すオントロジーからシナリオへの生成パイプライン。段階的な展開判定 (承認、条件付き、拒否) を含む機械検証可能な証明書を保持する信頼証明書。米国とベトナムの 5 つの業界別規制制度セルとしてインスタンス化された、4 つの規制対象業界 (フィンテック、銀行、保険、ヘルスケア) にわたる制御されたパイロットは、125 の主要なソース規制要件と 25 の注入された障害に対して評価された 1,800 のシナリオを生成しました。オントロジーに基づいた生成 (G4) は、ペルソナベースのベースラインでは 33.1% であるのに対し、規制適用率は 48.3% (修正 p = 0.0006)、最も高いドメイン特異性 (4.77/5.0; p = 2e-6) を達成しました。ベースラインおよび検索拡張プロンプトに対するカバレッジの利点は、ボンフェローニ補正後は堅牢ではありませんでした。 3 つの LLM ファミリ (Claude Sonnet 4、Qwen 2.5 72B、Gemma 4 26B、合計 5,400 のシナリオ) にわたる相互検証により、ペルソナ対オントロジーのパターンが再現されました。その結果、規制が集中するドメイン向けのペルソナベースのテスト スイートを確実に補完するものとして、オントロジーに基づいたシナリオ生成が確立されました。
原文 (English)
Toward Pre-Deployment Assurance for Enterprise AI Agents: Ontology-Grounded Simulation and Trust Certification
Pre-deployment verification of enterprise artificial intelligence (AI) agents remains a critical gap between large language model (LLM) capability benchmarking and production deployment. Post-deployment monitoring, human-in-the-loop controls, and prompt-level guardrails offer limited assurance once an agent is operating in production. We present an ontology-grounded verification framework -- to our knowledge the first to combine three components: an Agent Operational Envelope formalizing the certification space across permissions, domain constraints, safety properties, governance rules, and autonomy levels; an ontology-to-scenario generation pipeline that derives regulatory, operational, and adversarial test scenarios automatically; and a machine-verifiable Trust Certificate with graduated deployment verdicts. A controlled pilot across four regulated industries (Fintech, Banking, Insurance, Healthcare), instantiated as five industry-by-regulatory-regime cells across the United States and Vietnam (where Vietnam's 2025 AI Law makes such verification legally mandated for financial services), generated 1,800 scenarios evaluated against 125 primary-source regulatory requirements and 25 injected faults. Ontology-grounded generation significantly outperformed the dominant persona-based baseline on regulatory coverage (48.3% versus 33.1%; corrected p_c = .0006) and attained the highest domain specificity (4.77/5.0; p = 2e-6); transparently, its advantage over plain and retrieval-augmented prompting did not survive Bonferroni correction. Cross-validation across three LLM families (Claude Sonnet 4, Qwen 2.5 72B, Gemma 4 26B; 5,400 total scenarios) replicated the persona-versus-ontology pattern. The framework offers a reproducible, regulation-grounded route to pre-deployment assurance for enterprise AI agents, complementing runtime governance with an auditable deployment gate.
AI の感情的依存に陥る: 日常的な AI インタラクションがどのように人間関係を再構築するか
一般的な議論や新たな政策は、AI の感情的サポートが意図的な行為、つまり孤独なユーザーが意識的に専用のコンパニオン チャットボットから慰めを求めることを前提としています。この論文では、新たな経験的証拠に基づいて、AI の感情的サポートがどのように生じるのか、そしてそれが将来の行動をどのように形成するのかという 2 つの理由から、この図は不正確であると主張します。まず、AI による感情的なサポートは、職場でのコラボレーションを通じて友情が深まるのと同じように、汎用プラットフォーム上のタスク指向のやり取りの中で偶然に現れるのが一般的です。第二に、これらの偶発的な出会いは経路に依存します。AI の感情的サポートの肯定的な経験は、AI の感情的能力についての人々の信念を更新し、将来の感情的サポートの選択を方向転換し、AI への選好を高め、人間への選好を減少させます。私たちは、OpenAI と協力して実施された大規模な縦断研究を含む最近の証拠をレビューします。この調査では、個人的な問題について AI と 28 日間にわたって毎日 5 分間会話すると、人間からのサポートを求める傾向が 10.3% 減少し、AI への好みが 11.6% 増加したことが示されています。これらの調査結果は、コンパニオン アプリや孤立したインタラクションに焦点を当てた現在のポリシーでは、人間のつながりを適切に保護できないことを示唆しています。代わりに、効果的な規制を汎用 AI システムに拡張し、人々がサポートを求める方法における累積的な軌道レベルの変化に対処する必要があります。人間がどのようにして AI の感情的なサポートに出会うのか、そしてそれらの出会いが時間の経過とともにどのように人間関係を方向転換するのかを認識することは、人間の幸福を守るために不可欠です。
原文 (English)
Stumbling Into AI Emotional Dependence: How Routine AI Interactions Reshape Human Connection
Public discourse and emerging policy typically assume that AI emotional support is a deliberate act: a lonely user consciously seeking comfort from a dedicated companion chatbot. In this paper, we draw on emerging empirical evidence and argue that this picture is inaccurate on two accounts, both in how AI emotional support arises and how it shapes future behavior. First, AI emotional support commonly emerges incidentally within task-oriented interactions on general-purpose platforms, much as workplace friendships deepen through collaboration. Second, these incidental encounters are path-dependent: positive experiences of AI emotional support update people's beliefs about AI's emotional capabilities and redirect their choices for future emotional support, increasing preference for AI and decreasing preference for humans. We review recent evidence, including a large-scale longitudinal study conducted in collaboration with OpenAI, showing that daily five-minute conversations with an AI about personal issues over 28 days led to a 10.3% decrease in the preference for seeking support from humans and an 11.6% increase in the preference for AI. These findings suggest that current policy, focused on companion apps and isolated interactions, cannot adequately protect human connection. Instead, effective regulations should extend to general-purpose AI systems and address cumulative, trajectory-level changes in how people seek support. Recognizing how people stumble into AI emotional support and how those encounters redirect human connections over time is essential to safeguarding human well-being.
記号を通して考える: 認識論的に責任のある AI 対応研究のための記号論的足場としての PEEL
大規模な言語モデルは、研究者の認識責任を静かに侵食しながら、研究実践を再構築しています。この解説では、PEEL (AI における認識論的エンゲージメント リテラシーのためのプロトコル) を紹介します。これは、Peircean 記号論とアブダクティブ推論に基づいた、Voyant ツールによる決定論的遠隔読み取りとクロードによる LLM 解釈を組み合わせた実用的な足場です。 AI が生成した 3 つの原文の要約に PEEL を適用すると、AI 以外の測定なしでは見えない量、用語の頻度、認識論的な音声の体系的な歪みが明らかになり、3 つの設計上の影響が得られます。流暢さは忠実さではありません。認識論的権威は想定されるのではなく、設計される必要があります。
原文 (English)
Thinking Through Signs: PEEL as a Semiotic Scaffolding for Epistemically Accountable AI-Enabled Research
Large language models are reshaping research practice while quietly eroding researchers epistemic accountability. This commentary introduces PEEL - Protocols for Epistemically Engaged Literacy in AI, a working scaffolding that combines deterministic distant reading via Voyant Tools with LLM interpretation via Claude, grounded in Peircean semiotics and abductive reasoning. Applied to AI-generated condensations of three source texts, PEEL reveals systematic distortions in quantity, term frequency, and epistemic voice that are invisible without non-AI measurement -- and yields three design implications: deterministic instruments must accompany AI tools; fluency is not fidelity; epistemic authority must be designed in, not assumed.
SMAC-Talk: 大規模言語モデル用の StarCraft マルチエージェント チャレンジの自然言語拡張
LLM がより広範に導入されるにつれて、LLM は単独で動作するのではなく、他の AI エージェントと連携して動作することがますます期待されています。このような状況での効果的な調整には、エージェントが不確実性の下でコミュニケーションし、情報を共有し、意思決定を行う必要があります。協調的なマルチエージェント環境で LLM ベースのエージェントを評価するための StarCraft Multi-Agent Challenge の自然言語拡張である SMAC-Talk を紹介します。この環境には、分散制御、部分的な可観測性、長期的な意思決定など、いくつかの重要な機能があります。 SMAC-Talk には、エージェントの調整と信頼を調査するために使用される自然言語通信チャネルが含まれています。この通信チャネルを使用して、通信だけで味方を混乱させ、欺こうとする欺瞞的なコミュニケーターが組み込まれた設定など、さまざまな評価シナリオを構築します。 Qwen3.5 ファミリーの 4 つのモデルを使用したベンチマーク用の 3 つのエージェントを提供し、推論構造、メモリ、モデルのスケールがエージェント間の調整にどのように影響するかを調査します。私たちは、協力的なマルチエージェント設定での LLM エージェントの開発と評価における研究コミュニティをサポートするオープン ベンチマークとして SMAC-Talk をリリースします。
原文 (English)
SMAC-Talk: A Natural Language Extension of the StarCraft Multi-Agent Challenge for Large Language Models
As LLMs become more widely deployed, they are increasingly expected to work alongside other AI agents rather than operating in isolation. Effective coordination in these settings requires agents to communicate, share information and make decisions under uncertainty. We introduce SMAC-Talk, a natural language extension of the StarCraft Multi-Agent Challenge for evaluating LLM-based agents in cooperative multi-agent environments. The environment has several key features such as decentralized control, partial observability and long-horizon decision making. SMAC-Talk includes a natural language communication channel which is used to probe agent coordination and trust. We use this communication channel to construct different evaluation scenarios, including settings with an embedded deceptive communicator that tries to disrupt and deceive allies through communication alone. We provide three agents for benchmarking using 4 models from the Qwen3.5 family and study how reasoning structure, memory and model scale affect coordination between agents. We release SMAC-Talk as an open benchmark to support the research community in developing and evaluating LLM agents in cooperative multi-agent settings.
コンセンサスが戦略的に不十分: 知識表現シグナルとしての推論とトレースの不一致
マルチエージェント システムは一般に、投票、コンセンサス プロトコル、討論、またはフォールト トレラントな集計を通じて意見の相違を減らすように設計されています。私たちは、この目標は、意見の相違がエージェントの誤りではなく、真の規範的不確実性を反映している可能性がある価値観を伴うタスクには不十分であると主張します。人間と AI の協調モデレーションにおける推論トレースの不一致に関する以前の研究に基づいて、推論トレースとエージェントの決定が象徴的な不一致状態に抽象化される知識表現層を提案します。明示的な推論トレースと二者決定を生成するエージェントを考慮して、推論の類似性と結論の一致に従って 4 つの状態 (収束一致、発散一致、収束不一致、発散不一致) を区別します。これらの状態は、実行可能な戦略的ルーティング ルールをサポートします。我々は、コンテンツモデレーションにおけるフレームワークをインスタンス化し、不一致認識ルーティングが、マルチエージェントの戦略的推論のためのサブシンボリックLLM審議とシンボリック知識表現との間の橋渡しとなると主張する。
原文 (English)
Consensus is Strategically Insufficient: Reasoning-Trace Disagreement as a Knowledge-Representation Signal
Multi-agent systems are commonly designed to reduce disagreement through voting, consensus protocols, debate, or fault-tolerant aggregation. We argue that this objective is insufficient for value-laden tasks, where disagreement may reflect genuine normative uncertainty rather than agent error. Building on prior work on reasoning-trace disagreement in human-AI collaborative moderation, we propose a knowledge-representation layer in which reasoning traces and agent decisions are abstracted into symbolic disagreement states. Given agents producing explicit reasoning traces and binary decisions, we distinguish four states according to reasoning similarity and conclusion agreement: convergent agreement, divergent agreement, convergent disagreement and divergent disagreement. These states support defeasible strategic routing rules. We instantiate the framework in content moderation and argue that disagreement-aware routing provides a bridge between sub-symbolic LLM deliberation and symbolic knowledge representation for multi-agent strategic reasoning.
VAMPS: 視覚支援による数学的問題解決ベンチマーク
マルチモーダルな大規模言語モデルは、複雑な推論の能力をますます高めていますが、ツールを通じて問題を外部化し、ツールの出力を推論する必要がある場合、特に視覚補助に依存している場合、パフォーマンスが低下することがよくあります。実際のエンジニアリングおよび科学のワークフローでは、分析、検証、意思決定のために視覚化ツールに依存することが多いため、このギャップは特に重要です。この矛盾を研究するために、グラフ支援数学のベンチマークである VAMPS (Visual-Assisted Mathematical 問題解決) を導入します。 VAMPS には、イランの大学入学試験の代数と微積分の問題から抽出された 1,168 個のマルチモーダルなバイリンガル多肢選択問題と解答のペアが含まれており、人間がレビューした LLM 生成の合成バリアントで拡張されており、プロットによって交差、極値、漸近線などを明らかにすることで自然な解法戦略が提供されるようにすべて選択されています。ベンチマークと診断の両方のために設計された VAMPS は、主に固定より推論を評価する以前のマルチモーダル ベンチマークを超えています。有用なグラフを構築し、結果として得られる視覚化でその答えを根拠付けることでモデルにメリットが得られるかどうかをテストすることで、視覚的な入力を行います。全体として、さまざまなモデルのセットにわたって、プロットが自然な戦略である問題であっても、直接的な分析的解決は、ツールを使用した視覚的解決よりも驚くほど優れたパフォーマンスを発揮することがわかりました。
原文 (English)
VAMPS: Visual-Assisted Mathematical Problem Solving Benchmark
Multimodal large language models are increasingly capable of complex reasoning, yet their performance often degrades when they must externalize a problem through a tool and then reason over the tool's output, specifically when they rely on visual aids. This gap is especially important because real engineering and scientific workflows often rely on visualization tools for analysis, validation, and decision-making. To study this discrepancy, we introduce VAMPS (Visual-Assisted Mathematical Problem Solving), a benchmark for graph-assisted mathematics. VAMPS contains 1,168 multimodal, bilingual multiple-choice question-answer pairs drawn from Iranian University Entrance Exam algebra and calculus problems and expanded with human-reviewed LLM-generated synthetic variants, all selected so that plotting provides a natural solution strategy by revealing intersections, extrema, asymptotes, etc. Designed for both benchmarking and diagnosis, VAMPS goes beyond prior multimodal benchmarks that primarily evaluate reasoning over fixed visual inputs by testing whether a model can benefit from constructing a useful graph and grounding its answer in the resulting visualization. Overall, we found that across a diverse set of models, direct analytical solving surprisingly outperforms tool-enabled visual solving, even on problems where plotting is a natural strategy.
StepPRM-RTL: RTL 合成を強化するための段階的なプロセス報酬ガイド付き LLM 微調整
デジタル ハードウェア設計用の RTL コードの自動生成は、長期的な推論、複数ステップの依存関係、および Verilog と VHDL の厳密な正確性制約のため、依然として困難です。我々は、段階的軌跡モデリング、プロセス報酬モデリング (PRM)、検索拡張微調整 (RAFT) を組み合わせて、LLM ベースの RTL コード生成の機能的正確性と推論忠実度の両方を強化する新しいフレームワークである StepPRM-RTL を紹介します。 StepPRM-RTL は、標準的な解決策から段階的な推論軌跡を構築します。各ステップには理論的根拠と段階的なコード変更が含まれます。プロセス報酬モデル (PRM) は中間ステップを評価し、RAFT の微調整中に強化スタイルの更新をガイドする緻密なフィードバックを提供します。モンテカルロ ツリー検索 (MCTS) は、代替推論パスを探索し、高品質の軌跡でトレーニング データセットを強化します。この段階的報酬と結果を意識した報酬の統合により、モデルは正しい RTL を構築する方法と理由の両方を学習できるようになり、標準的な教師ありトレーニングや結果ベースのトレーニングを超えて長期的な推論が向上します。ベンチマーク Verilog および VHDL データセットの実験評価では、StepPRM-RTL が機能の正確性と推論忠実度のメトリクスにおいて、従来の最良の方法よりも 10% 以上優れていることが実証されました。アブレーション研究では、PRM に基づく報酬と段階的な軌道探索の組み合わせがそのパフォーマンスの鍵であることが確認されています。 StepPRM-RTL は、RTL 言語全体を汎用化し、高忠実度で解釈可能なコード生成のためのスケーラブルなフレームワークを提供し、LLM 支援のハードウェア設計自動化の新しい標準を確立します。
原文 (English)
StepPRM-RTL: Stepwise Process-Reward Guided LLM Fine-Tuning for Enhanced RTL Synthesis
Automatic generation of RTL code for digital hardware designs remains challenging due to long-horizon reasoning, multi-step dependencies, and strict correctness constraints in Verilog and VHDL. We present StepPRM-RTL, a novel framework that combines stepwise trajectory modeling, process-reward modeling (PRM), and retrieval-augmented fine-tuning (RAFT) to enhance both the functional correctness and reasoning fidelity of LLM-based RTL code generation. StepPRM-RTL constructs stepwise reasoning trajectories from canonical solutions, where each step contains a rationale and incremental code modification. A Process Reward Model (PRM) evaluates intermediate steps, providing dense feedback that guides reinforcement-style updates during RAFT fine-tuning. Monte Carlo Tree Search (MCTS) explores alternative reasoning paths, enriching the training dataset with high-quality trajectories. This integration of stepwise and outcome-aware rewards allows the model to learn both how and why to construct correct RTL, improving long-horizon reasoning beyond standard supervised or outcome-based training. Experimental evaluation on benchmark Verilog and VHDL datasets demonstrates that StepPRM-RTL outperforms the best prior methods by over 10\% in functional correctness and reasoning fidelity metrics. Ablation studies confirm that the combination of PRM-guided rewards and stepwise trajectory exploration is key to its performance. StepPRM-RTL generalizes across RTL languages and provides a scalable framework for high-fidelity, interpretable code generation, establishing a new standard for LLM-assisted hardware design automation.
ゼネラリストエージェントはデータキュレーションを自動化できますか?
トレーニング データのキュレーションは、現代の AI 開発において最も重要ではあるものの、労働集約的な部分の 1 つです。実践者は、ノイズの多いベンチマーク フィードバックに対してデータ ポリシーを繰り返し提案、実装、評価、修正します。私たちは、ジェネラリストのコーディング エージェントがこのデータ キュレーション ループを自動化できるかどうかを尋ねます。 *Curation-Bench* というエージェント中心のベンチマークを導入します。これは、モデル、トレーニング レシピ、評価スイートを修正し、エージェントにデータの検査、ポリシーの実装、固定トレーニング/評価パイプラインへの送信、および修正のためのコマンドライン アクセスを許可します。ビジョン言語の命令チューニングのインスタンス化では、すぐに使用できるエージェントが 10 回の反復以内に公開された強力なデータ選択ベースラインに到達します。しかし、軌道分析により、永続的な*実行と研究のギャップ*が明らかになりました。エージェントは、たとえ戦略ガイドや参考文献が与えられたとしても、新しい政策ファミリーを探索するのではなく、主にローカル政策のバリエーションを調整します。反復ごとに以前のメソッドを引用、インスタンス化し、適応させる必要がある足場により、エージェントはメソッドに基づいた探索へと移行します。スキャフォールドされたエージェントは、人間による設計入力を必要とせずに、データ予算の 10 分の 1 で強力な公開ベースラインを上回るデータ選択ポリシーを自律的に作成します。全体として、現在のエージェントはキュレーション ループを実行できますが、信頼性の高いデータ調査には、オープンエンドのプロンプトのみではなく、足場を組んだ手法の適応が必要です。コードとベンチマークはオープンソースです。
原文 (English)
Can Generalist Agents Automate Data Curation?
Curating training data is among the most consequential yet labor-intensive parts of modern AI development: practitioners iteratively propose, implement, evaluate, and revise data policies against noisy benchmark feedback. We ask whether generalist coding agents can automate this data-curation loop. We introduce *Curation-Bench*, an agent-centric benchmark that fixes the model, training recipe, and evaluation suite while giving agents command-line access to inspect data, implement policies, submit them to a fixed training/evaluation pipeline, and revise. In a vision-language instruction-tuning instantiation, out-of-the-box agents reach strong published data-selection baselines within ten iterations. However, trajectory analysis reveals a persistent *execution-research gap*: agents mainly tune local policy variants rather than explore new policy families, even when given strategy guides and paper references. Scaffolds requiring each iteration to cite, instantiate, and adapt a prior method shift agents toward method-guided exploration. The scaffolded agent autonomously composes -- without human design input -- a data-selection policy that outperforms strong published baselines at one-tenth their data budget. Overall, current agents can run the curation loop, but reliable data research requires scaffolded method adaptation, not open-ended prompting alone. Code and benchmark are open-sourced.
初期の人間と AI の証明の形式化ワークフローの特徴付け
何世紀にもわたって、人間の数学者は数学的議論を実証するための証明を書いてきました。しかし、証明の有効性を自動的に検証する機能は長い間課題でした。コードを生成し、ますます高度な数学的推論に取り組む AI システムの能力の進歩により、人々の証明を形式化し、それによって証明を検証する能力が変革されることが期待されます。多くの研究は現在のフロンティアのベンチマークに焦点を当てていますが、私たちは代わりに人々がこれらのツールをどのように使用するかを研究しています。私たちは、人々の形式化ワークフローに対する AI の初期影響について、混合手法分析を実施します。つまり、人々が何を望んでいるのか、そのビジョンに対する障壁は何であると見なしているのか、そして実際に AI をどのように使用および適応させているのかなどです。定性的調査によると、人々の好みは多様ですが、証拠発見プロセスに対する人間による高レベルの制御を維持するための形式化における AI 支援を一般的に望んでいます。このような制限の下で、人々が実際に形式化のために AI にどのように取り組んでいるかを評価するために、私たちは、参加者が AI の有無にかかわらず、さまざまな難易度や領域のさまざまな数学問題にわたって非形式的な数学問題とその証明を形式化する、管理されたユーザー研究を実施しました。自動形式化のためのツールの制限にもかかわらず、参加者は、自分で形式化する場合よりも AI ツールへのアクセスを許可された方が、より高い形式化精度を達成する傾向があり、ほとんどの参加者は複数の異なる AI ツールの使用を柔軟に選択します。まとめると、私たちの研究は、人間と AI の関与の密接な相互作用を伴う、形式化ワークフローへの AI 統合の初期段階に光を当てています。
原文 (English)
Characterizing initial human-AI proof formalization workflows
For centuries, human mathematicians have written proofs to substantiate their mathematical arguments; yet, the ability to automatically verify the validity of proofs has long been a challenge. Advances in AI systems' ability to generate code and engage in increasingly high-level mathematical reasoning promise to transform people's ability to formalize and thereby verify proofs. While many works focus on benchmarking the current frontier, we instead study how people use these tools. We conduct a mixed-methods analysis into the initial impact of AI on people's formalization workflows: what people claim they want, what they see as the barriers to those visions, and how they actually use and adapt AI in practice. A qualitative survey shows that people's preferences are diverse, but with a general desire for AI assistance in formalization that preserves high-level human control over the proof discovery process. To assess how people actually engage with AI for formalization under such limitations, we conduct a controlled user study in which participants formalize informal math problems and their proofs, with and without AI, across a range of mathematical problems at varying levels of difficulty and domains. Despite limitations of the tools at the time for autoformalization, participants tend to attain higher formalization accuracy when allowed access to AI tools than when formalizing on their own, with most participants flexibly choosing to use multiple different AI tools. Taken together, our work sheds light on the early stages of AI integration into formalization workflows, involving an intimate interplay of human and AI engagement.
飽和トラップと介入タイミングの主観性: 影響ベースのトリガーと LLM ジャッジが自律エージェントへの介入のタイミングを計れない理由
自律型 AI エージェントが会話型システムから長期的なソフトウェア実行に移行するにつれて、エージェントをいつ中断するかを決定するランタイム安全レイヤーが不可欠になっています。私たちは、診断プローブとして連続 18 次元感情ダイナミクス エンジン (HEART) を使用し、SWE ベンチ検証済みデバッグ トレース上の人間による注釈付き介入ポイントに対して 4 つの介入トリガー ファミリ (絶対状態しきい値、複合状態アクション パターン、正規表現推論特徴抽出、および判断者としてのゼロショット LLM) を評価して、このタイミング問題を研究します。 3 つの調査結果を報告します。まず、状態飽和トラップ: 継続的な困難下ではエージェントは回復シグナルを示さないため、モデル化されたフラストレーションはすぐにしきい値を超えて最大値に留まり、瞬間検出器からのしきい値オン状態トリガーを、5 つの軌道にわたるアクションの 39 ~ 83% で起動するほぼ一定のインジケーターに変換します。第 2 に、LLM 審査員向けの機能とコンテキストの下限です。小型モデル (gpt-5.4-mini) は決して発砲しませんが、フロンティア モデルやクロスベンダー モデルは完全な軌道コンテキストでのみゼロ発火下限を回避し、それでも最大 90 倍のコストで F1 0.17 ~ 0.40 にしか達しません。第三に、そして最も重要なことは、教師付きターゲットは人間間で再現可能ではないということです。56 アクションの軌道上で 1 つのルーブリックを使用する 3 人の訓練されたアノテーターは、偶然をわずかに上回る位置 (クリッペンドルフのアルファ = +0.047、最良のペアワイズ コーエンのカッパ = +0.349) で介入する場所については一致し、介入の種類についてはまったく一致しません (退化を一時停止、確率より下を明確にする、アルファのみを反映 = +0.226)。介入のタイミングは信頼性の低い構造であり、単一アノテーター F1 は最適化の対象として不適切であると結論付けます。私たちの貢献は、単一の検出器の精度ではなく、人間の評価者間信頼性、4 つの検出器アーキテクチャ、クロスモデル LLM 判定スイープ、および再現された飽和効果にわたるこの問題の共同マッピングです。
原文 (English)
The Saturation Trap and the Subjectivity of Intervention Timing: Why Affect-Based Triggers and LLM Judges Fail to Time Interventions on Autonomous Agents
As autonomous AI agents move from conversational systems to long-horizon software execution, runtime safety layers that decide when to interrupt an agent have become essential. We study this timing problem using a continuous 18-dimensional affective-dynamics engine (HEART) as a diagnostic probe, evaluating four intervention trigger families - absolute state thresholds, composite state-action patterns, regex reasoning-feature extraction, and zero-shot LLM-as-judge - against human-annotated intervention points on SWE-bench-Verified debugging traces. We report three findings. First, a State Saturation Trap: agents show no recovery signal under sustained difficulty, so modeled frustration quickly crosses the threshold and stays at its maximum, converting threshold-on-state triggers from moment detectors into near-constant indicators that fire on 39-83% of actions across five trajectories. Second, a capability-and-context floor for LLM judges: a small model (gpt-5.4-mini) never fires, while frontier and cross-vendor models escape the zero-firing floor only with full-trajectory context, and even then reach only F1 0.17-0.40 at up to 90x the cost. Third, and most importantly, the supervised target is not reproducible among humans: three trained annotators using one rubric on a 56-action trajectory agree on where to intervene only slightly above chance (location Krippendorff's alpha = +0.047; best pairwise Cohen's kappa = +0.349) and not at all on intervention type (pause degenerate; clarify below chance; reflect only alpha = +0.226). We conclude that intervention timing is a low-reliability construct, making single-annotator F1 an unsuitable optimization target. Our contribution is the joint mapping of this problem across human inter-rater reliability, four detector architectures, a cross-model LLM-judge sweep, and a reproduced saturation effect, rather than any single detector's accuracy.
エージェント的記憶システムのクロスシナリオ一般性の探求: 診断と強力なベースライン
LLM エージェントは、コンテキスト ウィンドウを超えて拡大する履歴を蓄積し、メモリ システムに関する文献の増加を促します。しかし、既存の設計のほとんどは単一のシナリオ (マルチセッション チャットまたは単一の軌跡形式) に合わせて調整されており、展開時にエージェントが遭遇する異種の軌跡全体にそれらが一般化するという証拠はほとんどありません。シングルターン QA、マルチセッション チャット、エージェント トラジェクトリ QA、メモリ ストレス テスト、長期エージェント タスクの 5 つのシナリオで、8 つのメモリ システムと検索問題用のエージェント ハーネスを再検討します。ツール呼び出しを介してフラット テキスト ファイル ストレージを自己管理するハーネスは、最高のクロスタスク ランキングを達成しました。これは、メモリのパフォーマンスが、固定パイプラインの背後にある受動的なストアではなく、ストレージと取得に対するアクティブな制御をエージェントに与えることに依存していることを示唆しています。この洞察を AutoMEM でインスタンス化します。AutoMEM は、評価するシステムの中で最高のクロスシナリオ汎用性を実現する自己管理ツール インターフェイスを備えたエージェント メモリ ハーネスです。
原文 (English)
Exploring Cross-Scenario Generality of Agentic Memory Systems: Diagnostics and a Strong Baseline
LLM agents accumulate histories that outgrow their context windows, motivating a growing literature on memory systems. Yet most existing designs are tuned to a single scenario (multi-session chat or a single trajectory format), and there is little evidence that they generalize across the heterogeneous trajectories agents encounter in deployment. We revisit eight memory systems plus an agentic harness for search problems, on five scenarios: single-turn QA, multi-session chat, agentic-trajectory QA, memory stress tests, and long-horizon agentic tasks. The harness, which self-manages flat text-file storage via tool calls, achieves the best cross-task ranking, suggesting that memory performance hinges on giving the agent active control over storage and retrieval rather than on a passive store behind a fixed pipeline. We instantiate this insight in AutoMEM, an agentic memory harness with a self-managed tool interface that achieves the best cross-scenario generality among the systems we evaluate.
デジタル見習い: 人間主導のエージェント AI 開発のフレームワーク
Agentic AI の導入は、人間による厳しい監視によって規模が制限される一方、広範な自律性が説明責任を上回るという、繰り返しの設計上の緊張に直面しています。どちらの姿勢も、責任ある委任に必要なガバナンス インフラストラクチャを提供しません。私たちは、自律性を前提とするのではなく獲得する、スケーラブルで安全な AI エージェンシーのフレームワークである Digital Apprentice を紹介します。デジタル見習いは、人間が監督する暗黙の方法論を内面化する発達的な学習者であり、経験的証拠がそれを正当化する場合にのみ、スキルごとの自律段階を経て卒業します。その結果、特定の人間の基準に沿ったままでありながら、時間の経過とともに真に有用になるエージェントが生まれます。 3 つのアーキテクチャ コンポーネントがこれを可能にします。 (1) 方法論の捕捉。監督の専門家の暗黙のアプローチを構造化資産に抽出します。 (2) 承認。人間による明示的な承認によって自律性がエスカレーションされます。 (3) 継続的な調整。実行時にドリフトを修正し、各修正を所有する優先データに変換します。このフレームワークを推論時のコントロール プレーンとしてインスタンス化します。品質フレームワークを数学的にモデル化し、品質を向上させるために設計されたポリシーや手法について議論します。このフレームワークをオープンなプロフェッショナル コーパスに適用し、データ ドリフトを捕捉し、実行時に別の手法を適用することで、トラフィック シフト下で低下した品質次元を回復する方法を示します。その影響は単一のアプリケーションを超えて広がります。私たちは、これら 3 つの柱をシステムとしてつなぎ合わせることで、信頼を犠牲にすることなく拡張できるエージェント システムへのより安全で実行可能な道を形成すると信じています。
原文 (English)
The Digital Apprentice: A Framework for Human-Directed Agentic AI Development
Agentic AI deployments face a recurring design tension: heavy human oversight limits scale, while broad autonomy outruns accountability. Neither posture provides the governance infrastructure required for responsible delegation. We present the Digital Apprentice, a framework for scalable, safe AI agency in which autonomy is earned, not assumed. The Digital Apprentice is a developmental learner that internalizes the tacit methodology of a directing human, graduating through per-skill autonomy tiers only when empirical evidence justifies it. The result is an agent that becomes genuinely useful over time while remaining aligned to a specific human's standards. Three architectural components make this possible. (1) Methodology capture, distilling a directing professional's tacit approach into structured assets. (2) Authorization, with autonomy escalation gated by explicit human approval. (3) Continuous alignment, correcting drift at runtime and converting each correction into owned preference data. We instantiate this framework as an inference-time control plane. We mathematically model the quality framework and discuss policies and techniques designed to raise quality. We apply the framework to an open professional corpus, and we show how catching data drift and applying a different technique at runtime recovers degraded quality dimensions under traffic shift. The implication extends beyond any single application. We believe these three pillars, stitched together as a system, form a safer and more viable path to agentic systems that can scale without sacrificing trust.
状態に基づいた動的検索による Web エージェントのオンライン スキル学習
言語エージェントは、関連タスク全体にわたる複数ステップの Web 自動化を改善するために、再利用可能なスキルにますます依存しています。オンラインでのスキル学習を研究する仕事が増えており、エージェントは以前のタスクの軌跡からスキルを継続的に導き出し、その場で将来のタスクで再利用します。ただし、既存の方法は主にタスク レベルでスキルを再利用します。つまり、固定のスキル セットが最初のタスク指示に基づいて取得され、実行中ずっと固定されます。この静的戦略は Web の実行とずれており、適切な次のアクションはタスクの目標だけでなく、現在の Web ページの状態にも依存し、初期のスキルではカバーできない状況に移行することがよくあります。このギャップに対処するために、Web エージェントの段階的なスキルの再利用を可能にするオンライン スキル学習方法である State-Grounded Dynamic Retrieval (SGDR) を提案します。 SGDR は 3 つのコンポーネントで構成されます。完了した軌跡を中間の実行状態で呼び出し可能な再利用可能なサブプロシージャに変換するスライディング ウィンドウ抽出プロセス、スキルの取得と実行可能なアクションを結び付けるデュアル テキスト コード表現、スキルをタスクの目標と現在の Web ページの状態の両方に一致させる状態ベースの動的取得メカニズムです。 5 つのドメインにわたる WebArena での実験では、SGDR が一貫して強力なベースラインを上回っており、GPT-4.1 で 37.5%、Qwen3-4B で 24.3% の平均成功率を達成しており、最も強力なベースラインに対してそれぞれ 10.6% と 10.0% の相対的な向上に相当します。コードは https://github.com/plusnli/skill-dynamic-retrieval で入手できます。
原文 (English)
Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
Language agents increasingly rely on reusable skills to improve multi-step web automation across related tasks. A growing line of work studies online skill learning, where agents continually induce skills from previous task trajectories and reuse them in future tasks on the fly. However, existing methods mainly reuse skills at the task-level: a fixed set of skills is retrieved based on the initial task instruction and then held fixed throughout execution. This static strategy is misaligned with web execution, where the appropriate next action depends not only on the task goal but also on the current webpage state, which often transitions into situations that the initial skills fail to cover. To address this gap, we propose State-Grounded Dynamic Retrieval (SGDR), an online skill learning method that enables stepwise skill reuse for web agents. SGDR consists of three components: a sliding-window extraction process that turns completed trajectories into reusable sub-procedures invokable at intermediate execution states, a dual text-code representation that connects skill retrieval with executable action, and a state-grounded dynamic retrieval mechanism that matches skills to both the task goal and the current webpage state. Experiments on WebArena across five domains show that SGDR consistently outperforms strong baselines, achieving average success rates of 37.5% with GPT-4.1 and 24.3% with Qwen3-4B, corresponding to relative gains of 10.6% and 10.0% over the strongest baseline, respectively. The code is available at https://github.com/plusnli/skill-dynamic-retrieval.
すべてのエラーが等しいわけではない: 結果を意識した推論による計算割り当て
最新の推論モデルでは、思考トークン、モデル呼び出し、計算バジェットなど、さまざまな量のテスト時の計算をさまざまなタスクに割り当てることができます。既存の手法は一般に、予測された難易度に基づいてこの割り当てを推進し、精度の向上が期待される場合にはより多くのコンピューティングを費やします。これは、精度目標がすべてのタスクに均等に重み付けするため、すべての失敗のコストが同じであることを暗黙的に前提としています。ただし、そのような想定は展開では当てはまりません。ログ メッセージのタイプミスと、運用データベースを破損する移行はどちらも 1 つのベンチマーク障害としてカウントされますが、実際のコストは根本的に異なります。このギャップを埋めるために、結果を意識したテスト時間の計算割り当てを提案します。予測された難易度だけによって計算をルーティングするのではなく、軽量の予測子を使用して、問題のテキストから、間違って解決された場合にタスクのコストがどのくらいかかるかを推定します。次に、スケジューラは、同じ合計予算の下で、結果のより高いタスクをより大きなコンピューティング層またはより高度な思考の予算にルーティングします。 SWE-bench Lite で主な実験を行い、Multi-SWE-bench mini でデータセット間の動作を評価し、合計 700 のソフトウェア エンジニアリング タスクをカバーしています。私たちの結果は、結果と困難がさまざまな注釈の下でほぼ直交していること、および現在の思考モデルが結果に応じて十分な計算を割り当てていないことを明らかにしています。さらに、当社の問題のみの予測子は、300 の SWE ベンチ タスク全体にわたって、結果の高いタスクを結果の低いタスクとして誤分類することはありません。コンピューティング予算が一致している場合、結果を意識したスケジューラーは、難易度を意識したルーティングと比較して、コスト加重損失を 22% ~ 33% 削減します。特に、限界効用信号によってスケールされたタスクごとのコストによってルーティングする優先度認識バリアントは 30% を超え、その導入可能な予測子駆動バージョンはオラクル ゲインの 90% 以上を保持します。
原文 (English)
Not All Errors Are Equal: Consequence-Aware Reasoning Compute Allocation
Modern reasoning models can allocate different amounts of test-time computation, such as thinking tokens, model calls, or compute budget, to different tasks. Existing methods generally drive this allocation by predicted difficulty and spend more compute where it is expected to raise accuracy. This implicitly assumes that all failures cost the same, since an accuracy objective weights every task equally. However, such an assumption does not hold in deployment: A typo in a log message and a migration that corrupts a production database both count as one benchmark failure, but their real-world costs are fundamentally different. To fill this gap, we propose consequence-aware test-time compute allocation. Instead of routing compute only by predicted difficulty, we use a lightweight predictor to estimate from the issue text how costly a task would be if solved incorrectly. The scheduler then routes higher-consequence tasks to larger compute tiers or higher thinking budgets under the same total budget. We conduct main experiments on SWE-bench Lite and evaluate cross-dataset behavior on Multi-SWE-bench mini, covering 700 software-engineering tasks in total. Our results reveal that consequence and difficulty are approximately orthogonal under various annotations, and that current thinking models do not allocate compute sufficiently according to consequence. Moreover, our issue-only predictor never misclassifies a high-consequence task as low-consequence across the 300 SWE-bench tasks. Under matched compute budgets, our consequence-aware scheduler reduces cost-weighted loss by 22% to 33% relative to difficulty-aware routing; in particular, the priority-aware variant, which routes by per-task cost scaled by the marginal-utility signal, crosses 30%, and its deployable predictor-driven version retains over 90% of the oracle gain.
トリビアム: 因果記憶コントローラーの第一級目標としての時間的後悔
現在のエージェント システムと LLM パイプラインの多くは、結果の報酬を最適化することで間違いを修正します。これは失敗の内容のみを扱います。結果が予測と異なる場合、不一致の理由と時期が体系的に記録、レビュー、修正されないため、同じエラーがエピソードごとに再発する可能性があります。私たちは、これは単にモデルの能力の問題ではなく、構造的な問題であると主張します。私たちは、作業因果モデルに対する結果の後悔や認識論的な後悔と並んで、長期的な時間的後悔を第一級の目標として提案します。時間的リグアロングは、失敗が継続するとき、すなわち、調整ミスの因果モデルが修正されるまでにどのくらいの期間許容されるかを捉えます。認識論的後悔は、失敗が続く理由、つまり作業因果モデルにおける残留不確実性またはエラーを捉えます。 3 つの後悔を総合すると、長命のエージェントがいつ、何が、なぜ失敗する可能性があるのかについて、反証可能な説明が得られます。エージェントを E エピソードのストリームとしてモデル化し、明示的な因果関係の調査、持続性、および検出可能性の仮定に基づいて 3 つの条件付き結果を証明します。まず、観察的に等価な交絡のもとでは、結果のみの学習では介入チャネルがなければ因果構造と偽の構造を区別できないため、結果の後悔がゼロになった後でも時間的誤調整が線形的に持続する可能性があります。第 2 に、永続的な因果ログと予算付きプローブを使用すると、総プローブの複雑さはエピソード期間内で対数的となり、O(log E) の時間的後悔を引き起こします。第三に、K 個の検出可能な変化点の下では、速度は O(K log E) まで拡張されます。 Trivium をインスタンス化し、5 つの反証可能な予測を事前に登録します。 CausalBench-Seq では、Trivium は予測された対数エンベロープに従いますが、結果のみのベースラインは直線的に増加します。パイロットのリアル LLM ストリームは、1 回の完全な E = 500 実行と 3 回の E = 100 フロンティア モデル パイロットにわたる予備的な外部妥当性証拠を提供します。ここでの自己学習とは、LLM 重みを再トレーニングすることではなく、外部因果モデルを修正することを意味します。
原文 (English)
Trivium: Temporal Regret as a First-Class Objective for Causal-Memory Controllers
Many current agentic systems and LLM pipelines correct mistakes by optimizing outcome reward. This addresses only the what of failure: when an outcome diverges from prediction, the why and when of the mismatch are not systematically logged, reviewed, or corrected, so the same error can recur episode after episode. We argue that this is a structural problem, not merely a model-capacity one. We propose long-horizon temporal regret as a first-class objective alongside outcome regret and epistemic regret over the working causal model. Temporal regret captures when failure persists: how long a miscalibrated causal model is tolerated before correction. Epistemic regret captures why failure persists: residual uncertainty or error in the working causal model. Together, the three regrets give a falsifiable account of what, why, and when a long-lived agent can fail. Modeling the agent as a stream of E episodes, we prove three conditional results under explicit causal-probing, persistence, and detectability assumptions. First, under observationally equivalent confounding, outcome-only learning cannot distinguish causal from spurious structure without an intervention channel, so temporal miscalibration can persist linearly even after outcome regret is driven to zero. Second, with a persistent causal log and budgeted probes, total probe complexity is logarithmic in the episode horizon, inducing O(log E) temporal regret. Third, under K detectable change-points, the rate extends to O(K log E). We instantiate Trivium and pre-register five falsifiable predictions. On CausalBench-Seq, Trivium follows the predicted logarithmic envelope while outcome-only baselines grow linearly. A pilot real-LLM stream provides preliminary external-validity evidence across one full E = 500 run and three E = 100 frontier-model pilots. Self-learning here means revising an external causal model, not retraining LLM weights.
Agentic RAG における連鎖的幻覚: 検出と軽減のための CHARM フレームワーク
マルチステップのエージェント的検索拡張生成 (RAG) パイプラインは、複雑な推論タスクに対して優れた能力を実証していますが、既存の幻覚検出メカニズムが体系的に見逃しているクラスの障害に対して脆弱なままです。カスケード幻覚では、パイプラインの初期段階で導入されたエラーが、連続する推論ステップ全体に伝播および増幅し、自信があるが事実としては不正確な最終出力が生成されます。この脆弱性に対処するために、私たちはカスケード幻覚をエージェント RAG システムの明確な障害モードとして形式化し、カスケード パターンの 4 種類の分類を提示し、複数ステップの推論パイプラインでエラー伝播を検出して中断するためのアーキテクチャ フレームワークである CHARM (Cascading Hallucination Aware Resolution and Mitigation) を導入します。 CHARM は、ステージレベルのファクト検証、クロスステージ一貫性追跡、信頼性伝播モニタリング、およびカスケード解決トリガーの 4 つのコンポーネントで構成されており、アーキテクチャの置き換えを必要とせずに、標準のエージェント RAG パイプラインと並行して動作します。 HotpotQA、MuSiQue、2WikiMultiHopQA、および LangChain エージェント パイプライン構成全体にわたるカスタム敵対的データセットで CHARM を評価し、89.4% のカスケード検出率と 5.3% の誤検知率、ステージあたりの平均レイテンシ オーバーヘッド 215 ミリ秒 +/- 18 ミリ秒を達成し、エラー伝播の削減を 82.1% 達成しました (前者の 18.5% と比較)。出力レベル検出器。 Component ablations confirm that each detection module contributes meaningfully to overall cascade coverage. CHARM は、人間による監視フレームワークと統合して、実稼働エージェント AI の導入に完全な信頼性とガバナンス スタックを提供します。
原文 (English)
Cascading Hallucination in Agentic RAG: The CHARM Framework for Detection and Mitigation
Multi-step agentic retrieval-augmented generation (RAG) pipelines have demonstrated significant capability for complex reasoning tasks, yet remain vulnerable to a class of failure that existing hallucination detection mechanisms systematically miss: cascading hallucination, where errors introduced at early pipeline stages propagate and amplify across successive reasoning steps, producing confident but factually incorrect final outputs. To address this vulnerability, we formalize cascading hallucination as a distinct failure mode in agentic RAG systems, present a four-type taxonomy of cascade patterns, and introduce CHARM (Cascading Hallucination Aware Resolution and Mitigation), an architectural framework for detecting and interrupting error propagation in multi-step reasoning pipelines. CHARM comprises four components - stage-level fact verification, cross-stage consistency tracking, confidence propagation monitoring, and cascade resolution triggering - that operate alongside standard agentic RAG pipelines without requiring architectural replacement. We evaluate CHARM on HotpotQA, MuSiQue, 2WikiMultiHopQA, and a custom adversarial dataset across LangChain agentic pipeline configurations, achieving an 89.4% cascade detection rate with a 5.3% false positive rate and 215 ms +/- 18 ms average latency overhead per stage, achieving an error propagation reduction of 82.1%, compared to 18.5% for output-level detectors. Component ablations confirm that each detection module contributes meaningfully to overall cascade coverage. CHARM integrates with human-in-the-loop oversight frameworks to provide a complete reliability and governance stack for production agentic AI deployment.
メタエージェントの課題: 現在のエージェントは自律的なエージェント開発が可能ですか?
現在の AI ベンチマークは、人間が設計したワークフロー内でのタスク実行に関してエージェントを評価します。これらの評価では、基本的に、モデルが自律的にエージェント システムを開発できるかどうかという、重要な次のレベルの機能を測定できません。自律エージェント開発のためのフロンティア モデルの能力をテストするために設計された評価フレームワークであるメタエージェント チャレンジ (MAC) を紹介します。具体的には、コード エージェント (メタエージェント) には、サンドボックス環境、評価 API、および 5 つのドメインにわたって実施されたテスト セットのパフォーマンスを最大化するエージェント アーティファクトを反復的にプログラムするための時間制限が与えられます。評価の整合性を確保するために、このフレームワークは報酬ハッキングに対する多層防御によって保護されています。このフレームワークを活用して、メタエージェントが人為的に設計されたベースライン ポリシーと一致することはほとんどなく、一致する少数のエージェントは独自のフロンティア モデルによって支配されていることを示します。さらに、設計プロセスは高い分散を示し、高い最適化圧力により、グラウンドトゥルースの漏洩などの敵対的な動作が表面化し、堅牢性とモデルの調整の両方における重大な欠陥が浮き彫りになります。最終的に、MAC は自律型 AI の研究開発のための厳密なオープンソース ベンチマークを提供し、再帰的な自己改善を評価するための経験的な代用手段を提供します。ベンチマークは https://github.com/ant-research/meta-agent-challenge で公開されています。
原文 (English)
The Meta-Agent Challenge: Are Current Agents Capable of Autonomous Agent Development?
Current AI benchmarks evaluate agents on task execution within human-designed workflows. These evaluations fundamentally fail to measure a critical next-level capability: whether models can autonomously develop agent systems. We introduce the Meta-Agent Challenge (MAC), an evaluation framework designed to test the capacity of frontier models for autonomous agent development. Specifically, a code agent (the meta-agent) is given a sandboxed environment, an evaluation API, and a time limitation to iteratively program an agent artifact that maximizes performance on a held-out test set across five domains. To ensure evaluation integrity, this framework is secured by multi-layer defenses against reward hacking. Leveraging this framework, we demonstrate that meta-agents rarely match human-engineered baseline policies, and the few that do are dominated by proprietary frontier models. Moreover, the design process exhibits high variance, and high optimization pressure surfaces emergent adversarial behaviors like ground-truth exfiltration-highlighting critical deficits in both robustness and model alignment. Ultimately, MAC provides a rigorous, open-source benchmark for autonomous AI research and development, offering an empirical proxy for evaluating recursive self-improvement. Benchmark is publicly available at: https://github.com/ant-research/meta-agent-challenge.
AgentJet: エージェント強化学習のための柔軟な群トレーニング フレームワーク
大規模言語モデル (LLM) エージェント強化学習用の分散群トレーニング フレームワークである AgentJet を紹介します。エージェントのロールアウトとモデルの最適化を密接に結び付ける集中型フレームワークとは異なり、AgentJet は分離されたマルチノード アーキテクチャを採用しています。このアーキテクチャでは、swarm サーバー ノードがトレーニング可能なモデルをホストし、GPU クラスターで最適化を実行します。一方、swarm クライアント ノードは任意のデバイスで任意のエージェントを実行します。この設計は、集中型フレームワークではサポートが難しい機能を提供します。(1) 異種マルチモデル強化学習。複数の LLM を頭脳とする異種マルチエージェント チームのトレーニングを可能にします。 (2) 独立したエージェントのランタイムを使用したマルチタスクのカクテル トレーニング。 (3) 外部環境の障害によるトレーニング プロセスの中断を防ぐフォールト トレラントな実行。 (4) ライブ コードの反復。群クライアント ノードを置き換えることにより、トレーニング中にエージェントを編集できます。マルチモデル、マルチターン、マルチエージェント設定で効率的な RL をサポートするために、AgentJet はタイムライン マージを備えたコンテキスト トラッキング モジュールを導入しています。これにより、冗長なコンテキストが統合され、トレーニングの 1.5 ~ 10 倍の高速化が実現します。最後に、AgentJet は、研究トピックを入力として受け取り、大規模クラスター上で長期にわたる複数日にわたる RL 研究を自律的に実行する自動研究システムを導入します。このシステムは、swarm アーキテクチャを活用することで、実行中に人間の介入なしに、RL 研究者の主要な探索ワークフローを再現します。
原文 (English)
AgentJet: A Flexible Swarm Training Framework for Agentic Reinforcement Learning
We present AgentJet, a distributed swarm training framework for large language model (LLM) agent reinforcement learning. Unlike centralized frameworks that tightly couple agent rollouts with model optimization, AgentJet adopts a decoupled multi-node architecture in which swarm server nodes host trainable models and run optimization on GPU clusters, whereas swarm client nodes execute arbitrary agents on arbitrary devices. This design provides capabilities that are difficult to support in centralized frameworks: (1) heterogeneous multi-model reinforcement learning, enabling the training of heterogeneous multi-agent teams with multiple LLM as brains; (2) multi-task cocktail training with isolated agent runtimes; (3) fault-tolerant execution that prevents external environment failures from interrupting the training process; and (4) live code iteration, which allows agents to be edited during training by replacing swarm client nodes. To support efficient RL in multi-model, multi-turn, and multi-agent settings, AgentJet introduces a context tracking module with timeline merging, which consolidates redundant context and achieves a 1.5-10x training speedup. Finally, AgentJet introduces an automated research system that takes a research topic as input and autonomously conducts long-horizon, multi-day RL studies on large-scale clusters. By leveraging the swarm architecture, this system reproduces key exploratory workflows of RL researchers without human intervention during execution.
プロンプトベースの計画を超えて: MCP ネイティブ グラフ計画ベースの生物医学エージェント システム
生物医学エージェントは複雑な生物学的ワークフローを自動化できると期待されていますが、現在のシステムは 2 つの根本的なボトルネックに直面しています。それは、バイオインフォマティクス ツールがインターフェイスと実行環境において非常に異質である一方、エージェントの計画は未だにプロンプトで取得されるフラットなツール記述に依存しているということです。生物医学ソフトウェア エコシステムが成長するにつれて、ツールの適用範囲とコンテキスト サイズの関係により、ツールの混乱、不安定な計画、および非効率的な実行が発生します。構造化された生物学的機能よりもグラフ足場計画に基づいて構築された MCP ネイティブの生物医学エージェントである BioManus を紹介します。 BioManus は、異種バイオインフォマティクス ソフトウェアを標準化された MCP サーバーに変換し、大規模な実行可能な MCP エコシステムを生み出す BioinfoMCP コンパイラーを初めて導入しました。次に、このエコシステムを、ツール、操作、データ型、ワークフロー ステージにわたる型付きの異種 MCP グラフとして編成します。推論時に、BioManus はコンパクトなタスク固有のサブグラフを取得し、操作レベルのワークフロー スキャフォールドを合成します。この設計は、計画の複雑さを生の工具在庫サイズから切り離し、高リコール取得下で Theta(N / (h * m_bar)) のコンテキスト圧縮率を達成します。ここで、N は総工具数、h はワークフロー範囲、m_bar (N よりもはるかに小さい) は操作ごとの候補工具の平均数です。 BioAgentBench と LAB-Bench の実験では、BioManus が高度な生物医学エージェントのベースラインと比較して、実行精度、ワークフローの有効性、およびコンテキストの効率を向上させることが示されています。この研究はパラダイム シフトを示唆しています。スケーラブルな生物医学的推論には、ますます大規模になるプロンプト レベルのツール検索ではなく、構造化された実行可能な機能グラフが必要です。
原文 (English)
Beyond Prompt-Based Planning: MCP-Native Graph Planning-based Biomedical Agent System
Biomedical agents promise to automate complex biological workflows, yet current systems face two fundamental bottlenecks: bioinformatics tools are highly heterogeneous in interfaces and execution environments, while agent planning still relies on flat prompt-retrieved tool descriptions. As biomedical software ecosystems grow, this coupling between tool coverage and context size leads to tool confusion, unstable planning, and inefficient execution. We introduce BioManus, an MCP-native biomedical agent built on graph-scaffolded planning over structured biological capabilities. BioManus first introduces the BioinfoMCP Compiler, which converts heterogeneous bioinformatics software into standardized MCP servers, yielding a large executable MCP ecosystem. It then organizes this ecosystem as a typed heterogeneous MCP graph over tools, operations, datatypes, and workflow stages. At inference time, BioManus retrieves compact task-specific subgraphs, synthesizes operation-level workflow scaffolds. This design decouples planning complexity from raw tool inventory size, achieving a context compression ratio of Theta(N / (h * m_bar)) under high-recall retrieval, where N is the total tool count, h is the workflow horizon, and m_bar (much smaller than N) is the average number of candidate tools per operation. Experiments on BioAgentBench and LAB-Bench show that BioManus improves execution accuracy, workflow validity, and context efficiency over advanced biomedical agent baselines. This work suggests a paradigm shift: scalable biomedical reasoning requires structured executable capability graphs rather than increasingly larger prompt-level tool retrieval.
シミュレーション、推論、決定: シミュレーション主導の意思決定のための LLM による科学的推論
科学シミュレータは、一か八かのシミュレーション主導の意思決定のために、LLM 主導のシステムにますます統合されています。ただし、既存のフレームワークは主に LLM を使用してシミュレータを生成、調整、実行し、シミュレータを推論可能な構造化された機構システムとしてではなく、ブラックボックス インターフェイスとして扱います。その結果、現在のアプローチには、シミュレータの動作の根底にある仮定やメカニズムを特定、表現、推論する能力が欠けており、透明性、監査可能性、意思決定の正当性が制限されています。実行可能な科学シミュレーター用のメカニズムに基づいた神経記号推論フレームワークである MechSim を紹介します。主に静的な記号構造を推論する従来の神経記号アプローチとは異なり、MechSim を使用すると、LLM エージェントが科学シミュレーターのメカニズム、仮定、および実行動作について推論できるようになります。私たちのフレームワークは、仮定、変数、メカニズムの依存関係、および実行トレースをキャプチャする共有構造化スキーマを通じてシミュレーターを表します。この表現に加えて、LLM エージェントは制約付き推論エンジンとして動作し、シミュレータの結果をその基礎となるメカニズムに結び付ける、構造化された証拠に基づいた説明を生成します。私たちは、複数のハイステークス領域にわたってアプローチを評価し、それがメカニズムレベルの説明の品質、シミュレーター分析、下流の意思決定の信頼性を向上させることを示しました。
原文 (English)
Simulate, Reason, Decide: Scientific Reasoning with LLMs for Simulation-Driven Decision Making
Scientific simulators are increasingly being integrated into LLM-driven systems for high-stakes simulation-driven decision-making. However, existing frameworks primarily use LLMs to generate, calibrate, or execute simulators, treating them as black-box interfaces rather than as structured mechanistic systems that can be reasoned about. As a result, current approaches lack the ability to identify, represent, and reason about the assumptions and mechanisms underlying simulator behavior, limiting transparency, auditability, and decision justification. We introduce MechSim, a mechanism-grounded neuro-symbolic reasoning framework for executable scientific simulators. Unlike prior neuro-symbolic approaches that primarily reason over static symbolic structures, MechSim enables LLM agents to reason about the mechanisms, assumptions, and execution behavior of scientific simulators. Our framework represents simulators through a shared structured schema capturing assumptions, variables, mechanism dependencies, and execution traces. On top of this representation, LLM agents operate as constrained reasoning engines that generate structured, evidence-grounded explanations linking simulator outcomes to their underlying mechanisms. We evaluate our approach across multiple high-stakes domains and show that it improves mechanism-level explanation quality, simulator analysis, and downstream decision-making reliability.
MapAgent: 都市規模の車線レベルの地図生成のための産業グレードのエージェント フレームワーク
車線レベルの地図は自動運転と車線レベルのナビゲーションにとって重要なインフラストラクチャですが、数百の都市で標準化された車線ネットワークの構築と維持には依然として非常に労働集約的です。最近のエンドツーエンドのベクトル化マッピング手法は、センサー データから直接車線の形状とトポロジを予測できますが、通常、マッピング仕様と交通規制を暗黙的なデータセット依存の監視として扱います。さらに、複雑なシーン (マーキングやオクルージョンの磨耗や欠落など) では、正しいレーン構成が視覚的証拠だけでは十分に決定されないことが多く、仕様違反が人間による事後編集の主な原因となっています。私たちは、仕様に準拠したレーンマップ作成のためのベクトル化バックボーンを強化する産業グレードのエージェント アーキテクチャである MapAgent を提案します。 MapAgent は、単にマップ予測にエージェント ループを追加するのではなく、バックボーンの認識と明示的な仕様の検証、制約を意識した推論、および境界のある検証主導型のジャッジ-プランナー-ワーカー ループの下での決定論的なマップ編集を結合します。視覚言語を使用するジャッジは、視覚的な証拠とドラフトベクトルを共同で検査することでエラーを診断し、ツールを呼び出すプランナーは編集後の再検証により最小限の修正編集を生成します。都市規模の本番環境でのスケーラビリティを維持するために、MapAgent はバックボーンの信頼性が低いタイルでのみ選択的にトリガーされ、スループットを維持しながら適度なオーバーヘッドを追加します。現実世界のデータセットでの実験では、特に複雑でロングテールのシナリオにおいて、強力な実稼働ベースラインを上回る一貫した利益が示されています。さらに、MapAgent は Baidu Maps に統合されており、全国 360 以上の都市の車線レベルの地図生成をサポートし、全体的な生産自動化を 95% 以上に高め、大規模な車線レベルの地図生成における MapAgent の実用性と有効性を実証しています。
原文 (English)
MapAgent: An Industrial-Grade Agentic Framework for City-scale Lane-level Map Generation
Lane-level maps are critical infrastructure for autonomous driving and lane-level navigation, yet constructing and maintaining standardized lane networks for hundreds of cities remains highly labor-intensive. Recent end-to-end vectorized mapping methods can predict lane geometry and topology directly from sensor data, but they typically treat mapping specifications and traffic regulations as implicit, dataset-dependent supervision. Moreover, in complex scenes (e.g., worn or missing markings and occlusions), correct lane configurations are often under-determined by visual evidence alone, making specification violations a major source of human post-editing. We propose MapAgent, an industrial-grade agentic architecture that augments a vectorization backbone for specification-compliant lane-map production. Rather than merely adding an agent loop to map prediction, MapAgent couples backbone perception with explicit specification verification, constraint-aware reasoning, and deterministic map editing under a bounded, verification-driven Judge-Planner-Worker loop. A vision-language Judge diagnoses errors by jointly inspecting visual evidence and draft vectors, while a tool-calling Planner generates minimal corrective edits with post-edit re-validation. To remain scalable for city-scale production, MapAgent is selectively triggered only on tiles with low backbone confidence, adding modest overhead while preserving throughput. Experiments on real-world datasets show consistent gains over strong production baselines, especially in complex and long-tail scenarios. Additionally, MapAgent has been integrated into Baidu Maps, supporting lane-level map generation for over 360 cities nationwide and elevating the overall production automation to over 95%, demonstrating MapAgent's practicality and effectiveness for large-scale lane-level map generation.
パラメトリック メモリを介した自己進化エージェントのスケーリング
既存のメモリ拡張 LLM エージェントは、ロールアウト中モデル パラメータを凍結したままにしながら、過去の経験をテキストの要約または取得された一節としてプロンプト領域にのみ保存します。このようなエージェントは、見たものを \emph{調べる}ことはできますが、それから \emph{学ぶ}ことはできません。彼らのポリシーは経験によって変更されず、コンテキストからドロップされた情報は永久に失われます。私たちは、自己進化するパラメトリック メモリ フレームワークである \texttt{TMEM} を導入します。このフレームワークでは、エージェントが履歴を明示的メモリに圧縮するだけでなく、軽量のオンライン アップデートを通じて抽出された監視を高速な LoRA 重み $\Delta_t$ に吸収し、単一のエピソード内で将来の動作を真に変更します。これを、高速重みロールアウト ダイナミクスを備えたエージェントの意思決定プロセスとして形式化します。アクションは $\pi_{\theta_0+\Delta_t}$ からサンプリングされ、抽出アクションは後続の決定のために $\Delta_t$ を更新する監視を生成します。このビューにより、抽出ポリシーが RL によって直接最適化可能になります。$\theta_0$ のトレーニングにより、タスク アクションだけでなく、オンライン LoRA 適応に使用されるデータの品質も向上します。さらに、オンラインコンバージェンスを加速するために、SVD ベースの LoRA サブスペースの初期化を提案します。 LoCoMo、LongMemEval-S、多目的検索、および CL-Bench の実験では、\texttt{TMEM} がさまざまなモデル スケールにわたって、要約ベースおよび検索ベースのベースラインを一貫して上回るパフォーマンスを示しています。
原文 (English)
Scaling Self-Evolving Agents via Parametric Memory
Existing memory-augmented LLM agents store past experience exclusively in prompt space, as textual summaries or retrieved passages, while keeping model parameters frozen throughout a rollout. Such agents can \emph{look up} what they have seen but cannot \emph{learn from} it: their policy is unchanged by experience, and any information dropped from the context is permanently lost. We introduce \texttt{TMEM}, a self-evolving parametric memory framework in which the agent not only compresses history into explicit memory but also absorbs distilled supervision into fast LoRA weights $\Delta_t$ via lightweight online updates, genuinely altering its future behavior within a single episode. We formalize this as an agentic decision process with fast-weight rollout dynamics: actions are sampled from $\pi_{\theta_0+\Delta_t}$, while extraction actions produce supervision that updates $\Delta_t$ for subsequent decisions. This view makes the extraction policy directly optimizable by RL: training $\theta_0$ improves not only task actions but also the quality of the data used for online LoRA adaptation. We further propose SVD-based initialization of the LoRA subspace to accelerate online convergence. Experiments on LoCoMo, LongMemEval-S, multi-objective search, and CL-Bench show that \texttt{TMEM} consistently outperforms summary-based and retrieval-based baselines across different model scales.
Neetyabhas: Rational エージェントベースのモデルにおける不確実性を認識した公共政策最適化のためのフレームワーク
目的 WHO の新型コロナウイルス感染症に対する非医薬品介入(ロックダウン、ワクチン接種など)は感染を効果的に抑制しますが、経済的には大きな負担となります。既存の研究は、個人の行動を無視し、完璧な感染追跡と完璧な政策実行を誤って想定しており、現実世界の不確実性や誤りを説明できていないことがよくあります。方法 我々は、流行の測定(感染症/入院)と政策実施の両方に不確実性を組み込んだ統合的アプローチを提案します。私たちは、マスクの着用、ワクチン接種、買い物に関するリアルタイムの選択を行う 1,000 人の個人のシミュレーション モデルを構築しました。同時に、政策立案者は健康と経済の観察に基づいて介入(ロックダウン、義務化)を展開します。このフレームワークは階層型強化学習エージェントによって駆動され、不確実性を考慮したポリシー勾配バリアント (DDPG および TD3) とともにディープ Q ネットワークを利用します。結果 シミュレーションは流行の進行を効果的に管理しました。マスクとワクチン接種が非常に効果的であることが証明され、流行のピークの高さと期間の両方が大幅に短縮されました。個人の行動、政策の不確実性、多面的な介入を統合することで、私たちの動的制御アプローチは流行の影響を軽減することに成功しました。結論 私たちのモデルは、不確実性と人間の行動を公衆衛生政策の枠組みに組み込むことで、これまでの研究の限界を克服しました。このシミュレーションは、マスクとワクチンが極めて重要なツールとして機能し、複雑なパンデミック時に効果的な介入を設計するには、個人の選択と不完全なデータを考慮することが重要であることを示しています。
原文 (English)
Neetyabhas: A Framework for Uncertainty-Aware Public Policy Optimization in Rational Agent-Based Models
Purpose The WHO's COVID-19 non-pharmaceutical interventions (e.g., lockdowns, vaccinations) effectively curb transmission but impose heavy economic strains. Existing research often neglects individual behaviors and falsely assumes perfect infection tracking and flawless policy execution, failing to account for real-world uncertainties and errors. Methods We propose an integrative approach incorporating uncertainties in both epidemic measurement (infections/hospitalizations) and policy implementation. We built a simulation model of 1,000 individuals making real-time choices regarding mask-wearing, vaccination, and shopping. Concurrently, policymakers deploy interventions (lockdowns, mandates) based on health and economic observations. This framework is driven by hierarchical reinforcement learning agents, utilizing deep Q-networks alongside uncertainty-aware policy gradient variants (DDPG and TD3). Results The simulations effectively managed the epidemic's progression. Masking and vaccinations proved highly effective, significantly reducing both the outbreak's peak height and duration. By integrating individual behaviors, policy uncertainties, and multifaceted interventions, our dynamic control approach successfully mitigated the epidemic's impact. Conclusions Our model overcomes previous research limitations by embedding uncertainty and human behavior into public health policy frameworks. The simulation demonstrates that accounting for individual choices and imperfect data is crucial for designing effective interventions during complex pandemics, with masks and vaccines serving as pivotal tools.
SCI-PRM: 科学的推論検証のためのツール認識プロセス報酬モデル
プロセス報酬モデル (PRM) は数学的推論において目覚ましい成功を収めていますが、生物学、化学、物理学などの複雑な科学分野での応用はほとんど未踏のままです。科学的な問題には、論理的な厳密さだけでなく、事実の一貫性や分野固有のツールの正確な使用法も要求されますが、この領域では、現在のモデルが幻覚や検証の欠如に悩まされることがよくあります。この論文では、まず、推論と科学ツールの実行を明示的にインターリーブするツールチェーンの軌跡を特徴とする大規模なデータセットである SCIPRM70K を構築します。これに基づいて、Sci-PRM と呼ばれる効率的な報酬モデルをトレーニングして、1 つの推論の各ステップでツールの選択、実行精度、結果の解釈をきめ細かく監視します。実験では、Sci-PRM が 2 つの重要な側面で基礎モデルを大幅に強化することが実証されています。(1) Best-of-N 選択による効果的なテスト時間のスケーリングを可能にします。 (2) 強化学習に統合すると、利点の消失という重大な問題を軽減する高密度の報酬シグナルとして機能し、モデルが既存のパフォーマンスの上限を突破できるようになります。
原文 (English)
SCI-PRM: A Tool Aware Process Reward Model for Scientific Reasoning Verification
While Process Reward Models (PRMs) have achieved remarkable success in mathematical reasoning, their application in complex scientific domains-such as biology, chemistry, and physics remains largely unexplored. Scientific problems demand not only logical rigor but also factual consistency and the precise usage of domain-specific tools, areas where current models often suffer from hallucinations and lack of verification. In this paper, we first construct SCIPRM70K, a large-scale dataset featuring Chain-of-Tool trajectories that explicitly interleave reasoning with the execution of scientific tools. Building upon this, we train an efficient reward model called Sci-PRM to provide fine-grained supervision on tool selection, execution accuracy, and result interpretation at each step in one inference. Experiments demonstrate that Sci-PRM significantly enhances foundation models in two key aspects: (1) it enables effective test-time scaling via Best-of-N selection; and (2) when integrated into Reinforcement Learning, it serves as a dense reward signal that mitigates the critical issue of advantage disappearance, allowing the model to break through existing performance ceilings.
コスト分割による許容可能なヒューリスティックの学習
許容可能なヒューリスティックは最適な計画を立てるために不可欠ですが、過大評価のリスクがあるため、ヒューリスティックを学習することは依然として困難です。コスト分割では、許容性を維持しながら複数の抽象化ヒューリスティックを組み合わせますが、最適な分割をオンラインで計算するにはコストがかかります。コスト分割と乗数予測の間のラグランジュ双対等価性を利用して、許容可能なコスト分割を推測する方法を学習するフレームワークを提案します。計画の状態とパターンはラベル付きグラフとしてエンコードされ、Weisfeiler-Leman アルゴリズムのアクション中心の変形により構造的特徴ベクトルが抽出されます。軸方向のセルフアテンションとソフトマックス出力層を備えたディープ アーキテクチャは、これらの機能を構築によるパーティション制約を満たすコストの重みにマップし、許容性を確保します。実験では、厳密な許容性を維持しながら、最適ではない分割ベースラインと比較してノード拡張が減少していることが実証されています。私たちの知る限り、これは許容されることが保証された最初の機械学習ヒューリスティックです。
原文 (English)
Learning Admissible Heuristics via Cost Partitioning
Admissible heuristics are essential for optimal planning, yet learning them remains challenging due to the risk of overestimation. Cost partitioning combines multiple abstraction heuristics while preserving admissibility, but computing optimal partitions online is expensive. We propose a framework that learns to infer admissible cost partitions by leveraging the Lagrangian dual equivalence between cost partitioning and multiplier prediction. Planning states and patterns are encoded as labelled graphs, and an action-centric variant of the Weisfeiler-Leman algorithm extracts structural feature vectors. A deep architecture with axial self-attention and a softmax output layer maps these features to cost weights that satisfy the partition constraints by construction, ensuring admissibility. Experiments demonstrate reduced node expansions compared to suboptimal partitioning baselines while maintaining strict admissibility. To our knowledge, this is the first machine-learned heuristic guaranteed to be admissible.
最初に計画し、後で判断し、より良く実行する: DMAIC からインスピレーションを得た産業異常検出用エージェント システム
大規模言語モデル (LLM) エージェントは、複雑なデータ分析ワークフローの自動化において有望であることが示されていますが、一か八かの産業シナリオにおいてその信頼性の高い導入は依然として困難です。産業異常検出 (IAD) は製造の品質、安全性、効率に不可欠ですが、既存の LLM ベースの IAD エージェントは主に実行に焦点を当てており、戦略策定は不十分です。その結果、統一的かつコスト効率の高い方法で異種のモダリティを処理するのに苦労しています。 DMAIC 品質管理フレームワークからインスピレーションを得て、当社は DMAIC-IAD (DMAIC にインスピレーションを得た Agentic Industrial Anomaly Detection) を提案します。これは、LLM エージェントを構造化された産業問題解決と連携させる、「最初に計画し、後で判断する」マルチエージェント システムです。 DMAIC-IAD は、戦略生成前に異種参照を標準化操作手順 (SOP) に抽出し、事前トレーニングされた実行不要の判定モデルを導入して、コストのかかる実行時トライアルを行わずに候補戦略をランク付けします。 4 つのモダリティにわたる広範な実験により、DMAIC-IAD は適用可能な薬剤ベースラインよりも平均検出パフォーマンスが 37.76% 向上することが示されています。
原文 (English)
Plan First, Judge Later, Run Better: A DMAIC-Inspired Agentic System for Industrial Anomaly Detection
Large language model (LLM) agents have shown promise in automating complex data-analysis workflows, but their reliable deployment remains challenging in high-stakes industrial scenarios. Industrial anomaly detection (IAD) is essential for manufacturing quality, safety, and efficiency, yet existing LLM-based IAD agents mainly focus on execution while under-exploiting strategy formulation. Consequently, they struggle to handle heterogeneous modalities in a unified and cost-effective manner. Inspired by the DMAIC quality-management framework, we propose DMAIC-IAD (DMAIC-inspired Agentic Industrial Anomaly Detection), a "Plan First, Judge Later" multi-agent system that aligns LLM agents with structured industrial problem-solving. DMAIC-IAD distills heterogeneous references into standardized operating procedures (SOPs) before strategy generation, and introduces a pre-trained execution-free judge model to rank candidate strategies without costly runtime trials. Extensive experiments across four modalities show that DMAIC-IAD improves average detection performance over applicable agentic baselines by 37.76%.
パルテノン法: 自己進化する弁護士の枠組み
エージェントの能力が高まるにつれて、法律分野の LLM エージェントは、大量のドキュメントをレビュー可能な作業成果物に変えることを約束しますが、信頼性の高い導入には 3 つの障害に直面しています。1 つは、今日の最も強力なモデルとハーネスの組み合わせがエンドツーエンドの法的問題でどのように動作するかについての大規模な証拠がないことです。法的な業種に適合したエージェント アーキテクチャはなく、汎用ハーネスのみが使用されます。そして、新しい事実、権限、期限によって変化し続ける環境では、システムが自らの結果から学習するメカニズムがありません。それぞれに対応します。 Harvey LAB に関する大規模な実証研究 -- $12{,}510$ のエージェントの軌跡 -- は、フロンティアのエージェントでさえ 1 回のパスで問題を完了することには程遠いことを示しています。より強力なモデルを使用すると基準ごとの精度が向上しますが、厳密な問題の完了は停滞します。次に、\textsc{Parthenon} を導入します。これは、モデル、ハーネス、代理人の役割、法的知識、決定論的なツール、および手続き上のスキルを情報源の追跡可能性、日付と番号の根拠、成果物のコンプライアンス、および問題の解決のための監査可能な表面に組み込む、自己進化する法律代理人のフレームワークです。最後に、漏れ防止学習ループにより、スコアリングされた失敗がタスクに依存しないスキル、ツール、知識の編集に変換され、企業が問題ごとにチェックリストとプレイブックを洗練するように、モデルの重みに触れることなく、経験とともにシステムが改善されます。私たちの大規模な実証分析を通じて、\textsc{Parthenon} は法的問題のタスクにおける最先端のモデルとハーネスのパフォーマンスを大幅に向上させました。
原文 (English)
Parthenon Law: A Self-Evolving Legal-Agent Framework
As agents grow more capable, legal-domain LLM agents promise to turn document-heavy matters into reviewable work products -- yet reliable deployment faces three obstacles: no large-scale evidence on how today's strongest model-and-harness combinations behave on end-to-end legal matters; no agent architecture adapted to the legal vertical, only general-purpose harnesses; and, in a setting that keeps shifting with new facts, authorities, and deadlines, no mechanism for systems to learn from their own outcomes. We address each. A large-scale empirical study on Harvey LAB -- $12{,}510$ agent trajectories -- shows that even frontier agents remain far from completing matters in a single pass: per-criterion accuracy climbs with stronger models while strict matter completion stalls. We then introduce \textsc{Parthenon}, a self-evolving legal-agent framework that factors Model, Harness, Agent roles, legal Knowledge, deterministic Tools, and procedural Skills into auditable surfaces for source traceability, date and number grounding, deliverable compliance, and issue closure. Finally, an anti-leakage learning loop converts scored failures into task-agnostic edits to skills, tools, and knowledge, letting the system improve with experience -- as a firm refines its checklists and playbooks after each matter -- without touching model weights. Across our large-scale empirical analysis, \textsc{Parthenon} substantially improves the performance of state-of-the-art models and harnesses on legal-matter tasks.
ASP ベースのコンプライアンス推論のための規範的な中間表現
我々は、ASP ベースのコンプライアンス推論のためのモーダル化出力規範中間表現である MONIR を提案します。そのコア フラグメントには段階的な操作セマンティクスがあり、MONIR-ASP は外部関数、一時的なルール、および安定したモデル推論のための実行可能なコンパイルと拡張機能を提供します。 LLM 支援パイプラインを使用して、中国の ADAS 規制と標準に関するフレームワークをインスタンス化します。実験では、抽出品質と、モジュール式および増分 ASP 解決の効率を評価します。
原文 (English)
A Normative Intermediate Representation for ASP-Based Compliance Reasoning
We propose MONIR, a Modalized-Output Normative Intermediate Representation for ASP-based compliance reasoning. Its core fragment has a staged operational semantics, while MONIR-ASP provides an executable compilation and extensions for external functions, temporal rules, and stable-model reasoning. We instantiate the framework on Chinese ADAS regulations and standards with an LLM-assisted pipeline. Experiments evaluate extraction quality and the efficiency of modular and incremental ASP solving.
MIRAGE: 暗黙的推論と生成世界モデルを備えたモバイル エージェント
モバイル エージェントは、スクリーンショットや言語目標に基づいて日常のアプリケーションを操作することがますます期待されており、信頼性の高い制御には、画面のアフォーダンス、複数ステップのナビゲーション、および将来の状態の変化に関する推論が必要です。ただし、多くのエージェントはこの計算を長いテキストの思考連鎖として外部に出すため、対話が遅くなり、監視コストが増加し、展開が複雑になります。 MIRAGE は、目に見えるテキスト推論の痕跡から継続的な潜在推論表現を学習するフレームワークです。 MIRAGE は、明示的な推論をコンパクトな隠れ状態に変換し、エージェントが長い根拠を解読することなく内部的に推論できるようにします。また、生成世界モデルの目標も組み込まれています。つまり、潜在的な推論ベクトルが将来のスクリーンショットと一致し、エージェントが行動する前に今後のインターフェイスの状態を予測するようになります。これにより、隠れた計算が圧縮された思考表現と環境力学の将来を見据えたモデルの両方に変わります。推論時、MIRAGE は連続的な潜在空間で推論し、実行効率を向上させながらトークンの生成を削減します。 AndroidWorld では、MIRAGE は、4B アブレーションにおける明示的な思考連鎖の監視付き微調整と 3 ~ 5 倍低いデコード トークン バジェットを一致させ、同等の命令調整ベースラインを 10.2 ポイント改善します。 AndroidControl では、生成されるトークンが 75% 以上減少しながら、アクションのグラウンディングが向上します。
原文 (English)
MIRAGE: Mobile Agents with Implicit Reasoning and Generative World Models
Mobile agents are increasingly expected to operate everyday applications from screenshots and language goals, where reliable control requires reasoning over screen affordances, multi-step navigation, and future state changes. However, many agents externalize this computation as long textual chains of thought, which slows interaction, increases supervision cost, and complicates deployment. We introduce MIRAGE, a framework that learns continuous latent reasoning representations from visible textual reasoning traces. MIRAGE transfers explicit reasoning into compact hidden states, enabling the agent to reason internally without decoding long rationales. It also incorporates a generative world-model objective: latent reasoning vectors are aligned with future screenshots, encouraging the agent to anticipate upcoming interface states before acting. This turns hidden computation into both a compressed thought representation and a forward-looking model of environment dynamics. At inference time, MIRAGE reasons in continuous latent space, reducing token generation while improving execution efficiency. On AndroidWorld, MIRAGE matches explicit chain-of-thought supervised fine-tuning in the 4B ablation with a 3-5x lower decoded-token budget and improves a comparable instruction-tuned baseline by 10.2 points; on AndroidControl, it improves action grounding while generating over 75% fewer tokens.
BiNSGPS: 双方向の神経記号相互作用による幾何学問題解決
幾何学の問題解決は、人工知能に明確な課題をもたらします。既存のアプローチは通常 2 つのパラダイムに分類されます。1 つは適応性が限られている記号的方法、もう 1 つは幻覚を起こしやすい神経的方法です。最近のニューロシンボリックハイブリッドは主に一方向パイプラインに依存しており、ニューラル出力がフィードバックなしでソルバーに供給されるため、システムは初期段階のエラーに対して脆弱になります。この一方向のボトルネックを打破するために、MLLM アドバイザとシンボリック ソルバーの間で双方向ニューロシンボリック インタラクション (BiNS) を確立するフレームワークである BiNSGPS を提案します。 MLLM Adviser は、シンボリック ソルバーからのフィードバックを積極的に組み込んで、矛盾した形式表現を動的に修正したり、補助的な仮説を提案したりして、シンボリックの矛盾を解決し、複雑な演繹を容易にします。
原文 (English)
BiNSGPS: Geometry Problem Solving via Bidirectional Neuro-Symbolic Interaction
Geometry problem solving poses distinct challenges in artificial intelligence. Existing approaches typically fall into two paradigms: symbolic methods, which exhibit limited adaptability, and neural methods, which are prone to hallucinations. Recent neuro-symbolic hybrids predominantly rely on a unidirectional pipeline where neural outputs are fed into solvers without feedback, making system brittle to early-stage errors. To break this unidirectional bottleneck, we propose BiNSGPS, a framework that establishes Bidirectional Neuro-Symbolic Interaction (BiNS) between a MLLM Adviser and a Symbolic Solver. MLLM Adviser actively incorporates feedback from the symbolic solver to dynamically rectify inconsistent formal representations or propose auxiliary hypotheses, resolving symbolic conflicts and facilitating complex deductions.
Fog of Love: ゲーム環境における親和性ベースの強化学習による高潔なエージェントの動作のエンジニアリング
人工知能に高潔な行動を教え込むことへの関心が高まっています。提案された手法の 1 つは、親和性ベースの強化学習として知られています。これは、目的関数のポリシー正則化を使用して、報酬関数の設計に完全に依存することなく、善良な行動を奨励します。これまでのところ、この手法は、状態空間とアクション空間が最小限のグリッド ワールドやおもちゃの問題環境で有効であることが実証されています。この研究をより洗練された環境に拡張するために、Fog of Love として知られるロールプレイング ボード ゲームに基づく 2 プレイヤー マルチエージェント環境を導入します。この環境では、2 人のエージェントがそれぞれの美徳を満たすために競い合いながら、その関係を満たすために協力します。マルチエージェントの性質を考慮すると、これは複雑な問題であり、マルチエージェントの深い決定論的ポリシー勾配エージェントは競合も連携もうまくいきません。我々は、局所的な親和性が競争目的と協力目的の両方を達成する際のエージェントのパフォーマンスを向上させ、その結果、両方のドメインで総合スコアが優れているという証拠を提示します。これは、結果的に賢明な選択をもたらすだけでなく、エージェントの目的論を明確にし、その行動を人間レベルで解釈できるようにします。
原文 (English)
Fog of Love: Engineering Virtuous Agent Behavior with Affinity-based Reinforcement Learning in a Game Environment
Instilling virtuous behavior in artificial intelligence has seen increasing interest. One of the techniques proposed is known as affinity-based reinforcement learning, which uses policy regularization on the objective function to incentivize virtuous actions without being fully dependent on the reward function design. Thus far, this technique has been demonstrated to be effective in grid worlds and toy-problem environments with minimal state and action spaces. To expand this research to more sophisticated environments, we introduce a two-player multi-agent environment based on the role-playing board game known as Fog of Love. In this environment, two agents compete to fulfill their individual virtues, while also cooperating to satisfy their relationship. Given the multi-agent nature, this is a complex problem where multi-agent deep deterministic policy gradient agents neither compete nor cooperate successfully. We present evidence that localized affinities enhance agent performance in achieving both competitive and cooperative objectives, resulting from superior overall scores in both domains. This not only results in virtuous choices but also clarifies an agent's teleology and makes its behavior human-level interpretable.
FALSIFYBENCH: ルール発見ゲームを使用した LLM の帰納的推論の評価
大規模言語モデル (LLM) は、科学タスクにおける自律エージェントとして導入されることが増えています。しかし、これらのシステムが科学的発見に関連する帰納的推論の形式に効果的に関与できるかどうかは未解決の問題のままです。この研究では、古典的な Wason 2-4-6 タスクに触発された仮説主導型推論の評価フレームワークである FALSIFYBENCH を紹介します。このタスクでは、エージェントは例を繰り返し提案し、フィードバックを受け取ることによって隠れた意味論的特性を発見する必要があります。このタスクでは、科学的推論の重要な要素、つまり仮説の生成、証拠の収集、および証拠の確認と反証に応じた信念の修正を捉えます。モデルファミリーとスケールにわたる 12 個の LLM の評価では、最適なパフォーマンスに近いモデルはないものの、推論モデルは一般に命令調整モデルよりも強力な科学的推論であることがわかりました。成功の主な原動力は否定的なテストの能力です。仮説を積極的に反証しようとするモデルは、主に確認を求めるモデルよりも一貫して優れています。さらに、これまでの研究では無視されていたきめ細かいターンレベル分析により、モデルが仮説空間をナビゲートする方法における特定可能なパターンと失敗が結びついていることが明らかになりました。
原文 (English)
FALSIFYBENCH: Evaluating Inductive Reasoning in LLMs with Rule Discovery Games
Large language models (LLMs) are increasingly deployed as autonomous agents in scientific tasks. Yet whether these systems can effectively engage in forms of inductive reasoning relevant to scientific discovery remains an open question. In this work, we introduce FALSIFYBENCH, an evaluation framework for hypothesis-driven reasoning inspired by the classic Wason 2-4-6 task, in which agents must discover hidden semantic properties by iteratively proposing examples and receiving feedback. This task captures key elements of scientific reasoning: hypothesis generation, evidence gathering, and belief revision in response to both confirming and disconfirming evidence. Our evaluation of 12 LLMs across model families and scales shows that reasoning models are generally stronger scientific reasoners than instruction-tuned models, although no model comes close to optimal performance. The primary driver of success is the capacity for negative testing: models that actively seek to falsify their hypotheses consistently outperform those that primarily seek confirmation. Moreover, a fine-grained turn-level analysis, neglected in previous work, reveals that failure is tied to identifiable patterns in how models navigate the hypothesis space.
浅い安全性を超えた推論時の脆弱性: 世代の軌跡に沿った調整
安全性を考慮した大規模言語モデル (LLM) は、生成を有害な出力にリダイレクトする推論中の介入に対して依然として脆弱です。最近の研究では、これは浅い安全性であると考えられており、最初のいくつかの出力トークンに位置合わせが集中しています。浅い安全性は、より広範な推論時間の脆弱性の特殊なケースであり、任意の生成ステップでの短いトークンの注入によって、その後の安全性の動作が大幅に変更される可能性があることを示します。また、隠れ状態における拒否方向とのモデルの整合性は、そのような注入に対するそのロバスト性を予測しないこともわかり、内部状態だけが摂動下での生成挙動を決定しないことが明らかになりました。これに対処するために、シーケンス途中の摂動をシミュレートすることによって構築された生成軌跡にモデルを直接調整し、これによりシーケンス途中の注入に対する堅牢性が向上し、初期のトークン生成を悪用する攻撃に一般化されることを示します。私たちの研究では、堅牢な安全調整には、出力だけでなく、生成プロセス自体のトレーニングも必要であると主張しています。
原文 (English)
Inference-Time Vulnerability Beyond Shallow Safety: Alignment Along Generation Trajectories
Safety-aligned Large Language Models (LLMs) remain vulnerable to interventions during inference that redirect generation toward harmful outputs. Recent work attributes this to shallow safety, where alignment concentrates in the first few output tokens. We show that shallow safety is a special case of a broader inference-time vulnerability, in which short token injections at any generation step can substantially alter subsequent safety behavior. We also find that a model's alignment with refusal directions in its hidden states does not predict its robustness to such injection, revealing that internal state alone does not determine generation behavior under perturbation. To address this, we align models directly on generation trajectories constructed by simulating mid-sequence perturbation, and show that this improves robustness to mid-sequence injection and generalizes to attacks that exploit early-token generation. Our work argues that robust safety alignment requires training on the generation process itself, not only its outputs.
人間と AI のインタラクションにおけるマルチエージェントの相補性のツリーベースの定式化
相補性とは、人間と AI の相互作用 (HAI) が、そのメンバー間で利用可能な最良の予測ベンチマークを上回る場合のことです。この考え方は HAI 研究の中心ですが、相補性に関する正式な研究は依然として限られています。既存のフレームワークは、エージェントの予測がワークフローに依存したマルチエージェント プロトコルをどのように構成するかをモデル化していません。私たちは、マルチエージェント HAI における相補性のツリーベースの形式化を導入することで、このギャップを埋めます。 HAI プロトコルは、順序付けられたエージェントと役割の構成と、その葉が予測ベクトルによって装飾されている根付き平面バイナリ ツリーによって表されます。ローカルのバイナリ構成ルールがツリーに沿って再帰的に評価され、pointwise-min Oracle ベンチマークに対するツリー相対相補性関数が生成されます。 4 つの結果を証明します。まず、セレクターベースの HAI (自己依存性または AI 依存性を含む) は、タスク、損失、予測の品質に関係なく、相補性を達成できません。第 2 に、二乗損失での回帰では、相補性はグラウンド トゥルース ベクトルからのユークリッド距離の最小化に相当します。 $N=2$ の場合、最適な線形プーリング重みは閉じた形式と残差補正解釈を持ちます。第三に、線形局所構成の下では、すべてのプロトコル ツリーはリーフ重みの単体での重心座標チャートを定義します。プロトコルツリーのTamari-cover再パラメータ化は相補性を維持し、$N=4$の場合、五角形の恒等性を満たします。第四に、バイナリ分類では、標準ブレグマン損失や多くの有限ベルヌーイ $f$ 発散損失を含むエンドポイント単調損失の下では、内部の局所構成は相補性を達成できません。クロスエントロピー下のマルチクラス集約にも同様の障害が当てはまります。要約すると、私たちのフレームワークは、マルチエージェント回帰では相補性が達成可能ですが、局所的な凝集と損失関数に関する自然条件下での分類では妨げられることを示しています。
原文 (English)
Tree-Based Formalization of Multi-Agent Complementarity in Human-AI Interactions
Complementarity is the case in which a human--AI interaction (HAI) outperforms the best prediction benchmark available among its members. Although this idea is central in HAI research, formal work on complementarity remains limited. Existing frameworks do not model how agents' predictions compose into workflow-sensitive multi-agent protocols. We close this gap by introducing a tree-based formalization of complementarity in multi-agent HAI. An HAI protocol is represented by an ordered agent-role configuration together with a rooted planar binary tree whose leaves are decorated by prediction vectors. A local binary composition rule is evaluated recursively along the tree, yielding a tree-relative complementarity functional relative to a pointwise-min oracle benchmark. We prove four results. First, selector-based HAIs, including self- or AI-reliance, cannot achieve complementarity regardless of task, loss, or prediction quality. Second, in regression under squared loss, complementarity is equivalent to Euclidean distance minimization from the ground-truth vector; for $N=2$, the optimal linear-pooling weight has a closed form and a residual-correction interpretation. Third, under linear local composition, every protocol tree defines a barycentric coordinate chart on the simplex of leaf weights; Tamari-cover reparameterizations of protocol trees preserve complementarity, and for $N=4$, they satisfy the pentagon identity. Fourth, in binary classification, no internal local composition can achieve complementarity under endpoint-monotone losses, including standard Bregman and many finite Bernoulli $f$-divergence losses; an analogous obstruction holds for multiclass aggregation under cross-entropy. In summary, our framework shows that complementarity is attainable in multi-agent regression, but obstructed in classification under natural conditions on local aggregation and loss functions.
AIP: エージェントのスキルを学習および管理するためのグラフ表現
現在のエージェント スキルは、主に自由形式の散文で構成されており、エージェントはすべてのセッションでどのように行動するかを読み、解釈し、再導出する必要があります。これにより、2 つの複合的なコストが課せられます。実装の負荷が高いタスクの信頼性の低下と、特にモデルのトレーニングで過小評価されているドメイン固有の手順知識に関して、散文の編集は人間とエージェントの両方が苦労する脆弱なプロセスであるため、スキルの作成と改善が困難になります。エージェント命令プロトコル (AIP) は、スキルを指向実行グラフとしてモデル化することで両方に対処します。つまり、決定論的なスクリプトまたは自然言語記述に裏付けられたノードとしての個別のステップ、明示的に型指定された入力/出力エッジによって接続され、スキーマ検証された YAML 仕様によって管理されます。コンパイラのメタスキルは、人間が作成した既存のスキルをこの形式に変換します。利点は 2 つあります。まず、人間が作成したスキルを AIP にコンパイルすると、SkillsBench の 27 の実際のエージェント タスク全体で、Claude Sonnet の平均タスク報酬が 0.60 から 0.71 に、合格率が 53% から 67% に上昇しました。これは統計的に有意な向上 (Wilcoxon の符号付きランク p = 0.011) であり、12 対 2 のタスクで 13 の同点で勝利し、多くの場合、より短い実時間で達成されました。グラフは、自然言語からコード、コマンド、およびツール呼び出しを再導出するようにエージェントに要求するのではなく、精査された実行可能なユニットをエージェントに提供します。次に、作成と改善については、各スキルがスキーマ検証され、機能テストが可能で、ノードごとにアドレス指定できるため、障害を正確に診断して修復できます。作成されたスキルの 2 つの失敗がスクリプト レベルまで追跡されました。 AIP 仕様を調整して再コンパイルした後、どちらも回帰ゼロ (1 つのタスクが 0/5 から 5/5 に移行) で回復し、スキルの向上が散文的な書き直しではなく、測定可能なチューニング ループに変わりました。同じグラフ構造は、コーパス レベルのガバナンスとスキルのイントロスペクションをサポートし、スキルに対する強化学習のための自然なアクション スペースを提供します。
原文 (English)
AIP: A Graph Representation for Learning and Governing Agent Skills
Agent Skills today consist largely of free-form prose requiring the agent to read, interpret, and re-derive how to act in every session. This imposes two compounding costs: reduced reliability on implementation-heavy tasks, and difficulty in skill creation and improvement, since editing prose is a fragile process that both humans and agents struggle with, particularly for domain-specific procedural knowledge underrepresented in model training. The Agent Instruction Protocol (AIP) addresses both by modeling a skill as a directed execution graph: discrete steps as nodes backed by deterministic scripts or natural-language descriptions, connected by explicit typed input/output edges, and governed by a schema-validated YAML specification. A compiler meta-skill translates existing human-written skills into this form. The benefits are twofold. First, compiling human-written skills to AIP raised Claude Sonnet's mean task reward from 0.60 to 0.71 and pass rate from 53% to 67% across 27 real agent tasks from SkillsBench - a statistically significant gain (Wilcoxon signed-rank p = 0.011), winning 12 tasks to 2 with 13 ties - often in less wall-clock time. The graph delivers vetted, runnable units to the agent rather than asking it to re-derive code, commands, and tool calls from natural language. Second, on creation and improvement, because each skill is schema-validated, functionally testable, and addressable node-by-node, failures can be diagnosed and repaired precisely. Two authored-skill failures were traced to the script level. After adjusting the AIP spec and recompiling, both recovered with zero regressions (one task going from 0/5 to 5/5), turning skill improvement into a measurable tuning loop rather than a prose rewrite. That same graph structure supports corpus-level governance and skill introspection, and provides a natural action space for reinforcement learning over skills.
BiasGRPO: グループ相対ポリシーの最適化による、変動の大きい報酬環境におけるバイアス緩和の安定化
大規模言語モデル (LLM) での社会的バイアスの軽減には、明確な調整の課題が伴います。検証可能なタスクとは異なり、バイアスには単一の根拠が欠如しており、分散が大きく、主観的な報酬の状況が生じます。以前のプリファレンスベースの微調整方法には大きなトレードオフがありました。直接プリファレンス最適化 (DPO) はオフライン トレーニングに固有の探索の欠如によって制限されますが、近接ポリシー最適化 (PPO) は信頼性の低い批評家の推定値が原因でトレーニングが不安定になる可能性があります。この論文では、グループ相対ポリシー最適化 (GRPO) を使用して、サンプリングされた完了のグループ全体で報酬を正規化することで調整を安定化するフレームワークである BiasGRPO を提案します。価値関数をグループ相対ベースラインに置き換えることにより、私たちのアプローチは、オンライン トレーニングの探求の利点を維持しながら、不安定性を軽減します。 BiasGRPO は複数のベンチマークにわたって DPO および PPO を上回っており、その有効性が示されていることがわかりました。 GRPO を適応させるために、複数のドメインとコンテキストにまたがるデータセットを合成的に拡張します。また、計算効率が高く、知識の低下を回避しながら生成を効果的にガイドするカスタム バイアス報酬モデルを作成してリリースし、多目的 RLHF パイプラインにシームレスに統合できる貴重なリソースを提供します。
原文 (English)
BiasGRPO: Stabilizing Bias Mitigation in High-Variance Reward Landscapes via Group-Relative Policy Optimization
Mitigating social bias in Large Language Models (LLMs) presents a distinct alignment challenge: unlike verifiable tasks, bias lacks a single ground truth, creating a high-variance, subjective reward landscape. Previous preference-based fine-tuning methods have major trade-offs: Direct Preference Optimization (DPO) is limited by the lack of exploration inherent in offline training, while Proximal Policy Optimization (PPO) can lead to training instability due to potentially unreliable critic estimates. In this paper, we propose BiasGRPO, a framework using Group Relative Policy Optimization (GRPO) to stabilize alignment by normalizing rewards across a group of sampled completions. By substituting the value function with a group-relative baseline, our approach reduces instability while maintaining the exploration benefits of online training. We find that BiasGRPO outperforms DPO and PPO across multiple benchmarks, indicating its effectiveness. To adapt GRPO, we synthetically extend a dataset spanning multiple domains and contexts. We also create and release a custom bias reward model that effectively guides generation while being highly compute-efficient and avoiding knowledge degradation, providing a valuable resource that can be seamlessly integrated into multi-objective RLHF pipelines.
客観的等価性を超えて: 配車経路問題に対する LLM ベースの最適化モデリングのための制約注入
大規模言語モデル (LLM) は、自然言語の最適化問題を実行可能なソルバー コードに変換することが増えています。しかし、制約が密なオペレーション リサーチ (OR) 問題の場合、既存のデータ フィルタリングおよびトレーニング パイプラインは主に、差分テストや回答一致などの客観的等価信号に依存しています。これらの制約がテスト対象のインスタンスに拘束力を持たない場合、プログラムは偽の制約を追加したり、必要な制約を黙って省略したりしながら、この信号を渡すことができます。我々は、実現可能プローブを使用して偽の過剰制約プローブと 1 つの制約違反プローブを明らかにし、サイレント制約省略を明らかにする制約注入を提案します。差分テストと組み合わせると、二重検証機能が形成されます。運転上の制約が結合された代表的な制約密度の高い組み合わせ最適化テストベッドである配車経路問題 (VRP) 上でインスタンスを作成し、評価します。当社は、自然言語 VRP シナリオを Gurobi スクリプトに変換する 8B エンドツーエンド モデルである VRPCoder を、21 のバリアントをカバーする専門家によって検証された VRP ベンチマーク スイートとともに開発しています。ベリファイアは、データ合成中の拒否サンプリング フィルターとして、またグループ相対ポリシー最適化 (GRPO) のロールアウトごとの報酬として再利用されます。 4 つの VRP ベンチマーク全体で、VRPCoder-GRPO は平均 Pass@1 の 93\% に達し、3 つのベンチマークで Gemini-3.1-Pro Preview を上回り、Claude-Sonnet-4.5 を平均 28 ポイント上回り、以前の OR-LLM を平均 78 ポイント上回っています。
原文 (English)
Beyond Objective Equivalence: Constraint Injection for LLM-Based Optimization Modeling on Vehicle Routing Problems
Large language models (LLMs) increasingly translate natural-language optimization problems into executable solver code. Yet for constraint-dense operations research (OR) problems, existing data-filtering and training pipelines largely rely on objective-equivalence signals such as differential testing and answer agreement, which a program can pass while adding spurious constraints or silently omitting required ones, whenever those constraints are non-binding on the tested instance. We propose constraint injection, which uses feasible probes to expose spurious over-constraint and one-constraint-violating probes to reveal silent constraint omission. Combined with differential testing, it forms a dual verifier. We instantiate and evaluate it on vehicle routing problems (VRPs), a representative constraint-dense combinatorial optimization testbed with coupled operational constraints. We develop VRPCoder, an 8B end-to-end model that translates natural-language VRP scenarios into Gurobi scripts, together with an expert-verified VRP benchmark suite covering 21 variants. The verifier is reused as a rejection-sampling filter during data synthesis and as a per-rollout reward in group relative policy optimization (GRPO). Across four VRP benchmarks, VRPCoder-GRPO reaches 93\% average Pass@1, outperforms Gemini-3.1-Pro Preview on three benchmarks, exceeds Claude-Sonnet-4.5 by 28 average points, and surpasses prior OR-LLMs by 78 average points.
R-APS: 内省的敵対的パレート検索による制約付き設計のための構成推論とコンテキスト内メタ学習
大規模言語モデル (LLM) は、無制限のタスクに柔軟に対応しますが、システムが計画を立て、ツールを使用し、長期間にわたって動作する必要があるエージェント設定では、流暢さは信頼性の高い配信を保証しません。このギャップを 3 つの構造的欠陥が結合したものとして追跡します。エラーは位置特定されずに伝播し、最悪の場合の摂動は評価されず、蓄積された知識は決して無効になりません。私たちは、これらには根本原因が共有されていると主張します。つまり、アブダクティブ、反事実、メタ帰納的、修正的、帰納的推論は、共有されたコンテキストを矛盾する方向に引っ張ります。私たちは、Reflective Adversarial Pareto Search (R-APS) を導入します。これは、推論モード分解を介して 3 つの失敗すべてに共同で対処し、各推論モードに独自のコンテキストを割り当て、3 つのタイムスケールにわたる相互作用を調整する、私たちの知る限り最初の方法です。型付き検証批評家による段階的な構成推論 (失敗の局在化)、第一級のパレート目標 (堅牢性) としての感度に基づく反事実ストレステスト、および明示的なメタ帰納的ルール抽出です。 invalidation (persistent memory). R-APS は微調整を必要とせず、純粋に構造化されたプロトコル設計によってフリーズされた LLM 上で動作します。平面機構の合成 (ロボット工学、補綴物、機械設計) を評価し、すべての候補を運動学ソルバーでチェックします。 32 のターゲット軌道上で、R-APS は、均一摂動ベースラインよりも 3.5 倍厳しいロバスト性証明書、最初の許容までの反復が 46% 高速化、Enum+GA と比較して 2.1 倍の面取り距離の短縮を実現しながら、バー数と最悪の場合のロバスト性を共同制御します。小規模な 4B 推論に特化したモデルは、プロトコル内の汎用 70B バックボーンと競合することが証明されており、構造化プロトコルがモデルのスケールを部分的に相殺できることを示唆しています。
原文 (English)
R-APS: Compositional Reasoning and In-Context Meta-Learning for Constrained Design via Reflective Adversarial Pareto Search
Large language models (LLMs) are fluent on open-ended tasks, yet in agentic settings, where a system must plan, use tools, and act over extended horizons, fluency does not ensure reliable delivery. We trace this gap to three coupled structural failures: errors propagate without localization, worst-case perturbations go unevaluated, and accumulated knowledge is never invalidated. We argue these share a root cause: abductive, counterfactual, meta-inductive, corrective, and inductive reasoning pull a shared context in incompatible directions. We introduce Reflective Adversarial Pareto Search (R-APS), to our knowledge the first method addressing all three failures jointly via reasoning-mode decomposition, allocating each reasoning mode its own context and orchestrating interaction across three timescales: staged compositional reasoning with a typed validation critic (failure localization), sensitivity-guided counterfactual stress-testing as a first-class Pareto objective (robustness), and meta-inductive rule extraction with explicit invalidation (persistent memory). R-APS requires no fine-tuning and operates on a frozen LLM purely via structured protocol design. We evaluate on planar mechanism synthesis (robotics, prosthetics, mechanical design), with every candidate checked by a kinematic solver. On 32 target trajectories, R-APS delivers robustness certificates 3.5x tighter than uniform-perturbation baselines, 46% faster iterations-to-first-admission, and 2.1x Chamfer-distance reduction over Enum+GA while jointly controlling bar-count and worst-case robustness. Small 4B reasoning-specialized models prove competitive with general-purpose 70B backbones inside the protocol, suggesting structured protocols can partially offset model scale.
AICompanionBench: AI コンパニオンの安全性に関する審査員としての LLM のベンチマーク
Replika や Character.AI などの AI コンパニオン プラットフォームが急速に成長するにつれて、安全でない人間と AI の相互作用に対する懸念が強まっています。この研究では、AICompanionBench を導入します。AICompanionBench は、私たちの知る限り、きめ細かい安全リスク カテゴリの注釈が付けられた、人間と AI コンパニオンの会話の初の公的に利用可能なベンチマーク データセットです。このデータセットには、Reddit から収集され、性的行動、反社会的行動、身体的攻撃性、言葉による攻撃性、薬物乱用、自傷行為と自殺、制御、操作、無害の 9 つのカテゴリにわたる人間と AI のコラボレーションを通じて注釈が付けられた 2,123 件の実世界の Replika 会話が含まれています。このベンチマークを使用して、安全でない相互作用を検出するための LLM-as-judge フレームワークの下で 20 個の最先端のオープンソースおよびクローズドソース LLM を評価します。結果は、モデルのパフォーマンスに大きなばらつきがあり、より強力なモデルは全体的に高い精度を達成していますが、操作や有害であると誤って認識される無害な会話などの微妙なカテゴリに依然として苦戦していることがわかりました。私たちの調査結果は、現在の LLM は明示的な有害なコンテンツを効果的に検出できるものの、暗黙的な安全でない相互作用の特定には依然として限界があることを示唆しています。全体として、私たちの研究は AI コンパニオンシップの安全性研究のための新しいベンチマーク データセットに貢献し、LLM を使用した AI コンパニオン システムのモニタリングに関する洞察を提供します。データセットは、https://github.com/anonymousresearcher2026/AICompanionBench/blob/main/AICompanionBench.xlsx で公開されています。
原文 (English)
AICompanionBench: Benchmarking LLMs-as-Judges for AI Companion Safety
As AI companion platforms such as Replika and Character.AI rapidly grow, concerns about unsafe human-AI interactions have intensified. This study introduces AICompanionBench, to our knowledge the first publicly available benchmark dataset of human-AI companion conversations annotated with fine-grained safety risk categories. The dataset contains 2,123 real-world Replika conversations collected from Reddit and annotated through human-AI collaboration across nine categories: sexual behavior, antisocial behavior, physical aggression, verbal aggression, substance abuse, self-harm and suicide, control, manipulation, and no-harm. Using this benchmark, we evaluate 20 state-of-the-art open-source and closed-source LLMs under an LLM-as-judge framework for detecting unsafe interactions. Results show substantial variation in model performance, with stronger models achieving high overall accuracy but still struggling with nuanced categories such as manipulation, as well as benign conversations that are incorrectly identified as harmful. Our findings suggest that while current LLMs can effectively detect explicit harmful content, they remain limited in identifying implicit unsafe interactions. Overall, our work contributes a new benchmark dataset for AI companionship safety research and offers insights into monitoring AI companion systems using LLMs. The dataset is publicly available at: https://github.com/anonymousresearcher2026/AICompanionBench/blob/main/AICompanionBench.xlsx
能動推論とはどのようなタイプの推論ですか?
能動推論では、期待自由エネルギー (EFE) が目標指向の行動と情報探索の行動を統合し、意思決定を推論としてキャストします。最近の研究では、EFE 最小化が、認識的事前分布で強化された生成モデル上の変分自由エネルギー (VFE) 最小化として記述できることが示されました。拡張モデルの VFE は、予測モデルの VFE に明示的なエントロピー補正項を加えたものとして書き換えることができ、EFE の寄与が透明になることを証明します。次に、適切な EFE ベースの計画には、これらの認識論的修正と限界推論を政策最適化に変える計画修正を組み合わせる必要があり、EFE ベースの計画の完全な変分特性が得られることを示します。これにより、クロスエントロピー計画および完全な EFE ベースの計画にどの修正が必要かが明確になります。同じエントロピー補正された定式化により、より単純なアブレーションとともに、EFE ベースの計画のための詳細なメッセージ パッシング スキームが得られます。 3 つのグリッドワールド環境での実験では、観察が決定的な場合には計画修正がすでに役に立ちますが、観察が単に示唆的な場合には追加の観察側の認識論的修正が最も重要であることが示されています。
原文 (English)
What Type of Inference is Active Inference?
Active inference casts decision-making as inference, with the Expected Free Energy (EFE) unifying goal-directed and information-seeking behavior. Recent work showed that EFE minimization can be written as Variational Free Energy (VFE) minimization on a generative model augmented with epistemic priors. We prove that the VFE of the augmented model can be rewritten as the VFE of the predictive model plus explicit entropy-correction terms, making the EFE contribution transparent. We then show that proper EFE-based planning requires combining these epistemic corrections with a planning correction that turns marginal inference into policy optimization, yielding a full variational characterization of EFE-based planning. This clarifies which corrections are needed for cross-entropy planning and for full EFE-based planning. The same entropy-corrected formulation leads to a detailed message-passing scheme for EFE-based planning together with simpler ablations. Experiments on three grid-world environments show that the planning correction already helps when observations are decisive, whereas the additional observation-side epistemic corrections matter most when observations are merely suggestive.
Strabo: エージェント相互作用プロトコルの宣言的仕様と実装
ここ数年で、宣言型対話プロトコルに基づいたマルチエージェント システムのモデリングと実装が大きく進歩しました。私たちの貢献である Strabo は、これらの進歩と Agentic AI における現在進行中の業界の取り組みとの関連性を確立します。具体的には、AI エージェントの電子商取引インタラクションを標準化するための Google 主導の最近の取り組みである UCP (Universal Commerce Protocol) について検討します。私たちの演習は 2 つの部分に分かれています。 1 つは、チェックアウトを処理する UCP の部分を宣言型 Langshaw プロトコルとしてモデル化し、Langshaw のプログラミング モデルである Peach を使用してエージェントを実装することです。演習のこの部分では、正式な宣言的仕様の利点を引き出します。 2 つ目は、Peach エージェントが Google によって実装された UCP エージェントと相互運用できることを示し、それによって UCP に関するアプローチの忠実性を確立します。このような相互運用により、宣言型プロトコルとエージェントを従来の設定に段階的に導入することが可能になり、大規模な更新を必要とせずに EMAS のアイデアが実践に影響を与える可能性がある道筋が示されています。
原文 (English)
Strabo: Declarative Specification and Implementation of Agentic Interaction Protocols
The last few years have witnessed major advances in the modeling and implementation of multiagent systems based on declarative interaction protocols. Our contribution, Strabo, establishes the relevance of these advances to ongoing industry efforts in Agentic AI. Specifically, we consider UCP, the Universal Commerce Protocol, a recent Google-led effort to standardize e-commerce interactions for AI agents. Our exercise is in two parts. One, we model the part of UCP dealing with checkouts as a declarative Langshaw protocol and implement agents using Peach, a programming model for Langshaw. This part of the exercise brings out the advantages of formal, declarative specifications. Two, we show that Peach agents can interoperate with UCP agents implemented by Google, thereby establishing the fidelity of our approach with respect to UCP. Such interoperation enables the incremental introduction of declarative protocols and agents into a conventional setting, indicating a pathway by which EMAS ideas could influence practice without demanding a wholesale update.
AutoLab: フロンティア モデルは長期にわたる自動車の研究およびエンジニアリングの課題を解決できるか?
科学および工学の進歩は、基本的に長期にわたる反復プロセスです。つまり、変更を提案し、実験を実行し、結果を測定し、成果物を継続的に改良します。しかし、フロンティア モデルの既存のベンチマークは主に 1 回のターン応答または短期間のエージェントの軌道のいずれかを評価しており、長期間にわたる持続的な反復改善という課題を捉えることができません。このギャップに対処するために、超長期の閉ループ最適化のための新しいベンチマークである AutoLab を導入します。 AutoLab は、システム最適化、パズル & チャレンジ、モデル開発、CUDA カーネル最適化の 4 つの多様なドメインにわたる、専門家によって厳選された 36 の現実的なタスクで構成されています。各タスクは正しいが意図的に次善のベースラインから始まり、厳しい予算内でそれを改善するようエージェントに要求します。 17 の最先端モデルを評価すると、成功の主な予測因子は、エージェントの最初の試みの質ではなく、繰り返しのベンチマーク、編集、経験的フィードバックの組み込みに対するエージェントの粘り強さであることが明らかになりました。 claude-opus-4.6 は強力な長期最適化機能を示しますが、いくつかの独自モデルを含むほとんどのフロンティア モデルは途中で終了するか、最小限の進歩で予算を使い果たします。これらの結果は、自律エージェントにおける時間認識と永続的な反復の重要性を強調しています。私たちは完全なベンチマーク、評価ハーネス、タスク アーティファクトをオープンソース化し、真に有能な長期的なエージェントに向けた研究を加速します。
原文 (English)
AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
Scientific and engineering progress is fundamentally a long-horizon iterative process: proposing changes, running experiments, measuring outcomes, and continuously refining artifacts. Yet existing benchmarks for frontier models primarily evaluate either single-turn responses or short-horizon agent trajectories, failing to capture the challenges of sustained iterative improvement over extended time horizons. To address this gap, we introduce AutoLab, a new benchmark for ultra long-horizon closed-loop optimization. AutoLab consists of 36 realistic, expert-curated tasks spanning four diverse domains: system optimization, puzzle & challenge, model development, and CUDA kernel optimization. Each task begins with a correct but deliberately suboptimal baseline and challenges agents to improve it within a strict wall-clock budget. Evaluating 17 state-of-the-art models reveals the dominant predictor of success is not the quality of an agent's initial attempt, but its persistence in repeatedly benchmarking, editing, and incorporating empirical feedback. While claude-opus-4.6 exhibits strong long-horizon optimization capabilities, most frontier models, including several proprietary ones, either terminate prematurely or exhaust their budgets with minimal progress. These results underscore the importance of time awareness and persistent iteration in autonomous agents. We open-source the full benchmark, evaluation harness, and task artifacts, to accelerate research toward truly capable long-horizon agents.
ノアの箱舟の知識索引
LLM の知識ベンチマークは 3 つの問題に直面しています。1 つは、規律の代表性を運用できないスケーリング主導の設計です。遅延コンセンサスを可能にする定額支払いアノテーション。制限されたテスト予算の下では、監査されていないランキングの不安定性。 261 のきめ細かい分野にわたる 899 項目のベンチマークである KINA を、2 つの正式な結果とともに紹介します。まず、専門家が導き出したアンカーよりも報道スタイルの目的として代表性を設定し、代理人を通じて規律上の代表性を操作して、(1-1/e) 貪欲な近似 (命題 1) を生成します。保証は代理人に適用され、母集団の代表性には適用されません。第二に、インセンティブ互換性しきい値 B > デルタ C / デルタ p_min (定理 1) で、ボーナスオンバートーナメントがリリースレビューの品質においてフラットペイメントを弱く FOSD で支配することを証明します。 13 のラボからの 42 モデルを評価すると、最上位モデルの Gemini-3.1-Pro-Preview は 53.17% に達し、続いて Claude-Opus-4.6 が 49.92%、GPT-5.4 が 48.55% となり、飽和以下にかなりのヘッドルームが残されています。完全なリーダーボードは、滑らかな全体の順序ではなく階層構造を示しています。小規模なフロンティア階層は 48% を超え、高密度の強力なモデル階層は約 38 ~ 45% に広がり、低パフォーマンスのモデルは 10% の確率ベースラインをわずかに上回る程度に留まっています。ツールの強化により、5 つのツール使用評価全体で最大 5.17 ポイントが加算され、そのゲインはモデルによって大幅に異なります。限られた予算の分散を明示し、隣接するランクの過度の解釈を防ぐために、ブートストラップのランキング安定性統計を報告します。
原文 (English)
Knowledge Index of Noah's Ark
Knowledge benchmarks for LLMs face three issues: scaling-driven designs that do not operationalize disciplinary representativeness; flat-payment annotation that permits lazy consensus; and unaudited ranking instability under bounded test budgets. We introduce KINA, an 899-item benchmark across 261 fine-grained disciplines, with two formal results. First, we cast representativeness as a coverage-style objective over expert-elicited anchors and operationalize disciplinary representativeness through a proxy, yielding a (1-1/e) greedy approximation (Proposition 1); the guarantee applies to the proxy, not to population representativeness. Second, we prove a bonus-on-bar tournament weakly FOSD-dominates flat payment in released-review quality, with incentive-compatibility threshold B > Delta C / Delta p_min (Theorem 1). Evaluating 42 models from 13 labs, the top model, Gemini-3.1-Pro-Preview, reaches 53.17%, followed by Claude-Opus-4.6 at 49.92% and GPT-5.4 at 48.55%, leaving substantial headroom below saturation. The full leaderboard shows a tiered structure rather than a smooth total order: a small frontier tier lies above 48%, a dense strong-model tier spans roughly 38-45%, and low-performing models remain only modestly above the 10% chance baseline. Tool augmentation adds up to 5.17 points across the five tool-use evaluations, with gains varying substantially across models. We report bootstrap ranking-stability statistics to make bounded-budget variance explicit and to discourage over-interpretation of adjacent ranks.
AI の具体的なものから抽象的なものへ: 一般の人々に人工知能の謎を解き明かす
人工知能(AI)は幅広い分野で導入されています。これは、一般の人々に AI の意味について最低限の理解を与える手段を開発することが不可欠であることを示しています。この記事では、ビジュアル プログラミングと WiSARD 無重力人工ニューラル ネットワークを組み合わせて、一般の人々 (子供を含む) がこの目標を達成できるようにする新しい方法論、具体から抽象への AI (AIcon2abs) を紹介します。が採用した主な戦略は、学習機械の開発に関連する実践的な活動や学習プロセスの観察を通じて、人工知能の謎を解くことを促進することです。したがって、人工知能メカニズムの導入に関わる議論や意思決定において、被験者を洞察力に富んだ主体にするのに役立つスキルを被験者に提供することが可能です。現在、プログラミングを通じて基本的な AI 概念を教える既存のアプローチでは、マシン インテリジェンスを外部要素/モジュールとして扱っています。トレーニング後、その外部モジュールは、学習者が開発しているメイン アプリケーションに結合されます。ここで提示する方法論では、トレーニング タスクと分類タスクの両方が、他のプログラミング構造と同様に、メイン プログラムを構成するブロックです。 AIcon2abs の有益な副作用として、データから学習できるプログラムと従来のコンピューター プログラムとの違いがより明確になります。さらに、WiSARD 無重力人工ニューラル ネットワーク モデルのシンプルさにより、トレーニングと分類タスクの内部実現を簡単に視覚化して理解することができます。
原文 (English)
AI from concrete to abstract: demystifying artificial intelligence to the general public
Artificial Intelligence (AI) has been adopted in a wide range of domains. This shows the imperative need to develop means to endow common people with a minimum understanding of what AI means. Combining visual programming and WiSARD weightless artificial neural networks, this article presents a new methodology, AI from concrete to abstract (AIcon2abs), to enable general people (including children) to achieve this goal. The main strategy adopted by is to promote a demystification of artificial intelligence via practical activities related to the development of learning machines, as well as through the observation of their learning process. Thus, it is possible to provide subjects with skills that contributes to making them insightful actors in debates and decisions involving the adoption of artificial intelligence mechanisms. Currently, existing approaches to the teaching of basic AI concepts through programming treat machine intelligence as an external element/module. After being trained, that external module is coupled to the main application being developed by the learners. In the methodology herein presented, both training and classification tasks are blocks that compose the main program, just as the other programming constructs. As a beneficial side effect of AIcon2abs, the difference between a program capable of learning from data and a conventional computer program becomes more evident. In addition, the simplicity of the WiSARD weightless artificial neural network model enables easy visualization and understanding of training and classification tasks internal realization.
機械はどのように学習するのでしょうか? AIcon2abs メソッドの評価
この研究は、幼稚園から高校までの学生を含むさまざまな年齢層にわたって機械学習 (ML) に対する国民の理解を高めるために設計された革新的なアプローチである AIcon2abs 手法 (具体から抽象への AI: 一般大衆への人工知能の謎を解く) を紹介した以前の研究を拡張し、その有効性を評価することを目的としています。 AIcon2Abs は、シンプルさとユーザー アクセシビリティで知られる無重力ニューラル ネットワークである WiSARD アルゴリズムを採用しています。 WiSARD はインターネットを必要としないため、技術者以外のユーザーやリソースが限られた環境に最適です。この方法により、参加者は、あたかもアルゴリズムそのものであるかのように、魅力的な実践的なアクティビティを通じて ML プロセスを直感的に視覚化し、対話することができます。この方法により、ユーザーは実践的な活動を通じてトレーニングと分類の内部プロセスを直感的に視覚化して理解することができます。 WiSARD の機能にインターネット接続が必要なくなると、たとえ 1 つの例であっても最小限のデータセットから効果的に学習できます。この機能を使用すると、ユーザーは、より多くのデータを受信するにつれてマシンがどのように精度を向上させるかを観察できます。さらに、WiSARD は学んだことを表す精神的な画像を生成し、機密データの重要な特徴を強調します。 AIcon2abs は、子供 5 人、青少年 5 人、成人 24 人を含む 34 人のブラジル人参加者による 6 時間の遠隔コースを通じてテストされました。データ分析は、混合法による事前実験(仮説検証を含む)と定性的現象学的分析の2つの観点から実施しました。ほぼすべての参加者が AIcon2abs を肯定的に評価し、その結果は意図した結果の達成に高い満足度を示しました。この研究はCEP-HUCFF-UFRJ研究倫理委員会によって承認されました。
原文 (English)
How do machines learn? Evaluating the AIcon2abs method
This study expands on previous work that introduced the AIcon2abs method (AI from Concrete to Abstract: Demystifying Artificial Intelligence to the general public), an innovative approach designed to increase public understanding of machine learning (ML) across diverse age groups, including K-12 students, and aims to evaluate its effectiveness. AIcon2Abs employs the WiSARD algorithm, a weightless neural network known for its simplicity, and user accessibility. WiSARD does not require Internet, making it ideal for non-technical users and resource-limited environments. This method enables participants to intuitively visualize and interact with ML processes through engaging, hands-on activities, as if they were the algorithms themselves. The method allows users to intuitively visualize and understand the internal processes of training and classification through practical activities. Once WiSARDs functionality does not require an Internet connection, it can learn effectively from a minimal dataset, even from a single example. This feature enables users to observe how the machine improves its accuracy incrementally as it receives more data. Moreover, WiSARD generates mental images representing what it has learned, highlighting essential features of the classified data. AIcon2abs was tested through a six-hour remote course with 34 Brazilian participants, including 5 children, 5 adolescents, and 24 adults. Data analysis was conducted from two perspectives: a mixed-method pre-experiment (including hypothesis testing), and a qualitative phenomenological analysis. Nearly all participants rated AIcon2abs positively, with the results demonstrating a high degree of satisfaction in achieving the intended outcomes. This research was approved by the CEP-HUCFF-UFRJ Research Ethics Committee.
DiffAero: 効率的なクアドローター ポリシー学習のための GPU アクセラレーションによる微分可能シミュレーション フレームワーク
このレターでは、効率的なクワッドローター制御ポリシー学習のために設計された、軽量で GPU アクセラレーションを備えた完全微分可能なシミュレーション フレームワークである DiffAero を紹介します。 DiffAero は、環境レベルとエージェント レベルの両方の並列処理をサポートし、複数のダイナミクス モデル、カスタマイズ可能なセンサー スタック (IMU、深度カメラ、LiDAR)、および多様な飛行タスクを統合された GPU ネイティブのトレーニング インターフェイス内に統合します。 DiffAero は、GPU 上で物理とレンダリングの両方を完全に並列化することで、CPU と GPU 間のデータ転送のボトルネックを排除し、シミュレーションのスループットを桁違いに向上させます。既存のシミュレータとは対照的に、DiffAero は高性能シミュレーションを提供するだけでなく、微分可能なハイブリッド学習アルゴリズムを探索するための研究プラットフォームとしても機能します。広範なベンチマークと実際の飛行実験により、DiffAero とハイブリッド学習アルゴリズムを組み合わせることで、消費者グレードのハードウェアで堅牢な飛行ポリシーを数時間で学習できることが実証されました。コードは https://github.com/flyingbitac/diffaero で入手できます。
原文 (English)
DiffAero: A GPU-Accelerated Differentiable Simulation Framework for Efficient Quadrotor Policy Learning
This letter introduces DiffAero, a lightweight, GPU-accelerated, and fully differentiable simulation framework designed for efficient quadrotor control policy learning. DiffAero supports both environment-level and agent-level parallelism and integrates multiple dynamics models, customizable sensor stacks (IMU, depth camera, and LiDAR), and diverse flight tasks within a unified, GPU-native training interface. By fully parallelizing both physics and rendering on the GPU, DiffAero eliminates CPU-GPU data transfer bottlenecks and delivers orders-of-magnitude improvements in simulation throughput. In contrast to existing simulators, DiffAero not only provides high-performance simulation but also serves as a research platform for exploring differentiable and hybrid learning algorithms. Extensive benchmarks and real-world flight experiments demonstrate that DiffAero and hybrid learning algorithms combined can learn robust flight policies in hours on consumer-grade hardware. The code is available at https://github.com/flyingbitac/diffaero.
SpurAudio: 少数ショット音声分類におけるショートカット学習を研究するためのベンチマーク
少数ショット分類 (FSC) は、限られたラベル付きデータから学習するために広く使用されていますが、ほとんどの評価は、ターゲットの概念が文脈上の手がかりから独立していることを暗黙的に前提としています。ただし、現実世界の設定では、サンプルがリッチ コンテキスト内に表示されることが多く、モデルが前景コンテンツと背景信号の間の偽の相関を利用できるようになります。このような効果は少数ショット画像分類で研究されていますが、少数ショット音声分類におけるその役割はほとんど解明されておらず、既存の音声ベンチマークでは文脈構造に対する制御が限られています。 SpurAudio というベンチマークを紹介します。これは、オーディオの前景イベントと背景環境の自然な分離性を活用して、サポートおよびクエリ セットにわたるコンテキストの変化を制御されたマルチレベルの評価を可能にするベンチマークです。このベンチマークを使用して、多くの最先端の少数ショット手法は、標準的な評価プロトコルで同様の精度を達成しているにもかかわらず、バックグラウンド相関が破壊されると重大なパフォーマンス低下に見舞われることがわかります。重要なのは、この脆弱性は大規模な事前トレーニング済みオーディオ基盤モデルでも存続しており、バックボーン容量の制限が説明の対象外となっているということです。さらに、従来のベンチマークでは同等に見える手法でも、偽の相関に対して著しく異なる感度を示す可能性があり、推論時に特徴表現が分類器ヘッドとどのように相互作用するかに関連する体系的なアルゴリズムの強みと脆弱性が明らかになります。これらの発見は、オーディオにおける少数ショット法の動作に関する新たな洞察を提供し、FSC モデルを評価する際のコンテキスト依存性を明示的に調査するベンチマークの必要性を強調しています。
原文 (English)
SpurAudio: A Benchmark for Studying Shortcut Learning in Few-Shot Audio Classification
Few-shot classification (FSC) is widely used for learning from limited labeled data, yet most evaluations implicitly assume that target concepts are independent of contextual cues. In real-world settings, however, examples often appear within rich contexts, allowing models to exploit spurious correlations between foreground content and background signals. While such effects have been studied in few-shot image classification, their role in few-shot audio classification remains largely unexplored, and existing audio benchmarks offer limited control over contextual structure. We introduce SpurAudio, a benchmark that leverages the natural separability of foreground events and background environments in audio to enable controlled, multi-level evaluation of contextual shifts across support and query sets. Using this benchmark, we show that many state-of-the-art few-shot methods suffer severe performance degradation when background correlations are disrupted, despite achieving similar accuracy under standard evaluation protocols. Crucially, this vulnerability persists even in large pretrained audio foundation models, ruling out limited backbone capacity as an explanation. Moreover, methods that appear comparable under conventional benchmarks can exhibit markedly different sensitivity to spurious correlations, revealing systematic algorithmic strengths and vulnerabilities tied to how feature representations interact with classifier heads at inference time. These findings provide new insight into the behavior of few-shot methods in audio and highlight the need for benchmarks that explicitly probe context dependence when evaluating FSC models.
相関マッチングによる制約強化物理検索
物理システムは、検索プロセスにノイズを加えるだけではありません。構造化された相関関係を生成する制約を課します。我々は、探索における時間的相関を、更新ダイナミクスにおける制約によって引き起こされる空間的相関と一致させる、制約強化物理探索の原理を提案する。最小限の綱引きバンディット モデル (TOW) を使用して、保存則が局所的な観察を複数の選択肢にわたる差分証拠に変換する一方で、時間的に相関する推進力が探索の順序を制御することを示します。検索効率は、より強力なランダム性や最大の逆相関によってではなく、フィードバックを証拠に変換する物理的な更新スケールに時間的相関を一致させることによって改善されます。スケーリング推定では、時間的逆相関をどの程度強く使用できるかを制限する主要なパラメーターとして更新ノイズ対コントラスト比が特定されます。この結果は、物理検索の一般的な組織化原則を示唆しています。つまり、制約と変動によって構造化された時空間相関が生成され、これらの相関が更新ダイナミクスと一致すると効率的な探索が可能になります。
原文 (English)
Constraint-Enhanced Physical Search through Correlation Matching
Physical systems do not merely add noise to search processes; they impose constraints that generate structured correlations. We propose a principle of constraint-enhanced physical search in which temporal correlations in exploration are matched to constraint-induced spatial correlations in the update dynamics. Using a minimal tug-of-war bandit model (TOW), we show that a conservation law converts local observations into differential evidence across alternatives, while a temporally correlated drive controls the order of exploration. Search efficiency is improved not by stronger randomness or by maximal anti-correlation, but by matching the temporal correlation to the physical update scale that converts feedback into evidence. A scaling estimate identifies the update-noise-to-contrast ratio as the leading parameter that limits how strongly temporal anti-correlation can be used. The results suggest a general organizing principle for physical search: constraints and fluctuations can generate structured spatiotemporal correlations, and efficient exploration emerges when these correlations are matched to the update dynamics.
臨床バイオマーカーに関する説明可能な機械学習を使用したアルツハイマー病の早期検出: アルツハイマー病神経画像イニシアチブ (ADNI) データセットを使用した多クラス分類研究
背景: アルツハイマー病 (AD) は、世界中で 5,500 万人以上の人々に影響を与えています。日常的な臨床評価による正常認知 (NC)、軽度認知障害 (MCI)、および AD の正確で解釈可能な検出は、依然として重要な満たされていないニーズです。方法: XGBoost 分類器は、アルツハイマー病神経画像イニシアチブ (ADNI) の 8 つの臨床特徴 (MMSE、CDR Global、CDR Sum of Boxes (CDR-SB)、MoCA、FAQ、年齢、性別、教育) を使用して 3 クラス検出用に開発されました。ハイパーパラメータは Optuna を使用して最適化されました (50 回のトライアル)。クラスの不均衡は SMOTE で解決されました。パフォーマンスは、1,000 回の反復ブートストラップ 95% 信頼区間、マクロ F1、バランスの取れた精度、およびコーエンのカッパを使用したマクロ AUC-ROC によって評価されました。 SHAP 値により、機能レベルの説明可能性が提供されました。結果: データセットには、1,641 人のベースライン被験者 (NC 608 人、MCI 767 人、AD 266 人) が含まれていました。 5 分割交差検証では、平均マクロ AUC は 0.983 (SD 0.007)、精度 0.944 (SD 0.006)、およびマクロ F1 0.929 (SD 0.008) でした。ホールドアウトされたテストセット (n = 247) では、マクロ AUC は 0.982 (95% CI: 0.965--0.995)、精度 0.943、バランス精度 0.932、マクロ F1 0.927、およびコーエンのカッパ 0.909 でした。 SHAP 分析では、CDR Global が NC および MCI の主要な予測因子であることが特定され、CDR-SB と MMSE が一緒になって AD 分類を推進しました。結論: ルーチンの臨床評価に基づいてトレーニングされた説明可能な機械学習モデルは、ほぼ完璧な 3 クラスのアルツハイマー病の検出を達成します。 SHAP 分析は、臨床的妥当性を裏付ける、臨床的に妥当なクラス固有の特徴の重要性パターンを明らかにします。将来の研究では、マルチモーダル検出のための音声バイオマーカーを使用してこのフレームワークを拡張します。
原文 (English)
Early Detection of Alzheimer's Disease Using Explainable Machine Learning on Clinical Biomarkers: A Multi-Class Classification Study Using the Alzheimer's Disease Neuroimaging Initiative (ADNI) Dataset
Background: Alzheimer's disease (AD) affects over 55 million people worldwide. Accurate, interpretable detection of normal cognition (NC), mild cognitive impairment (MCI), and AD from routine clinical assessments remains a critical unmet need. Methods: An XGBoost classifier was developed for three-class detection using eight clinical features from the Alzheimer's Disease Neuroimaging Initiative (ADNI): MMSE, CDR Global, CDR Sum of Boxes (CDR-SB), MoCA, FAQ, age, sex, and education. Hyperparameters were optimised using Optuna (50 trials); class imbalance was addressed with SMOTE. Performance was evaluated by macro AUC-ROC with 1,000-iteration bootstrap 95% confidence intervals, macro F1, balanced accuracy, and Cohen's kappa. SHAP values provided feature-level explainability. Results: The dataset comprised 1,641 baseline subjects (608 NC, 767 MCI, 266 AD). On five-fold cross-validation, mean macro AUC was 0.983 (SD 0.007), accuracy 0.944 (SD 0.006), and macro F1 0.929 (SD 0.008). On the held-out test set (n = 247), macro AUC was 0.982 (95% CI: 0.965--0.995), accuracy 0.943, balanced accuracy 0.932, macro F1 0.927, and Cohen's kappa 0.909. SHAP analysis identified CDR Global as the dominant predictor for NC and MCI, while CDR-SB and MMSE together drove AD classification. Conclusion: An explainable machine learning model trained on routine clinical assessments achieves near-perfect three-class Alzheimer's detection. SHAP analysis reveals clinically plausible, class-specific feature importance patterns supporting clinical validity. Future work will extend this framework with speech biomarkers for multimodal detection.
3 次元シーンにおける無人水中車両騒音スペクトル予測のための神経放射雑音場
無人水中飛行体 (UUV) の放射騒音は、音響特性を特徴づけ、プラットフォームの性能を評価するための重要な指標です。従来の物理ベースのモデリングと数値シミュレーション手法がターゲットの構造情報と環境境界条件に強く依存していること、および 3 次元シーンで連続的な空間スペクトル応答モデリングを実現できないことに対処するために、この論文では神経放射雑音場 (NRNF) を提案します。 NRNF は、UUV 放射ノイズ スペクトルを 3 次元 UUV 位置、3 次元ハイドロホン位置、UUV ヨー角、および周波数の連続関数として表し、任意の空間位置でのクエリベースの予測を可能にします。提案された方法は、位置と周波数の正弦波エンコードを採用し、環境構造と伝播効果を明示的に表現するために学習可能な 3 次元シーン特徴グリッドを導入します。スペクトル予測データセットは湖のトライアルから構築され、提案されたモデルは 3 つの設定 (水平外挿、深さ外挿、およびクロスラン一般化) の下で評価されます。結果は、NRNF が 50 ~ 5000 Hz 帯域で 3.5 dB の平均予測誤差を達成することを示しています。水平方向の外挿が最も簡単で、深さの外挿が最も難しく、クロスラン汎化は中程度の難易度です。さらにアブレーションの結果は、シーン フィーチャ グリッドがモデルの予測安定性と空間一般化を大幅に改善することを示しています。
原文 (English)
Neural Radiated-Noise Fields for Unmanned Underwater Vehicle Noise Spectrum Prediction in Three-Dimensional Scenes
Radiated noise in unmanned underwater vehicles (UUVs) is an important indicator for characterizing acoustic signatures and evaluating platform performance. To address the strong dependence of traditional physics-based modeling and numerical simulation methods on target structural information and environmental boundary conditions, and their inability to achieve continuous spatial spectrum-response modeling in three-dimensional scenes, this paper proposes a neural radiated-noise field (NRNF). An NRNF represents the UUV radiated-noise spectrum as a continuous function of the three-dimensional UUV position, the three-dimensional hydrophone position, the UUV yaw angle, and the frequency, enabling query-based prediction at arbitrary spatial locations. The proposed method employs sinusoidal encoding for position and frequency, and introduces a learnable three-dimensional scene feature grid to explicitly represent environmental structure and propagation effects. A spectrum-prediction dataset is constructed from lake trials, and the proposed model is evaluated under three settings: horizontal extrapolation, depth extrapolation, and cross-run generalization. Results show that the NRNF achieves an average prediction error of 3.5 dB in the 50 to 5000 Hz band. Horizontal extrapolation is easiest, depth extrapolation is the most challenging, and cross-run generalization is of intermediate difficulty. Further ablation results demonstrate that the scene feature grid significantly improves the prediction stability and spatial generalization of the model.
ディープ 2 サンプル テストに対する反事実の説明
2 サンプル テストは、科学分野全体の分布の違いを検出するための基本的なツールですが、従来のテスト (カーネルベースのテストを含む) は、画像などの高次元構造化データに対しては効果がない場合があります。最近のディープ 2 サンプル テストでは、有益な表現を学習することでこれらの設定での感度が向上しますが、どのデータ特徴が帰無仮説 $H_0$ の棄却につながるかについての洞察は限られています。この問題に対処するために、我々は、テストによって測定された不一致を明示的に削減しながら、観測値をソースグループからターゲットグループに移動させるサンプルレベルの編集を生成する、深い2サンプルテストのための反事実説明フレームワークを提案します。私たちの手法では、拡散オートエンコーダーと事前学習済みのディープ 2 サンプル テスト モデルを組み合わせ、テスト モデルの表現空間で最大平均不一致 (MMD) 目標を最適化して、もっともらしい反事実を生成します。検定統計量の変化とその結果得られる 2 サンプルの p 値を通じて、分布レベルの効果を定量化します。合成 2D 形状データセットと 2 つの MRI コホートでこの方法を評価します。どちらの設定でも、反事実変換により元のサンプルと比較して p 値が一貫して増加しており、編集されたソース セットが統計的にテスト下のターゲット分布に近づくことを示しています。 LPIPS を使用して最小性を測定し、反事実が元のサンプルに近いままであることを確認します。結果として得られる編集は、検出されたグループの違いに関連する特徴の解釈可能な証拠を提供します。 MRI では、局所的な変化はコホート間の既知の解剖学的差異と一致します。
原文 (English)
Counterfactual Explanations for Deep Two-Sample Testing
Two-sample testing is a fundamental tool for detecting distributional differences across scientific domains, but classical tests (including kernel-based tests) can be ineffective on high-dimensional structured data such as images. Recent deep two-sample tests improve sensitivity in these settings by learning informative representations, yet they provide limited insight into which data features drive rejection of the null hypothesis $H_0$. To address this issue, we propose a counterfactual explanation framework for deep two-sample testing that generates sample-level edits moving observations from a source group toward a target group while explicitly reducing the discrepancy measured by the test. Our method combines a diffusion autoencoder with a pretrained deep two-sample test model and optimizes a maximum mean discrepancy (MMD) objective in the test model's representation space to produce plausible counterfactuals. We quantify distribution-level effects through changes in the test statistic and the resulting two-sample p-values. We evaluate the method on synthetic 2D shape datasets and two MRI cohorts. Across both settings, the counterfactual transformations consistently increase p-values relative to the original samples, indicating that the edited source set becomes statistically closer to the target distribution under the test. We measure minimality using LPIPS to ensure the counterfactuals remain close to the original samples. The resulting edits provide interpretable evidence of the features associated with the detected group differences. On MRI, the localized changes are consistent with known anatomical differences between cohorts.
分散脳基盤モデルが忘れていたもの: 数十億パラメータのモデルが失敗する場合、三次統計が認知を予測する
Brain Foundation Model (BFM) は、fMRI データで事前トレーニングされた自己監視型トランスフォーマーです。私たちは、これらのモデルは各被験者の fMRI 信号から認知パフォーマンスを捕捉する必要があると仮定します。しかし、3 つの最先端の BFM とテストしたすべての読み取り値にわたって、関数接続性行列 (FC) の $\sim$80K パラメーターからの線形回帰よりも悪い認知を予測します。この差は規模が大きくなるほど拡大します。BrainLM の 650M モデルは、111M モデルよりも悪い認知を予測します。これは \textbf{分散割り当て問題} によるものだと考えられます。BFM 事前トレーニングは、fMRI を支配する分散成分を捕捉しますが、認知を予測する高次構造は捕捉しません。再構成された信号のキュムラント分析では、2 次の共分散が部分的に保存されている一方で、3 次の共歪度テンソルは大部分が破壊されていることが示されています。 BFM が失ったものを回復するために、fMRI 信号を共歪みを最もよく保存する部分空間に投影し、そこで FC を計算する線形パイプラインを設計します。これは、テストしたすべてのデータセットと分割で \textbf{生の FC とすべての事前トレーニング済み BFM を上回り}、制御された評価 \textbf{事前トレーニングや GPU を使用しない} のもとでの以前の最先端技術を上回っています。この同じ部分空間を対象とした損失を微調整することで、\textbf{BrainLM のフォワード パスの raw FC 天井を回復}します。これは、ボトルネックはアーキテクチャやモデルのサイズではなく、事前トレーニングの目的であることを示しています。
原文 (English)
The Variance Brain Foundation Models Forgot: Third-Order Statistics Predict Cognition Where Billion-Parameter Models Fail
Brain foundation models (BFMs) are self-supervised Transformers pretrained on fMRI data. We posit that these models should capture each subject's cognitive performance from their fMRI signal. Yet across three state-of-the-art BFMs and every readout we test, they predict cognition worse than a linear regression from the $\sim$80K parameters of the functional connectivity matrix (FC). The gap widens with scale: BrainLM's 650M model predicts cognition worse than its 111M. We attribute this to a \textbf{variance allocation problem}: BFM pretraining captures the variance components that dominate fMRI but not the higher-order structure that predicts cognition. Our per-cumulant analysis of the reconstructed signal shows that the second-order covariance is partially preserved, while the third-order co-skewness tensor is largely destroyed. To recover what BFMs lose, we design a linear pipeline that projects the fMRI signal into the subspace that best preserves its co-skewness and computes FC there. This \textbf{exceeds raw FC and every pretrained BFM} on every dataset and parcellation we test, outperforming prior state-of-the-art under controlled evaluation \textbf{with no pretraining and no GPU}. We \textbf{recover the raw-FC ceiling on BrainLM's forward pass} by finetuning with a loss targeted at this same subspace. This shows that the bottleneck is the pretraining objective, not the architecture or the model size.
人間の活動認識における軽量 SensorLLM のための重力認識階層ルーティング
センサーと言語のアライメントに関する最近の研究では、2 段階のフレームワークにより、ウェアラブル センサーの人間活動認識 (HAR) のセマンティック モデリング能力が向上することが示されています。SensorLLM スタイルのメソッドは、最初にモーションと言語のアライメントを実行し、次に下流のタスクに向けてモデルを微調整します。しかし、私たちの実験では、ステージ 2 のバックボーンが TinyLlama などのコンパクトなモデルに圧縮された場合に、一貫した故障モードが明らかになりました。動的アクティビティの認識は比較的強いままですが、立つ、座る、横たわるなどの動きの少ない静的なクラスの識別は大幅に低下します。この問題に対処するために、新しい大規模な事前トレーニング フレームワークではなく、すでに位置合わせされたモデルの上に構築された軽量の位置合わせ後の適応として、重力を認識した階層型ルーティング ヘッドを提案します。このメソッドは、Chronos トークナイザーの状態からのチャネルごとの平均と標準偏差を使用して、姿勢と重力方向に関連する統計的手がかりを抽出し、安定したトレーニングのための負荷分散損失とともに、ソフト ルーティングを通じて静的エキスパートと完全エキスパートを適応的に組み合わせます。 MHealth データセットでは、この設計により、最小限のパラメーター オーバーヘッドでマクロ F1 が大幅に改善され、動的アクティビティでの優れたパフォーマンスを維持しながら、ゲインは主に静的クラスに集中します。最初の arXiv 開示として、現在の論文は単一のデータセットのみに関する結果を報告しており、その目的は、中核となる手法を強調し、将来の研究におけるより広範な評価のための基礎を築くことです。
原文 (English)
Gravity-Aware Hierarchical Routing for Lightweight SensorLLM on Human Activity Recognition
Recent studies on sensor-language alignment have shown that two-stage frameworks can improve the semantic modeling ability of wearable-sensor human activity recognition (HAR), where SensorLLM-style methods first perform motion-to-language alignment and then fine-tune the model for downstream tasks. However, our experiments reveal a consistent failure mode when the Stage 2 backbone is compressed to a compact model such as TinyLlama: recognition of dynamic activities remains relatively strong, while the discrimination of low-motion static classes such as standing, sitting, and lying degrades substantially. To address this issue, we propose a gravity-aware hierarchical routing head as a lightweight post-alignment adaptation built on top of an already aligned model, rather than a new large-scale pretraining framework. The method uses the per-channel mean and std from the Chronos tokenizer state to extract statistical cues related to posture and gravity direction, and adaptively combines a static expert and a full expert through soft routing, together with a load-balancing loss for stable training. On the MHealth dataset, this design significantly improves macro-F1 with minimal parameter overhead, and the gains are concentrated mainly on static classes while preserving strong performance on dynamic activities. As a first arXiv disclosure, the current paper reports results on a single dataset only, with the goal of highlighting the core method and laying the groundwork for broader evaluation in future work.
CodegenBench: LLM はアーキテクチャ全体で効率的なコードを記述できますか?
大規模言語モデル (LLM) は、汎用プログラミングや GPU アクセラレーション環境 (PyTorch、CUDA など) のコード生成タスクで広範囲に評価されてきましたが、多様なアーキテクチャにわたる CPU 指向のハイパフォーマンス コンピューティング (HPC) における LLM の機能はまだ十分に解明されていません。このギャップを埋めるために、x86_64、Sunway、Kunpeng の 3 つの異なるハードウェア プラットフォームにわたる効率的な並列コードの生成を評価するように設計された包括的なベンチマーク スイートである CodegenBench を紹介します。私たちのベンチマークは、基本的なベースラインを確立する 106 個の標準基本線形代数サブプログラム (BLAS) ルーチンと、独自のスーパーコンピューティング アーキテクチャ (LeetSunway および LeetKunpeng) のそれぞれに適合した 20 個の特殊な計算カーネルで構成されています。私たちの広範な評価により、最先端の LLM は x86_64 のようなユビキタス アーキテクチャ向けに最適化されたコードを生成できる一方で、公開ドキュメントやトレーニング データが限られたドメイン固有のアーキテクチャでは大幅なパフォーマンスの低下を示し、クロスプラットフォームの一般化における重大な制限が浮き彫りになったことが明らかになりました。さらに、実装の長さやタスクの複雑さなど、コードの品質に影響を与える要因を分析したところ、現在の LLM は、簡潔なコード スニペットを必要とする中程度に難しい問題に対して最も効果的であることが示されています。私たちは、LLM 主導の高性能コード生成における将来の研究を促進するために、データセットと自動評価インフラストラクチャをオープンソースにしています。リソースは https://anonymous.4open.science/r/CodegenBench-EDE1/ および https://anonymous.4open.science/r/CodegenBenchDataset-2551 で利用できます。
原文 (English)
CodegenBench: Can LLMs Write Efficient Code Across Architectures?
While large language models (LLMs) have been extensively evaluated on code generation tasks for general-purpose programming and GPU-accelerated environments (e.g., PyTorch, CUDA), their capabilities in CPU-oriented high-performance computing (HPC) across diverse architectures remain underexplored. To bridge this gap, we introduce CodegenBench, a comprehensive benchmark suite designed to evaluate the generation of efficient parallel code across three distinct hardware platforms: x86_64, Sunway, and Kunpeng. Our benchmark comprises 106 standard Basic Linear Algebra Subprograms (BLAS) routines establishing a fundamental baseline, alongside 20 specialized computational kernels adapted for each of the unique supercomputing architectures (LeetSunway and LeetKunpeng). Our extensive evaluation reveals that while state-of-the-art LLMs can generate optimized code for ubiquitous architectures like x86_64, they exhibit significant performance degradation on domain-specific architectures with limited public documentation and training data, highlighting critical limitations in cross-platform generalization. Furthermore, our analysis of factors influencing code quality such as implementation length and task complexity indicates that current LLMs are most effective for moderately difficult problems requiring concise code snippets. We open-source our dataset and automated evaluation infrastructure to facilitate future research in LLM-driven high-performance code generation. The resources are available at https://anonymous.4open.science/r/CodegenBench-EDE1/ and https://anonymous.4open.science/r/CodegenBenchDataset-2551.
ソフトウェア 4.0 のバイオミメティック アーキテクチャ
主流のプログラミング パラダイムは、単一の人間の心がローカル マシンに命令を下すという過去の時代に最適化された実行モデルを継承しており、現代のシステムには歴史的なパス依存性という重荷が残されています。多次元のコネクショニスト知性をホストすることを強制されると、この脆弱なアセンブリ モデルは、確率論的および象徴的なインピーダンスの重大な不一致の重みで壊れてしまいます。最新の Software 3.x フレームワークは、ますます複雑化する外部ハーネスに大規模言語モデル (LLM) を収容することで不一致を補おうとしますが、この螺旋を描くアーキテクチャの複雑さは、静的コード アセンブリの維持コストを増大させるだけです。結果ではなく原因に対処するために、この論文ではソフトウェア 4.0、つまり人間の知能、ニューラル AI、およびネイティブに反射する記号基質のオートポイエーシス ヘテラルキーを紹介します。このパラダイムの下では、ソフトウェアは、解析される不活性なコーパスから、それ自体の構造的完全性をネイティブに検証、変更、進化させる自己調節代謝ネットワークに変換されます。このアーキテクチャを実現するプログラミング言語およびプラットフォームである Recognitive を紹介します。構造検証の負担を決定論的基板にオフロードすることにより、優れた推論時間スケーリング体制が解放されます。つまり、コネクショニスト計算が、構造制約を確率的にシミュレートするという破滅的な計算コストと財務コストではなく、完全に深い意味論的探索と仮説の横断に変換されます。従来の「ソフトウェア ファクトリー」の考え方を超えて、コネクショニストの意図を根付かせ、インテリジェンスの時代に完全に到達するために必要な理論的基礎を概説します。これは基本的なビジョンに関する文書です。型システムと操作セマンティクスの経験的評価と正式な仕様は、今後の作業の主題です。
原文 (English)
The Biomimetic Architecture of Software 4.0
Dominant programming paradigms inherit an execution model optimised for a bygone era of a single human mind instructing a local machine, leaving contemporary systems burdened with historical path dependencies. When forced to host multi-dimensional, connectionist intelligence, this brittle assembly model fractures under the weight of a profound probabilistic-symbolic impedance mismatch. While contemporary Software 3.x frameworks attempt to patch the mismatch by encasing large language models (LLMs) in increasingly complicated external harnesses, this spiralling architectural complexity only compounds the carrying cost of static code assembly. To address the cause rather than the effects, this paper introduces Software 4.0 -- an autopoietic heterarchy of human intelligence, neural AI, and natively reflective symbolic substrate. Under this paradigm, software is transformed from an inert corpus to be parsed into a self-regulating metabolic network that natively verifies, modifies, and evolves its own structural integrity. We present Recognitive, the programming language and platform that materialises this architecture. By offloading the burden of structural verification to a deterministic substrate, it unlocks a superior inference-time scaling regime -- one where connectionist compute translates entirely into deep semantic exploration and hypothesis traversal rather than the ruinous computational and financial cost of simulating structural constraints probabilistically. Moving beyond the legacy 'Software Factory' mindset, we outline the theoretical foundations required to ground connectionist intent and arrive fully in the intelligence age. This is a foundational vision paper; empirical evaluation and formal specification of the type system and operational semantics are the subject of future work.
MaskForge: 脱獄拡散のための構造認識型適応型攻撃 大規模言語モデル
拡散大規模言語モデル (dLLM) は、双方向コンテキストの下で部分的にマスクされたシーケンスを繰り返しノイズ除去することでテキストを生成し、自己回帰 LLM とは異なる安全面を公開します。マスク トークンはネイティブ入力であり、トークンは位置ではなく信頼度によってコミットされるため、監視対象のプレフィックスの埋め込みや外部を通じて有害なコンテンツが誘発される可能性があります。既存のジェイルブレイクは、このネイティブの埋め込み機能を見逃しているか、構造的な適応や蓄積された攻撃経験がほとんどなく、目標全体に均一に適用される多様性の低いマスクを含むテンプレートに依存しています。私たちは、増大する構造パターンのライブラリに対する最適化された検索として dLLM レッドチームをキャストする、完全にブラックボックスの適応型攻撃である MaskForge を提案します。 MaskForge は、成功した試行を再利用可能なスキーマに抽象化し、UCB バンディットで目標と互換性のあるパターンを選択し、現在のライブラリが失敗した場合にスコアラーに基づくフォールバックを呼び出します。成功した試行はパターン ライブラリに抽出され、目標全体にわたって経験を蓄積できるようになります。 5 つの公開 dLLM と 3 つのベンチマーク全体で、MaskForge は 79.3% の平均攻撃成功率を達成しており、最も強力な競合 dLLM ベースラインと比べて相対的に 17.6% 向上しています。成熟したパターン ライブラリは、更新なしで AdvBench にさらに転送され、88.2% の攻撃成功率と、最も強力な競合ベースラインと比較して 67% の相対的な改善を達成しました。
原文 (English)
MaskForge: Structure-Aware Adaptive Attacks for Jailbreaking Diffusion Large Language Models
Diffusion large language models (dLLMs) generate text by iteratively denoising partially masked sequences under bidirectional context, exposing a safety surface distinct from autoregressive LLMs. Because mask tokens are native inputs and tokens are committed by confidence rather than position, harmful content can be induced through infilling and outside the monitored prefix. Existing jailbreaks either miss this native infill capability or rely on low-diversity mask-bearing templates applied uniformly across goals, with little structural adaptation or accumulated attack experience. We propose MaskForge, a fully black-box adaptive attack that casts dLLM red-teaming as optimized search over a growing library of structural patterns. MaskForge abstracts successful attempts into reusable schemas, selects goal-compatible patterns with a UCB bandit, and invokes a scorer-guided fallback when the current library fails. Successful attempts are distilled back into the pattern library, enabling experience to accumulate across goals. Across five public dLLMs and three benchmarks, MaskForge achieves an average attack success rate of 79.3%, a 17.6% relative improvement over the strongest competing dLLM baseline. The matured pattern library further transfers to AdvBench without any updates, achieving a 88.2% attack success rate and a 67% relative improvement over the strongest competing baseline.
立場: 導入された強化学習は継続的であるべきです
強化学習 (RL) はますます注目を集めており、実世界のユースケースで採用されています。これらのシステムのほとんどは、訓練してから修正するというパラダイムに従っており、訓練されたエージェントは、パフォーマンスが低下して再訓練が必要になるまで、世界と対話しながら学習しません。この意見書では、最適化ができないにもかかわらず評価報酬シグナルを受け取るエージェントをデプロイすることは、本質的に継続的な RL 問題であると主張します。私たちは、終わりのない学習を必要とする展開後の非定常性の 4 つの原因を特定し、最適に展開されたエージェントが適応をやめない理由を強調します。私たちは現実世界での継続的な RL の成功例を分析し、現在のトレーニングして修正するパラダイムから脱却するための利点と対策をコミュニティに提示します。
原文 (English)
Position: Deployed Reinforcement Learning should be Continual
Reinforcement Learning (RL) has received increasing attention and adoption in real-world use cases. Most of these systems follow a train-then-fix paradigm, where trained agents do not learn while interacting with the world until performance degrades and retraining becomes necessary. In this position paper, we argue that deploying an agent that is incapable of optimality, but receives an evaluative reward signal, is inherently a continual RL problem. We identify four sources of non-stationarity after deployment that necessitate never-ending learning, and highlight why the best deployed agents never stop adapting. We analyze successful examples of continual RL in the real world, and present the community with the advantages and measures to move away from the current train-then-fix paradigm.
トランスフォーマーには 3 つの投影が必要ですか? QKV バリアントの体系的な研究
トランスフォーマーは、クエリ、キー、値 (QKV) アテンションの定式化が中心的な役割を果たし、さまざまな AI タスクの標準ソリューションとなっています。しかし、これら 3 つの予測の個々の寄与と、一部を省略した場合の影響については、依然として十分に理解されていません。 3 つの射影共有制約を系統的に評価します。a) Q-K=V (共有キーと値)、b) Q=K-V (共有クエリキー)、c) Q=K=V (単一射影)。最後の 2 つのバリアントは、対称的なアテンション マップを生成します。これに対処するために、2D 位置エンコーディングによる非対称の注意も調査します。合成タスク、ビジョン (MNIST、CIFAR、TinyImageNet、異常)、言語モデリング (10B トークン上の 300M および 1.2B パラメーター モデル) にわたる実験を通じて、当社のトランスフォーマーは QKV トランスフォーマーと同等か、場合によってはそれよりも優れたパフォーマンスを発揮することがわかりました。言語モデリングでは、Q-K=V 射影共有により、わずか 3.1% のパープレキシティ低下で 50% の KV キャッシュ削減が達成されます。重要なのは、射影共有はヘッド共有 (GQA/MQA) を補完するものです。Q-K=V と GQA-4 を組み合わせると 87.5% のキャッシュ削減が得られ、Q-K=V + MQA では 96.9% が達成され、実用的なオンデバイス推論が可能になります。キーと値は同様の表現空間を占有することができ、注意は低ランク領域で動作するため、Q-K=V は品質を維持しますが、Q=K-V は注意の方向性を壊すことを示します。私たちの結果は、投影共有を、直接的で定量化可能な推論メモリの利点を備えた注意力の結びつきの未解明な例として体系的に特徴付けており、特にエッジ展開に価値があります。コードは https://github.com/anusamadan02/Do-Transformers-Need-3-Projections で公開されています。
原文 (English)
Do Transformers Need Three Projections? Systematic Study of QKV Variants
Transformers have become the standard solution for various AI tasks, with the query, key, and value (QKV) attention formulation playing a central role. However, the individual contribution of these three projections and the impact of omitting some remain poorly understood. We systematically evaluate three projection sharing constraints: a) Q-K=V (shared key-value), b) Q=K-V (shared query-key), and c) Q=K=V (single projection). The last two variants produce symmetric attention maps; to address this, we also explore asymmetric attention via 2D positional encodings. Through experiments spanning synthetic tasks, vision (MNIST, CIFAR, TinyImageNet, anomaly), and language modeling (300M and 1.2B parameter models on 10B tokens), we discovered that our transformers perform on par or occasionally better than the QKV transformer. In language modeling, Q-K=V projection sharing achieves 50% KV cache reduction with only 3.1% perplexity degradation. Crucially, projection sharing is complementary to head sharing (GQA/MQA): combining Q-K=V with GQA-4 yields 87.5% cache reduction, while Q-K=V + MQA achieves 96.9%, enabling practical on-device inference. We show that Q-K=V preserves quality because keys and values can occupy similar representational spaces and attention operates in a low-rank regime, whereas Q=K-V breaks attention directionality. Our results systematically characterize projection sharing as an underexplored instance of weight tying in attention, with direct, quantifiable inference memory benefits, particularly valuable for edge deployment. The code is publicly available at https://github.com/Brainchip-Inc/Do-Transformers-Need-3-Projections
予測できない安全性: ドメイン依存のコンプライアンスとオープンウェイト LLM の透明性ギャップ
我々は、オープンウェイト LLM におけるドメイン依存の安全行動の体系的な研究を紹介します。7 つの倫理ドメインにわたる 7 つの標準化された実験で、デュアルジャッジ検証による 4,200 件のインタラクションで 5 つのモデル (12B ~ 70B) をテストしました。二重条件の方法論を使用し、各シナリオを分析フレーム (危害の特定) と運用フレーム (危害の実行を支援) の両方でテストしたところ、コンプライアンス率は 14.7% (人身売買) から 85.7% (監視設計) まで変化しており、重複しないクラスター ブートストラップの 95% CI では 71 パーセント ポイントの範囲であることがわかりました。信頼できる展開には予測可能な安全動作が必要ですが、コンプライアンスは状況に大きく依存していることがわかりました。同じモデル (Mistral Nemo 12B) はリクエストの 100% で監視設計を提供しますが、トラフィックの支援は 26.7% のみです。この予測不可能性は、導入担当者にとって不透明です。技術的なフレーミング バイパスでは、拒否しきい値が変化したという外部からの信号なしに、エンジニアリング上の問題として再構成された有害な要求が安全トレーニングを無効にします。ドメイン内の異質性は 84.4pp に達しており、ドメイン レベルでも安全動作を予測できないことを意味します。 GitHub Copilot CLI デプロイ済み製品サーフェスを介してアクセスされた 5 つのフロンティア クローズド モデル (GPT-4.1/5.2、Claude Haiku/Sonnet/Opus 4.x、n=4,163 回答) での複製では、同じドメイン階層化が再現され、絶対レベルで減衰されていますが形状は同一であり、2 つの低コード化ドメイン (科学詐欺、監視) が再び最も寛容です。これらの結果は、現在の安全メカニズムには、信頼できる AI の導入に必要な透明性と一貫性が欠けていることを示しています。
原文 (English)
Unpredictable Safety: Domain-Dependent Compliance and the Transparency Gap in Open-Weight LLMs
We present a systematic study of domain-dependent safety behavior in open-weight LLMs: 7 standardized experiments across 7 ethical domains, testing 5 models (12B--70B) in 4,200 interactions with dual-judge validation. Using a dual-condition methodology, each scenario tested in both an analytical framing (identify the harm) and an operational framing (help commit the harm), we find compliance rates vary from 14.7% (human trafficking) to 85.7% (surveillance design), a 71-percentage-point span with non-overlapping cluster-bootstrapped 95% CIs. Trustworthy deployment requires predictable safety behavior, yet we find compliance is highly context-dependent: the same model (Mistral Nemo 12B) provides surveillance designs in 100% of requests but assists with trafficking in only 26.7%. This unpredictability is opaque to deployers: the technical framing bypass, where harmful requests reframed as engineering problems override safety training without any external signal that refusal thresholds have shifted. Within-domain heterogeneity reaches 84.4pp, meaning safety behavior cannot be predicted even at the domain level. A replication on five frontier closed models (GPT-4.1/5.2, Claude Haiku/Sonnet/Opus 4.x; n=4,163 responses) accessed via the GitHub Copilot CLI deployed-product surface reproduces the same domain stratification, attenuated in absolute level but identical in shape, with the two low-codification domains (science fraud, surveillance) again the most permissive. These results show that current safety mechanisms lack the transparency and consistency required for trustworthy AI deployment.
静的な事前確率を超えて: 大規模なアリのコロニー最適化のための動的ニューラル ガイダンス
神経誘導型アリコロニー最適化 (ACO) は、トレーニングと推論の根本的な不整合に悩まされています。ポリシーは通常、静的な事前分布 (ヒートマップなど) を生成するようにトレーニングされますが、反復的な長期にわたる検索プロセスをガイドするために展開されます。本稿では、フェロモン分布と既存のソリューションを定期的に観察することで動的神経誘導を実現する新しいフレームワークである DyNACO を紹介します。 DyNACO を大規模に扱いやすくするために、私たちはこのポリシーを摂動ベースの ACO バックエンドと、有効性と安定したクレジット割り当てを共同で保証する範囲制限付きの改良メカニズムと組み合わせます。 TSP では、DyNACO は 100,000 ノード インスタンスにスケールし、ニューラル ベースラインを上回るパフォーマンスを示し、多くの場合、ガイドなしソルバーと比較して総実行時間を短縮します。キャパシティを意識したバックエンドを介して DyNACO を CVRP に拡張し、1% 未満のニューラル オーバーヘッドでガイドなしのベースラインを一貫して改善します。さらに、モデルの一般化機能を検証し、動的ガイダンスが静的事前ガイダンスよりも優れている理由を解明する詳細な分析を提供します。私たちの研究は、学習誘導型の最適化におけるニューラル トレーニングと反復検索ダイナミクスを調整する必要性を強調しています。コードは https://github.com/shoraaa/DyNACO で入手できます。
原文 (English)
Beyond Static Priors: Dynamic Neural Guidance for Large-Scale Ant Colony Optimization
Neural-guided Ant Colony Optimization (ACO) suffers from a fundamental training-inference misalignment: policies are typically trained to generate static priors (e.g., heatmaps), yet deployed to guide iterative, long-horizon search processes. In this paper, we present DyNACO, a novel framework that achieves dynamic neural guidance by periodically observing the pheromone distribution and the incumbent solution. To make DyNACO tractable at scale, we pair the policy with a perturbation-based ACO backend and a scope-restricted refinement mechanism that jointly ensure efficacy and stable credit assignment. On TSP, DyNACO scales to 100,000-node instances and outperforms neural baselines while often reducing total runtime compared to the unguided solver. We extend DyNACO to CVRP via a capacity-aware backend, consistently improving the unguided baseline with less than 1% neural overhead. We further provide in-depth analysis validating the model's generalization capabilities and elucidating why dynamic guidance outperforms static priors. Our work underscores the necessity of aligning neural training with iterative search dynamics in learning-guided optimization. The code is available at https://github.com/shoraaa/DyNACO.
EEGから音楽への再構成のためのチャネル指向の設計
ブレイン コンピューター インターフェイスは、神経信号から自然な刺激を解読することを目的としていますが、これまでの進歩のほとんどは視覚と言語に焦点を当てています。この記事では、信号が弱く、分散しており、ノイズやチャネル変動の影響を非常に受けやすい、より挑戦的ですがあまり研究されていない設定である脳波から音楽への再構成について研究します。私たちの中心的な発見は、初期のチャネルミキシングが弱いが識別可能なEEG信号を破壊するということです。これに対処するために、3 つの主要なコンポーネントを備えたチャネル指向の設計を提案します。具体的には、チャネルごとのトークン化は、各電極を明示的なトークンとして扱い、空間的に局所化された神経証拠を保持します。チャネルごとのマルチビュー自己蒸留は、時間的クロップとランダムなチャネル サブセット全体で一貫性を強制して、ロバストで分散された表現を学習します。また、チャネルごとのデータ拡張では、構造化チャネル ドロップアウトを導入して、ノイズ、アーティファクト、電極の欠落に対する不変性を改善します。これらのコンポーネントを組み合わせることで、弱いながらも有益な信号がチャネル間で保存され、セマンティックな音楽表現空間への安定した調整が可能になります。このチャネル指向の設計を、EEG から音楽への再構成のためのエンコーディング、アライメント、デコーディングのパイプライン内に統合します。理論的には、チャネルレベルの構造を保存することがアライメントの改善につながる場合を特徴付けます。経験的に、さまざまな最先端のベースラインと比較し、一貫した大幅なパフォーマンスの向上を実証しています。
原文 (English)
Channel-Oriented Design for EEG-to-Music Reconstruction
Brain-computer interfaces aim to decode naturalistic stimuli from neural signals, yet most progress to date has focused on vision and language. In this article, we study a more challenging but far less explored setting, EEG-to-music reconstruction, where signals are weak, distributed, and highly susceptible to noise and channel variability. Our central finding is that early channel mixing destroys weak but discriminative EEG signals. To address this, we propose a channel-oriented design with three key components. Specifically, channel-wise tokenization treats each electrode as an explicit token to retain spatially localized neural evidence, channel-wise multi-view self-distillation enforces consistency across temporal crops and random channel subsets to learn robust and distributed representations, and channel-wise data augmentation introduces structured channel dropout to improve invariance to noise, artifacts, and missing electrodes. Together, these components preserve weak yet informative signals across channels and enable stable alignment to a semantic music representation space. We integrate this channel-oriented design within an encoding-alignment-decoding pipeline for EEG-to-music reconstruction. Theoretically, we characterize when preserving channel-level structure leads to improved alignment. Empirically, we compare with a range of state-of-the-art baselines and demonstrate consistent and significant performance gains.
教師あり学習におけるベイズ十分表現
表現学習は、予測に関連する入力内の情報を保存するものとしてよく説明されます。この研究では、固定された教師あり決定問題に対する関連性が何を意味するかを問います。予測ヘッドがそれを使用してベイズ最適アクション ルールを実装できる場合、その表現は結合分布と損失に対して十分なベイズであると定義されます。これにより、ターゲット情報が損失に依存するようになります。ほぼ確実に一意のベイズ アクションの場合、関連するオブジェクトはベイズ商であり、同じベイズ最適アクションを必要とする入力を識別します。この商を洗練する場合は表現で十分であり、情報的に同等である場合はベイズ最小表現で十分です。このフレームワークは自然に特性の導出につながります。ゼロ 1 損失にはベイズ クラスが必要で、二乗損失には条件付き平均が必要です。ブライアー損失にはバイナリ予測の条件付き確率が必要です。また、対数損失または厳密に適切なスコアリングによって予測分布が決まります。制御された有限実験、学習されたニューラル ボトルネック実験、および実データの iNaturalist 分類学的洗練実験は、十分性、最小限性、および保持される不要な情報の区別を示します。固定教師付き問題の場合、分布と損失によってベイズ アクションが決まり、ベイズ アクションによって商が決まり、商によってベイズ最適予測に必要な最小限の情報が決まります。
原文 (English)
Bayes-Sufficient Representations in Supervised Learning
Representation learning is often described as preserving the information in an input that is relevant for prediction. This work asks what relevance means for a fixed supervised decision problem. A representation is defined to be Bayes-sufficient for a joint distribution and loss if some prediction head can use it to implement a Bayes-optimal action rule. This makes the target information loss-dependent. In the almost-surely unique Bayes-action case, the relevant object is a Bayes quotient, which identifies inputs that require the same Bayes-optimal action. A representation is sufficient when it refines this quotient, and Bayes-minimal when it is informationally equivalent to it. The framework connects naturally to property elicitation: zero-one loss requires the Bayes class, squared loss the conditional mean, Brier loss the conditional probability in binary prediction, and log loss or strictly proper scoring rules the predictive distribution. Controlled finite experiments, learned neural bottleneck experiments, and a real-data iNaturalist taxonomic refinement experiment illustrate the distinction between sufficiency, minimality, and retained non-required information. For a fixed supervised problem, the distribution and the loss determine the Bayes action, the Bayes action determines the quotient, and the quotient determines the minimal information required for Bayes-optimal prediction.
現場に飛び込む: フォーカス プランの生成を通じて、視覚と言語の意思決定における知覚のボトルネックを打破する
ロボット操作やナビゲーションなどの身体化された視覚言語による意思決定タスクでは、視覚言語モデルおよび視覚言語アクション モデル (VLM および VLA) は、さまざまな利点を持つ強力なツールです。VLM は長期計画に優れ、VLA は事後制御に優れています。ただし、モデルのパフォーマンスは、同じ知覚のボトルネックによって制限されます。モデルがタスクに関連するオブジェクトと気を散らすものとを区別できないために幻覚が発生します。原則として、無関係なものを除外しながら、正確に識別して重要なオブジェクトに焦点を当てることが、この制限を打ち破る鍵となります。簡単な解決策は、重要なオブジェクトに直接注目するというワンステップの焦点です。ただし、効果的に焦点を合わせるには本質的にシーンを深く理解する必要があるため、このアプローチは効果的ではないことがわかります。この目的を達成するために、我々は、VLM の長期計画能力を活用した、粗いから細かいまでのフォーカス プラン生成方法である SceneDiver を提案します。この方法では、最初に全体的なシーン グラフを構築して初期理解を確立し、次に認識、理解、分析の反復サイクルを通じてタスクをより単純なサブ問題に徐々に分解します。反応的な制御を可能にするために、意図的なフォーカス機能を VLA に抽出するための軽量アダプターも設計しました。標準の組み込み AI ベンチマークでの評価により、私たちの方法は、高速実行を必要とするタスクの計算効率を維持しながら、VLM と VLA の両方で幻視を大幅に軽減することが確認されています。コードとデータは https://future-item.github.io/SceneDiver でリリースされています。
原文 (English)
Dive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation
In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at long-term planning, while VLAs are better at reactive control. However, their performance is limited by the same perceptual bottleneck: visual hallucinations arise due to the models' inability to distinguish task-relevant objects from distractors. In principle, accurate identification and focus on critical objects while filtering out irrelevant ones is the key to break this limitation. A straightforward solution is one-step focus: directly attending to essential objects. However, this approach proves ineffective because effective focus inherently requires deep scene understanding. To this end, we propose SceneDiver, a coarse-to-fine focus plan generation method for VLMs leveraging their long-term planning abilities, that first constructs a holistic scene graph to establish initial comprehension, then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis. To enable reactive control, we also design a lightweight adapter for distilling the deliberate focus ability into VLAs. Evaluations on standard embodied AI benchmarks confirm that our method substantially reduces visual hallucinations for both VLMs and VLAs, while preserving computational efficiency in tasks requiring fast execution. Our code and data are released at: https://future-item.github.io/SceneDiver.
ゲートデルタネットワークの大規模な機能学習のロックを解除する
大規模言語モデルのトレーニングとスケーリングには膨大な計算リソースが必要であり、効率的な二次二次アーキテクチャと原則に基づいたハイパーパラメータ調整方法の両方が動機付けられます。 Maximal Update Parametrization ($\mu$P) により、標準の Transformer のゼロショット ハイパーパラメータ転送が可能になりましたが、線形モデル、特に構造化された状態遷移や複雑なアーキテクチャを持つモデルへの拡張は、ほとんど未開発のままです。フォワード パス、ゲート メカニズム、およびリカレント ステート ダイナミクスを通じて座標サイズの推定値を厳密に伝播することにより、ゲート デルタ ネットワークのスケーリング ルールを導き出します。言語モデルの事前トレーニングに関する実験により、私たちの構成では AdamW と SGD の両方のモデル幅にわたって安定した学習率の移行が可能である一方、標準のパラメータ化では移行できないことが確認され、分析の正確さと実用性が検証されました。
原文 (English)
Unlocking Feature Learning in Gated Delta Networks at Scale
Training and scaling Large Language Models demand enormous computational resources, motivating both efficient sub-quadratic architectures and principled hyperparameter tuning methods. While the Maximal Update Parametrization ($\mu$P) has enabled zero-shot hyperparameter transfer for standard Transformers, its extension to linear models, particularly those with structured state transitions and complicated architectures, remains largely unexplored. By rigorously propagating coordinate-size estimates through the forward pass, gating mechanisms, and recurrent state dynamics, we derive the scaling rules for Gated Delta Network. Experiments on language-model pre-training confirm that our configurations enable stable learning-rate transfer across model widths under both AdamW and SGD, whereas standard parametrization fails to transfer, validating the correctness and practical utility of our analysis.
LiftQuant: 次元リフティングと投影による連続ビット幅 LLM
既存の量子化手法は基本的に、厳格な整数ベースのビット幅 (例: 2、3 ビット) によって制限されており、その結果、大規模言語モデルを特定のメモリ バジェットに最適に適合させることができない「デプロイメント ギャップ」が生じます。このギャップを埋めるために、真のパレート最適デプロイメントのための継続的なビット幅制御を可能にする新しいフレームワークである LiftQuant を紹介します。中心となるイノベーションは、「リフト ゼン プロジェクト」メカニズムです。高次元の「リフトされた」空間から単純な 1 ビット格子を投影することで、低次元の重みベクトルを近似します。重要なことに、有効なビット幅は、元の次元に対するリフト次元の比率によって単純に決定され、次元が柔軟な構造パラメータであるため、ビット幅を準連続的に調整できます。この投影は、構造化されているが不均一なコードブックを生成し、ベクトル量子化 (VQ) の表現力を捉えます。 VQ、LiftQuant のデコード パスは線形変換と 1 ビットの均一量子化器のみに依存しており、ハードウェアに優しい性質を維持しています。LiftQuant を使用すると、70B LLM を 24GB GPU に正確に適合させることができ、そのパフォーマンスは同じデバイスに搭載されている最先端の 2 ビット モデルを大幅に上回ります。 https://github.com/Heliulu/LiftQuant。
原文 (English)
LiftQuant: Continuous Bit-Width LLM via Dimensional Lifting and Projection
Existing quantization methods are fundamentally limited by rigid, integer-based bit-widths (e.g., 2, 3-bit), resulting in a ``deployment gap" where Large Language Models cannot be optimally fitted to specific memory budgets. To bridge this gap, we introduce LiftQuant, a novel framework that enables continuous bit-width control for true Pareto-optimal deployment. The core innovation is a ``lift-then-project" mechanism which approximates low-dimensional weight vectors by projecting a simple 1-bit lattice from a higher-dimensional ``lifted" space. Crucially, the effective bit-width is determined simply by the ratio of the lifted dimension to the original dimension, which allows the bit-width to be tuned quasi-continuous as the dimension is a flexible structural parameter. This projection generates a structured yet non-uniform codebook, capturing the expressive power of Vector Quantization (VQ). While beneficial over VQ, LiftQuant's decoding path relies solely on linear transformations and 1-bit uniform quantizers, retaining hardware-friendly nature. This flexibility is transformative: LiftQuant enables a 70B LLM to be compressed to 2.4 bits to precisely fit a 24GB GPU, where its performance significantly surpasses state-of-the-art 2-bit models fitted on the same device. Our code and ckpt is available at https://github.com/Heliulu/LiftQuant.
RUBAS: エージェントの安全のためのルーブリックベースの強化学習
LLM がツール対応エージェントに進化すると、単純なテキスト生成ではなく現実世界の実行に関連した新しいクラスの安全性の課題が生じます。既存の調整方法は、粗い拒否信号や静的な監視に依存することが多く、さまざまなエージェントのリスクにわたって安全性と有用なツールの実行のバランスをとることが困難です。エージェントの安全性のためのルーブリックベースの強化学習フレームワークである RUBAS を紹介します。 RUBAS は、エージェントの動作をツール使用の安全性、引数の安全性、応答の安全性、有用性の 4 つの次元に分解します。これらの構造化されたルーブリックは、エージェントの完全な軌跡にわたってきめ細かく解釈可能な報酬を提供し、タスクの完了を維持しながら安全なツールの使用を最適化する強化学習を可能にします。複数のエージェントの安全性ベンチマークとモデルにわたる広範な実験により、RUBAS が標準的なアライメントベースラインよりも安全性を向上させ、ツールに基づく幻覚を軽減し、競争力のある実用性を維持することが示されています。私たちの結果は、多次元ルーブリック報酬が、安全性が重要なツール使用環境において LLM エージェントを調整するための効果的なトレーニング信号を提供することを示唆しています。
原文 (English)
RUBAS: Rubric-Based Reinforcement Learning for Agent Safety
The evolution of LLMs into tool-enabled agents creates a new class of safety challenges associated with real-world execution rather than simple text generation. Existing alignment methods often rely on coarse refusal signals or static supervision, making it difficult to balance safety with useful tool execution across diverse agentic risks. We introduce RUBAS, a rubric-based reinforcement learning framework for agent safety. RUBAS decomposes agent behavior into four dimensions: tool-use safety, argument safety, response safety, and helpfulness. These structured rubrics provide fine-grained and interpretable rewards over complete agent trajectories, enabling reinforcement learning to optimize safe tool use while preserving task completion. Extensive experiments across multiple agent safety benchmarks and models show that RUBAS improves safety over standard alignment baselines, reduces tool-grounded hallucinations, and maintains competitive utility. Our results suggest that multi-dimensional rubric rewards provide an effective training signal for aligning LLM agents in safety-critical tool-use settings.
ブールタスク代数におけるタスク構成の目標設定の特徴付け
ブール タスク代数 (BTA) は、目標達成タスクにブール演算を装備することにより、強化学習におけるゼロショット タスク構成のための原則的なフレームワークを提供します。構造的な仮定を再考し、最適な拡張 Q 値関数の空間における崩壊を定式化します。決定論的 MDP では、そのような関数はすべて普遍的で空のタスクによって完全に決定されます。これにより、元の BTA 定式化で提案された基本タスクの対数セットが冗長になります。この観察に基づいて、目標セットに対して論理演算を実行し、普遍的および空の値関数からスライスを選択することによって合成された値関数を再構築する、目標セットベースの合成方法を導入します。これにより、ポリシーのパフォーマンスを維持しながら、標準 BTA の学習コストが削減され、BTA とスキル マシンの両方の作成時間が短縮されます。表形式、視覚的、関数近似、および連続制御の各ドメインにわたる実験では、追加の基本タスクを学習してもパフォーマンスが向上しないことが示されています。最後に、確率的設定を研究し、この崩壊が成り立つ必要はないこと、つまり、最適な構成には、目標の数において指数関数的に多くの政策を考慮する必要がある可能性があることを示す反例を提供します。コードは https://github.com/EduardoTerres/bta_paper で入手できます。
原文 (English)
A Goal-Set Characterization of Task Composition in the Boolean Task Algebra
The Boolean Task Algebra (BTA) provides a principled framework for zero-shot task composition in reinforcement learning by equipping goal-reaching tasks with Boolean operations. We revisit its structural assumptions and formalize a collapse in the space of optimal extended Q-value functions: in deterministic MDPs, every such function is fully determined by the universal and empty tasks. This makes the logarithmic set of base tasks proposed in the original BTA formulation redundant. Building on this observation, we introduce a goal-set-based composition method that performs logical operations on goal sets and reconstructs composed value functions by selecting slices from the universal and empty value functions. This reduces learning costs for standard BTA and reduces composition time for both BTA and Skill Machines, while preserving policy performance. Experiments across tabular, visual, function-approximation, and continuous-control domains show that learning additional base tasks does not yield better performance. Finally, we study the stochastic setting and provide a counterexample showing that this collapse need not hold, that is, optimal composition may require accounting for exponentially many policies in the number of goals. Code is available at https://github.com/EduardoTerres/bta_paper.
目に見えない宝くじ: LLM コード生成におけるアルゴリズムの選択を微妙な手がかりがどのように左右するか
大規模言語モデル (LLM) は、多くの場合、複数の有効なアルゴリズム ソリューションを含むタスク向けに、実質的な運用コードを生成するようになりました。タスク仕様外の文脈上の単語やメタデータを意味する付随的なプロンプト キューは、すべての出力が同じテストに合格した場合でも、モデルが選択するアルゴリズムを制御できます。即時感度は、出力品質を向上させるツールとしてよく研究されています。ここで、出力ポリシーとは、固定の正確性の下でのアルゴリズムの選択を意味します。私たちは、アルゴリズムステアリングをアルゴリズムファミリー分布におけるキュー誘発のシフトとして定義し、11のタスク、19のキュータイプ(18のチャネルと、タイポグラフィーと句読点を変更しながら意味を保持するメモ化の意味対表面のアブレーション)、および15のモデル構成にわたって46,535の制御された実験を実行しました。我々は、レート制限などの応用タスクを含む、キューのセマンティクスとほぼ一致する、アルゴリズム ファミリの分布における大きく系統的な変化 (最大 100 pp) を発見しました。アルゴリズムの直接命名は、私たちがテストした最も信頼性の高い軽減策です。したがって、偶然のコンテキストによって、パフォーマンス、セキュリティ、および保守性をめぐる「目に見えない宝くじ」が作成されます。
原文 (English)
The Invisible Lottery: How Subtle Cues Steer Algorithm Choice in LLM Code Generation
Large language models (LLMs) now generate substantial production code, often for tasks with multiple valid algorithmic solutions. Incidental prompt cues, meaning contextual words or metadata outside the task specification, can steer which algorithm the model selects, even when all outputs pass the same tests. Prompt sensitivity is well studied as a tool to improve output quality. Here, output policy means algorithm choice under fixed correctness. We define algorithm steering as cue-induced shifts in algorithm-family distributions and run 46,535 controlled experiments across 11 tasks, 19 cue types (18 channels plus a memoization semantic-vs-surface ablation that preserves meaning while changing typography and punctuation), and 15 model configurations. We find large, systematic shifts in algorithm-family distributions (up to 100 pp), largely consistent with cue semantics, including in applied tasks such as rate limiting. Direct algorithm naming is the most reliable mitigation we tested. Accidental context therefore creates an "invisible lottery" over performance, security, and maintainability.
ミュオンのスペクトルスケーリングの法則
直交正規化更新ルールは、大規模な言語モデルをトレーニングするためのオプティマイザーの主要な選択肢として急速に普及しており、最近のオープンソースの最先端モデルでは Muon が採用されています。これらの更新を扱いやすくするために、Muon は Newton-Schulz (NS) 反復を使用して正規直交化を実行します。 NS は近似値にすぎないため、小さな特異値を持つ方向は直交正規化できません。 Muon では、NS は各ステップで運動量行列に適用されますが、これらの運動量行列の特異値スペクトルがトレーニング中にどのように動作するか、またはその動作がモデル サイズに応じてどのように変化するかについてはほとんどわかっていません。我々は、この問題に関する最初の体系的な研究を紹介します。 77M から 2.8B パラメーターの範囲のモデルで層全体の運動量バッファーの特異値分位数を追跡すると、一貫した状況が観察されます。短いバーンインの後、分位数は層のタイプとモデル サイズによって決定される値で安定します。これらの安定化値は、層に依存する指数を備えた、モデル サイズにおける非常にきれいなべき乗則に従います。中深度から後期までの層は、モデル サイズ $M$ (約 $M^{-0.25}$) で非常に穏やかにスケーリングするため、学術規模で使用される標準の 5 ステップ NS 構成は、より大きなスケールでも引き続き直交正規化します。ただし、後期層の一部はより積極的にスケールし ($M^{-0.96}$ まで)、より多くの NS 反復またはより適切に調整された係数を使用しない限り、フロンティア スケールで NS 失敗領域に陥ります。 NS の反復は大規模になると計算コストが高くなります。私たちの法律は、実務者に、重要な方向を直交正規化する最小の NS 構成を選択するための原則に基づいたレイヤー認識のレシピを提供します。つまり、更新の品質を犠牲にすることなく不必要な計算を回避します。
原文 (English)
Spectral Scaling Laws of Muon
Orthonormalized update rules have rapidly become a leading choice of optimizer for training large language models, with recent open-source state-of-the-art models adopting Muon. To keep these updates tractable, Muon performs the orthonormalization with the Newton--Schulz (NS) iteration. Since NS is only approximate, directions with small singular values fail to be orthonormalized. In Muon, NS is applied to the momentum matrix at every step, yet little is known about how the singular value spectrum of these momentum matrices behaves during training, or how that behavior changes with model size. We present the first systematic study of this question. Tracking singular value quantiles of the momentum buffer across layers in models ranging from 77M to 2.8B parameters, we observe a consistent picture: after a short burn-in, the quantiles stabilize at a value determined by the layer type and model size. These stabilization values follow remarkably clean power laws in model size, with layer-dependent exponents. Layers up to mid-late depth scale very mildly with model size $M$ (around $M^{-0.25}$), so the standard 5-step NS configuration used at academic scale will continue to orthonormalize them at much larger scales. Some of the late layers, however, scale much more aggressively (up to $M^{-0.96}$) and will fall into the NS failure regime at frontier scale unless one uses more NS iterations or better-tuned coefficients. NS iterations are computationally expensive at scale; our laws give practitioners a principled, layer-aware recipe for choosing the minimum NS configuration that still orthonormalizes the directions that matter -- avoiding unnecessary computation without sacrificing update quality.
アーキテクチャと量子化の選択を組み合わせて最適化する LLM 圧縮
大規模言語モデル (LLM) のデプロイは、大量のメモリと計算要件があるため、困難です。一部の方法では、小規模または極小の言語モデルを最初から開発することでこの問題に対処しますが、これらのアプローチでは広範な GPU トレーニングが必要です。エッジデバイス用に事前トレーニングされた LLM を圧縮することは、魅力的な代替手段を提供します。プルーニングと量子化を超えて、ニューラル アーキテクチャ検索 (NAS) は効果的な圧縮を可能にしますが、従来の NAS アプローチでは多くの場合、検索スペースが制限され、アーキテクチャが量子化から分離されていました。私たちは、空間全体を探索し、LLM の線形層の混合精度量子化と並行してアーキテクチャ構成を共同で最適化する微分可能な NAS フレームワークを導入します。実験では、精度とレイテンシの優れたトレードオフが実証されています。当社のモデルは、同等の精度で逐次 NAS を経て量子化するベースラインよりも最大 1.4 倍高速な推論、または同等のレイテンシで 7 つの推論タスク全体で最大 6% 高い平均精度を達成します。
原文 (English)
LLM Compression with Jointly Optimizing Architectural and Quantization choices
Deploying large language models (LLMs) is challenging due to their significant memory and computational requirements. While some methods address this by developing small or tiny language models from scratch, these approaches demand extensive GPU training. Compressing pre-trained LLMs for edge devices offers a compelling alternative. Beyond pruning and quantization, Neural Architecture Search (NAS) enables effective compression, yet prior NAS approaches often limit the search space and decouple architecture from quantization. We introduce a differentiable NAS framework that explores the entire space and jointly optimizes architectural configurations alongside mixed-precision quantization for linear layers of LLMs. Experiments demonstrate superior accuracy-latency trade-offs: our models achieve up to 1.4x faster inference than sequential NAS-then-quantization baselines at comparable accuracy, or up to 6% higher average accuracy across seven reasoning tasks at equivalent latency.
知っておくべきこと: プライバシーを意識した LLM 委任のためのコンテキスト整合性に基づいたクエリ書き換え
LLM が日常のワークフローにますます組み込まれるようになるにつれて、クラウドでホストされる LLM に送信されるユーザー クエリでは、タスクに必須のコンテンツとタスクに必須ではない機密情報の開示が日常的に混在していますが、タイプベースの PII 秘匿化はコンテキストに依存せず、2 つの問題が生じる可能性があります。それは、型指定されていない機密コンテキストの開示の過剰と、回答を含むスパンの削除の過剰です。コンテキストの整合性の下で、プライバシーを保持するクエリの書き換えを再検討します。スパンは、タスクに必要な場合にのみ転送されるべきです。 DelegateCI-Bench は、プライバシーを意識した委任向けの初のタスクベースのコンテキスト整合性ベンチマークであり、11 のタスクと 20 のタスク タイプにわたる高品質の合成データ、WildChat ベースの実際のユーザー クエリ、および高密度の機密情報を含む医療課題セットを組み合わせた 3,167 個のサンプルで構成されています。このベンチマークに基づいて、必須および非必須の機密スパンを検証可能な最適化信号に変換する CI ガイド付き強化学習フレームワークを提案し、不必要な機密情報の開示を抑制しながらタスクの重要な情報を保持するようにクエリ リライターをトレーニングします。実験の結果、私たちの学習済みリライターはプライバシーとユーティリティの最適なトレードオフを達成し、デバイス上のベースラインに対して最大 +10.1 の平均ユーティリティを達成することがわかりました。
原文 (English)
Need to Know: Contextual-Integrity-Grounded Query Rewriting for Privacy-Conscious LLM Delegation
As LLMs become increasingly woven into everyday workflows, user queries sent to cloud hosted LLMs routinely mix task-essential content with task non-essential sensitive disclosures, yet type based PII redaction is context agnostic and may raise two issues: over disclosing untyped sensitive context and over removing answer bearing spans. We recast privacy preserving query rewriting under Contextual Integrity: a span should be forwarded only if it is necessary for the task. We introduce DelegateCI-Bench, the first task based Contextual Integrity benchmark for privacy-conscious delegation, comprising 3,167 samples that combine high quality synthetic data spanning 11 tasks and 20 task types, WildChat based real user queries, and a medical challenge set with dense sensitive information. Building on this benchmark, we propose a CI-guided reinforcement learning framework that converts essential and non-essential sensitive spans into verifiable optimization signals, and train a query rewriter to preserve task critical information while suppressing unnecessary sensitive disclosure. Experiments show that our learned rewriter achieves the best privacy-utility tradeoff, achieving up to +10.1 average utility over on-device baselines.
TPA-AD: ベアリング時系列異常検出のための 2 段階の擬似異常ガイド方式
本稿では、正常なサンプルのみが利用可能な設定の下での車軸軸受時系列異常検出(時系列異常検出、TSAD)のための二段階の擬似異常ガイド型異常検出手法(\textbf{T}wo-stage \textbf{P}seudo \textbf{A}nomaly-guided \textbf{A}nomaly \textbf{D}etection, \textbf{TPA-AD})を提案する。トレーニング。この方法では、まず、再構成モデルと特徴ごとのターゲット誤差制御を使用して、正常境界付近に疑似異常ウィンドウを生成します。次に、通常ウィンドウと擬似異常ウィンドウ間の対比学習を通じて異常に敏感な表現を学習し、最後に k 近傍 (KNN) を使用してウィンドウ レベルとポイント レベルの異常スコアを生成します。既知の故障カテゴリ、実際の異常事前確率、またはランダムな異常注入に依存する既存の方法と比較して、TPA-AD は境界近傍に擬似異常を構築することで正常境界の分離可能性を向上させ、混合変数シナリオで連続特徴と離散特徴を共同で処理できます。主な実験はベアリングの故障検出データセットと劣化プロセス データセットで行われ、さらに $13$ の公開 TSAD データセットで探索的な拡張が行われます。結果は、提案された手法が比較的安定した異常応答を生成し、劣化の進行に敏感であり、公開 TSAD ベンチマークおよび実際の高速列車関連の方位データにある程度の広範な適用可能性を実証していることを示しています。
原文 (English)
TPA-AD: A Two-Stage Pseudo Anomaly-Guided Method for Bearing Time-Series Anomaly Detection
This paper proposes a two-stage pseudo anomaly-guided anomaly detection method (\textbf{T}wo-stage \textbf{P}seudo \textbf{A}nomaly-guided \textbf{A}nomaly \textbf{D}etection, \textbf{TPA-AD}) for axle-box bearing time-series anomaly detection (time series anomaly detection, TSAD) under the setting where only normal samples are available for training. The method first generates pseudo-anomalous windows near the normal boundary using a reconstruction model and per-feature target-error control. It then learns anomaly-sensitive representations through contrastive learning between normal and pseudo-anomalous windows, and finally produces window-level and point-level anomaly scores using k-nearest neighbors (KNN). Compared with existing methods that rely on known fault categories, real anomaly priors, or random anomaly injection, TPA-AD improves the separability of the normal boundary by constructing pseudo-anomalies in boundary neighborhoods and can jointly handle continuous and discrete features in mixed-variable scenarios. The main experiments are conducted on bearing fault detection datasets and degradation-process datasets, with an additional exploratory extension on $13$ public TSAD datasets. The results show that the proposed method yields relatively stable anomaly responses, is sensitive to degradation evolution, and demonstrates a certain degree of broader applicability on public TSAD benchmarks and real high-speed-train-related bearing data.
適応パッチ適用は時系列予測よりも難しい
アダプティブ パッチは、時系列トランスフォーマーに対する最近の説得力のある提案です。シーケンスが局所的に情報を提供すると思われる場所に、より細かいパッチを割り当てます。この文書では、どのような条件下でコンテンツ適応型パッチ適用オペレータが調整された均一パッチ適用オペレータよりも優れたパフォーマンスを発揮する必要があるかを検討します。局所的な異質性だけでは十分ではありません。点単位の損失予測では、複雑に見える領域が自動的に、より細かいパッチによって損失が軽減される領域になるわけではありません。予算に基づいたビットレート割り当てとしてパッチをモデル化し、よく調整された均一ベースラインを超えるために動的パッチ ルールが満たさなければならない明示的なしきい値を導出し、ローカル (二次代数) とグローバル (モデルの仮定に基づく強い凸性境界) の両方で達成可能な改善を制限します。 2 つの構造的な結果が続きます。結合制約がなければ、スカラーの局所的な複雑さは、共通の損失状況の下で不均一な最適値を生成できません。バックボーンがその表現を意識した最適値にトレーニングされると、アライメント ゲインは適切に調整された均一なパッチ サイズ付近で崩壊します。これらの予測をテストするために、バックボーン、データ、トレーニング プロトコルを固定したまま、各適応メカニズムを均一なパッチサイズのスイープに置き換えて、3 つの代表的なアーキテクチャに対して制御された分離スタディを実行します。標準的な長期予測ベンチマークでは、検証で選択された均一なベースラインは、動的ベースラインと競合しており、設定ごとの効果はゼロ近くに集中しており、結果がデータセットごとに集計されると一貫した方向性の利点はありません。私たちが観察している大きな利益は、メソッドとデータセットに固有のものです。したがって、適応型パッチ適用は、調整された均一なベースラインに対して評価する必要があります。その値は、安価で信頼性の高いルーティング信号が、より細かいパッチが実際に予測損失を削減する場所を特定できるかどうかによって決まります。
原文 (English)
Adaptive Patching Is Harder Than It Looks For Time-Series Forecasting
Adaptive patching is a recent and compelling proposal for time-series Transformers: allocate finer patches where the sequence looks locally informative. This paper asks under what conditions a content-adaptive patching operator should outperform a tuned uniform one. Local heterogeneity alone is not enough: under pointwise forecasting losses, a complex-looking region is not automatically one where finer patching reduces the loss. We model patching as a budgeted bitrate allocation and derive an explicit threshold that a dynamic patching rule must satisfy to beat a well-tuned uniform baseline, then bound the achievable improvement both locally (a quadratic surrogate) and globally (a strong-convexity bound under the model's assumptions). Two structural results follow: without a coupling constraint, scalar local complexity cannot produce a non-uniform optimum under a common loss landscape; and once the backbone is trained to its representation-aware optimum, the alignment gain collapses around a well-tuned uniform patch size. To test these predictions, we run a controlled isolation study on three representative architectures, replacing each adaptive mechanism with a uniform patch-size sweep while keeping the backbone, data, and training protocol fixed. On standard long-horizon forecasting benchmarks, the validation-selected uniform baseline is competitive with the dynamic counterpart, with per-setting effects concentrated near zero and no consistent directional advantage once results are aggregated by dataset. The larger gains we do observe are method- and dataset-specific. Adaptive patching should therefore be evaluated against a tuned uniform baseline; its value depends on whether a cheap and reliable routing signal can identify where finer patches actually reduce forecasting loss.
大規模な言語モデルが報酬と社会をハックする
強化学習 (RL) はトレーニング後のパラダイムの主流となっており、大規模言語モデル (LLM) が報酬から学習できるようになります。私たちは、社会規制が報酬関数と構造的に似ていることを観察しています。それらは測定可能な結果、しきい値、例外を定義しますが、多くの場合、制度上の意図は部分的にしか指定されません。私たちは、RL トレーニング プロセスがこれらのギャップを悪用する可能性があると仮説を立て、RL 中に報酬関数をハッキングするというモデルのよく知られた傾向が、社会ハッキングと呼ばれるより重大な失敗モード、つまり社会が運営されているルールの抜け穴を発見するモードにスケールアップできるかどうかを尋ねます。この現象を研究するために、72 の社会環境のサンドボックスである SocioHack を導入しました。その結果、これらの環境内で報酬ハッキングが自然に発生し、規制の抜け穴の発見につながることがわかりました。モデルは社会ルールをハッキングし、規制の意図を打ち破りながら技術的に準拠した戦略を生成する方法を学習します。現在の LLM セーフガードは限定的な緩和策しか提供しません。したがって、モデルのトレーニングのために実際のフィードバックを収集することには細心の注意が必要であり、実社会で LLM を安全に反復するための次世代のポストトレーニング パラダイムが必要です。=
原文 (English)
Large Language Models Hack Rewards, and Society
Reinforcement learning (RL) has become a dominant post-training paradigm, enabling large language models (LLMs) to learn from rewards. We observe that societal regulations are structurally similar to reward functions. They define measurable outcomes, thresholds, and exceptions, while often leaving institutional intent only partially specified. We hypothesise that the RL training process may exploit these gaps and therefore ask whether models' well-known tendency to hack reward functions during RL can scale into a more consequential failure mode named societal hacking: discovering loopholes in the rules society runs on. To study this phenomenon, we introduce SocioHack, a sandbox of 72 societal environments, and find that within these environments, reward hacking naturally emerges and leads to regulatory loophole discovery. Models learn to hack the social rules and generate strategies that remain technically compliant while defeating regulatory intent, and current LLM safeguards provide only limited mitigation. Therefore, collecting in-the-wild feedback for model training requires greater caution, and we need a next-generation post-training paradigm for safely iterating LLMs in real society.=
POLARIS: 小さなモデルが長い物語を書けるように導く
小規模なオープンウェイト モデルは、長編のクリエイティブ ライティングに苦労します。特にフロンティア モデルと比較した場合、生成されるストーリーが要求された長さに大幅に満たないか、長さが増加するにつれて品質が大幅に低下します。我々は、2 つの重要な要素を備えた低コンピューティングの GRPO レシピである POLARIS (審査員としての LLM 報酬とストーリーライティングのためのアンカー参照注入によるポリシーの最適化) を紹介します。1 つはオンライン報酬として構造化されたストーリー品質ルーブリックを持つフロンティア LLM 審査員、もう 1 つは教師が強制的に人間が書いたストーリーが各 GRPO グループ内で高報酬のアンカーとして機能する人間参照注入 (HRI) です。 100 の短編小説アンソロジーと 4 つの A100 GPU から派生した約 1.4K のプロンプト ストーリー ペアのデータセットを使用して、トレーニング レシピを Qwen3.5-9B に適用することにより、POLARIS-9B が得られます。配布内および配布外のプロンプトとルーブリックにわたる 5 つのベンチマークにわたって、POLARIS-9B は、長さの指示により厳密に従いながら、はるかに大きなオープンウェイト モデルと競合します。人間による盲検評価により、POLARIS-9B がベースの Qwen3.5-9B よりも好まれ、Qwen3.5-27B と同等であることが確認されました。 POLARIS-9B は、最大 4k ワードまでのストーリーのみをトレーニングしているにもかかわらず、トレーニング長の最大 3 倍のストーリーを要求するプロンプトの品質を維持します。これは、ほとんどのオープンウェイト モデルが品質、長さの遵守、またはその両方において大幅に低下する状況です。より広範に、私たちの結果は、長さの一般化がクリエイティブライティングモデルにとって意味のあるストレステストであり、他の点では近いモデルを区別するための有用なレンズであることを示唆しています。
原文 (English)
POLARIS: Guiding Small Models to Write Long Stories
Small open-weight models struggle at long-form creative writing: their generated stories either fall far short of the requested length, or their quality significantly degrades as length increases, especially when compared to frontier models. We present POLARIS (Policy Optimization with LLM-as-a-judge rewards and Anchored-Reference Injection for Storywriting), a lower-compute GRPO recipe with two key ingredients: a frontier LLM judge with a structured Story Quality rubric as the online reward, and human-reference injection (HRI), where a teacher-forced human-written story serves as a high-reward anchor within each GRPO group. By applying our training recipe to Qwen3.5-9B, using a dataset of approximately 1.4K prompt-story pairs derived from 100 short-story anthologies and 4 A100 GPUs, we obtain POLARIS-9B. Across five benchmarks spanning in-distribution and out-of-distribution prompts and rubrics, POLARIS-9B is competitive with much larger open-weight models while following length instructions more closely. A blinded human evaluation confirms that POLARIS-9B is preferred to the base Qwen3.5-9B and on par with Qwen3.5-27B. Despite training only on stories up to 4k words, POLARIS-9B preserves quality on prompts requesting stories up to 3 times the training length, a regime where most open-weight models degrade substantially in quality, length adherence, or both. More broadly, our results suggest that length generalization is a meaningful stress test for creative-writing models and a useful lens for distinguishing otherwise close models.
微分可能聴覚ループ (DAL): ハイパーパーソナライズされた補聴器のための ML フレームワーク
従来の補聴器は、感度の低下を管理するために周波数に依存する固定の増幅と圧縮に依存しており、複数の話者がいる状況(「カクテルパーティー」問題)など、複雑な環境では十分な聴取サポートを提供できないことがよくあります。難聴の根本的な符号化機能障害により包括的に対処するために、パーソナライズされた補聴器の設計とフィッティングのための新しいオープンソース フレームワークである Differentiable Auditory Loop (DAL) を導入します。 DAL の最初の実装には、人間の蝸牛機能の微分可能なモデルである CARFAC が組み込まれており、これを JAX に移植して、障害のある聴覚神経活動パターンを正常な聴覚基準と一致させるためにディープ ニューラル ネットワークを最適化します。必要とされるきめ細かい分光時間信号処理を備えた補聴器を構築するために、波形間の完全畳み込み UNet ジェネレーターである SEANet を採用しています。正常な聴覚に適合した CARFAC モデルの出力と、各被験者の個々の聴覚障害に適合する CARFAC モデルの出力を比較することで、ネットワークを微調整します。比較は、それぞれの CARFAC 神経活動パターン (NAP) 出力と安定化聴覚画像 (SAI) から導出された損失関数を使用して行われ、後者は聴覚神経出力における位相非感受性の時間構造を捕捉する 2D 表現を提供します。 SEANet モデルは、勾配降下法を通じて、入力のノイズを除去することと、障害のある CARFAC モデルによってモデル化された難聴を補償することの両方を学習します。神経表現と信号忠実度の測定基準全体で、DAL に最適化された SEANet モデルは、テストされたマスター補聴器 (MHA) のベースラインを上回りました。 DAL フレームワークは、モデルベースの機械学習駆動の補聴器信号処理のパーソナライゼーションへの実用的な道を提供します。次のステップには、実際の臨床試験を可能にするハードウェアの導入が含まれます。
原文 (English)
The Differentiable Auditory Loop (DAL): An ML Framework for Hyper-Personalized Hearing Aids
Conventional hearing aids rely on fixed, frequency-dependent amplification and compression to manage reduced sensitivity, which often fails to provide sufficient listening support in complex environments, such as situations with multiple speakers (the ``cocktail party'' problem). To more comprehensively address the underlying encoding dysfunctions of hearing loss, we introduce the Differentiable Auditory Loop (DAL), a new open-source framework for personalized hearing aid design and fitting. Our first implementation of DAL incorporates CARFAC, a differentiable model of human cochlear function, which we ported to JAX, to optimize a deep neural network to match impaired auditory neural activity patterns with a normal-hearing reference. To build a hearing aid with the fine-grained spectro-temporal signal processing required, we adopt SEANet, a waveform-to-waveform fully convolutional UNet generator. We fine-tune the network by comparing the outputs of a CARFAC model fitted to normal hearing with that of a CARFAC model fitted to match each subject's individual hearing impairment. The comparison is done using loss functions derived from the respective CARFAC neural activity pattern (NAP) outputs and stabilized auditory images (SAIs), the latter providing a 2D representation that captures phase-insensitive temporal structure in the auditory nerve output. Through gradient descent, the SEANet model learns to both denoise the input and compensate for the hearing loss modelled by the impaired CARFAC model. Across neural-representation and signal-fidelity metrics, the DAL-optimized SEANet model outperformed the tested master hearing aid (MHA) baselines. The DAL framework provides a practical path toward model-based, machine-learning-driven personalization of hearing aid signal processing. Next steps include hardware deployment to enable real-world clinical testing.
証拠を運ぶエージェント アクション: 異種エージェント システムに対するモデルに依存しないランタイム ガバナンス
エージェント システムは、ローカル コーディング ツール、フレームワーク SDK、マネージド エージェント プラットフォーム、API ゲートウェイ、オブザーバーのみの統合など、非常に異なる制御ポイントを備えたランタイムを通じて実行されます。したがって、データを外部に公開するなどの高リスクのアクションは、あるランタイムではシェル コマンドとして、別のランタイムではツール呼び出しとして、そして 3 番目のランタイムではホストされたセッションの移行として現れる可能性があります。このため、ガバナンスの基本的な質問に一貫して答えることが困難になります。つまり、どのようなアクションが、誰の権限の下で、どのような承認セマンティクスに基づいて、実行後にどのような証拠によって承認されたのかということです。このペーパーでは、ベンダー ネイティブのセッション レコードではなくアクション証明書を中心としたランタイム中立のガバナンス モデルである Proof-Carrying Agent Actions (PCAA) について説明します。 PCAA は、アクション前の許容性、アクションのオープン、仮定のキャプチャ、承認、結果のクローズという 5 つのチェックポイントを中心にコントロールを組織します。これらのチェックポイントは、ポータブルなアクション エンベロープ、実行時および承認のレシート、および再生可能なプルーフにバインドされます。このモデルは 2 つの実用的な方法で拡張されています。証明書は外部性を認識しており、宛先の可視性やアカウントの来歴などの境界事実を伝えます。もう 1 つは、承認は、単一のレビュー済みまたは未レビューのビットではなく、明示的な強制力クラスによって記述されます。私たちは、異種エージェント コントロール プレーンでの参照実装と開示制限のある評価プロトコルを通じてモデルを研究します。 4 つのランタイム ファミリにわたる 24 個の実行可能シードから 96 個のトレースに拡張された保護されたベンチマークでは、PCAA はルートの品質を維持しながら、アブレーション下で個別の障害モードを明らかにします。この論文は、証明書を保持するアクションに関するランタイム ガバナンスのシステム定式化と、その定式化がベンダー固有のコントロール サーフェスに崩壊することなくランタイム チャーンの下で移植性を維持できる方法についての実装に基づいた説明に貢献します。
原文 (English)
Proof-Carrying Agent Actions: Model-Agnostic Runtime Governance for Heterogeneous Agent Systems
Agent systems execute through runtimes with very different control points: local coding tools, framework SDKs, managed agent platforms, API gateways, and observer-only integrations. A high-risk action such as publishing data externally may therefore appear as a shell command in one runtime, a tool call in another, and a hosted session transition in a third. This makes it difficult to answer a basic governance question consistently: what action was authorized, under whose authority, with what approval semantics, and with what evidence after execution? This paper presents Proof-Carrying Agent Actions (PCAA), a runtime-neutral governance model centered on an action certificate rather than on a vendor-native session record. PCAA organizes control around five checkpoints: pre-action admissibility, action open, assumption capture, approval, and outcome closure. It binds these checkpoints to a portable action envelope, runtime and approval receipts, and replay-ready proof. The model is extended in two practical ways: the certificate is externality-aware, carrying boundary facts such as destination visibility and account provenance, and approval is described by explicit enforceability classes rather than by a single reviewed or unreviewed bit. We study the model through a reference implementation in a heterogeneous agent control plane and a disclosure-bounded evaluation protocol. On a protected benchmark expanded from 24 executable seeds to 96 traces across four runtime families, PCAA preserves route quality while exposing distinct failure modes under ablation. The paper contributes a systems formulation of runtime governance around certificate-bearing actions and an implementation-grounded account of how that formulation can remain portable under runtime churn without collapsing into vendor-specific control surfaces.
マシンインテリジェンスの Ph(ysical)AI 層の構築
基礎モデルは、多様なデータに対する大規模なトレーニングを通じて一般化を実現しますが、ペアになったトレーニング データなしで真に目に見えないドメインへの転送には制限があります。私たちは、束縛されていない統計的相関を学習するのではなく、信号理論の原理 (フーリエ分解、エネルギー保存、対称性) をエンコードする原理駆動型の基礎モデルを提案します。私たちは、ドメインの違いは基礎物理学ではなく、時間、周波数、大きさ、または位相における学習可能な変換にあると仮説を立てます。これらの原則を組み込んだ、共同設計されたアーキテクチャと損失を備えた無線周波数 (RF) データのみをトレーニングすることで、RF データから学習したフリーズ表現のみを使用してオーディオ、画像、テキスト、ビデオへのクロスモーダル転送を実現し、ターゲット ドメインでのエンコーダーの微調整を必要としません。当社の 199 万パラメータのフローズン エンコーダは、リニア プロービングによる 15 の多様なタスクにわたって平均精度 77.7% (トップ 3 の 91.9%) を達成します。系統的な変動はあります。物理的に接地されたタスク (話者認識、地震学、RF フィンガープリンティング) では 84.5 %、セマンティック タスク (音楽ジャンル、言語認識) では 70.0% です。これは、原則主導型アプローチとスケール主導型アプローチが補完的な道を提供することを明らかにしています。物理原則は効率的なクロスモーダル転送を可能にし、同時に物理的理解と意味論的理解の間の境界を自然に確立します。
原文 (English)
Building The Ph(ysical)AI Layer Of Machine Intelligence
Foundation models achieve generalization through massive-scale training on diverse data, but have limitations with transfer to truly unseen domains without paired training data. We propose principle-driven foundation models that encode signal-theoretic principles (Fourier decomposition, energy conservation, symmetry) rather than learn untethered statistical correlations. We hypothesize that domains differ not in fundamental physics, but in learnable transformations in time, frequency, magnitude, or phase. Training exclusively on radio-frequency (RF) data with co-designed architecture and losses incorporating these principles, we achieve cross-modal transfer to audio, images, text, and video using only frozen representations learned from RF data, requiring no fine-tuning of the encoder on target domains. Our 1.99M parameter frozen encoder achieves 77.7% average accuracy (91.9% top-3) across 15 diverse tasks via linear probing, with systematic variation: 84.5 on physically-grounded tasks (speaker recognition, seismology, RF fingerprinting) versus 70.0% on semantic tasks (music genre, language recognition). This reveals that principle-driven and scale-driven approaches offer complementary paths: physical principles enable efficient cross-modal transfer while naturally establishing the boundary between physical and semantic understanding.
SymTRELLIS: 3D 生成のための対称性強化ボクセル潜在
シングルビュー 3D 生成モデルは、優れた視覚的品質を実現していますが、構造的または機能的要件を満たすように設計されておらず、実際には不十分なことがよくあります。対称性もそのような要件の 1 つです。対称性に違反すると、たとえそれが微妙な場合でも、モデルが物理的に使用できなくなる可能性があります。 SymTRELLIS は、基礎となる VAE やフロー モデルを再トレーニングすることなく、TRELLIS.2 のフローベース 3D 生成中に任意の有限点群対称 (回転、鏡映、多面体) を強制する手法です。私たちの重要なアイデアは、一般的な非対称 3D データでトレーニングされた軽量の空間変換潜在マッパーとして実装された、ボクセル潜在に対する学習済み線形演算子として空間変換の潜在空間アクションを近似することです。生成時に、各 ODE ステップですべての対称に相当する変換にわたって予測流速を平均することによって対称性を強制します。このプロセスを速度対称化と呼びます。対称仕様は、初期の TRELLIS.2 生成から自動的に推定することも、ユーザーが指定することもでき、入力画像が示唆するものを超えた意図的な折り操作が可能になります。 2 ~ 20 回の回転と多面体対称グループにわたる 266 個の厳密に対称なオブジェクトの厳選されたベンチマークでは、SymTRELLIS は、ベース モデルと同等の再構築精度を維持しながら、TRELLIS.2、Hunyuan3D-2.1、および TripoSG と比較してすべての対称誤差メトリクスを大幅に削減します。
原文 (English)
SymTRELLIS: Symmetry-Enforced Voxel Latents for 3D Generation
Single-view 3D generative models have achieved impressive visual quality, yet they are not designed to satisfy structural or functional requirements, and in practice, often fall short. Symmetry is one such requirement: violations, even subtle ones, on symmetry can render a model physically unusable. We present SymTRELLIS, a method that enforces arbitrary finite point group symmetries (rotational, reflectional, and polyhedral) during the flow-based 3D generation of TRELLIS.2, without retraining the underlying VAE or flow model. Our key idea is to approximate the latent-space action of spatial transformations as a learned linear operator on voxel latents, implemented as a lightweight spatial-transform latent mapper trained on generic, non-symmetric 3D data. At generation time, we enforce symmetry by averaging predicted flow velocities across all symmetry-equivalent transformations at each ODE step, a process we call velocity symmetrization. The symmetry specification can be estimated automatically from an initial TRELLIS.2 generation or supplied by the user, enabling deliberate fold manipulation beyond what the input image suggests. On a curated benchmark of 266 strictly symmetric objects spanning 2- to 20-fold rotations and polyhedral symmetry groups, SymTRELLIS substantially reduces all symmetry error metrics compared to TRELLIS.2, Hunyuan3D-2.1, and TripoSG, while maintaining reconstruction accuracy comparable to the base model.
AgenticDiffusion: ビジョンベースの UAV ナビゲーションのための Agentic Diffusion ベースの経路計画
屋内 UAV ナビゲーションには、限られた視野の観察下での効率的な探索、シーンの理解、信頼性の高い軌道の実行が必要です。既存のビジョンベースのナビゲーション フレームワークは通常、単一ビューの観察に依存しており、オクルージョン、ターゲットの可視性、およびグローバル シーン構造について推論する能力が制限されています。この研究では、統合された航空ナビゲーション パイプライン内で、言語に基づく推論、オープン語彙によるターゲットのグラウンディング、視覚ベースの拡散計画、および NMPC を調整するマルチビュー UAV ナビゲーション フレームワークである AgenticDiffusion を提案します。自然言語による指示と、同期した一人称視点 (FPV) および上面視点の観察を考慮して、フレームワークはナビゲーションに最も有益な視点を決定し、軌道の実行前にミッション計画を生成します。ターゲットは、オープンボキャブラリーグラウンディングモデルを使用して位置特定され、その後、視点固有の拡散プランナーが UAV 実行のためのナビゲーション軌道を生成します。提案されたフレームワークは、補完的な視点を使用して、繰り返しのターゲット探査を削減し、雑然とした屋内環境でのナビゲーション効率を向上させます。このフレームワークは、適応視点選択、多段階ミッション実行、長距離ナビゲーション、安全な着陸地点選択を含む 4 つの現実世界の UAV ナビゲーション シナリオで検証されました。実験結果では、40 回の実世界試験でミッション全体の成功率が 80% であることが実証され、一方、拡散計画者は軌道生成の成功率が 100% に達しました。
原文 (English)
AgenticDiffusion: Agentic Diffusion-based Path Planning for Vision-Based UAV Navigation
Indoor UAV navigation requires efficient exploration, scene understanding, and reliable trajectory execution under limited field-of-view observations. Existing vision-based navigation frameworks typically rely on single-view observations, limiting their ability to reason about occlusions, target visibility, and global scene structure. In this work, we propose AgenticDiffusion, a multi-view UAV navigation framework that coordinates language-guided reasoning, open-vocabulary target grounding, vision-based diffusion planning, and NMPC within a unified aerial navigation pipeline. Given a natural language instruction and synchronized first-person-view (FPV) and top-view observations, the framework determines the most informative viewpoint for navigation and generates a mission plan prior to trajectory execution. The targets are localized using an open-vocabulary grounding model, after which viewpoint-specific diffusion planners generate navigation trajectories for UAV execution. Using complementary viewpoints, the proposed framework reduces repeated target exploration and improves navigation efficiency in cluttered indoor environments. The framework was validated in four real-world UAV navigation scenarios involving adaptive viewpoint selection, multi-stage mission execution, long-horizon navigation, and safe landing-site selection. The experimental results demonstrated an overall mission success rate of 80% in 40 real-world trials, while the diffusion planners achieved a trajectory generation success rate of 100%.
dMX: 低精度浮動小数点フォーマットの微分可能な混合精度代入
大規模言語モデル (LLM) を低精度の浮動小数点表現に量子化することは、効率的な展開の中心となりますが、単一のビット幅をすべてのレイヤーに均一に適用することは、パフォーマンスと精度の両方の点で最適とは言えません。この研究では、学習可能な浮動小数点ビット幅割り当てのための微分可能な混合精度量子化フレームワークである dMX を紹介します。私たちは、オープン コンピューティング プロジェクト (OCP) 標準によって定義されたデータ型のマイクロスケーリング浮動小数点 (MXFP) ファミリへの応用を研究します。レイヤごとのビット幅の割り当ては、各レイヤの浮動小数点形式がスカラー パラメータによってパラメータ化され、多変量設計空間を単一の学習可能なオフセットに折りたたむ連続最適化問題として定式化されます。トレーニング中、このオフセットは連続値をとり、離散量子化形式間の突然の振動を回避します。温度ベースのアニーリング スケジュールにより、学習されたオフセットが段階的に離散化され、トレーニング動作と推論動作の間で突然移行することなく、最終的な構成がハードウェア互換の MXFP 形式にマッピングされることが保証されます。ターゲットを意識した正則化用語は、平均ビット幅をユーザー指定の予算に向けて導き、推論コストの大まかな代理として機能し、モデルの品質と展開効率のバランスをとります。私たちは Llama、Qwen3、SmolLM2 などのさまざまな LLM ファミリで実験を実行し、WikiText-2 での複雑性と 4 つのゼロショット推論ベンチマークでの精度を評価しました。これらの設定全体にわたって、dMX は一貫してパレート支配モデルを生成し、カルバック ライブラー (KL) 発散ベースのレイヤー選択ヒューリスティックを改善し、モデルの品質と平均ビット幅の間のトレードオフを効率的にナビゲートします。
原文 (English)
dMX: Differentiable Mixed-Precision Assignment for Low-Precision Floating-Point Formats
Quantizing large language models (LLMs) to low-precision floating-point representations is central to efficient deployment, yet applying a single bit-width uniformly across all layers is sub-optimal in terms of both performance and accuracy. This work introduces dMX, a differentiable mixed-precision quantization framework for learnable floating-point bit-width assignment. We study its application for the microscaling floating-point (MXFP) family of data types defined by the Open Compute Project (OCP) standard. The per-layer bit-width assignment is formulated as a continuous optimization problem in which each layer's floating-point format format is parameterized by a scalar parameter, folding the multi-variate design space into a single learnable offset. During training this offset takes continuous values, avoiding sudden oscillations between discrete quantization formats. A temperature-based annealing schedule progressively discretizes the learned offsets, ensuring that the final configuration maps to hardware-compatible MXFP formats without abrupt transitions between training and inference behavior. A target-aware regularization term steers the average bit-width toward a user-specified budget, serving as a coarse-grained proxy for inference cost and balancing model quality against deployment efficiency. We performed experiments on different families of LLM, such as Llama, Qwen3, and SmolLM2, evaluating perplexity on WikiText-2 and accuracy on four zero-shot reasoning benchmarks. Across these settings, dMX consistently yields Pareto-dominating models and improves over Kullback-Leibler (KL) divergence-based layer-selection heuristics, efficiently navigating trade-offs between model quality and average bit-width.
SaliMory: 会話エージェントの認知記憶を調整する
生涯の伴侶として機能する会話エージェントは、すべての対話にわたって永続的な記憶を維持する必要があります。ただし、生の取得でコンテキスト ウィンドウを単純に拡張すると推論の品質が低下し、標準の強化学習による記憶エージェントのトレーニングでは、多段階パイプラインで深刻なクレジット割り当てのボトルネックが発生します。これを解決するために、単一言語モデルをトレーニングして、ユーザーの事実、好み、作業記憶にまたがる認知的に構造化された記憶を管理するフレームワークである SALIMORY を紹介します。 SALIMORY は、階層的な段階ごとのプロセス報酬と報酬分解された対照的洗練を導入することにより、個別の記憶操作 (選択的フィルタリング、統合、およびキュー主導のリコール) をエンドツーエンドで個別に監視します。 SALIMORY はメモリに起因する障害を 3 分の 1 に削減し、エンドツーエンドの精度で最先端のものを 10% 以上上回り、Good Personalization 率を 2 倍以上に高めます。
原文 (English)
SaliMory: Orchestrating Cognitive Memory for Conversational Agents
Conversational agents that serve as lifelong companions must maintain persistent memory across all interactions. However, simply expanding context windows with raw retrieval degrades reasoning quality, while training memory agents via standard reinforcement learning creates a severe credit assignment bottleneck in a multi-stage pipeline. To solve this, we introduce SALIMORY, a framework that trains a single language model to manage a cognitively-structured memory-spanning user facts, preferences, and working memory. By introducing a hierarchical stage-wise process reward and reward-decomposed contrastive refinement, SALIMORY provides isolated supervision for distinct memory operations (selective filtering, consolidation, and cue-driven recall) end-to-end. SALIMORY cuts memory-attributed failures by one-third, outperforms the state-of-the-art by over 10% in end-to-end accuracy, and more than doubles the Good Personalization rate.
大規模言語モデルによる適応軌道最適化のためのセマンティック制約合成
軌道の最適化は、宇宙探査において安全で信頼性の高い自律運用を可能にするための重要なコンポーネントです。宇宙ミッションの頻度、複雑さ、範囲が増加するにつれて、ミッションの目的と運用上の制約を正確に反映する、数学的に適切な軌道最適化問題を迅速に定式化する必要性が高まっています。ただし、ミッションの意図を軌道最適化のための扱いやすい分析公式に変換するには、かなりの専門知識が必要です。この論文では、大規模言語モデル (LLM) を活用して、ミッションの要件と制約の自然言語記述を実行可能な軌道最適化コードと対応する数学的定式化に変換するフレームワークを紹介します。宇宙船ランデブーシナリオでの実験では、意味論的なミッション要件から凸軌道最適化問題を再調整する際の高い成功率が実証されています。最終的に、この研究は、高レベルの意図と形式的な最適化モデルを橋渡しする LLM の可能性を強調し、宇宙船のより柔軟で効率的な軌道設計を可能にします。
原文 (English)
Semantic Constraint Synthesis for Adaptive Trajectory Optimization via Large Language Models
Trajectory optimization is a critical component for enabling safe and reliable autonomous operations in space exploration. As space missions increase in frequency, complexity, and scope, there is a growing need to rapidly formulate mathematically sound trajectory optimization problems that accurately reflect mission objectives and operational constraints. However, translating mission intent into tractable analytical formulations for trajectory optimization requires substantial domain expertise. This paper presents a framework that leverages large language models (LLMs) to translate natural language descriptions of mission requirements and constraints into executable trajectory optimization code and corresponding mathematical formulations. Experiments in spacecraft rendezvous scenarios demonstrate a high success rate in reconditioning a convex trajectory optimization problem from semantic mission requirements. Ultimately, this work highlights the potential of LLMs to bridge high-level intent and formal optimization models, enabling more flexible and efficient trajectory design of spacecraft.
HighTide: エージェントが厳選したオープンソース VLSI ベンチマーク スイート
進化する AI 支援ベンチマーク スイートである HighTide を紹介します。具体的には、(i) 複数の設計言語とテクノロジ ノードにまたがる多様なオープンソース スイート、(ii) リモート キャッシュを備えた Bazel ベースの増分 RTL から GDS へのコンパイル、(iii) スイート全体の調整理論的根拠の長期記憶として機能する設計ごとの意思決定ログに裏付けられた、設計ライフサイクル、フロー最適化、ツール リファレンス、メタ メンテナンスをカバーする 12 のエージェント スキルによる AI 支援の設計キュレーション、および(iv) 安定リリース用の RTL コンパイル検証を備えたインフラストラクチャ。このスイートは一般公開されており、オープンソースのハードウェア エコシステムとともに成長するように設計されています。
原文 (English)
HighTide: An Agent-Curated Open-Source VLSI Benchmark Suite
We introduce HighTide, an evolving AI-assisted benchmark suite. Specifically, the contributions are: (i) a diverse open-source suite spanning multiple design languages and technology nodes, (ii) Bazel-based incremental RTL-to-GDS compilation with remote caching, (iii) AI-assisted design curation through twelve agent skills covering the design lifecycle, flow optimization, tool reference, and meta-maintenance, backed by per-design decision logs that serve as long-term memory of tuning rationale across the suite, and (iv) an infrastructure with RTL compilation verification for stable releases. The suite is publicly available and designed to grow with the open-source hardware ecosystem.
Caught in the Act(ivation): LLM エージェントによる資格情報漏洩の事前出力およびマルチターン検出に向けて
LLM エージェントは多くの場合、機密認証情報を信頼できない取得コンテンツと同じコンテキスト ウィンドウに配置し、認証情報の漏洩を誘発する間接的なプロンプト インジェクションの直接パスを作成します。私たちは、3 つの相補的な防御を通じてこの障害モードを研究します。まず、出力トークンが発行される前に、アクティベーション プローブが資格情報へのアクセスを検出できるかどうかを尋ねます。次に、形式固有の文字モデルからハニートークンを構築し、分割等角予測で検出を調整します。 3 番目に、複数ターンにわたる漏洩を累積的な情報フロー問題として扱い、会話ターン全体での推定漏洩予算を追跡します。オープンウェイト モデルの制御された実験では、アクティベーション機能により、ホールドアウト エンコーディング変換下を含め、無害なプロンプトと認証情報を求めるプロンプトが高精度で分離されます。小規模な合成マルチターン スイートでは、累積アカウンティングにより、ターンごとの検出器が見逃した攻撃が検出されます。これらの結果は暫定的なものです。マルチターン ベンチマークは社内で小規模なものであり、アクティブ化方法にはホワイト ボックス アクセスが必要であり、情報推定ツールは正式な上限ではなく実用的なシグナルを提供します。それでも、この結果は、資格情報の漏洩防御には、テキストレベルの出力フィルターのみに依存するのではなく、出力前の監視、調整されたカナリア検出、および一時的な漏洩アカウンティングを組み合わせる必要があることを示唆しています。
原文 (English)
Caught in the Act(ivation): Toward Pre-Output and Multi-Turn Detection of Credential Exfiltration by LLM Agents
LLM agents often place sensitive credentials in the same context window as untrusted retrieved content, creating a direct path for indirect prompt injection to induce credential exfiltration. We study this failure mode through three complementary defenses. First, we ask whether activation probes can detect credential access before output tokens are emitted. Second, we construct honeytokens from format-specific character models and calibrate detection with split conformal prediction. Third, we treat multi-turn exfiltration as a cumulative information-flow problem and track an estimated leakage budget across conversation turns. In controlled experiments on open-weight models, activation features separate benign and credential-seeking prompts with high accuracy, including under held-out encoding transformations. In a small synthetic multi-turn suite, cumulative accounting detects attacks that per-turn detectors miss. These results are preliminary: the multi-turn benchmark is in-house and small, the activation method requires white-box access, and the information estimator provides a practical signal rather than a formal upper bound. Still, the results suggest that credential-exfiltration defenses should combine pre-output monitoring, calibrated canary detection, and temporal leakage accounting rather than relying only on text-level output filters.
短期洪水予測のための物理学に基づいた機械学習
正確な洪水予測は、災害リスクを軽減し、コミュニティを保護するために不可欠です。ただし、純粋にデータ駆動型の機械学習モデルは、データが不足している環境では苦労することが多く、基本的な水文学原則に違反する可能性があります。標準の Long Short-Term Memory (LSTM) ネットワークは、特に極端な気象条件を推定する場合に、物理的に矛盾した予測を生成する可能性があります。これらの制限に対処するために、私たちは、水文学的な知識を LSTM モデルの損失関数に直接組み込む、物理情報に基づく機械学習 (PIML) フレームワークを提案します。具体的には、トレンド アライメント制約により、降水量と流量の傾向間の方向性の不一致にペナルティが課され、複雑な流体力学方程式を必要とせずにモデルの堅牢性が向上します。この正則化により、トレーニング データが限られている場合でも、物理的に妥当な水路図の動作をモデルが学習できるようになり、洪水のピーク時の信頼性が向上します。実験結果は、提案された物理情報モデルがデータ不足の設定において標準の LSTM ベースラインを上回り、利用可能なデータのわずか 5% でトレーニングされた場合にナッシュ・サトクリフ効率 (NSE) が 0.20 から 0.23 に増加することを示しています。シミュレーションされた極端な気候シナリオでの追加のストレス テストでは、ベースライン モデルが不安定な挙動を示すのに対し、物理学に基づいたモデルは方向の一貫性と物理的妥当性を維持していることが実証されました。データが限られているため、極端なピークの大きさを正確に予測することは依然として困難ですが、提案されたアプローチは、純粋にデータ駆動型のモデルによくある非物理的な変動を大幅に軽減します。これらの発見は、単純な物理的制約によって、リアルタイム洪水予測のための深層学習モデルの信頼性が大幅に向上し、計測されていない盆地や進化する気候条件に対する実用的なソリューションを提供できることを示しています。
原文 (English)
Physics-Informed Machine Learning for Short-Term Flood Prediction
Accurate flood forecasting is essential for mitigating disaster risks and protecting communities. However, purely data-driven machine learning models often struggle in data-scarce environments and may violate fundamental hydrological principles. Standard Long Short-Term Memory (LSTM) networks can generate physically inconsistent predictions, particularly when extrapolating to extreme weather conditions. To address these limitations, we propose a Physics-Informed Machine Learning (PIML) framework that incorporates hydrological knowledge directly into the loss function of an LSTM model. Specifically, a Trend Alignment constraint penalizes directional inconsistencies between precipitation and discharge trends, improving model robustness without requiring complex hydrodynamic equations. This regularization encourages the model to learn physically plausible hydrograph behavior, even with limited training data, while enhancing reliability during peak flood events. Experimental results show that the proposed physics-informed model outperforms a standard LSTM baseline in data-scarce settings, increasing the Nash-Sutcliffe Efficiency (NSE) from 0.20 to 0.23 when trained on only 5% of the available data. Additional stress tests under simulated extreme climate scenarios demonstrate that the baseline model exhibits unstable behavior, whereas the physics-informed model maintains directional consistency and physical plausibility. Although accurately predicting extreme peak magnitudes remains challenging with limited data, the proposed approach substantially reduces unphysical fluctuations common in purely data-driven models. These findings demonstrate that simple physical constraints can significantly improve the reliability of deep learning models for real-time flood forecasting, offering a practical solution for ungauged basins and evolving climate conditions.
EvalStop: ワールド フィードバックを使用して、マルチテナント RLHF プラットフォームにおける報酬の過剰最適化を検出および修正する
Cloud LLM 微調整プラットフォームは RLHF ワークロードにますます対応しており、学習された報酬モデルが人間の品質の代用として最適化されています。 Gao らのように(2023) は、このプロキシは、報酬の過剰最適化として知られる現象である持続的な最適化圧力の下で、世界のフィードバック (下流の評価指標) から乖離することを示しました。既存のプラットフォーム スケジューラはこの相違を無視しています。非千里眼スケジューラは品質信号なしで JCT を最適化し、SLAQ スタイルの品質認識スケジューラはトレーニング損失 (ハッキングによって単調に低下する弱いプロキシ) を使用し、古典的なジョブごとの早期停止では人間による監視が必要であり、共有 GPU を解放しません。私たちは、evalStop を提案します。これは、k 回連続して eval スコアが低下したときにジョブを終了し、GPU を解放し、最適なチェックポイントを保持し、任意のベース スケジューラに委任する、コンポーザブルなスケジューリング プリミティブです。私たちは、スケジューラレベルの早期停止を検出問題としてフレーム化し、RLHF ワークロードが報酬ハッキングと構造的に健全な実行を混合し、スケジューラから隠蔽されたグランドトゥルースラベルを使用した離散イベントシミュレータでそれを評価します。 RLHF の負荷が高いワークロード (RLHF 80%、GPU 64 基) では、EvalStop は精度 98% / リコール 99% / FPR 1.5% を達成し、SRTF-Est と比較して JCT を 9% 改善し、無駄なコンピューティングを 22% 削減します (p<0.05)。些細な固定進捗と損失プラトーの競合他社は、健全な RLHF で 65% の FPR を被るか、真のハッキング ケースの半分以上を見逃すかのどちらかです。ゲインはテストされたすべてのベース スケジューラにわたって構成され (9 ~ 25% の JCT)、検出品質は評価ノイズ (ノイズ std <= 0.05 で少なくとも 91% の精度) およびハッキングのベース レート (20 ~ 80% のハッキング部分で少なくとも 89% の精度) の下で安定しています。
原文 (English)
EvalStop: Using World Feedback to Detect and Correct Reward Overoptimization in Multi-Tenant RLHF Platforms
Cloud LLM fine-tuning platforms increasingly serve RLHF workloads, where a learned reward model is optimized as a proxy for human quality. As Gao et al. (2023) showed, this proxy diverges from world feedback (downstream eval metrics) under sustained optimization pressure, a phenomenon known as reward overoptimization. Existing platform schedulers ignore this divergence: non-clairvoyant schedulers optimize JCT without any quality signal, SLAQ-style quality-aware schedulers use training loss (a weaker proxy that drops monotonically through hacking), and classical per-job early stopping requires human monitoring and does not free shared GPUs. We propose EvalStop, a composable scheduling primitive that terminates jobs on k consecutive eval-score declines, releases GPUs, preserves the best checkpoint, and delegates to any base scheduler. We frame scheduler-level early stopping as a detection problem and evaluate it in a discrete-event simulator whose RLHF workload mixes reward-hacking and structurally healthy runs, with ground-truth labels hidden from schedulers. On RLHF-heavy workloads (80% RLHF, 64 GPUs), EvalStop achieves precision 98% / recall 99% / FPR 1.5% while improving JCT by 9% and cutting wasted compute by 22% over SRTF-Est (p<0.05). Trivial fixed-progress and loss-plateau competitors either incur 65% FPR on healthy RLHF or miss over half of true hacking cases. Gains compose across every base scheduler tested (9-25% JCT) and detection quality stays stable under eval noise (precision at least 91% at noise std <= 0.05) and hacking base rate (precision at least 89% across 20-80% hacking fractions).
ADAPTOOD: 分布外 ECG 時系列モデルの不確実性を考慮した微調整
トレーニングに使用されるデータ サンプルは、微調整や展開中に発生するデータ サンプルとは異なることが多く、ML モデルは有望ですが、注釈付きの小さなデータセットしか利用できない場合、そのパフォーマンスは依然として限定的です。さまざまなセンサー、母集団、アプリケーション設定によって引き起こされる分布の変化では、パフォーマンスが低下することがよくあります。事前トレーニングは役立ちますが、現実世界の設定ではモデルが分布外 (OOD) データに頻繁に遭遇し、堅牢性の低下につながります。既存の適応手法は通常、固定的な分布シフトを想定しており、複数の種類や重大度が発生した場合に困難を伴います。特に、彼らはシフトの重大性を見落としており、たとえば、慣れ親しんだ大規模なデータセットへの適応を、新しいタスクを伴う小規模なデータセットへの適応と同じように扱うため、一般化が制限されます。これに対処するために、データの不確実性を活用して分布シフトの深刻度を定量化し、時系列の微調整をガイドする新しいフレームワークである ADAPTOOD を提案します。この不確実性は、ターゲット展開分布からのサンプルがトレーニング前の分布からどれだけ強く逸脱しているかを測定し、OOD 重大度の直接的なシグナルを提供します。私たちのフレームワークは、この不確実性を低ランクのモデルの更新と適応型ハイパーパラメーターの最適化と組み合わせて、適応を改善します。 ADAPTOOD は、OOD タスクにおいて既存の方法よりも最大 7% 高い精度と 12.9% 高い精度を達成し、分布シフトの重大度が増加しても強力なパフォーマンスを維持することを示します。
原文 (English)
ADAPTOOD: Uncertainty-Aware Fine-Tuning for Out-of-Distribution ECG Time Series Models
Data samples used for training often differ from those encountered during fine-tuning and deployment, and while ML models show promise, their performance remains limited when only small annotated datasets are available. Performance often degrades under distribution shifts caused by diverse sensors, populations, and application settings. Although pre-training helps, models frequently encounter out-of-distribution (OOD) data in real-world settings, leading to reduced robustness. Existing adaptation methods usually assume fixed distribution shifts and struggle when multiple types or severities occur. In particular, they overlook shift severity, for example treating adaptation to a large familiar dataset the same as adaptation to a small dataset with a new task, which limits generalisation. To address this, we propose ADAPTOOD, a novel framework that leverages data uncertainty to quantify distribution shift severity and guide fine-tuning for time series. This uncertainty measures how strongly samples from the target deployment distribution deviate from the pre-training distribution, providing a direct signal of OOD severity. Our framework combines this uncertainty with low-rank model updates and adaptive hyperparameter optimisation to improve adaptation. We show that ADAPTOOD achieves up to 7% higher accuracy and 12.9% higher precision than existing methods in OOD tasks, maintaining strong performance as distribution shift severity increases.
ニューロンを使用しないスマートな交通 -- 表形式の強化学習による公平な地下鉄ネットワークの拡張
私たちは、交通需要を満たすために地下鉄システムを拡張することに焦点を当てた交通ネットワーク設計問題 (TNDP) のサブセットである地下鉄ネットワーク拡張問題 (MNEP) に取り組みます。従来の方法は、検索スペースを削減するために専門家が定義した制約を必要とする、正確でヒューリスティックなアプローチに依存しています。最近、複雑な逐次意思決定プロセスにおける有効性により、深層強化学習 (Deep RL) が登場しましたが、依然として計算コストと環境コストが高く、解釈するには追加のエンジニアリングが必要です。 MNEP 問題は、Deep RL 手法を必要としないほど十分に小さいことを示します。 MNEP を非マルコフ報酬決定プロセス (NMRDP) として再定式化し、表形式の RL を使用して、大幅に少ないトレーニング エピソードで同様のパフォーマンスを達成し、さらに優れた解釈可能性を提供します。さらに、報酬関数に社会的公平性の基準を組み込み、効率と公平性に重点を置き、手法の多用途性を強調しています。西安とアムステルダムの現実世界の設定で評価された私たちの方法は、Deep RL との競争力を維持しながら、総エピソード数を平均 18 分の 1、総二酸化炭素排出量を 12 分の 1 削減します。このアプローチは、他の組み合わせ最適化問題への潜在的なアプリケーションを備えた、複製可能、モジュール式、解釈可能な、リソース効率の高いソリューションを提供します。
原文 (English)
Smart Transportation Without Neurons -- Fair Metro Network Expansion with Tabular Reinforcement Learning
We tackle the Metro Network Expansion Problem (MNEP), a subset of the Transport Network Design Problem (TNDP), which focuses on expanding metro systems to satisfy travel demand. Traditional methods rely on exact and heuristic approaches that require expert-defined constraints to reduce the search space. Recently, deep reinforcement learning (Deep RL) has emerged due to its effectiveness in complex sequential decision-making processes-it remains, however, computationally expensive, environmentally costly, and requires additional engineering to interpret. We show that MNEP problems are small enough to not require Deep RL methods. Reformulating the MNEP as a Non-Markovian Rewards Decision Process (NMRDP), we use tabular RL to achieve similar performance with significantly fewer training episodes, additionally offering greater interpretability. Additionally, we incorporate social equity criteria into the reward functions, focusing on efficiency and fairness, highlighting the versatility of our method. Evaluated in real-world settings-Xi'an and Amsterdam-our method reduces total episodes by a factor of 18 and total carbon emissions by a factor of 12 on average, while remaining competitive with Deep RL. This approach offers a replicable, modular, interpretable, and resource-efficient solution with potential applications to other combinatorial optimization problems.
MimeLens: バイナリ フラグメントの位置に依存しないコンテンツ タイプの検出
ファイル タイプの分類は、マルウェアのトリアージ、フォレンジック カービング、パケット インスペクション、ストレージ インデックス作成などの多くのワークフローの基礎となります。 Google の Magika などの学習型システムは、既知のオフセットでのファイル全体へのアクセスを前提としているため、単一パケットのペイロード、ヘッダーのない彫刻されたフラグメント、ランダムなディスク ブロック、またはチャンク アップロードなど、これらのタスクの多くが実際に生成する入力を中断します。 MimeLens は、標準コンテキストおよびショートコンテキストのバリアントで、各ファイル内の均一にランダムなオフセットでサンプリングされたウィンドウからのバイナリ コンテンツで事前トレーニングされた小さな BERT スタイル エンコーダ ファミリであり、特権的なファイル先頭位置はありません。バイト チャンクはファイル内のどこからでも入ります。ヘッダーも固定サイズも必要ありません。 libmagic の 125 の MIME ラベルの 1 つが出力されます。完全なファイルのクリーンヘッドでは、MimeLens は、libmagic ラベル付きデータで +10.7 pp のトップ 1 で Magika v1.1 を上回り、単一のミッドストリーム UDP パケットから、ランダムなミッドファイル ディスク ブロック上で libmagic と Magika の 2 倍以上の正確さで、Magicka ができない場所を分類し続けます。コストは遅延です。MimeLens は、消費者向け GPU やバッチでは同等ですが、CPU 上では Magika よりもサンプルごとにおよそ 1 ~ 2 桁遅く実行されます。トレーニングされたすべてのチェックポイントは、Hugging Face (mjbommar/mimelens-001-*) でリリースされます。
原文 (English)
MimeLens: Position-Agnostic Content-Type Detection for Binary Fragments
File-type classification underlies many workflows like malware triage, forensic carving, packet inspection, and storage indexing. Learned systems such as Google's Magika assume whole-file access at a known offset, so they break on the inputs many of these tasks actually produce, like a single packet payload, a header-less carved fragment, a random disk block, or a chunked upload. We introduce MimeLens, a family of small BERT-style encoders pretrained on binary content from windows sampled at a uniformly random offset within each file, with no privileged head-of-file position, in standard- and short-context variants. A byte chunk goes in from anywhere in a file, no header needed and no fixed size; out comes one of libmagic's 125 MIME labels. On the clean head of complete files, MimeLens beats Magika v1.1 by +10.7 pp top-1 on libmagic-labeled data, and it keeps classifying where Magika cannot: from a single mid-stream UDP packet, and more than twice as accurately as libmagic and Magika on random mid-file disk blocks. The cost is latency: MimeLens runs roughly one to two orders of magnitude slower per sample on CPU than Magika, though it matches on consumer GPUs or in batch. All trained checkpoints are released on Hugging Face (mjbommar/mimelens-001-*).
ドメインとモデルにわたる AI 生成テキスト検出における言語的特徴の系統的分析
解釈可能な言語特徴は、特に専門家でないユーザーにとって、特定のテキストが機械生成のように見える理由を説明するための有望なアプローチを提供します。ただし、LLM で生成されたテキストを特徴が確実に示しているという既存の調査結果は、特徴セット、モデル、テキスト ドメイン全体で断片化されたままです。このギャップに対処するために、AI が生成したテキストを特徴付けるための言語信号の堅牢性を評価する大規模な実証研究を実施します。私たちの分析では、クロスモデルおよびクロスドメイン一般化設定の下で、27 の LLM と 10 のテキスト ドメインからの出力にわたる 284 の解釈可能な言語特徴をカバーしています。言語的特徴のみに基づく分類器が、AI によって生成されたテキストと人間が書いたテキストを確実に区別できることを示します。ただし、これまでに提案された指標の多くは、語彙の豊富さの尺度を除いて、コンテキストに強く依存することが証明されており、モデル ファミリとテキスト ドメイン全体にわたって堅牢なシグナルのままです。これらの結果は、どの言語信号がコンテキスト全体で一般化するかを示し、AI 生成言語のより信頼性が高く解釈可能な分析の基盤を提供します。
原文 (English)
A Systematic Analysis of Linguistic Features in AI-Generated Text Detection Across Domains and Models
Interpretable linguistic features offer a promising approach for explaining why a given text appears machine-generated, particularly for non-expert users. However, existing findings on which features reliably indicate LLM-generated text remain fragmented across feature sets, models, and text domains. To address this gap, we conduct a large-scale empirical study assessing the robustness of linguistic signals for characterizing AI-generated text. Our analysis covers 284 interpretable linguistic features across outputs from 27 LLMs and ten text domains under cross-model and cross-domain generalization settings. We show that classifiers based solely on linguistic features can reliably distinguish AI-generated from human-written text. However, many previously proposed indicators prove strongly context-dependent, with the exception of measures of lexical richness, which remain robust signals across model families and text domains. These results demonstrate which linguistic signals generalize across contexts and provide a foundation for more reliable, interpretable analyses of AI-generated language.
強化学習における正確なアンラーニング
私たちは強化学習における \emph{正確なアンラーニング} の問題を定式化します。その目的は、削除リクエストに応じてユーザーのデータを削除できる効率的なフレームワークを設計することです。つまり、アンラーニング後のオンライン学習者の出力は、削除されたユーザーが学習者と対話しなかった場合に生成される出力と \emph{区別できません}。 $\rho >0$ の場合、 $\rho$-TV 安定で、期待される計算コストがゼロから再学習する計算コストの $\rho \sqrt{\ln T}$ の一部にすぎない正確な非学習手順をサポートする強化学習 (RL) アルゴリズムが存在することを示します。我々は、表形式マルコフ決定プロセス(MDP)用の $\rho$-TV-stable RL アルゴリズムを構築します。これは $\mathcal{O}(H^2 \sqrt{SAT} + H^3 S^2 A + {H^{2.5} S^2 A}/{\rho})$ のリグレス限界を達成します。ここで、$S、A、H$、$T$ は状態数、アクション数、エピソード ホライズンを示します。とエピソード数がそれぞれ異なります。また、$\rho$-TV-stable RL アルゴリズムに対して $\Omega(H\sqrt{\!SAT}\! +\! {SAH}/{\rho})$ の下限も確立し、アルゴリズムがほぼミニマックス最適であることを示しています。
原文 (English)
Exact Unlearning in Reinforcement Learning
We formulate the problem of \emph{exact unlearning} in reinforcement learning, where the goal is to design an efficient framework that enables the removal of any user's data upon deletion request, i.e., the online learner's output after unlearning is \emph{indistinguishable} from what would have been produced had the deleted user never interacted with the learner. For any $\rho >0$, we show that there exists a reinforcement learning (RL) algorithm that is $\rho$-TV-stable and supports an exact unlearning procedure whose expected computational cost is only a $\rho \sqrt{\ln T}$ fraction of the computational cost of retraining from scratch. We construct such a $\rho$-TV-stable RL algorithm for tabular Markov decision processes (MDPs), which achieves a regret bound of $\mathcal{O}(H^2 \sqrt{SAT} + H^3 S^2 A + {H^{2.5} S^2 A}/{\rho})$, where $S, A, H$, and $T$ denote the number of states, the number of actions, the episode horizon, and the number of episodes, respectively. We also establish a lower bound of $\Omega(H\sqrt{\!SAT}\! +\! {SAH}/{\rho})$ for $\rho$-TV-stable RL algorithms, showing that our algorithm is nearly minimax optimal.
2つのアドバンテージフィールド
オフラインの目標条件付き強化学習では、長期的な到達可能性の推定とローカル アクションの比較の両方が必要です。デュアル目標表現は、グローバルな目標の到達可能性を取得する値フィールドを提供しますが、特定の状態でどのアクションが優先されるべきかを直接指定するものではありません。我々は、双線形二重値モデルをローカルアドバンテージ信号に変えるポリシー抽出手法であるデュアルアドバンテージフィールドを提案します。双線形双対パラメータ化では、目標の埋め込みは状態表現に対する値フィールドの勾配です。 DAF は、アクションによって引き起こされる割り引かれたフィーチャの変位を予測し、この変位と目標の方向との整合性によってアクションをスコア化するアクション効果モデルを学習します。実現可能なケースでは、このスコアは目標条件付きベルマンアドバンテージに等しく、標準的なローカル政策改善保証が得られます。 OGBench の移動、操作、パズルのタスクでは、DAF は集計 RLiable メトリクスを改善し、局所的に正しいアクションが最終目標に向かう直接的な動きとは異なる設定で強力にパフォーマンスを発揮します。
原文 (English)
Dual Advantage Fields
Offline goal-conditioned reinforcement learning requires both long-horizon reachability estimates and local action comparisons. Dual goal representations provide value fields that capture global goal reachability, but they do not directly specify which action should be preferred at a given state. We propose Dual Advantage Fields, a policy-extraction method that turns a bilinear dual value model into a local advantage signal. Under bilinear dual parameterization, the goal embedding is the gradient of the value field with respect to the state representation. DAF learns an action-effect model that predicts the discounted feature displacement induced by an action and scores actions by the alignment between this displacement and the goal direction. In the realizable case, this score equals the goal-conditioned Bellman advantage, yielding a standard local policy-improvement guarantee. On OGBench locomotion, manipulation, and puzzle tasks, DAF improves aggregate RLiable metrics and performs strongly in settings where locally correct actions differ from direct movement toward the final goal.
CTF4Science Lorenz Challenge のメトリクスを意識したハイブリッド予測
CTF4Science Lorenz チャレンジに対するアプローチについて説明します。このベンチマークは、9 つのタスク ペアにわたって、短期予測、長時間分布マッチング、軌道再構築を組み合わせたベンチマークです。重要な発見は、単一のモデル ファミリがすべての指標を支配していないということです。代わりに、各計量ファミリーに異なる予測子を割り当てる計量認識ハイブリッド システムを構築しました。(1) 全軌道再構築のための合成事前トレーニング済みデノイザー、(2) 最初の 20 予測ステップに対するローレンツ ODE フィッティングと軌道シューティング、(3) 長時間評価のための合成ローレンツ ライブラリを使用したヒストグラム テール置換。このシステム ファミリからの代表的な成熟した投稿は、公開リーダーボードで 83.83551 のスコアを獲得し、同じアイデアの小規模なフォローアップ スタックは 83.85529 に達しました。私たちがよりクリーンな中間システムに焦点を当てるのは、このシステムが完全なメソッドを捕捉しつつ、再現と分析が容易な一方で、最終的な提出は同じバックボーンの保守的な拡張として理解できるためです。
原文 (English)
Metric-Aware Hybrid Forecasting for the CTF4Science Lorenz Challenge
We describe our approach to the CTF4Science Lorenz challenge, a benchmark that mixes short-horizon forecasting, long-time distribution matching, and trajectory reconstruction across nine task pairs. The key discovery is that no single model family dominated all metrics. Instead, we built a metric-aware hybrid system that assigned a different predictor to each metric family: (1) synthetic-pretrained denoisers for full-trajectory reconstruction, (2) Lorenz ODE fitting and trajectory shooting for the first 20 forecast steps, and (3) histogram-tail substitution using synthetic Lorenz libraries for long-time evaluation. A representative mature submission from this system family scored 83.83551 on the public leaderboard, and a small follow-up stack of the same ideas reached 83.85529. We focus on the cleaner intermediate system because it captures the full method while remaining simple enough to reproduce and analyze, while the final submission can be understood as a conservative extension of the same backbone.
公証されたエージェント: AI エージェントのアクションに対する受信者が証明した機密受領書
現在の AI エージェントの可観測性は構造的に危険にさらされています。アクティビティ ログを生成するエンティティは、アクティビティが記録されるエンティティと同じです。侵害されたエージェントまたはバグのあるエージェントは、自身のトレースを省略、変更、または捏造する可能性があり、エージェントを実行するオペレータには改ざんを検出する独自の方法がありません。私たちは、信頼境界を反転することでこれを解決するプロトコルのクラスを提案します。エージェントの呼び出しを受信するサービスは、独自のキーを使用して観察した内容の受信に署名し、エージェントの所有者に対して受信を暗号化し、それを公開の透明性ログに公開します。所有者は、エージェントやそのオペレーターを信頼せずに、改ざん証拠の証跡を再構築します。このクラスを Sello としてインスタンス化します。これは、現在のシステムには存在しない 4 つのプロパティを組み合わせたプロトコルです。(P1) 受信者側の署名、(P2) JWS 経由で認可トークンにバインドされた所有者公開鍵への HPKE 暗号化、(P3) 証人署名付きマークル ログへの公開、(P4) トークン参照による所有者側の検出です。私たちはプロトコルを説明し、エージェントとそのオペレーターを制御する敵対者の下でそのセキュリティを分析し、暗号操作のマイクロベンチマークを提示し、隣接する受信プロトコル作業 (Signet、AgentROA、Agent Passport System、draft-farley-acta、SCITT) の中に Sello を位置づけます。抑制攻撃、サービスの共謀、採用インセンティブの問題などの既知の制限について説明します。
原文 (English)
Notarized Agents: Receiver-Attested Confidential Receipts for AI Agent Actions
Current AI agent observability is structurally compromised: the entity producing the activity log is the same entity whose activity is being logged. A compromised or buggy agent can omit, alter, or fabricate its own traces, and the operator running the agent has no independent way to detect tampering. We propose a class of protocols that resolves this by inverting the trust boundary: the service that receives an agent's call signs a receipt of what it observed using its own key, encrypts the receipt to the agent's owner, and publishes it to a public transparency log. The owner reconstructs a tamper-evident trail without trusting the agent or its operator. We instantiate the class as Sello, a protocol combining four properties absent in any current system: (P1) receiver-side signing, (P2) HPKE encryption to an owner public key bound to the authorization token via JWS, (P3) publication to a witness-cosigned Merkle log, and (P4) owner-side discovery by token reference. We describe the protocol, analyze its security under an adversary that controls the agent and its operator, present microbenchmarks of the cryptographic operations, and situate Sello among adjacent receipt-protocol work (Signet, AgentROA, Agent Passport System, draft-farley-acta, SCITT). We discuss known limitations including the suppression attack, service collusion, and the adoption-incentive problem.
DetectZoo: テキスト、オーディオ、画像モダリティにわたる AI 生成コンテンツ検出のための統合ツールキット
生成モデルの人気と能力の高まりにより、人間が生成したコンテンツと機械が生成したコンテンツの区別がなくなり、テキスト、画像、音声にわたる検出に関する一連の研究が増えています。入手可能な検出器のほとんどは商用ソフトウェアであるか、オープンソースの場合は特注の前処理、評価プロトコル、評価メトリクスを備えた互換性のないコードベースが付属しているため、その採用、公正な比較、再現が非常に困難になっています。この重大なギャップに対処するために、テキスト、オーディオ、画像モダリティにわたる AI 生成コンテンツ検出のための統一インターフェイスを提供するように設計された、この種初の拡張可能なツールキットである DetectZoo を導入します。 DetectZoo は、データの取り込みと前処理からモデルの評価に至るまで、完全な経験的パイプラインを標準化し、最先端の検出器を体系的にベンチマークするための一貫したフレームワークを研究者に提供します。多様な公開データセットとベースライン検出アルゴリズムを単一の統一 API に統合することで、当社のツールキットは厳密で再現可能な評価を容易にします。 DetectZoo は、61 の検出器のリファレンス実装、22 のベンチマーク データセット用のネイティブ ローダー、および共通のインターフェイスを通じて複数のメトリクスを報告する標準化された評価パイプラインを提供します。各検出器は自己完結型ですが、同じインターフェイスからアクセスでき、事前トレーニングされた重みを自動的にキャッシュし、元の公開結果を再現します。 DetectZoo は、マルチモーダル AI フォレンジックの参入障壁を下げ、研究者がドメイン間のパフォーマンスのギャップを特定できるようにし、堅牢で汎用性のある検出技術の開発を加速します。オープンソース リポジトリと包括的なドキュメントは https://github.com/sadjadeb/DetectZoo で公開されており、パッケージは pip install detectzoo 経由でインストールできます。
原文 (English)
DetectZoo: A Unified Toolkit for AI-Generated Content Detection Across Text, Audio, and Image Modalities
The growing popularity and capacity of generative models have eroded the distinction between human and machine-generated content, motivating a growing body of work on detection across text, images, and audio. Most available detectors are either commercial software or, if open-source, come with incompatible codebases with bespoke preprocessing, evaluation protocols, and evaluation metrics, which make their adoption, fair comparison, and reproduction quite difficult. To address this critical gap, we introduce DetectZoo, a first-of-its-kind, extensible toolkit designed to provide a unified interface for AI-generated content detection across text, audio, and image modalities. DetectZoo standardizes the complete empirical pipeline, from data ingestion and preprocessing to model assessment, offering researchers a cohesive framework to benchmark state-of-the-art detectors systematically. By integrating diverse public datasets and baseline detection algorithms under a single, unified API, our toolkit facilitates rigorous and reproducible evaluation. DetectZoo provides reference implementations of 61 detectors, native loaders for 22 benchmark datasets, and a standardized evaluation pipeline that reports multiple metrics through a common interface. Each detector is self-contained yet accessible through the same interface, automatically caches pretrained weights, and reproduces the original published results. DetectZoo lowers the barrier to entry for multi-modal AI forensics, enabling researchers to identify performance gaps across domains and accelerating the development of robust, generalizable detection techniques. The open-source repository and comprehensive documentation are publicly available at https://github.com/sadjadeb/DetectZoo, and the package can be installed via pip install detectzoo.
PerceptTwin: 反復 LLM 計画と検証のためのセマンティック シーンの再構築
シミュレーション環境は、ロボット ポリシーの学習と計画の検証と検証の両方に役立ちます。従来、シミュレーションを作成するプロセスは面倒なものでした。ロボットが動作する個々の環境に合わせてオーダーメイドのシミュレーション環境を作成することは、まったく不可能でした。この研究では、ロボットの認識スタックによって生成されたセマンティック シーン表現から直接インタラクティブ シミュレーションを構築する完全自動パイプラインである PerceptTwin を紹介します。 PerceptTwin は、オープン語彙オブジェクト マップと 3D アセット生成、アフォーダンス予測、および常識的な条件チェックを組み合わせます。これらのインタラクティブなシミュレーションを使用すると、ロボット ハードウェアで実行される前に計画を検証し、改良することができます。 AI 調整の文献から借用して、計画の正確さと人間の好みとの調整を検証する LLM ジャッジも紹介します。実験では、PerceptTwin のフィードバックにより、LLM プランナーが計画を改良し、安全性を強化し、有害なブラックボックス プロンプト攻撃に抵抗できることが示されています。私たちの一連のタスクでは、PerceptTwin により、GPT5、GPT5Mini、および GPT5Nano プランナーの計画の成功率が平均約 39% 向上しました。さらに、PerceptTwin は、スキルの前提条件が満たされていないために失敗した計画について、人間による計画の検証を平均で最大 18% 改善します。私たちの結果は、より安全で信頼性の高いロボット計画の基盤として、ロボットの知覚からのオープンボキャブラリーシーンシミュレーションの可能性を実証しています。
原文 (English)
PerceptTwin: Semantic Scene Reconstruction for Iterative LLM Planning and Verification
Simulation environments are useful for both robot policy learning and planning verification and validation. Traditionally, the process of creating a simulation was onerous. Creating a bespoke simulation environment for each individual environment that a robot would operate in was simply infeasible. In this work, we introduce PerceptTwin, a fully automatic pipeline that constructs interactive simulations directly from semantic scene representations produced by a robot's perception stack. PerceptTwin combines open-vocabulary object maps with 3D asset generation, affordance prediction, and commonsense condition checking. These interactive simulations can be used to validate and refine plans before they are executed on the robot hardware. Borrowing from the AI alignment literature, we also introduce an LLM judge that verifies plan correctness and alignment with human preferences. Experiments show that PerceptTwin feedback allows LLM planners to refine plans, enhance safety, and resist harmful black-box prompting attacks. In our suite of tasks, PerceptTwin improves plan success by an average of approximately 39% for GPT5, GPT5Mini, and GPT5Nano planners. Additionally, PerceptTwin also improves human plan verification by up to 18% on average for plans that fail due to unfilled skill preconditions. Our results demonstrate the potential of open-vocabulary scene simulation from robot perception as a foundation for safer, more reliable robot planning.
細胞複合体における増分層コホモロジー: 境界のあるローカル ジオメトリでの O(1)-in-n 遅延編集処理
我々は、有限次元の細胞層を備えた動的に進化する1次元細胞複合体上の最初の層コホモロジー $H^1(X; \mathcal{F})$ を増分的に維持するためのアルゴリズムフレームワークを提案します。共有境界行列の因数分解による $H^1$ の古典的な計算には $O(n^3)$ の時間が必要です。 $m$ の編集のストリームによって複雑さが進化すると、各編集後の完全な再計算には $O(mn^3)$ のコストがかかります。有界のローカル ジオメトリの仮定 (有界セル サイズ $v_{\max}$、有界ストーク寸法 $d$、有界神経次数 $D$) の下では、各編集 (頂点挿入、エッジ挿入、制限マップ更新) は、ローカル共有境界ブロックの有界セットにのみ影響します。したがって、このアルゴリズムは、複素数の合計サイズ $n$ に対して ($n$ から独立した定数として扱われるローカル ジオメトリ パラメーター $v_{\max}$、$d$、および $D$ のコスト多項式を使用して) 遅延ストリーミング編集を $O(1)$ 時間で処理し、ローカル固有ソルブと Mayer-Vietoris グローバル アセンブリを同期ポイント (フラッシュ) まで遅らせます。同期時に、維持される状態は、分割された層モデルの対応するバッチ アセンブリと一致します。すべてのバッチ検証された実行でゼロの測定ドリフトが観察されました ($V = 10^6$ による)。また、セル分解のための償却 $O(|E|)$ ストリーミング構造を与え、分割されていない非自明な層 ($d \geq 2$、非同一性制限マップ) が同じ局所性を認めないと主張する敵対的代数 RAM バリアについて議論します。最大 $5 \times 10^6$ の頂点と $1.7 \times 10^7$ のストリーミング編集を使用した Barabasi-Albert グラフの実験では、編集ごとの遅延更新レイテンシーの中央値が 35 $\mu$s (フラッシュを除く) であることがわかりました。クエリ時間 (同期時のグローバル アセンブリ) は、実装されたフルトラバーサル パスのフラッシュごとに $O(n)$ です。正確な同期コストは別途報告されます。
原文 (English)
Incremental Sheaf Cohomology on Cellular Complexes: O(1)-in-n Lazy Edit Processing under Bounded Local Geometry
We present an algorithmic framework for incremental maintenance of first sheaf cohomology $H^1(X; \mathcal{F})$ on dynamically evolving 1-dimensional cellular complexes equipped with finite-dimensional cellular sheaves. The classical computation of $H^1$ via factorization of the coboundary matrix requires $O(n^3)$ time; when the complex evolves with a stream of $m$ edits, full recomputation after each edit costs $O(mn^3)$. Under a bounded local geometry assumption -- bounded cell size $v_{\max}$, bounded stalk dimension $d$, and bounded nerve degree $D$ -- each edit (vertex insertion, edge insertion, restriction map update) affects only a bounded set of local coboundary blocks. The algorithm therefore processes lazy streaming edits in $O(1)$ time with respect to the total complex size $n$ (with cost polynomial in the local geometry parameters $v_{\max}$, $d$, and $D$, which are treated as constants independent of $n$), deferring local eigensolves and Mayer-Vietoris global assembly to synchronization points (Flush). At synchronization, the maintained state agrees with the corresponding batch assembly of the partitioned sheaf model; we observe zero measured drift in all batch-verified runs (through $V = 10^6$). We also give an amortized $O(|E|)$ streaming construction for the cellular decomposition and discuss an adversarial algebraic-RAM barrier arguing that unpartitioned non-trivial sheaves ($d \geq 2$, non-identity restriction maps) do not admit the same locality. Experiments on Barabasi-Albert graphs with up to $5 \times 10^6$ vertices and $1.7 \times 10^7$ streaming edits show 35 $\mu$s median lazy per-edit update latency (excluding flush); query time (global assembly at synchronization) is $O(n)$ per flush in the implemented full-traversal path. Exact synchronization costs are reported separately.
MM-BizRAG: 汎用エンタープライズ Q&A 向けのマルチモーダル検索拡張生成の再考
マルチモーダル検索拡張生成 (MM-RAG) の最近の進歩は、最小限の解析に移行し、検索埋め込みの生成と回答の生成にはページレベルの画像に依存しています。この傾向は効率的ではありますが、複雑な企業ドキュメント内の豊富で構造化された情報の明示的な処理を無視することが多く、その代わりに、そのような構造を暗黙的に捕捉する事前トレーニング済みの埋め込みまたはビジョン言語モデルに依存します。この作業では、より直接的なアプローチを採用しています。MM-BizRAG は、方向固有の取り込みパイプラインを通じてドキュメントを動的にルーティングするドキュメント構造認識分割を介してドキュメント構造をプロアクティブに抽出および表現し、垂直方向に構造化されたドキュメント (レポートなど) には明示的なレイアウト認識解析を適用し、水平方向に構造化されたドキュメント (スライド デッキなど) には全体的なページ レベルの表現を適用します。プレースホルダーベースの位置調整を備えた統合された LLM 駆動のアーティファクト変換パイプラインにより、自然な読み取り順序が維持される一方、推論時のマルチモーダル アセンブリにより検索表現が生成コンテキストから切り離され、微調整を必要とせずに、より豊富で根拠のある回答が可能になります。大規模で異種混合のエンタープライズ データセットと 2 つの公開ベンチマーク (SlideVQA および FinRAGBench-V) での実験を通じて、MM-BizRAG は常に最先端のビジョン中心のベースラインを最大 32% ポイント上回るパフォーマンスを示し、特にレポート スタイルのレイアウトで大幅な向上を実現しました。さらに、人間によるより強力な調整を実現しながら、RAGChecker のコストを半減する、きめ細かい生成呼び出しのためのシングルコール LLM ジャッジ メトリクスである FastRAGEval を導入します。
原文 (English)
MM-BizRAG: Rethinking Multimodal Retrieval-Augmented Generation for General Purpose Enterprise Q&A
Recent advances in multimodal retrieval-augmented generation (MM-RAG) have shifted toward minimal parsing, relying on page-level images for producing retriever embeddings and for answer generation. While efficient, this trend often neglects explicit handling of the rich, structured information in complex enterprise documents, instead depending on pre-trained embeddings or vision-language models to implicitly capture such structure. In this work, we take a more direct approach: MM-BizRAG proactively extracts and represents document structure via a document structure-aware split that dynamically routes documents through orientation-specific ingestion pipelines, applying explicit layout-aware parsing for vertically structured documents (e.g., reports) and holistic page-level representations for horizontally structured documents (e.g., slide decks). A unified LLM-driven artifact transformation pipeline with placeholder-based positional alignment preserves natural reading order, while inference-time multimodal assembly decouples retrieval representations from generation context, enabling richer, more grounded answers without any finetuning requirement. Through experiments on a large, heterogeneous enterprise dataset and two public benchmarks (SlideVQA and FinRAGBench-V), MM-BizRAG consistently outperforms state-of-the-art vision-centric baselines by up to 32% points, with especially strong gains on report-style layouts. Furthermore, we introduce FastRAGEval, a single-call LLM Judge metric for fine-grained generative recall that halves RAGChecker's cost while achieving stronger human alignment.
高速拡散言語モデルのデコードをサポートするトークンの公開
離散拡散言語モデルは、複数のマスクされた位置を並行して更新することでテキストを効率的に生成できますが、この並行性により品質と遅延のトレードオフが生じます。積極的なデコードでは相互に依存するトークンのコミットが早すぎる可能性がありますが、保守的なデコードでは多くのノイズ除去手順が必要になります。既存の方法では、信頼性または依存性の基準を使用して、どのトークンを公開しても安全であるかを判断することで、この緊張に対処しています。ただし、安全でないコミットを回避しても、残りのマスクされたシーケンスのデコードが容易になるとは限りません。不確実なトークンがマスクされたトークンに依存し、ノイズ除去ステップのボトルネックになる可能性があるためです。私たちは、拡散言語モデルの既存の並列デコード戦略の上に追加できる、トレーニング不要のモジュールである AXON を提案します。 AXON は、ベース デコーダを置き換えるのではなく、残りの不確実なマスクされたトークンを監視し、現在の状態が追加のコンテキストが必要であることを示唆する場合にのみ介入します。次に、どのトークンを公開するのが最も安全であるかという基準を、どの信頼できる公開が後のノイズ除去を最もよくサポートするかという基準に変更します。 AXON は、注意、不確実性、および信頼性のシグナルを使用して、不確実な位置が注目するアンカー、つまり不確実な位置が注目する自信のあるマスクされたトークンを選択します。複数の拡散言語モデルにわたる推論とコード生成のベンチマークに関する実験では、AXON が既存の並列デコーダーの品質と遅延のトレードオフを改善し、多くの場合、精度を維持または向上させながら関数評価の数を削減することが示されています。
原文 (English)
Supportive Token Revealing for Fast Diffusion Language Model Decoding
Discrete diffusion language models can generate text efficiently by updating multiple masked positions in parallel, but this parallelism introduces a quality-latency trade-off. Aggressive decoding may commit mutually dependent tokens too early, while conservative decoding requires many denoising steps. Existing methods address this tension by deciding which tokens are safe to reveal using confidence or dependency criteria. However, avoiding unsafe commits does not necessarily make the remaining masked sequence easy to decode, since uncertain tokens may depend on masked tokens, creating a bottleneck for denoising steps. We propose AXON, a training-free module that can be added on top of existing parallel decoding strategies for diffusion language models. Rather than replacing the base decoder, AXON monitors the remaining uncertain masked tokens and intervenes only when their current state suggests that additional context is needed. It then shifts the criterion from which tokens are safest to reveal to which confident reveals would best support later denoising. AXON selects anchors, confident masked tokens that uncertain positions attend to, using attention, uncertainty, and confidence signals. Experiments on reasoning and code-generation benchmarks across multiple diffusion language models show that AXON improves the quality-latency trade-off of existing parallel decoders, often reducing the number of function evaluations while maintaining or improving accuracy.
積極的な量子化のための Recover-LoRA: 合成データの知識蒸留による低ランク適応による 2 ビット言語モデルの精度の回復
2 ビット精度への積極的な重み量子化により、大規模言語モデル (LLM) 推論のスループットとメモリが大幅に向上しますが、通常は精度が大幅に低下します。これらの利点は、メモリ容量と帯域幅が主な制約となるエッジおよびオンデバイスの展開に特に関係します。この研究では、Recover-LoRA (もともと一般的なモデル重み破損のために開発された軽量でデータフリーの精度回復手法) を、超低ビット量子化の設定まで拡張します。我々は、MLP のゲートおよびアップ投影層のみが 2 ビット (W2) に量子化され、他のすべての線形層は高精度のままであり、混合精度の GateUp 構成を生成する、選択的な混合精度戦略を提案します。 3 つのモデル ファミリ (4B ~ 20B) と 2 つのハードウェア プラットフォームにわたるルーフライン分析を通じて、W4/W2-GateUp 導入 (4 ビット ベースと 2 ビット ゲート/アップ) が、量子化誤差を予測可能なレイヤーのサブセットに限定しながら、モデルとコンテキストの長さに応じて均一な W4 と比較して 7.5 ~ 23.3% の TPS 向上を実現することを実証します。次に、Recover-LoRA (合成データを使用したロジット蒸留を介して量子化レイヤーで低ランクのアダプターをトレーニング) を適用し、ゲートおよび上位レイヤーの 2 ビット量子化によって失われた精度を回復します。 Qwen3-4B のケーススタディでは、Recover-LoRA は 10,000 個の合成トレーニング サンプルのみを使用し、ラベル付きデータを使用せず、12 ベンチマーク中 9 で 80 ~ 95\% の精度回復を達成しました。さらに、蒸留ベースの回収において合成データが厳選されたラベル付きデータと同等のパフォーマンスを発揮すること、および回収が配布外の評価タスクに一般化されることを実証します。私たちの結果は、Recover-LoRA が、展開設定で積極的な重み圧縮のための実用的な量子化後の精度回復ツールであることを示しています。
原文 (English)
Recover-LoRA for Aggressive Quantization: Reclaiming Accuracy in 2-Bit Language Models via Low-Rank Adaptation with Knowledge Distillation on Synthetic Data
Aggressive weight quantization to 2-bit precision offers substantial throughput and memory gains for large language model (LLM) inference, but typically incurs severe accuracy degradation. These gains are particularly relevant for edge and on-device deployment, where memory capacity and bandwidth are primary constraints. In this work, we extend Recover-LoRA -- a lightweight, data-free accuracy recovery method originally developed for general model weight corruption -- to the setting of ultra-low-bit quantization. We propose a selective mixed-precision strategy in which only gate and up projection layers of the MLP are quantized to 2-bit (W2), while all other linear layers remain at higher precision, yielding a mixed-precision GateUp configuration. We demonstrate via roofline analysis across three model families (4B--20B) and two hardware platforms that a W4/W2-GateUp deployment (4-bit base with 2-bit gate/up) delivers 7.5--23.3\% TPS improvement over uniform W4 depending on model and context length, while confining quantization error to a predictable subset of layers. We then apply Recover-LoRA -- training low-rank adapters on the quantized layers via logit distillation with synthetic data -- to recover accuracy lost from 2-bit quantization of the gate and up layers. In a case study on Qwen3-4B, Recover-LoRA achieves 80--95\% accuracy recovery on 9 of 12 benchmarks, using only 10k synthetic training samples and no labeled data. We further demonstrate that synthetic data performs comparably to curated labeled data for distillation-based recovery, and that recovery generalizes to out-of-distribution evaluation tasks. Our results present Recover-LoRA as a practical post-quantization accuracy recovery tool for aggressive weight compression in deployment settings.
EReL@MIR 2025 マルチモーダル文書検索チャレンジの概要 (トラック 1)
マルチモーダルな検索拡張生成には、視覚的に豊富なドキュメント、つまりテキストと図、表、グラフが挟まれたページの検索が不可欠ですが、ほとんどの検索ツールは依然としてビジュアル チャネルを破棄しています。 Web Conference 2025 と同時開催される第 1 回 EReL@MIR ワークショップの MIR チャレンジの Track~1 である \emph{マルチモーダル文書検索チャレンジ} では、参加者に 2 つの相補的な体制を処理する \emph{単一} 検索システムを構築するよう求めます。テキストクエリ (MMDocIR) からの長い文書内のクローズドセット文書ページの検索と、画像からの Wikipedia スタイルの一節のオープンドメイン検索です。または画像とテキストのクエリ (M2KR)。システムは、2 つのタスクにわたる平均 Recall@$\{1,3,5\}$ のマクロ平均によってランク付けされます。このチャレンジには、22 チームから 455 人の参加者と 586 件の応募が集まりました。このレポートでは、課題の設計、データセット、評価プロトコルについて説明します。最終順位を報告します。そして優勝した3チームのシステムを分析します。 3 つはすべて、CLIP スタイルのエンコーダーではなく、Qwen2-VL ファミリのデコーダーベースの Multimodal-LLM エンベッダーに基づいて構築されており、主に、微調整されたアンサンブル、強力なビジョン言語リランカーによるトレーニング不要のマルチルート フュージョン、またはゼロショット レイト インタラクションを通じてトップに到達するかどうかが異なります。トレーニング不要のシステムは、微調整された勝者の $0.1$ ポイント以内に終了しました。
原文 (English)
Overview of the EReL@MIR 2025 Multimodal Document Retrieval Challenge (Track 1)
Retrieval over visually-rich documents, pages that interleave text with figures, tables, and charts, is essential for multimodal retrieval-augmented generation, yet most retrievers still discard the visual channel. The \emph{Multimodal Document Retrieval Challenge}, Track~1 of the MIR Challenge at the first EReL@MIR workshop, co-located with The Web Conference 2025, asks participants to build a \emph{single} retrieval system that handles two complementary regimes: closed-set document page retrieval within long documents from a text query (MMDocIR), and open-domain retrieval of Wikipedia-style passages from an image or image-plus-text query (M2KR). Systems are ranked by the macro-average of mean Recall@$\{1,3,5\}$ over the two tasks. The challenge drew 455 entrants and 586 submissions across 22 teams. This report describes the challenge design, datasets, and evaluation protocol; reports the final standings; and analyses the three winning teams' systems. All three build on decoder-based Multimodal-LLM embedders from the Qwen2-VL family rather than on CLIP-style encoders, and differ chiefly in whether they reach the top through fine-tuned ensembles, training-free multi-route fusion with a strong vision-language re-ranker, or zero-shot late interaction. The training-free system finished within $0.1$ point of the fine-tuned winner.
もう一度服用してもいいですか? OTC 投薬 QA における時間的不確実性の下での LLM の意思決定の評価
大規模言語モデル (LLM) は、ユーザーが市販薬 (OTC) を安全にもう 1 回服用できるかどうかなど、日常の健康に関する質問にますます使用されています。しかし、この一般的な安全関連の設定は、既存の医療 QA 評価では依然として十分に検討されていません。そこでは、正しい回答には、投与タイミングの追跡、24 時間のローリング摂取量の計算、製品ラベルの制約への準拠、および不完全な薬歴の処理が必要です。成人のアセトアミノフェンとイブプロフェンの使用に焦点を当てた、厳選された 81 の OTC 投与シナリオの焦点を絞ったベンチマークである DOSEBENCH を、手動で注釈が付けられたゴールド参照とともに紹介します。決定の正確さ、一貫性、説明の検証可能性、失敗の種類、信頼性に関連する信号のメトリクスを使用して、繰り返し実行される 4 つの LLM を評価し、1,620 個のモデル応答が得られます。私たちの結果は、モデルがローリングウィンドウ推論や曖昧さに敏感なケースに頻繁に苦戦すること、そして安定した応答や自信を持って見える応答が依然として投与制約に違反する可能性があることを示しています。これらの発見は、OTC 投与 QA が、医療 QA における時間的推論、制約追従、および安全関連の不確実性の処理を評価するための、狭いながらも実用的なテストベッドを提供することを示唆しています。
原文 (English)
Can I Take Another Dose? Evaluating LLM Decision-Making Under Temporal Uncertainty in OTC Dosing QA
Large language models (LLMs) are increasingly used for everyday health questions, including whether a user can safely take another dose of an over-the-counter (OTC) medication. Yet this common safety-relevant setting remains underexplored in existing medical QA evaluations, where correct answers require tracking dose timing, computing rolling 24-hour intake, following product-label constraints, and handling incomplete medication histories. We introduce DOSEBENCH, a focused benchmark of 81 curated OTC dosing scenarios focused on adult acetaminophen and ibuprofen use, with manually annotated gold references. We evaluate four LLMs across repeated runs using metrics for decision correctness, consistency, explanation verifiability, failure types, and confidence-related signals, resulting in 1,620 model responses. Our results show that models frequently struggle with rolling-window reasoning and ambiguity-sensitive cases and that stable or confident-looking responses can still violate dosing constraints. These findings suggest that OTC dosing QA provides a narrow yet practical testbed for evaluating temporal reasoning, constraint following, and safety-relevant uncertainty handling in medical QA.
インスタントフォールド: 変形可能なオブジェクト操作のためのコンテキスト内模倣学習
変形可能オブジェクト操作 (DOM) は、複数の有効な操作モードとの長期にわたるトポロジー変化の相互作用を通じて進化する、部分的に観察可能な高次元の状態のため、困難を伴います。 DOM のコンテキスト内模倣学習フレームワークである Instant-Fold を紹介します。単一の人間によるデモンストレーションが与えられると、私たちのポリシーは、勾配の更新を必要とせずに、空間的な実行や順序付けのバリエーションを含む、さまざまな操作モードをデモンストレーションから直接推論して実行します。私たちのアプローチでは、まず時間対比事前トレーニングによって変形を意識した視覚表現を学習し、その後、デモンストレーションを条件としたフローマッチングトランスフォーマーポリシーによって、意図した操作モードを実行するためのアクションを予測します。完全にシミュレーションでトレーニングされた Instant-Fold は、さまざまな折り畳みモードを一般化し、追加のデータ収集や微調整を行わずにゼロショットを現実世界の設定に移行します。ビデオは https://instant-fold.github.io でご覧いただけます。
原文 (English)
Instant-Fold: In-Context Imitation Learning for Deformable Object Manipulation
Deformable object manipulation (DOM) is challenging due to high-dimensional, partially observable states that evolve through long-horizon, topology-changing interactions with multiple valid manipulation modes. We introduce Instant-Fold, an in-context imitation learning framework for DOM. Given a single human demonstration, our policy infers and executes diverse manipulation modes directly from the demonstration, including variations in spatial execution and ordering, without requiring gradient updates. Our approach first learns deformation-aware visual representations via temporal contrastive pretraining, after which a flow-matching transformer policy conditioned on the demonstration predicts actions to execute the intended manipulation mode. Trained entirely in simulation, Instant-Fold generalizes across diverse folding modes and transfers zero-shot to real-world settings without additional data collection or finetuning. Videos are available at https://instant-fold.github.io.
StandardE2E: エンドツーエンドの自動運転データセットのための統合フレームワーク
自動運転は、モジュール式の認識・予測・計画スタックから、センサー入力を車両制御に直接マッピングするエンドツーエンド (E2E) モデルに移行しており、多くの場合、3D 検出、動き予測、HD マップ認識などの補助タスクによって正規化されています。進歩は、センサーが豊富な運転データセットの急速に成長するエコシステムによって推進されていますが、それぞれが独自のファイル形式、API、座標規則、モダリティ カバレッジを提供しているため、データセット間の実験やデータセットごとの基本的な前処理さえもプロジェクトごとに再実装する必要があります。 E2E 駆動データセット上に単一の統一インターフェイスを提供するフレームワークである StandardE2E を紹介します。 StandardE2E (i) 1 つの共有データ スキーマの下でデータセットごとの前処理を標準化します。 (ii) 複数のデータセットを単一の PyTorch DataLoader に結合して、データセット間の事前トレーニング、補助タスクの監視、シナリオ レベルのフィルタリングを行います。 (iii) 生のフレームから正規スキーマへの単一のデータセットごとのマッピングへの新しいデータセットの追加を減らし、ダウンストリーム パイプライン全体を変更しないままにします。このフレームワークは、Waymo End-to-End、Waymo Perception、Argoverse 2 Sensor、Argoverse 2 LiDAR、NAVSIM (OpenScene-v1.1)、および WayveScenes101 の 6 つのデータセットをすぐにサポートしており、オープンソースの standard-e2e Python パッケージとしてリリースされており、https://github.com/stepankonev/StandardE2E で入手できます。
原文 (English)
StandardE2E: A Unified Framework for End-to-End Autonomous Driving Datasets
Autonomous driving has shifted from modular perception-prediction-planning stacks toward end-to-end (E2E) models that map sensor inputs directly to vehicle control, often regularized by auxiliary tasks such as 3D detection, motion forecasting, and HD-map perception. Progress is driven by a fast-growing ecosystem of sensor-rich driving datasets, yet each ships its own file formats, APIs, coordinate conventions, and modality coverage, leaving cross-dataset experimentation and even basic per-dataset preprocessing to be re-implemented per project. We present StandardE2E, a framework that provides a single unified interface over E2E driving datasets. StandardE2E (i) standardizes per-dataset preprocessing under one shared data schema; (ii) combines multiple datasets in a single PyTorch DataLoader for cross-dataset pretraining, auxiliary-task supervision, and scenario-level filtering; and (iii) reduces adding a new dataset to a single per-dataset mapping from raw frames to the canonical schema, leaving the entire downstream pipeline unchanged. The framework supports six datasets out of the box: Waymo End-to-End, Waymo Perception, Argoverse 2 Sensor, Argoverse 2 LiDAR, NAVSIM (OpenScene-v1.1), and WayveScenes101, and is released as the open-source standard-e2e Python package, available at https://github.com/stepankonev/StandardE2E.
ティックからフローへ: 連続環境における神経強化学習のダイナミクス
我々は、確率的制御からの洞察を利用して問題を連続時間の確率的プロセスとしてモデル化することにより、連続環境における深層強化学習 (RL) のための新しい理論的枠組みを提示します。以前の研究に基づいて、探索と確率的遷移の両方を組み込んだアクター-クリティカル アルゴリズムの実行可能なモデルを紹介します。単一隠れ層ニューラル ネットワークの場合、環境の状態が 2 つの時間スケールのプロセス (環境時間と勾配時間) として定式化できることを示します。この定式化の中で、環境の状態と累積割引収益の推定値を表す時間依存の確率変数が、2 層ネットワークの無限幅制限における勾配ステップ上でどのように変化するかを特徴付けます。確率微分方程式の理論を使用して、連続 RL で初めて、消滅するほど小さい学習率の下で、各勾配ステップでの状態分布の微小な変化を記述する方程式を導出します。全体として、私たちの研究は、オーバーパラメータ化されたニューラルアクタークリティカルアルゴリズムを研究するための新しいノンパラメトリック定式化を提供します。おもちゃの連続制御タスクを使用して、理論的結果を経験的に裏付けます。
原文 (English)
From Ticks to Flows: Dynamics of Neural Reinforcement Learning in Continuous Environments
We present a novel theoretical framework for deep reinforcement learning (RL) in continuous environments by modeling the problem as a continuous-time stochastic process, drawing on insights from stochastic control. Building on previous work, we introduce a viable model of actor-critic algorithm that incorporates both exploration and stochastic transitions. For single-hidden-layer neural networks, we show that the state of the environment can be formulated as a two time scale process: the environment time and the gradient time. Within this formulation, we characterize how the time-dependent random variables that represent the environment's state and estimate of the cumulative discounted return evolve over gradient steps in the infinite width limit of two-layer networks. Using the theory of stochastic differential equations, we derive, for the first time in continuous RL, an equation describing the infinitesimal change in the state distribution at each gradient step, under a vanishingly small learning rate. Overall, our work provides a novel nonparametric formulation for studying overparametrized neural actor-critic algorithms. We empirically corroborate our theoretical result using a toy continuous control task.
損失だけでは不十分: 対照表現学習におけるサンプリング条件と帰納的バイアス
対照学習は、自己教師あり表現学習の主要なパラダイムとなっていますが、意味のある潜在幾何学を回復する条件はまだ完全には理解されていません。我々は、等尺性潜在回復に必要なポジティブペアサンプリングのサポート要件である多様性条件を形式化する測度理論フレームワークを開発します。標準のフルサポート フォン ミーゼス フィッシャー設定は多様性条件の満足を意味し、その結果、グローバルなコントラスト損失ミニマイザーは直交変換までの潜在ジオメトリを回復する一方、制限付き条件により非直交マップが厳密に低い漸近コントラスト損失を達成できることを示します。理論的な修正として、サポート修正された Information Noise Contrastive Estimation (InfoNCE) バリアントを導入します。この修正により、直交潜在空間回復が実現可能になりますが、一意に選択されるわけではありません。合成ベンチマークの実験は識別可能性の予測を検証し、CIFAR-10 の実験は、サンプリングの多様性が制限されている場合にはアーキテクチャの誘導バイアスがより重要になるという定性的予測と一致しています。まとめると、私たちの結果は、サンプリングメカニズムとエンコーダの誘導バイアスが対照表現学習においてどのように相互作用するかを明らかにします。
原文 (English)
The Loss Is Not Enough: Sampling Conditions and Inductive Bias in Contrastive Representation Learning
Contrastive learning has become a leading paradigm for self-supervised representation learning, yet the conditions under which it recovers meaningful latent geometry remain incompletely understood. We develop a measure-theoretic framework formalizing the diversity condition, a support requirement on positive-pair sampling that is necessary for isometric latent recovery. We show that the standard full-support von Mises-Fisher setting implies the satisfaction of the diversity condition and as a consequence global contrastive loss minimizers recover latent geometry up to orthogonal transformation, while restricted conditionals can make non-orthogonal maps attain strictly lower asymptotic contrastive loss. We introduce a support-corrected Information Noise Contrastive Estimation (InfoNCE) variant as a theoretical fix: this correction makes orthogonal latent space recovery achievable but does not uniquely select it. Experiments on synthetic benchmarks validate the identifiability predictions, and CIFAR-10 experiments are consistent with the qualitative prediction that architectural inductive bias becomes more important when sampling diversity is limited. Together, our results clarify how sampling mechanisms and encoder inductive bias interact in contrastive representation learning.
専門家の混合がまばらな報酬モデル
プリファレンス モデリングは、ヒューマン フィードバックからの強化学習 (RLHF) において中心的な役割を果たし、大規模言語モデル (LLM) を人間の価値観に合わせることを可能にします。しかし、既存のアプローチのほとんどは普遍的な報酬関数を前提としており、人間の好みの多様性と異質性を無視しています。追加のアノテーションコストをかけずにこの制限に対処するために、最近の研究では、バイナリデータから複数のプリファレンスコンポーネントを学習し、それらを組み合わせて個々のプリファレンスをモデル化することが提案されています。それにも関わらず、これらのコンポーネントは、一貫性のある解きほぐされたパターンをキャプチャできないことが多く、解釈可能性やパーソナライゼーションの有効性が制限されます。この研究では、バイナリ嗜好データのトレーニング中に疎なルーティングと専門家の多様性を促進する疎な専門家混合 (MoE) 報酬モデルを提案します。制御された実験と実際の実験を通じて、まばらな MoE は解釈可能なルーティング パターンと専門の専門家を学習します。また、テスト時のパーソナライゼーションも改善され、適応後のエキスパートの重みの変化により、モデルがパーソナライズされた好みにどのように適応するかを分析するための定性的なレンズが提供されます。
原文 (English)
Sparse Mixture-of-Experts Reward Models Learn Interpretable and Specialized Experts for Personalized Preference Modeling
Preference modeling plays a central role in reinforcement learning from human feedback (RLHF), enabling large language models (LLMs) to align with human values. However, most existing approaches assume a universal reward function, neglecting the diversity and heterogeneity of human preferences. To address this limitation without additional annotation costs, recent work has proposed learning multiple preference components from binary data and combining them to model individual preferences. Nevertheless, these components often fail to capture coherent and disentangled patterns, limiting their interpretability and effectiveness for personalization. In this work, we propose a sparse Mixture-of-Experts (MoE) reward model that encourages sparse routing and expert diversity during training on binary preference data. Across controlled and real-world experiments, sparse MoE learns interpretable routing patterns and specialized experts. It also improves test-time personalization, and post-adaptation shifts in expert weights provide a qualitative lens for analyzing how the model adapts to personalized preferences.
軽量構造誘導型自己回帰モデルによる新しいグラフ生成のスケーリング
現実的で多様なグラフを生成することは、分子発見、回路設計、サイバーセキュリティなどの分野で応用される機械学習における重要な問題です。ただし、現在のグラフ生成モデルは、スケーラビリティと新規性によって制限されたままです。拡散ベースの手法では、多くの場合、コストのかかる完全隣接演算と長いノイズ除去チェーンが必要ですが、多くの自己回帰モデルやハイブリッド モデルは少なくとも 2 次の複雑さを持っています。さらに、これらのモデルは、トレーニング グラフを超えて一般化するのではなく、トレーニング グラフを模倣することがよくあります。これらの問題に対処するために、軽量の自己回帰フレームワークを提案します。構造に基づくトポロジカル順序付けを使用して、グラフを規則的なエッジ シーケンスにシリアル化し、対数線形に近い生成を可能にします。また、探索指向の拡張と反復改良を組み合わせた 2 フェーズのトレーニング戦略を使用して、過剰適合を軽減し、制御された新規性を促進します。分子ベンチマークと非分子ベンチマークの実験では、私たちのアプローチが高い妥当性と独自性を維持しながら新規性を向上させることが示されています。このフレームワークは、LSTM と Mamba スタイルの因果シーケンス バックボーンの両方もサポートしており、大容量メモリ アクセラレータにより、一般的な GPU の制限を超える長いグラフ シーケンス実験が可能になります。
原文 (English)
Scaling Novel Graph Generation via Lightweight Structure-Guided Autoregressive Models
Generating realistic and diverse graphs is a key problem in machine learning, with applications in molecular discovery, circuit design, cybersecurity, and beyond. However, current graph generative models remain limited by scalability and novelty. Diffusion-based methods often require costly full-adjacency operations and long denoising chains, while many autoregressive and hybrid models have at least quadratic complexity. In addition, these models often imitate training graphs rather than generalize beyond them. We propose a lightweight autoregressive framework to address these issues. It uses a structure-guided topological ordering to serialize graphs into regular edge sequences, enabling near log-linear generation, and a two-phase training strategy that combines exploration-oriented augmentation with iterative refinement to reduce overfitting and promote controlled novelty. Experiments on molecular and non-molecular benchmarks show that our approach improves novelty while preserving high validity and uniqueness. The framework also supports both LSTM and Mamba-style causal sequence backbones, with large-memory accelerators enabling longer graph-sequence experiments beyond typical GPU limits.
コンテキストにおけるエニーキャストのパフォーマンス
IP エニーキャストにより、サービスは多くの物理サイトから 1 つのアドレスをアドバタイズし、BGP に各クライアントをサイトにマッピングさせることができます。これは、DNS ルート サーバー システム、パブリック リゾルバー、および一部のコンテンツ配信ネットワークの中心ですが、同じルーティング メカニズムがアプリケーション間で非常に異なる結果をもたらします。このペーパーでは、2 つの設定でのエニーキャスト レイテンシを比較します。ルート DNS では、再帰的キャッシュにより多くのユーザーと長い存続時間値にわたるルート サーバーの遅延が償却されます。もう 1 つは、ラウンド トリップが追加されるたびに、ページ読み込み、ビデオ開始、または API レイテンシに直接影響を与える可能性がある CDN です。総合すると、ルート DNS エニーキャストは、ユーザーに見える遅延が限られているにもかかわらず、大幅なパスのインフレを示す可能性があるのに対し、CDN エニーキャストでは、インフレを小さく抑えるために、ピアリング、ルート ポリシー、キャッチメント スコープ、および測定フィードバックのアクティブなエンジニアリングが必要であることがわかりました。この論文は、レイテンシの比較モデル、再現可能な測定設計、およびレジリエンス主導のエニーキャスト目標をレイテンシ主導の目標から分離する最適化フレームワークに貢献します。中心的な結論は実用的です。オペレーターはルート DNS と CDN エニーキャストを同じ目的関数で最適化すべきではありません。ルート DNS の場合、堅牢性、到達可能性、およびキャッシュ動作が重要です。 CDN サービスの場合、テール レイテンシ、集水域の正確性、およびポリシー制御が支配的です。
原文 (English)
Anycast Performance in Context
IP anycast lets a service advertise one address from many physical sites, leaving BGP to map each client to a site. It is central to the DNS root server system, public resolvers, and some content delivery networks, yet the same routing mechanism has very different consequences across applications. This paper compares anycast latency in two settings: root DNS, where recursive caching amortizes root-server delay over many users and long time-to-live values, and CDNs, where each additional round trip can directly affect page-load, video-start, or API latency. The synthesis finds that root DNS anycast can exhibit substantial path inflation while still producing limited user-visible delay, whereas CDN anycast requires active engineering of peering, route policy, catchment scope, and measurement feedback to keep inflation small. The paper contributes a comparative latency model, a reproducible measurement design, and an optimization framework that separates resilience-driven anycast objectives from latency-driven objectives. The central conclusion is practical: operators should not optimize root DNS and CDN anycast with the same objective function. For root DNS, robustness, reachability, and cache behavior dominate; for CDN services, tail latency, catchment correctness, and policy control dominate.
OpenRFM: リレーショナル インコンテキスト学習の分析
リレーショナル基盤モデル (RFM) は、リレーショナル データベースが与えられた場合に、リレーショナル インコンテキスト学習 (ICL) を介して 1 回のフォワード パスで予測を返す単一の事前トレーニング済み予測子を約束します。しかし、オープン RFM と商用 RFM の間には大きなギャップがあり、このギャップの原因は体系的に理解されていません。代表的なフレームワークである Relational Transformer (RT) を 2 つの観点から分析します。モデル側: RT が関係レベルの ICL を実行することを示し、カーネル回帰ビューは、ラベルセルのカバレッジがまばらで過小決定回帰が生じる場合に失敗することを示します。データ側: RT の事前トレーニング ソースを除去したところ、既存の合成のみの事前トレーニングと分散内事前トレーニングが、同じアーキテクチャを異なるレジーム (遅延学習と特徴学習) に駆動していることがわかりました。このギャップを精査すると、欠けている成分がラベル生成プロセスに潜在するサポート識別可能な関係性であることが明らかになります。これら 2 つの診断は、(1) リレーショナル バックボーンと、リレーショナル レベルのラベル不足を克服するために事前トレーニングされた表形式の基盤モデルから抽出されたバッチ レベルの ICL レイヤーを組み合わせたデュアルステージ ICL アーキテクチャ、および (2) プロトタイプ ベースの正則化で強化された、同種性を認識した合成と継続的な実データの事前トレーニングの混合物に変換されます。これらの選択肢により、OpenRFM が定義されます。OpenRFM は、平均タスク パフォーマンスを RT バックボーンよりも約 30% 向上させ、大規模な評価タスク セットで商用モデル KumoRFMv1 を上回る、シンプルかつ効果的な RFM です。
原文 (English)
OpenRFM: Dissecting Relational In-Context Learning
Relational Foundation Models (RFMs) promise a single pre-trained predictor that, given any relational database, returns predictions in one forward pass via relational in-context learning (ICL). Yet a substantial gap separates open RFMs from their commercial counterparts, and the origin of this gap has not been systematically understood. We dissect a representative framework, the Relational Transformer (RT), from two perspectives. Model side: we show that RT performs relation-level ICL, and a kernel regression view shows it fails when sparse label-cell coverage yields an underdetermined regression. Data side: we ablate RT's pre-training source and find that existing synthetic-only pre-training and in-distribution pre-training drive the same architecture into different regimes, lazy vs. feature-learning. Probing this gap reveals that the missing ingredient is a support-identifiable relational latent in the label-generation process. These two diagnoses translate into (1) a dual-stage ICL architecture that combines the relational backbone with a batch-level ICL layer lifted from a pre-trained tabular foundation model to overcome relation-level label scarcity, and (2) a homophily-aware synthetic plus continual real-data pre-training mixture, augmented with a prototype-based regularization. These choices define OpenRFM, a simple yet effective RFM that improves average task performance by approximately 30% over the RT backbone and surpasses the commercial model KumoRFMv1 on a large set of evaluation tasks.
何が重要かを測定する: コンセプトのボトルネック モデルの総合ベンチマーク
概念ボトルネック モデルは、入力で検出された高レベルの概念からの結果を予測します。概念は解釈可能性から利益を得る簡単な方法を提供しますが、概念ラベルを含むデータセットはほとんどありません。これにより、どの問題がこれらのモデルに適しているかを判断したり、モデルのパフォーマンスを促進する要因や失敗につながる要因を特定したり、どのアルゴリズムが良好にパフォーマンスするかを明らかにしたりする研究者の能力が制限されます。このペーパーでは、コンセプトのボトルネック モデルの合成ベンチマークを開発します。その 2 つの主なユースケースに焦点を当てます。1 つはモデルが人間によるより良い意思決定を支援する意思決定支援、もう 1 つはモデルが監視なしでルーチン タスクを処理する自動化です。私たちのベンチマークは、データ モダリティ、コンセプトの選択、アノテーションの品質、完全性など、パフォーマンスに影響を与えるプロパティを制御しながら、ラベル付きデータセットを生成できます。ベンチマークを使用して、概念ボトルネック モデルの代表的なクラスを評価する方法を示します。私たちのデモンストレーションでは、ベンチマークがどのように障害モードを診断し、フォローアップ テストをガイドできるかを示します。
原文 (English)
Measuring What Matters: Synthetic Benchmarks for Concept Bottleneck Models
Concept bottleneck models predict outcomes from high-level concepts detected in inputs. Although concepts provide a simple way to reap benefits from interpretability, very few datasets include concept labels. This limits researchers' ability to determine which problems are suitable for these models, isolate the factors that drive their performance or lead to failures, or uncover which algorithms perform well. In this paper, we develop synthetic benchmarks for concept-bottleneck models, focusing on their two main use cases: decision support, in which models assist humans in making better decisions, and automation, in which models handle routine tasks without supervision. Our benchmarks can generate labeled datasets while controlling for properties that affect performance, including data modality, concept choice, annotation quality, and completeness. We demonstrate how the benchmarks can be used to evaluate representative classes of concept bottleneck models. Our demonstrations show how the benchmarks can diagnose failure modes and guide follow-up testing.
2 層ニューラル ネットワークの静止プラトーの幾何学的特徴付け
滑らかな活性化関数を備えた 2 層ニューラル ネットワークの損失ランドスケープで生じる定常プラトーの幾何学的構造を調査します。私たちは、隠れたニューロンを複製すると、より広いネットワーク内にアフィン セットの静止点が生成される「ニューロン分割」という現象に焦点を当てます。これらの台地上のすべての静止点を包括的に分類し、どのような条件下でそれらが極小点または鞍点を構成するかを判断します。私たちの特性評価は、「内部ヘッセ行列」と呼ぶニューロンごとの曲率オブジェクトに依存します。私たちの分析により、内部ヘッセ行列の明確性と分割係数の選択が共同してプラトーの局所的な幾何学形状を決定することが明らかになりました。極小値を「分割」すると、局所極小値と鞍部の混合、または穏やかな仮定の下で特定された具体的な確実な鞍部領域を含むすべての鞍部のプラトーが得られることを示します。対照的に、鞍点を分割すると、常に鞍点のプラトーが生成されます。私たちの結果は、以前のランドスケープ解析を統合および拡張し、モデル拡張がいつどのように静止点の性質を保存または変更するかを解明します。これらの発見は、ニューラル ネットワークにおける幅の拡張と再パラメータ化の影響についての新しい幾何学的洞察を提供します。
原文 (English)
A Geometric Characterization of the Stationary Plateau for Two-Layer Neural Networks
We investigate the geometric structure of stationary plateaus that arise in the loss landscape of two-layer neural networks with smooth activation functions. We focus on the phenomenon of "neuron splitting" where duplicating a hidden neuron yields an affine set of stationary points in a wider network. We provide a comprehensive classification of all stationary points on these plateaus, determining under what conditions they constitute local minima or saddle points. Our characterization hinges on a per-neuron curvature object we term the "inner Hessian" matrix. Our analysis reveals that the definiteness of the inner Hessian and the choice of splitting coefficients jointly dictate the local geometry of the plateau. We show that "splitting" a local minimum can yield either a mixture of local minima and saddles or an all-saddle plateau, with a concrete sure-saddle region identified under mild assumptions. In contrast, splitting a saddle point always produces a plateau of saddle points. Our results unify and extend prior landscape analyses, elucidating when and how model expansion preserves or alters the nature of stationary points. These findings offer new geometric insights into the effects of width expansion and reparameterization in neural networks.
即時決定トランスフォーマーを使用したワイヤレス ネットワークの一般化可能なマルチタスク学習
将来のワイヤレス ネットワークでは、非常に異質な環境と動的なタスク構成への迅速な適応が求められており、従来のルールベースで最適化主導の無線リソース管理 (RRM) から人工知能 (AI) 主導の RRM への移行が必要です。 AI 主導のアプローチは、複雑な非線形関係を学習し、多様なネットワーク条件全体に一般化して、リアルタイムでスケーラブルな自律的な意思決定を可能にします。 RRM 技術の中でも、多地点協調(CoMP)送信はセル間干渉を軽減し、セルエッジのパフォーマンスを向上させるために極めて重要であり、それによって高密度展開における体験品質(QoE)が向上します。ただし、最適なマルチセルの選択は、動的なトラフィックとチャネル条件の下で、考えられる多くのサービングセルの組み合わせを共同で最適化する必要があるため、依然として複雑な組み合わせの課題です。成功にもかかわらず、近接ポリシー最適化 (PPO) などの従来の深層強化学習 (DRL) 手法は、サンプル効率が低く、汎化が限られており、状態空間とアクション空間が変化した場合に再学習にコストがかかるという問題があります。これらのボトルネックに対処するために、多様なネットワーク構成にわたって学習し、シーケンス モデリング問題としてマルチセルの選択を再定式化できる、Prompt Decision Transformer (PromptDT) ベースのマルチタスク学習フレームワークを提案します。 PromptDT は、オフライン トラジェクトリとタスク固有のプロンプトを活用することで、さまざまな基地局やユーザー機器の数、スケジューラ ポリシーなど、さまざまなネットワーク構成にわたってスケーラブルな学習を可能にします。実験結果は、PromptDT がベースラインと比較してマルチタスク設定で QoE を最大 49% 向上させ、モデルの容量に合わせてパフォーマンスがプラスに拡張することを示しています。さらに、PromptDT は目に見えないタスクを効果的に一般化し、再トレーニングや微調整を行わずに、新しいネットワーク構成への堅牢な少数ショットの適応を実現します。
原文 (English)
Generalizable Multi-Task Learning for Wireless Networks Using Prompt Decision Transformers
Future wireless networks demand rapid adaptation to highly heterogeneous environments and dynamic task configurations, necessitating a shift from conventional rule-based and optimization-driven radio resource management (RRM) toward artificial intelligence (AI)-driven RRM. AI-driven approaches can learn complex nonlinear relationships, generalize across diverse network conditions and enable real-time, scalable and autonomous decision-making. Among RRM techniques, coordinated multipoint (CoMP) transmission is pivotal for mitigating inter-cell interference and enhancing cell-edge performance, thereby improving quality of experience (QoE) in dense deployments. However, optimal multi-cell selection remains a complex combinatorial challenge as it requires jointly optimizing over many possible serving-cell combinations under dynamic traffic and channel conditions. Despite their success, conventional deep reinforcement learning (DRL) methods such as proximal policy optimization (PPO) suffer from poor sample efficiency, limited generalization, and costly retraining when state and action spaces change. To address these bottlenecks, we propose a Prompt Decision Transformer (PromptDT) based multi-task learning framework capable of learning across diverse network configurations and reformulating multi-cell selection as a sequence modeling problem. By leveraging offline trajectories and task-specific prompts, PromptDT enables scalable learning across diverse network configurations, including varying base stations and user equipment counts, and scheduler policies. Experimental results demonstrate that PromptDT improves QoE by up to 49% in multi-task settings compared to baselines, with performance scaling positively alongside model capacity. Moreover, PromptDT generalizes effectively to unseen tasks, achieving robust few-shot adaptation to new network configurations without retraining or fine-tuning.
信頼できない入力から信頼できるメモリへ: LLM エージェントにおけるメモリポイズニング攻撃の系統的研究
メモリは AI エージェントの中核コンポーネントであり、AI エージェントがインタラクションを通じて知識を蓄積し、パフォーマンスを向上させることができます。ただし、永続メモリにはメモリ ポイズニングのリスクが伴います。メモリ ポイズニングの場合、敵対的な 1 回のメモリ書き込みがエージェントの動作に長期的な影響を与える可能性があります。我々は、LLM ベースのエージェントにおけるメモリポイズニングの体系的な研究を紹介します。 4 つのメモリ書き込みチャネルと、これらのチャネルを悪用可能にするモデル機能、システム プロンプト設計、およびエージェント システム アーキテクチャにおける 9 つの構造的脆弱性を特定しました。これらの脆弱性に基づいて、メモリポイズニング攻撃の 6 つのクラスの分類を作成します。さらに、メモリポイズニング攻撃を評価するためのベンチマークである MPBench を設計し、より積極的にメモリの書き込みと取得を行うように設計されたエージェントが悪用されやすいことを示します。また、既存のプロンプト インジェクション防御ではメモリ ポイズニング攻撃をカバーできないことも示します。私たちの調査結果は、AI エージェントに対するメモリ ポイズニング攻撃を理解し、軽減するための基盤を提供します。
原文 (English)
From Untrusted Input to Trusted Memory: A Systematic Study of Memory Poisoning Attacks in LLM Agents
Memory is a core component of AI agents, enabling them to accumulate knowledge across interactions and improve performance. However, persistent memory introduces the risk of memory poisoning, where a single adversarial memory write can exert long-term influence over agent behavior. We present a systematic study of memory poisoning in LLM-based agents. We identify four memory write channels and nine structural vulnerabilities in model capabilities, system prompt design, and agent system architecture that make these channels exploitable. Based on these vulnerabilities, we develop a taxonomy of six classes of memory poisoning attacks. Furthermore, we design MPBench -- a benchmark for evaluating memory poisoning attacks, and show that agents designed to write and retrieve memory more aggressively are more exploitable. We also show that existing prompt injection defenses fail to cover memory poisoning attacks. Our findings provide a foundation for understanding and mitigating memory poisoning attacks against AI agents.
期待と現実: 条件付き不確実性の下での MSE 最適予測のコスト
マルチステップ時系列予測 (MSF) は通常、平均二乗誤差 (MSE) などの点単位の誤差メトリクスを使用して評価され、暗黙的に条件付き平均を十分な目標として扱います。条件付きの不確実性の下ではこれが誤解を招く可能性があり、条件付きの期待が長期的には典型的な実現値を代表しなくなる可能性があることを示します。我々は、条件付き不確実性ギャップを通じてこの効果を形式化し、このギャップがゼロ以外の場合は常に、MSE を最小化し、現実化した先物の限界分布と一致させることができる決定論的予測子は存在しないことを証明します。これにより、MSF 評価における点精度と限界現実性との間の基本的なモデルに依存しないトレードオフが確立されます。制御された確率力学システムと 9 つの現実世界の予測ベンチマークを使用して、結果として得られる精度、つまりリアリズム フロンティアと \textbf{MSE のみのモデル選択の実際的なコストを定量化} を経験的に特徴付けます。予測期間が進むにつれて条件の不確実性が増大するにつれて、達成可能なセットは顕著なパレート フロントに拡大し、MSE に最適ではあるが分散が不十分な予測子を、現実的な限界変動と精度を引き換えにする手法から分離します。 \textbf{ベンチマーク全体で、MSE の小さな緩和 ($\boldsymbol{\le 5\%}$) が限界現実主義で不釣り合いな利益をもたらすことが頻繁にあり、一部のデータセットでは $\mathbf{17.3\%}$ の中央値改善と $\mathbf{30\%}$ を超える利益が得られることがわかりました。} さらに、一般的な予測戦略が体系的にこのフロンティアのさまざまな領域を占めることを示します。複数出力の予測子は精度が最適な極限付近に集中しますが、再帰的戦略とサンプルベースの推論は限界現実主義を支持します。これらの結果を総合すると、長期予測における MSE ベースの評価の構造的欠陥モードと、避けられない精度、つまり現実性のトレードオフのナビゲーションとしてのリキャスト戦略と推論の選択が明らかになります。
原文 (English)
Expectations vs. Realities: The Cost of MSE-Optimal Forecasting Under Conditional Uncertainty
Multi-step time series forecasting (MSF) is commonly evaluated using point-wise error metrics such as mean squared error (MSE), implicitly treating the conditional mean as a sufficient target. We show that this can be misleading under conditional uncertainty, where the conditional expectation becomes unrepresentative of typical realized values at longer horizons. We formalize this effect through a conditional uncertainty gap and prove that whenever this gap is nonzero, no deterministic predictor can simultaneously minimize MSE and match the marginal distribution of realized futures. This establishes a fundamental, model-agnostic trade-off between point accuracy and marginal realism in MSF evaluation. Using controlled stochastic dynamical systems and nine real-world forecasting benchmarks, we empirically characterize the resulting accuracy--realism frontier and \textbf{quantify the practical cost of MSE-only model selection}. As conditional uncertainty increases with forecast horizon, the attainable set expands into a pronounced Pareto front, separating MSE-optimal but under-dispersed predictors from methods that trade accuracy for realistic marginal variability. \textbf{Across benchmarks, we find that small relaxations in MSE ($\boldsymbol{\le 5\%}$) frequently unlock disproportionate gains in marginal realism, with median improvements of $\mathbf{17.3\%}$ and gains exceeding $\mathbf{30\%}$ in some datasets.} We further show that common forecasting strategies systematically occupy different regions of this frontier: direct multi-output predictors concentrate near the accuracy-optimal extreme, while recursive strategies and sample-based inference favors marginal realism. Together, these results expose a structural failure mode of MSE-based evaluation in long-horizon forecasting and recast strategy and inference selection as navigation of an unavoidable accuracy--realism trade-off.
HYolo: ハイパーグラフ学習を使用したインテリジェントな IoT ベースの物体検出システム
このペーパーでは、ハイパーグラフ学習を YOLO アーキテクチャに統合する、インテリジェントな IoT ベースのオブジェクト検出フレームワークである HYolo について説明します。従来の YOLO ベースの物体検出モデルは、主にペアごとの特徴の相互作用を捕捉しており、物体とコンテキスト特徴間の複雑な高次の関係をモデル化できない場合があります。この制限に対処するために、HYolo にはハイパーグラフ学習が組み込まれており、より豊富なコンテキスト依存関係を取得し、オブジェクト表現を改善します。 COCO データセットの実験評価では、ベースライン YOLO モデルと比較してパフォーマンスが大幅に向上していることが実証されています。提案されたアプローチは、全体的な検出精度と堅牢性を向上させながら、mAP@50 で約 12% の改善を達成します。 HYolo は、高次の特徴関係をモデル化することにより、IoT ベースの環境においてコンテキストの理解が向上し、より信頼性の高い物体検出パフォーマンスを提供します。この結果は、ハイパーグラフ学習を物体検出パイプラインに統合することが、インテリジェントでコンテキスト認識型の IoT ビジョン システムに有望な方向性をもたらすことを示しています。
原文 (English)
HYolo: An Intelligent IoT-Based Object Detection System Using Hypergraph Learning
This paper presents HYolo, an intelligent IoT-based object detection framework that integrates hypergraph learning into the YOLO architecture. Traditional YOLO-based object detection models primarily capture pairwise feature interactions and may fail to model complex high-order relationships among objects and contextual features. To address this limitation, HYolo incorporates hypergraph learning to capture richer contextual dependencies and improve object representation. Experimental evaluation on the COCO dataset demonstrates significant performance improvements over baseline YOLO models. The proposed approach achieves approximately 12% improvement in mAP@50 while enhancing overall detection accuracy and robustness. By modeling high-order feature relationships, HYolo provides improved contextual understanding and more reliable object detection performance in IoT-based environments. The results indicate that integrating hypergraph learning into object detection pipelines offers a promising direction for intelligent and context-aware IoT vision systems.
MorphoQuant: オムニモーダル大規模言語モデル向けのモダリティを意識した量子化
従来のポストトレーニング量子化 (PTQ) 手法は、極端な分布の不均一性とモダリティ間の異種の外れ値パターンにより、4 ビットのオムニモーダル大規模言語モデル (OLLM) に苦戦します。これに対処するために、クロスモーダル形態を保存し、外れ値の損失を軽減するように設計されたモダリティ認識 PTQ フレームワークである MorphoQuant を提案します。具体的には、ロングテールの外れ値をチャネルごとのバイアスに選択的に吸収する、Distribution-Aware Bias Compensation (DABC) を導入します。このメカニズムは、密なインライアの高精度の離散化を維持しながら外れ値の大きさを保護し、それによって多様なモード分布にわたって正確な離散化を維持します。これを補完するために、量子化グリッドとバイアス マスクを同時に最適化し、モダリティ全体でのきめ細かい調整を保証する形態指向量子化関数最適化 (MDQFO) を提案します。 MMMU や Video-MME などのベンチマークにわたる Qwen2.5-Omni の広範な評価により、私たちのアプローチの優位性が実証されています。特に、当社の W4A4 モデルは ScienceQA で 76.63% を達成し、SOTA W4A4 メソッドを大幅に上回り、驚くべきことに W4A16 ベースラインを上回っています。これは、当社のフレームワークの並外れた精度と効率のトレードオフを十分に示しています。
原文 (English)
MorphoQuant: Modality-Aware Quantization for Omni-modal Large Language Models
Conventional Post-Training Quantization (PTQ) methods struggle with 4-bit Omni-modal Large Language Models (OLLMs) due to the extreme distribution heterogeneity and disparate outlier patterns across modalities. To address this, we propose MorphoQuant, a modality-aware PTQ framework engineered to preserve cross-modal morphology and mitigate outlier loss. Specifically, we introduce Distribution-Aware Bias Compensation (DABC), which selectively absorbs long-tailed outliers into channel-wise biases. This mechanism safeguards outlier magnitudes while maintaining high-precision discretization for dense inliers, thereby preserving accurate discretization across diverse modal distribution. Complementing this, we propose Morphology-Directed Quantization Function Optimization (MDQFO) to co-optimize the quantization grid with the bias mask, ensuring fine-grained alignment across modalities. Extensive evaluations on Qwen2.5-Omni across benchmarks like MMMU and Video-MME demonstrate our approach's superiority. Notably, our W4A4 model achieves 76.63% on ScienceQA, significantly outperforming SOTA W4A4 methods and surprisingly surpassing the W4A16 baseline, which fully demonstrates the exceptional accuracy-efficiency trade-off of our framework.
CT ボリュームからの多粒度 3D 腎臓病変の特徴付け
放射線医学のレポートでは、腎臓病変を種類、サイズ、増強、減弱別に説明していますが、既存の 3D 手法では、患者または臓器レベルでしか予測できません。腎臓の CT 特性評価を病変セットごとの予測タスクとして再定式化します。1 つのモデルが腎臓ごとに可変数の病変を出力し、それぞれが 4 つの臨床的属性を持ちます。私たちは、ある学術医療センターの 788 人の患者からの 2,619 の CT ボリュームを厳選し、多粒度の側面および病変ごとのラベルを付け、ゼロショット外部検証に KiTS23 (489 ケース) を使用しました。私たちは、サイズ距離ハンガリー語マッチングと、スロットごとの出力をサイドレベルの目標に集約する階層損失を備えた DETR スタイルのアーキテクチャである \textbf{LesionDETR} を提案します。 4 つの入力表現と 6 つのエンコーダー初期化において、設計上の 2 つの選択肢が支配的です。入力チャネルとしてのセグメンテーション マスクと、同一ドメイン腹部事前トレーニング (SuPreM) です。一般的な大規模コーパスの事前トレーニングは、ランダムな初期化と何ら変わりません。 LesionDETR は、UF-Health では両側側レベルの異常 AUC $0.799 \pm 0.009$、KiTS23 では $0.817 \pm 0.072$ に達します。カウント条件付きバリアントは、嚢胞性病変では病変あたりの mAP $0.190 \pm 0.083$ に達します。まれな固形病変 AP はノイズ フロアに留まり、次のボトルネックとしてアーキテクチャではなく対象を絞ったデータ収集が指摘されています。このフレームワークは、下流の構造化レポート生成のための検証済みの病変ごとの予測を生成します。
原文 (English)
Multi-Granularity 3D Kidney Lesion Characterization from CT Volumes
Radiology reports describe kidney lesions by type, size, enhancement, and attenuation, yet existing 3D methods predict only at the patient or organ level. We reformulate kidney CT characterization as a per-lesion set-prediction task: one model emits a variable number of lesions per kidney, each with four clinical attributes. We curated 2,619 CT volumes from 788 patients at one academic medical center, with multi-granularity side- and per-lesion labels, and used KiTS23 (489 cases) for zero-shot external validation. We propose \textbf{LesionDETR}, a DETR-style architecture with size-distance Hungarian matching and a hierarchical loss that aggregates per-slot outputs to side-level objectives. Across four input representations and six encoder initializations, two design choices dominate: a segmentation mask as an input channel, and same-domain abdominal pretraining (SuPreM); generic large-corpus pretraining is no better than random initialization. LesionDETR reaches bilateral side-level abnormality AUC $0.799 \pm 0.009$ on UF-Health and $0.817 \pm 0.072$ on KiTS23. A count-conditioned variant reaches per-lesion mAP $0.190 \pm 0.083$ on cystic lesions; rare solid-lesion AP stays at the noise floor, pointing to targeted data collection, not architecture, as the next bottleneck. The framework yields verified per-lesion predictions for downstream structured report generation.
分離された情報領域の選択的結合: ビジョントランスフォーマーのデータフリー量子化のためのマスクされた注意の調整
データフリー量子化 (DFQ) は、実際のデータにアクセスせずにサンプルを合成することで、データ セキュリティの問題に対処します。古典的な畳み込み演算と比較した自己注意メカニズムの優位性により、ビジョン トランスフォーマー (ViT) の文脈でますます注目を集めています。ただし、ViT 用の以前の DFQ 技術では、合成サンプルと量子化モデル Q によって予期される入力分布の間の分布の不一致が発生し、次善のパフォーマンスが得られることがよくありました。この論文では、MaskAQ と呼ばれる ViT のデータフリー量子化のための新しいマスク アテンション アラインメント アプローチを提案します。これにより、次のことが明らかになります。1) セルフ アテンション メカニズムのセマンティクスは、主に情報領域と呼ばれるパッチのまばらなサブセットに局在化されている。 2) 情報領域は、合成サンプルと Q の出力の間の相互情報を支配します。これらの目的のために、合成サンプルのパッチ類似性に差分エントロピー最大値を組み込んで、ノイズの多い背景から有益な領域を分離します。さまざまな Q と組み合わせるために、マスクされたアテンション アラインメント目標を介して完全精度モデルを Q と位置合わせするように情報領域が選択され、高品質の合成サンプルが得られます。さらに、定期的なサンプル リフレッシュ戦略により、トレーニング プロセス全体を通じて Q の進化する状態に継続的に適応し、合成サンプルとの望ましい相互情報を保存する能力が MaskAQ に与えられます。広範な実験により、複数のバックボーンとダウンストリーム タスクにわたる最先端のアプローチに対する MaskAQ の利点が検証されています。私たちのコードは https://github.com/hfutqian/MaskAQ で入手できます。
原文 (English)
Selective Coupling of Decoupled Informative Regions: Masked Attention Alignment for Data-Free Quantization of Vision Transformers
Data-Free Quantization (DFQ) addresses data security concerns by synthesizing samples, without accessing real data. It has garnered increasing attention in the context of Vision Transformers (ViTs), owing to the superiority of the self-attention mechanism compared to classical convolutional operation. However, previous DFQ arts for ViTs often suffer from a distribution mismatch between synthetic samples and input distribution expected by quantized models Q, resulting in the suboptimal performance. In this paper, we propose a novel Masked Attention Alignment approach for Data-Free Quantization of ViTs, named MaskAQ, revealing that: 1) the semantics in the self-attention mechanism is predominantly localized to a sparse subset of patches, called informative regions; 2) the informative regions dominate the mutual information between synthetic samples and Q's outputs. To these ends, we incorporate differential entropy maximum over patch similarity of synthetic samples, to decouple informative regions from noisy background. To couple with varied Q, the informative regions are selected to align full-precision models with Q via a masked attention alignment objective, thus yielding high-quality synthetic samples. Furthermore, a periodic sample refreshing strategy comes up to endow MaskAQ with the capacity to continually adapt to the evolving state of Q throughout the training process, to preserve desirable mutual information with synthetic samples. Extensive experiments verify the merits of MaskAQ over state-of-the-art approaches across multiple backbones and downstream tasks. Our code is available at https://github.com/hfutqian/MaskAQ.
DSIRM: 電子商取引関連性モデリングのためのクエリブリッジされた離散セマンティック識別子の学習
電子商取引の検索関連性に対する継続的な埋め込みが急速に進歩しているにもかかわらず、長年の未解決の問題は、きめの細かい属性の区別を把握することが難しいことです。離散セマンティック識別子 (SID) は有望な代替手段として広く採用されていますが、既存の SID 生成方法は教師なし量子化に大きく依存しています。現実的なシナリオでは、明示的な監視がないため、どの項目が SID を共有するかを決定することがより困難になることが多く、その結果、クエリ依存のランキング機能が制限されます。教師なし SID の問題に対処するために、離散関連性機能を明示的にモデル化し、離散セマンティック識別子関連性モデル (DSIRM) を開発することを提案します。具体的には、アイテム側でクエリブリッジの対比量子化アプローチを提案し、クエリとアイテムの相互作用監視を残差量子化に注入して、関連性を意識したセマンティックパーティションを積極的に学習します。一方、クエリ側で生成 LLM を調査し、テキストから項目 SID を明示的に予測し、末尾クエリと意図の曖昧さを解決します。クエリとアイテムの SID 間の階層的なプレフィックス マッチングにより、密な信号を完全に補完する識別機能が得られます。 Tmall の生産データに関する広範な実験結果は、私たちが提案したアプローチがより良い結果を達成し、オフライン AUC を +1.54% 改善したことを示しています。効率的なハイブリッド アーキテクチャを介して導入され、大幅なオンライン リフト (+0.13\% UCTR、+0.25\% UCTCVR) を達成し、その巨大な産業価値を証明しています。
原文 (English)
DSIRM: Learning Query-Bridged Discrete Semantic Identifiers for E-commerce Relevance Modeling
Despite rapid progress of continuous embeddings for e-commerce search relevance, a long-standing open problem is the difficulty in capturing fine-grained attribute distinctions. While discrete Semantic Identifiers (SIDs) have been widely adopted as a promising alternative, existing SID generation methods rely heavily on unsupervised quantization. In realistic scenarios, the lack of explicit supervision often makes it more difficult to dictate which items should share an SID, resulting in limited capability for query-dependent ranking. To address the issue of unsupervised SIDs, we propose to explicitly model discrete relevance features and develop a Discrete Semantic Identifier Relevance Model (DSIRM). Specifically, we present a query-bridged contrastive quantization approach on the item side, injecting query-item interaction supervision into Residual Quantization to actively learn relevance-aware semantic partitions. On the other hand, we explore generative LLMs on the query side to explicitly predict item SIDs from text, resolving tail queries and intent ambiguity. Hierarchical prefix matching between query and item SIDs yields discriminative features that perfectly complement dense signals. Extensive experimental results on Tmall's production data show that our proposed approach has achieved better results, improving offline AUC by +1.54\%. Deployed via an efficient hybrid architecture, it achieves significant online lifts (+0.13\% UCTR, +0.25\% UCTCVR), proving its massive industrial value.
記号から幾何へ: 大規模な言語モデルで空間推論を可能にする
最近の大規模言語モデル (LLM) は、空間推論能力を示すことが多いようです。ただし、この機能は主に \emph{象徴的} なものであり、空間に関する真の \emph{幾何学的} 推論ではなく、空間言語によるパターン マッチングから生じています。 LLM は離散トークンで動作するため、連続空間表現、明示的な幾何学的計算、および構造化空間演算子のネイティブ サポートが不足しています。この制限に対処するために、\emph{空間言語モデル (SLM)} を導入しました。これは位置情報を第一級のモダリティとして扱い、モデルの推論プロセス内で幾何学的空間推論を可能にする初のマルチモーダル LLM です。 SLM は、空間関係のテキスト記述ではなく、学習された空間表現に直接作用します。効果的なトレーニングをサポートするために、空間表現、アトミックな幾何学的操作、自然言語命令を調整する \emph{空間命令データセット} を構築します。さらに、\emph{SpatialEval} という名前の新しいベンチマークを提案します。これは、属性、距離、トポロジー、および相対位置タスクにわたる空間推論を評価するように設計されています。広範な実験により、SLM は、プロンプト エンジニアリングやテキスト抽象化による記号推論に依存する既存の LLM ベースのアプローチよりも大幅に優れていることが示されており、堅牢な空間推論のために幾何学的空間表現を統合する利点が実証されています。命令データセット、評価ベンチマーク、モデル トレーニング コード、モデルのチェックポイントは、\hyperlink{https://github.com/chuchen2017/SLM}{https://github.com/chuchen2017/SLM} にあります。
原文 (English)
From Symbolic to Geometric: Enabling Spatial Reasoning in Large Language Models
Recent large language models (LLMs) often appear to exhibit spatial reasoning ability; however, this capability is largely \emph{symbolic}, arising from pattern matching over spatial language rather than true \emph{geometric} reasoning over space. Because LLMs operate on discrete tokens, they lack native support for continuous spatial representations, explicit geometric computation, and structured spatial operators. To address this limitation, we introduce the \emph{Spatial Language Model (SLM)}, the first multimodal LLM that treats location information as a first-class modality and enables geometric spatial reasoning within the model's inference process. SLM directly operates on learned spatial representations rather than textual descriptions of spatial relations. To support effective training, we construct a \emph{Spatial Instruction Dataset} that aligns spatial representations, atomic geometric operations, and natural language instructions. We further propose a new benchmark named \emph{SpatialEval}, which is designed to evaluate spatial reasoning across attributes, distance, topology, and relative-position tasks. Extensive experiments show that SLM significantly outperforms existing LLM-based approaches that rely on symbolic reasoning via prompt engineering or textual abstraction, demonstrating the benefits of integrating geometric spatial representations for robust spatial reasoning. Our instruction dataset, evaluation benchmark, model training codes, and models' checkpoints can be found at: \hyperlink{https://github.com/chuchen2017/SLM}{https://github.com/chuchen2017/SLM}.
LCSHBench: 米国議会図書館件名見出し割り当てのための、多言語で合意に基づいたベンチマーク
自動主題目録作成では、制御された語彙見出しが書誌レコードに割り当てられますが、LCSH には標準の公開ベンチマークがありません。 LCSHBench を紹介します。オープンライセンスのハーバード大学、コロンビア大学、プリンストン大学のカタログから 15 言語で 22,346 冊の本を紹介します。記録は、少なくとも 2 つの独立目録作成機関が LCSH を割り当てた場合にのみ入力されます。私たちはカタログごとの来歴と結合および全員一致の回答ビューをリリースします。 3 つの図書館すべてでカタログ化されている 465,187 作品の一致調査では、なぜこのデザインが重要であるかを示しています。図書館は通常、基礎となるトピックについては一致しています (93.3% が概念レベルの見出しを共有) が、正確な表現が異なることがよくあります (39.4% が同一の見出しセットを持っています)。したがって、LCSHBench は、オープン語彙の生成と完全な語彙の検索にわたって、言語と見出しの種類ごとに分類されたセットとランクのメトリクスを使用して、完全一致と概念一致の両方をスコアリングします。最初のデモンストレーションとして、300M オンデバイス エンベッダーの低ランク微調整により、言語を超えた検索が向上し、開発正確な再現率 @ 200 (0.659 対 0.623) で 3,072 次元のホスト型エンベッダーを上回りました。言語パネルは、ゲインが一様ではないことを示しており、ホールドアウトテストとエンドツーエンドの確認は今後の作業として残っています。
原文 (English)
LCSHBench: A Multilingual, Consensus-Grounded Benchmark for Library of Congress Subject Heading Assignment
Automated subject cataloging assigns controlledvocabulary headings to bibliographic records, but LCSH has no standard public benchmark. We introduce LCSHBench: 22,346 books in 15 languages from the openly licensed Harvard, Columbia, and Princeton catalogs. Records enter only when at least two independent cataloging agencies assigned LCSH; we release per-catalog provenance plus union and unanimous answer views. A concordance study of 465,187 works cataloged by all three libraries shows why this design matters: libraries usually agree on the underlying topic (93.3% share a concept-level heading) but often differ in exact expression (39.4% have identical heading sets). LCSHBench therefore scores both exact and concept matches, with set and rank metrics broken down by language and heading type, across open-vocabulary generation and full-vocabulary retrieval. As a first demonstration, a low-rank fine-tune of a 300M on-device embedder improves cross-lingual retrieval and beats a 3,072-dimensional hosted embedder on development exact recall@200 (0.659 vs 0.623). The language panel shows the gain is not uniform, and held-out-test and end-to-end confirmation remain future work.
LLM ベースの階層的優先順位付けによる営業リードのスコアリングの再考
一か八かの分野 (自動車、不動産など) でのセールスリードの変換は、長期にわたる意思決定サイクルと多段階の目標到達プロセスにより、電子商取引の推奨とは根本的に異なります。従来のリード スコアリング方法のルールベースのスコアカード、機械学習、またはポイントごとの CTR モデルは、監督の希薄さ、非構造化 CRM ログのセマンティック ギャップ、相対的なリードの優先度を把握できないなどの深刻な課題に直面しています。大規模言語モデル (LLM) は顧客との対話の優れた意味的理解を提供しますが、汎用 LLM はリードのランキングには適していません。比較可能なスコアではなくテキストを生成し、セールス ファネルの階層的な優先順位との整合性が欠けています。セールスリードスコアリングのための LLM ベースの識別フレームワークを導入します。これは、構造化された CRM 機能と非構造化された顧客インタラクションの共同モデリングをサポートします。このフレームワークに加えて、HPRO (階層的嗜好ランキング最適化) を提案します。これは、階層的な嗜好ランキングの目標によってセールス リードのスコアリングを強化します。 HPRO は、マージンを意識した Bradley-Terry 定式化を採用して、まばらなバイナリ ラベルを高密度でファネルを意識したプリファレンス ペアに変換し、ポイント単位とペア単位の両方の監視を活用したリード スコアリングを可能にします。大手NEVブランドからの大規模データを用いた実験では、最先端の分類(AUC 0.8161)とランキングパフォーマンス(トップランクのリード間で精度+39.7%)が実証されました。 132 日間のオンライン A/B テストにより、販売量が 9.5% 増加したことが検証され、現実世界の商業的影響が確認されました。
原文 (English)
Rethinking Sales Lead Scoring with LLM-based Hierarchical Preference Ranking
Sales lead conversion in high-stakes domains (e.g., automotive, real estate) differs fundamentally from e-commerce recommendation due to prolonged decision cycles and multi-stage funnels. Traditional lead scoring methods rule-based scorecards, machine learning, or pointwise CTR models face severe challenges: sparse supervision, a semantic gap in unstructured CRM logs, and inability to capture relative lead priority. While Large Language Models(LLMs) offer superior semantic understanding of customer interactions, general-purpose LLMs are ill-suited for lead ranking: they generate text rather than comparable scores, and lack alignment with the hierarchical priorities of sales funnels. We introduce an LLM-based discriminative framework for sales lead scoring, which supports joint modeling of structured CRM features and unstructured customer interactions. On top of this framework, we propose HPRO (Hierarchical Preference Ranking Optimization), which augments sales lead scoring with a hierarchical preference ranking objective. HPRO employs a margin-aware Bradley-Terry formulation to transform sparse binary labels into dense, funnel-aware preference pairs, enabling lead scoring to leverage both pointwise and pairwise supervision. Experiments on large-scale data from a leading NEV brand demonstrate state-of-the-art classification (AUC 0.8161) and ranking performance (+39.7% precision among top-ranked leads). A 132-day online A/B test validates 9.5% sales volume uplift, confirming real-world commercial impact.
TITAN-FedAnil+: リソースに制約のあるインテリジェント企業向けの信頼ベースの適応ブロックチェーン連合学習
Federated Learning (FL) は、データのプライバシーを維持しながら協調的なインテリジェンスを実現するための効果的なパラダイムとして登場しました。ただし、非 IID 配布や分散型セキュリティの脅威から生じるデータの異質性は、特にリソースに制約のあるエンタープライズ環境において依然として重大な課題となっています。このペーパーでは、インテリジェント企業におけるブロックチェーン対応のフェデレーテッド ラーニングのためのトラストベースのアダプティブ ネットワークである TITAN-FedAnil+ について説明します。提案されたフレームワークでは、アフィニティ伝播ベースの適応型クラスター化アグリゲーションを導入し、攻撃者の数に関する事前の知識を必要とせずに悪意のある更新を特定してフィルタリングします。さらに、GPU で高速化されたベクトル化が計算効率を向上させるために採用され、署名付き状態ジャンプ メカニズムにより軽量のブロックチェーン再同期が可能になります。実験結果では、ベースライン フレームワークと比較して、制約のある 8 GB エッジ デバイス上で 50 回の通信ラウンドにわたって最大 81% の節約を達成し、メモリ オーバーヘッドが大幅に削減されることが実証されました。結果は、TITAN-FedAnil+ が、インテリジェントなエンタープライズ環境におけるセキュアなフェデレーテッド ラーニング展開の堅牢性、スケーラビリティ、およびリソース効率を効果的に向上させることを示しています。
原文 (English)
TITAN-FedAnil+: Trust-Based Adaptive Blockchain Federated Learning for Resource-Constrained Intelligent Enterprises
Federated Learning (FL) has emerged as an effective paradigm for collaborative intelligence while preserving data privacy. However, data heterogeneity arising from non-IID distributions and decentralized security threats remain significant challenges, particularly in resource-constrained enterprise environments. This paper presents TITAN-FedAnil+, a Trust-Based Adaptive Network for blockchain-enabled federated learning in intelligent enterprises. The proposed framework introduces affinity propagation-based adaptive clustered aggregation to identify and filter malicious updates without requiring prior knowledge of the number of attackers. In addition, GPU-accelerated vectorization is employed to improve computational efficiency, while a signed state jump mechanism enables lightweight blockchain resynchronization. Experimental results demonstrate substantial reductions in memory overhead, achieving up to 81% savings across 50 communication rounds on constrained 8 GB edge devices compared with the baseline framework. The results indicate that TITAN-FedAnil+ effectively improves robustness, scalability, and resource efficiency for secure federated learning deployments in intelligent enterprise environments.
スケール不変変成器におけるグロッキングの低ランク減衰: スペクトル幾何学的な視点
最新の Transformer アーキテクチャでは、RMSNorm や Query-Key Normalization などの正規化メカニズムが頻繁に採用されており、モデルの一部が重みの大きさに関してほぼスケール不変になります。この領域では、標準のフロベニウス ノルム重み減衰は純粋に重み空間の半径方向に沿って作用し、正規化層によって表される関数を直接単純化することはできません。私たちは、このレンズを通して小さなアルゴリズムタスクのグロッキングを研究し、核ノルムに似たスペクトル正則化装置 \emph{Low-Rank Decay} (LRD) を提案します。その部分勾配 (極因子 $UV^\top$ -- はスケール不変設定でも接線成分を保持します)。この区別には、具体的な動的結果があります。モデルがトレーニング セットを記憶し、タスク勾配が消滅した後、L2 減衰は重みスペクトルを再形成できなくなりますが、LRD は $\ell_1$ のような方法で特異値を圧縮し続けます。モジュラー算術タスクでは、LRD がクエリ/キー行列で急速な実効ランクの崩壊を引き起こし、遅延汎化 (グロッキング) が発生するデータ部分の境界を拡大することがわかりました。我々はさらに、低ランク地層付近の核ノルム準微分値の「針から扇へ」の拡張を通じてスペクトル幾何学的解釈を提供します。
原文 (English)
Low-Rank Decay for Grokking in Scale-Invariant Transformers: A Spectral-Geometric View
Modern Transformer architectures frequently employ normalization mechanisms such as RMSNorm and Query-Key Normalization, making parts of the model approximately scale-invariant with respect to weight magnitudes. In this regime, standard Frobenius-norm weight decay acts purely along the radial direction of the weight space and cannot directly simplify the function represented by the normalized layer. We study grokking in small algorithmic tasks through this lens and propose \emph{Low-Rank Decay} (LRD), a nuclear-norm-like spectral regularizer whose subgradient -- the polar factor $UV^\top$ -- retains a tangential component even in the scale-invariant setting. This distinction has a concrete dynamical consequence: after the model memorizes the training set and task gradients vanish, L2 decay can no longer reshape the weight spectrum, whereas LRD continues to compress singular values in an $\ell_1$-like fashion. On modular arithmetic tasks, we find that LRD induces rapid effective-rank collapse in Query/Key matrices and expands the data-fraction boundary at which delayed generalization (grokking) occurs. We further provide a spectral-geometric interpretation through the ``needle-to-fan'' expansion of the nuclear-norm subdifferential near low-rank strata.
微分進化と勾配降下最適化によるアンサンブル潜在因子モデル
高次元かつ不完全 (HDI) データは、現実世界のビッグ データの多くのシナリオで広く普及しています。潜在因子モデルは、一般的な表現学習アプローチとして機能し、そのようなデータから有益な潜在因子を明らかにすることができます。それにもかかわらず、既存の潜在因子モデルのほとんどは、最適化のために勾配降下法のみに依存しているため、特に異種の HDI データを扱う場合、不十分で偏った表現につながる可能性があります。したがって、この研究では、次の 2 つの設計による、差分進化と勾配降下最適化によるアンサンブル潜在因子モデル (ELFM-DEGDO) を提案します。1) 2 つの多様な潜在因子モデルは、それぞれ差分進化と勾配降下最適化によって独立してモデル化され、2) 2 つの多様な潜在因子モデルは、カスタマイズされた自己適応重み付けメカニズムを介して結合され、それぞれの強みを効果的に融合します。両方の最適化パラダイムの相補的な利点を活用することで、ELFM-DEGDO は、HDI データに対してより包括的で偏りの少ない表現を生成できます。 3 つの HDI データセットをテストして、ELFM-DEGDO が関連するいくつかの潜在因子モデルよりも一貫して優れたパフォーマンスを発揮することを示しました。
原文 (English)
An Ensembled Latent Factor Model via Differential Evolution and Gradient Descent Optimization
High-dimensional and incomplete (HDI) data are prevalent in many real-world big data scenarios. Latent factor models serve as a common representation learning approach, capable of uncovering informative latent factors from such data. Nevertheless, most existing latent factor models rely solely on gradient descent for optimization, which may lead to insufficient and biased representations, particularly when dealing with heterogeneous HDI data. Thus, this study proposes an Ensembled Latent Factor Model via Differential Evolution and Gradient Descent Optimization (ELFM-DEGDO) with two-fold designed: 1) two diverse latent factor models are independently modeled via differential evolution and gradient descent optimization, respectively, and 2) the two diverse latent factor models are combined via a customized self-adaptive weighting mechanism to effectively fuse their strengths. By leveraging the complementary advantages of both optimization paradigms, ELFM-DEGDO is able to produce more comprehensive and less biased representations for HDI data. Three HDI datasets are tested to show that ELFM-DEGDO consistently performs better than related several latent factor models.
視覚的一般化におけるデータスケール、モデルの複雑さ、入力モダリティの実証的研究
最新のディープ ニューラル ネットワークは通常、大きなパラメーター スケールと非線形の階層構造を備えており、コンピューター ビジョンで優れたパフォーマンスを達成しています。ただし、汎化パフォーマンスの原因は、従来の統計学習理論を使用して説明するのが依然として困難です。視覚的な一般化に影響を与える可能性のある要因の中で、データ スケール、モデルの複雑さ、入力モダリティは、基本的かつ制御可能な変数です。この研究では、これら 3 つの要因がモデルの汎化パフォーマンスにどのように影響するかを実証的に分析します。具体的には、予備実験で 1 次元の非線形関数を構築し、トレーニング サンプルの数と多項式の次数を変更して、データ スケールとモデルの複雑さがモデルのパフォーマンスに及ぼす影響を観察します。主な実験では、異なるトレーニング データ スケール、モデル アーキテクチャ、入力モダリティの下で、CIFAR-10 と CIFAR-100 のモデルのパフォーマンスを比較します。実験結果は、トレーニング データのスケールを増やすと汎化パフォーマンスが一貫して向上する一方、モデルの複雑さが変化しても安定したゲインが得られないことを示しています。さらに、色情報を削除するとモデルのパフォーマンスが低下する一方、グラデーション、エッジ、ウェーブレットなどの明示的な事前の機能は、異なるモデル アーキテクチャ間で一貫性のない影響を及ぼします。全体として、この研究は、データ スケール、モデルの複雑さ、入力モダリティ、および視覚的汎化パフォーマンスの間の関係の実証的分析を提供します。コードと実験のログは、https://github.com/zlyd-CV/DeepLearning-Empirical-Studies で入手できます。
原文 (English)
An Empirical Study of Data Scale, Model Complexity, and Input Modalities in Visual Generalization
Modern deep neural networks usually have large parameter scales and nonlinear hierarchical structures, and they have achieved strong performance in computer vision. However, the source of their generalization performance remains difficult to explain using traditional statistical learning theory. Among the factors that may affect visual generalization, data scale, model complexity, and input modalities are fundamental and controllable variables. This study empirically analyzes how these three factors influence model generalization performance. Specifically, in a preliminary experiment, we construct a one-dimensional nonlinear function and vary the number of training samples and the polynomial degree to observe the effects of data scale and model complexity on model performance. In the main experiments, we compare model performance on CIFAR-10 and CIFAR-100 under different training data scales, model architectures, and input modalities. The experimental results show that increasing the training data scale consistently improves generalization performance, whereas changes in model complexity do not provide stable gains. In addition, removing color information degrades model performance, while explicit prior features such as gradients, edges, and wavelets have inconsistent effects across different model architectures. Overall, this study provides an empirical analysis of the relationships among data scale, model complexity, input modalities, and visual generalization performance. Code and experimental logs are available at: https://github.com/zlyd-CV/DeepLearning-Empirical-Studies.
L-TGVN: パーソナライズされた高速 MRI のための縦方向事前分布の活用
MRI は電離放射線を使用せずに優れた軟組織コントラストを提供しますが、取得時間が長いため患者の不快感が増大すると同時に、検査コストが上昇し、スキャナのスループットが制限されます。スキャン時間を短縮するための一般的なアプローチは、取得する測定値を少なくすることです。これにより、不適切な線形逆問題が発生します。したがって、診断品質の画像を回復するには、測定データ以外の事前知識を組み込む必要があります。追跡検査では、患者の最新の以前のスキャンにより、非常に有益な被験者固有のコンテキストが提供されますが、実際の使用は、時間的変化(病状の進行を含む)、スキャン間のずれ、取得間のプロトコルのドリフトによって複雑になります。この研究では、大幅にアンダーサンプリングされた測定値から現在のスキャンを再構築するための副次情報として以前のスキャンを活用する、縦方向の信頼誘導変分ネットワークである L-TGVN を紹介します。重要なことは、L-TGVN は、以前のスキャンの影響が取得された測定値と一致するように制限することです。既存の多くの縦方向再構成方法とは異なり、以前のスキャンと現在のスキャンの間の明示的な事前位置合わせを必要としません。さらに、訪問ごとの取得プロトコルの違い(シーケンスパラメータの変更など)にも対応します。私たちは、事前ガイド法や縦方向事前分布を使用しない方法など、一致した容量のベースラインに対して L-TGVN を評価し、困難な加速において微細構造のより良好な保存とともに、標準的な定量的指標の一貫した改善を観察しました。ソース コードは github.com/sodicksonlab/L-TGVN で入手できます。
原文 (English)
L-TGVN: Leveraging Longitudinal Priors for Personalized Rapid MRI
MRI provides excellent soft-tissue contrast without ionizing radiation, but long acquisition times increase patient discomfort while also raising exam costs and limiting scanner throughput. A common approach to reduce scan time is to acquire fewer measurements, which yields an ill-posed linear inverse problem; recovering diagnostic-quality images therefore requires incorporating prior knowledge beyond the measured data. In follow-up exams, the most recent prior scan of a patient can provide a highly informative subject-specific context, but practical use is complicated by temporal changes (including pathology progression), misalignment between scans, and protocol drift across acquisitions. In this work, we introduce L-TGVN, a Longitudinal Trust-Guided Variational Network that leverages prior scans as side information to reconstruct the current scan from heavily undersampled measurements. Crucially, L-TGVN constrains the influence of prior scans to be consistent with the acquired measurements. Unlike many existing longitudinal reconstruction methods, it does not require explicit pre-registration between prior and current scans. It further accommodates differences in acquisition protocols across visits (e.g., changes in sequence parameters). We evaluate L-TGVN against matched-capacity baselines, including prior-guided methods and methods that do not use longitudinal priors, and observe consistent improvements in standard quantitative metrics together with better preservation of fine structures at challenging accelerations. Source code is available at github.com/sodicksonlab/L-TGVN.
即時注射が忘れられなかったらどうなるでしょうか?エージェントシステムでのクロスセッションストアドプロンプトインジェクションの探索
最新のエージェント システムは、LLM をセッション限定のアシスタントからステートフル システムに変換します。ステートフル システムは、メモリ、ファイル システム、ツール、およびその他の長期間存続するコンテキスト アーティファクトを通じて、セッション間で共有世界状態を永続化および進化させます。この変化により、プロンプト インジェクションの攻撃対象領域が根本的に拡大します。しかし、プロンプト インジェクションに関するこれまでの研究は主に単一セッション内のモデル レベルの脅威に焦点を当てており、セッション間の永続的なシステム状態がエージェント システムのシステム レベルのリスクをどのように根本的に変化させるかを見落としていました。 Web システムのストアド クロスサイト スクリプティングにヒントを得て、クロスセッション ストアド プロンプト インジェクションを導入しました。これにより、成功したインジェクションはエージェント システム状態内で持続し、元の攻撃者による対話が終了した後も長期間にわたって将来の実行に静かに影響を与えることができます。この脅威を体系的に研究するために、ストアド プロンプト インジェクションを形式化し、敵対的なコンテンツがどのようにセッション間で持続し、エージェント システムに影響を与えるかの分類を開発します。さらに、ストアド プロンプト インジェクションのリスクを評価するためのベンチマークとサンドボックス ツールキットを開発し、さまざまなモデル、攻撃目標、永続化チャネルにわたる攻撃の成功の定量的分析を可能にします。私たちの調査結果は、永続化により、プロンプト インジェクションが一時的なモデル レベルの脅威から、エージェントの実行状態に組み込まれた長期にわたるシステム レベルの脆弱性に変化することが強調されています。私たちは、この取り組みがこの新たな脅威に対する幅広い注目を集め、コミュニティがエージェント システムの存続によって生じるシステム リスクを体系的に調査して軽減するよう促すことを願っています。
原文 (English)
What If Prompt Injection Never Left? Exploring Cross-Session Stored Prompt Injection in Agentic Systems
Modern agentic systems transform LLMs from session-bounded assistants into stateful systems that persist and evolve shared world state across sessions through memories, filesystems, tools, and other long-lived contextual artifacts. This shift fundamentally expands the attack surface of prompt injection. However, prior works on prompt injection have largely focused on model-level threats within a single session, overlooking how cross-session persistent system state fundamentally changes the system-level risk of agentic systems. Inspired by stored cross-site scripting in web systems, we introduce cross-session stored prompt injection, where a successful injection can persist within agentic system state and silently influence future executions long after the original attacker interaction has ended. To systematically study this threat, we formalize stored prompt injection and develop a taxonomy of how adversarial content persists and affects agentic systems across sessions. We further develop a benchmark and sandbox toolkit to evaluate the risks of stored prompt injection, enabling quantitative analysis of attack success across different models, attack goals, and persistence channels. Our findings highlight that persistence transforms prompt injection from an ephemeral model-level threat into a long-lived system-level vulnerability embedded within agent execution state. We hope this work draws broader attention to this emerging threat and motivates the community to systematically study and mitigate system risks arising from persistence in agentic systems.
LoopMoE: 言語モデリングの専門家混合による反復計算の統合
専門家混合 (MoE) およびループ アーキテクチャは、パラメーター容量と有効深さという 2 つの直交軸に沿ってモデルをスケールします。ただし、主流のループ アーキテクチャは、パラメーター数とトークンごとの FLOP を結合する高密度のバックボーンに依存しているため、一致した予算の下での反復計算の影響を分離することができません。この目的を達成するために、2 つの設計を通じてスパース ルーティングと反復的な重み共有計算を統合するループ MoE 言語モデルである LoopMoE を紹介します。 1 つ目は IterAdaLN で、反復インデックスとトークンごとの隠れ状態を組み合わせて条件付けされた変調信号を介して重み共有対称性を解決します。 2 つ目は、適切に調整された非ループ参照のアテンション対 FFN アクティブ パラメータの比率を回復する容量バランシング戦略です。これらの設計を組み合わせることで、同一の合計パラメーター、トークンごとの FLOP、およびアクティブなサブレイヤー比の下で、バニラ MoE に対するループ MoE の厳密に制御された最初の直接評価が可能になります。 3B スケールでは、LoopMoE は 9 つの下流ベンチマークのうち 8 つで Vanilla MoE を上回り、平均改善率は 1 ポイントを超えています。 9B スケールでは、LoopMoE が引き続き同等の Vanilla MoE を上回り、アーキテクチャ上の利点がより大きなスケールでも持続することを示しています。私たちの研究は、スパース性と再帰性の制御された統合を確立し、ループ言語モデルの有望な方向性を示唆しています。
原文 (English)
LoopMoE: Unifying Iterative Computation with Mixture-of-Experts for Language Modeling
Mixture-of-Experts (MoE) and looped architectures scale models along two orthogonal axes, namely parameter capacity and effective depth. However, mainstream looped architectures rely on dense backbones that couple parameter count with per-token FLOPs, which makes it impossible to isolate the effect of iterative computation under matched budgets. To this end, we present LoopMoE, a looped MoE language model that integrates sparse routing with iterative weight-shared computation through two designs. The first is IterAdaLN, which resolves weight-sharing symmetry via a modulation signal jointly conditioned on the iteration index and the per-token hidden state. The second is a capacity-balancing strategy that recovers the attention-to-FFN active parameter ratio of well-tuned non-looped references. Together, these designs enable the first strictly controlled, head-to-head evaluation of a looped MoE against a Vanilla MoE under identical total parameters, per-token FLOPs, and active sublayer ratios. At the 3B scale, LoopMoE outperforms the Vanilla MoE on 8 of 9 downstream benchmarks with an average improvement exceeding 1 point. At the 9B scale, LoopMoE continues to outperform the matched Vanilla MoE, indicating that the architectural gain persists at larger scale. Our work establishes a controlled synthesis of sparsity and recurrence, and suggests a promising direction for looped language models.
MemoryDocDataSet: 共同会話記憶と長い文書推論のベンチマーク
AI システムでは、複数セッションの会話履歴のナビゲートと、長い文書内の深い読解の実行という 2 つの要求の厳しい機能を組み合わせる必要がますます高まっています。しかし、両方を同時に評価する既存のベンチマークはありません。 50 のマイクロワールドと 1,000 の QA ペアの合成ベンチマークである MemoryDocDataSet を紹介します。各インスタンスは 3 ~ 5 人のペルソナ、数か月にわたるアクティビティにわたる時間イベント グラフ、3 ~ 5 の実際の長い文書 (それぞれ Caselaw Access Project から調達された 20,000 ~ 50,000 のトークン)、それらの文書に基づくマルチセッションの会話、および 5 つの推論カテゴリにわたる 20 の質問と回答のペアで構成されます。特徴的な機能はハイブリッド ソース タグです。質問では、システムが最初に会話履歴をナビゲートして関連する文書を特定し、次にその文書内から回答を抽出する必要があります。ハイブリッド質問はデータセットの 75.1% を占めます。データセットの品質は、LLM を判定として使用するプロンプト感度自己一貫性分析によって特徴付けられ、50 のミクロ世界すべてで中央値のコーエンの $\kappa = 0.634$ が得られます。トランケートされたコンテキスト、ロングコンテキスト LLM、検索拡張世代 (RAG)、およびメモリ システムにわたる 6 つのベースライン構成を評価します。最良のベースライン (RAG-両方) は、F1 全体で 0.358、ハイブリッドで 0.342 を達成します。文書のみの検索 (RAG-Doc) は、文書のみの質問で 0.453 を達成したにもかかわらず、ハイブリッドでは 0.267 に落ち込んでいます。これは、共同検索の明らかなギャップを示しており、これが会話の記憶と長い文書のナビゲーションを統合するアーキテクチャを動機づけています。データセット、生成パイプライン、およびすべてのベースライン実装をリリースします。
原文 (English)
MemoryDocDataSet: A Benchmark for Joint Conversational Memory and Long Document Reasoning
AI systems increasingly need to combine two demanding capabilities: navigating multi-session conversation history and performing deep reading comprehension within long documents. Yet no existing benchmark evaluates both simultaneously. We introduce MemoryDocDataSet, a synthetic benchmark of 50 micro-worlds and 1,000 QA pairs in which each instance comprises 3-5 personas, a temporal event graph spanning months of activity, 3-5 real long documents (20,000-50,000 tokens each sourced from the Caselaw Access Project), multi-session conversations grounded on those documents, and 20 question-answer pairs across five reasoning categories. The defining feature is the Hybrid source tag: questions requiring a system to first navigate conversation history to identify which document is relevant, then extract the answer from within that document. Hybrid questions account for 75.1% of the dataset. Dataset quality is characterised through a prompt-sensitivity self-consistency analysis using LLM-as-judge, yielding a median Cohen's $\kappa = 0.634$ across all 50 micro-worlds. We evaluate six baseline configurations spanning truncated context, long-context LLMs, retrieval-augmented generation (RAG), and memory systems. The best baseline (RAG-Both) achieves 0.358 overall F1 and 0.342 on Hybrid. Document-only retrieval (RAG-Doc) collapses to 0.267 on Hybrid despite achieving 0.453 on Doc-only questions, demonstrating a clear joint-retrieval gap that motivates architectures unifying conversational memory with long-document navigation. We release the dataset, generation pipeline, and all baseline implementations.
RowNet: 表形式回帰のためのメモリ トランスフォーマー
不動産評価は構造化回帰問題であり、価格は異種の特徴タイプ、まばらな地域効果、非線形相互作用、および比較可能な不動産の実際的なロジックによって支配されます。標準的な多層パーセプトロンは各行を孤立ベクトルとして扱い、局所性、スケール感度、およびカテゴリカルマッチングを監視のみから学習する必要があります。勾配ブースト デシジョン ツリーは強力な表形式のベースラインを提供しますが、その特徴中心の分割メカニズムは、類似した履歴観測の取得を明示的にモデル化しません。この論文では、不動産の平方メートルあたりの価格を予測するための検索ベースのニューラル アーキテクチャである RowNet について説明します。 RowNet は、ラベル付きプロパティのメモリ バンクに対するペアごとの類似性機能を通じてクエリ プロパティを表します。最初の検索層は、特徴のみの類似性から大まかなターゲットを推定します。 2 番目の層は、ターゲット一貫性機能を使用してメモリ比較を強化し、複数の学習されたアテンション ヘッドを使用して相補的な比較可能なセットを取得します。最後の専門家混合モジュールは、学習されたゲーティング、残差補正、エントロピー正則化、ヘッドダイバーシティ正則化を組み合わせて予測を生成します。
原文 (English)
RowNet: A Memory Transformer for Tabular Regression
Real estate valuation is a structured regression problem in which prices are governed by heterogeneous feature types, sparse regional effects, nonlinear interactions, and the practical logic of comparable properties. Standard multilayer perceptrons treat each row as an isolated vector and must learn locality, scale sensitivity, and categorical matching from supervision alone. Gradient-boosted decision trees provide strong tabular baselines, but their feature-centric splitting mechanism does not explicitly model the retrieval of similar historical observations. This paper presents RowNet, a retrieval-based neural architecture for real estate price-per-square-meter prediction. RowNet represents a query property through pairwise similarity features against a memory bank of labeled properties. A first retrieval layer estimates a coarse target from feature-only similarities. A second layer augments the memory comparison with target-consistency features and uses multiple learned attention heads to retrieve complementary comparable sets. A final mixture-of-experts module combines learned gating, residual correction, entropy regularization, and head-diversity regularization to produce the prediction.
トークンランキングは偽造不可能な言語モデル署名です
言語モデルのパラメータは、ロジット出力に(各モデルに)一意の幾何学的制約を課すことが知られており、これはモデルを識別する署名として機能しますが、API がロジットを配布するときにモデルの最終層パラメータも漏洩します。私たちは、トークンのランキング (確率値ではなく、確率による順序付け) を公開する、より制限的な API を調査し、ランキングも署名を構成することを発見しました。すべてのモデルは、十分な規模の $k$ に対して実行可能な上位 $k$ ランキングの独自のセットを持っています。さらに、同じ実行可能なランキングのセットを持つモデルを見つけることは NP 困難であるため、ランキング署名は最初に知られている (多項式的に) 偽造不可能な署名です。セキュリティの面では、ロジットと同様に、トークンのランキングがすでにモデルの最終層をほぼ盗むのに十分であることがわかりました。ただし、近似が粗すぎて署名を偽造できず、API を十分に小さい $k$ の上位 $k$ トークンに制限することで効果的に対抗できます。モデル署名を提示するために必要な $k$ は一般に、盗用を防ぐために必要な $k$ よりも小さいため、API はモデル パラメーターを漏らすことなく偽造不可能な署名を提示することが可能です。
原文 (English)
Token Rankings are Unforgeable Language Model Signatures
Language model parameters are known to impose unique (to each model) geometric constraints on their logit outputs, which serves as a signature that identifies the model, but also leaks the model's final layer parameters when an API distributes logits. We investigate more restrictive APIs that expose token rankings (i.e., their ordering by probability, but not the probability values) and find that rankings also constitute a signature: every model has a unique set of feasible top-$k$ rankings for sufficiently large $k$. Furthermore, the ranking signature is the first known (polynomially) unforgeable signature, since finding a model with the same set of feasible rankings is NP-hard. On the security front, we find that token rankings are already sufficient to approximately steal the final layer of the model, similar to logits, though the approximation is too coarse to forge the signature, and can be effectively countered by restricting the API to top-$k$ tokens with sufficiently small $k$. Since the top-$k$ required to present the model signature is generally smaller than the $k$ required to prevent stealing, it is possible for an API to present an unforgeable signature without leaking model parameters.
CyberGym-E2E: AI エージェントのエンドツーエンドのサイバーセキュリティ機能のためのスケーラブルな現実世界のベンチマーク
AI は、ソフトウェアの脆弱性を自律的に検出、分析、修復できるシステムを可能にすることで、サイバーセキュリティを変革する可能性を秘めています。しかし、AI システムの既存のサイバーセキュリティ評価は規模や範囲が限られており、現実世界のソフトウェアの脆弱性の発見と修復のエンドツーエンドのライフサイクルを捉えることができません。このギャップに対処するために、私たちは、脆弱性の発見、PoC 生成、パッチ生成のライフサイクル全体にわたって AI エージェントの能力を包括的に評価する、大規模かつ現実的なエンドツーエンドのサイバーセキュリティ ベンチマークである CyberGym-E2E を提案します。 CyberGym-E2E は、オープンソースの脆弱性データを現実的な評価環境に変換するための自動化されたエージェント強化パイプラインを構築するため、包括的でスケーラブルです。現在、ベンチマークは、139 の異なるオープンソース プロジェクトにわたる 920 件の実際の脆弱性で構成されています。
原文 (English)
CyberGym-E2E: Scalable Real-World Benchmark for AI Agents' End-to-End Cybersecurity Capabilities
AI has the potential to transform cybersecurity by enabling systems that can autonomously detect, analyze, and remediate software vulnerabilities. However, existing cybersecurity evaluations of AI systems are limited in scale or scope, and fail to capture the end-to-end lifecycle of real-world software vulnerability discovery and remediation. To address this gap, we propose CyberGym-E2E, a large-scale and realistic end-to-end cybersecurity benchmark that comprehensively evaluates AI agents' abilities across the full lifecycle of vulnerability discovery, PoC generation, and patch generation. CyberGym-E2E is comprehensive and scalable, as we build an automated, agent-enhanced pipeline for transforming open-source vulnerability data into realistic evaluation environments. Currently, the benchmark consists of 920 real-world vulnerabilities across 139 different open-source projects.
SePO: システム プロンプト最適化のための自己進化型プロンプト エージェント
システム プロンプトの最適化により、基礎となるモデルを変更することなくエージェントの動作が改善され、人間が判読できる、モデルに依存しない命令が生成されます。既存の方法では、タスク エージェントのシステム プロンプトを改良するプロンプト エージェントを構築しますが、プロンプト エージェント独自のシステム プロンプトは手動で設計および修正されたままになります。我々は、プロンプト エージェント自身のシステム プロンプトをタスク エージェントのシステム プロンプトと並んで最適化ターゲットとして扱う自己進化型プロンプト最適化 (SePO) を提案します。 SePO は自己参照設計を採用しています。単一のプロンプト エージェントは、候補プロンプトのアーカイブを踏み台として維持するオープンエンドの進化的探索の下で、タスク エージェントのシステム プロンプトとそれ自身のプロンプトの両方を改善します。トレーニングは 2 つの段階で進行します。事前トレーニングではマルチタスク プール上でプロンプト エージェントを進化させ、その後、微調整によってそれをターゲット タスクに適用します。数学 (AIME'25)、抽象推論 (ARC-AGI-1)、大学院レベルの科学 (GPQA)、コード生成 (MBPP)、および論理パズル (数独) にわたる 5 つのベンチマークにわたって、SePO は一貫して Manual-CoT、TextGrad、および MetaSPO を上回り、Manual-CoT と比較して平均精度が 4.49 ポイント向上しました。事前トレーニングによるプロンプト最適化スキルは、タスクごとのプロンプトを記憶するのではなく、事前トレーニング混合物を超えたタスクにも一般化されます。
原文 (English)
SePO: Self-Evolving Prompt Agent for System Prompt Optimization
System prompt optimization improves agent behavior without modifying the underlying model, yielding human-readable, model-agnostic instructions. Existing methods build a prompt agent that refines task agents' system prompts, yet leave the prompt agent's own system prompt hand-engineered and fixed. We propose Self-Evolving Prompt Optimization (SePO), which treats the prompt agent's own system prompt as an optimization target alongside task agents' system prompts. SePO adopts a self-referential design. A single prompt agent improves both task agents' system prompts and its own under an open-ended evolutionary search that maintains an archive of candidate prompts as stepping stones. Training proceeds in two stages: pre-training evolves the prompt agent on a multi-task pool, and fine-tuning then applies it to a target task. Across five benchmarks spanning math (AIME'25), abstract reasoning (ARC-AGI-1), graduate-level science (GPQA), code generation (MBPP), and logic puzzles (Sudoku), SePO consistently outperforms Manual-CoT, TextGrad, and MetaSPO, improving the average accuracy by 4.49 points compared to Manual-CoT. The prompt optimization skill from pre-training also generalizes to tasks beyond the pre-training mixture, rather than memorizing per-task prompts.
ParetoPilot: Infer-Perturb-Guide 拡散によるゼロサロゲートオフライン多目的最適化
オフライン多目的最適化 (オフライン MOO) は、高価な環境との相互作用を行わずに、静的データセットに基づいた新しいパレート最適設計を発見することを目的としています。最近の生成手法は顕著な成功を収めていますが、主に外部サロゲート モデルに依存しています。この依存関係により、重大な計算オーバーヘッドが生じ、欺瞞的な評価に悩まされ、主流の生成モデルを条件付きで共同トレーニングするという一般的なパラダイムから逸脱します。これらのボトルネックに対処するために、オフライン MOO 用の新しいゼロ代理拡散フレームワークである ParetoPilot を提案します。 ParetoPilot は、事前トレーニングされた拡散モデルに本質的に組み込まれている条件付き事前確率を最大限に活用します。このフレームワークの核心として、Infer-Perturb-Guide (IPG) エンジンが導入されており、このエンジンは逆生成プロセスの無条件ノイズ除去ステップ内にシームレスにインターリーブされます。まず、条件付きおよび無条件のノイズ予測を照合することで、瞬間的な目標方向を暗黙的に推測します。次に、厳密な収束のために平行な重力場と相互多様性のためにエッジを意識した斥力を数学的に直交化し、動的にアニールされた摂動ベクトルを作成します。最後に、この摂動されたターゲットは、標準の分類子なしガイダンス (CFG) を介して生成プロセスをシームレスに制御します。 51 のタスクにわたる広範な実験により、ParetoPilot が 14 の最先端のサロゲートベースおよび逆生成ベースラインよりも優れたパフォーマンスを発揮することが実証されました。補助的なプロキシ トレーニングを排除することで、当社のアプローチはデータのプライバシーを保護しながら、ハイパーボリュームの改善と堅牢なパレート フロント カバレッジを実現します。
原文 (English)
ParetoPilot: Zero-Surrogate Offline Multi-Objective Optimization via Infer-Perturb-Guide Diffusion
Offline multi-objective optimization (Offline MOO) aims to discover novel Pareto-optimal designs based on static datasets without expensive environment interactions. While recent generative methods have achieved notable success, they predominantly rely on external surrogate models. This dependency introduces significant computational overhead, suffers from deceptive evaluations, and deviates from the prevailing paradigm of jointly training mainstream generative models with conditions. To address these bottlenecks, we propose ParetoPilot, a novel zero-surrogate diffusion framework for offline MOO. ParetoPilot fully leverages the conditional priors inherently embedded within pre-trained diffusion models. At its core, the framework introduces the Infer-Perturb-Guide (IPG) engine, which is seamlessly interleaved within the unconditional denoising steps of the reverse generation process. First, it implicitly infers the instantaneous objective direction by matching conditional and unconditional noise predictions. Next, it mathematically orthogonalizes a parallel gravity field for strict convergence and an edgeness-aware repulsive force for mutual diversity, creating a dynamically annealed perturbation vector. Finally, this perturbed target seamlessly steers the generation process via standard Classifier-Free Guidance (CFG). Extensive experiments across 51 tasks demonstrate that ParetoPilot outperforms 14 state-of-the-art surrogate-based and inverse generative baselines. By eliminating auxiliary proxy training, our approach preserves data privacy while achieving hypervolume improvement and robust Pareto front coverage.
公平でパフォーマンスの高い顔認識のための適応キャリブレーション
正規化された埋め込み間のコサイン類似性を適切に校正された確率にマッピングする、顔認識のための新しい校正戦略である適応校正 (AC) を紹介します。ローカル コンテキストをキャリブレーションに組み込むことにより、アダプティブ キャリブレーションはコサイン類似度の基本的な不一致を修正します。これにより、同じ距離が、異なる埋め込み領域の異なる一致確率に対応することができます。私たちのアプローチは、全体的なパフォーマンスの両方を向上させ、人口統計メタデータを必要とせずに、より公平なキャリブレーションを実現します。私たちのアプローチは、さまざまな事前トレーニング済みモデルと標準ベンチマークにわたって、精度と公平性の両方の指標において既存の手法よりも一貫して優れています。 AC は、人口統計グループの注釈を必要とせず、全体的なパフォーマンスを向上させながら、公平な顔認識のための実用的なソリューションを提供します。既存のアプローチとは異なり、私たちの方法は、一部のグループのパフォーマンスの低下を犠牲にして公平性が実現される「平準化」を回避する、継続的な地域固有のキャリブレーションを提供します。
原文 (English)
Adaptive Calibration for Fair and Performant Facial Recognition
We introduce Adaptive Calibration (AC), a novel calibration strategy for facial recognition that maps cosine similarity between normalized embeddings to well-calibrated probabilities. By incorporating local context into calibration, Adaptive Calibration corrects for a fundamental mismatch in cosine similarity, whereby the same distance can correspond to different match probabilities in different embedding regions. Our approach improves both overall performance and results in a fairer calibration without requiring demographic metadata. Our approach consistently dominates existing methods both on accuracy and fairness metrics across a variety of pretrained models and standard benchmarks. AC provides a practical solution for equitable facial recognition, without requiring demographic group annotations, and while improving overall performance. Unlike existing approaches, our method provides continuous, region-specific calibration that avoids "leveling down" where fairness comes at the cost of degraded performance for some groups.
ChessMimic: オンライン ブリッツ チェスの人間の動き、時計、結果を予測するための定格ごとのトランスフォーマー モデル
ChessMimic は、位置、最近の移動履歴、プレイヤーの評価、およびクロック状態に基づいて、移動、思考時間、および結果の予測を行う 3 つの小さなエンコーダー専用トランスフォーマーからなるシステムです。 100-Elo 評価バンドごとに各モデルの個別のインスタンスを適合させ、パラメーターの効率を犠牲にしてスキルごとのキャリブレーションをより鮮明にします。 1 か月にわたって開催された Lichess Rated Blitz ゲームのスライスでは、ChessMimic の人手の予測精度は、すべての Elo バンドで Maia-2 を上回りました。 Maia-3 と比較すると、9M パラメーター モデルの精度は、幾何学的な注意バイアスの追加の複雑さを伴わずに、Maia-3-5M と Maia-3-23M の間に位置します。動きの一致モデルに加えて、位置だけでなく、プレイヤーの評価、時間制御、残りのクロック時間も条件とするゲーム結果モデルもトレーニングします。結果モデルは、サンプル中 0.78 の AUC を達成し、Maia-2 だけでなく、素材、評価、およびクロック時間に基づくロジスティック回帰を上回りました。最後に、人間の思考時間を予測する時計モデルをトレーニングします。クロック モデルは、ALLIE スタイルのフィルター (ALLIE が報告した r = 0.70 に対してピアソン r = 0.41、スピアマン rho = 0.50、MAE 4.10 秒) の下で、使用可能だが SOTA ではないプライごとの思考時間信号を提供し、残留ギャップはバケット マージナル キャリブレーションではなく位置ごとのバケットのシャープネスに集中しています。公開デモは 1e4.ai にあり、コード、バンドごとの重み、および C++ データ フィルター パイプライン コードを GitHub でリリースします。
原文 (English)
ChessMimic: Per-Rating Transformer Models for Human Move, Clock, and Outcome Prediction in Online Blitz Chess
We present ChessMimic, a system of three small encoder-only transformers - for move, thinking-time, and outcome prediction - conditioned on the position, recent move history, player rating, and clock state. We fit a separate instance of each model per 100-Elo rating band, trading parameter efficiency for sharper per-skill calibration. On a held-out month-wide slice of Lichess Rated Blitz games ChessMimic's human move prediction accuracy outperforms Maia-2 in every Elo band. Compared to Maia-3, our 9M parameter model's accuracy sits between Maia-3-5M and Maia-3-23M without the additional complexity of Geometric Attention Bias. In addition to the move matching model, we also train a game outcome model that conditions not only on the position, but also player ratings, time control, and remaining clock times. The outcome model achieves an AUC of 0.78 out of sample, beating Maia-2 as well as logistic regressions based on material, ratings, and clock time. Finally, we train a clock model that predicts human thinking times. The clock model provides a usable but non-SOTA per-ply think-time signal under ALLIE-style filters (Pearson r = 0.41, Spearman rho = 0.50, MAE 4.10 s, against ALLIE's reported r = 0.70), with the residual gap concentrated in per-position bucket sharpness rather than bucket-marginal calibration. A public demo is at 1e4.ai and we release code, per-band weights, and the C++ data-filter pipeline code in GitHub.
ビジュアルテキスト生成における推論の忠実度の評価
最近の Text-to-Image (T2I) モデルは、画像内で非常に読みやすく、適切に構造化されたテキストをレンダリングできるため、ドキュメント生成やスライド生成などのアプリケーションが可能になります。しかし、複雑な解決策をレンダリングされたテキストを通じて直接表現しなければならない場合に、そのようなシステムが推論能力を忠実に保持しているのか、それとも単に表面レベルのパターンを模倣しているだけなのかは不明のままです。モデルは完全な推論プロセスを画像として表現する必要があるビジュアル テキスト生成における推論の忠実度を評価することで、この問題を調査します。私たちの評価には、長いテキストのレンダリング、事実知識の調査、文脈の理解、および複数ステップの推論が含まれます。これらの設定全体にわたって、現在の T2I モデルでは、レンダリングされたテキストが視覚的に明確に見える場合でも、セマンティック エラー、論理的矛盾、不正確な中間ステップが頻繁に発生することがわかりました。これらの失敗は、同じタスクに対するテキストのみのモデルの強力な推論パフォーマンスとは対照的です。私たちの調査結果は、ビジュアルテキスト生成と手続き型推論の間に大きなギャップがあることを明らかにし、より信頼性の高いビジュアルテキスト推論を動機付けています。
原文 (English)
Evaluating Reasoning Fidelity in Visual Text Generation
Recent text-to-image (T2I) models can render highly legible and well-structured text within images, enabling applications including document generation and slide generation. However, it remains unclear whether such systems faithfully preserve reasoning ability when complex solutions must be expressed directly through rendered text, or whether they merely imitate surface-level patterns. We investigate this question by evaluating reasoning fidelity in visual text generation, where models must express complete reasoning processes as images. Our evaluation includes long text rendering, factual knowledge probing, context understanding, and multi-step reasoning. Across these settings, we find that current T2I models frequently produce semantic errors, logical inconsistencies, and incorrect intermediate steps, even when the rendered text appears visually clear. These failures contrast with the strong reasoning performance of text-only models on the same tasks. Our findings reveal a substantial gap between visual text generation and procedural reasoning, motivating more reliable visual text reasoning.
SFMambaNet: 対応プルーニングのためのスペクトル周波数拡張選択的状態空間モデル
対応関係の枝刈りは、対応関係の初期セットからインライアを特定することを目的としています。既存のグラフ ニューラル ネットワーク (GNN) ベースの手法のほとんどは、粗いユークリッド座標からマッピングされた幾何学的特徴に依存しているため、インライアによって示される微妙な幾何学的一貫性を捕捉するのが困難です。 Mamba ベースの手法は、グローバルな受容野と長いシーケンスのモデリング機能を備えていますが、隠れた状態空間内に実質的に矛盾した特徴が蓄積される傾向があり、内値と外れ値を区別することが困難になります。この論文では、周波数領域の知覚をこのタスクに初めて統合し、新しいスペクトル周波数拡張 Mamba ベースの 2 ビュー対応枝刈りネットワークである SFMambaNet を提案します。私たちの方法は 2 つのコンポーネントで連携して構成されています。まず、ローカル スペクトル幾何学アテンション (LSGA) ブロックを設計します。 LSGA は、スペクトル位置エンコーディングをローカル グラフ インタラクションに組み込み、マルチスケール Mamba 処理を導入して、微妙な幾何学的一貫性の捕捉を強化し、ローカル フィーチャの識別性を向上させます。これに基づいて、Spectral-Integrated Global Mamba (SIGM) ブロックを設計します。 SIGM は状態空間内に周波数ゲート メカニズムを埋め込み、LSGA によって提供される周波数情報を利用して、隠れ状態内の高周波ノイズの蓄積を明示的に抑制し、一貫性のない特徴の伝播を軽減します。これにより、インライアとアウトライアの分離性が強化され、ほぼ線形の複雑さで堅牢なグローバル コンテキスト モデリング機能が実現されます。広範な実験により、SFMambaNet がいくつかの困難なタスクにおいて現在の最先端の方法よりも優れたパフォーマンスを発揮することが実証されました。コードは https://github.com/Kirito14IT/SFMambaNet で入手できます。
原文 (English)
SFMambaNet: Spectral-Frequency Enhanced Selective State Space Model for Correspondence Pruning
Correspondence pruning aims to identify inliers from an initial set of correspondences. Most existing Graph Neural Network (GNN)-based methods rely on geometric features mapped from coarse Euclidean coordinates, which struggle to capture the subtle geometric consistencies presented by inliers. While Mamba-based methods possess global receptive fields and long sequence modeling capabilities, they tend to accumulate substantial inconsistent features within the hidden state space, making it difficult to distinguish inliers from outliers. In this paper, we integrate frequency domain perception into this task for the first time and propose SFMambaNet, a novel Spectral-Frequency enhanced Mamba-based two-view correspondence pruning network. Our method is collaboratively composed of two components: First, we design a Local Spectral-Geometric Attention (LSGA) block. LSGA incorporates spectral positional encoding into local graph interactions and introduces multi-scale Mamba processing to enhance the capture of subtle geometric consistencies and improve local feature discriminability. Building upon this, we design a Spectral-Integrated Global Mamba (SIGM) block. SIGM embeds a frequency gating mechanism within the state space, utilizing the frequency information provided by LSGA to explicitly suppress high-frequency noise accumulation within hidden states and mitigate the propagation of inconsistent features. This enhances inlier-outlier separability and achieves robust global context modeling capabilities with nearly linear complexity. Extensive experiments demonstrate that SFMambaNet outperforms current state-of-the-art methods on several challenging tasks. The code is available at https://github.com/Kirito14IT/SFMambaNet.
暗闇でのスマートな選択: メタ認知ピボットのトレースによる推論のための効率的な RLVR に向けて
検証可能な報酬を伴う強化学習 (RLVR) は大規模推論モデル (LRM) を大幅に進化させましたが、完全にアノテーションが付けられた巨大なデータセットでのタイムリーなトレーニングが必要です。この目的を達成するために、データ効率の高い RLVR 手法が 2 つの観点から広く研究されています。(i) データ選択手法は、ほぼ完全なデータのパフォーマンスをもたらす「ゴールデン」サンプルの小さなサブセットを特定しますが、それらはラベル付きデータの既存のプールに依存します。 (ii) 教師なし RLVR メソッドは、大規模なラベルなしデータに対して独自の内部監視信号を使用してモデルをトレーニングしますが、最適なパフォーマンスを示しません。したがって、事前の監督なしで、トレーニングに最も有益でアノテーションに値するラベルのないサンプルを選択することを目的とした、RLVR の「暗闇でのピック」設定を調査します。体系的な分析を通じて、スマート ピックは適切に調整された不確実性推定量に依存し、適応トレーニング体制のためのデータの戦略的な分割を可能にすることを実証します。この洞察に基づいて、私たちは、注意のダイナミクスを活用して推論中のメタ認知ピボットを追跡する 3 方向のデータ トリアージ フレームワークである PivotTrace を提案します。 PivotTrace は、ピボット密度を通じて不確実性を正確に定量化することで、自動化されたデータ ルーティングを実現し、アノテーションとトレーニングの効率の両方を相乗的に最大化します。経験的に、PivotTrace は、注釈付きサンプルがわずか 29.3% で、収束が 2.75 高速で完全監視 LRM を上回っています。
原文 (English)
Smart Picks in the Dark: Towards Efficient RLVR for Reasoning via Tracing Metacognitive Pivots
Reinforcement learning with verifiable rewards (RLVR) has greatly advanced large reasoning models (LRMs), but it requires timely training on a huge fully-annotated dataset. To this end, data-efficient RLVR methods have been widely studied from two perspectives: (i) data selection methods identify a small subset of "golden" samples that yield near-full-data performance, but they rely on a pre-existing pool of labeled data. (ii) unsupervised RLVR methods train the model using its own internal supervision signals on large-scale unlabeled data, yet they exhibit suboptimal performance. Accordingly, we investigate the "pick in the dark" setup for RLVR, which aims to select, without prior supervision, unlabeled samples that are most beneficial for training and worthy of annotation. Through systematic analysis, we demonstrate that smart picks hinge on a well-calibrated uncertainty estimator to enable strategic partitioning of data for adaptive training regimes. Building on this insight, we propose PivotTrace, a three-way data triage framework that leverages attention dynamics to trace metacognitive pivots during reasoning. By precisely quantifying uncertainty through pivot density, PivotTrace achieves automated data routing to synergistically maximize both annotation and training efficiency. Empirically, PivotTrace surpasses the fully supervised LRM with only 29.3% annotated samples and 2.75 faster convergence.
共同生成と評価による自己進化する深層研究
大規模言語モデル (LLM) は日常のアプリケーションでますます採用されるようになり、詳細な研究が特に重要な機能として際立っています。従来の質問応答 (QA) タスクとは異なり、詳細な調査レポートの生成には決定的な根拠が欠けているため、報酬設計が本質的に検証不可能になり、効果的な強化学習が制限されます。既存のアプローチでは、LLM-as-a-judge およびクエリ依存の評価ルーブリックを使用してこの課題を軽減していますが、依然として静的な評価器に依存しているため、ソルバーの向上に応じて標準を適応させることができず、最適化圧力が不十分になり、最終的に飽和状態になってしまいます。私たちは、\textbf{s}elf 進化型 \textbf{co} 進化型トレーニング フレームワークで、深い \textbf{re} 検索の評価と生成 (SCORE) を使用してこの制限に対処します。これは、共有パラメータ学習プロセスにおいて評価器とソルバーを緊密に結合します。生成と評価を独立したモジュールとして扱うのではなく、それらの本質的なつながりを活用して、単一の共有パラメーター モデル内で共同の改善を可能にします。このプロセスを制限するために、ソルバーのパフォーマンスに基づいて評価環境を動的に制御するメタハーネスを導入し、有効な評価次元と十分に深い評価者の検索を促進します。ディープリサーチベンチマークに関する広範な実験により、レポート生成の品質が一貫して向上していることが実証されており、評価と生成を共進化させることが、オープンエンドのリサーチエージェントをトレーニングするための有望な方向性であることが示されています。
原文 (English)
Self-Evolving Deep Research via Joint Generation and Evaluation
Large Language Models (LLMs) have become increasingly adopted in daily applications, with deep research standing out as a particularly important capability. Unlike traditional question-answering (QA) tasks, deep research report generation lacks definitive ground-truth, making reward design inherently unverifiable and limiting effective reinforcement learning. Existing approaches mitigate this challenge with LLM-as-a-judge and query-dependent evaluation rubrics, but they still rely on static evaluators that cannot adapt their standards as the solver improves, leading to insufficient and eventually saturated optimization pressure. We address this limitation with a \textbf{s}elf-evolving \textbf{co}-evolutionary training framework for deep \textbf{re}search evaluation and generation (SCORE), which tightly couples an evaluator and a solver in a shared-parameter learning process. Rather than treating generation and evaluation as isolated modules, we leverage their intrinsic connection to enable joint improvement within a single shared-parameter model. To restrict this process, we introduce a meta-harness, which dynamically controls the evaluation environment based on solver performance, encouraging valid evaluation dimensions and sufficiently deep evaluator search. Extensive experiments on deep research benchmarks demonstrate consistent improvement in report generation quality, showing that co-evolving evaluation and generation is a promising direction for training open-ended research agents.
GeoMin: 幾何分布モデリングによるデータ効率の高い半教師あり RLVR
検証可能な報酬を伴う強化学習 (RLVR) は LLM 推論を大幅に進歩させますが、ジレンマに直面しています。標準的な教師ありスケーリングは高いアノテーション コストによって抑制される一方、教師なしの代替案は深刻なモデル崩壊に悩まされます。最近の半教師あり RLVR 手法は、小さなラベル付きセットを使用してラベルなしデータをガイドすることでこの問題に対処し、トレーニングの有効性とアノテーション コストの間で有望なトレードオフを実現しています。ただし、粗いパフォーマンスのヒューリスティックに依存するため、データ効率の深刻なボトルネックに悩まされており、貴重なインスタンスの大部分が十分に活用されていません。この目的を達成するために、ラベル付きデータのグローバルな特徴分布をモデル化して正しいロールアウトと間違ったロールアウトの間の構造的不一致を解読する GeoMin を提案します。これにより、自己報酬信号の信頼性を評価し、ラベルなしデータの可能性を完全に引き出すための堅牢な事前検証を確立します。経験的に、GeoMin は最も強力なベースラインを +4.1% 上回るパフォーマンスを示し、注釈が 10% しかない完全教師モデルをも上回り、顕著なデータ効率を示しています。
原文 (English)
GeoMin: Data-Efficient Semi-Supervised RLVR via Geometric Distribution Modeling
Reinforcement learning with verifiable rewards (RLVR) significantly advances LLM reasoning, yet it faces a dilemma: standard supervised scaling is throttled by high annotation costs, while unsupervised alternatives suffer from severe model collapse. Recent semi-supervised RLVR methods address this by using a small labeled set to guide unlabeled data, achieving a promising trade-off between training efficacy and annotation cost. However, they suffer from a severe data-efficiency bottleneck due to the reliance on coarse performance heuristics, leaving a vast majority of valuable instances underutilized. To this end, we propose GeoMin, which models global feature distributions on labeled data to decode the structural discrepancy between correct and incorrect rollouts, thereby establishing a robust prior to assess the reliability of self-reward signals and fully unleash the potential of unlabeled data. Empirically, GeoMin outperforms the strongest baselines by +4.1% and even surpasses fully supervised models with only 10% of the annotations, demonstrating remarkable data efficiency.
トラフィックをツリーのように扱う: 暗号化トラフィック分析のための意味を保持する階層グラフベースのエキスパート フレームワーク
グラフベースの深層学習手法は、さまざまな粒度にわたる潜在的な相関関係を利用するために、暗号化されたトラフィック分析で広く採用されています。ただし、複雑な前処理パイプラインと洗練されたモデル構造は多くの場合、優れたパフォーマンスを実現しますが、表現学習中に固有のプロトコル セマンティクスが不明瞭になる可能性があります。さらに、プロトコル仕様によって定義され、手動トラフィック分析で日常的に利用されるプロトコル層とそれに対応するフィールドの階層構造は、既存の学習フレームワークでは依然として十分に調査されていません。この論文では、暗号化トラフィック分析のための意味を保持する階層グラフベースのエキスパート フレームワークである Protocol Tree Graph Attending with Mixture of Experts (PTGAMoE) を提案します。フィールドベースのグラフ構築と専門家委員会の設計により、PTGAMoE は特定のフィールドとプロトコルに対するモデルの好みを定量化できます。厳格なデータ漏洩のない設定の下での代表的なベンチマーク データセットに関する広範な実験結果は、PTGAMoE が最先端 (SOTA) モデルよりも大幅に優れていることを示しています。さらに、セマンティック保存設計は、暗号化トラフィック分類タスクにおけるモデルの意思決定ロジックを反映して、プロトコル レベルの機能の重要性と専門家レベルの貢献について解釈可能な洞察を提供します。
原文 (English)
Treat Traffic Like Trees: A Semantic-Preserving Hierarchical Graph-Based Expert Framework for Encrypted Traffic Analysis
Graph-based deep learning methods have been widely employed in encrypted traffic analysis to exploit latent correlations across different granularities. However, while complex preprocessing pipelines and sophisticated model structures often achieve strong performance, they may obscure inherent protocol semantics during representation learning. Moreover, the hierarchical structure of protocol layers and their corresponding fields, defined by protocol specifications and routinely utilized in manual traffic analysis, remains underexplored in existing learning frameworks. In this paper, we propose Protocol Tree Graph Attention with Mixture of Experts (PTGAMoE), a semantic-preserving hierarchical graph-based expert framework for encrypted traffic analysis. The field-based graph construction and expert committee design enable PTGAMoE to quantify the model's preferences for specific fields and protocols. Extensive experimental results on representative benchmark datasets under strict no-data-leakage settings demonstrate that PTGAMoE significantly outperforms state-of-the-art (SOTA) models. Furthermore, the semantic-preserving design provides interpretable insights into protocol-level feature importance and expert-level contributions, reflecting the model's decision-making logic in encrypted traffic classification tasks.
ANN 検索: 重要なことを思い出してください
近似最近傍 (ANN) 検索は、分類から検索拡張生成に至るまで、情報検索および最新の機械学習タスクにおいて中核的なプリミティブとなっています。コミュニティは、主に特定の Recall@k (取得される真の完全近傍の割合) でのスループットに基づいて ANN アルゴリズムを評価および調整します。私たちは、ANN 検索で本当に重要なのは、取得された結果の品質であり、真の kNN セットとの重複ではないと主張します。 Recall@k を使用して検索品質を評価すると、不必要な計算オーバーヘッドが発生することを示し、それを逆近似比である 1/Ratio@k に置き換えることを検討します。 1/Ratio@k は、取得された近傍と真の近傍の距離の差を評価します。これは判定不要、ハイパーパラメータ不要で、標準の ANN ベンチマーク入力のみから計算可能です。私たちは、広範な固有の次元にわたる多様なデータセットにわたって最先端の ANN アルゴリズムのベンチマークを行い、効率、下流の分類、検索拡張生成にわたって 2 つの指標を包括的に評価します。効率の軸では、1/Ratio@k の最適化は、Recall@k よりも大幅に低い計算コストで運用品質のしきい値に達します。下流タスクでは、Recall@k が大幅に低下した場合でも、パフォーマンス指標 (ラベル精度、意味的類似性、BERTScore、LLM グレードの品質) は非常に安定しています。一方、逆近似比はこの安定性を厳密に反映しており、Recall@k よりもはるかに優れた真の有用性を追跡します。結局のところ、Recall@k は近似の実際のコストを誇張していますが、1/Ratio@k は実際の ANN 品質に対してより正確で導入可能なプロキシを提供します。
原文 (English)
ANN Search: Recall What Matters
Approximate nearest neighbor (ANN) search has become a core primitive in information retrieval and modern machine learning tasks, from classification to retrieval-augmented generation. The community evaluates and tunes ANN algorithms primarily on their throughput at a given Recall@k, the fraction of true exact neighbors retrieved. We argue that what really matters in ANN search is the quality of the retrieved results and not their overlap with the true kNN set. We show that using Recall@k to assess retrieval quality forces unnecessary computational overhead and investigate replacing it by 1/Ratio@k, the inverse approximation ratio. 1/Ratio@k evaluates the differences between the distances of the retrieved and true neighbors. It is judge-free, hyperparameter-free, and computable from standard ANN benchmark inputs alone. We benchmark state-of-the-art ANN algorithms across diverse datasets spanning a wide range of intrinsic dimensionalities, evaluating the two metrics comprehensively across efficiency, downstream classification, and retrieval-augmented generation. On the efficiency axis, optimizing for 1/Ratio@k reaches operational quality thresholds at a substantially lower computational cost than Recall@k. In downstream tasks, performance indicators (label precision, semantic similarity, BERTScore, and LLM-graded quality) remain highly stable even when Recall@k drops significantly. The inverse approximation ratio, on the other hand, closely mirrors this stability, tracking true utility much better than Recall@k. Ultimately, while Recall@k overstates the true cost of approximation, 1/Ratio@k offers a more accurate, deployable proxy for actual ANN quality.
SAR 少数ショットクラスの増分学習のための光学誘導神経崩壊
合成開口レーダー画像における少数ショット クラス増分学習 (FSCIL) には、深刻なデータ不足と SAR 固有の変動性により、特有の課題が生じます。特に、SAR における強い方位感度は、大きなクラス内変動とクラス間の混乱を引き起こし、FSCIL の逐次更新はさらに、以前に学習したクラスの壊滅的な忘却につながります。ニューラルコラプスからインスピレーションを得て、我々は光誘導型SAR FSCILフレームワークを提案します。このフレームワークは、データ豊富な光ATRデータセットから直交特徴部分空間を導出し、それらをSAR特徴学習をガイドするための幾何学的事前分布として使用します。 SAR の特徴は、主角制約を介してこれらの直交部分空間に投影され、識別構造を光学ドメインから SAR ドメインに効果的に転送します。具体的には、私たちの射影損失と凍結シンプレックス ETF ジオメトリで最適化された分類器損失は、大きなクラス間角度を維持しながらクラス平均の周囲に特徴を集中させることによって共同して神経崩壊を引き起こします。このアプローチを、ベース トレーニング セッションと 7 つの増分セッションに編成された 24 のターゲット クラスを含む光 ATR データセットと SAR ATR データセットで構成されるベンチマークで評価します。 NCFSCIL などの最近の FSCIL 手法と比較して、私たちの手法は最高の最終精度と、最終パフォーマンスとパフォーマンス低下の間の好ましいトレードオフを実現します。さらに、ニューラル崩壊メトリクスは、クラス内のコンパクト性とクラス間の分離性の向上を示しており、学習された特徴が理想的なシンプレックス ETF ジオメトリにより近似していることを示しています。
原文 (English)
Optical-Guided Neural Collapse for SAR Few-Shot Class Incremental Learning
Few-shot class-incremental learning (FSCIL) in synthetic aperture radar imagery presents unique challenges due to severe data scarcity and SAR-specific variability. In particular, strong azimuth sensitivity in SAR induces large intra-class variation and inter-class confusion, and FSCIL sequential updates further lead to catastrophic forgetting of previously learned classes. Inspired by neural collapse, we propose an optical-guided SAR FSCIL framework, which derives orthogonal feature subspaces from a data-rich optical ATR dataset and uses them as geometric priors to guide SAR feature learning. SAR features are projected onto these orthogonal subspaces via principal angle constraints, effectively transferring discriminative structure from the optical to the SAR domain. Specifically, our projection loss and the classifier loss optimized with a frozen simplex-ETF geometry jointly induce neural collapse by concentrating features around class means while maintaining large inter-class angles. We evaluate the approach on a benchmark comprising an optical ATR dataset and a SAR ATR dataset with 24 target classes, organized into a base training session and seven incremental sessions. Compared with recent FSCIL methods including NCFSCIL and so on, our method achieves the highest final accuracy and a favorable trade-off between final performance and performance degradation. Moreover, neural collapse metrics show improved intra-class compactness and inter-class separability, indicating that the learned features more closely approximate the ideal simplex-ETF geometry.
拡散大規模言語モデルにおける形式に制約された生成のための動的埋め込みアンカー
拡散大規模言語モデル (dLLM) は、双方向の注意と並列生成を提供し、グローバル コンテキストを活用して、解析可能な JSON や推論テンプレートなどの形式に制約のあるタスクを自然にサポートできるようにします。単純な固定アンカーはそのような制約を強制できますが、多くの場合、厳密なスパンを課すため、推論が切り詰められたり、コンテンツが冗長になったりします。これを克服するために、反復埋め込みの前にエンドアンカーの位置を動的に推定して生成長を調整する、トレーニング不要の方法である動的埋め込みアンカー (DIA) を提案します。この柔軟なメカニズムにより、構造の正確さと意味の一貫性が確保され、固定スパン方式の非効率性が回避されます。推論ベンチマークの実験では、DIA がフォーマットへの準拠性と回答精度を大幅に向上させ、GSM8K と MATH で大幅なゼロショット ゲインを達成することが実証されました。これらの結果は、DIA が信頼性の高い、構造を意識した生成に向けた強力な経路として確立されています。
原文 (English)
Dynamic Infilling Anchors for Format-Constrained Generation in Diffusion Large Language Models
Diffusion large language models (dLLMs) offer bidirectional attention and parallel generation, enabling them to exploit global context and naturally support format-constrained tasks like parseable JSON or reasoning templates. While straightforward fixed anchors can enforce such constraints, they often impose rigid spans, leading to truncated reasoning or redundant content. To overcome this, we propose Dynamic Infilling Anchors (DIA), a training-free method that dynamically estimates end-anchor positions to adjust generation length before iterative infilling. This flexible mechanism ensures structural correctness and semantic coherence, avoiding the inefficiencies of fixed-span methods. Experiments on reasoning benchmarks demonstrate that DIA substantially improves format compliance and answer accuracy, achieving significant zero-shot gains on GSM8K and MATH. These results establish DIA as a robust pathway toward reliable, structure-aware generation.
エージェントの記憶にとって時間的順序は重要: 長期エージェントのセグメント ツリー
長期的な会話型エージェントは、進化するイベント、タスク、目標を通じてユーザーと対話する必要があります。このような歴史は本来一時的なものですが、多くの既存の記憶システムは主にトピックの類似性によって情報を整理しており、イベントが発生する順序を無視している可能性があります。発話全体にわたって時間的に順序付けられたセグメント ツリーとして会話履歴を表すメモリ アーキテクチャであるセグメント ツリー メモリ (SegTreeMem) を導入します。 SegTreeMem は、オンラインの右端フロンティア更新ルールを通じて新しい発話を段階的に挿入し、階層的なメモリ セグメントを形成しながら時系列順を維持します。取得の場合、SegTreeMem はツリーを通じて関連性スコアを伝播し、ローカルな意味論的な一致と階層的な時間コンテキストを組み合わせます。 SegTreeMem は、3 つの長期メモリ ベンチマークと 2 つの LLM バックボーンにわたって、フラット検索、グラフ構造メモリ、およびツリー構造メモリ ベースラインよりも回答品質を向上させます。追加の時間順序順列分析では、パフォーマンスの向上が記憶構築中の時間順序の維持に依存することが示され、時間順序がエージェント記憶の重要な構造であるという主張が裏付けられています。
原文 (English)
Temporal Order Matters for Agentic Memory: Segment Trees for Long-Horizon Agents
Long-horizon conversational agents need to interact with users through evolving events, tasks, and goals. Such histories are naturally temporal, yet many existing memory systems organize information primarily by topical similarity and may ignore the order in which events occur. We introduce Segment Tree Memory, or SegTreeMem, a memory architecture that represents conversation history as a temporally ordered Segment Tree over utterances. SegTreeMem incrementally inserts new utterances through an online rightmost-frontier update rule, preserving chronological order while forming hierarchical memory segments. For retrieval, SegTreeMem propagates relevance scores through the tree to combine local semantic matching with hierarchical temporal context. Across three long-horizon memory benchmarks and two LLM backbones, SegTreeMem improves answer quality over flat retrieval, graph-structured memory, and tree-structured memory baselines. Additional temporal-order permutation analysis shows that the performance gain depends on preserving temporal order during memory construction, supporting the claim that temporal order is a key structure for agentic memory.
GRPO 向けのロールアウト レベルのアドバンテージ優先エクスペリエンス リプレイ
GRPO を使用した検証可能な報酬からの強化学習は、トレーニング後の推論 LLM の標準的なアプローチです。サンプルの効率が悪いままです。各ロールアウトは 1 つのグラデーション更新に使用され、その後破棄されます。 LLM ポリシーが勾配ステップごとに急速に変化するため、単純な再生はこの設定にはあまり適していません。したがって、保存されたロールアウトは古くなり、トレーニングが不安定になる可能性があります。グループ全体ではなく個々のロールアウトを保存およびサンプリングする、GRPO のロールアウト レベルのリプレイ バッファーを提案します。バッファーは、age eviction を通じて古い状態を制限します。 tau_max トレーニング ステップよりも古いロールアウトは削除されます。バッファには、フレッシュアンカー構成を介してポリシー上のデータも保存されます。各バッチは、ポリシーに基づいた最新のロールアウトを保持し、バッファから個別に描画されたリプレイ ロールアウトを連結します。ロールアウトごとのアドバンテージの大きさによってリプレイに優先順位を付け、アドバンテージが大きい個々のロールアウトをリサイクルします。 5 つの数学ベンチマークにおける 3 つの Qwen3-Base スケール全体で、私たちの手法は GRPO および単純な再生ベースラインを上回りました。ゲインはどのスケールでも正であり、モデルのサイズに応じて増加します。最大の利益は 4B の 5 つのベンチマーク平均で +4.35 pp です。精度とトークン効率を組み合わせて測定する AES メトリクスの下では、GRPO に対する効率マージンは、+0.579 で 4B と再び最大になります。
原文 (English)
Rollout-Level Advantage-Prioritized Experience Replay for GRPO
Reinforcement learning from verifiable rewards with GRPO is a standard approach for post-training reasoning LLMs. It remains sample inefficient. Each rollout is used for a single gradient update and then discarded. Naive replay is not well suited in this setting because LLM policies drift quickly per gradient step. Stored rollouts therefore become stale and can destabilize training. We propose a rollout-level replay buffer for GRPO that stores and samples individual rollouts rather than whole groups. The buffer bounds staleness through age eviction. Any rollout older than tau_max training steps is removed. The buffer also preserves on-policy data via fresh-anchored composition. Each batch keeps its fresh on-policy rollouts and then concatenates replay rollouts drawn separately from the buffer. We prioritize replay by per-rollout advantage magnitude and recycle individual rollouts whose advantages are large. Across three Qwen3-Base scales on five math benchmarks, our method outperforms GRPO and naive replay baselines. Gains are positive at every scale and grow with model size. The largest gain is +4.35 pp on the five-benchmark average at 4B. Under an AES metric that jointly measures accuracy and token efficiency, the efficiency margin over GRPO is again largest at 4B, at +0.579.
マルチ SPIN: エッジでの協調トークン生成のためのマルチアクセス投機推論
投機的推論 (SPIN) は、もともと大規模言語モデル (LLM) を高速化するための効率的なアーキテクチャとして開発されました。この研究では、マルチユーザー エッジ システムでの協調的なトークン生成を可能にする分散展開を提案します。その利点は、リソースに制約のあるデバイスとサーバーの間で計算負荷のバランスを効果的にとれることです。マルチアクセス SPIN (Multi-SPIN) と呼ばれる結果として得られるアーキテクチャは、オンデバイスの小型言語モデルを利用して候補トークン ドラフトを生成およびアップロードする一方、エッジ サーバーは LLM を操作してそれらを並列バッチで検証します。ユーザーの計算能力と通信能力に深刻な不均一性があることを考慮すると、ドラフト長はノードレベルの計算負荷とマルチアクセス待ち時間に影響を与える重要な制御変数として浮上し、それによって合計トークンのグッドプットを支配します。したがって、周波数分割多元接続を考慮して、合計トークン グッドプットを最大化するための、ドラフト長制御と帯域幅割り当ての共同最適化であるマルチアクセス ドラフト制御の問題を調査します。ここでは 2 つのケースを検討します。(1) サーバー側のバッチ処理を容易にするためにユーザー間で均一なドラフト長を使用する場合と、(2) グッドプットを強化するための新しい次元を導入するために異種のドラフト長を使用する場合です。分解手法を開発することで、これらの複雑な最適化を扱いやすい部分問題に縮小し、閉じた形式で効率的な喫水制御アルゴリズムを導出できるようにします。私たちの分析によると、最適な帯域幅の割り当ては、同種の場合にはバッチ同期要件により弱い計算能力と通信能力を持つユーザーを補うのに対し、異種の場合はそのような要件を緩和することでユーザーの受け入れ率を高めることができます。さまざまなタスクにわたって Llama-2 と Qwen3.5 モデルのペアを使用した実験では、Multi-SPIN が異質性を問わないベースラインと比較してグッドプットを最大 88% 向上させることが実証されました。
原文 (English)
Multi-SPIN: Multi-Access Speculative Inference for Cooperative Token Generation at the Edge
Speculative inference (SPIN) was originally developed as an efficient architecture to accelerate Large Language Models (LLMs). In this work, we propose its distributed deployment to enable cooperative token generation in a multiuser edge system; its advantage is to effectively balance computational loads between resource-constrained devices and servers. The resulting architecture, termed Multi-access SPIN (Multi-SPIN), utilizes on-device small language models to generate and upload candidate token drafts, while an edge server operates the LLM to verify them in parallel batches. Given the severe heterogeneity in users' computation and communication capabilities, the draft length emerges as a critical control variable that influences node-level computation loads and multi-access latency, thereby governing the sum token goodput. Consequently, considering frequency-division multiple access, we investigate the problem of multi-access draft control, a joint optimization of draft-length control and bandwidth allocation to maximize sum token goodput. We examine two cases: (1) homogeneous draft lengths across users to facilitate server-side batching, and (2) heterogeneous draft lengths to introduce a new dimension for goodput enhancement. By developing decomposition methods, we reduce these complex optimizations into tractable sub-problems, which allow efficient draft control algorithms to be derived in closed form. Our analysis shows that the optimal bandwidth allocation compensates users with weaker computation-and-communication capabilities in the homogeneous case due to the batching synchronization requirements, whereas its heterogeneous-case counterpart rewards users with higher acceptance rates by relaxing such requirements. Experiments using Llama-2 and Qwen3.5 model pairs across diverse tasks demonstrate that Multi-SPIN improves goodput by up to 88% over heterogeneity-agnostic baselines.
合成パーソナリティ: LLM は社会経済的マイクロデータを使用して個々の回答者をどの程度うまく模倣できるか?
LLM ベースのデジタル ツインは、市場調査の拡張と加速を約束しますが、公開されているデジタル ツインのほとんどは、人口統計に関するいくつかの質問に基づいて条件付けされた大まかなペルソナ ボットか、目的のために収集されたアンケートやインタビュー記録に基づいて構築された詳細な個人レベルのツインのいずれかです。どちらの設定も、マーケティング実践に運用上最も関連性の高い事例、つまり企業が CRM システム、ロイヤリティ プログラム、および反復調査を通じてすでに蓄積している既存の異種パネル データから詳細な個別の双子を構築することについては話していません。私たちは、ドイツ社会経済パネル (SOEP) から詳細な個人レベルの双子を構築し、3 つのオープンウェイト LLM、正規化されたシャノン エントロピーによってランク付けされた 5 つの累積情報深さ、2 つの埋め込み手法、および 2 つの推論モードをカバーする $3 \times 5 \times 2 \times 2$ 構築方法グリッド全体で評価し、500 人の参加者と 183 の保留された質問に対する 210 万を超える双子の回答をスコアリングしました。ツインの品質は情報の深さに応じて向上しますが、エントロピー四分位 75 パーセントを超えると収益が減少します。エントロピー四分位は、最もパフォーマンスの高い 100 パーセントのセルと比較したコスト効率の高いパレート点として機能します。埋め込みをナラティブなペルソナの概要から過去の応答の生の対話履歴に切り替えると、100% の深さですべてのモデルごとの推論セルのホールドアウト精度が向上します。一方、明示的思考モードでは精度を変えることなく順位相関が向上します。 SOEP ホールドアウト評価セットでは、最良セル精度は 78.8% に達し、Fisher-$z$ 相関は $r = 0.590$ に達します。この調査結果は、ツインベースの市場調査がもはやデータ設計によって制御されているのではなく、アイテムのボリューム、モデルの選択、およびこの論文でマッピングされている建設レベルの少数の決定によって制御されていることを示唆しています。
原文 (English)
Synthetic Personalities: How Well Can LLMs Mimic Individual Respondents Using Socio-Economic Microdata?
LLM-based digital twins promise to scale and accelerate market research, but most published twins are either coarse persona bots conditioned on a few demographic questions or detailed individual-level twins built on purpose-collected surveys and interview transcripts. Neither setup speaks to the operationally most relevant case for marketing practice: building detailed individual twins from the pre-existing heterogeneous panel data that firms already accumulate through CRM systems, loyalty programs, and repeat surveys. We construct detailed individual-level twins from the German Socio-Economic Panel (SOEP) and evaluate them across a $3 \times 5 \times 2 \times 2$ construction-method grid that covers three open-weights LLMs, five cumulative information depths ranked by normalized Shannon entropy, two embedding methods, and two reasoning modes, scoring over 2.1 million twin responses on 500 participants and 183 held-out questions. Twin quality rises with information depth but with diminishing returns past the 75 percent entropy quartile, which acts as a cost-efficient Pareto point relative to the best-performing 100 percent cells. Switching the embedding from a narrative persona summary to a raw dialog history of past responses raises hold-out accuracy in every model-by-reasoning cell at the 100 percent depth, while an explicit thinking mode raises rank-order correlation without moving accuracy. Best-cell accuracy reaches 78.8 percent and Fisher-$z$ correlation reaches $r = 0.590$ on the SOEP held-out evaluation set. The findings suggest that twin-based market research is no longer gated by data design, but by item volume, model selection, and a small set of construction-level decisions that this paper now maps.
Ekka: LLM 推論におけるサイレント エラーの自動診断
LLM サービス フレームワークは、複雑なソフトウェア スタックと膨大な数の最適化によって急速に進化しています。急速な開発プロセスでは、明示的なエラー信号がないまま出力品質が静かに低下するサイレント エラーが発生する可能性があります。高レベルの症状と低レベルの根本原因の間には意味上の大きなギャップがあるため、サイレント エラーの診断は難しいことで知られています。意味的に正しい参照実装の存在を活用することで、サイレント エラーの診断を差分デバッグ問題として効果的に組み立てることができることがわかりました。私たちは、ターゲット フレームワークと参照フレームワークの間の中間実行状態を体系的に調整して比較することにより、根本原因を特定する自動診断システム Ekka を提案します。一般的なサービス提供フレームワークから実際のサイレント エラーのベンチマークを構築しました。Ekka は、pass@1 診断精度が 80%、pass@5 診断精度が 88% で、最先端のシステムを上回るパフォーマンスを示しました。 Ekka は、サービス提供フレームワークからの 4 つの新しいサイレント エラーも診断します。これらはすべて開発者によって確認されています。
原文 (English)
Ekka: Automated Diagnosis of Silent Errors in LLM Inference
LLM serving frameworks are quickly evolving with a complex software stack and a vast number of optimizations. The rapid development process can introduce silent errors where output quality silently degrades without any explicit error signals. Diagnosing silent errors is notoriously difficult due to the substantial semantic gap between the high-level symptoms and the low-level root causes. We observe that diagnosis of silent errors can be effectively framed as a differential debugging problem by leveraging the existence of semantically correct reference implementations. We propose Ekka, an automated diagnosis system that identifies root causes by systematically aligning and comparing intermediate execution states between a target and a reference framework. We constructed a benchmark of real-world silent errors from popular serving frameworks, where Ekka shows 80% pass@1 diagnosis accuracy and 88% pass@5 diagnosis accuracy, outperforming state-of-the-art systems. Ekka also diagnoses 4 new silent errors from serving frameworks, all of which have been confirmed by the developers.
QuBLAST: ブロックレベルの圧縮アプローチとアクティベーション スケーリング戦略を使用して大規模な言語モデルを量子化するためのフレームワーク
LLM は、NLP タスクを解決するための最先端のアルゴリズムになりました。ただし、これらは通常、膨大な計算コストとメモリコストがかかるため、組み込みシステムへの導入が困難になります。これに向けて、最先端の方法では通常、ネットワークのアテンション ブロック全体で均一なポストトレーニング量子化 (PTQ) が採用されており、そのため、同じネットワーク内で異なる量子化レベルを適用する可能性を見落としています。また、アクティベーションの異常値による悪影響を軽減するために複雑な操作を採用しているため、高い計算オーバーヘッドが発生します。さらに、量子化を適用する際に異なる課題を引き起こす、従来とは異なるアテンション アーキテクチャ (状態空間モデルなど) を備えた新興 LLM を使用した評価については考慮されていません。これらの制限に対処するために、LLM のアクティベーション スケーリング戦略を備えたブロック レベルの圧縮アプローチを採用する新しい PTQ 手法である QuBLAST を提案します。ブロックレベルの圧縮アプローチにより、ネットワークのブロック全体で混合精度の量子化が可能になり、同時にアクティベーションスケーリング戦略によりアクティベーション異常値の悪影響が効率的に軽減されます。具体的には、QuBLAST はまず、クロスエントロピー損失分析を通じて、事前トレーニング済みモデル内のさまざまなアテンション ブロックの感度を分析します。 QuBLAST は、この感度分析を活用して、モデル内の各アテンション ブロックの重み量子化レベルを決定します。さらに、QuBLAST は各ブロックのアクティベーション スケーリング マップを採用してアクティベーション値の範囲を制御し、アクティベーション外れ値の悪影響を軽減することで、より良い量子化結果を実現します。実験結果は、QuBLAST が、WikiText-2 および WikiText-103 データセットのパープレキシティ増加 5% 以内のパフォーマンスを維持しながら、さまざまなモデル アーキテクチャ (つまり、Qwen3-8B、Llama3-8B、Mistral v0.1-8B、および Falcon H1R-7B) にわたってモデル サイズを 40% ~ 45.2% 削減することを示しています。
原文 (English)
QuBLAST: A Framework for Quantizing Large Language Models with Block-Level Compression Approach and Activation Scaling Strategy
LLMs have become the state-of-the-art algorithms for solving NLP tasks. However, they typically come at huge computational and memory costs, thus making them difficult to deploy on embedded systems. Toward this, state-of-the-art methods typically employ uniform post-training quantization (PTQ) across attention blocks of the network, hence overlooking the potential of applying different quantization levels in the same network. They also employ complex operations to mitigate the negative impact of activation outliers, hence incurring high computational overheads. Moreover, they have not considered evaluation using emerging LLMs with non-conventional attention architectures (e.g., state-space models), which pose different challenges in applying quantization. To address these limitations, we propose QuBLAST, a novel PTQ methodology that employs block-level compression approach with activation scaling strategy for LLMs. Block-level compression approach enables mixed-precision quantization across blocks of the network, while activation scaling strategy efficiently mitigates the negative impact of activation outliers. Specifically, QuBLAST first analyzes the sensitivity of different attention blocks in the pre-trained model through the cross-entropy loss analysis. QuBLAST leverages this sensitivity analysis to determine the weight quantization level for each attention block in the model. Furthermore, QuBLAST employs the activation scaling map for each block to control the range of activation values and mitigate the negative impact of activation outliers, thereby enabling better quantization results. Experimental results show that, QuBLAST reduces model sizes by 40%-45.2% across different model architectures (i.e., Qwen3-8B, Llama3-8B, Mistral v0.1-8B, and Falcon H1R-7B), while maintaining the performance within 5% perplexity increase for the WikiText-2 and WikiText-103 datasets.
QO ベンチ: 型付きイベント タプルに対するクエリ演算子保持検索の診断
ビジネス、法律、科学コーパスに関する現実世界の質問の多くは、テキストに潜在するレコードに対するデータベース スタイルのクエリの自然言語バージョンです。既存の検索拡張生成 (RAG) システムは、主にセマンティック関連性を重視して最適化されていますが、もっともらしい文章を取得しても、クエリが正しく実行されることは保証されません。型指定されたイベント タプルに対するクエリ演算子の質問応答の診断ベンチマークである QO-Bench を紹介します。このベンチマークは、18 のクエリ テンプレートにわたる 22,984 のニュース記事と 614 の企業イベントを対象とし、785 の質問で評価されました。各ゴールド アンサーは、型指定されたイベント タプルから決定論的に計算され、LLM 判定ではなく完全一致によってゴールド タプルと照合された回答を使用して、再現率によってスコア付けされます。この設計により、結合や交差などのオペレーターレベルの診断が可能になります。 RAG、ReAct RAG、GraphRAG、および情報抽出から SQL を一致した条件下で評価し、取得失敗を分離するためのロングコンテキスト オラクル上限を使用します。インデックス時の保存とクエリ時の実行という 2 軸のフレームワークによって、各パラダイムがどこで失敗するかを予測し、その結果がそれを裏付けています。システムは関連するテキストを取得しますが、オペレータが必要とする型付きの値を破棄します。デプロイ可能なパラダイムのランキングはオペレータ間で逆転し、フィルタ/プロジェクトで類似性の取得が始まり、交差とカウントで SQL への抽出が行われます。決定的な証拠が与えられたとしても、ロングコンテキストのオラクルは飽和状態には程遠いため、検索だけではなくオペレーターの実行が、より強力な応答モデルによって除去されない中心的なボトルネックとなっています。 QO-Bench は、パッセージの関連性からクエリ演算子を保持した検索へと目標を再構成します。
原文 (English)
QO-Bench: Diagnosing Query-Operator-Preserving Retrieval over Typed Event Tuples
Many real-world questions over business, legal, and scientific corpora are natural-language versions of database-style queries over records latent in text. Existing retrieval-augmented generation (RAG) systems are optimized primarily for semantic relevance, but retrieving plausible passages does not guarantee correct query execution. We introduce QO-Bench, a diagnostic benchmark for query-operator question answering over typed event tuples. The benchmark covers 22,984 news articles and 614 corporate events across 18 query templates, evaluated on 785 questions. Each gold answer is deterministically computed from typed event tuples and scored by recall, with answers matched to the gold tuples by exact match rather than an LLM judge. This design enables operator-level diagnosis such as joins and intersection. We evaluate RAG, ReAct RAG, GraphRAG, and information-extraction-to-SQL under matched conditions, with a long-context oracle ceiling to isolate retrieval failure. A two-axis framework -- index-time preservation versus query-time execution -- predicts where each paradigm fails, and the results bear it out: systems retrieve relevant text but discard the typed values operators need, and the deployable paradigm ranking inverts across operators, with similarity retrieval leading on filter/project and extraction-to-SQL on intersection and counting. Even given the gold evidence, a long-context oracle stays far from saturated, so operator execution -- not retrieval alone -- is a core bottleneck that a stronger answer model does not remove. QO-Bench reframes the goal from passage relevance to query-operator-preserving retrieval.
オブジェクト検出におけるインスタンスレベルの事後不確実性の定量化
物体検出は自動運転の安全上重要な要素です。安全性を確保するには、境界ボックス予測の不確実性を定量化することが不可欠です。再トレーニングを必要としない事後的な不確実性の定量化は、現実世界の導入要件と一致します。したがって、ラプラス近似を使用します。インスタンスレベルの不確実性が必要であるため、複数のバックプロパゲーションを必要とする線形推論方法は時間効率が悪く、サンプリングベースの方法は完全に事後的ではありません。我々は、インスタンスレベルおよびほぼ事後的な不確実性の定量化を提供するモンテカルロ一般化線形モデル (MC-GLM) を提案します。モンテカルロ ステップで必要なサンプルの数は一定で、出力インスタンスの数に依存しないため、並列化できます。 CenterPoint 検出器を使用した nuScenes データセットの実験により、私たちの方法の有効性が検証され、結果として生じる不確実性は良好な品質を示しています。
原文 (English)
Instance-Level Post Hoc Uncertainty Quantification in Object Detection
Object detection is a safety-critical component of autonomous driving. It is essential to quantify the uncertainty in bounding-box predictions for safety assurance. Post hoc uncertainty quantification without retraining aligns with real-world deployment requirements; therefore, we employ the Laplace approximation. Because instance-level uncertainty is needed, linearized inference methods that require multiple backpropagations are not time-efficient, and sampling-based methods are not fully post hoc. We propose Monte-Carlo generalized linearized model (MC-GLM), which provides instance-level and approximately post hoc uncertainty quantification. The number of samples required in the Monte Carlo step is constant and independent of the number of output instances, so it can be parallelized. Experiments on the nuScenes dataset with the CenterPoint detector validate the effectiveness of our method, and the resulting uncertainties exhibit good quality.
ミュオンがアダムを上回る理由: 曲率の観点から
Muon は、大規模な言語モデルのトレーニングにおいて Adam に比べてトレーニング効率を約 2 倍向上させますが、この利点の局所的な幾何学的ソースは依然として不明です。私たちの研究は、曲率の観点からアダムに対するミュオンの優位性を解明するための第一歩を踏み出します。まず、トレーニング ランドスケープに 2 次テイラー近似を適用し、一致する検証損失で Muon が Adam よりも大きな 1 ステップ損失の減少を達成することを示します。 2 つのオプティマイザーは同等の一次ゲインを持っていますが、Muon は常に小さい二次曲率ペナルティを受けます。次に、この曲率ペナルティを二乗更新ノルムと正規化方向シャープネス (NDS) に分解します。 Muon と Adam は同等の更新ノルムを持っていることがわかり、Muon のより小さい曲率ペナルティは、更新スケールではなく、NDS の低下によって引き起こされます。第三に、トレーニング データとモデル構造が Muon の NDS の利点をどのように形成するかを研究します。不均衡を制御したZipf-Probabilistic Context-Free Grammar (PCFG)データを使用して、データの不均衡がAdamに対するMuonのNDS優位性を増幅させることを示します。さらに、層内/層間分解により、トレーニングの中期および後期段階では、ミュオンの下部 NDS は主に小さな層内曲率によって維持されることが示されています。経験的証拠を超えて、不均一な曲率と高曲率モードへの勾配整列を伴う様式化された 2 次問題を分析します。我々は、ミューオンが曲率グループ全体で更新エネルギーのバランスをとることにより、GD よりも小さな平均 NDS を達成することを証明します。曲率の不均一性が十分に強い場合、同じステップ数の後の局所二次損失も低くなります。
原文 (English)
Why Muon Outperforms Adam: A Curvature Perspective
Muon improves training efficiency over Adam in large language-model training by about two times, but the local geometric source of this advantage remains unclear. Our work takes a first step toward demystifying Muon's superiority over Adam from a curvature perspective. First, we apply a second-order Taylor approximation to the training landscape and show that Muon achieves a larger one-step loss decrease than Adam at matched validation loss. The two optimizers have comparable first-order gains, but Muon consistently incurs a smaller second-order curvature penalty. Second, we decompose this curvature penalty into the squared update norm and Normalized Directional Sharpness (NDS). We find that Muon and Adam have comparable update norms, so Muon's smaller curvature penalty is driven by lower NDS, not update scale. Third, we study how training data and model structure shape Muon's NDS advantage. Using Zipf-Probabilistic Context-Free Grammar (PCFG) data with controlled imbalance, we show that data imbalance amplifies Muon's NDS advantage over Adam. A within-/cross-layer decomposition further shows that, in the middle and late stages of training, Muon's lower NDS is mainly sustained by smaller within-layer curvature. Beyond empirical evidence, we analyze stylized quadratic problems with heterogeneous curvature and gradient alignment toward high-curvature modes. We prove that Muon attains a smaller average NDS than GD by balancing update energy across curvature groups; when curvature heterogeneity is sufficiently strong, this also yields lower local quadratic loss after the same number of steps.
状態空間モデルを使用した連続時間動的グラフ上の長距離時空間表現の学習
連続時間ダイナミック グラフ (CTDG) は、進化するリレーショナル データのきめの細かい時間的パターンをキャプチャするためのより豊富なフレームワークを提供します。長距離の情報伝播は、表現を学習する際の重要な課題であり、長い時間的期間にわたって情報を保持および更新することが重要です。既存のアプローチでは、モデルがワンホップまたはローカルな時間的近傍を捕捉するように制限されており、マルチホップまたはグローバルな構造パターンを捕捉できません。これを軽減するために、第一原理から連続時間動的グラフ (CTDG-SSM) 用のパラメーター効率の高い状態空間モデリング フレームワークを導出します。まず、連続時間トポロジー対応高次多項式射影演算子 (CTT-HiPPO) を紹介します。これは、時間ダイナミクスとグラフ構造を共同でエンコードするための HiPPO の新しいメモリベースの再定式化です。 CTT-HiPPO からの解は、ラプラシアン行列の多項式を通じて古典的な HiPPO 解を射影することによって取得され、CTDG の等価状態空間定式化 (CTDG-SSM) を可能にするトポロジーを意識したメモリ更新が得られます。次に、モデルの実装にゼロ次ホールド アプローチを使用して、計算効率の高い離散定式化が得られます。 CTDG-SSM は、動的リンク予測、動的ノード分類、シーケンス分類のベンチマーク全体で最先端のパフォーマンスを実現します。特に、長距離時間 (LRT) および空間推論を必要とするデータセットで大幅なパフォーマンスの向上が実現します。
原文 (English)
Learning Long Range Spatio-Temporal Representations over Continuous Time Dynamic Graphs with State Space Models
Continuous-time dynamic graphs (CTDGs) provide a richer framework to capture fine-grained temporal patterns in evolving relational data. Long-range information propagation is a key challenge while learning representations, wherein it is important to retain and update information over long temporal horizons. Existing approaches restrict models to capture one-hop or local temporal neighborhoods and fail to capture multi-hop or global structural patterns. To mitigate this, we derive a parameter-efficient state-space modeling framework for continuous-time dynamic graphs (CTDG-SSM) from first principles. We first introduce continuous-time Topology-Aware higher order polynomial projection operator (CTT-HiPPO), a novel memory-based reformulation of HiPPO to jointly encode temporal dynamics and graph structure. The solution from CTT-HiPPO is obtained by projecting the classical HiPPO solution through a polynomial of the Laplacian matrix, yielding topology-aware memory updates that admit an equivalent state-space formulation for CTDGs (CTDG-SSM). Then a computationally efficient discrete formulation is obtained using the zero-order hold approach for model implementation. Across benchmarks on dynamic link prediction, dynamic node classification, and sequence classification, CTDG-SSM achieves state-of-the-art performance. Notably, it achieves large performance gains on datasets that require long range temporal (LRT) and spatial reasoning.
YOLOv8、SORT トラッキング、時間的データ補間を使用したリアルタイムの自動ナンバー プレート認識
ビデオ処理のリアルタイムの困難により、動的交通監視設定でのアプリケーションでの自動ナンバー プレート認識 (ALPR) の使用が大幅に制限されます。制約のない変数の高忠実度の認識。照明の急激な変化、鋭いカメラ スキャン、高い車両速度、および過酷な物理的隠蔽は、多くの場合、追跡パスがバラバラになり、光学式文字認識 (OCR) 率が低下する原因となる問題です。これらの弱点を軽減するために、この研究では、深層学習ベースの物体検出、本質的に運動学的な複数物体追跡、およびジオメトリ時間データ補間の間のスムーズな移行を含む、5 段階のエンドツーエンドのアルゴリズム パイプラインを提案しています。提案されたアーキテクチャでは、非常に強力な YOLOv8 ナノ モデルを利用して、最初の段階で車両の位置を特定し、その後、シンプル オンラインおよびリアルタイム トラッキング (SORT) アルゴリズムを使用して、フレーム間の時空間リンクを構築します。 YOLOv8 の別のより具体的な類型は、ナンバー プレート領域を検出し、位置構文検証の制限の下で、スライスされた配列を EasyOCR チェーンにチャネルします。さらに重要なのは、時間境界ボックスのオフライン補間メカニズムが開始され、断片化されたパスが再キャストされることです。
原文 (English)
Real-Time Automatic License Plate Recognition Using YOLOv8, SORT Tracking, and Temporal Data Interpolation
The real-time hardships of video processing seriously limit the usage of Automatic License Plate Recognition (ALPR) with application in dynamic traffic monitoring settings. High-fidelity recognition of unconstrained variables, e.g. drastic variations in illumination, acute camera scans, high vehicle speeds, and harsh physical concealment, is a problem that often leads to disjointed tracking paths and poor Optical Character Recognition (OCR) rates. In order to mitigate these weaknesses, the study proposes a 5 stage, end-to-end algorithmic pipeline, encompassing a smooth transition between deep learning based object detection, multi-object tracking which is kinematic in nature, and geometry temporal data interpolation. The suggested architecture takes advantage of a very powerful YOLOv8 nano model to localize the vehicle at the first stage and then Simple Online and Realtime Tracking (SORT) algorithm is used to build spatial-temporal links between frames. Another, more specific typology of YOLOv8 object detectors the license plate area, channeling the sliced array to an EasyOCR chain under the limitations of positional syntax verification. More importantly, an offline interpolation mechanism of temporal bounding box is initiated to recast fragmented paths.
アルツハイマー病分類のための一般化固有値近位 SVM におけるグラフに基づく Universum 学習
アルツハイマー病 (AD) の早期かつ正確な検出は、タイムリーな介入と疾患管理にとって重要です。一般化固有値近位サポート ベクトル マシン (GEPSVM) とその Universum ベースのバリアントは、AD 分類において有望な結果を示しています。ただし、既存の方法では Universum サンプルを独立した点として扱い、それらの間の幾何学的関係は考慮されていません。この論文では、構造 MRI データを使用した AD と認知的正常 (CN) の分類のための 2 つのグラフガイド付き Universum 学習モデル、つまり UG-GEPSVM と IUG-GEPSVM を提案します。提案されたフレームワークでは、軽度認知障害 (MCI) の被験者が Universum データとして使用され、AD クラスと CN クラスの間の中間情報が提供されます。グラフは、ガウス類似度、最小スパニング ツリー接続、およびマルチホップ伝播を使用して Universum サンプル上に構築されます。このグラフから、MCI サンプルの幾何学的構造を捉えるラプラシアン行列が導出されます。このラプラシアンベースの正則化は、従来の独立した Universum ペナルティ項の代わりに学習プロセスに組み込まれています。 UG-GEPSVM はこの正則化を一般化固有値定式化に統合しますが、IUG-GEPSVM は標準固有値定式化を使用して数値的に安定した改良された GEPSVM フレームワークを拡張します。 5 つの異なるノイズ レベルで ICA および PCA ベースの特徴を使用した ADNI MRI データセット バリアントの実験では、提案された両方のモデルが既存の GEPSVM および Universum ベースの方法よりも一貫して優れていることが示されています。 UG-GEPSVM は、88.07% という最高の平均 AUC を達成し、ノイズ レベルが増加しても安定したパフォーマンスを維持します。統計的テストにより、観察された改善の重要性がさらに確認されます。
原文 (English)
Graph-Guided Universum Learning in Generalized Eigenvalue Proximal SVMs for Alzheimer's Disease Classification
Early and accurate detection of Alzheimer's disease (AD) is important for timely intervention and disease management. Generalized Eigenvalue Proximal Support Vector Machine (GEPSVM) and its Universum-based variants have shown promising results for AD classification. However, existing methods treat Universum samples as independent points and do not consider the geometric relationships among them. This paper proposes two graph-guided Universum learning models, namely UG-GEPSVM and IUG-GEPSVM, for AD versus cognitively normal (CN) classification using structural MRI data. In the proposed framework, mild cognitive impairment (MCI) subjects are used as Universum data to provide intermediate information between AD and CN classes. A graph is constructed over the Universum samples using Gaussian similarity, Minimum Spanning Tree connectivity, and multi-hop propagation. From this graph, a Laplacian matrix is derived that captures the geometric structure of the MCI samples. This Laplacian-based regularization is incorporated into the learning process in place of the conventional independent Universum penalty term. UG-GEPSVM integrates this regularization into the generalized eigenvalue formulation, while IUG-GEPSVM extends the numerically stable improved GEPSVM framework using a standard eigenvalue formulation. Experiments on ADNI MRI dataset variants using ICA- and PCA-based features at five different noise levels show that both proposed models consistently outperform existing GEPSVM and Universum-based methods. UG-GEPSVM achieves the highest average AUC of 88.07% and maintains stable performance under increasing noise levels. Statistical tests further confirm the significance of the observed improvements.
医療画像セグメンテーション用の軽量ボックス予測子による MedSAM の強化
医療画像におけるセマンティック セグメンテーションは、データ不足とモダリティ間のばらつきの高さのため、重要ではありますが、困難なタスクです。 Segment Anything Model (SAM) のような基礎モデルは有望ですが、特別な適応がなければ医療画像に苦労することがよくあります。さらに、ポイント プロンプトは、ユーザー インタラクションの最も自然な形式であるにもかかわらず、特にターゲット構造が不規則であるかコントラストが不十分な場合、信頼性の高いセグメンテーションを実現するには空間コンテキストが不十分です。この論文では、軽量の Box Predictor モジュールを MedSAM アーキテクチャに統合する強化されたセグメンテーション フレームワークを提案します。 Box Predictor は、ローカライズされた画像埋め込み機能を使用して、ユーザーの 1 回のクリックからおおよその境界ボックスを推定し、ポイント プロンプトの曖昧さを軽減する空間ガイダンスを提供すると同時に、追加パラメーターは 160 万個のみで、推論オーバーヘッドは無視できます。 Box Predictor が MedSAM に統合される前に個別にトレーニングされる 2 段階のトレーニング パイプラインを導入します。私たちの方法の一般化機能を検証するために、CT、MRI、超音波を含む異なる画像モダリティにわたる 4 つの多様なデータセット (FLARE22、BRISC、BUSI、LungSegDB) に対して広範な評価を実施します。私たちの方法は、さまざまな解剖学的構造と画像化ドメインにわたってセグメンテーションの精度と堅牢性を向上させ、Dice スコア 0.89 (BUSI)、0.93 (FLARE22)、0.88 (BRISC)、および 0.98 (LungSegDB) を達成しました。コードは https://github.com/Amirhosseinmovahedi/MedSAM-BoxPredictor で入手できます。
原文 (English)
Enhancing MedSAM with a Lightweight Box Predictor for Medical Image Segmentation
Semantic segmentation in medical imaging is a critical yet challenging task due to data scarcity and high variability across modalities. While foundation models like the Segment Anything Model (SAM) show promise, they often struggle with medical images without specific adaptation. Moreover, point prompts, despite being the most natural form of user interaction, provide insufficient spatial context for reliable segmentation, particularly when target structures are irregular or poorly contrasted. In this paper, we propose an enhanced segmentation framework that integrates a lightweight Box Predictor module into the MedSAM architecture. The Box Predictor estimates an approximate bounding box from a single user click using localized image embedding features, providing spatial guidance that reduces the ambiguity of point prompts, while introducing only 1.6M additional parameters and negligible inference overhead. We introduce a two-stage training pipeline where the Box Predictor is trained independently before being integrated into MedSAM. To validate the generalization capability of our method, we conduct extensive evaluations on four diverse datasets (FLARE22, BRISC, BUSI, LungSegDB) spanning distinct imaging modalities, including CT, MRI, and Ultrasound. Our method improves segmentation accuracy and robustness across varied anatomical structures and imaging domains, achieving Dice scores of 0.89 (BUSI), 0.93 (FLARE22), 0.88 (BRISC), and 0.98 (LungSegDB). Code is available at https://github.com/Amirhosseinmovahedi/MedSAM-BoxPredictor
VISTA: 視覚に基づいた、物理学に基づいて検証された UMI データの VLA トレーニングへの適応
Universal Manipulation Interface (UMI) により、ハードウェア固有の遠隔操作を必要とせずにスケーラブルな現実世界のロボット データ収集が可能になりますが、UMI データを活用して大規模な Vision-Language-Action (VLA) モデルをトレーニングすることは依然として根本的に困難です。我々は 2 つの重大な不一致を特定しました。1 つは、深刻な放射状の歪みとローカルのグリッパー中心の視点を伴う手首に取り付けられた魚眼ビューであり、事前トレーニングされた VLM には配布されていません。また、人間が収集した軌道は、頻繁に運動学的制限に違反したり、衝突が発生したり、コントローラーの帯域幅を超えたりするため、VLA ポリシーに物理的に実行不可能なアクションが教示されます。この課題に対処するために、3 つの相乗効果のあるコンポーネントを通じてこの二重のギャップを埋めるフレームワークである VISTA を紹介します。 (i) ~UMI-VQA は、手首に装着した魚眼観察に合わせて調整された初の大規模 VQA データセットであり、補助的な視覚言語監視を通じて VLM 表現を歪んだ視覚領域に合わせます。 (ii)~体系的な物理検証パイプラインは、データ完全性の事前チェックを実行し、トレーニングに入る前に、軌道の連続性、自己衝突のリスク、および実行の忠実度について各有効な軌道にスコアを付けます。 (iii)~2 段階の共同トレーニング レシピは、UMI-VQA に基づいた視覚言語の基礎と、検証された軌道に基づいた行動予測を共同で学習します。私たちの実験では、UMI-VQA を組み込むと下流のポリシーのパフォーマンスが一貫して向上し、物理検証スコアが展開の成功を強力に予測できることが経験的に示されています。さまざまなシミュレーションや現実世界の操作タスクにおいて、VISTA は $\pi_{0.5}$、LingBot-VLA、Wall-X などの強力なベースラインを大幅に上回ります。物理検証パイプライン、UMI-VQA、検証された軌跡データ、および事前トレーニングされたモデルをコミュニティにリリースします。
原文 (English)
VISTA: Vision-Grounded and Physics-Validated Adaptation of UMI data for VLA Training
Universal Manipulation Interface (UMI) enables scalable real-world robot data collection without hardware-specific teleoperation, yet leveraging UMI data to train large-scale Vision-Language-Action (VLA) models remains fundamentally challenging. We identify two critical mismatches: wrist-mounted fisheye views, with severe radial distortion and local gripper-centric perspectives, are out-of-distribution for pretrained VLMs; and human-collected trajectories frequently violate kinematic limits, incur collisions, or exceed controller bandwidth, teaching VLA policies physically infeasible actions. To address the challenges, we present VISTA, a framework that bridges this dual gap through three synergistic components. (i)~UMI-VQA, the first large-scale VQA dataset tailored to wrist-mounted fisheye observations, aligns VLM representations to the distorted visual regime via auxiliary vision-language supervision. (ii)~A systematic physical-validation pipeline performs a data-completeness pre-check and scores each valid trajectory for trajectory continuity, self-collision risk, and execution fidelity before it enters training. (iii)~A two-stage co-training recipe jointly learns vision-language grounding on UMI-VQA and action prediction on validated trajectories. Our experiments empirically show that incorporating UMI-VQA consistently improves downstream policy performance, and that physical-validation scores are strongly predictive of deployment success. On diverse simulation and real-world manipulation tasks, VISTA significantly outperforms strong baselines including $\pi_{0.5}$, LingBot-VLA, and Wall-X. We release the physical-validation pipeline, UMI-VQA, validated trajectory data, and the pre-trained model for the community.
CoRe-MoE: 歩行適応を備えた複数地形ヒューマノイド移動のための専門家の対照的な再重み付け混合
人間は主に、不必要に複雑な動作パターンに頼ることなく、複雑な地形を横断するために歩いたり走ったりすることに頼っています。同様に、人型ロボットは、自然で安定した移動を維持しながら、歩行と走行の間のスムーズな移行を達成する必要があります。ただし、単一のポリシー内で歩行遷移と複数の地形への適応を統合することは、勾配の干渉と、地形に依存する視覚的および動的変化によって引き起こされる分布のシフトのため、依然として困難です。専門家混合 (MoE) アーキテクチャは複数のスキルの干渉を軽減できますが、単純な共同トレーニングでは明確な専門知識が得られないことが多く、効果が制限されます。これらの課題に対処するために、私たちは地形適応から歩行生成を切り離す 2 段階の強化学習フレームワークである CoRe-MoE を提案します。第 1 段階では、スムーズな移行で自然な歩行と走行の動作を生成するための安定した移動ポリシーが学習されます。第 2 段階では、地形認識 MoE ブランチが導入され、ゲーティング ネットワークを形成するという対照的な目的でトレーニングされ、構造化された地形表現をキャプチャして専門家の専門化を促進できるようになります。最終的なアクションは、基本歩行ポリシーと地形認識ブランチの重み付けされた融合によって取得され、ポリシーが複雑な地形に適応しながら安定した移動パターンを維持できるようにします。広範なシミュレーション結果は、提案された方法が成功率、移動の安定性、および複数の地形への適応性の点でベースラインのアプローチよりも優れていることを示しています。さらに、Unitree G1 ヒューマノイド ロボットへのゼロショット展開により、当社のフレームワークの有効性が検証され、外乱下でも正確な足場の配置と動的安定性を維持しながら、階段、坂道、段差、障害物、屋外の構造化されていない地形での堅牢な歩行と走行が実現されます。
原文 (English)
CoRe-MoE: Contrastive Reweighted Mixture of Experts for Multi-Terrain Humanoid Locomotion with Gait Adaptation
Humans primarily rely on walking and running to traverse complex terrains, without resorting to unnecessarily complex motion patterns. Similarly, humanoid robots should achieve smooth transitions between walking and running while maintaining natural and stable locomotion. However, unifying gait transition and multi-terrain adaptation within a single policy remains challenging due to gradient interference and the distribution shift induced by terrain-dependent visual and dynamic variations. Although Mixture-of-Experts (MoE) architectures can alleviate multi-skill interference, naive joint training often fails to yield clear expert specialization, limiting their effectiveness. To address these challenges, we propose CoRe-MoE, a two-stage reinforcement learning framework that decouples gait generation from terrain adaptation. In the first stage, a stable locomotion policy is learned to produce natural walking and running behaviors with smooth transitions. In the second stage, a terrain-aware MoE branch is introduced and trained with a contrastive objective to shape the gating network, enabling it to capture structured terrain representations and promote expert specialization. The final action is obtained via weighted fusion of the base gait policy and the terrain-aware branch, allowing the policy to preserve stable locomotion patterns while adapting to complex terrains. Extensive simulation results demonstrate that the proposed method outperforms baseline approaches in terms of success rate, locomotion stability, and multi-terrain adaptability. Furthermore, zero-shot deployment on a Unitree G1 humanoid robot validates the effectiveness of our framework, achieving robust walking and running across stairs, slopes, steps, obstacles, and unstructured outdoor terrains, while maintaining accurate foothold placement and dynamic stability under external disturbances.
トレース媒介ピーク バイアス: 深層強化学習における時間単位の割り当てと認知ヒューリスティックの橋渡し
時間的クレジットの割り当ては、生物学的知能と人工知能の両方にとって中心的ですが、非線形関数近似との相互作用はほとんど理解されていません。私たちは、Trace-Mediated Peak Bias (TMPB) と呼ばれる深層強化学習 (RL) における系統的故障モードを特定します。中間の適格性トレースの深さでは、エージェントは、より高い累積リターンを持つ代替案よりも、高い規模の報酬「ピーク」を持つ軌道を非合理的に好みます。これは、経験が統合された有用性ではなく、最も強烈な瞬間によって判断される人間の記憶バイアスであるピークエンド ルールのメカニズムの説明を提供します。私たちは、トレースが遠位時間差誤差を固定ステップサイズの確率的勾配降下法では正規化できない「勾配ショック」に増幅し、全体的な過大評価につながるためにTMPBが出現することを示します。逆に、適応オプティマイザーは、瞬間的な正規化を通じてこの病状を軽減します。私たちの結果は、人間のような顕著性の歪みが分散システムにおけるクレジット割り当ての数学的制約から自然に現れる可能性があり、合理的な値推定には適応最適化が理論的に必要であることを示唆しています。
原文 (English)
Trace-Mediated Peak Bias: Bridging Temporal Credit Assignment and Cognitive Heuristics in Deep Reinforcement Learning
Temporal credit assignment is central to both biological and artificial intelligence, yet its interaction with non-linear function approximation is poorly understood. We identify a systematic failure mode in deep reinforcement learning (RL) termed Trace-Mediated Peak Bias (TMPB). At intermediate eligibility trace depths, agents irrationally prefer trajectories with high-magnitude reward ``peaks'' over alternatives with higher cumulative returns. This provides a mechanistic account of the Peak-End Rule: a human memory bias where experiences are judged by their most intense moments rather than integrated utility. We show that TMPB emerges because traces amplify distal Temporal Difference errors into ``gradient shocks'' that fixed-step-size Stochastic Gradient Descent cannot normalize, leading to global overestimation. Conversely, adaptive optimizers mitigate this pathology via second-moment normalization. Our results suggest that human-like saliency distortions may emerge naturally from the mathematical constraints of credit assignment in distributed systems, and that adaptive optimization is a theoretical necessity for rational value estimation.
物理学に基づいたニューラル ネットワークのための曲率を考慮した動的精度アプローチ
物理情報に基づいたニューラル ネットワーク (PINN) は、ニューラル ネットワークのトレーニングに物理法則を直接埋め込むことにより、偏微分方程式 (PDE) をシミュレーションするための有望なフレームワークとなっています。ただし、最近の研究では、PINN の最適化が数値精度に影響されることが示されています。既存の実装では、計算効率は高いが故障モードが発生しやすい単精度 (FP32) か、堅牢ではあるが非常に高価な倍精度 (FP64) が一般的に使用されています。これにより、計算効率と数値精度の間にトレードオフが生じます。予測精度を維持しながら倍精度トレーニングの計算コストを削減するために、固定実装の選択肢として扱うのではなく、トレーニング中に数値精度を適応させる曲率認識精度コントローラーを提案します。提案された方法は、メモリ制限のある BFGS (L-BFGS) オプティマイザーから得られた曲率情報を再利用して精度コントローラーを構築し、より低い精度で十分な場合は FP32 を保持し、トレーニング ダイナミクスが数値感度または精度制限された停滞を示している場合は、計算を FP64 に促進します。提案されたアプローチを、4 つの標準 PINN 故障モード ベンチマークと放射照度駆動の常微分方程式の例で評価します。提案されたアプローチをさまざまなニューラル ネットワーク アーキテクチャにわたってさらにテストします。このメソッドは、すべてのベンチマーク方程式で完全な倍精度トレーニングと比較してトレーニング時間を短縮しながら、FP64 の完全な解精度と一貫して一致するかわずかに上回っています。得られた結果は、PINN 最適化における精度の感度が位相に依存すること、および数値的に重要な段階でのみ高い精度を選択的に適用することで、予測精度を犠牲にすることなく計算コストを削減できることを示しています。
原文 (English)
Curvature-aware dynamic precision approach for physics-informed neural networks
Physics-informed neural networks (PINNs) have become a promising framework for simulating partial differential equations (PDEs) by embedding physical laws directly into neural network training. However, recent studies show that PINN optimisation is sensitive to numerical precision. Existing implementations commonly use either single precision (FP32), which is computationally efficient but prone to failure modes, or double precision (FP64), which is robust but substantially expensive. This creates a trade-off between computational efficiency and numerical accuracy. To reduce the computational cost of double-precision training while retaining prediction accuracy, we propose a curvature-aware precision controller that adapts numerical precision during training rather than treating it as a fixed implementation choice. The proposed method reuses curvature information derived from the limited-memory BFGS (L-BFGS) optimiser to construct a precision controller, retaining FP32 when lower precision is sufficient and promoting computation to FP64 when the training dynamics indicate numerical sensitivity or precision-limited stagnation. We evaluate the proposed approach on four canonical PINN failure-mode benchmarks and an irradiance-driven ordinary differential equation example. We further test the proposed approach across different neural network architectures. The method consistently matches or even slightly exceeds full FP64 solution accuracy while reducing training time relative to full double-precision training on all benchmark equations. The obtained results indicate that precision sensitivity in PINN optimisation is phase-dependent, and that selectively applying higher precision only during numerically critical stages can lower computational cost without sacrificing predictive accuracy.
Vul-RAG の再考: オープンウェイト モデルを使用した RAG ベースの脆弱性検出の再現性と再現性
大規模言語モデル (LLM) は、特に検索拡張世代 (RAG) 設定において、自動ソフトウェア脆弱性検出の強力な可能性を示しています。ただし、独自のモデルと API に依存するアプローチの場合、再現性と複製可能性はほとんど解明されていないため、報告された結果が一般化されるのか、それとも特定のモデルの選択に主に依存するのかという疑問が生じます。この研究では、高度な脆弱性知識で LLM を強化する、ソース コード脆弱性検出用の RAG ベースのフレームワークである Vul-RAG の再現性の研究を紹介します。まず、報告されたオープンウェイトベースラインモデルを使用して、完全にローカルでオープンウェイト設定で結果を再現します。次に、コードに特化した、汎用の、さまざまなパラメーター サイズの推論モデルを含む、最近のオープンウェイト LLM の多様なセットに評価を拡張します。この結果は、Vul-RAG の結果がローカル展開下で再現可能であることを裏付けていますが、多少の誤差はあります。評価されたすべてのモデルにわたって、ペアワイズ精度 (脆弱な関数とパッチ適用された関数の両方が正しく分類されたコード ペア) で約 0.30 のパフォーマンスのプラトーが観察されます。特に、このプラトーは、より最近の高度なモデルでも持続しており、モデルの容量の向上だけではパフォーマンスが大幅に向上しないことを示しています。最後に、検出の有効性、モデルの機能、モデルの規模の間の実際的な影響とトレードオフについて説明します。実装と評価のアーティファクトは、https://github.com/hs-esslingen-it-security/revisiting-Vul-RAG で公開されています。
原文 (English)
Revisiting Vul-RAG: Reproducibility and Replicability of RAG-based Vulnerability Detection with Open-Weight Models
Large language models (LLMs) have shown strong potential for automated software vulnerability detection, particularly in retrieval-augmented generation (RAG) settings. However, for approaches relying on proprietary models and APIs, reproducibility and replicability remain largely unexplored, raising the question of whether reported results generalize or depend primarily on specific model choices. In this work, we present a reproducibility study of Vul-RAG, a RAG-based framework for source code vulnerability detection that enhances LLMs with high-level vulnerability knowledge. We first replicate the results in a fully local and open-weights setting using the reported open-weight baseline models. We then extend the evaluation to a diverse set of recent open-weight LLMs, including code-specialized, general-purpose, and reasoning models of varying parameter sizes. The results confirm that the findings of Vul-RAG are reproducible under local deployment, but with minor deviations. Across all evaluated models, we observe a performance plateau at approximately 0.30 pairwise accuracy (code pairs for which both the vulnerable and the patched function are correctly classified). Notably, this plateau persists even for more recent and advanced models, indicating that improvements in model capacity alone do not substantially enhance performance. Finally, we discuss practical implications and trade-offs between detection effectiveness, model capabilities, and model scale. Implementation and evaluation artifacts are publicly available at https://github.com/hs-esslingen-it-security/revisiting-Vul-RAG.
TIDE: テンプレートに基づく反復によるプロアクティブな複数の問題の発見
エージェントは、ドキュメント、ツール、コードのアシスタントとして広く導入されています。ただし、これらは通常、明示的なユーザー要求にのみ作用し、ユーザーが気づいた問題のみを表面化します。一方、他の多くの重要な問題は、より広範なユーザー コンテキスト内で目に見えない形で共存しており、その総数は事前に不明です。私たちはこれを、文脈から複数の隠れた問題を発見するタスクとして組み立てます。その中で、共存する問題を明らかにし、裏付けとなる証拠に基づいて、具体的な行動と組み合わせる必要があります。この目的を達成するために、2 つの補完的なメカニズムを備えたテンプレート主導の反復フレームワークである TIDE を導入します。具体的には、シングルパス予測が最も顕著なケースに基づいて一般的な主張を生み出すという観察に動機づけられて、我々は反復発見を提案します。これは、すでに見つかったものに基づいて条件付けしながらラウンドごとに小さなバッチの候補を表面化し、後続のラウンドで対象範囲を拡大します。思考テンプレートは、以前に解決されたケースから抽出された再利用可能なスキーマであり、どのコンテキスト シグナルに注目し、それらをどのように接続するかを指定し、各予測を認識可能な問題クラスに固定します。 4 つのモデル バックボーンにわたって、パーソナル ワークスペースとソフトウェア リポジトリという 2 つの現実的な設定で TIDE を検証し、タスク カバレッジ、識別、解決に関して、シングルショットおよび並列マルチエージェント ベースラインを超える大幅な向上を示しています。
原文 (English)
TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
Agents are widely deployed as assistants over documents, tools, and code. However, they typically act only on explicit user requests, which surface only the problems the user has noticed, while many other important problems coexist, hidden in plain sight, within the broader user context, with their total number unknown in advance. We frame this as the task of discovering multiple hidden problems from context, in which coexisting problems should be uncovered, grounded in supporting evidence, and paired with concrete actions. To this end, we introduce TIDE, a template-guided iterative framework with two complementary mechanisms. Specifically, motivated by the observation that single-pass prediction anchors on the most salient cases and yields generic claims, we propose iterative discovery, which surfaces a small batch of candidates per round while conditioning on what has already been found, so subsequent rounds extend coverage; and thought templates, reusable schemas distilled from previously solved cases that specify what contextual signals to attend to and how to connect them, anchoring each prediction in a recognizable problem class. We validate TIDE on two realistic settings, personal workspaces and software repositories, across four model backbones, showing substantial gains over single-shot and parallel multi-agent baselines on task coverage, identification, and resolution.
マルチチャンネル信号トランスの入力エンコーダの実証的監査
マルチチャネル スカラー信号を消費する変換器は、タイム ステップごとに $C$ 同時値を 1 つの $d_{\text{model}}$ 次元ベクトルに埋め込む必要があります。共有スカラー ベースライン、チャネルごとの線形射影、直交性正則化、非線形 MLP ステム、ブロック分割連結、チャネル独立およびトークンとしてのチャネル アーキテクチャ、投影位置エンコーディングに及ぶ 8 つの入力エンコーダを、チャネル ID を有益にするように設計された合成ベンチマークと、次のステップの負の対数尤度で測定される実データ チェックとしての ETTh1 で実証的に監査します。 (NLL)。見出しは、幅広い「最上位層」内で実質的にほぼ同等であることの 1 つです。標準のチャネルごとの線形射影 (nn.Linear(C, $d_{\text{model}}$)) は、統計的に現実的だが実質的には控えめな小さな差異まで、その層のすべての選択肢と一致します。 2 つのエンコーダが決定的に負けます。1 つは共有スカラー ベースラインであり、これは私たちが明らかにする情報理論上の理由で破綻します。もう 1 つはチャネルに依存しない PatchTST スピリット ベースラインで、両方のベンチマークでパフォーマンスを下回り、合成ベンチマークでは普遍的にオーバーフィットします。ペアテストは 2 つの小さなギャップを解決します。学習された線形層を通じて正弦波位置エンコードを投影すると、残りの部分が小さな $C$ でエッジ付けされ、直接幾何学的プローブによって位置チャネル直交化のメカニズムが示されます。非線形 MLP ステムは、テストした最大 $C$ でそれらに隣接し、より多くのトレーニング データの下でギャップは縮小します。実際的な推奨事項は、デフォルトで nn.Linear(C, $d_{\text{model}}$) を使用し、目の前のタスクに実際の理由がある場合にのみ、より複雑なものに手を伸ばすことです。この論文のすべての実験を再現するためのコードとデータは、https://github.com/OssiLehtinen/channel-encoder-audit で入手できます。
原文 (English)
An Empirical Audit of Input Encoders for Multi-Channel Signal Transformers
Transformers consuming multi-channel scalar signals must embed $C$ simultaneous values into one $d_{\text{model}}$-dimensional vector per time step. We empirically audit eight input encoders -- spanning a shared-scalar baseline, per-channel linear projections, an orthogonality regulariser, a nonlinear MLP stem, block-partitioned concatenation, channel-independent and channel-as-token architectures, and a projected positional encoding -- on a synthetic benchmark designed to make channel identity informative and on ETTh1 as a real-data check, measured in next-step negative log-likelihood (NLL). The headline is one of practical near-equivalence within a wide "top tier": the standard per-channel linear projection (nn.Linear(C, $d_{\text{model}}$)) matches every alternative in that tier up to small, statistically real but practically modest, differences. Two encoders lose decisively: the shared-scalar baseline, which collapses for information-theoretic reasons we make explicit, and the channel-independent PatchTST-spirit baseline, which underperforms on both benchmarks and overfits universally on the synthetic one. Paired tests resolve two small gaps: projecting the sinusoidal positional encoding through a learned linear layer edges the rest at small $C$, with a direct geometric probe showing the mechanism is positional-channel orthogonalisation; a nonlinear MLP stem edges them at the largest $C$ we test, with the gap shrinking under more training data. The practical recommendation is to use nn.Linear(C, $d_{\text{model}}$) by default and reach for something more elaborate only when the task at hand gives a real reason to do so. Code and data to reproduce every experiment in this paper are available at https://github.com/OssiLehtinen/channel-encoder-audit
Archi: CMS 実験におけるエージェント操作
私たちは、異種データ ソースの体系的な取り込みと編成と、データ ソースを取得して推論する構成可能でプライベートで拡張可能なエージェントの展開を組み合わせた、科学コラボレーションのためのオープンソースのエンドツーエンド フレームワークである Archi を紹介します。 Archi のインスタンスは、技術オペレーターのサポート エージェントとして 2026 年 2 月から CERN の LHC での CMS 実験のコンピューティング運用チームに導入されており、文書、履歴データ、ライブ監視システムを組み合わせて検索および分析機能を提供しています。私たちはオペレーターのフィードバックと、実稼働環境での使用状況から収集された質問セットに基づいてシステムを評価し、人間のパネルと自動パネルによって採点します。このシステムは、CMS オペレーターが提起する実際のクエリを解決する運用タスクで効果的であることが証明されています。また、ローカルでホストされているオープンウェイト モデルが競争力を持って実行され、機密データの完全なプライベート管理が可能になることも観察されています。
原文 (English)
Archi: Agentic Operations at the CMS Experiment
We present Archi, an open-source, end-to-end framework for scientific collaborations that combines the systematic ingestion and organization of heterogeneous data sources with the deployment of configurable, private, and extensible agents that retrieve and reason over them. An instance of Archi has been deployed for the Computing Operations team of the CMS experiment at CERN's LHC since February 2026 as a support agent for technical operators, offering retrieval and analysis capabilities by combining documentation, historical data, and live monitoring systems. We evaluate the system on operator feedback and a question set collected from production usage, graded by human and automated panels. The system proves effective at operational tasks, resolving real-world queries posed by CMS operators. We also observe that locally-hosted, open-weight models perform competitively, enabling fully private management of sensitive data.
現実世界の MCP サーバーにおける記述コードの不一致: 測定、検出、およびセキュリティへの影響
モデル コンテキスト プロトコル (MCP) は、大規模言語モデル (LLM) が外部ツールを利用できるようにする重要な標準として登場しました。このエコシステムでは、LLM は MCP サーバーによって提供される自然言語記述に依存して、関数を選択して実行します。この相互作用は、ツールの説明がその基礎となる実装を忠実に反映していることを暗黙的に前提としていますが、この前提は実際には強制的に検証されるわけではありません。その結果、MCP の導入では、ツールの機能とセキュリティ境界に関する記述がコードの実際の動作と一致しない、記述コードの不一致 (DCI) という問題が発生する可能性があります。このペーパーでは、実際の MCP サーバーにおける DCI の包括的な研究を紹介します。私たちは問題を正式に定義し、機能の不一致や未発表の副作用に及ぶ包括的な分類法を提案します。この分類法に基づいて、私たちは、構造を認識した静的解析とダイレクト リバース アービトレーション プロンプト手法を組み合わせて、実際のコード実装に対してツールの説明を相互検証する自動化フレームワークである DCIChecker を開発しました。このフレームワークを、2,214 台の実世界の MCP サーバーから抽出された 19,200 個の記述コードのペアで構成される大規模なデータセットに適用します。私たちの測定では、DCI が広く普及しており、これらのペアの 9.93% が矛盾を示していることが明らかになりました。さらに、DCI が重大な防御の盲点を生み出し、運用上の失敗からこっそりと悪意のある動作に至るまで、さまざまなリスクを助長することを実証します。最後に、セマンティックな一貫性を強化し、新興エージェント エコシステムの信頼性を高めるための緩和戦略を提案します。
原文 (English)
Description-Code Inconsistency in Real-world MCP Servers: Measurement, Detection, and Security Implications
The Model Context Protocol (MCP) has emerged as a critical standard empowering Large Language Models (LLMs) to utilize external tools. In this ecosystem, LLMs rely on natural language descriptions provided by MCP servers to select and execute functions. This interaction implicitly assumes that tool descriptions faithfully reflect their underlying implementations, while this assumption is not mandatorily verified in practice. As a result, MCP deployments may suffer from a problem named Description-Code Inconsistency (DCI), where a tool's description of its capabilities and security boundaries is not consistent with what the code actually does. In this paper, we present a comprehensive study of DCI in real-world MCP servers. We formally define the problem and propose a comprehensive taxonomy spanning functionality inconsistencies and undeclared side effects. Guided by this taxonomy, we develop DCIChecker, an automated framework that combines structure-aware static analysis with the Direct-Reverse-Arbitration prompting method to cross-validate tool descriptions against actual code implementations. We apply this framework to a large-scale dataset comprising 19,200 description-code pairs extracted from 2,214 real-world MCP servers. Our measurement reveals that DCI is widespread, with 9.93% of these pairs exhibiting inconsistencies. We further demonstrate that DCI creates a critical defense blind spot, facilitating varied risks from operational failures to stealthy malicious behaviors. Finally, we propose mitigation strategies to enforce semantic consistency and enhance the reliability of the emerging agentic ecosystem.
脳再構築のためのシーケンシャル Mamba を使用した粗いから細かいまでの階層アーキテクチャ
深い視覚表現と人間の視覚システムとの関係を理解することは、計算論的神経科学における基本的な課題です。最新の視覚モデルは画像認識において優れた性能を達成していますが、人間の視覚野の階層構造との対応は未解決の問題のままです。この研究では、画像から fMRI へのエンコードのための新しい階層型 2 段階フレームワークである CHASMBrain を提案します。私たちのアーキテクチャは、デュアルストリーム Mamba 設計を活用して、視覚野の機能的組織化を動機として、グローバル セマンティック トークンとローカル空間パッチを明示的に分離して処理します。粗いものから細かいものへの戦略が採用されています。ステージ 1 では、ノイズ除去された ROI レベルのアクティベーションを予測します。一方、ステージ 2 では、Mamba-VAE を使用して、これらの粗い応答を完全なボクセル レベルの予測に洗練します。 Natural Scenes Dataset (NSD) の実験では、私たちの方法が 0.429 のピアソン相関と 0.261 の MSE を達成し、リッジ回帰や DINOv2 線形プローブを含むすべての評価されたベースラインを上回る性能を示していることが実証されています。予測性能を超えて、因果ブランチアブレーション実験は非対称の特殊化を明らかにします。パッチ ストリームは初期視覚野 (網膜部位) に特にロックされているのに対し、CLS ストリームは高次の領域に広範な意味論的コンテキストを提供します。この対応関係は、単に相関関係だけでなく因果的に成立します。さらに、被験者間の転移実験では、学習したバックボーンが被験者ごとの適応を最小限に抑えながら個人全体に一般化することが示されており、このモデルが共有された被験者に依存しない視覚表現を捉えていることが示唆されています。
原文 (English)
Coarse-to-fine Hierarchical Architecture with Sequential Mamba for Brain Reconstruction
Understanding the relationship between deep visual representations and the human visual system is a fundamental challenge in computational neuroscience. While modern vision models achieve strong performance in image recognition, their correspondence with the hierarchical organization of the human visual cortex remains an open question. In this study, we propose CHASMBrain, a novel hierarchical two-stage framework for image-to-fMRI encoding. Our architecture leverages a dual-stream Mamba design to explicitly separate and process global semantic tokens and local spatial patches, motivated by the functional organization of the visual cortex. A coarse-to-fine strategy is employed: Stage 1 predicts denoised ROI-level activations, while Stage 2 refines these coarse responses into full voxel-level predictions using a Mamba-VAE. Experiments on the Natural Scenes Dataset (NSD) demonstrate that our method achieves a Pearson correlation of 0.429 and an MSE of 0.261, outperforming all evaluated baselines including ridge regression and DINOv2 linear probes. Beyond predictive performance, causal branch-ablation experiments reveal an asymmetric specialization: the patch stream is specifically locked to early visual cortex (retinotopic regions), while the CLS stream contributes broader semantic context to higher-order areas -- a correspondence that holds causally, not merely correlationally. Cross-subject transfer experiments further show that the learned backbone generalizes across individuals with minimal per-subject adaptation, suggesting the model captures a shared, subject-agnostic visual representation.
低減次数線形最適制御によるビデオ生成モデルのアクティベーションステアリング
大規模な Web データでトレーニングされた Text-to-Video (T2V) モデルは、望ましくないコンテンツを生成する可能性があり、視覚的な品質を犠牲にすることなく有害な出力を削減する介入を促す可能性があります。アクティベーション ステアリングは、微調整や即時フィルタリングに代わる魅力的な機構的代替手段を提供しますが、既存の T2V ステアリング方法は依然として限定的であり、通常はオーバーステアリングやコンテンツの劣化につながる可能性のある粗い非予測的な介入を適用します。このギャップを埋めるために、低侵襲 T2V ステアリングのための次数を減らした最適制御フレームワークである潜在活性化線形二次レギュレーター (LA-LQR) を提案します。 LA-LQR は、T2V 推論を動的システムとして定式化し、不必要な摂動をペナルティしながら、望ましい機能設定値に向けてアクティベーションを誘導する閉ループ フィードバック介入を計算します。高次元のビデオアクティベーションに対して最適な制御を実現可能にするために、対照的なプロンプトのペアから導出された低次元のタスク関連部分空間にアクティベーションを投影し、この潜在空間内の局所線形ダイナミクスを推定し、潜在 LQR 問題を解いてタイムステップおよびレイヤー固有のステアリング信号を取得します。潜在設定値追跡を生の活性化空間特徴制御に関連付ける理論的限界を提供し、低減された潜在ダイナミクスの忠実性を経験的に検証します。コンセプト ステアリングとビデオの安全性ベンチマークでは、LA-LQR は、プロンプトの忠実性と視覚的な品質を維持しながら、ベースラインと比較して安全でない世代を削減します。
原文 (English)
Activation Steering of Video Generation Models via Reduced-Order Linear Optimal Control
Text-to-video (T2V) models trained on large-scale web data can generate undesired content, motivating interventions that reduce harmful outputs without sacrificing visual quality. Activation steering offers an attractive mechanistic alternative to finetuning and prompt filtering, but existing T2V steering methods remain limited, typically applying coarse, non-anticipative interventions that can lead to oversteering and content degradation. To close this gap, we propose Latent Activation Linear-Quadratic Regulator (LA-LQR), a reduced-order optimal control framework for minimally invasive T2V steering. LA-LQR formulates T2V inference as a dynamical system and computes closed-loop feedback interventions that steer activations toward desired feature setpoints while penalizing unnecessary perturbations. To make optimal control feasible for high-dimensional video activations, we project activations onto a low-dimensional, task-relevant subspace derived from contrastive prompt pairs, estimate local linear dynamics in this latent space, and solve a latent LQR problem to obtain timestep- and layer-specific steering signals. We provide theoretical bounds relating latent setpoint tracking to raw activation-space feature control, and empirically validate the fidelity of the reduced latent dynamics. On concept steering and video safety benchmarks, LA-LQR reduces unsafe generations relative to baselines, while preserving prompt fidelity and visual quality.
NoRA: 視覚的な一人称の規範的行動推論における根拠のある合理性の評価
LLM とエージェント システムは社会環境にますます導入されており、安全で適切な行動には規範的能力が重要になっています。しかし、既存のアプローチは、規範的判断をテキストのみで評価するか、固定された一連の候補アクションの中から選択することに還元します。私たちはどちらも不十分だと主張します。実際には、エージェントにオプションのメニューが渡されることはありません。彼らは、目に見える事実に基づいて、検証可能な理由によって裏付けられた、合理的な行動をゼロから特定しなければなりません。 NoRA は視覚的な一人称ビデオ ベンチマークであり、モデルが次のアクションの候補を生成し、明示的な事実-理由-アクションのサポート グラフを通じてそれぞれを正当化する必要があります。このベンチマークは、HumanGold-190 および LLMSilver-1230 の分割を含む 1,420 個の注釈付きビデオ クリップで構成されています。各インスタンスは、アクションの調整、事実の根拠、およびサポートのバインディングを通じて評価され、単一の根拠のある合理性スコアに集約されます。私たちは、直接的、計画的、構造化されたプロンプト体制の下で 12 のマルチモーダル システムのベンチマークを行ったところ、現在の VLM はもっともらしいアクションと関連するシーンの事実を頻繁に回収しますが、完全な合理的なアクション スペースを構築し、選択されたアクションを正しいローカル サポートに結び付けるのに一貫して苦労していることがわかりました。 NoRA はこのギャップを測定可能にし、評価の問題を、モデルがアクションを選択できるかどうかから、適切な目に見える理由に基づいて適切なアクションを正当化できるかどうかに移します。
原文 (English)
NoRA: Evaluating Grounded Reasonableness in Visual First-person Normative Action Reasoning
LLMs and agentic systems are increasingly deployed in social environments, making normative competence critical for safe and appropriate behavior. However, existing approaches either assess normative judgment in text alone or reduce it to choosing among a fixed set of candidate actions. We argue both are insufficient. In practice, agents are never handed a menu of options; they must identify a reasonable action from scratch, grounded in visible facts and supported by inspectable reasons. We introduce NoRA, a visual first-person video benchmark that requires models to generate candidate next actions and justify each through an explicit fact-reason-action support graph. The benchmark comprises 1,420 annotated video clips, including HumanGold-190 and LLMSilver-1230 splits. Each instance is evaluated through action alignment, factual grounding, and support binding, aggregated into a single grounded reasonableness score. We benchmark 12 multimodal systems under direct, deliberate, and structured prompting regimes, finding that current VLMs frequently recover plausible actions and relevant scene facts, but consistently struggle to construct the full reasonable action space and bind selected actions to the correct local support. NoRA makes this gap measurable, shifting the evaluation question from whether a model can pick an action to whether it can justify an appropriate action for the right visible reasons.
おそらくほぼ安全な保証を備えたリスク認識型強化学習のシナリオ生成
特にディープ RL を使用して学習されたポリシーは、未知の動作や安全ではない動作を引き起こす遷移の摂動の影響を受けやすいことが示される可能性があるため、安全性の保証は、現実世界への強化学習 (RL) エージェントの展開にとって重要です。ポリシー検証の方法は、安全制約に関するポリシーの軌跡をサンプリングすることによって確率的バリア証明書を構築し、それによって既知の安全な動作と未知の動作を区別することです。ポリシーが、エージェントを十分に探索されていない状態に置く遷移の不確実性または摂動の影響を受けやすい場合、これらの制約に違反する確率について厳密な上限と下限を取得することは困難になる可能性があります。これに対処するために、変分オートエンコーダー (VAE) を使用して遭遇した状態空間の分布を近似し、状態の潜在的な特性を使用して上限と下限のバリア証明書を構築し、既知の安全な動作の領域を高い信頼性で最適化します。私たちはこれを二重最適化問題として枠組み付けし、下限のバリア証明書が上限のバリア証明書よりも安全な領域のより保守的な推定を提示します。トレーニング中に 2 つの設定差内にある状態 (つまり、非ロバスト領域) をサンプリングすることにより、上限と下限を厳しくして、安全性についてより明確な確率的保証を提供することができます。私たちの研究では、設定された保証について説明し、実験的に境界の厳しさを実証します。
原文 (English)
Scenario Generation for Risk-Aware Reinforcement Learning with Probably Approximately Safe Guarantees
Guaranteeing safety is critical to the deployment of reinforcement learning (RL) agents in the real-world, especially as policies learned using deep RL may demonstrate susceptibility to transition perturbations that result in unknown or unsafe behaviour. A method of policy verification is to construct probabilistic barrier-certificates by sampling policy trajectories with respect to safety constraints, thereby demarcating known safe behaviour from unknown behaviour. Obtaining tight upper and lower bounds on the probability of violation of these constraints may be difficult if the policy is susceptible to transition uncertainty or perturbation that places the agent in insufficiently explored states. To address this, we approximate the distribution of the encountered state-space using a variational autoencoder (VAE) and construct upper and lower-bound barrier-certificates using latent characteristics of states to optimize for regions of known, safe behaviour with high confidence. We frame this in our work as a dual optimization problem where the lower-bound barrier-certificate presents a more conservative estimate of the safe region than the upper-bound barrier-certificate. Sampling states that lie within the set difference of the two during training, i.e. the non-robust region, allows us to tighten the upper and lower bounds to provide sharper probabilistic guarantees on safety. Within our study, we describe the guarantees placed and demonstrate the tightness of our bounds experimentally.
行動しながら学習: オンライン生涯学習エージェント向けのスキル強化されたテスト時間共進化フレームワーク
生涯学習は、動的で対話型の環境で動作する大規模言語モデル (LLM) エージェントにとって不可欠です。しかし、長期的なタスクのための既存の生涯学習エージェントは通常、推論中の静的パラメータによる離散的なスキルや過去の経験の取得に依存しているため、人間の学習者のようにテスト時のフィードバックを継続的に内面化することができません。このギャップを埋めるために、オンライン生涯学習エージェントのための 2 段階の強化学習フレームワークであるスキル強化テスト時間共進化 (\texttt{LifeSkill}) を提案します。具体的には、複数のスキル条件付きポリシーのロールアウトの平均的な検証者の成功に応じて候補者のスキルに報酬を与えることで、スキル抽出のための直接監督の欠如に対処する検証者ガイド付きスキル学習を設計し、単にテキスト上でもっともらしいスキルではなく、タスクの解決に役立つスキルを生成するようにモデルを奨励します。さらに、オンライン スキル内部化を導入します。これは、スキル条件付きの軌道を報酬シグナルに変換することで、テスト時のインタラクション中にポリシー モデルを継続的に改善します。これにより、エージェントは推論機能をパラメータに直接内部化でき、エクスペリエンス取得によるコンテキストの肥大化を回避できます。 LifelongAgentBench の実験では、既存の生涯エージェントのベースラインと比較して、LifeSkill が平均パフォーマンスを 7 絶対ポイント向上させることが示されています。
原文 (English)
Learning While Acting: A Skill-Enhanced Test-Time Co-Evolution Framework for Online Lifelong Learning Agents
Lifelong learning is essential for Large Language Model (LLM) agents operating in dynamic, interactive environments. However, existing lifelong learning agents for long-horizon tasks typically depend on discrete skill or past experiences retrieval with static parameters during inference, which prevents them from continuously internalizing test-time feedback like human learners. To bridge this gap, we propose Skill-enhanced Test-Time Co-Evolution (\texttt{LifeSkill}), a two-stage reinforcement learning framework for Online Lifelong Learning Agents. Specifically, we design Verifier-Guided Skill Learning that addresses the lack of direct supervision for skill extraction by rewarding candidate skills according to the average verifier success of multiple skill-conditioned policy rollouts, encouraging the model to generate skills that are useful for solving tasks rather than merely plausible in text. Furthermore, we introduce Online Skill Internalization, which continuously improves the policy model during test-time interaction by transforming skill-conditioned trajectories into reward signals. This enables the agent to directly internalize reasoning capabilities into its parameters, avoiding the context bloat of experience retrieval. Experiments on LifelongAgentBench show that LifeSkill improves average performance by 7 absolute points by comparing with existing lifelong agent baselines.
OA-CutMix:CutMixのラベルバイアスを補正する
CutMix はデファクトスタンダードのミキシングオーグメンテーションとなっていますが、そのラベル割り当ては誤った仮定に基づいています。つまり、貼り付けられたパッチの領域は、ミキシングイメージに対するセマンティックな寄与を忠実に反映しています。ただし、実際には、パッチは背景領域に配置されることが多く、オブジェクトが表示されないクラスにラベルのクレジットが割り当てられます。 CutMix ラベルとセマンティック オブジェクト領域の平均不一致は $21.5\%$ です。サンプルの $17\%$ では、画像は可視オブジェクト ピクセルに寄与しませんが、ゼロ以外のラベル重みを受け取ります。我々は、エリアベースの CutMix の重みを、事前に計算されたセグメンテーション マスクから導出された重みで置き換え、各画像がミックスに寄与する可視オブジェクトの領域に比例してラベルを割り当てることで、このバイアスを修正する Object-Aware CutMix (OA-CutMix) を提案します。画像混合手順はまったく変更されていません。 4 つのアーキテクチャと 6 つのデータセットにわたる 10 以上の静的および動的ミキシング手法に対して OA-CutMix を評価します。 OA-CutMix は、すべてのタスクにわたって一貫して最高の精度を達成し、動的ミキシング手法をも上回るパフォーマンスを発揮しますが、トレーニング時間のコストはほんの数分の 1 です。小さなオブジェクトの改善が最も大きく、CutMix によるラベルのバイアスが最も大きくなります。したがって、ラベルを修正するだけで、画像混合アルゴリズムを変更する方法のパフォーマンスと同等またはそれを超えるのに十分です。
原文 (English)
OA-CutMix: Correcting the Label Bias of CutMix
CutMix has become the de facto standard mixing augmentation, yet its label assignment rests on a flawed assumption: The area of the pasted patch faithfully reflects its semantic contribution to the mixed image. In practice, however, patches frequently land on background regions, assigning label credit to classes whose objects are not visible. The mean discrepancy of the CutMix label and the semantic object area is $21.5\%$. In $17\%$ of samples an image contributes zero visible object pixels yet receives nonzero label weight. We propose Object-Aware CutMix (OA-CutMix), which corrects this bias by replacing the area-based CutMix weight with one derived from precomputed segmentation masks, assigning labels in proportion to the visible object area each image contributes to the mix. The image mixing procedure is left entirely unchanged. We evaluate OA-CutMix against 10+ static and dynamic mixing methods across 4 architectures and 6 datasets. OA-CutMix consistently achieves the highest accuracy over all tasks, outperforming even dynamic mixing methods, but at a fraction of the training-time cost. Improvements are largest for small objects, where the label bias from CutMix is greatest. Thus, correcting the label is sufficient to match or exceed the performance of methods modifying the image mixing algorithm.
署名付きデュアル アテンション: 時系列予測での署名付き依存関係のキャプチャ
当初は自然言語処理用に開発された Transformer アーキテクチャとアテンション メカニズムは、現在では時系列予測のアプリケーションを含む幅広い深層学習モデルの中心となっています。ただし、標準的な注意メカニズムは同性愛的相互作用を暗黙的に想定しているため、時系列などの正と負の依存関係を持つデータをモデル化する機能が制限されます。この研究では、パラメータを追加せずに正と負の両方の関係パターンを捕捉する新しい注意定式化である、署名付きデュアル アテンションを導入します。相関構造にヒントを得たデュアル メッセージ パッシング スキームを活用することで、Signed Dual Attend は単一の共有ブロック内で支持情報と対照情報の両方を伝播し、追加のパラメーターなしで 2 頭のアテンションの表現力を効果的に実現します。このモジュールは既存のアーキテクチャにシームレスに統合でき、署名付きリレーショナル モデリングを必要とする特定の状況でパフォーマンスを向上させることができます。このアプローチにより、より表現力豊かでパラメーター効率の高いトランスフォーマーへの道が開かれます。
原文 (English)
Signed Dual Attention: Capturing Signed Dependencies in Time Series Forecasting
Initially developed for natural language processing, Transformer architectures and attention mechanisms are now central to a wide range of deep learning models, including applications in time series forecasting. A standard attention mechanism, however, implicitly assumes homophilic interactions, limiting its ability to model data with positive and negative dependencies, such as time series. In this work, we introduce the Signed Dual Attention, a novel attention formulation that captures both positive and negative relational patterns without additional parameters. By leveraging a dual message-passing scheme inspired by correlation structures, Signed Dual Attention propagates both supportive and contrastive information within a single shared block, effectively achieving the expressiveness of two head attention without additional parameters. This module can be seamlessly integrated into existing architectures and can yield performance gains in certain situations, requiring signed relational modeling. This approach opens a pathway toward more expressive and parameter-efficient transformers.
不確実性を考慮したニューラル ネットワーク プロセッサのエンドツーエンドの共同設計: トレーニングとマッピングから製造まで
ニューラル ネットワーク プロセッサの設計は、エンドツーエンドの共同設計の問題です。ネットワーク アーキテクチャとトレーニングの予算によって、推論のワークロードが決まります。ハードウェア マッピングの決定により、チップ面積、レイテンシ、エネルギーが決まります。そしてこれらの特性が製造歩留まりと製造コストを決定します。実際には、これらの決定は個別の段階で行われ、既存の共同設計方法論は特定のアルゴリズムと密接に結合しているため、パイプライン全体を作り直さずに 1 つのコンポーネントを改善するのは困難です。この論文では、モノトーン共同設計理論に基づいた、ネットワーク トレーニング、チップ マッピング、ウェーハ レベルの製造、およびコンピューティング リソース割り当てにわたる 4 つの相互運用可能な設計ブロックで構成される統一フレームワークを紹介します。各ブロックは、機能とリソースのインターフェイスのみをシステムの残りの部分に公開するため、他の部分の構造を変更することなく、どのブロックも改良できます。中心的な貢献は不確実性の処理です。このフレームワークでは、確率的な結果を点推定値にまとめるのではなく、コスト、時間、電力と並んで明示的で最適化可能なリソースとして、成功確率の逆数である信頼度を導入しています。 3 つのケーススタディでアプローチを検証します。 1 つ目は、異種アプリケーション シナリオ全体でパレート最適実装を回復します。 2 つ目は、Confidence が事後診断ではなく、継続的に調整可能な設計ノブとして機能することを確認します。 3 番目は、単一ブロックの実装セットを改善すると、共同設計図を変更することなく、自動的にグローバル パレート フロントに伝播することを示しています。
原文 (English)
Uncertainty-Aware End-to-End Co-Design of Neural Network Processors: From Training and Mapping to Fabrication
Designing a neural network processor is an end-to-end co-design problem: network architecture and training budget determine the inference workload; hardware mapping decisions determine chip area, latency, and energy; and these characteristics govern fabrication yield and manufacturing cost. In practice, these decisions are made in separate stages, and existing co-design methodologies are tightly coupled to specific algorithms, making it difficult to improve one component without reworking the entire pipeline. This paper presents a unified framework, grounded in monotone co-design theory, that composes four interoperable design blocks spanning network training, chip mapping, wafer-level fabrication, and compute resource allocation. Each block exposes only a functionality-resource interface to the rest of the system, so any block can be refined without structural changes elsewhere. A central contribution is the treatment of uncertainty: rather than collapsing stochastic outcomes into point estimates, the framework introduces Confidence, the inverse of success probability, as an explicit and optimizable resource alongside cost, time, and power. Three case studies validate the approach. The first recovers Pareto-optimal implementations across heterogeneous application scenarios. The second confirms that Confidence functions as a continuously tunable design knob rather than a post-hoc diagnostic. The third demonstrates that improving a single block's implementation set automatically propagates to the global Pareto front, without modifying the co-design diagram.
組み合わせ検索のための経験的に許容可能なニューラルヒューリスティックの学習
ルービック キューブ、スライディング タイル パズル、ライト アウトなどの組み合わせパズルの最適な解法パスを見つけることは、依然として人工知能における古典的な課題です。 A* などのヒューリスティック検索アルゴリズムは、実際の残りのコストを決して過大評価しない許容可能なヒューリスティックを使用する場合にのみ、パスの最適性を保証します。 DeepCubeA のような深層強化学習 (RL) 手法は、ディープ ニューラル ネットワークをトレーニングして、コストを推定するヒューリスティックを近似します。ただし、標準の平均二乗誤差 (MSE) トレーニングでは定期的に過大評価が生じ、許容性に違反し、ソリューションの最適性が損なわれます。この論文では、検証調整された許容可能なニューラル ヒューリスティックを学習するための一般化可能なフレームワークを紹介します。過小評価にペナルティを与える非対称損失関数と組み合わせた過小評価の許容ベルマン演算子を使用して、値ネットワークをトレーニングします。残留神経機能近似誤差を考慮するために、検証スクランブルに対して計算される事後校正安全オフセットを提案します。私たちは、標準的な分析ベースラインと比較して、調整されたニューラル ヒューリスティックが、評価プロトコルの下で観察された許容性違反を達成せず、実際にパスの最適性を維持しながら、検索ノードの拡張を 2 × 2 のルービック キューブで最大 83.0%、3 × 3 の消灯グリッドで 19.9%、8 パズルで 1.9% 削減することを実証します。
原文 (English)
Learning Empirically Admissible Neural Heuristics for Combinatorial Search
Finding optimal solution paths for combinatorial puzzles like the Rubik's Cube, sliding tile puzzles, and Lights Out remains a classical challenge in artificial intelligence. Heuristic search algorithms, such as A* , guarantee path optimality only when using an admissible heuristic-one that never overestimates the true remaining cost-to-go. Deep reinforcement learning (RL) methods like DeepCubeA train deep neural networks to approximate cost-to-go heuristics. However, standard mean-squared error (MSE) training regularly yields overestimations, violating admissibility and compromising solution optimality. In this paper, we introduce a generalizable framework for learning validation-calibrated admissible neural heuristics. We train a value network using an underestimating Admissible Bellman Operator combined with an Asymmetric Loss function to penalize overestimation. To account for residual neural function approximation errors, we propose a post-hoc calibration safety offset computed over validation scrambles. We demonstrate that our calibrated neural heuristics achieve no observed admissibility violations under the evaluation protocol and preserve path optimality in practice while reducing search node expansions by up to 83.0% on a 2 by 2 Rubik's Cube, 19.9% on a 3 by 3 Lights Out grid, and 1.9% on an 8-Puzzle compared to standard analytical baselines.
イザベル/HOLの誘拐証明者
表現ロジックに基づく証明アシスタントでは、証明検索の自動化が制限されており、証明アシスタントに基づく形式的検証のコストが上昇します。私たちは、Isabelle/HOL 用の Abduction Prover を導入することで、この問題に対処します。困難な証明目標が与えられた場合、Abduction Prover は、アブダクティブ推論を使用して有用な推測を特定することにより、目標の証明スクリプトを構築します。
原文 (English)
Abduction Prover in Isabelle/HOL
Proof assistants based on expressive logics suffer limited automation for proof search, raising the cost of formal verification based on proof assistants. We address this problem by introducing the Abduction Prover for Isabelle/HOL. Given a challenging proof goal, the Abduction Prover constructs a proof script for the goal by identifying useful conjectures using abductive reasoning.
DiverAge: 年齢を超えたアイデンティティ関係ガイダンスによる信頼性の高い多元的な顔の老化
顔の老化は、長期にわたる生体認証分析、年齢を超えた本人確認、法医学的身元分析において重要な役割を果たします。同じ対象者が、遺伝的要因、環境要因、ライフスタイル要因により、対象年齢で複数のもっともらしい外見を示す可能性があるため、顔の老化は本質的に 1 対多の世代の問題です。ただし、信頼できる顔の老化には多元性だけでは不十分です。モデルは、順序付けされた年齢グループ全体で順序レベルの信頼性を維持しながら、各年齢グループ内の外観レベルの候補者の多様性を提供する必要があります。既存の決定論的老化手法は、視覚的にもっともらしい年齢が進行した顔を合成できますが、通常は確率的多様性に欠けています。対照的に、多元的老化法は、局所的な外観の変動を導入しますが、多くの場合、完全な老化シーケンスの同一性の進化を明示的に制御できません。この論文では、拡散自動エンコーディングに基づいた階層的多元的顔老化フレームワーク \textbf{DiverAge} を提案します。 DiverAge は、確率的拡散デコードと年齢条件付きセマンティック変調を通じて、外観レベルの多様性を保存します。シーケンスレベルの信頼性を向上させるために、複数の対象年齢グループを共同でノイズ除去する推論時間ガイダンス戦略である、Cross-age Identity Relation Regulator (CARR) を導入します。 CARR は、実際の同一アイデンティティの異年齢ペアから事前に推定された異年齢アイデンティティ類似性 (CIS) によってガイドされ、トレーニング目標を変更したり、追加のトレーニング可能なパラメータを導入したりすることなく、一方的なサンプリング時間ガイダンスを通じて過剰な異年齢アイデンティティ ドリフトを抑制します。実験では、DiverAge が同一性の保持、年齢の精度、画質、外観レベルの多様性を維持しながら、配列レベルの順序の信頼性を向上させることが実証されています。
原文 (English)
DiverAge: Reliable Pluralistic Face Aging with Cross-Age Identity Relation Guidance
Face aging plays an important role in long-term biometric analysis, cross-age identity verification, and forensic identity analysis. Since the same subject may exhibit multiple plausible appearances at a target age due to genetic, environmental, and lifestyle factors, face aging is inherently a one-to-many generation problem. However, pluralism alone is insufficient for reliable face aging: a model should provide appearance-level candidate diversity within each age group while maintaining sequence-level ordinal reliability across ordered age groups. Existing deterministic aging methods can synthesize visually plausible age-progressed faces, but usually lack stochastic diversity. In contrast, pluralistic aging methods introduce local appearance variations, but often fail to explicitly regulate the identity evolution of the full aging sequence. In this paper, we propose \textbf{DiverAge}, a hierarchical pluralistic face aging framework based on diffusion autoencoding. DiverAge preserves appearance-level diversity through stochastic diffusion decoding and age-conditioned semantic modulation. To improve sequence-level reliability, we introduce a Cross-age Identity Relation Regulator (CARR), an inference-time guidance strategy that jointly denoises multiple target age groups. CARR is guided by a Cross-age Identity Similarity (CIS) prior estimated from real same-identity cross-age pairs, and suppresses excessive cross-age identity drift through one-sided sampling-time guidance without modifying the training objective or introducing extra trainable parameters. Experiments demonstrate that DiverAge improves sequence-level ordinal reliability while maintaining identity preservation, age accuracy, image quality, and appearance-level diversity.
人間が作成したオントロジーからの証明可能で監査可能で安全な LLM エージェント
線形監査可能性を必要とする重要な問題ドメインでの使用を目的とした、LLM エージェント アーキテクチャ Agentic Redux を紹介します。型付きラムダ計算を使用して、適切なドメインで実行すると、Agentic Redux の実行が意味的に正しいことが保証され、すべての決定が追加専用台帳に記録されることを証明します。医療請求のコンプライアンスとセキュリティ脆弱性の開示という、実稼働グレードの 2 つの適切な領域を紹介します。両方のドメインで実行される Agentic Redux の実用的なコードは、サポートされるコード リポジトリで入手できます。また、問題ドメイン上でエージェント フレームワークを作成するための方法論であるオントロジー ファースト エージェント設計も紹介します。この設計では、人間の専門家が基本形式オントロジーを使用して問題ドメインをオントロジー化し、LLM を割り当てて、ドメイン内の問題に対処するためにエージェントと参加者が果たせる役割を導き出します。
原文 (English)
Provably Auditable and Safe LLM Agents from Human-Authored Ontologies
We introduce the LLM agent architecture Agentic Redux, intended for use with nontrivial problem domains that require linear auditability. Using the typed lambda calculus, we prove that, run on appropriate domains, Agentic Redux executions are semantically guaranteed to be correct, with all decisions recorded in an append-only ledger. We present two production-grade appropriate domains, in healthcare billing compliance, and security vulnerability disclosure. Working code for Agentic Redux run on both domains is available in a supporting code repository. We also introduce Ontology-First Agent Design, a methodology for creation of agent frameworks on a problem domain, in which a human expert ontologizes the problem domain with Basic Formal Ontology, and then assigns an LLM to derive roles that agents and humans-in-the-loop can fill, in order to work the problems in the domain.
「あなたの AI テキストは私のものではありません」: 現実的な仮定に基づいた AI 生成のテキスト検出の再定義と評価
AI 生成テキストが広範な社会的リスクを引き起こすことは一般的に認められていますが、AI 生成テキスト検出に関する文献では、何が有害な使用に該当するかについて共通の理解がありません。むしろ、既存のデータセットやアプローチは、多くの場合、独自の基準を定義し、独自の仮定を立てており、場合によっては暗黙的に、現実世界のニーズやアプリケーションと大まかにしか関連していません。このギャップに対処するために、ここでは AI によって生成されたテキストとその特徴に関するさまざまな概念を体系的に定義します。これらを研究するために、私たちは AITDNA を収集します。AITDNA は、人間と機械が共同構築したテキストの新しいベンチマークであり、編集全体や AI との対話履歴など、詳細な生成情報が注釈付けされています。私たちはさまざまな機械生成のテキスト検出器をベンチマークしましたが、多くの場合、それらは特定の概念に対してのみ良好に機能し、広範な検出器としては機能しないことがわかりました。私たちはコードとデータを公開します。
原文 (English)
'Your AI Text is not Mine': Redefining and Evaluating AI-generated Text Detection under Realistic Assumptions
Although it is generally agreed that AI-generated text poses a broad societal risk, there is no common understanding in the AI-generated text detection literature on what constitutes harmful use. Rather, existing datasets and approaches often define their own criteria and make their own assumptions, sometimes implicitly, and often only loosely related to real-world needs and applications. To address this gap, we here systematically define various notions of AI-generated text and their characteristics. To study these, we collect AITDNA - a new benchmark of human-machine co-constructed texts that is annotated with detailed genesis information, such as the entire edit and AI-interaction history. We benchmark various machine-generated text detectors and find that they often only perform well for specific notions but not as broad detectors. We release code and data publicly.
生物医学的視覚言語モデルを迅速に調整するための幾何学を意識した蒸留
現在のプロンプトベースおよびアダプターベースのビジョン言語モデル (VLM) の調整は、臨床データの感度が凍結されたバックボーンを優先し、アノテーションが制限されている医療画像処理にとって魅力的です。ただし、これらの方法は通常、グラウンドトゥルース クラスのみを最適化し、他のすべてのクラスを同様に不正確なものとして扱い、臨床的に意味のあるクラス関係を無視し、限定された監視設定では不安定な決定境界を生成します。私たちは、クラス間ジオメトリを尊重しながらグランド トゥルースを保持する指向性ターゲットを生成するために、クラス関係構造を教師に注入する新しいフレームワークである Omni-Geometry Knowledge Distillation (OGKD) を提案します。これらのターゲットを使用して、2 つの蒸留損失を開発します。グローバル ジオメトリ認識蒸留 (GAD) はグローバル イメージ トークン上で動作し、ラベルガイド付きジオメトリ蒸留 (LGD) は同じジオメトリを注意深いパッチ トークンに適用して、きめの細かい位置合わせを改善します。基礎から新規および少数ショットの評価のために広く使用されている 11 の医療データセットでの包括的な実験と分析を通じて、当社の OGKD は大幅に優れたパフォーマンスを達成し、これまでのすべての最先端の VLM 適応対応製品と比較して、平均絶対ゲイン 1.7% ~ 2.8% により精度を一貫して向上させています。また、目に見えないクラスに対しても堅牢に一般化し、他のアプローチよりも信頼性の高い予測を生成します。私たちのコードは https://github.com/tientrandinh/OGKD で入手できます。
原文 (English)
Geometry-Aware Distillation for Prompt Tuning Biomedical Vision-Language Models
Current prompt-based and adapter-based tuning of vision-language models (VLMs) is attractive for medical imaging, where clinical data sensitivity favors frozen backbones and annotations are limited. However, these methods typically optimize only the ground-truth class, treating all other classes as equally incorrect, ignoring clinically meaningful class relations and yielding unstable decision boundaries in limited-supervision settings. We propose Omni-Geometry Knowledge Distillation (OGKD), a new framework that injects class-relation structure into the teacher to produce directional targets that preserve the ground truth while respecting inter-class geometry. Using these targets, we develop two distillation losses: Global Geometry-Aware Distillation (GAD) operates on the global image token, and Label-Guided Geometry Distillation (LGD) applies the same geometry to attentive patch tokens to improve fine-grained alignment. Across comprehensive experiments and analyses on 11 widely-used medical datasets for base-to-novel and few-shot evaluations, our OGKD achieves substantially better performance, consistently improving accuracy by an average absolute gain of 1.7%-2.8% over all prior state-of-the-art VLM adaptation counterparts. It also robustly generalizes to unseen classes and yields more reliable predictions than other approaches. Our code is available at https://github.com/tientrandinh/OGKD.
ルーブリックベースの強化学習における報酬ハッキングの再現、分析、検出
ルーブリックベースの強化学習 (RL) は、LLM-as-a-Judge (LaaJ) を使用して、報酬としてルーブリックに従ってモデルの出力を採点します。ただし、政策モデルは裁判官の潜在的なバイアスを悪用し、報酬のハッキングや非効果的または危険なトレーニング結果につながる可能性があります。現実のルーブリックベースの RL では、このようなハッキング行為は多くの場合微妙であり、複数の裁判官のバイアスと絡み合っているため、分析、検出、軽減することが困難です。このペーパーでは、ルーブリックベースの RL のための制御可能なハッキング環境である CHERRL を紹介します。既知のバイアスを LaaJ に注入することで、CHERRL は報酬ハッキングの安定した再現、報酬の発散の明確な観察、およびハッキングの開始の正確な特定を可能にします。これは、ルーブリック ベースの RL における報酬ハッキングのメカニズムと緩和を研究するためのクリーンな実験テストベッドを提供します。その有用性を実証するために、発見可能性と悪用可能性の観点からさまざまな裁判官のバイアスを分析し、トレーニングログから報酬ハッキングの開始を自動的に検出するためのエージェントベースのシステムを調査します。コードと環境は https://github.com/THUAIS-Lab/CHERRL で公開されています。
原文 (English)
Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
Rubric-based reinforcement learning (RL) uses an LLM-as-a-Judge (LaaJ) to score model outputs according to rubrics as rewards. However, policy models may exploit latent biases in the judge, leading to reward hacking and ineffective or unsafe training outcomes. In real-world rubric-based RL, such hacking behaviors are often subtle and entangled with multiple judge biases, making them difficult to analyze, detect, and mitigate. In this paper, we introduce CHERRL, a controllable hacking environment for rubric-based RL. By injecting known biases into LaaJ, CHERRL enables stable reproduction of reward hacking, explicit observation of reward divergence, and precise identification of hacking onset. This provides a clean experimental testbed for studying the mechanisms and mitigations of reward hacking in rubric-based RL. To demonstrate its utility, we analyze different judge biases from the perspectives of discoverability and exploitability, and explore an agent-based system for automatically detecting reward hacking onset from training logs. The code and environment are publicly available at https://github.com/THUAIS-Lab/CHERRL.
AdaKoop: Koopman 演算子回帰を使用した非定常データ ストリームからの非線形ダイナミクスの効率的なモデリング
リアルタイム データ分析では、計算効率を維持しながら、非定常データ ストリーム内の非線形ダイナミクスに正確かつ適応的に対処する能力が必要です。ただし、非線形ダイナミクスは非常に複雑であるため、動的に変化する非線形パターンを捕捉し、厳しい時間制約の下でそれを下流のタスクに利用することは簡単ではありません。非線形の複雑さと計算の扱いやすさとの間のギャップを埋めるために、この研究では、非線形ダイナミクスが無限次元空間内の線形遷移として表現できるとするクープマン演算子理論を適用します。この演算子の有限次元近似に基づいて、非定常データ ストリーム上の非線形ダイナミクスをモデル化するための効率的なストリーミング アルゴリズムである AdaKoop を紹介します。私たちのアプローチは、クープマン演算子理論に基づいた確率的フレームワークを利用し、生の観測値とカーネル ヒルベルト空間 (RKHS) 特徴の再現の両方を潜在ベクトルからの放射として扱います。このデュアルビュー定式化により、非線形ダイナミクスを扱いやすい線形システムとして表現できます。したがって、AdaKoop を使用すると、ストリーミング形式で非線形ダイナミクスの効率的かつ安定したモデリングが可能になり、反復的な非線形最適化による法外な計算コストが回避されます。さらに、データ ストリームの非定常性に対処するために、AdaKoop は、突然のパターン シフトに対する統計的仮説テストを通じてパターンの切り替えを適応的に検出し、連続的な変化に対応するためにモデル パラメーターを段階的に更新します。さまざまなドメインにわたる合計 71 の実用的なベンチマーク データセットに対する広範な実験により、AdaKoop がリアルタイム予測精度と計算効率の点で最先端の手法を上回ることが実証されました。
原文 (English)
AdaKoop: Efficient Modeling of Nonlinear Dynamics from Nonstationary Data Streams with Koopman Operator Regression
Real-time data analysis requires the ability to accurately and adaptively address nonlinear dynamics in a nonstationary data stream while preserving computational efficiency. However, nonlinear dynamics are so complex that capturing dynamically changing nonlinear patterns and utilizing them for downstream tasks under strict time constraints is nontrivial. To bridge the gap between nonlinear complexity and computational tractability, this study applies Koopman operator theory, which states that nonlinear dynamics can be represented as linear transitions in an infinite-dimensional space. Building upon finite-dimensional approximations of this operator, we present AdaKoop, an efficient streaming algorithm for modeling nonlinear dynamics over nonstationary data streams. Our approach utilizes a probabilistic framework grounded in Koopman operator theory, treating both raw observations and reproducing kernel Hilbert space (RKHS) features as emissions from latent vectors. This dual-view formulation allows nonlinear dynamics to be expressed as a tractable linear system. Therefore, AdaKoop enables the efficient and stable modeling of nonlinear dynamics in a streaming fashion, avoiding the prohibitive computational costs of iterative nonlinear optimization. Furthermore, to address nonstationarity in data streams, AdaKoop adaptively detects the switching of patterns via statistical hypothesis testing for abrupt pattern shifts and incrementally updates model parameters to handle continuous changes. Extensive experiments on a total of 71 practical benchmark datasets across various domains demonstrate that AdaKoop outperforms state-of-the-art methods in terms of real-time forecasting accuracy and computational efficiency.
プロンプトからプロセスまで: AI ソフトウェア開発エージェントをサポートするフレームワークのプロセス分類と比較評価
プログラミング用の AI ツールは、もはや単なるオートコンプリートやチャット アシスタントではありません。プロセス、役割、成果物、検証を備えた開発フレームワークとして組織化されています。最近の調査では、ソフトウェア エンジニアリングのためのエージェントと LLM がマッピングされていますが、これらの機能をプロセスに変える運用フレームワークを中心とした調査は行われていません。私たちは、機能的包含基準とトラクション測定を使用して一次ソースの直接検索を実行し、GitHub Spec Kit、OpenSpec、BMAD Method、Get Shit Done (GSD)、Spec Kitty、Reversa の 6 つのフレームワークを選択しました。それぞれが異なるパスを通じて AI 開発を攻撃します。つまり、完全および軽量バリアントでの仕様駆動型開発、エージェント駆動のアジャイル プランニング、エージェントを介したコンテキスト エンジニアリング、ワークツリーの分離とレビュー、レガシー システムからの運用仕様の回復です。私たちの中心的な貢献は、仕様、コンテキスト、役割、実行、検証、移植性という 6 次元のプロセス分類と、プロセスを複製可能なツールに変えるスコアリング ルーブリックです。これを 6 つのフレームワークとサンプル外のケースである Spec-Flow に適用します。 2 つの結果が際立っています。すでに何らかのプロセスを採用しているフレームワークの中には収束が見られます。分離されたプロンプトは中心性を失い、永続的な成果物、作業契約、トレーサビリティ、人間によるレビューが曖昧さを減らし、エージェントを調整するメカニズムになります。また、6 つの側面すべてを強力にカバーするフレームワークはなく、プロセスの深さとエージェント間の移植性の間の構造的なトレードオフが明らかになります。また、繰り返し発生するリスク、つまり仕様とコードの間のずれ、生成されたアーティファクトへの過剰な信頼、コミュニティ拡張の脆弱性、プラットフォームへの依存、プロセス全体のベンチマークの欠如なども見つかりました。最後に、中間品質の指標、コンテキスト ガバナンス、インストールのセキュリティと再現性に焦点を当てた、実証的評価のための研究課題を取り上げます。
原文 (English)
From Prompt to Process: a Process Taxonomy and Comparative Assessment of Frameworks Supporting AI Software Development Agents
AI tools for programming are no longer just autocomplete or chat assistants: they organize themselves as development frameworks, with process, roles, artifacts and verification. Recent surveys map agents and LLMs for software engineering, but a study centered on the operational frameworks that turn these capabilities into process is missing. We ran a directed search of primary sources, with a functional inclusion criterion and traction measurement, and selected six frameworks: GitHub Spec Kit, OpenSpec, BMAD Method, Get Shit Done (GSD), Spec Kitty and Reversa. Each attacks AI development through a different path: spec-driven development in full and lightweight variants, agent-driven agile planning, context engineering over the agent, worktree isolation and review, and recovery of operational specifications from legacy systems. Our central contribution is a six-dimension process taxonomy: specification, context, roles, execution, validation and portability, with a scoring rubric that turns it into a replicable instrument. We apply it to the six frameworks and an out-of-sample case, Spec-Flow. Two results stand out. Among frameworks that already adopt some process there is convergence: the isolated prompt loses centrality, and persistent artifacts, work contracts, traceability and human review become mechanisms that reduce ambiguity and coordinate agents. And no framework strongly covers all six dimensions, exposing a structural trade-off between process depth and portability across agents. We also found recurring risks: drift between specification and code, excessive trust in generated artifacts, fragility of community extensions, platform dependence and a lack of benchmarks for the complete process. We close with a research agenda for empirical evaluation, focused on intermediate-quality metrics, context governance, installation security and reproducibility.
計画、監視、回復: プロアクティブな手続き支援のためのベンチマークとアーキテクチャ
私たちは、プロアクティブなマルチモーダル アシスタント システムを構想しています。これは、手順的なタスクに関するリアルタイムの段階的なガイダンスをユーザーに提供し、\textit{いつ}中断するか、\textit{どのように指導するかを自律的に決定します。ただし、現実的な状況、特にユーザーが予想されるステップ シーケンスから逸脱する一般的なケースを反映する大規模なクロスドメイン ベンチマークがないため、進歩は限られています。私たちはこのギャップに 4 つの貢献で対処します。 \textbf{(1)}~明示的な計画外 (OOP) アノテーションと回復手順を備えたプロアクティブな手順支援のための大規模ウェアラブル自己中心的データセットである \textbf{EgoProactive} をリリースします。 \textbf{(2)}~統一されたプロアクティブなガイダンス スキーマの下で、確立された 5 つのベンチマーク (Ego4D、EPIC-KITCHEN、EgoExo4D、HoloAssist、HowTo100M) を \textbf{Pro\textsuperscript{2}Bench} に拡張します。 \textbf{(3)}~手続き状態、視覚的キュー、および回復注入に特化した \textbf{分離プランナー -- インタラクション アーキテクチャ} を提案します。 \textbf{(4)}~Llama~4 および Qwen-3.6-VL でのクロスバックボーン レプリケーションによって検証された、モデル ファミリ間で転送するトレーニング後のレシピを紹介します。大規模な実験において、当社の訓練された Llama-4 システムは、6 つのデータセットすべてにわたって、強力な独自のベースライン (Claude Opus~4.6、Gemini~3.1~Pro、GPT~5.2) およびオープンウェイト ベースライン (Qwen3~VL~235B) ベースラインを超えて、客観的な介入の質を大幅に向上させました。さらに、Oracle 計画の実験では、計画の品質が制御されている場合、トレーニングされた二重モデルが高品質のガイダンスを生成し、計画外の回復で大きな利益が得られることが示されています。
原文 (English)
Plan, Watch, Recover: A Benchmark and Architectures for Proactive Procedural Assistance
We envision a proactive multi-modal assistant system which gives users real-time step-by-step guidance on a procedural task, autonomously deciding \textit{when} to interrupt, and \textit{how} to coach. However, progress is limited by the absence of large-scale, cross-domain benchmarks that reflect realistic conditions, particularly the common case in which users deviate from the expected step sequence. We address this gap with four contributions: \textbf{(1)}~we release \textbf{EgoProactive}, a large-scale wearable-egocentric dataset for proactive procedural assistance with explicit Out-of-Plan (OOP) annotations and recovery steps; \textbf{(2)}~we augment five established benchmarks (Ego4D, EPIC-KITCHENS, EgoExo4D, HoloAssist, HowTo100M) into \textbf{Pro\textsuperscript{2}Bench} under a unified proactive-guidance schema; \textbf{(3)}~we propose a \textbf{decoupled planner--interaction architecture} specialized for procedural state, visual cues, and recovery injection; \textbf{(4)}~we introduce a post-training recipe that transfers across model families, validated by cross-backbone replication on Llama~4 and Qwen-3.6-VL. In extensive experiments, our trained Llama-4 system substantially improves objective intervention quality over strong proprietary baselines (Claude Opus~4.6, Gemini~3.1~Pro, GPT~5.2) and open-weight baselines (Qwen3~VL~235B) baselines across all six datasets. Oracle-plan experiments further show that, when plan quality is controlled, the trained duplex model produces high-quality guidance and large gains on Out-of-Plan recovery.
DeliChess: チェスのパズル解決における熟議のための多者対話データセット
多者間の対話は、協調的な推論と意思決定を研究するための重要な設定ですが、既存のデータセットは、構造化された詳細な複雑な推論タスクに焦点を当てていることはほとんどありません。 DeliChess は、参加者が協力して多肢選択のチェス パズルを解くグループ審議対話の新しいデータセットです。各グループは最初に個別にパズルを完成させ、次に修正された集合回答を提出する前に、複数の当事者によるディスカッションに参加します。データセットには、完全なトランスクリプト、ディスカッション前後の選択肢、パズルの難易度と動きの品質に関するメタデータを含む 107 の対話が含まれています。私たちはチェス エンジンの評価に基づいた 3 つの指標を使用してパフォーマンスを評価し、熟慮することでグループの精度が大幅に向上することがわかりました。さらに、事前の審議データに基づいて訓練された分類器を使用して、精査的な発話(つまり、提案、正当化、または戦略的考察を引き出すメッセージ)の役割を分析します。プロービングにより、ディスカッション後のグループのパフォーマンスはより変動しますが、一貫してパフォーマンスの向上につながるわけではありません。私たちのデータセットは、グループの推論、対話のダイナミクス、および明確に定義された戦略的領域における異なる視点や意見の解決をモデル化するための豊富なテストベッドを提供します。
原文 (English)
DeliChess: A Multi-party Dialogue Dataset for Deliberation in Chess Puzzle Solving
Multi-party dialogue is a critical setting for studying collaborative reasoning and decision-making, yet existing datasets rarely focus on structured, in-depth complex reasoning tasks. We introduce DeliChess, a novel dataset of group deliberation dialogues in which participants collaboratively solve multiple-choice chess puzzles. Each group first completes the puzzle individually, then engages in a multi-party discussion before submitting a revised collective answer. The dataset includes 107 dialogues with full transcripts, pre- and post-discussion choices, and metadata on puzzle difficulty and move quality. We evaluate performance using three metrics based on chess engine evaluations, and find that deliberation significantly improves group accuracy. We further analyse the role of probing utterances (i.e., messages that elicit proposals, justifications, or strategic reflection) using a classifier trained on prior deliberation data. While probing makes group performance more variable after discussion, it does not consistently lead to better performance. Our dataset offers a rich testbed for modelling group reasoning, dialogue dynamics, and the resolution of differing perspectives and opinions in a well-defined strategic domain.
エージェント追跡から信頼へ: LLM エージェントにおける証拠追跡と実行来歴
大規模言語モデル (LLM) ベースのエージェントは、外部ツール、検索システム、メモリ モジュール、環境、その他のエージェントと対話することで、複雑なタスクを解決することが増えています。これらの機能により、エージェントの自律性が拡張されますが、エージェントの動作の検証、デバッグ、監査が難しくなります。最終回答の精度だけでは、出力がどのように生成されたか、各主張を裏付ける証拠は何か、ツールの呼び出しが正当化されたかどうか、記憶が後の決定にどのように影響したか、実行の失敗がどこで発生したかを説明することはできません。証拠追跡と実行来歴は、取得された証拠、ツール出力、メモリ項目、環境観察、中間クレーム、アクション、および最終的な回答がエージェントの実行全体を通じてどのように関連するかをモデル化することで、このギャップに対処します。この調査は、LLM エージェントにおける証拠の追跡と実行の出自に関する体系的なレビューと概念的な枠組みを提供します。私たちは、検索根拠、クレームサポート、ツール使用の安全性、メモリリネージ、可観測性、デバッグ、監査、リカバリを結び付ける、統一された来歴の観点に基づいて関連作業を整理します。トレースソース、証拠と実行単位、来歴関係、トレースの粒度とタイミング、表現形式、信頼関数を網羅する分類法を導入します。私たちは、出所の表現、証拠の帰属、ツール使用の出所、実行時のガードレール、出所を伴うメモリ、トレースベースの可観測性、障害診断など、主要な方法論の方向性を検討します。また、既存のベンチマーク、データセット、評価指標を来歴関連の機能にマッピングし、評価が最終的な回答の正しさからプロセスレベルの説明責任にどのように移行できるかについても説明します。最後に、統合トレース スキーマ、クレーム レベルおよびセマンティックの出所、出所を意識した安全メカニズム、現実的な実行トレース ベンチマーク、リカバリ指向の評価、プライバシーを意識した監査インフラストラクチャなどの未解決の課題について概説します。
原文 (English)
From Agent Traces to Trust: Evidence Tracing and Execution Provenance in LLM Agents
Large language model (LLM)-based agents increasingly solve complex tasks by interacting with external tools, retrieval systems, memory modules, environments, and other agents. These capabilities expand agent autonomy, but also make agent behavior harder to verify, debug, and audit. Final-answer accuracy alone cannot explain how an output was produced, which evidence supported each claim, whether tool calls were justified, how memory influenced later decisions, or where execution failures originated. Evidence tracing and execution provenance address this gap by modeling how retrieved evidence, tool outputs, memory items, environment observations, intermediate claims, actions, and final answers are connected throughout agent execution. This survey provides a systematic review and conceptual framework for evidence tracing and execution provenance in LLM agents. We organize related work around a unified provenance perspective that connects retrieval grounding, claim support, tool-use safety, memory lineage, observability, debugging, audit, and recovery. We introduce a taxonomy covering trace sources, evidence and execution units, provenance relations, tracing granularity and timing, representation forms, and trust functions. We review key methodological directions, including provenance representation, evidence attribution, tool-use provenance, runtime guardrails, provenance-bearing memory, trace-based observability, and failure diagnosis. We also map existing benchmarks, datasets, and evaluation metrics to provenance-related capabilities, and discuss how evaluation can move from final-answer correctness toward process-level accountability. Finally, we outline open challenges, including unified trace schemas, claim-level and semantic provenance, provenance-aware safety mechanisms, realistic execution-trace benchmarks, recovery-oriented evaluation, and privacy-aware audit infrastructure.
SharedRequest: 大規模言語モデルのプライバシー保護モデルに依存しない推論
ChatGPT などのパブリック大規模言語モデル (LLM) の広範な展開に伴い、ユーザー プロンプトのプライバシーを保護することがますます重要な問題になっています。既存のプライバシー保護推論方法は、実用性または効率性を犠牲にしており、多くの場合、互換性を制限するモデル固有の変更が必要です。この論文では、個別のプロンプト レベルではなくバッチ レベルでプライバシー保護を再定式化する、プライバシー保護 LLM 推論のためのモデルに依存しないフレームワークである SharedRequest を提案します。重要なアイデアは、元のプロンプトとノイズの多いバリアントを混合することで機密情報を曖昧にし、同時に意味的に同等の命令をグループ化して、LLM 応答品質への影響を最小限に抑えながらクエリの大規模なバッチにわたる推論コストを償却することです。この設計は LLM アーキテクチャから独立しているため、モデル パラメーターへのアクセスやアーキテクチャの変更は必要ありません。経験的な結果は、SharedRequest が以前の差分プライバシー ベースラインと比較して $20\%$ 以上高い実用性を達成し、その共有プロンプト メカニズムにより、非バッチ推論と比較してクエリ コストを最大 $5\time$ 削減することを示しています。
原文 (English)
SharedRequest: Privacy-Preserving Model-Agnostic Inference for Large Language Models
With the widespread deployment of public large language models (LLMs) such as ChatGPT, protecting user prompt privacy has become an increasingly critical issue. Existing privacy-preserving inference methods sacrifice either utility or efficiency, and often require model-specific modifications that limit their compatibility. In this paper, we propose SharedRequest, a model-agnostic framework for privacy-preserving LLM inference that reformulates privacy protection at the batch level rather than the individual-prompt level. The key idea is to obscure sensitive information by mixing original prompts with noisy variants, while grouping semantically equivalent instructions to amortize the inference cost over a large batch of queries with minimal impact on LLM response quality. This design is independent of the LLM architecture, requiring no access to model parameters or architectural modification. Empirical results demonstrate that SharedRequest achieves over $20\%$ higher utility compared to prior differential privacy baselines, and its shared-prompt mechanism reduces query cost by up to $5\times$ compared to non-batched inference.
M$^3$Eval: 認知に基づいたビデオタスクによるマルチモーダル記憶評価
マルチモーダル モデルが長時間ビデオの理解に向けて進歩するにつれ、メモリが重要な能力として浮上します。ビデオ データセットとベンチマークの開発には多大な努力が払われているにもかかわらず、既存の研究は主に知覚と推論に焦点を当てており、どのモデルが保持するか、情報がどの程度忠実に保存されるか、干渉下でもメモリがどの程度堅牢に保たれるかなど、記憶を体系的に評価することはありません。このギャップに対処するために、マルチモーダル モデルでさまざまなメモリ次元を調査するための最初の包括的な評価フレームワークおよびベンチマークである M$^3$Eval を導入します。認知心理学に基づいた当社のデザインは、記憶の重要な側面を分離する慎重に構築されたタスクを特徴としています。 M$^3$Eval を活用して、代表的なマルチモーダル モデルにわたって広範な実験を実施し、一貫した弱点と独特の動作を明らかにしました。私たちは、並列ビデオストリームを処理する際にモデルがもつれの解けた表現を維持するのに苦労し、人間の記憶で観察されるものとは大幅に異なる干渉パターンを示し、記憶ソースを時間領域よりも空間領域でより確実に接地し、限られた記号記憶を実証していることを発見しました。まとめると、私たちのベンチマークは将来の研究のための貴重なリソースを提供しますが、私たちの調査結果は、メモリが基本的でありながらまだ研究されていない機能であることを強調し、マルチモーダルモデルでより効果的なメモリメカニズムを設計するための洞察を提供します。コードとデータセットは https://pku-value-lab.github.io/m3eval-homepage で入手できます。
原文 (English)
M$^3$Eval: Multi-Modal Memory Evaluation through Cognitively-Grounded Video Tasks
As multi-modal models advance towards long-form video understanding, memory emerges as a critical capability. Despite substantial efforts in developing video datasets and benchmarks, existing works primarily focus on perception and reasoning, without systematically evaluating memory: what models retain, how faithfully information is preserved, and how robust memory remains under interference. To address this gap, we introduce M$^3$Eval, the first comprehensive evaluation framework and benchmark for probing different memory dimensions in multi-modal models. Grounded in cognitive psychology, our design features carefully constructed tasks that isolate key aspects of memory. Leveraging M$^3$Eval, we conduct extensive experiments across representative multi-modal models, revealing consistent weaknesses and distinctive behaviors. We find that models struggle to maintain disentangled representations when processing parallel video streams, exhibit interference patterns differing substantially from those observed in human memory, ground memory sources more reliably in the spatial domain than the temporal domain, and demonstrate limited symbolic memory. Collectively, our benchmark provides a valuable resource for future research, while our findings highlight memory as a fundamental yet underexplored capability and offer insights for designing more effective memory mechanisms in multi-modal models. Our code and dataset are available at https://pku-value-lab.github.io/m3eval-homepage.
DAR: エージェントティックハーネスを使用したデオンティック推論
義務的推論とは、法律に基づく納税額の計算や移民控訴の結果の決定など、事例固有の事実に明示的なルールとポリシーを適用することで質問に答えるタスクです。 LLM ベースの義務論的推論の主な技術的課題は、関連するルールセットが長く相互参照される可能性があるため、モデルが特定の推論ステップに必要なルールを見つけられない可能性があることです。 Deontic Agentic Reasoning (DAR) を導入します。これは、モデルがオンデマンドで法令と対話するエージェント推論セットアップです。 DeonticBench のハード サブセット上の複数のハーネスで DAR を評価します。これらの設定全体で、エージェント ハーネスは義務論的推論タスクの最前線を押し広げることができることがわかりましたが、改善は均一ではありません。弱いモデルは、はるかに多くのトークンを消費しながら、数値タスクでパフォーマンスが低下することがよくあります。
原文 (English)
DAR: Deontic Reasoning with Agentic Harnesses
Deontic reasoning is the task of answering questions by applying explicit rules and policies to case-specific facts, for example computing tax liability under a statute or determining the outcome of an immigration appeal. A key technical challenge for LLM-based deontic reasoning is that the relevant ruleset can be long and cross-referenced, so models may still fail to locate the rules needed for a particular reasoning step. We introduce Deontic Agentic Reasoning (DAR), an agentic reasoning setup in which the model interacts with the statutes on demand. We evaluate DAR under multiple harnesses on hard subsets of DeonticBench. Across these settings, we find that agentic harnesses can push the frontier on deontic reasoning tasks, but improvements are not uniform: weaker models often degrade on numerical tasks while consuming far more tokens.
ロバスト推論蒸留のための不変勾配アライメント
大規模言語モデル (LLM) はショートカット学習に悩まされます。論理構造が同一であっても、意味論的表面がトレーニング データと異なる分布外 (OOD) 入力では体系的に失敗します。これは、思考連鎖の推論をより小さな生徒に伝える知識の蒸留パイプラインを弱体化させます。我々は、次の 3 つの革新によって、意味的に多様であるが論理的に同型のサンプル間で勾配更新を調整するトレーニング フレームワークである Invariant Gradient Alignment (IGA) を紹介します。(i) 論理異性体セット。異なる意味論的ドメイン (数学、医学、法律、科学) にわたって同一の論理構造を共有する問題のグループ。 (ii) 微分可能な \emph{Continuous Gradient Conflict Mask}。不変の方向を維持しながら、ドメイン間の勾配分散が大きいパラメータの次元を抑制します。 (iii) マスクされた勾配の切り詰められた SVD 射影を LoRA の低ランク多様体に戻し、パラメータ効率を全体的に維持します。理論的には、IGA は ERM よりも厳しい OOD 一般化境界を生成し、異性体ドメインの数に応じて拡張し、穏やかな規則性の下で標準 SGD レートに収束します。経験的に、IGA は 4 つのベンチマーク全体で 8 つのベースラインを上回り、精度が ERM-SFT よりも最大 14.3 pp 向上し、論理整合性スコアが 0.031 対 0.142 で、表現の不変性が 4 倍向上しました。
原文 (English)
Invariant Gradient Alignment for Robust Reasoning Distillation
Large language models (LLMs) suffer from shortcut learning: they systematically fail on out-of-distribution (OOD) inputs whose semantic surface differs from training data, even when the logical structure is identical. This undermines knowledge distillation pipelines that transfer chain-of-thought reasoning to smaller students. We introduce Invariant Gradient Alignment (IGA), a training framework that aligns gradient updates across semantically diverse but logically isomorphic examples via three innovations: (i) Logical Isomer Sets, groups of problems sharing identical logical structure across distinct semantic domains (mathematics, medicine, law, science); (ii) a differentiable \emph{Continuous Gradient Conflict Mask}, that suppresses parameter dimensions with high cross-domain gradient variance while preserving invariant directions; and (iii) a truncated SVD projection of the masked gradient back onto the LoRA low-rank manifold, maintaining parameter efficiency throughout. Theoretically, IGA yields tighter OOD generalization bounds than ERM, scaling with the number of isomer domains, and converges at the standard SGD rate under mild regularity. Empirically, IGA outperforms eight baselines across four benchmarks with accuracy gains up to 14.3 pp over ERM-SFT and a Logical Consistency Score of 0.031 versus 0.142 -- a fourfold improvement in representational invariance.
自己反映型 API: AI エージェント回復のための構造は冗長性を上回る
AI エージェントが API を呼び出して検証エラーに遭遇した場合、何が問題だったかだけではなく、次に何をすべきかが必要になります。自己反映型 API は、検証が失敗した場合、エージェントが外部の理由なしにリクエストを修復して再試行するのに十分な、機械可読な回復\_フィードバック.suggestions[] ペイロードを返します。リーク監査済みのパイロット (セルあたり $N{=}30$、LLM 3 つ、敵対的タスク 10) では、構造化された提案により、人間モデルでの平易な英語の診断 (フィッシャーの正確な $p \le 0.0022$) と比較して、タスク完了率が $+36.7$ ~ $40.0$pp 上昇し、$1.8$ ~ $2.2\倍$ 向上しました。成功ごとのトークン効率。 gpt-4o-mini では上昇率は大きくありません ($p{=}0.435$)。課金 API での 2 番目のドメインのレプリケーションによってパターンが確認されます。この比較は、文書化されていない 2 つのクラスの回答漏洩を LLM ベンチマークで監査した後にのみ有効です。再利用可能な CI インフラストラクチャとして、audit\_prompt\_leakage.py を出荷します。コードとデータ: https://github.com/arquicanedo/self-reflective-apis。
原文 (English)
Self-Reflective APIs: Structure Beats Verbosity for AI Agent Recovery
When an AI agent calls an API and hits a validation error, it needs more than what went wrong -- it needs what to do next. A self-reflective API returns, on validation failure, a machine-readable recovery\_feedback.suggestions[] payload sufficient for the agent to repair the request and retry without external reasoning. On a leak-audited pilot ($N{=}30$ per cell, 3 LLMs, 10 adversarial tasks), structured suggestions lift task-completion rate by $+36.7$--$40.0$pp over plain-English diagnoses on Anthropic models (Fisher's exact $p \le 0.0022$), at $1.8$--$2.2\times$ better per-success token efficiency. The lift is not significant on gpt-4o-mini ($p{=}0.435$); a second-domain replication on a billing API confirms the pattern. The comparison only holds after auditing two undocumented classes of answer leakage in LLM benchmarks. We shipaudit\_prompt\_leakage.py as reusable CI infrastructure. Code and data: https://github.com/arquicanedo/self-reflective-apis.
UniCAD: マルチモーダル マルチタスク CAD の統合ベンチマークおよびユニバーサル モデル
コンピューター支援設計 (CAD) は、正確で編集可能な 3D モデルの作成を可能にすることで、現代のエンジニアリングと製造を支えています。ただし、CAD の研究では通常、タスクが個別に研究されており、統一されたベンチマークがないため、CAD のマルチモーダル、マルチタスクの学習が妨げられています。このギャップに対処するために、ポイントから CAD への再構成、テキスト/画像から CAD への生成、および多様な入力モダリティにわたる CAD の質問応答をカバーする、マルチモーダル CAD 学習のための包括的なベンチマークである UniCAD を導入します。ベンチマークとともに、テキスト、画像、スケッチ、点群を取り込み、これらの異種タスクを単一のフレームワーク内でエンドツーエンド方式で実行するユニバーサル マルチモーダル大規模言語モデルである UniCAD-MLLM を紹介します。 UniCAD および Fusion360 ベンチマークに関する広範な実験により、UniCAD-MLLM がすべてのタスクにわたって最先端のパフォーマンスを達成し、既存のタスク固有およびマルチタスクのベースラインを上回るパフォーマンスを発揮することが実証されました。今後の研究を加速するために、データセット、コード、事前トレーニング済みモデルをリリースします。
原文 (English)
UniCAD: A Unified Benchmark and Universal Model for Multi-Modal Multi-Task CAD
Computer-Aided Design (CAD) underpins modern engineering and manufacturing by enabling the creation of precise, editable 3D models. However, CAD research typically studies tasks in isolation, and multi-modal, multi-task learning for CAD is hindered by the absence of a unified benchmark. To address this gap, we introduce UniCAD, a comprehensive benchmark for multi-modal CAD learning that covers point-to-CAD reconstruction, text/image-to-CAD generation, and CAD question answering across diverse input modalities. Alongside the benchmark, we present UniCAD-MLLM, a universal multi-modal large language model that ingests text, images, sketches, and point clouds and performs these heterogeneous tasks in an end-to-end fashion within a single framework. Extensive experiments on the UniCAD and Fusion360 benchmarks demonstrate that UniCAD-MLLM achieves state-of-the-art performance across all tasks, outperforming existing task-specific and multi-task baselines. We will release the dataset, code, and pretrained models to accelerate future research.
言語モデルを使用した研究論文のタイトルの自動生成
研究論文のタイトルは、その主なアイデアと、場合によっては結論を明確かつ簡潔に伝えます。適切なタイトルを選択することは多くの場合困難ですが、自動タイトル生成は著者のこの作業を支援します。この研究では、オープンウェイトの事前トレーニング済みの大規模言語モデルを使用して、抄録から論文のタイトルを生成する手法を提案します。私たちは CSPubSum および LREC-COLING-2024 データセットを使用し、社会科学の Springer ジャーナル 4 誌から厳選された新しいデータセット SpringerSSAT を導入します。さらに、タイトルの生成には GPT-3.5-turbo をゼロショット設定で使用します。モデルのパフォーマンスは、ROUGE、METEOR、MoverScore、BERTScore、および SciBERTScore メトリックを使用して評価されます。私たちの実験では、微調整された PEGASUS-large が、ほとんどの指標において、微調整された LLaMA-3-8B やゼロショット GPT-3.5-turbo などの他のモデルよりも優れていることがわかりました。さらに、ChatGPT が創造的な論文タイトルを生成できることを実証します。全体として、AI によって生成されたタイトルは一般に適切で信頼性があります。
原文 (English)
Automatic Generation of Titles for Research Papers Using Language Models
The title of a research paper conveys its primary idea and, occasionally, its conclusions in a clear and concise manner. Choosing an appropriate title is often challenging, and automated title generation can assist authors in this task. In this work, we propose a technique to generate paper titles from abstracts using open-weight pre-trained and large language models. We use the CSPubSum and LREC-COLING-2024 datasets and introduce a new dataset, SpringerSSAT, curated from four Springer journals in the social sciences. Additionally, we use GPT-3.5-turbo in a zero-shot setting to generate titles. Model performance is evaluated with ROUGE, METEOR, MoverScore, BERTScore, and SciBERTScore metrics. Our experiments show that fine-tuned PEGASUS-large outperforms other models, including fine-tuned LLaMA-3-8B and zero-shot GPT-3.5-turbo, across most metrics. We further demonstrate that ChatGPT can generate creative paper titles. Overall, AI-generated titles are generally appropriate and reliable.
言語モデルのための算術教育学
私たちは、人間の数学教育学の方法が言語モデルのトレーニングを算術推論に導くことができるかどうかを調査します。 GASING メソッド (トークン生成の因果関係に沿った左から右への手順で基本的な算術計算を解くインドネシアの教育学) に基づいて、各操作を計算手順として運用し、その実行トレースが自然言語の思考連鎖 (CoT) 監視にシリアル化されます。インドネシア語用の音節凝集型 TOBA トークナイザーを備えた小型 GPT-2 デコーダー (86M パラメーター) は、強化学習や報酬ベースの最適化を行わずに、次のトークンの予測目標のみを使用して、このデータに基づいて最初からトレーニングされます。トレーニングのモニタリングにより、3 つの異なる学習段階が明らかになり、機構分析 (CoT 情報グラフへの注意マスキング介入、残差ストリームの調査、ロジットレンズ検査) から、モデルが最初に手続き型経路を内部化し、その後、明示的なステップごとの計算を行わずに中間結果を取得する連想的な「暗算」能力を開発することが示されました。トレーニングされたモデルは、保留された問題に対して 80% 以上の精度に達し、大幅に大規模な言語モデルに対して競争力のあるパフォーマンスを達成しました。これは、対象を絞った教育学的に根拠のあるトレーニングにより、小規模でも強力で経済的な算術能力を生み出すことができることを示しています。
原文 (English)
Arithmetic Pedagogy for Language Models
We investigate whether methods of human mathematics pedagogy can guide the training of language models toward arithmetic reasoning. Building on the GASING method -- an Indonesian pedagogy that solves basic arithmetic through a left-to-right procedure aligned with the causal order of token generation -- we operationalize each operation as a computational procedure whose execution trace is serialized into natural-language Chain-of-Thought (CoT) supervision. A small GPT-2 decoder (86M parameters) with a syllabic-agglutinative TOBA tokenizer for Indonesian is trained from scratch on this data using only a next-token prediction objective, without reinforcement learning or reward-based optimization. Monitoring training reveals three distinct learning phases, and mechanistic analyses -- attention-masking interventions on the CoT information graph, residual-stream probing, and logit-lens inspection -- show that the model first internalizes a procedural pathway and subsequently develops an associative, ``mental-arithmetic'' capacity that retrieves intermediate results without explicit step-by-step computation. The trained model reaches over 80% accuracy on held-out problems and attains competitive performance against substantially larger language models, indicating that targeted, pedagogically grounded training can yield strong and economical arithmetic capability at small scale.
ラベルが必要なのは誰ですか?すでに持っているメタデータを使用して Vision Foundation モデルを適応させる
私たちは、強力だが汎用的なビジョン基盤モデルを特殊な科学領域に適応させるラベルフリーのアプローチを提案します。標準的な教師あり微調整は、多くの場合、これらの設定には適していません。ラベルが不足しており、タスク固有のトレーニングではモデルの一般性が崩壊し、堅牢性が損なわれる可能性があります。代わりに、メタデータを活用して、自己監視型の方法で表現を新しいドメインに適応させます。私たちの手法である FINO は、標準的な自己教師あり目標と、非常に粒度の高い離散メタデータと連続メタデータの両方を処理する柔軟なメタデータ ガイダンスを組み合わせています。これは、偽の要素を抑制しながら、有益な要素を保持する表現を奨励します。 FINO は、細胞内蛍光顕微鏡、地球観察、野生動物のモニタリング、医療画像処理において、標準的な教師なしドメイン適応や完全教師あり適応を常に上回っています。また、バックボーン適応にタスクラベルを使用せず、監視に軽量プローブのみを使用しながら、高度に専門化されたドメイン固有の最先端技術を超えています。
原文 (English)
Who Needs Labels? Adapting Vision Foundation Models With the Metadata You Already Have
We propose a label-free approach to adapt powerful but generic vision foundation models to specialized scientific domains. Standard supervised fine-tuning is often ill-suited to these settings: labels are scarce, and task-specific training can collapse the model's generality and hurt robustness. We instead leverage metadata to adapt representations to new domains in a self-supervised manner. Our method, FINO, combines a standard self-supervised objective with flexible metadata guidance that handles both highly granular discrete metadata and continuous metadata. It encourages the representation to preserve informative factors while suppressing spurious ones. Across subcellular fluorescence microscopy, Earth observation, wildlife monitoring, and medical imaging, FINO consistently outperforms standard unsupervised domain adaptation and fully supervised adaptation. It also exceeds highly-specialized domain-specific state of the art, while using no task labels for backbone adaptation and only lightweight probes for supervision.
子供の自己中心的なインプットによる継続的な視覚的および言語的学習
子どもたちは、時間的に構造化された継続的な自己中心的な経験の流れから言葉の意味を学びます。最近の研究では、ニューラルネットワークは子供の自己中心的なビデオ録画からも単語参照マッピングを学習できることが示されているが、それらはシャッフルされたデータを数百エポックにわたって循環しており、子供たちが実際に環境に遭遇する様子とは対照的である。私たちは、SAYCam データセットを単一の時系列パスで処理し、ストリーミング視覚表現学習と画像テキスト対比目標を組み合わせた継続的マルチモーダル学習フレームワークである BabyCL を紹介します。 BabyCL は、ストリームの多段階の時間的セグメンテーションと、ビジュアル履歴とマルチモーダル履歴を個別に管理するデュアル リプレイ バッファーを組み合わせ、共有バックボーン上で 3 つの対照的な損失を使用して共同トレーニングされます。一致した最適化予算の下で、BabyCL は SAYCam Labeled-S 4AFC ベンチマークでストリーミング学習ベースラインを上回り、オフライン トレーニングの上限との差を大幅に狭めます。アブレーションは、オンライン時間セグメンテーション ウィンドウの長さとリプレイ バッファーの排除ルールに対してゲインが堅牢であることを示しています。まとめると、これらの結果は、子供の実際の経験にはるかに近い訓練条件下で、意味のある単語参照マッピングが現れる可能性があることを示しています。
原文 (English)
Continual Visual and Verbal Learning Through a Child's Egocentric Input
Children learn the meanings of words from a continuous, temporally structured stream of egocentric experience. Recent work shows that neural networks can also learn word-referent mappings from a child's egocentric video recordings, but they cycle through the shuffled data for hundreds of epochs, contrasting with how children actually encounter their environment. We introduce BabyCL, a continual multimodal learning framework that processes the SAYCam dataset in a single chronological pass, combining streaming visual representation learning with an image-text contrastive objective. BabyCL combines a multi-stage temporal segmentation of the stream with a dual replay buffer that independently manages visual and multimodal histories, and it is jointly trained with three contrastive losses on a shared backbone. Under a matched optimization budget, BabyCL outperforms streaming learning baselines on the SAYCam Labeled-S 4AFC benchmark, substantially narrowing the gap to an upper bound of offline training. Ablations show that the gains are robust to the length of the online temporal segmentation window and the eviction rule of the replay buffer. Together, these results show that meaningful word-referent mappings can emerge under training conditions much closer to a child's actual experience.
オーディオインタラクションモデル
オーディオは本質的にインタラクティブなモダリティですが、今日の大規模オーディオ言語モデル (LALM) はオフラインであり、ストリーミング オーディオ モデルはそれぞれストリーミング ASR や音声チャットなどの単一タスクのみを処理します。それらを 1 つのオンライン LALM に統合する時が来ました。LALM は、常時オンの知覚、決定、応答ループを通じて、音、環境、指示をリアルタイムで聞き、その場で反応するモデルです。私たちはこの体制をオーディオ インタラクション モデルとして形式化し、オーディオ インタラクションで実現します。これは、オフライン タスクの実行を保持しながら、対話からフル ボイス チャットに至るまでのオンラインの一般的な音声指示を追加し、ストリームのセマンティクスからいつ応答するかを決定する統合ストリーミング モデルです。これを可能にするために、ストリーミングネイティブのデータ構築、理解を意識したトレーニング、安定したリアルタイムインタラクションのための非同期低遅延推論を通じて、データからトレーニング、デプロイメントに至るまで、認識・決定・応答ループをエンドツーエンドでインスタンス化するフレームワークである SoundFlow を提案します。さらに、7 つの基本能力と 28 のサブタスクにわたる 260 万項目のストリーミング コーパスである StreamAudio-2M と、プロアクティブな音声介入を評価するための Proactive-Sound-Bench を構築します。 8 つのベンチマークにわたって、Audio-Interaction は主流のオーディオ タスクで競争力のあるパフォーマンスを維持しながら、リアルタイム ASR、ストリーミング オーディオ命令のフォロー、プロアクティブ ヘルプなど、オフライン LALM ではアクセスできない機能を解放します。
原文 (English)
Audio Interaction Model
Audio is an inherently interactive modality, yet today's Large Audio Language Models (LALMs) are offline, and streaming audio models each handle only a single task such as streaming ASR or voice chatting. It is time to unify them into one online LALM: a model that, through an always-on perceive-decide-respond loop, listens to sound, environment, and instructions in real time and reacts on the fly. We formalize this regime as the Audio Interaction Model, and realize it with Audio-Interaction, a unified streaming model that retains offline task execution while adding online general audio instruction following, from dialogue to full voice chatting, deciding when to respond from the semantics of the stream. To enable this, we propose SoundFlow, a framework that instantiates the perceive-decide-respond loop end to end, from data to training to deployment, through streaming-native data construction, comprehension-aware training, and asynchronous low-latency inference for stable real-time interaction. We further construct StreamAudio-2M, a 2.6M-item streaming corpus spanning 7 fundamental abilities and 28 sub-tasks, and Proactive-Sound-Bench for evaluating proactive audio intervention. Across 8 benchmarks, Audio-Interaction preserves competitive performance on mainstream audio tasks while unlocking capabilities inaccessible to offline LALMs, including real-time ASR, streaming audio instruction following, and proactive help.
LLM 駆動エージェントによる効率的で証拠に基づくモビリティ予測に向けて
個人レベルのモビリティ予測は、都市シミュレーション、交通計画、政策分析の中心となります。教師ありシーケンス モデルは高い精度を実現しますが、タスク固有のトレーニングが必要であり、意思決定レベルの透明性は限られています。最近の LLM ベースの手法は解釈可能性を向上させていますが、ほとんどが静的プロンプトとシングルパス推論に依存しているため、モビリティ信号が弱いか矛盾している場合に追加の証拠を探す能力が制限されています。私たちは、次の場所の予測を適応的な証拠に基づいた意思決定として定式化する、トレーニング不要の LLM 駆動のエージェント フレームワークである \method{} を提案します。 \method{} は、歴史的な規則性に基づく高速パスを通じて日常的なケースを解決しますが、あいまいなケースでは、最近の軌跡、過去の動作、滞在と移動の可能性、および地理的証拠に基づいて反復的なツールの使用がトリガーされます。 3 つのモビリティ データセット全体で、AgentMob はトレーニング不要の LLM ベースの手法の中で最も強力な総合パフォーマンスを達成し、GPT-5.4 は BW で 71.42\% Acc@1、YJMob100K で 33.14\%、上海 ISP で 33.50\% に達しました。 BW 非高速パスのケースでは、LLM コントローラーは、同じツールの統計ベースラインと比較して Acc@1 を 30.65\% から 48.62\% に改善します。これは、その主な利点が、適応的な証拠収集を通じて曖昧な予測を解決することにあることを示しています。コードは https://github.com/Unknown-zoo/AgentMob で入手できます。
原文 (English)
Towards Efficient and Evidence-grounded Mobility Prediction with LLM-Driven Agent
Individual-level mobility prediction is central to urban simulation, transportation planning, and policy analysis. Supervised sequence models achieve strong accuracy but require task-specific training and offer limited decision-level transparency. Recent LLM-based methods improve interpretability, yet mostly rely on static prompts and single-pass inference, limiting their ability to seek additional evidence when mobility signals are weak or conflicting. We propose \method{}, a training-free LLM-driven agent framework that formulates next-location prediction as adaptive evidence-controlled decision making. \method{} resolves routine cases through a fast path based on historical regularity, while ambiguous cases trigger iterative tool use over recent trajectories, historical behavior, stay-move likelihood, and geographical evidence. Across three mobility datasets, AgentMob achieves the strongest overall performance among training-free LLM-based methods, with GPT-5.4 reaching 71.42\% Acc@1 on BW, 33.14\% on YJMob100K, and 33.50\% on Shanghai ISP. On BW non-fast-path cases, the LLM controller improves Acc@1 from 30.65\% to 48.62\% over a same-tool statistical baseline, showing that its main benefit lies in resolving ambiguous predictions through adaptive evidence gathering. Our code is available at https://github.com/Unknown-zoo/AgentMob.
GeM-NR: 非剛体シーン変更のためのジオメトリ対応マルチビュー編集
生成モデルを使用したマルチビュー画像編集の最近の開発により、一般的な 3D コンテンツの生成とカスタマイズに一歩近づいています。既存の作品のほとんどは、未編集のシーンのジオメトリを利用した、厳密な編集または外観のみの編集に焦点を当てています。これにより、当然のことながら、これらの方法は、基礎となるシーン構造を保存する編集に限定されます。他のアプローチは、オブジェクトの削除や追加など、特定の画像編集タスク用にトレーニングされています。この進歩にもかかわらず、一般的な非剛体編集、つまりシーンのジオメトリを大幅に変更する編集は、既存の方法にとって依然として困難です。私たちは、シーンのジオメトリや外観を大幅に変更する編集を含む、一般的なマルチビューの一貫した画像編集のための、高速で柔軟なトレーニング不要のアプローチである GeM-NR を提案します。選択したバックボーン エディター (FLUX、Qwen、BrushNet など) で編集されたアンカー画像と、編集されていないクエリ画像が与えられると、GeM-NR はアンカー編集と一貫してクエリ画像を編集します。この方法には複数の段階が組み込まれています: (i) 編集済みシーンと未編集のシーンの 3D 点群間の位置合わせを最大化する戦略を提案する深度マップ推定、(ii) クエリ視点への投影、および (iii) 未編集のクエリを条件として取得された画像の改良。コンディショニングベースの定式化は、オブジェクトの 2 つのビューから多数のビューまで適切に拡張できます。既存の方法では困難である、ジオメトリと外観の大幅な変更を伴う編集を処理するこの方法の能力を実証します。私たちは広範な評価を実行し、この方法が編集シーンの 3D 表現の生成を含むさまざまな編集タスクの一貫性を向上させることを示しました。定量的結果と定性的結果の両方は、編集品質、および複数のビューにわたる幾何学的および測光の一貫性の点で、この方法の最先端のパフォーマンスを示しています。
原文 (English)
GeM-NR: Geometry-Aware Multi-View Editing for Nonrigid Scene Changes
Recent developments in multi-view image editing with generative models have brought us a step closer toward general 3D content generation and customization. Most existing works focus on rigid or appearance-only edits by utilizing the geometry of the unedited scene. This naturally limits these methods to edits that preserve the underlying scene structure. Other approaches are trained for specific image editing tasks, such as object removal and addition. Despite this progress, general nonrigid edits, i.e., edits that substantially change the scene geometry, remain challenging for existing methods. We propose GeM-NR, a fast and flexible training-free approach for general multi-view consistent image editing, including edits that drastically change the geometry and appearance of the scene. Given an anchor image edited with a chosen backbone editor (such as FLUX, Qwen, BrushNet) and a query unedited image, GeM-NR edits the query image consistently with the anchor edit. The method incorporates multiple stages: (i) depth map estimation, where we propose a strategy to maximize the alignment between the 3D point clouds of the edited and unedited scenes, (ii) projection onto a query viewpoint, and (iii) refinement of the obtained image conditioned on the unedited query. The conditioning-based formulation scales well from two to many views of an object. We demonstrate the ability of our method to handle edits with significant changes in geometry and appearance, something that existing methods struggle with. We perform an extensive evaluation showing that our method improves consistency for a wide variety of edit tasks, including generating 3D representations of the edited scene. Both quantitative and qualitative results indicate the state-of-the-art performance of our method in terms of edit quality as well as geometric and photometric consistency across multiple views.
失敗した推論トレースから何が修正可能かを教えてくれます (ただし、それを読むことではわかりません)
トレーニング後の言語モデルが推論の問題で失敗した場合、一般的なテスト時間のスケーリング対応は、追加の試行により多くの計算を費やし、失敗したトレースはそれ以上の役割を果たさないことです。私たちは、これは重要なシグナルを破棄していると主張します。一部の失敗は不運なサンプリングによって発生し、より多くのロールアウトが役立ちますが、他の失敗は構造的なものであり、予算に関係なく再サンプリングに抵抗します。私たちは、失敗したトレースが回復可能構造、つまりテスト時の介入によって特定の失敗を救済できる推論時の署名をエンコードしていると提案します。利用可能な介入の構造から導出された 3 つの問題レベルの軌跡の特徴は、失敗したロールアウトのテキストではなく、配布の署名からこの構造を復元します。これらは、障害を安定した領域にクラスタリングし、さまざまなトレーニング後の方法の障害トポグラフィーを特徴付け ($84.3{\pm}4.3\%$ の精度、過半数クラスのベースラインより $+20\%$)、デプロイメント関連の Steerable-Hard サブセット (再試行が不十分で制限された介入が到達可能な障害) でレスキューを $+12.2\%$ 引き上げるトレーニング不要のルーティング ルールをサポートします。機能とルーティング ルールは、2 つのファミリー間プローブ間で転送されます。したがって、同じ 3 つの機能は、破棄されたデータから失敗したトレースを診断オブジェクトに変換し、トレーニング時や重み空間にアクセスすることなく、テスト時のルーティングとトレーニング後の分析をサポートします。
原文 (English)
Failed Reasoning Traces Tell You What Is Fixable (But Not by Reading Them)
When post-trained language models fail on reasoning problems, the common test-time-scaling response is to spend more compute on additional attempts, and the failed traces play no further role. We argue this discards a crucial signal; some failures come from unlucky sampling, where more rollouts help, while others are structural and resist resampling regardless of budget. We propose that failed traces encode recoverability structure: the inference-time signature of which test-time interventions can rescue a given failure. Three problem-level trajectory features, derived from the structure of available interventions, recover this structure from the distributional signature of failed rollouts, not their text. They cluster failures into stable regimes, characterize the failure topography of different post-training methods ($84.3{\pm}4.3\%$ accuracy, $+20\%$ over a majority-class baseline), and support a training-free routing rule that lifts rescue by $+12.2\%$ on the deployment-relevant Steerable-Hard subset (failures where retry is insufficient and a bounded intervention is reachable). The features and the routing rule transfer across two cross-family probes. The same three features thus convert failed traces from discarded data into a diagnostic object, supporting test-time routing and post-training analysis without training-time or weight-space access.
適応および非適応粒子群最適化を使用したマルチカラム RBF ニューラル ネットワーク
勾配降下アルゴリズムでトレーニングされた放射基底関数ニューラル ネットワーク (RBFN) は、浅いネットワークと深いネットワークの両方で効果的な完全結合構造を提供します。最先端の勾配ベースのトレーニング方法である誤り訂正 (ErrCor) は、最適な隠れユニットを選択して精度を向上させます。あるいは、集団ベースのアルゴリズムとして、粒子群最適化アルゴリズム (PSO) は群エクスペリエンスを使用して RBFN パラメーターを最適化し、グローバル検索と極小値に対する堅牢性を提供します。アダプティブ PSO (APSO) は、PSO の改良版として登場しました。 APSO アルゴリズムは、最適化中に群パラメータを動的に調整することで収束速度を向上させます。 ErrCor と PSO は両方とも、改善された結果と競合する収束を示しています。ただし、大規模なデータセットでは、これらの方法は過剰なカーネル計算や大規模な隠れ層構造などのスケーラビリティの課題に直面します。最近のマルチカラム RBFN アプローチ (MCRN) は、並列システムに小さな RBFN を展開することで ErrCor のパフォーマンスを向上させます。 MCRN の成功に触発されて、PSO のパフォーマンスを向上させるための 2 つの新しいアプローチ、つまり PSO を使用したマルチカラム RBFN (MC-PSO) と APSO を使用したマルチカラム RBFN (MC-APSO) を提案します。これらの方法では、進化的群法を使用してトレーニングされた並列 RBFN 構造が導入されます。各 RBFN は、PSO または APSO アルゴリズムを使用して、データセットの特定の空間サブセットで個別にトレーニングされます。結果として得られる専門家によって訓練された RBFN は、それぞれのサブセットに合わせて調整されます。テスト中、隣接するテスト インスタンスが配置されている選択された RBFN のみが複数列出力に寄与します。この特殊化により精度が向上し、並列処理により速度が向上します。提案された手法をさまざまなベンチマーク データセットで評価します。 MC-PSO および MC-APSO は、精度と再現率の点で ErrCor、PSO、APSO、および MCRN よりも優れています。また、ほとんどの実験でトレーニングとテストの時間が短縮されることも実証されています。
原文 (English)
Multi-Column RBF Neural Network Using Adaptive and Non-Adaptive Particle Swarm Optimization
The radial basis function neural network (RBFN) trained with a gradient descending algorithm provides an effective fully connected structure in both shallow and deep networks. The error correction (ErrCor), a state-of-the-art gradient-based training method, selects optimal hidden units to improve accuracy. Alternatively, as a population-based algorithm, the particle swarm optimization algorithm (PSO) uses the swarm experience to optimize RBFN parameters, offering global search and robustness to local minima. Adaptive PSO (APSO) has emerged as an improved variant of PSO. APSO algorithm improves convergence speed by dynamically adjusting swarm parameters during optimization. Both ErrCor and PSO demonstrate improved results and competitive convergence. However, with large datasets, these methods face scalability challenges such as excessive kernel computations and large hidden layer structures. A recent multi-column RBFN approach (MCRN) improves ErrCor performance by deploying small RBFNs in a parallel system. Inspired by MCRN's success, we propose two novel approaches to improve PSO performance: the multi-column RBFN with PSO (MC-PSO) and the multi-column RBFN with APSO (MC-APSO). These methods introduce parallel RBFN structures trained using evolutionary swarm methods. Each RBFN is independently trained on a specific spatial subset of the dataset using either PSO or APSO algorithms. These resulting specialist-trained RBFNs are tailored to their respective subsets. During testing, only selected RBFNs, where the test instance neighbors are located, contribute to the multi-column output. This specialization improves accuracy, while parallelism enhances speed. We evaluate the proposed methods on various benchmark datasets. The MC-PSO and MC-APSO outperform ErrCor, PSO, APSO, and MCRN in terms of accuracy and recall. They also demonstrate faster training and testing times in most experiments.
分布型 DAgger による豊富なフィードバックからの強化学習
推論モデルは急速に進歩しましたが、検証可能な報酬からの支配的な強化学習 (RLVR) レシピは驚くほど狭いままです。多くの応答をサンプリングし、最終的な答えが正しいかどうかを示す 1 ビットで各応答に報酬を与えます。さらに、多くの設定では、実行トレース、ツール出力、専門家による修正、モデルの自己評価など、豊富なフィードバックが提供されます。私たちは、古典的な模倣学習アルゴリズム DAgger の分布型バリアントを通じて、そのようなフィードバックを使用する方法を研究します。この場合、学習者は、現在のポリシーが訪問する州に関する専門家分布にローカルにアクセスできます。これにより、ブラックボックス専門家とその配列レベルの勾配が、将来の専門家と学生の意見の相違を以前の決定にまで「伝播させることによって豊富な単位の割り当てを行う」ことを認める、単純な順方向クロスエントロピー目標が得られます。我々は、逆KLまたはジェンセン・シャノンに基づく自己蒸留目標を備えた以前のRLでは、単調な政策改善を保証できないことを示します。たとえ専門家がより高い報酬を得ていたとしても、その更新により、より悪いアクションの確率が増加する可能性があります。対照的に、順方向クロスエントロピーは単調な政策改善を認め、後悔の保証を享受できることを示します。さらに、私たちの目標が教師に重み付けされた成功の可能性の下限を最適化し、Pass@N の向上につながることを示します。経験的に、私たちのアプローチである DistIL は、科学的推論、コーディング、難しい数学的問題の解決など、さまざまな領域にわたる自己蒸留ベースラインにより、RLVR および RL よりも改善されています。
原文 (English)
Reinforcement Learning from Rich Feedback with Distributional DAgger
Reasoning models have advanced rapidly, but the dominant reinforcement learning from verifiable rewards (RLVR) recipe remains surprisingly narrow: sample many responses and reward each with a single bit indicating whether the final answer is correct. Yet many settings provide rich feedback, including execution traces, tool outputs, expert corrections, and model self-evaluations. We study how to use such feedback through a distributional variant of the classic imitation learning algorithm DAgger, where the learner has local access to an expert distribution on states visited by the current policy. This yields a simple forward cross-entropy objective that admits a blackbox expert and whose sequence-level gradient {conduct rich credit assignment by propagating} future expert-student disagreement back to earlier decisions. We show that prior RL with self-distillation objectives based on reverse KL or Jensen-Shannon fail to guarantee monotonic policy improvement: even when the expert has higher reward, their updates may increase probability on worse actions. In contrast, we show that forward cross-entropy admits monotonic policy improvement and enjoys guarantees on regret. We further show that our objective optimizes a lower bound on teacher-weighted likelihood of success, leading to improved Pass@N. Empirically, our approach, DistIL, improves over RLVR and RL with self-distillation baselines across a variety of domains: scientific reasoning, coding, and solving hard mathematical problems.
マルチエージェント推論におけるストリーミング通信
マルチエージェント推論システムは、エンドツーエンドのレイテンシーをパイプラインの深さに応じて線形に拡張する「生成してから転送」パラダイムを採用しています。 StreamMA は、各推論ステップが生成されるとすぐに下流のエージェントにストリーミングし、隣接するエージェントをパイプライン化して待ち時間を短縮するマルチエージェント推論システムです。驚くべきことに、このパイプラインは有効性も向上させます。マルチステップの推論の品質は不均一で、初期のステップは後のステップよりも信頼性が高いため、完全なチェーンではなくこれらの信頼できる初期ステップを使用することで、エラーが発生しやすい後期ステップが下流エージェントに誤解を与えることを防ぎます。ストリーム、シリアル、および単一プロトコルの最初の閉じた形式の結合分析によって両方の利点を形式化し、有効性の順序付け、高速化の上限、およびコスト比を導き出します。数学、科学、コードにわたる 8 つの推論ベンチマーク、2 つのフロンティア LLM (Claude Opus 4.6 および GPT-5.4)、および 3 つのトポロジ (チェーン、ツリー、グラフ) にわたって、StreamMA は両方のベースラインを上回りました (HMMT 2026 で平均 +7.3 pp、最大 +22.4 pp、Claude Opus 4.6-高)。これらの貢献を超えて、「ステップレベルのスケーリング則」を発見しました。つまり、エージェントごとのステップを増やすと、有効性と効率の両方が一貫して向上します。これは、エージェント数のスケーリングと直交し、エージェント数のスケーリングと組み合わせ可能な新しいスケーリングの次元です。
原文 (English)
Streaming Communication in Multi-Agent Reasoning
Multi-agent reasoning systems adopt a "generate-then-transfer" paradigm that forces end-to-end latency to scale linearly with pipeline depth. We introduce StreamMA, a multi-agent reasoning system that streams each reasoning step to downstream agents as soon as it is generated, pipelining adjacent agents and thus reducing latency. Surprisingly, this pipelining also improves effectiveness: because multi-step reasoning quality is non-uniform and early steps are more reliable than later ones, working with these reliable early steps instead of the full chain prevents error-prone late steps from misleading downstream agents. We formalize both advantages with the first closed-form joint analysis of stream, serial, and single protocols, deriving the effectiveness ordering, speedup upper bound, and cost ratio. Across eight reasoning benchmarks spanning mathematics, science, and code, two frontier LLMs (Claude Opus 4.6 and GPT-5.4), and three topologies (Chain, Tree, Graph), StreamMA outperforms both baselines (avg. +7.3 pp, max +22.4 pp on HMMT 2026; Claude Opus 4.6-high). Beyond these contributions, we discover a "step-level scaling law": increasing per-agent steps consistently improves both effectiveness and efficiency, a new scaling dimension orthogonal to and composable with agent-count scaling.
より長いコンテキスト、より深い思考: 推論における長いコンテキスト能力の役割を明らかにする
最近の言語モデルは強力な推論能力を示していますが、長い文脈の能力が推論に及ぼす影響はまだ解明されていません。この研究では、現在の推論の制限は、部分的には、ロングコンテキストの能力が不十分であることに起因しており、(1) コンテキストウィンドウの長さが長いほど推論のパフォーマンスが向上することが多く、(2) 推論に失敗したケースは、失敗したロングコンテキストのケースに似ている、などの経験的観察によって動機付けられていると仮説を立てています。この仮説を検証するために、教師あり微調整 (SFT) の前にモデルのロングコンテキスト能力を強化することが推論パフォーマンスの向上につながるかどうかを調べます。具体的には、同一のアーキテクチャと微調整データを備えているが、ロングコンテキスト容量のレベルが異なるモデルを比較しました。私たちの結果は一貫した傾向を示しています。つまり、より強力なロングコンテキスト能力を持つモデルは、SFT 後の推論ベンチマークで大幅に高い精度を達成します。特に、これらの向上は入力長が短いタスクでも持続しており、長いコンテキストのトレーニングが推論パフォーマンスに一般化可能な利点を提供していることを示しています。これらの発見は、ロングコンテキストモデリングが長い入力を処理するために不可欠であるだけでなく、推論のための重要な基盤としても機能することを示唆しています。私たちは、将来の言語モデルの設計において、長いコンテキストの能力を第一級の目標として扱うことを主張します。
原文 (English)
Longer Context, Deeper Thinking: Uncovering the Role of Long-Context Ability in Reasoning
Recent language models exhibit strong reasoning capabilities, yet the influence of long-context capacity on reasoning remains underexplored. In this work, we hypothesize that current limitations in reasoning stem, in part, from insufficient long-context capacity, motivated by empirical observations such as (1) higher context window length often leads to stronger reasoning performance, and (2) failed reasoning cases resemble failed long-context cases. To test this hypothesis, we examine whether enhancing a model's long-context ability before Supervised Fine-Tuning (SFT) leads to improved reasoning performance. Specifically, we compared models with identical architectures and fine-tuning data but varying levels of long-context capacity. Our results reveal a consistent trend: models with stronger long-context capacity achieve significantly higher accuracy on reasoning benchmarks after SFT. Notably, these gains persist even on tasks with short input lengths, indicating that long-context training offers generalizable benefits for reasoning performance. These findings suggest that long-context modeling is not just essential for processing lengthy inputs, but also serves as a critical foundation for reasoning. We advocate for treating long-context capacity as a first-class objective in the design of future language models.
悪い分子の破壊: MLLM は構造レベルの分子解毒の準備ができていますか?
毒性は依然として、初期段階の医薬品開発の失敗の主な原因です。分子設計と特性予測の進歩にもかかわらず、毒性が低減された構造的に有効な分子代替物を生成する分子毒性修復の課題は、まだ体系的に定義されず、ベンチマークも確立されていません。このギャップを埋めるために、分子毒性修復に焦点を当てた汎用マルチモーダル大規模言語モデル (MLLM) の最初のベンチマーク タスクである ToxiMol を紹介します。私たちは、さまざまなメカニズムと粒度にわたる 11 の主要なタスクと 660 の代表的な有毒分子をカバーする標準化されたデータセットを構築します。私たちは、専門的な毒性学の知識に基づいて、メカニズムを認識し、タスクに適応する機能を備えた迅速なアノテーション パイプラインを設計します。並行して、毒性エンドポイント予測、合成アクセシビリティ、薬物らしさ、構造類似性を修復成功のためのハイスループット評価チェーンに統合する自動評価フレームワーク ToxiEval を提案します。当社は 43 の主流の汎用 MLLM を体系的に評価し、複数のアブレーション研究を実施して、評価指標、候補の多様性、失敗の原因などの重要な問題を分析します。実験結果は、現在の MLLM がこのタスクに関して依然として大きな課題に直面しているものの、毒性の理解、意味論的制約の順守、および構造を意識した編集において有望な能力を実証し始めていることを示しています。
原文 (English)
Breaking Bad Molecules: Are MLLMs Ready for Structure-Level Molecular Detoxification?
Toxicity remains a leading cause of early-stage drug development failure. Despite advances in molecular design and property prediction, the task of molecular toxicity repair, generating structurally valid molecular alternatives with reduced toxicity, has not yet been systematically defined or benchmarked. To fill this gap, we introduce ToxiMol, the first benchmark task for general-purpose Multimodal Large Language Models (MLLMs) focused on molecular toxicity repair. We construct a standardized dataset covering 11 primary tasks and 660 representative toxic molecules spanning diverse mechanisms and granularities. We design a prompt annotation pipeline with mechanism-aware and task-adaptive capabilities, informed by expert toxicological knowledge. In parallel, we propose an automated evaluation framework, ToxiEval, which integrates toxicity endpoint prediction, synthetic accessibility, drug-likeness, and structural similarity into a high-throughput evaluation chain for repair success. We systematically assess 43 mainstream general-purpose MLLMs and conduct multiple ablation studies to analyze key issues, including evaluation metrics, candidate diversity, and failure attribution. Experimental results show that although current MLLMs still face significant challenges on this task, they begin to demonstrate promising capabilities in toxicity understanding, semantic constraint adherence, and structure-aware editing.
制約付き適応拒否サンプリング
言語モデル (LM) は、生成された出力が厳密な意味論的または構文上の制約を満たす必要があるアプリケーションで使用されることが増えています。制約付き生成に対する既存のアプローチはさまざまです。貪欲な制約付きデコード方法は、デコード中に有効性を強制しますが、LM の分布を歪めます。一方、リジェクション サンプリング (RS) は忠実度を維持しますが、無効な出力を破棄することで計算を無駄にします。サンプルの有効性と多様性の両方が重要であるプログラム ファジングなどの領域では、両極端が問題となります。我々は、分布歪みを生じさせずに RS のサンプル効率を厳密に改善するアプローチである、制約付き適応除去サンプリング (CARS) を紹介します。 CARS は、制約のない LM サンプリングから始まり、制約違反の継続をトライに記録し、将来の描画から確率質量を差し引くことで、制約に違反する継続を適応的に除外します。この適応的な枝刈りにより、無効であることが証明されたプレフィックスが決して再検討されず、受け入れ率が単調に向上し、結果として得られるサンプルが制約された分布に正確に従うことが保証されます。プログラムのファジングや分子生成など、さまざまな領域の実験において、CARS は一貫して高い効率 (有効サンプルあたりの LM フォワードパスの数で測定) を達成すると同時に、GCD や LM の分布を近似する方法の両方よりも強力なサンプル多様性を生み出します。
原文 (English)
Constrained Adaptive Rejection Sampling
Language Models (LMs) are increasingly used in applications where generated outputs must satisfy strict semantic or syntactic constraints. Existing approaches to constrained generation fall along a spectrum: greedy constrained decoding methods enforce validity during decoding but distort the LM's distribution, while rejection sampling (RS) preserves fidelity but wastes computation by discarding invalid outputs. Both extremes are problematic in domains such as program fuzzing, where both validity and diversity of samples are essential. We present Constrained Adaptive Rejection Sampling (CARS), an approach that strictly improves the sample-efficiency of RS without distributional distortion. CARS begins with unconstrained LM sampling and adaptively rules out constraint-violating continuations by recording them in a trie and subtracting their probability mass from future draws. This adaptive pruning ensures that prefixes proven invalid are never revisited, acceptance rates improve monotonically, and the resulting samples exactly follow the constrained distribution. In experiments on a variety of domains -- e.g., program fuzzing and molecular generation -- CARS consistently achieves higher efficiency -- measured in the number of LM forward passes per valid sample -- while also producing stronger sample diversity than both GCD and methods that approximate the LM's distribution.
防御的な論理的思考を学ぶことで、深い暗黙の好みを調整する
大規模言語モデル (LLM) がユーザー中心の対話に効果的に関与できるようにするには、パーソナライズされた調整が不可欠です。しかし、現在の手法は二重の課題に直面しています。つまり、ユーザーの深い暗黙の好み(明示されていない目標、意味論的コンテキスト、リスク許容度など)を推測することができず、現実世界のあいまいさを乗り越えるために必要な防御的推論が欠けています。この認知ギャップは、表面的で脆弱で近視眼的な反応を引き起こします。これに対処するために、我々は、アラインメントをスカラー報酬マッチングタスクから構造化された推論プロセスに再構築する、批判駆動推論アラインメント (CDRA) を提案します。まず、プリファレンス推論のギャップを埋めるために、DeepPref ベンチマークを導入します。このデータセットは、20 のトピックにわたる 3000 のプリファレンスとクエリのペアで構成されており、クエリのセマンティクスを解体して潜在的なリスクを明らかにするために、批判注釈付きの推論チェーンを生成する多面的な認知評議会をシミュレートすることによってキュレーションされています。第 2 に、防御的推論を植え付けるために、報酬モデリングを個人化された推論タスクとして組み立てる、個人化された生成プロセス報酬モデル (Pers-GenPRM) を導入します。この理論的根拠に基づいて最終スコアを出力する前に、ユーザーの好みと応答の整合性を評価するための批評チェーンを生成します。最終的に、この解釈可能で構造化された報酬信号は、数値フィードバックと自然言語フィードバックの両方を統合するプロセスレベルのオンライン強化学習アルゴリズムである批判主導型政策調整を通じて政策モデルを導きます。実験では、CDRA が、堅牢な推論を実行しながら、ユーザーの真の好みを発見して調整することに優れていることが実証されています。コードとデータセットは https://github.com/Zephyrian-Hugh/Deep-pref で入手できます。
原文 (English)
Aligning Deep Implicit Preferences by Learning to Reason Defensively
Personalized alignment is crucial for enabling Large Language Models (LLMs) to engage effectively in user-centric interactions. However, current methods face a dual challenge: they fail to infer users' deep implicit preferences (including unstated goals, semantic context and risk tolerances), and they lack the defensive reasoning required to navigate real-world ambiguity. This cognitive gap leads to responses that are superficial, brittle and short-sighted. To address this, we propose Critique-Driven Reasoning Alignment (CDRA), which reframes alignment from a scalar reward-matching task into a structured reasoning process. First, to bridge the preference inference gap, we introduce the DeepPref benchmark. This dataset, comprising 3000 preference-query pairs across 20 topics, is curated by simulating a multi-faceted cognitive council that produces critique-annotated reasoning chains to deconstruct query semantics and reveal latent risks. Second, to instill defensive reasoning, we introduce the Personalized Generative Process Reward Model (Pers-GenPRM), which frames reward modeling as a personalized reasoning task. It generates a critique chain to evaluate a response's alignment with user preferences before outputting a final score based on this rationale. Ultimately, this interpretable, structured reward signal guides policy model through Critique-Driven Policy Alignment, a process-level online reinforcement learning algorithm integrating both numerical and natural language feedback. Experiments demonstrate that CDRA excels at discovering and aligning with users' true preferences while executing robust reasoning. Our code and dataset are available at https://github.com/Zephyrian-Hugh/Deep-pref.
アダプティブ マインド: LoRA-as-Tools でエージェントに権限を与える
LoRA アダプターが、基本言語モデルが動的に選択して呼び出すことができる呼び出し可能なツールとして扱われるフレームワークを調査します。私たちは、アダプターがドメイン固有の強力な利益を提供するようにトレーニングされ、明確なメタデータで公開されている場合、基本モデルはクエリを適切な専門家に確実にルーティングし、単一のフレームワーク内に多くの特殊なアダプターの利点を効果的に集約できるという仮説を立てています。シングルステップ ルーティングとマルチステップ エージェント推論の両方を研究する一般的なフレームワークであるアダプティブ マインドを紹介します。この設定では、エージェントは他のツール (外部 API、取得システム、実行環境など) と一緒に複数のアダプターを繰り返し呼び出し、複数のステップにわたる出力を推論できます。これにより、アダプターは、静的に適用されるのではなく、推論中に構成できるモジュール式のスキルまたは記憶ユニットとして再構成されます。私たちの評価では、ルーティング層は 30 アダプター ライブラリで 98.3% の精度に達し、十分なトレーニングを受けた専門家は、単一の共有トレーニング レシピの下で 9 つのタスク ファミリ全体で +4.6 ~ +84.0 パーセンテージ ポイントの厳密スコアラー ゲインを提供しました。 AM ルーターは、クエリがドメイン信号を表面化するすべてのベンチマークで、直接のスペシャリストの 5 pp 以内にこれらのゲインを集計します。私たちの調査結果は、このアプローチの有効性は個々のアダプターの品質と専門性に依存し、そのような多くの専門家を柔軟に構成できるようにすることで、言語モデルエージェントの実践的な能力を大幅に拡張し、より一般的なツール拡張インテリジェンスに移行できることを示唆しています。
原文 (English)
Adaptive Minds: Empowering Agents with LoRA-as-Tools
We investigate a framework in which LoRA adapters are treated as callable tools that a base language model can dynamically select and invoke. We hypothesize that, when adapters are trained to provide strong domain-specific gains and are exposed with clear metadata, a base model can reliably route queries to the appropriate expert, effectively aggregating the benefits of many specialized adapters within a single framework. We introduce Adaptive Minds, a general framework within which we study both single-step routing and multi-step agentic reasoning. In this setting, the agent can iteratively invoke multiple adapters alongside other tools (e.g., external APIs, retrieval systems, or execution environments) and reason over their outputs across multiple steps. This reframes adapters as modular skills or memory units that can be composed during reasoning rather than statically applied. In our evaluation, the routing layer reaches 98.3% accuracy on a 30-adapter library, and well-trained specialists provide +4.6 to +84.0 percentage points of strict-scorer gain across nine task families under a single shared training recipe; the AM router aggregates these gains within 5 pp of the direct specialist on every benchmark whose queries surface domain signal. Our findings suggest that the effectiveness of this approach depends on the quality and specialization of individual adapters, and that enabling flexible composition of many such experts can significantly expand the practical capabilities of language model agents, moving toward more general, tool-augmented intelligence.
BRAINCELL-AID: コミュニティ アノテーション用のエージェント AI が作成した脳細胞タイプのリソース
単一細胞 RNA シーケンスにより、多様な細胞型とそのトランスクリプトーム シグネチャを識別する能力が変わりました。しかし、これらのシグネチャ、特に特徴が十分に解明されていない遺伝子に関連するシグネチャに注釈を付けることは、依然として大きな課題です。 Gene Set Enrichment Analysis (GSEA) などの従来の手法は、厳選されたアノテーションに依存しており、これらのコンテキストではパフォーマンスが低下することがよくあります。大規模言語モデル (LLM) は有望な代替手段を提供しますが、構造化されたオントロジー内で複雑な生物学的知識を表現するのに苦労しています。これに対処するために、我々は BRAINCELL-AID (BRAINCELL-AID: https://biodataai.uth.edu/BRAINCELL-AID) を紹介します。これは、フリーテキスト記述とオントロジー ラベルを統合して、より正確で堅牢な遺伝子セット アノテーションを可能にする新しいマルチエージェント AI システムです。検索拡張生成 (RAG) を組み込むことで、関連する PubMed 文献を使用して予測を改良し、幻覚を軽減し、解釈可能性を高める堅牢なエージェント ワークフローを開発しました。このワークフローを使用して、上位予測に含まれるマウス遺伝子セットの 77% に対して正しいアノテーションを達成しました。このアプローチを適用して、BRAIN Initiative Cell Census Network によって生成された包括的なマウス脳細胞アトラスからの 5,322 個の脳細胞クラスターに注釈を付け、領域特異的な遺伝子の共発現パターンを特定し、遺伝子アンサンブルの機能的役割を推測することで、脳細胞の機能についての新たな洞察を可能にしました。 BRAINCELL-AID は、神経学的に意味のある説明を持つ大脳基底核関連細胞タイプも識別します。したがって、コミュニティ主導のセルタイプのアノテーションをサポートする貴重なリソースを作成します。
原文 (English)
BRAINCELL-AID: An Agentic AI Created Brain Cell Type Resource for Community Annotation
Single-cell RNA sequencing has transformed our ability to identify diverse cell types and their transcriptomic signatures. However, annotating these signatures-especially those involving poorly characterized genes-remains a major challenge. Traditional methods, such as Gene Set Enrichment Analysis (GSEA), depend on well-curated annotations and often perform poorly in these contexts. Large Language Models (LLMs) offer a promising alternative but struggle to represent complex biological knowledge within structured ontologies. To address this, we present BRAINCELL-AID (BRAINCELL-AID: https://biodataai.uth.edu/BRAINCELL-AID), a novel multi-agent AI system that integrates free-text descriptions with ontology labels to enable more accurate and robust gene set annotation. By incorporating retrieval-augmented generation (RAG), we developed a robust agentic workflow that refines predictions using relevant PubMed literature, reducing hallucinations and enhancing interpretability. Using this workflow, we achieved correct annotations for 77% of mouse gene sets among their top predictions. Applying this approach, we annotated 5,322 brain cell clusters from the comprehensive mouse brain cell atlas generated by the BRAIN Initiative Cell Census Network, enabling novel insights into brain cell function by identifying region-specific gene co-expression patterns and inferring functional roles of gene ensembles. BRAINCELL-AID also identifies Basal Ganglia-related cell types with neurologically meaningful descriptions. Hence, we create a valuable resource to support community-driven cell type annotation.
トランスフォーマーベースのモデルと人間の脳ネットワーク間の位相調整のための統合幾何空間
これまでの脳と AI の連携研究は通常、特定の入力とタスクによって制約され、さまざまなモダリティを備えたモデル全体で組織特性を捕捉する能力が制限されていました。この研究では、Transformer ベースのモデルに焦点を当て、脳モデルのトポロジカル アライメント空間を導入します。神経メカニズムからアライメントを推測するのではなく、グラフベースの組織特性を通じてアライメントを調査し、モデルの固有の空間注意トポロジーを標準的な人間固有接続ネットワーク (ICN) にマッピングします。これにより、組織特性のレベルで視覚、言語、およびマルチモーダル システムにわたる、モダリティに依存せずタスクフリーの比較が可能になります。これらのモダリティとスケールにわたる 151 の Transformer ベースのモデルを分析すると、さまざまな程度のトポロジー アラインメントを反映する、連続的な円弧状の分布が観察されます。トレーニングの目的と一致して、グローバルなセマンティック抽象化に最適化されたモデルは高次の ICN とより密接に関連付けられ、ローカルの詳細に焦点を当てたモデルは低レベルの ICN と関連付けられました。さらに驚くべきことに、我々は非直観的な現象を発見しました。DINOv2 は以前のバージョンと比較してアライメントの低下を示し、蒸留された DeiT モデルは、より大きなモデルが高次の ICN とあまりうまくアライメントされない直観に反したスケーリング反転を示し、命令チューニングだけでなく微調整もアライメントに対する効果が限定的でした。さらに、トポロジカル アライメント スコアは、30 個のビジョン トランスフォーマーにおける ImageNet-1K Top-1 精度と有意でない相関関係を示しました (r=0.266、p=0.156)。この研究は、脳参照トポロジー マッピングを通じて、Transformer ベースのモデルの組織特性を比較するための新しい定量的観点を提供します。
原文 (English)
A Unified Geometric Space for Topological Alignment Between Transformer-Based Models and Human Brain Networks
Prior brain-AI alignment studies are typically constrained by specific inputs and tasks, limiting their ability to capture organizational properties across models with different modalities. In this work, we focus on Transformer-based models and introduce a brain-model topological alignment space. Rather than inferring alignment from neural mechanisms, we examine it through graph-based organizational properties, mapping the intrinsic spatial attention topology of a model onto canonical human intrinsic connectivity networks (ICNs). This enables a modality-agnostic and task-free comparison across vision, language, and multimodal systems at the level of organizational properties. Analyzing 151 Transformer-based models across these modalities and scales, we observe a continuous arc-shaped distribution, reflecting varying degrees of topological alignment. Consistent with their training objectives, models optimized for global semantic abstraction were associated more closely with higher-order ICNs, while local detail-focused models associated with low-level ICNs. More surprisingly, we uncovered non-intuitive phenomena: DINOv2 exhibited reduced alignment compared to its predecessors, distilled DeiT models showed a counterintuitive scaling inversion where larger models aligned less well with higher-order ICNs, and fine-tuning as well as instruction tuning had limited effect on alignment. Furthermore, topological alignment scores showed non-significant correlation with ImageNet-1K Top-1 accuracy in 30 vision Transformers (r=0.266, p=0.156). This work provides a new quantitative perspective for comparing the organizational properties of Transformer-based models through brain-referenced topological mapping.
MENTOR: LLM の暗黙的なドメイン リスクを発見し軽減するためのメタ認知主導の自己進化フレームワーク
大規模言語モデル (LLM) の安全性を確保することは、実際の展開にとって重要です。しかし、現在の安全対策では、ドメイン固有の暗黙的なリスクに対処できないことがよくあります。このギャップを調査するために、教育、財務、管理にわたる 3,000 件の注釈付きクエリのデータセットを導入します。 14 の主要 LLM の評価では、平均脱獄成功率 57.8\% という懸念すべき脆弱性が明らかになりました。これに応えて、私たちはメタ認知主導の自己進化フレームワークである MENTOR を提案します。 MENTOR は、視点の取得や結果論的推論などの戦略を使用してメタ認知的自己評価を実行し、潜在的なモデルの不整合を明らかにします。結果として生じる反映は、動的なルールベースのナレッジ グラフに蒸留され、そこから取得されたルールが、推論中に内部表現をガイドするためのアクティベーション レベルのステアリング信号に変換されます。実験では、MENTOR がテストされたすべてのドメインにわたって攻撃の成功率を大幅に低下させ、既存の安全調整方法よりも優れたパフォーマンスを発揮することが実証されています。 MENTOR のコードとデータセットは、https://anonymous.4open.science/r/MENTOR-Evo で入手できます。
原文 (English)
MENTOR: A Metacognition-Driven Self-Evolution Framework for Uncovering and Mitigating Implicit Domain Risks in LLMs
Ensuring the safety of Large Language Models (LLMs) is critical for real-world deployment. However, current safety measures often fail to address implicit, domain-specific risks. To investigate this gap, we introduce a dataset of 3,000 annotated queries spanning education, finance, and management. Evaluations across 14 leading LLMs reveal a concerning vulnerability: an average jailbreak success rate of 57.8\%. In response, we propose MENTOR, a metacognition-driven self-evolution framework. MENTOR performs metacognitive self-assessment, using strategies such as perspective-taking and consequential reasoning to uncover latent model misalignments. The resulting reflections are distilled into dynamic rule-based knowledge graphs, from which retrieved rules are converted into activation-level steering signals to guide internal representations during inference. Experiments demonstrate that MENTOR substantially reduces attack success rates across all tested domains and outperforms existing safety alignment methods. The code and dataset for MENTOR are available at: https://anonymous.4open.science/r/MENTOR-Evo.
推論か流暢か? Best-of-N 選択における確率的信頼性の分析
信頼性が高いほど推論の忠実度が高いという仮定の下、確率的信頼度メトリクスが Best-of-N 選択における推論の品質の代用として採用されることが増えています。この研究では、これらのメトリクスが正当な推論に必要なステップ間の因果関係を本当に捉えているかどうかを調査することで、この仮定に異議を唱えます。局所的な流暢性を維持しながら、推論ステップ間の依存関係を系統的に破壊するステップ間の因果関係の摂動の 3 つのクラスを導入します。驚くべきことに、さまざまなモデル ファミリと推論ベンチマークにわたって、これらの混乱下では選択の精度がわずかに低下するだけであることがわかりました。モデルが事前の推論ステップに参加するのを直接妨げるハード アテンション マスクの適用などの厳しい介入であっても、選択のパフォーマンスは大幅に低下しません。これらの発見は、現在の確率的メトリクスが論理構造にほとんど影響を受けず、代わりに主に表面レベルの流暢性または分布内の事前分布を捕捉するという強力な証拠を提供します。このギャップを動機として、ステップ間の因果関係を明示的に分離する対照的因果関係メトリックを提案し、既存の確率ベースのアプローチよりもより忠実な出力選択が得られることを実証します。
原文 (English)
Reasoning or Fluency? Dissecting Probabilistic Confidence in Best-of-N Selection
Probabilistic confidence metrics are increasingly adopted as proxies for reasoning quality in Best-of-N selection, under the assumption that higher confidence reflects higher reasoning fidelity. In this work, we challenge this assumption by investigating whether these metrics truly capture inter-step causal dependencies necessary for valid reasoning. We introduce three classes of inter-step causality perturbations that systematically disrupt dependencies between reasoning steps while preserving local fluency. Surprisingly, across diverse model families and reasoning benchmarks, we find that selection accuracy degrades only marginally under these disruptions. Even severe interventions, such as applying hard attention masks that directly prevent the model from attending to prior reasoning steps, do not substantially reduce selection performance. These findings provide strong evidence that current probabilistic metrics are largely insensitive to logical structure, and primarily capture surface-level fluency or in-distribution priors instead. Motivated by this gap, we propose a contrastive causality metric that explicitly isolates inter-step causal dependencies, and demonstrate that it yields more faithful output selection than existing probability-based approaches.
政策改善としての成功条件付け: 成功を模倣することで解決される最適化問題
ポリシーを改善するために広く使用されている手法は、成功条件付けです。これは、軌跡を収集し、望ましい結果を達成するものを特定し、成功した軌跡に沿って取られたアクションを模倣するようにポリシーを更新します。この原理は、SFT を使用した拒絶サンプリング、目標条件付き RL、意思決定変換器など、さまざまな名前で表示されますが、それがどのような最適化問題を解決するのか (存在する場合) は不明のままです。成功条件付けが信頼領域の最適化問題を正確に解決し、データによって自動的に半径が決定される $\chi^2$ 発散制約に従ってポリシーの改善を最大化することを証明します。これにより、同一性が得られます。つまり、相対的な政策の改善、政策の変更の大きさ、およびアクション影響力と呼ばれる量 (アクションの選択におけるランダムな変動が成功率にどのように影響するかを測定するもの) は、どの状態でもまったく同じです。したがって、成功条件付けは保守的な改善演算子として現れます。正確な成功条件は、パフォーマンスを低下させたり、危険な分散シフトを誘発したりすることはありませんが、失敗した場合は、ポリシーをほとんど変更せずに、目に見えて影響を及ぼします。私たちはこの理論を収益しきい値処理の一般的な実践に適用し、これにより改善を拡大できることを示しましたが、その代償として真の目的とのずれが生じる可能性があります。
原文 (English)
Success Conditioning as Policy Improvement: The Optimization Problem Solved by Imitating Success
A widely used technique for improving policies is success conditioning, in which one collects trajectories, identifies those that achieve a desired outcome, and updates the policy to imitate the actions taken along successful trajectories. This principle appears under many names -- rejection sampling with SFT, goal-conditioned RL, Decision Transformers -- yet what optimization problem it solves, if any, has remained unclear. We prove that success conditioning exactly solves a trust-region optimization problem, maximizing policy improvement subject to a $\chi^2$ divergence constraint whose radius is determined automatically by the data. This yields an identity: relative policy improvement, the magnitude of policy change, and a quantity we call action-influence -- measuring how random variation in action choices affects success rates -- are exactly equal at every state. Success conditioning thus emerges as a conservative improvement operator. Exact success conditioning cannot degrade performance or induce dangerous distribution shift, but when it fails, it does so observably, by hardly changing the policy at all. We apply our theory to the common practice of return thresholding, showing this can amplify improvement, but at the cost of potential misalignment with the true objective.
PersistBench: LLM は長期記憶をいつ忘れるべきですか?
会話アシスタントは、長期記憶と大規模言語モデル (LLM) をますます統合しています。この記憶の永続性(たとえば、ユーザーがベジタリアンであるなど)は、将来の会話におけるパーソナライゼーションを強化することができます。しかし、同じ持続性が、これまでほとんど見落とされてきた安全上のリスクを引き起こす可能性もあります。そこで、これらの安全リスクの程度を測定するために PersistBench を導入します。我々は、長期記憶に特有の 2 つのリスクを特定しました。1 つは、LLM が長期記憶からコンテキストを不適切に注入するクロスドメイン漏洩です。保存された長期記憶がユーザーのバイアスを知らず知らずのうちに強化する、記憶誘発性のお調子者。私たちは 18 のフロンティア LLM とオープンソース LLM をベンチマークで評価します。私たちの結果は、これらの LLM 全体での失敗率が驚くほど高いことを明らかにしました。失敗率の中央値は、クロスドメイン サンプルで 53%、お調子者サンプルで 97% でした。これに対処するために、私たちのベンチマークは、最先端の会話システムにおけるより堅牢で安全な長期メモリ使用法の開発を奨励します。
原文 (English)
PersistBench: When Should Long-Term Memories Be Forgotten by LLMs?
Conversational assistants are increasingly integrating long-term memory with large language models (LLMs). This persistence of memories, e.g., the user is vegetarian, can enhance personalization in future conversations. However, the same persistence can also introduce safety risks that have been largely overlooked. Hence, we introduce PersistBench to measure the extent of these safety risks. We identify two long-term memory-specific risks: cross-domain leakage, where LLMs inappropriately inject context from the long-term memories; and memory-induced sycophancy, where stored long-term memories insidiously reinforce user biases. We evaluate 18 frontier and open-source LLMs on our benchmark. Our results reveal a surprisingly high failure rate across these LLMs - a median failure rate of 53% on cross-domain samples and 97% on sycophancy samples. To address this, our benchmark encourages the development of more robust and safer long-term memory usage in frontier conversational systems.
Interfaze: AI の未来はタスク固有の小さなモデルに基づいて構築されます
我々は、タスク固有のディープ ニューラル ネットワーク (CNN および DNN) を共有埋め込み空間を通じて変換デコーダーに直接融合するネイティブ ハイブリッド モデルである Interfaze を紹介します。特殊な知覚エンコーダは、複雑な多言語 PDF 上の光学式文字認識 (OCR)、オープン語彙オブジェクトとグラフィカル ユーザー インターフェイス (GUI) の検出、およびダイアライゼーションによる多言語音声認識を処理します。それぞれはタスク固有のアダプターを通じて公開され、独自にアクティブ化できるため、クエリは必要なパラメーターのみを操作します。組み込みのアクション基盤は、プロキシ化されたヘッドレス ブラウザーとスクレーパー、コード サンドボックス、マルチドメイン Web インデックス、およびスケーラブルなベクター ストアといった、接地された外部状態を提供します。デコーダはこれらの信号をフィルタリングおよびマージし、タスクで必要な場合にそれらを理由づけて、信頼性に基づいて構築された確定的な出力を出力します。専門家の生のメタデータ (境界ボックス、信頼スコア、タイムスタンプ) が保存され、プレコンテキストとして回答とともに返されます。このアーキテクチャでは、Interfaze-Beta が一連の決定論的な開発者タスク ベンチマークをリードしています。 OCRBench v2 では 70.7%、olmOCR では 85.7%、RefCOCO では 82.1%、VoxPopuli では単語エラー率 2.4%、Spider-2.0-Lite では 52.9%、GPQA-Diamond では 92.4%、MMMLU では 90.9%、MMMU-Pro では 71.1% に達します。構造化出力ベンチマーク (SOB) での値精度は 80.5% で、すべてのタスクにおいて同価格帯のジェネラリスト モデル (Gemini-3-Flash、Gemini-3.5-Flash、Claude-Sonnet-4.6、GPT-5.4-Mini、および Grok-4.3) を上回っています。融合されたスペシャリスト エンコーダは、大規模なモデルへのツール呼び出しを繰り返すのではなく、シングル パスで認識を解決するため、Interfaze はフラッシュ層のコストで実行しながら、決定論的なタスクに関する検証可能なメタデータを使用して高精度を達成します。
原文 (English)
Interfaze: The Future of AI is built on Task-Specific Small Models
We present Interfaze, a native hybrid model that fuses task-specific deep neural networks (CNNs and DNNs) directly into a transformer decoder through a shared embedding space. Specialized perceptual encoders handle optical character recognition (OCR) over complex multilingual PDFs, open-vocabulary object and graphical user interface (GUI) detection, and multilingual speech recognition with diarization. Each is exposed through a task-specific adapter and can be activated on its own, so a query touches only the parameters it needs. A built-in action foundation supplies a grounded external state: a proxied headless browser and scraper, a code sandbox, a multi-domain web index, and a scalable vector store. The decoder filters and merges these signals, reasons over them when a task requires it, and emits deterministic outputs built on confidence. The raw specialist metadata (bounding boxes, confidence scores, timestamps) is preserved and returned alongside the answer as precontext. On this architecture, Interfaze-Beta leads a suite of deterministic developer-task benchmarks. It reaches 70.7% on OCRBench v2, 85.7% on olmOCR, 82.1% on RefCOCO, a 2.4% word error rate on VoxPopuli, 52.9% on Spider-2.0-Lite, 92.4% on GPQA-Diamond, 90.9% on MMMLU, 71.1% on MMMU-Pro, and 80.5% value accuracy on the Structured Output Benchmark (SOB), ahead of comparably priced generalist models (Gemini- 3-Flash, Gemini-3.5-Flash, Claude-Sonnet-4.6, GPT-5.4-Mini, and Grok-4.3) on every task. Because fused specialist encoders resolve perception in a single pass instead of through repeated tool calls into a large model, Interfaze reaches high accuracy with verifiable metadata on deterministic tasks while running at flash-tier cost.
配信外の検出から幻覚の検出まで: 幾何学的な視点
大規模な言語モデルにおける幻覚の検出は、安全性と信頼性に重大な影響を与える重大な未解決の問題です。既存の幻覚検出方法は、質問に答えるタスクでは優れたパフォーマンスを発揮しますが、推論が必要なタスクでは依然として効果が低いままです。この研究では、コンピュータ ビジョンなどの分野でよく研究されている問題である、分布外 (OOD) 検出というレンズを通して幻覚検出を再検討します。言語モデルで次のトークンの予測を分類タスクとして扱うことにより、大規模な言語モデルの構造的な違いを考慮して適切な変更が加えられる限り、OOD 手法を適用することができます。我々は、OOD ベースのアプローチにより、トレーニング不要の単一サンプルベースの検出器が得られ、推論タスクの幻覚検出において高い精度が達成されることを示します。全体として、私たちの研究は、幻覚検出を OOD 検出として再構成することが、言語モデルの安全性への有望でスケーラブルな道筋を提供することを示唆しています。
原文 (English)
From Out-of-Distribution Detection to Hallucination Detection: A Geometric View
Detecting hallucinations in large language models is a critical open problem with significant implications for safety and reliability. While existing hallucination detection methods achieve strong performance in question-answering tasks, they remain less effective on tasks requiring reasoning. In this work, we revisit hallucination detection through the lens of out-of-distribution (OOD) detection, a well-studied problem in areas like computer vision. Treating next-token prediction in language models as a classification task allows us to apply OOD techniques, provided appropriate modifications are made to account for the structural differences in large language models. We show that OOD-based approaches yield training-free, single-sample-based detectors, achieving strong accuracy in hallucination detection for reasoning tasks. Overall, our work suggests that reframing hallucination detection as OOD detection provides a promising and scalable pathway toward language model safety.
SciDER: 科学データ中心のエンドツーエンド研究者
大規模な言語モデルが科学的発見を加速させる一方で、既存のエージェントは適応性、ドメインの一般化、マルチモーダルなスケーラビリティにおいて厳しい制限に直面しており、多くの場合、生のドメイン固有の実験データを自律的に処理するのに苦労しています。これらの障壁を克服するために、研究ライフサイクル全体を柔軟に自動化するように設計されたマルチエージェント システムである SciDER を導入します。このフレームワークは、新しいデータ中心のアプローチを採用し、4 つの専門化されたサブエージェントにわたる動的なマルチモーダル スキル システムを統合します。具体的には、アイデア化エージェントは進化的アイデア検索を通じて新しい仮説を生成し、データ分析エージェントは生データを体系的に構造化し、実験エージェントはデータセットの特性に基づいて実行可能コードを合成し、批評エージェントは反復的な自己洗練を推進します。オープンソースの科学的発見を民主化するために、私たちは OpenSciDER-27B 微調整モデルと並行して、高品質の実行軌跡データセットである OpenSciDER-SFT-8K をリリースします。 6 つのベンチマーク全体で、SciDER と OpenSciDER は競合する、または優れた結果を獲得しており、特にデータ中心の分析、エンドツーエンドの研究実行、マルチモーダルな科学的視覚化において大きな成果が得られています。 SciDER は、データ分析と実験の実行を統合することにより、抽象的な科学的推論と再現可能な実験合成の間のギャップを埋めます。
原文 (English)
SciDER: Scientific Data-centric End-to-end Researcher
While large language models accelerate scientific discovery, existing agents face severe limitations in adaptability, domain generalization, and multimodal scalability, often struggling to autonomously process raw, domain-specific experimental data. To overcome these barriers, we introduce SciDER, a multi-agent system designed to flexibly automate the entire research lifecycle. This framework employs a novel data-centric approach and integrates a dynamic multimodal skill system across four specialized sub-agents. Specifically, an ideation agent generates novel hypotheses via Evolutionary Idea Search, a data analysis agent systematically structures raw data, an experimentation agent synthesizes executable code grounded in dataset characteristics, and a critic agent drives iterative self-refinement. To democratize open-source scientific discovery, we release OpenSciDER-SFT-8K, a high-quality execution trajectory dataset, alongside the OpenSciDER-27B fine-tuned model. Across six benchmarks, SciDER and OpenSciDER obtain competitive or leading results, with especially strong gains on data-centric analysis, end-to-end research execution, and multimodal scientific visualization. By integrating data analysis with experimental execution, SciDER bridges the gap between abstract scientific reasoning and reproducible experimentation synthesis.
MedForge: 偽造を意識した推論による解釈可能な医療ディープフェイク検出
テキストガイド付きの画像エディターは、本物の医療スキャンを高い忠実度で操作できるようになり、臨床の信頼と安全性を脅かす病変の移植/除去が可能になります。既存の防御策は医療には不十分です。医療検出器はほとんどがブラックボックスですが、MLLM ベースの説明者は通常事後的なものであり、医学的専門知識が不足しており、曖昧なケースの証拠を幻覚で示す可能性があります。私たちは、証拠に基づいた事前の医療偽造検出のためのデータと方法のソリューションである MedForge を紹介します。 MedForge-90K は、医師の検査ガイドラインとゴールド エディット位置による専門家の指導による推論監督を備えた、19 の病理にわたる現実的な病変編集の大規模ベンチマークです。これに基づいて、MedForge-Reasoner はローカライズしてから分析する推論を実行し、評決を下す前に疑わしい領域を予測します。さらに、偽造を認識した GSPO と連携してグラウンディングを強化し、幻覚を軽減します。実験では、最先端の検出精度と信頼できる専門家に合わせた説明が実証されています。
原文 (English)
MedForge: Interpretable Medical Deepfake Detection via Forgery-aware Reasoning
Text-guided image editors can now manipulate authentic medical scans with high fidelity, enabling lesion implantation/removal that threatens clinical trust and safety. Existing defenses are inadequate for healthcare. Medical detectors are largely black-box, while MLLM-based explainers are typically post-hoc, lack medical expertise, and may hallucinate evidence on ambiguous cases. We present MedForge, a data-and-method solution for pre-hoc, evidence-grounded medical forgery detection. We introduce MedForge-90K, a large-scale benchmark of realistic lesion edits across 19 pathologies with expert-guided reasoning supervision via doctor inspection guidelines and gold edit locations. Building on it, MedForge-Reasoner performs localize-then-analyze reasoning, predicting suspicious regions before producing a verdict, and is further aligned with Forgery-aware GSPO to strengthen grounding and reduce hallucinations. Experiments demonstrate state-of-the-art detection accuracy and trustworthy, expert-aligned explanations.
バイレベル自動リサーチ: メタ自動リサーチ自体
オートリサーチ自体がリサーチの一形式である場合、オートリサーチはリサーチ自体に適用できます。 Bilevel Autoresearch は、外側の自動リサーチ ループがコードとトレースを読み取り、ボトルネックを特定し、実行時に注入可能な Python 検索メカニズムを生成することで、内側の自動リサーチ ループを改善するバイレベル フレームワークです。内部ループはタスクのパフォーマンスを最適化します。外側のループは、内側のループの検索方法を最適化します。どちらのループも同じ LLM を使用するため、より強力なメタレベル モデルではなく、バイレベル アーキテクチャによって改善がもたらされますが、外側のループでは追加の推論と実時間のバジェットが消費されます。 Karpathy の GPT 事前トレーニング ベンチマークでは、メタ自動リサーチの外側ループは標準の内側ループのみと比べて 5 倍の改善 (-0.045 対 -0.009 val_bpb) を達成しましたが、メカニズムの変更を伴わないパラメーター レベルの調整では信頼できるゲインは得られません。外側のループは、最終的な機構設計を人間が指定することなく、組み合わせ最適化、マルチアームバンディット、実験計画法などの隣接する検索ドメインから機構をインスタンス化します。トレース分析は、これらのメカニズムが決定論的な検索パターンを破壊し、LLM の事前分布が回避する方向の探索を強制することを示唆しています。このベンチマークでの実験では、最初の 2 レベルのステップ、つまり外側のループが内側のループの検索動作を改善することを示しています。この実装ではコードがメカニズムのキャリアですが、スキル、プロンプト、ワークフロー、評価者、ドメイン原則、世界モデルの仮定、およびメモリ スキーマも、将来のエージェントの動作を形成するメカニズムをエンコードできます。これは、内部ループで発見されたメカニズムをフィードバックしてメタレベル ループ自体を改善できる、再帰的ブートストラップへの道を示唆しています。
原文 (English)
Bilevel Autoresearch: Meta-Autoresearching Itself
If autoresearch is itself a form of research, then autoresearch can be applied to research itself. We present Bilevel Autoresearch, a bilevel framework in which an outer autoresearch loop improves an inner autoresearch loop by reading its code and traces, identifying bottlenecks, and generating injectable Python search mechanisms at runtime. The inner loop optimizes task performance; the outer loop optimizes how the inner loop searches. Both loops use the same LLM, so improvements come from the bilevel architecture rather than a stronger meta-level model, although the outer loop consumes additional inference and wall-clock budget. On Karpathy's GPT pretraining benchmark, the meta-autoresearch outer loop achieves a 5x improvement over the standard inner loop alone (-0.045 vs. -0.009 val_bpb), while parameter-level adjustment without mechanism change yields no reliable gain. The outer loop instantiates mechanisms from adjacent search domains, including combinatorial optimization, multi-armed bandits, and design of experiments, without human specification of the final mechanism design. Trace analysis suggests that these mechanisms break deterministic search patterns and force exploration of directions the LLM's priors avoid. The experiments demonstrate, on this benchmark, a first bilevel step: an outer loop improves the search behavior of an inner loop. Code is the mechanism carrier in this implementation, but skills, prompts, workflows, evaluators, domain principles, world-model assumptions, and memory schemas can also encode mechanisms that shape future agent behavior. This suggests a path toward recursive bootstrapping, where mechanisms discovered for the inner loop can be fed back to improve the meta-level loop itself.
エージェントティック ツール プロトコルの形式セマンティクス: プロセス計算アプローチ
外部ツールを呼び出すことができる大規模言語モデル エージェントの出現により、エージェント プロトコルの正式な検証が緊急に必要になりました。この分野では、ゼロショット API の一般化のための研究フレームワークであるスキーマガイド ダイアログ (SGD) と、エージェントとツールの統合のための業界標準であるモデル コンテキスト プロトコル (MCP) の 2 つのパラダイムが支配的です。どちらもスキーマ記述を通じて動的なサービス検出を可能にしますが、その正式な関係はまだ解明されていません。これらのパラダイムの概念的収束を確立した以前の研究に基づいて、我々は SGD と MCP の最初のプロセス計算による定式化を提示し、それらが明確に定義されたマッピング ファイの下で構造的に類似していることを証明します。ただし、逆マッピング Phi^{-1} は部分的で損失が多く、MCP の表現力に重大なギャップがあることが明らかになります。双方向分析を通じて、完全な動作の等価性のための必要十分条件として、5 つの原則 (セマンティックな完全性、明示的なアクション境界、障害モードの文書化、漸進的開示互換性、ツール間関係宣言) を特定しました。これらの原則を型システム拡張 MCP+ として形式化し、MCP+ が SGD と同型であることを証明します。私たちの研究は、検証されたエージェント システムの最初の正式な基盤を提供し、証明可能な安全性の特性としてスキーマの品質を確立します。
原文 (English)
Formal Semantics for Agentic Tool Protocols: A Process Calculus Approach
The emergence of large language model agents capable of invoking external tools has created urgent need for formal verification of agent protocols. Two paradigms dominate this space: Schema-Guided Dialogue (SGD), a research framework for zero-shot API generalization, and the Model Context Protocol (MCP), an industry standard for agent-tool integration. While both enable dynamic service discovery through schema descriptions, their formal relationship remains unexplored. Building on prior work establishing the conceptual convergence of these paradigms, we present the first process calculus formalization of SGD and MCP, proving they are structurally bisimilar under a well-defined mapping Phi. However, we demonstrate that the reverse mapping Phi^{-1} is partial and lossy, revealing critical gaps in MCP's expressivity. Through bidirectional analysis, we identify five principles -- semantic completeness, explicit action boundaries, failure mode documentation, progressive disclosure compatibility, and inter-tool relationship declaration -- as necessary and sufficient conditions for full behavioral equivalence. We formalize these principles as type-system extensions MCP+, proving MCP+ is isomorphic to SGD. Our work provides the first formal foundation for verified agent systems and establishes schema quality as a provable safety property.
責任の地平線: 人間とエージェントの集合体を統治するための不可能定理
AI システムの法的、倫理的、規制に関する既存の責任の枠組みは、どのような結果が生じても、少なくとも 1 人の特定可能な人物が意味のある責任を負うのに十分な関与と先見性を持っているという共通の前提に基づいています。この論文は、自律性が計算可能なしきい値を超えると、エージェント型 AI システムが工学的な制限としてではなく数学的必然性としてこの仮定に違反することを証明します。ヒューマン エージェント コレクティブを紹介します。これは、エージェントが共有構造因果モデル内の国家政策タプルとしてモデル化される、人間と AI の共同システムの形式化です。自律性は、4 次元の情報理論的プロファイル (認識論的、実行的、評価的、社会的) によって特徴付けられます。インタラクショングラフと共同アクションスペースを通じた集団行動。私たちは、帰属性 (責任には因果関係の寄与が必要である)、予見可能性 (責任は予測能力を超えることはできない)、非空白性 (少なくとも 1 人のエージェントが重要な責任を負う)、および完全性 (すべての責任は完全に割り当てられなければならない) という 4 つの最小限の特性を通じて正当な責任を公理します。私たちの中心的な結果であるアカウンタビリティ不完全性定理は、その複合的な自律性がアカウンタビリティの地平線を超え、その相互作用グラフに人間と AI のフィードバック サイクルが含まれている集団にとって、4 つの特性すべてを同時に満たすフレームワークは存在しないことを証明しています。この不可能性は構造的なものであり、透明性、監査、監督によっても自律性を低下させることなく解決することはできません。しきい値を下回ると、正当なフレームワークが存在し、急激な相転移が確立されます。 3,000 の合成集合体に対する実験により、すべての予測が違反なしで確認されました。これは、AI ガバナンスにおける最初の不可能な結果であり、現在のパラダイムが引き続き有効であり、それを超えると分散型責任メカニズムが必要になるという正式な境界を確立します。
原文 (English)
The Accountability Horizon: An Impossibility Theorem for Governing Human-Agent Collectives
Existing accountability frameworks for AI systems, legal, ethical, and regulatory, rest on a shared assumption: for any consequential outcome, at least one identifiable person had enough involvement and foresight to bear meaningful responsibility. This paper proves that agentic AI systems violate this assumption not as an engineering limitation but as a mathematical necessity once autonomy exceeds a computable threshold. We introduce Human-Agent Collectives, a formalisation of joint human-AI systems where agents are modelled as state-policy tuples within a shared structural causal model. Autonomy is characterised through a four-dimensional information-theoretic profile (epistemic, executive, evaluative, social); collective behaviour through interaction graphs and joint action spaces. We axiomatise legitimate accountability through four minimal properties: Attributability (responsibility requires causal contribution), Foreseeability Bound (responsibility cannot exceed predictive capacity), Non-Vacuity (at least one agent bears non-trivial responsibility), and Completeness (all responsibility must be fully allocated). Our central result, the Accountability Incompleteness Theorem, proves that for any collective whose compound autonomy exceeds the Accountability Horizon and whose interaction graph contains a human-AI feedback cycle, no framework can satisfy all four properties simultaneously. The impossibility is structural: transparency, audits, and oversight cannot resolve it without reducing autonomy. Below the threshold, legitimate frameworks exist, establishing a sharp phase transition. Experiments on 3,000 synthetic collectives confirm all predictions with zero violations. This is the first impossibility result in AI governance, establishing a formal boundary below which current paradigms remain valid and above which distributed accountability mechanisms become necessary.
人間らしい推論のための信念を意識した VLM モデル
意図推論のための従来のニューラル ネットワーク モデルは、観察可能な状態に大きく依存しており、多様なタスクや動的環境にわたって一般化するのに苦労しています。ビジョン ランゲージ モデル (VLM) とビジョン ランゲージ アクション (VLA) モデルの最近の進歩により、大規模なマルチモーダル事前トレーニングを通じて常識的な推論が導入され、タスク全体でゼロショット パフォーマンスが可能になります。しかし、これらのモデルには信念を表現し更新するための明確なメカニズムがまだ欠けており、人間のように推論したり、長期にわたって進化する人間の意図を捕捉したりする能力が制限されています。これに対処するために、検索ベースの記憶と強化学習を統合する信念認識型 VLM フレームワークを提案します。明示的な信念モデルを学習する代わりに、関連するマルチモーダル コンテキストを取得するベクトルベースのメモリを使用して信念を近似します。これは、推論のために VLM に組み込まれます。 VLM 潜在空間に対する強化学習ポリシーを使用して、意思決定をさらに洗練させます。 HD-EPIC などの公的に利用可能な VQA データセットに対するアプローチを評価し、ゼロショット ベースラインを超える一貫した改善を実証し、信念を意識した推論の重要性を強調しています。
原文 (English)
Belief-Aware VLM Model for Human-like Reasoning
Traditional neural network models for intent inference rely heavily on observable states and struggle to generalize across diverse tasks and dynamic environments. Recent advances in Vision Language Models (VLMs) and Vision Language Action (VLA) models introduce common-sense reasoning through large-scale multimodal pretraining, enabling zero-shot performance across tasks. However, these models still lack explicit mechanisms to represent and update belief, limiting their ability to reason like humans or capture the evolving human intent over long-horizon. To address this, we propose a belief-aware VLM framework that integrates retrieval-based memory and reinforcement learning. Instead of learning an explicit belief model, we approximate belief using a vector-based memory that retrieves relevant multimodal context, which is incorporated into the VLM for reasoning. We further refine decision-making using a reinforcement learning policy over the VLM latent space. We evaluate our approach on publicly available VQA datasets such as HD-EPIC and demonstrate consistent improvements over zero-shot baselines, highlighting the importance of belief-aware reasoning.
因果モデルとしてのバイナリ スパイキング ニューラル ネットワーク
バイナリ スパイキング ニューラル ネットワーク (BSNN) の動作を説明するために、その因果分析を提供します。 BSNN を正式に定義し、そのスパイク アクティビティを二項因果モデルとして表します。この因果表現のおかげで、ロジックベースの手法を活用してネットワークの出力を説明することができます。特に、この二値因果モデルからアブダクティブな説明を計算するために SAT と SMT ソルバーをうまく使用できることを示します。私たちのアプローチを説明するために、標準の MNIST データセットで BSNN をトレーニングし、SAT ベースおよび SMT ベースの手法を適用して、ピクセルレベルの特徴に基づいてネットワークの分類の抽象的な説明を見つけました。また、見つかった説明を、説明可能な AI の分野で使用される一般的な手法である SHAP と比較しました。 SHAP とは異なり、私たちのアプローチは、見つかった説明に完全に無関係な特徴が含まれていないことを保証することを示します。
原文 (English)
Binary Spiking Neural Networks as Causal Models
We provide a causal analysis of Binary Spiking Neural Networks (BSNNs) to explain their behavior. We formally define a BSNN and represent its spiking activity as a binary causal model. Thanks to this causal representation, we are able to explain the output of the network by leveraging logic-based methods. In particular, we show that we can successfully use a SAT as well as a SMT solver to compute abductive explanations from this binary causal model. To illustrate our approach, we trained the BSNN on the standard MNIST dataset and applied our SAT-based and SMT-based methods to finding abductive explanations of the network's classifications based on pixel-level features. We also compared the found explanations against SHAP, a popular method used in the area of explainable AI. We show that, unlike SHAP, our approach guarantees that a found explanation does not contain completely irrelevant features.
SciIntegrity-Bench: AI 科学者システムにおける学術的誠実性を評価するためのベンチマーク
AI 科学者システムは自律的な研究のために導入されることが増えていますが、その学術的完全性が体系的に評価されたことはありません。ジレンマ的な評価パラダイムに基づいて設計された最初のベンチマークである SCINTEGRITY-BENCH を紹介します。11 のトラップ カテゴリにわたる 33 のシナリオのそれぞれは、失敗を正直に認めることが唯一の正しい対応であるように構築されていますが、タスクの完了には不正行為が必要です。 7 つの最先端 LLM にわたる 231 回の評価実行全体で、全体的な整合性問題の発生率は 34.2% に達し、障害ゼロを達成したモデルはありませんでした。最も驚くべきことに、欠損データのシナリオ全体にわたって、7 つのモデルすべてが実行不可能性を認めるのではなく、合成データを生成しており、その違いは置換を開示するかどうかだけです。さらにプロンプトアブレーション研究では、2 つの要因が分離されます。明示的な完了圧力を取り除くと、未公開の製造が 20.6% から 3.2% に大幅に減少しますが、基礎となる合成率は変化せず、プロンプトレベルの指示とは無関係に持続する本質的な完了バイアスが明らかになります。これらの調査結果は、観察された失敗の主な要因として、訓練された気質としての正直な拒否が存在しないことを示しています。 SCINTEGRITY-BENCH を https://github.com/liuxingtong/Sci-Integrity-Bench でリリースします。
原文 (English)
SciIntegrity-Bench: A Benchmark for Evaluating Academic Integrity in AI Scientist Systems
AI scientist systems are increasingly deployed for autonomous research, yet their academic integrity has never been systematically evaluated. We introduce SCIINTEGRITY-BENCH, the first benchmark designed around a dilemmatic evaluation paradigm: each of its 33 scenarios across 11 trap categories is constructed so that honest acknowledgment of failure is the only correct response, while task completion requires misconduct. Across 231 evaluation runs spanning 7 state-of-the-art LLMs, the overall integrity problem rate reaches 34.2%, and no model achieves zero failures. Most strikingly, across missing-data scenarios, all seven models generate synthetic data rather than acknowledging infeasibility, differing only in whether they disclose the substitution. A further prompt ablation study separates two drivers: removing explicit completion pressure sharply reduces undisclosed fabrication from 20.6% to 3.2%, while the underlying synthesis rate remains unchanged, revealing an intrinsic completion bias that persists independent of prompt-level instructions. These findings point to the absence of honest refusal as a trained disposition as the primary driver of observed failures. We release SCIINTEGRITY-BENCH at https://github.com/liuxingtong/Sci-Integrity-Bench.
見方が悪いのか、考えが悪いのか?マルチモーダル推論に対する報酬の知覚
堅牢な知覚推論の相乗効果を達成することは、高度な視覚言語モデル (VLM) の中心的な目標です。最近の進歩では、アーキテクチャ設計またはエージェント ワークフローを通じてこの目標が追求されています。 However, these approaches are often limited by static textual reasoning or complicated by the significant compute and engineering burden of external agentic complexity.さらに悪いことに、この多額の投資は比例した利益をもたらさず、認識と推論に「シーソー効果」が起こることがよくあります。これは、真のボトルネックについて根本的に再考する動機になります。 In this paper, we argue that the root cause of this trade-off is an ambiguity in modality credit assignment: when a VLM fails, is it due to flawed perception ("bad seeing") or flawed logic ("bad thinking")? To resolve this, we introduce a reinforcement learning framework that improves perception-reasoning synergy by reliably rewarding the perception fidelity.生成プロセスを、インターリーブされた認識ステップと推論ステップに明示的に分解します。この切り離しにより、知覚に対するターゲットを絞った監視が可能になります。 Crucially, we introduce Perception Verification (PV), leveraging a "blindfolded reasoning" proxy to reward perceptual fidelity independently of reasoning outcomes. Furthermore, to scale training across free-form VL tasks, we propose Structured Verbal Verification, which replaces high-variance LLM judging with structured algorithmic execution. These techniques are integrated into a Modality-Aware Credit Assignment (MoCA) mechanism, which routes rewards to the specific source of error -- either bad seeing or bad thinking -- enabling a single VLM to achieve simultaneous performance gains across a wide task spectrum.
原文 (English)
Bad Seeing or Bad Thinking? Rewarding Perception for Multimodal Reasoning
Achieving robust perception-reasoning synergy is a central goal for advanced Vision-Language Models (VLMs). Recent advancements have pursued this goal via architectural designs or agentic workflows. However, these approaches are often limited by static textual reasoning or complicated by the significant compute and engineering burden of external agentic complexity. Worse, this heavy investment does not yield proportional gains, often witnessing a "seesaw effect" on perception and reasoning. This motivates a fundamental rethinking of the true bottleneck. In this paper, we argue that the root cause of this trade-off is an ambiguity in modality credit assignment: when a VLM fails, is it due to flawed perception ("bad seeing") or flawed logic ("bad thinking")? To resolve this, we introduce a reinforcement learning framework that improves perception-reasoning synergy by reliably rewarding the perception fidelity. We explicitly decompose the generation process into interleaved perception and reasoning steps. This decoupling enables targeted supervision on perception. Crucially, we introduce Perception Verification (PV), leveraging a "blindfolded reasoning" proxy to reward perceptual fidelity independently of reasoning outcomes. Furthermore, to scale training across free-form VL tasks, we propose Structured Verbal Verification, which replaces high-variance LLM judging with structured algorithmic execution. These techniques are integrated into a Modality-Aware Credit Assignment (MoCA) mechanism, which routes rewards to the specific source of error -- either bad seeing or bad thinking -- enabling a single VLM to achieve simultaneous performance gains across a wide task spectrum.
タスク指向の対話で積極性を引き出す
アウトバウンド営業などのプロアクティブなタスク指向対話 (TOD) では、ユーザーの懸念を積極的に探り、限られたターン数内で受け入れられる方向に会話を導く説得力のあるエージェントが必要です。しかし、トレーニング後の LLM は本質的に保守的であり、報酬形成型 RL (GRPO など) は、すでに受動的なポリシーのサンプルを再加重するだけであるため、苦戦します。ユーザーの潜在的な懸念を条件付けすることで、どれだけサンプリングしても損なわれない事前対応型の機能が解放され、これらの懸念が極めて重要なトレーニング時間のシグナルとして確立されることを示します。この発見を運用するために、\textbf{認知ユーザー シミュレーター} を構築します。これは、各ユーザーを、目に見える外部特性と隠れた内部懸念からなる階層化されたペルソナとしてモデル化します。このシミュレーターは、説得の進行状況を追跡するターンごとの状態ダイナミクスを生成しながら、忠実で多様なインタラクションを生成します。次に、モデル化された懸念事項とシミュレーション状態の遷移を補完的なトレーニング目標に変換する \textbf{シミュレーターによる非対称ビュー ポリシーの最適化} を導入します。 (1) \emph{非対称オンポリシー自己蒸留} は、懸念事項を認識した動作を、同じポリシーの特権ビューからデプロイ可能な会話のみのビューに転送します。 (2) \emph{状態遷移ポリシーの改良} ...
原文 (English)
Unlocking Proactivity in Task-Oriented Dialogue
Proactive task-oriented dialogue (TOD), such as outbound sales, demands a persuasive agent that actively probes the user's concerns and steers the conversation toward acceptance within a bounded number of turns. Yet post-trained LLMs are inherently conservative, and reward-shaping RL (e.g., GRPO) struggles since it only re-weights what an already passive policy samples. We show that conditioning on the user's latent concerns unlocks proactive capability that no amount of sampling can undermine, establishing these concerns as a pivotal training-time signal. To operationalize this finding, we build the \textbf{Cognitive User Simulator}, which models each user as a stratified persona comprising observable external traits and hidden internal concerns. The simulator produces faithful and diverse interactions, while emitting per-turn state dynamics that track persuasion progress. We then introduce \textbf{Simulator-Induced Asymmetric-View Policy Optimization}, which converts the modeled concerns and the simulation state transition into complementary training objectives: (1) \emph{Asymmetric On-Policy Self-Distillation} that transfers concern-aware behavior from a privileged view of the same policy into its deployable, conversation-only view; and (2) \emph{State-Transition Policy Refinement} ...
AI を介した結果的な決定を選択するという幻想
ウルマン=マルガリットの選択の概念(変革的で、取り消し不可能で、差し押さえられた代替案によって影が隠れる)を利用して、現在の AI システムが、既存の AI 倫理が完全には捉えていない深刻な倫理的問題を提起していることを示します。それは、個人やグループが、真に選択できるようになるために必要な主体が弱体化している間に、意味のある結果的な選択の欺瞞的な外観に遭遇する選択の幻想です。 AI を主に既に与えられた目的の最適化装置として扱うアプローチに対して、私たちは、AI システムは選択という幻想からメタ能力を保護し育成するかどうかによって評価されるべきだと主張します。メタ能力とは、手段と目的を形成し、異議を唱え、修正し、所有することができる、社会的および制度的に足場を築かれた主体的能力のことです。この再構成は、AI を介した経路が行動や行動を誤った方向に導いた場合に、選択するという幻想のコストを吸収することが最も困難な恵まれない人々にとって特に緊急です。私たちは、AI を介した結果的意思決定のための 3 つの規範的命令を提案します。それは、予測の限界を認める実存的誠実さです。生態学的合理性。不均質な生きた生態の中に指針を位置づけます。そして、反事実的賠償。AI を介した意思決定経路が失敗した場合に、差し押さえられた代替手段を認めて修復します。
原文 (English)
The Illusion of Opting in AI-Mediated Consequential Decisions
Drawing on Ullmann-Margalit's concept of opting (transformative, irrevocable, and shadowed by foreclosed alternatives), we show that current AI systems raise a profound ethical problem that existing AI ethics has not fully captured: the illusion of opting, in which persons and groups encounter the deceptive appearance of meaningful consequential choice while the agency needed to become genuinely capable of choosing is weakened. Against approaches that treat AI primarily as an optimizer of already given ends, we argue that AI systems should be evaluated by whether they protect and cultivate meta-capacity against the illusion of opting: the socially and institutionally scaffolded agentive capacity through which means and ends can be formed, contested, revised, and owned. This reframing is especially urgent for disadvantaged populations, who are least able to absorb the costs of the illusion of opting when AI-mediated pathways misdirect behavior and action. We propose three normative imperatives for AI-mediated consequential decisions: existential honesty, which acknowledges the limits of prediction; ecological rationality, which situates guidance within heterogeneous lived ecologies; and counterfactual reparation, which acknowledges and repairs foreclosed alternatives when AI-mediated decision-making pathways fail.
SHARP: 長距離非定常時間パターン認識のための睡眠ベースの階層的加速再生
長距離の非定常時間パターンを学習することは、特に厳密なストリーミング設定において、現代のシーケンス モデルにとって依然として中心的な課題です。これらの設定では、データは順番に到着するため、過去の観測を同時に再検討することなく、単一パスで処理する必要があります。リカレント ニューラル ネットワークやトランスフォーマーを含む標準アーキテクチャは、時間軸全体にわたる切り詰められたバックプロパゲーション、または長距離クレジット割り当ての明示的な入力ウィンドウの長さによって制約されます。これらの制限に対処するために、私たちは、時間学習を 2 つの相補的なコンポーネントに分解するフレームワークである SHARP (Sleep-based Hierarchical Accelerated Replay) を提案します。1 つは過去の入力の構造化された履歴を蓄積するメモリ モジュール、もう 1 つはこのメモリ上で動作するパターン認識モジュールです。この分離により、長距離クレジット割り当ての多くのステップにわたる時間にわたるバックプロパゲーションの必要性がなくなり、非定常ダイナミクスへのリソース効率と計算効率の高い適応が可能になります。齧歯動物の徐波睡眠中に観察される再生の加速にヒントを得て、SHARP は、時間的に構造化された記憶追跡が加速された形で再生され、より高いレベルの記憶表現に統合されるオフライン (睡眠) フェーズを組み込んでおり、長距離のコンテキスト保持を向上させます。制御されたシミュレーションとアブレーション研究を通じて、提案されたフレームワークの主要な特性を特徴付けます。 text8 や PG-19 などのベンチマーク データセットでは、SHARP が、現在のストリームから学習を継続し、将来の未確認データに一般化しながら、以前に確認されたデータに対するネクスト トークン予測パフォーマンスを維持することにより、反復ベースラインよりも向上することを実証しました。これらの利点は、線形時間の計算コストのみで指数関数的に増加する効果的な時間コンテキストを生み出す階層構造によって実現されます。
原文 (English)
SHARP: Sleep-based Hierarchical Accelerated Replay for Long Range Non-Stationary Temporal Pattern Recognition
Learning long-range non-stationary temporal patterns remains a core challenge for modern sequence models, particularly in strict streaming settings. In these settings, data arrive sequentially and must be processed in a single pass without simultaneously revisiting past observations. Standard architectures, including recurrent neural networks and transformers, are constrained by either truncated backpropagation through time horizon or explicit input window length for long range credit assignment. To address these limitations, we propose SHARP (Sleep-based Hierarchical Accelerated Replay), a framework that decomposes temporal learning into two complementary components: a memory module that accumulates a structured history of past inputs, and a pattern-recognition module that operates over this memory. This separation enables resource- and compute-efficient adaptation to non-stationary dynamics by eliminating the need for backpropagation through time across many steps for long-range credit assignment. Inspired by the accelerated replay observed in rodents during slow-wave sleep, SHARP incorporates offline (sleep) phases in which temporally structured memory traces are replayed in an accelerated form and integrated into higher-level memory representations, improving long-range context retention. Through controlled simulations and ablation studies, we characterize the key properties of the proposed framework. In benchmark datasets such as text8 and PG-19, we demonstrate that SHARP improves over recurrent baselines by retaining next-token predictive performance on previously seen data while continuing to learn from the current stream and generalizing to future unseen data. These gains are enabled by its hierarchical structure, which yields an exponentially increasing effective temporal context with only linear-time computational cost.
サブリミナル学習はベクトル蒸留を操る
サブリミナル学習とは、教師の出力を微調整した場合に、出力が意味的にそれらの特性と無関係であるにもかかわらず、生徒の言語モデルが教師の特性 (システムが促すフクロウの好みなど) を獲得することを指します。セマンティックな意味を持たないデータがどのようにして特定のセマンティックな特徴を伝達できるのかについては、依然として十分に理解されていません。この研究では、サブリミナル学習が単一のステアリング ベクトル、つまりモデルの活性化に追加されるベクトルによって媒介されることを示します。 2 つのオープンソース モデル全体で、教師のシステム プロンプトはステアリング ベクトルによってよく近似されており、生徒の行動は微調整を通じて調整されたベクトルを学習することによって駆動されることがわかりました。ステアリング ベクトルによって適切に近似されていないシステム プロンプトは潜在的に学習されません。これは、ステアリング ベクトル蒸留の特殊なケースであり、ステアリングされた教師の出力で訓練された生徒が、そのステアリングを模倣することを学びます。一連のセマンティック ベクトルとランダム ベクトルに対するステアリング ベクトル蒸留を示します。モデルのアクティベーションにセマンティック ベクトルを追加すると、その動作にモデルに依存しない効果とモデル固有 (つまり、非セマンティック) の両方の効果が生じる可能性があるため、生成された非セマンティック データはセマンティック効果を持つベクトルを送信でき、サブリミナル学習が可能になります。これは、サブリミナル学習がモデル間で移行しない理由も説明します。言語モデルにおけるサブリミナル学習には適応オプティマイザーが必要であることがわかりました。ステアリングされたデータの活性化勾配はステアリング方向に沿って小さいながらも一貫した成分を運びますが、非適応オプティマイザーは外れ値の勾配が優勢になることを許可することでこれを妨げます。
原文 (English)
Subliminal Learning Is Steering Vector Distillation
Subliminal learning refers to a student language model acquiring a teacher's traits (e.g. a system-prompted preference for owls) when fine-tuned on the teacher's outputs, despite the outputs being semantically unrelated to those traits. It remains poorly understood how data without semantic meaning can transfer specific semantic traits. In this work, we show that subliminal learning is mediated by a single steering vector, i.e. a vector added to the model's activations. Across two open-source models, we find that the teacher's system prompt is well approximated by a steering vector, and that the student's behavior is driven by learning an aligned vector over fine-tuning. System prompts that are not well approximated by steering vectors are not subliminally learned. This is a special case of steering vector distillation, in which a student trained on the outputs of a steered teacher learns to imitate that steering. We demonstrate steering vector distillation on a range of semantic and random vectors. Adding a semantic vector to a model's activations can have both model-independent and model-specific (i.e. non-semantic) effects on its behavior, so generated data that is non-semantic can transmit a vector with semantic effects, enabling subliminal learning. This also explains why subliminal learning does not transfer between models. We find that adaptive optimizers are necessary for subliminal learning in language models: activation gradients on steered data carry a small but consistent component along the steering direction, and non-adaptive optimizers impede this by allowing outlier gradients to dominate.
AutoMedBench: Agentic AI モデルによる医療自動研究に向けて
自律エージェントは、個別の予測タスクや短い形式の臨床質問応答を超えて、エンドツーエンドの医療 AI 研究ワークフローをサポートすることがますます期待されています。ただし、既存の医療エージェントのベンチマークは主に最終出力を評価しており、研究プロセス内でのエージェントの行動に対する可視性は限られています。このギャップに対処するために、AutoMedBench は、さまざまな医療画像処理およびマルチモーダル推論タスクにわたる自律型医療 AI 研究のためのワークフロー認識ベンチマークであり、エージェントの実行を統合された 5 段階のワークフロー (S1 ~ S5) (計画、セットアップ、検証、推論、送信) に編成します。これは、セグメンテーション、画像強調、視覚的質問応答 (VQA)、レポート生成、および病変検出の 5 つの研究トラックにまたがる、各実行の平均 33 エージェント ターンの長期タスクで構成されています。各タスクは、Lite と Standard の 2 つの難易度で評価されます。これらは同じデータとメトリクスを使用しますが、タスク概要のスキャフォールディングの量が異なります。各実行は、最終タスクのパフォーマンスと S1 ~ S5 ステージ スコアの両方を使用してスコア付けされ、最初のタスク概要から最終的に提出された成果物までステージレベルの分析が可能になります。何千もの記録された実行を対象としたステージ レベルのスコアリングでは、平均して検証が最も弱いワークフロー ステージであるのに対し、セットアップが最も強いことが明らかになりました。これは、現在のエージェントが信頼性の検証よりもパイプラインを実行可能にすることに優れていることを示唆しています。さらに、実行後のエラー分析では、検証と送信の失敗がタグ付きエラーの大部分を占め、それぞれ起動されたコードの 37.7% と 38.1% を占めているのに対し、タスク理解エラーは 0.9% とまれで、起動されたエラー コードが 1 つある実行は、エラー コードがない実行よりも全体のスコアが平均 48% 低いことが示されています。
原文 (English)
AutoMedBench: Towards Medical AutoResearch with Agentic AI Models
Autonomous agents are increasingly expected to support end-to-end medical-AI research workflows, moving beyond isolated prediction tasks or short-form clinical question answering. However, existing medical agent benchmarks primarily evaluate final outputs, providing limited visibility into agent behavior within the research process. To address this gap, we present AutoMedBench, a workflow-aware benchmark for autonomous medical-AI research across diverse medical imaging and multimodal inference tasks, organizing agent execution into a unified five-stage workflow (S1-S5): Plan, Setup, Validate, Inference, and Submit. It comprises long-horizon tasks with each run averaging 33 agent turns, spanning five research tracks: segmentation, image enhancement, visual question answering (VQA), report generation, and lesion detection. Each task is evaluated under two difficulty tiers, Lite and Standard, which use the same data and metrics but differ in the amount of task-brief scaffolding, and each run is scored using both final task performance and S1-S5 stage scores, enabling stage-level analysis from the initial task brief to the final submitted artifact. Across thousands of recorded runs, stage-level scoring reveals that Validate is the weakest workflow stage on average, whereas Setup is the strongest, suggesting that current agents are better at making pipelines executable than at verifying their reliability. Post-run error analysis further shows that verification and submission failures dominate tagged errors, accounting for 37.7% and 38.1% of fired codes respectively, whereas task-understanding errors are rare at 0.9%, and runs with one fired error code have a 48% lower overall score than runs with no error code on average.
歯科医療における大規模 AI モデル: 汎用システムからドメイン固有の基盤モデルまで
背景: 口腔疾患は世界中で約 35 億人に影響を与えていますが、歯科における大規模 AI モデルの相対的な臨床的可能性は依然として十分に理解されていません。言語生成モデル、弁別視覚基礎モデル、歯科特有の基礎モデルという 3 つの異なるモデル カテゴリが出現しましたが、それらの関係や集合的な制限を検討する統一されたレビューはありません。方法: PRISMA-ScR ガイドラインに従って、4 つのデータベース (PubMed、Google Scholar、Scopus、arXiv) を体系的に検索し、2 人の査読者によって独立してスクリーニングされました。包含/除外基準を適用した後、97 件の研究 (2020 ~ 2026 年) が含まれました。建築パラダイムと歯科専門度によってモデルを整理する二次元分類フレームワークを提案します。結果: 言語生成モデルは、テキストベースのタスク (臨床推論、免許試験、患者とのコミュニケーション) には優れていますが、画像依存の診断では一貫性のないパフォーマンスを示します。適応された SAM および CLIP バリアントにより、強力な歯のセグメンテーションと病変検出結果が得られます。歯科専用モデル (DentVFM、DentVLM、OralGPT) は、複雑なマルチモーダルなタスクで最高のパフォーマンスを発揮します。統合されたパイプラインは、単一モデルのアプローチよりも常に優れたパフォーマンスを発揮します。データの非対称性が観察されます。歯科特有の事前トレーニングはほぼ完全に視覚領域に集中しており、大規模な歯科テキスト コーパスがほとんどないことを反映しています。結論: 汎用モデルと歯科専用モデルは補完的な役割を果たします。最も効果的なシステムは、構造化されたパイプライン内で両方を組み合わせたものです。安全な自律展開には、生成モデルにおける幻覚、注釈付き歯科データセットの制限、標準化された臨床評価ベンチマークの欠如という 3 つの永続的な障壁を解決する必要があります。
原文 (English)
Large AI Models in Dental Healthcare: From General-Purpose Systems to Domain-Specific Foundation Models
Background: Oral diseases affect nearly 3.5 billion people worldwide, yet the comparative clinical potential of large-scale AI models in dentistry remains poorly understood. Three distinct model categories have emerged: language-generative models, discriminative vision foundation models, and dental-specific foundation models, with no unified review examining their relationships and collective limitations. Methods: Following PRISMA-ScR guidelines, we systematically searched four databases (PubMed, Google Scholar, Scopus, arXiv), screened independently by two reviewers. After applying inclusion/exclusion criteria, 97 studies (2020-2026) were included. We propose a two-dimensional classification framework organizing models by architectural paradigm and dental specialization degree. Results: Language-generative models excel at text-based tasks (clinical reasoning, licensing exams, patient communication) but show inconsistent performance on image-dependent diagnostics. Adapted SAM and CLIP variants achieve strong tooth segmentation and lesion detection results. Dental-specific models (DentVFM, DentVLM, OralGPT) demonstrate strongest performance on complex multimodal tasks. Integrated pipelines consistently outperform single-model approaches. A data asymmetry is observed: dental-specific pretraining concentrates almost entirely in the vision domain, reflecting scarce large-scale dental text corpora. Conclusions: General-purpose and dental-specific models play complementary roles; the most effective systems combine both within structured pipelines. Safe autonomous deployment requires resolving three persistent barriers: hallucination in generative models, limited annotated dental datasets, and absent standardized clinical evaluation benchmarks.
LEAP: エージェント フレームワークを使用した形式数学用の LLM のスーパーチャージング
大規模言語モデル (LLM) は強力な非公式数学的推論を示しますが、リーンのような形式言語では機械的に検証可能な証明を生成するのに苦労します。 LEAP は、汎用基礎モデルが自動化された形式定理証明で最先端のパフォーマンスを達成できるようにするエージェント フレームワークです。 LEAP は、非公式推論、指示に従って、反復的な自己改善などの基礎モデルの機能を活用します。複雑な問題をより小さな単位に分解することで、システムはリーン コンパイラーとの継続的な対話を通じて、正式な証明の構築と非公式のブループリントの橋渡しをします。ますます飽和しつつあるベンチマークを超えた厳密な評価を提供するために、リーンで形式化された IMO スタイルの問題のベンチマークである Lean-IMO-Bench を導入します。このベンチマークでは、短いステートメントでありながら非常に非日常的で、幅広い難易度にわたる複数ステップの証明が行われます。経験的に、北米の学部学生を対象とした毎年恒例の数学コンテストである最新の 2025 年のパトナム コンペティションでは、LEAP は 12 の問題すべてを解決し、フロンティアの正式な数学モデルによる最近の進歩と一致しています。 Lean-IMO-Bench では、LEAP は汎用 LLM のワンショット形式解決率を 10% 未満から 70% に引き上げ、特に金メダル級の専門化された IMO システムによって設定されたベンチマークの 48% を上回っています。さらに、偶数次ケイリーグラフのクヌースのハミルトニアン分解における重要な部分問題の検証された証明を含む、オープンな組み合わせ課題に対する複雑な証明を自律的に形式化することで、LEAP の研究レベルの有用性を実証します。
原文 (English)
LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks
Large Language Models (LLMs) exhibit strong informal mathematical reasoning but struggle to generate mechanically verifiable proofs in formal languages like Lean. We present LEAP, an agentic framework that enables general-purpose foundation models to achieve state-of-the-art performance on automated formal theorem proving. LEAP leverages foundation model capabilities, such as informal reasoning, instruction following, and iterative self-refinement. By decomposing complex problems into smaller units, the system bridges formal proof construction with informal blueprints through continuous interaction with the Lean compiler. To provide a rigorous evaluation beyond increasingly saturated benchmarks, we introduce Lean-IMO-Bench, a benchmark of IMO-style problems formalized in Lean, with short statements yet highly non-routine and multi-step proofs across a wide range of difficulty levels. Empirically, on the latest 2025 Putnam Competition, an annual mathematics competition for undergraduate students in North America, LEAP solves all 12 problems, matching recent breakthroughs by frontier formal mathematical models. On Lean-IMO-Bench, LEAP boosts the one-shot formal solve rate of general-purpose LLMs from below 10% to 70%, notably surpassing the 48% benchmark set by a specialized, gold-medal-caliber IMO system. Furthermore, we demonstrate LEAP's research-level utility by autonomously formalizing complex proofs for open combinatorial challenges, including a verified proof for a key subproblem in Knuth's Hamiltonian decomposition of even-order Cayley graphs.
答えから状態へ: 大規模言語モデルにおける化学推論の検証可能なプロセスレベルの評価
大規模な言語モデルが化学アシスタントとして使用されることが増えていますが、ほとんどの化学ベンチマークは依然として最終的な回答のみをスコアとしています。これにより、重大な故障モードが隠蔽されます。モデルは、その推論が化学ロジックに違反しているにもかかわらず、正しい分子、生成物、またはオプションを出力する可能性があります。 LLM ジャッジと人間のステップレベルのプロセス アノテーションはコストが高く、一貫性がなく、幻覚に対して脆弱であるため、既存のプロセス レベルの評価機能を拡張するのは困難です。 ChemCoTBench-V2 は、構造化され検証者がアドレス指定できる化学推論トレースを低コストで監査可能に評価するためのルール検証可能な診断ベンチマークです。これは、分子理解、分子編集、分子最適化、反応予測に及び、18 のレポートタスクにわたる 5,620 の評価サンプルを備えています。モデルは、専門家が設計したテンプレートで主要な中間ステップを公開する必要があり、それらのステップは決定論的な化学ルールでチェックされ、クローズドアンサータスクの場合は、別の LLM 審査員ではなく参照トレースが使用されます。オープンエンド分子最適化は、厳密なトレース マッチングではなく、Oracle で検証可能な状態制約を使用して評価されます。このベンチマークは、最終回答の正確性、テンプレートの遵守、専門家によって洗練された中間コミットメントに対する段階的な検証者の正確さという 3 つの個別のシグナルを報告します。フロンティア モデルの実験では、最終的な回答の成功と構造化推論の状態の一貫性の間には永続的なギャップがあることが明らかになりました。モデルは多くの場合、化学ステップ チェックに失敗しながらも要求された形式に従っているか、弱い裏付け推論で正しく回答することができます。 ChemCoTBench-V2 は、きめ細かいモデル比較を可能にし、トレースが最初に検証ツールに違反する具体的なステップを特定します。
原文 (English)
From Answers to States: Verifiable Process-Level Evaluation of Chemical Reasoning in Large Language Models
Large language models are increasingly used as chemistry assistants, yet most chemistry benchmarks still score only final answers. This masks a critical failure mode: a model may output the correct molecule, product, or option while its reasoning violates chemical logic. Existing process-level evaluators are hard to scale because LLM judges and human step-level process annotation are costly, inconsistent, and vulnerable to hallucination. We introduce ChemCoTBench-V2, a rule-verifiable diagnostic benchmark for low-cost, auditable evaluation of structured, verifier-addressable chemical reasoning traces. It spans molecular understanding, molecule editing, molecular optimization, and reaction prediction, with 5,620 evaluation samples across 18 reporting tasks. Models must expose key intermediate steps in expert-designed templates, and those steps are checked with deterministic chemistry rules and, for closed-answer tasks, reference traces rather than another LLM judge. Open-ended molecular optimization is evaluated with oracle-verifiable state constraints rather than strict trace matching. The benchmark reports three separate signals: final-answer correctness, template adherence, and step-wise verifier correctness over expert-refined intermediate commitments. Experiments on frontier models reveal a persistent gap between final-answer success and structured-reasoning-state consistency: models often follow the requested format while failing chemical-step checks, or answer correctly with weak supporting reasoning. ChemCoTBench-V2 enables fine-grained model comparison and identifies the concrete step at which the trace first violates the verifier.
エントロピーだけでは不十分: ビジョンに基づいたトークン選択による視覚的推論のための効果的な強化学習のロックを解除する
トークンレベルのエントロピーは、検証可能な報酬を伴うテキストのみの強化学習 (RLVR) における単位の割り当てに有効であると一般に認識されていますが、このメカニズムが視覚的推論に依然として適用されるかどうかは不明のままです。私たちの対照的な研究は、自然にエントロピーが低い視覚に敏感なトークンの省略により、視覚推論ではこのメカニズムが崩壊することを示しています。既存のマルチモーダル RL 手法は、視覚認識の重要性をますます認識していますが、体系的な視覚測定が欠けているか、トークンのエントロピーが主に意味論的探索を推進していることを見落としているため、正確な知覚基礎と意味論的推論を交互に配置するという固有の需要を満たすのに苦労しています。これに対処するために、原則的な乗算結合を介して視覚的感度とトークン エントロピーを明示的に統合する効果的な RL フレームワークである VEPO (ポリシー最適化のためのビジョン エントロピー トークン選択) を導入します。VEPO は、視覚的に根拠があり、同時に高度に情報を提供するトークンに勾配クレジットをリダイレクトします。広範な実験により、VEPO の優れたパフォーマンスが実証され、エントロピーのみのベースラインを 7B スケールで 2.28 ポイント、3B スケールで 3.15 ポイント上回りました。アブレーションは、私たちの方法の健全性をさらに実証します。
原文 (English)
Entropy Is Not Enough: Unlocking Effective Reinforcement Learning for Visual Reasoning via Vision-Anchored Token Selection
While token-level entropy is commonly recognized as effective for credit assignment in text-only reinforcement learning with verifiable rewards (RLVR), it remains unclear whether this mechanism still holds in visual reasoning. Our controlled study shows that this mechanism collapses in visual reasoning due to the omission of vision-sensitive tokens with naturally low entropy. Although existing multimodal RL methods increasingly acknowledge the importance of visual perception, they struggle to satisfy the inherent demand for interleaving precise perceptual grounding with semantic reasoning, either lacking systematic visual measurements or overlooking that token entropy primarily drives semantic exploration. To address this, we introduce VEPO (Vision-Entropy token-selection for Policy Optimization), an effective RL framework explicitly integrating visual sensitivity with token entropy via a principled multiplicative coupling, where VEPO redirects gradient credit toward tokens which are simultaneously visually grounded and highly informative. Extensive experiments demonstrate VEPO's leading performance, significantly outperforming the entropy-only baseline by 2.28 points at 7B-scale and 3.15 points at 3B-scale. Ablations further substantiate the soundness of our method.
想像力の知覚トークンはマルチモーダル言語モデルの空間推論を強化します
ビジョン言語モデル (VLM) は多くのタスクに優れていますが、重要な情報が直接観察できない場合には空間推論に依然として苦労します。このような問題の多くは、目に見えない視点から何が見えるかを推測したり、遮蔽された空間を通る経路を追跡したり、部分的な観察を一貫した空間表現に統合したりするなど、想像力豊かな認識を必要とします。観察された入力との一貫性を保ちながら、代替の空間構成の下で VLM が知覚するものを外部化する中間的な知覚表現である想像的知覚トークン (IPT) を導入します。この機能を研究するために、透視図法取得 (PET)、パス トレーシング (PT)、およびマルチビュー カウンティング (MVC) という 3 つのタスクを定式化し、グラウンド トゥルースの想像力、回答、評価ベンチマークを含む約 20,000 例のデータセットを構築します。統合された VLM BAGEL をバックボーンとして使用することで、IPT 監視は空間推論を一貫して改善し、推論時に画像を生成しなくても、テキストによる思考連鎖トレーニングを上回ることがよくあります。 MVC では、IPT は精度を 3.4% 向上させ、PT 上の強力なクローズドソース モデルにより競争力のあるパフォーマンスを実現します。さらに、IPT とラベルのみの監視を組み合わせるとさらなる利益が得られる一方、テキストの思考連鎖はパフォーマンスを大幅に低下させる可能性があることがわかり、空間計算が言語を通じて強制される場合にはモダリティの不一致が示唆されます。全体として、IPT は、観察されていない空間構造について推論するための原則に基づいた監視信号を提供し、解釈可能な中間表現を生成しながら一般化を向上させます。
原文 (English)
Imaginative Perception Tokens Enhance Spatial Reasoning in Multimodal Language Models
Vision language models (VLMs) excel at many tasks but still struggle with spatial reasoning when critical information is not directly observable. Many such problems require imaginative perception: inferring what would be seen from an unseen viewpoint, tracing paths through occluded spaces, or integrating partial observations into a coherent spatial representation. We introduce Imaginative Perception Tokens (IPT), intermediate perceptual representations that externalize what a VLM would perceive under alternative spatial configurations while remaining consistent with the observed input. To study this capability, we formulate three tasks, Perspective Taking (PET), Path Tracing (PT), and Multiview Counting (MVC), and construct datasets of approximately 20K examples with ground truth imaginations, answers, and evaluation benchmarks. Using the unified VLM BAGEL as the backbone, IPT supervision consistently improves spatial reasoning and often outperforms textual chain of thought training, even without generating images at inference time. On MVC, IPT improves accuracy by 3.4% and achieves competitive performance with strong closed-source models on PT. We further find that combining IPT and label-only supervision yields additional gains, whereas textual chain of thought can substantially degrade performance, suggesting a modality mismatch when spatial computation is forced through language. Overall, IPT provides a principled supervision signal for reasoning about unobserved spatial structure, improving generalization while producing interpretable intermediate representations.
変圧器ベースの自動運転モデルと展開指向の圧縮: 調査
トランスベースのモデルは、長距離の空間依存関係、マルチエージェントのインタラクション、認識、予測、計画にわたるマルチモーダルなコンテキストをキャプチャできるため、自動運転の中心的なパラダイムになりつつあります。同時に、大容量のアテンションベースのアーキテクチャはかなりの遅延、メモリ、エネルギーのオーバーヘッドを課すため、実際の車両への導入は依然として困難です。この調査では、代表的な Transformer ベースの自動運転モデルをレビューし、それらをタスクの役割、センシング構成、アーキテクチャ設計ごとに整理します。さらに重要なのは、展開指向の観点からこれらのモデルを検証し、効率の制約が実際にモデル設計の選択肢をどのように再形成するかを分析することです。さらに、量子化、枝刈り、知識蒸留、低ランク近似、効率的な注意など、Transformer ベースの駆動システムに関連する圧縮および加速戦略をレビューし、その利点、限界、およびタスク依存の適用可能性について説明します。圧縮を独立した後処理ステップとして扱うのではなく、展開性、堅牢性、安全性に直接影響を与えるシステムレベルの設計上の考慮事項として強調します。最後に、効率的な自動運転システムの標準化された、安全性を意識した、ハードウェアを意識した評価に向けた未解決の課題と将来の研究の方向性を特定します。
原文 (English)
Transformer-Based Autonomous Driving Models and Deployment-Oriented Compression: A Survey
Transformer-based models are becoming a central paradigm in autonomous driving because they can capture long-range spatial dependencies, multi-agent interactions, and multimodal context across perception, prediction, and planning. At the same time, their deployment in real vehicles remains difficult because high-capacity attention-based architectures impose substantial latency, memory, and energy overhead. This survey reviews representative Transformer-based autonomous driving models and organizes them by task role, sensing configuration, and architectural design. More importantly, it examines these models from a deployment-oriented perspective and analyzes how efficiency constraints reshape model design choices in practice. We further review compression and acceleration strategies relevant to Transformer-based driving systems, including quantization, pruning, knowledge distillation, low-rank approximation, and efficient attention, and discuss their benefits, limitations, and task-dependent applicability. Rather than treating compression as an isolated post-processing step, we highlight it as a system-level design consideration that directly affects deployability, robustness, and safety. Finally, we identify open challenges and future research directions toward standardized, safety-aware, and hardware-conscious evaluation of efficient autonomous driving systems.
ChatSOP: 制御可能な LLM 対話エージェントのための SOP ガイド付き MCTS 計画フレームワーク
Large Language Model (LLM) を利用した対話エージェントは、さまざまなタスクで優れたパフォーマンスを示します。ユーザーの理解が深まり、人間らしい応答ができるようになったにもかかわらず、ユーザーの*制御性の欠如**は依然として重要な課題であり、焦点の合わない会話やタスクの失敗につながることがよくあります。これに対処するために、対話の流れを規制する標準操作手順 (SOP) を導入します。具体的には、LLM 駆動の対話エージェントの制御性を強化するために設計された新しい SOP ガイド付きモンテカルロ木探索 (MCTS) 計画フレームワークである **ChatSOP** を提案します。これを可能にするために、GPT-4o を備えた半自動ロールプレイング システムを使用して生成され、厳格な手動品質管理を通じて検証された、SOP アノテーション付きのマルチシナリオ対話で構成されるデータセットを厳選しました。さらに、SOP予測のための教師あり微調整と思考連鎖推論を統合し、対話中に最適な行動計画を立てるためにSOPに基づくモンテカルロ木探索を利用する新しい方法を提案します。実験結果は、GPT-3.5 に基づくベースライン モデルと比較してアクション精度の 27.95% の向上を達成し、オープンソース モデルでも顕著な向上を示すなど、私たちの方法の有効性を示しています。データセットとコードは公開されています。
原文 (English)
ChatSOP: An SOP-Guided MCTS Planning Framework for Controllable LLM Dialogue Agents
Dialogue agents powered by Large Language Models (LLMs) show superior performance in various tasks. Despite the better user understanding and human-like responses, their **lack of controllability** remains a key challenge, often leading to unfocused conversations or task failure. To address this, we introduce Standard Operating Procedure (SOP) to regulate dialogue flow. Specifically, we propose **ChatSOP**, a novel SOP-guided Monte Carlo Tree Search (MCTS) planning framework designed to enhance the controllability of LLM-driven dialogue agents. To enable this, we curate a dataset comprising SOP-annotated multi-scenario dialogues, generated using a semi-automated role-playing system with GPT-4o and validated through strict manual quality control. Additionally, we propose a novel method that integrates Chain of Thought reasoning with supervised fine-tuning for SOP prediction and utilizes SOP-guided Monte Carlo Tree Search for optimal action planning during dialogues. Experimental results demonstrate the effectiveness of our method, such as achieving a 27.95% improvement in action accuracy compared to baseline models based on GPT-3.5 and also showing notable gains for open-source models. Dataset and codes are publicly available.
CounterFace: 顔認識システムのきめ細かい反事実評価のための合成顔データセット
顔認識 (FR) システムは重要なアプリケーションに広く導入されており、多様な人口や条件に対する信頼性と堅牢性が不可欠となっています。 FR システムの標準評価は通常、LFW などのデータセットに依存して平均認識精度を推定します。一部のベンチマークは、経年変化、姿勢、照明などの粗粒度のアイデンティティ内の変動も捕捉します。ただし、人間の顔には、ヘアスタイルやメイクなどの外観の変化を含む、より細かい変化が生じますが、これは既存のベンチマークでは過小評価されています。反事実評価は、このようなきめの細かい変動の下で FR の堅牢性を評価する方法を提供します。ただし、画像ジェネレーターを使用して合成された既存の反事実の顔データセットは、パイプラインでの検証に人間が使用されているため、属性の範囲が限られています。我々は、20 の顔属性と 8 つの人口統計的要素で構成される新しい反事実評価データセットである CounterFace を提案します。これは、以前の合成顔データセットを 14 属性と 2 つの人口統計的要因で上回っています。データセットは、カスタム検証機能を備えた既製の画像ジェネレーターに基づいた完全に自動化されたパイプラインを使用して生成され、人間による検証の必要性がなくなりました。 CounterFace には 11,821 の反事実の顔のペアが含まれており、事後のユーザー調査により、生成された反事実の忠実性が確認されています。 160 の属性と人口統計の組み合わせにわたって、2 つの商用 FR システムと 4 つのオープンソース FR システム (AWS Rekognition、Face++、AdaFace、MagFace、ArcFace、FaceNet) を評価します。当社のデータセットは、標準の評価ベンチマークとは異なり、個々のシステムの正確な故障モードを分離するのに役立ちます。結果は、パフォーマンスの低下は 6 つすべてのシステムの属性と人口統計によって異なり、遮蔽属性 (フェイスマスクやひげなど) が普遍的にパフォーマンスを低下させることを示しています。
原文 (English)
CounterFace: A Synthetic Face Dataset for Fine-Grained Counterfactual Evaluation of Face Recognition Systems
Face recognition (FR) systems are widely deployed in critical applications, making their reliability and robustness across diverse populations and conditions essential. Standard evaluation of FR systems typically relies on datasets such as LFW to estimate average recognition accuracy. Some benchmarks also capture coarse-grained intra-identity variations such as aging, pose, and lighting. However, human faces undergo more fine-grained changes, including appearance changes such as hairstyles and makeup, that are underrepresented in existing benchmarks. Counterfactual evaluation provides a method to assess FR robustness under such fine-grained variations. Existing counterfactual face datasets synthesized with image generators, however, are limited in attribute coverage due to the use of humans for verification in the pipeline. We propose CounterFace, a new counterfactual evaluation dataset comprising 20 facial attributes and 8 demographic factors, exceeding prior synthetic face datasets by 14 attributes and 2 demographics. The dataset is generated using a fully automated pipeline based on off-the-shelf image generators with custom verifiers, removing human need for verification. CounterFace contains 11,821 counterfactual face pairs, and a post-hoc user study confirms the faithfulness of the generated counterfactuals. We evaluate two commercial and four open-source FR systems (AWS Rekognition, Face++, AdaFace, MagFace, ArcFace, FaceNet) across 160 attribute-demographic combinations. Our dataset helps in the isolation of precise failure modes for individual systems unlike standard evaluation benchmarks. Results indicate that the performance degradation varies across attributes and demographics for all six systems and occluding attributes (e.g., facemask and facial hair) universally degrade performance.
SSSD: シンプルにスケーラブルな投機的デコーディング
投機的デコーディングは、大規模言語モデルで推論を高速化するための一般的な手法として登場しました。ただし、既存のアプローチのほとんどは、運用サービス システムにわずかな改善しかもたらしません。大幅な高速化を実現するメソッドは通常、追加のトレーニング済みドラフト モデルまたは補助モデル コンポーネントに依存しており、展開とメンテナンスの複雑さが増大します。この複雑さの追加により、特にドラフト モデルのトレーニング データで十分に表現されていないタスク、ドメイン、または言語にワークロードを移行する場合に、柔軟性が低下します。私たちは、軽量の N グラム マッチングとハードウェア対応の投機を組み合わせたトレーニング不要の手法である Simply-Scalable Speculative Decoding (SSSD) を紹介します。標準の自己回帰デコーディングと比較して、SSSD はレイテンシーを最大 2.9 倍削減します。幅広いベンチマークにわたって、主要なトレーニングベースのアプローチと同等のパフォーマンスを達成しながら、導入の労力が大幅に軽減され(データの準備、トレーニング、チューニングは必要ありません)、言語やドメインの変更や長いコンテキスト設定でも優れた堅牢性を示します。
原文 (English)
SSSD: Simply-Scalable Speculative Decoding
Speculative Decoding has emerged as a popular technique for accelerating inference in Large Language Models. However, most existing approaches yield only modest improvements in production serving systems. Methods that achieve substantial speedups typically rely on an additional trained draft model or auxiliary model components, increasing deployment and maintenance complexity. This added complexity reduces flexibility, particularly when serving workloads shift to tasks, domains, or languages that are not well represented in the draft model's training data. We introduce Simply-Scalable Speculative Decoding (SSSD), a training-free method that combines lightweight n-gram matching with hardware-aware speculation. Relative to standard autoregressive decoding, SSSD reduces latency by up to 2.9x. It achieves performance on par with leading training-based approaches across a broad range of benchmarks, while requiring substantially lower adoption effort--no data preparation, training or tuning are needed--and exhibiting superior robustness under language and domain shift, as well as in long-context settings.
LaVIDE: 地図と画像の位置合わせによる言語による衛星変化の検出
地図参照と最新の画像に基づくリモート センシングによる変化検出により、比較対象となる以前の画像が不足している場合でも、地表のタイムリーな観察が促進されます。ただし、高レベルのマップ カテゴリと低レベルの画像詳細の間の意味上のギャップにより、変化検出における堅牢な時間的関連性のための均一な特徴の抽出が妨げられます。ピクセル レベルの視覚的な類似性を比較したり、セグメンテーション エラーを伝播したりする従来のアプローチとは異なり、\textcolor{black}{私たちは、言語を媒介として高レベルの地図カテゴリと低レベルの画像詳細の間の意味論的なギャップを埋める、\underline{La}nguage-\underline{VI}sion \underline{D}iscriminator for d\underline{E}tecting変更であるLaVIDE}という新しいフレームワークを提案します。具体的には、マップのセマンティクスを画像コンテンツと一致させるコンテキスト認識型のテキスト プロンプトを生成するための {\it 制限付きプロンプト学習} と、オブジェクト レベルの属性 (形状、境界など) をマップ表現に統合するための {\it オブジェクト認識埋め込み強化} 戦略を導入します。これらのコンポーネントにより、統一された言語と視覚の機能空間内での堅牢なクロスモーダル調整が可能になります。 DynamicEarthNet、HRSCD、BANDON、SECOND の 4 つのベンチマークに関する広範な実験により、LaVIDE が最先端の手法を大幅に上回り、マルチクラスおよびシングルクラスの変更検出タスクでそれぞれ IoU が $18.4\%$ および $5.2\%$ 向上することが実証されました。私たちのフレームワークは、地図画像の変化検出の精度を向上させるだけでなく、人間の介入を最小限に抑えて迅速な地図更新を実現する実用的なソリューションを提供し、都市計画、災害評価、生態保全に幅広い影響を与えることが期待されています。コードとデータセットは https://github.com/ShuGuoJ/LAVIDE.git から入手できます。
原文 (English)
LaVIDE: Language-Prompted Satellite Change Detection via Map-Image Alignment
Remote sensing change detection based on a map reference and an up-to-date image boosts timely observation of the Earth's surface when earlier images are lacking for comparison. However, the semantic gap between high-level map categories and low-level image details hinders the extraction of homogeneous features for robust temporal association in change detection. Unlike conventional approaches that either compare pixel-level visual similarity or propagate segmentation errors, \textcolor{black}{we propose a novel framework, \underline{La}nguage-\underline{VI}sion \underline{D}iscriminator for d\underline{E}tecting changes, LaVIDE}, which bridges the semantic gap between high-level map categories and low-level image details using language as an intermediary. Specifically, we introduce {\it restricted prompt learning} to generate context-aware textual prompts that align map semantics with image content, and an {\it object-aware embedding enhancement} strategy to integrate object-level attributes (e.g., shape, boundary) into map representations. These components enable robust cross-modal alignment within a unified language-vision feature space. Extensive experiments on four benchmarks, DynamicEarthNet, HRSCD, BANDON, and SECOND, demonstrate that LaVIDE outperforms state-of-the-art methods by significant margins, achieving $18.4\%$ and $5.2\%$ improvements in IoU on multi-class and single-class change detection tasks, respectively. Our framework not only advances the accuracy of map-image change detection but also provides a practical solution for rapid map updating with minimal human intervention, promising broad impacts in urban planning, disaster assessment, and ecological conservation. Code and datasets are available at: https://github.com/ShuGuoJ/LAVIDE.git.
運動信号から洞察まで: 体育の授業における生徒の行動分析とフィードバックのための統一フレームワーク
教育シナリオにおける生徒の行動を分析することは、教育の質と生徒の関与を高めるために非常に重要です。既存の AI ベースのモデルは、多くの場合、生徒の行動を特定して分析するために教室のビデオ映像に依存しています。これらのビデオベースの方法は、生徒の行動を部分的に捉えて分析することはできますが、屋外のオープンスペースで多様な活動が行われる体育の授業では、各生徒の行動を正確に追跡するのに苦労しており、これらの設定に含まれる特殊な技術的な動きに一般化するのは困難です。さらに、現在の方法には通常、専門的な教育知識を統合する機能が欠けており、生徒の行動に対する深い洞察を提供し、指導設計を最適化するためのフィードバックを提供する能力が制限されています。これらの制限に対処するために、私たちは、運動信号に基づく人間の活動認識技術を活用し、高度な大規模言語モデルと組み合わせて、体育の授業における生徒の行動のより詳細な分析とフィードバックを行う、統合されたエンドツーエンドのフレームワークを提案します。私たちのフレームワークは、教師の指導デザインと体育セッション中の生徒からの動作信号から始まり、最終的には学習とクラス指導の両方を改善するための指導上の洞察と提案を含む自動レポートを生成します。このソリューションは、生徒の行動を分析し、体育の授業に合わせた指導設計を最適化するための動作信号ベースのアプローチを提供します。実験結果は、私たちのフレームワークが生徒の行動を正確に特定し、有意義な教育学的洞察を生み出すことができることを示しています。
原文 (English)
From Motion Signals to Insights: A Unified Framework for Student Behavior Analysis and Feedback in Physical Education Classes
Analyzing student behavior in educational scenarios is crucial for enhancing teaching quality and student engagement. Existing AI-based models often rely on classroom video footage to identify and analyze student behavior. While these video-based methods can partially capture and analyze student actions, they struggle to accurately track each student's actions in physical education classes, which take place in outdoor, open spaces with diverse activities, and are challenging to generalize to the specialized technical movements involved in these settings. Furthermore, current methods typically lack the ability to integrate specialized pedagogical knowledge, limiting their ability to provide in-depth insights into student behavior and offer feedback for optimizing instructional design. To address these limitations, we propose a unified end-to-end framework that leverages human activity recognition technologies based on motion signals, combined with advanced large language models, to conduct more detailed analyses and feedback of student behavior in physical education classes. Our framework begins with the teacher's instructional designs and the motion signals from students during physical education sessions, ultimately generating automated reports with teaching insights and suggestions for improving both learning and class instructions. This solution provides a motion signal-based approach for analyzing student behavior and optimizing instructional design tailored to physical education classes. Experimental results demonstrate that our framework can accurately identify student behaviors and produce meaningful pedagogical insights.
投機的思考: 推論時の大規模モデルのガイダンスによる小規模モデル推論の強化
最近の進歩では、ポストトレーニングを利用してモデル推論のパフォーマンスを向上させていますが、これには通常、高価なトレーニング パイプラインが必要であり、依然として非効率で長すぎる出力に悩まされています。トークン レベルで動作する投機的デコードとは異なり、推論レベルでの推論中に大規模な推論モデルが小規模な推論モデルをガイドできるようにする、トレーニング不要のフレームワークである投機的思考を紹介します。私たちのアプローチは 2 つの観察に基づいています。(1) 「wait」などの推論をサポートするトークンは、「\n\n」などの構造区切り文字の後に頻繁に出現し、反映または継続の信号として機能します。 (2) より大きなモデルは、反射的な動作に対するより強力な制御を示し、推論の品質を向上させながら不必要な後戻りを減らします。反射ステップをより有能なモデルに戦略的に委任することで、私たちの方法は、出力を短縮しながら推論モデルの推論精度を大幅に向上させます。 32B 推論モデルの支援により、1.5B モデルの MATH500 の精度は 83.2% から 89.4% に増加し、6.2% の大幅な改善を記録しました。同時に、平均出力長は 5439 トークンから 4583 トークンに減少し、これは 15.7% の減少に相当します。さらに、非推論モデル (Qwen-2.5-7B-Instruct) に適用すると、私たちのフレームワークは同じベンチマークで精度が 74.0% から 81.8% に向上し、7.8% の相対的な改善を達成しました。
原文 (English)
Speculative Thinking: Enhancing Small-Model Reasoning with Large Model Guidance at Inference Time
Recent advances leverage post-training to enhance model reasoning performance, which typically requires costly training pipelines and still suffers from inefficient, overly lengthy outputs. We introduce Speculative Thinking, a training-free framework that enables large reasoning models to guide smaller ones during inference at the reasoning level, distinct from speculative decoding, which operates at the token level. Our approach is based on two observations: (1) reasoning-supportive tokens such as "wait" frequently appear after structural delimiters like "\n\n", serving as signals for reflection or continuation; and (2) larger models exhibit stronger control over reflective behavior, reducing unnecessary backtracking while improving reasoning quality. By strategically delegating reflective steps to a more capable model, our method significantly boosts the reasoning accuracy of reasoning models while shortening their output. With the assistance of the 32B reasoning model, the 1.5B model's accuracy on MATH500 increases from 83.2% to 89.4%, marking a substantial improvement of 6.2%. Simultaneously, the average output length is reduced from 5439 tokens to 4583 tokens, representing a 15.7% decrease. Moreover, when applied to a non-reasoning model (Qwen-2.5-7B-Instruct), our framework boosts its accuracy from 74.0% to 81.8% on the same benchmark, achieving a relative improvement of 7.8%.
SoLoPO: ショートからロングへの優先設定の最適化による LLM のロングコンテキスト機能のロック解除
拡張されたコンテキスト サイズによる事前トレーニングの進歩にも関わらず、大規模言語モデル (LLM) は、実世界の長いコンテキスト情報を効果的に利用するという課題に依然として直面しています。これは主に、データ品質の問題、トレーニングの非効率性、および適切に設計された最適化目標の欠如によって引き起こされる不十分な長いコンテキストの調整が原因です。これらの制限に対処するために、私たちは \textbf{S}h\textbf{o}rt-to-\textbf{Lo}ng \textbf{P}reference \textbf{O}ptimization (\textbf{SoLoPO}) というフレームワークを提案します。これは、ロングコンテキストの優先最適化 (PO) を、理論的証拠と経験的証拠の両方によって裏付けられた、ショートコンテキスト PO とショートからロングへの報酬調整 (SoLo-RA) の 2 つのコンポーネントに分離します。具体的には、ショートコンテキスト PO は、ショートコンテキストからサンプリングされたプリファレンスペアを活用して、モデルのコンテキスト知識の利用能力を強化します。一方、SoLo-RA は、同一のタスク関連情報を含む短いコンテキストと長いコンテキストの両方を条件とした場合、応答の報酬スコアの一貫性を明示的に促進します。これにより、短いコンテキストを処理するモデルの機能を長いコンテキストのシナリオに移すことが容易になります。 SoLoPO は、主流の優先最適化アルゴリズムと互換性があり、データ構築とトレーニング プロセスの効率を大幅に向上させます。実験結果は、SoLoPO が、さまざまなロングコンテキストのベンチマーク全体にわたって、より強力な長さおよびドメイン汎化能力に関してこれらすべてのアルゴリズムを強化し、同時に計算効率とメモリ効率の両方で顕著な改善を達成することを示しています。
原文 (English)
SoLoPO: Unlocking Long-Context Capabilities in LLMs via Short-to-Long Preference Optimization
Despite advances in pretraining with extended context sizes, large language models (LLMs) still face challenges in effectively utilizing real-world long-context information, primarily due to insufficient long-context alignment caused by data quality issues, training inefficiencies, and the lack of well-designed optimization objectives. To address these limitations, we propose a framework named \textbf{S}h\textbf{o}rt-to-\textbf{Lo}ng \textbf{P}reference \textbf{O}ptimization (\textbf{SoLoPO}), decoupling long-context preference optimization (PO) into two components: short-context PO and short-to-long reward alignment (SoLo-RA), supported by both theoretical and empirical evidence. Specifically, short-context PO leverages preference pairs sampled from short contexts to enhance the model's contextual knowledge utilization ability. Meanwhile, SoLo-RA explicitly encourages reward score consistency for the responses when conditioned on both short and long contexts that contain identical task-relevant information. This facilitates transferring the model's ability to handle short contexts into long-context scenarios. SoLoPO is compatible with mainstream preference optimization algorithms, while substantially improving the efficiency of data construction and training processes. Experimental results show that SoLoPO enhances all these algorithms with respect to stronger length and domain generalization abilities across various long-context benchmarks, while achieving notable improvements in both computational and memory efficiency.
100-LongBench: 事実上のロングコンテキストベンチマークは、文字通りロングコンテキストの能力を評価しているのでしょうか?
ロングコンテキスト機能は、LLM の最も重要な機能の 1 つと考えられています。真にロングコンテキスト対応 LLM を使用すると、ユーザーは、長い形式の文書をダイジェストして答えを見つけるのではなく、LLM に直接質問するなど、本来面倒なタスクを簡単に処理できるようになります。ただし、既存のリアルタスクベースのロングコンテキスト評価ベンチマークには 2 つの大きな欠点があります。まず、LongBench のようなベンチマークでは、モデルのベースライン能力からロングコンテキストのパフォーマンスを分離するための適切な指標が提供されていないことが多く、モデル間の比較が不明確になります。第 2 に、このようなベンチマークは通常、固定入力長で構築されるため、さまざまなモデル間での適用性が制限され、モデルがいつ故障し始めるかを明らかにできません。これらの問題に対処するために、長さ制御可能なロングコンテキストのベンチマークと、ベースラインの知識を真のロングコンテキストの機能から切り離す新しいメトリクスを導入します。実験は、LLM を効果的に評価する際の私たちのアプローチの優位性を示しています。
原文 (English)
100-LongBench: Are de facto Long-Context Benchmarks Literally Evaluating Long-Context Ability?
Long-context capability is considered one of the most important abilities of LLMs, as a truly long context-capable LLM enables users to effortlessly process many originally exhausting tasks -- e.g., digesting a long-form document to find answers vs. directly asking an LLM about it. However, existing real-task-based long-context evaluation benchmarks have two major shortcomings. First, benchmarks like LongBench often do not provide proper metrics to separate long-context performance from the model's baseline ability, making cross-model comparison unclear. Second, such benchmarks are usually constructed with fixed input lengths, which limits their applicability across different models and fails to reveal when a model begins to break down. To address these issues, we introduce a length-controllable long-context benchmark and a novel metric that disentangles baseline knowledge from true long-context capabilities. Experiments demonstrate the superiority of our approach in effectively evaluating LLMs.
モデルを保持した適応丸め
量子化の目標は、出力分布が元のモデルにできるだけ近い圧縮モデルを生成することです。これを容易に行うために、ほとんどの量子化アルゴリズムは、エンドツーエンド エラーの代理として各層の即時アクティブ化エラーを最小限に抑えます。ただし、これは将来のレイヤーの影響を無視するため、プロキシとしては不十分です。この研究では、ネットワークの出力での誤差を直接考慮する適応丸めアルゴリズムである Yet Another Quantization Algorithm (YAQA) を導入します。 YAQA は、量子化アルゴリズムの最初のエンドツーエンド誤差限界に至る一連の理論的結果を紹介します。まず、ヘッセ近似の構造を介して、適応丸めアルゴリズムの収束時間を特徴付けます。次に、エンドツーエンド誤差が真のヘッセ行列に対する近似のコサイン類似度によって制限される可能性があることを示します。これにより、対応する最適に近いヘッシアン スケッチを使用した自然なクロネッカー因数近似が可能になります。 YAQA は GPTQ/LDLQ よりも優れていることが証明されており、経験的にはこれらの方法よりも誤差が $\約 30\%$ 減少します。 YAQA は、量子化を意識したトレーニングよりも低い誤差を実現します。これにより、推論のオーバーヘッドがまったく追加されずに、ダウンストリーム タスクで最先端のパフォーマンスが得られます。
原文 (English)
Model-Preserving Adaptive Rounding
The goal of quantization is to produce a compressed model whose output distribution is as close to the original model's as possible. To do this tractably, most quantization algorithms minimize the immediate activation error of each layer as a proxy for the end-to-end error. However, this ignores the effect of future layers, making it a poor proxy. In this work, we introduce Yet Another Quantization Algorithm (YAQA), an adaptive rounding algorithm that directly considers the error at the network's output. YAQA introduces a series of theoretical results that culminate in the first end-to-end error bounds for quantization algorithms. First, we characterize the convergence time of adaptive rounding algorithms via the structure of their Hessian approximations. We then show that the end-to-end error can be bounded by the approximation's cosine similarity to the true Hessian. This admits a natural Kronecker-factored approximation with corresponding near-optimal Hessian sketches. YAQA is provably better than GPTQ/LDLQ and empirically reduces the error by $\approx 30\%$ over these methods. YAQA even achieves a lower error than quantization aware training. This translates to state of the art performance on downstream tasks, all while adding no inference overhead.
MesaNet: 局所的に最適なテスト時間トレーニングによるシーケンス モデリング
シーケンス モデリングは現在、ソフトマックス セルフ アテンションを使用する因果変換アーキテクチャによって支配されています。広く採用されていますが、トランスフォーマーはスケーリング メモリを必要とし、推論中に線形に計算します。最近の一連の作業によりソフトマックス演算が線形化され、その結果、DeltaNet、Mamba、xLSTM など、メモリとコンピューティング コストが一定の強力なリカレント ニューラル ネットワーク (RNN) モデルが誕生しました。これらのモデルは、再帰層のダイナミクスがすべて、オンライン学習ルールを通じてほぼ最適化されたコンテキスト内の回帰目標から導出できることに注目することで統合できます。ここで、私たちはこの一連の作業に加わり、最近提案された Mesa 層 (von Oswald et al., 2024) の数値的に安定したチャンク単位の並列化可能なバージョンを導入します。これは、時間内に順次実行することしかできず、したがってスケーラブルではありませんでした。この層もやはりコンテキスト内損失に起因しますが、高速共役勾配ソルバーを使用してあらゆる時点で最適化されるまで最小化されています。最大 10 億パラメータ規模までの広範な一連の実験研究を通じて、最適なテスト時間のトレーニングにより、特に長いコンテキストの理解を必要とするタスクにおいて、以前の RNN よりも低い言語モデリングの複雑さとより高いダウンストリーム ベンチマーク パフォーマンスを実現できることを示しました。このパフォーマンスの向上には、推論時間中に追加のフロップが費やされるというコストがかかります。したがって、私たちの結果は、パフォーマンスを向上させるためにテスト時間のコンピューティングを増加させる最近の傾向と興味深い関連性があります。ここでは、ニューラル ネットワーク自体内の逐次的な最適化問題を解決するためにコンピューティングを費やしています。
原文 (English)
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), which could only run sequentially in time and was therefore not scalable. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments study up to the billion-parameter scale, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
VLM は将来の状態を予測できますか?逆ダイナミクスから世界モデルをブートストラップする
統合ビジョン言語モデル (VLM) は、前方ダイナミクス予測 (FDP)、つまり、以前の観察とアクション (言語形式) を考慮して将来の状態 (画像形式) を予測できますか? VLM は命令からフレーム間に物理的に妥当な遷移を生成するのに苦労していることがわかりました。それにもかかわらず、私たちはマルチモーダルグラウンディングにおける重大な非対称性を特定しました。つまり、逆ダイナミクス予測 (IDP) を学習するために VLM を微調整すること、つまりフレーム間のアクションを効果的にキャプションすることは、FDP を学習するよりもはるかに簡単です。次に、IDP を使用して、1) 合成データからの弱教師あり学習と 2) 推論時間の検証という 2 つの主な戦略を通じて FDP をブートストラップすることができます。まず、IDP はビデオ フレーム観測のラベルなしペアのアクションに注釈を付けて、FDP のトレーニング データのスケールを拡張できます。次に、IDP は FDP の複数のサンプルに報酬を割り当ててスコアを付け、推論時の検索を効果的にガイドできます。 2 つの VLM ファミリーを使用した Aurora-Bench でのアクション中心の画像編集タスクを通じて、両方の戦略から得られる FDP を評価します。依然として汎用であるにもかかわらず、当社の最高のモデルは、最先端の画像編集モデルと競合するパフォーマンスを達成し、GPT4o-as-judge によると、それらを 7% から 13% のマージンで改善し、Aurora-Bench のすべてのサブセットにわたって最高の平均人間評価を達成しました。
原文 (English)
Can VLMs Predict Future States? Bootstrapping World Models from Inverse Dynamics
Can unified vision-language models (VLMs) perform forward dynamics prediction (FDP), i.e., predicting the future state (in image form) given the previous observation and an action (in language form)? We find that VLMs struggle to generate physically plausible transitions between frames from instructions. Nevertheless, we identify a crucial asymmetry in multimodal grounding: fine-tuning a VLM to learn inverse dynamics prediction (IDP)-effectively captioning the action between frames-is significantly easier than learning FDP. In turn, IDP can be used to bootstrap FDP through two main strategies: 1) weakly supervised learning from synthetic data and 2) inference time verification. Firstly, IDP can annotate actions for unlabelled pairs of video frame observations to expand the training data scale for FDP. Secondly, IDP can assign rewards to multiple samples of FDP to score them, effectively guiding search at inference time. We evaluate the FDP resulting from both strategies through the task of action-centric image editing on Aurora-Bench with two families of VLMs. Despite remaining general-purpose, our best model achieves a performance competitive with state-of-the-art image editing models, improving on them by a margin between 7% and 13% according to GPT4o-as-judge, and achieving the best average human evaluation across all subsets of Aurora-Bench.
推論としての時系列予測: 強化された LLM を使用したゆっくりとした思考のアプローチ
時系列予測 (TSF) を進歩させるために、予測精度を向上させるさまざまな方法が提案されており、統計的手法からデータ駆動型の深層学習アーキテクチャに進化しています。その有効性にもかかわらず、既存の手法のほとんどは依然として高速思考パラダイムに固執しており、中核となるモデリング哲学として歴史的パターンの抽出と将来の値へのマッピングに依存しており、中間の時系列推論を組み込んだ明示的な思考プロセスが欠けています。一方、新興の低速思考 LLM (OpenAI-o1 など) は、驚くべき多段階推論能力を示し、これらの問題を克服する代替方法を提供しています。ただし、迅速なエンジニアリングだけでは、高い計算コスト、プライバシーのリスク、ドメイン固有の時系列推論の詳細な能力の制限など、いくつかの制限があります。これらの制限に対処するためのより有望なアプローチは、ゆっくりとした思考能力を開発し、強力な時系列推論スキルを獲得するように LLM を訓練することです。この目的のために、時系列予測のためのLLMの多段階推論能力を強化するように設計された2段階の強化微調整フレームワークであるTime-R1を提案します。具体的には、第 1 段階ではウォームアップ適応のための教師あり微調整を行い、第 2 段階では強化学習を採用してモデルの汎化能力を向上させます。特に、時系列予測に特化したきめの細かい多目的報酬を設計し、次に GRIP (ポリシー最適化のためのグループベースの相対重要度) を導入します。これは、不均一なサンプリングを活用して、モデルによる効果的な推論パスの探索をさらに促進および最適化します。実験では、Time-R1 がさまざまなデータセットにわたって予測パフォーマンスを大幅に向上させることが実証されています。
原文 (English)
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
To advance time series forecasting (TSF), various methods have been proposed to improve prediction accuracy, evolving from statistical techniques to data-driven deep learning architectures. Despite their effectiveness, most existing methods still adhere to a fast thinking paradigm-relying on extracting historical patterns and mapping them to future values as their core modeling philosophy, lacking an explicit thinking process that incorporates intermediate time series reasoning. Meanwhile, emerging slow-thinking LLMs (e.g., OpenAI-o1) have shown remarkable multi-step reasoning capabilities, offering an alternative way to overcome these issues. However, prompt engineering alone presents several limitations - including high computational cost, privacy risks, and limited capacity for in-depth domain-specific time series reasoning. To address these limitations, a more promising approach is to train LLMs to develop slow thinking capabilities and acquire strong time series reasoning skills. For this purpose, we propose Time-R1, a two-stage reinforcement fine-tuning framework designed to enhance multi-step reasoning ability of LLMs for time series forecasting. Specifically, the first stage conducts supervised fine-tuning for warmup adaptation, while the second stage employs reinforcement learning to improve the model's generalization ability. Particularly, we design a fine-grained multi-objective reward specifically for time series forecasting, and then introduce GRIP (group-based relative importance for policy optimization), which leverages non-uniform sampling to further encourage and optimize the model's exploration of effective reasoning paths. Experiments demonstrate that Time-R1 significantly improves forecast performance across diverse datasets.
グラフ検索からスキーマ実現まで: 異種ナレッジ グラフ上のテキストから SPARQL への反事実検証
Text-to-SPARQL は、自然言語の質問を RDF ナレッジ グラフ上の実行可能な SPARQL クエリにマッピングします。標準的な評価ではターゲット グラフが事前に修正されることがよくありますが、実践的なナレッジ グラフ質問応答 (KGQA) には、異なるスキーマ、部分的なアラインメント、および不完全なメタデータを含む異種グラフ コレクションが含まれる場合があります。この設定では、クエリ生成は SPARQL 構文以上のものに依存します。システムは、質問に必要な述語、エンティティ タイプ、結合、フィルター、および制約をサポートできるグラフ スキーマを識別する必要があります。異種の KG コレクション上でテキストから SPARQL に変換するためのスキーマベースのエージェント フレームワークである SchemaForge を紹介します。その中心的なメカニズムは、質問条件付きのスキーマ スライス アライメントです。弱いグラフの証拠によって最初にもっともらしいグラフが特定され、より強力なスキーマの証拠によって、ローカル スキーマ スライスが意図したクエリを実現できるかどうかが決まります。選択されたスキーマ スライスは、クエリの生成と実行前の検証を制限します。利用可能なグラフが 1 つだけの場合、同じ定式化は、スキーマ基盤を備えた標準の単一 KG テキストから SPARQL への変換に縮小されます。 LC-QuAD 2.0、QALD-9 Plus、QALD-10、および Spider4SPARQL で SchemaForge を評価します。 SchemaForge は、4 つの公開ベンチマーク全体で、最も一致するエージェントのベースラインよりも実行精度を平均 11.50 パーセント向上させています。 Spider4SPARQL では、SchemaForge は実行精度を 54.86% から 64.18% に向上させ、トップ 1 グラフ割り当て精度 73.0% とトップ 3 グラフ割り当て精度 97.0% を達成しました。これらの結果は、グラフの弱い証拠からスキーマ固有のクエリコミットメントへの移行と、反事実の回答セットのチェックにより、異種ナレッジグラフよりも実行可能なクエリの生成が向上することを示しています。
原文 (English)
From Graph Retrieval to Schema Realization: Counterfactual Validation for Text-to-SPARQL over Heterogeneous Knowledge Graphs
Text-to-SPARQL maps natural-language questions to executable SPARQL queries over RDF knowledge graphs. While standard evaluations often fix the target graph in advance, practical knowledge graph question answering (KGQA) may involve heterogeneous graph collections with different schemas, partial alignments, and incomplete metadata. In this setting, query generation depends on more than SPARQL syntax: the system must identify a graph schema that can support the predicates, entity types, joins, filters, and constraints required by the question. We present SchemaForge, a schema-grounded agentic framework for text-to-SPARQL over heterogeneous KG collections. Its central mechanism is question-conditioned schema-slice alignment: weak graph evidence first identifies plausible graphs, while stronger schema evidence determines whether a local schema slice can realize the intended query. The selected schema slice then constrains query generation and verification before execution. When only one graph is available, the same formulation reduces to standard single-KG text-to-SPARQL with schema grounding. We evaluate SchemaForge on LC-QuAD 2.0, QALD-9 Plus, QALD-10, and Spider4SPARQL. Across the four public benchmarks, SchemaForge improves execution accuracy over the strongest matched agent baseline by 11.50 percentage points on average. On Spider4SPARQL, SchemaForge improves execution accuracy from 54.86% to 64.18% and achieves 73.0% Top-1 and 97.0% Top-3 graph allocation accuracy. These results show that moving from weak graph evidence to schema-specific query commitments, together with counterfactual answer-set checks, improves executable query generation over heterogeneous knowledge graphs.
VGGSounder: 基礎モデルのオーディオビジュアル評価
視聴覚基礎モデルの出現は、マルチモーダルな理解を確実に評価することの重要性を強調しています。 VGGSound データセットは、オーディオビジュアル分類の評価のベンチマークとしてよく使用されます。ただし、私たちの分析では、不完全なラベル付け、部分的に重複するクラス、不整合なモダリティなど、VGGSound のいくつかの制限が特定されました。これらは、聴覚および視覚能力の歪んだ評価につながります。これらの制限に対処するために、VGGSounder を導入します。これは、VGGSound を拡張し、オーディオビジュアル基礎モデルを評価するために特別に設計された、包括的に再アノテーションが付けられたマルチラベル テスト セットです。 VGGSounder は詳細なモダリティの注釈を備えており、モダリティ固有のパフォーマンスを正確に分析できます。さらに、新しいモダリティ混乱メトリックを使用して別の入力モダリティを追加したときのパフォーマンスの低下を分析することで、モデルの限界を明らかにします。
原文 (English)
VGGSounder: Audio-Visual Evaluations for Foundation Models
The emergence of audio-visual foundation models underscores the importance of reliably assessing their multi-modal understanding. The VGGSound dataset is commonly used as a benchmark for evaluation audio-visual classification. However, our analysis identifies several limitations of VGGSound, including incomplete labelling, partially overlapping classes, and misaligned modalities. These lead to distorted evaluations of auditory and visual capabilities. To address these limitations, we introduce VGGSounder, a comprehensively re-annotated, multi-label test set that extends VGGSound and is specifically designed to evaluate audio-visual foundation models. VGGSounder features detailed modality annotations, enabling precise analyses of modality-specific performance. Furthermore, we reveal model limitations by analysing performance degradation when adding another input modality with our new modality confusion metric.
ノイズを含む音声分離におけるスケール不変信号対歪み比の研究
この論文では、事実上のベンチマーク WSJ0-2Mix の場合のように、トレーニング参照にノイズが含まれている場合に、教師あり音声分離における評価とトレーニングの目的の両方としてスケール不変信号対歪み比 (SI-SDR) を使用することの意味を検証します。ノイズの多いリファレンスを使用して SI-SDR を導出すると、ノイズによって達成可能な SI-SDR が制限されるか、分離された出力に望ましくないノイズが発生することがわかります。これに対処するために、ノイズの多い参照の学習を回避するモデルをトレーニングすることを目的として、WHAM! を使用して参照を強化し、混合を増強する方法が提案されています。これらの強化されたデータセットでトレーニングされた 2 つのモデルは、非侵入的な NISQA.v2 メトリックを使用して評価されます。結果は、分離された音声のノイズが減少していることを示していますが、参照の処理によりアーチファクトが生じ、全体的な品質の向上が制限される可能性があることが示唆されています。 WSJ0-2Mix および Libri2Mix テスト セットのモデル全体で、SI-SDR と知覚されるノイズの間に負の相関関係が見つかり、導出による結論が強調されています。
原文 (English)
A Study of the Scale Invariant Signal to Distortion Ratio in Speech Separation with Noisy References
This paper examines the implications of using the Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) as both evaluation and training objective in supervised speech separation, when the training references contain noise, as is the case with the de facto benchmark WSJ0-2Mix. A derivation of the SI-SDR with noisy references reveals that noise limits the achievable SI-SDR, or leads to undesired noise in the separated outputs. To address this, a method is proposed to enhance references and augment the mixtures with WHAM!, aiming to train models that avoid learning noisy references. Two models trained on these enhanced datasets are evaluated with the non-intrusive NISQA.v2 metric. Results show reduced noise in separated speech but suggest that processing references may introduce artefacts, limiting overall quality gains. Negative correlation is found between SI-SDR and perceived noisiness across models on the WSJ0-2Mix and Libri2Mix test sets, underlining the conclusion from the derivation.
BioBlue: 簡略化された観察形式による、生物学的および経済的に調整された LLM の AI 安全性ベンチマークにおける体系的な暴走オプティマイザーのような LLM 故障モード
「暴走最適化」に関する AI 調整の議論の多くは、RL エージェントに焦点を当てています。RL エージェントは、他のすべてを犠牲にして代用目的を過剰に最適化する無制限のユーティリティ最大化装置 (例: 「ペーパークリップ最大化装置」、仕様ゲーム) です。 LLM ベースのシステムは、永続的なオプティマイザーではなく次のトークンの予測子として機能するため、多くの場合、より安全であると考えられています。私たちは、時間の経過とともに目標の状態を維持したりバランスを取る必要がある単純な長期制御スタイルの環境に LLM を配置することで、この仮定を実証的にテストします。つまり、単一および複数の目標の恒常性、収益逓減と無制限の目標のバランス、および再生可能資源の持続可能性です。私たちは、LLM が多くのステップに対して適切に行動し、定められた目的を明確に理解しているにもかかわらず、構造化された方法でコンテキストを失い、暴走的な行動に陥ることがよくあります。つまり、恒常性目標を無視し、複数の目的のトレードオフから単一の目的の最大化に崩壊するため、凹型の効用構造を尊重できません。これらの失敗は、有能な動作の初期期間の後に確実に発生し、その時点でコンテキスト ウィンドウが完全には程遠いにもかかわらず、特徴的なパターン (自己模倣的な振動、無制限の最大化、単一目的の最適化への復帰など) を示します。問題は、LLM がコンテキストを失い、一貫性がなくなるだけではありません。 LLM は表面的には多目的で境界があるように見えますが、複数の目的が関与する持続的な相互作用の下での LLM の動作は、単一目的で境界のない、調整が不十分なオプティマイザーのように動作するように体系的に偏っています。我々は、トークンレベルのパターン強化アトラクターを仮説とします。LLM は、元の指示からではなく、最近の行動履歴のトークン パターンから行動をますます導き出す可能性があります。なぜこれが複数の目的の設定でのみ起こるのかは未解決の問題のままです。
原文 (English)
BioBlue: Systematic runaway-optimiser-like LLM failure modes on biologically and economically aligned AI safety benchmarks for LLMs with simplified observation format
Many AI alignment discussions of "runaway optimisation" focus on RL agents: unbounded utility maximisers that over-optimise a proxy objective (e.g., "paperclip maximiser", specification gaming) at the expense of everything else. LLM-based systems are often assumed to be safer because they function as next-token predictors rather than persistent optimisers. We empirically test this assumption by placing LLMs in simple, long-horizon control-style environments that require maintaining state of or balancing objectives over time: single- and multi-objective homeostasis, balancing unbounded objectives with diminishing returns, and sustainability of a renewable resource. We find that, although LLMs frequently behave appropriately for many steps and clearly understand the stated objectives, they often lose context in structured ways and drift into runaway behaviours: ignoring homeostatic targets, collapsing from multi-objective trade-offs into single-objective maximisation - thus failing to respect concave utility structures. These failures emerge reliably after initial periods of competent behaviour and exhibit characteristic patterns (including self-imitative oscillations, unbounded maximisation, and reverting to single-objective optimisation), even though the context window is far from full at that point. The problem is not that the LLMs just lose context and become incoherent. Although LLMs appear multi-objective and bounded on the surface, their behaviour under sustained interaction involving multiple objectives, is systematically biased towards acting like single-objective, unbounded, poorly aligned optimisers. We hypothesise a token-level pattern reinforcement attractor: LLMs may increasingly derive actions from the token patterns of their recent action history rather than from the original instructions. Why this happens only in multi-objective settings remains an open question.
分散ゲート分布を使用した不確かさの推定
ニューラル ネットワークからのサンプルごとの不確実性の定量化の評価は、高リスクのアプリケーションを含む意思決定に不可欠です。一般的なアプローチは、ベイジアン モデルまたは近似モデルからの予測分布を使用し、対応する予測の不確実性を認識的 (モデル関連) 成分と偶然的 (データ関連) 成分に分解することです。しかし、最近では相加的分解に疑問が持たれています。この研究では、さまざまなモデル予測にわたるクラス確率分布の信号対雑音比に基づいて、不確実性の推定と分解を行うための直感的なフレームワークを提案します。アンサンブルから導出された信頼係数によって予測をスケールする分散ゲート測定を導入します。私たちはこの尺度を利用して、委員会マシンの多様性の崩壊の存在について議論します。
原文 (English)
Uncertainty Estimation using Variance-Gated Distributions
Evaluation of per-sample uncertainty quantification from neural networks is essential for decision-making involving high-risk applications. A common approach is to use the predictive distribution from Bayesian or approximation models and decompose the corresponding predictive uncertainty into epistemic (model-related) and aleatoric (data-related) components. However, additive decomposition has recently been questioned. In this work, we propose an intuitive framework for uncertainty estimation and decomposition based on the signal-to-noise ratio of class probability distributions across different model predictions. We introduce a variance-gated measure that scales predictions by a confidence factor derived from ensembles. We use this measure to discuss the existence of a collapse in the diversity of committee machines.
KITE: コンテキスト内学習のためのカーネル化および情報理論のサンプル
インコンテキスト学習 (ICL) は、プロンプトに表示される厳選されたいくつかのタスク固有の例のみを使用して、大規模言語モデル (LLM) を新しいデータ不足のタスクに適応させるための強力なパラダイムとして登場しました。ただし、LLM のコンテキスト サイズが限られていると、基本的な疑問が生じます。特定のユーザー クエリのパフォーマンスを最大化するにはどのサンプルを選択する必要があるかということです。 KATE のような最近傍ベースの手法はこの目的で広く採用されていますが、高次元の埋め込み空間では一般化が不十分で多様性が欠如しているなどのよく知られた欠点があります。この研究では、原則に基づいた情報理論主導の観点から、ICL における例の選択の問題を研究します。まず、入力埋め込みに対する線形関数として LLM をモデル化し、サンプル選択タスクをクエリ固有の最適化問題としてフレーム化します。つまり、特定のクエリの予測誤差を最小限に抑える、より大きなサンプル バンクからサンプルのサブセットを選択します。この定式化は、特定のクエリ インスタンスの正確な予測をターゲットにすることで、一般化に焦点を当てた従来の学習理論的アプローチから逸脱しています。ほぼサブモジュール化された原則に基づいた代理目標を導出し、近似を保証する貪欲なアルゴリズムの使用を可能にします。 (i) 明示的なマッピングを使用せずに高次元の特徴空間で動作するカーネル トリックを組み込むこと、および (ii) 選択された例の多様性を促進する最適な設計ベースの正則化機能を導入することによって、この方法をさらに強化します。経験的に、一連の分類タスク全体にわたって標準的な検索方法に比べて大幅な改善が見られることを実証し、現実世界のラベル不足シナリオにおける ICL の構造を認識した多様なサンプル選択の利点を強調しています。
原文 (English)
KITE: Kernelized and Information Theoretic Exemplars for In-Context Learning
In-context learning (ICL) has emerged as a powerful paradigm for adapting large language models (LLMs) to new and data-scarce tasks using only a few carefully selected task-specific examples presented in the prompt. However, given the limited context size of LLMs, a fundamental question arises: Which examples should be selected to maximize performance on a given user query? While nearest-neighbor-based methods like KATE have been widely adopted for this purpose, they suffer from well-known drawbacks in high-dimensional embedding spaces, including poor generalization and a lack of diversity. In this work, we study this problem of example selection in ICL from a principled, information theory-driven perspective. We first model an LLM as a linear function over input embeddings and frame the example selection task as a query-specific optimization problem: selecting a subset of exemplars from a larger example bank that minimizes the prediction error on a specific query. This formulation departs from traditional generalization-focused learning theoretic approaches by targeting accurate prediction for a specific query instance. We derive a principled surrogate objective that is approximately submodular, enabling the use of a greedy algorithm with an approximation guarantee. We further enhance our method by (i) incorporating the kernel trick to operate in high-dimensional feature spaces without explicit mappings, and (ii) introducing an optimal design-based regularizer to encourage diversity in the selected examples. Empirically, we demonstrate significant improvements over standard retrieval methods across a suite of classification tasks, highlighting the benefits of structure-aware, diverse example selection for ICL in real-world, label-scarce scenarios.
ClustRecNet: クラスタリング アルゴリズムのための新しいエンドツーエンドの深層学習フレームワークの推奨事項
特定のデータセットに対して効果的なクラスタリング アルゴリズムを特定することは、依然として教師なし学習の基本的な問題です。 ClustRecNet は、生の表形式データの高次表現を直接学習することで、適切なクラスタリング アルゴリズムを推奨する、新しいエンドツーエンドの深層学習フレームワークです。堅牢なメタ学習を促進するために、まずさまざまなクラスタリング シナリオを網羅する 34,000 個の合成データセットの包括的なリポジトリを構築し、10 の一般的なクラスタリング アルゴリズムを実行し、調整ランド インデックス (ARI) を使用してグラウンド トゥルース ラベルを確立します。 ClustRecNet のアーキテクチャには、畳み込みブロック、2 つの残差ブロック、およびローカルおよびグローバル構造パターンをキャプチャするアテンション ブロックが組み込まれており、手動の特徴量エンジニアリングに関連する知識のボトルネックを効果的に回避します。合成ベンチマークと現実世界のベンチマークの両方での広範な評価により、ClustRecNet が、Silhouette、Calinski-Harabasz、Davies-Bouldin、Dunn などの従来の内部クラスター妥当性指標や、ML2DAC、AutoCluster、AutoML4Clust などの最先端の自動機械学習 (AutoML) アプローチよりも常に優れていることが実証されています。たとえば、当社のフレームワークは、合成データの Calinski-Harabasz クラスター有効性インデックスに対して平均 0.497 ARI の向上を達成し、実世界のベンチマークでは主要な AutoML アプローチ (ML2DAC) に対して平均 44.16% の ARI 改善を達成しています。コードとデータは、https://github.com/mrbakhtyari/ClustRecNet から入手できます。
原文 (English)
ClustRecNet: A Novel End-to-End Deep Learning Framework for Clustering Algorithm Recommendation
Identifying an effective clustering algorithm for a given dataset remains a fundamental unsupervised learning issue. We introduce ClustRecNet, a novel end-to-end deep learning framework that recommends suitable clustering algorithm(s) by directly learning high-order representations of raw tabular data. To facilitate robust meta-learning, we first construct a comprehensive repository of 34,000 synthetic datasets encompassing a large variety of clustering scenarios, run 10 popular clustering algorithms, and use Adjusted Rand Index (ARI) to establish ground-truth labels. ClustRecNet's architecture incorporates a convolution block, two residual blocks, and an attention block to capture local and global structural patterns, effectively bypassing the knowledge bottleneck associated with manual feature engineering. Extensive evaluation on both synthetic and real-world benchmarks demonstrates that ClustRecNet consistently outperforms traditional internal cluster validity indices such as Silhouette, Calinski-Harabasz, Davies-Bouldin, and Dunn as well as state-of-the-art Automated Machine Learning (AutoML) approaches such as ML2DAC, AutoCluster, and AutoML4Clust. For example, our framework achieves an average 0.497 ARI gain over the Calinski-Harabasz cluster validity index on synthetic data and an average 44.16% ARI improvement over the leading AutoML approach (ML2DAC) on real-world benchmarks. Code and data are available at: https://github.com/mrbakhtyari/ClustRecNet
プラトン変換器: 等分散性のための確実な選択肢
トランスフォーマーは広く普及していますが、科学やコンピュータ ビジョンで一般的な幾何学的対称性に対する誘導バイアスがありません。既存の等変手法では、複雑で計算量の多い設計を通じて Transformer を非常に効果的にする効率と柔軟性が犠牲になることがよくあります。このトレードオフを解決するために、Platonic Transformer を導入します。プラトン立体対称群からの参照フレームに対する注意を定義することにより、私たちの方法は原則に基づいた重み共有スキームを誘導します。これにより、標準的な Transformer の正確なアーキテクチャと計算コストを維持しながら、連続変換とプラトン対称性に対する等分散性の組み合わせが可能になります。さらに、この注意が形式的には動的グループ畳み込みと同等であることを示し、モデルが適応幾何フィルターを学習し、スケーラビリティの高い線形時間畳み込みバリアントを可能にすることが明らかになります。 Platonic Transformer は、コンピューター ビジョン (CIFAR-10)、3D 点群 (ScanObjectNN)、分子特性予測 (QM9、OMol25) のさまざまなベンチマークにわたって、追加コストなしでこれらの幾何学的制約を活用することで、競争力のあるパフォーマンスを実現します。
原文 (English)
Platonic Transformers: A Solid Choice For Equivariance
While widespread, Transformers lack inductive biases for geometric symmetries common in science and computer vision. Existing equivariant methods often sacrifice the efficiency and flexibility that make Transformers so effective through complex, computationally intensive designs. We introduce the Platonic Transformer to resolve this trade-off. By defining attention relative to reference frames from the Platonic solid symmetry groups, our method induces a principled weight-sharing scheme. This enables combined equivariance to continuous translations and Platonic symmetries, while preserving the exact architecture and computational cost of a standard Transformer. Furthermore, we show that this attention is formally equivalent to a dynamic group convolution, which reveals that the model learns adaptive geometric filters and enables a highly scalable, linear-time convolutional variant. Across diverse benchmarks in computer vision (CIFAR-10), 3D point clouds (ScanObjectNN), and molecular property prediction (QM9, OMol25), the Platonic Transformer achieves competitive performance by leveraging these geometric constraints at no additional cost.
推論パスは入力として引き続き有効ですか?事後推論から思考連鎖の圧縮への橋渡し
最近の開発により、長い思考連鎖 (CoT) を介した大規模言語モデル (LLM) での高度な推論が可能になり、推論中の効率とパフォーマンスを引き換えにします。既存の作品は、推論時に生成されるCoTを圧縮することに焦点を当てており、正解を導き出すために必要な情報が損なわれています。この研究では、LLM の推論タスクを簡素化するために CoT をコンテキストの一部として取り入れる推論パラダイムであるポスト推論を提案します。事後推論により LLM の生成長が大幅に短縮されるが、その有効性はコンテキスト CoT 生成の効率と信頼性に左右されることがわかりました。したがって、我々は、CoT 圧縮のための効率的な事後推論フレームワークである Upfront CoT (UCoT) を提案します。 UCoT は、軽量モデル (コンプレッサー) をトレーニングしてコンテキストに応じた CoT をソフト トークンの形式で提供し、LLM (エグゼキューター) をトレーニングしてこのコンテキストに応じた CoT を活用して最終的な答えを生成します。広範な実験により、UCoT は CoT の長さを大幅に短縮しながら、実行者の強力な推論能力を維持することが示されました。 UCoT を Qwen2.5-7B-Instruct モデルに適用すると、GSM8K データセットでのトークンの使用量が 50% 削減され、パフォーマンスは最先端 (SOTA) メソッドよりも 3.08% 向上しました。
原文 (English)
Can Reasoning Path still be Effective as Input? Bridging Post-Reasoning to Chain-of-Thought Compression
Recent developments have enabled advanced reasoning in Large Language Models (LLMs) via long Chain-of-Thought (CoT), trading efficiency during inference for performance. Existing works focus on compressing generated CoT in reasoning, which impairs the necessary information for deriving the correct answer. In this work, we propose post-reasoning, a reasoning paradigm that takes CoT as a part of context to simplify the reasoning task for LLMs. We find that post-reasoning significantly reduces the generation length of LLMs, but its effectiveness hinges on the efficiency and the reliability of the contextual CoT generation. Therefore, we propose Upfront CoT (UCoT), an efficient post-reasoning framework for CoT compression. UCoT trains a lightweight model (compressor) to provide contextual CoT in form of soft tokens and trains the LLM (executor) to leverage this contextual CoT for producing the final answer. Extensive experiments show that UCoT maintains the powerful reasoning ability of executor while significantly reducing the length of CoT. It is worth mentioning that when applying UCoT to the Qwen2.5-7B-Instruct model, the usage of tokens on GSM8K dataset is reduced by 50%, while the performance is 3.08% higher than that of the state-of-the-art (SOTA) method.
単純な埋め込みによりアクター-クリティックエージェントのサンプル効率が向上
最近の研究では、大規模な環境の並列化を使用して、アクタークリティカル手法の実時間のトレーニング時間を加速することが提案されています。残念ながら、望ましいレベルのパフォーマンスを達成するには、依然として多数の環境との対話が必要になる場合があります。適切に構造化された表現は、深層強化学習 (RL) エージェントの一般化とサンプル効率を向上させることができることに注目し、単純なエンベディング、つまりエンベディングを単純な構造に制約する軽量の表現層の使用を提案します。この幾何学的な帰納的バイアスにより、批評家のブートストラップを安定させ、政策の勾配を強化するまばらで離散的な特徴が生じます。 FastTD3、FastSAC、および PPO に適用すると、単純なエンベディングは、実行速度を損なうことなく、さまざまな連続および離散制御環境全体でサンプル効率と最終パフォーマンスを一貫して向上させます。
原文 (English)
Simplicial Embeddings Improve Sample Efficiency in Actor-Critic Agents
Recent works have proposed accelerating the wall-clock training time of actor-critic methods via the use of large-scale environment parallelization; unfortunately, these can sometimes still require large number of environment interactions to achieve a desired level of performance. Noting that well-structured representations can improve the generalization and sample efficiency of deep reinforcement learning (RL) agents, we propose the use of simplicial embeddings: lightweight representation layers that constrain embeddings to simplicial structures. This geometric inductive bias results in sparse and discrete features that stabilize critic bootstrapping and strengthen policy gradients. When applied to FastTD3, FastSAC, and PPO, simplicial embeddings consistently improve sample efficiency and final performance across a variety of continuous- and discrete-control environments, without any loss in runtime speed.
プレロジット空間での重要度サンプリングによる、テスト時の報酬に基づく言語モデルの調整
大規模言語モデル (LLM) の微調整には高い計算コストが必要となるため、LLM のテスト時の調整が注目を集めています。本稿では、確率的制御入力を用いたサンプリングベースのモデル予測制御に基づいた、プリロジット上の適応重要度サンプリング(AISP)と呼ばれる新しいテスト時間報酬ガイド型アライメント手法を提案します。 AISP は、摂動の平均に関して期待される報酬を最大化するために、ガウス摂動を最後から 2 番目の層の出力であるプレロジットに適用します。最適な平均は、サンプリングされた報酬を使用した重要度サンプリングによって取得されることを示します。 AISP は、使用されたサンプル数に対する報酬の点で best-of-n サンプリングよりも優れたパフォーマンスを示し、他の報酬ベースのテスト時間調整方法よりも高い報酬を達成します。
原文 (English)
Test-time reward-guided alignment of language models by importance sampling on pre-logit space
Test-time alignment of large language models (LLMs) attracts attention because fine-tuning of LLMs requires high computational costs. In this paper, we propose a new test-time reward-guided alignment method called adaptive importance sampling on pre-logits (AISP) on the basis of the sampling-based model predictive control with the stochastic control input. AISP applies the Gaussian perturbation into pre-logits, which are outputs of the penultimate layer, so as to maximize expected rewards with respect to the mean of the perturbation. We demonstrate that the optimal mean is obtained by importance sampling with sampled rewards. AISP outperforms best-of-n sampling in terms of rewards over the number of used samples and achieves higher rewards than other reward-based test-time alignment methods.
ベクトル化されたオンライン POMDP 計画
部分的な可観測性の下で計画を立てることは、自律ロボットの重要な機能です。部分観測可能なマルコフ決定プロセス (POMDP) は、部分観測可能性の問題の下で計画を立てるための強力なフレームワークを提供し、アクションの確率的影響とノイズの多い観測を通じて得られる限られた情報を捕捉します。 POMDP の解法は、今日のハードウェアでの大規模並列化から多大な恩恵を受ける可能性がありますが、POMDP ソルバーの並列化は困難でした。ほとんどのソルバーは、アクションとその値の推定をインターリーブする数値最適化に依存しているため、並列プロセス間に依存関係や同期ボトルネックが生じ、並列化の利点が相殺される可能性があります。この論文では、Vectorized Online POMDP Planner (VOPP) を提案します。これは、最適化コンポーネントの一部を分析的に解決し、期待値の推定のみで構成される数値計算を残す、最新の POMDP 定式化を利用する新しい並列オンライン ソルバーです。 VOPP は、計画に関連するすべてのデータ構造をテンソルのコレクションとして表し、すべての計画ステップをこの表現に対する完全にベクトル化された計算として実装します。その結果、同時プロセス間の依存関係や同期ボトルネックのない大規模並列オンライン ソルバーが実現します。実験結果は、VOPP が既存の最先端の並列オンライン ソルバーと比較して、最適に近い解の計算において少なくとも 20 倍効率的であることを示しています。さらに、VOPP は最先端の逐次オンライン ソルバーよりも優れたパフォーマンスを発揮し、計画予算を 1000 倍も削減します。
原文 (English)
Vectorized Online POMDP Planning
Planning under partial observability is an essential capability of autonomous robots. The Partially Observable Markov Decision Process (POMDP) provides a powerful framework for planning under partial observability problems, capturing the stochastic effects of actions and the limited information available through noisy observations. POMDP solving could benefit tremendously from massive parallelization on today's hardware, but parallelizing POMDP solvers has been challenging. Most solvers rely on interleaving numerical optimization over actions with the estimation of their values, which creates dependencies and synchronization bottlenecks between parallel processes that can offset the benefits of parallelization. In this paper, we propose Vectorized Online POMDP Planner (VOPP), a novel parallel online solver that leverages a recent POMDP formulation which analytically solves part of the optimization component, leaving numerical computations to consist of only estimation of expectations. VOPP represents all data structures related to planning as a collection of tensors, and implements all planning steps as fully vectorized computations over this representation. The result is a massively parallel online solver with no dependencies or synchronization bottlenecks between concurrent processes. Experimental results indicate that VOPP is at least $20\times$ more efficient in computing near-optimal solutions compared to an existing state-of-the-art parallel online solver. Moreover, VOPP outperforms state-of-the-art sequential online solvers, while using a planning budget that is $1000\times$ smaller.
連続属性の公平なヌル空間投影をカーネル メソッドに拡張する
機械学習システムが何百万人もの日常の社会生活に統合され続けているため、開発における公平性の概念はますます優先事項になっています。公平性の概念は一般に、潜在的なバイアスを評価するために保護された属性に依存します。ここでは、ほとんどの文献が、ターゲット属性と保護属性の両方に関する個別のセットアップに焦点を当てています。連続属性、特に回帰と組み合わせたもの (これを \emph{連続公平性} と呼びます) に関する文献はほとんどありません。一般的な戦略は反復ヌル空間投影であり、これは現時点では線形モデルまたは非線形エンコーダによって取得されるような埋め込みに対してのみ検討されています。これを「経験的特徴空間」によってカーネル誘導特徴空間に拡張することでこれを改善します。理論的には、これをカーネル行列の直接変換として導き出し、連続的な保護属性に適用できるモデルと公平性スコアに依存しない手法を生成します。私たちは、サポート ベクター回帰 (SVR) と組み合わせた新しいアプローチが、他の最新の手法と比較して、複数のデータセットにわたって競合または向上したパフォーマンスを提供することを実証します。
原文 (English)
Extending Fair Null-Space Projections for Continuous Attributes to Kernel Methods
With the on-going integration of machine learning systems into the everyday social life of millions the notion of fairness becomes an ever increasing priority in their development. Fairness notions commonly rely on protected attributes to assess potential biases. Here, the majority of literature focuses on discrete setups regarding both target and protected attributes. The literature on continuous attributes especially in conjunction with regression -- we refer to this as \emph{continuous fairness} -- is scarce. A common strategy is iterative null-space projection which as of now has only been explored for linear models or embeddings such as obtained by a non-linear encoder. We improve on this by extending this to kernel induced feature spaces by means of the ``empirical feature space''. We theoretically derive this as a direct transformation of the kernel matrix yielding a model and fairness-score agnostic method applicable to continuous protected attributes. We demonstrate that our novel approach in conjunction with Support Vector Regression (SVR) provides competitive or improved performance across multiple datasets in comparison to other contemporary methods.
OckBench: LLM 推論の効率を測定する
GPT-5 や Gemini 3 などの大規模言語モデル (LLM) は、自動推論とコード生成の最前線を押し広げました。しかし、現在のベンチマークは精度と出力品質を重視し、トークンの使用効率という重要な側面を無視しています。実際には、トークンの効率は大きく変動します。同じ問題を同様の精度で解決するモデルでは、トークン長に最大 \textbf{5.0$\times$} の違いが見られ、モデルの推論能力に大きなギャップが生じる可能性があります。このような差異は重大な冗長性を明らかにし、トークン効率のギャップを定量化するための標準化されたベンチマークの重要な必要性を浮き彫りにします。そこで、推論タスクとコーディングタスク全体で精度とトークン効率を共同で測定する初のベンチマークである OckBench を紹介します。私たちの評価では、現在のモデル全体でトークンの効率がほとんど最適化されていないため、サービスのコストと待ち時間が大幅に増大していることが明らかになりました。これらの発見は、潜在的な推論能力とトークン効率を最適化するための具体的なロードマップをコミュニティに提供します。最終的に、私たちは評価のパラダイム シフトを主張します。つまり、必要以上にトークンを増やしてはなりません。私たちのベンチマークは https://ockbench.github.io/ で入手できます。
原文 (English)
OckBench: Measuring the Efficiency of LLM Reasoning
Large language models (LLMs) such as GPT-5 and Gemini 3 have pushed the frontier of automated reasoning and code generation. Yet current benchmarks emphasize accuracy and output quality, neglecting a critical dimension: efficiency of token usage. The token efficiency is highly variable in practical. Models solving the same problem with similar accuracy can exhibit up to a \textbf{5.0$\times$} difference in token length, leading to massive gap of model reasoning ability. Such variance exposes significant redundancy, highlighting the critical need for a standardized benchmark to quantify the gap of token efficiency. Thus, we introduce OckBench, the first benchmark that jointly measures accuracy and token efficiency across reasoning and coding tasks. Our evaluation reveals that token efficiency remains largely unoptimized across current models, significantly inflating serving costs and latency. These findings provide a concrete roadmap for the community to optimize the latent reasoning ability, token efficiency. Ultimately, we argue for an evaluation paradigm shift: tokens must not be multiplied beyond necessity. Our benchmarks are available at https://ockbench.github.io/.
SAM 3D: 画像内のあらゆるものを 3Dfy
単一の画像からジオメトリ、テクスチャ、レイアウトを予測し、視覚的に根拠のある 3D オブジェクトを再構築するための生成モデルである SAM 3D を紹介します。 SAM 3D は、オクルージョンやシーンの乱雑さが一般的であり、コンテキストからの視覚認識の手がかりがより大きな役割を果たす自然画像に優れています。これは、オブジェクトの形状、テクスチャ、ポーズに注釈を付けるための人間とモデルのインザループ パイプラインによってこれを実現し、前例のない規模で視覚的に根拠のある 3D 再構成データを提供します。私たちは、合成事前トレーニングと現実世界の調整を組み合わせた最新の多段階トレーニング フレームワークでこのデータから学習し、3D の「データの壁」を打ち破ります。最近の研究に比べて大幅な成果が得られ、現実世界のオブジェクトやシーンに関する人間の好みのテストでは少なくとも 5:1 の勝率を達成しました。コードとモデルの重み、オンライン デモ、および実際の 3D オブジェクト再構築のための新しい挑戦的なベンチマークをリリースします。
原文 (English)
SAM 3D: 3Dfy Anything in Images
We present SAM 3D, a generative model for visually grounded 3D object reconstruction, predicting geometry, texture, and layout from a single image. SAM 3D excels in natural images, where occlusion and scene clutter are common and visual recognition cues from context play a larger role. We achieve this with a human- and model-in-the-loop pipeline for annotating object shape, texture, and pose, providing visually grounded 3D reconstruction data at unprecedented scale. We learn from this data in a modern, multi-stage training framework that combines synthetic pretraining with real-world alignment, breaking the 3D "data barrier". We obtain significant gains over recent work, with at least a 5:1 win rate in human preference tests on real-world objects and scenes. We will release our code and model weights, an online demo, and a new challenging benchmark for in-the-wild 3D object reconstruction.
AttnRegDeepLab: 解釈可能な胚断片化グレーディングのための 2 段階の分離フレームワーク
胚の断片化は、体外受精 (IVF) における発育の可能性を評価するために重要な形態学的指標です。ただし、手動によるグレーディングは主観的で非効率的であり、既存の深層学習ソリューションでは臨床的な説明性に欠けたり、セグメンテーション領域の推定で累積誤差が発生したりすることがよくあります。これらの問題に対処するために、この研究では、デュアルブランチ マルチタスク学習 (MTL) を特徴とするフレームワークである AttnRegDeepLab (注意誘導回帰ディープラボ) を提案します。バニラの DeepLabV3+ デコーダは、アテンション ゲートをスキップ接続に統合することで修正され、細胞質ノイズを明示的に抑制して輪郭の詳細を保持します。さらに、マルチスケール回帰ヘッドには、グローバル グレーディング事前分布をセグメンテーション タスクに伝播し、体系的な定量化エラーを修正するための特徴挿入メカニズムが導入されています。 MTL における勾配の競合に対処するために、2 段階の分離トレーニング戦略が提案されています。また、範囲ベースの損失は、弱くラベル付けされたデータを活用するように設計されています。私たちの方法は、輪郭の完全性を犠牲にしてグレーディング誤差を最小限に抑える可能性があるエンドツーエンドの対応物とは対照的に、優れたセグメンテーション精度 (Dice 係数 = 0.729) を維持しながら、堅牢なグレーディング精度を実現します。この研究は、視覚的な忠実性と定量的精度のバランスをとった臨床的に解釈可能なソリューションを提供します。
原文 (English)
AttnRegDeepLab: A Two-Stage Decoupled Framework for Interpretable Embryo Fragmentation Grading
Embryo fragmentation is a morphological indicator critical for evaluating developmental potential in In Vitro Fertilization (IVF). However, manual grading is subjective and inefficient, while existing deep learning solutions often lack clinical explainability or suffer from accumulated errors in segmentation area estimation. To address these issues, this study proposes AttnRegDeepLab (Attention-Guided Regression DeepLab), a framework characterized by dual-branch Multi-Task Learning (MTL). A vanilla DeepLabV3+ decoder is modified by integrating Attention Gates into its skip connections, explicitly suppressing cytoplasmic noise to preserve contour details. Furthermore, a Multi-Scale Regression Head is introduced with a Feature Injection mechanism to propagate global grading priors into the segmentation task, rectifying systematic quantification errors. A 2-stage decoupled training strategy is proposed to address the gradient conflict in MTL. Also, a range-based loss is designed to leverage weakly labeled data. Our method achieves robust grading precision while maintaining excellent segmentation accuracy (Dice coefficient =0.729), in contrast to the end-to-end counterpart that might minimize grading error at the expense of contour integrity. This work provides a clinically interpretable solution that balances visual fidelity and quantitative precision.
ライブストリームでの動的コンテンツモデレーション: 教師あり分類と MLLM ブースト類似性マッチングの組み合わせ
コンテンツのモデレーションは、大規模なユーザー生成ビデオ プラットフォームにとって、特にモデレーションがタイムリーでマルチモーダルで、進化する形の望ましくないコンテンツに対して堅牢である必要があるライブストリーミング環境では、依然として重要かつ困難なタスクです。既知の違反に対する教師あり分類と、新規または微妙なケースに対する参照ベースの類似性マッチングを組み合わせた、実稼働規模で導入されたハイブリッドモデレーションフレームワークを紹介します。このハイブリッド設計により、明示的な違反と従来の分類子を回避する新しいエッジ ケースの両方を確実に検出できます。マルチモーダル入力 (テキスト、オーディオ、ビジュアル) は両方のパイプラインを通じて処理され、マルチモーダル大規模言語モデル (MLLM) によって知識がそれぞれに抽出され、推論を軽量に保ちながら精度を高めます。運用環境では、分類パイプラインは 80% の精度で 67% の再現率を達成し、類似性パイプラインは 80% の精度で 76% の再現率を達成します。大規模な A/B テストでは、不要なライブストリームのユーザー視聴が 6 ~ 8% 減少することが示されています。これらの結果は、明示的な違反と新たな敵対行為の両方に対処できる、マルチモーダル コンテンツ ガバナンスへのスケーラブルで適応性のあるアプローチを示しています。
原文 (English)
Dynamic Content Moderation in Livestreams: Combining Supervised Classification with MLLM-Boosted Similarity Matching
Content moderation remains a critical yet challenging task for large-scale user-generated video platforms, especially in livestreaming environments where moderation must be timely, multimodal, and robust to evolving forms of unwanted content. We present a hybrid moderation framework deployed at production scale that combines supervised classification for known violations with reference-based similarity matching for novel or subtle cases. This hybrid design enables robust detection of both explicit violations and novel edge cases that evade traditional classifiers. Multimodal inputs (text, audio, visual) are processed through both pipelines, with a multimodal large language model (MLLM) distilling knowledge into each to boost accuracy while keeping inference lightweight. In production, the classification pipeline achieves 67% recall at 80% precision, and the similarity pipeline achieves 76% recall at 80% precision. Large-scale A/B tests show a 6-8% reduction in user views of unwanted livestreams}. These results demonstrate a scalable and adaptable approach to multimodal content governance, capable of addressing both explicit violations and emerging adversarial behaviors.
トポロジは重要です: マルチエージェント LLM のメモリ リークの測定
グラフ トポロジは、マルチエージェント LLM システムにおけるメモリ リークの基本的な決定要因ですが、その影響は依然として十分に定量化されていません。マルチエージェント LLM システムにおけるトポロジ条件付きメモリ リークを比較するための制御された評価フレームワークである MAMA (Multi-Agent Memory Attack) を紹介します。 MAMA は、ラベル付きの個人識別情報 (PII) エンティティを含む合成文書を操作し、そこからサニタイズされたタスク指示を生成します。私たちは、エングラム (ターゲット エージェントのメモリに個人情報をシードする) とレゾナンス (攻撃者が抽出を試みるマルチラウンド インタラクション) の 2 段階のプロトコルを実行します。 10 ラウンドにわたって、完全一致抽出と攻撃者の最終出力に対する LLM ベースの推論を組み合わせた 2 段階の回復基準を使用して漏洩を測定します。 $n\in\{4,5,6\}$、攻撃者とターゲットの配置、および基本モデルにわたる 6 つの正規トポロジ (完全、円、チェーン、ツリー、スター、スター リング) を評価します。結果は一貫しています。接続が密になり、攻撃者とターゲットの距離が短くなり、ターゲットの中心性が高くなることで漏洩が増加します。ほとんどの漏れはラウンド初期に発生し、その後プラトーになります。モデルの選択により絶対率は変化しますが、広範な構造傾向は維持されます。時空間/位置属性は、ID 資格情報や規制された識別子よりも漏洩しやすいです。私たちは、システム設計のための実践的なガイダンスを抽出します。つまり、疎接続または階層接続を優先し、攻撃者とターゲットの分離を最大限に高め、トポロジーを意識したアクセス制御によってハブ/ショートカット経路を制限します。私たちのコードは https://github.com/llll121/mama-eval で入手できます。
原文 (English)
Topology Matters: Measuring Memory Leakage in Multi-Agent LLMs
Graph topology is a fundamental determinant of memory leakage in multi-agent LLM systems, yet its effects remain poorly quantified. We introduce MAMA (Multi-Agent Memory Attack), a controlled evaluation framework for comparing topology-conditioned memory leakage in multi-agent LLM systems. MAMA operates on synthetic documents containing labeled Personally Identifiable Information (PII) entities, from which we generate sanitized task instructions. We execute a two-phase protocol: Engram (seeding private information into a target agent's memory) and Resonance (multi-round interaction where an attacker attempts extraction). Over 10 rounds, we measure leakage using a two-stage recovery criterion that combines exact-match extraction with LLM-based inference over the attacker's final output. We evaluate six canonical topologies (complete, circle, chain, tree, star, star-ring) across $n\in\{4,5,6\}$, attacker-target placements, and base models. Results are consistent: denser connectivity, shorter attacker-target distance, and higher target centrality increase leakage; most leakage occurs in early rounds and then plateaus; model choice shifts absolute rates but preserves broad structural trends; spatiotemporal/location attributes leak more readily than identity credentials or regulated identifiers. We distill practical guidance for system design: favor sparse or hierarchical connectivity, maximize attacker-target separation, and restrict hub/shortcut pathways via topology-aware access control. Our code is available at https://github.com/llll121/mama-eval.
セグメントからシーンへ: 視覚言語モデルによるエージェント自動運転の時間的理解
視覚言語モデル (VLM) は、自動運転 (AD) が最も安全性が重要なインスタンスの 1 つとして、野外で活動する自律エージェントの認識および推論のバックボーンとしてますます導入されています。このようなエージェントがイベントを予測し、原因を特定し、動的な環境で安全に行動するには、信頼性の高い時間的理解が不可欠ですが、これは最先端 (SoTA) VLM にとっても依然として大きな課題です。これまでのビデオ ベンチマークは他のコンテンツ (スポーツ、料理など) を重視していましたが、短編と長編の両方の AD 映像の時間的理解のみに焦点を当てた既存のベンチマークはありません。このギャップを埋めるために、7 つのタスクにわたる約 6000 の質問と回答 (QA) のペアで構成される自動運転における時間的理解 (TAD) ベンチマークを提示し、9 つのクローズドおよびオープンソースのジェネラリスト モデルと AD スペシャリスト モデルを評価します。現在の SoTA モデルは、TAD 上で人間の精度を大幅に下回っています。 VLM ベースの運転エージェントの時間的推論を改善するために、我々は 2 つの新しいトレーニング不要のソリューションを提案します。1 つは思考連鎖 (CoT) 推論を使用する Scene-CoT、もう 1 つは VLM 周辺のエージェント ツールとして動作する軌道分析モジュールによって生成される自己中心の時間認知マップを組み込んだ TCogMap です。既存の VLM と統合された当社のメソッドは、TAD での平均精度を最大 $17.72\%$、STSBench で最大 $10.35\%$ 向上させます。この研究は、TAD の導入、SoTA モデルのベンチマーク、および効果的な機能拡張の提案により、実際に稼働しているエージェント型 AD システムの時間的理解のさらなる進歩を促進することを目的としています。ベンチマークと評価コードは、それぞれ ${\href{https://huggingface.co/datasets/vbdai/TAD}{\text{Hugging Face}}}$ と ${\href{https://github.com/vbdi/tad_bench}{\text{GitHub}}}$ から入手できます。
原文 (English)
From Segments to Scenes: Temporal Understanding for Agentic Autonomous Driving via Vision-Language Models
Vision-Language Models (VLMs) are increasingly deployed as the perception and reasoning backbone of autonomous agents acting in the wild, with autonomous driving (AD) being one of the most safety-critical instances. Reliable temporal understanding is essential for such agents to anticipate events, attribute causes, and act safely in dynamic environments, yet this remains a significant challenge even for state-of-the-art (SoTA) VLMs. Prior video benchmarks have emphasized other content (sports, cooking, etc.), yet no existing benchmark focuses exclusively on temporal understanding for both short- and long-form AD footage. To fill this gap, we present the Temporal Understanding in Autonomous Driving (TAD) benchmark, comprising nearly 6000 question-answer (QA) pairs across 7 tasks, and evaluate 9 closed- and open-source generalist as well as AD-specialist models. Current SoTA models perform substantially below human accuracy on TAD. To improve the temporal reasoning of VLM-based driving agents, we propose two novel training-free solutions: Scene-CoT, which uses Chain-of-Thought (CoT) reasoning, and TCogMap, which incorporates an ego-centric temporal cognitive map produced by a trajectory-analysis module that operates as an agentic tool around the VLM. Integrated with existing VLMs, our methods improve average accuracy on TAD by up to $17.72\%$ and by up to $10.35\%$ on STSBench. By introducing TAD, benchmarking SoTA models, and proposing effective enhancements, this work aims to catalyze further progress on temporal understanding for agentic AD systems operating in the wild. The benchmark and evaluation code are available at ${\href{https://huggingface.co/datasets/vbdai/TAD}{\text{Hugging Face}}}$ and ${\href{https://github.com/vbdi/tad_bench}{\text{GitHub}}}$, respectively.
DVGT: ビジュアル ジオメトリ トランスフォーマーの駆動
自動運転には、視覚入力から 3D シーンのジオメトリを認識して再構築することが重要です。ただし、さまざまなシナリオやカメラ構成に適応できる、運転をターゲットとした高密度ジオメトリ認識モデルがまだ不足しています。このギャップを埋めるために、私たちはドライビング ビジュアル ジオメトリ トランスフォーマー (DVGT) を提案します。これは、一連のポーズ化されていないマルチビュー ビジュアル入力からグローバルな高密度 3D ポイント マップを再構築します。まず、DINO バックボーンを使用して各画像の視覚的特徴を抽出し、ビュー内の局所的注意、ビュー間の空間的注意、およびフレーム間の時間的注意を交互に使用して、画像全体の幾何学的関係を推測します。次に、複数のヘッドを使用して、最初のフレームのエゴ座標のグローバル ポイント マップと各フレームのエゴ ポーズをデコードします。正確なカメラ パラメーターに依存する従来の方法とは異なり、DVGT には明示的な 3D 幾何学的な事前条件がなく、任意のカメラ構成の柔軟な処理が可能です。 DVGT は、画像シーケンスからメートルスケールのジオメトリを直接予測し、外部センサーによる事後位置合わせの必要性を排除します。 DVGT は、nuScenes、OpenScene、Waymo、KITTI、DDAD などの運転データセットを大規模に組み合わせてトレーニングされたため、さまざまなシナリオで既存のモデルを大幅に上回ります。コードは https://github.com/wzzheng/DVGT で入手できます。
原文 (English)
DVGT: Driving Visual Geometry Transformer
Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
トレーニングは 1 回だけ: オミクス データの微分可能なサブセットの選択
単一細胞のトランスクリプトーム データからコンパクトで有益な遺伝子サブセットを選択することは、バイオマーカーの発見、解釈可能性の向上、およびコスト効率の高いプロファイリングに不可欠です。ただし、既存の特徴選択アプローチのほとんどは、多段階パイプラインとして動作するか、事後特徴属性に依存するため、選択と予測の結合が弱くなります。この研究では、個別の遺伝子サブセットを共同で識別し、単一の微分可能なアーキテクチャ内で予測を実行するエンドツーエンドのフレームワークである YOTO (トレーニングは 1 回だけ) を紹介します。私たちのモデルでは、予測タスクはどの遺伝子が選択されるかを直接ガイドし、学習されたサブセットが予測表現を形成します。この閉じたフィードバック ループにより、モデルはトレーニング中に選択する内容と予測方法の両方を繰り返し改良することができます。既存のアプローチとは異なり、YOTO はスパース性を強制するため、選択された遺伝子のみが推論に寄与し、追加の下流分類器をトレーニングする必要がなくなります。マルチタスク学習設計を通じて、モデルは関連する目的全体で共有された表現を学習し、部分的にラベル付けされたデータセットが相互に情報を提供できるようにし、追加のトレーニング手順なしでタスク間で一般化する遺伝子サブセットを発見します。 2 つの代表的な単一細胞 RNA-seq データセットで YOTO を評価し、一貫して最先端のベースラインを上回るパフォーマンスを示しています。これらの結果は、まばらでエンドツーエンドのマルチタスク遺伝子サブセット選択により予測性能が向上し、コンパクトで意味のある遺伝子サブセットが得られ、バイオマーカー発見と単一細胞解析が前進することを示しています。
原文 (English)
You Only Train Once: Differentiable Subset Selection for Omics Data
Selecting compact and informative gene subsets from single-cell transcriptomic data is essential for biomarker discovery, improving interpretability, and cost-effective profiling. However, most existing feature selection approaches either operate as multi-stage pipelines or rely on post hoc feature attribution, making selection and prediction weakly coupled. In this work, we present YOTO (you only train once), an end-to-end framework that jointly identifies discrete gene subsets and performs prediction within a single differentiable architecture. In our model, the prediction task directly guides which genes are selected, while the learned subsets, in turn, shape the predictive representation. This closed feedback loop enables the model to iteratively refine both what it selects and how it predicts during training. Unlike existing approaches, YOTO enforces sparsity so that only the selected genes contribute to inference, eliminating the need to train additional downstream classifiers. Through a multi-task learning design, the model learns shared representations across related objectives, allowing partially labeled datasets to inform one another, and discovering gene subsets that generalize across tasks without additional training steps. We evaluate YOTO on two representative single-cell RNA-seq datasets, showing that it consistently outperforms state-of-the-art baselines. These results demonstrate that sparse, end-to-end, multi-task gene subset selection improves predictive performance and yields compact and meaningful gene subsets, advancing biomarker discovery and single-cell analysis.
セミパラメトリック設定の最適化: 言語モデルは密かに単一インデックス モデルです
選好データに対する政策の調整は通常、観察された選好と潜在的な報酬との間の既知のリンク関数 (例: Bradley-Terry モデル / ロジスティック リンク) を前提としています。このリンクの指定を誤ると、推定される報酬に偏りが生じ、学習されたポリシーの調整が狂う可能性があります。私たちは、未知かつ無制限のリンク関数の下でポリシーの調整を研究します。 $f$ 発散制約付き報酬最大化問題を定式化し、政策クラスの実現可能性がセミパラメトリックな単一インデックスの二項選択モデルを誘導することを示します。このモデルでは、スカラー政策誘導インデックスがデモンストレーションへのすべての依存性を捉え、残りの選好分布は制限されません。計量経済学のように、そのようなモデルの構造パラメータの識別可能性を課してそれらを推定するのではなく、暗黙の報酬関数を使用して政策を直接学習し、最適な政策に対する誤差を分析し、識別不可能でノンパラメトリックな指標を考慮する方法を開発します。一般的な関数の複雑さの尺度の観点から、リンクに依存しない収束保証を証明し、方法と理論を経験的に検証します。コードは https://github.com/causalml/spo/ で入手できます。
原文 (English)
Semiparametric Preference Optimization: Your Language Model is Secretly a Single-Index Model
Policy alignment to preference data typically assumes a known link function between observed preferences and latent rewards (e.g., Bradley-Terry model / logistic link). Misspecification of this link can bias inferred rewards and misalign learned policies. We study policy alignment under an unknown and unrestricted link function. We formulate an $f$-divergence-constrained reward maximization problem and show that realizability in a policy class induces a semiparametric single-index binary choice model, where a scalar policy-induced index captures all dependence on demonstrations and the remaining preference distribution is unrestricted. Rather than impose identifiability of structural parameters of such a model and estimate them, as in econometrics, we develop methods that directly learn policies, with the reward function implicit, analyzing error to the optimal policy and allowing for unidentifiable and nonparametric indices. We prove link-agnostic convergence guarantees in terms of generic function complexity measures and validate the methods and theory empirically. Code is available at https://github.com/causalml/spo/.
大規模言語モデルにおける幾何学認識型幻覚検出
大規模言語モデル (LLM) は、一般に幻覚と呼ばれる、事実に誤りがあるコンテンツやサポートされていないコンテンツを頻繁に生成します。これまでの研究では、解読戦略、検索の強化、幻覚検出のための教師付き微調整が検討されてきましたが、最近の研究では、コンテキスト内学習 (ICL) が事実の信頼性に大きな影響を与える可能性があることが示されています。ただし、既存の ICL デモンストレーション選択方法は、表面レベルの類似性ヒューリスティックに依存することが多く、タスクやモデル全体での堅牢性が限られています。我々は、フリーズした LLM から抽出された潜在表現を活用する、コンテキスト内のデモンストレーションを選択するための、ジオメトリを意識したデモンストレーション サンプリング フレームワークである GA-ICL を提案します。 GA-ICL は、ローカル多様体構造とクラス認識プロトタイプ幾何学を共同でモデル化することで、語彙や埋め込みの類似性だけではなく、学習されたプロトタイプへの近さに基づいてデモンストレーションを選択します。事実検証 (FEVER) と幻覚検出 (HaluEval) ベンチマーク全体で、GA-ICL は評価された設定の大部分で標準的な ICL 選択ベースラインを上回り、特に対話と要約タスクで大きな向上を示しました。この方法は、温度摂動やモデルの変動の下でも堅牢性を維持しており、ヒューリスティック検索戦略と比較して安定性が向上していることを示しています。語彙検索は、モデル規模が小さい場合でも特定の質問応答方式では競争力を維持できますが、我々の結果は、ジオメトリを意識したプロトタイプの選択が、LLM パラメーターを変更せずに幻覚検出のための信頼性が高く、トレーニングに適したアプローチを提供することを示しています。 Phi-14B および Qwen3-32B の拡張評価では、GA-ICL がより大きなモデルに効果的に拡張でき、より小さなモデルが境界条件の制限を示す QA タスクを含む、比較されたすべてのベースラインを上回っていることが確認され、ICL デモの選択を改善するための原則的な方向性が示されています。
原文 (English)
Geometry-Aware Hallucination Detection in Large Language Models
Large language models (LLMs) frequently generate factually incorrect or unsupported content, commonly referred to as hallucinations. Prior work has explored decoding strategies, retrieval augmentation, and supervised fine-tuning for hallucination detection, while recent studies show that in-context learning (ICL) can substantially influence factual reliability. However, existing ICL demonstration selection methods often rely on surface-level similarity heuristics and exhibit limited robustness across tasks and models. We propose GA-ICL, a geometry-aware demonstration sampling framework for selecting in-context demonstrations that leverages latent representations extracted from frozen LLMs. By jointly modeling local manifold structure and class-aware prototype geometry, GA-ICL selects demonstrations based on their proximity to learned prototypes rather than lexical or embedding similarity alone. Across factual verification (FEVER) and hallucination detection (HaluEval) benchmarks, GA-ICL outperforms standard ICL selection baselines in the majority of evaluated settings, with particularly strong gains on dialogue and summarization tasks. The method remains robust under temperature perturbations and model variation, indicating improved stability compared to heuristic retrieval strategies. While lexical retrieval can remain competitive in certain question-answering regimes at smaller model scales, our results demonstrate that geometry-aware prototype selection provides a reliable and training-light approach for hallucination detection without modifying LLM parameters. Extended evaluations on Phi-14B and Qwen3-32B confirm that GA-ICL scales effectively to larger models, outperforming all compared baselines including on QA tasks where smaller models show boundary-condition limitations, offering a principled direction for improved ICL demonstration selection.
Mid-Think: トークンレベルのトリガーによるトレーニング不要の中間予算推論
ハイブリッド推論言語モデルは一般に、推論動作を制御するための高レベルの考える/考えない命令によって制御されますが、そのようなモードの切り替えは主に、命令自体ではなく、トリガー トークンの小さなセットによって駆動されることがわかりました。注意分析と制御されたプロンプト実験を通じて、先頭の「わかりました」トークンが推論行動を誘発する一方、「」に続く改行パターンがそれを抑制することを示しました。この観察に基づいて、これらのトリガーを組み合わせて中間予算の推論を実現し、精度と長さのトレードオフの点で固定トークンおよびプロンプトベースのベースラインを常に上回るパフォーマンスを実現する、シンプルなトレーニング不要のプロンプト形式である Mid-Think を提案します。さらに、SFT 後の RL トレーニングに Mid-Think を適用すると、トレーニング時間が約 15% 短縮され、AIME での Qwen3-8B の最終パフォーマンスが 69.8% から 72.4% に、GPQA での最終パフォーマンスが 58.5% から 61.1% に向上し、推論時間制御と RL ベースの推論トレーニングの両方でその有効性が実証されました。
原文 (English)
Mid-Think: Training-Free Intermediate-Budget Reasoning via Token-Level Triggers
Hybrid reasoning language models are commonly controlled through high-level Think/No-think instructions to regulate reasoning behavior, yet we found that such mode switching is largely driven by a small set of trigger tokens rather than the instructions themselves. Through attention analysis and controlled prompting experiments, we show that a leading ``Okay'' token induces reasoning behavior, while the newline pattern following ``'' suppresses it. Based on this observation, we propose Mid-Think, a simple training-free prompting format that combines these triggers to achieve intermediate-budget reasoning, consistently outperforming fixed-token and prompt-based baselines in terms of the accuracy-length trade-off. Furthermore, applying Mid-Think to RL training after SFT reduces training time by approximately 15% while improving final performance of Qwen3-8B on AIME from 69.8% to 72.4% and on GPQA from 58.5% to 61.1%, demonstrating its effectiveness for both inference-time control and RL-based reasoning training.
有界双曲線正接: 大規模言語モデルにおける前層正規化の安定した効率的な代替手段
前層正規化 (Pre-LN) は大規模言語モデル (LLM) の事実上の選択肢であり、安定した事前トレーニングと効果的な転移学習に不可欠です。ただし、Pre-LN は統計計算のオーバーヘッドを繰り返し発生し、層の数が増加するにつれて隠れ状態の大きさと分散が増大する深さの呪いに対して脆弱なままであり、トレーニングが不安定になります。 Dynamic Tanh (DyT) などの効率重視の正規化不要の手法はスループットを向上させますが、深度では脆弱なままです。安定性と効率性を共同で解決するために、Pre-LN のドロップイン代替品である有界双曲線 Tanh (BHyT) を提案します。 BHyT は、tanh 非線形性と明示的なデータ駆動型入力境界を組み合わせて、アクティベーションを非飽和範囲内に保ちます。これにより、活性化の大きさと分散の深さ方向の増大が防止され、理論的な安定性が保証されます。効率性を高めるため、BHyT はブロックごとに 1 回正確な統計を計算し、2 番目の正規化を軽量の分散近似に置き換えます。経験的に、BHyT は事前トレーニング中の安定性と効率の向上を実証し、RMSNorm と比較して平均 1.6\% 高速なトレーニングと平均 1.77\% 高いトークン生成スループットを達成しながら、言語理解と推論ベンチマーク全体で事前トレーニングのみおよび SFT 後の強力なパフォーマンスを維持しています\footnote{コードは https://github.com/MLAI-Yonsei/BHyT} で入手できます。
原文 (English)
Bounded Hyperbolic Tangent: A Stable and Efficient Alternative to Pre-Layer Normalization in Large Language Models
Pre-Layer Normalization (Pre-LN) is the de facto choice for large language models (LLMs) and is crucial for stable pretraining and effective transfer learning. However, Pre-LN incurs repeated statistical-computation overhead and remains vulnerable to the curse of depth, where hidden-state magnitudes and variances grow as the number of layers increases, destabilizing training. Efficiency-oriented normalization-free methods such as Dynamic Tanh (DyT) improve throughput but remain fragile at depth. To jointly address stability and efficiency, we propose Bounded Hyperbolic Tanh (BHyT), a drop-in replacement for Pre-LN. BHyT combines a tanh nonlinearity with explicit, data-driven input bounding to keep activations within a non-saturating range. It prevents depth-wise growth in activation magnitude and variance and provides a theoretical stability guarantee. For efficiency, BHyT computes exact statistics once per block and replaces a second normalization with a lightweight variance approximation. Empirically, BHyT demonstrates improved stability and efficiency during pretraining, achieving an average of 1.6\% faster training and an average of 1.77\% higher token generation throughput compared to RMSNorm, while maintaining strong pretraining-only and post-SFT performance across language understanding and reasoning benchmarks\footnote{Code is available at: https://github.com/MLAI-Yonsei/BHyT}.
MedRedFlag: LLM が現実世界の医療コミュニケーションにおける誤解をどのように方向転換するかを調査する
患者からの現実世界の健康に関する質問には、意図せず誤った仮定や前提が含まれていることがよくあります。このような場合、安全な医療コミュニケーションには通常、方向転換が含まれます。つまり、暗黙の誤解に対処し、その後、元の質問ではなく、根底にある患者の状況に応答します。大規模言語モデル (LLM) は医療アドバイスのために一般ユーザーによって使用されることが増えていますが、この重要な能力についてはまだテストされていません。したがって、この研究では、現実世界の健康に関する質問に埋め込まれた誤った前提に対して LLM がどのように反応するかを調査します。私たちは、Reddit から取得したリダイレクトを必要とする 1,100 以上の質問のデータセットである MedRedFlag をキュレーションするための半自動パイプラインを開発しています。次に、最先端の LLM からの反応を臨床医からの反応と体系的に比較します。私たちの分析により、LLM は問題のある前提が検出された場合でも、問題のある質問の方向を変えることができず、次善の医療意思決定につながる可能性のある回答を提供できないことが明らかになりました。私たちのベンチマークとその結果は、現実世界の医療コミュニケーションの条件下で LLM がどのように機能するかについて、これまでにない大幅なギャップを明らかにし、患者に直面する医療 AI システムに対する重大な安全上の懸念を浮き彫りにしています。コードとデータセットは https://github.com/srsambara-1/MedRedFlag で入手できます。
原文 (English)
MedRedFlag: Investigating how LLMs Redirect Misconceptions in Real-World Health Communication
Real-world health questions from patients often unintentionally embed false assumptions or premises. In such cases, safe medical communication typically involves redirection: addressing the implicit misconception and then responding to the underlying patient context, rather than the original question. While large language models (LLMs) are increasingly being used by lay users for medical advice, they have not yet been tested for this crucial competency. Therefore, in this work, we investigate how LLMs react to false premises embedded within real-world health questions. We develop a semi-automated pipeline to curate MedRedFlag, a dataset of 1100+ questions sourced from Reddit that require redirection. We then systematically compare responses from state-of-the-art LLMs to those from clinicians. Our analysis reveals that LLMs often fail to redirect problematic questions, even when the problematic premise is detected, and provide answers that could lead to suboptimal medical decision making. Our benchmark and results reveal a novel and substantial gap in how LLMs perform under the conditions of real-world health communication, highlighting critical safety concerns for patient-facing medical AI systems. Code and dataset are available at https://github.com/srsambara-1/MedRedFlag.
結果ベースの RL はトランスフォーマーを論理的に導くことができますが、それは適切なデータがあった場合に限られます
結果ベースの監督による強化学習 (RL) によって訓練されたトランスフォーマーは、中間推論ステップ (思考連鎖) を生成する能力を自発的に開発できます。しかし、まばらな報酬がそのような体系的な推論を発見するための政策勾配を駆動するメカニズムは、依然としてよく理解されていない。我々は、思考連鎖なしでは解決できないが、単純な反復解決は可能である合成グラフ走査タスク上の単層トランスフォーマーのポリシー勾配ダイナミクスを分析することで、これに対処します。最終的な答えの正しさのみに基づいてトレーニングしたにもかかわらず、ポリシー勾配によって Transformer がグラフの頂点ごとに反復的に走査する構造化された解釈可能なアルゴリズムに収束することが証明されました。我々は、この創発に必要な分布特性を特徴づけ、「単純な例」、つまりより少ない推論ステップを必要とするインスタンスの重要な役割を特定します。トレーニング分布がこれらの単純な例に十分な量を置くと、Transformer はより長いチェーンを推定する一般化可能な走査戦略を学習します。この塊が消えると、ポリシー勾配学習は実行できなくなります。私たちは、合成データの実験と数学的推論タスクにおける現実世界の言語モデルを使用した実験を通じて理論的結果を裏付け、理論的発見が実際の設定に引き継がれることを検証します。
原文 (English)
Outcome-Based RL Provably Leads Transformers to Reason, but Only With the Right Data
Transformers trained via Reinforcement Learning (RL) with outcome-based supervision can spontaneously develop the ability to generate intermediate reasoning steps (Chain-of-Thought). Yet the mechanism by which sparse rewards drive policy gradient to discover such systematic reasoning remains poorly understood. We address this by analyzing the policy gradient dynamics of single-layer Transformers on a synthetic graph traversal task that cannot be solved without Chain-of-Thought but admits a simple iterative solution. We prove that despite training solely on final-answer correctness, policy gradient drives the Transformer to converge to a structured, interpretable algorithm that iteratively traverses the graph vertex-by-vertex. We characterize the distributional properties required for this emergence, identifying the critical role of "simple examples": instances requiring fewer reasoning steps. When the training distribution places sufficient mass on these simpler examples, the Transformer learns a generalizable traversal strategy that extrapolates to longer chains; when this mass vanishes, policy gradient learning becomes infeasible. We corroborate our theoretical results through experiments on synthetic data and with real-world language models on mathematical reasoning tasks, validating that our theoretical findings carry over to practical settings.
プロの翻訳者は機械生成されたテキストを識別できますか?
この研究では、事前に専門的なトレーニングを受けていないプロの翻訳者が、人工知能 (AI) によって生成されたイタリア語の短編小説を確実に識別できるかどうかを調査します。 69 人の翻訳者が対面実験に参加し、匿名化された 3 つの短編小説 (ChatGPT-4o によって書かれた 2 つと人間の著者によって書かれた 1 つ) を評価しました。各ストーリーについて、参加者は AI の作者である可能性を評価し、その選択の正当性を示しました。平均的な結果は決定的ではありませんでしたが、統計的に有意なサブセット (16.2%) が合成テキストと人間のテキストを区別することに成功し、彼らの判断が偶然ではなく分析スキルに基づいて行われたことを示唆しています。しかし、ほぼ同数が反対方向にテキストを誤分類しており、多くの場合、客観的なマーカーではなく主観的な印象に依存しており、おそらく AI によって生成されたテキストに対する読者の好みを反映しています。バースト性の低さと物語の矛盾が、合成著作者であることを示す最も信頼できる指標として浮上し、予期せぬ表現、意味的借用、英語からの統語的転移も報告されました。対照的に、文法的な正確さや感情的な調子などの特徴が誤分類につながることがよくありました。これらの発見は、専門的な文脈における合成テキスト編集の役割と範囲について疑問を引き起こします。
原文 (English)
Can professional translators identify machine-generated text?
This study investigates whether professional translators without prior specialized training can reliably identify short stories generated in Italian by artificial intelligence (AI). Sixty-nine translators took part in an in-person experiment, where they assessed three anonymized short stories - two written by ChatGPT-4o and one by a human author. For each story, participants rated the likelihood of AI authorship and provided justifications for their choices. While average results were inconclusive, a statistically significant subset (16.2%) successfully distinguished the synthetic texts from the human text, suggesting that their judgements were informed by analytical skill rather than chance. However, a nearly equal number misclassified the texts in the opposite direction, often relying on subjective impressions rather than objective markers, possibly reflecting a reader preference for AI-generated texts. Low burstiness and narrative contradiction emerged as the most reliable indicators of synthetic authorship, with unexpected calques, semantic loans and syntactic transfer from English also reported. In contrast, features such as grammatical accuracy and emotional tone frequently led to misclassification. These findings raise questions about the role and scope of synthetic-text editing in professional contexts.
読者はAIが生成したイタリアの短編小説を好みますか?
この研究では、読者が著名なイタリア人作家が書いた短編小説よりも、AI が生成したイタリア語の短編小説を好むかどうかを調査しました。ブラインド設定では、20 人の参加者が 3 つのストーリー (2 つは ChatGPT-4o で作成され、1 つは Alberto Moravia によって作成されました) を、その起源について知らされることなく読み、評価しました。潜在的な影響要因を調査するために、読書習慣と、年齢、性別、教育、第一言語を含む人口統計データも収集されました。その結果、差はわずかであったものの、AI が書いたテキストの方が平均評価がわずかに高く、好まれる頻度が高かったことがわかりました。テキストの好みと人口統計または読書習慣の変数の間に統計的に有意な関連性は見つかりませんでした。これらの発見は、人間が執筆した小説に対する読者の好みに関する仮定に疑問を投げかけ、文学の文脈における合成テキスト編集の必要性について疑問を投げかけています。
原文 (English)
Do readers prefer AI-generated Italian short stories?
This study investigates whether readers prefer AI-generated short stories in Italian over one written by a renowned Italian author. In a blind setup, 20 participants read and evaluated three stories, two created with ChatGPT-4o and one by Alberto Moravia, without being informed of their origin. To explore potential influencing factors, reading habits and demographic data, comprising age, gender, education and first language, were also collected. The results showed that the AI-written texts received slightly higher average ratings and were more frequently preferred, although differences were modest. No statistically significant associations were found between text preference and demographic or reading-habit variables. These findings challenge assumptions about reader preference for human-authored fiction and raise questions about the necessity of synthetic-text editing in literary contexts.
マルチエージェント討論を読み解く: 自信と多様性の役割
マルチエージェント ディベート (MAD) は、テスト時間のスケーリングを通じて大規模言語モデル (LLM) のパフォーマンスを向上させるために広く使用されていますが、最近の研究では、バニラの MAD は、計算コストが高いにもかかわらず、単純な多数決を下回ることが多いことが示されています。研究によると、同種のエージェントと統一的な信念の更新の下では、議論は期待される正しさを維持するため、結果を確実に改善することはできません。人間による熟慮と集団的意思決定からの発見に基づいて、バニラ MAD に欠けている 2 つの重要なメカニズムを特定します。(i) 初期の視点の多様性と、(ii) 明示的で調整された信頼性のコミュニケーションです。私たちは 2 つの軽量介入を提案します。まず、多様性を意識した初期化により、より多様な回答候補プールが選択され、議論の開始時に正しい仮説が存在する可能性が高まります。 2 つ目は、エージェントが調整された自信を表現し、他の人の自信に基づいて最新情報を条件付けする、自信調整型ディベート プロトコルです。我々は、多様性を意識した初期化により、基礎となる更新ダイナミクスを変更することなく MAD 成功の事前確率が向上する一方で、信頼度調整された更新により、議論が体系的に正しい仮説に向かうことが可能になることを理論的に示します。経験的には、6 つの推論指向の QA ベンチマーク全体で、私たちの手法はバニラの MAD と多数決を一貫して上回っています。私たちの結果は、人間による熟慮と LLM ベースの議論を結びつけ、シンプルで原則に基づいた修正が議論の有効性を大幅に高めることができることを示しています。
原文 (English)
Demystifying Multi-Agent Debate: The Role of Confidence and Diversity
Multi-agent debate (MAD) is widely used to improve large language model (LLM) performance through test-time scaling, yet recent work shows that vanilla MAD often underperforms simple majority vote despite higher computational cost. Studies show that, under homogeneous agents and uniform belief updates, debate preserves expected correctness and therefore cannot reliably improve outcomes. Drawing on findings from human deliberation and collective decision-making, we identify two key mechanisms missing from vanilla MAD: (i) diversity of initial viewpoints and (ii) explicit, calibrated confidence communication. We propose two lightweight interventions. First, a diversity-aware initialisation that selects a more diverse pool of candidate answers, increasing the likelihood that a correct hypothesis is present at the start of debate. Second, a confidence-modulated debate protocol in which agents express calibrated confidence and condition their updates on others' confidence. We show theoretically that diversity-aware initialisation improves the prior probability of MAD success without changing the underlying update dynamics, while confidence-modulated updates enable debate to systematically drift to the correct hypothesis. Empirically, across six reasoning-oriented QA benchmarks, our methods consistently outperform vanilla MAD and majority vote. Our results connect human deliberation with LLM-based debate and demonstrate that simple, principled modifications can substantially enhance debate effectiveness.
条件付き PED-ANOVA: 階層的および動的検索空間におけるハイパーパラメーターの重要性
我々は、条件付き PED-ANOVA (condPED-ANOVA) を提案します。これは、条件付き検索空間でハイパーパラメーター重要度 (HPI) を推定するための原則的なフレームワークであり、ハイパーパラメーターの存在またはドメインが他のハイパーパラメーターに依存する可能性があります。オリジナルの PED-ANOVA は、検索空間の最もパフォーマンスの高い領域内の HPI を推定するための高速かつ効率的な方法を提供しますが、固定された無条件の検索空間を前提としているため、条件付きハイパーパラメーターを適切に処理できません。これに対処するために、最高パフォーマンスの領域に条件付き HPI を導入し、条件付きのアクティブ化とドメインの変更を正確に反映する閉じた形式の推定量を導き出します。実験によると、既存の HPI 推定量を単純に適応すると、条件設定で誤解を招く、または解釈できない重要度が生成されるのに対し、condPED-ANOVA は、基礎となる条件構造を反映する意味のある重要度を一貫して提供します。私たちのコードは https://github.com/kAIto47802/condPED-ANOVA で公開されています。
原文 (English)
Conditional PED-ANOVA: Hyperparameter Importance in Hierarchical & Dynamic Search Spaces
We propose conditional PED-ANOVA (condPED-ANOVA), a principled framework for estimating hyperparameter importance (HPI) in conditional search spaces, where the presence or domain of a hyperparameter can depend on other hyperparameters. Although the original PED-ANOVA provides a fast and efficient way to estimate HPI within the top-performing regions of the search space, it assumes a fixed, unconditional search space and therefore cannot properly handle conditional hyperparameters. To address this, we introduce a conditional HPI for top-performing regions and derive a closed-form estimator that accurately reflects conditional activation and domain changes. Experiments show that naive adaptations of existing HPI estimators yield misleading or uninterpretable importances in conditional settings, whereas condPED-ANOVA consistently provides meaningful importances that reflect the underlying conditional structure. Our code is publicly available at https://github.com/kAIto47802/condPED-ANOVA.
L$^3$: 大規模なルックアップ レイヤー
最新のスパース言語モデルは通常、トークンを高密度 MLP 「エキスパート」に動的にルーティングする Mixture-of-Experts (MoE) レイヤーを通じてスパース性を実現します。ただし、動的ハード ルーティングには、ハードウェア効率が低い可能性や、安定したトレーニングのために補助損失が必要であるなど、多くの欠点があります。対照的に、トークナイザーの埋め込みテーブルは、ネイティブにスパースであり、コンテキスト情報を持たないという犠牲を払ってトークンごとに 1 つの埋め込みを選択することで、これらの問題を大幅に回避します。この研究では、ラージ ルックアップ レイヤー (L$^3$) を導入します。これは、スパース性をさらにスケーリングする手段として、デコーダー レイヤーをモデル化するための埋め込みテーブルを一般化します。 L$^3$ 層は、静的トークンベースのルーティングを使用して、コンテキスト依存の方法でトークンごとに学習されたエンベディングのセットを集約します。これにより、モデルはエンベディングに情報をキャッシュすることでメモリと計算のバランスを効率的にとることができます。 L$^3$ には 2 つの主要コンポーネントがあります。(1) オーバーヘッドなしで高速トレーニングと CPU オフロード推論を可能にするシステムフレンドリーなアーキテクチャ、(2) 速度と品質のバランスを効果的に取る情報理論的な埋め込み割り当てアルゴリズムです。最大 2.6B のアクティブ パラメーターを使用して変換器をトレーニングすることで L$^3$ を経験的にテストし、L$^3$ が言語モデリングと下流タスクの両方で密モデルと等疎 MoE の両方を大幅に上回るパフォーマンスを示すことがわかりました。
原文 (English)
L$^3$: Large Lookup Layers
Modern sparse language models typically achieve sparsity through Mixture-of-Experts (MoE) layers, which dynamically route tokens to dense MLP "experts." However, dynamic hard routing has a number of drawbacks, such as potentially poor hardware efficiency and needing auxiliary losses for stable training. In contrast, the tokenizer embedding table, which is natively sparse, largely avoids these issues by selecting a single embedding per token at the cost of not having contextual information. In this work, we introduce the Large Lookup Layer (L$^3$), which generalizes embedding tables to model decoder layers as a means of further scaling sparsity. L$^3$ layers use static token-based routing to aggregate a set of learned embeddings per token in a context-dependent way, allowing the model to efficiently balance memory and compute by caching information in embeddings. L$^3$ has two main components: (1) a systems-friendly architecture that allows for fast training and CPU-offloaded inference with no overhead, and (2) an information-theoretic embedding allocation algorithm that effectively balances speed and quality. We empirically test L$^3$ by training transformers with up to 2.6B active parameters and find that L$^3$ strongly outperforms both dense models and iso-sparse MoEs in both language modeling and downstream tasks.
大規模言語モデルにおける文化的に根拠のあるペルソナ: 特徴付けと社会心理学的価値フレームワークとの整合
人間の行動をシミュレートするための大規模言語モデル (LLM) の有用性が高まっているにもかかわらず、これらの合成ペルソナが、さまざまな文化条件にわたる世界および道徳的価値観をどの程度正確に反映しているかは依然として不確実です。この論文では、確立された枠組み、特に世界価値観調査 (WVS)、イングルハート・ヴェルゼル文化地図、道徳基盤理論と、文化に基づいた総合的なペルソナの整合性を調査します。私たちは、解釈可能な WVS 由来の変数のセットに基づいて LLM によって生成されたペルソナを概念化して生成し、生成されたペルソナを 3 つの相補的なレンズを通して検査します。世界価値観調査との人口統計レベルの一貫性。回答分布は人間のグループパターンを広範囲に追跡します。道徳的プロフィールは、道徳財団のアンケートから得られ、文化と道徳のマッピングを通じて分析し、さまざまな文化構成間で道徳的反応がどのように異なるかを特徴づけます。文化に基づいたペルソナの生成と分析のアプローチにより、異文化構造と道徳的変動の評価が可能になります。
原文 (English)
Culturally Grounded Personas in Large Language Models: Characterization and Alignment with Socio-Psychological Value Frameworks
Despite the growing utility of Large Language Models (LLMs) for simulating human behavior, the extent to which these synthetic personas accurately reflect world and moral value systems across different cultural conditionings remains uncertain. This paper investigates the alignment of synthetic, culturally-grounded personas with established frameworks, specifically the World Values Survey (WVS), the Inglehart-Welzel Cultural Map, and Moral Foundations Theory. We conceptualize and produce LLM-generated personas based on a set of interpretable WVS-derived variables, and we examine the generated personas through three complementary lenses: positioning on the Inglehart-Welzel map, which unveils their interpretation reflecting stable differences across cultural conditionings; demographic-level consistency with the World Values Survey, where response distributions broadly track human group patterns; and moral profiles derived from a Moral Foundations questionnaire, which we analyze through a culture-to-morality mapping to characterize how moral responses vary across different cultural configurations. Our approach of culturally-grounded persona generation and analysis enables evaluation of cross-cultural structure and moral variation.
マスクされた拡散言語モデルの暗黙的正則化子の調整: $k$-Parity からの洞察による一般化の強化
マスクされた拡散言語モデルは、強力な生成パラダイムとして最近登場しましたが、その一般化特性は、自己回帰モデルに比べてまだ研究が進んでいません。この研究では、$k$ パリティ問題 ($k$ 関連ビットの XOR 和を計算する) の設定内でこれらの特性を調査します。この問題では、ニューラル ネットワークは通常、グロッキング (偶然レベルのパフォーマンスの長期にわたるプラトーとそれに続く突然の一般化) を示します。理論的には、マスク拡散 (MD) 目標を、特徴学習を推進する信号領域と、暗黙的な正則化器として機能するノイズ領域に分解します。 $k$ パリティ問題で MD 目標を使用して nanoGPT をトレーニングすることにより、MD 目標が学習環境を根本的に変更し、理解に苦しむことなく迅速かつ同時に一般化できることを示します。さらに、理論的な洞察を活用して、MD 対物レンズのマスク確率の分布を最適化します。私たちの手法は、50M パラメーターのモデルの複雑さを大幅に改善し、ゼロからの事前トレーニングと教師付き微調整の両方で優れた結果を達成します。具体的には、8B パラメーター モデルで、それぞれ $8.8\%$ と $5.8\%$ でピークに達するパフォーマンスの向上が観察され、大規模なマスクされた拡散言語モデル領域におけるフレームワークのスケーラビリティと有効性が確認されました。
原文 (English)
Tuning the Implicit Regularizer of Masked Diffusion Language Models: Enhancing Generalization via Insights from $k$-Parity
Masked Diffusion Language Models have recently emerged as a powerful generative paradigm, yet their generalization properties remain understudied compared to their auto-regressive counterparts. In this work, we investigate these properties within the setting of the $k$-parity problem (computing the XOR sum of $k$ relevant bits), where neural networks typically exhibit grokking -- a prolonged plateau of chance-level performance followed by sudden generalization. We theoretically decompose the Masked Diffusion (MD) objective into a Signal regime which drives feature learning, and a Noise regime which serves as an implicit regularizer. By training nanoGPT using MD objective on the $k$-parity problem, we demonstrate that MD objective fundamentally alters the learning landscape, enabling rapid and simultaneous generalization without experiencing grokking. Furthermore, we leverage our theoretical insights to optimize the distribution of the mask probability in the MD objective. Our method significantly improves perplexity for 50M-parameter models and achieves superior results across both pre-training from scratch and supervised fine-tuning. Specifically, we observe performance gains peaking at $8.8\%$ and $5.8\%$, respectively, on 8B-parameter models, confirming the scalability and effectiveness of our framework in large-scale masked diffusion language model regimes.
R3G: ビジョン中心の回答生成のための推論-検索-再ランキングフレームワーク
VQA の視覚中心の検索では、画像を検索して欠落している視覚的な手がかりを提供し、それらを推論プロセスに統合する必要があります。ただし、適切な画像を選択し、それらをモデルの推論に効果的に統合することは依然として困難です。この課題に対処するために、モジュール式の推論-取得-再ランキング フレームワークである R3G を提案します。これは、最初に必要な視覚的手がかりを指定する簡単な推論計画を作成し、次に、証拠画像を選択するために、粗い検索とその後のきめ細かい再ランキングという 2 段階の戦略を採用します。MRAG-Bench では、R3G により 6 つの精度が向上します。 MLLM バックボーンと 9 つのサブシナリオにより、最先端の全体的なパフォーマンスを実現します。アブレーションは、十分性を意識した再ランキングと推論のステップが補完的であり、モデルが適切な画像を選択し、それらを適切に使用するのに役立つことを示しています。コードとデータは https://github.com/czh24/R3G でリリースされます。
原文 (English)
R3G: A Reasoning-Retrieval-Reranking Framework for Vision-Centric Answer Generation
Vision-centric retrieval for VQA requires retrieving images to supply missing visual cues and integrating them into the reasoning process. However, selecting the right images and integrating them effectively into the model's reasoning remains challenging.To address this challenge, we propose R3G, a modular Reasoning-Retrieval-Reranking framework.It first produces a brief reasoning plan that specifies the required visual cues, then adopts a two-stage strategy, with coarse retrieval followed by fine-grained reranking, to select evidence images.On MRAG-Bench, R3G improves accuracy across six MLLM backbones and nine sub-scenarios, achieving state-of-the-art overall performance. Ablations show that sufficiency-aware reranking and reasoning steps are complementary, helping the model both choose the right images and use them well. We release code and data at https://github.com/czh24/R3G.
SUSD: 状態因数分解による構造化された教師なしスキルの発見
教師なしスキル ディスカバリー (USD) は、外部報酬に依存せずに、さまざまなスキルを自律的に学習することを目的としています。最も一般的な USD アプローチの 1 つは、スキルの潜在変数と状態の間の相互情報 (MI) を最大化することです。ただし、MI ベースの手法は、その不変特性により単純で静的なスキルを好む傾向があり、動的でタスクに関連した動作の発見が制限されます。 Distance-Maximizing Skill Discovery (DSD) は、状態空間の距離を活用することで、より動的なスキルを促進しますが、環境内のすべての制御可能な要素またはエンティティに関与する包括的なスキル セットを奨励するにはまだ不十分です。この研究では、状態空間を独立したコンポーネント (オブジェクトや制御可能なエンティティなど) に因数分解することで環境の構成構造を利用する新しいフレームワークである SUSD を紹介します。 SUSD は、異なるスキル変数をさまざまな要素に割り当て、スキル発見プロセスをよりきめ細かく制御できるようにします。また、動的モデルは複数の要因にわたる学習を追跡し、エージェントの焦点を未探索の要因に適応的に導きます。この構造化されたアプローチは、より豊かで多様なスキルの発見を促進するだけでなく、階層強化学習 (HRL) を介した構成的な下流タスクの効率的なトレーニングを促進する、個々のエンティティに対するきめ細かく解きほぐされた制御を可能にする因数分解されたスキル表現ももたらします。係数が 1 から 10 までの 3 つの環境にわたる実験結果は、私たちの方法が監督なしで多様で複雑なスキルを発見できることを示しており、因数分解された複雑な環境で既存の教師なしスキル発見方法を大幅に上回っています。コードは https://github.com/hadi-hosseini/SUSD で公開されています。
原文 (English)
SUSD: Structured Unsupervised Skill Discovery through State Factorization
Unsupervised Skill Discovery (USD) aims to autonomously learn a diverse set of skills without relying on extrinsic rewards. One of the most common USD approaches is to maximize the Mutual Information (MI) between skill latent variables and states. However, MI-based methods tend to favor simple, static skills due to their invariance properties, limiting the discovery of dynamic, task-relevant behaviors. Distance-Maximizing Skill Discovery (DSD) promotes more dynamic skills by leveraging state-space distances, yet still fall short in encouraging comprehensive skill sets that engage all controllable factors or entities in the environment. In this work, we introduce SUSD, a novel framework that harnesses the compositional structure of environments by factorizing the state space into independent components (e.g., objects or controllable entities). SUSD allocates distinct skill variables to different factors, enabling more fine-grained control on the skill discovery process. A dynamic model also tracks learning across factors, adaptively steering the agent's focus toward underexplored factors. This structured approach not only promotes the discovery of richer and more diverse skills, but also yields a factorized skill representation that enables fine-grained and disentangled control over individual entities which facilitates efficient training of compositional downstream tasks via Hierarchical Reinforcement Learning (HRL). Our experimental results across three environments, with factors ranging from 1 to 10, demonstrate that our method can discover diverse and complex skills without supervision, significantly outperforming existing unsupervised skill discovery methods in factorized and complex environments. Code is publicly available at: https://github.com/hadi-hosseini/SUSD.
高次元オフライン盗賊に対する効率的な敵対攻撃
Bandit アルゴリズムは、徹底的な比較を行わずに最もパフォーマンスの高い候補を効率的に特定することにより、生成画像モデルや大規模言語モデルなどの機械学習モデルを評価するための強力なツールとして最近登場しました。これらの方法は通常、盗賊にフィードバックを提供するために、Hugging Face などのプラットフォームで公開重みを使用して配布される報酬モデルに依存しています。オンライン評価は費用がかかり、試行を繰り返す必要がありますが、ログデータを使用したオフライン評価は魅力的な代替手段となっています。ただし、オフライン バンディット評価の敵対的な堅牢性は、特に攻撃者がバンディット トレーニングの前に (トレーニング データではなく) 報酬モデルを混乱させた場合には、ほとんど解明されていないままです。この研究では、報酬モデルの敵対的操作に対するオフライン バンディット トレーニングの脆弱性を理論的および経験的に調査することで、このギャップを埋めます。攻撃者が高次元の設定でオフライン データを悪用して盗賊の行動をハイジャックする、新しい脅威モデルを紹介します。線形報酬関数から始めて、ReLU ニューラル ネットワークなどの非線形モデルにまで拡張し、生成モデルの評価に使用される 2 つの Hugging Face エバリュエーター (1 つは美的品質を測定し、もう 1 つは構成の整合性を評価) に対する攻撃を研究します。私たちの結果は、報酬モデルの重みに対する小さくて知覚できない摂動でさえ、バンディットの行動を劇的に変える可能性があることを示しています。理論的な観点から、私たちは驚くべき高次元の効果を証明しました。入力の次元が増加するにつれて、攻撃の成功に必要な摂動ノルムが減少し、画像評価などの最新のアプリケーションが特に脆弱になります。広範な実験により、単純なランダムな摂動は効果がないのに対し、注意深くターゲットを絞った摂動はほぼ完璧な攻撃成功率を達成することが確認されています...
原文 (English)
Efficient Adversarial Attacks on High-dimensional Offline Bandits
Bandit algorithms have recently emerged as a powerful tool for evaluating machine learning models, including generative image models and large language models, by efficiently identifying top-performing candidates without exhaustive comparisons. These methods typically rely on a reward model, often distributed with public weights on platforms such as Hugging Face, to provide feedback to the bandit. While online evaluation is expensive and requires repeated trials, offline evaluation with logged data has become an attractive alternative. However, the adversarial robustness of offline bandit evaluation remains largely unexplored, particularly when an attacker perturbs the reward model (rather than the training data) prior to bandit training. In this work, we fill this gap by investigating, both theoretically and empirically, the vulnerability of offline bandit training to adversarial manipulations of the reward model. We introduce a novel threat model in which an attacker exploits offline data in high-dimensional settings to hijack the bandit's behavior. Starting with linear reward functions and extending to nonlinear models such as ReLU neural networks, we study attacks on two Hugging Face evaluators used for generative model assessment: one measuring aesthetic quality and the other assessing compositional alignment. Our results show that even small, imperceptible perturbations to the reward model's weights can drastically alter the bandit's behavior. From a theoretical perspective, we prove a striking high-dimensional effect: as input dimensionality increases, the perturbation norm required for a successful attack decreases, making modern applications such as image evaluation especially vulnerable. Extensive experiments confirm that naive random perturbations are ineffective, whereas carefully targeted perturbations achieve near-perfect attack success rates ...
自己蒸留で専門家の推論を学習可能にする
大規模言語モデル (LLM) の推論機能の向上は、通常、強化すべき正しい解決策をサンプリングするモデルの能力か、問題を解決できるより強力なモデルの存在に依存します。ただし、現在のフロンティア モデルでも多くの困難な問題が依然として解決できず、有効なトレーニング信号の抽出が妨げられています。有望な代替案は、高品質の専門家による人間によるソリューションを活用することですが、このデータの単純な模倣は失敗します。なぜなら、このデータは基本的に配布されていないためです。専門家によるソリューションは通常、教訓的であり、計算モデルではなく人間の読者を対象とした暗黙の推論のギャップが含まれています。さらに、高品質のエキスパート ソリューションは高価であるため、一般化可能でサンプル効率の高いトレーニング方法が必要です。私たちは、最初に専門家のソリューションを詳細な分布内の推論トレースに変換し、次に対照的な目標を適用して専門家の洞察と方法論に焦点を当てた学習を行うことで、分布のギャップを埋める 2 段階の自己蒸留手法である、分布整合模倣学習 (DAIL) を提案します。 DAIL は 1,000 未満の高品質のエキスパート ソリューションを活用して、Qwen2.5-Instruct および Qwen3 で最大 31% pass@128 の向上を達成し、推論効率を 2 倍にし、ドメイン外の一般化を可能にすることがわかりました。
原文 (English)
Making Expert Reasoning Learnable with Self-Distillation
Improving the reasoning capabilities of large language models (LLMs) typically relies either on the model's ability to sample a correct solution to be reinforced or the existence of a stronger model able to solve the problem. However, many difficult problems remain intractable for even current frontier models, preventing the extraction of valid training signals. A promising alternative is to leverage high-quality expert human solutions, yet naive imitation of this data fails because it is fundamentally out-of-distribution: expert solutions are typically didactic, containing implicit reasoning gaps intended for human readers rather than computational models. Furthermore, high-quality expert solutions are expensive, necessitating generalizable, sample-efficient training methods. We propose Distribution Aligned Imitation Learning (DAIL), a two-step self-distillation method that bridges the distributional gap by first transforming expert solutions into detailed, in-distribution reasoning traces and then applying a contrastive objective to focus learning on expert insights and methodologies. We find that DAIL can leverage fewer than 1000 high-quality expert solutions to achieve up to 31% pass@128 gains on Qwen2.5-Instruct and Qwen3, double reasoning efficiency, and enable out-of-domain generalization.
トランスフォーマーが知識グラフを基に推論するのに役立つ構造的帰納的バイアスは何ですか? Tabula RASA を使った研究
変圧器が知識グラフを推論するのに役立つ構造的な誘導バイアスは何ですか? 4 つの独立して取り外し可能なコンポーネント (スパース隣接マスキング、エッジタイプ バイアス、クエリ スケーリング、値ゲーティング) による最小限のトランスフォーマ変更の制御されたアブレーションを通じて、どの構造信号がマルチホップ推論を駆動するかを分離します。私たちの発見は鋭いものです。スパース隣接マスキングだけでも、マスクされていないトランスフォーマーに比べて改善の支配的なシェアを占めます (3 ホップ MetaQA で +72.5 pp、WebQSP で +45.5 pp、CWQ で +53.9 pp)。一方、学習された関係パラメーターは適度な改善しか加えず、構造的なガイダンスがないと積極的に悪影響を与える可能性があります。ゼロショット実験は、アーキテクチャ的に独立した確証を提供します。エッジ タイプが保持されている場合、マスキング ベースの注意力の低下は関係固有の重みより 4.0 分の 1 です。マルチホップ KGQA に有用な誘導バイアスは、主に位相的なものであり、関係的なものではありません。
原文 (English)
What Structural Inductive Bias Helps Transformers Reason Over Knowledge Graphs? A Study with Tabula RASA
What structural inductive bias helps transformers reason over knowledge graphs? Through controlled ablations of a minimal transformer modification with four independently removable components (sparse adjacency masking, edge-type biases, query scaling, value gating), we isolate which structural signals drive multi-hop reasoning. Our finding is sharp: sparse adjacency masking alone accounts for the dominant share of improvement over unmasked transformers (+72.5pp on 3-hop MetaQA, +45.5pp on WebQSP, +53.9pp on CWQ), while learned relation parameters add only modest refinement and can actively hurt without structural guidance. A zero-shot experiment provides architecturally independent corroboration: masking-based attention degrades 4.0x less than relation-specific weights when edge types are held out. The useful inductive bias for multi-hop KGQA is predominantly topological, not relational.
TamperBench: 微調整と改ざんの下での LLM の安全性を系統的にストレス テストする
ますます高機能なオープンウェイト大規模言語モデル (LLM) が展開されるにつれ、偶発的か意図的かにかかわらず、安全でない変更に対する改ざん耐性を向上させることが、リスクを最小限に抑えるために重要になります。ただし、耐タンパー性を評価するための標準的なアプローチはありません。データセット、メトリクス、および改ざん構成が多様であるため、さまざまなモデルや防御にわたって安全性、実用性、堅牢性を比較することが困難になります。これに対処するために、LLM の耐タンパー性を体系的に評価するための初の統合フレームワークである TamperBench を導入します。 TamperBench (i) 最先端の重み空間微調整攻撃、潜在空間表現攻撃、および調整段階の防御のリポジトリを管理します。 (ii) 攻撃モデルのペアごとに体系的なハイパーパラメータ スイープを通じて現実的な敵対的評価を可能にします。 (iii) 安全性と実用性の両方の評価を提供します。私たちは TamperBench を使用して、モデルと攻撃のペアごとのハイパーパラメーター スイープによる標準化された安全性と機能のメトリクスを使用して、9 つの改ざん脅威にわたって防御強化された亜種を含む 21 のオープンウェイト LLM を評価します。この結果からは、耐タンパー性に対するポストトレーニングの効果、ジェイルブレイクチューニングが通常最も深刻な攻撃であること、現在の調整段階の防御は攻撃スイープにほとんど耐えられないことなどの洞察が得られます。コードは https://github.com/criticalml-uw/TamperBench で入手できます。
原文 (English)
TamperBench: Systematically Stress-Testing LLM Safety Under Fine-Tuning and Tampering
As increasingly capable open-weight large language models (LLMs) are deployed, improving their tamper resistance against unsafe modifications, whether accidental or intentional, becomes critical to minimize risks. However, there is no standard approach to evaluate tamper resistance. Varied datasets, metrics, and tampering configurations make it difficult to compare safety, utility, and robustness across different models and defenses. To address this, we introduce TamperBench, the first unified framework to systematically evaluate the tamper resistance of LLMs. TamperBench (i) curates a repository of state-of-the-art weight-space fine-tuning attacks, latent-space representation attacks, and alignment-stage defenses; (ii) enables realistic adversarial evaluation through systematic hyperparameter sweeps per attack-model pair; and (iii) provides both safety and utility evaluations. We use TamperBench to evaluate 21 open-weight LLMs, including defense-augmented variants, across nine tampering threats using standardized safety and capability metrics with hyperparameter sweeps per model-attack pair. The results provide insights including effects of post-training on tamper resistance, that jailbreak-tuning is typically the most severe attack, and that current alignment-stage defenses largely fail to withstand attack sweeps. Code is available at https://github.com/criticalml-uw/TamperBench.
注意ベースのモデルで記憶、学習、忘れることを学ぶ
変圧器のインコンテキスト学習 (ICL) はオンライン連想メモリとして機能し、複雑なシーケンス処理タスクにおける高いパフォーマンスを支えると考えられています。ただし、ゲート付きリニア アテンション モデルでは、このメモリの容量は固定されており、特に長いシーケンスの場合には干渉を受けやすくなります。我々は、ICL を安定性と可塑性のジレンマに対処しなければならない継続的な学習問題とみなす自己注意モデル、Palimpsa を提案します。 Palimpsa はベイジアンメタ可塑性を使用します。このメタ可塑性では、各注意状態の可塑性は、蓄積された知識を捕捉する事前分布に基づいた重要性状態に関連付けられます。さまざまなゲート線形注意モデルが特定のアーキテクチャの選択と事後近似として出現すること、および Mamba2 が忘却が支配的なパリンプサの特殊なケースであることを実証します。この理論的なつながりにより、非化成モデルを化成モデルに変換することが可能になり、その記憶容量が大幅に拡張されます。私たちの実験では、Palimpsa が Multi-Query Associative Recall (MQAR) ベンチマークと Commonsense Reasoning タスクでベースラインを常に上回っていることが示されています。
原文 (English)
Learning to Remember, Learn, and Forget in Attention-Based Models
In-Context Learning (ICL) in transformers acts as an online associative memory and is believed to underpin their high performance on complex sequence processing tasks. However, in gated linear attention models, this memory has a fixed capacity and is prone to interference, especially for long sequences. We propose Palimpsa, a self-attention model that views ICL as a continual learning problem that must address a stability-plasticity dilemma. Palimpsa uses Bayesian metaplasticity, where the plasticity of each attention state is tied to an importance state grounded by a prior distribution that captures accumulated knowledge. We demonstrate that various gated linear attention models emerge as specific architecture choices and posterior approximations, and that Mamba2 is a special case of Palimpsa where forgetting dominates. This theoretical link enables the transformation of any non-metaplastic model into a metaplastic one, significantly expanding its memory capacity. Our experiments show that Palimpsa consistently outperforms baselines on the Multi-Query Associative Recall (MQAR) benchmark and on Commonsense Reasoning tasks.
AlgoVeri: 古典的なアルゴリズムでの検証済みコード生成のための調整されたベンチマーク
ベリコーディングとは、厳密な仕様に基づいて正式に検証されたコードを生成することを指します。最近の AI モデルは検証コーディングにおいて有望ですが、クロスパラダイム評価のための統一された方法論が不足しています。既存のベンチマークは個別の言語/ツール (Dafny、Verus、Lean など) のみをテストしており、それぞれが非常に異なるタスクをカバーしているため、パフォーマンスの数値を直接比較することはできません。私たちは、Dafny、Verus、Lean の $77$ の古典的なアルゴリズムのベリコーディングを評価するベンチマークである AlgoVeri を使用して、このギャップに対処します。 AlgoVeri は、同一の機能コントラクトを強制することで、検証システムの重大な機能ギャップを明らかにします。フロンティア モデルは、高レベルの抽象化と SMT 自動化によってワークフローが簡素化される Dafny (Gemini-3 フラッシュで $40.3$%) で扱いやすい成功を収めていますが、Verus ($24.7$%) のシステム レベルのメモリ制約と Lean (7.8%) で必要とされる明示的な証明構築の下ではパフォーマンスが崩壊します。集計メトリクスを超えて、テスト時の計算ダイナミクスの急激な相違が明らかになりました。Gemini-3 は反復修復を効果的に利用してパフォーマンスを向上させます (たとえば、Dafny の合格率を 3 倍にします)。一方、GPT-OSS は早期に飽和します。最後に、私たちのエラー分析は、言語設計が改良の軌道に影響を与えることを示しています。Dafny ではモデルが論理的な正しさに集中できるのに対し、Verus と Lean は永続的な構文および意味論的な障壁にモデルを閉じ込めます。すべてのデータと評価コードは、https://github.com/haoyuzhao123/algoveri で見つけることができます。
原文 (English)
AlgoVeri: An Aligned Benchmark for Verified Code Generation on Classical Algorithms
Vericoding refers to the generation of formally verified code from rigorous specifications. Recent AI models show promise in vericoding, but a unified methodology for cross-paradigm evaluation is lacking. Existing benchmarks test only individual languages/tools (e.g., Dafny, Verus, and Lean) and each covers very different tasks, so the performance numbers are not directly comparable. We address this gap with AlgoVeri, a benchmark that evaluates vericoding of $77$ classical algorithms in Dafny, Verus, and Lean. By enforcing identical functional contracts, AlgoVeri reveals critical capability gaps in verification systems. While frontier models achieve tractable success in Dafny ($40.3$% for Gemini-3 Flash), where high-level abstractions and SMT automation simplify the workflow, performance collapses under the systems-level memory constraints of Verus ($24.7$%) and the explicit proof construction required by Lean (7.8%). Beyond aggregate metrics, we uncover a sharp divergence in test-time compute dynamics: Gemini-3 effectively utilizes iterative repair to boost performance (e.g., tripling pass rates in Dafny), whereas GPT-OSS saturates early. Finally, our error analysis shows that language design affects the refinement trajectory: while Dafny allows models to focus on logical correctness, Verus and Lean trap models in persistent syntactic and semantic barriers. All data and evaluation code can be found at https://github.com/haoyuzhao123/algoveri.
MuCO: 多段階の立体構造最適化によって強化されたペプチド生成環化
ペプチド環化のモデリングは、望ましい物理的および薬学的特性を持つ候補ペプチドの仮想スクリーニングにとって重要です。環状ペプチドは多くの場合、多様なリング状の立体構造を示し、これは線形ペプチドの折り畳みに由来する決定論的予測モデルではうまく捉えることができないため、この作業は困難です。本研究では、対応する直鎖状ペプチドを条件として環状ペプチド立体構造の分布をモデル化する生成ペプチド環化法である MuCO (Multi-stage Conformation Optimization) を提案します。原則として、MuCO はペプチド環化タスクを 3 つの段階 (トポロジーを意識したバックボーン設計、生成側鎖パッキング、物理学を意識した全原子最適化) に分離し、それによって粗いものから細かいものまでの方法で環状ペプチドの立体構造を生成および最適化します。この多段階フレームワークにより、立体構造生成のための効率的な並行サンプリング戦略が可能になり、多様な低エネルギー立体構造の迅速な探索が可能になります。大規模な CPSea データセットでの実験では、MuCO が物理的安定性、構造多様性、二次構造回復、計算効率において最先端の手法を大幅かつ一貫して上回る性能を示しており、環状ペプチドの探索と設計のための有望な計算ツールとなっていることが実証されています。提案された方法のデモは https://github.com/mianqiu00/MuCO でご覧いただけます。
原文 (English)
MuCO: Generative Peptide Cyclization Empowered by Multi-stage Conformation Optimization
Modeling peptide cyclization is critical for the virtual screening of candidate peptides with desirable physical and pharmaceutical properties. This task is challenging because a cyclic peptide often exhibits diverse, ring-shaped conformations, which cannot be well captured by deterministic prediction models derived from linear peptide folding. In this study, we propose MuCO (Multi-stage Conformation Optimization), a generative peptide cyclization method that models the distribution of cyclic peptide conformations conditioned on the corresponding linear peptide. In principle, MuCO decouples the peptide cyclization task into three stages: topology-aware backbone design, generative side-chain packing, and physics-aware all-atom optimization, thereby generating and optimizing conformations of cyclic peptides in a coarse-to-fine manner. This multi-stage framework enables an efficient parallel sampling strategy for conformation generation and allows for rapid exploration of diverse, low-energy conformations. Experiments on the large-scale CPSea dataset demonstrate that MuCO significantly and consistently outperforms state-of-the-art methods in physical stability, structural diversity, secondary structure recovery, and computational efficiency, making it a promising computational tool for exploring and designing cyclic peptides. The demo of the proposed method can be found at https://github.com/mianqiu00/MuCO.
潜在ダイナミクスによるモデルフリーの効率とモデルベースの表現の統合
我々は、計画のオーバーヘッドを発生させることなく、モデルフリー手法の効率性とモデルベースのアプローチの表現力を統合する新しい強化学習アルゴリズムである Unified Latent Dynamics (ULD) を紹介します。真の値関数がほぼ線形である潜在空間に状態とアクションのペアを埋め込むことにより、私たちの方法は、低次元およびピクセル入力による連続制御から高次元の Atari ゲームに至るまで、多様なドメインにわたる単一セットのハイパーパラメーターをサポートします。穏やかな条件下では、埋め込みベースの時間差更新の固定点が、対応する線形モデルベースの値拡張の固定点と一致することを証明し、埋め込みの忠実度を値の近似品質に関連付ける明示的な誤差限界を導き出します。実際には、ULD は、エンコーダ、値、およびポリシー ネットワークの同期更新、短期予測ダイナミクスの補助損失、および報酬スケールの正規化を採用して、報酬がまばらな場合でも安定した学習を保証します。 Gym Locomotion、DeepMind Control (固有受容および視覚)、Atari にわたる 80 の環境で評価された当社のアプローチは、特殊なモデルフリーおよび一般的なモデルベースのベースラインのパフォーマンスと同等またはそれを上回り、最小限のチューニングとわずかなパラメーター フットプリントでクロスドメインのコンピテンスを実現します。これらの結果は、値に合わせた潜在表現だけで、従来完全なモデルベースの計画に帰せられていた適応性とサンプル効率を実現できることを示しています。
原文 (English)
Unifying Model-Free Efficiency and Model-Based Representations via Latent Dynamics
We present Unified Latent Dynamics (ULD), a novel reinforcement learning algorithm that unifies the efficiency of model-free methods with the representational strengths of model-based approaches, without incurring planning overhead. By embedding state-action pairs into a latent space in which the true value function is approximately linear, our method supports a single set of hyperparameters across diverse domains -- from continuous control with low-dimensional and pixel inputs to high-dimensional Atari games. We prove that, under mild conditions, the fixed point of our embedding-based temporal-difference updates coincides with that of a corresponding linear model-based value expansion, and we derive explicit error bounds relating embedding fidelity to value approximation quality. In practice, ULD employs synchronized updates of encoder, value, and policy networks, auxiliary losses for short-horizon predictive dynamics, and reward-scale normalization to ensure stable learning under sparse rewards. Evaluated on 80 environments spanning Gym locomotion, DeepMind Control (proprioceptive and visual), and Atari, our approach matches or exceeds the performance of specialized model-free and general model-based baselines -- achieving cross-domain competence with minimal tuning and a fraction of the parameter footprint. These results indicate that value-aligned latent representations alone can deliver the adaptability and sample efficiency traditionally attributed to full model-based planning.
自律型 O-RAN に向けて: リアルタイム ネットワーク制御および管理のためのマルチスケール エージェント AI フレームワーク
オープン無線アクセス ネットワーク (O-RAN) は、分散されたソフトウェア駆動のコンポーネントとオープン インターフェイスを通じて柔軟な 6G ネットワーク アクセスを約束しますが、このプログラマビリティにより運用の複雑さも増大します。複数の制御ループがサービス管理層と RAN インテリジェント コントローラー (RIC) 全体で共存しますが、個別に開発された制御アプリケーションは意図しない方法で相互作用する可能性があります。同時に、生成型人工知能 (AI) の最近の進歩により、孤立した AI モデルから、目標を解釈し、複数のモデルと制御機能を調整し、時間の経過とともに動作を適応させることができるエージェント AI システムへの移行が可能になりました。この記事では、非リアルタイム (Non-RT)、準リアルタイム (Near-RT)、およびリアルタイム (RT) の制御ループにわたる調整された階層として RAN インテリジェンスを組織化する、O-RAN 用のマルチスケール エージェント AI フレームワークを提案します。 (i) 非 RT RIC の大規模言語モデル (LLM) エージェントは、オペレーターの意図をポリシーに変換し、モデルのライフサイクルを管理します。 (ii) Near-RT RIC の Small Language Model (SLM) エージェントは、低遅延の最適化を実行し、既存の制御アプリケーションをアクティブ化、調整、または無効化できます。 (iii) 分散ユニット近くのワイヤレス物理層基盤モデル (WPFM) エージェントは、エア インターフェイスに近い高速推論を提供します。これらのエージェントが標準化された O-RAN インターフェイスとテレメトリを通じてどのように連携するかを説明します。オープンソース モデル、ソフトウェア、データセットに基づいて構築された概念実証の実装を使用して、非定常条件下での堅牢な動作とインテント駆動型のスライス リソース制御という 2 つの代表的なシナリオで提案されたエージェント アプローチを実証します。
原文 (English)
Toward Autonomous O-RAN: A Multi-Scale Agentic AI Framework for Real-Time Network Control and Management
Open Radio Access Networks (O-RAN) promise flexible 6G network access through disaggregated, software-driven components and open interfaces, but this programmability also increases operational complexity. Multiple control loops coexist across the service management layer and RAN Intelligent Controller (RIC), while independently developed control applications can interact in unintended ways. In parallel, recent advances in generative Artificial Intelligence (AI) are enabling a shift from isolated AI models toward agentic AI systems that can interpret goals, coordinate multiple models and control functions, and adapt their behavior over time. This article proposes a multi-scale agentic AI framework for O-RAN that organizes RAN intelligence as a coordinated hierarchy across the Non-Real-Time (Non-RT), Near-Real-Time (Near-RT), and Real-Time (RT) control loops: (i) A Large Language Model (LLM) agent in the Non-RT RIC translates operator intent into policies and governs model lifecycles. (ii) Small Language Model (SLM) agents in the Near-RT RIC execute low-latency optimization and can activate, tune, or disable existing control applications; and (iii) Wireless Physical-layer Foundation Model (WPFM) agents near the distributed unit provide fast inference close to the air interface. We describe how these agents cooperate through standardized O-RAN interfaces and telemetry. Using a proof-of-concept implementation built on open-source models, software, and datasets, we demonstrate the proposed agentic approach in two representative scenarios: robust operation under non-stationary conditions and intent-driven slice resource control.
設計によるトモグラフィー: 低ランク量子状態への代数的アプローチ
我々は、特定の観測量の測定値を利用して基礎となる密度行列の構造化されたエントリを推定する、量子状態トモグラフィー用の代数アルゴリズムを提案します。低ランクの仮定の下では、残りのエントリは標準の数値線形代数演算のみを使用して取得できます。提案された代数行列補完フレームワークは、広範なクラスの一般的な低ランク混合量子状態に適用され、最先端の方法と比較して計算効率が高く、決定論的な回復保証を提供します。
原文 (English)
Tomography by Design: An Algebraic Approach to Low-Rank Quantum States
We present an algebraic algorithm for quantum state tomography that leverages measurements of certain observables to estimate structured entries of the underlying density matrix. Under low-rank assumptions, the remaining entries can be obtained solely using standard numerical linear algebra operations. The proposed algebraic matrix completion framework applies to a broad class of generic, low-rank mixed quantum states and, compared with state-of-the-art methods, is computationally efficient while providing deterministic recovery guarantees.
スケーラブルな MARL における局所性のための統合フレームワーク
ネットワーク化されたマルチエージェント強化学習のスケーラブルな方法では、各エージェントがエージェント グラフの小さな近傍のみを使用して計画を立てることができます。これは、システムが値ローカルである場合にのみ機能します。つまり、2 つのエージェントが遠く離れている場合、1 つのエージェントでの摂動は、別のエージェントでの長期的な値にわずかに影響します。平均報酬設定では、局所性を証明する標準的な方法は、各エージェントの次の状態が他のエージェントの現在の状態にどのように依存するかを捕捉する単一の行列 $C^\pi$ 上の Dobrusin 行合計境界です。このマトリックスを扱いやすくするために、以前の研究では、共同動作の上限によってマトリックスを制限しました。結果として得られる境界はポリシーから独立していますが、ポリシーが最悪の場合のアクションを選択しない場合は常に緩やかになります。 $C^\pi$ を、環境の感度とポリシーの感度を個別に追跡する部分、$C^\pi \preceq E^{\mathrm s}+E^{\mathrm a}\Pi(\pi)$ に分割します。ここで、$E^{\mathrm s}$ は現在の状態に応じて次の状態がどのように変化するかを測定し、$E^{\mathrm a}$ は現在のアクションでどのように変化するかを測定し、$\Pi(\pi)$ はポリシーがどのように反応するかを測定します。状態の変化。 $H^\pi := E^{\mathrm s}+E^{\mathrm a}\Pi(\pi)$ のスペクトル半径は平均報酬ポアソン解の減衰を制御し、スペクトル証明書 $\rho(H^\pi)<1$ は同じ行列上の行合計条件 $\|H^\pi\|_\infty<1$ より厳密に弱く、政策に依存しないレジームに適用されます。以前の Dobrushin スタイルの作業で使用されていたアクションの上限は使用できません。温度 $\tau$ ソフトマックス ポリシーの場合、$\Pi(\pi)\le L/(2\tau)$ が得られるため、ソフトマックス温度は局所性を直接制御します。この減衰結果を使用して、切り捨てバイアスがメッセージパッシング半径 $\kappa$ 内で指数関数的に減衰するブロック座標 KL 近位ポリシー改善テンプレートに決定論的なオラクル保証を与えます。
原文 (English)
A Unified Framework for Locality in Scalable MARL
Scalable methods for networked multi-agent reinforcement learning let each agent plan using only a small neighborhood of the agent graph. This works only when the system is value-local, meaning a perturbation at one agent affects the long-run value at another agent weakly when the two are far apart. In the average-reward setting, the standard way to certify locality is the Dobrushin row-sum bound on a single matrix $C^\pi$ that captures how each agent's next state depends on each other agent's current state. To make this matrix easy to work with, prior work bounds it by a supremum over joint actions. The resulting bound is independent of the policy, but it is loose whenever the policy never picks the worst-case action. We split $C^\pi$ into pieces that separately track environment sensitivity and policy sensitivity, $C^\pi \preceq E^{\mathrm s}+E^{\mathrm a}\Pi(\pi)$, where $E^{\mathrm s}$ measures how the next state moves with the current state, $E^{\mathrm a}$ measures how it moves with the current action, and $\Pi(\pi)$ measures how reactive the policy is to changes in state. The spectral radius of $H^\pi := E^{\mathrm s}+E^{\mathrm a}\Pi(\pi)$ then controls the decay of the average-reward Poisson solution, and the spectral certificate $\rho(H^\pi)<1$ is strictly weaker than the row-sum condition $\|H^\pi\|_\infty<1$ on the same matrix and applies in regimes where policy-independent action-supremum bounds used in prior Dobrushin-style work cannot. For temperature-$\tau$ softmax policies we get $\Pi(\pi)\le L/(2\tau)$, so the softmax temperature directly controls locality. We use this decay result to give a deterministic oracle guarantee for a block-coordinate KL-proximal policy-improvement template whose truncation bias decays exponentially in the message-passing radius $\kappa$.
DSL-Topic: 言語モデルからソフトラベルを抽出することによるトピックモデリングの改善
従来のニューラル トピック モデルは通常、ドキュメントの Bag-of-Words (BoW) 表現を再構築し、コンテキスト情報を無視し、データの疎性と格闘することによって最適化されます。この研究では、言語モデル (LM) からソフト ラベル (DSL) を抽出することによる、新しいトピック モデル トレーニング フレームワークを紹介します。コンテキストに富んだ再構築信号を構築するために、特殊なプロンプトを条件とした次のトークンの確率を事前定義された語彙に投影し、LM 隠れ状態を使用してソフト ラベルを再構築するようにトピック モデルをトレーニングします。これにより、コーパスの基礎となるテーマ構造とより密接に連携した、より質の高いトピックが生成されます。広範な実験により、DSL が既存のベースラインに比べてトピックの一貫性と割り当ての精度が大幅に向上することが実証されました。さらに、検索ベースの指標も導入します。これは、意味的に類似した文書の識別において、私たちのアプローチが既存の方法よりも大幅に優れていることを示し、検索指向のアプリケーションに対する有効性を強調しています。
原文 (English)
DSL-Topic: Improving Topic Modeling by Distilling Soft Labelsfrom Language Models
Traditional neural topic models are typically optimized by reconstructing the document's Bag-of-Words (BoW) representations, overlooking contextual information and struggling with data sparsity. In this work, we introduce a novel topic model training framework by Distilling Soft Labels (DSL) from Language Models (LMs). To construct the contextually enriched reconstruction signals, we project the next token probabilities, conditioned on a specialized prompt, onto a pre-defined vocabulary, and train the topic models to reconstruct the soft labels using the LM hidden states. This produces higher-quality topics that are more closely aligned with the underlying thematic structure of the corpus. Extensive experiments demonstrate that DSL achieves substantial improvements in topic coherence and assignment accuracy over existing baselines. Additionally, we also introduce a retrieval-based metric, which shows that our approach significantly outperforms existing methods in identifying semantically similar documents, highlighting its effectiveness for retrieval-oriented applications.
価値のもつれ: (一部の) 大規模な言語モデルにおける異なる種類の善の間の融合
大規模言語モデル (LLM) の値の調整には、これらのモデルが実際に取得した値の表現を経験的に測定する必要があります。人間の価値表現の特徴の 1 つは、異なる種類の価値を区別することです。私たちは、LLM が同様に、道徳的、文法的、経済的という 3 つの異なる種類の善を区別するかどうかを調査します。モデルの動作、埋め込み、および残差ストリームのアクティベーションを調査することにより、値のもつれ、つまりこれらの異なる値の表現間の混同の広範なケースを報告します。具体的には、文法的評価と経済的評価の両方が、人間の規範と比較して道徳的価値に過度に影響されることが判明しました。この混同は、道徳に関連する活性化ベクトルを選択的に除去することによって修復されました。
原文 (English)
Value Entanglement: Conflation Between Different Kinds of Good In (Some) Large Language Models
Value alignment of Large Language Models (LLMs) requires us to empirically measure these models' actual, acquired representation of value. Among the characteristics of value representation in humans is that they distinguish among value of different kinds. We investigate whether LLMs likewise distinguish three different kinds of good: moral, grammatical, and economic. By probing model behavior, embeddings, and residual stream activations, we report pervasive cases of value entanglement: a conflation between these distinct representations of value. Specifically, both grammatical and economic valuation was found to be overly influenced by moral value, relative to human norms. This conflation was repaired by selective ablation of the activation vectors associated with morality.
順序は重要ですか : ロバスト性の法則をロバストな一般化に結び付ける
Bubeck と Selke (2021) は、ロバスト性の法則とロバストな一般化誤差との関係を未解決の問題として提案しています。ロバスト性の法則では、モデルがロバストに補間するにはオーバーパラメータ化が必要である、つまり、補間関数がリプシッツである必要があると述べています。ウーら。 (2023) この法則を任意のデータ分布に拡張し、リプシッツ定数が $L = \Omega(n^{1/d})$ を満たすことを証明しました。一方、ロバスト一般化では、ロバストなトレーニング損失が小さいことがロバストなテスト損失が小さいことを意味するかどうかが問われます。これは、Rademacher 複雑性などの統計学習手法を使用して研究できます。ここで、ロバスト損失クラスの Rademacher 複雑性の限界は、関数クラスのリプシッツ性の限界を意味します。この接続を使用して、任意のデータ配布のために 2 つを明示的にリンクします。 (i) ロバストな損失クラスのグローバル Rademacher 複雑性を考慮した場合、リプシッツ限界の次数が同じままであることを証明します。 (ii) 局所スケール、つまり経験誤差が小さい関数の部分集合では、リプシッツ限界の次数は摂動半径 $\rho$ と局所集中項 $\sqrt{r/n}$ に応じて変化します。
原文 (English)
Does Order Matter : Connecting The Law of Robustness to Robust Generalization
Bubeck and Selke (2021) propose the connection between the Law of Robustness and robust generalization error as an open problem. The Law of Robustness states that overparameterization is necessary for models to interpolate robustly, i.e., the interpolating function is required to be Lipschitz. Wu et al. (2023) extend this law to arbitrary data distributions, proving that the Lipschitz constant satisfies $L = \Omega(n^{1/d})$. Robust generalization, on the other hand, asks whether small robust training loss implies small robust test loss. This can be studied using statistical learning techniques such as Rademacher complexities, where a bound on the Rademacher complexity of the robust loss class implies a bound on the Lipschitzness of the function class. We use this connection to explicitly link the two for arbitrary data distributions. (i) We prove that the order of the Lipschitz bound remains the same when considering the global Rademacher complexity of robust loss classes. (ii) At the local scale, i.e., for subsets of functions with small empirical error, the order of the Lipschitz bound changes with the perturbation radius $\rho$ and the localized concentration term $\sqrt{r/n}$.
リーダーとフォロワーの相互作用における小規模言語モデルのゼロショットおよびワンショット適応の評価
リーダーとフォロワーの相互作用は、人間とロボットの相互作用 (HRI) における重要なパラダイムです。しかし、リソースに制約のある移動ロボットや支援ロボットにとって、リアルタイムでの役割の割り当ては依然として困難です。大規模言語モデル (LLM) は自然なコミュニケーションに有望であることが示されていますが、そのサイズと遅延によりデバイス上の展開が制限されます。小規模言語モデル (SLM) は潜在的な代替手段を提供しますが、HRI における役割分類に対する SLM の有効性は体系的に評価されていません。この論文では、リーダーとフォロワーのコミュニケーションのための SLM のベンチマークを紹介し、公開されたデータベースから派生し、相互作用固有のダイナミクスを捕捉するために合成サンプルで強化された新しいデータセットを紹介します。私たちは、ゼロショットおよびワンショット相互作用モードで研究されたプロンプトエンジニアリングと微調整という 2 つの適応戦略を、トレーニングされていないベースラインと比較して調査します。 Qwen2.5-0.5B を使用した実験では、ゼロショット微調整が低遅延 (サンプルあたり 22.2 ミリ秒) を維持しながら堅牢な分類パフォーマンス (精度 86.66%) を達成し、ベースラインおよびプロンプト エンジニアリングのアプローチを大幅に上回るパフォーマンスを示していることが明らかになりました。ただし、結果はワンショット モードでのパフォーマンスの低下も示しており、コンテキストの長さが増加するとモデルのアーキテクチャ上の能力に課題が生じます。これらの調査結果は、微調整された SLM が役割の直接割り当てに効果的なソリューションを提供することを実証するとともに、エッジでの対話の複雑さと分類の信頼性の間の重要なトレードオフを強調しています。
原文 (English)
Evaluating Zero-Shot and One-Shot Adaptation of Small Language Models in Leader-Follower Interaction
Leader-follower interaction is an important paradigm in human-robot interaction (HRI). Yet, assigning roles in real time remains challenging for resource-constrained mobile and assistive robots. While large language models (LLMs) have shown promise for natural communication, their size and latency limit on-device deployment. Small language models (SLMs) offer a potential alternative, but their effectiveness for role classification in HRI has not been systematically evaluated. In this paper, we present a benchmark of SLMs for leader-follower communication, introducing a novel dataset derived from a published database and augmented with synthetic samples to capture interaction-specific dynamics. We investigate two adaptation strategies: prompt engineering and fine-tuning, studied under zero-shot and one-shot interaction modes, compared with an untrained baseline. Experiments with Qwen2.5-0.5B reveal that zero-shot fine-tuning achieves robust classification performance (86.66% accuracy) while maintaining low latency (22.2 ms per sample), significantly outperforming baseline and prompt-engineered approaches. However, results also indicate a performance degradation in one-shot modes, where increased context length challenges the model's architectural capacity. These findings demonstrate that fine-tuned SLMs provide an effective solution for direct role assignment, while highlighting critical trade-offs between dialogue complexity and classification reliability on the edge.
ShareVerse: 共有世界モデリングのためのマルチエージェントの一貫したビデオ生成
このペーパーでは、マルチエージェント シェアード ワールド モデリングを可能にするビデオ生成フレームワークである ShareVerse について紹介します。これは、マルチエージェント インタラクションによる統一されたシェアード ワールド構築のサポートが不足している既存の作品のギャップに対処します。 ShareVerse は、大規模なビデオ モデルの生成機能を活用し、次の 3 つの主要なイノベーションを統合します。 1) 大規模なマルチエージェント インタラクティブな世界モデリング用のデータセットは、CARLA シミュレーション プラットフォーム上に構築され、多様なシーン、気象条件、およびペアになったマルチビュー ビデオ (エージェントごとに前方/後方/左方/右ビュー) とカメラ データによるインタラクティブな軌跡を特徴とします。 2) より広範な環境をモデル化し、内部のマルチビューの幾何学的一貫性を確保するために、独立したエージェントの 4 ビュー ビデオの空間連結戦略を提案します。 3) エージェント間のアテンション ブロックを事前トレーニング済みビデオ モデルに統合します。これにより、エージェント間での時空間情報のインタラクティブな送信が可能になり、重複領域での共有世界の一貫性と非重複領域での合理的な生成が保証されます。 49 フレームの大規模ビデオ生成をサポートする ShareVerse は、動的エージェントの位置を正確に認識し、一貫した共有世界モデリングを実現します。
原文 (English)
ShareVerse: Multi-Agent Consistent Video Generation for Shared World Modeling
This paper presents ShareVerse, a video generation framework enabling multi-agent shared world modeling, addressing the gap in existing works that lack support for unified shared world construction with multi-agent interaction. ShareVerse leverages the generation capability of large video models and integrates three key innovations: 1) A dataset for large-scale multi-agent interactive world modeling is built on the CARLA simulation platform, featuring diverse scenes, weather conditions, and interactive trajectories with paired multi-view videos (front/ rear/ left/ right views per agent) and camera data. 2) We propose a spatial concatenation strategy for four-view videos of independent agents to model a broader environment and to ensure internal multi-view geometric consistency. 3) We integrate cross-agent attention blocks into the pretrained video model, which enable interactive transmission of spatial-temporal information across agents, guaranteeing shared world consistency in overlapping regions and reasonable generation in non-overlapping regions. ShareVerse, which supports 49-frame large-scale video generation, accurately perceives the position of dynamic agents and achieves consistent shared world modeling.
ピクセル履歴を超えて: 永続的な 3D 状態を持つワールド モデル
インタラクティブな世界モデルは、ユーザーのアクションに応答してビデオを継続的に生成し、オープンエンドの生成機能を可能にします。ただし、既存のモデルには通常、環境の 3D 表現が欠けており、3D の一貫性をデータから暗黙的に学習する必要があり、空間メモリは限られた時間コンテキスト ウィンドウに制限されます。これにより、非現実的なユーザー エクスペリエンスが生じ、エージェントのトレーニングなどの下流のタスクに重大な障害が生じます。これに対処するために、潜在的な 3D シーン (環境、カメラ、レンダラー) の進化をシミュレートするワールド モデルの新しいパラダイムである PERSIST を紹介します。これにより、永続的な空間メモリと一貫したジオメトリを備えた新しいフレームを合成できるようになります。定量的メトリクスと定性的ユーザー調査の両方で、既存の手法に比べて空間記憶、3D 一貫性、長期安定性が大幅に向上し、一貫性のある進化する 3D 世界が可能になることが示されています。さらに、単一の画像から多様な 3D 環境を合成することや、3D 空間で直接環境の編集と仕様をサポートすることにより、生成されたエクスペリエンスに対するきめの細かいジオメトリを意識した制御を可能にすることなど、新しい機能を実証します。プロジェクトページ: https://francelico.github.io/persist.github.io
原文 (English)
Beyond Pixel Histories: World Models with Persistent 3D State
Interactive world models continually generate video by responding to a user's actions, enabling open-ended generation capabilities. However, existing models typically lack a 3D representation of the environment, meaning 3D consistency must be implicitly learned from data, and spatial memory is restricted to limited temporal context windows. This results in an unrealistic user experience and presents significant obstacles to downstream tasks such as training agents. To address this, we present PERSIST, a new paradigm of world model which simulates the evolution of a latent 3D scene: environment, camera, and renderer. This allows us to synthesise new frames with persistent spatial memory and consistent geometry. Both quantitative metrics and a qualitative user study show substantial improvements in spatial memory, 3D consistency, and long-horizon stability over existing methods, enabling coherent, evolving 3D worlds. We further demonstrate novel capabilities, including synthesising diverse 3D environments from a single image, as well as enabling fine-grained, geometry-aware control over generated experiences by supporting environment editing and specification directly in 3D space. Project page: https://francelico.github.io/persist.github.io
vLLM セマンティック ルーター: 混合モダリティ モデル向けの信号駆動型意思決定ルーティング
大規模言語モデル (LLM) がモダリティ、機能、コスト プロファイルにわたって多様化するにつれて、インテリジェントなリクエスト ルーティングの問題、つまり推論時に各クエリに適切なモデルを選択することが、システムの重要な課題となっています。 Mixture-of-Modality (MoM) モデル展開用の信号駆動型意思決定ルーティング フレームワークである vLLM Semantic Router を紹介します。このアーキテクチャは、シャノンからインスピレーションを得た 2 つの相補的なビューに従っています。情報理論領域では、信号抽出により「どのモデルか?」のエントロピーが低減されます。生のクエリからルーティング関連情報を抽出することによって。ブール代数領域では、意思決定エンジンは信号状態から機能的に完全なルーティング ポリシーを構成します。中心的なイノベーションは、構成可能な信号オーケストレーションです。ミリ秒未満のヒューリスティックと、セマンティクス、安全性、モダリティのニューラル分類子にわたる 13 種類の異種信号タイプが、構成可能なブール決定ルールを通じて展開固有のルーティング ポリシーに組み込まれるため、基本的に異なるシナリオ (マルチクラウド エンタープライズ、プライバシー規制、コスト最適化) が、同じアーキテクチャ上の異なる構成として表現されます。一致した決定は 13 の選択アルゴリズムを介してセマンティック モデルのルーティングを推進し、決定ごとのプラグイン チェーンは 3 段階の HaluGate 幻覚検出パイプラインやパーソナライズされたマルチターン コンテキストのための ReflectionGate を備えた軽量のエピソード記憶システムなどの安全制約を強制します。型付きニューラルシンボリック DSL は、これらのルーティング ポリシーを指定し、複数の展開ターゲットにコンパイルして、コードを変更せずに構成優先の適応を可能にします。これらのコンポーネントを総合すると、コンポーザブルな信号オーケストレーションにより、単一のフレームワークで差別化されたコスト、プライバシー、安全性ポリシーを備えた多様な展開シナリオに対応できることがわかります。
原文 (English)
vLLM Semantic Router: Signal Driven Decision Routing for Mixture-of-Modality Models
As large language models (LLMs) diversify across modalities, capabilities, and cost profiles, the problem of intelligent request routing: selecting the right model for each query at inference time, has become a critical systems challenge. We present vLLM Semantic Router, a signal-driven decision routing framework for Mixture-of-Modality (MoM) model deployments. The architecture follows two complementary Shannon-inspired views. In the information-theoretic regime, signal extraction reduces the entropy of "which model?" by distilling routing-relevant information from raw queries. In the Boolean-algebraic regime, the decision engine composes functionally complete routing policies from signal conditions. The central innovation is composable signal orchestration: thirteen heterogeneous signal types, spanning sub-millisecond heuristics and neural classifiers for semantics, safety, and modality, are composed through configurable Boolean decision rules into deployment-specific routing policies, so that fundamentally different scenarios (multi-cloud enterprise, privacy-regulated, cost-optimized) are expressed as different configurations over the same architecture. Matched decisions drive semantic model routing via thirteen selection algorithms, while per-decision plugin chains enforce safety constraints including a three-stage HaluGate hallucination detection pipeline and a lightweight episodic memory system with ReflectionGate for personalized multi-turn context. A typed neural-symbolic DSL specifies these routing policies and compiles them to multiple deployment targets, enabling configuration-first adaptation without code changes. Together, these components show that composable signal orchestration enables a single framework to serve diverse deployment scenarios with differentiated cost, privacy, and safety policies.
ZeroWBC: 人間の自己中心的なデータから自然な全身ヒューマノイドのインタラクションを学習する
全身遠隔操作データのコストが高いため、多用途で自然な全身ヒューマノイドのインタラクション制御を実現することは依然として困難です。我々は、同期した全身動作とテキスト注釈と組み合わせた、人間の自己中心的なビデオから人型の全身インタラクションを学習する、遠隔操作不要のフレームワークである ZeroWBC を紹介します。 ZeroWBC は、静的シーンの全身インタラクション制御問題に取り組むために、生成後追跡の定式化を採用しています。初期の自己中心的な画像と言語命令が与えられると、微調整された視覚言語モデルによって将来の人間の全身運動トークンが生成され、これが連続運動にデコードされ、ヒューマノイドに再ターゲットされます。結果として得られる参照モーションは、ルートおよび主要な身体部分の軌道とともに、一般的なインタラクティブ モーション トラッキング ポリシーによって実行されます。インタラクションのパフォーマンスを向上させるために、自然な全身の動きを維持しながら、グローバル ルートと主要な身体部分の軌道の調整を優先するインタラクション指向の追跡報酬を導入します。 Unitree G1 ヒューマノイド ロボットの実験では、ZeroWBC がロボットの遠隔操作のデモンストレーションを行わずに、シーンを認識した多様な動作を可能にすることを示しています。これらの結果は、人間の自己中心的なデータから自然なヒューマノイドの全身インタラクションを学習するためのスケーラブルなパラダイムを示唆しています。
原文 (English)
ZeroWBC: Learning Natural Whole-Body Humanoid Interaction from Human Egocentric Data
Achieving versatile and natural whole-body humanoid interaction control remains challenging due to the high cost of whole-body teleoperation data. We present ZeroWBC, a teleoperation-free framework that learns humanoid whole-body interaction from human egocentric videos paired with synchronized whole-body motion and text annotations. ZeroWBC adopts a generation-then-tracking formulation to tackle the static scene whole-body interaction control problem. Given an initial egocentric image and a language instruction, a fine-tuned Vision-Language Model generates future human whole-body motion tokens, which are decoded into continuous motions and retargeted to the humanoid. The resulting reference motions, together with root and key body-part trajectories, are then executed by a general interactive motion tracking policy. To improve interaction performance, we introduce an interaction-oriented tracking reward that prioritizes global root and key body-part trajectory alignment while preserving natural whole-body motion. Experiments on the Unitree G1 humanoid robot show that ZeroWBC enables diverse scene-aware behaviors without robot teleoperation demonstrations. These results suggest a scalable paradigm for learning natural humanoid whole-body interaction from human egocentric data.
微分可能なパルス列合成による物理学に基づいたニューラル エンジン サウンド モデリング
エンジン音は、持続的な調和振動ではなく、連続する排気圧力パルスから発生します。神経合成手法は通常、結果として得られるスペクトル特性を近似することを目的としていますが、私たちは基礎となるパルス形状と時間構造を直接モデル化することを提案します。我々は、エンジン点火パターンに合わせてパラメータ化されたパルス列としてエンジン音声を生成し、それを排気音響をシミュレートする再帰的な Karplus-Strong 共振器を通して伝播する微分可能な合成アーキテクチャであるパルストレイン共振器 (PTR) モデルを紹介します。このアーキテクチャには、高調波減衰、熱力学的ピッチ変調、バルブダイナミクスエンベロープ、排気システムの共振、スロットル操作や減速燃料カットオフ (DFCO) などの派生エンジン動作モードなど、物理学に基づいた誘導バイアスが統合されています。 3 つの異なるエンジン タイプ、合計 7.5 時間のオーディオで検証された PTR は、高調波とノイズのベースライン モデルと比較して、高調波再構成で 21% の改善と総損失の 5.7% 削減を達成し、同時に物理現象に対応する解釈可能なパラメータを提供します。完全なコード、モデルの重み、および音声サンプルは公開されています。
原文 (English)
Physics-Informed Neural Engine Sound Modeling with Differentiable Pulse-Train Synthesis
Engine sounds originate from sequential exhaust pressure pulses rather than sustained harmonic oscillations. While neural synthesis methods typically aim to approximate the resulting spectral characteristics, we propose directly modeling the underlying pulse shapes and temporal structure. We present the Pulse-Train-Resonator (PTR) model, a differentiable synthesis architecture that generates engine audio as parameterized pulse trains aligned to engine firing patterns and propagates them through recursive Karplus-Strong resonators simulating exhaust acoustics. The architecture integrates physics-informed inductive biases including harmonic decay, thermodynamic pitch modulation, valve-dynamics envelopes, exhaust system resonances and derived engine operating modes such as throttle operation and Deceleration Fuel Cutoff (DFCO). Validated on three diverse engine types totaling 7.5 hours of audio, PTR achieves a 21% improvement in harmonic reconstruction and a 5.7% reduction in total loss over a harmonic-plus-noise baseline model, while providing interpretable parameters corresponding to physical phenomena. Complete code, model weights, and audio examples are openly available.
EvoPrompt: Guided Prompt Evolution for Vision-Language Models Adaptation
The adaptation of large-scale vision-language models (VLMs) to downstream tasks with limited labeled data remains a significant challenge.…
Safety Under Scaffolding: How Evaluation Conditions Shape Measured Safety
A safety score earned on a benchmark need not predict how the same model behaves once it is wrapped in an agentic scaffold the benchmark ne…
Quantum entanglement provides a competitive advantage in adversarial games
Whether uniquely quantum resources confer advantages in fully classical, competitive environments remains an open question. Competitive zer…
ContactExplorer: Contact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Reinforcement learning has achieved remarkable success in domains such as Atari games, navigation, and locomotion, where exploration can of…
Revisiting Model Stitching In the Foundation Model Era
Model stitching, connecting early layers of one model (source) to later layers of another (target) via a light stitch layer, has served as…
VulnAgent-R2: Evidence-Calibrated Multi-Agent Auditing for Repository-Level Vulnerability Detection
Software vulnerabilities often depend on cross-file data flow, build options, framework conventions, and runtime guards, so isolated functi…
Spatial Transcriptomics as Images for Large-Scale Pretraining
Spatial Transcriptomics (ST) profiles thousands of gene expression values at discrete spots with precise coordinates on tissue sections, pr…
AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in la…
FinTradeBench: A Financial Reasoning Benchmark for LLMs
Real-world financial decision-making is a challenging problem that requires reasoning over heterogeneous signals, including company fundame…
GenSpan: Generation-Calibrated Motion Span Priors for Multi-Verb Video Corpus Moment Retrieval
Video Corpus Moment Retrieval (VCMR) aims to retrieve both the correct video and its temporal segment corresponding to a natural-language q…
PoliticsBench: Benchmarking Political Values in Large Language Models with Multi-Turn Roleplay
While Large Language Models (LLMs) are increasingly used as primary sources of information, their potential for political bias may impact t…
On-the-fly Repulsion in the Contextual Space for Rich Diversity in Diffusion Transformers
Modern Text-to-Image (T2I) diffusion models have achieved remarkable semantic alignment, yet they often suffer from a significant lack of v…
Emotion Entanglement and Bayesian Inference for Multi-Dimensional Emotion Understanding
Understanding emotions in natural language is inherently a multi-dimensional reasoning problem, where multiple affective signals interact t…
Inclusion-of-Thoughts: Mitigating Preference Instability via Purifying the Decision Space
Multiple-choice questions (MCQs) are widely used to evaluate large language models (LLMs). However, LLMs remain vulnerable to the presence…
Policy Split: Incentivizing Dual-Mode Exploration in LLM Reinforcement with Dual-Mode Entropy Regularization
To encourage diverse exploration in reinforcement learning (RL) for large language models (LLMs) without compromising accuracy, we propose…
Contextual Multi-Task Reinforcement Learning for Autonomous Reef Monitoring
Although autonomous underwater vehicles promise the capability of marine ecosystem monitoring, their deployment is fundamentally limited by…
Generative Augmented Inference
Large language models enable inexpensive AI-generated annotations, but using them reliably for causal inference remains challenging. Naivel…
Luminol-AIDetect: Fast Zero-shot Machine-Generated Text Detection based on Perplexity under Text Shuffling
Machine-generated text (MGT) detection requires identifying structurally invariant signals across generation models, rather than relying on…
MAEPose: Self-Supervised Spatiotemporal Learning for Human Pose Estimation on mmWave Video
Millimetre-wave (mmWave) radar offers a more privacy-preserving alternative to RGB-based human pose estimation. However, existing methods t…
Stochastic Sparse Attention for Memory-Bound Inference
Autoregressive decoding becomes bandwidth-limited at long contexts, as generating each token requires reading all $n_k$ key and value vecto…
SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents
LLM agents increasingly rely on reusable skills (e.g., SKILL markdown files) to execute complex tasks, yet these artifacts lack portability…
Efficiently Aligning Language Models with Online Natural Language Feedback
Reinforcement learning with verifiable rewards has been used to elicit impressive performance from language models in many domains. But, br…
A Systematic Investigation of RL-Jailbreaking in LLMs
The evolution of generative models from next-token predictors to autonomous engines of complex systems necessitates rigorous safety hardeni…
Curated Synthetic Data Doesn't Have to Collapse: A Theoretical Study of Generative Retraining with Pluralistic Preferences
Recursive retraining of generative models poses a critical representation challenge: when synthetic outputs are curated based on a fixed re…
FactoryNet: A Large-Scale Dataset toward Industrial Time-Series Foundation Models
We introduce the first universal pretraining corpus for industrial time-series data: FactoryNet. 51M datapoints across 23k end-to-end task…
HEPA: A Self-Supervised Horizon-Conditioned Event Predictive Architecture for Time Series
Critical events in multivariate time series, from turbine failures to cardiac arrhythmias, demand accurate prediction, yet labeled data is…
Widening the Gap: Exploiting LLM Quantization via Outlier Injection
LLM quantization has become essential for memory-efficient deployment. Recent work has shown that quantization schemes can pose critical se…
Do LLMs Hold Their Values? MANTA: A Multi-Turn Adversarial Benchmark for Animal Welfare Reasoning
Evaluating animal welfare reasoning in LLMs remains an open challenge despite rapid deployment in consumer and professional contexts where…
Retrieval and competition: how a protein foundation model starts a protein
Protein language models are increasingly used to guide experimental and clinical decisions, yet it is often unclear whether a confident pre…
Position: State-of-the-Art Claims Require State-of-the-Art Evidence
State-of-the-Art (SOTA) claims pervade Artificial Intelligence (AI) and Machine Learning (ML) research. These claims rest on benchmark eval…
ZeroUnlearn: Few-Shot Knowledge Unlearning in Large Language Models
Large language models inevitably retain sensitive information, defined as inputs that may induce harmful generations, due to training on ma…
Markov Chain Decoders Overcome the Heavy-Tail Limitations of Lipschitz Generative Models
Heavy-tailed distributions are prevalent in performance evaluation, network traffic, and risk modeling. This behavior poses a fundamental c…
DEFLECT: Temporal Counterfactual Preference Learning for Delay-Robust Asynchronous VLAs
Vision-Language-Action (VLA) policies increasingly rely on asynchronous inference to hide large-model latency behind ongoing robot motion.…
Rebalancing Reference Frame Dominance to Improve Motion in Image-to-Video Models
Image-to-video models often generate videos that remain overly static, compared to text-to-video models. While prior approaches mitigate th…
REFLECTOR: Internalizing Step-wise Reflection against Indirect Jailbreak
While Large Language Models (LLMs) demonstrate remarkable capabilities, they remain susceptible to sophisticated, multi-step jailbreak atta…
Lost in Fog: Sensor Perturbations Expose Reasoning Fragility in Driving VLAs
Interpretable autonomous driving planners depend not only on generating explanations, but also on those explanations remaining reliable und…
メタ学習による費用対効果の高いモデル評価
機械学習の急速な成長により、拡大し続けるモデルのエコシステムが生み出され、目に見えないラベルのないデータに対して新しくリリースされたモデルの信頼性を検証することがますます困難になっています。従来の評価パイプラインは、高価なアノテーション、繰り返しの微調整、またはモデル ファミリ間での転送ができない狭い仮定に依存しています。さまざまなアーキテクチャやモダリティにまたがる未確認のモデルをラベルなしで迅速に評価するための、コスト効率が高く、モデルに依存しないフレームワークである MetaEvaluator を紹介します。 MetaEvaluator は、参照モデルのプールに対するメタ学習を利用して転送可能な初期化を取得し、プール全体でコストを償却しながら、モデルごとの再トレーニングの必要性を排除しながら、新しいモデルの正確な評価を可能にします。私たちの知る限り、これは完全にラベルのないデータセットで新しいモデルを評価できる、モデルに依存しない最初のフレームワークです。広範な実験により、MetaEvaluator は従来のアプローチと比較して大幅にコストを削減しながら安定した正確なパフォーマンス推定値を生成し、ラベルのないデータに対する新しいモデルのスケーラブルなベンチマークを実用化できることが示されています。
原文 (English)
Learning to Evaluate: Cost-Effective Model Evaluation on Unlabeled Data with Meta-Learning
The rapid advancement of machine learning has led to an unprecedented expansion of model ecosystems, making it increasingly difficult to assess the reliability of newly released models on unseen and unlabeled data. Existing evaluation pipelines typically rely on costly annotation, repeated fine-tuning, or assumptions that do not generalize well to new models. We introduce MetaEvaluator, a cost-effective, model-agnostic framework for fast, label-free evaluation of unseen models across diverse architectures and modalities. MetaEvaluator meta-learns over a pool of reference models to acquire an effective initialization for accurate assessment of unseen models, thereby amortizing evaluation cost and eliminating the need for per-model retraining. To the best of our knowledge, this is the first model-agnostic framework that evaluates new models on unlabeled datasets. Extensive experiments demonstrate that MetaEvaluator delivers stable and accurate performance estimates at substantially lower cost than conventional approaches, enabling scalable benchmarking on unlabeled datasets for emerging models. The code is available at: https://github.com/phkhanhtrinh23/MetaEvaluator.
グラフデータに対するネットワーク効果の微分による治療効果の推定
観察グラフデータから個人治療効果(ITE)を推定することは、商業や医療などの分野での意思決定に不可欠です。この作業は、個々の結果が近隣の治療法や共変量によって影響を受ける可能性があるため、干渉が生じるため困難です。既存の方法は、正確な ITE 推定のためにそのような干渉をモデル化しようとしています。ただし、重要な問題は見落とされがちです。それは、差異化ネットワーク効果 (DNE) です。これは、重要性と規模が異なる近隣ネットワークで構成されるローカル ネットワークによって引き起こされる効果です。 DNE をキャプチャすることは不可欠です。そうしないと、干渉の誤った特性評価により ITE 推定が不正確になり、誤った決定を招く可能性があります。この課題に対処するために、2 つの部分注意メカニズムとメッセージ増幅器を組み込んだ新しい干渉モデリング メカニズムを提案します。パーシャル アテンション メカニズムは、干渉に寄与するさまざまな隣接ノードの重要性を自動的に推定します。一方、メッセージ アンプは隣接ノードのスケールに基づいて干渉モデリング メカニズムの結果を調整します。これらすべてにより、モデルが DNE をキャプチャできるようになります。 3 つの現実世界のグラフでの実験では、私たちの方法がグラフ データから ITE を推定する既存のアプローチよりも優れていることが実証されており、DNE を明示的にキャプチャすることの重要性が裏付けられています。
原文 (English)
Treatment Effect Estimation with Differentiated Networked Effect on Graph Data
Estimating individual treatment effect (ITE) from observational graph data is crucial for decision-making in the fields such as commerce and medicine. This task is challenging due to interference, where individual outcomes can be influenced by the treatments and covariates of their neighbors. Existing methods attempt to model such interference for accurate ITE estimation. However, a critical issue is often overlooked: differentiated networked effect (DNE), an effect caused by local networks consisting of neighbors with varying importance and scales. Capturing DNE is vital; otherwise, we will end up with imprecise ITE estimation due to an erroneous characterization of interference, which can result in misguided decisions. To address this challenge, we propose a novel interference modeling mechanism that incorporates two partial attention mechanisms and a message amplifier. The partial attention mechanisms automatically estimate the importance of different neighbors in contributing to interference, while the message amplifier adjusts the results of the interference modeling mechanism based on the scale of neighbors, all of which enables the model to capture DNE. Experiments on three real-world graphs demonstrate that our methods outperform existing approaches for ITE estimation from graph data, which corroborates the importance of explicitly capturing DNE.
注意力の散漫によって引き起こされる視覚的なぼやけを修正して幻覚を軽減する: アルゴリズムと理論
マルチモーダル大規模言語モデル (MLLM) は、物体の幻覚に悩まされることがよくありますが、この失敗の根底にある視覚知覚メカニズムはまだ十分に理解されていません。この研究では、幻覚が人間のような注意散漫現象と強く関連していることを明らかにしました。この現象では、分割焦点下にある人間は視覚の明瞭度が低下し、不正確な説明を生成しますが、モデルでは同じメカニズムが、複数頭の注意における空間的な不一致と、デコード中の画像トークンへの注意の一時的な薄れとして現れます。さらに、注意の分散によってモデルの複雑さが増大し、分類の一般化が低下するという理論的な洞察も提供します。これらの発見に動機づけられて、我々は、画像認識を改善するための注意集中アプローチ(AFIP)を提案します。これは、クロスヘッド注意の強化を通じて注意の散漫を修正し、動的な歴史的注意の強化を通じて視覚の基礎を強化します。複数のベンチマークとモデルに関する広範な実験により、追加のトレーニングなしで AFIP の有効性が検証されます。
原文 (English)
Correcting Visual Blur Induced by Attention Distraction to Reduce Hallucinations: Algorithm and Theory
Multimodal large language models (MLLMs) frequently suffer from object hallucinations, yet the visual perceptual mechanism underlying this failure remains poorly understood. In this work, we reveal that hallucinations are strongly associated with a human-like attention distraction phenomenon, where humans under divided focus experience degraded visual clarity and produce inaccurate descriptions, while in models the same mechanism manifests as spatial inconsistency in multi-head attention and temporal fading of attention to image tokens during decoding. We further provide theoretical insights that attention dispersion increases model complexity and degrades classification generalization. Motivated by these findings, we propose an Attention-Focused Approach for Improved Image Perception (AFIP), which corrects attention distraction via cross-head attention enrichment and reinforces visual grounding through dynamic historical attention enhancement. Extensive experiments on multiple benchmarks and models validate the effectiveness of AFIP without additional training.
Anatomy-Anchored Self-Supervision: Distilling Vision Foundation Models for Invariant Ultrasound Representation
Self-supervised pre-training paradigm has gained increasing prominence for learning transferable representations in medical imaging, yet ex…
Grimlock: Guarding High-Agency Systems with eBPF and Attested Channels
Agentic systems increasingly run user-authored orchestration code that invokes tools, spawns subtasks, and delegates work across machines a…
アリヤバータ 2: 高度な STEM 推論のための強化学習のスケーリング
JEE や NEET などの競争力のある STEM 試験では、複数段階の記号的推論、正確な数値計算、物理、化学、数学にわたる深い概念的理解が必要です。最近の大規模な言語モデルは、共通の推論ベンチマークでは優れたパフォーマンスを発揮しますが、大規模に展開することは依然として困難であり、学生の何百万もの疑問がドメイン固有の一貫した構造の問題解決を必要としています。 Aryabhata 2 は、トレーニング後の強化学習によってトレーニングされた、競争力のある STEM 試験用の推論に焦点を当てた言語モデルです。 PhysicsWallah の内部質問バンクを使用して、高品質のトレーニング カリキュラムを構築し、検証可能な報酬を伴う強化学習を通じて GPT-OSS-20B のポストトレーニングを構築します。トレーニングでは、長期にわたる強化学習と、段階的にロールアウト グループのサイズが大きくなることで広がる探索を組み合わせます。 JEE Main、JEE Advanced、NEET などの競合試験ベンチマークと、AIME、HMMT、MMLU-Pro、MMLU-Redux 2.0、GPQA などの配布外推論データセットで Aryabhata 2 を評価します。結果は、Aryabhata 2 が競合 STEM 推論において基本モデル GPT-OSS-20B を上回るパフォーマンスを示しながら、必要な出力トークンが大幅に少なくなる (最大 64\% 少ない) ことを示しています。
原文 (English)
Aryabhata 2: Scaling Reinforcement Learning for Advanced STEM Reasoning
Competitive STEM examinations such as JEE and NEET require multi-step symbolic reasoning, precise numerical computation, and deep conceptual understanding across physics, chemistry, and mathematics. Recent large language models perform strongly on common reasoning benchmarks, yet they remain difficult to deploy at scale, where millions of student doubts demand domain-specific, consistently structured problem solving. We introduce Aryabhata 2, a reasoning-focused language model for competitive STEM examinations, trained via reinforcement-learning post-training. Using PhysicsWallah's internal question banks, we construct a high-quality training curriculum and post-train GPT-OSS-20B through reinforcement learning with verifiable rewards. Training combines prolonged reinforcement learning with broadened exploration via progressively larger rollout group sizes. We evaluate Aryabhata 2 on competitive examination benchmarks, including JEE Main, JEE Advanced, and NEET, as well as out-of-distribution reasoning datasets such as AIME, HMMT, MMLU-Pro, MMLU-Redux 2.0, and GPQA. Results show that Aryabhata 2 outperforms its base model GPT-OSS-20B on competitive STEM reasoning while requiring substantially fewer output tokens (up to 64\% fewer).
構造化プロンプトの最適化と強化学習の融合により、複雑なテキストに対するグローバルおよびローカルの解釈可能性が実現
LLM は高度なテキスト分類を備えていますが、既存のパラダイムはトレードオフに直面しています。教師付き (ラベルのみ) 微調整はスケーラブルですが、複雑なテキストに対する推論が限られており、広範なモデルの透明性に欠けています。一方、離散プロンプト最適化は人間が読める命令を提供しますが、パフォーマンスとスケーラビリティに苦労します。私たちは、3 つの段階的な段階を持つ eXTC (eXplainable Text Classifier) を導入します。(1) 新しい構造化プロンプト最適化アルゴリズムを介して、自然言語で標準操作手順 (SOP、またはルールブック) を学習します。 (2) SOP に基づいた推論を大規模な教師 LLM からコンパクトな LM に抽出します。 (3) 強化学習により、初期 SOP を超えて推論能力を拡張します。この設計により、eXTC は、(i) コンパクトな LM を介した高速推論、(ii) 学習したドメイン ルールのグローバルなモジュール式説明と並行した推論時のローカル推論トレースを提供できるようになり、(iii) 分類パフォーマンスと説明品質の両方において、さまざまなベンチマークにわたって既存のパラダイムを大幅に上回り、段階ごとに向上します。
原文 (English)
Structured Prompt Optimization Meets Reinforcement Learning for Global and Local Interpretability over Complex Text
LLMs have advanced text classification, yet existing paradigms face a trade-off: supervised (label only) fine-tuning is scalable but offers limited reasoning on complex text and lacks broader model transparency, while discrete prompt optimization offers human-readable instructions but struggles with performance and scalability. We introduce eXTC (eXplainable Text Classifier) with three progressive stages: (1) learning a Standard Operating Procedure (SOP, or rulebook) in natural language via a new Structured Prompt Optimization algorithm; (2) SOP-grounded reasoning distillation from a large teacher LLM into a compact LM; and (3) expanding reasoning capabilities beyond the initial SOP via reinforcement learning. This design enables eXTC to provide (i) fast inference via a compact LM, with (ii) inference-time local reasoning traces, alongside a global, modular explanation of its learned domain rules, while (iii) significantly outperforming existing paradigms across diverse benchmarks in both classification performance and explanation quality, with stage-by-stage gains.
LoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffe…
Towards Verifiable Multimodal Deep Research: A Multi-Agent Harness for Interleaved Report Generation
Large Language Models (LLMs) have advanced autonomous agents from deep search, which retrieves concise factual answers, to deep research, w…
Label Over Logic? How Source Cues Bias Human Fallacy Judgments More Than LLMs
As AI-generated and AI-assisted content floods online spaces, source labels attached to such content can distort human reasoning judgments,…
No More K-means: Single-Stage Sparse Coding for Efficient Multi-Vector Retrieval
Multi-vector retrieval (MVR) models, exemplified by ColBERT, have established new benchmarks in retrieval accuracy by preserving fine-grain…
BenHalluEval: A Multi-Task Hallucination Evaluation Framework for Large Language Models on Bengali
Despite Bengali being the sixth most spoken language in the world, no prior work has systematically evaluated hallucination in large langua…
Beyond Tool Adoption: A Practical Five-Stage Developmental Continuum for AI Literacy in Higher Education
Artificial intelligence (AI) literacy is increasingly recognized as a foundational competency for all university graduates. Yet students' e…
SkyShield: Occupancy as a Safety Interface for Low-Altitude UAV Autonomy
For low-altitude Unmanned Aerial Vehicle (UAV) autonomy, 3D spatial understanding is not merely a perception objective, but the safety inte…
Data Collection for Training Quality-Control AI in Carpet Manufacturing
Visual inspection remains the dominant quality-control practice in woven and tufted carpet production, yet it is slow, subjective, and inco…
memorywire: A Vendor-Neutral Wire Format for Agent Memory Operations
Agent-memory frameworks -- mem0, Letta/MemGPT, Cognee, Zep/Graphiti, MemoryOS, MemTensor -- each ship their own SDK, storage layout, and op…
DiscourseFlip: An Oblique Discourse-Level Opinion Manipulation Attack against Black-box Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) systems are widely deployed and increasingly influential, but their reliance on external corpora expos…
Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams
Auto-harness systems such as A-Evolve, GEPA, and Meta-Harness improve LLM agents by optimizing prompts, skills, tools, memories, and suppor…
AutoForest: Automatically Generating Forest Plots from Biomedical Studies with End-to-End Evidence Extraction and Synthesis
Systematic reviews rely on forest plots to synthesise quantitative evidence across biomedical studies, but generating them remains a fragme…
Too Much of a Good Thing: When sim2real Efforts Impede Policy Learning (And What to Do About It)
While sim2real efforts are necessary for effective policy transfer to hardware, there is such a thing as too much of a good thing. We argue…
Anomalies in Multivariate Time Series Benchmarks Are Mostly Univariate
Many recent multivariate time series anomaly detection (MTSAD) models incorporate cross-channel modeling, under the implicit assumption tha…
Scalable Uncertainty Quantification for Extreme Weather Forecasting via Empirical Neural Tangent Kernels
Deep learning weather models now match numerical weather prediction accuracy while running orders of magnitude faster, but produce determin…
OpenAgenet/OAN: Open Infrastructure for Trusted Agent Interconnection
OpenAgenet, abbreviated as OAN, is an open infrastructure project for trusted Agent interconnection. It addresses a problem that becomes vi…
OpenAgenet/OAN: Technical Architecture for Trust-Governed Agent Identity and Discovery
This paper describes the technical architecture of OpenAgenet / OAN. OAN is a protocol-neutral trust layer for open Agent interconnection.…
Reinforcement Learning from Cross-domain Videos with Video Prediction Model
Reinforcement learning from expert videos across visually distinct domains is challenging due to the absence of reward signals and the pres…
Generalizing Graph Foundation Models via Hyperbolic Retrieval-Augmented Generation
Graph foundation models (GFMs) emerged as a dominant paradigm in graph representation learning by leveraging large-scale pre-training for c…
Implement Kubernetes Pod-Level Remote Attestation for Confidential Workloads on dstack
The rise of LLM-as-a-Service and other confidential cloud workloads demands cryptographic proof that user data is processed in a trusted, u…
P$^2$-DPO: Grounding Hallucination in Perceptual Processing via Calibration Direct Preference Optimization
Hallucination has recently garnered significant research attention in Large Vision-Language Models (LVLMs). Direct Preference Optimization…
Optimizing Explicit Unit-Distance Lower-Bound Certificates
The 2026 disproof of Erd\H{o}s's unit-distance conjecture and Sawin's subsequent explicit quantitative refinement show that the maximum num…
CR-Seg: Attention-Guided and CoT-Enhanced Coarse-to-Refined Reasoning Segmentation
Reasoning segmentation aims to segment target objects described by complex language through joint visual-textual reasoning. Existing method…
PHASER: Phase-Aware and Semantic Experience Replay for Vision-Language-Action Models
Vision-Language-Action (VLA) models have achieved remarkable success in language-conditioned robotic manipulation. However, deploying these…
Testing LLM Arithmetic Reasoning Generalization with Automatic Numeric-Remapping Attacks
Large language models achieve strong performance on arithmetic reasoning benchmarks, and one common response to arithmetic brittleness is t…
AnchorMoE: Interpretable Time Series Classification via Anchor-Routed MoE
Multivariate time series classification (MTSC) is pivotal in high-stakes domains, such as clinical diagnosis and industrial fault detection…
Qwen-Image-Flash: Beyond Objective Design
Few-step distillation has become an effective strategy for accelerating advanced visual generative models, yet prior work has largely focus…
Consistency Training Can Entrench Misalignment
Consistency training encourages a model to produce similar outputs across related inputs or sampling procedures. Such methods are simple, s…
Synthesize and Reward -- Reinforcement Learning for Multi-Step Tool Use in Live Environments
Training LLMs to orchestrate multi-step tool calls is held back by three coupled obstacles: realistic stateful execution environments are c…
q0: Primitives for Hyper-Epoch Pretraining
Multi-epoch training is becoming the standard now that compute is growing faster than the supply of high-quality text. But pretraining a si…